23 KiB
Práce s daty: Python a knihovna Pandas
 |
|---|
| Práce s Pythonem - Sketchnote od @nitya |
Databáze nabízejí velmi efektivní způsoby ukládání dat a jejich dotazování pomocí dotazovacích jazyků, ale nejflexibilnějším způsobem zpracování dat je napsání vlastního programu pro manipulaci s daty. V mnoha případech by bylo efektivnější použít dotaz na databázi. Nicméně v některých situacích, kdy je potřeba složitější zpracování dat, to nelze snadno provést pomocí SQL. Zpracování dat lze naprogramovat v jakémkoli programovacím jazyce, ale existují určité jazyky, které jsou na vyšší úrovni, pokud jde o práci s daty. Datoví vědci obvykle preferují jeden z následujících jazyků:
- Python, univerzální programovací jazyk, který je často považován za jednu z nejlepších možností pro začátečníky díky své jednoduchosti. Python má mnoho doplňkových knihoven, které vám mohou pomoci vyřešit praktické problémy, jako je extrakce dat ze ZIP archivu nebo převod obrázku na odstíny šedi. Kromě datové vědy se Python často používá i pro vývoj webových aplikací.
- R je tradiční nástroj vyvinutý s ohledem na statistické zpracování dat. Obsahuje také rozsáhlé úložiště knihoven (CRAN), což z něj činí dobrou volbu pro zpracování dat. Nicméně R není univerzální programovací jazyk a mimo oblast datové vědy se používá jen zřídka.
- Julia je další jazyk vyvinutý speciálně pro datovou vědu. Je navržen tak, aby poskytoval lepší výkon než Python, což z něj činí skvělý nástroj pro vědecké experimenty.
V této lekci se zaměříme na použití Pythonu pro jednoduché zpracování dat. Předpokládáme základní znalost tohoto jazyka. Pokud chcete hlubší úvod do Pythonu, můžete se podívat na některý z následujících zdrojů:
- Naučte se Python zábavným způsobem pomocí Turtle Graphics a fraktálů - rychlý úvodní kurz programování v Pythonu na GitHubu
- Udělejte své první kroky s Pythonem - vzdělávací cesta na Microsoft Learn
Data mohou mít mnoho podob. V této lekci se zaměříme na tři formy dat - tabulková data, text a obrázky.
Zaměříme se na několik příkladů zpracování dat, místo abychom vám poskytli kompletní přehled všech souvisejících knihoven. To vám umožní získat základní představu o tom, co je možné, a zanechá vás s pochopením, kde najít řešení vašich problémů, když je budete potřebovat.
Nejužitečnější rada. Když potřebujete provést určitou operaci na datech, kterou nevíte, jak udělat, zkuste ji vyhledat na internetu. Stackoverflow obvykle obsahuje mnoho užitečných ukázek kódu v Pythonu pro mnoho typických úkolů.
Kvíz před lekcí
Tabulková data a DataFrame
S tabulkovými daty jste se již setkali, když jsme mluvili o relačních databázích. Když máte hodně dat, která jsou obsažena v mnoha různých propojených tabulkách, rozhodně má smysl použít SQL pro práci s nimi. Nicméně existuje mnoho případů, kdy máme tabulku dat a potřebujeme získat nějaké pochopení nebo poznatky o těchto datech, jako je rozložení, korelace mezi hodnotami atd. V datové vědě existuje mnoho situací, kdy potřebujeme provést nějaké transformace původních dat, následované vizualizací. Oba tyto kroky lze snadno provést pomocí Pythonu.
Existují dvě nejdůležitější knihovny v Pythonu, které vám mohou pomoci pracovat s tabulkovými daty:
- Pandas umožňuje manipulovat s tzv. DataFrame, což jsou analogie relačních tabulek. Můžete mít pojmenované sloupce a provádět různé operace na řádcích, sloupcích a DataFrame obecně.
- Numpy je knihovna pro práci s tensory, tj. vícerozměrnými poli. Pole má hodnoty stejného základního typu a je jednodušší než DataFrame, ale nabízí více matematických operací a vytváří menší režii.
Existují také další knihovny, které byste měli znát:
- Matplotlib je knihovna používaná pro vizualizaci dat a vykreslování grafů
- SciPy je knihovna s některými dalšími vědeckými funkcemi. Již jsme se s touto knihovnou setkali, když jsme mluvili o pravděpodobnosti a statistice
Zde je kousek kódu, který byste obvykle použili k importování těchto knihoven na začátku vašeho programu v Pythonu:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import ... # you need to specify exact sub-packages that you need
Pandas se soustředí na několik základních konceptů.
Series
Series je sekvence hodnot, podobná seznamu nebo numpy poli. Hlavní rozdíl je v tom, že Series má také index, a když s nimi pracujeme (např. je sčítáme), index se bere v úvahu. Index může být tak jednoduchý jako číslo řádku (to je výchozí index při vytváření Series ze seznamu nebo pole), nebo může mít složitou strukturu, jako je časový interval.
Poznámka: V doprovodném notebooku
notebook.ipynbje úvodní kód pro Pandas. Zde uvádíme pouze některé příklady, ale určitě se podívejte na celý notebook.
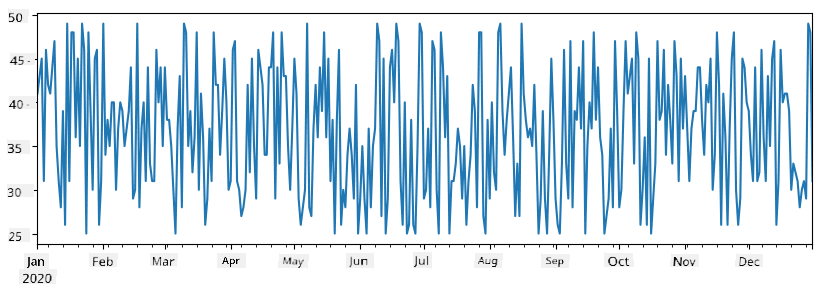
Představme si příklad: chceme analyzovat prodeje našeho stánku se zmrzlinou. Vygenerujeme sérii čísel prodejů (počet prodaných položek každý den) za určité časové období:
start_date = "Jan 1, 2020"
end_date = "Mar 31, 2020"
idx = pd.date_range(start_date,end_date)
print(f"Length of index is {len(idx)}")
items_sold = pd.Series(np.random.randint(25,50,size=len(idx)),index=idx)
items_sold.plot()
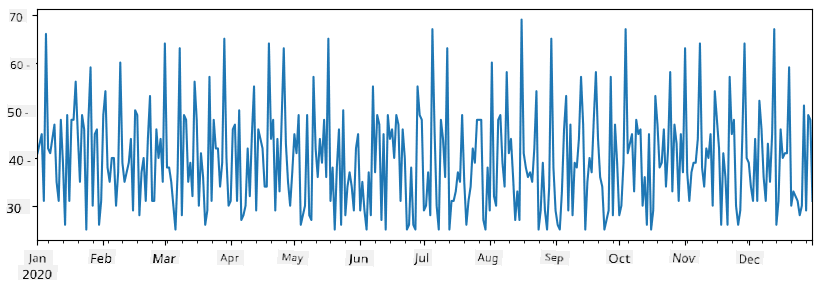
Předpokládejme, že každý týden pořádáme večírek pro přátele a bereme dalších 10 balení zmrzliny na večírek. Můžeme vytvořit další sérii, indexovanou podle týdne, abychom to ukázali:
additional_items = pd.Series(10,index=pd.date_range(start_date,end_date,freq="W"))
Když sečteme dvě série dohromady, získáme celkový počet:
total_items = items_sold.add(additional_items,fill_value=0)
total_items.plot()
Poznámka: Nepoužíváme jednoduchou syntaxi
total_items+additional_items. Pokud bychom to udělali, dostali bychom mnoho hodnotNaN(Not a Number) v výsledné sérii. To je proto, že v sériiadditional_itemschybí hodnoty pro některé indexové body, a přičteníNaNk čemukoli vede kNaN. Proto musíme při sčítání specifikovat parametrfill_value.
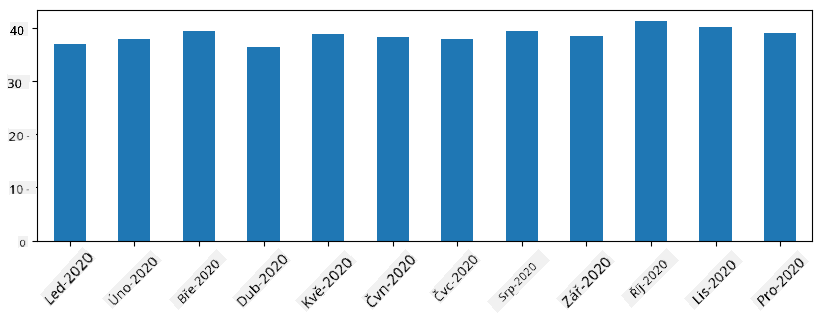
U časových řad můžeme také převzorkovat sérii na různé časové intervaly. Například pokud chceme vypočítat průměrný objem prodeje měsíčně, můžeme použít následující kód:
monthly = total_items.resample("1M").mean()
ax = monthly.plot(kind='bar')
DataFrame
DataFrame je v podstatě kolekce sérií se stejným indexem. Můžeme spojit několik sérií dohromady do DataFrame:
a = pd.Series(range(1,10))
b = pd.Series(["I","like","to","play","games","and","will","not","change"],index=range(0,9))
df = pd.DataFrame([a,b])
To vytvoří horizontální tabulku jako tuto:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 1 | I | like | to | use | Python | and | Pandas | very | much |
Můžeme také použít Series jako sloupce a specifikovat názvy sloupců pomocí slovníku:
df = pd.DataFrame({ 'A' : a, 'B' : b })
To nám dá tabulku jako tuto:
| A | B | |
|---|---|---|
| 0 | 1 | I |
| 1 | 2 | like |
| 2 | 3 | to |
| 3 | 4 | use |
| 4 | 5 | Python |
| 5 | 6 | and |
| 6 | 7 | Pandas |
| 7 | 8 | very |
| 8 | 9 | much |
Poznámka: Tuto tabulku můžeme také získat transpozicí předchozí tabulky, např. napsáním
df = pd.DataFrame([a,b]).T..rename(columns={ 0 : 'A', 1 : 'B' })
Zde .T znamená operaci transpozice DataFrame, tj. změnu řádků a sloupců, a operace rename nám umožňuje přejmenovat sloupce tak, aby odpovídaly předchozímu příkladu.
Zde je několik nejdůležitějších operací, které můžeme provádět na DataFrame:
Výběr sloupců. Můžeme vybrat jednotlivé sloupce napsáním df['A'] - tato operace vrací Series. Můžeme také vybrat podmnožinu sloupců do jiného DataFrame napsáním df[['B','A']] - to vrací další DataFrame.
Filtrování pouze určitých řádků podle kritérií. Například, abychom ponechali pouze řádky, kde je sloupec A větší než 5, můžeme napsat df[df['A']>5].
Poznámka: Způsob, jakým filtrování funguje, je následující. Výraz
df['A']<5vrací booleovskou sérii, která označuje, zda je výrazTrueneboFalsepro každý prvek původní sériedf['A']. Když je booleovská série použita jako index, vrací podmnožinu řádků v DataFrame. Proto není možné použít libovolný booleovský výraz v Pythonu, například napsánídf[df['A']>5 and df['A']<7]by bylo špatné. Místo toho byste měli použít speciální operaci&na booleovské sérii, napsánímdf[(df['A']>5) & (df['A']<7)](závorky jsou zde důležité).
Vytváření nových vypočítatelných sloupců. Můžeme snadno vytvořit nové vypočítatelné sloupce pro náš DataFrame pomocí intuitivního výrazu jako tento:
df['DivA'] = df['A']-df['A'].mean()
Tento příklad vypočítává odchylku A od její průměrné hodnoty. Co se zde vlastně děje, je to, že vypočítáváme sérii a poté tuto sérii přiřazujeme na levou stranu, čímž vytváříme další sloupec. Proto nemůžeme použít žádné operace, které nejsou kompatibilní se sériemi, například následující kód je špatný:
# Wrong code -> df['ADescr'] = "Low" if df['A'] < 5 else "Hi"
df['LenB'] = len(df['B']) # <- Wrong result
Poslední příklad, i když je syntakticky správný, nám dává špatný výsledek, protože přiřazuje délku série B ke všem hodnotám ve sloupci, a ne délku jednotlivých prvků, jak jsme zamýšleli.
Pokud potřebujeme vypočítat složité výrazy jako tento, můžeme použít funkci apply. Poslední příklad lze napsat následovně:
df['LenB'] = df['B'].apply(lambda x : len(x))
# or
df['LenB'] = df['B'].apply(len)
Po výše uvedených operacích skončíme s následujícím DataFrame:
| A | B | DivA | LenB | |
|---|---|---|---|---|
| 0 | 1 | I | -4.0 | 1 |
| 1 | 2 | like | -3.0 | 4 |
| 2 | 3 | to | -2.0 | 2 |
| 3 | 4 | use | -1.0 | 3 |
| 4 | 5 | Python | 0.0 | 6 |
| 5 | 6 | and | 1.0 | 3 |
| 6 | 7 | Pandas | 2.0 | 6 |
| 7 | 8 | very | 3.0 | 4 |
| 8 | 9 | much | 4.0 | 4 |
Výběr řádků podle čísel lze provést pomocí konstruktu iloc. Například, abychom vybrali prvních 5 řádků z DataFrame:
df.iloc[:5]
Seskupování se často používá k získání výsledku podobného kontingenčním tabulkám v Excelu. Předpokládejme, že chceme vypočítat průměrnou hodnotu sloupce A pro každé dané číslo LenB. Poté můžeme seskupit náš DataFrame podle LenB a zavolat mean:
df.groupby(by='LenB').mean()
Pokud potřebujeme vypočítat průměr a počet prvků ve skupině, můžeme použít složitější funkci aggregate:
df.groupby(by='LenB') \
.aggregate({ 'DivA' : len, 'A' : lambda x: x.mean() }) \
.rename(columns={ 'DivA' : 'Count', 'A' : 'Mean'})
To nám dá následující tabulku:
| LenB | Count | Mean |
|---|---|---|
| 1 | 1 | 1.000000 |
| 2 | 1 | 3.000000 |
| 3 | 2 | 5.000000 |
| 4 | 3 | 6.333333 |
| 6 | 2 | 6.000000 |
Získávání dat
Viděli jsme, jak snadné je vytvořit Series a DataFrames z objektů v Pythonu. Data však obvykle přicházejí ve formě textového souboru nebo tabulky v Excelu. Naštěstí nám Pandas nabízí jednoduchý způsob, jak načíst data z disku. Například čtení souboru CSV je tak jednoduché jako toto:
df = pd.read_csv('file.csv')
V sekci "Výzva" uvidíme více příkladů načítání dat, včetně jejich získávání z externích webových stránek.
Tisk a vizualizace
Datový vědec často potřebuje prozkoumat data, a proto je důležité umět je vizualizovat. Když je DataFrame velký, často chceme jen ověřit, že vše děláme správně, tím, že si vytiskneme prvních pár řádků. To lze provést voláním df.head(). Pokud to spustíte v Jupyter Notebooku, vytiskne se DataFrame v pěkné tabulkové podobě.
Také jsme viděli použití funkce plot pro vizualizaci některých sloupců. Zatímco plot je velmi užitečný pro mnoho úkolů a podporuje různé typy grafů prostřednictvím parametru kind=, vždy můžete použít knihovnu matplotlib pro vykreslení něčeho složitějšího. Vizualizaci dat se budeme podrobně věnovat v samostatných lekcích kurzu.
Tento přehled pokrývá nejdůležitější koncepty Pandas, avšak knihovna je velmi bohatá a neexistují žádné limity, co s ní můžete dělat! Pojďme nyní aplikovat tyto znalosti na řešení konkrétního problému.
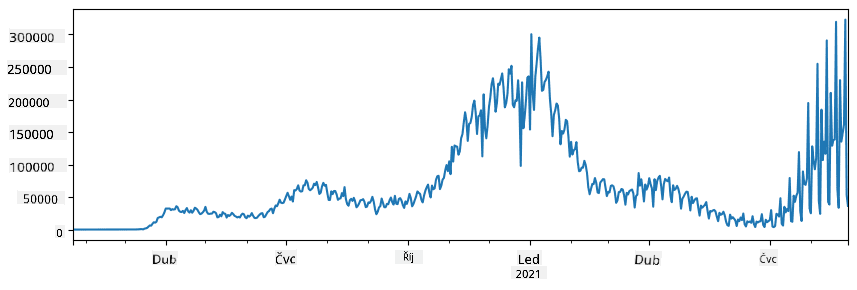
🚀 Výzva 1: Analýza šíření COVID
Prvním problémem, na který se zaměříme, je modelování epidemického šíření COVID-19. K tomu použijeme data o počtu nakažených osob v různých zemích, která poskytuje Center for Systems Science and Engineering (CSSE) na Johns Hopkins University. Dataset je dostupný v tomto GitHub repozitáři.
Protože chceme ukázat, jak pracovat s daty, zveme vás k otevření souboru notebook-covidspread.ipynb a jeho přečtení od začátku do konce. Můžete také spouštět buňky a vyzkoušet si některé výzvy, které jsme pro vás připravili na konci.
Pokud nevíte, jak spustit kód v Jupyter Notebooku, podívejte se na tento článek.
Práce s nestrukturovanými daty
I když data často přicházejí v tabulkové podobě, v některých případech musíme pracovat s méně strukturovanými daty, například textem nebo obrázky. V takovém případě, abychom mohli použít techniky zpracování dat, které jsme viděli výše, musíme nějakým způsobem extrahovat strukturovaná data. Zde je několik příkladů:
- Extrakce klíčových slov z textu a sledování, jak často se tato klíčová slova objevují
- Použití neuronových sítí k extrakci informací o objektech na obrázku
- Získávání informací o emocích lidí na videozáznamu
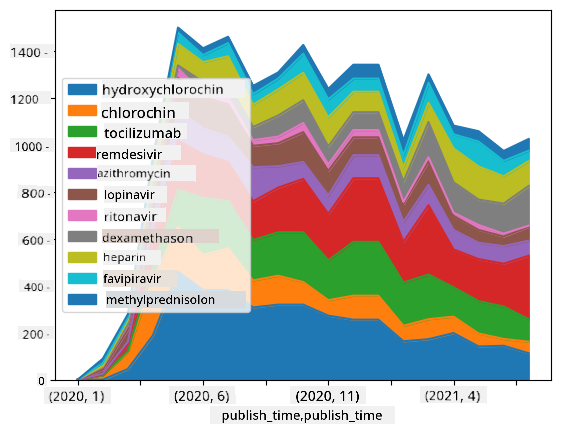
🚀 Výzva 2: Analýza COVID publikací
V této výzvě budeme pokračovat v tématu pandemie COVID a zaměříme se na zpracování vědeckých publikací na toto téma. Existuje CORD-19 Dataset s více než 7000 (v době psaní) publikacemi o COVID, dostupný s metadaty a abstrakty (a u přibližně poloviny z nich je k dispozici i celý text).
Kompletní příklad analýzy tohoto datasetu pomocí kognitivní služby Text Analytics for Health je popsán v tomto blogovém příspěvku. Probereme zjednodušenou verzi této analýzy.
NOTE: Kopii datasetu neposkytujeme jako součást tohoto repozitáře. Nejprve si možná budete muset stáhnout soubor
metadata.csvz tohoto datasetu na Kaggle. Může být vyžadována registrace na Kaggle. Dataset si také můžete stáhnout bez registrace zde, ale bude zahrnovat všechny plné texty kromě souboru s metadaty.
Otevřete soubor notebook-papers.ipynb a přečtěte si jej od začátku do konce. Můžete také spouštět buňky a vyzkoušet si některé výzvy, které jsme pro vás připravili na konci.
Zpracování obrazových dat
V poslední době byly vyvinuty velmi výkonné AI modely, které nám umožňují porozumět obrázkům. Existuje mnoho úkolů, které lze řešit pomocí předtrénovaných neuronových sítí nebo cloudových služeb. Některé příklady zahrnují:
- Klasifikace obrázků, která vám může pomoci zařadit obrázek do jedné z předdefinovaných kategorií. Svůj vlastní klasifikátor obrázků můžete snadno natrénovat pomocí služeb, jako je Custom Vision.
- Detekce objektů pro identifikaci různých objektů na obrázku. Služby jako computer vision dokážou detekovat řadu běžných objektů a můžete natrénovat model Custom Vision pro detekci specifických objektů.
- Detekce obličejů, včetně věku, pohlaví a emocí. To lze provést pomocí Face API.
Všechny tyto cloudové služby lze volat pomocí Python SDKs, a tak je snadno začlenit do vašeho workflow pro zkoumání dat.
Zde jsou některé příklady zkoumání dat z obrazových zdrojů:
- V blogovém příspěvku Jak se naučit datovou vědu bez programování zkoumáme fotografie z Instagramu a snažíme se pochopit, co způsobuje, že lidé dávají více lajků na fotografii. Nejprve extrahujeme co nejvíce informací z obrázků pomocí computer vision a poté použijeme Azure Machine Learning AutoML k vytvoření interpretovatelného modelu.
- V Workshopu o studiu obličejů používáme Face API k extrakci emocí lidí na fotografiích z událostí, abychom se pokusili pochopit, co lidi činí šťastnými.
Závěr
Ať už máte strukturovaná nebo nestrukturovaná data, pomocí Pythonu můžete provádět všechny kroky související se zpracováním a porozuměním dat. Je to pravděpodobně nejflexibilnější způsob zpracování dat, a proto většina datových vědců používá Python jako svůj hlavní nástroj. Naučit se Python do hloubky je pravděpodobně dobrý nápad, pokud to s cestou datové vědy myslíte vážně!
Kvíz po přednášce
Recenze a samostudium
Knihy
Online zdroje
- Oficiální 10 minut do Pandas tutoriál
- Dokumentace k vizualizaci v Pandas
Učení Pythonu
- Naučte se Python zábavnou formou s Turtle Graphics a fraktály
- Uděláte své první kroky s Pythonem na Microsoft Learn
Zadání
Proveďte podrobnější studii dat pro výzvy výše
Poděkování
Tuto lekci vytvořil s ♥️ Dmitry Soshnikov
Prohlášení:
Tento dokument byl přeložen pomocí služby pro automatický překlad Co-op Translator. Ačkoli se snažíme o přesnost, mějte prosím na paměti, že automatické překlady mohou obsahovat chyby nebo nepřesnosti. Původní dokument v jeho původním jazyce by měl být považován za autoritativní zdroj. Pro důležité informace doporučujeme profesionální lidský překlad. Neodpovídáme za žádná nedorozumění nebo nesprávné interpretace vyplývající z použití tohoto překladu.