11 KiB
Introduzione al Ciclo di Vita della Data Science
 |
|---|
| Introduzione al Ciclo di Vita della Data Science - Sketchnote di @nitya |
Quiz Pre-Lettura
A questo punto probabilmente hai capito che la data science è un processo. Questo processo può essere suddiviso in 5 fasi:
- Acquisizione
- Elaborazione
- Analisi
- Comunicazione
- Manutenzione
Questa lezione si concentra su 3 parti del ciclo di vita: acquisizione, elaborazione e manutenzione.
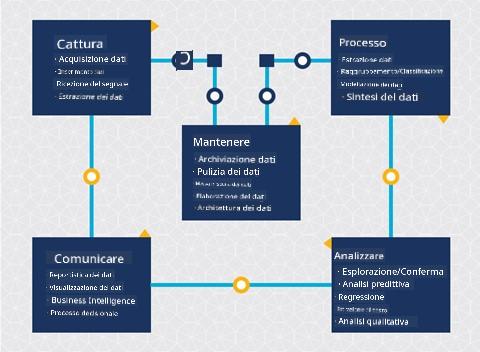
Foto di Berkeley School of Information
Acquisizione
La prima fase del ciclo di vita è molto importante poiché le fasi successive dipendono da essa. È praticamente due fasi combinate in una: acquisire i dati e definire lo scopo e i problemi che devono essere affrontati.
Definire gli obiettivi del progetto richiederà una comprensione più approfondita del problema o della domanda. Per prima cosa, dobbiamo identificare e coinvolgere coloro che hanno bisogno di risolvere il loro problema. Questi potrebbero essere stakeholder di un'azienda o sponsor del progetto, che possono aiutare a identificare chi o cosa trarrà beneficio da questo progetto, oltre a cosa e perché ne hanno bisogno. Un obiettivo ben definito dovrebbe essere misurabile e quantificabile per definire un risultato accettabile.
Domande che un data scientist potrebbe porsi:
- Questo problema è stato affrontato in precedenza? Cosa è stato scoperto?
- Lo scopo e l'obiettivo sono chiari a tutti i coinvolti?
- C'è ambiguità e come ridurla?
- Quali sono i vincoli?
- Come potrebbe apparire il risultato finale?
- Quante risorse (tempo, persone, capacità computazionale) sono disponibili?
Successivamente, bisogna identificare, raccogliere e infine esplorare i dati necessari per raggiungere gli obiettivi definiti. In questa fase di acquisizione, i data scientist devono anche valutare la quantità e la qualità dei dati. Questo richiede un'esplorazione dei dati per confermare che ciò che è stato acquisito supporti il raggiungimento del risultato desiderato.
Domande che un data scientist potrebbe porsi sui dati:
- Quali dati sono già disponibili?
- Chi possiede questi dati?
- Quali sono le preoccupazioni relative alla privacy?
- Ho abbastanza dati per risolvere questo problema?
- I dati sono di qualità accettabile per questo problema?
- Se scopro ulteriori informazioni attraverso questi dati, dovremmo considerare di cambiare o ridefinire gli obiettivi?
Elaborazione
La fase di elaborazione del ciclo di vita si concentra sulla scoperta di pattern nei dati e sulla modellazione. Alcune tecniche utilizzate in questa fase richiedono metodi statistici per individuare i pattern. Tipicamente, questo sarebbe un compito tedioso per un essere umano con un grande set di dati e si farà affidamento sui computer per accelerare il processo. Questa fase è anche il punto in cui la data science e il machine learning si intersecano. Come hai appreso nella prima lezione, il machine learning è il processo di costruzione di modelli per comprendere i dati. I modelli sono una rappresentazione della relazione tra variabili nei dati che aiutano a prevedere i risultati.
Tecniche comuni utilizzate in questa fase sono trattate nel curriculum ML for Beginners. Segui i link per saperne di più:
- Classificazione: Organizzare i dati in categorie per un uso più efficiente.
- Clustering: Raggruppare i dati in gruppi simili.
- Regressione: Determinare le relazioni tra variabili per prevedere o stimare valori.
Manutenzione
Nel diagramma del ciclo di vita, potresti aver notato che la manutenzione si trova tra acquisizione ed elaborazione. La manutenzione è un processo continuo di gestione, archiviazione e protezione dei dati durante l'intero processo di un progetto e dovrebbe essere considerata per tutta la durata del progetto.
Archiviazione dei Dati
Le considerazioni su come e dove i dati vengono archiviati possono influenzare il costo della loro archiviazione così come le prestazioni di accesso ai dati. Decisioni come queste non sono probabilmente prese solo da un data scientist, ma potrebbero trovarsi a fare scelte su come lavorare con i dati in base a come sono archiviati.
Ecco alcuni aspetti dei moderni sistemi di archiviazione dei dati che possono influenzare queste scelte:
On premise vs off premise vs cloud pubblico o privato
On premise si riferisce all'hosting e alla gestione dei dati su apparecchiature proprie, come possedere un server con dischi rigidi che archiviano i dati, mentre off premise si basa su apparecchiature che non si possiedono, come un data center. Il cloud pubblico è una scelta popolare per archiviare dati che non richiede conoscenze su come o dove esattamente i dati sono archiviati, dove pubblico si riferisce a un'infrastruttura unificata sottostante condivisa da tutti coloro che utilizzano il cloud. Alcune organizzazioni hanno politiche di sicurezza rigorose che richiedono l'accesso completo alle apparecchiature dove i dati sono ospitati e si affidano a un cloud privato che fornisce servizi cloud propri. Imparerai di più sui dati nel cloud nelle lezioni successive.
Dati freddi vs dati caldi
Quando alleni i tuoi modelli, potresti aver bisogno di più dati di addestramento. Se sei soddisfatto del tuo modello, arriveranno più dati affinché il modello svolga il suo scopo. In ogni caso, il costo di archiviazione e accesso ai dati aumenterà man mano che ne accumuli di più. Separare i dati raramente utilizzati, noti come dati freddi, dai dati frequentemente accessibili, noti come dati caldi, può essere un'opzione di archiviazione più economica tramite hardware o servizi software. Se i dati freddi devono essere accessibili, potrebbe richiedere un po' più di tempo per recuperarli rispetto ai dati caldi.
Gestione dei Dati
Mentre lavori con i dati, potresti scoprire che alcuni di essi devono essere puliti utilizzando alcune delle tecniche trattate nella lezione dedicata alla preparazione dei dati per costruire modelli accurati. Quando arrivano nuovi dati, sarà necessario applicare alcune delle stesse tecniche per mantenere la coerenza nella qualità. Alcuni progetti prevedono l'uso di uno strumento automatizzato per la pulizia, l'aggregazione e la compressione prima che i dati vengano spostati nella loro posizione finale. Azure Data Factory è un esempio di uno di questi strumenti.
Protezione dei Dati
Uno degli obiettivi principali della protezione dei dati è garantire che coloro che lavorano con essi abbiano il controllo su ciò che viene raccolto e sul contesto in cui viene utilizzato. Mantenere i dati sicuri implica limitare l'accesso solo a chi ne ha bisogno, rispettare le leggi e i regolamenti locali, oltre a mantenere standard etici, come trattato nella lezione sull'etica.
Ecco alcune cose che un team potrebbe fare con la sicurezza in mente:
- Confermare che tutti i dati siano crittografati
- Fornire ai clienti informazioni su come vengono utilizzati i loro dati
- Rimuovere l'accesso ai dati a chi ha lasciato il progetto
- Consentire solo a determinati membri del progetto di modificare i dati
🚀 Sfida
Esistono molte versioni del Ciclo di Vita della Data Science, dove ogni fase può avere nomi e numero di stadi diversi ma conterrà gli stessi processi menzionati in questa lezione.
Esplora il Ciclo di Vita del Team Data Science Process e il Processo standard cross-industriale per il data mining. Nomina 3 somiglianze e differenze tra i due.
| Team Data Science Process (TDSP) | Processo standard cross-industriale per il data mining (CRISP-DM) |
|---|---|
 |
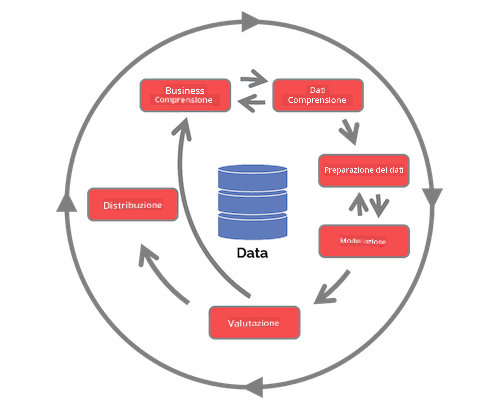 |
| Immagine di Microsoft | Immagine di Data Science Process Alliance |
Quiz Post-Lettura
Revisione e Studio Autonomo
Applicare il Ciclo di Vita della Data Science coinvolge diversi ruoli e compiti, dove alcuni possono concentrarsi su particolari parti di ogni fase. Il Team Data Science Process fornisce alcune risorse che spiegano i tipi di ruoli e compiti che qualcuno potrebbe avere in un progetto.
- Ruoli e compiti del Team Data Science Process
- Eseguire compiti di data science: esplorazione, modellazione e distribuzione
Compito
Disclaimer:
Questo documento è stato tradotto utilizzando il servizio di traduzione automatica Co-op Translator. Sebbene ci impegniamo per garantire l'accuratezza, si prega di notare che le traduzioni automatiche possono contenere errori o imprecisioni. Il documento originale nella sua lingua nativa dovrebbe essere considerato la fonte autorevole. Per informazioni critiche, si raccomanda una traduzione professionale eseguita da un traduttore umano. Non siamo responsabili per eventuali fraintendimenti o interpretazioni errate derivanti dall'uso di questa traduzione.