24 KiB
علم داده در فضای ابری: روش "Azure ML SDK"
 |
|---|
| علم داده در فضای ابری: Azure ML SDK - Sketchnote by @nitya |
فهرست مطالب:
- علم داده در فضای ابری: روش "Azure ML SDK"
پرسشهای پیش از درس
1. مقدمه
1.1 Azure ML SDK چیست؟
دانشمندان داده و توسعهدهندگان هوش مصنوعی از Azure Machine Learning SDK برای ساخت و اجرای جریانهای کاری یادگیری ماشین با استفاده از سرویس Azure Machine Learning استفاده میکنند. شما میتوانید در هر محیط پایتون، از جمله Jupyter Notebooks، Visual Studio Code یا IDE مورد علاقه خود، با این سرویس تعامل داشته باشید.
حوزههای کلیدی SDK شامل موارد زیر است:
- بررسی، آمادهسازی و مدیریت چرخه عمر مجموعه دادههایی که در آزمایشهای یادگیری ماشین استفاده میشوند.
- مدیریت منابع ابری برای نظارت، ثبت و سازماندهی آزمایشهای یادگیری ماشین.
- آموزش مدلها به صورت محلی یا با استفاده از منابع ابری، از جمله آموزش مدلهای شتابیافته با GPU.
- استفاده از یادگیری ماشین خودکار که پارامترهای پیکربندی و دادههای آموزشی را میپذیرد و به طور خودکار الگوریتمها و تنظیمات هایپرپارامترها را بررسی میکند تا بهترین مدل برای پیشبینیها را پیدا کند.
- استقرار خدمات وب برای تبدیل مدلهای آموزشدیده به خدمات RESTful که میتوانند در هر برنامهای مصرف شوند.
اطلاعات بیشتر درباره Azure Machine Learning SDK
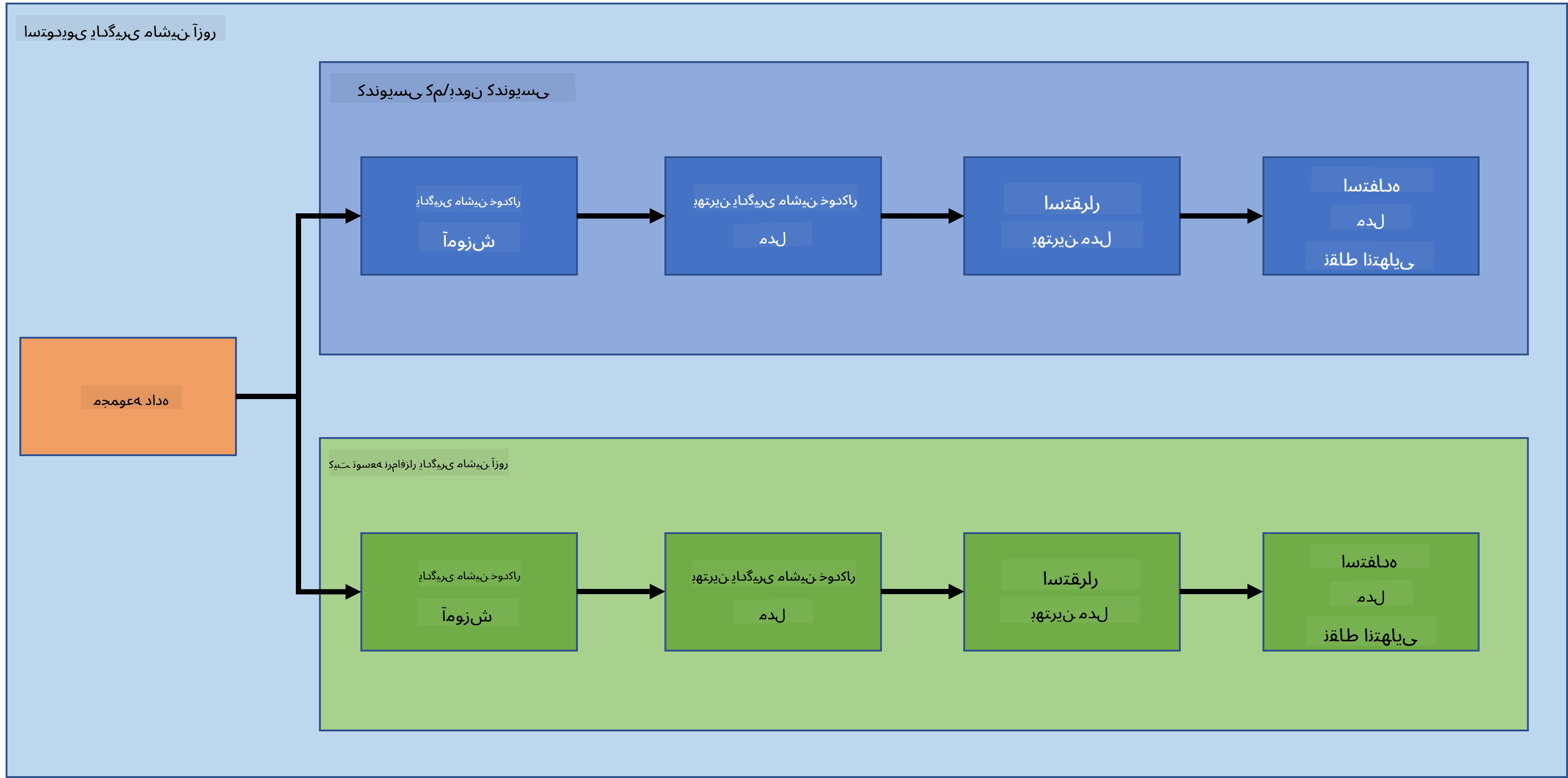
در درس قبلی، دیدیم که چگونه میتوان یک مدل را به صورت کمکد/بدونکد آموزش داد، استقرار داد و مصرف کرد. ما از مجموعه داده نارسایی قلبی برای ایجاد مدل پیشبینی نارسایی قلبی استفاده کردیم. در این درس، قصد داریم دقیقاً همین کار را انجام دهیم اما با استفاده از Azure Machine Learning SDK.
1.2 معرفی پروژه پیشبینی نارسایی قلبی و مجموعه داده
برای مشاهده معرفی پروژه پیشبینی نارسایی قلبی و مجموعه داده، اینجا کلیک کنید.
2. آموزش مدل با Azure ML SDK
2.1 ایجاد یک فضای کاری Azure ML
برای سادگی، ما قصد داریم در یک نوتبوک Jupyter کار کنیم. این به این معناست که شما قبلاً یک فضای کاری و یک نمونه محاسباتی دارید. اگر قبلاً فضای کاری دارید، میتوانید مستقیماً به بخش 2.3 ایجاد نوتبوک بروید.
اگر ندارید، لطفاً دستورالعملهای بخش 2.1 ایجاد یک فضای کاری Azure ML در درس قبلی را دنبال کنید تا یک فضای کاری ایجاد کنید.
2.2 ایجاد یک نمونه محاسباتی
در فضای کاری Azure ML که قبلاً ایجاد کردیم، به منوی محاسبات بروید و منابع محاسباتی مختلف موجود را مشاهده خواهید کرد.
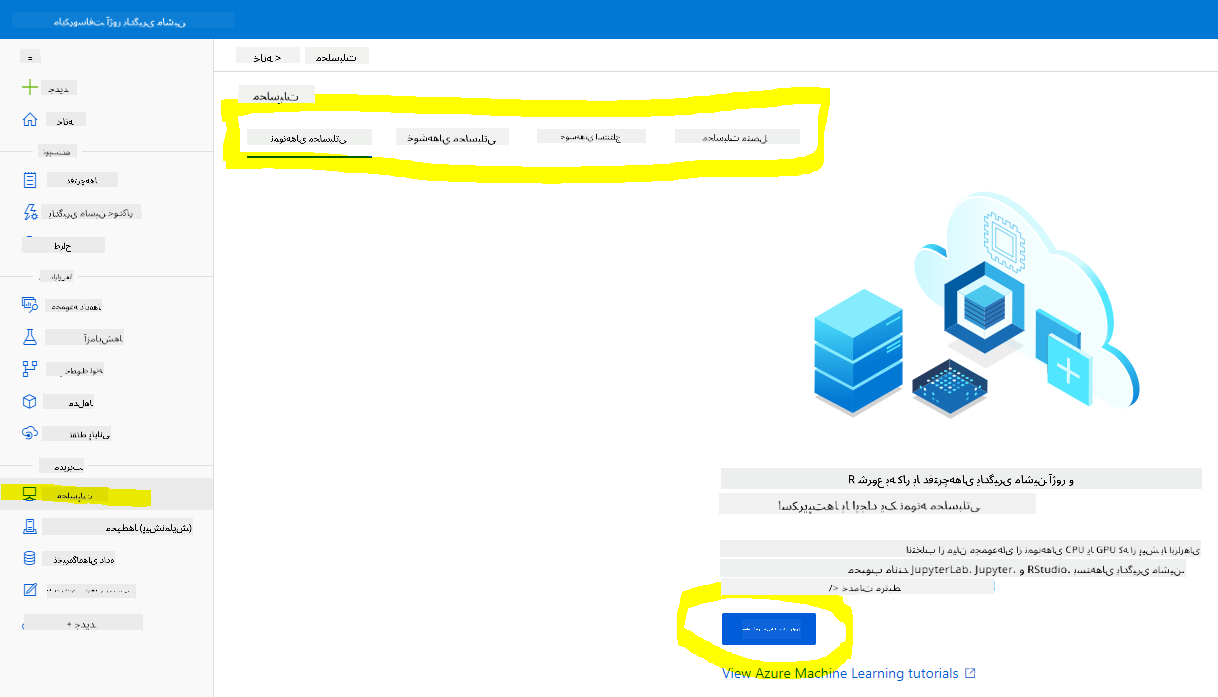
بیایید یک نمونه محاسباتی برای فراهم کردن یک نوتبوک Jupyter ایجاد کنیم.
- روی دکمه + New کلیک کنید.
- یک نام برای نمونه محاسباتی خود انتخاب کنید.
- گزینههای خود را انتخاب کنید: CPU یا GPU، اندازه VM و تعداد هستهها.
- روی دکمه Create کلیک کنید.
تبریک میگوییم، شما یک نمونه محاسباتی ایجاد کردید! ما از این نمونه محاسباتی برای ایجاد یک نوتبوک در بخش ایجاد نوتبوکها استفاده خواهیم کرد.
2.3 بارگذاری مجموعه داده
اگر هنوز مجموعه داده را بارگذاری نکردهاید، به بخش 2.3 بارگذاری مجموعه داده در درس قبلی مراجعه کنید.
2.4 ایجاد نوتبوکها
توجه: برای مرحله بعدی، میتوانید یک نوتبوک جدید از ابتدا ایجاد کنید یا نوتبوکی که قبلاً ایجاد کردیم را در Azure ML Studio خود آپلود کنید. برای آپلود، کافی است روی منوی "Notebook" کلیک کنید و نوتبوک را آپلود کنید.
نوتبوکها بخش بسیار مهمی از فرآیند علم داده هستند. آنها میتوانند برای انجام تحلیل دادههای اکتشافی (EDA)، فراخوانی به خوشه محاسباتی برای آموزش مدل، یا فراخوانی به خوشه استنتاج برای استقرار نقطه پایانی استفاده شوند.
برای ایجاد یک نوتبوک، به یک گره محاسباتی نیاز داریم که نمونه نوتبوک Jupyter را ارائه دهد. به فضای کاری Azure ML بازگردید و روی نمونههای محاسباتی کلیک کنید. در لیست نمونههای محاسباتی باید نمونه محاسباتی که قبلاً ایجاد کردیم را مشاهده کنید.
- در بخش Applications، روی گزینه Jupyter کلیک کنید.
- کادر "بله، من متوجه هستم" را علامت بزنید و روی دکمه Continue کلیک کنید.
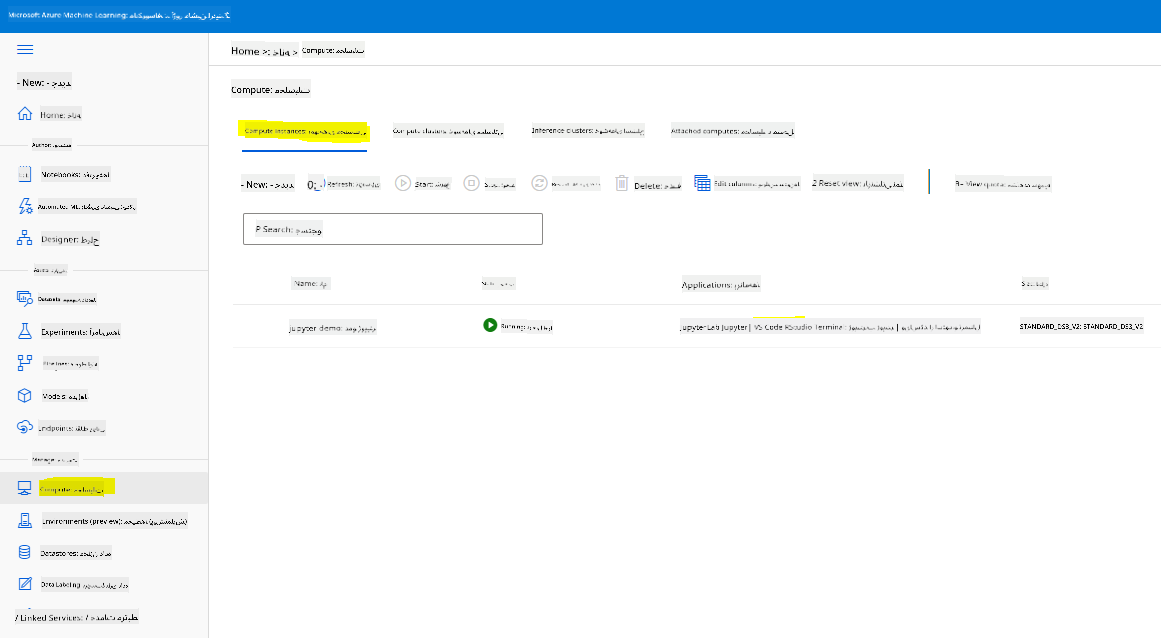
- این باید یک تب جدید در مرورگر شما باز کند که نمونه نوتبوک Jupyter شما را نشان میدهد. روی دکمه "New" کلیک کنید تا یک نوتبوک ایجاد کنید.
حالا که یک نوتبوک داریم، میتوانیم آموزش مدل با Azure ML SDK را شروع کنیم.
2.5 آموزش مدل
ابتدا، اگر شک دارید، به مستندات Azure ML SDK مراجعه کنید. این مستندات شامل تمام اطلاعات لازم برای درک ماژولهایی است که در این درس خواهیم دید.
2.5.1 تنظیم فضای کاری، آزمایش، خوشه محاسباتی و مجموعه داده
شما باید workspace را از فایل پیکربندی با استفاده از کد زیر بارگذاری کنید:
from azureml.core import Workspace
ws = Workspace.from_config()
این یک شیء از نوع Workspace بازمیگرداند که نمایانگر فضای کاری است. سپس باید یک experiment ایجاد کنید با استفاده از کد زیر:
from azureml.core import Experiment
experiment_name = 'aml-experiment'
experiment = Experiment(ws, experiment_name)
برای دریافت یا ایجاد یک آزمایش از فضای کاری، شما آزمایش را با استفاده از نام آزمایش درخواست میکنید. نام آزمایش باید بین 3 تا 36 کاراکتر باشد، با حرف یا عدد شروع شود و فقط شامل حروف، اعداد، زیرخط و خط تیره باشد. اگر آزمایش در فضای کاری پیدا نشود، یک آزمایش جدید ایجاد میشود.
حالا باید یک خوشه محاسباتی برای آموزش ایجاد کنید با استفاده از کد زیر. توجه داشته باشید که این مرحله ممکن است چند دقیقه طول بکشد.
from azureml.core.compute import AmlCompute
aml_name = "heart-f-cluster"
try:
aml_compute = AmlCompute(ws, aml_name)
print('Found existing AML compute context.')
except:
print('Creating new AML compute context.')
aml_config = AmlCompute.provisioning_configuration(vm_size = "Standard_D2_v2", min_nodes=1, max_nodes=3)
aml_compute = AmlCompute.create(ws, name = aml_name, provisioning_configuration = aml_config)
aml_compute.wait_for_completion(show_output = True)
cts = ws.compute_targets
compute_target = cts[aml_name]
شما میتوانید مجموعه داده را از فضای کاری با استفاده از نام مجموعه داده به روش زیر دریافت کنید:
dataset = ws.datasets['heart-failure-records']
df = dataset.to_pandas_dataframe()
df.describe()
2.5.2 پیکربندی AutoML و آموزش
برای تنظیم پیکربندی AutoML، از کلاس AutoMLConfig استفاده کنید.
همانطور که در مستندات توضیح داده شده است، پارامترهای زیادی وجود دارد که میتوانید با آنها بازی کنید. برای این پروژه، ما از پارامترهای زیر استفاده خواهیم کرد:
experiment_timeout_minutes: حداکثر زمان (به دقیقه) که آزمایش اجازه دارد اجرا شود قبل از اینکه به طور خودکار متوقف شود و نتایج به طور خودکار در دسترس قرار گیرد.max_concurrent_iterations: حداکثر تعداد تکرارهای آموزشی همزمان که برای آزمایش مجاز است.primary_metric: معیار اصلی که برای تعیین وضعیت آزمایش استفاده میشود.compute_target: هدف محاسباتی Azure Machine Learning برای اجرای آزمایش یادگیری ماشین خودکار.task: نوع وظیفهای که باید اجرا شود. مقادیر میتوانند 'classification'، 'regression' یا 'forecasting' باشند بسته به نوع مسئله یادگیری ماشین خودکار.training_data: دادههای آموزشی که باید در آزمایش استفاده شوند. باید شامل ویژگیهای آموزشی و یک ستون برچسب باشد (اختیاری یک ستون وزن نمونه).label_column_name: نام ستون برچسب.path: مسیر کامل به پوشه پروژه Azure Machine Learning.enable_early_stopping: آیا توقف زودهنگام در صورت عدم بهبود امتیاز در کوتاهمدت فعال شود یا خیر.featurization: نشانگر اینکه آیا مرحله ویژگیسازی باید به طور خودکار انجام شود یا خیر، یا اینکه آیا باید از ویژگیسازی سفارشی استفاده شود.debug_log: فایل لاگ برای نوشتن اطلاعات اشکالزدایی.
from azureml.train.automl import AutoMLConfig
project_folder = './aml-project'
automl_settings = {
"experiment_timeout_minutes": 20,
"max_concurrent_iterations": 3,
"primary_metric" : 'AUC_weighted'
}
automl_config = AutoMLConfig(compute_target=compute_target,
task = "classification",
training_data=dataset,
label_column_name="DEATH_EVENT",
path = project_folder,
enable_early_stopping= True,
featurization= 'auto',
debug_log = "automl_errors.log",
**automl_settings
)
حالا که پیکربندی شما تنظیم شده است، میتوانید مدل را با استفاده از کد زیر آموزش دهید. این مرحله ممکن است تا یک ساعت بسته به اندازه خوشه شما طول بکشد.
remote_run = experiment.submit(automl_config)
شما میتوانید ویجت RunDetails را اجرا کنید تا آزمایشهای مختلف را نشان دهد.
from azureml.widgets import RunDetails
RunDetails(remote_run).show()
3. استقرار مدل و مصرف نقطه پایانی با Azure ML SDK
3.1 ذخیره بهترین مدل
شیء remote_run از نوع AutoMLRun است. این شیء شامل متد get_output() است که بهترین اجرا و مدل مناسب مربوطه را بازمیگرداند.
best_run, fitted_model = remote_run.get_output()
شما میتوانید پارامترهای استفادهشده برای بهترین مدل را با چاپ fitted_model مشاهده کنید و خواص بهترین مدل را با استفاده از متد get_properties() مشاهده کنید.
best_run.get_properties()
حالا مدل را با استفاده از متد register_model ثبت کنید.
model_name = best_run.properties['model_name']
script_file_name = 'inference/score.py'
best_run.download_file('outputs/scoring_file_v_1_0_0.py', 'inference/score.py')
description = "aml heart failure project sdk"
model = best_run.register_model(model_name = model_name,
model_path = './outputs/',
description = description,
tags = None)
3.2 استقرار مدل
پس از ذخیره بهترین مدل، میتوانیم آن را با کلاس InferenceConfig مستقر کنیم. InferenceConfig نمایانگر تنظیمات پیکربندی برای محیط سفارشی استفادهشده برای استقرار است. کلاس AciWebservice نمایانگر یک مدل یادگیری ماشین مستقرشده به عنوان نقطه پایانی سرویس وب در Azure Container Instances است. یک سرویس مستقرشده از یک مدل، اسکریپت و فایلهای مرتبط ایجاد میشود. سرویس وب حاصل یک نقطه پایانی HTTP متعادلشده با REST API است. شما میتوانید دادهها را به این API ارسال کنید و پیشبینی بازگشتی توسط مدل را دریافت کنید.
مدل با استفاده از متد deploy مستقر میشود.
from azureml.core.model import InferenceConfig, Model
from azureml.core.webservice import AciWebservice
inference_config = InferenceConfig(entry_script=script_file_name, environment=best_run.get_environment())
aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1,
memory_gb = 1,
tags = {'type': "automl-heart-failure-prediction"},
description = 'Sample service for AutoML Heart Failure Prediction')
aci_service_name = 'automl-hf-sdk'
aci_service = Model.deploy(ws, aci_service_name, [model], inference_config, aciconfig)
aci_service.wait_for_deployment(True)
print(aci_service.state)
این مرحله باید چند دقیقه طول بکشد.
3.3 مصرف نقطه پایانی
شما نقطه پایانی خود را با ایجاد یک ورودی نمونه مصرف میکنید:
data = {
"data":
[
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
test_sample = str.encode(json.dumps(data))
و سپس میتوانید این ورودی را به مدل خود برای پیشبینی ارسال کنید:
response = aci_service.run(input_data=test_sample)
response
این باید خروجی '{"result": [false]}' را تولید کند. این به این معناست که ورودی بیمار که به نقطه پایانی ارسال کردیم، پیشبینی false را تولید کرده است، یعنی این فرد احتمالاً دچار حمله قلبی نخواهد شد.
تبریک میگوییم! شما مدل مستقر و آموزشدیده در Azure ML را با استفاده از Azure ML SDK مصرف کردید!
NOTE: پس از اتمام پروژه، فراموش نکنید که تمام منابع را حذف کنید.
🚀 چالش
کارهای زیادی وجود دارد که میتوانید از طریق SDK انجام دهید، اما متأسفانه نمیتوانیم همه آنها را در این درس بررسی کنیم. خبر خوب این است که یادگیری نحوه مرور مستندات SDK میتواند شما را در مسیر طولانی به جلو ببرد. به مستندات Azure ML SDK نگاهی بیندازید و کلاس Pipeline را پیدا کنید که به شما امکان ایجاد پایپلاینها را میدهد. پایپلاین مجموعهای از مراحل است که میتوانند به عنوان یک جریان کاری اجرا شوند.
راهنما: به مستندات SDK بروید و کلمات کلیدی مانند "Pipeline" را در نوار جستجو تایپ کنید. باید کلاس azureml.pipeline.core.Pipeline را در نتایج جستجو مشاهده کنید.
آزمون پس از درس
مرور و مطالعه شخصی
در این درس، یاد گرفتید که چگونه یک مدل را برای پیشبینی خطر نارسایی قلبی با Azure ML SDK در فضای ابری آموزش دهید، مستقر کنید و مصرف کنید. این مستندات را برای اطلاعات بیشتر درباره Azure ML SDK بررسی کنید. سعی کنید مدل خود را با Azure ML SDK ایجاد کنید.
تکلیف
پروژه علم داده با استفاده از Azure ML SDK
سلب مسئولیت:
این سند با استفاده از سرویس ترجمه هوش مصنوعی Co-op Translator ترجمه شده است. در حالی که ما تلاش میکنیم دقت را حفظ کنیم، لطفاً توجه داشته باشید که ترجمههای خودکار ممکن است شامل خطاها یا نادرستیها باشند. سند اصلی به زبان اصلی آن باید به عنوان منبع معتبر در نظر گرفته شود. برای اطلاعات حساس، توصیه میشود از ترجمه حرفهای انسانی استفاده کنید. ما مسئولیتی در قبال سوء تفاهمها یا تفسیرهای نادرست ناشی از استفاده از این ترجمه نداریم.