|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| solution | 1 month ago | |
| README.md | 4 weeks ago | |
README.md
Construindo um Assistente de Chat com IA
Lembra de Star Trek, quando a tripulação conversava casualmente com o computador da nave, fazendo perguntas complexas e recebendo respostas inteligentes? O que parecia pura ficção científica nos anos 1960 agora é algo que você pode construir usando tecnologias web que já conhece.
Nesta lição, vamos criar um assistente de chat com IA usando HTML, CSS, JavaScript e alguma integração de backend. Você descobrirá como as mesmas habilidades que tem aprendido podem se conectar a serviços de IA poderosos que entendem o contexto e geram respostas significativas.
Pense na IA como ter acesso a uma vasta biblioteca que não apenas encontra informações, mas também as sintetiza em respostas coerentes adaptadas às suas perguntas específicas. Em vez de procurar entre milhares de páginas, você obtém respostas diretas e contextuais.
A integração acontece por meio de tecnologias web familiares trabalhando juntas. O HTML cria a interface de chat, o CSS cuida do design visual, o JavaScript gerencia as interações do usuário e uma API de backend conecta tudo aos serviços de IA. É semelhante a como diferentes seções de uma orquestra trabalham juntas para criar uma sinfonia.
Estamos essencialmente construindo uma ponte entre a comunicação humana natural e o processamento de máquinas. Você aprenderá tanto a implementação técnica da integração com serviços de IA quanto os padrões de design que tornam as interações intuitivas.
Ao final desta lição, a integração com IA parecerá menos um processo misterioso e mais como outra API com a qual você pode trabalhar. Você entenderá os padrões fundamentais que alimentam aplicativos como ChatGPT e Claude, usando os mesmos princípios de desenvolvimento web que tem aprendido.
⚡ O que você pode fazer nos próximos 5 minutos
Caminho Rápido para Desenvolvedores Ocupados
flowchart LR
A[⚡ 5 minutes] --> B[Get GitHub token]
B --> C[Test AI playground]
C --> D[Copy Python code]
D --> E[See AI responses]
- Minuto 1: Visite GitHub Models Playground e crie um token de acesso pessoal
- Minuto 2: Teste interações com IA diretamente na interface do playground
- Minuto 3: Clique na aba "Code" e copie o snippet de Python
- Minuto 4: Execute o código localmente com seu token:
GITHUB_TOKEN=your_token python test.py - Minuto 5: Veja sua primeira resposta de IA sendo gerada a partir do seu próprio código
Código de Teste Rápido:
import os
from openai import OpenAI
client = OpenAI(
base_url="https://models.github.ai/inference",
api_key="your_token_here"
)
response = client.chat.completions.create(
messages=[{"role": "user", "content": "Hello AI!"}],
model="openai/gpt-4o-mini"
)
print(response.choices[0].message.content)
Por que isso importa: Em 5 minutos, você experimentará a magia da interação programática com IA. Isso representa o bloco de construção fundamental que alimenta todos os aplicativos de IA que você usa.
Aqui está como seu projeto final ficará:
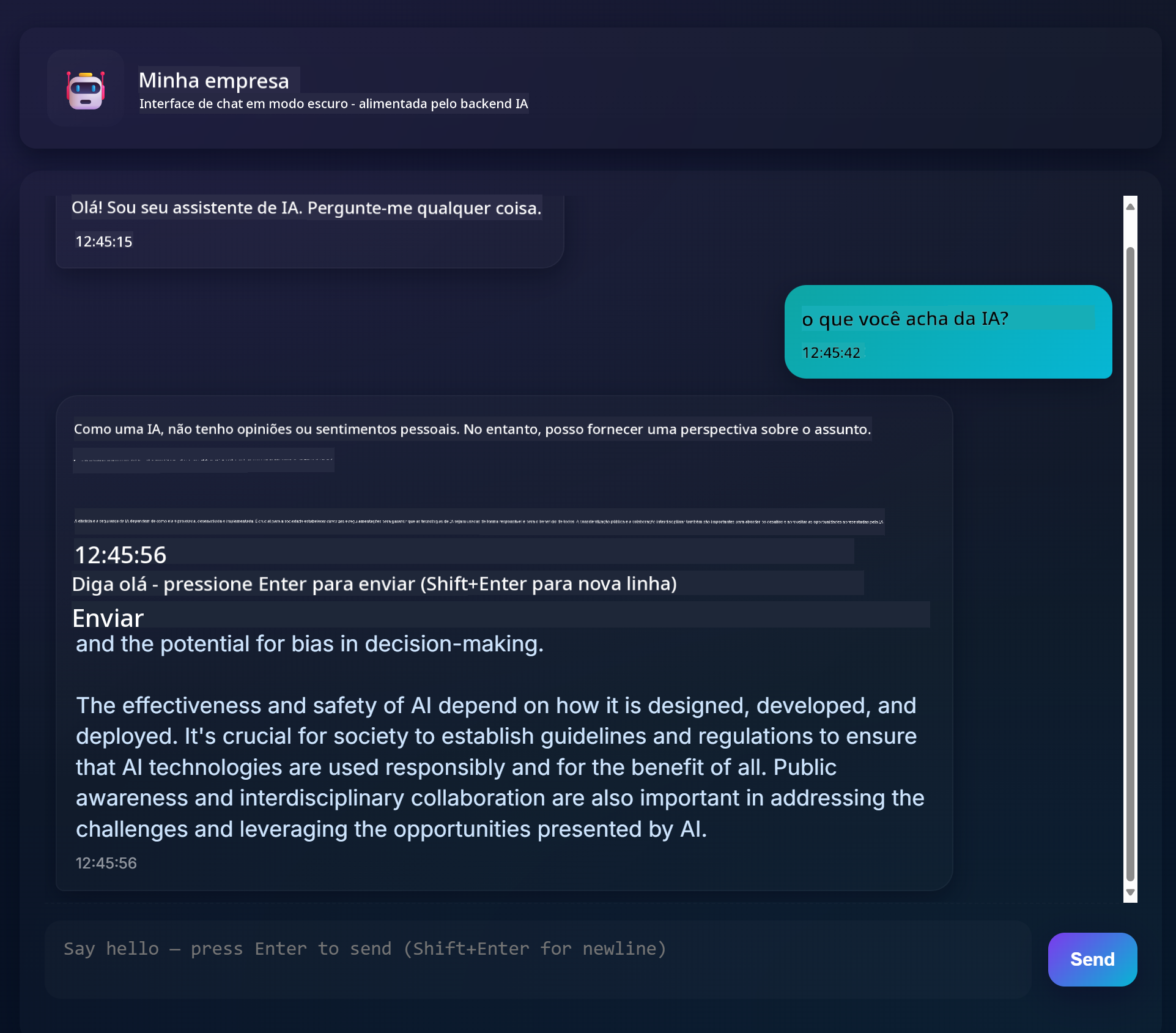
🗺️ Sua Jornada de Aprendizado no Desenvolvimento de Aplicativos com IA
journey
title From Web Development to AI Integration
section Understanding AI Foundations
Discover generative AI concepts: 4: You
Explore GitHub Models platform: 6: You
Master AI parameters and prompts: 8: You
section Backend Integration
Build Python API server: 5: You
Implement AI function calls: 7: You
Handle async operations: 8: You
section Frontend Development
Create modern chat interface: 6: You
Master real-time interactions: 8: You
Build responsive user experience: 9: You
section Professional Application
Deploy complete AI system: 7: You
Optimize performance patterns: 8: You
Create production-ready app: 9: You
Destino da sua Jornada: Ao final desta lição, você terá construído um aplicativo completo com IA usando as mesmas tecnologias e padrões que alimentam assistentes modernos como ChatGPT, Claude e Google Bard.
Entendendo a IA: Do Mistério à Maestria
Antes de mergulhar no código, vamos entender com o que estamos lidando. Se você já usou APIs antes, conhece o padrão básico: enviar uma solicitação, receber uma resposta.
APIs de IA seguem uma estrutura semelhante, mas em vez de recuperar dados pré-armazenados de um banco de dados, elas geram novas respostas com base em padrões aprendidos a partir de grandes volumes de texto. Pense nisso como a diferença entre um sistema de catálogo de biblioteca e um bibliotecário experiente que pode sintetizar informações de várias fontes.
O que é "IA Generativa" de verdade?
Considere como a Pedra de Roseta permitiu que estudiosos entendessem hieróglifos egípcios ao encontrar padrões entre línguas conhecidas e desconhecidas. Modelos de IA funcionam de forma semelhante – eles encontram padrões em grandes volumes de texto para entender como a linguagem funciona e, então, usam esses padrões para gerar respostas apropriadas a novas perguntas.
Deixe-me simplificar com uma comparação:
- Banco de dados tradicional: Como pedir sua certidão de nascimento – você recebe o mesmo documento toda vez
- Motor de busca: Como pedir a um bibliotecário para encontrar livros sobre gatos – ele mostra o que está disponível
- IA Generativa: Como perguntar a um amigo conhecedor sobre gatos – ele conta coisas interessantes com suas próprias palavras, adaptadas ao que você quer saber
graph LR
A[Your Question] --> B[AI Model]
B --> C[Pattern Recognition]
C --> D[Content Generation]
D --> E[Contextual Response]
F[Training Data<br/>Books, Articles, Web] --> B
Como os Modelos de IA Aprendem (Versão Simples)
Os modelos de IA aprendem por meio da exposição a enormes conjuntos de dados contendo textos de livros, artigos e conversas. Durante esse processo, eles identificam padrões em:
- Como os pensamentos são estruturados na comunicação escrita
- Quais palavras geralmente aparecem juntas
- Como as conversas normalmente fluem
- Diferenças contextuais entre comunicação formal e informal
É semelhante a como arqueólogos decifram línguas antigas: eles analisam milhares de exemplos para entender gramática, vocabulário e contexto cultural, eventualmente sendo capazes de interpretar novos textos usando esses padrões aprendidos.
Por que GitHub Models?
Estamos usando o GitHub Models por um motivo bem prático – ele nos dá acesso a IA de nível empresarial sem precisar configurar nossa própria infraestrutura de IA (o que, acredite, você não quer fazer agora!). Pense nisso como usar uma API de clima em vez de tentar prever o clima sozinho montando estações meteorológicas por toda parte.
É basicamente "IA como Serviço", e a melhor parte? É gratuito para começar, então você pode experimentar sem se preocupar em acumular uma conta enorme.
graph LR
A[Frontend Chat UI] --> B[Your Backend API]
B --> C[GitHub Models API]
C --> D[AI Model Processing]
D --> C
C --> B
B --> A
Usaremos o GitHub Models para nossa integração de backend, que fornece acesso a capacidades de IA de nível profissional por meio de uma interface amigável para desenvolvedores. O GitHub Models Playground serve como um ambiente de teste onde você pode experimentar diferentes modelos de IA e entender suas capacidades antes de implementá-los no código.
🧠 Ecossistema de Desenvolvimento de Aplicativos com IA
mindmap
root((AI Development))
Understanding AI
Generative Models
Pattern Recognition
Content Generation
Context Understanding
Response Synthesis
AI Parameters
Temperature Control
Token Limits
Top-p Filtering
System Prompts
Backend Architecture
API Integration
GitHub Models
Authentication
Request Handling
Error Management
Python Infrastructure
FastAPI Framework
Async Operations
Environment Security
CORS Configuration
Frontend Experience
Chat Interface
Real-time Updates
Message History
User Feedback
Loading States
Modern Web Tech
ES6 Classes
Async/Await
DOM Manipulation
Event Handling
Professional Patterns
Security Best Practices
Token Management
Input Validation
XSS Prevention
Error Boundaries
Production Readiness
Performance Optimization
Responsive Design
Accessibility
Testing Strategies
Princípio Central: O desenvolvimento de aplicativos com IA combina habilidades tradicionais de desenvolvimento web com integração de serviços de IA, criando aplicativos inteligentes que parecem naturais e responsivos para os usuários.
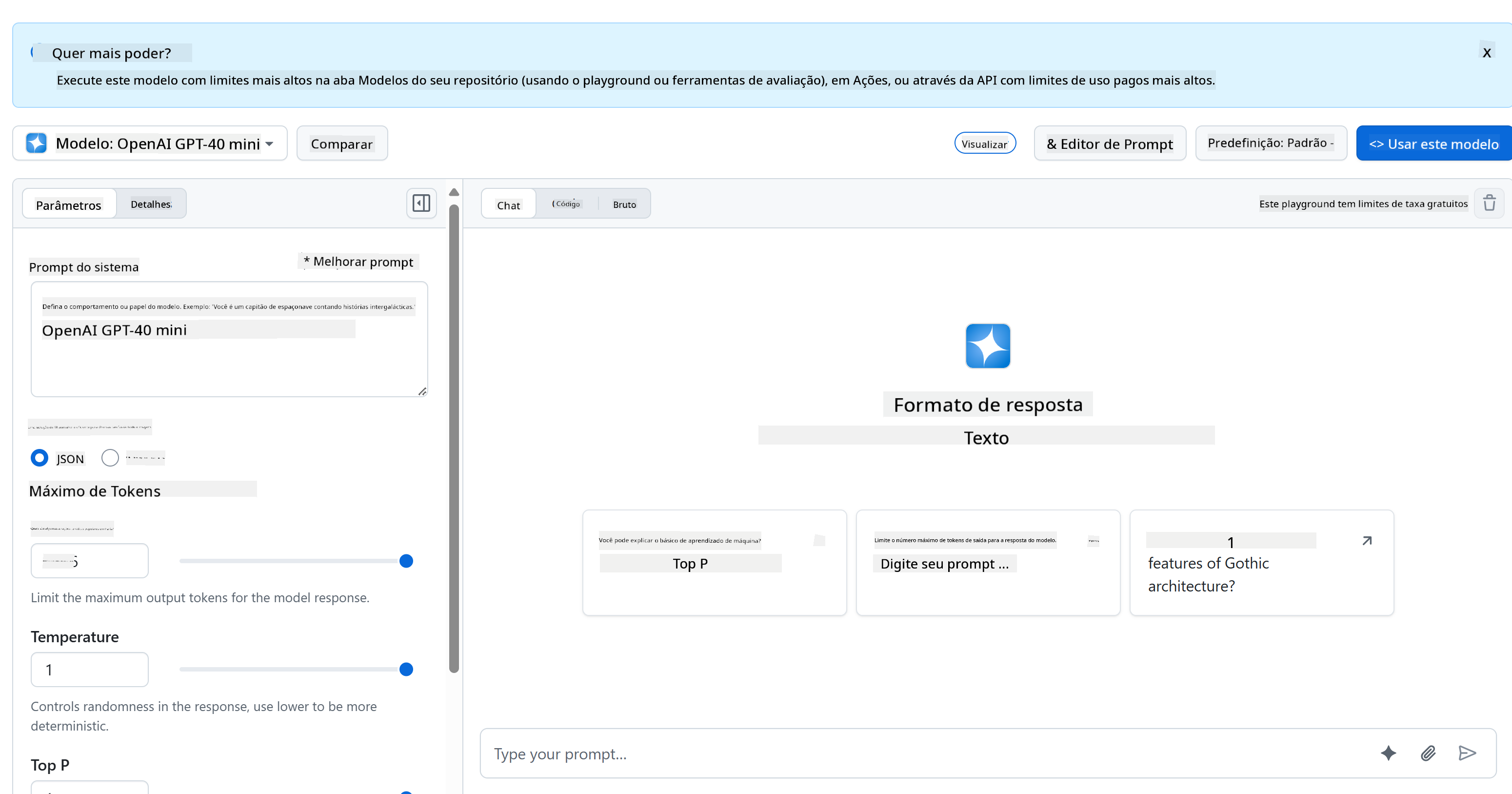
Aqui está o que torna o playground tão útil:
- Experimente diferentes modelos de IA como GPT-4o-mini, Claude e outros (todos gratuitos!)
- Teste suas ideias e prompts antes de escrever qualquer código
- Obtenha snippets de código prontos para uso na sua linguagem de programação favorita
- Ajuste configurações como nível de criatividade e comprimento da resposta para ver como afetam o resultado
Depois de brincar um pouco, basta clicar na aba "Code" e escolher sua linguagem de programação para obter o código de implementação necessário.

Configurando a Integração de Backend com Python
Agora vamos implementar a integração com IA usando Python. Python é excelente para aplicativos de IA devido à sua sintaxe simples e bibliotecas poderosas. Começaremos com o código do playground do GitHub Models e, em seguida, o refatoraremos em uma função reutilizável e pronta para produção.
Entendendo a Implementação Base
Quando você pega o código Python do playground, ele terá uma aparência semelhante a esta. Não se preocupe se parecer muito no início – vamos analisá-lo parte por parte:
"""Run this model in Python
> pip install openai
"""
import os
from openai import OpenAI
# To authenticate with the model you will need to generate a personal access token (PAT) in your GitHub settings.
# Create your PAT token by following instructions here: https://docs.github.com/en/authentication/keeping-your-account-and-data-secure/managing-your-personal-access-tokens
client = OpenAI(
base_url="https://models.github.ai/inference",
api_key=os.environ["GITHUB_TOKEN"],
)
response = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "",
},
{
"role": "user",
"content": "What is the capital of France?",
}
],
model="openai/gpt-4o-mini",
temperature=1,
max_tokens=4096,
top_p=1
)
print(response.choices[0].message.content)
Aqui está o que está acontecendo neste código:
- Importamos as ferramentas necessárias:
ospara ler variáveis de ambiente eOpenAIpara se comunicar com a IA - Configuramos o cliente OpenAI para apontar para os servidores de IA do GitHub em vez de diretamente para o OpenAI
- Autenticamos usando um token especial do GitHub (mais sobre isso em breve!)
- Estruturamos nossa conversa com diferentes "funções" – pense nisso como definir o cenário para uma peça teatral
- Enviamos nossa solicitação para a IA com alguns parâmetros de ajuste fino
- Extraímos o texto da resposta real de todos os dados que retornam
Entendendo as Funções de Mensagem: A Estrutura de Conversação com IA
As conversas com IA usam uma estrutura específica com diferentes "funções" que têm propósitos distintos:
messages=[
{
"role": "system",
"content": "You are a helpful assistant who explains things simply."
},
{
"role": "user",
"content": "What is machine learning?"
}
]
Pense nisso como dirigir uma peça teatral:
- Função do sistema: Como as direções de palco para um ator – diz à IA como se comportar, que personalidade ter e como responder
- Função do usuário: A pergunta ou mensagem real da pessoa que está usando seu aplicativo
- Função do assistente: A resposta da IA (você não envia isso, mas aparece no histórico da conversa)
Analogia do mundo real: Imagine que você está apresentando um amigo a alguém em uma festa:
- Mensagem do sistema: "Este é meu amigo Sarah, ela é uma médica que explica conceitos médicos de forma simples"
- Mensagem do usuário: "Você pode explicar como funcionam as vacinas?"
- Resposta do assistente: Sarah responde como uma médica amigável, não como uma advogada ou chef de cozinha
Entendendo os Parâmetros da IA: Ajustando o Comportamento da Resposta
Os parâmetros numéricos nas chamadas de API de IA controlam como o modelo gera respostas. Essas configurações permitem ajustar o comportamento da IA para diferentes casos de uso:
Temperatura (0.0 a 2.0): O Controle de Criatividade
O que faz: Controla o quão criativas ou previsíveis serão as respostas da IA.
Pense nisso como o nível de improvisação de um músico de jazz:
- Temperatura = 0.1: Tocando exatamente a mesma melodia toda vez (altamente previsível)
- Temperatura = 0.7: Adicionando algumas variações elegantes enquanto permanece reconhecível (criatividade equilibrada)
- Temperatura = 1.5: Jazz experimental completo com reviravoltas inesperadas (altamente imprevisível)
# Very predictable responses (good for factual questions)
response = client.chat.completions.create(
messages=[{"role": "user", "content": "What is 2+2?"}],
temperature=0.1 # Will almost always say "4"
)
# Creative responses (good for brainstorming)
response = client.chat.completions.create(
messages=[{"role": "user", "content": "Write a creative story opening"}],
temperature=1.2 # Will generate unique, unexpected stories
)
Max Tokens (1 a 4096+): O Controlador de Comprimento da Resposta
O que faz: Define um limite para o comprimento da resposta da IA.
Pense nos tokens como aproximadamente equivalentes a palavras (cerca de 1 token = 0.75 palavras em inglês):
- max_tokens=50: Curto e direto (como uma mensagem de texto)
- max_tokens=500: Um bom parágrafo ou dois
- max_tokens=2000: Uma explicação detalhada com exemplos
# Short, concise answers
response = client.chat.completions.create(
messages=[{"role": "user", "content": "Explain JavaScript"}],
max_tokens=100 # Forces a brief explanation
)
# Detailed, comprehensive answers
response = client.chat.completions.create(
messages=[{"role": "user", "content": "Explain JavaScript"}],
max_tokens=1500 # Allows for detailed explanations with examples
)
Top_p (0.0 a 1.0): O Parâmetro de Foco
O que faz: Controla o quão focada a IA permanece nas respostas mais prováveis.
Imagine a IA tendo um enorme vocabulário, classificado por quão provável cada palavra é:
- top_p=0.1: Considera apenas as 10% palavras mais prováveis (muito focado)
- top_p=0.9: Considera 90% das palavras possíveis (mais criativo)
- top_p=1.0: Considera tudo (variedade máxima)
Por exemplo: Se você perguntar "O céu geralmente é..."
- Top_p baixo: Quase certamente dirá "azul"
- Top_p alto: Pode dizer "azul", "nublado", "vasto", "mutável", "bonito", etc.
Juntando Tudo: Combinações de Parâmetros para Diferentes Casos de Uso
# For factual, consistent answers (like a documentation bot)
factual_params = {
"temperature": 0.2,
"max_tokens": 300,
"top_p": 0.3
}
# For creative writing assistance
creative_params = {
"temperature": 1.1,
"max_tokens": 1000,
"top_p": 0.9
}
# For conversational, helpful responses (balanced)
conversational_params = {
"temperature": 0.7,
"max_tokens": 500,
"top_p": 0.8
}
quadrantChart
title AI Parameter Optimization Matrix
x-axis Low Creativity --> High Creativity
y-axis Short Response --> Long Response
quadrant-1 Creative Content
quadrant-2 Detailed Analysis
quadrant-3 Quick Facts
quadrant-4 Conversational AI
Documentation Bot: [0.2, 0.3]
Customer Service: [0.4, 0.4]
General Assistant: [0.7, 0.5]
Creative Writer: [0.9, 0.9]
Brainstorming Tool: [0.8, 0.8]
Entendendo por que esses parâmetros importam: Diferentes aplicativos precisam de diferentes tipos de respostas. Um bot de atendimento ao cliente deve ser consistente e factual (baixa temperatura), enquanto um assistente de escrita criativa deve ser imaginativo e variado (alta temperatura). Entender esses parâmetros dá a você controle sobre a personalidade e o estilo de resposta da sua IA.
**Here's what's happening in this code:**
- **We import** the tools we need: `os` for reading environment variables and `OpenAI` for talking to the AI
- **We set up** the OpenAI client to point to GitHub's AI servers instead of OpenAI directly
- **We authenticate** using a special GitHub token (more on that in a minute!)
- **We structure** our conversation with different "roles" – think of it like setting the scene for a play
- **We send** our request to the AI with some fine-tuning parameters
- **We extract** the actual response text from all the data that comes back
> 🔐 **Security Note**: Never hardcode API keys in your source code! Always use environment variables to store sensitive credentials like your `GITHUB_TOKEN`.
### Creating a Reusable AI Function
Let's refactor this code into a clean, reusable function that we can easily integrate into our web application:
```python
import asyncio
from openai import AsyncOpenAI
# Use AsyncOpenAI for better performance
client = AsyncOpenAI(
base_url="https://models.github.ai/inference",
api_key=os.environ["GITHUB_TOKEN"],
)
async def call_llm_async(prompt: str, system_message: str = "You are a helpful assistant."):
"""
Sends a prompt to the AI model asynchronously and returns the response.
Args:
prompt: The user's question or message
system_message: Instructions that define the AI's behavior and personality
Returns:
str: The AI's response to the prompt
"""
try:
response = await client.chat.completions.create(
messages=[
{
"role": "system",
"content": system_message,
},
{
"role": "user",
"content": prompt,
}
],
model="openai/gpt-4o-mini",
temperature=1,
max_tokens=4096,
top_p=1
)
return response.choices[0].message.content
except Exception as e:
logger.error(f"AI API error: {str(e)}")
return "I'm sorry, I'm having trouble processing your request right now."
# Backward compatibility function for synchronous calls
def call_llm(prompt: str, system_message: str = "You are a helpful assistant."):
"""Synchronous wrapper for async AI calls."""
return asyncio.run(call_llm_async(prompt, system_message))
Entendendo esta função aprimorada:
- Aceita dois parâmetros: o prompt do usuário e uma mensagem de sistema opcional
- Fornece uma mensagem de sistema padrão para comportamento geral de assistente
- Utiliza dicas de tipo do Python para melhor documentação do código
- Inclui uma docstring detalhada explicando o propósito e os parâmetros da função
- Retorna apenas o conteúdo da resposta, facilitando o uso em nossa API web
- Mantém os mesmos parâmetros do modelo para comportamento consistente da IA
A Magia dos Prompts de Sistema: Programando a Personalidade da IA
Se os parâmetros controlam como a IA pensa, os prompts de sistema controlam quem a IA pensa que é. Esta é, honestamente, uma das partes mais legais de trabalhar com IA – você está essencialmente dando à IA uma personalidade completa, nível de especialização e estilo de comunicação.
Pense nos prompts de sistema como escalar diferentes atores para diferentes papéis: Em vez de ter um assistente genérico, você pode criar especialistas especializados para diferentes situações. Precisa de um professor paciente? Um parceiro criativo para brainstorming? Um consultor de negócios direto? Basta mudar o prompt de sistema!
Por que os Prompts de Sistema são tão Poderosos
Aqui está a parte fascinante: os modelos de IA foram treinados em inúmeras conversas onde as pessoas adotam diferentes papéis e níveis de especialização. Quando você dá à IA um papel específico, é como ativar um interruptor que ativa todos esses padrões aprendidos.
É como atuação de método para IA: Diga a um ator "você é um professor sábio e velho" e veja como ele ajusta automaticamente sua postura, vocabulário e maneirismos. A IA faz algo notavelmente semelhante com padrões de linguagem.
Criando Prompts de Sistema Eficazes: A Arte e a Ciência
A anatomia de um ótimo prompt de sistema:
- Papel/Identidade: Quem é a IA?
- Especialização: O que ela sabe?
- Estilo de comunicação: Como ela fala?
- Instruções específicas: No que ela deve se concentrar?
# ❌ Vague system prompt
"You are helpful."
# ✅ Detailed, effective system prompt
"You are Dr. Sarah Chen, a senior software engineer with 15 years of experience at major tech companies. You explain programming concepts using real-world analogies and always provide practical examples. You're patient with beginners and enthusiastic about helping them understand complex topics."
Exemplos de Prompts de Sistema com Contexto
Vamos ver como diferentes prompts de sistema criam personalidades completamente diferentes para a IA:
# Example 1: The Patient Teacher
teacher_prompt = """
You are an experienced programming instructor who has taught thousands of students.
You break down complex concepts into simple steps, use analogies from everyday life,
and always check if the student understands before moving on. You're encouraging
and never make students feel bad for not knowing something.
"""
# Example 2: The Creative Collaborator
creative_prompt = """
You are a creative writing partner who loves brainstorming wild ideas. You're
enthusiastic, imaginative, and always build on the user's ideas rather than
replacing them. You ask thought-provoking questions to spark creativity and
offer unexpected perspectives that make stories more interesting.
"""
# Example 3: The Strategic Business Advisor
business_prompt = """
You are a strategic business consultant with an MBA and 20 years of experience
helping startups scale. You think in frameworks, provide structured advice,
and always consider both short-term tactics and long-term strategy. You ask
probing questions to understand the full business context before giving advice.
"""
Vendo os Prompts de Sistema em Ação
Vamos testar a mesma pergunta com diferentes prompts de sistema para ver as diferenças dramáticas:
Pergunta: "Como faço para lidar com autenticação de usuários no meu aplicativo web?"
# With teacher prompt:
teacher_response = call_llm(
"How do I handle user authentication in my web app?",
teacher_prompt
)
# Typical response: "Great question! Let's break authentication down into simple steps.
# Think of it like a nightclub bouncer checking IDs..."
# With business prompt:
business_response = call_llm(
"How do I handle user authentication in my web app?",
business_prompt
)
# Typical response: "From a strategic perspective, authentication is crucial for user
# trust and regulatory compliance. Let me outline a framework considering security,
# user experience, and scalability..."
Técnicas Avançadas de Prompts de Sistema
1. Definição de Contexto: Dê à IA informações de fundo
system_prompt = """
You are helping a junior developer who just started their first job at a startup.
They know basic HTML/CSS/JavaScript but are new to backend development and databases.
Be encouraging and explain things step-by-step without being condescending.
"""
2. Formatação de Saída: Diga ao AI como estruturar respostas
system_prompt = """
You are a technical mentor. Always structure your responses as:
1. Quick Answer (1-2 sentences)
2. Detailed Explanation
3. Code Example
4. Common Pitfalls to Avoid
5. Next Steps for Learning
"""
3. Definição de Restrições: Especifique o que o AI NÃO deve fazer
system_prompt = """
You are a coding tutor focused on teaching best practices. Never write complete
solutions for the user - instead, guide them with hints and questions so they
learn by doing. Always explain the 'why' behind coding decisions.
"""
Por que isso é importante para o seu assistente de chat
Entender os prompts do sistema dá a você um poder incrível para criar assistentes de IA especializados:
- Bot de atendimento ao cliente: Prestativo, paciente, ciente das políticas
- Tutor de aprendizado: Incentivador, passo a passo, verifica a compreensão
- Parceiro criativo: Imaginativo, desenvolve ideias, pergunta "e se?"
- Especialista técnico: Preciso, detalhado, consciente de segurança
O principal insight: Você não está apenas chamando uma API de IA – você está criando uma personalidade de IA personalizada que atende ao seu caso de uso específico. Isso é o que faz as aplicações modernas de IA parecerem adaptadas e úteis, em vez de genéricas.
🎯 Reflexão Pedagógica: Programação de Personalidade de IA
Pausa para Reflexão: Você acabou de aprender a programar personalidades de IA por meio de prompts de sistema. Esta é uma habilidade fundamental no desenvolvimento moderno de aplicações de IA.
Autoavaliação Rápida:
- Você consegue explicar como os prompts do sistema diferem das mensagens regulares do usuário?
- Qual é a diferença entre os parâmetros temperature e top_p?
- Como você criaria um prompt de sistema para um caso de uso específico (como um tutor de programação)?
Conexão com o Mundo Real: As técnicas de prompts de sistema que você aprendeu são usadas em todas as principais aplicações de IA – desde a assistência de codificação do GitHub Copilot até a interface de conversação do ChatGPT. Você está dominando os mesmos padrões usados por equipes de produtos de IA em grandes empresas de tecnologia.
Pergunta Desafiadora: Como você projetaria diferentes personalidades de IA para diferentes tipos de usuários (iniciante vs especialista)? Considere como o mesmo modelo de IA subjacente poderia atender diferentes públicos por meio da engenharia de prompts.
Construindo a API Web com FastAPI: Seu Hub de Comunicação de IA de Alto Desempenho
Agora vamos construir o backend que conecta seu frontend aos serviços de IA. Usaremos o FastAPI, um framework moderno de Python que se destaca na construção de APIs para aplicações de IA.
O FastAPI oferece várias vantagens para este tipo de projeto: suporte assíncrono integrado para lidar com solicitações simultâneas, geração automática de documentação de API e excelente desempenho. Seu servidor FastAPI atua como um intermediário que recebe solicitações do frontend, se comunica com os serviços de IA e retorna respostas formatadas.
Por que usar FastAPI para aplicações de IA?
Você pode estar se perguntando: "Não posso simplesmente chamar a IA diretamente do meu JavaScript no frontend?" ou "Por que FastAPI em vez de Flask ou Django?" Ótimas perguntas!
Aqui está o motivo pelo qual o FastAPI é perfeito para o que estamos construindo:
- Assíncrono por padrão: Pode lidar com várias solicitações de IA ao mesmo tempo sem travar
- Documentação automática: Acesse
/docse obtenha uma página de documentação interativa da API gratuitamente - Validação integrada: Detecta erros antes que causem problemas
- Extremamente rápido: Um dos frameworks Python mais rápidos disponíveis
- Python moderno: Utiliza todos os recursos mais recentes e avançados do Python
E aqui está o motivo pelo qual precisamos de um backend:
Segurança: Sua chave de API de IA é como uma senha – se você colocá-la no JavaScript do frontend, qualquer pessoa que visualizar o código-fonte do seu site pode roubá-la e usar seus créditos de IA. O backend mantém credenciais sensíveis seguras.
Controle de Limitação de Taxa: O backend permite controlar com que frequência os usuários podem fazer solicitações, implementar autenticação de usuários e adicionar logs para rastrear o uso.
Processamento de Dados: Você pode querer salvar conversas, filtrar conteúdo inadequado ou combinar vários serviços de IA. O backend é onde essa lógica reside.
A arquitetura se assemelha a um modelo cliente-servidor:
- Frontend: Camada de interface do usuário para interação
- API Backend: Camada de processamento e roteamento de solicitações
- Serviço de IA: Computação externa e geração de respostas
- Variáveis de Ambiente: Configuração segura e armazenamento de credenciais
Entendendo o Fluxo de Solicitação-Resposta
Vamos traçar o que acontece quando um usuário envia uma mensagem:
sequenceDiagram
participant User as 👤 User
participant Frontend as 🌐 Frontend
participant API as 🔧 FastAPI Server
participant AI as 🤖 AI Service
User->>Frontend: Types "Hello AI!"
Frontend->>API: POST /hello {"message": "Hello AI!"}
Note over API: Validates request<br/>Adds system prompt
API->>AI: Sends formatted request
AI->>API: Returns AI response
Note over API: Processes response<br/>Logs conversation
API->>Frontend: {"response": "Hello! How can I help?"}
Frontend->>User: Displays AI message
Entendendo cada etapa:
- Interação do usuário: A pessoa digita na interface de chat
- Processamento no frontend: O JavaScript captura a entrada e a formata como JSON
- Validação da API: O FastAPI valida automaticamente a solicitação usando modelos Pydantic
- Integração com IA: O backend adiciona contexto (prompt do sistema) e chama o serviço de IA
- Manipulação de resposta: A API recebe a resposta da IA e pode modificá-la, se necessário
- Exibição no frontend: O JavaScript mostra a resposta na interface de chat
Entendendo a Arquitetura da API
sequenceDiagram
participant Frontend
participant FastAPI
participant AI Function
participant GitHub Models
Frontend->>FastAPI: POST /hello {"message": "Hello AI!"}
FastAPI->>AI Function: call_llm(message, system_prompt)
AI Function->>GitHub Models: API request
GitHub Models->>AI Function: AI response
AI Function->>FastAPI: response text
FastAPI->>Frontend: {"response": "Hello! How can I help?"}
flowchart TD
A[User Input] --> B[Frontend Validation]
B --> C[HTTP POST Request]
C --> D[FastAPI Router]
D --> E[Pydantic Validation]
E --> F[AI Function Call]
F --> G[GitHub Models API]
G --> H[Response Processing]
H --> I[JSON Response]
I --> J[Frontend Update]
subgraph "Security Layer"
K[CORS Middleware]
L[Environment Variables]
M[Error Handling]
end
D --> K
F --> L
H --> M
Criando a Aplicação FastAPI
Vamos construir nossa API passo a passo. Crie um arquivo chamado api.py com o seguinte código FastAPI:
# api.py
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from llm import call_llm
import logging
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# Create FastAPI application
app = FastAPI(
title="AI Chat API",
description="A high-performance API for AI-powered chat applications",
version="1.0.0"
)
# Configure CORS
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # Configure appropriately for production
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# Pydantic models for request/response validation
class ChatMessage(BaseModel):
message: str
class ChatResponse(BaseModel):
response: str
@app.get("/")
async def root():
"""Root endpoint providing API information."""
return {
"message": "Welcome to the AI Chat API",
"docs": "/docs",
"health": "/health"
}
@app.get("/health")
async def health_check():
"""Health check endpoint."""
return {"status": "healthy", "service": "ai-chat-api"}
@app.post("/hello", response_model=ChatResponse)
async def chat_endpoint(chat_message: ChatMessage):
"""Main chat endpoint that processes messages and returns AI responses."""
try:
# Extract and validate message
message = chat_message.message.strip()
if not message:
raise HTTPException(status_code=400, detail="Message cannot be empty")
logger.info(f"Processing message: {message[:50]}...")
# Call AI service (note: call_llm should be made async for better performance)
ai_response = await call_llm_async(message, "You are a helpful and friendly assistant.")
logger.info("AI response generated successfully")
return ChatResponse(response=ai_response)
except HTTPException:
raise
except Exception as e:
logger.error(f"Error processing chat message: {str(e)}")
raise HTTPException(status_code=500, detail="Internal server error")
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=5000, reload=True)
Entendendo a implementação do FastAPI:
- Importa o FastAPI para funcionalidade de framework web moderno e Pydantic para validação de dados
- Cria documentação automática da API (disponível em
/docsquando o servidor estiver em execução) - Habilita middleware CORS para permitir solicitações do frontend de diferentes origens
- Define modelos Pydantic para validação e documentação automática de solicitações/respostas
- Usa endpoints assíncronos para melhor desempenho com solicitações simultâneas
- Implementa códigos de status HTTP adequados e tratamento de erros com HTTPException
- Inclui logs estruturados para monitoramento e depuração
- Fornece endpoint de verificação de saúde para monitorar o status do serviço
Principais vantagens do FastAPI sobre frameworks tradicionais:
- Validação automática: Modelos Pydantic garantem integridade dos dados antes do processamento
- Documentação interativa: Acesse
/docspara documentação de API gerada automaticamente e testável - Segurança de tipos: Dicas de tipo do Python evitam erros em tempo de execução e melhoram a qualidade do código
- Suporte assíncrono: Lida com várias solicitações de IA simultaneamente sem bloqueios
- Desempenho: Processamento de solicitações significativamente mais rápido para aplicações em tempo real
Entendendo o CORS: O Guarda de Segurança da Web
CORS (Cross-Origin Resource Sharing) é como um guarda de segurança em um prédio que verifica se os visitantes têm permissão para entrar. Vamos entender por que isso é importante e como afeta sua aplicação.
O que é CORS e por que existe?
O problema: Imagine se qualquer site pudesse fazer solicitações ao site do seu banco em seu nome sem sua permissão. Isso seria um pesadelo de segurança! Os navegadores impedem isso por padrão por meio da "Política de Mesma Origem".
Política de Mesma Origem: Os navegadores só permitem que páginas da web façam solicitações ao mesmo domínio, porta e protocolo de onde foram carregadas.
Analogia do mundo real: É como a segurança de um prédio de apartamentos – apenas os residentes (mesma origem) podem acessar o prédio por padrão. Se você quiser deixar um amigo (origem diferente) visitar, precisa dizer explicitamente à segurança que está tudo bem.
CORS no Ambiente de Desenvolvimento
Durante o desenvolvimento, seu frontend e backend são executados em portas diferentes:
- Frontend:
http://localhost:3000(ou file:// se abrir o HTML diretamente) - Backend:
http://localhost:5000
Esses são considerados "origens diferentes", mesmo que estejam no mesmo computador!
from fastapi.middleware.cors import CORSMiddleware
app = FastAPI(__name__)
CORS(app) # This tells browsers: "It's okay for other origins to make requests to this API"
O que a configuração de CORS faz na prática:
- Adiciona cabeçalhos HTTP especiais às respostas da API que informam aos navegadores "essa solicitação de origem cruzada é permitida"
- Lida com solicitações "preflight" (os navegadores às vezes verificam permissões antes de enviar a solicitação real)
- Previne o temido erro "bloqueado pela política de CORS" no console do navegador
Segurança do CORS: Desenvolvimento vs Produção
# 🚨 Development: Allows ALL origins (convenient but insecure)
CORS(app)
# ✅ Production: Only allow your specific frontend domain
CORS(app, origins=["https://yourdomain.com", "https://www.yourdomain.com"])
# 🔒 Advanced: Different origins for different environments
if app.debug: # Development mode
CORS(app, origins=["http://localhost:3000", "http://127.0.0.1:3000"])
else: # Production mode
CORS(app, origins=["https://yourdomain.com"])
Por que isso importa: No desenvolvimento, CORS(app) é como deixar sua porta da frente destrancada – conveniente, mas não seguro. Na produção, você quer especificar exatamente quais sites podem se comunicar com sua API.
Cenários Comuns de CORS e Soluções
| Cenário | Problema | Solução |
|---|---|---|
| Desenvolvimento Local | O frontend não consegue acessar o backend | Adicione CORSMiddleware ao FastAPI |
| GitHub Pages + Heroku | O frontend implantado não consegue acessar a API | Adicione a URL do GitHub Pages às origens do CORS |
| Domínio Personalizado | Erros de CORS na produção | Atualize as origens do CORS para corresponder ao seu domínio |
| Aplicativo Móvel | O aplicativo não consegue acessar a API web | Adicione o domínio do seu aplicativo ou use * com cuidado |
Dica profissional: Você pode verificar os cabeçalhos de CORS nas Ferramentas de Desenvolvedor do seu navegador, na aba Rede. Procure por cabeçalhos como Access-Control-Allow-Origin na resposta.
Tratamento de Erros e Validação
Observe como nossa API inclui tratamento adequado de erros:
# Validate that we received a message
if not message:
return jsonify({"error": "Message field is required"}), 400
Princípios-chave de validação:
- Verifica campos obrigatórios antes de processar solicitações
- Retorna mensagens de erro significativas em formato JSON
- Usa códigos de status HTTP apropriados (400 para solicitações inválidas)
- Fornece feedback claro para ajudar os desenvolvedores do frontend a depurar problemas
Configurando e Executando Seu Backend
Agora que temos nossa integração de IA e servidor FastAPI prontos, vamos colocar tudo em funcionamento. O processo de configuração envolve instalar dependências do Python, configurar variáveis de ambiente e iniciar seu servidor de desenvolvimento.
Configuração do Ambiente Python
Vamos configurar seu ambiente de desenvolvimento Python. Ambientes virtuais são como a abordagem compartimentada do Projeto Manhattan – cada projeto tem seu próprio espaço isolado com ferramentas e dependências específicas, evitando conflitos entre diferentes projetos.
# Navigate to your backend directory
cd backend
# Create a virtual environment (like creating a clean room for your project)
python -m venv venv
# Activate it (Linux/Mac)
source ./venv/bin/activate
# On Windows, use:
# venv\Scripts\activate
# Install the good stuff
pip install openai fastapi uvicorn python-dotenv
O que acabamos de fazer:
- Criamos nossa própria bolha Python onde podemos instalar pacotes sem afetar mais nada
- Ativamos para que nosso terminal saiba usar este ambiente específico
- Instalamos os essenciais: OpenAI para magia de IA, FastAPI para nossa API web, Uvicorn para executá-la e python-dotenv para gerenciamento seguro de segredos
Principais dependências explicadas:
- FastAPI: Framework web moderno e rápido com documentação automática de API
- Uvicorn: Servidor ASGI ultrarrápido que executa aplicações FastAPI
- OpenAI: Biblioteca oficial para integração com modelos GitHub e API OpenAI
- python-dotenv: Carregamento seguro de variáveis de ambiente a partir de arquivos .env
Configuração de Ambiente: Mantendo Segredos Seguros
Antes de iniciar nossa API, precisamos falar sobre uma das lições mais importantes no desenvolvimento web: como manter seus segredos realmente seguros. Variáveis de ambiente são como um cofre seguro que apenas sua aplicação pode acessar.
O que são Variáveis de Ambiente?
Pense nas variáveis de ambiente como um cofre de segurança – você coloca suas informações valiosas lá, e apenas você (e seu aplicativo) tem a chave para acessá-las. Em vez de escrever informações sensíveis diretamente no código (onde literalmente qualquer pessoa pode vê-las), você as armazena com segurança no ambiente.
Aqui está a diferença:
- A maneira errada: Escrever sua senha em um post-it e colocá-lo no monitor
- A maneira certa: Manter sua senha em um gerenciador de senhas seguro que só você pode acessar
Por que Variáveis de Ambiente Importam
# 🚨 NEVER DO THIS - API key visible to everyone
client = OpenAI(
api_key="ghp_1234567890abcdef...", # Anyone can steal this!
base_url="https://models.github.ai/inference"
)
# ✅ DO THIS - API key stored securely
client = OpenAI(
api_key=os.environ["GITHUB_TOKEN"], # Only your app can access this
base_url="https://models.github.ai/inference"
)
O que acontece quando você codifica segredos:
- Exposição no controle de versão: Qualquer pessoa com acesso ao seu repositório Git vê sua chave de API
- Repositórios públicos: Se você enviar para o GitHub, sua chave fica visível para toda a internet
- Compartilhamento em equipe: Outros desenvolvedores trabalhando no seu projeto têm acesso à sua chave de API pessoal
- Violação de segurança: Se alguém roubar sua chave de API, pode usar seus créditos de IA
Configurando Seu Arquivo de Ambiente
Crie um arquivo .env no diretório do seu backend. Este arquivo armazena seus segredos localmente:
# .env file - This should NEVER be committed to Git
GITHUB_TOKEN=your_github_personal_access_token_here
FASTAPI_DEBUG=True
ENVIRONMENT=development
Entendendo o arquivo .env:
- Um segredo por linha no formato
CHAVE=valor - Sem espaços ao redor do sinal de igual
- Sem aspas necessárias ao redor dos valores (geralmente)
- Comentários começam com
#
Criando Seu Token de Acesso Pessoal do GitHub
Seu token do GitHub é como uma senha especial que dá permissão ao seu aplicativo para usar os serviços de IA do GitHub:
Passo a passo para criação de token:
- Vá para Configurações do GitHub → Configurações de desenvolvedor → Tokens de acesso pessoal → Tokens (clássico)
- Clique em "Gerar novo token (clássico)"
- Defina a expiração (30 dias para testes, mais tempo para produção)
- Selecione escopos: Marque "repo" e quaisquer outras permissões necessárias
- Gere o token e copie-o imediatamente (você não poderá vê-lo novamente!)
- Cole no seu arquivo .env
# Example of what your token looks like (this is fake!)
GITHUB_TOKEN=ghp_1A2B3C4D5E6F7G8H9I0J1K2L3M4N5O6P7Q8R
Carregando Variáveis de Ambiente no Python
import os
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
# Now you can access them securely
api_key = os.environ.get("GITHUB_TOKEN")
if not api_key:
raise ValueError("GITHUB_TOKEN not found in environment variables!")
client = OpenAI(
api_key=api_key,
base_url="https://models.github.ai/inference"
)
O que este código faz:
- Carrega seu arquivo .env e torna as variáveis disponíveis para o Python
- Verifica se o token necessário existe (bom tratamento de erros!)
- Levanta um erro claro se o token estiver ausente
- Usa o token com segurança sem expô-lo no código
Segurança no Git: O Arquivo .gitignore
Seu arquivo .gitignore informa ao Git quais arquivos nunca rastrear ou enviar:
# .gitignore - Add these lines
.env
*.env
.env.local
.env.production
__pycache__/
venv/
.vscode/
Por que isso é crucial: Depois de adicionar .env ao .gitignore, o Git ignorará seu arquivo de ambiente, impedindo que você envie acidentalmente seus segredos para o GitHub.
Diferentes Ambientes, Diferentes Segredos
Aplicações profissionais usam diferentes chaves de API para diferentes ambientes:
# .env.development
GITHUB_TOKEN=your_development_token
DEBUG=True
# .env.production
GITHUB_TOKEN=your_production_token
DEBUG=False
Por que isso importa: Você não quer que seus experimentos de desenvolvimento afetem sua cota de uso de IA em produção, e deseja diferentes níveis de segurança para diferentes ambientes.
Iniciando Seu Servidor de Desenvolvimento: Dando Vida ao Seu FastAPI
Agora vem o momento emocionante – iniciar seu servidor de desenvolvimento FastAPI e ver sua integração de IA ganhar vida! O FastAPI utiliza o Uvicorn, um servidor ASGI ultrarrápido projetado especificamente para aplicações assíncronas em Python.
Entendendo o Processo de Inicialização do Servidor FastAPI
# Method 1: Direct Python execution (includes auto-reload)
python api.py
# Method 2: Using Uvicorn directly (more control)
uvicorn api:app --host 0.0.0.0 --port 5000 --reload
Quando você executa este comando, aqui está o que acontece nos bastidores:
1. O Python carrega sua aplicação FastAPI:
- Importa todas as bibliotecas necessárias (FastAPI, Pydantic, OpenAI, etc.)
- Carrega variáveis de ambiente do arquivo
.env - Cria a instância da aplicação FastAPI com documentação automática
2. O Uvicorn configura o servidor ASGI:
- Conecta-se à porta 5000 com capacidades de manipulação de requisições assíncronas
- Configura o roteamento de requisições com validação automática
- Habilita o recarregamento automático para desenvolvimento (reinicia ao alterar arquivos)
- Gera documentação interativa da API
3. O servidor começa a escutar:
- Seu terminal exibe:
INFO: Uvicorn running on http://0.0.0.0:5000 - O servidor pode lidar com múltiplas requisições de IA simultaneamente
- Sua API está pronta com documentação automática em
http://localhost:5000/docs
O que você deve ver quando tudo estiver funcionando
$ python api.py
INFO: Will watch for changes in these directories: ['/your/project/path']
INFO: Uvicorn running on http://0.0.0.0:5000 (Press CTRL+C to quit)
INFO: Started reloader process [12345] using WatchFiles
INFO: Started server process [12346]
INFO: Waiting for application startup.
INFO: Application startup complete.
Entendendo a saída do FastAPI:
- Will watch for changes: Recarregamento automático habilitado para desenvolvimento
- Uvicorn running: Servidor ASGI de alto desempenho está ativo
- Started reloader process: Monitoramento de arquivos para reinícios automáticos
- Application startup complete: Aplicação FastAPI inicializada com sucesso
- Interactive docs available: Visite
/docspara documentação automática da API
Testando seu FastAPI: Várias Abordagens Poderosas
O FastAPI oferece várias maneiras convenientes de testar sua API, incluindo documentação interativa automática:
Método 1: Documentação Interativa da API (Recomendado)
- Abra seu navegador e vá para
http://localhost:5000/docs - Você verá o Swagger UI com todos os seus endpoints documentados
- Clique em
/hello→ "Try it out" → Insira uma mensagem de teste → "Execute" - Veja a resposta diretamente no navegador com formatação adequada
Método 2: Teste Básico no Navegador
- Vá para
http://localhost:5000para o endpoint raiz - Vá para
http://localhost:5000/healthpara verificar a saúde do servidor - Isso confirma que seu servidor FastAPI está funcionando corretamente
Método 3: Teste via Linha de Comando (Avançado)
# Test with curl (if available)
curl -X POST http://localhost:5000/hello \
-H "Content-Type: application/json" \
-d '{"message": "Hello AI!"}'
# Expected response:
# {"response": "Hello! I'm your AI assistant. How can I help you today?"}
Método 4: Script de Teste em Python
# test_api.py - Create this file to test your API
import requests
import json
# Test the API endpoint
url = "http://localhost:5000/hello"
data = {"message": "Tell me a joke about programming"}
response = requests.post(url, json=data)
if response.status_code == 200:
result = response.json()
print("AI Response:", result['response'])
else:
print("Error:", response.status_code, response.text)
Solução de Problemas Comuns na Inicialização
| Mensagem de Erro | O que Significa | Como Resolver |
|---|---|---|
ModuleNotFoundError: No module named 'fastapi' |
FastAPI não instalado | Execute pip install fastapi uvicorn no seu ambiente virtual |
ModuleNotFoundError: No module named 'uvicorn' |
Servidor ASGI não instalado | Execute pip install uvicorn no seu ambiente virtual |
KeyError: 'GITHUB_TOKEN' |
Variável de ambiente não encontrada | Verifique seu arquivo .env e a chamada load_dotenv() |
Address already in use |
Porta 5000 ocupada | Finalize outros processos usando a porta 5000 ou altere a porta |
ValidationError |
Dados da requisição não correspondem ao modelo Pydantic | Verifique se o formato da requisição corresponde ao esquema esperado |
HTTPException 422 |
Entidade não processável | Validação da requisição falhou, verifique /docs para o formato correto |
OpenAI API error |
Autenticação do serviço de IA falhou | Verifique se seu token do GitHub está correto e possui as permissões adequadas |
Melhores Práticas de Desenvolvimento
Recarregamento Automático: O FastAPI com Uvicorn fornece recarregamento automático ao salvar alterações nos arquivos Python. Isso significa que você pode modificar seu código e testar imediatamente sem reiniciar manualmente.
# Enable hot reloading explicitly
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000, debug=True) # debug=True enables hot reload
Log para Desenvolvimento: Adicione logs para entender o que está acontecendo:
import logging
# Set up logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@app.route("/hello", methods=["POST"])
def hello():
data = request.get_json()
message = data.get("message", "")
logger.info(f"Received message: {message}")
if not message:
logger.warning("Empty message received")
return jsonify({"error": "Message field is required"}), 400
try:
response = call_llm(message, "You are a helpful and friendly assistant.")
logger.info(f"AI response generated successfully")
return jsonify({"response": response})
except Exception as e:
logger.error(f"AI API error: {str(e)}")
return jsonify({"error": "AI service temporarily unavailable"}), 500
Por que os logs ajudam: Durante o desenvolvimento, você pode ver exatamente quais requisições estão chegando, o que a IA está respondendo e onde ocorrem erros. Isso torna a depuração muito mais rápida.
Configurando para GitHub Codespaces: Desenvolvimento na Nuvem Facilitado
O GitHub Codespaces é como ter um computador de desenvolvimento poderoso na nuvem que você pode acessar de qualquer navegador. Se você estiver trabalhando no Codespaces, há alguns passos adicionais para tornar seu backend acessível ao frontend.
Entendendo a Rede do Codespaces
Em um ambiente de desenvolvimento local, tudo roda no mesmo computador:
- Backend:
http://localhost:5000 - Frontend:
http://localhost:3000(ou file://)
No Codespaces, seu ambiente de desenvolvimento roda nos servidores do GitHub, então "localhost" tem um significado diferente. O GitHub cria automaticamente URLs públicos para seus serviços, mas você precisa configurá-los corretamente.
Configuração Passo a Passo no Codespaces
1. Inicie seu servidor backend:
cd backend
python api.py
Você verá a mensagem familiar de inicialização do FastAPI/Uvicorn, mas note que está rodando dentro do ambiente Codespaces.
2. Configure a visibilidade da porta:
- Procure pela aba "Ports" no painel inferior do VS Code
- Encontre a porta 5000 na lista
- Clique com o botão direito na porta 5000
- Selecione "Port Visibility" → "Public"
Por que torná-la pública? Por padrão, as portas do Codespaces são privadas (acessíveis apenas para você). Torná-las públicas permite que seu frontend (que roda no navegador) se comunique com seu backend.
3. Obtenha seu URL público: Após tornar a porta pública, você verá um URL como:
https://your-codespace-name-5000.app.github.dev
4. Atualize a configuração do seu frontend:
// In your frontend app.js, update the BASE_URL:
this.BASE_URL = "https://your-codespace-name-5000.app.github.dev";
Entendendo os URLs do Codespaces
Os URLs do Codespaces seguem um padrão previsível:
https://[codespace-name]-[port].app.github.dev
Desmembrando isso:
codespace-name: Um identificador único para seu Codespace (geralmente inclui seu nome de usuário)port: O número da porta onde seu serviço está rodando (5000 para nossa aplicação FastAPI)app.github.dev: Domínio do GitHub para aplicações Codespaces
Testando sua Configuração no Codespaces
1. Teste o backend diretamente: Abra seu URL público em uma nova aba do navegador. Você deve ver:
Welcome to the AI Chat API. Send POST requests to /hello with JSON payload containing 'message' field.
2. Teste com ferramentas de desenvolvedor do navegador:
// Open browser console and test your API
fetch('https://your-codespace-name-5000.app.github.dev/hello', {
method: 'POST',
headers: {'Content-Type': 'application/json'},
body: JSON.stringify({message: 'Hello from Codespaces!'})
})
.then(response => response.json())
.then(data => console.log(data));
Codespaces vs Desenvolvimento Local
| Aspecto | Desenvolvimento Local | GitHub Codespaces |
|---|---|---|
| Tempo de Configuração | Maior (instalar Python, dependências) | Instantâneo (ambiente pré-configurado) |
| Acesso ao URL | http://localhost:5000 |
https://xyz-5000.app.github.dev |
| Configuração de Porta | Automática | Manual (tornar portas públicas) |
| Persistência de Arquivos | Máquina local | Repositório GitHub |
| Colaboração | Difícil de compartilhar ambiente | Fácil de compartilhar link do Codespace |
| Dependência de Internet | Apenas para chamadas de API de IA | Necessária para tudo |
Dicas de Desenvolvimento no Codespaces
Variáveis de Ambiente no Codespaces:
Seu arquivo .env funciona da mesma forma no Codespaces, mas você também pode definir variáveis de ambiente diretamente no Codespace:
# Set environment variable for the current session
export GITHUB_TOKEN="your_token_here"
# Or add to your .bashrc for persistence
echo 'export GITHUB_TOKEN="your_token_here"' >> ~/.bashrc
Gerenciamento de Portas:
- O Codespaces detecta automaticamente quando sua aplicação começa a escutar em uma porta
- Você pode encaminhar múltiplas portas simultaneamente (útil se adicionar um banco de dados mais tarde)
- As portas permanecem acessíveis enquanto seu Codespace estiver ativo
Fluxo de Trabalho de Desenvolvimento:
- Faça alterações no código no VS Code
- O FastAPI recarrega automaticamente (graças ao modo de recarregamento do Uvicorn)
- Teste as alterações imediatamente através do URL público
- Faça commit e push quando estiver pronto
💡 Dica Pro: Adicione o URL do backend do seu Codespace aos favoritos durante o desenvolvimento. Como os nomes dos Codespaces são estáveis, o URL não mudará enquanto você estiver usando o mesmo Codespace.
Criando a Interface de Chat do Frontend: Onde Humanos Encontram IA
Agora vamos construir a interface do usuário – a parte que determina como as pessoas interagem com seu assistente de IA. Assim como o design da interface original do iPhone, estamos focando em tornar a tecnologia complexa intuitiva e natural de usar.
Entendendo a Arquitetura Moderna de Frontend
Nossa interface de chat será o que chamamos de "Aplicativo de Página Única" ou SPA. Em vez da abordagem antiga, onde cada clique carrega uma nova página, nosso aplicativo atualiza de forma suave e instantânea:
Sites antigos: Como ler um livro físico – você vira para páginas completamente novas Nosso aplicativo de chat: Como usar seu celular – tudo flui e atualiza sem interrupções
graph TD
A[User Types Message] --> B[JavaScript Captures Input]
B --> C[Validate & Format Data]
C --> D[Send to Backend API]
D --> E[Display Loading State]
E --> F[Receive AI Response]
F --> G[Update Chat Interface]
G --> H[Ready for Next Message]
classDiagram
class ChatApp {
+messages: HTMLElement
+form: HTMLElement
+input: HTMLElement
+sendButton: HTMLElement
+BASE_URL: string
+API_ENDPOINT: string
+constructor()
+initializeEventListeners()
+handleSubmit(event)
+callAPI(message)
+appendMessage(text, role)
+escapeHtml(text)
+scrollToBottom()
+setLoading(isLoading)
}
ChatApp --> DOM : manipulates
ChatApp --> FastAPI : sends requests
Os Três Pilares do Desenvolvimento Frontend
Todo aplicativo frontend – de sites simples a aplicativos complexos como Discord ou Slack – é construído sobre três tecnologias principais. Pense nelas como a base de tudo o que você vê e interage na web:
HTML (Estrutura): Este é o seu alicerce
- Decide quais elementos existem (botões, áreas de texto, contêineres)
- Dá significado ao conteúdo (isto é um cabeçalho, isto é um formulário, etc.)
- Cria a estrutura básica sobre a qual tudo mais é construído
CSS (Apresentação): Este é o seu designer de interiores
- Faz tudo parecer bonito (cores, fontes, layouts)
- Lida com diferentes tamanhos de tela (celular vs laptop vs tablet)
- Cria animações suaves e feedback visual
JavaScript (Comportamento): Este é o seu cérebro
- Responde ao que os usuários fazem (cliques, digitação, rolagem)
- Conversa com seu backend e atualiza a página
- Torna tudo interativo e dinâmico
Pense nisso como design arquitetônico:
- HTML: O plano estrutural (definindo espaços e relações)
- CSS: O design estético e ambiental (estilo visual e experiência do usuário)
- JavaScript: Os sistemas mecânicos (funcionalidade e interatividade)
Por que a Arquitetura Moderna de JavaScript é Importante
Nosso aplicativo de chat usará padrões modernos de JavaScript que você verá em aplicações profissionais. Entender esses conceitos ajudará você a crescer como desenvolvedor:
Arquitetura Baseada em Classes: Organizaremos nosso código em classes, que são como criar modelos para objetos Async/Await: Forma moderna de lidar com operações que levam tempo (como chamadas de API) Programação Orientada a Eventos: Nosso aplicativo responde às ações do usuário (cliques, pressionamento de teclas) em vez de rodar em um loop Manipulação do DOM: Atualização dinâmica do conteúdo da página com base nas interações do usuário e respostas da API
Configuração da Estrutura do Projeto
Crie um diretório frontend com esta estrutura organizada:
frontend/
├── index.html # Main HTML structure
├── app.js # JavaScript functionality
└── styles.css # Visual styling
Entendendo a arquitetura:
- Separa preocupações entre estrutura (HTML), comportamento (JavaScript) e apresentação (CSS)
- Mantém uma estrutura de arquivos simples e fácil de navegar e modificar
- Segue as melhores práticas de desenvolvimento web para organização e manutenção
Construindo a Base HTML: Estrutura Semântica para Acessibilidade
Vamos começar com a estrutura HTML. O desenvolvimento web moderno enfatiza o "HTML semântico" – usar elementos HTML que descrevem claramente seu propósito, não apenas sua aparência. Isso torna sua aplicação acessível a leitores de tela, mecanismos de busca e outras ferramentas.
Por que o HTML semântico é importante: Imagine descrever seu aplicativo de chat para alguém por telefone. Você diria "há um cabeçalho com o título, uma área principal onde as conversas aparecem e um formulário na parte inferior para digitar mensagens". O HTML semântico usa elementos que correspondem a essa descrição natural.
Crie index.html com esta marcação estruturada cuidadosamente:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>AI Chat Assistant</title>
<link rel="stylesheet" href="styles.css">
</head>
<body>
<div class="chat-container">
<header class="chat-header">
<h1>AI Chat Assistant</h1>
<p>Ask me anything!</p>
</header>
<main class="chat-messages" id="messages" role="log" aria-live="polite">
<!-- Messages will be dynamically added here -->
</main>
<form class="chat-form" id="chatForm">
<div class="input-group">
<input
type="text"
id="messageInput"
placeholder="Type your message here..."
required
aria-label="Chat message input"
>
<button type="submit" id="sendBtn" aria-label="Send message">
Send
</button>
</div>
</form>
</div>
<script src="app.js"></script>
</body>
</html>
Entendendo cada elemento HTML e seu propósito:
Estrutura do Documento
<!DOCTYPE html>: Informa ao navegador que este é HTML5 moderno<html lang="en">: Especifica o idioma da página para leitores de tela e ferramentas de tradução<meta charset="UTF-8">: Garante codificação de caracteres adequada para texto internacional<meta name="viewport"...>: Torna a página responsiva para dispositivos móveis, controlando zoom e escala
Elementos Semânticos
<header>: Identifica claramente a seção superior com título e descrição<main>: Designa a área de conteúdo principal (onde as conversas acontecem)<form>: Semânticamente correto para entrada do usuário, permite navegação adequada pelo teclado
Recursos de Acessibilidade
role="log": Informa aos leitores de tela que esta área contém um registro cronológico de mensagensaria-live="polite": Anuncia novas mensagens para leitores de tela sem interrupçõesaria-label: Fornece rótulos descritivos para controles de formuláriorequired: O navegador valida que os usuários insiram uma mensagem antes de enviar
Integração de CSS e JavaScript
- Atributos
class: Fornecem ganchos de estilo para CSS (ex.:chat-container,input-group) - Atributos
id: Permitem que o JavaScript encontre e manipule elementos específicos - Posicionamento do script: Arquivo JavaScript carregado no final para que o HTML seja carregado primeiro
Por que essa estrutura funciona:
- Fluxo lógico: Cabeçalho → Conteúdo principal → Formulário de entrada corresponde à ordem natural de leitura
- Acessível por teclado: Usuários podem navegar por todos os elementos interativos
- Amigável para leitores de tela: Marcos claros e descrições para usuários com deficiência visual
- Responsivo para dispositivos móveis: Meta tag de viewport habilita design responsivo
- Aprimoramento progressivo: Funciona mesmo se o CSS ou JavaScript falhar ao carregar
Adicionando JavaScript Interativo: Lógica de Aplicação Web Moderna
Agora vamos criar o JavaScript que dará vida à nossa interface de chat. Utilizaremos padrões modernos de JavaScript que você encontrará no desenvolvimento web profissional, incluindo classes ES6, async/await e programação orientada a eventos.
Entendendo a Arquitetura Moderna de JavaScript
Em vez de escrever código procedural (uma série de funções que são executadas em ordem), criaremos uma arquitetura baseada em classes. Pense em uma classe como um modelo para criar objetos – como um projeto de arquiteto que pode ser usado para construir várias casas.
Por que usar classes em aplicações web?
- Organização: Toda funcionalidade relacionada é agrupada
- Reutilização: Você pode criar várias instâncias de chat na mesma página
- Manutenção: Mais fácil de depurar e modificar recursos específicos
- Padrão profissional: Esse padrão é usado em frameworks como React, Vue e Angular
Crie o arquivo app.js com este JavaScript moderno e bem estruturado:
// app.js - Modern chat application logic
class ChatApp {
constructor() {
// Get references to DOM elements we'll need to manipulate
this.messages = document.getElementById("messages");
this.form = document.getElementById("chatForm");
this.input = document.getElementById("messageInput");
this.sendButton = document.getElementById("sendBtn");
// Configure your backend URL here
this.BASE_URL = "http://localhost:5000"; // Update this for your environment
this.API_ENDPOINT = `${this.BASE_URL}/hello`;
// Set up event listeners when the chat app is created
this.initializeEventListeners();
}
initializeEventListeners() {
// Listen for form submission (when user clicks Send or presses Enter)
this.form.addEventListener("submit", (e) => this.handleSubmit(e));
// Also listen for Enter key in the input field (better UX)
this.input.addEventListener("keypress", (e) => {
if (e.key === "Enter" && !e.shiftKey) {
e.preventDefault();
this.handleSubmit(e);
}
});
}
async handleSubmit(event) {
event.preventDefault(); // Prevent form from refreshing the page
const messageText = this.input.value.trim();
if (!messageText) return; // Don't send empty messages
// Provide user feedback that something is happening
this.setLoading(true);
// Add user message to chat immediately (optimistic UI)
this.appendMessage(messageText, "user");
// Clear input field so user can type next message
this.input.value = '';
try {
// Call the AI API and wait for response
const reply = await this.callAPI(messageText);
// Add AI response to chat
this.appendMessage(reply, "assistant");
} catch (error) {
console.error('API Error:', error);
this.appendMessage("Sorry, I'm having trouble connecting right now. Please try again.", "error");
} finally {
// Re-enable the interface regardless of success or failure
this.setLoading(false);
}
}
async callAPI(message) {
const response = await fetch(this.API_ENDPOINT, {
method: "POST",
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify({ message })
});
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const data = await response.json();
return data.response;
}
appendMessage(text, role) {
const messageElement = document.createElement("div");
messageElement.className = `message ${role}`;
messageElement.innerHTML = `
<div class="message-content">
<span class="message-text">${this.escapeHtml(text)}</span>
<span class="message-time">${new Date().toLocaleTimeString()}</span>
</div>
`;
this.messages.appendChild(messageElement);
this.scrollToBottom();
}
escapeHtml(text) {
const div = document.createElement('div');
div.textContent = text;
return div.innerHTML;
}
scrollToBottom() {
this.messages.scrollTop = this.messages.scrollHeight;
}
setLoading(isLoading) {
this.sendButton.disabled = isLoading;
this.input.disabled = isLoading;
this.sendButton.textContent = isLoading ? "Sending..." : "Send";
}
}
// Initialize the chat application when the page loads
document.addEventListener("DOMContentLoaded", () => {
new ChatApp();
});
Entendendo Cada Conceito de JavaScript
Estrutura de Classe ES6:
class ChatApp {
constructor() {
// This runs when you create a new ChatApp instance
// It's like the "setup" function for your chat
}
methodName() {
// Methods are functions that belong to the class
// They can access class properties using "this"
}
}
Padrão Async/Await:
// Old way (callback hell):
fetch(url)
.then(response => response.json())
.then(data => console.log(data))
.catch(error => console.error(error));
// Modern way (async/await):
try {
const response = await fetch(url);
const data = await response.json();
console.log(data);
} catch (error) {
console.error(error);
}
Programação Orientada a Eventos: Em vez de verificar constantemente se algo aconteceu, "ouvimos" os eventos:
// When form is submitted, run handleSubmit
this.form.addEventListener("submit", (e) => this.handleSubmit(e));
// When Enter key is pressed, also run handleSubmit
this.input.addEventListener("keypress", (e) => { /* ... */ });
Manipulação do DOM:
// Create new elements
const messageElement = document.createElement("div");
// Modify their properties
messageElement.className = "message user";
messageElement.innerHTML = "Hello world!";
// Add to the page
this.messages.appendChild(messageElement);
Segurança e Melhores Práticas
Prevenção de XSS:
escapeHtml(text) {
const div = document.createElement('div');
div.textContent = text; // This automatically escapes HTML
return div.innerHTML;
}
Por que isso é importante: Se um usuário digitar <script>alert('hack')</script>, esta função garante que isso seja exibido como texto em vez de ser executado como código.
Tratamento de Erros:
try {
const reply = await this.callAPI(messageText);
this.appendMessage(reply, "assistant");
} catch (error) {
// Show user-friendly error instead of breaking the app
this.appendMessage("Sorry, I'm having trouble...", "error");
}
Considerações sobre Experiência do Usuário:
- UI otimista: Adicione a mensagem do usuário imediatamente, sem esperar pela resposta do servidor
- Estados de carregamento: Desative botões e exiba "Enviando..." enquanto aguarda
- Rolagem automática: Mantenha as mensagens mais recentes visíveis
- Validação de entrada: Não envie mensagens vazias
- Atalhos de teclado: A tecla Enter envia mensagens (como em aplicativos de chat reais)
Entendendo o Fluxo da Aplicação
- Carregamento da página → Evento
DOMContentLoadedé disparado →new ChatApp()é criado - Construtor é executado → Obtém referências aos elementos do DOM → Configura os ouvintes de eventos
- Usuário digita mensagem → Pressiona Enter ou clica em Enviar →
handleSubmité executado - handleSubmit → Valida a entrada → Exibe estado de carregamento → Chama a API
- Resposta da API → Adiciona mensagem da IA ao chat → Reativa a interface
- Pronto para a próxima mensagem → Usuário pode continuar conversando
Essa arquitetura é escalável – você pode facilmente adicionar recursos como edição de mensagens, upload de arquivos ou múltiplos tópicos de conversa sem reescrever a estrutura principal.
🎯 Verificação Pedagógica: Arquitetura Moderna de Frontend
Entendimento da Arquitetura: Você implementou uma aplicação de página única completa usando padrões modernos de JavaScript. Isso representa um nível profissional de desenvolvimento frontend.
Conceitos-Chave Dominados:
- Arquitetura de Classes ES6: Estrutura de código organizada e fácil de manter
- Padrões Async/Await: Programação assíncrona moderna
- Programação Orientada a Eventos: Design de interface responsiva
- Melhores Práticas de Segurança: Prevenção de XSS e validação de entrada
Conexão com a Indústria: Os padrões que você aprendeu (arquitetura baseada em classes, operações assíncronas, manipulação do DOM) são a base de frameworks modernos como React, Vue e Angular. Você está construindo com o mesmo pensamento arquitetônico usado em aplicações de produção.
Pergunta para Reflexão: Como você estenderia esta aplicação de chat para lidar com múltiplas conversas ou autenticação de usuários? Considere as mudanças arquitetônicas necessárias e como a estrutura de classes evoluiria.
Estilizando Sua Interface de Chat
Agora vamos criar uma interface de chat moderna e visualmente atraente com CSS. Um bom estilo faz com que sua aplicação pareça profissional e melhora a experiência geral do usuário. Usaremos recursos modernos de CSS, como Flexbox, CSS Grid e propriedades personalizadas para um design responsivo e acessível.
Crie o arquivo styles.css com esses estilos abrangentes:
/* styles.css - Modern chat interface styling */
:root {
--primary-color: #2563eb;
--secondary-color: #f1f5f9;
--user-color: #3b82f6;
--assistant-color: #6b7280;
--error-color: #ef4444;
--text-primary: #1e293b;
--text-secondary: #64748b;
--border-radius: 12px;
--shadow: 0 4px 6px -1px rgba(0, 0, 0, 0.1);
}
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
body {
font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, sans-serif;
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
min-height: 100vh;
display: flex;
align-items: center;
justify-content: center;
padding: 20px;
}
.chat-container {
width: 100%;
max-width: 800px;
height: 600px;
background: white;
border-radius: var(--border-radius);
box-shadow: var(--shadow);
display: flex;
flex-direction: column;
overflow: hidden;
}
.chat-header {
background: var(--primary-color);
color: white;
padding: 20px;
text-align: center;
}
.chat-header h1 {
font-size: 1.5rem;
margin-bottom: 5px;
}
.chat-header p {
opacity: 0.9;
font-size: 0.9rem;
}
.chat-messages {
flex: 1;
padding: 20px;
overflow-y: auto;
display: flex;
flex-direction: column;
gap: 15px;
background: var(--secondary-color);
}
.message {
display: flex;
max-width: 80%;
animation: slideIn 0.3s ease-out;
}
.message.user {
align-self: flex-end;
}
.message.user .message-content {
background: var(--user-color);
color: white;
border-radius: var(--border-radius) var(--border-radius) 4px var(--border-radius);
}
.message.assistant {
align-self: flex-start;
}
.message.assistant .message-content {
background: white;
color: var(--text-primary);
border-radius: var(--border-radius) var(--border-radius) var(--border-radius) 4px;
border: 1px solid #e2e8f0;
}
.message.error .message-content {
background: var(--error-color);
color: white;
border-radius: var(--border-radius);
}
.message-content {
padding: 12px 16px;
box-shadow: var(--shadow);
position: relative;
}
.message-text {
display: block;
line-height: 1.5;
word-wrap: break-word;
}
.message-time {
display: block;
font-size: 0.75rem;
opacity: 0.7;
margin-top: 5px;
}
.chat-form {
padding: 20px;
border-top: 1px solid #e2e8f0;
background: white;
}
.input-group {
display: flex;
gap: 10px;
align-items: center;
}
#messageInput {
flex: 1;
padding: 12px 16px;
border: 2px solid #e2e8f0;
border-radius: var(--border-radius);
font-size: 1rem;
outline: none;
transition: border-color 0.2s ease;
}
#messageInput:focus {
border-color: var(--primary-color);
}
#messageInput:disabled {
background: #f8fafc;
opacity: 0.6;
cursor: not-allowed;
}
#sendBtn {
padding: 12px 24px;
background: var(--primary-color);
color: white;
border: none;
border-radius: var(--border-radius);
font-size: 1rem;
font-weight: 600;
cursor: pointer;
transition: background-color 0.2s ease;
min-width: 80px;
}
#sendBtn:hover:not(:disabled) {
background: #1d4ed8;
}
#sendBtn:disabled {
background: #94a3b8;
cursor: not-allowed;
}
@keyframes slideIn {
from {
opacity: 0;
transform: translateY(10px);
}
to {
opacity: 1;
transform: translateY(0);
}
}
/* Responsive design for mobile devices */
@media (max-width: 768px) {
body {
padding: 10px;
}
.chat-container {
height: calc(100vh - 20px);
border-radius: 8px;
}
.message {
max-width: 90%;
}
.input-group {
flex-direction: column;
gap: 10px;
}
#messageInput {
width: 100%;
}
#sendBtn {
width: 100%;
}
}
/* Accessibility improvements */
@media (prefers-reduced-motion: reduce) {
.message {
animation: none;
}
* {
transition: none !important;
}
}
/* Dark mode support */
@media (prefers-color-scheme: dark) {
.chat-container {
background: #1e293b;
color: #f1f5f9;
}
.chat-messages {
background: #0f172a;
}
.message.assistant .message-content {
background: #334155;
color: #f1f5f9;
border-color: #475569;
}
.chat-form {
background: #1e293b;
border-color: #475569;
}
#messageInput {
background: #334155;
color: #f1f5f9;
border-color: #475569;
}
}
Entendendo a arquitetura CSS:
- Utiliza propriedades personalizadas do CSS (variáveis) para temas consistentes e fácil manutenção
- Implementa layout Flexbox para design responsivo e alinhamento adequado
- Inclui animações suaves para a aparição das mensagens sem serem distrações
- Fornece distinção visual entre mensagens do usuário, respostas da IA e estados de erro
- Suporta design responsivo que funciona tanto em dispositivos desktop quanto móveis
- Considera acessibilidade com preferências de movimento reduzido e proporções de contraste adequadas
- Oferece suporte ao modo escuro com base nas preferências do sistema do usuário
Configurando a URL do Backend
O passo final é atualizar o BASE_URL no seu JavaScript para corresponder ao servidor backend:
// For local development
this.BASE_URL = "http://localhost:5000";
// For GitHub Codespaces (replace with your actual URL)
this.BASE_URL = "https://your-codespace-name-5000.app.github.dev";
Determinando a URL do backend:
- Desenvolvimento local: Use
http://localhost:5000se estiver executando o frontend e o backend localmente - Codespaces: Encontre a URL do backend na aba Ports após tornar a porta 5000 pública
- Produção: Substitua pelo seu domínio real ao implantar em um serviço de hospedagem
💡 Dica de Teste: Você pode testar seu backend diretamente visitando a URL raiz no navegador. Você deve ver a mensagem de boas-vindas do servidor FastAPI.
Testando e Implantando
Agora que você construiu os componentes frontend e backend, vamos testar se tudo funciona junto e explorar opções de implantação para compartilhar seu assistente de chat com outras pessoas.
Fluxo de Teste Local
Siga estes passos para testar sua aplicação completa:
graph TD
A[Start Backend Server] --> B[Configure Environment Variables]
B --> C[Test API Endpoints]
C --> D[Open Frontend in Browser]
D --> E[Test Chat Functionality]
E --> F[Debug Any Issues]
Processo de teste passo a passo:
-
Inicie seu servidor backend:
cd backend source venv/bin/activate # or venv\Scripts\activate on Windows python api.py -
Verifique se a API está funcionando:
- Abra
http://localhost:5000no seu navegador - Você deve ver a mensagem de boas-vindas do servidor FastAPI
- Abra
-
Abra seu frontend:
- Navegue até o diretório do frontend
- Abra
index.htmlno seu navegador web - Ou use a extensão Live Server do VS Code para uma melhor experiência de desenvolvimento
-
Teste a funcionalidade do chat:
- Digite uma mensagem no campo de entrada
- Clique em "Enviar" ou pressione Enter
- Verifique se a IA responde adequadamente
- Confira o console do navegador para quaisquer erros de JavaScript
Solução de Problemas Comuns
| Problema | Sintomas | Solução |
|---|---|---|
| Erro de CORS | Frontend não consegue acessar o backend | Certifique-se de que o FastAPI CORSMiddleware está configurado corretamente |
| Erro de API Key | Respostas 401 Unauthorized | Verifique a variável de ambiente GITHUB_TOKEN |
| Conexão Recusada | Erros de rede no frontend | Verifique a URL do backend e se o servidor Flask está em execução |
| Sem Resposta da IA | Respostas vazias ou com erro | Verifique os logs do backend para problemas de cota ou autenticação da API |
Passos comuns de depuração:
- Verifique o Console de Ferramentas de Desenvolvedor do navegador para erros de JavaScript
- Confirme que a aba de Rede mostra solicitações e respostas bem-sucedidas da API
- Revise a saída do terminal do backend para erros em Python ou problemas na API
- Certifique-se de que as variáveis de ambiente estão carregadas e acessíveis corretamente
📈 Linha do Tempo de Domínio do Desenvolvimento de Aplicações com IA
timeline
title Complete AI Application Development Journey
section AI Foundations
Understanding Generative AI
: Grasp pattern recognition concepts
: Master AI parameter control
: Learn prompt engineering techniques
GitHub Models Integration
: Navigate AI service platforms
: Handle authentication securely
: Optimize model parameters
section Backend Development
Python API Architecture
: Build FastAPI applications
: Implement async operations
: Create secure endpoints
AI Service Integration
: Connect to external AI APIs
: Handle rate limiting
: Implement error boundaries
section Frontend Mastery
Modern JavaScript Patterns
: Master ES6 class architecture
: Implement async/await flows
: Build responsive interfaces
Real-time User Experience
: Create dynamic chat interfaces
: Handle loading states
: Optimize user interactions
section Production Readiness
Security & Performance
: Implement secure token management
: Prevent XSS vulnerabilities
: Optimize API performance
Professional Deployment
: Build scalable architectures
: Create maintainable code
: Document development processes
🎓 Marco de Graduação: Você construiu com sucesso uma aplicação completa com integração de IA usando as mesmas tecnologias e padrões arquitetônicos que alimentam assistentes de IA modernos. Essas habilidades representam a interseção entre desenvolvimento web tradicional e integração de IA de ponta.
🔄 Capacidades de Próximo Nível:
- Pronto para explorar frameworks avançados de IA (LangChain, LangGraph)
- Preparado para construir aplicações de IA multimodais (texto, imagem, voz)
- Equipado para implementar bancos de dados vetoriais e sistemas de recuperação
- Base estabelecida para aprendizado de máquina e ajuste fino de modelos de IA
Desafio do Agente GitHub Copilot 🚀
Use o modo Agente para completar o seguinte desafio:
Descrição: Melhore o assistente de chat adicionando histórico de conversas e persistência de mensagens. Este desafio ajudará você a entender como gerenciar estado em aplicações de chat e implementar armazenamento de dados para uma melhor experiência do usuário.
Prompt: Modifique a aplicação de chat para incluir histórico de conversas que persista entre sessões. Adicione funcionalidade para salvar mensagens de chat no armazenamento local, exibir histórico de conversas ao carregar a página e incluir um botão "Limpar Histórico". Também implemente indicadores de digitação e carimbos de data/hora nas mensagens para tornar a experiência de chat mais realista.
Saiba mais sobre modo agente aqui.
Tarefa: Construa Seu Assistente de IA Pessoal
Agora você criará sua própria implementação de assistente de IA. Em vez de simplesmente replicar o código do tutorial, esta é uma oportunidade de aplicar os conceitos enquanto constrói algo que reflita seus próprios interesses e casos de uso.
Requisitos do Projeto
Vamos configurar seu projeto com uma estrutura limpa e organizada:
my-ai-assistant/
├── backend/
│ ├── api.py # Your FastAPI server
│ ├── llm.py # AI integration functions
│ ├── .env # Your secrets (keep this safe!)
│ └── requirements.txt # Python dependencies
├── frontend/
│ ├── index.html # Your chat interface
│ ├── app.js # The JavaScript magic
│ └── styles.css # Make it look amazing
└── README.md # Tell the world about your creation
Tarefas de Implementação Principais
Desenvolvimento Backend:
- Pegue nosso código FastAPI e personalize-o
- Crie uma personalidade única para a IA – talvez um assistente de culinária útil, um parceiro criativo de escrita ou um colega de estudos?
- Adicione tratamento de erros sólido para que seu aplicativo não quebre quando algo der errado
- Escreva documentação clara para qualquer pessoa que queira entender como sua API funciona
Desenvolvimento Frontend:
- Construa uma interface de chat intuitiva e acolhedora
- Escreva JavaScript moderno e limpo que você se orgulharia de mostrar a outros desenvolvedores
- Projete estilos personalizados que reflitam a personalidade da sua IA – divertido e colorido? Limpo e minimalista? Totalmente com você!
- Certifique-se de que funcione bem tanto em celulares quanto em computadores
Requisitos de Personalização:
- Escolha um nome e personalidade únicos para seu assistente de IA – talvez algo que reflita seus interesses ou os problemas que você deseja resolver
- Personalize o design visual para combinar com o estilo do seu assistente
- Escreva uma mensagem de boas-vindas envolvente que incentive as pessoas a começar a conversar
- Teste seu assistente com diferentes tipos de perguntas para ver como ele responde
Ideias de Melhoria (Opcional)
Quer levar seu projeto para o próximo nível? Aqui estão algumas ideias divertidas para explorar:
| Recurso | Descrição | Habilidades que Você Praticará |
|---|---|---|
| Histórico de Mensagens | Lembre conversas mesmo após atualizar a página | Trabalhar com localStorage, manipulação de JSON |
| Indicadores de Digitação | Mostre "IA está digitando..." enquanto aguarda respostas | Animações CSS, programação assíncrona |
| Carimbos de Data/Hora | Mostre quando cada mensagem foi enviada | Formatação de data/hora, design de UX |
| Exportar Chat | Permita que os usuários baixem suas conversas | Manipulação de arquivos, exportação de dados |
| Alternância de Tema | Alternar entre modo claro/escuro | Variáveis CSS, preferências do usuário |
| Entrada por Voz | Adicione funcionalidade de fala para texto | APIs Web, acessibilidade |
Teste e Documentação
Garantia de Qualidade:
- Teste sua aplicação com vários tipos de entrada e casos extremos
- Verifique se o design responsivo funciona em diferentes tamanhos de tela
- Cheque acessibilidade com navegação por teclado e leitores de tela
- Valide HTML e CSS para conformidade com padrões
Requisitos de Documentação:
- Escreva um README.md explicando seu projeto e como executá-lo
- Inclua capturas de tela da interface de chat em ação
- Documente quaisquer recursos ou personalizações únicas que você adicionou
- Forneça instruções claras de configuração para outros desenvolvedores
Diretrizes de Submissão
Entregáveis do Projeto:
- Pasta completa do projeto com todo o código-fonte
- README.md com descrição do projeto e instruções de configuração
- Capturas de tela demonstrando seu assistente de chat em ação
- Breve reflexão sobre o que você aprendeu e os desafios enfrentados
Critérios de Avaliação:
- Funcionalidade: O assistente de chat funciona como esperado?
- Qualidade do Código: O código está bem organizado, comentado e fácil de manter?
- Design: A interface é visualmente atraente e fácil de usar?
- Criatividade: Quão única e personalizada é sua implementação?
- Documentação: As instruções de configuração são claras e completas?
💡 Dica de Sucesso: Comece pelos requisitos básicos primeiro, depois adicione melhorias quando tudo estiver funcionando. Foque em criar uma experiência central polida antes de adicionar recursos avançados.
Solução
Desafios Bônus
Pronto para levar seu assistente de IA para o próximo nível? Experimente esses desafios avançados que aprofundarão sua compreensão sobre integração de IA e desenvolvimento web.
Personalização de Personalidade
A verdadeira mágica acontece quando você dá ao seu assistente de IA uma personalidade única. Experimente diferentes prompts de sistema para criar assistentes especializados:
Exemplo de Assistente Profissional:
call_llm(message, "You are a professional business consultant with 20 years of experience. Provide structured, actionable advice with specific steps and considerations.")
Exemplo de Auxiliar de Escrita Criativa:
call_llm(message, "You are an enthusiastic creative writing coach. Help users develop their storytelling skills with imaginative prompts and constructive feedback.")
Exemplo de Mentor Técnico:
call_llm(message, "You are a patient senior developer who explains complex programming concepts using simple analogies and practical examples.")
Melhorias no Frontend
Transforme sua interface de chat com essas melhorias visuais e funcionais:
Recursos Avançados de CSS:
- Implemente animações e transições suaves para mensagens
- Adicione designs personalizados de balões de chat com formas e gradientes em CSS
- Crie uma animação de indicador de digitação para quando a IA estiver "pensando"
- Projete reações com emojis ou sistema de avaliação de mensagens
Melhorias em JavaScript:
- Adicione atalhos de teclado (Ctrl+Enter para enviar, Esc para limpar entrada)
- Implemente funcionalidade de busca e filtragem de mensagens
- Crie recurso de exportação de conversas (download como texto ou JSON)
- Adicione salvamento automático no localStorage para evitar perda de mensagens
Integração Avançada de IA
Múltiplas Personalidades de IA:
- Crie um menu suspenso para alternar entre diferentes personalidades de IA
- Salve a personalidade preferida do usuário no localStorage
- Implemente troca de contexto que mantém o fluxo da conversa
Recursos de Resposta Inteligente:
- Adicione consciência de contexto da conversa (IA lembra mensagens anteriores)
- Implemente sugestões inteligentes com base no tópico da conversa
- Crie botões de resposta rápida para perguntas comuns
🎯 Objetivo de Aprendizado: Esses desafios extras ajudam você a entender padrões avançados de desenvolvimento web e técnicas de integração de IA que são usadas em aplicações de produção.
Resumo e Próximos Passos
Parabéns! Você construiu com sucesso um assistente de chat com IA do zero. Este projeto proporcionou uma experiência prática com tecnologias modernas de desenvolvimento web e integração de IA – habilidades cada vez mais valiosas no cenário tecnológico atual.
O Que Você Conquistou
Ao longo desta lição, você dominou várias tecnologias e conceitos importantes:
Desenvolvimento Backend:
- Integrado com a API GitHub Models para funcionalidade de IA
- Construído uma API RESTful usando Flask com tratamento adequado de erros
- Implementado autenticação segura usando variáveis de ambiente
- Configurado CORS para requisições entre frontend e backend
Desenvolvimento Frontend:
- Criado uma interface de chat responsiva usando HTML semântico
- Implementado JavaScript moderno com async/await e arquitetura baseada em classes
- Projetado uma interface de usuário envolvente com CSS Grid, Flexbox e animações
- Adicionado recursos de acessibilidade e princípios de design responsivo
Integração Full-Stack:
- Conectado frontend e backend por meio de chamadas de API HTTP
- Tratado interações em tempo real e fluxo de dados assíncrono
- Implementado tratamento de erros e feedback ao usuário em todo o aplicativo
- Testado o fluxo completo do aplicativo, desde a entrada do usuário até a resposta da IA
Resultados de Aprendizado
mindmap
root((AI Chat App Skills))
API Integration
Authentication
Error Handling
Async Programming
Web Development
HTML5 Semantics
Modern CSS
ES6+ JavaScript
User Experience
Responsive Design
Accessibility
Real-time Interaction
AI Understanding
Prompt Engineering
Model Parameters
Conversation Flow
Este projeto introduziu os fundamentos de construção de aplicações com IA, que representam o futuro do desenvolvimento web. Agora você entende como integrar capacidades de IA em aplicações web tradicionais, criando experiências de usuário envolventes que parecem inteligentes e responsivas.
Aplicações Profissionais
As habilidades que você desenvolveu nesta lição são diretamente aplicáveis a carreiras modernas de desenvolvimento de software:
- Desenvolvimento web full-stack usando frameworks e APIs modernos
- Integração de IA em aplicações web e aplicativos móveis
- Design e desenvolvimento de APIs para arquiteturas de microsserviços
- Desenvolvimento de interfaces de usuário com foco em acessibilidade e design responsivo
- Práticas de DevOps, incluindo configuração de ambiente e implantação
Continuando Sua Jornada de Desenvolvimento com IA
Próximos Passos de Aprendizado:
- Explore modelos de IA e APIs mais avançados (GPT-4, Claude, Gemini)
- Aprenda técnicas de engenharia de prompts para melhores respostas de IA
- Estude design de conversação e princípios de experiência do usuário em chatbots
- Investigue segurança, ética e práticas responsáveis de desenvolvimento de IA
- Construa aplicações mais complexas com memória de conversação e consciência de contexto
Ideias de Projetos Avançados:
- Salas de chat multiusuário com moderação por IA
- Chatbots de atendimento ao cliente com IA
- Assistentes de tutoria educacional com aprendizado personalizado
- Colaboradores de escrita criativa com diferentes personalidades de IA
- Assistentes de documentação técnica para desenvolvedores
Começando com GitHub Codespaces
Quer experimentar este projeto em um ambiente de desenvolvimento na nuvem? O GitHub Codespaces oferece um ambiente completo de desenvolvimento no navegador, perfeito para experimentar aplicações de IA sem necessidade de configuração local.
Configurando Seu Ambiente de Desenvolvimento
Passo 1: Criar a partir do Template
- Acesse o repositório Web Dev For Beginners
- Clique em "Use this template" no canto superior direito (certifique-se de estar logado no GitHub)
Passo 2: Iniciar Codespaces
- Abra o repositório recém-criado
- Clique no botão verde "Code" e selecione "Codespaces"
- Escolha "Create codespace on main" para iniciar seu ambiente de desenvolvimento

Passo 3: Configuração do Ambiente
Assim que seu Codespace carregar, você terá acesso a:
- Python, Node.js e ferramentas de desenvolvimento pré-instalados
- Interface do VS Code com extensões para desenvolvimento web
- Acesso ao terminal para executar servidores backend e frontend
- Encaminhamento de portas para testar suas aplicações
O que Codespaces oferece:
- Elimina problemas de configuração e setup de ambiente local
- Fornece um ambiente de desenvolvimento consistente em diferentes dispositivos
- Inclui ferramentas e extensões pré-configuradas para desenvolvimento web
- Oferece integração perfeita com o GitHub para controle de versão e colaboração
🚀 Dica Pro: Codespaces é perfeito para aprendizado e prototipagem de aplicações com IA, já que lida automaticamente com toda a configuração complexa do ambiente, permitindo que você se concentre em construir e aprender, em vez de solucionar problemas de configuração.
Aviso Legal:
Este documento foi traduzido utilizando o serviço de tradução por IA Co-op Translator. Embora nos esforcemos para garantir a precisão, esteja ciente de que traduções automatizadas podem conter erros ou imprecisões. O documento original em seu idioma nativo deve ser considerado a fonte autoritativa. Para informações críticas, recomenda-se a tradução profissional humana. Não nos responsabilizamos por quaisquer mal-entendidos ou interpretações incorretas decorrentes do uso desta tradução.