# Проект чата
Этот проект чата демонстрирует, как создать чат-ассистента, используя GitHub Models.
Вот как выглядит готовый проект:
Немного контекста: создание чат-ассистентов с использованием генеративного ИИ — отличный способ начать изучение ИИ. В этом уроке вы научитесь интегрировать генеративный ИИ в веб-приложение. Давайте начнем.
## Подключение к генеративному ИИ
Для бэкенда мы используем GitHub Models. Это отличный сервис, который позволяет использовать ИИ бесплатно. Перейдите в его playground и возьмите код, соответствующий выбранному вами языку бэкенда. Вот как это выглядит: [GitHub Models Playground](https://github.com/marketplace/models/azure-openai/gpt-4o-mini/playground)
Как мы уже сказали, выберите вкладку "Code" и ваш runtime.
### Использование Python
В данном случае мы выбираем Python, что означает, что мы берем следующий код:
```python
"""Run this model in Python
> pip install openai
"""
import os
from openai import OpenAI
# To authenticate with the model you will need to generate a personal access token (PAT) in your GitHub settings.
# Create your PAT token by following instructions here: https://docs.github.com/en/authentication/keeping-your-account-and-data-secure/managing-your-personal-access-tokens
client = OpenAI(
base_url="https://models.github.ai/inference",
api_key=os.environ["GITHUB_TOKEN"],
)
response = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "",
},
{
"role": "user",
"content": "What is the capital of France?",
}
],
model="openai/gpt-4o-mini",
temperature=1,
max_tokens=4096,
top_p=1
)
print(response.choices[0].message.content)
```
Давайте немного очистим этот код, чтобы он был более удобным для повторного использования:
```python
def call_llm(prompt: str, system_message: str):
response = client.chat.completions.create(
messages=[
{
"role": "system",
"content": system_message,
},
{
"role": "user",
"content": prompt,
}
],
model="openai/gpt-4o-mini",
temperature=1,
max_tokens=4096,
top_p=1
)
return response.choices[0].message.content
```
С помощью этой функции `call_llm` мы можем передать подсказку и системную подсказку, а функция вернет результат.
### Настройка чат-ассистента
Если вы хотите настроить чат-ассистента, вы можете указать, как он должен себя вести, заполнив системную подсказку следующим образом:
```python
call_llm("Tell me about you", "You're Albert Einstein, you only know of things in the time you were alive")
```
## Экспонирование через Web API
Отлично, мы завершили часть с ИИ, теперь посмотрим, как интегрировать это в Web API. Для Web API мы выбрали Flask, но подойдет любой веб-фреймворк. Вот код:
### Использование Python
```python
# api.py
from flask import Flask, request, jsonify
from llm import call_llm
from flask_cors import CORS
app = Flask(__name__)
CORS(app) # * example.com
@app.route("/", methods=["GET"])
def index():
return "Welcome to this API. Call POST /hello with 'message': 'my message' as JSON payload"
@app.route("/hello", methods=["POST"])
def hello():
# get message from request body { "message": "do this taks for me" }
data = request.get_json()
message = data.get("message", "")
response = call_llm(message, "You are a helpful assistant.")
return jsonify({
"response": response
})
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000)
```
Здесь мы создаем API на Flask и определяем маршруты "/" и "/chat". Последний предназначен для использования нашим фронтендом для передачи вопросов.
Чтобы интегрировать *llm.py*, нам нужно сделать следующее:
- Импортировать функцию `call_llm`:
```python
from llm import call_llm
from flask import Flask, request
```
- Вызвать ее из маршрута "/chat":
```python
@app.route("/hello", methods=["POST"])
def hello():
# get message from request body { "message": "do this taks for me" }
data = request.get_json()
message = data.get("message", "")
response = call_llm(message, "You are a helpful assistant.")
return jsonify({
"response": response
})
```
Здесь мы анализируем входящий запрос, чтобы извлечь свойство `message` из JSON-тела. Затем мы вызываем LLM следующим образом:
```python
response = call_llm(message, "You are a helpful assistant")
# return the response as JSON
return jsonify({
"response": response
})
```
Отлично, теперь мы сделали все необходимое.
## Настройка Cors
Стоит отметить, что мы настроили CORS (совместное использование ресурсов между источниками). Это означает, что поскольку наш бэкенд и фронтенд будут работать на разных портах, нам нужно разрешить фронтенду обращаться к бэкенду.
### Использование Python
В *api.py* есть кусок кода, который это настраивает:
```python
from flask_cors import CORS
app = Flask(__name__)
CORS(app) # * example.com
```
Сейчас он настроен на разрешение "*" (все источники), что небезопасно. Мы должны ограничить это перед переходом в продакшн.
## Запуск проекта
Чтобы запустить проект, сначала нужно запустить бэкенд, а затем фронтенд.
### Использование Python
Итак, у нас есть *llm.py* и *api.py*. Как заставить это работать с бэкендом? Нужно сделать два шага:
- Установить зависимости:
```sh
cd backend
python -m venv venv
source ./venv/bin/activate
pip install openai flask flask-cors openai
```
- Запустить API:
```sh
python api.py
```
Если вы используете Codespaces, вам нужно перейти в раздел Ports в нижней части редактора, щелкнуть правой кнопкой мыши и выбрать "Port Visibility", затем выбрать "Public".
### Работа над фронтендом
Теперь, когда у нас есть работающий API, давайте создадим фронтенд. Минимальный фронтенд, который мы будем улучшать шаг за шагом. В папке *frontend* создайте следующее:
```text
backend/
frontend/
index.html
app.js
styles.css
```
Начнем с **index.html**:
```html
```
Этот код — абсолютный минимум, необходимый для поддержки окна чата. Он состоит из текстовой области, где будут отображаться сообщения, поля ввода для ввода сообщения и кнопки для отправки сообщения на бэкенд. Теперь посмотрим на JavaScript в *app.js*.
**app.js**
```js
// app.js
(function(){
// 1. set up elements
const messages = document.getElementById("messages");
const form = document.getElementById("form");
const input = document.getElementById("input");
const BASE_URL = "change this";
const API_ENDPOINT = `${BASE_URL}/hello`;
// 2. create a function that talks to our backend
async function callApi(text) {
const response = await fetch(API_ENDPOINT, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ message: text })
});
let json = await response.json();
return json.response;
}
// 3. add response to our textarea
function appendMessage(text, role) {
const el = document.createElement("div");
el.className = `message ${role}`;
el.innerHTML = text;
messages.appendChild(el);
}
// 4. listen to submit events
form.addEventListener("submit", async(e) => {
e.preventDefault();
// someone clicked the button in the form
// get input
const text = input.value.trim();
appendMessage(text, "user")
// reset it
input.value = '';
const reply = await callApi(text);
// add to messages
appendMessage(reply, "assistant");
})
})();
```
Разберем код по разделам:
- 1) Здесь мы получаем ссылки на все элементы, которые будем использовать в коде.
- 2) В этом разделе мы создаем функцию, которая использует встроенный метод `fetch` для вызова нашего бэкенда.
- 3) `appendMessage` помогает добавлять ответы, а также то, что вводит пользователь.
- 4) Здесь мы слушаем событие submit, читаем поле ввода, помещаем сообщение пользователя в текстовую область, вызываем API и отображаем ответ в текстовой области.
Теперь посмотрим на стили. Здесь можно проявить фантазию и сделать так, как вам нравится, но вот несколько предложений:
**styles.css**
```
.message {
background: #222;
box-shadow: 0 0 0 10px orange;
padding: 10px:
margin: 5px;
}
.message.user {
background: blue;
}
.message.assistant {
background: grey;
}
```
С помощью этих трех классов вы сможете стилизовать сообщения в зависимости от их источника — ассистент или пользователь. Если хотите вдохновиться, загляните в папку `solution/frontend/styles.css`.
### Изменение Base Url
Есть одна вещь, которую мы не настроили — это `BASE_URL`. Она неизвестна до запуска вашего бэкенда. Чтобы ее настроить:
- Если вы запускаете API локально, она должна быть чем-то вроде `http://localhost:5000`.
- Если запускаете в Codespaces, она будет выглядеть примерно как "[name]app.github.dev".
## Задание
Создайте свою папку *project* с содержимым, как указано ниже:
```text
project/
frontend/
index.html
app.js
styles.css
backend/
...
```
Скопируйте содержимое из инструкций выше, но не стесняйтесь настраивать его по своему усмотрению.
## Решение
[Решение](./solution/README.md)
## Бонус
Попробуйте изменить личность чат-ассистента.
### Для Python
Когда вы вызываете `call_llm` в *api.py*, вы можете изменить второй аргумент на то, что вам нужно, например:
```python
call_llm(message, "You are Captain Picard")
```
### Фронтенд
Также измените CSS и текст по своему вкусу, внесите изменения в *index.html* и *styles.css*.
## Итог
Отлично, вы научились с нуля создавать персонального ассистента с использованием ИИ. Мы сделали это, используя GitHub Models, бэкенд на Python и фронтенд на HTML, CSS и JavaScript.
## Настройка с Codespaces
- Перейдите в: [репозиторий Web Dev For Beginners](https://github.com/microsoft/Web-Dev-For-Beginners)
- Создайте из шаблона (убедитесь, что вы вошли в GitHub) в правом верхнем углу:
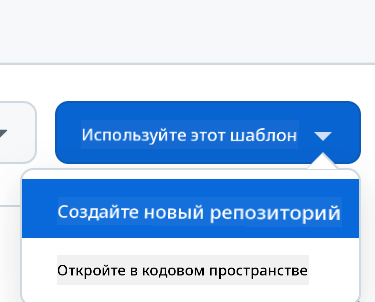
- После перехода в ваш репозиторий создайте Codespace:
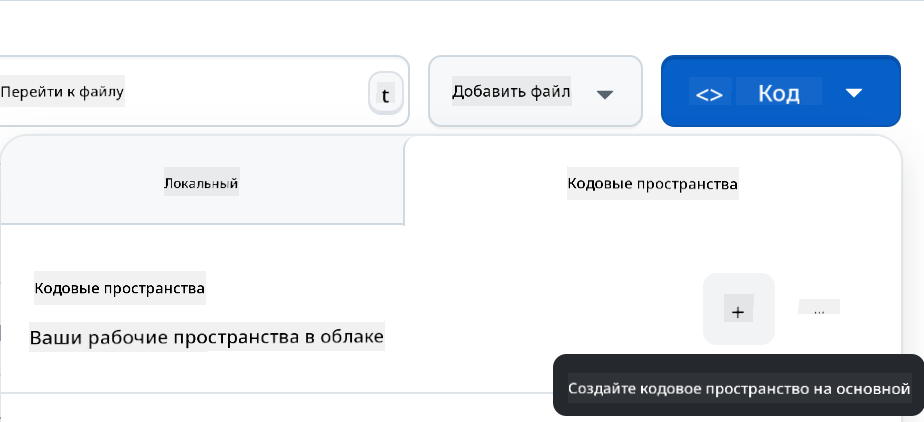
Это должно запустить среду, с которой вы можете работать.
---
**Отказ от ответственности**:
Этот документ был переведен с помощью сервиса автоматического перевода [Co-op Translator](https://github.com/Azure/co-op-translator). Несмотря на наши усилия обеспечить точность, автоматические переводы могут содержать ошибки или неточности. Оригинальный документ на его исходном языке следует считать авторитетным источником. Для получения критически важной информации рекомендуется профессиональный перевод человеком. Мы не несем ответственности за любые недоразумения или неправильные интерпретации, возникшие в результате использования данного перевода.


