|
|
1 year ago | |
|---|---|---|
| .. | ||
| img | 4 years ago | |
| src | 1 year ago | |
| README.md | 1 year ago | |
| README_cn.md | 1 year ago | |
| docker-compose.yaml | 4 years ago | |
| requirements.txt | 1 year ago | |
README.md
(简体中文|English)
Audio Searching
Introduction
As the Internet continues to evolve, unstructured data such as emails, social media photos, live videos, and customer service voice calls have become increasingly common. If we want to process the data on a computer, we need to use embedding technology to transform the data into vector and store, index, and query it.
However, when there is a large amount of data, such as hundreds of millions of audio tracks, it is more difficult to do a similarity search. The exhaustive method is feasible, but very time consuming. For this scenario, this demo will introduce how to build an audio similarity retrieval system using the open source vector database Milvus.
Audio retrieval (speech, music, speaker, etc.) enables querying and finding similar sounds (or the same speaker) in a large amount of audio data. The audio similarity retrieval system can be used to identify similar sound effects, minimize intellectual property infringement, quickly retrieve the voice print library, and help enterprises control fraud and identity theft. Audio retrieval also plays an important role in the classification and statistical analysis of audio data.
In this demo, you will learn how to build an audio retrieval system to retrieve similar sound snippets. The uploaded audio clips are converted into vector data using paddlespeech-based pre-training models (audio classification model, speaker recognition model, etc.) and stored in Milvus. Milvus automatically generates a unique ID for each vector, then stores the ID and the corresponding audio information (audio ID, audio speaker ID, etc.) in MySQL to complete the library construction. During retrieval, users upload test audio to obtain vector, and then conduct vector similarity search in Milvus.The retrieval result returned by Milvus is vector ID, and the corresponding audio information can be queried in MySQL by ID.
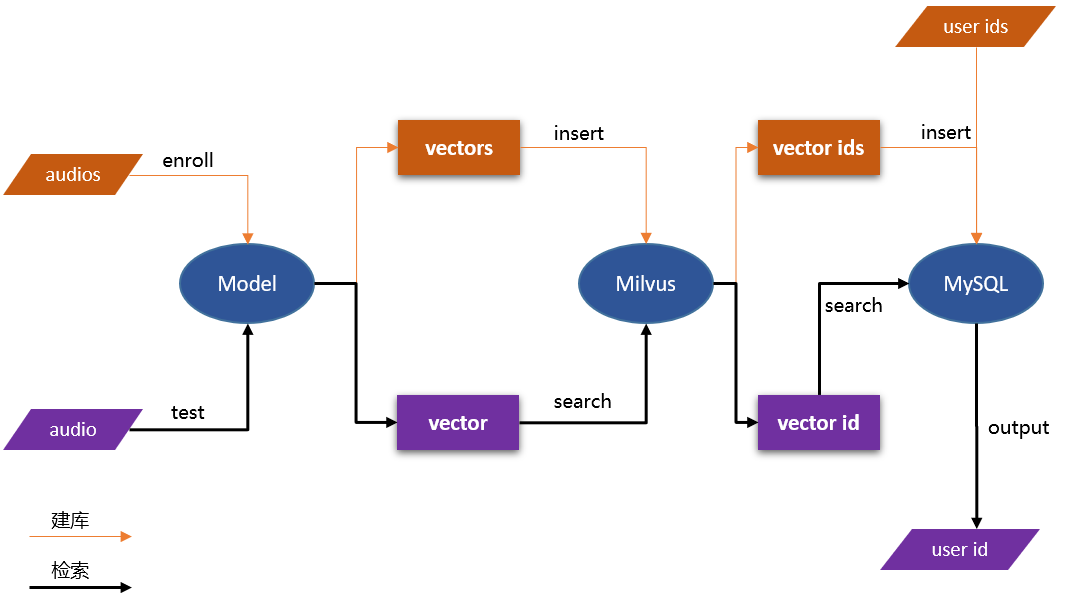
Note:this demo uses the CN-Celeb dataset of at least 650,000 audio entries and 3000 speakers to build the audio vector library, which is then retrieved using a preset distance calculation. The dataset can also use other, Adjust as needed, e.g. Librispeech, VoxCeleb, UrbanSound, GloVe, MNIST, etc.
Usage
1. Prepare PaddleSpeech
Audio vector extraction requires PaddleSpeech training model, so please make sure that PaddleSpeech has been installed before running. Specific installation steps: See installation.
You can choose one way from easy, medium and hard to install paddlespeech.
2. Prepare MySQL and Milvus services by docker-compose
The audio similarity search system requires Milvus, MySQL services. We can start these containers with one click through docker-compose.yaml, so please make sure you have installed Docker Engine and Docker Compose before running. then
## Enter the audio_searching directory for the following example
cd ~/PaddleSpeech/demos/audio_searching/
## Then start the related services within the container
docker-compose -f docker-compose.yaml up -d
You will see the that all containers are created:
Creating network "quick_deploy_app_net" with driver "bridge"
Creating milvus-minio ... done
Creating milvus-etcd ... done
Creating audio-mysql ... done
Creating milvus-standalone ... done
Creating audio-webclient ... done
And show all containers with docker ps, and you can use docker logs audio-mysql to get the logs of server container
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b2bcf279e599 milvusdb/milvus:v2.0.1 "/tini -- milvus run…" 22 hours ago Up 22 hours 0.0.0.0:19530->19530/tcp milvus-standalone
d8ef4c84e25c mysql:5.7 "docker-entrypoint.s…" 22 hours ago Up 22 hours 0.0.0.0:3306->3306/tcp, 33060/tcp audio-mysql
8fb501edb4f3 quay.io/coreos/etcd:v3.5.0 "etcd -advertise-cli…" 22 hours ago Up 22 hours 2379-2380/tcp milvus-etcd
ffce340b3790 minio/minio:RELEASE.2020-12-03T00-03-10Z "/usr/bin/docker-ent…" 22 hours ago Up 22 hours (healthy) 9000/tcp milvus-minio
15c84a506754 paddlepaddle/paddlespeech-audio-search-client:2.3 "/bin/bash -c '/usr/…" 22 hours ago Up 22 hours (healthy) 0.0.0.0:8068->80/tcp audio-webclient
3. Start API Server
Then to start the system server, and it provides HTTP backend services.
-
Install the Python packages
pip install -r requirements.txt -
Set configuration(In the case of local running, you can skip this step.)
## Method 1: Modify the source file vim src/config.py ## Method 2: Modify the environment variables, as shown in export MILVUS_HOST=127.0.0.1 export MYSQL_HOST=127.0.0.1Here listing some parameters that need to be set, for more information please refer to config.py.
Parameter Description Default setting MILVUS_HOST The IP address of Milvus, you can get it by ifconfig. If running everything on one machine, most likely 127.0.0.1 127.0.0.1 MILVUS_PORT Port of Milvus. 19530 VECTOR_DIMENSION Dimension of the vectors. 2048 MYSQL_HOST The IP address of Mysql. 127.0.0.1 MYSQL_PORT Port of Mysql. 3306 DEFAULT_TABLE The milvus and mysql default collection name. audio_table -
Run the code
Then start the server with Fastapi.
export PYTHONPATH=$PYTHONPATH:./src python src/audio_search.pyThen you will see the Application is started:
INFO: Started server process [13352] 2022-03-26 22:45:30,838 | INFO | server.py | serve | 75 | Started server process [13352] INFO: Waiting for application startup. 2022-03-26 22:45:30,839 | INFO | on.py | startup | 45 | Waiting for application startup. INFO: Application startup complete. 2022-03-26 22:45:30,839 | INFO | on.py | startup | 59 | Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8002 (Press CTRL+C to quit) 2022-03-26 22:45:30,840 | INFO | server.py | _log_started_message | 206 | Uvicorn running on http://0.0.0.0:8002 (Press CTRL+C to quit)
4. Usage
-
Prepare data
wget -c https://www.openslr.org/resources/82/cn-celeb_v2.tar.gz && tar -xvf cn-celeb_v2.tar.gzNote: If you want to build a quick demo, you can use ./src/test_audio_search.py:download_audio_data function, it downloads 20 audio files , Subsequent results show this collection as an example
-
Prepare model(Skip this step if you use the default model.)
## Modify model configuration parameters. Currently, only ecapatdnn_voxceleb12 is supported, and multiple types will be supported in the future vim ./src/encode.py -
Scripts test (Recommended)
The internal process is downloading data, loading the paddlespeech model, extracting embedding, storing library, retrieving and deleting library
python ./src/test_audio_search.pyOutput:
Downloading https://paddlespeech.cdn.bcebos.com/vector/audio/example_audio.tar.gz ... ... Unpacking ./example_audio.tar.gz ... [2022-03-26 22:50:54,987] [ INFO] - checking the aduio file format...... [2022-03-26 22:50:54,987] [ INFO] - The sample rate is 16000 [2022-03-26 22:50:54,987] [ INFO] - The audio file format is right [2022-03-26 22:50:54,988] [ INFO] - device type: cpu [2022-03-26 22:50:54,988] [ INFO] - load the pretrained model: ecapatdnn_voxceleb12-16k [2022-03-26 22:50:54,990] [ INFO] - Downloading sv0_ecapa_tdnn_voxceleb12_ckpt_0_1_0.tar.gz from https://paddlespeech.cdn.bcebos.com/vector/voxceleb/sv0_ecapa_tdnn_voxceleb12_ckpt_0_1_0.tar.gz ... [2022-03-26 22:51:17,285] [ INFO] - start to dynamic import the model class [2022-03-26 22:51:17,285] [ INFO] - model name ecapatdnn [2022-03-26 22:51:23,864] [ INFO] - start to set the model parameters to model [2022-03-26 22:54:08,115] [ INFO] - create the model instance success [2022-03-26 22:54:08,116] [ INFO] - Preprocess audio file: /home/zhaoqingen/PaddleSpeech/demos/audio_ searching/example_audio/knife_hit_iron3.wav [2022-03-26 22:54:08,116] [ INFO] - load the audio sample points, shape is: (11012,) [2022-03-26 22:54:08,150] [ INFO] - extract the audio feat, shape is: (80, 69) [2022-03-26 22:54:08,152] [ INFO] - feats shape: [1, 80, 69] [2022-03-26 22:54:08,154] [ INFO] - audio extract the feat success [2022-03-26 22:54:08,155] [ INFO] - start to do backbone network model forward [2022-03-26 22:54:08,155] [ INFO] - feats shape:[1, 80, 69], lengths shape: [1] [2022-03-26 22:54:08,433] [ INFO] - embedding size: (192,) Extracting feature from audio No. 1 , 20 audios in total [2022-03-26 22:54:08,435] [ INFO] - checking the aduio file format...... [2022-03-26 22:54:08,435] [ INFO] - The sample rate is 16000 [2022-03-26 22:54:08,436] [ INFO] - The audio file format is right [2022-03-26 22:54:08,436] [ INFO] - device type: cpu [2022-03-26 22:54:08,436] [ INFO] - Model has been initialized [2022-03-26 22:54:08,436] [ INFO] - Preprocess audio file: /home/zhaoqingen/PaddleSpeech/demos/audio_searching/example_audio/sword_wielding.wav [2022-03-26 22:54:08,436] [ INFO] - load the audio sample points, shape is: (6391,) [2022-03-26 22:54:08,452] [ INFO] - extract the audio feat, shape is: (80, 40) [2022-03-26 22:54:08,454] [ INFO] - feats shape: [1, 80, 40] [2022-03-26 22:54:08,454] [ INFO] - audio extract the feat success [2022-03-26 22:54:08,454] [ INFO] - start to do backbone network model forward [2022-03-26 22:54:08,455] [ INFO] - feats shape:[1, 80, 40], lengths shape: [1] [2022-03-26 22:54:08,633] [ INFO] - embedding size: (192,) Extracting feature from audio No. 2 , 20 audios in total ... 2022-03-26 22:54:15,892 | INFO | audio_search.py | load_audios | 85 | Successfully loaded data, total count: 20 2022-03-26 22:54:15,908 | INFO | audio_search.py | count_audio | 148 | Successfully count the number of data! [2022-03-26 22:54:15,916] [ INFO] - checking the aduio file format...... [2022-03-26 22:54:15,916] [ INFO] - The sample rate is 16000 [2022-03-26 22:54:15,916] [ INFO] - The audio file format is right [2022-03-26 22:54:15,916] [ INFO] - device type: cpu [2022-03-26 22:54:15,916] [ INFO] - Model has been initialized [2022-03-26 22:54:15,916] [ INFO] - Preprocess audio file: /home/zhaoqingen/PaddleSpeech/demos/audio_searching/example_audio/test.wav [2022-03-26 22:54:15,917] [ INFO] - load the audio sample points, shape is: (8456,) [2022-03-26 22:54:15,923] [ INFO] - extract the audio feat, shape is: (80, 53) [2022-03-26 22:54:15,924] [ INFO] - feats shape: [1, 80, 53] [2022-03-26 22:54:15,924] [ INFO] - audio extract the feat success [2022-03-26 22:54:15,924] [ INFO] - start to do backbone network model forward [2022-03-26 22:54:15,924] [ INFO] - feats shape:[1, 80, 53], lengths shape: [1] [2022-03-26 22:54:16,051] [ INFO] - embedding size: (192,) ... 2022-03-26 22:54:16,086 | INFO | audio_search.py | search_local_audio | 132 | search result http://testserver/data?audio_path=./example_audio/test.wav, score 100.0 2022-03-26 22:54:16,087 | INFO | audio_search.py | search_local_audio | 132 | search result http://testserver/data?audio_path=./example_audio/knife_chopping.wav, score 29.182177782058716 2022-03-26 22:54:16,087 | INFO | audio_search.py | search_local_audio | 132 | search result http://testserver/data?audio_path=./example_audio/knife_cut_into_body.wav, score 22.73637056350708 ... 2022-03-26 22:54:16,088 | INFO | audio_search.py | search_local_audio | 136 | Successfully searched similar audio! 2022-03-26 22:54:17,164 | INFO | audio_search.py | drop_tables | 160 | Successfully drop tables in Milvus and MySQL! -
GUI test (Optional)
Navigate to 127.0.0.1:8068 in your browser to access the front-end interface.
Note: If the browser and the service are not on the same machine, then the IP needs to be changed to the IP of the machine where the service is located, and the corresponding API_URL in docker-compose.yaml needs to be changed, and the docker-compose.yaml file needs to be re-executed for the change to take effect.
-
Insert data
Download the data on the server and decompress it to a file, for example, /home/speech/data/. Then enter /home/speech/data/ in the address bar of the upload page to upload the data.
-
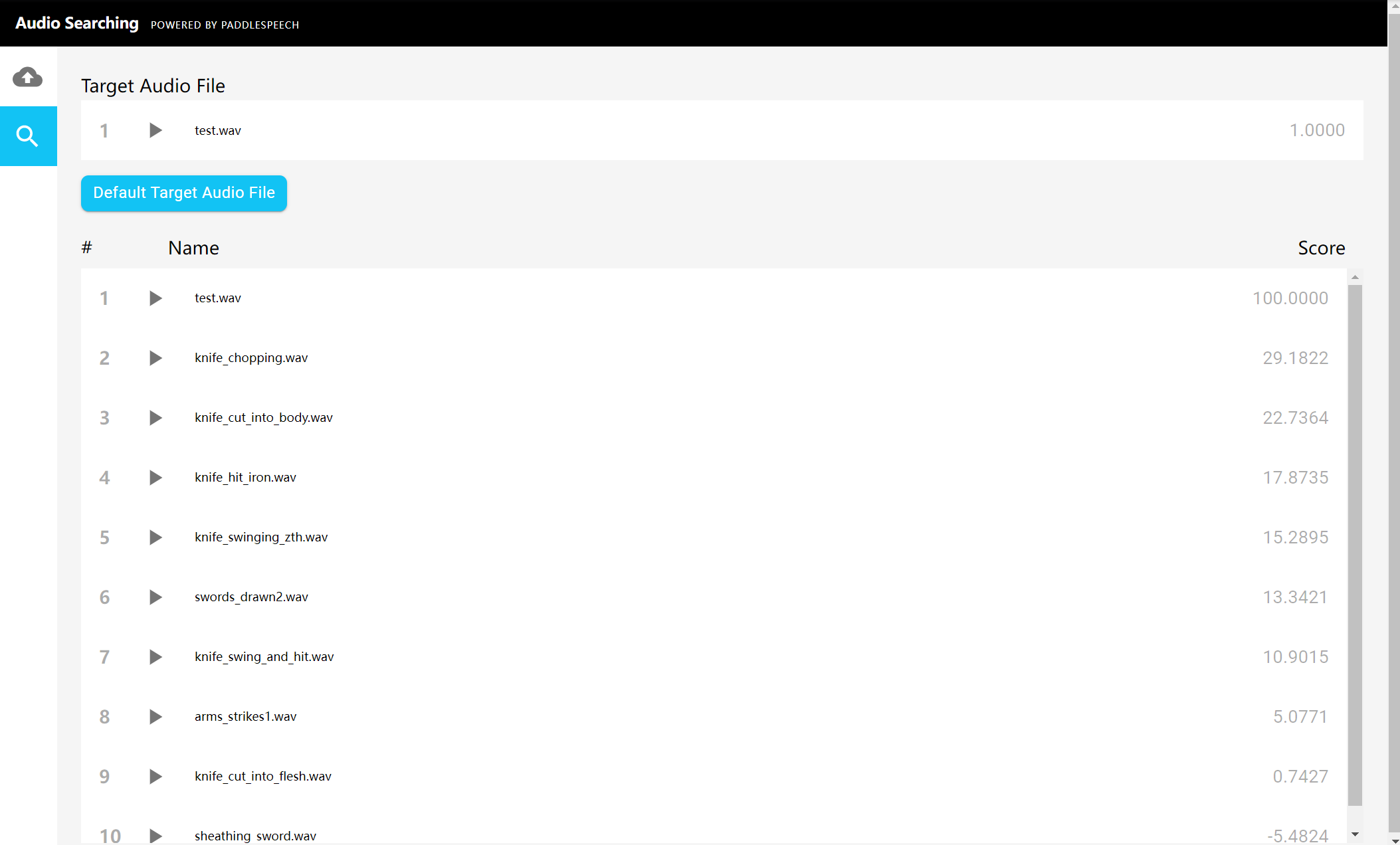
Search for similar audio
Select the magnifying glass icon on the left side of the interface. Then, press the "Default Target Audio File" button and upload a .wav sound file from the client you'd like to search. Results will be displayed.
-
5.Result
machine configuration:
- OS: CentOS release 7.6
- kernel:4.17.11-1.el7.elrepo.x86_64
- CPU:Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz
- memory:132G
dataset:
- CN-Celeb, train size 650,000, test size 10,000, dimension 192, distance L2
recall and elapsed time statistics are shown in the following figure:
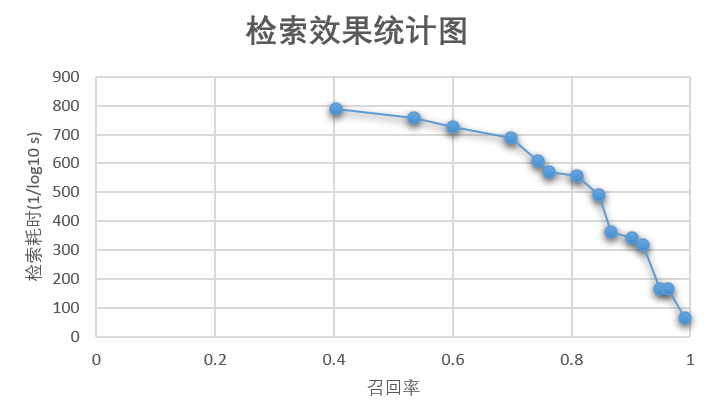
The retrieval framework based on Milvus takes about 2.9 milliseconds to retrieve on the premise of 90% recall rate, and it takes about 500 milliseconds for feature extraction (testing audio takes about 5 seconds), that is, a single audio test takes about 503 milliseconds in total, which can meet most application scenarios.
- compute embedding takes 500 ms
- retrieval with cosine takes 2.9 ms
- total takes 503 ms
test audio is 5 sec
6.Pretrained Models
Here is a list of pretrained models released by PaddleSpeech :
| Model | Sample Rate |
|---|---|
| ecapa_tdnn | 16000 |