10 KiB
Introduktion til Data Science-livscyklussen
 |
|---|
| Introduktion til Data Science-livscyklussen - Sketchnote af @nitya |
Quiz før lektionen
På nuværende tidspunkt har du sandsynligvis indset, at data science er en proces. Denne proces kan opdeles i 5 stadier:
- Indsamling
- Bearbejdning
- Analyse
- Kommunikation
- Vedligeholdelse
Denne lektion fokuserer på 3 dele af livscyklussen: indsamling, bearbejdning og vedligeholdelse.
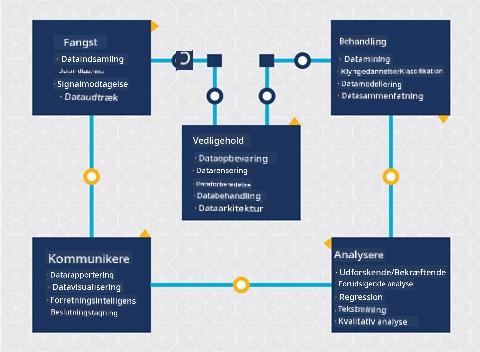
Foto af Berkeley School of Information
Indsamling
Det første stadie i livscyklussen er meget vigtigt, da de næste stadier afhænger af det. Det er praktisk talt to stadier kombineret i ét: at indsamle data og definere formålet og de problemer, der skal adresseres.
At definere projektets mål kræver en dybere forståelse af problemet eller spørgsmålet. Først skal vi identificere og engagere dem, der har brug for at få løst deres problem. Dette kan være interessenter i en virksomhed eller sponsorer af projektet, som kan hjælpe med at identificere, hvem eller hvad der vil drage fordel af projektet, samt hvad og hvorfor de har brug for det. Et veldefineret mål bør være målbart og kvantificerbart for at definere et acceptabelt resultat.
Spørgsmål, en data scientist kan stille:
- Er dette problem blevet adresseret før? Hvad blev opdaget?
- Er formålet og målet forstået af alle involverede?
- Er der uklarheder, og hvordan kan de reduceres?
- Hvad er begrænsningerne?
- Hvordan vil det endelige resultat potentielt se ud?
- Hvor mange ressourcer (tid, mennesker, computerkraft) er tilgængelige?
Næste skridt er at identificere, indsamle og derefter udforske de data, der er nødvendige for at opnå de definerede mål. På dette trin i indsamlingen skal data scientists også evaluere mængden og kvaliteten af dataene. Dette kræver en vis dataudforskning for at bekræfte, at det, der er indsamlet, vil understøtte opnåelsen af det ønskede resultat.
Spørgsmål, en data scientist kan stille om dataene:
- Hvilke data er allerede tilgængelige for mig?
- Hvem ejer disse data?
- Hvad er privatlivsbekymringerne?
- Har jeg nok til at løse dette problem?
- Er dataene af acceptabel kvalitet til dette problem?
- Hvis jeg opdager yderligere information gennem disse data, bør vi så overveje at ændre eller redefinere målene?
Bearbejdning
Bearbejdningstrinnet i livscyklussen fokuserer på at opdage mønstre i dataene samt modellering. Nogle teknikker, der bruges i bearbejdningstrinnet, kræver statistiske metoder for at afdække mønstre. Typisk ville dette være en tidskrævende opgave for et menneske med et stort datasæt, og derfor vil computere blive brugt til at lette processen og fremskynde arbejdet. Dette trin er også, hvor data science og machine learning krydser hinanden. Som du lærte i den første lektion, er machine learning processen med at bygge modeller for at forstå dataene. Modeller er en repræsentation af forholdet mellem variabler i dataene, som hjælper med at forudsige resultater.
Almindelige teknikker, der bruges i dette trin, er dækket i ML for Beginners-kurset. Følg linkene for at lære mere om dem:
- Klassifikation: Organisering af data i kategorier for mere effektiv brug.
- Klyngedannelse: Gruppering af data i lignende grupper.
- Regression: Bestemme forholdet mellem variabler for at forudsige eller forudsige værdier.
Vedligeholdelse
I diagrammet over livscyklussen har du måske bemærket, at vedligeholdelse ligger mellem indsamling og bearbejdning. Vedligeholdelse er en løbende proces med at administrere, opbevare og sikre data gennem hele projektets proces og bør tages i betragtning i hele projektets varighed.
Opbevaring af data
Overvejelser om, hvordan og hvor data opbevares, kan påvirke omkostningerne ved opbevaring samt ydeevnen for, hvor hurtigt data kan tilgås. Beslutninger som disse vil sandsynligvis ikke blive truffet af en data scientist alene, men de kan finde sig selv i at træffe valg om, hvordan de skal arbejde med dataene baseret på, hvordan de er opbevaret.
Her er nogle aspekter af moderne datalagringssystemer, der kan påvirke disse valg:
On-premise vs off-premise vs offentlig eller privat cloud
On-premise refererer til at hoste og administrere data på eget udstyr, som f.eks. at eje en server med harddiske, der opbevarer dataene, mens off-premise afhænger af udstyr, som du ikke ejer, såsom et datacenter. Den offentlige cloud er et populært valg til opbevaring af data, der ikke kræver viden om, hvordan eller hvor dataene præcist opbevares, hvor offentlig refererer til en samlet underliggende infrastruktur, der deles af alle, der bruger cloud'en. Nogle organisationer har strenge sikkerhedspolitikker, der kræver, at de har fuld adgang til det udstyr, hvor dataene hostes, og vil derfor benytte en privat cloud, der tilbyder egne cloud-tjenester. Du vil lære mere om data i cloud'en i senere lektioner.
Kold vs varm data
Når du træner dine modeller, kan du have brug for mere træningsdata. Hvis du er tilfreds med din model, vil der komme flere data til, så modellen kan tjene sit formål. Uanset hvad vil omkostningerne ved opbevaring og adgang til data stige, jo mere du akkumulerer. At adskille sjældent brugte data, kendt som kold data, fra ofte tilgået varm data kan være en billigere datalagringsmulighed gennem hardware- eller softwaretjenester. Hvis kold data skal tilgås, kan det tage lidt længere tid at hente i forhold til varm data.
Administration af data
Når du arbejder med data, kan du opdage, at nogle af dataene skal renses ved hjælp af nogle af de teknikker, der er dækket i lektionen om dataklargøring for at bygge præcise modeller. Når nye data ankommer, vil de kræve nogle af de samme applikationer for at opretholde konsistens i kvaliteten. Nogle projekter vil involvere brugen af et automatiseret værktøj til rensning, aggregering og komprimering, før dataene flyttes til deres endelige placering. Azure Data Factory er et eksempel på et af disse værktøjer.
Sikring af data
Et af hovedmålene med at sikre data er at sikre, at dem, der arbejder med dem, har kontrol over, hvad der indsamles, og i hvilken kontekst det bruges. At holde data sikre indebærer at begrænse adgangen til kun dem, der har brug for det, overholde lokale love og regler samt opretholde etiske standarder, som dækket i etiklektionen.
Her er nogle ting, som et team kan gøre med sikkerhed i tankerne:
- Bekræfte, at alle data er krypteret
- Give kunder information om, hvordan deres data bruges
- Fjerne dataadgang fra dem, der har forladt projektet
- Kun lade visse projektmedlemmer ændre dataene
🚀 Udfordring
Der findes mange versioner af Data Science-livscyklussen, hvor hvert trin kan have forskellige navne og antal stadier, men vil indeholde de samme processer nævnt i denne lektion.
Undersøg Team Data Science Process-livscyklussen og Cross-industry standard process for data mining. Nævn 3 ligheder og forskelle mellem de to.
| Team Data Science Process (TDSP) | Cross-industry standard process for data mining (CRISP-DM) |
|---|---|
 |
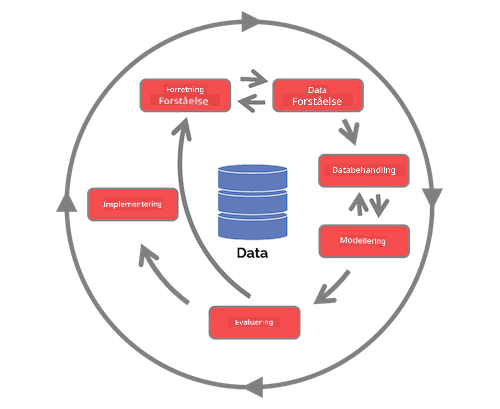 |
| Billede af Microsoft | Billede af Data Science Process Alliance |
Quiz efter lektionen
Gennemgang & Selvstudie
Anvendelse af Data Science-livscyklussen involverer flere roller og opgaver, hvor nogle kan fokusere på bestemte dele af hvert stadie. Team Data Science Process tilbyder nogle ressourcer, der forklarer de typer roller og opgaver, som nogen kan have i et projekt.
- Team Data Science Process roller og opgaver
- Udfør data science-opgaver: udforskning, modellering og implementering
Opgave
Ansvarsfraskrivelse:
Dette dokument er blevet oversat ved hjælp af AI-oversættelsestjenesten Co-op Translator. Selvom vi bestræber os på nøjagtighed, skal du være opmærksom på, at automatiserede oversættelser kan indeholde fejl eller unøjagtigheder. Det originale dokument på dets oprindelige sprog bør betragtes som den autoritative kilde. For kritisk information anbefales professionel menneskelig oversættelse. Vi er ikke ansvarlige for eventuelle misforståelser eller fejltolkninger, der opstår som følge af brugen af denne oversættelse.