27 KiB
עבודה עם נתונים: Python וספריית Pandas
 |
|---|
| עבודה עם Python - סקיצה מאת @nitya |

בעוד שמאגרי נתונים מציעים דרכים יעילות מאוד לאחסן נתונים ולבצע שאילתות באמצעות שפות שאילתה, הדרך הגמישה ביותר לעיבוד נתונים היא כתיבת תוכנית משלך כדי לטפל בנתונים. במקרים רבים, ביצוע שאילתה במאגר נתונים יהיה דרך יעילה יותר. עם זאת, במקרים שבהם נדרש עיבוד נתונים מורכב יותר, לא ניתן לבצע זאת בקלות באמצעות SQL.
ניתן לתכנת עיבוד נתונים בכל שפת תכנות, אך ישנן שפות מסוימות שהן ברמה גבוהה יותר בכל הנוגע לעבודה עם נתונים. מדעני נתונים בדרך כלל מעדיפים אחת מהשפות הבאות:
- Python, שפת תכנות כללית, שנחשבת לעיתים קרובות לאחת האפשרויות הטובות ביותר למתחילים בשל הפשטות שלה. ל-Python יש הרבה ספריות נוספות שיכולות לעזור לך לפתור בעיות מעשיות רבות, כמו חילוץ נתונים מארכיון ZIP או המרת תמונה לגווני אפור. בנוסף למדעי הנתונים, Python משמשת גם לעיתים קרובות לפיתוח אתרים.
- R היא כלי מסורתי שפותח עם מחשבה על עיבוד נתונים סטטיסטיים. היא מכילה גם מאגר גדול של ספריות (CRAN), מה שהופך אותה לבחירה טובה לעיבוד נתונים. עם זאת, R אינה שפת תכנות כללית, והיא משמשת לעיתים רחוקות מחוץ לתחום מדעי הנתונים.
- Julia היא שפה נוספת שפותחה במיוחד עבור מדעי הנתונים. היא נועדה לספק ביצועים טובים יותר מ-Python, מה שהופך אותה לכלי מצוין לניסויים מדעיים.
בשיעור זה, נתמקד בשימוש ב-Python לעיבוד נתונים פשוט. נניח היכרות בסיסית עם השפה. אם ברצונך לסייר לעומק ב-Python, תוכל לעיין באחד מהמשאבים הבאים:
- למד Python בדרך מהנה עם גרפיקה של צב ופרקטלים - קורס מבוא מהיר ל-Python מבוסס GitHub
- עשה את הצעדים הראשונים שלך עם Python מסלול למידה ב-Microsoft Learn
נתונים יכולים להגיע בצורות רבות. בשיעור זה, נתמקד בשלוש צורות של נתונים - נתונים טבלאיים, טקסט ותמונות.
נתמקד בכמה דוגמאות לעיבוד נתונים, במקום לתת סקירה מלאה של כל הספריות הקשורות. זה יאפשר לך להבין את הרעיון המרכזי של מה אפשרי, ולהשאיר אותך עם הבנה היכן למצוא פתרונות לבעיות שלך כשאתה זקוק להם.
העצה הכי מועילה. כשאתה צריך לבצע פעולה מסוימת על נתונים שאינך יודע כיצד לבצע, נסה לחפש אותה באינטרנט. Stackoverflow מכיל בדרך כלל הרבה דוגמאות קוד שימושיות ב-Python עבור משימות טיפוסיות רבות.
שאלון לפני השיעור
נתונים טבלאיים ו-Dataframes
כבר פגשת נתונים טבלאיים כשדיברנו על מאגרי נתונים יחסיים. כשיש לך הרבה נתונים, והם נמצאים בטבלאות רבות ומקושרות, בהחלט יש היגיון להשתמש ב-SQL לעבודה איתם. עם זאת, ישנם מקרים רבים שבהם יש לנו טבלה של נתונים, ואנו צריכים לקבל הבנה או תובנות לגבי נתונים אלו, כמו התפלגות, קשרים בין ערכים, וכו'. במדעי הנתונים, ישנם מקרים רבים שבהם אנו צריכים לבצע כמה טרנספורמציות של הנתונים המקוריים, ולאחר מכן לבצע ויזואליזציה. שני השלבים הללו יכולים להתבצע בקלות באמצעות Python.
ישנן שתי ספריות שימושיות ביותר ב-Python שיכולות לעזור לך להתמודד עם נתונים טבלאיים:
- Pandas מאפשרת לך לטפל ב-Dataframes, שהם אנלוגיים לטבלאות יחסיות. ניתן להגדיר עמודות עם שמות, ולבצע פעולות שונות על שורות, עמודות ו-Dataframes באופן כללי.
- Numpy היא ספרייה לעבודה עם tensors, כלומר מערכים רב-ממדיים. מערך מכיל ערכים מסוג בסיסי זהה, והוא פשוט יותר מ-Dataframe, אך מציע יותר פעולות מתמטיות ויוצר פחות עומס.
ישנן גם כמה ספריות נוספות שכדאי להכיר:
- Matplotlib היא ספרייה המשמשת לויזואליזציה של נתונים ולשרטוט גרפים
- SciPy היא ספרייה עם כמה פונקציות מדעיות נוספות. כבר נתקלנו בספרייה זו כשדיברנו על הסתברות וסטטיסטיקה
הנה קטע קוד שתשתמש בו בדרך כלל כדי לייבא את הספריות הללו בתחילת תוכנית Python:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import ... # you need to specify exact sub-packages that you need
Pandas מתמקדת בכמה מושגים בסיסיים.
Series
Series היא רצף של ערכים, בדומה לרשימה או מערך numpy. ההבדל העיקרי הוא ש-Series מכילה גם אינדקס, וכשאנחנו מבצעים פעולות על Series (למשל, חיבור), האינדקס נלקח בחשבון. האינדקס יכול להיות פשוט כמו מספר שורה שלם (זהו האינדקס המשמש כברירת מחדל בעת יצירת Series מרשימה או מערך), או שהוא יכול להיות בעל מבנה מורכב, כמו טווח תאריכים.
הערה: יש קוד מבוא ל-Pandas במחברת המצורפת
notebook.ipynb. אנו מציינים כאן רק כמה דוגמאות, ואתם בהחלט מוזמנים לבדוק את המחברת המלאה.
לדוגמה: נניח שאנחנו רוצים לנתח מכירות של חנות גלידה שלנו. בואו ניצור סדרה של מספרי מכירות (מספר פריטים שנמכרו בכל יום) עבור תקופת זמן מסוימת:
start_date = "Jan 1, 2020"
end_date = "Mar 31, 2020"
idx = pd.date_range(start_date,end_date)
print(f"Length of index is {len(idx)}")
items_sold = pd.Series(np.random.randint(25,50,size=len(idx)),index=idx)
items_sold.plot()
עכשיו נניח שבכל שבוע אנחנו מארגנים מסיבה לחברים, ולוקחים 10 חבילות גלידה נוספות למסיבה. נוכל ליצור סדרה נוספת, עם אינדקס לפי שבוע, כדי להדגים זאת:
additional_items = pd.Series(10,index=pd.date_range(start_date,end_date,freq="W"))
כשאנחנו מחברים שתי סדרות יחד, אנחנו מקבלים את המספר הכולל:
total_items = items_sold.add(additional_items,fill_value=0)
total_items.plot()
הערה שאנחנו לא משתמשים בתחביר הפשוט
total_items+additional_items. אם היינו עושים זאת, היינו מקבלים הרבה ערכיNaN(Not a Number) בסדרה המתקבלת. זאת מכיוון שיש ערכים חסרים עבור חלק מנקודות האינדקס בסדרהadditional_items, וחיבורNaNלכל דבר מביא ל-NaN. לכן עלינו לציין את הפרמטרfill_valueבמהלך החיבור.
עם סדרות זמן, אנחנו יכולים גם לדגום מחדש את הסדרה עם מרווחי זמן שונים. לדוגמה, נניח שאנחנו רוצים לחשב את ממוצע נפח המכירות חודשי. נוכל להשתמש בקוד הבא:
monthly = total_items.resample("1M").mean()
ax = monthly.plot(kind='bar')
DataFrame
DataFrame הוא למעשה אוסף של סדרות עם אותו אינדקס. אנחנו יכולים לשלב כמה סדרות יחד ל-DataFrame:
a = pd.Series(range(1,10))
b = pd.Series(["I","like","to","play","games","and","will","not","change"],index=range(0,9))
df = pd.DataFrame([a,b])
זה ייצור טבלה אופקית כמו זו:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 1 | I | like | to | use | Python | and | Pandas | very | much |
אנחנו יכולים גם להשתמש בסדרות כעמודות, ולציין שמות עמודות באמצעות מילון:
df = pd.DataFrame({ 'A' : a, 'B' : b })
זה ייתן לנו טבלה כמו זו:
| A | B | |
|---|---|---|
| 0 | 1 | I |
| 1 | 2 | like |
| 2 | 3 | to |
| 3 | 4 | use |
| 4 | 5 | Python |
| 5 | 6 | and |
| 6 | 7 | Pandas |
| 7 | 8 | very |
| 8 | 9 | much |
הערה שאנחנו יכולים גם לקבל את פריסת הטבלה הזו על ידי טרנספוזיציה של הטבלה הקודמת, למשל על ידי כתיבה
df = pd.DataFrame([a,b]).T..rename(columns={ 0 : 'A', 1 : 'B' })
כאן .T מתייחס לפעולת הטרנספוזיציה של ה-DataFrame, כלומר שינוי שורות ועמודות, ופעולת rename מאפשרת לנו לשנות את שמות העמודות כדי להתאים לדוגמה הקודמת.
הנה כמה מהפעולות החשובות ביותר שאנחנו יכולים לבצע על DataFrames:
בחירת עמודות. אנחנו יכולים לבחור עמודות בודדות על ידי כתיבה df['A'] - פעולה זו מחזירה סדרה. אנחנו יכולים גם לבחור תת-קבוצה של עמודות ל-DataFrame אחר על ידי כתיבה df[['B','A']] - זה מחזיר DataFrame נוסף.
סינון רק שורות מסוימות לפי קריטריונים. לדוגמה, כדי להשאיר רק שורות עם עמודה A גדולה מ-5, אנחנו יכולים לכתוב df[df['A']>5].
הערה: הדרך שבה סינון עובד היא כדלקמן. הביטוי
df['A']<5מחזיר סדרה בוליאנית, שמציינת האם הביטוי הואTrueאוFalseעבור כל אלמנט בסדרה המקוריתdf['A']. כאשר סדרה בוליאנית משמשת כאינדקס, היא מחזירה תת-קבוצה של שורות ב-DataFrame. לכן לא ניתן להשתמש בביטוי בוליאני שרירותי של Python, לדוגמה, כתיבהdf[df['A']>5 and df['A']<7]תהיה שגויה. במקום זאת, עליך להשתמש בפעולת&מיוחדת על סדרות בוליאניות, ולכתובdf[(df['A']>5) & (df['A']<7)](סוגריים חשובים כאן).
יצירת עמודות מחושבות חדשות. אנחנו יכולים ליצור בקלות עמודות מחושבות חדשות עבור ה-DataFrame שלנו באמצעות ביטוי אינטואיטיבי כמו זה:
df['DivA'] = df['A']-df['A'].mean()
דוגמה זו מחשבת את הסטייה של A מערך הממוצע שלה. מה שקורה כאן בפועל הוא שאנחנו מחשבים סדרה, ואז משייכים את הסדרה הזו לצד השמאלי, ויוצרים עמודה חדשה. לכן, אנחנו לא יכולים להשתמש בפעולות שאינן תואמות לסדרות, לדוגמה, הקוד הבא שגוי:
# Wrong code -> df['ADescr'] = "Low" if df['A'] < 5 else "Hi"
df['LenB'] = len(df['B']) # <- Wrong result
הדוגמה האחרונה, למרות שהיא נכונה מבחינה תחבירית, נותנת לנו תוצאה שגויה, מכיוון שהיא משייכת את אורך הסדרה B לכל הערכים בעמודה, ולא את אורך האלמנטים הבודדים כפי שהתכוונו.
אם אנחנו צריכים לחשב ביטויים מורכבים כמו זה, אנחנו יכולים להשתמש בפונקציה apply. הדוגמה האחרונה יכולה להיכתב כך:
df['LenB'] = df['B'].apply(lambda x : len(x))
# or
df['LenB'] = df['B'].apply(len)
לאחר הפעולות לעיל, נגיע ל-DataFrame הבא:
| A | B | DivA | LenB | |
|---|---|---|---|---|
| 0 | 1 | I | -4.0 | 1 |
| 1 | 2 | like | -3.0 | 4 |
| 2 | 3 | to | -2.0 | 2 |
| 3 | 4 | use | -1.0 | 3 |
| 4 | 5 | Python | 0.0 | 6 |
| 5 | 6 | and | 1.0 | 3 |
| 6 | 7 | Pandas | 2.0 | 6 |
| 7 | 8 | very | 3.0 | 4 |
| 8 | 9 | much | 4.0 | 4 |
בחירת שורות לפי מספרים יכולה להתבצע באמצעות מבנה iloc. לדוגמה, כדי לבחור את 5 השורות הראשונות מה-DataFrame:
df.iloc[:5]
קיבוץ משמש לעיתים קרובות כדי לקבל תוצאה דומה ל-טבלאות ציר ב-Excel. נניח שאנחנו רוצים לחשב את ערך הממוצע של עמודה A עבור כל מספר נתון של LenB. אז אנחנו יכולים לקבץ את ה-DataFrame שלנו לפי LenB, ולקרוא ל-mean:
df.groupby(by='LenB').mean()
אם אנחנו צריכים לחשב ממוצע ומספר האלמנטים בקבוצה, אז אנחנו יכולים להשתמש בפונקציה aggregate מורכבת יותר:
df.groupby(by='LenB') \
.aggregate({ 'DivA' : len, 'A' : lambda x: x.mean() }) \
.rename(columns={ 'DivA' : 'Count', 'A' : 'Mean'})
זה נותן לנו את הטבלה הבאה:
| LenB | Count | Mean |
|---|---|---|
| 1 | 1 | 1.000000 |
| 2 | 1 | 3.000000 |
| 3 | 2 | 5.000000 |
| 4 | 3 | 6.333333 |
| 6 | 2 | 6.000000 |
קבלת נתונים
ראינו כמה קל ליצור Series ו-DataFrames מאובייקטים של Python. עם זאת, נתונים בדרך כלל מגיעים בצורה של קובץ טקסט או טבלת Excel. למרבה המזל, Pandas מציעה לנו דרך פשוטה לטעון נתונים מהדיסק. לדוגמה, קריאת קובץ CSV היא פשוטה כמו זו:
df = pd.read_csv('file.csv')
נראה דוגמאות נוספות לטעינת נתונים, כולל הבאתם מאתרים חיצוניים, בסעיף "אתגר".
הדפסה וגרפים
מדען נתונים לעיתים קרובות צריך לחקור את הנתונים, ולכן חשוב להיות מסוגל להציג אותם בצורה חזותית. כאשר DataFrame גדול, פעמים רבות נרצה רק לוודא שאנחנו עושים הכל נכון על ידי הדפסת השורות הראשונות. ניתן לעשות זאת על ידי קריאה ל-df.head(). אם אתם מריצים זאת מתוך Jupyter Notebook, זה ידפיס את ה-DataFrame בצורה טבלאית יפה.
כמו כן, ראינו את השימוש בפונקציה plot כדי להציג גרפים של עמודות מסוימות. בעוד ש-plot מאוד שימושית למשימות רבות ותומכת בסוגי גרפים שונים באמצעות הפרמטר kind=, תמיד ניתן להשתמש בספריית matplotlib כדי ליצור גרפים מורכבים יותר. נעסוק בהדמיית נתונים בפירוט בשיעורים נפרדים של הקורס.
סקירה זו מכסה את הרעיונות החשובים ביותר של Pandas, אך הספרייה עשירה מאוד ואין גבול למה שניתן לעשות איתה! עכשיו ניישם את הידע הזה לפתרון בעיה ספציפית.
🚀 אתגר 1: ניתוח התפשטות COVID
הבעיה הראשונה שבה נתמקד היא מודלינג של התפשטות מגפת COVID-19. כדי לעשות זאת, נשתמש בנתונים על מספר הנדבקים במדינות שונות, המסופקים על ידי Center for Systems Science and Engineering (CSSE) ב-אוניברסיטת ג'ונס הופקינס. מערך הנתונים זמין ב-מאגר GitHub זה.
מכיוון שאנחנו רוצים להדגים כיצד להתמודד עם נתונים, אנו מזמינים אתכם לפתוח את notebook-covidspread.ipynb ולקרוא אותו מההתחלה ועד הסוף. תוכלו גם להריץ תאים ולעשות כמה אתגרים שהשארנו לכם בסוף.
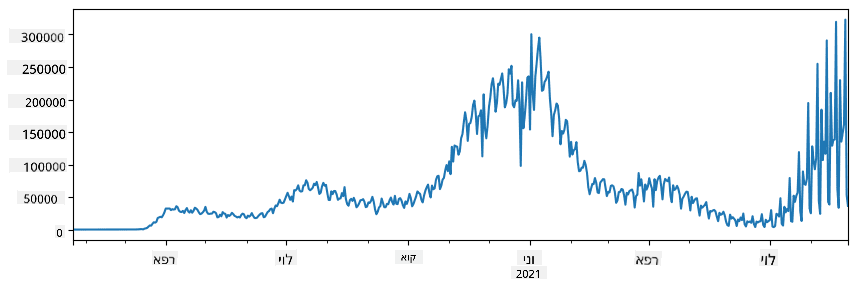
אם אינכם יודעים כיצד להריץ קוד ב-Jupyter Notebook, עיינו ב-מאמר זה.
עבודה עם נתונים לא מובנים
בעוד שנתונים מגיעים לעיתים קרובות בצורה טבלאית, במקרים מסוימים אנו צריכים להתמודד עם נתונים פחות מובנים, לדוגמה, טקסט או תמונות. במקרה כזה, כדי ליישם טכניקות עיבוד נתונים שראינו קודם, עלינו לחלץ נתונים מובנים. הנה כמה דוגמאות:
- חילוץ מילות מפתח מטקסט ובדיקת תדירות הופעתן
- שימוש ברשתות נוירונים לחילוץ מידע על אובייקטים בתמונה
- קבלת מידע על רגשות של אנשים מזרם מצלמת וידאו
🚀 אתגר 2: ניתוח מאמרים על COVID
באתגר זה, נמשיך עם נושא מגפת COVID, ונעסוק בעיבוד מאמרים מדעיים בנושא. ישנו מערך נתונים CORD-19 עם יותר מ-7000 (בזמן כתיבת שורות אלו) מאמרים על COVID, הזמינים עם מטא-נתונים ותקצירים (ובכחצי מהם גם טקסט מלא).
דוגמה מלאה לניתוח מערך נתונים זה באמצעות Text Analytics for Health מתוארת בפוסט בבלוג זה. נדון בגרסה פשוטה יותר של ניתוח זה.
NOTE: איננו מספקים עותק של מערך הנתונים כחלק ממאגר זה. ייתכן שתצטרכו להוריד תחילה את הקובץ
metadata.csvממערך נתונים זה ב-Kaggle. ייתכן שתידרש הרשמה ל-Kaggle. תוכלו גם להוריד את מערך הנתונים ללא הרשמה מכאן, אך הוא יכלול את כל הטקסטים המלאים בנוסף לקובץ המטא-נתונים.
פתחו את notebook-papers.ipynb וקראו אותו מההתחלה ועד הסוף. תוכלו גם להריץ תאים ולעשות כמה אתגרים שהשארנו לכם בסוף.
עיבוד נתוני תמונה
לאחרונה פותחו מודלים AI חזקים מאוד שמאפשרים לנו להבין תמונות. ישנם משימות רבות שניתן לפתור באמצעות רשתות נוירונים מוכנות מראש או שירותי ענן. כמה דוגמאות כוללות:
- סיווג תמונות, שיכול לעזור לכם לקטלג את התמונה לאחת מהקטגוריות המוגדרות מראש. תוכלו בקלות לאמן מסווגי תמונות משלכם באמצעות שירותים כמו Custom Vision
- זיהוי אובייקטים כדי לזהות אובייקטים שונים בתמונה. שירותים כמו computer vision יכולים לזהות מספר אובייקטים נפוצים, ותוכלו לאמן מודל Custom Vision לזהות אובייקטים ספציפיים שמעניינים אתכם.
- זיהוי פנים, כולל גיל, מגדר וזיהוי רגשות. ניתן לעשות זאת באמצעות Face API.
כל שירותי הענן הללו יכולים להיקרא באמצעות Python SDKs, ולכן ניתן לשלבם בקלות בתהליך חקר הנתונים שלכם.
הנה כמה דוגמאות לחקר נתונים ממקורות תמונה:
- בפוסט בבלוג איך ללמוד מדעי נתונים ללא קוד אנו חוקרים תמונות מאינסטגרם, בניסיון להבין מה גורם לאנשים לתת יותר לייקים לתמונה. תחילה אנו מחלצים כמה שיותר מידע מהתמונות באמצעות computer vision, ולאחר מכן משתמשים ב-Azure Machine Learning AutoML כדי לבנות מודל שניתן לפרש.
- ב-סדנת מחקרי פנים אנו משתמשים ב-Face API כדי לחלץ רגשות של אנשים בתמונות מאירועים, בניסיון להבין מה גורם לאנשים להיות שמחים.
סיכום
בין אם כבר יש לכם נתונים מובנים או לא מובנים, באמצעות Python תוכלו לבצע את כל השלבים הקשורים לעיבוד והבנת נתונים. זו כנראה הדרך הגמישה ביותר לעיבוד נתונים, ולכן רוב מדעני הנתונים משתמשים ב-Python ככלי העיקרי שלהם. לימוד Python לעומק הוא כנראה רעיון טוב אם אתם רציניים לגבי המסע שלכם במדעי הנתונים!
שאלון לאחר השיעור
סקירה ולימוד עצמי
ספרים
משאבים מקוונים
- מדריך רשמי 10 דקות ל-Pandas
- תיעוד על הדמיה ב-Pandas
לימוד Python
- למדו Python בצורה מהנה עם גרפיקת Turtle ופרקטלים
- עשו את הצעדים הראשונים שלכם עם Python מסלול לימוד ב-Microsoft Learn
משימה
בצעו מחקר נתונים מפורט יותר עבור האתגרים לעיל
קרדיטים
שיעור זה נכתב באהבה על ידי Dmitry Soshnikov
כתב ויתור:
מסמך זה תורגם באמצעות שירות תרגום מבוסס בינה מלאכותית Co-op Translator. בעוד שאנו שואפים לדיוק, יש לקחת בחשבון שתרגומים אוטומטיים עשויים להכיל שגיאות או אי-דיוקים. המסמך המקורי בשפתו המקורית נחשב למקור הסמכותי. למידע קריטי, מומלץ להשתמש בתרגום מקצועי על ידי מתרגם אנושי. איננו נושאים באחריות לכל אי-הבנה או פרשנות שגויה הנובעת משימוש בתרגום זה.