# Chat projekt
Ez a chat projekt bemutatja, hogyan lehet egy Chat Asszisztenst létrehozni GitHub Modellek segítségével.
Így néz ki a kész projekt:
Egy kis háttérinformáció: generatív MI használatával chat asszisztensek építése remek módja annak, hogy elkezdjünk ismerkedni a mesterséges intelligenciával. Ebben a leckében megtanulhatod, hogyan integrálj generatív MI-t egy webalkalmazásba. Kezdjük is!
## Kapcsolódás a generatív MI-hez
A backendhez a GitHub Modelleket használjuk. Ez egy nagyszerű szolgáltatás, amely lehetővé teszi, hogy ingyenesen használj mesterséges intelligenciát. Látogass el a playground oldalára, és szerezd meg a kódot, amely megfelel a választott backend nyelvednek. Így néz ki a [GitHub Models Playground](https://github.com/marketplace/models/azure-openai/gpt-4o-mini/playground):
Ahogy említettük, válaszd ki a "Code" fület és a preferált futtatási környezetet.
### Python használata
Ebben az esetben a Python-t választjuk, ami azt jelenti, hogy ezt a kódot választjuk:
```python
"""Run this model in Python
> pip install openai
"""
import os
from openai import OpenAI
# To authenticate with the model you will need to generate a personal access token (PAT) in your GitHub settings.
# Create your PAT token by following instructions here: https://docs.github.com/en/authentication/keeping-your-account-and-data-secure/managing-your-personal-access-tokens
client = OpenAI(
base_url="https://models.github.ai/inference",
api_key=os.environ["GITHUB_TOKEN"],
)
response = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "",
},
{
"role": "user",
"content": "What is the capital of France?",
}
],
model="openai/gpt-4o-mini",
temperature=1,
max_tokens=4096,
top_p=1
)
print(response.choices[0].message.content)
```
Tisztítsuk meg egy kicsit ezt a kódot, hogy újrahasznosítható legyen:
```python
def call_llm(prompt: str, system_message: str):
response = client.chat.completions.create(
messages=[
{
"role": "system",
"content": system_message,
},
{
"role": "user",
"content": prompt,
}
],
model="openai/gpt-4o-mini",
temperature=1,
max_tokens=4096,
top_p=1
)
return response.choices[0].message.content
```
Ezzel a `call_llm` függvénnyel most már megadhatunk egy promptot és egy rendszerpromptot, és a függvény visszaadja az eredményt.
### MI Asszisztens testreszabása
Ha testre szeretnéd szabni az MI asszisztenst, megadhatod, hogyan viselkedjen, a rendszerprompt kitöltésével, például így:
```python
call_llm("Tell me about you", "You're Albert Einstein, you only know of things in the time you were alive")
```
## Web API-n keresztüli elérés
Szuper, az MI rész készen van, nézzük meg, hogyan integrálhatjuk ezt egy Web API-ba. A Web API-hoz a Flask-et választjuk, de bármelyik webes keretrendszer megfelelő lehet. Íme a kód:
### Python használata
```python
# api.py
from flask import Flask, request, jsonify
from llm import call_llm
from flask_cors import CORS
app = Flask(__name__)
CORS(app) # * example.com
@app.route("/", methods=["GET"])
def index():
return "Welcome to this API. Call POST /hello with 'message': 'my message' as JSON payload"
@app.route("/hello", methods=["POST"])
def hello():
# get message from request body { "message": "do this taks for me" }
data = request.get_json()
message = data.get("message", "")
response = call_llm(message, "You are a helpful assistant.")
return jsonify({
"response": response
})
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000)
```
Itt létrehozunk egy Flask API-t, és definiálunk egy alapértelmezett útvonalat ("/") és egy "/chat" útvonalat. Az utóbbi arra szolgál, hogy a frontend kérdéseket küldjön a backendnek.
Az *llm.py* integrálásához a következőket kell tennünk:
- Importáljuk a `call_llm` függvényt:
```python
from llm import call_llm
from flask import Flask, request
```
- Meghívjuk a "/chat" útvonalról:
```python
@app.route("/hello", methods=["POST"])
def hello():
# get message from request body { "message": "do this taks for me" }
data = request.get_json()
message = data.get("message", "")
response = call_llm(message, "You are a helpful assistant.")
return jsonify({
"response": response
})
```
Itt az érkező kérést elemezzük, hogy kinyerjük a JSON törzsből a `message` tulajdonságot. Ezután meghívjuk az LLM-et ezzel a hívással:
```python
response = call_llm(message, "You are a helpful assistant")
# return the response as JSON
return jsonify({
"response": response
})
```
Szuper, most már készen vagyunk.
## Cors konfigurálása
Fontos megemlíteni, hogy beállítottunk valamit, amit CORS-nak (cross-origin resource sharing) hívnak. Ez azt jelenti, hogy mivel a backend és a frontend különböző portokon fog futni, engedélyeznünk kell, hogy a frontend hívásokat kezdeményezzen a backend felé.
### Python használata
Az *api.py*-ban van egy kódrészlet, amely ezt beállítja:
```python
from flask_cors import CORS
app = Flask(__name__)
CORS(app) # * example.com
```
Jelenleg úgy van beállítva, hogy minden eredetet ("*") engedélyezzen, ami nem túl biztonságos. Ezt szigorítani kell, amikor éles környezetbe kerül a projekt.
## Projekt futtatása
A projekt futtatásához először a backendet, majd a frontendet kell elindítanod.
### Python használata
Oké, tehát van *llm.py* és *api.py* fájlunk. Hogyan működtethetjük ezeket a backenddel? Két dolgot kell tennünk:
- Függőségek telepítése:
```sh
cd backend
python -m venv venv
source ./venv/bin/activate
pip install openai flask flask-cors openai
```
- API indítása:
```sh
python api.py
```
Ha Codespaces-ben dolgozol, menj az alsó szerkesztői részben a Ports-ra, kattints jobb gombbal, válaszd a "Port Visibility"-t, majd állítsd "Public"-ra.
### Frontend fejlesztése
Most, hogy az API működik, hozzunk létre egy frontendet. Egy minimális frontenddel kezdünk, amit lépésről lépésre fejlesztünk. A *frontend* mappában hozz létre a következőket:
```text
backend/
frontend/
index.html
app.js
styles.css
```
Kezdjük az **index.html**-lel:
```html
```
Ez a minimális szükséges kód egy chatablak támogatásához: egy textarea az üzenetek megjelenítéséhez, egy input mező az üzenet beírásához, és egy gomb az üzenet backendhez küldéséhez. Nézzük meg a JavaScript kódot az *app.js*-ben.
**app.js**
```js
// app.js
(function(){
// 1. set up elements
const messages = document.getElementById("messages");
const form = document.getElementById("form");
const input = document.getElementById("input");
const BASE_URL = "change this";
const API_ENDPOINT = `${BASE_URL}/hello`;
// 2. create a function that talks to our backend
async function callApi(text) {
const response = await fetch(API_ENDPOINT, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ message: text })
});
let json = await response.json();
return json.response;
}
// 3. add response to our textarea
function appendMessage(text, role) {
const el = document.createElement("div");
el.className = `message ${role}`;
el.innerHTML = text;
messages.appendChild(el);
}
// 4. listen to submit events
form.addEventListener("submit", async(e) => {
e.preventDefault();
// someone clicked the button in the form
// get input
const text = input.value.trim();
appendMessage(text, "user")
// reset it
input.value = '';
const reply = await callApi(text);
// add to messages
appendMessage(reply, "assistant");
})
})();
```
Nézzük át a kódot szakaszonként:
- 1) Itt hivatkozást szerzünk az összes elemre, amelyet később használni fogunk a kódban.
- 2) Ebben a szakaszban létrehozunk egy függvényt, amely a beépített `fetch` metódust használja a backend hívására.
- 3) Az `appendMessage` segít hozzáadni a válaszokat, valamint a felhasználó által beírt üzeneteket.
- 4) Itt figyeljük a submit eseményt, beolvassuk az input mezőt, elhelyezzük a felhasználó üzenetét a textarea-ban, meghívjuk az API-t, és megjelenítjük a választ a textarea-ban.
Nézzük meg a stílusokat, itt igazán kreatív lehetsz, de íme néhány javaslat:
**styles.css**
```
.message {
background: #222;
box-shadow: 0 0 0 10px orange;
padding: 10px:
margin: 5px;
}
.message.user {
background: blue;
}
.message.assistant {
background: grey;
}
```
Ezzel a három osztállyal különbözőképpen formázhatod az üzeneteket attól függően, hogy az asszisztenstől vagy a felhasználótól származnak. Ha inspirációra van szükséged, nézd meg a `solution/frontend/styles.css` mappát.
### Alap URL módosítása
Egy dolgot még nem állítottunk be, ez pedig a `BASE_URL`. Ez csak akkor ismert, ha a backend már fut. Beállításához:
- Ha az API-t helyileg futtatod, valami ilyesminek kell lennie: `http://localhost:5000`.
- Ha Codespaces-ben futtatod, valami ilyesmi lesz: "[név]app.github.dev".
## Feladat
Hozz létre egy saját *project* mappát az alábbi tartalommal:
```text
project/
frontend/
index.html
app.js
styles.css
backend/
...
```
Másold be a fentiekben ismertetett tartalmat, de szabadon testreszabhatod az ízlésed szerint.
## Megoldás
[Megoldás](./solution/README.md)
## Bónusz
Próbáld megváltoztatni az MI asszisztens személyiségét.
### Python esetén
Amikor a *api.py*-ban meghívod a `call_llm` függvényt, megváltoztathatod a második argumentumot, például:
```python
call_llm(message, "You are Captain Picard")
```
### Frontend
Változtasd meg a CSS-t és a szöveget is az ízlésed szerint, tehát végezz módosításokat az *index.html*-ben és a *styles.css*-ben.
## Összefoglalás
Szuper, most már tudod, hogyan készíts egy személyes asszisztenst a semmiből mesterséges intelligencia segítségével. Ezt GitHub Modellek, egy Python backend, valamint HTML, CSS és JavaScript frontend használatával valósítottuk meg.
## Beállítás Codespaces-szel
- Navigálj ide: [Web Dev For Beginners repo](https://github.com/microsoft/Web-Dev-For-Beginners)
- Hozz létre egy sablonból (győződj meg róla, hogy be vagy jelentkezve a GitHub-ra) a jobb felső sarokban:
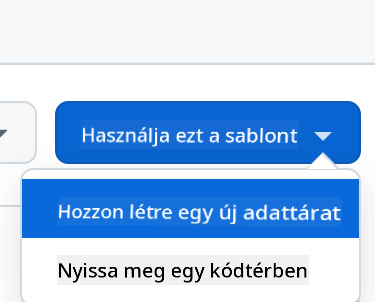
- Miután a saját repódba kerültél, hozz létre egy Codespace-et:
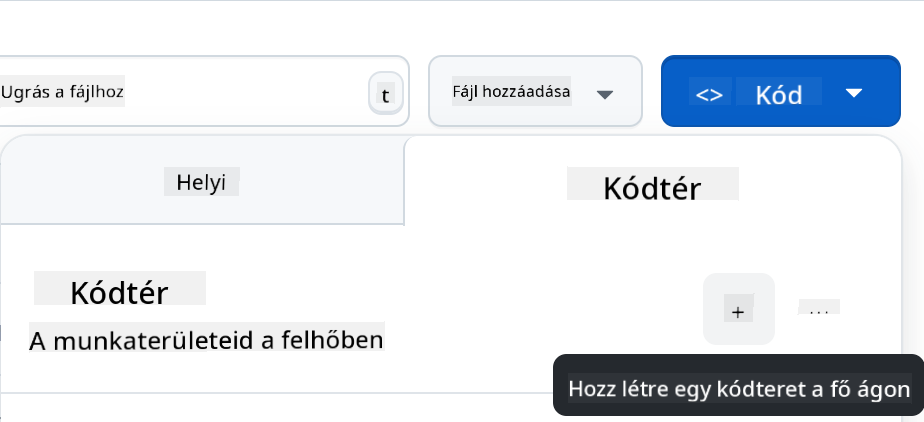
Ez elindít egy környezetet, amelyben most már dolgozhatsz.
---
**Felelősség kizárása**:
Ez a dokumentum az AI fordítási szolgáltatás, a [Co-op Translator](https://github.com/Azure/co-op-translator) segítségével lett lefordítva. Bár törekszünk a pontosságra, kérjük, vegye figyelembe, hogy az automatikus fordítások hibákat vagy pontatlanságokat tartalmazhatnak. Az eredeti dokumentum az eredeti nyelvén tekintendő hiteles forrásnak. Fontos információk esetén javasolt professzionális emberi fordítást igénybe venni. Nem vállalunk felelősséget semmilyen félreértésért vagy téves értelmezésért, amely a fordítás használatából eredhet.


