23 KiB
Práca s dátami: Python a knižnica Pandas
 |
|---|
| Práca s Pythonom - Sketchnote od @nitya |
Databázy ponúkajú veľmi efektívne spôsoby ukladania dát a ich dotazovania pomocou dotazovacích jazykov, no najflexibilnejším spôsobom spracovania dát je napísanie vlastného programu na manipuláciu s dátami. V mnohých prípadoch by bolo efektívnejšie použiť dotaz do databázy. Avšak v niektorých situáciách, keď je potrebné komplexnejšie spracovanie dát, to nie je jednoduché vykonať pomocou SQL. Spracovanie dát je možné programovať v akomkoľvek programovacom jazyku, ale existujú jazyky, ktoré sú na prácu s dátami na vyššej úrovni. Dátoví vedci zvyčajne preferujú jeden z nasledujúcich jazykov:
- Python, univerzálny programovací jazyk, ktorý je často považovaný za jednu z najlepších možností pre začiatočníkov vďaka svojej jednoduchosti. Python má množstvo doplnkových knižníc, ktoré vám môžu pomôcť vyriešiť praktické problémy, ako napríklad extrakciu dát zo ZIP archívu alebo konverziu obrázku na odtiene šedej. Okrem dátovej vedy sa Python často používa aj na vývoj webových aplikácií.
- R je tradičný nástroj vyvinutý s ohľadom na štatistické spracovanie dát. Obsahuje veľké úložisko knižníc (CRAN), čo z neho robí dobrú voľbu na spracovanie dát. R však nie je univerzálny programovací jazyk a mimo oblasti dátovej vedy sa používa len zriedka.
- Julia je ďalší jazyk vyvinutý špeciálne pre dátovú vedu. Je navrhnutý tak, aby poskytoval lepší výkon ako Python, čo z neho robí skvelý nástroj na vedecké experimentovanie.
V tejto lekcii sa zameriame na používanie Pythonu na jednoduché spracovanie dát. Predpokladáme základnú znalosť jazyka. Ak chcete hlbší úvod do Pythonu, môžete sa pozrieť na jeden z nasledujúcich zdrojov:
- Naučte sa Python zábavným spôsobom pomocou Turtle Graphics a fraktálov - rýchly úvodný kurz do programovania v Pythone na GitHube
- Urobte svoje prvé kroky s Pythonom - vzdelávacia cesta na Microsoft Learn
Dáta môžu mať rôzne formy. V tejto lekcii sa budeme zaoberať tromi formami dát - tabuľkovými dátami, textom a obrázkami.
Zameriame sa na niekoľko príkladov spracovania dát, namiesto toho, aby sme vám poskytli úplný prehľad všetkých súvisiacich knižníc. To vám umožní získať základnú predstavu o tom, čo je možné, a zanechá vám pochopenie, kde nájsť riešenia vašich problémov, keď ich budete potrebovať.
Najužitočnejšia rada. Keď potrebujete vykonať určitú operáciu na dátach, o ktorej neviete, ako ju vykonať, skúste ju vyhľadať na internete. Stackoverflow zvyčajne obsahuje množstvo užitočných ukážok kódu v Pythone pre mnohé typické úlohy.
Kvíz pred prednáškou
Tabuľkové dáta a DataFrame
S tabuľkovými dátami ste sa už stretli, keď sme hovorili o relačných databázach. Keď máte veľa dát, ktoré sú uložené v mnohých rôznych prepojených tabuľkách, určite má zmysel používať SQL na prácu s nimi. Existuje však veľa prípadov, keď máme tabuľku dát a potrebujeme získať nejaké pochopenie alebo poznatky o týchto dátach, ako napríklad rozdelenie, korelácia medzi hodnotami atď. V dátovej vede je veľa situácií, keď potrebujeme vykonať nejaké transformácie pôvodných dát, nasledované vizualizáciou. Obe tieto kroky je možné jednoducho vykonať pomocou Pythonu.
Existujú dve najužitočnejšie knižnice v Pythone, ktoré vám môžu pomôcť pracovať s tabuľkovými dátami:
- Pandas umožňuje manipulovať s tzv. DataFrame, ktoré sú analogické relačným tabuľkám. Môžete mať pomenované stĺpce a vykonávať rôzne operácie na riadkoch, stĺpcoch a DataFrame všeobecne.
- Numpy je knižnica na prácu s tenzormi, t.j. viacrozmernými poľami. Pole má hodnoty rovnakého základného typu a je jednoduchšie ako DataFrame, ale ponúka viac matematických operácií a vytvára menšiu režijnú záťaž.
Existuje aj niekoľko ďalších knižníc, o ktorých by ste mali vedieť:
- Matplotlib je knižnica používaná na vizualizáciu dát a kreslenie grafov
- SciPy je knižnica s niektorými doplnkovými vedeckými funkciami. Už sme sa s touto knižnicou stretli, keď sme hovorili o pravdepodobnosti a štatistike
Tu je kúsok kódu, ktorý by ste zvyčajne použili na import týchto knižníc na začiatku vášho programu v Pythone:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import ... # you need to specify exact sub-packages that you need
Pandas je založený na niekoľkých základných konceptoch.
Series
Series je sekvencia hodnôt, podobná zoznamu alebo numpy poľu. Hlavný rozdiel je v tom, že Series má tiež index, a keď pracujeme so Series (napr. ich sčítavame), index sa berie do úvahy. Index môže byť taký jednoduchý ako číslo riadku (je to predvolený index pri vytváraní Series zo zoznamu alebo poľa), alebo môže mať komplexnú štruktúru, ako napríklad časový interval.
Poznámka: V sprievodnom notebooku
notebook.ipynbje niekoľko úvodných ukážok kódu Pandas. Tu uvádzame len niektoré príklady, ale určite si môžete pozrieť celý notebook.
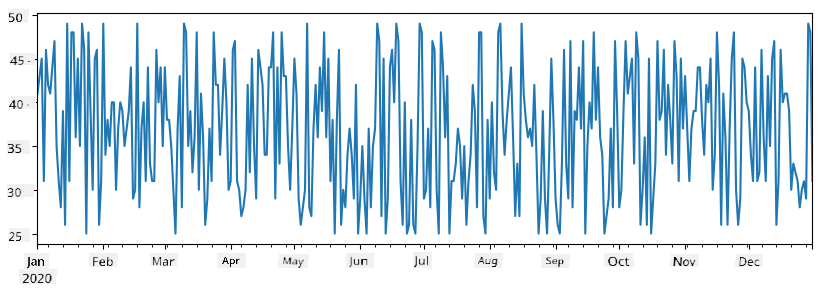
Zvážte príklad: chceme analyzovať predaj nášho stánku so zmrzlinou. Vygenerujme sériu čísel predaja (počet predaných položiek každý deň) za určité časové obdobie:
start_date = "Jan 1, 2020"
end_date = "Mar 31, 2020"
idx = pd.date_range(start_date,end_date)
print(f"Length of index is {len(idx)}")
items_sold = pd.Series(np.random.randint(25,50,size=len(idx)),index=idx)
items_sold.plot()
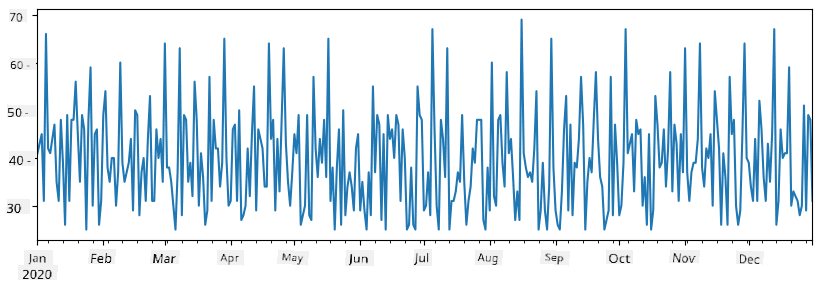
Predpokladajme, že každý týždeň organizujeme párty pre priateľov a berieme na párty ďalších 10 balení zmrzliny. Môžeme vytvoriť ďalšiu sériu, indexovanú podľa týždňov, aby sme to ukázali:
additional_items = pd.Series(10,index=pd.date_range(start_date,end_date,freq="W"))
Keď sčítame dve série, dostaneme celkový počet:
total_items = items_sold.add(additional_items,fill_value=0)
total_items.plot()
Poznámka: Nepoužívame jednoduchú syntax
total_items+additional_items. Ak by sme to urobili, dostali by sme veľa hodnôtNaN(Not a Number) v výslednej sérii. Je to preto, že pre niektoré indexové body v sériiadditional_itemschýbajú hodnoty, a sčítanieNaNs čímkoľvek vedie kNaN. Preto musíme počas sčítania špecifikovať parameterfill_value.
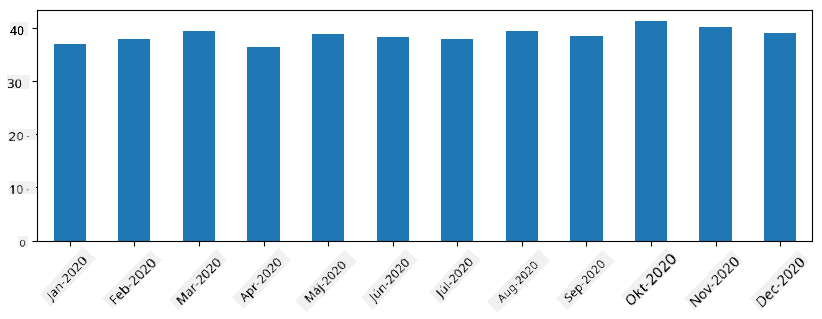
Pri časových sériách môžeme tiež preukladať sériu s rôznymi časovými intervalmi. Napríklad, ak chceme vypočítať priemerný objem predaja mesačne, môžeme použiť nasledujúci kód:
monthly = total_items.resample("1M").mean()
ax = monthly.plot(kind='bar')
DataFrame
DataFrame je v podstate kolekcia sérií s rovnakým indexom. Môžeme spojiť niekoľko sérií do jedného DataFrame:
a = pd.Series(range(1,10))
b = pd.Series(["I","like","to","play","games","and","will","not","change"],index=range(0,9))
df = pd.DataFrame([a,b])
Týmto vytvoríme horizontálnu tabuľku ako túto:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 1 | I | like | to | use | Python | and | Pandas | very | much |
Môžeme tiež použiť Series ako stĺpce a špecifikovať názvy stĺpcov pomocou slovníka:
df = pd.DataFrame({ 'A' : a, 'B' : b })
Týmto získame tabuľku ako túto:
| A | B | |
|---|---|---|
| 0 | 1 | I |
| 1 | 2 | like |
| 2 | 3 | to |
| 3 | 4 | use |
| 4 | 5 | Python |
| 5 | 6 | and |
| 6 | 7 | Pandas |
| 7 | 8 | very |
| 8 | 9 | much |
Poznámka: Túto tabuľku môžeme tiež získať transponovaním predchádzajúcej tabuľky, napr. napísaním
df = pd.DataFrame([a,b]).T..rename(columns={ 0 : 'A', 1 : 'B' })
Tu .T znamená operáciu transponovania DataFrame, t.j. zmenu riadkov a stĺpcov, a operácia rename nám umožňuje premenovať stĺpce tak, aby zodpovedali predchádzajúcemu príkladu.
Tu sú niektoré z najdôležitejších operácií, ktoré môžeme vykonávať na DataFrame:
Výber stĺpcov. Môžeme vybrať jednotlivé stĺpce napísaním df['A'] - táto operácia vráti Series. Môžeme tiež vybrať podmnožinu stĺpcov do iného DataFrame napísaním df[['B','A']] - to vráti ďalší DataFrame.
Filtrovanie len určitých riadkov podľa kritérií. Napríklad, ak chceme ponechať len riadky, kde je stĺpec A väčší ako 5, môžeme napísať df[df['A']>5].
Poznámka: Spôsob, akým filtrovanie funguje, je nasledujúci. Výraz
df['A']<5vráti booleovskú sériu, ktorá indikuje, či je výrazTruealeboFalsepre každý prvok pôvodnej sériedf['A']. Keď sa booleovská séria použije ako index, vráti podmnožinu riadkov v DataFrame. Preto nie je možné použiť ľubovoľný Python booleovský výraz, napríklad napísaniedf[df['A']>5 and df['A']<7]by bolo nesprávne. Namiesto toho by ste mali použiť špeciálnu operáciu&na booleovských sériách, napísanímdf[(df['A']>5) & (df['A']<7)](zátvorky sú tu dôležité).
Vytváranie nových vypočítateľných stĺpcov. Môžeme jednoducho vytvoriť nové vypočítateľné stĺpce pre náš DataFrame pomocou intuitívneho výrazu ako tento:
df['DivA'] = df['A']-df['A'].mean()
Tento príklad vypočíta odchýlku A od jeho priemernej hodnoty. Čo sa tu vlastne deje, je, že počítame sériu a potom túto sériu priraďujeme na ľavú stranu, čím vytvárame ďalší stĺpec. Preto nemôžeme použiť žiadne operácie, ktoré nie sú kompatibilné so sériami, napríklad nasledujúci kód je nesprávny:
# Wrong code -> df['ADescr'] = "Low" if df['A'] < 5 else "Hi"
df['LenB'] = len(df['B']) # <- Wrong result
Posledný príklad, hoci je syntakticky správny, nám dáva nesprávny výsledok, pretože priraďuje dĺžku série B všetkým hodnotám v stĺpci, a nie dĺžku jednotlivých prvkov, ako sme zamýšľali.
Ak potrebujeme vypočítať komplexné výrazy ako tento, môžeme použiť funkciu apply. Posledný príklad môžeme napísať takto:
df['LenB'] = df['B'].apply(lambda x : len(x))
# or
df['LenB'] = df['B'].apply(len)
Po vyššie uvedených operáciách skončíme s nasledujúcim DataFrame:
| A | B | DivA | LenB | |
|---|---|---|---|---|
| 0 | 1 | I | -4.0 | 1 |
| 1 | 2 | like | -3.0 | 4 |
| 2 | 3 | to | -2.0 | 2 |
| 3 | 4 | use | -1.0 | 3 |
| 4 | 5 | Python | 0.0 | 6 |
| 5 | 6 | and | 1.0 | 3 |
| 6 | 7 | Pandas | 2.0 | 6 |
| 7 | 8 | very | 3.0 | 4 |
| 8 | 9 | much | 4.0 | 4 |
Výber riadkov podľa čísel je možné vykonať pomocou konštruktu iloc. Napríklad, ak chceme vybrať prvých 5 riadkov z DataFrame:
df.iloc[:5]
Skupinovanie sa často používa na získanie výsledku podobného pivotným tabuľkám v Exceli. Predpokladajme, že chceme vypočítať priemernú hodnotu stĺpca A pre každé dané číslo LenB. Potom môžeme zoskupiť náš DataFrame podľa LenB a zavolať mean:
df.groupby(by='LenB').mean()
Ak potrebujeme vypočítať priemer a počet prvkov v skupine, môžeme použiť komplexnejšiu funkciu aggregate:
df.groupby(by='LenB') \
.aggregate({ 'DivA' : len, 'A' : lambda x: x.mean() }) \
.rename(columns={ 'DivA' : 'Count', 'A' : 'Mean'})
Týmto získame nasledujúcu tabuľku:
| LenB | Count | Mean |
|---|---|---|
| 1 | 1 | 1.000000 |
| 2 | 1 | 3.000000 |
| 3 | 2 | 5.000000 |
| 4 | 3 | 6.333333 |
| 6 | 2 | 6.000000 |
Získavanie dát
Videli sme, aké jednoduché je vytvoriť Series a DataFrames z objektov v Pythone. Dáta však zvyčajne prichádzajú vo forme textového súboru alebo Excel tabuľky. Našťastie, Pandas nám ponúka jednoduchý spôsob, ako načítať dáta z disku. Napríklad, čítanie CSV súboru je také jednoduché ako toto:
df = pd.read_csv('file.csv')
V sekcii "Výzva" uvidíme viac príkladov načítania dát, vrátane ich získavania z externých webových stránok.
Tlačenie a Vizualizácia
Dátový vedec často potrebuje preskúmať dáta, preto je dôležité vedieť ich vizualizovať. Keď je DataFrame veľký, často chceme len overiť, že robíme všetko správne, vytlačením prvých niekoľkých riadkov. To sa dá urobiť zavolaním df.head(). Ak to spustíte v Jupyter Notebooku, vytlačí sa DataFrame v peknej tabuľkovej forme.
Tiež sme videli použitie funkcie plot na vizualizáciu niektorých stĺpcov. Hoci je plot veľmi užitočný pre mnohé úlohy a podporuje rôzne typy grafov cez parameter kind=, vždy môžete použiť knižnicu matplotlib na vykreslenie niečoho zložitejšieho. Vizualizáciu dát podrobne pokryjeme v samostatných lekciách kurzu.
Tento prehľad pokrýva najdôležitejšie koncepty Pandas, avšak knižnica je veľmi bohatá a neexistujú žiadne limity, čo s ňou môžete robiť! Poďme teraz aplikovať tieto znalosti na riešenie konkrétneho problému.
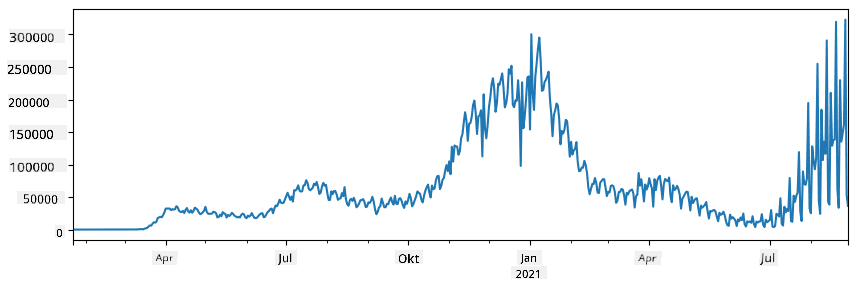
🚀 Výzva 1: Analýza šírenia COVID
Prvý problém, na ktorý sa zameriame, je modelovanie šírenia epidémie COVID-19. Na tento účel použijeme dáta o počte nakazených osôb v rôznych krajinách, ktoré poskytuje Center for Systems Science and Engineering (CSSE) na Johns Hopkins University. Dataset je dostupný v tomto GitHub repozitári.
Keďže chceme demonštrovať, ako pracovať s dátami, pozývame vás otvoriť notebook-covidspread.ipynb a prečítať si ho od začiatku do konca. Môžete tiež spustiť bunky a vyriešiť niektoré výzvy, ktoré sme pre vás nechali na konci.
Ak neviete, ako spustiť kód v Jupyter Notebooku, pozrite si tento článok.
Práca s neštruktúrovanými dátami
Hoci dáta často prichádzajú v tabuľkovej forme, v niektorých prípadoch musíme pracovať s menej štruktúrovanými dátami, napríklad textom alebo obrázkami. V takom prípade, aby sme mohli aplikovať techniky spracovania dát, ktoré sme videli vyššie, musíme nejako extrahovať štruktúrované dáta. Tu je niekoľko príkladov:
- Extrahovanie kľúčových slov z textu a zisťovanie, ako často sa tieto kľúčové slová objavujú
- Použitie neurónových sietí na extrakciu informácií o objektoch na obrázku
- Získavanie informácií o emóciách ľudí na videozázname
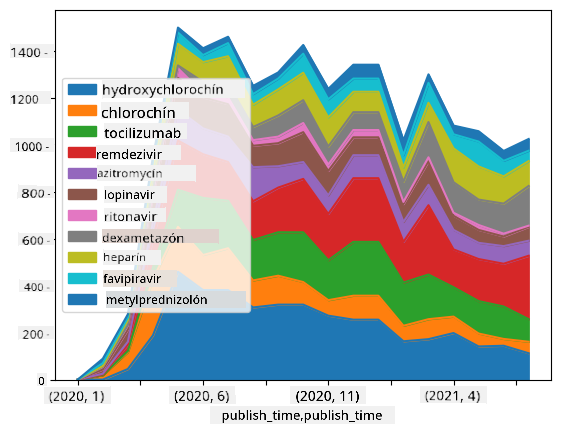
🚀 Výzva 2: Analýza COVID článkov
V tejto výzve budeme pokračovať v téme pandémie COVID a zameriame sa na spracovanie vedeckých článkov na túto tému. Existuje CORD-19 Dataset s viac ako 7000 (v čase písania) článkami o COVID, dostupný s metadátami a abstraktmi (a pre približne polovicu z nich je k dispozícii aj celý text).
Kompletný príklad analýzy tohto datasetu pomocou Text Analytics for Health kognitívnej služby je popísaný v tomto blogovom príspevku. Diskutujeme o zjednodušenej verzii tejto analýzy.
NOTE: Nekopírujeme dataset ako súčasť tohto repozitára. Možno budete musieť najskôr stiahnuť súbor
metadata.csvz tohto datasetu na Kaggle. Môže byť potrebná registrácia na Kaggle. Dataset si môžete stiahnuť aj bez registrácie odtiaľto, ale bude obsahovať všetky plné texty okrem súboru s metadátami.
Otvorte notebook-papers.ipynb a prečítajte si ho od začiatku do konca. Môžete tiež spustiť bunky a vyriešiť niektoré výzvy, ktoré sme pre vás nechali na konci.
Spracovanie obrazových dát
V poslednej dobe boli vyvinuté veľmi výkonné AI modely, ktoré nám umožňujú porozumieť obrázkom. Existuje mnoho úloh, ktoré je možné vyriešiť pomocou predtrénovaných neurónových sietí alebo cloudových služieb. Niektoré príklady zahŕňajú:
- Klasifikácia obrázkov, ktorá vám môže pomôcť kategorizovať obrázok do jednej z preddefinovaných tried. Svoje vlastné klasifikátory obrázkov môžete jednoducho trénovať pomocou služieb ako Custom Vision
- Detekcia objektov na detekciu rôznych objektov na obrázku. Služby ako computer vision dokážu detekovať množstvo bežných objektov a môžete trénovať model Custom Vision na detekciu špecifických objektov, ktoré vás zaujímajú.
- Detekcia tvárí, vrátane veku, pohlavia a detekcie emócií. Toto je možné vykonať pomocou Face API.
Všetky tieto cloudové služby je možné volať pomocou Python SDKs, a teda ich možno ľahko začleniť do vášho pracovného postupu pri skúmaní dát.
Tu sú niektoré príklady skúmania dát z obrazových zdrojov:
- V blogovom príspevku Ako sa naučiť dátovú vedu bez kódovania skúmame fotografie z Instagramu, snažiac sa pochopiť, čo spôsobuje, že ľudia dávajú viac lajkov na fotografiu. Najprv extrahujeme čo najviac informácií z obrázkov pomocou computer vision a potom použijeme Azure Machine Learning AutoML na vytvorenie interpretovateľného modelu.
- V Workshopu o štúdiách tvárí používame Face API na extrakciu emócií ľudí na fotografiách z udalostí, aby sme sa pokúsili pochopiť, čo robí ľudí šťastnými.
Záver
Či už máte štruktúrované alebo neštruktúrované dáta, pomocou Pythonu môžete vykonávať všetky kroky súvisiace so spracovaním a porozumením dát. Je to pravdepodobne najflexibilnejší spôsob spracovania dát, a preto väčšina dátových vedcov používa Python ako svoj primárny nástroj. Naučiť sa Python do hĺbky je pravdepodobne dobrý nápad, ak to s dátovou vedou myslíte vážne!
Kvíz po prednáške
Prehľad a samostatné štúdium
Knihy
Online zdroje
- Oficiálny 10 minútový Pandas tutoriál
- Dokumentácia o vizualizácii v Pandas
Učenie Pythonu
- Naučte sa Python zábavným spôsobom s Turtle Graphics a fraktálmi
- Urobte svoje prvé kroky s Pythonom vzdelávacia cesta na Microsoft Learn
Zadanie
Urobte podrobnejšiu štúdiu dát pre vyššie uvedené výzvy
Kredity
Táto lekcia bola vytvorená s ♥️ od Dmitry Soshnikov
Upozornenie:
Tento dokument bol preložený pomocou služby AI prekladu Co-op Translator. Hoci sa snažíme o presnosť, prosím, berte na vedomie, že automatizované preklady môžu obsahovať chyby alebo nepresnosti. Pôvodný dokument v jeho rodnom jazyku by mal byť považovaný za autoritatívny zdroj. Pre kritické informácie sa odporúča profesionálny ľudský preklad. Nenesieme zodpovednosť za akékoľvek nedorozumenia alebo nesprávne interpretácie vyplývajúce z použitia tohto prekladu.