{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"collapsed": false
},
"source": [
"<a href=\"https://github.com/PaddlePaddle/PaddleSpeech\"><img style=\"position: absolute; z-index: 999; top: 0; right: 0; border: 0; width: 128px; height: 128px;\" src=\"https://nosir.github.io/cleave.js/images/right-graphite@2x.png\" alt=\"Fork me on GitHub\"></a>\n",
"\n",
"\n",
"# End-to-End Speech (to Text) Translation "
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": false
},
"source": [
"# 前言"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": false
},
"source": [
"## 背景知识\n",
"语音翻译(ST, Speech Translation)是一项从一段源语言音频中翻译出目标语言的任务。\n",
"本章主要针对语音到文本的翻译,比如,从一段英文语音中,得到中文的翻译文本。"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": false
},
"source": [
"## 基本方法\n",
"### 级联模型(Cascaded), ASR -> MT\n",
"级联模型由独立的两个模型,语音识别模型(ASR)和机器翻译模型(MT)组成。先通过 ASR 模型从语音中识别出源语言的相应文本,在利用 MT 模型将相应文本翻译成目标语言。\n",
"\n",
"\n",
"\n",
"### 端到端模型 (End-to-End) \n",
"端到端模型不显式对输入语音做文字识别,而直接生成翻译结果。\n",
"\n",
"\n",
"\n",
"相对于端到端模型,级联模型存在以下一些问题:\n",
"\n",
"1.错误传播(error propagation),由 ASR 识别错误所产生的错误文本,也会传递给 MT 模型,往往会导致生成更糟糕的翻译结果。\n",
"\n",
"2.时延叠加(latency accumulation),因为使用两个级联的模型,需要对输入数据进行多次处理,实际的时延是两个模型时延的累加,效率低于端到端模型。"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": false
},
"source": [
"# 使用Transformer进行端到端语音翻译的的基本流程\n",
"## 基础模型\n",
"由于 ASR 章节已经介绍了 Transformer 以及语音特征抽取,在此便不做过多介绍,感兴趣的同学可以去相关章节进行了解。\n",
"\n",
"本小节,主要讨论利用 transformer(seq2seq)进行ST与ASR的异同。\n",
"\n",
"相似之处在于,两者都可以看做是从语音(speech)到文本(text)的任务。将语音作为输入,而将文字作为输出,区别只在于生成结果是对应语言的识别结果,还是另一语言的翻译结果。\n",
"\n",
"因此,我们只需要将数据中的目标文本替换为翻译文本($Y$),便可利用 ASR 的模型结构实现语音翻译。\n",
"\n",
"规范化地讲,对于 ASR,利用包含语音($S$)和转写文本($X$)的数据集,训练得到一个模型 $M_{ASR}$,能对任意输入的源语言语音 $\\hat{S}$ 进行文字识别,输出结果 $\\hat{X}$。\n",
"\n",
"而ST的语料集,通常包含语音($S$)、转写文本($X$)以及翻译文本($Y$),只需将ASR实践中的转写文本$X$替换为对应的翻译文本 $Y$,便可利用同样的流程得到一个翻译模型 $M_{ST}$,其能对任意输入的源语言语音 $\\hat{S}$ 进行翻译,输出结果 $\\hat{Y}$\n",
"\n",
"值得注意的是,相较于 ASR 任务而言,在 ST 中,因为翻译文本与源语音不存在单调对齐(monotonic aligned)的性质,因此 CTC 模块不能将翻译结果作为目标来使用,此处涉及一些学术细节,感兴趣的同学可以自行去了解 [CTC](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/topic/ctc/ctc_loss.ipynb) 的具体内容。\n",
"\n",
"> 我们会在 [PaddleSpeech](https://github.com/PaddlePaddle/PaddleSpeech) 中放一些 Topic 的技术文章(如 [CTC](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/topic/ctc/ctc_loss.ipynb) ),欢迎大家 star 关注。\n",
"\n",
"## 辅助任务训练,提升效果(ASR MTL)\n",
"\n",
"相比与 ASR 任务,ST 任务对于数据的标注和获取更加困难,通常很难获取大量的训练数据。\n",
"\n",
"因此,我们讲讨论如何更有效利用已有数据,提升 ST 模型的效果。\n",
"\n",
"1.先利用 ASR 对模型进行预训练,得到一个编码器能够有效的捕捉语音中的语义信息,在此基础上再进一步利用翻译数据训练ST模型。\n",
"\n",
"2.相较于 ASR 任务的二元组数据($S$,$X$),通常包含三元组数据($S$,$X$,$Y$)的ST任务能够自然有效的进行多任务学习。\n",
"顾名思义,我们可以将ASR任务作为辅助任务,将两个任务进行联合训练,利用ASR任务的辅助提升 ST 模型的效果。\n",
"具体上讲,如图所示,可以利用一个共享的编码器对语音进行编码,同时利用两个独立的解码器,分别执行 ASR 和 ST 任务。\n",
"\n",
"我们将实战中进行演示。\n",
"\n",
"## 引入预训练模型,提升效果 (FAT-ST PT)\n",
"\n",
"相比于文本到文本的机器翻译具有充足的语料(通常上百万条),语音到文本的翻译的语料很匮乏。那是否可以将文本到文本的翻译语料利用上来提升 ST 的模型效果呢?答案是肯定的。\n",
"\n",
"FAT 模型[1],借鉴了 Bert[2] 和 TLM[3]的 masked language model 预训练思路,并将其拓展到语音翻译的跨语言、跨模态(语音和文本)的场景。可以应对三元组($S$,$X$,$Y$)中任意的单一或组合的数据类型。\n",
"举例来说,它可以利用纯语音或文本数据集($S$|$X$|$Y$),也可以利用 ASR 数据集($S$,$Y$),甚至文本翻译数据($X$,$Y$)。在这种预训练模型的基础上进行 ST 的训练,能够有效解决训练数据匮乏的困境,提升最终的翻译效果。\n",
"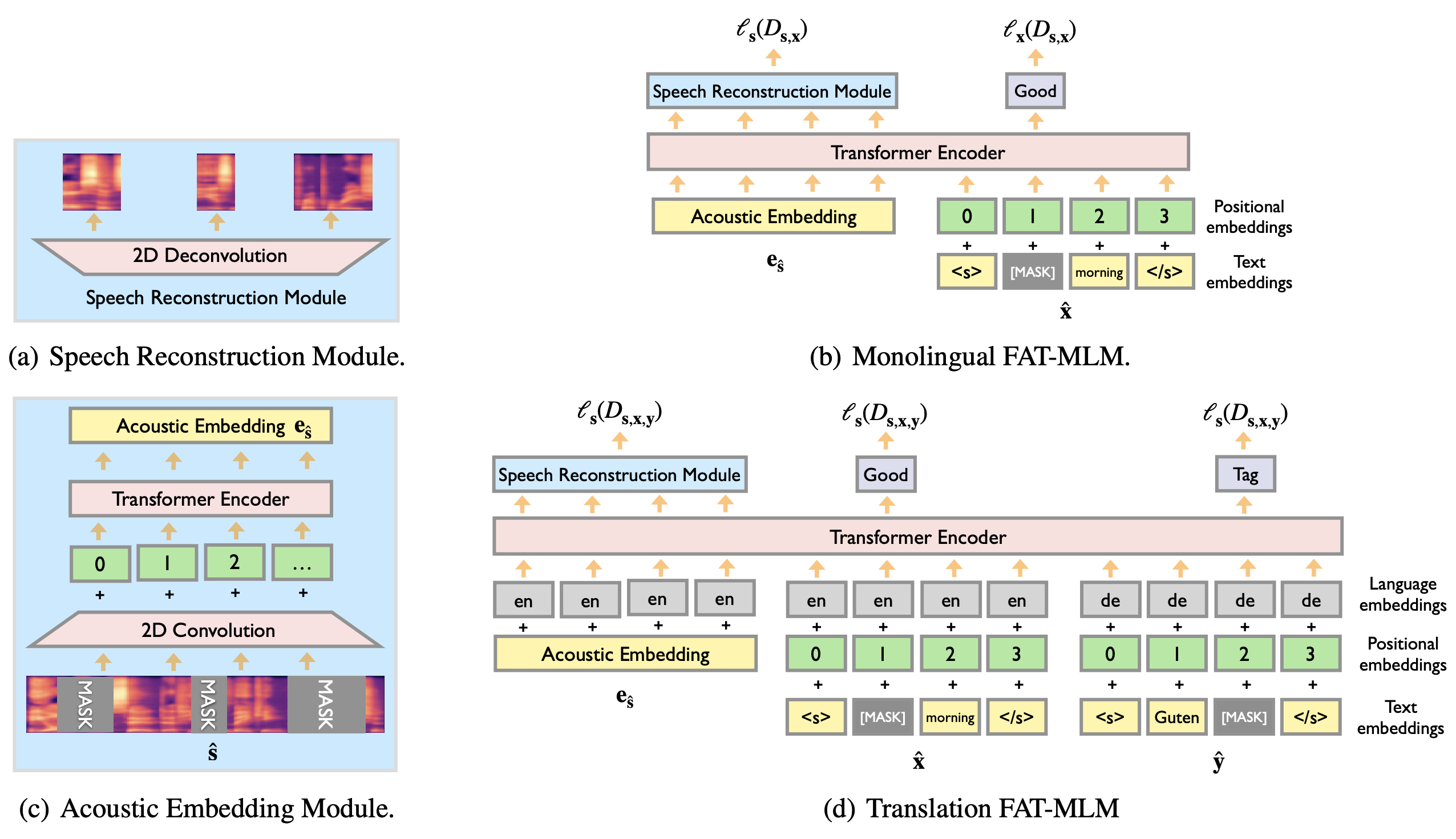\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": false
},
"source": [
"# 实战\n",
"## ST 多任务学习,将 ASR 作为辅助任务\n",
"### 数据集: [Ted语音翻译数据集](http://www.nlpr.ia.ac.cn/cip/dataset.htm)(英文语音$\\rightarrow$中文文本)[4]\n",
"## 准备工作\n",
"## 特征抽取\n",
"参考语音识别的相关章节,略。\n",
"## 多任务模型\n",
"Transformer 内容参考语音识别的相关章节,略。\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": false
},
"source": [
"## Stage 1 准备工作\n",
"### 安装 paddlespeech"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"!pip install -U pip\n",
"!pip install paddlespeech"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": false
},
"source": [
"### 导入 python 包"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"import os\n",
"import paddle\n",
"import numpy as np\n",
"import kaldiio\n",
"import subprocess\n",
"from kaldiio import WriteHelper\n",
"from yacs.config import CfgNode\n",
"import IPython.display as dp\n",
"import warnings\n",
"warnings.filterwarnings(\"ignore\")\n",
"\n",
"from paddlespeech.s2t.frontend.featurizer.text_featurizer import TextFeaturizer\n",
"from paddlespeech.s2t.models.u2_st import U2STModel"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": false
},
"source": [
"### 获取预训练模型和参数并配置"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"!wget -nc https://paddlespeech.bj.bcebos.com/s2t/ted_en_zh/st1/fat_st_ted-en-zh.tar.gz\n",
"!tar xzvf fat_st_ted-en-zh.tar.gz"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"config_path = \"conf/transformer_mtl_noam.yaml\" \n",
"\n",
"# 读取 conf 文件并结构化\n",
"st_config = CfgNode(new_allowed=True)\n",
"st_config.merge_from_file(config_path)"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": false
},
"source": [
"### 下载并配置 kaldi 环境"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"!wget -nc https://paddlespeech.bj.bcebos.com/s2t/ted_en_zh/st1/kaldi_bins.tar.gz\n",
"!tar xzvf kaldi_bins.tar.gz"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"kaldi_bins_path = os.path.abspath('kaldi_bins')\n",
"print(kaldi_bins_path)\n",
"if 'LD_LIBRARY_PATH' not in os.environ:\n",
" os.environ['LD_LIBRARY_PATH'] = f'{kaldi_bins_path}'\n",
"else:\n",
" os.environ['LD_LIBRARY_PATH'] += f':{kaldi_bins_path}'\n",
"os.environ['PATH'] += f':{kaldi_bins_path}'"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": false
},
"source": [
"## Stage 2 获取特征\n",
"### 提取 kaldi 特征"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"def get_kaldi_feat(wav_path, config=st_config):\n",
" \"\"\"\n",
" Input preprocess and return paddle.Tensor stored in self.input.\n",
" Input content can be a file(wav).\n",
" \"\"\"\n",
" wav_file = os.path.abspath(wav_path)\n",
" cmvn = config.collator.cmvn_path\n",
" utt_name = '_tmp'\n",
"\n",
" # Get the object for feature extraction\n",
" fbank_extract_command = [\n",
" 'compute-fbank-feats', '--num-mel-bins=80', '--verbose=2',\n",
" '--sample-frequency=16000', 'scp:-', 'ark:-'\n",
" ]\n",
" fbank_extract_process = subprocess.Popen(fbank_extract_command,\n",
" stdin=subprocess.PIPE,\n",
" stdout=subprocess.PIPE,\n",
" stderr=subprocess.PIPE)\n",
" fbank_extract_process.stdin.write(\n",
" f'{utt_name} {wav_file}'.encode('utf8'))\n",
" fbank_extract_process.stdin.close()\n",
" fbank_feat = dict(kaldiio.load_ark(\n",
" fbank_extract_process.stdout))[utt_name]\n",
"\n",
" extract_command = ['compute-kaldi-pitch-feats', 'scp:-', 'ark:-']\n",
" pitch_extract_process = subprocess.Popen(extract_command,\n",
" stdin=subprocess.PIPE,\n",
" stdout=subprocess.PIPE,\n",
" stderr=subprocess.PIPE)\n",
" pitch_extract_process.stdin.write(\n",
" f'{utt_name} {wav_file}'.encode('utf8'))\n",
" process_command = ['process-kaldi-pitch-feats', 'ark:', 'ark:-']\n",
" pitch_process = subprocess.Popen(process_command,\n",
" stdin=pitch_extract_process.stdout,\n",
" stdout=subprocess.PIPE,\n",
" stderr=subprocess.PIPE)\n",
" pitch_extract_process.stdin.close()\n",
" pitch_feat = dict(kaldiio.load_ark(\n",
" pitch_process.stdout))[utt_name]\n",
" concated_feat = np.concatenate((fbank_feat, pitch_feat), axis=1)\n",
" raw_feat = f\"{utt_name}.raw\"\n",
" with WriteHelper(f'ark,scp:{raw_feat}.ark,{raw_feat}.scp') as writer:\n",
" writer(utt_name, concated_feat)\n",
" cmvn_command = [\n",
" \"apply-cmvn\", \"--norm-vars=true\", cmvn, f'scp:{raw_feat}.scp',\n",
" 'ark:-'\n",
" ]\n",
" cmvn_process = subprocess.Popen(cmvn_command,\n",
" stdout=subprocess.PIPE,\n",
" stderr=subprocess.PIPE)\n",
" process_command = ['copy-feats', '--compress=true', 'ark:-', 'ark:-']\n",
" process = subprocess.Popen(process_command,\n",
" stdin=cmvn_process.stdout,\n",
" stdout=subprocess.PIPE,\n",
" stderr=subprocess.PIPE)\n",
" norm_feat = dict(kaldiio.load_ark(process.stdout))[utt_name]\n",
" audio = paddle.to_tensor(norm_feat).unsqueeze(0)\n",
" audio_len = paddle.to_tensor(audio.shape[1], dtype='int64')\n",
" return audio, audio_len"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": false
},
"source": [
"### 构建文本特征提取对象"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"text_feature = TextFeaturizer(\n",
" unit_type=st_config.collator.unit_type,\n",
" vocab=st_config.collator.vocab_filepath,\n",
" spm_model_prefix=st_config.collator.spm_model_prefix)"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": false
},
"source": [
"## Stage 3 使用模型获得结果"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": false
},
"source": [
"### 构建 ST 模型"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"model_conf = st_config.model\n",
"model_conf.input_dim = st_config.collator.feat_dim\n",
"model_conf.output_dim = text_feature.vocab_size\n",
"print(model_conf)\n",
"model = U2STModel.from_config(model_conf)"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": false
},
"source": [
"### 加载预训练模型"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"params_path = \"exp/transformer_mtl_noam/checkpoints/fat_st_ted-en-zh.pdparams\"\n",
"model_dict = paddle.load(params_path)\n",
"model.set_state_dict(model_dict)\n",
"model.eval()"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": false
},
"source": [
"### 预测"
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"# 下载wav\n",
"!wget -nc https://paddlespeech.bj.bcebos.com/PaddleAudio/74109_0147917-0156334.wav\n",
"!wget -nc https://paddlespeech.bj.bcebos.com/PaddleAudio/120221_0278694-0283831.wav\n",
"!wget -nc https://paddlespeech.bj.bcebos.com/PaddleAudio/15427_0822000-0833000.wav\n",
"\n",
"wav_file = '74109_0147917-0156334.wav'\n",
"# wav_file = '120221_0278694-0283831.wav'\n",
"# wav_file = '15427_0822000-0833000.wav'\n",
"\n",
"transcript = \"my hair is short like a boy 's and i wear boy 's clothes but i 'm a girl and you know how sometimes you like to wear a pink dress and sometimes you like to wear your comfy jammies\"\n",
"dp.Audio(wav_file)"
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"audio, audio_len = get_kaldi_feat(wav_file)\n",
"cfg = st_config.decoding\n",
"\n",
"\n",
"res = model.decode(audio,\n",
" audio_len,\n",
" text_feature=text_feature,\n",
" decoding_method=cfg.decoding_method,\n",
" beam_size=cfg.beam_size,\n",
" word_reward=cfg.word_reward,\n",
" decoding_chunk_size=cfg.decoding_chunk_size,\n",
" num_decoding_left_chunks=cfg.num_decoding_left_chunks,\n",
" simulate_streaming=cfg.simulate_streaming)\n",
"print(\"对应英文: {}\".format(transcript))\n",
"print(\"翻译结果: {}\".format(\"\".join(res[0].split())))\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": false
},
"source": [
"# 参考文献\n",
"\n",
"1.Zheng, Renjie, Junkun Chen, Mingbo Ma, and Liang Huang. \"Fused acoustic and text encoding for multimodal bilingual pretraining and speech translation.\" ICML 2021.\n",
"\n",
"2.Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. \"Bert: Pre-training of deep bidirectional transformers for language understanding.\" NAACL 2019.\n",
"\n",
"3.Conneau, Alexis, and Guillaume Lample. \"Cross-lingual language model pretraining.\" NIPS 2019.\n",
"\n",
"4.Liu, Yuchen, Hao Xiong, Zhongjun He, Jiajun Zhang, Hua Wu, Haifeng Wang, and Chengqing Zong. \"End-to-end speech translation with knowledge distillation.\" Interspeech 2019."
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": false
},
"source": [
"# PaddleSpeech\n",
"\n",
"请关注我们的 [Github Repo](https://github.com/PaddlePaddle/PaddleSpeech/),非常欢迎加入以下微信群参与讨论:\n",
"- 扫描二维码\n",
"- 添加运营小姐姐微信\n",
"- 通过后回复【语音】\n",
"- 系统自动邀请加入技术群\n",
"\n",
"<center><img src=\"https://ai-studio-static-online.cdn.bcebos.com/87bc7da42bcc401bae41d697f13d8b362bfdfd7198f14096b6d46b4004f09613\" width=\"300\" height=\"300\" ></center>"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "py35-paddle1.2.0"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.4"
}
},
"nbformat": 4,
"nbformat_minor": 1
}