53 KiB
क्लाउडमा डेटा साइन्स: "कम कोड/नो कोड" तरिका
 |
|---|
| क्लाउडमा डेटा साइन्स: कम कोड - @nitya द्वारा स्केच नोट |
सामग्रीको सूची:
- क्लाउडमा डेटा साइन्स: "कम कोड/नो कोड" तरिका
पाठ अघि क्विज
१. परिचय
१.१ Azure Machine Learning के हो?
Azure क्लाउड प्लेटफर्म २०० भन्दा बढी उत्पादन र क्लाउड सेवाहरूको संग्रह हो, जसले तपाईंलाई नयाँ समाधानहरू जीवनमा ल्याउन मद्दत गर्दछ।
डेटा वैज्ञानिकहरूले डेटा अन्वेषण र पूर्व-प्रक्रिया गर्न, विभिन्न प्रकारका मोडेल-प्रशिक्षण एल्गोरिदमहरू प्रयास गर्न, र सही मोडेल उत्पादन गर्न धेरै समय खर्च गर्छन्। यी कार्यहरू समय खपत गर्ने हुन्छन् र महँगो कम्प्युट हार्डवेयरको प्रभावकारी प्रयोगलाई बाधा पुर्याउन सक्छन्।
Azure ML Azure मा मेसिन लर्निङ समाधानहरू निर्माण र सञ्चालन गर्नका लागि क्लाउड-आधारित प्लेटफर्म हो। यसमा डेटा वैज्ञानिकहरूलाई डेटा तयार गर्न, मोडेल प्रशिक्षण गर्न, भविष्यवाणी सेवाहरू प्रकाशित गर्न, र तिनीहरूको प्रयोगको निगरानी गर्न मद्दत गर्ने सुविधाहरू र क्षमताहरूको विस्तृत श्रृंखला समावेश छ। सबैभन्दा महत्त्वपूर्ण कुरा, यसले मोडेल प्रशिक्षणसँग सम्बन्धित समय खपत गर्ने कार्यहरू स्वचालित गरेर तिनीहरूको दक्षता बढाउँछ; र यसले ठूलो मात्रामा डेटा ह्यान्डल गर्न प्रभावकारी रूपमा स्केल हुने क्लाउड-आधारित कम्प्युट स्रोतहरू प्रयोग गर्न सक्षम बनाउँछ, केवल प्रयोग गर्दा मात्र लागत लाग्ने गरी।
Azure ML ले डेभलपरहरू र डेटा वैज्ञानिकहरूलाई उनीहरूको मेसिन लर्निङ वर्कफ्लोका लागि आवश्यक सबै उपकरणहरू प्रदान गर्दछ। यसमा समावेश छन्:
- Azure Machine Learning Studio: मोडेल प्रशिक्षण, परिनियोजन, स्वचालन, ट्र्याकिङ, र सम्पत्ति व्यवस्थापनका लागि कम कोड र नो कोड विकल्पहरूको लागि वेब पोर्टल। स्टुडियो Azure Machine Learning SDK सँग एकीकृत छ।
- Jupyter Notebooks: छिटो प्रोटोटाइप र ML मोडेल परीक्षण गर्न।
- Azure Machine Learning Designer: प्रयोग गरेर मोड्युलहरू तान्न र छोड्न अनुमति दिन्छ र कम कोड वातावरणमा पाइपलाइनहरू परिनियोजन गर्न।
- Automated machine learning UI (AutoML): मेसिन लर्निङ मोडेल विकासको पुनरावृत्त कार्यहरू स्वचालित गर्दछ, उच्च स्केल, दक्षता, र उत्पादकता सहित ML मोडेलहरू निर्माण गर्न अनुमति दिन्छ।
- Data Labelling: डेटा स्वचालित रूपमा लेबल गर्न सहायक ML उपकरण।
- Machine learning extension for Visual Studio Code: ML परियोजनाहरू निर्माण र व्यवस्थापन गर्न पूर्ण-विशेषता विकास वातावरण प्रदान गर्दछ।
- Machine learning CLI: कमाण्ड लाइनबाट Azure ML स्रोतहरू व्यवस्थापन गर्न कमाण्डहरू प्रदान गर्दछ।
- खुला-स्रोत फ्रेमवर्कहरूसँग एकीकरण जस्तै PyTorch, TensorFlow, Scikit-learn र अन्य धेरै, प्रशिक्षण, परिनियोजन, र मेसिन लर्निङ प्रक्रियाको अन्त-देखि-अन्त व्यवस्थापन गर्न।
- MLflow: यो मेसिन लर्निङ प्रयोगहरूको जीवन चक्र व्यवस्थापन गर्न खुला-स्रोत पुस्तकालय हो। MLFlow Tracking MLflow को एक घटक हो जसले तपाईंको प्रशिक्षण रन मेट्रिक्स र मोडेल कलाकृतिहरू लग र ट्र्याक गर्दछ।
१.२ हार्ट फेल्यर प्रिडिक्शन प्रोजेक्ट:
आफ्नो सीप र ज्ञानलाई परीक्षण गर्न परियोजनाहरू बनाउनु र निर्माण गर्नु सबैभन्दा राम्रो तरिका हो। यस पाठमा, हामी Azure ML Studio मा हार्ट फेल्यर आक्रमणको भविष्यवाणीको लागि डेटा साइन्स परियोजना निर्माण गर्ने दुई फरक तरिकाहरू अन्वेषण गर्नेछौं: कम कोड/नो कोड र Azure ML SDK प्रयोग गरेर।
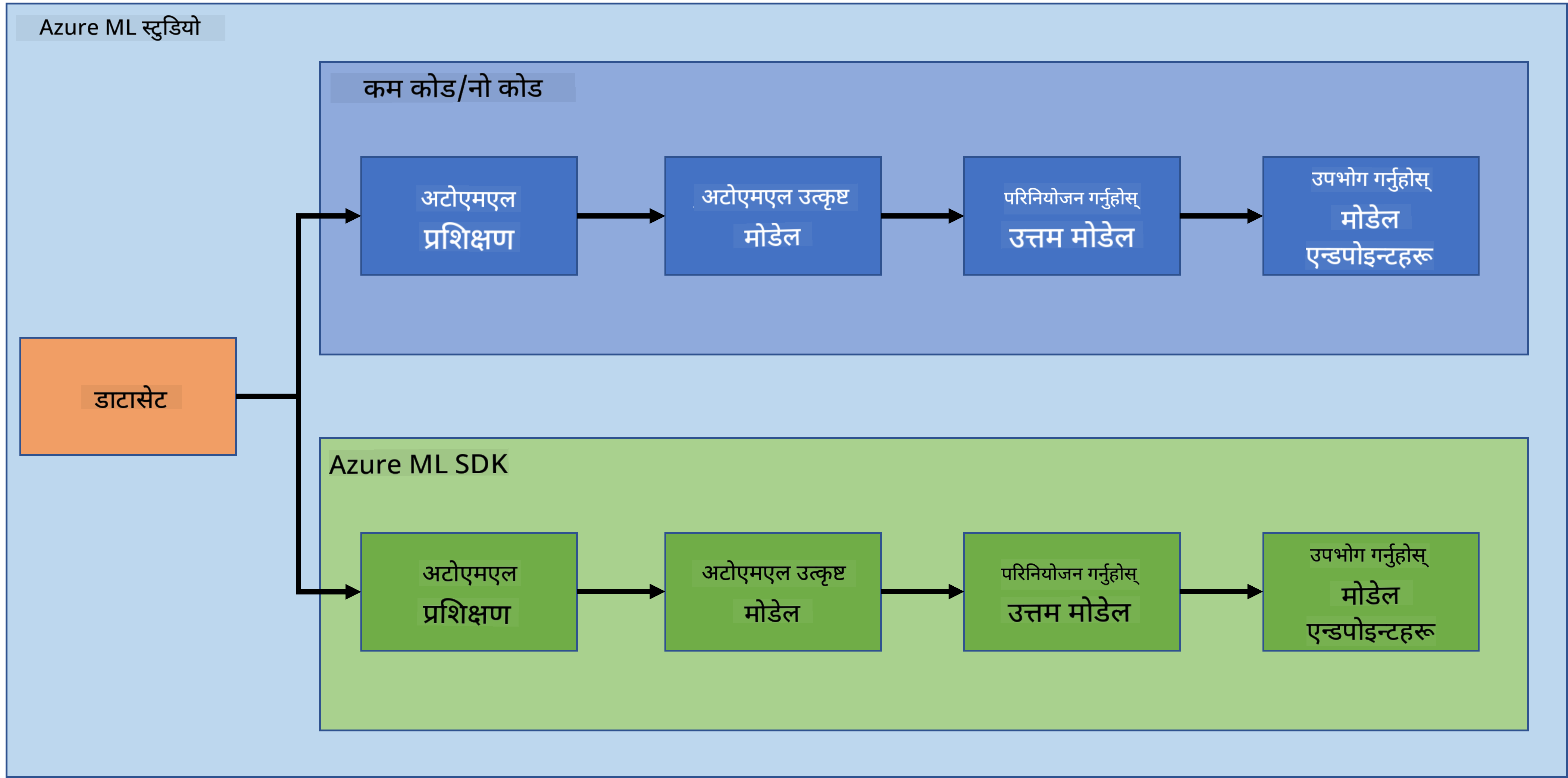
प्रत्येक तरिकाको आफ्नै फाइदा र बेफाइदा छन्। कम कोड/नो कोड तरिका सुरु गर्न सजिलो छ किनभने यसले GUI (ग्राफिकल युजर इन्टरफेस) सँग अन्तरक्रिया समावेश गर्दछ, कोडको कुनै पूर्व ज्ञान आवश्यक छैन। यो विधिले परियोजनाको व्यवहार्यता छिटो परीक्षण गर्न र POC (प्रूफ अफ कन्सेप्ट) सिर्जना गर्न सक्षम बनाउँछ। तर, जब परियोजना बढ्छ र उत्पादनको लागि तयार हुन आवश्यक हुन्छ, GUI मार्फत स्रोतहरू सिर्जना गर्नु व्यावहारिक हुँदैन। त्यसबेला Azure ML SDK प्रयोग गरेर सबै कुरा प्रोग्रामिङ्ग रूपमा स्वचालित गर्न जान्न आवश्यक हुन्छ।
| कम कोड/नो कोड | Azure ML SDK | |
|---|---|---|
| कोडको विशेषज्ञता | आवश्यक छैन | आवश्यक छ |
| विकासको समय | छिटो र सजिलो | कोड विशेषज्ञतामा निर्भर |
| उत्पादनको लागि तयार | छैन | हो |
१.३ हार्ट फेल्यर डेटासेट:
कार्डियोभास्कुलर रोगहरू (CVDs) विश्वव्यापी रूपमा मृत्युको नम्बर १ कारण हुन्, जसले विश्वव्यापी रूपमा ३१% मृत्युको लागि जिम्मेवार छन्।
पर्यावरणीय र व्यवहारजन्य जोखिम कारकहरू जस्तै सुर्तीको प्रयोग, अस्वस्थ आहार र मोटोपन, शारीरिक निष्क्रियता, र मदिराको हानिकारक प्रयोगलाई अनुमान मोडेलहरूको विशेषताका रूपमा प्रयोग गर्न सकिन्छ।
CVD को विकासको सम्भावना अनुमान गर्न सक्षम हुनु उच्च जोखिम भएका व्यक्तिहरूमा आक्रमण रोक्नको लागि धेरै उपयोगी हुन सक्छ।
Kaggle ले Heart Failure dataset सार्वजनिक रूपमा उपलब्ध गराएको छ, जुन हामी यस परियोजनाको लागि प्रयोग गर्नेछौं। तपाईं अहिले डेटासेट डाउनलोड गर्न सक्नुहुन्छ। यो १३ स्तम्भहरू (१२ विशेषताहरू र १ लक्ष्य चर) र २९९ पङ्क्तिहरू भएको ट्याबुलर डेटासेट हो।
| चरको नाम | प्रकार | विवरण | उदाहरण | |
|---|---|---|---|---|
| १ | उमेर | संख्यात्मक | बिरामीको उमेर | २५ |
| २ | एनिमिया | बूलियन | रातो रक्त कोशिका वा हेमोग्लोबिनको कमी | ० वा १ |
| ३ | क्रिएटिनिन फस्फोकाइनेज | संख्यात्मक | रगतमा CPK इन्जाइमको स्तर | ५४२ |
| ४ | मधुमेह | बूलियन | बिरामीलाई मधुमेह छ कि छैन | ० वा १ |
| ५ | इजेक्शन फ्र्याक्शन | संख्यात्मक | प्रत्येक संकुचनमा मुटुबाट बाहिर जाने रगतको प्रतिशत | ४५ |
| ६ | उच्च रक्तचाप | बूलियन | बिरामीलाई उच्च रक्तचाप छ कि छैन | ० वा १ |
| ७ | प्लेटलेट्स | संख्यात्मक | रगतमा प्लेटलेट्स | १४९००० |
| ८ | सिरम क्रिएटिनिन | संख्यात्मक | रगतमा सिरम क्रिएटिनिनको स्तर | ०.५ |
| ९ | सिरम सोडियम | संख्यात्मक | रगतमा सिरम सोडियमको स्तर | जुन |
| १० | लिङ्ग | बूलियन | महिला वा पुरुष | ० वा १ |
| ११ | धूम्रपान | बूलियन | बिरामी धूम्रपान गर्छ कि गर्दैन | ० वा १ |
| १२ | समय | संख्यात्मक | अनुगमन अवधि (दिनहरू) | ४ |
| ---- | --------------------------- | ----------------- | ----------------------------------------------------------- | ------------------- |
| २१ | DEATH_EVENT [लक्ष्य] | बूलियन | अनुगमन अवधिमा बिरामीको मृत्यु हुन्छ कि हुँदैन | ० वा १ |
डेटासेट प्राप्त गरेपछि, हामी Azure मा परियोजना सुरु गर्न सक्छौं।
२. Azure ML Studio मा कम कोड/नो कोड मोडेल प्रशिक्षण
२.१ Azure ML कार्यक्षेत्र सिर्जना गर्नुहोस्
Azure ML मा मोडेल प्रशिक्षण गर्न, तपाईंले पहिलो पटक Azure ML कार्यक्षेत्र सिर्जना गर्न आवश्यक छ। कार्यक्षेत्र Azure Machine Learning को शीर्ष-स्तर स्रोत हो, जसले तपाईंले Azure Machine Learning प्रयोग गर्दा सिर्जना गर्ने सबै कलाकृतिहरूको साथ काम गर्न केन्द्रित स्थान प्रदान गर्दछ। कार्यक्षेत्रले सबै प्रशिक्षण रनहरूको इतिहास राख्छ, जसमा लगहरू, मेट्रिक्स, आउटपुट, र तपाईंको स्क्रिप्टहरूको स्न्यापशट समावेश छ। तपाईंले कुन प्रशिक्षण रनले सबैभन्दा राम्रो मोडेल उत्पादन गर्छ भनेर निर्धारण गर्न यो जानकारी प्रयोग गर्नुहुन्छ। थप जान्नुहोस्
तपाईंको अपरेटिङ सिस्टमसँग उपयुक्त सबैभन्दा अद्यावधिक ब्राउजर प्रयोग गर्न सिफारिस गरिन्छ। निम्न ब्राउजरहरू समर्थित छन्:
- Microsoft Edge (नयाँ Microsoft Edge, पछिल्लो संस्करण। Microsoft Edge legacy होइन)
- Safari (पछिल्लो संस्करण, केवल Mac)
- Chrome (पछिल्लो संस्करण)
- Firefox (पछिल्लो संस्करण)
Azure Machine Learning प्रयोग गर्न, आफ्नो Azure सदस्यतामा कार्यक्षेत्र सिर्जना गर्नुहोस्। त्यसपछि तपाईंले यो कार्यक्षेत्रलाई डेटा, कम्प्युट स्रोतहरू, कोड, मोडेलहरू, र मेसिन लर्निङ वर्कलोडसँग सम्बन्धित अन्य कलाकृतिहरू व्यवस्थापन गर्न प्रयोग गर्न सक्नुहुन्छ।
नोट: तपाईंको Azure सदस्यता कार्यक्षेत्रको लागि डेटा भण्डारणको लागि सानो शुल्क लगाइनेछ, त्यसैले जब तपाईं Azure Machine Learning कार्यक्षेत्र प्रयोग गरिरहनुभएको छैन भने यसलाई मेटाउन सिफारिस गरिन्छ।
१. Azure पोर्टल मा Microsoft क्रेडेन्सियलहरू प्रयोग गरेर साइन इन गर्नुहोस्।
२. +Create a resource चयन गर्नुहोस्।
Machine Learning खोज्नुहोस् र Machine Learning टाइल चयन गर्नुहोस्।
Create बटनमा क्लिक गर्नुहोस्।

सेटिङहरू निम्नानुसार भर्नुहोस्:
- सदस्यता: तपाईंको Azure सदस्यता
- स्रोत समूह: स्रोत समूह सिर्जना गर्नुहोस् वा चयन गर्नुहोस्
- कार्यक्षेत्र नाम: तपाईंको कार्यक्षेत्रको लागि अद्वितीय नाम प्रविष्ट गर्नुहोस्
- क्षेत्र: तपाईंको नजिकको भौगोलिक क्षेत्र चयन गर्नुहोस्
- भण्डारण खाता: तपाईंको कार्यक्षेत्रको लागि सिर्जना गरिने नयाँ भण्डारण खाताको नोट गर्नुहोस्
- Key vault: तपाईंको कार्यक्षेत्रको लागि सिर्जना गरिने नयाँ key vault को नोट गर्नुहोस्
- Application insights: तपाईंको कार्यक्षेत्रको लागि सिर्जना गरिने नयाँ application insights स्रोतको नोट गर्नुहोस्
- Container registry: कुनै पनि छैन (पहिलो पटक तपाईंले मोडेललाई कन्टेनरमा परिनियोजन गर्दा स्वतः सिर्जना हुनेछ)

- Create + review मा क्लिक गर्नुहोस् र त्यसपछि Create बटनमा क्लिक गर्नुहोस्।
३. तपाईंको कार्यक्षेत्र सिर्जना गर्न प्रतीक्षा गर्नुहोस् (यसमा केही मिनेट लाग्न सक्छ)। त्यसपछि पोर्टलमा जानुहोस्। तपाईं यसलाई Machine Learning Azure सेवाबाट फेला पार्न सक्नुहुन्छ।
४. तपाईंको कार्यक्षेत्रको Overview पृष्ठमा, Azure Machine Learning studio सुरु गर्नुहोस् (वा नयाँ ब्राउजर ट्याब खोल्नुहोस् र https://ml.azure.com मा जानुहोस्), र Microsoft खाता प्रयोग गरेर Azure Machine Learning studio मा साइन इन गर्नुहोस्। यदि संकेत गरिएको छ भने, तपाईंको Azure directory र सदस्यता चयन गर्नुहोस्, र तपाईंको Azure Machine Learning कार्यक्षेत्र चयन गर्नुहोस्।
५. Azure Machine Learning studio मा, ☰ आइकनलाई माथि बायाँतिर टगल गर्नुहोस् र इन्टरफेसका विभिन्न पृष्ठहरू हेर्नुहोस्। तपाईंले यी पृष्ठहरू प्रयोग गरेर आफ्नो कार्यक्षेत्रका स्रोतहरू व्यवस्थापन गर्न सक्नुहुन्छ।
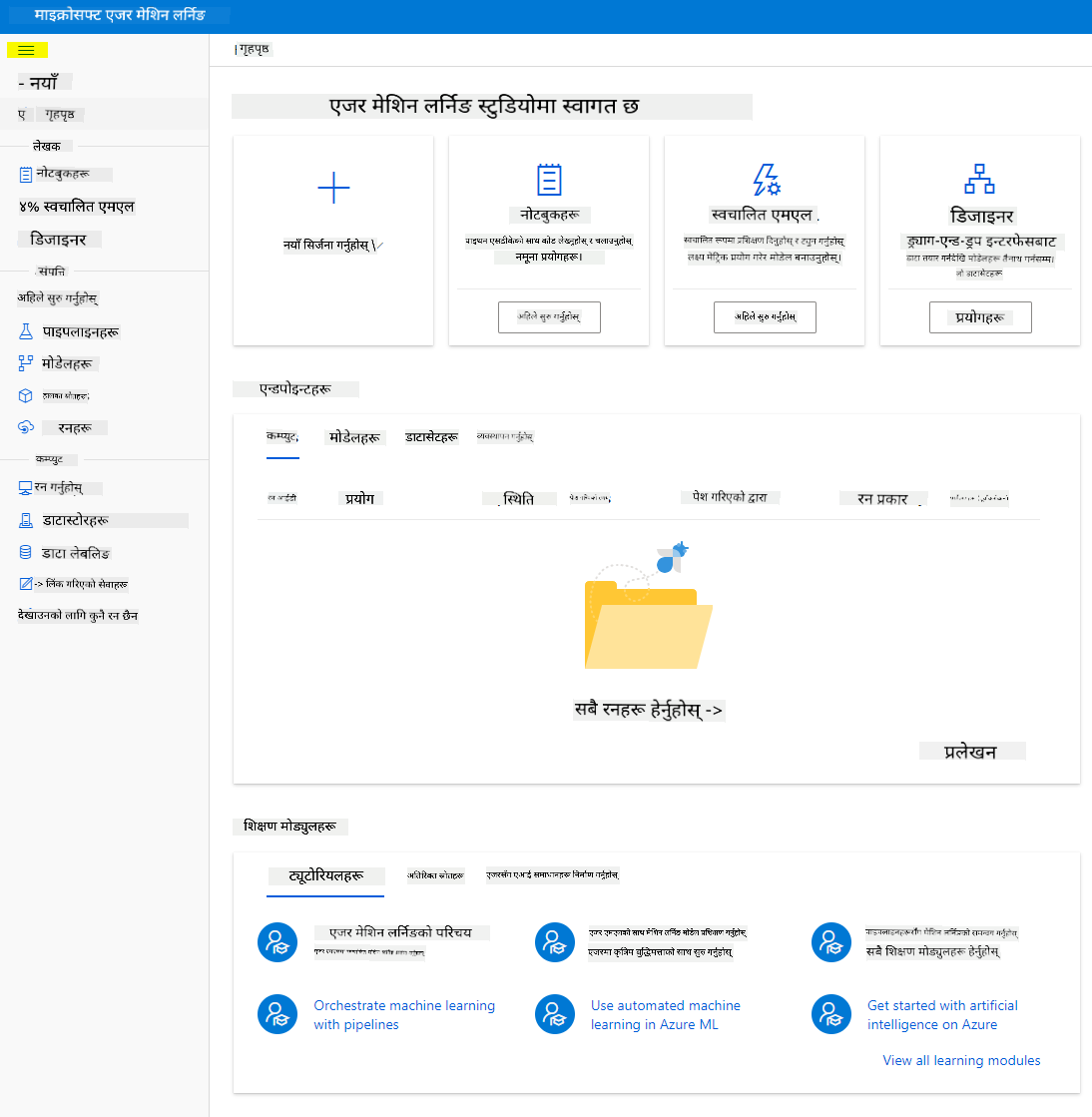
तपाईं आफ्नो कार्यक्षेत्रलाई Azure पोर्टल प्रयोग गरेर व्यवस्थापन गर्न सक्नुहुन्छ, तर डेटा वैज्ञानिकहरू र Machine Learning operations इन्जिनियरहरूका लागि, Azure Machine Learning Studio ले कार्यक्षेत्र स्रोतहरू व्यवस्थापन गर्न अधिक केन्द्रित प्रयोगकर्ता इन्टरफेस प्रदान गर्दछ।
२.२ कम्प्युट स्रोतहरू
कम्प्युट स्रोतहरू क्लाउड-आधारित स्रोतहरू हुन् जसमा तपाईं मोडेल प्रशिक्षण र डेटा अन्वेषण प्रक्रियाहरू चलाउन सक्नुहुन्छ। तपाईंले चार प्रकारका कम्प्युट स्रोतहरू सिर्जना गर्न सक्नुहुन्छ:
- Compute Instances: विकास कार्यस्थलहरू जसलाई डेटा वैज्ञानिकहरूले डेटा र मोडेलहरूसँग काम गर्न प्रयोग गर्न सक्छन्। यसमा Virtual Machine (VM) सिर्जना गर्ने र नोटबुक instance सुरु गर्ने समावेश छ। त्यसपछि तपाईंले कम्प्युट क्लस्टरलाई नोटबुकबाट कल गरेर मोडेल प्रशिक्षण गर्न सक्नुहुन्छ।
- Compute Clusters: VM को स्केलेबल क्लस्टरहरू जसले प्रयोगको माग अनुसार प्रयोगात्मक कोड प्रक्रिया गर्न सक्छ। तपाईंलाई मोडेल प्रशिक्षण गर्दा यसको आवश्यकता पर्छ। Compute clusters ले GPU वा CPU स्रोतहरू पनि प्रयोग गर्न सक्छ।
- Inference Clusters: तपाईंको प्रशिक्षित मोडेलहरू प्रयोग गर्ने भविष्यवाणी सेवाहरूको लागि परिनियोजन लक्ष्य।
- जोडिएको कम्प्युट: Azure कम्प्युट स्रोतहरू जस्तै Virtual Machines वा Azure Databricks क्लस्टरहरूमा लिंक गर्दछ।
2.2.1 कम्प्युट स्रोतहरूको लागि सही विकल्पहरू चयन गर्ने
कम्प्युट स्रोत सिर्जना गर्दा केही महत्त्वपूर्ण पक्षहरू विचार गर्नुपर्छ, र ती विकल्पहरू महत्त्वपूर्ण निर्णयहरू हुन सक्छन्।
तपाईंलाई CPU चाहिन्छ कि GPU?
CPU (Central Processing Unit) कम्प्युटर प्रोग्रामको निर्देशनहरू कार्यान्वयन गर्ने इलेक्ट्रोनिक सर्किट हो। GPU (Graphics Processing Unit) एक विशेष इलेक्ट्रोनिक सर्किट हो जसले ग्राफिक्ससँग सम्बन्धित कोड उच्च दरमा कार्यान्वयन गर्न सक्छ।
CPU र GPU आर्किटेक्चरको मुख्य भिन्नता भनेको CPU विभिन्न प्रकारका कार्यहरू छिटो (CPU घडीको गति अनुसार मापन गरिन्छ) गर्न डिजाइन गरिएको छ, तर एकै समयमा चल्न सक्ने कार्यहरूको सन्दर्भमा सीमित छ। GPU समानान्तर कम्प्युटिङका लागि डिजाइन गरिएको छ र त्यसैले गहिरो सिकाइ कार्यहरूमा धेरै राम्रो छ।
| CPU | GPU |
|---|---|
| कम महँगो | बढी महँगो |
| कम स्तरको समानान्तरता | उच्च स्तरको समानान्तरता |
| गहिरो सिकाइ मोडेलहरू प्रशिक्षणमा ढिलो | गहिरो सिकाइका लागि उपयुक्त |
क्लस्टर आकार
ठूला क्लस्टरहरू महँगो हुन्छन् तर राम्रो प्रतिक्रियाशीलता प्रदान गर्छन्। त्यसैले, यदि तपाईंसँग समय छ तर पर्याप्त पैसा छैन भने, सानो क्लस्टरबाट सुरु गर्नुहोस्। उल्टो, यदि तपाईंसँग पैसा छ तर धेरै समय छैन भने, ठूलो क्लस्टरबाट सुरु गर्नुहोस्।
VM आकार
तपाईंको समय र बजेटको सीमाहरूमा निर्भर गर्दै, तपाईं आफ्नो RAM, डिस्क, कोरहरूको संख्या र घडीको गति परिवर्तन गर्न सक्नुहुन्छ। यी सबै प्यारामिटरहरू बढाउँदा लागत बढ्छ, तर प्रदर्शन राम्रो हुन्छ।
समर्पित वा कम प्राथमिकता भएका उदाहरणहरू?
कम प्राथमिकता भएको उदाहरण भनेको यो बाधित हुनसक्छ भन्ने हो: Microsoft Azure ले ती स्रोतहरू लिन सक्छ र अर्को कार्यमा असाइन गर्न सक्छ, जसले कामलाई बाधा पुर्याउँछ। समर्पित उदाहरण, वा गैर-बाधित, भनेको तपाईंको अनुमति बिना काम कहिल्यै समाप्त हुनेछैन भन्ने हो। यो समय र पैसाको अर्को विचार हो, किनभने बाधित उदाहरणहरू समर्पित उदाहरणहरू भन्दा कम महँगो हुन्छन्।
2.2.2 कम्प्युट क्लस्टर सिर्जना गर्ने
हामीले पहिले सिर्जना गरेको Azure ML workspace मा जानुहोस्, कम्प्युटमा जानुहोस् र तपाईंले विभिन्न कम्प्युट स्रोतहरू देख्न सक्नुहुन्छ (जस्तै कम्प्युट उदाहरणहरू, कम्प्युट क्लस्टरहरू, इन्फरेन्स क्लस्टरहरू र जोडिएको कम्प्युट)। यस परियोजनाको लागि, हामीलाई मोडेल प्रशिक्षणको लागि कम्प्युट क्लस्टर आवश्यक छ। Studio मा, "Compute" मेनुमा क्लिक गर्नुहोस्, त्यसपछि "Compute cluster" ट्याबमा क्लिक गर्नुहोस् र "+ New" बटनमा क्लिक गरेर कम्प्युट क्लस्टर सिर्जना गर्नुहोस्।
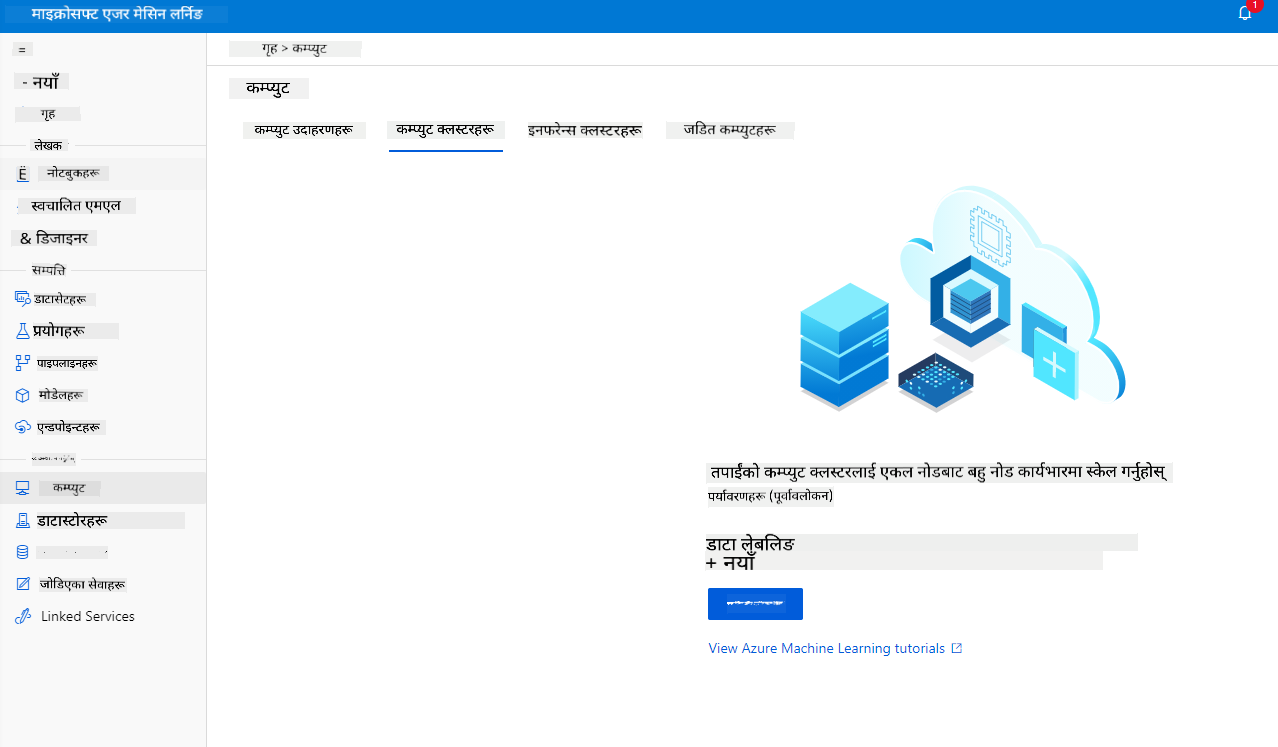
- आफ्नो विकल्पहरू चयन गर्नुहोस्: समर्पित बनाम कम प्राथमिकता, CPU वा GPU, VM आकार र कोर संख्या (यस परियोजनाको लागि डिफल्ट सेटिङहरू राख्न सक्नुहुन्छ)।
- Next बटनमा क्लिक गर्नुहोस्।
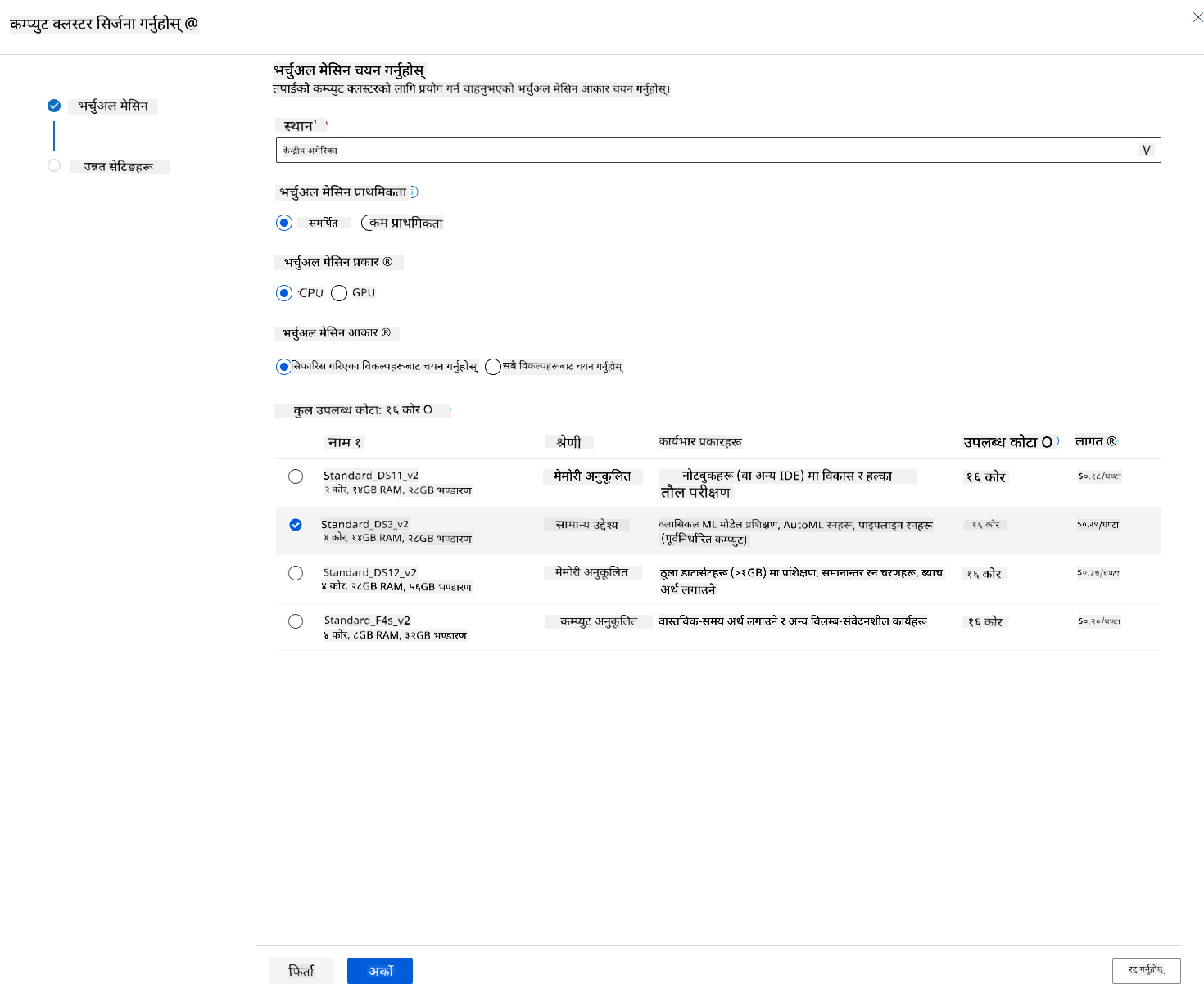
- क्लस्टरलाई कम्प्युट नाम दिनुहोस्।
- आफ्नो विकल्पहरू चयन गर्नुहोस्: न्यूनतम/अधिकतम नोडहरूको संख्या, स्केल डाउन अघि निष्क्रिय सेकेन्डहरू, SSH पहुँच। ध्यान दिनुहोस् कि यदि न्यूनतम नोडहरूको संख्या 0 छ भने, क्लस्टर निष्क्रिय हुँदा तपाईं पैसा बचत गर्नुहुनेछ। ध्यान दिनुहोस् कि अधिकतम नोडहरूको संख्या जति उच्च छ, प्रशिक्षण समय छोटो हुनेछ। अधिकतम नोडहरूको सिफारिस गरिएको संख्या 3 हो।
- "Create" बटनमा क्लिक गर्नुहोस्। यो चरण पूरा हुन केही मिनेट लाग्न सक्छ।
शानदार! अब हामीसँग कम्प्युट क्लस्टर छ, हामीले Azure ML Studio मा डेटा लोड गर्न आवश्यक छ।
2.3 डेटासेट लोड गर्ने
-
हामीले पहिले सिर्जना गरेको Azure ML workspace मा, बायाँ मेनुमा "Datasets" मा क्लिक गर्नुहोस् र "+ Create dataset" बटनमा क्लिक गरेर डेटासेट सिर्जना गर्नुहोस्। "From local files" विकल्प चयन गर्नुहोस् र हामीले पहिले डाउनलोड गरेको Kaggle डेटासेट चयन गर्नुहोस्।
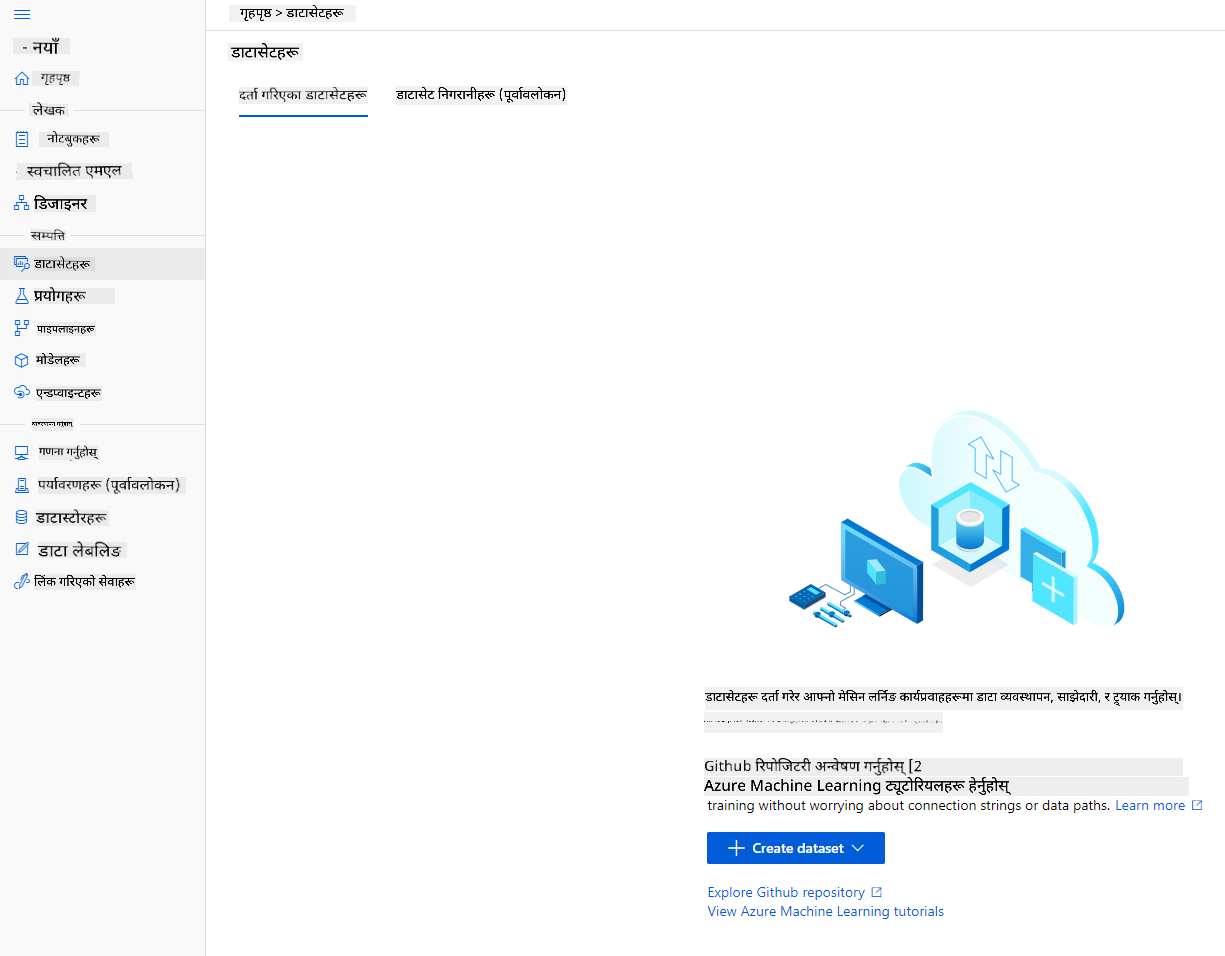
-
आफ्नो डेटासेटलाई नाम, प्रकार र विवरण दिनुहोस्। Next मा क्लिक गर्नुहोस्। फाइलहरूबाट डेटा अपलोड गर्नुहोस्। Next मा क्लिक गर्नुहोस्।
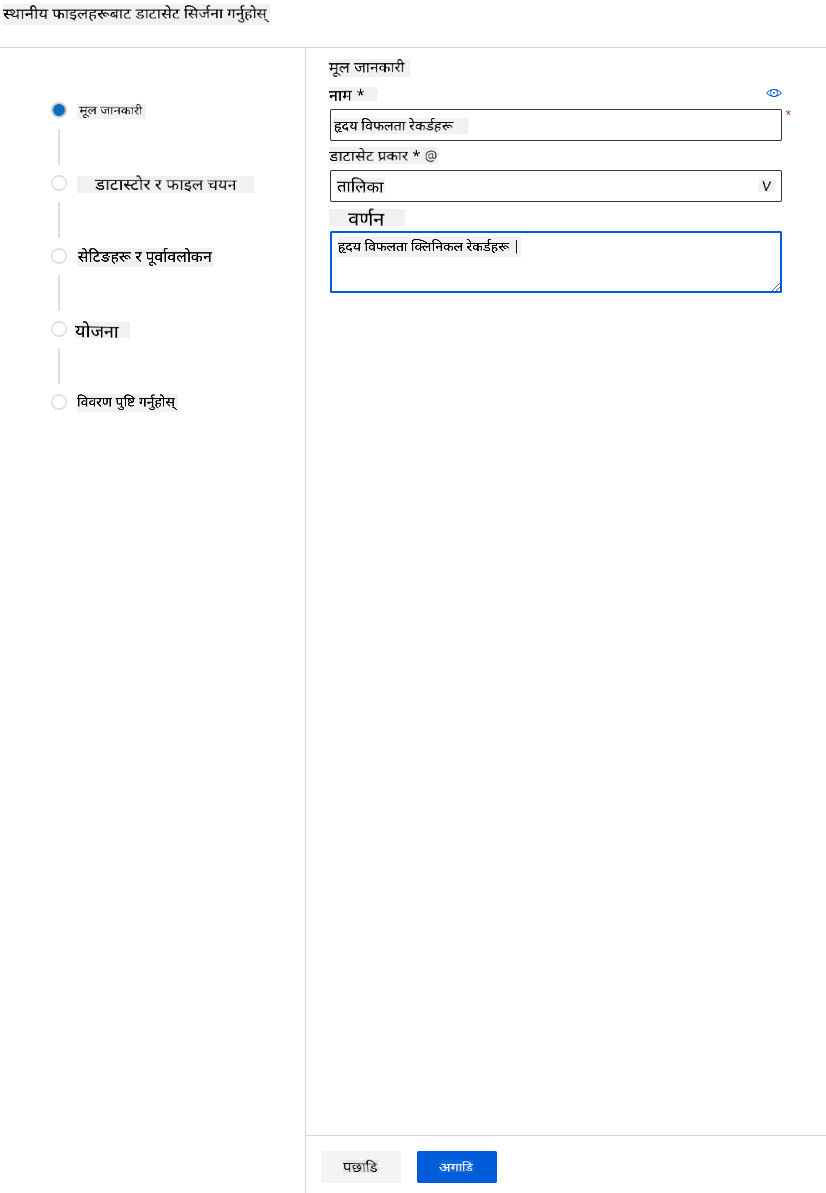
-
Schema मा, निम्न सुविधाहरूको लागि डेटा प्रकार Boolean मा परिवर्तन गर्नुहोस्: anaemia, diabetes, high blood pressure, sex, smoking, र DEATH_EVENT। Next मा क्लिक गर्नुहोस् र Create मा क्लिक गर्नुहोस्।
शानदार! अब डेटासेट तयार छ र कम्प्युट क्लस्टर सिर्जना गरिएको छ, हामी मोडेलको प्रशिक्षण सुरु गर्न सक्छौं!
2.4 कम कोड/नो कोड प्रशिक्षण AutoML प्रयोग गरेर
परम्परागत मेसिन लर्निङ मोडेल विकास स्रोत-गहन हुन्छ, महत्त्वपूर्ण डोमेन ज्ञान र दर्जनौं मोडेलहरू उत्पादन र तुलना गर्न समय आवश्यक हुन्छ। स्वचालित मेसिन लर्निङ (AutoML) भनेको मेसिन लर्निङ मोडेल विकासको समय-खपत गर्ने, पुनरावृत्त कार्यहरू स्वचालित गर्ने प्रक्रिया हो। यसले डेटा वैज्ञानिकहरू, विश्लेषकहरू, र विकासकर्ताहरूलाई उच्च स्केल, दक्षता, र उत्पादकता सहित ML मोडेलहरू निर्माण गर्न अनुमति दिन्छ, सबै मोडेलको गुणस्तर कायम राख्दै। यसले उत्पादन-तयार ML मोडेलहरू प्राप्त गर्न लाग्ने समयलाई कम गर्दछ, ठूलो सजिलो र दक्षताका साथ। थप जान्नुहोस्
-
हामीले पहिले सिर्जना गरेको Azure ML workspace मा, बायाँ मेनुमा "Automated ML" मा क्लिक गर्नुहोस् र तपाईंले अपलोड गरेको डेटासेट चयन गर्नुहोस्। Next मा क्लिक गर्नुहोस्।
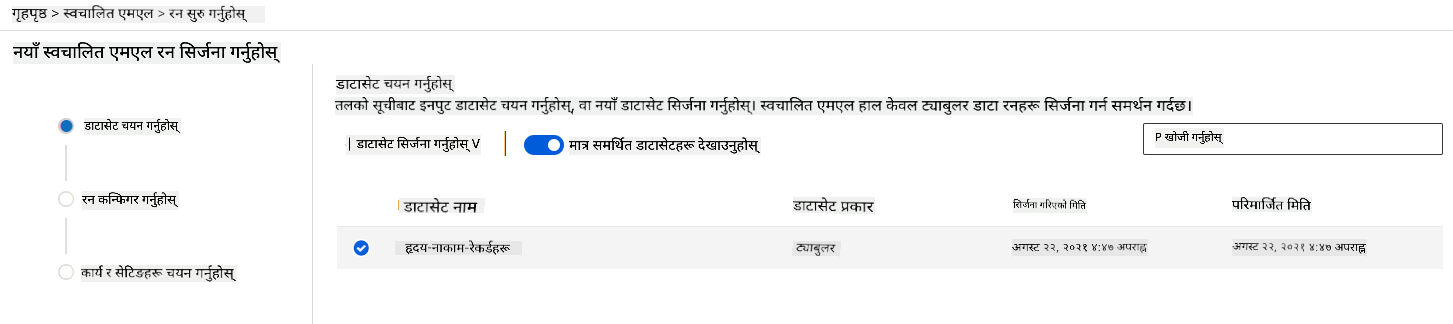
-
नयाँ प्रयोगको नाम, लक्ष्य स्तम्भ (DEATH_EVENT) र हामीले सिर्जना गरेको कम्प्युट क्लस्टर प्रविष्ट गर्नुहोस्। Next मा क्लिक गर्नुहोस्।
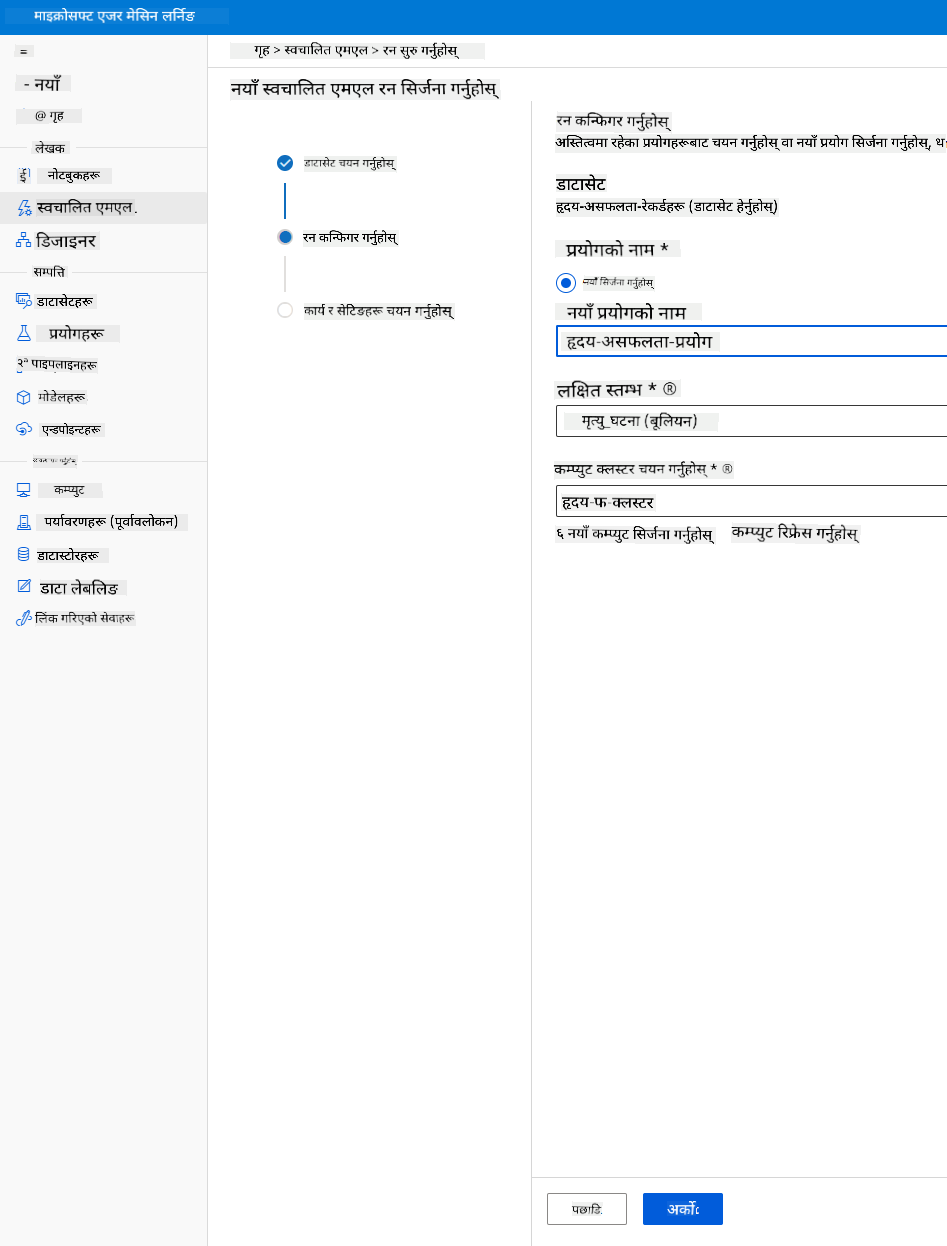
-
"Classification" चयन गर्नुहोस् र Finish मा क्लिक गर्नुहोस्। यो चरण कम्प्युट क्लस्टरको आकारमा निर्भर गर्दै 30 मिनेटदेखि 1 घण्टासम्म लाग्न सक्छ।
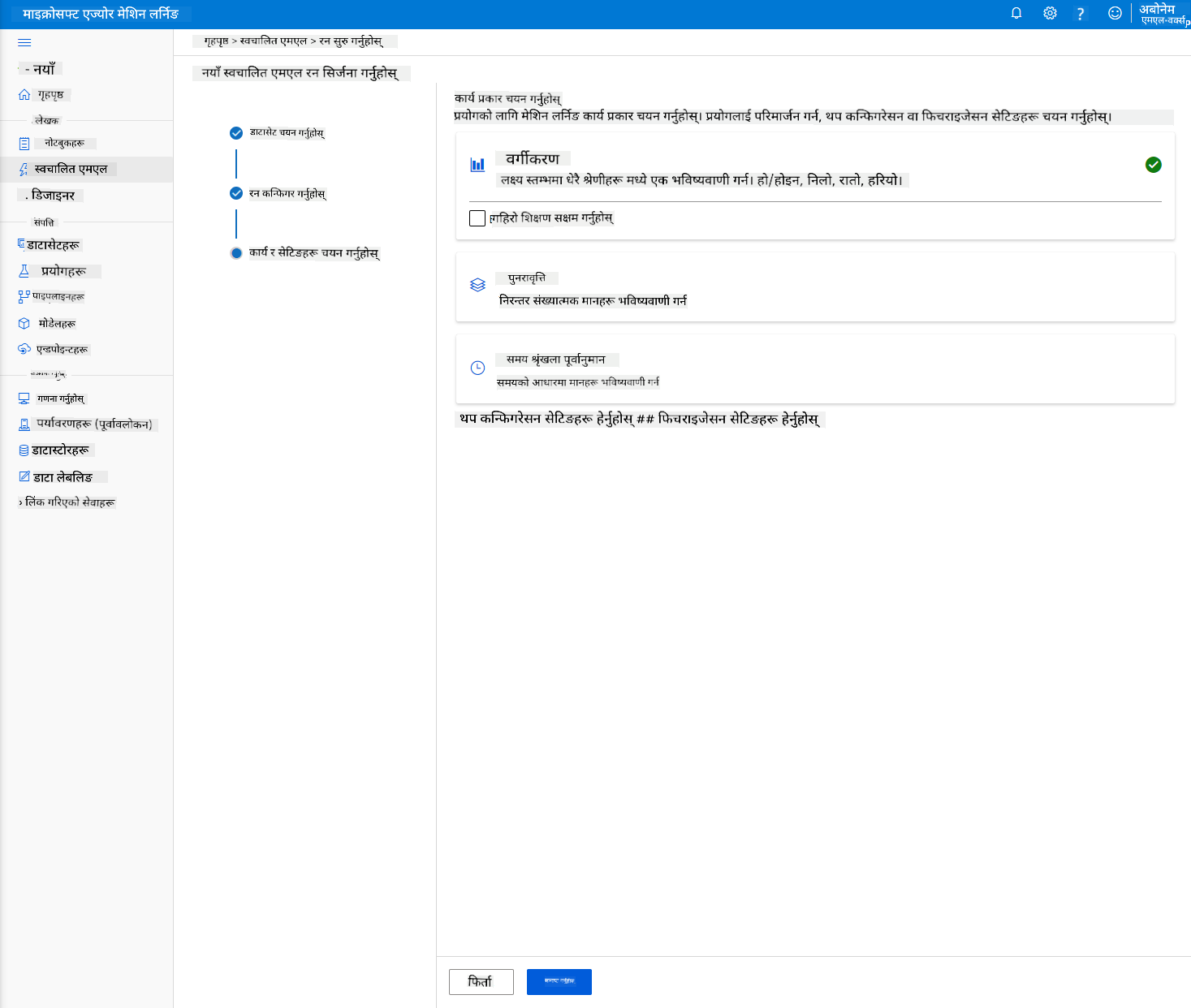
-
रन पूरा भएपछि, "Automated ML" ट्याबमा क्लिक गर्नुहोस्, आफ्नो रनमा क्लिक गर्नुहोस्, र "Best model summary" कार्डमा Algorithm मा क्लिक गर्नुहोस्।
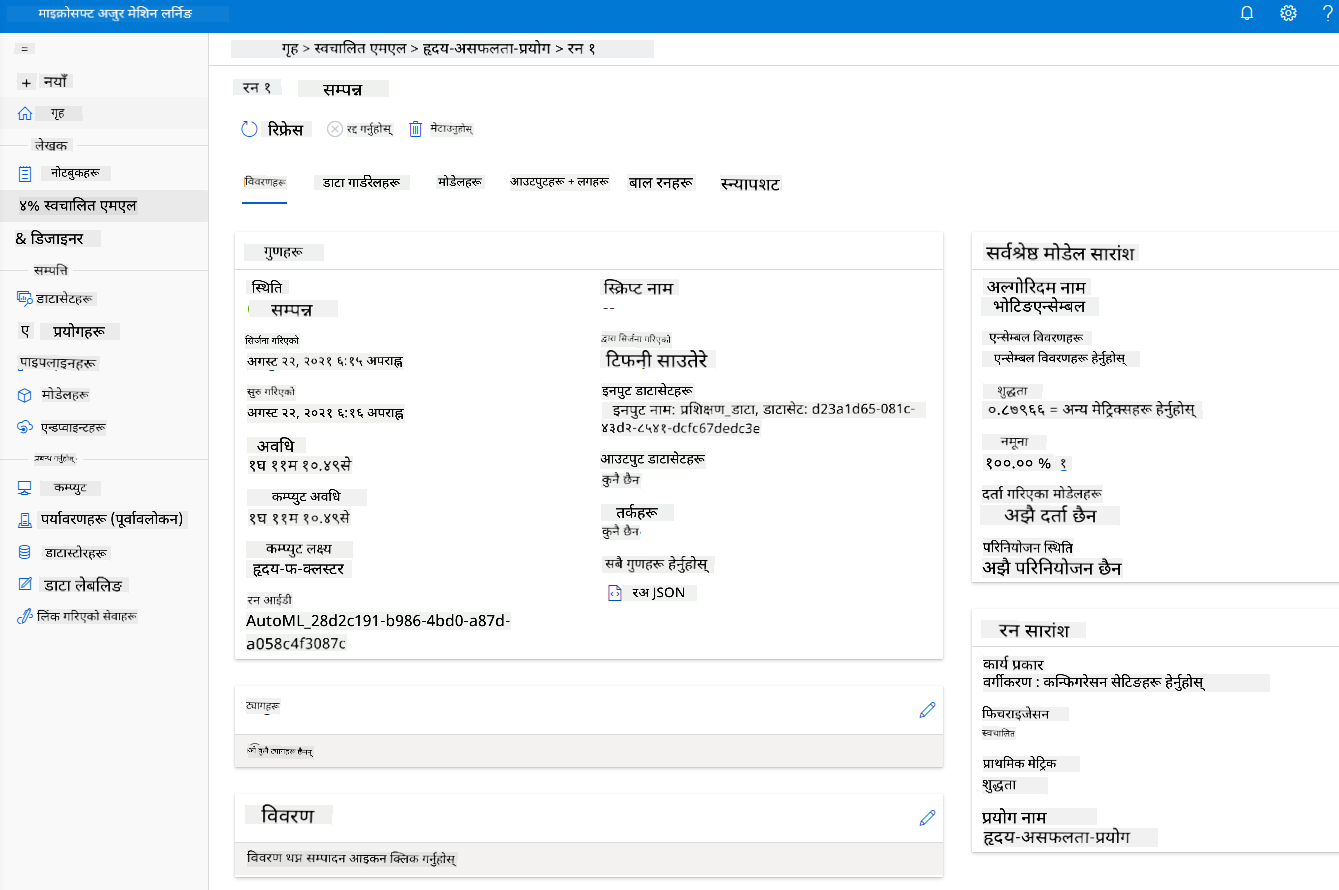
यहाँ तपाईं AutoML द्वारा उत्पन्न गरिएको उत्कृष्ट मोडेलको विस्तृत विवरण देख्न सक्नुहुन्छ। तपाईं अन्य मोडेलहरू Models ट्याबमा अन्वेषण गर्न सक्नुहुन्छ। Explanations (preview बटन) मा मोडेलहरू अन्वेषण गर्न केही समय लिनुहोस्। एकपटक तपाईंले प्रयोग गर्न चाहेको मोडेल चयन गरेपछि (यहाँ हामी AutoML द्वारा चयन गरिएको उत्कृष्ट मोडेल चयन गर्नेछौं), हामी यसलाई कसरी तैनाथ गर्न सकिन्छ हेर्नेछौं।
3. कम कोड/नो कोड मोडेल तैनाथी र अन्त बिन्दु उपभोग
3.1 मोडेल तैनाथी
स्वचालित मेसिन लर्निङ इन्टरफेसले उत्कृष्ट मोडेललाई वेब सेवाको रूपमा केही चरणहरूमा तैनाथ गर्न अनुमति दिन्छ। तैनाथी भनेको मोडेलको एकीकरण हो ताकि यसले नयाँ डेटा आधारमा भविष्यवाणी गर्न र अवसरका सम्भावित क्षेत्रहरू पहिचान गर्न सक्दछ। यस परियोजनाको लागि, वेब सेवामा तैनाथीको मतलब चिकित्सा अनुप्रयोगहरूले मोडेल उपभोग गर्न सक्नेछन् ताकि उनीहरूको बिरामीको हृदयघातको जोखिमको प्रत्यक्ष भविष्यवाणी गर्न सकियोस्।
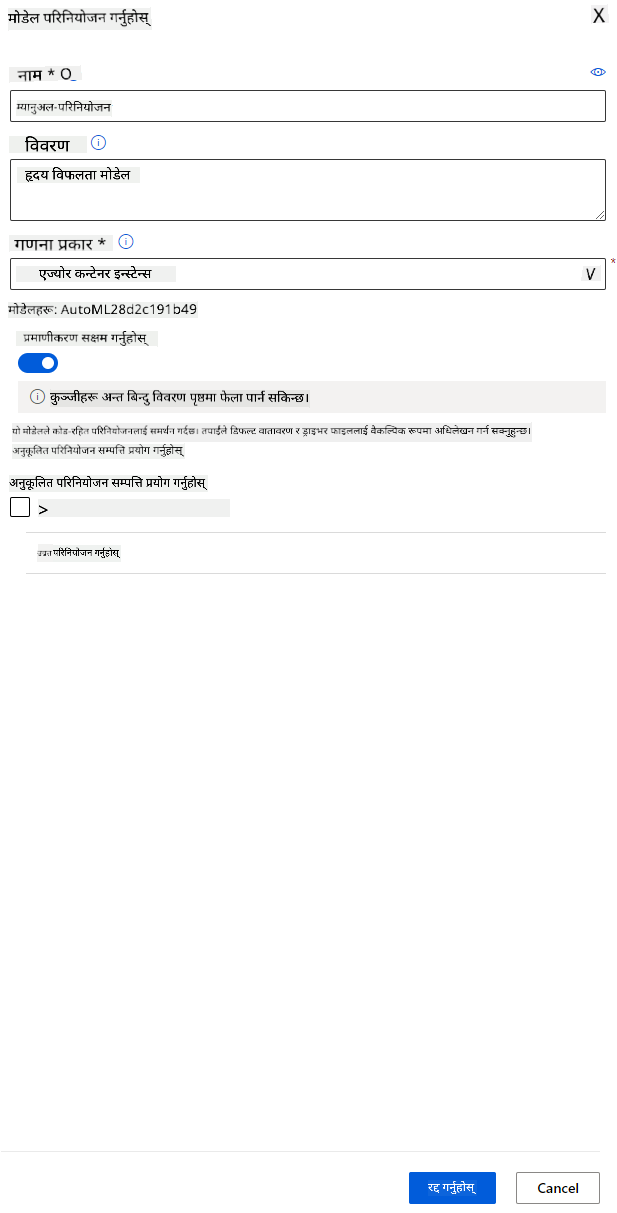
उत्कृष्ट मोडेल विवरणमा, "Deploy" बटनमा क्लिक गर्नुहोस्।
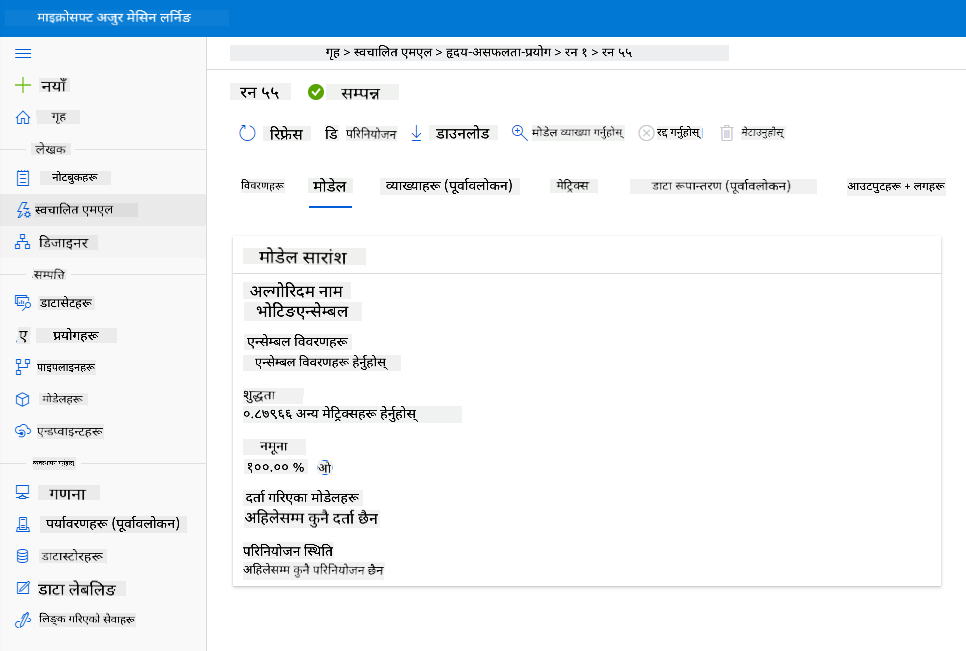
- यसलाई नाम, विवरण, कम्प्युट प्रकार (Azure Container Instance) दिनुहोस्, प्रमाणीकरण सक्षम गर्नुहोस् र Deploy मा क्लिक गर्नुहोस्। यो चरण पूरा हुन लगभग 20 मिनेट लाग्न सक्छ। तैनाथी प्रक्रियामा मोडेल दर्ता गर्ने, स्रोतहरू उत्पन्न गर्ने, र वेब सेवाको लागि तिनीहरूलाई कन्फिगर गर्ने चरणहरू समावेश छन्। Deploy status अन्तर्गत स्थिति सन्देश देखा पर्दछ। तैनाथी स्थिति जाँच गर्न Refresh चयन गर्नुहोस्। स्थिति "Healthy" हुँदा यो तैनाथ गरिएको र चलिरहेको हुन्छ।
- एकपटक तैनाथ भएपछि, Endpoint ट्याबमा क्लिक गर्नुहोस् र तपाईंले तैनाथ गरेको अन्त बिन्दुमा क्लिक गर्नुहोस्। यहाँ तपाईं अन्त बिन्दुका बारेमा जान्न आवश्यक सबै विवरणहरू पाउन सक्नुहुन्छ।
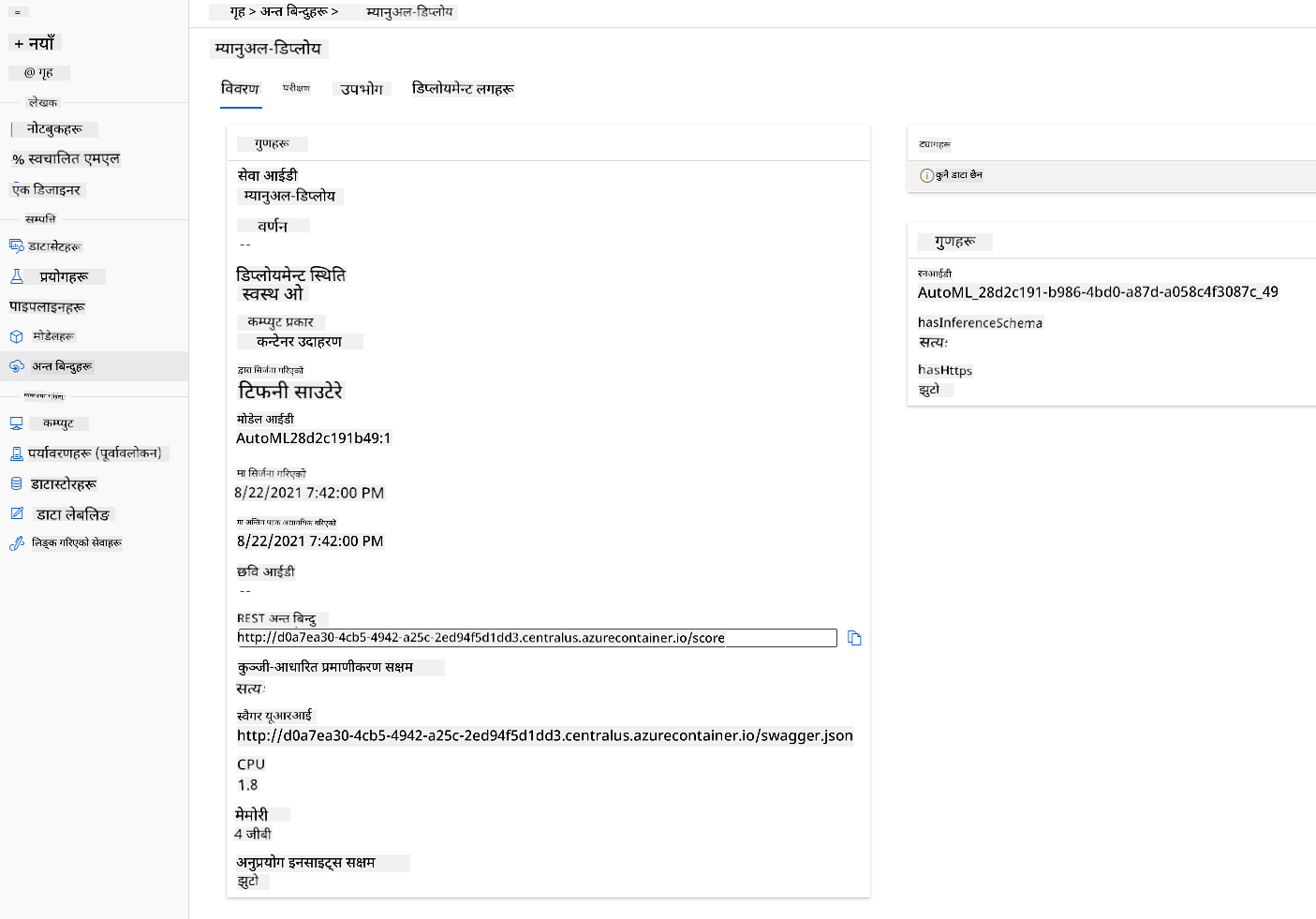
शानदार! अब हामीसँग मोडेल तैनाथ गरिएको छ, हामी अन्त बिन्दुको उपभोग सुरु गर्न सक्छौं।
3.2 अन्त बिन्दु उपभोग
"Consume" ट्याबमा क्लिक गर्नुहोस्। यहाँ तपाईं उपभोग विकल्पमा REST अन्त बिन्दु र पायथन स्क्रिप्ट पाउन सक्नुहुन्छ। पायथन कोडलाई पढ्न केही समय लिनुहोस्।
यो स्क्रिप्ट तपाईंको स्थानीय मेसिनबाट सिधै चलाउन सकिन्छ र तपाईंको अन्त बिन्दु उपभोग गर्नेछ।
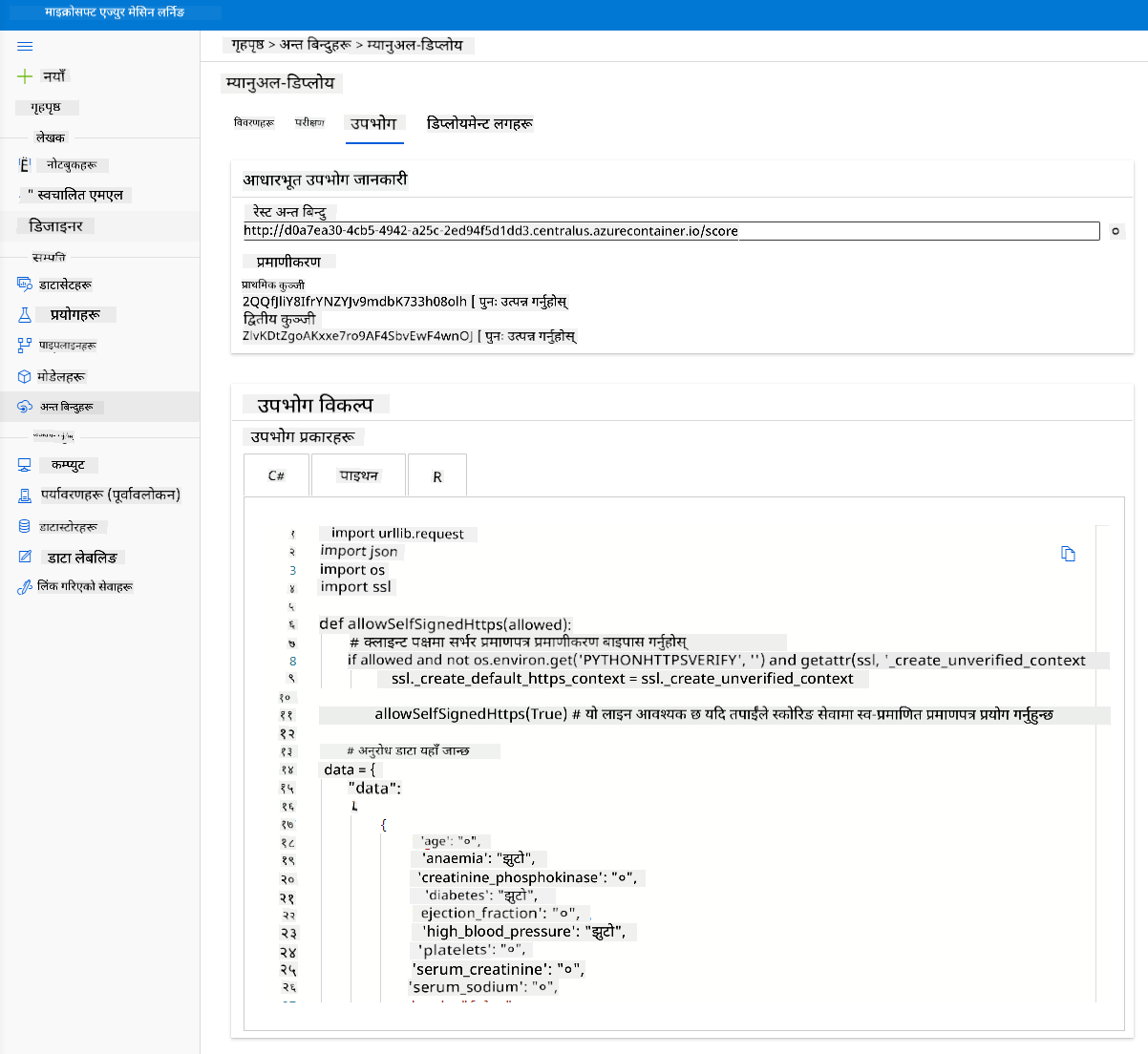
यी दुई लाइन कोड जाँच गर्न केही समय लिनुहोस्:
url = 'http://98e3715f-xxxx-xxxx-xxxx-9ec22d57b796.centralus.azurecontainer.io/score'
api_key = '' # Replace this with the API key for the web service
url भेरिएबल उपभोग ट्याबमा फेला परेको REST अन्त बिन्दु हो र api_key भेरिएबल प्रमाणीकरण सक्षम गरेको अवस्थामा उपभोग ट्याबमा फेला परेको प्राथमिक कुञ्जी हो। यसरी स्क्रिप्टले अन्त बिन्दु उपभोग गर्न सक्छ।
- स्क्रिप्ट चलाउँदा, तपाईंले निम्न आउटपुट देख्नुहुनेछ:
b'"{\\"result\\": [true]}"'
यसको मतलब दिएको डेटा अनुसार हृदय विफलताको भविष्यवाणी सत्य हो। यो अर्थपूर्ण छ किनभने यदि तपाईं स्क्रिप्टमा स्वतः उत्पन्न गरिएको डेटा नजिकबाट हेर्नुहुन्छ भने, सबै कुरा डिफल्ट रूपमा 0 र गलत छ। तपाईं निम्न इनपुट नमूनाको साथ डेटा परिवर्तन गर्न सक्नुहुन्छ:
data = {
"data":
[
{
'age': "0",
'anaemia': "false",
'creatinine_phosphokinase': "0",
'diabetes': "false",
'ejection_fraction': "0",
'high_blood_pressure': "false",
'platelets': "0",
'serum_creatinine': "0",
'serum_sodium': "0",
'sex': "false",
'smoking': "false",
'time': "0",
},
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
स्क्रिप्टले निम्न परिणाम फर्काउनु पर्छ:
python b'"{\\"result\\": [true, false]}"'
बधाई छ! तपाईंले तैनाथ गरिएको मोडेल उपभोग गर्नुभयो र यसलाई Azure ML मा प्रशिक्षण दिनुभयो!
NOTE: परियोजना समाप्त भएपछि, सबै स्रोतहरू मेटाउन नबिर्सनुहोस्।
🚀 चुनौती
AutoML द्वारा उत्पन्न शीर्ष मोडेलहरूको मोडेल व्याख्या र विवरणलाई नजिकबाट हेर्नुहोस्। उत्कृष्ट मोडेल अन्य मोडेलहरू भन्दा किन राम्रो छ भन्ने बुझ्ने प्रयास गर्नुहोस्। कुन एल्गोरिदमहरू तुलना गरिएका थिए? तिनीहरू बीच के भिन्नता छन्? यस अवस्थामा उत्कृष्ट मोडेल किन राम्रो प्रदर्शन गर्दैछ?
पोस्ट-व्याख्यान क्विज
समीक्षा र आत्म अध्ययन
यस पाठमा, तपाईंले कम कोड/नो कोड शैलीमा क्लाउडमा हृदय विफलताको जोखिमको भविष्यवाणी गर्न मोडेल प्रशिक्षण, तैनाथी र उपभोग गर्न सिक्नुभयो। यदि तपाईंले अझै गर्नुभएको छैन भने, AutoML द्वारा उत्पन्न शीर्ष मोडेलहरूको मोडेल व्याख्यामा गहिरो डुब्नुहोस् र उत्कृष्ट मोडेल अन्य मोडेलहरू भन्दा किन राम्रो छ भन्ने बुझ्ने प्रयास गर्नुहोस्।
तपाईं Low code/No code AutoML मा थप जान्न सक्नुहुन्छ यो डकुमेन्टेशन पढेर।
असाइनमेन्ट
Azure ML मा Low code/No code डेटा विज्ञान परियोजना
अस्वीकरण:
यो दस्तावेज़ AI अनुवाद सेवा Co-op Translator प्रयोग गरेर अनुवाद गरिएको छ। हामी शुद्धताको लागि प्रयास गर्छौं, तर कृपया ध्यान दिनुहोस् कि स्वचालित अनुवादमा त्रुटिहरू वा अशुद्धताहरू हुन सक्छ। यसको मूल भाषा मा रहेको मूल दस्तावेज़लाई आधिकारिक स्रोत मानिनुपर्छ। महत्वपूर्ण जानकारीको लागि, व्यावसायिक मानव अनुवाद सिफारिस गरिन्छ। यस अनुवादको प्रयोगबाट उत्पन्न हुने कुनै पनि गलतफहमी वा गलत व्याख्याको लागि हामी जिम्मेवार हुने छैनौं।