@@ -125,7 +125,7 @@ The current hyperlinks redirect to [Previous Parakeet](https://github.com/Paddle
| Acoustic Model |
Aishell |
- 2 Conv + 5 LSTM layers with only forward direction |
+ 2 Conv + 5 LSTM layers with only forward direction |
Ds2 Online Aishell Model
|
@@ -200,7 +200,7 @@ PaddleSpeech TTS mainly contains three modules: *Text Frontend*, *Acoustic Model
Text Frontend |
|
- chinese-fronted
+ chinese-fronted
|
@@ -208,41 +208,41 @@ PaddleSpeech TTS mainly contains three modules: *Text Frontend*, *Acoustic Model
| Tacotron2 |
LJSpeech |
- tacotron2-vctk
+ tacotron2-vctk
|
| TransformerTTS |
- transformer-ljspeech
+ transformer-ljspeech
|
| SpeedySpeech |
CSMSC |
- speedyspeech-csmsc
+ speedyspeech-csmsc
|
| FastSpeech2 |
AISHELL-3 |
- fastspeech2-aishell3
+ fastspeech2-aishell3
|
| VCTK |
- fastspeech2-vctk |
+ fastspeech2-vctk |
| LJSpeech |
- fastspeech2-ljspeech |
+ fastspeech2-ljspeech |
| CSMSC |
- fastspeech2-csmsc
+ fastspeech2-csmsc
|
@@ -250,26 +250,26 @@ PaddleSpeech TTS mainly contains three modules: *Text Frontend*, *Acoustic Model
| WaveFlow |
LJSpeech |
- waveflow-ljspeech
+ waveflow-ljspeech
|
| Parallel WaveGAN |
LJSpeech |
- PWGAN-ljspeech
+ PWGAN-ljspeech
|
| VCTK |
- PWGAN-vctk
+ PWGAN-vctk
|
| CSMSC |
- PWGAN-csmsc
+ PWGAN-csmsc
|
@@ -277,14 +277,14 @@ PaddleSpeech TTS mainly contains three modules: *Text Frontend*, *Acoustic Model
| GE2E |
AISHELL-3, etc. |
- ge2e
+ ge2e
|
| GE2E + Tactron2 |
AISHELL-3 |
- ge2e-tactron2-aishell3
+ ge2e-tactron2-aishell3
|
diff --git a/deepspeech/exps/deepspeech2/model.py b/deepspeech/exps/deepspeech2/model.py
index 7b929f8b7..6424cfdf3 100644
--- a/deepspeech/exps/deepspeech2/model.py
+++ b/deepspeech/exps/deepspeech2/model.py
@@ -167,6 +167,11 @@ class DeepSpeech2Trainer(Trainer):
logger.info(f"{model}")
layer_tools.print_params(model, logger.info)
+ self.model = model
+ logger.info("Setup model!")
+
+ if not self.train:
+ return
grad_clip = ClipGradByGlobalNormWithLog(
config.training.global_grad_clip)
@@ -180,74 +185,77 @@ class DeepSpeech2Trainer(Trainer):
weight_decay=paddle.regularizer.L2Decay(
config.training.weight_decay),
grad_clip=grad_clip)
-
- self.model = model
self.optimizer = optimizer
self.lr_scheduler = lr_scheduler
- logger.info("Setup model/optimizer/lr_scheduler!")
+ logger.info("Setup optimizer/lr_scheduler!")
+
def setup_dataloader(self):
config = self.config.clone()
config.defrost()
- config.collator.keep_transcription_text = False
-
- config.data.manifest = config.data.train_manifest
- train_dataset = ManifestDataset.from_config(config)
-
- config.data.manifest = config.data.dev_manifest
- dev_dataset = ManifestDataset.from_config(config)
-
- config.data.manifest = config.data.test_manifest
- test_dataset = ManifestDataset.from_config(config)
-
- if self.parallel:
- batch_sampler = SortagradDistributedBatchSampler(
+ if self.train:
+ # train
+ config.data.manifest = config.data.train_manifest
+ train_dataset = ManifestDataset.from_config(config)
+ if self.parallel:
+ batch_sampler = SortagradDistributedBatchSampler(
+ train_dataset,
+ batch_size=config.collator.batch_size,
+ num_replicas=None,
+ rank=None,
+ shuffle=True,
+ drop_last=True,
+ sortagrad=config.collator.sortagrad,
+ shuffle_method=config.collator.shuffle_method)
+ else:
+ batch_sampler = SortagradBatchSampler(
+ train_dataset,
+ shuffle=True,
+ batch_size=config.collator.batch_size,
+ drop_last=True,
+ sortagrad=config.collator.sortagrad,
+ shuffle_method=config.collator.shuffle_method)
+
+ config.collator.keep_transcription_text = False
+ collate_fn_train = SpeechCollator.from_config(config)
+ self.train_loader = DataLoader(
train_dataset,
- batch_size=config.collator.batch_size,
- num_replicas=None,
- rank=None,
- shuffle=True,
- drop_last=True,
- sortagrad=config.collator.sortagrad,
- shuffle_method=config.collator.shuffle_method)
+ batch_sampler=batch_sampler,
+ collate_fn=collate_fn_train,
+ num_workers=config.collator.num_workers)
+
+ # dev
+ config.data.manifest = config.data.dev_manifest
+ dev_dataset = ManifestDataset.from_config(config)
+
+ config.collator.augmentation_config = ""
+ config.collator.keep_transcription_text = False
+ collate_fn_dev = SpeechCollator.from_config(config)
+ self.valid_loader = DataLoader(
+ dev_dataset,
+ batch_size=int(config.collator.batch_size),
+ shuffle=False,
+ drop_last=False,
+ collate_fn=collate_fn_dev,
+ num_workers=config.collator.num_workers)
+ logger.info("Setup train/valid Dataloader!")
else:
- batch_sampler = SortagradBatchSampler(
- train_dataset,
- shuffle=True,
- batch_size=config.collator.batch_size,
- drop_last=True,
- sortagrad=config.collator.sortagrad,
- shuffle_method=config.collator.shuffle_method)
-
- collate_fn_train = SpeechCollator.from_config(config)
-
- config.collator.augmentation_config = ""
- collate_fn_dev = SpeechCollator.from_config(config)
-
- config.collator.keep_transcription_text = True
- config.collator.augmentation_config = ""
- collate_fn_test = SpeechCollator.from_config(config)
-
- self.train_loader = DataLoader(
- train_dataset,
- batch_sampler=batch_sampler,
- collate_fn=collate_fn_train,
- num_workers=config.collator.num_workers)
- self.valid_loader = DataLoader(
- dev_dataset,
- batch_size=int(config.collator.batch_size),
- shuffle=False,
- drop_last=False,
- collate_fn=collate_fn_dev,
- num_workers=config.collator.num_workers)
- self.test_loader = DataLoader(
- test_dataset,
- batch_size=config.decoding.batch_size,
- shuffle=False,
- drop_last=False,
- collate_fn=collate_fn_test,
- num_workers=config.collator.num_workers)
- logger.info("Setup train/valid/test Dataloader!")
+ # test
+ config.data.manifest = config.data.test_manifest
+ test_dataset = ManifestDataset.from_config(config)
+
+ config.collator.augmentation_config = ""
+ config.collator.keep_transcription_text = True
+ collate_fn_test = SpeechCollator.from_config(config)
+
+ self.test_loader = DataLoader(
+ test_dataset,
+ batch_size=config.decoding.batch_size,
+ shuffle=False,
+ drop_last=False,
+ collate_fn=collate_fn_test,
+ num_workers=config.collator.num_workers)
+ logger.info("Setup test Dataloader!")
class DeepSpeech2Tester(DeepSpeech2Trainer):
diff --git a/deepspeech/exps/u2/model.py b/deepspeech/exps/u2/model.py
index 7806aaa49..e47a59eda 100644
--- a/deepspeech/exps/u2/model.py
+++ b/deepspeech/exps/u2/model.py
@@ -172,7 +172,7 @@ class U2Trainer(Trainer):
dist.get_rank(), total_loss / num_seen_utts))
return total_loss, num_seen_utts
- def train(self):
+ def do_train(self):
"""The training process control by step."""
# !!!IMPORTANT!!!
# Try to export the model by script, if fails, we should refine
diff --git a/deepspeech/exps/u2_kaldi/model.py b/deepspeech/exps/u2_kaldi/model.py
index f86243269..663c36d8b 100644
--- a/deepspeech/exps/u2_kaldi/model.py
+++ b/deepspeech/exps/u2_kaldi/model.py
@@ -173,7 +173,7 @@ class U2Trainer(Trainer):
dist.get_rank(), total_loss / num_seen_utts))
return total_loss, num_seen_utts
- def train(self):
+ def do_train(self):
"""The training process control by step."""
# !!!IMPORTANT!!!
# Try to export the model by script, if fails, we should refine
diff --git a/deepspeech/exps/u2_st/model.py b/deepspeech/exps/u2_st/model.py
index c5df44c67..1f638e64c 100644
--- a/deepspeech/exps/u2_st/model.py
+++ b/deepspeech/exps/u2_st/model.py
@@ -184,7 +184,7 @@ class U2STTrainer(Trainer):
dist.get_rank(), total_loss / num_seen_utts))
return total_loss, num_seen_utts
- def train(self):
+ def do_train(self):
"""The training process control by step."""
# !!!IMPORTANT!!!
# Try to export the model by script, if fails, we should refine
diff --git a/deepspeech/training/trainer.py b/deepspeech/training/trainer.py
index 2c2389203..2da838047 100644
--- a/deepspeech/training/trainer.py
+++ b/deepspeech/training/trainer.py
@@ -134,6 +134,10 @@ class Trainer():
logger.info(
f"Benchmark reset batch-size: {self.args.benchmark_batch_size}")
+ @property
+ def train(self):
+ return self._train
+
@contextmanager
def eval(self):
self._train = False
@@ -248,7 +252,7 @@ class Trainer():
sys.exit(
f"Reach benchmark-max-step: {self.args.benchmark_max_step}")
- def train(self):
+ def do_train(self):
"""The training process control by epoch."""
self.before_train()
@@ -321,7 +325,7 @@ class Trainer():
"""
try:
with Timer("Training Done: {}"):
- self.train()
+ self.do_train()
except KeyboardInterrupt:
exit(-1)
finally:
@@ -432,7 +436,7 @@ class Trainer():
beginning of the experiment.
"""
config_file = self.config_dir / "config.yaml"
- if self._train and config_file.exists():
+ if self.train and config_file.exists():
time_stamp = time.strftime("%Y_%m_%d_%H_%M_%s", time.gmtime())
target_path = self.config_dir / ".".join(
[time_stamp, "config.yaml"])
diff --git a/docs/images/paddle.png b/docs/images/paddle.png
new file mode 100644
index 000000000..bc1135abf
Binary files /dev/null and b/docs/images/paddle.png differ
diff --git a/docs/images/tuning_error_surface.png b/docs/images/tuning_error_surface.png
new file mode 100644
index 000000000..2204cee2f
Binary files /dev/null and b/docs/images/tuning_error_surface.png differ
diff --git a/docs/requirements.txt b/docs/requirements.txt
new file mode 100644
index 000000000..11e0d4b46
--- /dev/null
+++ b/docs/requirements.txt
@@ -0,0 +1,7 @@
+myst-parser
+numpydoc
+recommonmark>=0.5.0
+sphinx
+sphinx-autobuild
+sphinx-markdown-tables
+sphinx_rtd_theme
diff --git a/docs/source/asr/deepspeech_architecture.md b/docs/source/asr/models_introduction.md
similarity index 80%
rename from docs/source/asr/deepspeech_architecture.md
rename to docs/source/asr/models_introduction.md
index be9471d93..c99093bd6 100644
--- a/docs/source/asr/deepspeech_architecture.md
+++ b/docs/source/asr/models_introduction.md
@@ -1,6 +1,5 @@
-# Deepspeech2
-## Streaming
-
+# Models introduction
+## Streaming DeepSpeech2
The implemented arcitecure of Deepspeech2 online model is based on [Deepspeech2 model](https://arxiv.org/pdf/1512.02595.pdf) with some changes.
The model is mainly composed of 2D convolution subsampling layer and stacked single direction rnn layers.
@@ -14,8 +13,8 @@ In addition, the training process and the testing process are also introduced.
The arcitecture of the model is shown in Fig.1.
- -
-
Fig.1 The Arcitecture of deepspeech2 online model
+ 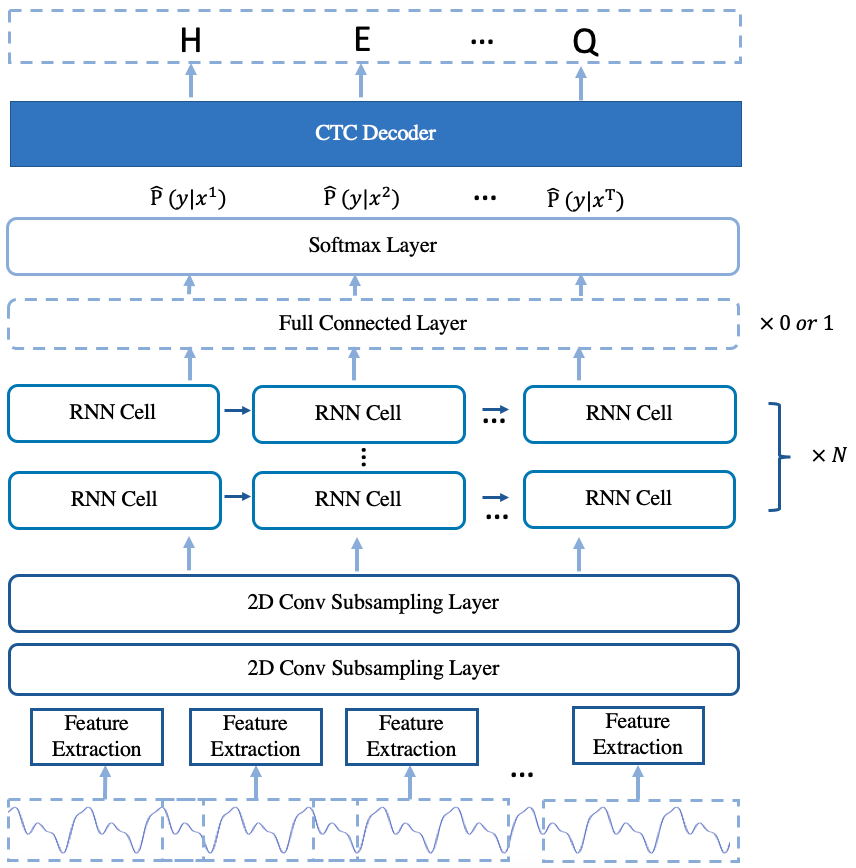 +
+
Fig.1 The Arcitecture of deepspeech2 online model
@@ -23,13 +22,13 @@ The arcitecture of the model is shown in Fig.1.
#### Vocabulary
For English data, the vocabulary dictionary is composed of 26 English characters with " ' ", space, \ and \. The \ represents the blank label in CTC, the \ represents the unknown character and the \ represents the start and the end characters. For mandarin, the vocabulary dictionary is composed of chinese characters statisticed from the training set and three additional characters are added. The added characters are \, \ and \. For both English and mandarin data, we set the default indexs that \=0, \=1 and \= last index.
```
- # The code to build vocabulary
- cd examples/aishell/s0
- python3 ../../../utils/build_vocab.py \
- --unit_type="char" \
- --count_threshold=0 \
- --vocab_path="data/vocab.txt" \
- --manifest_paths "data/manifest.train.raw" "data/manifest.dev.raw"
+# The code to build vocabulary
+cd examples/aishell/s0
+python3 ../../../utils/build_vocab.py \
+ --unit_type="char" \
+ --count_threshold=0 \
+ --vocab_path="data/vocab.txt" \
+ --manifest_paths "data/manifest.train.raw" "data/manifest.dev.raw"
# vocabulary for aishell dataset (Mandarin)
vi examples/aishell/s0/data/vocab.txt
@@ -41,29 +40,29 @@ vi examples/librispeech/s0/data/vocab.txt
#### CMVN
For CMVN, a subset or the full of traininig set is chosed and be used to compute the feature mean and std.
```
- # The code to compute the feature mean and std
+# The code to compute the feature mean and std
cd examples/aishell/s0
python3 ../../../utils/compute_mean_std.py \
- --manifest_path="data/manifest.train.raw" \
- --spectrum_type="linear" \
- --delta_delta=false \
- --stride_ms=10.0 \
- --window_ms=20.0 \
- --sample_rate=16000 \
- --use_dB_normalization=True \
- --num_samples=2000 \
- --num_workers=10 \
- --output_path="data/mean_std.json"
+ --manifest_path="data/manifest.train.raw" \
+ --spectrum_type="linear" \
+ --delta_delta=false \
+ --stride_ms=10.0 \
+ --window_ms=20.0 \
+ --sample_rate=16000 \
+ --use_dB_normalization=True \
+ --num_samples=2000 \
+ --num_workers=10 \
+ --output_path="data/mean_std.json"
```
#### Feature Extraction
- For feature extraction, three methods are implemented, which are linear (FFT without using filter bank), fbank and mfcc.
- Currently, the released deepspeech2 online model use the linear feature extraction method.
- ```
- The code for feature extraction
- vi deepspeech/frontend/featurizer/audio_featurizer.py
- ```
+For feature extraction, three methods are implemented, which are linear (FFT without using filter bank), fbank and mfcc.
+Currently, the released deepspeech2 online model use the linear feature extraction method.
+```
+The code for feature extraction
+vi deepspeech/frontend/featurizer/audio_featurizer.py
+```
### Encoder
The encoder is composed of two 2D convolution subsampling layers and a number of stacked single direction rnn layers. The 2D convolution subsampling layers extract feature representation from the raw audio feature and reduce the length of audio feature at the same time. After passing through the convolution subsampling layers, then the feature representation are input into the stacked rnn layers. For the stacked rnn layers, LSTM cell and GRU cell are provided to use. Adding one fully connected (fc) layer after the stacked rnn layers is optional. If the number of stacked rnn layers is less than 5, adding one fc layer after stacked rnn layers is recommand.
@@ -84,11 +83,11 @@ vi deepspeech/models/ds2_online/deepspeech2.py
vi deepspeech/modules/ctc.py
```
-## Training Process
+### Training Process
Using the command below, you can train the deepspeech2 online model.
```
- cd examples/aishell/s0
- bash run.sh --stage 0 --stop_stage 2 --model_type online --conf_path conf/deepspeech2_online.yaml
+cd examples/aishell/s0
+bash run.sh --stage 0 --stop_stage 2 --model_type online --conf_path conf/deepspeech2_online.yaml
```
The detail commands are:
```
@@ -127,11 +126,11 @@ fi
By using the command above, the training process can be started. There are 5 stages in "run.sh", and the first 3 stages are used for training process. The stage 0 is used for data preparation, in which the dataset will be downloaded, and the manifest files of the datasets, vocabulary dictionary and CMVN file will be generated in "./data/". The stage 1 is used for training the model, the log files and model checkpoint is saved in "exp/deepspeech2_online/". The stage 2 is used to generated final model for predicting by averaging the top-k model parameters based on validation loss.
-## Testing Process
+### Testing Process
Using the command below, you can test the deepspeech2 online model.
- ```
- bash run.sh --stage 3 --stop_stage 5 --model_type online --conf_path conf/deepspeech2_online.yaml
- ```
+```
+bash run.sh --stage 3 --stop_stage 5 --model_type online --conf_path conf/deepspeech2_online.yaml
+```
The detail commands are:
```
conf_path=conf/deepspeech2_online.yaml
@@ -139,7 +138,7 @@ avg_num=1
model_type=online
avg_ckpt=avg_${avg_num}
- if [ ${stage} -le 3 ] && [ ${stop_stage} -ge 3 ]; then
+if [ ${stage} -le 3 ] && [ ${stop_stage} -ge 3 ]; then
# test ckpt avg_n
CUDA_VISIBLE_DEVICES=2 ./local/test.sh ${conf_path} exp/${ckpt}/checkpoints/${avg_ckpt} ${model_type}|| exit -1
fi
@@ -156,19 +155,16 @@ fi
```
After the training process, we use stage 3,4,5 for testing process. The stage 3 is for testing the model generated in the stage 2 and provided the CER index of the test set. The stage 4 is for transforming the model from dynamic graph to static graph by using "paddle.jit" library. The stage 5 is for testing the model in static graph.
-
-## Non-Streaming
+## Non-Streaming DeepSpeech2
The deepspeech2 offline model is similarity to the deepspeech2 online model. The main difference between them is the offline model use the stacked bi-directional rnn layers while the online model use the single direction rnn layers and the fc layer is not used. For the stacked bi-directional rnn layers in the offline model, the rnn cell and gru cell are provided to use.
The arcitecture of the model is shown in Fig.2.
- -
-
Fig.2 The Arcitecture of deepspeech2 offline model
+ 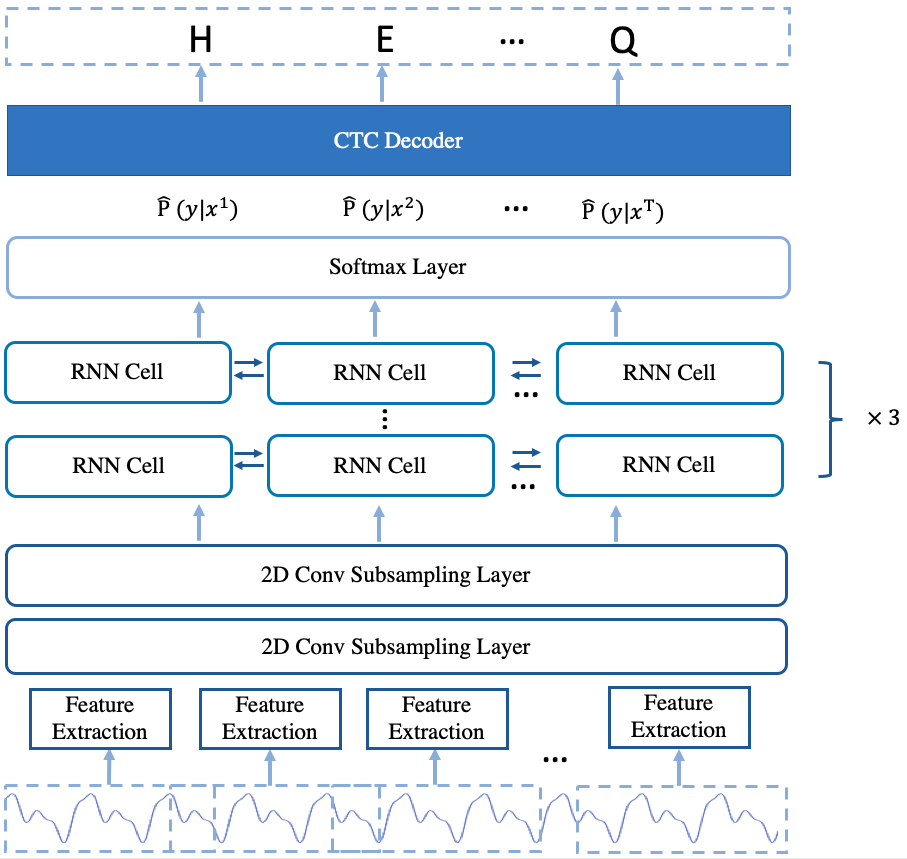 +
+
Fig.2 The Arcitecture of deepspeech2 offline model
-
-
For data preparation and decoder, the deepspeech2 offline model is same with the deepspeech2 online model.
The code of encoder and decoder for deepspeech2 offline model is in:
@@ -180,7 +176,7 @@ The training process and testing process of deepspeech2 offline model is very si
Only some changes should be noticed.
For training and testing, the "model_type" and the "conf_path" must be set.
- ```
+```
# Training offline
cd examples/aishell/s0
bash run.sh --stage 0 --stop_stage 2 --model_type offline --conf_path conf/deepspeech2.yaml
diff --git a/docs/source/asr/getting_started.md b/docs/source/asr/quick_start.md
similarity index 83%
rename from docs/source/asr/getting_started.md
rename to docs/source/asr/quick_start.md
index 478f3bb38..da1620e90 100644
--- a/docs/source/asr/getting_started.md
+++ b/docs/source/asr/quick_start.md
@@ -1,5 +1,4 @@
-# Getting Started
-
+# Quick Start of Speech-To-Text
Several shell scripts provided in `./examples/tiny/local` will help us to quickly give it a try, for most major modules, including data preparation, model training, case inference and model evaluation, with a few public dataset (e.g. [LibriSpeech](http://www.openslr.org/12/), [Aishell](http://www.openslr.org/33)). Reading these examples will also help you to understand how to make it work with your own data.
Some of the scripts in `./examples` are not configured with GPUs. If you want to train with 8 GPUs, please modify `CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7`. If you don't have any GPU available, please set `CUDA_VISIBLE_DEVICES=` to use CPUs instead. Besides, if out-of-memory problem occurs, just reduce `batch_size` to fit.
@@ -11,68 +10,52 @@ Let's take a tiny sampled subset of [LibriSpeech dataset](http://www.openslr.org
```bash
cd examples/tiny
```
-
Notice that this is only a toy example with a tiny sampled subset of LibriSpeech. If you would like to try with the complete dataset (would take several days for training), please go to `examples/librispeech` instead.
-
- Source env
-
```bash
source path.sh
```
- **Must do this before starting do anything.**
- Set `MAIN_ROOT` as project dir. Using defualt `deepspeech2` model as default, you can change this in the script.
-
+ **Must do this before you start to do anything.**
+ Set `MAIN_ROOT` as project dir. Using defualt `deepspeech2` model as `MODEL`, you can change this in the script.
- Main entrypoint
-
```bash
bash run.sh
```
- This just a demo, please make sure every `step` is work fine when do next `step`.
+ This is just a demo, please make sure every `step` works well before next `step`.
More detailed information are provided in the following sections. Wish you a happy journey with the *DeepSpeech on PaddlePaddle* ASR engine!
## Training a model
-The key steps of training for Mandarin language are same to that of English language and we have also provided an example for Mandarin training with Aishell in ```examples/aishell/local```. As mentioned above, please execute ```sh data.sh```, ```sh train.sh```, ```sh test.sh``` and ```sh infer.sh``` to do data preparation, training, testing and inference correspondingly. We have also prepared a pre-trained model (downloaded by local/download_model.sh) for users to try with ```sh infer_golden.sh``` and ```sh test_golden.sh```. Notice that, different from English LM, the Mandarin LM is character-based and please run ```local/tune.sh``` to find an optimal setting.
+The key steps of training for Mandarin language are same to that of English language and we have also provided an example for Mandarin training with Aishell in ```examples/aishell/local```. As mentioned above, please execute ```sh data.sh```, ```sh train.sh```, ```sh test.sh```and ```sh infer.sh```to do data preparation, training, testing and inference correspondingly. We have also prepared a pre-trained model (downloaded by local/download_model.sh) for users to try with ```sh infer_golden.sh```and ```sh test_golden.sh```. Notice that, different from English LM, the Mandarin LM is character-based and please run ```local/tune.sh```to find an optimal setting.
## Speech-to-text Inference
An inference module caller `infer.py` is provided to infer, decode and visualize speech-to-text results for several given audio clips. It might help to have an intuitive and qualitative evaluation of the ASR model's performance.
-
```bash
CUDA_VISIBLE_DEVICES=0 bash local/infer.sh
```
-
We provide two types of CTC decoders: *CTC greedy decoder* and *CTC beam search decoder*. The *CTC greedy decoder* is an implementation of the simple best-path decoding algorithm, selecting at each timestep the most likely token, thus being greedy and locally optimal. The [*CTC beam search decoder*](https://arxiv.org/abs/1408.2873) otherwise utilizes a heuristic breadth-first graph search for reaching a near global optimality; it also requires a pre-trained KenLM language model for better scoring and ranking. The decoder type can be set with argument `decoding_method`.
## Evaluate a Model
-
To evaluate a model's performance quantitatively, please run:
-
```bash
CUDA_VISIBLE_DEVICES=0 bash local/test.sh
```
-
The error rate (default: word error rate; can be set with `error_rate_type`) will be printed.
-For more help on arguments:
-
## Hyper-parameters Tuning
-
The hyper-parameters $\alpha$ (language model weight) and $\beta$ (word insertion weight) for the [*CTC beam search decoder*](https://arxiv.org/abs/1408.2873) often have a significant impact on the decoder's performance. It would be better to re-tune them on the validation set when the acoustic model is renewed.
`tune.py` performs a 2-D grid search over the hyper-parameter $\alpha$ and $\beta$. You must provide the range of $\alpha$ and $\beta$, as well as the number of their attempts.
-
-
```bash
CUDA_VISIBLE_DEVICES=0 bash local/tune.sh
```
-
The grid search will print the WER (word error rate) or CER (character error rate) at each point in the hyper-parameters space, and draw the error surface optionally. A proper hyper-parameters range should include the global minima of the error surface for WER/CER, as illustrated in the following figure.
- -
-
An example error surface for tuning on the dev-clean set of LibriSpeech
+ 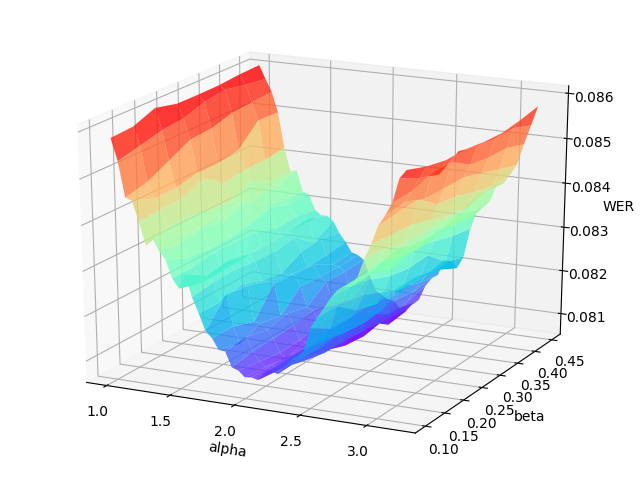 +
+
An example error surface for tuning on the dev-clean set of LibriSpeech
Usually, as the figure shows, the variation of language model weight ($\alpha$) significantly affect the performance of CTC beam search decoder. And a better procedure is to first tune on serveral data batches (the number can be specified) to find out the proper range of hyper-parameters, then change to the whole validation set to carray out an accurate tuning.
diff --git a/docs/source/asr/released_model.md b/docs/source/asr/released_model.md
deleted file mode 100644
index dc3a176b0..000000000
--- a/docs/source/asr/released_model.md
+++ /dev/null
@@ -1,28 +0,0 @@
-# Released Models
-
-## Acoustic Model Released in paddle 2.X
-Acoustic Model | Training Data | Token-based | Size | Descriptions | CER | WER | Hours of speech
-:-------------:| :------------:| :-----: | -----: | :----------------- |:--------- | :---------- | :---------
-[Ds2 Online Aishell Model](https://deepspeech.bj.bcebos.com/release2.1/aishell/s0/aishell.s0.ds_online.5rnn.debug.tar.gz) | Aishell Dataset | Char-based | 345 MB | 2 Conv + 5 LSTM layers with only forward direction | 0.0824 |-| 151 h
-[Ds2 Offline Aishell Model](https://deepspeech.bj.bcebos.com/release2.1/aishell/s0/aishell.s0.ds2.offline.cer6p65.release.tar.gz)| Aishell Dataset | Char-based | 306 MB | 2 Conv + 3 bidirectional GRU layers| 0.065 |-| 151 h
-[Conformer Online Aishell Model](https://deepspeech.bj.bcebos.com/release2.1/aishell/s1/aishell.chunk.release.tar.gz) | Aishell Dataset | Char-based | 283 MB | Encoder:Conformer, Decoder:Transformer, Decoding method: Attention + CTC | 0.0594 |-| 151 h
-[Conformer Offline Aishell Model](https://deepspeech.bj.bcebos.com/release2.1/aishell/s1/aishell.release.tar.gz) | Aishell Dataset | Char-based | 284 MB | Encoder:Conformer, Decoder:Transformer, Decoding method: Attention | 0.0547 |-| 151 h
-[Conformer Librispeech Model](https://deepspeech.bj.bcebos.com/release2.1/librispeech/s1/conformer.release.tar.gz) | Librispeech Dataset | Word-based | 287 MB | Encoder:Conformer, Decoder:Transformer, Decoding method: Attention |-| 0.0325 | 960 h
-[Transformer Librispeech Model](https://deepspeech.bj.bcebos.com/release2.1/librispeech/s1/transformer.release.tar.gz) | Librispeech Dataset | Word-based | 195 MB | Encoder:Transformer, Decoder:Transformer, Decoding method: Attention |-| 0.0544 | 960 h
-
-## Acoustic Model Transformed from paddle 1.8
-Acoustic Model | Training Data | Token-based | Size | Descriptions | CER | WER | Hours of speech
-:-------------:| :------------:| :-----: | -----: | :----------------- | :---------- | :---------- | :---------
-[Ds2 Offline Aishell model](https://deepspeech.bj.bcebos.com/mandarin_models/aishell_model_v1.8_to_v2.x.tar.gz)|Aishell Dataset| Char-based| 234 MB| 2 Conv + 3 bidirectional GRU layers| 0.0804 |-| 151 h|
-[Ds2 Offline Librispeech model](https://deepspeech.bj.bcebos.com/eng_models/librispeech_v1.8_to_v2.x.tar.gz)|Librispeech Dataset| Word-based| 307 MB| 2 Conv + 3 bidirectional sharing weight RNN layers |-| 0.0685| 960 h|
-[Ds2 Offline Baidu en8k model](https://deepspeech.bj.bcebos.com/eng_models/baidu_en8k_v1.8_to_v2.x.tar.gz)|Baidu Internal English Dataset| Word-based| 273 MB| 2 Conv + 3 bidirectional GRU layers |-| 0.0541 | 8628 h|
-
-
-
-## Language Model Released
-
-Language Model | Training Data | Token-based | Size | Descriptions
-:-------------:| :------------:| :-----: | -----: | :-----------------
-[English LM](https://deepspeech.bj.bcebos.com/en_lm/common_crawl_00.prune01111.trie.klm) | [CommonCrawl(en.00)](http://web-language-models.s3-website-us-east-1.amazonaws.com/ngrams/en/deduped/en.00.deduped.xz) | Word-based | 8.3 GB | Pruned with 0 1 1 1 1;
About 1.85 billion n-grams;
'trie' binary with '-a 22 -q 8 -b 8'
-[Mandarin LM Small](https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm) | Baidu Internal Corpus | Char-based | 2.8 GB | Pruned with 0 1 2 4 4;
About 0.13 billion n-grams;
'probing' binary with default settings
-[Mandarin LM Large](https://deepspeech.bj.bcebos.com/zh_lm/zhidao_giga.klm) | Baidu Internal Corpus | Char-based | 70.4 GB | No Pruning;
About 3.7 billion n-grams;
'probing' binary with default settings
diff --git a/docs/source/conf.py b/docs/source/conf.py
index 7e32a22c4..c41884ef8 100644
--- a/docs/source/conf.py
+++ b/docs/source/conf.py
@@ -23,6 +23,8 @@
import recommonmark.parser
import sphinx_rtd_theme
+autodoc_mock_imports = ["soundfile", "librosa"]
+
# -- Project information -----------------------------------------------------
project = 'paddle speech'
@@ -46,10 +48,10 @@ pygments_style = 'sphinx'
extensions = [
'sphinx.ext.autodoc',
'sphinx.ext.viewcode',
- 'sphinx_rtd_theme',
+ "sphinx_rtd_theme",
'sphinx.ext.mathjax',
- 'sphinx.ext.autosummary',
'numpydoc',
+ 'sphinx.ext.autosummary',
'myst_parser',
]
@@ -76,6 +78,7 @@ smartquotes = False
# relative to this directory. They are copied after the builtin static files,
# so a file named "default.css" will overwrite the builtin "default.css".
html_static_path = ['_static']
+html_logo = '../images/paddle.png'
# -- Extension configuration -------------------------------------------------
# numpydoc_show_class_members = False
diff --git a/docs/source/index.rst b/docs/source/index.rst
index 3c196d2d8..06bc2f3fa 100644
--- a/docs/source/index.rst
+++ b/docs/source/index.rst
@@ -10,34 +10,44 @@ Contents
.. toctree::
:maxdepth: 1
:caption: Introduction
-
- asr/deepspeech_architecture
+ introduction
.. toctree::
:maxdepth: 1
- :caption: Getting_started
-
- asr/install
- asr/getting_started
-
+ :caption: Quick Start
+ install
+ asr/quick_start
+ tts/quick_start
+
.. toctree::
:maxdepth: 1
- :caption: More Information
+ :caption: Speech-To-Text
+ asr/models_introduction
asr/data_preparation
asr/augmentation
asr/feature_list
- asr/ngram_lm
-
+ asr/ngram_lm
.. toctree::
:maxdepth: 1
- :caption: Released_model
+ :caption: Text-To-Speech
- asr/released_model
+ tts/basic_usage
+ tts/advanced_usage
+ tts/zh_text_frontend
+ tts/models_introduction
+ tts/gan_vocoder
+ tts/demo
+ tts/demo_2
+.. toctree::
+ :maxdepth: 1
+ :caption: Released Models
+
+ released_model
.. toctree::
:maxdepth: 1
@@ -45,3 +55,8 @@ Contents
asr/reference
+
+
+
+
+
diff --git a/docs/source/asr/install.md b/docs/source/install.md
similarity index 92%
rename from docs/source/asr/install.md
rename to docs/source/install.md
index 8cecba125..0c27a4db3 100644
--- a/docs/source/asr/install.md
+++ b/docs/source/install.md
@@ -8,7 +8,7 @@ To avoid the trouble of environment setup, [running in Docker container](#runnin
## Setup (Important)
-- Make sure these libraries or tools installed: `pkg-config`, `flac`, `ogg`, `vorbis`, `boost`, `sox, and `swig`, e.g. installing them via `apt-get`:
+- Make sure these libraries or tools installed: `pkg-config`, `flac`, `ogg`, `vorbis`, `boost`, `sox`, and `swig`, e.g. installing them via `apt-get`:
```bash
sudo apt-get install -y sox pkg-config libflac-dev libogg-dev libvorbis-dev libboost-dev swig python3-dev
@@ -44,6 +44,14 @@ bash setup.sh
source tools/venv/bin/activate
```
+## Simple Setup
+
+```python
+git clone https://github.com/PaddlePaddle/DeepSpeech.git
+cd DeepSpeech
+pip install -e .
+```
+
## Running in Docker Container (optional)
Docker is an open source tool to build, ship, and run distributed applications in an isolated environment. A Docker image for this project has been provided in [hub.docker.com](https://hub.docker.com) with all the dependencies installed. This Docker image requires the support of NVIDIA GPU, so please make sure its availiability and the [nvidia-docker](https://github.com/NVIDIA/nvidia-docker) has been installed.
diff --git a/docs/source/introduction.md b/docs/source/introduction.md
new file mode 100644
index 000000000..2f71b104f
--- /dev/null
+++ b/docs/source/introduction.md
@@ -0,0 +1,33 @@
+# PaddleSpeech
+
+## What is PaddleSpeech?
+PaddleSpeech is an open-source toolkit on PaddlePaddle platform for two critical tasks in Speech - Speech-To-Text (Automatic Speech Recognition, ASR) and Text-To-Speech Synthesis (TTS), with modules involving state-of-art and influential models.
+
+## What can PaddleSpeech do?
+
+### Speech-To-Text
+(An introduce of ASR in PaddleSpeech is needed here!)
+
+### Text-To-Speech
+TTS mainly consists of components below:
+- Implementation of models and commonly used neural network layers.
+- Dataset abstraction and common data preprocessing pipelines.
+- Ready-to-run experiments.
+
+PaddleSpeech TTS provides you with a complete TTS pipeline, including:
+- Text FrontEnd
+ - Rule based Chinese frontend.
+- Acoustic Models
+ - FastSpeech2
+ - SpeedySpeech
+ - TransformerTTS
+ - Tacotron2
+- Vocoders
+ - Multi Band MelGAN
+ - Parallel WaveGAN
+ - WaveFlow
+- Voice Cloning
+ - Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis
+ - GE2E
+
+Text-To-Speech helps you to train TTS models with simple commands.
diff --git a/docs/source/released_model.md b/docs/source/released_model.md
new file mode 100644
index 000000000..3b60f15a2
--- /dev/null
+++ b/docs/source/released_model.md
@@ -0,0 +1,55 @@
+# Released Models
+
+## Speech-To-Text Models
+### Acoustic Model Released in paddle 2.X
+Acoustic Model | Training Data | Token-based | Size | Descriptions | CER | WER | Hours of speech
+:-------------:| :------------:| :-----: | -----: | :----------------- |:--------- | :---------- | :---------
+[Ds2 Online Aishell Model](https://deepspeech.bj.bcebos.com/release2.1/aishell/s0/aishell.s0.ds_online.5rnn.debug.tar.gz) | Aishell Dataset | Char-based | 345 MB | 2 Conv + 5 LSTM layers with only forward direction | 0.0824 |-| 151 h
+[Ds2 Offline Aishell Model](https://deepspeech.bj.bcebos.com/release2.1/aishell/s0/aishell.s0.ds2.offline.cer6p65.release.tar.gz)| Aishell Dataset | Char-based | 306 MB | 2 Conv + 3 bidirectional GRU layers| 0.065 |-| 151 h
+[Conformer Online Aishell Model](https://deepspeech.bj.bcebos.com/release2.1/aishell/s1/aishell.chunk.release.tar.gz) | Aishell Dataset | Char-based | 283 MB | Encoder:Conformer, Decoder:Transformer, Decoding method: Attention + CTC | 0.0594 |-| 151 h
+[Conformer Offline Aishell Model](https://deepspeech.bj.bcebos.com/release2.1/aishell/s1/aishell.release.tar.gz) | Aishell Dataset | Char-based | 284 MB | Encoder:Conformer, Decoder:Transformer, Decoding method: Attention | 0.0547 |-| 151 h
+[Conformer Librispeech Model](https://deepspeech.bj.bcebos.com/release2.1/librispeech/s1/conformer.release.tar.gz) | Librispeech Dataset | Word-based | 287 MB | Encoder:Conformer, Decoder:Transformer, Decoding method: Attention |-| 0.0325 | 960 h
+[Transformer Librispeech Model](https://deepspeech.bj.bcebos.com/release2.1/librispeech/s1/transformer.release.tar.gz) | Librispeech Dataset | Word-based | 195 MB | Encoder:Transformer, Decoder:Transformer, Decoding method: Attention |-| 0.0544 | 960 h
+
+### Acoustic Model Transformed from paddle 1.8
+Acoustic Model | Training Data | Token-based | Size | Descriptions | CER | WER | Hours of speech
+:-------------:| :------------:| :-----: | -----: | :----------------- | :---------- | :---------- | :---------
+[Ds2 Offline Aishell model](https://deepspeech.bj.bcebos.com/mandarin_models/aishell_model_v1.8_to_v2.x.tar.gz)|Aishell Dataset| Char-based| 234 MB| 2 Conv + 3 bidirectional GRU layers| 0.0804 |-| 151 h|
+[Ds2 Offline Librispeech model](https://deepspeech.bj.bcebos.com/eng_models/librispeech_v1.8_to_v2.x.tar.gz)|Librispeech Dataset| Word-based| 307 MB| 2 Conv + 3 bidirectional sharing weight RNN layers |-| 0.0685| 960 h|
+[Ds2 Offline Baidu en8k model](https://deepspeech.bj.bcebos.com/eng_models/baidu_en8k_v1.8_to_v2.x.tar.gz)|Baidu Internal English Dataset| Word-based| 273 MB| 2 Conv + 3 bidirectional GRU layers |-| 0.0541 | 8628 h|
+
+### Language Model Released
+
+Language Model | Training Data | Token-based | Size | Descriptions
+:-------------:| :------------:| :-----: | -----: | :-----------------
+[English LM](https://deepspeech.bj.bcebos.com/en_lm/common_crawl_00.prune01111.trie.klm) | [CommonCrawl(en.00)](http://web-language-models.s3-website-us-east-1.amazonaws.com/ngrams/en/deduped/en.00.deduped.xz) | Word-based | 8.3 GB | Pruned with 0 1 1 1 1;
About 1.85 billion n-grams;
'trie' binary with '-a 22 -q 8 -b 8'
+[Mandarin LM Small](https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm) | Baidu Internal Corpus | Char-based | 2.8 GB | Pruned with 0 1 2 4 4;
About 0.13 billion n-grams;
'probing' binary with default settings
+[Mandarin LM Large](https://deepspeech.bj.bcebos.com/zh_lm/zhidao_giga.klm) | Baidu Internal Corpus | Char-based | 70.4 GB | No Pruning;
About 3.7 billion n-grams;
'probing' binary with default settings
+
+## Text-To-Speech Models
+### Acoustic Models
+Model Type | Dataset| Example Link | Pretrained Models
+:-------------:| :------------:| :-----: | :-----
+Tacotron2|LJSpeech|[tacotron2-vctk](https://github.com/PaddlePaddle/DeepSpeech/tree/develop/examples/ljspeech/tts0)|[tacotron2_ljspeech_ckpt_0.3.zip](https://paddlespeech.bj.bcebos.com/Parakeet/tacotron2_ljspeech_ckpt_0.3.zip)
+TransformerTTS| LJSpeech| [transformer-ljspeech](https://github.com/PaddlePaddle/DeepSpeech/tree/develop/examples/ljspeech/tts1)|[transformer_tts_ljspeech_ckpt_0.4.zip](https://paddlespeech.bj.bcebos.com/Parakeet/transformer_tts_ljspeech_ckpt_0.4.zip)
+SpeedySpeech| CSMSC | [speedyspeech-csmsc](https://github.com/PaddlePaddle/DeepSpeech/tree/develop/examples/csmsc/tts2) |[speedyspeech_nosil_baker_ckpt_0.5.zip](https://paddlespeech.bj.bcebos.com/Parakeet/speedyspeech_nosil_baker_ckpt_0.5.zip)
+FastSpeech2| CSMSC |[fastspeech2-csmsc](https://github.com/PaddlePaddle/DeepSpeech/tree/develop/examples/csmsc/tts3)|[fastspeech2_nosil_baker_ckpt_0.4.zip](https://paddlespeech.bj.bcebos.com/Parakeet/fastspeech2_nosil_baker_ckpt_0.4.zip)
+FastSpeech2| AISHELL-3 |[fastspeech2-aishell3](https://github.com/PaddlePaddle/DeepSpeech/tree/develop/examples/aishell3/tts3)|[fastspeech2_nosil_aishell3_ckpt_0.4.zip](https://paddlespeech.bj.bcebos.com/Parakeet/fastspeech2_nosil_aishell3_ckpt_0.4.zip)
+FastSpeech2| LJSpeech |[fastspeech2-ljspeech](https://github.com/PaddlePaddle/DeepSpeech/tree/develop/examples/ljspeech/tts3)|[fastspeech2_nosil_ljspeech_ckpt_0.5.zip](https://paddlespeech.bj.bcebos.com/Parakeet/fastspeech2_nosil_ljspeech_ckpt_0.5.zip)
+FastSpeech2| VCTK |[fastspeech2-csmsc](https://github.com/PaddlePaddle/DeepSpeech/tree/develop/examples/vctk/tts3)|[fastspeech2_nosil_vctk_ckpt_0.5.zip](https://paddlespeech.bj.bcebos.com/Parakeet/fastspeech2_nosil_vctk_ckpt_0.5.zip)
+
+
+### Vocoders
+
+Model Type | Dataset| Example Link | Pretrained Models
+:-------------:| :------------:| :-----: | :-----
+WaveFlow| LJSpeech |[waveflow-ljspeech](https://github.com/PaddlePaddle/DeepSpeech/tree/develop/examples/ljspeech/voc0)|[waveflow_ljspeech_ckpt_0.3.zip](https://paddlespeech.bj.bcebos.com/Parakeet/waveflow_ljspeech_ckpt_0.3.zip)
+Parallel WaveGAN| CSMSC |[PWGAN-csmsc](https://github.com/PaddlePaddle/DeepSpeech/tree/develop/examples/csmsc/voc1)|[pwg_baker_ckpt_0.4.zip.](https://paddlespeech.bj.bcebos.com/Parakeet/pwg_baker_ckpt_0.4.zip)
+Parallel WaveGAN| LJSpeech |[PWGAN-ljspeech](https://github.com/PaddlePaddle/DeepSpeech/tree/develop/examples/ljspeech/voc1)|[pwg_ljspeech_ckpt_0.5.zip](https://paddlespeech.bj.bcebos.com/Parakeet/pwg_ljspeech_ckpt_0.5.zip)
+Parallel WaveGAN| VCTK |[PWGAN-vctk](https://github.com/PaddlePaddle/DeepSpeech/tree/develop/examples/vctk/voc1)|[pwg_vctk_ckpt_0.5.zip](https://paddlespeech.bj.bcebos.com/Parakeet/pwg_vctk_ckpt_0.5.zip)
+
+### Voice Cloning
+Model Type | Dataset| Example Link | Pretrained Models
+:-------------:| :------------:| :-----: | :-----
+GE2E| AISHELL-3, etc. |[ge2e](https://github.com/PaddlePaddle/DeepSpeech/tree/develop/examples/other/ge2e)|[ge2e_ckpt_0.3.zip](https://paddlespeech.bj.bcebos.com/Parakeet/ge2e_ckpt_0.3.zip)
+GE2E + Tactron2| AISHELL-3 |[ge2e-tactron2-aishell3](https://github.com/PaddlePaddle/DeepSpeech/tree/develop/examples/aishell3/vc0)|[tacotron2_aishell3_ckpt_0.3.zip](https://paddlespeech.bj.bcebos.com/Parakeet/tacotron2_aishell3_ckpt_0.3.zip)
diff --git a/docs/source/tts/advanced_usage.md b/docs/source/tts/advanced_usage.md
index 529800444..297f274f7 100644
--- a/docs/source/tts/advanced_usage.md
+++ b/docs/source/tts/advanced_usage.md
@@ -1,6 +1,5 @@
-
# Advanced Usage
-This sections covers how to extend parakeet by implementing your own models and experiments. Guidelines on implementation are also elaborated.
+This sections covers how to extend TTS by implementing your own models and experiments. Guidelines on implementation are also elaborated.
For the general deep learning experiment, there are several parts to deal with:
1. Preprocess the data according to the needs of the model, and iterate the dataset by batch.
@@ -8,7 +7,7 @@ For the general deep learning experiment, there are several parts to deal with:
3. Write out the training process (generally including forward / backward calculation, parameter update, log recording, visualization, periodic evaluation, etc.).
5. Configure and run the experiment.
-## Parakeet's Model Components
+## PaddleSpeech TTS's Model Components
In order to balance the reusability and function of models, we divide models into several types according to its characteristics.
For the commonly used modules that can be used as part of other larger models, we try to implement them as simple and universal as possible, because they will be reused. Modules with trainable parameters are generally implemented as subclasses of `paddle.nn.Layer`. Modules without trainable parameters can be directly implemented as a function, and its input and output are `paddle.Tensor`.
@@ -68,11 +67,11 @@ There are two common ways to define a model which consists of several modules.
```
When a model is a complicated and made up of several components, each of which has a separate functionality, and can be replaced by other components with the same functionality, we prefer to define it in this way.
-In the directory structure of Parakeet, modules with high reusability are placed in `parakeet.modules`, but models for specific tasks are placed in `parakeet.models`. When developing a new model, developers need to consider the feasibility of splitting the modules, and the degree of generality of the modules, and place them in appropriate directories.
+In the directory structure of PaddleSpeech TTS, modules with high reusability are placed in `parakeet.modules`, but models for specific tasks are placed in `parakeet.models`. When developing a new model, developers need to consider the feasibility of splitting the modules, and the degree of generality of the modules, and place them in appropriate directories.
-## Parakeet's Data Components
+## PaddleSpeech TTS's Data Components
Another critical componnet for a deep learning project is data.
-Parakeet uses the following methods for training data:
+PaddleSpeech TTS uses the following methods for training data:
1. Preprocess the data.
2. Load the preprocessed data for training.
@@ -154,7 +153,7 @@ def _convert(self, meta_datum: Dict[str, Any]) -> Dict[str, Any]:
return example
```
-## Parakeet's Training Components
+## PaddleSpeech TTS's Training Components
A typical training process includes the following processes:
1. Iterate the dataset.
2. Process batch data.
@@ -164,7 +163,7 @@ A typical training process includes the following processes:
6. Write logs, visualize, and in some cases save necessary intermediate results.
7. Save the state of the model and optimizer.
-Here, we mainly introduce the training related components of Parakeet and why we designed it like this.
+Here, we mainly introduce the training related components of TTS in Pa and why we designed it like this.
### Global Repoter
When training and modifying Deep Learning models,logging is often needed, and it has even become the key to model debugging and modifying. We usually use various visualization tools,such as , `visualdl` in `paddle`, `tensorboard` in `tensorflow` and `vidsom`, `wnb` ,etc. Besides, `logging` and `print` are usuaally used for different purpose.
@@ -245,7 +244,7 @@ def test_reporter_scope():
In this way, when we write modular components, we can directly call `report`. The caller will decide where to report as long as it's ready for `OBSERVATION`, then it opens a `scope` and calls the component within this `scope`.
- The `Trainer` in Parakeet report the information in this way.
+ The `Trainer` in PaddleSpeech TTS report the information in this way.
```python
while True:
self.observation = {}
@@ -269,7 +268,7 @@ We made an abstraction for these intermediate processes, that is, `Updater`, whi
### Visualizer
Because we choose observation as the communication mode, we can simply write the things in observation into `visualizer`.
-## Parakeet's Configuration Components
+## PaddleSpeech TTS's Configuration Components
Deep learning experiments often have many options to configure. These configurations can be roughly divided into several categories.
1. Data source and data processing mode configuration.
2. Save path configuration of experimental results.
@@ -293,28 +292,26 @@ The following is the basic `ArgumentParser`:
3. `--output-dir` is the dir to save the training results.(if there are checkpoints in `checkpoints/` of `--output-dir` , it's defalut to reload the newest checkpoint to train)
4. `--device` and `--nprocs` determine operation modes,`--device` specifies the type of running device, whether to run on `cpu` or `gpu`. `--nprocs` refers to the number of training processes. If `nprocs` > 1, it means that multi process parallel training is used. (Note: currently only GPU multi card multi process training is supported.)
-Developers can refer to the examples in `Parakeet/examples` to write the default configuration file when adding new experiments.
+Developers can refer to the examples in `examples` to write the default configuration file when adding new experiments.
-## Parakeet's Experiment template
+## PaddleSpeech TTS's Experiment template
-The experimental codes in Parakeet are generally organized as follows:
+The experimental codes in PaddleSpeech TTS are generally organized as follows:
```text
-├── conf
-│ └── default.yaml (defalut config)
-├── README.md (help information)
-├── batch_fn.py (organize metadata into batch)
-├── config.py (code to read default config)
-├── *_updater.py (Updater of a specific model)
-├── preprocess.py (data preprocessing code)
-├── preprocess.sh (script to call data preprocessing.py)
-├── synthesis.py (synthesis from metadata)
-├── synthesis.sh (script to call synthesis.py)
-├── synthesis_e2e.py (synthesis from raw text)
-├── synthesis_e2e.sh (script to call synthesis_e2e.py)
-├── train.py (train code)
-└── run.sh (script to call train.py)
+.
+├── README.md (help information)
+├── conf
+│ └── default.yaml (defalut config)
+├── local
+│ ├── preprocess.sh (script to call data preprocessing.py)
+│ ├── synthesize.sh (script to call synthesis.py)
+│ ├── synthesize_e2e.sh (script to call synthesis_e2e.py)
+│ └──train.sh (script to call train.py)
+├── path.sh (script include paths to be sourced)
+└── run.sh (script to call scripts in local)
```
+The `*.py` files called by above `*.sh` are located `${BIN_DIR}/`
We add a named argument. `--output-dir` to each training script to specify the output directory. The directory structure is as follows, It's best for developers to follow this specification:
```text
@@ -330,4 +327,4 @@ exp/default/
└── test/ (output dir of synthesis results)
```
-You can view the examples we provide in `Parakeet/examples`. These experiments are provided to users as examples which can be run directly. Users are welcome to add new models and experiments and contribute code to Parakeet.
+You can view the examples we provide in `examples`. These experiments are provided to users as examples which can be run directly. Users are welcome to add new models and experiments and contribute code to PaddleSpeech.
diff --git a/docs/source/tts/basic_usage.md b/docs/source/tts/basic_usage.md
deleted file mode 100644
index fc2a5bad1..000000000
--- a/docs/source/tts/basic_usage.md
+++ /dev/null
@@ -1,115 +0,0 @@
-# Basic Usage
-This section shows how to use pretrained models provided by parakeet and make inference with them.
-
-Pretrained models in v0.4 are provided in a archive. Extract it to get a folder like this:
-```
-checkpoint_name/
-├──default.yaml
-├──snapshot_iter_76000.pdz
-├──speech_stats.npy
-└──phone_id_map.txt
-```
-`default.yaml` stores the config used to train the model.
-`snapshot_iter_N.pdz` is the chechpoint file, where `N` is the steps it has been trained.
-`*_stats.npy` is the stats file of feature if it has been normalized before training.
-`phone_id_map.txt` is the map of phonemes to phoneme_ids.
-
-The example code below shows how to use the models for prediction.
-## Acoustic Models (text to spectrogram)
-The code below show how to use a `FastSpeech2` model. After loading the pretrained model, use it and normalizer object to construct a prediction object,then use fastspeech2_inferencet(phone_ids) to generate spectrograms, which can be further used to synthesize raw audio with a vocoder.
-
-```python
-from pathlib import Path
-import numpy as np
-import paddle
-import yaml
-from yacs.config import CfgNode
-from parakeet.models.fastspeech2 import FastSpeech2
-from parakeet.models.fastspeech2 import FastSpeech2Inference
-from parakeet.modules.normalizer import ZScore
-# Parakeet/examples/fastspeech2/baker/frontend.py
-from frontend import Frontend
-
-# load the pretrained model
-checkpoint_dir = Path("fastspeech2_nosil_baker_ckpt_0.4")
-with open(checkpoint_dir / "phone_id_map.txt", "r") as f:
- phn_id = [line.strip().split() for line in f.readlines()]
-vocab_size = len(phn_id)
-with open(checkpoint_dir / "default.yaml") as f:
- fastspeech2_config = CfgNode(yaml.safe_load(f))
-odim = fastspeech2_config.n_mels
-model = FastSpeech2(
- idim=vocab_size, odim=odim, **fastspeech2_config["model"])
-model.set_state_dict(
- paddle.load(args.fastspeech2_checkpoint)["main_params"])
-model.eval()
-
-# load stats file
-stat = np.load(checkpoint_dir / "speech_stats.npy")
-mu, std = stat
-mu = paddle.to_tensor(mu)
-std = paddle.to_tensor(std)
-fastspeech2_normalizer = ZScore(mu, std)
-
-# construct a prediction object
-fastspeech2_inference = FastSpeech2Inference(fastspeech2_normalizer, model)
-
-# load Chinese Frontend
-frontend = Frontend(checkpoint_dir / "phone_id_map.txt")
-
-# text to spectrogram
-sentence = "你好吗?"
-input_ids = frontend.get_input_ids(sentence, merge_sentences=True)
-phone_ids = input_ids["phone_ids"]
-flags = 0
-# The output of Chinese text frontend is segmented
-for part_phone_ids in phone_ids:
- with paddle.no_grad():
- temp_mel = fastspeech2_inference(part_phone_ids)
- if flags == 0:
- mel = temp_mel
- flags = 1
- else:
- mel = paddle.concat([mel, temp_mel])
-```
-
-## Vocoder (spectrogram to wave)
-The code below show how to use a ` Parallel WaveGAN` model. Like the example above, after loading the pretrained model, use it and normalizer object to construct a prediction object,then use pwg_inference(mel) to generate raw audio (in wav format).
-
-```python
-from pathlib import Path
-import numpy as np
-import paddle
-import soundfile as sf
-import yaml
-from yacs.config import CfgNode
-from parakeet.models.parallel_wavegan import PWGGenerator
-from parakeet.models.parallel_wavegan import PWGInference
-from parakeet.modules.normalizer import ZScore
-
-# load the pretrained model
-checkpoint_dir = Path("parallel_wavegan_baker_ckpt_0.4")
-with open(checkpoint_dir / "pwg_default.yaml") as f:
- pwg_config = CfgNode(yaml.safe_load(f))
-vocoder = PWGGenerator(**pwg_config["generator_params"])
-vocoder.set_state_dict(paddle.load(args.pwg_params))
-vocoder.remove_weight_norm()
-vocoder.eval()
-
-# load stats file
-stat = np.load(checkpoint_dir / "pwg_stats.npy")
-mu, std = stat
-mu = paddle.to_tensor(mu)
-std = paddle.to_tensor(std)
-pwg_normalizer = ZScore(mu, std)
-
-# construct a prediction object
-pwg_inference = PWGInference(pwg_normalizer, vocoder)
-
-# spectrogram to wave
-wav = pwg_inference(mel)
-sf.write(
- audio_path,
- wav.numpy(),
- samplerate=fastspeech2_config.fs)
-```
diff --git a/docs/source/tts/demo.rst b/docs/source/tts/demo.rst
index a6f18f88d..948fc056e 100644
--- a/docs/source/tts/demo.rst
+++ b/docs/source/tts/demo.rst
@@ -11,7 +11,7 @@ The main processes of TTS include:
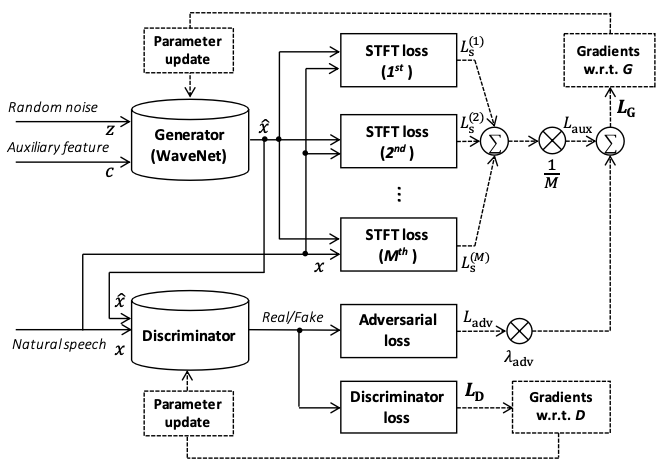
When training ``Tacotron2``、``TransformerTTS`` and ``WaveFlow``, we use English single speaker TTS dataset `LJSpeech `_ by default. However, when training ``SpeedySpeech``, ``FastSpeech2`` and ``ParallelWaveGAN``, we use Chinese single speaker dataset `CSMSC `_ by default.
-In the future, ``Parakeet`` will mainly use Chinese TTS datasets for default examples.
+In the future, ``PaddleSpeech TTS`` will mainly use Chinese TTS datasets for default examples.
Here, we will display three types of audio samples:
@@ -441,7 +441,7 @@ Audio samples generated by a TTS system. Text is first transformed into spectrog
Chinese TTS with/without text frontend
--------------------------------------
-We provide a complete Chinese text frontend module in ``Parakeet``. ``Text Normalization`` and ``G2P`` are the most important modules in text frontend, We assume that the texts are normalized already, and mainly compare ``G2P`` module here.
+We provide a complete Chinese text frontend module in ``PaddleSpeech TTS``. ``Text Normalization`` and ``G2P`` are the most important modules in text frontend, We assume that the texts are normalized already, and mainly compare ``G2P`` module here.
We use ``FastSpeech2`` + ``ParallelWaveGAN`` here.
diff --git a/docs/source/tts/demo_2.rst b/docs/source/tts/demo_2.rst
new file mode 100644
index 000000000..37922fcbf
--- /dev/null
+++ b/docs/source/tts/demo_2.rst
@@ -0,0 +1,7 @@
+Audio Sample (PaddleSpeech TTS VS Espnet TTS)
+==================
+
+This is an audio demo page to contrast PaddleSpeech TTS and Espnet TTS, We use their respective modules (Text Frontend, Acoustic model and Vocoder) here.
+We use Espnet's released models here.
+
+FastSpeech2 + Parallel WaveGAN in CSMSC
diff --git a/docs/source/tts/gan_vocoder.md b/docs/source/tts/gan_vocoder.md
new file mode 100644
index 000000000..4931f3072
--- /dev/null
+++ b/docs/source/tts/gan_vocoder.md
@@ -0,0 +1,9 @@
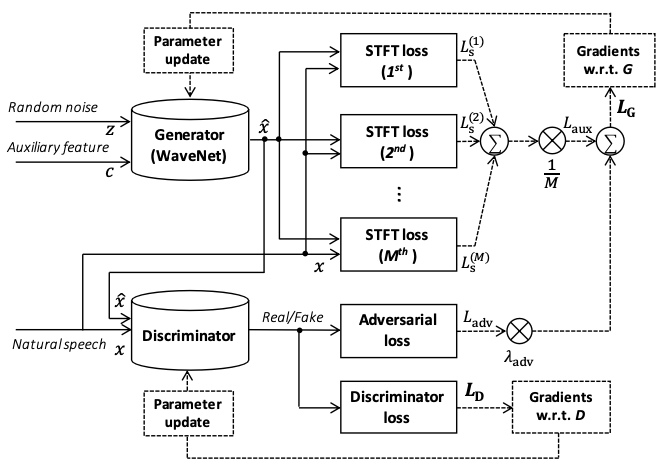
+# GAN Vocoders
+This is a brief introduction of GAN Vocoders, we mainly introduce the losses of different vocoders here.
+
+Model | Generator Loss |Discriminator Loss
+:-------------:| :------------:| :-----
+Parallel Wave GAN| adversial loss
Feature Matching | Multi-Scale Discriminator |
+Mel GAN |adversial loss
Multi-resolution STFT loss | adversial loss|
+Multi-Band Mel GAN | adversial loss
full band Multi-resolution STFT loss
sub band Multi-resolution STFT loss |Multi-Scale Discriminator|
+HiFi GAN |adversial loss
Feature Matching
Mel-Spectrogram Loss | Multi-Scale Discriminator
Multi-Period Discriminato |
diff --git a/docs/source/tts/index.rst b/docs/source/tts/index.rst
deleted file mode 100644
index 74abe60d7..000000000
--- a/docs/source/tts/index.rst
+++ /dev/null
@@ -1,45 +0,0 @@
-.. parakeet documentation master file, created by
- sphinx-quickstart on Fri Sep 10 14:22:24 2021.
- You can adapt this file completely to your liking, but it should at least
- contain the root `toctree` directive.
-
-Parakeet
-====================================
-
-``parakeet`` is a deep learning based text-to-speech toolkit built upon ``paddlepaddle`` framework. It aims to provide a flexible, efficient and state-of-the-art text-to-speech toolkit for the open-source community. It includes many influential TTS models proposed by `Baidu Research `_ and other research groups.
-
-``parakeet`` mainly consists of components below.
-
-#. Implementation of models and commonly used neural network layers.
-#. Dataset abstraction and common data preprocessing pipelines.
-#. Ready-to-run experiments.
-
-.. toctree::
- :maxdepth: 1
- :caption: Introduction
-
- introduction
-
-.. toctree::
- :maxdepth: 1
- :caption: Getting started
-
- install
- basic_usage
- advanced_usage
- cn_text_frontend
- released_models
-
-.. toctree::
- :maxdepth: 1
- :caption: Demos
-
- demo
-
-
-Indices and tables
-==================
-
-* :ref:`genindex`
-* :ref:`modindex`
-* :ref:`search`
diff --git a/docs/source/tts/install.md b/docs/source/tts/install.md
deleted file mode 100644
index b092acff0..000000000
--- a/docs/source/tts/install.md
+++ /dev/null
@@ -1,47 +0,0 @@
-# Installation
-## Install PaddlePaddle
-Parakeet requires PaddlePaddle as its backend. Note that 2.1.2 or newer versions of paddle is required.
-
-Since paddlepaddle has multiple packages depending on the device (cpu or gpu) and the dependency libraries, it is recommended to install a proper package of paddlepaddle with respect to the device and dependency library versons via `pip`.
-
-Installing paddlepaddle with conda or build paddlepaddle from source is also supported. Please refer to [PaddlePaddle installation](https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/install/pip/linux-pip.html) for more details.
-
-Example instruction to install paddlepaddle via pip is listed below.
-
-### PaddlePaddle with GPU
-```python
-# PaddlePaddle for CUDA10.1
-python -m pip install paddlepaddle-gpu==2.1.2.post101 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
-# PaddlePaddle for CUDA10.2
-python -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
-# PaddlePaddle for CUDA11.0
-python -m pip install paddlepaddle-gpu==2.1.2.post110 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
-# PaddlePaddle for CUDA11.2
-python -m pip install paddlepaddle-gpu==2.1.2.post112 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
-```
-### PaddlePaddle with CPU
-```python
-python -m pip install paddlepaddle==2.1.2 -i https://mirror.baidu.com/pypi/simple
-```
-## Install libsndfile
-Experimemts in parakeet often involve audio and spectrum processing, thus `librosa` and `soundfile` are required. `soundfile` requires a extra C library `libsndfile`, which is not always handled by pip.
-
-For Windows and Mac users, `libsndfile` is also installed when installing `soundfile` via pip, but for Linux users, installing `libsndfile` via system package manager is required. Example commands for popular distributions are listed below.
-```bash
-# ubuntu, debian
-sudo apt-get install libsndfile1
-# centos, fedora
-sudo yum install libsndfile
-# openSUSE
-sudo zypper in libsndfile
-```
-For any problem with installtion of soundfile, please refer to [SoundFile](https://pypi.org/project/SoundFile/).
-## Install Parakeet
-There are two ways to install parakeet according to the purpose of using it.
-
- 1. If you want to run experiments provided by parakeet or add new models and experiments, it is recommended to clone the project from github (Parakeet), and install it in editable mode.
- ```python
- git clone https://github.com/PaddlePaddle/Parakeet
- cd Parakeet
- pip install -e .
- ```
diff --git a/docs/source/tts/introduction.md b/docs/source/tts/introduction.md
deleted file mode 100644
index d350565cd..000000000
--- a/docs/source/tts/introduction.md
+++ /dev/null
@@ -1,27 +0,0 @@
-# Parakeet - PAddle PARAllel text-to-speech toolKIT
-
-## What is Parakeet?
-Parakeet is a deep learning based text-to-speech toolkit built upon paddlepaddle framework. It aims to provide a flexible, efficient and state-of-the-art text-to-speech toolkit for the open-source community. It includes many influential TTS models proposed by Baidu Research and other research groups.
-
-## What can Parakeet do?
-Parakeet mainly consists of components below:
-- Implementation of models and commonly used neural network layers.
-- Dataset abstraction and common data preprocessing pipelines.
-- Ready-to-run experiments.
-
-Parakeet provides you with a complete TTS pipeline, including:
-- Text FrontEnd
- - Rule based Chinese frontend.
-- Acoustic Models
- - FastSpeech2
- - SpeedySpeech
- - TransformerTTS
- - Tacotron2
-- Vocoders
- - Parallel WaveGAN
- - WaveFlow
-- Voice Cloning
- - Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis
- - GE2E
-
-Parakeet helps you to train TTS models with simple commands.
diff --git a/docs/source/tts/released_models.md b/docs/source/tts/models_introduction.md
similarity index 82%
rename from docs/source/tts/released_models.md
rename to docs/source/tts/models_introduction.md
index 7899c1c5d..b13297582 100644
--- a/docs/source/tts/released_models.md
+++ b/docs/source/tts/models_introduction.md
@@ -1,12 +1,12 @@
-# Released Models
-TTS system mainly includes three modules: `text frontend`, `Acoustic model` and `Vocoder`. We introduce a rule based Chinese text frontend in [cn_text_frontend.md](./cn_text_frontend.md). Here, we will introduce acoustic models and vocoders, which are trainable models.
+# Models introduction
+TTS system mainly includes three modules: `Text Frontend`, `Acoustic model` and `Vocoder`. We introduce a rule based Chinese text frontend in [cn_text_frontend.md](./cn_text_frontend.md). Here, we will introduce acoustic models and vocoders, which are trainable models.
The main processes of TTS include:
1. Convert the original text into characters/phonemes, through `text frontend` module.
2. Convert characters/phonemes into acoustic features , such as linear spectrogram, mel spectrogram, LPC features, etc. through `Acoustic models`.
3. Convert acoustic features into waveforms through `Vocoders`.
-A simple text frontend module can be implemented by rules. Acoustic models and vocoders need to be trained. The models provided by Parakeet are acoustic models and vocoders.
+A simple text frontend module can be implemented by rules. Acoustic models and vocoders need to be trained. The models provided by PaddleSpeech TTS are acoustic models and vocoders.
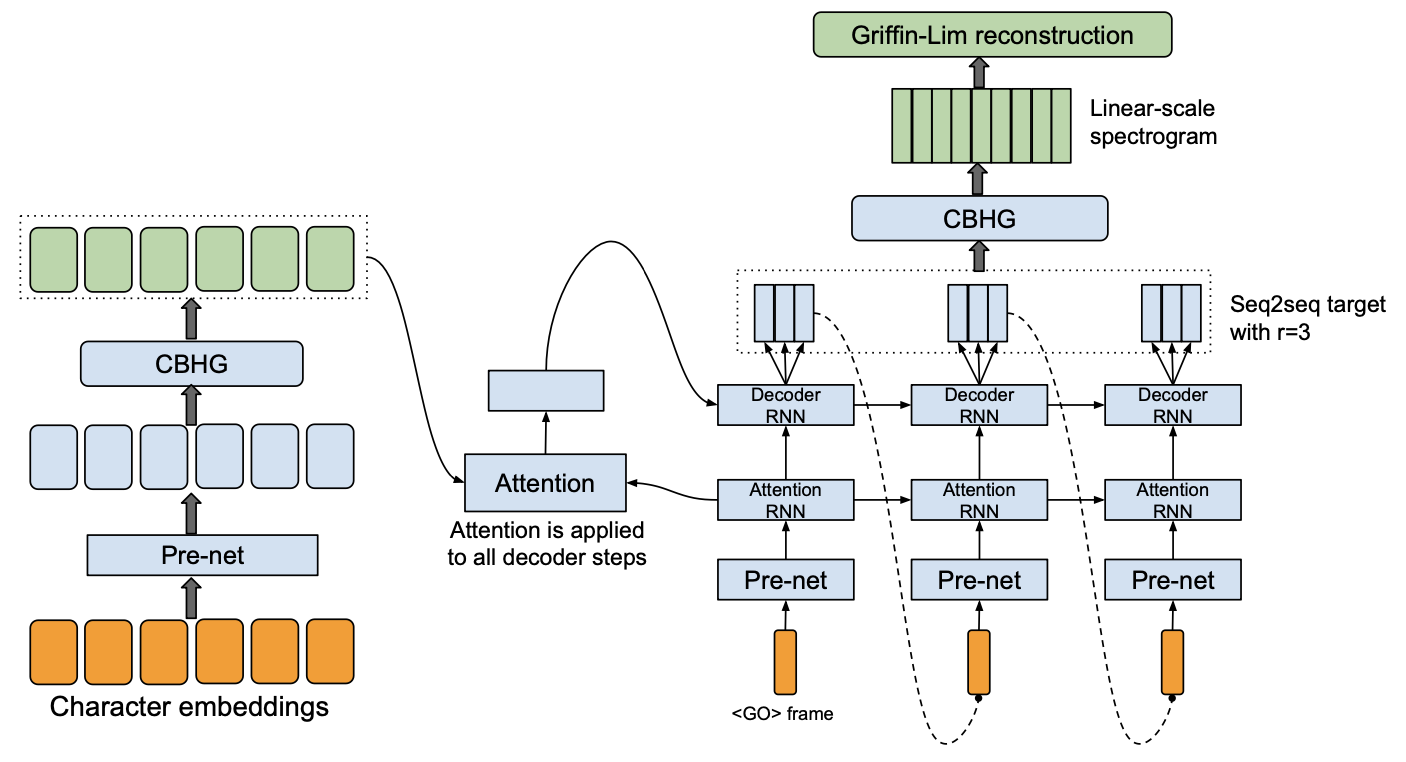
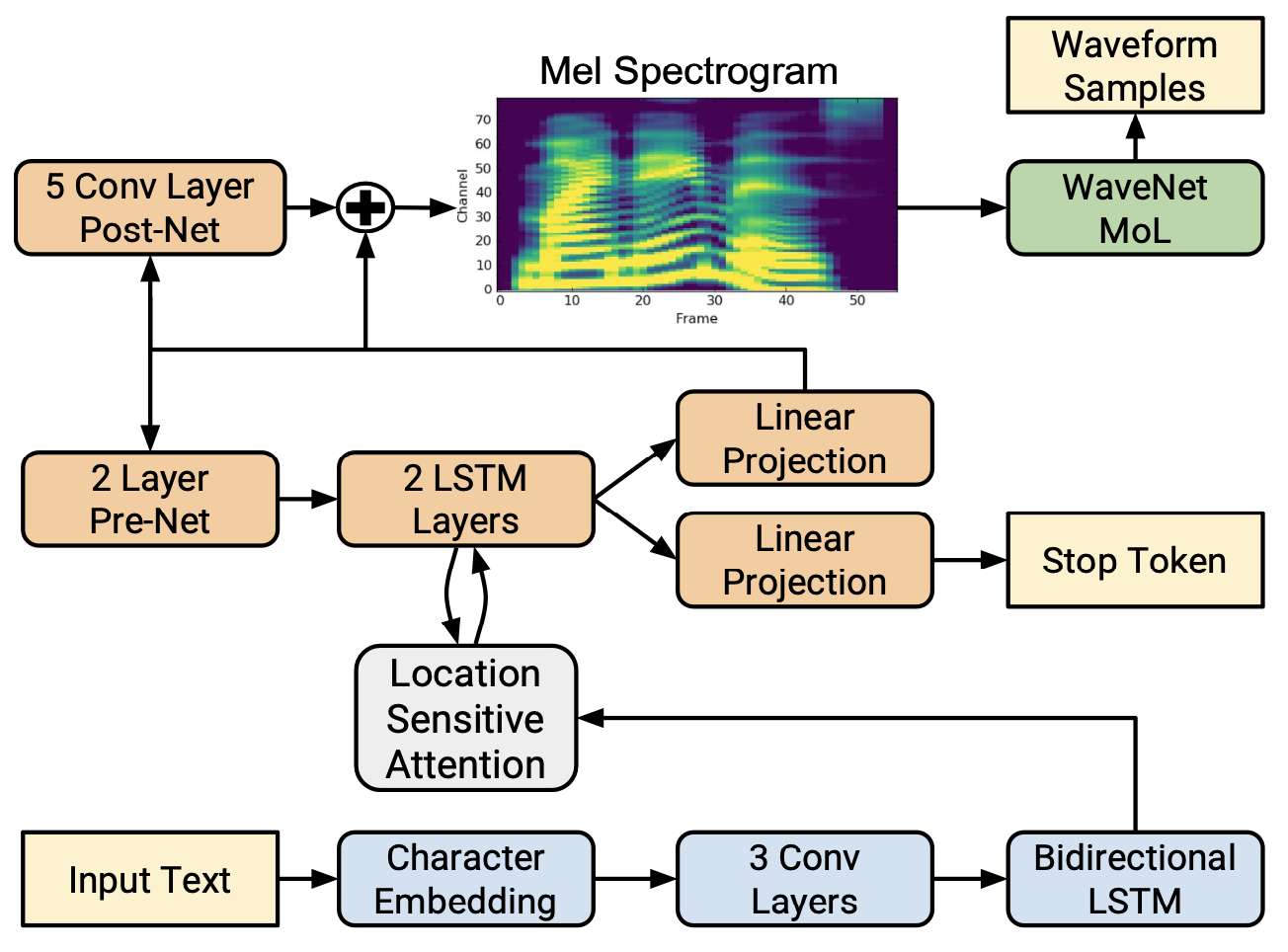
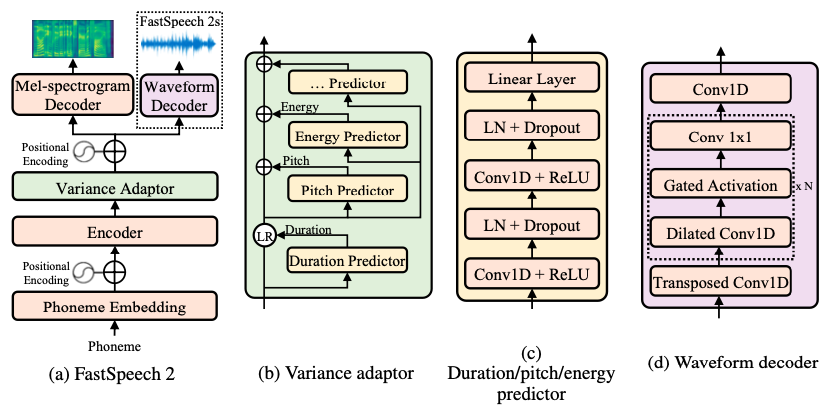
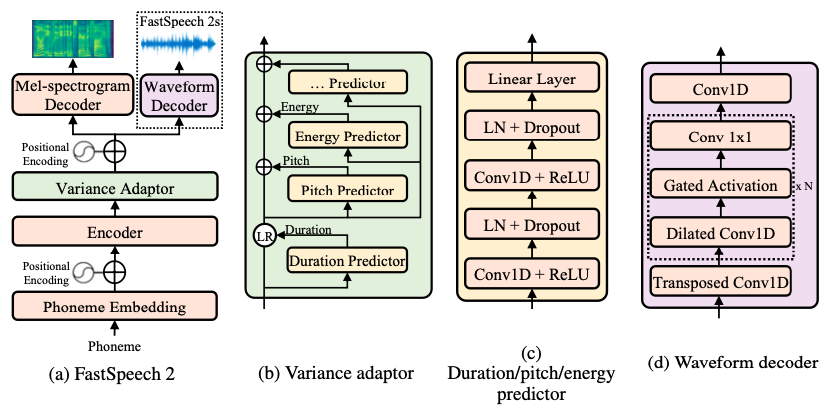
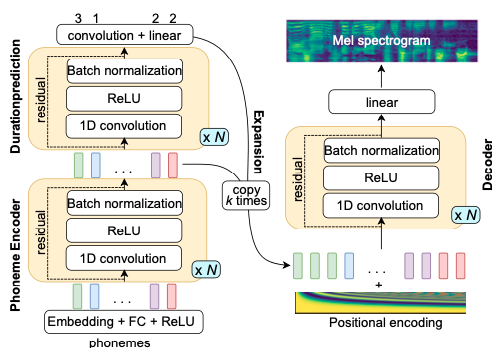
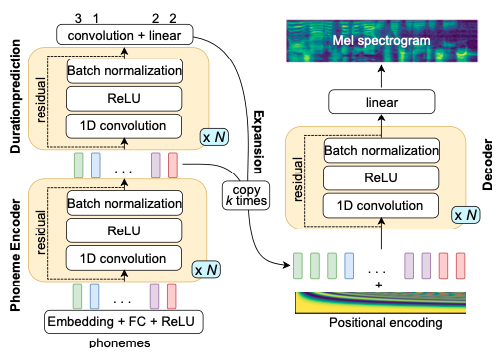
## Acoustic Models
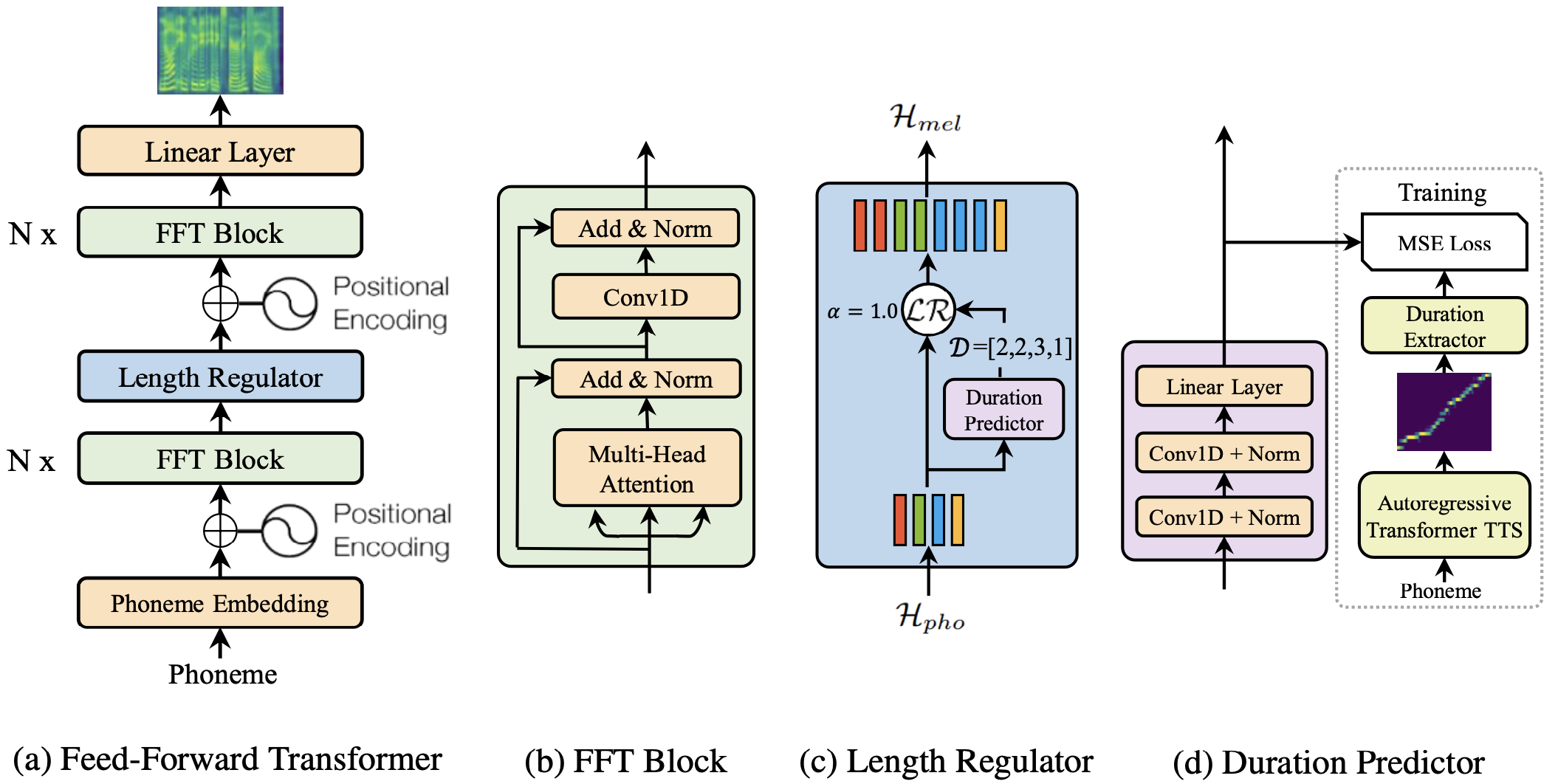
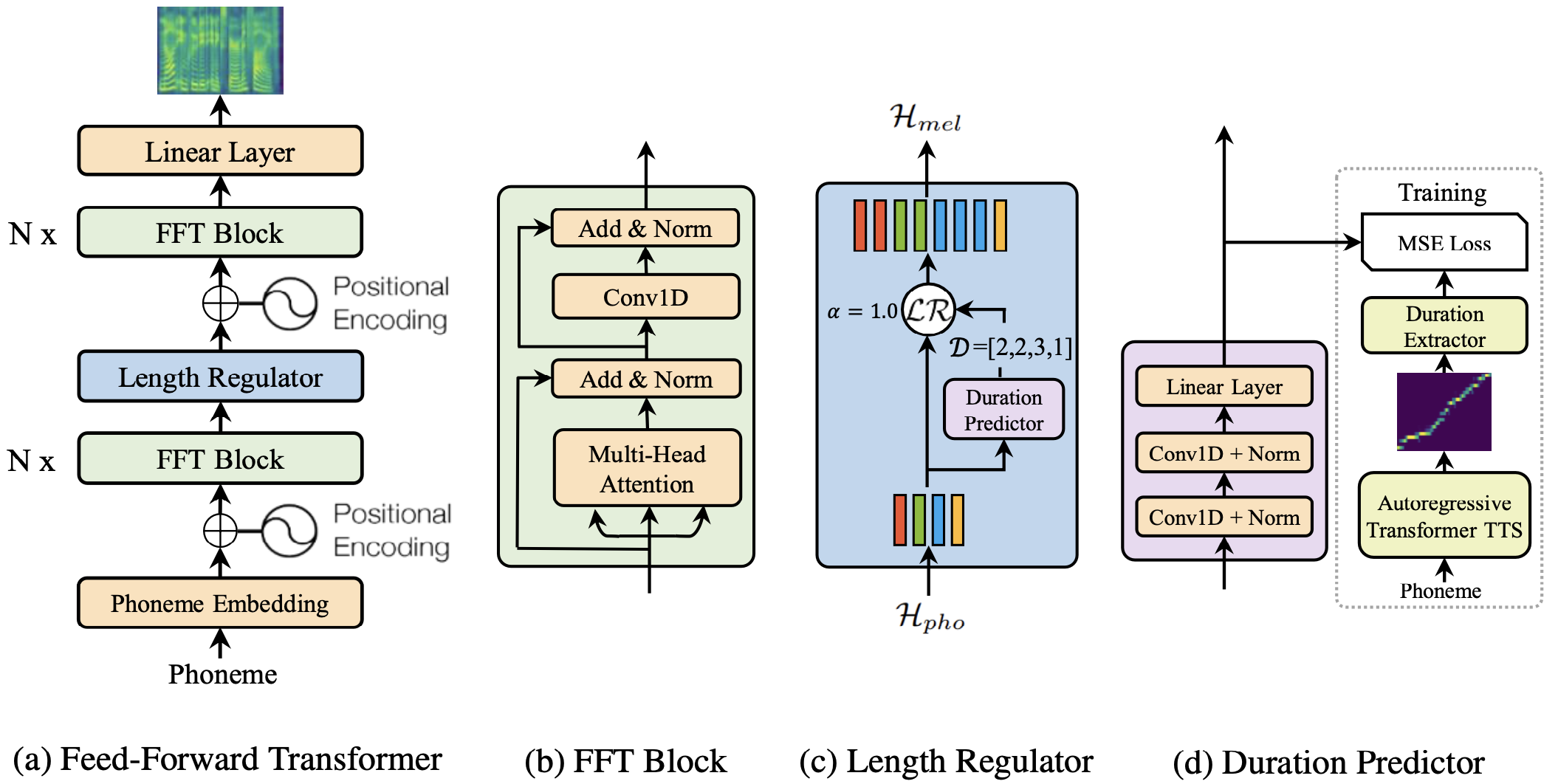
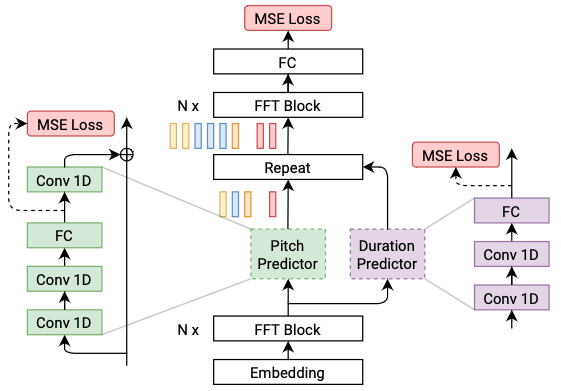
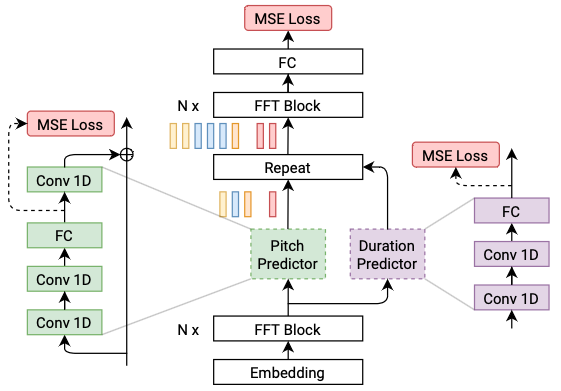
### Modeling Objectives of Acoustic Models
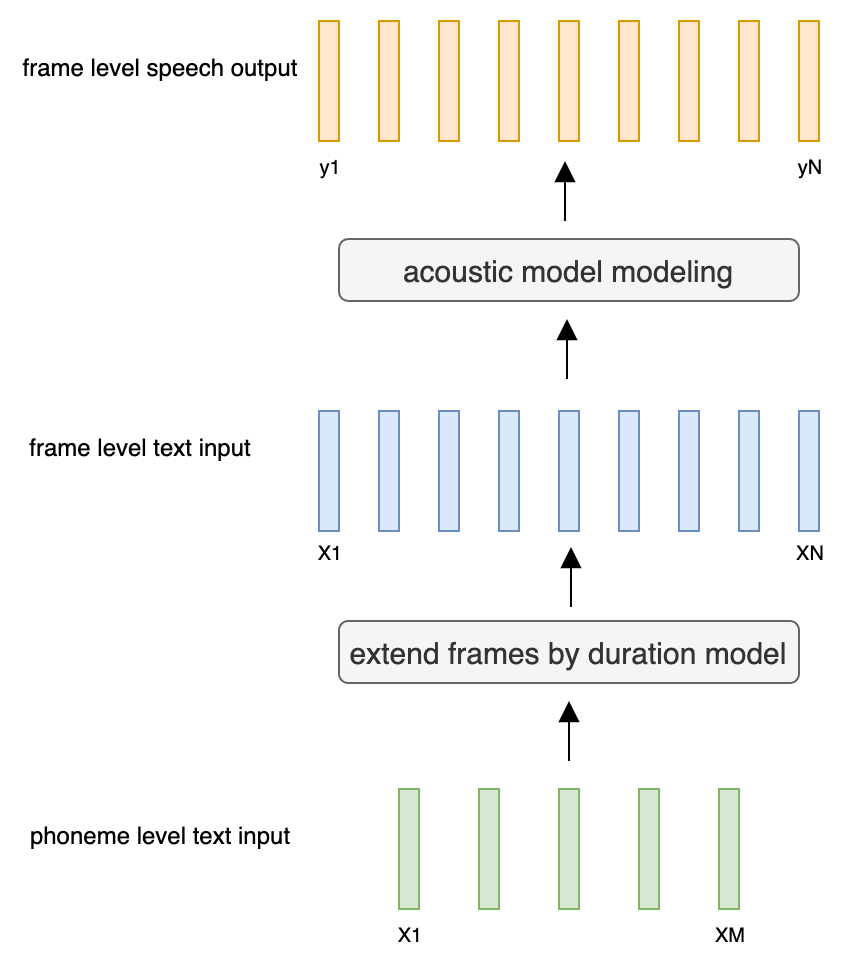
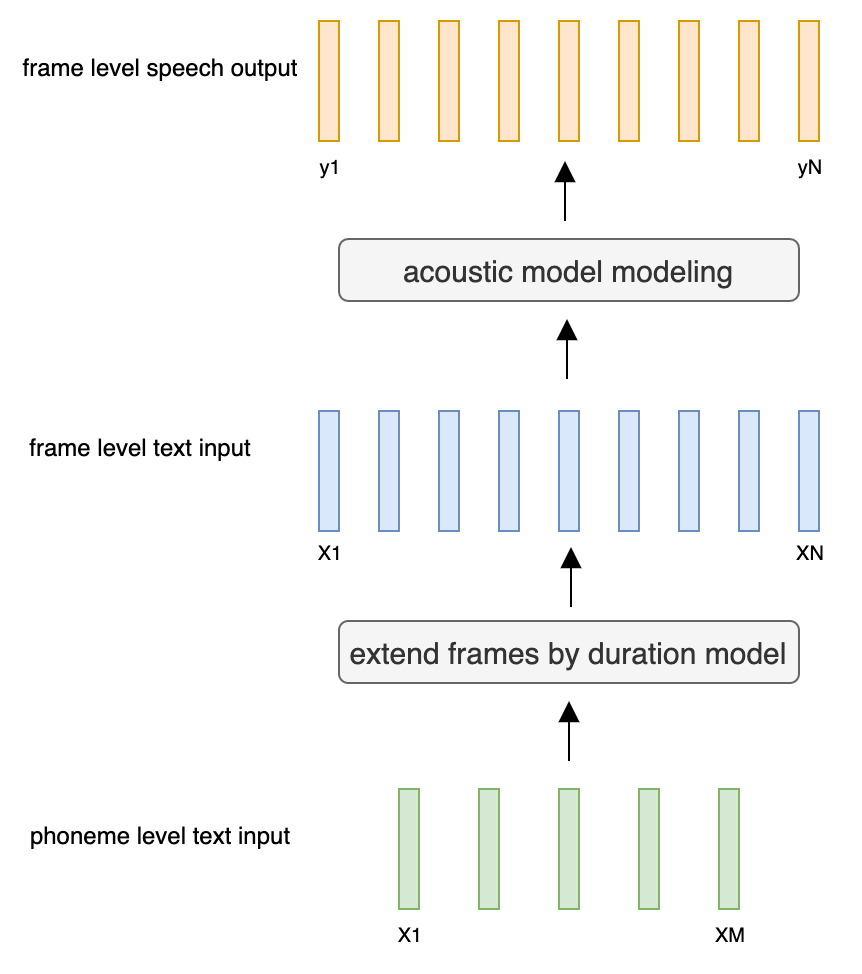
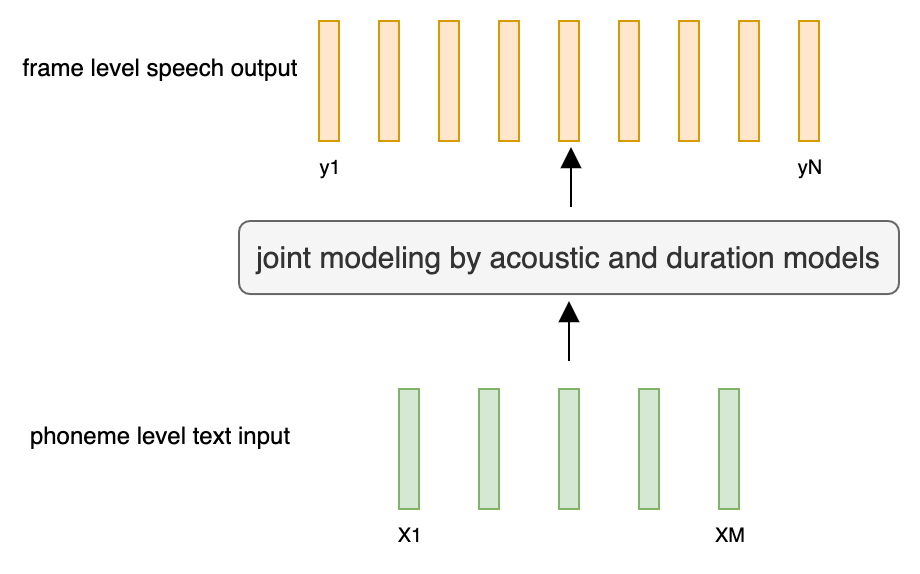
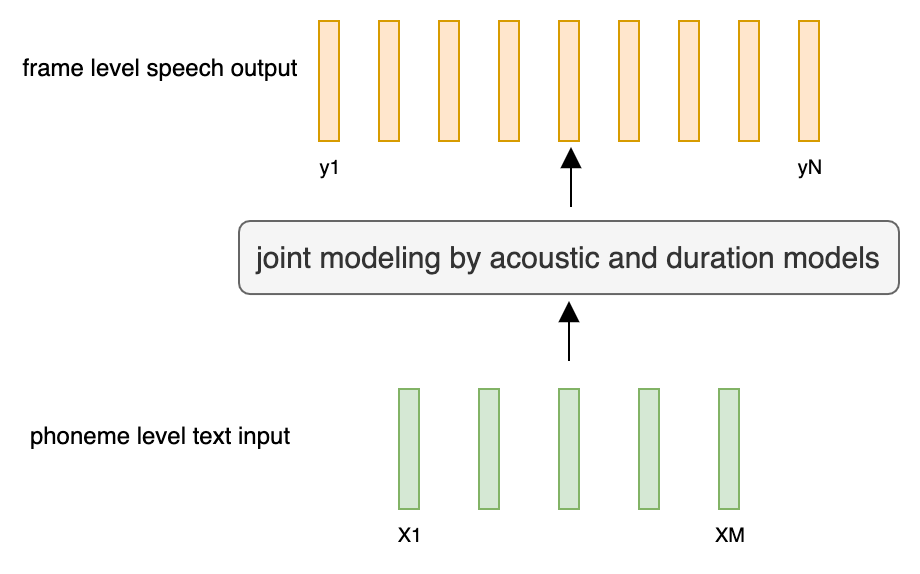
@@ -27,14 +27,14 @@ At present, there are two mainstream acoustic model structures.
- Acoustic decoder (N Frames - > N Frames).
-
+
-
+
-
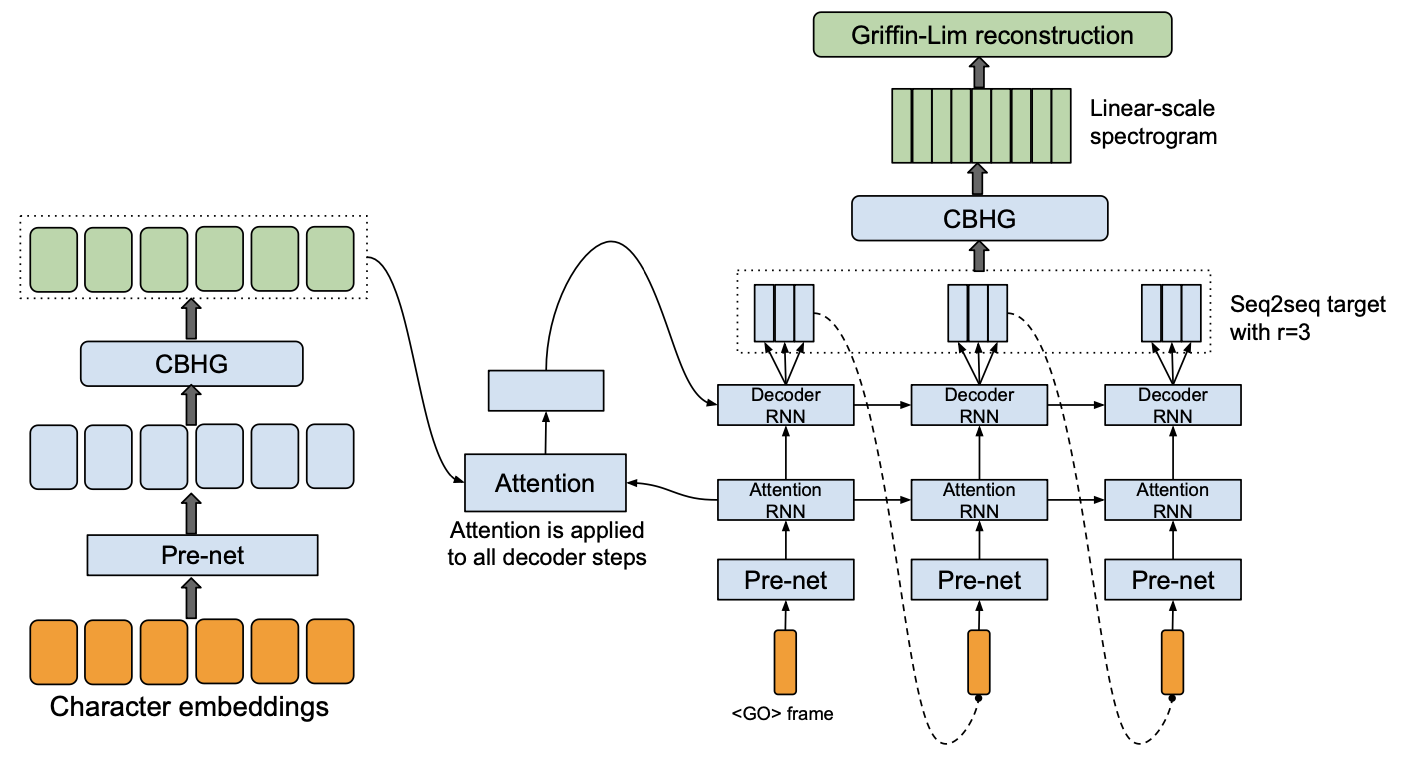
+
-
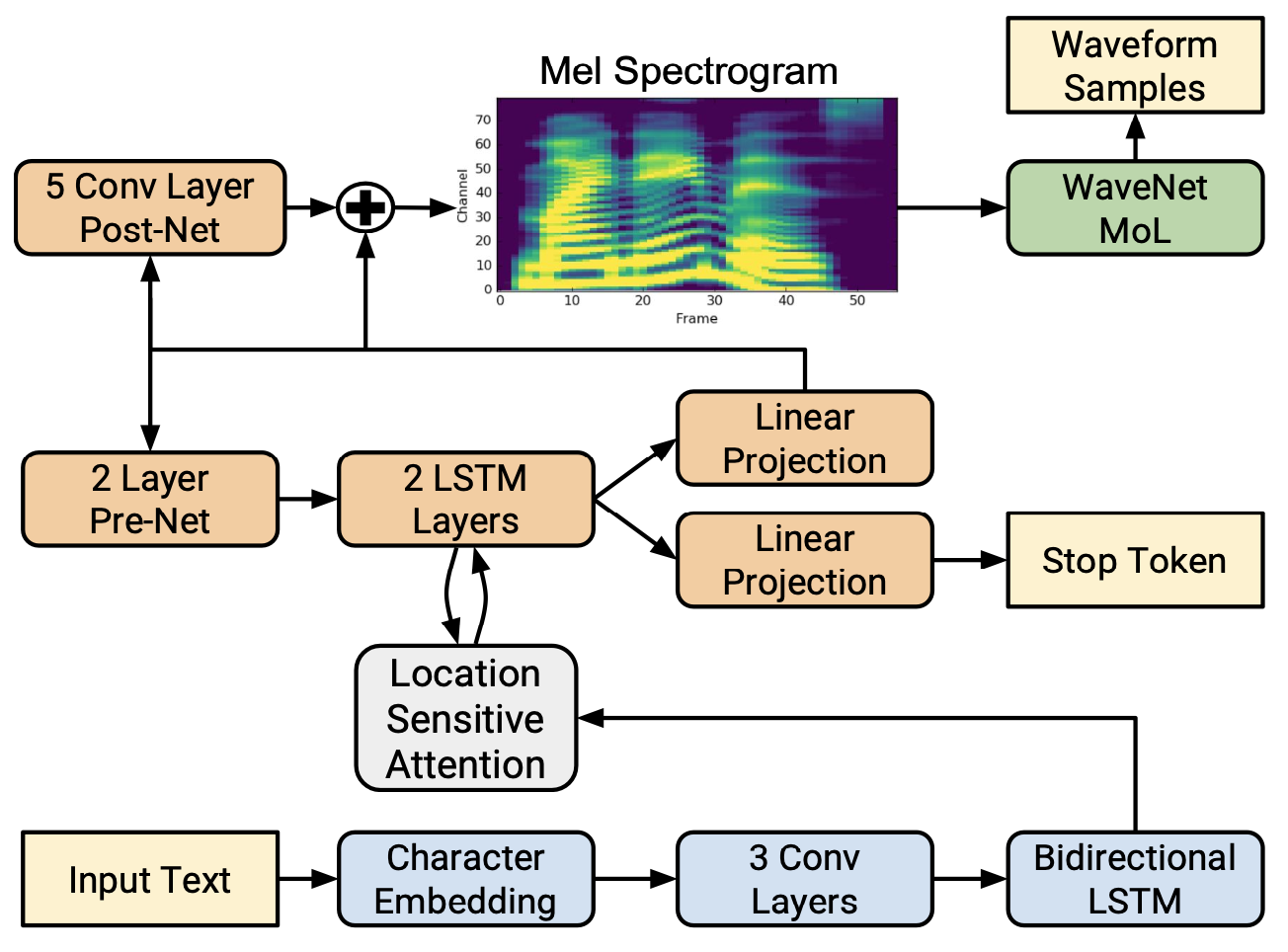
+
-
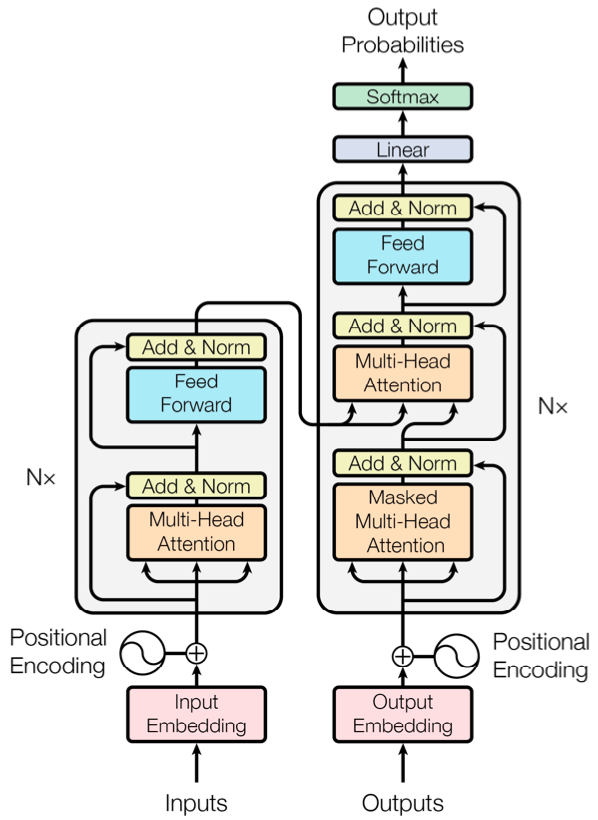
+
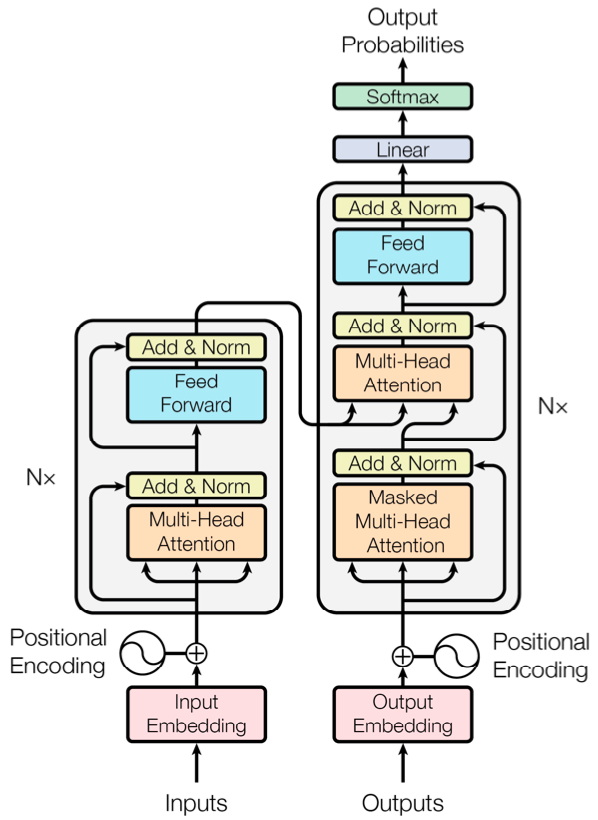
-
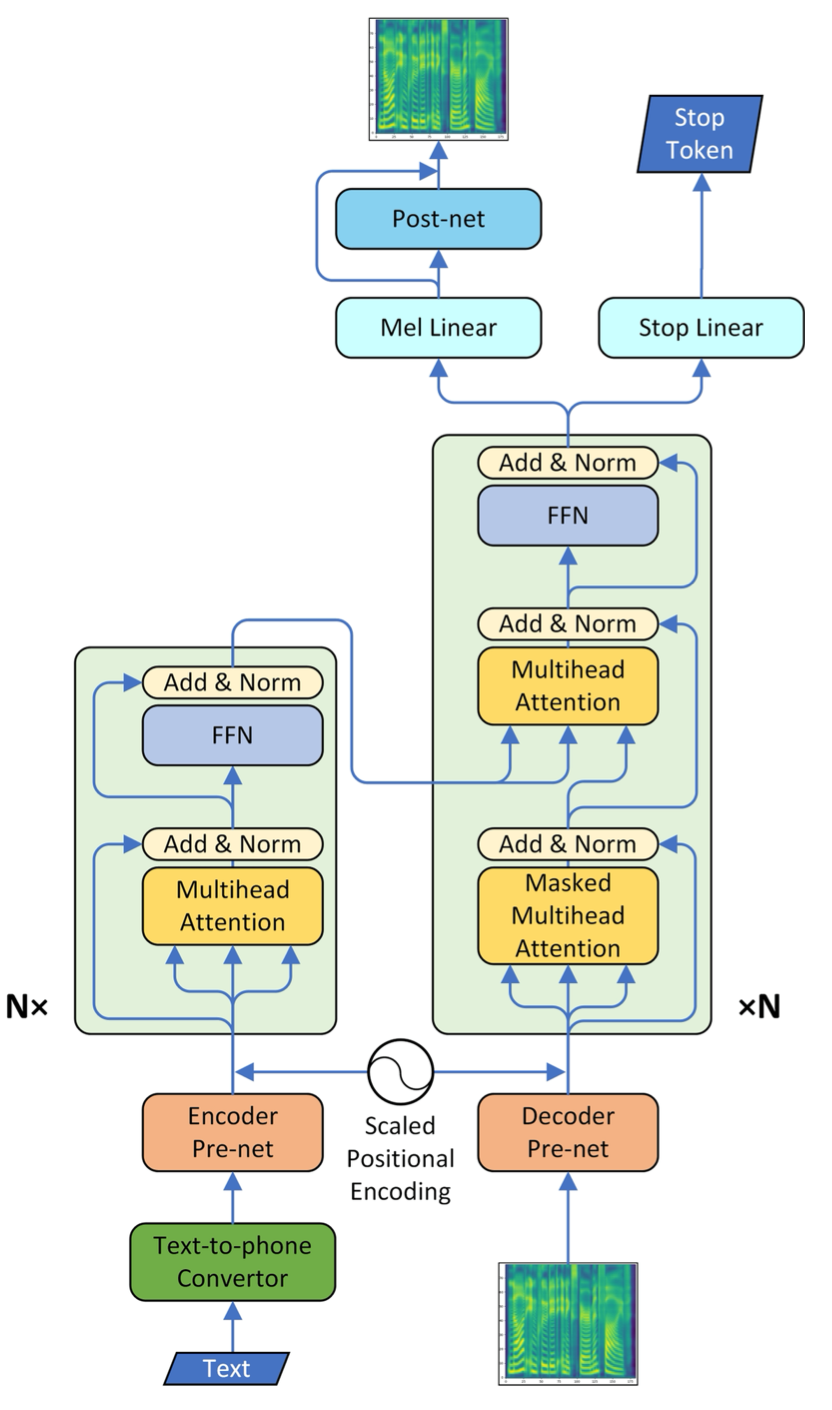
+
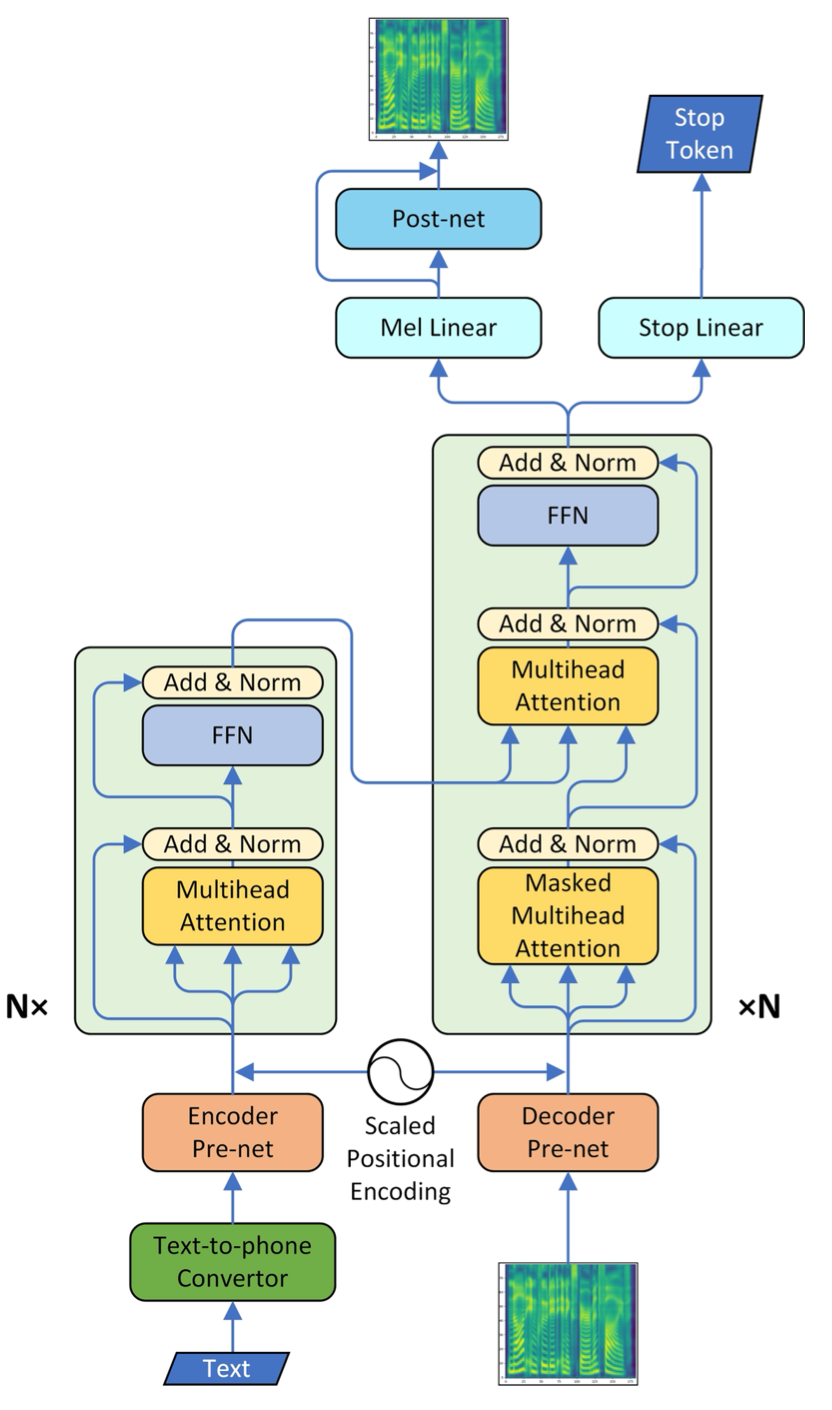
-
+
-
+
-
+
-
+
-
+