28 KiB
Bulutta Veri Bilimi: "Düşük Kod/Hiç Kod" Yöntemi
 |
|---|
| Bulutta Veri Bilimi: Düşük Kod - Sketchnote by @nitya |
İçindekiler:
- Bulutta Veri Bilimi: "Düşük Kod/Hiç Kod" Yöntemi
Ders Öncesi Test
1. Giriş
1.1 Azure Machine Learning Nedir?
Azure bulut platformu, yeni çözümleri hayata geçirmenize yardımcı olmak için tasarlanmış 200'den fazla ürün ve bulut hizmetinden oluşur. Veri bilimciler, verileri keşfetmek ve ön işlemek, çeşitli model eğitim algoritmalarını denemek ve doğru modeller üretmek için çok fazla çaba harcarlar. Bu görevler zaman alıcıdır ve genellikle pahalı hesaplama donanımını verimsiz bir şekilde kullanır.
Azure ML, Azure'da makine öğrenimi çözümleri oluşturmak ve işletmek için bulut tabanlı bir platformdur. Veri bilimcilerin verileri hazırlamasına, modelleri eğitmesine, tahmin hizmetlerini yayınlamasına ve kullanımını izlemesine yardımcı olan çok çeşitli özellikler ve yetenekler içerir. En önemlisi, model eğitimiyle ilgili zaman alıcı görevlerin çoğunu otomatikleştirerek verimliliklerini artırır; ve yalnızca kullanıldığında maliyet oluşturan, büyük veri hacimlerini etkili bir şekilde işlemek için ölçeklenen bulut tabanlı hesaplama kaynaklarını kullanmalarını sağlar.
Azure ML, geliştiriciler ve veri bilimciler için makine öğrenimi iş akışlarıyla ilgili tüm araçları sağlar. Bunlar şunları içerir:
- Azure Machine Learning Studio: Model eğitimi, dağıtımı, otomasyonu, takibi ve varlık yönetimi için düşük kod ve hiç kod seçenekleri sunan bir web portalıdır. Studio, Azure Machine Learning SDK ile entegre bir deneyim sağlar.
- Jupyter Notebooks: ML modellerini hızlı bir şekilde prototiplemek ve test etmek için kullanılır.
- Azure Machine Learning Designer: Modülleri sürükleyip bırakma yöntemiyle deneyler oluşturmanıza ve düşük kodlu bir ortamda ardışık düzenler dağıtmanıza olanak tanır.
- Otomatik Makine Öğrenimi Arayüzü (AutoML): Makine öğrenimi modeli geliştirme sürecindeki yinelemeli görevleri otomatikleştirir, yüksek ölçek, verimlilik ve üretkenlikle ML modelleri oluşturmanıza olanak tanır, model kalitesini korurken.
- Veri Etiketleme: Verileri otomatik olarak etiketlemek için destekli bir ML aracıdır.
- Visual Studio Code için Makine Öğrenimi Uzantısı: ML projeleri oluşturmak ve yönetmek için tam özellikli bir geliştirme ortamı sağlar.
- Makine Öğrenimi CLI: Komut satırından Azure ML kaynaklarını yönetmek için komutlar sağlar.
- PyTorch, TensorFlow, Scikit-learn gibi açık kaynaklı çerçevelerle entegrasyon: Eğitim, dağıtım ve uçtan uca makine öğrenimi sürecini yönetmek için.
- MLflow: Makine öğrenimi deneylerinizin yaşam döngüsünü yönetmek için açık kaynaklı bir kütüphanedir. MLFlow Takibi, deney ortamınızdan bağımsız olarak eğitim çalıştırma metriklerinizi ve model eserlerinizi kaydeden ve izleyen bir MLflow bileşenidir.
1.2 Kalp Yetmezliği Tahmin Projesi:
Projeler yapmak ve oluşturmak, becerilerinizi ve bilginizi test etmenin en iyi yoludur. Bu derste, Azure ML Studio'da kalp yetmezliği saldırılarını tahmin etmek için bir veri bilimi projesi oluşturmanın iki farklı yolunu keşfedeceğiz: Düşük kod/Hiç kod ve Azure ML SDK kullanarak. Aşağıdaki şemada gösterildiği gibi:
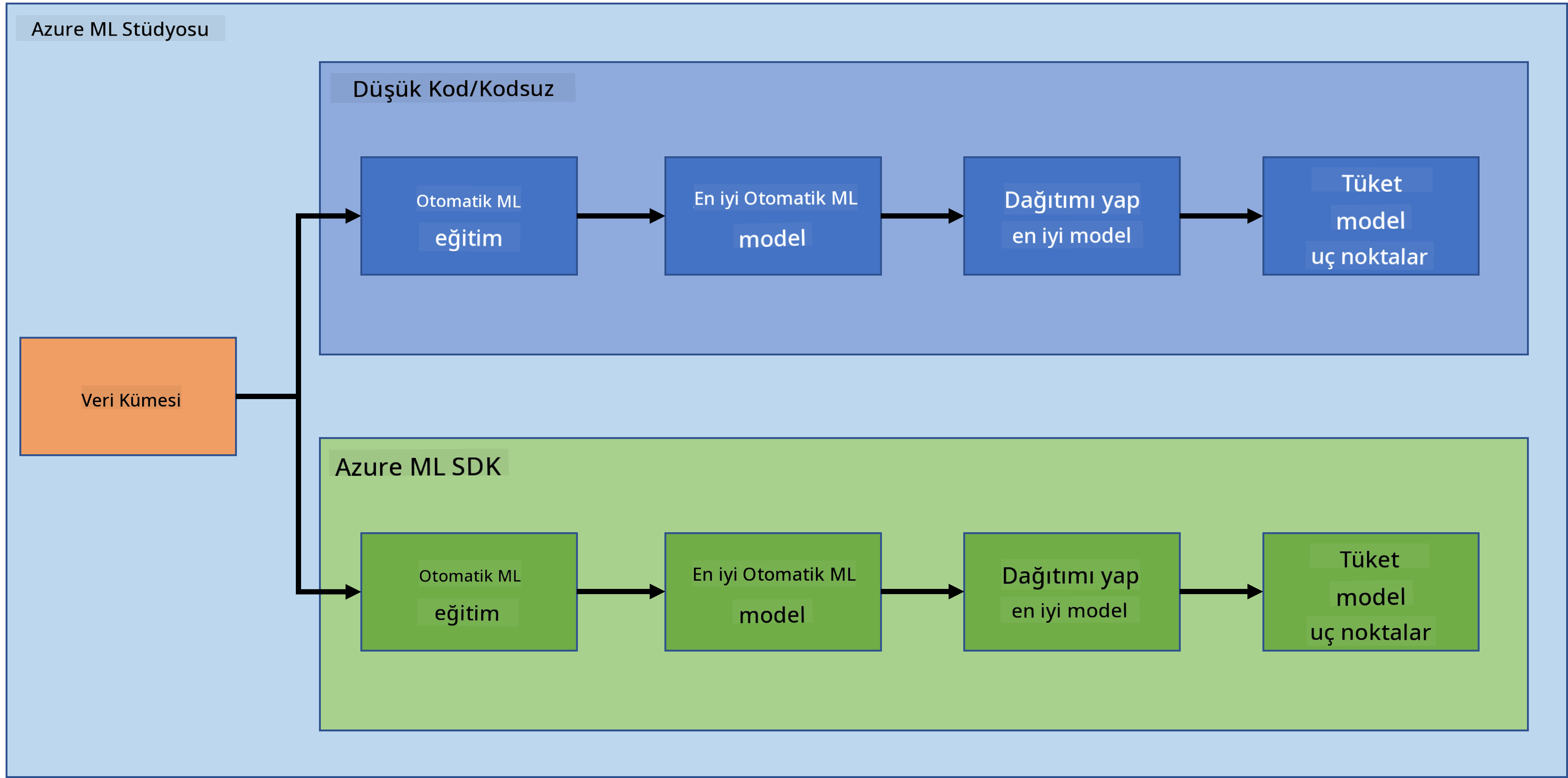
Her yöntemin kendi avantajları ve dezavantajları vardır. Düşük kod/Hiç kod yöntemi, bir GUI (Grafiksel Kullanıcı Arayüzü) ile etkileşim içerdiğinden, kod bilgisi gerektirmeden başlamak için daha kolaydır. Bu yöntem, projenin uygulanabilirliğini hızlı bir şekilde test etmeyi ve POC (Kavram Kanıtı) oluşturmayı sağlar. Ancak, proje büyüdükçe ve üretime hazır hale gelmesi gerektiğinde, GUI üzerinden kaynak oluşturmak uygun değildir. Kaynakların oluşturulmasından modelin dağıtımına kadar her şeyi programlı bir şekilde otomatikleştirmemiz gerekir. İşte bu noktada Azure ML SDK'yı nasıl kullanacağınızı bilmek kritik hale gelir.
| Düşük Kod/Hiç Kod | Azure ML SDK | |
|---|---|---|
| Kod Bilgisi | Gerekli değil | Gerekli |
| Geliştirme Süresi | Hızlı ve kolay | Kod bilgisine bağlı |
| Üretime Hazır | Hayır | Evet |
1.3 Kalp Yetmezliği Veri Seti:
Kardiyovasküler hastalıklar (CVD'ler), dünya çapında ölümlerin %31'ini oluşturarak küresel olarak bir numaralı ölüm nedenidir. Tütün kullanımı, sağlıksız beslenme ve obezite, fiziksel hareketsizlik ve zararlı alkol kullanımı gibi çevresel ve davranışsal risk faktörleri, tahmin modelleri için özellik olarak kullanılabilir. Bir CVD'nin gelişme olasılığını tahmin edebilmek, yüksek riskli kişilerde saldırıları önlemek için büyük fayda sağlayabilir.
Kaggle, bu proje için kullanacağımız Kalp Yetmezliği veri setini halka açık hale getirmiştir. Veri setini şimdi indirebilirsiniz. Bu, 13 sütun (12 özellik ve 1 hedef değişken) ve 299 satırdan oluşan bir tabular veri setidir.
| Değişken Adı | Tür | Açıklama | Örnek | |
|---|---|---|---|---|
| 1 | age | sayısal | Hastanın yaşı | 25 |
| 2 | anaemia | boolean | Kırmızı kan hücreleri veya hemoglobin azalması | 0 veya 1 |
| 3 | creatinine_phosphokinase | sayısal | Kanda CPK enzimi seviyesi | 542 |
| 4 | diabetes | boolean | Hastanın diyabeti olup olmadığı | 0 veya 1 |
| 5 | ejection_fraction | sayısal | Her kasılmada kalpten çıkan kan yüzdesi | 45 |
| 6 | high_blood_pressure | boolean | Hastanın hipertansiyonu olup olmadığı | 0 veya 1 |
| 7 | platelets | sayısal | Kanda bulunan trombositler | 149000 |
| 8 | serum_creatinine | sayısal | Kanda serum kreatinin seviyesi | 0.5 |
| 9 | serum_sodium | sayısal | Kanda serum sodyum seviyesi | jun |
| 10 | sex | boolean | Kadın veya erkek | 0 veya 1 |
| 11 | smoking | boolean | Hastanın sigara içip içmediği | 0 veya 1 |
| 12 | time | sayısal | Takip süresi (gün) | 4 |
| ---- | --------------------------- | ----------------- | -------------------------------------------------------- | ------------------- |
| 21 | DEATH_EVENT [Hedef] | boolean | Takip süresi içinde hastanın ölüp ölmediği | 0 veya 1 |
Veri setini aldıktan sonra, Azure'da projeye başlayabiliriz.
2. Azure ML Studio'da Düşük Kod/Hiç Kod ile Model Eğitimi
2.1 Azure ML Çalışma Alanı Oluşturma
Azure ML'de bir model eğitmek için önce bir Azure ML çalışma alanı oluşturmanız gerekir. Çalışma alanı, Azure Machine Learning için üst düzey bir kaynaktır ve Azure Machine Learning kullanırken oluşturduğunuz tüm eserlerle çalışmak için merkezi bir yer sağlar. Çalışma alanı, günlükler, metrikler, çıktı ve komut dosyalarınızın bir anlık görüntüsü dahil olmak üzere tüm eğitim çalıştırmalarının geçmişini tutar. Bu bilgileri, hangi eğitim çalıştırmasının en iyi modeli ürettiğini belirlemek için kullanırsınız. Daha fazla bilgi edinin
En güncel işletim sisteminizle uyumlu tarayıcıyı kullanmanız önerilir. Desteklenen tarayıcılar şunlardır:
- Microsoft Edge (Yeni Microsoft Edge, en son sürüm. Microsoft Edge legacy değil)
- Safari (en son sürüm, yalnızca Mac)
- Chrome (en son sürüm)
- Firefox (en son sürüm)
Azure Machine Learning'i kullanmak için Azure aboneliğinizde bir çalışma alanı oluşturun. Daha sonra bu çalışma alanını, makine öğrenimi iş yüklerinizle ilgili veri, hesaplama kaynakları, kod, modeller ve diğer eserleri yönetmek için kullanabilirsiniz.
NOT: Azure aboneliğiniz, Azure Machine Learning çalışma alanı aboneliğinizde var olduğu sürece veri depolama için küçük bir miktar ücretlendirilir, bu nedenle artık kullanmadığınızda Azure Machine Learning çalışma alanını silmenizi öneririz.
-
Microsoft kimlik bilgilerinizi kullanarak Azure portalına giriş yapın.
-
+Kaynak Oluştur seçeneğini seçin
Machine Learning'i arayın ve Machine Learning kutucuğunu seçin
Oluştur düğmesine tıklayın
Ayarları şu şekilde doldurun:
- Abonelik: Azure aboneliğiniz
- Kaynak grubu: Bir kaynak grubu oluşturun veya seçin
- Çalışma alanı adı: Çalışma alanınız için benzersiz bir ad girin
- Bölge: Size en yakın coğrafi bölgeyi seçin
- Depolama hesabı: Çalışma alanınız için oluşturulacak varsayılan yeni depolama hesabını not edin
- Anahtar kasası: Çalışma alanınız için oluşturulacak varsayılan yeni anahtar kasasını not edin
- Uygulama içgörüleri: Çalışma alanınız için oluşturulacak varsayılan yeni uygulama içgörüleri kaynağını not edin
- Kapsayıcı kaydı: Yok (bir model ilk kez bir kapsayıcıya dağıtıldığında otomatik olarak oluşturulacaktır)
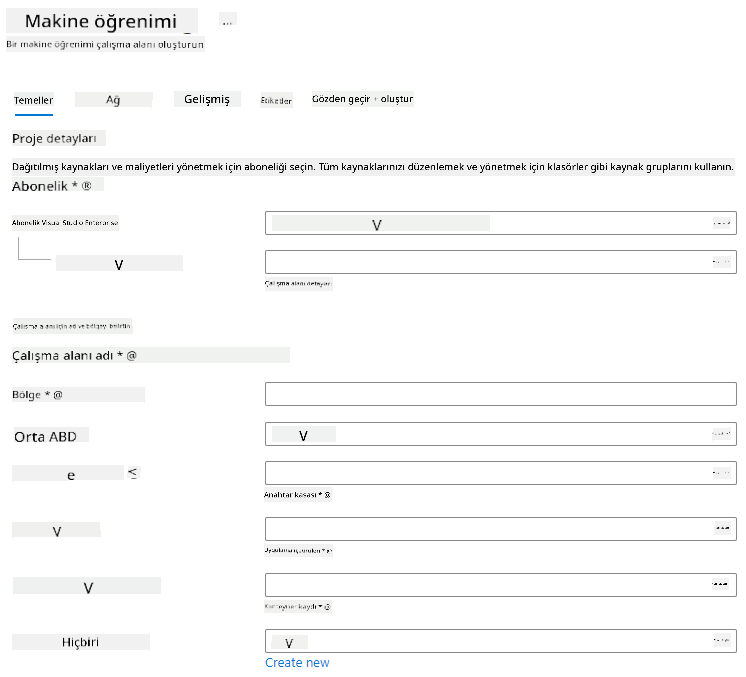
- İnceleme + oluştur düğmesine tıklayın ve ardından oluştur düğmesine tıklayın
-
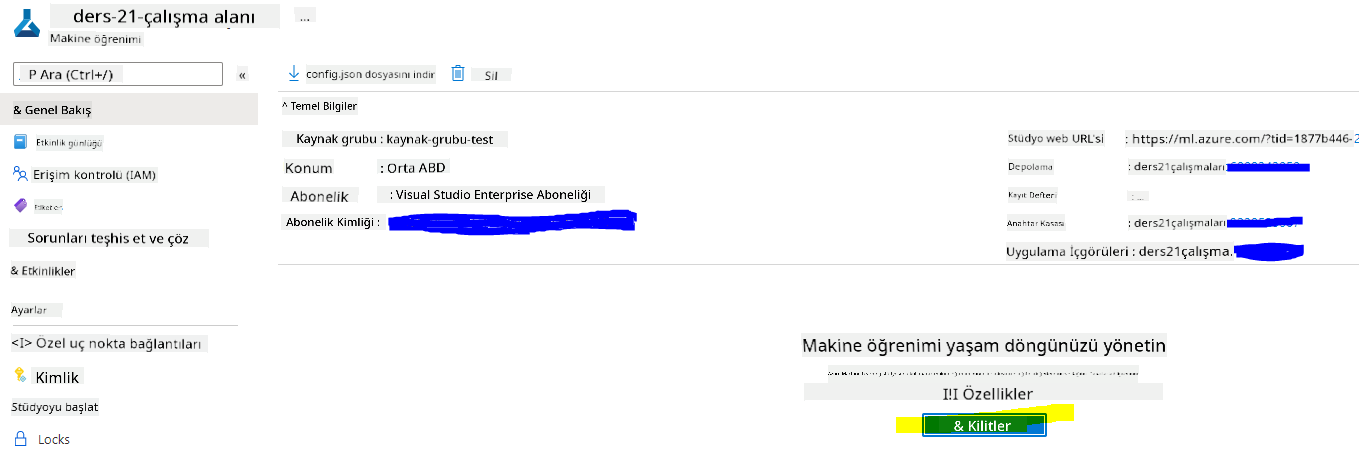
Çalışma alanınızın oluşturulmasını bekleyin (bu birkaç dakika sürebilir). Daha sonra Azure hizmeti üzerinden Machine Learning'i bulup portaldan ona gidin.
-
Çalışma alanınızın Genel Bakış sayfasında, Azure Machine Learning stüdyosunu başlatın (veya yeni bir tarayıcı sekmesi açarak https://ml.azure.com adresine gidin) ve Microsoft hesabınızı kullanarak Azure Machine Learning stüdyosuna giriş yapın. İstendiğinde, Azure dizininizi ve aboneliğinizi ve Azure Machine Learning çalışma alanınızı seçin.
- Azure Machine Learning stüdyosunda, arayüzdeki çeşitli sayfaları görüntülemek için sol üstteki ☰ simgesini değiştirin. Çalışma alanınızdaki kaynakları yönetmek için bu sayfaları kullanabilirsiniz.
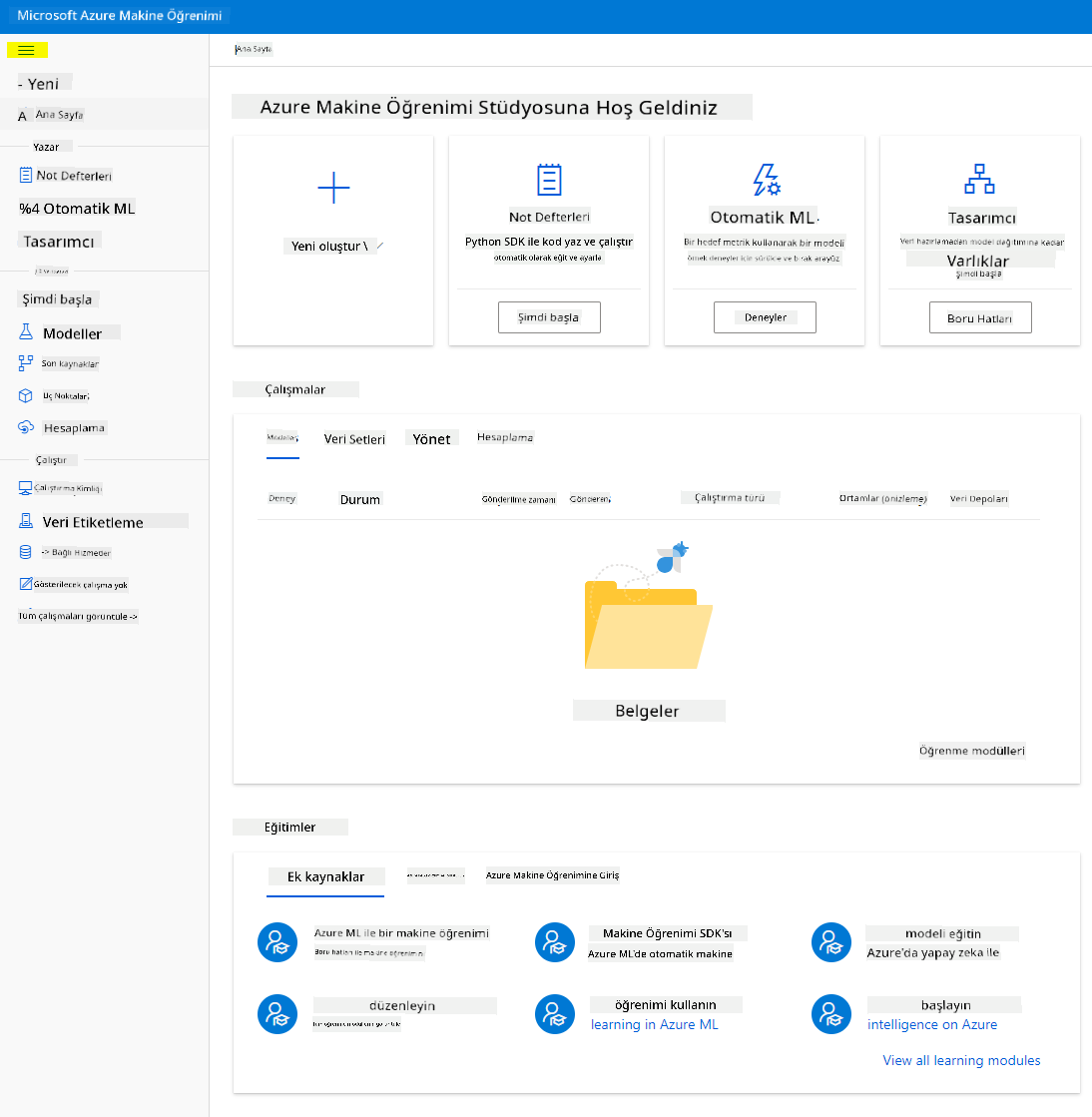
Çalışma alanınızı Azure portalını kullanarak yönetebilirsiniz, ancak veri bilimciler ve Makine Öğrenimi operasyon mühendisleri için Azure Machine Learning Studio, çalışma alanı kaynaklarını yönetmek için daha odaklanmış bir kullanıcı arayüzü sağlar.
2.2 Hesaplama Kaynakları
Hesaplama Kaynakları, model eğitimi ve veri keşfi süreçlerini çalıştırabileceğiniz bulut tabanlı kaynaklardır. Oluşturabileceğiniz dört tür hesaplama kaynağı vardır:
- Hesaplama Örnekleri: Veri bilimcilerin veri ve modellerle çalışmak için kullanabileceği geliştirme iş istasyonları. Bu, bir Sanal Makine (VM) oluşturmayı ve bir notebook örneğini başlatmayı içerir. Daha sonra bir notebook'tan bir hesaplama kümesi çağırarak bir model eğitebilirsiniz.
- Hesaplama Kümeleri: Deney kodunun talep üzerine işlenmesi için ölçeklenebilir VM kümeleri. Model eğitirken buna ihtiyacınız olacak. Hesaplama kümeleri ayrıca özel GPU veya CPU kaynaklarını da kullanabilir.
- Çıkarım Kümeleri: Eğitilmiş modellerinizi kullanan tahmin hizmetleri için dağıtım hedefleri.
- Bağlı Hesaplama: Sanal Makineler veya Azure Databricks kümeleri gibi mevcut Azure hesaplama kaynaklarına bağlantılar.
2.2.1 Hesaplama Kaynaklarınız için Doğru Seçenekleri Seçmek
Bir hesaplama kaynağı oluştururken dikkate alınması gereken bazı önemli faktörler vardır ve bu seçimler kritik kararlar olabilir.
CPU'ya mı yoksa GPU'ya mı ihtiyacınız var?
CPU (Merkezi İşlem Birimi), bir bilgisayar programını oluşturan talimatları yürüten elektronik devredir. GPU (Grafik İşlem Birimi) ise grafikle ilgili kodları çok yüksek bir hızda çalıştırabilen özel bir elektronik devredir.
CPU ve GPU mimarisi arasındaki temel fark, bir CPU'nun geniş bir görev yelpazesini hızlı bir şekilde (CPU saat hızıyla ölçülür) gerçekleştirmek için tasarlanmış olmasıdır, ancak aynı anda çalıştırılabilecek görevlerin eşzamanlılığı sınırlıdır. GPU'lar ise paralel hesaplama için tasarlanmıştır ve bu nedenle derin öğrenme görevlerinde çok daha iyidir.
| CPU | GPU |
|---|---|
| Daha ucuz | Daha pahalı |
| Daha düşük eşzamanlılık seviyesi | Daha yüksek eşzamanlılık seviyesi |
| Derin öğrenme modellerini eğitmede daha yavaş | Derin öğrenme için ideal |
Küme Boyutu
Daha büyük kümeler daha pahalıdır ancak daha iyi yanıt süresi sağlar. Bu nedenle, zamanınız varsa ancak yeterli paranız yoksa, küçük bir küme ile başlamalısınız. Tersine, paranız varsa ancak fazla zamanınız yoksa, daha büyük bir küme ile başlamalısınız.
VM Boyutu
Zaman ve bütçe kısıtlamalarınıza bağlı olarak, RAM boyutunu, disk kapasitesini, çekirdek sayısını ve saat hızını değiştirebilirsiniz. Bu parametrelerin tümünü artırmak daha maliyetli olacaktır, ancak daha iyi performans sağlayacaktır.
Adanmış mı Yoksa Düşük Öncelikli Örnekler mi?
Düşük öncelikli bir örnek, kesintiye uğrayabilir anlamına gelir: Temelde, Microsoft Azure bu kaynakları alıp başka bir göreve atayabilir ve böylece bir işi kesintiye uğratabilir. Adanmış bir örnek, yani kesintiye uğramayan bir örnek, işin sizin izniniz olmadan asla sonlandırılmayacağı anlamına gelir. Bu, zaman ve para arasında başka bir denge noktasıdır, çünkü kesintiye uğrayabilir örnekler adanmış olanlardan daha ucuzdur.
2.2.2 Bir Hesaplama Kümesi Oluşturma
Daha önce oluşturduğumuz Azure ML çalışma alanında, hesaplamaya gidin ve az önce tartıştığımız farklı hesaplama kaynaklarını (ör. hesaplama örnekleri, hesaplama kümeleri, çıkarım kümeleri ve bağlı hesaplama) görebilirsiniz. Bu proje için, model eğitimi için bir hesaplama kümesine ihtiyacımız olacak. Studio'da, "Hesaplama" menüsüne, ardından "Hesaplama kümesi" sekmesine tıklayın ve bir hesaplama kümesi oluşturmak için "+ Yeni" düğmesine tıklayın.
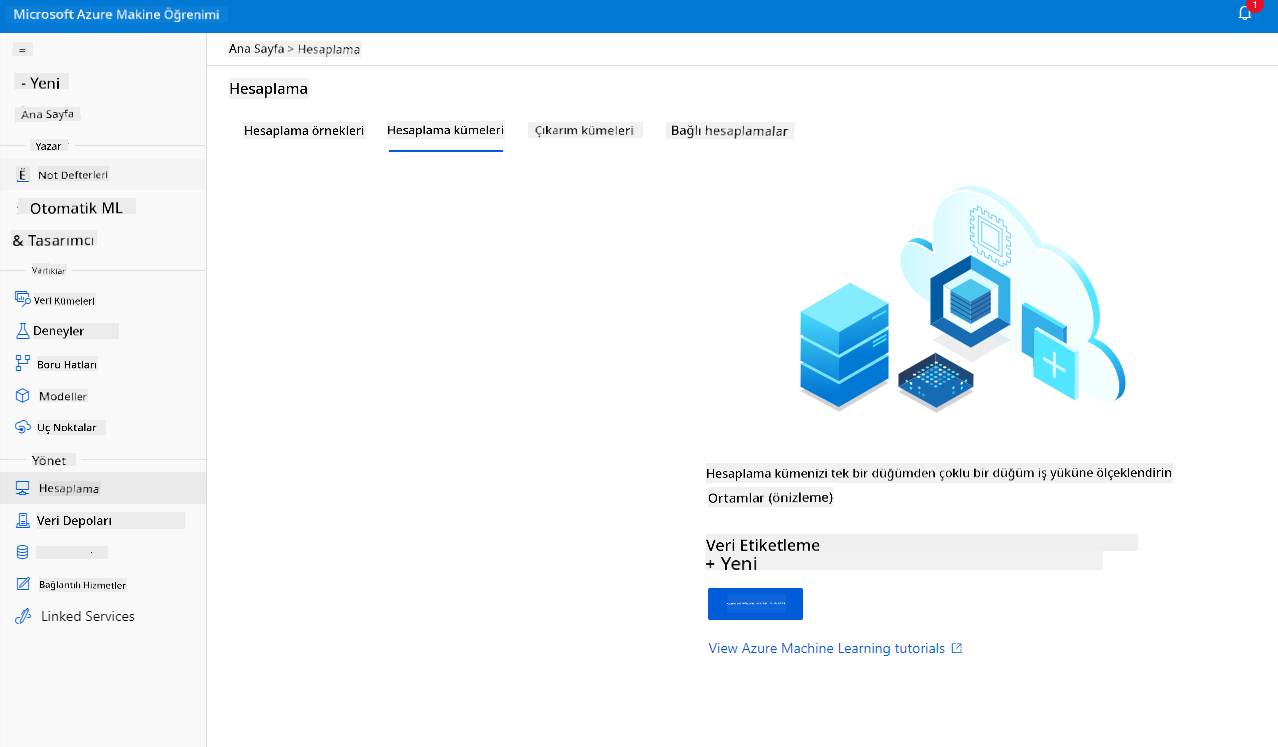
- Seçeneklerinizi seçin: Adanmış mı yoksa Düşük öncelikli mi, CPU mu yoksa GPU mu, VM boyutu ve çekirdek sayısı (bu proje için varsayılan ayarları koruyabilirsiniz).
- İleri düğmesine tıklayın.
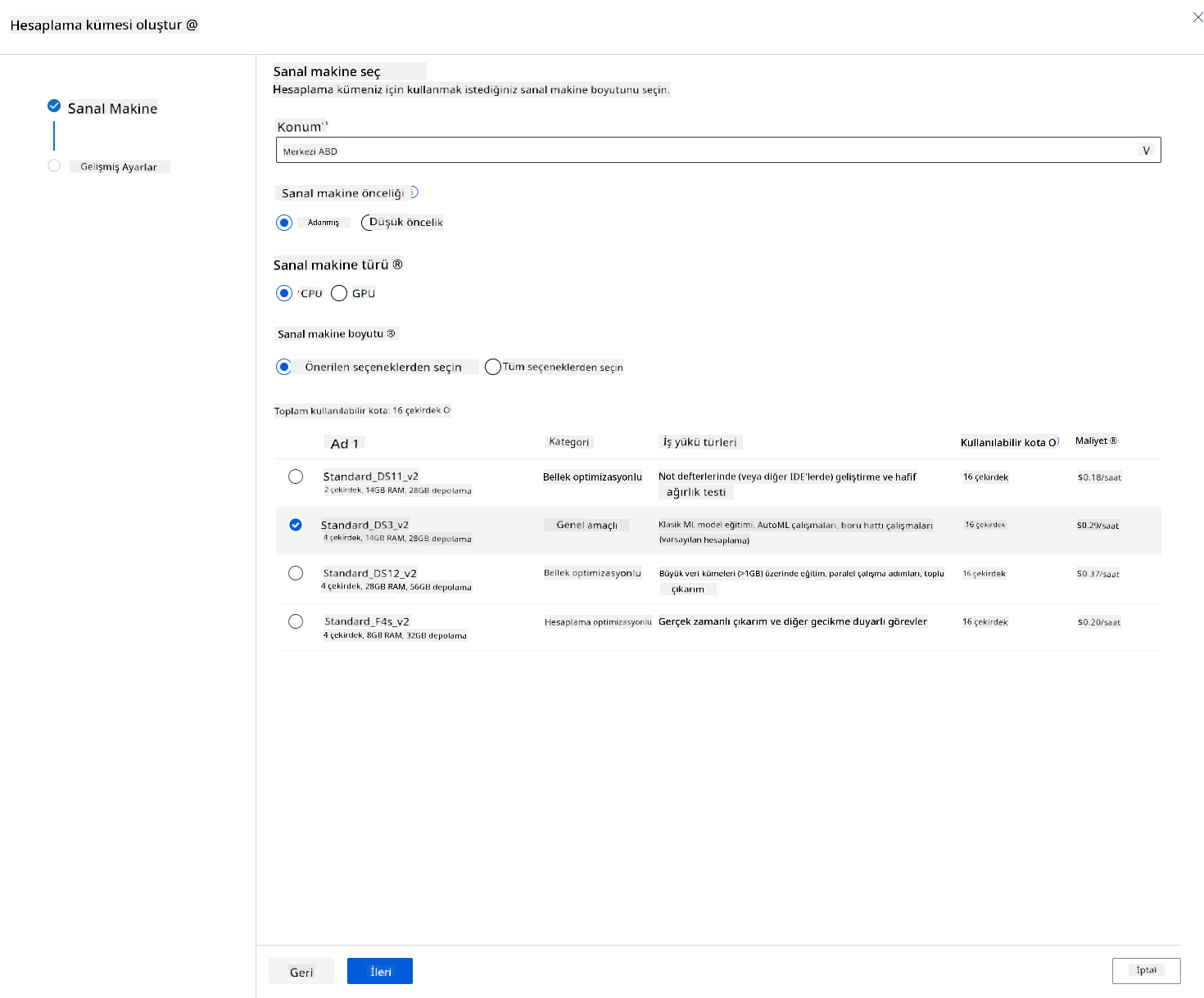
- Küme için bir ad verin.
- Seçeneklerinizi belirleyin: Minimum/Maksimum düğüm sayısı, ölçek küçültmeden önceki boşta bekleme süresi, SSH erişimi. Minimum düğüm sayısı 0 ise, küme boşta olduğunda para tasarrufu yaparsınız. Maksimum düğüm sayısı ne kadar yüksekse, eğitim o kadar kısa sürecektir. Önerilen maksimum düğüm sayısı 3'tür.
- "Oluştur" düğmesine tıklayın. Bu adım birkaç dakika sürebilir.
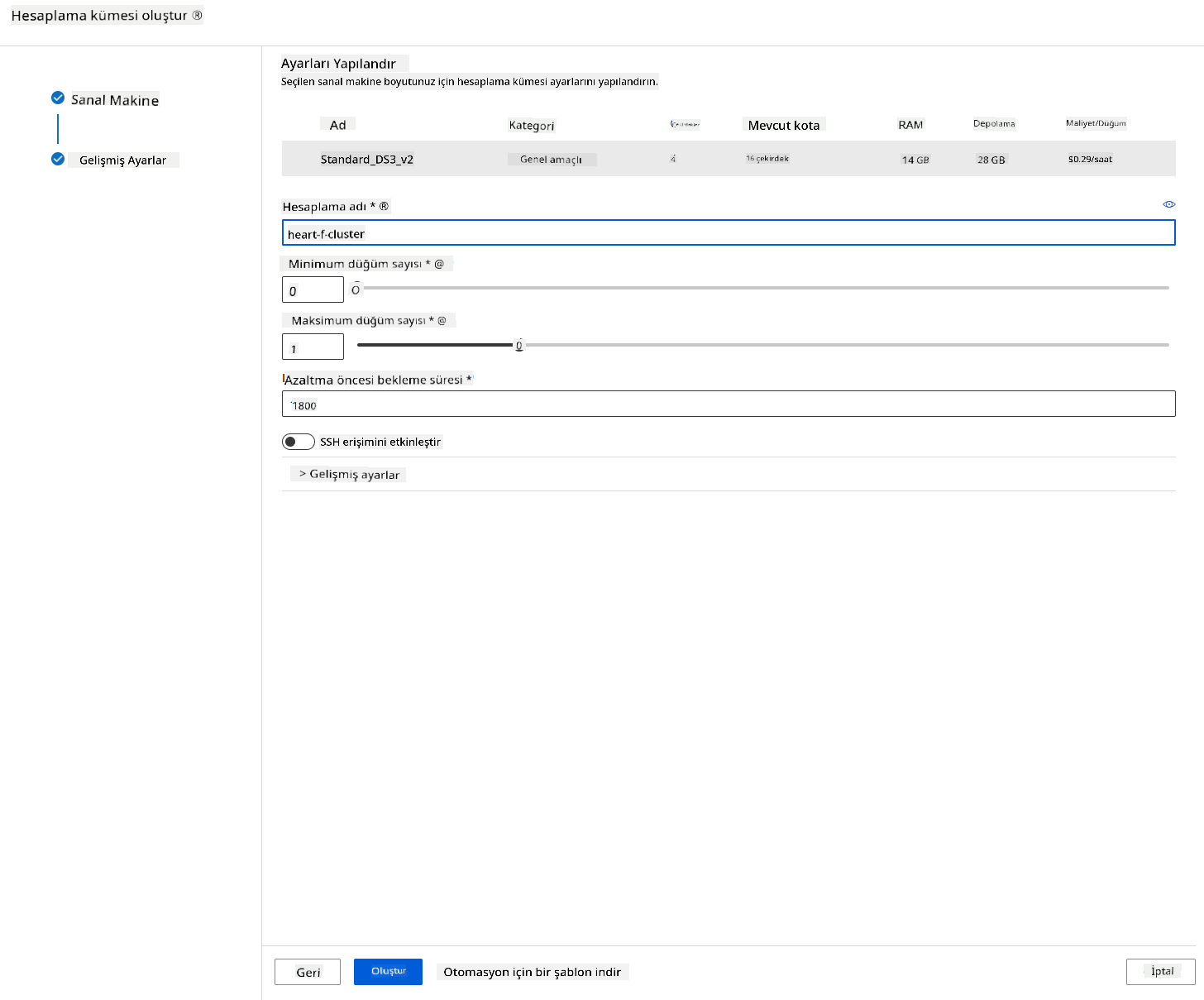
Harika! Artık bir Hesaplama kümesine sahibiz, şimdi verileri Azure ML Studio'ya yüklememiz gerekiyor.
2.3 Veri Kümesini Yükleme
-
Daha önce oluşturduğumuz Azure ML çalışma alanında, sol menüde "Veri Kümeleri"ne tıklayın ve bir veri kümesi oluşturmak için "+ Veri Kümesi Oluştur" düğmesine tıklayın. "Yerel dosyalardan" seçeneğini seçin ve daha önce indirdiğimiz Kaggle veri kümesini seçin.
-
Veri kümesine bir ad, bir tür ve bir açıklama verin. İleri'ye tıklayın. Dosyalardan veriyi yükleyin. İleri'ye tıklayın.

-
Şemada, şu özellikler için veri türünü Boolean olarak değiştirin: anemi, diyabet, yüksek tansiyon, cinsiyet, sigara içme ve ÖLÜM_OLAYI. İleri'ye ve ardından Oluştur'a tıklayın.
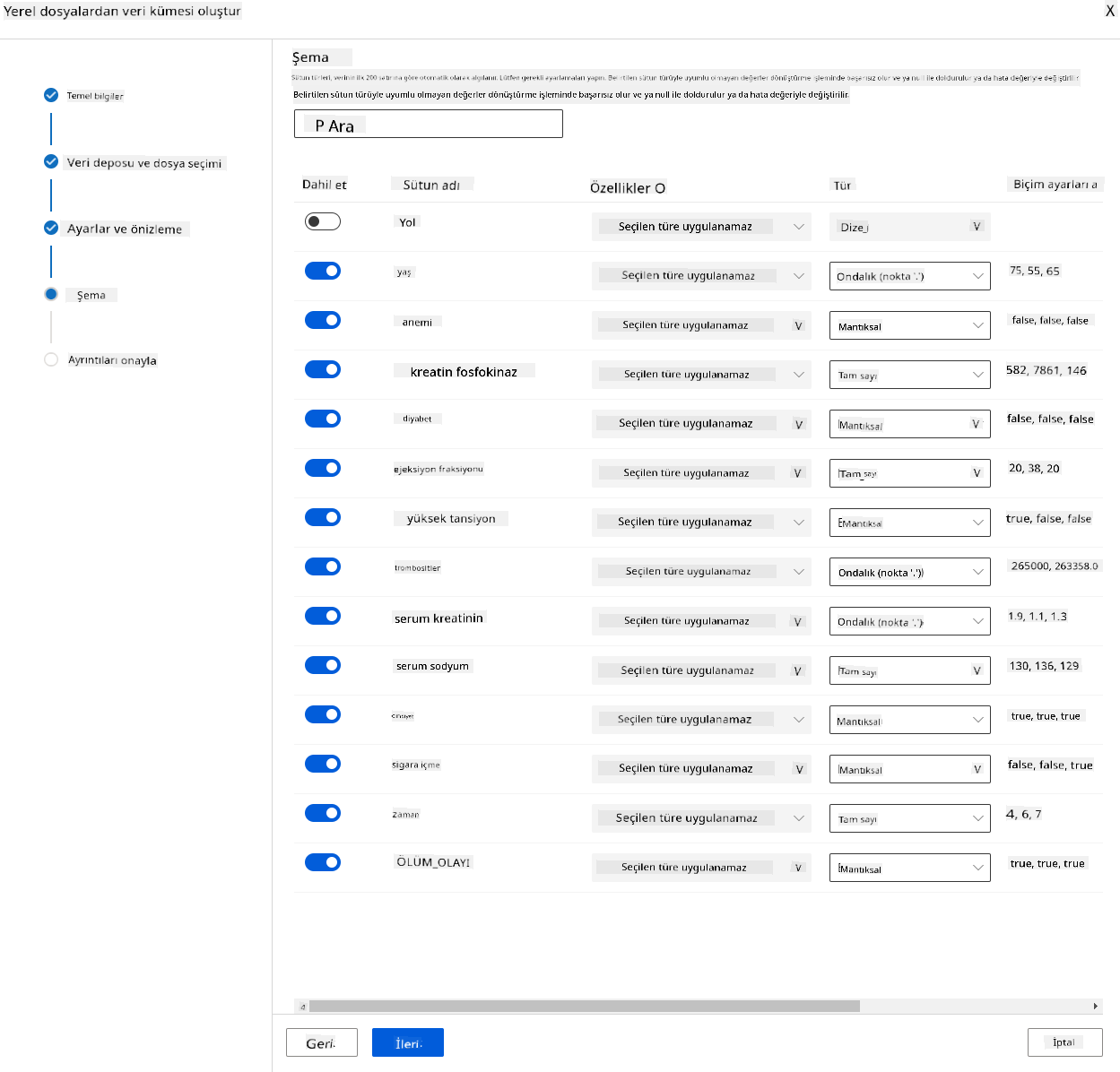
Harika! Artık veri kümesi yerinde ve hesaplama kümesi oluşturuldu, modelin eğitimine başlayabiliriz!
2.4 Kod Yazmadan veya Az Kodla AutoML ile Eğitim
Geleneksel makine öğrenimi modeli geliştirme, kaynak yoğun, önemli ölçüde alan bilgisi ve zaman gerektiren bir süreçtir ve onlarca modeli üretip karşılaştırmayı içerir. Otomatik makine öğrenimi (AutoML), makine öğrenimi modeli geliştirme sürecindeki zaman alıcı, yinelemeli görevleri otomatikleştirme sürecidir. Veri bilimcilerin, analistlerin ve geliştiricilerin yüksek ölçek, verimlilik ve üretkenlikle ML modelleri oluşturmasına olanak tanır ve model kalitesini korur. Üretime hazır ML modellerine ulaşma süresini büyük ölçüde kısaltır. Daha fazla bilgi edinin
-
Daha önce oluşturduğumuz Azure ML çalışma alanında sol menüde "Otomatik ML"ye tıklayın ve az önce yüklediğiniz veri kümesini seçin. İleri'ye tıklayın.
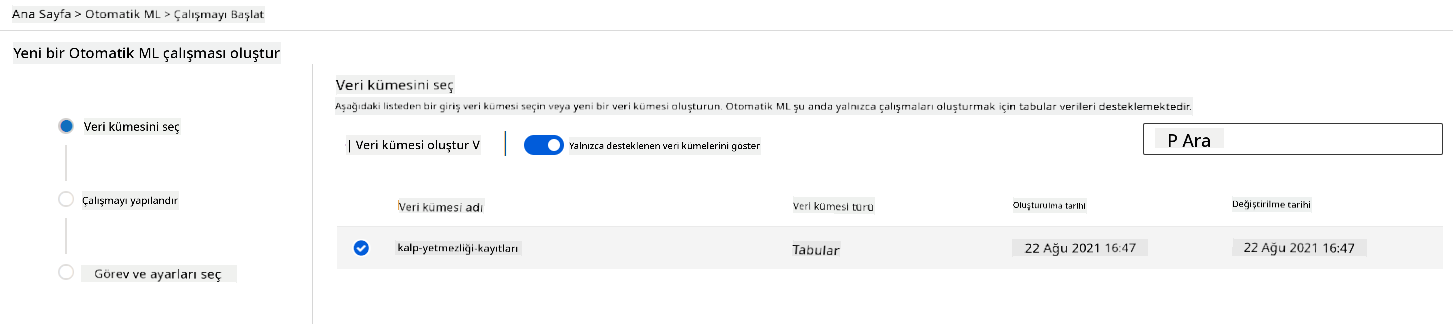
-
Yeni bir deney adı, hedef sütun (ÖLÜM_OLAYI) ve oluşturduğumuz hesaplama kümesini girin. İleri'ye tıklayın.
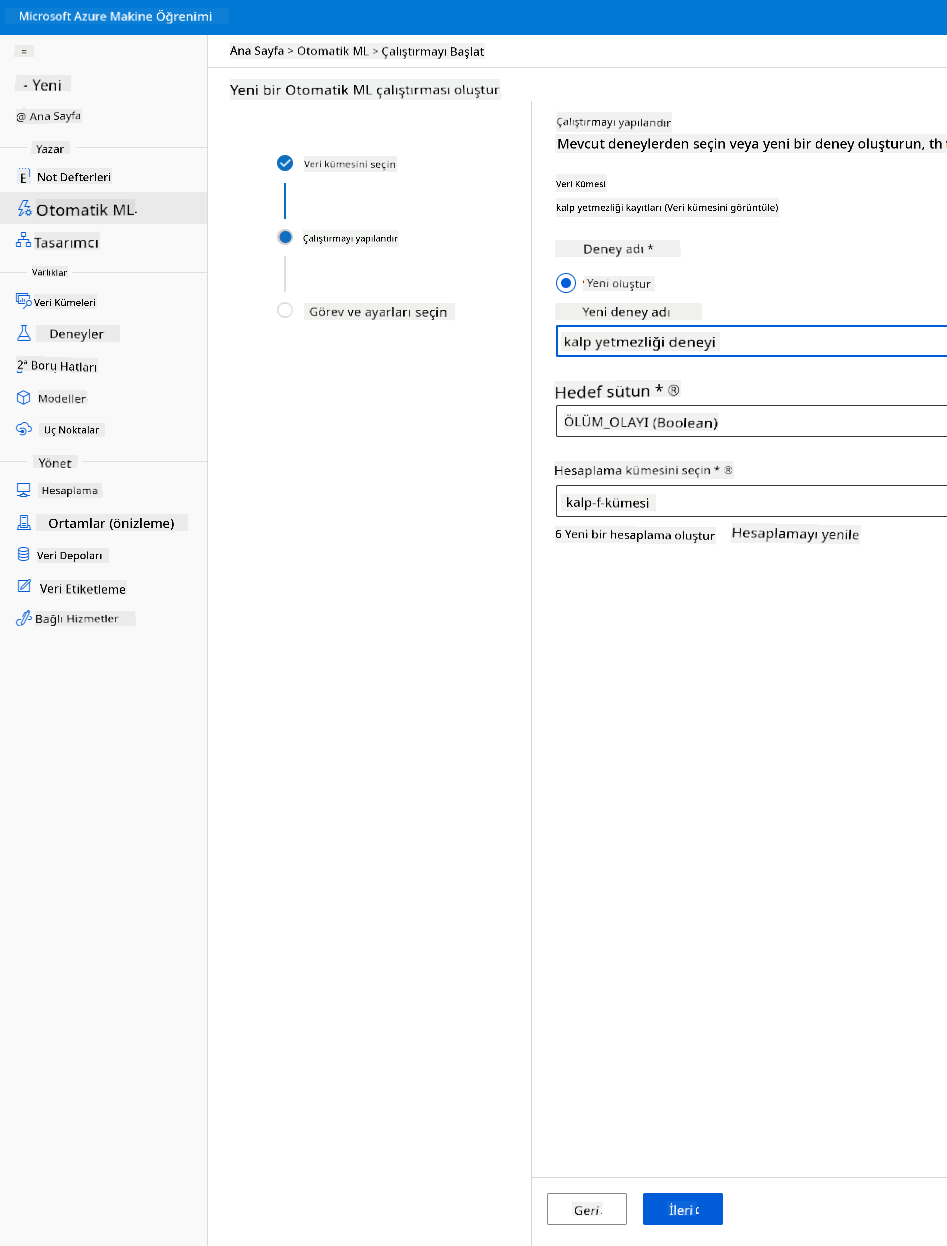
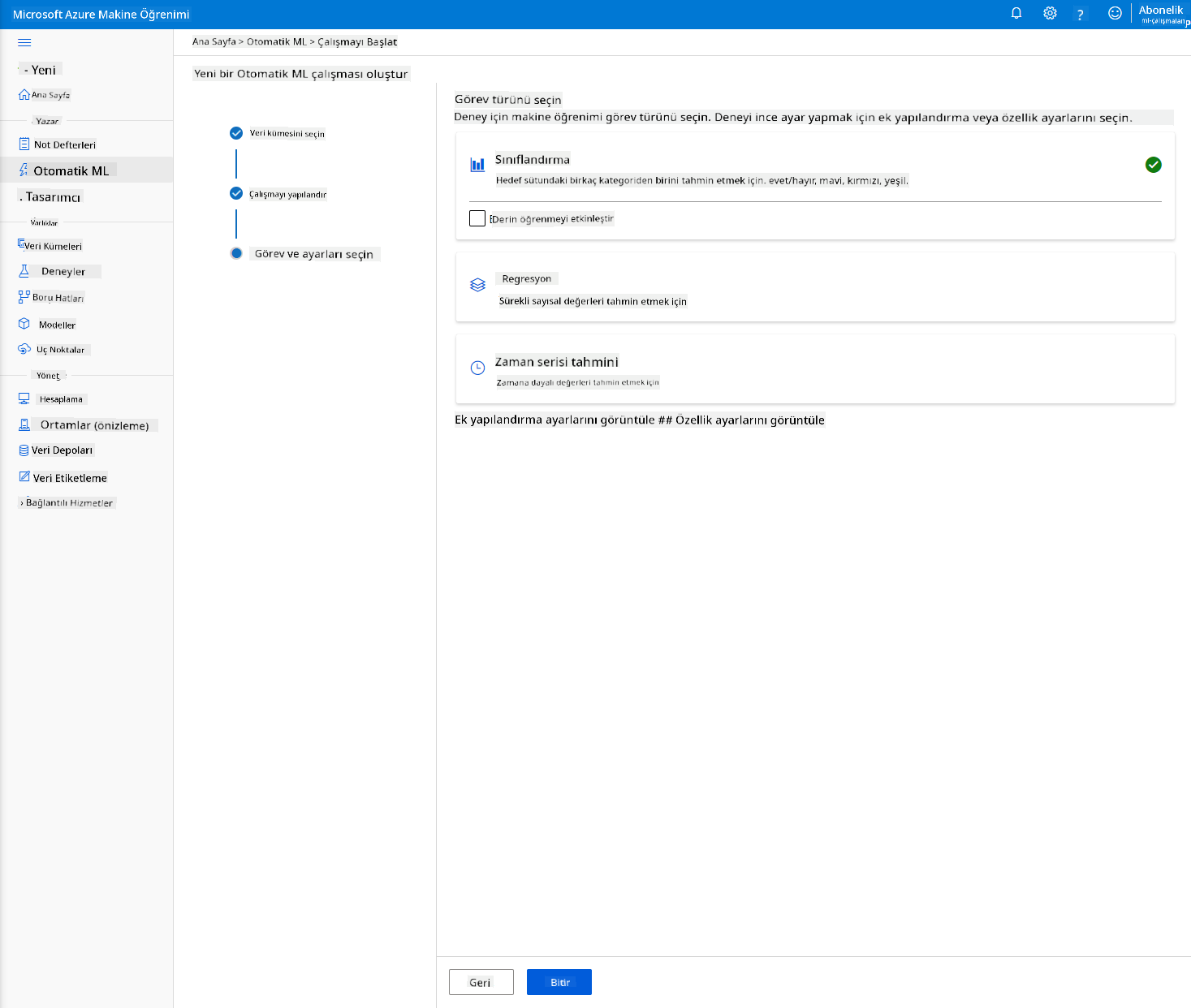
-
"Sınıflandırma"yı seçin ve Bitir'e tıklayın. Bu adım, hesaplama kümenizin boyutuna bağlı olarak 30 dakika ile 1 saat arasında sürebilir.
-
Çalışma tamamlandığında, "Otomatik ML" sekmesine tıklayın, çalışmanıza tıklayın ve "En iyi model özeti" kartındaki Algoritmaya tıklayın.
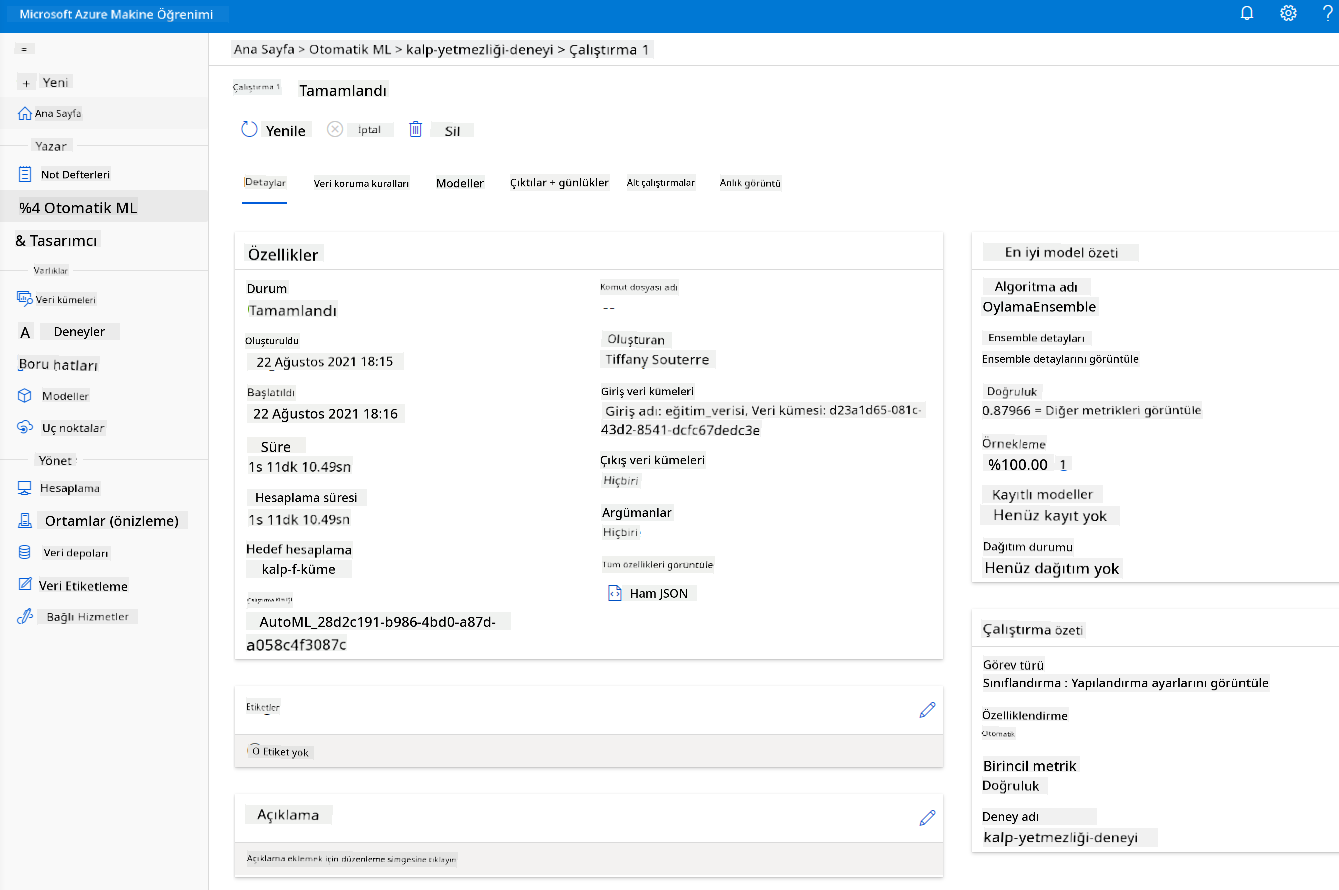
Burada AutoML'nin oluşturduğu en iyi modelin ayrıntılı bir açıklamasını görebilirsiniz. Modeller sekmesinde oluşturulan diğer modelleri de keşfedebilirsiniz. Açıklamalar (önizleme düğmesi) bölümünde modelleri birkaç dakika inceleyin. Kullanmak istediğiniz modeli seçtikten sonra (burada AutoML tarafından seçilen en iyi modeli seçeceğiz), modelin nasıl dağıtılacağını göreceğiz.
3. Kod Yazmadan veya Az Kodla Model Dağıtımı ve Uç Nokta Tüketimi
3.1 Model Dağıtımı
Otomatik makine öğrenimi arayüzü, en iyi modeli birkaç adımda bir web hizmeti olarak dağıtmanıza olanak tanır. Dağıtım, modelin yeni verilere dayalı tahminler yapabilmesi ve potansiyel fırsat alanlarını belirleyebilmesi için entegrasyonudur. Bu proje için, bir web hizmetine dağıtım, tıbbi uygulamaların modelden yararlanarak hastalarının kalp krizi riskini canlı olarak tahmin edebilmesi anlamına gelir.
En iyi model açıklamasında, "Dağıt" düğmesine tıklayın.
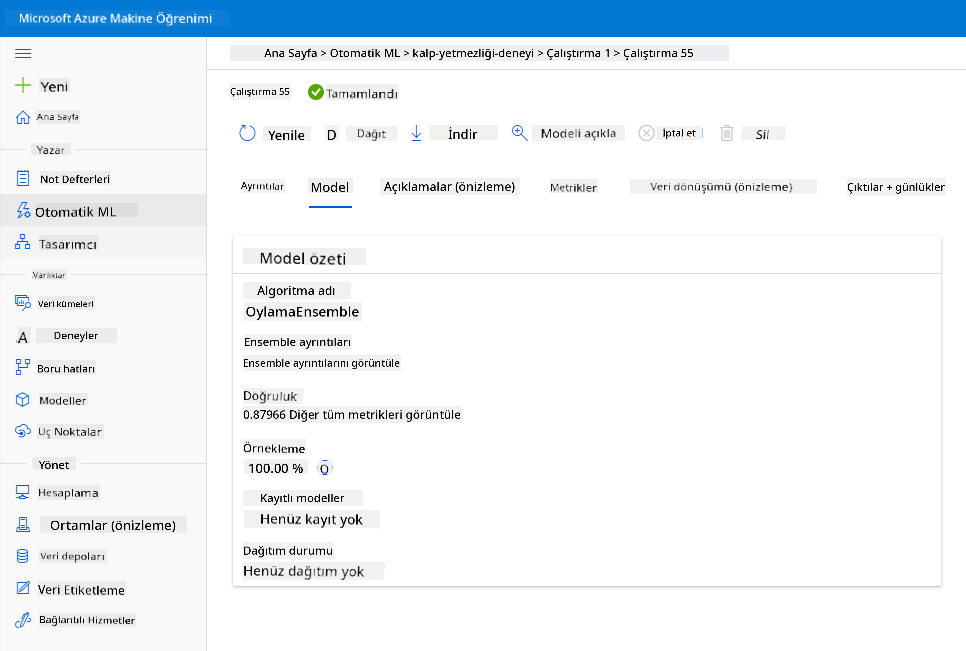
- Bir ad, bir açıklama, hesaplama türü (Azure Container Instance), kimlik doğrulamayı etkinleştirin ve Dağıt'a tıklayın. Bu adım yaklaşık 20 dakika sürebilir. Dağıtım süreci, modeli kaydetme, kaynakları oluşturma ve web hizmeti için yapılandırmayı içerir. Dağıtım durumu altında bir durum mesajı görünür. Dağıtım durumunu kontrol etmek için periyodik olarak Yenile'ye tıklayın. Durum "Sağlıklı" olduğunda dağıtılmış ve çalışıyor olacaktır.
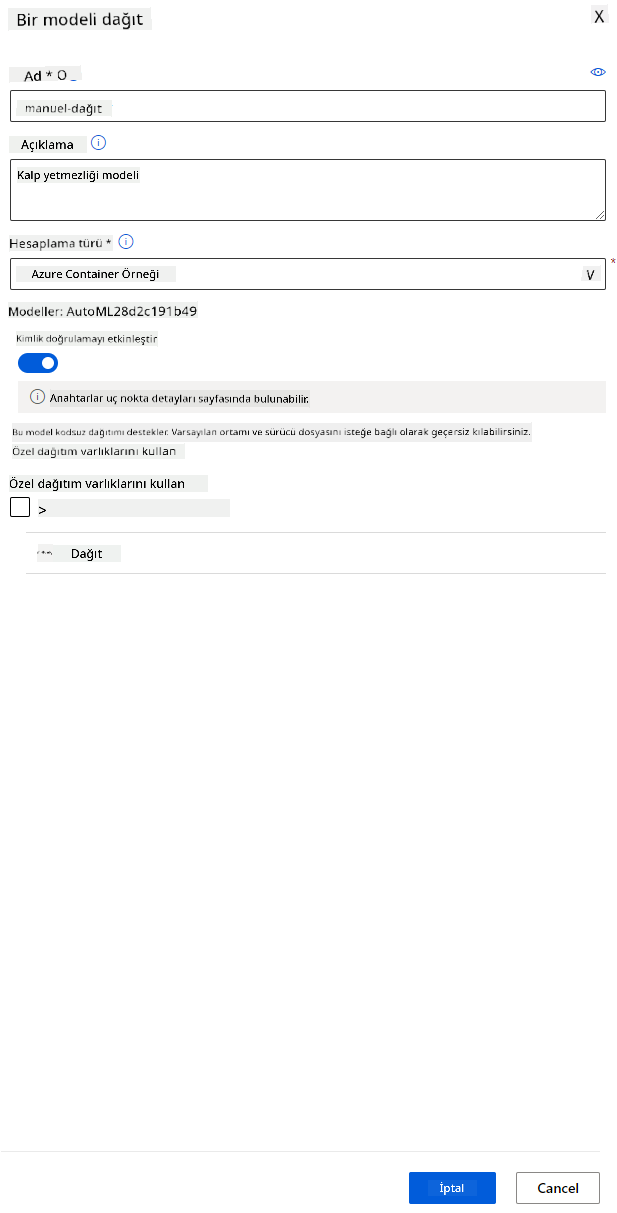
- Dağıtım tamamlandığında, Uç Nokta sekmesine tıklayın ve az önce dağıttığınız uç noktaya tıklayın. Burada uç nokta hakkında bilmeniz gereken tüm ayrıntıları bulabilirsiniz.
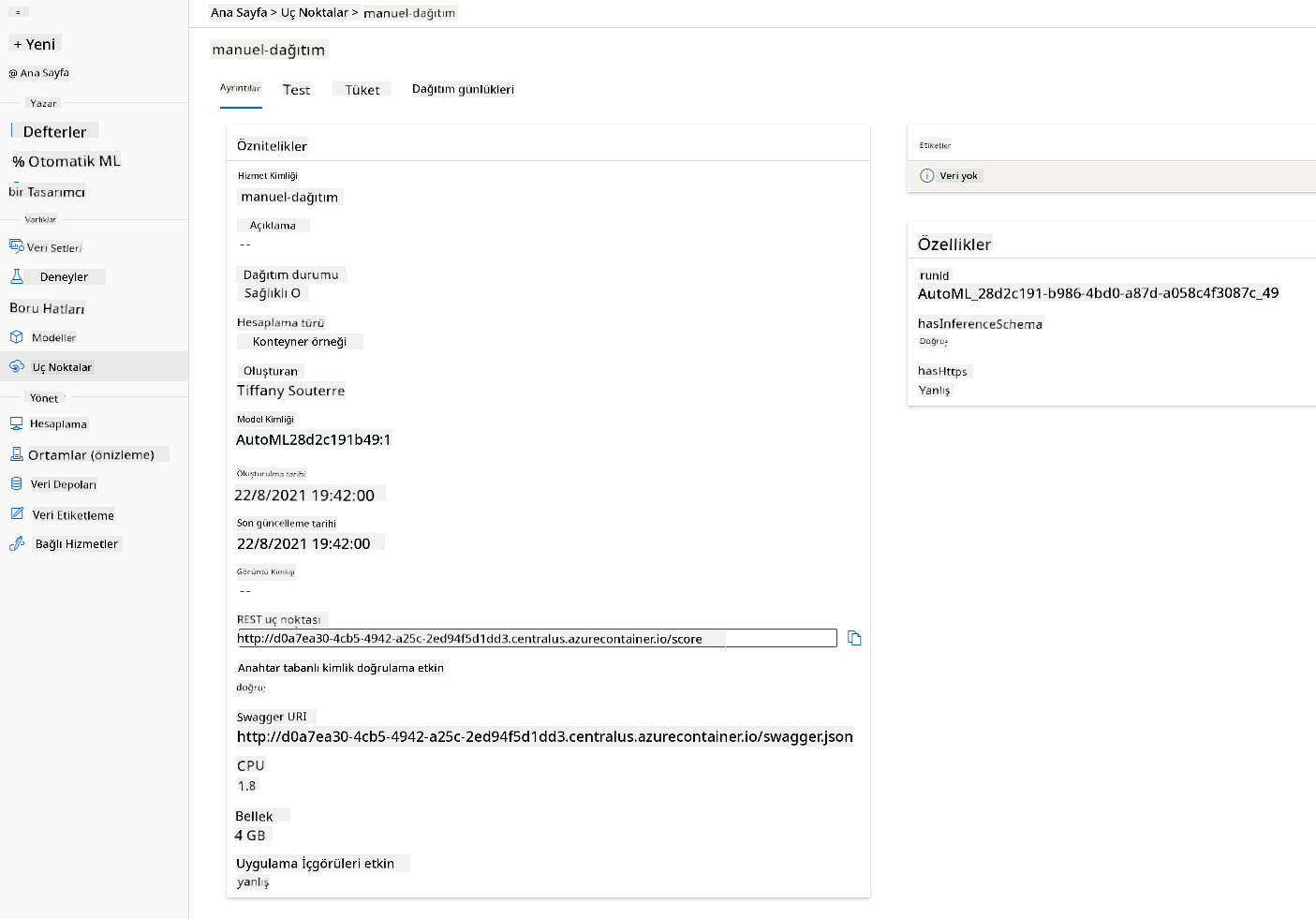
Harika! Artık bir model dağıttık, uç noktanın tüketimine başlayabiliriz.
3.2 Uç Nokta Tüketimi
"Consume" sekmesine tıklayın. Burada REST uç noktası ve tüketim seçeneğinde bir Python betiği bulabilirsiniz. Python kodunu okumak için biraz zaman ayırın.
Bu betik, doğrudan yerel makinenizden çalıştırılabilir ve uç noktanızı tüketecektir.

Bu iki satır koda dikkat edin:
url = 'http://98e3715f-xxxx-xxxx-xxxx-9ec22d57b796.centralus.azurecontainer.io/score'
api_key = '' # Replace this with the API key for the web service
url değişkeni, tüketim sekmesinde bulunan REST uç noktasıdır ve api_key değişkeni, kimlik doğrulamayı etkinleştirdiyseniz tüketim sekmesinde bulunan birincil anahtardır. Betik, uç noktayı bu şekilde tüketebilir.
- Betiği çalıştırdığınızda, aşağıdaki çıktıyı görmelisiniz:
b'"{\\"result\\": [true]}"'
Bu, verilen veriler için kalp yetmezliği tahmininin doğru olduğu anlamına gelir. Bu mantıklıdır çünkü betikte otomatik olarak oluşturulan verilere daha yakından bakarsanız, her şey varsayılan olarak 0 ve yanlış durumdadır. Verileri şu giriş örneğiyle değiştirebilirsiniz:
data = {
"data":
[
{
'age': "0",
'anaemia': "false",
'creatinine_phosphokinase': "0",
'diabetes': "false",
'ejection_fraction': "0",
'high_blood_pressure': "false",
'platelets': "0",
'serum_creatinine': "0",
'serum_sodium': "0",
'sex': "false",
'smoking': "false",
'time': "0",
},
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
Betik şu çıktıyı döndürmelidir:
python b'"{\\"result\\": [true, false]}"'
Tebrikler! Modeli dağıttınız ve Azure ML üzerinde eğittiniz!
NOT: Projeyi tamamladıktan sonra, tüm kaynakları silmeyi unutmayın.
🚀 Zorluk
AutoML'nin en iyi modeller için oluşturduğu model açıklamalarına ve ayrıntılarına yakından bakın. En iyi modelin neden diğerlerinden daha iyi olduğunu anlamaya çalışın. Hangi algoritmalar karşılaştırıldı? Aralarındaki farklar nelerdir? Bu durumda en iyi model neden daha iyi performans gösteriyor?
Ders Sonrası Test
Gözden Geçirme ve Kendi Kendine Çalışma
Bu derste, bulutta kod yazmadan veya az kodla kalp yetmezliği riskini tahmin etmek için bir modeli nasıl eğiteceğinizi, dağıtacağınızı ve tüketeceğinizi öğrendiniz. Henüz yapmadıysanız, AutoML'nin en iyi modeller için oluşturduğu model açıklamalarına daha derinlemesine dalın ve en iyi modelin neden diğerlerinden daha iyi olduğunu anlamaya çalışın.
Kod yazmadan veya az kodla AutoML hakkında daha fazla bilgi edinmek için bu belgeyi okuyabilirsiniz.
Ödev
Azure ML üzerinde Kod Yazmadan veya Az Kodla Veri Bilimi Projesi
Feragatname:
Bu belge, Co-op Translator adlı yapay zeka çeviri hizmeti kullanılarak çevrilmiştir. Doğruluk için çaba göstersek de, otomatik çevirilerin hata veya yanlışlıklar içerebileceğini lütfen unutmayın. Orijinal belgenin kendi dilindeki hali, yetkili kaynak olarak kabul edilmelidir. Kritik bilgiler için profesyonel insan çevirisi önerilir. Bu çevirinin kullanımından kaynaklanan yanlış anlamalar veya yanlış yorumlamalar için sorumluluk kabul etmiyoruz.