20 KiB
Working with Data: Python and the Pandas Library
 |
|---|
| Working With Python - Sketchnote by @nitya |

While databases provide highly efficient methods for storing and querying data using query languages, the most flexible way to process data is by writing your own program to manipulate it. In many cases, using a database query is more effective. However, when more complex data processing is required, it may not be easily achievable with SQL.
Data processing can be done in any programming language, but some languages are better suited for working with data. Data scientists often prefer one of the following languages:
- Python: A general-purpose programming language often considered one of the best options for beginners due to its simplicity. Python has many additional libraries that can help solve practical problems, such as extracting data from ZIP archives or converting images to grayscale. Beyond data science, Python is also widely used for web development.
- R: A traditional toolset designed specifically for statistical data processing. It has a large repository of libraries (CRAN), making it a strong choice for data analysis. However, R is not a general-purpose programming language and is rarely used outside the data science domain.
- Julia: A language developed specifically for data science, designed to offer better performance than Python, making it an excellent tool for scientific experimentation.
In this lesson, we will focus on using Python for simple data processing. We assume you have basic familiarity with the language. If you'd like a deeper dive into Python, you can explore the following resources:
- Learn Python in a Fun Way with Turtle Graphics and Fractals - A quick introductory course on Python programming hosted on GitHub.
- Take your First Steps with Python - A learning path available on Microsoft Learn.
Data can come in various forms. In this lesson, we will focus on three types of data: tabular data, text, and images.
Rather than providing a comprehensive overview of all related libraries, we will focus on a few examples of data processing. This approach will help you grasp the main concepts and equip you with the knowledge to find solutions to your problems when needed.
Most useful advice: When you need to perform a specific operation on data but don't know how, try searching for it online. Stackoverflow often contains many useful Python code samples for common tasks.
Pre-lecture quiz
Tabular Data and Dataframes
You’ve already encountered tabular data when we discussed relational databases. When dealing with large datasets stored in multiple linked tables, SQL is often the best tool for the job. However, there are many situations where you have a single table of data and need to derive insights or understanding from it, such as analyzing distributions or correlations between values. In data science, it’s common to transform the original data and then visualize it. Both steps can be easily accomplished using Python.
Two key libraries in Python are particularly useful for working with tabular data:
- Pandas: Enables manipulation of DataFrames, which are similar to relational tables. You can work with named columns and perform various operations on rows, columns, and entire DataFrames.
- Numpy: A library for working with tensors, or multi-dimensional arrays. Arrays contain values of the same type and are simpler than DataFrames, offering more mathematical operations with less overhead.
Additionally, there are other libraries worth knowing:
- Matplotlib: Used for data visualization and graph plotting.
- SciPy: Provides additional scientific functions. We’ve already encountered this library when discussing probability and statistics.
Here’s a typical code snippet for importing these libraries at the start of a Python program:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import ... # you need to specify exact sub-packages that you need
Pandas revolves around a few fundamental concepts.
Series
A Series is a sequence of values, similar to a list or numpy array. The key difference is that a Series also has an index, which is considered during operations (e.g., addition). The index can be as simple as an integer row number (the default when creating a Series from a list or array) or more complex, such as a date range.
Note: Some introductory Pandas code is available in the accompanying notebook
notebook.ipynb. We’ll outline a few examples here, but feel free to explore the full notebook.
For example, let’s analyze sales data for an ice cream shop. We’ll generate a Series of sales numbers (items sold each day) over a specific time period:
start_date = "Jan 1, 2020"
end_date = "Mar 31, 2020"
idx = pd.date_range(start_date,end_date)
print(f"Length of index is {len(idx)}")
items_sold = pd.Series(np.random.randint(25,50,size=len(idx)),index=idx)
items_sold.plot()
Now, suppose we host a weekly party for friends and take an additional 10 packs of ice cream for the event. We can create another Series, indexed by week, to represent this:
additional_items = pd.Series(10,index=pd.date_range(start_date,end_date,freq="W"))
When we add the two Series together, we get the total number:
total_items = items_sold.add(additional_items,fill_value=0)
total_items.plot()
Note: We don’t use the simple syntax
total_items + additional_items. If we did, the resulting Series would contain manyNaN(Not a Number) values. This happens because some index points in theadditional_itemsSeries lack values, and addingNaNto anything results inNaN. To avoid this, we specify thefill_valueparameter during addition.
With time series, we can also resample the data using different time intervals. For instance, to calculate the average monthly sales volume, we can use the following code:
monthly = total_items.resample("1M").mean()
ax = monthly.plot(kind='bar')
DataFrame
A DataFrame is essentially a collection of Series with the same index. We can combine multiple Series into a DataFrame:
a = pd.Series(range(1,10))
b = pd.Series(["I","like","to","play","games","and","will","not","change"],index=range(0,9))
df = pd.DataFrame([a,b])
This creates a horizontal table like this:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 1 | I | like | to | use | Python | and | Pandas | very | much |
We can also use Series as columns and specify column names using a dictionary:
df = pd.DataFrame({ 'A' : a, 'B' : b })
This results in the following table:
| A | B | |
|---|---|---|
| 0 | 1 | I |
| 1 | 2 | like |
| 2 | 3 | to |
| 3 | 4 | use |
| 4 | 5 | Python |
| 5 | 6 | and |
| 6 | 7 | Pandas |
| 7 | 8 | very |
| 8 | 9 | much |
Note: We can also achieve this table layout by transposing the previous table using:
df = pd.DataFrame([a,b]).T..rename(columns={ 0 : 'A', 1 : 'B' })
Here, .T performs the transposition (swapping rows and columns), and the rename operation allows us to rename columns to match the previous example.
Here are some key operations you can perform on DataFrames:
Column selection: Select individual columns using df['A'] (returns a Series). To select a subset of columns into another DataFrame, use df[['B', 'A']].
Filtering rows by criteria: For example, to keep only rows where column A is greater than 5, use df[df['A'] > 5].
Note: Filtering works as follows: The expression
df['A'] < 5returns a boolean Series indicating whether the condition isTrueorFalsefor each element indf['A']. When a boolean Series is used as an index, it returns a subset of rows in the DataFrame. You cannot use arbitrary Python boolean expressions likedf[df['A'] > 5 and df['A'] < 7]. Instead, use the special&operator for boolean Series:df[(df['A'] > 5) & (df['A'] < 7)](brackets are essential).
Creating new computed columns: Easily create new columns using expressions like:
df['DivA'] = df['A']-df['A'].mean()
This example calculates the divergence of A from its mean value. Here, we compute a Series and assign it to the left-hand side, creating a new column. However, operations incompatible with Series will result in errors, such as:
# Wrong code -> df['ADescr'] = "Low" if df['A'] < 5 else "Hi"
df['LenB'] = len(df['B']) # <- Wrong result
This example, while syntactically correct, produces incorrect results because it assigns the length of Series B to all values in the column, rather than the length of individual elements.
For complex expressions, use the apply function. The previous example can be rewritten as:
df['LenB'] = df['B'].apply(lambda x : len(x))
# or
df['LenB'] = df['B'].apply(len)
After these operations, the resulting DataFrame will look like this:
| A | B | DivA | LenB | |
|---|---|---|---|---|
| 0 | 1 | I | -4.0 | 1 |
| 1 | 2 | like | -3.0 | 4 |
| 2 | 3 | to | -2.0 | 2 |
| 3 | 4 | use | -1.0 | 3 |
| 4 | 5 | Python | 0.0 | 6 |
| 5 | 6 | and | 1.0 | 3 |
| 6 | 7 | Pandas | 2.0 | 6 |
| 7 | 8 | very | 3.0 | 4 |
| 8 | 9 | much | 4.0 | 4 |
Selecting rows by index: Use the iloc construct to select rows by their position. For example, to select the first 5 rows:
df.iloc[:5]
Grouping: Often used to create results similar to pivot tables in Excel. For instance, to compute the mean value of column A for each unique value in LenB, group the DataFrame by LenB and call mean:
df.groupby(by='LenB').mean()
To compute both the mean and the count of elements in each group, use the aggregate function:
df.groupby(by='LenB') \
.aggregate({ 'DivA' : len, 'A' : lambda x: x.mean() }) \
.rename(columns={ 'DivA' : 'Count', 'A' : 'Mean'})
This produces the following table:
| LenB | Count | Mean |
|---|---|---|
| 1 | 1 | 1.000000 |
| 2 | 1 | 3.000000 |
| 3 | 2 | 5.000000 |
| 4 | 3 | 6.333333 |
| 6 | 2 | 6.000000 |
Getting Data
We have seen how simple it is to create Series and DataFrames from Python objects. However, data is often stored in text files or Excel tables. Fortunately, Pandas provides an easy way to load data from disk. For example, reading a CSV file is as straightforward as this:
df = pd.read_csv('file.csv')
We will explore more examples of loading data, including retrieving it from external websites, in the "Challenge" section.
Printing and Plotting
A Data Scientist frequently needs to explore data, so being able to visualize it is crucial. When working with large DataFrames, we often want to ensure everything is functioning correctly by printing the first few rows. This can be done using df.head(). If you run this in Jupyter Notebook, it will display the DataFrame in a neat tabular format.
We’ve also seen how to use the plot function to visualize specific columns. While plot is highly versatile and supports various graph types via the kind= parameter, you can always use the raw matplotlib library for more complex visualizations. We will delve deeper into data visualization in separate course lessons.
This overview covers the key concepts of Pandas, but the library is incredibly rich, and the possibilities are endless! Let’s now apply this knowledge to solve specific problems.
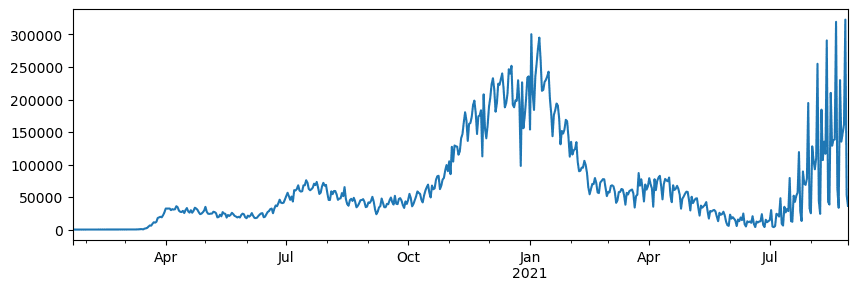
🚀 Challenge 1: Analyzing COVID Spread
The first problem we’ll tackle is modeling the spread of the COVID-19 epidemic. To do this, we’ll use data on the number of infected individuals in various countries, provided by the Center for Systems Science and Engineering (CSSE) at Johns Hopkins University. The dataset is available in this GitHub Repository.
To demonstrate how to work with data, we encourage you to open notebook-covidspread.ipynb and go through it from start to finish. You can also execute the cells and try out some challenges we’ve included at the end.
If you’re unfamiliar with running code in Jupyter Notebook, check out this article.
Working with Unstructured Data
While data often comes in tabular form, there are cases where we need to work with less structured data, such as text or images. In these situations, to apply the data processing techniques we’ve discussed, we need to extract structured data. Here are a few examples:
- Extracting keywords from text and analyzing their frequency
- Using neural networks to identify objects in images
- Detecting emotions in people from video camera feeds
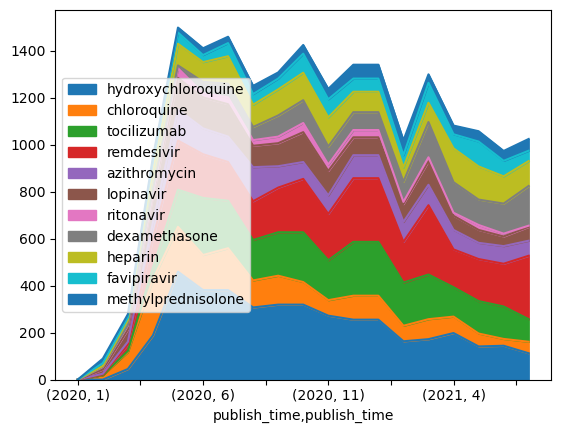
🚀 Challenge 2: Analyzing COVID Papers
In this challenge, we’ll continue exploring the COVID pandemic by focusing on processing scientific papers on the topic. The CORD-19 Dataset contains over 7,000 papers (at the time of writing) on COVID, along with metadata and abstracts (and full text for about half of them).
A complete example of analyzing this dataset using the Text Analytics for Health cognitive service is described in this blog post. We’ll discuss a simplified version of this analysis.
NOTE: This repository does not include a copy of the dataset. You may need to download the
metadata.csvfile from this Kaggle dataset. Registration with Kaggle may be required. Alternatively, you can download the dataset without registration from here, which includes all full texts in addition to the metadata file.
Open notebook-papers.ipynb and go through it from start to finish. You can also execute the cells and try out some challenges we’ve included at the end.
Processing Image Data
Recently, powerful AI models have been developed to analyze images. Many tasks can be accomplished using pre-trained neural networks or cloud services. Examples include:
- Image Classification, which categorizes images into predefined classes. You can train your own image classifiers using services like Custom Vision.
- Object Detection, which identifies various objects in an image. Services like computer vision can detect common objects, and you can train Custom Vision models to detect specific objects of interest.
- Face Detection, including age, gender, and emotion analysis. This can be achieved using Face API.
These cloud services can be accessed via Python SDKs, making it easy to integrate them into your data exploration workflow.
Here are some examples of working with image data sources:
- In the blog post How to Learn Data Science without Coding, we analyze Instagram photos to understand what makes people like a photo more. We extract information from images using computer vision and use Azure Machine Learning AutoML to build an interpretable model.
- In the Facial Studies Workshop, we use Face API to analyze emotions in event photographs to understand what makes people happy.
Conclusion
Whether you’re working with structured or unstructured data, Python allows you to perform all steps related to data processing and analysis. It’s one of the most flexible tools for data processing, which is why most data scientists use Python as their primary tool. If you’re serious about pursuing data science, learning Python in depth is highly recommended!
Post-lecture quiz
Review & Self Study
Books
Online Resources
- Official 10 minutes to Pandas tutorial
- Documentation on Pandas Visualization
Learning Python
- Learn Python in a Fun Way with Turtle Graphics and Fractals
- Take your First Steps with Python Learning Path on Microsoft Learn
Assignment
Perform more detailed data study for the challenges above
Credits
This lesson was created with ♥️ by Dmitry Soshnikov
Disclaimer:
This document has been translated using the AI translation service Co-op Translator. While we strive for accuracy, please note that automated translations may contain errors or inaccuracies. The original document in its native language should be regarded as the authoritative source. For critical information, professional human translation is recommended. We are not responsible for any misunderstandings or misinterpretations resulting from the use of this translation.