29 KiB
العمل مع البيانات: بايثون ومكتبة Pandas
 |
|---|
| العمل مع بايثون - رسم توضيحي بواسطة @nitya |
بينما توفر قواعد البيانات طرقًا فعالة جدًا لتخزين البيانات واستعلامها باستخدام لغات الاستعلام، فإن الطريقة الأكثر مرونة لمعالجة البيانات هي كتابة برنامج خاص بك لمعالجتها. في كثير من الحالات، يكون إجراء استعلام قاعدة بيانات أكثر فعالية. ومع ذلك، في بعض الحالات عندما تكون هناك حاجة إلى معالجة بيانات أكثر تعقيدًا، لا يمكن القيام بذلك بسهولة باستخدام SQL.
يمكن برمجة معالجة البيانات بأي لغة برمجة، ولكن هناك لغات معينة تعتبر عالية المستوى فيما يتعلق بالعمل مع البيانات. يفضل علماء البيانات عادةً إحدى اللغات التالية:
- Python، وهي لغة برمجة متعددة الأغراض، وغالبًا ما تعتبر واحدة من أفضل الخيارات للمبتدئين بسبب بساطتها. تحتوي بايثون على العديد من المكتبات الإضافية التي يمكن أن تساعدك في حل العديد من المشاكل العملية، مثل استخراج البيانات من أرشيف ZIP، أو تحويل الصور إلى درجات الرمادي. بالإضافة إلى علم البيانات، تُستخدم بايثون أيضًا بشكل شائع في تطوير الويب.
- R هي أداة تقليدية تم تطويرها مع معالجة البيانات الإحصائية في الاعتبار. تحتوي أيضًا على مستودع كبير من المكتبات (CRAN)، مما يجعلها خيارًا جيدًا لمعالجة البيانات. ومع ذلك، فإن R ليست لغة برمجة متعددة الأغراض، ونادرًا ما تُستخدم خارج نطاق علم البيانات.
- Julia هي لغة أخرى تم تطويرها خصيصًا لعلم البيانات. تهدف إلى تقديم أداء أفضل من بايثون، مما يجعلها أداة رائعة للتجارب العلمية.
في هذه الدرس، سنركز على استخدام بايثون لمعالجة البيانات البسيطة. سنفترض معرفة أساسية باللغة. إذا كنت ترغب في جولة أعمق في بايثون، يمكنك الرجوع إلى أحد الموارد التالية:
- تعلم بايثون بطريقة ممتعة باستخدام الرسومات الفركتالية - دورة مقدمة سريعة على GitHub لبرمجة بايثون
- ابدأ خطواتك الأولى مع بايثون مسار تعليمي على Microsoft Learn
يمكن أن تأتي البيانات بأشكال عديدة. في هذا الدرس، سننظر في ثلاثة أشكال من البيانات - البيانات الجدولية، النصوص و الصور.
سنركز على بعض الأمثلة لمعالجة البيانات، بدلاً من إعطائك نظرة عامة كاملة على جميع المكتبات ذات الصلة. سيسمح لك ذلك بفهم الفكرة الرئيسية لما هو ممكن، ويترك لك فهمًا حول كيفية العثور على حلول لمشاكلك عندما تحتاج إليها.
النصيحة الأكثر فائدة. عندما تحتاج إلى تنفيذ عملية معينة على البيانات ولا تعرف كيفية القيام بها، حاول البحث عنها على الإنترنت. Stackoverflow يحتوي عادةً على الكثير من عينات الكود المفيدة في بايثون للعديد من المهام النموذجية.
اختبار ما قبل المحاضرة
البيانات الجدولية وإطارات البيانات
لقد تعرفت بالفعل على البيانات الجدولية عندما تحدثنا عن قواعد البيانات العلائقية. عندما يكون لديك الكثير من البيانات، وهي موجودة في العديد من الجداول المرتبطة المختلفة، فمن المنطقي بالتأكيد استخدام SQL للعمل معها. ومع ذلك، هناك العديد من الحالات عندما يكون لدينا جدول بيانات، ونحتاج إلى الحصول على بعض الفهم أو الرؤى حول هذه البيانات، مثل التوزيع، العلاقة بين القيم، إلخ. في علم البيانات، هناك العديد من الحالات عندما نحتاج إلى تنفيذ بعض التحويلات للبيانات الأصلية، متبوعة بالتصور. يمكن تنفيذ كلا الخطوتين بسهولة باستخدام بايثون.
هناك مكتبتان مفيدتان جدًا في بايثون يمكن أن تساعدك في التعامل مع البيانات الجدولية:
- Pandas تتيح لك التعامل مع ما يسمى بـ إطارات البيانات، وهي مشابهة للجداول العلائقية. يمكنك الحصول على أعمدة مسماة، وتنفيذ عمليات مختلفة على الصفوف، الأعمدة، وإطارات البيانات بشكل عام.
- Numpy هي مكتبة للعمل مع التنسورات، أي المصفوفات متعددة الأبعاد. تحتوي المصفوفة على قيم من نفس النوع الأساسي، وهي أبسط من إطار البيانات، لكنها تقدم المزيد من العمليات الرياضية، وتخلق أقل قدر من الحمل.
هناك أيضًا بعض المكتبات الأخرى التي يجب أن تعرف عنها:
- Matplotlib هي مكتبة تُستخدم لتصور البيانات ورسم الرسوم البيانية
- SciPy هي مكتبة تحتوي على بعض الوظائف العلمية الإضافية. لقد واجهنا بالفعل هذه المكتبة عند الحديث عن الاحتمالات والإحصائيات
إليك قطعة من الكود التي ستستخدمها عادةً لاستيراد هذه المكتبات في بداية برنامج بايثون:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import ... # you need to specify exact sub-packages that you need
Pandas تركز على بعض المفاهيم الأساسية.
السلاسل
السلاسل هي تسلسل من القيم، مشابهة للقائمة أو مصفوفة numpy. الفرق الرئيسي هو أن السلاسل تحتوي أيضًا على فهرس، وعندما نعمل على السلاسل (مثل الجمع)، يتم أخذ الفهرس في الاعتبار. يمكن أن يكون الفهرس بسيطًا مثل رقم الصف الصحيح (وهو الفهرس المستخدم افتراضيًا عند إنشاء سلسلة من قائمة أو مصفوفة)، أو يمكن أن يكون له هيكل معقد، مثل فترة تاريخية.
ملاحظة: هناك بعض الكود التمهيدي لـ Pandas في الدفتر المرفق
notebook.ipynb. نحن فقط نوضح بعض الأمثلة هنا، وأنت مرحب بك بالتأكيد للتحقق من الدفتر الكامل.
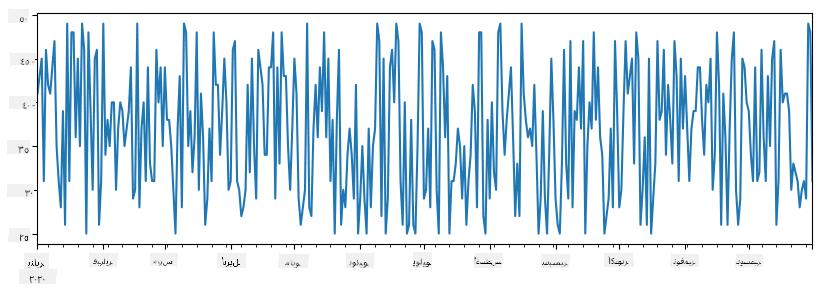
لنأخذ مثالًا: نريد تحليل مبيعات متجر الآيس كريم الخاص بنا. لنقم بإنشاء سلسلة من أرقام المبيعات (عدد العناصر المباعة كل يوم) لفترة زمنية معينة:
start_date = "Jan 1, 2020"
end_date = "Mar 31, 2020"
idx = pd.date_range(start_date,end_date)
print(f"Length of index is {len(idx)}")
items_sold = pd.Series(np.random.randint(25,50,size=len(idx)),index=idx)
items_sold.plot()
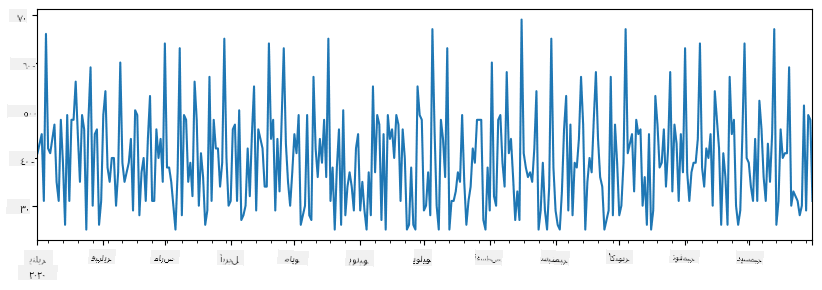
الآن لنفترض أنه كل أسبوع نقوم بتنظيم حفلة للأصدقاء، ونأخذ 10 عبوات إضافية من الآيس كريم للحفلة. يمكننا إنشاء سلسلة أخرى، مفهرسة حسب الأسبوع، لتوضيح ذلك:
additional_items = pd.Series(10,index=pd.date_range(start_date,end_date,freq="W"))
عندما نجمع السلسلتين معًا، نحصل على العدد الإجمالي:
total_items = items_sold.add(additional_items,fill_value=0)
total_items.plot()
ملاحظة أننا لا نستخدم الصيغة البسيطة
total_items+additional_items. إذا فعلنا ذلك، لكنا حصلنا على العديد من القيمNaN(ليس رقمًا) في السلسلة الناتجة. هذا لأن هناك قيم مفقودة لبعض نقاط الفهرس في سلسلةadditional_items، وإضافةNaNإلى أي شيء يؤدي إلىNaN. لذلك نحتاج إلى تحديد معلمةfill_valueأثناء الجمع.
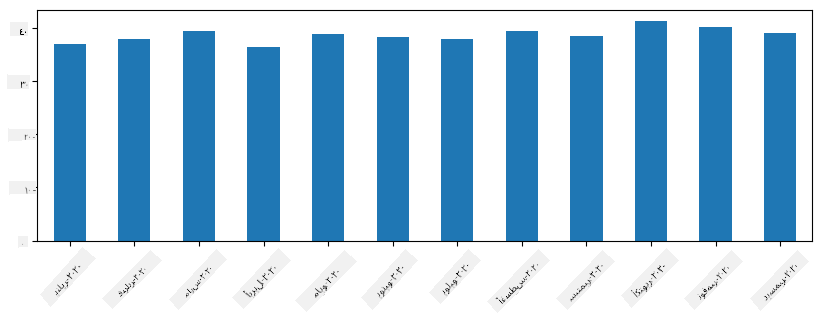
مع السلاسل الزمنية، يمكننا أيضًا إعادة أخذ العينات للسلسلة بفواصل زمنية مختلفة. على سبيل المثال، لنفترض أننا نريد حساب متوسط حجم المبيعات شهريًا. يمكننا استخدام الكود التالي:
monthly = total_items.resample("1M").mean()
ax = monthly.plot(kind='bar')
إطار البيانات
إطار البيانات هو في الأساس مجموعة من السلاسل بنفس الفهرس. يمكننا دمج عدة سلاسل معًا في إطار بيانات:
a = pd.Series(range(1,10))
b = pd.Series(["I","like","to","play","games","and","will","not","change"],index=range(0,9))
df = pd.DataFrame([a,b])
سيؤدي ذلك إلى إنشاء جدول أفقي مثل هذا:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 1 | I | like | to | use | Python | and | Pandas | very | much |
يمكننا أيضًا استخدام السلاسل كأعمدة، وتحديد أسماء الأعمدة باستخدام القاموس:
df = pd.DataFrame({ 'A' : a, 'B' : b })
سيعطينا هذا جدولًا مثل هذا:
| A | B | |
|---|---|---|
| 0 | 1 | I |
| 1 | 2 | like |
| 2 | 3 | to |
| 3 | 4 | use |
| 4 | 5 | Python |
| 5 | 6 | and |
| 6 | 7 | Pandas |
| 7 | 8 | very |
| 8 | 9 | much |
ملاحظة أنه يمكننا أيضًا الحصول على هذا التخطيط للجدول عن طريق تبديل الجدول السابق، على سبيل المثال بكتابة
df = pd.DataFrame([a,b]).T..rename(columns={ 0 : 'A', 1 : 'B' })
هنا .T تعني عملية تبديل إطار البيانات، أي تغيير الصفوف والأعمدة، وعملية rename تسمح لنا بإعادة تسمية الأعمدة لتتناسب مع المثال السابق.
إليك بعض العمليات الأكثر أهمية التي يمكننا تنفيذها على إطارات البيانات:
اختيار الأعمدة. يمكننا اختيار أعمدة فردية بكتابة df['A'] - هذه العملية تعيد سلسلة. يمكننا أيضًا اختيار مجموعة فرعية من الأعمدة في إطار بيانات آخر بكتابة df[['B','A']] - هذا يعيد إطار بيانات آخر.
تصفية الصفوف بناءً على معايير معينة. على سبيل المثال، لترك الصفوف فقط التي تحتوي على العمود A أكبر من 5، يمكننا كتابة df[df['A']>5].
ملاحظة: الطريقة التي تعمل بها التصفية هي كالتالي. التعبير
df['A']<5يعيد سلسلة من القيم المنطقية، والتي تشير إلى ما إذا كان التعبيرTrueأوFalseلكل عنصر من عناصر السلسلة الأصليةdf['A']. عندما تُستخدم السلسلة المنطقية كفهرس، فإنها تعيد مجموعة فرعية من الصفوف في إطار البيانات. لذلك، لا يمكن استخدام تعبير منطقي عشوائي في بايثون، على سبيل المثال، كتابةdf[df['A']>5 and df['A']<7]سيكون خطأ. بدلاً من ذلك، يجب استخدام عملية خاصة&على السلاسل المنطقية، بكتابةdf[(df['A']>5) & (df['A']<7)](الأقواس مهمة هنا).
إنشاء أعمدة جديدة قابلة للحساب. يمكننا بسهولة إنشاء أعمدة جديدة قابلة للحساب لإطار البيانات الخاص بنا باستخدام تعبير بديهي مثل هذا:
df['DivA'] = df['A']-df['A'].mean()
هذا المثال يحسب انحراف A عن قيمته المتوسطة. ما يحدث فعليًا هنا هو أننا نحسب سلسلة، ثم نخصص هذه السلسلة إلى الجانب الأيسر، مما يؤدي إلى إنشاء عمود جديد. لذلك، لا يمكننا استخدام أي عمليات غير متوافقة مع السلاسل، على سبيل المثال، الكود أدناه خاطئ:
# Wrong code -> df['ADescr'] = "Low" if df['A'] < 5 else "Hi"
df['LenB'] = len(df['B']) # <- Wrong result
المثال الأخير، رغم أنه صحيح نحويًا، يعطينا نتيجة خاطئة، لأنه يخصص طول السلسلة B لجميع القيم في العمود، وليس طول العناصر الفردية كما قصدنا.
إذا كنا بحاجة إلى حساب تعبيرات معقدة مثل هذه، يمكننا استخدام وظيفة apply. يمكن كتابة المثال الأخير كما يلي:
df['LenB'] = df['B'].apply(lambda x : len(x))
# or
df['LenB'] = df['B'].apply(len)
بعد العمليات أعلاه، سننتهي بإطار البيانات التالي:
| A | B | DivA | LenB | |
|---|---|---|---|---|
| 0 | 1 | I | -4.0 | 1 |
| 1 | 2 | like | -3.0 | 4 |
| 2 | 3 | to | -2.0 | 2 |
| 3 | 4 | use | -1.0 | 3 |
| 4 | 5 | Python | 0.0 | 6 |
| 5 | 6 | and | 1.0 | 3 |
| 6 | 7 | Pandas | 2.0 | 6 |
| 7 | 8 | very | 3.0 | 4 |
| 8 | 9 | much | 4.0 | 4 |
اختيار الصفوف بناءً على الأرقام يمكن القيام به باستخدام بناء iloc. على سبيل المثال، لاختيار أول 5 صفوف من إطار البيانات:
df.iloc[:5]
التجميع يُستخدم غالبًا للحصول على نتيجة مشابهة لـ جداول المحورية في Excel. لنفترض أننا نريد حساب متوسط قيمة العمود A لكل رقم معين من LenB. يمكننا تجميع إطار البيانات الخاص بنا بواسطة LenB، واستدعاء mean:
df.groupby(by='LenB').mean()
إذا كنا بحاجة إلى حساب المتوسط وعدد العناصر في المجموعة، يمكننا استخدام وظيفة aggregate الأكثر تعقيدًا:
df.groupby(by='LenB') \
.aggregate({ 'DivA' : len, 'A' : lambda x: x.mean() }) \
.rename(columns={ 'DivA' : 'Count', 'A' : 'Mean'})
هذا يعطينا الجدول التالي:
| LenB | Count | Mean |
|---|---|---|
| 1 | 1 | 1.000000 |
| 2 | 1 | 3.000000 |
| 3 | 2 | 5.000000 |
| 4 | 3 | 6.333333 |
| 6 | 2 | 6.000000 |
الحصول على البيانات
لقد رأينا مدى سهولة إنشاء Series و DataFrames من كائنات Python. ومع ذلك، غالبًا ما تأتي البيانات في شكل ملف نصي أو جدول Excel. لحسن الحظ، يوفر لنا Pandas طريقة بسيطة لتحميل البيانات من القرص. على سبيل المثال، قراءة ملف CSV بسيطة جدًا كما يلي:
df = pd.read_csv('file.csv')
سنرى المزيد من الأمثلة لتحميل البيانات، بما في ذلك جلبها من مواقع ويب خارجية، في قسم "التحدي".
الطباعة والرسم البياني
غالبًا ما يحتاج عالم البيانات إلى استكشاف البيانات، لذا من المهم أن يكون قادرًا على تصورها. عندما يكون DataFrame كبيرًا، نرغب في كثير من الأحيان فقط في التأكد من أننا نقوم بكل شيء بشكل صحيح عن طريق طباعة الصفوف القليلة الأولى. يمكن القيام بذلك عن طريق استدعاء df.head(). إذا كنت تقوم بتشغيله من Jupyter Notebook، فسيتم طباعة DataFrame في شكل جدولي جميل.
لقد رأينا أيضًا استخدام وظيفة plot لتصور بعض الأعمدة. بينما تعتبر plot مفيدة جدًا للعديد من المهام وتدعم أنواعًا مختلفة من الرسوم البيانية عبر معلمة kind=, يمكنك دائمًا استخدام مكتبة matplotlib الخام لرسم شيء أكثر تعقيدًا. سنغطي تصور البيانات بالتفصيل في دروس منفصلة ضمن الدورة.
يغطي هذا العرض المفاهيم الأكثر أهمية في Pandas، ومع ذلك، فإن المكتبة غنية جدًا، ولا يوجد حد لما يمكنك القيام به بها! دعونا الآن نطبق هذه المعرفة لحل مشكلة محددة.
🚀 التحدي 1: تحليل انتشار COVID
المشكلة الأولى التي سنركز عليها هي نمذجة انتشار وباء COVID-19. للقيام بذلك، سنستخدم البيانات المتعلقة بعدد الأفراد المصابين في مختلف البلدان، والتي يوفرها مركز علوم وهندسة الأنظمة (CSSE) في جامعة جونز هوبكنز. تتوفر مجموعة البيانات في هذا المستودع على GitHub.
نظرًا لأننا نريد توضيح كيفية التعامل مع البيانات، ندعوك لفتح notebook-covidspread.ipynb وقراءته من البداية إلى النهاية. يمكنك أيضًا تنفيذ الخلايا، والقيام ببعض التحديات التي تركناها لك في النهاية.
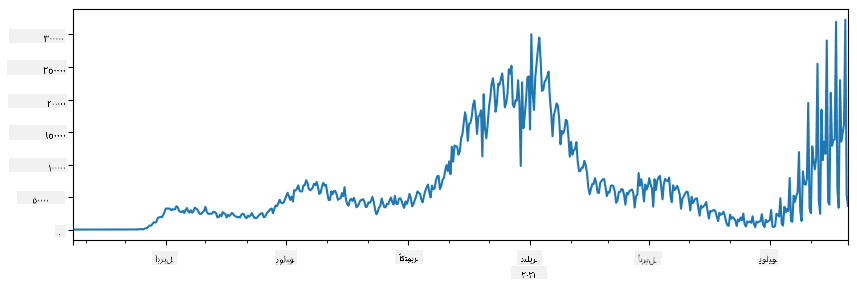
إذا كنت لا تعرف كيفية تشغيل الكود في Jupyter Notebook، يمكنك الاطلاع على هذه المقالة.
العمل مع البيانات غير المنظمة
بينما غالبًا ما تأتي البيانات في شكل جدولي، في بعض الحالات نحتاج إلى التعامل مع بيانات أقل تنظيمًا، مثل النصوص أو الصور. في هذه الحالة، لتطبيق تقنيات معالجة البيانات التي رأيناها أعلاه، نحتاج بطريقة ما إلى استخراج البيانات المنظمة. إليك بعض الأمثلة:
- استخراج الكلمات المفتاحية من النص، ومعرفة مدى تكرار ظهورها
- استخدام الشبكات العصبية لاستخراج معلومات حول الكائنات الموجودة في الصورة
- الحصول على معلومات حول مشاعر الأشخاص من تغذية كاميرا الفيديو
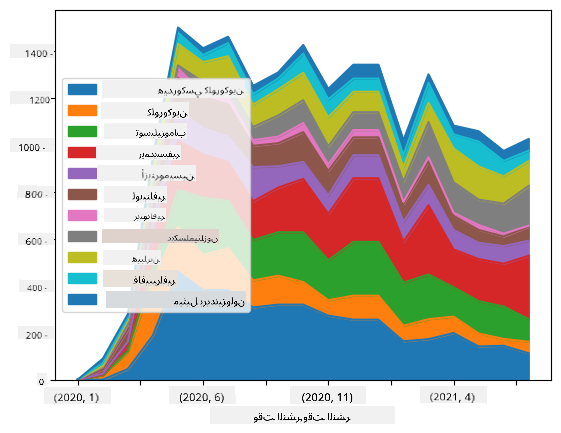
🚀 التحدي 2: تحليل أوراق COVID
في هذا التحدي، سنواصل موضوع جائحة COVID، ونركز على معالجة الأوراق العلمية حول الموضوع. هناك مجموعة بيانات CORD-19 تحتوي على أكثر من 7000 (في وقت الكتابة) ورقة حول COVID، متوفرة مع البيانات الوصفية والملخصات (ولحوالي نصفها يتوفر النص الكامل أيضًا).
مثال كامل لتحليل هذه المجموعة باستخدام خدمة Text Analytics for Health موصوف في هذه المقالة. سنناقش نسخة مبسطة من هذا التحليل.
NOTE: لا نقدم نسخة من مجموعة البيانات كجزء من هذا المستودع. قد تحتاج أولاً إلى تنزيل ملف
metadata.csvمن هذه المجموعة على Kaggle. قد تكون هناك حاجة للتسجيل في Kaggle. يمكنك أيضًا تنزيل المجموعة بدون تسجيل من هنا، لكنها ستتضمن جميع النصوص الكاملة بالإضافة إلى ملف البيانات الوصفية.
افتح notebook-papers.ipynb وقراءته من البداية إلى النهاية. يمكنك أيضًا تنفيذ الخلايا، والقيام ببعض التحديات التي تركناها لك في النهاية.
معالجة بيانات الصور
مؤخرًا، تم تطوير نماذج ذكاء اصطناعي قوية جدًا تسمح لنا بفهم الصور. هناك العديد من المهام التي يمكن حلها باستخدام الشبكات العصبية المدربة مسبقًا أو خدمات السحابة. بعض الأمثلة تشمل:
- تصنيف الصور، والذي يمكن أن يساعدك في تصنيف الصورة إلى واحدة من الفئات المحددة مسبقًا. يمكنك بسهولة تدريب مصنفات الصور الخاصة بك باستخدام خدمات مثل Custom Vision
- اكتشاف الكائنات لتحديد الكائنات المختلفة في الصورة. يمكن لخدمات مثل computer vision اكتشاف عدد من الكائنات الشائعة، ويمكنك تدريب نموذج Custom Vision لتحديد بعض الكائنات المحددة ذات الاهتمام.
- اكتشاف الوجه، بما في ذلك العمر والجنس والكشف عن المشاعر. يمكن القيام بذلك عبر Face API.
يمكن استدعاء جميع هذه الخدمات السحابية باستخدام Python SDKs، وبالتالي يمكن دمجها بسهولة في سير عمل استكشاف البيانات الخاص بك.
إليك بعض الأمثلة لاستكشاف البيانات من مصادر بيانات الصور:
- في المقالة كيف تتعلم علم البيانات بدون برمجة نستكشف صور Instagram، محاولين فهم ما يجعل الناس يعطون المزيد من الإعجابات للصورة. أولاً نستخرج أكبر قدر ممكن من المعلومات من الصور باستخدام computer vision، ثم نستخدم Azure Machine Learning AutoML لبناء نموذج قابل للتفسير.
- في ورشة عمل دراسات الوجه نستخدم Face API لاستخراج المشاعر على الأشخاص في الصور من الأحداث، لفهم ما يجعل الناس سعداء.
الخاتمة
سواء كانت لديك بيانات منظمة أو غير منظمة، باستخدام Python يمكنك تنفيذ جميع الخطوات المتعلقة بمعالجة البيانات وفهمها. إنها على الأرجح الطريقة الأكثر مرونة لمعالجة البيانات، ولهذا السبب يستخدم غالبية علماء البيانات Python كأداة رئيسية لهم. تعلم Python بعمق فكرة جيدة إذا كنت جادًا بشأن رحلتك في علم البيانات!
اختبار ما بعد المحاضرة
المراجعة والدراسة الذاتية
كتب
موارد عبر الإنترنت
- الدليل الرسمي 10 دقائق مع Pandas
- التوثيق حول تصور Pandas
تعلم Python
- تعلم Python بطريقة ممتعة باستخدام رسومات السلحفاة والكسور
- اتخذ خطواتك الأولى مع Python مسار التعلم على Microsoft Learn
الواجب
قم بإجراء دراسة بيانات أكثر تفصيلًا للتحديات أعلاه
الشكر
تم تأليف هذا الدرس بحب ♥️ بواسطة Dmitry Soshnikov
إخلاء المسؤولية:
تمت ترجمة هذا المستند باستخدام خدمة الترجمة الآلية Co-op Translator. بينما نسعى لتحقيق الدقة، يرجى العلم أن الترجمات الآلية قد تحتوي على أخطاء أو معلومات غير دقيقة. يجب اعتبار المستند الأصلي بلغته الأصلية هو المصدر الموثوق. للحصول على معلومات حساسة أو هامة، يُوصى بالاستعانة بترجمة بشرية احترافية. نحن غير مسؤولين عن أي سوء فهم أو تفسيرات خاطئة تنشأ عن استخدام هذه الترجمة.