Sorry, your browser doesn't support embedded videos.
diff --git a/docs/source/install.md b/docs/source/install.md
index 205d3e600..b78fdd864 100644
--- a/docs/source/install.md
+++ b/docs/source/install.md
@@ -68,7 +68,7 @@ pip install paddlepaddle==2.4.1 -i https://mirror.baidu.com/pypi/simple
# install develop version
pip install paddlepaddle==0.0.0 -f https://www.paddlepaddle.org.cn/whl/linux/cpu-mkl/develop.html
```
-> If you encounter problem with downloading **nltk_data** while using paddlespeech, it maybe due to your poor network, we suggest you download the [nltk_data](https://paddlespeech.bj.bcebos.com/Parakeet/tools/nltk_data.tar.gz) provided by us, and extract it to your `${HOME}`.
+> If you encounter problem with downloading **nltk_data** while using paddlespeech, it maybe due to your poor network, we suggest you download the [nltk_data](https://paddlespeech.cdn.bcebos.com/Parakeet/tools/nltk_data.tar.gz) provided by us, and extract it to your `${HOME}`.
> If you fail to install paddlespeech-ctcdecoders, you only can not use deepspeech2 model inference. For other models, it doesn't matter.
diff --git a/docs/source/install_cn.md b/docs/source/install_cn.md
index ecfb22f59..c47be0500 100644
--- a/docs/source/install_cn.md
+++ b/docs/source/install_cn.md
@@ -65,7 +65,7 @@ pip install paddlepaddle==2.3.1 -i https://mirror.baidu.com/pypi/simple
# 安装 develop 版本
pip install paddlepaddle==0.0.0 -f https://www.paddlepaddle.org.cn/whl/linux/cpu-mkl/develop.html
```
-> 如果您在使用 paddlespeech 的过程中遇到关于下载 **nltk_data** 的问题,可能是您的网络不佳,我们建议您下载我们提供的 [nltk_data](https://paddlespeech.bj.bcebos.com/Parakeet/tools/nltk_data.tar.gz) 并解压缩到您的 `${HOME}` 目录下。
+> 如果您在使用 paddlespeech 的过程中遇到关于下载 **nltk_data** 的问题,可能是您的网络不佳,我们建议您下载我们提供的 [nltk_data](https://paddlespeech.cdn.bcebos.com/Parakeet/tools/nltk_data.tar.gz) 并解压缩到您的 `${HOME}` 目录下。
> 如果出现 paddlespeech-ctcdecoders 无法安装的问题,无须担心,这个只影响 deepspeech2 模型的推理,不影响其他模型的使用。
diff --git a/docs/source/released_model.md b/docs/source/released_model.md
index 87619a558..7c67685d3 100644
--- a/docs/source/released_model.md
+++ b/docs/source/released_model.md
@@ -7,34 +7,34 @@
### Speech Recognition Model
Acoustic Model | Training Data | Token-based | Size | Descriptions | CER | WER | Hours of speech | Example Link | Inference Type | static_model |
:-------------:| :------------:| :-----: | -----: | :-----: |:-----:| :-----: | :-----: | :-----: | :-----: | :-----: |
-[Ds2 Online Wenetspeech ASR0 Model](https://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr0/asr0_deepspeech2_online_wenetspeech_ckpt_1.0.4.model.tar.gz) | Wenetspeech Dataset | Char-based | 1.2 GB | 2 Conv + 5 LSTM layers | 0.152 (test\_net, w/o LM)
-
+
Sorry, your browser doesn't support embedded videos.
diff --git a/docs/source/streaming_tts_demo_video.rst b/docs/source/streaming_tts_demo_video.rst
index 3ad9ca6cf..b2dcdba2c 100644
--- a/docs/source/streaming_tts_demo_video.rst
+++ b/docs/source/streaming_tts_demo_video.rst
@@ -5,7 +5,7 @@ Streaming TTS Demo Video
-
Sorry, your browser doesn't support embedded videos.
diff --git a/docs/source/tts/README.md b/docs/source/tts/README.md
index 835db08ee..97a426be5 100644
--- a/docs/source/tts/README.md
+++ b/docs/source/tts/README.md
@@ -35,39 +35,39 @@ Check our [website](https://paddlespeech.readthedocs.io/en/latest/tts/demo.html)
### Acoustic Model
#### FastSpeech2/FastPitch
-1. [fastspeech2_nosil_baker_ckpt_0.4.zip](https://paddlespeech.bj.bcebos.com/Parakeet/fastspeech2_nosil_baker_ckpt_0.4.zip)
-2. [fastspeech2_nosil_aishell3_ckpt_0.4.zip](https://paddlespeech.bj.bcebos.com/Parakeet/fastspeech2_nosil_aishell3_ckpt_0.4.zip)
-3. [fastspeech2_nosil_ljspeech_ckpt_0.5.zip](https://paddlespeech.bj.bcebos.com/Parakeet/fastspeech2_nosil_ljspeech_ckpt_0.5.zip)
+1. [fastspeech2_nosil_baker_ckpt_0.4.zip](https://paddlespeech.cdn.bcebos.com/Parakeet/fastspeech2_nosil_baker_ckpt_0.4.zip)
+2. [fastspeech2_nosil_aishell3_ckpt_0.4.zip](https://paddlespeech.cdn.bcebos.com/Parakeet/fastspeech2_nosil_aishell3_ckpt_0.4.zip)
+3. [fastspeech2_nosil_ljspeech_ckpt_0.5.zip](https://paddlespeech.cdn.bcebos.com/Parakeet/fastspeech2_nosil_ljspeech_ckpt_0.5.zip)
#### SpeedySpeech
-1. [speedyspeech_nosil_baker_ckpt_0.5.zip](https://paddlespeech.bj.bcebos.com/Parakeet/speedyspeech_nosil_baker_ckpt_0.5.zip)
+1. [speedyspeech_nosil_baker_ckpt_0.5.zip](https://paddlespeech.cdn.bcebos.com/Parakeet/speedyspeech_nosil_baker_ckpt_0.5.zip)
#### TransformerTTS
-1. [transformer_tts_ljspeech_ckpt_0.4.zip](https://paddlespeech.bj.bcebos.com/Parakeet/transformer_tts_ljspeech_ckpt_0.4.zip)
+1. [transformer_tts_ljspeech_ckpt_0.4.zip](https://paddlespeech.cdn.bcebos.com/Parakeet/transformer_tts_ljspeech_ckpt_0.4.zip)
#### Tacotron2
-1. [tacotron2_ljspeech_ckpt_0.3.zip](https://paddlespeech.bj.bcebos.com/Parakeet/tacotron2_ljspeech_ckpt_0.3.zip)
-2. [tacotron2_ljspeech_ckpt_0.3_alternative.zip](https://paddlespeech.bj.bcebos.com/Parakeet/tacotron2_ljspeech_ckpt_0.3_alternative.zip)
+1. [tacotron2_ljspeech_ckpt_0.3.zip](https://paddlespeech.cdn.bcebos.com/Parakeet/tacotron2_ljspeech_ckpt_0.3.zip)
+2. [tacotron2_ljspeech_ckpt_0.3_alternative.zip](https://paddlespeech.cdn.bcebos.com/Parakeet/tacotron2_ljspeech_ckpt_0.3_alternative.zip)
### Vocoder
#### WaveFlow
-1. [waveflow_ljspeech_ckpt_0.3.zip](https://paddlespeech.bj.bcebos.com/Parakeet/waveflow_ljspeech_ckpt_0.3.zip)
+1. [waveflow_ljspeech_ckpt_0.3.zip](https://paddlespeech.cdn.bcebos.com/Parakeet/waveflow_ljspeech_ckpt_0.3.zip)
#### Parallel WaveGAN
-1. [pwg_baker_ckpt_0.4.zip](https://paddlespeech.bj.bcebos.com/Parakeet/pwg_baker_ckpt_0.4.zip)
-2. [pwg_ljspeech_ckpt_0.5.zip](https://paddlespeech.bj.bcebos.com/Parakeet/pwg_ljspeech_ckpt_0.5.zip)
+1. [pwg_baker_ckpt_0.4.zip](https://paddlespeech.cdn.bcebos.com/Parakeet/pwg_baker_ckpt_0.4.zip)
+2. [pwg_ljspeech_ckpt_0.5.zip](https://paddlespeech.cdn.bcebos.com/Parakeet/pwg_ljspeech_ckpt_0.5.zip)
### Voice Cloning
#### Tacotron2_AISHELL3
-1. [tacotron2_aishell3_ckpt_0.3.zip](https://paddlespeech.bj.bcebos.com/Parakeet/tacotron2_aishell3_ckpt_0.3.zip)
+1. [tacotron2_aishell3_ckpt_0.3.zip](https://paddlespeech.cdn.bcebos.com/Parakeet/tacotron2_aishell3_ckpt_0.3.zip)
#### GE2E
-1. [ge2e_ckpt_0.3.zip](https://paddlespeech.bj.bcebos.com/Parakeet/ge2e_ckpt_0.3.zip)
+1. [ge2e_ckpt_0.3.zip](https://paddlespeech.cdn.bcebos.com/Parakeet/ge2e_ckpt_0.3.zip)
diff --git a/docs/source/tts/advanced_usage.md b/docs/source/tts/advanced_usage.md
index 4dd742b70..9f86689e7 100644
--- a/docs/source/tts/advanced_usage.md
+++ b/docs/source/tts/advanced_usage.md
@@ -303,7 +303,7 @@ The experimental codes in PaddleSpeech TTS are generally organized as follows:
.
├── README.md (help information)
├── conf
-│ └── default.yaml (defalut config)
+│ └── default.yaml (default config)
├── local
│ ├── preprocess.sh (script to call data preprocessing.py)
│ ├── synthesize.sh (script to call synthesis.py)
diff --git a/docs/source/tts/demo.rst b/docs/source/tts/demo.rst
index 1ae687f85..bb866e742 100644
--- a/docs/source/tts/demo.rst
+++ b/docs/source/tts/demo.rst
@@ -44,7 +44,7 @@ Audio samples generated from ground-truth spectrograms with a vocoder.
Your browser does not support the audio element.
@@ -52,7 +52,7 @@ Audio samples generated from ground-truth spectrograms with a vocoder.
Your browser does not support the audio element.
@@ -63,7 +63,7 @@ Audio samples generated from ground-truth spectrograms with a vocoder.
Your browser does not support the audio element.
@@ -72,7 +72,7 @@ Audio samples generated from ground-truth spectrograms with a vocoder.
Your browser does not support the audio element.
@@ -83,7 +83,7 @@ Audio samples generated from ground-truth spectrograms with a vocoder.
Your browser does not support the audio element.
@@ -91,7 +91,7 @@ Audio samples generated from ground-truth spectrograms with a vocoder.
Your browser does not support the audio element.
@@ -102,7 +102,7 @@ Audio samples generated from ground-truth spectrograms with a vocoder.
Your browser does not support the audio element.
@@ -110,7 +110,7 @@ Audio samples generated from ground-truth spectrograms with a vocoder.
Your browser does not support the audio element.
@@ -121,7 +121,7 @@ Audio samples generated from ground-truth spectrograms with a vocoder.
Your browser does not support the audio element.
@@ -129,7 +129,7 @@ Audio samples generated from ground-truth spectrograms with a vocoder.
Your browser does not support the audio element.
@@ -155,7 +155,7 @@ Audio samples generated from ground-truth spectrograms with a vocoder.
Your browser does not support the audio element.
@@ -163,7 +163,7 @@ Audio samples generated from ground-truth spectrograms with a vocoder.
Your browser does not support the audio element.
@@ -174,7 +174,7 @@ Audio samples generated from ground-truth spectrograms with a vocoder.
Your browser does not support the audio element.
@@ -182,7 +182,7 @@ Audio samples generated from ground-truth spectrograms with a vocoder.
Your browser does not support the audio element.
@@ -193,7 +193,7 @@ Audio samples generated from ground-truth spectrograms with a vocoder.
Your browser does not support the audio element.
@@ -201,7 +201,7 @@ Audio samples generated from ground-truth spectrograms with a vocoder.
Your browser does not support the audio element.
@@ -212,7 +212,7 @@ Audio samples generated from ground-truth spectrograms with a vocoder.
Your browser does not support the audio element.
@@ -220,7 +220,7 @@ Audio samples generated from ground-truth spectrograms with a vocoder.
Your browser does not support the audio element.
@@ -232,7 +232,7 @@ Audio samples generated from ground-truth spectrograms with a vocoder.
Your browser does not support the audio element.
@@ -240,7 +240,7 @@ Audio samples generated from ground-truth spectrograms with a vocoder.
Your browser does not support the audio element.
@@ -273,7 +273,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -281,7 +281,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -292,7 +292,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -300,7 +300,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -311,7 +311,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -320,7 +320,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -332,7 +332,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -341,7 +341,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -352,7 +352,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -361,7 +361,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -372,7 +372,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -381,7 +381,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -392,7 +392,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -401,7 +401,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -412,7 +412,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -421,7 +421,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -432,7 +432,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -441,7 +441,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -467,7 +467,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -475,7 +475,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -486,7 +486,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -494,7 +494,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -505,7 +505,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -513,7 +513,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -525,7 +525,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -533,7 +533,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -544,7 +544,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -552,7 +552,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -563,7 +563,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -571,7 +571,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -582,7 +582,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -590,7 +590,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -601,7 +601,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -609,7 +609,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -620,7 +620,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -628,7 +628,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -647,7 +647,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -657,7 +657,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -667,7 +667,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -678,7 +678,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -688,7 +688,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -698,7 +698,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -708,7 +708,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -718,7 +718,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -728,7 +728,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Your browser does not support the audio element.
@@ -758,7 +758,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -766,7 +766,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -776,7 +776,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -784,7 +784,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -794,7 +794,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -802,7 +802,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -812,7 +812,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -820,7 +820,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -830,7 +830,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -838,7 +838,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -848,7 +848,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -856,7 +856,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -866,7 +866,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -874,7 +874,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -884,7 +884,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -892,7 +892,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -902,7 +902,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -910,7 +910,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -920,7 +920,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -928,7 +928,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -938,7 +938,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -946,7 +946,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -956,7 +956,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -964,7 +964,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -974,7 +974,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -982,7 +982,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -992,7 +992,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -1000,7 +1000,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -1010,7 +1010,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -1018,7 +1018,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -1028,7 +1028,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -1036,7 +1036,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -1046,7 +1046,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -1054,7 +1054,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -1064,7 +1064,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -1072,7 +1072,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -1082,7 +1082,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -1090,7 +1090,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -1100,7 +1100,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -1108,7 +1108,7 @@ PaddleSpeech also support Multi-Speaker TTS, we provide the audio demos generate
Your browser does not support the audio element.
@@ -1144,7 +1144,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1152,7 +1152,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1160,7 +1160,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1170,7 +1170,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1178,7 +1178,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1186,7 +1186,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1196,7 +1196,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1204,7 +1204,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1212,7 +1212,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1222,7 +1222,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1230,7 +1230,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1238,7 +1238,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1248,7 +1248,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1256,7 +1256,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1264,7 +1264,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1274,7 +1274,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1282,7 +1282,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1290,7 +1290,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1300,7 +1300,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1308,7 +1308,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1316,7 +1316,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1326,7 +1326,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1334,7 +1334,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1342,7 +1342,7 @@ The duration control in FastSpeech2 can control the speed of audios will keep th
Your browser does not support the audio element.
@@ -1376,7 +1376,7 @@ The nomal audios are in the second column of the previous table.
Your browser does not support the audio element.
@@ -1384,7 +1384,7 @@ The nomal audios are in the second column of the previous table.
Your browser does not support the audio element.
@@ -1394,7 +1394,7 @@ The nomal audios are in the second column of the previous table.
Your browser does not support the audio element.
@@ -1402,7 +1402,7 @@ The nomal audios are in the second column of the previous table.
Your browser does not support the audio element.
@@ -1412,7 +1412,7 @@ The nomal audios are in the second column of the previous table.
Your browser does not support the audio element.
@@ -1420,7 +1420,7 @@ The nomal audios are in the second column of the previous table.
Your browser does not support the audio element.
@@ -1430,7 +1430,7 @@ The nomal audios are in the second column of the previous table.
Your browser does not support the audio element.
@@ -1438,7 +1438,7 @@ The nomal audios are in the second column of the previous table.
Your browser does not support the audio element.
@@ -1448,7 +1448,7 @@ The nomal audios are in the second column of the previous table.
Your browser does not support the audio element.
@@ -1456,7 +1456,7 @@ The nomal audios are in the second column of the previous table.
Your browser does not support the audio element.
@@ -1466,7 +1466,7 @@ The nomal audios are in the second column of the previous table.
Your browser does not support the audio element.
@@ -1474,7 +1474,7 @@ The nomal audios are in the second column of the previous table.
Your browser does not support the audio element.
@@ -1484,7 +1484,7 @@ The nomal audios are in the second column of the previous table.
Your browser does not support the audio element.
@@ -1492,7 +1492,7 @@ The nomal audios are in the second column of the previous table.
Your browser does not support the audio element.
@@ -1502,7 +1502,7 @@ The nomal audios are in the second column of the previous table.
Your browser does not support the audio element.
@@ -1510,7 +1510,7 @@ The nomal audios are in the second column of the previous table.
Your browser does not support the audio element.
@@ -1544,7 +1544,7 @@ We use ``FastSpeech2`` + ``ParallelWaveGAN`` here.
Your browser does not support the audio element.
@@ -1552,7 +1552,7 @@ We use ``FastSpeech2`` + ``ParallelWaveGAN`` here.
Your browser does not support the audio element.
@@ -1563,7 +1563,7 @@ We use ``FastSpeech2`` + ``ParallelWaveGAN`` here.
Your browser does not support the audio element.
@@ -1571,7 +1571,7 @@ We use ``FastSpeech2`` + ``ParallelWaveGAN`` here.
Your browser does not support the audio element.
@@ -1582,7 +1582,7 @@ We use ``FastSpeech2`` + ``ParallelWaveGAN`` here.
Your browser does not support the audio element.
@@ -1590,7 +1590,7 @@ We use ``FastSpeech2`` + ``ParallelWaveGAN`` here.
Your browser does not support the audio element.
@@ -1601,7 +1601,7 @@ We use ``FastSpeech2`` + ``ParallelWaveGAN`` here.
Your browser does not support the audio element.
@@ -1609,7 +1609,7 @@ We use ``FastSpeech2`` + ``ParallelWaveGAN`` here.
Your browser does not support the audio element.
@@ -1620,7 +1620,7 @@ We use ``FastSpeech2`` + ``ParallelWaveGAN`` here.
Your browser does not support the audio element.
@@ -1628,7 +1628,7 @@ We use ``FastSpeech2`` + ``ParallelWaveGAN`` here.
Your browser does not support the audio element.
@@ -1639,7 +1639,7 @@ We use ``FastSpeech2`` + ``ParallelWaveGAN`` here.
Your browser does not support the audio element.
@@ -1647,7 +1647,7 @@ We use ``FastSpeech2`` + ``ParallelWaveGAN`` here.
Your browser does not support the audio element.
@@ -1658,7 +1658,7 @@ We use ``FastSpeech2`` + ``ParallelWaveGAN`` here.
Your browser does not support the audio element.
@@ -1666,7 +1666,7 @@ We use ``FastSpeech2`` + ``ParallelWaveGAN`` here.
Your browser does not support the audio element.
@@ -1677,7 +1677,7 @@ We use ``FastSpeech2`` + ``ParallelWaveGAN`` here.
Your browser does not support the audio element.
@@ -1685,7 +1685,7 @@ We use ``FastSpeech2`` + ``ParallelWaveGAN`` here.
Your browser does not support the audio element.
@@ -1696,7 +1696,7 @@ We use ``FastSpeech2`` + ``ParallelWaveGAN`` here.
Your browser does not support the audio element.
@@ -1704,7 +1704,7 @@ We use ``FastSpeech2`` + ``ParallelWaveGAN`` here.
Your browser does not support the audio element.
@@ -1715,7 +1715,7 @@ We use ``FastSpeech2`` + ``ParallelWaveGAN`` here.
Your browser does not support the audio element.
@@ -1723,7 +1723,7 @@ We use ``FastSpeech2`` + ``ParallelWaveGAN`` here.
Your browser does not support the audio element.
@@ -1751,7 +1751,7 @@ When finetuning for CSMSC, we thought ``Freeze encoder`` > ``Non Frozen`` > ``Fr
Your browser does not support the audio element.
@@ -1770,7 +1770,7 @@ When finetuning for CSMSC, we thought ``Freeze encoder`` > ``Non Frozen`` > ``Fr
Your browser does not support the audio element.
@@ -1778,7 +1778,7 @@ When finetuning for CSMSC, we thought ``Freeze encoder`` > ``Non Frozen`` > ``Fr
Your browser does not support the audio element.
@@ -1786,7 +1786,7 @@ When finetuning for CSMSC, we thought ``Freeze encoder`` > ``Non Frozen`` > ``Fr
Your browser does not support the audio element.
@@ -1794,7 +1794,7 @@ When finetuning for CSMSC, we thought ``Freeze encoder`` > ``Non Frozen`` > ``Fr
Your browser does not support the audio element.
@@ -1805,7 +1805,7 @@ When finetuning for CSMSC, we thought ``Freeze encoder`` > ``Non Frozen`` > ``Fr
Your browser does not support the audio element.
@@ -1813,7 +1813,7 @@ When finetuning for CSMSC, we thought ``Freeze encoder`` > ``Non Frozen`` > ``Fr
Your browser does not support the audio element.
@@ -1821,7 +1821,7 @@ When finetuning for CSMSC, we thought ``Freeze encoder`` > ``Non Frozen`` > ``Fr
Your browser does not support the audio element.
@@ -1829,7 +1829,7 @@ When finetuning for CSMSC, we thought ``Freeze encoder`` > ``Non Frozen`` > ``Fr
Your browser does not support the audio element.
@@ -1840,7 +1840,7 @@ When finetuning for CSMSC, we thought ``Freeze encoder`` > ``Non Frozen`` > ``Fr
Your browser does not support the audio element.
@@ -1848,7 +1848,7 @@ When finetuning for CSMSC, we thought ``Freeze encoder`` > ``Non Frozen`` > ``Fr
Your browser does not support the audio element.
@@ -1856,7 +1856,7 @@ When finetuning for CSMSC, we thought ``Freeze encoder`` > ``Non Frozen`` > ``Fr
Your browser does not support the audio element.
@@ -1864,7 +1864,7 @@ When finetuning for CSMSC, we thought ``Freeze encoder`` > ``Non Frozen`` > ``Fr
Your browser does not support the audio element.
diff --git a/docs/source/tts/demo_2.rst b/docs/source/tts/demo_2.rst
index 06d0d0399..62db2c760 100644
--- a/docs/source/tts/demo_2.rst
+++ b/docs/source/tts/demo_2.rst
@@ -21,7 +21,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -29,7 +29,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -40,7 +40,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -48,7 +48,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -59,7 +59,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -67,7 +67,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -78,7 +78,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -86,7 +86,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -97,7 +97,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -105,7 +105,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -116,7 +116,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -124,7 +124,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -135,7 +135,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -143,7 +143,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -154,7 +154,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -162,7 +162,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -173,7 +173,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -181,7 +181,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -192,7 +192,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -200,7 +200,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -211,7 +211,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -219,7 +219,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -230,7 +230,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -238,7 +238,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -249,7 +249,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -257,7 +257,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -268,7 +268,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
@@ -276,7 +276,7 @@ FastSpeech2 + Parallel WaveGAN in CSMSC
Your browser does not support the audio element.
diff --git a/docs/source/tts/svs_music_score.md b/docs/source/tts/svs_music_score.md
index 9f351c001..8607ed28f 100644
--- a/docs/source/tts/svs_music_score.md
+++ b/docs/source/tts/svs_music_score.md
@@ -3,7 +3,7 @@
# 一、常见基础
## 1.1 简谱和音名(note)
-
上图从左往右的黑键音名分别是:C#/Db,D#/Db,F#/Db,G#/Ab,A#/Bb
@@ -11,20 +11,20 @@
钢琴八度音就是12345671八个音,最后一个音是高1。**遵循:全全半全全全半** 就会得到 1 2 3 4 5 6 7 (高)1 的音
-
## 1.2 十二大调
“#”表示升调
-
“b”表示降调
-
什么大调表示Do(简谱1) 这个音从哪个键开始,例如D大调,则用D这个键来表示 Do这个音。
@@ -39,7 +39,7 @@
Tempo 用于表示速度(Speed of the beat/pulse),一分钟里面有几拍(beats per mimute BPM)
-
whole note --> 4 beats
@@ -54,7 +54,7 @@ sixteenth note --> 1/4 beat
music scores 包含:note,note_dur,is_slur
-
从左上角的谱信息 *bE* 可以得出该谱子是 **降E大调**,可以对应1.2小节十二大调简谱音名对照表根据 简谱获取对应的note
@@ -111,7 +111,7 @@ music scores 包含:note,note_dur,is_slur
1
原始 opencpop 标注的 notes,note_durs,is_slurs,升F大调,起始在小字组(第3组)
-
+
@@ -119,7 +119,7 @@ music scores 包含:note,note_dur,is_slur
2
原始 opencpop 标注的 notes 和 is_slurs,note_durs 改变(从谱子获取)
-
+
@@ -127,7 +127,7 @@ music scores 包含:note,note_dur,is_slur
3
原始 opencpop 标注的 notes 去掉 rest(毛字一拍),is_slurs 和 note_durs 改变(从谱子获取)
-
+
@@ -135,7 +135,7 @@ music scores 包含:note,note_dur,is_slur
4
从谱子获取 notes,note durs,is_slurs,不含 rest(毛字一拍),起始在小字一组(第3组)
-
+
@@ -143,7 +143,7 @@ music scores 包含:note,note_dur,is_slur
5
从谱子获取 notes,note durs,is_slurs,加上 rest (毛字半拍,rest半拍),起始在小字一组(第3组)
-
+
@@ -151,7 +151,7 @@ music scores 包含:note,note_dur,is_slur
6
从谱子获取 notes, is_slurs,包含 rest,note_durs 从原始标注获取,起始在小字一组(第3组)
-
+
@@ -159,7 +159,7 @@ music scores 包含:note,note_dur,is_slur
7
从谱子获取 notes,note durs,is_slurs,不含 rest(毛字一拍),起始在小字一组(第4组)
-
+
diff --git a/docs/source/tts_demo_video.rst b/docs/source/tts_demo_video.rst
index 4f807165d..83890e572 100644
--- a/docs/source/tts_demo_video.rst
+++ b/docs/source/tts_demo_video.rst
@@ -5,7 +5,7 @@ TTS Demo Video
-
Sorry, your browser doesn't support embedded videos.
diff --git a/docs/topic/ctc/ctc_loss_speed_compare.ipynb b/docs/topic/ctc/ctc_loss_speed_compare.ipynb
index eb7a030c7..6d9187f7f 100644
--- a/docs/topic/ctc/ctc_loss_speed_compare.ipynb
+++ b/docs/topic/ctc/ctc_loss_speed_compare.ipynb
@@ -27,7 +27,7 @@
],
"source": [
"!mkdir -p ./test_data\n",
- "!test -f ./test_data/ctc_loss_compare_data.tgz || wget -P ./test_data https://paddlespeech.bj.bcebos.com/datasets/unit_test/asr/ctc_loss_compare_data.tgz\n",
+ "!test -f ./test_data/ctc_loss_compare_data.tgz || wget -P ./test_data https://paddlespeech.cdn.bcebos.com/datasets/unit_test/asr/ctc_loss_compare_data.tgz\n",
"!tar xzvf test_data/ctc_loss_compare_data.tgz -C ./test_data\n"
]
},
diff --git a/docs/topic/gan_vocoder/gan_vocoder.ipynb b/docs/topic/gan_vocoder/gan_vocoder.ipynb
index edb4eeb1d..4f53c32f7 100644
--- a/docs/topic/gan_vocoder/gan_vocoder.ipynb
+++ b/docs/topic/gan_vocoder/gan_vocoder.ipynb
@@ -156,7 +156,7 @@
"\n",
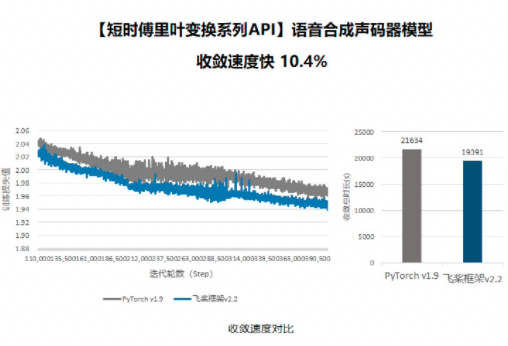
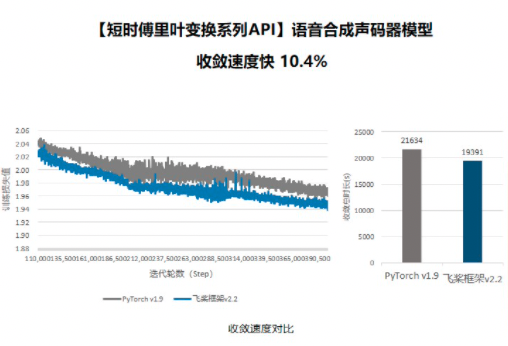
"以 `Parallel WaveGAN` 模型为例,我们复现了基于 `Pytorch` 和基于 `Paddle` 的 `Parallel WaveGAN`,并保持模型结构完全一致,在相同的实验环境下,基于 `Paddle` 的模型收敛速度比基于 `Pytorch` 的模型快 `10.4%`, 而基于 `Conv1D` 的 `stft` 实现的 Paddle 模型的收敛速度和收敛效果和收敛速度差于基于 `Pytorch` 的模型,更明显差于基于 `Paddle` 的模型,所以可以认为 `paddle.signal.stft` 算子大幅度提升了 `Parallel WaveGAN` 模型的效果。\n",
"\n",
- "\n"
+ "\n"
]
}
],
diff --git a/docs/tutorial/asr/tutorial_deepspeech2.ipynb b/docs/tutorial/asr/tutorial_deepspeech2.ipynb
index 34c0090ac..c40ada9fa 100644
--- a/docs/tutorial/asr/tutorial_deepspeech2.ipynb
+++ b/docs/tutorial/asr/tutorial_deepspeech2.ipynb
@@ -23,7 +23,7 @@
"outputs": [],
"source": [
"# 下载demo视频\n",
- "!test -f work/source/subtitle_demo1.mp4 || wget https://paddlespeech.bj.bcebos.com/demos/asr_demos/subtitle_demo1.mp4 -P work/source/"
+ "!test -f work/source/subtitle_demo1.mp4 || wget https://paddlespeech.cdn.bcebos.com/demos/asr_demos/subtitle_demo1.mp4 -P work/source/"
]
},
{
@@ -311,7 +311,7 @@
},
"outputs": [],
"source": [
- "!test -f ds2.model.tar.gz || wget -nc https://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/ds2.model.tar.gz\n",
+ "!test -f ds2.model.tar.gz || wget -nc https://paddlespeech.cdn.bcebos.com/s2t/aishell/asr0/ds2.model.tar.gz\n",
"!tar xzvf ds2.model.tar.gz"
]
},
@@ -329,7 +329,7 @@
"!mkdir -p data/lm\n",
"!test -f ./data/lm/zh_giga.no_cna_cmn.prune01244.klm || wget -nc https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm -P data/lm\n",
"# 获取用于预测的音频文件\n",
- "!test -f ./data/demo_01_03.wav || wget -nc https://paddlespeech.bj.bcebos.com/datasets/single_wav/zh/demo_01_03.wav -P ./data/"
+ "!test -f ./data/demo_01_03.wav || wget -nc https://paddlespeech.cdn.bcebos.com/datasets/single_wav/zh/demo_01_03.wav -P ./data/"
]
},
{
diff --git a/docs/tutorial/asr/tutorial_transformer.ipynb b/docs/tutorial/asr/tutorial_transformer.ipynb
index 77aed4bf8..bcfb57d53 100644
--- a/docs/tutorial/asr/tutorial_transformer.ipynb
+++ b/docs/tutorial/asr/tutorial_transformer.ipynb
@@ -22,7 +22,7 @@
"outputs": [],
"source": [
"# 下载demo视频\n",
- "!test -f work/source/subtitle_demo1.mp4 || wget -c https://paddlespeech.bj.bcebos.com/demos/asr_demos/subtitle_demo1.mp4 -P work/source/"
+ "!test -f work/source/subtitle_demo1.mp4 || wget -c https://paddlespeech.cdn.bcebos.com/demos/asr_demos/subtitle_demo1.mp4 -P work/source/"
]
},
{
@@ -181,11 +181,11 @@
"outputs": [],
"source": [
"# 获取模型\n",
- "!test -f transformer.model.tar.gz || wget -nc https://paddlespeech.bj.bcebos.com/s2t/aishell/asr1/transformer.model.tar.gz\n",
+ "!test -f transformer.model.tar.gz || wget -nc https://paddlespeech.cdn.bcebos.com/s2t/aishell/asr1/transformer.model.tar.gz\n",
"!tar xzvf transformer.model.tar.gz\n",
"\n",
"# 获取用于预测的音频文件\n",
- "!test -f ./data/demo_01_03.wav || wget -nc https://paddlespeech.bj.bcebos.com/datasets/single_wav/zh/demo_01_03.wav -P ./data/"
+ "!test -f ./data/demo_01_03.wav || wget -nc https://paddlespeech.cdn.bcebos.com/datasets/single_wav/zh/demo_01_03.wav -P ./data/"
]
},
{
diff --git a/docs/tutorial/cls/cls_tutorial.ipynb b/docs/tutorial/cls/cls_tutorial.ipynb
index 3cee64991..c976a2c63 100644
--- a/docs/tutorial/cls/cls_tutorial.ipynb
+++ b/docs/tutorial/cls/cls_tutorial.ipynb
@@ -35,7 +35,7 @@
"source": [
"%%HTML\n",
"\n",
- " \n",
+ " \n",
" 图片来源:https://ww2.mathworks.cn/help/audio/ref/mfcc.html \n",
"\n",
"` and
+ :ref:`"soundfile" backend with the new interface`.
+
+ :ivar int sample_rate: Sample rate
+ :ivar int num_frames: The number of frames
+ :ivar int num_channels: The number of channels
+ :ivar int bits_per_sample: The number of bits per sample. This is 0 for lossy formats,
+ or when it cannot be accurately inferred.
+ :ivar str encoding: Audio encoding
+ The values encoding can take are one of the following:
+
+ * ``PCM_S``: Signed integer linear PCM
+ * ``PCM_U``: Unsigned integer linear PCM
+ * ``PCM_F``: Floating point linear PCM
+ * ``FLAC``: Flac, Free Lossless Audio Codec
+ * ``ULAW``: Mu-law
+ * ``ALAW``: A-law
+ * ``MP3`` : MP3, MPEG-1 Audio Layer III
+ * ``VORBIS``: OGG Vorbis
+ * ``AMR_WB``: Adaptive Multi-Rate
+ * ``AMR_NB``: Adaptive Multi-Rate Wideband
+ * ``OPUS``: Opus
+ * ``HTK``: Single channel 16-bit PCM
+ * ``UNKNOWN`` : None of above
+ """
+
+ def __init__(
+ self,
+ sample_rate: int,
+ num_frames: int,
+ num_channels: int,
+ bits_per_sample: int,
+ encoding: str, ):
+ self.sample_rate = sample_rate
+ self.num_frames = num_frames
+ self.num_channels = num_channels
+ self.bits_per_sample = bits_per_sample
+ self.encoding = encoding
+
+ def __str__(self):
+ return (f"AudioMetaData("
+ f"sample_rate={self.sample_rate}, "
+ f"num_frames={self.num_frames}, "
+ f"num_channels={self.num_channels}, "
+ f"bits_per_sample={self.bits_per_sample}, "
+ f"encoding={self.encoding}"
+ f")")
diff --git a/paddlespeech/audio/backends/soundfile_backend.py b/paddlespeech/audio/backends/soundfile_backend.py
new file mode 100644
index 000000000..7611fd297
--- /dev/null
+++ b/paddlespeech/audio/backends/soundfile_backend.py
@@ -0,0 +1,677 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+import warnings
+from typing import Optional
+from typing import Tuple
+
+import numpy as np
+import paddle
+import resampy
+import soundfile
+from scipy.io import wavfile
+
+from ..utils import depth_convert
+from ..utils import ParameterError
+from .common import AudioInfo
+
+__all__ = [
+ 'resample',
+ 'to_mono',
+ 'normalize',
+ 'save',
+ 'soundfile_save',
+ 'load',
+ 'soundfile_load',
+ 'info',
+]
+NORMALMIZE_TYPES = ['linear', 'gaussian']
+MERGE_TYPES = ['ch0', 'ch1', 'random', 'average']
+RESAMPLE_MODES = ['kaiser_best', 'kaiser_fast']
+EPS = 1e-8
+
+
+def resample(y: np.ndarray,
+ src_sr: int,
+ target_sr: int,
+ mode: str='kaiser_fast') -> np.ndarray:
+ """Audio resampling.
+
+ Args:
+ y (np.ndarray): Input waveform array in 1D or 2D.
+ src_sr (int): Source sample rate.
+ target_sr (int): Target sample rate.
+ mode (str, optional): The resampling filter to use. Defaults to 'kaiser_fast'.
+
+ Returns:
+ np.ndarray: `y` resampled to `target_sr`
+ """
+
+ if mode == 'kaiser_best':
+ warnings.warn(
+ f'Using resampy in kaiser_best to {src_sr}=>{target_sr}. This function is pretty slow, \
+ we recommend the mode kaiser_fast in large scale audio training')
+
+ if not isinstance(y, np.ndarray):
+ raise ParameterError(
+ 'Only support numpy np.ndarray, but received y in {type(y)}')
+
+ if mode not in RESAMPLE_MODES:
+ raise ParameterError(f'resample mode must in {RESAMPLE_MODES}')
+
+ return resampy.resample(y, src_sr, target_sr, filter=mode)
+
+
+def to_mono(y: np.ndarray, merge_type: str='average') -> np.ndarray:
+ """Convert sterior audio to mono.
+
+ Args:
+ y (np.ndarray): Input waveform array in 1D or 2D.
+ merge_type (str, optional): Merge type to generate mono waveform. Defaults to 'average'.
+
+ Returns:
+ np.ndarray: `y` with mono channel.
+ """
+
+ if merge_type not in MERGE_TYPES:
+ raise ParameterError(
+ f'Unsupported merge type {merge_type}, available types are {MERGE_TYPES}'
+ )
+ if y.ndim > 2:
+ raise ParameterError(
+ f'Unsupported audio array, y.ndim > 2, the shape is {y.shape}')
+ if y.ndim == 1: # nothing to merge
+ return y
+
+ if merge_type == 'ch0':
+ return y[0]
+ if merge_type == 'ch1':
+ return y[1]
+ if merge_type == 'random':
+ return y[np.random.randint(0, 2)]
+
+ # need to do averaging according to dtype
+
+ if y.dtype == 'float32':
+ y_out = (y[0] + y[1]) * 0.5
+ elif y.dtype == 'int16':
+ y_out = y.astype('int32')
+ y_out = (y_out[0] + y_out[1]) // 2
+ y_out = np.clip(y_out, np.iinfo(y.dtype).min,
+ np.iinfo(y.dtype).max).astype(y.dtype)
+
+ elif y.dtype == 'int8':
+ y_out = y.astype('int16')
+ y_out = (y_out[0] + y_out[1]) // 2
+ y_out = np.clip(y_out, np.iinfo(y.dtype).min,
+ np.iinfo(y.dtype).max).astype(y.dtype)
+ else:
+ raise ParameterError(f'Unsupported dtype: {y.dtype}')
+ return y_out
+
+
+def soundfile_load_(file: os.PathLike,
+ offset: Optional[float]=None,
+ dtype: str='int16',
+ duration: Optional[int]=None) -> Tuple[np.ndarray, int]:
+ """Load audio using soundfile library. This function load audio file using libsndfile.
+
+ Args:
+ file (os.PathLike): File of waveform.
+ offset (Optional[float], optional): Offset to the start of waveform. Defaults to None.
+ dtype (str, optional): Data type of waveform. Defaults to 'int16'.
+ duration (Optional[int], optional): Duration of waveform to read. Defaults to None.
+
+ Returns:
+ Tuple[np.ndarray, int]: Waveform in ndarray and its samplerate.
+ """
+ with soundfile.SoundFile(file) as sf_desc:
+ sr_native = sf_desc.samplerate
+ if offset:
+ sf_desc.seek(int(offset * sr_native))
+ if duration is not None:
+ frame_duration = int(duration * sr_native)
+ else:
+ frame_duration = -1
+ y = sf_desc.read(frames=frame_duration, dtype=dtype, always_2d=False).T
+
+ return y, sf_desc.samplerate
+
+
+def normalize(y: np.ndarray, norm_type: str='linear',
+ mul_factor: float=1.0) -> np.ndarray:
+ """Normalize an input audio with additional multiplier.
+
+ Args:
+ y (np.ndarray): Input waveform array in 1D or 2D.
+ norm_type (str, optional): Type of normalization. Defaults to 'linear'.
+ mul_factor (float, optional): Scaling factor. Defaults to 1.0.
+
+ Returns:
+ np.ndarray: `y` after normalization.
+ """
+
+ if norm_type == 'linear':
+ amax = np.max(np.abs(y))
+ factor = 1.0 / (amax + EPS)
+ y = y * factor * mul_factor
+ elif norm_type == 'gaussian':
+ amean = np.mean(y)
+ astd = np.std(y)
+ astd = max(astd, EPS)
+ y = mul_factor * (y - amean) / astd
+ else:
+ raise NotImplementedError(f'norm_type should be in {NORMALMIZE_TYPES}')
+
+ return y
+
+
+def soundfile_save(y: np.ndarray, sr: int, file: os.PathLike) -> None:
+ """Save audio file to disk. This function saves audio to disk using scipy.io.wavfile, with additional step to convert input waveform to int16.
+
+ Args:
+ y (np.ndarray): Input waveform array in 1D or 2D.
+ sr (int): Sample rate.
+ file (os.PathLike): Path of audio file to save.
+ """
+ if not file.endswith('.wav'):
+ raise ParameterError(
+ f'only .wav file supported, but dst file name is: {file}')
+
+ if sr <= 0:
+ raise ParameterError(
+ f'Sample rate should be larger than 0, received sr = {sr}')
+
+ if y.dtype not in ['int16', 'int8']:
+ warnings.warn(
+ f'input data type is {y.dtype}, will convert data to int16 format before saving'
+ )
+ y_out = depth_convert(y, 'int16')
+ else:
+ y_out = y
+
+ wavfile.write(file, sr, y_out)
+
+
+def soundfile_load(
+ file: os.PathLike,
+ sr: Optional[int]=None,
+ mono: bool=True,
+ merge_type: str='average', # ch0,ch1,random,average
+ normal: bool=True,
+ norm_type: str='linear',
+ norm_mul_factor: float=1.0,
+ offset: float=0.0,
+ duration: Optional[int]=None,
+ dtype: str='float32',
+ resample_mode: str='kaiser_fast') -> Tuple[np.ndarray, int]:
+ """Load audio file from disk. This function loads audio from disk using using audio backend.
+
+ Args:
+ file (os.PathLike): Path of audio file to load.
+ sr (Optional[int], optional): Sample rate of loaded waveform. Defaults to None.
+ mono (bool, optional): Return waveform with mono channel. Defaults to True.
+ merge_type (str, optional): Merge type of multi-channels waveform. Defaults to 'average'.
+ normal (bool, optional): Waveform normalization. Defaults to True.
+ norm_type (str, optional): Type of normalization. Defaults to 'linear'.
+ norm_mul_factor (float, optional): Scaling factor. Defaults to 1.0.
+ offset (float, optional): Offset to the start of waveform. Defaults to 0.0.
+ duration (Optional[int], optional): Duration of waveform to read. Defaults to None.
+ dtype (str, optional): Data type of waveform. Defaults to 'float32'.
+ resample_mode (str, optional): The resampling filter to use. Defaults to 'kaiser_fast'.
+
+ Returns:
+ Tuple[np.ndarray, int]: Waveform in ndarray and its samplerate.
+ """
+
+ y, r = soundfile_load_(file, offset=offset, dtype=dtype, duration=duration)
+
+ if not ((y.ndim == 1 and len(y) > 0) or (y.ndim == 2 and len(y[0]) > 0)):
+ raise ParameterError(f'audio file {file} looks empty')
+
+ if mono:
+ y = to_mono(y, merge_type)
+
+ if sr is not None and sr != r:
+ y = resample(y, r, sr, mode=resample_mode)
+ r = sr
+
+ if normal:
+ y = normalize(y, norm_type, norm_mul_factor)
+ elif dtype in ['int8', 'int16']:
+ # still need to do normalization, before depth conversion
+ y = normalize(y, 'linear', 1.0)
+
+ y = depth_convert(y, dtype)
+ return y, r
+
+
+#The code below is taken from: https://github.com/pytorch/audio/blob/main/torchaudio/backend/soundfile_backend.py, with some modifications.
+
+
+def _get_subtype_for_wav(dtype: paddle.dtype,
+ encoding: str,
+ bits_per_sample: int):
+ if not encoding:
+ if not bits_per_sample:
+ subtype = {
+ paddle.uint8: "PCM_U8",
+ paddle.int16: "PCM_16",
+ paddle.int32: "PCM_32",
+ paddle.float32: "FLOAT",
+ paddle.float64: "DOUBLE",
+ }.get(dtype)
+ if not subtype:
+ raise ValueError(f"Unsupported dtype for wav: {dtype}")
+ return subtype
+ if bits_per_sample == 8:
+ return "PCM_U8"
+ return f"PCM_{bits_per_sample}"
+ if encoding == "PCM_S":
+ if not bits_per_sample:
+ return "PCM_32"
+ if bits_per_sample == 8:
+ raise ValueError("wav does not support 8-bit signed PCM encoding.")
+ return f"PCM_{bits_per_sample}"
+ if encoding == "PCM_U":
+ if bits_per_sample in (None, 8):
+ return "PCM_U8"
+ raise ValueError("wav only supports 8-bit unsigned PCM encoding.")
+ if encoding == "PCM_F":
+ if bits_per_sample in (None, 32):
+ return "FLOAT"
+ if bits_per_sample == 64:
+ return "DOUBLE"
+ raise ValueError("wav only supports 32/64-bit float PCM encoding.")
+ if encoding == "ULAW":
+ if bits_per_sample in (None, 8):
+ return "ULAW"
+ raise ValueError("wav only supports 8-bit mu-law encoding.")
+ if encoding == "ALAW":
+ if bits_per_sample in (None, 8):
+ return "ALAW"
+ raise ValueError("wav only supports 8-bit a-law encoding.")
+ raise ValueError(f"wav does not support {encoding}.")
+
+
+def _get_subtype_for_sphere(encoding: str, bits_per_sample: int):
+ if encoding in (None, "PCM_S"):
+ return f"PCM_{bits_per_sample}" if bits_per_sample else "PCM_32"
+ if encoding in ("PCM_U", "PCM_F"):
+ raise ValueError(f"sph does not support {encoding} encoding.")
+ if encoding == "ULAW":
+ if bits_per_sample in (None, 8):
+ return "ULAW"
+ raise ValueError("sph only supports 8-bit for mu-law encoding.")
+ if encoding == "ALAW":
+ return "ALAW"
+ raise ValueError(f"sph does not support {encoding}.")
+
+
+def _get_subtype(dtype: paddle.dtype,
+ format: str,
+ encoding: str,
+ bits_per_sample: int):
+ if format == "wav":
+ return _get_subtype_for_wav(dtype, encoding, bits_per_sample)
+ if format == "flac":
+ if encoding:
+ raise ValueError("flac does not support encoding.")
+ if not bits_per_sample:
+ return "PCM_16"
+ if bits_per_sample > 24:
+ raise ValueError("flac does not support bits_per_sample > 24.")
+ return "PCM_S8" if bits_per_sample == 8 else f"PCM_{bits_per_sample}"
+ if format in ("ogg", "vorbis"):
+ if encoding or bits_per_sample:
+ raise ValueError(
+ "ogg/vorbis does not support encoding/bits_per_sample.")
+ return "VORBIS"
+ if format == "sph":
+ return _get_subtype_for_sphere(encoding, bits_per_sample)
+ if format in ("nis", "nist"):
+ return "PCM_16"
+ raise ValueError(f"Unsupported format: {format}")
+
+
+def save(
+ filepath: str,
+ src: paddle.Tensor,
+ sample_rate: int,
+ channels_first: bool=True,
+ compression: Optional[float]=None,
+ format: Optional[str]=None,
+ encoding: Optional[str]=None,
+ bits_per_sample: Optional[int]=None, ):
+ """Save audio data to file.
+
+ Note:
+ The formats this function can handle depend on the soundfile installation.
+ This function is tested on the following formats;
+
+ * WAV
+
+ * 32-bit floating-point
+ * 32-bit signed integer
+ * 16-bit signed integer
+ * 8-bit unsigned integer
+
+ * FLAC
+ * OGG/VORBIS
+ * SPHERE
+
+ Note:
+ ``filepath`` argument is intentionally annotated as ``str`` only, even though it accepts
+ ``pathlib.Path`` object as well. This is for the consistency with ``"sox_io"`` backend,
+
+ Args:
+ filepath (str or pathlib.Path): Path to audio file.
+ src (paddle.Tensor): Audio data to save. must be 2D tensor.
+ sample_rate (int): sampling rate
+ channels_first (bool, optional): If ``True``, the given tensor is interpreted as `[channel, time]`,
+ otherwise `[time, channel]`.
+ compression (float of None, optional): Not used.
+ It is here only for interface compatibility reason with "sox_io" backend.
+ format (str or None, optional): Override the audio format.
+ When ``filepath`` argument is path-like object, audio format is
+ inferred from file extension. If the file extension is missing or
+ different, you can specify the correct format with this argument.
+
+ When ``filepath`` argument is file-like object,
+ this argument is required.
+
+ Valid values are ``"wav"``, ``"ogg"``, ``"vorbis"``,
+ ``"flac"`` and ``"sph"``.
+ encoding (str or None, optional): Changes the encoding for supported formats.
+ This argument is effective only for supported formats, such as
+ ``"wav"``, ``""flac"`` and ``"sph"``. Valid values are:
+
+ - ``"PCM_S"`` (signed integer Linear PCM)
+ - ``"PCM_U"`` (unsigned integer Linear PCM)
+ - ``"PCM_F"`` (floating point PCM)
+ - ``"ULAW"`` (mu-law)
+ - ``"ALAW"`` (a-law)
+
+ bits_per_sample (int or None, optional): Changes the bit depth for the
+ supported formats.
+ When ``format`` is one of ``"wav"``, ``"flac"`` or ``"sph"``,
+ you can change the bit depth.
+ Valid values are ``8``, ``16``, ``24``, ``32`` and ``64``.
+
+ Supported formats/encodings/bit depth/compression are:
+
+ ``"wav"``
+ - 32-bit floating-point PCM
+ - 32-bit signed integer PCM
+ - 24-bit signed integer PCM
+ - 16-bit signed integer PCM
+ - 8-bit unsigned integer PCM
+ - 8-bit mu-law
+ - 8-bit a-law
+
+ Note:
+ Default encoding/bit depth is determined by the dtype of
+ the input Tensor.
+
+ ``"flac"``
+ - 8-bit
+ - 16-bit (default)
+ - 24-bit
+
+ ``"ogg"``, ``"vorbis"``
+ - Doesn't accept changing configuration.
+
+ ``"sph"``
+ - 8-bit signed integer PCM
+ - 16-bit signed integer PCM
+ - 24-bit signed integer PCM
+ - 32-bit signed integer PCM (default)
+ - 8-bit mu-law
+ - 8-bit a-law
+ - 16-bit a-law
+ - 24-bit a-law
+ - 32-bit a-law
+
+ """
+ if src.ndim != 2:
+ raise ValueError(f"Expected 2D Tensor, got {src.ndim}D.")
+ if compression is not None:
+ warnings.warn(
+ '`save` function of "soundfile" backend does not support "compression" parameter. '
+ "The argument is silently ignored.")
+ if hasattr(filepath, "write"):
+ if format is None:
+ raise RuntimeError(
+ "`format` is required when saving to file object.")
+ ext = format.lower()
+ else:
+ ext = str(filepath).split(".")[-1].lower()
+
+ if bits_per_sample not in (None, 8, 16, 24, 32, 64):
+ raise ValueError("Invalid bits_per_sample.")
+ if bits_per_sample == 24:
+ warnings.warn(
+ "Saving audio with 24 bits per sample might warp samples near -1. "
+ "Using 16 bits per sample might be able to avoid this.")
+ subtype = _get_subtype(src.dtype, ext, encoding, bits_per_sample)
+
+ # sph is a extension used in TED-LIUM but soundfile does not recognize it as NIST format,
+ # so we extend the extensions manually here
+ if ext in ["nis", "nist", "sph"] and format is None:
+ format = "NIST"
+
+ if channels_first:
+ src = src.t()
+
+ soundfile.write(
+ file=filepath,
+ data=src,
+ samplerate=sample_rate,
+ subtype=subtype,
+ format=format)
+
+
+_SUBTYPE2DTYPE = {
+ "PCM_S8": "int8",
+ "PCM_U8": "uint8",
+ "PCM_16": "int16",
+ "PCM_32": "int32",
+ "FLOAT": "float32",
+ "DOUBLE": "float64",
+}
+
+
+def load(
+ filepath: str,
+ frame_offset: int=0,
+ num_frames: int=-1,
+ normalize: bool=True,
+ channels_first: bool=True,
+ format: Optional[str]=None, ) -> Tuple[paddle.Tensor, int]:
+ """Load audio data from file.
+
+ Note:
+ The formats this function can handle depend on the soundfile installation.
+ This function is tested on the following formats;
+
+ * WAV
+
+ * 32-bit floating-point
+ * 32-bit signed integer
+ * 16-bit signed integer
+ * 8-bit unsigned integer
+
+ * FLAC
+ * OGG/VORBIS
+ * SPHERE
+
+ By default (``normalize=True``, ``channels_first=True``), this function returns Tensor with
+ ``float32`` dtype and the shape of `[channel, time]`.
+ The samples are normalized to fit in the range of ``[-1.0, 1.0]``.
+
+ When the input format is WAV with integer type, such as 32-bit signed integer, 16-bit
+ signed integer and 8-bit unsigned integer (24-bit signed integer is not supported),
+ by providing ``normalize=False``, this function can return integer Tensor, where the samples
+ are expressed within the whole range of the corresponding dtype, that is, ``int32`` tensor
+ for 32-bit signed PCM, ``int16`` for 16-bit signed PCM and ``uint8`` for 8-bit unsigned PCM.
+
+ ``normalize`` parameter has no effect on 32-bit floating-point WAV and other formats, such as
+ ``flac`` and ``mp3``.
+ For these formats, this function always returns ``float32`` Tensor with values normalized to
+ ``[-1.0, 1.0]``.
+
+ Note:
+ ``filepath`` argument is intentionally annotated as ``str`` only, even though it accepts
+ ``pathlib.Path`` object as well. This is for the consistency with ``"sox_io"`` backend.
+
+ Args:
+ filepath (path-like object or file-like object):
+ Source of audio data.
+ frame_offset (int, optional):
+ Number of frames to skip before start reading data.
+ num_frames (int, optional):
+ Maximum number of frames to read. ``-1`` reads all the remaining samples,
+ starting from ``frame_offset``.
+ This function may return the less number of frames if there is not enough
+ frames in the given file.
+ normalize (bool, optional):
+ When ``True``, this function always return ``float32``, and sample values are
+ normalized to ``[-1.0, 1.0]``.
+ If input file is integer WAV, giving ``False`` will change the resulting Tensor type to
+ integer type.
+ This argument has no effect for formats other than integer WAV type.
+ channels_first (bool, optional):
+ When True, the returned Tensor has dimension `[channel, time]`.
+ Otherwise, the returned Tensor's dimension is `[time, channel]`.
+ format (str or None, optional):
+ Not used. PySoundFile does not accept format hint.
+
+ Returns:
+ (paddle.Tensor, int): Resulting Tensor and sample rate.
+ If the input file has integer wav format and normalization is off, then it has
+ integer type, else ``float32`` type. If ``channels_first=True``, it has
+ `[channel, time]` else `[time, channel]`.
+ """
+ with soundfile.SoundFile(filepath, "r") as file_:
+ if file_.format != "WAV" or normalize:
+ dtype = "float32"
+ elif file_.subtype not in _SUBTYPE2DTYPE:
+ raise ValueError(f"Unsupported subtype: {file_.subtype}")
+ else:
+ dtype = _SUBTYPE2DTYPE[file_.subtype]
+
+ frames = file_._prepare_read(frame_offset, None, num_frames)
+ waveform = file_.read(frames, dtype, always_2d=True)
+ sample_rate = file_.samplerate
+
+ waveform = paddle.to_tensor(waveform)
+ if channels_first:
+ waveform = paddle.transpose(waveform, perm=[1, 0])
+ return waveform, sample_rate
+
+
+# Mapping from soundfile subtype to number of bits per sample.
+# This is mostly heuristical and the value is set to 0 when it is irrelevant
+# (lossy formats) or when it can't be inferred.
+# For ADPCM (and G72X) subtypes, it's hard to infer the bit depth because it's not part of the standard:
+# According to https://en.wikipedia.org/wiki/Adaptive_differential_pulse-code_modulation#In_telephony,
+# the default seems to be 8 bits but it can be compressed further to 4 bits.
+# The dict is inspired from
+# https://github.com/bastibe/python-soundfile/blob/744efb4b01abc72498a96b09115b42a4cabd85e4/soundfile.py#L66-L94
+_SUBTYPE_TO_BITS_PER_SAMPLE = {
+ "PCM_S8": 8, # Signed 8 bit data
+ "PCM_16": 16, # Signed 16 bit data
+ "PCM_24": 24, # Signed 24 bit data
+ "PCM_32": 32, # Signed 32 bit data
+ "PCM_U8": 8, # Unsigned 8 bit data (WAV and RAW only)
+ "FLOAT": 32, # 32 bit float data
+ "DOUBLE": 64, # 64 bit float data
+ "ULAW": 8, # U-Law encoded. See https://en.wikipedia.org/wiki/G.711#Types
+ "ALAW": 8, # A-Law encoded. See https://en.wikipedia.org/wiki/G.711#Types
+ "IMA_ADPCM": 0, # IMA ADPCM.
+ "MS_ADPCM": 0, # Microsoft ADPCM.
+ "GSM610":
+ 0, # GSM 6.10 encoding. (Wikipedia says 1.625 bit depth?? https://en.wikipedia.org/wiki/Full_Rate)
+ "VOX_ADPCM": 0, # OKI / Dialogix ADPCM
+ "G721_32": 0, # 32kbs G721 ADPCM encoding.
+ "G723_24": 0, # 24kbs G723 ADPCM encoding.
+ "G723_40": 0, # 40kbs G723 ADPCM encoding.
+ "DWVW_12": 12, # 12 bit Delta Width Variable Word encoding.
+ "DWVW_16": 16, # 16 bit Delta Width Variable Word encoding.
+ "DWVW_24": 24, # 24 bit Delta Width Variable Word encoding.
+ "DWVW_N": 0, # N bit Delta Width Variable Word encoding.
+ "DPCM_8": 8, # 8 bit differential PCM (XI only)
+ "DPCM_16": 16, # 16 bit differential PCM (XI only)
+ "VORBIS": 0, # Xiph Vorbis encoding. (lossy)
+ "ALAC_16": 16, # Apple Lossless Audio Codec (16 bit).
+ "ALAC_20": 20, # Apple Lossless Audio Codec (20 bit).
+ "ALAC_24": 24, # Apple Lossless Audio Codec (24 bit).
+ "ALAC_32": 32, # Apple Lossless Audio Codec (32 bit).
+}
+
+
+def _get_bit_depth(subtype):
+ if subtype not in _SUBTYPE_TO_BITS_PER_SAMPLE:
+ warnings.warn(
+ f"The {subtype} subtype is unknown to PaddleAudio. As a result, the bits_per_sample "
+ "attribute will be set to 0. If you are seeing this warning, please "
+ "report by opening an issue on github (after checking for existing/closed ones). "
+ "You may otherwise ignore this warning.")
+ return _SUBTYPE_TO_BITS_PER_SAMPLE.get(subtype, 0)
+
+
+_SUBTYPE_TO_ENCODING = {
+ "PCM_S8": "PCM_S",
+ "PCM_16": "PCM_S",
+ "PCM_24": "PCM_S",
+ "PCM_32": "PCM_S",
+ "PCM_U8": "PCM_U",
+ "FLOAT": "PCM_F",
+ "DOUBLE": "PCM_F",
+ "ULAW": "ULAW",
+ "ALAW": "ALAW",
+ "VORBIS": "VORBIS",
+}
+
+
+def _get_encoding(format: str, subtype: str):
+ if format == "FLAC":
+ return "FLAC"
+ return _SUBTYPE_TO_ENCODING.get(subtype, "UNKNOWN")
+
+
+def info(filepath: str, format: Optional[str]=None) -> AudioInfo:
+ """Get signal information of an audio file.
+
+ Note:
+ ``filepath`` argument is intentionally annotated as ``str`` only, even though it accepts
+ ``pathlib.Path`` object as well. This is for the consistency with ``"sox_io"`` backend,
+
+ Args:
+ filepath (path-like object or file-like object):
+ Source of audio data.
+ format (str or None, optional):
+ Not used. PySoundFile does not accept format hint.
+
+ Returns:
+ AudioInfo: meta data of the given audio.
+
+ """
+ sinfo = soundfile.info(filepath)
+ return AudioInfo(
+ sinfo.samplerate,
+ sinfo.frames,
+ sinfo.channels,
+ bits_per_sample=_get_bit_depth(sinfo.subtype),
+ encoding=_get_encoding(sinfo.format, sinfo.subtype), )
diff --git a/paddlespeech/audio/compliance/__init__.py b/paddlespeech/audio/compliance/__init__.py
new file mode 100644
index 000000000..c08f9ab11
--- /dev/null
+++ b/paddlespeech/audio/compliance/__init__.py
@@ -0,0 +1,15 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from . import kaldi
+from . import librosa
diff --git a/paddlespeech/audio/compliance/kaldi.py b/paddlespeech/audio/compliance/kaldi.py
new file mode 100644
index 000000000..a94ec4053
--- /dev/null
+++ b/paddlespeech/audio/compliance/kaldi.py
@@ -0,0 +1,643 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# Modified from torchaudio(https://github.com/pytorch/audio)
+import math
+from typing import Tuple
+
+import paddle
+from paddle import Tensor
+
+from ..functional import create_dct
+from ..functional.window import get_window
+
+__all__ = [
+ 'spectrogram',
+ 'fbank',
+ 'mfcc',
+]
+
+# window types
+HANNING = 'hann'
+HAMMING = 'hamming'
+POVEY = 'povey'
+RECTANGULAR = 'rect'
+BLACKMAN = 'blackman'
+
+
+def _get_epsilon(dtype):
+ return paddle.to_tensor(1e-07, dtype=dtype)
+
+
+def _next_power_of_2(x: int) -> int:
+ return 1 if x == 0 else 2**(x - 1).bit_length()
+
+
+def _get_strided(waveform: Tensor,
+ window_size: int,
+ window_shift: int,
+ snip_edges: bool) -> Tensor:
+ assert waveform.dim() == 1
+ num_samples = waveform.shape[0]
+
+ if snip_edges:
+ if num_samples < window_size:
+ return paddle.empty((0, 0), dtype=waveform.dtype)
+ else:
+ m = 1 + (num_samples - window_size) // window_shift
+ else:
+ reversed_waveform = paddle.flip(waveform, [0])
+ m = (num_samples + (window_shift // 2)) // window_shift
+ pad = window_size // 2 - window_shift // 2
+ pad_right = reversed_waveform
+ if pad > 0:
+ pad_left = reversed_waveform[-pad:]
+ waveform = paddle.concat((pad_left, waveform, pad_right), axis=0)
+ else:
+ waveform = paddle.concat((waveform[-pad:], pad_right), axis=0)
+
+ return paddle.signal.frame(waveform, window_size, window_shift)[:, :m].T
+
+
+def _feature_window_function(
+ window_type: str,
+ window_size: int,
+ blackman_coeff: float,
+ dtype: int, ) -> Tensor:
+ if window_type == "hann":
+ return get_window('hann', window_size, fftbins=False, dtype=dtype)
+ elif window_type == "hamming":
+ return get_window('hamming', window_size, fftbins=False, dtype=dtype)
+ elif window_type == "povey":
+ return get_window(
+ 'hann', window_size, fftbins=False, dtype=dtype).pow(0.85)
+ elif window_type == "rect":
+ return paddle.ones([window_size], dtype=dtype)
+ elif window_type == "blackman":
+ a = 2 * math.pi / (window_size - 1)
+ window_function = paddle.arange(window_size, dtype=dtype)
+ return (blackman_coeff - 0.5 * paddle.cos(a * window_function) +
+ (0.5 - blackman_coeff) * paddle.cos(2 * a * window_function)
+ ).astype(dtype)
+ else:
+ raise Exception('Invalid window type ' + window_type)
+
+
+def _get_log_energy(strided_input: Tensor, epsilon: Tensor,
+ energy_floor: float) -> Tensor:
+ log_energy = paddle.maximum(strided_input.pow(2).sum(1), epsilon).log()
+ if energy_floor == 0.0:
+ return log_energy
+ return paddle.maximum(
+ log_energy,
+ paddle.to_tensor(math.log(energy_floor), dtype=strided_input.dtype))
+
+
+def _get_waveform_and_window_properties(
+ waveform: Tensor,
+ channel: int,
+ sr: int,
+ frame_shift: float,
+ frame_length: float,
+ round_to_power_of_two: bool,
+ preemphasis_coefficient: float) -> Tuple[Tensor, int, int, int]:
+ channel = max(channel, 0)
+ assert channel < waveform.shape[0], (
+ 'Invalid channel {} for size {}'.format(channel, waveform.shape[0]))
+ waveform = waveform[channel, :] # size (n)
+ window_shift = int(
+ sr * frame_shift *
+ 0.001) # pass frame_shift and frame_length in milliseconds
+ window_size = int(sr * frame_length * 0.001)
+ padded_window_size = _next_power_of_2(
+ window_size) if round_to_power_of_two else window_size
+
+ assert 2 <= window_size <= len(waveform), (
+ 'choose a window size {} that is [2, {}]'.format(window_size,
+ len(waveform)))
+ assert 0 < window_shift, '`window_shift` must be greater than 0'
+ assert padded_window_size % 2 == 0, 'the padded `window_size` must be divisible by two.' \
+ ' use `round_to_power_of_two` or change `frame_length`'
+ assert 0. <= preemphasis_coefficient <= 1.0, '`preemphasis_coefficient` must be between [0,1]'
+ assert sr > 0, '`sr` must be greater than zero'
+ return waveform, window_shift, window_size, padded_window_size
+
+
+def _get_window(waveform: Tensor,
+ padded_window_size: int,
+ window_size: int,
+ window_shift: int,
+ window_type: str,
+ blackman_coeff: float,
+ snip_edges: bool,
+ raw_energy: bool,
+ energy_floor: float,
+ dither: float,
+ remove_dc_offset: bool,
+ preemphasis_coefficient: float) -> Tuple[Tensor, Tensor]:
+ dtype = waveform.dtype
+ epsilon = _get_epsilon(dtype)
+
+ # (m, window_size)
+ strided_input = _get_strided(waveform, window_size, window_shift,
+ snip_edges)
+
+ if dither != 0.0:
+ x = paddle.maximum(epsilon,
+ paddle.rand(strided_input.shape, dtype=dtype))
+ rand_gauss = paddle.sqrt(-2 * x.log()) * paddle.cos(2 * math.pi * x)
+ strided_input = strided_input + rand_gauss * dither
+
+ if remove_dc_offset:
+ row_means = paddle.mean(strided_input, axis=1).unsqueeze(1) # (m, 1)
+ strided_input = strided_input - row_means
+
+ if raw_energy:
+ signal_log_energy = _get_log_energy(strided_input, epsilon,
+ energy_floor) # (m)
+
+ if preemphasis_coefficient != 0.0:
+ offset_strided_input = paddle.nn.functional.pad(
+ strided_input.unsqueeze(0), (1, 0),
+ data_format='NCL',
+ mode='replicate').squeeze(0) # (m, window_size + 1)
+ strided_input = strided_input - preemphasis_coefficient * offset_strided_input[:, :
+ -1]
+
+ window_function = _feature_window_function(
+ window_type, window_size, blackman_coeff,
+ dtype).unsqueeze(0) # (1, window_size)
+ strided_input = strided_input * window_function # (m, window_size)
+
+ # (m, padded_window_size)
+ if padded_window_size != window_size:
+ padding_right = padded_window_size - window_size
+ strided_input = paddle.nn.functional.pad(
+ strided_input.unsqueeze(0), (0, padding_right),
+ data_format='NCL',
+ mode='constant',
+ value=0).squeeze(0)
+
+ if not raw_energy:
+ signal_log_energy = _get_log_energy(strided_input, epsilon,
+ energy_floor) # size (m)
+
+ return strided_input, signal_log_energy
+
+
+def _subtract_column_mean(tensor: Tensor, subtract_mean: bool) -> Tensor:
+ if subtract_mean:
+ col_means = paddle.mean(tensor, axis=0).unsqueeze(0)
+ tensor = tensor - col_means
+ return tensor
+
+
+def spectrogram(waveform: Tensor,
+ blackman_coeff: float=0.42,
+ channel: int=-1,
+ dither: float=0.0,
+ energy_floor: float=1.0,
+ frame_length: float=25.0,
+ frame_shift: float=10.0,
+ preemphasis_coefficient: float=0.97,
+ raw_energy: bool=True,
+ remove_dc_offset: bool=True,
+ round_to_power_of_two: bool=True,
+ sr: int=16000,
+ snip_edges: bool=True,
+ subtract_mean: bool=False,
+ window_type: str="povey") -> Tensor:
+ """Compute and return a spectrogram from a waveform. The output is identical to Kaldi's.
+
+ Args:
+ waveform (Tensor): A waveform tensor with shape `(C, T)`.
+ blackman_coeff (float, optional): Coefficient for Blackman window.. Defaults to 0.42.
+ channel (int, optional): Select the channel of waveform. Defaults to -1.
+ dither (float, optional): Dithering constant . Defaults to 0.0.
+ energy_floor (float, optional): Floor on energy of the output Spectrogram. Defaults to 1.0.
+ frame_length (float, optional): Frame length in milliseconds. Defaults to 25.0.
+ frame_shift (float, optional): Shift between adjacent frames in milliseconds. Defaults to 10.0.
+ preemphasis_coefficient (float, optional): Preemphasis coefficient for input waveform. Defaults to 0.97.
+ raw_energy (bool, optional): Whether to compute before preemphasis and windowing. Defaults to True.
+ remove_dc_offset (bool, optional): Whether to subtract mean from waveform on frames. Defaults to True.
+ round_to_power_of_two (bool, optional): If True, round window size to power of two by zero-padding input
+ to FFT. Defaults to True.
+ sr (int, optional): Sample rate of input waveform. Defaults to 16000.
+ snip_edges (bool, optional): Drop samples in the end of waveform that cann't fit a signal frame when it
+ is set True. Otherwise performs reflect padding to the end of waveform. Defaults to True.
+ subtract_mean (bool, optional): Whether to subtract mean of feature files. Defaults to False.
+ window_type (str, optional): Choose type of window for FFT computation. Defaults to "povey".
+
+ Returns:
+ Tensor: A spectrogram tensor with shape `(m, padded_window_size // 2 + 1)` where m is the number of frames
+ depends on frame_length and frame_shift.
+ """
+ dtype = waveform.dtype
+ epsilon = _get_epsilon(dtype)
+
+ waveform, window_shift, window_size, padded_window_size = _get_waveform_and_window_properties(
+ waveform, channel, sr, frame_shift, frame_length, round_to_power_of_two,
+ preemphasis_coefficient)
+
+ strided_input, signal_log_energy = _get_window(
+ waveform, padded_window_size, window_size, window_shift, window_type,
+ blackman_coeff, snip_edges, raw_energy, energy_floor, dither,
+ remove_dc_offset, preemphasis_coefficient)
+
+ # (m, padded_window_size // 2 + 1, 2)
+ fft = paddle.fft.rfft(strided_input)
+
+ power_spectrum = paddle.maximum(
+ fft.abs().pow(2.), epsilon).log() # (m, padded_window_size // 2 + 1)
+ power_spectrum[:, 0] = signal_log_energy
+
+ power_spectrum = _subtract_column_mean(power_spectrum, subtract_mean)
+ return power_spectrum
+
+
+def _inverse_mel_scale_scalar(mel_freq: float) -> float:
+ return 700.0 * (math.exp(mel_freq / 1127.0) - 1.0)
+
+
+def _inverse_mel_scale(mel_freq: Tensor) -> Tensor:
+ return 700.0 * ((mel_freq / 1127.0).exp() - 1.0)
+
+
+def _mel_scale_scalar(freq: float) -> float:
+ return 1127.0 * math.log(1.0 + freq / 700.0)
+
+
+def _mel_scale(freq: Tensor) -> Tensor:
+ return 1127.0 * (1.0 + freq / 700.0).log()
+
+
+def _vtln_warp_freq(vtln_low_cutoff: float,
+ vtln_high_cutoff: float,
+ low_freq: float,
+ high_freq: float,
+ vtln_warp_factor: float,
+ freq: Tensor) -> Tensor:
+ assert vtln_low_cutoff > low_freq, 'be sure to set the vtln_low option higher than low_freq'
+ assert vtln_high_cutoff < high_freq, 'be sure to set the vtln_high option lower than high_freq [or negative]'
+ l = vtln_low_cutoff * max(1.0, vtln_warp_factor)
+ h = vtln_high_cutoff * min(1.0, vtln_warp_factor)
+ scale = 1.0 / vtln_warp_factor
+ Fl = scale * l
+ Fh = scale * h
+ assert l > low_freq and h < high_freq
+ scale_left = (Fl - low_freq) / (l - low_freq)
+ scale_right = (high_freq - Fh) / (high_freq - h)
+ res = paddle.empty_like(freq)
+
+ outside_low_high_freq = paddle.less_than(freq, paddle.to_tensor(low_freq)) \
+ | paddle.greater_than(freq, paddle.to_tensor(high_freq))
+ before_l = paddle.less_than(freq, paddle.to_tensor(l))
+ before_h = paddle.less_than(freq, paddle.to_tensor(h))
+ after_h = paddle.greater_equal(freq, paddle.to_tensor(h))
+
+ res[after_h] = high_freq + scale_right * (freq[after_h] - high_freq)
+ res[before_h] = scale * freq[before_h]
+ res[before_l] = low_freq + scale_left * (freq[before_l] - low_freq)
+ res[outside_low_high_freq] = freq[outside_low_high_freq]
+
+ return res
+
+
+def _vtln_warp_mel_freq(vtln_low_cutoff: float,
+ vtln_high_cutoff: float,
+ low_freq,
+ high_freq: float,
+ vtln_warp_factor: float,
+ mel_freq: Tensor) -> Tensor:
+ return _mel_scale(
+ _vtln_warp_freq(vtln_low_cutoff, vtln_high_cutoff, low_freq, high_freq,
+ vtln_warp_factor, _inverse_mel_scale(mel_freq)))
+
+
+def _get_mel_banks(num_bins: int,
+ window_length_padded: int,
+ sample_freq: float,
+ low_freq: float,
+ high_freq: float,
+ vtln_low: float,
+ vtln_high: float,
+ vtln_warp_factor: float) -> Tuple[Tensor, Tensor]:
+ assert num_bins > 3, 'Must have at least 3 mel bins'
+ assert window_length_padded % 2 == 0
+ num_fft_bins = window_length_padded / 2
+ nyquist = 0.5 * sample_freq
+
+ if high_freq <= 0.0:
+ high_freq += nyquist
+
+ assert (0.0 <= low_freq < nyquist) and (0.0 < high_freq <= nyquist) and (low_freq < high_freq), \
+ ('Bad values in options: low-freq {} and high-freq {} vs. nyquist {}'.format(low_freq, high_freq, nyquist))
+
+ fft_bin_width = sample_freq / window_length_padded
+ mel_low_freq = _mel_scale_scalar(low_freq)
+ mel_high_freq = _mel_scale_scalar(high_freq)
+
+ mel_freq_delta = (mel_high_freq - mel_low_freq) / (num_bins + 1)
+
+ if vtln_high < 0.0:
+ vtln_high += nyquist
+
+ assert vtln_warp_factor == 1.0 or ((low_freq < vtln_low < high_freq) and
+ (0.0 < vtln_high < high_freq) and (vtln_low < vtln_high)), \
+ ('Bad values in options: vtln-low {} and vtln-high {}, versus '
+ 'low-freq {} and high-freq {}'.format(vtln_low, vtln_high, low_freq, high_freq))
+
+ bin = paddle.arange(num_bins, dtype=paddle.float32).unsqueeze(1)
+ # left_mel = mel_low_freq + bin * mel_freq_delta # (num_bins, 1)
+ # center_mel = mel_low_freq + (bin + 1.0) * mel_freq_delta # (num_bins, 1)
+ # right_mel = mel_low_freq + (bin + 2.0) * mel_freq_delta # (num_bins, 1)
+ left_mel = mel_low_freq + bin * mel_freq_delta # (num_bins, 1)
+ center_mel = left_mel + mel_freq_delta
+ right_mel = center_mel + mel_freq_delta
+
+ if vtln_warp_factor != 1.0:
+ left_mel = _vtln_warp_mel_freq(vtln_low, vtln_high, low_freq, high_freq,
+ vtln_warp_factor, left_mel)
+ center_mel = _vtln_warp_mel_freq(vtln_low, vtln_high, low_freq,
+ high_freq, vtln_warp_factor,
+ center_mel)
+ right_mel = _vtln_warp_mel_freq(vtln_low, vtln_high, low_freq,
+ high_freq, vtln_warp_factor, right_mel)
+
+ center_freqs = _inverse_mel_scale(center_mel) # (num_bins)
+ # (1, num_fft_bins)
+ mel = _mel_scale(fft_bin_width * paddle.arange(
+ num_fft_bins, dtype=paddle.float32)).unsqueeze(0)
+
+ # (num_bins, num_fft_bins)
+ up_slope = (mel - left_mel) / (center_mel - left_mel)
+ down_slope = (right_mel - mel) / (right_mel - center_mel)
+
+ if vtln_warp_factor == 1.0:
+ bins = paddle.maximum(
+ paddle.zeros([1]), paddle.minimum(up_slope, down_slope))
+ else:
+ bins = paddle.zeros_like(up_slope)
+ up_idx = paddle.greater_than(mel, left_mel) & paddle.less_than(
+ mel, center_mel)
+ down_idx = paddle.greater_than(mel, center_mel) & paddle.less_than(
+ mel, right_mel)
+ bins[up_idx] = up_slope[up_idx]
+ bins[down_idx] = down_slope[down_idx]
+
+ return bins, center_freqs
+
+
+def fbank(waveform: Tensor,
+ blackman_coeff: float=0.42,
+ channel: int=-1,
+ dither: float=0.0,
+ energy_floor: float=1.0,
+ frame_length: float=25.0,
+ frame_shift: float=10.0,
+ high_freq: float=0.0,
+ htk_compat: bool=False,
+ low_freq: float=20.0,
+ n_mels: int=23,
+ preemphasis_coefficient: float=0.97,
+ raw_energy: bool=True,
+ remove_dc_offset: bool=True,
+ round_to_power_of_two: bool=True,
+ sr: int=16000,
+ snip_edges: bool=True,
+ subtract_mean: bool=False,
+ use_energy: bool=False,
+ use_log_fbank: bool=True,
+ use_power: bool=True,
+ vtln_high: float=-500.0,
+ vtln_low: float=100.0,
+ vtln_warp: float=1.0,
+ window_type: str="povey") -> Tensor:
+ """Compute and return filter banks from a waveform. The output is identical to Kaldi's.
+
+ Args:
+ waveform (Tensor): A waveform tensor with shape `(C, T)`. `C` is in the range [0,1].
+ blackman_coeff (float, optional): Coefficient for Blackman window.. Defaults to 0.42.
+ channel (int, optional): Select the channel of waveform. Defaults to -1.
+ dither (float, optional): Dithering constant . Defaults to 0.0.
+ energy_floor (float, optional): Floor on energy of the output Spectrogram. Defaults to 1.0.
+ frame_length (float, optional): Frame length in milliseconds. Defaults to 25.0.
+ frame_shift (float, optional): Shift between adjacent frames in milliseconds. Defaults to 10.0.
+ high_freq (float, optional): The upper cut-off frequency. Defaults to 0.0.
+ htk_compat (bool, optional): Put energy to the last when it is set True. Defaults to False.
+ low_freq (float, optional): The lower cut-off frequency. Defaults to 20.0.
+ n_mels (int, optional): Number of output mel bins. Defaults to 23.
+ preemphasis_coefficient (float, optional): Preemphasis coefficient for input waveform. Defaults to 0.97.
+ raw_energy (bool, optional): Whether to compute before preemphasis and windowing. Defaults to True.
+ remove_dc_offset (bool, optional): Whether to subtract mean from waveform on frames. Defaults to True.
+ round_to_power_of_two (bool, optional): If True, round window size to power of two by zero-padding input
+ to FFT. Defaults to True.
+ sr (int, optional): Sample rate of input waveform. Defaults to 16000.
+ snip_edges (bool, optional): Drop samples in the end of waveform that cann't fit a signal frame when it
+ is set True. Otherwise performs reflect padding to the end of waveform. Defaults to True.
+ subtract_mean (bool, optional): Whether to subtract mean of feature files. Defaults to False.
+ use_energy (bool, optional): Add an dimension with energy of spectrogram to the output. Defaults to False.
+ use_log_fbank (bool, optional): Return log fbank when it is set True. Defaults to True.
+ use_power (bool, optional): Whether to use power instead of magnitude. Defaults to True.
+ vtln_high (float, optional): High inflection point in piecewise linear VTLN warping function. Defaults to -500.0.
+ vtln_low (float, optional): Low inflection point in piecewise linear VTLN warping function. Defaults to 100.0.
+ vtln_warp (float, optional): Vtln warp factor. Defaults to 1.0.
+ window_type (str, optional): Choose type of window for FFT computation. Defaults to "povey".
+
+ Returns:
+ Tensor: A filter banks tensor with shape `(m, n_mels)`.
+ """
+ dtype = waveform.dtype
+
+ waveform, window_shift, window_size, padded_window_size = _get_waveform_and_window_properties(
+ waveform, channel, sr, frame_shift, frame_length, round_to_power_of_two,
+ preemphasis_coefficient)
+
+ strided_input, signal_log_energy = _get_window(
+ waveform, padded_window_size, window_size, window_shift, window_type,
+ blackman_coeff, snip_edges, raw_energy, energy_floor, dither,
+ remove_dc_offset, preemphasis_coefficient)
+
+ # (m, padded_window_size // 2 + 1)
+ spectrum = paddle.fft.rfft(strided_input).abs()
+ if use_power:
+ spectrum = spectrum.pow(2.)
+
+ # (n_mels, padded_window_size // 2)
+ mel_energies, _ = _get_mel_banks(n_mels, padded_window_size, sr, low_freq,
+ high_freq, vtln_low, vtln_high, vtln_warp)
+ # mel_energies = mel_energies.astype(dtype)
+ assert mel_energies.dtype == dtype
+
+ # (n_mels, padded_window_size // 2 + 1)
+ mel_energies = paddle.nn.functional.pad(
+ mel_energies.unsqueeze(0), (0, 1),
+ data_format='NCL',
+ mode='constant',
+ value=0).squeeze(0)
+
+ # (m, n_mels)
+ mel_energies = paddle.mm(spectrum, mel_energies.T)
+ if use_log_fbank:
+ mel_energies = paddle.maximum(mel_energies, _get_epsilon(dtype)).log()
+
+ if use_energy:
+ signal_log_energy = signal_log_energy.unsqueeze(1)
+ if htk_compat:
+ mel_energies = paddle.concat(
+ (mel_energies, signal_log_energy), axis=1)
+ else:
+ mel_energies = paddle.concat(
+ (signal_log_energy, mel_energies), axis=1)
+
+ # (m, n_mels + 1)
+ mel_energies = _subtract_column_mean(mel_energies, subtract_mean)
+ return mel_energies
+
+
+def _get_dct_matrix(n_mfcc: int, n_mels: int) -> Tensor:
+ dct_matrix = create_dct(n_mels, n_mels, 'ortho')
+ dct_matrix[:, 0] = math.sqrt(1 / float(n_mels))
+ dct_matrix = dct_matrix[:, :n_mfcc] # (n_mels, n_mfcc)
+ return dct_matrix
+
+
+def _get_lifter_coeffs(n_mfcc: int, cepstral_lifter: float) -> Tensor:
+ i = paddle.arange(n_mfcc)
+ return 1.0 + 0.5 * cepstral_lifter * paddle.sin(math.pi * i /
+ cepstral_lifter)
+
+
+def mfcc(waveform: Tensor,
+ blackman_coeff: float=0.42,
+ cepstral_lifter: float=22.0,
+ channel: int=-1,
+ dither: float=0.0,
+ energy_floor: float=1.0,
+ frame_length: float=25.0,
+ frame_shift: float=10.0,
+ high_freq: float=0.0,
+ htk_compat: bool=False,
+ low_freq: float=20.0,
+ n_mfcc: int=13,
+ n_mels: int=23,
+ preemphasis_coefficient: float=0.97,
+ raw_energy: bool=True,
+ remove_dc_offset: bool=True,
+ round_to_power_of_two: bool=True,
+ sr: int=16000,
+ snip_edges: bool=True,
+ subtract_mean: bool=False,
+ use_energy: bool=False,
+ vtln_high: float=-500.0,
+ vtln_low: float=100.0,
+ vtln_warp: float=1.0,
+ window_type: str="povey") -> Tensor:
+ """Compute and return mel frequency cepstral coefficients from a waveform. The output is
+ identical to Kaldi's.
+
+ Args:
+ waveform (Tensor): A waveform tensor with shape `(C, T)`.
+ blackman_coeff (float, optional): Coefficient for Blackman window.. Defaults to 0.42.
+ cepstral_lifter (float, optional): Scaling of output mfccs. Defaults to 22.0.
+ channel (int, optional): Select the channel of waveform. Defaults to -1.
+ dither (float, optional): Dithering constant . Defaults to 0.0.
+ energy_floor (float, optional): Floor on energy of the output Spectrogram. Defaults to 1.0.
+ frame_length (float, optional): Frame length in milliseconds. Defaults to 25.0.
+ frame_shift (float, optional): Shift between adjacent frames in milliseconds. Defaults to 10.0.
+ high_freq (float, optional): The upper cut-off frequency. Defaults to 0.0.
+ htk_compat (bool, optional): Put energy to the last when it is set True. Defaults to False.
+ low_freq (float, optional): The lower cut-off frequency. Defaults to 20.0.
+ n_mfcc (int, optional): Number of cepstra in MFCC. Defaults to 13.
+ n_mels (int, optional): Number of output mel bins. Defaults to 23.
+ preemphasis_coefficient (float, optional): Preemphasis coefficient for input waveform. Defaults to 0.97.
+ raw_energy (bool, optional): Whether to compute before preemphasis and windowing. Defaults to True.
+ remove_dc_offset (bool, optional): Whether to subtract mean from waveform on frames. Defaults to True.
+ round_to_power_of_two (bool, optional): If True, round window size to power of two by zero-padding input
+ to FFT. Defaults to True.
+ sr (int, optional): Sample rate of input waveform. Defaults to 16000.
+ snip_edges (bool, optional): Drop samples in the end of waveform that cann't fit a signal frame when it
+ is set True. Otherwise performs reflect padding to the end of waveform. Defaults to True.
+ subtract_mean (bool, optional): Whether to subtract mean of feature files. Defaults to False.
+ use_energy (bool, optional): Add an dimension with energy of spectrogram to the output. Defaults to False.
+ vtln_high (float, optional): High inflection point in piecewise linear VTLN warping function. Defaults to -500.0.
+ vtln_low (float, optional): Low inflection point in piecewise linear VTLN warping function. Defaults to 100.0.
+ vtln_warp (float, optional): Vtln warp factor. Defaults to 1.0.
+ window_type (str, optional): Choose type of window for FFT computation. Defaults to POVEY.
+
+ Returns:
+ Tensor: A mel frequency cepstral coefficients tensor with shape `(m, n_mfcc)`.
+ """
+ assert n_mfcc <= n_mels, 'n_mfcc cannot be larger than n_mels: %d vs %d' % (
+ n_mfcc, n_mels)
+
+ dtype = waveform.dtype
+
+ # (m, n_mels + use_energy)
+ feature = fbank(
+ waveform=waveform,
+ blackman_coeff=blackman_coeff,
+ channel=channel,
+ dither=dither,
+ energy_floor=energy_floor,
+ frame_length=frame_length,
+ frame_shift=frame_shift,
+ high_freq=high_freq,
+ htk_compat=htk_compat,
+ low_freq=low_freq,
+ n_mels=n_mels,
+ preemphasis_coefficient=preemphasis_coefficient,
+ raw_energy=raw_energy,
+ remove_dc_offset=remove_dc_offset,
+ round_to_power_of_two=round_to_power_of_two,
+ sr=sr,
+ snip_edges=snip_edges,
+ subtract_mean=False,
+ use_energy=use_energy,
+ use_log_fbank=True,
+ use_power=True,
+ vtln_high=vtln_high,
+ vtln_low=vtln_low,
+ vtln_warp=vtln_warp,
+ window_type=window_type)
+
+ if use_energy:
+ # (m)
+ signal_log_energy = feature[:, n_mels if htk_compat else 0]
+ mel_offset = int(not htk_compat)
+ feature = feature[:, mel_offset:(n_mels + mel_offset)]
+
+ # (n_mels, n_mfcc)
+ dct_matrix = _get_dct_matrix(n_mfcc, n_mels).astype(dtype=dtype)
+
+ # (m, n_mfcc)
+ feature = feature.matmul(dct_matrix)
+
+ if cepstral_lifter != 0.0:
+ # (1, n_mfcc)
+ lifter_coeffs = _get_lifter_coeffs(n_mfcc, cepstral_lifter).unsqueeze(0)
+ feature *= lifter_coeffs.astype(dtype=dtype)
+
+ if use_energy:
+ feature[:, 0] = signal_log_energy
+
+ if htk_compat:
+ energy = feature[:, 0].unsqueeze(1) # (m, 1)
+ feature = feature[:, 1:] # (m, n_mfcc - 1)
+ if not use_energy:
+ energy *= math.sqrt(2)
+
+ feature = paddle.concat((feature, energy), axis=1)
+
+ feature = _subtract_column_mean(feature, subtract_mean)
+ return feature
diff --git a/paddlespeech/audio/compliance/librosa.py b/paddlespeech/audio/compliance/librosa.py
new file mode 100644
index 000000000..c671d4fb8
--- /dev/null
+++ b/paddlespeech/audio/compliance/librosa.py
@@ -0,0 +1,788 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# Modified from librosa(https://github.com/librosa/librosa)
+import warnings
+from typing import List
+from typing import Optional
+from typing import Union
+
+import numpy as np
+import scipy
+from numpy.lib.stride_tricks import as_strided
+from scipy import signal
+
+from ..utils import depth_convert
+from ..utils import ParameterError
+
+__all__ = [
+ # dsp
+ 'stft',
+ 'mfcc',
+ 'hz_to_mel',
+ 'mel_to_hz',
+ 'mel_frequencies',
+ 'power_to_db',
+ 'compute_fbank_matrix',
+ 'melspectrogram',
+ 'spectrogram',
+ 'mu_encode',
+ 'mu_decode',
+ # augmentation
+ 'depth_augment',
+ 'spect_augment',
+ 'random_crop1d',
+ 'random_crop2d',
+ 'adaptive_spect_augment',
+]
+
+
+def _pad_center(data: np.ndarray, size: int, axis: int=-1,
+ **kwargs) -> np.ndarray:
+ """Pad an array to a target length along a target axis.
+
+ This differs from `np.pad` by centering the data prior to padding,
+ analogous to `str.center`
+ """
+
+ kwargs.setdefault("mode", "constant")
+ n = data.shape[axis]
+ lpad = int((size - n) // 2)
+ lengths = [(0, 0)] * data.ndim
+ lengths[axis] = (lpad, int(size - n - lpad))
+
+ if lpad < 0:
+ raise ParameterError(("Target size ({size:d}) must be "
+ "at least input size ({n:d})"))
+
+ return np.pad(data, lengths, **kwargs)
+
+
+def _split_frames(x: np.ndarray,
+ frame_length: int,
+ hop_length: int,
+ axis: int=-1) -> np.ndarray:
+ """Slice a data array into (overlapping) frames.
+
+ This function is aligned with librosa.frame
+ """
+
+ if not isinstance(x, np.ndarray):
+ raise ParameterError(
+ f"Input must be of type numpy.ndarray, given type(x)={type(x)}")
+
+ if x.shape[axis] < frame_length:
+ raise ParameterError(f"Input is too short (n={x.shape[axis]:d})"
+ f" for frame_length={frame_length:d}")
+
+ if hop_length < 1:
+ raise ParameterError(f"Invalid hop_length: {hop_length:d}")
+
+ if axis == -1 and not x.flags["F_CONTIGUOUS"]:
+ warnings.warn(f"librosa.util.frame called with axis={axis} "
+ "on a non-contiguous input. This will result in a copy.")
+ x = np.asfortranarray(x)
+ elif axis == 0 and not x.flags["C_CONTIGUOUS"]:
+ warnings.warn(f"librosa.util.frame called with axis={axis} "
+ "on a non-contiguous input. This will result in a copy.")
+ x = np.ascontiguousarray(x)
+
+ n_frames = 1 + (x.shape[axis] - frame_length) // hop_length
+ strides = np.asarray(x.strides)
+
+ new_stride = np.prod(strides[strides > 0] // x.itemsize) * x.itemsize
+
+ if axis == -1:
+ shape = list(x.shape)[:-1] + [frame_length, n_frames]
+ strides = list(strides) + [hop_length * new_stride]
+
+ elif axis == 0:
+ shape = [n_frames, frame_length] + list(x.shape)[1:]
+ strides = [hop_length * new_stride] + list(strides)
+
+ else:
+ raise ParameterError(f"Frame axis={axis} must be either 0 or -1")
+
+ return as_strided(x, shape=shape, strides=strides)
+
+
+def _check_audio(y, mono=True) -> bool:
+ """Determine whether a variable contains valid audio data.
+
+ The audio y must be a np.ndarray, ether 1-channel or two channel
+ """
+ if not isinstance(y, np.ndarray):
+ raise ParameterError("Audio data must be of type numpy.ndarray")
+ if y.ndim > 2:
+ raise ParameterError(
+ f"Invalid shape for audio ndim={y.ndim:d}, shape={y.shape}")
+
+ if mono and y.ndim == 2:
+ raise ParameterError(
+ f"Invalid shape for mono audio ndim={y.ndim:d}, shape={y.shape}")
+
+ if (mono and len(y) == 0) or (not mono and y.shape[1] < 0):
+ raise ParameterError(f"Audio is empty ndim={y.ndim:d}, shape={y.shape}")
+
+ if not np.issubdtype(y.dtype, np.floating):
+ raise ParameterError("Audio data must be floating-point")
+
+ if not np.isfinite(y).all():
+ raise ParameterError("Audio buffer is not finite everywhere")
+
+ return True
+
+
+def hz_to_mel(frequencies: Union[float, List[float], np.ndarray],
+ htk: bool=False) -> np.ndarray:
+ """Convert Hz to Mels.
+
+ Args:
+ frequencies (Union[float, List[float], np.ndarray]): Frequencies in Hz.
+ htk (bool, optional): Use htk scaling. Defaults to False.
+
+ Returns:
+ np.ndarray: Frequency in mels.
+ """
+ freq = np.asanyarray(frequencies)
+
+ if htk:
+ return 2595.0 * np.log10(1.0 + freq / 700.0)
+
+ # Fill in the linear part
+ f_min = 0.0
+ f_sp = 200.0 / 3
+
+ mels = (freq - f_min) / f_sp
+
+ # Fill in the log-scale part
+
+ min_log_hz = 1000.0 # beginning of log region (Hz)
+ min_log_mel = (min_log_hz - f_min) / f_sp # same (Mels)
+ logstep = np.log(6.4) / 27.0 # step size for log region
+
+ if freq.ndim:
+ # If we have array data, vectorize
+ log_t = freq >= min_log_hz
+ mels[log_t] = min_log_mel + \
+ np.log(freq[log_t] / min_log_hz) / logstep
+ elif freq >= min_log_hz:
+ # If we have scalar data, heck directly
+ mels = min_log_mel + np.log(freq / min_log_hz) / logstep
+
+ return mels
+
+
+def mel_to_hz(mels: Union[float, List[float], np.ndarray],
+ htk: int=False) -> np.ndarray:
+ """Convert mel bin numbers to frequencies.
+
+ Args:
+ mels (Union[float, List[float], np.ndarray]): Frequency in mels.
+ htk (bool, optional): Use htk scaling. Defaults to False.
+
+ Returns:
+ np.ndarray: Frequencies in Hz.
+ """
+ mel_array = np.asanyarray(mels)
+
+ if htk:
+ return 700.0 * (10.0**(mel_array / 2595.0) - 1.0)
+
+ # Fill in the linear scale
+ f_min = 0.0
+ f_sp = 200.0 / 3
+ freqs = f_min + f_sp * mel_array
+
+ # And now the nonlinear scale
+ min_log_hz = 1000.0 # beginning of log region (Hz)
+ min_log_mel = (min_log_hz - f_min) / f_sp # same (Mels)
+ logstep = np.log(6.4) / 27.0 # step size for log region
+
+ if mel_array.ndim:
+ # If we have vector data, vectorize
+ log_t = mel_array >= min_log_mel
+ freqs[log_t] = min_log_hz * \
+ np.exp(logstep * (mel_array[log_t] - min_log_mel))
+ elif mel_array >= min_log_mel:
+ # If we have scalar data, check directly
+ freqs = min_log_hz * np.exp(logstep * (mel_array - min_log_mel))
+
+ return freqs
+
+
+def mel_frequencies(n_mels: int=128,
+ fmin: float=0.0,
+ fmax: float=11025.0,
+ htk: bool=False) -> np.ndarray:
+ """Compute mel frequencies.
+
+ Args:
+ n_mels (int, optional): Number of mel bins. Defaults to 128.
+ fmin (float, optional): Minimum frequency in Hz. Defaults to 0.0.
+ fmax (float, optional): Maximum frequency in Hz. Defaults to 11025.0.
+ htk (bool, optional): Use htk scaling. Defaults to False.
+
+ Returns:
+ np.ndarray: Vector of n_mels frequencies in Hz with shape `(n_mels,)`.
+ """
+ # 'Center freqs' of mel bands - uniformly spaced between limits
+ min_mel = hz_to_mel(fmin, htk=htk)
+ max_mel = hz_to_mel(fmax, htk=htk)
+
+ mels = np.linspace(min_mel, max_mel, n_mels)
+
+ return mel_to_hz(mels, htk=htk)
+
+
+def fft_frequencies(sr: int, n_fft: int) -> np.ndarray:
+ """Compute fourier frequencies.
+
+ Args:
+ sr (int): Sample rate.
+ n_fft (int): FFT size.
+
+ Returns:
+ np.ndarray: FFT frequencies in Hz with shape `(n_fft//2 + 1,)`.
+ """
+ return np.linspace(0, float(sr) / 2, int(1 + n_fft // 2), endpoint=True)
+
+
+def compute_fbank_matrix(sr: int,
+ n_fft: int,
+ n_mels: int=128,
+ fmin: float=0.0,
+ fmax: Optional[float]=None,
+ htk: bool=False,
+ norm: str="slaney",
+ dtype: type=np.float32) -> np.ndarray:
+ """Compute fbank matrix.
+
+ Args:
+ sr (int): Sample rate.
+ n_fft (int): FFT size.
+ n_mels (int, optional): Number of mel bins. Defaults to 128.
+ fmin (float, optional): Minimum frequency in Hz. Defaults to 0.0.
+ fmax (Optional[float], optional): Maximum frequency in Hz. Defaults to None.
+ htk (bool, optional): Use htk scaling. Defaults to False.
+ norm (str, optional): Type of normalization. Defaults to "slaney".
+ dtype (type, optional): Data type. Defaults to np.float32.
+
+
+ Returns:
+ np.ndarray: Mel transform matrix with shape `(n_mels, n_fft//2 + 1)`.
+ """
+ if norm != "slaney":
+ raise ParameterError('norm must set to slaney')
+
+ if fmax is None:
+ fmax = float(sr) / 2
+
+ # Initialize the weights
+ n_mels = int(n_mels)
+ weights = np.zeros((n_mels, int(1 + n_fft // 2)), dtype=dtype)
+
+ # Center freqs of each FFT bin
+ fftfreqs = fft_frequencies(sr=sr, n_fft=n_fft)
+
+ # 'Center freqs' of mel bands - uniformly spaced between limits
+ mel_f = mel_frequencies(n_mels + 2, fmin=fmin, fmax=fmax, htk=htk)
+
+ fdiff = np.diff(mel_f)
+ ramps = np.subtract.outer(mel_f, fftfreqs)
+
+ for i in range(n_mels):
+ # lower and upper slopes for all bins
+ lower = -ramps[i] / fdiff[i]
+ upper = ramps[i + 2] / fdiff[i + 1]
+
+ # .. then intersect them with each other and zero
+ weights[i] = np.maximum(0, np.minimum(lower, upper))
+
+ if norm == "slaney":
+ # Slaney-style mel is scaled to be approx constant energy per channel
+ enorm = 2.0 / (mel_f[2:n_mels + 2] - mel_f[:n_mels])
+ weights *= enorm[:, np.newaxis]
+
+ # Only check weights if f_mel[0] is positive
+ if not np.all((mel_f[:-2] == 0) | (weights.max(axis=1) > 0)):
+ # This means we have an empty channel somewhere
+ warnings.warn("Empty filters detected in mel frequency basis. "
+ "Some channels will produce empty responses. "
+ "Try increasing your sampling rate (and fmax) or "
+ "reducing n_mels.")
+
+ return weights
+
+
+def stft(x: np.ndarray,
+ n_fft: int=2048,
+ hop_length: Optional[int]=None,
+ win_length: Optional[int]=None,
+ window: str="hann",
+ center: bool=True,
+ dtype: type=np.complex64,
+ pad_mode: str="reflect") -> np.ndarray:
+ """Short-time Fourier transform (STFT).
+
+ Args:
+ x (np.ndarray): Input waveform in one dimension.
+ n_fft (int, optional): FFT size. Defaults to 2048.
+ hop_length (Optional[int], optional): Number of steps to advance between adjacent windows. Defaults to None.
+ win_length (Optional[int], optional): The size of window. Defaults to None.
+ window (str, optional): A string of window specification. Defaults to "hann".
+ center (bool, optional): Whether to pad `x` to make that the :math:`t \times hop\\_length` at the center of `t`-th frame. Defaults to True.
+ dtype (type, optional): Data type of STFT results. Defaults to np.complex64.
+ pad_mode (str, optional): Choose padding pattern when `center` is `True`. Defaults to "reflect".
+
+ Returns:
+ np.ndarray: The complex STFT output with shape `(n_fft//2 + 1, num_frames)`.
+ """
+ _check_audio(x)
+
+ # By default, use the entire frame
+ if win_length is None:
+ win_length = n_fft
+
+ # Set the default hop, if it's not already specified
+ if hop_length is None:
+ hop_length = int(win_length // 4)
+
+ fft_window = signal.get_window(window, win_length, fftbins=True)
+
+ # Pad the window out to n_fft size
+ fft_window = _pad_center(fft_window, n_fft)
+
+ # Reshape so that the window can be broadcast
+ fft_window = fft_window.reshape((-1, 1))
+
+ # Pad the time series so that frames are centered
+ if center:
+ if n_fft > x.shape[-1]:
+ warnings.warn(
+ f"n_fft={n_fft} is too small for input signal of length={x.shape[-1]}"
+ )
+ x = np.pad(x, int(n_fft // 2), mode=pad_mode)
+
+ elif n_fft > x.shape[-1]:
+ raise ParameterError(
+ f"n_fft={n_fft} is too small for input signal of length={x.shape[-1]}"
+ )
+
+ # Window the time series.
+ x_frames = _split_frames(x, frame_length=n_fft, hop_length=hop_length)
+ # Pre-allocate the STFT matrix
+ stft_matrix = np.empty(
+ (int(1 + n_fft // 2), x_frames.shape[1]), dtype=dtype, order="F")
+ fft = np.fft # use numpy fft as default
+ # Constrain STFT block sizes to 256 KB
+ MAX_MEM_BLOCK = 2**8 * 2**10
+ # how many columns can we fit within MAX_MEM_BLOCK?
+ n_columns = MAX_MEM_BLOCK // (stft_matrix.shape[0] * stft_matrix.itemsize)
+ n_columns = max(n_columns, 1)
+
+ for bl_s in range(0, stft_matrix.shape[1], n_columns):
+ bl_t = min(bl_s + n_columns, stft_matrix.shape[1])
+ stft_matrix[:, bl_s:bl_t] = fft.rfft(
+ fft_window * x_frames[:, bl_s:bl_t], axis=0)
+
+ return stft_matrix
+
+
+def power_to_db(spect: np.ndarray,
+ ref: float=1.0,
+ amin: float=1e-10,
+ top_db: Optional[float]=80.0) -> np.ndarray:
+ """Convert a power spectrogram (amplitude squared) to decibel (dB) units. The function computes the scaling `10 * log10(x / ref)` in a numerically stable way.
+
+ Args:
+ spect (np.ndarray): STFT power spectrogram of an input waveform.
+ ref (float, optional): The reference value. If smaller than 1.0, the db level of the signal will be pulled up accordingly. Otherwise, the db level is pushed down. Defaults to 1.0.
+ amin (float, optional): Minimum threshold. Defaults to 1e-10.
+ top_db (Optional[float], optional): Threshold the output at `top_db` below the peak. Defaults to 80.0.
+
+ Returns:
+ np.ndarray: Power spectrogram in db scale.
+ """
+ spect = np.asarray(spect)
+
+ if amin <= 0:
+ raise ParameterError("amin must be strictly positive")
+
+ if np.issubdtype(spect.dtype, np.complexfloating):
+ warnings.warn(
+ "power_to_db was called on complex input so phase "
+ "information will be discarded. To suppress this warning, "
+ "call power_to_db(np.abs(D)**2) instead.")
+ magnitude = np.abs(spect)
+ else:
+ magnitude = spect
+
+ if callable(ref):
+ # User supplied a function to calculate reference power
+ ref_value = ref(magnitude)
+ else:
+ ref_value = np.abs(ref)
+
+ log_spec = 10.0 * np.log10(np.maximum(amin, magnitude))
+ log_spec -= 10.0 * np.log10(np.maximum(amin, ref_value))
+
+ if top_db is not None:
+ if top_db < 0:
+ raise ParameterError("top_db must be non-negative")
+ log_spec = np.maximum(log_spec, log_spec.max() - top_db)
+
+ return log_spec
+
+
+def mfcc(x: np.ndarray,
+ sr: int=16000,
+ spect: Optional[np.ndarray]=None,
+ n_mfcc: int=20,
+ dct_type: int=2,
+ norm: str="ortho",
+ lifter: int=0,
+ **kwargs) -> np.ndarray:
+ """Mel-frequency cepstral coefficients (MFCCs)
+
+ Args:
+ x (np.ndarray): Input waveform in one dimension.
+ sr (int, optional): Sample rate. Defaults to 16000.
+ spect (Optional[np.ndarray], optional): Input log-power Mel spectrogram. Defaults to None.
+ n_mfcc (int, optional): Number of cepstra in MFCC. Defaults to 20.
+ dct_type (int, optional): Discrete cosine transform (DCT) type. Defaults to 2.
+ norm (str, optional): Type of normalization. Defaults to "ortho".
+ lifter (int, optional): Cepstral filtering. Defaults to 0.
+
+ Returns:
+ np.ndarray: Mel frequency cepstral coefficients array with shape `(n_mfcc, num_frames)`.
+ """
+ if spect is None:
+ spect = melspectrogram(x, sr=sr, **kwargs)
+
+ M = scipy.fftpack.dct(spect, axis=0, type=dct_type, norm=norm)[:n_mfcc]
+
+ if lifter > 0:
+ factor = np.sin(np.pi * np.arange(1, 1 + n_mfcc, dtype=M.dtype) /
+ lifter)
+ return M * factor[:, np.newaxis]
+ elif lifter == 0:
+ return M
+ else:
+ raise ParameterError(
+ f"MFCC lifter={lifter} must be a non-negative number")
+
+
+def melspectrogram(x: np.ndarray,
+ sr: int=16000,
+ window_size: int=512,
+ hop_length: int=320,
+ n_mels: int=64,
+ fmin: float=50.0,
+ fmax: Optional[float]=None,
+ window: str='hann',
+ center: bool=True,
+ pad_mode: str='reflect',
+ power: float=2.0,
+ to_db: bool=True,
+ ref: float=1.0,
+ amin: float=1e-10,
+ top_db: Optional[float]=None) -> np.ndarray:
+ """Compute mel-spectrogram.
+
+ Args:
+ x (np.ndarray): Input waveform in one dimension.
+ sr (int, optional): Sample rate. Defaults to 16000.
+ window_size (int, optional): Size of FFT and window length. Defaults to 512.
+ hop_length (int, optional): Number of steps to advance between adjacent windows. Defaults to 320.
+ n_mels (int, optional): Number of mel bins. Defaults to 64.
+ fmin (float, optional): Minimum frequency in Hz. Defaults to 50.0.
+ fmax (Optional[float], optional): Maximum frequency in Hz. Defaults to None.
+ window (str, optional): A string of window specification. Defaults to "hann".
+ center (bool, optional): Whether to pad `x` to make that the :math:`t \times hop\\_length` at the center of `t`-th frame. Defaults to True.
+ pad_mode (str, optional): Choose padding pattern when `center` is `True`. Defaults to "reflect".
+ power (float, optional): Exponent for the magnitude melspectrogram. Defaults to 2.0.
+ to_db (bool, optional): Enable db scale. Defaults to True.
+ ref (float, optional): The reference value. If smaller than 1.0, the db level of the signal will be pulled up accordingly. Otherwise, the db level is pushed down. Defaults to 1.0.
+ amin (float, optional): Minimum threshold. Defaults to 1e-10.
+ top_db (Optional[float], optional): Threshold the output at `top_db` below the peak. Defaults to None.
+
+ Returns:
+ np.ndarray: The mel-spectrogram in power scale or db scale with shape `(n_mels, num_frames)`.
+ """
+ _check_audio(x, mono=True)
+ if len(x) <= 0:
+ raise ParameterError('The input waveform is empty')
+
+ if fmax is None:
+ fmax = sr // 2
+ if fmin < 0 or fmin >= fmax:
+ raise ParameterError('fmin and fmax must statisfy 0 np.ndarray:
+ """Compute spectrogram.
+
+ Args:
+ x (np.ndarray): Input waveform in one dimension.
+ sr (int, optional): Sample rate. Defaults to 16000.
+ window_size (int, optional): Size of FFT and window length. Defaults to 512.
+ hop_length (int, optional): Number of steps to advance between adjacent windows. Defaults to 320.
+ window (str, optional): A string of window specification. Defaults to "hann".
+ center (bool, optional): Whether to pad `x` to make that the :math:`t \times hop\\_length` at the center of `t`-th frame. Defaults to True.
+ pad_mode (str, optional): Choose padding pattern when `center` is `True`. Defaults to "reflect".
+ power (float, optional): Exponent for the magnitude melspectrogram. Defaults to 2.0.
+
+ Returns:
+ np.ndarray: The STFT spectrogram in power scale `(n_fft//2 + 1, num_frames)`.
+ """
+
+ s = stft(
+ x,
+ n_fft=window_size,
+ hop_length=hop_length,
+ win_length=window_size,
+ window=window,
+ center=center,
+ pad_mode=pad_mode)
+
+ return np.abs(s)**power
+
+
+def mu_encode(x: np.ndarray, mu: int=255, quantized: bool=True) -> np.ndarray:
+ """Mu-law encoding. Encode waveform based on mu-law companding. When quantized is True, the result will be converted to integer in range `[0,mu-1]`. Otherwise, the resulting waveform is in range `[-1,1]`.
+
+ Args:
+ x (np.ndarray): The input waveform to encode.
+ mu (int, optional): The endoceding parameter. Defaults to 255.
+ quantized (bool, optional): If `True`, quantize the encoded values into `1 + mu` distinct integer values. Defaults to True.
+
+ Returns:
+ np.ndarray: The mu-law encoded waveform.
+ """
+ mu = 255
+ y = np.sign(x) * np.log1p(mu * np.abs(x)) / np.log1p(mu)
+ if quantized:
+ y = np.floor((y + 1) / 2 * mu + 0.5) # convert to [0 , mu-1]
+ return y
+
+
+def mu_decode(y: np.ndarray, mu: int=255, quantized: bool=True) -> np.ndarray:
+ """Mu-law decoding. Compute the mu-law decoding given an input code. It assumes that the input `y` is in range `[0,mu-1]` when quantize is True and `[-1,1]` otherwise.
+
+ Args:
+ y (np.ndarray): The encoded waveform.
+ mu (int, optional): The endoceding parameter. Defaults to 255.
+ quantized (bool, optional): If `True`, the input is assumed to be quantized to `1 + mu` distinct integer values. Defaults to True.
+
+ Returns:
+ np.ndarray: The mu-law decoded waveform.
+ """
+ if mu < 1:
+ raise ParameterError('mu is typically set as 2**k-1, k=1, 2, 3,...')
+
+ mu = mu - 1
+ if quantized: # undo the quantization
+ y = y * 2 / mu - 1
+ x = np.sign(y) / mu * ((1 + mu)**np.abs(y) - 1)
+ return x
+
+
+def _randint(high: int) -> int:
+ """Generate one random integer in range [0 high)
+
+ This is a helper function for random data augmentation
+ """
+ return int(np.random.randint(0, high=high))
+
+
+def depth_augment(y: np.ndarray,
+ choices: List=['int8', 'int16'],
+ probs: List[float]=[0.5, 0.5]) -> np.ndarray:
+ """ Audio depth augmentation. Do audio depth augmentation to simulate the distortion brought by quantization.
+
+ Args:
+ y (np.ndarray): Input waveform array in 1D or 2D.
+ choices (List, optional): A list of data type to depth conversion. Defaults to ['int8', 'int16'].
+ probs (List[float], optional): Probabilities to depth conversion. Defaults to [0.5, 0.5].
+
+ Returns:
+ np.ndarray: The augmented waveform.
+ """
+ assert len(probs) == len(
+ choices
+ ), 'number of choices {} must be equal to size of probs {}'.format(
+ len(choices), len(probs))
+ depth = np.random.choice(choices, p=probs)
+ src_depth = y.dtype
+ y1 = depth_convert(y, depth)
+ y2 = depth_convert(y1, src_depth)
+
+ return y2
+
+
+def adaptive_spect_augment(spect: np.ndarray,
+ tempo_axis: int=0,
+ level: float=0.1) -> np.ndarray:
+ """Do adaptive spectrogram augmentation. The level of the augmentation is govern by the parameter level, ranging from 0 to 1, with 0 represents no augmentation.
+
+ Args:
+ spect (np.ndarray): Input spectrogram.
+ tempo_axis (int, optional): Indicate the tempo axis. Defaults to 0.
+ level (float, optional): The level factor of masking. Defaults to 0.1.
+
+ Returns:
+ np.ndarray: The augmented spectrogram.
+ """
+ assert spect.ndim == 2., 'only supports 2d tensor or numpy array'
+ if tempo_axis == 0:
+ nt, nf = spect.shape
+ else:
+ nf, nt = spect.shape
+
+ time_mask_width = int(nt * level * 0.5)
+ freq_mask_width = int(nf * level * 0.5)
+
+ num_time_mask = int(10 * level)
+ num_freq_mask = int(10 * level)
+
+ if tempo_axis == 0:
+ for _ in range(num_time_mask):
+ start = _randint(nt - time_mask_width)
+ spect[start:start + time_mask_width, :] = 0
+ for _ in range(num_freq_mask):
+ start = _randint(nf - freq_mask_width)
+ spect[:, start:start + freq_mask_width] = 0
+ else:
+ for _ in range(num_time_mask):
+ start = _randint(nt - time_mask_width)
+ spect[:, start:start + time_mask_width] = 0
+ for _ in range(num_freq_mask):
+ start = _randint(nf - freq_mask_width)
+ spect[start:start + freq_mask_width, :] = 0
+
+ return spect
+
+
+def spect_augment(spect: np.ndarray,
+ tempo_axis: int=0,
+ max_time_mask: int=3,
+ max_freq_mask: int=3,
+ max_time_mask_width: int=30,
+ max_freq_mask_width: int=20) -> np.ndarray:
+ """Do spectrogram augmentation in both time and freq axis.
+
+ Args:
+ spect (np.ndarray): Input spectrogram.
+ tempo_axis (int, optional): Indicate the tempo axis. Defaults to 0.
+ max_time_mask (int, optional): Maximum number of time masking. Defaults to 3.
+ max_freq_mask (int, optional): Maximum number of frequency masking. Defaults to 3.
+ max_time_mask_width (int, optional): Maximum width of time masking. Defaults to 30.
+ max_freq_mask_width (int, optional): Maximum width of frequency masking. Defaults to 20.
+
+ Returns:
+ np.ndarray: The augmented spectrogram.
+ """
+ assert spect.ndim == 2., 'only supports 2d tensor or numpy array'
+ if tempo_axis == 0:
+ nt, nf = spect.shape
+ else:
+ nf, nt = spect.shape
+
+ num_time_mask = _randint(max_time_mask)
+ num_freq_mask = _randint(max_freq_mask)
+
+ time_mask_width = _randint(max_time_mask_width)
+ freq_mask_width = _randint(max_freq_mask_width)
+
+ if tempo_axis == 0:
+ for _ in range(num_time_mask):
+ start = _randint(nt - time_mask_width)
+ spect[start:start + time_mask_width, :] = 0
+ for _ in range(num_freq_mask):
+ start = _randint(nf - freq_mask_width)
+ spect[:, start:start + freq_mask_width] = 0
+ else:
+ for _ in range(num_time_mask):
+ start = _randint(nt - time_mask_width)
+ spect[:, start:start + time_mask_width] = 0
+ for _ in range(num_freq_mask):
+ start = _randint(nf - freq_mask_width)
+ spect[start:start + freq_mask_width, :] = 0
+
+ return spect
+
+
+def random_crop1d(y: np.ndarray, crop_len: int) -> np.ndarray:
+ """ Random cropping on a input waveform.
+
+ Args:
+ y (np.ndarray): Input waveform array in 1D.
+ crop_len (int): Length of waveform to crop.
+
+ Returns:
+ np.ndarray: The cropped waveform.
+ """
+ if y.ndim != 1:
+ 'only accept 1d tensor or numpy array'
+ n = len(y)
+ idx = _randint(n - crop_len)
+ return y[idx:idx + crop_len]
+
+
+def random_crop2d(s: np.ndarray, crop_len: int,
+ tempo_axis: int=0) -> np.ndarray:
+ """ Random cropping on a spectrogram.
+
+ Args:
+ s (np.ndarray): Input spectrogram in 2D.
+ crop_len (int): Length of spectrogram to crop.
+ tempo_axis (int, optional): Indicate the tempo axis. Defaults to 0.
+
+ Returns:
+ np.ndarray: The cropped spectrogram.
+ """
+ if tempo_axis >= s.ndim:
+ raise ParameterError('axis out of range')
+
+ n = s.shape[tempo_axis]
+ idx = _randint(high=n - crop_len)
+ sli = [slice(None) for i in range(s.ndim)]
+ sli[tempo_axis] = slice(idx, idx + crop_len)
+ out = s[tuple(sli)]
+ return out
diff --git a/paddlespeech/audio/datasets/__init__.py b/paddlespeech/audio/datasets/__init__.py
new file mode 100644
index 000000000..8068fa9d3
--- /dev/null
+++ b/paddlespeech/audio/datasets/__init__.py
@@ -0,0 +1,15 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from .esc50 import ESC50
+from .voxceleb import VoxCeleb
diff --git a/paddlespeech/audio/datasets/dataset.py b/paddlespeech/audio/datasets/dataset.py
new file mode 100644
index 000000000..170e91669
--- /dev/null
+++ b/paddlespeech/audio/datasets/dataset.py
@@ -0,0 +1,100 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import List
+
+import numpy as np
+import paddle
+
+from ..backends.soundfile_backend import soundfile_load as load_audio
+from ..compliance.kaldi import fbank as kaldi_fbank
+from ..compliance.kaldi import mfcc as kaldi_mfcc
+from ..compliance.librosa import melspectrogram
+from ..compliance.librosa import mfcc
+
+feat_funcs = {
+ 'raw': None,
+ 'melspectrogram': melspectrogram,
+ 'mfcc': mfcc,
+ 'kaldi_fbank': kaldi_fbank,
+ 'kaldi_mfcc': kaldi_mfcc,
+}
+
+
+class AudioClassificationDataset(paddle.io.Dataset):
+ """
+ Base class of audio classification dataset.
+ """
+
+ def __init__(self,
+ files: List[str],
+ labels: List[int],
+ feat_type: str='raw',
+ sample_rate: int=None,
+ **kwargs):
+ """
+ Ags:
+ files (:obj:`List[str]`): A list of absolute path of audio files.
+ labels (:obj:`List[int]`): Labels of audio files.
+ feat_type (:obj:`str`, `optional`, defaults to `raw`):
+ It identifies the feature type that user wants to extract of an audio file.
+ """
+ super(AudioClassificationDataset, self).__init__()
+
+ if feat_type not in feat_funcs.keys():
+ raise RuntimeError(
+ f"Unknown feat_type: {feat_type}, it must be one in {list(feat_funcs.keys())}"
+ )
+
+ self.files = files
+ self.labels = labels
+
+ self.feat_type = feat_type
+ self.sample_rate = sample_rate
+ self.feat_config = kwargs # Pass keyword arguments to customize feature config
+
+ def _get_data(self, input_file: str):
+ raise NotImplementedError
+
+ def _convert_to_record(self, idx):
+ file, label = self.files[idx], self.labels[idx]
+
+ if self.sample_rate is None:
+ waveform, sample_rate = load_audio(file)
+ else:
+ waveform, sample_rate = load_audio(file, sr=self.sample_rate)
+
+ feat_func = feat_funcs[self.feat_type]
+
+ record = {}
+ if self.feat_type in ['kaldi_fbank', 'kaldi_mfcc']:
+ waveform = paddle.to_tensor(waveform).unsqueeze(0) # (C, T)
+ record['feat'] = feat_func(
+ waveform=waveform, sr=self.sample_rate, **self.feat_config)
+ else:
+ record['feat'] = feat_func(
+ waveform, sample_rate,
+ **self.feat_config) if feat_func else waveform
+ record['label'] = label
+ return record
+
+ def __getitem__(self, idx):
+ record = self._convert_to_record(idx)
+ if self.feat_type in ['kaldi_fbank', 'kaldi_mfcc']:
+ return self.keys[idx], record['feat'], record['label']
+ else:
+ return np.array(record['feat']).transpose(), np.array(
+ record['label'], dtype=np.int64)
+
+ def __len__(self):
+ return len(self.files)
diff --git a/paddlespeech/audio/datasets/esc50.py b/paddlespeech/audio/datasets/esc50.py
new file mode 100644
index 000000000..684a8b8f5
--- /dev/null
+++ b/paddlespeech/audio/datasets/esc50.py
@@ -0,0 +1,152 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import collections
+import os
+from typing import List
+from typing import Tuple
+
+from ...utils.env import DATA_HOME
+from ..utils.download import download_and_decompress
+from .dataset import AudioClassificationDataset
+
+__all__ = ['ESC50']
+
+
+class ESC50(AudioClassificationDataset):
+ """
+ The ESC-50 dataset is a labeled collection of 2000 environmental audio recordings
+ suitable for benchmarking methods of environmental sound classification. The dataset
+ consists of 5-second-long recordings organized into 50 semantical classes (with
+ 40 examples per class)
+
+ Reference:
+ ESC: Dataset for Environmental Sound Classification
+ http://dx.doi.org/10.1145/2733373.2806390
+ """
+
+ archieves = [
+ {
+ 'url':
+ 'https://paddleaudio.bj.bcebos.com/datasets/ESC-50-master.zip',
+ 'md5': '7771e4b9d86d0945acce719c7a59305a',
+ },
+ ]
+ label_list = [
+ # Animals
+ 'Dog',
+ 'Rooster',
+ 'Pig',
+ 'Cow',
+ 'Frog',
+ 'Cat',
+ 'Hen',
+ 'Insects (flying)',
+ 'Sheep',
+ 'Crow',
+ # Natural soundscapes & water sounds
+ 'Rain',
+ 'Sea waves',
+ 'Crackling fire',
+ 'Crickets',
+ 'Chirping birds',
+ 'Water drops',
+ 'Wind',
+ 'Pouring water',
+ 'Toilet flush',
+ 'Thunderstorm',
+ # Human, non-speech sounds
+ 'Crying baby',
+ 'Sneezing',
+ 'Clapping',
+ 'Breathing',
+ 'Coughing',
+ 'Footsteps',
+ 'Laughing',
+ 'Brushing teeth',
+ 'Snoring',
+ 'Drinking, sipping',
+ # Interior/domestic sounds
+ 'Door knock',
+ 'Mouse click',
+ 'Keyboard typing',
+ 'Door, wood creaks',
+ 'Can opening',
+ 'Washing machine',
+ 'Vacuum cleaner',
+ 'Clock alarm',
+ 'Clock tick',
+ 'Glass breaking',
+ # Exterior/urban noises
+ 'Helicopter',
+ 'Chainsaw',
+ 'Siren',
+ 'Car horn',
+ 'Engine',
+ 'Train',
+ 'Church bells',
+ 'Airplane',
+ 'Fireworks',
+ 'Hand saw',
+ ]
+ meta = os.path.join('ESC-50-master', 'meta', 'esc50.csv')
+ meta_info = collections.namedtuple(
+ 'META_INFO',
+ ('filename', 'fold', 'target', 'category', 'esc10', 'src_file', 'take'))
+ audio_path = os.path.join('ESC-50-master', 'audio')
+
+ def __init__(self,
+ mode: str='train',
+ split: int=1,
+ feat_type: str='raw',
+ **kwargs):
+ """
+ Ags:
+ mode (:obj:`str`, `optional`, defaults to `train`):
+ It identifies the dataset mode (train or dev).
+ split (:obj:`int`, `optional`, defaults to 1):
+ It specify the fold of dev dataset.
+ feat_type (:obj:`str`, `optional`, defaults to `raw`):
+ It identifies the feature type that user wants to extract of an audio file.
+ """
+ files, labels = self._get_data(mode, split)
+ super(ESC50, self).__init__(
+ files=files, labels=labels, feat_type=feat_type, **kwargs)
+
+ def _get_meta_info(self) -> List[collections.namedtuple]:
+ ret = []
+ with open(os.path.join(DATA_HOME, self.meta), 'r') as rf:
+ for line in rf.readlines()[1:]:
+ ret.append(self.meta_info(*line.strip().split(',')))
+ return ret
+
+ def _get_data(self, mode: str, split: int) -> Tuple[List[str], List[int]]:
+ if not os.path.isdir(os.path.join(DATA_HOME, self.audio_path)) or \
+ not os.path.isfile(os.path.join(DATA_HOME, self.meta)):
+ download_and_decompress(self.archieves, DATA_HOME)
+
+ meta_info = self._get_meta_info()
+
+ files = []
+ labels = []
+ for sample in meta_info:
+ filename, fold, target, _, _, _, _ = sample
+ if mode == 'train' and int(fold) != split:
+ files.append(os.path.join(DATA_HOME, self.audio_path, filename))
+ labels.append(int(target))
+
+ if mode != 'train' and int(fold) == split:
+ files.append(os.path.join(DATA_HOME, self.audio_path, filename))
+ labels.append(int(target))
+
+ return files, labels
diff --git a/paddlespeech/audio/datasets/voxceleb.py b/paddlespeech/audio/datasets/voxceleb.py
new file mode 100644
index 000000000..4daa6bf6f
--- /dev/null
+++ b/paddlespeech/audio/datasets/voxceleb.py
@@ -0,0 +1,356 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import collections
+import csv
+import glob
+import os
+import random
+from multiprocessing import cpu_count
+from typing import List
+
+from paddle.io import Dataset
+from pathos.multiprocessing import Pool
+from tqdm import tqdm
+
+from ...utils.env import DATA_HOME
+from ..backends.soundfile_backend import soundfile_load as load_audio
+from ..utils.download import decompress
+from ..utils.download import download_and_decompress
+from .dataset import feat_funcs
+
+__all__ = ['VoxCeleb']
+
+
+class VoxCeleb(Dataset):
+ source_url = 'https://thor.robots.ox.ac.uk/~vgg/data/voxceleb/vox1a/'
+ archieves_audio_dev = [
+ {
+ 'url': source_url + 'vox1_dev_wav_partaa',
+ 'md5': 'e395d020928bc15670b570a21695ed96',
+ },
+ {
+ 'url': source_url + 'vox1_dev_wav_partab',
+ 'md5': 'bbfaaccefab65d82b21903e81a8a8020',
+ },
+ {
+ 'url': source_url + 'vox1_dev_wav_partac',
+ 'md5': '017d579a2a96a077f40042ec33e51512',
+ },
+ {
+ 'url': source_url + 'vox1_dev_wav_partad',
+ 'md5': '7bb1e9f70fddc7a678fa998ea8b3ba19',
+ },
+ ]
+ archieves_audio_test = [
+ {
+ 'url': source_url + 'vox1_test_wav.zip',
+ 'md5': '185fdc63c3c739954633d50379a3d102',
+ },
+ ]
+ archieves_meta = [
+ {
+ 'url':
+ 'https://www.robots.ox.ac.uk/~vgg/data/voxceleb/meta/veri_test2.txt',
+ 'md5':
+ 'b73110731c9223c1461fe49cb48dddfc',
+ },
+ ]
+
+ num_speakers = 1211 # 1211 vox1, 5994 vox2, 7205 vox1+2, test speakers: 41
+ sample_rate = 16000
+ meta_info = collections.namedtuple(
+ 'META_INFO', ('id', 'duration', 'wav', 'start', 'stop', 'spk_id'))
+ base_path = os.path.join(DATA_HOME, 'vox1')
+ wav_path = os.path.join(base_path, 'wav')
+ meta_path = os.path.join(base_path, 'meta')
+ veri_test_file = os.path.join(meta_path, 'veri_test2.txt')
+ csv_path = os.path.join(base_path, 'csv')
+ subsets = ['train', 'dev', 'enroll', 'test']
+
+ def __init__(
+ self,
+ subset: str='train',
+ feat_type: str='raw',
+ random_chunk: bool=True,
+ chunk_duration: float=3.0, # seconds
+ split_ratio: float=0.9, # train split ratio
+ seed: int=0,
+ target_dir: str=None,
+ vox2_base_path=None,
+ **kwargs):
+ """VoxCeleb data prepare and get the specific dataset audio info
+
+ Args:
+ subset (str, optional): dataset name, such as train, dev, enroll or test. Defaults to 'train'.
+ feat_type (str, optional): feat type, such raw, melspectrogram(fbank) or mfcc . Defaults to 'raw'.
+ random_chunk (bool, optional): random select a duration from audio. Defaults to True.
+ chunk_duration (float, optional): chunk duration if random_chunk flag is set. Defaults to 3.0.
+ target_dir (str, optional): data dir, audio info will be stored in this directory. Defaults to None.
+ vox2_base_path (_type_, optional): vox2 directory. vox2 data must be converted from m4a to wav. Defaults to None.
+ """
+ assert subset in self.subsets, \
+ 'Dataset subset must be one in {}, but got {}'.format(self.subsets, subset)
+
+ self.subset = subset
+ self.spk_id2label = {}
+ self.feat_type = feat_type
+ self.feat_config = kwargs
+ self.random_chunk = random_chunk
+ self.chunk_duration = chunk_duration
+ self.split_ratio = split_ratio
+ self.target_dir = target_dir if target_dir else VoxCeleb.base_path
+ self.vox2_base_path = vox2_base_path
+
+ # if we set the target dir, we will change the vox data info data from base path to target dir
+ VoxCeleb.csv_path = os.path.join(
+ target_dir, "voxceleb", 'csv') if target_dir else VoxCeleb.csv_path
+ VoxCeleb.meta_path = os.path.join(
+ target_dir, "voxceleb",
+ 'meta') if target_dir else VoxCeleb.meta_path
+ VoxCeleb.veri_test_file = os.path.join(VoxCeleb.meta_path,
+ 'veri_test2.txt')
+ # self._data = self._get_data()[:1000] # KP: Small dataset test.
+ self._data = self._get_data()
+ super(VoxCeleb, self).__init__()
+
+ # Set up a seed to reproduce training or predicting result.
+ # random.seed(seed)
+
+ def _get_data(self):
+ # Download audio files.
+ # We need the users to decompress all vox1/dev/wav and vox1/test/wav/ to vox1/wav/ dir
+ # so, we check the vox1/wav dir status
+ print(f"wav base path: {self.wav_path}")
+ if not os.path.isdir(self.wav_path):
+ print("start to download the voxceleb1 dataset")
+ download_and_decompress( # multi-zip parts concatenate to vox1_dev_wav.zip
+ self.archieves_audio_dev,
+ self.base_path,
+ decompress=False)
+ download_and_decompress( # download the vox1_test_wav.zip and unzip
+ self.archieves_audio_test,
+ self.base_path,
+ decompress=True)
+
+ # Download all parts and concatenate the files into one zip file.
+ dev_zipfile = os.path.join(self.base_path, 'vox1_dev_wav.zip')
+ print(f'Concatenating all parts to: {dev_zipfile}')
+ os.system(
+ f'cat {os.path.join(self.base_path, "vox1_dev_wav_parta*")} > {dev_zipfile}'
+ )
+
+ # Extract all audio files of dev and test set.
+ decompress(dev_zipfile, self.base_path)
+
+ # Download meta files.
+ if not os.path.isdir(self.meta_path):
+ print("prepare the meta data")
+ download_and_decompress(
+ self.archieves_meta, self.meta_path, decompress=False)
+
+ # Data preparation.
+ if not os.path.isdir(self.csv_path):
+ os.makedirs(self.csv_path)
+ self.prepare_data()
+
+ data = []
+ print(
+ f"read the {self.subset} from {os.path.join(self.csv_path, f'{self.subset}.csv')}"
+ )
+ with open(os.path.join(self.csv_path, f'{self.subset}.csv'), 'r') as rf:
+ for line in rf.readlines()[1:]:
+ audio_id, duration, wav, start, stop, spk_id = line.strip(
+ ).split(',')
+ data.append(
+ self.meta_info(audio_id,
+ float(duration), wav,
+ int(start), int(stop), spk_id))
+
+ with open(os.path.join(self.meta_path, 'spk_id2label.txt'), 'r') as f:
+ for line in f.readlines():
+ spk_id, label = line.strip().split(' ')
+ self.spk_id2label[spk_id] = int(label)
+
+ return data
+
+ def _convert_to_record(self, idx: int):
+ sample = self._data[idx]
+
+ record = {}
+ # To show all fields in a namedtuple: `type(sample)._fields`
+ for field in type(sample)._fields:
+ record[field] = getattr(sample, field)
+
+ waveform, sr = load_audio(record['wav'])
+
+ # random select a chunk audio samples from the audio
+ if self.random_chunk:
+ num_wav_samples = waveform.shape[0]
+ num_chunk_samples = int(self.chunk_duration * sr)
+ start = random.randint(0, num_wav_samples - num_chunk_samples - 1)
+ stop = start + num_chunk_samples
+ else:
+ start = record['start']
+ stop = record['stop']
+
+ waveform = waveform[start:stop]
+
+ assert self.feat_type in feat_funcs.keys(), \
+ f"Unknown feat_type: {self.feat_type}, it must be one in {list(feat_funcs.keys())}"
+ feat_func = feat_funcs[self.feat_type]
+ feat = feat_func(
+ waveform, sr=sr, **self.feat_config) if feat_func else waveform
+
+ record.update({'feat': feat})
+ if self.subset in ['train',
+ 'dev']: # Labels are available in train and dev.
+ record.update({'label': self.spk_id2label[record['spk_id']]})
+
+ return record
+
+ @staticmethod
+ def _get_chunks(seg_dur, audio_id, audio_duration):
+ num_chunks = int(audio_duration / seg_dur) # all in milliseconds
+
+ chunk_lst = [
+ audio_id + "_" + str(i * seg_dur) + "_" + str(i * seg_dur + seg_dur)
+ for i in range(num_chunks)
+ ]
+ return chunk_lst
+
+ def _get_audio_info(self, wav_file: str,
+ split_chunks: bool) -> List[List[str]]:
+ waveform, sr = load_audio(wav_file)
+ spk_id, sess_id, utt_id = wav_file.split("/")[-3:]
+ audio_id = '-'.join([spk_id, sess_id, utt_id.split(".")[0]])
+ audio_duration = waveform.shape[0] / sr
+
+ ret = []
+ if split_chunks: # Split into pieces of self.chunk_duration seconds.
+ uniq_chunks_list = self._get_chunks(self.chunk_duration, audio_id,
+ audio_duration)
+
+ for chunk in uniq_chunks_list:
+ s, e = chunk.split("_")[-2:] # Timestamps of start and end
+ start_sample = int(float(s) * sr)
+ end_sample = int(float(e) * sr)
+ # id, duration, wav, start, stop, spk_id
+ ret.append([
+ chunk, audio_duration, wav_file, start_sample, end_sample,
+ spk_id
+ ])
+ else: # Keep whole audio.
+ ret.append([
+ audio_id, audio_duration, wav_file, 0, waveform.shape[0], spk_id
+ ])
+ return ret
+
+ def generate_csv(self,
+ wav_files: List[str],
+ output_file: str,
+ split_chunks: bool=True):
+ print(f'Generating csv: {output_file}')
+ header = ["id", "duration", "wav", "start", "stop", "spk_id"]
+ # Note: this may occurs c++ exception, but the program will execute fine
+ # so we can ignore the exception
+ with Pool(cpu_count()) as p:
+ infos = list(
+ tqdm(
+ p.imap(lambda x: self._get_audio_info(x, split_chunks),
+ wav_files),
+ total=len(wav_files)))
+
+ csv_lines = []
+ for info in infos:
+ csv_lines.extend(info)
+
+ with open(output_file, mode="w") as csv_f:
+ csv_writer = csv.writer(
+ csv_f, delimiter=",", quotechar='"', quoting=csv.QUOTE_MINIMAL)
+ csv_writer.writerow(header)
+ for line in csv_lines:
+ csv_writer.writerow(line)
+
+ def prepare_data(self):
+ # Audio of speakers in veri_test_file should not be included in training set.
+ print("start to prepare the data csv file")
+ enroll_files = set()
+ test_files = set()
+ # get the enroll and test audio file path
+ with open(self.veri_test_file, 'r') as f:
+ for line in f.readlines():
+ _, enrol_file, test_file = line.strip().split(' ')
+ enroll_files.add(os.path.join(self.wav_path, enrol_file))
+ test_files.add(os.path.join(self.wav_path, test_file))
+ enroll_files = sorted(enroll_files)
+ test_files = sorted(test_files)
+
+ # get the enroll and test speakers
+ test_spks = set()
+ for file in (enroll_files + test_files):
+ spk = file.split('/wav/')[1].split('/')[0]
+ test_spks.add(spk)
+
+ # get all the train and dev audios file path
+ audio_files = []
+ speakers = set()
+ print("Getting file list...")
+ for path in [self.wav_path, self.vox2_base_path]:
+ # if vox2 directory is not set and vox2 is not a directory
+ # we will not process this directory
+ if not path or not os.path.exists(path):
+ print(f"{path} is an invalid path, please check again, "
+ "and we will ignore the vox2 base path")
+ continue
+ for file in glob.glob(
+ os.path.join(path, "**", "*.wav"), recursive=True):
+ spk = file.split('/wav/')[1].split('/')[0]
+ if spk in test_spks:
+ continue
+ speakers.add(spk)
+ audio_files.append(file)
+
+ print(
+ f"start to generate the {os.path.join(self.meta_path, 'spk_id2label.txt')}"
+ )
+ # encode the train and dev speakers label to spk_id2label.txt
+ with open(os.path.join(self.meta_path, 'spk_id2label.txt'), 'w') as f:
+ for label, spk_id in enumerate(
+ sorted(speakers)): # 1211 vox1, 5994 vox2, 7205 vox1+2
+ f.write(f'{spk_id} {label}\n')
+
+ audio_files = sorted(audio_files)
+ random.shuffle(audio_files)
+ split_idx = int(self.split_ratio * len(audio_files))
+ # split_ratio to train
+ train_files, dev_files = audio_files[:split_idx], audio_files[
+ split_idx:]
+
+ self.generate_csv(train_files, os.path.join(self.csv_path, 'train.csv'))
+ self.generate_csv(dev_files, os.path.join(self.csv_path, 'dev.csv'))
+
+ self.generate_csv(
+ enroll_files,
+ os.path.join(self.csv_path, 'enroll.csv'),
+ split_chunks=False)
+ self.generate_csv(
+ test_files,
+ os.path.join(self.csv_path, 'test.csv'),
+ split_chunks=False)
+
+ def __getitem__(self, idx):
+ return self._convert_to_record(idx)
+
+ def __len__(self):
+ return len(self._data)
diff --git a/paddlespeech/audio/functional/__init__.py b/paddlespeech/audio/functional/__init__.py
new file mode 100644
index 000000000..c85232df1
--- /dev/null
+++ b/paddlespeech/audio/functional/__init__.py
@@ -0,0 +1,20 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from .functional import compute_fbank_matrix
+from .functional import create_dct
+from .functional import fft_frequencies
+from .functional import hz_to_mel
+from .functional import mel_frequencies
+from .functional import mel_to_hz
+from .functional import power_to_db
diff --git a/paddlespeech/audio/functional/functional.py b/paddlespeech/audio/functional/functional.py
new file mode 100644
index 000000000..7c20f9013
--- /dev/null
+++ b/paddlespeech/audio/functional/functional.py
@@ -0,0 +1,266 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# Modified from librosa(https://github.com/librosa/librosa)
+import math
+from typing import Optional
+from typing import Union
+
+import paddle
+from paddle import Tensor
+
+__all__ = [
+ 'hz_to_mel',
+ 'mel_to_hz',
+ 'mel_frequencies',
+ 'fft_frequencies',
+ 'compute_fbank_matrix',
+ 'power_to_db',
+ 'create_dct',
+]
+
+
+def hz_to_mel(freq: Union[Tensor, float],
+ htk: bool=False) -> Union[Tensor, float]:
+ """Convert Hz to Mels.
+
+ Args:
+ freq (Union[Tensor, float]): The input tensor with arbitrary shape.
+ htk (bool, optional): Use htk scaling. Defaults to False.
+
+ Returns:
+ Union[Tensor, float]: Frequency in mels.
+ """
+
+ if htk:
+ if isinstance(freq, Tensor):
+ return 2595.0 * paddle.log10(1.0 + freq / 700.0)
+ else:
+ return 2595.0 * math.log10(1.0 + freq / 700.0)
+
+ # Fill in the linear part
+ f_min = 0.0
+ f_sp = 200.0 / 3
+
+ mels = (freq - f_min) / f_sp
+
+ # Fill in the log-scale part
+
+ min_log_hz = 1000.0 # beginning of log region (Hz)
+ min_log_mel = (min_log_hz - f_min) / f_sp # same (Mels)
+ logstep = math.log(6.4) / 27.0 # step size for log region
+
+ if isinstance(freq, Tensor):
+ target = min_log_mel + paddle.log(
+ freq / min_log_hz + 1e-10) / logstep # prevent nan with 1e-10
+ mask = (freq > min_log_hz).astype(freq.dtype)
+ mels = target * mask + mels * (
+ 1 - mask) # will replace by masked_fill OP in future
+ else:
+ if freq >= min_log_hz:
+ mels = min_log_mel + math.log(freq / min_log_hz + 1e-10) / logstep
+
+ return mels
+
+
+def mel_to_hz(mel: Union[float, Tensor],
+ htk: bool=False) -> Union[float, Tensor]:
+ """Convert mel bin numbers to frequencies.
+
+ Args:
+ mel (Union[float, Tensor]): The mel frequency represented as a tensor with arbitrary shape.
+ htk (bool, optional): Use htk scaling. Defaults to False.
+
+ Returns:
+ Union[float, Tensor]: Frequencies in Hz.
+ """
+ if htk:
+ return 700.0 * (10.0**(mel / 2595.0) - 1.0)
+
+ f_min = 0.0
+ f_sp = 200.0 / 3
+ freqs = f_min + f_sp * mel
+ # And now the nonlinear scale
+ min_log_hz = 1000.0 # beginning of log region (Hz)
+ min_log_mel = (min_log_hz - f_min) / f_sp # same (Mels)
+ logstep = math.log(6.4) / 27.0 # step size for log region
+ if isinstance(mel, Tensor):
+ target = min_log_hz * paddle.exp(logstep * (mel - min_log_mel))
+ mask = (mel > min_log_mel).astype(mel.dtype)
+ freqs = target * mask + freqs * (
+ 1 - mask) # will replace by masked_fill OP in future
+ else:
+ if mel >= min_log_mel:
+ freqs = min_log_hz * math.exp(logstep * (mel - min_log_mel))
+
+ return freqs
+
+
+def mel_frequencies(n_mels: int=64,
+ f_min: float=0.0,
+ f_max: float=11025.0,
+ htk: bool=False,
+ dtype: str='float32') -> Tensor:
+ """Compute mel frequencies.
+
+ Args:
+ n_mels (int, optional): Number of mel bins. Defaults to 64.
+ f_min (float, optional): Minimum frequency in Hz. Defaults to 0.0.
+ fmax (float, optional): Maximum frequency in Hz. Defaults to 11025.0.
+ htk (bool, optional): Use htk scaling. Defaults to False.
+ dtype (str, optional): The data type of the return frequencies. Defaults to 'float32'.
+
+ Returns:
+ Tensor: Tensor of n_mels frequencies in Hz with shape `(n_mels,)`.
+ """
+ # 'Center freqs' of mel bands - uniformly spaced between limits
+ min_mel = hz_to_mel(f_min, htk=htk)
+ max_mel = hz_to_mel(f_max, htk=htk)
+ mels = paddle.linspace(min_mel, max_mel, n_mels, dtype=dtype)
+ freqs = mel_to_hz(mels, htk=htk)
+ return freqs
+
+
+def fft_frequencies(sr: int, n_fft: int, dtype: str='float32') -> Tensor:
+ """Compute fourier frequencies.
+
+ Args:
+ sr (int): Sample rate.
+ n_fft (int): Number of fft bins.
+ dtype (str, optional): The data type of the return frequencies. Defaults to 'float32'.
+
+ Returns:
+ Tensor: FFT frequencies in Hz with shape `(n_fft//2 + 1,)`.
+ """
+ return paddle.linspace(0, float(sr) / 2, int(1 + n_fft // 2), dtype=dtype)
+
+
+def compute_fbank_matrix(sr: int,
+ n_fft: int,
+ n_mels: int=64,
+ f_min: float=0.0,
+ f_max: Optional[float]=None,
+ htk: bool=False,
+ norm: Union[str, float]='slaney',
+ dtype: str='float32') -> Tensor:
+ """Compute fbank matrix.
+
+ Args:
+ sr (int): Sample rate.
+ n_fft (int): Number of fft bins.
+ n_mels (int, optional): Number of mel bins. Defaults to 64.
+ f_min (float, optional): Minimum frequency in Hz. Defaults to 0.0.
+ f_max (Optional[float], optional): Maximum frequency in Hz. Defaults to None.
+ htk (bool, optional): Use htk scaling. Defaults to False.
+ norm (Union[str, float], optional): Type of normalization. Defaults to 'slaney'.
+ dtype (str, optional): The data type of the return matrix. Defaults to 'float32'.
+
+ Returns:
+ Tensor: Mel transform matrix with shape `(n_mels, n_fft//2 + 1)`.
+ """
+
+ if f_max is None:
+ f_max = float(sr) / 2
+
+ # Initialize the weights
+ weights = paddle.zeros((n_mels, int(1 + n_fft // 2)), dtype=dtype)
+
+ # Center freqs of each FFT bin
+ fftfreqs = fft_frequencies(sr=sr, n_fft=n_fft, dtype=dtype)
+
+ # 'Center freqs' of mel bands - uniformly spaced between limits
+ mel_f = mel_frequencies(
+ n_mels + 2, f_min=f_min, f_max=f_max, htk=htk, dtype=dtype)
+
+ fdiff = mel_f[1:] - mel_f[:-1] #np.diff(mel_f)
+ ramps = mel_f.unsqueeze(1) - fftfreqs.unsqueeze(0)
+ #ramps = np.subtract.outer(mel_f, fftfreqs)
+
+ for i in range(n_mels):
+ # lower and upper slopes for all bins
+ lower = -ramps[i] / fdiff[i]
+ upper = ramps[i + 2] / fdiff[i + 1]
+
+ # .. then intersect them with each other and zero
+ weights[i] = paddle.maximum(
+ paddle.zeros_like(lower), paddle.minimum(lower, upper))
+
+ # Slaney-style mel is scaled to be approx constant energy per channel
+ if norm == 'slaney':
+ enorm = 2.0 / (mel_f[2:n_mels + 2] - mel_f[:n_mels])
+ weights *= enorm.unsqueeze(1)
+ elif isinstance(norm, int) or isinstance(norm, float):
+ weights = paddle.nn.functional.normalize(weights, p=norm, axis=-1)
+
+ return weights
+
+
+def power_to_db(spect: Tensor,
+ ref_value: float=1.0,
+ amin: float=1e-10,
+ top_db: Optional[float]=None) -> Tensor:
+ """Convert a power spectrogram (amplitude squared) to decibel (dB) units. The function computes the scaling `10 * log10(x / ref)` in a numerically stable way.
+
+ Args:
+ spect (Tensor): STFT power spectrogram.
+ ref_value (float, optional): The reference value. If smaller than 1.0, the db level of the signal will be pulled up accordingly. Otherwise, the db level is pushed down. Defaults to 1.0.
+ amin (float, optional): Minimum threshold. Defaults to 1e-10.
+ top_db (Optional[float], optional): Threshold the output at `top_db` below the peak. Defaults to None.
+
+ Returns:
+ Tensor: Power spectrogram in db scale.
+ """
+ if amin <= 0:
+ raise Exception("amin must be strictly positive")
+
+ if ref_value <= 0:
+ raise Exception("ref_value must be strictly positive")
+
+ ones = paddle.ones_like(spect)
+ log_spec = 10.0 * paddle.log10(paddle.maximum(ones * amin, spect))
+ log_spec -= 10.0 * math.log10(max(ref_value, amin))
+
+ if top_db is not None:
+ if top_db < 0:
+ raise Exception("top_db must be non-negative")
+ log_spec = paddle.maximum(log_spec, ones * (log_spec.max() - top_db))
+
+ return log_spec
+
+
+def create_dct(n_mfcc: int,
+ n_mels: int,
+ norm: Optional[str]='ortho',
+ dtype: str='float32') -> Tensor:
+ """Create a discrete cosine transform(DCT) matrix.
+
+ Args:
+ n_mfcc (int): Number of mel frequency cepstral coefficients.
+ n_mels (int): Number of mel filterbanks.
+ norm (Optional[str], optional): Normalization type. Defaults to 'ortho'.
+ dtype (str, optional): The data type of the return matrix. Defaults to 'float32'.
+
+ Returns:
+ Tensor: The DCT matrix with shape `(n_mels, n_mfcc)`.
+ """
+ n = paddle.arange(n_mels, dtype=dtype)
+ k = paddle.arange(n_mfcc, dtype=dtype).unsqueeze(1)
+ dct = paddle.cos(math.pi / float(n_mels) * (n + 0.5) *
+ k) # size (n_mfcc, n_mels)
+ if norm is None:
+ dct *= 2.0
+ else:
+ assert norm == "ortho"
+ dct[0] *= 1.0 / math.sqrt(2.0)
+ dct *= math.sqrt(2.0 / float(n_mels))
+ return dct.T
diff --git a/paddlespeech/audio/functional/window.py b/paddlespeech/audio/functional/window.py
new file mode 100644
index 000000000..c518dbab3
--- /dev/null
+++ b/paddlespeech/audio/functional/window.py
@@ -0,0 +1,373 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+import math
+from typing import List
+from typing import Tuple
+from typing import Union
+
+import paddle
+from paddle import Tensor
+
+
+class WindowFunctionRegister(object):
+ def __init__(self):
+ self._functions_dict = dict()
+
+ def register(self):
+ def add_subfunction(func):
+ name = func.__name__
+ self._functions_dict[name] = func
+ return func
+
+ return add_subfunction
+
+ def get(self, name):
+ return self._functions_dict[name]
+
+
+window_function_register = WindowFunctionRegister()
+
+
+@window_function_register.register()
+def _cat(x: List[Tensor], data_type: str) -> Tensor:
+ l = [paddle.to_tensor(_, data_type) for _ in x]
+ return paddle.concat(l)
+
+
+@window_function_register.register()
+def _acosh(x: Union[Tensor, float]) -> Tensor:
+ if isinstance(x, float):
+ return math.log(x + math.sqrt(x**2 - 1))
+ return paddle.log(x + paddle.sqrt(paddle.square(x) - 1))
+
+
+@window_function_register.register()
+def _extend(M: int, sym: bool) -> bool:
+ """Extend window by 1 sample if needed for DFT-even symmetry."""
+ if not sym:
+ return M + 1, True
+ else:
+ return M, False
+
+
+@window_function_register.register()
+def _len_guards(M: int) -> bool:
+ """Handle small or incorrect window lengths."""
+ if int(M) != M or M < 0:
+ raise ValueError('Window length M must be a non-negative integer')
+
+ return M <= 1
+
+
+@window_function_register.register()
+def _truncate(w: Tensor, needed: bool) -> Tensor:
+ """Truncate window by 1 sample if needed for DFT-even symmetry."""
+ if needed:
+ return w[:-1]
+ else:
+ return w
+
+
+@window_function_register.register()
+def _general_gaussian(M: int, p, sig, sym: bool=True,
+ dtype: str='float64') -> Tensor:
+ """Compute a window with a generalized Gaussian shape.
+ This function is consistent with scipy.signal.windows.general_gaussian().
+ """
+ if _len_guards(M):
+ return paddle.ones((M, ), dtype=dtype)
+ M, needs_trunc = _extend(M, sym)
+
+ n = paddle.arange(0, M, dtype=dtype) - (M - 1.0) / 2.0
+ w = paddle.exp(-0.5 * paddle.abs(n / sig)**(2 * p))
+
+ return _truncate(w, needs_trunc)
+
+
+@window_function_register.register()
+def _general_cosine(M: int, a: float, sym: bool=True,
+ dtype: str='float64') -> Tensor:
+ """Compute a generic weighted sum of cosine terms window.
+ This function is consistent with scipy.signal.windows.general_cosine().
+ """
+ if _len_guards(M):
+ return paddle.ones((M, ), dtype=dtype)
+ M, needs_trunc = _extend(M, sym)
+ fac = paddle.linspace(-math.pi, math.pi, M, dtype=dtype)
+ w = paddle.zeros((M, ), dtype=dtype)
+ for k in range(len(a)):
+ w += a[k] * paddle.cos(k * fac)
+ return _truncate(w, needs_trunc)
+
+
+@window_function_register.register()
+def _general_hamming(M: int, alpha: float, sym: bool=True,
+ dtype: str='float64') -> Tensor:
+ """Compute a generalized Hamming window.
+ This function is consistent with scipy.signal.windows.general_hamming()
+ """
+ return _general_cosine(M, [alpha, 1.0 - alpha], sym, dtype=dtype)
+
+
+@window_function_register.register()
+def _taylor(M: int,
+ nbar=4,
+ sll=30,
+ norm=True,
+ sym: bool=True,
+ dtype: str='float64') -> Tensor:
+ """Compute a Taylor window.
+ The Taylor window taper function approximates the Dolph-Chebyshev window's
+ constant sidelobe level for a parameterized number of near-in sidelobes.
+ """
+ if _len_guards(M):
+ return paddle.ones((M, ), dtype=dtype)
+ M, needs_trunc = _extend(M, sym)
+ # Original text uses a negative sidelobe level parameter and then negates
+ # it in the calculation of B. To keep consistent with other methods we
+ # assume the sidelobe level parameter to be positive.
+ B = 10**(sll / 20)
+ A = _acosh(B) / math.pi
+ s2 = nbar**2 / (A**2 + (nbar - 0.5)**2)
+ ma = paddle.arange(1, nbar, dtype=dtype)
+
+ Fm = paddle.empty((nbar - 1, ), dtype=dtype)
+ signs = paddle.empty_like(ma)
+ signs[::2] = 1
+ signs[1::2] = -1
+ m2 = ma * ma
+ for mi in range(len(ma)):
+ numer = signs[mi] * paddle.prod(1 - m2[mi] / s2 / (A**2 + (ma - 0.5)**2
+ ))
+ if mi == 0:
+ denom = 2 * paddle.prod(1 - m2[mi] / m2[mi + 1:])
+ elif mi == len(ma) - 1:
+ denom = 2 * paddle.prod(1 - m2[mi] / m2[:mi])
+ else:
+ denom = (2 * paddle.prod(1 - m2[mi] / m2[:mi]) *
+ paddle.prod(1 - m2[mi] / m2[mi + 1:]))
+
+ Fm[mi] = numer / denom
+
+ def W(n):
+ return 1 + 2 * paddle.matmul(
+ Fm.unsqueeze(0),
+ paddle.cos(2 * math.pi * ma.unsqueeze(1) *
+ (n - M / 2.0 + 0.5) / M), )
+
+ w = W(paddle.arange(0, M, dtype=dtype))
+
+ # normalize (Note that this is not described in the original text [1])
+ if norm:
+ scale = 1.0 / W((M - 1) / 2)
+ w *= scale
+ w = w.squeeze()
+ return _truncate(w, needs_trunc)
+
+
+@window_function_register.register()
+def _hamming(M: int, sym: bool=True, dtype: str='float64') -> Tensor:
+ """Compute a Hamming window.
+ The Hamming window is a taper formed by using a raised cosine with
+ non-zero endpoints, optimized to minimize the nearest side lobe.
+ """
+ return _general_hamming(M, 0.54, sym, dtype=dtype)
+
+
+@window_function_register.register()
+def _hann(M: int, sym: bool=True, dtype: str='float64') -> Tensor:
+ """Compute a Hann window.
+ The Hann window is a taper formed by using a raised cosine or sine-squared
+ with ends that touch zero.
+ """
+ return _general_hamming(M, 0.5, sym, dtype=dtype)
+
+
+@window_function_register.register()
+def _tukey(M: int, alpha=0.5, sym: bool=True, dtype: str='float64') -> Tensor:
+ """Compute a Tukey window.
+ The Tukey window is also known as a tapered cosine window.
+ """
+ if _len_guards(M):
+ return paddle.ones((M, ), dtype=dtype)
+
+ if alpha <= 0:
+ return paddle.ones((M, ), dtype=dtype)
+ elif alpha >= 1.0:
+ return hann(M, sym=sym)
+
+ M, needs_trunc = _extend(M, sym)
+
+ n = paddle.arange(0, M, dtype=dtype)
+ width = int(alpha * (M - 1) / 2.0)
+ n1 = n[0:width + 1]
+ n2 = n[width + 1:M - width - 1]
+ n3 = n[M - width - 1:]
+
+ w1 = 0.5 * (1 + paddle.cos(math.pi * (-1 + 2.0 * n1 / alpha / (M - 1))))
+ w2 = paddle.ones(n2.shape, dtype=dtype)
+ w3 = 0.5 * (1 + paddle.cos(math.pi * (-2.0 / alpha + 1 + 2.0 * n3 / alpha /
+ (M - 1))))
+ w = paddle.concat([w1, w2, w3])
+
+ return _truncate(w, needs_trunc)
+
+
+@window_function_register.register()
+def _gaussian(M: int, std: float, sym: bool=True,
+ dtype: str='float64') -> Tensor:
+ """Compute a Gaussian window.
+ The Gaussian widows has a Gaussian shape defined by the standard deviation(std).
+ """
+ if _len_guards(M):
+ return paddle.ones((M, ), dtype=dtype)
+ M, needs_trunc = _extend(M, sym)
+
+ n = paddle.arange(0, M, dtype=dtype) - (M - 1.0) / 2.0
+ sig2 = 2 * std * std
+ w = paddle.exp(-(n**2) / sig2)
+
+ return _truncate(w, needs_trunc)
+
+
+@window_function_register.register()
+def _exponential(M: int,
+ center=None,
+ tau=1.0,
+ sym: bool=True,
+ dtype: str='float64') -> Tensor:
+ """Compute an exponential (or Poisson) window."""
+ if sym and center is not None:
+ raise ValueError("If sym==True, center must be None.")
+ if _len_guards(M):
+ return paddle.ones((M, ), dtype=dtype)
+ M, needs_trunc = _extend(M, sym)
+
+ if center is None:
+ center = (M - 1) / 2
+
+ n = paddle.arange(0, M, dtype=dtype)
+ w = paddle.exp(-paddle.abs(n - center) / tau)
+
+ return _truncate(w, needs_trunc)
+
+
+@window_function_register.register()
+def _triang(M: int, sym: bool=True, dtype: str='float64') -> Tensor:
+ """Compute a triangular window."""
+ if _len_guards(M):
+ return paddle.ones((M, ), dtype=dtype)
+ M, needs_trunc = _extend(M, sym)
+
+ n = paddle.arange(1, (M + 1) // 2 + 1, dtype=dtype)
+ if M % 2 == 0:
+ w = (2 * n - 1.0) / M
+ w = paddle.concat([w, w[::-1]])
+ else:
+ w = 2 * n / (M + 1.0)
+ w = paddle.concat([w, w[-2::-1]])
+
+ return _truncate(w, needs_trunc)
+
+
+@window_function_register.register()
+def _bohman(M: int, sym: bool=True, dtype: str='float64') -> Tensor:
+ """Compute a Bohman window.
+ The Bohman window is the autocorrelation of a cosine window.
+ """
+ if _len_guards(M):
+ return paddle.ones((M, ), dtype=dtype)
+ M, needs_trunc = _extend(M, sym)
+
+ fac = paddle.abs(paddle.linspace(-1, 1, M, dtype=dtype)[1:-1])
+ w = (1 - fac) * paddle.cos(math.pi * fac) + 1.0 / math.pi * paddle.sin(
+ math.pi * fac)
+ w = _cat([0, w, 0], dtype)
+
+ return _truncate(w, needs_trunc)
+
+
+@window_function_register.register()
+def _blackman(M: int, sym: bool=True, dtype: str='float64') -> Tensor:
+ """Compute a Blackman window.
+ The Blackman window is a taper formed by using the first three terms of
+ a summation of cosines. It was designed to have close to the minimal
+ leakage possible. It is close to optimal, only slightly worse than a
+ Kaiser window.
+ """
+ return _general_cosine(M, [0.42, 0.50, 0.08], sym, dtype=dtype)
+
+
+@window_function_register.register()
+def _cosine(M: int, sym: bool=True, dtype: str='float64') -> Tensor:
+ """Compute a window with a simple cosine shape."""
+ if _len_guards(M):
+ return paddle.ones((M, ), dtype=dtype)
+ M, needs_trunc = _extend(M, sym)
+ w = paddle.sin(math.pi / M * (paddle.arange(0, M, dtype=dtype) + 0.5))
+
+ return _truncate(w, needs_trunc)
+
+
+def get_window(
+ window: Union[str, Tuple[str, float]],
+ win_length: int,
+ fftbins: bool=True,
+ dtype: str='float64', ) -> Tensor:
+ """Return a window of a given length and type.
+
+ Args:
+ window (Union[str, Tuple[str, float]]): The window function applied to the signal before the Fourier transform. Supported window functions: 'hamming', 'hann', 'gaussian', 'general_gaussian', 'exponential', 'triang', 'bohman', 'blackman', 'cosine', 'tukey', 'taylor'.
+ win_length (int): Number of samples.
+ fftbins (bool, optional): If True, create a "periodic" window. Otherwise, create a "symmetric" window, for use in filter design. Defaults to True.
+ dtype (str, optional): The data type of the return window. Defaults to 'float64'.
+
+ Returns:
+ Tensor: The window represented as a tensor.
+
+ Examples:
+ .. code-block:: python
+
+ import paddle
+
+ n_fft = 512
+ cosine_window = paddle.audio.functional.get_window('cosine', n_fft)
+
+ std = 7
+ gaussian_window = paddle.audio.functional.get_window(('gaussian',std), n_fft)
+ """
+ sym = not fftbins
+
+ args = ()
+ if isinstance(window, tuple):
+ winstr = window[0]
+ if len(window) > 1:
+ args = window[1:]
+ elif isinstance(window, str):
+ if window in ['gaussian', 'exponential']:
+ raise ValueError("The '" + window + "' window needs one or "
+ "more parameters -- pass a tuple.")
+ else:
+ winstr = window
+ else:
+ raise ValueError("%s as window type is not supported." %
+ str(type(window)))
+
+ try:
+ winfunc = window_function_register.get('_' + winstr)
+ except KeyError as e:
+ raise ValueError("Unknown window type.") from e
+
+ params = (win_length, ) + args
+ kwargs = {'sym': sym}
+ return winfunc(*params, dtype=dtype, **kwargs)
diff --git a/paddlespeech/audio/streamdata/autodecode.py b/paddlespeech/audio/streamdata/autodecode.py
index 2e82226df..664509842 100644
--- a/paddlespeech/audio/streamdata/autodecode.py
+++ b/paddlespeech/audio/streamdata/autodecode.py
@@ -304,13 +304,11 @@ def paddle_audio(key, data):
if extension not in ["flac", "mp3", "sox", "wav", "m4a", "ogg", "wma"]:
return None
- import paddleaudio
-
with tempfile.TemporaryDirectory() as dirname:
fname = os.path.join(dirname, f"file.{extension}")
with open(fname, "wb") as stream:
stream.write(data)
- return paddleaudio.backends.soundfile_load(fname)
+ return paddlespeech.audio.backends.soundfile_load(fname)
################################################################
diff --git a/paddlespeech/audio/streamdata/filters.py b/paddlespeech/audio/streamdata/filters.py
index 110b4a304..9a00c2dc6 100644
--- a/paddlespeech/audio/streamdata/filters.py
+++ b/paddlespeech/audio/streamdata/filters.py
@@ -22,8 +22,6 @@ from fnmatch import fnmatch
from functools import reduce
import paddle
-from paddleaudio import backends
-from paddleaudio.compliance import kaldi
from . import autodecode
from . import utils
@@ -33,6 +31,8 @@ from ..transform.spec_augment import time_mask
from ..transform.spec_augment import time_warp
from ..utils.tensor_utils import pad_sequence
from .utils import PipelineStage
+from paddlespeech.audio import backends
+from paddlespeech.audio.compliance import kaldi
class FilterFunction(object):
diff --git a/paddlespeech/audio/streamdata/soundfile.py b/paddlespeech/audio/streamdata/soundfile.py
new file mode 100644
index 000000000..7611fd297
--- /dev/null
+++ b/paddlespeech/audio/streamdata/soundfile.py
@@ -0,0 +1,677 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+import warnings
+from typing import Optional
+from typing import Tuple
+
+import numpy as np
+import paddle
+import resampy
+import soundfile
+from scipy.io import wavfile
+
+from ..utils import depth_convert
+from ..utils import ParameterError
+from .common import AudioInfo
+
+__all__ = [
+ 'resample',
+ 'to_mono',
+ 'normalize',
+ 'save',
+ 'soundfile_save',
+ 'load',
+ 'soundfile_load',
+ 'info',
+]
+NORMALMIZE_TYPES = ['linear', 'gaussian']
+MERGE_TYPES = ['ch0', 'ch1', 'random', 'average']
+RESAMPLE_MODES = ['kaiser_best', 'kaiser_fast']
+EPS = 1e-8
+
+
+def resample(y: np.ndarray,
+ src_sr: int,
+ target_sr: int,
+ mode: str='kaiser_fast') -> np.ndarray:
+ """Audio resampling.
+
+ Args:
+ y (np.ndarray): Input waveform array in 1D or 2D.
+ src_sr (int): Source sample rate.
+ target_sr (int): Target sample rate.
+ mode (str, optional): The resampling filter to use. Defaults to 'kaiser_fast'.
+
+ Returns:
+ np.ndarray: `y` resampled to `target_sr`
+ """
+
+ if mode == 'kaiser_best':
+ warnings.warn(
+ f'Using resampy in kaiser_best to {src_sr}=>{target_sr}. This function is pretty slow, \
+ we recommend the mode kaiser_fast in large scale audio training')
+
+ if not isinstance(y, np.ndarray):
+ raise ParameterError(
+ 'Only support numpy np.ndarray, but received y in {type(y)}')
+
+ if mode not in RESAMPLE_MODES:
+ raise ParameterError(f'resample mode must in {RESAMPLE_MODES}')
+
+ return resampy.resample(y, src_sr, target_sr, filter=mode)
+
+
+def to_mono(y: np.ndarray, merge_type: str='average') -> np.ndarray:
+ """Convert sterior audio to mono.
+
+ Args:
+ y (np.ndarray): Input waveform array in 1D or 2D.
+ merge_type (str, optional): Merge type to generate mono waveform. Defaults to 'average'.
+
+ Returns:
+ np.ndarray: `y` with mono channel.
+ """
+
+ if merge_type not in MERGE_TYPES:
+ raise ParameterError(
+ f'Unsupported merge type {merge_type}, available types are {MERGE_TYPES}'
+ )
+ if y.ndim > 2:
+ raise ParameterError(
+ f'Unsupported audio array, y.ndim > 2, the shape is {y.shape}')
+ if y.ndim == 1: # nothing to merge
+ return y
+
+ if merge_type == 'ch0':
+ return y[0]
+ if merge_type == 'ch1':
+ return y[1]
+ if merge_type == 'random':
+ return y[np.random.randint(0, 2)]
+
+ # need to do averaging according to dtype
+
+ if y.dtype == 'float32':
+ y_out = (y[0] + y[1]) * 0.5
+ elif y.dtype == 'int16':
+ y_out = y.astype('int32')
+ y_out = (y_out[0] + y_out[1]) // 2
+ y_out = np.clip(y_out, np.iinfo(y.dtype).min,
+ np.iinfo(y.dtype).max).astype(y.dtype)
+
+ elif y.dtype == 'int8':
+ y_out = y.astype('int16')
+ y_out = (y_out[0] + y_out[1]) // 2
+ y_out = np.clip(y_out, np.iinfo(y.dtype).min,
+ np.iinfo(y.dtype).max).astype(y.dtype)
+ else:
+ raise ParameterError(f'Unsupported dtype: {y.dtype}')
+ return y_out
+
+
+def soundfile_load_(file: os.PathLike,
+ offset: Optional[float]=None,
+ dtype: str='int16',
+ duration: Optional[int]=None) -> Tuple[np.ndarray, int]:
+ """Load audio using soundfile library. This function load audio file using libsndfile.
+
+ Args:
+ file (os.PathLike): File of waveform.
+ offset (Optional[float], optional): Offset to the start of waveform. Defaults to None.
+ dtype (str, optional): Data type of waveform. Defaults to 'int16'.
+ duration (Optional[int], optional): Duration of waveform to read. Defaults to None.
+
+ Returns:
+ Tuple[np.ndarray, int]: Waveform in ndarray and its samplerate.
+ """
+ with soundfile.SoundFile(file) as sf_desc:
+ sr_native = sf_desc.samplerate
+ if offset:
+ sf_desc.seek(int(offset * sr_native))
+ if duration is not None:
+ frame_duration = int(duration * sr_native)
+ else:
+ frame_duration = -1
+ y = sf_desc.read(frames=frame_duration, dtype=dtype, always_2d=False).T
+
+ return y, sf_desc.samplerate
+
+
+def normalize(y: np.ndarray, norm_type: str='linear',
+ mul_factor: float=1.0) -> np.ndarray:
+ """Normalize an input audio with additional multiplier.
+
+ Args:
+ y (np.ndarray): Input waveform array in 1D or 2D.
+ norm_type (str, optional): Type of normalization. Defaults to 'linear'.
+ mul_factor (float, optional): Scaling factor. Defaults to 1.0.
+
+ Returns:
+ np.ndarray: `y` after normalization.
+ """
+
+ if norm_type == 'linear':
+ amax = np.max(np.abs(y))
+ factor = 1.0 / (amax + EPS)
+ y = y * factor * mul_factor
+ elif norm_type == 'gaussian':
+ amean = np.mean(y)
+ astd = np.std(y)
+ astd = max(astd, EPS)
+ y = mul_factor * (y - amean) / astd
+ else:
+ raise NotImplementedError(f'norm_type should be in {NORMALMIZE_TYPES}')
+
+ return y
+
+
+def soundfile_save(y: np.ndarray, sr: int, file: os.PathLike) -> None:
+ """Save audio file to disk. This function saves audio to disk using scipy.io.wavfile, with additional step to convert input waveform to int16.
+
+ Args:
+ y (np.ndarray): Input waveform array in 1D or 2D.
+ sr (int): Sample rate.
+ file (os.PathLike): Path of audio file to save.
+ """
+ if not file.endswith('.wav'):
+ raise ParameterError(
+ f'only .wav file supported, but dst file name is: {file}')
+
+ if sr <= 0:
+ raise ParameterError(
+ f'Sample rate should be larger than 0, received sr = {sr}')
+
+ if y.dtype not in ['int16', 'int8']:
+ warnings.warn(
+ f'input data type is {y.dtype}, will convert data to int16 format before saving'
+ )
+ y_out = depth_convert(y, 'int16')
+ else:
+ y_out = y
+
+ wavfile.write(file, sr, y_out)
+
+
+def soundfile_load(
+ file: os.PathLike,
+ sr: Optional[int]=None,
+ mono: bool=True,
+ merge_type: str='average', # ch0,ch1,random,average
+ normal: bool=True,
+ norm_type: str='linear',
+ norm_mul_factor: float=1.0,
+ offset: float=0.0,
+ duration: Optional[int]=None,
+ dtype: str='float32',
+ resample_mode: str='kaiser_fast') -> Tuple[np.ndarray, int]:
+ """Load audio file from disk. This function loads audio from disk using using audio backend.
+
+ Args:
+ file (os.PathLike): Path of audio file to load.
+ sr (Optional[int], optional): Sample rate of loaded waveform. Defaults to None.
+ mono (bool, optional): Return waveform with mono channel. Defaults to True.
+ merge_type (str, optional): Merge type of multi-channels waveform. Defaults to 'average'.
+ normal (bool, optional): Waveform normalization. Defaults to True.
+ norm_type (str, optional): Type of normalization. Defaults to 'linear'.
+ norm_mul_factor (float, optional): Scaling factor. Defaults to 1.0.
+ offset (float, optional): Offset to the start of waveform. Defaults to 0.0.
+ duration (Optional[int], optional): Duration of waveform to read. Defaults to None.
+ dtype (str, optional): Data type of waveform. Defaults to 'float32'.
+ resample_mode (str, optional): The resampling filter to use. Defaults to 'kaiser_fast'.
+
+ Returns:
+ Tuple[np.ndarray, int]: Waveform in ndarray and its samplerate.
+ """
+
+ y, r = soundfile_load_(file, offset=offset, dtype=dtype, duration=duration)
+
+ if not ((y.ndim == 1 and len(y) > 0) or (y.ndim == 2 and len(y[0]) > 0)):
+ raise ParameterError(f'audio file {file} looks empty')
+
+ if mono:
+ y = to_mono(y, merge_type)
+
+ if sr is not None and sr != r:
+ y = resample(y, r, sr, mode=resample_mode)
+ r = sr
+
+ if normal:
+ y = normalize(y, norm_type, norm_mul_factor)
+ elif dtype in ['int8', 'int16']:
+ # still need to do normalization, before depth conversion
+ y = normalize(y, 'linear', 1.0)
+
+ y = depth_convert(y, dtype)
+ return y, r
+
+
+#The code below is taken from: https://github.com/pytorch/audio/blob/main/torchaudio/backend/soundfile_backend.py, with some modifications.
+
+
+def _get_subtype_for_wav(dtype: paddle.dtype,
+ encoding: str,
+ bits_per_sample: int):
+ if not encoding:
+ if not bits_per_sample:
+ subtype = {
+ paddle.uint8: "PCM_U8",
+ paddle.int16: "PCM_16",
+ paddle.int32: "PCM_32",
+ paddle.float32: "FLOAT",
+ paddle.float64: "DOUBLE",
+ }.get(dtype)
+ if not subtype:
+ raise ValueError(f"Unsupported dtype for wav: {dtype}")
+ return subtype
+ if bits_per_sample == 8:
+ return "PCM_U8"
+ return f"PCM_{bits_per_sample}"
+ if encoding == "PCM_S":
+ if not bits_per_sample:
+ return "PCM_32"
+ if bits_per_sample == 8:
+ raise ValueError("wav does not support 8-bit signed PCM encoding.")
+ return f"PCM_{bits_per_sample}"
+ if encoding == "PCM_U":
+ if bits_per_sample in (None, 8):
+ return "PCM_U8"
+ raise ValueError("wav only supports 8-bit unsigned PCM encoding.")
+ if encoding == "PCM_F":
+ if bits_per_sample in (None, 32):
+ return "FLOAT"
+ if bits_per_sample == 64:
+ return "DOUBLE"
+ raise ValueError("wav only supports 32/64-bit float PCM encoding.")
+ if encoding == "ULAW":
+ if bits_per_sample in (None, 8):
+ return "ULAW"
+ raise ValueError("wav only supports 8-bit mu-law encoding.")
+ if encoding == "ALAW":
+ if bits_per_sample in (None, 8):
+ return "ALAW"
+ raise ValueError("wav only supports 8-bit a-law encoding.")
+ raise ValueError(f"wav does not support {encoding}.")
+
+
+def _get_subtype_for_sphere(encoding: str, bits_per_sample: int):
+ if encoding in (None, "PCM_S"):
+ return f"PCM_{bits_per_sample}" if bits_per_sample else "PCM_32"
+ if encoding in ("PCM_U", "PCM_F"):
+ raise ValueError(f"sph does not support {encoding} encoding.")
+ if encoding == "ULAW":
+ if bits_per_sample in (None, 8):
+ return "ULAW"
+ raise ValueError("sph only supports 8-bit for mu-law encoding.")
+ if encoding == "ALAW":
+ return "ALAW"
+ raise ValueError(f"sph does not support {encoding}.")
+
+
+def _get_subtype(dtype: paddle.dtype,
+ format: str,
+ encoding: str,
+ bits_per_sample: int):
+ if format == "wav":
+ return _get_subtype_for_wav(dtype, encoding, bits_per_sample)
+ if format == "flac":
+ if encoding:
+ raise ValueError("flac does not support encoding.")
+ if not bits_per_sample:
+ return "PCM_16"
+ if bits_per_sample > 24:
+ raise ValueError("flac does not support bits_per_sample > 24.")
+ return "PCM_S8" if bits_per_sample == 8 else f"PCM_{bits_per_sample}"
+ if format in ("ogg", "vorbis"):
+ if encoding or bits_per_sample:
+ raise ValueError(
+ "ogg/vorbis does not support encoding/bits_per_sample.")
+ return "VORBIS"
+ if format == "sph":
+ return _get_subtype_for_sphere(encoding, bits_per_sample)
+ if format in ("nis", "nist"):
+ return "PCM_16"
+ raise ValueError(f"Unsupported format: {format}")
+
+
+def save(
+ filepath: str,
+ src: paddle.Tensor,
+ sample_rate: int,
+ channels_first: bool=True,
+ compression: Optional[float]=None,
+ format: Optional[str]=None,
+ encoding: Optional[str]=None,
+ bits_per_sample: Optional[int]=None, ):
+ """Save audio data to file.
+
+ Note:
+ The formats this function can handle depend on the soundfile installation.
+ This function is tested on the following formats;
+
+ * WAV
+
+ * 32-bit floating-point
+ * 32-bit signed integer
+ * 16-bit signed integer
+ * 8-bit unsigned integer
+
+ * FLAC
+ * OGG/VORBIS
+ * SPHERE
+
+ Note:
+ ``filepath`` argument is intentionally annotated as ``str`` only, even though it accepts
+ ``pathlib.Path`` object as well. This is for the consistency with ``"sox_io"`` backend,
+
+ Args:
+ filepath (str or pathlib.Path): Path to audio file.
+ src (paddle.Tensor): Audio data to save. must be 2D tensor.
+ sample_rate (int): sampling rate
+ channels_first (bool, optional): If ``True``, the given tensor is interpreted as `[channel, time]`,
+ otherwise `[time, channel]`.
+ compression (float of None, optional): Not used.
+ It is here only for interface compatibility reason with "sox_io" backend.
+ format (str or None, optional): Override the audio format.
+ When ``filepath`` argument is path-like object, audio format is
+ inferred from file extension. If the file extension is missing or
+ different, you can specify the correct format with this argument.
+
+ When ``filepath`` argument is file-like object,
+ this argument is required.
+
+ Valid values are ``"wav"``, ``"ogg"``, ``"vorbis"``,
+ ``"flac"`` and ``"sph"``.
+ encoding (str or None, optional): Changes the encoding for supported formats.
+ This argument is effective only for supported formats, such as
+ ``"wav"``, ``""flac"`` and ``"sph"``. Valid values are:
+
+ - ``"PCM_S"`` (signed integer Linear PCM)
+ - ``"PCM_U"`` (unsigned integer Linear PCM)
+ - ``"PCM_F"`` (floating point PCM)
+ - ``"ULAW"`` (mu-law)
+ - ``"ALAW"`` (a-law)
+
+ bits_per_sample (int or None, optional): Changes the bit depth for the
+ supported formats.
+ When ``format`` is one of ``"wav"``, ``"flac"`` or ``"sph"``,
+ you can change the bit depth.
+ Valid values are ``8``, ``16``, ``24``, ``32`` and ``64``.
+
+ Supported formats/encodings/bit depth/compression are:
+
+ ``"wav"``
+ - 32-bit floating-point PCM
+ - 32-bit signed integer PCM
+ - 24-bit signed integer PCM
+ - 16-bit signed integer PCM
+ - 8-bit unsigned integer PCM
+ - 8-bit mu-law
+ - 8-bit a-law
+
+ Note:
+ Default encoding/bit depth is determined by the dtype of
+ the input Tensor.
+
+ ``"flac"``
+ - 8-bit
+ - 16-bit (default)
+ - 24-bit
+
+ ``"ogg"``, ``"vorbis"``
+ - Doesn't accept changing configuration.
+
+ ``"sph"``
+ - 8-bit signed integer PCM
+ - 16-bit signed integer PCM
+ - 24-bit signed integer PCM
+ - 32-bit signed integer PCM (default)
+ - 8-bit mu-law
+ - 8-bit a-law
+ - 16-bit a-law
+ - 24-bit a-law
+ - 32-bit a-law
+
+ """
+ if src.ndim != 2:
+ raise ValueError(f"Expected 2D Tensor, got {src.ndim}D.")
+ if compression is not None:
+ warnings.warn(
+ '`save` function of "soundfile" backend does not support "compression" parameter. '
+ "The argument is silently ignored.")
+ if hasattr(filepath, "write"):
+ if format is None:
+ raise RuntimeError(
+ "`format` is required when saving to file object.")
+ ext = format.lower()
+ else:
+ ext = str(filepath).split(".")[-1].lower()
+
+ if bits_per_sample not in (None, 8, 16, 24, 32, 64):
+ raise ValueError("Invalid bits_per_sample.")
+ if bits_per_sample == 24:
+ warnings.warn(
+ "Saving audio with 24 bits per sample might warp samples near -1. "
+ "Using 16 bits per sample might be able to avoid this.")
+ subtype = _get_subtype(src.dtype, ext, encoding, bits_per_sample)
+
+ # sph is a extension used in TED-LIUM but soundfile does not recognize it as NIST format,
+ # so we extend the extensions manually here
+ if ext in ["nis", "nist", "sph"] and format is None:
+ format = "NIST"
+
+ if channels_first:
+ src = src.t()
+
+ soundfile.write(
+ file=filepath,
+ data=src,
+ samplerate=sample_rate,
+ subtype=subtype,
+ format=format)
+
+
+_SUBTYPE2DTYPE = {
+ "PCM_S8": "int8",
+ "PCM_U8": "uint8",
+ "PCM_16": "int16",
+ "PCM_32": "int32",
+ "FLOAT": "float32",
+ "DOUBLE": "float64",
+}
+
+
+def load(
+ filepath: str,
+ frame_offset: int=0,
+ num_frames: int=-1,
+ normalize: bool=True,
+ channels_first: bool=True,
+ format: Optional[str]=None, ) -> Tuple[paddle.Tensor, int]:
+ """Load audio data from file.
+
+ Note:
+ The formats this function can handle depend on the soundfile installation.
+ This function is tested on the following formats;
+
+ * WAV
+
+ * 32-bit floating-point
+ * 32-bit signed integer
+ * 16-bit signed integer
+ * 8-bit unsigned integer
+
+ * FLAC
+ * OGG/VORBIS
+ * SPHERE
+
+ By default (``normalize=True``, ``channels_first=True``), this function returns Tensor with
+ ``float32`` dtype and the shape of `[channel, time]`.
+ The samples are normalized to fit in the range of ``[-1.0, 1.0]``.
+
+ When the input format is WAV with integer type, such as 32-bit signed integer, 16-bit
+ signed integer and 8-bit unsigned integer (24-bit signed integer is not supported),
+ by providing ``normalize=False``, this function can return integer Tensor, where the samples
+ are expressed within the whole range of the corresponding dtype, that is, ``int32`` tensor
+ for 32-bit signed PCM, ``int16`` for 16-bit signed PCM and ``uint8`` for 8-bit unsigned PCM.
+
+ ``normalize`` parameter has no effect on 32-bit floating-point WAV and other formats, such as
+ ``flac`` and ``mp3``.
+ For these formats, this function always returns ``float32`` Tensor with values normalized to
+ ``[-1.0, 1.0]``.
+
+ Note:
+ ``filepath`` argument is intentionally annotated as ``str`` only, even though it accepts
+ ``pathlib.Path`` object as well. This is for the consistency with ``"sox_io"`` backend.
+
+ Args:
+ filepath (path-like object or file-like object):
+ Source of audio data.
+ frame_offset (int, optional):
+ Number of frames to skip before start reading data.
+ num_frames (int, optional):
+ Maximum number of frames to read. ``-1`` reads all the remaining samples,
+ starting from ``frame_offset``.
+ This function may return the less number of frames if there is not enough
+ frames in the given file.
+ normalize (bool, optional):
+ When ``True``, this function always return ``float32``, and sample values are
+ normalized to ``[-1.0, 1.0]``.
+ If input file is integer WAV, giving ``False`` will change the resulting Tensor type to
+ integer type.
+ This argument has no effect for formats other than integer WAV type.
+ channels_first (bool, optional):
+ When True, the returned Tensor has dimension `[channel, time]`.
+ Otherwise, the returned Tensor's dimension is `[time, channel]`.
+ format (str or None, optional):
+ Not used. PySoundFile does not accept format hint.
+
+ Returns:
+ (paddle.Tensor, int): Resulting Tensor and sample rate.
+ If the input file has integer wav format and normalization is off, then it has
+ integer type, else ``float32`` type. If ``channels_first=True``, it has
+ `[channel, time]` else `[time, channel]`.
+ """
+ with soundfile.SoundFile(filepath, "r") as file_:
+ if file_.format != "WAV" or normalize:
+ dtype = "float32"
+ elif file_.subtype not in _SUBTYPE2DTYPE:
+ raise ValueError(f"Unsupported subtype: {file_.subtype}")
+ else:
+ dtype = _SUBTYPE2DTYPE[file_.subtype]
+
+ frames = file_._prepare_read(frame_offset, None, num_frames)
+ waveform = file_.read(frames, dtype, always_2d=True)
+ sample_rate = file_.samplerate
+
+ waveform = paddle.to_tensor(waveform)
+ if channels_first:
+ waveform = paddle.transpose(waveform, perm=[1, 0])
+ return waveform, sample_rate
+
+
+# Mapping from soundfile subtype to number of bits per sample.
+# This is mostly heuristical and the value is set to 0 when it is irrelevant
+# (lossy formats) or when it can't be inferred.
+# For ADPCM (and G72X) subtypes, it's hard to infer the bit depth because it's not part of the standard:
+# According to https://en.wikipedia.org/wiki/Adaptive_differential_pulse-code_modulation#In_telephony,
+# the default seems to be 8 bits but it can be compressed further to 4 bits.
+# The dict is inspired from
+# https://github.com/bastibe/python-soundfile/blob/744efb4b01abc72498a96b09115b42a4cabd85e4/soundfile.py#L66-L94
+_SUBTYPE_TO_BITS_PER_SAMPLE = {
+ "PCM_S8": 8, # Signed 8 bit data
+ "PCM_16": 16, # Signed 16 bit data
+ "PCM_24": 24, # Signed 24 bit data
+ "PCM_32": 32, # Signed 32 bit data
+ "PCM_U8": 8, # Unsigned 8 bit data (WAV and RAW only)
+ "FLOAT": 32, # 32 bit float data
+ "DOUBLE": 64, # 64 bit float data
+ "ULAW": 8, # U-Law encoded. See https://en.wikipedia.org/wiki/G.711#Types
+ "ALAW": 8, # A-Law encoded. See https://en.wikipedia.org/wiki/G.711#Types
+ "IMA_ADPCM": 0, # IMA ADPCM.
+ "MS_ADPCM": 0, # Microsoft ADPCM.
+ "GSM610":
+ 0, # GSM 6.10 encoding. (Wikipedia says 1.625 bit depth?? https://en.wikipedia.org/wiki/Full_Rate)
+ "VOX_ADPCM": 0, # OKI / Dialogix ADPCM
+ "G721_32": 0, # 32kbs G721 ADPCM encoding.
+ "G723_24": 0, # 24kbs G723 ADPCM encoding.
+ "G723_40": 0, # 40kbs G723 ADPCM encoding.
+ "DWVW_12": 12, # 12 bit Delta Width Variable Word encoding.
+ "DWVW_16": 16, # 16 bit Delta Width Variable Word encoding.
+ "DWVW_24": 24, # 24 bit Delta Width Variable Word encoding.
+ "DWVW_N": 0, # N bit Delta Width Variable Word encoding.
+ "DPCM_8": 8, # 8 bit differential PCM (XI only)
+ "DPCM_16": 16, # 16 bit differential PCM (XI only)
+ "VORBIS": 0, # Xiph Vorbis encoding. (lossy)
+ "ALAC_16": 16, # Apple Lossless Audio Codec (16 bit).
+ "ALAC_20": 20, # Apple Lossless Audio Codec (20 bit).
+ "ALAC_24": 24, # Apple Lossless Audio Codec (24 bit).
+ "ALAC_32": 32, # Apple Lossless Audio Codec (32 bit).
+}
+
+
+def _get_bit_depth(subtype):
+ if subtype not in _SUBTYPE_TO_BITS_PER_SAMPLE:
+ warnings.warn(
+ f"The {subtype} subtype is unknown to PaddleAudio. As a result, the bits_per_sample "
+ "attribute will be set to 0. If you are seeing this warning, please "
+ "report by opening an issue on github (after checking for existing/closed ones). "
+ "You may otherwise ignore this warning.")
+ return _SUBTYPE_TO_BITS_PER_SAMPLE.get(subtype, 0)
+
+
+_SUBTYPE_TO_ENCODING = {
+ "PCM_S8": "PCM_S",
+ "PCM_16": "PCM_S",
+ "PCM_24": "PCM_S",
+ "PCM_32": "PCM_S",
+ "PCM_U8": "PCM_U",
+ "FLOAT": "PCM_F",
+ "DOUBLE": "PCM_F",
+ "ULAW": "ULAW",
+ "ALAW": "ALAW",
+ "VORBIS": "VORBIS",
+}
+
+
+def _get_encoding(format: str, subtype: str):
+ if format == "FLAC":
+ return "FLAC"
+ return _SUBTYPE_TO_ENCODING.get(subtype, "UNKNOWN")
+
+
+def info(filepath: str, format: Optional[str]=None) -> AudioInfo:
+ """Get signal information of an audio file.
+
+ Note:
+ ``filepath`` argument is intentionally annotated as ``str`` only, even though it accepts
+ ``pathlib.Path`` object as well. This is for the consistency with ``"sox_io"`` backend,
+
+ Args:
+ filepath (path-like object or file-like object):
+ Source of audio data.
+ format (str or None, optional):
+ Not used. PySoundFile does not accept format hint.
+
+ Returns:
+ AudioInfo: meta data of the given audio.
+
+ """
+ sinfo = soundfile.info(filepath)
+ return AudioInfo(
+ sinfo.samplerate,
+ sinfo.frames,
+ sinfo.channels,
+ bits_per_sample=_get_bit_depth(sinfo.subtype),
+ encoding=_get_encoding(sinfo.format, sinfo.subtype), )
diff --git a/paddlespeech/audio/streamdata/tariterators.py b/paddlespeech/audio/streamdata/tariterators.py
index 3adf4892a..8429e6f77 100644
--- a/paddlespeech/audio/streamdata/tariterators.py
+++ b/paddlespeech/audio/streamdata/tariterators.py
@@ -20,9 +20,9 @@ trace = False
meta_prefix = "__"
meta_suffix = "__"
-import paddleaudio
import paddle
import numpy as np
+from paddlespeech.audio.backends import soundfile_load
AUDIO_FORMAT_SETS = set(['flac', 'mp3', 'm4a', 'ogg', 'opus', 'wav', 'wma'])
@@ -111,7 +111,7 @@ def tar_file_iterator(fileobj,
assert pos > 0
prefix, postfix = name[:pos], name[pos + 1:]
if postfix == 'wav':
- waveform, sample_rate = paddleaudio.backends.soundfile_load(
+ waveform, sample_rate = soundfile_load(
stream.extractfile(tarinfo), normal=False)
result = dict(
fname=prefix, wav=waveform, sample_rate=sample_rate)
@@ -163,7 +163,7 @@ def tar_file_and_group_iterator(fileobj,
if postfix == 'txt':
example['txt'] = file_obj.read().decode('utf8').strip()
elif postfix in AUDIO_FORMAT_SETS:
- waveform, sample_rate = paddleaudio.backends.soundfile_load(
+ waveform, sample_rate = soundfile_load(
file_obj, normal=False)
waveform = paddle.to_tensor(
np.expand_dims(np.array(waveform), 0),
diff --git a/paddlespeech/audio/transform/spectrogram.py b/paddlespeech/audio/transform/spectrogram.py
index f2dab3169..a4da86ec7 100644
--- a/paddlespeech/audio/transform/spectrogram.py
+++ b/paddlespeech/audio/transform/spectrogram.py
@@ -15,9 +15,10 @@
import librosa
import numpy as np
import paddle
-from paddleaudio.compliance import kaldi
from python_speech_features import logfbank
+from paddlespeech.audio.compliance import kaldi
+
def stft(x,
n_fft,
diff --git a/paddlespeech/audio/utils/tensor_utils.py b/paddlespeech/audio/utils/tensor_utils.py
index b246a6459..b67b2dd81 100644
--- a/paddlespeech/audio/utils/tensor_utils.py
+++ b/paddlespeech/audio/utils/tensor_utils.py
@@ -79,7 +79,7 @@ def pad_sequence(sequences: List[paddle.Tensor],
# assuming trailing dimensions and type of all the Tensors
# in sequences are same and fetching those from sequences[0]
max_size = paddle.shape(sequences[0])
- # (TODO Hui Zhang): slice not supprot `end==start`
+ # (TODO Hui Zhang): slice not support `end==start`
# trailing_dims = max_size[1:]
trailing_dims = tuple(
max_size[1:].numpy().tolist()) if sequences[0].ndim >= 2 else ()
@@ -93,7 +93,7 @@ def pad_sequence(sequences: List[paddle.Tensor],
length = tensor.shape[0]
# use index notation to prevent duplicate references to the tensor
if batch_first:
- # TODO (Hui Zhang): set_value op not supprot `end==start`
+ # TODO (Hui Zhang): set_value op not support `end==start`
# TODO (Hui Zhang): set_value op not support int16
# TODO (Hui Zhang): set_varbase 2 rank not support [0,0,...]
# out_tensor[i, :length, ...] = tensor
@@ -102,7 +102,7 @@ def pad_sequence(sequences: List[paddle.Tensor],
else:
out_tensor[i, length] = tensor
else:
- # TODO (Hui Zhang): set_value op not supprot `end==start`
+ # TODO (Hui Zhang): set_value op not support `end==start`
# out_tensor[:length, i, ...] = tensor
if length != 0:
out_tensor[:length, i] = tensor
diff --git a/paddlespeech/audiotools/core/__init__.py b/paddlespeech/audiotools/core/__init__.py
index 96ff69b5b..3443a7676 100644
--- a/paddlespeech/audiotools/core/__init__.py
+++ b/paddlespeech/audiotools/core/__init__.py
@@ -12,8 +12,8 @@
# See the License for the specific language governing permissions and
# limitations under the License.
from . import util
-# from ._julius import fft_conv1d
-# from ._julius import FFTConv1D
+from ...t2s.modules import fft_conv1d
+from ...t2s.modules import FFTConv1D
from ._julius import highpass_filter
from ._julius import highpass_filters
from ._julius import lowpass_filter
diff --git a/paddlespeech/audiotools/core/_julius.py b/paddlespeech/audiotools/core/_julius.py
index fce6f6d72..c4f986086 100644
--- a/paddlespeech/audiotools/core/_julius.py
+++ b/paddlespeech/audiotools/core/_julius.py
@@ -20,7 +20,6 @@ import paddle
import paddle.nn as nn
import paddle.nn.functional as F
-
from paddlespeech.utils import satisfy_paddle_version
__all__ = [
@@ -64,9 +63,6 @@ def sinc(x: paddle.Tensor):
__Warning__: the input is not multiplied by `pi`!
"""
- if satisfy_paddle_version("3.0"):
- return paddle.sinc(x)
-
return paddle.where(
x == 0,
paddle.to_tensor(1.0, dtype=x.dtype, place=x.place),
@@ -132,7 +128,8 @@ class ResampleFrac(paddle.nn.Layer):
idx = paddle.arange(
-self._width, self._width + self.old_sr, dtype="float32")
for i in range(self.new_sr):
- t = (-i / self.new_sr + idx / self.old_sr) * sr
+ t = (-i / self.new_sr + idx / paddle.full(idx.shape, self.old_sr)
+ ) * sr
t = paddle.clip(t, -self.zeros, self.zeros)
t *= math.pi
window = paddle.cos(t / self.zeros / 2)**2
@@ -311,7 +308,7 @@ class LowPassFilters(nn.Layer):
mode="replicate",
data_format="NCL")
if self.fft:
- from paddlespeech.t2s.modules.fftconv1d import fft_conv1d
+ from paddlespeech.t2s.modules import fft_conv1d
out = fft_conv1d(_input, self.filters, stride=self.stride)
else:
out = F.conv1d(_input, self.filters, stride=self.stride)
diff --git a/paddlespeech/audiotools/core/util.py b/paddlespeech/audiotools/core/util.py
index d675a30e8..a5891a470 100644
--- a/paddlespeech/audiotools/core/util.py
+++ b/paddlespeech/audiotools/core/util.py
@@ -29,7 +29,6 @@ import soundfile
from flatten_dict import flatten
from flatten_dict import unflatten
-from .audio_signal import AudioSignal
from paddlespeech.utils import satisfy_paddle_version
__all__ = [
@@ -228,8 +227,7 @@ def ensure_tensor(
def _get_value(other):
#
- from . import AudioSignal
-
+ from .audio_signal import AudioSignal
if isinstance(other, AudioSignal):
return other.audio_data
return other
@@ -780,6 +778,8 @@ def collate(list_of_dicts: list, n_splits: int=None):
Dictionary containing batched data.
"""
+ from .audio_signal import AudioSignal
+
batches = []
list_len = len(list_of_dicts)
@@ -869,7 +869,7 @@ def generate_chord_dataset(
"""
import librosa
- from . import AudioSignal
+ from .audio_signal import AudioSignal
from ..data.preprocess import create_csv
min_midi = librosa.note_to_midi(min_note)
diff --git a/paddlespeech/audiotools/ml/basemodel.py b/paddlespeech/audiotools/ml/basemodel.py
index 8ab6c8309..cd4ca5213 100644
--- a/paddlespeech/audiotools/ml/basemodel.py
+++ b/paddlespeech/audiotools/ml/basemodel.py
@@ -111,7 +111,8 @@ class BaseModel(nn.Layer):
state_dict = {"state_dict": self.state_dict(), "metadata": metadata}
paddle.save(state_dict, str(path))
else:
- self._save_package(path, intern=intern, extern=extern, mock=mock)
+ raise NotImplementedError(
+ "Currently Paddle does not support packaging")
return path
@@ -152,31 +153,21 @@ class BaseModel(nn.Layer):
BaseModel
A model that inherits from BaseModel.
"""
- try:
- model = cls._load_package(location, package_name=package_name)
- except:
- model_dict = paddle.load(location)
- metadata = model_dict["metadata"]
- metadata["kwargs"].update(kwargs)
-
- sig = inspect.signature(cls)
- class_keys = list(sig.parameters.keys())
- for k in list(metadata["kwargs"].keys()):
- if k not in class_keys:
- metadata["kwargs"].pop(k)
-
- model = cls(*args, **metadata["kwargs"])
- model.set_state_dict(model_dict["state_dict"])
- model.metadata = metadata
+ model_dict = paddle.load(location)
+ metadata = model_dict["metadata"]
+ metadata["kwargs"].update(kwargs)
- return model
+ sig = inspect.signature(cls)
+ class_keys = list(sig.parameters.keys())
+ for k in list(metadata["kwargs"].keys()):
+ if k not in class_keys:
+ metadata["kwargs"].pop(k)
- def _save_package(self, path, intern=[], extern=[], mock=[], **kwargs):
- raise NotImplementedError("Currently Paddle does not support packaging")
+ model = cls(*args, **metadata["kwargs"])
+ model.set_state_dict(model_dict["state_dict"])
+ model.metadata = metadata
- @classmethod
- def _load_package(cls, path, package_name=None):
- raise NotImplementedError("Currently Paddle does not support packaging")
+ return model
def save_to_folder(
self,
diff --git a/paddlespeech/audiotools/requirements.txt b/paddlespeech/audiotools/requirements.txt
deleted file mode 100644
index 0a018002e..000000000
--- a/paddlespeech/audiotools/requirements.txt
+++ /dev/null
@@ -1,5 +0,0 @@
-ffmpeg-python
-ffmpy
-flatten_dict
-pyloudnorm
-rich
\ No newline at end of file
diff --git a/paddlespeech/cli/asr/infer.py b/paddlespeech/cli/asr/infer.py
index 231a00f4d..548beb7ba 100644
--- a/paddlespeech/cli/asr/infer.py
+++ b/paddlespeech/cli/asr/infer.py
@@ -79,7 +79,7 @@ class ASRExecutor(BaseExecutor):
'--config',
type=str,
default=None,
- help='Config of asr task. Use deault config when it is None.')
+ help='Config of asr task. Use default config when it is None.')
self.parser.add_argument(
'--decode_method',
type=str,
diff --git a/paddlespeech/cli/base_commands.py b/paddlespeech/cli/base_commands.py
index dfeb5cae5..fb5a190ed 100644
--- a/paddlespeech/cli/base_commands.py
+++ b/paddlespeech/cli/base_commands.py
@@ -122,6 +122,9 @@ class StatsCommand:
elif "multilingual" in key:
line[4], line[1] = line[1].split("_")[0], line[1].split(
"_")[1:]
+ # Avoid having arrays within the elements of the input parameters when passing them to numpy.array
+ if type(line[1]) is list:
+ line[1] = "/".join(line[1])
tmp = numpy.array(line)
idx = [0, 5, 3, 4, 1, 2]
line = tmp[idx]
diff --git a/paddlespeech/cli/cls/infer.py b/paddlespeech/cli/cls/infer.py
index 5e2168e3d..54780fdd2 100644
--- a/paddlespeech/cli/cls/infer.py
+++ b/paddlespeech/cli/cls/infer.py
@@ -22,11 +22,11 @@ import numpy as np
import paddle
import yaml
from paddle.audio.features import LogMelSpectrogram
-from paddleaudio.backends import soundfile_load as load
from ..executor import BaseExecutor
from ..log import logger
from ..utils import stats_wrapper
+from paddlespeech.audio.backends import soundfile_load as load
__all__ = ['CLSExecutor']
@@ -51,7 +51,7 @@ class CLSExecutor(BaseExecutor):
'--config',
type=str,
default=None,
- help='Config of cls task. Use deault config when it is None.')
+ help='Config of cls task. Use default config when it is None.')
self.parser.add_argument(
'--ckpt_path',
type=str,
diff --git a/paddlespeech/cli/kws/infer.py b/paddlespeech/cli/kws/infer.py
index ce2f3f461..467b463f7 100644
--- a/paddlespeech/cli/kws/infer.py
+++ b/paddlespeech/cli/kws/infer.py
@@ -20,12 +20,12 @@ from typing import Union
import paddle
import yaml
-from paddleaudio.backends import soundfile_load as load_audio
-from paddleaudio.compliance.kaldi import fbank as kaldi_fbank
from ..executor import BaseExecutor
from ..log import logger
from ..utils import stats_wrapper
+from paddlespeech.audio.backends import soundfile_load as load_audio
+from paddlespeech.audio.compliance.kaldi import fbank as kaldi_fbank
__all__ = ['KWSExecutor']
@@ -58,7 +58,7 @@ class KWSExecutor(BaseExecutor):
'--config',
type=str,
default=None,
- help='Config of kws task. Use deault config when it is None.')
+ help='Config of kws task. Use default config when it is None.')
self.parser.add_argument(
'--ckpt_path',
type=str,
diff --git a/paddlespeech/cli/ssl/infer.py b/paddlespeech/cli/ssl/infer.py
index 33cdf7637..37ad0bd9d 100644
--- a/paddlespeech/cli/ssl/infer.py
+++ b/paddlespeech/cli/ssl/infer.py
@@ -76,7 +76,7 @@ class SSLExecutor(BaseExecutor):
'--config',
type=str,
default=None,
- help='Config of asr task. Use deault config when it is None.')
+ help='Config of asr task. Use default config when it is None.')
self.parser.add_argument(
'--decode_method',
type=str,
diff --git a/paddlespeech/cli/st/infer.py b/paddlespeech/cli/st/infer.py
index 0867e8158..5dab6f53b 100644
--- a/paddlespeech/cli/st/infer.py
+++ b/paddlespeech/cli/st/infer.py
@@ -38,7 +38,7 @@ __all__ = ["STExecutor"]
kaldi_bins = {
"url":
- "https://paddlespeech.bj.bcebos.com/s2t/ted_en_zh/st1/kaldi_bins.tar.gz",
+ "https://paddlespeech.cdn.bcebos.com/s2t/ted_en_zh/st1/kaldi_bins.tar.gz",
"md5":
"c0682303b3f3393dbf6ed4c4e35a53eb",
}
@@ -82,7 +82,7 @@ class STExecutor(BaseExecutor):
"--config",
type=str,
default=None,
- help="Config of st task. Use deault config when it is None.")
+ help="Config of st task. Use default config when it is None.")
self.parser.add_argument(
"--ckpt_path",
type=str,
diff --git a/paddlespeech/cli/text/infer.py b/paddlespeech/cli/text/infer.py
index bd76a13d0..59286ea31 100644
--- a/paddlespeech/cli/text/infer.py
+++ b/paddlespeech/cli/text/infer.py
@@ -63,7 +63,7 @@ class TextExecutor(BaseExecutor):
'--config',
type=str,
default=None,
- help='Config of cls task. Use deault config when it is None.')
+ help='Config of cls task. Use default config when it is None.')
self.parser.add_argument(
'--ckpt_path',
type=str,
diff --git a/paddlespeech/cli/tts/infer.py b/paddlespeech/cli/tts/infer.py
index beba7f602..1f128dfe9 100644
--- a/paddlespeech/cli/tts/infer.py
+++ b/paddlespeech/cli/tts/infer.py
@@ -90,7 +90,7 @@ class TTSExecutor(BaseExecutor):
'--am_config',
type=str,
default=None,
- help='Config of acoustic model. Use deault config when it is None.')
+ help='Config of acoustic model. Use default config when it is None.')
self.parser.add_argument(
'--am_ckpt',
type=str,
@@ -148,7 +148,7 @@ class TTSExecutor(BaseExecutor):
'--voc_config',
type=str,
default=None,
- help='Config of voc. Use deault config when it is None.')
+ help='Config of voc. Use default config when it is None.')
self.parser.add_argument(
'--voc_ckpt',
type=str,
diff --git a/paddlespeech/cli/vector/infer.py b/paddlespeech/cli/vector/infer.py
index 57a781656..29c32e516 100644
--- a/paddlespeech/cli/vector/infer.py
+++ b/paddlespeech/cli/vector/infer.py
@@ -22,13 +22,13 @@ from typing import Union
import paddle
import soundfile
-from paddleaudio.backends import soundfile_load as load_audio
-from paddleaudio.compliance.librosa import melspectrogram
from yacs.config import CfgNode
from ..executor import BaseExecutor
from ..log import logger
from ..utils import stats_wrapper
+from paddlespeech.audio.backends import soundfile_load as load_audio
+from paddlespeech.audio.compliance.librosa import melspectrogram
from paddlespeech.vector.io.batch import feature_normalize
from paddlespeech.vector.modules.sid_model import SpeakerIdetification
@@ -82,7 +82,7 @@ class VectorExecutor(BaseExecutor):
'--config',
type=str,
default=None,
- help='Config of asr task. Use deault config when it is None.')
+ help='Config of asr task. Use default config when it is None.')
self.parser.add_argument(
"--device",
type=str,
diff --git a/paddlespeech/cli/whisper/infer.py b/paddlespeech/cli/whisper/infer.py
index 17e8c0b8c..5649b757f 100644
--- a/paddlespeech/cli/whisper/infer.py
+++ b/paddlespeech/cli/whisper/infer.py
@@ -96,7 +96,7 @@ class WhisperExecutor(BaseExecutor):
'--config',
type=str,
default=None,
- help='Config of asr task. Use deault config when it is None.')
+ help='Config of asr task. Use default config when it is None.')
self.parser.add_argument(
'--decode_method',
type=str,
diff --git a/paddlespeech/cls/exps/panns/deploy/predict.py b/paddlespeech/cls/exps/panns/deploy/predict.py
index a6b735335..3085a8482 100644
--- a/paddlespeech/cls/exps/panns/deploy/predict.py
+++ b/paddlespeech/cls/exps/panns/deploy/predict.py
@@ -19,10 +19,10 @@ import paddle
from paddle import inference
from paddle.audio.datasets import ESC50
from paddle.audio.features import LogMelSpectrogram
-from paddleaudio.backends import soundfile_load as load_audio
from scipy.special import softmax
import paddlespeech.utils
+from paddlespeech.audio.backends import soundfile_load as load_audio
# yapf: disable
parser = argparse.ArgumentParser()
diff --git a/paddlespeech/cls/exps/panns/export_model.py b/paddlespeech/cls/exps/panns/export_model.py
index e860b54aa..5163dbacf 100644
--- a/paddlespeech/cls/exps/panns/export_model.py
+++ b/paddlespeech/cls/exps/panns/export_model.py
@@ -15,8 +15,8 @@ import argparse
import os
import paddle
-from paddleaudio.datasets import ESC50
+from paddlespeech.audio.datasets import ESC50
from paddlespeech.cls.models import cnn14
from paddlespeech.cls.models import SoundClassifier
diff --git a/paddlespeech/cls/exps/panns/predict.py b/paddlespeech/cls/exps/panns/predict.py
index 4681e4dc9..6b0eb9f68 100644
--- a/paddlespeech/cls/exps/panns/predict.py
+++ b/paddlespeech/cls/exps/panns/predict.py
@@ -18,12 +18,11 @@ import paddle
import paddle.nn.functional as F
import yaml
from paddle.audio.features import LogMelSpectrogram
-from paddleaudio.backends import soundfile_load as load_audio
-from paddleaudio.utils import logger
+from paddlespeech.audio.backends import soundfile_load as load_audio
+from paddlespeech.audio.utils import logger
from paddlespeech.cls.models import SoundClassifier
from paddlespeech.utils.dynamic_import import dynamic_import
-#from paddleaudio.features import LogMelSpectrogram
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
diff --git a/paddlespeech/cls/exps/panns/train.py b/paddlespeech/cls/exps/panns/train.py
index b768919be..5e5e0809d 100644
--- a/paddlespeech/cls/exps/panns/train.py
+++ b/paddlespeech/cls/exps/panns/train.py
@@ -17,9 +17,9 @@ import os
import paddle
import yaml
from paddle.audio.features import LogMelSpectrogram
-from paddleaudio.utils import logger
-from paddleaudio.utils import Timer
+from paddlespeech.audio.utils import logger
+from paddlespeech.audio.utils import Timer
from paddlespeech.cls.models import SoundClassifier
from paddlespeech.utils.dynamic_import import dynamic_import
diff --git a/paddlespeech/cls/models/panns/panns.py b/paddlespeech/cls/models/panns/panns.py
index 6f9af9b52..37deae80c 100644
--- a/paddlespeech/cls/models/panns/panns.py
+++ b/paddlespeech/cls/models/panns/panns.py
@@ -15,8 +15,8 @@ import os
import paddle.nn as nn
import paddle.nn.functional as F
-from paddleaudio.utils.download import load_state_dict_from_url
+from paddlespeech.audio.utils.download import load_state_dict_from_url
from paddlespeech.utils.env import MODEL_HOME
__all__ = ['CNN14', 'CNN10', 'CNN6', 'cnn14', 'cnn10', 'cnn6']
diff --git a/paddlespeech/dataset/aidatatang_200zh/aidatatang_200zh.py b/paddlespeech/dataset/aidatatang_200zh/aidatatang_200zh.py
index 5d914a438..7250a50b9 100644
--- a/paddlespeech/dataset/aidatatang_200zh/aidatatang_200zh.py
+++ b/paddlespeech/dataset/aidatatang_200zh/aidatatang_200zh.py
@@ -62,7 +62,7 @@ def create_manifest(data_dir, manifest_path_prefix):
if line == '':
continue
audio_id, text = line.split(' ', 1)
- # remove withespace, charactor text
+ # remove withespace, character text
text = ''.join(text.split())
transcript_dict[audio_id] = text
diff --git a/paddlespeech/dataset/aishell/aishell.py b/paddlespeech/dataset/aishell/aishell.py
index 7ea4d6766..f227cfbd5 100644
--- a/paddlespeech/dataset/aishell/aishell.py
+++ b/paddlespeech/dataset/aishell/aishell.py
@@ -65,7 +65,7 @@ def create_manifest(data_dir, manifest_path_prefix):
if line == '':
continue
audio_id, text = line.split(' ', 1)
- # remove withespace, charactor text
+ # remove withespace, character text
text = ''.join(text.split())
transcript_dict[audio_id] = text
@@ -159,7 +159,7 @@ def check_dataset(data_dir):
if line == '':
continue
audio_id, text = line.split(' ', 1)
- # remove withespace, charactor text
+ # remove withespace, character text
text = ''.join(text.split())
transcript_dict[audio_id] = text
diff --git a/paddlespeech/kws/exps/mdtc/train.py b/paddlespeech/kws/exps/mdtc/train.py
index bb727d36a..d5bb5e020 100644
--- a/paddlespeech/kws/exps/mdtc/train.py
+++ b/paddlespeech/kws/exps/mdtc/train.py
@@ -14,10 +14,10 @@
import os
import paddle
-from paddleaudio.utils import logger
-from paddleaudio.utils import Timer
from yacs.config import CfgNode
+from paddlespeech.audio.utils import logger
+from paddlespeech.audio.utils import Timer
from paddlespeech.kws.exps.mdtc.collate import collate_features
from paddlespeech.kws.models.loss import max_pooling_loss
from paddlespeech.kws.models.mdtc import KWSModel
diff --git a/paddlespeech/resource/pretrained_models.py b/paddlespeech/resource/pretrained_models.py
index e539c0018..64ef44481 100644
--- a/paddlespeech/resource/pretrained_models.py
+++ b/paddlespeech/resource/pretrained_models.py
@@ -42,7 +42,7 @@ ssl_dynamic_pretrained_models = {
"wav2vec2-en-16k": {
'1.3': {
'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/librispeech/asr3/wav2vec2-large-960h-lv60-self_ckpt_1.3.0.model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/s2t/librispeech/asr3/wav2vec2-large-960h-lv60-self_ckpt_1.3.0.model.tar.gz',
'md5':
'acc46900680e341e500437aa59193518',
'cfg_path':
@@ -58,7 +58,7 @@ ssl_dynamic_pretrained_models = {
"wav2vec2ASR_librispeech-en-16k": {
'1.3': {
'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/librispeech/asr3/wav2vec2ASR-large-960h-librispeech_ckpt_1.3.1.model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/s2t/librispeech/asr3/wav2vec2ASR-large-960h-librispeech_ckpt_1.3.1.model.tar.gz',
'md5':
'cbe28d6c78f3dd2e189968402381f454',
'cfg_path':
@@ -74,7 +74,7 @@ ssl_dynamic_pretrained_models = {
"wav2vec2-zh-16k": {
'1.3': {
'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/aishell/asr3/wav2vec2-large-wenetspeech-self_ckpt_1.3.0.model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/s2t/aishell/asr3/wav2vec2-large-wenetspeech-self_ckpt_1.3.0.model.tar.gz',
'md5':
'00ea4975c05d1bb58181205674052fe1',
'cfg_path':
@@ -90,7 +90,7 @@ ssl_dynamic_pretrained_models = {
"wav2vec2ASR_aishell1-zh-16k": {
'1.3': {
'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/aishell/asr3/wav2vec2ASR-large-aishell1_ckpt_1.3.0.model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/s2t/aishell/asr3/wav2vec2ASR-large-aishell1_ckpt_1.3.0.model.tar.gz',
'md5':
'ac8fa0a6345e6a7535f6fabb5e59e218',
'cfg_path':
@@ -104,7 +104,7 @@ ssl_dynamic_pretrained_models = {
},
'1.4': {
'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/aishell/asr3/wav2vec2ASR-large-aishell1_ckpt_1.4.0.model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/s2t/aishell/asr3/wav2vec2ASR-large-aishell1_ckpt_1.4.0.model.tar.gz',
'md5':
'150e51b8ea5d255ccce6b395de8d916a',
'cfg_path':
@@ -120,7 +120,7 @@ ssl_dynamic_pretrained_models = {
"hubert-en-16k": {
'1.4': {
'url':
- 'https://paddlespeech.bj.bcebos.com/hubert/hubert-large-lv60_ckpt_1.4.0.model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/hubert/hubert-large-lv60_ckpt_1.4.0.model.tar.gz',
'md5':
'efecfb87a8718aa9253b7459c1fe9b54',
'cfg_path':
@@ -136,7 +136,7 @@ ssl_dynamic_pretrained_models = {
"hubertASR_librispeech-100h-en-16k": {
'1.4': {
'url':
- 'https://paddlespeech.bj.bcebos.com/hubert/hubertASR-large-100h-librispeech_ckpt_1.4.0.model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/hubert/hubertASR-large-100h-librispeech_ckpt_1.4.0.model.tar.gz',
'md5':
'574cefd11aaef5737969ce22a7f33ea2',
'cfg_path':
@@ -151,12 +151,18 @@ ssl_dynamic_pretrained_models = {
},
"wavlmASR_librispeech-en-16k": {
"1.0": {
- "url": "https://paddlespeech.bj.bcebos.com/wavlm/wavlm_baseplus_libriclean_100h.tar.gz",
- "md5": "f2238e982bb8bcf046e536201f5ea629",
- "cfg_path": "model.yaml",
- "ckpt_path": "exp/wavlmASR/checkpoints/46",
- "model": "exp/wavlmASR/checkpoints/46.pdparams",
- "params": "exp/wavlmASR/checkpoints/46.pdparams",
+ "url":
+ "https://paddlespeech.cdn.bcebos.com/wavlm/wavlm_baseplus_libriclean_100h.tar.gz",
+ "md5":
+ "f2238e982bb8bcf046e536201f5ea629",
+ "cfg_path":
+ "model.yaml",
+ "ckpt_path":
+ "exp/wavlmASR/checkpoints/46",
+ "model":
+ "exp/wavlmASR/checkpoints/46.pdparams",
+ "params":
+ "exp/wavlmASR/checkpoints/46.pdparams",
}
}
}
@@ -168,7 +174,7 @@ asr_dynamic_pretrained_models = {
"conformer_wenetspeech-zh-16k": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr1_conformer_wenetspeech_ckpt_0.1.1.model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/s2t/wenetspeech/asr1_conformer_wenetspeech_ckpt_0.1.1.model.tar.gz',
'md5':
'76cb19ed857e6623856b7cd7ebbfeda4',
'cfg_path':
@@ -180,7 +186,7 @@ asr_dynamic_pretrained_models = {
"conformer_online_wenetspeech-zh-16k": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr1/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/s2t/wenetspeech/asr1/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar.gz',
'md5':
'b8c02632b04da34aca88459835be54a6',
'cfg_path':
@@ -200,7 +206,7 @@ asr_dynamic_pretrained_models = {
"conformer_u2pp_online_wenetspeech-zh-16k": {
'1.3': {
'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr1/asr1_chunk_conformer_u2pp_wenetspeech_ckpt_1.3.0.model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/s2t/wenetspeech/asr1/asr1_chunk_conformer_u2pp_wenetspeech_ckpt_1.3.0.model.tar.gz',
'md5':
'62d230c1bf27731192aa9d3b8deca300',
'cfg_path':
@@ -220,7 +226,7 @@ asr_dynamic_pretrained_models = {
"conformer_online_multicn-zh-16k": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/multi_cn/asr1/asr1_chunk_conformer_multi_cn_ckpt_0.2.0.model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/s2t/multi_cn/asr1/asr1_chunk_conformer_multi_cn_ckpt_0.2.0.model.tar.gz',
'md5':
'7989b3248c898070904cf042fd656003',
'cfg_path':
@@ -230,7 +236,7 @@ asr_dynamic_pretrained_models = {
},
'2.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/multi_cn/asr1/asr1_chunk_conformer_multi_cn_ckpt_0.2.3.model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/s2t/multi_cn/asr1/asr1_chunk_conformer_multi_cn_ckpt_0.2.3.model.tar.gz',
'md5':
'0ac93d390552336f2a906aec9e33c5fa',
'cfg_path':
@@ -250,7 +256,7 @@ asr_dynamic_pretrained_models = {
"conformer_aishell-zh-16k": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/aishell/asr1/asr1_conformer_aishell_ckpt_0.1.2.model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/s2t/aishell/asr1/asr1_conformer_aishell_ckpt_0.1.2.model.tar.gz',
'md5':
'3f073eccfa7bb14e0c6867d65fc0dc3a',
'cfg_path':
@@ -262,7 +268,7 @@ asr_dynamic_pretrained_models = {
"conformer_online_aishell-zh-16k": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/aishell/asr1/asr1_chunk_conformer_aishell_ckpt_0.2.0.model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/s2t/aishell/asr1/asr1_chunk_conformer_aishell_ckpt_0.2.0.model.tar.gz',
'md5':
'b374cfb93537761270b6224fb0bfc26a',
'cfg_path':
@@ -272,7 +278,7 @@ asr_dynamic_pretrained_models = {
},
'1.4': {
'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/aishell/asr1/asr1_conformer_aishell_ckpt_1.5.0.model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/s2t/aishell/asr1/asr1_conformer_aishell_ckpt_1.5.0.model.tar.gz',
'md5':
'38924b8adc28ef458847c3571e87e3cb',
'cfg_path':
@@ -284,7 +290,7 @@ asr_dynamic_pretrained_models = {
"transformer_librispeech-en-16k": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/librispeech/asr1/asr1_transformer_librispeech_ckpt_0.1.1.model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/s2t/librispeech/asr1/asr1_transformer_librispeech_ckpt_0.1.1.model.tar.gz',
'md5':
'2c667da24922aad391eacafe37bc1660',
'cfg_path':
@@ -296,7 +302,7 @@ asr_dynamic_pretrained_models = {
"deepspeech2online_wenetspeech-zh-16k": {
'1.0.3': {
'url':
- 'http://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr0/asr0_deepspeech2_online_wenetspeech_ckpt_1.0.3.model.tar.gz',
+ 'http://paddlespeech.cdn.bcebos.com/s2t/wenetspeech/asr0/asr0_deepspeech2_online_wenetspeech_ckpt_1.0.3.model.tar.gz',
'md5':
'cfe273793e68f790f742b411c98bc75e',
'cfg_path':
@@ -316,7 +322,7 @@ asr_dynamic_pretrained_models = {
},
'1.0.4': {
'url':
- 'http://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr0/asr0_deepspeech2_online_wenetspeech_ckpt_1.0.4.model.tar.gz',
+ 'http://paddlespeech.cdn.bcebos.com/s2t/wenetspeech/asr0/asr0_deepspeech2_online_wenetspeech_ckpt_1.0.4.model.tar.gz',
'md5':
'c595cb76902b5a5d01409171375989f4',
'cfg_path':
@@ -338,7 +344,7 @@ asr_dynamic_pretrained_models = {
"deepspeech2offline_aishell-zh-16k": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_offline_aishell_ckpt_1.0.1.model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_offline_aishell_ckpt_1.0.1.model.tar.gz',
'md5':
'4d26066c6f19f52087425dc722ae5b13',
'cfg_path':
@@ -354,7 +360,7 @@ asr_dynamic_pretrained_models = {
"deepspeech2online_aishell-zh-16k": {
'1.0.2': {
'url':
- 'http://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_online_aishell_fbank161_ckpt_1.0.2.model.tar.gz',
+ 'http://paddlespeech.cdn.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_online_aishell_fbank161_ckpt_1.0.2.model.tar.gz',
'md5':
'4dd42cfce9aaa54db0ec698da6c48ec5',
'cfg_path':
@@ -376,7 +382,7 @@ asr_dynamic_pretrained_models = {
"deepspeech2offline_librispeech-en-16k": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/librispeech/asr0/asr0_deepspeech2_offline_librispeech_ckpt_1.0.1.model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/s2t/librispeech/asr0/asr0_deepspeech2_offline_librispeech_ckpt_1.0.1.model.tar.gz',
'md5':
'ed9e2b008a65268b3484020281ab048c',
'cfg_path':
@@ -392,7 +398,7 @@ asr_dynamic_pretrained_models = {
"conformer_talcs-codeswitch_zh_en-16k": {
'1.4': {
'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/tal_cs/asr1/asr1_conformer_talcs_ckpt_1.4.0.model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/s2t/tal_cs/asr1/asr1_conformer_talcs_ckpt_1.4.0.model.tar.gz',
'md5':
'01962c5d0a70878fe41cacd4f61e14d1',
'cfg_path':
@@ -407,7 +413,7 @@ asr_static_pretrained_models = {
"deepspeech2offline_aishell-zh-16k": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_offline_aishell_ckpt_1.0.1.model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_offline_aishell_ckpt_1.0.1.model.tar.gz',
'md5':
'4d26066c6f19f52087425dc722ae5b13',
'cfg_path':
@@ -427,7 +433,7 @@ asr_static_pretrained_models = {
"deepspeech2online_aishell-zh-16k": {
'1.0.1': {
'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_online_aishell_fbank161_ckpt_1.0.1.model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_online_aishell_fbank161_ckpt_1.0.1.model.tar.gz',
'md5':
'df5ddeac8b679a470176649ac4b78726',
'cfg_path':
@@ -445,7 +451,7 @@ asr_static_pretrained_models = {
},
'1.0.2': {
'url':
- 'http://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_online_aishell_fbank161_ckpt_1.0.2.model.tar.gz',
+ 'http://paddlespeech.cdn.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_online_aishell_fbank161_ckpt_1.0.2.model.tar.gz',
'md5':
'4dd42cfce9aaa54db0ec698da6c48ec5',
'cfg_path':
@@ -467,7 +473,7 @@ asr_static_pretrained_models = {
"deepspeech2online_wenetspeech-zh-16k": {
'1.0.3': {
'url':
- 'http://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr0/asr0_deepspeech2_online_wenetspeech_ckpt_1.0.3.model.tar.gz',
+ 'http://paddlespeech.cdn.bcebos.com/s2t/wenetspeech/asr0/asr0_deepspeech2_online_wenetspeech_ckpt_1.0.3.model.tar.gz',
'md5':
'cfe273793e68f790f742b411c98bc75e',
'cfg_path':
@@ -487,7 +493,7 @@ asr_static_pretrained_models = {
},
'1.0.4': {
'url':
- 'http://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr0/asr0_deepspeech2_online_wenetspeech_ckpt_1.0.4.model.tar.gz',
+ 'http://paddlespeech.cdn.bcebos.com/s2t/wenetspeech/asr0/asr0_deepspeech2_online_wenetspeech_ckpt_1.0.4.model.tar.gz',
'md5':
'c595cb76902b5a5d01409171375989f4',
'cfg_path':
@@ -512,7 +518,7 @@ asr_onnx_pretrained_models = {
"deepspeech2online_aishell-zh-16k": {
'1.0.2': {
'url':
- 'http://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_online_aishell_fbank161_ckpt_1.0.2.model.tar.gz',
+ 'http://paddlespeech.cdn.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_online_aishell_fbank161_ckpt_1.0.2.model.tar.gz',
'md5':
'4dd42cfce9aaa54db0ec698da6c48ec5',
'cfg_path':
@@ -534,7 +540,7 @@ asr_onnx_pretrained_models = {
"deepspeech2online_wenetspeech-zh-16k": {
'1.0.3': {
'url':
- 'http://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr0/asr0_deepspeech2_online_wenetspeech_ckpt_1.0.3.model.tar.gz',
+ 'http://paddlespeech.cdn.bcebos.com/s2t/wenetspeech/asr0/asr0_deepspeech2_online_wenetspeech_ckpt_1.0.3.model.tar.gz',
'md5':
'cfe273793e68f790f742b411c98bc75e',
'cfg_path':
@@ -554,7 +560,7 @@ asr_onnx_pretrained_models = {
},
'1.0.4': {
'url':
- 'http://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr0/asr0_deepspeech2_online_wenetspeech_ckpt_1.0.4.model.tar.gz',
+ 'http://paddlespeech.cdn.bcebos.com/s2t/wenetspeech/asr0/asr0_deepspeech2_online_wenetspeech_ckpt_1.0.4.model.tar.gz',
'md5':
'c595cb76902b5a5d01409171375989f4',
'cfg_path':
@@ -579,7 +585,7 @@ whisper_dynamic_pretrained_models = {
"whisper-large-16k": {
'1.3': {
'url':
- 'https://paddlespeech.bj.bcebos.com/whisper/whisper_model_20221122/whisper-large-model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/whisper/whisper_model_20221122/whisper-large-model.tar.gz',
'md5':
'cf1557af9d8ffa493fefad9cb08ae189',
'cfg_path':
@@ -591,7 +597,7 @@ whisper_dynamic_pretrained_models = {
'params':
'whisper-large-model.pdparams',
'resource_data':
- 'https://paddlespeech.bj.bcebos.com/whisper/whisper_model_20221108/assets.tar',
+ 'https://paddlespeech.cdn.bcebos.com/whisper/whisper_model_20221108/assets.tar',
'resource_data_md5':
'37a0a8abdb3641a51194f79567a93b61',
},
@@ -599,7 +605,7 @@ whisper_dynamic_pretrained_models = {
"whisper-base-en-16k": {
'1.3': {
'url':
- 'https://paddlespeech.bj.bcebos.com/whisper/whisper_model_20221122/whisper-base-en-model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/whisper/whisper_model_20221122/whisper-base-en-model.tar.gz',
'md5':
'b156529aefde6beb7726d2ea98fd067a',
'cfg_path':
@@ -611,7 +617,7 @@ whisper_dynamic_pretrained_models = {
'params':
'whisper-base-en-model.pdparams',
'resource_data':
- 'https://paddlespeech.bj.bcebos.com/whisper/whisper_model_20221108/assets.tar',
+ 'https://paddlespeech.cdn.bcebos.com/whisper/whisper_model_20221108/assets.tar',
'resource_data_md5':
'37a0a8abdb3641a51194f79567a93b61',
},
@@ -619,7 +625,7 @@ whisper_dynamic_pretrained_models = {
"whisper-base-16k": {
'1.3': {
'url':
- 'https://paddlespeech.bj.bcebos.com/whisper/whisper_model_20221122/whisper-base-model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/whisper/whisper_model_20221122/whisper-base-model.tar.gz',
'md5':
'6b012a5abd583db14398c3492e47120b',
'cfg_path':
@@ -631,7 +637,7 @@ whisper_dynamic_pretrained_models = {
'params':
'whisper-base-model.pdparams',
'resource_data':
- 'https://paddlespeech.bj.bcebos.com/whisper/whisper_model_20221108/assets.tar',
+ 'https://paddlespeech.cdn.bcebos.com/whisper/whisper_model_20221108/assets.tar',
'resource_data_md5':
'37a0a8abdb3641a51194f79567a93b61',
},
@@ -639,7 +645,7 @@ whisper_dynamic_pretrained_models = {
"whisper-medium-en-16k": {
'1.3': {
'url':
- 'https://paddlespeech.bj.bcebos.com/whisper/whisper_model_20221122/whisper-medium-en-model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/whisper/whisper_model_20221122/whisper-medium-en-model.tar.gz',
'md5':
'c7f57d270bd20c7b170ba9dcf6c16f74',
'cfg_path':
@@ -651,7 +657,7 @@ whisper_dynamic_pretrained_models = {
'params':
'whisper-medium-en-model.pdparams',
'resource_data':
- 'https://paddlespeech.bj.bcebos.com/whisper/whisper_model_20221108/assets.tar',
+ 'https://paddlespeech.cdn.bcebos.com/whisper/whisper_model_20221108/assets.tar',
'resource_data_md5':
'37a0a8abdb3641a51194f79567a93b61',
},
@@ -659,7 +665,7 @@ whisper_dynamic_pretrained_models = {
"whisper-medium-16k": {
'1.3': {
'url':
- 'https://paddlespeech.bj.bcebos.com/whisper/whisper_model_20221122/whisper-medium-model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/whisper/whisper_model_20221122/whisper-medium-model.tar.gz',
'md5':
'4c7dcd0df25f408199db4a4548336786',
'cfg_path':
@@ -671,7 +677,7 @@ whisper_dynamic_pretrained_models = {
'params':
'whisper-medium-model.pdparams',
'resource_data':
- 'https://paddlespeech.bj.bcebos.com/whisper/whisper_model_20221108/assets.tar',
+ 'https://paddlespeech.cdn.bcebos.com/whisper/whisper_model_20221108/assets.tar',
'resource_data_md5':
'37a0a8abdb3641a51194f79567a93b61',
},
@@ -679,7 +685,7 @@ whisper_dynamic_pretrained_models = {
"whisper-small-en-16k": {
'1.3': {
'url':
- 'https://paddlespeech.bj.bcebos.com/whisper/whisper_model_20221122/whisper-small-en-model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/whisper/whisper_model_20221122/whisper-small-en-model.tar.gz',
'md5':
'2b24efcb2e93f3275af7c0c7f598ff1c',
'cfg_path':
@@ -691,7 +697,7 @@ whisper_dynamic_pretrained_models = {
'params':
'whisper-small-en-model.pdparams',
'resource_data':
- 'https://paddlespeech.bj.bcebos.com/whisper/whisper_model_20221108/assets.tar',
+ 'https://paddlespeech.cdn.bcebos.com/whisper/whisper_model_20221108/assets.tar',
'resource_data_md5':
'37a0a8abdb3641a51194f79567a93b61',
},
@@ -699,7 +705,7 @@ whisper_dynamic_pretrained_models = {
"whisper-small-16k": {
'1.3': {
'url':
- 'https://paddlespeech.bj.bcebos.com/whisper/whisper_model_20221122/whisper-small-model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/whisper/whisper_model_20221122/whisper-small-model.tar.gz',
'md5':
'5a57911dd41651dd6ed78c5763912825',
'cfg_path':
@@ -711,7 +717,7 @@ whisper_dynamic_pretrained_models = {
'params':
'whisper-small-model.pdparams',
'resource_data':
- 'https://paddlespeech.bj.bcebos.com/whisper/whisper_model_20221108/assets.tar',
+ 'https://paddlespeech.cdn.bcebos.com/whisper/whisper_model_20221108/assets.tar',
'resource_data_md5':
'37a0a8abdb3641a51194f79567a93b61',
},
@@ -719,7 +725,7 @@ whisper_dynamic_pretrained_models = {
"whisper-tiny-en-16k": {
'1.3': {
'url':
- 'https://paddlespeech.bj.bcebos.com/whisper/whisper_model_20221122/whisper-tiny-en-model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/whisper/whisper_model_20221122/whisper-tiny-en-model.tar.gz',
'md5':
'14969164a3f713fd58e56978c34188f6',
'cfg_path':
@@ -731,7 +737,7 @@ whisper_dynamic_pretrained_models = {
'params':
'whisper-tiny-en-model.pdparams',
'resource_data':
- 'https://paddlespeech.bj.bcebos.com/whisper/whisper_model_20221108/assets.tar',
+ 'https://paddlespeech.cdn.bcebos.com/whisper/whisper_model_20221108/assets.tar',
'resource_data_md5':
'37a0a8abdb3641a51194f79567a93b61',
},
@@ -739,7 +745,7 @@ whisper_dynamic_pretrained_models = {
"whisper-tiny-16k": {
'1.3': {
'url':
- 'https://paddlespeech.bj.bcebos.com/whisper/whisper_model_20221122/whisper-tiny-model.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/whisper/whisper_model_20221122/whisper-tiny-model.tar.gz',
'md5':
'a5b82a1f2067a2ca400f17fabd62b81b',
'cfg_path':
@@ -751,7 +757,7 @@ whisper_dynamic_pretrained_models = {
'params':
'whisper-tiny-model.pdparams',
'resource_data':
- 'https://paddlespeech.bj.bcebos.com/whisper/whisper_model_20221108/assets.tar',
+ 'https://paddlespeech.cdn.bcebos.com/whisper/whisper_model_20221108/assets.tar',
'resource_data_md5':
'37a0a8abdb3641a51194f79567a93b61',
},
@@ -764,7 +770,7 @@ whisper_dynamic_pretrained_models = {
cls_dynamic_pretrained_models = {
"panns_cnn6-32k": {
'1.0': {
- 'url': 'https://paddlespeech.bj.bcebos.com/cls/panns_cnn6.tar.gz',
+ 'url': 'https://paddlespeech.cdn.bcebos.com/cls/panns_cnn6.tar.gz',
'md5': '4cf09194a95df024fd12f84712cf0f9c',
'cfg_path': 'panns.yaml',
'ckpt_path': 'cnn6.pdparams',
@@ -773,7 +779,7 @@ cls_dynamic_pretrained_models = {
},
"panns_cnn10-32k": {
'1.0': {
- 'url': 'https://paddlespeech.bj.bcebos.com/cls/panns_cnn10.tar.gz',
+ 'url': 'https://paddlespeech.cdn.bcebos.com/cls/panns_cnn10.tar.gz',
'md5': 'cb8427b22176cc2116367d14847f5413',
'cfg_path': 'panns.yaml',
'ckpt_path': 'cnn10.pdparams',
@@ -782,7 +788,7 @@ cls_dynamic_pretrained_models = {
},
"panns_cnn14-32k": {
'1.0': {
- 'url': 'https://paddlespeech.bj.bcebos.com/cls/panns_cnn14.tar.gz',
+ 'url': 'https://paddlespeech.cdn.bcebos.com/cls/panns_cnn14.tar.gz',
'md5': 'e3b9b5614a1595001161d0ab95edee97',
'cfg_path': 'panns.yaml',
'ckpt_path': 'cnn14.pdparams',
@@ -795,7 +801,7 @@ cls_static_pretrained_models = {
"panns_cnn6-32k": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/cls/inference_model/panns_cnn6_static.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/cls/inference_model/panns_cnn6_static.tar.gz',
'md5':
'da087c31046d23281d8ec5188c1967da',
'cfg_path':
@@ -811,7 +817,7 @@ cls_static_pretrained_models = {
"panns_cnn10-32k": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/cls/inference_model/panns_cnn10_static.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/cls/inference_model/panns_cnn10_static.tar.gz',
'md5':
'5460cc6eafbfaf0f261cc75b90284ae1',
'cfg_path':
@@ -827,7 +833,7 @@ cls_static_pretrained_models = {
"panns_cnn14-32k": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/cls/inference_model/panns_cnn14_static.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/cls/inference_model/panns_cnn14_static.tar.gz',
'md5':
'ccc80b194821274da79466862b2ab00f',
'cfg_path':
@@ -849,7 +855,7 @@ st_dynamic_pretrained_models = {
"fat_st_ted-en-zh": {
'1.0': {
"url":
- "https://paddlespeech.bj.bcebos.com/s2t/ted_en_zh/st1/st1_transformer_mtl_noam_ted-en-zh_ckpt_0.1.1.model.tar.gz",
+ "https://paddlespeech.cdn.bcebos.com/s2t/ted_en_zh/st1/st1_transformer_mtl_noam_ted-en-zh_ckpt_0.1.1.model.tar.gz",
"md5":
"d62063f35a16d91210a71081bd2dd557",
"cfg_path":
@@ -862,7 +868,7 @@ st_dynamic_pretrained_models = {
st_kaldi_bins = {
"url":
- "https://paddlespeech.bj.bcebos.com/s2t/ted_en_zh/st1/kaldi_bins.tar.gz",
+ "https://paddlespeech.cdn.bcebos.com/s2t/ted_en_zh/st1/kaldi_bins.tar.gz",
"md5":
"c0682303b3f3393dbf6ed4c4e35a53eb",
}
@@ -874,7 +880,7 @@ text_dynamic_pretrained_models = {
"ernie_linear_p7_wudao-punc-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/text/ernie_linear_p7_wudao-punc-zh.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/text/ernie_linear_p7_wudao-punc-zh.tar.gz',
'md5':
'12283e2ddde1797c5d1e57036b512746',
'cfg_path':
@@ -888,7 +894,7 @@ text_dynamic_pretrained_models = {
"ernie_linear_p3_wudao-punc-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/text/ernie_linear_p3_wudao-punc-zh.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/text/ernie_linear_p3_wudao-punc-zh.tar.gz',
'md5':
'448eb2fdf85b6a997e7e652e80c51dd2',
'cfg_path':
@@ -902,7 +908,7 @@ text_dynamic_pretrained_models = {
"ernie_linear_p3_wudao_fast-punc-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/text/ernie_linear_p3_wudao_fast-punc-zh.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/text/ernie_linear_p3_wudao_fast-punc-zh.tar.gz',
'md5':
'c93f9594119541a5dbd763381a751d08',
'cfg_path':
@@ -923,7 +929,7 @@ tts_dynamic_pretrained_models = {
"speedyspeech_csmsc-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/speedyspeech/speedyspeech_csmsc_ckpt_0.2.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/speedyspeech/speedyspeech_csmsc_ckpt_0.2.0.zip',
'md5':
'6f6fa967b408454b6662c8c00c0027cb',
'config':
@@ -942,7 +948,7 @@ tts_dynamic_pretrained_models = {
"fastspeech2_csmsc-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_baker_ckpt_0.4.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_baker_ckpt_0.4.zip',
'md5':
'637d28a5e53aa60275612ba4393d5f22',
'config':
@@ -958,7 +964,7 @@ tts_dynamic_pretrained_models = {
"fastspeech2_canton-canton": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_canton_ckpt_1.4.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_canton_ckpt_1.4.0.zip',
'md5':
'504560c082deba82120927627c900374',
'config':
@@ -976,7 +982,7 @@ tts_dynamic_pretrained_models = {
"fastspeech2_ljspeech-en": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_ljspeech_ckpt_0.5.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_ljspeech_ckpt_0.5.zip',
'md5':
'ffed800c93deaf16ca9b3af89bfcd747',
'config':
@@ -992,7 +998,7 @@ tts_dynamic_pretrained_models = {
"fastspeech2_aishell3-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_aishell3_ckpt_0.4.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_aishell3_ckpt_0.4.zip',
'md5':
'f4dd4a5f49a4552b77981f544ab3392e',
'config':
@@ -1010,7 +1016,7 @@ tts_dynamic_pretrained_models = {
"fastspeech2_vctk-en": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_vctk_ckpt_0.5.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_vctk_ckpt_0.5.zip',
'md5':
'743e5024ca1e17a88c5c271db9779ba4',
'config':
@@ -1028,7 +1034,7 @@ tts_dynamic_pretrained_models = {
"fastspeech2_cnndecoder_csmsc-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_cnndecoder_csmsc_ckpt_1.0.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_cnndecoder_csmsc_ckpt_1.0.0.zip',
'md5':
'6eb28e22ace73e0ebe7845f86478f89f',
'config':
@@ -1044,7 +1050,7 @@ tts_dynamic_pretrained_models = {
"fastspeech2_mix-mix": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/t2s/chinse_english_mixed/models/fastspeech2_csmscljspeech_add-zhen.zip',
+ 'https://paddlespeech.cdn.bcebos.com/t2s/chinse_english_mixed/models/fastspeech2_csmscljspeech_add-zhen.zip',
'md5':
'77d9d4b5a79ed6203339ead7ef6c74f9',
'config':
@@ -1060,7 +1066,7 @@ tts_dynamic_pretrained_models = {
},
'2.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/t2s/chinse_english_mixed/models/fastspeech2_mix_ckpt_0.2.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/t2s/chinse_english_mixed/models/fastspeech2_mix_ckpt_0.2.0.zip',
'md5':
'1d938e104e972386c8bfcbcc98a91587',
'config':
@@ -1078,7 +1084,7 @@ tts_dynamic_pretrained_models = {
"fastspeech2_male-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_male_zh_ckpt_1.4.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_male_zh_ckpt_1.4.0.zip',
'md5':
'43a9f4bc48a91f5a6f53017474e6c788',
'config':
@@ -1094,7 +1100,7 @@ tts_dynamic_pretrained_models = {
"fastspeech2_male-en": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_male_en_ckpt_1.4.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_male_en_ckpt_1.4.0.zip',
'md5':
'cc9f44f1f20a8173f63e2d1d41ef1a9c',
'config':
@@ -1110,7 +1116,7 @@ tts_dynamic_pretrained_models = {
"fastspeech2_male-mix": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_male_mix_ckpt_1.4.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_male_mix_ckpt_1.4.0.zip',
'md5':
'6d48ad60ef0ab2cee89a5d8cfd93dd86',
'config':
@@ -1127,7 +1133,7 @@ tts_dynamic_pretrained_models = {
"tacotron2_csmsc-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/tacotron2/tacotron2_csmsc_ckpt_0.2.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/tacotron2/tacotron2_csmsc_ckpt_0.2.0.zip',
'md5':
'0df4b6f0bcbe0d73c5ed6df8867ab91a',
'config':
@@ -1143,7 +1149,7 @@ tts_dynamic_pretrained_models = {
"tacotron2_ljspeech-en": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/tacotron2/tacotron2_ljspeech_ckpt_0.2.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/tacotron2/tacotron2_ljspeech_ckpt_0.2.0.zip',
'md5':
'6a5eddd81ae0e81d16959b97481135f3',
'config':
@@ -1160,7 +1166,7 @@ tts_dynamic_pretrained_models = {
"pwgan_csmsc-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwg_baker_ckpt_0.4.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/pwgan/pwg_baker_ckpt_0.4.zip',
'md5':
'2e481633325b5bdf0a3823c714d2c117',
'config':
@@ -1174,7 +1180,7 @@ tts_dynamic_pretrained_models = {
"pwgan_ljspeech-en": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwg_ljspeech_ckpt_0.5.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/pwgan/pwg_ljspeech_ckpt_0.5.zip',
'md5':
'53610ba9708fd3008ccaf8e99dacbaf0',
'config':
@@ -1188,7 +1194,7 @@ tts_dynamic_pretrained_models = {
"pwgan_aishell3-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwg_aishell3_ckpt_0.5.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/pwgan/pwg_aishell3_ckpt_0.5.zip',
'md5':
'd7598fa41ad362d62f85ffc0f07e3d84',
'config':
@@ -1202,7 +1208,7 @@ tts_dynamic_pretrained_models = {
"pwgan_vctk-en": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwg_vctk_ckpt_0.1.1.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/pwgan/pwg_vctk_ckpt_0.1.1.zip',
'md5':
'b3da1defcde3e578be71eb284cb89f2c',
'config':
@@ -1216,7 +1222,7 @@ tts_dynamic_pretrained_models = {
"pwgan_male-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwg_male_ckpt_1.4.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/pwgan/pwg_male_ckpt_1.4.0.zip',
'md5':
'a443d6253bf9be377f27ae5972a03c65',
'config':
@@ -1231,7 +1237,7 @@ tts_dynamic_pretrained_models = {
"mb_melgan_csmsc-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/mb_melgan/mb_melgan_csmsc_ckpt_0.1.1.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/mb_melgan/mb_melgan_csmsc_ckpt_0.1.1.zip',
'md5':
'ee5f0604e20091f0d495b6ec4618b90d',
'config':
@@ -1246,7 +1252,7 @@ tts_dynamic_pretrained_models = {
"style_melgan_csmsc-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/style_melgan/style_melgan_csmsc_ckpt_0.1.1.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/style_melgan/style_melgan_csmsc_ckpt_0.1.1.zip',
'md5':
'5de2d5348f396de0c966926b8c462755',
'config':
@@ -1261,7 +1267,7 @@ tts_dynamic_pretrained_models = {
"hifigan_csmsc-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_csmsc_ckpt_0.1.1.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/hifigan/hifigan_csmsc_ckpt_0.1.1.zip',
'md5':
'dd40a3d88dfcf64513fba2f0f961ada6',
'config':
@@ -1275,7 +1281,7 @@ tts_dynamic_pretrained_models = {
"hifigan_ljspeech-en": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_ljspeech_ckpt_0.2.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/hifigan/hifigan_ljspeech_ckpt_0.2.0.zip',
'md5':
'70e9131695decbca06a65fe51ed38a72',
'config':
@@ -1289,7 +1295,7 @@ tts_dynamic_pretrained_models = {
"hifigan_aishell3-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_aishell3_ckpt_0.2.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/hifigan/hifigan_aishell3_ckpt_0.2.0.zip',
'md5':
'3bb49bc75032ed12f79c00c8cc79a09a',
'config':
@@ -1303,7 +1309,7 @@ tts_dynamic_pretrained_models = {
"hifigan_vctk-en": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_vctk_ckpt_0.2.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/hifigan/hifigan_vctk_ckpt_0.2.0.zip',
'md5':
'7da8f88359bca2457e705d924cf27bd4',
'config':
@@ -1317,7 +1323,7 @@ tts_dynamic_pretrained_models = {
"hifigan_male-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_male_ckpt_1.4.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/hifigan/hifigan_male_ckpt_1.4.0.zip',
'md5':
'a709830596e102c2b83f8adc26d41d85',
'config':
@@ -1332,7 +1338,7 @@ tts_dynamic_pretrained_models = {
"wavernn_csmsc-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/wavernn/wavernn_csmsc_ckpt_0.2.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/wavernn/wavernn_csmsc_ckpt_0.2.0.zip',
'md5':
'ee37b752f09bcba8f2af3b777ca38e13',
'config':
@@ -1359,7 +1365,7 @@ tts_static_pretrained_models = {
"speedyspeech_csmsc-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/speedyspeech/speedyspeech_nosil_baker_static_0.5.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/speedyspeech/speedyspeech_nosil_baker_static_0.5.zip',
'md5':
'f10cbdedf47dc7a9668d2264494e1823',
'model':
@@ -1378,7 +1384,7 @@ tts_static_pretrained_models = {
"fastspeech2_csmsc-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_baker_static_0.4.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_baker_static_0.4.zip',
'md5':
'9788cd9745e14c7a5d12d32670b2a5a7',
'model':
@@ -1394,7 +1400,7 @@ tts_static_pretrained_models = {
"fastspeech2_ljspeech-en": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_ljspeech_static_1.1.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_ljspeech_static_1.1.0.zip',
'md5':
'c49f70b52973423ec45aaa6184fb5bc6',
'model':
@@ -1410,7 +1416,7 @@ tts_static_pretrained_models = {
"fastspeech2_aishell3-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_aishell3_static_1.1.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_aishell3_static_1.1.0.zip',
'md5':
'695af44679f48eb4abc159977ddaee16',
'model':
@@ -1428,7 +1434,7 @@ tts_static_pretrained_models = {
"fastspeech2_vctk-en": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_vctk_static_1.1.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_vctk_static_1.1.0.zip',
'md5':
'92d8c082f180bda2fd05a534fb4a1b62',
'model':
@@ -1446,7 +1452,7 @@ tts_static_pretrained_models = {
"fastspeech2_mix-mix": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/t2s/chinse_english_mixed/models/fastspeech2_csmscljspeech_add-zhen_static.zip',
+ 'https://paddlespeech.cdn.bcebos.com/t2s/chinse_english_mixed/models/fastspeech2_csmscljspeech_add-zhen_static.zip',
'md5':
'b5001f66cccafdde07707e1b6269fa58',
'model':
@@ -1462,7 +1468,7 @@ tts_static_pretrained_models = {
},
'2.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/t2s/chinse_english_mixed/models/fastspeech2_mix_static_0.2.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/t2s/chinse_english_mixed/models/fastspeech2_mix_static_0.2.0.zip',
'md5':
'c6dd138fab3ba261299c0b2efee51d5a',
'model':
@@ -1480,7 +1486,7 @@ tts_static_pretrained_models = {
"fastspeech2_male-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_male_zh_static_1.4.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_male_zh_static_1.4.0.zip',
'md5':
'9b7218829e7fa01aa33dbb2c5f6ef20f',
'model':
@@ -1496,7 +1502,7 @@ tts_static_pretrained_models = {
"fastspeech2_male-en": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_male_en_static_1.4.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_male_en_static_1.4.0.zip',
'md5':
'33cea19b6821b371d242969ffd8b6cbf',
'model':
@@ -1512,7 +1518,7 @@ tts_static_pretrained_models = {
"fastspeech2_male-mix": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_male_mix_static_1.4.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_male_mix_static_1.4.0.zip',
'md5':
'66585b04c0ced72f3cb82ee85b814d80',
'model':
@@ -1528,7 +1534,7 @@ tts_static_pretrained_models = {
"fastspeech2_canton-canton": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_canton_static_1.4.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_canton_static_1.4.0.zip',
'md5':
'5da80931666503b9b6aed25e894d2ade',
'model':
@@ -1547,7 +1553,7 @@ tts_static_pretrained_models = {
"pwgan_csmsc-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwg_baker_static_0.4.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/pwgan/pwg_baker_static_0.4.zip',
'md5':
'e3504aed9c5a290be12d1347836d2742',
'model':
@@ -1561,7 +1567,7 @@ tts_static_pretrained_models = {
"pwgan_ljspeech-en": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwgan_ljspeech_static_1.1.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/pwgan/pwgan_ljspeech_static_1.1.0.zip',
'md5':
'6f457a069da99c6814ac1fb4677281e4',
'model':
@@ -1575,7 +1581,7 @@ tts_static_pretrained_models = {
"pwgan_aishell3-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwgan_aishell3_static_1.1.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/pwgan/pwgan_aishell3_static_1.1.0.zip',
'md5':
'199f64010238275fbdacb326a5cf82d1',
'model':
@@ -1589,7 +1595,7 @@ tts_static_pretrained_models = {
"pwgan_vctk-en": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwgan_vctk_static_1.1.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/pwgan/pwgan_vctk_static_1.1.0.zip',
'md5':
'ee0fc571ad5a7fbe4ca20e49df22b819',
'model':
@@ -1603,7 +1609,7 @@ tts_static_pretrained_models = {
"pwgan_male-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwgan_male_static_1.4.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/pwgan/pwgan_male_static_1.4.0.zip',
'md5':
'52a480ad35694b96603e0a92e9fb3f95',
'model':
@@ -1618,7 +1624,7 @@ tts_static_pretrained_models = {
"mb_melgan_csmsc-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/mb_melgan/mb_melgan_csmsc_static_0.1.1.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/mb_melgan/mb_melgan_csmsc_static_0.1.1.zip',
'md5':
'ac6eee94ba483421d750433f4c3b8d36',
'model':
@@ -1633,7 +1639,7 @@ tts_static_pretrained_models = {
"hifigan_csmsc-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_csmsc_static_0.1.1.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/hifigan/hifigan_csmsc_static_0.1.1.zip',
'md5':
'7edd8c436b3a5546b3a7cb8cff9d5a0c',
'model':
@@ -1647,7 +1653,7 @@ tts_static_pretrained_models = {
"hifigan_ljspeech-en": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_ljspeech_static_1.1.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/hifigan/hifigan_ljspeech_static_1.1.0.zip',
'md5':
'8c674e79be7c45f6eda74825316438a0',
'model':
@@ -1661,7 +1667,7 @@ tts_static_pretrained_models = {
"hifigan_aishell3-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_aishell3_static_1.1.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/hifigan/hifigan_aishell3_static_1.1.0.zip',
'md5':
'7a10ec5d8d851e2000128f040d30cc01',
'model':
@@ -1675,7 +1681,7 @@ tts_static_pretrained_models = {
"hifigan_vctk-en": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_vctk_static_1.1.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/hifigan/hifigan_vctk_static_1.1.0.zip',
'md5':
'130f791dfac84ccdd44ccbdfb67bf08e',
'model':
@@ -1689,7 +1695,7 @@ tts_static_pretrained_models = {
"hifigan_male-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_male_static_1.4.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/hifigan/hifigan_male_static_1.4.0.zip',
'md5':
'9011fa2738b501e909d1a61054bed29b',
'model':
@@ -1718,7 +1724,7 @@ tts_onnx_pretrained_models = {
"speedyspeech_csmsc_onnx-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/speedyspeech/speedyspeech_csmsc_onnx_0.2.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/speedyspeech/speedyspeech_csmsc_onnx_0.2.0.zip',
'md5':
'3e9c45af9ef70675fc1968ed5074fc88',
'ckpt':
@@ -1735,7 +1741,7 @@ tts_onnx_pretrained_models = {
"fastspeech2_csmsc_onnx-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_csmsc_onnx_0.2.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_csmsc_onnx_0.2.0.zip',
'md5':
'fd3ad38d83273ad51f0ea4f4abf3ab4e',
'ckpt':
@@ -1749,7 +1755,7 @@ tts_onnx_pretrained_models = {
"fastspeech2_ljspeech_onnx-en": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_ljspeech_onnx_1.1.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_ljspeech_onnx_1.1.0.zip',
'md5':
'00754307636a48c972a5f3e65cda3d18',
'ckpt':
@@ -1763,7 +1769,7 @@ tts_onnx_pretrained_models = {
"fastspeech2_aishell3_onnx-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_aishell3_onnx_1.1.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_aishell3_onnx_1.1.0.zip',
'md5':
'a1d6ee21de897ce394f5469e2bb4df0d',
'ckpt':
@@ -1779,7 +1785,7 @@ tts_onnx_pretrained_models = {
"fastspeech2_vctk_onnx-en": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_vctk_onnx_1.1.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_vctk_onnx_1.1.0.zip',
'md5':
'd9c3a9b02204a2070504dd99f5f959bf',
'ckpt':
@@ -1795,7 +1801,7 @@ tts_onnx_pretrained_models = {
"fastspeech2_cnndecoder_csmsc_onnx-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_cnndecoder_csmsc_streaming_onnx_1.0.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_cnndecoder_csmsc_streaming_onnx_1.0.0.zip',
'md5':
'5f70e1a6bcd29d72d54e7931aa86f266',
'ckpt': [
@@ -1814,7 +1820,7 @@ tts_onnx_pretrained_models = {
"fastspeech2_mix_onnx-mix": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/t2s/chinse_english_mixed/models/fastspeech2_csmscljspeech_add-zhen_onnx.zip',
+ 'https://paddlespeech.cdn.bcebos.com/t2s/chinse_english_mixed/models/fastspeech2_csmscljspeech_add-zhen_onnx.zip',
'md5':
'73052520202957920cf54700980933d0',
'ckpt':
@@ -1828,7 +1834,7 @@ tts_onnx_pretrained_models = {
},
'2.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/t2s/chinse_english_mixed/models/fastspeech2_mix_onnx_0.2.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/t2s/chinse_english_mixed/models/fastspeech2_mix_onnx_0.2.0.zip',
'md5':
'43b8ca5f85709c503777f808eb02a39e',
'ckpt':
@@ -1844,7 +1850,7 @@ tts_onnx_pretrained_models = {
"fastspeech2_male_onnx-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_male_zh_onnx_1.4.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_male_zh_onnx_1.4.0.zip',
'md5':
'46c66f5ab86f4fcb493d899d9901c863',
'ckpt':
@@ -1858,7 +1864,7 @@ tts_onnx_pretrained_models = {
"fastspeech2_male_onnx-en": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_male_en_onnx_1.4.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_male_en_onnx_1.4.0.zip',
'md5':
'401fb5cc31fdb25e22e901c9acba79c8',
'ckpt':
@@ -1872,7 +1878,7 @@ tts_onnx_pretrained_models = {
"fastspeech2_male_onnx-mix": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_male_mix_onnx_1.4.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_male_mix_onnx_1.4.0.zip',
'md5':
'07e51c5991c529b78603034547e9d0fa',
'ckpt':
@@ -1886,7 +1892,7 @@ tts_onnx_pretrained_models = {
"fastspeech2_canton_onnx-canton": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_canton_onnx_1.4.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_canton_onnx_1.4.0.zip',
'md5':
'1c8d51ceb2f9bdd168e23be575c2ccf8',
'ckpt':
@@ -1903,7 +1909,7 @@ tts_onnx_pretrained_models = {
"pwgan_csmsc_onnx-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwgan_csmsc_onnx_0.2.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/pwgan/pwgan_csmsc_onnx_0.2.0.zip',
'md5':
'711d0ade33e73f3b721efc9f20669f9c',
'ckpt':
@@ -1915,7 +1921,7 @@ tts_onnx_pretrained_models = {
"pwgan_ljspeech_onnx-en": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwgan_ljspeech_onnx_1.1.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/pwgan/pwgan_ljspeech_onnx_1.1.0.zip',
'md5':
'73cdeeccb77f2ea6ed4d07e71d8ac8b8',
'ckpt':
@@ -1927,7 +1933,7 @@ tts_onnx_pretrained_models = {
"pwgan_aishell3_onnx-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwgan_aishell3_onnx_1.1.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/pwgan/pwgan_aishell3_onnx_1.1.0.zip',
'md5':
'096ab64e152a4fa476aff79ebdadb01b',
'ckpt':
@@ -1939,7 +1945,7 @@ tts_onnx_pretrained_models = {
"pwgan_vctk_onnx-en": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwgan_vctk_onnx_1.1.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/pwgan/pwgan_vctk_onnx_1.1.0.zip',
'md5':
'4e754d42cf85f6428f0af887c923d86c',
'ckpt':
@@ -1951,7 +1957,7 @@ tts_onnx_pretrained_models = {
"pwgan_male_onnx-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwgan_male_onnx_1.4.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/pwgan/pwgan_male_onnx_1.4.0.zip',
'md5':
'13163fd1326f555650dc7141d31767c3',
'ckpt':
@@ -1964,7 +1970,7 @@ tts_onnx_pretrained_models = {
"mb_melgan_csmsc_onnx-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/mb_melgan/mb_melgan_csmsc_onnx_0.2.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/mb_melgan/mb_melgan_csmsc_onnx_0.2.0.zip',
'md5':
'5b83ec746e8414bc29032d954ffd07ec',
'ckpt':
@@ -1977,7 +1983,7 @@ tts_onnx_pretrained_models = {
"hifigan_csmsc_onnx-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_csmsc_onnx_0.2.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/hifigan/hifigan_csmsc_onnx_0.2.0.zip',
'md5':
'1a7dc0385875889e46952e50c0994a6b',
'ckpt':
@@ -1989,7 +1995,7 @@ tts_onnx_pretrained_models = {
"hifigan_ljspeech_onnx-en": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_ljspeech_onnx_1.1.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/hifigan/hifigan_ljspeech_onnx_1.1.0.zip',
'md5':
'062f54b79c1135a50adb5fc8406260b2',
'ckpt':
@@ -2001,7 +2007,7 @@ tts_onnx_pretrained_models = {
"hifigan_aishell3_onnx-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_aishell3_onnx_1.1.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/hifigan/hifigan_aishell3_onnx_1.1.0.zip',
'md5':
'd6c0d684ad148583ca57837d5e870167',
'ckpt':
@@ -2013,7 +2019,7 @@ tts_onnx_pretrained_models = {
"hifigan_vctk_onnx-en": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_vctk_onnx_1.1.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/hifigan/hifigan_vctk_onnx_1.1.0.zip',
'md5':
'fd714df3be283c0efbefc8510160ff6d',
'ckpt':
@@ -2025,7 +2031,7 @@ tts_onnx_pretrained_models = {
"hifigan_male_onnx-zh": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_male_onnx_1.4.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/hifigan/hifigan_male_onnx_1.4.0.zip',
'md5':
'ec6b35417b1fe811d3b1641d4b527769',
'ckpt':
@@ -2056,7 +2062,7 @@ vector_dynamic_pretrained_models = {
"ecapatdnn_voxceleb12-16k": {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/vector/voxceleb/sv0_ecapa_tdnn_voxceleb12_ckpt_0_2_0.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/vector/voxceleb/sv0_ecapa_tdnn_voxceleb12_ckpt_0_2_0.tar.gz',
'md5':
'cc33023c54ab346cd318408f43fcaf95',
'cfg_path':
@@ -2076,7 +2082,7 @@ kws_dynamic_pretrained_models = {
'mdtc_heysnips-16k': {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/kws/heysnips/kws0_mdtc_heysnips_ckpt.tar.gz',
+ 'https://paddlespeech.cdn.bcebos.com/kws/heysnips/kws0_mdtc_heysnips_ckpt.tar.gz',
'md5':
'c0de0a9520d66c3c8d6679460893578f',
'cfg_path':
@@ -2094,13 +2100,13 @@ g2pw_onnx_models = {
'G2PWModel': {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/g2p/G2PWModel_1.0.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/g2p/G2PWModel_1.0.zip',
'md5':
'7e049a55547da840502cf99e8a64f20e',
},
'1.1': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/g2p/G2PWModel_1.1.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/g2p/new/G2PWModel_1.1.zip',
'md5':
'f8b60501770bff92ed6ce90860a610e6',
},
@@ -2114,7 +2120,7 @@ rhy_frontend_models = {
'rhy_e2e': {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Rhy_e2e/rhy_frontend.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Rhy_e2e/rhy_frontend.zip',
'md5': '6624a77393de5925d5a84400b363d8ef',
},
},
@@ -2127,7 +2133,7 @@ rhy_frontend_models = {
StarGANv2VC_source = {
'1.0': {
'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/starganv2vc/StarGANv2VC_source.zip',
+ 'https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/starganv2vc/StarGANv2VC_source.zip',
'md5':
'195e169419163f5648030ba84c71f866',
}
diff --git a/paddlespeech/s2t/exps/hubert/model.py b/paddlespeech/s2t/exps/hubert/model.py
index bc05921dd..c2bd63583 100644
--- a/paddlespeech/s2t/exps/hubert/model.py
+++ b/paddlespeech/s2t/exps/hubert/model.py
@@ -362,7 +362,7 @@ class HubertASRTrainer(Trainer):
scratch = None
if self.args.resume:
# just restore ckpt
- # lr will resotre from optimizer ckpt
+ # lr will restore from optimizer ckpt
resume_json_path = os.path.join(self.checkpoint_dir,
self.args.resume + '.json')
with open(resume_json_path, 'r', encoding='utf8') as f:
@@ -370,20 +370,20 @@ class HubertASRTrainer(Trainer):
self.iteration = 0
self.epoch = resume_json["epoch"]
- # resotre model from *.pdparams
+ # restore model from *.pdparams
params_path = os.path.join(self.checkpoint_dir,
"{}".format(self.epoch)) + '.pdparams'
model_dict = paddle.load(params_path)
self.model.set_state_dict(model_dict)
- # resotre optimizer from *.pdopt
+ # restore optimizer from *.pdopt
optimizer_path = os.path.join(self.checkpoint_dir,
"{}".format(self.epoch)) + '.pdopt'
optimizer_dict = paddle.load(optimizer_path)
self.model_optimizer.set_state_dict(optimizer_dict['model'])
self.hubert_optimizer.set_state_dict(optimizer_dict['hubert'])
- # resotre lr_scheduler from *.pdlrs
+ # restore lr_scheduler from *.pdlrs
scheduler_path = os.path.join(self.checkpoint_dir,
"{}".format(self.epoch)) + '.pdlrs'
if os.path.isfile(os.path.join(scheduler_path)):
diff --git a/paddlespeech/s2t/exps/wav2vec2/model.py b/paddlespeech/s2t/exps/wav2vec2/model.py
index 6c90f99e1..7ba86c774 100644
--- a/paddlespeech/s2t/exps/wav2vec2/model.py
+++ b/paddlespeech/s2t/exps/wav2vec2/model.py
@@ -361,7 +361,7 @@ class Wav2Vec2ASRTrainer(Trainer):
scratch = None
if self.args.resume:
# just restore ckpt
- # lr will resotre from optimizer ckpt
+ # lr will restore from optimizer ckpt
resume_json_path = os.path.join(self.checkpoint_dir,
self.args.resume + '.json')
with open(resume_json_path, 'r', encoding='utf8') as f:
@@ -369,20 +369,20 @@ class Wav2Vec2ASRTrainer(Trainer):
self.iteration = 0
self.epoch = resume_json["epoch"]
- # resotre model from *.pdparams
+ # restore model from *.pdparams
params_path = os.path.join(self.checkpoint_dir,
"{}".format(self.epoch)) + '.pdparams'
model_dict = paddle.load(params_path)
self.model.set_state_dict(model_dict)
- # resotre optimizer from *.pdopt
+ # restore optimizer from *.pdopt
optimizer_path = os.path.join(self.checkpoint_dir,
"{}".format(self.epoch)) + '.pdopt'
optimizer_dict = paddle.load(optimizer_path)
self.model_optimizer.set_state_dict(optimizer_dict['model'])
self.wav2vec2_optimizer.set_state_dict(optimizer_dict['wav2vec2'])
- # resotre lr_scheduler from *.pdlrs
+ # restore lr_scheduler from *.pdlrs
scheduler_path = os.path.join(self.checkpoint_dir,
"{}".format(self.epoch)) + '.pdlrs'
if os.path.isfile(os.path.join(scheduler_path)):
diff --git a/paddlespeech/s2t/exps/wavlm/model.py b/paddlespeech/s2t/exps/wavlm/model.py
index 606867eae..5dfbf3b2e 100644
--- a/paddlespeech/s2t/exps/wavlm/model.py
+++ b/paddlespeech/s2t/exps/wavlm/model.py
@@ -361,7 +361,7 @@ class WavLMASRTrainer(Trainer):
scratch = None
if self.args.resume:
# just restore ckpt
- # lr will resotre from optimizer ckpt
+ # lr will restore from optimizer ckpt
resume_json_path = os.path.join(self.checkpoint_dir,
self.args.resume + '.json')
with open(resume_json_path, 'r', encoding='utf8') as f:
@@ -369,20 +369,20 @@ class WavLMASRTrainer(Trainer):
self.iteration = 0
self.epoch = resume_json["epoch"]
- # resotre model from *.pdparams
+ # restore model from *.pdparams
params_path = os.path.join(self.checkpoint_dir,
"{}".format(self.epoch)) + '.pdparams'
model_dict = paddle.load(params_path)
self.model.set_state_dict(model_dict)
- # resotre optimizer from *.pdopt
+ # restore optimizer from *.pdopt
optimizer_path = os.path.join(self.checkpoint_dir,
"{}".format(self.epoch)) + '.pdopt'
optimizer_dict = paddle.load(optimizer_path)
self.model_optimizer.set_state_dict(optimizer_dict['model'])
self.wavlm_optimizer.set_state_dict(optimizer_dict['wavlm'])
- # resotre lr_scheduler from *.pdlrs
+ # restore lr_scheduler from *.pdlrs
scheduler_path = os.path.join(self.checkpoint_dir,
"{}".format(self.epoch)) + '.pdlrs'
if os.path.isfile(os.path.join(scheduler_path)):
diff --git a/paddlespeech/s2t/frontend/featurizer/audio_featurizer.py b/paddlespeech/s2t/frontend/featurizer/audio_featurizer.py
index 22329d5e0..ac5720fd5 100644
--- a/paddlespeech/s2t/frontend/featurizer/audio_featurizer.py
+++ b/paddlespeech/s2t/frontend/featurizer/audio_featurizer.py
@@ -14,10 +14,11 @@
"""Contains the audio featurizer class."""
import numpy as np
import paddle
-import paddleaudio.compliance.kaldi as kaldi
from python_speech_features import delta
from python_speech_features import mfcc
+import paddlespeech.audio.compliance.kaldi as kaldi
+
class AudioFeaturizer():
"""Audio featurizer, for extracting features from audio contents of
diff --git a/paddlespeech/s2t/models/whisper/whisper.py b/paddlespeech/s2t/models/whisper/whisper.py
index d20cc04b6..fdd3a6974 100644
--- a/paddlespeech/s2t/models/whisper/whisper.py
+++ b/paddlespeech/s2t/models/whisper/whisper.py
@@ -835,8 +835,14 @@ class BeamSearchDecoder(TokenDecoder):
logprob, token = paddle.topk(
logprobs[idx], k=self.beam_size + 1)
for logprob, token in zip(logprob, token):
- new_logprob = (sum_logprobs[idx] + logprob).tolist()[0]
- sequence = tuple(prefix + [token.tolist()[0]])
+ # after Paddle 3.0, tolist in 0-D tensor will return a float/int value instead of a list
+ new_logprob = (sum_logprobs[idx] + logprob).tolist()
+ new_logprob = new_logprob if isinstance(
+ new_logprob, float) else new_logprob[0]
+ new_token = token.tolist()
+ new_token = new_token if isinstance(new_token,
+ int) else new_token[0]
+ sequence = tuple(prefix + [new_token])
scores[sequence] = new_logprob
sources[sequence] = idx
diff --git a/paddlespeech/s2t/modules/align.py b/paddlespeech/s2t/modules/align.py
index 46d8796ab..a206a350c 100644
--- a/paddlespeech/s2t/modules/align.py
+++ b/paddlespeech/s2t/modules/align.py
@@ -17,7 +17,7 @@ import paddle
from paddle import nn
"""
To align the initializer between paddle and torch,
- the API below are set defalut initializer with priority higger than global initializer.
+ the API below are set default initializer with priority higger than global initializer.
"""
global_init_type = None
diff --git a/paddlespeech/s2t/modules/fbank.py b/paddlespeech/s2t/modules/fbank.py
index 30671c274..8d76a4727 100644
--- a/paddlespeech/s2t/modules/fbank.py
+++ b/paddlespeech/s2t/modules/fbank.py
@@ -1,7 +1,7 @@
import paddle
from paddle import nn
-from paddleaudio.compliance import kaldi
+from paddlespeech.audio.compliance import kaldi
from paddlespeech.s2t.utils.log import Log
logger = Log(__name__).getlog()
diff --git a/paddlespeech/s2t/training/cli.py b/paddlespeech/s2t/training/cli.py
index ded2aff9f..fc0caf10a 100644
--- a/paddlespeech/s2t/training/cli.py
+++ b/paddlespeech/s2t/training/cli.py
@@ -47,7 +47,7 @@ def default_argument_parser(parser=None):
other experiments with t2s. It requires a minimal set of command line
arguments to start a training script.
- The ``--config`` and ``--opts`` are used for overwrite the deault
+ The ``--config`` and ``--opts`` are used for overwrite the default
configuration.
The ``--data`` and ``--output`` specifies the data path and output path.
diff --git a/paddlespeech/s2t/training/trainer.py b/paddlespeech/s2t/training/trainer.py
index a8f36f91b..3facddc0e 100644
--- a/paddlespeech/s2t/training/trainer.py
+++ b/paddlespeech/s2t/training/trainer.py
@@ -215,7 +215,7 @@ class Trainer():
checkpoint_path=self.args.checkpoint_path)
if infos:
# just restore ckpt
- # lr will resotre from optimizer ckpt
+ # lr will restore from optimizer ckpt
self.iteration = infos["step"]
self.epoch = infos["epoch"]
diff --git a/paddlespeech/s2t/utils/error_rate.py b/paddlespeech/s2t/utils/error_rate.py
index 548376aa2..9e3357b91 100644
--- a/paddlespeech/s2t/utils/error_rate.py
+++ b/paddlespeech/s2t/utils/error_rate.py
@@ -171,7 +171,7 @@ def wer(reference, hypothesis, ignore_case=False, delimiter=' '):
def cer(reference, hypothesis, ignore_case=False, remove_space=False):
- """Calculate charactor error rate (CER). CER compares reference text and
+ """Calculate character error rate (CER). CER compares reference text and
hypothesis text in char-level. CER is defined as:
.. math::
diff --git a/paddlespeech/s2t/utils/tensor_utils.py b/paddlespeech/s2t/utils/tensor_utils.py
index 0d91b9cfb..15f4abdda 100644
--- a/paddlespeech/s2t/utils/tensor_utils.py
+++ b/paddlespeech/s2t/utils/tensor_utils.py
@@ -80,7 +80,7 @@ def pad_sequence(sequences: List[paddle.Tensor],
# assuming trailing dimensions and type of all the Tensors
# in sequences are same and fetching those from sequences[0]
max_size = paddle.shape(sequences[0])
- # (TODO Hui Zhang): slice not supprot `end==start`
+ # (TODO Hui Zhang): slice not support `end==start`
# trailing_dims = max_size[1:]
trailing_dims = tuple(
max_size[1:].numpy().tolist()) if sequences[0].ndim >= 2 else ()
@@ -98,7 +98,7 @@ def pad_sequence(sequences: List[paddle.Tensor],
f"length {length}, out_tensor {out_tensor.shape}, tensor {tensor.shape}"
)
if batch_first:
- # TODO (Hui Zhang): set_value op not supprot `end==start`
+ # TODO (Hui Zhang): set_value op not support `end==start`
# TODO (Hui Zhang): set_value op not support int16
# TODO (Hui Zhang): set_varbase 2 rank not support [0,0,...]
# out_tensor[i, :length, ...] = tensor
@@ -107,7 +107,7 @@ def pad_sequence(sequences: List[paddle.Tensor],
else:
out_tensor[i, length] = tensor
else:
- # TODO (Hui Zhang): set_value op not supprot `end==start`
+ # TODO (Hui Zhang): set_value op not support `end==start`
# out_tensor[:length, i, ...] = tensor
if length != 0:
out_tensor[:length, i] = tensor
diff --git a/paddlespeech/server/engine/vector/python/vector_engine.py b/paddlespeech/server/engine/vector/python/vector_engine.py
index 7d86f3df7..f02a942fb 100644
--- a/paddlespeech/server/engine/vector/python/vector_engine.py
+++ b/paddlespeech/server/engine/vector/python/vector_engine.py
@@ -16,9 +16,9 @@ from collections import OrderedDict
import numpy as np
import paddle
-from paddleaudio.backends import soundfile_load as load_audio
-from paddleaudio.compliance.librosa import melspectrogram
+from paddlespeech.audio.backends import soundfile_load as load_audio
+from paddlespeech.audio.compliance.librosa import melspectrogram
from paddlespeech.cli.log import logger
from paddlespeech.cli.vector.infer import VectorExecutor
from paddlespeech.server.engine.base_engine import BaseEngine
diff --git a/paddlespeech/server/restful/request.py b/paddlespeech/server/restful/request.py
index b7a32481f..068694de3 100644
--- a/paddlespeech/server/restful/request.py
+++ b/paddlespeech/server/restful/request.py
@@ -65,7 +65,7 @@ class TTSRequest(BaseModel):
speed: float = 1.0
volume: float = 1.0
sample_rate: int = 0
- save_path: str = None
+ save_path: Optional[str] = None
#****************************************************************************************/
diff --git a/paddlespeech/server/restful/response.py b/paddlespeech/server/restful/response.py
index 3d991de43..12b264c02 100644
--- a/paddlespeech/server/restful/response.py
+++ b/paddlespeech/server/restful/response.py
@@ -12,6 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import List
+from typing import Optional
from pydantic import BaseModel
@@ -62,7 +63,7 @@ class TTSResult(BaseModel):
volume: float = 1.0
sample_rate: int
duration: float
- save_path: str = None
+ save_path: Optional[str] = None
audio: str
diff --git a/paddlespeech/server/tests/asr/online/README.md b/paddlespeech/server/tests/asr/online/README.md
index 1d7fa8824..586836dc1 100644
--- a/paddlespeech/server/tests/asr/online/README.md
+++ b/paddlespeech/server/tests/asr/online/README.md
@@ -23,7 +23,7 @@ The input of ASR client demo should be a WAV file(`.wav`), and the sample rate
Here are sample files for thisASR client demo that can be downloaded:
```bash
-wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
+wget -c https://paddlespeech.cdn.bcebos.com/PaddleAudio/zh.wav
```
### 2. Streaming ASR Client Usage
diff --git a/paddlespeech/server/tests/asr/online/README_cn.md b/paddlespeech/server/tests/asr/online/README_cn.md
index 403216369..494209469 100644
--- a/paddlespeech/server/tests/asr/online/README_cn.md
+++ b/paddlespeech/server/tests/asr/online/README_cn.md
@@ -20,7 +20,7 @@
可以下载此 ASR client的示例音频:
```bash
-wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
+wget -c https://paddlespeech.cdn.bcebos.com/PaddleAudio/zh.wav
```
### 2. 流式 ASR 客户端使用方法
diff --git a/paddlespeech/server/util.py b/paddlespeech/server/util.py
index 6aa6fd589..47871922b 100644
--- a/paddlespeech/server/util.py
+++ b/paddlespeech/server/util.py
@@ -24,13 +24,13 @@ from typing import Any
from typing import Dict
import paddle
-import paddleaudio
import requests
import yaml
from paddle.framework import load
from .entry import client_commands
from .entry import server_commands
+from paddlespeech.audio.backends import soundfile_load
from paddlespeech.cli import download
try:
from .. import __version__
@@ -289,7 +289,7 @@ def _note_one_stat(cls_name, params={}):
if 'audio_file' in params:
try:
- _, sr = paddleaudio.backends.soundfile_load(params['audio_file'])
+ _, sr = soundfile_load(params['audio_file'])
except Exception:
sr = -1
diff --git a/paddlespeech/server/utils/audio_handler.py b/paddlespeech/server/utils/audio_handler.py
index 4df651337..08f15fe70 100644
--- a/paddlespeech/server/utils/audio_handler.py
+++ b/paddlespeech/server/utils/audio_handler.py
@@ -79,7 +79,7 @@ class ASRWsAudioHandler:
punc_server_ip=None,
punc_server_port=None):
"""PaddleSpeech Online ASR Server Client audio handler
- Online asr server use the websocket protocal
+ Online asr server use the websocket protocol
Args:
url (str, optional): the server ip. Defaults to None.
port (int, optional): the server port. Defaults to None.
@@ -144,10 +144,10 @@ class ASRWsAudioHandler:
logger.error("No asr server, please input valid ip and port")
return ""
- # 1. send websocket handshake protocal
+ # 1. send websocket handshake protocol
start_time = time.time()
async with websockets.connect(self.url) as ws:
- # 2. server has already received handshake protocal
+ # 2. server has already received handshake protocol
# client start to send the command
audio_info = json.dumps(
{
@@ -255,7 +255,7 @@ class ASRHttpHandler:
class TTSWsHandler:
def __init__(self, server="127.0.0.1", port=8092, play: bool=False):
"""PaddleSpeech Online TTS Server Client audio handler
- Online tts server use the websocket protocal
+ Online tts server use the websocket protocol
Args:
server (str, optional): the server ip. Defaults to "127.0.0.1".
port (int, optional): the server port. Defaults to 8092.
@@ -405,7 +405,7 @@ class TTSWsHandler:
class TTSHttpHandler:
def __init__(self, server="127.0.0.1", port=8092, play: bool=False):
"""PaddleSpeech Online TTS Server Client audio handler
- Online tts server use the websocket protocal
+ Online tts server use the websocket protocol
Args:
server (str, optional): the server ip. Defaults to "127.0.0.1".
port (int, optional): the server port. Defaults to 8092.
diff --git a/paddlespeech/server/ws/asr_api.py b/paddlespeech/server/ws/asr_api.py
index b3ad0b7c5..3f90ac3b4 100644
--- a/paddlespeech/server/ws/asr_api.py
+++ b/paddlespeech/server/ws/asr_api.py
@@ -31,7 +31,7 @@ async def websocket_endpoint(websocket: WebSocket):
websocket (WebSocket): the websocket instance
"""
- #1. the interface wait to accept the websocket protocal header
+ #1. the interface wait to accept the websocket protocol header
# and only we receive the header, it establish the connection with specific thread
await websocket.accept()
@@ -45,7 +45,7 @@ async def websocket_endpoint(websocket: WebSocket):
connection_handler = None
try:
- #4. we do a loop to process the audio package by package according the protocal
+ #4. we do a loop to process the audio package by package according the protocol
# and only if the client send finished signal, we will break the loop
while True:
# careful here, changed the source code from starlette.websockets
diff --git a/paddlespeech/server/ws/tts_api.py b/paddlespeech/server/ws/tts_api.py
index 275711f58..11194958c 100644
--- a/paddlespeech/server/ws/tts_api.py
+++ b/paddlespeech/server/ws/tts_api.py
@@ -32,7 +32,7 @@ async def websocket_endpoint(websocket: WebSocket):
websocket (WebSocket): the websocket instance
"""
- #1. the interface wait to accept the websocket protocal header
+ #1. the interface wait to accept the websocket protocol header
# and only we receive the header, it establish the connection with specific thread
await websocket.accept()
diff --git a/paddlespeech/t2s/exps/ernie_sat/align.py b/paddlespeech/t2s/exps/ernie_sat/align.py
index a802d0295..e7c8083a8 100755
--- a/paddlespeech/t2s/exps/ernie_sat/align.py
+++ b/paddlespeech/t2s/exps/ernie_sat/align.py
@@ -41,11 +41,11 @@ def _readtg(tg_path: str, lang: str='en', fs: int=24000, n_shift: int=300):
ends = []
words = []
- for interval in alignment.tierDict['words'].entryList:
+ for interval in alignment.getTier('words').entries:
word = interval.label
if word:
words.append(word)
- for interval in alignment.tierDict['phones'].entryList:
+ for interval in alignment.getTier('phones').entries:
phone = interval.label
phones.append(phone)
ends.append(interval.end)
diff --git a/paddlespeech/t2s/exps/stream_play_tts.py b/paddlespeech/t2s/exps/stream_play_tts.py
index 4dcf4794f..070bfff03 100644
--- a/paddlespeech/t2s/exps/stream_play_tts.py
+++ b/paddlespeech/t2s/exps/stream_play_tts.py
@@ -13,8 +13,8 @@
# limitations under the License.
# stream play TTS
# Before first execution, download and decompress the models in the execution directory
-# wget https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_cnndecoder_csmsc_streaming_onnx_1.0.0.zip
-# wget https://paddlespeech.bj.bcebos.com/Parakeet/released_models/mb_melgan/mb_melgan_csmsc_onnx_0.2.0.zip
+# wget https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_cnndecoder_csmsc_streaming_onnx_1.0.0.zip
+# wget https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/mb_melgan/mb_melgan_csmsc_onnx_0.2.0.zip
# unzip fastspeech2_cnndecoder_csmsc_streaming_onnx_1.0.0.zip
# unzip mb_melgan_csmsc_onnx_0.2.0.zip
import math
diff --git a/paddlespeech/t2s/frontend/tone_sandhi.py b/paddlespeech/t2s/frontend/tone_sandhi.py
index 3558064cd..d8688115b 100644
--- a/paddlespeech/t2s/frontend/tone_sandhi.py
+++ b/paddlespeech/t2s/frontend/tone_sandhi.py
@@ -243,8 +243,10 @@ class ToneSandhi():
if skip_next:
skip_next = False
continue
- if i - 1 >= 0 and word == "一" and i + 1 < len(seg) and seg[i - 1][0] == seg[i + 1][0] and seg[i - 1][1] == "v":
- new_seg[-1] = (new_seg[-1][0] + "一" + seg[i + 1][0], new_seg[-1][1])
+ if i - 1 >= 0 and word == "一" and i + 1 < len(seg) and seg[i - 1][
+ 0] == seg[i + 1][0] and seg[i - 1][1] == "v":
+ new_seg[-1] = (new_seg[-1][0] + "一" + seg[i + 1][0],
+ new_seg[-1][1])
skip_next = True
else:
new_seg.append((word, pos))
@@ -262,11 +264,16 @@ class ToneSandhi():
def _merge_continuous_three_tones(
self, seg: List[Tuple[str, str]]) -> List[Tuple[str, str]]:
new_seg = []
- sub_finals_list = [
- lazy_pinyin(
+ sub_finals_list = []
+ for (word, pos) in seg:
+ orig_finals = lazy_pinyin(
word, neutral_tone_with_five=True, style=Style.FINALS_TONE3)
- for (word, pos) in seg
- ]
+ # after pypinyin==0.44.0, '嗯' need to be n2, cause the initial and final consonants cannot be empty at the same time
+ en_index = [index for index, c in enumerate(word) if c == "嗯"]
+ for i in en_index:
+ orig_finals[i] = "n2"
+ sub_finals_list.append(orig_finals)
+
assert len(sub_finals_list) == len(seg)
merge_last = [False] * len(seg)
for i, (word, pos) in enumerate(seg):
@@ -292,11 +299,15 @@ class ToneSandhi():
def _merge_continuous_three_tones_2(
self, seg: List[Tuple[str, str]]) -> List[Tuple[str, str]]:
new_seg = []
- sub_finals_list = [
- lazy_pinyin(
+ sub_finals_list = []
+ for (word, pos) in seg:
+ orig_finals = lazy_pinyin(
word, neutral_tone_with_five=True, style=Style.FINALS_TONE3)
- for (word, pos) in seg
- ]
+ # after pypinyin==0.44.0, '嗯' need to be n2, cause the initial and final consonants cannot be empty at the same time
+ en_index = [index for index, c in enumerate(word) if c == "嗯"]
+ for i in en_index:
+ orig_finals[i] = "n2"
+ sub_finals_list.append(orig_finals)
assert len(sub_finals_list) == len(seg)
merge_last = [False] * len(seg)
for i, (word, pos) in enumerate(seg):
diff --git a/paddlespeech/t2s/frontend/zh_frontend.py b/paddlespeech/t2s/frontend/zh_frontend.py
index 1431bc6d8..3c87c6827 100644
--- a/paddlespeech/t2s/frontend/zh_frontend.py
+++ b/paddlespeech/t2s/frontend/zh_frontend.py
@@ -173,6 +173,11 @@ class Frontend():
word, neutral_tone_with_five=True, style=Style.INITIALS)
orig_finals = lazy_pinyin(
word, neutral_tone_with_five=True, style=Style.FINALS_TONE3)
+ # after pypinyin==0.44.0, '嗯' need to be n2, cause the initial and final consonants cannot be empty at the same time
+ en_index = [index for index, c in enumerate(word) if c == "嗯"]
+ for i in en_index:
+ orig_finals[i] = "n2"
+
for c, v in zip(orig_initials, orig_finals):
if re.match(r'i\d', v):
if c in ['z', 'c', 's']:
@@ -518,7 +523,7 @@ class Frontend():
initials = []
finals = []
- # to charactor list
+ # to character list
words = self._split_word_to_char(words[0])
for pinyin, char in zip(pinyin_spec, words):
diff --git a/paddlespeech/t2s/models/starganv2_vc/AuxiliaryASR/layers.py b/paddlespeech/t2s/models/starganv2_vc/AuxiliaryASR/layers.py
index 5901c805a..b29d0863e 100644
--- a/paddlespeech/t2s/models/starganv2_vc/AuxiliaryASR/layers.py
+++ b/paddlespeech/t2s/models/starganv2_vc/AuxiliaryASR/layers.py
@@ -13,9 +13,9 @@
# limitations under the License.
import paddle
import paddle.nn.functional as F
-import paddleaudio.functional as audio_F
from paddle import nn
+from paddlespeech.audio.functional import create_dct
from paddlespeech.utils.initialize import _calculate_gain
from paddlespeech.utils.initialize import xavier_uniform_
@@ -243,7 +243,7 @@ class MFCC(nn.Layer):
self.n_mfcc = n_mfcc
self.n_mels = n_mels
self.norm = 'ortho'
- dct_mat = audio_F.create_dct(self.n_mfcc, self.n_mels, self.norm)
+ dct_mat = create_dct(self.n_mfcc, self.n_mels, self.norm)
self.register_buffer('dct_mat', dct_mat)
def forward(self, mel_specgram: paddle.Tensor):
diff --git a/paddlespeech/t2s/models/vits/residual_coupling.py b/paddlespeech/t2s/models/vits/residual_coupling.py
index afa6d1fa7..09916484d 100644
--- a/paddlespeech/t2s/models/vits/residual_coupling.py
+++ b/paddlespeech/t2s/models/vits/residual_coupling.py
@@ -76,7 +76,7 @@ class ResidualAffineCouplingBlock(nn.Layer):
use_weight_norm (bool):
Whether to use weight normalization in WaveNet.
bias (bool):
- Whether to use bias paramters in WaveNet.
+ Whether to use bias parameters in WaveNet.
use_only_mean (bool):
Whether to estimate only mean.
@@ -169,7 +169,7 @@ class ResidualAffineCouplingLayer(nn.Layer):
use_weight_norm (bool):
Whether to use weight normalization in WaveNet.
bias (bool):
- Whether to use bias paramters in WaveNet.
+ Whether to use bias parameters in WaveNet.
use_only_mean (bool):
Whether to estimate only mean.
diff --git a/paddlespeech/t2s/modules/diffusion.py b/paddlespeech/t2s/modules/diffusion.py
index adbd9ce7f..f00ddc595 100644
--- a/paddlespeech/t2s/modules/diffusion.py
+++ b/paddlespeech/t2s/modules/diffusion.py
@@ -40,7 +40,7 @@ class GaussianDiffusion(nn.Layer):
num_max_timesteps (int, optional):
The max timestep transition from real to noise, by default None.
stretch (bool, optional):
- Whether to stretch before diffusion, by defalut True.
+ Whether to stretch before diffusion, by default True.
min_values: (paddle.Tensor):
The minimum value of the feature to stretch.
max_values: (paddle.Tensor):
diff --git a/paddlespeech/t2s/modules/losses.py b/paddlespeech/t2s/modules/losses.py
index f819352d6..b437be93d 100644
--- a/paddlespeech/t2s/modules/losses.py
+++ b/paddlespeech/t2s/modules/losses.py
@@ -12,7 +12,11 @@
# See the License for the specific language governing permissions and
# limitations under the License.
import math
+from typing import Callable
+from typing import List
+from typing import Optional
from typing import Tuple
+from typing import Union
import librosa
import numpy as np
@@ -23,6 +27,8 @@ from scipy import signal
from scipy.stats import betabinom
from typeguard import typechecked
+from paddlespeech.audiotools.core.audio_signal import AudioSignal
+from paddlespeech.audiotools.core.audio_signal import STFTParams
from paddlespeech.t2s.modules.nets_utils import make_non_pad_mask
from paddlespeech.t2s.modules.predictor.duration_predictor import (
DurationPredictorLoss, # noqa: H301
@@ -1326,3 +1332,276 @@ class ForwardSumLoss(nn.Layer):
bb_prior[bidx, :T, :N] = prob
return bb_prior
+
+
+class MultiScaleSTFTLoss(nn.Layer):
+ """Computes the multi-scale STFT loss from [1].
+
+ References
+ ----------
+
+ 1. Engel, Jesse, Chenjie Gu, and Adam Roberts.
+ "DDSP: Differentiable Digital Signal Processing."
+ International Conference on Learning Representations. 2019.
+
+ Implementation copied from: https://github.com/descriptinc/audiotools/blob/master/audiotools/metrics/spectral.py
+ """
+
+ def __init__(
+ self,
+ window_lengths: List[int]=[2048, 512],
+ loss_fn: Callable=nn.L1Loss(),
+ clamp_eps: float=1e-5,
+ mag_weight: float=1.0,
+ log_weight: float=1.0,
+ pow: float=2.0,
+ weight: float=1.0,
+ match_stride: bool=False,
+ window_type: Optional[str]=None, ):
+ """
+ Args:
+ window_lengths : List[int], optional
+ Length of each window of each STFT, by default [2048, 512]
+ loss_fn : typing.Callable, optional
+ How to compare each loss, by default nn.L1Loss()
+ clamp_eps : float, optional
+ Clamp on the log magnitude, below, by default 1e-5
+ mag_weight : float, optional
+ Weight of raw magnitude portion of loss, by default 1.0
+ log_weight : float, optional
+ Weight of log magnitude portion of loss, by default 1.0
+ pow : float, optional
+ Power to raise magnitude to before taking log, by default 2.0
+ weight : float, optional
+ Weight of this loss, by default 1.0
+ match_stride : bool, optional
+ Whether to match the stride of convolutional layers, by default False
+ window_type : str, optional
+ Type of window to use, by default None.
+ """
+ super().__init__()
+
+ self.stft_params = [
+ STFTParams(
+ window_length=w,
+ hop_length=w // 4,
+ match_stride=match_stride,
+ window_type=window_type, ) for w in window_lengths
+ ]
+ self.loss_fn = loss_fn
+ self.log_weight = log_weight
+ self.mag_weight = mag_weight
+ self.clamp_eps = clamp_eps
+ self.weight = weight
+ self.pow = pow
+
+ def forward(self, x: AudioSignal, y: AudioSignal):
+ """Computes multi-scale STFT between an estimate and a reference
+ signal.
+
+ Args:
+ x : AudioSignal
+ Estimate signal
+ y : AudioSignal
+ Reference signal
+
+ Returns:
+ paddle.Tensor
+ Multi-scale STFT loss.
+
+ Example:
+ >>> from paddlespeech.audiotools.core.audio_signal import AudioSignal
+ >>> import paddle
+
+ >>> x = AudioSignal("https://paddlespeech.cdn.bcebos.com/PaddleAudio/en.wav", 2_05)
+ >>> y = x * 0.01
+ >>> loss = MultiScaleSTFTLoss()
+ >>> loss(x, y).numpy()
+ 7.562150
+ """
+ for s in self.stft_params:
+ x.stft(s.window_length, s.hop_length, s.window_type)
+ y.stft(s.window_length, s.hop_length, s.window_type)
+ loss += self.log_weight * self.loss_fn(
+ x.magnitude.clip(self.clamp_eps).pow(self.pow).log10(),
+ y.magnitude.clip(self.clamp_eps).pow(self.pow).log10(), )
+ loss += self.mag_weight * self.loss_fn(x.magnitude, y.magnitude)
+ return loss
+
+
+class GANLoss(nn.Layer):
+ """
+ Computes a discriminator loss, given a discriminator on
+ generated waveforms/spectrograms compared to ground truth
+ waveforms/spectrograms. Computes the loss for both the
+ discriminator and the generator in separate functions.
+
+ Example:
+ >>> from paddlespeech.audiotools.core.audio_signal import AudioSignal
+ >>> import paddle
+
+ >>> x = AudioSignal("https://paddlespeech.cdn.bcebos.com/PaddleAudio/en.wav", 2_05)
+ >>> y = x * 0.01
+ >>> class My_discriminator0:
+ >>> def __call__(self, x):
+ >>> return x.sum()
+ >>> loss = GANLoss(My_discriminator0())
+ >>> [loss(x, y)[0].numpy(), loss(x, y)[1].numpy()]
+ [-0.102722, -0.001027]
+
+ >>> class My_discriminator1:
+ >>> def __call__(self, x):
+ >>> return x.sum()
+ >>> loss = GANLoss(My_discriminator1())
+ >>> [loss.generator_loss(x, y)[0].numpy(), loss.generator_loss(x, y)[1].numpy()]
+ [1.00019, 0]
+
+ >>> loss.discriminator_loss(x, y)
+ 1.000200
+ """
+
+ def __init__(self, discriminator):
+ """
+ Args:
+ discriminator : paddle.nn.layer
+ Discriminator model
+ """
+ super().__init__()
+ self.discriminator = discriminator
+
+ def forward(self,
+ fake: Union[AudioSignal, paddle.Tensor],
+ real: Union[AudioSignal, paddle.Tensor]):
+ if isinstance(fake, AudioSignal):
+ d_fake = self.discriminator(fake.audio_data)
+ else:
+ d_fake = self.discriminator(fake)
+
+ if isinstance(real, AudioSignal):
+ d_real = self.discriminator(real.audio_data)
+ else:
+ d_real = self.discriminator(real)
+ return d_fake, d_real
+
+ def discriminator_loss(self, fake, real):
+ d_fake, d_real = self.forward(fake, real)
+
+ loss_d = 0
+ for x_fake, x_real in zip(d_fake, d_real):
+ loss_d += paddle.mean(x_fake[-1]**2)
+ loss_d += paddle.mean((1 - x_real[-1])**2)
+ return loss_d
+
+ def generator_loss(self, fake, real):
+ d_fake, d_real = self.forward(fake, real)
+
+ loss_g = 0
+ for x_fake in d_fake:
+ loss_g += paddle.mean((1 - x_fake[-1])**2)
+
+ loss_feature = 0
+
+ for i in range(len(d_fake)):
+ for j in range(len(d_fake[i]) - 1):
+ loss_feature += F.l1_loss(d_fake[i][j], d_real[i][j]())
+ return loss_g, loss_feature
+
+
+class SISDRLoss(nn.Layer):
+ """
+ Computes the Scale-Invariant Source-to-Distortion Ratio between a batch
+ of estimated and reference audio signals or aligned features.
+
+ Implementation copied from: https://github.com/descriptinc/audiotools/blob/master/audiotools/metrics/distance.py
+
+ Example:
+ >>> from paddlespeech.audiotools.core.audio_signal import AudioSignal
+ >>> import paddle
+
+ >>> x = AudioSignal("https://paddlespeech.cdn.bcebos.com/PaddleAudio/en.wav", 2_05)
+ >>> y = x * 0.01
+ >>> sisdr = SISDRLoss()
+ >>> sisdr(x, y).numpy()
+ -145.377640
+ """
+
+ def __init__(
+ self,
+ scaling: bool=True,
+ reduction: str="mean",
+ zero_mean: bool=True,
+ clip_min: Optional[int]=None,
+ weight: float=1.0, ):
+ """
+ Args:
+ scaling : bool, optional
+ Whether to use scale-invariant (True) or
+ signal-to-noise ratio (False), by default True
+ reduction : str, optional
+ How to reduce across the batch (either 'mean',
+ 'sum', or none).], by default ' mean'
+ zero_mean : bool, optional
+ Zero mean the references and estimates before
+ computing the loss, by default True
+ clip_min : int, optional
+ The minimum possible loss value. Helps network
+ to not focus on making already good examples better, by default None
+ weight : float, optional
+ Weight of this loss, defaults to 1.0.
+ """
+ self.scaling = scaling
+ self.reduction = reduction
+ self.zero_mean = zero_mean
+ self.clip_min = clip_min
+ self.weight = weight
+ super().__init__()
+
+ def forward(self,
+ x: Union[AudioSignal, paddle.Tensor],
+ y: Union[AudioSignal, paddle.Tensor]):
+ eps = 1e-8
+ # B, C, T
+ if isinstance(x, AudioSignal):
+ references = x.audio_data
+ estimates = y.audio_data
+ else:
+ references = x
+ estimates = y
+
+ nb = references.shape[0]
+ references = references.reshape([nb, 1, -1]).transpose([0, 2, 1])
+ estimates = estimates.reshape([nb, 1, -1]).transpose([0, 2, 1])
+
+ # samples now on axis 1
+ if self.zero_mean:
+ mean_reference = references.mean(axis=1, keepdim=True)
+ mean_estimate = estimates.mean(axis=1, keepdim=True)
+ else:
+ mean_reference = 0
+ mean_estimate = 0
+
+ _references = references - mean_reference
+ _estimates = estimates - mean_estimate
+
+ references_projection = (_references**2).sum(axis=-2) + eps
+ references_on_estimates = (_estimates * _references).sum(axis=-2) + eps
+
+ scale = (
+ (references_on_estimates / references_projection).unsqueeze(axis=1)
+ if self.scaling else 1)
+
+ e_true = scale * _references
+ e_res = _estimates - e_true
+
+ signal = (e_true**2).sum(axis=1)
+ noise = (e_res**2).sum(axis=1)
+ sdr = -10 * paddle.log10(signal / noise + eps)
+
+ if self.clip_min != None:
+ sdr = paddle.clip(sdr, min=self.clip_min)
+
+ if self.reduction == "mean":
+ sdr = sdr.mean()
+ elif self.reduction == "sum":
+ sdr = sdr.sum()
+ return sdr
diff --git a/paddlespeech/t2s/training/cli.py b/paddlespeech/t2s/training/cli.py
index 83dae1177..d503744d5 100644
--- a/paddlespeech/t2s/training/cli.py
+++ b/paddlespeech/t2s/training/cli.py
@@ -21,7 +21,7 @@ def default_argument_parser():
other experiments with t2s. It requires a minimal set of command line
arguments to start a training script.
- The ``--config`` and ``--opts`` are used for overwrite the deault
+ The ``--config`` and ``--opts`` are used for overwrite the default
configuration.
The ``--data`` and ``--output`` specifies the data path and output path.
diff --git a/paddlespeech/t2s/utils/error_rate.py b/paddlespeech/t2s/utils/error_rate.py
index 76a4f45be..1298680ed 100644
--- a/paddlespeech/t2s/utils/error_rate.py
+++ b/paddlespeech/t2s/utils/error_rate.py
@@ -159,7 +159,7 @@ def wer(reference, hypothesis, ignore_case=False, delimiter=' '):
def cer(reference, hypothesis, ignore_case=False, remove_space=False):
- """Calculate charactor error rate (CER). CER compares reference text and
+ """Calculate character error rate (CER). CER compares reference text and
hypothesis text in char-level. CER is defined as:
.. math::
CER = (Sc + Dc + Ic) / Nc
diff --git a/paddlespeech/utils/initialize.py b/paddlespeech/utils/initialize.py
index 8ebe6845e..efa6ee6d5 100644
--- a/paddlespeech/utils/initialize.py
+++ b/paddlespeech/utils/initialize.py
@@ -234,7 +234,7 @@ def kaiming_uniform_(tensor,
Modified tensor inspace using kaiming_uniform method
Args:
tensor (paddle.Tensor): paddle Tensor
- mode (str): ['fan_in', 'fan_out'], 'fin_in' defalut
+ mode (str): ['fan_in', 'fan_out'], 'fin_in' default
nonlinearity (str): nonlinearity method name
reverse (bool): reverse (bool: False): tensor data format order, False by default as [fout, fin, ...].
Return:
@@ -256,7 +256,7 @@ def kaiming_normal_(tensor,
Modified tensor inspace using kaiming_normal_
Args:
tensor (paddle.Tensor): paddle Tensor
- mode (str): ['fan_in', 'fan_out'], 'fin_in' defalut
+ mode (str): ['fan_in', 'fan_out'], 'fin_in' default
nonlinearity (str): nonlinearity method name
reverse (bool): reverse (bool: False): tensor data format order, False by default as [fout, fin, ...].
Return:
diff --git a/paddlespeech/vector/exps/ecapa_tdnn/extract_emb.py b/paddlespeech/vector/exps/ecapa_tdnn/extract_emb.py
index 821b1deed..a2a19cb66 100644
--- a/paddlespeech/vector/exps/ecapa_tdnn/extract_emb.py
+++ b/paddlespeech/vector/exps/ecapa_tdnn/extract_emb.py
@@ -16,10 +16,10 @@ import os
import time
import paddle
-from paddleaudio.backends import soundfile_load as load_audio
-from paddleaudio.compliance.librosa import melspectrogram
from yacs.config import CfgNode
+from paddlespeech.audio.backends import soundfile_load as load_audio
+from paddlespeech.audio.compliance.librosa import melspectrogram
from paddlespeech.s2t.utils.log import Log
from paddlespeech.vector.io.batch import feature_normalize
from paddlespeech.vector.models.ecapa_tdnn import EcapaTdnn
diff --git a/paddlespeech/vector/exps/ecapa_tdnn/test.py b/paddlespeech/vector/exps/ecapa_tdnn/test.py
index f15dbf9b7..167b82422 100644
--- a/paddlespeech/vector/exps/ecapa_tdnn/test.py
+++ b/paddlespeech/vector/exps/ecapa_tdnn/test.py
@@ -18,7 +18,7 @@ import numpy as np
import paddle
from paddle.io import BatchSampler
from paddle.io import DataLoader
-from paddleaudio.metric import compute_eer
+from sklearn.metrics import roc_curve
from tqdm import tqdm
from yacs.config import CfgNode
@@ -129,6 +129,23 @@ def compute_verification_scores(id2embedding, train_cohort, config):
return scores, labels
+def compute_eer(labels: np.ndarray, scores: np.ndarray) -> List[float]:
+ """Compute EER and return score threshold.
+
+ Args:
+ labels (np.ndarray): the trial label, shape: [N], one-dimension, N refer to the samples num
+ scores (np.ndarray): the trial scores, shape: [N], one-dimension, N refer to the samples num
+
+ Returns:
+ List[float]: eer and the specific threshold
+ """
+ fpr, tpr, threshold = roc_curve(y_true=labels, y_score=scores)
+ fnr = 1 - tpr
+ eer_threshold = threshold[np.nanargmin(np.absolute((fnr - fpr)))]
+ eer = fpr[np.nanargmin(np.absolute((fnr - fpr)))]
+ return eer, eer_threshold
+
+
def main(args, config):
"""The main process for test the speaker verification model
diff --git a/paddlespeech/vector/exps/ecapa_tdnn/train.py b/paddlespeech/vector/exps/ecapa_tdnn/train.py
index 2dc7a7164..3966a900d 100644
--- a/paddlespeech/vector/exps/ecapa_tdnn/train.py
+++ b/paddlespeech/vector/exps/ecapa_tdnn/train.py
@@ -20,9 +20,9 @@ import paddle
from paddle.io import BatchSampler
from paddle.io import DataLoader
from paddle.io import DistributedBatchSampler
-from paddleaudio.compliance.librosa import melspectrogram
from yacs.config import CfgNode
+from paddlespeech.audio.compliance.librosa import melspectrogram
from paddlespeech.s2t.utils.log import Log
from paddlespeech.vector.io.augment import build_augment_pipeline
from paddlespeech.vector.io.augment import waveform_augment
diff --git a/paddlespeech/vector/io/dataset.py b/paddlespeech/vector/io/dataset.py
index dff8ad9fd..ae5c83637 100644
--- a/paddlespeech/vector/io/dataset.py
+++ b/paddlespeech/vector/io/dataset.py
@@ -15,9 +15,9 @@ from dataclasses import dataclass
from dataclasses import fields
from paddle.io import Dataset
-from paddleaudio.backends import soundfile_load as load_audio
-from paddleaudio.compliance.librosa import melspectrogram
+from paddlespeech.audio.backends import soundfile_load as load_audio
+from paddlespeech.audio.compliance.librosa import melspectrogram
from paddlespeech.s2t.utils.log import Log
logger = Log(__name__).getlog()
diff --git a/paddlespeech/vector/io/dataset_from_json.py b/paddlespeech/vector/io/dataset_from_json.py
index 852f39a94..1d1a4ad9c 100644
--- a/paddlespeech/vector/io/dataset_from_json.py
+++ b/paddlespeech/vector/io/dataset_from_json.py
@@ -16,9 +16,10 @@ from dataclasses import dataclass
from dataclasses import fields
from paddle.io import Dataset
-from paddleaudio.backends import soundfile_load as load_audio
-from paddleaudio.compliance.librosa import melspectrogram
-from paddleaudio.compliance.librosa import mfcc
+
+from paddlespeech.audio.backends import soundfile_load as load_audio
+from paddlespeech.audio.compliance.librosa import melspectrogram
+from paddlespeech.audio.compliance.librosa import mfcc
@dataclass
diff --git a/runtime/cmake/fastdeploy.cmake b/runtime/cmake/fastdeploy.cmake
index e095cd4c2..5e9e365f5 100644
--- a/runtime/cmake/fastdeploy.cmake
+++ b/runtime/cmake/fastdeploy.cmake
@@ -26,7 +26,7 @@ if(NOT FASTDEPLOY_INSTALL_DIR)
else() # Linux
FetchContent_Declare(
fastdeploy
- URL https://paddlespeech.bj.bcebos.com/speechx/fastdeploy/fastdeploy-1.0.5-x86_64-onnx.tar.gz
+ URL https://paddlespeech.cdn.bcebos.com/speechx/fastdeploy/fastdeploy-1.0.5-x86_64-onnx.tar.gz
URL_HASH MD5=33900d986ea71aa78635e52f0733227c
${EXTERNAL_PROJECT_LOG_ARGS}
)
diff --git a/runtime/engine/asr/decoder/ctc_prefix_beam_search_decoder.cc b/runtime/engine/asr/decoder/ctc_prefix_beam_search_decoder.cc
index bf912af2e..1bda492c8 100644
--- a/runtime/engine/asr/decoder/ctc_prefix_beam_search_decoder.cc
+++ b/runtime/engine/asr/decoder/ctc_prefix_beam_search_decoder.cc
@@ -157,7 +157,7 @@ void CTCPrefixBeamSearch::AdvanceDecoding(
next_score.v_b = prefix_score.ViterbiScore() + prob;
next_score.times_b = prefix_score.Times();
- // Prefix not changed, copy the context from pefix
+ // Prefix not changed, copy the context from prefix
if (context_graph_ && !next_score.has_context) {
next_score.CopyContext(prefix_score);
next_score.has_context = true;
@@ -183,7 +183,7 @@ void CTCPrefixBeamSearch::AdvanceDecoding(
}
}
- // Prefix not changed, copy the context from pefix
+ // Prefix not changed, copy the context from prefix
if (context_graph_ && !next_score1.has_context) {
next_score1.CopyContext(prefix_score);
next_score1.has_context = true;
diff --git a/runtime/engine/common/frontend/cmvn.cc b/runtime/engine/common/frontend/cmvn.cc
index 0f1108208..bfb02a840 100644
--- a/runtime/engine/common/frontend/cmvn.cc
+++ b/runtime/engine/common/frontend/cmvn.cc
@@ -72,7 +72,7 @@ bool CMVN::Read(std::vector* feats) {
return false;
}
- // appply cmvn
+ // apply cmvn
kaldi::Timer timer;
Compute(feats);
VLOG(1) << "CMVN::Read cost: " << timer.Elapsed() << " sec.";
diff --git a/runtime/engine/common/frontend/cmvn.h b/runtime/engine/common/frontend/cmvn.h
index c515b6aeb..2d8917d95 100644
--- a/runtime/engine/common/frontend/cmvn.h
+++ b/runtime/engine/common/frontend/cmvn.h
@@ -29,7 +29,7 @@ class CMVN : public FrontendInterface {
// the length of feats = feature_row * feature_dim,
// the Matrix is squashed into Vector
virtual bool Read(std::vector* feats);
- // the dim_ is the feautre dim.
+ // the dim_ is the feature dim.
virtual size_t Dim() const { return dim_; }
virtual void SetFinished() { base_extractor_->SetFinished(); }
virtual bool IsFinished() const { return base_extractor_->IsFinished(); }
diff --git a/runtime/engine/common/frontend/db_norm.h b/runtime/engine/common/frontend/db_norm.h
index 425971437..e9f8b6995 100644
--- a/runtime/engine/common/frontend/db_norm.h
+++ b/runtime/engine/common/frontend/db_norm.h
@@ -47,7 +47,7 @@ class DecibelNormalizer : public FrontendInterface {
std::unique_ptr base_extractor);
virtual void Accept(const kaldi::VectorBase& waves);
virtual bool Read(kaldi::Vector* waves);
- // noramlize audio, the dim is 1.
+ // normalize audio, the dim is 1.
virtual size_t Dim() const { return dim_; }
virtual void SetFinished() { base_extractor_->SetFinished(); }
virtual bool IsFinished() const { return base_extractor_->IsFinished(); }
diff --git a/runtime/engine/common/matrix/kaldi-matrix.cc b/runtime/engine/common/matrix/kaldi-matrix.cc
index 6f65fb0a0..65e8e09a6 100644
--- a/runtime/engine/common/matrix/kaldi-matrix.cc
+++ b/runtime/engine/common/matrix/kaldi-matrix.cc
@@ -244,8 +244,8 @@ void MatrixBase::SymAddMat2(const Real alpha,
/// function will produce NaN in the output. This is a bug in the
/// ATLAS library. To overcome this, the AddMatMat function, which calls
/// cblas_Xgemm(...) rather than cblas_Xsyrk(...), is used in this special
- /// sitation.
- /// Wei Shi: Note this bug is observerd for single precision matrix
+ /// situation.
+ /// Wei Shi: Note this bug is observed for single precision matrix
/// on a 64-bit machine
#ifdef HAVE_ATLAS
if (transA == kTrans && num_rows_ >= 56) {
@@ -683,7 +683,7 @@ empty.
if (V_in == NULL) tmpV.Resize(1, this->num_cols_); // work-space if V_in
empty.
- /// Impementation notes:
+ /// Implementation notes:
/// Lapack works in column-order, therefore the dimensions of *this are
/// swapped as well as the U and V matrices.
@@ -2378,7 +2378,7 @@ bool ReadHtk(std::istream &is, Matrix *M_ptr, HtkHeader *header_ptr)
Matrix &M = *M_ptr;
HtkHeader htk_hdr;
- // TODO(arnab): this fails if the HTK file has CRC cheksum or is compressed.
+ // TODO(arnab): this fails if the HTK file has CRC checksum or is compressed.
is.read((char*)&htk_hdr, sizeof(htk_hdr)); // we're being really POSIX here!
if (is.fail()) {
KALDI_WARN << "Could not read header from HTK feature file ";
diff --git a/runtime/engine/common/matrix/kaldi-vector.cc b/runtime/engine/common/matrix/kaldi-vector.cc
index 3ab9a7ffa..790ebe128 100644
--- a/runtime/engine/common/matrix/kaldi-vector.cc
+++ b/runtime/engine/common/matrix/kaldi-vector.cc
@@ -235,7 +235,7 @@ void VectorBase::CopyRowsFromMat(const MatrixBase &mat) {
memcpy(inc_data, mat.Data(), cols * rows * sizeof(Real));
} else {
for (MatrixIndexT i = 0; i < rows; i++) {
- // copy the data to the propper position
+ // copy the data to the proper position
memcpy(inc_data, mat.RowData(i), cols * sizeof(Real));
// set new copy position
inc_data += cols;
diff --git a/runtime/engine/common/utils/file_utils.cc b/runtime/engine/common/utils/file_utils.cc
index 385f2b656..59bb64482 100644
--- a/runtime/engine/common/utils/file_utils.cc
+++ b/runtime/engine/common/utils/file_utils.cc
@@ -44,7 +44,7 @@ std::string ReadFile2String(const std::string& path) {
}
bool FileExists(const std::string& strFilename) {
- // this funciton if from:
+ // this function if from:
// https://github.com/kaldi-asr/kaldi/blob/master/src/fstext/deterministic-fst-test.cc
struct stat stFileInfo;
bool blnReturn;
diff --git a/runtime/engine/kaldi/lat/kaldi-lattice.cc b/runtime/engine/kaldi/lat/kaldi-lattice.cc
index 744cc5384..0bd291ee1 100644
--- a/runtime/engine/kaldi/lat/kaldi-lattice.cc
+++ b/runtime/engine/kaldi/lat/kaldi-lattice.cc
@@ -407,7 +407,7 @@ bool WriteLattice(std::ostream &os, bool binary, const Lattice &t) {
if (os.fail())
KALDI_WARN << "Stream failure detected.";
// Write another newline as a terminating character. The read routine will
- // detect this [this is a Kaldi mechanism, not somethig in the original
+ // detect this [this is a Kaldi mechanism, not something in the original
// OpenFst code].
os << '\n';
return os.good();
diff --git a/runtime/examples/README.md b/runtime/examples/README.md
index de27bd94b..6d316d649 100644
--- a/runtime/examples/README.md
+++ b/runtime/examples/README.md
@@ -34,7 +34,7 @@ bash run.sh --stop_stage 4
## Display Model with [Netron](https://github.com/lutzroeder/netron)
-If you have a model, we can using this commnd to show model graph.
+If you have a model, we can using this commend to show model graph.
For example:
```
diff --git a/runtime/examples/audio_classification/README.md b/runtime/examples/audio_classification/README.md
index 6d7a37423..7fb8d611a 100644
--- a/runtime/examples/audio_classification/README.md
+++ b/runtime/examples/audio_classification/README.md
@@ -74,7 +74,7 @@ includes/
#### set path
push resource into android phone
-1. change resource path in conf to gloabal path, such as:
+1. change resource path in conf to global path, such as:
[CONF]
wav_normal=true
@@ -92,9 +92,9 @@ push resource into android phone
high_freq=14000
dither=0.0
2. adb push conf label_list scp test.wav /data/local/tmp/
-3. set reource path in android demo(android_demo/app/src/main/cpp/native-lib.cpp) to actual path, such as:
+3. set resource path in android demo(android_demo/app/src/main/cpp/native-lib.cpp) to actual path, such as:
std::string conf_path = "/data/local/tmp/conf";
std::string wav_path = "/data/local/tmp/test.wav";
-4. excecute android_demo in android studio
+4. execute android_demo in android studio
diff --git a/runtime/examples/codelab/decoder/run.sh b/runtime/examples/codelab/decoder/run.sh
index 1a9e3cd7e..5e43d5cca 100755
--- a/runtime/examples/codelab/decoder/run.sh
+++ b/runtime/examples/codelab/decoder/run.sh
@@ -28,7 +28,7 @@ mkdir -p $exp_dir
if [[ ! -f data/model/asr0_deepspeech2_online_aishell_ckpt_0.2.0.model.tar.gz ]]; then
mkdir -p data/model
pushd data/model
- wget -c https://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_online_aishell_ckpt_0.2.0.model.tar.gz
+ wget -c https://paddlespeech.cdn.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_online_aishell_ckpt_0.2.0.model.tar.gz
tar xzfv asr0_deepspeech2_online_aishell_ckpt_0.2.0.model.tar.gz
popd
fi
@@ -36,7 +36,7 @@ fi
# produce wav scp
if [ ! -f data/wav.scp ]; then
pushd data
- wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
+ wget -c https://paddlespeech.cdn.bcebos.com/PaddleAudio/zh.wav
echo "utt1 " $PWD/zh.wav > wav.scp
popd
fi
diff --git a/runtime/examples/codelab/feat/run.sh b/runtime/examples/codelab/feat/run.sh
index 5d7612ae5..ffb373b9c 100755
--- a/runtime/examples/codelab/feat/run.sh
+++ b/runtime/examples/codelab/feat/run.sh
@@ -15,7 +15,7 @@ fi
if [ ! -e data/model/asr0_deepspeech2_online_aishell_ckpt_0.2.0.model.tar.gz ]; then
mkdir -p data/model
pushd data/model
- wget -c https://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_online_aishell_ckpt_0.2.0.model.tar.gz
+ wget -c https://paddlespeech.cdn.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_online_aishell_ckpt_0.2.0.model.tar.gz
tar xzfv asr0_deepspeech2_online_aishell_ckpt_0.2.0.model.tar.gz
popd
fi
@@ -24,7 +24,7 @@ fi
if [ ! -f data/wav.scp ]; then
mkdir -p data
pushd data
- wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
+ wget -c https://paddlespeech.cdn.bcebos.com/PaddleAudio/zh.wav
echo "utt1 " $PWD/zh.wav > wav.scp
popd
fi
diff --git a/runtime/examples/codelab/nnet/run.sh b/runtime/examples/codelab/nnet/run.sh
index 842499ba2..210928db2 100755
--- a/runtime/examples/codelab/nnet/run.sh
+++ b/runtime/examples/codelab/nnet/run.sh
@@ -15,7 +15,7 @@ fi
if [ ! -f data/model/asr0_deepspeech2_online_aishell_ckpt_0.2.0.model.tar.gz ]; then
mkdir -p data/model
pushd data/model
- wget -c https://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_online_aishell_ckpt_0.2.0.model.tar.gz
+ wget -c https://paddlespeech.cdn.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_online_aishell_ckpt_0.2.0.model.tar.gz
tar xzfv asr0_deepspeech2_online_aishell_ckpt_0.2.0.model.tar.gz
popd
fi
diff --git a/runtime/examples/codelab/u2/run.sh b/runtime/examples/codelab/u2/run.sh
index d314262ba..8f6787571 100755
--- a/runtime/examples/codelab/u2/run.sh
+++ b/runtime/examples/codelab/u2/run.sh
@@ -15,7 +15,7 @@ fi
if [ ! -f data/model/asr1_chunk_conformer_u2pp_wenetspeech_static_1.1.0.model.tar.gz ]; then
mkdir -p data/model
pushd data/model
- wget -c https://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr1/static/asr1_chunk_conformer_u2pp_wenetspeech_static_1.1.0.model.tar.gz
+ wget -c https://paddlespeech.cdn.bcebos.com/s2t/wenetspeech/asr1/static/asr1_chunk_conformer_u2pp_wenetspeech_static_1.1.0.model.tar.gz
tar xzfv asr1_chunk_conformer_u2pp_wenetspeech_static_1.1.0.model.tar.gz
popd
fi
@@ -24,7 +24,7 @@ fi
if [ ! -f data/wav.scp ]; then
mkdir -p data
pushd data
- wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
+ wget -c https://paddlespeech.cdn.bcebos.com/PaddleAudio/zh.wav
echo "utt1 " $PWD/zh.wav > wav.scp
popd
fi
diff --git a/runtime/examples/custom_asr/README.md b/runtime/examples/custom_asr/README.md
index 33cf4ff03..992e5aac5 100644
--- a/runtime/examples/custom_asr/README.md
+++ b/runtime/examples/custom_asr/README.md
@@ -13,7 +13,7 @@ eg:
* after replace operation, G = fstreplace(G_with_slot, address_slot), we will get the customized graph.

-These operations are in the scripts, please check out. we will lanuch more detail scripts.
+These operations are in the scripts, please check out. we will launch more detail scripts.
## How to run
diff --git a/runtime/examples/custom_asr/run.sh b/runtime/examples/custom_asr/run.sh
index ed67a52be..b60d7c9ac 100644
--- a/runtime/examples/custom_asr/run.sh
+++ b/runtime/examples/custom_asr/run.sh
@@ -21,7 +21,7 @@ text_with_slot=$data/text_with_slot
resource=$PWD/resource
# download resource
if [ ! -f $cmvn ]; then
- wget -c https://paddlespeech.bj.bcebos.com/s2t/paddle_asr_online/resource.tar.gz
+ wget -c https://paddlespeech.cdn.bcebos.com/s2t/paddle_asr_online/resource.tar.gz
tar xzfv resource.tar.gz
ln -s ./resource/data .
fi
diff --git a/runtime/examples/text_lm/local/mmseg.py b/runtime/examples/text_lm/local/mmseg.py
index 74295cd3c..4d72afd39 100755
--- a/runtime/examples/text_lm/local/mmseg.py
+++ b/runtime/examples/text_lm/local/mmseg.py
@@ -156,8 +156,8 @@ class Analysis:
return self.text[self.pos]
#判断该字符是否是中文字符(不包括中文标点)
- def isChineseChar(self, charater):
- return 0x4e00 <= ord(charater) < 0x9fa6
+ def isChineseChar(self, character):
+ return 0x4e00 <= ord(character) < 0x9fa6
#判断是否是ASCII码
def isASCIIChar(self, ch):
@@ -253,7 +253,6 @@ class Analysis:
# print(word3.length, word3.text)
if word3.length == -1:
chunk = Chunk(word1, word2)
- # print("Ture")
else:
chunk = Chunk(word1, word2, word3)
chunks.append(chunk)
diff --git a/runtime/examples/u2pp_ol/wenetspeech/local/recognizer_wfst.sh b/runtime/examples/u2pp_ol/wenetspeech/local/recognizer_wfst.sh
index 57d69a4c0..fba6ecc42 100755
--- a/runtime/examples/u2pp_ol/wenetspeech/local/recognizer_wfst.sh
+++ b/runtime/examples/u2pp_ol/wenetspeech/local/recognizer_wfst.sh
@@ -23,7 +23,7 @@ if [ ! -f $graph ]; then
# download ngram, if you want to make graph by yourself, please refer local/run_build_tlg.sh
mkdir -p $lang_dir
pushd $lang_dir
- wget -c https://paddlespeech.bj.bcebos.com/speechx/examples/ngram/zh/tlg.zip
+ wget -c https://paddlespeech.cdn.bcebos.com/speechx/examples/ngram/zh/tlg.zip
unzip tlg.zip
popd
fi
diff --git a/runtime/examples/u2pp_ol/wenetspeech/local/recognizer_wfst_fastdeploy.sh b/runtime/examples/u2pp_ol/wenetspeech/local/recognizer_wfst_fastdeploy.sh
index fb0a19e88..77f2bcd34 100755
--- a/runtime/examples/u2pp_ol/wenetspeech/local/recognizer_wfst_fastdeploy.sh
+++ b/runtime/examples/u2pp_ol/wenetspeech/local/recognizer_wfst_fastdeploy.sh
@@ -23,7 +23,7 @@ if [ ! -f $graph ]; then
# download ngram, if you want to make graph by yourself, please refer local/run_build_tlg.sh
mkdir -p $lang_dir
pushd $lang_dir
- wget -c https://paddlespeech.bj.bcebos.com/speechx/examples/ngram/zh/tlg.zip
+ wget -c https://paddlespeech.cdn.bcebos.com/speechx/examples/ngram/zh/tlg.zip
unzip tlg.zip
popd
fi
diff --git a/runtime/examples/u2pp_ol/wenetspeech/local/run_build_tlg.sh b/runtime/examples/u2pp_ol/wenetspeech/local/run_build_tlg.sh
index c061e910a..74d5c5493 100755
--- a/runtime/examples/u2pp_ol/wenetspeech/local/run_build_tlg.sh
+++ b/runtime/examples/u2pp_ol/wenetspeech/local/run_build_tlg.sh
@@ -23,7 +23,7 @@ if [ $stage -le -1 ] && [ $stop_stage -ge -1 ]; then
if [ ! -f $data/speech.ngram.zh.tar.gz ];then
# download ngram
pushd $data
- wget -c http://paddlespeech.bj.bcebos.com/speechx/examples/ngram/zh/speech.ngram.zh.tar.gz
+ wget -c http://paddlespeech.cdn.bcebos.com/speechx/examples/ngram/zh/speech.ngram.zh.tar.gz
tar xvzf speech.ngram.zh.tar.gz
popd
fi
diff --git a/runtime/examples/u2pp_ol/wenetspeech/run.sh b/runtime/examples/u2pp_ol/wenetspeech/run.sh
index 1d4657e70..13849170c 100755
--- a/runtime/examples/u2pp_ol/wenetspeech/run.sh
+++ b/runtime/examples/u2pp_ol/wenetspeech/run.sh
@@ -30,7 +30,7 @@ if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ];then
mkdir -p $ckpt_dir
pushd $ckpt_dir
- wget -c https://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr1/static/asr1_chunk_conformer_u2pp_wenetspeech_static_1.3.0.model.tar.gz
+ wget -c https://paddlespeech.cdn.bcebos.com/s2t/wenetspeech/asr1/static/asr1_chunk_conformer_u2pp_wenetspeech_static_1.3.0.model.tar.gz
tar xzfv asr1_chunk_conformer_u2pp_wenetspeech_static_1.3.0.model.tar.gz
popd
@@ -41,7 +41,7 @@ if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ];then
mkdir -p $ckpt_dir
pushd $ckpt_dir
- wget -c https://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr1/static/asr1_chunk_conformer_u2pp_wenetspeech_static_quant_1.3.0.model.tar.gz
+ wget -c https://paddlespeech.cdn.bcebos.com/s2t/wenetspeech/asr1/static/asr1_chunk_conformer_u2pp_wenetspeech_static_quant_1.3.0.model.tar.gz
tar xzfv asr1_chunk_conformer_u2pp_wenetspeech_static_quant_1.3.0.model.tar.gz
popd
@@ -51,7 +51,7 @@ if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ];then
if [ ! -f data/wav.scp ]; then
mkdir -p $data
pushd $data
- wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
+ wget -c https://paddlespeech.cdn.bcebos.com/PaddleAudio/zh.wav
echo "utt1 " $PWD/zh.wav > wav.scp
popd
fi
@@ -59,7 +59,7 @@ if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ];then
# aishell wav scp
if [ ! -d $data/test ]; then
pushd $data
- wget -c https://paddlespeech.bj.bcebos.com/s2t/paddle_asr_online/aishell_test.zip
+ wget -c https://paddlespeech.cdn.bcebos.com/s2t/paddle_asr_online/aishell_test.zip
unzip aishell_test.zip
popd
diff --git a/runtime/patch/openfst/src/include/fst/flags.h b/runtime/patch/openfst/src/include/fst/flags.h
index b5ec8ff74..54dd30cc2 100644
--- a/runtime/patch/openfst/src/include/fst/flags.h
+++ b/runtime/patch/openfst/src/include/fst/flags.h
@@ -181,8 +181,8 @@ template
class FlagRegisterer {
public:
FlagRegisterer(const string &name, const FlagDescription &desc) {
- auto registr = FlagRegister::GetRegister();
- registr->SetDescription(name, desc);
+ auto r = FlagRegister::GetRegister();
+ r->SetDescription(name, desc);
}
private:
diff --git a/setup.py b/setup.py
index 59a3e7db1..47e543ce4 100644
--- a/setup.py
+++ b/setup.py
@@ -32,6 +32,14 @@ VERSION = '0.0.0'
COMMITID = 'none'
+def determine_python_version():
+ """
+ Determine the current python version. The function return a string such as '3.7'.
+ """
+ python_version = f"{sys.version_info.major}.{sys.version_info.minor}"
+ return python_version
+
+
def determine_opencc_version():
# get gcc version
gcc_version = None
@@ -46,11 +54,31 @@ def determine_opencc_version():
# determine opencc version
if gcc_version:
- if int(gcc_version.split(".")[0]) <= 9:
- return "opencc==1.1.6" # GCC<=9 need opencc==1.1.6
+ if int(gcc_version.split(".")[0]) < 9:
+ return "opencc==1.1.6" # GCC<9 need opencc==1.1.6
return "opencc" # default
+def determine_scipy_version():
+ # get python version
+ python_version = determine_python_version()
+
+ # determine scipy version
+ if python_version == "3.8":
+ return "scipy>=1.4.0, <=1.12.0" # Python3.8 need scipy>=1.4.0, <=1.12.0
+ return "scipy" # default
+
+
+def determine_matplotlib_version():
+ # get python version
+ python_version = determine_python_version()
+
+ # determine matplotlib version
+ if python_version == "3.8" or python_version == "3.9":
+ return "matplotlib<=3.8.4" # Python3.8/9 need matplotlib<=3.8.4
+ return "matplotlib" # default
+
+
base = [
"braceexpand",
"editdistance",
@@ -60,26 +88,24 @@ base = [
"hyperpyyaml",
"inflect",
"jsonlines",
- # paddleaudio align with librosa==0.8.1, which need numpy==1.23.x
- "numpy==1.23.5",
- "librosa==0.8.1",
- "scipy>=1.4.0, <=1.12.0",
+ "numpy",
+ "librosa>=0.9",
+ determine_scipy_version(), # scipy or scipy>=1.4.0, <=1.12.0
"loguru",
- "matplotlib<=3.8.4",
+ determine_matplotlib_version(), # matplotlib or matplotlib<=3.8.4
"nara_wpe",
"onnxruntime>=1.11.0",
determine_opencc_version(), # opencc or opencc==1.1.6
"opencc-python-reimplemented",
"pandas",
- "paddleaudio>=1.1.0",
"paddlenlp>=2.4.8",
"paddleslim>=2.3.4",
"ppdiffusers>=0.9.0",
"paddlespeech_feat",
- "praatio>=5.0.0, <=5.1.1",
+ "praatio>=6.0.0",
"prettytable",
- "pydantic>=1.10.14, <2.0",
- "pypinyin<=0.44.0",
+ "pydantic",
+ "pypinyin",
"pypinyin-dict",
"python-dateutil",
"pyworld>=0.2.12",
@@ -92,8 +118,16 @@ base = [
"ToJyutping",
"typeguard",
"webrtcvad",
- "yacs~=0.1.8",
+ "yacs>=0.1.8",
"zhon",
+ "scikit-learn",
+ "pathos",
+ "kaldiio",
+ "ffmpeg-python",
+ "ffmpy",
+ "flatten_dict",
+ "pyloudnorm",
+ "rich",
]
server = ["pattern_singleton", "websockets"]
diff --git a/tests/benchmark/pwgan/run_all.sh b/tests/benchmark/pwgan/run_all.sh
index 874e9aa25..817ed057c 100755
--- a/tests/benchmark/pwgan/run_all.sh
+++ b/tests/benchmark/pwgan/run_all.sh
@@ -22,7 +22,7 @@ if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
wget https://weixinxcxdb.oss-cn-beijing.aliyuncs.com/gwYinPinKu/BZNSYP.rar
mkdir BZNSYP
unrar x BZNSYP.rar BZNSYP
- wget https://paddlespeech.bj.bcebos.com/Parakeet/benchmark/durations.txt
+ wget https://paddlespeech.cdn.bcebos.com/Parakeet/benchmark/durations.txt
fi
# 数据预处理
if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
diff --git a/tests/chains/speedyspeech/prepare.sh b/tests/chains/speedyspeech/prepare.sh
index 1ddcd6776..ab4620465 100755
--- a/tests/chains/speedyspeech/prepare.sh
+++ b/tests/chains/speedyspeech/prepare.sh
@@ -32,23 +32,23 @@ trainer_list=$(func_parser_value "${lines[14]}")
# MODE be one of ['lite_train_infer' 'whole_infer' 'whole_train_infer']
if [ ${MODE} = "lite_train_infer" ];then
# pretrain lite train data
- wget -nc -P ./pretrain_models/ https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwg_baker_ckpt_0.4.zip
+ wget -nc -P ./pretrain_models/ https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/pwgan/pwg_baker_ckpt_0.4.zip
(cd ./pretrain_models && unzip pwg_baker_ckpt_0.4.zip)
# download data
rm -rf ./train_data/mini_BZNSYP
- wget -nc -P ./train_data/ https://paddlespeech.bj.bcebos.com/datasets/CE/speedyspeech_v0.5/mini_BZNSYP.tar.gz
+ wget -nc -P ./train_data/ https://paddlespeech.cdn.bcebos.com/datasets/CE/speedyspeech_v0.5/mini_BZNSYP.tar.gz
cd ./train_data/ && tar xzf mini_BZNSYP.tar.gz
cd ../
elif [ ${MODE} = "whole_train_infer" ];then
- wget -nc -P ./pretrain_models/ https://paddlespeech.bj.bcebos.com/Parakeet/released_models/speedyspeech/speedyspeech_nosil_baker_ckpt_0.5.zip
- wget -nc -P ./pretrain_models/ https://paddlespeech.bj.bcebos.com/Parakeet/pwg_baker_ckpt_0.4.zip
+ wget -nc -P ./pretrain_models/ https://paddlespeech.cdn.bcebos.com/Parakeet/released_models/speedyspeech/speedyspeech_nosil_baker_ckpt_0.5.zip
+ wget -nc -P ./pretrain_models/ https://paddlespeech.cdn.bcebos.com/Parakeet/pwg_baker_ckpt_0.4.zip
(cd ./pretrain_models && unzip speedyspeech_nosil_baker_ckpt_0.5.zip && unzip pwg_baker_ckpt_0.4.zip)
rm -rf ./train_data/processed_BZNSYP
- wget -nc -P ./train_data/ https://paddlespeech.bj.bcebos.com/datasets/CE/speedyspeech_v0.5/processed_BZNSYP.tar.gz
+ wget -nc -P ./train_data/ https://paddlespeech.cdn.bcebos.com/datasets/CE/speedyspeech_v0.5/processed_BZNSYP.tar.gz
cd ./train_data/ && tar xzf processed_BZNSYP.tar.gz
cd ../
else
# whole infer using paddle inference library
- wget -nc -P ./pretrain_models/ https://paddlespeech.bj.bcebos.com/Parakeet/speedyspeech_pwg_inference_0.5.zip
+ wget -nc -P ./pretrain_models/ https://paddlespeech.cdn.bcebos.com/Parakeet/speedyspeech_pwg_inference_0.5.zip
(cd ./pretrain_models && unzip speedyspeech_pwg_inference_0.5.zip)
fi
diff --git a/tests/test_tipc/conformer/scripts/aishell_tiny.py b/tests/test_tipc/conformer/scripts/aishell_tiny.py
index c87463b50..27b713a55 100644
--- a/tests/test_tipc/conformer/scripts/aishell_tiny.py
+++ b/tests/test_tipc/conformer/scripts/aishell_tiny.py
@@ -62,7 +62,7 @@ def create_manifest(data_dir, manifest_path_prefix):
if line == '':
continue
audio_id, text = line.split(' ', 1)
- # remove withespace, charactor text
+ # remove withespace, character text
text = ''.join(text.split())
transcript_dict[audio_id] = text
diff --git a/tests/test_tipc/prepare.sh b/tests/test_tipc/prepare.sh
index 7d4dd8b16..296067d55 100755
--- a/tests/test_tipc/prepare.sh
+++ b/tests/test_tipc/prepare.sh
@@ -74,9 +74,9 @@ if [[ ${MODE} = "benchmark_train" ]];then
wget -nc https://paddle-wheel.bj.bcebos.com/benchmark/BZNSYP.rar
mkdir -p BZNSYP
unrar x BZNSYP.rar BZNSYP
- wget -nc https://paddlespeech.bj.bcebos.com/Parakeet/benchmark/durations.txt
+ wget -nc https://paddlespeech.cdn.bcebos.com/Parakeet/benchmark/durations.txt
# 避免网络问题导致的 nltk_data 无法下载使程序 hang 住
- wget -nc https://paddlespeech.bj.bcebos.com/Parakeet/tools/nltk_data.tar.gz
+ wget -nc https://paddlespeech.cdn.bcebos.com/Parakeet/tools/nltk_data.tar.gz
tar -xzf nltk_data.tar.gz -C ${HOME}
# 数据预处理
python ../paddlespeech/t2s/exps/gan_vocoder/preprocess.py --rootdir=BZNSYP/ --dumpdir=dump --num-cpu=20 --cut-sil=True --dur-file=durations.txt --config=../examples/csmsc/voc1/conf/default.yaml
@@ -92,8 +92,8 @@ if [[ ${MODE} = "benchmark_train" ]];then
if [[ ${model_name} == "mdtc" ]]; then
# 下载 Snips 数据集并解压缩
- wget https://paddlespeech.bj.bcebos.com/datasets/hey_snips_kws_4.0.tar.gz.1
- wget https://paddlespeech.bj.bcebos.com/datasets/hey_snips_kws_4.0.tar.gz.2
+ wget https://paddlespeech.cdn.bcebos.com/datasets/hey_snips_kws_4.0.tar.gz.1
+ wget https://paddlespeech.cdn.bcebos.com/datasets/hey_snips_kws_4.0.tar.gz.2
cat hey_snips_kws_4.0.tar.gz.* > hey_snips_kws_4.0.tar.gz
rm hey_snips_kws_4.0.tar.gz.*
tar -xzf hey_snips_kws_4.0.tar.gz
diff --git a/tests/unit/asr/deepspeech2_online_model_test.sh b/tests/unit/asr/deepspeech2_online_model_test.sh
index 629238fd0..69d79bdb6 100644
--- a/tests/unit/asr/deepspeech2_online_model_test.sh
+++ b/tests/unit/asr/deepspeech2_online_model_test.sh
@@ -1,3 +1,3 @@
mkdir -p ./test_data
-wget -P ./test_data https://paddlespeech.bj.bcebos.com/datasets/unit_test/asr/static_ds2online_inputs.pickle
+wget -P ./test_data https://paddlespeech.cdn.bcebos.com/datasets/unit_test/asr/static_ds2online_inputs.pickle
python deepspeech2_online_model_test.py
diff --git a/tests/unit/asr/reverse_pad_list.py b/tests/unit/asr/reverse_pad_list.py
index 215ed5ceb..1b63890a0 100644
--- a/tests/unit/asr/reverse_pad_list.py
+++ b/tests/unit/asr/reverse_pad_list.py
@@ -65,14 +65,16 @@ def reverse_pad_list_with_sos_eos(r_hyps,
max_len = paddle.max(r_hyps_lens)
index_range = paddle.arange(0, max_len, 1)
seq_len_expand = r_hyps_lens.unsqueeze(1)
- seq_mask = seq_len_expand > index_range # (beam, max_len)
+ seq_mask = seq_len_expand > index_range.astype(
+ seq_len_expand.dtype) # (beam, max_len)
- index = (seq_len_expand - 1) - index_range # (beam, max_len)
+ index = (seq_len_expand - 1) - index_range.astype(
+ seq_len_expand.dtype) # (beam, max_len)
# >>> index
# >>> tensor([[ 2, 1, 0],
# >>> [ 2, 1, 0],
# >>> [ 0, -1, -2]])
- index = index * seq_mask
+ index = index * seq_mask.astype(index.dtype)
# >>> index
# >>> tensor([[2, 1, 0],
@@ -103,7 +105,8 @@ def reverse_pad_list_with_sos_eos(r_hyps,
# >>> tensor([[3, 2, 1],
# >>> [4, 8, 9],
# >>> [2, 2, 2]])
- r_hyps = paddle.where(seq_mask, r_hyps, eos)
+ r_hyps = paddle.where(seq_mask, r_hyps,
+ paddle.to_tensor(eos, dtype=r_hyps.dtype))
# >>> r_hyps
# >>> tensor([[3, 2, 1],
# >>> [4, 8, 9],
diff --git a/tests/unit/audiotools/core/test_audio_signal.py b/tests/unit/audiotools/core/test_audio_signal.py
index 0e82ae9d5..19575828c 100644
--- a/tests/unit/audiotools/core/test_audio_signal.py
+++ b/tests/unit/audiotools/core/test_audio_signal.py
@@ -26,14 +26,14 @@ def test_io():
signal_from_file = AudioSignal(f.name)
mp3_signal = AudioSignal(audio_path.replace("wav", "mp3"))
- print(mp3_signal)
assert signal == signal_from_file
- print(signal)
- print(signal.markdown())
mp3_signal = AudioSignal.excerpt(
audio_path.replace("wav", "mp3"), offset=5, duration=5)
+
+ assert mp3_signal.sample_rate == 44100
+ assert mp3_signal.signal_length == 220500
assert mp3_signal.signal_duration == 5.0
assert mp3_signal.duration == 5.0
assert mp3_signal.length == mp3_signal.signal_length
diff --git a/tests/unit/audiotools/core/test_util.py b/tests/unit/audiotools/core/test_util.py
index 155686acd..16e5d5e92 100644
--- a/tests/unit/audiotools/core/test_util.py
+++ b/tests/unit/audiotools/core/test_util.py
@@ -13,7 +13,6 @@ import pytest
from paddlespeech.audiotools import util
from paddlespeech.audiotools.core.audio_signal import AudioSignal
-from paddlespeech.vector.training.seeding import seed_everything
def test_check_random_state():
@@ -36,12 +35,12 @@ def test_check_random_state():
def test_seed():
- seed_everything(0)
+ util.seed_everything(0)
paddle_result_a = paddle.randn([1])
np_result_a = np.random.randn(1)
py_result_a = random.random()
- seed_everything(0)
+ util.seed_everything(0)
paddle_result_b = paddle.randn([1])
np_result_b = np.random.randn(1)
py_result_b = random.random()
diff --git a/tests/unit/audiotools/test_audiotools.sh b/tests/unit/audiotools/test_audiotools.sh
index 3a0161900..bb8f693b7 100644
--- a/tests/unit/audiotools/test_audiotools.sh
+++ b/tests/unit/audiotools/test_audiotools.sh
@@ -1,6 +1,5 @@
-python -m pip install -r ../../../paddlespeech/audiotools/requirements.txt
-wget https://paddlespeech.bj.bcebos.com/PaddleAudio/audio_tools/audio.tar.gz
-wget https://paddlespeech.bj.bcebos.com/PaddleAudio/audio_tools/regression.tar.gz
+wget -c https://paddlespeech.cdn.bcebos.com/PaddleAudio/audio_tools/audio.tar.gz
+wget -c https://paddlespeech.cdn.bcebos.com/PaddleAudio/audio_tools/regression.tar.gz
tar -zxvf audio.tar.gz
tar -zxvf regression.tar.gz
-python -m pytest
\ No newline at end of file
+python -m pytest
diff --git a/tests/unit/ci.sh b/tests/unit/ci.sh
index 6beff0707..c298e3ae8 100644
--- a/tests/unit/ci.sh
+++ b/tests/unit/ci.sh
@@ -16,6 +16,7 @@ function main(){
python test_enfrontend.py
python test_fftconv1d.py
python test_mixfrontend.py
+ python test_losses.py
echo "End TTS"
echo "Start Vector"
diff --git a/tests/unit/cli/aishell_test_prepare.py b/tests/unit/cli/aishell_test_prepare.py
index c364e4fd9..ef582426c 100644
--- a/tests/unit/cli/aishell_test_prepare.py
+++ b/tests/unit/cli/aishell_test_prepare.py
@@ -63,7 +63,7 @@ def create_manifest(data_dir, manifest_path_prefix):
if line == '':
continue
audio_id, text = line.split(' ', 1)
- # remove withespace, charactor text
+ # remove withespace, character text
text = ''.join(text.split())
transcript_dict[audio_id] = text
diff --git a/tests/unit/cli/test_cli.sh b/tests/unit/cli/test_cli.sh
index 3903e6597..4526f6e4c 100755
--- a/tests/unit/cli/test_cli.sh
+++ b/tests/unit/cli/test_cli.sh
@@ -3,19 +3,19 @@ set -e
echo -e "\e[1;31monly if you see 'Test success !!!', the cli testing is successful\e[0m"
# Audio classification
-wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/cat.wav https://paddlespeech.bj.bcebos.com/PaddleAudio/dog.wav
+wget -c https://paddlespeech.cdn.bcebos.com/PaddleAudio/cat.wav https://paddlespeech.cdn.bcebos.com/PaddleAudio/dog.wav
paddlespeech cls --input ./cat.wav --topk 10
# Punctuation_restoration
paddlespeech text --input 今天的天气真不错啊你下午有空吗我想约你一起去吃饭 --model ernie_linear_p3_wudao_fast
# Speech SSL
-wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/en.wav
+wget -c https://paddlespeech.cdn.bcebos.com/PaddleAudio/en.wav
paddlespeech ssl --task asr --lang en --input ./en.wav
paddlespeech ssl --task vector --lang en --input ./en.wav
# Speech_recognition
-wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespeech.bj.bcebos.com/PaddleAudio/ch_zh_mix.wav
+wget -c https://paddlespeech.cdn.bcebos.com/PaddleAudio/zh.wav https://paddlespeech.cdn.bcebos.com/PaddleAudio/ch_zh_mix.wav
paddlespeech asr --input ./zh.wav
paddlespeech asr --model conformer_aishell --input ./zh.wav
paddlespeech asr --model conformer_online_aishell --input ./zh.wav
@@ -34,7 +34,7 @@ paddlespeech asr --model conformer_online_wenetspeech --num_decoding_left_chunks
# long audio restriction
{
-wget -c https://paddlespeech.bj.bcebos.com/datasets/single_wav/zh/test_long_audio_01.wav
+wget -c https://paddlespeech.cdn.bcebos.com/datasets/single_wav/zh/test_long_audio_01.wav
paddlespeech asr --model deepspeech2online_wenetspeech --input test_long_audio_01.wav -y
if [ $? -ne 255 ]; then
echo -e "\e[1;31mTime restriction not passed\e[0m"
@@ -81,7 +81,7 @@ paddlespeech tts --am fastspeech2_male --voc pwgan_male --lang mix --input "我
paddlespeech st --input ./en.wav
# Speaker Verification
-wget -c https://paddlespeech.bj.bcebos.com/vector/audio/85236145389.wav
+wget -c https://paddlespeech.cdn.bcebos.com/vector/audio/85236145389.wav
paddlespeech vector --task spk --input 85236145389.wav
# batch process
diff --git a/tests/unit/server/offline/test_server_client.sh b/tests/unit/server/offline/test_server_client.sh
index 29bdd4032..26fb100a3 100644
--- a/tests/unit/server/offline/test_server_client.sh
+++ b/tests/unit/server/offline/test_server_client.sh
@@ -66,8 +66,8 @@ config_file=./conf/application.yaml
server_ip=$(cat $config_file | grep "host" | awk -F " " '{print $2}')
port=$(cat $config_file | grep "port" | awk '/port:/ {print $2}')
-echo "Sevice ip: $server_ip" | tee ./log/test_result.log
-echo "Sevice port: $port" | tee -a ./log/test_result.log
+echo "Service ip: $server_ip" | tee ./log/test_result.log
+echo "Service port: $port" | tee -a ./log/test_result.log
# whether a process is listening on $port
pid=`lsof -i :"$port"|grep -v "PID" | awk '{print $2}'`
@@ -77,7 +77,7 @@ if [ "$pid" != "" ]; then
fi
# download test audios for ASR client
-wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespeech.bj.bcebos.com/PaddleAudio/en.wav
+wget -c https://paddlespeech.cdn.bcebos.com/PaddleAudio/zh.wav https://paddlespeech.cdn.bcebos.com/PaddleAudio/en.wav
target_start_num=0 # the number of start service
@@ -190,7 +190,7 @@ echo "**************************************************************************
echo "All tests completed." | tee -a ./log/test_result.log
-# sohw all the test results
+# show all the test results
echo "***************** Here are all the test results ********************"
cat ./log/test_result.log
diff --git a/tests/unit/server/online/tts/check_server/test.sh b/tests/unit/server/online/tts/check_server/test.sh
index c62c54c76..998a07b3f 100644
--- a/tests/unit/server/online/tts/check_server/test.sh
+++ b/tests/unit/server/online/tts/check_server/test.sh
@@ -76,8 +76,8 @@ config_file=./conf/application.yaml
server_ip=$(cat $config_file | grep "host" | awk -F " " '{print $2}')
port=$(cat $config_file | grep "port" | awk '/port:/ {print $2}')
-echo "Sevice ip: $server_ip" | tee $log/test_result.log
-echo "Sevice port: $port" | tee -a $log/test_result.log
+echo "Service ip: $server_ip" | tee $log/test_result.log
+echo "Service port: $port" | tee -a $log/test_result.log
# whether a process is listening on $port
pid=`lsof -i :"$port"|grep -v "PID" | awk '{print $2}'`
@@ -307,7 +307,7 @@ echo "**************************************************************************
echo "All tests completed." | tee -a $log/test_result.log
-# sohw all the test results
+# show all the test results
echo "***************** Here are all the test results ********************"
cat $log/test_result.log
diff --git a/tests/unit/tts/test_losses.py b/tests/unit/tts/test_losses.py
new file mode 100644
index 000000000..1e6270542
--- /dev/null
+++ b/tests/unit/tts/test_losses.py
@@ -0,0 +1,61 @@
+# Copyright (c) 2025 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import numpy as np
+
+from paddlespeech.audiotools.core.audio_signal import AudioSignal
+from paddlespeech.t2s.modules.losses import GANLoss
+from paddlespeech.t2s.modules.losses import MultiScaleSTFTLoss
+from paddlespeech.t2s.modules.losses import SISDRLoss
+
+
+def get_input():
+ x = AudioSignal("https://paddlespeech.cdn.bcebos.com/PaddleAudio/en.wav",
+ 2_05)
+ y = x * 0.01
+ return x, y
+
+
+def test_multi_scale_stft_loss():
+ x, y = get_input()
+ loss = MultiScaleSTFTLoss()
+ pd_loss = loss(x, y)
+ assert np.abs(pd_loss.numpy() - 7.562150) < 1e-06
+
+
+def test_sisdr_loss():
+ x, y = get_input()
+ loss = SISDRLoss()
+ pd_loss = loss(x, y)
+ assert np.abs(pd_loss.numpy() - (-145.377640)) < 1e-06
+
+
+def test_gan_loss():
+ class My_discriminator0:
+ def __call__(self, x):
+ return x.sum()
+
+ class My_discriminator1:
+ def __call__(self, x):
+ return x * (-0.2)
+
+ x, y = get_input()
+ loss = GANLoss(My_discriminator0())
+ pd_loss0, pd_loss1 = loss(x, y)
+ assert np.abs(pd_loss0.numpy() - (-0.102722)) < 1e-06
+ assert np.abs(pd_loss1.numpy() - (-0.001027)) < 1e-06
+ loss = GANLoss(My_discriminator1())
+ pd_loss0, _ = loss.generator_loss(x, y)
+ assert np.abs(pd_loss0.numpy() - 1.000199) < 1e-06
+ pd_loss = loss.discriminator_loss(x, y)
+ assert np.abs(pd_loss.numpy() - 1.000200) < 1e-06
diff --git a/tests/unit/tts/test_pwg.py b/tests/unit/tts/test_pwg.py
index 10c82c9fd..bcdb5aafc 100644
--- a/tests/unit/tts/test_pwg.py
+++ b/tests/unit/tts/test_pwg.py
@@ -14,16 +14,16 @@
import paddle
import torch
from paddle.device.cuda import synchronize
+from parallel_wavegan import models as pwgan
from parallel_wavegan.layers import residual_block
from parallel_wavegan.layers import upsample
-from parallel_wavegan.models import parallel_wavegan as pwgan
from timer import timer
from paddlespeech.t2s.models.parallel_wavegan import ConvInUpsampleNet
from paddlespeech.t2s.models.parallel_wavegan import PWGDiscriminator
from paddlespeech.t2s.models.parallel_wavegan import PWGGenerator
-from paddlespeech.t2s.models.parallel_wavegan import ResidualBlock
from paddlespeech.t2s.models.parallel_wavegan import ResidualPWGDiscriminator
+from paddlespeech.t2s.modules.residual_block import WaveNetResidualBlock
from paddlespeech.t2s.utils.layer_tools import summary
paddle.set_device("gpu:0")
@@ -79,8 +79,8 @@ def test_convin_upsample_net():
def test_residual_block():
- net = ResidualBlock(dilation=9)
- net2 = residual_block.ResidualBlock(dilation=9)
+ net = WaveNetResidualBlock(dilation=9)
+ net2 = residual_block.WaveNetResidualBlock(dilation=9)
summary(net)
summary(net2)
for k, v in net2.named_parameters():
diff --git a/tests/unit/tts/test_snapshot.py b/tests/unit/tts/test_snapshot.py
index 6ceff3e5a..750e6b68d 100644
--- a/tests/unit/tts/test_snapshot.py
+++ b/tests/unit/tts/test_snapshot.py
@@ -19,17 +19,18 @@ from paddle.optimizer import Adam
from paddlespeech.t2s.training.extensions.snapshot import Snapshot
from paddlespeech.t2s.training.trainer import Trainer
-from paddlespeech.t2s.training.updater import StandardUpdater
+# from paddlespeech.t2s.training.updater import StandardUpdater
-def test_snapshot():
+
+def _test_snapshot():
model = nn.Linear(3, 4)
optimizer = Adam(parameters=model.parameters())
# use a simplest iterable object as dataloader
dataloader = count()
- # hack the training proecss: training does nothing except increse iteration
+ # hack the training proecss: training does nothing except increase iteration
updater = StandardUpdater(model, optimizer, dataloader=dataloader)
updater.update_core = lambda x: None
diff --git a/tools/Makefile b/tools/Makefile
index c6c667cd0..1fd7675f2 100644
--- a/tools/Makefile
+++ b/tools/Makefile
@@ -42,7 +42,7 @@ kenlm.done:
mfa.done:
- test -d montreal-forced-aligner || $(WGET) https://paddlespeech.bj.bcebos.com/Parakeet/montreal-forced-aligner_linux.tar.gz
+ test -d montreal-forced-aligner || $(WGET) https://paddlespeech.cdn.bcebos.com/Parakeet/montreal-forced-aligner_linux.tar.gz
tar xvf montreal-forced-aligner_linux.tar.gz
touch mfa.done
diff --git a/tools/extras/install_liblbfgs.sh b/tools/extras/install_liblbfgs.sh
index 8d6ae4ab7..0148bd841 100755
--- a/tools/extras/install_liblbfgs.sh
+++ b/tools/extras/install_liblbfgs.sh
@@ -17,13 +17,13 @@ cd liblbfgs-$VER
./configure --prefix=`pwd`
make
# due to the liblbfgs project directory structure, we have to use -i
-# but the erros are completely harmless
+# but the errors are completely harmless
make -i install
cd ..
(
[ ! -z "${LIBLBFGS}" ] && \
- echo >&2 "LIBLBFGS variable is aleady defined. Undefining..." && \
+ echo >&2 "LIBLBFGS variable is already defined. Undefining..." && \
unset LIBLBFGS
[ -f ./env.sh ] && . ./env.sh
diff --git a/tools/extras/install_srilm.sh b/tools/extras/install_srilm.sh
index f359e70ce..fdbcf5d97 100755
--- a/tools/extras/install_srilm.sh
+++ b/tools/extras/install_srilm.sh
@@ -68,7 +68,7 @@ make || exit
cd ..
(
[ ! -z "${SRILM}" ] && \
- echo >&2 "SRILM variable is aleady defined. Undefining..." && \
+ echo >&2 "SRILM variable is already defined. Undefining..." && \
unset SRILM
[ -f ./env.sh ] && . ./env.sh
diff --git a/utils/format_triplet_data.py b/utils/format_triplet_data.py
index e9a0cf54c..029ea2d9b 100755
--- a/utils/format_triplet_data.py
+++ b/utils/format_triplet_data.py
@@ -44,7 +44,7 @@ add_arg('manifest_paths', str,
# bpe
add_arg('spm_model_prefix', str, None,
"spm model prefix, spm_model_%(bpe_mode)_%(count_threshold), only need when `unit_type` is spm")
-add_arg('output_path', str, None, "filepath of formated manifest.", required=True)
+add_arg('output_path', str, None, "filepath of formatted manifest.", required=True)
# yapf: disable
args = parser.parse_args()
diff --git a/utils/fst/ctc_token_fst.py b/utils/fst/ctc_token_fst.py
index f63e9cdac..85974f27f 100755
--- a/utils/fst/ctc_token_fst.py
+++ b/utils/fst/ctc_token_fst.py
@@ -32,7 +32,7 @@ def main(args):
# leaving `token`
print('{} {} {} {}'.format(node, 2, '', ''))
node += 1
- # Fianl node
+ # Final node
print('0')
diff --git a/utils/fst/make_tlg.sh b/utils/fst/make_tlg.sh
index c68387af9..944b8b1f3 100755
--- a/utils/fst/make_tlg.sh
+++ b/utils/fst/make_tlg.sh
@@ -21,7 +21,7 @@ cp -r $src_lang $tgt_lang
# eps2disambig.pl: replace epsilons on the input side with the special disambiguation symbol #0.
# s2eps.pl: replaces and with (on both input and output sides), for the G.fst acceptor.
# G.fst, the disambiguation symbol #0 only appears on the input side
-# do eps2disambig.pl and s2eps.pl maybe just for fallowing `fstrmepsilon`.
+# do eps2disambig.pl and s2eps.pl maybe just for following `fstrmepsilon`.
cat $arpa_lm | \
grep -v ' ' | \
grep -v ' ' | \
diff --git a/utils/gen_duration_from_textgrid.py b/utils/gen_duration_from_textgrid.py
index 9ee0c05cc..54427665a 100755
--- a/utils/gen_duration_from_textgrid.py
+++ b/utils/gen_duration_from_textgrid.py
@@ -26,7 +26,7 @@ def readtg(tg_path, sample_rate=24000, n_shift=300):
alignment = textgrid.openTextgrid(tg_path, includeEmptyIntervals=True)
phones = []
ends = []
- for interval in alignment.tierDict["phones"].entryList:
+ for interval in alignment.getTier("phones").entries:
phone = interval.label
phones.append(phone)
ends.append(interval.end)
diff --git a/utils/generate_infer_yaml.py b/utils/generate_infer_yaml.py
index ca8d6b60d..bd45a1bbd 100755
--- a/utils/generate_infer_yaml.py
+++ b/utils/generate_infer_yaml.py
@@ -3,7 +3,7 @@
'''
Merge training configs into a single inference config.
The single inference config is for CLI, which only takes a single config to do inferencing.
- The trainig configs includes: model config, preprocess config, decode config, vocab file and cmvn file.
+ The training configs includes: model config, preprocess config, decode config, vocab file and cmvn file.
Process:
# step 1: prepare dir
@@ -11,7 +11,7 @@
cp -r exp conf data release_dir
cd release_dir
- # step 2: get "model.yaml" which conatains all configuration info.
+ # step 2: get "model.yaml" which contains all configuration info.
# if does not contain preprocess.yaml file. e.g ds2:
python generate_infer_yaml.py --cfg_pth conf/deepspeech2_online.yaml --dcd_pth conf/tuning/chunk_decode.yaml --vb_pth data/lang_char/vocab.txt --cmvn_pth data/mean_std.json --save_pth model.yaml --pre_pth null
# if contains preprocess.yaml file. e.g u2:
diff --git a/utils/tokenizer.perl b/utils/tokenizer.perl
index 836fe19c6..babf81886 100644
--- a/utils/tokenizer.perl
+++ b/utils/tokenizer.perl
@@ -79,7 +79,7 @@ if ($HELP)
print " -b ... disable Perl buffering.\n";
print " -time ... enable processing time calculation.\n";
print " -penn ... use Penn treebank-like tokenization.\n";
- print " -protected FILE ... specify file with patters to be protected in tokenisation.\n";
+ print " -protected FILE ... specify file with patterns to be protected in tokenisation.\n";
print " -no-escape ... don't perform HTML escaping on apostrophy, quotes, etc.\n";
exit;
}
diff --git a/utils/train_arpa_with_kenlm.sh b/utils/train_arpa_with_kenlm.sh
index 8af646ceb..b435239af 100755
--- a/utils/train_arpa_with_kenlm.sh
+++ b/utils/train_arpa_with_kenlm.sh
@@ -37,7 +37,7 @@ fi
# the text should be properly pre-processed, e.g:
# cleand, normalized and possibly word-segmented
-# get rid off irrelavent symbols
+# get rid off irrelevant symbols
grep -v '' $symbol_table \
| grep -v '#0' \
| grep -v '' | grep -v '' \
@@ -51,7 +51,7 @@ grep -v '' $symbol_table \
#
# TL;DR reason:
# Unlike SRILM's -limit-vocab, kenlm's --limit_vocab_file option
-# spcifies a *valid* set of vocabulary, whereas *valid but unseen*
+# specifies a *valid* set of vocabulary, whereas *valid but unseen*
# words are discarded in final arpa.
# So the trick is,
# we explicitly add kaldi's vocab(one word per line) to training text,
diff --git a/utils/zh_tn.py b/utils/zh_tn.py
index 6fee626bd..4bb684a1e 100755
--- a/utils/zh_tn.py
+++ b/utils/zh_tn.py
@@ -1288,7 +1288,7 @@ def normalize_corpus(corpus,
def char_token(s: Text) -> List[Text]:
- """chinese charactor
+ """chinese character
Args:
s (Text): "我爱中国“