|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
README.md
Visualisering af Proportioner
 |
|---|
| Visualisering af Proportioner - Sketchnote af @nitya |
I denne lektion vil du bruge et andet naturfokuseret datasæt til at visualisere proportioner, såsom hvor mange forskellige typer svampe der findes i et givet datasæt om svampe. Lad os udforske disse fascinerende svampe ved hjælp af et datasæt fra Audubon, der indeholder detaljer om 23 arter af lamelsvampe i Agaricus- og Lepiota-familierne. Du vil eksperimentere med lækre visualiseringer som:
- Lagkagediagrammer 🥧
- Donutdiagrammer 🍩
- Vaffeldiagrammer 🧇
💡 Et meget interessant projekt kaldet Charticulator fra Microsoft Research tilbyder en gratis drag-and-drop-grænseflade til datavisualiseringer. I en af deres tutorials bruger de også dette svampedatasæt! Så du kan udforske dataene og lære biblioteket på samme tid: Charticulator tutorial.
Quiz før lektionen
Lær dine svampe at kende 🍄
Svampe er meget interessante. Lad os importere et datasæt for at studere dem:
import pandas as pd
import matplotlib.pyplot as plt
mushrooms = pd.read_csv('../../data/mushrooms.csv')
mushrooms.head()
En tabel bliver printet med nogle fantastiske data til analyse:
| class | cap-shape | cap-surface | cap-color | bruises | odor | gill-attachment | gill-spacing | gill-size | gill-color | stalk-shape | stalk-root | stalk-surface-above-ring | stalk-surface-below-ring | stalk-color-above-ring | stalk-color-below-ring | veil-type | veil-color | ring-number | ring-type | spore-print-color | population | habitat |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Giftig | Konveks | Glat | Brun | Blå mærker | Stikkende | Fri | Tæt | Smal | Sort | Udvidende | Lige | Glat | Glat | Hvid | Hvid | Delvis | Hvid | En | Hængende | Sort | Spredt | By |
| Spiselig | Konveks | Glat | Gul | Blå mærker | Mandel | Fri | Tæt | Bred | Sort | Udvidende | Kølle | Glat | Glat | Hvid | Hvid | Delvis | Hvid | En | Hængende | Brun | Talrig | Græsarealer |
| Spiselig | Klokke | Glat | Hvid | Blå mærker | Anis | Fri | Tæt | Bred | Brun | Udvidende | Kølle | Glat | Glat | Hvid | Hvid | Delvis | Hvid | En | Hængende | Brun | Talrig | Enge |
| Giftig | Konveks | Skællet | Hvid | Blå mærker | Stikkende | Fri | Tæt | Smal | Brun | Udvidende | Lige | Glat | Glat | Hvid | Hvid | Delvis | Hvid | En | Hængende | Sort | Spredt | By |
Med det samme bemærker du, at alle data er tekstuelle. Du bliver nødt til at konvertere disse data for at kunne bruge dem i et diagram. Faktisk er de fleste af dataene repræsenteret som et objekt:
print(mushrooms.select_dtypes(["object"]).columns)
Outputtet er:
Index(['class', 'cap-shape', 'cap-surface', 'cap-color', 'bruises', 'odor',
'gill-attachment', 'gill-spacing', 'gill-size', 'gill-color',
'stalk-shape', 'stalk-root', 'stalk-surface-above-ring',
'stalk-surface-below-ring', 'stalk-color-above-ring',
'stalk-color-below-ring', 'veil-type', 'veil-color', 'ring-number',
'ring-type', 'spore-print-color', 'population', 'habitat'],
dtype='object')
Tag disse data og konverter 'class'-kolonnen til en kategori:
cols = mushrooms.select_dtypes(["object"]).columns
mushrooms[cols] = mushrooms[cols].astype('category')
edibleclass=mushrooms.groupby(['class']).count()
edibleclass
Nu, hvis du printer svampedataene, kan du se, at de er blevet grupperet i kategorier baseret på klassen giftig/spiselig:
| cap-shape | cap-surface | cap-color | bruises | odor | gill-attachment | gill-spacing | gill-size | gill-color | stalk-shape | ... | stalk-surface-below-ring | stalk-color-above-ring | stalk-color-below-ring | veil-type | veil-color | ring-number | ring-type | spore-print-color | population | habitat | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| class | |||||||||||||||||||||
| Spiselig | 4208 | 4208 | 4208 | 4208 | 4208 | 4208 | 4208 | 4208 | 4208 | 4208 | ... | 4208 | 4208 | 4208 | 4208 | 4208 | 4208 | 4208 | 4208 | 4208 | 4208 |
| Giftig | 3916 | 3916 | 3916 | 3916 | 3916 | 3916 | 3916 | 3916 | 3916 | 3916 | ... | 3916 | 3916 | 3916 | 3916 | 3916 | 3916 | 3916 | 3916 | 3916 | 3916 |
Hvis du følger rækkefølgen i denne tabel for at oprette dine klassekategorimærker, kan du lave et lagkagediagram:
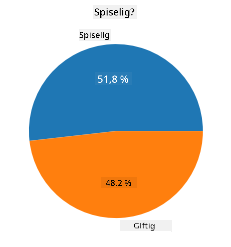
Lagkage!
labels=['Edible','Poisonous']
plt.pie(edibleclass['population'],labels=labels,autopct='%.1f %%')
plt.title('Edible?')
plt.show()
Voila, et lagkagediagram, der viser proportionerne af disse data i henhold til de to svampeklasser. Det er ret vigtigt at få rækkefølgen af mærkerne korrekt, især her, så sørg for at verificere rækkefølgen, når du opbygger mærke-arrayet!
Donuts!
Et lidt mere visuelt interessant lagkagediagram er et donutdiagram, som er et lagkagediagram med et hul i midten. Lad os se på vores data ved hjælp af denne metode.
Se på de forskellige levesteder, hvor svampe vokser:
habitat=mushrooms.groupby(['habitat']).count()
habitat
Her grupperer du dine data efter levested. Der er 7 listede, så brug dem som mærker til dit donutdiagram:
labels=['Grasses','Leaves','Meadows','Paths','Urban','Waste','Wood']
plt.pie(habitat['class'], labels=labels,
autopct='%1.1f%%', pctdistance=0.85)
center_circle = plt.Circle((0, 0), 0.40, fc='white')
fig = plt.gcf()
fig.gca().add_artist(center_circle)
plt.title('Mushroom Habitats')
plt.show()
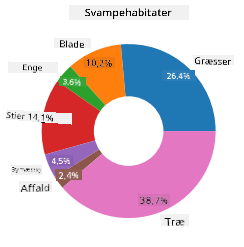
Denne kode tegner et diagram og en cirkel i midten og tilføjer derefter den midterste cirkel i diagrammet. Rediger bredden af den midterste cirkel ved at ændre 0.40 til en anden værdi.
Donutdiagrammer kan justeres på flere måder for at ændre mærkerne. Mærkerne kan især fremhæves for bedre læsbarhed. Læs mere i dokumentationen.
Nu hvor du ved, hvordan du grupperer dine data og derefter viser dem som lagkage eller donut, kan du udforske andre typer diagrammer. Prøv et vaffeldiagram, som blot er en anden måde at udforske mængder på.
Vafler!
Et 'vaffel'-diagram er en anden måde at visualisere mængder som et 2D-array af firkanter. Prøv at visualisere de forskellige mængder af svampehatfarver i dette datasæt. For at gøre dette skal du installere et hjælpebibliotek kaldet PyWaffle og bruge Matplotlib:
pip install pywaffle
Vælg et segment af dine data til gruppering:
capcolor=mushrooms.groupby(['cap-color']).count()
capcolor
Opret et vaffeldiagram ved at oprette mærker og derefter gruppere dine data:
import pandas as pd
import matplotlib.pyplot as plt
from pywaffle import Waffle
data ={'color': ['brown', 'buff', 'cinnamon', 'green', 'pink', 'purple', 'red', 'white', 'yellow'],
'amount': capcolor['class']
}
df = pd.DataFrame(data)
fig = plt.figure(
FigureClass = Waffle,
rows = 100,
values = df.amount,
labels = list(df.color),
figsize = (30,30),
colors=["brown", "tan", "maroon", "green", "pink", "purple", "red", "whitesmoke", "yellow"],
)
Ved hjælp af et vaffeldiagram kan du tydeligt se proportionerne af hatfarver i dette svampedatasæt. Interessant nok er der mange svampe med grønne hatte!

✅ Pywaffle understøtter ikoner i diagrammer, der bruger ethvert ikon tilgængeligt i Font Awesome. Lav nogle eksperimenter for at skabe et endnu mere interessant vaffeldiagram ved at bruge ikoner i stedet for firkanter.
I denne lektion lærte du tre måder at visualisere proportioner på. Først skal du gruppere dine data i kategorier og derefter beslutte, hvilken der er den bedste måde at vise dataene på - lagkage, donut eller vaffel. Alle er lækre og giver brugeren et øjeblikkeligt overblik over et datasæt.
🚀 Udfordring
Prøv at genskabe disse lækre diagrammer i Charticulator.
Quiz efter lektionen
Gennemgang & Selvstudie
Nogle gange er det ikke indlysende, hvornår man skal bruge et lagkage-, donut- eller vaffeldiagram. Her er nogle artikler, du kan læse om dette emne:
https://www.beautiful.ai/blog/battle-of-the-charts-pie-chart-vs-donut-chart
https://medium.com/@hypsypops/pie-chart-vs-donut-chart-showdown-in-the-ring-5d24fd86a9ce
https://www.mit.edu/~mbarker/formula1/f1help/11-ch-c6.htm
Lav noget research for at finde mere information om denne vanskelige beslutning.
Opgave
Ansvarsfraskrivelse:
Dette dokument er blevet oversat ved hjælp af AI-oversættelsestjenesten Co-op Translator. Selvom vi bestræber os på nøjagtighed, skal du være opmærksom på, at automatiserede oversættelser kan indeholde fejl eller unøjagtigheder. Det originale dokument på dets oprindelige sprog bør betragtes som den autoritative kilde. For kritisk information anbefales professionel menneskelig oversættelse. Vi er ikke ansvarlige for eventuelle misforståelser eller fejltolkninger, der måtte opstå som følge af brugen af denne oversættelse.