22 KiB
ডেটা সায়েন্স লাইফসাইকেলের পরিচিতি
 |
|---|
| ডেটা সায়েন্স লাইফসাইকেলের পরিচিতি - @nitya দ্বারা স্কেচনোট |
পূর্ব-লেকচার কুইজ
এ পর্যায়ে আপনি সম্ভবত বুঝতে পেরেছেন যে ডেটা সায়েন্স একটি প্রক্রিয়া। এই প্রক্রিয়াটি ৫টি ধাপে ভাগ করা যায়:
- ডেটা সংগ্রহ
- প্রক্রিয়াকরণ
- বিশ্লেষণ
- যোগাযোগ
- রক্ষণাবেক্ষণ
এই পাঠটি লাইফসাইকেলের ৩টি অংশের উপর আলোকপাত করে: ডেটা সংগ্রহ, প্রক্রিয়াকরণ এবং রক্ষণাবেক্ষণ।
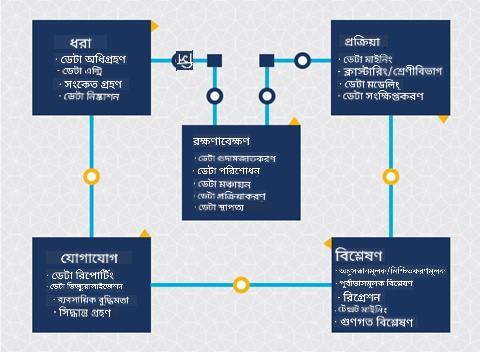
ছবি Berkeley School of Information দ্বারা
ডেটা সংগ্রহ
লাইফসাইকেলের প্রথম ধাপটি অত্যন্ত গুরুত্বপূর্ণ কারণ পরবর্তী ধাপগুলো এর উপর নির্ভরশীল। এটি মূলত দুটি ধাপকে একত্রিত করে: ডেটা সংগ্রহ এবং প্রকল্পের উদ্দেশ্য ও সমস্যাগুলো সংজ্ঞায়িত করা।
প্রকল্পের লক্ষ্য সংজ্ঞায়িত করতে সমস্যার বা প্রশ্নের গভীর প্রেক্ষাপটের প্রয়োজন হবে। প্রথমে, আমাদের তাদের চিহ্নিত করতে হবে এবং তাদের সাথে যোগাযোগ করতে হবে যাদের সমস্যার সমাধান প্রয়োজন। এরা হতে পারে ব্যবসার স্টেকহোল্ডার বা প্রকল্পের স্পনসর, যারা প্রকল্পটি থেকে উপকৃত হবে এবং কেন এটি প্রয়োজন তা চিহ্নিত করতে সাহায্য করতে পারে। একটি ভালোভাবে সংজ্ঞায়িত লক্ষ্য পরিমাপযোগ্য এবং পরিমাণগত হওয়া উচিত যাতে একটি গ্রহণযোগ্য ফলাফল নির্ধারণ করা যায়।
একজন ডেটা সায়েন্টিস্ট যে প্রশ্নগুলো করতে পারেন:
- এই সমস্যাটি আগে সমাধানের চেষ্টা করা হয়েছে কি? কী আবিষ্কৃত হয়েছে?
- উদ্দেশ্য এবং লক্ষ্য কি সংশ্লিষ্ট সকলের দ্বারা বোঝা যাচ্ছে?
- কোন অস্পষ্টতা আছে এবং কীভাবে তা কমানো যায়?
- সীমাবদ্ধতাগুলো কী?
- সম্ভাব্য চূড়ান্ত ফলাফল কেমন হতে পারে?
- কতটুকু সম্পদ (সময়, জনবল, কম্পিউটেশনাল) উপলব্ধ?
পরবর্তী ধাপটি হলো ডেটা চিহ্নিত করা, সংগ্রহ করা এবং তারপর প্রকল্পের সংজ্ঞায়িত লক্ষ্য অর্জনের জন্য ডেটা অন্বেষণ করা। এই সংগ্রহের ধাপে, ডেটা সায়েন্টিস্টদের ডেটার পরিমাণ এবং গুণমান মূল্যায়ন করতে হবে। এটি নিশ্চিত করতে কিছু ডেটা অন্বেষণ প্রয়োজন যে যা সংগ্রহ করা হয়েছে তা কাঙ্ক্ষিত ফলাফল অর্জনে সহায়ক হবে।
ডেটা সম্পর্কে একজন ডেটা সায়েন্টিস্ট যে প্রশ্নগুলো করতে পারেন:
- আমার কাছে ইতিমধ্যে কী ডেটা উপলব্ধ?
- এই ডেটার মালিক কে?
- গোপনীয়তার উদ্বেগগুলো কী?
- এই সমস্যার সমাধানের জন্য আমার কাছে যথেষ্ট ডেটা আছে কি?
- এই সমস্যার জন্য ডেটার গুণমান গ্রহণযোগ্য কি?
- যদি আমি এই ডেটার মাধ্যমে অতিরিক্ত তথ্য আবিষ্কার করি, তাহলে কি আমাদের লক্ষ্য পরিবর্তন বা পুনঃসংজ্ঞায়িত করা উচিত?
প্রক্রিয়াকরণ
লাইফসাইকেলের প্রক্রিয়াকরণ ধাপটি ডেটায় প্যাটার্ন আবিষ্কার এবং মডেলিংয়ের উপর আলোকপাত করে। প্রক্রিয়াকরণ ধাপে ব্যবহৃত কিছু কৌশল পরিসংখ্যান পদ্ধতির প্রয়োজন হয় প্যাটার্নগুলো উন্মোচন করতে। সাধারণত, এটি একটি বড় ডেটাসেটের ক্ষেত্রে মানুষের জন্য একটি ক্লান্তিকর কাজ হবে এবং প্রক্রিয়াটি দ্রুত করার জন্য কম্পিউটারের উপর নির্ভর করতে হবে। এই ধাপটি ডেটা সায়েন্স এবং মেশিন লার্নিংয়ের সংযোগস্থলও। প্রথম পাঠে আপনি শিখেছেন, মেশিন লার্নিং হলো ডেটা বোঝার জন্য মডেল তৈরি করার প্রক্রিয়া। মডেল হলো ডেটার ভেরিয়েবলগুলোর মধ্যে সম্পর্কের একটি উপস্থাপনা যা ফলাফল পূর্বাভাসে সাহায্য করে।
এই ধাপে ব্যবহৃত সাধারণ কৌশলগুলো ML for Beginners কারিকুলামে অন্তর্ভুক্ত করা হয়েছে। আরও জানতে লিঙ্কগুলো অনুসরণ করুন:
- Classification: ডেটাকে ক্যাটাগরিতে সংগঠিত করা যাতে এটি আরও দক্ষতার সাথে ব্যবহার করা যায়।
- Clustering: ডেটাকে একই ধরনের গ্রুপে ভাগ করা।
- Regression: ভেরিয়েবলগুলোর মধ্যে সম্পর্ক নির্ধারণ করে মান পূর্বাভাস বা পূর্বাভাস দেওয়া।
রক্ষণাবেক্ষণ
লাইফসাইকেলের চিত্রে আপনি লক্ষ্য করতে পারেন যে রক্ষণাবেক্ষণ ডেটা সংগ্রহ এবং প্রক্রিয়াকরণের মধ্যে অবস্থান করছে। রক্ষণাবেক্ষণ হলো একটি চলমান প্রক্রিয়া যা প্রকল্পের সময় ডেটা পরিচালনা, সংরক্ষণ এবং সুরক্ষিত করার উপর আলোকপাত করে এবং এটি প্রকল্পের পুরো সময়কাল জুড়ে বিবেচনা করা উচিত।
ডেটা সংরক্ষণ
ডেটা কীভাবে এবং কোথায় সংরক্ষণ করা হবে তা এর সংরক্ষণের খরচ এবং ডেটা কত দ্রুত অ্যাক্সেস করা যাবে তার উপর প্রভাব ফেলতে পারে। এই ধরনের সিদ্ধান্ত সাধারণত শুধুমাত্র একজন ডেটা সায়েন্টিস্ট দ্বারা নেওয়া হয় না, তবে তারা ডেটা কীভাবে সংরক্ষণ করা হয়েছে তার উপর ভিত্তি করে কাজ করার পছন্দ করতে পারেন।
আধুনিক ডেটা সংরক্ষণ ব্যবস্থার কিছু দিক যা এই পছন্দগুলোকে প্রভাবিত করতে পারে:
অন-প্রিমাইজ বনাম অফ-প্রিমাইজ বনাম পাবলিক বা প্রাইভেট ক্লাউড
অন-প্রিমাইজ বলতে বোঝায় নিজের সরঞ্জামে ডেটা হোস্টিং এবং পরিচালনা করা, যেমন একটি সার্ভার থাকা যেখানে হার্ড ড্রাইভে ডেটা সংরক্ষণ করা হয়। অন্যদিকে, অফ-প্রিমাইজ এমন সরঞ্জামের উপর নির্ভর করে যা আপনি মালিকানাধীন নন, যেমন একটি ডেটা সেন্টার। পাবলিক ক্লাউড হলো ডেটা সংরক্ষণের একটি জনপ্রিয় পছন্দ যা কীভাবে বা কোথায় ডেটা সংরক্ষণ করা হয়েছে তার কোনো জ্ঞান প্রয়োজন হয় না। পাবলিক বলতে বোঝায় একটি অভিন্ন অন্তর্নিহিত অবকাঠামো যা ক্লাউড ব্যবহারকারী সকলের দ্বারা ভাগ করা হয়। কিছু সংস্থার কঠোর নিরাপত্তা নীতি রয়েছে যা তাদের ডেটা হোস্ট করা সরঞ্জামে সম্পূর্ণ অ্যাক্সেস প্রয়োজন এবং তারা একটি প্রাইভেট ক্লাউড ব্যবহার করবে যা নিজস্ব ক্লাউড পরিষেবা প্রদান করে। আপনি পরবর্তী পাঠে ক্লাউডে ডেটা সম্পর্কে আরও শিখবেন।
কোল্ড বনাম হট ডেটা
আপনার মডেল প্রশিক্ষণ করার সময়, আপনার আরও প্রশিক্ষণ ডেটার প্রয়োজন হতে পারে। যদি আপনি আপনার মডেল নিয়ে সন্তুষ্ট হন, আরও ডেটা আসবে যাতে মডেল তার উদ্দেশ্য পূরণ করতে পারে। যেকোনো ক্ষেত্রে, ডেটা সংরক্ষণ এবং অ্যাক্সেস করার খরচ বাড়বে যত বেশি ডেটা জমা হবে। কম ব্যবহৃত ডেটা, যা কোল্ড ডেটা নামে পরিচিত, এবং ঘন ঘন অ্যাক্সেস করা হট ডেটা আলাদা করা একটি সস্তা ডেটা সংরক্ষণ বিকল্প হতে পারে হার্ডওয়্যার বা সফটওয়্যার পরিষেবার মাধ্যমে। যদি কোল্ড ডেটা অ্যাক্সেস করতে হয়, তাহলে এটি হট ডেটার তুলনায় একটু বেশি সময় নিতে পারে।
ডেটা পরিচালনা
ডেটা নিয়ে কাজ করার সময় আপনি আবিষ্কার করতে পারেন যে কিছু ডেটা পরিষ্কার করার প্রয়োজন রয়েছে, যা ডেটা প্রস্তুতি পাঠে আলোচনা করা কৌশলগুলো ব্যবহার করে সঠিক মডেল তৈরি করতে সাহায্য করে। নতুন ডেটা এলে, এটি একই ধরনের অ্যাপ্লিকেশন প্রয়োজন হবে যাতে গুণমানের ধারাবাহিকতা বজায় থাকে। কিছু প্রকল্পে একটি স্বয়ংক্রিয় টুল ব্যবহার করা হবে যা ডেটা পরিষ্কার, একত্রিত এবং সংকুচিত করে চূড়ান্ত অবস্থানে সরানোর আগে। Azure Data Factory এমন একটি টুলের উদাহরণ।
ডেটা সুরক্ষা
ডেটা সুরক্ষার প্রধান লক্ষ্যগুলোর একটি হলো নিশ্চিত করা যে যারা এটি নিয়ে কাজ করছে তারা কী সংগ্রহ করা হচ্ছে এবং এটি কী প্রসঙ্গে ব্যবহার করা হচ্ছে তার উপর নিয়ন্ত্রণে রয়েছে। ডেটা সুরক্ষিত রাখা মানে শুধুমাত্র তাদের অ্যাক্সেস সীমিত করা যারা এটি প্রয়োজন, স্থানীয় আইন এবং নিয়ম মেনে চলা, এবং নৈতিক মান বজায় রাখা, যা নৈতিকতা পাঠে আলোচনা করা হয়েছে।
নিরাপত্তার কথা মাথায় রেখে একটি দল যা করতে পারে:
- নিশ্চিত করা যে সমস্ত ডেটা এনক্রিপ্ট করা হয়েছে
- গ্রাহকদের তাদের ডেটা কীভাবে ব্যবহার করা হচ্ছে সে সম্পর্কে তথ্য প্রদান করা
- প্রকল্প ছেড়ে যাওয়া ব্যক্তিদের ডেটা অ্যাক্সেস সরিয়ে ফেলা
- শুধুমাত্র নির্দিষ্ট প্রকল্প সদস্যদের ডেটা পরিবর্তন করার অনুমতি দেওয়া
🚀 চ্যালেঞ্জ
ডেটা সায়েন্স লাইফসাইকেলের অনেক সংস্করণ রয়েছে, যেখানে প্রতিটি ধাপের বিভিন্ন নাম এবং ধাপের সংখ্যা থাকতে পারে তবে এই পাঠে উল্লেখিত একই প্রক্রিয়াগুলো অন্তর্ভুক্ত থাকবে।
টিম ডেটা সায়েন্স প্রক্রিয়া লাইফসাইকেল এবং ক্রস-ইন্ডাস্ট্রি স্ট্যান্ডার্ড প্রক্রিয়া ফর ডেটা মাইনিং অন্বেষণ করুন। এই দুটি প্রক্রিয়ার মধ্যে ৩টি মিল এবং পার্থক্য উল্লেখ করুন।
| টিম ডেটা সায়েন্স প্রক্রিয়া (TDSP) | ক্রস-ইন্ডাস্ট্রি স্ট্যান্ডার্ড প্রক্রিয়া ফর ডেটা মাইনিং (CRISP-DM) |
|---|---|
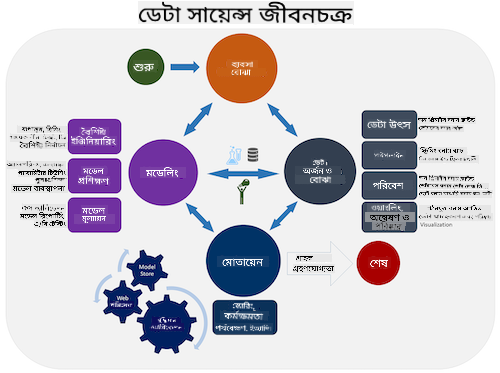 |
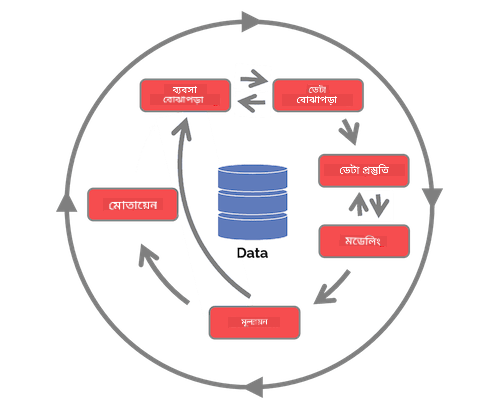 |
| ছবি Microsoft দ্বারা | ছবি Data Science Process Alliance দ্বারা |
পোস্ট-লেকচার কুইজ
পর্যালোচনা ও স্ব-অধ্যয়ন
ডেটা সায়েন্স লাইফসাইকেল প্রয়োগে একাধিক ভূমিকা এবং কাজ জড়িত থাকে, যেখানে কিছু নির্দিষ্ট ধাপের উপর আলোকপাত করে। টিম ডেটা সায়েন্স প্রক্রিয়া কিছু সংস্থান প্রদান করে যা ব্যাখ্যা করে যে কেউ প্রকল্পে কী ধরনের ভূমিকা এবং কাজ করতে পারে।
- টিম ডেটা সায়েন্স প্রক্রিয়ার ভূমিকা এবং কাজ
- ডেটা সায়েন্স কাজ সম্পাদন: অন্বেষণ, মডেলিং এবং ডিপ্লয়মেন্ট
অ্যাসাইনমেন্ট
অস্বীকৃতি:
এই নথিটি AI অনুবাদ পরিষেবা Co-op Translator ব্যবহার করে অনুবাদ করা হয়েছে। আমরা যথাসম্ভব সঠিক অনুবাদের চেষ্টা করি, তবে অনুগ্রহ করে মনে রাখবেন যে স্বয়ংক্রিয় অনুবাদে ত্রুটি বা অসঙ্গতি থাকতে পারে। নথিটির মূল ভাষায় রচিত সংস্করণটিকেই প্রামাণিক উৎস হিসেবে বিবেচনা করা উচিত। গুরুত্বপূর্ণ তথ্যের জন্য, পেশাদার মানব অনুবাদ ব্যবহার করার পরামর্শ দেওয়া হয়। এই অনুবাদ ব্যবহারের ফলে সৃষ্ট কোনো ভুল বোঝাবুঝি বা ভুল ব্যাখ্যার জন্য আমরা দায়ী নই।