32 KiB
クラウドでのデータサイエンス: 「ローコード/ノーコード」アプローチ
 |
|---|
| クラウドでのデータサイエンス: ローコード - スケッチノート by @nitya |
目次:
- クラウドでのデータサイエンス: 「ローコード/ノーコード」アプローチ
講義前のクイズ
1. はじめに
1.1 Azure Machine Learningとは?
Azureクラウドプラットフォームは、200以上の製品とクラウドサービスを提供し、新しいソリューションを実現するための支援を行います。
データサイエンティストは、データの探索や前処理、さまざまなモデルトレーニングアルゴリズムの試行に多くの時間を費やします。これらの作業は時間がかかり、高価なコンピュートハードウェアを非効率的に使用することがよくあります。
Azure MLは、Azure上で機械学習ソリューションを構築・運用するためのクラウドベースのプラットフォームです。データの準備、モデルのトレーニング、予測サービスの公開、使用状況の監視を支援する幅広い機能を備えています。特に、モデルトレーニングに関連する時間のかかる作業を自動化することで効率を向上させ、クラウドベースのコンピュートリソースを効果的にスケールさせ、大量のデータを処理しながら実際に使用した分だけのコストを発生させることができます。
Azure MLは、開発者やデータサイエンティストが機械学習ワークフローを実行するために必要なツールをすべて提供します。これには以下が含まれます:
- Azure Machine Learning Studio: モデルのトレーニング、デプロイ、オートメーション、トラッキング、資産管理をローコード/ノーコードで行うためのウェブポータル。Azure Machine Learning SDKと統合されています。
- Jupyter Notebooks: MLモデルを迅速にプロトタイプ化し、テストするためのツール。
- Azure Machine Learning Designer: モジュールをドラッグ&ドロップして実験を構築し、ローコード環境でパイプラインをデプロイ可能。
- 自動化された機械学習UI (AutoML): 機械学習モデル開発の反復作業を自動化し、高いスケール、効率、生産性を維持しながらモデル品質を確保。
- データラベリング: データを自動的にラベル付けする支援ツール。
- Visual Studio Code用機械学習拡張機能: MLプロジェクトを構築・管理するためのフル機能の開発環境。
- 機械学習CLI: コマンドラインからAzure MLリソースを管理するためのコマンドを提供。
- PyTorch、TensorFlow、Scikit-learnなどのオープンソースフレームワークとの統合: トレーニング、デプロイ、エンドツーエンドの機械学習プロセス管理をサポート。
- MLflow: 機械学習実験のライフサイクルを管理するオープンソースライブラリ。MLFlow Trackingは、トレーニング実行のメトリクスやモデルアーティファクトをログ・トラッキングするコンポーネント。
1.2 心不全予測プロジェクト:
プロジェクトを作成・構築することは、スキルや知識を試す最良の方法であることは間違いありません。このレッスンでは、Azure ML Studioを使用して心不全発作を予測するデータサイエンスプロジェクトを構築する2つの異なる方法を探ります。ローコード/ノーコードとAzure ML SDKを以下のスキーマで示します:
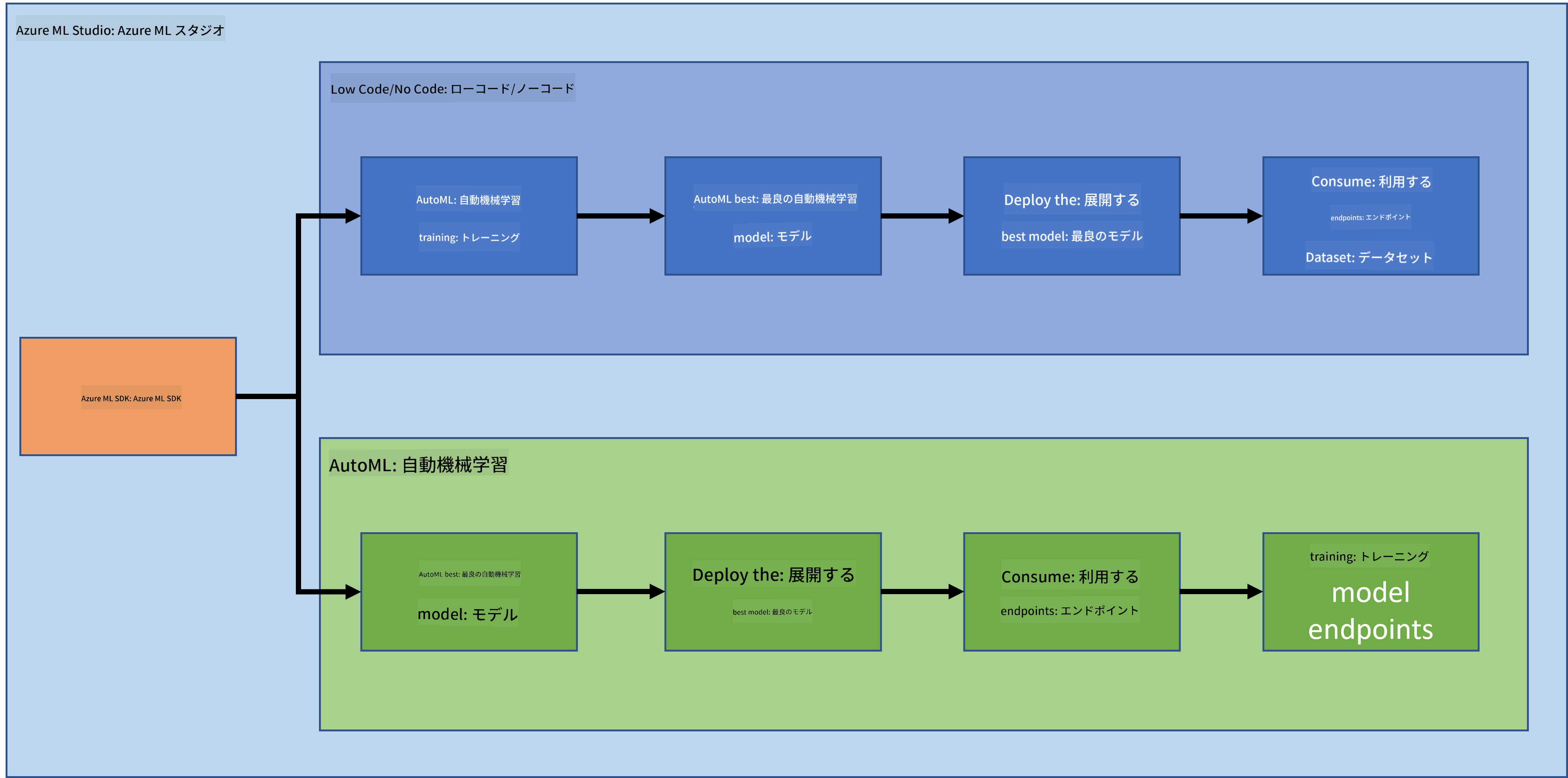
それぞれの方法には利点と欠点があります。ローコード/ノーコードの方法は、GUI(グラフィカルユーザーインターフェース)を使用するため、コードの事前知識が不要で、簡単に始められます。この方法はプロジェクトの実現可能性を迅速にテストし、POC(概念実証)を作成するのに適しています。しかし、プロジェクトが成長し、プロダクション対応が必要になると、GUIを使用してリソースを作成することは現実的ではありません。この場合、Azure ML SDKを使用して、リソースの作成からモデルのデプロイまでをプログラム的に自動化する方法を知ることが重要になります。
| ローコード/ノーコード | Azure ML SDK | |
|---|---|---|
| コードの専門知識 | 不要 | 必要 |
| 開発時間 | 簡単で迅速 | コードの専門知識に依存 |
| プロダクション対応 | いいえ | はい |
1.3 心不全データセット:
心血管疾患(CVD)は世界的に死因の第1位であり、全死亡の31%を占めています。タバコの使用、不健康な食事と肥満、身体活動の欠如、アルコールの有害な使用などの環境的および行動的リスク要因は、推定モデルの特徴として使用できます。CVDの発症確率を推定できることは、高リスクの人々の発作を予防するために非常に役立ちます。
Kaggleでは、心不全データセットが公開されており、このプロジェクトで使用します。このデータセットを今すぐダウンロードできます。このデータセットは13列(12の特徴量と1つのターゲット変数)と299行のタブ形式のデータです。
| 変数名 | 型 | 説明 | 例 | |
|---|---|---|---|---|
| 1 | age | 数値型 | 患者の年齢 | 25 |
| 2 | anaemia | ブール型 | 赤血球またはヘモグロビンの減少 | 0 または 1 |
| 3 | creatinine_phosphokinase | 数値型 | 血中のCPK酵素のレベル | 542 |
| 4 | diabetes | ブール型 | 患者が糖尿病かどうか | 0 または 1 |
| 5 | ejection_fraction | 数値型 | 心臓の収縮ごとに心臓から出る血液の割合 | 45 |
| 6 | high_blood_pressure | ブール型 | 患者が高血圧かどうか | 0 または 1 |
| 7 | platelets | 数値型 | 血中の血小板数 | 149000 |
| 8 | serum_creatinine | 数値型 | 血中の血清クレアチニンのレベル | 0.5 |
| 9 | serum_sodium | 数値型 | 血中の血清ナトリウムのレベル | jun |
| 10 | sex | ブール型 | 女性または男性 | 0 または 1 |
| 11 | smoking | ブール型 | 患者が喫煙しているかどうか | 0 または 1 |
| 12 | time | 数値型 | フォローアップ期間(日数) | 4 |
| ---- | --------------------------- | ----------------- | --------------------------------------------------------- | ------------------- |
| 21 | DEATH_EVENT [ターゲット] | ブール型 | フォローアップ期間中に患者が死亡したかどうか | 0 または 1 |
データセットを取得したら、Azureでプロジェクトを開始できます。
2. Azure ML Studioでのローコード/ノーコードによるモデルのトレーニング
2.1 Azure MLワークスペースの作成
Azure MLでモデルをトレーニングするには、まずAzure MLワークスペースを作成する必要があります。ワークスペースはAzure Machine Learningのトップレベルリソースであり、Azure Machine Learningを使用して作成するすべてのアーティファクトを集中管理する場所を提供します。ワークスペースはすべてのトレーニング実行履歴を保持し、ログ、メトリクス、出力、スクリプトのスナップショットを含みます。この情報を使用して、最良のモデルを生成するトレーニング実行を特定できます。詳細はこちら
最も最新のブラウザを使用することを推奨します。以下のブラウザがサポートされています:
- Microsoft Edge(新しいMicrosoft Edge、最新バージョン。Microsoft Edgeレガシーではありません)
- Safari(最新バージョン、Macのみ)
- Chrome(最新バージョン)
- Firefox(最新バージョン)
Azure Machine Learningを使用するには、Azureサブスクリプション内にワークスペースを作成します。このワークスペースを使用して、データ、コンピュートリソース、コード、モデル、その他の機械学習ワークロードに関連するアーティファクトを管理できます。
注意: Azure Machine Learningワークスペースがサブスクリプション内に存在する限り、データストレージに少額の料金が発生します。そのため、使用しなくなった場合はAzure Machine Learningワークスペースを削除することをお勧めします。
-
AzureポータルにMicrosoftの資格情報でサインインします。
-
+リソースの作成を選択します。
Machine Learningを検索し、Machine Learningタイルを選択します。
作成ボタンをクリックします。
以下の設定を入力します:
- サブスクリプション: Azureサブスクリプション
- リソースグループ: リソースグループを作成または選択
- ワークスペース名: ワークスペースの一意の名前を入力
- リージョン: 最も近い地理的リージョンを選択
- ストレージアカウント: ワークスペース用に作成される新しいストレージアカウントを確認
- キーボールト: ワークスペース用に作成される新しいキーボールトを確認
- Application Insights: ワークスペース用に作成される新しいApplication Insightsリソースを確認
- コンテナレジストリ: なし(モデルをコンテナにデプロイする際に自動的に作成されます)
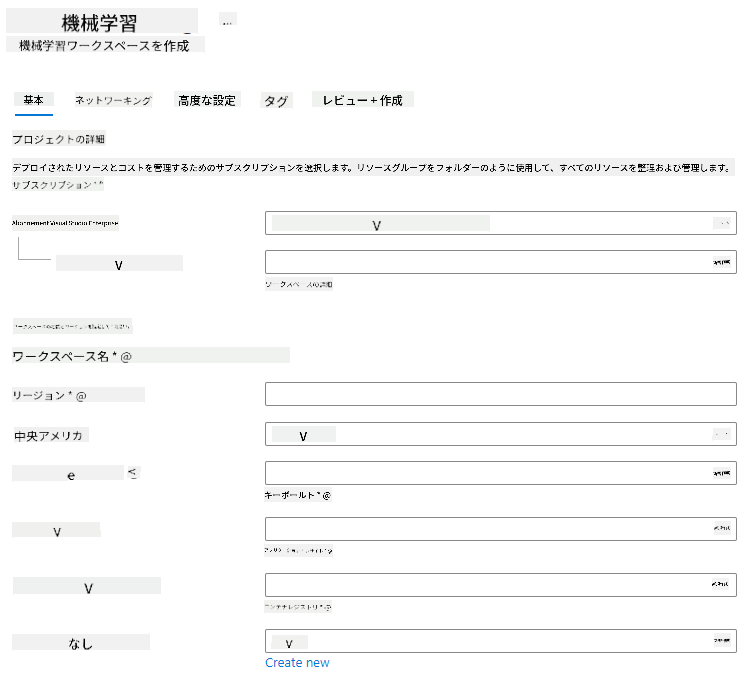
- 作成+レビューをクリックし、その後作成ボタンをクリックします。
-
ワークスペースが作成されるのを待ちます(数分かかる場合があります)。その後、ポータルでワークスペースに移動します。Machine Learning Azureサービスを通じて見つけることができます。
-
ワークスペースの概要ページでAzure Machine Learning Studioを起動します(または新しいブラウザタブを開き、https://ml.azure.com に移動します)。MicrosoftアカウントでAzure Machine Learning Studioにサインインします。プロンプトが表示された場合は、Azureディレクトリとサブスクリプション、Azure Machine Learningワークスペースを選択します。
- Azure Machine Learning Studioで、左上の☰アイコンを切り替えてインターフェース内のさまざまなページを表示します。これらのページを使用してワークスペース内のリソースを管理できます。
Azureポータルを使用してワークスペースを管理できますが、データサイエンティストや機械学習運用エンジニアにとっては、Azure Machine Learning Studioがワークスペースリソースを管理するためのより集中したユーザーインターフェースを提供します。
2.2 コンピュートリソース
コンピュートリソースは、モデルのトレーニングやデータ探索プロセスを実行するためのクラウドベースのリソースです。作成できるコンピュートリソースには以下の4種類があります:
- コンピュートインスタンス: データサイエンティストがデータやモデルを操作するための開発用ワークステーション。これには仮想マシン(VM)の作成とノートブックインスタンスの起動が含まれます。その後、ノートブックからコンピュートクラスターを呼び出してモデルをトレーニングできます。
- コンピュートクラスター: 実験コードのオンデマンド処理のためのスケーラブルなVMクラスター。モデルをトレーニングする際に必要です。コンピュートクラスターは、特殊なGPUやCPUリソースを利用することもできます。
- 推論クラスター: トレーニング済みモデルを使用する予測サービスのデプロイターゲット。
- 接続されたコンピュート: Azureの既存のコンピュートリソース(仮想マシンやAzure Databricksクラスターなど)へのリンク。
2.2.1 コンピュートリソースに適したオプションを選ぶ
コンピュートリソースを作成する際に考慮すべき重要な要素がいくつかあります。これらの選択は重要な決定となる場合があります。
CPUが必要ですか、それともGPUが必要ですか?
CPU(中央処理装置)は、コンピュータプログラムを構成する命令を実行する電子回路です。GPU(グラフィックス処理装置)は、グラフィックス関連のコードを非常に高速で実行できる特殊な電子回路です。
CPUとGPUのアーキテクチャの主な違いは、CPUは幅広いタスクを迅速に処理するよう設計されています(CPUクロックスピードで測定される)が、同時に実行できるタスクの数には制限があります。一方、GPUは並列計算に特化しており、深層学習タスクに非常に適しています。
| CPU | GPU |
|---|---|
| 安価 | 高価 |
| 同時実行性が低い | 同時実行性が高い |
| 深層学習モデルのトレーニングが遅い | 深層学習に最適 |
クラスターサイズ
クラスターが大きいほど費用がかかりますが、応答性が向上します。そのため、時間はあるが予算が限られている場合は、小さなクラスターから始めるべきです。逆に、予算はあるが時間が限られている場合は、大きなクラスターから始めるべきです。
VMサイズ
時間と予算の制約に応じて、RAM、ディスク、コア数、クロックスピードのサイズを変更できます。これらのパラメータをすべて増やすと費用がかかりますが、パフォーマンスが向上します。
専用インスタンスか低優先度インスタンスか?
低優先度インスタンスは中断可能であることを意味します。つまり、Microsoft Azureがこれらのリソースを別のタスクに割り当てることができ、ジョブが中断される可能性があります。一方、専用インスタンス(中断不可)は、許可なしにジョブが終了することはありません。 これは時間と費用のトレードオフのもう一つの考慮事項であり、中断可能なインスタンスは専用インスタンスよりも安価です。
2.2.2 コンピュートクラスターの作成
以前に作成したAzure MLワークスペースで、コンピュートに移動すると、先ほど説明したさまざまなコンピュートリソース(コンピュートインスタンス、コンピュートクラスター、推論クラスター、接続されたコンピュート)を確認できます。このプロジェクトでは、モデルトレーニング用にコンピュートクラスターが必要です。Studioで「Compute」メニューをクリックし、「Compute cluster」タブを選択して「+ New」ボタンをクリックし、コンピュートクラスターを作成します。
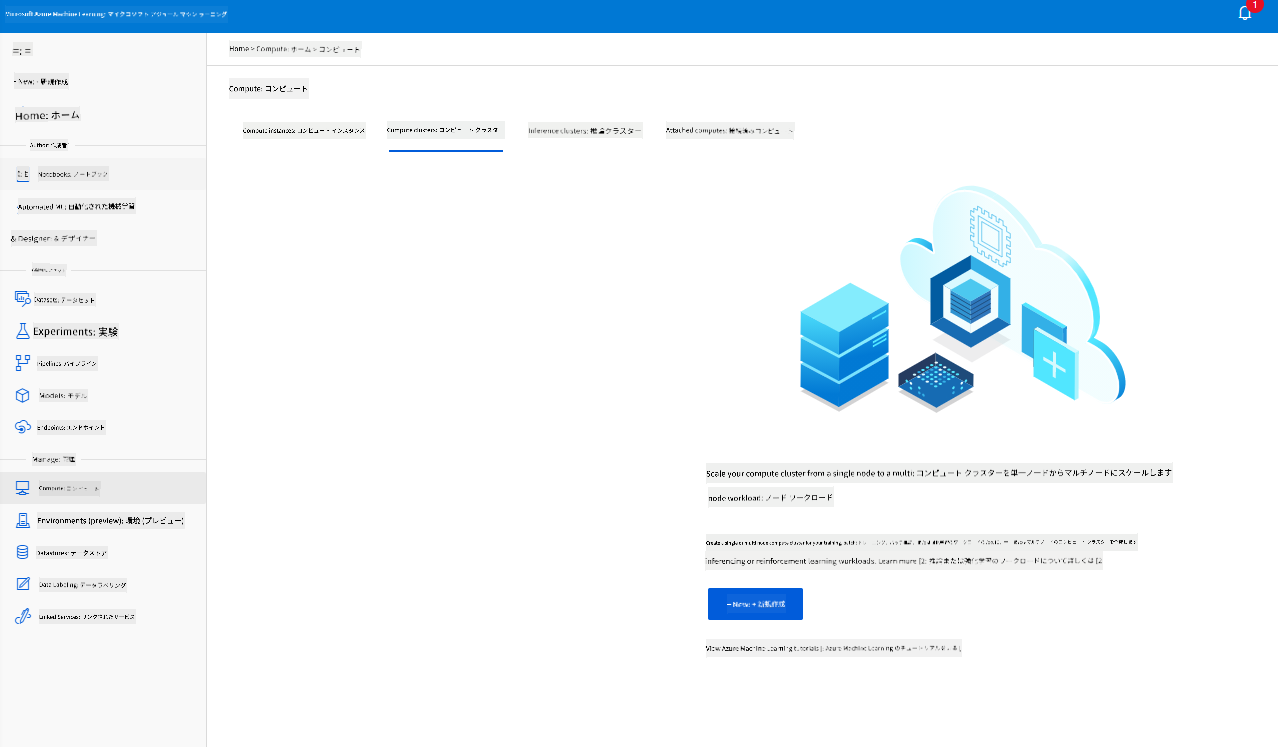
- オプションを選択します: 専用 vs 低優先度、CPUまたはGPU、VMサイズ、コア数(このプロジェクトではデフォルト設定を使用できます)。
- 「Next」ボタンをクリックします。
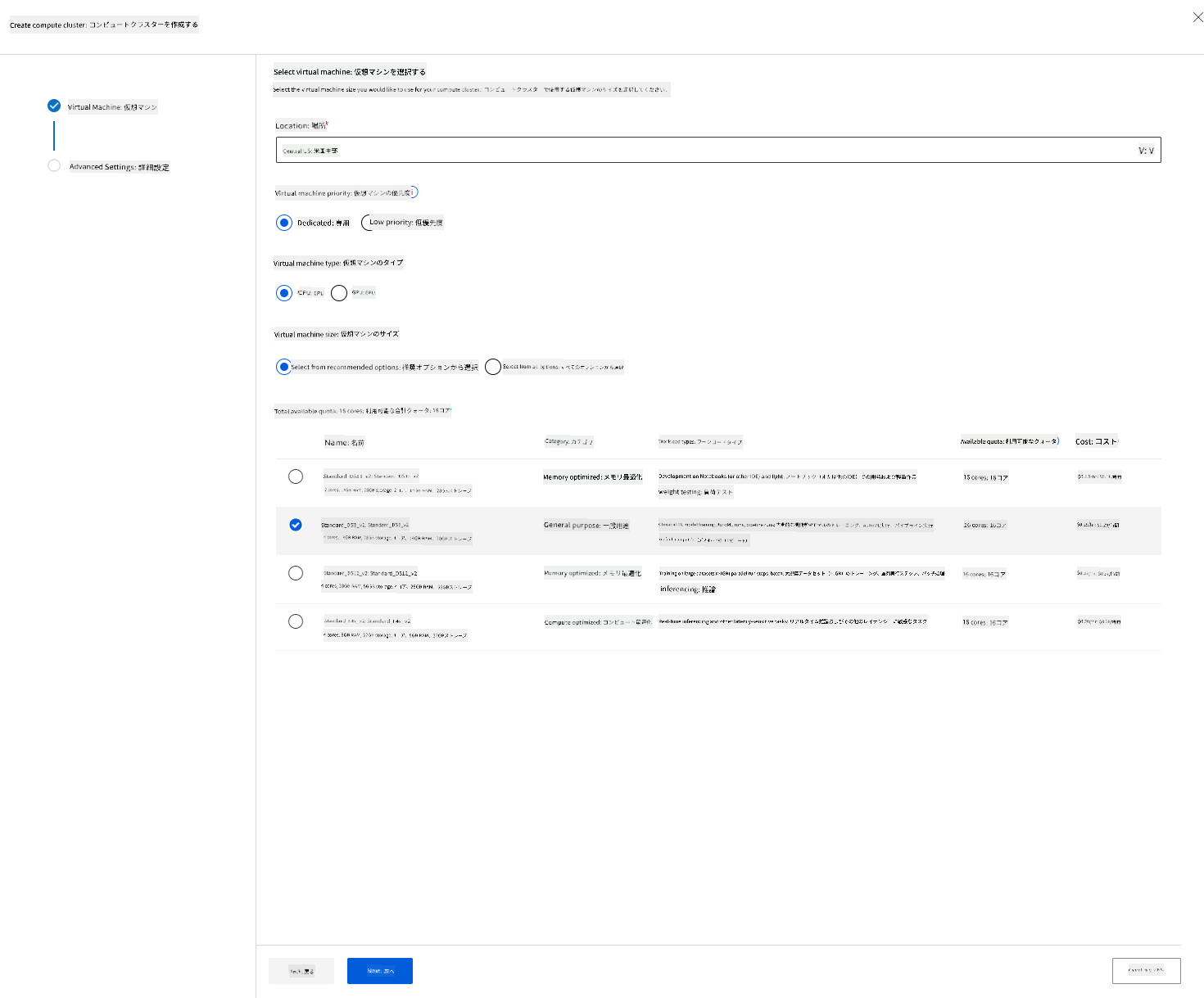
- クラスターに名前を付けます。
- オプションを選択します: ノードの最小/最大数、スケールダウンまでのアイドル秒数、SSHアクセス。最小ノード数が0の場合、クラスターがアイドル状態のときに費用を節約できます。最大ノード数が多いほどトレーニング時間が短くなります。推奨される最大ノード数は3です。
- 「Create」ボタンをクリックします。このステップには数分かかる場合があります。
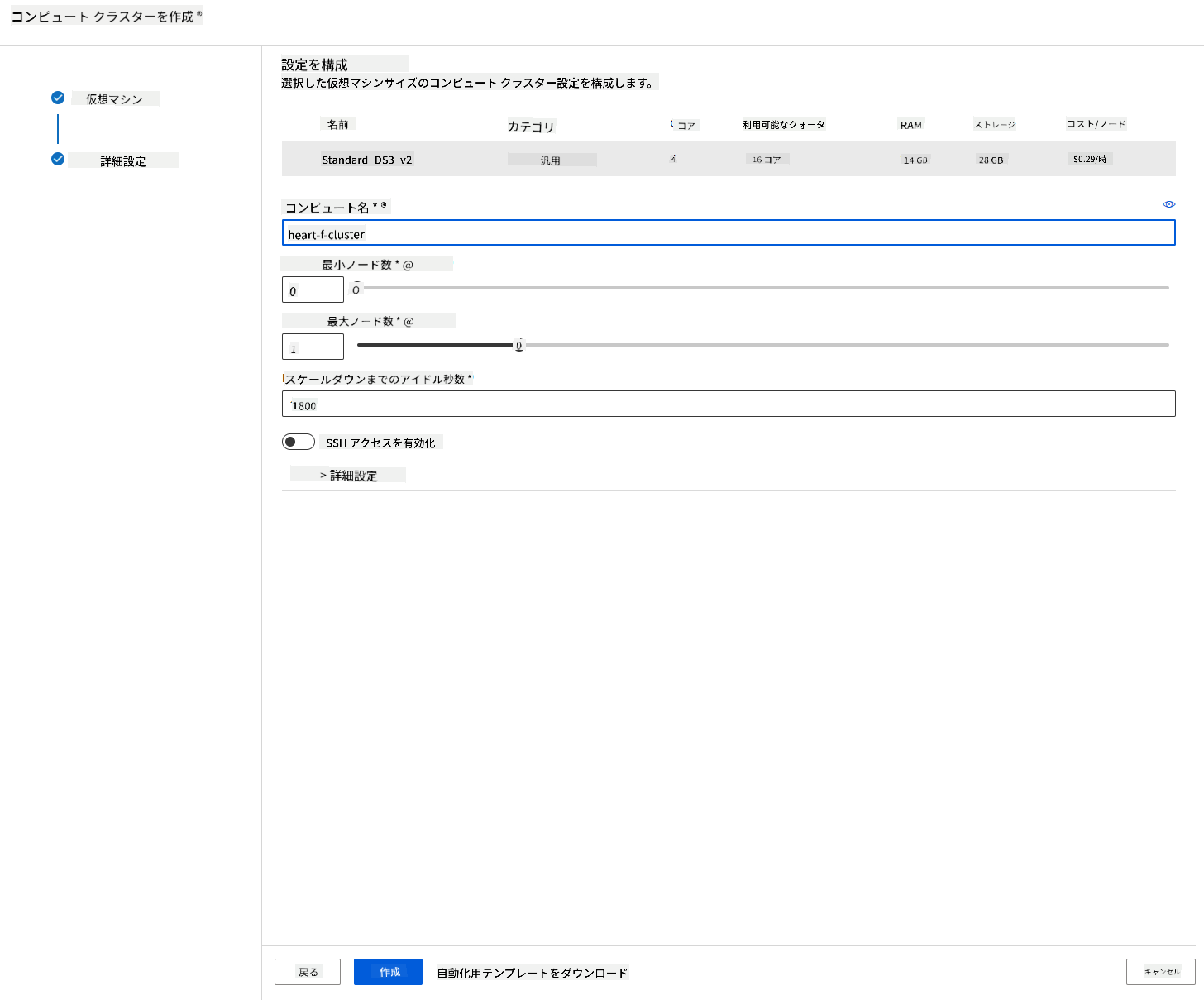
素晴らしい!これでコンピュートクラスターが作成されましたので、Azure ML Studioにデータをロードする必要があります。
2.3 データセットのロード
-
以前に作成したAzure MLワークスペースで、左メニューの「Datasets」をクリックし、「+ Create dataset」ボタンをクリックしてデータセットを作成します。「From local files」オプションを選択し、以前にダウンロードしたKaggleデータセットを選択します。
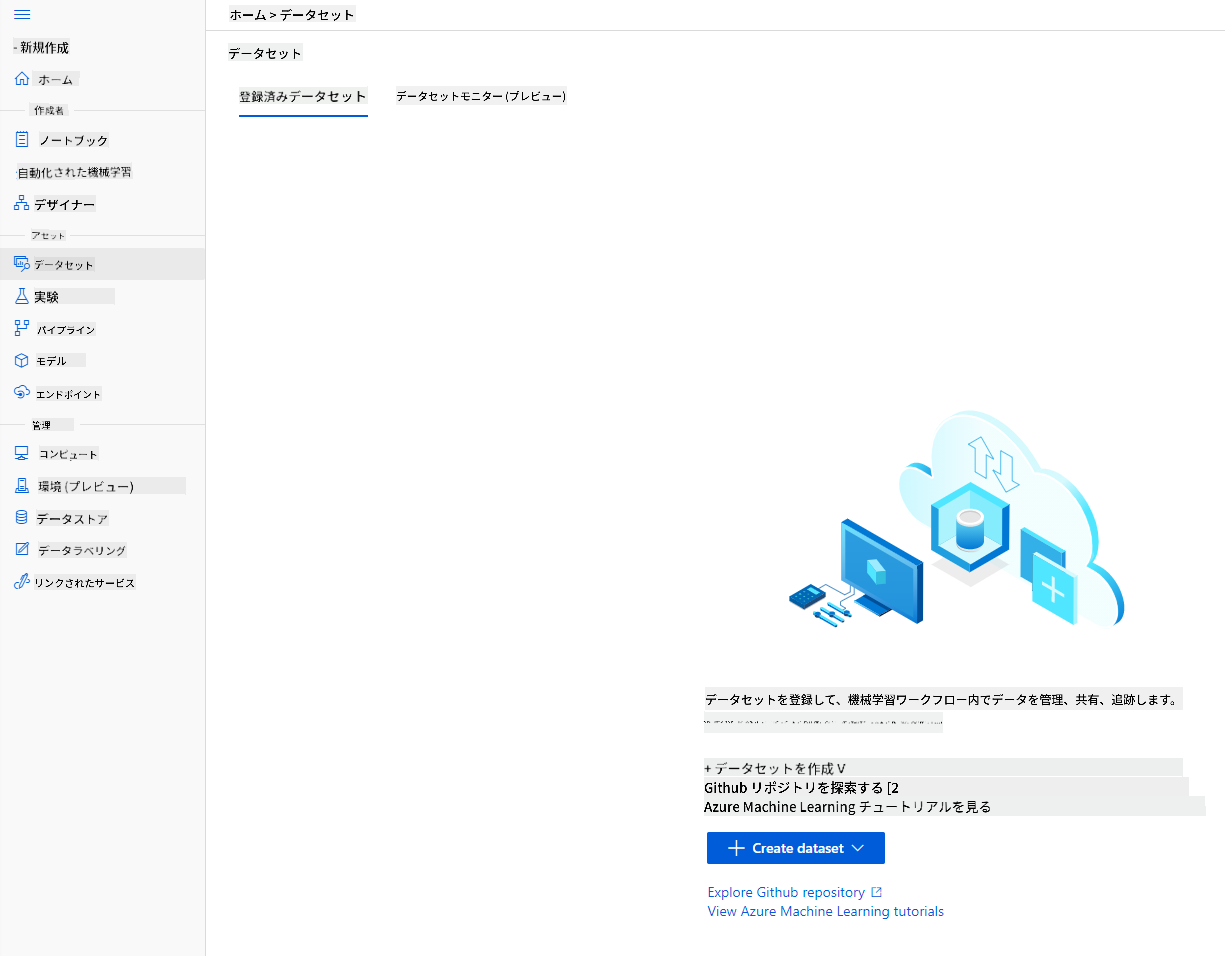
-
データセットに名前、タイプ、説明を付けます。「Next」をクリックします。ファイルからデータをアップロードします。「Next」をクリックします。
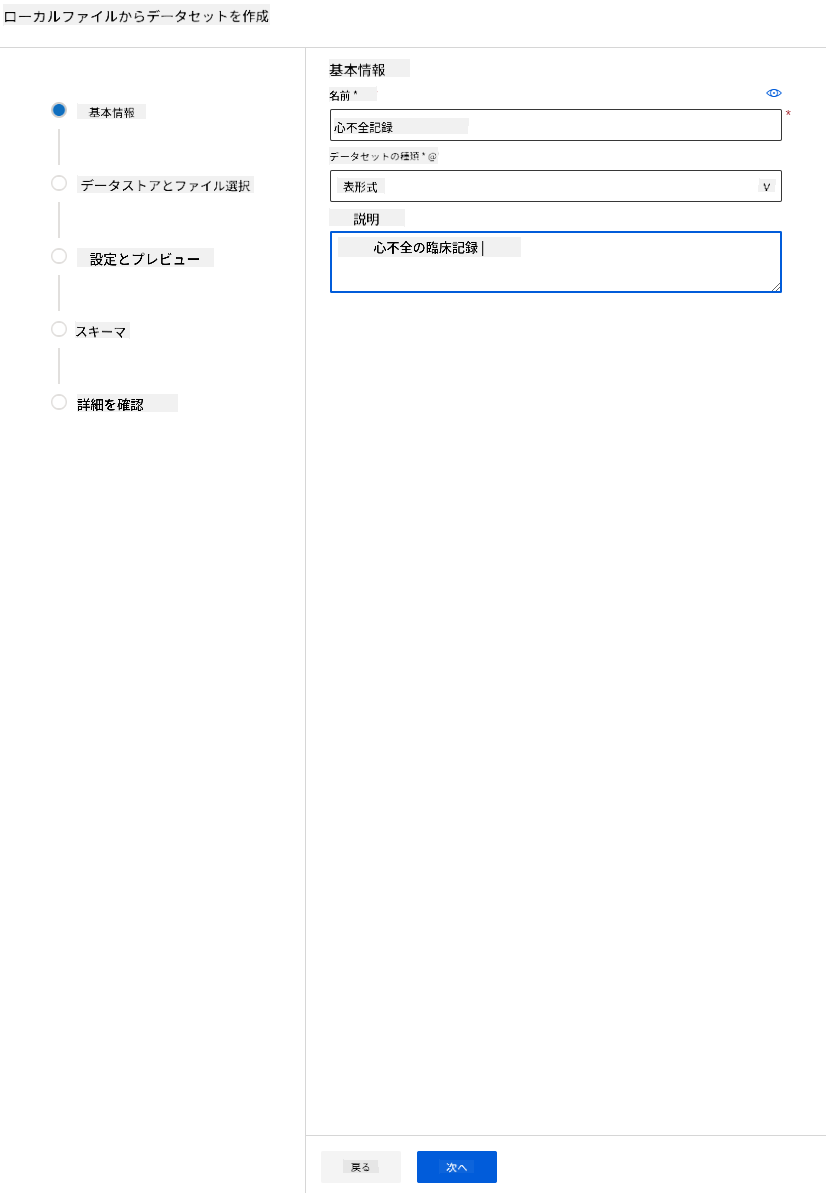
-
スキーマで、以下の特徴のデータ型をBooleanに変更します: anaemia、diabetes、high blood pressure、sex、smoking、DEATH_EVENT。「Next」をクリックし、「Create」をクリックします。
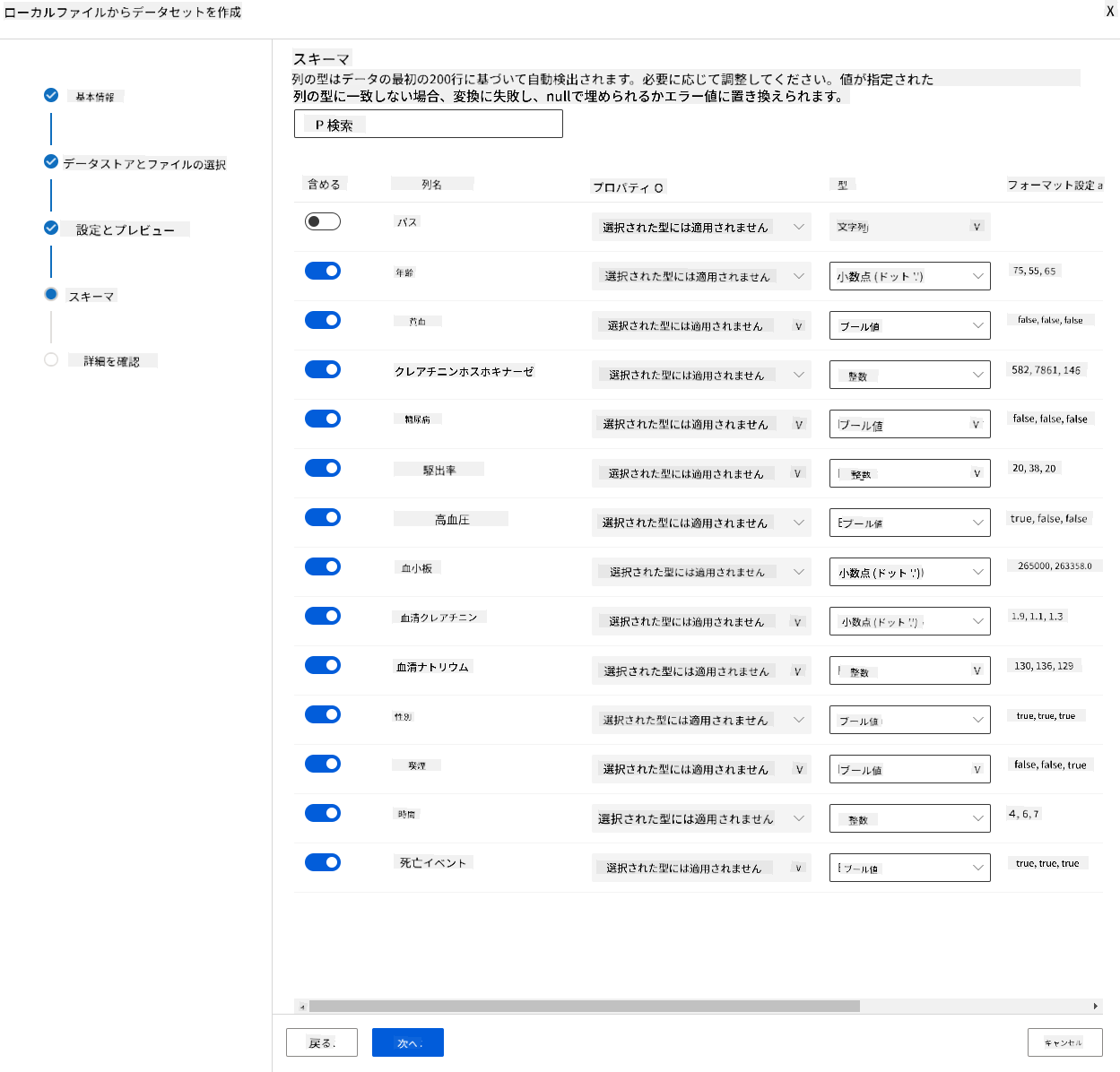
素晴らしい!これでデータセットが準備され、コンピュートクラスターが作成されましたので、モデルのトレーニングを開始できます。
2.4 AutoMLを使ったローコード/ノーコードトレーニング
従来の機械学習モデルの開発はリソース集約型であり、ドメイン知識と時間を必要とし、数十のモデルを生成して比較する必要があります。
自動化された機械学習(AutoML)は、機械学習モデル開発の時間のかかる反復的なタスクを自動化するプロセスです。これにより、データサイエンティスト、アナリスト、開発者が高いスケール、効率性、生産性でMLモデルを構築できるようになります。モデル品質を維持しながら、プロダクション対応のMLモデルを迅速に作成できるようになります。詳細はこちら
-
以前に作成したAzure MLワークスペースで、左メニューの「Automated ML」をクリックし、アップロードしたデータセットを選択します。「Next」をクリックします。
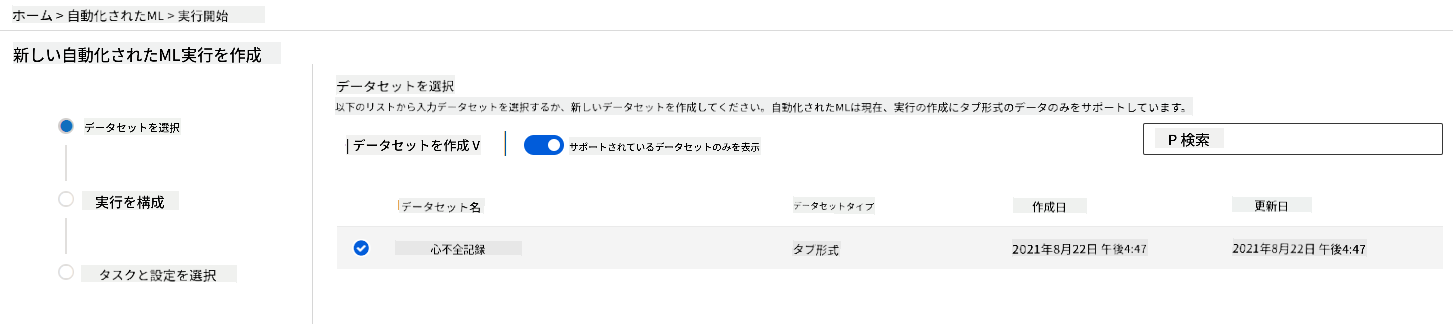
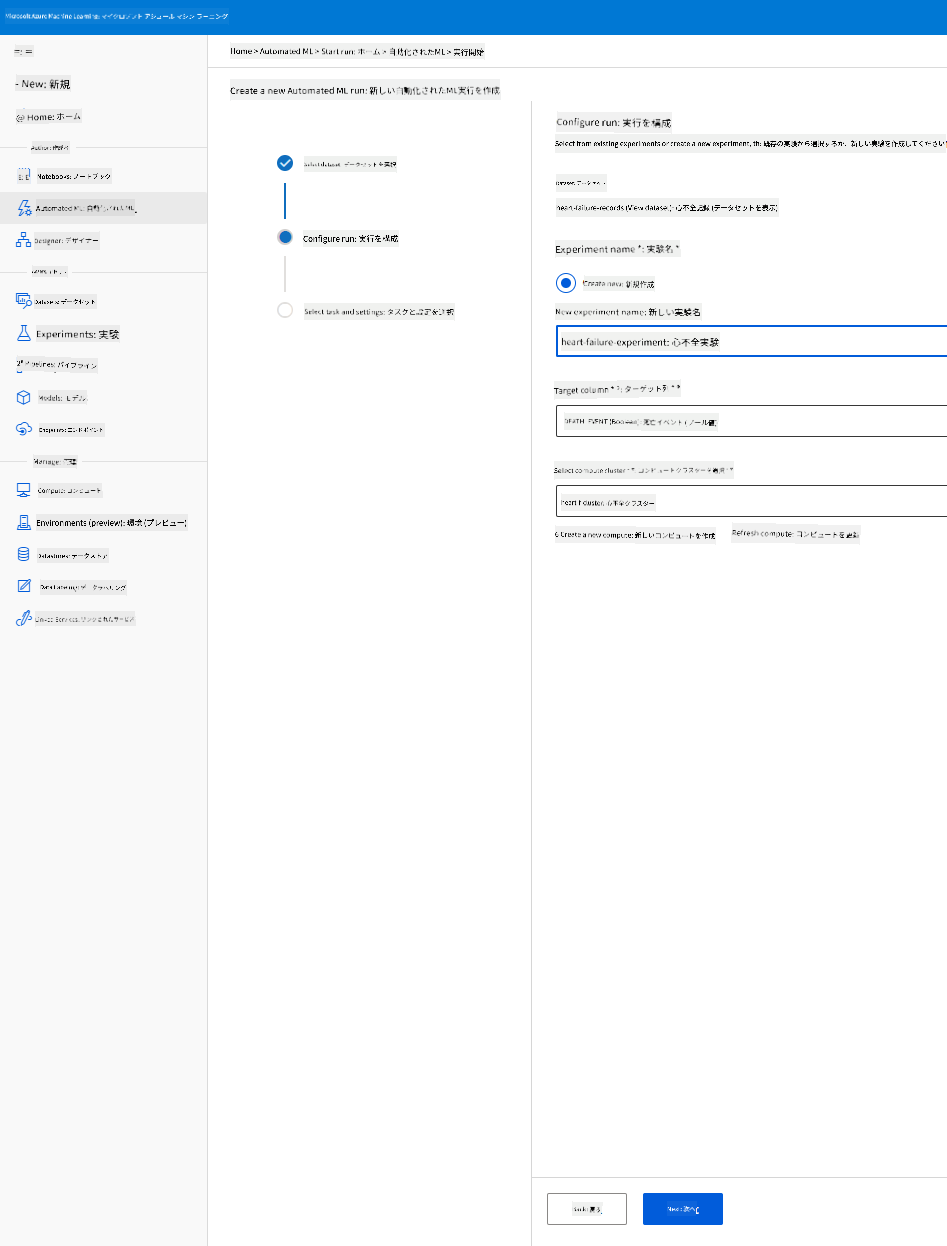
-
新しい実験名、ターゲット列(DEATH_EVENT)、作成したコンピュートクラスターを入力します。「Next」をクリックします。
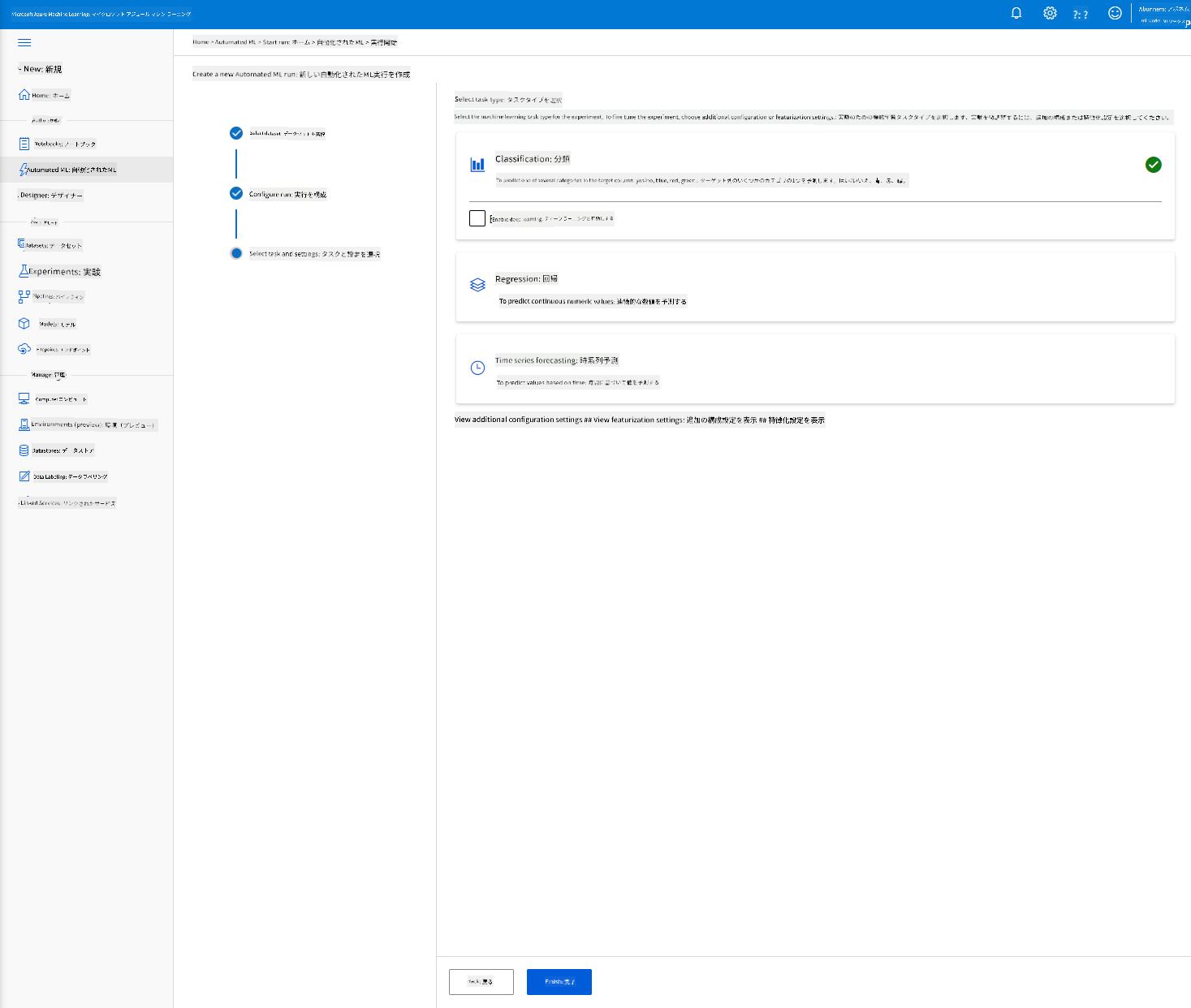
-
「Classification」を選択し、「Finish」をクリックします。このステップはコンピュートクラスターのサイズによって30分から1時間かかる場合があります。
-
実行が完了したら、「Automated ML」タブをクリックし、実行を選択して、「Best model summary」カードのアルゴリズムをクリックします。
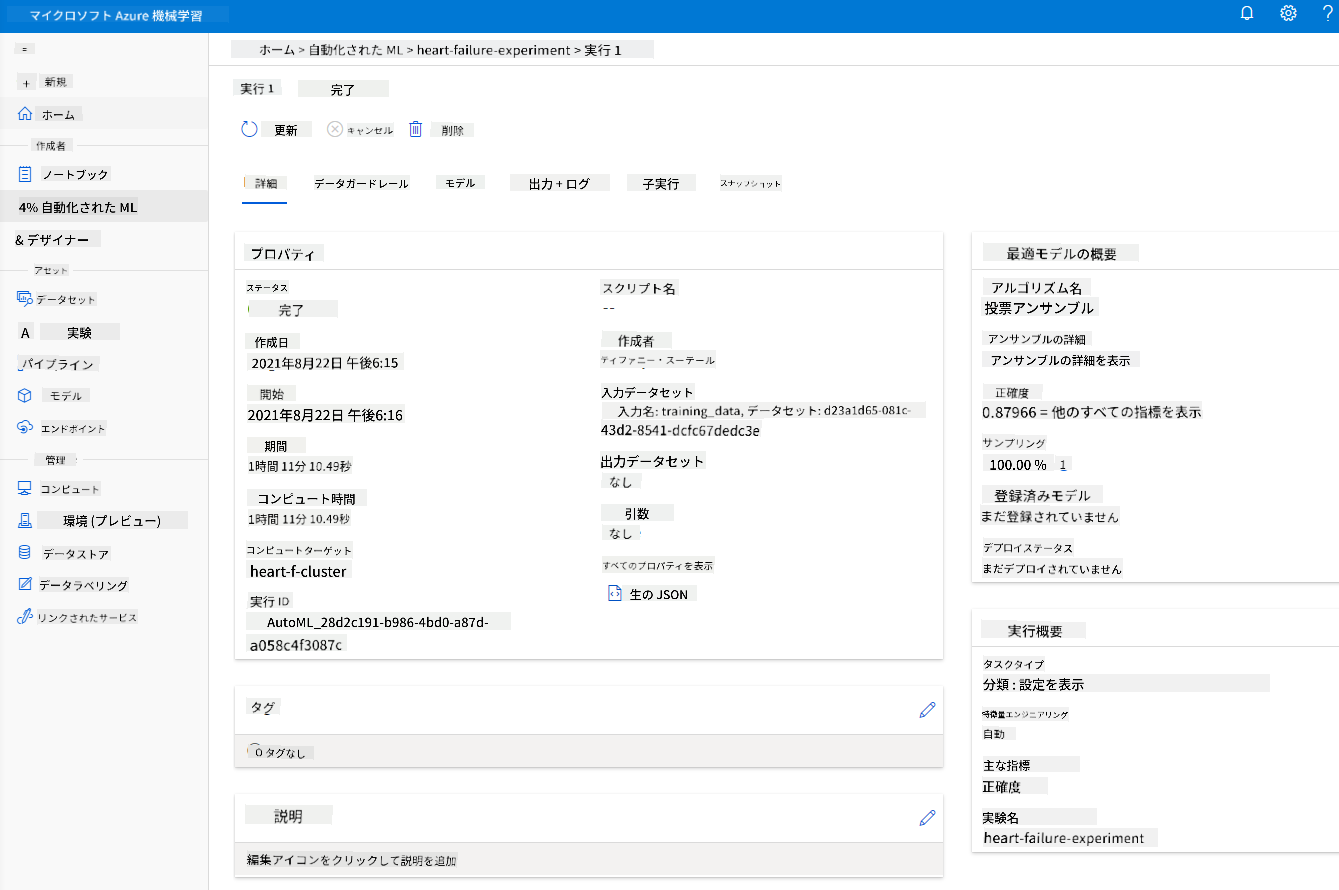
ここでは、AutoMLが生成した最適なモデルの詳細な説明を見ることができます。また、「Models」タブで他のモデルも探索できます。「Explanations(プレビュー)」ボタンでモデルを数分間探索してみてください。使用したいモデルを選択したら(ここではAutoMLが選択した最適なモデルを使用します)、次にそのモデルをデプロイする方法を見ていきます。
3. ローコード/ノーコードモデルのデプロイとエンドポイントの利用
3.1 モデルのデプロイ
自動化された機械学習インターフェースを使用すると、最適なモデルを数ステップでWebサービスとしてデプロイできます。デプロイメントは、モデルを統合して新しいデータに基づいて予測を行い、潜在的な機会領域を特定できるようにするプロセスです。このプロジェクトでは、Webサービスへのデプロイメントにより、医療アプリケーションがモデルを利用して患者の心臓発作リスクをリアルタイムで予測できるようになります。
最適なモデルの説明で「Deploy」ボタンをクリックします。
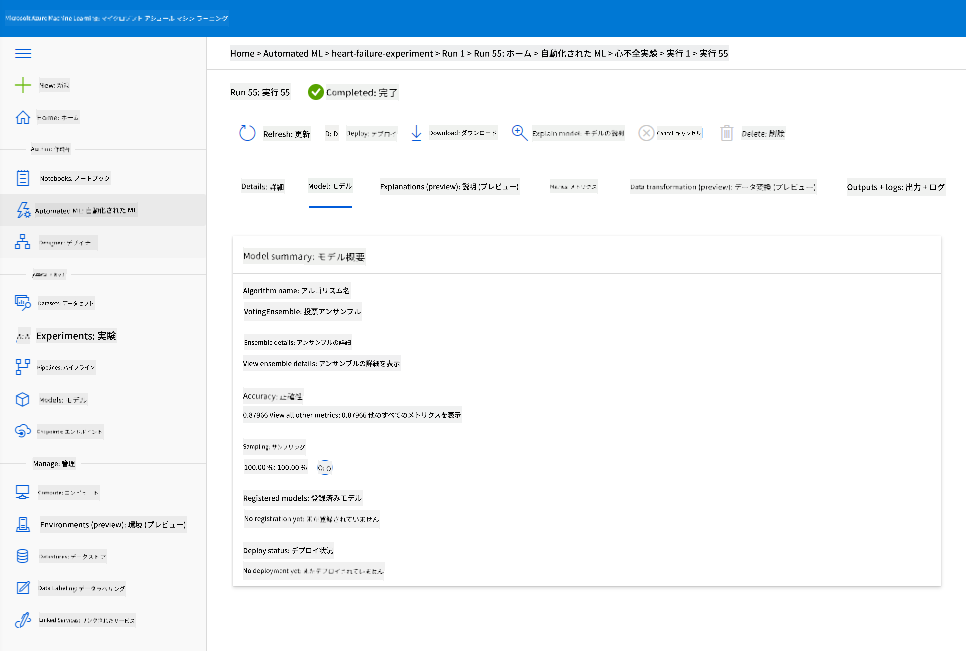
- 名前、説明、コンピュートタイプ(Azure Container Instance)、認証を有効にして「Deploy」をクリックします。このステップは約20分かかる場合があります。デプロイメントプロセスには、モデルの登録、リソースの生成、それらをWebサービス用に構成するステップが含まれます。「Deploy status」下にステータスメッセージが表示されます。「Refresh」を定期的に選択してデプロイメントステータスを確認してください。ステータスが「Healthy」になるとデプロイメントが完了し、実行中です。
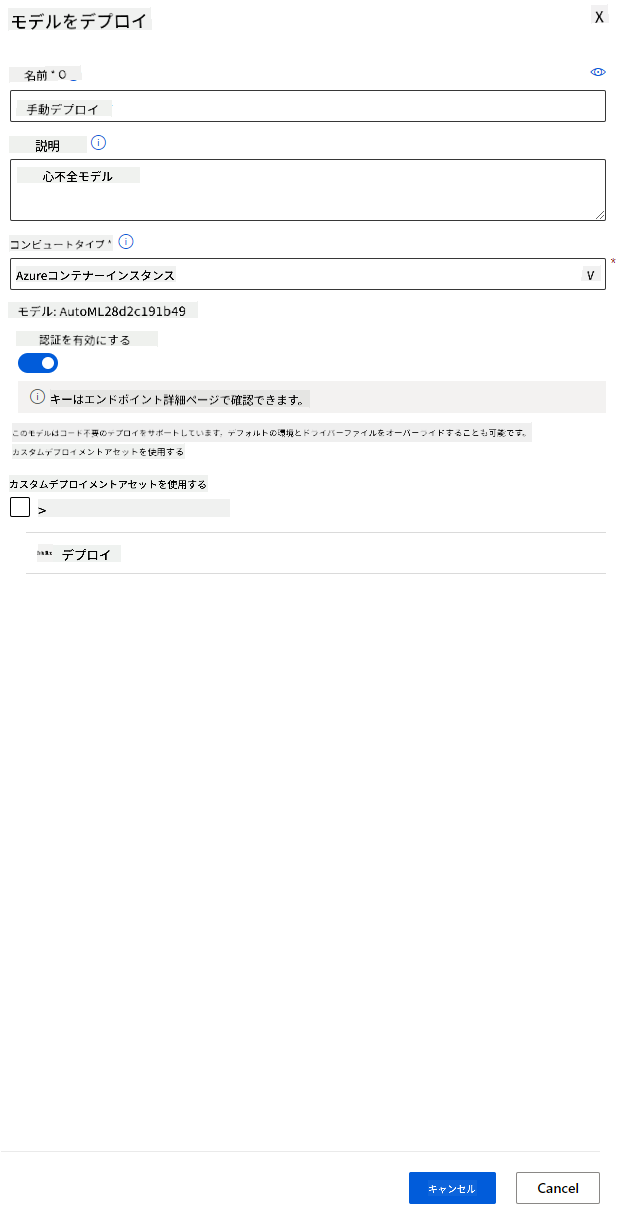
- デプロイメントが完了したら、「Endpoint」タブをクリックし、デプロイしたエンドポイントを選択します。ここではエンドポイントに関するすべての詳細を確認できます。
素晴らしい!これでモデルがデプロイされましたので、エンドポイントの利用を開始できます。
3.2 エンドポイントの利用
「Consume」タブをクリックします。ここでは、RESTエンドポイントと消費オプションのPythonスクリプトを確認できます。Pythonコードをよく読んでみてください。
このスクリプトはローカルマシンから直接実行でき、エンドポイントを利用します。
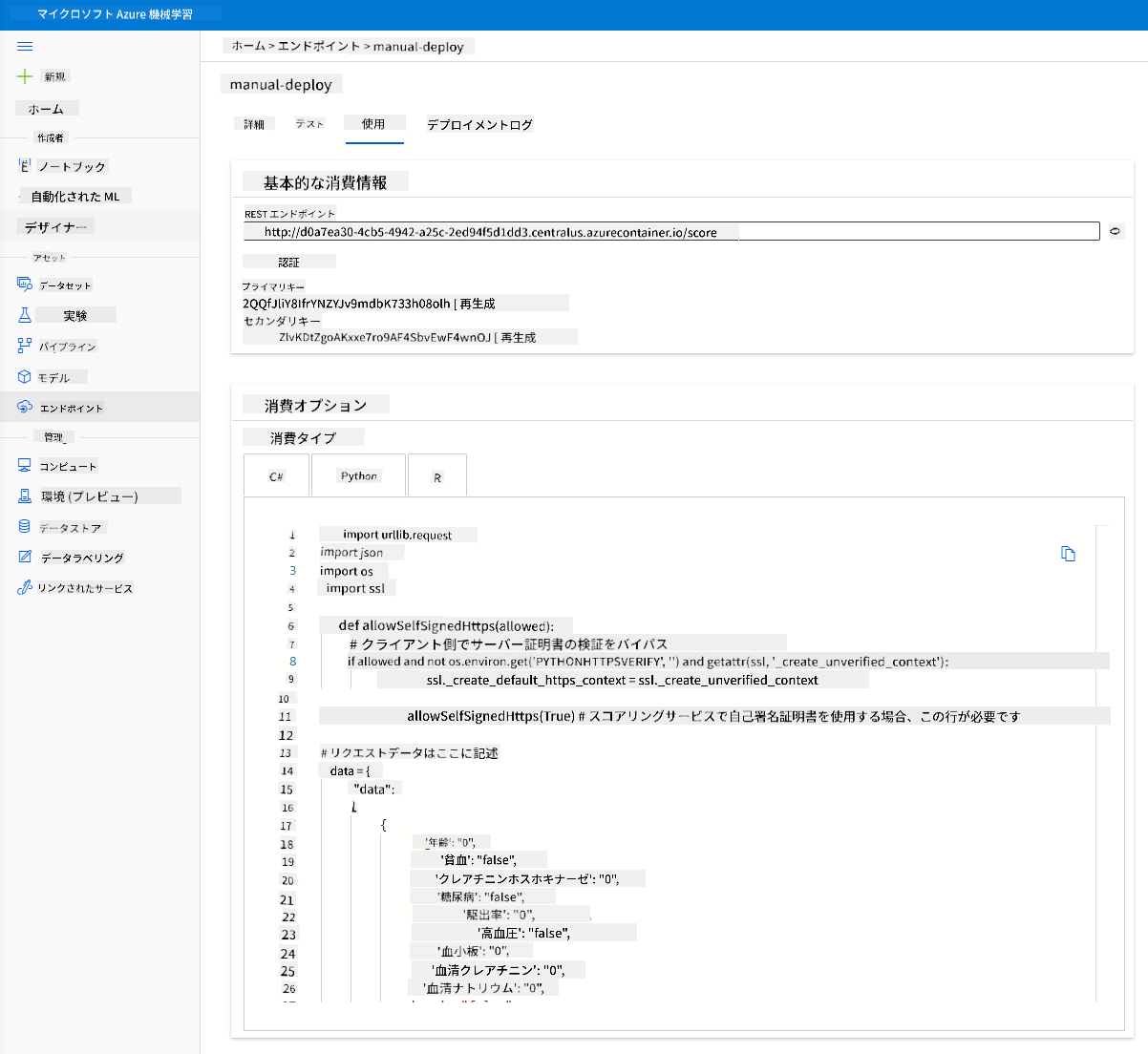
以下の2行のコードを確認してください:
url = 'http://98e3715f-xxxx-xxxx-xxxx-9ec22d57b796.centralus.azurecontainer.io/score'
api_key = '' # Replace this with the API key for the web service
url変数は「Consume」タブにあるRESTエンドポイントであり、api_key変数は認証を有効にした場合に「Consume」タブにあるプライマリキーです。このスクリプトはこの情報を使用してエンドポイントを利用します。
- スクリプトを実行すると、以下の出力が表示されるはずです:
b'"{\\"result\\": [true]}"'
これは、与えられたデータに基づいて心不全の予測が「true」であることを意味します。スクリプトに自動生成されたデータをよく見ると、すべてがデフォルトで0およびfalseであることがわかります。以下の入力サンプルでデータを変更できます:
data = {
"data":
[
{
'age': "0",
'anaemia': "false",
'creatinine_phosphokinase': "0",
'diabetes': "false",
'ejection_fraction': "0",
'high_blood_pressure': "false",
'platelets': "0",
'serum_creatinine': "0",
'serum_sodium': "0",
'sex': "false",
'smoking': "false",
'time': "0",
},
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
スクリプトは以下を返すはずです:
python b'"{\\"result\\": [true, false]}"'
おめでとうございます!デプロイされたモデルを利用し、Azure MLでトレーニングを行いました!
注意: プロジェクトが完了したら、すべてのリソースを削除することを忘れないでください。
🚀 チャレンジ
AutoMLが生成したトップモデルの説明と詳細をよく見てください。最適なモデルが他のモデルより優れている理由を理解してみてください。どのアルゴリズムが比較されましたか?それらの違いは何ですか?このケースで最適なモデルがより良いパフォーマンスを発揮している理由は何ですか?
講義後のクイズ
復習と自己学習
このレッスンでは、クラウドで心不全リスクを予測するモデルをローコード/ノーコードでトレーニング、デプロイ、利用する方法を学びました。まだ行っていない場合は、AutoMLが生成したトップモデルの説明をさらに深く掘り下げ、最適なモデルが他のモデルより優れている理由を理解してみてください。
ローコード/ノーコードAutoMLについてさらに詳しく知りたい場合は、このドキュメントを読んでみてください。
課題
Azure MLでのローコード/ノーコードデータサイエンスプロジェクト
免責事項:
この文書はAI翻訳サービスCo-op Translatorを使用して翻訳されています。正確性を追求しておりますが、自動翻訳には誤りや不正確な部分が含まれる可能性があります。元の言語で記載された文書が正式な情報源とみなされるべきです。重要な情報については、専門の人間による翻訳を推奨します。この翻訳の使用に起因する誤解や誤解について、当社は責任を負いません。