33 KiB
Робота з даними: Python та бібліотека Pandas
 |
|---|
| Робота з Python - Скетчнот від @nitya |
Хоча бази даних пропонують дуже ефективні способи зберігання даних і запитів до них за допомогою мов запитів, найгнучкішим способом обробки даних є написання власної програми для їх маніпуляції. У багатьох випадках запит до бази даних буде більш ефективним. Однак у деяких випадках, коли потрібна складніша обробка даних, це не завжди легко зробити за допомогою SQL.
Обробка даних може бути запрограмована на будь-якій мові програмування, але є певні мови, які краще підходять для роботи з даними. Дата-сайентисти зазвичай віддають перевагу одній із наступних мов:
- Python — універсальна мова програмування, яка часто вважається одним із найкращих варіантів для початківців завдяки своїй простоті. Python має багато додаткових бібліотек, які можуть допомогти вирішити практичні завдання, наприклад, витягти дані з ZIP-архіву або перетворити зображення в градації сірого. Крім науки про дані, Python також часто використовується для веброзробки.
- R — традиційний інструмент, розроблений для статистичної обробки даних. Він також містить великий репозиторій бібліотек (CRAN), що робить його хорошим вибором для обробки даних. Однак R не є універсальною мовою програмування і рідко використовується поза межами науки про дані.
- Julia — ще одна мова, розроблена спеціально для науки про дані. Вона створена для забезпечення кращої продуктивності, ніж Python, що робить її чудовим інструментом для наукових експериментів.
У цьому уроці ми зосередимося на використанні Python для простої обробки даних. Ми припускаємо, що ви вже маєте базові знання мови. Якщо ви хочете глибше ознайомитися з Python, зверніться до одного з наступних ресурсів:
- Вивчайте Python весело за допомогою Turtle Graphics та фракталів — швидкий вступний курс на GitHub.
- Зробіть перші кроки з Python — навчальний шлях на Microsoft Learn.
Дані можуть бути представлені в багатьох формах. У цьому уроці ми розглянемо три форми даних — табличні дані, текст і зображення.
Ми зосередимося на кількох прикладах обробки даних, замість того щоб надавати повний огляд усіх пов’язаних бібліотек. Це дозволить вам зрозуміти основні можливості та залишить вас із розумінням, де шукати рішення для ваших завдань, коли це буде потрібно.
Найкорисніша порада. Коли вам потрібно виконати певну операцію з даними, але ви не знаєте, як це зробити, спробуйте пошукати це в інтернеті. Stackoverflow зазвичай містить багато корисних прикладів коду на Python для багатьох типових завдань.
Тест перед лекцією
Табличні дані та DataFrame
Ви вже зустрічалися з табличними даними, коли ми говорили про реляційні бази даних. Коли у вас є багато даних, і вони містяться в багатьох різних пов’язаних таблицях, безумовно, має сенс використовувати SQL для роботи з ними. Однак є багато випадків, коли у нас є таблиця даних, і нам потрібно отримати розуміння або інсайти про ці дані, наприклад, розподіл, кореляцію між значеннями тощо. У науці про дані часто потрібно виконувати певні перетворення початкових даних із подальшою візуалізацією. Обидва ці кроки легко виконати за допомогою Python.
Є дві найкорисніші бібліотеки в Python, які допоможуть вам працювати з табличними даними:
- Pandas дозволяє маніпулювати так званими DataFrame, які аналогічні реляційним таблицям. Ви можете мати названі стовпці та виконувати різні операції над рядками, стовпцями та DataFrame загалом.
- Numpy — це бібліотека для роботи з тензорами, тобто багатовимірними масивами. Масив має значення одного типу, він простіший за DataFrame, але пропонує більше математичних операцій і створює менше накладних витрат.
Також є кілька інших бібліотек, про які варто знати:
- Matplotlib — бібліотека для візуалізації даних і побудови графіків.
- SciPy — бібліотека з додатковими науковими функціями. Ми вже стикалися з цією бібліотекою, коли говорили про ймовірність і статистику.
Ось приклад коду, який зазвичай використовується для імпорту цих бібліотек на початку вашої програми на Python:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import ... # you need to specify exact sub-packages that you need
Pandas зосереджена на кількох базових концепціях.
Series
Series — це послідовність значень, схожа на список або масив numpy. Головна відмінність полягає в тому, що Series також має індекс, і коли ми виконуємо операції над Series (наприклад, додаємо їх), індекс враховується. Індекс може бути простим, наприклад, номером рядка (використовується за замовчуванням при створенні Series зі списку або масиву), або мати складну структуру, наприклад, інтервал дат.
Примітка: У супровідному ноутбуці
notebook.ipynbє вступний код для Pandas. Тут ми лише окреслимо деякі приклади, але ви можете переглянути повний ноутбук.
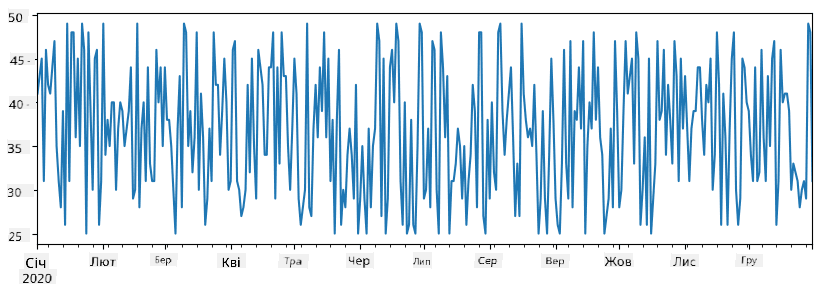
Розглянемо приклад: ми хочемо проаналізувати продажі нашого магазину морозива. Давайте створимо Series із числами продажів (кількість проданих одиниць щодня) за певний період часу:
start_date = "Jan 1, 2020"
end_date = "Mar 31, 2020"
idx = pd.date_range(start_date,end_date)
print(f"Length of index is {len(idx)}")
items_sold = pd.Series(np.random.randint(25,50,size=len(idx)),index=idx)
items_sold.plot()
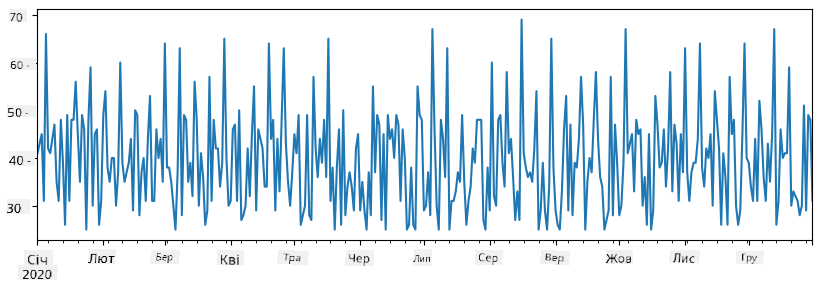
Тепер припустимо, що щотижня ми організовуємо вечірку для друзів і беремо додатково 10 упаковок морозива для вечірки. Ми можемо створити ще один Series, індексований за тижнями, щоб це продемонструвати:
additional_items = pd.Series(10,index=pd.date_range(start_date,end_date,freq="W"))
Коли ми додаємо два Series разом, ми отримуємо загальну кількість:
total_items = items_sold.add(additional_items,fill_value=0)
total_items.plot()
Примітка: Ми не використовуємо простий синтаксис
total_items+additional_items. Якби ми це зробили, ми отримали б багато значеньNaN(Not a Number) у результаті. Це тому, що для деяких індексів у Seriesadditional_itemsвідсутні значення, і додаванняNaNдо будь-чого даєNaN. Тому під час додавання потрібно вказувати параметрfill_value.
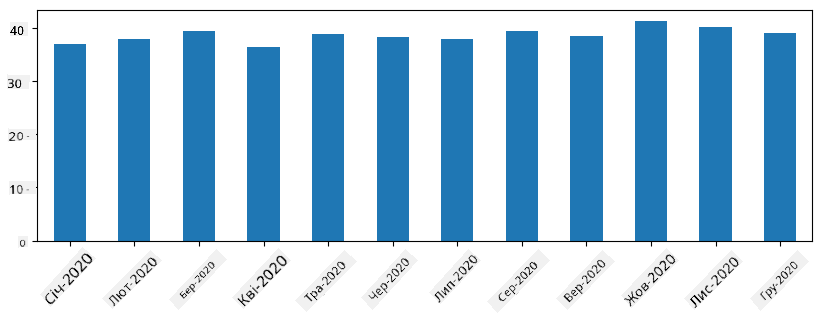
З часовими рядами ми також можемо перевибірковувати Series із різними часовими інтервалами. Наприклад, якщо ми хочемо обчислити середній обсяг продажів щомісяця, ми можемо використати наступний код:
monthly = total_items.resample("1M").mean()
ax = monthly.plot(kind='bar')
DataFrame
DataFrame — це, по суті, колекція Series із однаковим індексом. Ми можемо об’єднати кілька Series у DataFrame:
a = pd.Series(range(1,10))
b = pd.Series(["I","like","to","play","games","and","will","not","change"],index=range(0,9))
df = pd.DataFrame([a,b])
Це створить горизонтальну таблицю такого вигляду:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 1 | I | like | to | use | Python | and | Pandas | very | much |
Ми також можемо використовувати Series як стовпці та задавати назви стовпців за допомогою словника:
df = pd.DataFrame({ 'A' : a, 'B' : b })
Це дасть нам таблицю такого вигляду:
| A | B | |
|---|---|---|
| 0 | 1 | I |
| 1 | 2 | like |
| 2 | 3 | to |
| 3 | 4 | use |
| 4 | 5 | Python |
| 5 | 6 | and |
| 6 | 7 | Pandas |
| 7 | 8 | very |
| 8 | 9 | much |
Примітка: Ми також можемо отримати цей макет таблиці, транспонуючи попередню таблицю, наприклад, написавши:
df = pd.DataFrame([a,b]).T..rename(columns={ 0 : 'A', 1 : 'B' })
Тут .T означає операцію транспонування DataFrame, тобто зміну рядків і стовпців, а операція rename дозволяє перейменувати стовпці, щоб вони відповідали попередньому прикладу.
Ось кілька найважливіших операцій, які ми можемо виконувати з DataFrame:
Вибір стовпців. Ми можемо вибрати окремі стовпці, написавши df['A'] — ця операція повертає Series. Ми також можемо вибрати підмножину стовпців у інший DataFrame, написавши df[['B','A']] — це повертає інший DataFrame.
Фільтрація лише певних рядків за критеріями. Наприклад, щоб залишити лише рядки зі стовпцем A, більшим за 5, ми можемо написати df[df['A']>5].
Примітка: Фільтрація працює таким чином. Вираз
df['A']<5повертає булеву серію, яка вказує, чи є виразTrueабоFalseдля кожного елемента початкової серіїdf['A']. Коли булева серія використовується як індекс, вона повертає підмножину рядків у DataFrame. Таким чином, неможливо використовувати довільний булевий вираз Python, наприклад, написанняdf[df['A']>5 and df['A']<7]буде неправильним. Натомість слід використовувати спеціальну операцію&для булевих серій, написавшиdf[(df['A']>5) & (df['A']<7)](дужки тут важливі).
Створення нових обчислюваних стовпців. Ми можемо легко створювати нові обчислювані стовпці для нашого DataFrame, використовуючи інтуїтивно зрозумілі вирази, наприклад:
df['DivA'] = df['A']-df['A'].mean()
Цей приклад обчислює відхилення A від його середнього значення. Насправді ми обчислюємо серію, а потім призначаємо цю серію лівій частині, створюючи інший стовпець. Таким чином, ми не можемо використовувати жодні операції, які не сумісні з серіями, наприклад, наступний код є неправильним:
# Wrong code -> df['ADescr'] = "Low" if df['A'] < 5 else "Hi"
df['LenB'] = len(df['B']) # <- Wrong result
Останній приклад, хоча й синтаксично правильний, дає неправильний результат, оскільки він призначає довжину серії B усім значенням у стовпці, а не довжину окремих елементів, як ми мали на увазі.
Якщо нам потрібно обчислити складні вирази, ми можемо використовувати функцію apply. Останній приклад можна записати так:
df['LenB'] = df['B'].apply(lambda x : len(x))
# or
df['LenB'] = df['B'].apply(len)
Після виконання наведених вище операцій ми отримаємо такий DataFrame:
| A | B | DivA | LenB | |
|---|---|---|---|---|
| 0 | 1 | I | -4.0 | 1 |
| 1 | 2 | like | -3.0 | 4 |
| 2 | 3 | to | -2.0 | 2 |
| 3 | 4 | use | -1.0 | 3 |
| 4 | 5 | Python | 0.0 | 6 |
| 5 | 6 | and | 1.0 | 3 |
| 6 | 7 | Pandas | 2.0 | 6 |
| 7 | 8 | very | 3.0 | 4 |
| 8 | 9 | much | 4.0 | 4 |
Вибір рядків за номерами можна виконати за допомогою конструкції iloc. Наприклад, щоб вибрати перші 5 рядків із DataFrame:
df.iloc[:5]
Групування часто використовується для отримання результату, схожого на зведені таблиці в Excel. Припустимо, ми хочемо обчислити середнє значення стовпця A для кожного заданого числа LenB. Тоді ми можемо згрупувати наш DataFrame за LenB і викликати mean:
df.groupby(by='LenB').mean()
Якщо нам потрібно обчислити середнє значення та кількість елементів у групі, ми можемо використовувати складнішу функцію aggregate:
df.groupby(by='LenB') \
.aggregate({ 'DivA' : len, 'A' : lambda x: x.mean() }) \
.rename(columns={ 'DivA' : 'Count', 'A' : 'Mean'})
Це дає нам таку таблицю:
| LenB | Count | Mean |
|---|---|---|
| 1 | 1 | 1.000000 |
| 2 | 1 | 3.000000 |
| 3 | 2 | 5.000000 |
| 4 | 3 | 6.333333 |
| 6 | 2 | 6.000000 |
Отримання даних
Ми бачили, як легко створювати Series та DataFrames з об'єктів Python. Однак дані зазвичай надходять у вигляді текстового файлу або таблиці Excel. На щастя, Pandas пропонує простий спосіб завантаження даних з диска. Наприклад, читання файлу CSV так само просто, як це:
df = pd.read_csv('file.csv')
Ми побачимо більше прикладів завантаження даних, включаючи отримання їх із зовнішніх веб-сайтів, у розділі "Виклик".
Друк та Візуалізація
Дослідник даних часто має досліджувати дані, тому важливо мати можливість їх візуалізувати. Коли DataFrame великий, часто ми хочемо просто переконатися, що все робимо правильно, друкуючи перші кілька рядків. Це можна зробити, викликавши df.head(). Якщо ви запускаєте це з Jupyter Notebook, він надрукує DataFrame у гарній табличній формі.
Ми також бачили використання функції plot для візуалізації деяких колонок. Хоча plot дуже корисний для багатьох завдань і підтримує багато різних типів графіків через параметр kind=, ви завжди можете використовувати бібліотеку matplotlib для побудови чогось більш складного. Ми детально розглянемо візуалізацію даних у окремих уроках курсу.
Цей огляд охоплює найважливіші концепції Pandas, однак бібліотека дуже багата, і немає меж тому, що ви можете з нею зробити! Тепер застосуємо ці знання для вирішення конкретної задачі.
🚀 Виклик 1: Аналіз поширення COVID
Перша проблема, на якій ми зосередимося, — це моделювання епідемічного поширення COVID-19. Для цього ми використаємо дані про кількість інфікованих осіб у різних країнах, надані Центром системної науки та інженерії (CSSE) при Університеті Джонса Гопкінса. Набір даних доступний у цьому репозиторії GitHub.
Оскільки ми хочемо продемонструвати, як працювати з даними, ми запрошуємо вас відкрити notebook-covidspread.ipynb і прочитати його від початку до кінця. Ви також можете виконувати комірки та виконувати завдання, які ми залишили для вас наприкінці.
Якщо ви не знаєте, як запускати код у Jupyter Notebook, перегляньте цю статтю.
Робота з неструктурованими даними
Хоча дані дуже часто надходять у табличній формі, у деяких випадках нам потрібно працювати з менш структурованими даними, наприклад, текстом або зображеннями. У цьому випадку, щоб застосувати методи обробки даних, які ми бачили вище, нам потрібно якось витягти структуровані дані. Ось кілька прикладів:
- Витяг ключових слів із тексту та аналіз частоти їх появи
- Використання нейронних мереж для отримання інформації про об'єкти на зображенні
- Отримання інформації про емоції людей із відеопотоку камери
🚀 Виклик 2: Аналіз наукових статей про COVID
У цьому виклику ми продовжимо тему пандемії COVID і зосередимося на обробці наукових статей на цю тему. Існує набір даних CORD-19 з понад 7000 (на момент написання) статей про COVID, доступних із метаданими та анотаціями (а для приблизно половини з них також надається повний текст).
Повний приклад аналізу цього набору даних за допомогою когнітивної служби Text Analytics for Health описаний у цьому блозі. Ми обговоримо спрощену версію цього аналізу.
NOTE: Ми не надаємо копію набору даних у цьому репозиторії. Спочатку вам може знадобитися завантажити файл
metadata.csvіз цього набору даних на Kaggle. Може знадобитися реєстрація на Kaggle. Ви також можете завантажити набір даних без реєстрації звідси, але він включатиме всі повні тексти на додаток до файлу метаданих.
Відкрийте notebook-papers.ipynb і прочитайте його від початку до кінця. Ви також можете виконувати комірки та виконувати завдання, які ми залишили для вас наприкінці.
Обробка даних зображень
Останнім часом були розроблені дуже потужні моделі штучного інтелекту, які дозволяють розуміти зображення. Існує багато завдань, які можна вирішити за допомогою попередньо навчених нейронних мереж або хмарних сервісів. Деякі приклади включають:
- Класифікація зображень, яка може допомогти вам категоризувати зображення в одну з попередньо визначених категорій. Ви можете легко навчити власні класифікатори зображень, використовуючи сервіси, такі як Custom Vision
- Виявлення об'єктів для визначення різних об'єктів на зображенні. Сервіси, такі як computer vision, можуть виявляти низку загальних об'єктів, а ви можете навчити модель Custom Vision для виявлення конкретних об'єктів, які вас цікавлять.
- Виявлення облич, включаючи визначення віку, статі та емоцій. Це можна зробити за допомогою Face API.
Усі ці хмарні сервіси можна викликати за допомогою Python SDKs, і таким чином їх можна легко інтегрувати у ваш робочий процес дослідження даних.
Ось кілька прикладів дослідження даних із джерел зображень:
- У блозі Як вивчати Data Science без програмування ми досліджуємо фотографії з Instagram, намагаючись зрозуміти, що змушує людей ставити більше лайків на фото. Спочатку ми витягуємо якомога більше інформації з фотографій за допомогою computer vision, а потім використовуємо Azure Machine Learning AutoML для створення інтерпретованої моделі.
- У Workshop Facial Studies ми використовуємо Face API для витягу емоцій людей на фотографіях із заходів, щоб спробувати зрозуміти, що робить людей щасливими.
Висновок
Незалежно від того, чи у вас вже є структуровані або неструктуровані дані, використовуючи Python, ви можете виконувати всі етапи, пов’язані з обробкою та розумінням даних. Це, мабуть, найгнучкіший спосіб обробки даних, і саме тому більшість дослідників даних використовують Python як свій основний інструмент. Вивчення Python на глибокому рівні — це, мабуть, гарна ідея, якщо ви серйозно ставитеся до своєї подорожі в Data Science!
Тест після лекції
Огляд та Самостійне Вивчення
Книги
Онлайн ресурси
- Офіційний 10 хвилин до Pandas туторіал
- Документація про візуалізацію в Pandas
Вивчення Python
- Вивчайте Python весело з Turtle Graphics та фракталами
- Зробіть свої перші кроки з Python Навчальний шлях на Microsoft Learn
Завдання
Виконайте більш детальне дослідження даних для викликів вище
Авторство
Цей урок створено з ♥️ Дмитром Сошниковим
Відмова від відповідальності:
Цей документ було перекладено за допомогою сервісу автоматичного перекладу Co-op Translator. Хоча ми прагнемо до точності, звертаємо вашу увагу, що автоматичні переклади можуть містити помилки або неточності. Оригінальний документ мовою оригіналу слід вважати авторитетним джерелом. Для критично важливої інформації рекомендується звертатися до професійного людського перекладу. Ми не несемо відповідальності за будь-які непорозуміння або неправильні тлумачення, що виникли внаслідок використання цього перекладу.