36 KiB
علم البيانات في السحابة: الطريقة "قليلة الكود/بدون كود"
 |
|---|
| علم البيانات في السحابة: قليلة الكود - رسم توضيحي بواسطة @nitya |
جدول المحتويات:
- علم البيانات في السحابة: الطريقة "قليلة الكود/بدون كود"
اختبار ما قبل المحاضرة
1. المقدمة
1.1 ما هو Azure Machine Learning؟
منصة السحابة Azure تحتوي على أكثر من 200 منتج وخدمة سحابية مصممة لمساعدتك في إحياء حلول جديدة. يبذل علماء البيانات جهودًا كبيرة لاستكشاف البيانات ومعالجتها مسبقًا وتجربة أنواع مختلفة من خوارزميات تدريب النماذج لإنتاج نماذج دقيقة. هذه المهام تستغرق وقتًا طويلاً وغالبًا ما تؤدي إلى استخدام غير فعال لموارد الحوسبة المكلفة.
Azure ML هي منصة قائمة على السحابة لبناء وتشغيل حلول التعلم الآلي في Azure. تتضمن مجموعة واسعة من الميزات والقدرات التي تساعد علماء البيانات في إعداد البيانات، تدريب النماذج، نشر خدمات التنبؤ، ومراقبة استخدامها. الأهم من ذلك، أنها تساعدهم على زيادة كفاءتهم من خلال أتمتة العديد من المهام التي تستغرق وقتًا طويلاً المرتبطة بتدريب النماذج؛ وتمكنهم من استخدام موارد الحوسبة القائمة على السحابة التي تتوسع بشكل فعال للتعامل مع كميات كبيرة من البيانات مع تكبد تكاليف فقط عند الاستخدام الفعلي.
يوفر Azure ML جميع الأدوات التي يحتاجها المطورون وعلماء البيانات لعمليات التعلم الآلي الخاصة بهم. وتشمل هذه الأدوات:
- Azure Machine Learning Studio: بوابة ويب في Azure Machine Learning توفر خيارات قليلة الكود وبدون كود لتدريب النماذج، نشرها، أتمتتها، تتبعها وإدارة الأصول. يتكامل الاستوديو مع Azure Machine Learning SDK لتجربة سلسة.
- Jupyter Notebooks: لتجربة واختبار نماذج التعلم الآلي بسرعة.
- Azure Machine Learning Designer: يسمح بسحب وإفلات الوحدات لبناء التجارب ثم نشر خطوط الأنابيب في بيئة قليلة الكود.
- واجهة المستخدم للتعلم الآلي التلقائي (AutoML): تقوم بأتمتة المهام التكرارية لتطوير نماذج التعلم الآلي، مما يسمح ببناء نماذج بكفاءة وإنتاجية عالية مع الحفاظ على جودة النموذج.
- تصنيف البيانات: أداة تعلم آلي مساعدة لتصنيف البيانات تلقائيًا.
- امتداد التعلم الآلي لـ Visual Studio Code: يوفر بيئة تطوير كاملة لبناء وإدارة مشاريع التعلم الآلي.
- واجهة الأوامر للتعلم الآلي: توفر أوامر لإدارة موارد Azure ML من خلال سطر الأوامر.
- التكامل مع الأطر مفتوحة المصدر مثل PyTorch، TensorFlow، Scikit-learn وغيرها لتدريب، نشر، وإدارة عملية التعلم الآلي من البداية إلى النهاية.
- MLflow: مكتبة مفتوحة المصدر لإدارة دورة حياة تجارب التعلم الآلي. MLFlow Tracking هو مكون من MLflow يقوم بتسجيل وتتبع مقاييس تشغيل التدريب وقطع النموذج، بغض النظر عن بيئة التجربة.
1.2 مشروع التنبؤ بفشل القلب:
لا شك أن إنشاء وبناء المشاريع هو أفضل طريقة لاختبار مهاراتك ومعرفتك. في هذه الدرس، سنستكشف طريقتين مختلفتين لبناء مشروع علم بيانات للتنبؤ بنوبات فشل القلب في Azure ML Studio، من خلال الطريقة قليلة الكود/بدون كود ومن خلال Azure ML SDK كما هو موضح في المخطط التالي:
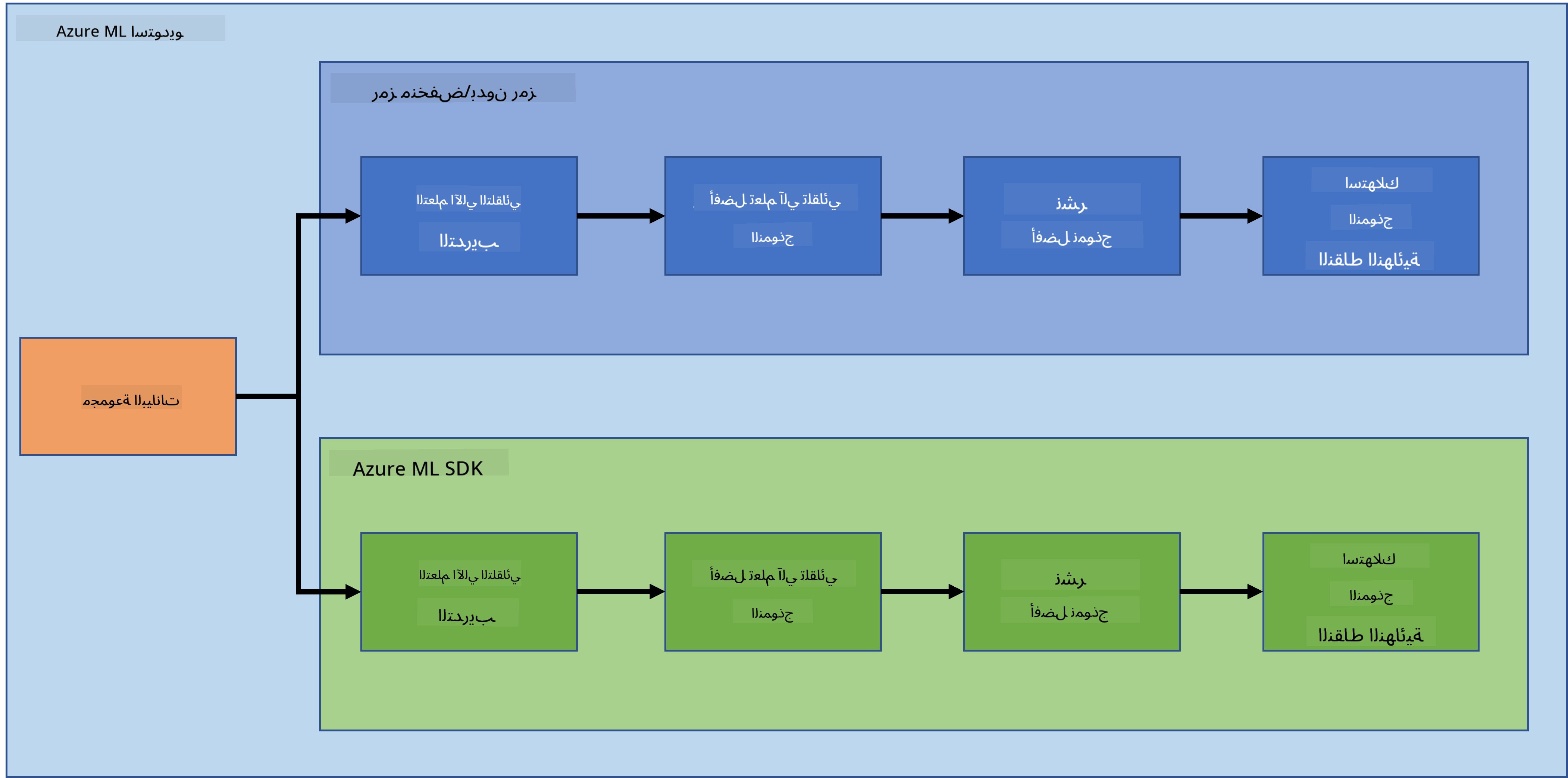
لكل طريقة مزايا وعيوب. الطريقة قليلة الكود/بدون كود أسهل للبدء بها لأنها تتضمن التفاعل مع واجهة مستخدم رسومية (GUI)، دون الحاجة إلى معرفة مسبقة بالكود. هذه الطريقة تمكن من اختبار سريع لجدوى المشروع وإنشاء إثبات المفهوم (POC). ومع ذلك، مع نمو المشروع واحتياج الأمور إلى أن تكون جاهزة للإنتاج، يصبح من غير الممكن إنشاء الموارد من خلال واجهة المستخدم الرسومية. نحتاج إلى أتمتة كل شيء برمجيًا، بدءًا من إنشاء الموارد إلى نشر النموذج. هنا تصبح معرفة كيفية استخدام Azure ML SDK أمرًا بالغ الأهمية.
| قليلة الكود/بدون كود | Azure ML SDK | |
|---|---|---|
| الخبرة في الكود | غير مطلوبة | مطلوبة |
| وقت التطوير | سريع وسهل | يعتمد على خبرة الكود |
| جاهزية الإنتاج | لا | نعم |
1.3 مجموعة بيانات فشل القلب:
تعد أمراض القلب والأوعية الدموية (CVDs) السبب الأول للوفاة عالميًا، حيث تمثل 31% من جميع الوفيات حول العالم. يمكن استخدام العوامل البيئية والسلوكية مثل استخدام التبغ، النظام الغذائي غير الصحي والسمنة، قلة النشاط البدني، والاستخدام الضار للكحول كميزات لنماذج التقدير. القدرة على تقدير احتمال تطور مرض القلب والأوعية الدموية يمكن أن تكون ذات فائدة كبيرة لمنع النوبات لدى الأشخاص المعرضين لخطر كبير.
قام موقع Kaggle بجعل مجموعة بيانات فشل القلب متاحة للجمهور، والتي سنستخدمها في هذا المشروع. يمكنك تنزيل مجموعة البيانات الآن. هذه مجموعة بيانات جدولة تحتوي على 13 عمودًا (12 ميزة و1 متغير الهدف) و299 صفًا.
| اسم المتغير | النوع | الوصف | المثال | |
|---|---|---|---|---|
| 1 | العمر | رقمي | عمر المريض | 25 |
| 2 | فقر الدم | منطقي | انخفاض خلايا الدم الحمراء أو الهيموجلوبين | 0 أو 1 |
| 3 | كرياتينين الفوسفوكايناز | رقمي | مستوى إنزيم CPK في الدم | 542 |
| 4 | السكري | منطقي | إذا كان المريض يعاني من السكري | 0 أو 1 |
| 5 | نسبة القذف | رقمي | نسبة الدم التي تغادر القلب في كل انقباض | 45 |
| 6 | ضغط الدم المرتفع | منطقي | إذا كان المريض يعاني من ارتفاع ضغط الدم | 0 أو 1 |
| 7 | الصفائح الدموية | رقمي | الصفائح الدموية في الدم | 149000 |
| 8 | كرياتينين المصل | رقمي | مستوى كرياتينين المصل في الدم | 0.5 |
| 9 | صوديوم المصل | رقمي | مستوى صوديوم المصل في الدم | jun |
| 10 | الجنس | منطقي | امرأة أو رجل | 0 أو 1 |
| 11 | التدخين | منطقي | إذا كان المريض يدخن | 0 أو 1 |
| 12 | الوقت | رقمي | فترة المتابعة (بالأيام) | 4 |
| ---- | --------------------------- | ----------------- | ----------------------------------------------------- | ------------------- |
| 21 | حدث الوفاة [الهدف] | منطقي | إذا توفي المريض خلال فترة المتابعة | 0 أو 1 |
بمجرد الحصول على مجموعة البيانات، يمكننا بدء المشروع في Azure.
2. تدريب نموذج بطريقة قليلة الكود/بدون كود في Azure ML Studio
2.1 إنشاء مساحة عمل Azure ML
لتدريب نموذج في Azure ML، تحتاج أولاً إلى إنشاء مساحة عمل Azure ML. مساحة العمل هي المورد الأعلى مستوى في Azure Machine Learning، وتوفر مكانًا مركزيًا للعمل مع جميع العناصر التي تنشئها عند استخدام Azure Machine Learning. تحتفظ مساحة العمل بسجل لجميع عمليات التدريب، بما في ذلك السجلات، المقاييس، النتائج، ولقطة من النصوص البرمجية الخاصة بك. يمكنك استخدام هذه المعلومات لتحديد أي عملية تدريب تنتج أفضل نموذج. تعرف على المزيد
يوصى باستخدام أحدث متصفح متوافق مع نظام التشغيل الخاص بك. المتصفحات التالية مدعومة:
- Microsoft Edge (الإصدار الجديد من Microsoft Edge، أحدث إصدار. ليس Microsoft Edge القديم)
- Safari (أحدث إصدار، فقط على Mac)
- Chrome (أحدث إصدار)
- Firefox (أحدث إصدار)
لاستخدام Azure Machine Learning، قم بإنشاء مساحة عمل في اشتراك Azure الخاص بك. يمكنك بعد ذلك استخدام هذه المساحة لإدارة البيانات، موارد الحوسبة، الكود، النماذج، وغيرها من العناصر المتعلقة بأعباء العمل الخاصة بالتعلم الآلي.
ملاحظة: سيتم خصم مبلغ صغير من اشتراك Azure الخاص بك لتخزين البيانات طالما أن مساحة عمل Azure Machine Learning موجودة في اشتراكك، لذلك نوصي بحذف مساحة عمل Azure Machine Learning عندما لا تكون بحاجة إليها.
-
قم بتسجيل الدخول إلى بوابة Azure باستخدام بيانات اعتماد Microsoft المرتبطة باشتراك Azure الخاص بك.
-
اختر +إنشاء مورد
ابحث عن التعلم الآلي واختر مربع التعلم الآلي
اضغط على زر الإنشاء
قم بملء الإعدادات كما يلي:
- الاشتراك: اشتراك Azure الخاص بك
- مجموعة الموارد: قم بإنشاء أو اختيار مجموعة موارد
- اسم مساحة العمل: أدخل اسمًا فريدًا لمساحة العمل الخاصة بك
- المنطقة: اختر المنطقة الجغرافية الأقرب إليك
- حساب التخزين: لاحظ الحساب الجديد الافتراضي للتخزين الذي سيتم إنشاؤه لمساحة العمل الخاصة بك
- المفتاح السري: لاحظ المفتاح السري الجديد الافتراضي الذي سيتم إنشاؤه لمساحة العمل الخاصة بك
- رؤى التطبيق: لاحظ مورد رؤى التطبيق الجديد الافتراضي الذي سيتم إنشاؤه لمساحة العمل الخاصة بك
- سجل الحاويات: لا شيء (سيتم إنشاؤه تلقائيًا في المرة الأولى التي تقوم فيها بنشر نموذج في حاوية)
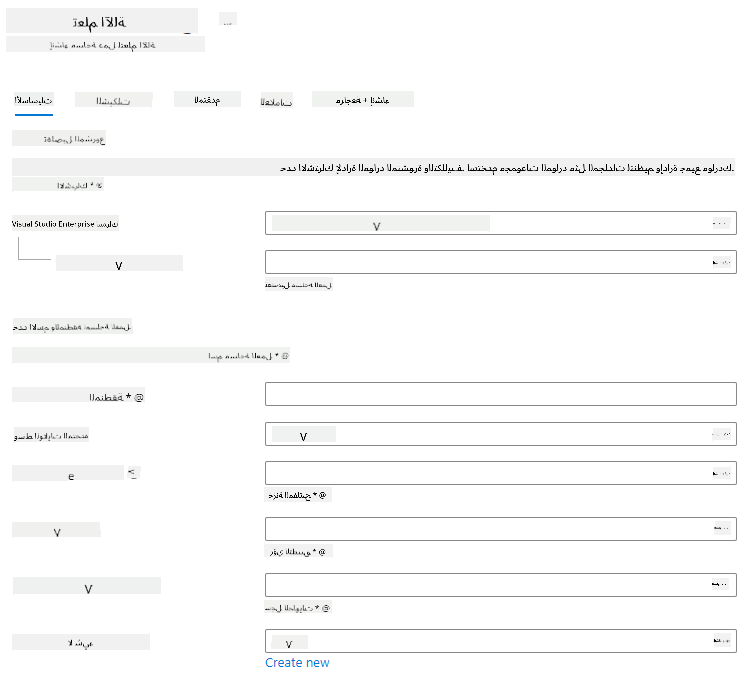
- اضغط على زر المراجعة + الإنشاء ثم على زر الإنشاء
-
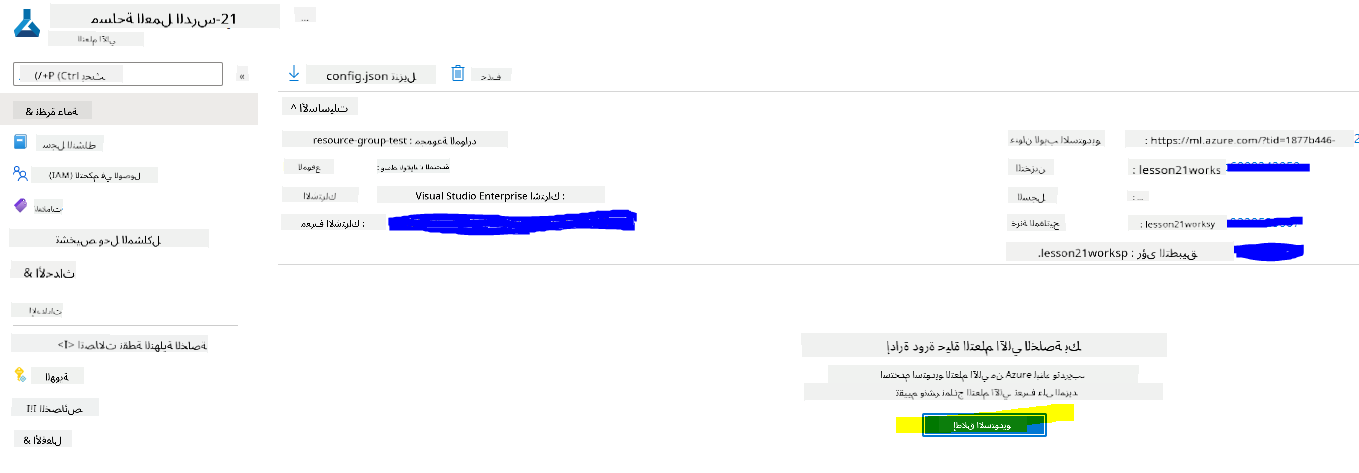
انتظر حتى يتم إنشاء مساحة العمل الخاصة بك (قد يستغرق ذلك بضع دقائق). ثم انتقل إليها في البوابة. يمكنك العثور عليها من خلال خدمة Azure Machine Learning.
-
في صفحة النظرة العامة لمساحة العمل الخاصة بك، قم بتشغيل Azure Machine Learning Studio (أو افتح علامة تبويب جديدة في المتصفح وانتقل إلى https://ml.azure.com)، وقم بتسجيل الدخول إلى Azure Machine Learning Studio باستخدام حساب Microsoft الخاص بك. إذا طُلب منك، اختر دليل Azure الخاص بك واشتراكك، ومساحة عمل Azure Machine Learning الخاصة بك.
- في Azure Machine Learning Studio، قم بتبديل رمز ☰ في الجزء العلوي الأيسر لعرض الصفحات المختلفة في الواجهة. يمكنك استخدام هذه الصفحات لإدارة الموارد في مساحة العمل الخاصة بك.
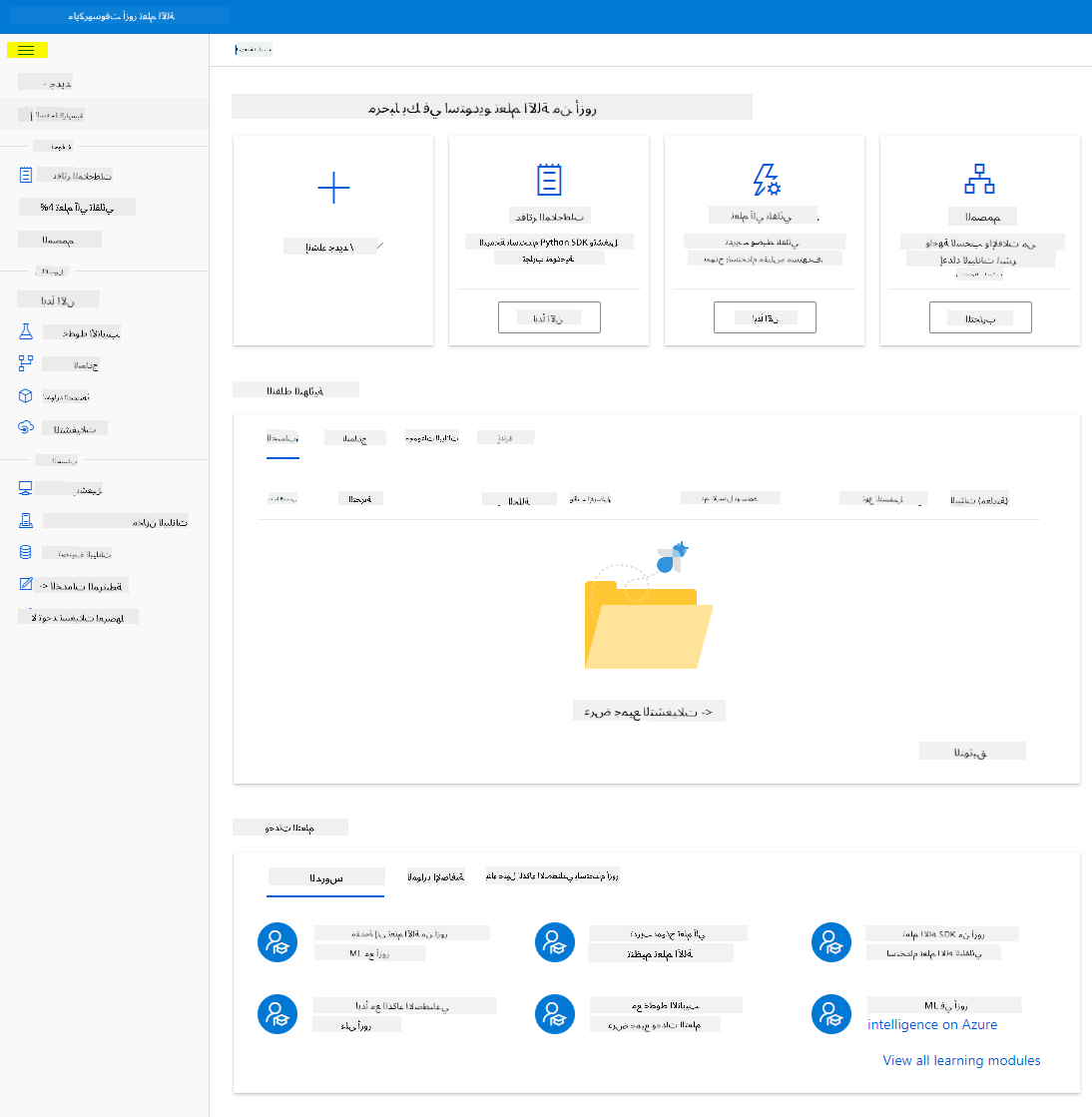
يمكنك إدارة مساحة العمل الخاصة بك باستخدام بوابة Azure، ولكن بالنسبة لعلماء البيانات ومهندسي عمليات التعلم الآلي، يوفر Azure Machine Learning Studio واجهة مستخدم أكثر تركيزًا لإدارة موارد مساحة العمل.
2.2 موارد الحوسبة
موارد الحوسبة هي موارد قائمة على السحابة يمكنك تشغيل عمليات تدريب النماذج واستكشاف البيانات عليها. هناك أربعة أنواع من موارد الحوسبة التي يمكنك إنشاؤها:
- مثيلات الحوسبة: محطات عمل تطويرية يمكن لعلماء البيانات استخدامها للعمل مع البيانات والنماذج. يتضمن ذلك إنشاء جهاز افتراضي (VM) وتشغيل مثيل دفتر ملاحظات. يمكنك بعد ذلك تدريب نموذج عن طريق استدعاء مجموعة حوسبة من دفتر الملاحظات.
- مجموعات الحوسبة: مجموعات قابلة للتوسع من الأجهزة الافتراضية لمعالجة التعليمات البرمجية التجريبية عند الطلب. ستحتاج إليها عند تدريب نموذج. يمكن لمجموعات الحوسبة أيضًا استخدام موارد GPU أو CPU المتخصصة.
- مجموعات الاستنتاج: أهداف النشر للخدمات التنبؤية التي تستخدم النماذج المدربة الخاصة بك.
- الحوسبة المرفقة: روابط إلى موارد الحوسبة الموجودة في Azure، مثل الأجهزة الافتراضية أو مجموعات Azure Databricks.
2.2.1 اختيار الخيارات المناسبة لموارد الحوسبة الخاصة بك
هناك عوامل رئيسية يجب أخذها في الاعتبار عند إنشاء مورد حوسبة، وهذه الخيارات قد تكون قرارات حاسمة.
هل تحتاج إلى CPU أم GPU؟
وحدة المعالجة المركزية (CPU) هي الدائرة الإلكترونية التي تنفذ التعليمات التي يتكون منها برنامج الكمبيوتر. وحدة معالجة الرسومات (GPU) هي دائرة إلكترونية متخصصة يمكنها تنفيذ التعليمات المتعلقة بالرسومات بمعدل عالٍ جدًا.
الفرق الرئيسي بين بنية CPU وGPU هو أن CPU مصممة للتعامل مع مجموعة واسعة من المهام بسرعة (كما يتم قياسها بسرعة الساعة)، ولكنها محدودة في التزامن بين المهام التي يمكن تشغيلها. أما GPU فهي مصممة للحوسبة المتوازية وبالتالي فهي أفضل بكثير في مهام التعلم العميق.
| وحدة المعالجة المركزية (CPU) | وحدة معالجة الرسومات (GPU) |
|---|---|
| أقل تكلفة | أكثر تكلفة |
| مستوى تزامن أقل | مستوى تزامن أعلى |
| أبطأ في تدريب نماذج التعلم العميق | مثالية للتعلم العميق |
حجم المجموعة
المجموعات الأكبر تكون أكثر تكلفة ولكنها تؤدي إلى استجابة أفضل. لذلك، إذا كان لديك وقت ولكن ليس لديك مال كافٍ، يجب أن تبدأ بمجموعة صغيرة. وعلى العكس، إذا كان لديك مال ولكن ليس لديك وقت كافٍ، يجب أن تبدأ بمجموعة أكبر.
حجم الجهاز الافتراضي (VM)
اعتمادًا على قيود الوقت والميزانية، يمكنك تغيير حجم ذاكرة الوصول العشوائي (RAM)، القرص، عدد النوى وسرعة الساعة. زيادة جميع هذه المعايير ستكون أكثر تكلفة، ولكنها ستؤدي إلى أداء أفضل.
مثيلات مخصصة أم منخفضة الأولوية؟
المثيل منخفض الأولوية يعني أنه قابل للمقاطعة: بمعنى أن Microsoft Azure يمكنها أخذ هذه الموارد وتخصيصها لمهمة أخرى، مما يؤدي إلى مقاطعة المهمة. المثيل المخصص، أو غير القابل للمقاطعة، يعني أن المهمة لن يتم إنهاؤها دون إذنك.
هذا اعتبار آخر بين الوقت والمال، حيث أن المثيلات القابلة للمقاطعة أقل تكلفة من المثيلات المخصصة.
2.2.2 إنشاء مجموعة حوسبة
في مساحة عمل Azure ML التي أنشأناها سابقًا، انتقل إلى الحوسبة وستتمكن من رؤية موارد الحوسبة المختلفة التي ناقشناها للتو (مثل مثيلات الحوسبة، مجموعات الحوسبة، مجموعات الاستدلال والحوسبة المرفقة). لهذا المشروع، سنحتاج إلى مجموعة حوسبة لتدريب النموذج. في الاستوديو، انقر على قائمة "Compute"، ثم علامة التبويب "Compute cluster" وانقر على زر "+ New" لإنشاء مجموعة حوسبة.
- اختر خياراتك: مخصص مقابل منخفض الأولوية، CPU أو GPU، حجم الجهاز الافتراضي وعدد النوى (يمكنك الاحتفاظ بالإعدادات الافتراضية لهذا المشروع).
- انقر على زر التالي.
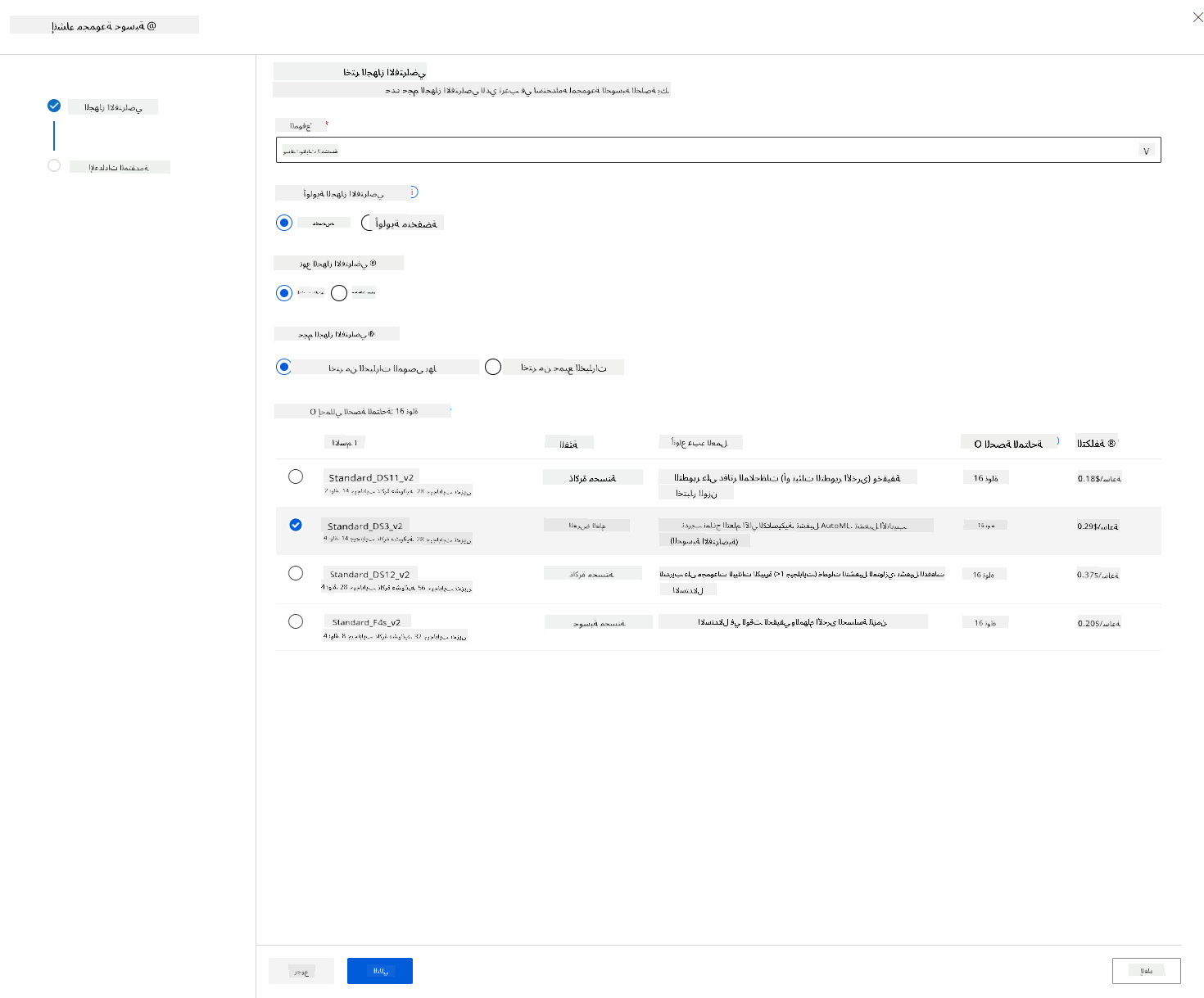
- أعطِ المجموعة اسمًا للحوسبة.
- اختر خياراتك: الحد الأدنى/الحد الأقصى لعدد العقد، الثواني الخاملة قبل التوسع للأسفل، الوصول عبر SSH. لاحظ أنه إذا كان الحد الأدنى لعدد العقد هو 0، ستوفر المال عندما تكون المجموعة خاملة. لاحظ أيضًا أنه كلما زاد عدد العقد القصوى، كلما كان التدريب أسرع. العدد الأقصى الموصى به للعقد هو 3.
- انقر على زر "Create". قد تستغرق هذه الخطوة بضع دقائق.
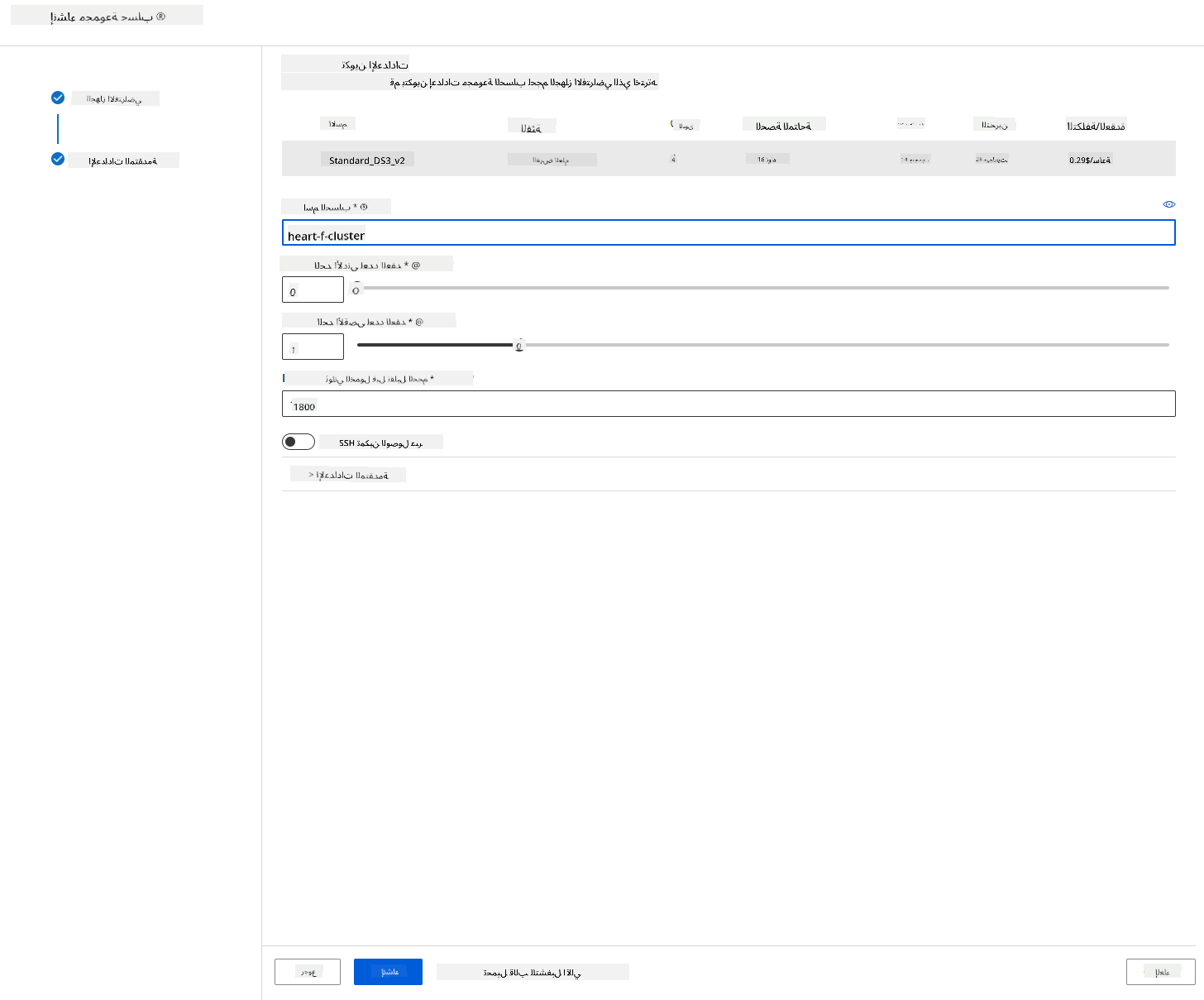
رائع! الآن بعد أن لدينا مجموعة حوسبة، نحتاج إلى تحميل البيانات إلى Azure ML Studio.
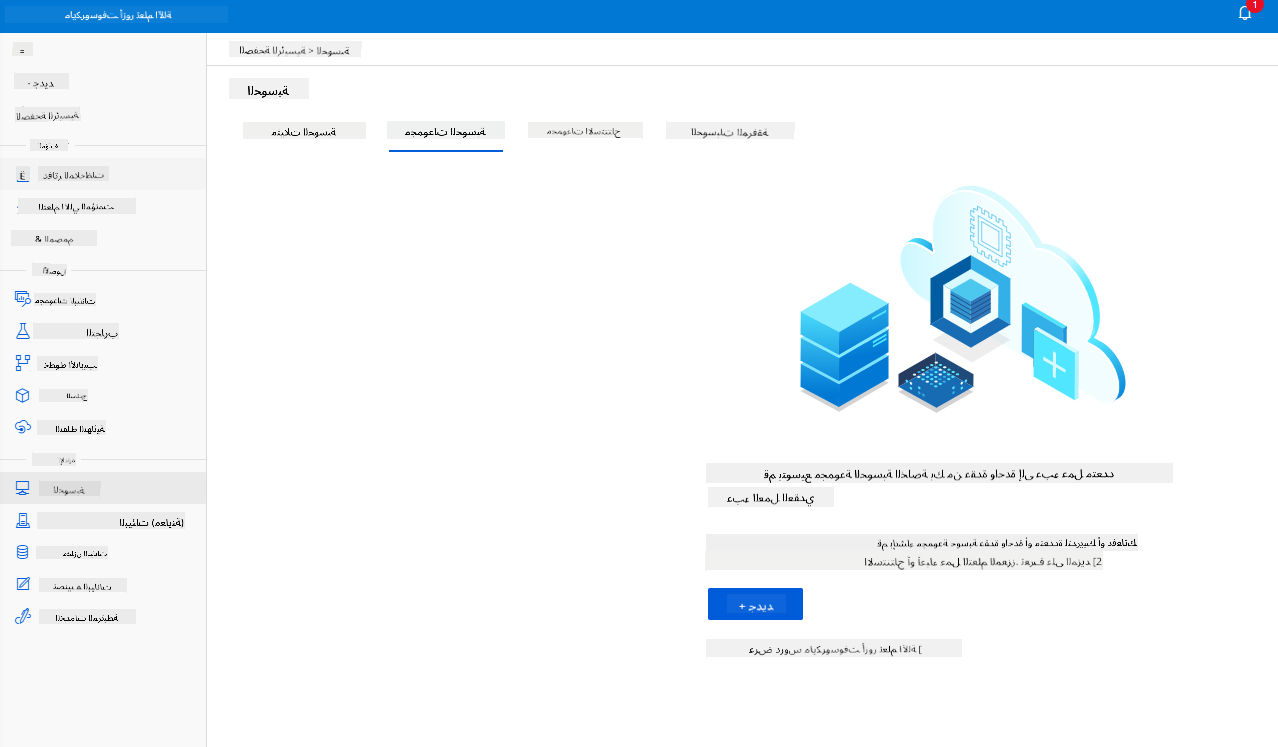
2.3 تحميل مجموعة البيانات
-
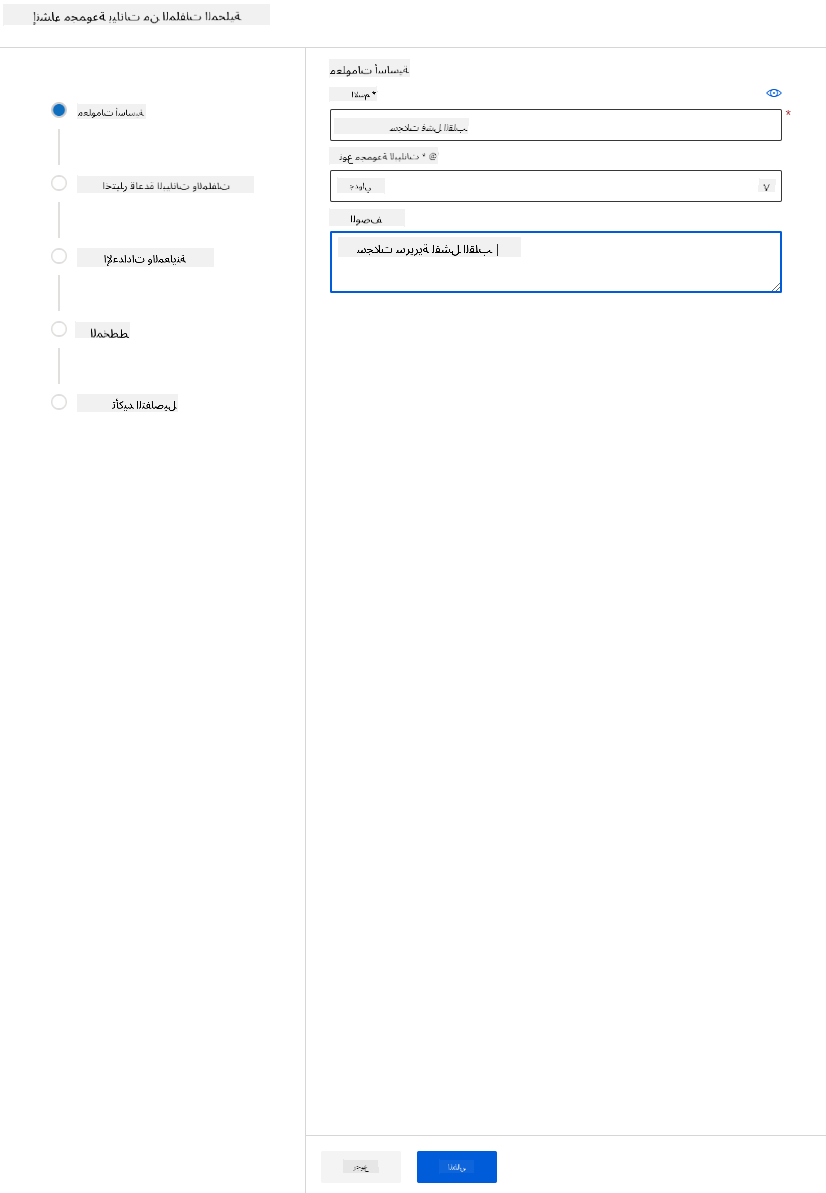
في مساحة عمل Azure ML التي أنشأناها سابقًا، انقر على "Datasets" في القائمة اليسرى وانقر على زر "+ Create dataset" لإنشاء مجموعة بيانات. اختر خيار "From local files" وحدد مجموعة بيانات Kaggle التي قمنا بتنزيلها سابقًا.
-
أعطِ مجموعة البيانات اسمًا، نوعًا ووصفًا. انقر على التالي. قم بتحميل البيانات من الملفات. انقر على التالي.
-
في المخطط، قم بتغيير نوع البيانات إلى Boolean للميزات التالية: فقر الدم، السكري، ارتفاع ضغط الدم، الجنس، التدخين، وDEATH_EVENT. انقر على التالي ثم انقر على إنشاء.
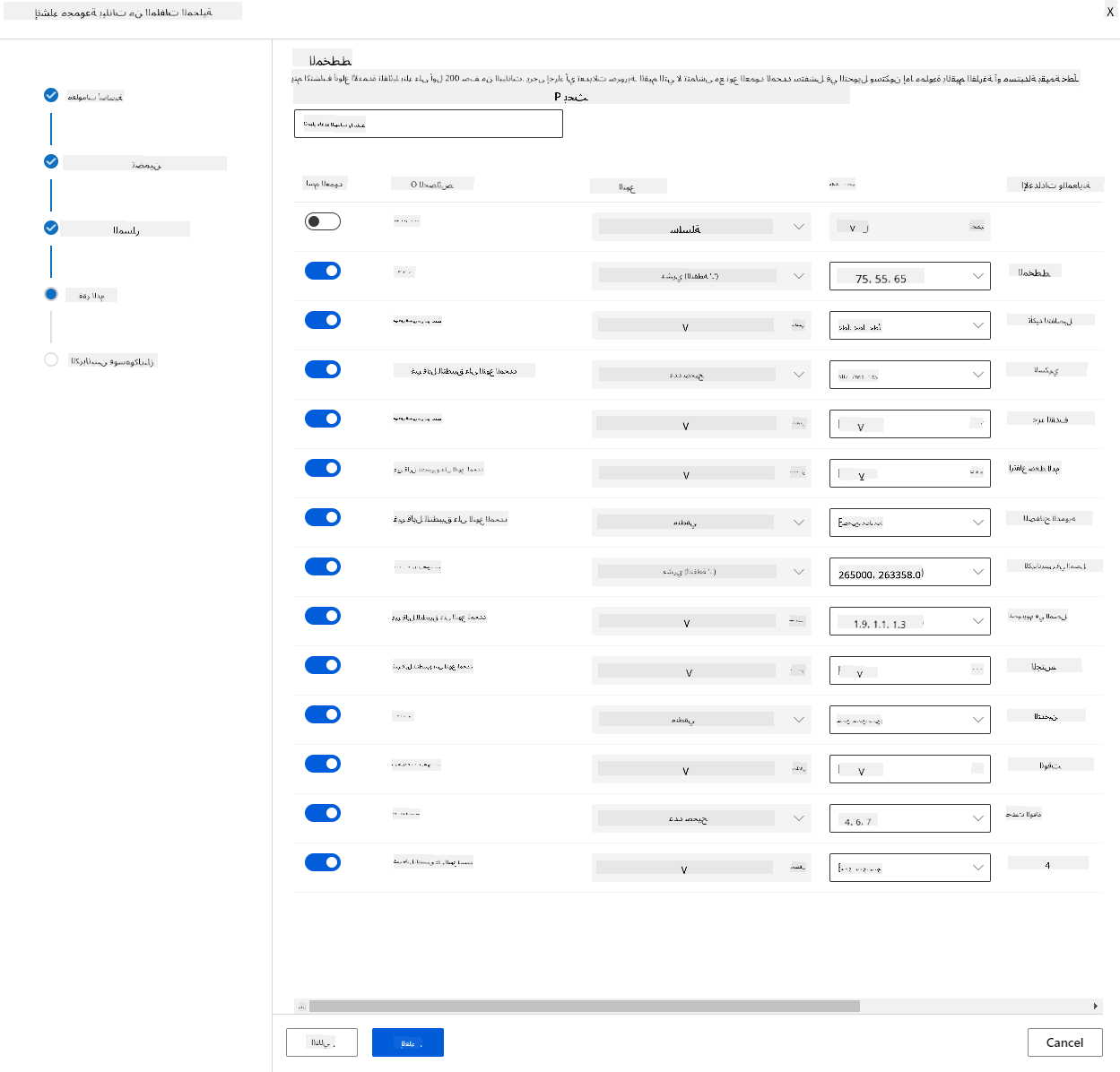
رائع! الآن بعد أن أصبحت مجموعة البيانات في مكانها وتم إنشاء مجموعة الحوسبة، يمكننا البدء في تدريب النموذج!
2.4 التدريب باستخدام AutoML بدون كود أو بقليل من الكود
تطوير نماذج التعلم الآلي التقليدية يتطلب موارد مكثفة، معرفة كبيرة بالمجال ووقتًا لإنتاج ومقارنة عشرات النماذج.
التعلم الآلي التلقائي (AutoML) هو عملية أتمتة المهام المتكررة والمستهلكة للوقت في تطوير نماذج التعلم الآلي. يسمح AutoML لعلماء البيانات، المحللين والمطورين ببناء نماذج تعلم آلي بكفاءة وإنتاجية عالية، مع الحفاظ على جودة النموذج. يقلل من الوقت اللازم للحصول على نماذج جاهزة للإنتاج بسهولة وكفاءة. تعرف على المزيد
-
في مساحة عمل Azure ML التي أنشأناها سابقًا، انقر على "Automated ML" في القائمة اليسرى وحدد مجموعة البيانات التي قمت بتحميلها للتو. انقر على التالي.
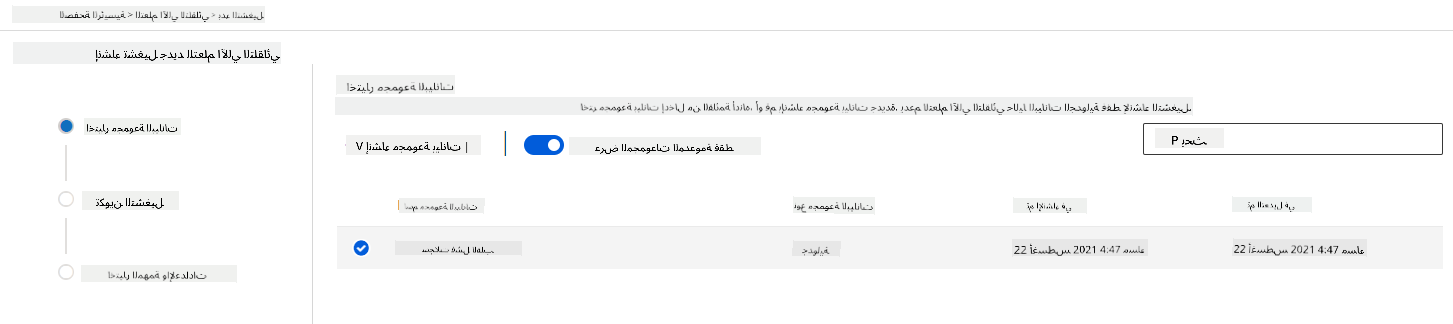
-
أدخل اسم تجربة جديدة، العمود المستهدف (DEATH_EVENT) ومجموعة الحوسبة التي أنشأناها. انقر على التالي.
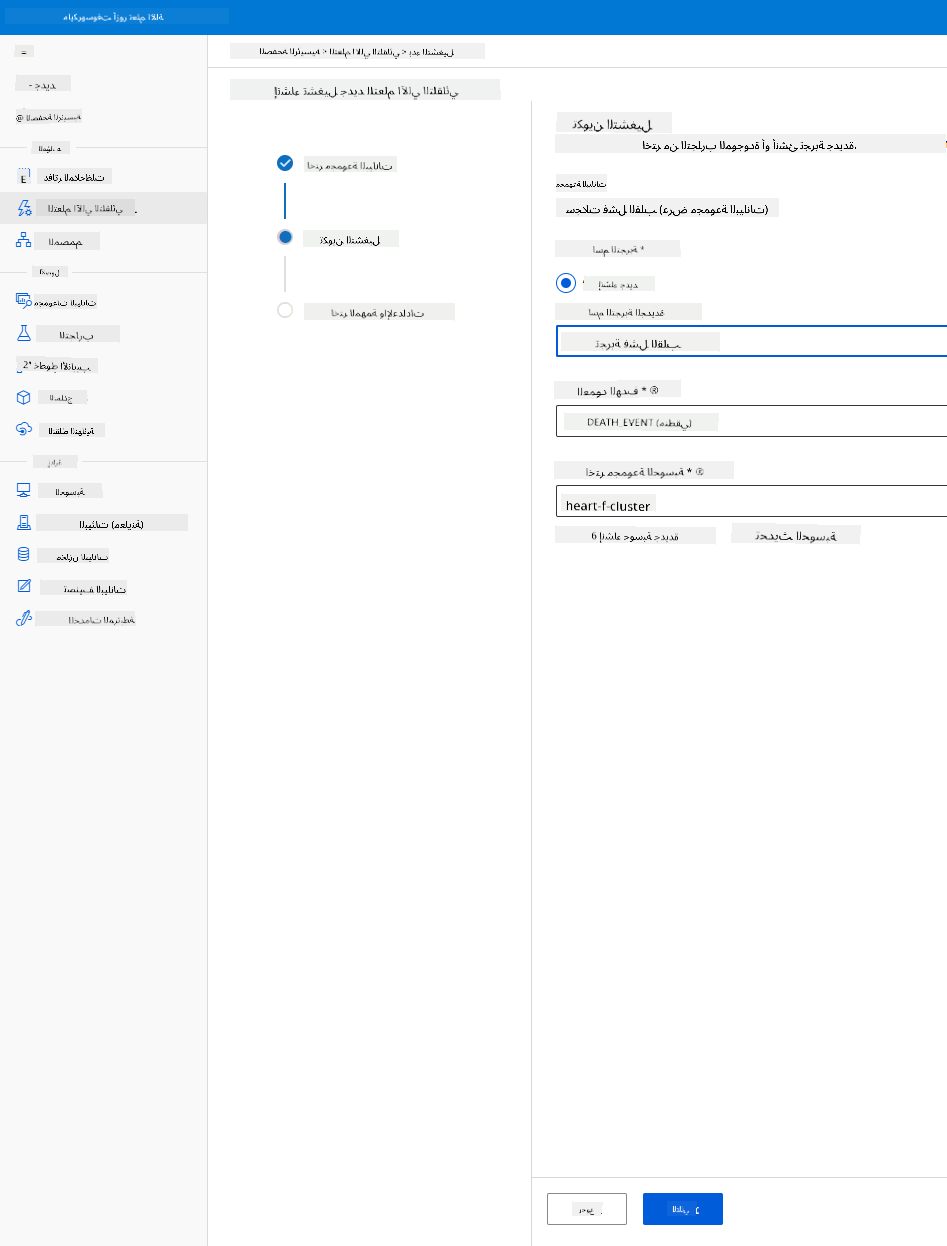
-
اختر "Classification" وانقر على إنهاء. قد تستغرق هذه الخطوة بين 30 دقيقة إلى ساعة، اعتمادًا على حجم مجموعة الحوسبة.
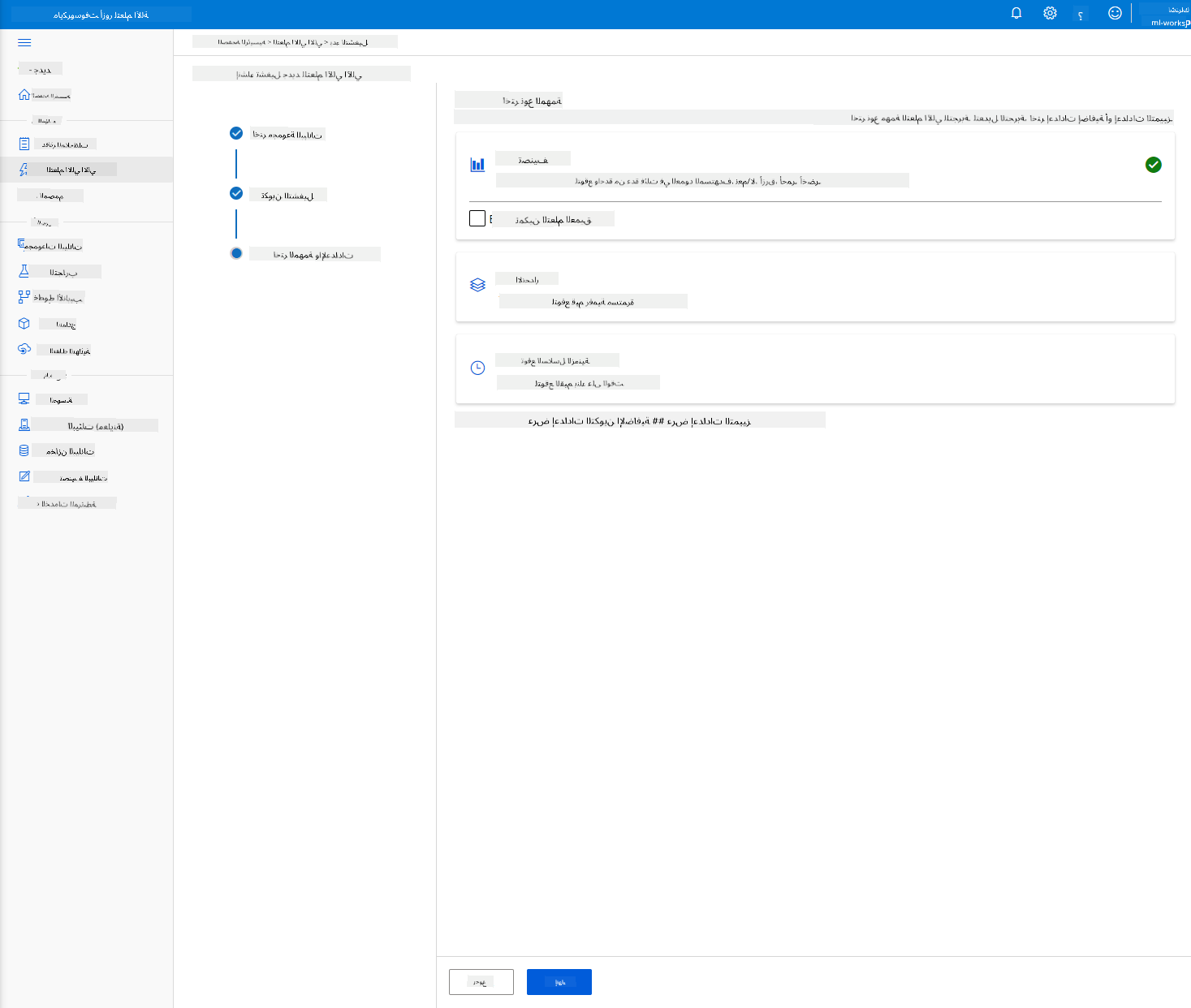
-
بمجرد اكتمال التشغيل، انقر على علامة التبويب "Automated ML"، انقر على التشغيل الخاص بك، وانقر على الخوارزمية في بطاقة "Best model summary".
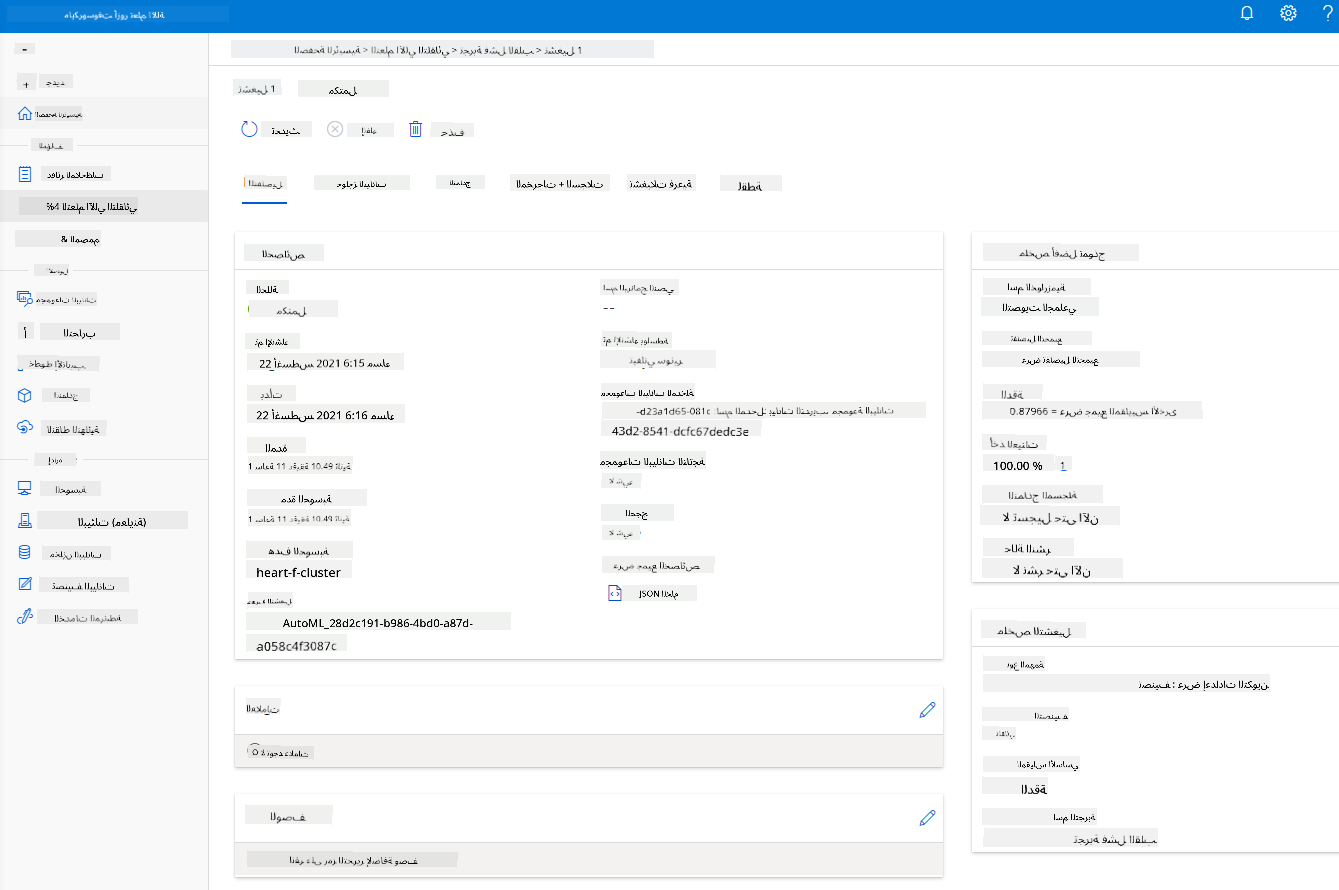
هنا يمكنك رؤية وصف تفصيلي لأفضل نموذج تم إنشاؤه بواسطة AutoML. يمكنك أيضًا استكشاف النماذج الأخرى التي تم إنشاؤها في علامة التبويب "Models". خذ بضع دقائق لاستكشاف النماذج في زر "Explanations (preview)". بمجرد اختيار النموذج الذي تريد استخدامه (هنا سنختار أفضل نموذج تم اختياره بواسطة AutoML)، سنرى كيف يمكننا نشره.
3. نشر النموذج واستهلاك النقاط النهائية بدون كود أو بقليل من الكود
3.1 نشر النموذج
واجهة التعلم الآلي التلقائي تسمح لك بنشر أفضل نموذج كخدمة ويب في خطوات قليلة. النشر هو دمج النموذج بحيث يمكنه تقديم توقعات بناءً على بيانات جديدة وتحديد مناطق الفرص المحتملة. لهذا المشروع، يعني النشر كخدمة ويب أن التطبيقات الطبية ستكون قادرة على استهلاك النموذج لتقديم توقعات مباشرة عن خطر الإصابة بنوبة قلبية للمرضى.
في وصف أفضل نموذج، انقر على زر "Deploy".
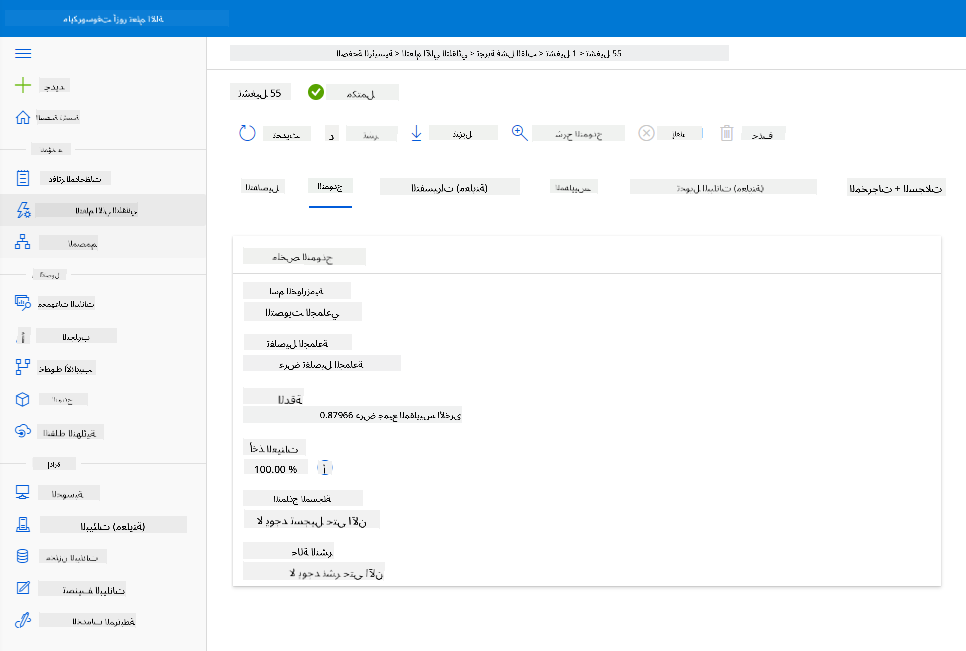
- أعطِه اسمًا، وصفًا، نوع الحوسبة (Azure Container Instance)، قم بتمكين المصادقة وانقر على نشر. قد تستغرق هذه الخطوة حوالي 20 دقيقة لإكمالها. تتضمن عملية النشر عدة خطوات بما في ذلك تسجيل النموذج، إنشاء الموارد، وتكوينها لخدمة الويب. تظهر رسالة حالة تحت حالة النشر. اختر تحديث بشكل دوري للتحقق من حالة النشر. يتم نشره وتشغيله عندما تكون الحالة "Healthy".
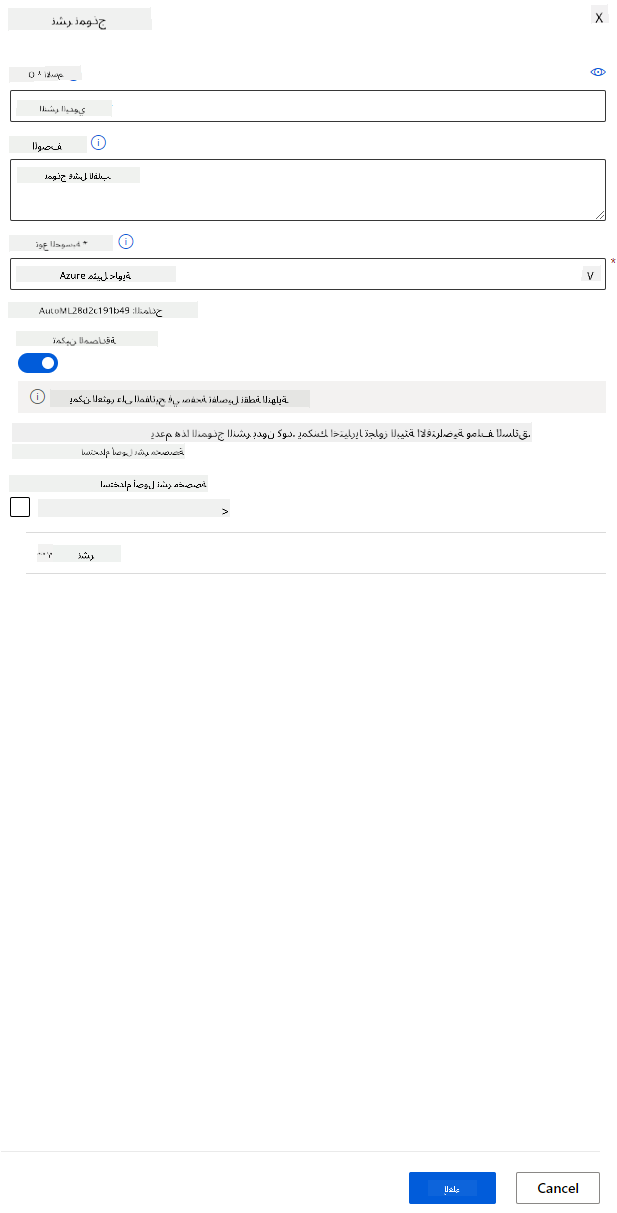
- بمجرد نشره، انقر على علامة التبويب "Endpoint" وانقر على النقطة النهائية التي قمت بنشرها للتو. يمكنك العثور هنا على جميع التفاصيل التي تحتاج إلى معرفتها عن النقطة النهائية.
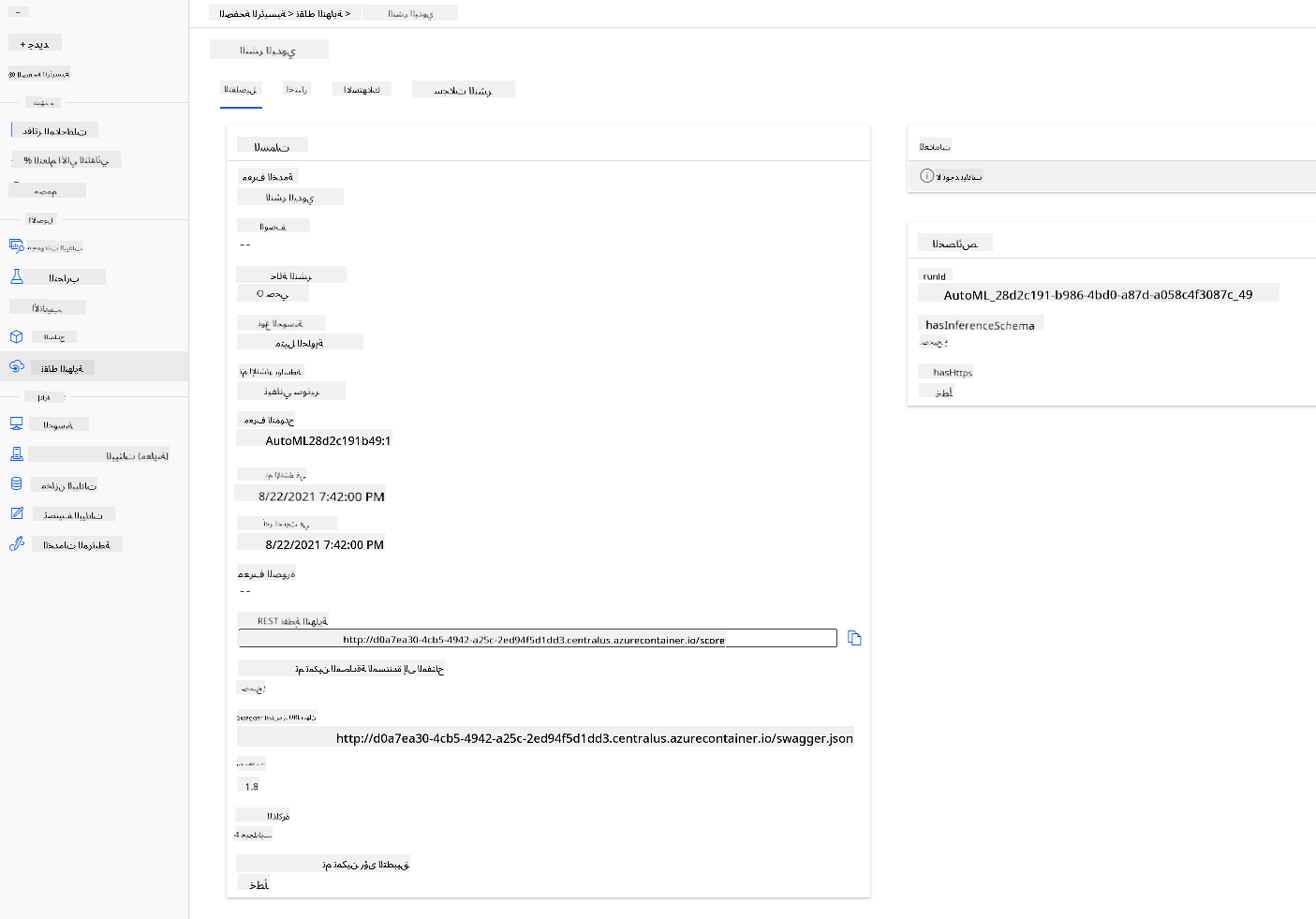
رائع! الآن بعد أن لدينا نموذج منشور، يمكننا البدء في استهلاك النقطة النهائية.
3.2 استهلاك النقطة النهائية
انقر على علامة التبويب "Consume". هنا يمكنك العثور على نقطة النهاية REST ونص برمجي بلغة Python في خيار الاستهلاك. خذ بعض الوقت لقراءة الكود البرمجي.
يمكن تشغيل هذا النص مباشرة من جهازك المحلي وسيستهلك النقطة النهائية.
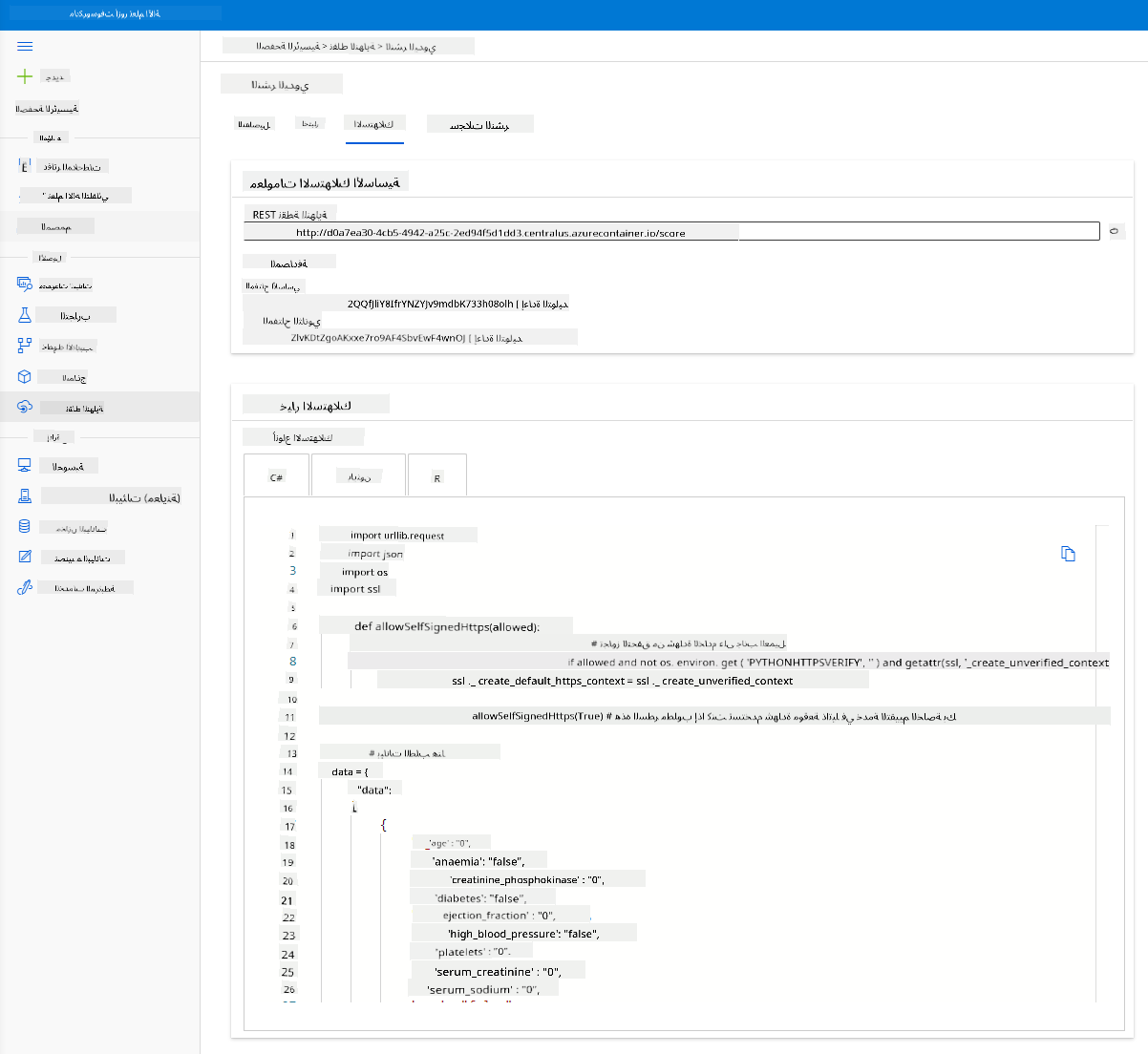
خذ لحظة للتحقق من هذين السطرين من الكود:
url = 'http://98e3715f-xxxx-xxxx-xxxx-9ec22d57b796.centralus.azurecontainer.io/score'
api_key = '' # Replace this with the API key for the web service
المتغير url هو نقطة النهاية REST الموجودة في علامة التبويب "Consume"، والمتغير api_key هو المفتاح الأساسي الموجود أيضًا في علامة التبويب "Consume" (فقط في حالة تمكين المصادقة). هذا هو كيفية استهلاك النص للنقطة النهائية.
- عند تشغيل النص، يجب أن ترى الإخراج التالي:
b'"{\\"result\\": [true]}"'
هذا يعني أن التوقع لفشل القلب للبيانات المقدمة هو صحيح. هذا منطقي لأنه إذا نظرت عن كثب إلى البيانات التي تم إنشاؤها تلقائيًا في النص، كل شيء هو 0 وخاطئ افتراضيًا. يمكنك تغيير البيانات باستخدام عينة الإدخال التالية:
data = {
"data":
[
{
'age': "0",
'anaemia': "false",
'creatinine_phosphokinase': "0",
'diabetes': "false",
'ejection_fraction': "0",
'high_blood_pressure': "false",
'platelets': "0",
'serum_creatinine': "0",
'serum_sodium': "0",
'sex': "false",
'smoking': "false",
'time': "0",
},
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
يجب أن يعيد النص:
python b'"{\\"result\\": [true, false]}"'
تهانينا! لقد قمت باستهلاك النموذج المنشور وتدريبه على Azure ML!
ملاحظة: بمجرد الانتهاء من المشروع، لا تنسَ حذف جميع الموارد.
🚀 التحدي
انظر عن كثب إلى تفسيرات النموذج والتفاصيل التي أنشأها AutoML للنماذج الأعلى. حاول فهم لماذا النموذج الأفضل أفضل من النماذج الأخرى. ما هي الخوارزميات التي تمت مقارنتها؟ ما هي الاختلافات بينها؟ لماذا النموذج الأفضل يقدم أداءً أفضل في هذه الحالة؟
اختبار ما بعد المحاضرة
المراجعة والدراسة الذاتية
في هذا الدرس، تعلمت كيفية تدريب، نشر واستهلاك نموذج للتنبؤ بخطر فشل القلب بطريقة بدون كود أو بقليل من الكود في السحابة. إذا لم تقم بذلك بعد، تعمق في تفسيرات النموذج التي أنشأها AutoML للنماذج الأعلى وحاول فهم لماذا النموذج الأفضل أفضل من الآخرين.
يمكنك التعمق أكثر في AutoML بدون كود أو بقليل من الكود من خلال قراءة هذا التوثيق.
الواجب
مشروع علوم البيانات بدون كود أو بقليل من الكود على Azure ML
إخلاء المسؤولية:
تمت ترجمة هذا المستند باستخدام خدمة الترجمة الآلية Co-op Translator. بينما نسعى لتحقيق الدقة، يرجى العلم أن الترجمات الآلية قد تحتوي على أخطاء أو عدم دقة. يجب اعتبار المستند الأصلي بلغته الأصلية هو المصدر الموثوق. للحصول على معلومات حساسة أو هامة، يُوصى بالاستعانة بترجمة بشرية احترافية. نحن غير مسؤولين عن أي سوء فهم أو تفسيرات خاطئة تنشأ عن استخدام هذه الترجمة.