23 KiB
Työskentely datan kanssa: Python ja Pandas-kirjasto
 |
|---|
| Työskentely Pythonin kanssa - Sketchnote by @nitya |
Vaikka tietokannat tarjoavat erittäin tehokkaita tapoja tallentaa dataa ja tehdä kyselyitä kyselykielillä, joustavin tapa käsitellä dataa on kirjoittaa oma ohjelma datan muokkaamiseen. Monissa tapauksissa tietokantakysely on tehokkaampi tapa. Kuitenkin joissain tilanteissa, joissa tarvitaan monimutkaisempaa datan käsittelyä, sitä ei voida helposti tehdä SQL:llä.
Datan käsittely voidaan ohjelmoida millä tahansa ohjelmointikielellä, mutta on olemassa tiettyjä kieliä, jotka ovat korkeamman tason työkaluja datan käsittelyyn. Datatieteilijät suosivat yleensä seuraavia kieliä:
- Python, yleiskäyttöinen ohjelmointikieli, jota pidetään usein yhtenä parhaista vaihtoehdoista aloittelijoille sen yksinkertaisuuden vuoksi. Pythonilla on paljon lisäkirjastoja, jotka voivat auttaa ratkaisemaan monia käytännön ongelmia, kuten datan purkaminen ZIP-arkistosta tai kuvan muuntaminen harmaasävyksi. Pythonia käytetään datatieteen lisäksi myös usein verkkokehityksessä.
- R on perinteinen työkalu, joka on kehitetty tilastollisen datan käsittelyyn. Siinä on myös laaja kirjastoarkisto (CRAN), mikä tekee siitä hyvän valinnan datan käsittelyyn. R ei kuitenkaan ole yleiskäyttöinen ohjelmointikieli, ja sitä käytetään harvoin datatieteen ulkopuolella.
- Julia on toinen kieli, joka on kehitetty erityisesti datatieteeseen. Sen tarkoituksena on tarjota parempaa suorituskykyä kuin Python, mikä tekee siitä erinomaisen työkalun tieteellisiin kokeiluihin.
Tässä oppitunnissa keskitymme Pythonin käyttöön yksinkertaisessa datan käsittelyssä. Oletamme, että sinulla on perustiedot kielestä. Jos haluat syvemmän katsauksen Pythoniin, voit tutustua seuraaviin resursseihin:
- Learn Python in a Fun Way with Turtle Graphics and Fractals - GitHub-pohjainen pikaopas Python-ohjelmointiin
- Take your First Steps with Python Oppimispolku Microsoft Learn -sivustolla
Data voi olla monessa eri muodossa. Tässä oppitunnissa tarkastelemme kolmea datamuotoa - taulukkomuotoinen data, teksti ja kuvat.
Keskitymme muutamaan esimerkkiin datan käsittelystä sen sijaan, että antaisimme kattavan yleiskatsauksen kaikista asiaan liittyvistä kirjastoista. Tämä antaa sinulle käsityksen siitä, mitä on mahdollista tehdä, ja auttaa sinua ymmärtämään, mistä löytää ratkaisuja ongelmiisi tarvittaessa.
Hyödyllisin neuvo. Kun sinun täytyy suorittaa jokin tietty operaatio datalle, mutta et tiedä miten se tehdään, kokeile etsiä sitä internetistä. Stackoverflow sisältää yleensä paljon hyödyllisiä Python-koodiesimerkkejä moniin tyypillisiin tehtäviin.
Esiluentakysely
Taulukkomuotoinen data ja DataFrame-rakenteet
Olet jo tutustunut taulukkomuotoiseen dataan, kun puhuimme relaatiotietokannoista. Kun sinulla on paljon dataa, joka on tallennettu useisiin eri linkitettyihin tauluihin, SQL:n käyttö on ehdottomasti järkevää. On kuitenkin monia tilanteita, joissa meillä on yksittäinen datataulukko, ja haluamme saada siitä ymmärrystä tai oivalluksia, kuten jakauman tai arvojen välisen korrelaation. Datatieteessä on myös paljon tilanteita, joissa alkuperäistä dataa täytyy muokata ja sen jälkeen visualisoida. Molemmat vaiheet voidaan helposti toteuttaa Pythonilla.
Pythonissa on kaksi hyödyllistä kirjastoa, jotka auttavat sinua käsittelemään taulukkomuotoista dataa:
- Pandas mahdollistaa niin sanottujen DataFrame-rakenteiden käsittelyn, jotka ovat analogisia relaatiotaulukoille. Voit käyttää nimettyjä sarakkeita ja suorittaa erilaisia operaatioita riveille, sarakkeille ja DataFrameille yleisesti.
- Numpy on kirjasto, joka on tarkoitettu tensorien, eli monidimensionaalisten taulukoiden, käsittelyyn. Taulukon arvot ovat samaa tyyppiä, ja se on yksinkertaisempi kuin DataFrame, mutta tarjoaa enemmän matemaattisia operaatioita ja vähemmän ylikuormitusta.
On myös muutamia muita kirjastoja, jotka sinun kannattaa tietää:
- Matplotlib on kirjasto, jota käytetään datan visualisointiin ja kaavioiden piirtämiseen
- SciPy on kirjasto, joka sisältää lisätieteellisiä funktioita. Olemme jo törmänneet tähän kirjastoon, kun puhuimme todennäköisyyksistä ja tilastoista
Tässä on koodinpätkä, jota käytetään tyypillisesti näiden kirjastojen tuomiseen Python-ohjelman alkuun:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import ... # you need to specify exact sub-packages that you need
Pandas-kirjasto perustuu muutamaan peruskäsitteeseen.
Series
Series on arvojen jono, joka muistuttaa listaa tai numpy-taulukkoa. Tärkein ero on, että Series sisältää myös indeksin, ja kun operoimme Series-rakenteilla (esim. lisäämme niitä yhteen), indeksi otetaan huomioon. Indeksi voi olla yksinkertainen kokonaisluku (oletusindeksi, kun luodaan Series listasta tai taulukosta), tai sillä voi olla monimutkaisempi rakenne, kuten aikaväli.
Huom: Pandas-kirjaston johdantokoodia löytyy mukana olevasta muistikirjasta
notebook.ipynb. Tässä esittelemme vain joitakin esimerkkejä, mutta voit ehdottomasti tutustua koko muistikirjaan.
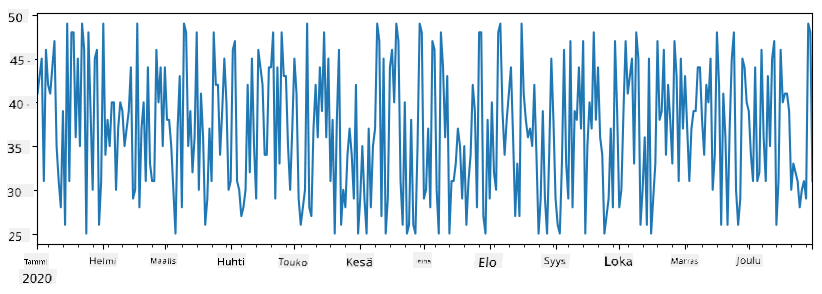
Tarkastellaan esimerkkiä: haluamme analysoida jäätelökioskimme myyntiä. Luodaan myyntilukujen sarja (myytyjen tuotteiden määrä päivittäin) tietylle ajanjaksolle:
start_date = "Jan 1, 2020"
end_date = "Mar 31, 2020"
idx = pd.date_range(start_date,end_date)
print(f"Length of index is {len(idx)}")
items_sold = pd.Series(np.random.randint(25,50,size=len(idx)),index=idx)
items_sold.plot()
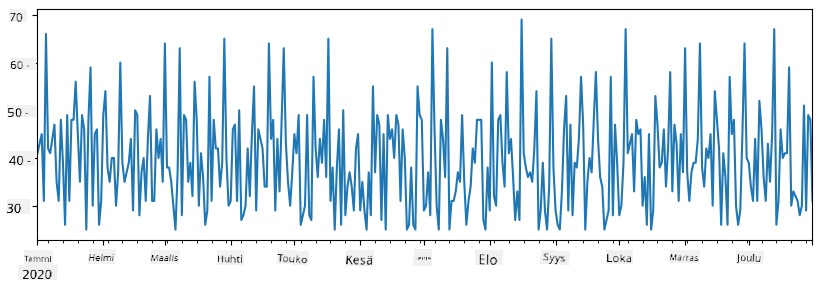
Oletetaan nyt, että järjestämme joka viikko juhlat ystäville, ja otamme juhliin 10 ylimääräistä jäätelöpakettia. Voimme luoda toisen sarjan, joka on indeksoitu viikoittain, osoittamaan tämän:
additional_items = pd.Series(10,index=pd.date_range(start_date,end_date,freq="W"))
Kun lisäämme kaksi sarjaa yhteen, saamme kokonaismäärän:
total_items = items_sold.add(additional_items,fill_value=0)
total_items.plot()
Huom: Emme käytä yksinkertaista syntaksia
total_items+additional_items. Jos tekisimme niin, saisimme paljonNaN(Not a Number) -arvoja tuloksena olevaan sarjaan. Tämä johtuu siitä, ettäadditional_items-sarjassa on puuttuvia arvoja joillekin indeksipisteille, jaNaN-arvon lisääminen mihin tahansa johtaaNaN-arvoon. Siksi meidän täytyy määrittääfill_value-parametri yhteenlaskun aikana.
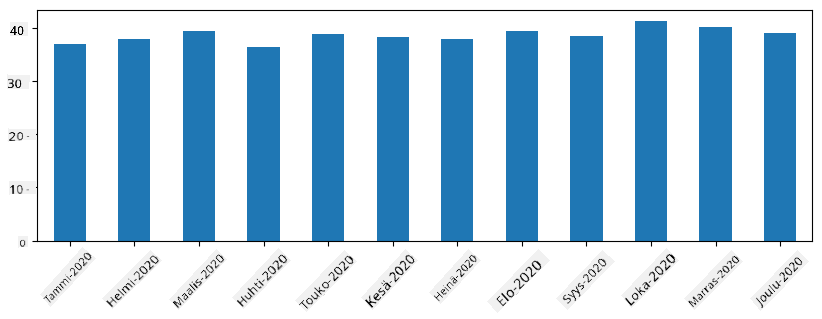
Aikasarjojen avulla voimme myös näytteistää uudelleen sarjan eri aikaväleillä. Esimerkiksi, jos haluamme laskea keskimääräisen myyntimäärän kuukausittain, voimme käyttää seuraavaa koodia:
monthly = total_items.resample("1M").mean()
ax = monthly.plot(kind='bar')
DataFrame
DataFrame on käytännössä kokoelma sarjoja, joilla on sama indeksi. Voimme yhdistää useita sarjoja yhteen DataFrameen:
a = pd.Series(range(1,10))
b = pd.Series(["I","like","to","play","games","and","will","not","change"],index=range(0,9))
df = pd.DataFrame([a,b])
Tämä luo vaakasuuntaisen taulukon, joka näyttää tältä:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 1 | I | like | to | use | Python | and | Pandas | very | much |
Voimme myös käyttää sarjoja sarakkeina ja määrittää sarakenimet sanakirjan avulla:
df = pd.DataFrame({ 'A' : a, 'B' : b })
Tämä antaa meille taulukon, joka näyttää tältä:
| A | B | |
|---|---|---|
| 0 | 1 | I |
| 1 | 2 | like |
| 2 | 3 | to |
| 3 | 4 | use |
| 4 | 5 | Python |
| 5 | 6 | and |
| 6 | 7 | Pandas |
| 7 | 8 | very |
| 8 | 9 | much |
Huom: Voimme myös saada tämän taulukon asettelun transponoimalla edellisen taulukon, esim. kirjoittamalla
df = pd.DataFrame([a,b]).T..rename(columns={ 0 : 'A', 1 : 'B' })
Tässä .T tarkoittaa DataFramen transponointia, eli rivien ja sarakkeiden vaihtamista, ja rename-operaatio mahdollistaa sarakkeiden uudelleennimeämisen vastaamaan edellistä esimerkkiä.
Tässä on muutamia tärkeimpiä operaatioita, joita voimme suorittaa DataFrameille:
Sarakkeiden valinta. Voimme valita yksittäisiä sarakkeita kirjoittamalla df['A'] - tämä operaatio palauttaa Series-rakenteen. Voimme myös valita osajoukon sarakkeista toiseen DataFrameen kirjoittamalla df[['B','A']] - tämä palauttaa toisen DataFramen.
Rivien suodatus kriteerien perusteella. Esimerkiksi, jos haluamme jättää vain rivit, joissa sarakkeen A arvo on suurempi kuin 5, voimme kirjoittaa df[df['A']>5].
Huom: Suodatuksen toiminta on seuraava. Lauseke
df['A']<5palauttaa totuusarvosarjan, joka osoittaa, onko lausekeTruevaiFalsekullekin alkuperäisen sarjandf['A']elementille. Kun totuusarvosarjaa käytetään indeksinä, se palauttaa DataFramen rivien osajoukon. Siksi ei ole mahdollista käyttää mielivaltaisia Pythonin totuusarvolausekkeita, esimerkiksi kirjoittamalladf[df['A']>5 and df['A']<7]olisi väärin. Sen sijaan sinun tulisi käyttää erityistä&-operaatiota totuusarvosarjoille, kirjoittamalladf[(df['A']>5) & (df['A']<7)](sulut ovat tässä tärkeitä).
Uusien laskettavien sarakkeiden luominen. Voimme helposti luoda uusia laskettavia sarakkeita DataFrameemme käyttämällä intuitiivisia lausekkeita, kuten tämä:
df['DivA'] = df['A']-df['A'].mean()
Tämä esimerkki laskee sarakkeen A poikkeaman sen keskiarvosta. Tässä lasketaan sarja ja sitten määritetään tämä sarja vasemmalle puolelle, luoden uuden sarakkeen. Siksi emme voi käyttää mitään operaatioita, jotka eivät ole yhteensopivia sarjojen kanssa, esimerkiksi alla oleva koodi on väärin:
# Wrong code -> df['ADescr'] = "Low" if df['A'] < 5 else "Hi"
df['LenB'] = len(df['B']) # <- Wrong result
Viimeinen esimerkki, vaikka se onkin syntaktisesti oikein, antaa meille väärän tuloksen, koska se määrittää sarjan B pituuden kaikille sarakkeen arvoille, eikä yksittäisten elementtien pituutta, kuten oli tarkoitus.
Jos meidän täytyy laskea monimutkaisia lausekkeita, voimme käyttää apply-funktiota. Viimeinen esimerkki voidaan kirjoittaa seuraavasti:
df['LenB'] = df['B'].apply(lambda x : len(x))
# or
df['LenB'] = df['B'].apply(len)
Yllä olevien operaatioiden jälkeen päädymme seuraavaan DataFrameen:
| A | B | DivA | LenB | |
|---|---|---|---|---|
| 0 | 1 | I | -4.0 | 1 |
| 1 | 2 | like | -3.0 | 4 |
| 2 | 3 | to | -2.0 | 2 |
| 3 | 4 | use | -1.0 | 3 |
| 4 | 5 | Python | 0.0 | 6 |
| 5 | 6 | and | 1.0 | 3 |
| 6 | 7 | Pandas | 2.0 | 6 |
| 7 | 8 | very | 3.0 | 4 |
| 8 | 9 | much | 4.0 | 4 |
Rivien valinta numeroiden perusteella voidaan tehdä käyttämällä iloc-rakennetta. Esimerkiksi, jos haluamme valita ensimmäiset 5 riviä DataFramesta:
df.iloc[:5]
Ryhmittely on usein käytetty tapa saada tuloksia, jotka muistuttavat Excelin pivot-taulukoita. Oletetaan, että haluamme laskea sarakkeen A keskiarvon jokaiselle annetulle LenB-arvolle. Voimme ryhmitellä DataFramen LenB-sarakkeen mukaan ja kutsua mean:
df.groupby(by='LenB').mean()
Jos meidän täytyy laskea keskiarvo ja elementtien määrä ryhmässä, voimme käyttää monimutkaisempaa aggregate-funktiota:
df.groupby(by='LenB') \
.aggregate({ 'DivA' : len, 'A' : lambda x: x.mean() }) \
.rename(columns={ 'DivA' : 'Count', 'A' : 'Mean'})
Tämä antaa meille seuraavan taulukon:
| LenB | Count | Mean |
|---|---|---|
| 1 | 1 | 1.000000 |
| 2 | 1 | 3.000000 |
| 3 | 2 | 5.000000 |
| 4 | 3 | 6.333333 |
| 6 | 2 | 6.000000 |
Datan hankinta
Olemme nähneet, kuinka helppoa on luoda Series- ja DataFrame-objekteja Pythonin avulla. Usein data kuitenkin tulee tekstimuodossa tai Excel-taulukkona. Onneksi Pandas tarjoaa yksinkertaisen tavan ladata dataa levyltä. Esimerkiksi CSV-tiedoston lukeminen on näin helppoa:
df = pd.read_csv('file.csv')
Näemme lisää esimerkkejä datan lataamisesta, mukaan lukien sen hakeminen ulkoisilta verkkosivustoilta, "Haaste"-osiossa.
Tulostaminen ja Visualisointi
Data Scientistin täytyy usein tutkia dataa, joten sen visualisointi on tärkeää. Kun DataFrame on suuri, haluamme monesti varmistaa, että kaikki toimii oikein, tulostamalla vain muutaman ensimmäisen rivin. Tämä onnistuu kutsumalla df.head(). Jos suoritat sen Jupyter Notebookissa, se tulostaa DataFramen siistissä taulukkomuodossa.
Olemme myös nähneet plot-funktion käytön tiettyjen sarakkeiden visualisointiin. Vaikka plot on erittäin hyödyllinen moniin tehtäviin ja tukee monia eri kaaviotyyppejä kind=-parametrin avulla, voit aina käyttää raakaa matplotlib-kirjastoa monimutkaisempien kaavioiden luomiseen. Käsittelemme datan visualisointia yksityiskohtaisesti erillisissä kurssin osioissa.
Tämä yleiskatsaus kattaa Pandasin tärkeimmät käsitteet, mutta kirjasto on erittäin monipuolinen, eikä sen käyttömahdollisuuksilla ole rajoja! Käytetään nyt tätä tietoa tietyn ongelman ratkaisemiseen.
🚀 Haaste 1: COVID-leviämisen analysointi
Ensimmäinen ongelma, johon keskitymme, on COVID-19:n epidemian leviämisen mallintaminen. Tätä varten käytämme dataa tartunnan saaneiden henkilöiden määrästä eri maissa, jonka tarjoaa Center for Systems Science and Engineering (CSSE) Johns Hopkins University:sta. Datasetti on saatavilla tässä GitHub-repositoriossa.
Koska haluamme demonstroida, kuinka dataa käsitellään, kutsumme sinut avaamaan notebook-covidspread.ipynb ja lukemaan sen alusta loppuun. Voit myös suorittaa soluja ja tehdä joitakin haasteita, jotka olemme jättäneet sinulle loppuun.
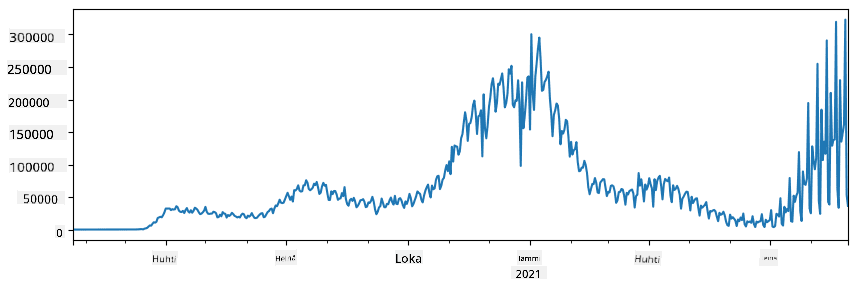
Jos et tiedä, kuinka suorittaa koodia Jupyter Notebookissa, tutustu tähän artikkeliin.
Työskentely jäsentämättömän datan kanssa
Vaikka data usein tulee taulukkomuodossa, joissakin tapauksissa meidän täytyy käsitellä vähemmän jäsenneltyä dataa, kuten tekstiä tai kuvia. Tällöin, jotta voimme soveltaa edellä nähtyjä datankäsittelytekniikoita, meidän täytyy jollain tavalla jäsentää data. Tässä muutamia esimerkkejä:
- Avainsanojen poimiminen tekstistä ja niiden esiintymistiheyden tarkastelu
- Neuroverkkojen käyttö tiedon poimimiseen kuvassa olevista objekteista
- Tunteiden analysointi videokameran syötteestä
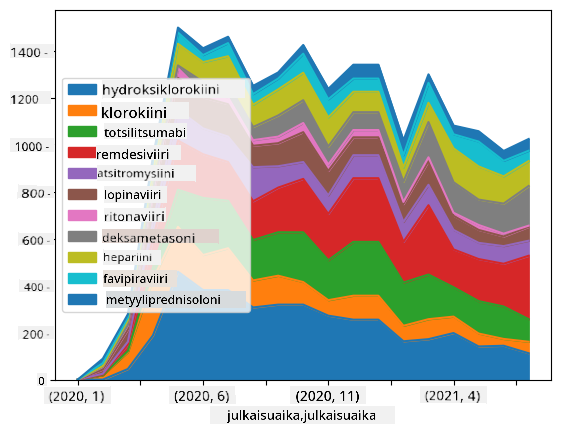
🚀 Haaste 2: COVID-tutkimuspapereiden analysointi
Tässä haasteessa jatkamme COVID-pandemian aihetta ja keskitymme tieteellisten papereiden käsittelyyn aiheesta. CORD-19 Dataset sisältää yli 7000 (kirjoitushetkellä) paperia COVIDista, saatavilla metadatan ja tiivistelmien kanssa (ja noin puolessa tapauksista myös koko teksti).
Täydellinen esimerkki tämän datasetin analysoinnista Text Analytics for Health -kognitiivisen palvelun avulla on kuvattu tässä blogikirjoituksessa. Keskustelemme yksinkertaistetusta versiosta tästä analyysistä.
NOTE: Emme tarjoa datasetin kopiota osana tätä repositoriota. Sinun täytyy ensin ladata
metadata.csvtiedosto tästä Kaggle-datasetistä. Rekisteröityminen Kaggleen saattaa olla tarpeen. Voit myös ladata datasetin ilman rekisteröitymistä täältä, mutta se sisältää kaikki kokotekstit metadatatiedoston lisäksi.
Avaa notebook-papers.ipynb ja lue se alusta loppuun. Voit myös suorittaa soluja ja tehdä joitakin haasteita, jotka olemme jättäneet sinulle loppuun.
Kuvadatan käsittely
Viime aikoina on kehitetty erittäin tehokkaita AI-malleja, jotka mahdollistavat kuvien ymmärtämisen. Monet tehtävät voidaan ratkaista esikoulutettujen neuroverkkojen tai pilvipalveluiden avulla. Esimerkkejä:
- Kuvien luokittelu, joka auttaa kategorisoimaan kuvan ennalta määriteltyihin luokkiin. Voit helposti kouluttaa omia kuvien luokittelijoita palveluilla, kuten Custom Vision.
- Objektien tunnistus kuvassa. Palvelut, kuten computer vision, voivat tunnistaa useita yleisiä objekteja, ja voit kouluttaa Custom Vision -mallin tunnistamaan tiettyjä kiinnostavia objekteja.
- Kasvojen tunnistus, mukaan lukien ikä-, sukupuoli- ja tunnetilojen tunnistus. Tämä voidaan tehdä Face API:n avulla.
Kaikki nämä pilvipalvelut voidaan kutsua Python SDK:iden avulla, ja ne voidaan helposti sisällyttää datan tutkimustyöhön.
Tässä muutamia esimerkkejä kuvadatalähteiden tutkimisesta:
- Blogikirjoituksessa How to Learn Data Science without Coding tutkimme Instagram-kuvia, yrittäen ymmärtää, mikä saa ihmiset antamaan enemmän tykkäyksiä kuvalle. Ensin poimimme mahdollisimman paljon tietoa kuvista computer vision:n avulla, ja sitten käytämme Azure Machine Learning AutoML:ia tulkittavan mallin rakentamiseen.
- Facial Studies Workshop-työpajassa käytämme Face API:a poimimaan tunteita tapahtumakuvien ihmisistä, yrittäen ymmärtää, mikä tekee ihmiset onnellisiksi.
Yhteenveto
Olipa sinulla jo jäsenneltyä tai jäsentämätöntä dataa, Pythonin avulla voit suorittaa kaikki datankäsittelyyn ja ymmärtämiseen liittyvät vaiheet. Se on luultavasti joustavin tapa käsitellä dataa, ja siksi suurin osa data scientist -ammattilaisista käyttää Pythonia ensisijaisena työkalunaan. Pythonin syvällinen oppiminen on luultavasti hyvä idea, jos olet vakavissasi datatieteen urasi suhteen!
Luennon jälkeinen kysely
Kertaus ja Itseopiskelu
Kirjat
Verkkoresurssit
- Virallinen 10 minutes to Pandas -tutoriaali
- Dokumentaatio Pandas-visualisoinnista
Pythonin oppiminen
- Learn Python in a Fun Way with Turtle Graphics and Fractals
- Take your First Steps with Python -oppimispolku Microsoft Learn:ssa
Tehtävä
Tee yksityiskohtaisempi datatutkimus yllä olevista haasteista
Tekijät
Tämän oppitunnin on kirjoittanut ♥️:lla Dmitry Soshnikov
Vastuuvapauslauseke:
Tämä asiakirja on käännetty käyttämällä tekoälypohjaista käännöspalvelua Co-op Translator. Vaikka pyrimme tarkkuuteen, huomioithan, että automaattiset käännökset voivat sisältää virheitä tai epätarkkuuksia. Alkuperäistä asiakirjaa sen alkuperäisellä kielellä tulisi pitää ensisijaisena lähteenä. Kriittisen tiedon osalta suositellaan ammattimaista ihmiskäännöstä. Emme ole vastuussa tämän käännöksen käytöstä johtuvista väärinkäsityksistä tai virhetulkinnoista.