{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# GAN Vocoders 总览\n",
"\n",
"Loss 函数简称与全称的对应关系\n",
"\n",
"|Short Name|Full Name|\n",
":-----:|:-----|\n",
"|adv|adversial loss|\n",
"|FM|Feature Matching|\n",
"|MSD|Multi-Scale Discriminator|\n",
"|mr-STFT|Multi-resolution STFT loss|\n",
"|fmr-STFT|full band Multi-resolution STFT loss|\n",
"|smr-STFT|sub band Multi-resolution STFT loss|\n",
"|Mel|Mel-Spectrogram Loss|\n",
"|MPD|Multi-Period Discriminator|\n",
"|FB-RAWs|Filter Bank Random Window Discriminators|\n",
"\n",
"
\n",
"csmsc 数据集上 GAN Vocoder 整体对比\n",
"\n",
"Model|Date|Input|Generator
Loss|Discriminator
Loss|Need
Finetune|Training
Steps|Finetune
Steps|Batch
Size|ips
(gen only)
(gen + dis)|Static Model
Size (gen)|RTF
(GPU)|\n",
":-----:|:-----:|:-----:|:-----:|:-----:|:-----:|:-----:|:-----:|:-----:|:-----:|:-----:|:-----:|\n",
"Mel GAN|9 Dec 2019|mel|adv
FM |MSD|——|——|——|——|——|——|——|\n",
"Parallel Wave GAN |6 Feb 2020|mel
noise|adv
mr-STFT|adv|No|40W|——|8|18
10|5.1MB|0.01786|\n",
"HiFi GAN|23 Oct 2020|mel|adv
FM
Mel|MSD
MPD|Yes|250W|no need|16|——
31|50MB|0.00825|\n",
"Multi-Band Mel GAN|17 Nov 2020|mel|adv
fmr-STFT
smr-STFT|MSD|Yes|100W|100W
(not good enough,
need to adjust parameters)|64|305
148|8.2MB|0.00457|\n",
"Style Mel GAN|12 Feb 2021|mel
noise|adv
mr-STFT|FB-RAWs|No|150W|——|32|58
24|——|0.01343|\n",
"\n"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"# 网络结构\n",
"## Mel GAN\n",
" \n",
"
\n",
"
Mel GAN 网络结构图\n",
"\n",
"## Parallel Wave GAN\n",
" \n",
"
\n",
"
Parallel Wave GAN 网络结构图\n",
"\n",
"## HiFi GAN\n",
" \n",
"
\n",
"
HiFi GAN 生成器网络结构图\n",
"\n",
"
\n",
"\n",
" \n",
"
\n",
"
HiFi GAN 判别器网络结构图\n",
"\n",
"## Multi-Band Mel GAN\n",
" \n",
"
\n",
"
Multi-Band Mel GAN 网络结构图\n",
"\n",
"## Style Mel GAN\n",
" \n",
"
\n",
"
Style Mel GAN TADE 网络结构图\n",
"\n",
"
\n",
"\n",
" \n",
"
\n",
"
Style Mel GAN 生成器网络结构图\n",
"\n",
"
\n",
"\n",
" \n",
"
\n",
"
Style Mel GAN 判别器网络结构图"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 需要注意的点\n",
"## 输入\n",
"1. 一般情况下,若训练时输入中没有 `noise`,容易过拟合,需要 finetune\n",
" - 参考 [espent issue](https://github.com/espnet/espnet/issues/3536)\n",
"2. 若输入中有 `noise`, 在预测时需要自己在 `inference` 代码中生成 `noise`, 而不能作为参数输入给 `inference`, 否则动转静可能走不通\n",
" - 参考 [pwgan 动转静修复 pr](https://github.com/PaddlePaddle/Parakeet/pull/132/files)\n",
"\n",
"\n",
"## 生成器\n",
"1. `hop_size` 和 `n_shift` 的含义一样\n",
"2. `upsample_scales` 的乘积一定等于 `hop_size`\n",
"3. `采样点 = hop_size * 帧数`\n",
"4. `librosa 帧数 = 采样点 // hop_size + 1`, 具体要不要 `+1` 看不同的库,看 `center` 这个参数 \n",
"5. `Mel GAN` 和 `Multi-Band Mel GAN` 生成器的代码是一样的,只是参数不一样,通道数不一样\n",
"6. `Parallel Wave GAN` 的生成器是 `WaveNet` like\n",
" - 用非因果卷积替换了因果卷积\n",
" - 输入是满足高斯分布的随机噪声\n",
" - 训练和预测时都是非自回归的\n",
"7. `Style MelGAN` 的 noise 的上采样需要额外注意,输入的长度是固定的\n",
" - `batch_max_steps(24000) == prod(noise_upsample_scales)(80) * prod(upsample_scales)(300, n_shift)`\n",
"\n",
"## 判别器\n",
"1. HiFi GAN 判别器的能力很强\n",
"\n",
"## 速度\n",
"1. 为什么 `Multi-Band Mel GAN` 的预测会更快?因为上采样的倍数变为了原来的 `1/4`"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# FFT 在语音合成声码器上的应用\n",
"\n",
"语音合成是一种将任意文本转换成语音的技术,目前在深度学习领域,语音合成主要分为 `3` 个模块:\n",
"- 文本前端\n",
"- 声学模型\n",
"- 声码器\n",
"\n",
"其中,文本前端模块将输入文本转换为音素序列或语言学特征;声学模型将音素序列或语言学特征转换为声学特征,在语音合成领域,常用的声学特征是 mel 频谱;声码器将声学特征转换为语音波形。\n",
"\n",
"声码器的输入是频域特征 mel 频谱图,输出是对应的语音波形。\n",
"\n",
"STFT 全称 Short-Time Fourier Transform,短时傅里叶变换,它是用滑动帧 FFT 生成频率与时间的 2D 矩阵,通常被称为频谱图(Spectrogram), 而人耳对于频率的敏感程度是非线性的,可以通过 mel 三角滤波器对频谱图处理,生成 mel 频谱图。\n",
"\n",
"生成 mel 频谱图的计算离不开 fft 系列的算子,若模型的输入是 mel 频谱图,可以使用 `librosa` 等科学计算库进行计算再输入模型。然而,现有的大多数基于 `GAN` 的声码器模型,在计算 `loss` 时需要将生成器合成的音频及原始音频转换到频率域再做计算,这时需要用到短时傅里叶变换算子 `stft`,且由于 `stft` 算子出现在了模型图中,其需要参与到模型的前向和反向计算过程中,此时,则需要深度学习框架提供 `stft` 算子。\n",
"\n",
"最新的 `PaddleSpeech` 语音合成模块的声码器,用到了 paddle 2.2.0 提供的 fft 系列算子 `paddle.signal.stft`。\n",
"\n",
"`PaddleSpeech` 模型库目前已经实现的基于 `GAN` 的声码器包括 `Parallel WaveGAN`、`Multi Band MelGAN`、`HiFiGAN` 和 `Style MelGAN`,这些模型的 `loss` 中都包含基于 `stft` 算子的 `loss`,其中主要包含 `Multi-resolution STFT loss` 和 `Mel-Spectrogram Loss`。\n",
"\n",
"`Multi-resolution STFT loss` 公式如下所示:\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"`Mel-Spectrogram Loss` 公式如下所示:\n",
"\n",
"\n",
"\n",
"\n",
"其中 `Φ` 表示将音频转换为对应 mel 频谱的函数。\n",
"\n",
"如上述公式所示,现在主流的基于 `GAN` 的声码器的 `loss` 设计需要用到 `stft`,在 Paddle 中尚未实现 fft 系列算子时,`PaddleSpeech` 模型库使用基于 `Conv1D` 算子的函数来模拟 `stft` 算子,然而经过计算,该模拟函数前向结果正确,反向梯度计算结果不正确,这导致了模型收敛效果不佳,听感略差于竞品。\n",
"\n",
"Paddle 主框架中加入 fft 系列算子后,我们将语音合成声码器 loss 模块中的基于 `Conv1D` 的 `stft` 均替换为 `paddle.signal.stft`,在模型收敛效果和合成音频听感上,`paddle.signal.stft` 的效果明显优于基于 `Conv1D` 的 `stft` 实现。\n",
"\n",
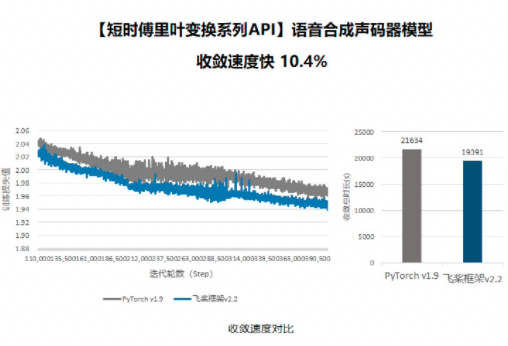
"以 `Parallel WaveGAN` 模型为例,我们复现了基于 `Pytorch` 和基于 `Paddle` 的 `Parallel WaveGAN`,并保持模型结构完全一致,在相同的实验环境下,基于 `Paddle` 的模型收敛速度比基于 `Pytorch` 的模型快 `10.4%`, 而基于 `Conv1D` 的 `stft` 实现的 Paddle 模型的收敛速度和收敛效果和收敛速度差于基于 `Pytorch` 的模型,更明显差于基于 `Paddle` 的模型,所以可以认为 `paddle.signal.stft` 算子大幅度提升了 `Parallel WaveGAN` 模型的效果。\n",
"\n",
"\n"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3.7.0 64-bit ('yt_py37_develop': venv)",
"language": "python",
"name": "python37064bitytpy37developvenv88cd689abeac41d886f9210a708a170b"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.0"
},
"toc": {
"base_numbering": 1,
"nav_menu": {},
"number_sections": true,
"sideBar": true,
"skip_h1_title": false,
"title_cell": "Table of Contents",
"title_sidebar": "Contents",
"toc_cell": false,
"toc_position": {},
"toc_section_display": true,
"toc_window_display": false
}
},
"nbformat": 4,
"nbformat_minor": 4
}