12 KiB
מבוא למחזור החיים של מדעי הנתונים
 |
|---|
| מבוא למחזור החיים של מדעי הנתונים - סקצ'נוט מאת @nitya |
שאלון לפני השיעור
בשלב זה כנראה כבר הבנתם שמדעי הנתונים הם תהליך. תהליך זה ניתן לחלק לחמישה שלבים:
- איסוף
- עיבוד
- ניתוח
- תקשורת
- תחזוקה
השיעור הזה מתמקד בשלושה חלקים מתוך מחזור החיים: איסוף, עיבוד ותחזוקה.
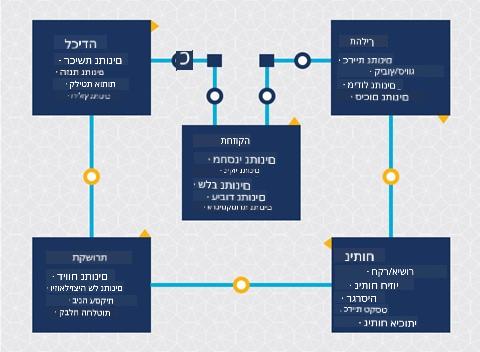
תמונה מאת Berkeley School of Information
איסוף
השלב הראשון במחזור החיים הוא קריטי, שכן השלבים הבאים תלויים בו. למעשה, מדובר בשני שלבים שמאוחדים לאחד: רכישת הנתונים והגדרת המטרה והבעיות שיש לטפל בהן.
הגדרת מטרות הפרויקט תדרוש הבנה מעמיקה יותר של הבעיה או השאלה. ראשית, יש לזהות ולרכוש את מי שזקוקים לפתרון הבעיה שלהם. אלו יכולים להיות בעלי עניין בעסק או נותני חסות לפרויקט, שיכולים לעזור לזהות מי או מה ייהנה מהפרויקט הזה, כמו גם מה הם צריכים ולמה. מטרה מוגדרת היטב צריכה להיות מדידה וכמותית כדי להגדיר תוצאה מקובלת.
שאלות שמדען נתונים עשוי לשאול:
- האם הבעיה הזו נבחנה בעבר? מה התגלה?
- האם המטרה והיעד מובנים לכל המעורבים?
- האם יש עמימות וכיצד ניתן להפחית אותה?
- מהם המגבלות?
- איך תיראה התוצאה הסופית?
- כמה משאבים (זמן, אנשים, חישוביים) זמינים?
השלב הבא הוא זיהוי, איסוף ולבסוף חקר הנתונים הדרושים להשגת המטרות שהוגדרו. בשלב זה של רכישת הנתונים, מדעני נתונים חייבים גם להעריך את הכמות והאיכות של הנתונים. זה דורש חקר נתונים כדי לאשר שהנתונים שנאספו יתמכו בהשגת התוצאה הרצויה.
שאלות שמדען נתונים עשוי לשאול על הנתונים:
- אילו נתונים כבר זמינים לי?
- מי הבעלים של הנתונים האלה?
- מהם החששות לגבי פרטיות?
- האם יש לי מספיק נתונים כדי לפתור את הבעיה?
- האם הנתונים באיכות מספקת עבור הבעיה הזו?
- אם אני מגלה מידע נוסף דרך הנתונים האלה, האם כדאי לשקול לשנות או להגדיר מחדש את המטרות?
עיבוד
שלב העיבוד במחזור החיים מתמקד בגילוי דפוסים בנתונים ובבניית מודלים. חלק מהטכניקות בשלב העיבוד דורשות שיטות סטטיסטיות כדי לחשוף את הדפוסים. בדרך כלל, זו תהיה משימה מייגעת עבור אדם להתמודד עם מערך נתונים גדול, ולכן מסתמכים על מחשבים כדי להאיץ את התהליך. בשלב זה מדעי הנתונים ולמידת מכונה מצטלבים. כפי שלמדתם בשיעור הראשון, למידת מכונה היא תהליך של בניית מודלים להבנת הנתונים. מודלים הם ייצוג של הקשר בין משתנים בנתונים שמסייעים לחזות תוצאות.
טכניקות נפוצות בשלב זה מכוסות בתוכנית הלימודים של ML למתחילים. עקבו אחר הקישורים כדי ללמוד עוד עליהן:
- סיווג: ארגון נתונים לקטגוריות לשימוש יעיל יותר.
- אשכולות: קיבוץ נתונים לקבוצות דומות.
- רגרסיה: קביעת הקשרים בין משתנים כדי לחזות או לצפות ערכים.
תחזוקה
בתרשים של מחזור החיים, אולי שמתם לב שתחזוקה נמצאת בין איסוף לעיבוד. תחזוקה היא תהליך מתמשך של ניהול, אחסון ואבטחת הנתונים לאורך כל תהליך הפרויקט ויש לקחת אותה בחשבון לאורך כל הפרויקט.
אחסון נתונים
שיקולים לגבי איך והיכן הנתונים מאוחסנים יכולים להשפיע על עלות האחסון כמו גם על ביצועי הגישה לנתונים. החלטות כאלה לא סביר שיתקבלו על ידי מדען נתונים בלבד, אך ייתכן שהוא יצטרך לבחור כיצד לעבוד עם הנתונים בהתאם לאופן שבו הם מאוחסנים.
הנה כמה היבטים של מערכות אחסון נתונים מודרניות שיכולים להשפיע על הבחירות הללו:
במקום מול מחוץ למקום מול ענן ציבורי או פרטי
"במקום" מתייחס לאחסון וניהול הנתונים על ציוד בבעלותכם, כמו שרת עם כוננים קשיחים שמאחסנים את הנתונים, בעוד "מחוץ למקום" מסתמך על ציוד שאינו בבעלותכם, כמו מרכז נתונים. הענן הציבורי הוא בחירה פופולרית לאחסון נתונים שאינה דורשת ידע על איך או איפה בדיוק הנתונים מאוחסנים, כאשר "ציבורי" מתייחס לתשתית אחידה שמשותפת לכל מי שמשתמש בענן. חלק מהארגונים מחזיקים במדיניות אבטחה מחמירה שדורשת גישה מלאה לציוד שבו הנתונים מאוחסנים, ולכן הם מסתמכים על ענן פרטי שמספק שירותי ענן משלו. תלמדו עוד על נתונים בענן בשיעורים מאוחרים יותר.
נתונים "קרים" מול נתונים "חמים"
כאשר אתם מאמנים את המודלים שלכם, ייתכן שתזדקקו ליותר נתוני אימון. אם אתם מרוצים מהמודל שלכם, יגיעו נתונים נוספים כדי שהמודל יוכל לשרת את מטרתו. בכל מקרה, עלות אחסון וגישה לנתונים תגדל ככל שתצברו יותר מהם. הפרדת נתונים שנעשה בהם שימוש לעיתים רחוקות, המכונים נתונים "קרים", מנתונים שנעשה בהם שימוש תדיר, המכונים נתונים "חמים", יכולה להיות אפשרות אחסון נתונים זולה יותר באמצעות שירותי חומרה או תוכנה. אם יש צורך לגשת לנתונים "קרים", ייתכן שייקח מעט יותר זמן לשלוף אותם בהשוואה לנתונים "חמים".
ניהול נתונים
במהלך העבודה עם נתונים, ייתכן שתגלו שחלק מהנתונים צריכים לעבור ניקוי באמצעות חלק מהטכניקות שנלמדו בשיעור על הכנת נתונים כדי לבנות מודלים מדויקים. כאשר מגיעים נתונים חדשים, יהיה צורך ליישם את אותן טכניקות כדי לשמור על עקביות באיכות. חלק מהפרויקטים יכללו שימוש בכלי אוטומטי לניקוי, צבירה ודחיסה לפני שהנתונים מועברים למיקומם הסופי. Azure Data Factory הוא דוגמה לאחד מהכלים הללו.
אבטחת נתונים
אחד היעדים המרכזיים של אבטחת נתונים הוא להבטיח שמי שעובד עם הנתונים שולט במה שנאסף ובאיזה הקשר נעשה בו שימוש. שמירה על אבטחת נתונים כוללת הגבלת גישה רק למי שזקוק לה, עמידה בחוקים ובתקנות המקומיים, כמו גם שמירה על סטנדרטים אתיים, כפי שנלמד בשיעור על אתיקה.
הנה כמה דברים שצוות עשוי לעשות מתוך מחשבה על אבטחה:
- לוודא שכל הנתונים מוצפנים
- לספק ללקוחות מידע על איך הנתונים שלהם משמשים
- להסיר גישה לנתונים ממי שעזב את הפרויקט
- לאפשר רק לחברי צוות מסוימים לשנות את הנתונים
🚀 אתגר
ישנם גרסאות רבות למחזור החיים של מדעי הנתונים, כאשר כל שלב עשוי להיקרא בשם שונה או לכלול מספר שונה של שלבים, אך יכיל את אותם תהליכים שהוזכרו בשיעור זה.
חקור את מחזור החיים של תהליך מדעי הנתונים של הצוות ואת התקן התעשייתי לתהליך כריית נתונים. ציין 3 דמיון ו-3 הבדלים בין השניים.
| תהליך מדעי הנתונים של הצוות (TDSP) | התקן התעשייתי לתהליך כריית נתונים (CRISP-DM) |
|---|---|
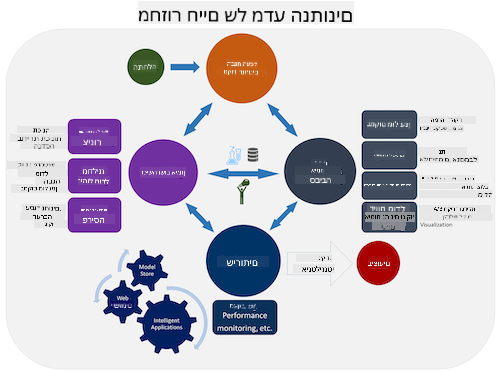 |
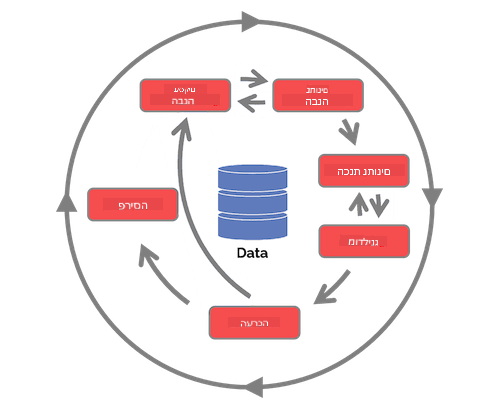 |
| תמונה מאת Microsoft | תמונה מאת Data Science Process Alliance |
שאלון אחרי השיעור
סקירה ולימוד עצמי
יישום מחזור החיים של מדעי הנתונים כולל תפקידים ומשימות מרובים, כאשר חלקם עשויים להתמקד בחלקים מסוימים בכל שלב. תהליך מדעי הנתונים של הצוות מספק כמה משאבים שמסבירים את סוגי התפקידים והמשימות שמישהו עשוי לבצע בפרויקט.
משימה
כתב ויתור:
מסמך זה תורגם באמצעות שירות תרגום מבוסס בינה מלאכותית Co-op Translator. בעוד שאנו שואפים לדיוק, יש להיות מודעים לכך שתרגומים אוטומטיים עשויים להכיל שגיאות או אי דיוקים. המסמך המקורי בשפתו המקורית צריך להיחשב כמקור הסמכותי. עבור מידע קריטי, מומלץ להשתמש בתרגום מקצועי על ידי אדם. איננו נושאים באחריות לאי הבנות או לפרשנויות שגויות הנובעות משימוש בתרגום זה.