diff --git a/docs/source/vpr/PPVPR.md b/docs/source/vpr/PPVPR.md
new file mode 100644
index 00000000..2c0ed8f5
--- /dev/null
+++ b/docs/source/vpr/PPVPR.md
@@ -0,0 +1,79 @@
+([简体中文](./PPVPR_cn.md)|English)
+# PP-VPR
+
+## Catalogue
+- [1. Introduction](#1)
+- [2. Characteristic](#2)
+- [3. Tutorials](#3)
+ - [3.1 Pre-trained Models](#31)
+ - [3.2 Training](#32)
+ - [3.3 Inference](#33)
+ - [3.4 Service Deployment](#33)
+- [4. Quick Start](#4)
+
+
+## 1. Introduction
+
+PP-VPR is a tool that provides voice print feature extraction and retrieval functions. Provides a variety of quasi-industrial solutions, easy to solve the difficult problems in complex scenes, support the use of command line model reasoning. PP-VPR also supports interface operations and container deployment.
+
+
+## 2. Characteristic
+The basic process of VPR is shown in the figure below:
+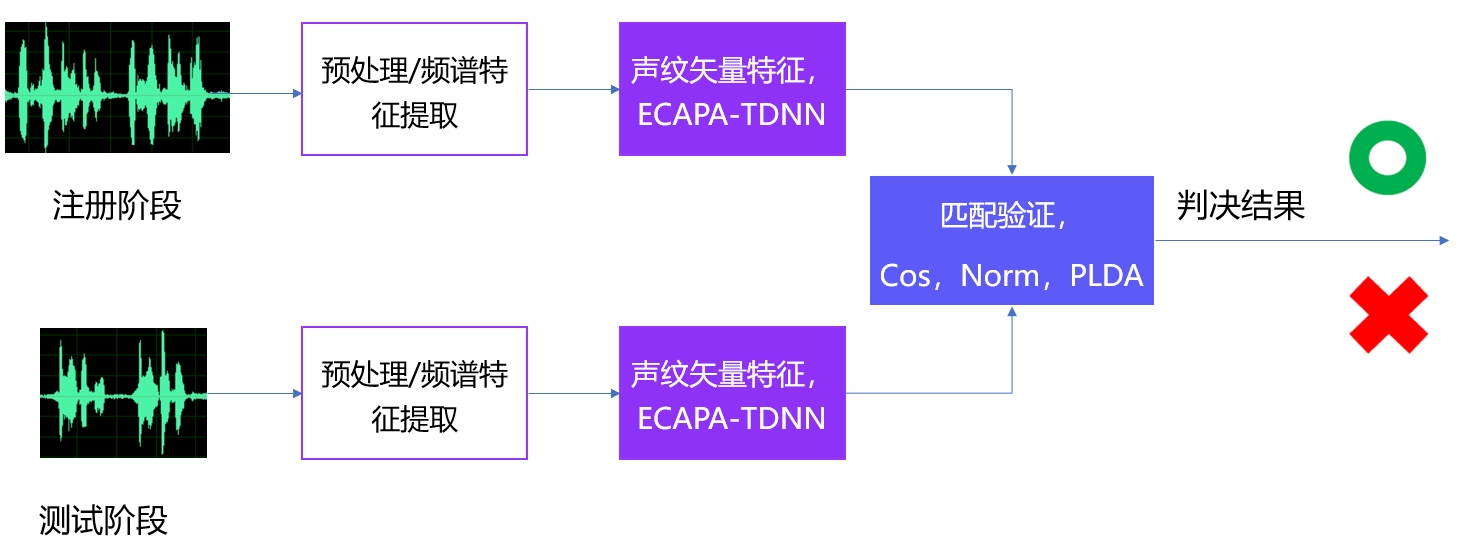 +
+
+The main characteristics of PP-ASR are shown below:
+- Provides pre-trained models on Chinese open source datasets: VoxCeleb(English). The models include ecapa-tdnn.
+- Complete quasi-industrial solutions, including labelless training, cross-domain adaptive, super-large scale speaker training, data long tail problem solving, etc.
+- Support model training/evaluation.
+- Support model inference using the command line. You can use to use `paddlespeech vector --task spk --input xxx.wav` to use the pre-trained model to do model inference.
+- Support interface operations and container deployment.
+
+
+## 3. Tutorials
+
+
+## 3.1 Pre-trained Models
+The support pre-trained model list: [released_model](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/released_model.md).
+For more information about model design, you can refer to the aistudio tutorial:
+- [ecapa-tdnn](https://aistudio.baidu.com/aistudio/projectdetail/4027664)
+
+
+## 3.2 Training
+The referenced script for model training is stored in [examples](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples) and stored according to "examples/dataset/model". The dataset mainly supports VoxCeleb. The model supports ecapa-tdnn.
+The specific steps of executing the script are recorded in `run.sh`.
+
+For more information, you can refer to [sv0](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/voxceleb/sv0)
+
+
+
+## 3.3 Inference
+
+PP-VPR supports use `paddlespeech vector --task spk --input xxx.wav` to use the pre-trained model to do inference after install `paddlespeech` by `pip install paddlespeech`.
+
+Specific supported functions include:
+
+- Prediction of single audio
+- Score the similarity between the two audios
+- Support RTF calculation
+
+For specific usage, please refer to: [speaker_verification](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/demos/speaker_verification/README_cn.md)
+
+
+
+## 3.4 Service Deployment
+
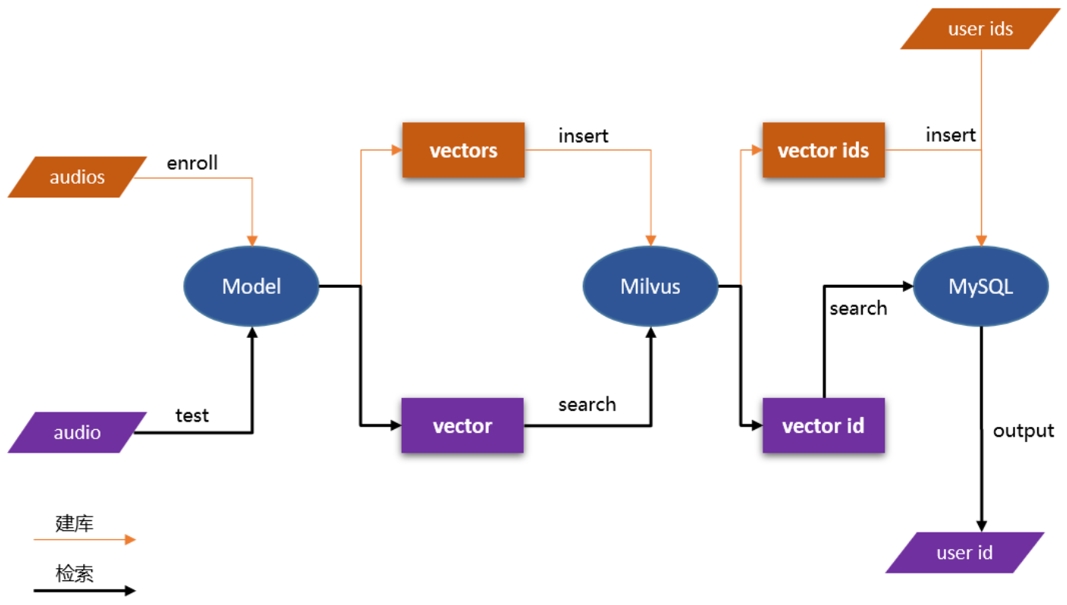
+PP-VPR supports Docker containerized service deployment. Through Milvus, MySQL performs high performance library building search.
+
+Demo of VPR Server: [audio_searching](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/audio_searching)
+
+
+
+For more information about service deployment, you can refer to the aistudio tutorial:
+- [speaker_recognition](https://aistudio.baidu.com/aistudio/projectdetail/4027664)
+
+
+
+## 4. Quick Start
+
+To use PP-VPR, you can see here [install](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install_cn.md), It supplies three methods to install `paddlespeech`, which are **Easy**, **Medium** and **Hard**. If you want to experience the inference function of paddlespeech, you can use **Easy** installation method.
diff --git a/docs/source/vpr/PPVPR_cn.md b/docs/source/vpr/PPVPR_cn.md
new file mode 100644
index 00000000..87e8897f
--- /dev/null
+++ b/docs/source/vpr/PPVPR_cn.md
@@ -0,0 +1,80 @@
+(简体中文|[English](./PPVPR.md))
+# PP-VPR
+
+## 目录
+- [1. 简介](#1)
+- [2. 特点](#2)
+- [3. 使用教程](#3)
+ - [3.1 预训练模型](#31)
+ - [3.2 模型训练](#32)
+ - [3.3 模型推理](#33)
+ - [3.4 服务部署](#33)
+- [4. 快速开始](#4)
+
+
+## 1. 简介
+
+PP-VPR 是一个 提供声纹特征提取,检索功能的工具。提供了多种准工业化的方案,轻松搞定复杂场景中的难题,支持使用命令行的方式进行模型的推理。 PP-VPR 也支持界面化的操作,容器化的部署。
+
+
+## 2. 特点
+VPR 的基本流程如下图所示:
+
+
+
+PP-VPR 的主要特点如下:
+- 提供在英文开源数据集 VoxCeleb(英文)上的预训练模型,ecapa-tdnn。
+- 完备的准工业化方案,包括无标签训练,跨域自适应,超大规模说话人训练,解决数据长尾问题等。
+- 支持模型训练评估功能。
+- 支持命令行方式的模型推理,可使用 `paddlespeech vector --task spk --input xxx.wav` 方式调用预训练模型进行推理。
+- 支持 VPR 的服务容器化部署,界面化操作。
+
+
+
+## 3. 使用教程
+
+
+## 3.1 预训练模型
+支持的预训练模型列表:[released_model](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/released_model.md)。
+更多关于模型设计的部分,可以参考 AIStudio 教程:
+- [ecapa-tdnn](https://aistudio.baidu.com/aistudio/projectdetail/4027664)
+
+
+## 3.2 模型训练
+
+模型的训练的参考脚本存放在 [examples](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples) 中,并按照 `examples/数据集/模型` 存放,数据集主要支持 VoxCeleb,模型支持 ecapa-tdnn 模型。
+具体的执行脚本的步骤记录在 `run.sh` 当中。具体可参考: [sv0](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/voxceleb/sv0)
+
+
+
+## 3.3 模型推理
+
+PP-VPR 支持在使用`pip install paddlespeech`后 使用命令行的方式来使用预训练模型进行推理。
+
+具体支持的功能包括:
+
+- 对单条音频进行预测
+- 对两条音频进行打分
+- 支持 RTF 的计算
+
+具体的使用方式可以参考: [speaker_verification](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/demos/speaker_verification/README_cn.md)
+
+
+
+## 3.4 服务部署
+
+PP-VPR 支持 Docker 容器化服务部署。通过 Milvus, MySQL 进行高性能建库检索。
+
+server 的 demo: [audio_searching](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/audio_searching)
+
+
+
+
+关于服务部署方面的更多资料,可以参考 AIStudio 教程:
+- [speaker_recognition](https://aistudio.baidu.com/aistudio/projectdetail/4027664)
+
+
+
+## 4. 快速开始
+
+关于如何使用 PP-VPR,可以看这里的 [install](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install_cn.md),其中提供了 **简单**、**中等**、**困难** 三种安装方式。如果想体验 paddlespeech 的推理功能,可以用 **简单** 安装方式。
+
+
+The main characteristics of PP-ASR are shown below:
+- Provides pre-trained models on Chinese open source datasets: VoxCeleb(English). The models include ecapa-tdnn.
+- Complete quasi-industrial solutions, including labelless training, cross-domain adaptive, super-large scale speaker training, data long tail problem solving, etc.
+- Support model training/evaluation.
+- Support model inference using the command line. You can use to use `paddlespeech vector --task spk --input xxx.wav` to use the pre-trained model to do model inference.
+- Support interface operations and container deployment.
+
+
+## 3. Tutorials
+
+
+## 3.1 Pre-trained Models
+The support pre-trained model list: [released_model](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/released_model.md).
+For more information about model design, you can refer to the aistudio tutorial:
+- [ecapa-tdnn](https://aistudio.baidu.com/aistudio/projectdetail/4027664)
+
+
+## 3.2 Training
+The referenced script for model training is stored in [examples](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples) and stored according to "examples/dataset/model". The dataset mainly supports VoxCeleb. The model supports ecapa-tdnn.
+The specific steps of executing the script are recorded in `run.sh`.
+
+For more information, you can refer to [sv0](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/voxceleb/sv0)
+
+
+
+## 3.3 Inference
+
+PP-VPR supports use `paddlespeech vector --task spk --input xxx.wav` to use the pre-trained model to do inference after install `paddlespeech` by `pip install paddlespeech`.
+
+Specific supported functions include:
+
+- Prediction of single audio
+- Score the similarity between the two audios
+- Support RTF calculation
+
+For specific usage, please refer to: [speaker_verification](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/demos/speaker_verification/README_cn.md)
+
+
+
+## 3.4 Service Deployment
+
+PP-VPR supports Docker containerized service deployment. Through Milvus, MySQL performs high performance library building search.
+
+Demo of VPR Server: [audio_searching](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/audio_searching)
+
+
+
+For more information about service deployment, you can refer to the aistudio tutorial:
+- [speaker_recognition](https://aistudio.baidu.com/aistudio/projectdetail/4027664)
+
+
+
+## 4. Quick Start
+
+To use PP-VPR, you can see here [install](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install_cn.md), It supplies three methods to install `paddlespeech`, which are **Easy**, **Medium** and **Hard**. If you want to experience the inference function of paddlespeech, you can use **Easy** installation method.
diff --git a/docs/source/vpr/PPVPR_cn.md b/docs/source/vpr/PPVPR_cn.md
new file mode 100644
index 00000000..87e8897f
--- /dev/null
+++ b/docs/source/vpr/PPVPR_cn.md
@@ -0,0 +1,80 @@
+(简体中文|[English](./PPVPR.md))
+# PP-VPR
+
+## 目录
+- [1. 简介](#1)
+- [2. 特点](#2)
+- [3. 使用教程](#3)
+ - [3.1 预训练模型](#31)
+ - [3.2 模型训练](#32)
+ - [3.3 模型推理](#33)
+ - [3.4 服务部署](#33)
+- [4. 快速开始](#4)
+
+
+## 1. 简介
+
+PP-VPR 是一个 提供声纹特征提取,检索功能的工具。提供了多种准工业化的方案,轻松搞定复杂场景中的难题,支持使用命令行的方式进行模型的推理。 PP-VPR 也支持界面化的操作,容器化的部署。
+
+
+## 2. 特点
+VPR 的基本流程如下图所示:
+
+
+
+PP-VPR 的主要特点如下:
+- 提供在英文开源数据集 VoxCeleb(英文)上的预训练模型,ecapa-tdnn。
+- 完备的准工业化方案,包括无标签训练,跨域自适应,超大规模说话人训练,解决数据长尾问题等。
+- 支持模型训练评估功能。
+- 支持命令行方式的模型推理,可使用 `paddlespeech vector --task spk --input xxx.wav` 方式调用预训练模型进行推理。
+- 支持 VPR 的服务容器化部署,界面化操作。
+
+
+
+## 3. 使用教程
+
+
+## 3.1 预训练模型
+支持的预训练模型列表:[released_model](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/released_model.md)。
+更多关于模型设计的部分,可以参考 AIStudio 教程:
+- [ecapa-tdnn](https://aistudio.baidu.com/aistudio/projectdetail/4027664)
+
+
+## 3.2 模型训练
+
+模型的训练的参考脚本存放在 [examples](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples) 中,并按照 `examples/数据集/模型` 存放,数据集主要支持 VoxCeleb,模型支持 ecapa-tdnn 模型。
+具体的执行脚本的步骤记录在 `run.sh` 当中。具体可参考: [sv0](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/voxceleb/sv0)
+
+
+
+## 3.3 模型推理
+
+PP-VPR 支持在使用`pip install paddlespeech`后 使用命令行的方式来使用预训练模型进行推理。
+
+具体支持的功能包括:
+
+- 对单条音频进行预测
+- 对两条音频进行打分
+- 支持 RTF 的计算
+
+具体的使用方式可以参考: [speaker_verification](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/demos/speaker_verification/README_cn.md)
+
+
+
+## 3.4 服务部署
+
+PP-VPR 支持 Docker 容器化服务部署。通过 Milvus, MySQL 进行高性能建库检索。
+
+server 的 demo: [audio_searching](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/audio_searching)
+
+
+
+
+关于服务部署方面的更多资料,可以参考 AIStudio 教程:
+- [speaker_recognition](https://aistudio.baidu.com/aistudio/projectdetail/4027664)
+
+
+
+## 4. 快速开始
+
+关于如何使用 PP-VPR,可以看这里的 [install](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install_cn.md),其中提供了 **简单**、**中等**、**困难** 三种安装方式。如果想体验 paddlespeech 的推理功能,可以用 **简单** 安装方式。