18 KiB
Sains Data di Awan: Cara "Azure ML SDK"
 |
|---|
| Sains Data di Awan: Azure ML SDK - Sketchnote oleh @nitya |
Kandungan:
- Sains Data di Awan: Cara "Azure ML SDK"
Kuiz Pra-Kuliah
1. Pengenalan
1.1 Apa itu Azure ML SDK?
Saintis data dan pembangun AI menggunakan Azure Machine Learning SDK untuk membina dan menjalankan alur kerja pembelajaran mesin dengan perkhidmatan Azure Machine Learning. Anda boleh berinteraksi dengan perkhidmatan ini dalam mana-mana persekitaran Python, termasuk Jupyter Notebooks, Visual Studio Code, atau IDE Python kegemaran anda.
Bidang utama SDK termasuk:
- Meneroka, menyediakan, dan mengurus kitaran hayat dataset yang digunakan dalam eksperimen pembelajaran mesin.
- Mengurus sumber awan untuk pemantauan, log, dan pengorganisasian eksperimen pembelajaran mesin anda.
- Melatih model sama ada secara tempatan atau menggunakan sumber awan, termasuk latihan model yang dipercepatkan GPU.
- Menggunakan pembelajaran mesin automatik, yang menerima parameter konfigurasi dan data latihan. Ia secara automatik mengulangi algoritma dan tetapan hiperparameter untuk mencari model terbaik untuk menjalankan ramalan.
- Menyebarkan perkhidmatan web untuk menukar model yang telah dilatih menjadi perkhidmatan RESTful yang boleh digunakan dalam mana-mana aplikasi.
Ketahui lebih lanjut tentang Azure Machine Learning SDK
Dalam pelajaran sebelumnya, kita telah melihat cara melatih, menyebarkan, dan menggunakan model dengan cara Low code/No code. Kita menggunakan dataset Kegagalan Jantung untuk menghasilkan model ramalan kegagalan jantung. Dalam pelajaran ini, kita akan melakukan perkara yang sama tetapi menggunakan Azure Machine Learning SDK.
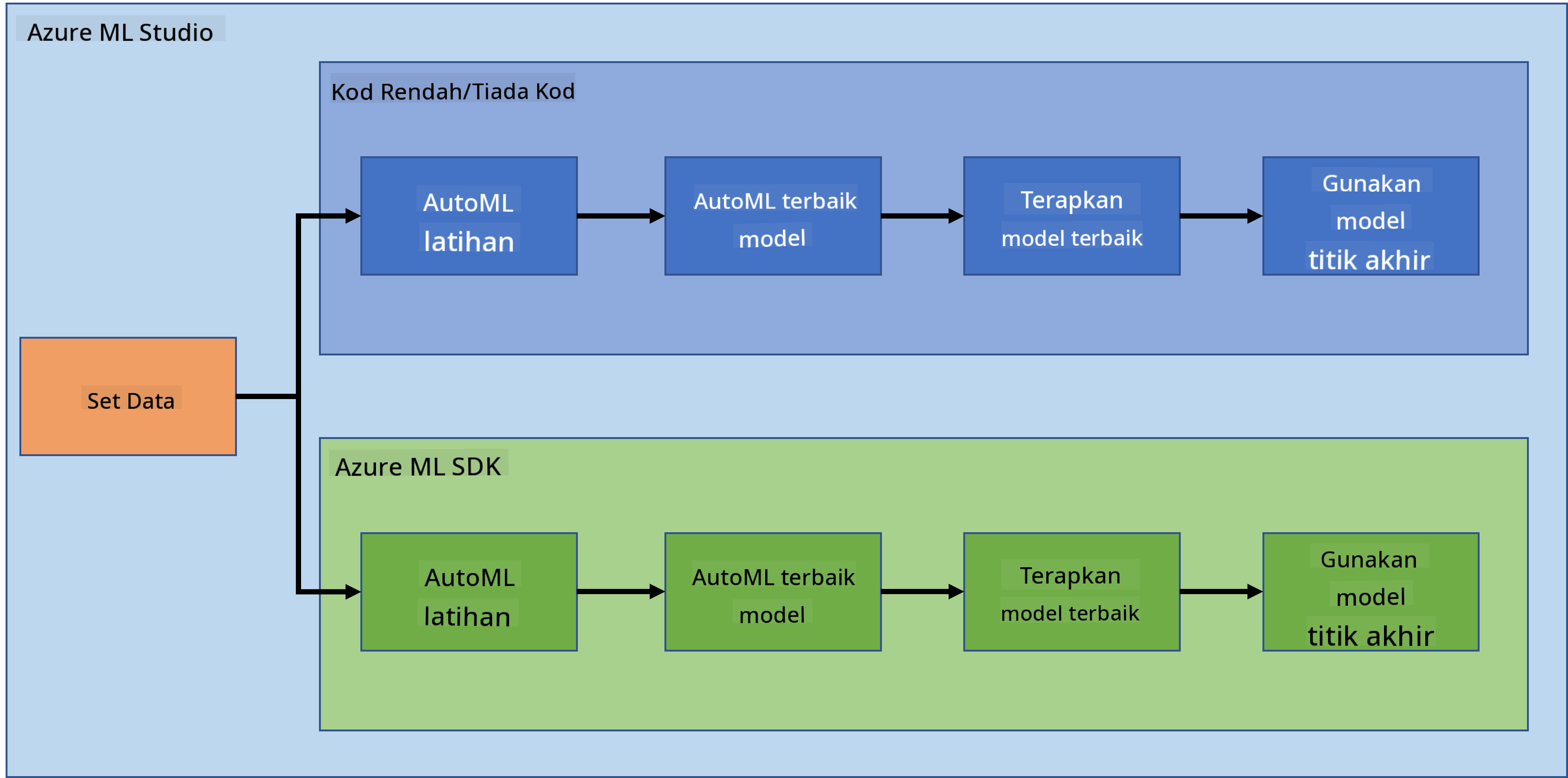
1.2 Pengenalan projek dan dataset ramalan kegagalan jantung
Rujuk di sini untuk pengenalan projek dan dataset ramalan kegagalan jantung.
2. Melatih model dengan Azure ML SDK
2.1 Membuat ruang kerja Azure ML
Untuk kemudahan, kita akan bekerja di jupyter notebook. Ini bermakna anda sudah mempunyai Ruang Kerja dan instans pengiraan. Jika anda sudah mempunyai Ruang Kerja, anda boleh terus ke bahagian 2.3 Penciptaan Notebook.
Jika tidak, sila ikuti arahan dalam bahagian 2.1 Membuat ruang kerja Azure ML dalam pelajaran sebelumnya untuk membuat ruang kerja.
2.2 Membuat instans pengiraan
Dalam ruang kerja Azure ML yang telah kita buat sebelum ini, pergi ke menu pengiraan dan anda akan melihat pelbagai sumber pengiraan yang tersedia.
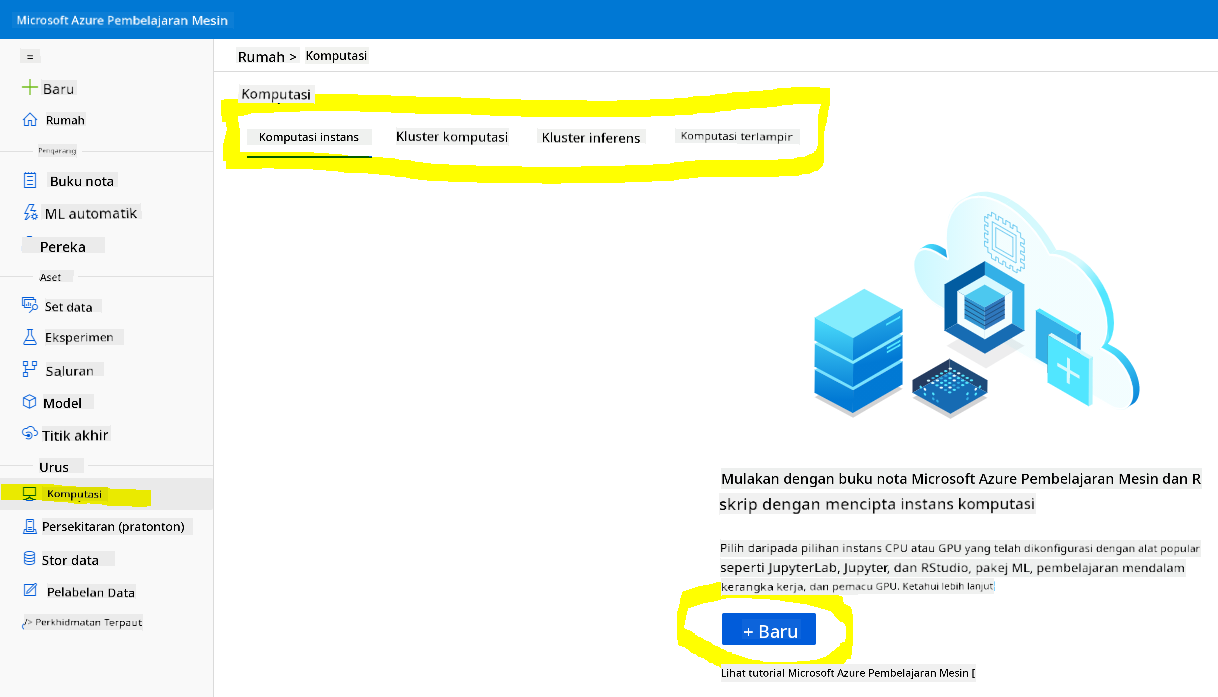
Mari kita buat instans pengiraan untuk menyediakan jupyter notebook.
- Klik pada butang + Baru.
- Berikan nama kepada instans pengiraan anda.
- Pilih pilihan anda: CPU atau GPU, saiz VM dan bilangan teras.
- Klik pada butang Cipta.
Tahniah, anda baru sahaja mencipta instans pengiraan! Kita akan menggunakan instans pengiraan ini untuk mencipta Notebook di bahagian Membuat Notebook.
2.3 Memuat dataset
Rujuk pelajaran sebelumnya dalam bahagian 2.3 Memuat dataset jika anda belum memuat naik dataset.
2.4 Membuat Notebook
NOTA: Untuk langkah seterusnya, anda boleh sama ada mencipta notebook baru dari awal, atau anda boleh memuat naik notebook yang telah kita buat ke dalam Azure ML Studio anda. Untuk memuat naiknya, klik sahaja pada menu "Notebook" dan muat naik notebook tersebut.
Notebook adalah bahagian yang sangat penting dalam proses sains data. Ia boleh digunakan untuk Melakukan Analisis Data Eksplorasi (EDA), memanggil kluster komputer untuk melatih model, atau memanggil kluster inferens untuk menyebarkan endpoint.
Untuk mencipta Notebook, kita memerlukan nod pengiraan yang menyediakan instans jupyter notebook. Kembali ke ruang kerja Azure ML dan klik pada Instans Pengiraan. Dalam senarai instans pengiraan, anda sepatutnya melihat instans pengiraan yang kita buat sebelum ini.
- Dalam bahagian Aplikasi, klik pada pilihan Jupyter.
- Tandakan kotak "Ya, saya faham" dan klik pada butang Teruskan.
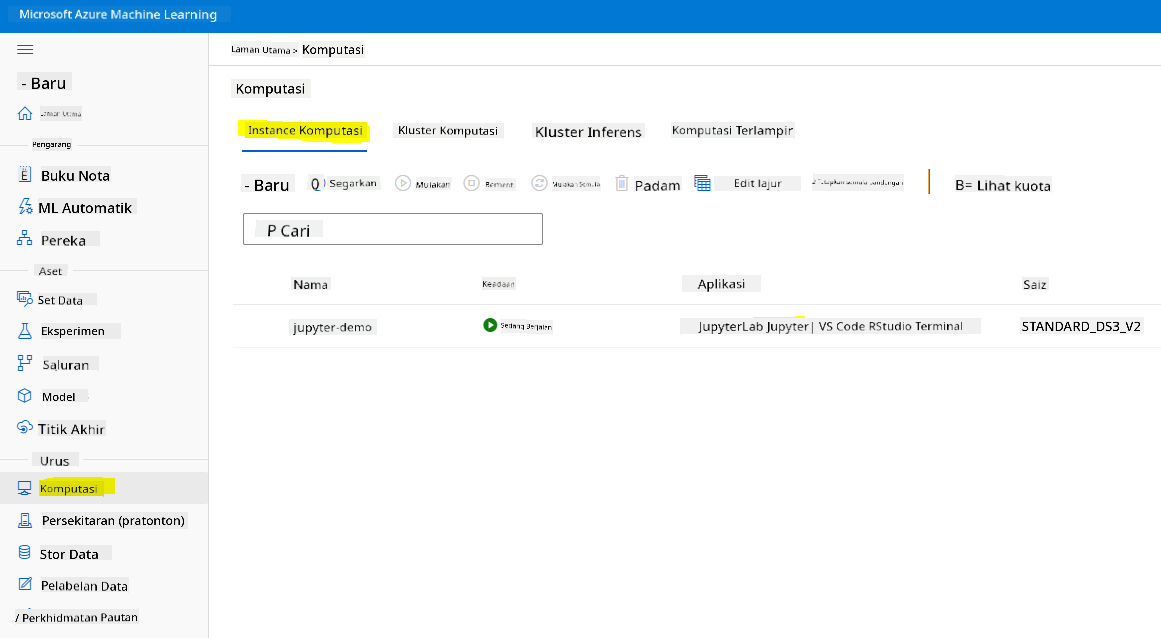
- Ini akan membuka tab pelayar baru dengan instans jupyter notebook anda seperti berikut. Klik pada butang "Baru" untuk mencipta notebook.
Sekarang kita mempunyai Notebook, kita boleh mula melatih model dengan Azure ML SDK.
2.5 Melatih model
Pertama sekali, jika anda mempunyai keraguan, rujuk dokumentasi Azure ML SDK. Ia mengandungi semua maklumat yang diperlukan untuk memahami modul yang akan kita lihat dalam pelajaran ini.
2.5.1 Menyediakan ruang kerja, eksperimen, kluster pengiraan, dan dataset
Anda perlu memuatkan workspace dari fail konfigurasi menggunakan kod berikut:
from azureml.core import Workspace
ws = Workspace.from_config()
Ini akan mengembalikan objek jenis Workspace yang mewakili ruang kerja. Kemudian anda perlu mencipta experiment menggunakan kod berikut:
from azureml.core import Experiment
experiment_name = 'aml-experiment'
experiment = Experiment(ws, experiment_name)
Untuk mendapatkan atau mencipta eksperimen dari ruang kerja, anda meminta eksperimen menggunakan nama eksperimen. Nama eksperimen mesti terdiri daripada 3-36 aksara, bermula dengan huruf atau nombor, dan hanya boleh mengandungi huruf, nombor, garis bawah, dan tanda hubung. Jika eksperimen tidak dijumpai dalam ruang kerja, eksperimen baru akan dicipta.
Sekarang anda perlu mencipta kluster pengiraan untuk latihan menggunakan kod berikut. Perhatikan bahawa langkah ini mungkin mengambil masa beberapa minit.
from azureml.core.compute import AmlCompute
aml_name = "heart-f-cluster"
try:
aml_compute = AmlCompute(ws, aml_name)
print('Found existing AML compute context.')
except:
print('Creating new AML compute context.')
aml_config = AmlCompute.provisioning_configuration(vm_size = "Standard_D2_v2", min_nodes=1, max_nodes=3)
aml_compute = AmlCompute.create(ws, name = aml_name, provisioning_configuration = aml_config)
aml_compute.wait_for_completion(show_output = True)
cts = ws.compute_targets
compute_target = cts[aml_name]
Anda boleh mendapatkan dataset dari ruang kerja menggunakan nama dataset dengan cara berikut:
dataset = ws.datasets['heart-failure-records']
df = dataset.to_pandas_dataframe()
df.describe()
2.5.2 Konfigurasi dan latihan AutoML
Untuk menetapkan konfigurasi AutoML, gunakan kelas AutoMLConfig.
Seperti yang diterangkan dalam dokumen, terdapat banyak parameter yang boleh anda ubah suai. Untuk projek ini, kita akan menggunakan parameter berikut:
experiment_timeout_minutes: Masa maksimum (dalam minit) yang dibenarkan untuk eksperimen berjalan sebelum ia dihentikan secara automatik dan hasilnya tersedia secara automatik.max_concurrent_iterations: Bilangan maksimum iterasi latihan serentak yang dibenarkan untuk eksperimen.primary_metric: Metrik utama yang digunakan untuk menentukan status eksperimen.compute_target: Sasaran pengiraan Azure Machine Learning untuk menjalankan eksperimen Pembelajaran Mesin Automatik.task: Jenis tugas yang akan dijalankan. Nilai boleh 'classification', 'regression', atau 'forecasting' bergantung pada jenis masalah ML automatik yang ingin diselesaikan.training_data: Data latihan yang akan digunakan dalam eksperimen. Ia harus mengandungi ciri latihan dan lajur label (secara opsional lajur berat sampel).label_column_name: Nama lajur label.path: Laluan penuh ke folder projek Azure Machine Learning.enable_early_stopping: Sama ada untuk membolehkan penamatan awal jika skor tidak bertambah baik dalam jangka pendek.featurization: Penunjuk sama ada langkah featurization harus dilakukan secara automatik atau tidak, atau sama ada featurization tersuai harus digunakan.debug_log: Fail log untuk menulis maklumat debug.
from azureml.train.automl import AutoMLConfig
project_folder = './aml-project'
automl_settings = {
"experiment_timeout_minutes": 20,
"max_concurrent_iterations": 3,
"primary_metric" : 'AUC_weighted'
}
automl_config = AutoMLConfig(compute_target=compute_target,
task = "classification",
training_data=dataset,
label_column_name="DEATH_EVENT",
path = project_folder,
enable_early_stopping= True,
featurization= 'auto',
debug_log = "automl_errors.log",
**automl_settings
)
Sekarang setelah konfigurasi anda ditetapkan, anda boleh melatih model menggunakan kod berikut. Langkah ini mungkin mengambil masa sehingga satu jam bergantung pada saiz kluster anda.
remote_run = experiment.submit(automl_config)
Anda boleh menjalankan widget RunDetails untuk menunjukkan eksperimen yang berbeza.
from azureml.widgets import RunDetails
RunDetails(remote_run).show()
3. Penyebaran model dan penggunaan endpoint dengan Azure ML SDK
3.1 Menyimpan model terbaik
remote_run adalah objek jenis AutoMLRun. Objek ini mengandungi kaedah get_output() yang mengembalikan eksperimen terbaik dan model yang sesuai.
best_run, fitted_model = remote_run.get_output()
Anda boleh melihat parameter yang digunakan untuk model terbaik dengan hanya mencetak fitted_model dan melihat sifat model terbaik dengan menggunakan kaedah get_properties().
best_run.get_properties()
Sekarang daftarkan model dengan kaedah register_model.
model_name = best_run.properties['model_name']
script_file_name = 'inference/score.py'
best_run.download_file('outputs/scoring_file_v_1_0_0.py', 'inference/score.py')
description = "aml heart failure project sdk"
model = best_run.register_model(model_name = model_name,
model_path = './outputs/',
description = description,
tags = None)
3.2 Penyebaran model
Setelah model terbaik disimpan, kita boleh menyebarkannya dengan kelas InferenceConfig. InferenceConfig mewakili tetapan konfigurasi untuk persekitaran tersuai yang digunakan untuk penyebaran. Kelas AciWebservice mewakili model pembelajaran mesin yang disebarkan sebagai endpoint perkhidmatan web pada Azure Container Instances. Perkhidmatan web yang disebarkan adalah endpoint HTTP yang seimbang beban dengan API REST. Anda boleh menghantar data ke API ini dan menerima ramalan yang dikembalikan oleh model.
Model disebarkan menggunakan kaedah deploy.
from azureml.core.model import InferenceConfig, Model
from azureml.core.webservice import AciWebservice
inference_config = InferenceConfig(entry_script=script_file_name, environment=best_run.get_environment())
aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1,
memory_gb = 1,
tags = {'type': "automl-heart-failure-prediction"},
description = 'Sample service for AutoML Heart Failure Prediction')
aci_service_name = 'automl-hf-sdk'
aci_service = Model.deploy(ws, aci_service_name, [model], inference_config, aciconfig)
aci_service.wait_for_deployment(True)
print(aci_service.state)
Langkah ini mungkin mengambil masa beberapa minit.
3.3 Penggunaan endpoint
Anda boleh menggunakan endpoint anda dengan mencipta input sampel:
data = {
"data":
[
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
test_sample = str.encode(json.dumps(data))
Dan kemudian anda boleh menghantar input ini ke model anda untuk mendapatkan ramalan:
response = aci_service.run(input_data=test_sample)
response
Ini sepatutnya menghasilkan '{"result": [false]}'. Ini bermaksud bahawa input pesakit yang kita hantar ke endpoint menghasilkan ramalan false yang bermaksud orang ini tidak berkemungkinan mengalami serangan jantung.
Tahniah! Anda baru sahaja menggunakan model yang telah dideploy dan dilatih di Azure ML dengan Azure ML SDK!
NOTA: Setelah anda selesai dengan projek ini, jangan lupa untuk memadam semua sumber.
🚀 Cabaran
Terdapat banyak perkara lain yang boleh anda lakukan melalui SDK, malangnya, kita tidak dapat melihat semuanya dalam pelajaran ini. Tetapi berita baik, belajar cara untuk menyemak imbas dokumentasi SDK boleh membantu anda jauh secara sendiri. Lihat dokumentasi Azure ML SDK dan cari kelas Pipeline yang membolehkan anda mencipta pipeline. Pipeline adalah koleksi langkah-langkah yang boleh dilaksanakan sebagai satu aliran kerja.
PETUNJUK: Pergi ke dokumentasi SDK dan taip kata kunci seperti "Pipeline" di bar carian. Anda sepatutnya melihat kelas azureml.pipeline.core.Pipeline dalam hasil carian.
Kuiz selepas kuliah
Ulasan & Kajian Kendiri
Dalam pelajaran ini, anda telah belajar cara melatih, mendeply dan menggunakan model untuk meramal risiko kegagalan jantung dengan Azure ML SDK di awan. Semak dokumentasi ini untuk maklumat lanjut tentang Azure ML SDK. Cuba cipta model anda sendiri dengan Azure ML SDK.
Tugasan
Projek Sains Data menggunakan Azure ML SDK
Penafian:
Dokumen ini telah diterjemahkan menggunakan perkhidmatan terjemahan AI Co-op Translator. Walaupun kami berusaha untuk memastikan ketepatan, sila ambil perhatian bahawa terjemahan automatik mungkin mengandungi kesilapan atau ketidaktepatan. Dokumen asal dalam bahasa asalnya harus dianggap sebagai sumber yang berwibawa. Untuk maklumat yang kritikal, terjemahan manusia profesional adalah disyorkan. Kami tidak bertanggungjawab atas sebarang salah faham atau salah tafsir yang timbul daripada penggunaan terjemahan ini.