|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
README.md
Data Science i molnet: "Low code/No code"-metoden
 |
|---|
| Data Science i molnet: Low Code - Sketchnote av @nitya |
Innehållsförteckning:
- Data Science i molnet: "Low code/No code"-metoden
Quiz före föreläsningen
1. Introduktion
1.1 Vad är Azure Machine Learning?
Azure-molnplattformen består av över 200 produkter och molntjänster som är utformade för att hjälpa dig att skapa nya lösningar. Dataforskare lägger mycket tid på att utforska och förbehandla data samt att testa olika algoritmer för modellträning för att skapa exakta modeller. Dessa uppgifter är tidskrävande och kan ofta leda till ineffektiv användning av dyr hårdvara.
Azure ML är en molnbaserad plattform för att bygga och driva lösningar för maskininlärning i Azure. Den innehåller ett brett utbud av funktioner som hjälper dataforskare att förbereda data, träna modeller, publicera prediktiva tjänster och övervaka deras användning. Framför allt ökar den effektiviteten genom att automatisera många av de tidskrävande uppgifterna som är förknippade med modellträning, och den gör det möjligt att använda molnbaserade beräkningsresurser som kan skalas effektivt för att hantera stora datamängder, med kostnader endast när resurserna används.
Azure ML erbjuder alla verktyg som utvecklare och dataforskare behöver för sina arbetsflöden inom maskininlärning. Dessa inkluderar:
- Azure Machine Learning Studio: En webbportal i Azure Machine Learning för low-code och no-code-alternativ för modellträning, implementering, automatisering, spårning och hantering av tillgångar. Studion integreras med Azure Machine Learning SDK för en smidig upplevelse.
- Jupyter Notebooks: Snabbt prototypa och testa ML-modeller.
- Azure Machine Learning Designer: Möjliggör drag-och-släpp-moduler för att bygga experiment och sedan implementera pipelines i en low-code-miljö.
- Automated machine learning UI (AutoML): Automatiserar iterativa uppgifter inom utveckling av maskininlärningsmodeller, vilket möjliggör skapande av ML-modeller med hög skala, effektivitet och produktivitet, samtidigt som modellkvaliteten bibehålls.
- Data Labelling: Ett assisterat ML-verktyg för att automatiskt märka data.
- Maskininlärningstillägg för Visual Studio Code: Ger en fullständig utvecklingsmiljö för att bygga och hantera ML-projekt.
- Maskininlärning CLI: Ger kommandon för att hantera Azure ML-resurser från kommandoraden.
- Integration med open-source-ramverk som PyTorch, TensorFlow, Scikit-learn och många fler för att träna, implementera och hantera hela processen för maskininlärning.
- MLflow: Ett open-source-bibliotek för att hantera livscykeln för dina experiment inom maskininlärning. MLFlow Tracking är en komponent av MLflow som loggar och spårar dina träningskörningsmetrik och modellartefakter, oavsett experimentets miljö.
1.2 Projektet för att förutsäga hjärtsvikt:
Det råder ingen tvekan om att skapa och bygga projekt är det bästa sättet att sätta dina färdigheter och kunskaper på prov. I denna lektion ska vi utforska två olika sätt att bygga ett datavetenskapsprojekt för att förutsäga hjärtsvikt i Azure ML Studio, genom Low code/No code och genom Azure ML SDK, som visas i följande schema:
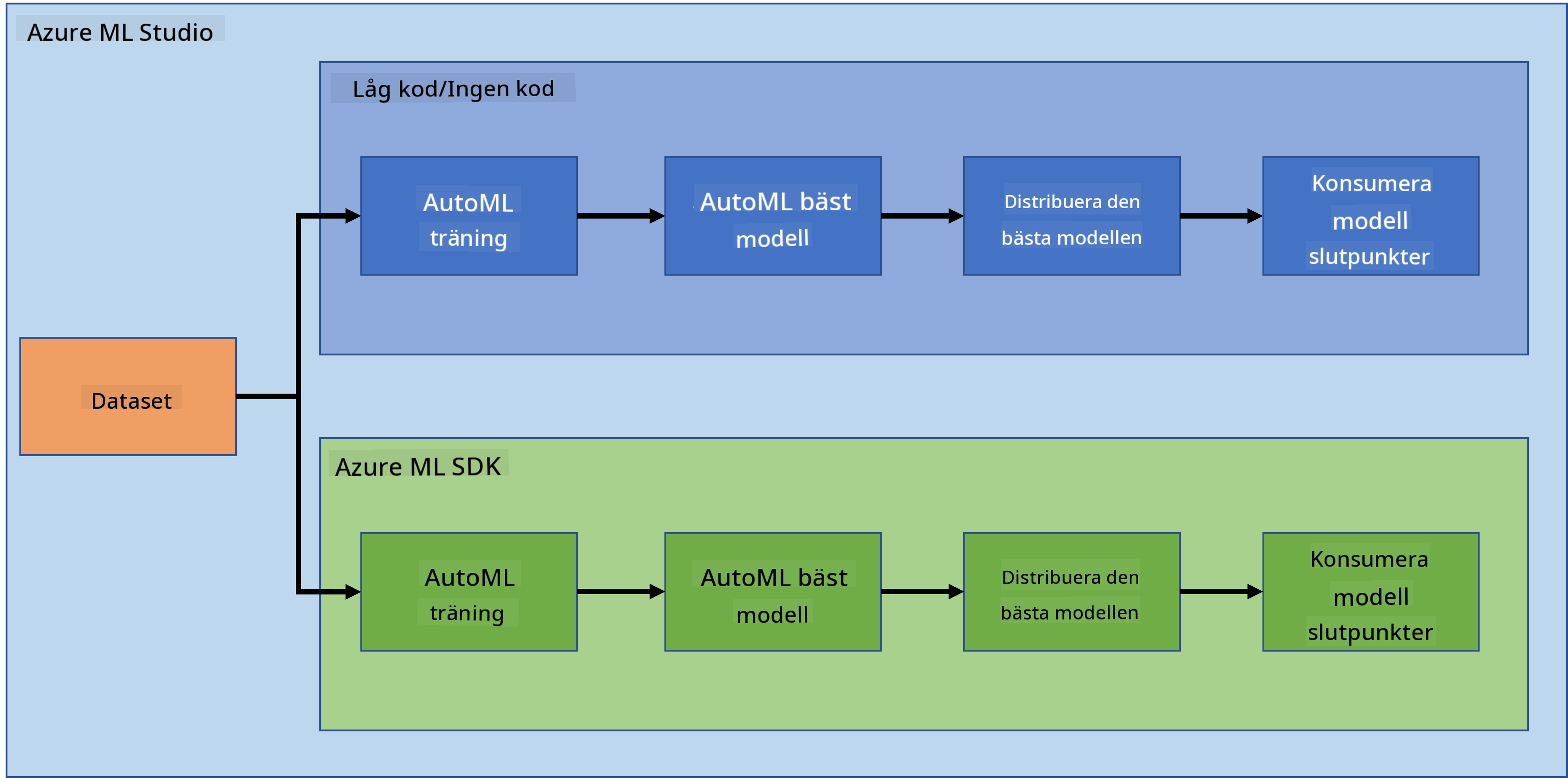
Varje metod har sina egna för- och nackdelar. Low code/No code-metoden är enklare att börja med eftersom den innebär interaktion med en GUI (grafiskt användargränssnitt), utan krav på tidigare kunskaper i kod. Denna metod möjliggör snabb testning av projektets genomförbarhet och skapande av POC (Proof Of Concept). Men när projektet växer och saker behöver vara produktionsklara är det inte hållbart att skapa resurser via GUI. Då behöver vi programmera och automatisera allt, från skapandet av resurser till implementeringen av en modell. Här blir kunskaper i Azure ML SDK avgörande.
| Low code/No code | Azure ML SDK | |
|---|---|---|
| Kodkunskaper | Ej nödvändigt | Nödvändigt |
| Utvecklingstid | Snabb och enkel | Beror på kodkunskaper |
| Produktionsklar | Nej | Ja |
1.3 Datasetet för hjärtsvikt:
Kardiovaskulära sjukdomar (CVDs) är den främsta dödsorsaken globalt och står för 31% av alla dödsfall världen över. Miljö- och beteenderiskfaktorer som tobaksanvändning, ohälsosam kost och fetma, fysisk inaktivitet och skadlig alkoholkonsumtion kan användas som funktioner för uppskattningsmodeller. Att kunna uppskatta sannolikheten för att utveckla en CVD kan vara mycket användbart för att förebygga attacker hos högriskpersoner.
Kaggle har gjort ett dataset för hjärtsvikt offentligt tillgängligt, som vi ska använda för detta projekt. Du kan ladda ner datasetet nu. Detta är ett tabellformat dataset med 13 kolumner (12 funktioner och 1 målvariabel) och 299 rader.
| Variabelnamn | Typ | Beskrivning | Exempel | |
|---|---|---|---|---|
| 1 | age | numerisk | Patientens ålder | 25 |
| 2 | anaemia | boolean | Minskning av röda blodkroppar eller hemoglobin | 0 eller 1 |
| 3 | creatinine_phosphokinase | numerisk | Nivå av CPK-enzym i blodet | 542 |
| 4 | diabetes | boolean | Om patienten har diabetes | 0 eller 1 |
| 5 | ejection_fraction | numerisk | Procentandel blod som lämnar hjärtat vid varje sammandragning | 45 |
| 6 | high_blood_pressure | boolean | Om patienten har högt blodtryck | 0 eller 1 |
| 7 | platelets | numerisk | Trombocyter i blodet | 149000 |
| 8 | serum_creatinine | numerisk | Nivå av serumkreatinin i blodet | 0.5 |
| 9 | serum_sodium | numerisk | Nivå av serumnatrium i blodet | jun |
| 10 | sex | boolean | Kvinna eller man | 0 eller 1 |
| 11 | smoking | boolean | Om patienten röker | 0 eller 1 |
| 12 | time | numerisk | Uppföljningsperiod (dagar) | 4 |
| ---- | --------------------------- | ----------------- | ----------------------------------------------------------- | ------------------- |
| 21 | DEATH_EVENT [Målvariabel] | boolean | Om patienten dör under uppföljningsperioden | 0 eller 1 |
När du har datasetet kan vi börja projektet i Azure.
2. Low code/No code-träning av en modell i Azure ML Studio
2.1 Skapa en Azure ML-arbetsyta
För att träna en modell i Azure ML måste du först skapa en Azure ML-arbetsyta. Arbetsytan är den översta resursen för Azure Machine Learning och ger en central plats för att arbeta med alla artefakter du skapar när du använder Azure Machine Learning. Arbetsytan håller en historik över alla träningskörningar, inklusive loggar, metrik, utdata och en ögonblicksbild av dina skript. Du använder denna information för att avgöra vilken träningskörning som producerar den bästa modellen. Läs mer
Det rekommenderas att använda den mest uppdaterade webbläsaren som är kompatibel med ditt operativsystem. Följande webbläsare stöds:
- Microsoft Edge (Den nya Microsoft Edge, senaste versionen. Inte Microsoft Edge legacy)
- Safari (senaste versionen, endast Mac)
- Chrome (senaste versionen)
- Firefox (senaste versionen)
För att använda Azure Machine Learning, skapa en arbetsyta i din Azure-prenumeration. Du kan sedan använda denna arbetsyta för att hantera data, beräkningsresurser, kod, modeller och andra artefakter relaterade till dina arbetsflöden inom maskininlärning.
OBS: Din Azure-prenumeration kommer att debiteras en liten summa för datalagring så länge som Azure Machine Learning-arbetsytan finns i din prenumeration, så vi rekommenderar att du tar bort arbetsytan när du inte längre använder den.
-
Logga in på Azure-portalen med de Microsoft-uppgifter som är kopplade till din Azure-prenumeration.
-
Välj +Skapa en resurs
Sök efter Machine Learning och välj Machine Learning-tile
Klicka på skapa-knappen
Fyll i inställningarna enligt följande:
- Prenumeration: Din Azure-prenumeration
- Resursgrupp: Skapa eller välj en resursgrupp
- Arbetsytans namn: Ange ett unikt namn för din arbetsyta
- Region: Välj den geografiska regionen närmast dig
- Lagringskonto: Notera det nya standardlagringskonto som kommer att skapas för din arbetsyta
- Nyckelvalv: Notera det nya standardnyckelvalv som kommer att skapas för din arbetsyta
- Application insights: Notera den nya standardresursen för application insights som kommer att skapas för din arbetsyta
- Containerregister: Ingen (ett kommer att skapas automatiskt första gången du implementerar en modell till en container)
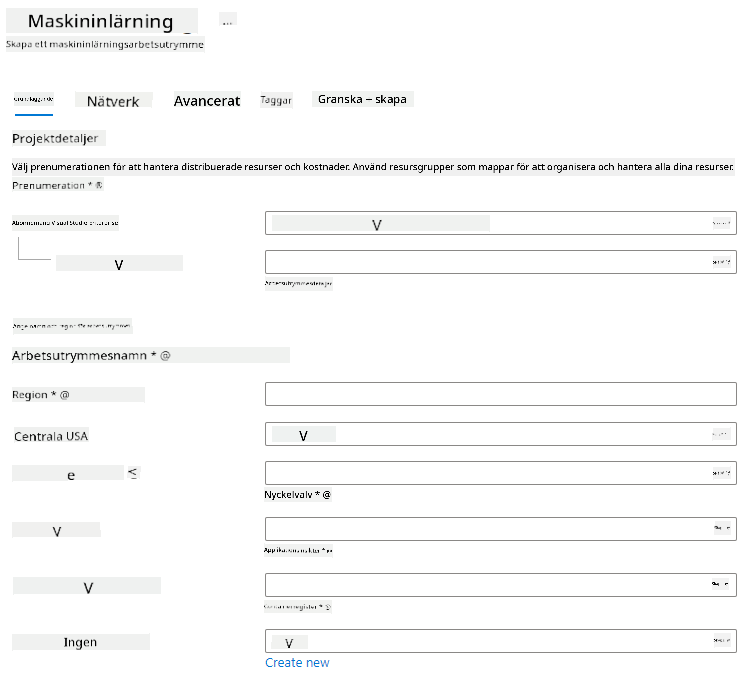
- Klicka på skapa + granska och sedan på skapa-knappen
-
Vänta på att din arbetsyta ska skapas (detta kan ta några minuter). Gå sedan till den i portalen. Du kan hitta den via Azure-tjänsten Machine Learning.
-
På översiktssidan för din arbetsyta, starta Azure Machine Learning Studio (eller öppna en ny webbläsarflik och navigera till https://ml.azure.com), och logga in på Azure Machine Learning Studio med ditt Microsoft-konto. Om du blir ombedd, välj din Azure-katalog och prenumeration, samt din Azure Machine Learning-arbetsyta.
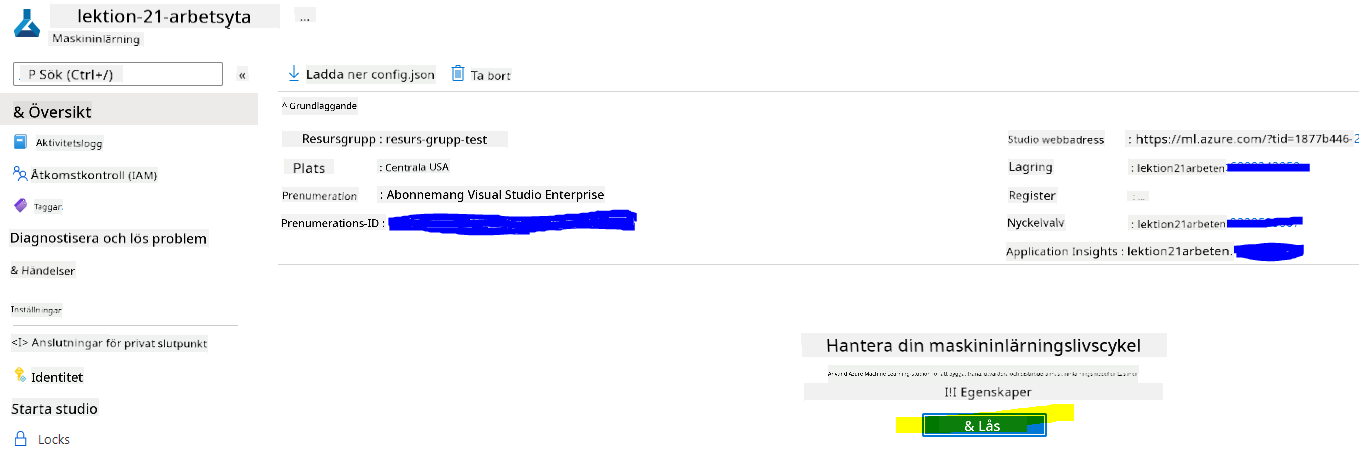
- I Azure Machine Learning Studio, växla ☰-ikonen längst upp till vänster för att visa de olika sidorna i gränssnittet. Du kan använda dessa sidor för att hantera resurserna i din arbetsyta.
Du kan hantera din arbetsyta via Azure-portalen, men för dataforskare och ingenjörer inom maskininlärningsoperationer erbjuder Azure Machine Learning Studio ett mer fokuserat användargränssnitt för att hantera arbetsytans resurser.
2.2 Beräkningsresurser
Beräkningsresurser är molnbaserade resurser där du kan köra modellträning och datautforskningsprocesser. Det finns fyra typer av beräkningsresurser du kan skapa:
- Beräkningsinstanser: Utvecklingsarbetsstationer som dataforskare kan använda för att arbeta med data och modeller. Detta innebär skapandet av en virtuell maskin (VM) och start av en notebook-instans. Du kan sedan träna en modell genom att kalla på en beräkningskluster från notebooken.
- Beräkningskluster: Skalbara kluster av virtuella maskiner för on-demand bearbetning av experimentkod. Du kommer att behöva det när du tränar en modell. Beräkningskluster kan också använda specialiserade GPU- eller CPU-resurser.
- Inferenskluster: Implementeringsmål för prediktiva tjänster som använder dina tränade modeller.
- Attached Compute: Länkar till befintliga Azure-beräkningsresurser, såsom virtuella maskiner eller Azure Databricks-kluster.
2.2.1 Välja rätt alternativ för dina beräkningsresurser
Det finns några viktiga faktorer att tänka på när du skapar en beräkningsresurs, och dessa val kan vara avgörande beslut.
Behöver du CPU eller GPU?
En CPU (Central Processing Unit) är den elektroniska kretsen som utför instruktioner i ett datorprogram. En GPU (Graphics Processing Unit) är en specialiserad elektronisk krets som kan köra grafikrelaterad kod i mycket hög hastighet.
Den huvudsakliga skillnaden mellan CPU och GPU-arkitektur är att en CPU är designad för att hantera ett brett spektrum av uppgifter snabbt (mätt i CPU-klockhastighet), men är begränsad i antalet samtidiga uppgifter som kan köras. GPUs är designade för parallell databehandling och är därför mycket bättre på djupinlärningsuppgifter.
| CPU | GPU |
|---|---|
| Mindre kostsam | Dyrare |
| Lägre nivå av samtidighet | Högre nivå av samtidighet |
| Långsammare vid träning av djupinlärningsmodeller | Optimal för djupinlärning |
Klusterstorlek
Större kluster är dyrare men ger bättre responsivitet. Om du har tid men begränsad budget bör du börja med ett mindre kluster. Omvänt, om du har pengar men ont om tid, bör du börja med ett större kluster.
VM-storlek
Beroende på dina tids- och budgetbegränsningar kan du variera storleken på RAM, disk, antal kärnor och klockhastighet. Att öka alla dessa parametrar blir dyrare, men ger bättre prestanda.
Dedikerade eller lågprioriterade instanser?
En lågprioriterad instans innebär att den är avbrytbar: Microsoft Azure kan ta dessa resurser och tilldela dem till en annan uppgift, vilket avbryter jobbet. En dedikerad instans, eller icke-avbrytbar, innebär att jobbet aldrig kommer att avslutas utan ditt tillstånd. Detta är ytterligare en övervägning mellan tid och pengar, eftersom avbrytbara instanser är billigare än dedikerade.
2.2.2 Skapa ett beräkningskluster
I Azure ML-arbetsytan som vi skapade tidigare, gå till Compute och du kommer att kunna se de olika beräkningsresurserna vi just diskuterade (dvs. beräkningsinstanser, beräkningskluster, inferenskluster och anslutna beräkningar). För detta projekt kommer vi att behöva ett beräkningskluster för modellträning. I Studio, klicka på menyn "Compute", sedan fliken "Compute cluster" och klicka på knappen "+ New" för att skapa ett beräkningskluster.
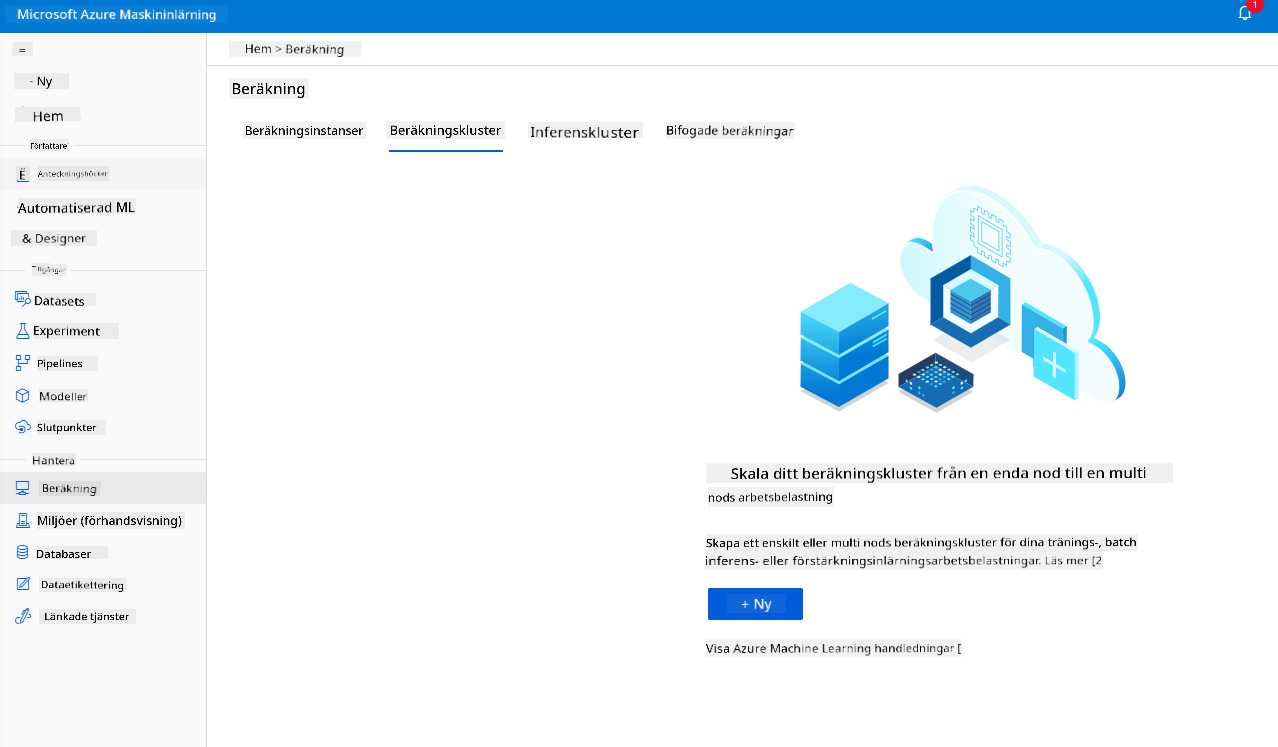
- Välj dina alternativ: Dedikerad vs lågprioriterad, CPU eller GPU, VM-storlek och antal kärnor (du kan behålla standardinställningarna för detta projekt).
- Klicka på knappen Nästa.
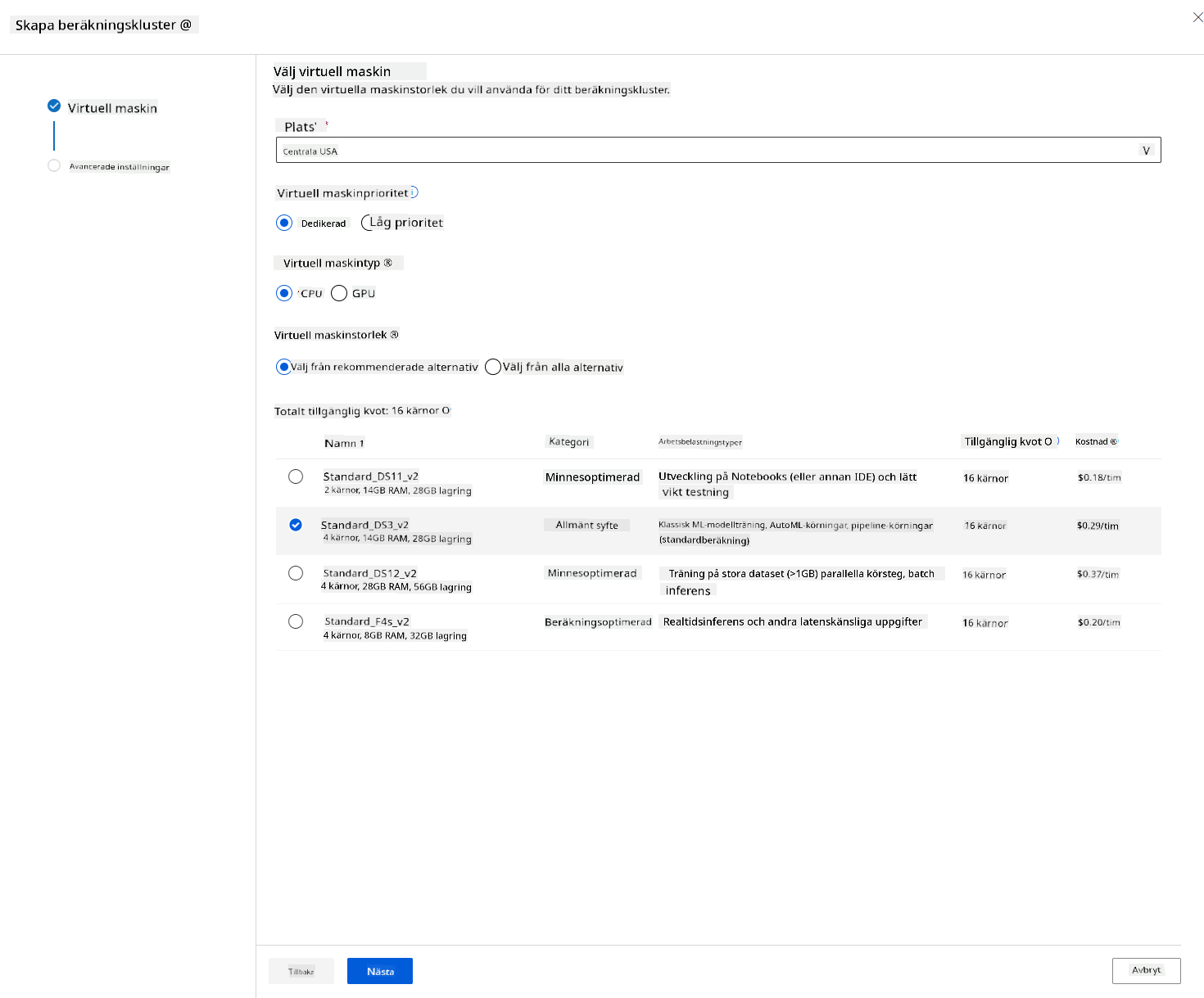
- Ge klustret ett namn.
- Välj dina alternativ: Minsta/maximala antal noder, antal sekunder i viloläge innan nedskalning, SSH-åtkomst. Observera att om det minsta antalet noder är 0, sparar du pengar när klustret är vilande. Observera att ju högre antal maximala noder, desto kortare blir träningen. Det rekommenderade maximala antalet noder är 3.
- Klicka på knappen "Create". Detta steg kan ta några minuter.
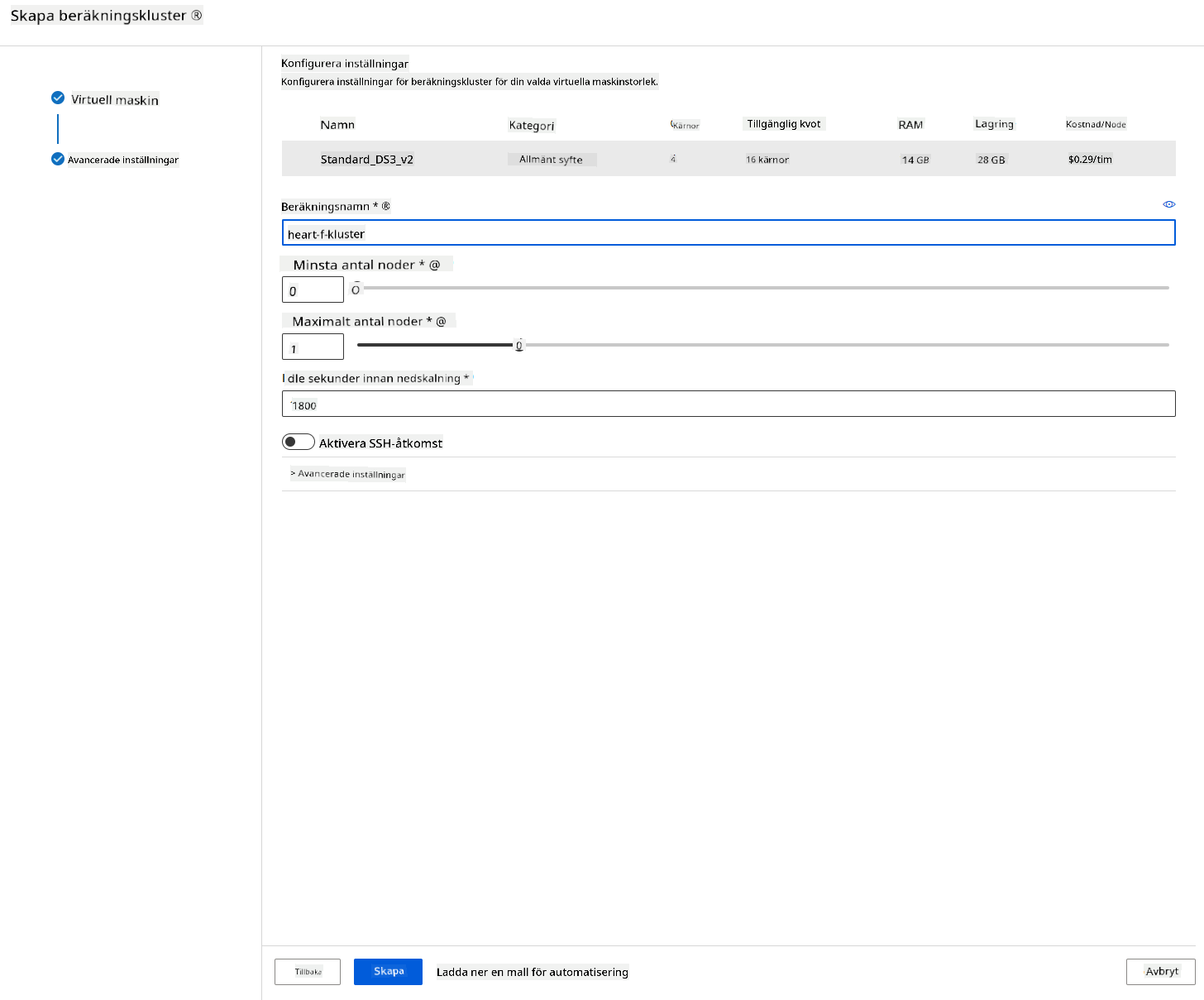
Fantastiskt! Nu när vi har ett beräkningskluster behöver vi ladda upp data till Azure ML Studio.
2.3 Ladda upp datasetet
-
I Azure ML-arbetsytan som vi skapade tidigare, klicka på "Datasets" i vänstermenyn och klicka på knappen "+ Create dataset" för att skapa ett dataset. Välj alternativet "From local files" och välj Kaggle-datasetet vi laddade ner tidigare.
-
Ge ditt dataset ett namn, en typ och en beskrivning. Klicka på Nästa. Ladda upp data från filer. Klicka på Nästa.
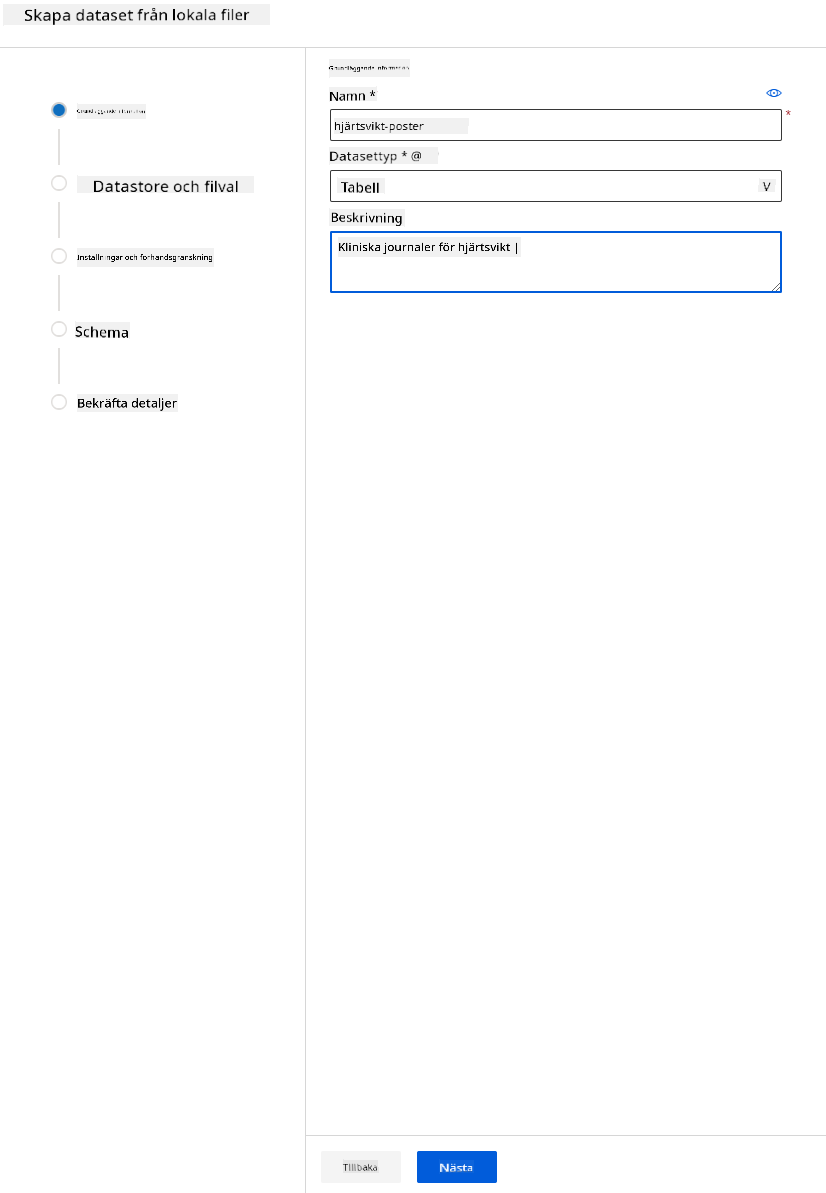
-
I schemat, ändra datatypen till Boolean för följande funktioner: anaemia, diabetes, high blood pressure, sex, smoking och DEATH_EVENT. Klicka på Nästa och klicka på Create.
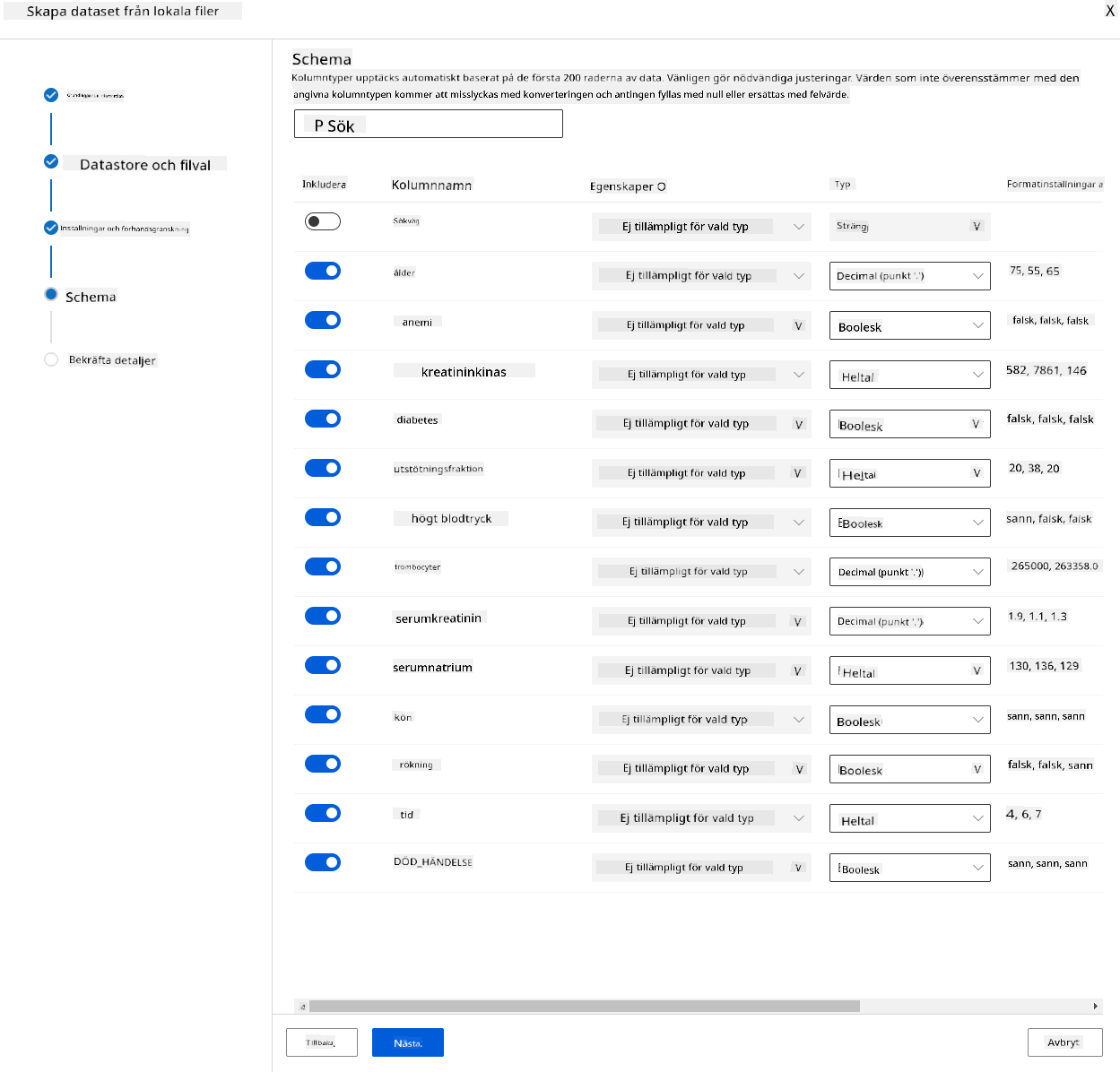
Bra! Nu när datasetet är på plats och beräkningsklustret är skapat kan vi börja träna modellen!
2.4 Lågkod/Ingen kod-träning med AutoML
Traditionell utveckling av maskininlärningsmodeller är resurskrävande, kräver betydande domänkunskap och tid för att producera och jämföra dussintals modeller. Automatiserad maskininlärning (AutoML) är processen att automatisera de tidskrävande, iterativa uppgifterna vid utveckling av maskininlärningsmodeller. Det gör det möjligt för dataforskare, analytiker och utvecklare att bygga ML-modeller med hög skala, effektivitet och produktivitet, samtidigt som modellkvaliteten bibehålls. Det minskar tiden det tar att få produktionsklara ML-modeller, med stor enkelhet och effektivitet. Läs mer
-
I Azure ML-arbetsytan som vi skapade tidigare, klicka på "Automated ML" i vänstermenyn och välj datasetet du just laddade upp. Klicka på Nästa.
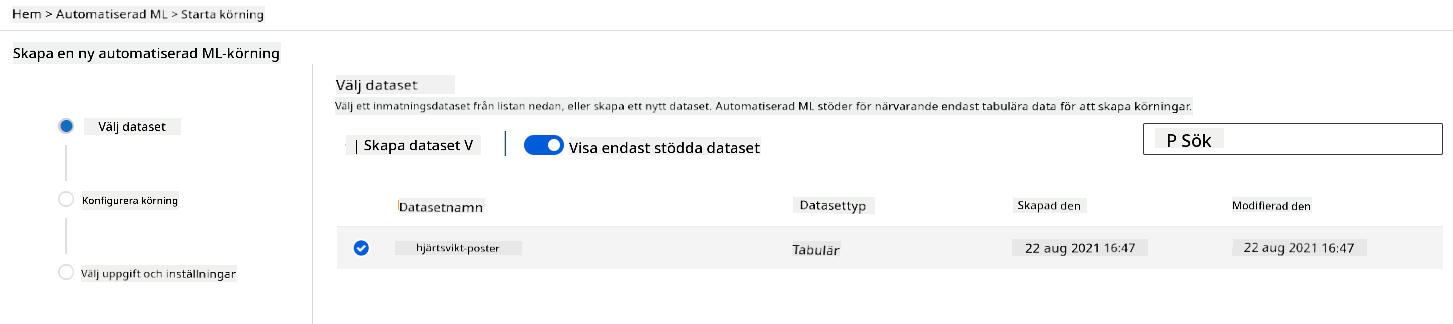
-
Ange ett nytt experimentnamn, målkollumnen (DEATH_EVENT) och beräkningsklustret vi skapade. Klicka på Nästa.
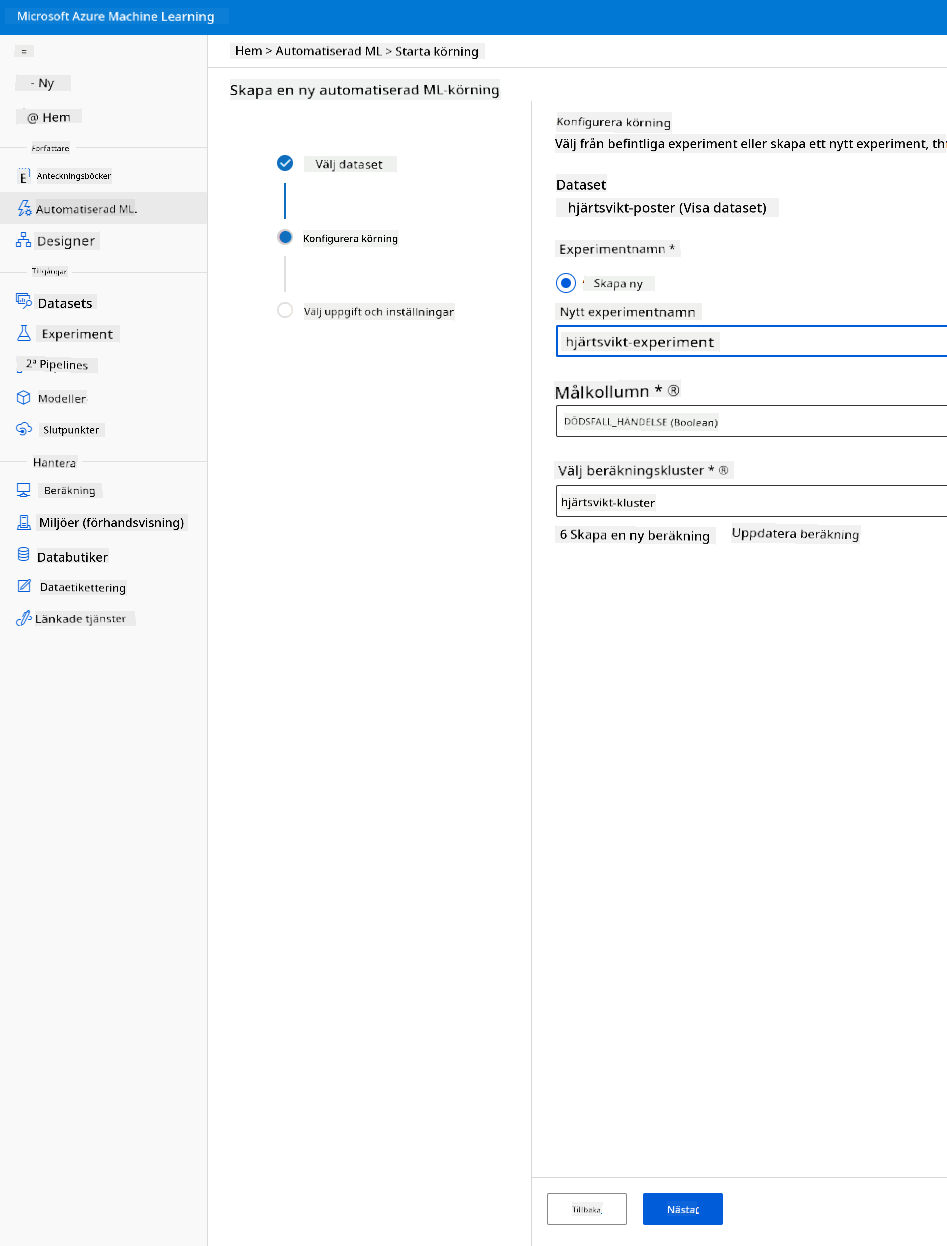
-
Välj "Classification" och klicka på Finish. Detta steg kan ta mellan 30 minuter och 1 timme, beroende på storleken på ditt beräkningskluster.
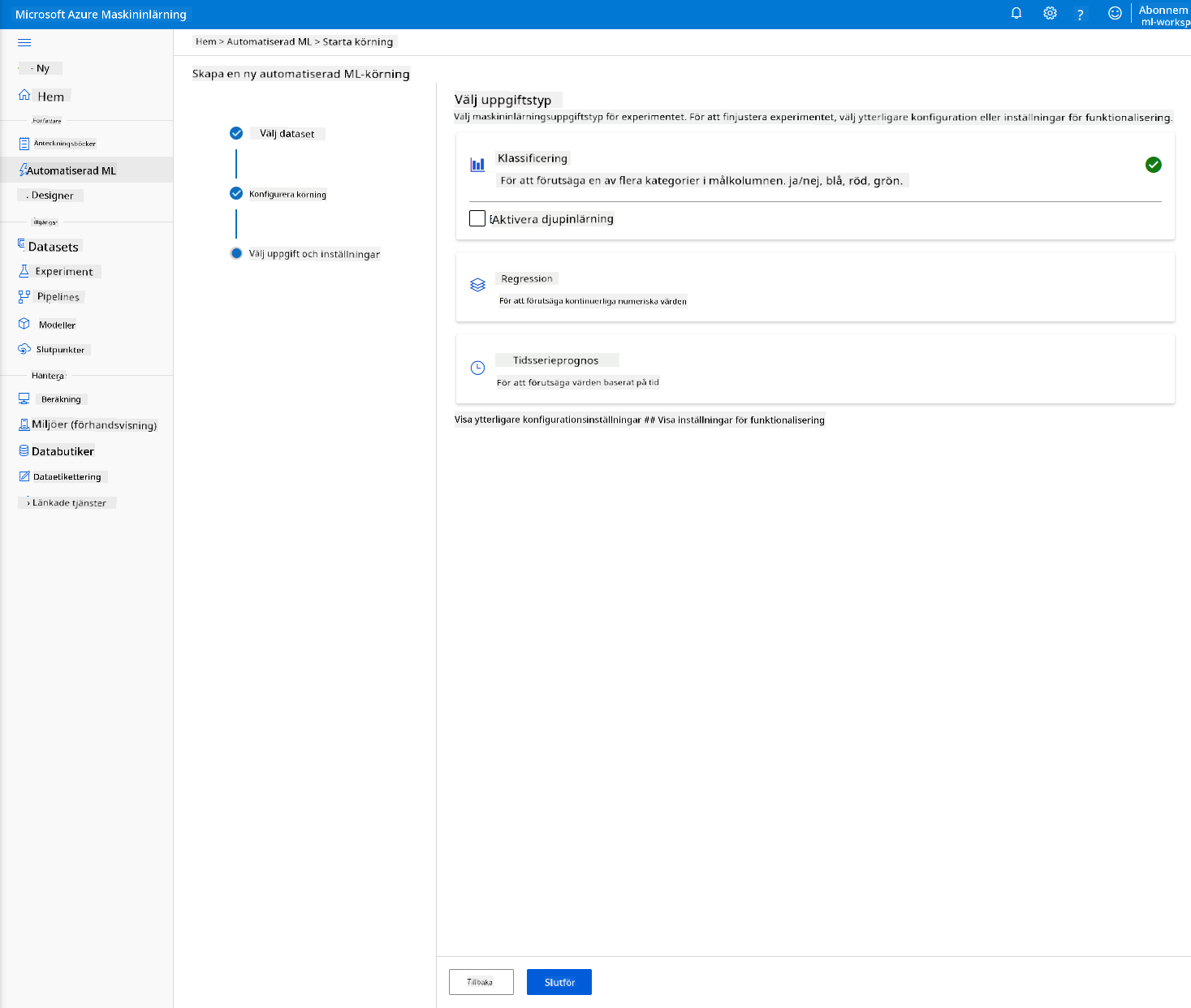
-
När körningen är klar, klicka på fliken "Automated ML", klicka på din körning och klicka på algoritmen i kortet "Best model summary".
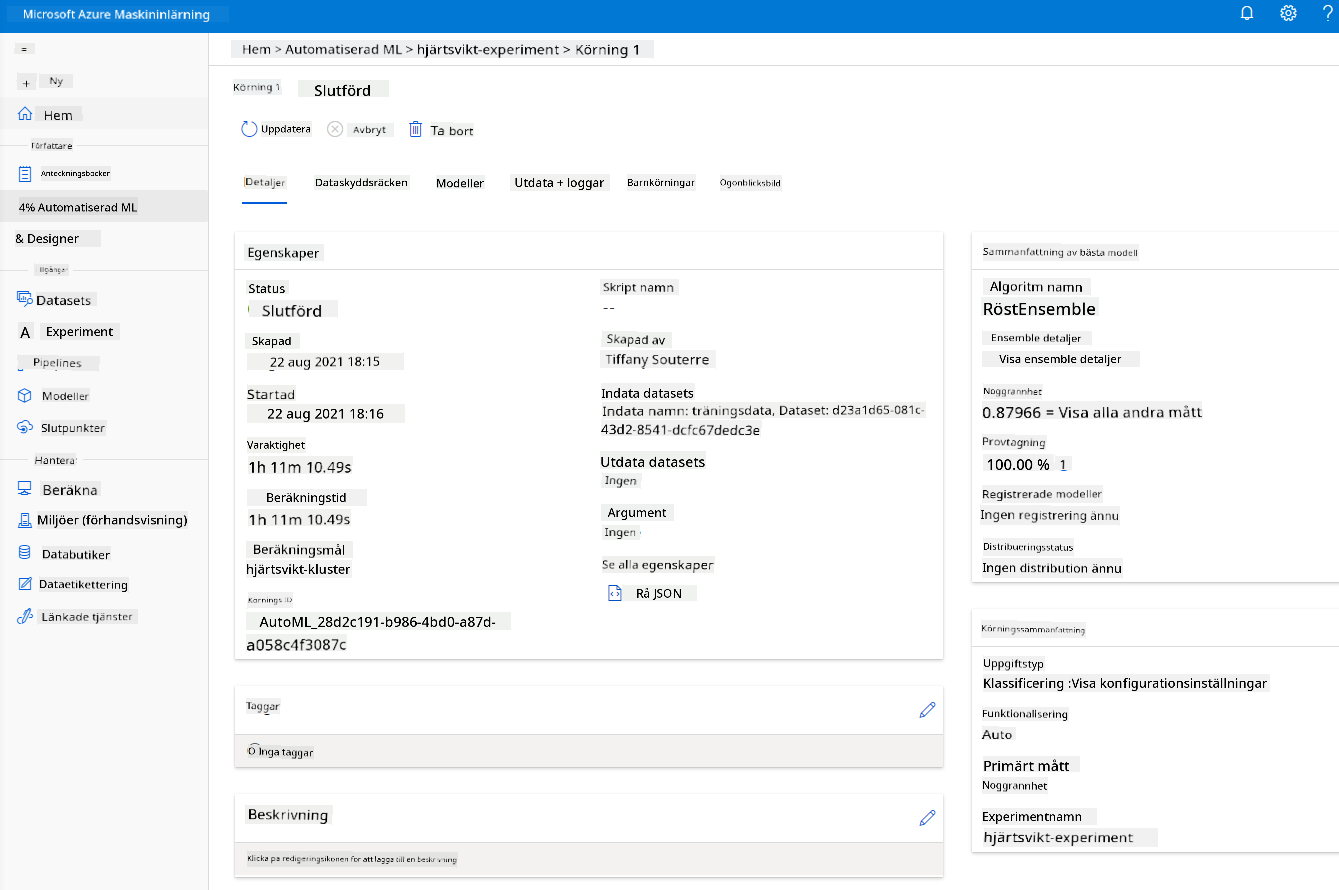
Här kan du se en detaljerad beskrivning av den bästa modellen som AutoML genererade. Du kan också utforska andra modeller som genererats i fliken Models. Ta några minuter att utforska modellerna i knappen Explanations (preview). När du har valt den modell du vill använda (här väljer vi den bästa modellen som valts av AutoML), kommer vi att se hur vi kan distribuera den.
3. Lågkod/Ingen kod-modelldistribution och endpoint-konsumtion
3.1 Modelldistribution
Gränssnittet för automatiserad maskininlärning gör det möjligt att distribuera den bästa modellen som en webbtjänst i några få steg. Distribution är integreringen av modellen så att den kan göra förutsägelser baserat på ny data och identifiera potentiella möjligheter. För detta projekt innebär distribution till en webbtjänst att medicinska applikationer kommer att kunna använda modellen för att göra liveförutsägelser om deras patienters risk att få en hjärtattack.
I den bästa modellbeskrivningen, klicka på knappen "Deploy".
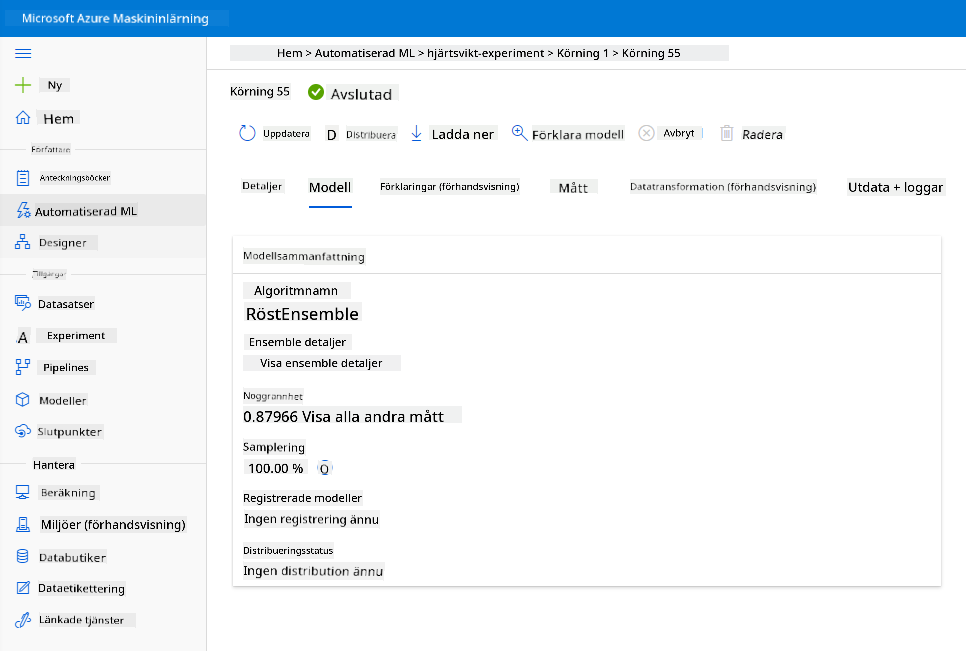
- Ge den ett namn, en beskrivning, beräkningstyp (Azure Container Instance), aktivera autentisering och klicka på Deploy. Detta steg kan ta cirka 20 minuter att slutföra. Distributionsprocessen innefattar flera steg, inklusive registrering av modellen, generering av resurser och konfigurering av dem för webbtjänsten. Ett statusmeddelande visas under Deploy status. Välj Refresh regelbundet för att kontrollera distributionsstatusen. Den är distribuerad och körs när statusen är "Healthy".
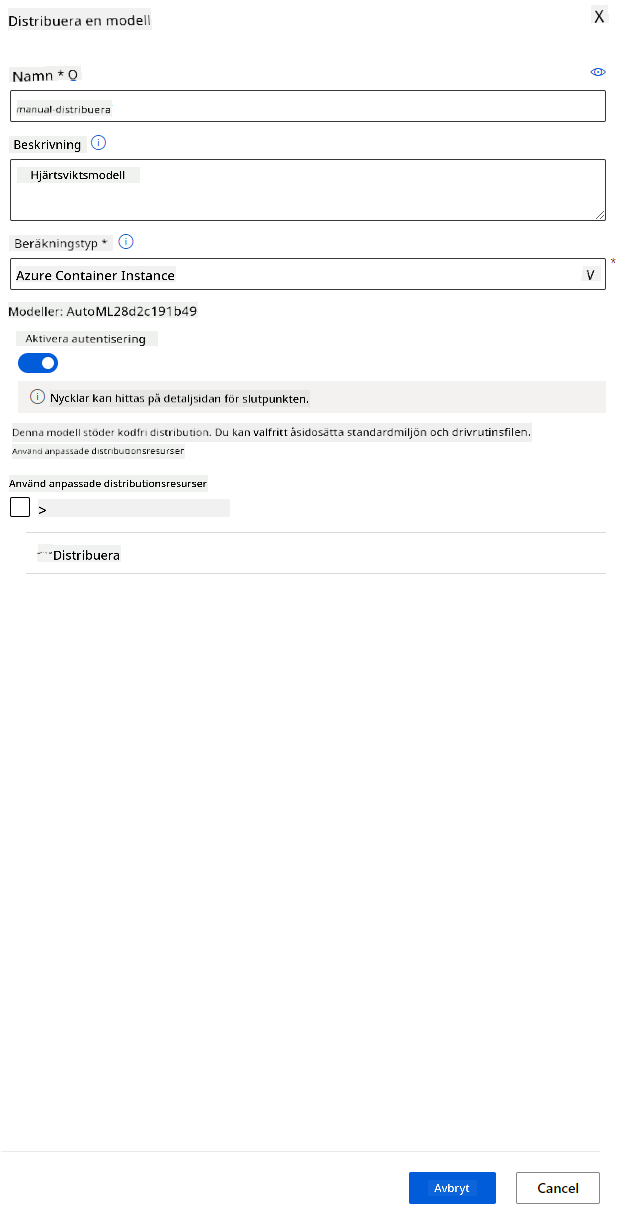
- När den har distribuerats, klicka på fliken Endpoint och klicka på den endpoint du just distribuerade. Här kan du hitta alla detaljer du behöver veta om endpointen.
Fantastiskt! Nu när vi har en modell distribuerad kan vi börja konsumera endpointen.
3.2 Endpoint-konsumtion
Klicka på fliken "Consume". Här kan du hitta REST-endpointen och ett Python-skript i konsumtionsalternativet. Ta dig tid att läsa Python-koden.
Detta skript kan köras direkt från din lokala maskin och kommer att konsumera din endpoint.
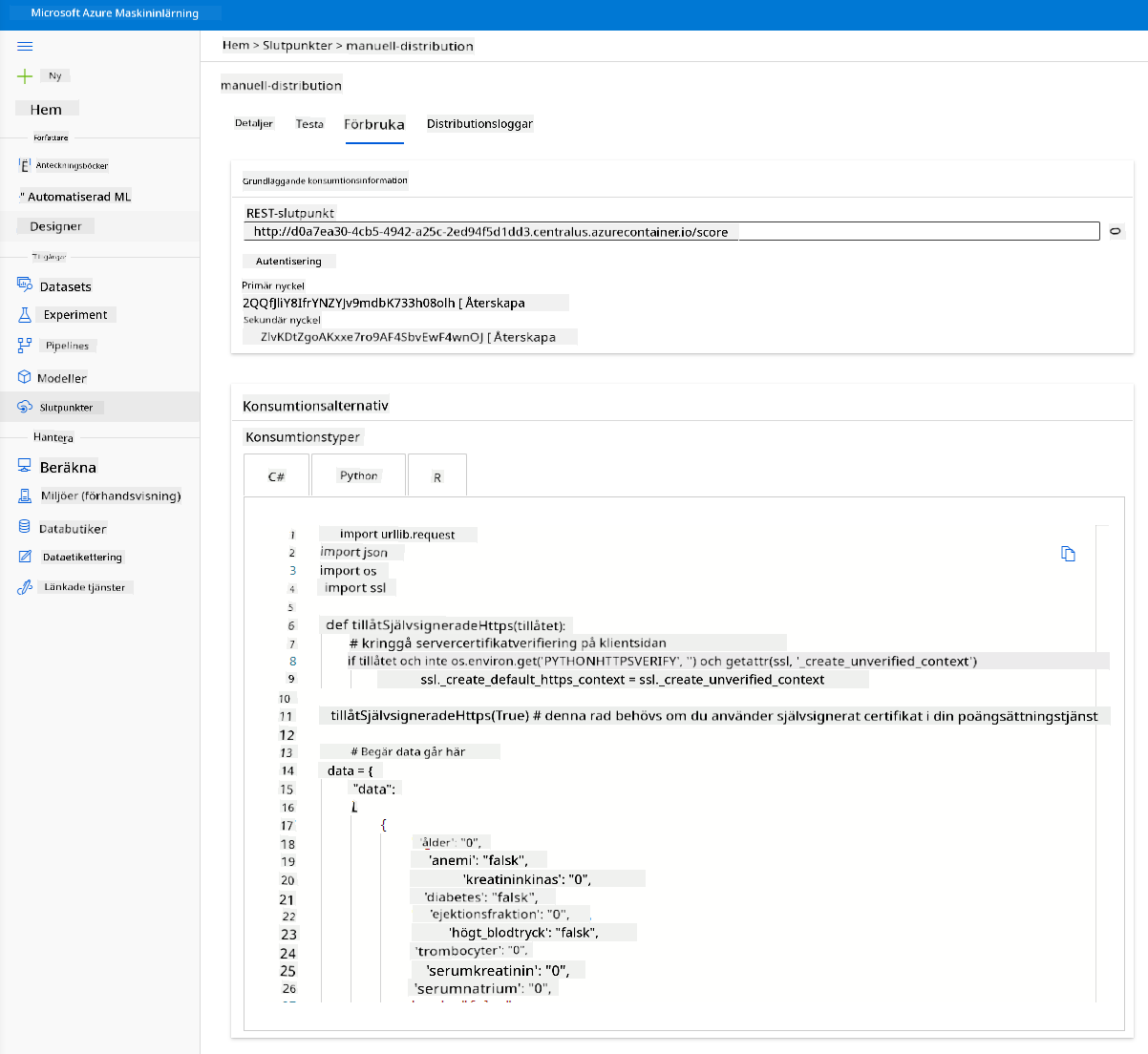
Ta en stund att kontrollera dessa två rader kod:
url = 'http://98e3715f-xxxx-xxxx-xxxx-9ec22d57b796.centralus.azurecontainer.io/score'
api_key = '' # Replace this with the API key for the web service
Variabeln url är REST-endpointen som finns i fliken Consume och variabeln api_key är den primära nyckeln som också finns i fliken Consume (endast om du har aktiverat autentisering). Detta är hur skriptet kan konsumera endpointen.
- När du kör skriptet bör du se följande output:
b'"{\\"result\\": [true]}"'
Detta betyder att förutsägelsen av hjärtsvikt för den givna datan är sann. Detta är logiskt eftersom om du tittar närmare på datan som automatiskt genereras i skriptet, är allt satt till 0 och falskt som standard. Du kan ändra datan med följande inmatningsprov:
data = {
"data":
[
{
'age': "0",
'anaemia': "false",
'creatinine_phosphokinase': "0",
'diabetes': "false",
'ejection_fraction': "0",
'high_blood_pressure': "false",
'platelets': "0",
'serum_creatinine': "0",
'serum_sodium': "0",
'sex': "false",
'smoking': "false",
'time': "0",
},
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
Skriptet bör returnera:
python b'"{\\"result\\": [true, false]}"'
Grattis! Du har just konsumerat den distribuerade modellen och tränat den på Azure ML!
NOTE: När du är klar med projektet, glöm inte att ta bort alla resurser.
🚀 Utmaning
Titta noga på modellförklaringarna och detaljerna som AutoML genererade för de bästa modellerna. Försök att förstå varför den bästa modellen är bättre än de andra. Vilka algoritmer jämfördes? Vilka är skillnaderna mellan dem? Varför presterar den bästa modellen bättre i detta fall?
Post-Lecture Quiz
Granskning & Självstudie
I denna lektion lärde du dig hur man tränar, distribuerar och konsumerar en modell för att förutsäga hjärtsviktsrisk på ett lågkod/ingen kod-sätt i molnet. Om du inte har gjort det ännu, fördjupa dig i modellförklaringarna som AutoML genererade för de bästa modellerna och försök att förstå varför den bästa modellen är bättre än de andra.
Du kan gå vidare med lågkod/ingen kod AutoML genom att läsa denna dokumentation.
Uppgift
Projekt med lågkod/ingen kod inom datavetenskap på Azure ML
Ansvarsfriskrivning:
Detta dokument har översatts med hjälp av AI-översättningstjänsten Co-op Translator. Även om vi strävar efter noggrannhet, bör det noteras att automatiserade översättningar kan innehålla fel eller brister. Det ursprungliga dokumentet på dess originalspråk bör betraktas som den auktoritativa källan. För kritisk information rekommenderas professionell mänsklig översättning. Vi ansvarar inte för eventuella missförstånd eller feltolkningar som kan uppstå vid användning av denna översättning.