18 KiB
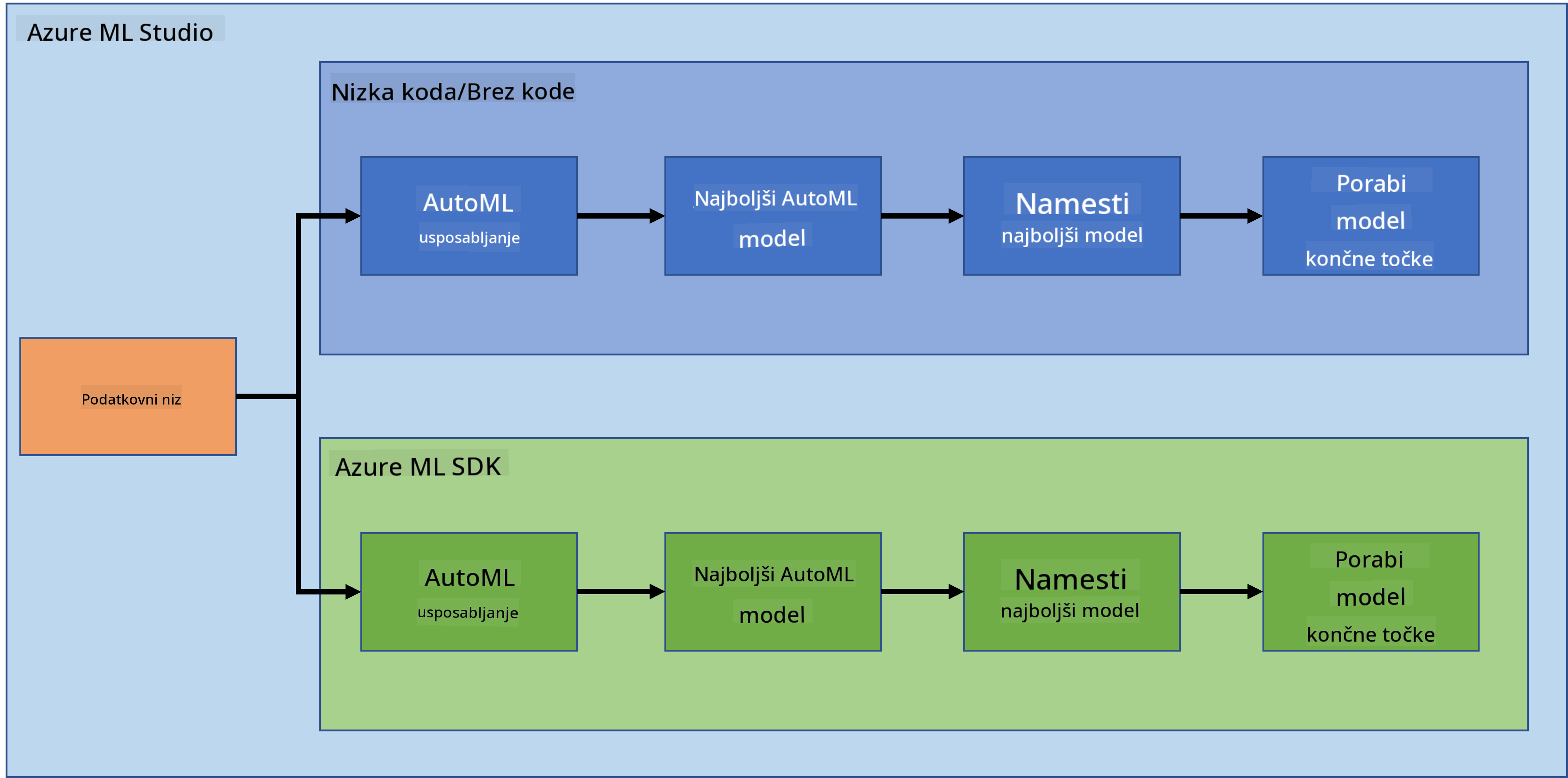
Podatkovna znanost v oblaku: Način "Azure ML SDK"
 |
|---|
| Podatkovna znanost v oblaku: Azure ML SDK - Sketchnote avtorja @nitya |
Kazalo:
- Podatkovna znanost v oblaku: Način "Azure ML SDK"
Predhodni kviz
1. Uvod
1.1 Kaj je Azure ML SDK?
Podatkovni znanstveniki in razvijalci umetne inteligence uporabljajo Azure Machine Learning SDK za gradnjo in izvajanje delovnih tokov strojnega učenja z uporabo storitve Azure Machine Learning. S storitvijo lahko komunicirate v katerem koli okolju Python, vključno z Jupyter Notebooks, Visual Studio Code ali vašim najljubšim IDE za Python.
Ključna področja SDK vključujejo:
- Raziskovanje, pripravo in upravljanje življenjskega cikla podatkovnih zbirk, uporabljenih v eksperimentih strojnega učenja.
- Upravljanje oblačnih virov za spremljanje, beleženje in organizacijo eksperimentov strojnega učenja.
- Učenje modelov lokalno ali z uporabo oblačnih virov, vključno z GPU-pospešenim učenjem modelov.
- Uporabo avtomatiziranega strojnega učenja, ki sprejema konfiguracijske parametre in podatke za učenje. Samodejno preizkuša algoritme in nastavitve hiperparametrov, da najde najboljši model za napovedovanje.
- Implementacijo spletnih storitev za pretvorbo naučenih modelov v RESTful storitve, ki jih je mogoče uporabiti v katerikoli aplikaciji.
Več o Azure Machine Learning SDK
V prejšnji lekciji smo videli, kako naučiti, implementirati in uporabiti model na način z malo ali brez kode. Uporabili smo podatkovno zbirko o srčnem popuščanju za ustvarjanje modela za napovedovanje srčnega popuščanja. V tej lekciji bomo naredili enako, vendar z uporabo Azure Machine Learning SDK.
1.2 Predstavitev projekta in podatkovne zbirke za napovedovanje srčnega popuščanja
Oglejte si tukaj predstavitev projekta in podatkovne zbirke za napovedovanje srčnega popuščanja.
2. Učenje modela z Azure ML SDK
2.1 Ustvarjanje delovnega prostora Azure ML
Za enostavnost bomo delali v Jupyter Notebooku. To pomeni, da že imate delovni prostor in računalniški primerek. Če že imate delovni prostor, lahko neposredno preskočite na razdelek 2.3 Ustvarjanje beležk.
Če ne, sledite navodilom v razdelku 2.1 Ustvarjanje delovnega prostora Azure ML v prejšnji lekciji za ustvarjanje delovnega prostora.
2.2 Ustvarjanje računalniškega primerka
V delovnem prostoru Azure ML, ki smo ga ustvarili prej, pojdite v meni za računalniške vire, kjer boste videli različne razpoložljive računalniške vire.
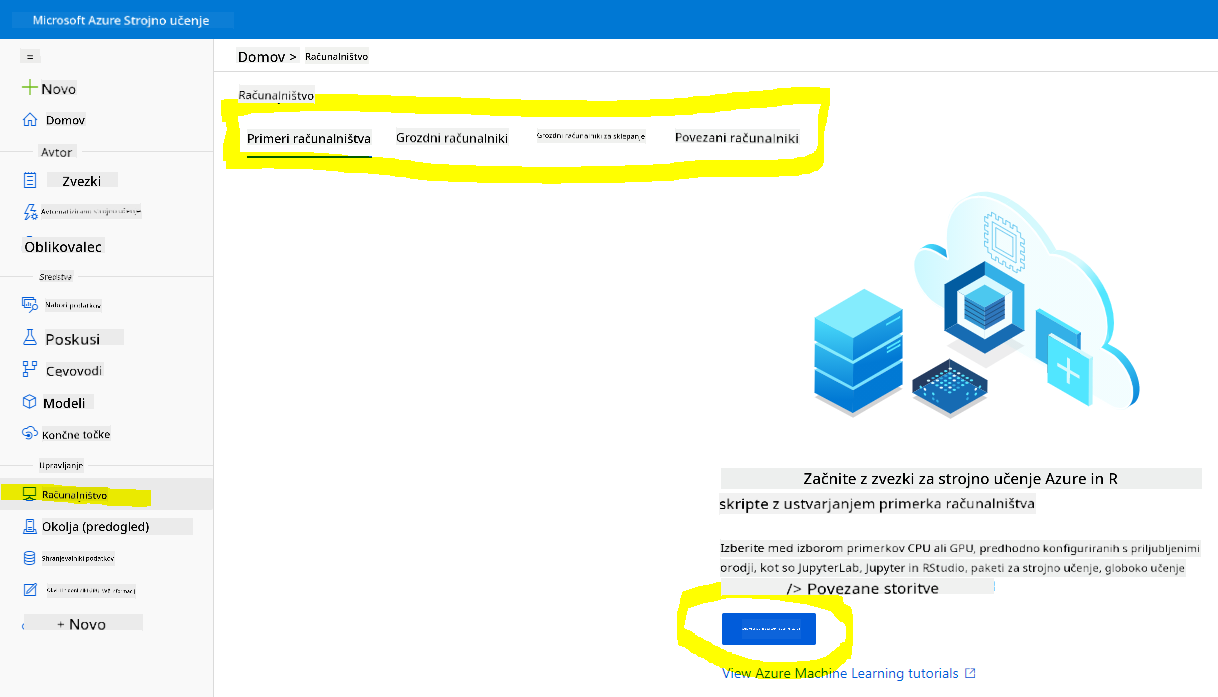
Ustvarimo računalniški primerek za zagotavljanje Jupyter Notebooka.
- Kliknite na gumb + New.
- Dajte ime svojemu računalniškemu primerku.
- Izberite možnosti: CPU ali GPU, velikost VM in število jeder.
- Kliknite na gumb Create.
Čestitamo, pravkar ste ustvarili računalniški primerek! Ta primerek bomo uporabili za ustvarjanje beležke v razdelku Ustvarjanje beležk.
2.3 Nalaganje podatkovne zbirke
Če še niste naložili podatkovne zbirke, si oglejte razdelek 2.3 Nalaganje podatkovne zbirke v prejšnji lekciji.
2.4 Ustvarjanje beležk
OPOMBA: Za naslednji korak lahko ustvarite novo beležko iz nič ali pa naložite beležko, ki smo jo ustvarili v Azure ML Studio. Za nalaganje preprosto kliknite na meni "Notebook" in naložite beležko.
Beležke so zelo pomemben del procesa podatkovne znanosti. Uporabljajo se lahko za izvedbo raziskovalne analize podatkov (EDA), klicanje računalniškega grozda za učenje modela ali klicanje grozda za sklepanje za implementacijo končne točke.
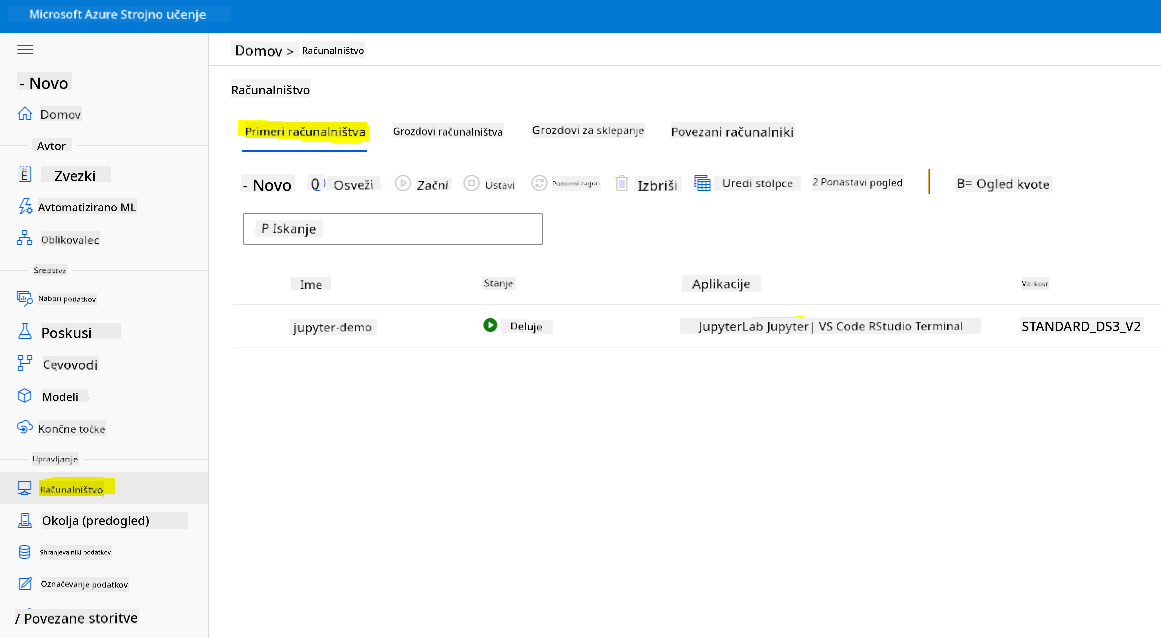
Za ustvarjanje beležke potrebujemo računalniško vozlišče, ki zagotavlja instanco Jupyter Notebooka. Vrnite se v delovni prostor Azure ML in kliknite na Računalniški primerki. Na seznamu računalniških primerkov bi morali videti računalniški primerek, ki smo ga ustvarili prej.
- V razdelku Aplikacije kliknite na možnost Jupyter.
- Označite polje "Yes, I understand" in kliknite na gumb Continue.
- To bi moralo odpreti nov zavihek brskalnika z vašo instanco Jupyter Notebooka, kot je prikazano spodaj. Kliknite na gumb "New" za ustvarjanje beležke.
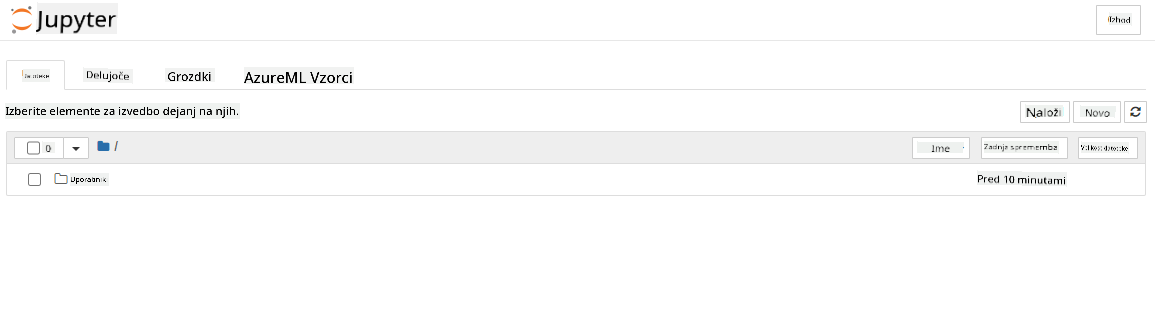
Zdaj, ko imamo beležko, lahko začnemo z učenjem modela z Azure ML SDK.
2.5 Učenje modela
Najprej, če imate kakršen koli dvom, si oglejte dokumentacijo Azure ML SDK. Vsebuje vse potrebne informacije za razumevanje modulov, ki jih bomo obravnavali v tej lekciji.
2.5.1 Nastavitev delovnega prostora, eksperimenta, računalniškega grozda in podatkovne zbirke
Delovni prostor naložite iz konfiguracijske datoteke z naslednjo kodo:
from azureml.core import Workspace
ws = Workspace.from_config()
To vrne objekt tipa Workspace, ki predstavlja delovni prostor. Nato morate ustvariti eksperiment z naslednjo kodo:
from azureml.core import Experiment
experiment_name = 'aml-experiment'
experiment = Experiment(ws, experiment_name)
Za pridobitev ali ustvarjanje eksperimenta iz delovnega prostora zahtevate eksperiment z imenom eksperimenta. Ime eksperimenta mora imeti od 3 do 36 znakov, se začeti s črko ali številko in lahko vsebuje le črke, številke, podčrtaje in vezaje. Če eksperiment ni najden v delovnem prostoru, se ustvari nov eksperiment.
Zdaj morate ustvariti računalniški grozd za učenje z naslednjo kodo. Upoštevajte, da lahko ta korak traja nekaj minut.
from azureml.core.compute import AmlCompute
aml_name = "heart-f-cluster"
try:
aml_compute = AmlCompute(ws, aml_name)
print('Found existing AML compute context.')
except:
print('Creating new AML compute context.')
aml_config = AmlCompute.provisioning_configuration(vm_size = "Standard_D2_v2", min_nodes=1, max_nodes=3)
aml_compute = AmlCompute.create(ws, name = aml_name, provisioning_configuration = aml_config)
aml_compute.wait_for_completion(show_output = True)
cts = ws.compute_targets
compute_target = cts[aml_name]
Podatkovno zbirko lahko pridobite iz delovnega prostora z uporabo imena podatkovne zbirke na naslednji način:
dataset = ws.datasets['heart-failure-records']
df = dataset.to_pandas_dataframe()
df.describe()
2.5.2 Konfiguracija AutoML in učenje
Za nastavitev konfiguracije AutoML uporabite razred AutoMLConfig.
Kot je opisano v dokumentaciji, je na voljo veliko parametrov, s katerimi se lahko igrate. Za ta projekt bomo uporabili naslednje parametre:
experiment_timeout_minutes: Najdaljši čas (v minutah), ki je dovoljen za izvajanje eksperimenta, preden se samodejno ustavi in rezultati postanejo na voljo.max_concurrent_iterations: Največje število hkratnih iteracij učenja, dovoljenih za eksperiment.primary_metric: Primarna metrika, ki se uporablja za določanje statusa eksperimenta.compute_target: Ciljni računalniški vir Azure Machine Learning za izvajanje eksperimenta avtomatiziranega strojnega učenja.task: Vrsta naloge, ki jo je treba izvesti. Vrednosti so lahko 'classification', 'regression' ali 'forecasting', odvisno od vrste problema avtomatiziranega strojnega učenja.training_data: Podatki za učenje, ki se uporabljajo v eksperimentu. Vsebujejo tako značilnosti za učenje kot stolpec z oznakami (po želji tudi stolpec z utežmi vzorcev).label_column_name: Ime stolpca z oznakami.path: Celotna pot do mape projekta Azure Machine Learning.enable_early_stopping: Ali omogočiti zgodnjo zaustavitev, če se rezultat kratkoročno ne izboljšuje.featurization: Indikator, ali naj se korak featurizacije izvede samodejno ali ne, ali naj se uporabi prilagojena featurizacija.debug_log: Dnevniška datoteka za zapisovanje informacij za odpravljanje napak.
from azureml.train.automl import AutoMLConfig
project_folder = './aml-project'
automl_settings = {
"experiment_timeout_minutes": 20,
"max_concurrent_iterations": 3,
"primary_metric" : 'AUC_weighted'
}
automl_config = AutoMLConfig(compute_target=compute_target,
task = "classification",
training_data=dataset,
label_column_name="DEATH_EVENT",
path = project_folder,
enable_early_stopping= True,
featurization= 'auto',
debug_log = "automl_errors.log",
**automl_settings
)
Zdaj, ko imate konfiguracijo nastavljeno, lahko model naučite z naslednjo kodo. Ta korak lahko traja do ene ure, odvisno od velikosti vašega grozda.
remote_run = experiment.submit(automl_config)
Za prikaz različnih eksperimentov lahko zaženete pripomoček RunDetails.
from azureml.widgets import RunDetails
RunDetails(remote_run).show()
3. Implementacija modela in uporaba končne točke z Azure ML SDK
3.1 Shranjevanje najboljšega modela
remote_run je objekt tipa AutoMLRun. Ta objekt vsebuje metodo get_output(), ki vrne najboljši zagon in ustrezni naučeni model.
best_run, fitted_model = remote_run.get_output()
Parametre, uporabljene za najboljši model, si lahko ogledate tako, da preprosto natisnete fitted_model, lastnosti najboljšega modela pa z metodo get_properties().
best_run.get_properties()
Zdaj registrirajte model z metodo register_model.
model_name = best_run.properties['model_name']
script_file_name = 'inference/score.py'
best_run.download_file('outputs/scoring_file_v_1_0_0.py', 'inference/score.py')
description = "aml heart failure project sdk"
model = best_run.register_model(model_name = model_name,
model_path = './outputs/',
description = description,
tags = None)
3.2 Implementacija modela
Ko je najboljši model shranjen, ga lahko implementiramo z razredom InferenceConfig. InferenceConfig predstavlja nastavitve konfiguracije za prilagojeno okolje, uporabljeno za implementacijo. Razred AciWebservice predstavlja model strojnega učenja, implementiran kot spletna storitev na kontejnerskih primerkih Azure. Implementirana storitev je uravnotežena HTTP-končna točka z REST API-jem. Temu API-ju lahko pošljete podatke in prejmete napoved, ki jo vrne model.
Model je implementiran z metodo deploy.
from azureml.core.model import InferenceConfig, Model
from azureml.core.webservice import AciWebservice
inference_config = InferenceConfig(entry_script=script_file_name, environment=best_run.get_environment())
aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1,
memory_gb = 1,
tags = {'type': "automl-heart-failure-prediction"},
description = 'Sample service for AutoML Heart Failure Prediction')
aci_service_name = 'automl-hf-sdk'
aci_service = Model.deploy(ws, aci_service_name, [model], inference_config, aciconfig)
aci_service.wait_for_deployment(True)
print(aci_service.state)
Ta korak lahko traja nekaj minut.
3.3 Uporaba končne točke
Končno točko uporabite tako, da ustvarite vzorčni vhod:
data = {
"data":
[
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
test_sample = str.encode(json.dumps(data))
Nato lahko ta vhod pošljete svojemu modelu za napovedovanje:
response = aci_service.run(input_data=test_sample)
response
To bi moralo vrniti '{"result": [false]}'. To pomeni, da je vnos pacienta, ki smo ga poslali na končno točko, ustvaril napoved false, kar pomeni, da ta oseba verjetno ne bo doživela srčnega napada.
Čestitke! Pravkar ste uporabili model, ki je bil razporejen in treniran na Azure ML z uporabo Azure ML SDK!
NOTE: Ko zaključite projekt, ne pozabite izbrisati vseh virov.
🚀 Izziv
Obstaja veliko drugih stvari, ki jih lahko naredite prek SDK-ja, žal pa jih v tej lekciji ne moremo obravnavati vseh. Ampak dobra novica je, da vas lahko sposobnost hitrega pregledovanja dokumentacije SDK popelje daleč. Oglejte si dokumentacijo Azure ML SDK in poiščite razred Pipeline, ki vam omogoča ustvarjanje cevovodov. Cevovod je zbirka korakov, ki jih je mogoče izvesti kot delovni tok.
NAMIG: Obiščite SDK dokumentacijo in v iskalno vrstico vnesite ključne besede, kot je "Pipeline". Med rezultati iskanja bi morali najti razred azureml.pipeline.core.Pipeline.
Kvizi po predavanju
Pregled in samostojno učenje
V tej lekciji ste se naučili, kako trenirati, razporediti in uporabiti model za napovedovanje tveganja srčnega popuščanja z uporabo Azure ML SDK v oblaku. Oglejte si to dokumentacijo za dodatne informacije o Azure ML SDK. Poskusite ustvariti svoj model z uporabo Azure ML SDK.
Naloga
Projekt podatkovne znanosti z uporabo Azure ML SDK
Omejitev odgovornosti:
Ta dokument je bil preveden z uporabo storitve za strojno prevajanje Co-op Translator. Čeprav si prizadevamo za natančnost, vas prosimo, da upoštevate, da lahko avtomatizirani prevodi vsebujejo napake ali netočnosti. Izvirni dokument v njegovem maternem jeziku je treba obravnavati kot avtoritativni vir. Za ključne informacije priporočamo profesionalni človeški prevod. Ne prevzemamo odgovornosti za morebitne nesporazume ali napačne razlage, ki izhajajo iz uporabe tega prevoda.