diff --git a/README.md b/README.md
index e0769720f..468f42a61 100644
--- a/README.md
+++ b/README.md
@@ -9,34 +9,34 @@ English | [简体中文](README_ch.md)
-
+
------------------------------------------------------------------------------------



-**PaddleSpeech** is an open-source toolkit on [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) platform for two critical tasks in Speech - **Automatic Speech Recognition (ASR)** and **Text-To-Speech Synthesis (TTS)**, with modules involving state-of-art and influential models.
+**PaddleSpeech** is an open-source toolkit on [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) platform for two critical tasks in Speech - **Automatic Speech Recognition (ASR)** and **Text-To-Speech Synthesis (TTS)**, with modules involving state-of-art and influential models.
Via the easy-to-use, efficient, flexible and scalable implementation, our vision is to empower both industrial application and academic research, including training, inference & testing module, and deployment. Besides, this toolkit also features at:
- **Fast and Light-weight**: we provide a high-speed and ultra-lightweight model that is convenient for industrial deployment.
-- **Rule-based Chinese frontend**: our frontend contains Text Normalization (TN) and Grapheme-to-Phoneme (G2P, including Polyphone and Tone Sandhi). Moreover, we use self-defined linguistic rules to adapt Chinese context.
-- **Varieties of Functions that Vitalize Research**:
+- **Rule-based Chinese frontend**: our frontend contains Text Normalization (TN) and Grapheme-to-Phoneme (G2P, including Polyphone and Tone Sandhi). Moreover, we use self-defined linguistic rules to adapt Chinese context.
+- **Varieties of Functions that Vitalize Research**:
- *Integration of mainstream models and datasets*: the toolkit implements modules that participate in the whole pipeline of both ASR and TTS, and uses datasets like LibriSpeech, LJSpeech, AIShell, etc. See also [model lists](#models-list) for more details.
- *Support of ASR streaming and non-streaming data*: This toolkit contains non-streaming/streaming models like [DeepSpeech2](http://proceedings.mlr.press/v48/amodei16.pdf), [Transformer](https://arxiv.org/abs/1706.03762), [Conformer](https://arxiv.org/abs/2005.08100) and [U2](https://arxiv.org/pdf/2012.05481.pdf).
-
-Let's install PaddleSpeech with only a few lines of code!
+
+Let's install PaddleSpeech with only a few lines of code!
>Note: The official name is still deepspeech. 2021/10/26
@@ -44,7 +44,7 @@ Let's install PaddleSpeech with only a few lines of code!
# 1. Install essential libraries and paddlepaddle first.
# install prerequisites
sudo apt-get install -y sox pkg-config libflac-dev libogg-dev libvorbis-dev libboost-dev swig python3-dev libsndfile1
-# `pip install paddlepaddle-gpu` instead if you are using GPU.
+# `pip install paddlepaddle-gpu` instead if you are using GPU.
pip install paddlepaddle
# 2.Then install PaddleSpeech.
@@ -109,7 +109,7 @@ If you want to try more functions like training and tuning, please see [ASR gett
PaddleSpeech ASR supports a lot of mainstream models, which are summarized as follow. For more information, please refer to [ASR Models](./docs/source/asr/released_model.md).
@@ -125,7 +125,7 @@ The current hyperlinks redirect to [Previous Parakeet](https://github.com/Paddle
| Acoustic Model |
Aishell |
- 2 Conv + 5 LSTM layers with only forward direction |
+ 2 Conv + 5 LSTM layers with only forward direction |
Ds2 Online Aishell Model
|
@@ -199,7 +199,7 @@ PaddleSpeech TTS mainly contains three modules: *Text Frontend*, *Acoustic Model
| Text Frontend |
|
-
+ |
chinese-fronted
|
@@ -292,11 +292,11 @@ PaddleSpeech TTS mainly contains three modules: *Text Frontend*, *Acoustic Model
-## Tutorials
+## Tutorials
Normally, [Speech SoTA](https://paperswithcode.com/area/speech) gives you an overview of the hot academic topics in speech. If you want to focus on the two tasks in PaddleSpeech, you will find the following guidelines are helpful to grasp the core ideas.
-The original ASR module is based on [Baidu's DeepSpeech](https://arxiv.org/abs/1412.5567) which is an independent product named [DeepSpeech](https://deepspeech.readthedocs.io). However, the toolkit aligns almost all the SoTA modules in the pipeline. Specifically, these modules are
+The original ASR module is based on [Baidu's DeepSpeech](https://arxiv.org/abs/1412.5567) which is an independent product named [DeepSpeech](https://deepspeech.readthedocs.io). However, the toolkit aligns almost all the SoTA modules in the pipeline. Specifically, these modules are
* [Data Prepration](docs/source/asr/data_preparation.md)
* [Data Augmentation](docs/source/asr/augmentation.md)
@@ -318,4 +318,3 @@ PaddleSpeech is provided under the [Apache-2.0 License](./LICENSE).
## Acknowledgement
PaddleSpeech depends on a lot of open source repos. See [references](docs/source/asr/reference.md) for more information.
-
diff --git a/docs/source/asr/models_introduction.md b/docs/source/asr/models_introduction.md
index ab2b8bac9..c99093bd6 100644
--- a/docs/source/asr/models_introduction.md
+++ b/docs/source/asr/models_introduction.md
@@ -13,7 +13,7 @@ In addition, the training process and the testing process are also introduced.
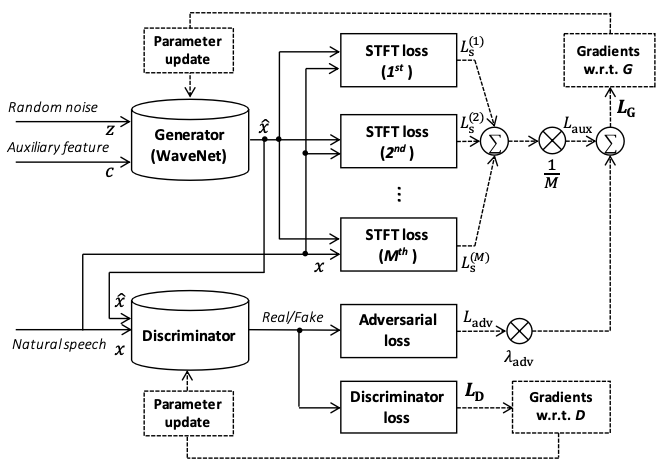
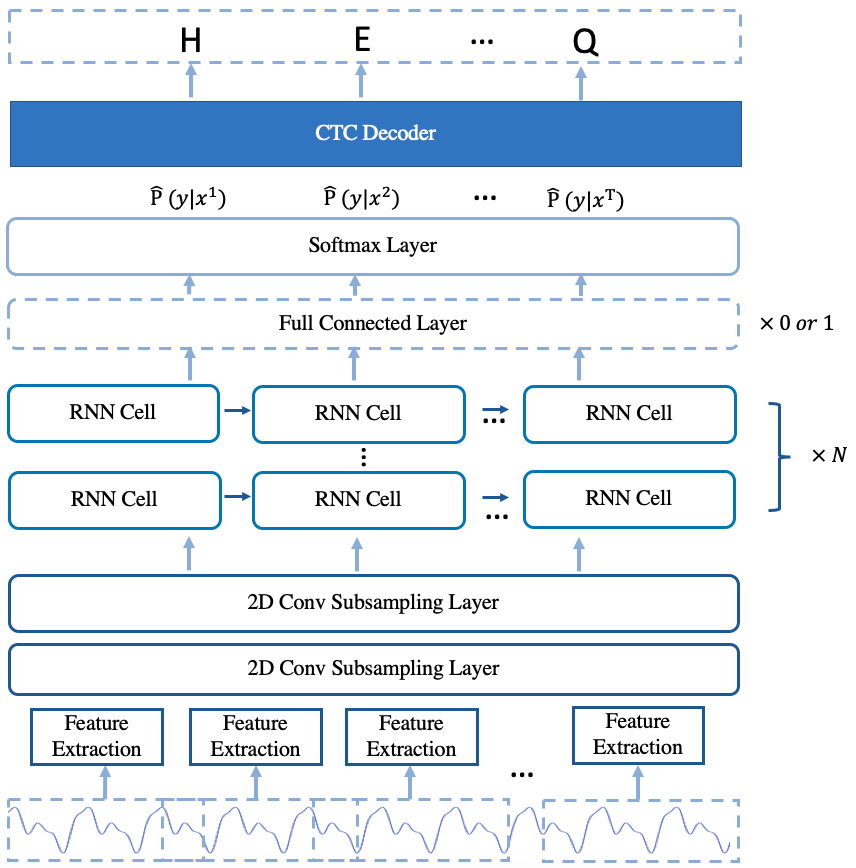
The arcitecture of the model is shown in Fig.1.
-  +
+ 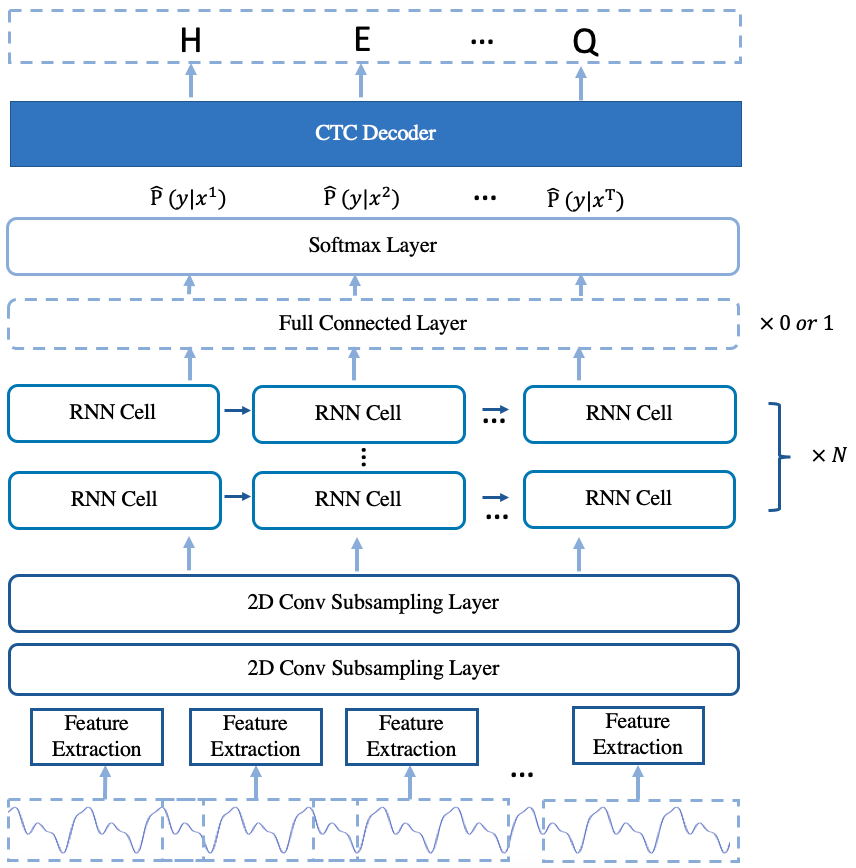
Fig.1 The Arcitecture of deepspeech2 online model
@@ -160,7 +160,7 @@ The deepspeech2 offline model is similarity to the deepspeech2 online model. The
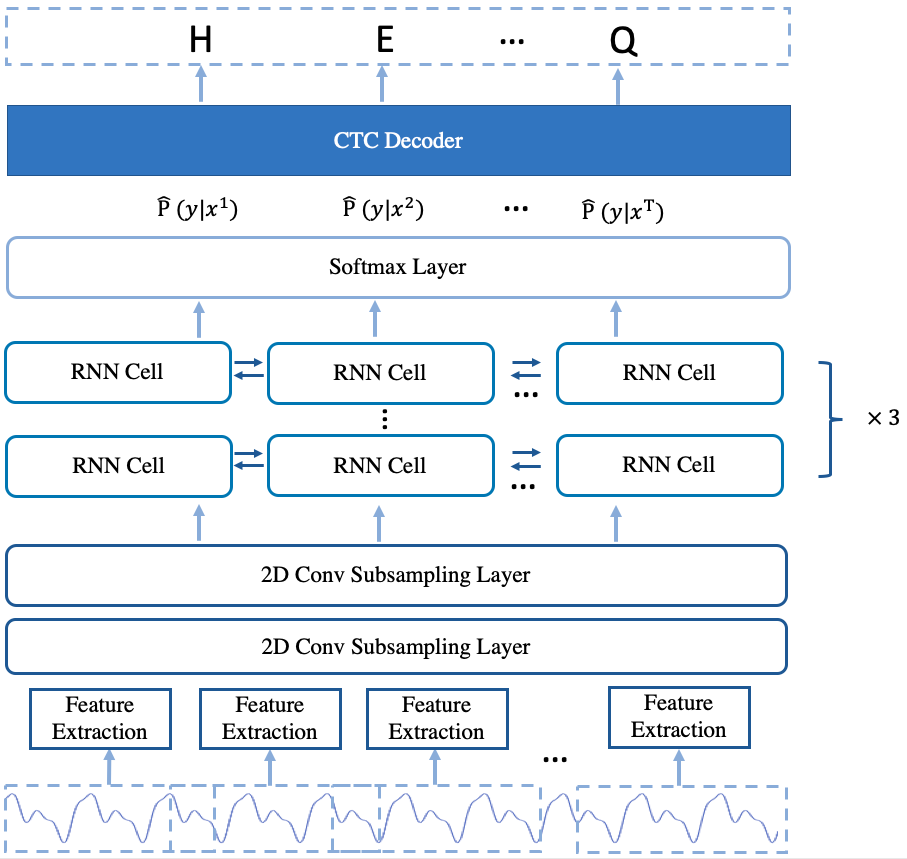
The arcitecture of the model is shown in Fig.2.
-  +
+ 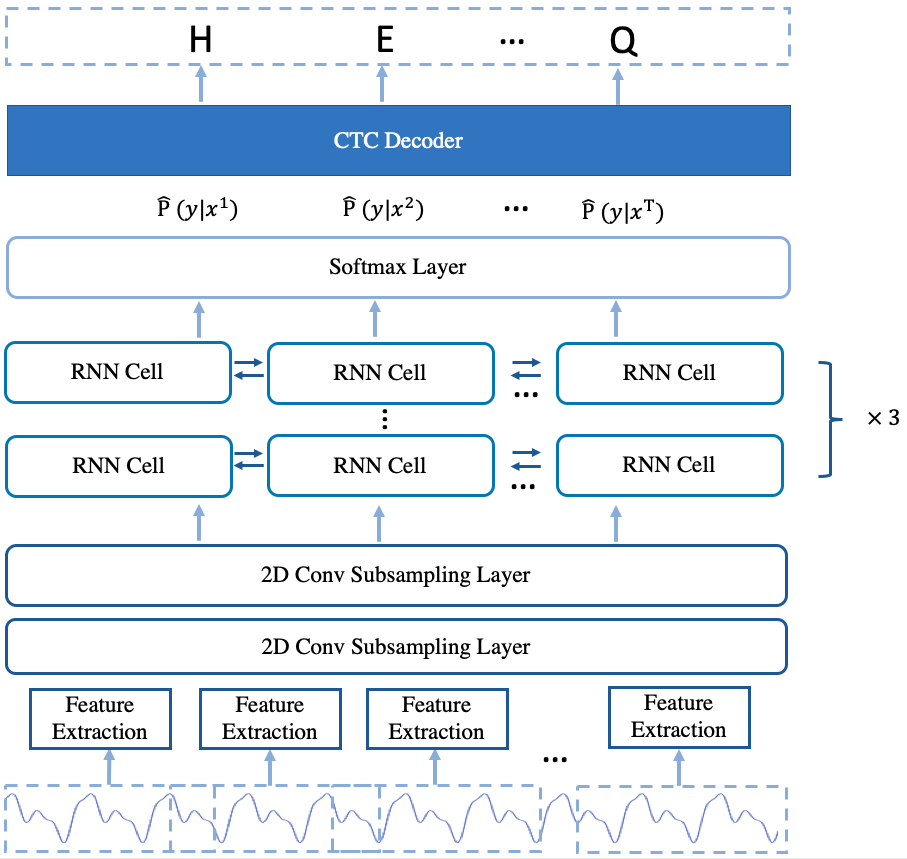
Fig.2 The Arcitecture of deepspeech2 offline model
diff --git a/docs/source/asr/quick_start.md b/docs/source/asr/quick_start.md
index ecce07434..da1620e90 100644
--- a/docs/source/asr/quick_start.md
+++ b/docs/source/asr/quick_start.md
@@ -54,7 +54,7 @@ CUDA_VISIBLE_DEVICES=0 bash local/tune.sh
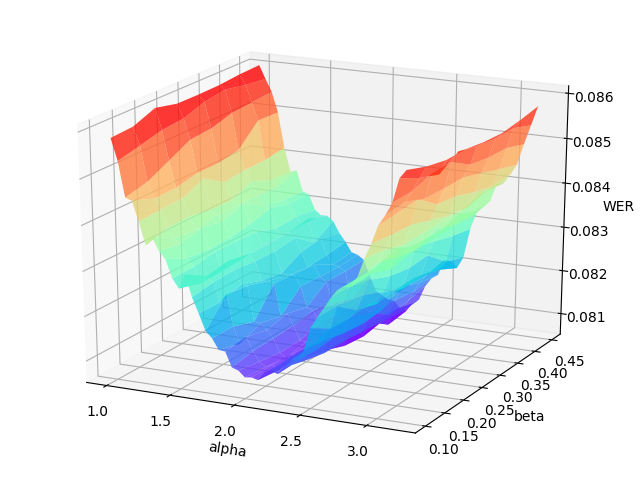
The grid search will print the WER (word error rate) or CER (character error rate) at each point in the hyper-parameters space, and draw the error surface optionally. A proper hyper-parameters range should include the global minima of the error surface for WER/CER, as illustrated in the following figure.
-  +
+ 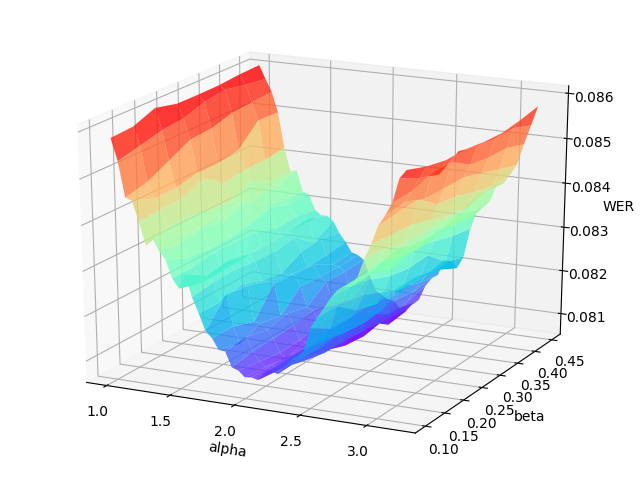
An example error surface for tuning on the dev-clean set of LibriSpeech
diff --git a/docs/source/tts/models_introduction.md b/docs/source/tts/models_introduction.md
index 87b65c514..b13297582 100644
--- a/docs/source/tts/models_introduction.md
+++ b/docs/source/tts/models_introduction.md
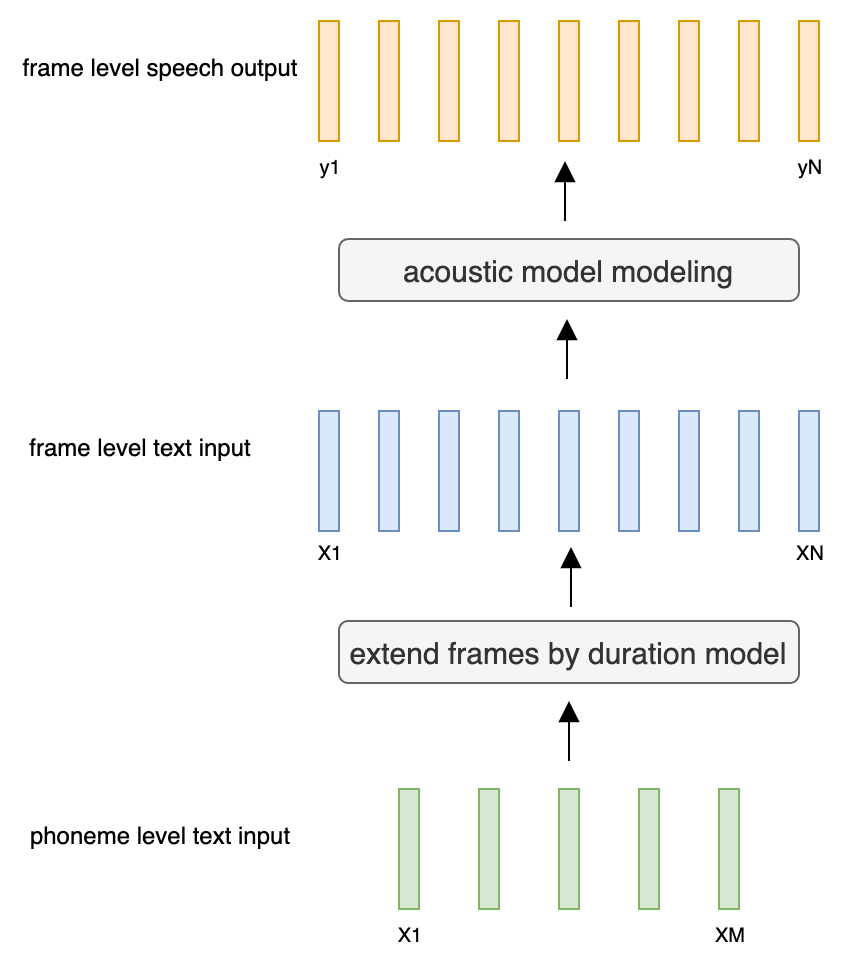
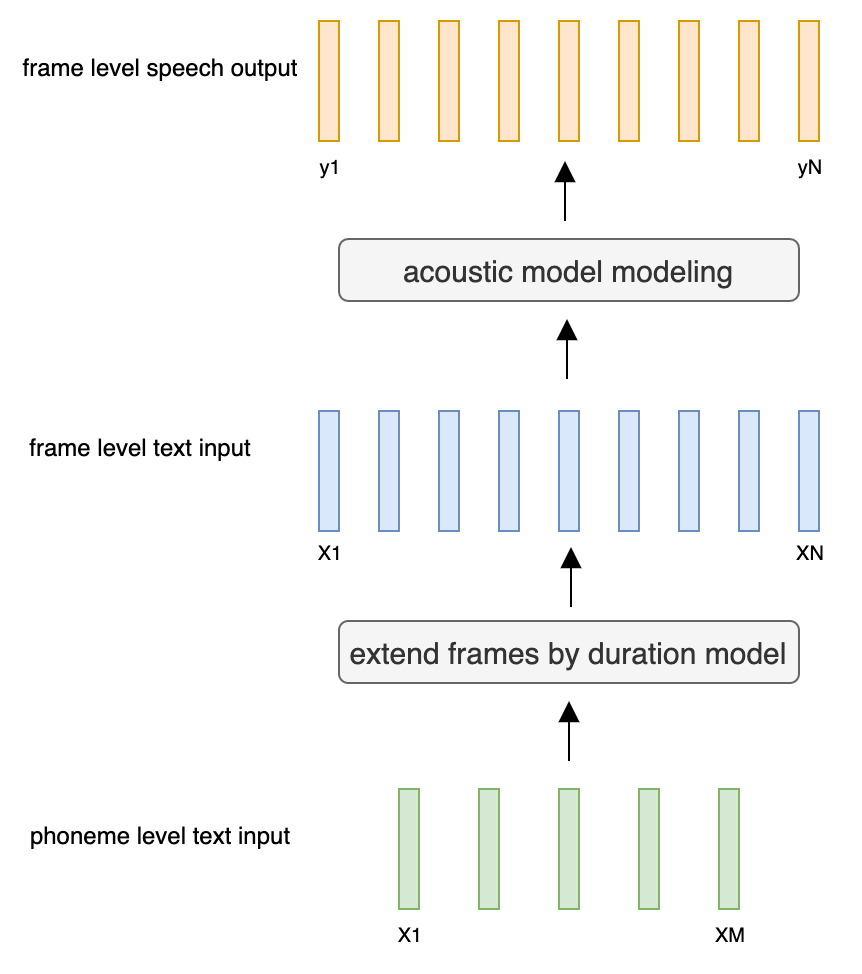
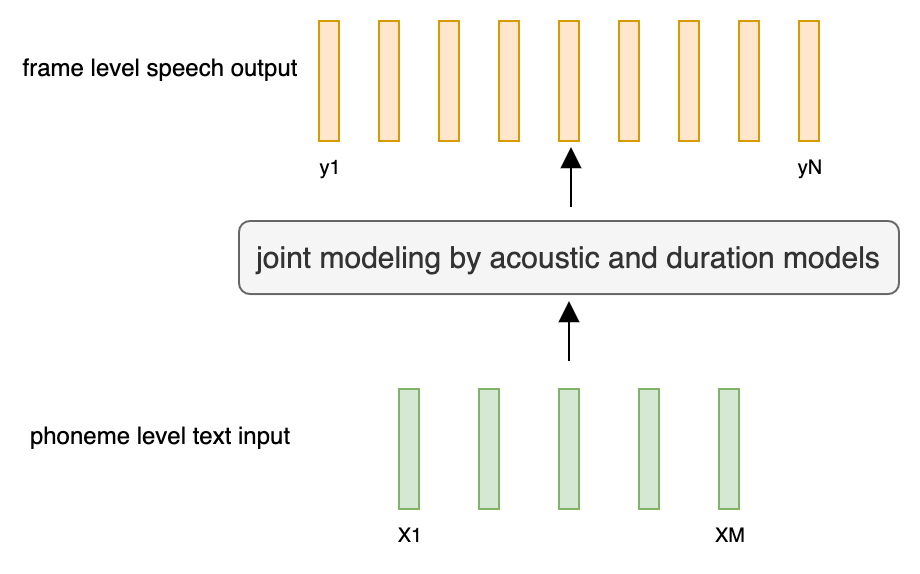
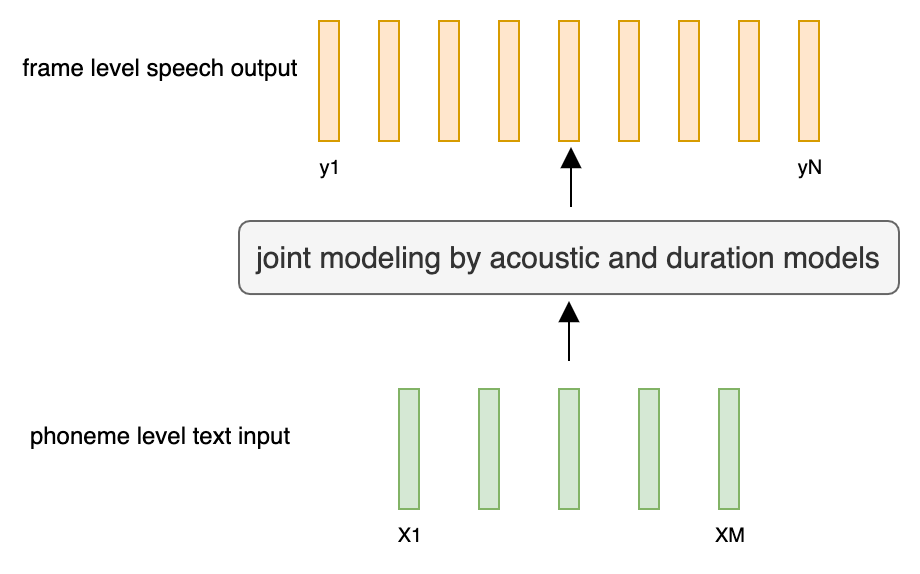
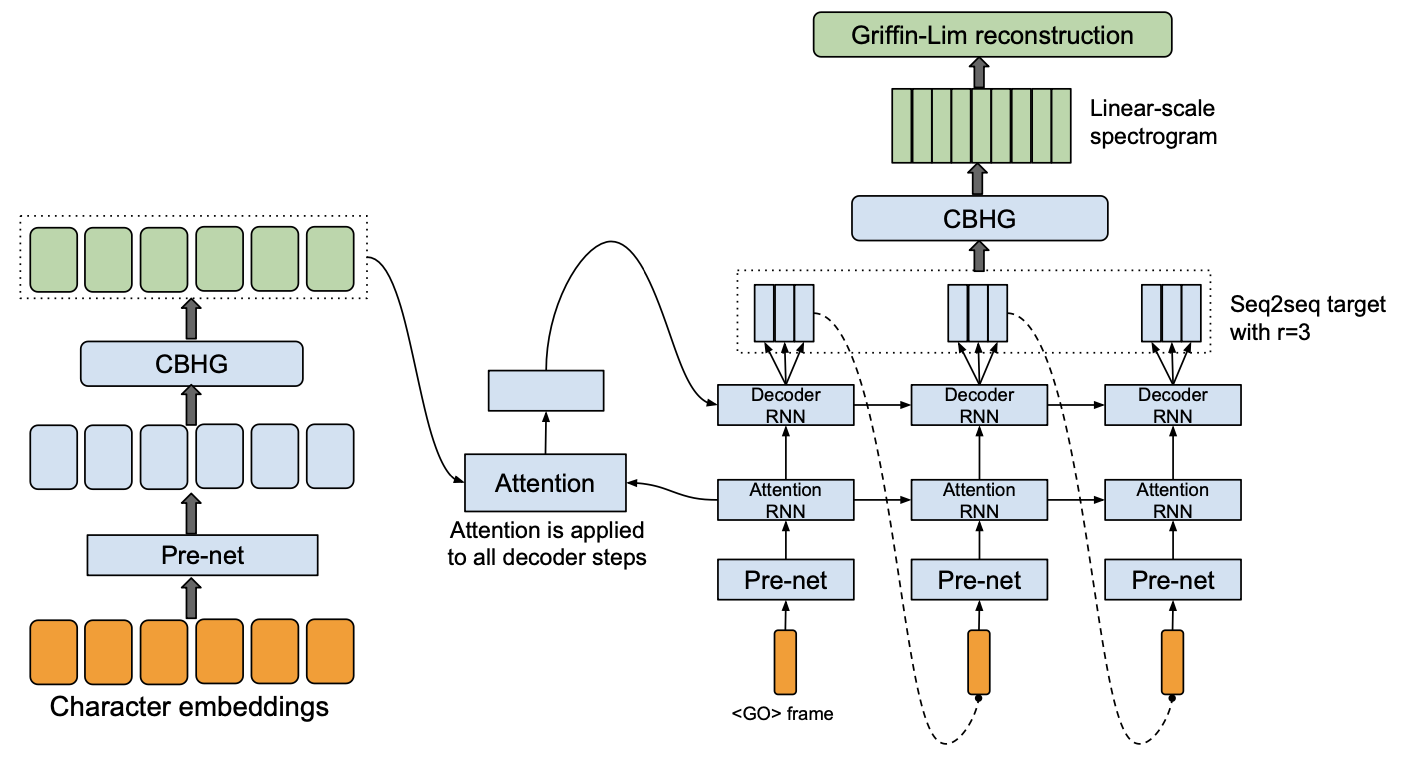
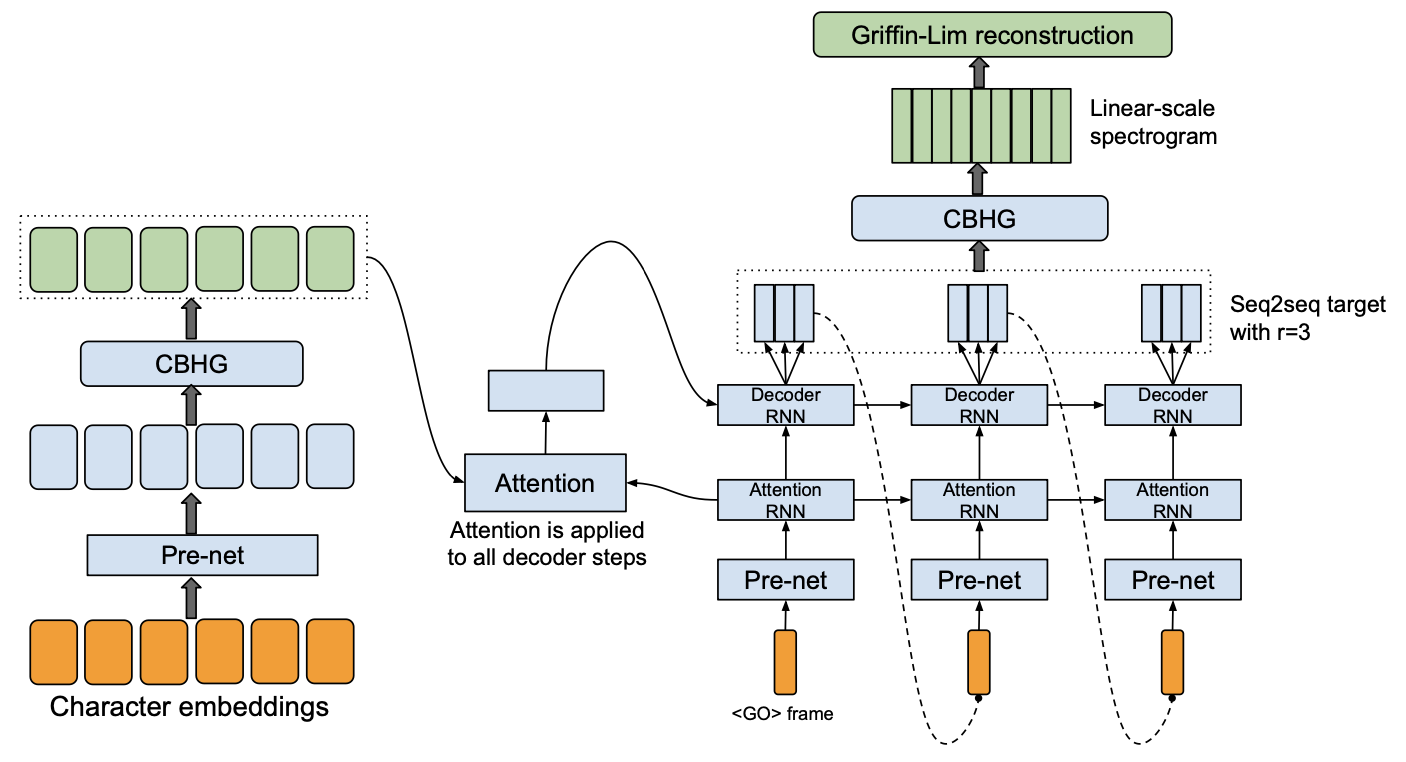
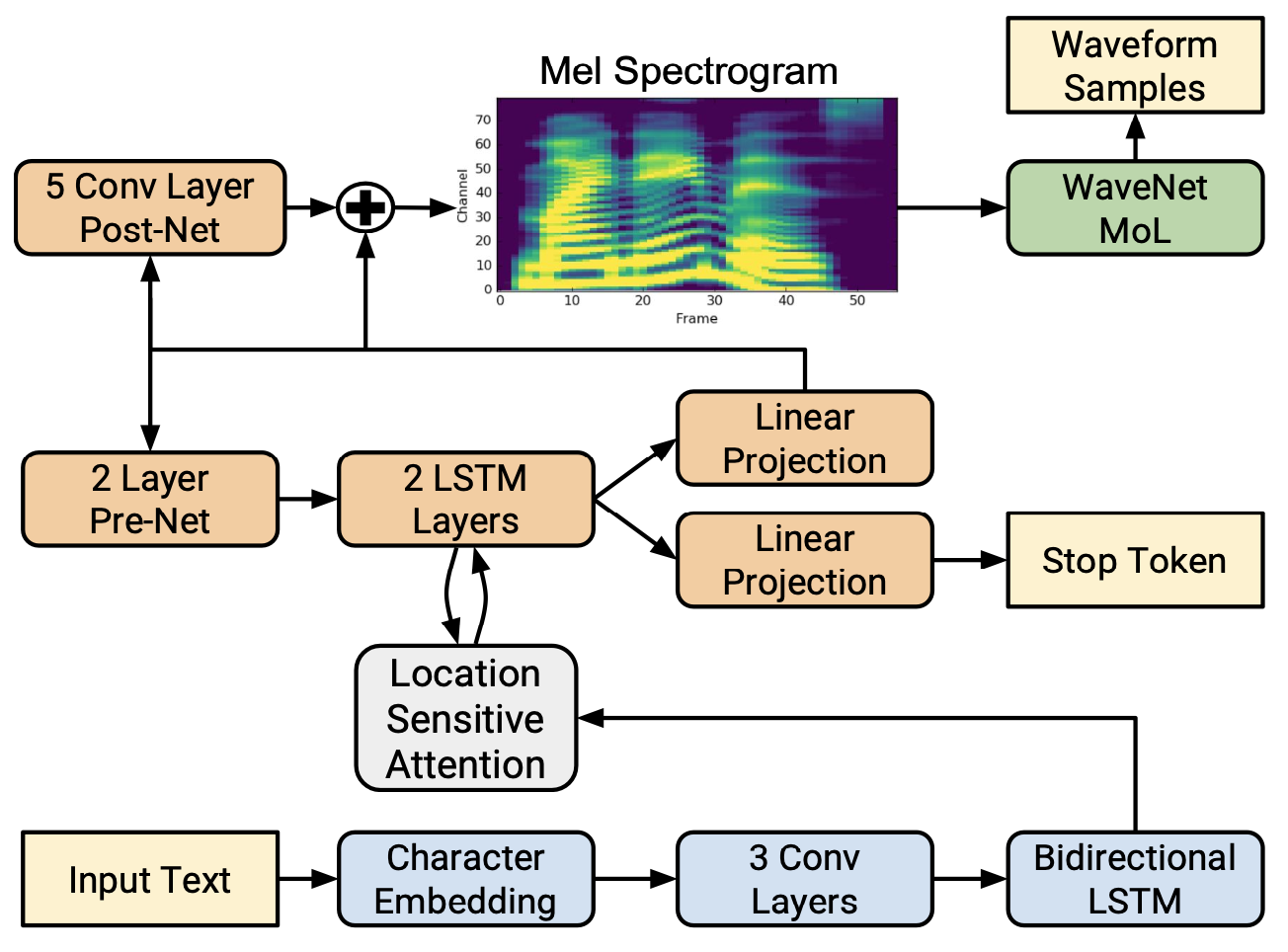
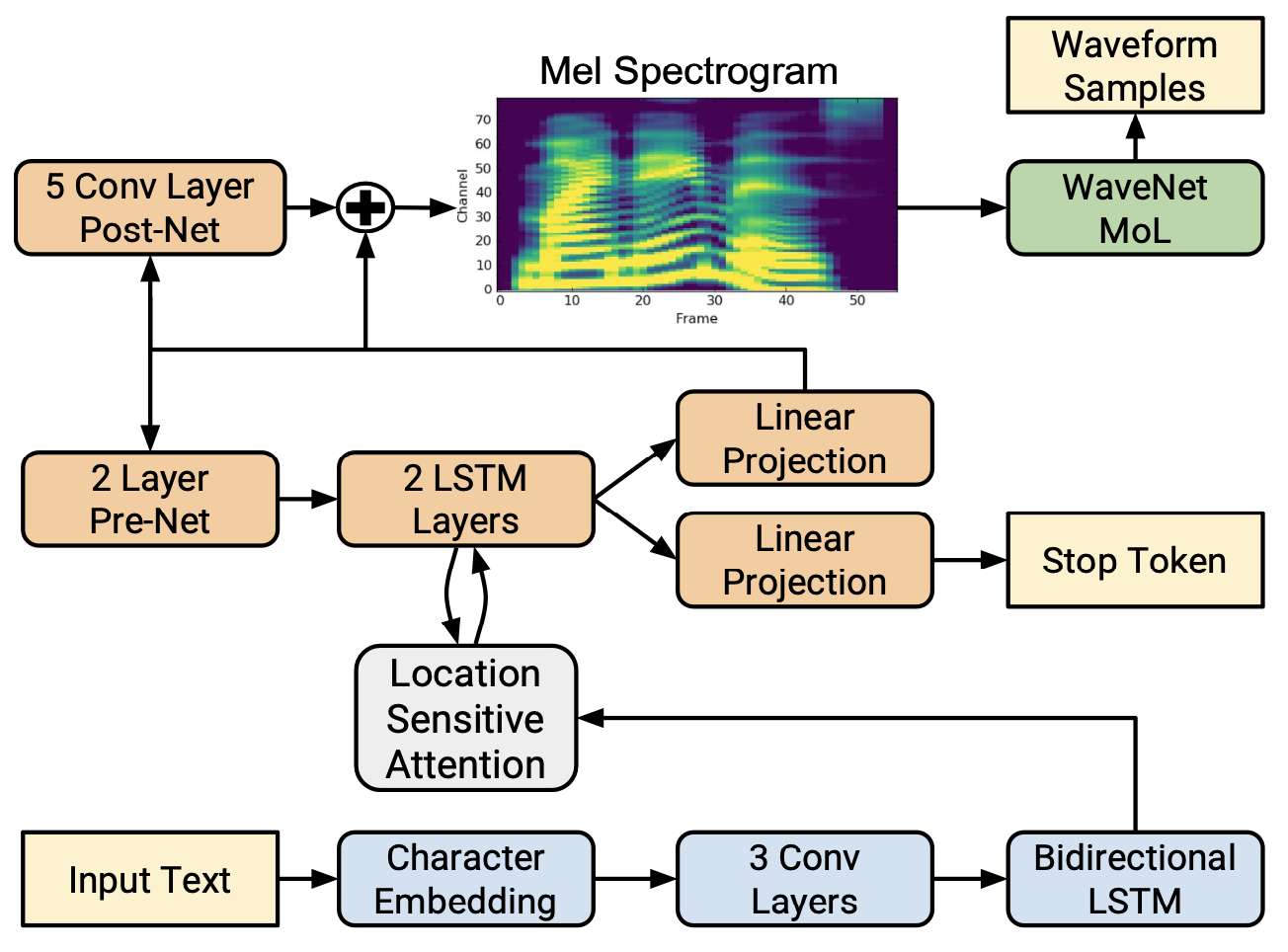
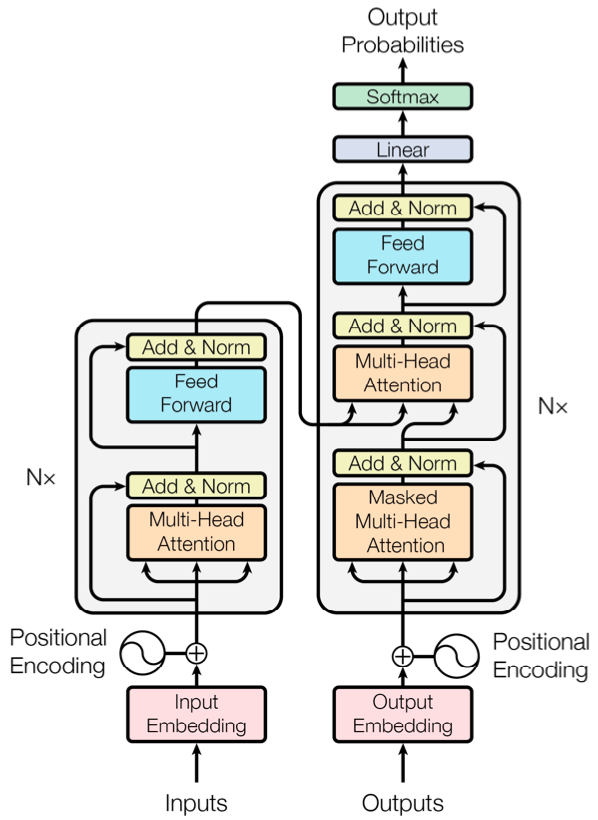
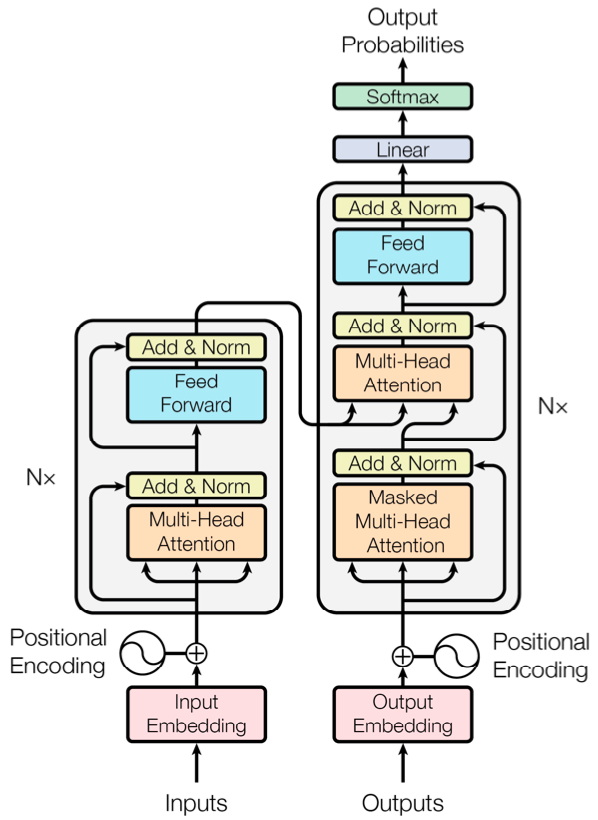
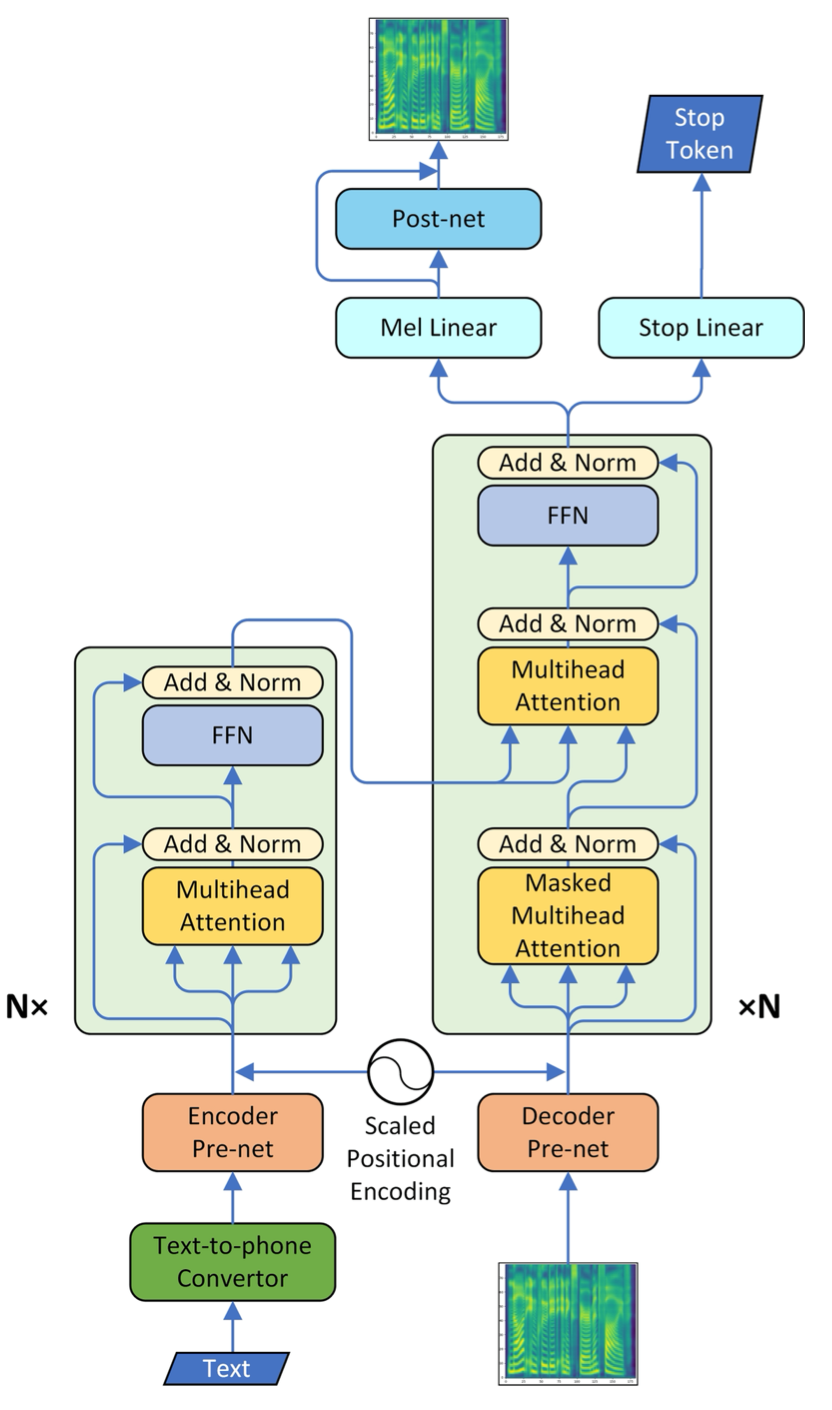
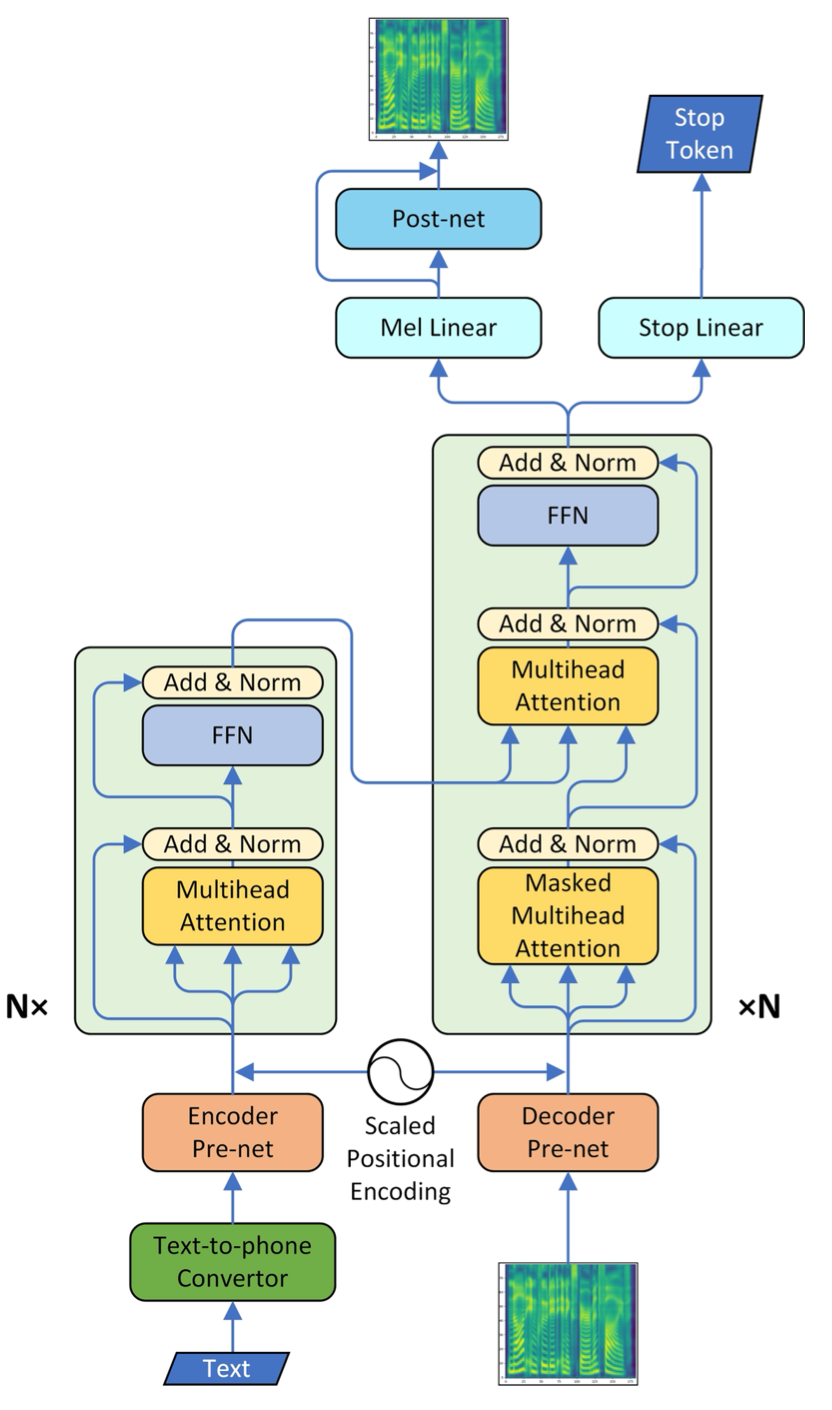
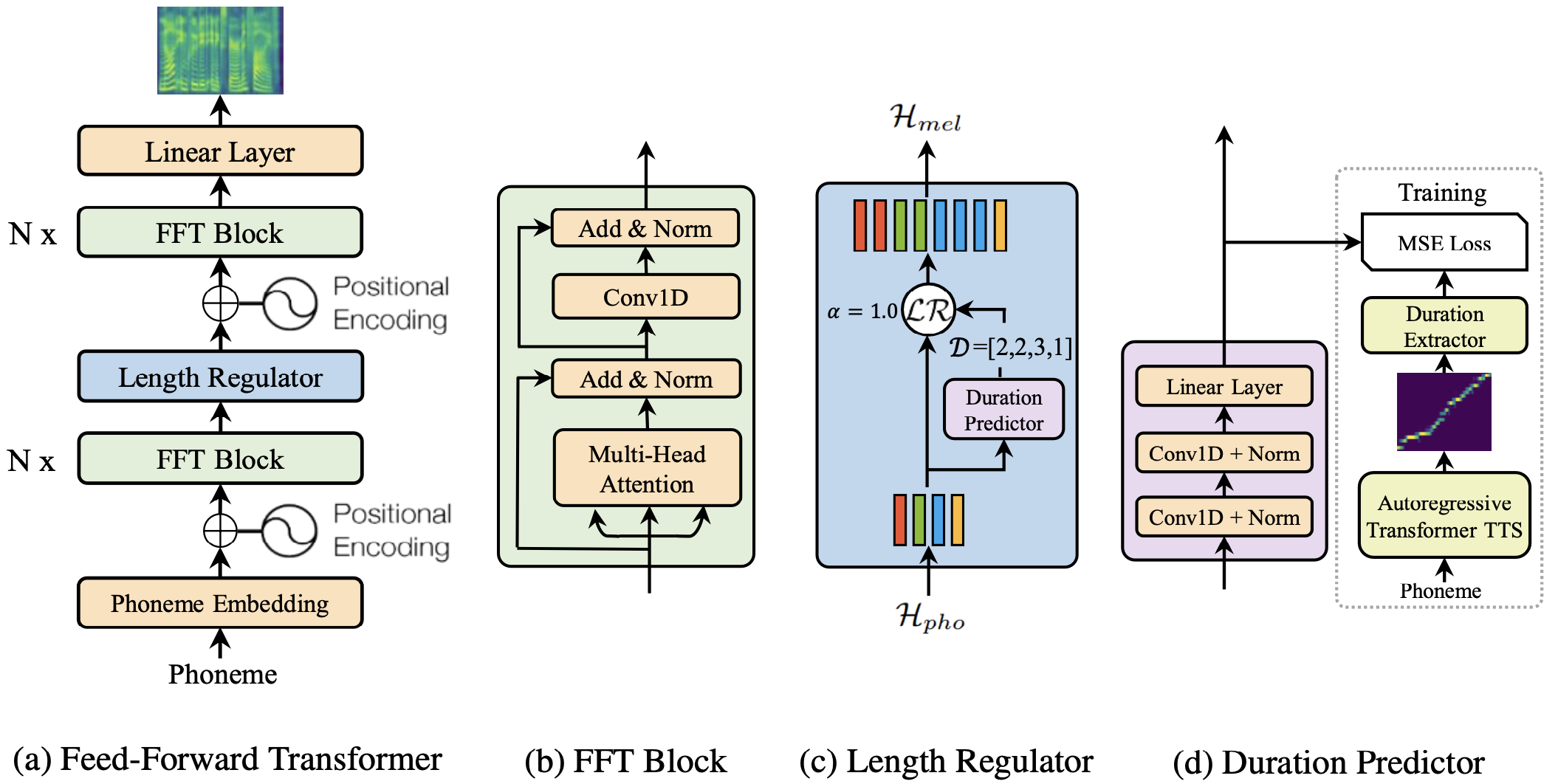
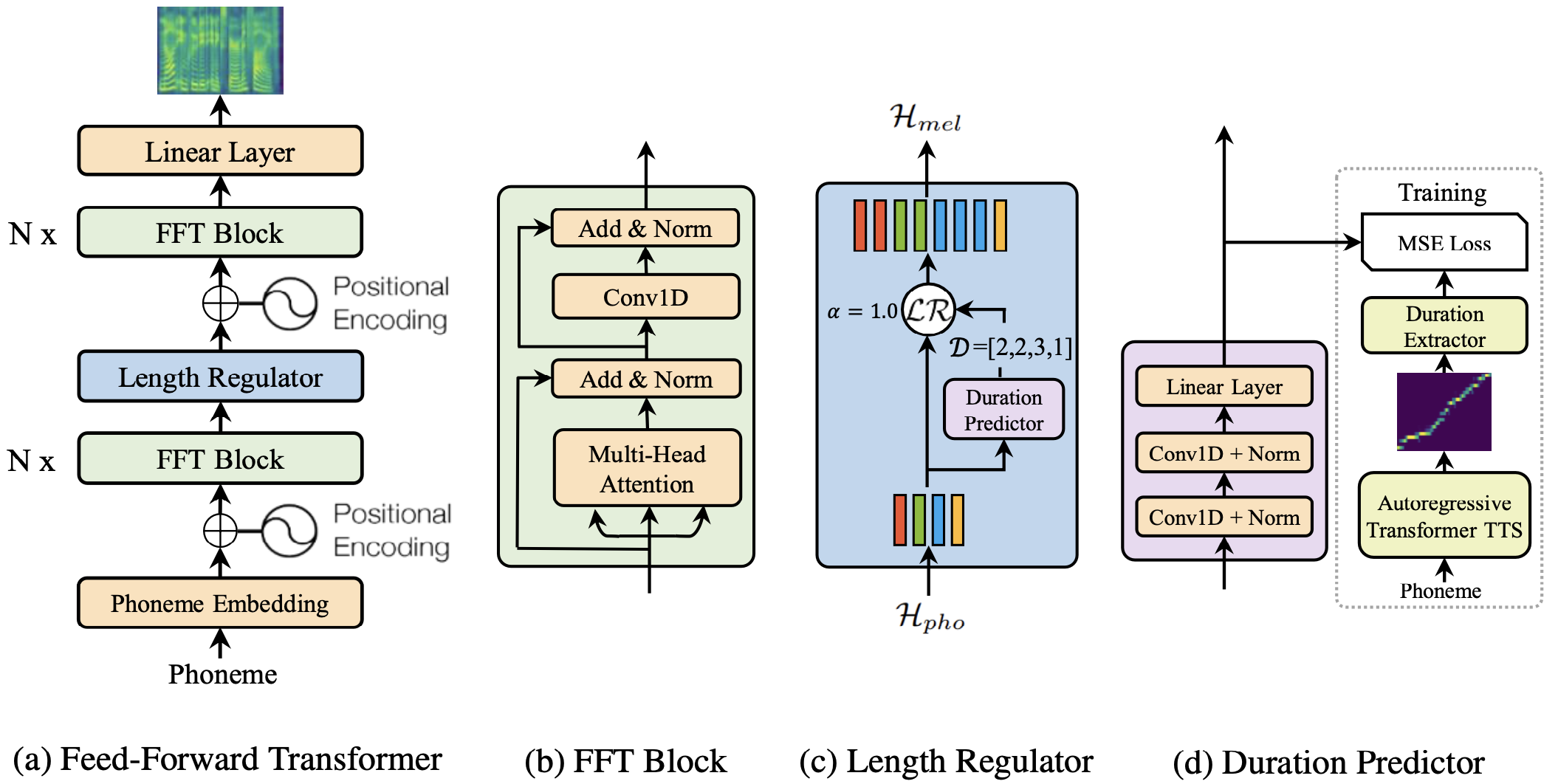
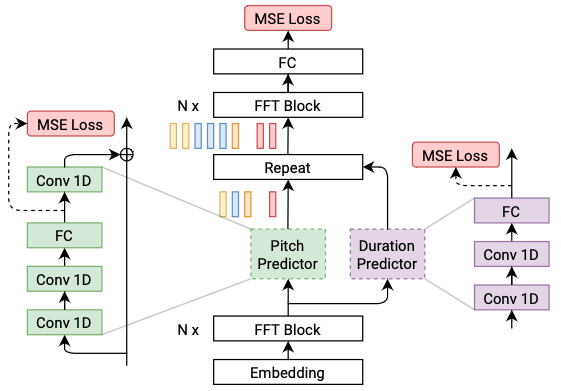
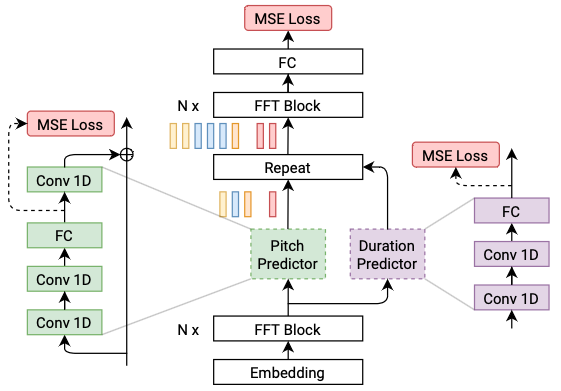
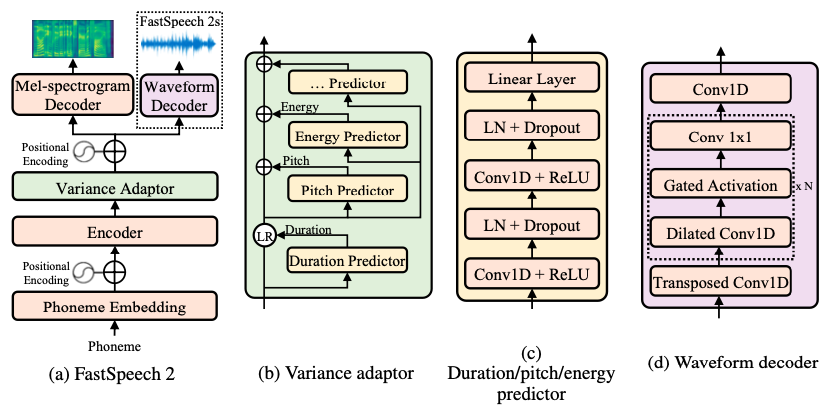
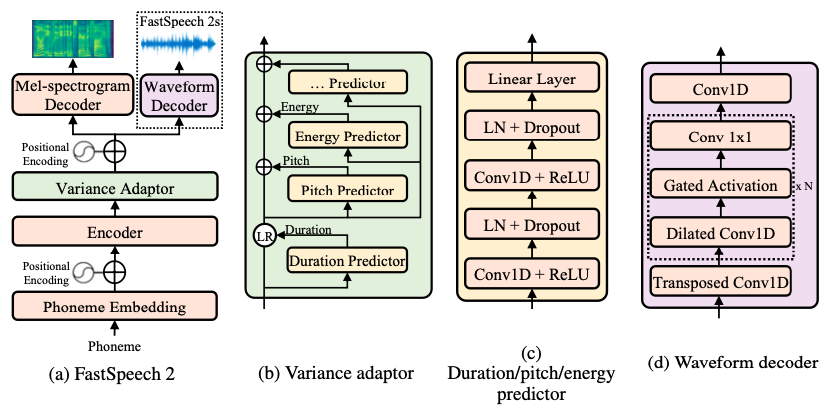
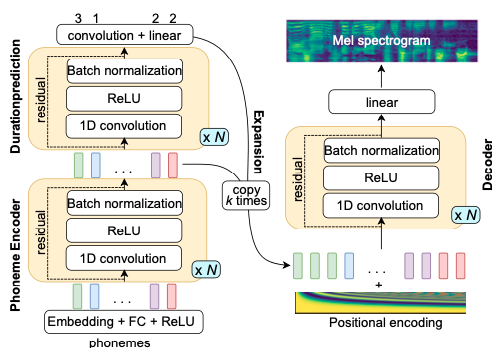
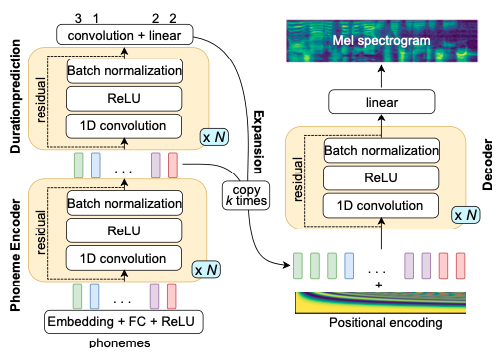
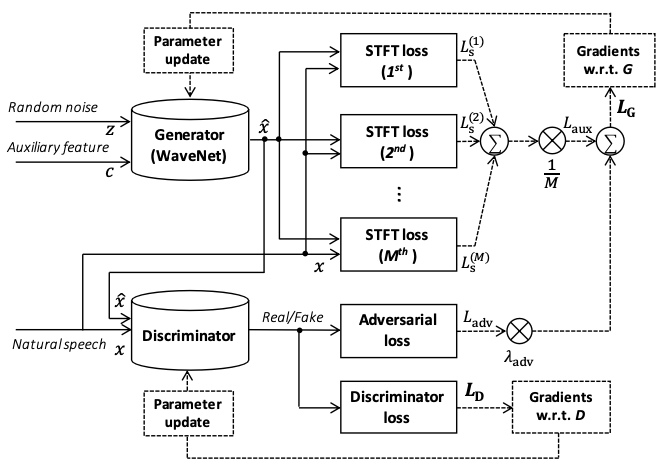
@@ -27,14 +27,14 @@ At present, there are two mainstream acoustic model structures.
- Acoustic decoder (N Frames - > N Frames).
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+