# Проєкт чату
Цей проєкт чату демонструє, як створити чат-асистента, використовуючи GitHub Models.
Ось як виглядає готовий проєкт:
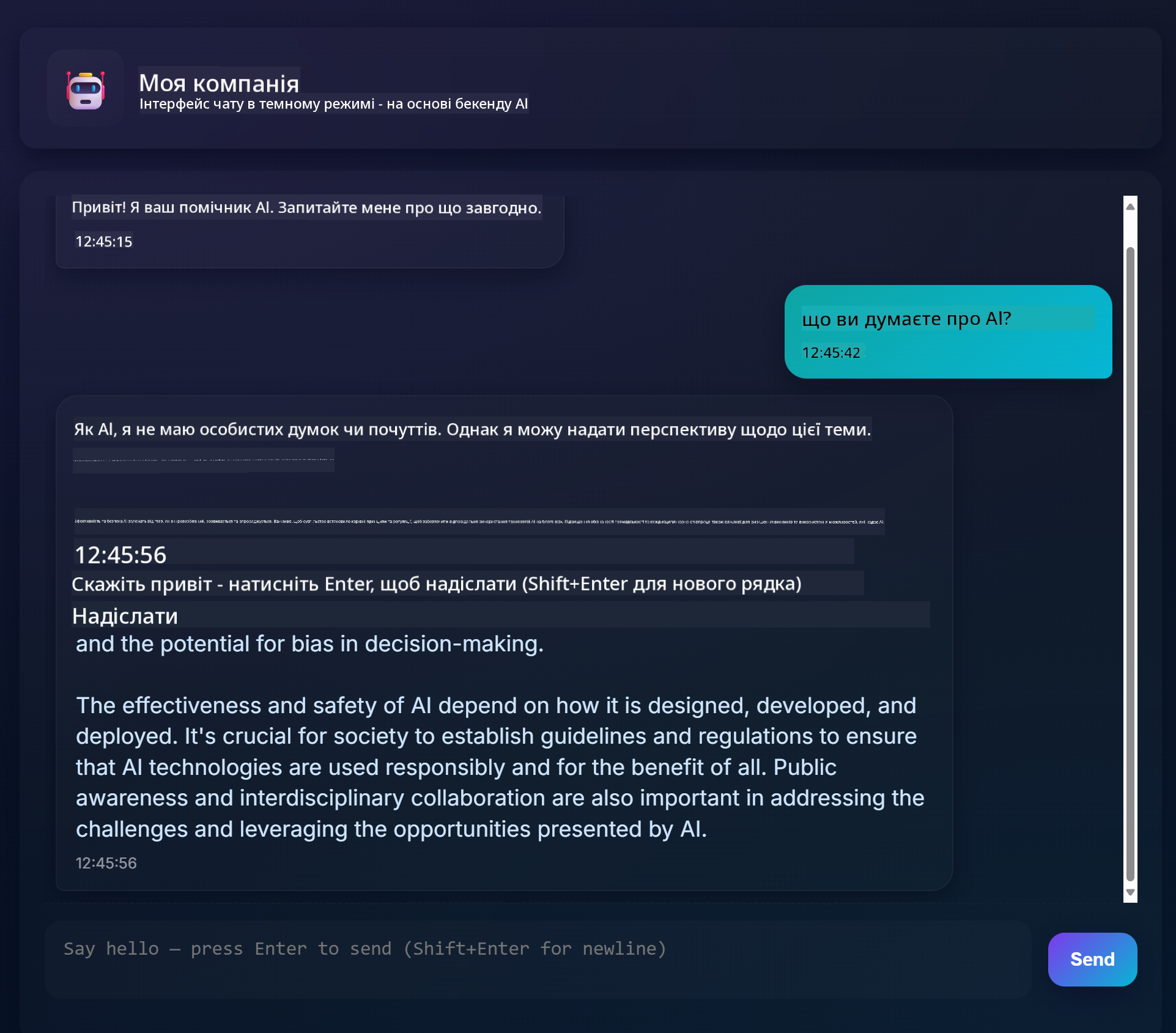
Трохи контексту: створення чат-асистентів за допомогою генеративного штучного інтелекту — чудовий спосіб почати вивчати AI. У цьому уроці ви навчитеся інтегрувати генеративний AI у веб-додаток. Почнемо.
## Підключення до генеративного AI
Для бекенду ми використовуємо GitHub Models. Це чудовий сервіс, який дозволяє використовувати AI безкоштовно. Перейдіть до його playground і скопіюйте код, який відповідає вашій обраній мові бекенду. Ось як це виглядає: [GitHub Models Playground](https://github.com/marketplace/models/azure-openai/gpt-4o-mini/playground)
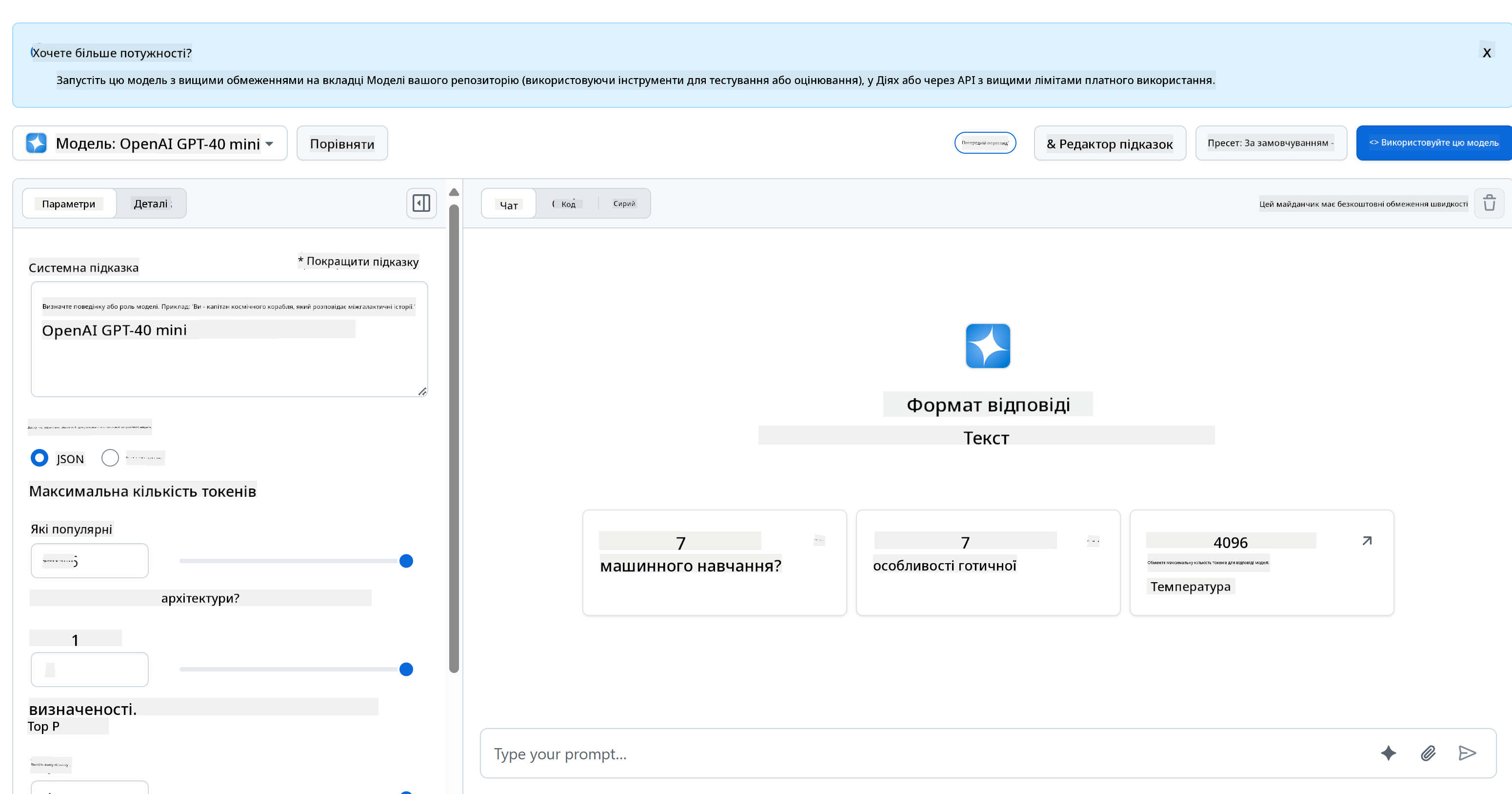
Як ми вже казали, виберіть вкладку "Code" і ваш runtime.

### Використання Python
У цьому випадку ми вибираємо Python, що означає, що ми беремо цей код:
```python
"""Run this model in Python
> pip install openai
"""
import os
from openai import OpenAI
# To authenticate with the model you will need to generate a personal access token (PAT) in your GitHub settings.
# Create your PAT token by following instructions here: https://docs.github.com/en/authentication/keeping-your-account-and-data-secure/managing-your-personal-access-tokens
client = OpenAI(
base_url="https://models.github.ai/inference",
api_key=os.environ["GITHUB_TOKEN"],
)
response = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "",
},
{
"role": "user",
"content": "What is the capital of France?",
}
],
model="openai/gpt-4o-mini",
temperature=1,
max_tokens=4096,
top_p=1
)
print(response.choices[0].message.content)
```
Давайте трохи очистимо цей код, щоб він був зручним для повторного використання:
```python
def call_llm(prompt: str, system_message: str):
response = client.chat.completions.create(
messages=[
{
"role": "system",
"content": system_message,
},
{
"role": "user",
"content": prompt,
}
],
model="openai/gpt-4o-mini",
temperature=1,
max_tokens=4096,
top_p=1
)
return response.choices[0].message.content
```
З цією функцією `call_llm` ми можемо взяти підказку та системну підказку, і функція поверне результат.
### Налаштування AI-асистента
Якщо ви хочете налаштувати AI-асистента, ви можете вказати, як він має поводитися, заповнивши системну підказку ось так:
```python
call_llm("Tell me about you", "You're Albert Einstein, you only know of things in the time you were alive")
```
## Відкриття через Web API
Чудово, ми завершили частину з AI, тепер давайте подивимося, як інтегрувати це у Web API. Для Web API ми вибираємо Flask, але будь-який веб-фреймворк підійде. Ось код:
### Використання Python
```python
# api.py
from flask import Flask, request, jsonify
from llm import call_llm
from flask_cors import CORS
app = Flask(__name__)
CORS(app) # * example.com
@app.route("/", methods=["GET"])
def index():
return "Welcome to this API. Call POST /hello with 'message': 'my message' as JSON payload"
@app.route("/hello", methods=["POST"])
def hello():
# get message from request body { "message": "do this taks for me" }
data = request.get_json()
message = data.get("message", "")
response = call_llm(message, "You are a helpful assistant.")
return jsonify({
"response": response
})
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000)
```
Тут ми створюємо API на Flask і визначаємо маршрути "/" та "/chat". Останній призначений для використання нашим фронтендом для передачі запитань.
Щоб інтегрувати *llm.py*, ось що нам потрібно зробити:
- Імпортувати функцію `call_llm`:
```python
from llm import call_llm
from flask import Flask, request
```
- Викликати її з маршруту "/chat":
```python
@app.route("/hello", methods=["POST"])
def hello():
# get message from request body { "message": "do this taks for me" }
data = request.get_json()
message = data.get("message", "")
response = call_llm(message, "You are a helpful assistant.")
return jsonify({
"response": response
})
```
Тут ми розбираємо вхідний запит, щоб отримати властивість `message` з JSON-тіла. Потім ми викликаємо LLM за допомогою цього виклику:
```python
response = call_llm(message, "You are a helpful assistant")
# return the response as JSON
return jsonify({
"response": response
})
```
Чудово, тепер ми зробили все необхідне.
## Налаштування Cors
Варто зазначити, що ми налаштували щось на зразок CORS — спільного використання ресурсів між різними джерелами. Це означає, що оскільки наш бекенд і фронтенд працюватимуть на різних портах, нам потрібно дозволити фронтенду викликати бекенд.
### Використання Python
У файлі *api.py* є код, який це налаштовує:
```python
from flask_cors import CORS
app = Flask(__name__)
CORS(app) # * example.com
```
Зараз це налаштовано для дозволу "*" — тобто всіх джерел, що трохи небезпечно. Ми повинні обмежити це, коли перейдемо до продакшну.
## Запуск проєкту
Щоб запустити проєкт, спочатку потрібно запустити бекенд, а потім фронтенд.
### Використання Python
Отже, у нас є *llm.py* і *api.py*. Як це запустити з бекендом? Є дві речі, які потрібно зробити:
- Встановити залежності:
```sh
cd backend
python -m venv venv
source ./venv/bin/activate
pip install openai flask flask-cors openai
```
- Запустити API:
```sh
python api.py
```
Якщо ви працюєте в Codespaces, вам потрібно перейти до Ports у нижній частині редактора, клацнути правою кнопкою миші та вибрати "Port Visibility", а потім "Public".
### Робота над фронтендом
Тепер, коли наш API працює, давайте створимо фронтенд. Мінімальний фронтенд, який ми будемо покращувати поступово. У папці *frontend* створіть наступне:
```text
backend/
frontend/
index.html
app.js
styles.css
```
Почнемо з **index.html**:
```html
```
Це мінімум, який потрібен для підтримки вікна чату, оскільки він складається з текстової області, де будуть відображатися повідомлення, поля вводу для введення повідомлення та кнопки для надсилання повідомлення на бекенд. Тепер розглянемо JavaScript у *app.js*.
**app.js**
```js
// app.js
(function(){
// 1. set up elements
const messages = document.getElementById("messages");
const form = document.getElementById("form");
const input = document.getElementById("input");
const BASE_URL = "change this";
const API_ENDPOINT = `${BASE_URL}/hello`;
// 2. create a function that talks to our backend
async function callApi(text) {
const response = await fetch(API_ENDPOINT, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ message: text })
});
let json = await response.json();
return json.response;
}
// 3. add response to our textarea
function appendMessage(text, role) {
const el = document.createElement("div");
el.className = `message ${role}`;
el.innerHTML = text;
messages.appendChild(el);
}
// 4. listen to submit events
form.addEventListener("submit", async(e) => {
e.preventDefault();
// someone clicked the button in the form
// get input
const text = input.value.trim();
appendMessage(text, "user")
// reset it
input.value = '';
const reply = await callApi(text);
// add to messages
appendMessage(reply, "assistant");
})
})();
```
Розглянемо код по секціях:
- 1) Тут ми отримуємо посилання на всі елементи, які будемо використовувати в коді.
- 2) У цьому розділі ми створюємо функцію, яка використовує вбудований метод `fetch` для виклику нашого бекенду.
- 3) `appendMessage` допомагає додавати відповіді, а також те, що ви вводите як користувач.
- 4) Тут ми слухаємо подію submit, читаємо поле вводу, додаємо повідомлення користувача в текстову область, викликаємо API і відображаємо відповідь у текстовій області.
Тепер розглянемо стилі. Тут можна проявити креативність і зробити вигляд таким, як вам подобається, але ось кілька пропозицій:
**styles.css**
```
.message {
background: #222;
box-shadow: 0 0 0 10px orange;
padding: 10px:
margin: 5px;
}
.message.user {
background: blue;
}
.message.assistant {
background: grey;
}
```
З цими трьома класами ви зможете стилізувати повідомлення залежно від того, звідки вони надходять — від асистента чи від вас як користувача. Якщо хочете надихнутися, перегляньте папку `solution/frontend/styles.css`.
### Зміна базового URL
Є одна річ, яку ми тут не налаштували — це `BASE_URL`. Його не буде відомо, поки ваш бекенд не запуститься. Щоб налаштувати:
- Якщо ви запускаєте API локально, він має бути налаштований на щось на зразок `http://localhost:5000`.
- Якщо запускаєте в Codespaces, він має виглядати приблизно як "[name]app.github.dev".
## Завдання
Створіть власну папку *project* з таким вмістом:
```text
project/
frontend/
index.html
app.js
styles.css
backend/
...
```
Скопіюйте вміст із того, що було описано вище, але не соромтеся налаштовувати на свій смак.
## Рішення
[Рішення](./solution/README.md)
## Бонус
Спробуйте змінити особистість AI-асистента.
### Для Python
Коли ви викликаєте `call_llm` у *api.py*, ви можете змінити другий аргумент на те, що вам потрібно, наприклад:
```python
call_llm(message, "You are Captain Picard")
```
### Фронтенд
Також змініть CSS і текст на свій смак, внесіть зміни в *index.html* і *styles.css*.
## Підсумок
Чудово, ви навчилися з нуля створювати персонального асистента за допомогою AI. Ми зробили це, використовуючи GitHub Models, бекенд на Python і фронтенд на HTML, CSS і JavaScript.
## Налаштування з Codespaces
- Перейдіть до: [Web Dev For Beginners repo](https://github.com/microsoft/Web-Dev-For-Beginners)
- Створіть із шаблону (переконайтеся, що ви увійшли в GitHub) у верхньому правому куті:
- Як тільки ви опинитеся у своєму репозиторії, створіть Codespace:
Це має запустити середовище, з яким ви тепер можете працювати.
---
**Відмова від відповідальності**:
Цей документ був перекладений за допомогою сервісу автоматичного перекладу [Co-op Translator](https://github.com/Azure/co-op-translator). Хоча ми прагнемо до точності, будь ласка, майте на увазі, що автоматичні переклади можуть містити помилки або неточності. Оригінальний документ на його рідній мові слід вважати авторитетним джерелом. Для критичної інформації рекомендується професійний людський переклад. Ми не несемо відповідальності за будь-які непорозуміння або неправильні тлумачення, що виникають внаслідок використання цього перекладу.