+------------------------------------------------------------------------------------
**PaddleSpeech** is an open-source toolkit on [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) platform for a variety of critical tasks in speech and audio, with the state-of-art and influential models.
@@ -142,53 +143,35 @@ For more synthesized audios, please refer to [PaddleSpeech Text-to-Speech sample
-### ⭐ Examples
-- **[PaddleBoBo](https://github.com/JiehangXie/PaddleBoBo): Use PaddleSpeech TTS to generate virtual human voice.**
-
-
-
-- [PaddleSpeech Demo Video](https://paddlespeech.readthedocs.io/en/latest/demo_video.html)
-
-- **[VTuberTalk](https://github.com/jerryuhoo/VTuberTalk): Use PaddleSpeech TTS and ASR to clone voice from videos.**
-
-
-
-
-
-### 🔥 Hot Activities
-
-- 2021.12.21~12.24
-
- 4 Days Live Courses: Depth interpretation of PaddleSpeech!
-
- **Courses videos and related materials: https://aistudio.baidu.com/aistudio/education/group/info/25130**
### Features
Via the easy-to-use, efficient, flexible and scalable implementation, our vision is to empower both industrial application and academic research, including training, inference & testing modules, and deployment process. To be more specific, this toolkit features at:
-- 📦 **Ease of Use**: low barriers to install, and [CLI](#quick-start) is available to quick-start your journey.
+- 📦 **Ease of Use**: low barriers to install, [CLI](#quick-start), [Server](#quick-start-server), and [Streaming Server](#quick-start-streaming-server) is available to quick-start your journey.
- 🏆 **Align to the State-of-the-Art**: we provide high-speed and ultra-lightweight models, and also cutting-edge technology.
+- 🏆 **Streaming ASR and TTS System**: we provide production ready streaming asr and streaming tts system.
- 💯 **Rule-based Chinese frontend**: our frontend contains Text Normalization and Grapheme-to-Phoneme (G2P, including Polyphone and Tone Sandhi). Moreover, we use self-defined linguistic rules to adapt Chinese context.
-- **Varieties of Functions that Vitalize both Industrial and Academia**:
- - 🛎️ *Implementation of critical audio tasks*: this toolkit contains audio functions like Audio Classification, Speech Translation, Automatic Speech Recognition, Text-to-Speech Synthesis, etc.
+- 📦 **Varieties of Functions that Vitalize both Industrial and Academia**:
+ - 🛎️ *Implementation of critical audio tasks*: this toolkit contains audio functions like Automatic Speech Recognition, Text-to-Speech Synthesis, Speaker Verfication, KeyWord Spotting, Audio Classification, and Speech Translation, etc.
- 🔬 *Integration of mainstream models and datasets*: the toolkit implements modules that participate in the whole pipeline of the speech tasks, and uses mainstream datasets like LibriSpeech, LJSpeech, AIShell, CSMSC, etc. See also [model list](#model-list) for more details.
- 🧩 *Cascaded models application*: as an extension of the typical traditional audio tasks, we combine the workflows of the aforementioned tasks with other fields like Natural language processing (NLP) and Computer Vision (CV).
### Recent Update
+- 👑 2022.05.13: Release [PP-ASR](./docs/source/asr/PPASR.md)、[PP-TTS](./docs/source/tts/PPTTS.md)、[PP-VPR](docs/source/vpr/PPVPR.md)
+- 👏🏻 2022.05.06: `Streaming ASR` with `Punctuation Restoration` and `Token Timestamp`.
+- 👏🏻 2022.05.06: `Server` is available for `Speaker Verification`, and `Punctuation Restoration`.
+- 👏🏻 2022.04.28: `Streaming Server` is available for `Automatic Speech Recognition` and `Text-to-Speech`.
+- 👏🏻 2022.03.28: `Server` is available for `Audio Classification`, `Automatic Speech Recognition` and `Text-to-Speech`.
+- 👏🏻 2022.03.28: `CLI` is available for `Speaker Verification`.
+- 🤗 2021.12.14: [ASR](https://huggingface.co/spaces/KPatrick/PaddleSpeechASR) and [TTS](https://huggingface.co/spaces/KPatrick/PaddleSpeechTTS) Demos on Hugging Face Spaces are available!
+- 👏🏻 2021.12.10: `CLI` is available for `Audio Classification`, `Automatic Speech Recognition`, `Speech Translation (English to Chinese)` and `Text-to-Speech`.
-
-- 👏🏻 2022.03.28: PaddleSpeech Server is available for Audio Classification, Automatic Speech Recognition and Text-to-Speech.
-- 👏🏻 2022.03.28: PaddleSpeech CLI is available for Speaker Verification.
-- 🤗 2021.12.14: Our PaddleSpeech [ASR](https://huggingface.co/spaces/KPatrick/PaddleSpeechASR) and [TTS](https://huggingface.co/spaces/KPatrick/PaddleSpeechTTS) Demos on Hugging Face Spaces are available!
-- 👏🏻 2021.12.10: PaddleSpeech CLI is available for Audio Classification, Automatic Speech Recognition, Speech Translation (English to Chinese) and Text-to-Speech.
### Community
-- Scan the QR code below with your Wechat (reply【语音】after your friend's application is approved), you can access to official technical exchange group. Look forward to your participation.
+- Scan the QR code below with your Wechat, you can access to official technical exchange group and get the bonus ( more than 20GB learning materials, such as papers, codes and videos ) and the live link of the lessons. Look forward to your participation.
-
+
## Installation
@@ -196,6 +179,7 @@ Via the easy-to-use, efficient, flexible and scalable implementation, our vision
We strongly recommend our users to install PaddleSpeech in **Linux** with *python>=3.7*.
Up to now, **Linux** supports CLI for the all our tasks, **Mac OSX** and **Windows** only supports PaddleSpeech CLI for Audio Classification, Speech-to-Text and Text-to-Speech. To install `PaddleSpeech`, please see [installation](./docs/source/install.md).
+
## Quick Start
@@ -238,7 +222,7 @@ paddlespeech tts --input "你好,欢迎使用飞桨深度学习框架!" --ou
**Batch Process**
```
echo -e "1 欢迎光临。\n2 谢谢惠顾。" | paddlespeech tts
-```
+```
**Shell Pipeline**
- ASR + Punctuation Restoration
@@ -257,16 +241,19 @@ If you want to try more functions like training and tuning, please have a look a
Developers can have a try of our speech server with [PaddleSpeech Server Command Line](./paddlespeech/server/README.md).
**Start server**
+
```shell
paddlespeech_server start --config_file ./paddlespeech/server/conf/application.yaml
```
**Access Speech Recognition Services**
+
```shell
paddlespeech_client asr --server_ip 127.0.0.1 --port 8090 --input input_16k.wav
```
**Access Text to Speech Services**
+
```shell
paddlespeech_client tts --server_ip 127.0.0.1 --port 8090 --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
```
@@ -280,6 +267,37 @@ paddlespeech_client cls --server_ip 127.0.0.1 --port 8090 --input input.wav
For more information about server command lines, please see: [speech server demos](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/speech_server)
+
+## Quick Start Streaming Server
+
+Developers can have a try of [streaming asr](./demos/streaming_asr_server/README.md) and [streaming tts](./demos/streaming_tts_server/README.md) server.
+
+**Start Streaming Speech Recognition Server**
+
+```
+paddlespeech_server start --config_file ./demos/streaming_asr_server/conf/application.yaml
+```
+
+**Access Streaming Speech Recognition Services**
+
+```
+paddlespeech_client asr_online --server_ip 127.0.0.1 --port 8090 --input input_16k.wav
+```
+
+**Start Streaming Text to Speech Server**
+
+```
+paddlespeech_server start --config_file ./demos/streaming_tts_server/conf/tts_online_application.yaml
+```
+
+**Access Streaming Text to Speech Services**
+
+```
+paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8092 --protocol http --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
+```
+
+For more information please see: [streaming asr](./demos/streaming_asr_server/README.md) and [streaming tts](./demos/streaming_tts_server/README.md)
+
## Model List
@@ -296,7 +314,7 @@ PaddleSpeech supports a series of most popular models. They are summarized in [r
Speech-to-Text Module Type
Dataset
Model Type
-
Link
+
Example
@@ -371,7 +389,7 @@ PaddleSpeech supports a series of most popular models. They are summarized in [r
Text-to-Speech Module Type
Model Type
Dataset
-
Link
+
Example
@@ -489,7 +507,7 @@ PaddleSpeech supports a series of most popular models. They are summarized in [r
Task
Dataset
Model Type
-
Link
+
Example
@@ -514,7 +532,7 @@ PaddleSpeech supports a series of most popular models. They are summarized in [r
Task
Dataset
Model Type
-
Link
+
Example
@@ -539,7 +557,7 @@ PaddleSpeech supports a series of most popular models. They are summarized in [r
Task
Dataset
Model Type
-
Link
+
Example
@@ -589,6 +607,21 @@ Normally, [Speech SoTA](https://paperswithcode.com/area/speech), [Audio SoTA](ht
The Text-to-Speech module is originally called [Parakeet](https://github.com/PaddlePaddle/Parakeet), and now merged with this repository. If you are interested in academic research about this task, please see [TTS research overview](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/docs/source/tts#overview). Also, [this document](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/tts/models_introduction.md) is a good guideline for the pipeline components.
+
+## ⭐ Examples
+- **[PaddleBoBo](https://github.com/JiehangXie/PaddleBoBo): Use PaddleSpeech TTS to generate virtual human voice.**
+
+
+
+- [PaddleSpeech Demo Video](https://paddlespeech.readthedocs.io/en/latest/demo_video.html)
+
+- **[VTuberTalk](https://github.com/jerryuhoo/VTuberTalk): Use PaddleSpeech TTS and ASR to clone voice from videos.**
+
+
+
+
+
+
## Citation
To cite PaddleSpeech for research, please use the following format.
@@ -655,7 +688,6 @@ You are warmly welcome to submit questions in [discussions](https://github.com/P
## Acknowledgement
-
- Many thanks to [yeyupiaoling](https://github.com/yeyupiaoling)/[PPASR](https://github.com/yeyupiaoling/PPASR)/[PaddlePaddle-DeepSpeech](https://github.com/yeyupiaoling/PaddlePaddle-DeepSpeech)/[VoiceprintRecognition-PaddlePaddle](https://github.com/yeyupiaoling/VoiceprintRecognition-PaddlePaddle)/[AudioClassification-PaddlePaddle](https://github.com/yeyupiaoling/AudioClassification-PaddlePaddle) for years of attention, constructive advice and great help.
- Many thanks to [mymagicpower](https://github.com/mymagicpower) for the Java implementation of ASR upon [short](https://github.com/mymagicpower/AIAS/tree/main/3_audio_sdks/asr_sdk) and [long](https://github.com/mymagicpower/AIAS/tree/main/3_audio_sdks/asr_long_audio_sdk) audio files.
- Many thanks to [JiehangXie](https://github.com/JiehangXie)/[PaddleBoBo](https://github.com/JiehangXie/PaddleBoBo) for developing Virtual Uploader(VUP)/Virtual YouTuber(VTuber) with PaddleSpeech TTS function.
diff --git a/README_cn.md b/README_cn.md
index 228d5d783..c751b061d 100644
--- a/README_cn.md
+++ b/README_cn.md
@@ -2,34 +2,36 @@
@@ -658,6 +691,7 @@ PaddleSpeech 的 **语音合成** 主要包含三个模块:文本前端、声
- 非常感谢 [jerryuhoo](https://github.com/jerryuhoo)/[VTuberTalk](https://github.com/jerryuhoo/VTuberTalk) 基于 PaddleSpeech 的 TTS GUI 界面和基于 ASR 制作数据集的相关代码。
+
此外,PaddleSpeech 依赖于许多开源存储库。有关更多信息,请参阅 [references](./docs/source/reference.md)。
## License
diff --git a/audio/.gitignore b/audio/.gitignore
deleted file mode 100644
index 1c930053d..000000000
--- a/audio/.gitignore
+++ /dev/null
@@ -1,2 +0,0 @@
-.eggs
-*.wav
diff --git a/audio/CHANGELOG.md b/audio/CHANGELOG.md
deleted file mode 100644
index 925d77696..000000000
--- a/audio/CHANGELOG.md
+++ /dev/null
@@ -1,9 +0,0 @@
-# Changelog
-
-Date: 2022-3-15, Author: Xiaojie Chen.
- - kaldi and librosa mfcc, fbank, spectrogram.
- - unit test and benchmark.
-
-Date: 2022-2-25, Author: Hui Zhang.
- - Refactor architecture.
- - dtw distance and mcd style dtw.
diff --git a/audio/README.md b/audio/README.md
deleted file mode 100644
index 697c01739..000000000
--- a/audio/README.md
+++ /dev/null
@@ -1,7 +0,0 @@
-# PaddleAudio
-
-PaddleAudio is an audio library for PaddlePaddle.
-
-## Install
-
-`pip install .`
diff --git a/audio/docs/Makefile b/audio/docs/Makefile
deleted file mode 100644
index 69fe55ecf..000000000
--- a/audio/docs/Makefile
+++ /dev/null
@@ -1,19 +0,0 @@
-# Minimal makefile for Sphinx documentation
-#
-
-# You can set these variables from the command line.
-SPHINXOPTS =
-SPHINXBUILD = sphinx-build
-SOURCEDIR = source
-BUILDDIR = build
-
-# Put it first so that "make" without argument is like "make help".
-help:
- @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
-
-.PHONY: help Makefile
-
-# Catch-all target: route all unknown targets to Sphinx using the new
-# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
-%: Makefile
- @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
\ No newline at end of file
diff --git a/audio/docs/README.md b/audio/docs/README.md
deleted file mode 100644
index 20626f52b..000000000
--- a/audio/docs/README.md
+++ /dev/null
@@ -1,24 +0,0 @@
-# Build docs for PaddleAudio
-
-Execute the following steps in **current directory**.
-
-## 1. Install
-
-`pip install Sphinx sphinx_rtd_theme`
-
-
-## 2. Generate API docs
-
-Generate API docs from doc string.
-
-`sphinx-apidoc -fMeT -o source ../paddleaudio ../paddleaudio/utils --templatedir source/_templates`
-
-
-## 3. Build
-
-`sphinx-build source _html`
-
-
-## 4. Preview
-
-Open `_html/index.html` for page preview.
diff --git a/audio/docs/images/paddle.png b/audio/docs/images/paddle.png
deleted file mode 100644
index bc1135abf..000000000
Binary files a/audio/docs/images/paddle.png and /dev/null differ
diff --git a/audio/docs/make.bat b/audio/docs/make.bat
deleted file mode 100644
index 543c6b13b..000000000
--- a/audio/docs/make.bat
+++ /dev/null
@@ -1,35 +0,0 @@
-@ECHO OFF
-
-pushd %~dp0
-
-REM Command file for Sphinx documentation
-
-if "%SPHINXBUILD%" == "" (
- set SPHINXBUILD=sphinx-build
-)
-set SOURCEDIR=source
-set BUILDDIR=build
-
-if "%1" == "" goto help
-
-%SPHINXBUILD% >NUL 2>NUL
-if errorlevel 9009 (
- echo.
- echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
- echo.installed, then set the SPHINXBUILD environment variable to point
- echo.to the full path of the 'sphinx-build' executable. Alternatively you
- echo.may add the Sphinx directory to PATH.
- echo.
- echo.If you don't have Sphinx installed, grab it from
- echo.http://sphinx-doc.org/
- exit /b 1
-)
-
-%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS%
-goto end
-
-:help
-%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS%
-
-:end
-popd
diff --git a/audio/paddleaudio/metric/dtw.py b/audio/paddleaudio/metric/dtw.py
deleted file mode 100644
index 662e4506d..000000000
--- a/audio/paddleaudio/metric/dtw.py
+++ /dev/null
@@ -1,44 +0,0 @@
-# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import numpy as np
-from dtaidistance import dtw_ndim
-
-__all__ = [
- 'dtw_distance',
-]
-
-
-def dtw_distance(xs: np.ndarray, ys: np.ndarray) -> float:
- """Dynamic Time Warping.
- This function keeps a compact matrix, not the full warping paths matrix.
- Uses dynamic programming to compute:
-
- Examples:
- .. code-block:: python
-
- wps[i, j] = (s1[i]-s2[j])**2 + min(
- wps[i-1, j ] + penalty, // vertical / insertion / expansion
- wps[i , j-1] + penalty, // horizontal / deletion / compression
- wps[i-1, j-1]) // diagonal / match
-
- dtw = sqrt(wps[-1, -1])
-
- Args:
- xs (np.ndarray): ref sequence, [T,D]
- ys (np.ndarray): hyp sequence, [T,D]
-
- Returns:
- float: dtw distance
- """
- return dtw_ndim.distance(xs, ys)
diff --git a/audio/paddleaudio/utils/env.py b/audio/paddleaudio/utils/env.py
deleted file mode 100644
index a2d14b89e..000000000
--- a/audio/paddleaudio/utils/env.py
+++ /dev/null
@@ -1,60 +0,0 @@
-# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License"
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-'''
-This module is used to store environmental variables in PaddleAudio.
-PPAUDIO_HOME --> the root directory for storing PaddleAudio related data. Default to ~/.paddleaudio. Users can change the
-├ default value through the PPAUDIO_HOME environment variable.
-├─ MODEL_HOME --> Store model files.
-└─ DATA_HOME --> Store automatically downloaded datasets.
-'''
-import os
-
-__all__ = [
- 'USER_HOME',
- 'PPAUDIO_HOME',
- 'MODEL_HOME',
- 'DATA_HOME',
-]
-
-
-def _get_user_home():
- return os.path.expanduser('~')
-
-
-def _get_ppaudio_home():
- if 'PPAUDIO_HOME' in os.environ:
- home_path = os.environ['PPAUDIO_HOME']
- if os.path.exists(home_path):
- if os.path.isdir(home_path):
- return home_path
- else:
- raise RuntimeError(
- 'The environment variable PPAUDIO_HOME {} is not a directory.'.
- format(home_path))
- else:
- return home_path
- return os.path.join(_get_user_home(), '.paddleaudio')
-
-
-def _get_sub_home(directory):
- home = os.path.join(_get_ppaudio_home(), directory)
- if not os.path.exists(home):
- os.makedirs(home)
- return home
-
-
-USER_HOME = _get_user_home()
-PPAUDIO_HOME = _get_ppaudio_home()
-MODEL_HOME = _get_sub_home('models')
-DATA_HOME = _get_sub_home('datasets')
diff --git a/audio/setup.py b/audio/setup.py
deleted file mode 100644
index bf6c4d163..000000000
--- a/audio/setup.py
+++ /dev/null
@@ -1,150 +0,0 @@
-# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import glob
-import os
-import subprocess
-
-import pybind11
-import setuptools
-from setuptools import Extension
-from setuptools.command.build_ext import build_ext
-from setuptools.command.test import test
-
-# set the version here
-VERSION = '1.0.0a'
-
-
-# Inspired by the example at https://pytest.org/latest/goodpractises.html
-class TestCommand(test):
- def finalize_options(self):
- test.finalize_options(self)
- self.test_args = []
- self.test_suite = True
-
- def run(self):
- self.run_benchmark()
- super(TestCommand, self).run()
-
- def run_tests(self):
- # Run nose ensuring that argv simulates running nosetests directly
- import nose
- nose.run_exit(argv=['nosetests', '-w', 'tests'])
-
- def run_benchmark(self):
- for benchmark_item in glob.glob('tests/benchmark/*py'):
- os.system(f'pytest {benchmark_item}')
-
-
-class ExtBuildCommand(build_ext):
- def run(self):
- try:
- subprocess.check_output(["cmake", "--version"])
- except OSError:
- raise RuntimeError("CMake is not available.") from None
- super().run()
-
- def build_extension(self, ext):
- extdir = os.path.abspath(
- os.path.dirname(self.get_ext_fullpath(ext.name)))
- cfg = "Debug" if self.debug else "Release"
- cmake_args = [
- f"-DCMAKE_BUILD_TYPE={cfg}",
- f"-Dpybind11_DIR={pybind11.get_cmake_dir()}",
- f"-DCMAKE_INSTALL_PREFIX={extdir}",
- "-DCMAKE_VERBOSE_MAKEFILE=ON",
- "-DBUILD_SOX:BOOL=ON",
- ]
- build_args = ["--target", "install"]
-
- # Set CMAKE_BUILD_PARALLEL_LEVEL to control the parallel build level
- # across all generators.
- if "CMAKE_BUILD_PARALLEL_LEVEL" not in os.environ:
- if hasattr(self, "parallel") and self.parallel:
- build_args += ["-j{}".format(self.parallel)]
-
- if not os.path.exists(self.build_temp):
- os.makedirs(self.build_temp)
-
- subprocess.check_call(
- ["cmake", os.path.abspath(os.path.dirname(__file__))] + cmake_args,
- cwd=self.build_temp)
- subprocess.check_call(
- ["cmake", "--build", "."] + build_args, cwd=self.build_temp)
-
- def get_ext_filename(self, fullname):
- ext_filename = super().get_ext_filename(fullname)
- ext_filename_parts = ext_filename.split(".")
- without_abi = ext_filename_parts[:-2] + ext_filename_parts[-1:]
- ext_filename = ".".join(without_abi)
- return ext_filename
-
-
-def write_version_py(filename='paddleaudio/__init__.py'):
- with open(filename, "a") as f:
- f.write(f"__version__ = '{VERSION}'")
-
-
-def remove_version_py(filename='paddleaudio/__init__.py'):
- with open(filename, "r") as f:
- lines = f.readlines()
- with open(filename, "w") as f:
- for line in lines:
- if "__version__" not in line:
- f.write(line)
-
-
-def get_ext_modules():
- modules = [
- Extension(name="paddleaudio._paddleaudio", sources=[]),
- ]
-
- return modules
-
-
-remove_version_py()
-write_version_py()
-
-setuptools.setup(
- name="paddleaudio",
- version=VERSION,
- author="",
- author_email="",
- description="PaddleAudio, in development",
- long_description="",
- long_description_content_type="text/markdown",
- url="",
- packages=setuptools.find_packages(include=['paddleaudio*']),
- classifiers=[
- "Programming Language :: Python :: 3",
- "License :: OSI Approved :: MIT License",
- "Operating System :: OS Independent",
- ],
- python_requires='>=3.6',
- install_requires=[
- 'numpy >= 1.15.0', 'scipy >= 1.0.0', 'resampy >= 0.2.2',
- 'soundfile >= 0.9.0', 'colorlog', 'dtaidistance == 2.3.1', 'pathos'
- ],
- extras_require={
- 'test': [
- 'nose', 'librosa==0.8.1', 'soundfile==0.10.3.post1',
- 'torchaudio==0.10.2', 'pytest-benchmark'
- ],
- },
- ext_modules=get_ext_modules(),
- cmdclass={
- "build_ext": ExtBuildCommand,
- 'test': TestCommand,
- }, )
-
-remove_version_py()
diff --git a/audio/tests/.gitkeep b/audio/tests/.gitkeep
deleted file mode 100644
index e69de29bb..000000000
diff --git a/demos/README.md b/demos/README.md
index 8abd67249..2a306df6b 100644
--- a/demos/README.md
+++ b/demos/README.md
@@ -2,14 +2,14 @@
([简体中文](./README_cn.md)|English)
-The directory containes many speech applications in multi scenarios.
+This directory contains many speech applications in multiple scenarios.
* audio searching - mass audio similarity retrieval
* audio tagging - multi-label tagging of an audio file
-* automatic_video_subtitiles - generate subtitles from a video
+* automatic_video_subtitles - generate subtitles from a video
* metaverse - 2D AR with TTS
* punctuation_restoration - restore punctuation from raw text
-* speech recogintion - recognize text of an audio file
+* speech recognition - recognize text of an audio file
* speech server - Server for Speech Task, e.g. ASR,TTS,CLS
* streaming asr server - receive audio stream from websocket, and recognize to transcript.
* speech translation - end to end speech translation
diff --git a/demos/audio_content_search/README.md b/demos/audio_content_search/README.md
new file mode 100644
index 000000000..4428bf389
--- /dev/null
+++ b/demos/audio_content_search/README.md
@@ -0,0 +1,79 @@
+([简体中文](./README_cn.md)|English)
+# ACS (Audio Content Search)
+
+## Introduction
+ACS, or Audio Content Search, refers to the problem of getting the key word time stamp from automatically transcribe spoken language (speech-to-text).
+
+This demo is an implementation of obtaining the keyword timestamp in the text from a given audio file. It can be done by a single command or a few lines in python using `PaddleSpeech`.
+Now, the search word in demo is:
+```
+我
+康
+```
+## Usage
+### 1. Installation
+see [installation](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install.md).
+
+You can choose one way from meduim and hard to install paddlespeech.
+
+The dependency refers to the requirements.txt, and install the dependency as follows:
+
+```
+pip install -r requriement.txt
+```
+
+### 2. Prepare Input File
+The input of this demo should be a WAV file(`.wav`), and the sample rate must be the same as the model.
+
+Here are sample files for this demo that can be downloaded:
+```bash
+wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
+```
+
+### 3. Usage
+- Command Line(Recommended)
+ ```bash
+ # Chinese
+ paddlespeech_client acs --server_ip 127.0.0.1 --port 8090 --input ./zh.wav
+ ```
+
+ Usage:
+ ```bash
+ paddlespeech asr --help
+ ```
+ Arguments:
+ - `input`(required): Audio file to recognize.
+ - `server_ip`: the server ip.
+ - `port`: the server port.
+ - `lang`: the language type of the model. Default: `zh`.
+ - `sample_rate`: Sample rate of the model. Default: `16000`.
+ - `audio_format`: The audio format.
+
+ Output:
+ ```bash
+ [2022-05-15 15:00:58,185] [ INFO] - acs http client start
+ [2022-05-15 15:00:58,185] [ INFO] - endpoint: http://127.0.0.1:8490/paddlespeech/asr/search
+ [2022-05-15 15:01:03,220] [ INFO] - acs http client finished
+ [2022-05-15 15:01:03,221] [ INFO] - ACS result: {'transcription': '我认为跑步最重要的就是给我带来了身体健康', 'acs': [{'w': '我', 'bg': 0, 'ed': 1.6800000000000002}, {'w': '我', 'bg': 2.1, 'ed': 4.28}, {'w': '康', 'bg': 3.2, 'ed': 4.92}]}
+ [2022-05-15 15:01:03,221] [ INFO] - Response time 5.036084 s.
+ ```
+
+- Python API
+ ```python
+ from paddlespeech.server.bin.paddlespeech_client import ACSClientExecutor
+
+ acs_executor = ACSClientExecutor()
+ res = acs_executor(
+ input='./zh.wav',
+ server_ip="127.0.0.1",
+ port=8490,)
+ print(res)
+ ```
+
+ Output:
+ ```bash
+ [2022-05-15 15:08:13,955] [ INFO] - acs http client start
+ [2022-05-15 15:08:13,956] [ INFO] - endpoint: http://127.0.0.1:8490/paddlespeech/asr/search
+ [2022-05-15 15:08:19,026] [ INFO] - acs http client finished
+ {'transcription': '我认为跑步最重要的就是给我带来了身体健康', 'acs': [{'w': '我', 'bg': 0, 'ed': 1.6800000000000002}, {'w': '我', 'bg': 2.1, 'ed': 4.28}, {'w': '康', 'bg': 3.2, 'ed': 4.92}]}
+ ```
diff --git a/demos/audio_content_search/README_cn.md b/demos/audio_content_search/README_cn.md
new file mode 100644
index 000000000..6f51c4cf2
--- /dev/null
+++ b/demos/audio_content_search/README_cn.md
@@ -0,0 +1,78 @@
+(简体中文|[English](./README.md))
+
+# 语音内容搜索
+## 介绍
+语音内容搜索是一项用计算机程序获取转录语音内容关键词时间戳的技术。
+
+这个 demo 是一个从给定音频文件获取其文本中关键词时间戳的实现,它可以通过使用 `PaddleSpeech` 的单个命令或 python 中的几行代码来实现。
+
+当前示例中检索词是
+```
+我
+康
+```
+## 使用方法
+### 1. 安装
+请看[安装文档](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install_cn.md)。
+
+你可以从 medium,hard 三中方式中选择一种方式安装。
+依赖参见 requirements.txt, 安装依赖
+
+```
+pip install -r requriement.txt
+```
+
+### 2. 准备输入
+这个 demo 的输入应该是一个 WAV 文件(`.wav`),并且采样率必须与模型的采样率相同。
+
+可以下载此 demo 的示例音频:
+```bash
+wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
+```
+### 3. 使用方法
+- 命令行 (推荐使用)
+ ```bash
+ # 中文
+ paddlespeech_client acs --server_ip 127.0.0.1 --port 8090 --input ./zh.wav
+ ```
+
+ 使用方法:
+ ```bash
+ paddlespeech acs --help
+ ```
+ 参数:
+ - `input`(必须输入):用于识别的音频文件。
+ - `server_ip`: 服务的ip。
+ - `port`:服务的端口。
+ - `lang`:模型语言,默认值:`zh`。
+ - `sample_rate`:音频采样率,默认值:`16000`。
+ - `audio_format`: 音频的格式。
+
+ 输出:
+ ```bash
+ [2022-05-15 15:00:58,185] [ INFO] - acs http client start
+ [2022-05-15 15:00:58,185] [ INFO] - endpoint: http://127.0.0.1:8490/paddlespeech/asr/search
+ [2022-05-15 15:01:03,220] [ INFO] - acs http client finished
+ [2022-05-15 15:01:03,221] [ INFO] - ACS result: {'transcription': '我认为跑步最重要的就是给我带来了身体健康', 'acs': [{'w': '我', 'bg': 0, 'ed': 1.6800000000000002}, {'w': '我', 'bg': 2.1, 'ed': 4.28}, {'w': '康', 'bg': 3.2, 'ed': 4.92}]}
+ [2022-05-15 15:01:03,221] [ INFO] - Response time 5.036084 s.
+ ```
+
+- Python API
+ ```python
+ from paddlespeech.server.bin.paddlespeech_client import ACSClientExecutor
+
+ acs_executor = ACSClientExecutor()
+ res = acs_executor(
+ input='./zh.wav',
+ server_ip="127.0.0.1",
+ port=8490,)
+ print(res)
+ ```
+
+ 输出:
+ ```bash
+ [2022-05-15 15:08:13,955] [ INFO] - acs http client start
+ [2022-05-15 15:08:13,956] [ INFO] - endpoint: http://127.0.0.1:8490/paddlespeech/asr/search
+ [2022-05-15 15:08:19,026] [ INFO] - acs http client finished
+ {'transcription': '我认为跑步最重要的就是给我带来了身体健康', 'acs': [{'w': '我', 'bg': 0, 'ed': 1.6800000000000002}, {'w': '我', 'bg': 2.1, 'ed': 4.28}, {'w': '康', 'bg': 3.2, 'ed': 4.92}]}
+ ```
diff --git a/demos/audio_content_search/acs_clinet.py b/demos/audio_content_search/acs_clinet.py
new file mode 100644
index 000000000..11f99aca7
--- /dev/null
+++ b/demos/audio_content_search/acs_clinet.py
@@ -0,0 +1,49 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+
+from paddlespeech.cli.log import logger
+from paddlespeech.server.utils.audio_handler import ASRHttpHandler
+
+
+def main(args):
+ logger.info("asr http client start")
+ audio_format = "wav"
+ sample_rate = 16000
+ lang = "zh"
+ handler = ASRHttpHandler(
+ server_ip=args.server_ip, port=args.port, endpoint=args.endpoint)
+ res = handler.run(args.wavfile, audio_format, sample_rate, lang)
+ # res = res['result']
+ logger.info(f"the final result: {res}")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description="audio content search client")
+ parser.add_argument(
+ '--server_ip', type=str, default='127.0.0.1', help='server ip')
+ parser.add_argument('--port', type=int, default=8090, help='server port')
+ parser.add_argument(
+ "--wavfile",
+ action="store",
+ help="wav file path ",
+ default="./16_audio.wav")
+ parser.add_argument(
+ '--endpoint',
+ type=str,
+ default='/paddlespeech/asr/search',
+ help='server endpoint')
+ args = parser.parse_args()
+
+ main(args)
diff --git a/demos/audio_content_search/conf/acs_application.yaml b/demos/audio_content_search/conf/acs_application.yaml
new file mode 100644
index 000000000..dbddd06fb
--- /dev/null
+++ b/demos/audio_content_search/conf/acs_application.yaml
@@ -0,0 +1,35 @@
+#################################################################################
+# SERVER SETTING #
+#################################################################################
+host: 0.0.0.0
+port: 8490
+
+# The task format in the engin_list is: _
+# task choices = ['acs_python']
+# protocol = ['http'] (only one can be selected).
+# http only support offline engine type.
+protocol: 'http'
+engine_list: ['acs_python']
+
+
+#################################################################################
+# ENGINE CONFIG #
+#################################################################################
+
+################################### ACS #########################################
+################### acs task: engine_type: python ###############################
+acs_python:
+ task: acs
+ asr_protocol: 'websocket' # 'websocket'
+ offset: 1.0 # second
+ asr_server_ip: 127.0.0.1
+ asr_server_port: 8390
+ lang: 'zh'
+ word_list: "./conf/words.txt"
+ sample_rate: 16000
+ device: 'cpu' # set 'gpu:id' or 'cpu'
+ ping_timeout: 100 # seconds
+
+
+
+
diff --git a/demos/audio_content_search/conf/words.txt b/demos/audio_content_search/conf/words.txt
new file mode 100644
index 000000000..25510eb42
--- /dev/null
+++ b/demos/audio_content_search/conf/words.txt
@@ -0,0 +1,2 @@
+我
+康
\ No newline at end of file
diff --git a/demos/audio_content_search/conf/ws_conformer_application.yaml b/demos/audio_content_search/conf/ws_conformer_application.yaml
new file mode 100644
index 000000000..97201382f
--- /dev/null
+++ b/demos/audio_content_search/conf/ws_conformer_application.yaml
@@ -0,0 +1,43 @@
+#################################################################################
+# SERVER SETTING #
+#################################################################################
+host: 0.0.0.0
+port: 8390
+
+# The task format in the engin_list is: _
+# task choices = ['asr_online']
+# protocol = ['websocket'] (only one can be selected).
+# websocket only support online engine type.
+protocol: 'websocket'
+engine_list: ['asr_online']
+
+
+#################################################################################
+# ENGINE CONFIG #
+#################################################################################
+
+################################### ASR #########################################
+################### speech task: asr; engine_type: online #######################
+asr_online:
+ model_type: 'conformer_online_multicn'
+ am_model: # the pdmodel file of am static model [optional]
+ am_params: # the pdiparams file of am static model [optional]
+ lang: 'zh'
+ sample_rate: 16000
+ cfg_path:
+ decode_method: 'attention_rescoring'
+ force_yes: True
+ device: 'cpu' # cpu or gpu:id
+ am_predictor_conf:
+ device: # set 'gpu:id' or 'cpu'
+ switch_ir_optim: True
+ glog_info: False # True -> print glog
+ summary: True # False -> do not show predictor config
+
+ chunk_buffer_conf:
+ window_n: 7 # frame
+ shift_n: 4 # frame
+ window_ms: 25 # ms
+ shift_ms: 10 # ms
+ sample_rate: 16000
+ sample_width: 2
diff --git a/paddlespeech/server/conf/ws_application.yaml b/demos/audio_content_search/conf/ws_conformer_wenetspeech_application.yaml
similarity index 85%
rename from paddlespeech/server/conf/ws_application.yaml
rename to demos/audio_content_search/conf/ws_conformer_wenetspeech_application.yaml
index dee8d78ba..c23680bd5 100644
--- a/paddlespeech/server/conf/ws_application.yaml
+++ b/demos/audio_content_search/conf/ws_conformer_wenetspeech_application.yaml
@@ -4,11 +4,11 @@
# SERVER SETTING #
#################################################################################
host: 0.0.0.0
-port: 8090
+port: 8390
# The task format in the engin_list is: _
-# task choices = ['asr_online', 'tts_online']
-# protocol = ['websocket', 'http'] (only one can be selected).
+# task choices = ['asr_online']
+# protocol = ['websocket'] (only one can be selected).
# websocket only support online engine type.
protocol: 'websocket'
engine_list: ['asr_online']
@@ -21,7 +21,7 @@ engine_list: ['asr_online']
################################### ASR #########################################
################### speech task: asr; engine_type: online #######################
asr_online:
- model_type: 'deepspeech2online_aishell'
+ model_type: 'conformer_online_wenetspeech'
am_model: # the pdmodel file of am static model [optional]
am_params: # the pdiparams file of am static model [optional]
lang: 'zh'
@@ -29,7 +29,8 @@ asr_online:
cfg_path:
decode_method:
force_yes: True
-
+ device: 'cpu' # cpu or gpu:id
+ decode_method: "attention_rescoring"
am_predictor_conf:
device: # set 'gpu:id' or 'cpu'
switch_ir_optim: True
@@ -37,11 +38,9 @@ asr_online:
summary: True # False -> do not show predictor config
chunk_buffer_conf:
- frame_duration_ms: 80
- shift_ms: 40
- sample_rate: 16000
- sample_width: 2
window_n: 7 # frame
shift_n: 4 # frame
- window_ms: 20 # ms
+ window_ms: 25 # ms
shift_ms: 10 # ms
+ sample_rate: 16000
+ sample_width: 2
diff --git a/demos/audio_content_search/requirements.txt b/demos/audio_content_search/requirements.txt
new file mode 100644
index 000000000..4126a4868
--- /dev/null
+++ b/demos/audio_content_search/requirements.txt
@@ -0,0 +1 @@
+websocket-client
\ No newline at end of file
diff --git a/demos/audio_content_search/run.sh b/demos/audio_content_search/run.sh
new file mode 100755
index 000000000..e322a37c5
--- /dev/null
+++ b/demos/audio_content_search/run.sh
@@ -0,0 +1,7 @@
+export CUDA_VISIBLE_DEVICE=0,1,2,3
+# we need the streaming asr server
+nohup python3 streaming_asr_server.py --config_file conf/ws_conformer_application.yaml > streaming_asr.log 2>&1 &
+
+# start the acs server
+nohup paddlespeech_server start --config_file conf/acs_application.yaml > acs.log 2>&1 &
+
diff --git a/demos/audio_content_search/streaming_asr_server.py b/demos/audio_content_search/streaming_asr_server.py
new file mode 100644
index 000000000..011b009aa
--- /dev/null
+++ b/demos/audio_content_search/streaming_asr_server.py
@@ -0,0 +1,38 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+
+from paddlespeech.cli.log import logger
+from paddlespeech.server.bin.paddlespeech_server import ServerExecutor
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(
+ prog='paddlespeech_server.start', add_help=True)
+ parser.add_argument(
+ "--config_file",
+ action="store",
+ help="yaml file of the app",
+ default=None,
+ required=True)
+
+ parser.add_argument(
+ "--log_file",
+ action="store",
+ help="log file",
+ default="./log/paddlespeech.log")
+ logger.info("start to parse the args")
+ args = parser.parse_args()
+
+ logger.info("start to launch the streaming asr server")
+ streaming_asr_server = ServerExecutor()
+ streaming_asr_server(config_file=args.config_file, log_file=args.log_file)
diff --git a/demos/audio_searching/README.md b/demos/audio_searching/README.md
index e829d991a..db38d14ed 100644
--- a/demos/audio_searching/README.md
+++ b/demos/audio_searching/README.md
@@ -89,7 +89,7 @@ Then to start the system server, and it provides HTTP backend services.
Then start the server with Fastapi.
```bash
- export PYTHONPATH=$PYTHONPATH:./src:../../paddleaudio
+ export PYTHONPATH=$PYTHONPATH:./src
python src/audio_search.py
```
diff --git a/demos/audio_searching/README_cn.md b/demos/audio_searching/README_cn.md
index c13742af7..6d38b91f5 100644
--- a/demos/audio_searching/README_cn.md
+++ b/demos/audio_searching/README_cn.md
@@ -91,7 +91,7 @@ ffce340b3790 minio/minio:RELEASE.2020-12-03T00-03-10Z "/usr/bin/docker-ent…"
启动用 Fastapi 构建的服务
```bash
- export PYTHONPATH=$PYTHONPATH:./src:../../paddleaudio
+ export PYTHONPATH=$PYTHONPATH:./src
python src/audio_search.py
```
diff --git a/demos/audio_searching/src/encode.py b/demos/audio_searching/src/encode.py
index c89a11c1f..f6bcb00ad 100644
--- a/demos/audio_searching/src/encode.py
+++ b/demos/audio_searching/src/encode.py
@@ -14,7 +14,7 @@
import numpy as np
from logs import LOGGER
-from paddlespeech.cli import VectorExecutor
+from paddlespeech.cli.vector import VectorExecutor
vector_executor = VectorExecutor()
diff --git a/demos/audio_tagging/README.md b/demos/audio_tagging/README.md
index 9d4af0be6..fc4a334ea 100644
--- a/demos/audio_tagging/README.md
+++ b/demos/audio_tagging/README.md
@@ -57,7 +57,7 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/cat.wav https://paddlespe
- Python API
```python
import paddle
- from paddlespeech.cli import CLSExecutor
+ from paddlespeech.cli.cls import CLSExecutor
cls_executor = CLSExecutor()
result = cls_executor(
diff --git a/demos/audio_tagging/README_cn.md b/demos/audio_tagging/README_cn.md
index 79f87bf8c..36b5d8aaf 100644
--- a/demos/audio_tagging/README_cn.md
+++ b/demos/audio_tagging/README_cn.md
@@ -57,7 +57,7 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/cat.wav https://paddlespe
- Python API
```python
import paddle
- from paddlespeech.cli import CLSExecutor
+ from paddlespeech.cli.cls import CLSExecutor
cls_executor = CLSExecutor()
result = cls_executor(
diff --git a/demos/automatic_video_subtitiles/README.md b/demos/automatic_video_subtitiles/README.md
index db6da40db..b815425ec 100644
--- a/demos/automatic_video_subtitiles/README.md
+++ b/demos/automatic_video_subtitiles/README.md
@@ -28,7 +28,8 @@ ffmpeg -i subtitle_demo1.mp4 -ac 1 -ar 16000 -vn input.wav
- Python API
```python
import paddle
- from paddlespeech.cli import ASRExecutor, TextExecutor
+ from paddlespeech.cli.asr import ASRExecutor
+ from paddlespeech.cli.text import TextExecutor
asr_executor = ASRExecutor()
text_executor = TextExecutor()
diff --git a/demos/automatic_video_subtitiles/README_cn.md b/demos/automatic_video_subtitiles/README_cn.md
index fc7b2cf6a..990ff6dbd 100644
--- a/demos/automatic_video_subtitiles/README_cn.md
+++ b/demos/automatic_video_subtitiles/README_cn.md
@@ -23,7 +23,8 @@ ffmpeg -i subtitle_demo1.mp4 -ac 1 -ar 16000 -vn input.wav
- Python API
```python
import paddle
- from paddlespeech.cli import ASRExecutor, TextExecutor
+ from paddlespeech.cli.asr import ASRExecutor
+ from paddlespeech.cli.text import TextExecutor
asr_executor = ASRExecutor()
text_executor = TextExecutor()
diff --git a/demos/automatic_video_subtitiles/recognize.py b/demos/automatic_video_subtitiles/recognize.py
index 72e3c3a85..304599d19 100644
--- a/demos/automatic_video_subtitiles/recognize.py
+++ b/demos/automatic_video_subtitiles/recognize.py
@@ -16,8 +16,8 @@ import os
import paddle
-from paddlespeech.cli import ASRExecutor
-from paddlespeech.cli import TextExecutor
+from paddlespeech.cli.asr import ASRExecutor
+from paddlespeech.cli.text import TextExecutor
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
diff --git a/demos/custom_streaming_asr/README.md b/demos/custom_streaming_asr/README.md
new file mode 100644
index 000000000..da86e90ab
--- /dev/null
+++ b/demos/custom_streaming_asr/README.md
@@ -0,0 +1,68 @@
+([简体中文](./README_cn.md)|English)
+
+# Customized Auto Speech Recognition
+
+## introduction
+
+In some cases, we need to recognize the specific rare words with high accuracy. eg: address recognition in navigation apps. customized ASR can slove those issues.
+
+this demo is customized for expense account, which need to recognize rare address.
+
+the scripts are in https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/speechx/examples/custom_asr
+
+* G with slot: 打车到 "address_slot"。
+
+
+* this is address slot wfst, you can add the address which want to recognize.
+
+
+* after replace operation, G = fstreplace(G_with_slot, address_slot), we will get the customized graph.
+
+
+## Usage
+### 1. Installation
+install paddle:2.2.2 docker.
+```
+sudo docker pull registry.baidubce.com/paddlepaddle/paddle:2.2.2
+
+sudo docker run --privileged --net=host --ipc=host -it --rm -v $PWD:/paddle --name=paddle_demo_docker registry.baidubce.com/paddlepaddle/paddle:2.2.2 /bin/bash
+```
+
+### 2. demo
+* run websocket_server.sh. This script will download resources and libs, and launch the service.
+```
+cd /paddle
+bash websocket_server.sh
+```
+this script run in two steps:
+1. download the resources.tar.gz, those direcotries will be found in resource directory.
+model: acustic model
+graph: the decoder graph (TLG.fst)
+lib: some libs
+bin: binary
+data: audio and wav.scp
+
+2. websocket_server_main launch the service.
+some params:
+port: the service port
+graph_path: the decoder graph path
+model_path: acustic model path
+please refer other params in those files:
+PaddleSpeech/speechx/speechx/decoder/param.h
+PaddleSpeech/speechx/examples/ds2_ol/websocket/websocket_server_main.cc
+
+* In other terminal, run script websocket_client.sh, the client will send data and get the results.
+```
+bash websocket_client.sh
+```
+websocket_client_main will launch the client, the wav_scp is the wav set, port is the server service port.
+
+* result:
+In the log of client, you will see the message below:
+```
+0513 10:58:13.827821 41768 recognizer_test_main.cc:56] wav len (sample): 70208
+I0513 10:58:13.884493 41768 feature_cache.h:52] set finished
+I0513 10:58:24.247171 41768 paddle_nnet.h:76] Tensor neml: 10240
+I0513 10:58:24.247249 41768 paddle_nnet.h:76] Tensor neml: 10240
+LOG ([5.5.544~2-f21d7]:main():decoder/recognizer_test_main.cc:90) the result of case_10 is 五月十二日二十二点三十六分加班打车回家四十一元
+```
diff --git a/demos/custom_streaming_asr/README_cn.md b/demos/custom_streaming_asr/README_cn.md
new file mode 100644
index 000000000..f9981a6ae
--- /dev/null
+++ b/demos/custom_streaming_asr/README_cn.md
@@ -0,0 +1,65 @@
+(简体中文|[English](./README.md))
+
+# 定制化语音识别演示
+## 介绍
+在一些场景中,识别系统需要高精度的识别一些稀有词,例如导航软件中地名识别。而通过定制化识别可以满足这一需求。
+
+这个 demo 是打车报销单的场景识别,需要识别一些稀有的地名,可以通过如下操作实现。
+
+相关脚本:https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/speechx/examples/custom_asr
+
+* G with slot: 打车到 "address_slot"。
+
+
+* 这是 address slot wfst, 可以添加一些需要识别的地名.
+
+
+* 通过 replace 操作, G = fstreplace(G_with_slot, address_slot), 最终可以得到定制化的解码图。
+
+
+## 使用方法
+### 1. 配置环境
+安装paddle:2.2.2 docker镜像。
+```
+sudo docker pull registry.baidubce.com/paddlepaddle/paddle:2.2.2
+
+sudo docker run --privileged --net=host --ipc=host -it --rm -v $PWD:/paddle --name=paddle_demo_docker registry.baidubce.com/paddlepaddle/paddle:2.2.2 /bin/bash
+```
+
+### 2. 演示
+* 运行如下命令,完成相关资源和库的下载和服务启动。
+```
+cd /paddle
+bash websocket_server.sh
+```
+上面脚本完成了如下两个功能:
+1. 完成 resource.tar.gz 下载,解压后,会在 resource 中发现如下目录:
+model: 声学模型
+graph: 解码构图
+lib: 相关库
+bin: 运行程序
+data: 语音数据
+
+2. 通过 websocket_server_main 来启动服务。
+这里简单的介绍几个参数:
+port 是服务端口,
+graph_path 用来指定解码图文件,
+其他参数说明可参见代码:
+PaddleSpeech/speechx/speechx/decoder/param.h
+PaddleSpeech/speechx/examples/ds2_ol/websocket/websocket_server_main.cc
+
+* 在另一个终端中, 通过 client 发送数据,得到结果。运行如下命令:
+```
+bash websocket_client.sh
+```
+通过 websocket_client_main 来启动 client 服务,其中 wav_scp 是发送的语音句子集合,port 为服务端口。
+
+* 结果:
+client 的 log 中可以看到如下类似的结果
+```
+0513 10:58:13.827821 41768 recognizer_test_main.cc:56] wav len (sample): 70208
+I0513 10:58:13.884493 41768 feature_cache.h:52] set finished
+I0513 10:58:24.247171 41768 paddle_nnet.h:76] Tensor neml: 10240
+I0513 10:58:24.247249 41768 paddle_nnet.h:76] Tensor neml: 10240
+LOG ([5.5.544~2-f21d7]:main():decoder/recognizer_test_main.cc:90) the result of case_10 is 五月十二日二十二点三十六分加班打车回家四十一元
+```
diff --git a/demos/custom_streaming_asr/path.sh b/demos/custom_streaming_asr/path.sh
new file mode 100644
index 000000000..47462324d
--- /dev/null
+++ b/demos/custom_streaming_asr/path.sh
@@ -0,0 +1,2 @@
+export LD_LIBRARY_PATH=$PWD/resource/lib
+export PATH=$PATH:$PWD/resource/bin
diff --git a/demos/custom_streaming_asr/setup_docker.sh b/demos/custom_streaming_asr/setup_docker.sh
new file mode 100644
index 000000000..329a75db0
--- /dev/null
+++ b/demos/custom_streaming_asr/setup_docker.sh
@@ -0,0 +1 @@
+sudo nvidia-docker run --privileged --net=host --ipc=host -it --rm -v $PWD:/paddle --name=paddle_demo_docker registry.baidubce.com/paddlepaddle/paddle:2.2.2 /bin/bash
diff --git a/demos/custom_streaming_asr/websocket_client.sh b/demos/custom_streaming_asr/websocket_client.sh
new file mode 100755
index 000000000..ede076caf
--- /dev/null
+++ b/demos/custom_streaming_asr/websocket_client.sh
@@ -0,0 +1,18 @@
+#!/bin/bash
+set +x
+set -e
+
+. path.sh
+# input
+data=$PWD/data
+
+# output
+wav_scp=wav.scp
+
+export GLOG_logtostderr=1
+
+# websocket client
+websocket_client_main \
+ --wav_rspecifier=scp:$data/$wav_scp \
+ --streaming_chunk=0.36 \
+ --port=8881
diff --git a/demos/custom_streaming_asr/websocket_server.sh b/demos/custom_streaming_asr/websocket_server.sh
new file mode 100755
index 000000000..041c345be
--- /dev/null
+++ b/demos/custom_streaming_asr/websocket_server.sh
@@ -0,0 +1,33 @@
+#!/bin/bash
+set +x
+set -e
+
+export GLOG_logtostderr=1
+
+. path.sh
+#test websocket server
+
+model_dir=./resource/model
+graph_dir=./resource/graph
+cmvn=./data/cmvn.ark
+
+
+#paddle_asr_online/resource.tar.gz
+if [ ! -f $cmvn ]; then
+ wget -c https://paddlespeech.bj.bcebos.com/s2t/paddle_asr_online/resource.tar.gz
+ tar xzfv resource.tar.gz
+ ln -s ./resource/data .
+fi
+
+websocket_server_main \
+ --cmvn_file=$cmvn \
+ --streaming_chunk=0.1 \
+ --use_fbank=true \
+ --model_path=$model_dir/avg_10.jit.pdmodel \
+ --param_path=$model_dir/avg_10.jit.pdiparams \
+ --model_cache_shapes="5-1-2048,5-1-2048" \
+ --model_output_names=softmax_0.tmp_0,tmp_5,concat_0.tmp_0,concat_1.tmp_0 \
+ --word_symbol_table=$graph_dir/words.txt \
+ --graph_path=$graph_dir/TLG.fst --max_active=7500 \
+ --port=8881 \
+ --acoustic_scale=12
diff --git a/demos/punctuation_restoration/README.md b/demos/punctuation_restoration/README.md
index 518d437dc..458ab92f9 100644
--- a/demos/punctuation_restoration/README.md
+++ b/demos/punctuation_restoration/README.md
@@ -42,7 +42,7 @@ The input of this demo should be a text of the specific language that can be pas
- Python API
```python
import paddle
- from paddlespeech.cli import TextExecutor
+ from paddlespeech.cli.text import TextExecutor
text_executor = TextExecutor()
result = text_executor(
diff --git a/demos/punctuation_restoration/README_cn.md b/demos/punctuation_restoration/README_cn.md
index 9d4be8bf0..f25acdadb 100644
--- a/demos/punctuation_restoration/README_cn.md
+++ b/demos/punctuation_restoration/README_cn.md
@@ -44,7 +44,7 @@
- Python API
```python
import paddle
- from paddlespeech.cli import TextExecutor
+ from paddlespeech.cli.text import TextExecutor
text_executor = TextExecutor()
result = text_executor(
diff --git a/demos/speaker_verification/README.md b/demos/speaker_verification/README.md
index b79f3f7a1..900b5ae40 100644
--- a/demos/speaker_verification/README.md
+++ b/demos/speaker_verification/README.md
@@ -14,7 +14,7 @@ see [installation](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/doc
You can choose one way from easy, meduim and hard to install paddlespeech.
### 2. Prepare Input File
-The input of this demo should be a WAV file(`.wav`), and the sample rate must be the same as the model.
+The input of this cli demo should be a WAV file(`.wav`), and the sample rate must be the same as the model.
Here are sample files for this demo that can be downloaded:
```bash
@@ -53,51 +53,50 @@ wget -c https://paddlespeech.bj.bcebos.com/vector/audio/85236145389.wav
Output:
```bash
- demo [ 1.4217498 5.626253 -5.342073 1.1773866 3.308055
- 1.756596 5.167894 10.80636 -3.8226728 -5.6141334
- 2.623845 -0.8072968 1.9635103 -7.3128724 0.01103897
- -9.723131 0.6619743 -6.976803 10.213478 7.494748
- 2.9105635 3.8949256 3.7999806 7.1061673 16.905321
- -7.1493764 8.733103 3.4230042 -4.831653 -11.403367
- 11.232214 7.1274667 -4.2828417 2.452362 -5.130748
- -18.177666 -2.6116815 -11.000337 -6.7314315 1.6564683
- 0.7618269 1.1253023 -2.083836 4.725744 -8.782597
- -3.539873 3.814236 5.1420674 2.162061 4.096431
- -6.4162116 12.747448 1.9429878 -15.152943 6.417416
- 16.097002 -9.716668 -1.9920526 -3.3649497 -1.871939
- 11.567354 3.69788 11.258265 7.442363 9.183411
- 4.5281515 -1.2417862 4.3959084 6.6727695 5.8898783
- 7.627124 -0.66919386 -11.889693 -9.208865 -7.4274073
- -3.7776625 6.917234 -9.848748 -2.0944717 -5.135116
- 0.49563864 9.317534 -5.9141874 -1.8098574 -0.11738578
- -7.169265 -1.0578263 -5.7216787 -5.1173844 16.137651
- -4.473626 7.6624317 -0.55381083 9.631587 -6.4704556
- -8.548508 4.3716145 -0.79702514 4.478997 -2.9758704
- 3.272176 2.8382776 5.134597 -9.190781 -0.5657382
- -4.8745747 2.3165567 -5.984303 -2.1798875 0.35541576
- -0.31784213 9.493548 2.1144536 4.358092 -12.089823
- 8.451689 -7.925461 4.6242585 4.4289427 18.692003
- -2.6204622 -5.149185 -0.35821092 8.488551 4.981496
- -9.32683 -2.2544234 6.6417594 1.2119585 10.977129
- 16.555033 3.3238444 9.551863 -1.6676947 -0.79539716
- -8.605674 -0.47356385 2.6741948 -5.359179 -2.6673796
- 0.66607 15.443222 4.740594 -3.4725387 11.592567
- -2.054497 1.7361217 -8.265324 -9.30447 5.4068313
- -1.5180256 -7.746615 -6.089606 0.07112726 -0.34904733
- -8.649895 -9.998958 -2.564841 -0.53999114 2.601808
- -0.31927416 -1.8815292 -2.07215 -3.4105783 -8.2998085
- 1.483641 -15.365992 -8.288208 3.8847756 -3.4876456
- 7.3629923 0.4657332 3.132599 12.438889 -1.8337058
- 4.532936 2.7264361 10.145339 -6.521951 2.897153
- -3.3925855 5.079156 7.759716 4.677565 5.8457737
- 2.402413 7.7071047 3.9711342 -6.390043 6.1268735
- -3.7760346 -11.118123 ]
+ demo [ -1.3251206 7.8606825 -4.620626 0.3000721 2.2648535
+ -1.1931441 3.0647137 7.673595 -6.0044727 -12.02426
+ -1.9496069 3.1269536 1.618838 -7.6383104 -1.2299773
+ -12.338331 2.1373026 -5.3957124 9.717328 5.6752305
+ 3.7805123 3.0597172 3.429692 8.97601 13.174125
+ -0.53132284 8.9424715 4.46511 -4.4262476 -9.726503
+ 8.399328 7.2239175 -7.435854 2.9441683 -4.3430395
+ -13.886965 -1.6346735 -10.9027405 -5.311245 3.8007221
+ 3.8976038 -2.1230774 -2.3521194 4.151031 -7.4048667
+ 0.13911647 2.4626107 4.9664545 0.9897574 5.4839754
+ -3.3574002 10.1340065 -0.6120171 -10.403095 4.6007543
+ 16.00935 -7.7836914 -4.1945305 -6.9368606 1.1789556
+ 11.490801 4.2380238 9.550931 8.375046 7.5089145
+ -0.65707296 -0.30051577 2.8406055 3.0828028 0.730817
+ 6.148354 0.13766119 -13.424735 -7.7461405 -2.3227983
+ -8.305252 2.9879124 -10.995229 0.15211068 -2.3820348
+ -1.7984174 8.495629 -5.8522367 -3.755498 0.6989711
+ -5.2702994 -2.6188622 -1.8828466 -4.64665 14.078544
+ -0.5495333 10.579158 -3.2160501 9.349004 -4.381078
+ -11.675817 -2.8630207 4.5721755 2.246612 -4.574342
+ 1.8610188 2.3767874 5.6257877 -9.784078 0.64967257
+ -1.4579505 0.4263264 -4.9211264 -2.454784 3.4869802
+ -0.42654222 8.341269 1.356552 7.0966883 -13.102829
+ 8.016734 -7.1159344 1.8699781 0.208721 14.699384
+ -1.025278 -2.6107233 -2.5082312 8.427193 6.9138527
+ -6.2912464 0.6157366 2.489688 -3.4668267 9.921763
+ 11.200815 -0.1966403 7.4916005 -0.62312716 -0.25848144
+ -9.947997 -0.9611041 1.1649219 -2.1907122 -1.5028487
+ -0.51926106 15.165954 2.4649463 -0.9980445 7.4416637
+ -2.0768049 3.5896823 -7.3055434 -7.5620847 4.323335
+ 0.0804418 -6.56401 -2.3148053 -1.7642345 -2.4708817
+ -7.675618 -9.548878 -1.0177554 0.16986446 2.5877135
+ -1.8752296 -0.36614323 -6.0493784 -2.3965611 -5.9453387
+ 0.9424033 -13.155974 -7.457801 0.14658108 -3.742797
+ 5.8414927 -1.2872906 5.5694313 12.57059 1.0939219
+ 2.2142086 1.9181576 6.9914207 -5.888139 3.1409824
+ -2.003628 2.4434285 9.973139 5.03668 2.0051203
+ 2.8615603 5.860224 2.9176188 -1.6311141 2.0292206
+ -4.070415 -6.831437 ]
```
- Python API
```python
- import paddle
- from paddlespeech.cli import VectorExecutor
+ from paddlespeech.cli.vector import VectorExecutor
vector_executor = VectorExecutor()
audio_emb = vector_executor(
@@ -128,88 +127,88 @@ wget -c https://paddlespeech.bj.bcebos.com/vector/audio/85236145389.wav
```bash
# Vector Result:
Audio embedding Result:
- [ 1.4217498 5.626253 -5.342073 1.1773866 3.308055
- 1.756596 5.167894 10.80636 -3.8226728 -5.6141334
- 2.623845 -0.8072968 1.9635103 -7.3128724 0.01103897
- -9.723131 0.6619743 -6.976803 10.213478 7.494748
- 2.9105635 3.8949256 3.7999806 7.1061673 16.905321
- -7.1493764 8.733103 3.4230042 -4.831653 -11.403367
- 11.232214 7.1274667 -4.2828417 2.452362 -5.130748
- -18.177666 -2.6116815 -11.000337 -6.7314315 1.6564683
- 0.7618269 1.1253023 -2.083836 4.725744 -8.782597
- -3.539873 3.814236 5.1420674 2.162061 4.096431
- -6.4162116 12.747448 1.9429878 -15.152943 6.417416
- 16.097002 -9.716668 -1.9920526 -3.3649497 -1.871939
- 11.567354 3.69788 11.258265 7.442363 9.183411
- 4.5281515 -1.2417862 4.3959084 6.6727695 5.8898783
- 7.627124 -0.66919386 -11.889693 -9.208865 -7.4274073
- -3.7776625 6.917234 -9.848748 -2.0944717 -5.135116
- 0.49563864 9.317534 -5.9141874 -1.8098574 -0.11738578
- -7.169265 -1.0578263 -5.7216787 -5.1173844 16.137651
- -4.473626 7.6624317 -0.55381083 9.631587 -6.4704556
- -8.548508 4.3716145 -0.79702514 4.478997 -2.9758704
- 3.272176 2.8382776 5.134597 -9.190781 -0.5657382
- -4.8745747 2.3165567 -5.984303 -2.1798875 0.35541576
- -0.31784213 9.493548 2.1144536 4.358092 -12.089823
- 8.451689 -7.925461 4.6242585 4.4289427 18.692003
- -2.6204622 -5.149185 -0.35821092 8.488551 4.981496
- -9.32683 -2.2544234 6.6417594 1.2119585 10.977129
- 16.555033 3.3238444 9.551863 -1.6676947 -0.79539716
- -8.605674 -0.47356385 2.6741948 -5.359179 -2.6673796
- 0.66607 15.443222 4.740594 -3.4725387 11.592567
- -2.054497 1.7361217 -8.265324 -9.30447 5.4068313
- -1.5180256 -7.746615 -6.089606 0.07112726 -0.34904733
- -8.649895 -9.998958 -2.564841 -0.53999114 2.601808
- -0.31927416 -1.8815292 -2.07215 -3.4105783 -8.2998085
- 1.483641 -15.365992 -8.288208 3.8847756 -3.4876456
- 7.3629923 0.4657332 3.132599 12.438889 -1.8337058
- 4.532936 2.7264361 10.145339 -6.521951 2.897153
- -3.3925855 5.079156 7.759716 4.677565 5.8457737
- 2.402413 7.7071047 3.9711342 -6.390043 6.1268735
- -3.7760346 -11.118123 ]
+ [ -1.3251206 7.8606825 -4.620626 0.3000721 2.2648535
+ -1.1931441 3.0647137 7.673595 -6.0044727 -12.02426
+ -1.9496069 3.1269536 1.618838 -7.6383104 -1.2299773
+ -12.338331 2.1373026 -5.3957124 9.717328 5.6752305
+ 3.7805123 3.0597172 3.429692 8.97601 13.174125
+ -0.53132284 8.9424715 4.46511 -4.4262476 -9.726503
+ 8.399328 7.2239175 -7.435854 2.9441683 -4.3430395
+ -13.886965 -1.6346735 -10.9027405 -5.311245 3.8007221
+ 3.8976038 -2.1230774 -2.3521194 4.151031 -7.4048667
+ 0.13911647 2.4626107 4.9664545 0.9897574 5.4839754
+ -3.3574002 10.1340065 -0.6120171 -10.403095 4.6007543
+ 16.00935 -7.7836914 -4.1945305 -6.9368606 1.1789556
+ 11.490801 4.2380238 9.550931 8.375046 7.5089145
+ -0.65707296 -0.30051577 2.8406055 3.0828028 0.730817
+ 6.148354 0.13766119 -13.424735 -7.7461405 -2.3227983
+ -8.305252 2.9879124 -10.995229 0.15211068 -2.3820348
+ -1.7984174 8.495629 -5.8522367 -3.755498 0.6989711
+ -5.2702994 -2.6188622 -1.8828466 -4.64665 14.078544
+ -0.5495333 10.579158 -3.2160501 9.349004 -4.381078
+ -11.675817 -2.8630207 4.5721755 2.246612 -4.574342
+ 1.8610188 2.3767874 5.6257877 -9.784078 0.64967257
+ -1.4579505 0.4263264 -4.9211264 -2.454784 3.4869802
+ -0.42654222 8.341269 1.356552 7.0966883 -13.102829
+ 8.016734 -7.1159344 1.8699781 0.208721 14.699384
+ -1.025278 -2.6107233 -2.5082312 8.427193 6.9138527
+ -6.2912464 0.6157366 2.489688 -3.4668267 9.921763
+ 11.200815 -0.1966403 7.4916005 -0.62312716 -0.25848144
+ -9.947997 -0.9611041 1.1649219 -2.1907122 -1.5028487
+ -0.51926106 15.165954 2.4649463 -0.9980445 7.4416637
+ -2.0768049 3.5896823 -7.3055434 -7.5620847 4.323335
+ 0.0804418 -6.56401 -2.3148053 -1.7642345 -2.4708817
+ -7.675618 -9.548878 -1.0177554 0.16986446 2.5877135
+ -1.8752296 -0.36614323 -6.0493784 -2.3965611 -5.9453387
+ 0.9424033 -13.155974 -7.457801 0.14658108 -3.742797
+ 5.8414927 -1.2872906 5.5694313 12.57059 1.0939219
+ 2.2142086 1.9181576 6.9914207 -5.888139 3.1409824
+ -2.003628 2.4434285 9.973139 5.03668 2.0051203
+ 2.8615603 5.860224 2.9176188 -1.6311141 2.0292206
+ -4.070415 -6.831437 ]
# get the test embedding
Test embedding Result:
- [ -1.902964 2.0690894 -8.034194 3.5472693 0.18089125
- 6.9085927 1.4097427 -1.9487704 -10.021278 -0.20755845
- -8.04332 4.344489 2.3200977 -14.306299 5.184692
- -11.55602 -3.8497238 0.6444722 1.2833948 2.6766639
- 0.5878921 0.7946299 1.7207596 2.5791872 14.998469
- -1.3385371 15.031221 -0.8006958 1.99287 -9.52007
- 2.435466 4.003221 -4.33817 -4.898601 -5.304714
- -18.033886 10.790787 -12.784645 -5.641755 2.9761686
- -10.566622 1.4839455 6.152458 -5.7195854 2.8603241
- 6.112133 8.489869 5.5958056 1.2836679 -1.2293907
- 0.89927405 7.0288725 -2.854029 -0.9782962 5.8255906
- 14.905906 -5.025907 0.7866458 -4.2444224 -16.354029
- 10.521315 0.9604709 -3.3257897 7.144871 -13.592733
- -8.568869 -1.7953678 0.26313916 10.916714 -6.9374123
- 1.857403 -6.2746415 2.8154466 -7.2338667 -2.293357
- -0.05452765 5.4287076 5.0849075 -6.690375 -1.6183422
- 3.654291 0.94352573 -9.200294 -5.4749465 -3.5235846
- 1.3420814 4.240421 -2.772944 -2.8451524 16.311104
- 4.2969875 -1.762936 -12.5758915 8.595198 -0.8835239
- -1.5708797 1.568961 1.1413603 3.5032008 -0.45251232
- -6.786333 16.89443 5.3366146 -8.789056 0.6355629
- 3.2579517 -3.328322 7.5969577 0.66025066 -6.550468
- -9.148656 2.020372 -0.4615173 1.1965656 -3.8764873
- 11.6562195 -6.0750933 12.182899 3.2218833 0.81969476
- 5.570001 -3.8459578 -7.205299 7.9262037 -7.6611166
- -5.249467 -2.2671914 7.2658715 -13.298164 4.821147
- -2.7263982 11.691089 -3.8918593 -2.838112 -1.0336838
- -3.8034165 2.8536487 -5.60398 -1.1972581 1.3455094
- -3.4903061 2.2408795 5.5010734 -3.970756 11.99696
- -7.8858757 0.43160373 -5.5059714 4.3426995 16.322706
- 11.635366 0.72157705 -9.245714 -3.91465 -4.449838
- -1.5716927 7.713747 -2.2430465 -6.198303 -13.481864
- 2.8156567 -5.7812386 5.1456156 2.7289324 -14.505571
- 13.270688 3.448231 -7.0659585 4.5886116 -4.466099
- -0.296428 -11.463529 -2.6076477 14.110243 -6.9725137
- -1.9962958 2.7119343 19.391657 0.01961198 14.607133
- -1.6695905 -4.391516 1.3131028 -6.670972 -5.888604
- 12.0612335 5.9285784 3.3715196 1.492534 10.723728
- -0.95514804 -12.085431 ]
+ [ 2.5247195 5.119042 -4.335273 4.4583654 5.047907
+ 3.5059214 1.6159848 0.49364898 -11.6899185 -3.1014526
+ -5.6589785 -0.42684984 2.674276 -11.937654 6.2248464
+ -10.776924 -5.694543 1.112041 1.5709964 1.0961034
+ 1.3976512 2.324352 1.339981 5.279319 13.734659
+ -2.5753925 13.651442 -2.2357535 5.1575427 -3.251567
+ 1.4023279 6.1191974 -6.0845175 -1.3646189 -2.6789894
+ -15.220778 9.779349 -9.411551 -6.388947 6.8313975
+ -9.245996 0.31196198 2.5509644 -4.413065 6.1649427
+ 6.793837 2.6328635 8.620976 3.4832475 0.52491665
+ 2.9115407 5.8392377 0.6702376 -3.2726715 2.6694255
+ 16.91701 -5.5811176 0.23362345 -4.5573606 -11.801059
+ 14.728292 -0.5198082 -3.999922 7.0927105 -7.0459595
+ -5.4389 -0.46420583 -5.1085467 10.376568 -8.889225
+ -0.37705845 -1.659806 2.6731026 -7.1909504 1.4608804
+ -2.163136 -0.17949677 4.0241547 0.11319201 0.601279
+ 2.039692 3.1910992 -11.649526 -8.121584 -4.8707457
+ 0.3851982 1.4231744 -2.3321972 0.99332285 14.121717
+ 5.899413 0.7384519 -17.760096 10.555021 4.1366534
+ -0.3391071 -0.20792882 3.208204 0.8847948 -8.721497
+ -6.432868 13.006379 4.8956 -9.155822 -1.9441519
+ 5.7815638 -2.066733 10.425042 -0.8802383 -2.4314315
+ -9.869258 0.35095334 -5.3549943 2.1076174 -8.290468
+ 8.4433365 -4.689333 9.334139 -2.172678 -3.0250976
+ 8.394216 -3.2110903 -7.93868 2.3960824 -2.3213403
+ -1.4963245 -3.476059 4.132903 -10.893354 4.362673
+ -0.45456508 10.258634 -1.1655927 -6.7799754 0.22885278
+ -4.399287 2.333433 -4.84745 -4.2752337 -1.3577863
+ -1.0685898 9.505196 7.3062205 0.08708266 12.927811
+ -9.57974 1.3936648 -1.9444873 5.776769 15.251903
+ 10.6118355 -1.4903594 -9.535318 -3.6553776 -1.6699586
+ -0.5933151 7.600357 -4.8815503 -8.698617 -15.855757
+ 0.25632986 -7.2235737 0.9506656 0.7128582 -9.051738
+ 8.74869 -1.6426028 -6.5762258 2.506905 -6.7431564
+ 5.129912 -12.189555 -3.6435068 12.068113 -6.0059533
+ -2.3535995 2.9014351 22.3082 -1.5563312 13.193291
+ 2.7583609 -7.468798 1.3407065 -4.599617 -6.2345777
+ 10.7689295 7.137627 5.099476 0.3473359 9.647881
+ -2.0484571 -5.8549366 ]
# get the score between enroll and test
- Eembeddings Score: 0.4292638301849365
+ Eembeddings Score: 0.45332613587379456
```
### 4.Pretrained Models
diff --git a/demos/speaker_verification/README_cn.md b/demos/speaker_verification/README_cn.md
index db382f298..f6afa86ac 100644
--- a/demos/speaker_verification/README_cn.md
+++ b/demos/speaker_verification/README_cn.md
@@ -4,16 +4,16 @@
## 介绍
声纹识别是一项用计算机程序自动提取说话人特征的技术。
-这个 demo 是一个从给定音频文件提取说话人特征,它可以通过使用 `PaddleSpeech` 的单个命令或 python 中的几行代码来实现。
+这个 demo 是从一个给定音频文件中提取说话人特征,它可以通过使用 `PaddleSpeech` 的单个命令或 python 中的几行代码来实现。
## 使用方法
### 1. 安装
请看[安装文档](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install_cn.md)。
-你可以从 easy,medium,hard 三中方式中选择一种方式安装。
+你可以从easy medium,hard 三种方式中选择一种方式安装。
### 2. 准备输入
-这个 demo 的输入应该是一个 WAV 文件(`.wav`),并且采样率必须与模型的采样率相同。
+声纹cli demo 的输入应该是一个 WAV 文件(`.wav`),并且采样率必须与模型的采样率相同。
可以下载此 demo 的示例音频:
```bash
@@ -51,51 +51,51 @@ wget -c https://paddlespeech.bj.bcebos.com/vector/audio/85236145389.wav
输出:
```bash
- demo [ 1.4217498 5.626253 -5.342073 1.1773866 3.308055
- 1.756596 5.167894 10.80636 -3.8226728 -5.6141334
- 2.623845 -0.8072968 1.9635103 -7.3128724 0.01103897
- -9.723131 0.6619743 -6.976803 10.213478 7.494748
- 2.9105635 3.8949256 3.7999806 7.1061673 16.905321
- -7.1493764 8.733103 3.4230042 -4.831653 -11.403367
- 11.232214 7.1274667 -4.2828417 2.452362 -5.130748
- -18.177666 -2.6116815 -11.000337 -6.7314315 1.6564683
- 0.7618269 1.1253023 -2.083836 4.725744 -8.782597
- -3.539873 3.814236 5.1420674 2.162061 4.096431
- -6.4162116 12.747448 1.9429878 -15.152943 6.417416
- 16.097002 -9.716668 -1.9920526 -3.3649497 -1.871939
- 11.567354 3.69788 11.258265 7.442363 9.183411
- 4.5281515 -1.2417862 4.3959084 6.6727695 5.8898783
- 7.627124 -0.66919386 -11.889693 -9.208865 -7.4274073
- -3.7776625 6.917234 -9.848748 -2.0944717 -5.135116
- 0.49563864 9.317534 -5.9141874 -1.8098574 -0.11738578
- -7.169265 -1.0578263 -5.7216787 -5.1173844 16.137651
- -4.473626 7.6624317 -0.55381083 9.631587 -6.4704556
- -8.548508 4.3716145 -0.79702514 4.478997 -2.9758704
- 3.272176 2.8382776 5.134597 -9.190781 -0.5657382
- -4.8745747 2.3165567 -5.984303 -2.1798875 0.35541576
- -0.31784213 9.493548 2.1144536 4.358092 -12.089823
- 8.451689 -7.925461 4.6242585 4.4289427 18.692003
- -2.6204622 -5.149185 -0.35821092 8.488551 4.981496
- -9.32683 -2.2544234 6.6417594 1.2119585 10.977129
- 16.555033 3.3238444 9.551863 -1.6676947 -0.79539716
- -8.605674 -0.47356385 2.6741948 -5.359179 -2.6673796
- 0.66607 15.443222 4.740594 -3.4725387 11.592567
- -2.054497 1.7361217 -8.265324 -9.30447 5.4068313
- -1.5180256 -7.746615 -6.089606 0.07112726 -0.34904733
- -8.649895 -9.998958 -2.564841 -0.53999114 2.601808
- -0.31927416 -1.8815292 -2.07215 -3.4105783 -8.2998085
- 1.483641 -15.365992 -8.288208 3.8847756 -3.4876456
- 7.3629923 0.4657332 3.132599 12.438889 -1.8337058
- 4.532936 2.7264361 10.145339 -6.521951 2.897153
- -3.3925855 5.079156 7.759716 4.677565 5.8457737
- 2.402413 7.7071047 3.9711342 -6.390043 6.1268735
- -3.7760346 -11.118123 ]
+ [ -1.3251206 7.8606825 -4.620626 0.3000721 2.2648535
+ -1.1931441 3.0647137 7.673595 -6.0044727 -12.02426
+ -1.9496069 3.1269536 1.618838 -7.6383104 -1.2299773
+ -12.338331 2.1373026 -5.3957124 9.717328 5.6752305
+ 3.7805123 3.0597172 3.429692 8.97601 13.174125
+ -0.53132284 8.9424715 4.46511 -4.4262476 -9.726503
+ 8.399328 7.2239175 -7.435854 2.9441683 -4.3430395
+ -13.886965 -1.6346735 -10.9027405 -5.311245 3.8007221
+ 3.8976038 -2.1230774 -2.3521194 4.151031 -7.4048667
+ 0.13911647 2.4626107 4.9664545 0.9897574 5.4839754
+ -3.3574002 10.1340065 -0.6120171 -10.403095 4.6007543
+ 16.00935 -7.7836914 -4.1945305 -6.9368606 1.1789556
+ 11.490801 4.2380238 9.550931 8.375046 7.5089145
+ -0.65707296 -0.30051577 2.8406055 3.0828028 0.730817
+ 6.148354 0.13766119 -13.424735 -7.7461405 -2.3227983
+ -8.305252 2.9879124 -10.995229 0.15211068 -2.3820348
+ -1.7984174 8.495629 -5.8522367 -3.755498 0.6989711
+ -5.2702994 -2.6188622 -1.8828466 -4.64665 14.078544
+ -0.5495333 10.579158 -3.2160501 9.349004 -4.381078
+ -11.675817 -2.8630207 4.5721755 2.246612 -4.574342
+ 1.8610188 2.3767874 5.6257877 -9.784078 0.64967257
+ -1.4579505 0.4263264 -4.9211264 -2.454784 3.4869802
+ -0.42654222 8.341269 1.356552 7.0966883 -13.102829
+ 8.016734 -7.1159344 1.8699781 0.208721 14.699384
+ -1.025278 -2.6107233 -2.5082312 8.427193 6.9138527
+ -6.2912464 0.6157366 2.489688 -3.4668267 9.921763
+ 11.200815 -0.1966403 7.4916005 -0.62312716 -0.25848144
+ -9.947997 -0.9611041 1.1649219 -2.1907122 -1.5028487
+ -0.51926106 15.165954 2.4649463 -0.9980445 7.4416637
+ -2.0768049 3.5896823 -7.3055434 -7.5620847 4.323335
+ 0.0804418 -6.56401 -2.3148053 -1.7642345 -2.4708817
+ -7.675618 -9.548878 -1.0177554 0.16986446 2.5877135
+ -1.8752296 -0.36614323 -6.0493784 -2.3965611 -5.9453387
+ 0.9424033 -13.155974 -7.457801 0.14658108 -3.742797
+ 5.8414927 -1.2872906 5.5694313 12.57059 1.0939219
+ 2.2142086 1.9181576 6.9914207 -5.888139 3.1409824
+ -2.003628 2.4434285 9.973139 5.03668 2.0051203
+ 2.8615603 5.860224 2.9176188 -1.6311141 2.0292206
+ -4.070415 -6.831437 ]
```
- Python API
```python
import paddle
- from paddlespeech.cli import VectorExecutor
+ from paddlespeech.cli.vector import VectorExecutor
vector_executor = VectorExecutor()
audio_emb = vector_executor(
@@ -125,88 +125,88 @@ wget -c https://paddlespeech.bj.bcebos.com/vector/audio/85236145389.wav
```bash
# Vector Result:
Audio embedding Result:
- [ 1.4217498 5.626253 -5.342073 1.1773866 3.308055
- 1.756596 5.167894 10.80636 -3.8226728 -5.6141334
- 2.623845 -0.8072968 1.9635103 -7.3128724 0.01103897
- -9.723131 0.6619743 -6.976803 10.213478 7.494748
- 2.9105635 3.8949256 3.7999806 7.1061673 16.905321
- -7.1493764 8.733103 3.4230042 -4.831653 -11.403367
- 11.232214 7.1274667 -4.2828417 2.452362 -5.130748
- -18.177666 -2.6116815 -11.000337 -6.7314315 1.6564683
- 0.7618269 1.1253023 -2.083836 4.725744 -8.782597
- -3.539873 3.814236 5.1420674 2.162061 4.096431
- -6.4162116 12.747448 1.9429878 -15.152943 6.417416
- 16.097002 -9.716668 -1.9920526 -3.3649497 -1.871939
- 11.567354 3.69788 11.258265 7.442363 9.183411
- 4.5281515 -1.2417862 4.3959084 6.6727695 5.8898783
- 7.627124 -0.66919386 -11.889693 -9.208865 -7.4274073
- -3.7776625 6.917234 -9.848748 -2.0944717 -5.135116
- 0.49563864 9.317534 -5.9141874 -1.8098574 -0.11738578
- -7.169265 -1.0578263 -5.7216787 -5.1173844 16.137651
- -4.473626 7.6624317 -0.55381083 9.631587 -6.4704556
- -8.548508 4.3716145 -0.79702514 4.478997 -2.9758704
- 3.272176 2.8382776 5.134597 -9.190781 -0.5657382
- -4.8745747 2.3165567 -5.984303 -2.1798875 0.35541576
- -0.31784213 9.493548 2.1144536 4.358092 -12.089823
- 8.451689 -7.925461 4.6242585 4.4289427 18.692003
- -2.6204622 -5.149185 -0.35821092 8.488551 4.981496
- -9.32683 -2.2544234 6.6417594 1.2119585 10.977129
- 16.555033 3.3238444 9.551863 -1.6676947 -0.79539716
- -8.605674 -0.47356385 2.6741948 -5.359179 -2.6673796
- 0.66607 15.443222 4.740594 -3.4725387 11.592567
- -2.054497 1.7361217 -8.265324 -9.30447 5.4068313
- -1.5180256 -7.746615 -6.089606 0.07112726 -0.34904733
- -8.649895 -9.998958 -2.564841 -0.53999114 2.601808
- -0.31927416 -1.8815292 -2.07215 -3.4105783 -8.2998085
- 1.483641 -15.365992 -8.288208 3.8847756 -3.4876456
- 7.3629923 0.4657332 3.132599 12.438889 -1.8337058
- 4.532936 2.7264361 10.145339 -6.521951 2.897153
- -3.3925855 5.079156 7.759716 4.677565 5.8457737
- 2.402413 7.7071047 3.9711342 -6.390043 6.1268735
- -3.7760346 -11.118123 ]
+ [ -1.3251206 7.8606825 -4.620626 0.3000721 2.2648535
+ -1.1931441 3.0647137 7.673595 -6.0044727 -12.02426
+ -1.9496069 3.1269536 1.618838 -7.6383104 -1.2299773
+ -12.338331 2.1373026 -5.3957124 9.717328 5.6752305
+ 3.7805123 3.0597172 3.429692 8.97601 13.174125
+ -0.53132284 8.9424715 4.46511 -4.4262476 -9.726503
+ 8.399328 7.2239175 -7.435854 2.9441683 -4.3430395
+ -13.886965 -1.6346735 -10.9027405 -5.311245 3.8007221
+ 3.8976038 -2.1230774 -2.3521194 4.151031 -7.4048667
+ 0.13911647 2.4626107 4.9664545 0.9897574 5.4839754
+ -3.3574002 10.1340065 -0.6120171 -10.403095 4.6007543
+ 16.00935 -7.7836914 -4.1945305 -6.9368606 1.1789556
+ 11.490801 4.2380238 9.550931 8.375046 7.5089145
+ -0.65707296 -0.30051577 2.8406055 3.0828028 0.730817
+ 6.148354 0.13766119 -13.424735 -7.7461405 -2.3227983
+ -8.305252 2.9879124 -10.995229 0.15211068 -2.3820348
+ -1.7984174 8.495629 -5.8522367 -3.755498 0.6989711
+ -5.2702994 -2.6188622 -1.8828466 -4.64665 14.078544
+ -0.5495333 10.579158 -3.2160501 9.349004 -4.381078
+ -11.675817 -2.8630207 4.5721755 2.246612 -4.574342
+ 1.8610188 2.3767874 5.6257877 -9.784078 0.64967257
+ -1.4579505 0.4263264 -4.9211264 -2.454784 3.4869802
+ -0.42654222 8.341269 1.356552 7.0966883 -13.102829
+ 8.016734 -7.1159344 1.8699781 0.208721 14.699384
+ -1.025278 -2.6107233 -2.5082312 8.427193 6.9138527
+ -6.2912464 0.6157366 2.489688 -3.4668267 9.921763
+ 11.200815 -0.1966403 7.4916005 -0.62312716 -0.25848144
+ -9.947997 -0.9611041 1.1649219 -2.1907122 -1.5028487
+ -0.51926106 15.165954 2.4649463 -0.9980445 7.4416637
+ -2.0768049 3.5896823 -7.3055434 -7.5620847 4.323335
+ 0.0804418 -6.56401 -2.3148053 -1.7642345 -2.4708817
+ -7.675618 -9.548878 -1.0177554 0.16986446 2.5877135
+ -1.8752296 -0.36614323 -6.0493784 -2.3965611 -5.9453387
+ 0.9424033 -13.155974 -7.457801 0.14658108 -3.742797
+ 5.8414927 -1.2872906 5.5694313 12.57059 1.0939219
+ 2.2142086 1.9181576 6.9914207 -5.888139 3.1409824
+ -2.003628 2.4434285 9.973139 5.03668 2.0051203
+ 2.8615603 5.860224 2.9176188 -1.6311141 2.0292206
+ -4.070415 -6.831437 ]
# get the test embedding
Test embedding Result:
- [ -1.902964 2.0690894 -8.034194 3.5472693 0.18089125
- 6.9085927 1.4097427 -1.9487704 -10.021278 -0.20755845
- -8.04332 4.344489 2.3200977 -14.306299 5.184692
- -11.55602 -3.8497238 0.6444722 1.2833948 2.6766639
- 0.5878921 0.7946299 1.7207596 2.5791872 14.998469
- -1.3385371 15.031221 -0.8006958 1.99287 -9.52007
- 2.435466 4.003221 -4.33817 -4.898601 -5.304714
- -18.033886 10.790787 -12.784645 -5.641755 2.9761686
- -10.566622 1.4839455 6.152458 -5.7195854 2.8603241
- 6.112133 8.489869 5.5958056 1.2836679 -1.2293907
- 0.89927405 7.0288725 -2.854029 -0.9782962 5.8255906
- 14.905906 -5.025907 0.7866458 -4.2444224 -16.354029
- 10.521315 0.9604709 -3.3257897 7.144871 -13.592733
- -8.568869 -1.7953678 0.26313916 10.916714 -6.9374123
- 1.857403 -6.2746415 2.8154466 -7.2338667 -2.293357
- -0.05452765 5.4287076 5.0849075 -6.690375 -1.6183422
- 3.654291 0.94352573 -9.200294 -5.4749465 -3.5235846
- 1.3420814 4.240421 -2.772944 -2.8451524 16.311104
- 4.2969875 -1.762936 -12.5758915 8.595198 -0.8835239
- -1.5708797 1.568961 1.1413603 3.5032008 -0.45251232
- -6.786333 16.89443 5.3366146 -8.789056 0.6355629
- 3.2579517 -3.328322 7.5969577 0.66025066 -6.550468
- -9.148656 2.020372 -0.4615173 1.1965656 -3.8764873
- 11.6562195 -6.0750933 12.182899 3.2218833 0.81969476
- 5.570001 -3.8459578 -7.205299 7.9262037 -7.6611166
- -5.249467 -2.2671914 7.2658715 -13.298164 4.821147
- -2.7263982 11.691089 -3.8918593 -2.838112 -1.0336838
- -3.8034165 2.8536487 -5.60398 -1.1972581 1.3455094
- -3.4903061 2.2408795 5.5010734 -3.970756 11.99696
- -7.8858757 0.43160373 -5.5059714 4.3426995 16.322706
- 11.635366 0.72157705 -9.245714 -3.91465 -4.449838
- -1.5716927 7.713747 -2.2430465 -6.198303 -13.481864
- 2.8156567 -5.7812386 5.1456156 2.7289324 -14.505571
- 13.270688 3.448231 -7.0659585 4.5886116 -4.466099
- -0.296428 -11.463529 -2.6076477 14.110243 -6.9725137
- -1.9962958 2.7119343 19.391657 0.01961198 14.607133
- -1.6695905 -4.391516 1.3131028 -6.670972 -5.888604
- 12.0612335 5.9285784 3.3715196 1.492534 10.723728
- -0.95514804 -12.085431 ]
+ [ 2.5247195 5.119042 -4.335273 4.4583654 5.047907
+ 3.5059214 1.6159848 0.49364898 -11.6899185 -3.1014526
+ -5.6589785 -0.42684984 2.674276 -11.937654 6.2248464
+ -10.776924 -5.694543 1.112041 1.5709964 1.0961034
+ 1.3976512 2.324352 1.339981 5.279319 13.734659
+ -2.5753925 13.651442 -2.2357535 5.1575427 -3.251567
+ 1.4023279 6.1191974 -6.0845175 -1.3646189 -2.6789894
+ -15.220778 9.779349 -9.411551 -6.388947 6.8313975
+ -9.245996 0.31196198 2.5509644 -4.413065 6.1649427
+ 6.793837 2.6328635 8.620976 3.4832475 0.52491665
+ 2.9115407 5.8392377 0.6702376 -3.2726715 2.6694255
+ 16.91701 -5.5811176 0.23362345 -4.5573606 -11.801059
+ 14.728292 -0.5198082 -3.999922 7.0927105 -7.0459595
+ -5.4389 -0.46420583 -5.1085467 10.376568 -8.889225
+ -0.37705845 -1.659806 2.6731026 -7.1909504 1.4608804
+ -2.163136 -0.17949677 4.0241547 0.11319201 0.601279
+ 2.039692 3.1910992 -11.649526 -8.121584 -4.8707457
+ 0.3851982 1.4231744 -2.3321972 0.99332285 14.121717
+ 5.899413 0.7384519 -17.760096 10.555021 4.1366534
+ -0.3391071 -0.20792882 3.208204 0.8847948 -8.721497
+ -6.432868 13.006379 4.8956 -9.155822 -1.9441519
+ 5.7815638 -2.066733 10.425042 -0.8802383 -2.4314315
+ -9.869258 0.35095334 -5.3549943 2.1076174 -8.290468
+ 8.4433365 -4.689333 9.334139 -2.172678 -3.0250976
+ 8.394216 -3.2110903 -7.93868 2.3960824 -2.3213403
+ -1.4963245 -3.476059 4.132903 -10.893354 4.362673
+ -0.45456508 10.258634 -1.1655927 -6.7799754 0.22885278
+ -4.399287 2.333433 -4.84745 -4.2752337 -1.3577863
+ -1.0685898 9.505196 7.3062205 0.08708266 12.927811
+ -9.57974 1.3936648 -1.9444873 5.776769 15.251903
+ 10.6118355 -1.4903594 -9.535318 -3.6553776 -1.6699586
+ -0.5933151 7.600357 -4.8815503 -8.698617 -15.855757
+ 0.25632986 -7.2235737 0.9506656 0.7128582 -9.051738
+ 8.74869 -1.6426028 -6.5762258 2.506905 -6.7431564
+ 5.129912 -12.189555 -3.6435068 12.068113 -6.0059533
+ -2.3535995 2.9014351 22.3082 -1.5563312 13.193291
+ 2.7583609 -7.468798 1.3407065 -4.599617 -6.2345777
+ 10.7689295 7.137627 5.099476 0.3473359 9.647881
+ -2.0484571 -5.8549366 ]
# get the score between enroll and test
- Eembeddings Score: 0.4292638301849365
+ Eembeddings Score: 0.45332613587379456
```
### 4.预训练模型
diff --git a/demos/speech_recognition/README.md b/demos/speech_recognition/README.md
index 636548801..c815a88af 100644
--- a/demos/speech_recognition/README.md
+++ b/demos/speech_recognition/README.md
@@ -24,13 +24,13 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespee
- Command Line(Recommended)
```bash
# Chinese
- paddlespeech asr --input ./zh.wav
+ paddlespeech asr --input ./zh.wav -v
# English
- paddlespeech asr --model transformer_librispeech --lang en --input ./en.wav
+ paddlespeech asr --model transformer_librispeech --lang en --input ./en.wav -v
# Chinese ASR + Punctuation Restoration
- paddlespeech asr --input ./zh.wav | paddlespeech text --task punc
+ paddlespeech asr --input ./zh.wav -v | paddlespeech text --task punc -v
```
- (It doesn't matter if package `paddlespeech-ctcdecoders` is not found, this package is optional.)
+ (If you don't want to see the log information, you can remove "-v". Besides, it doesn't matter if package `paddlespeech-ctcdecoders` is not found, this package is optional.)
Usage:
```bash
@@ -45,6 +45,7 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespee
- `ckpt_path`: Model checkpoint. Use pretrained model when it is None. Default: `None`.
- `yes`: No additional parameters required. Once set this parameter, it means accepting the request of the program by default, which includes transforming the audio sample rate. Default: `False`.
- `device`: Choose device to execute model inference. Default: default device of paddlepaddle in current environment.
+ - `verbose`: Show the log information.
Output:
```bash
@@ -57,7 +58,7 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespee
- Python API
```python
import paddle
- from paddlespeech.cli import ASRExecutor
+ from paddlespeech.cli.asr import ASRExecutor
asr_executor = ASRExecutor()
text = asr_executor(
@@ -84,8 +85,12 @@ Here is a list of pretrained models released by PaddleSpeech that can be used by
| Model | Language | Sample Rate
| :--- | :---: | :---: |
-| conformer_wenetspeech| zh| 16k
-| transformer_librispeech| en| 16k
+| conformer_wenetspeech | zh | 16k
+| conformer_online_multicn | zh | 16k
+| conformer_aishell | zh | 16k
+| conformer_online_aishell | zh | 16k
+| transformer_librispeech | en | 16k
+| deepspeech2online_wenetspeech | zh | 16k
| deepspeech2offline_aishell| zh| 16k
| deepspeech2online_aishell | zh | 16k
-|deepspeech2offline_librispeech|en| 16k
+| deepspeech2offline_librispeech | en | 16k
diff --git a/demos/speech_recognition/README_cn.md b/demos/speech_recognition/README_cn.md
index 8033dbd81..13aa9f277 100644
--- a/demos/speech_recognition/README_cn.md
+++ b/demos/speech_recognition/README_cn.md
@@ -22,13 +22,13 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespee
- 命令行 (推荐使用)
```bash
# 中文
- paddlespeech asr --input ./zh.wav
+ paddlespeech asr --input ./zh.wav -v
# 英文
- paddlespeech asr --model transformer_librispeech --lang en --input ./en.wav
+ paddlespeech asr --model transformer_librispeech --lang en --input ./en.wav -v
# 中文 + 标点恢复
- paddlespeech asr --input ./zh.wav | paddlespeech text --task punc
+ paddlespeech asr --input ./zh.wav -v | paddlespeech text --task punc -v
```
- (如果显示 `paddlespeech-ctcdecoders` 这个 python 包没有找到的 Error,没有关系,这个包是非必须的。)
+ (如果不想显示 log 信息,可以不使用"-v", 另外如果显示 `paddlespeech-ctcdecoders` 这个 python 包没有找到的 Error,没有关系,这个包是非必须的。)
使用方法:
```bash
@@ -43,6 +43,7 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespee
- `ckpt_path`:模型参数文件,若不设置则下载预训练模型使用,默认值:`None`。
- `yes`;不需要设置额外的参数,一旦设置了该参数,说明你默认同意程序的所有请求,其中包括自动转换输入音频的采样率。默认值:`False`。
- `device`:执行预测的设备,默认值:当前系统下 paddlepaddle 的默认 device。
+ - `verbose`: 如果使用,显示 logger 信息。
输出:
```bash
@@ -55,7 +56,7 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespee
- Python API
```python
import paddle
- from paddlespeech.cli import ASRExecutor
+ from paddlespeech.cli.asr import ASRExecutor
asr_executor = ASRExecutor()
text = asr_executor(
@@ -82,7 +83,11 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespee
| 模型 | 语言 | 采样率
| :--- | :---: | :---: |
| conformer_wenetspeech | zh | 16k
+| conformer_online_multicn | zh | 16k
+| conformer_aishell | zh | 16k
+| conformer_online_aishell | zh | 16k
| transformer_librispeech | en | 16k
+| deepspeech2online_wenetspeech | zh | 16k
| deepspeech2offline_aishell| zh| 16k
| deepspeech2online_aishell | zh | 16k
| deepspeech2offline_librispeech | en | 16k
diff --git a/demos/speech_server/README.md b/demos/speech_server/README.md
index 0323d3983..14a88f078 100644
--- a/demos/speech_server/README.md
+++ b/demos/speech_server/README.md
@@ -10,7 +10,7 @@ This demo is an implementation of starting the voice service and accessing the s
### 1. Installation
see [installation](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install.md).
-It is recommended to use **paddlepaddle 2.2.1** or above.
+It is recommended to use **paddlepaddle 2.2.2** or above.
You can choose one way from meduim and hard to install paddlespeech.
### 2. Prepare config File
@@ -18,6 +18,7 @@ The configuration file can be found in `conf/application.yaml` .
Among them, `engine_list` indicates the speech engine that will be included in the service to be started, in the format of `_`.
At present, the speech tasks integrated by the service include: asr (speech recognition), tts (text to sppech) and cls (audio classification).
Currently the engine type supports two forms: python and inference (Paddle Inference)
+**Note:** If the service can be started normally in the container, but the client access IP is unreachable, you can try to replace the `host` address in the configuration file with the local IP address.
The input of ASR client demo should be a WAV file(`.wav`), and the sample rate must be the same as the model.
@@ -83,6 +84,9 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespee
### 4. ASR Client Usage
**Note:** The response time will be slightly longer when using the client for the first time
- Command Line (Recommended)
+
+ If `127.0.0.1` is not accessible, you need to use the actual service IP address.
+
```
paddlespeech_client asr --server_ip 127.0.0.1 --port 8090 --input ./zh.wav
```
@@ -131,6 +135,9 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespee
### 5. TTS Client Usage
**Note:** The response time will be slightly longer when using the client for the first time
- Command Line (Recommended)
+
+ If `127.0.0.1` is not accessible, you need to use the actual service IP address
+
```bash
paddlespeech_client tts --server_ip 127.0.0.1 --port 8090 --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
```
@@ -191,6 +198,9 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespee
### 6. CLS Client Usage
**Note:** The response time will be slightly longer when using the client for the first time
- Command Line (Recommended)
+
+ If `127.0.0.1` is not accessible, you need to use the actual service IP address.
+
```
paddlespeech_client cls --server_ip 127.0.0.1 --port 8090 --input ./zh.wav
```
@@ -235,6 +245,173 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespee
```
+### 7. Speaker Verification Client Usage
+
+#### 7.1 Extract speaker embedding
+**Note:** The response time will be slightly longer when using the client for the first time
+- Command Line (Recommended)
+
+ If `127.0.0.1` is not accessible, you need to use the actual service IP address.
+
+ ``` bash
+ paddlespeech_client vector --task spk --server_ip 127.0.0.1 --port 8090 --input 85236145389.wav
+ ```
+
+ Usage:
+
+ ``` bash
+ paddlespeech_client vector --help
+ ```
+
+ Arguments:
+ * server_ip: server ip. Default: 127.0.0.1
+ * port: server port. Default: 8090
+ * input(required): Input text to generate.
+ * task: the task of vector, can be use 'spk' or 'score。Default is 'spk'。
+ * enroll: enroll audio
+ * test: test audio
+
+ Output:
+
+ ```bash
+ [2022-05-25 12:25:36,165] [ INFO] - vector http client start
+ [2022-05-25 12:25:36,165] [ INFO] - the input audio: 85236145389.wav
+ [2022-05-25 12:25:36,165] [ INFO] - endpoint: http://127.0.0.1:8790/paddlespeech/vector
+ [2022-05-25 12:25:36,166] [ INFO] - http://127.0.0.1:8790/paddlespeech/vector
+ [2022-05-25 12:25:36,324] [ INFO] - The vector: {'success': True, 'code': 200, 'message': {'description': 'success'}, 'result': {'vec': [-1.3251205682754517, 7.860682487487793, -4.620625972747803, 0.3000721037387848, 2.2648534774780273, -1.1931440830230713, 3.064713716506958, 7.673594951629639, -6.004472732543945, -12.024259567260742, -1.9496068954467773, 3.126953601837158, 1.6188379526138306, -7.638310432434082, -1.2299772500991821, -12.33833122253418, 2.1373026371002197, -5.395712375640869, 9.717328071594238, 5.675230503082275, 3.7805123329162598, 3.0597171783447266, 3.429692029953003, 8.9760103225708, 13.174124717712402, -0.5313228368759155, 8.942471504211426, 4.465109825134277, -4.426247596740723, -9.726503372192383, 8.399328231811523, 7.223917484283447, -7.435853958129883, 2.9441683292388916, -4.343039512634277, -13.886964797973633, -1.6346734762191772, -10.902740478515625, -5.311244964599609, 3.800722122192383, 3.897603750228882, -2.123077392578125, -2.3521194458007812, 4.151031017303467, -7.404866695404053, 0.13911646604537964, 2.4626107215881348, 4.96645450592041, 0.9897574186325073, 5.483975410461426, -3.3574001789093018, 10.13400650024414, -0.6120170950889587, -10.403095245361328, 4.600754261016846, 16.009349822998047, -7.78369140625, -4.194530487060547, -6.93686056137085, 1.1789555549621582, 11.490800857543945, 4.23802375793457, 9.550930976867676, 8.375045776367188, 7.508914470672607, -0.6570729613304138, -0.3005157709121704, 2.8406054973602295, 3.0828027725219727, 0.7308170199394226, 6.1483540534973145, 0.1376611888408661, -13.424735069274902, -7.746140480041504, -2.322798252105713, -8.305252075195312, 2.98791241645813, -10.99522876739502, 0.15211068093776703, -2.3820347785949707, -1.7984174489974976, 8.49562931060791, -5.852236747741699, -3.755497932434082, 0.6989710927009583, -5.270299434661865, -2.6188621520996094, -1.8828465938568115, -4.6466498374938965, 14.078543663024902, -0.5495333075523376, 10.579157829284668, -3.216050148010254, 9.349003791809082, -4.381077766418457, -11.675816535949707, -2.863020658493042, 4.5721755027771, 2.246612071990967, -4.574341773986816, 1.8610187768936157, 2.3767874240875244, 5.625787734985352, -9.784077644348145, 0.6496725678443909, -1.457950472831726, 0.4263263940811157, -4.921126365661621, -2.4547839164733887, 3.4869801998138428, -0.4265422224998474, 8.341268539428711, 1.356552004814148, 7.096688270568848, -13.102828979492188, 8.01673412322998, -7.115934371948242, 1.8699780702590942, 0.20872099697589874, 14.699383735656738, -1.0252779722213745, -2.6107232570648193, -2.5082311630249023, 8.427192687988281, 6.913852691650391, -6.29124641418457, 0.6157366037368774, 2.489687919616699, -3.4668266773223877, 9.92176342010498, 11.200815200805664, -0.19664029777050018, 7.491600513458252, -0.6231271624565125, -0.2584814429283142, -9.947997093200684, -0.9611040949821472, 1.1649218797683716, -2.1907122135162354, -1.502848744392395, -0.5192610621452332, 15.165953636169434, 2.4649462699890137, -0.998044490814209, 7.44166374206543, -2.0768048763275146, 3.5896823406219482, -7.305543422698975, -7.562084674835205, 4.32333517074585, 0.08044180274009705, -6.564010143280029, -2.314805269241333, -1.7642345428466797, -2.470881700515747, -7.6756181716918945, -9.548877716064453, -1.017755389213562, 0.1698644608259201, 2.5877134799957275, -1.8752295970916748, -0.36614322662353516, -6.049378395080566, -2.3965611457824707, -5.945338726043701, 0.9424033164978027, -13.155974388122559, -7.45780086517334, 0.14658108353614807, -3.7427968978881836, 5.841492652893066, -1.2872905731201172, 5.569431304931641, 12.570590019226074, 1.0939218997955322, 2.2142086029052734, 1.9181575775146484, 6.991420745849609, -5.888138771057129, 3.1409823894500732, -2.0036280155181885, 2.4434285163879395, 9.973138809204102, 5.036680221557617, 2.005120277404785, 2.861560344696045, 5.860223770141602, 2.917618751525879, -1.63111412525177, 2.0292205810546875, -4.070415019989014, -6.831437110900879]}}
+ [2022-05-25 12:25:36,324] [ INFO] - Response time 0.159053 s.
+ ```
+
+* Python API
+
+ ``` python
+ from paddlespeech.server.bin.paddlespeech_client import VectorClientExecutor
+
+ vectorclient_executor = VectorClientExecutor()
+ res = vectorclient_executor(
+ input="85236145389.wav",
+ server_ip="127.0.0.1",
+ port=8090,
+ task="spk")
+ print(res)
+ ```
+
+ Output:
+
+ ``` bash
+ {'success': True, 'code': 200, 'message': {'description': 'success'}, 'result': {'vec': [-1.3251205682754517, 7.860682487487793, -4.620625972747803, 0.3000721037387848, 2.2648534774780273, -1.1931440830230713, 3.064713716506958, 7.673594951629639, -6.004472732543945, -12.024259567260742, -1.9496068954467773, 3.126953601837158, 1.6188379526138306, -7.638310432434082, -1.2299772500991821, -12.33833122253418, 2.1373026371002197, -5.395712375640869, 9.717328071594238, 5.675230503082275, 3.7805123329162598, 3.0597171783447266, 3.429692029953003, 8.9760103225708, 13.174124717712402, -0.5313228368759155, 8.942471504211426, 4.465109825134277, -4.426247596740723, -9.726503372192383, 8.399328231811523, 7.223917484283447, -7.435853958129883, 2.9441683292388916, -4.343039512634277, -13.886964797973633, -1.6346734762191772, -10.902740478515625, -5.311244964599609, 3.800722122192383, 3.897603750228882, -2.123077392578125, -2.3521194458007812, 4.151031017303467, -7.404866695404053, 0.13911646604537964, 2.4626107215881348, 4.96645450592041, 0.9897574186325073, 5.483975410461426, -3.3574001789093018, 10.13400650024414, -0.6120170950889587, -10.403095245361328, 4.600754261016846, 16.009349822998047, -7.78369140625, -4.194530487060547, -6.93686056137085, 1.1789555549621582, 11.490800857543945, 4.23802375793457, 9.550930976867676, 8.375045776367188, 7.508914470672607, -0.6570729613304138, -0.3005157709121704, 2.8406054973602295, 3.0828027725219727, 0.7308170199394226, 6.1483540534973145, 0.1376611888408661, -13.424735069274902, -7.746140480041504, -2.322798252105713, -8.305252075195312, 2.98791241645813, -10.99522876739502, 0.15211068093776703, -2.3820347785949707, -1.7984174489974976, 8.49562931060791, -5.852236747741699, -3.755497932434082, 0.6989710927009583, -5.270299434661865, -2.6188621520996094, -1.8828465938568115, -4.6466498374938965, 14.078543663024902, -0.5495333075523376, 10.579157829284668, -3.216050148010254, 9.349003791809082, -4.381077766418457, -11.675816535949707, -2.863020658493042, 4.5721755027771, 2.246612071990967, -4.574341773986816, 1.8610187768936157, 2.3767874240875244, 5.625787734985352, -9.784077644348145, 0.6496725678443909, -1.457950472831726, 0.4263263940811157, -4.921126365661621, -2.4547839164733887, 3.4869801998138428, -0.4265422224998474, 8.341268539428711, 1.356552004814148, 7.096688270568848, -13.102828979492188, 8.01673412322998, -7.115934371948242, 1.8699780702590942, 0.20872099697589874, 14.699383735656738, -1.0252779722213745, -2.6107232570648193, -2.5082311630249023, 8.427192687988281, 6.913852691650391, -6.29124641418457, 0.6157366037368774, 2.489687919616699, -3.4668266773223877, 9.92176342010498, 11.200815200805664, -0.19664029777050018, 7.491600513458252, -0.6231271624565125, -0.2584814429283142, -9.947997093200684, -0.9611040949821472, 1.1649218797683716, -2.1907122135162354, -1.502848744392395, -0.5192610621452332, 15.165953636169434, 2.4649462699890137, -0.998044490814209, 7.44166374206543, -2.0768048763275146, 3.5896823406219482, -7.305543422698975, -7.562084674835205, 4.32333517074585, 0.08044180274009705, -6.564010143280029, -2.314805269241333, -1.7642345428466797, -2.470881700515747, -7.6756181716918945, -9.548877716064453, -1.017755389213562, 0.1698644608259201, 2.5877134799957275, -1.8752295970916748, -0.36614322662353516, -6.049378395080566, -2.3965611457824707, -5.945338726043701, 0.9424033164978027, -13.155974388122559, -7.45780086517334, 0.14658108353614807, -3.7427968978881836, 5.841492652893066, -1.2872905731201172, 5.569431304931641, 12.570590019226074, 1.0939218997955322, 2.2142086029052734, 1.9181575775146484, 6.991420745849609, -5.888138771057129, 3.1409823894500732, -2.0036280155181885, 2.4434285163879395, 9.973138809204102, 5.036680221557617, 2.005120277404785, 2.861560344696045, 5.860223770141602, 2.917618751525879, -1.63111412525177, 2.0292205810546875, -4.070415019989014, -6.831437110900879]}}
+ ```
+
+#### 7.2 Get the score between speaker audio embedding
+
+**Note:** The response time will be slightly longer when using the client for the first time
+
+- Command Line (Recommended)
+
+ If `127.0.0.1` is not accessible, you need to use the actual service IP address.
+
+ ``` bash
+ paddlespeech_client vector --task score --server_ip 127.0.0.1 --port 8090 --enroll 85236145389.wav --test 123456789.wav
+ ```
+
+ Usage:
+
+ ``` bash
+ paddlespeech_client vector --help
+ ```
+
+ Arguments:
+ * server_ip: server ip. Default: 127.0.0.1
+ * port: server port. Default: 8090
+ * input(required): Input text to generate.
+ * task: the task of vector, can be use 'spk' or 'score。If get the score, this must be 'score' parameter.
+ * enroll: enroll audio
+ * test: test audio
+
+ Output:
+
+ ``` bash
+ [2022-05-25 12:33:24,527] [ INFO] - vector score http client start
+ [2022-05-25 12:33:24,527] [ INFO] - enroll audio: 85236145389.wav, test audio: 123456789.wav
+ [2022-05-25 12:33:24,528] [ INFO] - endpoint: http://127.0.0.1:8790/paddlespeech/vector/score
+ [2022-05-25 12:33:24,695] [ INFO] - The vector score is: {'success': True, 'code': 200, 'message': {'description': 'success'}, 'result': {'score': 0.45332613587379456}}
+ [2022-05-25 12:33:24,696] [ INFO] - The vector: {'success': True, 'code': 200, 'message': {'description': 'success'}, 'result': {'score': 0.45332613587379456}}
+ [2022-05-25 12:33:24,696] [ INFO] - Response time 0.168271 s.
+ ```
+
+* Python API
+
+ ``` python
+ from paddlespeech.server.bin.paddlespeech_client import VectorClientExecutor
+
+ vectorclient_executor = VectorClientExecutor()
+ res = vectorclient_executor(
+ input=None,
+ enroll_audio="85236145389.wav",
+ test_audio="123456789.wav",
+ server_ip="127.0.0.1",
+ port=8090,
+ task="score")
+ print(res)
+ ```
+
+ Output:
+
+ ``` bash
+ [2022-05-25 12:30:14,143] [ INFO] - vector score http client start
+ [2022-05-25 12:30:14,143] [ INFO] - enroll audio: 85236145389.wav, test audio: 123456789.wav
+ [2022-05-25 12:30:14,143] [ INFO] - endpoint: http://127.0.0.1:8790/paddlespeech/vector/score
+ [2022-05-25 12:30:14,363] [ INFO] - The vector score is: {'success': True, 'code': 200, 'message': {'description': 'success'}, 'result': {'score': 0.45332613587379456}}
+ {'success': True, 'code': 200, 'message': {'description': 'success'}, 'result': {'score': 0.45332613587379456}}
+ ```
+
+### 8. Punctuation prediction
+
+**Note:** The response time will be slightly longer when using the client for the first time
+
+- Command Line (Recommended)
+
+ If `127.0.0.1` is not accessible, you need to use the actual service IP address.
+
+ ``` bash
+ paddlespeech_client text --server_ip 127.0.0.1 --port 8090 --input "我认为跑步最重要的就是给我带来了身体健康"
+ ```
+
+ Usage:
+
+ ```bash
+ paddlespeech_client text --help
+ ```
+ Arguments:
+ - `server_ip`: server ip. Default: 127.0.0.1
+ - `port`: server port. Default: 8090
+ - `input`(required): Input text to get punctuation.
+
+ Output:
+ ```bash
+ [2022-05-09 18:19:04,397] [ INFO] - The punc text: 我认为跑步最重要的就是给我带来了身体健康。
+ [2022-05-09 18:19:04,397] [ INFO] - Response time 0.092407 s.
+ ```
+
+- Python API
+ ```python
+ from paddlespeech.server.bin.paddlespeech_client import TextClientExecutor
+
+ textclient_executor = TextClientExecutor()
+ res = textclient_executor(
+ input="我认为跑步最重要的就是给我带来了身体健康",
+ server_ip="127.0.0.1",
+ port=8090,)
+ print(res)
+
+ ```
+
+ Output:
+ ```bash
+ 我认为跑步最重要的就是给我带来了身体健康。
+ ```
+
+
## Models supported by the service
### ASR model
Get all models supported by the ASR service via `paddlespeech_server stats --task asr`, where static models can be used for paddle inference inference.
@@ -244,3 +421,9 @@ Get all models supported by the TTS service via `paddlespeech_server stats --tas
### CLS model
Get all models supported by the CLS service via `paddlespeech_server stats --task cls`, where static models can be used for paddle inference inference.
+
+### Vector model
+Get all models supported by the TTS service via `paddlespeech_server stats --task vector`, where static models can be used for paddle inference inference.
+
+### Text model
+Get all models supported by the CLS service via `paddlespeech_server stats --task text`, where static models can be used for paddle inference inference.
diff --git a/demos/speech_server/README_cn.md b/demos/speech_server/README_cn.md
index 4a7c7447e..29629b7e8 100644
--- a/demos/speech_server/README_cn.md
+++ b/demos/speech_server/README_cn.md
@@ -1,29 +1,30 @@
-([简体中文](./README_cn.md)|English)
+(简体中文|[English](./README.md))
# 语音服务
## 介绍
-这个demo是一个启动语音服务和访问服务的实现。 它可以通过使用`paddlespeech_server` 和 `paddlespeech_client`的单个命令或 python 的几行代码来实现。
+这个 demo 是一个启动离线语音服务和访问服务的实现。它可以通过使用`paddlespeech_server` 和 `paddlespeech_client`的单个命令或 python 的几行代码来实现。
## 使用方法
### 1. 安装
请看 [安装文档](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install.md).
-推荐使用 **paddlepaddle 2.2.1** 或以上版本。
-你可以从 medium,hard 三中方式中选择一种方式安装 PaddleSpeech。
+推荐使用 **paddlepaddle 2.2.2** 或以上版本。
+你可以从 medium,hard 两种方式中选择一种方式安装 PaddleSpeech。
### 2. 准备配置文件
配置文件可参见 `conf/application.yaml` 。
其中,`engine_list`表示即将启动的服务将会包含的语音引擎,格式为 <语音任务>_<引擎类型>。
-目前服务集成的语音任务有: asr(语音识别)、tts(语音合成)以及cls(音频分类)。
+目前服务集成的语音任务有: asr(语音识别)、tts(语音合成)、cls(音频分类)、vector(声纹识别)以及text(文本处理)。
目前引擎类型支持两种形式:python 及 inference (Paddle Inference)
+**注意:** 如果在容器里可正常启动服务,但客户端访问 ip 不可达,可尝试将配置文件中 `host` 地址换成本地 ip 地址。
-这个 ASR client 的输入应该是一个 WAV 文件(`.wav`),并且采样率必须与模型的采样率相同。
+ASR client 的输入是一个 WAV 文件(`.wav`),并且采样率必须与模型的采样率相同。
-可以下载此 ASR client的示例音频:
+可以下载此 ASR client 的示例音频:
```bash
wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespeech.bj.bcebos.com/PaddleAudio/en.wav
```
@@ -83,31 +84,34 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespee
### 4. ASR 客户端使用方法
**注意:** 初次使用客户端时响应时间会略长
- 命令行 (推荐使用)
- ```
- paddlespeech_client asr --server_ip 127.0.0.1 --port 8090 --input ./zh.wav
- ```
+ 若 `127.0.0.1` 不能访问,则需要使用实际服务 IP 地址
- 使用帮助:
-
- ```bash
- paddlespeech_client asr --help
- ```
+ ```
+ paddlespeech_client asr --server_ip 127.0.0.1 --port 8090 --input ./zh.wav
- 参数:
- - `server_ip`: 服务端ip地址,默认: 127.0.0.1。
- - `port`: 服务端口,默认: 8090。
- - `input`(必须输入): 用于识别的音频文件。
- - `sample_rate`: 音频采样率,默认值:16000。
- - `lang`: 模型语言,默认值:zh_cn。
- - `audio_format`: 音频格式,默认值:wav。
+ ```
- 输出:
+ 使用帮助:
- ```bash
- [2022-02-23 18:11:22,819] [ INFO] - {'success': True, 'code': 200, 'message': {'description': 'success'}, 'result': {'transcription': '我认为跑步最重要的就是给我带来了身体健康'}}
- [2022-02-23 18:11:22,820] [ INFO] - time cost 0.689145 s.
- ```
+ ```bash
+ paddlespeech_client asr --help
+ ```
+
+ 参数:
+ - `server_ip`: 服务端 ip 地址,默认: 127.0.0.1。
+ - `port`: 服务端口,默认: 8090。
+ - `input`(必须输入): 用于识别的音频文件。
+ - `sample_rate`: 音频采样率,默认值:16000。
+ - `lang`: 模型语言,默认值:zh_cn。
+ - `audio_format`: 音频格式,默认值:wav。
+
+ 输出:
+
+ ```bash
+ [2022-02-23 18:11:22,819] [ INFO] - {'success': True, 'code': 200, 'message': {'description': 'success'}, 'result': {'transcription': '我认为跑步最重要的就是给我带来了身体健康'}}
+ [2022-02-23 18:11:22,820] [ INFO] - time cost 0.689145 s.
+ ```
- Python API
```python
@@ -134,33 +138,35 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespee
### 5. TTS 客户端使用方法
**注意:** 初次使用客户端时响应时间会略长
- 命令行 (推荐使用)
-
- ```bash
- paddlespeech_client tts --server_ip 127.0.0.1 --port 8090 --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
- ```
- 使用帮助:
- ```bash
- paddlespeech_client tts --help
- ```
-
- 参数:
- - `server_ip`: 服务端ip地址,默认: 127.0.0.1。
- - `port`: 服务端口,默认: 8090。
- - `input`(必须输入): 待合成的文本。
- - `spk_id`: 说话人 id,用于多说话人语音合成,默认值: 0。
- - `speed`: 音频速度,该值应设置在 0 到 3 之间。 默认值:1.0
- - `volume`: 音频音量,该值应设置在 0 到 3 之间。 默认值: 1.0
- - `sample_rate`: 采样率,可选 [0, 8000, 16000],默认与模型相同。 默认值:0
- - `output`: 输出音频的路径, 默认值:None,表示不保存音频到本地。
-
- 输出:
- ```bash
- [2022-02-23 15:20:37,875] [ INFO] - {'description': 'success.'}
- [2022-02-23 15:20:37,875] [ INFO] - Save synthesized audio successfully on output.wav.
- [2022-02-23 15:20:37,875] [ INFO] - Audio duration: 3.612500 s.
- [2022-02-23 15:20:37,875] [ INFO] - Response time: 0.348050 s.
- ```
+ 若 `127.0.0.1` 不能访问,则需要使用实际服务 IP 地址
+
+ ```bash
+ paddlespeech_client tts --server_ip 127.0.0.1 --port 8090 --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
+ ```
+ 使用帮助:
+
+ ```bash
+ paddlespeech_client tts --help
+ ```
+
+ 参数:
+ - `server_ip`: 服务端ip地址,默认: 127.0.0.1。
+ - `port`: 服务端口,默认: 8090。
+ - `input`(必须输入): 待合成的文本。
+ - `spk_id`: 说话人 id,用于多说话人语音合成,默认值: 0。
+ - `speed`: 音频速度,该值应设置在 0 到 3 之间。 默认值:1.0
+ - `volume`: 音频音量,该值应设置在 0 到 3 之间。 默认值: 1.0
+ - `sample_rate`: 采样率,可选 [0, 8000, 16000],默认与模型相同。 默认值:0
+ - `output`: 输出音频的路径, 默认值:None,表示不保存音频到本地。
+
+ 输出:
+ ```bash
+ [2022-02-23 15:20:37,875] [ INFO] - {'description': 'success.'}
+ [2022-02-23 15:20:37,875] [ INFO] - Save synthesized audio successfully on output.wav.
+ [2022-02-23 15:20:37,875] [ INFO] - Audio duration: 3.612500 s.
+ [2022-02-23 15:20:37,875] [ INFO] - Response time: 0.348050 s.
+ ```
- Python API
```python
@@ -192,12 +198,17 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespee
```
- ### 6. CLS 客户端使用方法
- **注意:** 初次使用客户端时响应时间会略长
- - 命令行 (推荐使用)
- ```
- paddlespeech_client cls --server_ip 127.0.0.1 --port 8090 --input ./zh.wav
- ```
+### 6. CLS 客户端使用方法
+
+**注意:** 初次使用客户端时响应时间会略长
+
+- 命令行 (推荐使用)
+
+ 若 `127.0.0.1` 不能访问,则需要使用实际服务 IP 地址
+
+ ```
+ paddlespeech_client cls --server_ip 127.0.0.1 --port 8090 --input ./zh.wav
+ ```
使用帮助:
@@ -205,7 +216,7 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespee
paddlespeech_client cls --help
```
参数:
- - `server_ip`: 服务端ip地址,默认: 127.0.0.1。
+ - `server_ip`: 服务端 ip 地址,默认: 127.0.0.1。
- `port`: 服务端口,默认: 8090。
- `input`(必须输入): 用于分类的音频文件。
- `topk`: 分类结果的topk。
@@ -239,13 +250,181 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespee
```
+### 7. 声纹客户端使用方法
+
+#### 7.1 提取声纹特征
+注意: 初次使用客户端时响应时间会略长
+* 命令行 (推荐使用)
+
+ 若 `127.0.0.1` 不能访问,则需要使用实际服务 IP 地址
+
+ ``` bash
+ paddlespeech_client vector --task spk --server_ip 127.0.0.1 --port 8090 --input 85236145389.wav
+ ```
+
+ 使用帮助:
+
+ ``` bash
+ paddlespeech_client vector --help
+ ```
+ 参数:
+ * server_ip: 服务端ip地址,默认: 127.0.0.1。
+ * port: 服务端口,默认: 8090。
+ * input(必须输入): 用于识别的音频文件。
+ * task: vector 的任务,可选spk或者score。默认是 spk。
+ * enroll: 注册音频;。
+ * test: 测试音频。
+ 输出:
+
+ ``` bash
+ [2022-05-25 12:25:36,165] [ INFO] - vector http client start
+ [2022-05-25 12:25:36,165] [ INFO] - the input audio: 85236145389.wav
+ [2022-05-25 12:25:36,165] [ INFO] - endpoint: http://127.0.0.1:8790/paddlespeech/vector
+ [2022-05-25 12:25:36,166] [ INFO] - http://127.0.0.1:8790/paddlespeech/vector
+ [2022-05-25 12:25:36,324] [ INFO] - The vector: {'success': True, 'code': 200, 'message': {'description': 'success'}, 'result': {'vec': [-1.3251205682754517, 7.860682487487793, -4.620625972747803, 0.3000721037387848, 2.2648534774780273, -1.1931440830230713, 3.064713716506958, 7.673594951629639, -6.004472732543945, -12.024259567260742, -1.9496068954467773, 3.126953601837158, 1.6188379526138306, -7.638310432434082, -1.2299772500991821, -12.33833122253418, 2.1373026371002197, -5.395712375640869, 9.717328071594238, 5.675230503082275, 3.7805123329162598, 3.0597171783447266, 3.429692029953003, 8.9760103225708, 13.174124717712402, -0.5313228368759155, 8.942471504211426, 4.465109825134277, -4.426247596740723, -9.726503372192383, 8.399328231811523, 7.223917484283447, -7.435853958129883, 2.9441683292388916, -4.343039512634277, -13.886964797973633, -1.6346734762191772, -10.902740478515625, -5.311244964599609, 3.800722122192383, 3.897603750228882, -2.123077392578125, -2.3521194458007812, 4.151031017303467, -7.404866695404053, 0.13911646604537964, 2.4626107215881348, 4.96645450592041, 0.9897574186325073, 5.483975410461426, -3.3574001789093018, 10.13400650024414, -0.6120170950889587, -10.403095245361328, 4.600754261016846, 16.009349822998047, -7.78369140625, -4.194530487060547, -6.93686056137085, 1.1789555549621582, 11.490800857543945, 4.23802375793457, 9.550930976867676, 8.375045776367188, 7.508914470672607, -0.6570729613304138, -0.3005157709121704, 2.8406054973602295, 3.0828027725219727, 0.7308170199394226, 6.1483540534973145, 0.1376611888408661, -13.424735069274902, -7.746140480041504, -2.322798252105713, -8.305252075195312, 2.98791241645813, -10.99522876739502, 0.15211068093776703, -2.3820347785949707, -1.7984174489974976, 8.49562931060791, -5.852236747741699, -3.755497932434082, 0.6989710927009583, -5.270299434661865, -2.6188621520996094, -1.8828465938568115, -4.6466498374938965, 14.078543663024902, -0.5495333075523376, 10.579157829284668, -3.216050148010254, 9.349003791809082, -4.381077766418457, -11.675816535949707, -2.863020658493042, 4.5721755027771, 2.246612071990967, -4.574341773986816, 1.8610187768936157, 2.3767874240875244, 5.625787734985352, -9.784077644348145, 0.6496725678443909, -1.457950472831726, 0.4263263940811157, -4.921126365661621, -2.4547839164733887, 3.4869801998138428, -0.4265422224998474, 8.341268539428711, 1.356552004814148, 7.096688270568848, -13.102828979492188, 8.01673412322998, -7.115934371948242, 1.8699780702590942, 0.20872099697589874, 14.699383735656738, -1.0252779722213745, -2.6107232570648193, -2.5082311630249023, 8.427192687988281, 6.913852691650391, -6.29124641418457, 0.6157366037368774, 2.489687919616699, -3.4668266773223877, 9.92176342010498, 11.200815200805664, -0.19664029777050018, 7.491600513458252, -0.6231271624565125, -0.2584814429283142, -9.947997093200684, -0.9611040949821472, 1.1649218797683716, -2.1907122135162354, -1.502848744392395, -0.5192610621452332, 15.165953636169434, 2.4649462699890137, -0.998044490814209, 7.44166374206543, -2.0768048763275146, 3.5896823406219482, -7.305543422698975, -7.562084674835205, 4.32333517074585, 0.08044180274009705, -6.564010143280029, -2.314805269241333, -1.7642345428466797, -2.470881700515747, -7.6756181716918945, -9.548877716064453, -1.017755389213562, 0.1698644608259201, 2.5877134799957275, -1.8752295970916748, -0.36614322662353516, -6.049378395080566, -2.3965611457824707, -5.945338726043701, 0.9424033164978027, -13.155974388122559, -7.45780086517334, 0.14658108353614807, -3.7427968978881836, 5.841492652893066, -1.2872905731201172, 5.569431304931641, 12.570590019226074, 1.0939218997955322, 2.2142086029052734, 1.9181575775146484, 6.991420745849609, -5.888138771057129, 3.1409823894500732, -2.0036280155181885, 2.4434285163879395, 9.973138809204102, 5.036680221557617, 2.005120277404785, 2.861560344696045, 5.860223770141602, 2.917618751525879, -1.63111412525177, 2.0292205810546875, -4.070415019989014, -6.831437110900879]}}
+ [2022-05-25 12:25:36,324] [ INFO] - Response time 0.159053 s.
+ ```
+
+* Python API
+
+ ``` python
+ from paddlespeech.server.bin.paddlespeech_client import VectorClientExecutor
+
+ vectorclient_executor = VectorClientExecutor()
+ res = vectorclient_executor(
+ input="85236145389.wav",
+ server_ip="127.0.0.1",
+ port=8090,
+ task="spk")
+ print(res)
+ ```
+
+ 输出:
+
+ ``` bash
+ {'success': True, 'code': 200, 'message': {'description': 'success'}, 'result': {'vec': [-1.3251205682754517, 7.860682487487793, -4.620625972747803, 0.3000721037387848, 2.2648534774780273, -1.1931440830230713, 3.064713716506958, 7.673594951629639, -6.004472732543945, -12.024259567260742, -1.9496068954467773, 3.126953601837158, 1.6188379526138306, -7.638310432434082, -1.2299772500991821, -12.33833122253418, 2.1373026371002197, -5.395712375640869, 9.717328071594238, 5.675230503082275, 3.7805123329162598, 3.0597171783447266, 3.429692029953003, 8.9760103225708, 13.174124717712402, -0.5313228368759155, 8.942471504211426, 4.465109825134277, -4.426247596740723, -9.726503372192383, 8.399328231811523, 7.223917484283447, -7.435853958129883, 2.9441683292388916, -4.343039512634277, -13.886964797973633, -1.6346734762191772, -10.902740478515625, -5.311244964599609, 3.800722122192383, 3.897603750228882, -2.123077392578125, -2.3521194458007812, 4.151031017303467, -7.404866695404053, 0.13911646604537964, 2.4626107215881348, 4.96645450592041, 0.9897574186325073, 5.483975410461426, -3.3574001789093018, 10.13400650024414, -0.6120170950889587, -10.403095245361328, 4.600754261016846, 16.009349822998047, -7.78369140625, -4.194530487060547, -6.93686056137085, 1.1789555549621582, 11.490800857543945, 4.23802375793457, 9.550930976867676, 8.375045776367188, 7.508914470672607, -0.6570729613304138, -0.3005157709121704, 2.8406054973602295, 3.0828027725219727, 0.7308170199394226, 6.1483540534973145, 0.1376611888408661, -13.424735069274902, -7.746140480041504, -2.322798252105713, -8.305252075195312, 2.98791241645813, -10.99522876739502, 0.15211068093776703, -2.3820347785949707, -1.7984174489974976, 8.49562931060791, -5.852236747741699, -3.755497932434082, 0.6989710927009583, -5.270299434661865, -2.6188621520996094, -1.8828465938568115, -4.6466498374938965, 14.078543663024902, -0.5495333075523376, 10.579157829284668, -3.216050148010254, 9.349003791809082, -4.381077766418457, -11.675816535949707, -2.863020658493042, 4.5721755027771, 2.246612071990967, -4.574341773986816, 1.8610187768936157, 2.3767874240875244, 5.625787734985352, -9.784077644348145, 0.6496725678443909, -1.457950472831726, 0.4263263940811157, -4.921126365661621, -2.4547839164733887, 3.4869801998138428, -0.4265422224998474, 8.341268539428711, 1.356552004814148, 7.096688270568848, -13.102828979492188, 8.01673412322998, -7.115934371948242, 1.8699780702590942, 0.20872099697589874, 14.699383735656738, -1.0252779722213745, -2.6107232570648193, -2.5082311630249023, 8.427192687988281, 6.913852691650391, -6.29124641418457, 0.6157366037368774, 2.489687919616699, -3.4668266773223877, 9.92176342010498, 11.200815200805664, -0.19664029777050018, 7.491600513458252, -0.6231271624565125, -0.2584814429283142, -9.947997093200684, -0.9611040949821472, 1.1649218797683716, -2.1907122135162354, -1.502848744392395, -0.5192610621452332, 15.165953636169434, 2.4649462699890137, -0.998044490814209, 7.44166374206543, -2.0768048763275146, 3.5896823406219482, -7.305543422698975, -7.562084674835205, 4.32333517074585, 0.08044180274009705, -6.564010143280029, -2.314805269241333, -1.7642345428466797, -2.470881700515747, -7.6756181716918945, -9.548877716064453, -1.017755389213562, 0.1698644608259201, 2.5877134799957275, -1.8752295970916748, -0.36614322662353516, -6.049378395080566, -2.3965611457824707, -5.945338726043701, 0.9424033164978027, -13.155974388122559, -7.45780086517334, 0.14658108353614807, -3.7427968978881836, 5.841492652893066, -1.2872905731201172, 5.569431304931641, 12.570590019226074, 1.0939218997955322, 2.2142086029052734, 1.9181575775146484, 6.991420745849609, -5.888138771057129, 3.1409823894500732, -2.0036280155181885, 2.4434285163879395, 9.973138809204102, 5.036680221557617, 2.005120277404785, 2.861560344696045, 5.860223770141602, 2.917618751525879, -1.63111412525177, 2.0292205810546875, -4.070415019989014, -6.831437110900879]}}
+ ```
+
+#### 7.2 音频声纹打分
+
+注意: 初次使用客户端时响应时间会略长
+* 命令行 (推荐使用)
+
+ 若 `127.0.0.1` 不能访问,则需要使用实际服务 IP 地址
+
+ ``` bash
+ paddlespeech_client vector --task score --server_ip 127.0.0.1 --port 8090 --enroll 85236145389.wav --test 123456789.wav
+ ```
+
+ 使用帮助:
+
+ ``` bash
+ paddlespeech_client vector --help
+ ```
+
+ 参数:
+ * server_ip: 服务端ip地址,默认: 127.0.0.1。
+ * port: 服务端口,默认: 8090。
+ * input(必须输入): 用于识别的音频文件。
+ * task: vector 的任务,可选spk或者score。默认是 spk。
+ * enroll: 注册音频;。
+ * test: 测试音频。
+
+ 输出:
+
+ ``` bash
+ [2022-05-25 12:33:24,527] [ INFO] - vector score http client start
+ [2022-05-25 12:33:24,527] [ INFO] - enroll audio: 85236145389.wav, test audio: 123456789.wav
+ [2022-05-25 12:33:24,528] [ INFO] - endpoint: http://127.0.0.1:8790/paddlespeech/vector/score
+ [2022-05-25 12:33:24,695] [ INFO] - The vector score is: {'success': True, 'code': 200, 'message': {'description': 'success'}, 'result': {'score': 0.45332613587379456}}
+ [2022-05-25 12:33:24,696] [ INFO] - The vector: {'success': True, 'code': 200, 'message': {'description': 'success'}, 'result': {'score': 0.45332613587379456}}
+ [2022-05-25 12:33:24,696] [ INFO] - Response time 0.168271 s.
+ ```
+
+* Python API
+
+ ``` python
+ from paddlespeech.server.bin.paddlespeech_client import VectorClientExecutor
+
+ vectorclient_executor = VectorClientExecutor()
+ res = vectorclient_executor(
+ input=None,
+ enroll_audio="85236145389.wav",
+ test_audio="123456789.wav",
+ server_ip="127.0.0.1",
+ port=8090,
+ task="score")
+ print(res)
+ ```
+
+ 输出:
+
+ ``` bash
+ [2022-05-25 12:30:14,143] [ INFO] - vector score http client start
+ [2022-05-25 12:30:14,143] [ INFO] - enroll audio: 85236145389.wav, test audio: 123456789.wav
+ [2022-05-25 12:30:14,143] [ INFO] - endpoint: http://127.0.0.1:8790/paddlespeech/vector/score
+ [2022-05-25 12:30:14,363] [ INFO] - The vector score is: {'success': True, 'code': 200, 'message': {'description': 'success'}, 'result': {'score': 0.45332613587379456}}
+ {'success': True, 'code': 200, 'message': {'description': 'success'}, 'result': {'score': 0.45332613587379456}}
+ ```
+
+
+### 8. 标点预测
+
+ **注意:** 初次使用客户端时响应时间会略长
+- 命令行 (推荐使用)
+
+ 若 `127.0.0.1` 不能访问,则需要使用实际服务 IP 地址
+
+ ``` bash
+ paddlespeech_client text --server_ip 127.0.0.1 --port 8090 --input "我认为跑步最重要的就是给我带来了身体健康"
+ ```
+
+ 使用帮助:
+
+ ```bash
+ paddlespeech_client text --help
+ ```
+ 参数:
+ - `server_ip`: 服务端ip地址,默认: 127.0.0.1。
+ - `port`: 服务端口,默认: 8090。
+ - `input`(必须输入): 用于标点预测的文本内容。
+
+ 输出:
+ ```bash
+ [2022-05-09 18:19:04,397] [ INFO] - The punc text: 我认为跑步最重要的就是给我带来了身体健康。
+ [2022-05-09 18:19:04,397] [ INFO] - Response time 0.092407 s.
+ ```
+
+- Python API
+ ```python
+ from paddlespeech.server.bin.paddlespeech_client import TextClientExecutor
+
+ textclient_executor = TextClientExecutor()
+ res = textclient_executor(
+ input="我认为跑步最重要的就是给我带来了身体健康",
+ server_ip="127.0.0.1",
+ port=8090,)
+ print(res)
+
+ ```
+
+ 输出:
+ ```bash
+ 我认为跑步最重要的就是给我带来了身体健康。
+ ```
## 服务支持的模型
-### ASR支持的模型
-通过 `paddlespeech_server stats --task asr` 获取ASR服务支持的所有模型,其中静态模型可用于 paddle inference 推理。
+### ASR 支持的模型
+通过 `paddlespeech_server stats --task asr` 获取 ASR 服务支持的所有模型,其中静态模型可用于 paddle inference 推理。
+
+### TTS 支持的模型
+通过 `paddlespeech_server stats --task tts` 获取 TTS 服务支持的所有模型,其中静态模型可用于 paddle inference 推理。
+
+### CLS 支持的模型
+通过 `paddlespeech_server stats --task cls` 获取 CLS 服务支持的所有模型,其中静态模型可用于 paddle inference 推理。
-### TTS支持的模型
-通过 `paddlespeech_server stats --task tts` 获取TTS服务支持的所有模型,其中静态模型可用于 paddle inference 推理。
+### Vector 支持的模型
+通过 `paddlespeech_server stats --task vector` 获取 Vector 服务支持的所有模型。
-### CLS支持的模型
-通过 `paddlespeech_server stats --task cls` 获取CLS服务支持的所有模型,其中静态模型可用于 paddle inference 推理。
+### Text支持的模型
+通过 `paddlespeech_server stats --task text` 获取 Text 服务支持的所有模型。
diff --git a/demos/speech_server/asr_client.sh b/demos/speech_server/asr_client.sh
index afe2f8218..37a7ab0b0 100644
--- a/demos/speech_server/asr_client.sh
+++ b/demos/speech_server/asr_client.sh
@@ -1,4 +1,6 @@
#!/bin/bash
wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespeech.bj.bcebos.com/PaddleAudio/en.wav
+
+# If `127.0.0.1` is not accessible, you need to use the actual service IP address.
paddlespeech_client asr --server_ip 127.0.0.1 --port 8090 --input ./zh.wav
diff --git a/demos/speech_server/cls_client.sh b/demos/speech_server/cls_client.sh
index 5797aa204..67012648c 100644
--- a/demos/speech_server/cls_client.sh
+++ b/demos/speech_server/cls_client.sh
@@ -1,4 +1,6 @@
#!/bin/bash
wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespeech.bj.bcebos.com/PaddleAudio/en.wav
+
+# If `127.0.0.1` is not accessible, you need to use the actual service IP address.
paddlespeech_client cls --server_ip 127.0.0.1 --port 8090 --input ./zh.wav --topk 1
diff --git a/demos/speech_server/conf/application.yaml b/demos/speech_server/conf/application.yaml
index 2b1a05998..c6588ce80 100644
--- a/demos/speech_server/conf/application.yaml
+++ b/demos/speech_server/conf/application.yaml
@@ -1,15 +1,15 @@
-# This is the parameter configuration file for PaddleSpeech Serving.
+# This is the parameter configuration file for PaddleSpeech Offline Serving.
#################################################################################
# SERVER SETTING #
#################################################################################
-host: 127.0.0.1
+host: 0.0.0.0
port: 8090
# The task format in the engin_list is: _
-# task choices = ['asr_python', 'asr_inference', 'tts_python', 'tts_inference']
-
-engine_list: ['asr_python', 'tts_python', 'cls_python']
+# task choices = ['asr_python', 'asr_inference', 'tts_python', 'tts_inference', 'cls_python', 'cls_inference']
+protocol: 'http'
+engine_list: ['asr_python', 'tts_python', 'cls_python', 'text_python', 'vector_python']
#################################################################################
@@ -135,3 +135,26 @@ cls_inference:
glog_info: False # True -> print glog
summary: True # False -> do not show predictor config
+
+################################### Text #########################################
+################### text task: punc; engine_type: python #######################
+text_python:
+ task: punc
+ model_type: 'ernie_linear_p3_wudao'
+ lang: 'zh'
+ sample_rate: 16000
+ cfg_path: # [optional]
+ ckpt_path: # [optional]
+ vocab_file: # [optional]
+ device: # set 'gpu:id' or 'cpu'
+
+
+################################### Vector ######################################
+################### Vector task: spk; engine_type: python #######################
+vector_python:
+ task: spk
+ model_type: 'ecapatdnn_voxceleb12'
+ sample_rate: 16000
+ cfg_path: # [optional]
+ ckpt_path: # [optional]
+ device: # set 'gpu:id' or 'cpu'
diff --git a/demos/speech_server/start_multi_progress_server.py b/demos/speech_server/start_multi_progress_server.py
new file mode 100644
index 000000000..5e86befb7
--- /dev/null
+++ b/demos/speech_server/start_multi_progress_server.py
@@ -0,0 +1,70 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+import warnings
+
+import uvicorn
+from fastapi import FastAPI
+from starlette.middleware.cors import CORSMiddleware
+
+from paddlespeech.server.engine.engine_pool import init_engine_pool
+from paddlespeech.server.restful.api import setup_router as setup_http_router
+from paddlespeech.server.utils.config import get_config
+from paddlespeech.server.ws.api import setup_router as setup_ws_router
+warnings.filterwarnings("ignore")
+import sys
+
+app = FastAPI(
+ title="PaddleSpeech Serving API", description="Api", version="0.0.1")
+app.add_middleware(
+ CORSMiddleware,
+ allow_origins=["*"],
+ allow_credentials=True,
+ allow_methods=["*"],
+ allow_headers=["*"])
+
+# change yaml file here
+config_file = "./conf/application.yaml"
+config = get_config(config_file)
+
+# init engine
+if not init_engine_pool(config):
+ print("Failed to init engine.")
+ sys.exit(-1)
+
+# get api_router
+api_list = list(engine.split("_")[0] for engine in config.engine_list)
+if config.protocol == "websocket":
+ api_router = setup_ws_router(api_list)
+elif config.protocol == "http":
+ api_router = setup_http_router(api_list)
+else:
+ raise Exception("unsupported protocol")
+ sys.exit(-1)
+
+# app needs to operate outside the main function
+app.include_router(api_router)
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(add_help=True)
+ parser.add_argument(
+ "--workers", type=int, help="workers of server", default=1)
+ args = parser.parse_args()
+
+ uvicorn.run(
+ "start_multi_progress_server:app",
+ host=config.host,
+ port=config.port,
+ debug=True,
+ workers=args.workers)
diff --git a/demos/speech_server/tts_client.sh b/demos/speech_server/tts_client.sh
index a756dfd3e..a443a0a94 100644
--- a/demos/speech_server/tts_client.sh
+++ b/demos/speech_server/tts_client.sh
@@ -1,3 +1,4 @@
#!/bin/bash
+# If `127.0.0.1` is not accessible, you need to use the actual service IP address.
paddlespeech_client tts --server_ip 127.0.0.1 --port 8090 --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
diff --git a/demos/speech_translation/README.md b/demos/speech_translation/README.md
index f675a4eda..00a9c7932 100644
--- a/demos/speech_translation/README.md
+++ b/demos/speech_translation/README.md
@@ -47,7 +47,7 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespee
- Python API
```python
import paddle
- from paddlespeech.cli import STExecutor
+ from paddlespeech.cli.st import STExecutor
st_executor = STExecutor()
text = st_executor(
diff --git a/demos/speech_translation/README_cn.md b/demos/speech_translation/README_cn.md
index bad9b392f..5119bf9f4 100644
--- a/demos/speech_translation/README_cn.md
+++ b/demos/speech_translation/README_cn.md
@@ -47,7 +47,7 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav https://paddlespee
- Python API
```python
import paddle
- from paddlespeech.cli import STExecutor
+ from paddlespeech.cli.st import STExecutor
st_executor = STExecutor()
text = st_executor(
diff --git a/demos/streaming_asr_server/.gitignore b/demos/streaming_asr_server/.gitignore
new file mode 100644
index 000000000..0f09019de
--- /dev/null
+++ b/demos/streaming_asr_server/.gitignore
@@ -0,0 +1,2 @@
+exp
+
diff --git a/demos/streaming_asr_server/README.md b/demos/streaming_asr_server/README.md
index 6a2f21aa4..a770f58c3 100644
--- a/demos/streaming_asr_server/README.md
+++ b/demos/streaming_asr_server/README.md
@@ -1,10 +1,11 @@
([简体中文](./README_cn.md)|English)
-# Speech Server
+# Streaming ASR Server
## Introduction
This demo is an implementation of starting the streaming speech service and accessing the service. It can be achieved with a single command using `paddlespeech_server` and `paddlespeech_client` or a few lines of code in python.
+Streaming ASR server only support `websocket` protocol, and doesn't support `http` protocol.
## Usage
### 1. Installation
@@ -14,7 +15,7 @@ It is recommended to use **paddlepaddle 2.2.1** or above.
You can choose one way from meduim and hard to install paddlespeech.
### 2. Prepare config File
-The configuration file can be found in `conf/ws_application.yaml` 和 `conf/ws_conformer_application.yaml`.
+The configuration file can be found in `conf/ws_application.yaml` 和 `conf/ws_conformer_wenetspeech_application.yaml`.
At present, the speech tasks integrated by the model include: DeepSpeech2 and conformer.
@@ -28,10 +29,12 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
### 3. Server Usage
- Command Line (Recommended)
-
+ **Note:** The default deployment of the server is on the 'CPU' device, which can be deployed on the 'GPU' by modifying the 'device' parameter in the service configuration file.
```bash
- # start the service
- paddlespeech_server start --config_file ./conf/ws_conformer_application.yaml
+ # in PaddleSpeech/demos/streaming_asr_server start the service
+ paddlespeech_server start --config_file ./conf/ws_conformer_wenetspeech_application.yaml
+ # if you want to increase decoding speed, you can use the config file below, it will increase decoding speed and reduce accuracy
+ paddlespeech_server start --config_file ./conf/ws_conformer_wenetspeech_application_faster.yaml
```
Usage:
@@ -45,151 +48,77 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
Output:
```bash
- [2022-04-21 15:52:18,126] [ INFO] - create the online asr engine instance
- [2022-04-21 15:52:18,127] [ INFO] - paddlespeech_server set the device: cpu
- [2022-04-21 15:52:18,128] [ INFO] - Load the pretrained model, tag = conformer_online_multicn-zh-16k
- [2022-04-21 15:52:18,128] [ INFO] - File /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k/asr1_chunk_conformer_multi_cn_ckpt_0.2.3.model.tar.gz md5 checking...
- [2022-04-21 15:52:18,727] [ INFO] - Use pretrained model stored in: /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k
- [2022-04-21 15:52:18,727] [ INFO] - /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k
- [2022-04-21 15:52:18,727] [ INFO] - /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k/model.yaml
- [2022-04-21 15:52:18,727] [ INFO] - /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k/exp/chunk_conformer/checkpoints/multi_cn.pdparams
- [2022-04-21 15:52:18,727] [ INFO] - /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k/exp/chunk_conformer/checkpoints/multi_cn.pdparams
- [2022-04-21 15:52:19,446] [ INFO] - start to create the stream conformer asr engine
- [2022-04-21 15:52:19,473] [ INFO] - model name: conformer_online
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- [2022-04-21 15:52:21,731] [ INFO] - create the transformer like model success
- [2022-04-21 15:52:21,733] [ INFO] - Initialize ASR server engine successfully.
- INFO: Started server process [11173]
- [2022-04-21 15:52:21] [INFO] [server.py:75] Started server process [11173]
- INFO: Waiting for application startup.
- [2022-04-21 15:52:21] [INFO] [on.py:45] Waiting for application startup.
- INFO: Application startup complete.
- [2022-04-21 15:52:21] [INFO] [on.py:59] Application startup complete.
- /home/users/xiongxinlei/.conda/envs/paddlespeech/lib/python3.9/asyncio/base_events.py:1460: DeprecationWarning: The loop argument is deprecated since Python 3.8, and scheduled for removal in Python 3.10.
- infos = await tasks.gather(*fs, loop=self)
- /home/users/xiongxinlei/.conda/envs/paddlespeech/lib/python3.9/asyncio/base_events.py:1518: DeprecationWarning: The loop argument is deprecated since Python 3.8, and scheduled for removal in Python 3.10.
- await tasks.sleep(0, loop=self)
- INFO: Uvicorn running on http://0.0.0.0:8090 (Press CTRL+C to quit)
- [2022-04-21 15:52:21] [INFO] [server.py:206] Uvicorn running on http://0.0.0.0:8090 (Press CTRL+C to quit)
+ [2022-05-14 04:56:13,086] [ INFO] - create the online asr engine instance
+ [2022-05-14 04:56:13,086] [ INFO] - paddlespeech_server set the device: cpu
+ [2022-05-14 04:56:13,087] [ INFO] - Load the pretrained model, tag = conformer_online_wenetspeech-zh-16k
+ [2022-05-14 04:56:13,087] [ INFO] - File /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar.gz md5 checking...
+ [2022-05-14 04:56:17,542] [ INFO] - Use pretrained model stored in: /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1. 0.0a.model.tar
+ [2022-05-14 04:56:17,543] [ INFO] - /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar
+ [2022-05-14 04:56:17,543] [ INFO] - /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar/model.yaml
+ [2022-05-14 04:56:17,543] [ INFO] - /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar/exp/ chunk_conformer/checkpoints/avg_10.pdparams
+ [2022-05-14 04:56:17,543] [ INFO] - /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar/exp/ chunk_conformer/checkpoints/avg_10.pdparams
+ [2022-05-14 04:56:17,852] [ INFO] - start to create the stream conformer asr engine
+ [2022-05-14 04:56:17,863] [ INFO] - model name: conformer_online
+ [2022-05-14 04:56:22,756] [ INFO] - create the transformer like model success
+ [2022-05-14 04:56:22,758] [ INFO] - Initialize ASR server engine successfully.
+ INFO: Started server process [4242]
+ [2022-05-14 04:56:22] [INFO] [server.py:75] Started server process [4242]
+ INFO: Waiting for application startup.
+ [2022-05-14 04:56:22] [INFO] [on.py:45] Waiting for application startup.
+ INFO: Application startup complete.
+ [2022-05-14 04:56:22] [INFO] [on.py:59] Application startup complete.
+ INFO: Uvicorn running on http://0.0.0.0:8090 (Press CTRL+C to quit)
+ [2022-05-14 04:56:22] [INFO] [server.py:211] Uvicorn running on http://0.0.0.0:8090 (Press CTRL+C to quit)
```
- Python API
+ **Note:** The default deployment of the server is on the 'CPU' device, which can be deployed on the 'GPU' by modifying the 'device' parameter in the service configuration file.
```python
+ # in PaddleSpeech/demos/streaming_asr_server directory
from paddlespeech.server.bin.paddlespeech_server import ServerExecutor
server_executor = ServerExecutor()
server_executor(
- config_file="./conf/ws_conformer_application.yaml",
+ config_file="./conf/ws_conformer_wenetspeech_application.yaml",
log_file="./log/paddlespeech.log")
```
Output:
```bash
- [2022-04-21 15:52:18,126] [ INFO] - create the online asr engine instance
- [2022-04-21 15:52:18,127] [ INFO] - paddlespeech_server set the device: cpu
- [2022-04-21 15:52:18,128] [ INFO] - Load the pretrained model, tag = conformer_online_multicn-zh-16k
- [2022-04-21 15:52:18,128] [ INFO] - File /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k/asr1_chunk_conformer_multi_cn_ckpt_0.2.3.model.tar.gz md5 checking...
- [2022-04-21 15:52:18,727] [ INFO] - Use pretrained model stored in: /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k
- [2022-04-21 15:52:18,727] [ INFO] - /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k
- [2022-04-21 15:52:18,727] [ INFO] - /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k/model.yaml
- [2022-04-21 15:52:18,727] [ INFO] - /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k/exp/chunk_conformer/checkpoints/multi_cn.pdparams
- [2022-04-21 15:52:18,727] [ INFO] - /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k/exp/chunk_conformer/checkpoints/multi_cn.pdparams
- [2022-04-21 15:52:19,446] [ INFO] - start to create the stream conformer asr engine
- [2022-04-21 15:52:19,473] [ INFO] - model name: conformer_online
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- [2022-04-21 15:52:21,731] [ INFO] - create the transformer like model success
- [2022-04-21 15:52:21,733] [ INFO] - Initialize ASR server engine successfully.
- INFO: Started server process [11173]
- [2022-04-21 15:52:21] [INFO] [server.py:75] Started server process [11173]
- INFO: Waiting for application startup.
- [2022-04-21 15:52:21] [INFO] [on.py:45] Waiting for application startup.
- INFO: Application startup complete.
- [2022-04-21 15:52:21] [INFO] [on.py:59] Application startup complete.
- /home/users/xiongxinlei/.conda/envs/paddlespeech/lib/python3.9/asyncio/base_events.py:1460: DeprecationWarning: The loop argument is deprecated since Python 3.8, and scheduled for removal in Python 3.10.
- infos = await tasks.gather(*fs, loop=self)
- /home/users/xiongxinlei/.conda/envs/paddlespeech/lib/python3.9/asyncio/base_events.py:1518: DeprecationWarning: The loop argument is deprecated since Python 3.8, and scheduled for removal in Python 3.10.
- await tasks.sleep(0, loop=self)
- INFO: Uvicorn running on http://0.0.0.0:8090 (Press CTRL+C to quit)
- [2022-04-21 15:52:21] [INFO] [server.py:206] Uvicorn running on http://0.0.0.0:8090 (Press CTRL+C to quit)
+ [2022-05-14 04:56:13,086] [ INFO] - create the online asr engine instance
+ [2022-05-14 04:56:13,086] [ INFO] - paddlespeech_server set the device: cpu
+ [2022-05-14 04:56:13,087] [ INFO] - Load the pretrained model, tag = conformer_online_wenetspeech-zh-16k
+ [2022-05-14 04:56:13,087] [ INFO] - File /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar.gz md5 checking...
+ [2022-05-14 04:56:17,542] [ INFO] - Use pretrained model stored in: /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1. 0.0a.model.tar
+ [2022-05-14 04:56:17,543] [ INFO] - /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar
+ [2022-05-14 04:56:17,543] [ INFO] - /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar/model.yaml
+ [2022-05-14 04:56:17,543] [ INFO] - /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar/exp/ chunk_conformer/checkpoints/avg_10.pdparams
+ [2022-05-14 04:56:17,543] [ INFO] - /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar/exp/ chunk_conformer/checkpoints/avg_10.pdparams
+ [2022-05-14 04:56:17,852] [ INFO] - start to create the stream conformer asr engine
+ [2022-05-14 04:56:17,863] [ INFO] - model name: conformer_online
+ [2022-05-14 04:56:22,756] [ INFO] - create the transformer like model success
+ [2022-05-14 04:56:22,758] [ INFO] - Initialize ASR server engine successfully.
+ INFO: Started server process [4242]
+ [2022-05-14 04:56:22] [INFO] [server.py:75] Started server process [4242]
+ INFO: Waiting for application startup.
+ [2022-05-14 04:56:22] [INFO] [on.py:45] Waiting for application startup.
+ INFO: Application startup complete.
+ [2022-05-14 04:56:22] [INFO] [on.py:59] Application startup complete.
+ INFO: Uvicorn running on http://0.0.0.0:8090 (Press CTRL+C to quit)
+ [2022-05-14 04:56:22] [INFO] [server.py:211] Uvicorn running on http://0.0.0.0:8090 (Press CTRL+C to quit)
```
### 4. ASR Client Usage
+
**Note:** The response time will be slightly longer when using the client for the first time
- Command Line (Recommended)
- ```
- paddlespeech_client asr_online --server_ip 127.0.0.1 --port 8090 --input ./zh.wav
- ```
+
+ If `127.0.0.1` is not accessible, you need to use the actual service IP address.
+
+ ```
+ paddlespeech_client asr_online --server_ip 127.0.0.1 --port 8090 --input ./zh.wav
+ ```
Usage:
@@ -203,81 +132,86 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
- `sample_rate`: Audio ampling rate, default: 16000.
- `lang`: Language. Default: "zh_cn".
- `audio_format`: Audio format. Default: "wav".
+ - `punc.server_ip`: punctuation server ip. Default: None.
+ - `punc.server_port`: punctuation server port. Default: None.
Output:
```bash
- [2022-04-21 15:59:03,904] [ INFO] - receive msg={"status": "ok", "signal": "server_ready"}
- [2022-04-21 15:59:03,960] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:03,973] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:03,987] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,000] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,012] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,024] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,036] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,047] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,607] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,620] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,633] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,645] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,657] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,669] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,680] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:05,176] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,185] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,192] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,200] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,208] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,216] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,224] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,232] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,724] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,732] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,740] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,747] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,755] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,763] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,770] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:06,271] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,279] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,287] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,294] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,302] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,310] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,318] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,326] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,833] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,842] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,850] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,858] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,866] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,874] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,882] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:07,400] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,408] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,416] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,424] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,432] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,440] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,447] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,455] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,984] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:07,992] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:08,001] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:08,008] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:08,016] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:08,024] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:12,883] [ INFO] - final receive msg={'status': 'ok', 'signal': 'finished', 'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:12,884] [ INFO] - 我认为跑步最重要的就是给我带来了身体健康
- [2022-04-21 15:59:12,884] [ INFO] - Response time 9.051567 s.
+ [2022-05-06 21:10:35,598] [ INFO] - Start to do streaming asr client
+ [2022-05-06 21:10:35,600] [ INFO] - asr websocket client start
+ [2022-05-06 21:10:35,600] [ INFO] - endpoint: ws://127.0.0.1:8390/paddlespeech/asr/streaming
+ [2022-05-06 21:10:35,600] [ INFO] - start to process the wavscp: ./zh.wav
+ [2022-05-06 21:10:35,670] [ INFO] - client receive msg={"status": "ok", "signal": "server_ready"}
+ [2022-05-06 21:10:35,699] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:35,713] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:35,726] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:35,738] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:35,750] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:35,762] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:35,774] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:35,786] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:36,387] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:36,398] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:36,407] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:36,416] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:36,425] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:36,434] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:36,442] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:36,930] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:10:36,938] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:10:36,946] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:10:36,954] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:10:36,962] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:10:36,970] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:10:36,977] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:10:36,985] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:10:37,484] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:10:37,492] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:10:37,500] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:10:37,508] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:10:37,517] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:10:37,525] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:10:37,532] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:10:38,050] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:10:38,058] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:10:38,066] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:10:38,073] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:10:38,081] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:10:38,089] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:10:38,097] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:10:38,105] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:10:38,630] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:10:38,639] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:10:38,647] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:10:38,655] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:10:38,663] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:10:38,671] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:10:38,679] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:10:39,216] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:10:39,224] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:10:39,232] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:10:39,240] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:10:39,248] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:10:39,256] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:10:39,264] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:10:39,272] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:10:39,885] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:10:39,896] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:10:39,905] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:10:39,915] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:10:39,924] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:10:39,934] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:10:44,827] [ INFO] - client final receive msg={'status': 'ok', 'signal': 'finished', 'result': '我认为跑步最重要的就是给我带来了身体健康', 'times': [{'w': '我', 'bg': 0.0, 'ed': 0.7000000000000001}, {'w': '认', 'bg': 0.7000000000000001, 'ed': 0.84}, {'w': '为', 'bg': 0.84, 'ed': 1.0}, {'w': '跑', 'bg': 1.0, 'ed': 1.18}, {'w': '步', 'bg': 1.18, 'ed': 1.36}, {'w': '最', 'bg': 1.36, 'ed': 1.5}, {'w': '重', 'bg': 1.5, 'ed': 1.6400000000000001}, {'w': '要', 'bg': 1.6400000000000001, 'ed': 1.78}, {'w': '的', 'bg': 1.78, 'ed': 1.9000000000000001}, {'w': '就', 'bg': 1.9000000000000001, 'ed': 2.06}, {'w': '是', 'bg': 2.06, 'ed': 2.62}, {'w': '给', 'bg': 2.62, 'ed': 3.16}, {'w': '我', 'bg': 3.16, 'ed': 3.3200000000000003}, {'w': '带', 'bg': 3.3200000000000003, 'ed': 3.48}, {'w': '来', 'bg': 3.48, 'ed': 3.62}, {'w': '了', 'bg': 3.62, 'ed': 3.7600000000000002}, {'w': '身', 'bg': 3.7600000000000002, 'ed': 3.9}, {'w': '体', 'bg': 3.9, 'ed': 4.0600000000000005}, {'w': '健', 'bg': 4.0600000000000005, 'ed': 4.26}, {'w': '康', 'bg': 4.26, 'ed': 4.96}]}
+ [2022-05-06 21:10:44,827] [ INFO] - audio duration: 4.9968125, elapsed time: 9.225094079971313, RTF=1.846195765794957
+ [2022-05-06 21:10:44,828] [ INFO] - asr websocket client finished : 我认为跑步最重要的就是给我带来了身体健康
```
- Python API
```python
- from paddlespeech.server.bin.paddlespeech_client import ASRClientExecutor
- import json
+ from paddlespeech.server.bin.paddlespeech_client import ASROnlineClientExecutor
- asrclient_executor = ASRClientExecutor()
+ asrclient_executor = ASROnlineClientExecutor()
res = asrclient_executor(
input="./zh.wav",
server_ip="127.0.0.1",
@@ -285,71 +219,359 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
sample_rate=16000,
lang="zh_cn",
audio_format="wav")
- print(res.json())
+ print(res)
```
Output:
```bash
- [2022-04-21 15:59:03,904] [ INFO] - receive msg={"status": "ok", "signal": "server_ready"}
- [2022-04-21 15:59:03,960] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:03,973] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:03,987] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,000] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,012] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,024] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,036] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,047] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,607] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,620] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,633] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,645] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,657] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,669] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,680] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:05,176] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,185] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,192] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,200] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,208] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,216] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,224] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,232] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,724] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,732] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,740] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,747] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,755] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,763] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,770] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:06,271] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,279] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,287] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,294] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,302] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,310] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,318] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,326] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,833] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,842] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,850] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,858] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,866] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,874] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,882] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:07,400] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,408] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,416] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,424] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,432] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,440] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,447] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,455] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,984] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:07,992] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:08,001] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:08,008] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:08,016] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:08,024] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:12,883] [ INFO] - final receive msg={'status': 'ok', 'signal': 'finished', 'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:12,884] [ INFO] - 我认为跑步最重要的就是给我带来了身体健康
+ [2022-05-06 21:14:03,137] [ INFO] - asr websocket client start
+ [2022-05-06 21:14:03,137] [ INFO] - endpoint: ws://127.0.0.1:8390/paddlespeech/asr/streaming
+ [2022-05-06 21:14:03,149] [ INFO] - client receive msg={"status": "ok", "signal": "server_ready"}
+ [2022-05-06 21:14:03,167] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,181] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,194] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,207] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,219] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,230] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,241] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,252] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,768] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,776] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,784] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,792] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,800] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,807] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,815] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:04,301] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:14:04,309] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:14:04,317] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:14:04,325] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:14:04,333] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:14:04,341] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:14:04,349] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:14:04,356] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:14:04,855] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:14:04,864] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:14:04,871] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:14:04,879] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:14:04,887] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:14:04,894] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:14:04,902] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:14:05,418] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:14:05,426] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:14:05,434] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:14:05,442] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:14:05,449] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:14:05,457] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:14:05,465] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:14:05,473] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:14:05,996] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:14:06,006] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:14:06,013] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:14:06,021] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:14:06,029] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:14:06,037] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:14:06,045] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:14:06,581] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:14:06,589] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:14:06,597] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:14:06,605] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:14:06,613] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:14:06,621] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:14:06,628] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:14:06,636] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:14:07,188] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:14:07,196] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:14:07,203] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:14:07,211] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:14:07,219] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:14:07,226] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:14:12,158] [ INFO] - client final receive msg={'status': 'ok', 'signal': 'finished', 'result': '我认为跑步最重要的就是给我带来了身体健康', 'times': [{'w': '我', 'bg': 0.0, 'ed': 0.7000000000000001}, {'w': '认', 'bg': 0.7000000000000001, 'ed': 0.84}, {'w': '为', 'bg': 0.84, 'ed': 1.0}, {'w': '跑', 'bg': 1.0, 'ed': 1.18}, {'w': '步', 'bg': 1.18, 'ed': 1.36}, {'w': '最', 'bg': 1.36, 'ed': 1.5}, {'w': '重', 'bg': 1.5, 'ed': 1.6400000000000001}, {'w': '要', 'bg': 1.6400000000000001, 'ed': 1.78}, {'w': '的', 'bg': 1.78, 'ed': 1.9000000000000001}, {'w': '就', 'bg': 1.9000000000000001, 'ed': 2.06}, {'w': '是', 'bg': 2.06, 'ed': 2.62}, {'w': '给', 'bg': 2.62, 'ed': 3.16}, {'w': '我', 'bg': 3.16, 'ed': 3.3200000000000003}, {'w': '带', 'bg': 3.3200000000000003, 'ed': 3.48}, {'w': '来', 'bg': 3.48, 'ed': 3.62}, {'w': '了', 'bg': 3.62, 'ed': 3.7600000000000002}, {'w': '身', 'bg': 3.7600000000000002, 'ed': 3.9}, {'w': '体', 'bg': 3.9, 'ed': 4.0600000000000005}, {'w': '健', 'bg': 4.0600000000000005, 'ed': 4.26}, {'w': '康', 'bg': 4.26, 'ed': 4.96}]}
+ [2022-05-06 21:14:12,159] [ INFO] - audio duration: 4.9968125, elapsed time: 9.019973039627075, RTF=1.8051453881103354
+ [2022-05-06 21:14:12,160] [ INFO] - asr websocket client finished
+ ```
+
+
+## Punctuation service
+
+### 1. Server usage
+
+- Command Line
+ **Note:** The default deployment of the server is on the 'CPU' device, which can be deployed on the 'GPU' by modifying the 'device' parameter in the service configuration file.
+ ``` bash
+ In PaddleSpeech/demos/streaming_asr_server directory to lanuch punctuation service
+ paddlespeech_server start --config_file conf/punc_application.yaml
+ ```
+
+
+ Usage:
+ ```bash
+ paddlespeech_server start --help
+ ```
+
+ Arguments:
+ - `config_file`: configuration file.
+ - `log_file`: log file.
+
+
+ Output:
+ ``` bash
+ [2022-05-02 17:59:26,285] [ INFO] - Create the TextEngine Instance
+ [2022-05-02 17:59:26,285] [ INFO] - Init the text engine
+ [2022-05-02 17:59:26,285] [ INFO] - Text Engine set the device: gpu:0
+ [2022-05-02 17:59:26,286] [ INFO] - File /home/users/xiongxinlei/.paddlespeech/models/ernie_linear_p3_wudao-punc-zh/ernie_linear_p3_wudao-punc-zh.tar.gz md5 checking...
+ [2022-05-02 17:59:30,810] [ INFO] - Use pretrained model stored in: /home/users/xiongxinlei/.paddlespeech/models/ernie_linear_p3_wudao-punc-zh/ernie_linear_p3_wudao-punc-zh.tar
+ W0502 17:59:31.486552 9595 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 6.1, Driver API Version: 10.2, Runtime API Version: 10.2
+ W0502 17:59:31.491360 9595 device_context.cc:465] device: 0, cuDNN Version: 7.6.
+ [2022-05-02 17:59:34,688] [ INFO] - Already cached /home/users/xiongxinlei/.paddlenlp/models/ernie-1.0/vocab.txt
+ [2022-05-02 17:59:34,701] [ INFO] - Init the text engine successfully
+ INFO: Started server process [9595]
+ [2022-05-02 17:59:34] [INFO] [server.py:75] Started server process [9595]
+ INFO: Waiting for application startup.
+ [2022-05-02 17:59:34] [INFO] [on.py:45] Waiting for application startup.
+ INFO: Application startup complete.
+ [2022-05-02 17:59:34] [INFO] [on.py:59] Application startup complete.
+ INFO: Uvicorn running on http://0.0.0.0:8190 (Press CTRL+C to quit)
+ [2022-05-02 17:59:34] [INFO] [server.py:206] Uvicorn running on http://0.0.0.0:8190 (Press CTRL+C to quit)
+ ```
+
+- Python API
+ **Note:** The default deployment of the server is on the 'CPU' device, which can be deployed on the 'GPU' by modifying the 'device' parameter in the service configuration file.
+ ```python
+ # 在 PaddleSpeech/demos/streaming_asr_server 目录
+ from paddlespeech.server.bin.paddlespeech_server import ServerExecutor
+
+ server_executor = ServerExecutor()
+ server_executor(
+ config_file="./conf/punc_application.yaml",
+ log_file="./log/paddlespeech.log")
+ ```
+
+ Output:
+ ```
+ [2022-05-02 18:09:02,542] [ INFO] - Create the TextEngine Instance
+ [2022-05-02 18:09:02,543] [ INFO] - Init the text engine
+ [2022-05-02 18:09:02,543] [ INFO] - Text Engine set the device: gpu:0
+ [2022-05-02 18:09:02,545] [ INFO] - File /home/users/xiongxinlei/.paddlespeech/models/ernie_linear_p3_wudao-punc-zh/ernie_linear_p3_wudao-punc-zh.tar.gz md5 checking...
+ [2022-05-02 18:09:06,919] [ INFO] - Use pretrained model stored in: /home/users/xiongxinlei/.paddlespeech/models/ernie_linear_p3_wudao-punc-zh/ernie_linear_p3_wudao-punc-zh.tar
+ W0502 18:09:07.523002 22615 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 6.1, Driver API Version: 10.2, Runtime API Version: 10.2
+ W0502 18:09:07.527882 22615 device_context.cc:465] device: 0, cuDNN Version: 7.6.
+ [2022-05-02 18:09:10,900] [ INFO] - Already cached /home/users/xiongxinlei/.paddlenlp/models/ernie-1.0/vocab.txt
+ [2022-05-02 18:09:10,913] [ INFO] - Init the text engine successfully
+ INFO: Started server process [22615]
+ [2022-05-02 18:09:10] [INFO] [server.py:75] Started server process [22615]
+ INFO: Waiting for application startup.
+ [2022-05-02 18:09:10] [INFO] [on.py:45] Waiting for application startup.
+ INFO: Application startup complete.
+ [2022-05-02 18:09:10] [INFO] [on.py:59] Application startup complete.
+ INFO: Uvicorn running on http://0.0.0.0:8190 (Press CTRL+C to quit)
+ [2022-05-02 18:09:10] [INFO] [server.py:206] Uvicorn running on http://0.0.0.0:8190 (Press CTRL+C to quit)
+ ```
+
+### 2. Client usage
+**Note** The response time will be slightly longer when using the client for the first time
+
+- Command line:
+
+ If `127.0.0.1` is not accessible, you need to use the actual service IP address.
+
+ ```
+ paddlespeech_client text --server_ip 127.0.0.1 --port 8190 --input "我认为跑步最重要的就是给我带来了身体健康"
+ ```
+
+ Output
+ ```
+ [2022-05-02 18:12:29,767] [ INFO] - The punc text: 我认为跑步最重要的就是给我带来了身体健康。
+ [2022-05-02 18:12:29,767] [ INFO] - Response time 0.096548 s.
+ ```
+
+- Python3 API
+
+ ```python
+ from paddlespeech.server.bin.paddlespeech_client import TextClientExecutor
+
+ textclient_executor = TextClientExecutor()
+ res = textclient_executor(
+ input="我认为跑步最重要的就是给我带来了身体健康",
+ server_ip="127.0.0.1",
+ port=8190,)
+ print(res)
+ ```
+
+ Output:
+ ``` bash
+ 我认为跑步最重要的就是给我带来了身体健康。
+ ```
+
+
+## Join streaming asr and punctuation server
+
+By default, each server is deployed on the 'CPU' device and speech recognition and punctuation prediction can be deployed on different 'GPU' by modifying the' device 'parameter in the service configuration file respectively.
+
+We use `streaming_ asr_server.py` and `punc_server.py` two services to lanuch streaming speech recognition and punctuation prediction services respectively. And the `websocket_client.py` script can be used to call streaming speech recognition and punctuation prediction services at the same time.
+
+### 1. Start two server
+
+``` bash
+Note: streaming speech recognition and punctuation prediction are configured on different graphics cards through configuration files
+bash server.sh
+```
+
+### 2. Call client
+- Command line
+
+ If `127.0.0.1` is not accessible, you need to use the actual service IP address.
+
+ ```
+ paddlespeech_client asr_online --server_ip 127.0.0.1 --port 8290 --punc.server_ip 127.0.0.1 --punc.port 8190 --input ./zh.wav
+ ```
+ Output:
+ ```
+ [2022-05-07 11:21:47,060] [ INFO] - asr websocket client start
+ [2022-05-07 11:21:47,060] [ INFO] - endpoint: ws://127.0.0.1:8490/paddlespeech/asr/streaming
+ [2022-05-07 11:21:47,080] [ INFO] - client receive msg={"status": "ok", "signal": "server_ready"}
+ [2022-05-07 11:21:47,096] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,108] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,120] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,131] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,142] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,152] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,163] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,173] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,705] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,713] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,721] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,728] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,736] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,743] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,751] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:48,459] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:21:48,572] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:21:48,681] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:21:48,790] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:21:48,898] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:21:49,005] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:21:49,112] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:21:49,219] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:21:49,935] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:21:50,062] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:21:50,186] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:21:50,310] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:21:50,435] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:21:50,560] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:21:50,686] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:21:51,444] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:21:51,606] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:21:51,744] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:21:51,882] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:21:52,020] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:21:52,159] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:21:52,298] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:21:52,437] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:21:53,298] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:21:53,450] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:21:53,589] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:21:53,728] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:21:53,867] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:21:54,007] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:21:54,146] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:21:55,002] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:21:55,148] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:21:55,292] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:21:55,437] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:21:55,584] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:21:55,731] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:21:55,877] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:21:56,021] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:21:56,842] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:21:57,013] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:21:57,174] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:21:57,336] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:21:57,497] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:21:57,659] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:22:03,035] [ INFO] - client final receive msg={'status': 'ok', 'signal': 'finished', 'result': '我认为跑步最重要的就是给我带来了身体健康。', 'times': [{'w': '我', 'bg': 0.0, 'ed': 0.7000000000000001}, {'w': '认', 'bg': 0.7000000000000001, 'ed': 0.84}, {'w': '为', 'bg': 0.84, 'ed': 1.0}, {'w': '跑', 'bg': 1.0, 'ed': 1.18}, {'w': '步', 'bg': 1.18, 'ed': 1.36}, {'w': '最', 'bg': 1.36, 'ed': 1.5}, {'w': '重', 'bg': 1.5, 'ed': 1.6400000000000001}, {'w': '要', 'bg': 1.6400000000000001, 'ed': 1.78}, {'w': '的', 'bg': 1.78, 'ed': 1.9000000000000001}, {'w': '就', 'bg': 1.9000000000000001, 'ed': 2.06}, {'w': '是', 'bg': 2.06, 'ed': 2.62}, {'w': '给', 'bg': 2.62, 'ed': 3.16}, {'w': '我', 'bg': 3.16, 'ed': 3.3200000000000003}, {'w': '带', 'bg': 3.3200000000000003, 'ed': 3.48}, {'w': '来', 'bg': 3.48, 'ed': 3.62}, {'w': '了', 'bg': 3.62, 'ed': 3.7600000000000002}, {'w': '身', 'bg': 3.7600000000000002, 'ed': 3.9}, {'w': '体', 'bg': 3.9, 'ed': 4.0600000000000005}, {'w': '健', 'bg': 4.0600000000000005, 'ed': 4.26}, {'w': '康', 'bg': 4.26, 'ed': 4.96}]}
+ [2022-05-07 11:22:03,035] [ INFO] - audio duration: 4.9968125, elapsed time: 15.974023818969727, RTF=3.1968427510477384
+ [2022-05-07 11:22:03,037] [ INFO] - asr websocket client finished
+ [2022-05-07 11:22:03,037] [ INFO] - 我认为跑步最重要的就是给我带来了身体健康。
+ [2022-05-07 11:22:03,037] [ INFO] - Response time 15.977116 s.
```
+
+- Use script
+
+ If `127.0.0.1` is not accessible, you need to use the actual service IP address.
+
+ ```
+ python3 websocket_client.py --server_ip 127.0.0.1 --port 8290 --punc.server_ip 127.0.0.1 --punc.port 8190 --wavfile ./zh.wav
+ ```
+ Output:
+ ```
+ [2022-05-07 11:11:02,984] [ INFO] - Start to do streaming asr client
+ [2022-05-07 11:11:02,985] [ INFO] - asr websocket client start
+ [2022-05-07 11:11:02,985] [ INFO] - endpoint: ws://127.0.0.1:8490/paddlespeech/asr/streaming
+ [2022-05-07 11:11:02,986] [ INFO] - start to process the wavscp: ./zh.wav
+ [2022-05-07 11:11:03,006] [ INFO] - client receive msg={"status": "ok", "signal": "server_ready"}
+ [2022-05-07 11:11:03,021] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,034] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,046] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,058] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,070] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,081] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,092] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,102] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,629] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,638] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,645] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,653] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,661] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,668] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,676] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:04,402] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:11:04,510] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:11:04,619] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:11:04,743] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:11:04,849] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:11:04,956] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:11:05,063] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:11:05,170] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:11:05,876] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:11:06,019] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:11:06,184] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:11:06,342] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:11:06,537] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:11:06,727] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:11:06,871] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:11:07,617] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:11:07,769] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:11:07,905] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:11:08,043] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:11:08,186] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:11:08,326] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:11:08,466] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:11:08,611] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:11:09,431] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:11:09,571] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:11:09,714] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:11:09,853] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:11:09,992] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:11:10,129] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:11:10,266] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:11:11,113] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:11:11,296] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:11:11,439] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:11:11,582] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:11:11,727] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:11:11,869] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:11:12,011] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:11:12,153] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:11:12,969] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:11:13,137] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:11:13,297] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:11:13,456] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:11:13,615] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:11:13,776] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:11:18,915] [ INFO] - client final receive msg={'status': 'ok', 'signal': 'finished', 'result': '我认为跑步最重要的就是给我带来了身体健康。', 'times': [{'w': '我', 'bg': 0.0, 'ed': 0.7000000000000001}, {'w': '认', 'bg': 0.7000000000000001, 'ed': 0.84}, {'w': '为', 'bg': 0.84, 'ed': 1.0}, {'w': '跑', 'bg': 1.0, 'ed': 1.18}, {'w': '步', 'bg': 1.18, 'ed': 1.36}, {'w': '最', 'bg': 1.36, 'ed': 1.5}, {'w': '重', 'bg': 1.5, 'ed': 1.6400000000000001}, {'w': '要', 'bg': 1.6400000000000001, 'ed': 1.78}, {'w': '的', 'bg': 1.78, 'ed': 1.9000000000000001}, {'w': '就', 'bg': 1.9000000000000001, 'ed': 2.06}, {'w': '是', 'bg': 2.06, 'ed': 2.62}, {'w': '给', 'bg': 2.62, 'ed': 3.16}, {'w': '我', 'bg': 3.16, 'ed': 3.3200000000000003}, {'w': '带', 'bg': 3.3200000000000003, 'ed': 3.48}, {'w': '来', 'bg': 3.48, 'ed': 3.62}, {'w': '了', 'bg': 3.62, 'ed': 3.7600000000000002}, {'w': '身', 'bg': 3.7600000000000002, 'ed': 3.9}, {'w': '体', 'bg': 3.9, 'ed': 4.0600000000000005}, {'w': '健', 'bg': 4.0600000000000005, 'ed': 4.26}, {'w': '康', 'bg': 4.26, 'ed': 4.96}]}
+ [2022-05-07 11:11:18,915] [ INFO] - audio duration: 4.9968125, elapsed time: 15.928460597991943, RTF=3.187724293835709
+ [2022-05-07 11:11:18,916] [ INFO] - asr websocket client finished : 我认为跑步最重要的就是给我带来了身体健康
+ ```
+
+
diff --git a/demos/streaming_asr_server/README_cn.md b/demos/streaming_asr_server/README_cn.md
index 9224206b6..c771869e9 100644
--- a/demos/streaming_asr_server/README_cn.md
+++ b/demos/streaming_asr_server/README_cn.md
@@ -1,22 +1,30 @@
([English](./README.md)|中文)
-# 语音服务
+# 流式语音识别服务
## 介绍
这个demo是一个启动流式语音服务和访问服务的实现。 它可以通过使用`paddlespeech_server` 和 `paddlespeech_client`的单个命令或 python 的几行代码来实现。
+**流式语音识别服务只支持 `weboscket` 协议,不支持 `http` 协议。**
## 使用方法
### 1. 安装
-请看 [安装文档](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install.md).
+安装 PaddleSpeech 的详细过程请看 [安装文档](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install.md)。
推荐使用 **paddlepaddle 2.2.1** 或以上版本。
-你可以从 medium,hard 三中方式中选择一种方式安装 PaddleSpeech。
+你可以从medium,hard 两种方式中选择一种方式安装 PaddleSpeech。
### 2. 准备配置文件
-配置文件可参见 `conf/ws_application.yaml` 和 `conf/ws_conformer_application.yaml` 。
-目前服务集成的模型有: DeepSpeech2和conformer模型。
+
+流式ASR的服务启动脚本和服务测试脚本存放在 `PaddleSpeech/demos/streaming_asr_server` 目录。
+下载好 `PaddleSpeech` 之后,进入到 `PaddleSpeech/demos/streaming_asr_server` 目录。
+配置文件可参见该目录下 `conf/ws_application.yaml` 和 `conf/ws_conformer_wenetspeech_application.yaml` 。
+
+目前服务集成的模型有: DeepSpeech2 和 conformer模型,对应的配置文件如下:
+* DeepSpeech: `conf/ws_application.yaml`
+* conformer: `conf/ws_conformer_wenetspeech_application.yaml`
+
这个 ASR client 的输入应该是一个 WAV 文件(`.wav`),并且采样率必须与模型的采样率相同。
@@ -28,10 +36,12 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
### 3. 服务端使用方法
- 命令行 (推荐使用)
-
+ **注意:** 默认部署在 `cpu` 设备上,可以通过修改服务配置文件中 `device` 参数部署在 `gpu` 上。
```bash
- # 启动服务
- paddlespeech_server start --config_file ./conf/ws_conformer_application.yaml
+ # 在 PaddleSpeech/demos/streaming_asr_server 目录启动服务
+ paddlespeech_server start --config_file ./conf/ws_conformer_wenetspeech_application.yaml
+ # 你如果愿意为了增加解码的速度而牺牲一定的模型精度,你可以使用如下的脚本
+ paddlespeech_server start --config_file ./conf/ws_conformer_wenetspeech_application_faster.yaml
```
使用方法:
@@ -45,150 +55,75 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
输出:
```bash
- [2022-04-21 15:52:18,126] [ INFO] - create the online asr engine instance
- [2022-04-21 15:52:18,127] [ INFO] - paddlespeech_server set the device: cpu
- [2022-04-21 15:52:18,128] [ INFO] - Load the pretrained model, tag = conformer_online_multicn-zh-16k
- [2022-04-21 15:52:18,128] [ INFO] - File /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k/asr1_chunk_conformer_multi_cn_ckpt_0.2.3.model.tar.gz md5 checking...
- [2022-04-21 15:52:18,727] [ INFO] - Use pretrained model stored in: /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k
- [2022-04-21 15:52:18,727] [ INFO] - /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k
- [2022-04-21 15:52:18,727] [ INFO] - /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k/model.yaml
- [2022-04-21 15:52:18,727] [ INFO] - /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k/exp/chunk_conformer/checkpoints/multi_cn.pdparams
- [2022-04-21 15:52:18,727] [ INFO] - /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k/exp/chunk_conformer/checkpoints/multi_cn.pdparams
- [2022-04-21 15:52:19,446] [ INFO] - start to create the stream conformer asr engine
- [2022-04-21 15:52:19,473] [ INFO] - model name: conformer_online
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- [2022-04-21 15:52:21,731] [ INFO] - create the transformer like model success
- [2022-04-21 15:52:21,733] [ INFO] - Initialize ASR server engine successfully.
- INFO: Started server process [11173]
- [2022-04-21 15:52:21] [INFO] [server.py:75] Started server process [11173]
- INFO: Waiting for application startup.
- [2022-04-21 15:52:21] [INFO] [on.py:45] Waiting for application startup.
- INFO: Application startup complete.
- [2022-04-21 15:52:21] [INFO] [on.py:59] Application startup complete.
- /home/users/xiongxinlei/.conda/envs/paddlespeech/lib/python3.9/asyncio/base_events.py:1460: DeprecationWarning: The loop argument is deprecated since Python 3.8, and scheduled for removal in Python 3.10.
- infos = await tasks.gather(*fs, loop=self)
- /home/users/xiongxinlei/.conda/envs/paddlespeech/lib/python3.9/asyncio/base_events.py:1518: DeprecationWarning: The loop argument is deprecated since Python 3.8, and scheduled for removal in Python 3.10.
- await tasks.sleep(0, loop=self)
- INFO: Uvicorn running on http://0.0.0.0:8090 (Press CTRL+C to quit)
- [2022-04-21 15:52:21] [INFO] [server.py:206] Uvicorn running on http://0.0.0.0:8090 (Press CTRL+C to quit)
+ [2022-05-14 04:56:13,086] [ INFO] - create the online asr engine instance
+ [2022-05-14 04:56:13,086] [ INFO] - paddlespeech_server set the device: cpu
+ [2022-05-14 04:56:13,087] [ INFO] - Load the pretrained model, tag = conformer_online_wenetspeech-zh-16k
+ [2022-05-14 04:56:13,087] [ INFO] - File /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar.gz md5 checking...
+ [2022-05-14 04:56:17,542] [ INFO] - Use pretrained model stored in: /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1. 0.0a.model.tar
+ [2022-05-14 04:56:17,543] [ INFO] - /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar
+ [2022-05-14 04:56:17,543] [ INFO] - /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar/model.yaml
+ [2022-05-14 04:56:17,543] [ INFO] - /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar/exp/ chunk_conformer/checkpoints/avg_10.pdparams
+ [2022-05-14 04:56:17,543] [ INFO] - /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar/exp/ chunk_conformer/checkpoints/avg_10.pdparams
+ [2022-05-14 04:56:17,852] [ INFO] - start to create the stream conformer asr engine
+ [2022-05-14 04:56:17,863] [ INFO] - model name: conformer_online
+ [2022-05-14 04:56:22,756] [ INFO] - create the transformer like model success
+ [2022-05-14 04:56:22,758] [ INFO] - Initialize ASR server engine successfully.
+ INFO: Started server process [4242]
+ [2022-05-14 04:56:22] [INFO] [server.py:75] Started server process [4242]
+ INFO: Waiting for application startup.
+ [2022-05-14 04:56:22] [INFO] [on.py:45] Waiting for application startup.
+ INFO: Application startup complete.
+ [2022-05-14 04:56:22] [INFO] [on.py:59] Application startup complete.
+ INFO: Uvicorn running on http://0.0.0.0:8090 (Press CTRL+C to quit)
+ [2022-05-14 04:56:22] [INFO] [server.py:211] Uvicorn running on http://0.0.0.0:8090 (Press CTRL+C to quit)
```
- Python API
+ **注意:** 默认部署在 `cpu` 设备上,可以通过修改服务配置文件中 `device` 参数部署在 `gpu` 上。
```python
+ # 在 PaddleSpeech/demos/streaming_asr_server 目录
from paddlespeech.server.bin.paddlespeech_server import ServerExecutor
server_executor = ServerExecutor()
server_executor(
- config_file="./conf/ws_conformer_application.yaml",
+ config_file="./conf/ws_conformer_wenetspeech_application",
log_file="./log/paddlespeech.log")
```
输出:
```bash
- [2022-04-21 15:52:18,126] [ INFO] - create the online asr engine instance
- [2022-04-21 15:52:18,127] [ INFO] - paddlespeech_server set the device: cpu
- [2022-04-21 15:52:18,128] [ INFO] - Load the pretrained model, tag = conformer_online_multicn-zh-16k
- [2022-04-21 15:52:18,128] [ INFO] - File /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k/asr1_chunk_conformer_multi_cn_ckpt_0.2.3.model.tar.gz md5 checking...
- [2022-04-21 15:52:18,727] [ INFO] - Use pretrained model stored in: /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k
- [2022-04-21 15:52:18,727] [ INFO] - /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k
- [2022-04-21 15:52:18,727] [ INFO] - /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k/model.yaml
- [2022-04-21 15:52:18,727] [ INFO] - /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k/exp/chunk_conformer/checkpoints/multi_cn.pdparams
- [2022-04-21 15:52:18,727] [ INFO] - /home/users/xiongxinlei/.paddlespeech/models/conformer_online_multicn-zh-16k/exp/chunk_conformer/checkpoints/multi_cn.pdparams
- [2022-04-21 15:52:19,446] [ INFO] - start to create the stream conformer asr engine
- [2022-04-21 15:52:19,473] [ INFO] - model name: conformer_online
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- set kaiming_uniform
- [2022-04-21 15:52:21,731] [ INFO] - create the transformer like model success
- [2022-04-21 15:52:21,733] [ INFO] - Initialize ASR server engine successfully.
- INFO: Started server process [11173]
- [2022-04-21 15:52:21] [INFO] [server.py:75] Started server process [11173]
- INFO: Waiting for application startup.
- [2022-04-21 15:52:21] [INFO] [on.py:45] Waiting for application startup.
- INFO: Application startup complete.
- [2022-04-21 15:52:21] [INFO] [on.py:59] Application startup complete.
- /home/users/xiongxinlei/.conda/envs/paddlespeech/lib/python3.9/asyncio/base_events.py:1460: DeprecationWarning: The loop argument is deprecated since Python 3.8, and scheduled for removal in Python 3.10.
- infos = await tasks.gather(*fs, loop=self)
- /home/users/xiongxinlei/.conda/envs/paddlespeech/lib/python3.9/asyncio/base_events.py:1518: DeprecationWarning: The loop argument is deprecated since Python 3.8, and scheduled for removal in Python 3.10.
- await tasks.sleep(0, loop=self)
- INFO: Uvicorn running on http://0.0.0.0:8090 (Press CTRL+C to quit)
- [2022-04-21 15:52:21] [INFO] [server.py:206] Uvicorn running on http://0.0.0.0:8090 (Press CTRL+C to quit)
+ [2022-05-14 04:56:13,086] [ INFO] - create the online asr engine instance
+ [2022-05-14 04:56:13,086] [ INFO] - paddlespeech_server set the device: cpu
+ [2022-05-14 04:56:13,087] [ INFO] - Load the pretrained model, tag = conformer_online_wenetspeech-zh-16k
+ [2022-05-14 04:56:13,087] [ INFO] - File /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar.gz md5 checking...
+ [2022-05-14 04:56:17,542] [ INFO] - Use pretrained model stored in: /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1. 0.0a.model.tar
+ [2022-05-14 04:56:17,543] [ INFO] - /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar
+ [2022-05-14 04:56:17,543] [ INFO] - /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar/model.yaml
+ [2022-05-14 04:56:17,543] [ INFO] - /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar/exp/ chunk_conformer/checkpoints/avg_10.pdparams
+ [2022-05-14 04:56:17,543] [ INFO] - /root/.paddlespeech/models/conformer_online_wenetspeech-zh-16k/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar/exp/ chunk_conformer/checkpoints/avg_10.pdparams
+ [2022-05-14 04:56:17,852] [ INFO] - start to create the stream conformer asr engine
+ [2022-05-14 04:56:17,863] [ INFO] - model name: conformer_online
+ [2022-05-14 04:56:22,756] [ INFO] - create the transformer like model success
+ [2022-05-14 04:56:22,758] [ INFO] - Initialize ASR server engine successfully.
+ INFO: Started server process [4242]
+ [2022-05-14 04:56:22] [INFO] [server.py:75] Started server process [4242]
+ INFO: Waiting for application startup.
+ [2022-05-14 04:56:22] [INFO] [on.py:45] Waiting for application startup.
+ INFO: Application startup complete.
+ [2022-05-14 04:56:22] [INFO] [on.py:59] Application startup complete.
+ INFO: Uvicorn running on http://0.0.0.0:8090 (Press CTRL+C to quit)
+ [2022-05-14 04:56:22] [INFO] [server.py:211] Uvicorn running on http://0.0.0.0:8090 (Press CTRL+C to quit)
```
### 4. ASR 客户端使用方法
+
**注意:** 初次使用客户端时响应时间会略长
- 命令行 (推荐使用)
+
+ 若 `127.0.0.1` 不能访问,则需要使用实际服务 IP 地址
+
```
paddlespeech_client asr_online --server_ip 127.0.0.1 --port 8090 --input ./zh.wav
-
```
使用帮助:
@@ -204,79 +139,84 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
- `sample_rate`: 音频采样率,默认值:16000。
- `lang`: 模型语言,默认值:zh_cn。
- `audio_format`: 音频格式,默认值:wav。
+ - `punc.server_ip` 标点预测服务的ip。默认是None。
+ - `punc.server_port` 标点预测服务的端口port。默认是None。
输出:
```bash
- [2022-04-21 15:59:03,904] [ INFO] - receive msg={"status": "ok", "signal": "server_ready"}
- [2022-04-21 15:59:03,960] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:03,973] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:03,987] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,000] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,012] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,024] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,036] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,047] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,607] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,620] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,633] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,645] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,657] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,669] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,680] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:05,176] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,185] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,192] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,200] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,208] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,216] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,224] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,232] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,724] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,732] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,740] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,747] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,755] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,763] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,770] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:06,271] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,279] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,287] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,294] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,302] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,310] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,318] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,326] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,833] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,842] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,850] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,858] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,866] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,874] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,882] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:07,400] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,408] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,416] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,424] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,432] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,440] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,447] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,455] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,984] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:07,992] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:08,001] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:08,008] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:08,016] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:08,024] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:12,883] [ INFO] - final receive msg={'status': 'ok', 'signal': 'finished', 'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:12,884] [ INFO] - 我认为跑步最重要的就是给我带来了身体健康
- [2022-04-21 15:59:12,884] [ INFO] - Response time 9.051567 s.
+ [2022-05-06 21:10:35,598] [ INFO] - Start to do streaming asr client
+ [2022-05-06 21:10:35,600] [ INFO] - asr websocket client start
+ [2022-05-06 21:10:35,600] [ INFO] - endpoint: ws://127.0.0.1:8390/paddlespeech/asr/streaming
+ [2022-05-06 21:10:35,600] [ INFO] - start to process the wavscp: ./zh.wav
+ [2022-05-06 21:10:35,670] [ INFO] - client receive msg={"status": "ok", "signal": "server_ready"}
+ [2022-05-06 21:10:35,699] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:35,713] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:35,726] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:35,738] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:35,750] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:35,762] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:35,774] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:35,786] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:36,387] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:36,398] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:36,407] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:36,416] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:36,425] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:36,434] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:36,442] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:10:36,930] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:10:36,938] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:10:36,946] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:10:36,954] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:10:36,962] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:10:36,970] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:10:36,977] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:10:36,985] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:10:37,484] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:10:37,492] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:10:37,500] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:10:37,508] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:10:37,517] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:10:37,525] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:10:37,532] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:10:38,050] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:10:38,058] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:10:38,066] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:10:38,073] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:10:38,081] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:10:38,089] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:10:38,097] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:10:38,105] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:10:38,630] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:10:38,639] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:10:38,647] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:10:38,655] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:10:38,663] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:10:38,671] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:10:38,679] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:10:39,216] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:10:39,224] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:10:39,232] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:10:39,240] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:10:39,248] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:10:39,256] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:10:39,264] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:10:39,272] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:10:39,885] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:10:39,896] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:10:39,905] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:10:39,915] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:10:39,924] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:10:39,934] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:10:44,827] [ INFO] - client final receive msg={'status': 'ok', 'signal': 'finished', 'result': '我认为跑步最重要的就是给我带来了身体健康', 'times': [{'w': '我', 'bg': 0.0, 'ed': 0.7000000000000001}, {'w': '认', 'bg': 0.7000000000000001, 'ed': 0.84}, {'w': '为', 'bg': 0.84, 'ed': 1.0}, {'w': '跑', 'bg': 1.0, 'ed': 1.18}, {'w': '步', 'bg': 1.18, 'ed': 1.36}, {'w': '最', 'bg': 1.36, 'ed': 1.5}, {'w': '重', 'bg': 1.5, 'ed': 1.6400000000000001}, {'w': '要', 'bg': 1.6400000000000001, 'ed': 1.78}, {'w': '的', 'bg': 1.78, 'ed': 1.9000000000000001}, {'w': '就', 'bg': 1.9000000000000001, 'ed': 2.06}, {'w': '是', 'bg': 2.06, 'ed': 2.62}, {'w': '给', 'bg': 2.62, 'ed': 3.16}, {'w': '我', 'bg': 3.16, 'ed': 3.3200000000000003}, {'w': '带', 'bg': 3.3200000000000003, 'ed': 3.48}, {'w': '来', 'bg': 3.48, 'ed': 3.62}, {'w': '了', 'bg': 3.62, 'ed': 3.7600000000000002}, {'w': '身', 'bg': 3.7600000000000002, 'ed': 3.9}, {'w': '体', 'bg': 3.9, 'ed': 4.0600000000000005}, {'w': '健', 'bg': 4.0600000000000005, 'ed': 4.26}, {'w': '康', 'bg': 4.26, 'ed': 4.96}]}
+ [2022-05-06 21:10:44,827] [ INFO] - audio duration: 4.9968125, elapsed time: 9.225094079971313, RTF=1.846195765794957
+ [2022-05-06 21:10:44,828] [ INFO] - asr websocket client finished : 我认为跑步最重要的就是给我带来了身体健康
```
- Python API
```python
from paddlespeech.server.bin.paddlespeech_client import ASROnlineClientExecutor
- import json
asrclient_executor = ASROnlineClientExecutor()
res = asrclient_executor(
@@ -286,71 +226,360 @@ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
sample_rate=16000,
lang="zh_cn",
audio_format="wav")
- print(res.json())
+ print(res)
```
输出:
```bash
- [2022-04-21 15:59:03,904] [ INFO] - receive msg={"status": "ok", "signal": "server_ready"}
- [2022-04-21 15:59:03,960] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:03,973] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:03,987] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,000] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,012] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,024] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,036] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,047] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,607] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,620] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,633] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,645] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,657] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,669] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:04,680] [ INFO] - receive msg={'asr_results': ''}
- [2022-04-21 15:59:05,176] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,185] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,192] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,200] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,208] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,216] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,224] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,232] [ INFO] - receive msg={'asr_results': '我认为跑'}
- [2022-04-21 15:59:05,724] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,732] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,740] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,747] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,755] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,763] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:05,770] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的'}
- [2022-04-21 15:59:06,271] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,279] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,287] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,294] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,302] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,310] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,318] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,326] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是'}
- [2022-04-21 15:59:06,833] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,842] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,850] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,858] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,866] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,874] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:06,882] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给'}
- [2022-04-21 15:59:07,400] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,408] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,416] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,424] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,432] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,440] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,447] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,455] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了'}
- [2022-04-21 15:59:07,984] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:07,992] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:08,001] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:08,008] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:08,016] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:08,024] [ INFO] - receive msg={'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:12,883] [ INFO] - final receive msg={'status': 'ok', 'signal': 'finished', 'asr_results': '我认为跑步最重要的就是给我带来了身体健康'}
- [2022-04-21 15:59:12,884] [ INFO] - 我认为跑步最重要的就是给我带来了身体健康
+ [2022-05-06 21:14:03,137] [ INFO] - asr websocket client start
+ [2022-05-06 21:14:03,137] [ INFO] - endpoint: ws://127.0.0.1:8390/paddlespeech/asr/streaming
+ [2022-05-06 21:14:03,149] [ INFO] - client receive msg={"status": "ok", "signal": "server_ready"}
+ [2022-05-06 21:14:03,167] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,181] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,194] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,207] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,219] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,230] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,241] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,252] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,768] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,776] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,784] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,792] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,800] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,807] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:03,815] [ INFO] - client receive msg={'result': ''}
+ [2022-05-06 21:14:04,301] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:14:04,309] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:14:04,317] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:14:04,325] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:14:04,333] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:14:04,341] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:14:04,349] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:14:04,356] [ INFO] - client receive msg={'result': '我认为跑'}
+ [2022-05-06 21:14:04,855] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:14:04,864] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:14:04,871] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:14:04,879] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:14:04,887] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:14:04,894] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:14:04,902] [ INFO] - client receive msg={'result': '我认为跑步最重要的'}
+ [2022-05-06 21:14:05,418] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:14:05,426] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:14:05,434] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:14:05,442] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:14:05,449] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:14:05,457] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:14:05,465] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:14:05,473] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是'}
+ [2022-05-06 21:14:05,996] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:14:06,006] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:14:06,013] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:14:06,021] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:14:06,029] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:14:06,037] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:14:06,045] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给'}
+ [2022-05-06 21:14:06,581] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:14:06,589] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:14:06,597] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:14:06,605] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:14:06,613] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:14:06,621] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:14:06,628] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:14:06,636] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了'}
+ [2022-05-06 21:14:07,188] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:14:07,196] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:14:07,203] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:14:07,211] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:14:07,219] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:14:07,226] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康'}
+ [2022-05-06 21:14:12,158] [ INFO] - client final receive msg={'status': 'ok', 'signal': 'finished', 'result': '我认为跑步最重要的就是给我带来了身体健康', 'times': [{'w': '我', 'bg': 0.0, 'ed': 0.7000000000000001}, {'w': '认', 'bg': 0.7000000000000001, 'ed': 0.84}, {'w': '为', 'bg': 0.84, 'ed': 1.0}, {'w': '跑', 'bg': 1.0, 'ed': 1.18}, {'w': '步', 'bg': 1.18, 'ed': 1.36}, {'w': '最', 'bg': 1.36, 'ed': 1.5}, {'w': '重', 'bg': 1.5, 'ed': 1.6400000000000001}, {'w': '要', 'bg': 1.6400000000000001, 'ed': 1.78}, {'w': '的', 'bg': 1.78, 'ed': 1.9000000000000001}, {'w': '就', 'bg': 1.9000000000000001, 'ed': 2.06}, {'w': '是', 'bg': 2.06, 'ed': 2.62}, {'w': '给', 'bg': 2.62, 'ed': 3.16}, {'w': '我', 'bg': 3.16, 'ed': 3.3200000000000003}, {'w': '带', 'bg': 3.3200000000000003, 'ed': 3.48}, {'w': '来', 'bg': 3.48, 'ed': 3.62}, {'w': '了', 'bg': 3.62, 'ed': 3.7600000000000002}, {'w': '身', 'bg': 3.7600000000000002, 'ed': 3.9}, {'w': '体', 'bg': 3.9, 'ed': 4.0600000000000005}, {'w': '健', 'bg': 4.0600000000000005, 'ed': 4.26}, {'w': '康', 'bg': 4.26, 'ed': 4.96}]}
+ [2022-05-06 21:14:12,159] [ INFO] - audio duration: 4.9968125, elapsed time: 9.019973039627075, RTF=1.8051453881103354
+ [2022-05-06 21:14:12,160] [ INFO] - asr websocket client finished
+ ```
+
+
+
+## 标点预测
+
+### 1. 服务端使用方法
+
+- 命令行
+ **注意:** 默认部署在 `cpu` 设备上,可以通过修改服务配置文件中 `device` 参数部署在 `gpu` 上。
+ ``` bash
+ 在 PaddleSpeech/demos/streaming_asr_server 目录下启动标点预测服务
+ paddlespeech_server start --config_file conf/punc_application.yaml
+ ```
+
+
+ 使用方法:
+
+ ```bash
+ paddlespeech_server start --help
+ ```
+
+ 参数:
+ - `config_file`: 服务的配置文件。
+ - `log_file`: log 文件。
+
+
+ 输出:
+ ``` bash
+ [2022-05-02 17:59:26,285] [ INFO] - Create the TextEngine Instance
+ [2022-05-02 17:59:26,285] [ INFO] - Init the text engine
+ [2022-05-02 17:59:26,285] [ INFO] - Text Engine set the device: gpu:0
+ [2022-05-02 17:59:26,286] [ INFO] - File /home/users/xiongxinlei/.paddlespeech/models/ernie_linear_p3_wudao-punc-zh/ernie_linear_p3_wudao-punc-zh.tar.gz md5 checking...
+ [2022-05-02 17:59:30,810] [ INFO] - Use pretrained model stored in: /home/users/xiongxinlei/.paddlespeech/models/ernie_linear_p3_wudao-punc-zh/ernie_linear_p3_wudao-punc-zh.tar
+ W0502 17:59:31.486552 9595 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 6.1, Driver API Version: 10.2, Runtime API Version: 10.2
+ W0502 17:59:31.491360 9595 device_context.cc:465] device: 0, cuDNN Version: 7.6.
+ [2022-05-02 17:59:34,688] [ INFO] - Already cached /home/users/xiongxinlei/.paddlenlp/models/ernie-1.0/vocab.txt
+ [2022-05-02 17:59:34,701] [ INFO] - Init the text engine successfully
+ INFO: Started server process [9595]
+ [2022-05-02 17:59:34] [INFO] [server.py:75] Started server process [9595]
+ INFO: Waiting for application startup.
+ [2022-05-02 17:59:34] [INFO] [on.py:45] Waiting for application startup.
+ INFO: Application startup complete.
+ [2022-05-02 17:59:34] [INFO] [on.py:59] Application startup complete.
+ INFO: Uvicorn running on http://0.0.0.0:8190 (Press CTRL+C to quit)
+ [2022-05-02 17:59:34] [INFO] [server.py:206] Uvicorn running on http://0.0.0.0:8190 (Press CTRL+C to quit)
+ ```
+
+- Python API
+ **注意:** 默认部署在 `cpu` 设备上,可以通过修改服务配置文件中 `device` 参数部署在 `gpu` 上。
+ ```python
+ # 在 PaddleSpeech/demos/streaming_asr_server 目录
+ from paddlespeech.server.bin.paddlespeech_server import ServerExecutor
+
+ server_executor = ServerExecutor()
+ server_executor(
+ config_file="./conf/punc_application.yaml",
+ log_file="./log/paddlespeech.log")
```
+
+ 输出
+ ```
+ [2022-05-02 18:09:02,542] [ INFO] - Create the TextEngine Instance
+ [2022-05-02 18:09:02,543] [ INFO] - Init the text engine
+ [2022-05-02 18:09:02,543] [ INFO] - Text Engine set the device: gpu:0
+ [2022-05-02 18:09:02,545] [ INFO] - File /home/users/xiongxinlei/.paddlespeech/models/ernie_linear_p3_wudao-punc-zh/ernie_linear_p3_wudao-punc-zh.tar.gz md5 checking...
+ [2022-05-02 18:09:06,919] [ INFO] - Use pretrained model stored in: /home/users/xiongxinlei/.paddlespeech/models/ernie_linear_p3_wudao-punc-zh/ernie_linear_p3_wudao-punc-zh.tar
+ W0502 18:09:07.523002 22615 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 6.1, Driver API Version: 10.2, Runtime API Version: 10.2
+ W0502 18:09:07.527882 22615 device_context.cc:465] device: 0, cuDNN Version: 7.6.
+ [2022-05-02 18:09:10,900] [ INFO] - Already cached /home/users/xiongxinlei/.paddlenlp/models/ernie-1.0/vocab.txt
+ [2022-05-02 18:09:10,913] [ INFO] - Init the text engine successfully
+ INFO: Started server process [22615]
+ [2022-05-02 18:09:10] [INFO] [server.py:75] Started server process [22615]
+ INFO: Waiting for application startup.
+ [2022-05-02 18:09:10] [INFO] [on.py:45] Waiting for application startup.
+ INFO: Application startup complete.
+ [2022-05-02 18:09:10] [INFO] [on.py:59] Application startup complete.
+ INFO: Uvicorn running on http://0.0.0.0:8190 (Press CTRL+C to quit)
+ [2022-05-02 18:09:10] [INFO] [server.py:206] Uvicorn running on http://0.0.0.0:8190 (Press CTRL+C to quit)
+ ```
+
+### 2. 标点预测客户端使用方法
+**注意:** 初次使用客户端时响应时间会略长
+
+- 命令行 (推荐使用)
+
+ 若 `127.0.0.1` 不能访问,则需要使用实际服务 IP 地址
+
+ ```
+ paddlespeech_client text --server_ip 127.0.0.1 --port 8190 --input "我认为跑步最重要的就是给我带来了身体健康"
+ ```
+
+ 输出
+ ```
+ [2022-05-02 18:12:29,767] [ INFO] - The punc text: 我认为跑步最重要的就是给我带来了身体健康。
+ [2022-05-02 18:12:29,767] [ INFO] - Response time 0.096548 s.
+ ```
+
+- Python3 API
+
+ ```python
+ from paddlespeech.server.bin.paddlespeech_client import TextClientExecutor
+
+ textclient_executor = TextClientExecutor()
+ res = textclient_executor(
+ input="我认为跑步最重要的就是给我带来了身体健康",
+ server_ip="127.0.0.1",
+ port=8190,)
+ print(res)
+ ```
+
+ 输出:
+ ``` bash
+ 我认为跑步最重要的就是给我带来了身体健康。
+ ```
+
+
+## 联合流式语音识别和标点预测
+**注意:** 默认部署在 `cpu` 设备上,可以通过修改服务配置文件中 `device` 参数将语音识别和标点预测部署在不同的 `gpu` 上。
+
+使用 `streaming_asr_server.py` 和 `punc_server.py` 两个服务,分别启动流式语音识别和标点预测服务。调用 `websocket_client.py` 脚本可以同时调用流式语音识别和标点预测服务。
+
+### 1. 启动服务
+
+``` bash
+注意:流式语音识别和标点预测通过配置文件配置到不同的显卡上
+bash server.sh
+```
+
+### 2. 调用服务
+- 使用命令行:
+
+ 若 `127.0.0.1` 不能访问,则需要使用实际服务 IP 地址
+
+ ```
+ paddlespeech_client asr_online --server_ip 127.0.0.1 --port 8290 --punc.server_ip 127.0.0.1 --punc.port 8190 --input ./zh.wav
+ ```
+ 输出:
+ ```
+ [2022-05-07 11:21:47,060] [ INFO] - asr websocket client start
+ [2022-05-07 11:21:47,060] [ INFO] - endpoint: ws://127.0.0.1:8490/paddlespeech/asr/streaming
+ [2022-05-07 11:21:47,080] [ INFO] - client receive msg={"status": "ok", "signal": "server_ready"}
+ [2022-05-07 11:21:47,096] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,108] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,120] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,131] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,142] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,152] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,163] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,173] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,705] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,713] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,721] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,728] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,736] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,743] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:47,751] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:21:48,459] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:21:48,572] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:21:48,681] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:21:48,790] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:21:48,898] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:21:49,005] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:21:49,112] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:21:49,219] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:21:49,935] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:21:50,062] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:21:50,186] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:21:50,310] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:21:50,435] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:21:50,560] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:21:50,686] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:21:51,444] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:21:51,606] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:21:51,744] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:21:51,882] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:21:52,020] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:21:52,159] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:21:52,298] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:21:52,437] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:21:53,298] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:21:53,450] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:21:53,589] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:21:53,728] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:21:53,867] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:21:54,007] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:21:54,146] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:21:55,002] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:21:55,148] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:21:55,292] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:21:55,437] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:21:55,584] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:21:55,731] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:21:55,877] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:21:56,021] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:21:56,842] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:21:57,013] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:21:57,174] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:21:57,336] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:21:57,497] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:21:57,659] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:22:03,035] [ INFO] - client final receive msg={'status': 'ok', 'signal': 'finished', 'result': '我认为跑步最重要的就是给我带来了身体健康。', 'times': [{'w': '我', 'bg': 0.0, 'ed': 0.7000000000000001}, {'w': '认', 'bg': 0.7000000000000001, 'ed': 0.84}, {'w': '为', 'bg': 0.84, 'ed': 1.0}, {'w': '跑', 'bg': 1.0, 'ed': 1.18}, {'w': '步', 'bg': 1.18, 'ed': 1.36}, {'w': '最', 'bg': 1.36, 'ed': 1.5}, {'w': '重', 'bg': 1.5, 'ed': 1.6400000000000001}, {'w': '要', 'bg': 1.6400000000000001, 'ed': 1.78}, {'w': '的', 'bg': 1.78, 'ed': 1.9000000000000001}, {'w': '就', 'bg': 1.9000000000000001, 'ed': 2.06}, {'w': '是', 'bg': 2.06, 'ed': 2.62}, {'w': '给', 'bg': 2.62, 'ed': 3.16}, {'w': '我', 'bg': 3.16, 'ed': 3.3200000000000003}, {'w': '带', 'bg': 3.3200000000000003, 'ed': 3.48}, {'w': '来', 'bg': 3.48, 'ed': 3.62}, {'w': '了', 'bg': 3.62, 'ed': 3.7600000000000002}, {'w': '身', 'bg': 3.7600000000000002, 'ed': 3.9}, {'w': '体', 'bg': 3.9, 'ed': 4.0600000000000005}, {'w': '健', 'bg': 4.0600000000000005, 'ed': 4.26}, {'w': '康', 'bg': 4.26, 'ed': 4.96}]}
+ [2022-05-07 11:22:03,035] [ INFO] - audio duration: 4.9968125, elapsed time: 15.974023818969727, RTF=3.1968427510477384
+ [2022-05-07 11:22:03,037] [ INFO] - asr websocket client finished
+ [2022-05-07 11:22:03,037] [ INFO] - 我认为跑步最重要的就是给我带来了身体健康。
+ [2022-05-07 11:22:03,037] [ INFO] - Response time 15.977116 s.
+ ```
+
+- 使用脚本调用
+
+ 若 `127.0.0.1` 不能访问,则需要使用实际服务 IP 地址
+
+ ```
+ python3 websocket_client.py --server_ip 127.0.0.1 --port 8290 --punc.server_ip 127.0.0.1 --punc.port 8190 --wavfile ./zh.wav
+ ```
+ 输出:
+ ```
+ [2022-05-07 11:11:02,984] [ INFO] - Start to do streaming asr client
+ [2022-05-07 11:11:02,985] [ INFO] - asr websocket client start
+ [2022-05-07 11:11:02,985] [ INFO] - endpoint: ws://127.0.0.1:8490/paddlespeech/asr/streaming
+ [2022-05-07 11:11:02,986] [ INFO] - start to process the wavscp: ./zh.wav
+ [2022-05-07 11:11:03,006] [ INFO] - client receive msg={"status": "ok", "signal": "server_ready"}
+ [2022-05-07 11:11:03,021] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,034] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,046] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,058] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,070] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,081] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,092] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,102] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,629] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,638] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,645] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,653] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,661] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,668] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:03,676] [ INFO] - client receive msg={'result': ''}
+ [2022-05-07 11:11:04,402] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:11:04,510] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:11:04,619] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:11:04,743] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:11:04,849] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:11:04,956] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:11:05,063] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:11:05,170] [ INFO] - client receive msg={'result': '我认为,跑'}
+ [2022-05-07 11:11:05,876] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:11:06,019] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:11:06,184] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:11:06,342] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:11:06,537] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:11:06,727] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:11:06,871] [ INFO] - client receive msg={'result': '我认为,跑步最重要的。'}
+ [2022-05-07 11:11:07,617] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:11:07,769] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:11:07,905] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:11:08,043] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:11:08,186] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:11:08,326] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:11:08,466] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:11:08,611] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是。'}
+ [2022-05-07 11:11:09,431] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:11:09,571] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:11:09,714] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:11:09,853] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:11:09,992] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:11:10,129] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:11:10,266] [ INFO] - client receive msg={'result': '我认为,跑步最重要的就是给。'}
+ [2022-05-07 11:11:11,113] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:11:11,296] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:11:11,439] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:11:11,582] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:11:11,727] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:11:11,869] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:11:12,011] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:11:12,153] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了。'}
+ [2022-05-07 11:11:12,969] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:11:13,137] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:11:13,297] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:11:13,456] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:11:13,615] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:11:13,776] [ INFO] - client receive msg={'result': '我认为跑步最重要的就是给我带来了身体健康。'}
+ [2022-05-07 11:11:18,915] [ INFO] - client final receive msg={'status': 'ok', 'signal': 'finished', 'result': '我认为跑步最重要的就是给我带来了身体健康。', 'times': [{'w': '我', 'bg': 0.0, 'ed': 0.7000000000000001}, {'w': '认', 'bg': 0.7000000000000001, 'ed': 0.84}, {'w': '为', 'bg': 0.84, 'ed': 1.0}, {'w': '跑', 'bg': 1.0, 'ed': 1.18}, {'w': '步', 'bg': 1.18, 'ed': 1.36}, {'w': '最', 'bg': 1.36, 'ed': 1.5}, {'w': '重', 'bg': 1.5, 'ed': 1.6400000000000001}, {'w': '要', 'bg': 1.6400000000000001, 'ed': 1.78}, {'w': '的', 'bg': 1.78, 'ed': 1.9000000000000001}, {'w': '就', 'bg': 1.9000000000000001, 'ed': 2.06}, {'w': '是', 'bg': 2.06, 'ed': 2.62}, {'w': '给', 'bg': 2.62, 'ed': 3.16}, {'w': '我', 'bg': 3.16, 'ed': 3.3200000000000003}, {'w': '带', 'bg': 3.3200000000000003, 'ed': 3.48}, {'w': '来', 'bg': 3.48, 'ed': 3.62}, {'w': '了', 'bg': 3.62, 'ed': 3.7600000000000002}, {'w': '身', 'bg': 3.7600000000000002, 'ed': 3.9}, {'w': '体', 'bg': 3.9, 'ed': 4.0600000000000005}, {'w': '健', 'bg': 4.0600000000000005, 'ed': 4.26}, {'w': '康', 'bg': 4.26, 'ed': 4.96}]}
+ [2022-05-07 11:11:18,915] [ INFO] - audio duration: 4.9968125, elapsed time: 15.928460597991943, RTF=3.187724293835709
+ [2022-05-07 11:11:18,916] [ INFO] - asr websocket client finished : 我认为跑步最重要的就是给我带来了身体健康
+ ```
+
+
diff --git a/demos/streaming_asr_server/conf/ws_application.yaml b/demos/streaming_asr_server/conf/application.yaml
similarity index 82%
rename from demos/streaming_asr_server/conf/ws_application.yaml
rename to demos/streaming_asr_server/conf/application.yaml
index dee8d78ba..683d86f03 100644
--- a/demos/streaming_asr_server/conf/ws_application.yaml
+++ b/demos/streaming_asr_server/conf/application.yaml
@@ -7,8 +7,8 @@ host: 0.0.0.0
port: 8090
# The task format in the engin_list is: _
-# task choices = ['asr_online', 'tts_online']
-# protocol = ['websocket', 'http'] (only one can be selected).
+# task choices = ['asr_online']
+# protocol = ['websocket'] (only one can be selected).
# websocket only support online engine type.
protocol: 'websocket'
engine_list: ['asr_online']
@@ -21,7 +21,7 @@ engine_list: ['asr_online']
################################### ASR #########################################
################### speech task: asr; engine_type: online #######################
asr_online:
- model_type: 'deepspeech2online_aishell'
+ model_type: 'conformer_online_wenetspeech'
am_model: # the pdmodel file of am static model [optional]
am_params: # the pdiparams file of am static model [optional]
lang: 'zh'
@@ -29,6 +29,9 @@ asr_online:
cfg_path:
decode_method:
force_yes: True
+ device: 'cpu' # cpu or gpu:id
+ decode_method: "attention_rescoring"
+ continuous_decoding: True # enable continue decoding when endpoint detected
am_predictor_conf:
device: # set 'gpu:id' or 'cpu'
@@ -37,11 +40,9 @@ asr_online:
summary: True # False -> do not show predictor config
chunk_buffer_conf:
- frame_duration_ms: 80
- shift_ms: 40
- sample_rate: 16000
- sample_width: 2
window_n: 7 # frame
shift_n: 4 # frame
- window_ms: 20 # ms
+ window_ms: 25 # ms
shift_ms: 10 # ms
+ sample_rate: 16000
+ sample_width: 2
diff --git a/demos/streaming_asr_server/conf/punc_application.yaml b/demos/streaming_asr_server/conf/punc_application.yaml
new file mode 100644
index 000000000..f947525e1
--- /dev/null
+++ b/demos/streaming_asr_server/conf/punc_application.yaml
@@ -0,0 +1,35 @@
+# This is the parameter configuration file for PaddleSpeech Serving.
+
+#################################################################################
+# SERVER SETTING #
+#################################################################################
+host: 0.0.0.0
+port: 8190
+
+# The task format in the engin_list is: _
+# task choices = ['asr_python']
+# protocol = ['http'] (only one can be selected).
+# http only support offline engine type.
+protocol: 'http'
+engine_list: ['text_python']
+
+
+#################################################################################
+# ENGINE CONFIG #
+#################################################################################
+
+################################### Text #########################################
+################### text task: punc; engine_type: python #######################
+text_python:
+ task: punc
+ model_type: 'ernie_linear_p3_wudao'
+ lang: 'zh'
+ sample_rate: 16000
+ cfg_path: # [optional]
+ ckpt_path: # [optional]
+ vocab_file: # [optional]
+ device: 'cpu' # set 'gpu:id' or 'cpu'
+
+
+
+
diff --git a/demos/streaming_asr_server/conf/ws_conformer_application.yaml b/demos/streaming_asr_server/conf/ws_conformer_application.yaml
index 8f0114859..01bb1e9c9 100644
--- a/demos/streaming_asr_server/conf/ws_conformer_application.yaml
+++ b/demos/streaming_asr_server/conf/ws_conformer_application.yaml
@@ -4,11 +4,11 @@
# SERVER SETTING #
#################################################################################
host: 0.0.0.0
-port: 8090
+port: 8091
# The task format in the engin_list is: _
-# task choices = ['asr_online', 'tts_online']
-# protocol = ['websocket', 'http'] (only one can be selected).
+# task choices = ['asr_online']
+# protocol = ['websocket'] (only one can be selected).
# websocket only support online engine type.
protocol: 'websocket'
engine_list: ['asr_online']
@@ -28,8 +28,12 @@ asr_online:
sample_rate: 16000
cfg_path:
decode_method:
+ num_decoding_left_chunks: -1
force_yes: True
- device: # cpu or gpu:id
+ device: 'cpu' # cpu or gpu:id
+ decode_method: "attention_rescoring"
+ continuous_decoding: True # enable continue decoding when endpoint detected
+
am_predictor_conf:
device: # set 'gpu:id' or 'cpu'
switch_ir_optim: True
@@ -42,4 +46,4 @@ asr_online:
window_ms: 25 # ms
shift_ms: 10 # ms
sample_rate: 16000
- sample_width: 2
\ No newline at end of file
+ sample_width: 2
diff --git a/demos/streaming_asr_server/conf/ws_conformer_wenetspeech_application.yaml b/demos/streaming_asr_server/conf/ws_conformer_wenetspeech_application.yaml
new file mode 100644
index 000000000..d30bcd025
--- /dev/null
+++ b/demos/streaming_asr_server/conf/ws_conformer_wenetspeech_application.yaml
@@ -0,0 +1,48 @@
+# This is the parameter configuration file for PaddleSpeech Serving.
+
+#################################################################################
+# SERVER SETTING #
+#################################################################################
+host: 0.0.0.0
+port: 8090
+
+# The task format in the engin_list is: _
+# task choices = ['asr_online']
+# protocol = ['websocket'] (only one can be selected).
+# websocket only support online engine type.
+protocol: 'websocket'
+engine_list: ['asr_online']
+
+
+#################################################################################
+# ENGINE CONFIG #
+#################################################################################
+
+################################### ASR #########################################
+################### speech task: asr; engine_type: online #######################
+asr_online:
+ model_type: 'conformer_online_wenetspeech'
+ am_model: # the pdmodel file of am static model [optional]
+ am_params: # the pdiparams file of am static model [optional]
+ lang: 'zh'
+ sample_rate: 16000
+ cfg_path:
+ decode_method:
+ force_yes: True
+ device: 'cpu' # cpu or gpu:id
+ decode_method: "attention_rescoring"
+ continuous_decoding: True # enable continue decoding when endpoint detected
+ num_decoding_left_chunks: -1
+ am_predictor_conf:
+ device: # set 'gpu:id' or 'cpu'
+ switch_ir_optim: True
+ glog_info: False # True -> print glog
+ summary: True # False -> do not show predictor config
+
+ chunk_buffer_conf:
+ window_n: 7 # frame
+ shift_n: 4 # frame
+ window_ms: 25 # ms
+ shift_ms: 10 # ms
+ sample_rate: 16000
+ sample_width: 2
diff --git a/demos/streaming_asr_server/conf/ws_conformer_wenetspeech_application_faster.yaml b/demos/streaming_asr_server/conf/ws_conformer_wenetspeech_application_faster.yaml
new file mode 100644
index 000000000..ba413c802
--- /dev/null
+++ b/demos/streaming_asr_server/conf/ws_conformer_wenetspeech_application_faster.yaml
@@ -0,0 +1,48 @@
+# This is the parameter configuration file for PaddleSpeech Serving.
+
+#################################################################################
+# SERVER SETTING #
+#################################################################################
+host: 0.0.0.0
+port: 8090
+
+# The task format in the engin_list is: _
+# task choices = ['asr_online']
+# protocol = ['websocket'] (only one can be selected).
+# websocket only support online engine type.
+protocol: 'websocket'
+engine_list: ['asr_online']
+
+
+#################################################################################
+# ENGINE CONFIG #
+#################################################################################
+
+################################### ASR #########################################
+################### speech task: asr; engine_type: online #######################
+asr_online:
+ model_type: 'conformer_online_wenetspeech'
+ am_model: # the pdmodel file of am static model [optional]
+ am_params: # the pdiparams file of am static model [optional]
+ lang: 'zh'
+ sample_rate: 16000
+ cfg_path:
+ decode_method:
+ force_yes: True
+ device: 'cpu' # cpu or gpu:id
+ decode_method: "attention_rescoring"
+ continuous_decoding: True # enable continue decoding when endpoint detected
+ num_decoding_left_chunks: 16
+ am_predictor_conf:
+ device: # set 'gpu:id' or 'cpu'
+ switch_ir_optim: True
+ glog_info: False # True -> print glog
+ summary: True # False -> do not show predictor config
+
+ chunk_buffer_conf:
+ window_n: 7 # frame
+ shift_n: 4 # frame
+ window_ms: 25 # ms
+ shift_ms: 10 # ms
+ sample_rate: 16000
+ sample_width: 2
diff --git a/demos/streaming_asr_server/conf/ws_ds2_application.yaml b/demos/streaming_asr_server/conf/ws_ds2_application.yaml
new file mode 100644
index 000000000..e36a829cc
--- /dev/null
+++ b/demos/streaming_asr_server/conf/ws_ds2_application.yaml
@@ -0,0 +1,84 @@
+# This is the parameter configuration file for PaddleSpeech Serving.
+
+#################################################################################
+# SERVER SETTING #
+#################################################################################
+host: 0.0.0.0
+port: 8090
+
+# The task format in the engin_list is: _
+# task choices = ['asr_online-inference', 'asr_online-onnx']
+# protocol = ['websocket'] (only one can be selected).
+# websocket only support online engine type.
+protocol: 'websocket'
+engine_list: ['asr_online-onnx']
+
+
+#################################################################################
+# ENGINE CONFIG #
+#################################################################################
+
+################################### ASR #########################################
+################### speech task: asr; engine_type: online-inference #######################
+asr_online-inference:
+ model_type: 'deepspeech2online_wenetspeech'
+ am_model: # the pdmodel file of am static model [optional]
+ am_params: # the pdiparams file of am static model [optional]
+ lang: 'zh'
+ sample_rate: 16000
+ cfg_path:
+ decode_method:
+ num_decoding_left_chunks:
+ force_yes: True
+ device: 'cpu' # cpu or gpu:id
+
+ am_predictor_conf:
+ device: # set 'gpu:id' or 'cpu'
+ switch_ir_optim: True
+ glog_info: False # True -> print glog
+ summary: True # False -> do not show predictor config
+
+ chunk_buffer_conf:
+ frame_duration_ms: 85
+ shift_ms: 40
+ sample_rate: 16000
+ sample_width: 2
+ window_n: 7 # frame
+ shift_n: 4 # frame
+ window_ms: 25 # ms
+ shift_ms: 10 # ms
+
+
+
+################################### ASR #########################################
+################### speech task: asr; engine_type: online-onnx #######################
+asr_online-onnx:
+ model_type: 'deepspeech2online_wenetspeech'
+ am_model: # the pdmodel file of onnx am static model [optional]
+ am_params: # the pdiparams file of am static model [optional]
+ lang: 'zh'
+ sample_rate: 16000
+ cfg_path:
+ decode_method:
+ num_decoding_left_chunks:
+ force_yes: True
+ device: 'cpu' # cpu or gpu:id
+
+ # https://onnxruntime.ai/docs/api/python/api_summary.html#inferencesession
+ am_predictor_conf:
+ device: 'cpu' # set 'gpu:id' or 'cpu'
+ graph_optimization_level: 0
+ intra_op_num_threads: 0 # Sets the number of threads used to parallelize the execution within nodes.
+ inter_op_num_threads: 0 # Sets the number of threads used to parallelize the execution of the graph (across nodes).
+ log_severity_level: 2 # Log severity level. Applies to session load, initialization, etc. 0:Verbose, 1:Info, 2:Warning. 3:Error, 4:Fatal. Default is 2.
+ log_verbosity_level: 0 # VLOG level if DEBUG build and session_log_severity_level is 0. Applies to session load, initialization, etc. Default is 0.
+
+ chunk_buffer_conf:
+ frame_duration_ms: 80
+ shift_ms: 40
+ sample_rate: 16000
+ sample_width: 2
+ window_n: 7 # frame
+ shift_n: 4 # frame
+ window_ms: 25 # ms
+ shift_ms: 10 # ms
diff --git a/demos/streaming_asr_server/local/rtf_from_log.py b/demos/streaming_asr_server/local/rtf_from_log.py
new file mode 100755
index 000000000..a5634388b
--- /dev/null
+++ b/demos/streaming_asr_server/local/rtf_from_log.py
@@ -0,0 +1,40 @@
+#!/usr/bin/env python3
+import argparse
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(prog=__doc__)
+ parser.add_argument(
+ '--logfile', type=str, required=True, help='ws client log file')
+
+ args = parser.parse_args()
+
+ rtfs = []
+ with open(args.logfile, 'r') as f:
+ for line in f:
+ if 'RTF=' in line:
+ # udio duration: 6.126, elapsed time: 3.471978187561035, RTF=0.5667610492264177
+ line = line.strip()
+ beg = line.index("audio")
+ line = line[beg:]
+
+ items = line.split(',')
+ vals = []
+ for elem in items:
+ if "RTF=" in elem:
+ continue
+ _, val = elem.split(":")
+ vals.append(eval(val))
+ keys = ['T', 'P']
+ meta = dict(zip(keys, vals))
+
+ rtfs.append(meta)
+
+ T = 0.0
+ P = 0.0
+ n = 0
+ for m in rtfs:
+ n += 1
+ T += m['T']
+ P += m['P']
+
+ print(f"RTF: {P/T}, utts: {n}")
diff --git a/demos/streaming_asr_server/local/test.sh b/demos/streaming_asr_server/local/test.sh
new file mode 100755
index 000000000..d70dd336f
--- /dev/null
+++ b/demos/streaming_asr_server/local/test.sh
@@ -0,0 +1,21 @@
+#!/bin/bash
+
+if [ $# != 1 ];then
+ echo "usage: $0 wav_scp"
+ exit -1
+fi
+
+scp=$1
+
+# calc RTF
+# wav_scp can generate from `speechx/examples/ds2_ol/aishell`
+
+exp=exp
+mkdir -p $exp
+
+python3 local/websocket_client.py --server_ip 127.0.0.1 --port 8090 --wavscp $scp &> $exp/log.rsl
+
+python3 local/rtf_from_log.py --logfile $exp/log.rsl
+
+
+
\ No newline at end of file
diff --git a/demos/streaming_asr_server/websocket_client.py b/demos/streaming_asr_server/local/websocket_client.py
similarity index 82%
rename from demos/streaming_asr_server/websocket_client.py
rename to demos/streaming_asr_server/local/websocket_client.py
index 523ef482d..51ae7a2f4 100644
--- a/demos/streaming_asr_server/websocket_client.py
+++ b/demos/streaming_asr_server/local/websocket_client.py
@@ -1,3 +1,4 @@
+#!/usr/bin/python
# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
@@ -11,8 +12,9 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-#!/usr/bin/python
-# -*- coding: UTF-8 -*-
+# calc avg RTF(NOT Accurate): grep -rn RTF log.txt | awk '{print $NF}' | awk -F "=" '{sum += $NF} END {print "all time",sum, "audio num", NR, "RTF", sum/NR}'
+# python3 websocket_client.py --server_ip 127.0.0.1 --port 8290 --punc.server_ip 127.0.0.1 --punc.port 8190 --wavfile ./zh.wav
+# python3 websocket_client.py --server_ip 127.0.0.1 --port 8290 --wavfile ./zh.wav
import argparse
import asyncio
import codecs
@@ -28,6 +30,7 @@ def main(args):
handler = ASRWsAudioHandler(
args.server_ip,
args.port,
+ endpoint=args.endpoint,
punc_server_ip=args.punc_server_ip,
punc_server_port=args.punc_server_port)
loop = asyncio.get_event_loop()
@@ -39,7 +42,7 @@ def main(args):
result = result["result"]
logger.info(f"asr websocket client finished : {result}")
- # support to process batch audios from wav.scp
+ # support to process batch audios from wav.scp
if args.wavscp and os.path.exists(args.wavscp):
logging.info(f"start to process the wavscp: {args.wavscp}")
with codecs.open(args.wavscp, 'r', encoding='utf-8') as f,\
@@ -69,7 +72,11 @@ if __name__ == "__main__":
default=8091,
dest="punc_server_port",
help='Punctuation server port')
-
+ parser.add_argument(
+ "--endpoint",
+ type=str,
+ default="/paddlespeech/asr/streaming",
+ help="ASR websocket endpoint")
parser.add_argument(
"--wavfile",
action="store",
diff --git a/demos/streaming_asr_server/punc_server.py b/demos/streaming_asr_server/punc_server.py
new file mode 100644
index 000000000..eefa0fb40
--- /dev/null
+++ b/demos/streaming_asr_server/punc_server.py
@@ -0,0 +1,38 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+
+from paddlespeech.cli.log import logger
+from paddlespeech.server.bin.paddlespeech_server import ServerExecutor
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(
+ prog='paddlespeech_server.start', add_help=True)
+ parser.add_argument(
+ "--config_file",
+ action="store",
+ help="yaml file of the app",
+ default=None,
+ required=True)
+
+ parser.add_argument(
+ "--log_file",
+ action="store",
+ help="log file",
+ default="./log/paddlespeech.log")
+ logger.info("start to parse the args")
+ args = parser.parse_args()
+
+ logger.info("start to launch the punctuation server")
+ punc_server = ServerExecutor()
+ punc_server(config_file=args.config_file, log_file=args.log_file)
diff --git a/demos/streaming_asr_server/server.sh b/demos/streaming_asr_server/server.sh
new file mode 100755
index 000000000..f532546e7
--- /dev/null
+++ b/demos/streaming_asr_server/server.sh
@@ -0,0 +1,9 @@
+export CUDA_VISIBLE_DEVICE=0,1,2,3
+ export CUDA_VISIBLE_DEVICE=0,1,2,3
+
+# nohup python3 punc_server.py --config_file conf/punc_application.yaml > punc.log 2>&1 &
+paddlespeech_server start --config_file conf/punc_application.yaml &> punc.log &
+
+# nohup python3 streaming_asr_server.py --config_file conf/ws_conformer_wenetspeech_application.yaml > streaming_asr.log 2>&1 &
+paddlespeech_server start --config_file conf/ws_conformer_wenetspeech_application.yaml &> streaming_asr.log &
+
diff --git a/demos/streaming_asr_server/streaming_asr_server.py b/demos/streaming_asr_server/streaming_asr_server.py
new file mode 100644
index 000000000..011b009aa
--- /dev/null
+++ b/demos/streaming_asr_server/streaming_asr_server.py
@@ -0,0 +1,38 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+
+from paddlespeech.cli.log import logger
+from paddlespeech.server.bin.paddlespeech_server import ServerExecutor
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(
+ prog='paddlespeech_server.start', add_help=True)
+ parser.add_argument(
+ "--config_file",
+ action="store",
+ help="yaml file of the app",
+ default=None,
+ required=True)
+
+ parser.add_argument(
+ "--log_file",
+ action="store",
+ help="log file",
+ default="./log/paddlespeech.log")
+ logger.info("start to parse the args")
+ args = parser.parse_args()
+
+ logger.info("start to launch the streaming asr server")
+ streaming_asr_server = ServerExecutor()
+ streaming_asr_server(config_file=args.config_file, log_file=args.log_file)
diff --git a/demos/streaming_asr_server/test.sh b/demos/streaming_asr_server/test.sh
old mode 100644
new mode 100755
index fe8155cf3..67a5ec4c5
--- a/demos/streaming_asr_server/test.sh
+++ b/demos/streaming_asr_server/test.sh
@@ -1,5 +1,11 @@
# download the test wav
wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
-# read the wav and pass it to service
-python3 websocket_client.py --wavfile ./zh.wav
+# read the wav and pass it to only streaming asr service
+# If `127.0.0.1` is not accessible, you need to use the actual service IP address.
+paddlespeech_client asr_online --server_ip 127.0.0.1 --port 8090 --input ./zh.wav
+
+# read the wav and call streaming and punc service
+# If `127.0.0.1` is not accessible, you need to use the actual service IP address.
+paddlespeech_client asr_online --server_ip 127.0.0.1 --port 8290 --punc.server_ip 127.0.0.1 --punc.port 8190 --input ./zh.wav
+
diff --git a/demos/streaming_asr_server/web/templates/index.html b/demos/streaming_asr_server/web/templates/index.html
index 56c630808..768aebb8c 100644
--- a/demos/streaming_asr_server/web/templates/index.html
+++ b/demos/streaming_asr_server/web/templates/index.html
@@ -93,6 +93,7 @@
function parseResult(data) {
var data = JSON.parse(data)
+ console.log('result json:', data)
var result = data.result
console.log(result)
$("#resultPanel").html(result)
diff --git a/demos/streaming_tts_server/README.md b/demos/streaming_tts_server/README.md
index c974cd9d1..860d9a978 100644
--- a/demos/streaming_tts_server/README.md
+++ b/demos/streaming_tts_server/README.md
@@ -10,13 +10,13 @@ This demo is an implementation of starting the streaming speech synthesis servic
### 1. Installation
see [installation](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install.md).
-It is recommended to use **paddlepaddle 2.2.1** or above.
+It is recommended to use **paddlepaddle 2.2.2** or above.
You can choose one way from meduim and hard to install paddlespeech.
### 2. Prepare config File
The configuration file can be found in `conf/tts_online_application.yaml`.
-- `protocol` indicates the network protocol used by the streaming TTS service. Currently, both http and websocket are supported.
+- `protocol` indicates the network protocol used by the streaming TTS service. Currently, both **http and websocket** are supported.
- `engine_list` indicates the speech engine that will be included in the service to be started, in the format of `_`.
- This demo mainly introduces the streaming speech synthesis service, so the speech task should be set to `tts`.
- the engine type supports two forms: **online** and **online-onnx**. `online` indicates an engine that uses python for dynamic graph inference; `online-onnx` indicates an engine that uses onnxruntime for inference. The inference speed of online-onnx is faster.
@@ -27,16 +27,18 @@ The configuration file can be found in `conf/tts_online_application.yaml`.
- In streaming voc inference, one chunk of data is inferred at a time to achieve a streaming effect. Where `voc_block` indicates the number of valid frames in the chunk, and `voc_pad` indicates the number of frames added before and after the voc_block in a chunk. The existence of voc_pad is used to eliminate errors caused by streaming inference and avoid the influence of streaming inference on the quality of synthesized audio.
- Both hifigan and mb_melgan support streaming voc inference.
- When the voc model is mb_melgan, when voc_pad=14, the synthetic audio for streaming inference is consistent with the non-streaming synthetic audio; the minimum voc_pad can be set to 7, and the synthetic audio has no abnormal hearing. If the voc_pad is less than 7, the synthetic audio sounds abnormal.
- - When the voc model is hifigan, when voc_pad=20, the streaming inference synthetic audio is consistent with the non-streaming synthetic audio; when voc_pad=14, the synthetic audio has no abnormal hearing.
+ - When the voc model is hifigan, when voc_pad=19, the streaming inference synthetic audio is consistent with the non-streaming synthetic audio; when voc_pad=14, the synthetic audio has no abnormal hearing.
- Inference speed: mb_melgan > hifigan; Audio quality: mb_melgan < hifigan
+- **Note:** If the service can be started normally in the container, but the client access IP is unreachable, you can try to replace the `host` address in the configuration file with the local IP address.
-### 3. Server Usage
+### 3. Streaming speech synthesis server and client using http protocol
+#### 3.1 Server Usage
- Command Line (Recommended)
+ Start the service (the configuration file uses http by default):
```bash
- # start the service
paddlespeech_server start --config_file ./conf/tts_online_application.yaml
```
@@ -61,8 +63,8 @@ The configuration file can be found in `conf/tts_online_application.yaml`.
[2022-04-24 20:05:28] [INFO] [on.py:45] Waiting for application startup.
INFO: Application startup complete.
[2022-04-24 20:05:28] [INFO] [on.py:59] Application startup complete.
- INFO: Uvicorn running on http://127.0.0.1:8092 (Press CTRL+C to quit)
- [2022-04-24 20:05:28] [INFO] [server.py:211] Uvicorn running on http://127.0.0.1:8092 (Press CTRL+C to quit)
+ INFO: Uvicorn running on http://0.0.0.0:8092 (Press CTRL+C to quit)
+ [2022-04-24 20:05:28] [INFO] [server.py:211] Uvicorn running on http://0.0.0.0:8092 (Press CTRL+C to quit)
```
@@ -76,7 +78,7 @@ The configuration file can be found in `conf/tts_online_application.yaml`.
log_file="./log/paddlespeech.log")
```
- Output:
+ Output:
```bash
[2022-04-24 21:00:16,934] [ INFO] - The first response time of the 0 warm up: 1.268730878829956 s
[2022-04-24 21:00:17,046] [ INFO] - The first response time of the 1 warm up: 0.11168622970581055 s
@@ -88,23 +90,23 @@ The configuration file can be found in `conf/tts_online_application.yaml`.
[2022-04-24 21:00:17] [INFO] [on.py:45] Waiting for application startup.
INFO: Application startup complete.
[2022-04-24 21:00:17] [INFO] [on.py:59] Application startup complete.
- INFO: Uvicorn running on http://127.0.0.1:8092 (Press CTRL+C to quit)
- [2022-04-24 21:00:17] [INFO] [server.py:211] Uvicorn running on http://127.0.0.1:8092 (Press CTRL+C to quit)
+ INFO: Uvicorn running on http://0.0.0.0:8092 (Press CTRL+C to quit)
+ [2022-04-24 21:00:17] [INFO] [server.py:211] Uvicorn running on http://0.0.0.0:8092 (Press CTRL+C to quit)
```
-
-### 4. Streaming TTS client Usage
+#### 3.2 Streaming TTS client Usage
- Command Line (Recommended)
- ```bash
- # Access http streaming TTS service
- paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8092 --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
+ Access http streaming TTS service:
- # Access websocket streaming TTS service
- paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8092 --protocol websocket --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
+ If `127.0.0.1` is not accessible, you need to use the actual service IP address.
+
+ ```bash
+ paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8092 --protocol http --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
```
+
Usage:
```bash
@@ -122,7 +124,7 @@ The configuration file can be found in `conf/tts_online_application.yaml`.
- `sample_rate`: Sampling rate, choices: [0, 8000, 16000], the default is the same as the model. Default: 0
- `output`: Output wave filepath. Default: None, which means not to save the audio to the local.
- `play`: Whether to play audio, play while synthesizing, default value: False, which means not playing. **Playing audio needs to rely on the pyaudio library**.
-
+ - `spk_id, speed, volume, sample_rate` do not take effect in streaming speech synthesis service temporarily.
Output:
```bash
@@ -165,8 +167,147 @@ The configuration file can be found in `conf/tts_online_application.yaml`.
[2022-04-24 21:11:16,802] [ INFO] - 音频时长:3.825 s
[2022-04-24 21:11:16,802] [ INFO] - RTF: 0.7846773683635238
[2022-04-24 21:11:16,837] [ INFO] - 音频保存至:./output.wav
+ ```
+
+
+### 4. Streaming speech synthesis server and client using websocket protocol
+#### 4.1 Server Usage
+- Command Line (Recommended)
+ First modify the configuration file `conf/tts_online_application.yaml`, **set `protocol` to `websocket`**.
+ Start the service:
+ ```bash
+ paddlespeech_server start --config_file ./conf/tts_online_application.yaml
+ ```
+
+ Usage:
+
+ ```bash
+ paddlespeech_server start --help
+ ```
+ Arguments:
+ - `config_file`: yaml file of the app, defalut: ./conf/tts_online_application.yaml
+ - `log_file`: log file. Default: ./log/paddlespeech.log
+
+ Output:
+ ```bash
+ [2022-04-27 10:18:09,107] [ INFO] - The first response time of the 0 warm up: 1.1551103591918945 s
+ [2022-04-27 10:18:09,219] [ INFO] - The first response time of the 1 warm up: 0.11204338073730469 s
+ [2022-04-27 10:18:09,324] [ INFO] - The first response time of the 2 warm up: 0.1051797866821289 s
+ [2022-04-27 10:18:09,325] [ INFO] - **********************************************************************
+ INFO: Started server process [17600]
+ [2022-04-27 10:18:09] [INFO] [server.py:75] Started server process [17600]
+ INFO: Waiting for application startup.
+ [2022-04-27 10:18:09] [INFO] [on.py:45] Waiting for application startup.
+ INFO: Application startup complete.
+ [2022-04-27 10:18:09] [INFO] [on.py:59] Application startup complete.
+ INFO: Uvicorn running on http://0.0.0.0:8092 (Press CTRL+C to quit)
+ [2022-04-27 10:18:09] [INFO] [server.py:211] Uvicorn running on http://0.0.0.0:8092 (Press CTRL+C to quit)
+
+
+ ```
+
+- Python API
+ ```python
+ from paddlespeech.server.bin.paddlespeech_server import ServerExecutor
+
+ server_executor = ServerExecutor()
+ server_executor(
+ config_file="./conf/tts_online_application.yaml",
+ log_file="./log/paddlespeech.log")
+ ```
+
+ Output:
+ ```bash
+ [2022-04-27 10:20:16,660] [ INFO] - The first response time of the 0 warm up: 1.0945196151733398 s
+ [2022-04-27 10:20:16,773] [ INFO] - The first response time of the 1 warm up: 0.11222052574157715 s
+ [2022-04-27 10:20:16,878] [ INFO] - The first response time of the 2 warm up: 0.10494542121887207 s
+ [2022-04-27 10:20:16,878] [ INFO] - **********************************************************************
+ INFO: Started server process [23466]
+ [2022-04-27 10:20:16] [INFO] [server.py:75] Started server process [23466]
+ INFO: Waiting for application startup.
+ [2022-04-27 10:20:16] [INFO] [on.py:45] Waiting for application startup.
+ INFO: Application startup complete.
+ [2022-04-27 10:20:16] [INFO] [on.py:59] Application startup complete.
+ INFO: Uvicorn running on http://0.0.0.0:8092 (Press CTRL+C to quit)
+ [2022-04-27 10:20:16] [INFO] [server.py:211] Uvicorn running on http://0.0.0.0:8092 (Press CTRL+C to quit)
+
+ ```
+
+#### 4.2 Streaming TTS client Usage
+- Command Line (Recommended)
+
+ Access websocket streaming TTS service:
+
+ If `127.0.0.1` is not accessible, you need to use the actual service IP address.
+
+ ```bash
+ paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8092 --protocol websocket --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
+ ```
+
+ Usage:
+
+ ```bash
+ paddlespeech_client tts_online --help
+ ```
+
+ Arguments:
+ - `server_ip`: erver ip. Default: 127.0.0.1
+ - `port`: server port. Default: 8092
+ - `protocol`: Service protocol, choices: [http, websocket], default: http.
+ - `input`: (required): Input text to generate.
+ - `spk_id`: Speaker id for multi-speaker text to speech. Default: 0
+ - `speed`: Audio speed, the value should be set between 0 and 3. Default: 1.0
+ - `volume`: Audio volume, the value should be set between 0 and 3. Default: 1.0
+ - `sample_rate`: Sampling rate, choices: [0, 8000, 16000], the default is the same as the model. Default: 0
+ - `output`: Output wave filepath. Default: None, which means not to save the audio to the local.
+ - `play`: Whether to play audio, play while synthesizing, default value: False, which means not playing. **Playing audio needs to rely on the pyaudio library**.
+ - `spk_id, speed, volume, sample_rate` do not take effect in streaming speech synthesis service temporarily.
+
+
+ Output:
+ ```bash
+ [2022-04-27 10:21:04,262] [ INFO] - tts websocket client start
+ [2022-04-27 10:21:04,496] [ INFO] - 句子:您好,欢迎使用百度飞桨语音合成服务。
+ [2022-04-27 10:21:04,496] [ INFO] - 首包响应:0.2124948501586914 s
+ [2022-04-27 10:21:07,483] [ INFO] - 尾包响应:3.199106454849243 s
+ [2022-04-27 10:21:07,484] [ INFO] - 音频时长:3.825 s
+ [2022-04-27 10:21:07,484] [ INFO] - RTF: 0.8363677006141812
+ [2022-04-27 10:21:07,516] [ INFO] - 音频保存至:output.wav
+ ```
+
+- Python API
+ ```python
+ from paddlespeech.server.bin.paddlespeech_client import TTSOnlineClientExecutor
+ import json
+
+ executor = TTSOnlineClientExecutor()
+ executor(
+ input="您好,欢迎使用百度飞桨语音合成服务。",
+ server_ip="127.0.0.1",
+ port=8092,
+ protocol="websocket",
+ spk_id=0,
+ speed=1.0,
+ volume=1.0,
+ sample_rate=0,
+ output="./output.wav",
+ play=False)
+
+ ```
+
+ Output:
+ ```bash
+ [2022-04-27 10:22:48,852] [ INFO] - tts websocket client start
+ [2022-04-27 10:22:49,080] [ INFO] - 句子:您好,欢迎使用百度飞桨语音合成服务。
+ [2022-04-27 10:22:49,080] [ INFO] - 首包响应:0.21017956733703613 s
+ [2022-04-27 10:22:52,100] [ INFO] - 尾包响应:3.2304444313049316 s
+ [2022-04-27 10:22:52,101] [ INFO] - 音频时长:3.825 s
+ [2022-04-27 10:22:52,101] [ INFO] - RTF: 0.8445606356352762
+ [2022-04-27 10:22:52,134] [ INFO] - 音频保存至:./output.wav
```
+
+
diff --git a/demos/streaming_tts_server/README_cn.md b/demos/streaming_tts_server/README_cn.md
index 01194b2f7..254ec26a2 100644
--- a/demos/streaming_tts_server/README_cn.md
+++ b/demos/streaming_tts_server/README_cn.md
@@ -1,4 +1,4 @@
-([简体中文](./README_cn.md)|English)
+(简体中文|[English](./README.md))
# 流式语音合成服务
@@ -10,31 +10,34 @@
### 1. 安装
请看 [安装文档](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install.md).
-推荐使用 **paddlepaddle 2.2.1** 或以上版本。
+推荐使用 **paddlepaddle 2.2.2** 或以上版本。
你可以从 medium,hard 两种方式中选择一种方式安装 PaddleSpeech。
### 2. 准备配置文件
配置文件可参见 `conf/tts_online_application.yaml` 。
-- `protocol`表示该流式TTS服务使用的网络协议,目前支持 http 和 websocket 两种。
-- `engine_list`表示即将启动的服务将会包含的语音引擎,格式为 <语音任务>_<引擎类型>。
- - 该demo主要介绍流式语音合成服务,因此语音任务应设置为tts。
- - 目前引擎类型支持两种形式:**online** 表示使用python进行动态图推理的引擎;**online-onnx** 表示使用onnxruntime进行推理的引擎。其中,online-onnx的推理速度更快。
-- 流式TTS引擎的AM模型支持:fastspeech2 以及fastspeech2_cnndecoder; Voc 模型支持:hifigan, mb_melgan
-- 流式am推理中,每次会对一个chunk的数据进行推理以达到流式的效果。其中`am_block`表示chunk中的有效帧数,`am_pad` 表示一个chunk中am_block前后各加的帧数。am_pad的存在用于消除流式推理产生的误差,避免由流式推理对合成音频质量的影响。
- - fastspeech2不支持流式am推理,因此am_pad与am_block对它无效
- - fastspeech2_cnndecoder 支持流式推理,当am_pad=12时,流式推理合成音频与非流式合成音频一致
-- 流式voc推理中,每次会对一个chunk的数据进行推理以达到流式的效果。其中`voc_block`表示chunk中的有效帧数,`voc_pad` 表示一个chunk中voc_block前后各加的帧数。voc_pad的存在用于消除流式推理产生的误差,避免由流式推理对合成音频质量的影响。
- - hifigan, mb_melgan 均支持流式voc 推理
- - 当voc模型为mb_melgan,当voc_pad=14时,流式推理合成音频与非流式合成音频一致;voc_pad最小可以设置为7,合成音频听感上没有异常,若voc_pad小于7,合成音频听感上存在异常。
- - 当voc模型为hifigan,当voc_pad=20时,流式推理合成音频与非流式合成音频一致;当voc_pad=14时,合成音频听感上没有异常。
+- `protocol` 表示该流式 TTS 服务使用的网络协议,目前支持 **http 和 websocket** 两种。
+- `engine_list` 表示即将启动的服务将会包含的语音引擎,格式为 <语音任务>_<引擎类型>。
+ - 该 demo 主要介绍流式语音合成服务,因此语音任务应设置为 tts。
+ - 目前引擎类型支持两种形式:**online** 表示使用python进行动态图推理的引擎;**online-onnx** 表示使用 onnxruntime 进行推理的引擎。其中,online-onnx 的推理速度更快。
+- 流式 TTS 引擎的 AM 模型支持:**fastspeech2 以及fastspeech2_cnndecoder**; Voc 模型支持:**hifigan, mb_melgan**
+- 流式 am 推理中,每次会对一个 chunk 的数据进行推理以达到流式的效果。其中 `am_block` 表示 chunk 中的有效帧数,`am_pad` 表示一个 chunk 中 am_block 前后各加的帧数。am_pad 的存在用于消除流式推理产生的误差,避免由流式推理对合成音频质量的影响。
+ - fastspeech2 不支持流式 am 推理,因此 am_pad 与 m_block 对它无效
+ - fastspeech2_cnndecoder 支持流式推理,当 am_pad=12 时,流式推理合成音频与非流式合成音频一致
+- 流式 voc 推理中,每次会对一个 chunk 的数据进行推理以达到流式的效果。其中 `voc_block` 表示chunk中的有效帧数,`voc_pad` 表示一个 chunk 中 voc_block 前后各加的帧数。voc_pad 的存在用于消除流式推理产生的误差,避免由流式推理对合成音频质量的影响。
+ - hifigan, mb_melgan 均支持流式 voc 推理
+ - 当 voc 模型为 mb_melgan,当 voc_pad=14 时,流式推理合成音频与非流式合成音频一致;voc_pad 最小可以设置为7,合成音频听感上没有异常,若 voc_pad 小于7,合成音频听感上存在异常。
+ - 当 voc 模型为 hifigan,当 voc_pad=19 时,流式推理合成音频与非流式合成音频一致;当 voc_pad=14 时,合成音频听感上没有异常。
- 推理速度:mb_melgan > hifigan; 音频质量:mb_melgan < hifigan
+- **注意:** 如果在容器里可正常启动服务,但客户端访问 ip 不可达,可尝试将配置文件中 `host` 地址换成本地 ip 地址。
-### 3. 服务端使用方法
+
+### 3. 使用http协议的流式语音合成服务端及客户端使用方法
+#### 3.1 服务端使用方法
- 命令行 (推荐使用)
+ 启动服务(配置文件默认使用http):
```bash
- # 启动服务
paddlespeech_server start --config_file ./conf/tts_online_application.yaml
```
@@ -44,7 +47,7 @@
paddlespeech_server start --help
```
参数:
- - `config_file`: 服务的配置文件,默认: ./conf/application.yaml
+ - `config_file`: 服务的配置文件,默认: ./conf/tts_online_application.yaml
- `log_file`: log 文件. 默认:./log/paddlespeech.log
输出:
@@ -59,8 +62,8 @@
[2022-04-24 20:05:28] [INFO] [on.py:45] Waiting for application startup.
INFO: Application startup complete.
[2022-04-24 20:05:28] [INFO] [on.py:59] Application startup complete.
- INFO: Uvicorn running on http://127.0.0.1:8092 (Press CTRL+C to quit)
- [2022-04-24 20:05:28] [INFO] [server.py:211] Uvicorn running on http://127.0.0.1:8092 (Press CTRL+C to quit)
+ INFO: Uvicorn running on http://0.0.0.0:8092 (Press CTRL+C to quit)
+ [2022-04-24 20:05:28] [INFO] [server.py:211] Uvicorn running on http://0.0.0.0:8092 (Press CTRL+C to quit)
```
@@ -86,23 +89,23 @@
[2022-04-24 21:00:17] [INFO] [on.py:45] Waiting for application startup.
INFO: Application startup complete.
[2022-04-24 21:00:17] [INFO] [on.py:59] Application startup complete.
- INFO: Uvicorn running on http://127.0.0.1:8092 (Press CTRL+C to quit)
- [2022-04-24 21:00:17] [INFO] [server.py:211] Uvicorn running on http://127.0.0.1:8092 (Press CTRL+C to quit)
+ INFO: Uvicorn running on http://0.0.0.0:8092 (Press CTRL+C to quit)
+ [2022-04-24 21:00:17] [INFO] [server.py:211] Uvicorn running on http://0.0.0.0:8092 (Press CTRL+C to quit)
```
-
-### 4. 流式TTS 客户端使用方法
+#### 3.2 客户端使用方法
- 命令行 (推荐使用)
- ```bash
- # 访问 http 流式TTS服务
- paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8092 --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
+ 访问 http 流式TTS服务:
- # 访问 websocket 流式TTS服务
- paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8092 --protocol websocket --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
+ 若 `127.0.0.1` 不能访问,则需要使用实际服务 IP 地址
+
+ ```bash
+ paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8092 --protocol http --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
```
+
使用帮助:
```bash
@@ -120,6 +123,7 @@
- `sample_rate`: 采样率,可选 [0, 8000, 16000],默认值:0,表示与模型采样率相同
- `output`: 输出音频的路径, 默认值:None,表示不保存音频到本地。
- `play`: 是否播放音频,边合成边播放, 默认值:False,表示不播放。**播放音频需要依赖pyaudio库**。
+ - `spk_id, speed, volume, sample_rate` 在流式语音合成服务中暂时不生效。
输出:
@@ -163,8 +167,146 @@
[2022-04-24 21:11:16,802] [ INFO] - 音频时长:3.825 s
[2022-04-24 21:11:16,802] [ INFO] - RTF: 0.7846773683635238
[2022-04-24 21:11:16,837] [ INFO] - 音频保存至:./output.wav
+ ```
+
+
+### 4. 使用websocket协议的流式语音合成服务端及客户端使用方法
+#### 4.1 服务端使用方法
+- 命令行 (推荐使用)
+ 首先修改配置文件 `conf/tts_online_application.yaml`, **将 `protocol` 设置为 `websocket`**。
+ 启动服务:
+ ```bash
+ paddlespeech_server start --config_file ./conf/tts_online_application.yaml
+ ```
+
+ 使用方法:
+
+ ```bash
+ paddlespeech_server start --help
+ ```
+ 参数:
+ - `config_file`: 服务的配置文件,默认: ./conf/tts_online_application.yaml
+ - `log_file`: log 文件. 默认:./log/paddlespeech.log
+
+ 输出:
+ ```bash
+ [2022-04-27 10:18:09,107] [ INFO] - The first response time of the 0 warm up: 1.1551103591918945 s
+ [2022-04-27 10:18:09,219] [ INFO] - The first response time of the 1 warm up: 0.11204338073730469 s
+ [2022-04-27 10:18:09,324] [ INFO] - The first response time of the 2 warm up: 0.1051797866821289 s
+ [2022-04-27 10:18:09,325] [ INFO] - **********************************************************************
+ INFO: Started server process [17600]
+ [2022-04-27 10:18:09] [INFO] [server.py:75] Started server process [17600]
+ INFO: Waiting for application startup.
+ [2022-04-27 10:18:09] [INFO] [on.py:45] Waiting for application startup.
+ INFO: Application startup complete.
+ [2022-04-27 10:18:09] [INFO] [on.py:59] Application startup complete.
+ INFO: Uvicorn running on http://0.0.0.0:8092 (Press CTRL+C to quit)
+ [2022-04-27 10:18:09] [INFO] [server.py:211] Uvicorn running on http://0.0.0.0:8092 (Press CTRL+C to quit)
```
+- Python API
+ ```python
+ from paddlespeech.server.bin.paddlespeech_server import ServerExecutor
+
+ server_executor = ServerExecutor()
+ server_executor(
+ config_file="./conf/tts_online_application.yaml",
+ log_file="./log/paddlespeech.log")
+ ```
+
+ 输出:
+ ```bash
+ [2022-04-27 10:20:16,660] [ INFO] - The first response time of the 0 warm up: 1.0945196151733398 s
+ [2022-04-27 10:20:16,773] [ INFO] - The first response time of the 1 warm up: 0.11222052574157715 s
+ [2022-04-27 10:20:16,878] [ INFO] - The first response time of the 2 warm up: 0.10494542121887207 s
+ [2022-04-27 10:20:16,878] [ INFO] - **********************************************************************
+ INFO: Started server process [23466]
+ [2022-04-27 10:20:16] [INFO] [server.py:75] Started server process [23466]
+ INFO: Waiting for application startup.
+ [2022-04-27 10:20:16] [INFO] [on.py:45] Waiting for application startup.
+ INFO: Application startup complete.
+ [2022-04-27 10:20:16] [INFO] [on.py:59] Application startup complete.
+ INFO: Uvicorn running on http://0.0.0.0:8092 (Press CTRL+C to quit)
+ [2022-04-27 10:20:16] [INFO] [server.py:211] Uvicorn running on http://0.0.0.0:8092 (Press CTRL+C to quit)
+
+ ```
+
+#### 4.2 客户端使用方法
+- 命令行 (推荐使用)
+
+ 访问 websocket 流式TTS服务:
+
+ 若 `127.0.0.1` 不能访问,则需要使用实际服务 IP 地址
+
+ ```bash
+ paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8092 --protocol websocket --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
+ ```
+
+ 使用帮助:
+
+ ```bash
+ paddlespeech_client tts_online --help
+ ```
+
+ 参数:
+ - `server_ip`: 服务端ip地址,默认: 127.0.0.1。
+ - `port`: 服务端口,默认: 8092。
+ - `protocol`: 服务协议,可选 [http, websocket], 默认: http。
+ - `input`: (必须输入): 待合成的文本。
+ - `spk_id`: 说话人 id,用于多说话人语音合成,默认值: 0。
+ - `speed`: 音频速度,该值应设置在 0 到 3 之间。 默认值:1.0
+ - `volume`: 音频音量,该值应设置在 0 到 3 之间。 默认值: 1.0
+ - `sample_rate`: 采样率,可选 [0, 8000, 16000],默认值:0,表示与模型采样率相同
+ - `output`: 输出音频的路径, 默认值:None,表示不保存音频到本地。
+ - `play`: 是否播放音频,边合成边播放, 默认值:False,表示不播放。**播放音频需要依赖pyaudio库**。
+ - `spk_id, speed, volume, sample_rate` 在流式语音合成服务中暂时不生效。
+
+
+ 输出:
+ ```bash
+ [2022-04-27 10:21:04,262] [ INFO] - tts websocket client start
+ [2022-04-27 10:21:04,496] [ INFO] - 句子:您好,欢迎使用百度飞桨语音合成服务。
+ [2022-04-27 10:21:04,496] [ INFO] - 首包响应:0.2124948501586914 s
+ [2022-04-27 10:21:07,483] [ INFO] - 尾包响应:3.199106454849243 s
+ [2022-04-27 10:21:07,484] [ INFO] - 音频时长:3.825 s
+ [2022-04-27 10:21:07,484] [ INFO] - RTF: 0.8363677006141812
+ [2022-04-27 10:21:07,516] [ INFO] - 音频保存至:output.wav
+
+ ```
+
+- Python API
+ ```python
+ from paddlespeech.server.bin.paddlespeech_client import TTSOnlineClientExecutor
+ import json
+
+ executor = TTSOnlineClientExecutor()
+ executor(
+ input="您好,欢迎使用百度飞桨语音合成服务。",
+ server_ip="127.0.0.1",
+ port=8092,
+ protocol="websocket",
+ spk_id=0,
+ speed=1.0,
+ volume=1.0,
+ sample_rate=0,
+ output="./output.wav",
+ play=False)
+
+ ```
+
+ 输出:
+ ```bash
+ [2022-04-27 10:22:48,852] [ INFO] - tts websocket client start
+ [2022-04-27 10:22:49,080] [ INFO] - 句子:您好,欢迎使用百度飞桨语音合成服务。
+ [2022-04-27 10:22:49,080] [ INFO] - 首包响应:0.21017956733703613 s
+ [2022-04-27 10:22:52,100] [ INFO] - 尾包响应:3.2304444313049316 s
+ [2022-04-27 10:22:52,101] [ INFO] - 音频时长:3.825 s
+ [2022-04-27 10:22:52,101] [ INFO] - RTF: 0.8445606356352762
+ [2022-04-27 10:22:52,134] [ INFO] - 音频保存至:./output.wav
+
+ ```
+
+
diff --git a/demos/streaming_tts_server/conf/tts_online_application.yaml b/demos/streaming_tts_server/conf/tts_online_application.yaml
index 67d4641a0..0460a5e16 100644
--- a/demos/streaming_tts_server/conf/tts_online_application.yaml
+++ b/demos/streaming_tts_server/conf/tts_online_application.yaml
@@ -3,7 +3,7 @@
#################################################################################
# SERVER SETTING #
#################################################################################
-host: 127.0.0.1
+host: 0.0.0.0
port: 8092
# The task format in the engin_list is: _
@@ -43,12 +43,12 @@ tts_online:
device: 'cpu' # set 'gpu:id' or 'cpu'
# am_block and am_pad only for fastspeech2_cnndecoder_onnx model to streaming am infer,
# when am_pad set 12, streaming synthetic audio is the same as non-streaming synthetic audio
- am_block: 42
+ am_block: 72
am_pad: 12
# voc_pad and voc_block voc model to streaming voc infer,
# when voc model is mb_melgan_csmsc, voc_pad set 14, streaming synthetic audio is the same as non-streaming synthetic audio; The minimum value of pad can be set to 7, streaming synthetic audio sounds normal
- # when voc model is hifigan_csmsc, voc_pad set 20, streaming synthetic audio is the same as non-streaming synthetic audio; voc_pad set 14, streaming synthetic audio sounds normal
- voc_block: 14
+ # when voc model is hifigan_csmsc, voc_pad set 19, streaming synthetic audio is the same as non-streaming synthetic audio; voc_pad set 14, streaming synthetic audio sounds normal
+ voc_block: 36
voc_pad: 14
@@ -91,12 +91,12 @@ tts_online-onnx:
lang: 'zh'
# am_block and am_pad only for fastspeech2_cnndecoder_onnx model to streaming am infer,
# when am_pad set 12, streaming synthetic audio is the same as non-streaming synthetic audio
- am_block: 42
+ am_block: 72
am_pad: 12
# voc_pad and voc_block voc model to streaming voc infer,
# when voc model is mb_melgan_csmsc_onnx, voc_pad set 14, streaming synthetic audio is the same as non-streaming synthetic audio; The minimum value of pad can be set to 7, streaming synthetic audio sounds normal
- # when voc model is hifigan_csmsc_onnx, voc_pad set 20, streaming synthetic audio is the same as non-streaming synthetic audio; voc_pad set 14, streaming synthetic audio sounds normal
- voc_block: 14
+ # when voc model is hifigan_csmsc_onnx, voc_pad set 19, streaming synthetic audio is the same as non-streaming synthetic audio; voc_pad set 14, streaming synthetic audio sounds normal
+ voc_block: 36
voc_pad: 14
# voc_upsample should be same as n_shift on voc config.
voc_upsample: 300
diff --git a/demos/streaming_tts_server/test_client.sh b/demos/streaming_tts_server/test_client.sh
index 869820952..bd88f20b1 100644
--- a/demos/streaming_tts_server/test_client.sh
+++ b/demos/streaming_tts_server/test_client.sh
@@ -1,7 +1,9 @@
#!/bin/bash
# http client test
+# If `127.0.0.1` is not accessible, you need to use the actual service IP address.
paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8092 --protocol http --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
# websocket client test
-#paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8092 --protocol websocket --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
+# If `127.0.0.1` is not accessible, you need to use the actual service IP address.
+# paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8092 --protocol websocket --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
diff --git a/demos/text_to_speech/README.md b/demos/text_to_speech/README.md
index 2df72a82d..389847a12 100644
--- a/demos/text_to_speech/README.md
+++ b/demos/text_to_speech/README.md
@@ -77,7 +77,7 @@ The input of this demo should be a text of the specific language that can be pas
- Python API
```python
import paddle
- from paddlespeech.cli import TTSExecutor
+ from paddlespeech.cli.tts import TTSExecutor
tts_executor = TTSExecutor()
wav_file = tts_executor(
diff --git a/demos/text_to_speech/README_cn.md b/demos/text_to_speech/README_cn.md
index 7e02b9624..f967d3d4d 100644
--- a/demos/text_to_speech/README_cn.md
+++ b/demos/text_to_speech/README_cn.md
@@ -80,7 +80,7 @@
- Python API
```python
import paddle
- from paddlespeech.cli import TTSExecutor
+ from paddlespeech.cli.tts import TTSExecutor
tts_executor = TTSExecutor()
wav_file = tts_executor(
diff --git a/docker/ubuntu18-cpu/Dockerfile b/docker/ubuntu18-cpu/Dockerfile
new file mode 100644
index 000000000..d14c01858
--- /dev/null
+++ b/docker/ubuntu18-cpu/Dockerfile
@@ -0,0 +1,15 @@
+FROM registry.baidubce.com/paddlepaddle/paddle:2.2.2
+LABEL maintainer="paddlesl@baidu.com"
+
+RUN git clone --depth 1 https://github.com/PaddlePaddle/PaddleSpeech.git /home/PaddleSpeech
+RUN pip3 uninstall mccabe -y ; exit 0;
+RUN pip3 install multiprocess==0.70.12 importlib-metadata==4.2.0 dill==0.3.4
+
+RUN cd /home/PaddleSpeech/audio
+RUN python setup.py bdist_wheel
+
+RUN cd /home/PaddleSpeech
+RUN python setup.py bdist_wheel
+RUN pip install audio/dist/*.whl dist/*.whl
+
+WORKDIR /home/PaddleSpeech/
diff --git a/docs/paddlespeech.pdf b/docs/paddlespeech.pdf
new file mode 100644
index 000000000..a1c498ad2
Binary files /dev/null and b/docs/paddlespeech.pdf differ
diff --git a/docs/source/asr/PPASR.md b/docs/source/asr/PPASR.md
new file mode 100644
index 000000000..3779434e3
--- /dev/null
+++ b/docs/source/asr/PPASR.md
@@ -0,0 +1,96 @@
+([简体中文](./PPASR_cn.md)|English)
+# PP-ASR
+
+## Catalogue
+- [1. Introduction](#1)
+- [2. Characteristic](#2)
+- [3. Tutorials](#3)
+ - [3.1 Pre-trained Models](#31)
+ - [3.2 Training](#32)
+ - [3.3 Inference](#33)
+ - [3.4 Service Deployment](#33)
+ - [3.5 Customized Auto Speech Recognition and Deployment](#33)
+- [4. Quick Start](#4)
+
+
+## 1. Introduction
+
+PP-ASR is a tool to provide ASR(Automatic speech recognition) function. It provides a variety of Chinese and English models and supports model training. It also supports model inference using the command line. In addition, PP-ASR supports the deployment of streaming models and customized ASR.
+
+
+## 2. Characteristic
+The basic process of ASR is shown in the figure below:
+
+
+
+The main characteristics of PP-ASR are shown below:
+- Provides pre-trained models on Chinese/English open source datasets: aishell(Chinese), wenetspeech(Chinese) and librispeech(English). The models include deepspeech2 and conformer/transformer.
+- Support model training on Chinese/English datasets.
+- Support model inference using the command line. You can use to use `paddlespeech asr --model xxx --input xxx.wav` to use the pre-trained model to do model inference.
+- Support deployment of streaming ASR server. Besides ASR function, the server supports timestamp function.
+- Support customized auto speech recognition and deployment.
+
+
+## 3. Tutorials
+
+
+## 3.1 Pre-trained Models
+The support pre-trained model list: [released_model](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/released_model.md).
+The model with good effect are Ds2 Online Wenetspeech ASR0 Model and Conformer Online Wenetspeech ASR1 Model. Both two models support streaming ASR.
+For more information about model design, you can refer to the aistudio tutorial:
+- [Deepspeech2](https://aistudio.baidu.com/aistudio/projectdetail/3866807)
+- [Transformer](https://aistudio.baidu.com/aistudio/projectdetail/3470110)
+
+
+## 3.2 Training
+The referenced script for model training is stored in [examples](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples) and stored according to "examples/dataset/model". The dataset mainly supports aishell and librispeech. The model supports deepspeech2 and u2(conformer/transformer).
+The specific steps of executing the script are recorded in `run.sh`.
+
+For more information, you can refer to [asr1](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/aishell/asr1)
+
+
+
+## 3.3 Inference
+
+PP-ASR supports use `paddlespeech asr --model xxx --input xxx.wav` to use the pre-trained model to do model inference after install `paddlespeech` by `pip install paddlespeech`.
+
+Specific supported functions include:
+
+- Prediction of single audio
+- Use the pipe to predict multiple audio
+- Support RTF calculation
+
+For specific usage, please refer to: [speech_recognition](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/demos/speech_recognition/README_cn.md)
+
+
+
+## 3.4 Service Deployment
+
+PP-ASR supports the service deployment of streaming ASR. Support the simultaneous use of speech recognition and punctuation processing.
+
+Demo of ASR Server: [streaming_asr_server](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/streaming_asr_server)
+
+
+
+Display of using ASR server on Web page: [streaming_asr_demo_video](https://paddlespeech.readthedocs.io/en/latest/streaming_asr_demo_video.html)
+
+
+For more information about service deployment, you can refer to the aistudio tutorial:
+- [Streaming service - model part](https://aistudio.baidu.com/aistudio/projectdetail/3839884)
+- [Streaming service](https://aistudio.baidu.com/aistudio/projectdetail/4017905)
+
+
+## 3.5 Customized Auto Speech Recognition and Deployment
+
+For customized auto speech recognition and deployment, PP-ASR provides feature extraction(fbank) => Inference model(Scoring Library)=> C++ program of TLG(WFST, token, lexion, grammer). For specific usage, please refer to: [speechx](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/speechx)
+If you want to quickly use it, you can refer to [custom_streaming_asr](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/demos/custom_streaming_asr/README_cn.md)
+
+For more information about customized auto speech recognition and deployment, you can refer to the aistudio tutorial:
+- [Customized Auto Speech Recognition](https://aistudio.baidu.com/aistudio/projectdetail/4021561)
+
+
+
+
+## 4. Quick Start
+
+To use PP-ASR, you can see here [install](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install_cn.md), It supplies three methods to install `paddlespeech`, which are **Easy**, **Medium** and **Hard**. If you want to experience the inference function of paddlespeech, you can use **Easy** installation method.
diff --git a/docs/source/asr/PPASR_cn.md b/docs/source/asr/PPASR_cn.md
new file mode 100644
index 000000000..2e3f1cd97
--- /dev/null
+++ b/docs/source/asr/PPASR_cn.md
@@ -0,0 +1,94 @@
+(简体中文|[English](./PPASR.md))
+# PP-ASR
+
+## 目录
+- [1. 简介](#1)
+- [2. 特点](#2)
+- [3. 使用教程](#3)
+ - [3.1 预训练模型](#31)
+ - [3.2 模型训练](#32)
+ - [3.3 模型推理](#33)
+ - [3.4 服务部署](#33)
+ - [3.5 支持个性化场景部署](#33)
+- [4. 快速开始](#4)
+
+
+## 1. 简介
+
+PP-ASR 是一个 提供 ASR 功能的工具。其提供了多种中文和英文的模型,支持模型的训练,并且支持使用命令行的方式进行模型的推理。 PP-ASR 也支持流式模型的部署,以及个性化场景的部署。
+
+
+## 2. 特点
+语音识别的基本流程如下图所示:
+
+
+
+PP-ASR 的主要特点如下:
+- 提供在中/英文开源数据集 aishell (中文),wenetspeech(中文),librispeech (英文)上的预训练模型。模型包含 deepspeech2 模型以及 conformer/transformer 模型。
+- 支持中/英文的模型训练功能。
+- 支持命令行方式的模型推理,可使用 `paddlespeech asr --model xxx --input xxx.wav` 方式调用各个预训练模型进行推理。
+- 支持流式 ASR 的服务部署,也支持输出时间戳。
+- 支持个性化场景的部署。
+
+
+## 3. 使用教程
+
+
+## 3.1 预训练模型
+支持的预训练模型列表:[released_model](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/released_model.md)。
+其中效果较好的模型为 Ds2 Online Wenetspeech ASR0 Model 以及 Conformer Online Wenetspeech ASR1 Model。 两个模型都支持流式 ASR。
+更多关于模型设计的部分,可以参考 AIStudio 教程:
+- [Deepspeech2](https://aistudio.baidu.com/aistudio/projectdetail/3866807)
+- [Transformer](https://aistudio.baidu.com/aistudio/projectdetail/3470110)
+
+
+## 3.2 模型训练
+
+模型的训练的参考脚本存放在 [examples](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples) 中,并按照 `examples/数据集/模型` 存放,数据集主要支持 aishell 和 librispeech,模型支持 deepspeech2 模型和 u2 (conformer/transformer) 模型。
+具体的执行脚本的步骤记录在 `run.sh` 当中。具体可参考: [asr1](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/aishell/asr1)
+
+
+
+## 3.3 模型推理
+
+PP-ASR 支持在使用`pip install paddlespeech`后 使用命令行的方式来使用预训练模型进行推理。
+
+具体支持的功能包括:
+
+- 对单条音频进行预测
+- 使用管道的方式对多条音频进行预测
+- 支持 RTF 的计算
+
+具体的使用方式可以参考: [speech_recognition](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/demos/speech_recognition/README_cn.md)
+
+
+
+## 3.4 服务部署
+
+PP-ASR 支持流式ASR的服务部署。支持 语音识别 + 标点处理两个功能同时使用。
+
+server 的 demo: [streaming_asr_server](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/streaming_asr_server)
+
+
+
+网页上使用 asr server 的效果展示:[streaming_asr_demo_video](https://paddlespeech.readthedocs.io/en/latest/streaming_asr_demo_video.html)
+
+关于服务部署方面的更多资料,可以参考 AIStudio 教程:
+- [流式服务-模型部分](https://aistudio.baidu.com/aistudio/projectdetail/3839884)
+- [流式服务](https://aistudio.baidu.com/aistudio/projectdetail/4017905)
+
+
+## 3.5 支持个性化场景部署
+
+针对个性化场景部署,提供了特征提取(fbank) => 推理模型(打分库)=> TLG(WFST, token, lexion, grammer)的 C++ 程序。具体参考 [speechx](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/speechx)。
+如果想快速了解和使用,可以参考: [custom_streaming_asr](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/demos/custom_streaming_asr/README_cn.md)
+
+关于支持个性化场景部署的更多资料,可以参考 AIStudio 教程:
+- [定制化识别](https://aistudio.baidu.com/aistudio/projectdetail/4021561)
+
+
+
+
+## 4. 快速开始
+
+关于如果使用 PP-ASR,可以看这里的 [install](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install_cn.md),其中提供了 **简单**、**中等**、**困难** 三种安装方式。如果想体验 paddlespeech 的推理功能,可以用 **简单** 安装方式。
diff --git a/audio/docs/source/_static/custom.css b/docs/source/audio/_static/custom.css
similarity index 100%
rename from audio/docs/source/_static/custom.css
rename to docs/source/audio/_static/custom.css
diff --git a/audio/docs/source/_templates/module.rst_t b/docs/source/audio/_templates/module.rst_t
similarity index 100%
rename from audio/docs/source/_templates/module.rst_t
rename to docs/source/audio/_templates/module.rst_t
diff --git a/audio/docs/source/_templates/package.rst_t b/docs/source/audio/_templates/package.rst_t
similarity index 100%
rename from audio/docs/source/_templates/package.rst_t
rename to docs/source/audio/_templates/package.rst_t
diff --git a/audio/docs/source/_templates/toc.rst_t b/docs/source/audio/_templates/toc.rst_t
similarity index 100%
rename from audio/docs/source/_templates/toc.rst_t
rename to docs/source/audio/_templates/toc.rst_t
diff --git a/audio/docs/source/conf.py b/docs/source/audio/conf.py
similarity index 100%
rename from audio/docs/source/conf.py
rename to docs/source/audio/conf.py
diff --git a/audio/docs/source/index.rst b/docs/source/audio/index.rst
similarity index 100%
rename from audio/docs/source/index.rst
rename to docs/source/audio/index.rst
diff --git a/docs/source/cls/custom_dataset.md b/docs/source/cls/custom_dataset.md
index aaf5943c5..e39dcf12d 100644
--- a/docs/source/cls/custom_dataset.md
+++ b/docs/source/cls/custom_dataset.md
@@ -1,8 +1,8 @@
# Customize Dataset for Audio Classification
-Following this tutorial you can customize your dataset for audio classification task by using `paddlespeech` and `paddleaudio`.
+Following this tutorial you can customize your dataset for audio classification task by using `paddlespeech`.
-A base class of classification dataset is `paddleaudio.dataset.AudioClassificationDataset`. To customize your dataset you should write a dataset class derived from `AudioClassificationDataset`.
+A base class of classification dataset is `paddlespeech.audio.dataset.AudioClassificationDataset`. To customize your dataset you should write a dataset class derived from `AudioClassificationDataset`.
Assuming you have some wave files that stored in your own directory. You should prepare a meta file with the information of filepaths and labels. For example the absolute path of it is `/PATH/TO/META_FILE.txt`:
```
@@ -14,7 +14,7 @@ Assuming you have some wave files that stored in your own directory. You should
Here is an example to build your custom dataset in `custom_dataset.py`:
```python
-from paddleaudio.datasets.dataset import AudioClassificationDataset
+from paddlespeech.audio.datasets.dataset import AudioClassificationDataset
class CustomDataset(AudioClassificationDataset):
meta_file = '/PATH/TO/META_FILE.txt'
@@ -48,7 +48,7 @@ class CustomDataset(AudioClassificationDataset):
Then you can build dataset and data loader from `CustomDataset`:
```python
import paddle
-from paddleaudio.features import LogMelSpectrogram
+from paddlespeech.audio.features import LogMelSpectrogram
from custom_dataset import CustomDataset
diff --git a/docs/source/index.rst b/docs/source/index.rst
index 7f9c87bdb..fc1649eb3 100644
--- a/docs/source/index.rst
+++ b/docs/source/index.rst
@@ -54,7 +54,9 @@ Contents
:caption: Demos
demo_video
+ streaming_asr_demo_video
tts_demo_video
+ streaming_tts_demo_video
.. toctree::
diff --git a/docs/source/install.md b/docs/source/install.md
index bdeb37cec..ac48d88ba 100644
--- a/docs/source/install.md
+++ b/docs/source/install.md
@@ -4,7 +4,7 @@ There are 3 ways to use `PaddleSpeech`. According to the degree of difficulty, t
| Way | Function | Support|
|:---- |:----------------------------------------------------------- |:----|
-| Easy | (1) Use command-line functions of PaddleSpeech. (2) Experience PaddleSpeech on Ai Studio. | Linux, Mac(not support M1 chip),Windows |
+| Easy | (1) Use command-line functions of PaddleSpeech. (2) Experience PaddleSpeech on Ai Studio. | Linux, Mac(not support M1 chip),Windows ( For more information about installation, see [#1195](https://github.com/PaddlePaddle/PaddleSpeech/discussions/1195)) |
| Medium | Support major functions ,such as using the` ready-made `examples and using PaddleSpeech to train your model. | Linux |
| Hard | Support full function of Paddlespeech, including using join ctc decoder with kaldi, training n-gram language model, Montreal-Forced-Aligner, and so on. And you are more able to be a developer! | Ubuntu |
@@ -139,28 +139,13 @@ pip install . -i https://pypi.tuna.tsinghua.edu.cn/simple
To avoid the trouble of environment setup, running in a Docker container is highly recommended. Otherwise, if you work on `Ubuntu` with `root` privilege, you can still complete the installation.
### Choice 1: Running in Docker Container (Recommend)
-Docker is an open-source tool to build, ship, and run distributed applications in an isolated environment. A Docker image for this project has been provided in [hub.docker.com](https://hub.docker.com) with all the dependencies installed. This Docker image requires the support of NVIDIA GPU, so please make sure its availability and the [nvidia-docker](https://github.com/NVIDIA/nvidia-docker) has been installed.
+Docker is an open-source tool to build, ship, and run distributed applications in an isolated environment. If you do not have a Docker environment, please refer to [Docker](https://www.docker.com/). If you will use GPU version, you also need to install [nvidia-docker](https://github.com/NVIDIA/nvidia-docker).
-Take several steps to launch the Docker image:
-- Download the Docker image
+We provide docker images containing the latest PaddleSpeech code, and all environment and package dependencies are pre-installed. All you have to do is to **pull and run the docker image**. Then you can enjoy PaddleSpeech without any extra steps.
-For example, pull paddle 2.2.0 image:
-```bash
-sudo nvidia-docker pull registry.baidubce.com/paddlepaddle/paddle:2.2.0-gpu-cuda10.2-cudnn7
-```
-- Clone this repository
-```bash
-git clone https://github.com/PaddlePaddle/PaddleSpeech.git
-```
-- Run the Docker image
-```bash
-sudo nvidia-docker run --net=host --ipc=host --rm -it -v $(pwd)/PaddleSpeech:/PaddleSpeech registry.baidubce.com/paddlepaddle/paddle:2.2.0-gpu-cuda10.2-cudnn7 /bin/bash
-```
-- Enter PaddleSpeech directory.
-```bash
-cd /PaddleSpeech
-```
-Now you can execute training, inference, and hyper-parameters tuning in Docker container.
+Get these images and guidance in [docker hub](https://hub.docker.com/repository/docker/paddlecloud/paddlespeech), including CPU, GPU, ROCm environment versions.
+
+If you have some customized requirements about automatic building docker images, you can get it in github repo [PaddlePaddle/PaddleCloud](https://github.com/PaddlePaddle/PaddleCloud/tree/main/tekton).
### Choice 2: Running in Ubuntu with Root Privilege
- Install `build-essential` by apt
diff --git a/docs/source/install_cn.md b/docs/source/install_cn.md
index 55fef93d5..345e79bb5 100644
--- a/docs/source/install_cn.md
+++ b/docs/source/install_cn.md
@@ -3,7 +3,7 @@
`PaddleSpeech` 有三种安装方法。根据安装的难易程度,这三种方法可以分为 **简单**, **中等** 和 **困难**.
| 方式 | 功能 | 支持系统 |
| :--- | :----------------------------------------------------------- | :------------------ |
-| 简单 | (1) 使用 PaddleSpeech 的命令行功能. (2) 在 Aistudio上体验 PaddleSpeech. | Linux, Mac(不支持M1芯片),Windows |
+| 简单 | (1) 使用 PaddleSpeech 的命令行功能. (2) 在 Aistudio上体验 PaddleSpeech. | Linux, Mac(不支持M1芯片),Windows (安装详情查看[#1195](https://github.com/PaddlePaddle/PaddleSpeech/discussions/1195)) |
| 中等 | 支持 PaddleSpeech 主要功能,比如使用已有 examples 中的模型和使用 PaddleSpeech 来训练自己的模型. | Linux |
| 困难 | 支持 PaddleSpeech 的各项功能,包含结合kaldi使用 join ctc decoder 方式解码,训练语言模型,使用强制对齐等。并且你更能成为一名开发者! | Ubuntu |
## 先决条件
@@ -130,26 +130,14 @@ pip install . -i https://pypi.tuna.tsinghua.edu.cn/simple
- 选择 2: 使用`Ubuntu` ,并且拥有 root 权限。
为了避免各种环境配置问题,我们非常推荐你使用 docker 容器。如果你不想使用 docker,但是可以使用拥有 root 权限的 Ubuntu 系统,你也可以完成**困难**方式的安装。
-### 选择1: 使用Docker容器(推荐)
-Docker 是一种开源工具,用于在和系统本身环境相隔离的环境中构建、发布和运行各类应用程序。你可以访问 [hub.docker.com](https://hub.docker.com) 来下载各种版本的 docker,目前已经有适用于 `PaddleSpeech` 的 docker 提供在了该网站上。Docker 镜像需要使用 Nvidia GPU,所以你也需要提前安装好 [nvidia-docker](https://github.com/NVIDIA/nvidia-docker) 。
-你需要完成几个步骤来启动docker:
-- 下载 docker 镜像:
- 例如,拉取 paddle2.2.0 镜像:
-```bash
-sudo nvidia-docker pull registry.baidubce.com/paddlepaddle/paddle:2.2.0-gpu-cuda10.2-cudnn7
-```
-- 克隆 `PaddleSpeech` 仓库
-```bash
-git clone https://github.com/PaddlePaddle/PaddleSpeech.git
-```
-- 启动 docker 镜像
-```bash
-sudo nvidia-docker run --net=host --ipc=host --rm -it -v $(pwd)/PaddleSpeech:/PaddleSpeech registry.baidubce.com/paddlepaddle/paddle:2.2.0-gpu-cuda10.2-cudnn7 /bin/bash
-```
-- 进入 PaddleSpeech 目录
-```bash
-cd /PaddleSpeech
-```
+### 选择1: 使用 Docker 容器(推荐)
+Docker 是一种开源工具,用于在和系统本身环境相隔离的环境中构建、发布和运行各类应用程序。如果您没有 Docker 运行环境,请参考 [Docker 官网](https://www.docker.com/)进行安装,如果您准备使用 GPU 版本镜像,还需要提前安装好 [nvidia-docker](https://github.com/NVIDIA/nvidia-docker) 。
+
+我们提供了包含最新 PaddleSpeech 代码的 docker 镜像,并预先安装好了所有的环境和库依赖,您只需要**拉取并运行 docker 镜像**,无需其他任何额外操作,即可开始享用 PaddleSpeech 的所有功能。
+
+在 [Docker Hub](https://hub.docker.com/repository/docker/paddlecloud/paddlespeech) 中获取这些镜像及相应的使用指南,包括 CPU、GPU、ROCm 版本。
+
+如果您对自动化制作docker镜像感兴趣,或有自定义需求,请访问 [PaddlePaddle/PaddleCloud](https://github.com/PaddlePaddle/PaddleCloud/tree/main/tekton) 做进一步了解。
完成这些以后,你就可以在 docker 容器中执行训练、推理和超参 fine-tune。
### 选择2: 使用有 root 权限的 Ubuntu
- 使用apt安装 `build-essential`
diff --git a/docs/source/reference.md b/docs/source/reference.md
index f1a02d200..ed91c2066 100644
--- a/docs/source/reference.md
+++ b/docs/source/reference.md
@@ -13,6 +13,7 @@ We borrowed a lot of code from these repos to build `model` and `engine`, thanks
- Apache-2.0 License
- U2 model
- Building TLG based Graph
+- websocket server & client
* [kaldi](https://github.com/kaldi-asr/kaldi/blob/master/COPYING)
- Apache-2.0 License
diff --git a/docs/source/released_model.md b/docs/source/released_model.md
index aae882ef6..5afd3c478 100644
--- a/docs/source/released_model.md
+++ b/docs/source/released_model.md
@@ -6,13 +6,15 @@
### Speech Recognition Model
Acoustic Model | Training Data | Token-based | Size | Descriptions | CER | WER | Hours of speech | Example Link
:-------------:| :------------:| :-----: | -----: | :-----: |:-----:| :-----: | :-----: | :-----:
-[Ds2 Online Aishell ASR0 Model](https://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_online_aishell_fbank161_ckpt_0.2.0.model.tar.gz) | Aishell Dataset | Char-based | 479 MB | 2 Conv + 5 LSTM layers with only forward direction | 0.0718 |-| 151 h | [D2 Online Aishell ASR0](../../examples/aishell/asr0)
-[Ds2 Offline Aishell ASR0 Model](https://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_aishell_ckpt_0.1.1.model.tar.gz)| Aishell Dataset | Char-based | 306 MB | 2 Conv + 3 bidirectional GRU layers| 0.064 |-| 151 h | [Ds2 Offline Aishell ASR0](../../examples/aishell/asr0)
+[Ds2 Online Wenetspeech ASR0 Model](https://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr0/asr0_deepspeech2_online_wenetspeech_ckpt_1.0.2.model.tar.gz) | Wenetspeech Dataset | Char-based | 1.2 GB | 2 Conv + 5 LSTM layers | 0.152 (test\_net, w/o LM) 0.2417 (test\_meeting, w/o LM) 0.053 (aishell, w/ LM) |-| 10000 h |-
+[Ds2 Online Aishell ASR0 Model](https://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_online_aishell_fbank161_ckpt_0.2.1.model.tar.gz) | Aishell Dataset | Char-based | 491 MB | 2 Conv + 5 LSTM layers | 0.0666 |-| 151 h | [D2 Online Aishell ASR0](../../examples/aishell/asr0)
+[Ds2 Offline Aishell ASR0 Model](https://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_offline_aishell_ckpt_1.0.1.model.tar.gz)| Aishell Dataset | Char-based | 1.4 GB | 2 Conv + 5 bidirectional LSTM layers| 0.0554 |-| 151 h | [Ds2 Offline Aishell ASR0](../../examples/aishell/asr0)
+[Conformer Online Wenetspeech ASR1 Model](https://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr1/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar.gz) | WenetSpeech Dataset | Char-based | 457 MB | Encoder:Conformer, Decoder:Transformer, Decoding method: Attention rescoring| 0.11 (test\_net) 0.1879 (test\_meeting) |-| 10000 h |-
[Conformer Online Aishell ASR1 Model](https://paddlespeech.bj.bcebos.com/s2t/aishell/asr1/asr1_chunk_conformer_aishell_ckpt_0.2.0.model.tar.gz) | Aishell Dataset | Char-based | 189 MB | Encoder:Conformer, Decoder:Transformer, Decoding method: Attention rescoring| 0.0544 |-| 151 h | [Conformer Online Aishell ASR1](../../examples/aishell/asr1)
[Conformer Offline Aishell ASR1 Model](https://paddlespeech.bj.bcebos.com/s2t/aishell/asr1/asr1_conformer_aishell_ckpt_0.1.2.model.tar.gz) | Aishell Dataset | Char-based | 189 MB | Encoder:Conformer, Decoder:Transformer, Decoding method: Attention rescoring | 0.0464 |-| 151 h | [Conformer Offline Aishell ASR1](../../examples/aishell/asr1)
[Transformer Aishell ASR1 Model](https://paddlespeech.bj.bcebos.com/s2t/aishell/asr1/asr1_transformer_aishell_ckpt_0.1.1.model.tar.gz) | Aishell Dataset | Char-based | 128 MB | Encoder:Transformer, Decoder:Transformer, Decoding method: Attention rescoring | 0.0523 || 151 h | [Transformer Aishell ASR1](../../examples/aishell/asr1)
-[Ds2 Offline Librispeech ASR0 Model](https://paddlespeech.bj.bcebos.com/s2t/librispeech/asr0/asr0_deepspeech2_librispeech_ckpt_0.1.1.model.tar.gz)| Librispeech Dataset | Char-based | 518 MB | 2 Conv + 3 bidirectional LSTM layers| - |0.0725| 960 h | [Ds2 Offline Librispeech ASR0](../../examples/librispeech/asr0)
-[Conformer Librispeech ASR1 Model](https://paddlespeech.bj.bcebos.com/s2t/librispeech/asr1/asr1_conformer_librispeech_ckpt_0.1.1.model.tar.gz) | Librispeech Dataset | subword-based | 191 MB | Encoder:Conformer, Decoder:Transformer, Decoding method: Attention rescoring |-| 0.0337 | 960 h | [Conformer Librispeech ASR1](../../examples/librispeech/asr1)
+[Ds2 Offline Librispeech ASR0 Model](https://paddlespeech.bj.bcebos.com/s2t/librispeech/asr0/asr0_deepspeech2_offline_librispeech_ckpt_1.0.1.model.tar.gz)| Librispeech Dataset | Char-based | 1.3 GB | 2 Conv + 5 bidirectional LSTM layers| - |0.0467| 960 h | [Ds2 Offline Librispeech ASR0](../../examples/librispeech/asr0)
+[Conformer Librispeech ASR1 Model](https://paddlespeech.bj.bcebos.com/s2t/librispeech/asr1/asr1_conformer_librispeech_ckpt_0.1.1.model.tar.gz) | Librispeech Dataset | subword-based | 191 MB | Encoder:Conformer, Decoder:Transformer, Decoding method: Attention rescoring |-| 0.0338 | 960 h | [Conformer Librispeech ASR1](../../examples/librispeech/asr1)
[Transformer Librispeech ASR1 Model](https://paddlespeech.bj.bcebos.com/s2t/librispeech/asr1/asr1_transformer_librispeech_ckpt_0.1.1.model.tar.gz) | Librispeech Dataset | subword-based | 131 MB | Encoder:Transformer, Decoder:Transformer, Decoding method: Attention rescoring |-| 0.0381 | 960 h | [Transformer Librispeech ASR1](../../examples/librispeech/asr1)
[Transformer Librispeech ASR2 Model](https://paddlespeech.bj.bcebos.com/s2t/librispeech/asr2/asr2_transformer_librispeech_ckpt_0.1.1.model.tar.gz) | Librispeech Dataset | subword-based | 131 MB | Encoder:Transformer, Decoder:Transformer, Decoding method: JoinCTC w/ LM |-| 0.0240 | 960 h | [Transformer Librispeech ASR2](../../examples/librispeech/asr2)
@@ -80,17 +82,9 @@ PANN | ESC-50 |[pann-esc50](../../examples/esc50/cls0)|[esc50_cnn6.tar.gz](https
Model Type | Dataset| Example Link | Pretrained Models | Static Models
:-------------:| :------------:| :-----: | :-----: | :-----:
-PANN | VoxCeleb| [voxceleb_ecapatdnn](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/voxceleb/sv0) | [ecapatdnn.tar.gz](https://paddlespeech.bj.bcebos.com/vector/voxceleb/sv0_ecapa_tdnn_voxceleb12_ckpt_0_2_0.tar.gz) | -
+ECAPA-TDNN | VoxCeleb| [voxceleb_ecapatdnn](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/voxceleb/sv0) | [ecapatdnn.tar.gz](https://paddlespeech.bj.bcebos.com/vector/voxceleb/sv0_ecapa_tdnn_voxceleb12_ckpt_0_2_1.tar.gz) | -
## Punctuation Restoration Models
Model Type | Dataset| Example Link | Pretrained Models
:-------------:| :------------:| :-----: | :-----:
Ernie Linear | IWLST2012_zh |[iwslt2012_punc0](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/iwslt2012/punc0)|[ernie_linear_p3_iwslt2012_zh_ckpt_0.1.1.zip](https://paddlespeech.bj.bcebos.com/text/ernie_linear_p3_iwslt2012_zh_ckpt_0.1.1.zip)
-
-## Speech Recognition Model from paddle 1.8
-
-| Acoustic Model |Training Data| Token-based | Size | Descriptions | CER | WER | Hours of speech |
-| :-----:| :-----: | :-----: | :-----: | :-----: | :-----: | :-----: | :-----: |
-| [Ds2 Offline Aishell model](https://deepspeech.bj.bcebos.com/mandarin_models/aishell_model_v1.8_to_v2.x.tar.gz) | Aishell Dataset | Char-based | 234 MB | 2 Conv + 3 bidirectional GRU layers | 0.0804 | — | 151 h |
-| [Ds2 Offline Librispeech model](https://deepspeech.bj.bcebos.com/eng_models/librispeech_v1.8_to_v2.x.tar.gz) | Librispeech Dataset | Word-based | 307 MB | 2 Conv + 3 bidirectional sharing weight RNN layers | — | 0.0685 | 960 h |
-| [Ds2 Offline Baidu en8k model](https://deepspeech.bj.bcebos.com/eng_models/baidu_en8k_v1.8_to_v2.x.tar.gz) | Baidu Internal English Dataset | Word-based | 273 MB | 2 Conv + 3 bidirectional GRU layers |— | 0.0541 | 8628 h|
diff --git a/docs/source/streaming_asr_demo_video.rst b/docs/source/streaming_asr_demo_video.rst
new file mode 100644
index 000000000..6c96fea04
--- /dev/null
+++ b/docs/source/streaming_asr_demo_video.rst
@@ -0,0 +1,10 @@
+Streaming ASR Demo Video
+==================
+
+.. raw:: html
+
+
diff --git a/docs/source/streaming_tts_demo_video.rst b/docs/source/streaming_tts_demo_video.rst
new file mode 100644
index 000000000..3ad9ca6cf
--- /dev/null
+++ b/docs/source/streaming_tts_demo_video.rst
@@ -0,0 +1,12 @@
+Streaming TTS Demo Video
+==================
+
+.. raw:: html
+
+
+
diff --git a/docs/source/tts/PPTTS.md b/docs/source/tts/PPTTS.md
new file mode 100644
index 000000000..ef0baa07d
--- /dev/null
+++ b/docs/source/tts/PPTTS.md
@@ -0,0 +1,76 @@
+([简体中文](./PPTTS_cn.md)|English)
+
+# PPTTS
+
+- [1. Introduction](#1)
+- [2. Characteristic](#2)
+- [3. Benchmark](#3)
+- [4. Demo](#4)
+- [5. Tutorials](#5)
+ - [5.1 Training and Inference Optimization](#51)
+ - [5.2 Characteristic APPs of TTS](#52)
+ - [5.3 TTS Server](#53)
+
+
+## 1. Introduction
+
+PP-TTS is a streaming speech synthesis system developed by PaddleSpeech. Based on the implementation of [SOTA Algorithms](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/released_model.md#text-to-speech-models), a faster inference engine is used to realize streaming speech synthesis technology to meet the needs of commercial speech interaction scenarios.
+
+#### PP-TTS
+Pipline of TTS:
+
+
+PP-TTS provides a Chinese streaming speech synthesis system based on FastSpeech2 and HiFiGAN by default:
+
+- Text Frontend: The rule-based Chinese text frontend system is adopted to optimize Chinese text such as text normalization, polyphony, and tone sandhi.
+- Acoustic Model: The decoder of FastSpeech2 is improved so that it can be stream synthesized
+- Vocoder: Streaming synthesis of GAN vocoder is supported
+- Inference Engine: Using ONNXRuntime to optimize the inference of TTS models, so that the TTS system can also achieve RTF < 1 on low-voltage, meeting the requirements of streaming synthesis
+
+
+## 2. Characteristic
+- Open source leading Chinese TTS system
+- Using ONNXRuntime to optimize the inference of TTS models
+- The only open-source streaming TTS system
+- Easy disassembly: Developers can easily replace different acoustic models and vocoders in different languages, use different inference engines (Paddle dynamic graph, PaddleInference, ONNXRuntime, etc.), and use different network services (HTTP, WebSocket)
+
+
+## 3. Benchmark
+PaddleSpeech TTS models' benchmark: [TTS-Benchmark](https://github.com/PaddlePaddle/PaddleSpeech/wiki/TTS-Benchmark)。
+
+
+## 4. Demo
+See: [Streaming TTS Demo Video](https://paddlespeech.readthedocs.io/en/latest/streaming_tts_demo_video.html)
+
+
+## 5. Tutorials
+
+
+### 5.1 Training and Inference Optimization
+
+Default FastSpeech2: [tts3/run.sh](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/examples/csmsc/tts3/run.sh)
+
+Streaming FastSpeech2: [tts3/run_cnndecoder.sh](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/examples/csmsc/tts3/run_cnndecoder.sh)
+
+HiFiGAN:[voc5/run.sh](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/examples/csmsc/voc5/run.sh)
+
+
+### 5.2 Characteristic APPs of TTS
+text_to_speech - convert text into speech: [text_to_speech](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/text_to_speech)
+
+style_fs2 - multi style control for FastSpeech2 model: [style_fs2](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/style_fs2)
+
+story talker - book reader based on OCR and TTS: [story_talker](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/story_talker)
+
+metaverse - 2D AR with TTS: [metaverse](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/metaverse)
+
+
+### 5.3 TTS Server
+
+Non-streaming TTS Server: [speech_server](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/speech_server)
+
+Streaming TTS Server: [streaming_tts_server](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/streaming_tts_server)
+
+
+For more tutorials please see: [PP-TTS:流式语音合成原理及服务部署
+](https://aistudio.baidu.com/aistudio/projectdetail/3885352)
diff --git a/docs/source/tts/PPTTS_cn.md b/docs/source/tts/PPTTS_cn.md
new file mode 100644
index 000000000..2b650d62e
--- /dev/null
+++ b/docs/source/tts/PPTTS_cn.md
@@ -0,0 +1,76 @@
+(简体中文|[English](./PPTTS.md))
+
+# PP-TTS
+
+- [1. 简介](#1)
+- [2. 特性](#2)
+- [3. Benchmark](#3)
+- [4. 效果展示](#4)
+- [5. 使用教程](#5)
+ - [5.1 模型训练与推理优化](#51)
+ - [5.2 语音合成特色应用](#52)
+ - [5.3 语音合成服务搭建](#53)
+
+
+## 1. 简介
+
+PP-TTS 是 PaddleSpeech 自研的流式语音合成系统。在实现[前沿算法](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/released_model.md#text-to-speech-models)的基础上,使用了更快的推理引擎,实现了流式语音合成技术,使其满足商业语音交互场景的需求。
+
+#### PP-TTS
+语音合成基本流程如下图所示:
+
+
+PP-TTS 默认提供基于 FastSpeech2 声学模型和 HiFiGAN 声码器的中文流式语音合成系统:
+
+- 文本前端:采用基于规则的中文文本前端系统,对文本正则、多音字、变调等中文文本场景进行了优化。
+- 声学模型:对 FastSpeech2 模型的 Decoder 进行改进,使其可以流式合成
+- 声码器:支持对 GAN Vocoder 的流式合成
+- 推理引擎:使用 ONNXRuntime 推理引擎优化模型推理性能,使得语音合成系统在低压 CPU 上也能达到 RTF<1,满足流式合成的要求
+
+
+## 2. 特性
+- 开源领先的中文语音合成系统
+- 使用 ONNXRuntime 推理引擎优化模型推理性能
+- 唯一开源的流式语音合成系统
+- 易拆卸性:可以很方便地更换不同语种上的不同声学模型和声码器、使用不同的推理引擎(Paddle 动态图、PaddleInference 和 ONNXRuntime 等)、使用不同的网络服务(HTTP、Websocket)
+
+
+## 3. Benchmark
+PaddleSpeech TTS 模型之间的性能对比,请查看 [TTS-Benchmark](https://github.com/PaddlePaddle/PaddleSpeech/wiki/TTS-Benchmark)。
+
+
+## 4. 效果展示
+请参考:[Streaming TTS Demo Video](https://paddlespeech.readthedocs.io/en/latest/streaming_tts_demo_video.html)
+
+
+## 5. 使用教程
+
+
+### 5.1 模型训练与推理优化
+
+Default FastSpeech2:[tts3/run.sh](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/examples/csmsc/tts3/run.sh)
+
+流式 FastSpeech2:[tts3/run_cnndecoder.sh](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/examples/csmsc/tts3/run_cnndecoder.sh)
+
+HiFiGAN:[voc5/run.sh](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/examples/csmsc/voc5/run.sh)
+
+
+### 5.2 语音合成特色应用
+一键式实现语音合成:[text_to_speech](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/text_to_speech)
+
+个性化语音合成 - 基于 FastSpeech2 模型的个性化语音合成:[style_fs2](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/style_fs2)
+
+会说话的故事书 - 基于 OCR 和语音合成的会说话的故事书:[story_talker](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/story_talker)
+
+元宇宙 - 基于语音合成的 2D 增强现实:[metaverse](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/metaverse)
+
+
+### 5.3 语音合成服务搭建
+
+一键式搭建非流式语音合成服务:[speech_server](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/speech_server)
+
+一键式搭建流式语音合成服务:[streaming_tts_server](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/streaming_tts_server)
+
+
+更多教程,包括模型设计、模型训练、推理部署等,请参考 AIStudio 教程:[PP-TTS:流式语音合成原理及服务部署
+](https://aistudio.baidu.com/aistudio/projectdetail/3885352)
diff --git a/docs/source/vpr/PPVPR.md b/docs/source/vpr/PPVPR.md
new file mode 100644
index 000000000..a87dd621b
--- /dev/null
+++ b/docs/source/vpr/PPVPR.md
@@ -0,0 +1,78 @@
+([简体中文](./PPVPR_cn.md)|English)
+# PP-VPR
+
+## Catalogue
+- [1. Introduction](#1)
+- [2. Characteristic](#2)
+- [3. Tutorials](#3)
+ - [3.1 Pre-trained Models](#31)
+ - [3.2 Training](#32)
+ - [3.3 Inference](#33)
+ - [3.4 Service Deployment](#33)
+- [4. Quick Start](#4)
+
+
+## 1. Introduction
+
+PP-VPR is a tool that provides voice print feature extraction and retrieval functions. Provides a variety of quasi-industrial solutions, easy to solve the difficult problems in complex scenes, support the use of command line model reasoning. PP-VPR also supports interface operations and container deployment.
+
+
+## 2. Characteristic
+The basic process of VPR is shown in the figure below:
+
+
+
+The main characteristics of PP-ASR are shown below:
+- Provides pre-trained models on Chinese open source datasets: VoxCeleb(English). The models include ecapa-tdnn.
+- Support model training/evaluation.
+- Support model inference using the command line. You can use to use `paddlespeech vector --task spk --input xxx.wav` to use the pre-trained model to do model inference.
+- Support interface operations and container deployment.
+
+
+## 3. Tutorials
+
+
+## 3.1 Pre-trained Models
+The support pre-trained model list: [released_model](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/released_model.md).
+For more information about model design, you can refer to the aistudio tutorial:
+- [ecapa-tdnn](https://aistudio.baidu.com/aistudio/projectdetail/4027664)
+
+
+## 3.2 Training
+The referenced script for model training is stored in [examples](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples) and stored according to "examples/dataset/model". The dataset mainly supports VoxCeleb. The model supports ecapa-tdnn.
+The specific steps of executing the script are recorded in `run.sh`.
+
+For more information, you can refer to [sv0](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/voxceleb/sv0)
+
+
+
+## 3.3 Inference
+
+PP-VPR supports use `paddlespeech vector --task spk --input xxx.wav` to use the pre-trained model to do inference after install `paddlespeech` by `pip install paddlespeech`.
+
+Specific supported functions include:
+
+- Prediction of single audio
+- Score the similarity between the two audios
+- Support RTF calculation
+
+For specific usage, please refer to: [speaker_verification](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/demos/speaker_verification/README_cn.md)
+
+
+
+## 3.4 Service Deployment
+
+PP-VPR supports Docker containerized service deployment. Through Milvus, MySQL performs high performance library building search.
+
+Demo of VPR Server: [audio_searching](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/audio_searching)
+
+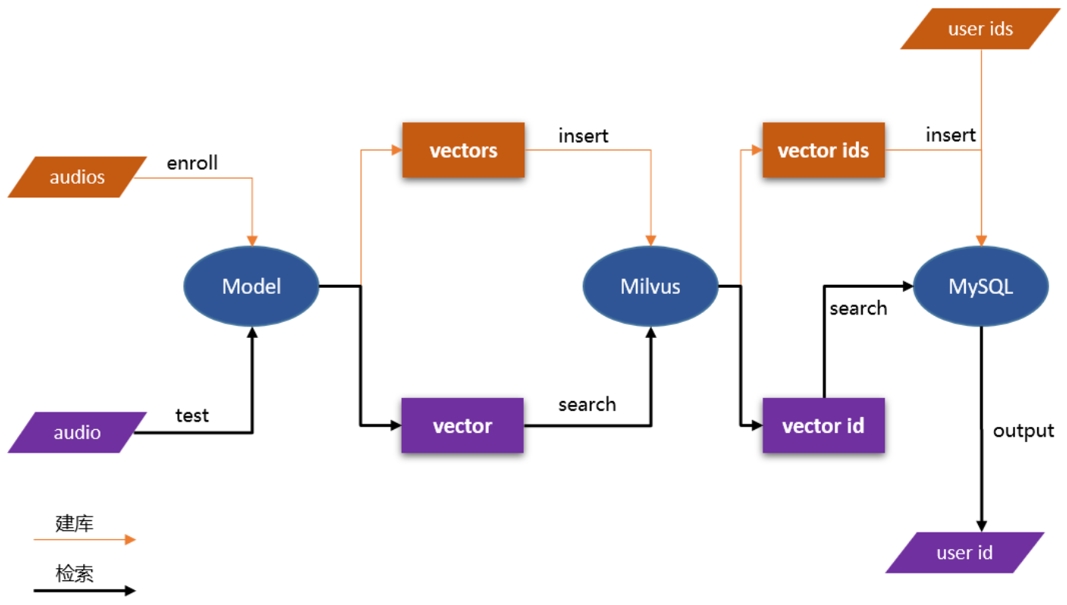
+
+For more information about service deployment, you can refer to the aistudio tutorial:
+- [speaker_recognition](https://aistudio.baidu.com/aistudio/projectdetail/4027664)
+
+
+
+## 4. Quick Start
+
+To use PP-VPR, you can see here [install](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install_cn.md), It supplies three methods to install `paddlespeech`, which are **Easy**, **Medium** and **Hard**. If you want to experience the inference function of paddlespeech, you can use **Easy** installation method.
diff --git a/docs/source/vpr/PPVPR_cn.md b/docs/source/vpr/PPVPR_cn.md
new file mode 100644
index 000000000..f0e562d1e
--- /dev/null
+++ b/docs/source/vpr/PPVPR_cn.md
@@ -0,0 +1,79 @@
+(简体中文|[English](./PPVPR.md))
+# PP-VPR
+
+## 目录
+- [1. 简介](#1)
+- [2. 特点](#2)
+- [3. 使用教程](#3)
+ - [3.1 预训练模型](#31)
+ - [3.2 模型训练](#32)
+ - [3.3 模型推理](#33)
+ - [3.4 服务部署](#33)
+- [4. 快速开始](#4)
+
+
+## 1. 简介
+
+PP-VPR 是一个 提供声纹特征提取,检索功能的工具。提供了多种准工业化的方案,轻松搞定复杂场景中的难题,支持使用命令行的方式进行模型的推理。 PP-VPR 也支持界面化的操作,容器化的部署。
+
+
+## 2. 特点
+VPR 的基本流程如下图所示:
+
+
+
+PP-VPR 的主要特点如下:
+- 提供在英文开源数据集 VoxCeleb(英文)上的预训练模型,ecapa-tdnn。
+- 支持模型训练评估功能。
+- 支持命令行方式的模型推理,可使用 `paddlespeech vector --task spk --input xxx.wav` 方式调用预训练模型进行推理。
+- 支持 VPR 的服务容器化部署,界面化操作。
+
+
+
+## 3. 使用教程
+
+
+## 3.1 预训练模型
+支持的预训练模型列表:[released_model](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/released_model.md)。
+更多关于模型设计的部分,可以参考 AIStudio 教程:
+- [ecapa-tdnn](https://aistudio.baidu.com/aistudio/projectdetail/4027664)
+
+
+## 3.2 模型训练
+
+模型的训练的参考脚本存放在 [examples](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples) 中,并按照 `examples/数据集/模型` 存放,数据集主要支持 VoxCeleb,模型支持 ecapa-tdnn 模型。
+具体的执行脚本的步骤记录在 `run.sh` 当中。具体可参考: [sv0](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/voxceleb/sv0)
+
+
+
+## 3.3 模型推理
+
+PP-VPR 支持在使用`pip install paddlespeech`后 使用命令行的方式来使用预训练模型进行推理。
+
+具体支持的功能包括:
+
+- 对单条音频进行预测
+- 对两条音频进行打分
+- 支持 RTF 的计算
+
+具体的使用方式可以参考: [speaker_verification](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/demos/speaker_verification/README_cn.md)
+
+
+
+## 3.4 服务部署
+
+PP-VPR 支持 Docker 容器化服务部署。通过 Milvus, MySQL 进行高性能建库检索。
+
+server 的 demo: [audio_searching](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/audio_searching)
+
+
+
+
+关于服务部署方面的更多资料,可以参考 AIStudio 教程:
+- [speaker_recognition](https://aistudio.baidu.com/aistudio/projectdetail/4027664)
+
+
+
+## 4. 快速开始
+
+关于如何使用 PP-VPR,可以看这里的 [install](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install_cn.md),其中提供了 **简单**、**中等**、**困难** 三种安装方式。如果想体验 paddlespeech 的推理功能,可以用 **简单** 安装方式。
diff --git a/examples/aishell/asr0/RESULTS.md b/examples/aishell/asr0/RESULTS.md
index fb1dbffe0..299445b77 100644
--- a/examples/aishell/asr0/RESULTS.md
+++ b/examples/aishell/asr0/RESULTS.md
@@ -4,6 +4,7 @@
| Model | Number of Params | Release | Config | Test set | Valid Loss | CER |
| --- | --- | --- | --- | --- | --- | --- |
+| DeepSpeech2 | 45.18M | r0.2.0 | conf/deepspeech2_online.yaml + U2 Data pipline and spec aug + fbank161 | test | 6.876979827880859 | 0.0666 |
| DeepSpeech2 | 45.18M | r0.2.0 | conf/deepspeech2_online.yaml + spec aug + fbank161 | test | 7.679287910461426 | 0.0718 |
| DeepSpeech2 | 45.18M | r0.2.0 | conf/deepspeech2_online.yaml + spec aug | test | 7.708217620849609| 0.078 |
| DeepSpeech2 | 45.18M | v2.2.0 | conf/deepspeech2_online.yaml + spec aug | test | 7.994938373565674 | 0.080 |
@@ -11,7 +12,8 @@
## Deepspeech2 Non-Streaming
| Model | Number of Params | Release | Config | Test set | Valid Loss | CER |
-| --- | --- | --- | --- | --- | --- | --- |
+| --- | --- | --- | --- | --- | --- | --- |
+| DeepSpeech2 | 122.3M | r1.0.1 | conf/deepspeech2.yaml + U2 Data pipline and spec aug + fbank161 | test | 5.780756044387817 | 0.055400 |
| DeepSpeech2 | 58.4M | v2.2.0 | conf/deepspeech2.yaml + spec aug | test | 5.738585948944092 | 0.064000 |
| DeepSpeech2 | 58.4M | v2.1.0 | conf/deepspeech2.yaml + spec aug | test | 7.483316898345947 | 0.077860 |
| DeepSpeech2 | 58.4M | v2.1.0 | conf/deepspeech2.yaml | test | 7.299022197723389 | 0.078671 |
diff --git a/examples/aishell/asr0/conf/augmentation.json b/examples/aishell/asr0/conf/augmentation.json
deleted file mode 100644
index 31c481c8d..000000000
--- a/examples/aishell/asr0/conf/augmentation.json
+++ /dev/null
@@ -1,36 +0,0 @@
-[
- {
- "type": "speed",
- "params": {
- "min_speed_rate": 0.9,
- "max_speed_rate": 1.1,
- "num_rates": 3
- },
- "prob": 0.0
- },
- {
- "type": "shift",
- "params": {
- "min_shift_ms": -5,
- "max_shift_ms": 5
- },
- "prob": 1.0
- },
- {
- "type": "specaug",
- "params": {
- "W": 0,
- "warp_mode": "PIL",
- "F": 10,
- "n_freq_masks": 2,
- "T": 50,
- "n_time_masks": 2,
- "p": 1.0,
- "adaptive_number_ratio": 0,
- "adaptive_size_ratio": 0,
- "max_n_time_masks": 20,
- "replace_with_zero": true
- },
- "prob": 1.0
- }
-]
diff --git a/examples/aishell/asr0/conf/deepspeech2.yaml b/examples/aishell/asr0/conf/deepspeech2.yaml
index fb6998647..913354f5d 100644
--- a/examples/aishell/asr0/conf/deepspeech2.yaml
+++ b/examples/aishell/asr0/conf/deepspeech2.yaml
@@ -15,50 +15,53 @@ max_output_input_ratio: .inf
###########################################
# Dataloader #
###########################################
-batch_size: 64 # one gpu
-mean_std_filepath: data/mean_std.json
-unit_type: char
vocab_filepath: data/lang_char/vocab.txt
-augmentation_config: conf/augmentation.json
-random_seed: 0
-spm_model_prefix:
-spectrum_type: linear
+spm_model_prefix: ''
+unit_type: 'char'
+preprocess_config: conf/preprocess.yaml
feat_dim: 161
-delta_delta: False
stride_ms: 10.0
-window_ms: 20.0
-n_fft: None
-max_freq: None
-target_sample_rate: 16000
-use_dB_normalization: True
-target_dB: -20
-dither: 1.0
-keep_transcription_text: False
-sortagrad: True
-shuffle_method: batch_shuffle
-num_workers: 2
+window_ms: 25.0
+sortagrad: 0 # Feed samples from shortest to longest ; -1: enabled for all epochs, 0: disabled, other: enabled for 'other' epochs
+batch_size: 64
+maxlen_in: 512 # if input length > maxlen-in, batchsize is automatically reduced
+maxlen_out: 150 # if output length > maxlen-out, batchsize is automatically reduced
+minibatches: 0 # for debug
+batch_count: auto
+batch_bins: 0
+batch_frames_in: 0
+batch_frames_out: 0
+batch_frames_inout: 0
+num_workers: 8
+subsampling_factor: 1
+num_encs: 1
############################################
# Network Architecture #
############################################
num_conv_layers: 2
-num_rnn_layers: 3
+num_rnn_layers: 5
rnn_layer_size: 1024
-use_gru: True
-share_rnn_weights: False
+rnn_direction: bidirect # [forward, bidirect]
+num_fc_layers: 0
+fc_layers_size_list: -1,
+use_gru: False
blank_id: 0
-ctc_grad_norm_type: instance
-
+
+
###########################################
# Training #
###########################################
-n_epoch: 80
+n_epoch: 50
accum_grad: 1
-lr: 2.0e-3
-lr_decay: 0.83
+lr: 5.0e-4
+lr_decay: 0.93
weight_decay: 1.0e-6
global_grad_clip: 3.0
-log_interval: 100
+dist_sampler: False
+log_interval: 1
checkpoint:
kbest_n: 50
latest_n: 5
+
+
diff --git a/examples/aishell/asr0/conf/deepspeech2_online.yaml b/examples/aishell/asr0/conf/deepspeech2_online.yaml
index ef01ac595..a53e19f37 100644
--- a/examples/aishell/asr0/conf/deepspeech2_online.yaml
+++ b/examples/aishell/asr0/conf/deepspeech2_online.yaml
@@ -15,28 +15,26 @@ max_output_input_ratio: .inf
###########################################
# Dataloader #
###########################################
-batch_size: 64 # one gpu
-mean_std_filepath: data/mean_std.json
-unit_type: char
vocab_filepath: data/lang_char/vocab.txt
-augmentation_config: conf/augmentation.json
-random_seed: 0
-spm_model_prefix:
-spectrum_type: linear #linear, mfcc, fbank
+spm_model_prefix: ''
+unit_type: 'char'
+preprocess_config: conf/preprocess.yaml
feat_dim: 161
-delta_delta: False
stride_ms: 10.0
-window_ms: 20.0
-n_fft: None
-max_freq: None
-target_sample_rate: 16000
-use_dB_normalization: True
-target_dB: -20
-dither: 1.0
-keep_transcription_text: False
-sortagrad: True
-shuffle_method: batch_shuffle
-num_workers: 0
+window_ms: 25.0
+sortagrad: 0 # Feed samples from shortest to longest ; -1: enabled for all epochs, 0: disabled, other: enabled for 'other' epochs
+batch_size: 64
+maxlen_in: 512 # if input length > maxlen-in, batchsize is automatically reduced
+maxlen_out: 150 # if output length > maxlen-out, batchsize is automatically reduced
+minibatches: 0 # for debug
+batch_count: auto
+batch_bins: 0
+batch_frames_in: 0
+batch_frames_out: 0
+batch_frames_inout: 0
+num_workers: 8
+subsampling_factor: 1
+num_encs: 1
############################################
# Network Architecture #
@@ -54,12 +52,13 @@ blank_id: 0
###########################################
# Training #
###########################################
-n_epoch: 65
+n_epoch: 30
accum_grad: 1
lr: 5.0e-4
lr_decay: 0.93
weight_decay: 1.0e-6
global_grad_clip: 3.0
+dist_sampler: False
log_interval: 100
checkpoint:
kbest_n: 50
diff --git a/examples/aishell/asr0/conf/preprocess.yaml b/examples/aishell/asr0/conf/preprocess.yaml
new file mode 100644
index 000000000..3f526e0ad
--- /dev/null
+++ b/examples/aishell/asr0/conf/preprocess.yaml
@@ -0,0 +1,25 @@
+process:
+ # extract kaldi fbank from PCM
+ - type: fbank_kaldi
+ fs: 16000
+ n_mels: 161
+ n_shift: 160
+ win_length: 400
+ dither: 0.1
+ - type: cmvn_json
+ cmvn_path: data/mean_std.json
+ # these three processes are a.k.a. SpecAugument
+ - type: time_warp
+ max_time_warp: 5
+ inplace: true
+ mode: PIL
+ - type: freq_mask
+ F: 30
+ n_mask: 2
+ inplace: true
+ replace_with_zero: false
+ - type: time_mask
+ T: 40
+ n_mask: 2
+ inplace: true
+ replace_with_zero: false
diff --git a/examples/aishell/asr0/conf/tuning/decode.yaml b/examples/aishell/asr0/conf/tuning/decode.yaml
index 5778e6565..7dbc6fa82 100644
--- a/examples/aishell/asr0/conf/tuning/decode.yaml
+++ b/examples/aishell/asr0/conf/tuning/decode.yaml
@@ -2,9 +2,9 @@ decode_batch_size: 128
error_rate_type: cer
decoding_method: ctc_beam_search
lang_model_path: data/lm/zh_giga.no_cna_cmn.prune01244.klm
-alpha: 1.9
-beta: 5.0
-beam_size: 300
+alpha: 2.2
+beta: 4.3
+beam_size: 500
cutoff_prob: 0.99
cutoff_top_n: 40
num_proc_bsearch: 10
diff --git a/examples/aishell/asr0/local/data.sh b/examples/aishell/asr0/local/data.sh
index ec692eba6..8722c1ca3 100755
--- a/examples/aishell/asr0/local/data.sh
+++ b/examples/aishell/asr0/local/data.sh
@@ -33,12 +33,13 @@ if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then
num_workers=$(nproc)
python3 ${MAIN_ROOT}/utils/compute_mean_std.py \
--manifest_path="data/manifest.train.raw" \
- --spectrum_type="linear" \
+ --spectrum_type="fbank" \
+ --feat_dim=161 \
--delta_delta=false \
--stride_ms=10 \
- --window_ms=20 \
+ --window_ms=25 \
--sample_rate=16000 \
- --use_dB_normalization=True \
+ --use_dB_normalization=False \
--num_samples=2000 \
--num_workers=${num_workers} \
--output_path="data/mean_std.json"
diff --git a/examples/aishell/asr0/local/export.sh b/examples/aishell/asr0/local/export.sh
index 426a72fe5..ce7e6d642 100755
--- a/examples/aishell/asr0/local/export.sh
+++ b/examples/aishell/asr0/local/export.sh
@@ -1,7 +1,7 @@
#!/bin/bash
-if [ $# != 4 ];then
- echo "usage: $0 config_path ckpt_prefix jit_model_path model_type"
+if [ $# != 3 ];then
+ echo "usage: $0 config_path ckpt_prefix jit_model_path"
exit -1
fi
@@ -11,14 +11,12 @@ echo "using $ngpu gpus..."
config_path=$1
ckpt_path_prefix=$2
jit_model_export_path=$3
-model_type=$4
python3 -u ${BIN_DIR}/export.py \
--ngpu ${ngpu} \
--config ${config_path} \
--checkpoint_path ${ckpt_path_prefix} \
---export_path ${jit_model_export_path} \
---model_type ${model_type}
+--export_path ${jit_model_export_path}
if [ $? -ne 0 ]; then
echo "Failed in export!"
diff --git a/examples/aishell/asr0/local/test.sh b/examples/aishell/asr0/local/test.sh
index 363dbf0ab..778c7142e 100755
--- a/examples/aishell/asr0/local/test.sh
+++ b/examples/aishell/asr0/local/test.sh
@@ -1,7 +1,7 @@
#!/bin/bash
-if [ $# != 4 ];then
- echo "usage: ${0} config_path decode_config_path ckpt_path_prefix model_type"
+if [ $# != 3 ];then
+ echo "usage: ${0} config_path decode_config_path ckpt_path_prefix"
exit -1
fi
@@ -13,7 +13,6 @@ echo "using $ngpu gpus..."
config_path=$1
decode_config_path=$2
ckpt_prefix=$3
-model_type=$4
# download language model
bash local/download_lm_ch.sh
@@ -23,7 +22,7 @@ fi
if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then
# format the reference test file
- python utils/format_rsl.py \
+ python3 utils/format_rsl.py \
--origin_ref data/manifest.test.raw \
--trans_ref data/manifest.test.text
@@ -32,8 +31,7 @@ if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then
--config ${config_path} \
--decode_cfg ${decode_config_path} \
--result_file ${ckpt_prefix}.rsl \
- --checkpoint_path ${ckpt_prefix} \
- --model_type ${model_type}
+ --checkpoint_path ${ckpt_prefix}
if [ $? -ne 0 ]; then
echo "Failed in evaluation!"
@@ -41,25 +39,25 @@ if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then
fi
# format the hyp file
- python utils/format_rsl.py \
+ python3 utils/format_rsl.py \
--origin_hyp ${ckpt_prefix}.rsl \
--trans_hyp ${ckpt_prefix}.rsl.text
- python utils/compute-wer.py --char=1 --v=1 \
- data/manifest.test.text ${ckpt_prefix}.rsl.text > ${ckpt_prefix}.error
+ python3 utils/compute-wer.py --char=1 --v=1 \
+ data/manifest.test.text ${ckpt_prefix}.rsl.text > ${ckpt_prefix}.error
fi
if [ ${stage} -le 101 ] && [ ${stop_stage} -ge 101 ]; then
- python utils/format_rsl.py \
+ python3 utils/format_rsl.py \
--origin_ref data/manifest.test.raw \
--trans_ref_sclite data/manifest.test.text.sclite
- python utils/format_rsl.py \
- --origin_hyp ${ckpt_prefix}.rsl \
- --trans_hyp_sclite ${ckpt_prefix}.rsl.text.sclite
+ python3 utils/format_rsl.py \
+ --origin_hyp ${ckpt_prefix}.rsl \
+ --trans_hyp_sclite ${ckpt_prefix}.rsl.text.sclite
- mkdir -p ${ckpt_prefix}_sclite
- sclite -i wsj -r data/manifest.test.text.sclite -h ${ckpt_prefix}.rsl.text.sclite -e utf-8 -o all -O ${ckpt_prefix}_sclite -c NOASCII
+ mkdir -p ${ckpt_prefix}_sclite
+ sclite -i wsj -r data/manifest.test.text.sclite -h ${ckpt_prefix}.rsl.text.sclite -e utf-8 -o all -O ${ckpt_prefix}_sclite -c NOASCII
fi
exit 0
diff --git a/examples/aishell/asr0/local/test_export.sh b/examples/aishell/asr0/local/test_export.sh
index 7a4b87f8c..a46a0d876 100755
--- a/examples/aishell/asr0/local/test_export.sh
+++ b/examples/aishell/asr0/local/test_export.sh
@@ -1,7 +1,7 @@
#!/bin/bash
-if [ $# != 4 ];then
- echo "usage: ${0} config_path decode_config_path ckpt_path_prefix model_type"
+if [ $# != 3 ];then
+ echo "usage: ${0} config_path decode_config_path ckpt_path_prefix"
exit -1
fi
@@ -11,7 +11,6 @@ echo "using $ngpu gpus..."
config_path=$1
decode_config_path=$2
jit_model_export_path=$3
-model_type=$4
# download language model
bash local/download_lm_ch.sh > /dev/null 2>&1
@@ -24,8 +23,7 @@ python3 -u ${BIN_DIR}/test_export.py \
--config ${config_path} \
--decode_cfg ${decode_config_path} \
--result_file ${jit_model_export_path}.rsl \
---export_path ${jit_model_export_path} \
---model_type ${model_type}
+--export_path ${jit_model_export_path}
if [ $? -ne 0 ]; then
echo "Failed in evaluation!"
diff --git a/examples/aishell/asr0/local/test_wav.sh b/examples/aishell/asr0/local/test_wav.sh
index 62b005a6a..a228dda5a 100755
--- a/examples/aishell/asr0/local/test_wav.sh
+++ b/examples/aishell/asr0/local/test_wav.sh
@@ -1,7 +1,7 @@
#!/bin/bash
-if [ $# != 5 ];then
- echo "usage: ${0} config_path decode_config_path ckpt_path_prefix model_type audio_file"
+if [ $# != 4 ];then
+ echo "usage: ${0} config_path decode_config_path ckpt_path_prefix audio_file"
exit -1
fi
@@ -11,8 +11,7 @@ echo "using $ngpu gpus..."
config_path=$1
decode_config_path=$2
ckpt_prefix=$3
-model_type=$4
-audio_file=$5
+audio_file=$4
mkdir -p data
wget -nc https://paddlespeech.bj.bcebos.com/datasets/single_wav/zh/demo_01_03.wav -P data/
@@ -37,7 +36,6 @@ python3 -u ${BIN_DIR}/test_wav.py \
--decode_cfg ${decode_config_path} \
--result_file ${ckpt_prefix}.rsl \
--checkpoint_path ${ckpt_prefix} \
---model_type ${model_type} \
--audio_file ${audio_file}
if [ $? -ne 0 ]; then
diff --git a/examples/aishell/asr0/local/train.sh b/examples/aishell/asr0/local/train.sh
index 54c642b63..256b30d22 100755
--- a/examples/aishell/asr0/local/train.sh
+++ b/examples/aishell/asr0/local/train.sh
@@ -1,7 +1,7 @@
#!/bin/bash
-if [ $# != 3 ];then
- echo "usage: CUDA_VISIBLE_DEVICES=0 ${0} config_path ckpt_name model_type"
+if [ $# -lt 2 ] && [ $# -gt 3 ];then
+ echo "usage: CUDA_VISIBLE_DEVICES=0 ${0} config_path ckpt_name ips(optional)"
exit -1
fi
@@ -10,7 +10,13 @@ echo "using $ngpu gpus..."
config_path=$1
ckpt_name=$2
-model_type=$3
+ips=$3
+
+if [ ! $ips ];then
+ ips_config=
+else
+ ips_config="--ips="${ips}
+fi
mkdir -p exp
@@ -20,12 +26,19 @@ if [ ${seed} != 0 ]; then
export FLAGS_cudnn_deterministic=True
fi
+if [ ${ngpu} == 0 ]; then
python3 -u ${BIN_DIR}/train.py \
--ngpu ${ngpu} \
--config ${config_path} \
--output exp/${ckpt_name} \
---model_type ${model_type} \
--seed ${seed}
+else
+python3 -m paddle.distributed.launch --gpus=${CUDA_VISIBLE_DEVICES} ${ips_config} ${BIN_DIR}/train.py \
+--ngpu ${ngpu} \
+--config ${config_path} \
+--output exp/${ckpt_name} \
+--seed ${seed}
+fi
if [ ${seed} != 0 ]; then
unset FLAGS_cudnn_deterministic
diff --git a/examples/aishell/asr0/run.sh b/examples/aishell/asr0/run.sh
index 114af5a97..530c013ac 100755
--- a/examples/aishell/asr0/run.sh
+++ b/examples/aishell/asr0/run.sh
@@ -6,9 +6,9 @@ gpus=0,1,2,3
stage=0
stop_stage=100
conf_path=conf/deepspeech2.yaml #conf/deepspeech2.yaml or conf/deepspeech2_online.yaml
+ips= #xx.xx.xx.xx,xx.xx.xx.xx
decode_conf_path=conf/tuning/decode.yaml
-avg_num=1
-model_type=offline # offline or online
+avg_num=10
audio_file=data/demo_01_03.wav
source ${MAIN_ROOT}/utils/parse_options.sh || exit 1;
@@ -25,7 +25,7 @@ fi
if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
# train model, all `ckpt` under `exp` dir
- CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt} ${model_type}
+ CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt} ${ips}
fi
if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
@@ -35,21 +35,21 @@ fi
if [ ${stage} -le 3 ] && [ ${stop_stage} -ge 3 ]; then
# test ckpt avg_n
- CUDA_VISIBLE_DEVICES=0 ./local/test.sh ${conf_path} ${decode_conf_path} exp/${ckpt}/checkpoints/${avg_ckpt} ${model_type}|| exit -1
+ CUDA_VISIBLE_DEVICES=0 ./local/test.sh ${conf_path} ${decode_conf_path} exp/${ckpt}/checkpoints/${avg_ckpt}|| exit -1
fi
if [ ${stage} -le 4 ] && [ ${stop_stage} -ge 4 ]; then
# export ckpt avg_n
- CUDA_VISIBLE_DEVICES=0 ./local/export.sh ${conf_path} exp/${ckpt}/checkpoints/${avg_ckpt} exp/${ckpt}/checkpoints/${avg_ckpt}.jit ${model_type}
+ CUDA_VISIBLE_DEVICES=0 ./local/export.sh ${conf_path} exp/${ckpt}/checkpoints/${avg_ckpt} exp/${ckpt}/checkpoints/${avg_ckpt}.jit
fi
if [ ${stage} -le 5 ] && [ ${stop_stage} -ge 5 ]; then
# test export ckpt avg_n
- CUDA_VISIBLE_DEVICES=0 ./local/test_export.sh ${conf_path} ${decode_conf_path} exp/${ckpt}/checkpoints/${avg_ckpt}.jit ${model_type}|| exit -1
+ CUDA_VISIBLE_DEVICES=0 ./local/test_export.sh ${conf_path} ${decode_conf_path} exp/${ckpt}/checkpoints/${avg_ckpt}.jit|| exit -1
fi
# Optionally, you can add LM and test it with runtime.
if [ ${stage} -le 6 ] && [ ${stop_stage} -ge 6 ]; then
# test a single .wav file
- CUDA_VISIBLE_DEVICES=0 ./local/test_wav.sh ${conf_path} ${decode_conf_path} exp/${ckpt}/checkpoints/${avg_ckpt} ${model_type} ${audio_file} || exit -1
+ CUDA_VISIBLE_DEVICES=0 ./local/test_wav.sh ${conf_path} ${decode_conf_path} exp/${ckpt}/checkpoints/${avg_ckpt} ${audio_file} || exit -1
fi
diff --git a/examples/aishell/asr1/RESULTS.md b/examples/aishell/asr1/RESULTS.md
index db188450a..f16d423a2 100644
--- a/examples/aishell/asr1/RESULTS.md
+++ b/examples/aishell/asr1/RESULTS.md
@@ -11,7 +11,7 @@ paddlespeech version: 0.2.0
| conformer | 47.07M | conf/conformer.yaml | spec_aug | test | attention_rescoring | - | 0.0464 |
-## Chunk Conformer
+## Conformer Streaming
paddle version: 2.2.2
paddlespeech version: 0.2.0
Need set `decoding.decoding_chunk_size=16` when decoding.
diff --git a/examples/aishell/asr1/conf/chunk_conformer.yaml b/examples/aishell/asr1/conf/chunk_conformer.yaml
index 3cfe9b1b0..b389e367c 100644
--- a/examples/aishell/asr1/conf/chunk_conformer.yaml
+++ b/examples/aishell/asr1/conf/chunk_conformer.yaml
@@ -10,7 +10,7 @@ encoder_conf:
attention_heads: 4
linear_units: 2048 # the number of units of position-wise feed forward
num_blocks: 12 # the number of encoder blocks
- dropout_rate: 0.1
+ dropout_rate: 0.1 # sublayer output dropout
positional_dropout_rate: 0.1
attention_dropout_rate: 0.0
input_layer: conv2d # encoder input type, you can chose conv2d, conv2d6 and conv2d8
@@ -30,7 +30,7 @@ decoder_conf:
attention_heads: 4
linear_units: 2048
num_blocks: 6
- dropout_rate: 0.1
+ dropout_rate: 0.1 # sublayer output dropout
positional_dropout_rate: 0.1
self_attention_dropout_rate: 0.0
src_attention_dropout_rate: 0.0
@@ -39,7 +39,7 @@ model_conf:
ctc_weight: 0.3
lsm_weight: 0.1 # label smoothing option
length_normalized_loss: false
- init_type: 'kaiming_uniform'
+ init_type: 'kaiming_uniform' # !Warning: need to convergence
###########################################
# Data #
diff --git a/examples/aishell/asr1/conf/conformer.yaml b/examples/aishell/asr1/conf/conformer.yaml
index a150a04d5..2419d07a4 100644
--- a/examples/aishell/asr1/conf/conformer.yaml
+++ b/examples/aishell/asr1/conf/conformer.yaml
@@ -37,7 +37,7 @@ model_conf:
ctc_weight: 0.3
lsm_weight: 0.1 # label smoothing option
length_normalized_loss: false
- init_type: 'kaiming_uniform'
+ init_type: 'kaiming_uniform' # !Warning: need to convergence
###########################################
# Data #
diff --git a/examples/aishell/asr1/conf/transformer.yaml b/examples/aishell/asr1/conf/transformer.yaml
index 9e08ea0ec..4e068420d 100644
--- a/examples/aishell/asr1/conf/transformer.yaml
+++ b/examples/aishell/asr1/conf/transformer.yaml
@@ -10,7 +10,7 @@ encoder_conf:
attention_heads: 4
linear_units: 2048 # the number of units of position-wise feed forward
num_blocks: 12 # the number of encoder blocks
- dropout_rate: 0.1
+ dropout_rate: 0.1 # sublayer output dropout
positional_dropout_rate: 0.1
attention_dropout_rate: 0.0
input_layer: conv2d # encoder input type, you can chose conv2d, conv2d6 and conv2d8
@@ -21,7 +21,7 @@ decoder_conf:
attention_heads: 4
linear_units: 2048
num_blocks: 6
- dropout_rate: 0.1
+ dropout_rate: 0.1 # sublayer output dropout
positional_dropout_rate: 0.1
self_attention_dropout_rate: 0.0
src_attention_dropout_rate: 0.0
diff --git a/examples/aishell/asr1/local/train.sh b/examples/aishell/asr1/local/train.sh
index 1c8593bdd..f514de303 100755
--- a/examples/aishell/asr1/local/train.sh
+++ b/examples/aishell/asr1/local/train.sh
@@ -17,24 +17,43 @@ if [ ${seed} != 0 ]; then
echo "using seed $seed & FLAGS_cudnn_deterministic=True ..."
fi
-if [ $# != 2 ];then
- echo "usage: CUDA_VISIBLE_DEVICES=0 ${0} config_path ckpt_name"
+if [ $# -lt 2 ] && [ $# -gt 3 ];then
+ echo "usage: CUDA_VISIBLE_DEVICES=0 ${0} config_path ckpt_name ips(optional)"
exit -1
fi
config_path=$1
ckpt_name=$2
+ips=$3
+
+if [ ! $ips ];then
+ ips_config=
+else
+ ips_config="--ips="${ips}
+fi
+echo ${ips_config}
mkdir -p exp
+if [ ${ngpu} == 0 ]; then
python3 -u ${BIN_DIR}/train.py \
+--ngpu ${ngpu} \
--seed ${seed} \
+--config ${config_path} \
+--output exp/${ckpt_name} \
+--profiler-options "${profiler_options}" \
+--benchmark-batch-size ${benchmark_batch_size} \
+--benchmark-max-step ${benchmark_max_step}
+else
+python3 -m paddle.distributed.launch --gpus=${CUDA_VISIBLE_DEVICES} ${ips_config} ${BIN_DIR}/train.py \
--ngpu ${ngpu} \
+--seed ${seed} \
--config ${config_path} \
--output exp/${ckpt_name} \
--profiler-options "${profiler_options}" \
--benchmark-batch-size ${benchmark_batch_size} \
--benchmark-max-step ${benchmark_max_step}
+fi
if [ ${seed} != 0 ]; then
diff --git a/examples/aishell/asr1/run.sh b/examples/aishell/asr1/run.sh
index cb781b208..bd4f50e3f 100644
--- a/examples/aishell/asr1/run.sh
+++ b/examples/aishell/asr1/run.sh
@@ -6,6 +6,7 @@ gpus=0,1,2,3
stage=0
stop_stage=50
conf_path=conf/conformer.yaml
+ips= #xx.xx.xx.xx,xx.xx.xx.xx
decode_conf_path=conf/tuning/decode.yaml
avg_num=30
audio_file=data/demo_01_03.wav
@@ -23,7 +24,7 @@ fi
if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
# train model, all `ckpt` under `exp` dir
- CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt}
+ CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt} ${ips}
fi
if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
diff --git a/examples/aishell3/tts3/README.md b/examples/aishell3/tts3/README.md
index d02ad1b63..31c99898c 100644
--- a/examples/aishell3/tts3/README.md
+++ b/examples/aishell3/tts3/README.md
@@ -6,15 +6,8 @@ AISHELL-3 is a large-scale and high-fidelity multi-speaker Mandarin speech corpu
We use AISHELL-3 to train a multi-speaker fastspeech2 model here.
## Dataset
### Download and Extract
-Download AISHELL-3.
-```bash
-wget https://www.openslr.org/resources/93/data_aishell3.tgz
-```
-Extract AISHELL-3.
-```bash
-mkdir data_aishell3
-tar zxvf data_aishell3.tgz -C data_aishell3
-```
+Download AISHELL-3 from it's [Official Website](http://www.aishelltech.com/aishell_3) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/data_aishell3`.
+
### Get MFA Result and Extract
We use [MFA2.x](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner) to get durations for aishell3_fastspeech2.
You can download from here [aishell3_alignment_tone.tar.gz](https://paddlespeech.bj.bcebos.com/MFA/AISHELL-3/with_tone/aishell3_alignment_tone.tar.gz), or train your MFA model reference to [mfa example](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/other/mfa) (use MFA1.x now) of our repo.
@@ -120,12 +113,12 @@ CUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize.sh ${conf_path} ${train_output_p
```
```text
usage: synthesize.py [-h]
- [--am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}]
+ [--am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech,tacotron2_aishell3}]
[--am_config AM_CONFIG] [--am_ckpt AM_CKPT]
[--am_stat AM_STAT] [--phones_dict PHONES_DICT]
[--tones_dict TONES_DICT] [--speaker_dict SPEAKER_DICT]
[--voice-cloning VOICE_CLONING]
- [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}]
+ [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,wavernn_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,style_melgan_csmsc}]
[--voc_config VOC_CONFIG] [--voc_ckpt VOC_CKPT]
[--voc_stat VOC_STAT] [--ngpu NGPU]
[--test_metadata TEST_METADATA] [--output_dir OUTPUT_DIR]
@@ -134,11 +127,10 @@ Synthesize with acoustic model & vocoder
optional arguments:
-h, --help show this help message and exit
- --am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}
+ --am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech,tacotron2_aishell3}
Choose acoustic model type of tts task.
--am_config AM_CONFIG
- Config of acoustic model. Use deault config when it is
- None.
+ Config of acoustic model.
--am_ckpt AM_CKPT Checkpoint file of acoustic model.
--am_stat AM_STAT mean and standard deviation used to normalize
spectrogram when training acoustic model.
@@ -150,10 +142,10 @@ optional arguments:
speaker id map file.
--voice-cloning VOICE_CLONING
whether training voice cloning model.
- --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}
+ --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,wavernn_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,style_melgan_csmsc}
Choose vocoder type of tts task.
--voc_config VOC_CONFIG
- Config of voc. Use deault config when it is None.
+ Config of voc.
--voc_ckpt VOC_CKPT Checkpoint file of voc.
--voc_stat VOC_STAT mean and standard deviation used to normalize
spectrogram when training voc.
@@ -169,12 +161,12 @@ CUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize_e2e.sh ${conf_path} ${train_outp
```
```text
usage: synthesize_e2e.py [-h]
- [--am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}]
+ [--am {speedyspeech_csmsc,speedyspeech_aishell3,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech}]
[--am_config AM_CONFIG] [--am_ckpt AM_CKPT]
[--am_stat AM_STAT] [--phones_dict PHONES_DICT]
[--tones_dict TONES_DICT]
[--speaker_dict SPEAKER_DICT] [--spk_id SPK_ID]
- [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}]
+ [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,style_melgan_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,wavernn_csmsc}]
[--voc_config VOC_CONFIG] [--voc_ckpt VOC_CKPT]
[--voc_stat VOC_STAT] [--lang LANG]
[--inference_dir INFERENCE_DIR] [--ngpu NGPU]
@@ -184,11 +176,10 @@ Synthesize with acoustic model & vocoder
optional arguments:
-h, --help show this help message and exit
- --am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}
+ --am {speedyspeech_csmsc,speedyspeech_aishell3,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech}
Choose acoustic model type of tts task.
--am_config AM_CONFIG
- Config of acoustic model. Use deault config when it is
- None.
+ Config of acoustic model.
--am_ckpt AM_CKPT Checkpoint file of acoustic model.
--am_stat AM_STAT mean and standard deviation used to normalize
spectrogram when training acoustic model.
@@ -199,10 +190,10 @@ optional arguments:
--speaker_dict SPEAKER_DICT
speaker id map file.
--spk_id SPK_ID spk id for multi speaker acoustic model
- --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}
+ --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,style_melgan_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,wavernn_csmsc}
Choose vocoder type of tts task.
--voc_config VOC_CONFIG
- Config of voc. Use deault config when it is None.
+ Config of voc.
--voc_ckpt VOC_CKPT Checkpoint file of voc.
--voc_stat VOC_STAT mean and standard deviation used to normalize
spectrogram when training voc.
@@ -215,9 +206,9 @@ optional arguments:
output dir.
```
1. `--am` is acoustic model type with the format {model_name}_{dataset}
-2. `--am_config`, `--am_checkpoint`, `--am_stat`, `--phones_dict` `--speaker_dict` are arguments for acoustic model, which correspond to the 5 files in the fastspeech2 pretrained model.
+2. `--am_config`, `--am_ckpt`, `--am_stat`, `--phones_dict` `--speaker_dict` are arguments for acoustic model, which correspond to the 5 files in the fastspeech2 pretrained model.
3. `--voc` is vocoder type with the format {model_name}_{dataset}
-4. `--voc_config`, `--voc_checkpoint`, `--voc_stat` are arguments for vocoder, which correspond to the 3 files in the parallel wavegan pretrained model.
+4. `--voc_config`, `--voc_ckpt`, `--voc_stat` are arguments for vocoder, which correspond to the 3 files in the parallel wavegan pretrained model.
5. `--lang` is the model language, which can be `zh` or `en`.
6. `--test_metadata` should be the metadata file in the normalized subfolder of `test` in the `dump` folder.
7. `--text` is the text file, which contains sentences to synthesize.
diff --git a/examples/aishell3/vc0/README.md b/examples/aishell3/vc0/README.md
index 925663ab1..d64f961ad 100644
--- a/examples/aishell3/vc0/README.md
+++ b/examples/aishell3/vc0/README.md
@@ -6,15 +6,8 @@ This example contains code used to train a [Tacotron2](https://arxiv.org/abs/171
## Dataset
### Download and Extract
-Download AISHELL-3.
-```bash
-wget https://www.openslr.org/resources/93/data_aishell3.tgz
-```
-Extract AISHELL-3.
-```bash
-mkdir data_aishell3
-tar zxvf data_aishell3.tgz -C data_aishell3
-```
+Download AISHELL-3 from it's [Official Website](http://www.aishelltech.com/aishell_3) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/data_aishell3`.
+
### Get MFA Result and Extract
We use [MFA2.x](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner) to get phonemes for Tacotron2, the durations of MFA are not needed here.
You can download from here [aishell3_alignment_tone.tar.gz](https://paddlespeech.bj.bcebos.com/MFA/AISHELL-3/with_tone/aishell3_alignment_tone.tar.gz), or train your MFA model reference to [mfa example](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/other/mfa) (use MFA1.x now) of our repo.
diff --git a/examples/aishell3/vc1/README.md b/examples/aishell3/vc1/README.md
index 8ab0f9c8c..aab525103 100644
--- a/examples/aishell3/vc1/README.md
+++ b/examples/aishell3/vc1/README.md
@@ -6,15 +6,8 @@ This example contains code used to train a [FastSpeech2](https://arxiv.org/abs/2
## Dataset
### Download and Extract
-Download AISHELL-3.
-```bash
-wget https://www.openslr.org/resources/93/data_aishell3.tgz
-```
-Extract AISHELL-3.
-```bash
-mkdir data_aishell3
-tar zxvf data_aishell3.tgz -C data_aishell3
-```
+Download AISHELL-3 from it's [Official Website](http://www.aishelltech.com/aishell_3) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/data_aishell3`.
+
### Get MFA Result and Extract
We use [MFA2.x](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner) to get durations for aishell3_fastspeech2.
You can download from here [aishell3_alignment_tone.tar.gz](https://paddlespeech.bj.bcebos.com/MFA/AISHELL-3/with_tone/aishell3_alignment_tone.tar.gz), or train your MFA model reference to [mfa example](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/other/mfa) (use MFA1.x now) of our repo.
diff --git a/examples/aishell3/voc1/README.md b/examples/aishell3/voc1/README.md
index eb30e7c40..a3daf3dfd 100644
--- a/examples/aishell3/voc1/README.md
+++ b/examples/aishell3/voc1/README.md
@@ -4,15 +4,8 @@ This example contains code used to train a [parallel wavegan](http://arxiv.org/a
AISHELL-3 is a large-scale and high-fidelity multi-speaker Mandarin speech corpus that could be used to train multi-speaker Text-to-Speech (TTS) systems.
## Dataset
### Download and Extract
-Download AISHELL-3.
-```bash
-wget https://www.openslr.org/resources/93/data_aishell3.tgz
-```
-Extract AISHELL-3.
-```bash
-mkdir data_aishell3
-tar zxvf data_aishell3.tgz -C data_aishell3
-```
+Download AISHELL-3 from it's [Official Website](http://www.aishelltech.com/aishell_3) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/data_aishell3`.
+
### Get MFA Result and Extract
We use [MFA2.x](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner) to get durations for aishell3_fastspeech2.
You can download from here [aishell3_alignment_tone.tar.gz](https://paddlespeech.bj.bcebos.com/MFA/AISHELL-3/with_tone/aishell3_alignment_tone.tar.gz), or train your MFA model reference to [mfa example](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/other/mfa) (use MFA1.x now) of our repo.
@@ -75,7 +68,7 @@ Train a ParallelWaveGAN model.
optional arguments:
-h, --help show this help message and exit
- --config CONFIG config file to overwrite default config.
+ --config CONFIG ParallelWaveGAN config file.
--train-metadata TRAIN_METADATA
training data.
--dev-metadata DEV_METADATA
diff --git a/examples/aishell3/voc5/README.md b/examples/aishell3/voc5/README.md
index c957c4a3a..c3e3197d6 100644
--- a/examples/aishell3/voc5/README.md
+++ b/examples/aishell3/voc5/README.md
@@ -4,15 +4,7 @@ This example contains code used to train a [HiFiGAN](https://arxiv.org/abs/2010.
AISHELL-3 is a large-scale and high-fidelity multi-speaker Mandarin speech corpus that could be used to train multi-speaker Text-to-Speech (TTS) systems.
## Dataset
### Download and Extract
-Download AISHELL-3.
-```bash
-wget https://www.openslr.org/resources/93/data_aishell3.tgz
-```
-Extract AISHELL-3.
-```bash
-mkdir data_aishell3
-tar zxvf data_aishell3.tgz -C data_aishell3
-```
+Download AISHELL-3 from it's [Official Website](http://www.aishelltech.com/aishell_3) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/data_aishell3`.
### Get MFA Result and Extract
We use [MFA2.x](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner) to get durations for aishell3_fastspeech2.
You can download from here [aishell3_alignment_tone.tar.gz](https://paddlespeech.bj.bcebos.com/MFA/AISHELL-3/with_tone/aishell3_alignment_tone.tar.gz), or train your MFA model reference to [mfa example](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/other/mfa) (use MFA1.x now) of our repo.
@@ -67,15 +59,13 @@ Here's the complete help message.
```text
usage: train.py [-h] [--config CONFIG] [--train-metadata TRAIN_METADATA]
[--dev-metadata DEV_METADATA] [--output-dir OUTPUT_DIR]
- [--ngpu NGPU] [--batch-size BATCH_SIZE] [--max-iter MAX_ITER]
- [--run-benchmark RUN_BENCHMARK]
- [--profiler_options PROFILER_OPTIONS]
+ [--ngpu NGPU]
-Train a ParallelWaveGAN model.
+Train a HiFiGAN model.
optional arguments:
-h, --help show this help message and exit
- --config CONFIG config file to overwrite default config.
+ --config CONFIG HiFiGAN config file.
--train-metadata TRAIN_METADATA
training data.
--dev-metadata DEV_METADATA
@@ -83,19 +73,6 @@ optional arguments:
--output-dir OUTPUT_DIR
output dir.
--ngpu NGPU if ngpu == 0, use cpu.
-
-benchmark:
- arguments related to benchmark.
-
- --batch-size BATCH_SIZE
- batch size.
- --max-iter MAX_ITER train max steps.
- --run-benchmark RUN_BENCHMARK
- runing benchmark or not, if True, use the --batch-size
- and --max-iter.
- --profiler_options PROFILER_OPTIONS
- The option of profiler, which should be in format
- "key1=value1;key2=value2;key3=value3".
```
1. `--config` is a config file in yaml format to overwrite the default config, which can be found at `conf/default.yaml`.
diff --git a/examples/ami/README.md b/examples/ami/README.md
index a038eaebe..adc9dc4b0 100644
--- a/examples/ami/README.md
+++ b/examples/ami/README.md
@@ -1,3 +1,3 @@
# Speaker Diarization on AMI corpus
-* sd0 - speaker diarization by AHC,SC base on x-vectors
+* sd0 - speaker diarization by AHC,SC base on embeddings
diff --git a/examples/ami/sd0/README.md b/examples/ami/sd0/README.md
index ffe95741a..30f7a438d 100644
--- a/examples/ami/sd0/README.md
+++ b/examples/ami/sd0/README.md
@@ -7,7 +7,26 @@
The script performs diarization using x-vectors(TDNN,ECAPA-TDNN) on the AMI mix-headset data. We demonstrate the use of different clustering methods: AHC, spectral.
## How to Run
+### prepare annotations and audios
+Download AMI corpus, You need around 10GB of free space to get whole data
+The signals are too large to package in this way, so you need to use the chooser to indicate which ones you wish to download
+
+```bash
+## download annotations
+wget http://groups.inf.ed.ac.uk/ami/AMICorpusAnnotations/ami_public_manual_1.6.2.zip && unzip ami_public_manual_1.6.2.zip
+```
+
+then please follow https://groups.inf.ed.ac.uk/ami/download/ to download the Signals:
+1) Select one or more AMI meetings: the IDs please follow ./ami_split.py
+2) Select media streams: Just select Headset mix
+
+### start running
Use the following command to run diarization on AMI corpus.
-`bash ./run.sh`
+```bash
+./run.sh --data_folder ./amicorpus --manual_annot_folder ./ami_public_manual_1.6.2
+```
-## Results (DER) coming soon! :)
+## Best performance in terms of Diarization Error Rate (DER).
+ | System | Mic. |Orcl. (Dev)|Orcl. (Eval)| Est. (Dev) |Est. (Eval)|
+ | --------|-------- | ---------|----------- | --------|-----------|
+ | ECAPA-TDNN + SC | HeadsetMix| 1.54 % | 3.07 %| 1.56 %| 3.28 % |
diff --git a/examples/ami/sd0/run.sh b/examples/ami/sd0/run.sh
index 9035f5955..1fcec269d 100644
--- a/examples/ami/sd0/run.sh
+++ b/examples/ami/sd0/run.sh
@@ -17,18 +17,6 @@ device=gpu
. ${MAIN_ROOT}/utils/parse_options.sh || exit 1;
-if [ $stage -le 0 ]; then
- # Prepare data
- # Download AMI corpus, You need around 10GB of free space to get whole data
- # The signals are too large to package in this way,
- # so you need to use the chooser to indicate which ones you wish to download
- echo "Please follow https://groups.inf.ed.ac.uk/ami/download/ to download the data."
- echo "Annotations: AMI manual annotations v1.6.2 "
- echo "Signals: "
- echo "1) Select one or more AMI meetings: the IDs please follow ./ami_split.py"
- echo "2) Select media streams: Just select Headset mix"
-fi
-
if [ $stage -le 1 ]; then
# Download the pretrained model
wget https://paddlespeech.bj.bcebos.com/vector/voxceleb/sv0_ecapa_tdnn_voxceleb12_ckpt_0_1_1.tar.gz
diff --git a/examples/callcenter/asr1/local/train.sh b/examples/callcenter/asr1/local/train.sh
index 3e92fd162..41da89e22 100755
--- a/examples/callcenter/asr1/local/train.sh
+++ b/examples/callcenter/asr1/local/train.sh
@@ -1,7 +1,7 @@
#! /usr/bin/env bash
-if [ $# != 2 ];then
- echo "usage: CUDA_VISIBLE_DEVICES=0 ${0} config_path ckpt_name"
+if [ $# -lt 2 ] && [ $# -gt 3 ];then
+ echo "usage: CUDA_VISIBLE_DEVICES=0 ${0} config_path ckpt_name ips(optional)"
exit -1
fi
@@ -10,6 +10,13 @@ echo "using $ngpu gpus..."
config_path=$1
ckpt_name=$2
+ips=$3
+
+if [ ! $ips ];then
+ ips_config=
+else
+ ips_config="--ips="${ips}
+fi
echo "using ${device}..."
@@ -21,11 +28,19 @@ if [ ${seed} != 0 ]; then
export FLAGS_cudnn_deterministic=True
fi
+if [ ${ngpu} == 0 ]; then
python3 -u ${BIN_DIR}/train.py \
--ngpu ${ngpu} \
--config ${config_path} \
--output exp/${ckpt_name} \
--seed ${seed}
+else
+python3 -m paddle.distributed.launch --gpus=${CUDA_VISIBLE_DEVICES} ${ips_config} ${BIN_DIR}/train.py \
+--ngpu ${ngpu} \
+--config ${config_path} \
+--output exp/${ckpt_name} \
+--seed ${seed}
+fi
if [ ${seed} != 0 ]; then
unset FLAGS_cudnn_deterministic
diff --git a/examples/callcenter/asr1/run.sh b/examples/callcenter/asr1/run.sh
index 0c7ffc1e7..7e3b912ab 100644
--- a/examples/callcenter/asr1/run.sh
+++ b/examples/callcenter/asr1/run.sh
@@ -6,6 +6,7 @@ gpus=0,1,2,3
stage=0
stop_stage=50
conf_path=conf/conformer.yaml
+ips= #xx.xx.xx.xx,xx.xx.xx.xx
decode_conf_path=conf/tuning/decode.yaml
avg_num=20
@@ -22,7 +23,7 @@ fi
if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
# train model, all `ckpt` under `exp` dir
- CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt}
+ CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt} ${ips}
fi
if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
diff --git a/examples/csmsc/tts0/README.md b/examples/csmsc/tts0/README.md
index 01376bd61..bc7769d15 100644
--- a/examples/csmsc/tts0/README.md
+++ b/examples/csmsc/tts0/README.md
@@ -3,7 +3,7 @@ This example contains code used to train a [Tacotron2](https://arxiv.org/abs/171
## Dataset
### Download and Extract
-Download CSMSC from it's [Official Website](https://test.data-baker.com/data/index/source).
+Download CSMSC from it's [Official Website](https://test.data-baker.com/data/index/TNtts/) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/BZNSYP`.
### Get MFA Result and Extract
We use [MFA](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner) to get phonemes for Tacotron2, the durations of MFA are not needed here.
@@ -103,12 +103,12 @@ CUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize.sh ${conf_path} ${train_output_p
```
```text
usage: synthesize.py [-h]
- [--am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc}]
+ [--am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech,tacotron2_aishell3}]
[--am_config AM_CONFIG] [--am_ckpt AM_CKPT]
[--am_stat AM_STAT] [--phones_dict PHONES_DICT]
[--tones_dict TONES_DICT] [--speaker_dict SPEAKER_DICT]
[--voice-cloning VOICE_CLONING]
- [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}]
+ [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,wavernn_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,style_melgan_csmsc}]
[--voc_config VOC_CONFIG] [--voc_ckpt VOC_CKPT]
[--voc_stat VOC_STAT] [--ngpu NGPU]
[--test_metadata TEST_METADATA] [--output_dir OUTPUT_DIR]
@@ -117,11 +117,10 @@ Synthesize with acoustic model & vocoder
optional arguments:
-h, --help show this help message and exit
- --am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc}
+ --am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech,tacotron2_aishell3}
Choose acoustic model type of tts task.
--am_config AM_CONFIG
- Config of acoustic model. Use deault config when it is
- None.
+ Config of acoustic model.
--am_ckpt AM_CKPT Checkpoint file of acoustic model.
--am_stat AM_STAT mean and standard deviation used to normalize
spectrogram when training acoustic model.
@@ -133,10 +132,10 @@ optional arguments:
speaker id map file.
--voice-cloning VOICE_CLONING
whether training voice cloning model.
- --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}
+ --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,wavernn_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,style_melgan_csmsc}
Choose vocoder type of tts task.
--voc_config VOC_CONFIG
- Config of voc. Use deault config when it is None.
+ Config of voc.
--voc_ckpt VOC_CKPT Checkpoint file of voc.
--voc_stat VOC_STAT mean and standard deviation used to normalize
spectrogram when training voc.
@@ -152,12 +151,12 @@ CUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize_e2e.sh ${conf_path} ${train_outp
```
```text
usage: synthesize_e2e.py [-h]
- [--am {speedyspeech_csmsc,speedyspeech_aishell3,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc}]
+ [--am {speedyspeech_csmsc,speedyspeech_aishell3,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech}]
[--am_config AM_CONFIG] [--am_ckpt AM_CKPT]
[--am_stat AM_STAT] [--phones_dict PHONES_DICT]
[--tones_dict TONES_DICT]
[--speaker_dict SPEAKER_DICT] [--spk_id SPK_ID]
- [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,style_melgan_csmsc,hifigan_csmsc}]
+ [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,style_melgan_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,wavernn_csmsc}]
[--voc_config VOC_CONFIG] [--voc_ckpt VOC_CKPT]
[--voc_stat VOC_STAT] [--lang LANG]
[--inference_dir INFERENCE_DIR] [--ngpu NGPU]
@@ -167,11 +166,10 @@ Synthesize with acoustic model & vocoder
optional arguments:
-h, --help show this help message and exit
- --am {speedyspeech_csmsc,speedyspeech_aishell3,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc}
+ --am {speedyspeech_csmsc,speedyspeech_aishell3,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech}
Choose acoustic model type of tts task.
--am_config AM_CONFIG
- Config of acoustic model. Use deault config when it is
- None.
+ Config of acoustic model.
--am_ckpt AM_CKPT Checkpoint file of acoustic model.
--am_stat AM_STAT mean and standard deviation used to normalize
spectrogram when training acoustic model.
@@ -182,10 +180,10 @@ optional arguments:
--speaker_dict SPEAKER_DICT
speaker id map file.
--spk_id SPK_ID spk id for multi speaker acoustic model
- --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,style_melgan_csmsc,hifigan_csmsc}
+ --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,style_melgan_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,wavernn_csmsc}
Choose vocoder type of tts task.
--voc_config VOC_CONFIG
- Config of voc. Use deault config when it is None.
+ Config of voc.
--voc_ckpt VOC_CKPT Checkpoint file of voc.
--voc_stat VOC_STAT mean and standard deviation used to normalize
spectrogram when training voc.
@@ -198,9 +196,9 @@ optional arguments:
output dir.
```
1. `--am` is acoustic model type with the format {model_name}_{dataset}
-2. `--am_config`, `--am_checkpoint`, `--am_stat` and `--phones_dict` are arguments for acoustic model, which correspond to the 4 files in the Tacotron2 pretrained model.
+2. `--am_config`, `--am_ckpt`, `--am_stat` and `--phones_dict` are arguments for acoustic model, which correspond to the 4 files in the Tacotron2 pretrained model.
3. `--voc` is vocoder type with the format {model_name}_{dataset}
-4. `--voc_config`, `--voc_checkpoint`, `--voc_stat` are arguments for vocoder, which correspond to the 3 files in the parallel wavegan pretrained model.
+4. `--voc_config`, `--voc_ckpt`, `--voc_stat` are arguments for vocoder, which correspond to the 3 files in the parallel wavegan pretrained model.
5. `--lang` is the model language, which can be `zh` or `en`.
6. `--test_metadata` should be the metadata file in the normalized subfolder of `test` in the `dump` folder.
7. `--text` is the text file, which contains sentences to synthesize.
diff --git a/examples/csmsc/tts2/README.md b/examples/csmsc/tts2/README.md
index 081d85848..f45561719 100644
--- a/examples/csmsc/tts2/README.md
+++ b/examples/csmsc/tts2/README.md
@@ -3,7 +3,7 @@ This example contains code used to train a [SpeedySpeech](http://arxiv.org/abs/2
## Dataset
### Download and Extract
-Download CSMSC from it's [Official Website](https://test.data-baker.com/data/index/source).
+Download CSMSC from it's [Official Website](https://test.data-baker.com/data/index/TNtts/) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/BZNSYP`.
### Get MFA Result and Extract
We use [MFA](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner) to get durations for SPEEDYSPEECH.
@@ -109,12 +109,12 @@ CUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize.sh ${conf_path} ${train_output_p
```
```text
usage: synthesize.py [-h]
- [--am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}]
+ [--am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech,tacotron2_aishell3}]
[--am_config AM_CONFIG] [--am_ckpt AM_CKPT]
[--am_stat AM_STAT] [--phones_dict PHONES_DICT]
[--tones_dict TONES_DICT] [--speaker_dict SPEAKER_DICT]
[--voice-cloning VOICE_CLONING]
- [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}]
+ [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,wavernn_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,style_melgan_csmsc}]
[--voc_config VOC_CONFIG] [--voc_ckpt VOC_CKPT]
[--voc_stat VOC_STAT] [--ngpu NGPU]
[--test_metadata TEST_METADATA] [--output_dir OUTPUT_DIR]
@@ -123,11 +123,10 @@ Synthesize with acoustic model & vocoder
optional arguments:
-h, --help show this help message and exit
- --am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}
+ --am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech,tacotron2_aishell3}
Choose acoustic model type of tts task.
--am_config AM_CONFIG
- Config of acoustic model. Use deault config when it is
- None.
+ Config of acoustic model.
--am_ckpt AM_CKPT Checkpoint file of acoustic model.
--am_stat AM_STAT mean and standard deviation used to normalize
spectrogram when training acoustic model.
@@ -139,10 +138,10 @@ optional arguments:
speaker id map file.
--voice-cloning VOICE_CLONING
whether training voice cloning model.
- --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}
+ --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,wavernn_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,style_melgan_csmsc}
Choose vocoder type of tts task.
--voc_config VOC_CONFIG
- Config of voc. Use deault config when it is None.
+ Config of voc.
--voc_ckpt VOC_CKPT Checkpoint file of voc.
--voc_stat VOC_STAT mean and standard deviation used to normalize
spectrogram when training voc.
@@ -158,12 +157,12 @@ CUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize_e2e.sh ${conf_path} ${train_outp
```
```text
usage: synthesize_e2e.py [-h]
- [--am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}]
+ [--am {speedyspeech_csmsc,speedyspeech_aishell3,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech}]
[--am_config AM_CONFIG] [--am_ckpt AM_CKPT]
[--am_stat AM_STAT] [--phones_dict PHONES_DICT]
[--tones_dict TONES_DICT]
[--speaker_dict SPEAKER_DICT] [--spk_id SPK_ID]
- [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}]
+ [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,style_melgan_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,wavernn_csmsc}]
[--voc_config VOC_CONFIG] [--voc_ckpt VOC_CKPT]
[--voc_stat VOC_STAT] [--lang LANG]
[--inference_dir INFERENCE_DIR] [--ngpu NGPU]
@@ -173,11 +172,10 @@ Synthesize with acoustic model & vocoder
optional arguments:
-h, --help show this help message and exit
- --am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}
+ --am {speedyspeech_csmsc,speedyspeech_aishell3,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech}
Choose acoustic model type of tts task.
--am_config AM_CONFIG
- Config of acoustic model. Use deault config when it is
- None.
+ Config of acoustic model.
--am_ckpt AM_CKPT Checkpoint file of acoustic model.
--am_stat AM_STAT mean and standard deviation used to normalize
spectrogram when training acoustic model.
@@ -188,10 +186,10 @@ optional arguments:
--speaker_dict SPEAKER_DICT
speaker id map file.
--spk_id SPK_ID spk id for multi speaker acoustic model
- --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}
+ --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,style_melgan_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,wavernn_csmsc}
Choose vocoder type of tts task.
--voc_config VOC_CONFIG
- Config of voc. Use deault config when it is None.
+ Config of voc.
--voc_ckpt VOC_CKPT Checkpoint file of voc.
--voc_stat VOC_STAT mean and standard deviation used to normalize
spectrogram when training voc.
@@ -204,9 +202,9 @@ optional arguments:
output dir.
```
1. `--am` is acoustic model type with the format {model_name}_{dataset}
-2. `--am_config`, `--am_checkpoint`, `--am_stat`, `--phones_dict` and `--tones_dict` are arguments for acoustic model, which correspond to the 5 files in the speedyspeech pretrained model.
+2. `--am_config`, `--am_ckpt`, `--am_stat`, `--phones_dict` and `--tones_dict` are arguments for acoustic model, which correspond to the 5 files in the speedyspeech pretrained model.
3. `--voc` is vocoder type with the format {model_name}_{dataset}
-4. `--voc_config`, `--voc_checkpoint`, `--voc_stat` are arguments for vocoder, which correspond to the 3 files in the parallel wavegan pretrained model.
+4. `--voc_config`, `--voc_ckpt`, `--voc_stat` are arguments for vocoder, which correspond to the 3 files in the parallel wavegan pretrained model.
5. `--lang` is the model language, which can be `zh` or `en`.
6. `--test_metadata` should be the metadata file in the normalized subfolder of `test` in the `dump` folder.
7. `--text` is the text file, which contains sentences to synthesize.
diff --git a/examples/csmsc/tts3/README.md b/examples/csmsc/tts3/README.md
index c734199b4..371034e77 100644
--- a/examples/csmsc/tts3/README.md
+++ b/examples/csmsc/tts3/README.md
@@ -4,7 +4,7 @@ This example contains code used to train a [Fastspeech2](https://arxiv.org/abs/2
## Dataset
### Download and Extract
-Download CSMSC from it's [Official Website](https://test.data-baker.com/data/index/source).
+Download CSMSC from it's [Official Website](https://test.data-baker.com/data/index/TNtts/) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/BZNSYP`.
### Get MFA Result and Extract
We use [MFA](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner) to get durations for fastspeech2.
@@ -111,12 +111,12 @@ CUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize.sh ${conf_path} ${train_output_p
```
```text
usage: synthesize.py [-h]
- [--am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}]
+ [--am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech,tacotron2_aishell3}]
[--am_config AM_CONFIG] [--am_ckpt AM_CKPT]
[--am_stat AM_STAT] [--phones_dict PHONES_DICT]
[--tones_dict TONES_DICT] [--speaker_dict SPEAKER_DICT]
[--voice-cloning VOICE_CLONING]
- [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}]
+ [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,wavernn_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,style_melgan_csmsc}]
[--voc_config VOC_CONFIG] [--voc_ckpt VOC_CKPT]
[--voc_stat VOC_STAT] [--ngpu NGPU]
[--test_metadata TEST_METADATA] [--output_dir OUTPUT_DIR]
@@ -125,11 +125,10 @@ Synthesize with acoustic model & vocoder
optional arguments:
-h, --help show this help message and exit
- --am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}
+ --am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech,tacotron2_aishell3}
Choose acoustic model type of tts task.
--am_config AM_CONFIG
- Config of acoustic model. Use deault config when it is
- None.
+ Config of acoustic model.
--am_ckpt AM_CKPT Checkpoint file of acoustic model.
--am_stat AM_STAT mean and standard deviation used to normalize
spectrogram when training acoustic model.
@@ -141,10 +140,10 @@ optional arguments:
speaker id map file.
--voice-cloning VOICE_CLONING
whether training voice cloning model.
- --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}
+ --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,wavernn_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,style_melgan_csmsc}
Choose vocoder type of tts task.
--voc_config VOC_CONFIG
- Config of voc. Use deault config when it is None.
+ Config of voc.
--voc_ckpt VOC_CKPT Checkpoint file of voc.
--voc_stat VOC_STAT mean and standard deviation used to normalize
spectrogram when training voc.
@@ -160,12 +159,12 @@ CUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize_e2e.sh ${conf_path} ${train_outp
```
```text
usage: synthesize_e2e.py [-h]
- [--am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}]
+ [--am {speedyspeech_csmsc,speedyspeech_aishell3,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech}]
[--am_config AM_CONFIG] [--am_ckpt AM_CKPT]
[--am_stat AM_STAT] [--phones_dict PHONES_DICT]
[--tones_dict TONES_DICT]
[--speaker_dict SPEAKER_DICT] [--spk_id SPK_ID]
- [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}]
+ [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,style_melgan_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,wavernn_csmsc}]
[--voc_config VOC_CONFIG] [--voc_ckpt VOC_CKPT]
[--voc_stat VOC_STAT] [--lang LANG]
[--inference_dir INFERENCE_DIR] [--ngpu NGPU]
@@ -175,11 +174,10 @@ Synthesize with acoustic model & vocoder
optional arguments:
-h, --help show this help message and exit
- --am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}
+ --am {speedyspeech_csmsc,speedyspeech_aishell3,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech}
Choose acoustic model type of tts task.
--am_config AM_CONFIG
- Config of acoustic model. Use deault config when it is
- None.
+ Config of acoustic model.
--am_ckpt AM_CKPT Checkpoint file of acoustic model.
--am_stat AM_STAT mean and standard deviation used to normalize
spectrogram when training acoustic model.
@@ -190,10 +188,10 @@ optional arguments:
--speaker_dict SPEAKER_DICT
speaker id map file.
--spk_id SPK_ID spk id for multi speaker acoustic model
- --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}
+ --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,style_melgan_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,wavernn_csmsc}
Choose vocoder type of tts task.
--voc_config VOC_CONFIG
- Config of voc. Use deault config when it is None.
+ Config of voc.
--voc_ckpt VOC_CKPT Checkpoint file of voc.
--voc_stat VOC_STAT mean and standard deviation used to normalize
spectrogram when training voc.
@@ -204,11 +202,12 @@ optional arguments:
--text TEXT text to synthesize, a 'utt_id sentence' pair per line.
--output_dir OUTPUT_DIR
output dir.
+
```
1. `--am` is acoustic model type with the format {model_name}_{dataset}
-2. `--am_config`, `--am_checkpoint`, `--am_stat` and `--phones_dict` are arguments for acoustic model, which correspond to the 4 files in the fastspeech2 pretrained model.
+2. `--am_config`, `--am_ckpt`, `--am_stat` and `--phones_dict` are arguments for acoustic model, which correspond to the 4 files in the fastspeech2 pretrained model.
3. `--voc` is vocoder type with the format {model_name}_{dataset}
-4. `--voc_config`, `--voc_checkpoint`, `--voc_stat` are arguments for vocoder, which correspond to the 3 files in the parallel wavegan pretrained model.
+4. `--voc_config`, `--voc_ckpt`, `--voc_stat` are arguments for vocoder, which correspond to the 3 files in the parallel wavegan pretrained model.
5. `--lang` is the model language, which can be `zh` or `en`.
6. `--test_metadata` should be the metadata file in the normalized subfolder of `test` in the `dump` folder.
7. `--text` is the text file, which contains sentences to synthesize.
diff --git a/examples/csmsc/tts3/README_cn.md b/examples/csmsc/tts3/README_cn.md
index 25931ecb1..1829b7706 100644
--- a/examples/csmsc/tts3/README_cn.md
+++ b/examples/csmsc/tts3/README_cn.md
@@ -5,7 +5,7 @@
## 数据集
### 下载并解压
-从 [官方网站](https://test.data-baker.com/data/index/source) 下载数据集
+从 [官方网站](https://test.data-baker.com/data/index/TNtts/) 下载数据集
### 获取MFA结果并解压
我们使用 [MFA](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner) 去获得 fastspeech2 的音素持续时间。
@@ -117,12 +117,12 @@ CUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize.sh ${conf_path} ${train_output_p
```
```text
usage: synthesize.py [-h]
- [--am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}]
+ [--am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech,tacotron2_aishell3}]
[--am_config AM_CONFIG] [--am_ckpt AM_CKPT]
[--am_stat AM_STAT] [--phones_dict PHONES_DICT]
[--tones_dict TONES_DICT] [--speaker_dict SPEAKER_DICT]
[--voice-cloning VOICE_CLONING]
- [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}]
+ [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,wavernn_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,style_melgan_csmsc}]
[--voc_config VOC_CONFIG] [--voc_ckpt VOC_CKPT]
[--voc_stat VOC_STAT] [--ngpu NGPU]
[--test_metadata TEST_METADATA] [--output_dir OUTPUT_DIR]
@@ -131,11 +131,10 @@ Synthesize with acoustic model & vocoder
optional arguments:
-h, --help show this help message and exit
- --am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}
+ --am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech,tacotron2_aishell3}
Choose acoustic model type of tts task.
--am_config AM_CONFIG
- Config of acoustic model. Use deault config when it is
- None.
+ Config of acoustic model.
--am_ckpt AM_CKPT Checkpoint file of acoustic model.
--am_stat AM_STAT mean and standard deviation used to normalize
spectrogram when training acoustic model.
@@ -147,10 +146,10 @@ optional arguments:
speaker id map file.
--voice-cloning VOICE_CLONING
whether training voice cloning model.
- --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}
+ --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,wavernn_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,style_melgan_csmsc}
Choose vocoder type of tts task.
--voc_config VOC_CONFIG
- Config of voc. Use deault config when it is None.
+ Config of voc.
--voc_ckpt VOC_CKPT Checkpoint file of voc.
--voc_stat VOC_STAT mean and standard deviation used to normalize
spectrogram when training voc.
@@ -167,12 +166,12 @@ CUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize_e2e.sh ${conf_path} ${train_outp
```
```text
usage: synthesize_e2e.py [-h]
- [--am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}]
+ [--am {speedyspeech_csmsc,speedyspeech_aishell3,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech}]
[--am_config AM_CONFIG] [--am_ckpt AM_CKPT]
[--am_stat AM_STAT] [--phones_dict PHONES_DICT]
[--tones_dict TONES_DICT]
[--speaker_dict SPEAKER_DICT] [--spk_id SPK_ID]
- [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}]
+ [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,style_melgan_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,wavernn_csmsc}]
[--voc_config VOC_CONFIG] [--voc_ckpt VOC_CKPT]
[--voc_stat VOC_STAT] [--lang LANG]
[--inference_dir INFERENCE_DIR] [--ngpu NGPU]
@@ -182,11 +181,10 @@ Synthesize with acoustic model & vocoder
optional arguments:
-h, --help show this help message and exit
- --am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}
+ --am {speedyspeech_csmsc,speedyspeech_aishell3,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech}
Choose acoustic model type of tts task.
--am_config AM_CONFIG
- Config of acoustic model. Use deault config when it is
- None.
+ Config of acoustic model.
--am_ckpt AM_CKPT Checkpoint file of acoustic model.
--am_stat AM_STAT mean and standard deviation used to normalize
spectrogram when training acoustic model.
@@ -197,10 +195,10 @@ optional arguments:
--speaker_dict SPEAKER_DICT
speaker id map file.
--spk_id SPK_ID spk id for multi speaker acoustic model
- --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}
+ --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,style_melgan_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,wavernn_csmsc}
Choose vocoder type of tts task.
--voc_config VOC_CONFIG
- Config of voc. Use deault config when it is None.
+ Config of voc.
--voc_ckpt VOC_CKPT Checkpoint file of voc.
--voc_stat VOC_STAT mean and standard deviation used to normalize
spectrogram when training voc.
@@ -213,9 +211,9 @@ optional arguments:
output dir.
```
1. `--am` 声学模型格式是否符合 {model_name}_{dataset}
-2. `--am_config`, `--am_checkpoint`, `--am_stat` 和 `--phones_dict` 是声学模型的参数,对应于 fastspeech2 预训练模型中的 4 个文件。
+2. `--am_config`, `--am_ckpt`, `--am_stat` 和 `--phones_dict` 是声学模型的参数,对应于 fastspeech2 预训练模型中的 4 个文件。
3. `--voc` 声码器(vocoder)格式是否符合 {model_name}_{dataset}
-4. `--voc_config`, `--voc_checkpoint`, `--voc_stat` 是声码器的参数,对应于 parallel wavegan 预训练模型中的 3 个文件。
+4. `--voc_config`, `--voc_ckpt`, `--voc_stat` 是声码器的参数,对应于 parallel wavegan 预训练模型中的 3 个文件。
5. `--lang` 对应模型的语言可以是 `zh` 或 `en` 。
6. `--test_metadata` 应为 `dump` 文件夹中 `test` 下的规范化元数据文件、
7. `--text` 是文本文件,其中包含要合成的句子。
diff --git a/examples/csmsc/tts3/conf/default.yaml b/examples/csmsc/tts3/conf/default.yaml
index 2c2a1ea10..08b6f75ba 100644
--- a/examples/csmsc/tts3/conf/default.yaml
+++ b/examples/csmsc/tts3/conf/default.yaml
@@ -86,8 +86,8 @@ updater:
# OPTIMIZER SETTING #
###########################################################
optimizer:
- optim: adam # optimizer type
- learning_rate: 0.001 # learning rate
+ optim: adam # optimizer type
+ learning_rate: 0.001 # learning rate
###########################################################
# TRAINING SETTING #
diff --git a/examples/csmsc/vits/README.md b/examples/csmsc/vits/README.md
new file mode 100644
index 000000000..0c16840a0
--- /dev/null
+++ b/examples/csmsc/vits/README.md
@@ -0,0 +1,146 @@
+# VITS with CSMSC
+This example contains code used to train a [VITS](https://arxiv.org/abs/2106.06103) model with [Chinese Standard Mandarin Speech Copus](https://www.data-baker.com/open_source.html).
+
+## Dataset
+### Download and Extract
+Download CSMSC from it's [Official Website](https://test.data-baker.com/data/index/source).
+
+### Get MFA Result and Extract
+We use [MFA](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner) to get phonemes for VITS, the durations of MFA are not needed here.
+You can download from here [baker_alignment_tone.tar.gz](https://paddlespeech.bj.bcebos.com/MFA/BZNSYP/with_tone/baker_alignment_tone.tar.gz), or train your MFA model reference to [mfa example](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/other/mfa) of our repo.
+
+## Get Started
+Assume the path to the dataset is `~/datasets/BZNSYP`.
+Assume the path to the MFA result of CSMSC is `./baker_alignment_tone`.
+Run the command below to
+1. **source path**.
+2. preprocess the dataset.
+3. train the model.
+4. synthesize wavs.
+ - synthesize waveform from `metadata.jsonl`.
+ - synthesize waveform from a text file.
+
+```bash
+./run.sh
+```
+You can choose a range of stages you want to run, or set `stage` equal to `stop-stage` to use only one stage, for example, running the following command will only preprocess the dataset.
+```bash
+./run.sh --stage 0 --stop-stage 0
+```
+### Data Preprocessing
+```bash
+./local/preprocess.sh ${conf_path}
+```
+When it is done. A `dump` folder is created in the current directory. The structure of the dump folder is listed below.
+
+```text
+dump
+├── dev
+│ ├── norm
+│ └── raw
+├── phone_id_map.txt
+├── speaker_id_map.txt
+├── test
+│ ├── norm
+│ └── raw
+└── train
+ ├── feats_stats.npy
+ ├── norm
+ └── raw
+```
+The dataset is split into 3 parts, namely `train`, `dev`, and` test`, each of which contains a `norm` and `raw` subfolder. The raw folder contains wave and linear spectrogram of each utterance, while the norm folder contains normalized ones. The statistics used to normalize features are computed from the training set, which is located in `dump/train/feats_stats.npy`.
+
+Also, there is a `metadata.jsonl` in each subfolder. It is a table-like file that contains phones, text_lengths, feats, feats_lengths, the path of linear spectrogram features, the path of raw waves, speaker, and the id of each utterance.
+
+### Model Training
+```bash
+CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${train_output_path}
+```
+`./local/train.sh` calls `${BIN_DIR}/train.py`.
+Here's the complete help message.
+```text
+usage: train.py [-h] [--config CONFIG] [--train-metadata TRAIN_METADATA]
+ [--dev-metadata DEV_METADATA] [--output-dir OUTPUT_DIR]
+ [--ngpu NGPU] [--phones-dict PHONES_DICT]
+
+Train a VITS model.
+
+optional arguments:
+ -h, --help show this help message and exit
+ --config CONFIG config file to overwrite default config.
+ --train-metadata TRAIN_METADATA
+ training data.
+ --dev-metadata DEV_METADATA
+ dev data.
+ --output-dir OUTPUT_DIR
+ output dir.
+ --ngpu NGPU if ngpu == 0, use cpu.
+ --phones-dict PHONES_DICT
+ phone vocabulary file.
+```
+1. `--config` is a config file in yaml format to overwrite the default config, which can be found at `conf/default.yaml`.
+2. `--train-metadata` and `--dev-metadata` should be the metadata file in the normalized subfolder of `train` and `dev` in the `dump` folder.
+3. `--output-dir` is the directory to save the results of the experiment. Checkpoints are saved in `checkpoints/` inside this directory.
+4. `--ngpu` is the number of gpus to use, if ngpu == 0, use cpu.
+5. `--phones-dict` is the path of the phone vocabulary file.
+
+### Synthesizing
+
+`./local/synthesize.sh` calls `${BIN_DIR}/synthesize.py`, which can synthesize waveform from `metadata.jsonl`.
+
+```bash
+CUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize.sh ${conf_path} ${train_output_path} ${ckpt_name}
+```
+```text
+usage: synthesize.py [-h] [--config CONFIG] [--ckpt CKPT]
+ [--phones_dict PHONES_DICT] [--ngpu NGPU]
+ [--test_metadata TEST_METADATA] [--output_dir OUTPUT_DIR]
+
+Synthesize with VITS
+
+optional arguments:
+ -h, --help show this help message and exit
+ --config CONFIG Config of VITS.
+ --ckpt CKPT Checkpoint file of VITS.
+ --phones_dict PHONES_DICT
+ phone vocabulary file.
+ --ngpu NGPU if ngpu == 0, use cpu.
+ --test_metadata TEST_METADATA
+ test metadata.
+ --output_dir OUTPUT_DIR
+ output dir.
+```
+`./local/synthesize_e2e.sh` calls `${BIN_DIR}/synthesize_e2e.py`, which can synthesize waveform from text file.
+```bash
+CUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize_e2e.sh ${conf_path} ${train_output_path} ${ckpt_name}
+```
+```text
+usage: synthesize_e2e.py [-h] [--config CONFIG] [--ckpt CKPT]
+ [--phones_dict PHONES_DICT] [--lang LANG]
+ [--inference_dir INFERENCE_DIR] [--ngpu NGPU]
+ [--text TEXT] [--output_dir OUTPUT_DIR]
+
+Synthesize with VITS
+
+optional arguments:
+ -h, --help show this help message and exit
+ --config CONFIG Config of VITS.
+ --ckpt CKPT Checkpoint file of VITS.
+ --phones_dict PHONES_DICT
+ phone vocabulary file.
+ --lang LANG Choose model language. zh or en
+ --inference_dir INFERENCE_DIR
+ dir to save inference models
+ --ngpu NGPU if ngpu == 0, use cpu.
+ --text TEXT text to synthesize, a 'utt_id sentence' pair per line.
+ --output_dir OUTPUT_DIR
+ output dir.
+```
+1. `--config`, `--ckpt`, and `--phones_dict` are arguments for acoustic model, which correspond to the 3 files in the VITS pretrained model.
+2. `--lang` is the model language, which can be `zh` or `en`.
+3. `--test_metadata` should be the metadata file in the normalized subfolder of `test` in the `dump` folder.
+4. `--text` is the text file, which contains sentences to synthesize.
+5. `--output_dir` is the directory to save synthesized audio files.
+6. `--ngpu` is the number of gpus to use, if ngpu == 0, use cpu.
+
+## Pretrained Model
diff --git a/examples/csmsc/vits/conf/default.yaml b/examples/csmsc/vits/conf/default.yaml
new file mode 100644
index 000000000..47af780dc
--- /dev/null
+++ b/examples/csmsc/vits/conf/default.yaml
@@ -0,0 +1,183 @@
+# This configuration tested on 4 GPUs (V100) with 32GB GPU
+# memory. It takes around 2 weeks to finish the training
+# but 100k iters model should generate reasonable results.
+###########################################################
+# FEATURE EXTRACTION SETTING #
+###########################################################
+
+fs: 22050 # sr
+n_fft: 1024 # FFT size (samples).
+n_shift: 256 # Hop size (samples). 12.5ms
+win_length: null # Window length (samples). 50ms
+ # If set to null, it will be the same as fft_size.
+window: "hann" # Window function.
+
+
+##########################################################
+# TTS MODEL SETTING #
+##########################################################
+model:
+ # generator related
+ generator_type: vits_generator
+ generator_params:
+ hidden_channels: 192
+ spks: -1
+ global_channels: -1
+ segment_size: 32
+ text_encoder_attention_heads: 2
+ text_encoder_ffn_expand: 4
+ text_encoder_blocks: 6
+ text_encoder_positionwise_layer_type: "conv1d"
+ text_encoder_positionwise_conv_kernel_size: 3
+ text_encoder_positional_encoding_layer_type: "rel_pos"
+ text_encoder_self_attention_layer_type: "rel_selfattn"
+ text_encoder_activation_type: "swish"
+ text_encoder_normalize_before: True
+ text_encoder_dropout_rate: 0.1
+ text_encoder_positional_dropout_rate: 0.0
+ text_encoder_attention_dropout_rate: 0.1
+ use_macaron_style_in_text_encoder: True
+ use_conformer_conv_in_text_encoder: False
+ text_encoder_conformer_kernel_size: -1
+ decoder_kernel_size: 7
+ decoder_channels: 512
+ decoder_upsample_scales: [8, 8, 2, 2]
+ decoder_upsample_kernel_sizes: [16, 16, 4, 4]
+ decoder_resblock_kernel_sizes: [3, 7, 11]
+ decoder_resblock_dilations: [[1, 3, 5], [1, 3, 5], [1, 3, 5]]
+ use_weight_norm_in_decoder: True
+ posterior_encoder_kernel_size: 5
+ posterior_encoder_layers: 16
+ posterior_encoder_stacks: 1
+ posterior_encoder_base_dilation: 1
+ posterior_encoder_dropout_rate: 0.0
+ use_weight_norm_in_posterior_encoder: True
+ flow_flows: 4
+ flow_kernel_size: 5
+ flow_base_dilation: 1
+ flow_layers: 4
+ flow_dropout_rate: 0.0
+ use_weight_norm_in_flow: True
+ use_only_mean_in_flow: True
+ stochastic_duration_predictor_kernel_size: 3
+ stochastic_duration_predictor_dropout_rate: 0.5
+ stochastic_duration_predictor_flows: 4
+ stochastic_duration_predictor_dds_conv_layers: 3
+ # discriminator related
+ discriminator_type: hifigan_multi_scale_multi_period_discriminator
+ discriminator_params:
+ scales: 1
+ scale_downsample_pooling: "AvgPool1D"
+ scale_downsample_pooling_params:
+ kernel_size: 4
+ stride: 2
+ padding: 2
+ scale_discriminator_params:
+ in_channels: 1
+ out_channels: 1
+ kernel_sizes: [15, 41, 5, 3]
+ channels: 128
+ max_downsample_channels: 1024
+ max_groups: 16
+ bias: True
+ downsample_scales: [2, 2, 4, 4, 1]
+ nonlinear_activation: "leakyrelu"
+ nonlinear_activation_params:
+ negative_slope: 0.1
+ use_weight_norm: True
+ use_spectral_norm: False
+ follow_official_norm: False
+ periods: [2, 3, 5, 7, 11]
+ period_discriminator_params:
+ in_channels: 1
+ out_channels: 1
+ kernel_sizes: [5, 3]
+ channels: 32
+ downsample_scales: [3, 3, 3, 3, 1]
+ max_downsample_channels: 1024
+ bias: True
+ nonlinear_activation: "leakyrelu"
+ nonlinear_activation_params:
+ negative_slope: 0.1
+ use_weight_norm: True
+ use_spectral_norm: False
+ # others
+ sampling_rate: 22050 # needed in the inference for saving wav
+ cache_generator_outputs: True # whether to cache generator outputs in the training
+
+###########################################################
+# LOSS SETTING #
+###########################################################
+# loss function related
+generator_adv_loss_params:
+ average_by_discriminators: False # whether to average loss value by #discriminators
+ loss_type: mse # loss type, "mse" or "hinge"
+discriminator_adv_loss_params:
+ average_by_discriminators: False # whether to average loss value by #discriminators
+ loss_type: mse # loss type, "mse" or "hinge"
+feat_match_loss_params:
+ average_by_discriminators: False # whether to average loss value by #discriminators
+ average_by_layers: False # whether to average loss value by #layers of each discriminator
+ include_final_outputs: True # whether to include final outputs for loss calculation
+mel_loss_params:
+ fs: 22050 # must be the same as the training data
+ fft_size: 1024 # fft points
+ hop_size: 256 # hop size
+ win_length: null # window length
+ window: hann # window type
+ num_mels: 80 # number of Mel basis
+ fmin: 0 # minimum frequency for Mel basis
+ fmax: null # maximum frequency for Mel basis
+ log_base: null # null represent natural log
+
+###########################################################
+# ADVERSARIAL LOSS SETTING #
+###########################################################
+lambda_adv: 1.0 # loss scaling coefficient for adversarial loss
+lambda_mel: 45.0 # loss scaling coefficient for Mel loss
+lambda_feat_match: 2.0 # loss scaling coefficient for feat match loss
+lambda_dur: 1.0 # loss scaling coefficient for duration loss
+lambda_kl: 1.0 # loss scaling coefficient for KL divergence loss
+# others
+sampling_rate: 22050 # needed in the inference for saving wav
+cache_generator_outputs: True # whether to cache generator outputs in the training
+
+
+###########################################################
+# DATA LOADER SETTING #
+###########################################################
+batch_size: 64 # Batch size.
+num_workers: 4 # Number of workers in DataLoader.
+
+##########################################################
+# OPTIMIZER & SCHEDULER SETTING #
+##########################################################
+# optimizer setting for generator
+generator_optimizer_params:
+ beta1: 0.8
+ beta2: 0.99
+ epsilon: 1.0e-9
+ weight_decay: 0.0
+generator_scheduler: exponential_decay
+generator_scheduler_params:
+ learning_rate: 2.0e-4
+ gamma: 0.999875
+
+# optimizer setting for discriminator
+discriminator_optimizer_params:
+ beta1: 0.8
+ beta2: 0.99
+ epsilon: 1.0e-9
+ weight_decay: 0.0
+discriminator_scheduler: exponential_decay
+discriminator_scheduler_params:
+ learning_rate: 2.0e-4
+ gamma: 0.999875
+generator_first: False # whether to start updating generator first
+
+##########################################################
+# OTHER TRAINING SETTING #
+##########################################################
+max_epoch: 1000 # number of epochs
+num_snapshots: 10 # max number of snapshots to keep while training
+seed: 777 # random seed number
diff --git a/examples/csmsc/vits/local/preprocess.sh b/examples/csmsc/vits/local/preprocess.sh
new file mode 100755
index 000000000..1d3ae5937
--- /dev/null
+++ b/examples/csmsc/vits/local/preprocess.sh
@@ -0,0 +1,64 @@
+#!/bin/bash
+
+stage=0
+stop_stage=100
+
+config_path=$1
+
+if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then
+ # get durations from MFA's result
+ echo "Generate durations.txt from MFA results ..."
+ python3 ${MAIN_ROOT}/utils/gen_duration_from_textgrid.py \
+ --inputdir=./baker_alignment_tone \
+ --output=durations.txt \
+ --config=${config_path}
+fi
+
+if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
+ # extract features
+ echo "Extract features ..."
+ python3 ${BIN_DIR}/preprocess.py \
+ --dataset=baker \
+ --rootdir=~/datasets/BZNSYP/ \
+ --dumpdir=dump \
+ --dur-file=durations.txt \
+ --config=${config_path} \
+ --num-cpu=20 \
+ --cut-sil=True
+fi
+
+if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
+ # get features' stats(mean and std)
+ echo "Get features' stats ..."
+ python3 ${MAIN_ROOT}/utils/compute_statistics.py \
+ --metadata=dump/train/raw/metadata.jsonl \
+ --field-name="feats"
+fi
+
+if [ ${stage} -le 3 ] && [ ${stop_stage} -ge 3 ]; then
+ # normalize and covert phone/speaker to id, dev and test should use train's stats
+ echo "Normalize ..."
+ python3 ${BIN_DIR}/normalize.py \
+ --metadata=dump/train/raw/metadata.jsonl \
+ --dumpdir=dump/train/norm \
+ --feats-stats=dump/train/feats_stats.npy \
+ --phones-dict=dump/phone_id_map.txt \
+ --speaker-dict=dump/speaker_id_map.txt \
+ --skip-wav-copy
+
+ python3 ${BIN_DIR}/normalize.py \
+ --metadata=dump/dev/raw/metadata.jsonl \
+ --dumpdir=dump/dev/norm \
+ --feats-stats=dump/train/feats_stats.npy \
+ --phones-dict=dump/phone_id_map.txt \
+ --speaker-dict=dump/speaker_id_map.txt \
+ --skip-wav-copy
+
+ python3 ${BIN_DIR}/normalize.py \
+ --metadata=dump/test/raw/metadata.jsonl \
+ --dumpdir=dump/test/norm \
+ --feats-stats=dump/train/feats_stats.npy \
+ --phones-dict=dump/phone_id_map.txt \
+ --speaker-dict=dump/speaker_id_map.txt \
+ --skip-wav-copy
+fi
diff --git a/examples/csmsc/vits/local/synthesize.sh b/examples/csmsc/vits/local/synthesize.sh
new file mode 100755
index 000000000..c15d5f99f
--- /dev/null
+++ b/examples/csmsc/vits/local/synthesize.sh
@@ -0,0 +1,18 @@
+#!/bin/bash
+
+config_path=$1
+train_output_path=$2
+ckpt_name=$3
+stage=0
+stop_stage=0
+
+if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then
+ FLAGS_allocator_strategy=naive_best_fit \
+ FLAGS_fraction_of_gpu_memory_to_use=0.01 \
+ python3 ${BIN_DIR}/synthesize.py \
+ --config=${config_path} \
+ --ckpt=${train_output_path}/checkpoints/${ckpt_name} \
+ --phones_dict=dump/phone_id_map.txt \
+ --test_metadata=dump/test/norm/metadata.jsonl \
+ --output_dir=${train_output_path}/test
+fi
\ No newline at end of file
diff --git a/examples/csmsc/vits/local/synthesize_e2e.sh b/examples/csmsc/vits/local/synthesize_e2e.sh
new file mode 100755
index 000000000..edbb07bfc
--- /dev/null
+++ b/examples/csmsc/vits/local/synthesize_e2e.sh
@@ -0,0 +1,18 @@
+#!/bin/bash
+
+config_path=$1
+train_output_path=$2
+ckpt_name=$3
+stage=0
+stop_stage=0
+
+if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then
+ FLAGS_allocator_strategy=naive_best_fit \
+ FLAGS_fraction_of_gpu_memory_to_use=0.01 \
+ python3 ${BIN_DIR}/synthesize_e2e.py \
+ --config=${config_path} \
+ --ckpt=${train_output_path}/checkpoints/${ckpt_name} \
+ --phones_dict=dump/phone_id_map.txt \
+ --output_dir=${train_output_path}/test_e2e \
+ --text=${BIN_DIR}/../sentences.txt
+fi
diff --git a/examples/csmsc/vits/local/train.sh b/examples/csmsc/vits/local/train.sh
new file mode 100755
index 000000000..42fff26ca
--- /dev/null
+++ b/examples/csmsc/vits/local/train.sh
@@ -0,0 +1,12 @@
+#!/bin/bash
+
+config_path=$1
+train_output_path=$2
+
+python3 ${BIN_DIR}/train.py \
+ --train-metadata=dump/train/norm/metadata.jsonl \
+ --dev-metadata=dump/dev/norm/metadata.jsonl \
+ --config=${config_path} \
+ --output-dir=${train_output_path} \
+ --ngpu=4 \
+ --phones-dict=dump/phone_id_map.txt
diff --git a/examples/csmsc/vits/path.sh b/examples/csmsc/vits/path.sh
new file mode 100755
index 000000000..52d0c3783
--- /dev/null
+++ b/examples/csmsc/vits/path.sh
@@ -0,0 +1,13 @@
+#!/bin/bash
+export MAIN_ROOT=`realpath ${PWD}/../../../`
+
+export PATH=${MAIN_ROOT}:${MAIN_ROOT}/utils:${PATH}
+export LC_ALL=C
+
+export PYTHONDONTWRITEBYTECODE=1
+# Use UTF-8 in Python to avoid UnicodeDecodeError when LC_ALL=C
+export PYTHONIOENCODING=UTF-8
+export PYTHONPATH=${MAIN_ROOT}:${PYTHONPATH}
+
+MODEL=vits
+export BIN_DIR=${MAIN_ROOT}/paddlespeech/t2s/exps/${MODEL}
\ No newline at end of file
diff --git a/examples/csmsc/vits/run.sh b/examples/csmsc/vits/run.sh
new file mode 100755
index 000000000..80e56e7c1
--- /dev/null
+++ b/examples/csmsc/vits/run.sh
@@ -0,0 +1,36 @@
+#!/bin/bash
+
+set -e
+source path.sh
+
+gpus=0,1
+stage=0
+stop_stage=100
+
+conf_path=conf/default.yaml
+train_output_path=exp/default
+ckpt_name=snapshot_iter_153.pdz
+
+# with the following command, you can choose the stage range you want to run
+# such as `./run.sh --stage 0 --stop-stage 0`
+# this can not be mixed use with `$1`, `$2` ...
+source ${MAIN_ROOT}/utils/parse_options.sh || exit 1
+
+if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then
+ # prepare data
+ ./local/preprocess.sh ${conf_path} || exit -1
+fi
+
+if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
+ # train model, all `ckpt` under `train_output_path/checkpoints/` dir
+ CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${train_output_path} || exit -1
+fi
+
+if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
+ CUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize.sh ${conf_path} ${train_output_path} ${ckpt_name} || exit -1
+fi
+
+if [ ${stage} -le 3 ] && [ ${stop_stage} -ge 3 ]; then
+ # synthesize_e2e, vocoder is pwgan
+ CUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize_e2e.sh ${conf_path} ${train_output_path} ${ckpt_name} || exit -1
+fi
diff --git a/examples/csmsc/voc1/README.md b/examples/csmsc/voc1/README.md
index 77da5b185..4646a0345 100644
--- a/examples/csmsc/voc1/README.md
+++ b/examples/csmsc/voc1/README.md
@@ -2,7 +2,7 @@
This example contains code used to train a [parallel wavegan](http://arxiv.org/abs/1910.11480) model with [Chinese Standard Mandarin Speech Copus](https://www.data-baker.com/open_source.html).
## Dataset
### Download and Extract
-Download CSMSC from the [official website](https://www.data-baker.com/data/index/source) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/BZNSYP`.
+Download CSMSC from it's [official website](https://test.data-baker.com/data/index/TNtts/) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/BZNSYP`.
### Get MFA Result and Extract
We use [MFA](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner) results to cut silence at the edge of audio.
@@ -65,7 +65,7 @@ Train a ParallelWaveGAN model.
optional arguments:
-h, --help show this help message and exit
- --config CONFIG config file to overwrite default config.
+ --config CONFIG ParallelWaveGAN config file.
--train-metadata TRAIN_METADATA
training data.
--dev-metadata DEV_METADATA
diff --git a/examples/csmsc/voc3/README.md b/examples/csmsc/voc3/README.md
index 12adaf7f4..09fb8836c 100644
--- a/examples/csmsc/voc3/README.md
+++ b/examples/csmsc/voc3/README.md
@@ -2,7 +2,7 @@
This example contains code used to train a [Multi Band MelGAN](https://arxiv.org/abs/2005.05106) model with [Chinese Standard Mandarin Speech Copus](https://www.data-baker.com/open_source.html).
## Dataset
### Download and Extract
-Download CSMSC from the [official website](https://www.data-baker.com/data/index/source) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/BZNSYP`.
+Download CSMSC from it's [official website](https://test.data-baker.com/data/index/TNtts/) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/BZNSYP`.
### Get MFA Result and Extract
We use [MFA](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner) results to cut the silence in the edge of audio.
@@ -63,7 +63,7 @@ Train a Multi-Band MelGAN model.
optional arguments:
-h, --help show this help message and exit
- --config CONFIG config file to overwrite default config.
+ --config CONFIG Multi-Band MelGAN config file.
--train-metadata TRAIN_METADATA
training data.
--dev-metadata DEV_METADATA
diff --git a/examples/csmsc/voc4/README.md b/examples/csmsc/voc4/README.md
index b7add3e57..f1a132a84 100644
--- a/examples/csmsc/voc4/README.md
+++ b/examples/csmsc/voc4/README.md
@@ -2,7 +2,7 @@
This example contains code used to train a [Style MelGAN](https://arxiv.org/abs/2011.01557) model with [Chinese Standard Mandarin Speech Copus](https://www.data-baker.com/open_source.html).
## Dataset
### Download and Extract
-Download CSMSC from the [official website](https://www.data-baker.com/data/index/source) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/BZNSYP`.
+Download CSMSC from it's [official website](https://test.data-baker.com/data/index/TNtts/) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/BZNSYP`.
### Get MFA Result and Extract
We use [MFA](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner) results to cut the silence in the edge of audio.
@@ -63,7 +63,7 @@ Train a Style MelGAN model.
optional arguments:
-h, --help show this help message and exit
- --config CONFIG config file to overwrite default config.
+ --config CONFIG Style MelGAN config file.
--train-metadata TRAIN_METADATA
training data.
--dev-metadata DEV_METADATA
diff --git a/examples/csmsc/voc5/README.md b/examples/csmsc/voc5/README.md
index 33e676165..ef552fd30 100644
--- a/examples/csmsc/voc5/README.md
+++ b/examples/csmsc/voc5/README.md
@@ -2,7 +2,7 @@
This example contains code used to train a [HiFiGAN](https://arxiv.org/abs/2010.05646) model with [Chinese Standard Mandarin Speech Copus](https://www.data-baker.com/open_source.html).
## Dataset
### Download and Extract
-Download CSMSC from the [official website](https://www.data-baker.com/data/index/source) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/BZNSYP`.
+Download CSMSC from it's [official website](https://test.data-baker.com/data/index/TNtts/) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/BZNSYP`.
### Get MFA Result and Extract
We use [MFA](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner) results to cut silence at the edge of audio.
@@ -63,7 +63,7 @@ Train a HiFiGAN model.
optional arguments:
-h, --help show this help message and exit
- --config CONFIG config file to overwrite default config.
+ --config CONFIG HiFiGAN config file.
--train-metadata TRAIN_METADATA
training data.
--dev-metadata DEV_METADATA
@@ -130,7 +130,7 @@ HiFiGAN checkpoint contains files listed below.
```text
hifigan_csmsc_ckpt_0.1.1
├── default.yaml # default config used to train hifigan
-├── feats_stats.npy # statistics used to normalize spectrogram when training hifigan
+├── feats_stats.npy # statistics used to normalize spectrogram when training hifigan
└── snapshot_iter_2500000.pdz # generator parameters of hifigan
```
diff --git a/examples/csmsc/voc6/README.md b/examples/csmsc/voc6/README.md
index 7dcf133bd..b48c36414 100644
--- a/examples/csmsc/voc6/README.md
+++ b/examples/csmsc/voc6/README.md
@@ -2,7 +2,7 @@
This example contains code used to train a [WaveRNN](https://arxiv.org/abs/1802.08435) model with [Chinese Standard Mandarin Speech Copus](https://www.data-baker.com/open_source.html).
## Dataset
### Download and Extract
-Download CSMSC from the [official website](https://www.data-baker.com/data/index/source) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/BZNSYP`.
+Download CSMSC from it's [official website](https://test.data-baker.com/data/index/TNtts/) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/BZNSYP`.
### Get MFA Result and Extract
We use [MFA](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner) results to cut silence at the edge of audio.
@@ -63,7 +63,7 @@ Train a WaveRNN model.
optional arguments:
-h, --help show this help message and exit
- --config CONFIG config file to overwrite default config.
+ --config CONFIG WaveRNN config file.
--train-metadata TRAIN_METADATA
training data.
--dev-metadata DEV_METADATA
diff --git a/examples/esc50/cls0/conf/panns.yaml b/examples/esc50/cls0/conf/panns.yaml
index 3a9d42aa5..1f0323f0d 100644
--- a/examples/esc50/cls0/conf/panns.yaml
+++ b/examples/esc50/cls0/conf/panns.yaml
@@ -1,5 +1,5 @@
data:
- dataset: 'paddleaudio.datasets:ESC50'
+ dataset: 'paddlespeech.audio.datasets:ESC50'
num_classes: 50
train:
mode: 'train'
diff --git a/examples/hey_snips/kws0/conf/mdtc.yaml b/examples/hey_snips/kws0/conf/mdtc.yaml
index 4bd0708ce..76e47bc7c 100644
--- a/examples/hey_snips/kws0/conf/mdtc.yaml
+++ b/examples/hey_snips/kws0/conf/mdtc.yaml
@@ -2,7 +2,7 @@
###########################################
# Data #
###########################################
-dataset: 'paddleaudio.datasets:HeySnips'
+dataset: 'paddlespeech.audio.datasets:HeySnips'
data_dir: '/PATH/TO/DATA/hey_snips_research_6k_en_train_eval_clean_ter'
############################################
diff --git a/examples/librispeech/asr0/RESULTS.md b/examples/librispeech/asr0/RESULTS.md
index 77f92a2b7..5e5ce387b 100644
--- a/examples/librispeech/asr0/RESULTS.md
+++ b/examples/librispeech/asr0/RESULTS.md
@@ -1,8 +1,9 @@
# LibriSpeech
-## Deepspeech2
+## Deepspeech2 Non-Streaming
| Model | Params | release | Config | Test set | Loss | WER |
| --- | --- | --- | --- | --- | --- | --- |
+| DeepSpeech2 | 113.96M | r1.0.1 | conf/deepspeech2.yaml + U2 Data pipline and spec aug + fbank161 | test-clean | 10.76069622039795 | 0.046700 |
| DeepSpeech2 | 42.96M | 2.2.0 | conf/deepspeech2.yaml + spec_aug | test-clean | 14.49190807 | 0.067283 |
| DeepSpeech2 | 42.96M | 2.1.0 | conf/deepspeech2.yaml | test-clean | 15.184467315673828 | 0.072154 |
| DeepSpeech2 | 42.96M | 2.0.0 | conf/deepspeech2.yaml | test-clean | - | 0.073973 |
diff --git a/examples/librispeech/asr0/conf/augmentation.json b/examples/librispeech/asr0/conf/augmentation.json
deleted file mode 100644
index 31c481c8d..000000000
--- a/examples/librispeech/asr0/conf/augmentation.json
+++ /dev/null
@@ -1,36 +0,0 @@
-[
- {
- "type": "speed",
- "params": {
- "min_speed_rate": 0.9,
- "max_speed_rate": 1.1,
- "num_rates": 3
- },
- "prob": 0.0
- },
- {
- "type": "shift",
- "params": {
- "min_shift_ms": -5,
- "max_shift_ms": 5
- },
- "prob": 1.0
- },
- {
- "type": "specaug",
- "params": {
- "W": 0,
- "warp_mode": "PIL",
- "F": 10,
- "n_freq_masks": 2,
- "T": 50,
- "n_time_masks": 2,
- "p": 1.0,
- "adaptive_number_ratio": 0,
- "adaptive_size_ratio": 0,
- "max_n_time_masks": 20,
- "replace_with_zero": true
- },
- "prob": 1.0
- }
-]
diff --git a/examples/librispeech/asr0/conf/deepspeech2.yaml b/examples/librispeech/asr0/conf/deepspeech2.yaml
index 0307b9f39..cca695fe5 100644
--- a/examples/librispeech/asr0/conf/deepspeech2.yaml
+++ b/examples/librispeech/asr0/conf/deepspeech2.yaml
@@ -15,51 +15,51 @@ max_output_input_ratio: .inf
###########################################
# Dataloader #
###########################################
-batch_size: 20
-mean_std_filepath: data/mean_std.json
-unit_type: char
-vocab_filepath: data/lang_char/vocab.txt
-augmentation_config: conf/augmentation.json
-random_seed: 0
-spm_model_prefix:
-spectrum_type: linear
-feat_dim:
-target_sample_rate: 16000
-max_freq: None
-n_fft: None
+vocab_filepath: data/lang_char/vocab.txt
+spm_model_prefix: ''
+unit_type: 'char'
+preprocess_config: conf/preprocess.yaml
+feat_dim: 161
stride_ms: 10.0
-window_ms: 20.0
-delta_delta: False
-dither: 1.0
-use_dB_normalization: True
-target_dB: -20
-random_seed: 0
-keep_transcription_text: False
-sortagrad: True
-shuffle_method: batch_shuffle
-num_workers: 2
+window_ms: 25.0
+sortagrad: 0 # Feed samples from shortest to longest ; -1: enabled for all epochs, 0: disabled, other: enabled for 'other' epochs
+batch_size: 64
+maxlen_in: 512 # if input length > maxlen-in, batchsize is automatically reduced
+maxlen_out: 150 # if output length > maxlen-out, batchsize is automatically reduced
+minibatches: 0 # for debug
+batch_count: auto
+batch_bins: 0
+batch_frames_in: 0
+batch_frames_out: 0
+batch_frames_inout: 0
+num_workers: 8
+subsampling_factor: 1
+num_encs: 1
############################################
# Network Architecture #
############################################
num_conv_layers: 2
-num_rnn_layers: 3
-rnn_layer_size: 2048
+num_rnn_layers: 5
+rnn_layer_size: 1024
+rnn_direction: bidirect
+num_fc_layers: 0
+fc_layers_size_list: -1
use_gru: False
-share_rnn_weights: True
blank_id: 0
###########################################
# Training #
###########################################
-n_epoch: 50
+n_epoch: 15
accum_grad: 1
-lr: 1.0e-3
-lr_decay: 0.83
+lr: 5.0e-4
+lr_decay: 0.93
weight_decay: 1.0e-6
global_grad_clip: 5.0
-log_interval: 100
+dist_sampler: False
+log_interval: 1
checkpoint:
kbest_n: 50
latest_n: 5
diff --git a/examples/librispeech/asr0/conf/deepspeech2_online.yaml b/examples/librispeech/asr0/conf/deepspeech2_online.yaml
index a0d2bcfe2..93421ef44 100644
--- a/examples/librispeech/asr0/conf/deepspeech2_online.yaml
+++ b/examples/librispeech/asr0/conf/deepspeech2_online.yaml
@@ -15,39 +15,36 @@ max_output_input_ratio: .inf
###########################################
# Dataloader #
###########################################
-batch_size: 15
-mean_std_filepath: data/mean_std.json
-unit_type: char
-vocab_filepath: data/lang_char/vocab.txt
-augmentation_config: conf/augmentation.json
-random_seed: 0
-spm_model_prefix:
-spectrum_type: linear
-feat_dim:
-target_sample_rate: 16000
-max_freq: None
-n_fft: None
+vocab_filepath: data/lang_char/vocab.txt
+spm_model_prefix: ''
+unit_type: 'char'
+preprocess_config: conf/preprocess.yaml
+feat_dim: 161
stride_ms: 10.0
-window_ms: 20.0
-delta_delta: False
-dither: 1.0
-use_dB_normalization: True
-target_dB: -20
-random_seed: 0
-keep_transcription_text: False
-sortagrad: True
-shuffle_method: batch_shuffle
-num_workers: 0
+window_ms: 25.0
+sortagrad: 0 # Feed samples from shortest to longest ; -1: enabled for all epochs, 0: disabled, other: enabled for 'other' epochs
+batch_size: 64
+maxlen_in: 512 # if input length > maxlen-in, batchsize is automatically reduced
+maxlen_out: 150 # if output length > maxlen-out, batchsize is automatically reduced
+minibatches: 0 # for debug
+batch_count: auto
+batch_bins: 0
+batch_frames_in: 0
+batch_frames_out: 0
+batch_frames_inout: 0
+num_workers: 8
+subsampling_factor: 1
+num_encs: 1
############################################
# Network Architecture #
############################################
num_conv_layers: 2
-num_rnn_layers: 3
-rnn_layer_size: 2048
+num_rnn_layers: 5
+rnn_layer_size: 1024
rnn_direction: forward
-num_fc_layers: 2
-fc_layers_size_list: 512, 256
+num_fc_layers: 0
+fc_layers_size_list: -1
use_gru: False
blank_id: 0
@@ -55,13 +52,13 @@ blank_id: 0
###########################################
# Training #
###########################################
-n_epoch: 50
-accum_grad: 4
-lr: 1.0e-3
-lr_decay: 0.83
+n_epoch: 65
+accum_grad: 1
+lr: 5.0e-4
+lr_decay: 0.93
weight_decay: 1.0e-6
global_grad_clip: 5.0
-log_interval: 100
+log_interval: 1
checkpoint:
kbest_n: 50
latest_n: 5
diff --git a/examples/librispeech/asr0/conf/preprocess.yaml b/examples/librispeech/asr0/conf/preprocess.yaml
new file mode 100644
index 000000000..3f526e0ad
--- /dev/null
+++ b/examples/librispeech/asr0/conf/preprocess.yaml
@@ -0,0 +1,25 @@
+process:
+ # extract kaldi fbank from PCM
+ - type: fbank_kaldi
+ fs: 16000
+ n_mels: 161
+ n_shift: 160
+ win_length: 400
+ dither: 0.1
+ - type: cmvn_json
+ cmvn_path: data/mean_std.json
+ # these three processes are a.k.a. SpecAugument
+ - type: time_warp
+ max_time_warp: 5
+ inplace: true
+ mode: PIL
+ - type: freq_mask
+ F: 30
+ n_mask: 2
+ inplace: true
+ replace_with_zero: false
+ - type: time_mask
+ T: 40
+ n_mask: 2
+ inplace: true
+ replace_with_zero: false
diff --git a/examples/librispeech/asr0/local/data.sh b/examples/librispeech/asr0/local/data.sh
index b97e8c211..a28fddc96 100755
--- a/examples/librispeech/asr0/local/data.sh
+++ b/examples/librispeech/asr0/local/data.sh
@@ -49,12 +49,13 @@ if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then
python3 ${MAIN_ROOT}/utils/compute_mean_std.py \
--manifest_path="data/manifest.train.raw" \
--num_samples=2000 \
- --spectrum_type="linear" \
+ --spectrum_type="fbank" \
+ --feat_dim=161 \
--delta_delta=false \
--sample_rate=16000 \
--stride_ms=10 \
- --window_ms=20 \
- --use_dB_normalization=True \
+ --window_ms=25 \
+ --use_dB_normalization=False \
--num_workers=${num_workers} \
--output_path="data/mean_std.json"
diff --git a/examples/librispeech/asr0/local/export.sh b/examples/librispeech/asr0/local/export.sh
index 426a72fe5..ce7e6d642 100755
--- a/examples/librispeech/asr0/local/export.sh
+++ b/examples/librispeech/asr0/local/export.sh
@@ -1,7 +1,7 @@
#!/bin/bash
-if [ $# != 4 ];then
- echo "usage: $0 config_path ckpt_prefix jit_model_path model_type"
+if [ $# != 3 ];then
+ echo "usage: $0 config_path ckpt_prefix jit_model_path"
exit -1
fi
@@ -11,14 +11,12 @@ echo "using $ngpu gpus..."
config_path=$1
ckpt_path_prefix=$2
jit_model_export_path=$3
-model_type=$4
python3 -u ${BIN_DIR}/export.py \
--ngpu ${ngpu} \
--config ${config_path} \
--checkpoint_path ${ckpt_path_prefix} \
---export_path ${jit_model_export_path} \
---model_type ${model_type}
+--export_path ${jit_model_export_path}
if [ $? -ne 0 ]; then
echo "Failed in export!"
diff --git a/examples/librispeech/asr0/local/test.sh b/examples/librispeech/asr0/local/test.sh
index ea40046b1..728569d1f 100755
--- a/examples/librispeech/asr0/local/test.sh
+++ b/examples/librispeech/asr0/local/test.sh
@@ -1,9 +1,11 @@
#!/bin/bash
-if [ $# != 4 ];then
- echo "usage: ${0} config_path decode_config_path ckpt_path_prefix model_type"
+if [ $# != 3 ];then
+ echo "usage: ${0} config_path decode_config_path ckpt_path_prefix"
exit -1
fi
+stage=0
+stop_stage=100
ngpu=$(echo $CUDA_VISIBLE_DEVICES | awk -F "," '{print NF}')
echo "using $ngpu gpus..."
@@ -11,7 +13,6 @@ echo "using $ngpu gpus..."
config_path=$1
decode_config_path=$2
ckpt_prefix=$3
-model_type=$4
# download language model
bash local/download_lm_en.sh
@@ -19,17 +20,43 @@ if [ $? -ne 0 ]; then
exit 1
fi
-python3 -u ${BIN_DIR}/test.py \
---ngpu ${ngpu} \
---config ${config_path} \
---decode_cfg ${decode_config_path} \
---result_file ${ckpt_prefix}.rsl \
---checkpoint_path ${ckpt_prefix} \
---model_type ${model_type}
+if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then
+ # format the reference test file
+ python3 utils/format_rsl.py \
+ --origin_ref data/manifest.test-clean.raw \
+ --trans_ref data/manifest.test-clean.text
+
+ python3 -u ${BIN_DIR}/test.py \
+ --ngpu ${ngpu} \
+ --config ${config_path} \
+ --decode_cfg ${decode_config_path} \
+ --result_file ${ckpt_prefix}.rsl \
+ --checkpoint_path ${ckpt_prefix}
+
+ if [ $? -ne 0 ]; then
+ echo "Failed in evaluation!"
+ exit 1
+ fi
+
+ python3 utils/format_rsl.py \
+ --origin_hyp ${ckpt_prefix}.rsl \
+ --trans_hyp ${ckpt_prefix}.rsl.text
+
+ python3 utils/compute-wer.py --char=1 --v=1 \
+ data/manifest.test-clean.text ${ckpt_prefix}.rsl.text > ${ckpt_prefix}.error
+fi
-if [ $? -ne 0 ]; then
- echo "Failed in evaluation!"
- exit 1
+if [ ${stage} -le 101 ] && [ ${stop_stage} -ge 101 ]; then
+ python3 utils/format_rsl.py \
+ --origin_ref data/manifest.test-clean.raw \
+ --trans_ref_sclite data/manifest.test.text-clean.sclite
+
+ python3 utils/format_rsl.py \
+ --origin_hyp ${ckpt_prefix}.rsl \
+ --trans_hyp_sclite ${ckpt_prefix}.rsl.text.sclite
+
+ mkdir -p ${ckpt_prefix}_sclite
+ sclite -i wsj -r data/manifest.test-clean.text.sclite -h ${ckpt_prefix}.rsl.text.sclite -e utf-8 -o all -O ${ckpt_prefix}_sclite -c NOASCII
fi
diff --git a/examples/librispeech/asr0/local/test_wav.sh b/examples/librispeech/asr0/local/test_wav.sh
index 25cfc45e3..a5712b608 100755
--- a/examples/librispeech/asr0/local/test_wav.sh
+++ b/examples/librispeech/asr0/local/test_wav.sh
@@ -1,7 +1,7 @@
#!/bin/bash
-if [ $# != 5 ];then
- echo "usage: ${0} config_path decode_config_path ckpt_path_prefix model_type audio_file"
+if [ $# != 4 ];then
+ echo "usage: ${0} config_path decode_config_path ckpt_path_prefix audio_file"
exit -1
fi
@@ -11,8 +11,7 @@ echo "using $ngpu gpus..."
config_path=$1
decode_config_path=$2
ckpt_prefix=$3
-model_type=$4
-audio_file=$5
+audio_file=$4
mkdir -p data
wget -nc https://paddlespeech.bj.bcebos.com/datasets/single_wav/en/demo_002_en.wav -P data/
@@ -37,7 +36,6 @@ python3 -u ${BIN_DIR}/test_wav.py \
--decode_cfg ${decode_config_path} \
--result_file ${ckpt_prefix}.rsl \
--checkpoint_path ${ckpt_prefix} \
---model_type ${model_type} \
--audio_file ${audio_file}
if [ $? -ne 0 ]; then
diff --git a/examples/librispeech/asr0/local/train.sh b/examples/librispeech/asr0/local/train.sh
index 0479398ff..71659e28d 100755
--- a/examples/librispeech/asr0/local/train.sh
+++ b/examples/librispeech/asr0/local/train.sh
@@ -1,7 +1,7 @@
#!/bin/bash
-if [ $# != 3 ];then
- echo "usage: CUDA_VISIBLE_DEVICES=0 ${0} config_path ckpt_name model_type"
+if [ $# -lt 2 ] && [ $# -gt 3 ];then
+ echo "usage: CUDA_VISIBLE_DEVICES=0 ${0} config_path ckpt_name ips(optional)"
exit -1
fi
@@ -10,7 +10,13 @@ echo "using $ngpu gpus..."
config_path=$1
ckpt_name=$2
-model_type=$3
+ips=$3
+
+if [ ! $ips ];then
+ ips_config=
+else
+ ips_config="--ips="${ips}
+fi
mkdir -p exp
@@ -20,12 +26,19 @@ if [ ${seed} != 0 ]; then
export FLAGS_cudnn_deterministic=True
fi
+if [ ${ngpu} == 0 ]; then
python3 -u ${BIN_DIR}/train.py \
--ngpu ${ngpu} \
--config ${config_path} \
--output exp/${ckpt_name} \
---model_type ${model_type} \
--seed ${seed}
+else
+python3 -m paddle.distributed.launch --gpus=${CUDA_VISIBLE_DEVICES} ${ips_config} ${BIN_DIR}/train.py \
+--ngpu ${ngpu} \
+--config ${config_path} \
+--output exp/${ckpt_name} \
+--seed ${seed}
+fi
if [ ${seed} != 0 ]; then
unset FLAGS_cudnn_deterministic
diff --git a/examples/librispeech/asr0/run.sh b/examples/librispeech/asr0/run.sh
index ca2c2b9da..38112398a 100755
--- a/examples/librispeech/asr0/run.sh
+++ b/examples/librispeech/asr0/run.sh
@@ -2,13 +2,13 @@
set -e
source path.sh
-gpus=0,1,2,3,4,5,6,7
+gpus=0,1,2,3
stage=0
stop_stage=100
conf_path=conf/deepspeech2.yaml
+ips= #xx.xx.xx.xx,xx.xx.xx.xx
decode_conf_path=conf/tuning/decode.yaml
-avg_num=30
-model_type=offline
+avg_num=5
audio_file=data/demo_002_en.wav
source ${MAIN_ROOT}/utils/parse_options.sh || exit 1;
@@ -24,7 +24,7 @@ fi
if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
# train model, all `ckpt` under `exp` dir
- CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt} ${model_type}
+ CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt} ${ips}
fi
if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
@@ -34,15 +34,20 @@ fi
if [ ${stage} -le 3 ] && [ ${stop_stage} -ge 3 ]; then
# test ckpt avg_n
- CUDA_VISIBLE_DEVICES=0 ./local/test.sh ${conf_path} ${decode_conf_path} exp/${ckpt}/checkpoints/${avg_ckpt} ${model_type} || exit -1
+ CUDA_VISIBLE_DEVICES=0 ./local/test.sh ${conf_path} ${decode_conf_path} exp/${ckpt}/checkpoints/${avg_ckpt}|| exit -1
fi
if [ ${stage} -le 4 ] && [ ${stop_stage} -ge 4 ]; then
# export ckpt avg_n
- CUDA_VISIBLE_DEVICES= ./local/export.sh ${conf_path} exp/${ckpt}/checkpoints/${avg_ckpt} exp/${ckpt}/checkpoints/${avg_ckpt}.jit ${model_type}
+ CUDA_VISIBLE_DEVICES= ./local/export.sh ${conf_path} exp/${ckpt}/checkpoints/${avg_ckpt} exp/${ckpt}/checkpoints/${avg_ckpt}.jit
fi
if [ ${stage} -le 5 ] && [ ${stop_stage} -ge 5 ]; then
+ # test export ckpt avg_n
+ CUDA_VISIBLE_DEVICES=0 ./local/test_export.sh ${conf_path} ${decode_conf_path} exp/${ckpt}/checkpoints/${avg_ckpt}.jit|| exit -1
+fi
+
+if [ ${stage} -le 6 ] && [ ${stop_stage} -ge 6 ]; then
# test a single .wav file
- CUDA_VISIBLE_DEVICES=0 ./local/test_wav.sh ${conf_path} ${decode_conf_path} exp/${ckpt}/checkpoints/${avg_ckpt} ${model_type} ${audio_file} || exit -1
+ CUDA_VISIBLE_DEVICES=0 ./local/test_wav.sh ${conf_path} ${decode_conf_path} exp/${ckpt}/checkpoints/${avg_ckpt} ${audio_file} || exit -1
fi
diff --git a/examples/librispeech/asr1/RESULTS.md b/examples/librispeech/asr1/RESULTS.md
index 10f0fe33d..6f39ae146 100644
--- a/examples/librispeech/asr1/RESULTS.md
+++ b/examples/librispeech/asr1/RESULTS.md
@@ -11,7 +11,7 @@ train: Epoch 70, 4 V100-32G, best avg: 20
| conformer | 47.63 M | conf/conformer.yaml | spec_aug | test-clean | attention_rescoring | 6.433612394332886 | 0.033761 |
-## Chunk Conformer
+## Conformer Streaming
| Model | Params | Config | Augmentation| Test set | Decode method | Chunk Size & Left Chunks | Loss | WER |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
diff --git a/examples/librispeech/asr1/local/test.sh b/examples/librispeech/asr1/local/test.sh
index 51ced18b2..03cef9a62 100755
--- a/examples/librispeech/asr1/local/test.sh
+++ b/examples/librispeech/asr1/local/test.sh
@@ -42,6 +42,11 @@ echo "chunk mode ${chunk_mode}"
if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then
+ # format the reference test file
+ python3 utils/format_rsl.py \
+ --origin_ref data/manifest.test-clean.raw \
+ --trans_ref data/manifest.test-clean.text
+
for type in attention; do
echo "decoding ${type}"
if [ ${chunk_mode} == true ];then
@@ -63,54 +68,90 @@ if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then
echo "Failed in evaluation!"
exit 1
fi
+ python3 utils/format_rsl.py \
+ --origin_hyp ${ckpt_prefix}.${type}.rsl \
+ --trans_hyp ${ckpt_prefix}.${type}.rsl.text
+
+ python3 utils/compute-wer.py --char=1 --v=1 \
+ data/manifest.test-clean.text ${ckpt_prefix}.${type}.rsl.text > ${ckpt_prefix}.${type}.error
+ echo "decoding ${type} done."
+ done
+
+ for type in ctc_greedy_search; do
+ echo "decoding ${type}"
+ if [ ${chunk_mode} == true ];then
+ # stream decoding only support batchsize=1
+ batch_size=1
+ else
+ batch_size=64
+ fi
+ python3 -u ${BIN_DIR}/test.py \
+ --ngpu ${ngpu} \
+ --config ${config_path} \
+ --decode_cfg ${decode_config_path} \
+ --result_file ${ckpt_prefix}.${type}.rsl \
+ --checkpoint_path ${ckpt_prefix} \
+ --opts decode.decoding_method ${type} \
+ --opts decode.decode_batch_size ${batch_size}
+
+ if [ $? -ne 0 ]; then
+ echo "Failed in evaluation!"
+ exit 1
+ fi
+ python3 utils/format_rsl.py \
+ --origin_hyp ${ckpt_prefix}.${type}.rsl \
+ --trans_hyp ${ckpt_prefix}.${type}.rsl.text
+
+ python3 utils/compute-wer.py --char=1 --v=1 \
+ data/manifest.test-clean.text ${ckpt_prefix}.${type}.rsl.text > ${ckpt_prefix}.${type}.error
echo "decoding ${type} done."
done
-fi
-for type in ctc_greedy_search; do
- echo "decoding ${type}"
- if [ ${chunk_mode} == true ];then
- # stream decoding only support batchsize=1
+
+
+ for type in ctc_prefix_beam_search attention_rescoring; do
+ echo "decoding ${type}"
batch_size=1
- else
- batch_size=64
- fi
- python3 -u ${BIN_DIR}/test.py \
- --ngpu ${ngpu} \
- --config ${config_path} \
- --decode_cfg ${decode_config_path} \
- --result_file ${ckpt_prefix}.${type}.rsl \
- --checkpoint_path ${ckpt_prefix} \
- --opts decode.decoding_method ${type} \
- --opts decode.decode_batch_size ${batch_size}
-
- if [ $? -ne 0 ]; then
- echo "Failed in evaluation!"
- exit 1
- fi
- echo "decoding ${type} done."
-done
-
-
-
-for type in ctc_prefix_beam_search attention_rescoring; do
- echo "decoding ${type}"
- batch_size=1
- python3 -u ${BIN_DIR}/test.py \
- --ngpu ${ngpu} \
- --config ${config_path} \
- --decode_cfg ${decode_config_path} \
- --result_file ${ckpt_prefix}.${type}.rsl \
- --checkpoint_path ${ckpt_prefix} \
- --opts decode.decoding_method ${type} \
- --opts decode.decode_batch_size ${batch_size}
-
- if [ $? -ne 0 ]; then
- echo "Failed in evaluation!"
- exit 1
- fi
- echo "decoding ${type} done."
-done
+ python3 -u ${BIN_DIR}/test.py \
+ --ngpu ${ngpu} \
+ --config ${config_path} \
+ --decode_cfg ${decode_config_path} \
+ --result_file ${ckpt_prefix}.${type}.rsl \
+ --checkpoint_path ${ckpt_prefix} \
+ --opts decode.decoding_method ${type} \
+ --opts decode.decode_batch_size ${batch_size}
+
+ if [ $? -ne 0 ]; then
+ echo "Failed in evaluation!"
+ exit 1
+ fi
+ python3 utils/format_rsl.py \
+ --origin_hyp ${ckpt_prefix}.${type}.rsl \
+ --trans_hyp ${ckpt_prefix}.${type}.rsl.text
+
+ python3 utils/compute-wer.py --char=1 --v=1 \
+ data/manifest.test-clean.text ${ckpt_prefix}.${type}.rsl.text > ${ckpt_prefix}.${type}.error
+ echo "decoding ${type} done."
+ done
+fi
+
+if [ ${stage} -le 101 ] && [ ${stop_stage} -ge 101 ]; then
+ python3 utils/format_rsl.py \
+ --origin_ref data/manifest.test-clean.raw \
+ --trans_ref_sclite data/manifest.test.text-clean.sclite
+
+
+ output_dir=${ckpt_prefix}
+ for type in attention ctc_greedy_search ctc_prefix_beam_search attention_rescoring; do
+ python utils/format_rsl.py \
+ --origin_hyp ${output_dir}/${type}.rsl \
+ --trans_hyp_sclite ${output_dir}/${type}.rsl.text.sclite
+
+ mkdir -p ${output_dir}/${type}_sclite
+ sclite -i wsj -r data/manifest.test-clean.text.sclite -h ${output_dir}/${type}.rsl.text.sclite -e utf-8 -o all -O ${output_dir}/${type}_sclite -c NOASCII
+ done
+fi
+
echo "Finished"
diff --git a/examples/librispeech/asr1/local/train.sh b/examples/librispeech/asr1/local/train.sh
index 275d3a490..f729ed22c 100755
--- a/examples/librispeech/asr1/local/train.sh
+++ b/examples/librispeech/asr1/local/train.sh
@@ -1,7 +1,7 @@
#!/bin/bash
-if [ $# != 2 ];then
- echo "usage: CUDA_VISIBLE_DEVICES=0 ${0} config_path ckpt_name"
+if [ $# -lt 2 ] && [ $# -gt 3 ];then
+ echo "usage: CUDA_VISIBLE_DEVICES=0 ${0} config_path ckpt_name ips(optional)"
exit -1
fi
@@ -10,6 +10,13 @@ echo "using $ngpu gpus..."
config_path=$1
ckpt_name=$2
+ips=$3
+
+if [ ! $ips ];then
+ ips_config=
+else
+ ips_config="--ips="${ips}
+fi
mkdir -p exp
@@ -22,11 +29,19 @@ fi
# export FLAGS_cudnn_exhaustive_search=true
# export FLAGS_conv_workspace_size_limit=4000
+if [ ${ngpu} == 0 ]; then
python3 -u ${BIN_DIR}/train.py \
--ngpu ${ngpu} \
--config ${config_path} \
--output exp/${ckpt_name} \
--seed ${seed}
+else
+python3 -m paddle.distributed.launch --gpus=${CUDA_VISIBLE_DEVICES} ${ips_config} ${BIN_DIR}/train.py \
+--ngpu ${ngpu} \
+--config ${config_path} \
+--output exp/${ckpt_name} \
+--seed ${seed}
+fi
if [ ${seed} != 0 ]; then
unset FLAGS_cudnn_deterministic
diff --git a/examples/librispeech/asr1/run.sh b/examples/librispeech/asr1/run.sh
index 116dae126..a14240ee0 100755
--- a/examples/librispeech/asr1/run.sh
+++ b/examples/librispeech/asr1/run.sh
@@ -8,6 +8,7 @@ gpus=0,1,2,3
stage=0
stop_stage=50
conf_path=conf/transformer.yaml
+ips= #xx.xx.xx.xx,xx.xx.xx.xx
decode_conf_path=conf/tuning/decode.yaml
avg_num=30
audio_file=data/demo_002_en.wav
@@ -25,7 +26,7 @@ fi
if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
# train model, all `ckpt` under `exp` dir
- CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt}
+ CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt} ${ips}
fi
if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
diff --git a/examples/librispeech/asr2/local/train.sh b/examples/librispeech/asr2/local/train.sh
index 898391f4e..1f414ad41 100755
--- a/examples/librispeech/asr2/local/train.sh
+++ b/examples/librispeech/asr2/local/train.sh
@@ -1,7 +1,7 @@
#!/bin/bash
-if [ $# != 2 ];then
- echo "usage: CUDA_VISIBLE_DEVICES=0 ${0} config_path ckpt_name"
+if [ $# -lt 2 ] && [ $# -gt 3 ];then
+ echo "usage: CUDA_VISIBLE_DEVICES=0 ${0} config_path ckpt_name ips(optional)"
exit -1
fi
@@ -10,6 +10,13 @@ echo "using $ngpu gpus..."
config_path=$1
ckpt_name=$2
+ips=$3
+
+if [ ! $ips ];then
+ ips_config=
+else
+ ips_config="--ips="${ips}
+fi
mkdir -p exp
@@ -19,12 +26,21 @@ if [ ${seed} != 0 ]; then
export FLAGS_cudnn_deterministic=True
fi
+if [ ${ngpu} == 0 ]; then
python3 -u ${BIN_DIR}/train.py \
+--ngpu ${ngpu} \
--model-name u2_kaldi \
+--config ${config_path} \
+--output exp/${ckpt_name} \
+--seed ${seed}
+else
+python3 -m paddle.distributed.launch --gpus=${CUDA_VISIBLE_DEVICES} ${ips_config} ${BIN_DIR}/train.py \
--ngpu ${ngpu} \
+--model-name u2_kaldi \
--config ${config_path} \
--output exp/${ckpt_name} \
--seed ${seed}
+fi
if [ ${seed} != 0 ]; then
unset FLAGS_cudnn_deterministic
diff --git a/examples/librispeech/asr2/run.sh b/examples/librispeech/asr2/run.sh
index c9a794e34..d156159f2 100755
--- a/examples/librispeech/asr2/run.sh
+++ b/examples/librispeech/asr2/run.sh
@@ -9,6 +9,7 @@ gpus=0,1,2,3,4,5,6,7
stage=0
stop_stage=50
conf_path=conf/transformer.yaml
+ips= #xx.xx.xx.xx,xx.xx.xx.xx
decode_conf_path=conf/decode/decode_base.yaml
dict_path=data/lang_char/train_960_unigram5000_units.txt
avg_num=10
@@ -26,7 +27,7 @@ fi
if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
# train model, all `ckpt` under `exp` dir
- CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt}
+ CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt} ${ips}
fi
if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
diff --git a/examples/ljspeech/tts0/README.md b/examples/ljspeech/tts0/README.md
index ba7ad6193..85d9e448b 100644
--- a/examples/ljspeech/tts0/README.md
+++ b/examples/ljspeech/tts0/README.md
@@ -3,7 +3,7 @@ This example contains code used to train a [Tacotron2](https://arxiv.org/abs/171
## Dataset
### Download and Extract
-Download LJSpeech-1.1 from the [official website](https://keithito.com/LJ-Speech-Dataset/).
+Download LJSpeech-1.1 from it's [Official Website](https://keithito.com/LJ-Speech-Dataset/) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/LJSpeech-1.1`.
### Get MFA Result and Extract
We use [MFA](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner) to get phonemes for Tacotron2, the durations of MFA are not needed here.
@@ -103,12 +103,12 @@ CUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize.sh ${conf_path} ${train_output_p
```
```text
usage: synthesize.py [-h]
- [--am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc}]
+ [--am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech,tacotron2_aishell3}]
[--am_config AM_CONFIG] [--am_ckpt AM_CKPT]
[--am_stat AM_STAT] [--phones_dict PHONES_DICT]
[--tones_dict TONES_DICT] [--speaker_dict SPEAKER_DICT]
[--voice-cloning VOICE_CLONING]
- [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}]
+ [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,wavernn_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,style_melgan_csmsc}]
[--voc_config VOC_CONFIG] [--voc_ckpt VOC_CKPT]
[--voc_stat VOC_STAT] [--ngpu NGPU]
[--test_metadata TEST_METADATA] [--output_dir OUTPUT_DIR]
@@ -117,11 +117,10 @@ Synthesize with acoustic model & vocoder
optional arguments:
-h, --help show this help message and exit
- --am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc}
+ --am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech,tacotron2_aishell3}
Choose acoustic model type of tts task.
--am_config AM_CONFIG
- Config of acoustic model. Use deault config when it is
- None.
+ Config of acoustic model.
--am_ckpt AM_CKPT Checkpoint file of acoustic model.
--am_stat AM_STAT mean and standard deviation used to normalize
spectrogram when training acoustic model.
@@ -133,10 +132,10 @@ optional arguments:
speaker id map file.
--voice-cloning VOICE_CLONING
whether training voice cloning model.
- --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}
+ --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,wavernn_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,style_melgan_csmsc}
Choose vocoder type of tts task.
--voc_config VOC_CONFIG
- Config of voc. Use deault config when it is None.
+ Config of voc.
--voc_ckpt VOC_CKPT Checkpoint file of voc.
--voc_stat VOC_STAT mean and standard deviation used to normalize
spectrogram when training voc.
@@ -152,12 +151,12 @@ CUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize_e2e.sh ${conf_path} ${train_outp
```
```text
usage: synthesize_e2e.py [-h]
- [--am {speedyspeech_csmsc,speedyspeech_aishell3,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc}]
+ [--am {speedyspeech_csmsc,speedyspeech_aishell3,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech}]
[--am_config AM_CONFIG] [--am_ckpt AM_CKPT]
[--am_stat AM_STAT] [--phones_dict PHONES_DICT]
[--tones_dict TONES_DICT]
[--speaker_dict SPEAKER_DICT] [--spk_id SPK_ID]
- [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,style_melgan_csmsc,hifigan_csmsc}]
+ [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,style_melgan_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,wavernn_csmsc}]
[--voc_config VOC_CONFIG] [--voc_ckpt VOC_CKPT]
[--voc_stat VOC_STAT] [--lang LANG]
[--inference_dir INFERENCE_DIR] [--ngpu NGPU]
@@ -167,11 +166,10 @@ Synthesize with acoustic model & vocoder
optional arguments:
-h, --help show this help message and exit
- --am {speedyspeech_csmsc,speedyspeech_aishell3,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc}
+ --am {speedyspeech_csmsc,speedyspeech_aishell3,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech}
Choose acoustic model type of tts task.
--am_config AM_CONFIG
- Config of acoustic model. Use deault config when it is
- None.
+ Config of acoustic model.
--am_ckpt AM_CKPT Checkpoint file of acoustic model.
--am_stat AM_STAT mean and standard deviation used to normalize
spectrogram when training acoustic model.
@@ -182,10 +180,10 @@ optional arguments:
--speaker_dict SPEAKER_DICT
speaker id map file.
--spk_id SPK_ID spk id for multi speaker acoustic model
- --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,style_melgan_csmsc,hifigan_csmsc}
+ --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,style_melgan_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,wavernn_csmsc}
Choose vocoder type of tts task.
--voc_config VOC_CONFIG
- Config of voc. Use deault config when it is None.
+ Config of voc.
--voc_ckpt VOC_CKPT Checkpoint file of voc.
--voc_stat VOC_STAT mean and standard deviation used to normalize
spectrogram when training voc.
@@ -198,9 +196,9 @@ optional arguments:
output dir.
```
1. `--am` is acoustic model type with the format {model_name}_{dataset}
-2. `--am_config`, `--am_checkpoint`, `--am_stat` and `--phones_dict` are arguments for acoustic model, which correspond to the 4 files in the Tacotron2 pretrained model.
+2. `--am_config`, `--am_ckpt`, `--am_stat` and `--phones_dict` are arguments for acoustic model, which correspond to the 4 files in the Tacotron2 pretrained model.
3. `--voc` is vocoder type with the format {model_name}_{dataset}
-4. `--voc_config`, `--voc_checkpoint`, `--voc_stat` are arguments for vocoder, which correspond to the 3 files in the parallel wavegan pretrained model.
+4. `--voc_config`, `--voc_ckpt`, `--voc_stat` are arguments for vocoder, which correspond to the 3 files in the parallel wavegan pretrained model.
5. `--lang` is the model language, which can be `zh` or `en`.
6. `--test_metadata` should be the metadata file in the normalized subfolder of `test` in the `dump` folder.
7. `--text` is the text file, which contains sentences to synthesize.
diff --git a/examples/ljspeech/tts1/README.md b/examples/ljspeech/tts1/README.md
index 7f32522ac..85621653f 100644
--- a/examples/ljspeech/tts1/README.md
+++ b/examples/ljspeech/tts1/README.md
@@ -1,13 +1,10 @@
# TransformerTTS with LJSpeech
## Dataset
-We experiment with the LJSpeech dataset. Download and unzip [LJSpeech](https://keithito.com/LJ-Speech-Dataset/).
-
-```bash
-wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
-tar xjvf LJSpeech-1.1.tar.bz2
-```
+### Download and Extract
+Download LJSpeech-1.1 from it's [Official Website](https://keithito.com/LJ-Speech-Dataset/) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/LJSpeech-1.1`.
## Get Started
-Assume the path to the dataset is `~/datasets/LJSpeech-1.1`.
+Assume the path to the dataset is `~/datasets/LJSpeech-1.1` and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/LJSpeech-1.1`.
+
Run the command below to
1. **source path**.
2. preprocess the dataset.
@@ -61,7 +58,7 @@ Train a TransformerTTS model with LJSpeech TTS dataset.
optional arguments:
-h, --help show this help message and exit
- --config CONFIG config file to overwrite default config.
+ --config CONFIG TransformerTTS config file.
--train-metadata TRAIN_METADATA
training data.
--dev-metadata DEV_METADATA
diff --git a/examples/ljspeech/tts3/README.md b/examples/ljspeech/tts3/README.md
index e028fa05d..81a0580c0 100644
--- a/examples/ljspeech/tts3/README.md
+++ b/examples/ljspeech/tts3/README.md
@@ -3,7 +3,7 @@ This example contains code used to train a [Fastspeech2](https://arxiv.org/abs/2
## Dataset
### Download and Extract
-Download LJSpeech-1.1 from the [official website](https://keithito.com/LJ-Speech-Dataset/).
+Download LJSpeech-1.1 from it's [Official Website](https://keithito.com/LJ-Speech-Dataset/) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/LJSpeech-1.1`.
### Get MFA Result and Extract
We use [MFA](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner) to get durations for fastspeech2.
@@ -107,14 +107,14 @@ pwg_ljspeech_ckpt_0.5
```bash
CUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize.sh ${conf_path} ${train_output_path} ${ckpt_name}
```
-``text
+```text
usage: synthesize.py [-h]
- [--am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}]
+ [--am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech,tacotron2_aishell3}]
[--am_config AM_CONFIG] [--am_ckpt AM_CKPT]
[--am_stat AM_STAT] [--phones_dict PHONES_DICT]
[--tones_dict TONES_DICT] [--speaker_dict SPEAKER_DICT]
[--voice-cloning VOICE_CLONING]
- [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}]
+ [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,wavernn_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,style_melgan_csmsc}]
[--voc_config VOC_CONFIG] [--voc_ckpt VOC_CKPT]
[--voc_stat VOC_STAT] [--ngpu NGPU]
[--test_metadata TEST_METADATA] [--output_dir OUTPUT_DIR]
@@ -123,11 +123,10 @@ Synthesize with acoustic model & vocoder
optional arguments:
-h, --help show this help message and exit
- --am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}
+ --am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech,tacotron2_aishell3}
Choose acoustic model type of tts task.
--am_config AM_CONFIG
- Config of acoustic model. Use deault config when it is
- None.
+ Config of acoustic model.
--am_ckpt AM_CKPT Checkpoint file of acoustic model.
--am_stat AM_STAT mean and standard deviation used to normalize
spectrogram when training acoustic model.
@@ -139,10 +138,10 @@ optional arguments:
speaker id map file.
--voice-cloning VOICE_CLONING
whether training voice cloning model.
- --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}
+ --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,wavernn_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,style_melgan_csmsc}
Choose vocoder type of tts task.
--voc_config VOC_CONFIG
- Config of voc. Use deault config when it is None.
+ Config of voc.
--voc_ckpt VOC_CKPT Checkpoint file of voc.
--voc_stat VOC_STAT mean and standard deviation used to normalize
spectrogram when training voc.
@@ -158,12 +157,12 @@ CUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize_e2e.sh ${conf_path} ${train_outp
```
```text
usage: synthesize_e2e.py [-h]
- [--am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}]
+ [--am {speedyspeech_csmsc,speedyspeech_aishell3,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech}]
[--am_config AM_CONFIG] [--am_ckpt AM_CKPT]
[--am_stat AM_STAT] [--phones_dict PHONES_DICT]
[--tones_dict TONES_DICT]
[--speaker_dict SPEAKER_DICT] [--spk_id SPK_ID]
- [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}]
+ [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,style_melgan_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,wavernn_csmsc}]
[--voc_config VOC_CONFIG] [--voc_ckpt VOC_CKPT]
[--voc_stat VOC_STAT] [--lang LANG]
[--inference_dir INFERENCE_DIR] [--ngpu NGPU]
@@ -173,11 +172,10 @@ Synthesize with acoustic model & vocoder
optional arguments:
-h, --help show this help message and exit
- --am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}
+ --am {speedyspeech_csmsc,speedyspeech_aishell3,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech}
Choose acoustic model type of tts task.
--am_config AM_CONFIG
- Config of acoustic model. Use deault config when it is
- None.
+ Config of acoustic model.
--am_ckpt AM_CKPT Checkpoint file of acoustic model.
--am_stat AM_STAT mean and standard deviation used to normalize
spectrogram when training acoustic model.
@@ -188,10 +186,10 @@ optional arguments:
--speaker_dict SPEAKER_DICT
speaker id map file.
--spk_id SPK_ID spk id for multi speaker acoustic model
- --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}
+ --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,style_melgan_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,wavernn_csmsc}
Choose vocoder type of tts task.
--voc_config VOC_CONFIG
- Config of voc. Use deault config when it is None.
+ Config of voc.
--voc_ckpt VOC_CKPT Checkpoint file of voc.
--voc_stat VOC_STAT mean and standard deviation used to normalize
spectrogram when training voc.
@@ -204,9 +202,9 @@ optional arguments:
output dir.
```
1. `--am` is acoustic model type with the format {model_name}_{dataset}
-2. `--am_config`, `--am_checkpoint`, `--am_stat` and `--phones_dict` are arguments for acoustic model, which correspond to the 4 files in the fastspeech2 pretrained model.
+2. `--am_config`, `--am_ckpt`, `--am_stat` and `--phones_dict` are arguments for acoustic model, which correspond to the 4 files in the fastspeech2 pretrained model.
3. `--voc` is vocoder type with the format {model_name}_{dataset}
-4. `--voc_config`, `--voc_checkpoint`, `--voc_stat` are arguments for vocoder, which correspond to the 3 files in the parallel wavegan pretrained model.
+4. `--voc_config`, `--voc_ckpt`, `--voc_stat` are arguments for vocoder, which correspond to the 3 files in the parallel wavegan pretrained model.
5. `--lang` is the model language, which can be `zh` or `en`.
6. `--test_metadata` should be the metadata file in the normalized subfolder of `test` in the `dump` folder.
7. `--text` is the text file, which contains sentences to synthesize.
diff --git a/examples/ljspeech/voc0/README.md b/examples/ljspeech/voc0/README.md
index 41b08d57f..ae48a9a7f 100644
--- a/examples/ljspeech/voc0/README.md
+++ b/examples/ljspeech/voc0/README.md
@@ -1,11 +1,7 @@
# WaveFlow with LJSpeech
## Dataset
-We experiment with the LJSpeech dataset. Download and unzip [LJSpeech](https://keithito.com/LJ-Speech-Dataset/).
-
-```bash
-wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
-tar xjvf LJSpeech-1.1.tar.bz2
-```
+### Download and Extract
+Download LJSpeech-1.1 from it's [Official Website](https://keithito.com/LJ-Speech-Dataset/) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/LJSpeech-1.1`.
## Get Started
Assume the path to the dataset is `~/datasets/LJSpeech-1.1`.
Assume the path to the Tacotron2 generated mels is `../tts0/output/test`.
diff --git a/examples/ljspeech/voc1/README.md b/examples/ljspeech/voc1/README.md
index 4513b2a05..d16c0e35f 100644
--- a/examples/ljspeech/voc1/README.md
+++ b/examples/ljspeech/voc1/README.md
@@ -2,7 +2,7 @@
This example contains code used to train a [parallel wavegan](http://arxiv.org/abs/1910.11480) model with [LJSpeech-1.1](https://keithito.com/LJ-Speech-Dataset/).
## Dataset
### Download and Extract
-Download LJSpeech-1.1 from the [official website](https://keithito.com/LJ-Speech-Dataset/).
+Download LJSpeech-1.1 from it's [Official Website](https://keithito.com/LJ-Speech-Dataset/) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/LJSpeech-1.1`.
### Get MFA Result and Extract
We use [MFA](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner) results to cut the silence in the edge of audio.
You can download from here [ljspeech_alignment.tar.gz](https://paddlespeech.bj.bcebos.com/MFA/LJSpeech-1.1/ljspeech_alignment.tar.gz), or train your MFA model reference to [mfa example](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/other/mfa) of our repo.
@@ -65,7 +65,7 @@ Train a ParallelWaveGAN model.
optional arguments:
-h, --help show this help message and exit
- --config CONFIG config file to overwrite default config.
+ --config CONFIG ParallelWaveGAN config file.
--train-metadata TRAIN_METADATA
training data.
--dev-metadata DEV_METADATA
diff --git a/examples/ljspeech/voc5/README.md b/examples/ljspeech/voc5/README.md
index 9b31e2650..d856cfecf 100644
--- a/examples/ljspeech/voc5/README.md
+++ b/examples/ljspeech/voc5/README.md
@@ -2,7 +2,7 @@
This example contains code used to train a [HiFiGAN](https://arxiv.org/abs/2010.05646) model with [LJSpeech-1.1](https://keithito.com/LJ-Speech-Dataset/).
## Dataset
### Download and Extract
-Download LJSpeech-1.1 from the [official website](https://keithito.com/LJ-Speech-Dataset/).
+Download LJSpeech-1.1 from it's [Official Website](https://keithito.com/LJ-Speech-Dataset/) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/LJSpeech-1.1`.
### Get MFA Result and Extract
We use [MFA](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner) results to cut the silence in the edge of audio.
You can download from here [ljspeech_alignment.tar.gz](https://paddlespeech.bj.bcebos.com/MFA/LJSpeech-1.1/ljspeech_alignment.tar.gz), or train your MFA model reference to [mfa example](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/other/mfa) of our repo.
@@ -57,15 +57,13 @@ Here's the complete help message.
```text
usage: train.py [-h] [--config CONFIG] [--train-metadata TRAIN_METADATA]
[--dev-metadata DEV_METADATA] [--output-dir OUTPUT_DIR]
- [--ngpu NGPU] [--batch-size BATCH_SIZE] [--max-iter MAX_ITER]
- [--run-benchmark RUN_BENCHMARK]
- [--profiler_options PROFILER_OPTIONS]
+ [--ngpu NGPU]
-Train a ParallelWaveGAN model.
+Train a HiFiGAN model.
optional arguments:
-h, --help show this help message and exit
- --config CONFIG config file to overwrite default config.
+ --config CONFIG HiFiGAN config file.
--train-metadata TRAIN_METADATA
training data.
--dev-metadata DEV_METADATA
@@ -73,19 +71,6 @@ optional arguments:
--output-dir OUTPUT_DIR
output dir.
--ngpu NGPU if ngpu == 0, use cpu.
-
-benchmark:
- arguments related to benchmark.
-
- --batch-size BATCH_SIZE
- batch size.
- --max-iter MAX_ITER train max steps.
- --run-benchmark RUN_BENCHMARK
- runing benchmark or not, if True, use the --batch-size
- and --max-iter.
- --profiler_options PROFILER_OPTIONS
- The option of profiler, which should be in format
- "key1=value1;key2=value2;key3=value3".
```
1. `--config` is a config file in yaml format to overwrite the default config, which can be found at `conf/default.yaml`.
diff --git a/examples/mustc/st1/local/train.sh b/examples/mustc/st1/local/train.sh
index 456c94169..db2a575a6 100755
--- a/examples/mustc/st1/local/train.sh
+++ b/examples/mustc/st1/local/train.sh
@@ -1,7 +1,7 @@
#!/bin/bash
-if [ $# != 3 ];then
- echo "usage: CUDA_VISIBLE_DEVICES=0 ${0} config_path ckpt_name ckpt_path"
+if [ $# -lt 3 ] && [ $# -gt 4 ];then
+ echo "usage: CUDA_VISIBLE_DEVICES=0 ${0} config_path ckpt_name ckpt_path ips(optional)"
exit -1
fi
@@ -11,6 +11,13 @@ echo "using $ngpu gpus..."
config_path=$1
ckpt_name=$2
ckpt_path=$3
+ips=$3
+
+if [ ! $ips ];then
+ ips_config=
+else
+ ips_config="--ips="${ips}
+fi
mkdir -p exp
@@ -21,12 +28,21 @@ if [ ${seed} != 0 ]; then
export FLAGS_cudnn_deterministic=True
fi
+if [ ${ngpu} == 0 ]; then
python3 -u ${BIN_DIR}/train.py \
--ngpu ${ngpu} \
--config ${config_path} \
--output exp/${ckpt_name} \
--checkpoint_path "${ckpt_path}" \
--seed ${seed}
+else
+python3 -m paddle.distributed.launch --gpus=${CUDA_VISIBLE_DEVICES} ${ips_config} ${BIN_DIR}/train.py \
+--ngpu ${ngpu} \
+--config ${config_path} \
+--output exp/${ckpt_name} \
+--checkpoint_path "${ckpt_path}" \
+--seed ${seed}
+fi
if [ ${seed} != 0 ]; then
unset FLAGS_cudnn_deterministic
diff --git a/examples/mustc/st1/run.sh b/examples/mustc/st1/run.sh
index 6ceae3b84..99ee2295c 100755
--- a/examples/mustc/st1/run.sh
+++ b/examples/mustc/st1/run.sh
@@ -7,6 +7,7 @@ gpus=0,1,2,3
stage=0
stop_stage=3
conf_path=conf/transformer_es.yaml
+ips= #xx.xx.xx.xx,xx.xx.xx.xx
decode_conf_path=conf/tuning/decode.yaml
must_c_path=
lang=es
@@ -25,7 +26,7 @@ fi
if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
# train model, all `ckpt` under `exp` dir
- CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt} "${ckpt_path}"
+ CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt} "${ckpt_path}" ${ips}
fi
if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
@@ -36,4 +37,4 @@ fi
if [ ${stage} -le 3 ] && [ ${stop_stage} -ge 3 ]; then
# test ckpt avg_n
CUDA_VISIBLE_DEVICES=0 ./local/test.sh ${conf_path} ${decode_conf_path} exp/${ckpt}/checkpoints/${avg_ckpt} ${lang} || exit -1
-fi
\ No newline at end of file
+fi
diff --git a/examples/other/1xt2x/.gitignore b/examples/other/1xt2x/.gitignore
deleted file mode 100644
index a9a5aecf4..000000000
--- a/examples/other/1xt2x/.gitignore
+++ /dev/null
@@ -1 +0,0 @@
-tmp
diff --git a/examples/other/1xt2x/README.md b/examples/other/1xt2x/README.md
deleted file mode 100644
index 49f850d26..000000000
--- a/examples/other/1xt2x/README.md
+++ /dev/null
@@ -1,19 +0,0 @@
-# 1xt2x
-
-Convert Deepspeech 1.8 released model to 2.x.
-
-## Model source directory
-* Deepspeech2x
-
-## Expriment directory
-* aishell
-* librispeech
-* baidu_en8k
-
-# The released model
-
-Acoustic Model | Training Data | Hours of Speech | Token-based | CER | WER
-:-------------:| :------------:| :---------------: | :---------: | :---: | :----:
-Ds2 Offline Aishell 1xt2x model| Aishell Dataset | 151 h | Char-based | 0.080447 |
-Ds2 Offline Librispeech 1xt2x model | Librispeech Dataset | 960 h | Word-based | | 0.068548
-Ds2 Offline Baidu en8k 1x2x model | Baidu Internal English Dataset | 8628 h |Word-based | | 0.054112
diff --git a/examples/other/1xt2x/aishell/.gitignore b/examples/other/1xt2x/aishell/.gitignore
deleted file mode 100644
index 3631e544a..000000000
--- a/examples/other/1xt2x/aishell/.gitignore
+++ /dev/null
@@ -1,5 +0,0 @@
-exp
-data
-*log
-tmp
-nohup*
diff --git a/examples/other/1xt2x/aishell/conf/augmentation.json b/examples/other/1xt2x/aishell/conf/augmentation.json
deleted file mode 100644
index fe51488c7..000000000
--- a/examples/other/1xt2x/aishell/conf/augmentation.json
+++ /dev/null
@@ -1 +0,0 @@
-[]
diff --git a/examples/other/1xt2x/aishell/conf/deepspeech2.yaml b/examples/other/1xt2x/aishell/conf/deepspeech2.yaml
deleted file mode 100644
index c2db2c7c2..000000000
--- a/examples/other/1xt2x/aishell/conf/deepspeech2.yaml
+++ /dev/null
@@ -1,65 +0,0 @@
-# https://yaml.org/type/float.html
-###########################################
-# Data #
-###########################################
-train_manifest: data/manifest.train
-dev_manifest: data/manifest.dev
-test_manifest: data/manifest.test
-min_input_len: 0.0
-max_input_len: 27.0 # second
-min_output_len: 0.0
-max_output_len: .inf
-min_output_input_ratio: 0.00
-max_output_input_ratio: .inf
-
-###########################################
-# Dataloader #
-###########################################
-batch_size: 64 # one gpu
-mean_std_filepath: data/mean_std.npz
-unit_type: char
-vocab_filepath: data/vocab.txt
-augmentation_config: conf/augmentation.json
-random_seed: 0
-spm_model_prefix:
-spectrum_type: linear
-feat_dim:
-delta_delta: False
-stride_ms: 10.0
-window_ms: 20.0
-n_fft: None
-max_freq: None
-target_sample_rate: 16000
-use_dB_normalization: True
-target_dB: -20
-dither: 1.0
-keep_transcription_text: False
-sortagrad: True
-shuffle_method: batch_shuffle
-num_workers: 2
-
-############################################
-# Network Architecture #
-############################################
-num_conv_layers: 2
-num_rnn_layers: 3
-rnn_layer_size: 1024
-use_gru: True
-share_rnn_weights: False
-blank_id: 4333
-
-###########################################
-# Training #
-###########################################
-n_epoch: 80
-accum_grad: 1
-lr: 2e-3
-lr_decay: 0.83
-weight_decay: 1e-06
-global_grad_clip: 3.0
-log_interval: 100
-checkpoint:
- kbest_n: 50
- latest_n: 5
-
-
diff --git a/examples/other/1xt2x/aishell/conf/tuning/decode.yaml b/examples/other/1xt2x/aishell/conf/tuning/decode.yaml
deleted file mode 100644
index b5283a934..000000000
--- a/examples/other/1xt2x/aishell/conf/tuning/decode.yaml
+++ /dev/null
@@ -1,10 +0,0 @@
-decode_batch_size: 32
-error_rate_type: cer
-decoding_method: ctc_beam_search
-lang_model_path: data/lm/zh_giga.no_cna_cmn.prune01244.klm
-alpha: 2.6
-beta: 5.0
-beam_size: 300
-cutoff_prob: 0.99
-cutoff_top_n: 40
-num_proc_bsearch: 8
\ No newline at end of file
diff --git a/examples/other/1xt2x/aishell/local/data.sh b/examples/other/1xt2x/aishell/local/data.sh
deleted file mode 100755
index a9d5b1412..000000000
--- a/examples/other/1xt2x/aishell/local/data.sh
+++ /dev/null
@@ -1,69 +0,0 @@
-#!/bin/bash
-if [ $# != 1 ];then
- echo "usage: ${0} ckpt_dir"
- exit -1
-fi
-
-ckpt_dir=$1
-
-stage=-1
-stop_stage=100
-
-source ${MAIN_ROOT}/utils/parse_options.sh
-
-mkdir -p data
-TARGET_DIR=${MAIN_ROOT}/dataset
-mkdir -p ${TARGET_DIR}
-
-bash local/download_model.sh ${ckpt_dir}
-if [ $? -ne 0 ]; then
- exit 1
-fi
-
-cd ${ckpt_dir}
-tar xzvf aishell_model_v1.8_to_v2.x.tar.gz
-cd -
-mv ${ckpt_dir}/mean_std.npz data/
-mv ${ckpt_dir}/vocab.txt data/
-
-
-if [ ${stage} -le -1 ] && [ ${stop_stage} -ge -1 ]; then
- # download data, generate manifests
- python3 ${TARGET_DIR}/aishell/aishell.py \
- --manifest_prefix="data/manifest" \
- --target_dir="${TARGET_DIR}/aishell"
-
- if [ $? -ne 0 ]; then
- echo "Prepare Aishell failed. Terminated."
- exit 1
- fi
-
- for dataset in train dev test; do
- mv data/manifest.${dataset} data/manifest.${dataset}.raw
- done
-fi
-
-
-
-if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
- # format manifest with tokenids, vocab size
- for dataset in train dev test; do
- {
- python3 ${MAIN_ROOT}/utils/format_data.py \
- --cmvn_path "data/mean_std.npz" \
- --unit_type "char" \
- --vocab_path="data/vocab.txt" \
- --manifest_path="data/manifest.${dataset}.raw" \
- --output_path="data/manifest.${dataset}"
-
- if [ $? -ne 0 ]; then
- echo "Formt mnaifest failed. Terminated."
- exit 1
- fi
- } &
- done
- wait
-fi
-
-echo "Aishell data preparation done."
-exit 0
diff --git a/examples/other/1xt2x/aishell/local/download_lm_ch.sh b/examples/other/1xt2x/aishell/local/download_lm_ch.sh
deleted file mode 100755
index 47153f4b6..000000000
--- a/examples/other/1xt2x/aishell/local/download_lm_ch.sh
+++ /dev/null
@@ -1,23 +0,0 @@
-#!/bin/bash
-
-. ${MAIN_ROOT}/utils/utility.sh
-
-DIR=data/lm
-mkdir -p ${DIR}
-
-URL='https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm'
-MD5="29e02312deb2e59b3c8686c7966d4fe3"
-TARGET=${DIR}/zh_giga.no_cna_cmn.prune01244.klm
-
-
-echo "Start downloading the language model. The language model is large, please wait for a moment ..."
-download $URL $MD5 $TARGET > /dev/null 2>&1
-if [ $? -ne 0 ]; then
- echo "Fail to download the language model!"
- exit 1
-else
- echo "Download the language model sucessfully"
-fi
-
-
-exit 0
diff --git a/examples/other/1xt2x/aishell/local/download_model.sh b/examples/other/1xt2x/aishell/local/download_model.sh
deleted file mode 100644
index ffa2f8101..000000000
--- a/examples/other/1xt2x/aishell/local/download_model.sh
+++ /dev/null
@@ -1,25 +0,0 @@
-#! /usr/bin/env bash
-
-if [ $# != 1 ];then
- echo "usage: ${0} ckpt_dir"
- exit -1
-fi
-
-ckpt_dir=$1
-
-. ${MAIN_ROOT}/utils/utility.sh
-
-URL='https://deepspeech.bj.bcebos.com/mandarin_models/aishell_model_v1.8_to_v2.x.tar.gz'
-MD5=87e7577d4bea737dbf3e8daab37aa808
-TARGET=${ckpt_dir}/aishell_model_v1.8_to_v2.x.tar.gz
-
-
-echo "Download Aishell model ..."
-download $URL $MD5 $TARGET
-if [ $? -ne 0 ]; then
- echo "Fail to download Aishell model!"
- exit 1
-fi
-
-
-exit 0
diff --git a/examples/other/1xt2x/aishell/local/test.sh b/examples/other/1xt2x/aishell/local/test.sh
deleted file mode 100755
index 463593ef3..000000000
--- a/examples/other/1xt2x/aishell/local/test.sh
+++ /dev/null
@@ -1,36 +0,0 @@
-#!/bin/bash
-
-if [ $# != 4 ];then
- echo "usage: ${0} config_path decode_config_path ckpt_path_prefix model_type"
- exit -1
-fi
-
-ngpu=$(echo $CUDA_VISIBLE_DEVICES | awk -F "," '{print NF}')
-echo "using $ngpu gpus..."
-
-config_path=$1
-decode_config_path=$2
-ckpt_prefix=$3
-model_type=$4
-
-# download language model
-bash local/download_lm_ch.sh
-if [ $? -ne 0 ]; then
- exit 1
-fi
-
-python3 -u ${BIN_DIR}/test.py \
---ngpu ${ngpu} \
---config ${config_path} \
---decode_cfg ${decode_config_path} \
---result_file ${ckpt_prefix}.rsl \
---checkpoint_path ${ckpt_prefix} \
---model_type ${model_type}
-
-if [ $? -ne 0 ]; then
- echo "Failed in evaluation!"
- exit 1
-fi
-
-
-exit 0
diff --git a/examples/other/1xt2x/aishell/path.sh b/examples/other/1xt2x/aishell/path.sh
deleted file mode 100644
index ce44e65cb..000000000
--- a/examples/other/1xt2x/aishell/path.sh
+++ /dev/null
@@ -1,17 +0,0 @@
-export MAIN_ROOT=`realpath ${PWD}/../../../../`
-export LOCAL_DEEPSPEECH2=`realpath ${PWD}/../`
-
-export PATH=${MAIN_ROOT}:${MAIN_ROOT}/utils:${PATH}
-export LC_ALL=C
-
-export PYTHONDONTWRITEBYTECODE=1
-# Use UTF-8 in Python to avoid UnicodeDecodeError when LC_ALL=C
-export PYTHONIOENCODING=UTF-8
-export PYTHONPATH=${MAIN_ROOT}:${PYTHONPATH}
-export PYTHONPATH=${LOCAL_DEEPSPEECH2}:${PYTHONPATH}
-
-export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/lib/
-
-MODEL=deepspeech2
-export BIN_DIR=${LOCAL_DEEPSPEECH2}/src_deepspeech2x/bin
-echo "BIN_DIR "${BIN_DIR}
diff --git a/examples/other/1xt2x/aishell/run.sh b/examples/other/1xt2x/aishell/run.sh
deleted file mode 100755
index 89a634119..000000000
--- a/examples/other/1xt2x/aishell/run.sh
+++ /dev/null
@@ -1,29 +0,0 @@
-#!/bin/bash
-set -e
-source path.sh
-
-stage=0
-stop_stage=100
-conf_path=conf/deepspeech2.yaml
-decode_conf_path=conf/tuning/decode.yaml
-avg_num=1
-model_type=offline
-gpus=2
-
-source ${MAIN_ROOT}/utils/parse_options.sh || exit 1;
-
-v18_ckpt=aishell_v1.8
-ckpt=$(basename ${conf_path} | awk -F'.' '{print $1}')
-echo "checkpoint name ${ckpt}"
-
-if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then
- # prepare data
- mkdir -p exp/${ckpt}/checkpoints
- bash ./local/data.sh exp/${ckpt}/checkpoints || exit -1
-fi
-
-if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
- # test ckpt avg_n
- CUDA_VISIBLE_DEVICES=${gpus} ./local/test.sh ${conf_path} ${decode_conf_path} exp/${ckpt}/checkpoints/${v18_ckpt} ${model_type}|| exit -1
-fi
-
diff --git a/examples/other/1xt2x/baidu_en8k/.gitignore b/examples/other/1xt2x/baidu_en8k/.gitignore
deleted file mode 100644
index 3631e544a..000000000
--- a/examples/other/1xt2x/baidu_en8k/.gitignore
+++ /dev/null
@@ -1,5 +0,0 @@
-exp
-data
-*log
-tmp
-nohup*
diff --git a/examples/other/1xt2x/baidu_en8k/conf/augmentation.json b/examples/other/1xt2x/baidu_en8k/conf/augmentation.json
deleted file mode 100644
index fe51488c7..000000000
--- a/examples/other/1xt2x/baidu_en8k/conf/augmentation.json
+++ /dev/null
@@ -1 +0,0 @@
-[]
diff --git a/examples/other/1xt2x/baidu_en8k/conf/deepspeech2.yaml b/examples/other/1xt2x/baidu_en8k/conf/deepspeech2.yaml
deleted file mode 100644
index 0c08fbc63..000000000
--- a/examples/other/1xt2x/baidu_en8k/conf/deepspeech2.yaml
+++ /dev/null
@@ -1,64 +0,0 @@
-# https://yaml.org/type/float.html
-###########################################
-# Data #
-###########################################
-train_manifest: data/manifest.train
-dev_manifest: data/manifest.dev
-test_manifest: data/manifest.test-clean
-min_input_len: 0.0
-max_input_len: .inf # second
-min_output_len: 0.0
-max_output_len: .inf
-min_output_input_ratio: 0.00
-max_output_input_ratio: .inf
-
-###########################################
-# Dataloader #
-###########################################
-batch_size: 64 # one gpu
-mean_std_filepath: data/mean_std.npz
-unit_type: char
-vocab_filepath: data/vocab.txt
-augmentation_config: conf/augmentation.json
-random_seed: 0
-spm_model_prefix:
-spectrum_type: linear
-feat_dim:
-delta_delta: False
-stride_ms: 10.0
-window_ms: 20.0
-n_fft: None
-max_freq: None
-target_sample_rate: 16000
-use_dB_normalization: True
-target_dB: -20
-dither: 1.0
-keep_transcription_text: False
-sortagrad: True
-shuffle_method: batch_shuffle
-num_workers: 2
-
-############################################
-# Network Architecture #
-############################################
-num_conv_layers: 2
-num_rnn_layers: 3
-rnn_layer_size: 1024
-use_gru: True
-share_rnn_weights: False
-blank_id: 28
-
-###########################################
-# Training #
-###########################################
-n_epoch: 80
-accum_grad: 1
-lr: 2e-3
-lr_decay: 0.83
-weight_decay: 1e-06
-global_grad_clip: 3.0
-log_interval: 100
-checkpoint:
- kbest_n: 50
- latest_n: 5
-
diff --git a/examples/other/1xt2x/baidu_en8k/conf/tuning/decode.yaml b/examples/other/1xt2x/baidu_en8k/conf/tuning/decode.yaml
deleted file mode 100644
index f52dde320..000000000
--- a/examples/other/1xt2x/baidu_en8k/conf/tuning/decode.yaml
+++ /dev/null
@@ -1,10 +0,0 @@
-decode_batch_size: 32
-error_rate_type: wer
-decoding_method: ctc_beam_search
-lang_model_path: data/lm/common_crawl_00.prune01111.trie.klm
-alpha: 1.4
-beta: 0.35
-beam_size: 500
-cutoff_prob: 1.0
-cutoff_top_n: 40
-num_proc_bsearch: 8
\ No newline at end of file
diff --git a/examples/other/1xt2x/baidu_en8k/local/data.sh b/examples/other/1xt2x/baidu_en8k/local/data.sh
deleted file mode 100755
index 9b017324d..000000000
--- a/examples/other/1xt2x/baidu_en8k/local/data.sh
+++ /dev/null
@@ -1,85 +0,0 @@
-#!/bin/bash
-if [ $# != 1 ];then
- echo "usage: ${0} ckpt_dir"
- exit -1
-fi
-
-ckpt_dir=$1
-
-stage=-1
-stop_stage=100
-unit_type=char
-
-source ${MAIN_ROOT}/utils/parse_options.sh
-
-mkdir -p data
-TARGET_DIR=${MAIN_ROOT}/dataset
-mkdir -p ${TARGET_DIR}
-
-
-bash local/download_model.sh ${ckpt_dir}
-if [ $? -ne 0 ]; then
- exit 1
-fi
-
-cd ${ckpt_dir}
-tar xzvf baidu_en8k_v1.8_to_v2.x.tar.gz
-cd -
-mv ${ckpt_dir}/mean_std.npz data/
-mv ${ckpt_dir}/vocab.txt data/
-
-
-if [ ${stage} -le -1 ] && [ ${stop_stage} -ge -1 ]; then
- # download data, generate manifests
- python3 ${TARGET_DIR}/librispeech/librispeech.py \
- --manifest_prefix="data/manifest" \
- --target_dir="${TARGET_DIR}/librispeech" \
- --full_download="True"
-
- if [ $? -ne 0 ]; then
- echo "Prepare LibriSpeech failed. Terminated."
- exit 1
- fi
-
- for set in train-clean-100 train-clean-360 train-other-500 dev-clean dev-other test-clean test-other; do
- mv data/manifest.${set} data/manifest.${set}.raw
- done
-
- rm -rf data/manifest.train.raw data/manifest.dev.raw data/manifest.test.raw
- for set in train-clean-100 train-clean-360 train-other-500; do
- cat data/manifest.${set}.raw >> data/manifest.train.raw
- done
-
- for set in dev-clean dev-other; do
- cat data/manifest.${set}.raw >> data/manifest.dev.raw
- done
-
- for set in test-clean test-other; do
- cat data/manifest.${set}.raw >> data/manifest.test.raw
- done
-fi
-
-
-if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
- # format manifest with tokenids, vocab size
- for set in train dev test dev-clean dev-other test-clean test-other; do
- {
- python3 ${MAIN_ROOT}/utils/format_data.py \
- --cmvn_path "data/mean_std.npz" \
- --unit_type ${unit_type} \
- --vocab_path="data/vocab.txt" \
- --manifest_path="data/manifest.${set}.raw" \
- --output_path="data/manifest.${set}"
-
- if [ $? -ne 0 ]; then
- echo "Formt mnaifest.${set} failed. Terminated."
- exit 1
- fi
- }&
- done
- wait
-fi
-
-echo "LibriSpeech Data preparation done."
-exit 0
-
diff --git a/examples/other/1xt2x/baidu_en8k/local/download_lm_en.sh b/examples/other/1xt2x/baidu_en8k/local/download_lm_en.sh
deleted file mode 100755
index 390fffc93..000000000
--- a/examples/other/1xt2x/baidu_en8k/local/download_lm_en.sh
+++ /dev/null
@@ -1,22 +0,0 @@
-#!/bin/bash
-
-. ${MAIN_ROOT}/utils/utility.sh
-
-DIR=data/lm
-mkdir -p ${DIR}
-
-URL=https://deepspeech.bj.bcebos.com/en_lm/common_crawl_00.prune01111.trie.klm
-MD5="099a601759d467cd0a8523ff939819c5"
-TARGET=${DIR}/common_crawl_00.prune01111.trie.klm
-
-echo "Start downloading the language model. The language model is large, please wait for a moment ..."
-download $URL $MD5 $TARGET > /dev/null 2>&1
-if [ $? -ne 0 ]; then
- echo "Fail to download the language model!"
- exit 1
-else
- echo "Download the language model sucessfully"
-fi
-
-
-exit 0
diff --git a/examples/other/1xt2x/baidu_en8k/local/download_model.sh b/examples/other/1xt2x/baidu_en8k/local/download_model.sh
deleted file mode 100644
index a8fbc31e8..000000000
--- a/examples/other/1xt2x/baidu_en8k/local/download_model.sh
+++ /dev/null
@@ -1,25 +0,0 @@
-#! /usr/bin/env bash
-if [ $# != 1 ];then
- echo "usage: ${0} ckpt_dir"
- exit -1
-fi
-
-ckpt_dir=$1
-
-
-. ${MAIN_ROOT}/utils/utility.sh
-
-URL='https://deepspeech.bj.bcebos.com/eng_models/baidu_en8k_v1.8_to_v2.x.tar.gz'
-MD5=c1676be8505cee436e6f312823e9008c
-TARGET=${ckpt_dir}/baidu_en8k_v1.8_to_v2.x.tar.gz
-
-
-echo "Download BaiduEn8k model ..."
-download $URL $MD5 $TARGET
-if [ $? -ne 0 ]; then
- echo "Fail to download BaiduEn8k model!"
- exit 1
-fi
-
-
-exit 0
diff --git a/examples/other/1xt2x/baidu_en8k/local/test.sh b/examples/other/1xt2x/baidu_en8k/local/test.sh
deleted file mode 100755
index ea40046b1..000000000
--- a/examples/other/1xt2x/baidu_en8k/local/test.sh
+++ /dev/null
@@ -1,36 +0,0 @@
-#!/bin/bash
-
-if [ $# != 4 ];then
- echo "usage: ${0} config_path decode_config_path ckpt_path_prefix model_type"
- exit -1
-fi
-
-ngpu=$(echo $CUDA_VISIBLE_DEVICES | awk -F "," '{print NF}')
-echo "using $ngpu gpus..."
-
-config_path=$1
-decode_config_path=$2
-ckpt_prefix=$3
-model_type=$4
-
-# download language model
-bash local/download_lm_en.sh
-if [ $? -ne 0 ]; then
- exit 1
-fi
-
-python3 -u ${BIN_DIR}/test.py \
---ngpu ${ngpu} \
---config ${config_path} \
---decode_cfg ${decode_config_path} \
---result_file ${ckpt_prefix}.rsl \
---checkpoint_path ${ckpt_prefix} \
---model_type ${model_type}
-
-if [ $? -ne 0 ]; then
- echo "Failed in evaluation!"
- exit 1
-fi
-
-
-exit 0
diff --git a/examples/other/1xt2x/baidu_en8k/path.sh b/examples/other/1xt2x/baidu_en8k/path.sh
deleted file mode 100644
index ce44e65cb..000000000
--- a/examples/other/1xt2x/baidu_en8k/path.sh
+++ /dev/null
@@ -1,17 +0,0 @@
-export MAIN_ROOT=`realpath ${PWD}/../../../../`
-export LOCAL_DEEPSPEECH2=`realpath ${PWD}/../`
-
-export PATH=${MAIN_ROOT}:${MAIN_ROOT}/utils:${PATH}
-export LC_ALL=C
-
-export PYTHONDONTWRITEBYTECODE=1
-# Use UTF-8 in Python to avoid UnicodeDecodeError when LC_ALL=C
-export PYTHONIOENCODING=UTF-8
-export PYTHONPATH=${MAIN_ROOT}:${PYTHONPATH}
-export PYTHONPATH=${LOCAL_DEEPSPEECH2}:${PYTHONPATH}
-
-export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/lib/
-
-MODEL=deepspeech2
-export BIN_DIR=${LOCAL_DEEPSPEECH2}/src_deepspeech2x/bin
-echo "BIN_DIR "${BIN_DIR}
diff --git a/examples/other/1xt2x/baidu_en8k/run.sh b/examples/other/1xt2x/baidu_en8k/run.sh
deleted file mode 100755
index 82de56b09..000000000
--- a/examples/other/1xt2x/baidu_en8k/run.sh
+++ /dev/null
@@ -1,29 +0,0 @@
-#!/bin/bash
-set -e
-source path.sh
-
-stage=0
-stop_stage=100
-conf_path=conf/deepspeech2.yaml
-decode_conf_path=conf/tuning/decode.yaml
-avg_num=1
-model_type=offline
-gpus=0
-
-source ${MAIN_ROOT}/utils/parse_options.sh || exit 1;
-
-v18_ckpt=baidu_en8k_v1.8
-ckpt=$(basename ${conf_path} | awk -F'.' '{print $1}')
-echo "checkpoint name ${ckpt}"
-
-if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then
- # prepare data
- mkdir -p exp/${ckpt}/checkpoints
- bash ./local/data.sh exp/${ckpt}/checkpoints || exit -1
-fi
-
-if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
- # test ckpt avg_n
- CUDA_VISIBLE_DEVICES=${gpus} ./local/test.sh ${conf_path} ${decode_conf_path} exp/${ckpt}/checkpoints/${v18_ckpt} ${model_type}|| exit -1
-fi
-
diff --git a/examples/other/1xt2x/librispeech/.gitignore b/examples/other/1xt2x/librispeech/.gitignore
deleted file mode 100644
index 3631e544a..000000000
--- a/examples/other/1xt2x/librispeech/.gitignore
+++ /dev/null
@@ -1,5 +0,0 @@
-exp
-data
-*log
-tmp
-nohup*
diff --git a/examples/other/1xt2x/librispeech/conf/augmentation.json b/examples/other/1xt2x/librispeech/conf/augmentation.json
deleted file mode 100644
index fe51488c7..000000000
--- a/examples/other/1xt2x/librispeech/conf/augmentation.json
+++ /dev/null
@@ -1 +0,0 @@
-[]
diff --git a/examples/other/1xt2x/librispeech/conf/deepspeech2.yaml b/examples/other/1xt2x/librispeech/conf/deepspeech2.yaml
deleted file mode 100644
index a2a5649ba..000000000
--- a/examples/other/1xt2x/librispeech/conf/deepspeech2.yaml
+++ /dev/null
@@ -1,64 +0,0 @@
-# https://yaml.org/type/float.html
-###########################################
-# Data #
-###########################################
-train_manifest: data/manifest.train
-dev_manifest: data/manifest.dev
-test_manifest: data/manifest.test-clean
-min_input_len: 0.0
-max_input_len: 1000.0 # second
-min_output_len: 0.0
-max_output_len: .inf
-min_output_input_ratio: 0.00
-max_output_input_ratio: .inf
-
-###########################################
-# Dataloader #
-###########################################
-batch_size: 64 # one gpu
-mean_std_filepath: data/mean_std.npz
-unit_type: char
-vocab_filepath: data/vocab.txt
-augmentation_config: conf/augmentation.json
-random_seed: 0
-spm_model_prefix:
-spectrum_type: linear
-feat_dim:
-delta_delta: False
-stride_ms: 10.0
-window_ms: 20.0
-n_fft: None
-max_freq: None
-target_sample_rate: 16000
-use_dB_normalization: True
-target_dB: -20
-dither: 1.0
-keep_transcription_text: False
-sortagrad: True
-shuffle_method: batch_shuffle
-num_workers: 2
-
-############################################
-# Network Architecture #
-############################################
-num_conv_layers: 2
-num_rnn_layers: 3
-rnn_layer_size: 2048
-use_gru: False
-share_rnn_weights: True
-blank_id: 28
-
-###########################################
-# Training #
-###########################################
-n_epoch: 80
-accum_grad: 1
-lr: 2e-3
-lr_decay: 0.83
-weight_decay: 1e-06
-global_grad_clip: 3.0
-log_interval: 100
-checkpoint:
- kbest_n: 50
- latest_n: 5
-
diff --git a/examples/other/1xt2x/librispeech/conf/tuning/decode.yaml b/examples/other/1xt2x/librispeech/conf/tuning/decode.yaml
deleted file mode 100644
index f3b51defe..000000000
--- a/examples/other/1xt2x/librispeech/conf/tuning/decode.yaml
+++ /dev/null
@@ -1,10 +0,0 @@
-decode_batch_size: 32
-error_rate_type: wer
-decoding_method: ctc_beam_search
-lang_model_path: data/lm/common_crawl_00.prune01111.trie.klm
-alpha: 2.5
-beta: 0.3
-beam_size: 500
-cutoff_prob: 1.0
-cutoff_top_n: 40
-num_proc_bsearch: 8
\ No newline at end of file
diff --git a/examples/other/1xt2x/librispeech/local/data.sh b/examples/other/1xt2x/librispeech/local/data.sh
deleted file mode 100755
index 43b5426d9..000000000
--- a/examples/other/1xt2x/librispeech/local/data.sh
+++ /dev/null
@@ -1,83 +0,0 @@
-#!/bin/bash
-
-if [ $# != 1 ];then
- echo "usage: ${0} ckpt_dir"
- exit -1
-fi
-
-ckpt_dir=$1
-
-stage=-1
-stop_stage=100
-unit_type=char
-
-source ${MAIN_ROOT}/utils/parse_options.sh
-
-mkdir -p data
-TARGET_DIR=${MAIN_ROOT}/dataset
-mkdir -p ${TARGET_DIR}
-
-bash local/download_model.sh ${ckpt_dir}
-if [ $? -ne 0 ]; then
- exit 1
-fi
-
-cd ${ckpt_dir}
-tar xzvf librispeech_v1.8_to_v2.x.tar.gz
-cd -
-mv ${ckpt_dir}/mean_std.npz data/
-mv ${ckpt_dir}/vocab.txt data/
-
-if [ ${stage} -le -1 ] && [ ${stop_stage} -ge -1 ]; then
- # download data, generate manifests
- python3 ${TARGET_DIR}/librispeech/librispeech.py \
- --manifest_prefix="data/manifest" \
- --target_dir="${TARGET_DIR}/librispeech" \
- --full_download="True"
-
- if [ $? -ne 0 ]; then
- echo "Prepare LibriSpeech failed. Terminated."
- exit 1
- fi
-
- for set in train-clean-100 train-clean-360 train-other-500 dev-clean dev-other test-clean test-other; do
- mv data/manifest.${set} data/manifest.${set}.raw
- done
-
- rm -rf data/manifest.train.raw data/manifest.dev.raw data/manifest.test.raw
- for set in train-clean-100 train-clean-360 train-other-500; do
- cat data/manifest.${set}.raw >> data/manifest.train.raw
- done
-
- for set in dev-clean dev-other; do
- cat data/manifest.${set}.raw >> data/manifest.dev.raw
- done
-
- for set in test-clean test-other; do
- cat data/manifest.${set}.raw >> data/manifest.test.raw
- done
-fi
-
-if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
- # format manifest with tokenids, vocab size
- for set in train dev test dev-clean dev-other test-clean test-other; do
- {
- python3 ${MAIN_ROOT}/utils/format_data.py \
- --cmvn_path "data/mean_std.npz" \
- --unit_type ${unit_type} \
- --vocab_path="data/vocab.txt" \
- --manifest_path="data/manifest.${set}.raw" \
- --output_path="data/manifest.${set}"
-
- if [ $? -ne 0 ]; then
- echo "Formt mnaifest.${set} failed. Terminated."
- exit 1
- fi
- }&
- done
- wait
-fi
-
-echo "LibriSpeech Data preparation done."
-exit 0
-
diff --git a/examples/other/1xt2x/librispeech/local/download_lm_en.sh b/examples/other/1xt2x/librispeech/local/download_lm_en.sh
deleted file mode 100755
index 390fffc93..000000000
--- a/examples/other/1xt2x/librispeech/local/download_lm_en.sh
+++ /dev/null
@@ -1,22 +0,0 @@
-#!/bin/bash
-
-. ${MAIN_ROOT}/utils/utility.sh
-
-DIR=data/lm
-mkdir -p ${DIR}
-
-URL=https://deepspeech.bj.bcebos.com/en_lm/common_crawl_00.prune01111.trie.klm
-MD5="099a601759d467cd0a8523ff939819c5"
-TARGET=${DIR}/common_crawl_00.prune01111.trie.klm
-
-echo "Start downloading the language model. The language model is large, please wait for a moment ..."
-download $URL $MD5 $TARGET > /dev/null 2>&1
-if [ $? -ne 0 ]; then
- echo "Fail to download the language model!"
- exit 1
-else
- echo "Download the language model sucessfully"
-fi
-
-
-exit 0
diff --git a/examples/other/1xt2x/librispeech/local/download_model.sh b/examples/other/1xt2x/librispeech/local/download_model.sh
deleted file mode 100644
index 375d66404..000000000
--- a/examples/other/1xt2x/librispeech/local/download_model.sh
+++ /dev/null
@@ -1,25 +0,0 @@
-#! /usr/bin/env bash
-
-if [ $# != 1 ];then
- echo "usage: ${0} ckpt_dir"
- exit -1
-fi
-
-ckpt_dir=$1
-
-. ${MAIN_ROOT}/utils/utility.sh
-
-URL='https://deepspeech.bj.bcebos.com/eng_models/librispeech_v1.8_to_v2.x.tar.gz'
-MD5=a06d9aadb560ea113984dc98d67232c8
-TARGET=${ckpt_dir}/librispeech_v1.8_to_v2.x.tar.gz
-
-
-echo "Download LibriSpeech model ..."
-download $URL $MD5 $TARGET
-if [ $? -ne 0 ]; then
- echo "Fail to download LibriSpeech model!"
- exit 1
-fi
-
-
-exit 0
diff --git a/examples/other/1xt2x/librispeech/local/test.sh b/examples/other/1xt2x/librispeech/local/test.sh
deleted file mode 100755
index ea40046b1..000000000
--- a/examples/other/1xt2x/librispeech/local/test.sh
+++ /dev/null
@@ -1,36 +0,0 @@
-#!/bin/bash
-
-if [ $# != 4 ];then
- echo "usage: ${0} config_path decode_config_path ckpt_path_prefix model_type"
- exit -1
-fi
-
-ngpu=$(echo $CUDA_VISIBLE_DEVICES | awk -F "," '{print NF}')
-echo "using $ngpu gpus..."
-
-config_path=$1
-decode_config_path=$2
-ckpt_prefix=$3
-model_type=$4
-
-# download language model
-bash local/download_lm_en.sh
-if [ $? -ne 0 ]; then
- exit 1
-fi
-
-python3 -u ${BIN_DIR}/test.py \
---ngpu ${ngpu} \
---config ${config_path} \
---decode_cfg ${decode_config_path} \
---result_file ${ckpt_prefix}.rsl \
---checkpoint_path ${ckpt_prefix} \
---model_type ${model_type}
-
-if [ $? -ne 0 ]; then
- echo "Failed in evaluation!"
- exit 1
-fi
-
-
-exit 0
diff --git a/examples/other/1xt2x/librispeech/run.sh b/examples/other/1xt2x/librispeech/run.sh
deleted file mode 100755
index 8b614bbbf..000000000
--- a/examples/other/1xt2x/librispeech/run.sh
+++ /dev/null
@@ -1,28 +0,0 @@
-#!/bin/bash
-set -e
-source path.sh
-
-stage=0
-stop_stage=100
-conf_path=conf/deepspeech2.yaml
-decode_conf_path=conf/tuning/decode.yaml
-avg_num=1
-model_type=offline
-gpus=1
-
-source ${MAIN_ROOT}/utils/parse_options.sh || exit 1;
-
-v18_ckpt=librispeech_v1.8
-ckpt=$(basename ${conf_path} | awk -F'.' '{print $1}')
-echo "checkpoint name ${ckpt}"
-
-if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then
- # prepare data
- mkdir -p exp/${ckpt}/checkpoints
- bash ./local/data.sh exp/${ckpt}/checkpoints || exit -1
-fi
-
-if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
- # test ckpt avg_n
- CUDA_VISIBLE_DEVICES=${gpus} ./local/test.sh ${conf_path} ${decode_conf_path} exp/${ckpt}/checkpoints/${v18_ckpt} ${model_type}|| exit -1
-fi
diff --git a/examples/other/1xt2x/src_deepspeech2x/__init__.py b/examples/other/1xt2x/src_deepspeech2x/__init__.py
deleted file mode 100644
index 74be4a254..000000000
--- a/examples/other/1xt2x/src_deepspeech2x/__init__.py
+++ /dev/null
@@ -1,370 +0,0 @@
-# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-from typing import Any
-from typing import List
-from typing import Tuple
-from typing import Union
-
-import paddle
-from paddle import nn
-from paddle.fluid import core
-from paddle.nn import functional as F
-
-from paddlespeech.s2t.utils.log import Log
-
-#TODO(Hui Zhang): remove fluid import
-logger = Log(__name__).getlog()
-
-########### hack logging #############
-logger.warn = logger.warning
-
-########### hack paddle #############
-paddle.half = 'float16'
-paddle.float = 'float32'
-paddle.double = 'float64'
-paddle.short = 'int16'
-paddle.int = 'int32'
-paddle.long = 'int64'
-paddle.uint16 = 'uint16'
-paddle.cdouble = 'complex128'
-
-
-def convert_dtype_to_string(tensor_dtype):
- """
- Convert the data type in numpy to the data type in Paddle
- Args:
- tensor_dtype(core.VarDesc.VarType): the data type in numpy.
- Returns:
- core.VarDesc.VarType: the data type in Paddle.
- """
- dtype = tensor_dtype
- if dtype == core.VarDesc.VarType.FP32:
- return paddle.float32
- elif dtype == core.VarDesc.VarType.FP64:
- return paddle.float64
- elif dtype == core.VarDesc.VarType.FP16:
- return paddle.float16
- elif dtype == core.VarDesc.VarType.INT32:
- return paddle.int32
- elif dtype == core.VarDesc.VarType.INT16:
- return paddle.int16
- elif dtype == core.VarDesc.VarType.INT64:
- return paddle.int64
- elif dtype == core.VarDesc.VarType.BOOL:
- return paddle.bool
- elif dtype == core.VarDesc.VarType.BF16:
- # since there is still no support for bfloat16 in NumPy,
- # uint16 is used for casting bfloat16
- return paddle.uint16
- elif dtype == core.VarDesc.VarType.UINT8:
- return paddle.uint8
- elif dtype == core.VarDesc.VarType.INT8:
- return paddle.int8
- elif dtype == core.VarDesc.VarType.COMPLEX64:
- return paddle.complex64
- elif dtype == core.VarDesc.VarType.COMPLEX128:
- return paddle.complex128
- else:
- raise ValueError("Not supported tensor dtype %s" % dtype)
-
-
-if not hasattr(paddle, 'softmax'):
- logger.warn("register user softmax to paddle, remove this when fixed!")
- setattr(paddle, 'softmax', paddle.nn.functional.softmax)
-
-if not hasattr(paddle, 'log_softmax'):
- logger.warn("register user log_softmax to paddle, remove this when fixed!")
- setattr(paddle, 'log_softmax', paddle.nn.functional.log_softmax)
-
-if not hasattr(paddle, 'sigmoid'):
- logger.warn("register user sigmoid to paddle, remove this when fixed!")
- setattr(paddle, 'sigmoid', paddle.nn.functional.sigmoid)
-
-if not hasattr(paddle, 'log_sigmoid'):
- logger.warn("register user log_sigmoid to paddle, remove this when fixed!")
- setattr(paddle, 'log_sigmoid', paddle.nn.functional.log_sigmoid)
-
-if not hasattr(paddle, 'relu'):
- logger.warn("register user relu to paddle, remove this when fixed!")
- setattr(paddle, 'relu', paddle.nn.functional.relu)
-
-
-def cat(xs, dim=0):
- return paddle.concat(xs, axis=dim)
-
-
-if not hasattr(paddle, 'cat'):
- logger.warn(
- "override cat of paddle if exists or register, remove this when fixed!")
- paddle.cat = cat
-
-
-########### hack paddle.Tensor #############
-def item(x: paddle.Tensor):
- return x.numpy().item()
-
-
-if not hasattr(paddle.Tensor, 'item'):
- logger.warn(
- "override item of paddle.Tensor if exists or register, remove this when fixed!"
- )
- paddle.Tensor.item = item
-
-
-def func_long(x: paddle.Tensor):
- return paddle.cast(x, paddle.long)
-
-
-if not hasattr(paddle.Tensor, 'long'):
- logger.warn(
- "override long of paddle.Tensor if exists or register, remove this when fixed!"
- )
- paddle.Tensor.long = func_long
-
-if not hasattr(paddle.Tensor, 'numel'):
- logger.warn(
- "override numel of paddle.Tensor if exists or register, remove this when fixed!"
- )
- paddle.Tensor.numel = paddle.numel
-
-
-def new_full(x: paddle.Tensor,
- size: Union[List[int], Tuple[int], paddle.Tensor],
- fill_value: Union[float, int, bool, paddle.Tensor],
- dtype=None):
- return paddle.full(size, fill_value, dtype=x.dtype)
-
-
-if not hasattr(paddle.Tensor, 'new_full'):
- logger.warn(
- "override new_full of paddle.Tensor if exists or register, remove this when fixed!"
- )
- paddle.Tensor.new_full = new_full
-
-
-def eq(xs: paddle.Tensor, ys: Union[paddle.Tensor, float]) -> paddle.Tensor:
- if convert_dtype_to_string(xs.dtype) == paddle.bool:
- xs = xs.astype(paddle.int)
- return xs.equal(
- paddle.to_tensor(
- ys, dtype=convert_dtype_to_string(xs.dtype), place=xs.place))
-
-
-if not hasattr(paddle.Tensor, 'eq'):
- logger.warn(
- "override eq of paddle.Tensor if exists or register, remove this when fixed!"
- )
- paddle.Tensor.eq = eq
-
-if not hasattr(paddle, 'eq'):
- logger.warn(
- "override eq of paddle if exists or register, remove this when fixed!")
- paddle.eq = eq
-
-
-def contiguous(xs: paddle.Tensor) -> paddle.Tensor:
- return xs
-
-
-if not hasattr(paddle.Tensor, 'contiguous'):
- logger.warn(
- "override contiguous of paddle.Tensor if exists or register, remove this when fixed!"
- )
- paddle.Tensor.contiguous = contiguous
-
-
-def size(xs: paddle.Tensor, *args: int) -> paddle.Tensor:
- nargs = len(args)
- assert (nargs <= 1)
- s = paddle.shape(xs)
- if nargs == 1:
- return s[args[0]]
- else:
- return s
-
-
-#`to_static` do not process `size` property, maybe some `paddle` api dependent on it.
-logger.warn(
- "override size of paddle.Tensor "
- "(`to_static` do not process `size` property, maybe some `paddle` api dependent on it), remove this when fixed!"
-)
-paddle.Tensor.size = size
-
-
-def view(xs: paddle.Tensor, *args: int) -> paddle.Tensor:
- return xs.reshape(args)
-
-
-if not hasattr(paddle.Tensor, 'view'):
- logger.warn("register user view to paddle.Tensor, remove this when fixed!")
- paddle.Tensor.view = view
-
-
-def view_as(xs: paddle.Tensor, ys: paddle.Tensor) -> paddle.Tensor:
- return xs.reshape(ys.size())
-
-
-if not hasattr(paddle.Tensor, 'view_as'):
- logger.warn(
- "register user view_as to paddle.Tensor, remove this when fixed!")
- paddle.Tensor.view_as = view_as
-
-
-def is_broadcastable(shp1, shp2):
- for a, b in zip(shp1[::-1], shp2[::-1]):
- if a == 1 or b == 1 or a == b:
- pass
- else:
- return False
- return True
-
-
-def masked_fill(xs: paddle.Tensor,
- mask: paddle.Tensor,
- value: Union[float, int]):
- assert is_broadcastable(xs.shape, mask.shape) is True
- bshape = paddle.broadcast_shape(xs.shape, mask.shape)
- mask = mask.broadcast_to(bshape)
- trues = paddle.ones_like(xs) * value
- xs = paddle.where(mask, trues, xs)
- return xs
-
-
-if not hasattr(paddle.Tensor, 'masked_fill'):
- logger.warn(
- "register user masked_fill to paddle.Tensor, remove this when fixed!")
- paddle.Tensor.masked_fill = masked_fill
-
-
-def masked_fill_(xs: paddle.Tensor,
- mask: paddle.Tensor,
- value: Union[float, int]) -> paddle.Tensor:
- assert is_broadcastable(xs.shape, mask.shape) is True
- bshape = paddle.broadcast_shape(xs.shape, mask.shape)
- mask = mask.broadcast_to(bshape)
- trues = paddle.ones_like(xs) * value
- ret = paddle.where(mask, trues, xs)
- paddle.assign(ret.detach(), output=xs)
- return xs
-
-
-if not hasattr(paddle.Tensor, 'masked_fill_'):
- logger.warn(
- "register user masked_fill_ to paddle.Tensor, remove this when fixed!")
- paddle.Tensor.masked_fill_ = masked_fill_
-
-
-def fill_(xs: paddle.Tensor, value: Union[float, int]) -> paddle.Tensor:
- val = paddle.full_like(xs, value)
- paddle.assign(val.detach(), output=xs)
- return xs
-
-
-if not hasattr(paddle.Tensor, 'fill_'):
- logger.warn("register user fill_ to paddle.Tensor, remove this when fixed!")
- paddle.Tensor.fill_ = fill_
-
-
-def repeat(xs: paddle.Tensor, *size: Any) -> paddle.Tensor:
- return paddle.tile(xs, size)
-
-
-if not hasattr(paddle.Tensor, 'repeat'):
- logger.warn(
- "register user repeat to paddle.Tensor, remove this when fixed!")
- paddle.Tensor.repeat = repeat
-
-if not hasattr(paddle.Tensor, 'softmax'):
- logger.warn(
- "register user softmax to paddle.Tensor, remove this when fixed!")
- setattr(paddle.Tensor, 'softmax', paddle.nn.functional.softmax)
-
-if not hasattr(paddle.Tensor, 'sigmoid'):
- logger.warn(
- "register user sigmoid to paddle.Tensor, remove this when fixed!")
- setattr(paddle.Tensor, 'sigmoid', paddle.nn.functional.sigmoid)
-
-if not hasattr(paddle.Tensor, 'relu'):
- logger.warn("register user relu to paddle.Tensor, remove this when fixed!")
- setattr(paddle.Tensor, 'relu', paddle.nn.functional.relu)
-
-
-def type_as(x: paddle.Tensor, other: paddle.Tensor) -> paddle.Tensor:
- return x.astype(other.dtype)
-
-
-if not hasattr(paddle.Tensor, 'type_as'):
- logger.warn(
- "register user type_as to paddle.Tensor, remove this when fixed!")
- setattr(paddle.Tensor, 'type_as', type_as)
-
-
-def to(x: paddle.Tensor, *args, **kwargs) -> paddle.Tensor:
- assert len(args) == 1
- if isinstance(args[0], str): # dtype
- return x.astype(args[0])
- elif isinstance(args[0], paddle.Tensor): #Tensor
- return x.astype(args[0].dtype)
- else: # Device
- return x
-
-
-if not hasattr(paddle.Tensor, 'to'):
- logger.warn("register user to to paddle.Tensor, remove this when fixed!")
- setattr(paddle.Tensor, 'to', to)
-
-
-def func_float(x: paddle.Tensor) -> paddle.Tensor:
- return x.astype(paddle.float)
-
-
-if not hasattr(paddle.Tensor, 'float'):
- logger.warn("register user float to paddle.Tensor, remove this when fixed!")
- setattr(paddle.Tensor, 'float', func_float)
-
-
-def func_int(x: paddle.Tensor) -> paddle.Tensor:
- return x.astype(paddle.int)
-
-
-if not hasattr(paddle.Tensor, 'int'):
- logger.warn("register user int to paddle.Tensor, remove this when fixed!")
- setattr(paddle.Tensor, 'int', func_int)
-
-
-def tolist(x: paddle.Tensor) -> List[Any]:
- return x.numpy().tolist()
-
-
-if not hasattr(paddle.Tensor, 'tolist'):
- logger.warn(
- "register user tolist to paddle.Tensor, remove this when fixed!")
- setattr(paddle.Tensor, 'tolist', tolist)
-
-
-########### hack paddle.nn #############
-class GLU(nn.Layer):
- """Gated Linear Units (GLU) Layer"""
-
- def __init__(self, dim: int=-1):
- super().__init__()
- self.dim = dim
-
- def forward(self, xs):
- return F.glu(xs, axis=self.dim)
-
-
-if not hasattr(paddle.nn, 'GLU'):
- logger.warn("register user GLU to paddle.nn, remove this when fixed!")
- setattr(paddle.nn, 'GLU', GLU)
diff --git a/examples/other/1xt2x/src_deepspeech2x/bin/test.py b/examples/other/1xt2x/src_deepspeech2x/bin/test.py
deleted file mode 100644
index 88a13fdca..000000000
--- a/examples/other/1xt2x/src_deepspeech2x/bin/test.py
+++ /dev/null
@@ -1,59 +0,0 @@
-# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Evaluation for DeepSpeech2 model."""
-from src_deepspeech2x.test_model import DeepSpeech2Tester as Tester
-from yacs.config import CfgNode
-
-from paddlespeech.s2t.training.cli import default_argument_parser
-from paddlespeech.s2t.utils.utility import print_arguments
-
-
-def main_sp(config, args):
- exp = Tester(config, args)
- exp.setup()
- exp.run_test()
-
-
-def main(config, args):
- main_sp(config, args)
-
-
-if __name__ == "__main__":
- parser = default_argument_parser()
- parser.add_argument(
- "--model_type", type=str, default='offline', help='offline/online')
- # save asr result to
- parser.add_argument(
- "--result_file", type=str, help="path of save the asr result")
- args = parser.parse_args()
- print_arguments(args, globals())
- print("model_type:{}".format(args.model_type))
-
- # https://yaml.org/type/float.html
- config = CfgNode(new_allowed=True)
- if args.config:
- config.merge_from_file(args.config)
- if args.decode_cfg:
- decode_confs = CfgNode(new_allowed=True)
- decode_confs.merge_from_file(args.decode_cfg)
- config.decode = decode_confs
- if args.opts:
- config.merge_from_list(args.opts)
- config.freeze()
- print(config)
- if args.dump_config:
- with open(args.dump_config, 'w') as f:
- print(config, file=f)
-
- main(config, args)
diff --git a/examples/other/1xt2x/src_deepspeech2x/models/ds2/deepspeech2.py b/examples/other/1xt2x/src_deepspeech2x/models/ds2/deepspeech2.py
deleted file mode 100644
index f6e185ff1..000000000
--- a/examples/other/1xt2x/src_deepspeech2x/models/ds2/deepspeech2.py
+++ /dev/null
@@ -1,275 +0,0 @@
-# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Deepspeech2 ASR Model"""
-import paddle
-from paddle import nn
-from src_deepspeech2x.models.ds2.rnn import RNNStack
-
-from paddlespeech.s2t.models.ds2.conv import ConvStack
-from paddlespeech.s2t.modules.ctc import CTCDecoder
-from paddlespeech.s2t.utils import layer_tools
-from paddlespeech.s2t.utils.checkpoint import Checkpoint
-from paddlespeech.s2t.utils.log import Log
-logger = Log(__name__).getlog()
-
-__all__ = ['DeepSpeech2Model', 'DeepSpeech2InferModel']
-
-
-class CRNNEncoder(nn.Layer):
- def __init__(self,
- feat_size,
- dict_size,
- num_conv_layers=2,
- num_rnn_layers=3,
- rnn_size=1024,
- use_gru=False,
- share_rnn_weights=True):
- super().__init__()
- self.rnn_size = rnn_size
- self.feat_size = feat_size # 161 for linear
- self.dict_size = dict_size
-
- self.conv = ConvStack(feat_size, num_conv_layers)
-
- i_size = self.conv.output_height # H after conv stack
- self.rnn = RNNStack(
- i_size=i_size,
- h_size=rnn_size,
- num_stacks=num_rnn_layers,
- use_gru=use_gru,
- share_rnn_weights=share_rnn_weights)
-
- @property
- def output_size(self):
- return self.rnn_size * 2
-
- def forward(self, audio, audio_len):
- """Compute Encoder outputs
-
- Args:
- audio (Tensor): [B, Tmax, D]
- text (Tensor): [B, Umax]
- audio_len (Tensor): [B]
- text_len (Tensor): [B]
- Returns:
- x (Tensor): encoder outputs, [B, T, D]
- x_lens (Tensor): encoder length, [B]
- """
- # [B, T, D] -> [B, D, T]
- audio = audio.transpose([0, 2, 1])
- # [B, D, T] -> [B, C=1, D, T]
- x = audio.unsqueeze(1)
- x_lens = audio_len
-
- # convolution group
- x, x_lens = self.conv(x, x_lens)
- x_val = x.numpy()
-
- # convert data from convolution feature map to sequence of vectors
- #B, C, D, T = paddle.shape(x) # not work under jit
- x = x.transpose([0, 3, 1, 2]) #[B, T, C, D]
- #x = x.reshape([B, T, C * D]) #[B, T, C*D] # not work under jit
- x = x.reshape([0, 0, -1]) #[B, T, C*D]
-
- # remove padding part
- x, x_lens = self.rnn(x, x_lens) #[B, T, D]
- return x, x_lens
-
-
-class DeepSpeech2Model(nn.Layer):
- """The DeepSpeech2 network structure.
-
- :param audio_data: Audio spectrogram data layer.
- :type audio_data: Variable
- :param text_data: Transcription text data layer.
- :type text_data: Variable
- :param audio_len: Valid sequence length data layer.
- :type audio_len: Variable
- :param masks: Masks data layer to reset padding.
- :type masks: Variable
- :param dict_size: Dictionary size for tokenized transcription.
- :type dict_size: int
- :param num_conv_layers: Number of stacking convolution layers.
- :type num_conv_layers: int
- :param num_rnn_layers: Number of stacking RNN layers.
- :type num_rnn_layers: int
- :param rnn_size: RNN layer size (dimension of RNN cells).
- :type rnn_size: int
- :param use_gru: Use gru if set True. Use simple rnn if set False.
- :type use_gru: bool
- :param share_rnn_weights: Whether to share input-hidden weights between
- forward and backward direction RNNs.
- It is only available when use_gru=False.
- :type share_weights: bool
- :return: A tuple of an output unnormalized log probability layer (
- before softmax) and a ctc cost layer.
- :rtype: tuple of LayerOutput
- """
-
- def __init__(self,
- feat_size,
- dict_size,
- num_conv_layers=2,
- num_rnn_layers=3,
- rnn_size=1024,
- use_gru=False,
- share_rnn_weights=True,
- blank_id=0):
- super().__init__()
- self.encoder = CRNNEncoder(
- feat_size=feat_size,
- dict_size=dict_size,
- num_conv_layers=num_conv_layers,
- num_rnn_layers=num_rnn_layers,
- rnn_size=rnn_size,
- use_gru=use_gru,
- share_rnn_weights=share_rnn_weights)
- assert (self.encoder.output_size == rnn_size * 2)
-
- self.decoder = CTCDecoder(
- odim=dict_size, # is in vocab
- enc_n_units=self.encoder.output_size,
- blank_id=blank_id, # first token is
- dropout_rate=0.0,
- reduction=True, # sum
- batch_average=True) # sum / batch_size
-
- def forward(self, audio, audio_len, text, text_len):
- """Compute Model loss
-
- Args:
- audio (Tensor): [B, T, D]
- audio_len (Tensor): [B]
- text (Tensor): [B, U]
- text_len (Tensor): [B]
-
- Returns:
- loss (Tensor): [1]
- """
- eouts, eouts_len = self.encoder(audio, audio_len)
- loss = self.decoder(eouts, eouts_len, text, text_len)
- return loss
-
- @paddle.no_grad()
- def decode(self, audio, audio_len):
- # decoders only accept string encoded in utf-8
-
- # Make sure the decoder has been initialized
- eouts, eouts_len = self.encoder(audio, audio_len)
- probs = self.decoder.softmax(eouts)
- batch_size = probs.shape[0]
- self.decoder.reset_decoder(batch_size=batch_size)
- self.decoder.next(probs, eouts_len)
- trans_best, trans_beam = self.decoder.decode()
- return trans_best
-
- @classmethod
- def from_pretrained(cls, dataloader, config, checkpoint_path):
- """Build a DeepSpeech2Model model from a pretrained model.
- Parameters
- ----------
- dataloader: paddle.io.DataLoader
-
- config: yacs.config.CfgNode
- model configs
-
- checkpoint_path: Path or str
- the path of pretrained model checkpoint, without extension name
-
- Returns
- -------
- DeepSpeech2Model
- The model built from pretrained result.
- """
- model = cls(feat_size=dataloader.collate_fn.feature_size,
- dict_size=len(dataloader.collate_fn.vocab_list),
- num_conv_layers=config.num_conv_layers,
- num_rnn_layers=config.num_rnn_layers,
- rnn_size=config.rnn_layer_size,
- use_gru=config.use_gru,
- share_rnn_weights=config.share_rnn_weights)
- infos = Checkpoint().load_parameters(
- model, checkpoint_path=checkpoint_path)
- logger.info(f"checkpoint info: {infos}")
- layer_tools.summary(model)
- return model
-
- @classmethod
- def from_config(cls, config):
- """Build a DeepSpeec2Model from config
- Parameters
-
- config: yacs.config.CfgNode
- config
- Returns
- -------
- DeepSpeech2Model
- The model built from config.
- """
- model = cls(feat_size=config.feat_size,
- dict_size=config.dict_size,
- num_conv_layers=config.num_conv_layers,
- num_rnn_layers=config.num_rnn_layers,
- rnn_size=config.rnn_layer_size,
- use_gru=config.use_gru,
- share_rnn_weights=config.share_rnn_weights,
- blank_id=config.blank_id)
- return model
-
-
-class DeepSpeech2InferModel(DeepSpeech2Model):
- def __init__(self,
- feat_size,
- dict_size,
- num_conv_layers=2,
- num_rnn_layers=3,
- rnn_size=1024,
- use_gru=False,
- share_rnn_weights=True,
- blank_id=0):
- super().__init__(
- feat_size=feat_size,
- dict_size=dict_size,
- num_conv_layers=num_conv_layers,
- num_rnn_layers=num_rnn_layers,
- rnn_size=rnn_size,
- use_gru=use_gru,
- share_rnn_weights=share_rnn_weights,
- blank_id=blank_id)
-
- def forward(self, audio, audio_len):
- """export model function
-
- Args:
- audio (Tensor): [B, T, D]
- audio_len (Tensor): [B]
-
- Returns:
- probs: probs after softmax
- """
- eouts, eouts_len = self.encoder(audio, audio_len)
- probs = self.decoder.softmax(eouts)
- return probs, eouts_len
-
- def export(self):
- static_model = paddle.jit.to_static(
- self,
- input_spec=[
- paddle.static.InputSpec(
- shape=[None, None, self.encoder.feat_size],
- dtype='float32'), # audio, [B,T,D]
- paddle.static.InputSpec(shape=[None],
- dtype='int64'), # audio_length, [B]
- ])
- return static_model
diff --git a/examples/other/1xt2x/src_deepspeech2x/models/ds2/rnn.py b/examples/other/1xt2x/src_deepspeech2x/models/ds2/rnn.py
deleted file mode 100644
index 383a07467..000000000
--- a/examples/other/1xt2x/src_deepspeech2x/models/ds2/rnn.py
+++ /dev/null
@@ -1,334 +0,0 @@
-# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import math
-
-import paddle
-from paddle import nn
-from paddle.nn import functional as F
-from paddle.nn import initializer as I
-
-from paddlespeech.s2t.modules.activation import brelu
-from paddlespeech.s2t.modules.mask import make_non_pad_mask
-from paddlespeech.s2t.utils.log import Log
-logger = Log(__name__).getlog()
-
-__all__ = ['RNNStack']
-
-
-class RNNCell(nn.RNNCellBase):
- r"""
- Elman RNN (SimpleRNN) cell. Given the inputs and previous states, it
- computes the outputs and updates states.
- The formula used is as follows:
- .. math::
- h_{t} & = act(x_{t} + b_{ih} + W_{hh}h_{t-1} + b_{hh})
- y_{t} & = h_{t}
-
- where :math:`act` is for :attr:`activation`.
- """
-
- def __init__(self,
- hidden_size: int,
- activation="tanh",
- weight_ih_attr=None,
- weight_hh_attr=None,
- bias_ih_attr=None,
- bias_hh_attr=None,
- name=None):
- super().__init__()
- std = 1.0 / math.sqrt(hidden_size)
- self.weight_hh = self.create_parameter(
- (hidden_size, hidden_size),
- weight_hh_attr,
- default_initializer=I.Uniform(-std, std))
- self.bias_ih = None
- self.bias_hh = self.create_parameter(
- (hidden_size, ),
- bias_hh_attr,
- is_bias=True,
- default_initializer=I.Uniform(-std, std))
-
- self.hidden_size = hidden_size
- if activation not in ["tanh", "relu", "brelu"]:
- raise ValueError(
- "activation for SimpleRNNCell should be tanh or relu, "
- "but get {}".format(activation))
- self.activation = activation
- self._activation_fn = paddle.tanh \
- if activation == "tanh" \
- else F.relu
- if activation == 'brelu':
- self._activation_fn = brelu
-
- def forward(self, inputs, states=None):
- if states is None:
- states = self.get_initial_states(inputs, self.state_shape)
- pre_h = states
- i2h = inputs
- if self.bias_ih is not None:
- i2h += self.bias_ih
- h2h = paddle.matmul(pre_h, self.weight_hh, transpose_y=True)
- if self.bias_hh is not None:
- h2h += self.bias_hh
- h = self._activation_fn(i2h + h2h)
- return h, h
-
- @property
- def state_shape(self):
- return (self.hidden_size, )
-
-
-class GRUCell(nn.RNNCellBase):
- r"""
- Gated Recurrent Unit (GRU) RNN cell. Given the inputs and previous states,
- it computes the outputs and updates states.
- The formula for GRU used is as follows:
- .. math::
- r_{t} & = \sigma(W_{ir}x_{t} + b_{ir} + W_{hr}h_{t-1} + b_{hr})
- z_{t} & = \sigma(W_{iz}x_{t} + b_{iz} + W_{hz}h_{t-1} + b_{hz})
- \widetilde{h}_{t} & = \tanh(W_{ic}x_{t} + b_{ic} + r_{t} * (W_{hc}h_{t-1} + b_{hc}))
- h_{t} & = z_{t} * h_{t-1} + (1 - z_{t}) * \widetilde{h}_{t}
- y_{t} & = h_{t}
-
- where :math:`\sigma` is the sigmoid fucntion, and * is the elemetwise
- multiplication operator.
- """
-
- def __init__(self,
- input_size: int,
- hidden_size: int,
- weight_ih_attr=None,
- weight_hh_attr=None,
- bias_ih_attr=None,
- bias_hh_attr=None,
- name=None):
- super().__init__()
- std = 1.0 / math.sqrt(hidden_size)
- self.weight_hh = self.create_parameter(
- (3 * hidden_size, hidden_size),
- weight_hh_attr,
- default_initializer=I.Uniform(-std, std))
- self.bias_ih = None
- self.bias_hh = self.create_parameter(
- (3 * hidden_size, ),
- bias_hh_attr,
- is_bias=True,
- default_initializer=I.Uniform(-std, std))
-
- self.hidden_size = hidden_size
- self.input_size = input_size
- self._gate_activation = F.sigmoid
- self._activation = paddle.relu
-
- def forward(self, inputs, states=None):
- if states is None:
- states = self.get_initial_states(inputs, self.state_shape)
-
- pre_hidden = states # shape [batch_size, hidden_size]
-
- x_gates = inputs
- if self.bias_ih is not None:
- x_gates = x_gates + self.bias_ih
- bias_u, bias_r, bias_c = paddle.split(
- self.bias_hh, num_or_sections=3, axis=0)
-
- weight_hh = paddle.transpose(
- self.weight_hh,
- perm=[1, 0]) #weight_hh:shape[hidden_size, 3 * hidden_size]
- w_u_r_c = paddle.flatten(weight_hh)
- size_u_r = self.hidden_size * 2 * self.hidden_size
- w_u_r = paddle.reshape(w_u_r_c[:size_u_r],
- (self.hidden_size, self.hidden_size * 2))
- w_u, w_r = paddle.split(w_u_r, num_or_sections=2, axis=1)
- w_c = paddle.reshape(w_u_r_c[size_u_r:],
- (self.hidden_size, self.hidden_size))
-
- h_u = paddle.matmul(
- pre_hidden, w_u,
- transpose_y=False) + bias_u #shape [batch_size, hidden_size]
- h_r = paddle.matmul(
- pre_hidden, w_r,
- transpose_y=False) + bias_r #shape [batch_size, hidden_size]
-
- x_u, x_r, x_c = paddle.split(
- x_gates, num_or_sections=3, axis=1) #shape[batch_size, hidden_size]
-
- u = self._gate_activation(x_u + h_u) #shape [batch_size, hidden_size]
- r = self._gate_activation(x_r + h_r) #shape [batch_size, hidden_size]
- c = self._activation(
- x_c + paddle.matmul(r * pre_hidden, w_c, transpose_y=False) +
- bias_c) # [batch_size, hidden_size]
-
- h = (1 - u) * pre_hidden + u * c
- # https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/fluid/layers/dynamic_gru_cn.html#dynamic-gru
- return h, h
-
- @property
- def state_shape(self):
- r"""
- The `state_shape` of GRUCell is a shape `[hidden_size]` (-1 for batch
- size would be automatically inserted into shape). The shape corresponds
- to the shape of :math:`h_{t-1}`.
- """
- return (self.hidden_size, )
-
-
-class BiRNNWithBN(nn.Layer):
- """Bidirectonal simple rnn layer with sequence-wise batch normalization.
- The batch normalization is only performed on input-state weights.
-
- :param size: Dimension of RNN cells.
- :type size: int
- :param share_weights: Whether to share input-hidden weights between
- forward and backward directional RNNs.
- :type share_weights: bool
- :return: Bidirectional simple rnn layer.
- :rtype: Variable
- """
-
- def __init__(self, i_size: int, h_size: int, share_weights: bool):
- super().__init__()
- self.share_weights = share_weights
- if self.share_weights:
- #input-hidden weights shared between bi-directional rnn.
- self.fw_fc = nn.Linear(i_size, h_size, bias_attr=False)
- # batch norm is only performed on input-state projection
- self.fw_bn = nn.BatchNorm1D(
- h_size, bias_attr=None, data_format='NLC')
- self.bw_fc = self.fw_fc
- self.bw_bn = self.fw_bn
- else:
- self.fw_fc = nn.Linear(i_size, h_size, bias_attr=False)
- self.fw_bn = nn.BatchNorm1D(
- h_size, bias_attr=None, data_format='NLC')
- self.bw_fc = nn.Linear(i_size, h_size, bias_attr=False)
- self.bw_bn = nn.BatchNorm1D(
- h_size, bias_attr=None, data_format='NLC')
-
- self.fw_cell = RNNCell(hidden_size=h_size, activation='brelu')
- self.bw_cell = RNNCell(hidden_size=h_size, activation='brelu')
- self.fw_rnn = nn.RNN(
- self.fw_cell, is_reverse=False, time_major=False) #[B, T, D]
- self.bw_rnn = nn.RNN(
- self.bw_cell, is_reverse=True, time_major=False) #[B, T, D]
-
- def forward(self, x: paddle.Tensor, x_len: paddle.Tensor):
- # x, shape [B, T, D]
- fw_x = self.fw_bn(self.fw_fc(x))
- bw_x = self.bw_bn(self.bw_fc(x))
- fw_x, _ = self.fw_rnn(inputs=fw_x, sequence_length=x_len)
- bw_x, _ = self.bw_rnn(inputs=bw_x, sequence_length=x_len)
- x = paddle.concat([fw_x, bw_x], axis=-1)
- return x, x_len
-
-
-class BiGRUWithBN(nn.Layer):
- """Bidirectonal gru layer with sequence-wise batch normalization.
- The batch normalization is only performed on input-state weights.
-
- :param name: Name of the layer.
- :type name: string
- :param input: Input layer.
- :type input: Variable
- :param size: Dimension of GRU cells.
- :type size: int
- :param act: Activation type.
- :type act: string
- :return: Bidirectional GRU layer.
- :rtype: Variable
- """
-
- def __init__(self, i_size: int, h_size: int):
- super().__init__()
- hidden_size = h_size * 3
-
- self.fw_fc = nn.Linear(i_size, hidden_size, bias_attr=False)
- self.fw_bn = nn.BatchNorm1D(
- hidden_size, bias_attr=None, data_format='NLC')
- self.bw_fc = nn.Linear(i_size, hidden_size, bias_attr=False)
- self.bw_bn = nn.BatchNorm1D(
- hidden_size, bias_attr=None, data_format='NLC')
-
- self.fw_cell = GRUCell(input_size=hidden_size, hidden_size=h_size)
- self.bw_cell = GRUCell(input_size=hidden_size, hidden_size=h_size)
- self.fw_rnn = nn.RNN(
- self.fw_cell, is_reverse=False, time_major=False) #[B, T, D]
- self.bw_rnn = nn.RNN(
- self.bw_cell, is_reverse=True, time_major=False) #[B, T, D]
-
- def forward(self, x, x_len):
- # x, shape [B, T, D]
- fw_x = self.fw_bn(self.fw_fc(x))
-
- bw_x = self.bw_bn(self.bw_fc(x))
- fw_x, _ = self.fw_rnn(inputs=fw_x, sequence_length=x_len)
- bw_x, _ = self.bw_rnn(inputs=bw_x, sequence_length=x_len)
- x = paddle.concat([fw_x, bw_x], axis=-1)
- return x, x_len
-
-
-class RNNStack(nn.Layer):
- """RNN group with stacked bidirectional simple RNN or GRU layers.
-
- :param input: Input layer.
- :type input: Variable
- :param size: Dimension of RNN cells in each layer.
- :type size: int
- :param num_stacks: Number of stacked rnn layers.
- :type num_stacks: int
- :param use_gru: Use gru if set True. Use simple rnn if set False.
- :type use_gru: bool
- :param share_rnn_weights: Whether to share input-hidden weights between
- forward and backward directional RNNs.
- It is only available when use_gru=False.
- :type share_weights: bool
- :return: Output layer of the RNN group.
- :rtype: Variable
- """
-
- def __init__(self,
- i_size: int,
- h_size: int,
- num_stacks: int,
- use_gru: bool,
- share_rnn_weights: bool):
- super().__init__()
- rnn_stacks = []
- for i in range(num_stacks):
- if use_gru:
- #default:GRU using tanh
- rnn_stacks.append(BiGRUWithBN(i_size=i_size, h_size=h_size))
- else:
- rnn_stacks.append(
- BiRNNWithBN(
- i_size=i_size,
- h_size=h_size,
- share_weights=share_rnn_weights))
- i_size = h_size * 2
-
- self.rnn_stacks = nn.LayerList(rnn_stacks)
-
- def forward(self, x: paddle.Tensor, x_len: paddle.Tensor):
- """
- x: shape [B, T, D]
- x_len: shpae [B]
- """
- for i, rnn in enumerate(self.rnn_stacks):
- x, x_len = rnn(x, x_len)
- masks = make_non_pad_mask(x_len) #[B, T]
- masks = masks.unsqueeze(-1) # [B, T, 1]
- # TODO(Hui Zhang): not support bool multiply
- masks = masks.astype(x.dtype)
- x = x.multiply(masks)
- return x, x_len
diff --git a/examples/other/1xt2x/src_deepspeech2x/test_model.py b/examples/other/1xt2x/src_deepspeech2x/test_model.py
deleted file mode 100644
index 11b85442d..000000000
--- a/examples/other/1xt2x/src_deepspeech2x/test_model.py
+++ /dev/null
@@ -1,357 +0,0 @@
-# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Contains DeepSpeech2 and DeepSpeech2Online model."""
-import time
-from collections import defaultdict
-from contextlib import nullcontext
-
-import numpy as np
-import paddle
-from paddle import distributed as dist
-from paddle.io import DataLoader
-from src_deepspeech2x.models.ds2 import DeepSpeech2InferModel
-from src_deepspeech2x.models.ds2 import DeepSpeech2Model
-
-from paddlespeech.s2t.frontend.featurizer.text_featurizer import TextFeaturizer
-from paddlespeech.s2t.io.collator import SpeechCollator
-from paddlespeech.s2t.io.dataset import ManifestDataset
-from paddlespeech.s2t.io.sampler import SortagradBatchSampler
-from paddlespeech.s2t.io.sampler import SortagradDistributedBatchSampler
-from paddlespeech.s2t.models.ds2_online import DeepSpeech2InferModelOnline
-from paddlespeech.s2t.models.ds2_online import DeepSpeech2ModelOnline
-from paddlespeech.s2t.training.gradclip import ClipGradByGlobalNormWithLog
-from paddlespeech.s2t.training.trainer import Trainer
-from paddlespeech.s2t.utils import error_rate
-from paddlespeech.s2t.utils import layer_tools
-from paddlespeech.s2t.utils import mp_tools
-from paddlespeech.s2t.utils.log import Log
-
-logger = Log(__name__).getlog()
-
-
-class DeepSpeech2Trainer(Trainer):
- def __init__(self, config, args):
- super().__init__(config, args)
-
- def train_batch(self, batch_index, batch_data, msg):
- train_conf = self.config
- start = time.time()
-
- # forward
- utt, audio, audio_len, text, text_len = batch_data
- loss = self.model(audio, audio_len, text, text_len)
- losses_np = {
- 'train_loss': float(loss),
- }
-
- # loss backward
- if (batch_index + 1) % train_conf.accum_grad != 0:
- # Disable gradient synchronizations across DDP processes.
- # Within this context, gradients will be accumulated on module
- # variables, which will later be synchronized.
- context = self.model.no_sync
- else:
- # Used for single gpu training and DDP gradient synchronization
- # processes.
- context = nullcontext
-
- with context():
- loss.backward()
- layer_tools.print_grads(self.model, print_func=None)
-
- # optimizer step
- if (batch_index + 1) % train_conf.accum_grad == 0:
- self.optimizer.step()
- self.optimizer.clear_grad()
- self.iteration += 1
-
- iteration_time = time.time() - start
-
- msg += "train time: {:>.3f}s, ".format(iteration_time)
- msg += "batch size: {}, ".format(self.config.batch_size)
- msg += "accum: {}, ".format(train_conf.accum_grad)
- msg += ', '.join('{}: {:>.6f}'.format(k, v)
- for k, v in losses_np.items())
- logger.info(msg)
-
- if dist.get_rank() == 0 and self.visualizer:
- for k, v in losses_np.items():
- # `step -1` since we update `step` after optimizer.step().
- self.visualizer.add_scalar("train/{}".format(k), v,
- self.iteration - 1)
-
- @paddle.no_grad()
- def valid(self):
- logger.info(f"Valid Total Examples: {len(self.valid_loader.dataset)}")
- self.model.eval()
- valid_losses = defaultdict(list)
- num_seen_utts = 1
- total_loss = 0.0
- for i, batch in enumerate(self.valid_loader):
- utt, audio, audio_len, text, text_len = batch
- loss = self.model(audio, audio_len, text, text_len)
- if paddle.isfinite(loss):
- num_utts = batch[1].shape[0]
- num_seen_utts += num_utts
- total_loss += float(loss) * num_utts
- valid_losses['val_loss'].append(float(loss))
-
- if (i + 1) % self.config.log_interval == 0:
- valid_dump = {k: np.mean(v) for k, v in valid_losses.items()}
- valid_dump['val_history_loss'] = total_loss / num_seen_utts
-
- # logging
- msg = f"Valid: Rank: {dist.get_rank()}, "
- msg += "epoch: {}, ".format(self.epoch)
- msg += "step: {}, ".format(self.iteration)
- msg += "batch : {}/{}, ".format(i + 1, len(self.valid_loader))
- msg += ', '.join('{}: {:>.6f}'.format(k, v)
- for k, v in valid_dump.items())
- logger.info(msg)
-
- logger.info('Rank {} Val info val_loss {}'.format(
- dist.get_rank(), total_loss / num_seen_utts))
- return total_loss, num_seen_utts
-
- def setup_model(self):
- config = self.config.clone()
- config.defrost()
- config.feat_size = self.train_loader.collate_fn.feature_size
- #config.dict_size = self.train_loader.collate_fn.vocab_size
- config.dict_size = len(self.train_loader.collate_fn.vocab_list)
- config.freeze()
-
- if self.args.model_type == 'offline':
- model = DeepSpeech2Model.from_config(config)
- elif self.args.model_type == 'online':
- model = DeepSpeech2ModelOnline.from_config(config)
- else:
- raise Exception("wrong model type")
- if self.parallel:
- model = paddle.DataParallel(model)
-
- logger.info(f"{model}")
- layer_tools.print_params(model, logger.info)
-
- grad_clip = ClipGradByGlobalNormWithLog(config.global_grad_clip)
- lr_scheduler = paddle.optimizer.lr.ExponentialDecay(
- learning_rate=config.lr, gamma=config.lr_decay, verbose=True)
- optimizer = paddle.optimizer.Adam(
- learning_rate=lr_scheduler,
- parameters=model.parameters(),
- weight_decay=paddle.regularizer.L2Decay(config.weight_decay),
- grad_clip=grad_clip)
-
- self.model = model
- self.optimizer = optimizer
- self.lr_scheduler = lr_scheduler
- logger.info("Setup model/optimizer/lr_scheduler!")
-
- def setup_dataloader(self):
- config = self.config.clone()
- config.defrost()
- config.keep_transcription_text = False
-
- config.manifest = config.train_manifest
- train_dataset = ManifestDataset.from_config(config)
-
- config.manifest = config.dev_manifest
- dev_dataset = ManifestDataset.from_config(config)
-
- config.manifest = config.test_manifest
- test_dataset = ManifestDataset.from_config(config)
-
- if self.parallel:
- batch_sampler = SortagradDistributedBatchSampler(
- train_dataset,
- batch_size=config.batch_size,
- num_replicas=None,
- rank=None,
- shuffle=True,
- drop_last=True,
- sortagrad=config.sortagrad,
- shuffle_method=config.shuffle_method)
- else:
- batch_sampler = SortagradBatchSampler(
- train_dataset,
- shuffle=True,
- batch_size=config.batch_size,
- drop_last=True,
- sortagrad=config.sortagrad,
- shuffle_method=config.shuffle_method)
-
- collate_fn_train = SpeechCollator.from_config(config)
-
- config.augmentation_config = ""
- collate_fn_dev = SpeechCollator.from_config(config)
-
- config.keep_transcription_text = True
- config.augmentation_config = ""
- collate_fn_test = SpeechCollator.from_config(config)
-
- self.train_loader = DataLoader(
- train_dataset,
- batch_sampler=batch_sampler,
- collate_fn=collate_fn_train,
- num_workers=config.num_workers)
- self.valid_loader = DataLoader(
- dev_dataset,
- batch_size=config.batch_size,
- shuffle=False,
- drop_last=False,
- collate_fn=collate_fn_dev)
- self.test_loader = DataLoader(
- test_dataset,
- batch_size=config.decode.decode_batch_size,
- shuffle=False,
- drop_last=False,
- collate_fn=collate_fn_test)
- if "" in self.test_loader.collate_fn.vocab_list:
- self.test_loader.collate_fn.vocab_list.remove("")
- if "" in self.valid_loader.collate_fn.vocab_list:
- self.valid_loader.collate_fn.vocab_list.remove("")
- if "" in self.train_loader.collate_fn.vocab_list:
- self.train_loader.collate_fn.vocab_list.remove("")
- logger.info("Setup train/valid/test Dataloader!")
-
-
-class DeepSpeech2Tester(DeepSpeech2Trainer):
- def __init__(self, config, args):
-
- self._text_featurizer = TextFeaturizer(
- unit_type=config.unit_type, vocab=None)
- super().__init__(config, args)
-
- def ordid2token(self, texts, texts_len):
- """ ord() id to chr() chr """
- trans = []
- for text, n in zip(texts, texts_len):
- n = n.numpy().item()
- ids = text[:n]
- trans.append(''.join([chr(i) for i in ids]))
- return trans
-
- def compute_metrics(self,
- utts,
- audio,
- audio_len,
- texts,
- texts_len,
- fout=None):
- cfg = self.config.decode
- errors_sum, len_refs, num_ins = 0.0, 0, 0
- errors_func = error_rate.char_errors if cfg.error_rate_type == 'cer' else error_rate.word_errors
- error_rate_func = error_rate.cer if cfg.error_rate_type == 'cer' else error_rate.wer
-
- target_transcripts = self.ordid2token(texts, texts_len)
-
- result_transcripts = self.compute_result_transcripts(audio, audio_len)
-
- for utt, target, result in zip(utts, target_transcripts,
- result_transcripts):
- errors, len_ref = errors_func(target, result)
- errors_sum += errors
- len_refs += len_ref
- num_ins += 1
- if fout:
- fout.write(utt + " " + result + "\n")
- logger.info("\nTarget Transcription: %s\nOutput Transcription: %s" %
- (target, result))
- logger.info("Current error rate [%s] = %f" %
- (cfg.error_rate_type, error_rate_func(target, result)))
-
- return dict(
- errors_sum=errors_sum,
- len_refs=len_refs,
- num_ins=num_ins,
- error_rate=errors_sum / len_refs,
- error_rate_type=cfg.error_rate_type)
-
- def compute_result_transcripts(self, audio, audio_len):
- result_transcripts = self.model.decode(audio, audio_len)
-
- result_transcripts = [
- self._text_featurizer.detokenize(item)
- for item in result_transcripts
- ]
- return result_transcripts
-
- @mp_tools.rank_zero_only
- @paddle.no_grad()
- def test(self):
- logger.info(f"Test Total Examples: {len(self.test_loader.dataset)}")
- self.model.eval()
- cfg = self.config
- error_rate_type = None
- errors_sum, len_refs, num_ins = 0.0, 0, 0
-
- # Initialized the decoder in model
- decode_cfg = self.config.decode
- vocab_list = self.test_loader.collate_fn.vocab_list
- decode_batch_size = self.test_loader.batch_size
- self.model.decoder.init_decoder(
- decode_batch_size, vocab_list, decode_cfg.decoding_method,
- decode_cfg.lang_model_path, decode_cfg.alpha, decode_cfg.beta,
- decode_cfg.beam_size, decode_cfg.cutoff_prob,
- decode_cfg.cutoff_top_n, decode_cfg.num_proc_bsearch)
-
- with open(self.args.result_file, 'w') as fout:
- for i, batch in enumerate(self.test_loader):
- utts, audio, audio_len, texts, texts_len = batch
- metrics = self.compute_metrics(utts, audio, audio_len, texts,
- texts_len, fout)
- errors_sum += metrics['errors_sum']
- len_refs += metrics['len_refs']
- num_ins += metrics['num_ins']
- error_rate_type = metrics['error_rate_type']
- logger.info("Error rate [%s] (%d/?) = %f" %
- (error_rate_type, num_ins, errors_sum / len_refs))
-
- # logging
- msg = "Test: "
- msg += "epoch: {}, ".format(self.epoch)
- msg += "step: {}, ".format(self.iteration)
- msg += "Final error rate [%s] (%d/%d) = %f" % (
- error_rate_type, num_ins, num_ins, errors_sum / len_refs)
- logger.info(msg)
- self.model.decoder.del_decoder()
-
- def run_test(self):
- self.resume_or_scratch()
- try:
- self.test()
- except KeyboardInterrupt:
- exit(-1)
-
- def export(self):
- if self.args.model_type == 'offline':
- infer_model = DeepSpeech2InferModel.from_pretrained(
- self.test_loader, self.config, self.args.checkpoint_path)
- elif self.args.model_type == 'online':
- infer_model = DeepSpeech2InferModelOnline.from_pretrained(
- self.test_loader, self.config, self.args.checkpoint_path)
- else:
- raise Exception("wrong model type")
-
- infer_model.eval()
- feat_dim = self.test_loader.collate_fn.feature_size
- static_model = infer_model.export()
- logger.info(f"Export code: {static_model.forward.code}")
- paddle.jit.save(static_model, self.args.export_path)
-
- def run_export(self):
- try:
- self.export()
- except KeyboardInterrupt:
- exit(-1)
diff --git a/examples/other/mfa/local/reorganize_aishell3.py b/examples/other/mfa/local/reorganize_aishell3.py
index 0ad306626..a97ee29ed 100644
--- a/examples/other/mfa/local/reorganize_aishell3.py
+++ b/examples/other/mfa/local/reorganize_aishell3.py
@@ -46,22 +46,22 @@ def write_lab(root_dir: Union[str, Path],
text_path = root_dir / sub_set / 'content.txt'
new_dir = output_dir / sub_set
- with open(text_path, 'r') as rf:
- for line in rf:
- wav_id, context = line.strip().split('\t')
- spk_id = wav_id[:7]
- transcript_name = wav_id.split('.')[0] + '.lab'
- transcript_path = new_dir / spk_id / transcript_name
- context_list = context.split()
- word_list = context_list[0:-1:2]
- pinyin_list = context_list[1::2]
- wf = open(transcript_path, 'w')
- if script_type == 'word':
- # add space between chinese char
- new_context = ' '.join(word_list)
- elif script_type == 'pinyin':
- new_context = ' '.join(pinyin_list)
- wf.write(new_context + '\n')
+ with open(text_path, 'r') as rf:
+ for line in rf:
+ wav_id, context = line.strip().split('\t')
+ spk_id = wav_id[:7]
+ transcript_name = wav_id.split('.')[0] + '.lab'
+ transcript_path = new_dir / spk_id / transcript_name
+ context_list = context.split()
+ word_list = context_list[0:-1:2]
+ pinyin_list = context_list[1::2]
+ wf = open(transcript_path, 'w')
+ if script_type == 'word':
+ # add space between chinese char
+ new_context = ' '.join(word_list)
+ elif script_type == 'pinyin':
+ new_context = ' '.join(pinyin_list)
+ wf.write(new_context + '\n')
def reorganize_aishell3(root_dir: Union[str, Path],
diff --git a/examples/other/mfa/local/reorganize_baker.py b/examples/other/mfa/local/reorganize_baker.py
index 8adad834f..153e01d13 100644
--- a/examples/other/mfa/local/reorganize_baker.py
+++ b/examples/other/mfa/local/reorganize_baker.py
@@ -42,9 +42,6 @@ def get_transcripts(path: Union[str, Path]):
for i in range(0, len(lines), 2):
sentence_id = lines[i].split()[0]
transcription = lines[i + 1].strip()
- # tones are dropped here
- # since the lexicon does not consider tones, too
- transcription = " ".join([item[:-1] for item in transcription.split()])
transcripts[sentence_id] = transcription
return transcripts
diff --git a/examples/other/mfa/run.sh b/examples/other/mfa/run.sh
old mode 100644
new mode 100755
index 1fef58b4e..29dacc9b1
--- a/examples/other/mfa/run.sh
+++ b/examples/other/mfa/run.sh
@@ -4,7 +4,7 @@ mkdir -p $EXP_DIR
LEXICON_NAME='simple'
if [ ! -f "$EXP_DIR/$LEXICON_NAME.lexicon" ]; then
echo "generating lexicon..."
- python local/generate_lexicon.py "$EXP_DIR/$LEXICON_NAME" --with-r
+ python local/generate_lexicon.py "$EXP_DIR/$LEXICON_NAME" --with-r --with-tone
echo "lexicon done"
fi
@@ -16,6 +16,7 @@ if [ ! -d $EXP_DIR/baker_corpus ]; then
echo "transcription for each audio file is saved with the same namd in $EXP_DIR/baker_corpus "
fi
+
echo "detecting oov..."
python local/detect_oov.py $EXP_DIR/baker_corpus $EXP_DIR/"$LEXICON_NAME.lexicon"
echo "detecting oov done. you may consider regenerate lexicon if there is unexpected OOVs."
@@ -44,6 +45,3 @@ if [ ! -d "$EXP_DIR/baker_alignment" ]; then
echo "model: $EXP_DIR/baker_model"
fi
-
-
-
diff --git a/examples/ted_en_zh/st0/local/train.sh b/examples/ted_en_zh/st0/local/train.sh
index e366376bb..71659e28d 100755
--- a/examples/ted_en_zh/st0/local/train.sh
+++ b/examples/ted_en_zh/st0/local/train.sh
@@ -1,7 +1,7 @@
#!/bin/bash
-if [ $# != 2 ];then
- echo "usage: CUDA_VISIBLE_DEVICES=0 ${0} config_path ckpt_name"
+if [ $# -lt 2 ] && [ $# -gt 3 ];then
+ echo "usage: CUDA_VISIBLE_DEVICES=0 ${0} config_path ckpt_name ips(optional)"
exit -1
fi
@@ -10,6 +10,13 @@ echo "using $ngpu gpus..."
config_path=$1
ckpt_name=$2
+ips=$3
+
+if [ ! $ips ];then
+ ips_config=
+else
+ ips_config="--ips="${ips}
+fi
mkdir -p exp
@@ -19,11 +26,19 @@ if [ ${seed} != 0 ]; then
export FLAGS_cudnn_deterministic=True
fi
+if [ ${ngpu} == 0 ]; then
python3 -u ${BIN_DIR}/train.py \
--ngpu ${ngpu} \
--config ${config_path} \
--output exp/${ckpt_name} \
--seed ${seed}
+else
+python3 -m paddle.distributed.launch --gpus=${CUDA_VISIBLE_DEVICES} ${ips_config} ${BIN_DIR}/train.py \
+--ngpu ${ngpu} \
+--config ${config_path} \
+--output exp/${ckpt_name} \
+--seed ${seed}
+fi
if [ ${seed} != 0 ]; then
unset FLAGS_cudnn_deterministic
diff --git a/examples/ted_en_zh/st0/run.sh b/examples/ted_en_zh/st0/run.sh
index 1746c0251..c5a59f657 100755
--- a/examples/ted_en_zh/st0/run.sh
+++ b/examples/ted_en_zh/st0/run.sh
@@ -6,6 +6,7 @@ gpus=0,1,2,3
stage=0
stop_stage=50
conf_path=conf/transformer_mtl_noam.yaml
+ips= #xx.xx.xx.xx,xx.xx.xx.xx
decode_conf_path=conf/tuning/decode.yaml
avg_num=5
data_path=./TED_EnZh # path to unzipped data
@@ -23,7 +24,7 @@ fi
if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
# train model, all `ckpt` under `exp` dir
- CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt}
+ CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt} ${ips}
fi
if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
diff --git a/examples/ted_en_zh/st1/local/train.sh b/examples/ted_en_zh/st1/local/train.sh
index a8e4acaa0..3e9295e53 100755
--- a/examples/ted_en_zh/st1/local/train.sh
+++ b/examples/ted_en_zh/st1/local/train.sh
@@ -1,7 +1,7 @@
#!/bin/bash
-if [ $# != 3 ];then
- echo "usage: CUDA_VISIBLE_DEVICES=0 ${0} config_path ckpt_name ckpt_path"
+if [ $# -lt 3 ] && [ $# -gt 4 ];then
+ echo "usage: CUDA_VISIBLE_DEVICES=0 ${0} config_path ckpt_name ips(optional)"
exit -1
fi
@@ -11,6 +11,15 @@ echo "using $ngpu gpus..."
config_path=$1
ckpt_name=$2
ckpt_path=$3
+ips=$3
+
+if [ ! $ips ];then
+ ips_config=
+else
+ ips_config="--ips="${ips}
+fi
+
+mkdir -p exp
mkdir -p exp
@@ -20,12 +29,21 @@ if [ ${seed} != 0 ]; then
export FLAGS_cudnn_deterministic=True
fi
+if [ ${ngpu} == 0 ]; then
python3 -u ${BIN_DIR}/train.py \
--ngpu ${ngpu} \
--config ${config_path} \
--output exp/${ckpt_name} \
--checkpoint_path "${ckpt_path}" \
--seed ${seed}
+else
+python3 -m paddle.distributed.launch --gpus=${CUDA_VISIBLE_DEVICES} ${ips_config} ${BIN_DIR}/train.py \
+--ngpu ${ngpu} \
+--config ${config_path} \
+--output exp/${ckpt_name} \
+--checkpoint_path "${ckpt_path}" \
+--seed ${seed}
+fi
if [ ${seed} != 0 ]; then
unset FLAGS_cudnn_deterministic
@@ -36,4 +54,4 @@ if [ $? -ne 0 ]; then
exit 1
fi
-exit 0
\ No newline at end of file
+exit 0
diff --git a/examples/ted_en_zh/st1/run.sh b/examples/ted_en_zh/st1/run.sh
index 1808e37b4..06a407d44 100755
--- a/examples/ted_en_zh/st1/run.sh
+++ b/examples/ted_en_zh/st1/run.sh
@@ -7,6 +7,7 @@ gpus=0,1,2,3
stage=1
stop_stage=4
conf_path=conf/transformer_mtl_noam.yaml
+ips= #xx.xx.xx.xx,xx.xx.xx.xx
decode_conf_path=conf/tuning/decode.yaml
ckpt_path= # paddle.98 # (finetune from FAT-ST pretrained model)
avg_num=5
@@ -29,7 +30,7 @@ if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
echo "Finetune from Pretrained Model" ${ckpt_path}
./local/download_pretrain.sh || exit -1
fi
- CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt} "${ckpt_path}"
+ CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt} "${ckpt_path}" ${ips}
fi
if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
diff --git a/examples/timit/asr1/local/train.sh b/examples/timit/asr1/local/train.sh
index 9b3fa1775..661407582 100755
--- a/examples/timit/asr1/local/train.sh
+++ b/examples/timit/asr1/local/train.sh
@@ -19,11 +19,19 @@ if [ ${seed} != 0 ]; then
export FLAGS_cudnn_deterministic=True
fi
+if [ ${ngpu} == 0 ]; then
python3 -u ${BIN_DIR}/train.py \
--ngpu ${ngpu} \
--config ${config_path} \
--output exp/${ckpt_name} \
--seed ${seed}
+else
+python3 -m paddle.distributed.launch --gpus=${CUDA_VISIBLE_DEVICES} ${BIN_DIR}/train.py \
+--ngpu ${ngpu} \
+--config ${config_path} \
+--output exp/${ckpt_name} \
+--seed ${seed}
+fi
if [ ${seed} != 0 ]; then
unset FLAGS_cudnn_deterministic
diff --git a/examples/tiny/asr0/conf/augmentation.json b/examples/tiny/asr0/conf/augmentation.json
deleted file mode 100644
index 4480307b9..000000000
--- a/examples/tiny/asr0/conf/augmentation.json
+++ /dev/null
@@ -1,36 +0,0 @@
-[
- {
- "type": "speed",
- "params": {
- "min_speed_rate": 0.9,
- "max_speed_rate": 1.1,
- "num_rates": 3
- },
- "prob": 0.0
- },
- {
- "type": "shift",
- "params": {
- "min_shift_ms": -5,
- "max_shift_ms": 5
- },
- "prob": 1.0
- },
- {
- "type": "specaug",
- "params": {
- "W": 5,
- "warp_mode": "PIL",
- "F": 30,
- "n_freq_masks": 2,
- "T": 40,
- "n_time_masks": 2,
- "p": 1.0,
- "adaptive_number_ratio": 0,
- "adaptive_size_ratio": 0,
- "max_n_time_masks": 20,
- "replace_with_zero": true
- },
- "prob": 1.0
- }
-]
diff --git a/examples/tiny/asr0/conf/deepspeech2.yaml b/examples/tiny/asr0/conf/deepspeech2.yaml
index 64d432e26..a94143b95 100644
--- a/examples/tiny/asr0/conf/deepspeech2.yaml
+++ b/examples/tiny/asr0/conf/deepspeech2.yaml
@@ -16,28 +16,26 @@ max_output_input_ratio: 10.0
###########################################
# Dataloader #
###########################################
-mean_std_filepath: data/mean_std.json
-unit_type: char
-vocab_filepath: data/lang_char/vocab.txt
-augmentation_config: conf/augmentation.json
-random_seed: 0
-spm_model_prefix:
-spectrum_type: linear
+vocab_filepath: data/lang_char/vocab.txt
+spm_model_prefix: ''
+unit_type: 'char'
+preprocess_config: conf/preprocess.yaml
feat_dim: 161
-delta_delta: False
stride_ms: 10.0
-window_ms: 20.0
-n_fft: None
-max_freq: None
-target_sample_rate: 16000
-use_dB_normalization: True
-target_dB: -20
-dither: 1.0
-keep_transcription_text: False
-sortagrad: True
-shuffle_method: batch_shuffle
-num_workers: 2
+window_ms: 25.0
+sortagrad: 0 # Feed samples from shortest to longest ; -1: enabled for all epochs, 0: disabled, other: enabled for 'other' epochs
batch_size: 4
+maxlen_in: 512 # if input length > maxlen-in, batchsize is automatically reduced
+maxlen_out: 150 # if output length > maxlen-out, batchsize is automatically reduced
+minibatches: 0 # for debug
+batch_count: auto
+batch_bins: 0
+batch_frames_in: 0
+batch_frames_out: 0
+batch_frames_inout: 0
+num_workers: 8
+subsampling_factor: 1
+num_encs: 1
############################################
# Network Architecture #
@@ -45,8 +43,10 @@ batch_size: 4
num_conv_layers: 2
num_rnn_layers: 3
rnn_layer_size: 2048
+rnn_direction: bidirect # [forward, bidirect]
+num_fc_layers: 0
+fc_layers_size_list: -1,
use_gru: False
-share_rnn_weights: True
blank_id: 0
@@ -59,6 +59,7 @@ lr: 1.0e-5
lr_decay: 0.8
weight_decay: 1.0e-6
global_grad_clip: 5.0
+dist_sampler: False
log_interval: 1
checkpoint:
kbest_n: 3
diff --git a/examples/tiny/asr0/conf/deepspeech2_online.yaml b/examples/tiny/asr0/conf/deepspeech2_online.yaml
index 74a4dc814..1bd8da19c 100644
--- a/examples/tiny/asr0/conf/deepspeech2_online.yaml
+++ b/examples/tiny/asr0/conf/deepspeech2_online.yaml
@@ -16,29 +16,27 @@ max_output_input_ratio: 10.0
###########################################
# Dataloader #
###########################################
-mean_std_filepath: data/mean_std.json
-unit_type: char
-vocab_filepath: data/lang_char/vocab.txt
-augmentation_config: conf/augmentation.json
-random_seed: 0
-spm_model_prefix:
-spectrum_type: linear
+vocab_filepath: data/lang_char/vocab.txt
+spm_model_prefix: ''
+unit_type: 'char'
+preprocess_config: conf/preprocess.yaml
feat_dim: 161
-delta_delta: False
stride_ms: 10.0
-window_ms: 20.0
-n_fft: None
-max_freq: None
-target_sample_rate: 16000
-use_dB_normalization: True
-target_dB: -20
-dither: 1.0
-keep_transcription_text: False
-sortagrad: True
-shuffle_method: batch_shuffle
-num_workers: 0
+window_ms: 25.0
+sortagrad: 0 # Feed samples from shortest to longest ; -1: enabled for all epochs, 0: disabled, other: enabled for 'other' epochs
batch_size: 4
-
+maxlen_in: 512 # if input length > maxlen-in, batchsize is automatically reduced
+maxlen_out: 150 # if output length > maxlen-out, batchsize is automatically reduced
+minibatches: 0 # for debug
+batch_count: auto
+batch_bins: 0
+batch_frames_in: 0
+batch_frames_out: 0
+batch_frames_inout: 0
+num_workers: 8
+subsampling_factor: 1
+num_encs: 1
+
############################################
# Network Architecture #
############################################
@@ -61,6 +59,7 @@ lr: 1.0e-5
lr_decay: 1.0
weight_decay: 1.0e-6
global_grad_clip: 5.0
+dist_sampler: False
log_interval: 1
checkpoint:
kbest_n: 3
diff --git a/examples/tiny/asr0/conf/preprocess.yaml b/examples/tiny/asr0/conf/preprocess.yaml
new file mode 100644
index 000000000..3f526e0ad
--- /dev/null
+++ b/examples/tiny/asr0/conf/preprocess.yaml
@@ -0,0 +1,25 @@
+process:
+ # extract kaldi fbank from PCM
+ - type: fbank_kaldi
+ fs: 16000
+ n_mels: 161
+ n_shift: 160
+ win_length: 400
+ dither: 0.1
+ - type: cmvn_json
+ cmvn_path: data/mean_std.json
+ # these three processes are a.k.a. SpecAugument
+ - type: time_warp
+ max_time_warp: 5
+ inplace: true
+ mode: PIL
+ - type: freq_mask
+ F: 30
+ n_mask: 2
+ inplace: true
+ replace_with_zero: false
+ - type: time_mask
+ T: 40
+ n_mask: 2
+ inplace: true
+ replace_with_zero: false
diff --git a/examples/tiny/asr0/local/export.sh b/examples/tiny/asr0/local/export.sh
index 426a72fe5..ce7e6d642 100755
--- a/examples/tiny/asr0/local/export.sh
+++ b/examples/tiny/asr0/local/export.sh
@@ -1,7 +1,7 @@
#!/bin/bash
-if [ $# != 4 ];then
- echo "usage: $0 config_path ckpt_prefix jit_model_path model_type"
+if [ $# != 3 ];then
+ echo "usage: $0 config_path ckpt_prefix jit_model_path"
exit -1
fi
@@ -11,14 +11,12 @@ echo "using $ngpu gpus..."
config_path=$1
ckpt_path_prefix=$2
jit_model_export_path=$3
-model_type=$4
python3 -u ${BIN_DIR}/export.py \
--ngpu ${ngpu} \
--config ${config_path} \
--checkpoint_path ${ckpt_path_prefix} \
---export_path ${jit_model_export_path} \
---model_type ${model_type}
+--export_path ${jit_model_export_path}
if [ $? -ne 0 ]; then
echo "Failed in export!"
diff --git a/examples/tiny/asr0/local/test.sh b/examples/tiny/asr0/local/test.sh
index ea40046b1..55f97d2ec 100755
--- a/examples/tiny/asr0/local/test.sh
+++ b/examples/tiny/asr0/local/test.sh
@@ -1,7 +1,7 @@
#!/bin/bash
-if [ $# != 4 ];then
- echo "usage: ${0} config_path decode_config_path ckpt_path_prefix model_type"
+if [ $# != 3 ];then
+ echo "usage: ${0} config_path decode_config_path ckpt_path_prefix"
exit -1
fi
@@ -11,7 +11,6 @@ echo "using $ngpu gpus..."
config_path=$1
decode_config_path=$2
ckpt_prefix=$3
-model_type=$4
# download language model
bash local/download_lm_en.sh
@@ -24,8 +23,7 @@ python3 -u ${BIN_DIR}/test.py \
--config ${config_path} \
--decode_cfg ${decode_config_path} \
--result_file ${ckpt_prefix}.rsl \
---checkpoint_path ${ckpt_prefix} \
---model_type ${model_type}
+--checkpoint_path ${ckpt_prefix}
if [ $? -ne 0 ]; then
echo "Failed in evaluation!"
diff --git a/examples/tiny/asr0/local/train.sh b/examples/tiny/asr0/local/train.sh
index a69b6ddb9..8b67902fe 100755
--- a/examples/tiny/asr0/local/train.sh
+++ b/examples/tiny/asr0/local/train.sh
@@ -15,24 +15,38 @@ if [ ${seed} != 0 ]; then
echo "using seed $seed & FLAGS_cudnn_deterministic=True ..."
fi
-if [ $# != 3 ];then
- echo "usage: CUDA_VISIBLE_DEVICES=0 ${0} config_path ckpt_name model_type"
+if [ $# -lt 2 ] && [ $# -gt 3 ];then
+ echo "usage: CUDA_VISIBLE_DEVICES=0 ${0} config_path ckpt_name ips(optional)"
exit -1
fi
config_path=$1
ckpt_name=$2
-model_type=$3
+ips=$3
+
+if [ ! $ips ];then
+ ips_config=
+else
+ ips_config="--ips="${ips}
+fi
mkdir -p exp
+if [ ${ngpu} == 0 ]; then
python3 -u ${BIN_DIR}/train.py \
--ngpu ${ngpu} \
--config ${config_path} \
--output exp/${ckpt_name} \
---model_type ${model_type} \
--profiler-options "${profiler_options}" \
--seed ${seed}
+else
+python3 -m paddle.distributed.launch --gpus=${CUDA_VISIBLE_DEVICES} ${ips_config} ${BIN_DIR}/train.py \
+--ngpu ${ngpu} \
+--config ${config_path} \
+--output exp/${ckpt_name} \
+--profiler-options "${profiler_options}" \
+--seed ${seed}
+fi
if [ ${seed} != 0 ]; then
unset FLAGS_cudnn_deterministic
diff --git a/examples/tiny/asr0/run.sh b/examples/tiny/asr0/run.sh
index 25f046245..3e84d4224 100755
--- a/examples/tiny/asr0/run.sh
+++ b/examples/tiny/asr0/run.sh
@@ -2,14 +2,13 @@
set -e
source path.sh
-gpus=0
+gpus=4
stage=0
stop_stage=100
conf_path=conf/deepspeech2.yaml
+ips= #xx.xx.xx.xx,xx.xx.xx.xx
decode_conf_path=conf/tuning/decode.yaml
avg_num=1
-model_type=offline
-
source ${MAIN_ROOT}/utils/parse_options.sh || exit 1;
avg_ckpt=avg_${avg_num}
@@ -23,7 +22,7 @@ fi
if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
# train model, all `ckpt` under `exp` dir
- CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt} ${model_type}
+ CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt} ${ips}
fi
if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
@@ -33,10 +32,10 @@ fi
if [ ${stage} -le 3 ] && [ ${stop_stage} -ge 3 ]; then
# test ckpt avg_n
- CUDA_VISIBLE_DEVICES=${gpus} ./local/test.sh ${conf_path} ${decode_conf_path} exp/${ckpt}/checkpoints/${avg_ckpt} ${model_type} || exit -1
+ CUDA_VISIBLE_DEVICES=${gpus} ./local/test.sh ${conf_path} ${decode_conf_path} exp/${ckpt}/checkpoints/${avg_ckpt}|| exit -1
fi
if [ ${stage} -le 4 ] && [ ${stop_stage} -ge 4 ]; then
# export ckpt avg_n
- CUDA_VISIBLE_DEVICES=${gpus} ./local/export.sh ${conf_path} exp/${ckpt}/checkpoints/${avg_ckpt} exp/${ckpt}/checkpoints/${avg_ckpt}.jit ${model_type}
+ CUDA_VISIBLE_DEVICES=${gpus} ./local/export.sh ${conf_path} exp/${ckpt}/checkpoints/${avg_ckpt} exp/${ckpt}/checkpoints/${avg_ckpt}.jit
fi
diff --git a/examples/tiny/asr1/local/train.sh b/examples/tiny/asr1/local/train.sh
index 1c8593bdd..459f2e218 100755
--- a/examples/tiny/asr1/local/train.sh
+++ b/examples/tiny/asr1/local/train.sh
@@ -17,24 +17,42 @@ if [ ${seed} != 0 ]; then
echo "using seed $seed & FLAGS_cudnn_deterministic=True ..."
fi
-if [ $# != 2 ];then
- echo "usage: CUDA_VISIBLE_DEVICES=0 ${0} config_path ckpt_name"
+if [ $# -lt 2 ] && [ $# -gt 3 ];then
+ echo "usage: CUDA_VISIBLE_DEVICES=0 ${0} config_path ckpt_name ips(optional)"
exit -1
fi
config_path=$1
ckpt_name=$2
+ips=$3
+
+if [ ! $ips ];then
+ ips_config=
+else
+ ips_config="--ips="${ips}
+fi
mkdir -p exp
+if [ ${ngpu} == 0 ]; then
python3 -u ${BIN_DIR}/train.py \
+--ngpu ${ngpu} \
--seed ${seed} \
+--config ${config_path} \
+--output exp/${ckpt_name} \
+--profiler-options "${profiler_options}" \
+--benchmark-batch-size ${benchmark_batch_size} \
+--benchmark-max-step ${benchmark_max_step}
+else
+python3 -m paddle.distributed.launch --gpus=${CUDA_VISIBLE_DEVICES} ${ips_config} ${BIN_DIR}/train.py \
--ngpu ${ngpu} \
+--seed ${seed} \
--config ${config_path} \
--output exp/${ckpt_name} \
--profiler-options "${profiler_options}" \
--benchmark-batch-size ${benchmark_batch_size} \
--benchmark-max-step ${benchmark_max_step}
+fi
if [ ${seed} != 0 ]; then
diff --git a/examples/tiny/asr1/run.sh b/examples/tiny/asr1/run.sh
index 1651c034c..ca0a7a013 100755
--- a/examples/tiny/asr1/run.sh
+++ b/examples/tiny/asr1/run.sh
@@ -2,10 +2,11 @@
set -e
source path.sh
-gpus=0
+gpus=4
stage=0
stop_stage=50
conf_path=conf/transformer.yaml
+ips= #xx.xx.xx.xx,xx.xx.xx.xx
decode_conf_path=conf/tuning/decode.yaml
avg_num=1
@@ -22,7 +23,7 @@ fi
if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
# train model, all `ckpt` under `exp` dir
- CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt}
+ CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt} ${ips}
fi
if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
diff --git a/examples/vctk/tts3/README.md b/examples/vctk/tts3/README.md
index f373ca6a3..0b0ce0934 100644
--- a/examples/vctk/tts3/README.md
+++ b/examples/vctk/tts3/README.md
@@ -3,7 +3,7 @@ This example contains code used to train a [Fastspeech2](https://arxiv.org/abs/2
## Dataset
### Download and Extract the dataset
-Download VCTK-0.92 from the [official website](https://datashare.ed.ac.uk/handle/10283/3443).
+Download VCTK-0.92 from it's [Official Website](https://datashare.ed.ac.uk/handle/10283/3443) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/VCTK-Corpus-0.92`.
### Get MFA Result and Extract
We use [MFA](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner) to get durations for fastspeech2.
@@ -112,12 +112,12 @@ CUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize.sh ${conf_path} ${train_output_p
```
```text
usage: synthesize.py [-h]
- [--am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}]
+ [--am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech,tacotron2_aishell3}]
[--am_config AM_CONFIG] [--am_ckpt AM_CKPT]
[--am_stat AM_STAT] [--phones_dict PHONES_DICT]
[--tones_dict TONES_DICT] [--speaker_dict SPEAKER_DICT]
[--voice-cloning VOICE_CLONING]
- [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}]
+ [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,wavernn_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,style_melgan_csmsc}]
[--voc_config VOC_CONFIG] [--voc_ckpt VOC_CKPT]
[--voc_stat VOC_STAT] [--ngpu NGPU]
[--test_metadata TEST_METADATA] [--output_dir OUTPUT_DIR]
@@ -126,11 +126,10 @@ Synthesize with acoustic model & vocoder
optional arguments:
-h, --help show this help message and exit
- --am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}
+ --am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech,tacotron2_aishell3}
Choose acoustic model type of tts task.
--am_config AM_CONFIG
- Config of acoustic model. Use deault config when it is
- None.
+ Config of acoustic model.
--am_ckpt AM_CKPT Checkpoint file of acoustic model.
--am_stat AM_STAT mean and standard deviation used to normalize
spectrogram when training acoustic model.
@@ -142,10 +141,10 @@ optional arguments:
speaker id map file.
--voice-cloning VOICE_CLONING
whether training voice cloning model.
- --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}
+ --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,wavernn_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,style_melgan_csmsc}
Choose vocoder type of tts task.
--voc_config VOC_CONFIG
- Config of voc. Use deault config when it is None.
+ Config of voc.
--voc_ckpt VOC_CKPT Checkpoint file of voc.
--voc_stat VOC_STAT mean and standard deviation used to normalize
spectrogram when training voc.
@@ -161,12 +160,12 @@ CUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize_e2e.sh ${conf_path} ${train_outp
```
```text
usage: synthesize_e2e.py [-h]
- [--am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}]
+ [--am {speedyspeech_csmsc,speedyspeech_aishell3,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech}]
[--am_config AM_CONFIG] [--am_ckpt AM_CKPT]
[--am_stat AM_STAT] [--phones_dict PHONES_DICT]
[--tones_dict TONES_DICT]
[--speaker_dict SPEAKER_DICT] [--spk_id SPK_ID]
- [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}]
+ [--voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,style_melgan_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,wavernn_csmsc}]
[--voc_config VOC_CONFIG] [--voc_ckpt VOC_CKPT]
[--voc_stat VOC_STAT] [--lang LANG]
[--inference_dir INFERENCE_DIR] [--ngpu NGPU]
@@ -176,11 +175,10 @@ Synthesize with acoustic model & vocoder
optional arguments:
-h, --help show this help message and exit
- --am {speedyspeech_csmsc,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk}
+ --am {speedyspeech_csmsc,speedyspeech_aishell3,fastspeech2_csmsc,fastspeech2_ljspeech,fastspeech2_aishell3,fastspeech2_vctk,tacotron2_csmsc,tacotron2_ljspeech}
Choose acoustic model type of tts task.
--am_config AM_CONFIG
- Config of acoustic model. Use deault config when it is
- None.
+ Config of acoustic model.
--am_ckpt AM_CKPT Checkpoint file of acoustic model.
--am_stat AM_STAT mean and standard deviation used to normalize
spectrogram when training acoustic model.
@@ -191,10 +189,10 @@ optional arguments:
--speaker_dict SPEAKER_DICT
speaker id map file.
--spk_id SPK_ID spk id for multi speaker acoustic model
- --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc}
+ --voc {pwgan_csmsc,pwgan_ljspeech,pwgan_aishell3,pwgan_vctk,mb_melgan_csmsc,style_melgan_csmsc,hifigan_csmsc,hifigan_ljspeech,hifigan_aishell3,hifigan_vctk,wavernn_csmsc}
Choose vocoder type of tts task.
--voc_config VOC_CONFIG
- Config of voc. Use deault config when it is None.
+ Config of voc.
--voc_ckpt VOC_CKPT Checkpoint file of voc.
--voc_stat VOC_STAT mean and standard deviation used to normalize
spectrogram when training voc.
@@ -207,9 +205,9 @@ optional arguments:
output dir.
```
1. `--am` is acoustic model type with the format {model_name}_{dataset}
-2. `--am_config`, `--am_checkpoint`, `--am_stat`, `--phones_dict` `--speaker_dict` are arguments for acoustic model, which correspond to the 5 files in the fastspeech2 pretrained model.
+2. `--am_config`, `--am_ckpt`, `--am_stat`, `--phones_dict` `--speaker_dict` are arguments for acoustic model, which correspond to the 5 files in the fastspeech2 pretrained model.
3. `--voc` is vocoder type with the format {model_name}_{dataset}
-4. `--voc_config`, `--voc_checkpoint`, `--voc_stat` are arguments for vocoder, which correspond to the 3 files in the parallel wavegan pretrained model.
+4. `--voc_config`, `--voc_ckpt`, `--voc_stat` are arguments for vocoder, which correspond to the 3 files in the parallel wavegan pretrained model.
5. `--lang` is the model language, which can be `zh` or `en`.
6. `--test_metadata` should be the metadata file in the normalized subfolder of `test` in the `dump` folder.
7. `--text` is the text file, which contains sentences to synthesize.
diff --git a/examples/vctk/voc1/README.md b/examples/vctk/voc1/README.md
index 1c3016f88..a0e06a420 100644
--- a/examples/vctk/voc1/README.md
+++ b/examples/vctk/voc1/README.md
@@ -3,7 +3,7 @@ This example contains code used to train a [parallel wavegan](http://arxiv.org/a
## Dataset
### Download and Extract
-Download VCTK-0.92 from the [official website](https://datashare.ed.ac.uk/handle/10283/3443) and extract it to `~/datasets`. Then the dataset is in directory `~/datasets/VCTK-Corpus-0.92`.
+Download VCTK-0.92 from it's [Official Website](https://datashare.ed.ac.uk/handle/10283/3443) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/VCTK-Corpus-0.92`.
### Get MFA Result and Extract
We use [MFA](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner) results to cut the silence in the edge of audio.
@@ -70,7 +70,7 @@ Train a ParallelWaveGAN model.
optional arguments:
-h, --help show this help message and exit
- --config CONFIG config file to overwrite default config.
+ --config CONFIG ParallelWaveGAN config file.
--train-metadata TRAIN_METADATA
training data.
--dev-metadata DEV_METADATA
diff --git a/examples/vctk/voc5/README.md b/examples/vctk/voc5/README.md
index 4eb25c02d..f2cbf27d2 100644
--- a/examples/vctk/voc5/README.md
+++ b/examples/vctk/voc5/README.md
@@ -3,7 +3,7 @@ This example contains code used to train a [HiFiGAN](https://arxiv.org/abs/2010.
## Dataset
### Download and Extract
-Download VCTK-0.92 from the [official website](https://datashare.ed.ac.uk/handle/10283/3443) and extract it to `~/datasets`. Then the dataset is in directory `~/datasets/VCTK-Corpus-0.92`.
+Download VCTK-0.92 from it's [Official Website](https://datashare.ed.ac.uk/handle/10283/3443) and extract it to `~/datasets`. Then the dataset is in the directory `~/datasets/VCTK-Corpus-0.92`.
### Get MFA Result and Extract
We use [MFA](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner) results to cut the silence in the edge of audio.
@@ -62,15 +62,13 @@ Here's the complete help message.
```text
usage: train.py [-h] [--config CONFIG] [--train-metadata TRAIN_METADATA]
[--dev-metadata DEV_METADATA] [--output-dir OUTPUT_DIR]
- [--ngpu NGPU] [--batch-size BATCH_SIZE] [--max-iter MAX_ITER]
- [--run-benchmark RUN_BENCHMARK]
- [--profiler_options PROFILER_OPTIONS]
+ [--ngpu NGPU]
-Train a ParallelWaveGAN model.
+Train a HiFiGAN model.
optional arguments:
-h, --help show this help message and exit
- --config CONFIG config file to overwrite default config.
+ --config CONFIG HiFiGAN config file.
--train-metadata TRAIN_METADATA
training data.
--dev-metadata DEV_METADATA
@@ -78,19 +76,6 @@ optional arguments:
--output-dir OUTPUT_DIR
output dir.
--ngpu NGPU if ngpu == 0, use cpu.
-
-benchmark:
- arguments related to benchmark.
-
- --batch-size BATCH_SIZE
- batch size.
- --max-iter MAX_ITER train max steps.
- --run-benchmark RUN_BENCHMARK
- runing benchmark or not, if True, use the --batch-size
- and --max-iter.
- --profiler_options PROFILER_OPTIONS
- The option of profiler, which should be in format
- "key1=value1;key2=value2;key3=value3".
```
1. `--config` is a config file in yaml format to overwrite the default config, which can be found at `conf/default.yaml`.
diff --git a/examples/voxceleb/sv0/README.md b/examples/voxceleb/sv0/README.md
index 567963e5f..26c95aca9 100644
--- a/examples/voxceleb/sv0/README.md
+++ b/examples/voxceleb/sv0/README.md
@@ -141,11 +141,11 @@ using the `tar` scripts to unpack the model and then you can use the script to t
For example:
```
-wget https://paddlespeech.bj.bcebos.com/vector/voxceleb/sv0_ecapa_tdnn_voxceleb12_ckpt_0_2_0.tar.gz
-tar xzvf sv0_ecapa_tdnn_voxceleb12_ckpt_0_2_0.tar.gz
+wget https://paddlespeech.bj.bcebos.com/vector/voxceleb/sv0_ecapa_tdnn_voxceleb12_ckpt_0_2_1.tar.gz
+tar -xvf sv0_ecapa_tdnn_voxceleb12_ckpt_0_2_1.tar.gz
source path.sh
# If you have processed the data and get the manifest file, you can skip the following 2 steps
-CUDA_VISIBLE_DEVICES= ./local/test.sh ./data sv0_ecapa_tdnn_voxceleb12_ckpt_0_1_2 conf/ecapa_tdnn.yaml
+CUDA_VISIBLE_DEVICES= bash ./local/test.sh ./data sv0_ecapa_tdnn_voxceleb12_ckpt_0_2_1/model/ conf/ecapa_tdnn.yaml
```
The performance of the released models are shown in [this](./RESULTS.md)
diff --git a/examples/voxceleb/sv0/RESULT.md b/examples/voxceleb/sv0/RESULT.md
index 3a3f67d09..56ee887c6 100644
--- a/examples/voxceleb/sv0/RESULT.md
+++ b/examples/voxceleb/sv0/RESULT.md
@@ -4,4 +4,4 @@
| Model | Number of Params | Release | Config | dim | Test set | Cosine | Cosine + S-Norm |
| --- | --- | --- | --- | --- | --- | --- | ---- |
-| ECAPA-TDNN | 85M | 0.2.0 | conf/ecapa_tdnn.yaml |192 | test | 1.02 | 0.95 |
+| ECAPA-TDNN | 85M | 0.2.1 | conf/ecapa_tdnn.yaml | 192 | test | 0.8188 | 0.7815|
diff --git a/examples/voxceleb/sv0/conf/ecapa_tdnn.yaml b/examples/voxceleb/sv0/conf/ecapa_tdnn.yaml
index 3e3a13072..b7b71d77d 100644
--- a/examples/voxceleb/sv0/conf/ecapa_tdnn.yaml
+++ b/examples/voxceleb/sv0/conf/ecapa_tdnn.yaml
@@ -59,3 +59,11 @@ global_embedding_norm: True
embedding_mean_norm: True
embedding_std_norm: False
+###########################################
+# score-norm #
+###########################################
+score_norm: s-norm
+cohort_size: 20000 # amount of imposter utterances in normalization cohort
+n_train_snts: 400000 # used for normalization stats
+
+
diff --git a/examples/voxceleb/sv0/conf/ecapa_tdnn_small.yaml b/examples/voxceleb/sv0/conf/ecapa_tdnn_small.yaml
index 5925e5730..40498c874 100644
--- a/examples/voxceleb/sv0/conf/ecapa_tdnn_small.yaml
+++ b/examples/voxceleb/sv0/conf/ecapa_tdnn_small.yaml
@@ -58,3 +58,10 @@ global_embedding_norm: True
embedding_mean_norm: True
embedding_std_norm: False
+###########################################
+# score-norm #
+###########################################
+score_norm: s-norm
+cohort_size: 20000 # amount of imposter utterances in normalization cohort
+n_train_snts: 400000 # used for normalization stats
+
diff --git a/examples/voxceleb/sv0/local/data_prepare.py b/examples/voxceleb/sv0/local/data_prepare.py
index b4486b6f0..e5a5dff7b 100644
--- a/examples/voxceleb/sv0/local/data_prepare.py
+++ b/examples/voxceleb/sv0/local/data_prepare.py
@@ -14,9 +14,9 @@
import argparse
import paddle
-from paddleaudio.datasets.voxceleb import VoxCeleb
from yacs.config import CfgNode
+from paddlespeech.audio.datasets.voxceleb import VoxCeleb
from paddlespeech.s2t.utils.log import Log
from paddlespeech.vector.io.augment import build_augment_pipeline
from paddlespeech.vector.training.seeding import seed_everything
diff --git a/examples/voxceleb/sv0/local/make_rirs_noise_csv_dataset_from_json.py b/examples/voxceleb/sv0/local/make_rirs_noise_csv_dataset_from_json.py
index 0d0163f15..7ad9bd6ec 100644
--- a/examples/voxceleb/sv0/local/make_rirs_noise_csv_dataset_from_json.py
+++ b/examples/voxceleb/sv0/local/make_rirs_noise_csv_dataset_from_json.py
@@ -21,9 +21,9 @@ import os
from typing import List
import tqdm
-from paddleaudio import load as load_audio
from yacs.config import CfgNode
+from paddlespeech.audio import load as load_audio
from paddlespeech.s2t.utils.log import Log
from paddlespeech.vector.utils.vector_utils import get_chunks
diff --git a/examples/voxceleb/sv0/local/make_vox_csv_dataset_from_json.py b/examples/voxceleb/sv0/local/make_vox_csv_dataset_from_json.py
index ffd0d212d..40adf53de 100644
--- a/examples/voxceleb/sv0/local/make_vox_csv_dataset_from_json.py
+++ b/examples/voxceleb/sv0/local/make_vox_csv_dataset_from_json.py
@@ -22,9 +22,9 @@ import os
import random
import tqdm
-from paddleaudio import load as load_audio
from yacs.config import CfgNode
+from paddlespeech.audio import load as load_audio
from paddlespeech.s2t.utils.log import Log
from paddlespeech.vector.utils.vector_utils import get_chunks
diff --git a/examples/voxceleb/sv0/local/test.sh b/examples/voxceleb/sv0/local/test.sh
index 4460a165a..800fa67da 100644
--- a/examples/voxceleb/sv0/local/test.sh
+++ b/examples/voxceleb/sv0/local/test.sh
@@ -33,10 +33,26 @@ dir=$1
exp_dir=$2
conf_path=$3
+# get the gpu nums for training
+ngpu=$(echo $CUDA_VISIBLE_DEVICES | awk -F "," '{print NF}')
+echo "using $ngpu gpus..."
+
+# setting training device
+device="cpu"
+if ${use_gpu}; then
+ device="gpu"
+fi
+if [ $ngpu -le 0 ]; then
+ echo "no gpu, training in cpu mode"
+ device='cpu'
+ use_gpu=false
+fi
+
if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
# test the model and compute the eer metrics
python3 ${BIN_DIR}/test.py \
--data-dir ${dir} \
--load-checkpoint ${exp_dir} \
- --config ${conf_path}
+ --config ${conf_path} \
+ --device ${device}
fi
diff --git a/examples/voxceleb/sv0/local/train.sh b/examples/voxceleb/sv0/local/train.sh
index 5477d0a34..674fedb32 100755
--- a/examples/voxceleb/sv0/local/train.sh
+++ b/examples/voxceleb/sv0/local/train.sh
@@ -42,15 +42,25 @@ device="cpu"
if ${use_gpu}; then
device="gpu"
fi
+if [ $ngpu -le 0 ]; then
+ echo "no gpu, training in cpu mode"
+ device='cpu'
+ use_gpu=false
+fi
if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
# train the speaker identification task with voxceleb data
# and we will create the trained model parameters in ${exp_dir}/model.pdparams as the soft link
# Note: we will store the log file in exp/log directory
- python3 -m paddle.distributed.launch --gpus=$CUDA_VISIBLE_DEVICES \
- ${BIN_DIR}/train.py --device ${device} --checkpoint-dir ${exp_dir} \
- --data-dir ${dir} --config ${conf_path}
-
+ if $use_gpu; then
+ python3 -m paddle.distributed.launch --gpus=$CUDA_VISIBLE_DEVICES \
+ ${BIN_DIR}/train.py --device ${device} --checkpoint-dir ${exp_dir} \
+ --data-dir ${dir} --config ${conf_path}
+ else
+ python3 \
+ ${BIN_DIR}/train.py --device ${device} --checkpoint-dir ${exp_dir} \
+ --data-dir ${dir} --config ${conf_path}
+ fi
fi
if [ $? -ne 0 ]; then
diff --git a/examples/wenetspeech/asr0/RESULTS.md b/examples/wenetspeech/asr0/RESULTS.md
new file mode 100644
index 000000000..0796b7bca
--- /dev/null
+++ b/examples/wenetspeech/asr0/RESULTS.md
@@ -0,0 +1,8 @@
+# Wenetspeech
+
+## Deepspeech2 Streaming
+
+| Model | Number of Params | Release | Config | Test set | Valid Loss | CER |
+| --- | --- | --- | --- | --- | --- | --- |
+| DeepSpeech2 | 1.2G | r1.0.0a | conf/deepspeech2\_online.yaml + spec aug + fbank161, w/o LM | test\_net | 13.307 | 15.02 |
+| DeepSpeech2 | 1.2G | r1.0.0a | conf/deepspeech2\_online.yaml + spec aug + fbank161, w/o LM | test\_meeting | 13.307 | 24.17 |
diff --git a/examples/wenetspeech/asr1/RESULTS.md b/examples/wenetspeech/asr1/RESULTS.md
index 5c2b8143c..cc209db75 100644
--- a/examples/wenetspeech/asr1/RESULTS.md
+++ b/examples/wenetspeech/asr1/RESULTS.md
@@ -1,9 +1,21 @@
# WenetSpeech
+## Conformer Streaming
+
+| Model | Params | Config | Augmentation| Test set | Decode method | Valid Loss | CER |
+| --- | --- | --- | --- | --- | --- | --- | --- |
+| conformer_online | 123.47 M | conf/chunk_conformer.yaml | spec_aug | test net | attention | 9.329 | 0.1102 |
+| conformer_online | 123.47 M | conf/chunk_conformer.yaml | spec_aug | test net | ctc_greedy_search | 9.329 | 0.1207 |
+| conformer_online | 123.47 M | conf/chunk_conformer.yaml | spec_aug | test net | ctc_prefix_beam_search | 9.329 | 0.1203 |
+| conformer_online | 123.47 M | conf/chunk_conformer.yaml | spec_aug | test net | attention_rescoring | 9.329 | 0.1100 |
+| conformer_online | 123.47 M | conf/chunk_conformer.yaml | spec_aug | test meeting | attention | 9.329 | 0.1992 |
+| conformer_online | 123.47 M | conf/chunk_conformer.yaml | spec_aug | test meeting | ctc_greedy_search | 9.329 | 0.1960 |
+| conformer_online | 123.47 M | conf/chunk_conformer.yaml | spec_aug | test meeting | ctc_prefix_beam_search | 9.329 | 0.1946 |
+| conformer_online | 123.47 M | conf/chunk_conformer.yaml | spec_aug | test meeting | attention_rescoring | 9.329 | 0.1879|
## Conformer
-| Model | Params | Config | Augmentation| Test set | Decode method | Loss | WER |
+| Model | Params | Config | Augmentation| Test set | Decode method | Loss | CER |
| --- | --- | --- | --- | --- | --- | --- | --- |
| conformer | 32.52 M | conf/conformer.yaml | spec_aug | dev | attention | | |
| conformer | 32.52 M | conf/conformer.yaml | spec_aug | test net | ctc_greedy_search | | |
@@ -16,7 +28,7 @@
Pretrain model from http://mobvoi-speech-public.ufile.ucloud.cn/public/wenet/wenetspeech/20211025_conformer_exp.tar.gz
-| Model | Params | Config | Augmentation| Test set | Decode method | Loss | WER |
+| Model | Params | Config | Augmentation| Test set | Decode method | Loss | CER |
| --- | --- | --- | --- | --- | --- | --- | --- |
| conformer | 32.52 M | conf/conformer.yaml | spec_aug | aishell1 | attention | - | 0.048456 |
| conformer | 32.52 M | conf/conformer.yaml | spec_aug | aishell1 | ctc_greedy_search | - | 0.052534 |
diff --git a/examples/wenetspeech/asr1/local/extract_meta.py b/examples/wenetspeech/asr1/local/extract_meta.py
index 0e1b27278..954dbd780 100644
--- a/examples/wenetspeech/asr1/local/extract_meta.py
+++ b/examples/wenetspeech/asr1/local/extract_meta.py
@@ -1,18 +1,7 @@
-# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
# Copyright 2021 Xiaomi Corporation (Author: Yongqing Wang)
# Mobvoi Inc(Author: Di Wu, Binbin Zhang)
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
diff --git a/audio/paddleaudio/__init__.py b/paddlespeech/audio/__init__.py
similarity index 100%
rename from audio/paddleaudio/__init__.py
rename to paddlespeech/audio/__init__.py
diff --git a/audio/paddleaudio/backends/__init__.py b/paddlespeech/audio/backends/__init__.py
similarity index 100%
rename from audio/paddleaudio/backends/__init__.py
rename to paddlespeech/audio/backends/__init__.py
diff --git a/audio/paddleaudio/backends/soundfile_backend.py b/paddlespeech/audio/backends/soundfile_backend.py
similarity index 100%
rename from audio/paddleaudio/backends/soundfile_backend.py
rename to paddlespeech/audio/backends/soundfile_backend.py
diff --git a/audio/paddleaudio/backends/sox_backend.py b/paddlespeech/audio/backends/sox_backend.py
similarity index 100%
rename from audio/paddleaudio/backends/sox_backend.py
rename to paddlespeech/audio/backends/sox_backend.py
diff --git a/audio/paddleaudio/compliance/__init__.py b/paddlespeech/audio/compliance/__init__.py
similarity index 100%
rename from audio/paddleaudio/compliance/__init__.py
rename to paddlespeech/audio/compliance/__init__.py
diff --git a/audio/paddleaudio/compliance/kaldi.py b/paddlespeech/audio/compliance/kaldi.py
similarity index 100%
rename from audio/paddleaudio/compliance/kaldi.py
rename to paddlespeech/audio/compliance/kaldi.py
diff --git a/audio/paddleaudio/compliance/librosa.py b/paddlespeech/audio/compliance/librosa.py
similarity index 100%
rename from audio/paddleaudio/compliance/librosa.py
rename to paddlespeech/audio/compliance/librosa.py
diff --git a/audio/paddleaudio/datasets/__init__.py b/paddlespeech/audio/datasets/__init__.py
similarity index 100%
rename from audio/paddleaudio/datasets/__init__.py
rename to paddlespeech/audio/datasets/__init__.py
diff --git a/audio/paddleaudio/datasets/dataset.py b/paddlespeech/audio/datasets/dataset.py
similarity index 100%
rename from audio/paddleaudio/datasets/dataset.py
rename to paddlespeech/audio/datasets/dataset.py
diff --git a/audio/paddleaudio/datasets/esc50.py b/paddlespeech/audio/datasets/esc50.py
similarity index 99%
rename from audio/paddleaudio/datasets/esc50.py
rename to paddlespeech/audio/datasets/esc50.py
index e7477d40e..f5c7050f3 100644
--- a/audio/paddleaudio/datasets/esc50.py
+++ b/paddlespeech/audio/datasets/esc50.py
@@ -16,8 +16,8 @@ import os
from typing import List
from typing import Tuple
+from ..utils import DATA_HOME
from ..utils.download import download_and_decompress
-from ..utils.env import DATA_HOME
from .dataset import AudioClassificationDataset
__all__ = ['ESC50']
diff --git a/audio/paddleaudio/datasets/gtzan.py b/paddlespeech/audio/datasets/gtzan.py
similarity index 99%
rename from audio/paddleaudio/datasets/gtzan.py
rename to paddlespeech/audio/datasets/gtzan.py
index cfea6f37e..1f6835a5a 100644
--- a/audio/paddleaudio/datasets/gtzan.py
+++ b/paddlespeech/audio/datasets/gtzan.py
@@ -17,8 +17,8 @@ import random
from typing import List
from typing import Tuple
+from ..utils import DATA_HOME
from ..utils.download import download_and_decompress
-from ..utils.env import DATA_HOME
from .dataset import AudioClassificationDataset
__all__ = ['GTZAN']
diff --git a/audio/paddleaudio/datasets/hey_snips.py b/paddlespeech/audio/datasets/hey_snips.py
similarity index 100%
rename from audio/paddleaudio/datasets/hey_snips.py
rename to paddlespeech/audio/datasets/hey_snips.py
diff --git a/audio/paddleaudio/datasets/rirs_noises.py b/paddlespeech/audio/datasets/rirs_noises.py
similarity index 100%
rename from audio/paddleaudio/datasets/rirs_noises.py
rename to paddlespeech/audio/datasets/rirs_noises.py
diff --git a/audio/paddleaudio/datasets/tess.py b/paddlespeech/audio/datasets/tess.py
similarity index 99%
rename from audio/paddleaudio/datasets/tess.py
rename to paddlespeech/audio/datasets/tess.py
index 8faab9c39..1469fa5e2 100644
--- a/audio/paddleaudio/datasets/tess.py
+++ b/paddlespeech/audio/datasets/tess.py
@@ -17,8 +17,8 @@ import random
from typing import List
from typing import Tuple
+from ..utils import DATA_HOME
from ..utils.download import download_and_decompress
-from ..utils.env import DATA_HOME
from .dataset import AudioClassificationDataset
__all__ = ['TESS']
diff --git a/audio/paddleaudio/datasets/urban_sound.py b/paddlespeech/audio/datasets/urban_sound.py
similarity index 99%
rename from audio/paddleaudio/datasets/urban_sound.py
rename to paddlespeech/audio/datasets/urban_sound.py
index d97c4d1dc..0389cd5f9 100644
--- a/audio/paddleaudio/datasets/urban_sound.py
+++ b/paddlespeech/audio/datasets/urban_sound.py
@@ -16,8 +16,8 @@ import os
from typing import List
from typing import Tuple
+from ..utils import DATA_HOME
from ..utils.download import download_and_decompress
-from ..utils.env import DATA_HOME
from .dataset import AudioClassificationDataset
__all__ = ['UrbanSound8K']
diff --git a/audio/paddleaudio/datasets/voxceleb.py b/paddlespeech/audio/datasets/voxceleb.py
similarity index 100%
rename from audio/paddleaudio/datasets/voxceleb.py
rename to paddlespeech/audio/datasets/voxceleb.py
diff --git a/audio/paddleaudio/features/__init__.py b/paddlespeech/audio/features/__init__.py
similarity index 100%
rename from audio/paddleaudio/features/__init__.py
rename to paddlespeech/audio/features/__init__.py
diff --git a/audio/paddleaudio/features/layers.py b/paddlespeech/audio/features/layers.py
similarity index 100%
rename from audio/paddleaudio/features/layers.py
rename to paddlespeech/audio/features/layers.py
diff --git a/audio/paddleaudio/functional/__init__.py b/paddlespeech/audio/functional/__init__.py
similarity index 100%
rename from audio/paddleaudio/functional/__init__.py
rename to paddlespeech/audio/functional/__init__.py
diff --git a/audio/paddleaudio/functional/functional.py b/paddlespeech/audio/functional/functional.py
similarity index 100%
rename from audio/paddleaudio/functional/functional.py
rename to paddlespeech/audio/functional/functional.py
diff --git a/audio/paddleaudio/functional/window.py b/paddlespeech/audio/functional/window.py
similarity index 100%
rename from audio/paddleaudio/functional/window.py
rename to paddlespeech/audio/functional/window.py
diff --git a/audio/paddleaudio/io/__init__.py b/paddlespeech/audio/io/__init__.py
similarity index 100%
rename from audio/paddleaudio/io/__init__.py
rename to paddlespeech/audio/io/__init__.py
diff --git a/audio/paddleaudio/metric/__init__.py b/paddlespeech/audio/metric/__init__.py
similarity index 95%
rename from audio/paddleaudio/metric/__init__.py
rename to paddlespeech/audio/metric/__init__.py
index d2b3a1360..7ce6f5cff 100644
--- a/audio/paddleaudio/metric/__init__.py
+++ b/paddlespeech/audio/metric/__init__.py
@@ -11,6 +11,5 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-from .dtw import dtw_distance
from .eer import compute_eer
from .eer import compute_minDCF
diff --git a/audio/paddleaudio/metric/eer.py b/paddlespeech/audio/metric/eer.py
similarity index 100%
rename from audio/paddleaudio/metric/eer.py
rename to paddlespeech/audio/metric/eer.py
diff --git a/audio/paddleaudio/sox_effects/__init__.py b/paddlespeech/audio/sox_effects/__init__.py
similarity index 100%
rename from audio/paddleaudio/sox_effects/__init__.py
rename to paddlespeech/audio/sox_effects/__init__.py
diff --git a/audio/paddleaudio/utils/__init__.py b/paddlespeech/audio/utils/__init__.py
similarity index 88%
rename from audio/paddleaudio/utils/__init__.py
rename to paddlespeech/audio/utils/__init__.py
index afb9cedd8..742f9f8ef 100644
--- a/audio/paddleaudio/utils/__init__.py
+++ b/paddlespeech/audio/utils/__init__.py
@@ -11,13 +11,11 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
+from ...cli.utils import DATA_HOME
+from ...cli.utils import MODEL_HOME
from .download import decompress
from .download import download_and_decompress
from .download import load_state_dict_from_url
-from .env import DATA_HOME
-from .env import MODEL_HOME
-from .env import PPAUDIO_HOME
-from .env import USER_HOME
from .error import ParameterError
from .log import Logger
from .log import logger
diff --git a/audio/paddleaudio/utils/download.py b/paddlespeech/audio/utils/download.py
similarity index 100%
rename from audio/paddleaudio/utils/download.py
rename to paddlespeech/audio/utils/download.py
diff --git a/audio/paddleaudio/utils/error.py b/paddlespeech/audio/utils/error.py
similarity index 100%
rename from audio/paddleaudio/utils/error.py
rename to paddlespeech/audio/utils/error.py
diff --git a/audio/paddleaudio/utils/log.py b/paddlespeech/audio/utils/log.py
similarity index 100%
rename from audio/paddleaudio/utils/log.py
rename to paddlespeech/audio/utils/log.py
diff --git a/audio/paddleaudio/utils/numeric.py b/paddlespeech/audio/utils/numeric.py
similarity index 100%
rename from audio/paddleaudio/utils/numeric.py
rename to paddlespeech/audio/utils/numeric.py
diff --git a/audio/paddleaudio/utils/time.py b/paddlespeech/audio/utils/time.py
similarity index 100%
rename from audio/paddleaudio/utils/time.py
rename to paddlespeech/audio/utils/time.py
diff --git a/paddlespeech/cli/__init__.py b/paddlespeech/cli/__init__.py
index ddf0359bc..ca6993f2b 100644
--- a/paddlespeech/cli/__init__.py
+++ b/paddlespeech/cli/__init__.py
@@ -13,14 +13,7 @@
# limitations under the License.
import _locale
-from .asr import ASRExecutor
from .base_commands import BaseCommand
from .base_commands import HelpCommand
-from .cls import CLSExecutor
-from .st import STExecutor
-from .stats import StatsExecutor
-from .text import TextExecutor
-from .tts import TTSExecutor
-from .vector import VectorExecutor
_locale._getdefaultlocale = (lambda *args: ['en_US', 'utf8'])
diff --git a/paddlespeech/cli/asr/infer.py b/paddlespeech/cli/asr/infer.py
index 0fb548683..a943ccfa7 100644
--- a/paddlespeech/cli/asr/infer.py
+++ b/paddlespeech/cli/asr/infer.py
@@ -14,6 +14,7 @@
import argparse
import os
import sys
+import time
from collections import OrderedDict
from typing import List
from typing import Optional
@@ -28,27 +29,21 @@ from yacs.config import CfgNode
from ..download import get_path_from_url
from ..executor import BaseExecutor
from ..log import logger
-from ..utils import cli_register
+from ..utils import CLI_TIMER
from ..utils import MODEL_HOME
from ..utils import stats_wrapper
-from .pretrained_models import model_alias
-from .pretrained_models import pretrained_models
+from ..utils import timer_register
from paddlespeech.s2t.frontend.featurizer.text_featurizer import TextFeaturizer
from paddlespeech.s2t.transform.transformation import Transformation
-from paddlespeech.s2t.utils.dynamic_import import dynamic_import
from paddlespeech.s2t.utils.utility import UpdateConfig
__all__ = ['ASRExecutor']
-@cli_register(
- name='paddlespeech.asr', description='Speech to text infer command.')
+@timer_register
class ASRExecutor(BaseExecutor):
def __init__(self):
- super().__init__()
- self.model_alias = model_alias
- self.pretrained_models = pretrained_models
-
+ super().__init__(task='asr', inference_type='offline')
self.parser = argparse.ArgumentParser(
prog='paddlespeech.asr', add_help=True)
self.parser.add_argument(
@@ -58,7 +53,8 @@ class ASRExecutor(BaseExecutor):
type=str,
default='conformer_wenetspeech',
choices=[
- tag[:tag.index('-')] for tag in self.pretrained_models.keys()
+ tag[:tag.index('-')]
+ for tag in self.task_resource.pretrained_models.keys()
],
help='Choose model type of asr task.')
self.parser.add_argument(
@@ -87,6 +83,12 @@ class ASRExecutor(BaseExecutor):
'attention_rescoring'
],
help='only support transformer and conformer model')
+ self.parser.add_argument(
+ '--num_decoding_left_chunks',
+ '-num_left',
+ type=str,
+ default=-1,
+ help='only support transformer and conformer online model')
self.parser.add_argument(
'--ckpt_path',
type=str,
@@ -99,6 +101,11 @@ class ASRExecutor(BaseExecutor):
default=False,
help='No additional parameters required. Once set this parameter, it means accepting the request of the program by default, which includes transforming the audio sample rate'
)
+ self.parser.add_argument(
+ '--rtf',
+ action="store_true",
+ default=False,
+ help='Show Real-time Factor(RTF).')
self.parser.add_argument(
'--device',
type=str,
@@ -121,11 +128,14 @@ class ASRExecutor(BaseExecutor):
sample_rate: int=16000,
cfg_path: Optional[os.PathLike]=None,
decode_method: str='attention_rescoring',
+ num_decoding_left_chunks: int=-1,
ckpt_path: Optional[os.PathLike]=None):
"""
Init model and other resources from a specific path.
"""
logger.info("start to init the model")
+ # default max_len: unit:second
+ self.max_len = 50
if hasattr(self, 'model'):
logger.info('Model had been initialized.')
return
@@ -133,14 +143,15 @@ class ASRExecutor(BaseExecutor):
if cfg_path is None or ckpt_path is None:
sample_rate_str = '16k' if sample_rate == 16000 else '8k'
tag = model_type + '-' + lang + '-' + sample_rate_str
- res_path = self._get_pretrained_path(tag) # wenetspeech_zh
- self.res_path = res_path
+ self.task_resource.set_task_model(tag, version=None)
+ self.res_path = self.task_resource.res_dir
+
self.cfg_path = os.path.join(
- res_path, self.pretrained_models[tag]['cfg_path'])
+ self.res_path, self.task_resource.res_dict['cfg_path'])
self.ckpt_path = os.path.join(
- res_path,
- self.pretrained_models[tag]['ckpt_path'] + ".pdparams")
- logger.info(res_path)
+ self.res_path,
+ self.task_resource.res_dict['ckpt_path'] + ".pdparams")
+ logger.info(self.res_path)
else:
self.cfg_path = os.path.abspath(cfg_path)
@@ -155,34 +166,35 @@ class ASRExecutor(BaseExecutor):
self.config.merge_from_file(self.cfg_path)
with UpdateConfig(self.config):
- if "deepspeech2online" in model_type or "deepspeech2offline" in model_type:
- from paddlespeech.s2t.io.collator import SpeechCollator
- self.vocab = self.config.vocab_filepath
+ if self.config.spm_model_prefix:
+ self.config.spm_model_prefix = os.path.join(
+ self.res_path, self.config.spm_model_prefix)
+ self.text_feature = TextFeaturizer(
+ unit_type=self.config.unit_type,
+ vocab=self.config.vocab_filepath,
+ spm_model_prefix=self.config.spm_model_prefix)
+ if "deepspeech2" in model_type:
self.config.decode.lang_model_path = os.path.join(
MODEL_HOME, 'language_model',
self.config.decode.lang_model_path)
- self.collate_fn_test = SpeechCollator.from_config(self.config)
- self.text_feature = TextFeaturizer(
- unit_type=self.config.unit_type, vocab=self.vocab)
- lm_url = self.pretrained_models[tag]['lm_url']
- lm_md5 = self.pretrained_models[tag]['lm_md5']
+
+ lm_url = self.task_resource.res_dict['lm_url']
+ lm_md5 = self.task_resource.res_dict['lm_md5']
self.download_lm(
lm_url,
os.path.dirname(self.config.decode.lang_model_path), lm_md5)
- elif "conformer" in model_type or "transformer" in model_type or "wenetspeech" in model_type:
- self.config.spm_model_prefix = os.path.join(
- self.res_path, self.config.spm_model_prefix)
- self.text_feature = TextFeaturizer(
- unit_type=self.config.unit_type,
- vocab=self.config.vocab_filepath,
- spm_model_prefix=self.config.spm_model_prefix)
+ elif "conformer" in model_type or "transformer" in model_type:
self.config.decode.decoding_method = decode_method
+ if num_decoding_left_chunks:
+ assert num_decoding_left_chunks == -1 or num_decoding_left_chunks >= 0, "num_decoding_left_chunks should be -1 or >=0"
+ self.config.num_decoding_left_chunks = num_decoding_left_chunks
+
else:
raise Exception("wrong type")
model_name = model_type[:model_type.rindex(
'_')] # model_type: {model_name}_{dataset}
- model_class = dynamic_import(model_name, self.model_alias)
+ model_class = self.task_resource.get_model_class(model_name)
model_conf = self.config
model = model_class.from_config(model_conf)
self.model = model
@@ -192,6 +204,21 @@ class ASRExecutor(BaseExecutor):
model_dict = paddle.load(self.ckpt_path)
self.model.set_state_dict(model_dict)
+ # compute the max len limit
+ if "conformer" in model_type or "transformer" in model_type:
+ # in transformer like model, we may use the subsample rate cnn network
+ subsample_rate = self.model.subsampling_rate()
+ frame_shift_ms = self.config.preprocess_config.process[0][
+ 'n_shift'] / self.config.preprocess_config.process[0]['fs']
+ max_len = self.model.encoder.embed.pos_enc.max_len
+
+ if self.config.encoder_conf.get("max_len", None):
+ max_len = self.config.encoder_conf.max_len
+
+ self.max_len = frame_shift_ms * max_len * subsample_rate
+ logger.info(
+ f"The asr server limit max duration len: {self.max_len}")
+
def preprocess(self, model_type: str, input: Union[str, os.PathLike]):
"""
Input preprocess and return paddle.Tensor stored in self.input.
@@ -203,19 +230,7 @@ class ASRExecutor(BaseExecutor):
logger.info("Preprocess audio_file:" + audio_file)
# Get the object for feature extraction
- if "deepspeech2online" in model_type or "deepspeech2offline" in model_type:
- audio, _ = self.collate_fn_test.process_utterance(
- audio_file=audio_file, transcript=" ")
- audio_len = audio.shape[0]
- audio = paddle.to_tensor(audio, dtype='float32')
- audio_len = paddle.to_tensor(audio_len)
- audio = paddle.unsqueeze(audio, axis=0)
- # vocab_list = collate_fn_test.vocab_list
- self._inputs["audio"] = audio
- self._inputs["audio_len"] = audio_len
- logger.info(f"audio feat shape: {audio.shape}")
-
- elif "conformer" in model_type or "transformer" in model_type or "wenetspeech" in model_type:
+ if "deepspeech2" in model_type or "conformer" in model_type or "transformer" in model_type:
logger.info("get the preprocess conf")
preprocess_conf = self.config.preprocess_config
preprocess_args = {"train": False}
@@ -223,7 +238,6 @@ class ASRExecutor(BaseExecutor):
logger.info("read the audio file")
audio, audio_sample_rate = soundfile.read(
audio_file, dtype="int16", always_2d=True)
-
if self.change_format:
if audio.shape[1] >= 2:
audio = audio.mean(axis=1, dtype=np.int16)
@@ -266,7 +280,7 @@ class ASRExecutor(BaseExecutor):
cfg = self.config.decode
audio = self._inputs["audio"]
audio_len = self._inputs["audio_len"]
- if "deepspeech2online" in model_type or "deepspeech2offline" in model_type:
+ if "deepspeech2" in model_type:
decode_batch_size = audio.shape[0]
self.model.decoder.init_decoder(
decode_batch_size, self.text_feature.vocab_list,
@@ -343,9 +357,10 @@ class ASRExecutor(BaseExecutor):
audio, audio_sample_rate = soundfile.read(
audio_file, dtype="int16", always_2d=True)
audio_duration = audio.shape[0] / audio_sample_rate
- max_duration = 50.0
- if audio_duration >= max_duration:
- logger.error("Please input audio file less then 50 seconds.\n")
+ if audio_duration > self.max_len:
+ logger.error(
+ f"Please input audio file less then {self.max_len} seconds.\n"
+ )
return False
except Exception as e:
logger.exception(e)
@@ -407,24 +422,28 @@ class ASRExecutor(BaseExecutor):
ckpt_path = parser_args.ckpt_path
decode_method = parser_args.decode_method
force_yes = parser_args.yes
+ rtf = parser_args.rtf
device = parser_args.device
if not parser_args.verbose:
self.disable_task_loggers()
- task_source = self.get_task_source(parser_args.input)
+ task_source = self.get_input_source(parser_args.input)
task_results = OrderedDict()
has_exceptions = False
for id_, input_ in task_source.items():
try:
res = self(input_, model, lang, sample_rate, config, ckpt_path,
- decode_method, force_yes, device)
+ decode_method, force_yes, rtf, device)
task_results[id_] = res
except Exception as e:
has_exceptions = True
task_results[id_] = f'{e.__class__.__name__}: {e}'
+ if rtf:
+ self.show_rtf(CLI_TIMER[self.__class__.__name__])
+
self.process_task_results(parser_args.input, task_results,
parser_args.job_dump_result)
@@ -442,19 +461,31 @@ class ASRExecutor(BaseExecutor):
config: os.PathLike=None,
ckpt_path: os.PathLike=None,
decode_method: str='attention_rescoring',
+ num_decoding_left_chunks: int=-1,
force_yes: bool=False,
+ rtf: bool=False,
device=paddle.get_device()):
"""
Python API to call an executor.
"""
audio_file = os.path.abspath(audio_file)
- if not self._check(audio_file, sample_rate, force_yes):
- sys.exit(-1)
paddle.set_device(device)
self._init_from_path(model, lang, sample_rate, config, decode_method,
- ckpt_path)
+ num_decoding_left_chunks, ckpt_path)
+ if not self._check(audio_file, sample_rate, force_yes):
+ sys.exit(-1)
+ if rtf:
+ k = self.__class__.__name__
+ CLI_TIMER[k]['start'].append(time.time())
+
self.preprocess(model, audio_file)
self.infer(model)
res = self.postprocess() # Retrieve result of asr.
+ if rtf:
+ CLI_TIMER[k]['end'].append(time.time())
+ audio, audio_sample_rate = soundfile.read(
+ audio_file, dtype="int16", always_2d=True)
+ CLI_TIMER[k]['extra'].append(audio.shape[0] / audio_sample_rate)
+
return res
diff --git a/paddlespeech/cli/asr/pretrained_models.py b/paddlespeech/cli/asr/pretrained_models.py
deleted file mode 100644
index 44db55686..000000000
--- a/paddlespeech/cli/asr/pretrained_models.py
+++ /dev/null
@@ -1,117 +0,0 @@
-# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-pretrained_models = {
- # The tags for pretrained_models should be "{model_name}[_{dataset}][-{lang}][-...]".
- # e.g. "conformer_wenetspeech-zh-16k" and "panns_cnn6-32k".
- # Command line and python api use "{model_name}[_{dataset}]" as --model, usage:
- # "paddlespeech asr --model conformer_wenetspeech --lang zh --sr 16000 --input ./input.wav"
- "conformer_wenetspeech-zh-16k": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr1_conformer_wenetspeech_ckpt_0.1.1.model.tar.gz',
- 'md5':
- '76cb19ed857e6623856b7cd7ebbfeda4',
- 'cfg_path':
- 'model.yaml',
- 'ckpt_path':
- 'exp/conformer/checkpoints/wenetspeech',
- },
- "conformer_aishell-zh-16k": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/aishell/asr1/asr1_conformer_aishell_ckpt_0.1.2.model.tar.gz',
- 'md5':
- '3f073eccfa7bb14e0c6867d65fc0dc3a',
- 'cfg_path':
- 'model.yaml',
- 'ckpt_path':
- 'exp/conformer/checkpoints/avg_30',
- },
- "conformer_online_aishell-zh-16k": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/aishell/asr1/asr1_chunk_conformer_aishell_ckpt_0.2.0.model.tar.gz',
- 'md5':
- 'b374cfb93537761270b6224fb0bfc26a',
- 'cfg_path':
- 'model.yaml',
- 'ckpt_path':
- 'exp/chunk_conformer/checkpoints/avg_30',
- },
- "transformer_librispeech-en-16k": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/librispeech/asr1/asr1_transformer_librispeech_ckpt_0.1.1.model.tar.gz',
- 'md5':
- '2c667da24922aad391eacafe37bc1660',
- 'cfg_path':
- 'model.yaml',
- 'ckpt_path':
- 'exp/transformer/checkpoints/avg_10',
- },
- "deepspeech2offline_aishell-zh-16k": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_aishell_ckpt_0.1.1.model.tar.gz',
- 'md5':
- '932c3593d62fe5c741b59b31318aa314',
- 'cfg_path':
- 'model.yaml',
- 'ckpt_path':
- 'exp/deepspeech2/checkpoints/avg_1',
- 'lm_url':
- 'https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm',
- 'lm_md5':
- '29e02312deb2e59b3c8686c7966d4fe3'
- },
- "deepspeech2online_aishell-zh-16k": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_online_aishell_fbank161_ckpt_0.2.0.model.tar.gz',
- 'md5':
- 'd314960e83cc10dcfa6b04269f3054d4',
- 'cfg_path':
- 'model.yaml',
- 'ckpt_path':
- 'exp/deepspeech2_online/checkpoints/avg_1',
- 'lm_url':
- 'https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm',
- 'lm_md5':
- '29e02312deb2e59b3c8686c7966d4fe3'
- },
- "deepspeech2offline_librispeech-en-16k": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/librispeech/asr0/asr0_deepspeech2_librispeech_ckpt_0.1.1.model.tar.gz',
- 'md5':
- 'f5666c81ad015c8de03aac2bc92e5762',
- 'cfg_path':
- 'model.yaml',
- 'ckpt_path':
- 'exp/deepspeech2/checkpoints/avg_1',
- 'lm_url':
- 'https://deepspeech.bj.bcebos.com/en_lm/common_crawl_00.prune01111.trie.klm',
- 'lm_md5':
- '099a601759d467cd0a8523ff939819c5'
- },
-}
-
-model_alias = {
- "deepspeech2offline":
- "paddlespeech.s2t.models.ds2:DeepSpeech2Model",
- "deepspeech2online":
- "paddlespeech.s2t.models.ds2_online:DeepSpeech2ModelOnline",
- "conformer":
- "paddlespeech.s2t.models.u2:U2Model",
- "conformer_online":
- "paddlespeech.s2t.models.u2:U2Model",
- "transformer":
- "paddlespeech.s2t.models.u2:U2Model",
- "wenetspeech":
- "paddlespeech.s2t.models.u2:U2Model",
-}
diff --git a/paddlespeech/cli/base_commands.py b/paddlespeech/cli/base_commands.py
index 97d5cd7fa..f5e2246d8 100644
--- a/paddlespeech/cli/base_commands.py
+++ b/paddlespeech/cli/base_commands.py
@@ -11,16 +11,18 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
+import argparse
from typing import List
+from prettytable import PrettyTable
+
+from ..resource import CommonTaskResource
from .entry import commands
from .utils import cli_register
+from .utils import explicit_command_register
from .utils import get_command
-__all__ = [
- 'BaseCommand',
- 'HelpCommand',
-]
+__all__ = ['BaseCommand', 'HelpCommand', 'StatsCommand']
@cli_register(name='paddlespeech')
@@ -47,3 +49,99 @@ class HelpCommand:
print(msg)
return True
+
+
+@cli_register(
+ name='paddlespeech.version',
+ description='Show version and commit id of current package.')
+class VersionCommand:
+ def execute(self, argv: List[str]) -> bool:
+ try:
+ from .. import __version__
+ version = __version__
+ except ImportError:
+ version = 'Not an official release'
+
+ try:
+ from .. import __commit__
+ commit_id = __commit__
+ except ImportError:
+ commit_id = 'Not found'
+
+ msg = 'Package Version:\n'
+ msg += ' {}\n\n'.format(version)
+ msg += 'Commit ID:\n'
+ msg += ' {}\n\n'.format(commit_id)
+
+ print(msg)
+ return True
+
+
+model_name_format = {
+ 'asr': 'Model-Language-Sample Rate',
+ 'cls': 'Model-Sample Rate',
+ 'st': 'Model-Source language-Target language',
+ 'text': 'Model-Task-Language',
+ 'tts': 'Model-Language',
+ 'vector': 'Model-Sample Rate'
+}
+
+
+@cli_register(
+ name='paddlespeech.stats',
+ description='Get speech tasks support models list.')
+class StatsCommand:
+ def __init__(self):
+ self.parser = argparse.ArgumentParser(
+ prog='paddlespeech.stats', add_help=True)
+ self.task_choices = ['asr', 'cls', 'st', 'text', 'tts', 'vector']
+ self.parser.add_argument(
+ '--task',
+ type=str,
+ default='asr',
+ choices=self.task_choices,
+ help='Choose speech task.',
+ required=True)
+
+ def show_support_models(self, pretrained_models: dict):
+ fields = model_name_format[self.task].split("-")
+ table = PrettyTable(fields)
+ for key in pretrained_models:
+ table.add_row(key.split("-"))
+ print(table)
+
+ def execute(self, argv: List[str]) -> bool:
+ parser_args = self.parser.parse_args(argv)
+ self.task = parser_args.task
+ if self.task not in self.task_choices:
+ print("Please input correct speech task, choices = " + str(
+ self.task_choices))
+ return
+
+ pretrained_models = CommonTaskResource(task=self.task).pretrained_models
+
+ try:
+ print(
+ "Here is the list of {} pretrained models released by PaddleSpeech that can be used by command line and python API"
+ .format(self.task.upper()))
+ self.show_support_models(pretrained_models)
+ except BaseException:
+ print("Failed to get the list of {} pretrained models.".format(
+ self.task.upper()))
+
+
+# Dynamic import when running specific command
+_commands = {
+ 'asr': ['Speech to text infer command.', 'ASRExecutor'],
+ 'cls': ['Audio classification infer command.', 'CLSExecutor'],
+ 'st': ['Speech translation infer command.', 'STExecutor'],
+ 'text': ['Text command.', 'TextExecutor'],
+ 'tts': ['Text to Speech infer command.', 'TTSExecutor'],
+ 'vector': ['Speech to vector embedding infer command.', 'VectorExecutor'],
+}
+
+for com, info in _commands.items():
+ explicit_command_register(
+ name='paddlespeech.{}'.format(com),
+ description=info[0],
+ cls='paddlespeech.cli.{}.{}'.format(com, info[1]))
diff --git a/paddlespeech/cli/cls/infer.py b/paddlespeech/cli/cls/infer.py
index 1f637a8fe..942dc3b92 100644
--- a/paddlespeech/cli/cls/infer.py
+++ b/paddlespeech/cli/cls/infer.py
@@ -24,25 +24,16 @@ import yaml
from ..executor import BaseExecutor
from ..log import logger
-from ..utils import cli_register
from ..utils import stats_wrapper
-from .pretrained_models import model_alias
-from .pretrained_models import pretrained_models
-from paddleaudio import load
-from paddleaudio.features import LogMelSpectrogram
-from paddlespeech.s2t.utils.dynamic_import import dynamic_import
+from paddlespeech.audio import load
+from paddlespeech.audio.features import LogMelSpectrogram
__all__ = ['CLSExecutor']
-@cli_register(
- name='paddlespeech.cls', description='Audio classification infer command.')
class CLSExecutor(BaseExecutor):
def __init__(self):
- super().__init__()
- self.model_alias = model_alias
- self.pretrained_models = pretrained_models
-
+ super().__init__(task='cls')
self.parser = argparse.ArgumentParser(
prog='paddlespeech.cls', add_help=True)
self.parser.add_argument(
@@ -52,7 +43,8 @@ class CLSExecutor(BaseExecutor):
type=str,
default='panns_cnn14',
choices=[
- tag[:tag.index('-')] for tag in self.pretrained_models.keys()
+ tag[:tag.index('-')]
+ for tag in self.task_resource.pretrained_models.keys()
],
help='Choose model type of cls task.')
self.parser.add_argument(
@@ -105,13 +97,16 @@ class CLSExecutor(BaseExecutor):
if label_file is None or ckpt_path is None:
tag = model_type + '-' + '32k' # panns_cnn14-32k
- self.res_path = self._get_pretrained_path(tag)
+ self.task_resource.set_task_model(tag, version=None)
self.cfg_path = os.path.join(
- self.res_path, self.pretrained_models[tag]['cfg_path'])
+ self.task_resource.res_dir,
+ self.task_resource.res_dict['cfg_path'])
self.label_file = os.path.join(
- self.res_path, self.pretrained_models[tag]['label_file'])
+ self.task_resource.res_dir,
+ self.task_resource.res_dict['label_file'])
self.ckpt_path = os.path.join(
- self.res_path, self.pretrained_models[tag]['ckpt_path'])
+ self.task_resource.res_dir,
+ self.task_resource.res_dict['ckpt_path'])
else:
self.cfg_path = os.path.abspath(cfg_path)
self.label_file = os.path.abspath(label_file)
@@ -128,7 +123,7 @@ class CLSExecutor(BaseExecutor):
self._label_list.append(line.strip())
# model
- model_class = dynamic_import(model_type, self.model_alias)
+ model_class = self.task_resource.get_model_class(model_type)
model_dict = paddle.load(self.ckpt_path)
self.model = model_class(extract_embedding=False)
self.model.set_state_dict(model_dict)
@@ -205,7 +200,7 @@ class CLSExecutor(BaseExecutor):
if not parser_args.verbose:
self.disable_task_loggers()
- task_source = self.get_task_source(parser_args.input)
+ task_source = self.get_input_source(parser_args.input)
task_results = OrderedDict()
has_exceptions = False
diff --git a/paddlespeech/cli/cls/pretrained_models.py b/paddlespeech/cli/cls/pretrained_models.py
deleted file mode 100644
index 1d66850aa..000000000
--- a/paddlespeech/cli/cls/pretrained_models.py
+++ /dev/null
@@ -1,47 +0,0 @@
-# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-pretrained_models = {
- # The tags for pretrained_models should be "{model_name}[_{dataset}][-{lang}][-...]".
- # e.g. "conformer_wenetspeech-zh-16k", "transformer_aishell-zh-16k" and "panns_cnn6-32k".
- # Command line and python api use "{model_name}[_{dataset}]" as --model, usage:
- # "paddlespeech asr --model conformer_wenetspeech --lang zh --sr 16000 --input ./input.wav"
- "panns_cnn6-32k": {
- 'url': 'https://paddlespeech.bj.bcebos.com/cls/panns_cnn6.tar.gz',
- 'md5': '4cf09194a95df024fd12f84712cf0f9c',
- 'cfg_path': 'panns.yaml',
- 'ckpt_path': 'cnn6.pdparams',
- 'label_file': 'audioset_labels.txt',
- },
- "panns_cnn10-32k": {
- 'url': 'https://paddlespeech.bj.bcebos.com/cls/panns_cnn10.tar.gz',
- 'md5': 'cb8427b22176cc2116367d14847f5413',
- 'cfg_path': 'panns.yaml',
- 'ckpt_path': 'cnn10.pdparams',
- 'label_file': 'audioset_labels.txt',
- },
- "panns_cnn14-32k": {
- 'url': 'https://paddlespeech.bj.bcebos.com/cls/panns_cnn14.tar.gz',
- 'md5': 'e3b9b5614a1595001161d0ab95edee97',
- 'cfg_path': 'panns.yaml',
- 'ckpt_path': 'cnn14.pdparams',
- 'label_file': 'audioset_labels.txt',
- },
-}
-
-model_alias = {
- "panns_cnn6": "paddlespeech.cls.models.panns:CNN6",
- "panns_cnn10": "paddlespeech.cls.models.panns:CNN10",
- "panns_cnn14": "paddlespeech.cls.models.panns:CNN14",
-}
diff --git a/paddlespeech/cli/download.py b/paddlespeech/cli/download.py
index 0f09b6fad..ec7258747 100644
--- a/paddlespeech/cli/download.py
+++ b/paddlespeech/cli/download.py
@@ -86,7 +86,7 @@ def get_path_from_url(url,
str: a local path to save downloaded models & weights & datasets.
"""
- from paddle.fluid.dygraph.parallel import ParallelEnv
+ from paddle.distributed import ParallelEnv
assert _is_url(url), "downloading from {} not a url".format(url)
# parse path after download to decompress under root_dir
diff --git a/paddlespeech/cli/entry.py b/paddlespeech/cli/entry.py
index 32123ece7..e0c306d62 100644
--- a/paddlespeech/cli/entry.py
+++ b/paddlespeech/cli/entry.py
@@ -34,6 +34,11 @@ def _execute():
# The method 'execute' of a command instance returns 'True' for a success
# while 'False' for a failure. Here converts this result into a exit status
# in bash: 0 for a success and 1 for a failure.
+ if not callable(com['_entry']):
+ i = com['_entry'].rindex('.')
+ module, cls = com['_entry'][:i], com['_entry'][i + 1:]
+ exec("from {} import {}".format(module, cls))
+ com['_entry'] = locals()[cls]
status = 0 if com['_entry']().execute(sys.argv[idx:]) else 1
return status
diff --git a/paddlespeech/cli/executor.py b/paddlespeech/cli/executor.py
index df0b67838..d390f947d 100644
--- a/paddlespeech/cli/executor.py
+++ b/paddlespeech/cli/executor.py
@@ -24,9 +24,8 @@ from typing import Union
import paddle
+from ..resource import CommonTaskResource
from .log import logger
-from .utils import download_and_decompress
-from .utils import MODEL_HOME
class BaseExecutor(ABC):
@@ -34,11 +33,10 @@ class BaseExecutor(ABC):
An abstract executor of paddlespeech tasks.
"""
- def __init__(self):
+ def __init__(self, task: str, **kwargs):
self._inputs = OrderedDict()
self._outputs = OrderedDict()
- self.pretrained_models = OrderedDict()
- self.model_alias = OrderedDict()
+ self.task_resource = CommonTaskResource(task=task, **kwargs)
@abstractmethod
def _init_from_path(self, *args, **kwargs):
@@ -98,8 +96,8 @@ class BaseExecutor(ABC):
"""
pass
- def get_task_source(self, input_: Union[str, os.PathLike, None]
- ) -> Dict[str, Union[str, os.PathLike]]:
+ def get_input_source(self, input_: Union[str, os.PathLike, None]
+ ) -> Dict[str, Union[str, os.PathLike]]:
"""
Get task input source from command line input.
@@ -115,15 +113,17 @@ class BaseExecutor(ABC):
ret = OrderedDict()
if input_ is None: # Take input from stdin
- for i, line in enumerate(sys.stdin):
- line = line.strip()
- if len(line.split(' ')) == 1:
- ret[str(i + 1)] = line
- elif len(line.split(' ')) == 2:
- id_, info = line.split(' ')
- ret[id_] = info
- else: # No valid input info from one line.
- continue
+ if not sys.stdin.isatty(
+ ): # Avoid getting stuck when stdin is empty.
+ for i, line in enumerate(sys.stdin):
+ line = line.strip()
+ if len(line.split(' ')) == 1:
+ ret[str(i + 1)] = line
+ elif len(line.split(' ')) == 2:
+ id_, info = line.split(' ')
+ ret[id_] = info
+ else: # No valid input info from one line.
+ continue
else:
ret[1] = input_
return ret
@@ -219,19 +219,18 @@ class BaseExecutor(ABC):
for l in loggers:
l.disabled = True
- def _get_pretrained_path(self, tag: str) -> os.PathLike:
+ def show_rtf(self, info: Dict[str, List[float]]):
"""
- Download and returns pretrained resources path of current task.
+ Calculate rft of current task and show results.
"""
- support_models = list(self.pretrained_models.keys())
- assert tag in self.pretrained_models, 'The model "{}" you want to use has not been supported, please choose other models.\nThe support models includes:\n\t\t{}\n'.format(
- tag, '\n\t\t'.join(support_models))
+ num_samples = 0
+ task_duration = 0.0
+ wav_duration = 0.0
- res_path = os.path.join(MODEL_HOME, tag)
- decompressed_path = download_and_decompress(self.pretrained_models[tag],
- res_path)
- decompressed_path = os.path.abspath(decompressed_path)
- logger.info(
- 'Use pretrained model stored in: {}'.format(decompressed_path))
+ for start, end, dur in zip(info['start'], info['end'], info['extra']):
+ num_samples += 1
+ task_duration += end - start
+ wav_duration += dur
- return decompressed_path
+ logger.info('Sample Count: {}'.format(num_samples))
+ logger.info('Avg RTF: {}'.format(task_duration / wav_duration))
diff --git a/paddlespeech/cli/st/infer.py b/paddlespeech/cli/st/infer.py
index 29d95f799..e1ce181af 100644
--- a/paddlespeech/cli/st/infer.py
+++ b/paddlespeech/cli/st/infer.py
@@ -28,27 +28,25 @@ from yacs.config import CfgNode
from ..executor import BaseExecutor
from ..log import logger
-from ..utils import cli_register
from ..utils import download_and_decompress
from ..utils import MODEL_HOME
from ..utils import stats_wrapper
-from .pretrained_models import kaldi_bins
-from .pretrained_models import model_alias
-from .pretrained_models import pretrained_models
from paddlespeech.s2t.frontend.featurizer.text_featurizer import TextFeaturizer
-from paddlespeech.s2t.utils.dynamic_import import dynamic_import
from paddlespeech.s2t.utils.utility import UpdateConfig
__all__ = ["STExecutor"]
+kaldi_bins = {
+ "url":
+ "https://paddlespeech.bj.bcebos.com/s2t/ted_en_zh/st1/kaldi_bins.tar.gz",
+ "md5":
+ "c0682303b3f3393dbf6ed4c4e35a53eb",
+}
+
-@cli_register(
- name="paddlespeech.st", description="Speech translation infer command.")
class STExecutor(BaseExecutor):
def __init__(self):
- super().__init__()
- self.model_alias = model_alias
- self.pretrained_models = pretrained_models
+ super().__init__(task='st')
self.kaldi_bins = kaldi_bins
self.parser = argparse.ArgumentParser(
@@ -60,7 +58,8 @@ class STExecutor(BaseExecutor):
type=str,
default="fat_st_ted",
choices=[
- tag[:tag.index('-')] for tag in self.pretrained_models.keys()
+ tag[:tag.index('-')]
+ for tag in self.task_resource.pretrained_models.keys()
],
help="Choose model type of st task.")
self.parser.add_argument(
@@ -134,14 +133,16 @@ class STExecutor(BaseExecutor):
if cfg_path is None or ckpt_path is None:
tag = model_type + "-" + src_lang + "-" + tgt_lang
- res_path = self._get_pretrained_path(tag)
- self.cfg_path = os.path.join(res_path,
- pretrained_models[tag]["cfg_path"])
- self.ckpt_path = os.path.join(res_path,
- pretrained_models[tag]["ckpt_path"])
- logger.info(res_path)
+ self.task_resource.set_task_model(tag, version=None)
+ self.cfg_path = os.path.join(
+ self.task_resource.res_dir,
+ self.task_resource.res_dict['cfg_path'])
+ self.ckpt_path = os.path.join(
+ self.task_resource.res_dir,
+ self.task_resource.res_dict['ckpt_path'])
logger.info(self.cfg_path)
logger.info(self.ckpt_path)
+ res_path = self.task_resource.res_dir
else:
self.cfg_path = os.path.abspath(cfg_path)
self.ckpt_path = os.path.abspath(ckpt_path)
@@ -166,7 +167,7 @@ class STExecutor(BaseExecutor):
model_conf = self.config
model_name = model_type[:model_type.rindex(
'_')] # model_type: {model_name}_{dataset}
- model_class = dynamic_import(model_name, self.model_alias)
+ model_class = self.task_resource.get_model_class(model_name)
self.model = model_class.from_config(model_conf)
self.model.eval()
@@ -304,7 +305,7 @@ class STExecutor(BaseExecutor):
if not parser_args.verbose:
self.disable_task_loggers()
- task_source = self.get_task_source(parser_args.input)
+ task_source = self.get_input_source(parser_args.input)
task_results = OrderedDict()
has_exceptions = False
diff --git a/paddlespeech/cli/st/pretrained_models.py b/paddlespeech/cli/st/pretrained_models.py
deleted file mode 100644
index cc7410d25..000000000
--- a/paddlespeech/cli/st/pretrained_models.py
+++ /dev/null
@@ -1,35 +0,0 @@
-# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-pretrained_models = {
- "fat_st_ted-en-zh": {
- "url":
- "https://paddlespeech.bj.bcebos.com/s2t/ted_en_zh/st1/st1_transformer_mtl_noam_ted-en-zh_ckpt_0.1.1.model.tar.gz",
- "md5":
- "d62063f35a16d91210a71081bd2dd557",
- "cfg_path":
- "model.yaml",
- "ckpt_path":
- "exp/transformer_mtl_noam/checkpoints/fat_st_ted-en-zh.pdparams",
- }
-}
-
-model_alias = {"fat_st": "paddlespeech.s2t.models.u2_st:U2STModel"}
-
-kaldi_bins = {
- "url":
- "https://paddlespeech.bj.bcebos.com/s2t/ted_en_zh/st1/kaldi_bins.tar.gz",
- "md5":
- "c0682303b3f3393dbf6ed4c4e35a53eb",
-}
diff --git a/paddlespeech/cli/stats/infer.py b/paddlespeech/cli/stats/infer.py
deleted file mode 100644
index 7cf4f2368..000000000
--- a/paddlespeech/cli/stats/infer.py
+++ /dev/null
@@ -1,146 +0,0 @@
-# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import argparse
-from typing import List
-
-from prettytable import PrettyTable
-
-from ..utils import cli_register
-from ..utils import stats_wrapper
-
-__all__ = ['StatsExecutor']
-
-model_name_format = {
- 'asr': 'Model-Language-Sample Rate',
- 'cls': 'Model-Sample Rate',
- 'st': 'Model-Source language-Target language',
- 'text': 'Model-Task-Language',
- 'tts': 'Model-Language',
- 'vector': 'Model-Sample Rate'
-}
-
-
-@cli_register(
- name='paddlespeech.stats',
- description='Get speech tasks support models list.')
-class StatsExecutor():
- def __init__(self):
- super().__init__()
-
- self.parser = argparse.ArgumentParser(
- prog='paddlespeech.stats', add_help=True)
- self.task_choices = ['asr', 'cls', 'st', 'text', 'tts', 'vector']
- self.parser.add_argument(
- '--task',
- type=str,
- default='asr',
- choices=self.task_choices,
- help='Choose speech task.',
- required=True)
-
- def show_support_models(self, pretrained_models: dict):
- fields = model_name_format[self.task].split("-")
- table = PrettyTable(fields)
- for key in pretrained_models:
- table.add_row(key.split("-"))
- print(table)
-
- def execute(self, argv: List[str]) -> bool:
- """
- Command line entry.
- """
- parser_args = self.parser.parse_args(argv)
- has_exceptions = False
- try:
- self(parser_args.task)
- except Exception as e:
- has_exceptions = True
- if has_exceptions:
- return False
- else:
- return True
-
- @stats_wrapper
- def __call__(
- self,
- task: str=None, ):
- """
- Python API to call an executor.
- """
- self.task = task
- if self.task not in self.task_choices:
- print("Please input correct speech task, choices = " + str(
- self.task_choices))
-
- elif self.task == 'asr':
- try:
- from ..asr.pretrained_models import pretrained_models
- print(
- "Here is the list of ASR pretrained models released by PaddleSpeech that can be used by command line and python API"
- )
- self.show_support_models(pretrained_models)
- except BaseException:
- print("Failed to get the list of ASR pretrained models.")
-
- elif self.task == 'cls':
- try:
- from ..cls.pretrained_models import pretrained_models
- print(
- "Here is the list of CLS pretrained models released by PaddleSpeech that can be used by command line and python API"
- )
- self.show_support_models(pretrained_models)
- except BaseException:
- print("Failed to get the list of CLS pretrained models.")
-
- elif self.task == 'st':
- try:
- from ..st.pretrained_models import pretrained_models
- print(
- "Here is the list of ST pretrained models released by PaddleSpeech that can be used by command line and python API"
- )
- self.show_support_models(pretrained_models)
- except BaseException:
- print("Failed to get the list of ST pretrained models.")
-
- elif self.task == 'text':
- try:
- from ..text.pretrained_models import pretrained_models
- print(
- "Here is the list of TEXT pretrained models released by PaddleSpeech that can be used by command line and python API"
- )
- self.show_support_models(pretrained_models)
- except BaseException:
- print("Failed to get the list of TEXT pretrained models.")
-
- elif self.task == 'tts':
- try:
- from ..tts.pretrained_models import pretrained_models
- print(
- "Here is the list of TTS pretrained models released by PaddleSpeech that can be used by command line and python API"
- )
- self.show_support_models(pretrained_models)
- except BaseException:
- print("Failed to get the list of TTS pretrained models.")
-
- elif self.task == 'vector':
- try:
- from ..vector.pretrained_models import pretrained_models
- print(
- "Here is the list of Speaker Recognition pretrained models released by PaddleSpeech that can be used by command line and python API"
- )
- self.show_support_models(pretrained_models)
- except BaseException:
- print(
- "Failed to get the list of Speaker Recognition pretrained models."
- )
diff --git a/paddlespeech/cli/text/infer.py b/paddlespeech/cli/text/infer.py
index 69e62e4b4..7b8faf99c 100644
--- a/paddlespeech/cli/text/infer.py
+++ b/paddlespeech/cli/text/infer.py
@@ -21,26 +21,16 @@ from typing import Union
import paddle
-from ...s2t.utils.dynamic_import import dynamic_import
from ..executor import BaseExecutor
from ..log import logger
-from ..utils import cli_register
from ..utils import stats_wrapper
-from .pretrained_models import model_alias
-from .pretrained_models import pretrained_models
-from .pretrained_models import tokenizer_alias
__all__ = ['TextExecutor']
-@cli_register(name='paddlespeech.text', description='Text infer command.')
class TextExecutor(BaseExecutor):
def __init__(self):
- super().__init__()
- self.model_alias = model_alias
- self.pretrained_models = pretrained_models
- self.tokenizer_alias = tokenizer_alias
-
+ super().__init__(task='text')
self.parser = argparse.ArgumentParser(
prog='paddlespeech.text', add_help=True)
self.parser.add_argument(
@@ -56,7 +46,8 @@ class TextExecutor(BaseExecutor):
type=str,
default='ernie_linear_p7_wudao',
choices=[
- tag[:tag.index('-')] for tag in self.pretrained_models.keys()
+ tag[:tag.index('-')]
+ for tag in self.task_resource.pretrained_models.keys()
],
help='Choose model type of text task.')
self.parser.add_argument(
@@ -114,13 +105,16 @@ class TextExecutor(BaseExecutor):
if cfg_path is None or ckpt_path is None or vocab_file is None:
tag = '-'.join([model_type, task, lang])
- self.res_path = self._get_pretrained_path(tag)
+ self.task_resource.set_task_model(tag, version=None)
self.cfg_path = os.path.join(
- self.res_path, self.pretrained_models[tag]['cfg_path'])
+ self.task_resource.res_dir,
+ self.task_resource.res_dict['cfg_path'])
self.ckpt_path = os.path.join(
- self.res_path, self.pretrained_models[tag]['ckpt_path'])
+ self.task_resource.res_dir,
+ self.task_resource.res_dict['ckpt_path'])
self.vocab_file = os.path.join(
- self.res_path, self.pretrained_models[tag]['vocab_file'])
+ self.task_resource.res_dir,
+ self.task_resource.res_dict['vocab_file'])
else:
self.cfg_path = os.path.abspath(cfg_path)
self.ckpt_path = os.path.abspath(ckpt_path)
@@ -135,8 +129,8 @@ class TextExecutor(BaseExecutor):
self._punc_list.append(line.strip())
# model
- model_class = dynamic_import(model_name, self.model_alias)
- tokenizer_class = dynamic_import(model_name, self.tokenizer_alias)
+ model_class, tokenizer_class = self.task_resource.get_model_class(
+ model_name)
self.model = model_class(
cfg_path=self.cfg_path, ckpt_path=self.ckpt_path)
self.tokenizer = tokenizer_class.from_pretrained('ernie-1.0')
@@ -226,7 +220,7 @@ class TextExecutor(BaseExecutor):
if not parser_args.verbose:
self.disable_task_loggers()
- task_source = self.get_task_source(parser_args.input)
+ task_source = self.get_input_source(parser_args.input)
task_results = OrderedDict()
has_exceptions = False
diff --git a/paddlespeech/cli/text/pretrained_models.py b/paddlespeech/cli/text/pretrained_models.py
deleted file mode 100644
index 817d3caa3..000000000
--- a/paddlespeech/cli/text/pretrained_models.py
+++ /dev/null
@@ -1,54 +0,0 @@
-# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-pretrained_models = {
- # The tags for pretrained_models should be "{model_name}[_{dataset}][-{lang}][-...]".
- # e.g. "conformer_wenetspeech-zh-16k", "transformer_aishell-zh-16k" and "panns_cnn6-32k".
- # Command line and python api use "{model_name}[_{dataset}]" as --model, usage:
- # "paddlespeech asr --model conformer_wenetspeech --lang zh --sr 16000 --input ./input.wav"
- "ernie_linear_p7_wudao-punc-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/text/ernie_linear_p7_wudao-punc-zh.tar.gz',
- 'md5':
- '12283e2ddde1797c5d1e57036b512746',
- 'cfg_path':
- 'ckpt/model_config.json',
- 'ckpt_path':
- 'ckpt/model_state.pdparams',
- 'vocab_file':
- 'punc_vocab.txt',
- },
- "ernie_linear_p3_wudao-punc-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/text/ernie_linear_p3_wudao-punc-zh.tar.gz',
- 'md5':
- '448eb2fdf85b6a997e7e652e80c51dd2',
- 'cfg_path':
- 'ckpt/model_config.json',
- 'ckpt_path':
- 'ckpt/model_state.pdparams',
- 'vocab_file':
- 'punc_vocab.txt',
- },
-}
-
-model_alias = {
- "ernie_linear_p7": "paddlespeech.text.models:ErnieLinear",
- "ernie_linear_p3": "paddlespeech.text.models:ErnieLinear",
-}
-
-tokenizer_alias = {
- "ernie_linear_p7": "paddlenlp.transformers:ErnieTokenizer",
- "ernie_linear_p3": "paddlenlp.transformers:ErnieTokenizer",
-}
diff --git a/paddlespeech/cli/tts/infer.py b/paddlespeech/cli/tts/infer.py
index 1c7199306..4e0337bcc 100644
--- a/paddlespeech/cli/tts/infer.py
+++ b/paddlespeech/cli/tts/infer.py
@@ -28,11 +28,7 @@ from yacs.config import CfgNode
from ..executor import BaseExecutor
from ..log import logger
-from ..utils import cli_register
from ..utils import stats_wrapper
-from .pretrained_models import model_alias
-from .pretrained_models import pretrained_models
-from paddlespeech.s2t.utils.dynamic_import import dynamic_import
from paddlespeech.t2s.frontend import English
from paddlespeech.t2s.frontend.zh_frontend import Frontend
from paddlespeech.t2s.modules.normalizer import ZScore
@@ -40,14 +36,9 @@ from paddlespeech.t2s.modules.normalizer import ZScore
__all__ = ['TTSExecutor']
-@cli_register(
- name='paddlespeech.tts', description='Text to Speech infer command.')
class TTSExecutor(BaseExecutor):
def __init__(self):
- super().__init__()
- self.model_alias = model_alias
- self.pretrained_models = pretrained_models
-
+ super().__init__('tts')
self.parser = argparse.ArgumentParser(
prog='paddlespeech.tts', add_help=True)
self.parser.add_argument(
@@ -186,19 +177,23 @@ class TTSExecutor(BaseExecutor):
return
# am
am_tag = am + '-' + lang
+ self.task_resource.set_task_model(
+ model_tag=am_tag,
+ model_type=0, # am
+ version=None, # default version
+ )
if am_ckpt is None or am_config is None or am_stat is None or phones_dict is None:
- am_res_path = self._get_pretrained_path(am_tag)
- self.am_res_path = am_res_path
- self.am_config = os.path.join(
- am_res_path, self.pretrained_models[am_tag]['config'])
- self.am_ckpt = os.path.join(am_res_path,
- self.pretrained_models[am_tag]['ckpt'])
+ self.am_res_path = self.task_resource.res_dir
+ self.am_config = os.path.join(self.am_res_path,
+ self.task_resource.res_dict['config'])
+ self.am_ckpt = os.path.join(self.am_res_path,
+ self.task_resource.res_dict['ckpt'])
self.am_stat = os.path.join(
- am_res_path, self.pretrained_models[am_tag]['speech_stats'])
+ self.am_res_path, self.task_resource.res_dict['speech_stats'])
# must have phones_dict in acoustic
self.phones_dict = os.path.join(
- am_res_path, self.pretrained_models[am_tag]['phones_dict'])
- logger.info(am_res_path)
+ self.am_res_path, self.task_resource.res_dict['phones_dict'])
+ logger.info(self.am_res_path)
logger.info(self.am_config)
logger.info(self.am_ckpt)
else:
@@ -210,32 +205,37 @@ class TTSExecutor(BaseExecutor):
# for speedyspeech
self.tones_dict = None
- if 'tones_dict' in self.pretrained_models[am_tag]:
+ if 'tones_dict' in self.task_resource.res_dict:
self.tones_dict = os.path.join(
- am_res_path, self.pretrained_models[am_tag]['tones_dict'])
+ self.am_res_path, self.task_resource.res_dict['tones_dict'])
if tones_dict:
self.tones_dict = tones_dict
# for multi speaker fastspeech2
self.speaker_dict = None
- if 'speaker_dict' in self.pretrained_models[am_tag]:
+ if 'speaker_dict' in self.task_resource.res_dict:
self.speaker_dict = os.path.join(
- am_res_path, self.pretrained_models[am_tag]['speaker_dict'])
+ self.am_res_path, self.task_resource.res_dict['speaker_dict'])
if speaker_dict:
self.speaker_dict = speaker_dict
# voc
voc_tag = voc + '-' + lang
+ self.task_resource.set_task_model(
+ model_tag=voc_tag,
+ model_type=1, # vocoder
+ version=None, # default version
+ )
if voc_ckpt is None or voc_config is None or voc_stat is None:
- voc_res_path = self._get_pretrained_path(voc_tag)
- self.voc_res_path = voc_res_path
+ self.voc_res_path = self.task_resource.voc_res_dir
self.voc_config = os.path.join(
- voc_res_path, self.pretrained_models[voc_tag]['config'])
+ self.voc_res_path, self.task_resource.voc_res_dict['config'])
self.voc_ckpt = os.path.join(
- voc_res_path, self.pretrained_models[voc_tag]['ckpt'])
+ self.voc_res_path, self.task_resource.voc_res_dict['ckpt'])
self.voc_stat = os.path.join(
- voc_res_path, self.pretrained_models[voc_tag]['speech_stats'])
- logger.info(voc_res_path)
+ self.voc_res_path,
+ self.task_resource.voc_res_dict['speech_stats'])
+ logger.info(self.voc_res_path)
logger.info(self.voc_config)
logger.info(self.voc_ckpt)
else:
@@ -285,9 +285,9 @@ class TTSExecutor(BaseExecutor):
# model: {model_name}_{dataset}
am_name = am[:am.rindex('_')]
- am_class = dynamic_import(am_name, self.model_alias)
- am_inference_class = dynamic_import(am_name + '_inference',
- self.model_alias)
+ am_class = self.task_resource.get_model_class(am_name)
+ am_inference_class = self.task_resource.get_model_class(am_name +
+ '_inference')
if am_name == 'fastspeech2':
am = am_class(
@@ -316,9 +316,9 @@ class TTSExecutor(BaseExecutor):
# vocoder
# model: {model_name}_{dataset}
voc_name = voc[:voc.rindex('_')]
- voc_class = dynamic_import(voc_name, self.model_alias)
- voc_inference_class = dynamic_import(voc_name + '_inference',
- self.model_alias)
+ voc_class = self.task_resource.get_model_class(voc_name)
+ voc_inference_class = self.task_resource.get_model_class(voc_name +
+ '_inference')
if voc_name != 'wavernn':
voc = voc_class(**self.voc_config["generator_params"])
voc.set_state_dict(paddle.load(self.voc_ckpt)["generator_params"])
@@ -446,7 +446,7 @@ class TTSExecutor(BaseExecutor):
if not args.verbose:
self.disable_task_loggers()
- task_source = self.get_task_source(args.input)
+ task_source = self.get_input_source(args.input)
task_results = OrderedDict()
has_exceptions = False
diff --git a/paddlespeech/cli/tts/pretrained_models.py b/paddlespeech/cli/tts/pretrained_models.py
deleted file mode 100644
index 65254a935..000000000
--- a/paddlespeech/cli/tts/pretrained_models.py
+++ /dev/null
@@ -1,300 +0,0 @@
-# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-pretrained_models = {
- # speedyspeech
- "speedyspeech_csmsc-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/speedyspeech/speedyspeech_csmsc_ckpt_0.2.0.zip',
- 'md5':
- '6f6fa967b408454b6662c8c00c0027cb',
- 'config':
- 'default.yaml',
- 'ckpt':
- 'snapshot_iter_30600.pdz',
- 'speech_stats':
- 'feats_stats.npy',
- 'phones_dict':
- 'phone_id_map.txt',
- 'tones_dict':
- 'tone_id_map.txt',
- },
-
- # fastspeech2
- "fastspeech2_csmsc-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_baker_ckpt_0.4.zip',
- 'md5':
- '637d28a5e53aa60275612ba4393d5f22',
- 'config':
- 'default.yaml',
- 'ckpt':
- 'snapshot_iter_76000.pdz',
- 'speech_stats':
- 'speech_stats.npy',
- 'phones_dict':
- 'phone_id_map.txt',
- },
- "fastspeech2_ljspeech-en": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_ljspeech_ckpt_0.5.zip',
- 'md5':
- 'ffed800c93deaf16ca9b3af89bfcd747',
- 'config':
- 'default.yaml',
- 'ckpt':
- 'snapshot_iter_100000.pdz',
- 'speech_stats':
- 'speech_stats.npy',
- 'phones_dict':
- 'phone_id_map.txt',
- },
- "fastspeech2_aishell3-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_aishell3_ckpt_0.4.zip',
- 'md5':
- 'f4dd4a5f49a4552b77981f544ab3392e',
- 'config':
- 'default.yaml',
- 'ckpt':
- 'snapshot_iter_96400.pdz',
- 'speech_stats':
- 'speech_stats.npy',
- 'phones_dict':
- 'phone_id_map.txt',
- 'speaker_dict':
- 'speaker_id_map.txt',
- },
- "fastspeech2_vctk-en": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_vctk_ckpt_0.5.zip',
- 'md5':
- '743e5024ca1e17a88c5c271db9779ba4',
- 'config':
- 'default.yaml',
- 'ckpt':
- 'snapshot_iter_66200.pdz',
- 'speech_stats':
- 'speech_stats.npy',
- 'phones_dict':
- 'phone_id_map.txt',
- 'speaker_dict':
- 'speaker_id_map.txt',
- },
- # tacotron2
- "tacotron2_csmsc-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/tacotron2/tacotron2_csmsc_ckpt_0.2.0.zip',
- 'md5':
- '0df4b6f0bcbe0d73c5ed6df8867ab91a',
- 'config':
- 'default.yaml',
- 'ckpt':
- 'snapshot_iter_30600.pdz',
- 'speech_stats':
- 'speech_stats.npy',
- 'phones_dict':
- 'phone_id_map.txt',
- },
- "tacotron2_ljspeech-en": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/tacotron2/tacotron2_ljspeech_ckpt_0.2.0.zip',
- 'md5':
- '6a5eddd81ae0e81d16959b97481135f3',
- 'config':
- 'default.yaml',
- 'ckpt':
- 'snapshot_iter_60300.pdz',
- 'speech_stats':
- 'speech_stats.npy',
- 'phones_dict':
- 'phone_id_map.txt',
- },
-
- # pwgan
- "pwgan_csmsc-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwg_baker_ckpt_0.4.zip',
- 'md5':
- '2e481633325b5bdf0a3823c714d2c117',
- 'config':
- 'pwg_default.yaml',
- 'ckpt':
- 'pwg_snapshot_iter_400000.pdz',
- 'speech_stats':
- 'pwg_stats.npy',
- },
- "pwgan_ljspeech-en": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwg_ljspeech_ckpt_0.5.zip',
- 'md5':
- '53610ba9708fd3008ccaf8e99dacbaf0',
- 'config':
- 'pwg_default.yaml',
- 'ckpt':
- 'pwg_snapshot_iter_400000.pdz',
- 'speech_stats':
- 'pwg_stats.npy',
- },
- "pwgan_aishell3-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwg_aishell3_ckpt_0.5.zip',
- 'md5':
- 'd7598fa41ad362d62f85ffc0f07e3d84',
- 'config':
- 'default.yaml',
- 'ckpt':
- 'snapshot_iter_1000000.pdz',
- 'speech_stats':
- 'feats_stats.npy',
- },
- "pwgan_vctk-en": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwg_vctk_ckpt_0.1.1.zip',
- 'md5':
- 'b3da1defcde3e578be71eb284cb89f2c',
- 'config':
- 'default.yaml',
- 'ckpt':
- 'snapshot_iter_1500000.pdz',
- 'speech_stats':
- 'feats_stats.npy',
- },
- # mb_melgan
- "mb_melgan_csmsc-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/mb_melgan/mb_melgan_csmsc_ckpt_0.1.1.zip',
- 'md5':
- 'ee5f0604e20091f0d495b6ec4618b90d',
- 'config':
- 'default.yaml',
- 'ckpt':
- 'snapshot_iter_1000000.pdz',
- 'speech_stats':
- 'feats_stats.npy',
- },
- # style_melgan
- "style_melgan_csmsc-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/style_melgan/style_melgan_csmsc_ckpt_0.1.1.zip',
- 'md5':
- '5de2d5348f396de0c966926b8c462755',
- 'config':
- 'default.yaml',
- 'ckpt':
- 'snapshot_iter_1500000.pdz',
- 'speech_stats':
- 'feats_stats.npy',
- },
- # hifigan
- "hifigan_csmsc-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_csmsc_ckpt_0.1.1.zip',
- 'md5':
- 'dd40a3d88dfcf64513fba2f0f961ada6',
- 'config':
- 'default.yaml',
- 'ckpt':
- 'snapshot_iter_2500000.pdz',
- 'speech_stats':
- 'feats_stats.npy',
- },
- "hifigan_ljspeech-en": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_ljspeech_ckpt_0.2.0.zip',
- 'md5':
- '70e9131695decbca06a65fe51ed38a72',
- 'config':
- 'default.yaml',
- 'ckpt':
- 'snapshot_iter_2500000.pdz',
- 'speech_stats':
- 'feats_stats.npy',
- },
- "hifigan_aishell3-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_aishell3_ckpt_0.2.0.zip',
- 'md5':
- '3bb49bc75032ed12f79c00c8cc79a09a',
- 'config':
- 'default.yaml',
- 'ckpt':
- 'snapshot_iter_2500000.pdz',
- 'speech_stats':
- 'feats_stats.npy',
- },
- "hifigan_vctk-en": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_vctk_ckpt_0.2.0.zip',
- 'md5':
- '7da8f88359bca2457e705d924cf27bd4',
- 'config':
- 'default.yaml',
- 'ckpt':
- 'snapshot_iter_2500000.pdz',
- 'speech_stats':
- 'feats_stats.npy',
- },
-
- # wavernn
- "wavernn_csmsc-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/wavernn/wavernn_csmsc_ckpt_0.2.0.zip',
- 'md5':
- 'ee37b752f09bcba8f2af3b777ca38e13',
- 'config':
- 'default.yaml',
- 'ckpt':
- 'snapshot_iter_400000.pdz',
- 'speech_stats':
- 'feats_stats.npy',
- }
-}
-
-model_alias = {
- # acoustic model
- "speedyspeech":
- "paddlespeech.t2s.models.speedyspeech:SpeedySpeech",
- "speedyspeech_inference":
- "paddlespeech.t2s.models.speedyspeech:SpeedySpeechInference",
- "fastspeech2":
- "paddlespeech.t2s.models.fastspeech2:FastSpeech2",
- "fastspeech2_inference":
- "paddlespeech.t2s.models.fastspeech2:FastSpeech2Inference",
- "tacotron2":
- "paddlespeech.t2s.models.tacotron2:Tacotron2",
- "tacotron2_inference":
- "paddlespeech.t2s.models.tacotron2:Tacotron2Inference",
- # voc
- "pwgan":
- "paddlespeech.t2s.models.parallel_wavegan:PWGGenerator",
- "pwgan_inference":
- "paddlespeech.t2s.models.parallel_wavegan:PWGInference",
- "mb_melgan":
- "paddlespeech.t2s.models.melgan:MelGANGenerator",
- "mb_melgan_inference":
- "paddlespeech.t2s.models.melgan:MelGANInference",
- "style_melgan":
- "paddlespeech.t2s.models.melgan:StyleMelGANGenerator",
- "style_melgan_inference":
- "paddlespeech.t2s.models.melgan:StyleMelGANInference",
- "hifigan":
- "paddlespeech.t2s.models.hifigan:HiFiGANGenerator",
- "hifigan_inference":
- "paddlespeech.t2s.models.hifigan:HiFiGANInference",
- "wavernn":
- "paddlespeech.t2s.models.wavernn:WaveRNN",
- "wavernn_inference":
- "paddlespeech.t2s.models.wavernn:WaveRNNInference",
-}
diff --git a/paddlespeech/cli/utils.py b/paddlespeech/cli/utils.py
index 8e094894c..0161629e8 100644
--- a/paddlespeech/cli/utils.py
+++ b/paddlespeech/cli/utils.py
@@ -24,8 +24,8 @@ from typing import Any
from typing import Dict
import paddle
-import paddleaudio
import requests
+import soundfile as sf
import yaml
from paddle.framework import load
@@ -39,13 +39,22 @@ except ImportError:
requests.adapters.DEFAULT_RETRIES = 3
__all__ = [
+ 'timer_register',
'cli_register',
+ 'explicit_command_register',
'get_command',
'download_and_decompress',
'load_state_dict_from_url',
'stats_wrapper',
]
+CLI_TIMER = {}
+
+
+def timer_register(command):
+ CLI_TIMER[command.__name__] = {'start': [], 'end': [], 'extra': []}
+ return command
+
def cli_register(name: str, description: str='') -> Any:
def _warpper(command):
@@ -62,6 +71,16 @@ def cli_register(name: str, description: str='') -> Any:
return _warpper
+def explicit_command_register(name: str, description: str='', cls: str=''):
+ items = name.split('.')
+ com = commands
+ for item in items:
+ com = com[item]
+ com['_entry'] = cls
+ if description:
+ com['_description'] = description
+
+
def get_command(name: str) -> Any:
items = name.split('.')
com = commands
@@ -171,6 +190,7 @@ def _get_sub_home(directory):
PPSPEECH_HOME = _get_paddlespcceh_home()
MODEL_HOME = _get_sub_home('models')
CONF_HOME = _get_sub_home('conf')
+DATA_HOME = _get_sub_home('datasets')
def _md5(text: str):
@@ -262,7 +282,8 @@ def _note_one_stat(cls_name, params={}):
if 'audio_file' in params:
try:
- _, sr = paddleaudio.load(params['audio_file'])
+ # recursive import cased by: utils.DATA_HOME
+ _, sr = sf.read(params['audio_file'])
except Exception:
sr = -1
diff --git a/paddlespeech/cli/vector/infer.py b/paddlespeech/cli/vector/infer.py
index 37e193919..4bc8e135a 100644
--- a/paddlespeech/cli/vector/infer.py
+++ b/paddlespeech/cli/vector/infer.py
@@ -22,30 +22,20 @@ from typing import Union
import paddle
import soundfile
-from paddleaudio.backends import load as load_audio
-from paddleaudio.compliance.librosa import melspectrogram
from yacs.config import CfgNode
from ..executor import BaseExecutor
from ..log import logger
-from ..utils import cli_register
from ..utils import stats_wrapper
-from .pretrained_models import model_alias
-from .pretrained_models import pretrained_models
-from paddlespeech.s2t.utils.dynamic_import import dynamic_import
+from paddlespeech.audio.backends import load as load_audio
+from paddlespeech.audio.compliance.librosa import melspectrogram
from paddlespeech.vector.io.batch import feature_normalize
from paddlespeech.vector.modules.sid_model import SpeakerIdetification
-@cli_register(
- name="paddlespeech.vector",
- description="Speech to vector embedding infer command.")
class VectorExecutor(BaseExecutor):
def __init__(self):
- super().__init__()
- self.model_alias = model_alias
- self.pretrained_models = pretrained_models
-
+ super().__init__('vector')
self.parser = argparse.ArgumentParser(
prog="paddlespeech.vector", add_help=True)
@@ -53,7 +43,10 @@ class VectorExecutor(BaseExecutor):
"--model",
type=str,
default="ecapatdnn_voxceleb12",
- choices=["ecapatdnn_voxceleb12"],
+ choices=[
+ tag[:tag.index('-')]
+ for tag in self.task_resource.pretrained_models.keys()
+ ],
help="Choose model type of vector task.")
self.parser.add_argument(
"--task",
@@ -123,7 +116,7 @@ class VectorExecutor(BaseExecutor):
self.disable_task_loggers()
# stage 2: read the input data and store them as a list
- task_source = self.get_task_source(parser_args.input)
+ task_source = self.get_input_source(parser_args.input)
logger.info(f"task source: {task_source}")
# stage 3: process the audio one by one
@@ -272,7 +265,8 @@ class VectorExecutor(BaseExecutor):
model_type: str='ecapatdnn_voxceleb12',
sample_rate: int=16000,
cfg_path: Optional[os.PathLike]=None,
- ckpt_path: Optional[os.PathLike]=None):
+ ckpt_path: Optional[os.PathLike]=None,
+ task=None):
"""Init the neural network from the model path
Args:
@@ -284,8 +278,10 @@ class VectorExecutor(BaseExecutor):
Defaults to None.
ckpt_path (Optional[os.PathLike], optional): the pretrained model path, which is stored in the disk.
Defaults to None.
+ task (str, optional): the model task type
"""
# stage 0: avoid to init the mode again
+ self.task = task
if hasattr(self, "model"):
logger.info("Model has been initialized")
return
@@ -297,17 +293,18 @@ class VectorExecutor(BaseExecutor):
# get the mode from pretrained list
sample_rate_str = "16k" if sample_rate == 16000 else "8k"
tag = model_type + "-" + sample_rate_str
+ self.task_resource.set_task_model(tag, version=None)
logger.info(f"load the pretrained model: {tag}")
# get the model from the pretrained list
# we download the pretrained model and store it in the res_path
- res_path = self._get_pretrained_path(tag)
- self.res_path = res_path
+ self.res_path = self.task_resource.res_dir
self.cfg_path = os.path.join(
- res_path, self.pretrained_models[tag]['cfg_path'])
+ self.task_resource.res_dir,
+ self.task_resource.res_dict['cfg_path'])
self.ckpt_path = os.path.join(
- res_path,
- self.pretrained_models[tag]['ckpt_path'] + '.pdparams')
+ self.task_resource.res_dir,
+ self.task_resource.res_dict['ckpt_path'] + '.pdparams')
else:
# get the model from disk
self.cfg_path = os.path.abspath(cfg_path)
@@ -326,8 +323,8 @@ class VectorExecutor(BaseExecutor):
# stage 3: get the model name to instance the model network with dynamic_import
logger.info("start to dynamic import the model class")
model_name = model_type[:model_type.rindex('_')]
+ model_class = self.task_resource.get_model_class(model_name)
logger.info(f"model name {model_name}")
- model_class = dynamic_import(model_name, self.model_alias)
model_conf = self.config.model
backbone = model_class(**model_conf)
model = SpeakerIdetification(
@@ -434,6 +431,9 @@ class VectorExecutor(BaseExecutor):
if self.sample_rate != 16000 and self.sample_rate != 8000:
logger.error(
"invalid sample rate, please input --sr 8000 or --sr 16000")
+ logger.error(
+ f"The model sample rate: {self.sample_rate}, the external sample rate is: {sample_rate}"
+ )
return False
if isinstance(audio_file, (str, os.PathLike)):
diff --git a/paddlespeech/cli/vector/pretrained_models.py b/paddlespeech/cli/vector/pretrained_models.py
deleted file mode 100644
index 686a22d8f..000000000
--- a/paddlespeech/cli/vector/pretrained_models.py
+++ /dev/null
@@ -1,36 +0,0 @@
-# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-pretrained_models = {
- # The tags for pretrained_models should be "{model_name}[-{dataset}][-{sr}][-...]".
- # e.g. "ecapatdnn_voxceleb12-16k".
- # Command line and python api use "{model_name}[-{dataset}]" as --model, usage:
- # "paddlespeech vector --task spk --model ecapatdnn_voxceleb12-16k --sr 16000 --input ./input.wav"
- "ecapatdnn_voxceleb12-16k": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/vector/voxceleb/sv0_ecapa_tdnn_voxceleb12_ckpt_0_2_0.tar.gz',
- 'md5':
- 'cc33023c54ab346cd318408f43fcaf95',
- 'cfg_path':
- 'conf/model.yaml', # the yaml config path
- 'ckpt_path':
- 'model/model', # the format is ${dir}/{model_name},
- # so the first 'model' is dir, the second 'model' is the name
- # this means we have a model stored as model/model.pdparams
- },
-}
-
-model_alias = {
- "ecapatdnn": "paddlespeech.vector.models.ecapa_tdnn:EcapaTdnn",
-}
diff --git a/paddlespeech/cls/exps/panns/deploy/predict.py b/paddlespeech/cls/exps/panns/deploy/predict.py
index ee566ed4f..fe1c93fa8 100644
--- a/paddlespeech/cls/exps/panns/deploy/predict.py
+++ b/paddlespeech/cls/exps/panns/deploy/predict.py
@@ -16,11 +16,12 @@ import os
import numpy as np
from paddle import inference
-from paddleaudio.backends import load as load_audio
-from paddleaudio.datasets import ESC50
-from paddleaudio.features import melspectrogram
from scipy.special import softmax
+from paddlespeech.audio.backends import load as load_audio
+from paddlespeech.audio.datasets import ESC50
+from paddlespeech.audio.features import melspectrogram
+
# yapf: disable
parser = argparse.ArgumentParser()
parser.add_argument("--model_dir", type=str, required=True, default="./export", help="The directory to static model.")
diff --git a/paddlespeech/cls/exps/panns/export_model.py b/paddlespeech/cls/exps/panns/export_model.py
index 63b22981a..e62d58f02 100644
--- a/paddlespeech/cls/exps/panns/export_model.py
+++ b/paddlespeech/cls/exps/panns/export_model.py
@@ -15,8 +15,8 @@ import argparse
import os
import paddle
-from paddleaudio.datasets import ESC50
+from paddlespeech.audio.datasets import ESC50
from paddlespeech.cls.models import cnn14
from paddlespeech.cls.models import SoundClassifier
diff --git a/paddlespeech/cls/exps/panns/predict.py b/paddlespeech/cls/exps/panns/predict.py
index a3f9f9a9b..97759a89d 100644
--- a/paddlespeech/cls/exps/panns/predict.py
+++ b/paddlespeech/cls/exps/panns/predict.py
@@ -17,12 +17,12 @@ import os
import paddle
import paddle.nn.functional as F
import yaml
-from paddleaudio.backends import load as load_audio
-from paddleaudio.features import LogMelSpectrogram
-from paddleaudio.utils import logger
+from paddlespeech.audio.backends import load as load_audio
+from paddlespeech.audio.features import LogMelSpectrogram
+from paddlespeech.audio.utils import logger
from paddlespeech.cls.models import SoundClassifier
-from paddlespeech.s2t.utils.dynamic_import import dynamic_import
+from paddlespeech.utils.dynamic_import import dynamic_import
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
diff --git a/paddlespeech/cls/exps/panns/train.py b/paddlespeech/cls/exps/panns/train.py
index 5a2f3042a..fba38a01c 100644
--- a/paddlespeech/cls/exps/panns/train.py
+++ b/paddlespeech/cls/exps/panns/train.py
@@ -16,12 +16,12 @@ import os
import paddle
import yaml
-from paddleaudio.features import LogMelSpectrogram
-from paddleaudio.utils import logger
-from paddleaudio.utils import Timer
+from paddlespeech.audio.features import LogMelSpectrogram
+from paddlespeech.audio.utils import logger
+from paddlespeech.audio.utils import Timer
from paddlespeech.cls.models import SoundClassifier
-from paddlespeech.s2t.utils.dynamic_import import dynamic_import
+from paddlespeech.utils.dynamic_import import dynamic_import
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
diff --git a/paddlespeech/cls/models/panns/panns.py b/paddlespeech/cls/models/panns/panns.py
index b442b2fd1..4befe7aa4 100644
--- a/paddlespeech/cls/models/panns/panns.py
+++ b/paddlespeech/cls/models/panns/panns.py
@@ -15,8 +15,9 @@ import os
import paddle.nn as nn
import paddle.nn.functional as F
-from paddleaudio.utils.download import load_state_dict_from_url
-from paddleaudio.utils.env import MODEL_HOME
+
+from paddlespeech.audio.utils import MODEL_HOME
+from paddlespeech.audio.utils.download import load_state_dict_from_url
__all__ = ['CNN14', 'CNN10', 'CNN6', 'cnn14', 'cnn10', 'cnn6']
diff --git a/paddlespeech/kws/exps/mdtc/compute_det.py b/paddlespeech/kws/exps/mdtc/compute_det.py
index e43a953db..853056966 100644
--- a/paddlespeech/kws/exps/mdtc/compute_det.py
+++ b/paddlespeech/kws/exps/mdtc/compute_det.py
@@ -1,3 +1,5 @@
+# Copyright (c) 2021 Binbin Zhang(binbzha@qq.com)
+# 2022 Shaoqing Yu(954793264@qq.com)
# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
diff --git a/paddlespeech/kws/exps/mdtc/plot_det_curve.py b/paddlespeech/kws/exps/mdtc/plot_det_curve.py
index a3ea21eff..4960281ee 100644
--- a/paddlespeech/kws/exps/mdtc/plot_det_curve.py
+++ b/paddlespeech/kws/exps/mdtc/plot_det_curve.py
@@ -1,3 +1,5 @@
+# Copyright (c) 2021 Binbin Zhang(binbzha@qq.com)
+# Menglong Xu
# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
diff --git a/paddlespeech/kws/exps/mdtc/score.py b/paddlespeech/kws/exps/mdtc/score.py
index 1b5e1e296..556455ca1 100644
--- a/paddlespeech/kws/exps/mdtc/score.py
+++ b/paddlespeech/kws/exps/mdtc/score.py
@@ -1,4 +1,6 @@
-# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+# Copyright (c) 2021 Binbin Zhang(binbzha@qq.com)
+# 2022 Shaoqing Yu(954793264@qq.com)
+# 2022 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
diff --git a/paddlespeech/kws/exps/mdtc/train.py b/paddlespeech/kws/exps/mdtc/train.py
index 5a9ca92d1..94e45d590 100644
--- a/paddlespeech/kws/exps/mdtc/train.py
+++ b/paddlespeech/kws/exps/mdtc/train.py
@@ -14,10 +14,10 @@
import os
import paddle
-from paddleaudio.utils import logger
-from paddleaudio.utils import Timer
from yacs.config import CfgNode
+from paddlespeech.audio.utils import logger
+from paddlespeech.audio.utils import Timer
from paddlespeech.kws.exps.mdtc.collate import collate_features
from paddlespeech.kws.models.loss import max_pooling_loss
from paddlespeech.kws.models.mdtc import KWSModel
diff --git a/paddlespeech/kws/models/loss.py b/paddlespeech/kws/models/loss.py
index 64c9a32c9..bda77f2ba 100644
--- a/paddlespeech/kws/models/loss.py
+++ b/paddlespeech/kws/models/loss.py
@@ -1,3 +1,4 @@
+# Copyright (c) 2021 Binbin Zhang
# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
diff --git a/paddlespeech/kws/models/mdtc.py b/paddlespeech/kws/models/mdtc.py
index 5d2e5de64..c605a02b6 100644
--- a/paddlespeech/kws/models/mdtc.py
+++ b/paddlespeech/kws/models/mdtc.py
@@ -1,3 +1,4 @@
+# Copyright (c) 2021 Jingyong Hou (houjingyong@gmail.com)
# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
diff --git a/examples/other/1xt2x/src_deepspeech2x/models/ds2/__init__.py b/paddlespeech/resource/__init__.py
similarity index 72%
rename from examples/other/1xt2x/src_deepspeech2x/models/ds2/__init__.py
rename to paddlespeech/resource/__init__.py
index 39bea5bf9..e143413af 100644
--- a/examples/other/1xt2x/src_deepspeech2x/models/ds2/__init__.py
+++ b/paddlespeech/resource/__init__.py
@@ -1,4 +1,4 @@
-# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
@@ -11,7 +11,4 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-from .deepspeech2 import DeepSpeech2InferModel
-from .deepspeech2 import DeepSpeech2Model
-
-__all__ = ['DeepSpeech2Model', 'DeepSpeech2InferModel']
+from .resource import CommonTaskResource
diff --git a/paddlespeech/resource/model_alias.py b/paddlespeech/resource/model_alias.py
new file mode 100644
index 000000000..5309fd86f
--- /dev/null
+++ b/paddlespeech/resource/model_alias.py
@@ -0,0 +1,86 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+__all__ = [
+ 'model_alias',
+]
+
+# Records of model name to import class
+model_alias = {
+ # ---------------------------------
+ # -------------- ASR --------------
+ # ---------------------------------
+ "deepspeech2offline": ["paddlespeech.s2t.models.ds2:DeepSpeech2Model"],
+ "deepspeech2online": ["paddlespeech.s2t.models.ds2:DeepSpeech2Model"],
+ "conformer": ["paddlespeech.s2t.models.u2:U2Model"],
+ "conformer_online": ["paddlespeech.s2t.models.u2:U2Model"],
+ "transformer": ["paddlespeech.s2t.models.u2:U2Model"],
+ "wenetspeech": ["paddlespeech.s2t.models.u2:U2Model"],
+
+ # ---------------------------------
+ # -------------- CLS --------------
+ # ---------------------------------
+ "panns_cnn6": ["paddlespeech.cls.models.panns:CNN6"],
+ "panns_cnn10": ["paddlespeech.cls.models.panns:CNN10"],
+ "panns_cnn14": ["paddlespeech.cls.models.panns:CNN14"],
+
+ # ---------------------------------
+ # -------------- ST ---------------
+ # ---------------------------------
+ "fat_st": ["paddlespeech.s2t.models.u2_st:U2STModel"],
+
+ # ---------------------------------
+ # -------------- TEXT -------------
+ # ---------------------------------
+ "ernie_linear_p7": [
+ "paddlespeech.text.models:ErnieLinear",
+ "paddlenlp.transformers:ErnieTokenizer"
+ ],
+ "ernie_linear_p3": [
+ "paddlespeech.text.models:ErnieLinear",
+ "paddlenlp.transformers:ErnieTokenizer"
+ ],
+
+ # ---------------------------------
+ # -------------- TTS --------------
+ # ---------------------------------
+ # acoustic model
+ "speedyspeech": ["paddlespeech.t2s.models.speedyspeech:SpeedySpeech"],
+ "speedyspeech_inference":
+ ["paddlespeech.t2s.models.speedyspeech:SpeedySpeechInference"],
+ "fastspeech2": ["paddlespeech.t2s.models.fastspeech2:FastSpeech2"],
+ "fastspeech2_inference":
+ ["paddlespeech.t2s.models.fastspeech2:FastSpeech2Inference"],
+ "tacotron2": ["paddlespeech.t2s.models.tacotron2:Tacotron2"],
+ "tacotron2_inference":
+ ["paddlespeech.t2s.models.tacotron2:Tacotron2Inference"],
+ # voc
+ "pwgan": ["paddlespeech.t2s.models.parallel_wavegan:PWGGenerator"],
+ "pwgan_inference":
+ ["paddlespeech.t2s.models.parallel_wavegan:PWGInference"],
+ "mb_melgan": ["paddlespeech.t2s.models.melgan:MelGANGenerator"],
+ "mb_melgan_inference": ["paddlespeech.t2s.models.melgan:MelGANInference"],
+ "style_melgan": ["paddlespeech.t2s.models.melgan:StyleMelGANGenerator"],
+ "style_melgan_inference":
+ ["paddlespeech.t2s.models.melgan:StyleMelGANInference"],
+ "hifigan": ["paddlespeech.t2s.models.hifigan:HiFiGANGenerator"],
+ "hifigan_inference": ["paddlespeech.t2s.models.hifigan:HiFiGANInference"],
+ "wavernn": ["paddlespeech.t2s.models.wavernn:WaveRNN"],
+ "wavernn_inference": ["paddlespeech.t2s.models.wavernn:WaveRNNInference"],
+
+ # ---------------------------------
+ # ------------ Vector -------------
+ # ---------------------------------
+ "ecapatdnn": ["paddlespeech.vector.models.ecapa_tdnn:EcapaTdnn"],
+}
diff --git a/paddlespeech/resource/pretrained_models.py b/paddlespeech/resource/pretrained_models.py
new file mode 100644
index 000000000..37303331b
--- /dev/null
+++ b/paddlespeech/resource/pretrained_models.py
@@ -0,0 +1,956 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+__all__ = [
+ 'asr_dynamic_pretrained_models',
+ 'asr_static_pretrained_models',
+ 'asr_onnx_pretrained_models',
+ 'cls_dynamic_pretrained_models',
+ 'cls_static_pretrained_models',
+ 'st_dynamic_pretrained_models',
+ 'st_kaldi_bins',
+ 'text_dynamic_pretrained_models',
+ 'tts_dynamic_pretrained_models',
+ 'tts_static_pretrained_models',
+ 'tts_onnx_pretrained_models',
+ 'vector_dynamic_pretrained_models',
+]
+
+# The tags for pretrained_models should be "{model_name}[_{dataset}][-{lang}][-...]".
+# e.g. "conformer_wenetspeech-zh-16k" and "panns_cnn6-32k".
+# Command line and python api use "{model_name}[_{dataset}]" as --model, usage:
+# "paddlespeech asr --model conformer_wenetspeech --lang zh --sr 16000 --input ./input.wav"
+
+# ---------------------------------
+# -------------- ASR --------------
+# ---------------------------------
+asr_dynamic_pretrained_models = {
+ "conformer_wenetspeech-zh-16k": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr1_conformer_wenetspeech_ckpt_0.1.1.model.tar.gz',
+ 'md5':
+ '76cb19ed857e6623856b7cd7ebbfeda4',
+ 'cfg_path':
+ 'model.yaml',
+ 'ckpt_path':
+ 'exp/conformer/checkpoints/wenetspeech',
+ },
+ },
+ "conformer_online_wenetspeech-zh-16k": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr1/asr1_chunk_conformer_wenetspeech_ckpt_1.0.0a.model.tar.gz',
+ 'md5':
+ 'b8c02632b04da34aca88459835be54a6',
+ 'cfg_path':
+ 'model.yaml',
+ 'ckpt_path':
+ 'exp/chunk_conformer/checkpoints/avg_10',
+ 'model':
+ 'exp/chunk_conformer/checkpoints/avg_10.pdparams',
+ 'params':
+ 'exp/chunk_conformer/checkpoints/avg_10.pdparams',
+ 'lm_url':
+ '',
+ 'lm_md5':
+ '',
+ },
+ },
+ "conformer_online_multicn-zh-16k": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/s2t/multi_cn/asr1/asr1_chunk_conformer_multi_cn_ckpt_0.2.0.model.tar.gz',
+ 'md5':
+ '7989b3248c898070904cf042fd656003',
+ 'cfg_path':
+ 'model.yaml',
+ 'ckpt_path':
+ 'exp/chunk_conformer/checkpoints/multi_cn',
+ },
+ '2.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/s2t/multi_cn/asr1/asr1_chunk_conformer_multi_cn_ckpt_0.2.3.model.tar.gz',
+ 'md5':
+ '0ac93d390552336f2a906aec9e33c5fa',
+ 'cfg_path':
+ 'model.yaml',
+ 'ckpt_path':
+ 'exp/chunk_conformer/checkpoints/multi_cn',
+ 'model':
+ 'exp/chunk_conformer/checkpoints/multi_cn.pdparams',
+ 'params':
+ 'exp/chunk_conformer/checkpoints/multi_cn.pdparams',
+ 'lm_url':
+ 'https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm',
+ 'lm_md5':
+ '29e02312deb2e59b3c8686c7966d4fe3',
+ },
+ },
+ "conformer_aishell-zh-16k": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/s2t/aishell/asr1/asr1_conformer_aishell_ckpt_0.1.2.model.tar.gz',
+ 'md5':
+ '3f073eccfa7bb14e0c6867d65fc0dc3a',
+ 'cfg_path':
+ 'model.yaml',
+ 'ckpt_path':
+ 'exp/conformer/checkpoints/avg_30',
+ },
+ },
+ "conformer_online_aishell-zh-16k": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/s2t/aishell/asr1/asr1_chunk_conformer_aishell_ckpt_0.2.0.model.tar.gz',
+ 'md5':
+ 'b374cfb93537761270b6224fb0bfc26a',
+ 'cfg_path':
+ 'model.yaml',
+ 'ckpt_path':
+ 'exp/chunk_conformer/checkpoints/avg_30',
+ },
+ },
+ "transformer_librispeech-en-16k": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/s2t/librispeech/asr1/asr1_transformer_librispeech_ckpt_0.1.1.model.tar.gz',
+ 'md5':
+ '2c667da24922aad391eacafe37bc1660',
+ 'cfg_path':
+ 'model.yaml',
+ 'ckpt_path':
+ 'exp/transformer/checkpoints/avg_10',
+ },
+ },
+ "deepspeech2online_wenetspeech-zh-16k": {
+ '1.0.3': {
+ 'url':
+ 'http://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr0/asr0_deepspeech2_online_wenetspeech_ckpt_1.0.3.model.tar.gz',
+ 'md5':
+ 'cfe273793e68f790f742b411c98bc75e',
+ 'cfg_path':
+ 'model.yaml',
+ 'ckpt_path':
+ 'exp/deepspeech2_online/checkpoints/avg_10',
+ 'model':
+ 'exp/deepspeech2_online/checkpoints/avg_10.jit.pdmodel',
+ 'params':
+ 'exp/deepspeech2_online/checkpoints/avg_10.jit.pdiparams',
+ 'onnx_model':
+ 'onnx/model.onnx',
+ 'lm_url':
+ 'https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm',
+ 'lm_md5':
+ '29e02312deb2e59b3c8686c7966d4fe3'
+ },
+ },
+ "deepspeech2offline_aishell-zh-16k": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_offline_aishell_ckpt_1.0.1.model.tar.gz',
+ 'md5':
+ '4d26066c6f19f52087425dc722ae5b13',
+ 'cfg_path':
+ 'model.yaml',
+ 'ckpt_path':
+ 'exp/deepspeech2/checkpoints/avg_10',
+ 'lm_url':
+ 'https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm',
+ 'lm_md5':
+ '29e02312deb2e59b3c8686c7966d4fe3'
+ },
+ },
+ "deepspeech2online_aishell-zh-16k": {
+ '1.0.2': {
+ 'url':
+ 'http://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_online_aishell_fbank161_ckpt_1.0.2.model.tar.gz',
+ 'md5':
+ '4dd42cfce9aaa54db0ec698da6c48ec5',
+ 'cfg_path':
+ 'model.yaml',
+ 'ckpt_path':
+ 'exp/deepspeech2_online/checkpoints/avg_1',
+ 'model':
+ 'exp/deepspeech2_online/checkpoints/avg_1.jit.pdmodel',
+ 'params':
+ 'exp/deepspeech2_online/checkpoints/avg_1.jit.pdiparams',
+ 'onnx_model':
+ 'onnx/model.onnx',
+ 'lm_url':
+ 'https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm',
+ 'lm_md5':
+ '29e02312deb2e59b3c8686c7966d4fe3'
+ },
+ },
+ "deepspeech2offline_librispeech-en-16k": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/s2t/librispeech/asr0/asr0_deepspeech2_offline_librispeech_ckpt_1.0.1.model.tar.gz',
+ 'md5':
+ 'ed9e2b008a65268b3484020281ab048c',
+ 'cfg_path':
+ 'model.yaml',
+ 'ckpt_path':
+ 'exp/deepspeech2/checkpoints/avg_5',
+ 'lm_url':
+ 'https://deepspeech.bj.bcebos.com/en_lm/common_crawl_00.prune01111.trie.klm',
+ 'lm_md5':
+ '099a601759d467cd0a8523ff939819c5'
+ },
+ },
+}
+
+asr_static_pretrained_models = {
+ "deepspeech2offline_aishell-zh-16k": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_offline_aishell_ckpt_1.0.1.model.tar.gz',
+ 'md5':
+ '4d26066c6f19f52087425dc722ae5b13',
+ 'cfg_path':
+ 'model.yaml',
+ 'ckpt_path':
+ 'exp/deepspeech2/checkpoints/avg_10',
+ 'model':
+ 'exp/deepspeech2/checkpoints/avg_10.jit.pdmodel',
+ 'params':
+ 'exp/deepspeech2/checkpoints/avg_10.jit.pdiparams',
+ 'lm_url':
+ 'https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm',
+ 'lm_md5':
+ '29e02312deb2e59b3c8686c7966d4fe3'
+ }
+ },
+ "deepspeech2online_aishell-zh-16k": {
+ '1.0.1': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_online_aishell_fbank161_ckpt_1.0.1.model.tar.gz',
+ 'md5':
+ 'df5ddeac8b679a470176649ac4b78726',
+ 'cfg_path':
+ 'model.yaml',
+ 'ckpt_path':
+ 'exp/deepspeech2_online/checkpoints/avg_1',
+ 'model':
+ 'exp/deepspeech2_online/checkpoints/avg_1.jit.pdmodel',
+ 'params':
+ 'exp/deepspeech2_online/checkpoints/avg_1.jit.pdiparams',
+ 'lm_url':
+ 'https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm',
+ 'lm_md5':
+ '29e02312deb2e59b3c8686c7966d4fe3'
+ },
+ '1.0.2': {
+ 'url':
+ 'http://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_online_aishell_fbank161_ckpt_1.0.2.model.tar.gz',
+ 'md5':
+ '4dd42cfce9aaa54db0ec698da6c48ec5',
+ 'cfg_path':
+ 'model.yaml',
+ 'ckpt_path':
+ 'exp/deepspeech2_online/checkpoints/avg_1',
+ 'model':
+ 'exp/deepspeech2_online/checkpoints/avg_1.jit.pdmodel',
+ 'params':
+ 'exp/deepspeech2_online/checkpoints/avg_1.jit.pdiparams',
+ 'onnx_model':
+ 'onnx/model.onnx',
+ 'lm_url':
+ 'https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm',
+ 'lm_md5':
+ '29e02312deb2e59b3c8686c7966d4fe3'
+ },
+ },
+ "deepspeech2online_wenetspeech-zh-16k": {
+ '1.0.3': {
+ 'url':
+ 'http://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr0/asr0_deepspeech2_online_wenetspeech_ckpt_1.0.3.model.tar.gz',
+ 'md5':
+ 'cfe273793e68f790f742b411c98bc75e',
+ 'cfg_path':
+ 'model.yaml',
+ 'ckpt_path':
+ 'exp/deepspeech2_online/checkpoints/avg_10',
+ 'model':
+ 'exp/deepspeech2_online/checkpoints/avg_10.jit.pdmodel',
+ 'params':
+ 'exp/deepspeech2_online/checkpoints/avg_10.jit.pdiparams',
+ 'onnx_model':
+ 'onnx/model.onnx',
+ 'lm_url':
+ 'https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm',
+ 'lm_md5':
+ '29e02312deb2e59b3c8686c7966d4fe3'
+ },
+ },
+}
+
+asr_onnx_pretrained_models = {
+ "deepspeech2online_aishell-zh-16k": {
+ '1.0.2': {
+ 'url':
+ 'http://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_online_aishell_fbank161_ckpt_1.0.2.model.tar.gz',
+ 'md5':
+ '4dd42cfce9aaa54db0ec698da6c48ec5',
+ 'cfg_path':
+ 'model.yaml',
+ 'ckpt_path':
+ 'exp/deepspeech2_online/checkpoints/avg_1',
+ 'model':
+ 'exp/deepspeech2_online/checkpoints/avg_1.jit.pdmodel',
+ 'params':
+ 'exp/deepspeech2_online/checkpoints/avg_1.jit.pdiparams',
+ 'onnx_model':
+ 'onnx/model.onnx',
+ 'lm_url':
+ 'https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm',
+ 'lm_md5':
+ '29e02312deb2e59b3c8686c7966d4fe3'
+ },
+ },
+ "deepspeech2online_wenetspeech-zh-16k": {
+ '1.0.3': {
+ 'url':
+ 'http://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr0/asr0_deepspeech2_online_wenetspeech_ckpt_1.0.3.model.tar.gz',
+ 'md5':
+ 'cfe273793e68f790f742b411c98bc75e',
+ 'cfg_path':
+ 'model.yaml',
+ 'ckpt_path':
+ 'exp/deepspeech2_online/checkpoints/avg_10',
+ 'model':
+ 'exp/deepspeech2_online/checkpoints/avg_10.jit.pdmodel',
+ 'params':
+ 'exp/deepspeech2_online/checkpoints/avg_10.jit.pdiparams',
+ 'onnx_model':
+ 'onnx/model.onnx',
+ 'lm_url':
+ 'https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm',
+ 'lm_md5':
+ '29e02312deb2e59b3c8686c7966d4fe3'
+ },
+ },
+}
+
+# ---------------------------------
+# -------------- CLS --------------
+# ---------------------------------
+cls_dynamic_pretrained_models = {
+ "panns_cnn6-32k": {
+ '1.0': {
+ 'url': 'https://paddlespeech.bj.bcebos.com/cls/panns_cnn6.tar.gz',
+ 'md5': '4cf09194a95df024fd12f84712cf0f9c',
+ 'cfg_path': 'panns.yaml',
+ 'ckpt_path': 'cnn6.pdparams',
+ 'label_file': 'audioset_labels.txt',
+ },
+ },
+ "panns_cnn10-32k": {
+ '1.0': {
+ 'url': 'https://paddlespeech.bj.bcebos.com/cls/panns_cnn10.tar.gz',
+ 'md5': 'cb8427b22176cc2116367d14847f5413',
+ 'cfg_path': 'panns.yaml',
+ 'ckpt_path': 'cnn10.pdparams',
+ 'label_file': 'audioset_labels.txt',
+ },
+ },
+ "panns_cnn14-32k": {
+ '1.0': {
+ 'url': 'https://paddlespeech.bj.bcebos.com/cls/panns_cnn14.tar.gz',
+ 'md5': 'e3b9b5614a1595001161d0ab95edee97',
+ 'cfg_path': 'panns.yaml',
+ 'ckpt_path': 'cnn14.pdparams',
+ 'label_file': 'audioset_labels.txt',
+ },
+ },
+}
+
+cls_static_pretrained_models = {
+ "panns_cnn6-32k": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/cls/inference_model/panns_cnn6_static.tar.gz',
+ 'md5':
+ 'da087c31046d23281d8ec5188c1967da',
+ 'cfg_path':
+ 'panns.yaml',
+ 'model_path':
+ 'inference.pdmodel',
+ 'params_path':
+ 'inference.pdiparams',
+ 'label_file':
+ 'audioset_labels.txt',
+ },
+ },
+ "panns_cnn10-32k": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/cls/inference_model/panns_cnn10_static.tar.gz',
+ 'md5':
+ '5460cc6eafbfaf0f261cc75b90284ae1',
+ 'cfg_path':
+ 'panns.yaml',
+ 'model_path':
+ 'inference.pdmodel',
+ 'params_path':
+ 'inference.pdiparams',
+ 'label_file':
+ 'audioset_labels.txt',
+ },
+ },
+ "panns_cnn14-32k": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/cls/inference_model/panns_cnn14_static.tar.gz',
+ 'md5':
+ 'ccc80b194821274da79466862b2ab00f',
+ 'cfg_path':
+ 'panns.yaml',
+ 'model_path':
+ 'inference.pdmodel',
+ 'params_path':
+ 'inference.pdiparams',
+ 'label_file':
+ 'audioset_labels.txt',
+ },
+ },
+}
+
+# ---------------------------------
+# -------------- ST ---------------
+# ---------------------------------
+st_dynamic_pretrained_models = {
+ "fat_st_ted-en-zh": {
+ '1.0': {
+ "url":
+ "https://paddlespeech.bj.bcebos.com/s2t/ted_en_zh/st1/st1_transformer_mtl_noam_ted-en-zh_ckpt_0.1.1.model.tar.gz",
+ "md5":
+ "d62063f35a16d91210a71081bd2dd557",
+ "cfg_path":
+ "model.yaml",
+ "ckpt_path":
+ "exp/transformer_mtl_noam/checkpoints/fat_st_ted-en-zh.pdparams",
+ },
+ },
+}
+
+st_kaldi_bins = {
+ "url":
+ "https://paddlespeech.bj.bcebos.com/s2t/ted_en_zh/st1/kaldi_bins.tar.gz",
+ "md5":
+ "c0682303b3f3393dbf6ed4c4e35a53eb",
+}
+
+# ---------------------------------
+# -------------- TEXT -------------
+# ---------------------------------
+text_dynamic_pretrained_models = {
+ "ernie_linear_p7_wudao-punc-zh": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/text/ernie_linear_p7_wudao-punc-zh.tar.gz',
+ 'md5':
+ '12283e2ddde1797c5d1e57036b512746',
+ 'cfg_path':
+ 'ckpt/model_config.json',
+ 'ckpt_path':
+ 'ckpt/model_state.pdparams',
+ 'vocab_file':
+ 'punc_vocab.txt',
+ },
+ },
+ "ernie_linear_p3_wudao-punc-zh": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/text/ernie_linear_p3_wudao-punc-zh.tar.gz',
+ 'md5':
+ '448eb2fdf85b6a997e7e652e80c51dd2',
+ 'cfg_path':
+ 'ckpt/model_config.json',
+ 'ckpt_path':
+ 'ckpt/model_state.pdparams',
+ 'vocab_file':
+ 'punc_vocab.txt',
+ },
+ },
+}
+
+# ---------------------------------
+# -------------- TTS --------------
+# ---------------------------------
+tts_dynamic_pretrained_models = {
+ # speedyspeech
+ "speedyspeech_csmsc-zh": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/speedyspeech/speedyspeech_csmsc_ckpt_0.2.0.zip',
+ 'md5':
+ '6f6fa967b408454b6662c8c00c0027cb',
+ 'config':
+ 'default.yaml',
+ 'ckpt':
+ 'snapshot_iter_30600.pdz',
+ 'speech_stats':
+ 'feats_stats.npy',
+ 'phones_dict':
+ 'phone_id_map.txt',
+ 'tones_dict':
+ 'tone_id_map.txt',
+ },
+ },
+ # fastspeech2
+ "fastspeech2_csmsc-zh": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_baker_ckpt_0.4.zip',
+ 'md5':
+ '637d28a5e53aa60275612ba4393d5f22',
+ 'config':
+ 'default.yaml',
+ 'ckpt':
+ 'snapshot_iter_76000.pdz',
+ 'speech_stats':
+ 'speech_stats.npy',
+ 'phones_dict':
+ 'phone_id_map.txt',
+ },
+ },
+ "fastspeech2_ljspeech-en": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_ljspeech_ckpt_0.5.zip',
+ 'md5':
+ 'ffed800c93deaf16ca9b3af89bfcd747',
+ 'config':
+ 'default.yaml',
+ 'ckpt':
+ 'snapshot_iter_100000.pdz',
+ 'speech_stats':
+ 'speech_stats.npy',
+ 'phones_dict':
+ 'phone_id_map.txt',
+ },
+ },
+ "fastspeech2_aishell3-zh": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_aishell3_ckpt_0.4.zip',
+ 'md5':
+ 'f4dd4a5f49a4552b77981f544ab3392e',
+ 'config':
+ 'default.yaml',
+ 'ckpt':
+ 'snapshot_iter_96400.pdz',
+ 'speech_stats':
+ 'speech_stats.npy',
+ 'phones_dict':
+ 'phone_id_map.txt',
+ 'speaker_dict':
+ 'speaker_id_map.txt',
+ },
+ },
+ "fastspeech2_vctk-en": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_vctk_ckpt_0.5.zip',
+ 'md5':
+ '743e5024ca1e17a88c5c271db9779ba4',
+ 'config':
+ 'default.yaml',
+ 'ckpt':
+ 'snapshot_iter_66200.pdz',
+ 'speech_stats':
+ 'speech_stats.npy',
+ 'phones_dict':
+ 'phone_id_map.txt',
+ 'speaker_dict':
+ 'speaker_id_map.txt',
+ },
+ },
+ # tacotron2
+ "tacotron2_csmsc-zh": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/tacotron2/tacotron2_csmsc_ckpt_0.2.0.zip',
+ 'md5':
+ '0df4b6f0bcbe0d73c5ed6df8867ab91a',
+ 'config':
+ 'default.yaml',
+ 'ckpt':
+ 'snapshot_iter_30600.pdz',
+ 'speech_stats':
+ 'speech_stats.npy',
+ 'phones_dict':
+ 'phone_id_map.txt',
+ },
+ },
+ "tacotron2_ljspeech-en": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/tacotron2/tacotron2_ljspeech_ckpt_0.2.0.zip',
+ 'md5':
+ '6a5eddd81ae0e81d16959b97481135f3',
+ 'config':
+ 'default.yaml',
+ 'ckpt':
+ 'snapshot_iter_60300.pdz',
+ 'speech_stats':
+ 'speech_stats.npy',
+ 'phones_dict':
+ 'phone_id_map.txt',
+ },
+ },
+ # pwgan
+ "pwgan_csmsc-zh": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwg_baker_ckpt_0.4.zip',
+ 'md5':
+ '2e481633325b5bdf0a3823c714d2c117',
+ 'config':
+ 'pwg_default.yaml',
+ 'ckpt':
+ 'pwg_snapshot_iter_400000.pdz',
+ 'speech_stats':
+ 'pwg_stats.npy',
+ },
+ },
+ "pwgan_ljspeech-en": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwg_ljspeech_ckpt_0.5.zip',
+ 'md5':
+ '53610ba9708fd3008ccaf8e99dacbaf0',
+ 'config':
+ 'pwg_default.yaml',
+ 'ckpt':
+ 'pwg_snapshot_iter_400000.pdz',
+ 'speech_stats':
+ 'pwg_stats.npy',
+ },
+ },
+ "pwgan_aishell3-zh": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwg_aishell3_ckpt_0.5.zip',
+ 'md5':
+ 'd7598fa41ad362d62f85ffc0f07e3d84',
+ 'config':
+ 'default.yaml',
+ 'ckpt':
+ 'snapshot_iter_1000000.pdz',
+ 'speech_stats':
+ 'feats_stats.npy',
+ },
+ },
+ "pwgan_vctk-en": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwg_vctk_ckpt_0.1.1.zip',
+ 'md5':
+ 'b3da1defcde3e578be71eb284cb89f2c',
+ 'config':
+ 'default.yaml',
+ 'ckpt':
+ 'snapshot_iter_1500000.pdz',
+ 'speech_stats':
+ 'feats_stats.npy',
+ },
+ },
+ # mb_melgan
+ "mb_melgan_csmsc-zh": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/mb_melgan/mb_melgan_csmsc_ckpt_0.1.1.zip',
+ 'md5':
+ 'ee5f0604e20091f0d495b6ec4618b90d',
+ 'config':
+ 'default.yaml',
+ 'ckpt':
+ 'snapshot_iter_1000000.pdz',
+ 'speech_stats':
+ 'feats_stats.npy',
+ },
+ },
+ # style_melgan
+ "style_melgan_csmsc-zh": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/style_melgan/style_melgan_csmsc_ckpt_0.1.1.zip',
+ 'md5':
+ '5de2d5348f396de0c966926b8c462755',
+ 'config':
+ 'default.yaml',
+ 'ckpt':
+ 'snapshot_iter_1500000.pdz',
+ 'speech_stats':
+ 'feats_stats.npy',
+ },
+ },
+ # hifigan
+ "hifigan_csmsc-zh": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_csmsc_ckpt_0.1.1.zip',
+ 'md5':
+ 'dd40a3d88dfcf64513fba2f0f961ada6',
+ 'config':
+ 'default.yaml',
+ 'ckpt':
+ 'snapshot_iter_2500000.pdz',
+ 'speech_stats':
+ 'feats_stats.npy',
+ },
+ },
+ "hifigan_ljspeech-en": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_ljspeech_ckpt_0.2.0.zip',
+ 'md5':
+ '70e9131695decbca06a65fe51ed38a72',
+ 'config':
+ 'default.yaml',
+ 'ckpt':
+ 'snapshot_iter_2500000.pdz',
+ 'speech_stats':
+ 'feats_stats.npy',
+ },
+ },
+ "hifigan_aishell3-zh": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_aishell3_ckpt_0.2.0.zip',
+ 'md5':
+ '3bb49bc75032ed12f79c00c8cc79a09a',
+ 'config':
+ 'default.yaml',
+ 'ckpt':
+ 'snapshot_iter_2500000.pdz',
+ 'speech_stats':
+ 'feats_stats.npy',
+ },
+ },
+ "hifigan_vctk-en": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_vctk_ckpt_0.2.0.zip',
+ 'md5':
+ '7da8f88359bca2457e705d924cf27bd4',
+ 'config':
+ 'default.yaml',
+ 'ckpt':
+ 'snapshot_iter_2500000.pdz',
+ 'speech_stats':
+ 'feats_stats.npy',
+ },
+ },
+ # wavernn
+ "wavernn_csmsc-zh": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/wavernn/wavernn_csmsc_ckpt_0.2.0.zip',
+ 'md5':
+ 'ee37b752f09bcba8f2af3b777ca38e13',
+ 'config':
+ 'default.yaml',
+ 'ckpt':
+ 'snapshot_iter_400000.pdz',
+ 'speech_stats':
+ 'feats_stats.npy',
+ },
+ },
+ "fastspeech2_cnndecoder_csmsc-zh": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_cnndecoder_csmsc_ckpt_1.0.0.zip',
+ 'md5':
+ '6eb28e22ace73e0ebe7845f86478f89f',
+ 'config':
+ 'cnndecoder.yaml',
+ 'ckpt':
+ 'snapshot_iter_153000.pdz',
+ 'speech_stats':
+ 'speech_stats.npy',
+ 'phones_dict':
+ 'phone_id_map.txt',
+ },
+ },
+}
+
+tts_static_pretrained_models = {
+ # speedyspeech
+ "speedyspeech_csmsc-zh": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/speedyspeech/speedyspeech_nosil_baker_static_0.5.zip',
+ 'md5':
+ 'f10cbdedf47dc7a9668d2264494e1823',
+ 'model':
+ 'speedyspeech_csmsc.pdmodel',
+ 'params':
+ 'speedyspeech_csmsc.pdiparams',
+ 'phones_dict':
+ 'phone_id_map.txt',
+ 'tones_dict':
+ 'tone_id_map.txt',
+ 'sample_rate':
+ 24000,
+ },
+ },
+ # fastspeech2
+ "fastspeech2_csmsc-zh": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_baker_static_0.4.zip',
+ 'md5':
+ '9788cd9745e14c7a5d12d32670b2a5a7',
+ 'model':
+ 'fastspeech2_csmsc.pdmodel',
+ 'params':
+ 'fastspeech2_csmsc.pdiparams',
+ 'phones_dict':
+ 'phone_id_map.txt',
+ 'sample_rate':
+ 24000,
+ },
+ },
+ # pwgan
+ "pwgan_csmsc-zh": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwg_baker_static_0.4.zip',
+ 'md5':
+ 'e3504aed9c5a290be12d1347836d2742',
+ 'model':
+ 'pwgan_csmsc.pdmodel',
+ 'params':
+ 'pwgan_csmsc.pdiparams',
+ 'sample_rate':
+ 24000,
+ },
+ },
+ # mb_melgan
+ "mb_melgan_csmsc-zh": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/mb_melgan/mb_melgan_csmsc_static_0.1.1.zip',
+ 'md5':
+ 'ac6eee94ba483421d750433f4c3b8d36',
+ 'model':
+ 'mb_melgan_csmsc.pdmodel',
+ 'params':
+ 'mb_melgan_csmsc.pdiparams',
+ 'sample_rate':
+ 24000,
+ },
+ },
+ # hifigan
+ "hifigan_csmsc-zh": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_csmsc_static_0.1.1.zip',
+ 'md5':
+ '7edd8c436b3a5546b3a7cb8cff9d5a0c',
+ 'model':
+ 'hifigan_csmsc.pdmodel',
+ 'params':
+ 'hifigan_csmsc.pdiparams',
+ 'sample_rate':
+ 24000,
+ },
+ },
+}
+
+tts_onnx_pretrained_models = {
+ # fastspeech2
+ "fastspeech2_csmsc_onnx-zh": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_csmsc_onnx_0.2.0.zip',
+ 'md5':
+ 'fd3ad38d83273ad51f0ea4f4abf3ab4e',
+ 'ckpt': ['fastspeech2_csmsc.onnx'],
+ 'phones_dict':
+ 'phone_id_map.txt',
+ 'sample_rate':
+ 24000,
+ },
+ },
+ "fastspeech2_cnndecoder_csmsc_onnx-zh": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_cnndecoder_csmsc_streaming_onnx_1.0.0.zip',
+ 'md5':
+ '5f70e1a6bcd29d72d54e7931aa86f266',
+ 'ckpt': [
+ 'fastspeech2_csmsc_am_encoder_infer.onnx',
+ 'fastspeech2_csmsc_am_decoder.onnx',
+ 'fastspeech2_csmsc_am_postnet.onnx',
+ ],
+ 'speech_stats':
+ 'speech_stats.npy',
+ 'phones_dict':
+ 'phone_id_map.txt',
+ 'sample_rate':
+ 24000,
+ },
+ },
+ # mb_melgan
+ "mb_melgan_csmsc_onnx-zh": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/mb_melgan/mb_melgan_csmsc_onnx_0.2.0.zip',
+ 'md5':
+ '5b83ec746e8414bc29032d954ffd07ec',
+ 'ckpt':
+ 'mb_melgan_csmsc.onnx',
+ 'sample_rate':
+ 24000,
+ },
+ },
+ # hifigan
+ "hifigan_csmsc_onnx-zh": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_csmsc_onnx_0.2.0.zip',
+ 'md5':
+ '1a7dc0385875889e46952e50c0994a6b',
+ 'ckpt':
+ 'hifigan_csmsc.onnx',
+ 'sample_rate':
+ 24000,
+ },
+ },
+}
+
+# ---------------------------------
+# ------------ Vector -------------
+# ---------------------------------
+vector_dynamic_pretrained_models = {
+ "ecapatdnn_voxceleb12-16k": {
+ '1.0': {
+ 'url':
+ 'https://paddlespeech.bj.bcebos.com/vector/voxceleb/sv0_ecapa_tdnn_voxceleb12_ckpt_0_2_0.tar.gz',
+ 'md5':
+ 'cc33023c54ab346cd318408f43fcaf95',
+ 'cfg_path':
+ 'conf/model.yaml', # the yaml config path
+ 'ckpt_path':
+ 'model/model', # the format is ${dir}/{model_name},
+ # so the first 'model' is dir, the second 'model' is the name
+ # this means we have a model stored as model/model.pdparams
+ },
+ },
+}
diff --git a/paddlespeech/resource/resource.py b/paddlespeech/resource/resource.py
new file mode 100644
index 000000000..15112ba7d
--- /dev/null
+++ b/paddlespeech/resource/resource.py
@@ -0,0 +1,234 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+from collections import OrderedDict
+from typing import Dict
+from typing import List
+from typing import Optional
+
+from ..cli.utils import download_and_decompress
+from ..cli.utils import MODEL_HOME
+from ..utils.dynamic_import import dynamic_import
+from .model_alias import model_alias
+
+task_supported = ['asr', 'cls', 'st', 'text', 'tts', 'vector']
+model_format_supported = ['dynamic', 'static', 'onnx']
+inference_mode_supported = ['online', 'offline']
+
+
+class CommonTaskResource:
+ def __init__(self, task: str, model_format: str='dynamic', **kwargs):
+ assert task in task_supported, 'Arg "task" must be one of {}.'.format(
+ task_supported)
+ assert model_format in model_format_supported, 'Arg "model_format" must be one of {}.'.format(
+ model_format_supported)
+
+ self.task = task
+ self.model_format = model_format
+ self.pretrained_models = self._get_pretrained_models()
+
+ if 'inference_mode' in kwargs:
+ assert kwargs[
+ 'inference_mode'] in inference_mode_supported, 'Arg "inference_mode" must be one of {}.'.format(
+ inference_mode_supported)
+ self._inference_mode_filter(kwargs['inference_mode'])
+
+ # Initialize after model and version had been set.
+ self.model_tag = None
+ self.version = None
+ self.res_dict = None
+ self.res_dir = None
+
+ if self.task == 'tts':
+ # For vocoder
+ self.voc_model_tag = None
+ self.voc_version = None
+ self.voc_res_dict = None
+ self.voc_res_dir = None
+
+ def set_task_model(self,
+ model_tag: str,
+ model_type: int=0,
+ version: Optional[str]=None):
+ """Set model tag and version of current task.
+
+ Args:
+ model_tag (str): Model tag.
+ model_type (int): 0 for acoustic model otherwise vocoder in tts task.
+ version (Optional[str], optional): Version of pretrained model. Defaults to None.
+ """
+ assert model_tag in self.pretrained_models, \
+ "Can't find \"{}\" in resource. Model name must be one of {}".format(model_tag, list(self.pretrained_models.keys()))
+
+ if version is None:
+ version = self._get_default_version(model_tag)
+
+ assert version in self.pretrained_models[model_tag], \
+ "Can't find version \"{}\" in \"{}\". Model name must be one of {}".format(
+ version, model_tag, list(self.pretrained_models[model_tag].keys()))
+
+ if model_type == 0:
+ self.model_tag = model_tag
+ self.version = version
+ self.res_dict = self.pretrained_models[model_tag][version]
+ self._format_path(self.res_dict)
+ self.res_dir = self._fetch(self.res_dict,
+ self._get_model_dir(model_type))
+ else:
+ assert self.task == 'tts', 'Vocoder will only be used in tts task.'
+ self.voc_model_tag = model_tag
+ self.voc_version = version
+ self.voc_res_dict = self.pretrained_models[model_tag][version]
+ self._format_path(self.voc_res_dict)
+ self.voc_res_dir = self._fetch(self.voc_res_dict,
+ self._get_model_dir(model_type))
+
+ @staticmethod
+ def get_model_class(model_name) -> List[object]:
+ """Dynamic import model class.
+ Args:
+ model_name (str): Model name.
+
+ Returns:
+ List[object]: Return a list of model class.
+ """
+ assert model_name in model_alias, 'No model classes found for "{}"'.format(
+ model_name)
+
+ ret = []
+ for import_path in model_alias[model_name]:
+ ret.append(dynamic_import(import_path))
+
+ if len(ret) == 1:
+ return ret[0]
+ else:
+ return ret
+
+ def get_versions(self, model_tag: str) -> List[str]:
+ """List all available versions.
+
+ Args:
+ model_tag (str): Model tag.
+
+ Returns:
+ List[str]: Version list of model.
+ """
+ return list(self.pretrained_models[model_tag].keys())
+
+ def _get_default_version(self, model_tag: str) -> str:
+ """Get default version of model.
+
+ Args:
+ model_tag (str): Model tag.
+
+ Returns:
+ str: Default version.
+ """
+ return self.get_versions(model_tag)[-1] # get latest version
+
+ def _get_model_dir(self, model_type: int=0) -> os.PathLike:
+ """Get resource directory.
+
+ Args:
+ model_type (int): 0 for acoustic model otherwise vocoder in tts task.
+
+ Returns:
+ os.PathLike: Directory of model resource.
+ """
+ if model_type == 0:
+ model_tag = self.model_tag
+ version = self.version
+ else:
+ model_tag = self.voc_model_tag
+ version = self.voc_version
+
+ return os.path.join(MODEL_HOME, model_tag, version)
+
+ def _get_pretrained_models(self) -> Dict[str, str]:
+ """Get all available models for current task.
+
+ Returns:
+ Dict[str, str]: A dictionary with model tag and resources info.
+ """
+ try:
+ import_models = '{}_{}_pretrained_models'.format(self.task,
+ self.model_format)
+ print(f"from .pretrained_models import {import_models}")
+ exec('from .pretrained_models import {}'.format(import_models))
+ models = OrderedDict(locals()[import_models])
+ except Exception as e:
+ models = OrderedDict({}) # no models.
+ finally:
+ return models
+
+ def _inference_mode_filter(self, inference_mode: Optional[str]):
+ """Filter models dict based on inference_mode.
+
+ Args:
+ inference_mode (Optional[str]): 'online', 'offline' or None.
+ """
+ if inference_mode is None:
+ return
+
+ if self.task == 'asr':
+ online_flags = [
+ 'online' in model_tag
+ for model_tag in self.pretrained_models.keys()
+ ]
+ for online_flag, model_tag in zip(
+ online_flags, list(self.pretrained_models.keys())):
+ if inference_mode == 'online' and online_flag:
+ continue
+ elif inference_mode == 'offline' and not online_flag:
+ continue
+ else:
+ del self.pretrained_models[model_tag]
+ elif self.task == 'tts':
+ # Hardcode for tts online models.
+ tts_online_models = [
+ 'fastspeech2_csmsc-zh', 'fastspeech2_cnndecoder_csmsc-zh',
+ 'mb_melgan_csmsc-zh', 'hifigan_csmsc-zh'
+ ]
+ for model_tag in list(self.pretrained_models.keys()):
+ if inference_mode == 'online' and model_tag in tts_online_models:
+ continue
+ elif inference_mode == 'offline':
+ continue
+ else:
+ del self.pretrained_models[model_tag]
+ else:
+ raise NotImplementedError('Only supports asr and tts task.')
+
+ @staticmethod
+ def _fetch(res_dict: Dict[str, str],
+ target_dir: os.PathLike) -> os.PathLike:
+ """Fetch archive from url.
+
+ Args:
+ res_dict (Dict[str, str]): Info dict of a resource.
+ target_dir (os.PathLike): Directory to save archives.
+
+ Returns:
+ os.PathLike: Directory of model resource.
+ """
+ return download_and_decompress(res_dict, target_dir)
+
+ @staticmethod
+ def _format_path(res_dict: Dict[str, str]):
+ for k, v in res_dict.items():
+ if isinstance(v, str) and '/' in v:
+ if v.startswith('https://') or v.startswith('http://'):
+ continue
+ else:
+ res_dict[k] = os.path.join(*(v.split('/')))
diff --git a/paddlespeech/s2t/__init__.py b/paddlespeech/s2t/__init__.py
index 29402fc44..2da68435c 100644
--- a/paddlespeech/s2t/__init__.py
+++ b/paddlespeech/s2t/__init__.py
@@ -189,25 +189,6 @@ if not hasattr(paddle.Tensor, 'contiguous'):
paddle.static.Variable.contiguous = contiguous
-def size(xs: paddle.Tensor, *args: int) -> paddle.Tensor:
- nargs = len(args)
- assert (nargs <= 1)
- s = paddle.shape(xs)
- if nargs == 1:
- return s[args[0]]
- else:
- return s
-
-
-#`to_static` do not process `size` property, maybe some `paddle` api dependent on it.
-logger.debug(
- "override size of paddle.Tensor "
- "(`to_static` do not process `size` property, maybe some `paddle` api dependent on it), remove this when fixed!"
-)
-paddle.Tensor.size = size
-paddle.static.Variable.size = size
-
-
def view(xs: paddle.Tensor, *args: int) -> paddle.Tensor:
return xs.reshape(args)
@@ -219,7 +200,7 @@ if not hasattr(paddle.Tensor, 'view'):
def view_as(xs: paddle.Tensor, ys: paddle.Tensor) -> paddle.Tensor:
- return xs.reshape(ys.size())
+ return xs.reshape(paddle.shape(ys))
if not hasattr(paddle.Tensor, 'view_as'):
@@ -325,7 +306,6 @@ if not hasattr(paddle.Tensor, 'type_as'):
setattr(paddle.static.Variable, 'type_as', type_as)
-
def to(x: paddle.Tensor, *args, **kwargs) -> paddle.Tensor:
assert len(args) == 1
if isinstance(args[0], str): # dtype
@@ -372,7 +352,6 @@ if not hasattr(paddle.Tensor, 'tolist'):
"register user tolist to paddle.Tensor, remove this when fixed!")
setattr(paddle.Tensor, 'tolist', tolist)
setattr(paddle.static.Variable, 'tolist', tolist)
-
########### hack paddle.nn #############
from paddle.nn import Layer
diff --git a/paddlespeech/s2t/decoders/beam_search/beam_search.py b/paddlespeech/s2t/decoders/beam_search/beam_search.py
index f331cb1c9..f6a2b4b0a 100644
--- a/paddlespeech/s2t/decoders/beam_search/beam_search.py
+++ b/paddlespeech/s2t/decoders/beam_search/beam_search.py
@@ -194,7 +194,7 @@ class BeamSearch(paddle.nn.Layer):
Args:
hyp (Hypothesis): Hypothesis with prefix tokens to score
- ids (paddle.Tensor): 1D tensor of new partial tokens to score,
+ ids (paddle.Tensor): 1D tensor of new partial tokens to score,
len(ids) < n_vocab
x (paddle.Tensor): Corresponding input feature, (T, D)
@@ -224,14 +224,14 @@ class BeamSearch(paddle.nn.Layer):
ids (paddle.Tensor): The partial token ids(Global) to compute topk.
Returns:
- Tuple[paddle.Tensor, paddle.Tensor]:
+ Tuple[paddle.Tensor, paddle.Tensor]:
The topk full token ids and partial token ids.
Their shapes are `(self.beam_size,)`.
i.e. (global ids, global relative local ids).
"""
# no pre beam performed, `ids` equal to `weighted_scores`
- if weighted_scores.size(0) == ids.size(0):
+ if paddle.shape(weighted_scores)[0] == paddle.shape(ids)[0]:
top_ids = weighted_scores.topk(
self.beam_size)[1] # index in n_vocab
return top_ids, top_ids
@@ -370,13 +370,13 @@ class BeamSearch(paddle.nn.Layer):
"""
# set length bounds
if maxlenratio == 0:
- maxlen = x.shape[0]
+ maxlen = paddle.shape(x)[0]
elif maxlenratio < 0:
maxlen = -1 * int(maxlenratio)
else:
- maxlen = max(1, int(maxlenratio * x.size(0)))
- minlen = int(minlenratio * x.size(0))
- logger.info("decoder input length: " + str(x.shape[0]))
+ maxlen = max(1, int(maxlenratio * paddle.shape(x)[0]))
+ minlen = int(minlenratio * paddle.shape(x)[0])
+ logger.info("decoder input length: " + str(paddle.shape(x)[0]))
logger.info("max output length: " + str(maxlen))
logger.info("min output length: " + str(minlen))
diff --git a/paddlespeech/s2t/decoders/scorers/ctc.py b/paddlespeech/s2t/decoders/scorers/ctc.py
index 81d8b0783..3c1d4cf80 100644
--- a/paddlespeech/s2t/decoders/scorers/ctc.py
+++ b/paddlespeech/s2t/decoders/scorers/ctc.py
@@ -69,7 +69,7 @@ class CTCPrefixScorer(BatchPartialScorerInterface):
return sc[i], st[i]
else: # for CTCPrefixScorePD (need new_id > 0)
r, log_psi, f_min, f_max, scoring_idmap = state
- s = log_psi[i, new_id].expand(log_psi.size(1))
+ s = log_psi[i, new_id].expand(paddle.shape(log_psi)[1])
if scoring_idmap is not None:
return r[:, :, i, scoring_idmap[i, new_id]], s, f_min, f_max
else:
@@ -107,7 +107,7 @@ class CTCPrefixScorer(BatchPartialScorerInterface):
"""
logp = self.ctc.log_softmax(x.unsqueeze(0)) # assuming batch_size = 1
- xlen = paddle.to_tensor([logp.size(1)])
+ xlen = paddle.to_tensor([paddle.shape(logp)[1]])
self.impl = CTCPrefixScorePD(logp, xlen, 0, self.eos)
return None
diff --git a/paddlespeech/s2t/decoders/scorers/ctc_prefix_score.py b/paddlespeech/s2t/decoders/scorers/ctc_prefix_score.py
index 78b8fe36c..a994412e0 100644
--- a/paddlespeech/s2t/decoders/scorers/ctc_prefix_score.py
+++ b/paddlespeech/s2t/decoders/scorers/ctc_prefix_score.py
@@ -33,9 +33,9 @@ class CTCPrefixScorePD():
self.logzero = -10000000000.0
self.blank = blank
self.eos = eos
- self.batch = x.size(0)
- self.input_length = x.size(1)
- self.odim = x.size(2)
+ self.batch = paddle.shape(x)[0]
+ self.input_length = paddle.shape(x)[1]
+ self.odim = paddle.shape(x)[2]
self.dtype = x.dtype
# Pad the rest of posteriors in the batch
@@ -76,8 +76,8 @@ class CTCPrefixScorePD():
last_ids = [yi[-1] for yi in y] # last output label ids
n_bh = len(last_ids) # batch * hyps
n_hyps = n_bh // self.batch # assuming each utterance has the same # of hyps
- self.scoring_num = scoring_ids.size(
- -1) if scoring_ids is not None else 0
+ self.scoring_num = paddle.shape(scoring_ids)[
+ -1] if scoring_ids is not None else 0
# prepare state info
if state is None:
r_prev = paddle.full(
@@ -153,7 +153,7 @@ class CTCPrefixScorePD():
# compute forward probabilities log(r_t^n(h)) and log(r_t^b(h))
for t in range(start, end):
- rp = r[t - 1] # (2 x BW x O')
+ rp = r[t - 1] # (2 x BW x O')
rr = paddle.stack([rp[0], log_phi[t - 1], rp[0], rp[1]]).view(
2, 2, n_bh, snum) # (2,2,BW,O')
r[t] = paddle.logsumexp(rr, 1) + x_[:, t]
@@ -227,7 +227,7 @@ class CTCPrefixScorePD():
if self.x.shape[1] < x.shape[1]: # self.x (2,T,B,O); x (B,T,O)
# Pad the rest of posteriors in the batch
# TODO(takaaki-hori): need a better way without for-loops
- xlens = [x.size(1)]
+ xlens = [paddle.shape(x)[1]]
for i, l in enumerate(xlens):
if l < self.input_length:
x[i, l:, :] = self.logzero
@@ -237,7 +237,7 @@ class CTCPrefixScorePD():
xb = xn[:, :, self.blank].unsqueeze(2).expand(-1, -1, self.odim)
self.x = paddle.stack([xn, xb]) # (2, T, B, O)
self.x[:, :tmp_x.shape[1], :, :] = tmp_x
- self.input_length = x.size(1)
+ self.input_length = paddle.shape(x)[1]
self.end_frames = paddle.to_tensor(xlens) - 1
def extend_state(self, state):
@@ -318,16 +318,16 @@ class CTCPrefixScore():
r[0, 0] = xs[0]
r[0, 1] = self.logzero
else:
- # Although the code does not exactly follow Algorithm 2,
- # we don't have to change it because we can assume
- # r_t(h)=0 for t < |h| in CTC forward computation
+ # Although the code does not exactly follow Algorithm 2,
+ # we don't have to change it because we can assume
+ # r_t(h)=0 for t < |h| in CTC forward computation
# (Note: we assume here that index t starts with 0).
# The purpose of this difference is to reduce the number of for-loops.
# https://github.com/espnet/espnet/pull/3655
- # where we start to accumulate r_t(h) from t=|h|
- # and iterate r_t(h) = (r_{t-1}(h) + ...) to T-1,
+ # where we start to accumulate r_t(h) from t=|h|
+ # and iterate r_t(h) = (r_{t-1}(h) + ...) to T-1,
# avoiding accumulating zeros for t=1~|h|-1.
- # Thus, we need to set r_{|h|-1}(h) = 0,
+ # Thus, we need to set r_{|h|-1}(h) = 0,
# i.e., r[output_length-1] = logzero, for initialization.
# This is just for reducing the computation.
r[output_length - 1] = self.logzero
diff --git a/paddlespeech/s2t/exps/deepspeech2/bin/export.py b/paddlespeech/s2t/exps/deepspeech2/bin/export.py
index ee013d79e..049e7b688 100644
--- a/paddlespeech/s2t/exps/deepspeech2/bin/export.py
+++ b/paddlespeech/s2t/exps/deepspeech2/bin/export.py
@@ -32,13 +32,16 @@ def main(config, args):
if __name__ == "__main__":
parser = default_argument_parser()
- # save jit model to
+ # save jit model to
parser.add_argument(
"--export_path", type=str, help="path of the jit model to save")
parser.add_argument(
- "--model_type", type=str, default='offline', help="offline/online")
+ '--nxpu',
+ type=int,
+ default=0,
+ choices=[0, 1],
+ help="if nxpu == 0 and ngpu == 0, use cpu.")
args = parser.parse_args()
- print("model_type:{}".format(args.model_type))
print_arguments(args)
# https://yaml.org/type/float.html
diff --git a/paddlespeech/s2t/exps/deepspeech2/bin/test.py b/paddlespeech/s2t/exps/deepspeech2/bin/test.py
index 388b380d1..a9828f6e7 100644
--- a/paddlespeech/s2t/exps/deepspeech2/bin/test.py
+++ b/paddlespeech/s2t/exps/deepspeech2/bin/test.py
@@ -32,14 +32,17 @@ def main(config, args):
if __name__ == "__main__":
parser = default_argument_parser()
- parser.add_argument(
- "--model_type", type=str, default='offline', help='offline/online')
- # save asr result to
+ # save asr result to
parser.add_argument(
"--result_file", type=str, help="path of save the asr result")
+ parser.add_argument(
+ '--nxpu',
+ type=int,
+ default=0,
+ choices=[0, 1],
+ help="if nxpu == 0 and ngpu == 0, use cpu.")
args = parser.parse_args()
print_arguments(args, globals())
- print("model_type:{}".format(args.model_type))
# https://yaml.org/type/float.html
config = CfgNode(new_allowed=True)
diff --git a/paddlespeech/s2t/exps/deepspeech2/bin/test_export.py b/paddlespeech/s2t/exps/deepspeech2/bin/test_export.py
index 707eb9e1b..8db081e7b 100644
--- a/paddlespeech/s2t/exps/deepspeech2/bin/test_export.py
+++ b/paddlespeech/s2t/exps/deepspeech2/bin/test_export.py
@@ -39,12 +39,15 @@ if __name__ == "__main__":
parser.add_argument(
"--export_path", type=str, help="path of the jit model to save")
parser.add_argument(
- "--model_type", type=str, default='offline', help='offline/online')
+ '--nxpu',
+ type=int,
+ default=0,
+ choices=[0, 1],
+ help="if nxpu == 0 and ngpu == 0, use cpu.")
parser.add_argument(
"--enable-auto-log", action="store_true", help="use auto log")
args = parser.parse_args()
print_arguments(args, globals())
- print("model_type:{}".format(args.model_type))
# https://yaml.org/type/float.html
config = CfgNode(new_allowed=True)
diff --git a/paddlespeech/s2t/exps/deepspeech2/bin/test_wav.py b/paddlespeech/s2t/exps/deepspeech2/bin/test_wav.py
index a909dd416..90b7d8a18 100644
--- a/paddlespeech/s2t/exps/deepspeech2/bin/test_wav.py
+++ b/paddlespeech/s2t/exps/deepspeech2/bin/test_wav.py
@@ -23,7 +23,6 @@ from yacs.config import CfgNode
from paddlespeech.s2t.frontend.featurizer.text_featurizer import TextFeaturizer
from paddlespeech.s2t.io.collator import SpeechCollator
from paddlespeech.s2t.models.ds2 import DeepSpeech2Model
-from paddlespeech.s2t.models.ds2_online import DeepSpeech2ModelOnline
from paddlespeech.s2t.training.cli import default_argument_parser
from paddlespeech.s2t.utils import mp_tools
from paddlespeech.s2t.utils.checkpoint import Checkpoint
@@ -113,12 +112,7 @@ class DeepSpeech2Tester_hub():
config.input_dim = self.collate_fn_test.feature_size
config.output_dim = self.collate_fn_test.vocab_size
- if self.args.model_type == 'offline':
- model = DeepSpeech2Model.from_config(config)
- elif self.args.model_type == 'online':
- model = DeepSpeech2ModelOnline.from_config(config)
- else:
- raise Exception("wrong model type")
+ model = DeepSpeech2Model.from_config(config)
self.model = model
@@ -172,8 +166,6 @@ def main(config, args):
if __name__ == "__main__":
parser = default_argument_parser()
- parser.add_argument(
- "--model_type", type=str, default='offline', help='offline/online')
parser.add_argument("--audio_file", type=str, help='audio file path')
# save asr result to
parser.add_argument(
@@ -184,7 +176,6 @@ if __name__ == "__main__":
print("Please input the audio file path")
sys.exit(-1)
check(args.audio_file)
- print("model_type:{}".format(args.model_type))
# https://yaml.org/type/float.html
config = CfgNode(new_allowed=True)
diff --git a/paddlespeech/s2t/exps/deepspeech2/bin/train.py b/paddlespeech/s2t/exps/deepspeech2/bin/train.py
index 09e8662f1..fee7079d9 100644
--- a/paddlespeech/s2t/exps/deepspeech2/bin/train.py
+++ b/paddlespeech/s2t/exps/deepspeech2/bin/train.py
@@ -12,7 +12,6 @@
# See the License for the specific language governing permissions and
# limitations under the License.
"""Trainer for DeepSpeech2 model."""
-from paddle import distributed as dist
from yacs.config import CfgNode
from paddlespeech.s2t.exps.deepspeech2.model import DeepSpeech2Trainer as Trainer
@@ -27,18 +26,18 @@ def main_sp(config, args):
def main(config, args):
- if args.ngpu > 1:
- dist.spawn(main_sp, args=(config, args), nprocs=args.ngpu)
- else:
- main_sp(config, args)
+ main_sp(config, args)
if __name__ == "__main__":
parser = default_argument_parser()
parser.add_argument(
- "--model_type", type=str, default='offline', help='offline/online')
+ '--nxpu',
+ type=int,
+ default=0,
+ choices=[0, 1],
+ help="if nxpu == 0 and ngpu == 0, use cpu.")
args = parser.parse_args()
- print("model_type:{}".format(args.model_type))
print_arguments(args, globals())
# https://yaml.org/type/float.html
diff --git a/paddlespeech/s2t/exps/deepspeech2/model.py b/paddlespeech/s2t/exps/deepspeech2/model.py
index 3c2eaab72..511997a7c 100644
--- a/paddlespeech/s2t/exps/deepspeech2/model.py
+++ b/paddlespeech/s2t/exps/deepspeech2/model.py
@@ -22,17 +22,11 @@ import numpy as np
import paddle
from paddle import distributed as dist
from paddle import inference
-from paddle.io import DataLoader
from paddlespeech.s2t.frontend.featurizer.text_featurizer import TextFeaturizer
-from paddlespeech.s2t.io.collator import SpeechCollator
-from paddlespeech.s2t.io.dataset import ManifestDataset
-from paddlespeech.s2t.io.sampler import SortagradBatchSampler
-from paddlespeech.s2t.io.sampler import SortagradDistributedBatchSampler
+from paddlespeech.s2t.io.dataloader import BatchDataLoader
from paddlespeech.s2t.models.ds2 import DeepSpeech2InferModel
from paddlespeech.s2t.models.ds2 import DeepSpeech2Model
-from paddlespeech.s2t.models.ds2_online import DeepSpeech2InferModelOnline
-from paddlespeech.s2t.models.ds2_online import DeepSpeech2ModelOnline
from paddlespeech.s2t.training.gradclip import ClipGradByGlobalNormWithLog
from paddlespeech.s2t.training.reporter import report
from paddlespeech.s2t.training.timer import Timer
@@ -136,18 +130,13 @@ class DeepSpeech2Trainer(Trainer):
config = self.config.clone()
with UpdateConfig(config):
if self.train:
- config.input_dim = self.train_loader.collate_fn.feature_size
- config.output_dim = self.train_loader.collate_fn.vocab_size
+ config.input_dim = self.train_loader.feat_dim
+ config.output_dim = self.train_loader.vocab_size
else:
- config.input_dim = self.test_loader.collate_fn.feature_size
- config.output_dim = self.test_loader.collate_fn.vocab_size
+ config.input_dim = self.test_loader.feat_dim
+ config.output_dim = self.test_loader.vocab_size
- if self.args.model_type == 'offline':
- model = DeepSpeech2Model.from_config(config)
- elif self.args.model_type == 'online':
- model = DeepSpeech2ModelOnline.from_config(config)
- else:
- raise Exception("wrong model type")
+ model = DeepSpeech2Model.from_config(config)
if self.parallel:
model = paddle.DataParallel(model)
@@ -175,76 +164,80 @@ class DeepSpeech2Trainer(Trainer):
config = self.config.clone()
config.defrost()
if self.train:
- # train
- config.manifest = config.train_manifest
- train_dataset = ManifestDataset.from_config(config)
- if self.parallel:
- batch_sampler = SortagradDistributedBatchSampler(
- train_dataset,
- batch_size=config.batch_size,
- num_replicas=None,
- rank=None,
- shuffle=True,
- drop_last=True,
- sortagrad=config.sortagrad,
- shuffle_method=config.shuffle_method)
- else:
- batch_sampler = SortagradBatchSampler(
- train_dataset,
- shuffle=True,
- batch_size=config.batch_size,
- drop_last=True,
- sortagrad=config.sortagrad,
- shuffle_method=config.shuffle_method)
-
- config.keep_transcription_text = False
- collate_fn_train = SpeechCollator.from_config(config)
- self.train_loader = DataLoader(
- train_dataset,
- batch_sampler=batch_sampler,
- collate_fn=collate_fn_train,
- num_workers=config.num_workers)
-
- # dev
- config.manifest = config.dev_manifest
- dev_dataset = ManifestDataset.from_config(config)
-
- config.augmentation_config = ""
- config.keep_transcription_text = False
- collate_fn_dev = SpeechCollator.from_config(config)
- self.valid_loader = DataLoader(
- dev_dataset,
- batch_size=int(config.batch_size),
- shuffle=False,
- drop_last=False,
- collate_fn=collate_fn_dev,
- num_workers=config.num_workers)
- logger.info("Setup train/valid Dataloader!")
+ # train/valid dataset, return token ids
+ self.train_loader = BatchDataLoader(
+ json_file=config.train_manifest,
+ train_mode=True,
+ sortagrad=config.sortagrad,
+ batch_size=config.batch_size,
+ maxlen_in=config.maxlen_in,
+ maxlen_out=config.maxlen_out,
+ minibatches=config.minibatches,
+ mini_batch_size=self.args.ngpu,
+ batch_count=config.batch_count,
+ batch_bins=config.batch_bins,
+ batch_frames_in=config.batch_frames_in,
+ batch_frames_out=config.batch_frames_out,
+ batch_frames_inout=config.batch_frames_inout,
+ preprocess_conf=config.preprocess_config,
+ n_iter_processes=config.num_workers,
+ subsampling_factor=1,
+ num_encs=1,
+ dist_sampler=config.get('dist_sampler', False),
+ shortest_first=False)
+
+ self.valid_loader = BatchDataLoader(
+ json_file=config.dev_manifest,
+ train_mode=False,
+ sortagrad=False,
+ batch_size=config.batch_size,
+ maxlen_in=float('inf'),
+ maxlen_out=float('inf'),
+ minibatches=0,
+ mini_batch_size=self.args.ngpu,
+ batch_count='auto',
+ batch_bins=0,
+ batch_frames_in=0,
+ batch_frames_out=0,
+ batch_frames_inout=0,
+ preprocess_conf=config.preprocess_config,
+ n_iter_processes=config.num_workers,
+ subsampling_factor=1,
+ num_encs=1,
+ dist_sampler=config.get('dist_sampler', False),
+ shortest_first=False)
+ logger.info("Setup train/valid Dataloader!")
else:
- # test
- config.manifest = config.test_manifest
- test_dataset = ManifestDataset.from_config(config)
-
- config.augmentation_config = ""
- config.keep_transcription_text = True
- collate_fn_test = SpeechCollator.from_config(config)
decode_batch_size = config.get('decode', dict()).get(
'decode_batch_size', 1)
- self.test_loader = DataLoader(
- test_dataset,
+ # test dataset, return raw text
+ self.test_loader = BatchDataLoader(
+ json_file=config.test_manifest,
+ train_mode=False,
+ sortagrad=False,
batch_size=decode_batch_size,
- shuffle=False,
- drop_last=False,
- collate_fn=collate_fn_test,
- num_workers=config.num_workers)
- logger.info("Setup test Dataloader!")
+ maxlen_in=float('inf'),
+ maxlen_out=float('inf'),
+ minibatches=0,
+ mini_batch_size=1,
+ batch_count='auto',
+ batch_bins=0,
+ batch_frames_in=0,
+ batch_frames_out=0,
+ batch_frames_inout=0,
+ preprocess_conf=config.preprocess_config,
+ n_iter_processes=1,
+ subsampling_factor=1,
+ num_encs=1)
+ logger.info("Setup test/align Dataloader!")
class DeepSpeech2Tester(DeepSpeech2Trainer):
def __init__(self, config, args):
super().__init__(config, args)
self._text_featurizer = TextFeaturizer(
- unit_type=config.unit_type, vocab=None)
+ unit_type=config.unit_type, vocab=config.vocab_filepath)
+ self.vocab_list = self._text_featurizer.vocab_list
def ordid2token(self, texts, texts_len):
""" ord() id to chr() chr """
@@ -252,7 +245,8 @@ class DeepSpeech2Tester(DeepSpeech2Trainer):
for text, n in zip(texts, texts_len):
n = n.numpy().item()
ids = text[:n]
- trans.append(''.join([chr(i) for i in ids]))
+ trans.append(
+ self._text_featurizer.defeaturize(ids.numpy().tolist()))
return trans
def compute_metrics(self,
@@ -307,8 +301,8 @@ class DeepSpeech2Tester(DeepSpeech2Trainer):
# Initialized the decoder in model
decode_cfg = self.config.decode
- vocab_list = self.test_loader.collate_fn.vocab_list
- decode_batch_size = self.test_loader.batch_size
+ vocab_list = self.vocab_list
+ decode_batch_size = decode_cfg.decode_batch_size
self.model.decoder.init_decoder(
decode_batch_size, vocab_list, decode_cfg.decoding_method,
decode_cfg.lang_model_path, decode_cfg.alpha, decode_cfg.beta,
@@ -338,17 +332,9 @@ class DeepSpeech2Tester(DeepSpeech2Trainer):
@paddle.no_grad()
def export(self):
- if self.args.model_type == 'offline':
- infer_model = DeepSpeech2InferModel.from_pretrained(
- self.test_loader, self.config, self.args.checkpoint_path)
- elif self.args.model_type == 'online':
- infer_model = DeepSpeech2InferModelOnline.from_pretrained(
- self.test_loader, self.config, self.args.checkpoint_path)
- else:
- raise Exception("wrong model type")
-
+ infer_model = DeepSpeech2InferModel.from_pretrained(
+ self.test_loader, self.config, self.args.checkpoint_path)
infer_model.eval()
- feat_dim = self.test_loader.collate_fn.feature_size
static_model = infer_model.export()
logger.info(f"Export code: {static_model.forward.code}")
paddle.jit.save(static_model, self.args.export_path)
@@ -376,10 +362,10 @@ class DeepSpeech2ExportTester(DeepSpeech2Tester):
# Initialized the decoder in model
decode_cfg = self.config.decode
- vocab_list = self.test_loader.collate_fn.vocab_list
- if self.args.model_type == "online":
+ vocab_list = self.vocab_list
+ if self.config.rnn_direction == "forward":
decode_batch_size = 1
- elif self.args.model_type == "offline":
+ elif self.config.rnn_direction == "bidirect":
decode_batch_size = self.test_loader.batch_size
else:
raise Exception("wrong model type")
@@ -412,11 +398,11 @@ class DeepSpeech2ExportTester(DeepSpeech2Tester):
self.model.decoder.del_decoder()
def compute_result_transcripts(self, audio, audio_len):
- if self.args.model_type == "online":
+ if self.config.rnn_direction == "forward":
output_probs, output_lens, trans_batch = self.static_forward_online(
audio, audio_len, decoder_chunk_size=1)
result_transcripts = [trans[-1] for trans in trans_batch]
- elif self.args.model_type == "offline":
+ elif self.config.rnn_direction == "bidirect":
output_probs, output_lens = self.static_forward_offline(audio,
audio_len)
batch_size = output_probs.shape[0]
diff --git a/paddlespeech/s2t/exps/u2/bin/train.py b/paddlespeech/s2t/exps/u2/bin/train.py
index 53c223283..dc3a87c16 100644
--- a/paddlespeech/s2t/exps/u2/bin/train.py
+++ b/paddlespeech/s2t/exps/u2/bin/train.py
@@ -15,7 +15,6 @@
import cProfile
import os
-from paddle import distributed as dist
from yacs.config import CfgNode
from paddlespeech.s2t.exps.u2.model import U2Trainer as Trainer
@@ -32,10 +31,7 @@ def main_sp(config, args):
def main(config, args):
- if args.ngpu > 1:
- dist.spawn(main_sp, args=(config, args), nprocs=args.ngpu)
- else:
- main_sp(config, args)
+ main_sp(config, args)
if __name__ == "__main__":
diff --git a/paddlespeech/s2t/exps/u2_kaldi/bin/train.py b/paddlespeech/s2t/exps/u2_kaldi/bin/train.py
index fcfc05a8a..b11da7154 100644
--- a/paddlespeech/s2t/exps/u2_kaldi/bin/train.py
+++ b/paddlespeech/s2t/exps/u2_kaldi/bin/train.py
@@ -15,7 +15,6 @@
import cProfile
import os
-from paddle import distributed as dist
from yacs.config import CfgNode
from paddlespeech.s2t.training.cli import default_argument_parser
@@ -36,10 +35,7 @@ def main_sp(config, args):
def main(config, args):
- if args.ngpu > 1:
- dist.spawn(main_sp, args=(config, args), nprocs=args.ngpu)
- else:
- main_sp(config, args)
+ main_sp(config, args)
if __name__ == "__main__":
diff --git a/paddlespeech/s2t/exps/u2_st/bin/train.py b/paddlespeech/s2t/exps/u2_st/bin/train.py
index 4dec9ec8a..574942e5a 100644
--- a/paddlespeech/s2t/exps/u2_st/bin/train.py
+++ b/paddlespeech/s2t/exps/u2_st/bin/train.py
@@ -15,7 +15,6 @@
import cProfile
import os
-from paddle import distributed as dist
from yacs.config import CfgNode
from paddlespeech.s2t.exps.u2_st.model import U2STTrainer as Trainer
@@ -30,10 +29,7 @@ def main_sp(config, args):
def main(config, args):
- if args.ngpu > 1:
- dist.spawn(main_sp, args=(config, args), nprocs=args.ngpu)
- else:
- main_sp(config, args)
+ main_sp(config, args)
if __name__ == "__main__":
diff --git a/paddlespeech/s2t/frontend/featurizer/audio_featurizer.py b/paddlespeech/s2t/frontend/featurizer/audio_featurizer.py
index 22329d5e0..ac5720fd5 100644
--- a/paddlespeech/s2t/frontend/featurizer/audio_featurizer.py
+++ b/paddlespeech/s2t/frontend/featurizer/audio_featurizer.py
@@ -14,10 +14,11 @@
"""Contains the audio featurizer class."""
import numpy as np
import paddle
-import paddleaudio.compliance.kaldi as kaldi
from python_speech_features import delta
from python_speech_features import mfcc
+import paddlespeech.audio.compliance.kaldi as kaldi
+
class AudioFeaturizer():
"""Audio featurizer, for extracting features from audio contents of
diff --git a/paddlespeech/s2t/io/dataset.py b/paddlespeech/s2t/io/dataset.py
index 0e94f047b..9987b5110 100644
--- a/paddlespeech/s2t/io/dataset.py
+++ b/paddlespeech/s2t/io/dataset.py
@@ -1,4 +1,5 @@
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+# Copyright 2021 Mobvoi Inc. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
diff --git a/paddlespeech/s2t/models/ds2/__init__.py b/paddlespeech/s2t/models/ds2/__init__.py
index b32220673..480f6d3af 100644
--- a/paddlespeech/s2t/models/ds2/__init__.py
+++ b/paddlespeech/s2t/models/ds2/__init__.py
@@ -11,6 +11,8 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
+import sys
+
from .deepspeech2 import DeepSpeech2InferModel
from .deepspeech2 import DeepSpeech2Model
from paddlespeech.s2t.utils import dynamic_pip_install
@@ -20,7 +22,8 @@ try:
except ImportError:
try:
package_name = 'paddlespeech_ctcdecoders'
- dynamic_pip_install.install(package_name)
+ if sys.platform != "win32":
+ dynamic_pip_install.install(package_name)
except Exception:
raise RuntimeError(
"Can not install package paddlespeech_ctcdecoders on your system. \
diff --git a/paddlespeech/s2t/models/ds2/conv.py b/paddlespeech/s2t/models/ds2/conv.py
index 4e766e793..448d4d1bb 100644
--- a/paddlespeech/s2t/models/ds2/conv.py
+++ b/paddlespeech/s2t/models/ds2/conv.py
@@ -11,161 +11,23 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-from paddle import nn
-from paddle.nn import functional as F
+import paddle
-from paddlespeech.s2t.modules.activation import brelu
-from paddlespeech.s2t.modules.mask import make_non_pad_mask
-from paddlespeech.s2t.utils.log import Log
+from paddlespeech.s2t.modules.subsampling import Conv2dSubsampling4
-logger = Log(__name__).getlog()
-__all__ = ['ConvStack', "conv_output_size"]
+class Conv2dSubsampling4Pure(Conv2dSubsampling4):
+ def __init__(self, idim: int, odim: int, dropout_rate: float):
+ super().__init__(idim, odim, dropout_rate, None)
+ self.output_dim = ((idim - 1) // 2 - 1) // 2 * odim
+ self.receptive_field_length = 2 * (
+ 3 - 1) + 3 # stride_1 * (kernel_size_2 - 1) + kerel_size_1
-
-def conv_output_size(I, F, P, S):
- # https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-convolutional-neural-networks#hyperparameters
- # Output size after Conv:
- # By noting I the length of the input volume size,
- # F the length of the filter,
- # P the amount of zero padding,
- # S the stride,
- # then the output size O of the feature map along that dimension is given by:
- # O = (I - F + Pstart + Pend) // S + 1
- # When Pstart == Pend == P, we can replace Pstart + Pend by 2P.
- # When Pstart == Pend == 0
- # O = (I - F - S) // S
- # https://iq.opengenus.org/output-size-of-convolution/
- # Output height = (Input height + padding height top + padding height bottom - kernel height) / (stride height) + 1
- # Output width = (Output width + padding width right + padding width left - kernel width) / (stride width) + 1
- return (I - F + 2 * P - S) // S
-
-
-# receptive field calculator
-# https://fomoro.com/research/article/receptive-field-calculator
-# https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-convolutional-neural-networks#hyperparameters
-# https://distill.pub/2019/computing-receptive-fields/
-# Rl-1 = Sl * Rl + (Kl - Sl)
-
-
-class ConvBn(nn.Layer):
- """Convolution layer with batch normalization.
-
- :param kernel_size: The x dimension of a filter kernel. Or input a tuple for
- two image dimension.
- :type kernel_size: int|tuple|list
- :param num_channels_in: Number of input channels.
- :type num_channels_in: int
- :param num_channels_out: Number of output channels.
- :type num_channels_out: int
- :param stride: The x dimension of the stride. Or input a tuple for two
- image dimension.
- :type stride: int|tuple|list
- :param padding: The x dimension of the padding. Or input a tuple for two
- image dimension.
- :type padding: int|tuple|list
- :param act: Activation type, relu|brelu
- :type act: string
- :return: Batch norm layer after convolution layer.
- :rtype: Variable
-
- """
-
- def __init__(self, num_channels_in, num_channels_out, kernel_size, stride,
- padding, act):
-
- super().__init__()
- assert len(kernel_size) == 2
- assert len(stride) == 2
- assert len(padding) == 2
- self.kernel_size = kernel_size
- self.stride = stride
- self.padding = padding
-
- self.conv = nn.Conv2D(
- num_channels_in,
- num_channels_out,
- kernel_size=kernel_size,
- stride=stride,
- padding=padding,
- weight_attr=None,
- bias_attr=False,
- data_format='NCHW')
-
- self.bn = nn.BatchNorm2D(
- num_channels_out,
- weight_attr=None,
- bias_attr=None,
- data_format='NCHW')
- self.act = F.relu if act == 'relu' else brelu
-
- def forward(self, x, x_len):
- """
- x(Tensor): audio, shape [B, C, D, T]
- """
+ def forward(self, x: paddle.Tensor,
+ x_len: paddle.Tensor) -> [paddle.Tensor, paddle.Tensor]:
+ x = x.unsqueeze(1) # (b, c=1, t, f)
x = self.conv(x)
- x = self.bn(x)
- x = self.act(x)
-
- x_len = (x_len - self.kernel_size[1] + 2 * self.padding[1]
- ) // self.stride[1] + 1
-
- # reset padding part to 0
- masks = make_non_pad_mask(x_len) #[B, T]
- masks = masks.unsqueeze(1).unsqueeze(1) # [B, 1, 1, T]
- # TODO(Hui Zhang): not support bool multiply
- # masks = masks.type_as(x)
- masks = masks.astype(x.dtype)
- x = x.multiply(masks)
- return x, x_len
-
-
-class ConvStack(nn.Layer):
- """Convolution group with stacked convolution layers.
-
- :param feat_size: audio feature dim.
- :type feat_size: int
- :param num_stacks: Number of stacked convolution layers.
- :type num_stacks: int
- """
-
- def __init__(self, feat_size, num_stacks):
- super().__init__()
- self.feat_size = feat_size # D
- self.num_stacks = num_stacks
-
- self.conv_in = ConvBn(
- num_channels_in=1,
- num_channels_out=32,
- kernel_size=(41, 11), #[D, T]
- stride=(2, 3),
- padding=(20, 5),
- act='brelu')
-
- out_channel = 32
- convs = [
- ConvBn(
- num_channels_in=32,
- num_channels_out=out_channel,
- kernel_size=(21, 11),
- stride=(2, 1),
- padding=(10, 5),
- act='brelu') for i in range(num_stacks - 1)
- ]
- self.conv_stack = nn.LayerList(convs)
-
- # conv output feat_dim
- output_height = (feat_size - 1) // 2 + 1
- for i in range(self.num_stacks - 1):
- output_height = (output_height - 1) // 2 + 1
- self.output_height = out_channel * output_height
-
- def forward(self, x, x_len):
- """
- x: shape [B, C, D, T]
- x_len : shape [B]
- """
- x, x_len = self.conv_in(x, x_len)
- for i, conv in enumerate(self.conv_stack):
- x, x_len = conv(x, x_len)
+ #b, c, t, f = paddle.shape(x) #not work under jit
+ x = x.transpose([0, 2, 1, 3]).reshape([0, 0, -1])
+ x_len = ((x_len - 1) // 2 - 1) // 2
return x, x_len
diff --git a/paddlespeech/s2t/models/ds2/deepspeech2.py b/paddlespeech/s2t/models/ds2/deepspeech2.py
index 9c6b66c25..b7ee80a7d 100644
--- a/paddlespeech/s2t/models/ds2/deepspeech2.py
+++ b/paddlespeech/s2t/models/ds2/deepspeech2.py
@@ -13,15 +13,14 @@
# limitations under the License.
"""Deepspeech2 ASR Model"""
import paddle
+import paddle.nn.functional as F
from paddle import nn
-from paddlespeech.s2t.models.ds2.conv import ConvStack
-from paddlespeech.s2t.models.ds2.rnn import RNNStack
+from paddlespeech.s2t.models.ds2.conv import Conv2dSubsampling4Pure
from paddlespeech.s2t.modules.ctc import CTCDecoder
from paddlespeech.s2t.utils import layer_tools
from paddlespeech.s2t.utils.checkpoint import Checkpoint
from paddlespeech.s2t.utils.log import Log
-
logger = Log(__name__).getlog()
__all__ = ['DeepSpeech2Model', 'DeepSpeech2InferModel']
@@ -32,72 +31,197 @@ class CRNNEncoder(nn.Layer):
feat_size,
dict_size,
num_conv_layers=2,
- num_rnn_layers=3,
+ num_rnn_layers=4,
rnn_size=1024,
- use_gru=False,
- share_rnn_weights=True):
+ rnn_direction='forward',
+ num_fc_layers=2,
+ fc_layers_size_list=[512, 256],
+ use_gru=False):
super().__init__()
self.rnn_size = rnn_size
self.feat_size = feat_size # 161 for linear
self.dict_size = dict_size
-
- self.conv = ConvStack(feat_size, num_conv_layers)
-
- i_size = self.conv.output_height # H after conv stack
- self.rnn = RNNStack(
- i_size=i_size,
- h_size=rnn_size,
- num_stacks=num_rnn_layers,
- use_gru=use_gru,
- share_rnn_weights=share_rnn_weights)
+ self.num_rnn_layers = num_rnn_layers
+ self.num_fc_layers = num_fc_layers
+ self.rnn_direction = rnn_direction
+ self.fc_layers_size_list = fc_layers_size_list
+ self.use_gru = use_gru
+ self.conv = Conv2dSubsampling4Pure(feat_size, 32, dropout_rate=0.0)
+
+ self.output_dim = self.conv.output_dim
+
+ i_size = self.conv.output_dim
+ self.rnn = nn.LayerList()
+ self.layernorm_list = nn.LayerList()
+ self.fc_layers_list = nn.LayerList()
+ if rnn_direction == 'bidirect' or rnn_direction == 'bidirectional':
+ layernorm_size = 2 * rnn_size
+ elif rnn_direction == 'forward':
+ layernorm_size = rnn_size
+ else:
+ raise Exception("Wrong rnn direction")
+ for i in range(0, num_rnn_layers):
+ if i == 0:
+ rnn_input_size = i_size
+ else:
+ rnn_input_size = layernorm_size
+ if use_gru is True:
+ self.rnn.append(
+ nn.GRU(
+ input_size=rnn_input_size,
+ hidden_size=rnn_size,
+ num_layers=1,
+ direction=rnn_direction))
+ else:
+ self.rnn.append(
+ nn.LSTM(
+ input_size=rnn_input_size,
+ hidden_size=rnn_size,
+ num_layers=1,
+ direction=rnn_direction))
+ self.layernorm_list.append(nn.LayerNorm(layernorm_size))
+ self.output_dim = layernorm_size
+
+ fc_input_size = layernorm_size
+ for i in range(self.num_fc_layers):
+ self.fc_layers_list.append(
+ nn.Linear(fc_input_size, fc_layers_size_list[i]))
+ fc_input_size = fc_layers_size_list[i]
+ self.output_dim = fc_layers_size_list[i]
@property
def output_size(self):
- return self.rnn_size * 2
+ return self.output_dim
- def forward(self, audio, audio_len):
+ def forward(self, x, x_lens, init_state_h_box=None, init_state_c_box=None):
"""Compute Encoder outputs
Args:
- audio (Tensor): [B, Tmax, D]
- text (Tensor): [B, Umax]
- audio_len (Tensor): [B]
- text_len (Tensor): [B]
- Returns:
+ x (Tensor): [B, T, D]
+ x_lens (Tensor): [B]
+ init_state_h_box(Tensor): init_states h for RNN layers: [num_rnn_layers * num_directions, batch_size, hidden_size]
+ init_state_c_box(Tensor): init_states c for RNN layers: [num_rnn_layers * num_directions, batch_size, hidden_size]
+ Return:
x (Tensor): encoder outputs, [B, T, D]
x_lens (Tensor): encoder length, [B]
+ final_state_h_box(Tensor): final_states h for RNN layers: [num_rnn_layers * num_directions, batch_size, hidden_size]
+ final_state_c_box(Tensor): final_states c for RNN layers: [num_rnn_layers * num_directions, batch_size, hidden_size]
"""
- # [B, T, D] -> [B, D, T]
- audio = audio.transpose([0, 2, 1])
- # [B, D, T] -> [B, C=1, D, T]
- x = audio.unsqueeze(1)
- x_lens = audio_len
+ if init_state_h_box is not None:
+ init_state_list = None
+
+ if self.use_gru is True:
+ init_state_h_list = paddle.split(
+ init_state_h_box, self.num_rnn_layers, axis=0)
+ init_state_list = init_state_h_list
+ else:
+ init_state_h_list = paddle.split(
+ init_state_h_box, self.num_rnn_layers, axis=0)
+ init_state_c_list = paddle.split(
+ init_state_c_box, self.num_rnn_layers, axis=0)
+ init_state_list = [(init_state_h_list[i], init_state_c_list[i])
+ for i in range(self.num_rnn_layers)]
+ else:
+ init_state_list = [None] * self.num_rnn_layers
- # convolution group
x, x_lens = self.conv(x, x_lens)
+ final_chunk_state_list = []
+ for i in range(0, self.num_rnn_layers):
+ x, final_state = self.rnn[i](x, init_state_list[i],
+ x_lens) #[B, T, D]
+ final_chunk_state_list.append(final_state)
+ x = self.layernorm_list[i](x)
+
+ for i in range(self.num_fc_layers):
+ x = self.fc_layers_list[i](x)
+ x = F.relu(x)
+
+ if self.use_gru is True:
+ final_chunk_state_h_box = paddle.concat(
+ final_chunk_state_list, axis=0)
+ final_chunk_state_c_box = init_state_c_box
+ else:
+ final_chunk_state_h_list = [
+ final_chunk_state_list[i][0] for i in range(self.num_rnn_layers)
+ ]
+ final_chunk_state_c_list = [
+ final_chunk_state_list[i][1] for i in range(self.num_rnn_layers)
+ ]
+ final_chunk_state_h_box = paddle.concat(
+ final_chunk_state_h_list, axis=0)
+ final_chunk_state_c_box = paddle.concat(
+ final_chunk_state_c_list, axis=0)
+
+ return x, x_lens, final_chunk_state_h_box, final_chunk_state_c_box
+
+ def forward_chunk_by_chunk(self, x, x_lens, decoder_chunk_size=8):
+ """Compute Encoder outputs
- # convert data from convolution feature map to sequence of vectors
- #B, C, D, T = paddle.shape(x) # not work under jit
- x = x.transpose([0, 3, 1, 2]) #[B, T, C, D]
- #x = x.reshape([B, T, C * D]) #[B, T, C*D] # not work under jit
- x = x.reshape([0, 0, -1]) #[B, T, C*D]
-
- # remove padding part
- x, x_lens = self.rnn(x, x_lens) #[B, T, D]
- return x, x_lens
+ Args:
+ x (Tensor): [B, T, D]
+ x_lens (Tensor): [B]
+ decoder_chunk_size: The chunk size of decoder
+ Returns:
+ eouts_list (List of Tensor): The list of encoder outputs in chunk_size: [B, chunk_size, D] * num_chunks
+ eouts_lens_list (List of Tensor): The list of encoder length in chunk_size: [B] * num_chunks
+ final_state_h_box(Tensor): final_states h for RNN layers: [num_rnn_layers * num_directions, batch_size, hidden_size]
+ final_state_c_box(Tensor): final_states c for RNN layers: [num_rnn_layers * num_directions, batch_size, hidden_size]
+ """
+ subsampling_rate = self.conv.subsampling_rate
+ receptive_field_length = self.conv.receptive_field_length
+ chunk_size = (decoder_chunk_size - 1
+ ) * subsampling_rate + receptive_field_length
+ chunk_stride = subsampling_rate * decoder_chunk_size
+ max_len = x.shape[1]
+ assert (chunk_size <= max_len)
+
+ eouts_chunk_list = []
+ eouts_chunk_lens_list = []
+ if (max_len - chunk_size) % chunk_stride != 0:
+ padding_len = chunk_stride - (max_len - chunk_size) % chunk_stride
+ else:
+ padding_len = 0
+ padding = paddle.zeros((x.shape[0], padding_len, x.shape[2]))
+ padded_x = paddle.concat([x, padding], axis=1)
+ num_chunk = (max_len + padding_len - chunk_size) / chunk_stride + 1
+ num_chunk = int(num_chunk)
+ chunk_state_h_box = None
+ chunk_state_c_box = None
+ final_state_h_box = None
+ final_state_c_box = None
+ for i in range(0, num_chunk):
+ start = i * chunk_stride
+ end = start + chunk_size
+ x_chunk = padded_x[:, start:end, :]
+
+ x_len_left = paddle.where(x_lens - i * chunk_stride < 0,
+ paddle.zeros_like(x_lens),
+ x_lens - i * chunk_stride)
+ x_chunk_len_tmp = paddle.ones_like(x_lens) * chunk_size
+ x_chunk_lens = paddle.where(x_len_left < x_chunk_len_tmp,
+ x_len_left, x_chunk_len_tmp)
+
+ eouts_chunk, eouts_chunk_lens, chunk_state_h_box, chunk_state_c_box = self.forward(
+ x_chunk, x_chunk_lens, chunk_state_h_box, chunk_state_c_box)
+
+ eouts_chunk_list.append(eouts_chunk)
+ eouts_chunk_lens_list.append(eouts_chunk_lens)
+ final_state_h_box = chunk_state_h_box
+ final_state_c_box = chunk_state_c_box
+ return eouts_chunk_list, eouts_chunk_lens_list, final_state_h_box, final_state_c_box
class DeepSpeech2Model(nn.Layer):
"""The DeepSpeech2 network structure.
- :param audio_data: Audio spectrogram data layer.
- :type audio_data: Variable
- :param text_data: Transcription text data layer.
- :type text_data: Variable
+ :param audio: Audio spectrogram data layer.
+ :type audio: Variable
+ :param text: Transcription text data layer.
+ :type text: Variable
:param audio_len: Valid sequence length data layer.
:type audio_len: Variable
- :param masks: Masks data layer to reset padding.
- :type masks: Variable
+ :param feat_size: feature size for audio.
+ :type feat_size: int
:param dict_size: Dictionary size for tokenized transcription.
:type dict_size: int
:param num_conv_layers: Number of stacking convolution layers.
@@ -106,37 +230,41 @@ class DeepSpeech2Model(nn.Layer):
:type num_rnn_layers: int
:param rnn_size: RNN layer size (dimension of RNN cells).
:type rnn_size: int
+ :param num_fc_layers: Number of stacking FC layers.
+ :type num_fc_layers: int
+ :param fc_layers_size_list: The list of FC layer sizes.
+ :type fc_layers_size_list: [int,]
:param use_gru: Use gru if set True. Use simple rnn if set False.
:type use_gru: bool
- :param share_rnn_weights: Whether to share input-hidden weights between
- forward and backward direction RNNs.
- It is only available when use_gru=False.
- :type share_weights: bool
:return: A tuple of an output unnormalized log probability layer (
before softmax) and a ctc cost layer.
:rtype: tuple of LayerOutput
"""
- def __init__(self,
- feat_size,
- dict_size,
- num_conv_layers=2,
- num_rnn_layers=3,
- rnn_size=1024,
- use_gru=False,
- share_rnn_weights=True,
- blank_id=0,
- ctc_grad_norm_type=None):
+ def __init__(
+ self,
+ feat_size,
+ dict_size,
+ num_conv_layers=2,
+ num_rnn_layers=4,
+ rnn_size=1024,
+ rnn_direction='forward',
+ num_fc_layers=2,
+ fc_layers_size_list=[512, 256],
+ use_gru=False,
+ blank_id=0,
+ ctc_grad_norm_type=None, ):
super().__init__()
self.encoder = CRNNEncoder(
feat_size=feat_size,
dict_size=dict_size,
num_conv_layers=num_conv_layers,
num_rnn_layers=num_rnn_layers,
+ rnn_direction=rnn_direction,
+ num_fc_layers=num_fc_layers,
+ fc_layers_size_list=fc_layers_size_list,
rnn_size=rnn_size,
- use_gru=use_gru,
- share_rnn_weights=share_rnn_weights)
- assert (self.encoder.output_size == rnn_size * 2)
+ use_gru=use_gru)
self.decoder = CTCDecoder(
odim=dict_size, # is in vocab
@@ -151,7 +279,7 @@ class DeepSpeech2Model(nn.Layer):
"""Compute Model loss
Args:
- audio (Tensors): [B, T, D]
+ audio (Tensor): [B, T, D]
audio_len (Tensor): [B]
text (Tensor): [B, U]
text_len (Tensor): [B]
@@ -159,22 +287,22 @@ class DeepSpeech2Model(nn.Layer):
Returns:
loss (Tensor): [1]
"""
- eouts, eouts_len = self.encoder(audio, audio_len)
+ eouts, eouts_len, final_state_h_box, final_state_c_box = self.encoder(
+ audio, audio_len, None, None)
loss = self.decoder(eouts, eouts_len, text, text_len)
return loss
@paddle.no_grad()
def decode(self, audio, audio_len):
# decoders only accept string encoded in utf-8
-
# Make sure the decoder has been initialized
- eouts, eouts_len = self.encoder(audio, audio_len)
+ eouts, eouts_len, final_state_h_box, final_state_c_box = self.encoder(
+ audio, audio_len, None, None)
probs = self.decoder.softmax(eouts)
batch_size = probs.shape[0]
self.decoder.reset_decoder(batch_size=batch_size)
self.decoder.next(probs, eouts_len)
trans_best, trans_beam = self.decoder.decode()
-
return trans_best
@classmethod
@@ -196,13 +324,15 @@ class DeepSpeech2Model(nn.Layer):
The model built from pretrained result.
"""
model = cls(
- feat_size=dataloader.collate_fn.feature_size,
- dict_size=dataloader.collate_fn.vocab_size,
+ feat_size=dataloader.feat_dim,
+ dict_size=dataloader.vocab_size,
num_conv_layers=config.num_conv_layers,
num_rnn_layers=config.num_rnn_layers,
rnn_size=config.rnn_layer_size,
+ rnn_direction=config.rnn_direction,
+ num_fc_layers=config.num_fc_layers,
+ fc_layers_size_list=config.fc_layers_size_list,
use_gru=config.use_gru,
- share_rnn_weights=config.share_rnn_weights,
blank_id=config.blank_id,
ctc_grad_norm_type=config.get('ctc_grad_norm_type', None), )
infos = Checkpoint().load_parameters(
@@ -229,8 +359,10 @@ class DeepSpeech2Model(nn.Layer):
num_conv_layers=config.num_conv_layers,
num_rnn_layers=config.num_rnn_layers,
rnn_size=config.rnn_layer_size,
+ rnn_direction=config.rnn_direction,
+ num_fc_layers=config.num_fc_layers,
+ fc_layers_size_list=config.fc_layers_size_list,
use_gru=config.use_gru,
- share_rnn_weights=config.share_rnn_weights,
blank_id=config.blank_id,
ctc_grad_norm_type=config.get('ctc_grad_norm_type', None), )
return model
@@ -240,28 +372,50 @@ class DeepSpeech2InferModel(DeepSpeech2Model):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
- def forward(self, audio, audio_len):
- """export model function
-
- Args:
- audio (Tensor): [B, T, D]
- audio_len (Tensor): [B]
-
- Returns:
- probs: probs after softmax
- """
- eouts, eouts_len = self.encoder(audio, audio_len)
- probs = self.decoder.softmax(eouts)
- return probs, eouts_len
+ def forward(self,
+ audio_chunk,
+ audio_chunk_lens,
+ chunk_state_h_box=None,
+ chunk_state_c_box=None):
+ if self.encoder.rnn_direction == "forward":
+ eouts_chunk, eouts_chunk_lens, final_state_h_box, final_state_c_box = self.encoder(
+ audio_chunk, audio_chunk_lens, chunk_state_h_box,
+ chunk_state_c_box)
+ probs_chunk = self.decoder.softmax(eouts_chunk)
+ return probs_chunk, eouts_chunk_lens, final_state_h_box, final_state_c_box
+ elif self.encoder.rnn_direction == "bidirect":
+ eouts, eouts_len, _, _ = self.encoder(audio_chunk, audio_chunk_lens)
+ probs = self.decoder.softmax(eouts)
+ return probs, eouts_len
+ else:
+ raise Exception("wrong model type")
def export(self):
- static_model = paddle.jit.to_static(
- self,
- input_spec=[
- paddle.static.InputSpec(
- shape=[None, None, self.encoder.feat_size],
- dtype='float32'), # audio, [B,T,D]
- paddle.static.InputSpec(shape=[None],
- dtype='int64'), # audio_length, [B]
- ])
+ if self.encoder.rnn_direction == "forward":
+ static_model = paddle.jit.to_static(
+ self,
+ input_spec=[
+ paddle.static.InputSpec(
+ shape=[None, None, self.encoder.feat_size
+ ], #[B, chunk_size, feat_dim]
+ dtype='float32'),
+ paddle.static.InputSpec(shape=[None],
+ dtype='int64'), # audio_length, [B]
+ paddle.static.InputSpec(
+ shape=[None, None, None], dtype='float32'),
+ paddle.static.InputSpec(
+ shape=[None, None, None], dtype='float32')
+ ])
+ elif self.encoder.rnn_direction == "bidirect":
+ static_model = paddle.jit.to_static(
+ self,
+ input_spec=[
+ paddle.static.InputSpec(
+ shape=[None, None, self.encoder.feat_size],
+ dtype='float32'), # audio, [B,T,D]
+ paddle.static.InputSpec(shape=[None],
+ dtype='int64'), # audio_length, [B]
+ ])
+ else:
+ raise Exception("wrong model type")
return static_model
diff --git a/paddlespeech/s2t/models/ds2/rnn.py b/paddlespeech/s2t/models/ds2/rnn.py
deleted file mode 100644
index f655b2d82..000000000
--- a/paddlespeech/s2t/models/ds2/rnn.py
+++ /dev/null
@@ -1,315 +0,0 @@
-# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import math
-
-import paddle
-from paddle import nn
-from paddle.nn import functional as F
-from paddle.nn import initializer as I
-
-from paddlespeech.s2t.modules.activation import brelu
-from paddlespeech.s2t.modules.mask import make_non_pad_mask
-from paddlespeech.s2t.utils.log import Log
-
-logger = Log(__name__).getlog()
-
-__all__ = ['RNNStack']
-
-
-class RNNCell(nn.RNNCellBase):
- r"""
- Elman RNN (SimpleRNN) cell. Given the inputs and previous states, it
- computes the outputs and updates states.
- The formula used is as follows:
- .. math::
- h_{t} & = act(x_{t} + b_{ih} + W_{hh}h_{t-1} + b_{hh})
- y_{t} & = h_{t}
-
- where :math:`act` is for :attr:`activation`.
- """
-
- def __init__(self,
- hidden_size: int,
- activation="tanh",
- weight_ih_attr=None,
- weight_hh_attr=None,
- bias_ih_attr=None,
- bias_hh_attr=None,
- name=None):
- super().__init__()
- std = 1.0 / math.sqrt(hidden_size)
- self.weight_hh = self.create_parameter(
- (hidden_size, hidden_size),
- weight_hh_attr,
- default_initializer=I.Uniform(-std, std))
- self.bias_ih = None
- self.bias_hh = self.create_parameter(
- (hidden_size, ),
- bias_hh_attr,
- is_bias=True,
- default_initializer=I.Uniform(-std, std))
-
- self.hidden_size = hidden_size
- if activation not in ["tanh", "relu", "brelu"]:
- raise ValueError(
- "activation for SimpleRNNCell should be tanh or relu, "
- "but get {}".format(activation))
- self.activation = activation
- self._activation_fn = paddle.tanh \
- if activation == "tanh" \
- else F.relu
- if activation == 'brelu':
- self._activation_fn = brelu
-
- def forward(self, inputs, states=None):
- if states is None:
- states = self.get_initial_states(inputs, self.state_shape)
- pre_h = states
- i2h = inputs
- if self.bias_ih is not None:
- i2h += self.bias_ih
- h2h = paddle.matmul(pre_h, self.weight_hh, transpose_y=True)
- if self.bias_hh is not None:
- h2h += self.bias_hh
- h = self._activation_fn(i2h + h2h)
- return h, h
-
- @property
- def state_shape(self):
- return (self.hidden_size, )
-
-
-class GRUCell(nn.RNNCellBase):
- r"""
- Gated Recurrent Unit (GRU) RNN cell. Given the inputs and previous states,
- it computes the outputs and updates states.
- The formula for GRU used is as follows:
- .. math::
- r_{t} & = \sigma(W_{ir}x_{t} + b_{ir} + W_{hr}h_{t-1} + b_{hr})
- z_{t} & = \sigma(W_{iz}x_{t} + b_{iz} + W_{hz}h_{t-1} + b_{hz})
- \widetilde{h}_{t} & = \tanh(W_{ic}x_{t} + b_{ic} + r_{t} * (W_{hc}h_{t-1} + b_{hc}))
- h_{t} & = z_{t} * h_{t-1} + (1 - z_{t}) * \widetilde{h}_{t}
- y_{t} & = h_{t}
-
- where :math:`\sigma` is the sigmoid fucntion, and * is the elemetwise
- multiplication operator.
- """
-
- def __init__(self,
- input_size: int,
- hidden_size: int,
- weight_ih_attr=None,
- weight_hh_attr=None,
- bias_ih_attr=None,
- bias_hh_attr=None,
- name=None):
- super().__init__()
- std = 1.0 / math.sqrt(hidden_size)
- self.weight_hh = self.create_parameter(
- (3 * hidden_size, hidden_size),
- weight_hh_attr,
- default_initializer=I.Uniform(-std, std))
- self.bias_ih = None
- self.bias_hh = self.create_parameter(
- (3 * hidden_size, ),
- bias_hh_attr,
- is_bias=True,
- default_initializer=I.Uniform(-std, std))
-
- self.hidden_size = hidden_size
- self.input_size = input_size
- self._gate_activation = F.sigmoid
- self._activation = paddle.tanh
-
- def forward(self, inputs, states=None):
- if states is None:
- states = self.get_initial_states(inputs, self.state_shape)
-
- pre_hidden = states
- x_gates = inputs
- if self.bias_ih is not None:
- x_gates = x_gates + self.bias_ih
- h_gates = paddle.matmul(pre_hidden, self.weight_hh, transpose_y=True)
- if self.bias_hh is not None:
- h_gates = h_gates + self.bias_hh
-
- x_r, x_z, x_c = paddle.split(x_gates, num_or_sections=3, axis=1)
- h_r, h_z, h_c = paddle.split(h_gates, num_or_sections=3, axis=1)
-
- r = self._gate_activation(x_r + h_r)
- z = self._gate_activation(x_z + h_z)
- c = self._activation(x_c + r * h_c) # apply reset gate after mm
- h = (pre_hidden - c) * z + c
- # https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/fluid/layers/dynamic_gru_cn.html#dynamic-gru
-
- return h, h
-
- @property
- def state_shape(self):
- r"""
- The `state_shape` of GRUCell is a shape `[hidden_size]` (-1 for batch
- size would be automatically inserted into shape). The shape corresponds
- to the shape of :math:`h_{t-1}`.
- """
- return (self.hidden_size, )
-
-
-class BiRNNWithBN(nn.Layer):
- """Bidirectonal simple rnn layer with sequence-wise batch normalization.
- The batch normalization is only performed on input-state weights.
-
- :param size: Dimension of RNN cells.
- :type size: int
- :param share_weights: Whether to share input-hidden weights between
- forward and backward directional RNNs.
- :type share_weights: bool
- :return: Bidirectional simple rnn layer.
- :rtype: Variable
- """
-
- def __init__(self, i_size: int, h_size: int, share_weights: bool):
- super().__init__()
- self.share_weights = share_weights
- if self.share_weights:
- #input-hidden weights shared between bi-directional rnn.
- self.fw_fc = nn.Linear(i_size, h_size, bias_attr=False)
- # batch norm is only performed on input-state projection
- self.fw_bn = nn.BatchNorm1D(
- h_size, bias_attr=None, data_format='NLC')
- self.bw_fc = self.fw_fc
- self.bw_bn = self.fw_bn
- else:
- self.fw_fc = nn.Linear(i_size, h_size, bias_attr=False)
- self.fw_bn = nn.BatchNorm1D(
- h_size, bias_attr=None, data_format='NLC')
- self.bw_fc = nn.Linear(i_size, h_size, bias_attr=False)
- self.bw_bn = nn.BatchNorm1D(
- h_size, bias_attr=None, data_format='NLC')
-
- self.fw_cell = RNNCell(hidden_size=h_size, activation='brelu')
- self.bw_cell = RNNCell(hidden_size=h_size, activation='brelu')
- self.fw_rnn = nn.RNN(
- self.fw_cell, is_reverse=False, time_major=False) #[B, T, D]
- self.bw_rnn = nn.RNN(
- self.fw_cell, is_reverse=True, time_major=False) #[B, T, D]
-
- def forward(self, x: paddle.Tensor, x_len: paddle.Tensor):
- # x, shape [B, T, D]
- fw_x = self.fw_bn(self.fw_fc(x))
- bw_x = self.bw_bn(self.bw_fc(x))
- fw_x, _ = self.fw_rnn(inputs=fw_x, sequence_length=x_len)
- bw_x, _ = self.bw_rnn(inputs=bw_x, sequence_length=x_len)
- x = paddle.concat([fw_x, bw_x], axis=-1)
- return x, x_len
-
-
-class BiGRUWithBN(nn.Layer):
- """Bidirectonal gru layer with sequence-wise batch normalization.
- The batch normalization is only performed on input-state weights.
-
- :param name: Name of the layer.
- :type name: string
- :param input: Input layer.
- :type input: Variable
- :param size: Dimension of GRU cells.
- :type size: int
- :param act: Activation type.
- :type act: string
- :return: Bidirectional GRU layer.
- :rtype: Variable
- """
-
- def __init__(self, i_size: int, h_size: int):
- super().__init__()
- hidden_size = h_size * 3
-
- self.fw_fc = nn.Linear(i_size, hidden_size, bias_attr=False)
- self.fw_bn = nn.BatchNorm1D(
- hidden_size, bias_attr=None, data_format='NLC')
- self.bw_fc = nn.Linear(i_size, hidden_size, bias_attr=False)
- self.bw_bn = nn.BatchNorm1D(
- hidden_size, bias_attr=None, data_format='NLC')
-
- self.fw_cell = GRUCell(input_size=hidden_size, hidden_size=h_size)
- self.bw_cell = GRUCell(input_size=hidden_size, hidden_size=h_size)
- self.fw_rnn = nn.RNN(
- self.fw_cell, is_reverse=False, time_major=False) #[B, T, D]
- self.bw_rnn = nn.RNN(
- self.fw_cell, is_reverse=True, time_major=False) #[B, T, D]
-
- def forward(self, x, x_len):
- # x, shape [B, T, D]
- fw_x = self.fw_bn(self.fw_fc(x))
- bw_x = self.bw_bn(self.bw_fc(x))
- fw_x, _ = self.fw_rnn(inputs=fw_x, sequence_length=x_len)
- bw_x, _ = self.bw_rnn(inputs=bw_x, sequence_length=x_len)
- x = paddle.concat([fw_x, bw_x], axis=-1)
- return x, x_len
-
-
-class RNNStack(nn.Layer):
- """RNN group with stacked bidirectional simple RNN or GRU layers.
-
- :param input: Input layer.
- :type input: Variable
- :param size: Dimension of RNN cells in each layer.
- :type size: int
- :param num_stacks: Number of stacked rnn layers.
- :type num_stacks: int
- :param use_gru: Use gru if set True. Use simple rnn if set False.
- :type use_gru: bool
- :param share_rnn_weights: Whether to share input-hidden weights between
- forward and backward directional RNNs.
- It is only available when use_gru=False.
- :type share_weights: bool
- :return: Output layer of the RNN group.
- :rtype: Variable
- """
-
- def __init__(self,
- i_size: int,
- h_size: int,
- num_stacks: int,
- use_gru: bool,
- share_rnn_weights: bool):
- super().__init__()
- rnn_stacks = []
- for i in range(num_stacks):
- if use_gru:
- #default:GRU using tanh
- rnn_stacks.append(BiGRUWithBN(i_size=i_size, h_size=h_size))
- else:
- rnn_stacks.append(
- BiRNNWithBN(
- i_size=i_size,
- h_size=h_size,
- share_weights=share_rnn_weights))
- i_size = h_size * 2
-
- self.rnn_stacks = nn.LayerList(rnn_stacks)
-
- def forward(self, x: paddle.Tensor, x_len: paddle.Tensor):
- """
- x: shape [B, T, D]
- x_len: shpae [B]
- """
- for i, rnn in enumerate(self.rnn_stacks):
- x, x_len = rnn(x, x_len)
- masks = make_non_pad_mask(x_len) #[B, T]
- masks = masks.unsqueeze(-1) # [B, T, 1]
- # TODO(Hui Zhang): not support bool multiply
- masks = masks.astype(x.dtype)
- x = x.multiply(masks)
-
- return x, x_len
diff --git a/paddlespeech/s2t/models/ds2_online/__init__.py b/paddlespeech/s2t/models/ds2_online/__init__.py
deleted file mode 100644
index c5fdab1bc..000000000
--- a/paddlespeech/s2t/models/ds2_online/__init__.py
+++ /dev/null
@@ -1,29 +0,0 @@
-# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-from .deepspeech2 import DeepSpeech2InferModelOnline
-from .deepspeech2 import DeepSpeech2ModelOnline
-from paddlespeech.s2t.utils import dynamic_pip_install
-
-try:
- import paddlespeech_ctcdecoders
-except ImportError:
- try:
- package_name = 'paddlespeech_ctcdecoders'
- dynamic_pip_install.install(package_name)
- except Exception:
- raise RuntimeError(
- "Can not install package paddlespeech_ctcdecoders on your system. \
- The DeepSpeech2 model is not supported for your system")
-
-__all__ = ['DeepSpeech2ModelOnline', 'DeepSpeech2InferModelOnline']
diff --git a/paddlespeech/s2t/models/ds2_online/conv.py b/paddlespeech/s2t/models/ds2_online/conv.py
deleted file mode 100644
index 25a9715a3..000000000
--- a/paddlespeech/s2t/models/ds2_online/conv.py
+++ /dev/null
@@ -1,33 +0,0 @@
-# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import paddle
-
-from paddlespeech.s2t.modules.subsampling import Conv2dSubsampling4
-
-
-class Conv2dSubsampling4Online(Conv2dSubsampling4):
- def __init__(self, idim: int, odim: int, dropout_rate: float):
- super().__init__(idim, odim, dropout_rate, None)
- self.output_dim = ((idim - 1) // 2 - 1) // 2 * odim
- self.receptive_field_length = 2 * (
- 3 - 1) + 3 # stride_1 * (kernel_size_2 - 1) + kerel_size_1
-
- def forward(self, x: paddle.Tensor,
- x_len: paddle.Tensor) -> [paddle.Tensor, paddle.Tensor]:
- x = x.unsqueeze(1) # (b, c=1, t, f)
- x = self.conv(x)
- #b, c, t, f = paddle.shape(x) #not work under jit
- x = x.transpose([0, 2, 1, 3]).reshape([0, 0, -1])
- x_len = ((x_len - 1) // 2 - 1) // 2
- return x, x_len
diff --git a/paddlespeech/s2t/models/ds2_online/deepspeech2.py b/paddlespeech/s2t/models/ds2_online/deepspeech2.py
deleted file mode 100644
index 9574a62bd..000000000
--- a/paddlespeech/s2t/models/ds2_online/deepspeech2.py
+++ /dev/null
@@ -1,397 +0,0 @@
-# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Deepspeech2 ASR Online Model"""
-import paddle
-import paddle.nn.functional as F
-from paddle import nn
-
-from paddlespeech.s2t.models.ds2_online.conv import Conv2dSubsampling4Online
-from paddlespeech.s2t.modules.ctc import CTCDecoder
-from paddlespeech.s2t.utils import layer_tools
-from paddlespeech.s2t.utils.checkpoint import Checkpoint
-from paddlespeech.s2t.utils.log import Log
-logger = Log(__name__).getlog()
-
-__all__ = ['DeepSpeech2ModelOnline', 'DeepSpeech2InferModelOnline']
-
-
-class CRNNEncoder(nn.Layer):
- def __init__(self,
- feat_size,
- dict_size,
- num_conv_layers=2,
- num_rnn_layers=4,
- rnn_size=1024,
- rnn_direction='forward',
- num_fc_layers=2,
- fc_layers_size_list=[512, 256],
- use_gru=False):
- super().__init__()
- self.rnn_size = rnn_size
- self.feat_size = feat_size # 161 for linear
- self.dict_size = dict_size
- self.num_rnn_layers = num_rnn_layers
- self.num_fc_layers = num_fc_layers
- self.rnn_direction = rnn_direction
- self.fc_layers_size_list = fc_layers_size_list
- self.use_gru = use_gru
- self.conv = Conv2dSubsampling4Online(feat_size, 32, dropout_rate=0.0)
-
- self.output_dim = self.conv.output_dim
-
- i_size = self.conv.output_dim
- self.rnn = nn.LayerList()
- self.layernorm_list = nn.LayerList()
- self.fc_layers_list = nn.LayerList()
- if rnn_direction == 'bidirect' or rnn_direction == 'bidirectional':
- layernorm_size = 2 * rnn_size
- elif rnn_direction == 'forward':
- layernorm_size = rnn_size
- else:
- raise Exception("Wrong rnn direction")
- for i in range(0, num_rnn_layers):
- if i == 0:
- rnn_input_size = i_size
- else:
- rnn_input_size = layernorm_size
- if use_gru is True:
- self.rnn.append(
- nn.GRU(
- input_size=rnn_input_size,
- hidden_size=rnn_size,
- num_layers=1,
- direction=rnn_direction))
- else:
- self.rnn.append(
- nn.LSTM(
- input_size=rnn_input_size,
- hidden_size=rnn_size,
- num_layers=1,
- direction=rnn_direction))
- self.layernorm_list.append(nn.LayerNorm(layernorm_size))
- self.output_dim = layernorm_size
-
- fc_input_size = layernorm_size
- for i in range(self.num_fc_layers):
- self.fc_layers_list.append(
- nn.Linear(fc_input_size, fc_layers_size_list[i]))
- fc_input_size = fc_layers_size_list[i]
- self.output_dim = fc_layers_size_list[i]
-
- @property
- def output_size(self):
- return self.output_dim
-
- def forward(self, x, x_lens, init_state_h_box=None, init_state_c_box=None):
- """Compute Encoder outputs
-
- Args:
- x (Tensor): [B, T, D]
- x_lens (Tensor): [B]
- init_state_h_box(Tensor): init_states h for RNN layers: [num_rnn_layers * num_directions, batch_size, hidden_size]
- init_state_c_box(Tensor): init_states c for RNN layers: [num_rnn_layers * num_directions, batch_size, hidden_size]
- Return:
- x (Tensor): encoder outputs, [B, T, D]
- x_lens (Tensor): encoder length, [B]
- final_state_h_box(Tensor): final_states h for RNN layers: [num_rnn_layers * num_directions, batch_size, hidden_size]
- final_state_c_box(Tensor): final_states c for RNN layers: [num_rnn_layers * num_directions, batch_size, hidden_size]
- """
- if init_state_h_box is not None:
- init_state_list = None
-
- if self.use_gru is True:
- init_state_h_list = paddle.split(
- init_state_h_box, self.num_rnn_layers, axis=0)
- init_state_list = init_state_h_list
- else:
- init_state_h_list = paddle.split(
- init_state_h_box, self.num_rnn_layers, axis=0)
- init_state_c_list = paddle.split(
- init_state_c_box, self.num_rnn_layers, axis=0)
- init_state_list = [(init_state_h_list[i], init_state_c_list[i])
- for i in range(self.num_rnn_layers)]
- else:
- init_state_list = [None] * self.num_rnn_layers
-
- x, x_lens = self.conv(x, x_lens)
- final_chunk_state_list = []
- for i in range(0, self.num_rnn_layers):
- x, final_state = self.rnn[i](x, init_state_list[i],
- x_lens) #[B, T, D]
- final_chunk_state_list.append(final_state)
- x = self.layernorm_list[i](x)
-
- for i in range(self.num_fc_layers):
- x = self.fc_layers_list[i](x)
- x = F.relu(x)
-
- if self.use_gru is True:
- final_chunk_state_h_box = paddle.concat(
- final_chunk_state_list, axis=0)
- final_chunk_state_c_box = init_state_c_box
- else:
- final_chunk_state_h_list = [
- final_chunk_state_list[i][0] for i in range(self.num_rnn_layers)
- ]
- final_chunk_state_c_list = [
- final_chunk_state_list[i][1] for i in range(self.num_rnn_layers)
- ]
- final_chunk_state_h_box = paddle.concat(
- final_chunk_state_h_list, axis=0)
- final_chunk_state_c_box = paddle.concat(
- final_chunk_state_c_list, axis=0)
-
- return x, x_lens, final_chunk_state_h_box, final_chunk_state_c_box
-
- def forward_chunk_by_chunk(self, x, x_lens, decoder_chunk_size=8):
- """Compute Encoder outputs
-
- Args:
- x (Tensor): [B, T, D]
- x_lens (Tensor): [B]
- decoder_chunk_size: The chunk size of decoder
- Returns:
- eouts_list (List of Tensor): The list of encoder outputs in chunk_size: [B, chunk_size, D] * num_chunks
- eouts_lens_list (List of Tensor): The list of encoder length in chunk_size: [B] * num_chunks
- final_state_h_box(Tensor): final_states h for RNN layers: [num_rnn_layers * num_directions, batch_size, hidden_size]
- final_state_c_box(Tensor): final_states c for RNN layers: [num_rnn_layers * num_directions, batch_size, hidden_size]
- """
- subsampling_rate = self.conv.subsampling_rate
- receptive_field_length = self.conv.receptive_field_length
- chunk_size = (decoder_chunk_size - 1
- ) * subsampling_rate + receptive_field_length
- chunk_stride = subsampling_rate * decoder_chunk_size
- max_len = x.shape[1]
- assert (chunk_size <= max_len)
-
- eouts_chunk_list = []
- eouts_chunk_lens_list = []
- if (max_len - chunk_size) % chunk_stride != 0:
- padding_len = chunk_stride - (max_len - chunk_size) % chunk_stride
- else:
- padding_len = 0
- padding = paddle.zeros((x.shape[0], padding_len, x.shape[2]))
- padded_x = paddle.concat([x, padding], axis=1)
- num_chunk = (max_len + padding_len - chunk_size) / chunk_stride + 1
- num_chunk = int(num_chunk)
- chunk_state_h_box = None
- chunk_state_c_box = None
- final_state_h_box = None
- final_state_c_box = None
- for i in range(0, num_chunk):
- start = i * chunk_stride
- end = start + chunk_size
- x_chunk = padded_x[:, start:end, :]
-
- x_len_left = paddle.where(x_lens - i * chunk_stride < 0,
- paddle.zeros_like(x_lens),
- x_lens - i * chunk_stride)
- x_chunk_len_tmp = paddle.ones_like(x_lens) * chunk_size
- x_chunk_lens = paddle.where(x_len_left < x_chunk_len_tmp,
- x_len_left, x_chunk_len_tmp)
-
- eouts_chunk, eouts_chunk_lens, chunk_state_h_box, chunk_state_c_box = self.forward(
- x_chunk, x_chunk_lens, chunk_state_h_box, chunk_state_c_box)
-
- eouts_chunk_list.append(eouts_chunk)
- eouts_chunk_lens_list.append(eouts_chunk_lens)
- final_state_h_box = chunk_state_h_box
- final_state_c_box = chunk_state_c_box
- return eouts_chunk_list, eouts_chunk_lens_list, final_state_h_box, final_state_c_box
-
-
-class DeepSpeech2ModelOnline(nn.Layer):
- """The DeepSpeech2 network structure for online.
-
- :param audio: Audio spectrogram data layer.
- :type audio: Variable
- :param text: Transcription text data layer.
- :type text: Variable
- :param audio_len: Valid sequence length data layer.
- :type audio_len: Variable
- :param feat_size: feature size for audio.
- :type feat_size: int
- :param dict_size: Dictionary size for tokenized transcription.
- :type dict_size: int
- :param num_conv_layers: Number of stacking convolution layers.
- :type num_conv_layers: int
- :param num_rnn_layers: Number of stacking RNN layers.
- :type num_rnn_layers: int
- :param rnn_size: RNN layer size (dimension of RNN cells).
- :type rnn_size: int
- :param num_fc_layers: Number of stacking FC layers.
- :type num_fc_layers: int
- :param fc_layers_size_list: The list of FC layer sizes.
- :type fc_layers_size_list: [int,]
- :param use_gru: Use gru if set True. Use simple rnn if set False.
- :type use_gru: bool
- :return: A tuple of an output unnormalized log probability layer (
- before softmax) and a ctc cost layer.
- :rtype: tuple of LayerOutput
- """
-
- def __init__(
- self,
- feat_size,
- dict_size,
- num_conv_layers=2,
- num_rnn_layers=4,
- rnn_size=1024,
- rnn_direction='forward',
- num_fc_layers=2,
- fc_layers_size_list=[512, 256],
- use_gru=False,
- blank_id=0,
- ctc_grad_norm_type=None, ):
- super().__init__()
- self.encoder = CRNNEncoder(
- feat_size=feat_size,
- dict_size=dict_size,
- num_conv_layers=num_conv_layers,
- num_rnn_layers=num_rnn_layers,
- rnn_direction=rnn_direction,
- num_fc_layers=num_fc_layers,
- fc_layers_size_list=fc_layers_size_list,
- rnn_size=rnn_size,
- use_gru=use_gru)
-
- self.decoder = CTCDecoder(
- odim=dict_size, # is in vocab
- enc_n_units=self.encoder.output_size,
- blank_id=blank_id,
- dropout_rate=0.0,
- reduction=True, # sum
- batch_average=True, # sum / batch_size
- grad_norm_type=ctc_grad_norm_type)
-
- def forward(self, audio, audio_len, text, text_len):
- """Compute Model loss
-
- Args:
- audio (Tensor): [B, T, D]
- audio_len (Tensor): [B]
- text (Tensor): [B, U]
- text_len (Tensor): [B]
-
- Returns:
- loss (Tensor): [1]
- """
- eouts, eouts_len, final_state_h_box, final_state_c_box = self.encoder(
- audio, audio_len, None, None)
- loss = self.decoder(eouts, eouts_len, text, text_len)
- return loss
-
- @paddle.no_grad()
- def decode(self, audio, audio_len):
- # decoders only accept string encoded in utf-8
- # Make sure the decoder has been initialized
- eouts, eouts_len, final_state_h_box, final_state_c_box = self.encoder(
- audio, audio_len, None, None)
- probs = self.decoder.softmax(eouts)
- batch_size = probs.shape[0]
- self.decoder.reset_decoder(batch_size=batch_size)
- self.decoder.next(probs, eouts_len)
- trans_best, trans_beam = self.decoder.decode()
- return trans_best
-
- @classmethod
- def from_pretrained(cls, dataloader, config, checkpoint_path):
- """Build a DeepSpeech2Model model from a pretrained model.
- Parameters
- ----------
- dataloader: paddle.io.DataLoader
-
- config: yacs.config.CfgNode
- model configs
-
- checkpoint_path: Path or str
- the path of pretrained model checkpoint, without extension name
-
- Returns
- -------
- DeepSpeech2ModelOnline
- The model built from pretrained result.
- """
- model = cls(
- feat_size=dataloader.collate_fn.feature_size,
- dict_size=dataloader.collate_fn.vocab_size,
- num_conv_layers=config.num_conv_layers,
- num_rnn_layers=config.num_rnn_layers,
- rnn_size=config.rnn_layer_size,
- rnn_direction=config.rnn_direction,
- num_fc_layers=config.num_fc_layers,
- fc_layers_size_list=config.fc_layers_size_list,
- use_gru=config.use_gru,
- blank_id=config.blank_id,
- ctc_grad_norm_type=config.get('ctc_grad_norm_type', None), )
- infos = Checkpoint().load_parameters(
- model, checkpoint_path=checkpoint_path)
- logger.info(f"checkpoint info: {infos}")
- layer_tools.summary(model)
- return model
-
- @classmethod
- def from_config(cls, config):
- """Build a DeepSpeec2ModelOnline from config
- Parameters
-
- config: yacs.config.CfgNode
- config
- Returns
- -------
- DeepSpeech2ModelOnline
- The model built from config.
- """
- model = cls(
- feat_size=config.input_dim,
- dict_size=config.output_dim,
- num_conv_layers=config.num_conv_layers,
- num_rnn_layers=config.num_rnn_layers,
- rnn_size=config.rnn_layer_size,
- rnn_direction=config.rnn_direction,
- num_fc_layers=config.num_fc_layers,
- fc_layers_size_list=config.fc_layers_size_list,
- use_gru=config.use_gru,
- blank_id=config.blank_id,
- ctc_grad_norm_type=config.get('ctc_grad_norm_type', None), )
- return model
-
-
-class DeepSpeech2InferModelOnline(DeepSpeech2ModelOnline):
- def __init__(self, *args, **kwargs):
- super().__init__(*args, **kwargs)
-
- def forward(self, audio_chunk, audio_chunk_lens, chunk_state_h_box,
- chunk_state_c_box):
- eouts_chunk, eouts_chunk_lens, final_state_h_box, final_state_c_box = self.encoder(
- audio_chunk, audio_chunk_lens, chunk_state_h_box, chunk_state_c_box)
- probs_chunk = self.decoder.softmax(eouts_chunk)
- return probs_chunk, eouts_chunk_lens, final_state_h_box, final_state_c_box
-
- def export(self):
- static_model = paddle.jit.to_static(
- self,
- input_spec=[
- paddle.static.InputSpec(
- shape=[None, None,
- self.encoder.feat_size], #[B, chunk_size, feat_dim]
- dtype='float32'),
- paddle.static.InputSpec(shape=[None],
- dtype='int64'), # audio_length, [B]
- paddle.static.InputSpec(
- shape=[None, None, None], dtype='float32'),
- paddle.static.InputSpec(
- shape=[None, None, None], dtype='float32')
- ])
- return static_model
diff --git a/paddlespeech/s2t/models/lm/transformer.py b/paddlespeech/s2t/models/lm/transformer.py
index 85bd7c232..04ddddf86 100644
--- a/paddlespeech/s2t/models/lm/transformer.py
+++ b/paddlespeech/s2t/models/lm/transformer.py
@@ -90,7 +90,7 @@ class TransformerLM(nn.Layer, LMInterface, BatchScorerInterface):
def _target_mask(self, ys_in_pad):
ys_mask = ys_in_pad != 0
- m = subsequent_mask(ys_mask.size(-1)).unsqueeze(0)
+ m = subsequent_mask(paddle.shape(ys_mask)[-1]).unsqueeze(0)
return ys_mask.unsqueeze(-2) & m
def forward(self, x: paddle.Tensor, t: paddle.Tensor
@@ -112,7 +112,7 @@ class TransformerLM(nn.Layer, LMInterface, BatchScorerInterface):
in perplexity: p(t)^{-n} = exp(-log p(t) / n)
"""
- batch_size = x.size(0)
+ batch_size = paddle.shape(x)[0]
xm = x != 0
xlen = xm.sum(axis=1)
if self.embed_drop is not None:
@@ -122,7 +122,7 @@ class TransformerLM(nn.Layer, LMInterface, BatchScorerInterface):
h, _ = self.encoder(emb, xlen)
y = self.decoder(h)
loss = F.cross_entropy(
- y.view(-1, y.shape[-1]), t.view(-1), reduction="none")
+ y.view(-1, paddle.shape(y)[-1]), t.view(-1), reduction="none")
mask = xm.to(loss.dtype)
logp = loss * mask.view(-1)
nll = logp.view(batch_size, -1).sum(-1)
diff --git a/paddlespeech/s2t/models/u2/u2.py b/paddlespeech/s2t/models/u2/u2.py
index 530840d0f..b4b61666f 100644
--- a/paddlespeech/s2t/models/u2/u2.py
+++ b/paddlespeech/s2t/models/u2/u2.py
@@ -1,3 +1,4 @@
+# Copyright 2021 Mobvoi Inc. All Rights Reserved.
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
@@ -775,7 +776,7 @@ class U2DecodeModel(U2BaseModel):
"""
self.eval()
x = paddle.to_tensor(x).unsqueeze(0)
- ilen = x.size(1)
+ ilen = paddle.shape(x)[1]
enc_output, _ = self._forward_encoder(x, ilen)
return enc_output.squeeze(0)
diff --git a/paddlespeech/s2t/models/u2/updater.py b/paddlespeech/s2t/models/u2/updater.py
index c59090a84..bb18fe416 100644
--- a/paddlespeech/s2t/models/u2/updater.py
+++ b/paddlespeech/s2t/models/u2/updater.py
@@ -11,7 +11,6 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-# Modified from wenet(https://github.com/wenet-e2e/wenet)
from contextlib import nullcontext
import paddle
diff --git a/paddlespeech/s2t/modules/ctc.py b/paddlespeech/s2t/modules/ctc.py
index 33ad472de..0f50db21d 100644
--- a/paddlespeech/s2t/modules/ctc.py
+++ b/paddlespeech/s2t/modules/ctc.py
@@ -11,6 +11,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
+import sys
from typing import Union
import paddle
@@ -34,7 +35,8 @@ except ImportError:
try:
from paddlespeech.s2t.utils import dynamic_pip_install
package_name = 'paddlespeech_ctcdecoders'
- dynamic_pip_install.install(package_name)
+ if sys.platform != "win32":
+ dynamic_pip_install.install(package_name)
from paddlespeech.s2t.decoders.ctcdecoder import ctc_beam_search_decoding_batch # noqa: F401
from paddlespeech.s2t.decoders.ctcdecoder import ctc_greedy_decoding # noqa: F401
from paddlespeech.s2t.decoders.ctcdecoder import Scorer # noqa: F401
diff --git a/paddlespeech/s2t/modules/decoder.py b/paddlespeech/s2t/modules/decoder.py
index 3a851ec62..ccc8482d5 100644
--- a/paddlespeech/s2t/modules/decoder.py
+++ b/paddlespeech/s2t/modules/decoder.py
@@ -62,21 +62,21 @@ class TransformerDecoder(BatchScorerInterface, nn.Layer):
False: x -> x + att(x)
"""
- def __init__(
- self,
- vocab_size: int,
- encoder_output_size: int,
- attention_heads: int=4,
- linear_units: int=2048,
- num_blocks: int=6,
- dropout_rate: float=0.1,
- positional_dropout_rate: float=0.1,
- self_attention_dropout_rate: float=0.0,
- src_attention_dropout_rate: float=0.0,
- input_layer: str="embed",
- use_output_layer: bool=True,
- normalize_before: bool=True,
- concat_after: bool=False, ):
+ def __init__(self,
+ vocab_size: int,
+ encoder_output_size: int,
+ attention_heads: int=4,
+ linear_units: int=2048,
+ num_blocks: int=6,
+ dropout_rate: float=0.1,
+ positional_dropout_rate: float=0.1,
+ self_attention_dropout_rate: float=0.0,
+ src_attention_dropout_rate: float=0.0,
+ input_layer: str="embed",
+ use_output_layer: bool=True,
+ normalize_before: bool=True,
+ concat_after: bool=False,
+ max_len: int=5000):
assert check_argument_types()
@@ -87,7 +87,8 @@ class TransformerDecoder(BatchScorerInterface, nn.Layer):
if input_layer == "embed":
self.embed = nn.Sequential(
Embedding(vocab_size, attention_dim),
- PositionalEncoding(attention_dim, positional_dropout_rate), )
+ PositionalEncoding(
+ attention_dim, positional_dropout_rate, max_len=max_len), )
else:
raise ValueError(f"only 'embed' is supported: {input_layer}")
@@ -241,7 +242,7 @@ class TransformerDecoder(BatchScorerInterface, nn.Layer):
]
# batch decoding
- ys_mask = subsequent_mask(ys.size(-1)).unsqueeze(0) # (B,L,L)
+ ys_mask = subsequent_mask(paddle.shape(ys)[-1]).unsqueeze(0) # (B,L,L)
xs_mask = make_xs_mask(xs).unsqueeze(1) # (B,1,T)
logp, states = self.forward_one_step(
xs, xs_mask, ys, ys_mask, cache=batch_state)
diff --git a/paddlespeech/s2t/modules/embedding.py b/paddlespeech/s2t/modules/embedding.py
index 5d4e91753..51e558eb8 100644
--- a/paddlespeech/s2t/modules/embedding.py
+++ b/paddlespeech/s2t/modules/embedding.py
@@ -112,8 +112,10 @@ class PositionalEncoding(nn.Layer, PositionalEncodingInterface):
paddle.Tensor: for compatibility to RelPositionalEncoding, (batch=1, time, ...)
"""
T = x.shape[1]
- assert offset + x.shape[1] < self.max_len
- #TODO(Hui Zhang): using T = x.size(1), __getitem__ not support Tensor
+ assert offset + x.shape[
+ 1] < self.max_len, "offset: {} + x.shape[1]: {} is larger than the max_len: {}".format(
+ offset, x.shape[1], self.max_len)
+ #TODO(Hui Zhang): using T = paddle.shape(x)[1], __getitem__ not support Tensor
pos_emb = self.pe[:, offset:offset + T]
x = x * self.xscale + pos_emb
return self.dropout(x), self.dropout(pos_emb)
@@ -148,6 +150,7 @@ class RelPositionalEncoding(PositionalEncoding):
max_len (int, optional): [Maximum input length.]. Defaults to 5000.
"""
super().__init__(d_model, dropout_rate, max_len, reverse=True)
+ logger.info(f"max len: {max_len}")
def forward(self, x: paddle.Tensor,
offset: int=0) -> Tuple[paddle.Tensor, paddle.Tensor]:
@@ -158,8 +161,10 @@ class RelPositionalEncoding(PositionalEncoding):
paddle.Tensor: Encoded tensor (batch, time, `*`).
paddle.Tensor: Positional embedding tensor (1, time, `*`).
"""
- assert offset + x.shape[1] < self.max_len
+ assert offset + x.shape[
+ 1] < self.max_len, "offset: {} + x.shape[1]: {} is larger than the max_len: {}".format(
+ offset, x.shape[1], self.max_len)
x = x * self.xscale
- #TODO(Hui Zhang): using x.size(1), __getitem__ not support Tensor
+ #TODO(Hui Zhang): using paddle.shape(x)[1], __getitem__ not support Tensor
pos_emb = self.pe[:, offset:offset + x.shape[1]]
return self.dropout(x), self.dropout(pos_emb)
diff --git a/paddlespeech/s2t/modules/encoder.py b/paddlespeech/s2t/modules/encoder.py
index c843c0e20..4d31acf1a 100644
--- a/paddlespeech/s2t/modules/encoder.py
+++ b/paddlespeech/s2t/modules/encoder.py
@@ -47,24 +47,24 @@ __all__ = ["BaseEncoder", 'TransformerEncoder', "ConformerEncoder"]
class BaseEncoder(nn.Layer):
- def __init__(
- self,
- input_size: int,
- output_size: int=256,
- attention_heads: int=4,
- linear_units: int=2048,
- num_blocks: int=6,
- dropout_rate: float=0.1,
- positional_dropout_rate: float=0.1,
- attention_dropout_rate: float=0.0,
- input_layer: str="conv2d",
- pos_enc_layer_type: str="abs_pos",
- normalize_before: bool=True,
- concat_after: bool=False,
- static_chunk_size: int=0,
- use_dynamic_chunk: bool=False,
- global_cmvn: paddle.nn.Layer=None,
- use_dynamic_left_chunk: bool=False, ):
+ def __init__(self,
+ input_size: int,
+ output_size: int=256,
+ attention_heads: int=4,
+ linear_units: int=2048,
+ num_blocks: int=6,
+ dropout_rate: float=0.1,
+ positional_dropout_rate: float=0.1,
+ attention_dropout_rate: float=0.0,
+ input_layer: str="conv2d",
+ pos_enc_layer_type: str="abs_pos",
+ normalize_before: bool=True,
+ concat_after: bool=False,
+ static_chunk_size: int=0,
+ use_dynamic_chunk: bool=False,
+ global_cmvn: paddle.nn.Layer=None,
+ use_dynamic_left_chunk: bool=False,
+ max_len: int=5000):
"""
Args:
input_size (int): input dim, d_feature
@@ -127,7 +127,9 @@ class BaseEncoder(nn.Layer):
odim=output_size,
dropout_rate=dropout_rate,
pos_enc_class=pos_enc_class(
- d_model=output_size, dropout_rate=positional_dropout_rate), )
+ d_model=output_size,
+ dropout_rate=positional_dropout_rate,
+ max_len=max_len), )
self.normalize_before = normalize_before
self.after_norm = LayerNorm(output_size, epsilon=1e-12)
@@ -216,7 +218,7 @@ class BaseEncoder(nn.Layer):
assert xs.shape[0] == 1 # batch size must be one
# tmp_masks is just for interface compatibility
# TODO(Hui Zhang): stride_slice not support bool tensor
- # tmp_masks = paddle.ones([1, xs.size(1)], dtype=paddle.bool)
+ # tmp_masks = paddle.ones([1, paddle.shape(xs)[1]], dtype=paddle.bool)
tmp_masks = paddle.ones([1, xs.shape[1]], dtype=paddle.int32)
tmp_masks = tmp_masks.unsqueeze(1) #[B=1, C=1, T]
@@ -415,32 +417,32 @@ class TransformerEncoder(BaseEncoder):
class ConformerEncoder(BaseEncoder):
"""Conformer encoder module."""
- def __init__(
- self,
- input_size: int,
- output_size: int=256,
- attention_heads: int=4,
- linear_units: int=2048,
- num_blocks: int=6,
- dropout_rate: float=0.1,
- positional_dropout_rate: float=0.1,
- attention_dropout_rate: float=0.0,
- input_layer: str="conv2d",
- pos_enc_layer_type: str="rel_pos",
- normalize_before: bool=True,
- concat_after: bool=False,
- static_chunk_size: int=0,
- use_dynamic_chunk: bool=False,
- global_cmvn: nn.Layer=None,
- use_dynamic_left_chunk: bool=False,
- positionwise_conv_kernel_size: int=1,
- macaron_style: bool=True,
- selfattention_layer_type: str="rel_selfattn",
- activation_type: str="swish",
- use_cnn_module: bool=True,
- cnn_module_kernel: int=15,
- causal: bool=False,
- cnn_module_norm: str="batch_norm", ):
+ def __init__(self,
+ input_size: int,
+ output_size: int=256,
+ attention_heads: int=4,
+ linear_units: int=2048,
+ num_blocks: int=6,
+ dropout_rate: float=0.1,
+ positional_dropout_rate: float=0.1,
+ attention_dropout_rate: float=0.0,
+ input_layer: str="conv2d",
+ pos_enc_layer_type: str="rel_pos",
+ normalize_before: bool=True,
+ concat_after: bool=False,
+ static_chunk_size: int=0,
+ use_dynamic_chunk: bool=False,
+ global_cmvn: nn.Layer=None,
+ use_dynamic_left_chunk: bool=False,
+ positionwise_conv_kernel_size: int=1,
+ macaron_style: bool=True,
+ selfattention_layer_type: str="rel_selfattn",
+ activation_type: str="swish",
+ use_cnn_module: bool=True,
+ cnn_module_kernel: int=15,
+ causal: bool=False,
+ cnn_module_norm: str="batch_norm",
+ max_len: int=5000):
"""Construct ConformerEncoder
Args:
input_size to use_dynamic_chunk, see in BaseEncoder
@@ -464,7 +466,7 @@ class ConformerEncoder(BaseEncoder):
attention_dropout_rate, input_layer,
pos_enc_layer_type, normalize_before, concat_after,
static_chunk_size, use_dynamic_chunk, global_cmvn,
- use_dynamic_left_chunk)
+ use_dynamic_left_chunk, max_len)
activation = get_activation(activation_type)
# self-attention module definition
diff --git a/paddlespeech/s2t/training/trainer.py b/paddlespeech/s2t/training/trainer.py
index 84da251aa..a7eb9892d 100644
--- a/paddlespeech/s2t/training/trainer.py
+++ b/paddlespeech/s2t/training/trainer.py
@@ -112,7 +112,16 @@ class Trainer():
logger.info(f"Rank: {self.rank}/{self.world_size}")
# set device
- paddle.set_device('gpu' if self.args.ngpu > 0 else 'cpu')
+ if self.args.ngpu == 0:
+ if self.args.nxpu == 0:
+ paddle.set_device('cpu')
+ else:
+ paddle.set_device('xpu')
+ elif self.args.ngpu > 0:
+ paddle.set_device("gpu")
+ else:
+ raise Exception("invalid device")
+
if self.parallel:
self.init_parallel()
diff --git a/paddlespeech/s2t/transform/perturb.py b/paddlespeech/s2t/transform/perturb.py
index 9e41b824b..b18caefb8 100644
--- a/paddlespeech/s2t/transform/perturb.py
+++ b/paddlespeech/s2t/transform/perturb.py
@@ -154,7 +154,8 @@ class SpeedPerturbationSox():
package = "sox"
dynamic_pip_install.install(package)
package = "soxbindings"
- dynamic_pip_install.install(package)
+ if sys.platform != "win32":
+ dynamic_pip_install.install(package)
import soxbindings as sox
except Exception:
raise RuntimeError(
diff --git a/paddlespeech/s2t/transform/spectrogram.py b/paddlespeech/s2t/transform/spectrogram.py
index 2a93bedc8..19f0237bf 100644
--- a/paddlespeech/s2t/transform/spectrogram.py
+++ b/paddlespeech/s2t/transform/spectrogram.py
@@ -15,9 +15,10 @@
import librosa
import numpy as np
import paddle
-import paddleaudio.compliance.kaldi as kaldi
from python_speech_features import logfbank
+import paddlespeech.audio.compliance.kaldi as kaldi
+
def stft(x,
n_fft,
diff --git a/paddlespeech/s2t/utils/ctc_utils.py b/paddlespeech/s2t/utils/ctc_utils.py
index 886b72033..42564d8e1 100644
--- a/paddlespeech/s2t/utils/ctc_utils.py
+++ b/paddlespeech/s2t/utils/ctc_utils.py
@@ -1,3 +1,4 @@
+# Copyright 2021 Mobvoi Inc. All Rights Reserved.
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
diff --git a/paddlespeech/s2t/utils/tensor_utils.py b/paddlespeech/s2t/utils/tensor_utils.py
index 0dbaa0b6b..f9a843ea1 100644
--- a/paddlespeech/s2t/utils/tensor_utils.py
+++ b/paddlespeech/s2t/utils/tensor_utils.py
@@ -58,7 +58,7 @@ def pad_sequence(sequences: List[paddle.Tensor],
>>> a = paddle.ones(25, 300)
>>> b = paddle.ones(22, 300)
>>> c = paddle.ones(15, 300)
- >>> pad_sequence([a, b, c]).size()
+ >>> pad_sequence([a, b, c]).shape
paddle.Tensor([25, 3, 300])
Note:
@@ -79,10 +79,11 @@ def pad_sequence(sequences: List[paddle.Tensor],
# assuming trailing dimensions and type of all the Tensors
# in sequences are same and fetching those from sequences[0]
- max_size = sequences[0].size()
+ max_size = paddle.shape(sequences[0])
# (TODO Hui Zhang): slice not supprot `end==start`
# trailing_dims = max_size[1:]
- trailing_dims = max_size[1:] if max_size.ndim >= 2 else ()
+ trailing_dims = tuple(
+ max_size[1:].numpy().tolist()) if sequences[0].ndim >= 2 else ()
max_len = max([s.shape[0] for s in sequences])
if batch_first:
out_dims = (len(sequences), max_len) + trailing_dims
@@ -99,7 +100,7 @@ def pad_sequence(sequences: List[paddle.Tensor],
if batch_first:
# TODO (Hui Zhang): set_value op not supprot `end==start`
# TODO (Hui Zhang): set_value op not support int16
- # TODO (Hui Zhang): set_varbase 2 rank not support [0,0,...]
+ # TODO (Hui Zhang): set_varbase 2 rank not support [0,0,...]
# out_tensor[i, :length, ...] = tensor
if length != 0:
out_tensor[i, :length] = tensor
@@ -145,7 +146,7 @@ def add_sos_eos(ys_pad: paddle.Tensor, sos: int, eos: int,
[ 4, 5, 6, 11, -1, -1],
[ 7, 8, 9, 11, -1, -1]])
"""
- # TODO(Hui Zhang): using comment code,
+ # TODO(Hui Zhang): using comment code,
#_sos = paddle.to_tensor(
# [sos], dtype=paddle.long, stop_gradient=True, place=ys_pad.place)
#_eos = paddle.to_tensor(
diff --git a/paddlespeech/s2t/utils/text_grid.py b/paddlespeech/s2t/utils/text_grid.py
index cbd9856e4..e696f43d5 100644
--- a/paddlespeech/s2t/utils/text_grid.py
+++ b/paddlespeech/s2t/utils/text_grid.py
@@ -1,3 +1,4 @@
+# Copyright 2021 Mobvoi Inc. All Rights Reserved.
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
diff --git a/paddlespeech/server/README.md b/paddlespeech/server/README.md
index 98ec1e28c..34b7fc2ae 100644
--- a/paddlespeech/server/README.md
+++ b/paddlespeech/server/README.md
@@ -10,7 +10,9 @@
paddlespeech_server help
```
### Start the server
- First set the service-related configuration parameters, similar to `./conf/application.yaml`. Set `engine_list`, which represents the speech tasks included in the service to be started
+ First set the service-related configuration parameters, similar to `./conf/application.yaml`. Set `engine_list`, which represents the speech tasks included in the service to be started.
+ **Note:** If the service can be started normally in the container, but the client access IP is unreachable, you can try to replace the `host` address in the configuration file with the local IP address.
+
Then start the service:
```bash
paddlespeech_server start --config_file ./conf/application.yaml
@@ -61,3 +63,24 @@ paddlespeech_server start --config_file conf/tts_online_application.yaml
```
paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8092 --input "您好,欢迎使用百度飞桨深度学习框架!" --output output.wav
```
+
+
+## Speaker Verification
+
+### Lanuch speaker verification server
+
+```
+paddlespeech_server start --config_file conf/vector_application.yaml
+```
+
+### Extract speaker embedding from aduio
+
+```
+paddlespeech_client vector --task spk --server_ip 127.0.0.1 --port 8090 --input 85236145389.wav
+```
+
+### Get score with speaker audio embedding
+
+```
+paddlespeech_client vector --task score --server_ip 127.0.0.1 --port 8090 --enroll 123456789.wav --test 85236145389.wav
+```
diff --git a/paddlespeech/server/README_cn.md b/paddlespeech/server/README_cn.md
index e799bca86..4bd4d873f 100644
--- a/paddlespeech/server/README_cn.md
+++ b/paddlespeech/server/README_cn.md
@@ -11,6 +11,7 @@
```
### 启动服务
首先设置服务相关配置文件,类似于 `./conf/application.yaml`,设置 `engine_list`,该值表示即将启动的服务中包含的语音任务。
+ **注意:** 如果在容器里可正常启动服务,但客户端访问 ip 不可达,可尝试将配置文件中 `host` 地址换成本地 ip 地址。
然后启动服务:
```bash
paddlespeech_server start --config_file ./conf/application.yaml
@@ -63,3 +64,23 @@ paddlespeech_server start --config_file conf/tts_online_application.yaml
```
paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8092 --input "您好,欢迎使用百度飞桨深度学习框架!" --output output.wav
```
+
+## 声纹识别
+
+### 启动声纹识别服务
+
+```
+paddlespeech_server start --config_file conf/vector_application.yaml
+```
+
+### 获取说话人音频声纹
+
+```
+paddlespeech_client vector --task spk --server_ip 127.0.0.1 --port 8090 --input 85236145389.wav
+```
+
+### 两个说话人音频声纹打分
+
+```
+paddlespeech_client vector --task score --server_ip 127.0.0.1 --port 8090 --enroll 123456789.wav --test 85236145389.wav
+```
diff --git a/paddlespeech/server/bin/main.py b/paddlespeech/server/bin/main.py
deleted file mode 100644
index 81824c85c..000000000
--- a/paddlespeech/server/bin/main.py
+++ /dev/null
@@ -1,77 +0,0 @@
-# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import argparse
-
-import uvicorn
-from fastapi import FastAPI
-
-from paddlespeech.server.engine.engine_pool import init_engine_pool
-from paddlespeech.server.restful.api import setup_router as setup_http_router
-from paddlespeech.server.utils.config import get_config
-from paddlespeech.server.ws.api import setup_router as setup_ws_router
-
-app = FastAPI(
- title="PaddleSpeech Serving API", description="Api", version="0.0.1")
-
-
-def init(config):
- """system initialization
-
- Args:
- config (CfgNode): config object
-
- Returns:
- bool:
- """
- # init api
- api_list = list(engine.split("_")[0] for engine in config.engine_list)
- if config.protocol == "websocket":
- api_router = setup_ws_router(api_list)
- elif config.protocol == "http":
- api_router = setup_http_router(api_list)
- else:
- raise Exception("unsupported protocol")
- app.include_router(api_router)
-
- if not init_engine_pool(config):
- return False
-
- return True
-
-
-def main(args):
- """main function"""
-
- config = get_config(args.config_file)
-
- if init(config):
- uvicorn.run(app, host=config.host, port=config.port, debug=True)
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "--config_file",
- action="store",
- help="yaml file of the app",
- default="./conf/application.yaml")
-
- parser.add_argument(
- "--log_file",
- action="store",
- help="log file",
- default="./log/paddlespeech.log")
- args = parser.parse_args()
-
- main(args)
diff --git a/paddlespeech/server/bin/paddlespeech_client.py b/paddlespeech/server/bin/paddlespeech_client.py
index 715e64a05..fb521b309 100644
--- a/paddlespeech/server/bin/paddlespeech_client.py
+++ b/paddlespeech/server/bin/paddlespeech_client.py
@@ -18,7 +18,9 @@ import io
import json
import os
import random
+import sys
import time
+import warnings
from typing import List
import numpy as np
@@ -31,11 +33,13 @@ from ..util import stats_wrapper
from paddlespeech.cli.log import logger
from paddlespeech.server.utils.audio_handler import ASRWsAudioHandler
from paddlespeech.server.utils.audio_process import wav2pcm
+from paddlespeech.server.utils.util import compute_delay
from paddlespeech.server.utils.util import wav2base64
+warnings.filterwarnings("ignore")
__all__ = [
'TTSClientExecutor', 'TTSOnlineClientExecutor', 'ASRClientExecutor',
- 'CLSClientExecutor'
+ 'ASROnlineClientExecutor', 'CLSClientExecutor', 'VectorClientExecutor'
]
@@ -90,7 +94,7 @@ class TTSClientExecutor(BaseExecutor):
temp_wav = str(random.getrandbits(128)) + ".wav"
soundfile.write(temp_wav, samples, sample_rate)
wav2pcm(temp_wav, outfile, data_type=np.int16)
- os.system("rm %s" % (temp_wav))
+ os.remove(temp_wav)
else:
logger.error("The format for saving audio only supports wav or pcm")
@@ -127,6 +131,7 @@ class TTSClientExecutor(BaseExecutor):
return True
except Exception as e:
logger.error("Failed to synthesized audio.")
+ logger.error(e)
return False
@stats_wrapper
@@ -221,7 +226,7 @@ class TTSOnlineClientExecutor(BaseExecutor):
play = args.play
try:
- res = self(
+ self(
input=input_,
server_ip=server_ip,
port=port,
@@ -235,6 +240,7 @@ class TTSOnlineClientExecutor(BaseExecutor):
return True
except Exception as e:
logger.error("Failed to synthesized audio.")
+ logger.error(e)
return False
@stats_wrapper
@@ -257,17 +263,42 @@ class TTSOnlineClientExecutor(BaseExecutor):
logger.info("tts http client start")
from paddlespeech.server.utils.audio_handler import TTSHttpHandler
handler = TTSHttpHandler(server_ip, port, play)
- handler.run(input, spk_id, speed, volume, sample_rate, output)
+ first_response, final_response, duration, save_audio_success, receive_time_list, chunk_duration_list = handler.run(
+ input, spk_id, speed, volume, sample_rate, output)
+ delay_time_list = compute_delay(receive_time_list,
+ chunk_duration_list)
elif protocol == "websocket":
from paddlespeech.server.utils.audio_handler import TTSWsHandler
logger.info("tts websocket client start")
handler = TTSWsHandler(server_ip, port, play)
loop = asyncio.get_event_loop()
- loop.run_until_complete(handler.run(input, output))
+ first_response, final_response, duration, save_audio_success, receive_time_list, chunk_duration_list = loop.run_until_complete(
+ handler.run(input, output))
+ delay_time_list = compute_delay(receive_time_list,
+ chunk_duration_list)
else:
logger.error("Please set correct protocol, http or websocket")
+ sys.exit(-1)
+
+ logger.info(f"sentence: {input}")
+ logger.info(f"duration: {duration} s")
+ logger.info(f"first response: {first_response} s")
+ logger.info(f"final response: {final_response} s")
+ logger.info(f"RTF: {final_response/duration}")
+ if output is not None:
+ if save_audio_success:
+ logger.info(f"Audio successfully saved in {output}")
+ else:
+ logger.error("Audio save failed.")
+
+ if delay_time_list != []:
+ logger.info(
+ f"Delay situation: total number of packages: {len(receive_time_list)}, the number of delayed packets: {len(delay_time_list)}, minimum delay time: {min(delay_time_list)} s, maximum delay time: {max(delay_time_list)} s, average delay time: {sum(delay_time_list)/len(delay_time_list)} s, delay rate:{len(delay_time_list)/len(receive_time_list)}"
+ )
+ else:
+ logger.info("The sentence has no delay in streaming synthesis.")
@cli_client_register(
@@ -353,8 +384,8 @@ class ASRClientExecutor(BaseExecutor):
lang: str="zh_cn",
audio_format: str="wav",
protocol: str="http",
- punc_server_ip: str="127.0.0.1",
- punc_server_port: int=8091):
+ punc_server_ip: str=None,
+ punc_server_port: int=None):
"""Python API to call an executor.
Args:
@@ -370,6 +401,8 @@ class ASRClientExecutor(BaseExecutor):
str: The ASR results
"""
# we use the asr server to recognize the audio text content
+ # and paddlespeech_client asr only support http protocol
+ protocol = "http"
if protocol.lower() == "http":
from paddlespeech.server.utils.audio_handler import ASRHttpHandler
logger.info("asr http client start")
@@ -377,18 +410,6 @@ class ASRClientExecutor(BaseExecutor):
res = handler.run(input, audio_format, sample_rate, lang)
res = res['result']['transcription']
logger.info("asr http client finished")
-
- elif protocol.lower() == "websocket":
- logger.info("asr websocket client start")
- handler = ASRWsAudioHandler(
- server_ip,
- port,
- punc_server_ip=punc_server_ip,
- punc_server_port=punc_server_port)
- loop = asyncio.get_event_loop()
- res = loop.run_until_complete(handler.run(input))
- res = res['result']
- logger.info("asr websocket client finished")
else:
logger.error(f"Sorry, we have not support protocol: {protocol},"
"please use http or websocket protocol")
@@ -397,6 +418,110 @@ class ASRClientExecutor(BaseExecutor):
return res
+@cli_client_register(
+ name='paddlespeech_client.asr_online',
+ description='visit asr online service')
+class ASROnlineClientExecutor(BaseExecutor):
+ def __init__(self):
+ super(ASROnlineClientExecutor, self).__init__()
+ self.parser = argparse.ArgumentParser(
+ prog='paddlespeech_client.asr_online', add_help=True)
+ self.parser.add_argument(
+ '--server_ip', type=str, default='127.0.0.1', help='server ip')
+ self.parser.add_argument(
+ '--port', type=int, default=8091, help='server port')
+ self.parser.add_argument(
+ '--input',
+ type=str,
+ default=None,
+ help='Audio file to be recognized',
+ required=True)
+ self.parser.add_argument(
+ '--sample_rate', type=int, default=16000, help='audio sample rate')
+ self.parser.add_argument(
+ '--lang', type=str, default="zh_cn", help='language')
+ self.parser.add_argument(
+ '--audio_format', type=str, default="wav", help='audio format')
+ self.parser.add_argument(
+ '--punc.server_ip',
+ type=str,
+ default=None,
+ dest="punc_server_ip",
+ help='Punctuation server ip')
+ self.parser.add_argument(
+ '--punc.port',
+ type=int,
+ default=8190,
+ dest="punc_server_port",
+ help='Punctuation server port')
+
+ def execute(self, argv: List[str]) -> bool:
+ args = self.parser.parse_args(argv)
+ input_ = args.input
+ server_ip = args.server_ip
+ port = args.port
+ sample_rate = args.sample_rate
+ lang = args.lang
+ audio_format = args.audio_format
+ try:
+ time_start = time.time()
+ res = self(
+ input=input_,
+ server_ip=server_ip,
+ port=port,
+ sample_rate=sample_rate,
+ lang=lang,
+ audio_format=audio_format,
+ punc_server_ip=args.punc_server_ip,
+ punc_server_port=args.punc_server_port)
+ time_end = time.time()
+ logger.info(res)
+ logger.info("Response time %f s." % (time_end - time_start))
+ return True
+ except Exception as e:
+ logger.error("Failed to speech recognition.")
+ logger.error(e)
+ return False
+
+ @stats_wrapper
+ def __call__(self,
+ input: str,
+ server_ip: str="127.0.0.1",
+ port: int=8091,
+ sample_rate: int=16000,
+ lang: str="zh_cn",
+ audio_format: str="wav",
+ punc_server_ip: str=None,
+ punc_server_port: str=None):
+ """Python API to call asr online executor.
+
+ Args:
+ input (str): the audio file to be send to streaming asr service.
+ server_ip (str, optional): streaming asr server ip. Defaults to "127.0.0.1".
+ port (int, optional): streaming asr server port. Defaults to 8091.
+ sample_rate (int, optional): audio sample rate. Defaults to 16000.
+ lang (str, optional): audio language type. Defaults to "zh_cn".
+ audio_format (str, optional): audio format. Defaults to "wav".
+ punc_server_ip (str, optional): punctuation server ip. Defaults to None.
+ punc_server_port (str, optional): punctuation server port. Defaults to None.
+
+ Returns:
+ str: the audio text
+ """
+
+ logger.info("asr websocket client start")
+ handler = ASRWsAudioHandler(
+ server_ip,
+ port,
+ punc_server_ip=punc_server_ip,
+ punc_server_port=punc_server_port)
+ loop = asyncio.get_event_loop()
+ res = loop.run_until_complete(handler.run(input))
+ logger.info("asr websocket client finished")
+
+ return res['result']
+
+
@cli_client_register(
name='paddlespeech_client.cls', description='visit cls service')
class CLSClientExecutor(BaseExecutor):
@@ -436,6 +561,7 @@ class CLSClientExecutor(BaseExecutor):
return True
except Exception as e:
logger.error("Failed to speech classification.")
+ logger.error(e)
return False
@stats_wrapper
@@ -487,7 +613,6 @@ class TextClientExecutor(BaseExecutor):
input_ = args.input
server_ip = args.server_ip
port = args.port
- output = args.output
try:
time_start = time.time()
@@ -523,3 +648,195 @@ class TextClientExecutor(BaseExecutor):
response_dict = res.json()
punc_text = response_dict["result"]["punc_text"]
return punc_text
+
+
+@cli_client_register(
+ name='paddlespeech_client.vector', description='visit the vector service')
+class VectorClientExecutor(BaseExecutor):
+ def __init__(self):
+ super(VectorClientExecutor, self).__init__()
+ self.parser = argparse.ArgumentParser(
+ prog='paddlespeech_client.vector', add_help=True)
+ self.parser.add_argument(
+ '--server_ip', type=str, default='127.0.0.1', help='server ip')
+ self.parser.add_argument(
+ '--port', type=int, default=8090, help='server port')
+ self.parser.add_argument(
+ '--input',
+ type=str,
+ default=None,
+ help='sentence to be process by text server.')
+ self.parser.add_argument(
+ '--task',
+ type=str,
+ default="spk",
+ choices=["spk", "score"],
+ help="The vector service task")
+ self.parser.add_argument(
+ "--enroll", type=str, default=None, help="The enroll audio")
+ self.parser.add_argument(
+ "--test", type=str, default=None, help="The test audio")
+
+ def execute(self, argv: List[str]) -> bool:
+ """Execute the request from the argv.
+
+ Args:
+ argv (List): the request arguments
+
+ Returns:
+ str: the request flag
+ """
+ args = self.parser.parse_args(argv)
+ input_ = args.input
+ server_ip = args.server_ip
+ port = args.port
+ task = args.task
+
+ try:
+ time_start = time.time()
+ res = self(
+ input=input_,
+ server_ip=server_ip,
+ port=port,
+ enroll_audio=args.enroll,
+ test_audio=args.test,
+ task=task)
+ time_end = time.time()
+ logger.info(f"The vector: {res}")
+ logger.info("Response time %f s." % (time_end - time_start))
+ return True
+ except Exception as e:
+ logger.error("Failed to extract vector.")
+ logger.error(e)
+ return False
+
+ @stats_wrapper
+ def __call__(self,
+ input: str,
+ server_ip: str="127.0.0.1",
+ port: int=8090,
+ audio_format: str="wav",
+ sample_rate: int=16000,
+ enroll_audio: str=None,
+ test_audio: str=None,
+ task="spk"):
+ """
+ Python API to call text executor.
+
+ Args:
+ input (str): the request audio data
+ server_ip (str, optional): the server ip. Defaults to "127.0.0.1".
+ port (int, optional): the server port. Defaults to 8090.
+ audio_format (str, optional): audio format. Defaults to "wav".
+ sample_rate (str, optional): audio sample rate. Defaults to 16000.
+ enroll_audio (str, optional): enroll audio data. Defaults to None.
+ test_audio (str, optional): test audio data. Defaults to None.
+ task (str, optional): the task type, "spk" or "socre". Defaults to "spk"
+ Returns:
+ str: the audio embedding or score between enroll and test audio
+ """
+
+ if task == "spk":
+ from paddlespeech.server.utils.audio_handler import VectorHttpHandler
+ logger.info("vector http client start")
+ logger.info(f"the input audio: {input}")
+ handler = VectorHttpHandler(server_ip=server_ip, port=port)
+ res = handler.run(input, audio_format, sample_rate)
+ return res
+ elif task == "score":
+ from paddlespeech.server.utils.audio_handler import VectorScoreHttpHandler
+ logger.info("vector score http client start")
+ logger.info(
+ f"enroll audio: {enroll_audio}, test audio: {test_audio}")
+ handler = VectorScoreHttpHandler(server_ip=server_ip, port=port)
+ res = handler.run(enroll_audio, test_audio, audio_format,
+ sample_rate)
+ logger.info(f"The vector score is: {res}")
+ return res
+ else:
+ logger.error(f"Sorry, we have not support such task {task}")
+
+
+@cli_client_register(
+ name='paddlespeech_client.acs', description='visit acs service')
+class ACSClientExecutor(BaseExecutor):
+ def __init__(self):
+ super(ACSClientExecutor, self).__init__()
+ self.parser = argparse.ArgumentParser(
+ prog='paddlespeech_client.acs', add_help=True)
+ self.parser.add_argument(
+ '--server_ip', type=str, default='127.0.0.1', help='server ip')
+ self.parser.add_argument(
+ '--port', type=int, default=8090, help='server port')
+ self.parser.add_argument(
+ '--input',
+ type=str,
+ default=None,
+ help='Audio file to be recognized',
+ required=True)
+ self.parser.add_argument(
+ '--sample_rate', type=int, default=16000, help='audio sample rate')
+ self.parser.add_argument(
+ '--lang', type=str, default="zh_cn", help='language')
+ self.parser.add_argument(
+ '--audio_format', type=str, default="wav", help='audio format')
+
+ def execute(self, argv: List[str]) -> bool:
+ args = self.parser.parse_args(argv)
+ input_ = args.input
+ server_ip = args.server_ip
+ port = args.port
+ sample_rate = args.sample_rate
+ lang = args.lang
+ audio_format = args.audio_format
+
+ try:
+ time_start = time.time()
+ res = self(
+ input=input_,
+ server_ip=server_ip,
+ port=port,
+ sample_rate=sample_rate,
+ lang=lang,
+ audio_format=audio_format, )
+ time_end = time.time()
+ logger.info(f"ACS result: {res}")
+ logger.info("Response time %f s." % (time_end - time_start))
+ return True
+ except Exception as e:
+ logger.error("Failed to speech recognition.")
+ logger.error(e)
+ return False
+
+ @stats_wrapper
+ def __call__(
+ self,
+ input: str,
+ server_ip: str="127.0.0.1",
+ port: int=8090,
+ sample_rate: int=16000,
+ lang: str="zh_cn",
+ audio_format: str="wav", ):
+ """Python API to call an executor.
+
+ Args:
+ input (str): The input audio file path
+ server_ip (str, optional): The ASR server ip. Defaults to "127.0.0.1".
+ port (int, optional): The ASR server port. Defaults to 8090.
+ sample_rate (int, optional): The audio sample rate. Defaults to 16000.
+ lang (str, optional): The audio language type. Defaults to "zh_cn".
+ audio_format (str, optional): The audio format information. Defaults to "wav".
+
+ Returns:
+ str: The ACS results
+ """
+ # we use the acs server to get the key word time stamp in audio text content
+ logger.info("acs http client start")
+ from paddlespeech.server.utils.audio_handler import ASRHttpHandler
+ handler = ASRHttpHandler(
+ server_ip=server_ip, port=port, endpoint="/paddlespeech/asr/search")
+ res = handler.run(input, audio_format, sample_rate, lang)
+ res = res['result']
+ logger.info("acs http client finished")
+
+ return res
diff --git a/paddlespeech/server/bin/paddlespeech_server.py b/paddlespeech/server/bin/paddlespeech_server.py
index 474a8b79f..11f50655f 100644
--- a/paddlespeech/server/bin/paddlespeech_server.py
+++ b/paddlespeech/server/bin/paddlespeech_server.py
@@ -12,26 +12,39 @@
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
+import sys
+import warnings
from typing import List
import uvicorn
from fastapi import FastAPI
from prettytable import PrettyTable
+from starlette.middleware.cors import CORSMiddleware
from ..executor import BaseExecutor
from ..util import cli_server_register
from ..util import stats_wrapper
from paddlespeech.cli.log import logger
+from paddlespeech.resource import CommonTaskResource
from paddlespeech.server.engine.engine_pool import init_engine_pool
+from paddlespeech.server.engine.engine_warmup import warm_up
from paddlespeech.server.restful.api import setup_router as setup_http_router
from paddlespeech.server.utils.config import get_config
from paddlespeech.server.ws.api import setup_router as setup_ws_router
+warnings.filterwarnings("ignore")
__all__ = ['ServerExecutor', 'ServerStatsExecutor']
app = FastAPI(
title="PaddleSpeech Serving API", description="Api", version="0.0.1")
+app.add_middleware(
+ CORSMiddleware,
+ allow_origins=["*"],
+ allow_credentials=True,
+ allow_methods=["*"],
+ allow_headers=["*"])
+
@cli_server_register(
name='paddlespeech_server.start', description='Start the service')
@@ -71,18 +84,25 @@ class ServerExecutor(BaseExecutor):
else:
raise Exception("unsupported protocol")
app.include_router(api_router)
-
+ logger.info("start to init the engine")
if not init_engine_pool(config):
return False
+ # warm up
+ for engine_and_type in config.engine_list:
+ if not warm_up(engine_and_type):
+ return False
+
return True
def execute(self, argv: List[str]) -> bool:
args = self.parser.parse_args(argv)
- config = get_config(args.config_file)
-
- if self.init(config):
- uvicorn.run(app, host=config.host, port=config.port, debug=True)
+ try:
+ self(args.config_file, args.log_file)
+ except Exception as e:
+ logger.error("Failed to start server.")
+ logger.error(e)
+ sys.exit(-1)
@stats_wrapper
def __call__(self,
@@ -109,14 +129,16 @@ class ServerStatsExecutor():
'--task',
type=str,
default=None,
- choices=['asr', 'tts', 'cls'],
+ choices=['asr', 'tts', 'cls', 'text', 'vector'],
help='Choose speech task.',
required=True)
- self.task_choices = ['asr', 'tts', 'cls']
+ self.task_choices = ['asr', 'tts', 'cls', 'text', 'vector']
self.model_name_format = {
'asr': 'Model-Language-Sample Rate',
'tts': 'Model-Language',
- 'cls': 'Model-Sample Rate'
+ 'cls': 'Model-Sample Rate',
+ 'text': 'Model-Task-Language',
+ 'vector': 'Model-Sample Rate'
}
def show_support_models(self, pretrained_models: dict):
@@ -137,68 +159,30 @@ class ServerStatsExecutor():
"Please input correct speech task, choices = ['asr', 'tts']")
return False
- elif self.task == 'asr':
- try:
- from paddlespeech.cli.asr.infer import pretrained_models
- logger.info(
- "Here is the table of ASR pretrained models supported in the service."
- )
- self.show_support_models(pretrained_models)
-
- # show ASR static pretrained model
- from paddlespeech.server.engine.asr.paddleinference.asr_engine import pretrained_models
- logger.info(
- "Here is the table of ASR static pretrained models supported in the service."
- )
- self.show_support_models(pretrained_models)
-
- return True
- except BaseException:
- logger.error(
- "Failed to get the table of ASR pretrained models supported in the service."
- )
- return False
+ try:
+ # Dynamic models
+ dynamic_pretrained_models = CommonTaskResource(
+ task=self.task, model_format='dynamic').pretrained_models
- elif self.task == 'tts':
- try:
- from paddlespeech.cli.tts.infer import pretrained_models
+ if len(dynamic_pretrained_models) > 0:
logger.info(
- "Here is the table of TTS pretrained models supported in the service."
- )
- self.show_support_models(pretrained_models)
-
- # show TTS static pretrained model
- from paddlespeech.server.engine.tts.paddleinference.tts_engine import pretrained_models
+ "Here is the table of {} pretrained models supported in the service.".
+ format(self.task.upper()))
+ self.show_support_models(dynamic_pretrained_models)
+
+ # Static models
+ static_pretrained_models = CommonTaskResource(
+ task=self.task, model_format='static').pretrained_models
+ if len(static_pretrained_models) > 0:
logger.info(
- "Here is the table of TTS static pretrained models supported in the service."
- )
+ "Here is the table of {} static pretrained models supported in the service.".
+ format(self.task.upper()))
self.show_support_models(pretrained_models)
- return True
- except BaseException:
- logger.error(
- "Failed to get the table of TTS pretrained models supported in the service."
- )
- return False
-
- elif self.task == 'cls':
- try:
- from paddlespeech.cli.cls.infer import pretrained_models
- logger.info(
- "Here is the table of CLS pretrained models supported in the service."
- )
- self.show_support_models(pretrained_models)
+ return True
- # show CLS static pretrained model
- from paddlespeech.server.engine.cls.paddleinference.cls_engine import pretrained_models
- logger.info(
- "Here is the table of CLS static pretrained models supported in the service."
- )
- self.show_support_models(pretrained_models)
-
- return True
- except BaseException:
- logger.error(
- "Failed to get the table of CLS pretrained models supported in the service."
- )
- return False
+ except BaseException:
+ logger.error(
+ "Failed to get the table of {} pretrained models supported in the service.".
+ format(self.task.upper()))
+ return False
diff --git a/paddlespeech/server/conf/application.yaml b/paddlespeech/server/conf/application.yaml
index c87530595..8650154e9 100644
--- a/paddlespeech/server/conf/application.yaml
+++ b/paddlespeech/server/conf/application.yaml
@@ -1,17 +1,15 @@
-# This is the parameter configuration file for PaddleSpeech Serving.
+# This is the parameter configuration file for PaddleSpeech Offline Serving..
#################################################################################
# SERVER SETTING #
#################################################################################
-host: 127.0.0.1
+host: 0.0.0.0
port: 8090
# The task format in the engin_list is: _
-# task choices = ['asr_python', 'asr_inference', 'tts_python', 'tts_inference']
-# protocol = ['websocket', 'http'] (only one can be selected).
-# http only support offline engine type.
+# task choices = ['asr_python', 'asr_inference', 'tts_python', 'tts_inference', 'cls_python', 'cls_inference']
protocol: 'http'
-engine_list: ['asr_python', 'tts_python', 'cls_python', 'text_python']
+engine_list: ['asr_python', 'tts_python', 'cls_python', 'text_python', 'vector_python']
#################################################################################
@@ -50,24 +48,6 @@ asr_inference:
summary: True # False -> do not show predictor config
-################### speech task: asr; engine_type: online #######################
-asr_online:
- model_type: 'deepspeech2online_aishell'
- am_model: # the pdmodel file of am static model [optional]
- am_params: # the pdiparams file of am static model [optional]
- lang: 'zh'
- sample_rate: 16000
- cfg_path:
- decode_method:
- force_yes: True
-
- am_predictor_conf:
- device: # set 'gpu:id' or 'cpu'
- switch_ir_optim: True
- glog_info: False # True -> print glog
- summary: True # False -> do not show predictor config
-
-
################################### TTS #########################################
################### speech task: tts; engine_type: python #######################
tts_python:
@@ -166,4 +146,15 @@ text_python:
cfg_path: # [optional]
ckpt_path: # [optional]
vocab_file: # [optional]
- device: # set 'gpu:id' or 'cpu'
\ No newline at end of file
+ device: # set 'gpu:id' or 'cpu'
+
+
+################################### Vector ######################################
+################### Vector task: spk; engine_type: python #######################
+vector_python:
+ task: spk
+ model_type: 'ecapatdnn_voxceleb12'
+ sample_rate: 16000
+ cfg_path: # [optional]
+ ckpt_path: # [optional]
+ device: # set 'gpu:id' or 'cpu'
diff --git a/paddlespeech/server/conf/tts_online_application.yaml b/paddlespeech/server/conf/tts_online_application.yaml
index 67d4641a0..0460a5e16 100644
--- a/paddlespeech/server/conf/tts_online_application.yaml
+++ b/paddlespeech/server/conf/tts_online_application.yaml
@@ -3,7 +3,7 @@
#################################################################################
# SERVER SETTING #
#################################################################################
-host: 127.0.0.1
+host: 0.0.0.0
port: 8092
# The task format in the engin_list is: _
@@ -43,12 +43,12 @@ tts_online:
device: 'cpu' # set 'gpu:id' or 'cpu'
# am_block and am_pad only for fastspeech2_cnndecoder_onnx model to streaming am infer,
# when am_pad set 12, streaming synthetic audio is the same as non-streaming synthetic audio
- am_block: 42
+ am_block: 72
am_pad: 12
# voc_pad and voc_block voc model to streaming voc infer,
# when voc model is mb_melgan_csmsc, voc_pad set 14, streaming synthetic audio is the same as non-streaming synthetic audio; The minimum value of pad can be set to 7, streaming synthetic audio sounds normal
- # when voc model is hifigan_csmsc, voc_pad set 20, streaming synthetic audio is the same as non-streaming synthetic audio; voc_pad set 14, streaming synthetic audio sounds normal
- voc_block: 14
+ # when voc model is hifigan_csmsc, voc_pad set 19, streaming synthetic audio is the same as non-streaming synthetic audio; voc_pad set 14, streaming synthetic audio sounds normal
+ voc_block: 36
voc_pad: 14
@@ -91,12 +91,12 @@ tts_online-onnx:
lang: 'zh'
# am_block and am_pad only for fastspeech2_cnndecoder_onnx model to streaming am infer,
# when am_pad set 12, streaming synthetic audio is the same as non-streaming synthetic audio
- am_block: 42
+ am_block: 72
am_pad: 12
# voc_pad and voc_block voc model to streaming voc infer,
# when voc model is mb_melgan_csmsc_onnx, voc_pad set 14, streaming synthetic audio is the same as non-streaming synthetic audio; The minimum value of pad can be set to 7, streaming synthetic audio sounds normal
- # when voc model is hifigan_csmsc_onnx, voc_pad set 20, streaming synthetic audio is the same as non-streaming synthetic audio; voc_pad set 14, streaming synthetic audio sounds normal
- voc_block: 14
+ # when voc model is hifigan_csmsc_onnx, voc_pad set 19, streaming synthetic audio is the same as non-streaming synthetic audio; voc_pad set 14, streaming synthetic audio sounds normal
+ voc_block: 36
voc_pad: 14
# voc_upsample should be same as n_shift on voc config.
voc_upsample: 300
diff --git a/paddlespeech/server/conf/vector_application.yaml b/paddlespeech/server/conf/vector_application.yaml
new file mode 100644
index 000000000..c78659e35
--- /dev/null
+++ b/paddlespeech/server/conf/vector_application.yaml
@@ -0,0 +1,32 @@
+# This is the parameter configuration file for PaddleSpeech Serving.
+
+#################################################################################
+# SERVER SETTING #
+#################################################################################
+host: 0.0.0.0
+port: 8090
+
+# The task format in the engin_list is: _
+# protocol = ['http'] (only one can be selected).
+# http only support offline engine type.
+protocol: 'http'
+engine_list: ['vector_python']
+
+
+#################################################################################
+# ENGINE CONFIG #
+#################################################################################
+
+################################### Vector ######################################
+################### Vector task: spk; engine_type: python #######################
+vector_python:
+ task: spk
+ model_type: 'ecapatdnn_voxceleb12'
+ sample_rate: 16000
+ cfg_path: # [optional]
+ ckpt_path: # [optional]
+ device: # set 'gpu:id' or 'cpu'
+
+
+
+
diff --git a/paddlespeech/server/conf/ws_conformer_application.yaml b/paddlespeech/server/conf/ws_conformer_application.yaml
index 9c0425345..d72eb2379 100644
--- a/paddlespeech/server/conf/ws_conformer_application.yaml
+++ b/paddlespeech/server/conf/ws_conformer_application.yaml
@@ -28,8 +28,11 @@ asr_online:
sample_rate: 16000
cfg_path:
decode_method:
+ num_decoding_left_chunks: -1
force_yes: True
device: # cpu or gpu:id
+ continuous_decoding: True # enable continue decoding when endpoint detected
+
am_predictor_conf:
device: # set 'gpu:id' or 'cpu'
switch_ir_optim: True
@@ -42,4 +45,4 @@ asr_online:
window_ms: 25 # ms
shift_ms: 10 # ms
sample_rate: 16000
- sample_width: 2
\ No newline at end of file
+ sample_width: 2
diff --git a/paddlespeech/server/conf/ws_conformer_wenetspeech_application_faster.yaml b/paddlespeech/server/conf/ws_conformer_wenetspeech_application_faster.yaml
new file mode 100644
index 000000000..ba413c802
--- /dev/null
+++ b/paddlespeech/server/conf/ws_conformer_wenetspeech_application_faster.yaml
@@ -0,0 +1,48 @@
+# This is the parameter configuration file for PaddleSpeech Serving.
+
+#################################################################################
+# SERVER SETTING #
+#################################################################################
+host: 0.0.0.0
+port: 8090
+
+# The task format in the engin_list is: _
+# task choices = ['asr_online']
+# protocol = ['websocket'] (only one can be selected).
+# websocket only support online engine type.
+protocol: 'websocket'
+engine_list: ['asr_online']
+
+
+#################################################################################
+# ENGINE CONFIG #
+#################################################################################
+
+################################### ASR #########################################
+################### speech task: asr; engine_type: online #######################
+asr_online:
+ model_type: 'conformer_online_wenetspeech'
+ am_model: # the pdmodel file of am static model [optional]
+ am_params: # the pdiparams file of am static model [optional]
+ lang: 'zh'
+ sample_rate: 16000
+ cfg_path:
+ decode_method:
+ force_yes: True
+ device: 'cpu' # cpu or gpu:id
+ decode_method: "attention_rescoring"
+ continuous_decoding: True # enable continue decoding when endpoint detected
+ num_decoding_left_chunks: 16
+ am_predictor_conf:
+ device: # set 'gpu:id' or 'cpu'
+ switch_ir_optim: True
+ glog_info: False # True -> print glog
+ summary: True # False -> do not show predictor config
+
+ chunk_buffer_conf:
+ window_n: 7 # frame
+ shift_n: 4 # frame
+ window_ms: 25 # ms
+ shift_ms: 10 # ms
+ sample_rate: 16000
+ sample_width: 2
diff --git a/paddlespeech/server/conf/ws_ds2_application.yaml b/paddlespeech/server/conf/ws_ds2_application.yaml
new file mode 100644
index 000000000..909c2f187
--- /dev/null
+++ b/paddlespeech/server/conf/ws_ds2_application.yaml
@@ -0,0 +1,84 @@
+# This is the parameter configuration file for PaddleSpeech Serving.
+
+#################################################################################
+# SERVER SETTING #
+#################################################################################
+host: 0.0.0.0
+port: 8090
+
+# The task format in the engin_list is: _
+# task choices = ['asr_online-inference', 'asr_online-onnx']
+# protocol = ['websocket'] (only one can be selected).
+# websocket only support online engine type.
+protocol: 'websocket'
+engine_list: ['asr_online-onnx']
+
+
+#################################################################################
+# ENGINE CONFIG #
+#################################################################################
+
+################################### ASR #########################################
+################### speech task: asr; engine_type: online-inference #######################
+asr_online-inference:
+ model_type: 'deepspeech2online_wenetspeech'
+ am_model: # the pdmodel file of am static model [optional]
+ am_params: # the pdiparams file of am static model [optional]
+ lang: 'zh'
+ sample_rate: 16000
+ cfg_path:
+ decode_method:
+ num_decoding_left_chunks:
+ force_yes: True
+ device: 'cpu' # cpu or gpu:id
+
+ am_predictor_conf:
+ device: # set 'gpu:id' or 'cpu'
+ switch_ir_optim: True
+ glog_info: False # True -> print glog
+ summary: True # False -> do not show predictor config
+
+ chunk_buffer_conf:
+ frame_duration_ms: 80
+ shift_ms: 40
+ sample_rate: 16000
+ sample_width: 2
+ window_n: 7 # frame
+ shift_n: 4 # frame
+ window_ms: 25 # ms
+ shift_ms: 10 # ms
+
+
+
+################################### ASR #########################################
+################### speech task: asr; engine_type: online-onnx #######################
+asr_online-onnx:
+ model_type: 'deepspeech2online_wenetspeech'
+ am_model: # the pdmodel file of onnx am static model [optional]
+ am_params: # the pdiparams file of am static model [optional]
+ lang: 'zh'
+ sample_rate: 16000
+ cfg_path:
+ decode_method:
+ num_decoding_left_chunks:
+ force_yes: True
+ device: 'cpu' # cpu or gpu:id
+
+ # https://onnxruntime.ai/docs/api/python/api_summary.html#inferencesession
+ am_predictor_conf:
+ device: 'cpu' # set 'gpu:id' or 'cpu'
+ graph_optimization_level: 0
+ intra_op_num_threads: 0 # Sets the number of threads used to parallelize the execution within nodes.
+ inter_op_num_threads: 0 # Sets the number of threads used to parallelize the execution of the graph (across nodes).
+ log_severity_level: 2 # Log severity level. Applies to session load, initialization, etc. 0:Verbose, 1:Info, 2:Warning. 3:Error, 4:Fatal. Default is 2.
+ log_verbosity_level: 0 # VLOG level if DEBUG build and session_log_severity_level is 0. Applies to session load, initialization, etc. Default is 0.
+
+ chunk_buffer_conf:
+ frame_duration_ms: 85
+ shift_ms: 40
+ sample_rate: 16000
+ sample_width: 2
+ window_n: 7 # frame
+ shift_n: 4 # frame
+ window_ms: 25 # ms
+ shift_ms: 10 # ms
diff --git a/paddlespeech/server/download.py b/paddlespeech/server/download.py
deleted file mode 100644
index ea943dd87..000000000
--- a/paddlespeech/server/download.py
+++ /dev/null
@@ -1,329 +0,0 @@
-# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import hashlib
-import os
-import os.path as osp
-import shutil
-import subprocess
-import tarfile
-import time
-import zipfile
-
-import requests
-from tqdm import tqdm
-
-from paddlespeech.cli.log import logger
-
-__all__ = ['get_path_from_url']
-
-DOWNLOAD_RETRY_LIMIT = 3
-
-
-def _is_url(path):
- """
- Whether path is URL.
- Args:
- path (string): URL string or not.
- """
- return path.startswith('http://') or path.startswith('https://')
-
-
-def _map_path(url, root_dir):
- # parse path after download under root_dir
- fname = osp.split(url)[-1]
- fpath = fname
- return osp.join(root_dir, fpath)
-
-
-def _get_unique_endpoints(trainer_endpoints):
- # Sorting is to avoid different environmental variables for each card
- trainer_endpoints.sort()
- ips = set()
- unique_endpoints = set()
- for endpoint in trainer_endpoints:
- ip = endpoint.split(":")[0]
- if ip in ips:
- continue
- ips.add(ip)
- unique_endpoints.add(endpoint)
- logger.info("unique_endpoints {}".format(unique_endpoints))
- return unique_endpoints
-
-
-def get_path_from_url(url,
- root_dir,
- md5sum=None,
- check_exist=True,
- decompress=True,
- method='get'):
- """ Download from given url to root_dir.
- if file or directory specified by url is exists under
- root_dir, return the path directly, otherwise download
- from url and decompress it, return the path.
- Args:
- url (str): download url
- root_dir (str): root dir for downloading, it should be
- WEIGHTS_HOME or DATASET_HOME
- md5sum (str): md5 sum of download package
- decompress (bool): decompress zip or tar file. Default is `True`
- method (str): which download method to use. Support `wget` and `get`. Default is `get`.
- Returns:
- str: a local path to save downloaded models & weights & datasets.
- """
-
- from paddle.fluid.dygraph.parallel import ParallelEnv
-
- assert _is_url(url), "downloading from {} not a url".format(url)
- # parse path after download to decompress under root_dir
- fullpath = _map_path(url, root_dir)
- # Mainly used to solve the problem of downloading data from different
- # machines in the case of multiple machines. Different ips will download
- # data, and the same ip will only download data once.
- unique_endpoints = _get_unique_endpoints(ParallelEnv().trainer_endpoints[:])
- if osp.exists(fullpath) and check_exist and _md5check(fullpath, md5sum):
- logger.info("Found {}".format(fullpath))
- else:
- if ParallelEnv().current_endpoint in unique_endpoints:
- fullpath = _download(url, root_dir, md5sum, method=method)
- else:
- while not os.path.exists(fullpath):
- time.sleep(1)
-
- if ParallelEnv().current_endpoint in unique_endpoints:
- if decompress and (tarfile.is_tarfile(fullpath) or
- zipfile.is_zipfile(fullpath)):
- fullpath = _decompress(fullpath)
-
- return fullpath
-
-
-def _get_download(url, fullname):
- # using requests.get method
- fname = osp.basename(fullname)
- try:
- req = requests.get(url, stream=True)
- except Exception as e: # requests.exceptions.ConnectionError
- logger.info("Downloading {} from {} failed with exception {}".format(
- fname, url, str(e)))
- return False
-
- if req.status_code != 200:
- raise RuntimeError("Downloading from {} failed with code "
- "{}!".format(url, req.status_code))
-
- # For protecting download interupted, download to
- # tmp_fullname firstly, move tmp_fullname to fullname
- # after download finished
- tmp_fullname = fullname + "_tmp"
- total_size = req.headers.get('content-length')
- with open(tmp_fullname, 'wb') as f:
- if total_size:
- with tqdm(total=(int(total_size) + 1023) // 1024) as pbar:
- for chunk in req.iter_content(chunk_size=1024):
- f.write(chunk)
- pbar.update(1)
- else:
- for chunk in req.iter_content(chunk_size=1024):
- if chunk:
- f.write(chunk)
- shutil.move(tmp_fullname, fullname)
-
- return fullname
-
-
-def _wget_download(url, fullname):
- # using wget to download url
- tmp_fullname = fullname + "_tmp"
- # –user-agent
- command = 'wget -O {} -t {} {}'.format(tmp_fullname, DOWNLOAD_RETRY_LIMIT,
- url)
- subprc = subprocess.Popen(
- command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
- _ = subprc.communicate()
-
- if subprc.returncode != 0:
- raise RuntimeError(
- '{} failed. Please make sure `wget` is installed or {} exists'.
- format(command, url))
-
- shutil.move(tmp_fullname, fullname)
-
- return fullname
-
-
-_download_methods = {
- 'get': _get_download,
- 'wget': _wget_download,
-}
-
-
-def _download(url, path, md5sum=None, method='get'):
- """
- Download from url, save to path.
- url (str): download url
- path (str): download to given path
- md5sum (str): md5 sum of download package
- method (str): which download method to use. Support `wget` and `get`. Default is `get`.
- """
- assert method in _download_methods, 'make sure `{}` implemented'.format(
- method)
-
- if not osp.exists(path):
- os.makedirs(path)
-
- fname = osp.split(url)[-1]
- fullname = osp.join(path, fname)
- retry_cnt = 0
-
- logger.info("Downloading {} from {}".format(fname, url))
- while not (osp.exists(fullname) and _md5check(fullname, md5sum)):
- if retry_cnt < DOWNLOAD_RETRY_LIMIT:
- retry_cnt += 1
- else:
- raise RuntimeError("Download from {} failed. "
- "Retry limit reached".format(url))
-
- if not _download_methods[method](url, fullname):
- time.sleep(1)
- continue
-
- return fullname
-
-
-def _md5check(fullname, md5sum=None):
- if md5sum is None:
- return True
-
- logger.info("File {} md5 checking...".format(fullname))
- md5 = hashlib.md5()
- with open(fullname, 'rb') as f:
- for chunk in iter(lambda: f.read(4096), b""):
- md5.update(chunk)
- calc_md5sum = md5.hexdigest()
-
- if calc_md5sum != md5sum:
- logger.info("File {} md5 check failed, {}(calc) != "
- "{}(base)".format(fullname, calc_md5sum, md5sum))
- return False
- return True
-
-
-def _decompress(fname):
- """
- Decompress for zip and tar file
- """
- logger.info("Decompressing {}...".format(fname))
-
- # For protecting decompressing interupted,
- # decompress to fpath_tmp directory firstly, if decompress
- # successed, move decompress files to fpath and delete
- # fpath_tmp and remove download compress file.
-
- if tarfile.is_tarfile(fname):
- uncompressed_path = _uncompress_file_tar(fname)
- elif zipfile.is_zipfile(fname):
- uncompressed_path = _uncompress_file_zip(fname)
- else:
- raise TypeError("Unsupport compress file type {}".format(fname))
-
- return uncompressed_path
-
-
-def _uncompress_file_zip(filepath):
- files = zipfile.ZipFile(filepath, 'r')
- file_list = files.namelist()
-
- file_dir = os.path.dirname(filepath)
-
- if _is_a_single_file(file_list):
- rootpath = file_list[0]
- uncompressed_path = os.path.join(file_dir, rootpath)
-
- for item in file_list:
- files.extract(item, file_dir)
-
- elif _is_a_single_dir(file_list):
- rootpath = os.path.splitext(file_list[0])[0].split(os.sep)[0]
- uncompressed_path = os.path.join(file_dir, rootpath)
-
- for item in file_list:
- files.extract(item, file_dir)
-
- else:
- rootpath = os.path.splitext(filepath)[0].split(os.sep)[-1]
- uncompressed_path = os.path.join(file_dir, rootpath)
- if not os.path.exists(uncompressed_path):
- os.makedirs(uncompressed_path)
- for item in file_list:
- files.extract(item, os.path.join(file_dir, rootpath))
-
- files.close()
-
- return uncompressed_path
-
-
-def _uncompress_file_tar(filepath, mode="r:*"):
- files = tarfile.open(filepath, mode)
- file_list = files.getnames()
-
- file_dir = os.path.dirname(filepath)
-
- if _is_a_single_file(file_list):
- rootpath = file_list[0]
- uncompressed_path = os.path.join(file_dir, rootpath)
- for item in file_list:
- files.extract(item, file_dir)
- elif _is_a_single_dir(file_list):
- rootpath = os.path.splitext(file_list[0])[0].split(os.sep)[-1]
- uncompressed_path = os.path.join(file_dir, rootpath)
- for item in file_list:
- files.extract(item, file_dir)
- else:
- rootpath = os.path.splitext(filepath)[0].split(os.sep)[-1]
- uncompressed_path = os.path.join(file_dir, rootpath)
- if not os.path.exists(uncompressed_path):
- os.makedirs(uncompressed_path)
-
- for item in file_list:
- files.extract(item, os.path.join(file_dir, rootpath))
-
- files.close()
-
- return uncompressed_path
-
-
-def _is_a_single_file(file_list):
- if len(file_list) == 1 and file_list[0].find(os.sep) < -1:
- return True
- return False
-
-
-def _is_a_single_dir(file_list):
- new_file_list = []
- for file_path in file_list:
- if '/' in file_path:
- file_path = file_path.replace('/', os.sep)
- elif '\\' in file_path:
- file_path = file_path.replace('\\', os.sep)
- new_file_list.append(file_path)
-
- file_name = new_file_list[0].split(os.sep)[0]
- for i in range(1, len(new_file_list)):
- if file_name != new_file_list[i].split(os.sep)[0]:
- return False
- return True
diff --git a/audio/tests/backends/__init__.py b/paddlespeech/server/engine/acs/__init__.py
similarity index 100%
rename from audio/tests/backends/__init__.py
rename to paddlespeech/server/engine/acs/__init__.py
diff --git a/audio/tests/backends/soundfile/__init__.py b/paddlespeech/server/engine/acs/python/__init__.py
similarity index 100%
rename from audio/tests/backends/soundfile/__init__.py
rename to paddlespeech/server/engine/acs/python/__init__.py
diff --git a/paddlespeech/server/engine/acs/python/acs_engine.py b/paddlespeech/server/engine/acs/python/acs_engine.py
new file mode 100644
index 000000000..930101ac9
--- /dev/null
+++ b/paddlespeech/server/engine/acs/python/acs_engine.py
@@ -0,0 +1,221 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import io
+import json
+import os
+import re
+
+import numpy as np
+import paddle
+import soundfile
+import websocket
+
+from paddlespeech.cli.log import logger
+from paddlespeech.server.engine.base_engine import BaseEngine
+
+
+class ACSEngine(BaseEngine):
+ def __init__(self):
+ """The ACSEngine Engine
+ """
+ super(ACSEngine, self).__init__()
+ logger.info("Create the ACSEngine Instance")
+ self.word_list = []
+
+ def init(self, config: dict):
+ """Init the ACSEngine Engine
+
+ Args:
+ config (dict): The server configuation
+
+ Returns:
+ bool: The engine instance flag
+ """
+ logger.info("Init the acs engine")
+ try:
+ self.config = config
+ self.device = self.config.get("device", paddle.get_device())
+
+ # websocket default ping timeout is 20 seconds
+ self.ping_timeout = self.config.get("ping_timeout", 20)
+ paddle.set_device(self.device)
+ logger.info(f"ACS Engine set the device: {self.device}")
+
+ except BaseException as e:
+ logger.error(
+ "Set device failed, please check if device is already used and the parameter 'device' in the yaml file"
+ )
+ logger.error("Initialize Text server engine Failed on device: %s." %
+ (self.device))
+ return False
+
+ self.read_search_words()
+
+ # init the asr url
+ self.url = "ws://" + self.config.asr_server_ip + ":" + str(
+ self.config.asr_server_port) + "/paddlespeech/asr/streaming"
+
+ logger.info("Init the acs engine successfully")
+ return True
+
+ def read_search_words(self):
+ word_list = self.config.word_list
+ if word_list is None:
+ logger.error(
+ "No word list file in config, please set the word list parameter"
+ )
+ return
+
+ if not os.path.exists(word_list):
+ logger.error("Please input correct word list file")
+ return
+
+ with open(word_list, 'r') as fp:
+ self.word_list = [line.strip() for line in fp.readlines()]
+
+ logger.info(f"word list: {self.word_list}")
+
+ def get_asr_content(self, audio_data):
+ """Get the streaming asr result
+
+ Args:
+ audio_data (_type_): _description_
+
+ Returns:
+ _type_: _description_
+ """
+ logger.info("send a message to the server")
+ if self.url is None:
+ logger.error("No asr server, please input valid ip and port")
+ return ""
+ ws = websocket.WebSocket()
+ logger.info(f"set the ping timeout: {self.ping_timeout} seconds")
+ ws.connect(self.url, ping_timeout=self.ping_timeout)
+ audio_info = json.dumps(
+ {
+ "name": "test.wav",
+ "signal": "start",
+ "nbest": 1
+ },
+ sort_keys=True,
+ indent=4,
+ separators=(',', ': '))
+ ws.send(audio_info)
+ msg = ws.recv()
+ logger.info("client receive msg={}".format(msg))
+
+ # send the total audio data
+ for chunk_data in self.read_wave(audio_data):
+ ws.send_binary(chunk_data.tobytes())
+ msg = ws.recv()
+ msg = json.loads(msg)
+ logger.info(f"audio result: {msg}")
+
+ # 3. send chunk audio data to engine
+ logger.info("send the end signal")
+ audio_info = json.dumps(
+ {
+ "name": "test.wav",
+ "signal": "end",
+ "nbest": 1
+ },
+ sort_keys=True,
+ indent=4,
+ separators=(',', ': '))
+ ws.send(audio_info)
+ msg = ws.recv()
+ msg = json.loads(msg)
+
+ logger.info(f"the final result: {msg}")
+ ws.close()
+
+ return msg
+
+ def read_wave(self, audio_data: str):
+ """read the audio file from specific wavfile path
+
+ Args:
+ audio_data (str): the audio data,
+ we assume that audio sample rate matches the model
+
+ Yields:
+ numpy.array: the samall package audio pcm data
+ """
+ samples, sample_rate = soundfile.read(audio_data, dtype='int16')
+ x_len = len(samples)
+ assert sample_rate == 16000
+
+ chunk_size = int(85 * sample_rate / 1000) # 85ms, sample_rate = 16kHz
+
+ if x_len % chunk_size != 0:
+ padding_len_x = chunk_size - x_len % chunk_size
+ else:
+ padding_len_x = 0
+
+ padding = np.zeros((padding_len_x), dtype=samples.dtype)
+ padded_x = np.concatenate([samples, padding], axis=0)
+
+ assert (x_len + padding_len_x) % chunk_size == 0
+ num_chunk = (x_len + padding_len_x) / chunk_size
+ num_chunk = int(num_chunk)
+ for i in range(0, num_chunk):
+ start = i * chunk_size
+ end = start + chunk_size
+ x_chunk = padded_x[start:end]
+ yield x_chunk
+
+ def get_macthed_word(self, msg):
+ """Get the matched info in msg
+
+ Args:
+ msg (dict): the asr info, including the asr result and time stamp
+
+ Returns:
+ acs_result, asr_result: the acs result and the asr result
+ """
+ asr_result = msg['result']
+ time_stamp = msg['times']
+ acs_result = []
+
+ # search for each word in self.word_list
+ offset = self.config.offset
+ max_ed = time_stamp[-1]['ed']
+ for w in self.word_list:
+ # search the w in asr_result and the index in asr_result
+ for m in re.finditer(w, asr_result):
+ start = max(time_stamp[m.start(0)]['bg'] - offset, 0)
+
+ end = min(time_stamp[m.end(0) - 1]['ed'] + offset, max_ed)
+ logger.info(f'start: {start}, end: {end}')
+ acs_result.append({'w': w, 'bg': start, 'ed': end})
+
+ return acs_result, asr_result
+
+ def run(self, audio_data):
+ """process the audio data in acs engine
+ the engine does not store any data, so all the request use the self.run api
+
+ Args:
+ audio_data (str): the audio data
+
+ Returns:
+ acs_result, asr_result: the acs result and the asr result
+ """
+ logger.info("start to process the audio content search")
+ msg = self.get_asr_content(io.BytesIO(audio_data))
+
+ acs_result, asr_result = self.get_macthed_word(msg)
+ logger.info(f'the asr result {asr_result}')
+ logger.info(f'the acs result: {acs_result}')
+ return acs_result, asr_result
diff --git a/paddlespeech/server/engine/asr/online/asr_engine.py b/paddlespeech/server/engine/asr/online/asr_engine.py
deleted file mode 100644
index 59382e64e..000000000
--- a/paddlespeech/server/engine/asr/online/asr_engine.py
+++ /dev/null
@@ -1,1094 +0,0 @@
-# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import copy
-import os
-from typing import Optional
-
-import numpy as np
-import paddle
-from numpy import float32
-from yacs.config import CfgNode
-
-from paddlespeech.cli.asr.infer import ASRExecutor
-from paddlespeech.cli.asr.infer import model_alias
-from paddlespeech.cli.log import logger
-from paddlespeech.cli.utils import download_and_decompress
-from paddlespeech.cli.utils import MODEL_HOME
-from paddlespeech.s2t.frontend.featurizer.text_featurizer import TextFeaturizer
-from paddlespeech.s2t.frontend.speech import SpeechSegment
-from paddlespeech.s2t.modules.ctc import CTCDecoder
-from paddlespeech.s2t.transform.transformation import Transformation
-from paddlespeech.s2t.utils.dynamic_import import dynamic_import
-from paddlespeech.s2t.utils.tensor_utils import add_sos_eos
-from paddlespeech.s2t.utils.tensor_utils import pad_sequence
-from paddlespeech.s2t.utils.utility import UpdateConfig
-from paddlespeech.server.engine.asr.online.ctc_search import CTCPrefixBeamSearch
-from paddlespeech.server.engine.base_engine import BaseEngine
-from paddlespeech.server.utils.audio_process import pcm2float
-from paddlespeech.server.utils.paddle_predictor import init_predictor
-
-__all__ = ['ASREngine']
-
-pretrained_models = {
- "deepspeech2online_aishell-zh-16k": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_online_aishell_fbank161_ckpt_0.2.0.model.tar.gz',
- 'md5':
- 'd314960e83cc10dcfa6b04269f3054d4',
- 'cfg_path':
- 'model.yaml',
- 'ckpt_path':
- 'exp/deepspeech2_online/checkpoints/avg_1',
- 'model':
- 'exp/deepspeech2_online/checkpoints/avg_1.jit.pdmodel',
- 'params':
- 'exp/deepspeech2_online/checkpoints/avg_1.jit.pdiparams',
- 'lm_url':
- 'https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm',
- 'lm_md5':
- '29e02312deb2e59b3c8686c7966d4fe3'
- },
- "conformer_online_multicn-zh-16k": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/multi_cn/asr1/asr1_chunk_conformer_multi_cn_ckpt_0.2.3.model.tar.gz',
- 'md5':
- '0ac93d390552336f2a906aec9e33c5fa',
- 'cfg_path':
- 'model.yaml',
- 'ckpt_path':
- 'exp/chunk_conformer/checkpoints/multi_cn',
- 'model':
- 'exp/chunk_conformer/checkpoints/multi_cn.pdparams',
- 'params':
- 'exp/chunk_conformer/checkpoints/multi_cn.pdparams',
- 'lm_url':
- 'https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm',
- 'lm_md5':
- '29e02312deb2e59b3c8686c7966d4fe3'
- },
-}
-
-
-# ASR server connection process class
-class PaddleASRConnectionHanddler:
- def __init__(self, asr_engine):
- """Init a Paddle ASR Connection Handler instance
-
- Args:
- asr_engine (ASREngine): the global asr engine
- """
- super().__init__()
- logger.info(
- "create an paddle asr connection handler to process the websocket connection"
- )
- self.config = asr_engine.config
- self.model_config = asr_engine.executor.config
- self.asr_engine = asr_engine
-
- self.init()
- self.reset()
-
- def init(self):
- # model_type, sample_rate and text_feature is shared for deepspeech2 and conformer
- self.model_type = self.asr_engine.executor.model_type
- self.sample_rate = self.asr_engine.executor.sample_rate
- # tokens to text
- self.text_feature = self.asr_engine.executor.text_feature
-
- if "deepspeech2online" in self.model_type or "deepspeech2offline" in self.model_type:
- from paddlespeech.s2t.io.collator import SpeechCollator
- self.am_predictor = self.asr_engine.executor.am_predictor
-
- self.collate_fn_test = SpeechCollator.from_config(self.model_config)
- self.decoder = CTCDecoder(
- odim=self.model_config.output_dim, # is in vocab
- enc_n_units=self.model_config.rnn_layer_size * 2,
- blank_id=self.model_config.blank_id,
- dropout_rate=0.0,
- reduction=True, # sum
- batch_average=True, # sum / batch_size
- grad_norm_type=self.model_config.get('ctc_grad_norm_type',
- None))
-
- cfg = self.model_config.decode
- decode_batch_size = 1 # for online
- self.decoder.init_decoder(
- decode_batch_size, self.text_feature.vocab_list,
- cfg.decoding_method, cfg.lang_model_path, cfg.alpha, cfg.beta,
- cfg.beam_size, cfg.cutoff_prob, cfg.cutoff_top_n,
- cfg.num_proc_bsearch)
- # frame window samples length and frame shift samples length
-
- self.win_length = int(self.model_config.window_ms / 1000 *
- self.sample_rate)
- self.n_shift = int(self.model_config.stride_ms / 1000 *
- self.sample_rate)
-
- elif "conformer" in self.model_type or "transformer" in self.model_type:
- # acoustic model
- self.model = self.asr_engine.executor.model
-
- # ctc decoding config
- self.ctc_decode_config = self.asr_engine.executor.config.decode
- self.searcher = CTCPrefixBeamSearch(self.ctc_decode_config)
-
- # extract feat, new only fbank in conformer model
- self.preprocess_conf = self.model_config.preprocess_config
- self.preprocess_args = {"train": False}
- self.preprocessing = Transformation(self.preprocess_conf)
-
- # frame window samples length and frame shift samples length
- self.win_length = self.preprocess_conf.process[0]['win_length']
- self.n_shift = self.preprocess_conf.process[0]['n_shift']
-
- def extract_feat(self, samples):
- if "deepspeech2online" in self.model_type:
- # self.reamined_wav stores all the samples,
- # include the original remained_wav and this package samples
- samples = np.frombuffer(samples, dtype=np.int16)
- assert samples.ndim == 1
-
- # pcm16 -> pcm 32
- # pcm2float will change the orignal samples,
- # so we shoule do pcm2float before concatenate
- samples = pcm2float(samples)
-
- if self.remained_wav is None:
- self.remained_wav = samples
- else:
- assert self.remained_wav.ndim == 1
- self.remained_wav = np.concatenate([self.remained_wav, samples])
- logger.info(
- f"The connection remain the audio samples: {self.remained_wav.shape}"
- )
-
- # read audio
- speech_segment = SpeechSegment.from_pcm(
- self.remained_wav, self.sample_rate, transcript=" ")
- # audio augment
- self.collate_fn_test.augmentation.transform_audio(speech_segment)
-
- # extract speech feature
- spectrum, transcript_part = self.collate_fn_test._speech_featurizer.featurize(
- speech_segment, self.collate_fn_test.keep_transcription_text)
- # CMVN spectrum
- if self.collate_fn_test._normalizer:
- spectrum = self.collate_fn_test._normalizer.apply(spectrum)
-
- # spectrum augment
- audio = self.collate_fn_test.augmentation.transform_feature(
- spectrum)
-
- audio_len = audio.shape[0]
- audio = paddle.to_tensor(audio, dtype='float32')
- # audio_len = paddle.to_tensor(audio_len)
- audio = paddle.unsqueeze(audio, axis=0)
-
- if self.cached_feat is None:
- self.cached_feat = audio
- else:
- assert (len(audio.shape) == 3)
- assert (len(self.cached_feat.shape) == 3)
- self.cached_feat = paddle.concat(
- [self.cached_feat, audio], axis=1)
-
- # set the feat device
- if self.device is None:
- self.device = self.cached_feat.place
-
- self.num_frames += audio_len
- self.remained_wav = self.remained_wav[self.n_shift * audio_len:]
-
- logger.info(
- f"process the audio feature success, the connection feat shape: {self.cached_feat.shape}"
- )
- logger.info(
- f"After extract feat, the connection remain the audio samples: {self.remained_wav.shape}"
- )
- elif "conformer_online" in self.model_type:
- logger.info("Online ASR extract the feat")
- samples = np.frombuffer(samples, dtype=np.int16)
- assert samples.ndim == 1
-
- logger.info(f"This package receive {samples.shape[0]} pcm data")
- self.num_samples += samples.shape[0]
-
- # self.reamined_wav stores all the samples,
- # include the original remained_wav and this package samples
- if self.remained_wav is None:
- self.remained_wav = samples
- else:
- assert self.remained_wav.ndim == 1
- self.remained_wav = np.concatenate([self.remained_wav, samples])
- logger.info(
- f"The connection remain the audio samples: {self.remained_wav.shape}"
- )
- if len(self.remained_wav) < self.win_length:
- return 0
-
- # fbank
- x_chunk = self.preprocessing(self.remained_wav,
- **self.preprocess_args)
- x_chunk = paddle.to_tensor(
- x_chunk, dtype="float32").unsqueeze(axis=0)
- if self.cached_feat is None:
- self.cached_feat = x_chunk
- else:
- assert (len(x_chunk.shape) == 3)
- assert (len(self.cached_feat.shape) == 3)
- self.cached_feat = paddle.concat(
- [self.cached_feat, x_chunk], axis=1)
-
- # set the feat device
- if self.device is None:
- self.device = self.cached_feat.place
-
- num_frames = x_chunk.shape[1]
- self.num_frames += num_frames
- self.remained_wav = self.remained_wav[self.n_shift * num_frames:]
-
- logger.info(
- f"process the audio feature success, the connection feat shape: {self.cached_feat.shape}"
- )
- logger.info(
- f"After extract feat, the connection remain the audio samples: {self.remained_wav.shape}"
- )
- # logger.info(f"accumulate samples: {self.num_samples}")
-
- def reset(self):
- if "deepspeech2online" in self.model_type or "deepspeech2offline" in self.model_type:
- # for deepspeech2
- self.chunk_state_h_box = copy.deepcopy(
- self.asr_engine.executor.chunk_state_h_box)
- self.chunk_state_c_box = copy.deepcopy(
- self.asr_engine.executor.chunk_state_c_box)
- self.decoder.reset_decoder(batch_size=1)
-
- # for conformer online
- self.subsampling_cache = None
- self.elayers_output_cache = None
- self.conformer_cnn_cache = None
- self.encoder_out = None
- self.cached_feat = None
- self.remained_wav = None
- self.offset = 0
- self.num_samples = 0
- self.device = None
- self.hyps = []
- self.num_frames = 0
- self.chunk_num = 0
- self.global_frame_offset = 0
- self.result_transcripts = ['']
-
- def decode(self, is_finished=False):
- if "deepspeech2online" in self.model_type:
- # x_chunk 是特征数据
- decoding_chunk_size = 1 # decoding_chunk_size=1 in deepspeech2 model
- context = 7 # context=7 in deepspeech2 model
- subsampling = 4 # subsampling=4 in deepspeech2 model
- stride = subsampling * decoding_chunk_size
- cached_feature_num = context - subsampling
- # decoding window for model
- decoding_window = (decoding_chunk_size - 1) * subsampling + context
-
- if self.cached_feat is None:
- logger.info("no audio feat, please input more pcm data")
- return
-
- num_frames = self.cached_feat.shape[1]
- logger.info(
- f"Required decoding window {decoding_window} frames, and the connection has {num_frames} frames"
- )
- # the cached feat must be larger decoding_window
- if num_frames < decoding_window and not is_finished:
- logger.info(
- f"frame feat num is less than {decoding_window}, please input more pcm data"
- )
- return None, None
-
- # if is_finished=True, we need at least context frames
- if num_frames < context:
- logger.info(
- "flast {num_frames} is less than context {context} frames, and we cannot do model forward"
- )
- return None, None
- logger.info("start to do model forward")
- # num_frames - context + 1 ensure that current frame can get context window
- if is_finished:
- # if get the finished chunk, we need process the last context
- left_frames = context
- else:
- # we only process decoding_window frames for one chunk
- left_frames = decoding_window
-
- for cur in range(0, num_frames - left_frames + 1, stride):
- end = min(cur + decoding_window, num_frames)
- # extract the audio
- x_chunk = self.cached_feat[:, cur:end, :].numpy()
- x_chunk_lens = np.array([x_chunk.shape[1]])
- trans_best = self.decode_one_chunk(x_chunk, x_chunk_lens)
-
- self.result_transcripts = [trans_best]
-
- self.cached_feat = self.cached_feat[:, end - cached_feature_num:, :]
- # return trans_best[0]
- elif "conformer" in self.model_type or "transformer" in self.model_type:
- try:
- logger.info(
- f"we will use the transformer like model : {self.model_type}"
- )
- self.advance_decoding(is_finished)
- self.update_result()
-
- except Exception as e:
- logger.exception(e)
- else:
- raise Exception("invalid model name")
-
- @paddle.no_grad()
- def decode_one_chunk(self, x_chunk, x_chunk_lens):
- logger.info("start to decoce one chunk with deepspeech2 model")
- input_names = self.am_predictor.get_input_names()
- audio_handle = self.am_predictor.get_input_handle(input_names[0])
- audio_len_handle = self.am_predictor.get_input_handle(input_names[1])
- h_box_handle = self.am_predictor.get_input_handle(input_names[2])
- c_box_handle = self.am_predictor.get_input_handle(input_names[3])
-
- audio_handle.reshape(x_chunk.shape)
- audio_handle.copy_from_cpu(x_chunk)
-
- audio_len_handle.reshape(x_chunk_lens.shape)
- audio_len_handle.copy_from_cpu(x_chunk_lens)
-
- h_box_handle.reshape(self.chunk_state_h_box.shape)
- h_box_handle.copy_from_cpu(self.chunk_state_h_box)
-
- c_box_handle.reshape(self.chunk_state_c_box.shape)
- c_box_handle.copy_from_cpu(self.chunk_state_c_box)
-
- output_names = self.am_predictor.get_output_names()
- output_handle = self.am_predictor.get_output_handle(output_names[0])
- output_lens_handle = self.am_predictor.get_output_handle(
- output_names[1])
- output_state_h_handle = self.am_predictor.get_output_handle(
- output_names[2])
- output_state_c_handle = self.am_predictor.get_output_handle(
- output_names[3])
-
- self.am_predictor.run()
-
- output_chunk_probs = output_handle.copy_to_cpu()
- output_chunk_lens = output_lens_handle.copy_to_cpu()
- self.chunk_state_h_box = output_state_h_handle.copy_to_cpu()
- self.chunk_state_c_box = output_state_c_handle.copy_to_cpu()
-
- self.decoder.next(output_chunk_probs, output_chunk_lens)
- trans_best, trans_beam = self.decoder.decode()
- logger.info(f"decode one best result: {trans_best[0]}")
- return trans_best[0]
-
- @paddle.no_grad()
- def advance_decoding(self, is_finished=False):
- logger.info("start to decode with advanced_decoding method")
- cfg = self.ctc_decode_config
- decoding_chunk_size = cfg.decoding_chunk_size
- num_decoding_left_chunks = cfg.num_decoding_left_chunks
-
- assert decoding_chunk_size > 0
- subsampling = self.model.encoder.embed.subsampling_rate
- context = self.model.encoder.embed.right_context + 1
- stride = subsampling * decoding_chunk_size
- cached_feature_num = context - subsampling # processed chunk feature cached for next chunk
-
- # decoding window for model
- decoding_window = (decoding_chunk_size - 1) * subsampling + context
- if self.cached_feat is None:
- logger.info("no audio feat, please input more pcm data")
- return
-
- num_frames = self.cached_feat.shape[1]
- logger.info(
- f"Required decoding window {decoding_window} frames, and the connection has {num_frames} frames"
- )
-
- # the cached feat must be larger decoding_window
- if num_frames < decoding_window and not is_finished:
- logger.info(
- f"frame feat num is less than {decoding_window}, please input more pcm data"
- )
- return None, None
-
- # if is_finished=True, we need at least context frames
- if num_frames < context:
- logger.info(
- "flast {num_frames} is less than context {context} frames, and we cannot do model forward"
- )
- return None, None
-
- logger.info("start to do model forward")
- required_cache_size = decoding_chunk_size * num_decoding_left_chunks
- outputs = []
-
- # num_frames - context + 1 ensure that current frame can get context window
- if is_finished:
- # if get the finished chunk, we need process the last context
- left_frames = context
- else:
- # we only process decoding_window frames for one chunk
- left_frames = decoding_window
-
- # record the end for removing the processed feat
- end = None
- for cur in range(0, num_frames - left_frames + 1, stride):
- end = min(cur + decoding_window, num_frames)
-
- self.chunk_num += 1
- chunk_xs = self.cached_feat[:, cur:end, :]
- (y, self.subsampling_cache, self.elayers_output_cache,
- self.conformer_cnn_cache) = self.model.encoder.forward_chunk(
- chunk_xs, self.offset, required_cache_size,
- self.subsampling_cache, self.elayers_output_cache,
- self.conformer_cnn_cache)
- outputs.append(y)
-
- # update the offset
- self.offset += y.shape[1]
-
- ys = paddle.cat(outputs, 1)
- if self.encoder_out is None:
- self.encoder_out = ys
- else:
- self.encoder_out = paddle.concat([self.encoder_out, ys], axis=1)
-
- # get the ctc probs
- ctc_probs = self.model.ctc.log_softmax(ys) # (1, maxlen, vocab_size)
- ctc_probs = ctc_probs.squeeze(0)
-
- self.searcher.search(ctc_probs, self.cached_feat.place)
-
- self.hyps = self.searcher.get_one_best_hyps()
- assert self.cached_feat.shape[0] == 1
- assert end >= cached_feature_num
-
- self.cached_feat = self.cached_feat[0, end -
- cached_feature_num:, :].unsqueeze(0)
- assert len(
- self.cached_feat.shape
- ) == 3, f"current cache feat shape is: {self.cached_feat.shape}"
-
- logger.info(
- f"This connection handler encoder out shape: {self.encoder_out.shape}"
- )
-
- def update_result(self):
- logger.info("update the final result")
- hyps = self.hyps
- self.result_transcripts = [
- self.text_feature.defeaturize(hyp) for hyp in hyps
- ]
- self.result_tokenids = [hyp for hyp in hyps]
-
- def get_result(self):
- if len(self.result_transcripts) > 0:
- return self.result_transcripts[0]
- else:
- return ''
-
- @paddle.no_grad()
- def rescoring(self):
- if "deepspeech2online" in self.model_type or "deepspeech2offline" in self.model_type:
- return
-
- logger.info("rescoring the final result")
- if "attention_rescoring" != self.ctc_decode_config.decoding_method:
- return
-
- self.searcher.finalize_search()
- self.update_result()
-
- beam_size = self.ctc_decode_config.beam_size
- hyps = self.searcher.get_hyps()
- if hyps is None or len(hyps) == 0:
- return
-
- # assert len(hyps) == beam_size
- hyp_list = []
- for hyp in hyps:
- hyp_content = hyp[0]
- # Prevent the hyp is empty
- if len(hyp_content) == 0:
- hyp_content = (self.model.ctc.blank_id, )
- hyp_content = paddle.to_tensor(
- hyp_content, place=self.device, dtype=paddle.long)
- hyp_list.append(hyp_content)
- hyps_pad = pad_sequence(hyp_list, True, self.model.ignore_id)
- hyps_lens = paddle.to_tensor(
- [len(hyp[0]) for hyp in hyps], place=self.device,
- dtype=paddle.long) # (beam_size,)
- hyps_pad, _ = add_sos_eos(hyps_pad, self.model.sos, self.model.eos,
- self.model.ignore_id)
- hyps_lens = hyps_lens + 1 # Add at begining
-
- encoder_out = self.encoder_out.repeat(beam_size, 1, 1)
- encoder_mask = paddle.ones(
- (beam_size, 1, encoder_out.shape[1]), dtype=paddle.bool)
- decoder_out, _ = self.model.decoder(
- encoder_out, encoder_mask, hyps_pad,
- hyps_lens) # (beam_size, max_hyps_len, vocab_size)
- # ctc score in ln domain
- decoder_out = paddle.nn.functional.log_softmax(decoder_out, axis=-1)
- decoder_out = decoder_out.numpy()
-
- # Only use decoder score for rescoring
- best_score = -float('inf')
- best_index = 0
- # hyps is List[(Text=List[int], Score=float)], len(hyps)=beam_size
- for i, hyp in enumerate(hyps):
- score = 0.0
- for j, w in enumerate(hyp[0]):
- score += decoder_out[i][j][w]
- # last decoder output token is `eos`, for laste decoder input token.
- score += decoder_out[i][len(hyp[0])][self.model.eos]
- # add ctc score (which in ln domain)
- score += hyp[1] * self.ctc_decode_config.ctc_weight
- if score > best_score:
- best_score = score
- best_index = i
-
- # update the one best result
- logger.info(f"best index: {best_index}")
- self.hyps = [hyps[best_index][0]]
- self.update_result()
-
-
-class ASRServerExecutor(ASRExecutor):
- def __init__(self):
- super().__init__()
- pass
-
- def _get_pretrained_path(self, tag: str) -> os.PathLike:
- """
- Download and returns pretrained resources path of current task.
- """
- support_models = list(pretrained_models.keys())
- assert tag in pretrained_models, 'The model "{}" you want to use has not been supported, please choose other models.\nThe support models includes:\n\t\t{}\n'.format(
- tag, '\n\t\t'.join(support_models))
-
- res_path = os.path.join(MODEL_HOME, tag)
- decompressed_path = download_and_decompress(pretrained_models[tag],
- res_path)
- decompressed_path = os.path.abspath(decompressed_path)
- logger.info(
- 'Use pretrained model stored in: {}'.format(decompressed_path))
-
- return decompressed_path
-
- def _init_from_path(self,
- model_type: str='deepspeech2online_aishell',
- am_model: Optional[os.PathLike]=None,
- am_params: Optional[os.PathLike]=None,
- lang: str='zh',
- sample_rate: int=16000,
- cfg_path: Optional[os.PathLike]=None,
- decode_method: str='attention_rescoring',
- am_predictor_conf: dict=None):
- """
- Init model and other resources from a specific path.
- """
- self.model_type = model_type
- self.sample_rate = sample_rate
- if cfg_path is None or am_model is None or am_params is None:
- sample_rate_str = '16k' if sample_rate == 16000 else '8k'
- tag = model_type + '-' + lang + '-' + sample_rate_str
- logger.info(f"Load the pretrained model, tag = {tag}")
- res_path = self._get_pretrained_path(tag) # wenetspeech_zh
- self.res_path = res_path
-
- self.cfg_path = os.path.join(res_path,
- pretrained_models[tag]['cfg_path'])
-
- self.am_model = os.path.join(res_path,
- pretrained_models[tag]['model'])
- self.am_params = os.path.join(res_path,
- pretrained_models[tag]['params'])
- logger.info(res_path)
- else:
- self.cfg_path = os.path.abspath(cfg_path)
- self.am_model = os.path.abspath(am_model)
- self.am_params = os.path.abspath(am_params)
- self.res_path = os.path.dirname(
- os.path.dirname(os.path.abspath(self.cfg_path)))
-
- logger.info(self.cfg_path)
- logger.info(self.am_model)
- logger.info(self.am_params)
-
- #Init body.
- self.config = CfgNode(new_allowed=True)
- self.config.merge_from_file(self.cfg_path)
-
- with UpdateConfig(self.config):
- if "deepspeech2online" in model_type or "deepspeech2offline" in model_type:
- from paddlespeech.s2t.io.collator import SpeechCollator
- self.vocab = self.config.vocab_filepath
- self.config.decode.lang_model_path = os.path.join(
- MODEL_HOME, 'language_model',
- self.config.decode.lang_model_path)
- self.collate_fn_test = SpeechCollator.from_config(self.config)
- self.text_feature = TextFeaturizer(
- unit_type=self.config.unit_type, vocab=self.vocab)
-
- lm_url = pretrained_models[tag]['lm_url']
- lm_md5 = pretrained_models[tag]['lm_md5']
- logger.info(f"Start to load language model {lm_url}")
- self.download_lm(
- lm_url,
- os.path.dirname(self.config.decode.lang_model_path), lm_md5)
- elif "conformer" in model_type or "transformer" in model_type:
- logger.info("start to create the stream conformer asr engine")
- if self.config.spm_model_prefix:
- self.config.spm_model_prefix = os.path.join(
- self.res_path, self.config.spm_model_prefix)
- self.vocab = self.config.vocab_filepath
- self.text_feature = TextFeaturizer(
- unit_type=self.config.unit_type,
- vocab=self.config.vocab_filepath,
- spm_model_prefix=self.config.spm_model_prefix)
- # update the decoding method
- if decode_method:
- self.config.decode.decoding_method = decode_method
-
- # we only support ctc_prefix_beam_search and attention_rescoring dedoding method
- # Generally we set the decoding_method to attention_rescoring
- if self.config.decode.decoding_method not in [
- "ctc_prefix_beam_search", "attention_rescoring"
- ]:
- logger.info(
- "we set the decoding_method to attention_rescoring")
- self.config.decode.decoding = "attention_rescoring"
- assert self.config.decode.decoding_method in [
- "ctc_prefix_beam_search", "attention_rescoring"
- ], f"we only support ctc_prefix_beam_search and attention_rescoring dedoding method, current decoding method is {self.config.decode.decoding_method}"
- else:
- raise Exception("wrong type")
- if "deepspeech2online" in model_type or "deepspeech2offline" in model_type:
- # AM predictor
- logger.info("ASR engine start to init the am predictor")
- self.am_predictor_conf = am_predictor_conf
- self.am_predictor = init_predictor(
- model_file=self.am_model,
- params_file=self.am_params,
- predictor_conf=self.am_predictor_conf)
-
- # decoder
- logger.info("ASR engine start to create the ctc decoder instance")
- self.decoder = CTCDecoder(
- odim=self.config.output_dim, # is in vocab
- enc_n_units=self.config.rnn_layer_size * 2,
- blank_id=self.config.blank_id,
- dropout_rate=0.0,
- reduction=True, # sum
- batch_average=True, # sum / batch_size
- grad_norm_type=self.config.get('ctc_grad_norm_type', None))
-
- # init decoder
- logger.info("ASR engine start to init the ctc decoder")
- cfg = self.config.decode
- decode_batch_size = 1 # for online
- self.decoder.init_decoder(
- decode_batch_size, self.text_feature.vocab_list,
- cfg.decoding_method, cfg.lang_model_path, cfg.alpha, cfg.beta,
- cfg.beam_size, cfg.cutoff_prob, cfg.cutoff_top_n,
- cfg.num_proc_bsearch)
-
- # init state box
- self.chunk_state_h_box = np.zeros(
- (self.config.num_rnn_layers, 1, self.config.rnn_layer_size),
- dtype=float32)
- self.chunk_state_c_box = np.zeros(
- (self.config.num_rnn_layers, 1, self.config.rnn_layer_size),
- dtype=float32)
- elif "conformer" in model_type or "transformer" in model_type:
- model_name = model_type[:model_type.rindex(
- '_')] # model_type: {model_name}_{dataset}
- logger.info(f"model name: {model_name}")
- model_class = dynamic_import(model_name, model_alias)
- model_conf = self.config
- model = model_class.from_config(model_conf)
- self.model = model
- self.model.eval()
-
- # load model
- model_dict = paddle.load(self.am_model)
- self.model.set_state_dict(model_dict)
- logger.info("create the transformer like model success")
-
- # update the ctc decoding
- self.searcher = CTCPrefixBeamSearch(self.config.decode)
- self.transformer_decode_reset()
-
- def reset_decoder_and_chunk(self):
- """reset decoder and chunk state for an new audio
- """
- if "deepspeech2online" in self.model_type or "deepspeech2offline" in self.model_type:
- self.decoder.reset_decoder(batch_size=1)
- # init state box, for new audio request
- self.chunk_state_h_box = np.zeros(
- (self.config.num_rnn_layers, 1, self.config.rnn_layer_size),
- dtype=float32)
- self.chunk_state_c_box = np.zeros(
- (self.config.num_rnn_layers, 1, self.config.rnn_layer_size),
- dtype=float32)
- elif "conformer" in self.model_type or "transformer" in self.model_type:
- self.transformer_decode_reset()
-
- def decode_one_chunk(self, x_chunk, x_chunk_lens, model_type: str):
- """decode one chunk
-
- Args:
- x_chunk (numpy.array): shape[B, T, D]
- x_chunk_lens (numpy.array): shape[B]
- model_type (str): online model type
-
- Returns:
- str: one best result
- """
- logger.info("start to decoce chunk by chunk")
- if "deepspeech2online" in model_type:
- input_names = self.am_predictor.get_input_names()
- audio_handle = self.am_predictor.get_input_handle(input_names[0])
- audio_len_handle = self.am_predictor.get_input_handle(
- input_names[1])
- h_box_handle = self.am_predictor.get_input_handle(input_names[2])
- c_box_handle = self.am_predictor.get_input_handle(input_names[3])
-
- audio_handle.reshape(x_chunk.shape)
- audio_handle.copy_from_cpu(x_chunk)
-
- audio_len_handle.reshape(x_chunk_lens.shape)
- audio_len_handle.copy_from_cpu(x_chunk_lens)
-
- h_box_handle.reshape(self.chunk_state_h_box.shape)
- h_box_handle.copy_from_cpu(self.chunk_state_h_box)
-
- c_box_handle.reshape(self.chunk_state_c_box.shape)
- c_box_handle.copy_from_cpu(self.chunk_state_c_box)
-
- output_names = self.am_predictor.get_output_names()
- output_handle = self.am_predictor.get_output_handle(output_names[0])
- output_lens_handle = self.am_predictor.get_output_handle(
- output_names[1])
- output_state_h_handle = self.am_predictor.get_output_handle(
- output_names[2])
- output_state_c_handle = self.am_predictor.get_output_handle(
- output_names[3])
-
- self.am_predictor.run()
-
- output_chunk_probs = output_handle.copy_to_cpu()
- output_chunk_lens = output_lens_handle.copy_to_cpu()
- self.chunk_state_h_box = output_state_h_handle.copy_to_cpu()
- self.chunk_state_c_box = output_state_c_handle.copy_to_cpu()
-
- self.decoder.next(output_chunk_probs, output_chunk_lens)
- trans_best, trans_beam = self.decoder.decode()
- logger.info(f"decode one best result: {trans_best[0]}")
- return trans_best[0]
-
- elif "conformer" in model_type or "transformer" in model_type:
- try:
- logger.info(
- f"we will use the transformer like model : {self.model_type}"
- )
- self.advanced_decoding(x_chunk, x_chunk_lens)
- self.update_result()
-
- return self.result_transcripts[0]
- except Exception as e:
- logger.exception(e)
- else:
- raise Exception("invalid model name")
-
- def advanced_decoding(self, xs: paddle.Tensor, x_chunk_lens):
- logger.info("start to decode with advanced_decoding method")
- encoder_out, encoder_mask = self.encoder_forward(xs)
- ctc_probs = self.model.ctc.log_softmax(
- encoder_out) # (1, maxlen, vocab_size)
- ctc_probs = ctc_probs.squeeze(0)
- self.searcher.search(ctc_probs, xs.place)
- # update the one best result
- self.hyps = self.searcher.get_one_best_hyps()
-
- # now we supprot ctc_prefix_beam_search and attention_rescoring
- if "attention_rescoring" in self.config.decode.decoding_method:
- self.rescoring(encoder_out, xs.place)
-
- def encoder_forward(self, xs):
- logger.info("get the model out from the feat")
- cfg = self.config.decode
- decoding_chunk_size = cfg.decoding_chunk_size
- num_decoding_left_chunks = cfg.num_decoding_left_chunks
-
- assert decoding_chunk_size > 0
- subsampling = self.model.encoder.embed.subsampling_rate
- context = self.model.encoder.embed.right_context + 1
- stride = subsampling * decoding_chunk_size
-
- # decoding window for model
- decoding_window = (decoding_chunk_size - 1) * subsampling + context
- num_frames = xs.shape[1]
- required_cache_size = decoding_chunk_size * num_decoding_left_chunks
-
- logger.info("start to do model forward")
- outputs = []
-
- # num_frames - context + 1 ensure that current frame can get context window
- for cur in range(0, num_frames - context + 1, stride):
- end = min(cur + decoding_window, num_frames)
- chunk_xs = xs[:, cur:end, :]
- (y, self.subsampling_cache, self.elayers_output_cache,
- self.conformer_cnn_cache) = self.model.encoder.forward_chunk(
- chunk_xs, self.offset, required_cache_size,
- self.subsampling_cache, self.elayers_output_cache,
- self.conformer_cnn_cache)
- outputs.append(y)
- self.offset += y.shape[1]
-
- ys = paddle.cat(outputs, 1)
- masks = paddle.ones([1, ys.shape[1]], dtype=paddle.bool)
- masks = masks.unsqueeze(1)
- return ys, masks
-
- def rescoring(self, encoder_out, device):
- logger.info("start to rescoring the hyps")
- beam_size = self.config.decode.beam_size
- hyps = self.searcher.get_hyps()
- assert len(hyps) == beam_size
-
- hyp_list = []
- for hyp in hyps:
- hyp_content = hyp[0]
- # Prevent the hyp is empty
- if len(hyp_content) == 0:
- hyp_content = (self.model.ctc.blank_id, )
- hyp_content = paddle.to_tensor(
- hyp_content, place=device, dtype=paddle.long)
- hyp_list.append(hyp_content)
- hyps_pad = pad_sequence(hyp_list, True, self.model.ignore_id)
- hyps_lens = paddle.to_tensor(
- [len(hyp[0]) for hyp in hyps], place=device,
- dtype=paddle.long) # (beam_size,)
- hyps_pad, _ = add_sos_eos(hyps_pad, self.model.sos, self.model.eos,
- self.model.ignore_id)
- hyps_lens = hyps_lens + 1 # Add at begining
-
- encoder_out = encoder_out.repeat(beam_size, 1, 1)
- encoder_mask = paddle.ones(
- (beam_size, 1, encoder_out.shape[1]), dtype=paddle.bool)
- decoder_out, _ = self.model.decoder(
- encoder_out, encoder_mask, hyps_pad,
- hyps_lens) # (beam_size, max_hyps_len, vocab_size)
- # ctc score in ln domain
- decoder_out = paddle.nn.functional.log_softmax(decoder_out, axis=-1)
- decoder_out = decoder_out.numpy()
-
- # Only use decoder score for rescoring
- best_score = -float('inf')
- best_index = 0
- # hyps is List[(Text=List[int], Score=float)], len(hyps)=beam_size
- for i, hyp in enumerate(hyps):
- score = 0.0
- for j, w in enumerate(hyp[0]):
- score += decoder_out[i][j][w]
- # last decoder output token is `eos`, for laste decoder input token.
- score += decoder_out[i][len(hyp[0])][self.model.eos]
- # add ctc score (which in ln domain)
- score += hyp[1] * self.config.decode.ctc_weight
- if score > best_score:
- best_score = score
- best_index = i
-
- # update the one best result
- self.hyps = [hyps[best_index][0]]
- return hyps[best_index][0]
-
- def transformer_decode_reset(self):
- self.subsampling_cache = None
- self.elayers_output_cache = None
- self.conformer_cnn_cache = None
- self.offset = 0
- # decoding reset
- self.searcher.reset()
-
- def update_result(self):
- logger.info("update the final result")
- hyps = self.hyps
- self.result_transcripts = [
- self.text_feature.defeaturize(hyp) for hyp in hyps
- ]
- self.result_tokenids = [hyp for hyp in hyps]
-
- def extract_feat(self, samples, sample_rate):
- """extract feat
-
- Args:
- samples (numpy.array): numpy.float32
- sample_rate (int): sample rate
-
- Returns:
- x_chunk (numpy.array): shape[B, T, D]
- x_chunk_lens (numpy.array): shape[B]
- """
-
- if "deepspeech2online" in self.model_type:
- # pcm16 -> pcm 32
- samples = pcm2float(samples)
- # read audio
- speech_segment = SpeechSegment.from_pcm(
- samples, sample_rate, transcript=" ")
- # audio augment
- self.collate_fn_test.augmentation.transform_audio(speech_segment)
-
- # extract speech feature
- spectrum, transcript_part = self.collate_fn_test._speech_featurizer.featurize(
- speech_segment, self.collate_fn_test.keep_transcription_text)
- # CMVN spectrum
- if self.collate_fn_test._normalizer:
- spectrum = self.collate_fn_test._normalizer.apply(spectrum)
-
- # spectrum augment
- audio = self.collate_fn_test.augmentation.transform_feature(
- spectrum)
-
- audio_len = audio.shape[0]
- audio = paddle.to_tensor(audio, dtype='float32')
- # audio_len = paddle.to_tensor(audio_len)
- audio = paddle.unsqueeze(audio, axis=0)
-
- x_chunk = audio.numpy()
- x_chunk_lens = np.array([audio_len])
-
- return x_chunk, x_chunk_lens
- elif "conformer_online" in self.model_type:
-
- if sample_rate != self.sample_rate:
- logger.info(f"audio sample rate {sample_rate} is not match,"
- "the model sample_rate is {self.sample_rate}")
- logger.info(f"ASR Engine use the {self.model_type} to process")
- logger.info("Create the preprocess instance")
- preprocess_conf = self.config.preprocess_config
- preprocess_args = {"train": False}
- preprocessing = Transformation(preprocess_conf)
-
- logger.info("Read the audio file")
- logger.info(f"audio shape: {samples.shape}")
- # fbank
- x_chunk = preprocessing(samples, **preprocess_args)
- x_chunk_lens = paddle.to_tensor(x_chunk.shape[0])
- x_chunk = paddle.to_tensor(
- x_chunk, dtype="float32").unsqueeze(axis=0)
- logger.info(
- f"process the audio feature success, feat shape: {x_chunk.shape}"
- )
- return x_chunk, x_chunk_lens
-
-
-class ASREngine(BaseEngine):
- """ASR server engine
-
- Args:
- metaclass: Defaults to Singleton.
- """
-
- def __init__(self):
- super(ASREngine, self).__init__()
- logger.info("create the online asr engine instance")
-
- def init(self, config: dict) -> bool:
- """init engine resource
-
- Args:
- config_file (str): config file
-
- Returns:
- bool: init failed or success
- """
- self.input = None
- self.output = ""
- self.executor = ASRServerExecutor()
- self.config = config
- try:
- if self.config.get("device", None):
- self.device = self.config.device
- else:
- self.device = paddle.get_device()
- logger.info(f"paddlespeech_server set the device: {self.device}")
- paddle.set_device(self.device)
- except BaseException:
- logger.error(
- "Set device failed, please check if device is already used and the parameter 'device' in the yaml file"
- )
-
- self.executor._init_from_path(
- model_type=self.config.model_type,
- am_model=self.config.am_model,
- am_params=self.config.am_params,
- lang=self.config.lang,
- sample_rate=self.config.sample_rate,
- cfg_path=self.config.cfg_path,
- decode_method=self.config.decode_method,
- am_predictor_conf=self.config.am_predictor_conf)
-
- logger.info("Initialize ASR server engine successfully.")
- return True
-
- def preprocess(self,
- samples,
- sample_rate,
- model_type="deepspeech2online_aishell-zh-16k"):
- """preprocess
-
- Args:
- samples (numpy.array): numpy.float32
- sample_rate (int): sample rate
-
- Returns:
- x_chunk (numpy.array): shape[B, T, D]
- x_chunk_lens (numpy.array): shape[B]
- """
- # if "deepspeech" in model_type:
- x_chunk, x_chunk_lens = self.executor.extract_feat(samples, sample_rate)
- return x_chunk, x_chunk_lens
-
- def run(self, x_chunk, x_chunk_lens, decoder_chunk_size=1):
- """run online engine
-
- Args:
- x_chunk (numpy.array): shape[B, T, D]
- x_chunk_lens (numpy.array): shape[B]
- decoder_chunk_size(int)
- """
- self.output = self.executor.decode_one_chunk(x_chunk, x_chunk_lens,
- self.config.model_type)
-
- def postprocess(self):
- """postprocess
- """
- return self.output
-
- def reset(self):
- """reset engine decoder and inference state
- """
- self.executor.reset_decoder_and_chunk()
- self.output = ""
diff --git a/paddlespeech/server/engine/asr/online/ctc_endpoint.py b/paddlespeech/server/engine/asr/online/ctc_endpoint.py
new file mode 100644
index 000000000..2dba36417
--- /dev/null
+++ b/paddlespeech/server/engine/asr/online/ctc_endpoint.py
@@ -0,0 +1,118 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from dataclasses import dataclass
+
+import numpy as np
+
+from paddlespeech.cli.log import logger
+
+
+@dataclass
+class OnlineCTCEndpointRule:
+ must_contain_nonsilence: bool = True
+ min_trailing_silence: int = 1000
+ min_utterance_length: int = 0
+
+
+@dataclass
+class OnlineCTCEndpoingOpt:
+ frame_shift_in_ms: int = 10
+
+ blank: int = 0 # blank id, that we consider as silence for purposes of endpointing.
+ blank_threshold: float = 0.8 # above blank threshold is silence
+
+ # We support three rules. We terminate decoding if ANY of these rules
+ # evaluates to "true". If you want to add more rules, do it by changing this
+ # code. If you want to disable a rule, you can set the silence-timeout for
+ # that rule to a very large number.
+
+ # rule1 times out after 5 seconds of silence, even if we decoded nothing.
+ rule1: OnlineCTCEndpointRule = OnlineCTCEndpointRule(False, 5000, 0)
+ # rule4 times out after 1.0 seconds of silence after decoding something,
+ # even if we did not reach a final-state at all.
+ rule2: OnlineCTCEndpointRule = OnlineCTCEndpointRule(True, 1000, 0)
+ # rule5 times out after the utterance is 20 seconds long, regardless of
+ # anything else.
+ rule3: OnlineCTCEndpointRule = OnlineCTCEndpointRule(False, 0, 20000)
+
+
+class OnlineCTCEndpoint:
+ """
+ [END-TO-END AUTOMATIC SPEECH RECOGNITION INTEGRATED WITH CTC-BASED VOICE ACTIVITY DETECTION](https://arxiv.org/pdf/2002.00551.pdf)
+ """
+
+ def __init__(self, opts: OnlineCTCEndpoingOpt):
+ self.opts = opts
+ logger.info(f"Endpont Opts: {opts}")
+ self.frame_shift_in_ms = opts.frame_shift_in_ms
+
+ self.num_frames_decoded = 0
+ self.trailing_silence_frames = 0
+
+ self.reset()
+
+ def reset(self):
+ self.num_frames_decoded = 0
+ self.trailing_silence_frames = 0
+
+ def rule_activated(self,
+ rule: OnlineCTCEndpointRule,
+ rule_name: str,
+ decoding_something: bool,
+ trailine_silence: int,
+ utterance_length: int) -> bool:
+ ans = (
+ decoding_something or (not rule.must_contain_nonsilence)
+ ) and trailine_silence >= rule.min_trailing_silence and utterance_length >= rule.min_utterance_length
+ if (ans):
+ logger.info(f"Endpoint Rule: {rule_name} activated: {rule}")
+ return ans
+
+ def endpoint_detected(self,
+ ctc_log_probs: np.ndarray,
+ decoding_something: bool) -> bool:
+ """detect endpoint.
+
+ Args:
+ ctc_log_probs (np.ndarray): (T, D)
+ decoding_something (bool): contain nonsilince.
+
+ Returns:
+ bool: whether endpoint detected.
+ """
+ for logprob in ctc_log_probs:
+ blank_prob = np.exp(logprob[self.opts.blank])
+
+ self.num_frames_decoded += 1
+ if blank_prob > self.opts.blank_threshold:
+ self.trailing_silence_frames += 1
+ else:
+ self.trailing_silence_frames = 0
+
+ assert self.num_frames_decoded >= self.trailing_silence_frames
+ assert self.frame_shift_in_ms > 0
+
+ utterance_length = self.num_frames_decoded * self.frame_shift_in_ms
+ trailing_silence = self.trailing_silence_frames * self.frame_shift_in_ms
+
+ if self.rule_activated(self.opts.rule1, 'rule1', decoding_something,
+ trailing_silence, utterance_length):
+ return True
+ if self.rule_activated(self.opts.rule2, 'rule2', decoding_something,
+ trailing_silence, utterance_length):
+ return True
+ if self.rule_activated(self.opts.rule3, 'rule3', decoding_something,
+ trailing_silence, utterance_length):
+ return True
+ return False
diff --git a/paddlespeech/server/engine/asr/online/ctc_search.py b/paddlespeech/server/engine/asr/online/ctc_search.py
index be5fb15bd..46f310c80 100644
--- a/paddlespeech/server/engine/asr/online/ctc_search.py
+++ b/paddlespeech/server/engine/asr/online/ctc_search.py
@@ -11,6 +11,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
+import copy
from collections import defaultdict
import paddle
@@ -26,11 +27,32 @@ class CTCPrefixBeamSearch:
"""Implement the ctc prefix beam search
Args:
- config (yacs.config.CfgNode): _description_
+ config (yacs.config.CfgNode): the ctc prefix beam search configuration
"""
self.config = config
+
+ # beam size
+ self.first_beam_size = self.config.beam_size
+ # TODO(support second beam size)
+ self.second_beam_size = int(self.first_beam_size * 1.0)
+ logger.info(
+ f"first and second beam size: {self.first_beam_size}, {self.second_beam_size}"
+ )
+
+ # state
+ self.cur_hyps = None
+ self.hyps = None
+ self.abs_time_step = 0
+
self.reset()
+ def reset(self):
+ """Rest the search cache value
+ """
+ self.cur_hyps = None
+ self.hyps = None
+ self.abs_time_step = 0
+
@paddle.no_grad()
def search(self, ctc_probs, device, blank_id=0):
"""ctc prefix beam search method decode a chunk feature
@@ -46,59 +68,121 @@ class CTCPrefixBeamSearch:
"""
# decode
logger.info("start to ctc prefix search")
-
+ assert len(ctc_probs.shape) == 2
batch_size = 1
- beam_size = self.config.beam_size
- maxlen = ctc_probs.shape[0]
- assert len(ctc_probs.shape) == 2
+ vocab_size = ctc_probs.shape[1]
+ first_beam_size = min(self.first_beam_size, vocab_size)
+ second_beam_size = min(self.second_beam_size, vocab_size)
+ logger.info(
+ f"effect first and second beam size: {self.first_beam_size}, {self.second_beam_size}"
+ )
+
+ maxlen = ctc_probs.shape[0]
# cur_hyps: (prefix, (blank_ending_score, none_blank_ending_score))
- # blank_ending_score and none_blank_ending_score in ln domain
+ # 0. blank_ending_score,
+ # 1. none_blank_ending_score,
+ # 2. viterbi_blank ending,
+ # 3. viterbi_non_blank,
+ # 4. current_token_prob,
+ # 5. times_viterbi_blank,
+ # 6. times_titerbi_non_blank
if self.cur_hyps is None:
- self.cur_hyps = [(tuple(), (0.0, -float('inf')))]
+ self.cur_hyps = [(tuple(), (0.0, -float('inf'), 0.0, 0.0,
+ -float('inf'), [], []))]
+ # self.cur_hyps = [(tuple(), (0.0, -float('inf')))]
# 2. CTC beam search step by step
for t in range(0, maxlen):
logp = ctc_probs[t] # (vocab_size,)
- # key: prefix, value (pb, pnb), default value(-inf, -inf)
- next_hyps = defaultdict(lambda: (-float('inf'), -float('inf')))
+ # next_hyps = defaultdict(lambda: (-float('inf'), -float('inf')))
+ next_hyps = defaultdict(
+ lambda: (-float('inf'), -float('inf'), -float('inf'), -float('inf'), -float('inf'), [], []))
# 2.1 First beam prune: select topk best
# do token passing process
- top_k_logp, top_k_index = logp.topk(beam_size) # (beam_size,)
+ top_k_logp, top_k_index = logp.topk(
+ first_beam_size) # (first_beam_size,)
for s in top_k_index:
s = s.item()
ps = logp[s].item()
- for prefix, (pb, pnb) in self.cur_hyps:
+ for prefix, (pb, pnb, v_b_s, v_nb_s, cur_token_prob, times_s,
+ times_ns) in self.cur_hyps:
last = prefix[-1] if len(prefix) > 0 else None
if s == blank_id: # blank
- n_pb, n_pnb = next_hyps[prefix]
+ n_pb, n_pnb, n_v_s, n_v_ns, n_cur_token_prob, n_times_s, n_times_ns = next_hyps[
+ prefix]
n_pb = log_add([n_pb, pb + ps, pnb + ps])
- next_hyps[prefix] = (n_pb, n_pnb)
+
+ pre_times = times_s if v_b_s > v_nb_s else times_ns
+ n_times_s = copy.deepcopy(pre_times)
+ viterbi_score = v_b_s if v_b_s > v_nb_s else v_nb_s
+ n_v_s = viterbi_score + ps
+ next_hyps[prefix] = (n_pb, n_pnb, n_v_s, n_v_ns,
+ n_cur_token_prob, n_times_s,
+ n_times_ns)
elif s == last:
# Update *ss -> *s;
- n_pb, n_pnb = next_hyps[prefix]
+ # case1: *a + a => *a
+ n_pb, n_pnb, n_v_s, n_v_ns, n_cur_token_prob, n_times_s, n_times_ns = next_hyps[
+ prefix]
n_pnb = log_add([n_pnb, pnb + ps])
- next_hyps[prefix] = (n_pb, n_pnb)
+ if n_v_ns < v_nb_s + ps:
+ n_v_ns = v_nb_s + ps
+ if n_cur_token_prob < ps:
+ n_cur_token_prob = ps
+ n_times_ns = copy.deepcopy(times_ns)
+ n_times_ns[
+ -1] = self.abs_time_step # 注意,这里要重新使用绝对时间
+ next_hyps[prefix] = (n_pb, n_pnb, n_v_s, n_v_ns,
+ n_cur_token_prob, n_times_s,
+ n_times_ns)
+
# Update *s-s -> *ss, - is for blank
+ # Case 2: *aε + a => *aa
n_prefix = prefix + (s, )
- n_pb, n_pnb = next_hyps[n_prefix]
+ n_pb, n_pnb, n_v_s, n_v_ns, n_cur_token_prob, n_times_s, n_times_ns = next_hyps[
+ n_prefix]
+ if n_v_ns < v_b_s + ps:
+ n_v_ns = v_b_s + ps
+ n_cur_token_prob = ps
+ n_times_ns = copy.deepcopy(times_s)
+ n_times_ns.append(self.abs_time_step)
n_pnb = log_add([n_pnb, pb + ps])
- next_hyps[n_prefix] = (n_pb, n_pnb)
+ next_hyps[n_prefix] = (n_pb, n_pnb, n_v_s, n_v_ns,
+ n_cur_token_prob, n_times_s,
+ n_times_ns)
else:
+ # Case 3: *a + b => *ab, *aε + b => *ab
n_prefix = prefix + (s, )
- n_pb, n_pnb = next_hyps[n_prefix]
+ n_pb, n_pnb, n_v_s, n_v_ns, n_cur_token_prob, n_times_s, n_times_ns = next_hyps[
+ n_prefix]
+ viterbi_score = v_b_s if v_b_s > v_nb_s else v_nb_s
+ pre_times = times_s if v_b_s > v_nb_s else times_ns
+ if n_v_ns < viterbi_score + ps:
+ n_v_ns = viterbi_score + ps
+ n_cur_token_prob = ps
+ n_times_ns = copy.deepcopy(pre_times)
+ n_times_ns.append(self.abs_time_step)
+
n_pnb = log_add([n_pnb, pb + ps, pnb + ps])
- next_hyps[n_prefix] = (n_pb, n_pnb)
+ next_hyps[n_prefix] = (n_pb, n_pnb, n_v_s, n_v_ns,
+ n_cur_token_prob, n_times_s,
+ n_times_ns)
# 2.2 Second beam prune
next_hyps = sorted(
next_hyps.items(),
- key=lambda x: log_add(list(x[1])),
+ key=lambda x: log_add([x[1][0], x[1][1]]),
reverse=True)
- self.cur_hyps = next_hyps[:beam_size]
+ self.cur_hyps = next_hyps[:second_beam_size]
+
+ # 2.3 update the absolute time step
+ self.abs_time_step += 1
+
+ self.hyps = [(y[0], log_add([y[1][0], y[1][1]]), y[1][2], y[1][3],
+ y[1][4], y[1][5], y[1][6]) for y in self.cur_hyps]
- self.hyps = [(y[0], log_add([y[1][0], y[1][1]])) for y in self.cur_hyps]
logger.info("ctc prefix search success")
return self.hyps
@@ -106,7 +190,7 @@ class CTCPrefixBeamSearch:
"""Return the one best result
Returns:
- list: the one best result
+ list: the one best result, List[str]
"""
return [self.hyps[0][0]]
@@ -114,16 +198,10 @@ class CTCPrefixBeamSearch:
"""Return the search hyps
Returns:
- list: return the search hyps
+ list: return the search hyps, List[Tuple[str, float, ...]]
"""
return self.hyps
- def reset(self):
- """Rest the search cache value
- """
- self.cur_hyps = None
- self.hyps = None
-
def finalize_search(self):
"""do nothing in ctc_prefix_beam_search
"""
diff --git a/audio/tests/features/__init__.py b/paddlespeech/server/engine/asr/online/onnx/__init__.py
similarity index 100%
rename from audio/tests/features/__init__.py
rename to paddlespeech/server/engine/asr/online/onnx/__init__.py
diff --git a/paddlespeech/server/engine/asr/online/onnx/asr_engine.py b/paddlespeech/server/engine/asr/online/onnx/asr_engine.py
new file mode 100644
index 000000000..aab29f78e
--- /dev/null
+++ b/paddlespeech/server/engine/asr/online/onnx/asr_engine.py
@@ -0,0 +1,530 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+import sys
+from typing import ByteString
+from typing import Optional
+
+import numpy as np
+import paddle
+from numpy import float32
+from yacs.config import CfgNode
+
+from paddlespeech.cli.asr.infer import ASRExecutor
+from paddlespeech.cli.log import logger
+from paddlespeech.cli.utils import MODEL_HOME
+from paddlespeech.resource import CommonTaskResource
+from paddlespeech.s2t.frontend.featurizer.text_featurizer import TextFeaturizer
+from paddlespeech.s2t.modules.ctc import CTCDecoder
+from paddlespeech.s2t.transform.transformation import Transformation
+from paddlespeech.s2t.utils.utility import UpdateConfig
+from paddlespeech.server.engine.base_engine import BaseEngine
+from paddlespeech.server.utils import onnx_infer
+
+__all__ = ['PaddleASRConnectionHanddler', 'ASRServerExecutor', 'ASREngine']
+
+
+# ASR server connection process class
+class PaddleASRConnectionHanddler:
+ def __init__(self, asr_engine):
+ """Init a Paddle ASR Connection Handler instance
+
+ Args:
+ asr_engine (ASREngine): the global asr engine
+ """
+ super().__init__()
+ logger.info(
+ "create an paddle asr connection handler to process the websocket connection"
+ )
+ self.config = asr_engine.config # server config
+ self.model_config = asr_engine.executor.config
+ self.asr_engine = asr_engine
+
+ # model_type, sample_rate and text_feature is shared for deepspeech2 and conformer
+ self.model_type = self.asr_engine.executor.model_type
+ self.sample_rate = self.asr_engine.executor.sample_rate
+ # tokens to text
+ self.text_feature = self.asr_engine.executor.text_feature
+
+ # extract feat, new only fbank in conformer model
+ self.preprocess_conf = self.model_config.preprocess_config
+ self.preprocess_args = {"train": False}
+ self.preprocessing = Transformation(self.preprocess_conf)
+
+ # frame window and frame shift, in samples unit
+ self.win_length = self.preprocess_conf.process[0]['win_length']
+ self.n_shift = self.preprocess_conf.process[0]['n_shift']
+
+ assert self.preprocess_conf.process[0]['fs'] == self.sample_rate, (
+ self.sample_rate, self.preprocess_conf.process[0]['fs'])
+ self.frame_shift_in_ms = int(
+ self.n_shift / self.preprocess_conf.process[0]['fs'] * 1000)
+
+ self.continuous_decoding = self.config.get("continuous_decoding", False)
+ self.init_decoder()
+ self.reset()
+
+ def init_decoder(self):
+ if "deepspeech2" in self.model_type:
+ assert self.continuous_decoding is False, "ds2 model not support endpoint"
+ self.am_predictor = self.asr_engine.executor.am_predictor
+
+ self.decoder = CTCDecoder(
+ odim=self.model_config.output_dim, # is in vocab
+ enc_n_units=self.model_config.rnn_layer_size * 2,
+ blank_id=self.model_config.blank_id,
+ dropout_rate=0.0,
+ reduction=True, # sum
+ batch_average=True, # sum / batch_size
+ grad_norm_type=self.model_config.get('ctc_grad_norm_type',
+ None))
+
+ cfg = self.model_config.decode
+ decode_batch_size = 1 # for online
+ self.decoder.init_decoder(
+ decode_batch_size, self.text_feature.vocab_list,
+ cfg.decoding_method, cfg.lang_model_path, cfg.alpha, cfg.beta,
+ cfg.beam_size, cfg.cutoff_prob, cfg.cutoff_top_n,
+ cfg.num_proc_bsearch)
+ else:
+ raise ValueError(f"Not supported: {self.model_type}")
+
+ def model_reset(self):
+ # cache for audio and feat
+ self.remained_wav = None
+ self.cached_feat = None
+
+ def output_reset(self):
+ ## outputs
+ # partial/ending decoding results
+ self.result_transcripts = ['']
+
+ def reset_continuous_decoding(self):
+ """
+ when in continous decoding, reset for next utterance.
+ """
+ self.global_frame_offset = self.num_frames
+ self.model_reset()
+
+ def reset(self):
+ if "deepspeech2" in self.model_type:
+ # for deepspeech2
+ # init state
+ self.chunk_state_h_box = np.zeros(
+ (self.model_config.num_rnn_layers, 1,
+ self.model_config.rnn_layer_size),
+ dtype=float32)
+ self.chunk_state_c_box = np.zeros(
+ (self.model_config.num_rnn_layers, 1,
+ self.model_config.rnn_layer_size),
+ dtype=float32)
+ self.decoder.reset_decoder(batch_size=1)
+ else:
+ raise NotImplementedError(f"{self.model_type} not support.")
+
+ self.device = None
+
+ ## common
+ # global sample and frame step
+ self.num_samples = 0
+ self.global_frame_offset = 0
+ # frame step of cur utterance
+ self.num_frames = 0
+
+ ## endpoint
+ self.endpoint_state = False # True for detect endpoint
+
+ ## conformer
+ self.model_reset()
+
+ ## outputs
+ self.output_reset()
+
+ def extract_feat(self, samples: ByteString):
+ logger.info("Online ASR extract the feat")
+ samples = np.frombuffer(samples, dtype=np.int16)
+ assert samples.ndim == 1
+
+ self.num_samples += samples.shape[0]
+ logger.info(
+ f"This package receive {samples.shape[0]} pcm data. Global samples:{self.num_samples}"
+ )
+
+ # self.reamined_wav stores all the samples,
+ # include the original remained_wav and this package samples
+ if self.remained_wav is None:
+ self.remained_wav = samples
+ else:
+ assert self.remained_wav.ndim == 1 # (T,)
+ self.remained_wav = np.concatenate([self.remained_wav, samples])
+ logger.info(
+ f"The concatenation of remain and now audio samples length is: {self.remained_wav.shape}"
+ )
+
+ if len(self.remained_wav) < self.win_length:
+ # samples not enough for feature window
+ return 0
+
+ # fbank
+ x_chunk = self.preprocessing(self.remained_wav, **self.preprocess_args)
+ x_chunk = paddle.to_tensor(x_chunk, dtype="float32").unsqueeze(axis=0)
+
+ # feature cache
+ if self.cached_feat is None:
+ self.cached_feat = x_chunk
+ else:
+ assert (len(x_chunk.shape) == 3) # (B,T,D)
+ assert (len(self.cached_feat.shape) == 3) # (B,T,D)
+ self.cached_feat = paddle.concat(
+ [self.cached_feat, x_chunk], axis=1)
+
+ # set the feat device
+ if self.device is None:
+ self.device = self.cached_feat.place
+
+ # cur frame step
+ num_frames = x_chunk.shape[1]
+
+ # global frame step
+ self.num_frames += num_frames
+
+ # update remained wav
+ self.remained_wav = self.remained_wav[self.n_shift * num_frames:]
+
+ logger.info(
+ f"process the audio feature success, the cached feat shape: {self.cached_feat.shape}"
+ )
+ logger.info(
+ f"After extract feat, the cached remain the audio samples: {self.remained_wav.shape}"
+ )
+ logger.info(f"global samples: {self.num_samples}")
+ logger.info(f"global frames: {self.num_frames}")
+
+ def decode(self, is_finished=False):
+ """advance decoding
+
+ Args:
+ is_finished (bool, optional): Is last frame or not. Defaults to False.
+
+ Returns:
+ None:
+ """
+ if "deepspeech2" in self.model_type:
+ decoding_chunk_size = 1 # decoding chunk size = 1. int decoding frame unit
+
+ context = 7 # context=7, in audio frame unit
+ subsampling = 4 # subsampling=4, in audio frame unit
+
+ cached_feature_num = context - subsampling
+ # decoding window for model, in audio frame unit
+ decoding_window = (decoding_chunk_size - 1) * subsampling + context
+ # decoding stride for model, in audio frame unit
+ stride = subsampling * decoding_chunk_size
+
+ if self.cached_feat is None:
+ logger.info("no audio feat, please input more pcm data")
+ return
+
+ num_frames = self.cached_feat.shape[1]
+ logger.info(
+ f"Required decoding window {decoding_window} frames, and the connection has {num_frames} frames"
+ )
+
+ # the cached feat must be larger decoding_window
+ if num_frames < decoding_window and not is_finished:
+ logger.info(
+ f"frame feat num is less than {decoding_window}, please input more pcm data"
+ )
+ return None, None
+
+ # if is_finished=True, we need at least context frames
+ if num_frames < context:
+ logger.info(
+ "flast {num_frames} is less than context {context} frames, and we cannot do model forward"
+ )
+ return None, None
+
+ logger.info("start to do model forward")
+ # num_frames - context + 1 ensure that current frame can get context window
+ if is_finished:
+ # if get the finished chunk, we need process the last context
+ left_frames = context
+ else:
+ # we only process decoding_window frames for one chunk
+ left_frames = decoding_window
+
+ end = None
+ for cur in range(0, num_frames - left_frames + 1, stride):
+ end = min(cur + decoding_window, num_frames)
+
+ # extract the audio
+ x_chunk = self.cached_feat[:, cur:end, :].numpy()
+ x_chunk_lens = np.array([x_chunk.shape[1]])
+
+ trans_best = self.decode_one_chunk(x_chunk, x_chunk_lens)
+
+ self.result_transcripts = [trans_best]
+
+ # update feat cache
+ self.cached_feat = self.cached_feat[:, end - cached_feature_num:, :]
+
+ # return trans_best[0]
+ else:
+ raise Exception(f"{self.model_type} not support paddleinference.")
+
+ @paddle.no_grad()
+ def decode_one_chunk(self, x_chunk, x_chunk_lens):
+ """forward one chunk frames
+
+ Args:
+ x_chunk (np.ndarray): (B,T,D), audio frames.
+ x_chunk_lens ([type]): (B,), audio frame lens
+
+ Returns:
+ logprob: poster probability.
+ """
+ logger.info("start to decoce one chunk for deepspeech2")
+ # state_c, state_h, audio_lens, audio
+ # 'chunk_state_c_box', 'chunk_state_h_box', 'audio_chunk_lens', 'audio_chunk'
+ input_names = [n.name for n in self.am_predictor.get_inputs()]
+ logger.info(f"ort inputs: {input_names}")
+ # 'softmax_0.tmp_0', 'tmp_5', 'concat_0.tmp_0', 'concat_1.tmp_0'
+ # audio, audio_lens, state_h, state_c
+ output_names = [n.name for n in self.am_predictor.get_outputs()]
+ logger.info(f"ort outpus: {output_names}")
+ assert (len(input_names) == len(output_names))
+ assert isinstance(input_names[0], str)
+
+ input_datas = [
+ self.chunk_state_c_box, self.chunk_state_h_box, x_chunk_lens,
+ x_chunk
+ ]
+ feeds = dict(zip(input_names, input_datas))
+
+ outputs = self.am_predictor.run([*output_names], {**feeds})
+
+ output_chunk_probs, output_chunk_lens, self.chunk_state_h_box, self.chunk_state_c_box = outputs
+ self.decoder.next(output_chunk_probs, output_chunk_lens)
+ trans_best, trans_beam = self.decoder.decode()
+ logger.info(f"decode one best result for deepspeech2: {trans_best[0]}")
+ return trans_best[0]
+
+ def get_result(self):
+ """return partial/ending asr result.
+
+ Returns:
+ str: one best result of partial/ending.
+ """
+ if len(self.result_transcripts) > 0:
+ return self.result_transcripts[0]
+ else:
+ return ''
+
+ def get_word_time_stamp(self):
+ return []
+
+ @paddle.no_grad()
+ def rescoring(self):
+ ...
+
+
+class ASRServerExecutor(ASRExecutor):
+ def __init__(self):
+ super().__init__()
+ self.task_resource = CommonTaskResource(
+ task='asr', model_format='onnx', inference_mode='online')
+
+ def update_config(self) -> None:
+ if "deepspeech2" in self.model_type:
+ with UpdateConfig(self.config):
+ # download lm
+ self.config.decode.lang_model_path = os.path.join(
+ MODEL_HOME, 'language_model',
+ self.config.decode.lang_model_path)
+
+ lm_url = self.task_resource.res_dict['lm_url']
+ lm_md5 = self.task_resource.res_dict['lm_md5']
+ logger.info(f"Start to load language model {lm_url}")
+ self.download_lm(
+ lm_url,
+ os.path.dirname(self.config.decode.lang_model_path), lm_md5)
+ else:
+ raise NotImplementedError(
+ f"{self.model_type} not support paddleinference.")
+
+ def init_model(self) -> None:
+
+ if "deepspeech2" in self.model_type:
+ # AM predictor
+ logger.info("ASR engine start to init the am predictor")
+ self.am_predictor = onnx_infer.get_sess(
+ model_path=self.am_model, sess_conf=self.am_predictor_conf)
+ else:
+ raise NotImplementedError(
+ f"{self.model_type} not support paddleinference.")
+
+ def _init_from_path(self,
+ model_type: str=None,
+ am_model: Optional[os.PathLike]=None,
+ am_params: Optional[os.PathLike]=None,
+ lang: str='zh',
+ sample_rate: int=16000,
+ cfg_path: Optional[os.PathLike]=None,
+ decode_method: str='attention_rescoring',
+ num_decoding_left_chunks: int=-1,
+ am_predictor_conf: dict=None):
+ """
+ Init model and other resources from a specific path.
+ """
+ if not model_type or not lang or not sample_rate:
+ logger.error(
+ "The model type or lang or sample rate is None, please input an valid server parameter yaml"
+ )
+ return False
+ assert am_params is None, "am_params not used in onnx engine"
+
+ self.model_type = model_type
+ self.sample_rate = sample_rate
+ self.decode_method = decode_method
+ self.num_decoding_left_chunks = num_decoding_left_chunks
+ # conf for paddleinference predictor or onnx
+ self.am_predictor_conf = am_predictor_conf
+ logger.info(f"model_type: {self.model_type}")
+
+ sample_rate_str = '16k' if sample_rate == 16000 else '8k'
+ tag = model_type + '-' + lang + '-' + sample_rate_str
+ self.task_resource.set_task_model(model_tag=tag)
+
+ if cfg_path is None:
+ self.res_path = self.task_resource.res_dir
+ self.cfg_path = os.path.join(
+ self.res_path, self.task_resource.res_dict['cfg_path'])
+ else:
+ self.cfg_path = os.path.abspath(cfg_path)
+ self.res_path = os.path.dirname(
+ os.path.dirname(os.path.abspath(self.cfg_path)))
+
+ self.am_model = os.path.join(self.res_path, self.task_resource.res_dict[
+ 'onnx_model']) if am_model is None else os.path.abspath(am_model)
+
+ # self.am_params = os.path.join(
+ # self.res_path, self.task_resource.res_dict[
+ # 'params']) if am_params is None else os.path.abspath(am_params)
+
+ logger.info("Load the pretrained model:")
+ logger.info(f" tag = {tag}")
+ logger.info(f" res_path: {self.res_path}")
+ logger.info(f" cfg path: {self.cfg_path}")
+ logger.info(f" am_model path: {self.am_model}")
+ # logger.info(f" am_params path: {self.am_params}")
+
+ #Init body.
+ self.config = CfgNode(new_allowed=True)
+ self.config.merge_from_file(self.cfg_path)
+
+ if self.config.spm_model_prefix:
+ self.config.spm_model_prefix = os.path.join(
+ self.res_path, self.config.spm_model_prefix)
+ logger.info(f"spm model path: {self.config.spm_model_prefix}")
+
+ self.vocab = self.config.vocab_filepath
+
+ self.text_feature = TextFeaturizer(
+ unit_type=self.config.unit_type,
+ vocab=self.config.vocab_filepath,
+ spm_model_prefix=self.config.spm_model_prefix)
+
+ self.update_config()
+
+ # AM predictor
+ self.init_model()
+
+ logger.info(f"create the {model_type} model success")
+ return True
+
+
+class ASREngine(BaseEngine):
+ """ASR model resource
+
+ Args:
+ metaclass: Defaults to Singleton.
+ """
+
+ def __init__(self):
+ super(ASREngine, self).__init__()
+
+ def init_model(self) -> bool:
+ if not self.executor._init_from_path(
+ model_type=self.config.model_type,
+ am_model=self.config.am_model,
+ am_params=self.config.am_params,
+ lang=self.config.lang,
+ sample_rate=self.config.sample_rate,
+ cfg_path=self.config.cfg_path,
+ decode_method=self.config.decode_method,
+ num_decoding_left_chunks=self.config.num_decoding_left_chunks,
+ am_predictor_conf=self.config.am_predictor_conf):
+ return False
+ return True
+
+ def init(self, config: dict) -> bool:
+ """init engine resource
+
+ Args:
+ config_file (str): config file
+
+ Returns:
+ bool: init failed or success
+ """
+ self.config = config
+ self.executor = ASRServerExecutor()
+
+ try:
+ self.device = self.config.get("device", paddle.get_device())
+ paddle.set_device(self.device)
+ except BaseException as e:
+ logger.error(
+ f"Set device failed, please check if device '{self.device}' is already used and the parameter 'device' in the yaml file"
+ )
+ logger.error(
+ "If all GPU or XPU is used, you can set the server to 'cpu'")
+ sys.exit(-1)
+
+ logger.info(f"paddlespeech_server set the device: {self.device}")
+
+ if not self.init_model():
+ logger.error(
+ "Init the ASR server occurs error, please check the server configuration yaml"
+ )
+ return False
+
+ logger.info("Initialize ASR server engine successfully.")
+ return True
+
+ def new_handler(self):
+ """New handler from model.
+
+ Returns:
+ PaddleASRConnectionHanddler: asr handler instance
+ """
+ return PaddleASRConnectionHanddler(self)
+
+ def preprocess(self, *args, **kwargs):
+ raise NotImplementedError("Online not using this.")
+
+ def run(self, *args, **kwargs):
+ raise NotImplementedError("Online not using this.")
+
+ def postprocess(self):
+ raise NotImplementedError("Online not using this.")
diff --git a/paddlespeech/cli/stats/__init__.py b/paddlespeech/server/engine/asr/online/paddleinference/__init__.py
similarity index 84%
rename from paddlespeech/cli/stats/__init__.py
rename to paddlespeech/server/engine/asr/online/paddleinference/__init__.py
index 9fe6c4aba..97043fd7b 100644
--- a/paddlespeech/cli/stats/__init__.py
+++ b/paddlespeech/server/engine/asr/online/paddleinference/__init__.py
@@ -1,4 +1,4 @@
-# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
@@ -11,4 +11,3 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-from .infer import StatsExecutor
diff --git a/paddlespeech/server/engine/asr/online/paddleinference/asr_engine.py b/paddlespeech/server/engine/asr/online/paddleinference/asr_engine.py
new file mode 100644
index 000000000..a450e430b
--- /dev/null
+++ b/paddlespeech/server/engine/asr/online/paddleinference/asr_engine.py
@@ -0,0 +1,545 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+import sys
+from typing import ByteString
+from typing import Optional
+
+import numpy as np
+import paddle
+from numpy import float32
+from yacs.config import CfgNode
+
+from paddlespeech.cli.asr.infer import ASRExecutor
+from paddlespeech.cli.log import logger
+from paddlespeech.cli.utils import MODEL_HOME
+from paddlespeech.resource import CommonTaskResource
+from paddlespeech.s2t.frontend.featurizer.text_featurizer import TextFeaturizer
+from paddlespeech.s2t.modules.ctc import CTCDecoder
+from paddlespeech.s2t.transform.transformation import Transformation
+from paddlespeech.s2t.utils.utility import UpdateConfig
+from paddlespeech.server.engine.base_engine import BaseEngine
+from paddlespeech.server.utils.paddle_predictor import init_predictor
+
+__all__ = ['PaddleASRConnectionHanddler', 'ASRServerExecutor', 'ASREngine']
+
+
+# ASR server connection process class
+class PaddleASRConnectionHanddler:
+ def __init__(self, asr_engine):
+ """Init a Paddle ASR Connection Handler instance
+
+ Args:
+ asr_engine (ASREngine): the global asr engine
+ """
+ super().__init__()
+ logger.info(
+ "create an paddle asr connection handler to process the websocket connection"
+ )
+ self.config = asr_engine.config # server config
+ self.model_config = asr_engine.executor.config
+ self.asr_engine = asr_engine
+
+ # model_type, sample_rate and text_feature is shared for deepspeech2 and conformer
+ self.model_type = self.asr_engine.executor.model_type
+ self.sample_rate = self.asr_engine.executor.sample_rate
+ # tokens to text
+ self.text_feature = self.asr_engine.executor.text_feature
+
+ # extract feat, new only fbank in conformer model
+ self.preprocess_conf = self.model_config.preprocess_config
+ self.preprocess_args = {"train": False}
+ self.preprocessing = Transformation(self.preprocess_conf)
+
+ # frame window and frame shift, in samples unit
+ self.win_length = self.preprocess_conf.process[0]['win_length']
+ self.n_shift = self.preprocess_conf.process[0]['n_shift']
+
+ assert self.preprocess_conf.process[0]['fs'] == self.sample_rate, (
+ self.sample_rate, self.preprocess_conf.process[0]['fs'])
+ self.frame_shift_in_ms = int(
+ self.n_shift / self.preprocess_conf.process[0]['fs'] * 1000)
+
+ self.continuous_decoding = self.config.get("continuous_decoding", False)
+ self.init_decoder()
+ self.reset()
+
+ def init_decoder(self):
+ if "deepspeech2" in self.model_type:
+ assert self.continuous_decoding is False, "ds2 model not support endpoint"
+ self.am_predictor = self.asr_engine.executor.am_predictor
+
+ self.decoder = CTCDecoder(
+ odim=self.model_config.output_dim, # is in vocab
+ enc_n_units=self.model_config.rnn_layer_size * 2,
+ blank_id=self.model_config.blank_id,
+ dropout_rate=0.0,
+ reduction=True, # sum
+ batch_average=True, # sum / batch_size
+ grad_norm_type=self.model_config.get('ctc_grad_norm_type',
+ None))
+
+ cfg = self.model_config.decode
+ decode_batch_size = 1 # for online
+ self.decoder.init_decoder(
+ decode_batch_size, self.text_feature.vocab_list,
+ cfg.decoding_method, cfg.lang_model_path, cfg.alpha, cfg.beta,
+ cfg.beam_size, cfg.cutoff_prob, cfg.cutoff_top_n,
+ cfg.num_proc_bsearch)
+ else:
+ raise ValueError(f"Not supported: {self.model_type}")
+
+ def model_reset(self):
+ # cache for audio and feat
+ self.remained_wav = None
+ self.cached_feat = None
+
+ def output_reset(self):
+ ## outputs
+ # partial/ending decoding results
+ self.result_transcripts = ['']
+
+ def reset_continuous_decoding(self):
+ """
+ when in continous decoding, reset for next utterance.
+ """
+ self.global_frame_offset = self.num_frames
+ self.model_reset()
+
+ def reset(self):
+ if "deepspeech2" in self.model_type:
+ # for deepspeech2
+ # init state
+ self.chunk_state_h_box = np.zeros(
+ (self.model_config.num_rnn_layers, 1,
+ self.model_config.rnn_layer_size),
+ dtype=float32)
+ self.chunk_state_c_box = np.zeros(
+ (self.model_config.num_rnn_layers, 1,
+ self.model_config.rnn_layer_size),
+ dtype=float32)
+ self.decoder.reset_decoder(batch_size=1)
+ else:
+ raise NotImplementedError(f"{self.model_type} not support.")
+
+ self.device = None
+
+ ## common
+ # global sample and frame step
+ self.num_samples = 0
+ self.global_frame_offset = 0
+ # frame step of cur utterance
+ self.num_frames = 0
+
+ ## endpoint
+ self.endpoint_state = False # True for detect endpoint
+
+ ## conformer
+ self.model_reset()
+
+ ## outputs
+ self.output_reset()
+
+ def extract_feat(self, samples: ByteString):
+ logger.info("Online ASR extract the feat")
+ samples = np.frombuffer(samples, dtype=np.int16)
+ assert samples.ndim == 1
+
+ self.num_samples += samples.shape[0]
+ logger.info(
+ f"This package receive {samples.shape[0]} pcm data. Global samples:{self.num_samples}"
+ )
+
+ # self.reamined_wav stores all the samples,
+ # include the original remained_wav and this package samples
+ if self.remained_wav is None:
+ self.remained_wav = samples
+ else:
+ assert self.remained_wav.ndim == 1 # (T,)
+ self.remained_wav = np.concatenate([self.remained_wav, samples])
+ logger.info(
+ f"The concatenation of remain and now audio samples length is: {self.remained_wav.shape}"
+ )
+
+ if len(self.remained_wav) < self.win_length:
+ # samples not enough for feature window
+ return 0
+
+ # fbank
+ x_chunk = self.preprocessing(self.remained_wav, **self.preprocess_args)
+ x_chunk = paddle.to_tensor(x_chunk, dtype="float32").unsqueeze(axis=0)
+
+ # feature cache
+ if self.cached_feat is None:
+ self.cached_feat = x_chunk
+ else:
+ assert (len(x_chunk.shape) == 3) # (B,T,D)
+ assert (len(self.cached_feat.shape) == 3) # (B,T,D)
+ self.cached_feat = paddle.concat(
+ [self.cached_feat, x_chunk], axis=1)
+
+ # set the feat device
+ if self.device is None:
+ self.device = self.cached_feat.place
+
+ # cur frame step
+ num_frames = x_chunk.shape[1]
+
+ # global frame step
+ self.num_frames += num_frames
+
+ # update remained wav
+ self.remained_wav = self.remained_wav[self.n_shift * num_frames:]
+
+ logger.info(
+ f"process the audio feature success, the cached feat shape: {self.cached_feat.shape}"
+ )
+ logger.info(
+ f"After extract feat, the cached remain the audio samples: {self.remained_wav.shape}"
+ )
+ logger.info(f"global samples: {self.num_samples}")
+ logger.info(f"global frames: {self.num_frames}")
+
+ def decode(self, is_finished=False):
+ """advance decoding
+
+ Args:
+ is_finished (bool, optional): Is last frame or not. Defaults to False.
+
+ Returns:
+ None:
+ """
+ if "deepspeech2" in self.model_type:
+ decoding_chunk_size = 1 # decoding chunk size = 1. int decoding frame unit
+
+ context = 7 # context=7, in audio frame unit
+ subsampling = 4 # subsampling=4, in audio frame unit
+
+ cached_feature_num = context - subsampling
+ # decoding window for model, in audio frame unit
+ decoding_window = (decoding_chunk_size - 1) * subsampling + context
+ # decoding stride for model, in audio frame unit
+ stride = subsampling * decoding_chunk_size
+
+ if self.cached_feat is None:
+ logger.info("no audio feat, please input more pcm data")
+ return
+
+ num_frames = self.cached_feat.shape[1]
+ logger.info(
+ f"Required decoding window {decoding_window} frames, and the connection has {num_frames} frames"
+ )
+
+ # the cached feat must be larger decoding_window
+ if num_frames < decoding_window and not is_finished:
+ logger.info(
+ f"frame feat num is less than {decoding_window}, please input more pcm data"
+ )
+ return None, None
+
+ # if is_finished=True, we need at least context frames
+ if num_frames < context:
+ logger.info(
+ "flast {num_frames} is less than context {context} frames, and we cannot do model forward"
+ )
+ return None, None
+
+ logger.info("start to do model forward")
+ # num_frames - context + 1 ensure that current frame can get context window
+ if is_finished:
+ # if get the finished chunk, we need process the last context
+ left_frames = context
+ else:
+ # we only process decoding_window frames for one chunk
+ left_frames = decoding_window
+
+ end = None
+ for cur in range(0, num_frames - left_frames + 1, stride):
+ end = min(cur + decoding_window, num_frames)
+
+ # extract the audio
+ x_chunk = self.cached_feat[:, cur:end, :].numpy()
+ x_chunk_lens = np.array([x_chunk.shape[1]])
+
+ trans_best = self.decode_one_chunk(x_chunk, x_chunk_lens)
+
+ self.result_transcripts = [trans_best]
+
+ # update feat cache
+ self.cached_feat = self.cached_feat[:, end - cached_feature_num:, :]
+
+ # return trans_best[0]
+ else:
+ raise Exception(f"{self.model_type} not support paddleinference.")
+
+ @paddle.no_grad()
+ def decode_one_chunk(self, x_chunk, x_chunk_lens):
+ """forward one chunk frames
+
+ Args:
+ x_chunk (np.ndarray): (B,T,D), audio frames.
+ x_chunk_lens ([type]): (B,), audio frame lens
+
+ Returns:
+ logprob: poster probability.
+ """
+ logger.info("start to decoce one chunk for deepspeech2")
+ input_names = self.am_predictor.get_input_names()
+ audio_handle = self.am_predictor.get_input_handle(input_names[0])
+ audio_len_handle = self.am_predictor.get_input_handle(input_names[1])
+ h_box_handle = self.am_predictor.get_input_handle(input_names[2])
+ c_box_handle = self.am_predictor.get_input_handle(input_names[3])
+
+ audio_handle.reshape(x_chunk.shape)
+ audio_handle.copy_from_cpu(x_chunk)
+
+ audio_len_handle.reshape(x_chunk_lens.shape)
+ audio_len_handle.copy_from_cpu(x_chunk_lens)
+
+ h_box_handle.reshape(self.chunk_state_h_box.shape)
+ h_box_handle.copy_from_cpu(self.chunk_state_h_box)
+
+ c_box_handle.reshape(self.chunk_state_c_box.shape)
+ c_box_handle.copy_from_cpu(self.chunk_state_c_box)
+
+ output_names = self.am_predictor.get_output_names()
+ output_handle = self.am_predictor.get_output_handle(output_names[0])
+ output_lens_handle = self.am_predictor.get_output_handle(
+ output_names[1])
+ output_state_h_handle = self.am_predictor.get_output_handle(
+ output_names[2])
+ output_state_c_handle = self.am_predictor.get_output_handle(
+ output_names[3])
+
+ self.am_predictor.run()
+
+ output_chunk_probs = output_handle.copy_to_cpu()
+ output_chunk_lens = output_lens_handle.copy_to_cpu()
+ self.chunk_state_h_box = output_state_h_handle.copy_to_cpu()
+ self.chunk_state_c_box = output_state_c_handle.copy_to_cpu()
+
+ self.decoder.next(output_chunk_probs, output_chunk_lens)
+ trans_best, trans_beam = self.decoder.decode()
+ logger.info(f"decode one best result for deepspeech2: {trans_best[0]}")
+ return trans_best[0]
+
+ def get_result(self):
+ """return partial/ending asr result.
+
+ Returns:
+ str: one best result of partial/ending.
+ """
+ if len(self.result_transcripts) > 0:
+ return self.result_transcripts[0]
+ else:
+ return ''
+
+ def get_word_time_stamp(self):
+ return []
+
+ @paddle.no_grad()
+ def rescoring(self):
+ ...
+
+
+class ASRServerExecutor(ASRExecutor):
+ def __init__(self):
+ super().__init__()
+ self.task_resource = CommonTaskResource(
+ task='asr', model_format='static', inference_mode='online')
+
+ def update_config(self) -> None:
+ if "deepspeech2" in self.model_type:
+ with UpdateConfig(self.config):
+ # download lm
+ self.config.decode.lang_model_path = os.path.join(
+ MODEL_HOME, 'language_model',
+ self.config.decode.lang_model_path)
+
+ lm_url = self.task_resource.res_dict['lm_url']
+ lm_md5 = self.task_resource.res_dict['lm_md5']
+ logger.info(f"Start to load language model {lm_url}")
+ self.download_lm(
+ lm_url,
+ os.path.dirname(self.config.decode.lang_model_path), lm_md5)
+ else:
+ raise NotImplementedError(
+ f"{self.model_type} not support paddleinference.")
+
+ def init_model(self) -> None:
+
+ if "deepspeech2" in self.model_type:
+ # AM predictor
+ logger.info("ASR engine start to init the am predictor")
+ self.am_predictor = init_predictor(
+ model_file=self.am_model,
+ params_file=self.am_params,
+ predictor_conf=self.am_predictor_conf)
+ else:
+ raise NotImplementedError(
+ f"{self.model_type} not support paddleinference.")
+
+ def _init_from_path(self,
+ model_type: str=None,
+ am_model: Optional[os.PathLike]=None,
+ am_params: Optional[os.PathLike]=None,
+ lang: str='zh',
+ sample_rate: int=16000,
+ cfg_path: Optional[os.PathLike]=None,
+ decode_method: str='attention_rescoring',
+ num_decoding_left_chunks: int=-1,
+ am_predictor_conf: dict=None):
+ """
+ Init model and other resources from a specific path.
+ """
+ if not model_type or not lang or not sample_rate:
+ logger.error(
+ "The model type or lang or sample rate is None, please input an valid server parameter yaml"
+ )
+ return False
+
+ self.model_type = model_type
+ self.sample_rate = sample_rate
+ self.decode_method = decode_method
+ self.num_decoding_left_chunks = num_decoding_left_chunks
+ # conf for paddleinference predictor or onnx
+ self.am_predictor_conf = am_predictor_conf
+ logger.info(f"model_type: {self.model_type}")
+
+ sample_rate_str = '16k' if sample_rate == 16000 else '8k'
+ tag = model_type + '-' + lang + '-' + sample_rate_str
+ self.task_resource.set_task_model(model_tag=tag)
+
+ if cfg_path is None or am_model is None or am_params is None:
+ self.res_path = self.task_resource.res_dir
+ self.cfg_path = os.path.join(
+ self.res_path, self.task_resource.res_dict['cfg_path'])
+
+ self.am_model = os.path.join(self.res_path,
+ self.task_resource.res_dict['model'])
+ self.am_params = os.path.join(self.res_path,
+ self.task_resource.res_dict['params'])
+ else:
+ self.cfg_path = os.path.abspath(cfg_path)
+ self.am_model = os.path.abspath(am_model)
+ self.am_params = os.path.abspath(am_params)
+ self.res_path = os.path.dirname(
+ os.path.dirname(os.path.abspath(self.cfg_path)))
+
+ logger.info("Load the pretrained model:")
+ logger.info(f" tag = {tag}")
+ logger.info(f" res_path: {self.res_path}")
+ logger.info(f" cfg path: {self.cfg_path}")
+ logger.info(f" am_model path: {self.am_model}")
+ logger.info(f" am_params path: {self.am_params}")
+
+ #Init body.
+ self.config = CfgNode(new_allowed=True)
+ self.config.merge_from_file(self.cfg_path)
+
+ if self.config.spm_model_prefix:
+ self.config.spm_model_prefix = os.path.join(
+ self.res_path, self.config.spm_model_prefix)
+ logger.info(f"spm model path: {self.config.spm_model_prefix}")
+
+ self.vocab = self.config.vocab_filepath
+
+ self.text_feature = TextFeaturizer(
+ unit_type=self.config.unit_type,
+ vocab=self.config.vocab_filepath,
+ spm_model_prefix=self.config.spm_model_prefix)
+
+ self.update_config()
+
+ # AM predictor
+ self.init_model()
+
+ logger.info(f"create the {model_type} model success")
+ return True
+
+
+class ASREngine(BaseEngine):
+ """ASR model resource
+
+ Args:
+ metaclass: Defaults to Singleton.
+ """
+
+ def __init__(self):
+ super(ASREngine, self).__init__()
+
+ def init_model(self) -> bool:
+ if not self.executor._init_from_path(
+ model_type=self.config.model_type,
+ am_model=self.config.am_model,
+ am_params=self.config.am_params,
+ lang=self.config.lang,
+ sample_rate=self.config.sample_rate,
+ cfg_path=self.config.cfg_path,
+ decode_method=self.config.decode_method,
+ num_decoding_left_chunks=self.config.num_decoding_left_chunks,
+ am_predictor_conf=self.config.am_predictor_conf):
+ return False
+ return True
+
+ def init(self, config: dict) -> bool:
+ """init engine resource
+
+ Args:
+ config_file (str): config file
+
+ Returns:
+ bool: init failed or success
+ """
+ self.config = config
+ self.executor = ASRServerExecutor()
+
+ try:
+ self.device = self.config.get("device", paddle.get_device())
+ paddle.set_device(self.device)
+ except BaseException as e:
+ logger.error(
+ f"Set device failed, please check if device '{self.device}' is already used and the parameter 'device' in the yaml file"
+ )
+ logger.error(
+ "If all GPU or XPU is used, you can set the server to 'cpu'")
+ sys.exit(-1)
+
+ logger.info(f"paddlespeech_server set the device: {self.device}")
+
+ if not self.init_model():
+ logger.error(
+ "Init the ASR server occurs error, please check the server configuration yaml"
+ )
+ return False
+
+ logger.info("Initialize ASR server engine successfully.")
+ return True
+
+ def new_handler(self):
+ """New handler from model.
+
+ Returns:
+ PaddleASRConnectionHanddler: asr handler instance
+ """
+ return PaddleASRConnectionHanddler(self)
+
+ def preprocess(self, *args, **kwargs):
+ raise NotImplementedError("Online not using this.")
+
+ def run(self, *args, **kwargs):
+ raise NotImplementedError("Online not using this.")
+
+ def postprocess(self):
+ raise NotImplementedError("Online not using this.")
diff --git a/paddlespeech/server/engine/asr/online/python/__init__.py b/paddlespeech/server/engine/asr/online/python/__init__.py
new file mode 100644
index 000000000..97043fd7b
--- /dev/null
+++ b/paddlespeech/server/engine/asr/online/python/__init__.py
@@ -0,0 +1,13 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
diff --git a/paddlespeech/server/engine/asr/online/python/asr_engine.py b/paddlespeech/server/engine/asr/online/python/asr_engine.py
new file mode 100644
index 000000000..c22cbbe5f
--- /dev/null
+++ b/paddlespeech/server/engine/asr/online/python/asr_engine.py
@@ -0,0 +1,912 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+import sys
+from typing import ByteString
+from typing import Optional
+
+import numpy as np
+import paddle
+from numpy import float32
+from yacs.config import CfgNode
+
+from paddlespeech.cli.asr.infer import ASRExecutor
+from paddlespeech.cli.log import logger
+from paddlespeech.cli.utils import MODEL_HOME
+from paddlespeech.resource import CommonTaskResource
+from paddlespeech.s2t.frontend.featurizer.text_featurizer import TextFeaturizer
+from paddlespeech.s2t.modules.ctc import CTCDecoder
+from paddlespeech.s2t.transform.transformation import Transformation
+from paddlespeech.s2t.utils.tensor_utils import add_sos_eos
+from paddlespeech.s2t.utils.tensor_utils import pad_sequence
+from paddlespeech.s2t.utils.utility import UpdateConfig
+from paddlespeech.server.engine.asr.online.ctc_endpoint import OnlineCTCEndpoingOpt
+from paddlespeech.server.engine.asr.online.ctc_endpoint import OnlineCTCEndpoint
+from paddlespeech.server.engine.asr.online.ctc_search import CTCPrefixBeamSearch
+from paddlespeech.server.engine.base_engine import BaseEngine
+from paddlespeech.server.utils.paddle_predictor import init_predictor
+
+__all__ = ['PaddleASRConnectionHanddler', 'ASRServerExecutor', 'ASREngine']
+
+
+# ASR server connection process class
+class PaddleASRConnectionHanddler:
+ def __init__(self, asr_engine):
+ """Init a Paddle ASR Connection Handler instance
+
+ Args:
+ asr_engine (ASREngine): the global asr engine
+ """
+ super().__init__()
+ logger.info(
+ "create an paddle asr connection handler to process the websocket connection"
+ )
+ self.config = asr_engine.config # server config
+ self.model_config = asr_engine.executor.config
+ self.asr_engine = asr_engine
+
+ # model_type, sample_rate and text_feature is shared for deepspeech2 and conformer
+ self.model_type = self.asr_engine.executor.model_type
+ self.sample_rate = self.asr_engine.executor.sample_rate
+ # tokens to text
+ self.text_feature = self.asr_engine.executor.text_feature
+
+ # extract feat, new only fbank in conformer model
+ self.preprocess_conf = self.model_config.preprocess_config
+ self.preprocess_args = {"train": False}
+ self.preprocessing = Transformation(self.preprocess_conf)
+
+ # frame window and frame shift, in samples unit
+ self.win_length = self.preprocess_conf.process[0]['win_length']
+ self.n_shift = self.preprocess_conf.process[0]['n_shift']
+
+ assert self.preprocess_conf.process[0]['fs'] == self.sample_rate, (
+ self.sample_rate, self.preprocess_conf.process[0]['fs'])
+ self.frame_shift_in_ms = int(
+ self.n_shift / self.preprocess_conf.process[0]['fs'] * 1000)
+
+ self.continuous_decoding = self.config.get("continuous_decoding", False)
+ self.init_decoder()
+ self.reset()
+
+ def init_decoder(self):
+ if "deepspeech2" in self.model_type:
+ assert self.continuous_decoding is False, "ds2 model not support endpoint"
+ self.am_predictor = self.asr_engine.executor.am_predictor
+
+ self.decoder = CTCDecoder(
+ odim=self.model_config.output_dim, # is in vocab
+ enc_n_units=self.model_config.rnn_layer_size * 2,
+ blank_id=self.model_config.blank_id,
+ dropout_rate=0.0,
+ reduction=True, # sum
+ batch_average=True, # sum / batch_size
+ grad_norm_type=self.model_config.get('ctc_grad_norm_type',
+ None))
+
+ cfg = self.model_config.decode
+ decode_batch_size = 1 # for online
+ self.decoder.init_decoder(
+ decode_batch_size, self.text_feature.vocab_list,
+ cfg.decoding_method, cfg.lang_model_path, cfg.alpha, cfg.beta,
+ cfg.beam_size, cfg.cutoff_prob, cfg.cutoff_top_n,
+ cfg.num_proc_bsearch)
+
+ elif "conformer" in self.model_type or "transformer" in self.model_type:
+ # acoustic model
+ self.model = self.asr_engine.executor.model
+ self.continuous_decoding = self.config.continuous_decoding
+ logger.info(f"continue decoding: {self.continuous_decoding}")
+
+ # ctc decoding config
+ self.ctc_decode_config = self.asr_engine.executor.config.decode
+ self.searcher = CTCPrefixBeamSearch(self.ctc_decode_config)
+
+ # ctc endpoint
+ self.endpoint_opt = OnlineCTCEndpoingOpt(
+ frame_shift_in_ms=self.frame_shift_in_ms, blank=0)
+ self.endpointer = OnlineCTCEndpoint(self.endpoint_opt)
+ else:
+ raise ValueError(f"Not supported: {self.model_type}")
+
+ def model_reset(self):
+ # cache for audio and feat
+ self.remained_wav = None
+ self.cached_feat = None
+
+ if "deepspeech2" in self.model_type:
+ return
+
+ ## conformer
+ # cache for conformer online
+ self.subsampling_cache = None
+ self.elayers_output_cache = None
+ self.conformer_cnn_cache = None
+ self.encoder_out = None
+ # conformer decoding state
+ self.offset = 0 # global offset in decoding frame unit
+
+ ## just for record info
+ self.chunk_num = 0 # global decoding chunk num, not used
+
+ def output_reset(self):
+ ## outputs
+ # partial/ending decoding results
+ self.result_transcripts = ['']
+ # token timestamp result
+ self.word_time_stamp = []
+
+ ## just for record
+ self.hyps = []
+
+ # one best timestamp viterbi prob is large.
+ self.time_stamp = []
+
+ def reset_continuous_decoding(self):
+ """
+ when in continous decoding, reset for next utterance.
+ """
+ self.global_frame_offset = self.num_frames
+ self.model_reset()
+ self.searcher.reset()
+ self.endpointer.reset()
+
+ # reset hys will trancate history transcripts.
+ # self.output_reset()
+
+ def reset(self):
+ if "deepspeech2" in self.model_type:
+ # for deepspeech2
+ # init state
+ self.chunk_state_h_box = np.zeros(
+ (self.model_config.num_rnn_layers, 1,
+ self.model_config.rnn_layer_size),
+ dtype=float32)
+ self.chunk_state_c_box = np.zeros(
+ (self.model_config.num_rnn_layers, 1,
+ self.model_config.rnn_layer_size),
+ dtype=float32)
+ self.decoder.reset_decoder(batch_size=1)
+
+ if "conformer" in self.model_type or "transformer" in self.model_type:
+ self.searcher.reset()
+ self.endpointer.reset()
+
+ self.device = None
+
+ ## common
+ # global sample and frame step
+ self.num_samples = 0
+ self.global_frame_offset = 0
+ # frame step of cur utterance
+ self.num_frames = 0
+
+ ## endpoint
+ self.endpoint_state = False # True for detect endpoint
+
+ ## conformer
+ self.model_reset()
+
+ ## outputs
+ self.output_reset()
+
+ def extract_feat(self, samples: ByteString):
+ logger.info("Online ASR extract the feat")
+ samples = np.frombuffer(samples, dtype=np.int16)
+ assert samples.ndim == 1
+
+ self.num_samples += samples.shape[0]
+ logger.info(
+ f"This package receive {samples.shape[0]} pcm data. Global samples:{self.num_samples}"
+ )
+
+ # self.reamined_wav stores all the samples,
+ # include the original remained_wav and this package samples
+ if self.remained_wav is None:
+ self.remained_wav = samples
+ else:
+ assert self.remained_wav.ndim == 1 # (T,)
+ self.remained_wav = np.concatenate([self.remained_wav, samples])
+ logger.info(
+ f"The concatenation of remain and now audio samples length is: {self.remained_wav.shape}"
+ )
+
+ if len(self.remained_wav) < self.win_length:
+ # samples not enough for feature window
+ return 0
+
+ # fbank
+ x_chunk = self.preprocessing(self.remained_wav, **self.preprocess_args)
+ x_chunk = paddle.to_tensor(x_chunk, dtype="float32").unsqueeze(axis=0)
+
+ # feature cache
+ if self.cached_feat is None:
+ self.cached_feat = x_chunk
+ else:
+ assert (len(x_chunk.shape) == 3) # (B,T,D)
+ assert (len(self.cached_feat.shape) == 3) # (B,T,D)
+ self.cached_feat = paddle.concat(
+ [self.cached_feat, x_chunk], axis=1)
+
+ # set the feat device
+ if self.device is None:
+ self.device = self.cached_feat.place
+
+ # cur frame step
+ num_frames = x_chunk.shape[1]
+
+ # global frame step
+ self.num_frames += num_frames
+
+ # update remained wav
+ self.remained_wav = self.remained_wav[self.n_shift * num_frames:]
+
+ logger.info(
+ f"process the audio feature success, the cached feat shape: {self.cached_feat.shape}"
+ )
+ logger.info(
+ f"After extract feat, the cached remain the audio samples: {self.remained_wav.shape}"
+ )
+ logger.info(f"global samples: {self.num_samples}")
+ logger.info(f"global frames: {self.num_frames}")
+
+ def decode(self, is_finished=False):
+ """advance decoding
+
+ Args:
+ is_finished (bool, optional): Is last frame or not. Defaults to False.
+
+ Returns:
+ None:
+ """
+ if "deepspeech2" in self.model_type:
+ decoding_chunk_size = 1 # decoding chunk size = 1. int decoding frame unit
+
+ context = 7 # context=7, in audio frame unit
+ subsampling = 4 # subsampling=4, in audio frame unit
+
+ cached_feature_num = context - subsampling
+ # decoding window for model, in audio frame unit
+ decoding_window = (decoding_chunk_size - 1) * subsampling + context
+ # decoding stride for model, in audio frame unit
+ stride = subsampling * decoding_chunk_size
+
+ if self.cached_feat is None:
+ logger.info("no audio feat, please input more pcm data")
+ return
+
+ num_frames = self.cached_feat.shape[1]
+ logger.info(
+ f"Required decoding window {decoding_window} frames, and the connection has {num_frames} frames"
+ )
+
+ # the cached feat must be larger decoding_window
+ if num_frames < decoding_window and not is_finished:
+ logger.info(
+ f"frame feat num is less than {decoding_window}, please input more pcm data"
+ )
+ return None, None
+
+ # if is_finished=True, we need at least context frames
+ if num_frames < context:
+ logger.info(
+ "flast {num_frames} is less than context {context} frames, and we cannot do model forward"
+ )
+ return None, None
+
+ logger.info("start to do model forward")
+ # num_frames - context + 1 ensure that current frame can get context window
+ if is_finished:
+ # if get the finished chunk, we need process the last context
+ left_frames = context
+ else:
+ # we only process decoding_window frames for one chunk
+ left_frames = decoding_window
+
+ end = None
+ for cur in range(0, num_frames - left_frames + 1, stride):
+ end = min(cur + decoding_window, num_frames)
+
+ # extract the audio
+ x_chunk = self.cached_feat[:, cur:end, :].numpy()
+ x_chunk_lens = np.array([x_chunk.shape[1]])
+
+ trans_best = self.decode_one_chunk(x_chunk, x_chunk_lens)
+
+ self.result_transcripts = [trans_best]
+
+ # update feat cache
+ self.cached_feat = self.cached_feat[:, end - cached_feature_num:, :]
+
+ # return trans_best[0]
+ elif "conformer" in self.model_type or "transformer" in self.model_type:
+ try:
+ logger.info(
+ f"we will use the transformer like model : {self.model_type}"
+ )
+ self.advance_decoding(is_finished)
+ self.update_result()
+
+ except Exception as e:
+ logger.exception(e)
+ else:
+ raise Exception("invalid model name")
+
+ @paddle.no_grad()
+ def decode_one_chunk(self, x_chunk, x_chunk_lens):
+ """forward one chunk frames
+
+ Args:
+ x_chunk (np.ndarray): (B,T,D), audio frames.
+ x_chunk_lens ([type]): (B,), audio frame lens
+
+ Returns:
+ logprob: poster probability.
+ """
+ logger.info("start to decoce one chunk for deepspeech2")
+ input_names = self.am_predictor.get_input_names()
+ audio_handle = self.am_predictor.get_input_handle(input_names[0])
+ audio_len_handle = self.am_predictor.get_input_handle(input_names[1])
+ h_box_handle = self.am_predictor.get_input_handle(input_names[2])
+ c_box_handle = self.am_predictor.get_input_handle(input_names[3])
+
+ audio_handle.reshape(x_chunk.shape)
+ audio_handle.copy_from_cpu(x_chunk)
+
+ audio_len_handle.reshape(x_chunk_lens.shape)
+ audio_len_handle.copy_from_cpu(x_chunk_lens)
+
+ h_box_handle.reshape(self.chunk_state_h_box.shape)
+ h_box_handle.copy_from_cpu(self.chunk_state_h_box)
+
+ c_box_handle.reshape(self.chunk_state_c_box.shape)
+ c_box_handle.copy_from_cpu(self.chunk_state_c_box)
+
+ output_names = self.am_predictor.get_output_names()
+ output_handle = self.am_predictor.get_output_handle(output_names[0])
+ output_lens_handle = self.am_predictor.get_output_handle(
+ output_names[1])
+ output_state_h_handle = self.am_predictor.get_output_handle(
+ output_names[2])
+ output_state_c_handle = self.am_predictor.get_output_handle(
+ output_names[3])
+
+ self.am_predictor.run()
+
+ output_chunk_probs = output_handle.copy_to_cpu()
+ output_chunk_lens = output_lens_handle.copy_to_cpu()
+ self.chunk_state_h_box = output_state_h_handle.copy_to_cpu()
+ self.chunk_state_c_box = output_state_c_handle.copy_to_cpu()
+
+ self.decoder.next(output_chunk_probs, output_chunk_lens)
+ trans_best, trans_beam = self.decoder.decode()
+ logger.info(f"decode one best result for deepspeech2: {trans_best[0]}")
+ return trans_best[0]
+
+ @paddle.no_grad()
+ def advance_decoding(self, is_finished=False):
+ if "deepspeech" in self.model_type:
+ return
+
+ # reset endpiont state
+ self.endpoint_state = False
+
+ logger.info(
+ "Conformer/Transformer: start to decode with advanced_decoding method"
+ )
+ cfg = self.ctc_decode_config
+
+ # cur chunk size, in decoding frame unit, e.g. 16
+ decoding_chunk_size = cfg.decoding_chunk_size
+ # using num of history chunks, e.g -1
+ num_decoding_left_chunks = cfg.num_decoding_left_chunks
+ assert decoding_chunk_size > 0
+
+ # e.g. 4
+ subsampling = self.model.encoder.embed.subsampling_rate
+ # e.g. 7
+ context = self.model.encoder.embed.right_context + 1
+
+ # processed chunk feature cached for next chunk, e.g. 3
+ cached_feature_num = context - subsampling
+
+ # decoding window, in audio frame unit
+ decoding_window = (decoding_chunk_size - 1) * subsampling + context
+ # decoding stride, in audio frame unit
+ stride = subsampling * decoding_chunk_size
+
+ if self.cached_feat is None:
+ logger.info("no audio feat, please input more pcm data")
+ return
+
+ # (B=1,T,D)
+ num_frames = self.cached_feat.shape[1]
+ logger.info(
+ f"Required decoding window {decoding_window} frames, and the connection has {num_frames} frames"
+ )
+
+ # the cached feat must be larger decoding_window
+ if num_frames < decoding_window and not is_finished:
+ logger.info(
+ f"frame feat num is less than {decoding_window}, please input more pcm data"
+ )
+ return None, None
+
+ # if is_finished=True, we need at least context frames
+ if num_frames < context:
+ logger.info(
+ "flast {num_frames} is less than context {context} frames, and we cannot do model forward"
+ )
+ return None, None
+
+ logger.info("start to do model forward")
+
+ # num_frames - context + 1 ensure that current frame can get context window
+ if is_finished:
+ # if get the finished chunk, we need process the last context
+ left_frames = context
+ else:
+ # we only process decoding_window frames for one chunk
+ left_frames = decoding_window
+
+ # hist of chunks, in deocding frame unit
+ required_cache_size = decoding_chunk_size * num_decoding_left_chunks
+
+ # record the end for removing the processed feat
+ outputs = []
+ end = None
+ for cur in range(0, num_frames - left_frames + 1, stride):
+ end = min(cur + decoding_window, num_frames)
+
+ # global chunk_num
+ self.chunk_num += 1
+ # cur chunk
+ chunk_xs = self.cached_feat[:, cur:end, :]
+ # forward chunk
+ (y, self.subsampling_cache, self.elayers_output_cache,
+ self.conformer_cnn_cache) = self.model.encoder.forward_chunk(
+ chunk_xs, self.offset, required_cache_size,
+ self.subsampling_cache, self.elayers_output_cache,
+ self.conformer_cnn_cache)
+ outputs.append(y)
+
+ # update the global offset, in decoding frame unit
+ self.offset += y.shape[1]
+
+ ys = paddle.cat(outputs, 1)
+ if self.encoder_out is None:
+ self.encoder_out = ys
+ else:
+ self.encoder_out = paddle.concat([self.encoder_out, ys], axis=1)
+ logger.info(
+ f"This connection handler encoder out shape: {self.encoder_out.shape}"
+ )
+
+ # get the ctc probs
+ ctc_probs = self.model.ctc.log_softmax(ys) # (1, maxlen, vocab_size)
+ ctc_probs = ctc_probs.squeeze(0)
+
+ ## decoding
+ # advance decoding
+ self.searcher.search(ctc_probs, self.cached_feat.place)
+ # get one best hyps
+ self.hyps = self.searcher.get_one_best_hyps()
+
+ # endpoint
+ if not is_finished:
+
+ def contain_nonsilence():
+ return len(self.hyps) > 0 and len(self.hyps[0]) > 0
+
+ decoding_something = contain_nonsilence()
+ if self.endpointer.endpoint_detected(ctc_probs.numpy(),
+ decoding_something):
+ self.endpoint_state = True
+ logger.info(f"Endpoint is detected at {self.num_frames} frame.")
+
+ # advance cache of feat
+ assert self.cached_feat.shape[0] == 1 #(B=1,T,D)
+ assert end >= cached_feature_num
+ self.cached_feat = self.cached_feat[:, end - cached_feature_num:, :]
+ assert len(
+ self.cached_feat.shape
+ ) == 3, f"current cache feat shape is: {self.cached_feat.shape}"
+
+ def update_result(self):
+ """Conformer/Transformer hyps to result.
+ """
+ logger.info("update the final result")
+ hyps = self.hyps
+
+ # output results and tokenids
+ self.result_transcripts = [
+ self.text_feature.defeaturize(hyp) for hyp in hyps
+ ]
+ self.result_tokenids = [hyp for hyp in hyps]
+
+ def get_result(self):
+ """return partial/ending asr result.
+
+ Returns:
+ str: one best result of partial/ending.
+ """
+ if len(self.result_transcripts) > 0:
+ return self.result_transcripts[0]
+ else:
+ return ''
+
+ def get_word_time_stamp(self):
+ """return token timestamp result.
+
+ Returns:
+ list: List of ('w':token, 'bg':time, 'ed':time)
+ """
+ return self.word_time_stamp
+
+ @paddle.no_grad()
+ def rescoring(self):
+ """Second-Pass Decoding,
+ only for conformer and transformer model.
+ """
+ if "deepspeech2" in self.model_type:
+ logger.info("deepspeech2 not support rescoring decoding.")
+ return
+
+ if "attention_rescoring" != self.ctc_decode_config.decoding_method:
+ logger.info(
+ f"decoding method not match: {self.ctc_decode_config.decoding_method}, need attention_rescoring"
+ )
+ return
+
+ logger.info("rescoring the final result")
+
+ # last decoding for last audio
+ self.searcher.finalize_search()
+ # update beam search results
+ self.update_result()
+
+ beam_size = self.ctc_decode_config.beam_size
+ hyps = self.searcher.get_hyps()
+ if hyps is None or len(hyps) == 0:
+ logger.info("No Hyps!")
+ return
+
+ # rescore by decoder post probability
+
+ # assert len(hyps) == beam_size
+ # list of Tensor
+ hyp_list = []
+ for hyp in hyps:
+ hyp_content = hyp[0]
+ # Prevent the hyp is empty
+ if len(hyp_content) == 0:
+ hyp_content = (self.model.ctc.blank_id, )
+
+ hyp_content = paddle.to_tensor(
+ hyp_content, place=self.device, dtype=paddle.long)
+ hyp_list.append(hyp_content)
+
+ hyps_pad = pad_sequence(
+ hyp_list, batch_first=True, padding_value=self.model.ignore_id)
+ hyps_lens = paddle.to_tensor(
+ [len(hyp[0]) for hyp in hyps], place=self.device,
+ dtype=paddle.long) # (beam_size,)
+ hyps_pad, _ = add_sos_eos(hyps_pad, self.model.sos, self.model.eos,
+ self.model.ignore_id)
+ hyps_lens = hyps_lens + 1 # Add at begining
+
+ encoder_out = self.encoder_out.repeat(beam_size, 1, 1)
+ encoder_mask = paddle.ones(
+ (beam_size, 1, encoder_out.shape[1]), dtype=paddle.bool)
+ decoder_out, _ = self.model.decoder(
+ encoder_out, encoder_mask, hyps_pad,
+ hyps_lens) # (beam_size, max_hyps_len, vocab_size)
+ # ctc score in ln domain
+ decoder_out = paddle.nn.functional.log_softmax(decoder_out, axis=-1)
+ decoder_out = decoder_out.numpy()
+
+ # Only use decoder score for rescoring
+ best_score = -float('inf')
+ best_index = 0
+ # hyps is List[(Text=List[int], Score=float)], len(hyps)=beam_size
+ for i, hyp in enumerate(hyps):
+ score = 0.0
+ for j, w in enumerate(hyp[0]):
+ score += decoder_out[i][j][w]
+
+ # last decoder output token is `eos`, for laste decoder input token.
+ score += decoder_out[i][len(hyp[0])][self.model.eos]
+ # add ctc score (which in ln domain)
+ score += hyp[1] * self.ctc_decode_config.ctc_weight
+
+ if score > best_score:
+ best_score = score
+ best_index = i
+
+ # update the one best result
+ # hyps stored the beam results and each fields is:
+
+ logger.info(f"best hyp index: {best_index}")
+ # logger.info(f'best result: {hyps[best_index]}')
+ # the field of the hyps is:
+ ## asr results
+ # hyps[0][0]: the sentence word-id in the vocab with a tuple
+ # hyps[0][1]: the sentence decoding probability with all paths
+ ## timestamp
+ # hyps[0][2]: viterbi_blank ending probability
+ # hyps[0][3]: viterbi_non_blank dending probability
+ # hyps[0][4]: current_token_prob,
+ # hyps[0][5]: times_viterbi_blank ending timestamp,
+ # hyps[0][6]: times_titerbi_non_blank encding timestamp.
+ self.hyps = [hyps[best_index][0]]
+ logger.info(f"best hyp ids: {self.hyps}")
+
+ # update the hyps time stamp
+ self.time_stamp = hyps[best_index][5] if hyps[best_index][2] > hyps[
+ best_index][3] else hyps[best_index][6]
+ logger.info(f"time stamp: {self.time_stamp}")
+
+ # update one best result
+ self.update_result()
+
+ # update each word start and end time stamp
+ # decoding frame to audio frame
+ decode_frame_shift = self.model.encoder.embed.subsampling_rate
+ decode_frame_shift_in_sec = decode_frame_shift * (self.n_shift /
+ self.sample_rate)
+ logger.info(f"decode frame shift in sec: {decode_frame_shift_in_sec}")
+
+ global_offset_in_sec = self.global_frame_offset * self.frame_shift_in_ms / 1000.0
+ logger.info(f"global offset: {global_offset_in_sec} sec.")
+
+ word_time_stamp = []
+ for idx, _ in enumerate(self.time_stamp):
+ start = (self.time_stamp[idx - 1] + self.time_stamp[idx]
+ ) / 2.0 if idx > 0 else 0
+ start = start * decode_frame_shift_in_sec
+
+ end = (self.time_stamp[idx] + self.time_stamp[idx + 1]
+ ) / 2.0 if idx < len(self.time_stamp) - 1 else self.offset
+
+ end = end * decode_frame_shift_in_sec
+ word_time_stamp.append({
+ "w": self.result_transcripts[0][idx],
+ "bg": global_offset_in_sec + start,
+ "ed": global_offset_in_sec + end
+ })
+ # logger.info(f"{word_time_stamp[-1]}")
+
+ self.word_time_stamp = word_time_stamp
+ logger.info(f"word time stamp: {self.word_time_stamp}")
+
+
+class ASRServerExecutor(ASRExecutor):
+ def __init__(self):
+ super().__init__()
+ self.task_resource = CommonTaskResource(
+ task='asr', model_format='dynamic', inference_mode='online')
+
+ def update_config(self) -> None:
+ if "deepspeech2" in self.model_type:
+ with UpdateConfig(self.config):
+ # download lm
+ self.config.decode.lang_model_path = os.path.join(
+ MODEL_HOME, 'language_model',
+ self.config.decode.lang_model_path)
+
+ lm_url = self.task_resource.res_dict['lm_url']
+ lm_md5 = self.task_resource.res_dict['lm_md5']
+ logger.info(f"Start to load language model {lm_url}")
+ self.download_lm(
+ lm_url,
+ os.path.dirname(self.config.decode.lang_model_path), lm_md5)
+ elif "conformer" in self.model_type or "transformer" in self.model_type:
+ with UpdateConfig(self.config):
+ logger.info("start to create the stream conformer asr engine")
+ # update the decoding method
+ if self.decode_method:
+ self.config.decode.decoding_method = self.decode_method
+ # update num_decoding_left_chunks
+ if self.num_decoding_left_chunks:
+ assert self.num_decoding_left_chunks == -1 or self.num_decoding_left_chunks >= 0, "num_decoding_left_chunks should be -1 or >=0"
+ self.config.decode.num_decoding_left_chunks = self.num_decoding_left_chunks
+ # we only support ctc_prefix_beam_search and attention_rescoring dedoding method
+ # Generally we set the decoding_method to attention_rescoring
+ if self.config.decode.decoding_method not in [
+ "ctc_prefix_beam_search", "attention_rescoring"
+ ]:
+ logger.info(
+ "we set the decoding_method to attention_rescoring")
+ self.config.decode.decoding_method = "attention_rescoring"
+
+ assert self.config.decode.decoding_method in [
+ "ctc_prefix_beam_search", "attention_rescoring"
+ ], f"we only support ctc_prefix_beam_search and attention_rescoring dedoding method, current decoding method is {self.config.decode.decoding_method}"
+ else:
+ raise Exception(f"not support: {self.model_type}")
+
+ def init_model(self) -> None:
+ if "deepspeech2" in self.model_type:
+ # AM predictor
+ logger.info("ASR engine start to init the am predictor")
+ self.am_predictor = init_predictor(
+ model_file=self.am_model,
+ params_file=self.am_params,
+ predictor_conf=self.am_predictor_conf)
+ elif "conformer" in self.model_type or "transformer" in self.model_type:
+ # load model
+ # model_type: {model_name}_{dataset}
+ model_name = self.model_type[:self.model_type.rindex('_')]
+ logger.info(f"model name: {model_name}")
+ model_class = self.task_resource.get_model_class(model_name)
+ model = model_class.from_config(self.config)
+ self.model = model
+ self.model.set_state_dict(paddle.load(self.am_model))
+ self.model.eval()
+ else:
+ raise Exception(f"not support: {self.model_type}")
+
+ def _init_from_path(self,
+ model_type: str=None,
+ am_model: Optional[os.PathLike]=None,
+ am_params: Optional[os.PathLike]=None,
+ lang: str='zh',
+ sample_rate: int=16000,
+ cfg_path: Optional[os.PathLike]=None,
+ decode_method: str='attention_rescoring',
+ num_decoding_left_chunks: int=-1,
+ am_predictor_conf: dict=None):
+ """
+ Init model and other resources from a specific path.
+ """
+ if not model_type or not lang or not sample_rate:
+ logger.error(
+ "The model type or lang or sample rate is None, please input an valid server parameter yaml"
+ )
+ return False
+
+ self.model_type = model_type
+ self.sample_rate = sample_rate
+ self.decode_method = decode_method
+ self.num_decoding_left_chunks = num_decoding_left_chunks
+ # conf for paddleinference predictor or onnx
+ self.am_predictor_conf = am_predictor_conf
+ logger.info(f"model_type: {self.model_type}")
+
+ sample_rate_str = '16k' if sample_rate == 16000 else '8k'
+ tag = model_type + '-' + lang + '-' + sample_rate_str
+ self.task_resource.set_task_model(model_tag=tag)
+
+ if cfg_path is None or am_model is None or am_params is None:
+ self.res_path = self.task_resource.res_dir
+ self.cfg_path = os.path.join(
+ self.res_path, self.task_resource.res_dict['cfg_path'])
+
+ self.am_model = os.path.join(self.res_path,
+ self.task_resource.res_dict['model'])
+ self.am_params = os.path.join(self.res_path,
+ self.task_resource.res_dict['params'])
+ else:
+ self.cfg_path = os.path.abspath(cfg_path)
+ self.am_model = os.path.abspath(am_model)
+ self.am_params = os.path.abspath(am_params)
+ self.res_path = os.path.dirname(
+ os.path.dirname(os.path.abspath(self.cfg_path)))
+
+ logger.info("Load the pretrained model:")
+ logger.info(f" tag = {tag}")
+ logger.info(f" res_path: {self.res_path}")
+ logger.info(f" cfg path: {self.cfg_path}")
+ logger.info(f" am_model path: {self.am_model}")
+ logger.info(f" am_params path: {self.am_params}")
+
+ #Init body.
+ self.config = CfgNode(new_allowed=True)
+ self.config.merge_from_file(self.cfg_path)
+
+ if self.config.spm_model_prefix:
+ self.config.spm_model_prefix = os.path.join(
+ self.res_path, self.config.spm_model_prefix)
+ logger.info(f"spm model path: {self.config.spm_model_prefix}")
+
+ self.vocab = self.config.vocab_filepath
+
+ self.text_feature = TextFeaturizer(
+ unit_type=self.config.unit_type,
+ vocab=self.config.vocab_filepath,
+ spm_model_prefix=self.config.spm_model_prefix)
+
+ self.update_config()
+
+ # AM predictor
+ self.init_model()
+
+ logger.info(f"create the {model_type} model success")
+ return True
+
+
+class ASREngine(BaseEngine):
+ """ASR server resource
+
+ Args:
+ metaclass: Defaults to Singleton.
+ """
+
+ def __init__(self):
+ super(ASREngine, self).__init__()
+
+ def init_model(self) -> bool:
+ if not self.executor._init_from_path(
+ model_type=self.config.model_type,
+ am_model=self.config.am_model,
+ am_params=self.config.am_params,
+ lang=self.config.lang,
+ sample_rate=self.config.sample_rate,
+ cfg_path=self.config.cfg_path,
+ decode_method=self.config.decode_method,
+ num_decoding_left_chunks=self.config.num_decoding_left_chunks,
+ am_predictor_conf=self.config.am_predictor_conf):
+ return False
+ return True
+
+ def init(self, config: dict) -> bool:
+ """init engine resource
+
+ Args:
+ config_file (str): config file
+
+ Returns:
+ bool: init failed or success
+ """
+ self.config = config
+ self.executor = ASRServerExecutor()
+
+ try:
+ self.device = self.config.get("device", paddle.get_device())
+ paddle.set_device(self.device)
+ except BaseException as e:
+ logger.error(
+ f"Set device failed, please check if device '{self.device}' is already used and the parameter 'device' in the yaml file"
+ )
+ logger.error(
+ "If all GPU or XPU is used, you can set the server to 'cpu'")
+ sys.exit(-1)
+
+ logger.info(f"paddlespeech_server set the device: {self.device}")
+
+ if not self.init_model():
+ logger.error(
+ "Init the ASR server occurs error, please check the server configuration yaml"
+ )
+ return False
+
+ logger.info("Initialize ASR server engine successfully.")
+ return True
+
+ def new_handler(self):
+ """New handler from model.
+
+ Returns:
+ PaddleASRConnectionHanddler: asr handler instance
+ """
+ return PaddleASRConnectionHanddler(self)
+
+ def preprocess(self, *args, **kwargs):
+ raise NotImplementedError("Online not using this.")
+
+ def run(self, *args, **kwargs):
+ raise NotImplementedError("Online not using this.")
+
+ def postprocess(self):
+ raise NotImplementedError("Online not using this.")
diff --git a/paddlespeech/server/engine/asr/paddleinference/asr_engine.py b/paddlespeech/server/engine/asr/paddleinference/asr_engine.py
index 1925bf1d6..1a3b4620a 100644
--- a/paddlespeech/server/engine/asr/paddleinference/asr_engine.py
+++ b/paddlespeech/server/engine/asr/paddleinference/asr_engine.py
@@ -22,6 +22,7 @@ from yacs.config import CfgNode
from paddlespeech.cli.asr.infer import ASRExecutor
from paddlespeech.cli.log import logger
from paddlespeech.cli.utils import MODEL_HOME
+from paddlespeech.resource import CommonTaskResource
from paddlespeech.s2t.frontend.featurizer.text_featurizer import TextFeaturizer
from paddlespeech.s2t.modules.ctc import CTCDecoder
from paddlespeech.s2t.utils.utility import UpdateConfig
@@ -29,34 +30,14 @@ from paddlespeech.server.engine.base_engine import BaseEngine
from paddlespeech.server.utils.paddle_predictor import init_predictor
from paddlespeech.server.utils.paddle_predictor import run_model
-__all__ = ['ASREngine']
-
-pretrained_models = {
- "deepspeech2offline_aishell-zh-16k": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/s2t/aishell/asr0/asr0_deepspeech2_aishell_ckpt_0.1.1.model.tar.gz',
- 'md5':
- '932c3593d62fe5c741b59b31318aa314',
- 'cfg_path':
- 'model.yaml',
- 'ckpt_path':
- 'exp/deepspeech2/checkpoints/avg_1',
- 'model':
- 'exp/deepspeech2/checkpoints/avg_1.jit.pdmodel',
- 'params':
- 'exp/deepspeech2/checkpoints/avg_1.jit.pdiparams',
- 'lm_url':
- 'https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm',
- 'lm_md5':
- '29e02312deb2e59b3c8686c7966d4fe3'
- },
-}
+__all__ = ['ASREngine', 'PaddleASRConnectionHandler']
class ASRServerExecutor(ASRExecutor):
def __init__(self):
super().__init__()
- pass
+ self.task_resource = CommonTaskResource(
+ task='asr', model_format='static')
def _init_from_path(self,
model_type: str='wenetspeech',
@@ -70,20 +51,21 @@ class ASRServerExecutor(ASRExecutor):
"""
Init model and other resources from a specific path.
"""
-
+ self.max_len = 50
+ sample_rate_str = '16k' if sample_rate == 16000 else '8k'
+ tag = model_type + '-' + lang + '-' + sample_rate_str
+ self.max_len = 50
+ self.task_resource.set_task_model(model_tag=tag)
if cfg_path is None or am_model is None or am_params is None:
- sample_rate_str = '16k' if sample_rate == 16000 else '8k'
- tag = model_type + '-' + lang + '-' + sample_rate_str
- res_path = self._get_pretrained_path(tag) # wenetspeech_zh
- self.res_path = res_path
- self.cfg_path = os.path.join(res_path,
- pretrained_models[tag]['cfg_path'])
-
- self.am_model = os.path.join(res_path,
- pretrained_models[tag]['model'])
- self.am_params = os.path.join(res_path,
- pretrained_models[tag]['params'])
- logger.info(res_path)
+ self.res_path = self.task_resource.res_dir
+ self.cfg_path = os.path.join(
+ self.res_path, self.task_resource.res_dict['cfg_path'])
+
+ self.am_model = os.path.join(self.res_path,
+ self.task_resource.res_dict['model'])
+ self.am_params = os.path.join(self.res_path,
+ self.task_resource.res_dict['params'])
+ logger.info(self.res_path)
logger.info(self.cfg_path)
logger.info(self.am_model)
logger.info(self.am_params)
@@ -99,22 +81,25 @@ class ASRServerExecutor(ASRExecutor):
self.config.merge_from_file(self.cfg_path)
with UpdateConfig(self.config):
- if "deepspeech2online" in model_type or "deepspeech2offline" in model_type:
- from paddlespeech.s2t.io.collator import SpeechCollator
+ if "deepspeech2" in model_type:
self.vocab = self.config.vocab_filepath
+ if self.config.spm_model_prefix:
+ self.config.spm_model_prefix = os.path.join(
+ self.res_path, self.config.spm_model_prefix)
+ self.text_feature = TextFeaturizer(
+ unit_type=self.config.unit_type,
+ vocab=self.vocab,
+ spm_model_prefix=self.config.spm_model_prefix)
self.config.decode.lang_model_path = os.path.join(
MODEL_HOME, 'language_model',
self.config.decode.lang_model_path)
- self.collate_fn_test = SpeechCollator.from_config(self.config)
- self.text_feature = TextFeaturizer(
- unit_type=self.config.unit_type, vocab=self.vocab)
- lm_url = pretrained_models[tag]['lm_url']
- lm_md5 = pretrained_models[tag]['lm_md5']
+ lm_url = self.task_resource.res_dict['lm_url']
+ lm_md5 = self.task_resource.res_dict['lm_md5']
self.download_lm(
lm_url,
os.path.dirname(self.config.decode.lang_model_path), lm_md5)
- elif "conformer" in model_type or "transformer" in model_type or "wenetspeech" in model_type:
+ elif "conformer" in model_type or "transformer" in model_type:
raise Exception("wrong type")
else:
raise Exception("wrong type")
@@ -144,7 +129,7 @@ class ASRServerExecutor(ASRExecutor):
cfg = self.config.decode
audio = self._inputs["audio"]
audio_len = self._inputs["audio_len"]
- if "deepspeech2online" in model_type or "deepspeech2offline" in model_type:
+ if "deepspeech2" in model_type:
decode_batch_size = audio.shape[0]
# init once
self.decoder.init_decoder(
@@ -192,10 +177,23 @@ class ASREngine(BaseEngine):
Returns:
bool: init failed or success
"""
- self.input = None
- self.output = None
self.executor = ASRServerExecutor()
self.config = config
+ self.engine_type = "inference"
+
+ try:
+ if self.config.am_predictor_conf.device is not None:
+ self.device = self.config.am_predictor_conf.device
+ else:
+ self.device = paddle.get_device()
+
+ paddle.set_device(self.device)
+ except Exception as e:
+ logger.error(
+ "Set device failed, please check if device is already used and the parameter 'device' in the yaml file"
+ )
+ logger.error(e)
+ return False
self.executor._init_from_path(
model_type=self.config.model_type,
@@ -210,22 +208,41 @@ class ASREngine(BaseEngine):
logger.info("Initialize ASR server engine successfully.")
return True
+
+class PaddleASRConnectionHandler(ASRServerExecutor):
+ def __init__(self, asr_engine):
+ """The PaddleSpeech ASR Server Connection Handler
+ This connection process every asr server request
+ Args:
+ asr_engine (ASREngine): The ASR engine
+ """
+ super().__init__()
+ self.input = None
+ self.output = None
+ self.asr_engine = asr_engine
+ self.executor = self.asr_engine.executor
+ self.config = self.executor.config
+ self.max_len = self.executor.max_len
+ self.decoder = self.executor.decoder
+ self.am_predictor = self.executor.am_predictor
+ self.text_feature = self.executor.text_feature
+
def run(self, audio_data):
- """engine run
+ """engine run
Args:
audio_data (bytes): base64.b64decode
"""
- if self.executor._check(
- io.BytesIO(audio_data), self.config.sample_rate,
- self.config.force_yes):
+ if self._check(
+ io.BytesIO(audio_data), self.asr_engine.config.sample_rate,
+ self.asr_engine.config.force_yes):
logger.info("start running asr engine")
- self.executor.preprocess(self.config.model_type,
- io.BytesIO(audio_data))
+ self.preprocess(self.asr_engine.config.model_type,
+ io.BytesIO(audio_data))
st = time.time()
- self.executor.infer(self.config.model_type)
+ self.infer(self.asr_engine.config.model_type)
infer_time = time.time() - st
- self.output = self.executor.postprocess() # Retrieve result of asr.
+ self.output = self.postprocess() # Retrieve result of asr.
logger.info("end inferring asr engine")
else:
logger.info("file check failed!")
@@ -233,8 +250,3 @@ class ASREngine(BaseEngine):
logger.info("inference time: {}".format(infer_time))
logger.info("asr engine type: paddle inference")
-
- def postprocess(self):
- """postprocess
- """
- return self.output
diff --git a/paddlespeech/server/engine/asr/python/asr_engine.py b/paddlespeech/server/engine/asr/python/asr_engine.py
index e76c49a79..f9cc3a665 100644
--- a/paddlespeech/server/engine/asr/python/asr_engine.py
+++ b/paddlespeech/server/engine/asr/python/asr_engine.py
@@ -12,6 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
import io
+import sys
import time
import paddle
@@ -20,7 +21,7 @@ from paddlespeech.cli.asr.infer import ASRExecutor
from paddlespeech.cli.log import logger
from paddlespeech.server.engine.base_engine import BaseEngine
-__all__ = ['ASREngine']
+__all__ = ['ASREngine', 'PaddleASRConnectionHandler']
class ASRServerExecutor(ASRExecutor):
@@ -48,20 +49,23 @@ class ASREngine(BaseEngine):
Returns:
bool: init failed or success
"""
- self.input = None
- self.output = None
self.executor = ASRServerExecutor()
self.config = config
+ self.engine_type = "python"
+
try:
- if self.config.device:
+ if self.config.device is not None:
self.device = self.config.device
else:
self.device = paddle.get_device()
+
paddle.set_device(self.device)
- except BaseException:
+ except Exception as e:
logger.error(
"Set device failed, please check if device is already used and the parameter 'device' in the yaml file"
)
+ logger.error(e)
+ return False
self.executor._init_from_path(
self.config.model, self.config.lang, self.config.sample_rate,
@@ -72,29 +76,47 @@ class ASREngine(BaseEngine):
(self.device))
return True
+
+class PaddleASRConnectionHandler(ASRServerExecutor):
+ def __init__(self, asr_engine):
+ """The PaddleSpeech ASR Server Connection Handler
+ This connection process every asr server request
+ Args:
+ asr_engine (ASREngine): The ASR engine
+ """
+ super().__init__()
+ self.input = None
+ self.output = None
+ self.asr_engine = asr_engine
+ self.executor = self.asr_engine.executor
+ self.max_len = self.executor.max_len
+ self.text_feature = self.executor.text_feature
+ self.model = self.executor.model
+ self.config = self.executor.config
+
def run(self, audio_data):
"""engine run
Args:
audio_data (bytes): base64.b64decode
"""
- if self.executor._check(
- io.BytesIO(audio_data), self.config.sample_rate,
- self.config.force_yes):
- logger.info("start run asr engine")
- self.executor.preprocess(self.config.model, io.BytesIO(audio_data))
- st = time.time()
- self.executor.infer(self.config.model)
- infer_time = time.time() - st
- self.output = self.executor.postprocess() # Retrieve result of asr.
- else:
- logger.info("file check failed!")
- self.output = None
-
- logger.info("inference time: {}".format(infer_time))
- logger.info("asr engine type: python")
-
- def postprocess(self):
- """postprocess
- """
- return self.output
+ try:
+ if self._check(
+ io.BytesIO(audio_data), self.asr_engine.config.sample_rate,
+ self.asr_engine.config.force_yes):
+ logger.info("start run asr engine")
+ self.preprocess(self.asr_engine.config.model,
+ io.BytesIO(audio_data))
+ st = time.time()
+ self.infer(self.asr_engine.config.model)
+ infer_time = time.time() - st
+ self.output = self.postprocess() # Retrieve result of asr.
+ else:
+ logger.info("file check failed!")
+ self.output = None
+
+ logger.info("inference time: {}".format(infer_time))
+ logger.info("asr engine type: python")
+ except Exception as e:
+ logger.info(e)
+ sys.exit(-1)
diff --git a/paddlespeech/server/engine/cls/paddleinference/cls_engine.py b/paddlespeech/server/engine/cls/paddleinference/cls_engine.py
index 3982effd9..389d56055 100644
--- a/paddlespeech/server/engine/cls/paddleinference/cls_engine.py
+++ b/paddlespeech/server/engine/cls/paddleinference/cls_engine.py
@@ -14,6 +14,7 @@
import io
import os
import time
+from collections import OrderedDict
from typing import Optional
import numpy as np
@@ -22,85 +23,23 @@ import yaml
from paddlespeech.cli.cls.infer import CLSExecutor
from paddlespeech.cli.log import logger
-from paddlespeech.cli.utils import download_and_decompress
-from paddlespeech.cli.utils import MODEL_HOME
+from paddlespeech.resource import CommonTaskResource
from paddlespeech.server.engine.base_engine import BaseEngine
from paddlespeech.server.utils.paddle_predictor import init_predictor
from paddlespeech.server.utils.paddle_predictor import run_model
-__all__ = ['CLSEngine']
-
-pretrained_models = {
- "panns_cnn6-32k": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/cls/inference_model/panns_cnn6_static.tar.gz',
- 'md5':
- 'da087c31046d23281d8ec5188c1967da',
- 'cfg_path':
- 'panns.yaml',
- 'model_path':
- 'inference.pdmodel',
- 'params_path':
- 'inference.pdiparams',
- 'label_file':
- 'audioset_labels.txt',
- },
- "panns_cnn10-32k": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/cls/inference_model/panns_cnn10_static.tar.gz',
- 'md5':
- '5460cc6eafbfaf0f261cc75b90284ae1',
- 'cfg_path':
- 'panns.yaml',
- 'model_path':
- 'inference.pdmodel',
- 'params_path':
- 'inference.pdiparams',
- 'label_file':
- 'audioset_labels.txt',
- },
- "panns_cnn14-32k": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/cls/inference_model/panns_cnn14_static.tar.gz',
- 'md5':
- 'ccc80b194821274da79466862b2ab00f',
- 'cfg_path':
- 'panns.yaml',
- 'model_path':
- 'inference.pdmodel',
- 'params_path':
- 'inference.pdiparams',
- 'label_file':
- 'audioset_labels.txt',
- },
-}
+__all__ = ['CLSEngine', 'PaddleCLSConnectionHandler']
class CLSServerExecutor(CLSExecutor):
def __init__(self):
super().__init__()
- pass
-
- def _get_pretrained_path(self, tag: str) -> os.PathLike:
- """
- Download and returns pretrained resources path of current task.
- """
- support_models = list(pretrained_models.keys())
- assert tag in pretrained_models, 'The model "{}" you want to use has not been supported, please choose other models.\nThe support models includes:\n\t\t{}\n'.format(
- tag, '\n\t\t'.join(support_models))
-
- res_path = os.path.join(MODEL_HOME, tag)
- decompressed_path = download_and_decompress(pretrained_models[tag],
- res_path)
- decompressed_path = os.path.abspath(decompressed_path)
- logger.info(
- 'Use pretrained model stored in: {}'.format(decompressed_path))
-
- return decompressed_path
+ self.task_resource = CommonTaskResource(
+ task='cls', model_format='static')
def _init_from_path(
self,
- model_type: str='panns_cnn14',
+ model_type: str='panns_cnn14_audioset',
cfg_path: Optional[os.PathLike]=None,
model_path: Optional[os.PathLike]=None,
params_path: Optional[os.PathLike]=None,
@@ -112,15 +51,16 @@ class CLSServerExecutor(CLSExecutor):
if cfg_path is None or model_path is None or params_path is None or label_file is None:
tag = model_type + '-' + '32k'
- self.res_path = self._get_pretrained_path(tag)
- self.cfg_path = os.path.join(self.res_path,
- pretrained_models[tag]['cfg_path'])
- self.model_path = os.path.join(self.res_path,
- pretrained_models[tag]['model_path'])
+ self.task_resource.set_task_model(model_tag=tag)
+ self.res_path = self.task_resource.res_dir
+ self.cfg_path = os.path.join(
+ self.res_path, self.task_resource.res_dict['cfg_path'])
+ self.model_path = os.path.join(
+ self.res_path, self.task_resource.res_dict['model_path'])
self.params_path = os.path.join(
- self.res_path, pretrained_models[tag]['params_path'])
- self.label_file = os.path.join(self.res_path,
- pretrained_models[tag]['label_file'])
+ self.res_path, self.task_resource.res_dict['params_path'])
+ self.label_file = os.path.join(
+ self.res_path, self.task_resource.res_dict['label_file'])
else:
self.cfg_path = os.path.abspath(cfg_path)
self.model_path = os.path.abspath(model_path)
@@ -182,14 +122,55 @@ class CLSEngine(BaseEngine):
"""
self.executor = CLSServerExecutor()
self.config = config
- self.executor._init_from_path(
- self.config.model_type, self.config.cfg_path,
- self.config.model_path, self.config.params_path,
- self.config.label_file, self.config.predictor_conf)
+ self.engine_type = "inference"
+
+ try:
+ if self.config.predictor_conf.device is not None:
+ self.device = self.config.predictor_conf.device
+ else:
+ self.device = paddle.get_device()
+ paddle.set_device(self.device)
+ except Exception as e:
+ logger.error(
+ "Set device failed, please check if device is already used and the parameter 'device' in the yaml file"
+ )
+ logger.error(e)
+ return False
+
+ try:
+ self.executor._init_from_path(
+ self.config.model_type, self.config.cfg_path,
+ self.config.model_path, self.config.params_path,
+ self.config.label_file, self.config.predictor_conf)
+
+ except Exception as e:
+ logger.error("Initialize CLS server engine Failed.")
+ logger.error(e)
+ return False
logger.info("Initialize CLS server engine successfully.")
return True
+
+class PaddleCLSConnectionHandler(CLSServerExecutor):
+ def __init__(self, cls_engine):
+ """The PaddleSpeech CLS Server Connection Handler
+ This connection process every cls server request
+ Args:
+ cls_engine (CLSEngine): The CLS engine
+ """
+ super().__init__()
+ logger.info(
+ "Create PaddleCLSConnectionHandler to process the cls request")
+
+ self._inputs = OrderedDict()
+ self._outputs = OrderedDict()
+ self.cls_engine = cls_engine
+ self.executor = self.cls_engine.executor
+ self._conf = self.executor._conf
+ self._label_list = self.executor._label_list
+ self.predictor = self.executor.predictor
+
def run(self, audio_data):
"""engine run
@@ -197,9 +178,9 @@ class CLSEngine(BaseEngine):
audio_data (bytes): base64.b64decode
"""
- self.executor.preprocess(io.BytesIO(audio_data))
+ self.preprocess(io.BytesIO(audio_data))
st = time.time()
- self.executor.infer()
+ self.infer()
infer_time = time.time() - st
logger.info("inference time: {}".format(infer_time))
@@ -208,15 +189,15 @@ class CLSEngine(BaseEngine):
def postprocess(self, topk: int):
"""postprocess
"""
- assert topk <= len(self.executor._label_list
- ), 'Value of topk is larger than number of labels.'
+ assert topk <= len(
+ self._label_list), 'Value of topk is larger than number of labels.'
- result = np.squeeze(self.executor._outputs['logits'], axis=0)
+ result = np.squeeze(self._outputs['logits'], axis=0)
topk_idx = (-result).argsort()[:topk]
topk_results = []
for idx in topk_idx:
res = {}
- label, score = self.executor._label_list[idx], result[idx]
+ label, score = self._label_list[idx], result[idx]
res['class_name'] = label
res['prob'] = score
topk_results.append(res)
diff --git a/paddlespeech/server/engine/cls/python/cls_engine.py b/paddlespeech/server/engine/cls/python/cls_engine.py
index 1a975b0a0..f8d8f20ef 100644
--- a/paddlespeech/server/engine/cls/python/cls_engine.py
+++ b/paddlespeech/server/engine/cls/python/cls_engine.py
@@ -13,7 +13,7 @@
# limitations under the License.
import io
import time
-from typing import List
+from collections import OrderedDict
import paddle
@@ -21,7 +21,7 @@ from paddlespeech.cli.cls.infer import CLSExecutor
from paddlespeech.cli.log import logger
from paddlespeech.server.engine.base_engine import BaseEngine
-__all__ = ['CLSEngine']
+__all__ = ['CLSEngine', 'PaddleCLSConnectionHandler']
class CLSServerExecutor(CLSExecutor):
@@ -29,21 +29,6 @@ class CLSServerExecutor(CLSExecutor):
super().__init__()
pass
- def get_topk_results(self, topk: int) -> List:
- assert topk <= len(
- self._label_list), 'Value of topk is larger than number of labels.'
-
- result = self._outputs['logits'].squeeze(0).numpy()
- topk_idx = (-result).argsort()[:topk]
- res = {}
- topk_results = []
- for idx in topk_idx:
- label, score = self._label_list[idx], result[idx]
- res['class'] = label
- res['prob'] = score
- topk_results.append(res)
- return topk_results
-
class CLSEngine(BaseEngine):
"""CLS server engine
@@ -64,42 +49,65 @@ class CLSEngine(BaseEngine):
Returns:
bool: init failed or success
"""
- self.input = None
- self.output = None
self.executor = CLSServerExecutor()
self.config = config
+ self.engine_type = "python"
+
try:
- if self.config.device:
+ if self.config.device is not None:
self.device = self.config.device
else:
self.device = paddle.get_device()
paddle.set_device(self.device)
- except BaseException:
+ except Exception as e:
logger.error(
"Set device failed, please check if device is already used and the parameter 'device' in the yaml file"
)
+ logger.error(e)
+ return False
try:
self.executor._init_from_path(
self.config.model, self.config.cfg_path, self.config.ckpt_path,
self.config.label_file)
- except BaseException:
+ except Exception as e:
logger.error("Initialize CLS server engine Failed.")
+ logger.error(e)
return False
logger.info("Initialize CLS server engine successfully on device: %s." %
(self.device))
return True
+
+class PaddleCLSConnectionHandler(CLSServerExecutor):
+ def __init__(self, cls_engine):
+ """The PaddleSpeech CLS Server Connection Handler
+ This connection process every cls server request
+ Args:
+ cls_engine (CLSEngine): The CLS engine
+ """
+ super().__init__()
+ logger.info(
+ "Create PaddleCLSConnectionHandler to process the cls request")
+
+ self._inputs = OrderedDict()
+ self._outputs = OrderedDict()
+ self.cls_engine = cls_engine
+ self.executor = self.cls_engine.executor
+ self._conf = self.executor._conf
+ self._label_list = self.executor._label_list
+ self.model = self.executor.model
+
def run(self, audio_data):
"""engine run
Args:
audio_data (bytes): base64.b64decode
"""
- self.executor.preprocess(io.BytesIO(audio_data))
+ self.preprocess(io.BytesIO(audio_data))
st = time.time()
- self.executor.infer()
+ self.infer()
infer_time = time.time() - st
logger.info("inference time: {}".format(infer_time))
@@ -108,15 +116,15 @@ class CLSEngine(BaseEngine):
def postprocess(self, topk: int):
"""postprocess
"""
- assert topk <= len(self.executor._label_list
- ), 'Value of topk is larger than number of labels.'
+ assert topk <= len(
+ self._label_list), 'Value of topk is larger than number of labels.'
- result = self.executor._outputs['logits'].squeeze(0).numpy()
+ result = self._outputs['logits'].squeeze(0).numpy()
topk_idx = (-result).argsort()[:topk]
topk_results = []
for idx in topk_idx:
res = {}
- label, score = self.executor._label_list[idx], result[idx]
+ label, score = self._label_list[idx], result[idx]
res['class_name'] = label
res['prob'] = score
topk_results.append(res)
diff --git a/paddlespeech/server/engine/engine_factory.py b/paddlespeech/server/engine/engine_factory.py
index 30e48de77..6a66a002e 100644
--- a/paddlespeech/server/engine/engine_factory.py
+++ b/paddlespeech/server/engine/engine_factory.py
@@ -13,12 +13,16 @@
# limitations under the License.
from typing import Text
+from ..utils.log import logger
+
__all__ = ['EngineFactory']
class EngineFactory(object):
@staticmethod
def get_engine(engine_name: Text, engine_type: Text):
+ logger.info(f"{engine_name} : {engine_type} engine.")
+
if engine_name == 'asr' and engine_type == 'inference':
from paddlespeech.server.engine.asr.paddleinference.asr_engine import ASREngine
return ASREngine()
@@ -26,7 +30,13 @@ class EngineFactory(object):
from paddlespeech.server.engine.asr.python.asr_engine import ASREngine
return ASREngine()
elif engine_name == 'asr' and engine_type == 'online':
- from paddlespeech.server.engine.asr.online.asr_engine import ASREngine
+ from paddlespeech.server.engine.asr.online.python.asr_engine import ASREngine
+ return ASREngine()
+ elif engine_name == 'asr' and engine_type == 'online-inference':
+ from paddlespeech.server.engine.asr.online.paddleinference.asr_engine import ASREngine
+ return ASREngine()
+ elif engine_name == 'asr' and engine_type == 'online-onnx':
+ from paddlespeech.server.engine.asr.online.onnx.asr_engine import ASREngine
return ASREngine()
elif engine_name == 'tts' and engine_type == 'inference':
from paddlespeech.server.engine.tts.paddleinference.tts_engine import TTSEngine
@@ -49,5 +59,11 @@ class EngineFactory(object):
elif engine_name.lower() == 'text' and engine_type.lower() == 'python':
from paddlespeech.server.engine.text.python.text_engine import TextEngine
return TextEngine()
+ elif engine_name.lower() == 'vector' and engine_type.lower() == 'python':
+ from paddlespeech.server.engine.vector.python.vector_engine import VectorEngine
+ return VectorEngine()
+ elif engine_name.lower() == 'acs' and engine_type.lower() == 'python':
+ from paddlespeech.server.engine.acs.python.acs_engine import ACSEngine
+ return ACSEngine()
else:
return None
diff --git a/paddlespeech/server/engine/engine_pool.py b/paddlespeech/server/engine/engine_pool.py
index 9de73567e..5300303f6 100644
--- a/paddlespeech/server/engine/engine_pool.py
+++ b/paddlespeech/server/engine/engine_pool.py
@@ -34,6 +34,7 @@ def init_engine_pool(config) -> bool:
engine_type = engine_and_type.split("_")[1]
ENGINE_POOL[engine] = EngineFactory.get_engine(
engine_name=engine, engine_type=engine_type)
+
if not ENGINE_POOL[engine].init(config=config[engine_and_type]):
return False
diff --git a/paddlespeech/server/engine/engine_warmup.py b/paddlespeech/server/engine/engine_warmup.py
new file mode 100644
index 000000000..5f548f71d
--- /dev/null
+++ b/paddlespeech/server/engine/engine_warmup.py
@@ -0,0 +1,75 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import time
+
+from paddlespeech.cli.log import logger
+from paddlespeech.server.engine.engine_pool import get_engine_pool
+
+
+def warm_up(engine_and_type: str, warm_up_time: int=3) -> bool:
+ engine_pool = get_engine_pool()
+
+ if "tts" in engine_and_type:
+ tts_engine = engine_pool['tts']
+ flag_online = False
+ if tts_engine.lang == 'zh':
+ sentence = "您好,欢迎使用语音合成服务。"
+ elif tts_engine.lang == 'en':
+ sentence = "Hello and welcome to the speech synthesis service."
+ else:
+ logger.error("tts engine only support lang: zh or en.")
+ sys.exit(-1)
+
+ if engine_and_type == "tts_python":
+ from paddlespeech.server.engine.tts.python.tts_engine import PaddleTTSConnectionHandler
+ elif engine_and_type == "tts_inference":
+ from paddlespeech.server.engine.tts.paddleinference.tts_engine import PaddleTTSConnectionHandler
+ elif engine_and_type == "tts_online":
+ from paddlespeech.server.engine.tts.online.python.tts_engine import PaddleTTSConnectionHandler
+ flag_online = True
+ elif engine_and_type == "tts_online-onnx":
+ from paddlespeech.server.engine.tts.online.onnx.tts_engine import PaddleTTSConnectionHandler
+ flag_online = True
+ else:
+ logger.error("Please check tte engine type.")
+
+ try:
+ logger.info("Start to warm up tts engine.")
+ for i in range(warm_up_time):
+ connection_handler = PaddleTTSConnectionHandler(tts_engine)
+ if flag_online:
+ for wav in connection_handler.infer(
+ text=sentence,
+ lang=tts_engine.lang,
+ am=tts_engine.config.am):
+ logger.info(
+ f"The first response time of the {i} warm up: {connection_handler.first_response_time} s"
+ )
+ break
+
+ else:
+ st = time.time()
+ connection_handler.infer(text=sentence)
+ et = time.time()
+ logger.info(
+ f"The response time of the {i} warm up: {et - st} s")
+ except Exception as e:
+ logger.error("Failed to warm up on tts engine.")
+ logger.error(e)
+ return False
+
+ else:
+ pass
+
+ return True
diff --git a/paddlespeech/server/engine/tts/online/onnx/tts_engine.py b/paddlespeech/server/engine/tts/online/onnx/tts_engine.py
index 22c1c9607..cb9155a2d 100644
--- a/paddlespeech/server/engine/tts/online/onnx/tts_engine.py
+++ b/paddlespeech/server/engine/tts/online/onnx/tts_engine.py
@@ -22,8 +22,7 @@ import paddle
from paddlespeech.cli.log import logger
from paddlespeech.cli.tts.infer import TTSExecutor
-from paddlespeech.cli.utils import download_and_decompress
-from paddlespeech.cli.utils import MODEL_HOME
+from paddlespeech.resource import CommonTaskResource
from paddlespeech.server.engine.base_engine import BaseEngine
from paddlespeech.server.utils.audio_process import float2pcm
from paddlespeech.server.utils.onnx_infer import get_sess
@@ -32,113 +31,13 @@ from paddlespeech.server.utils.util import get_chunks
from paddlespeech.t2s.frontend import English
from paddlespeech.t2s.frontend.zh_frontend import Frontend
-__all__ = ['TTSEngine']
-
-# support online model
-pretrained_models = {
- # fastspeech2
- "fastspeech2_csmsc_onnx-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_csmsc_onnx_0.2.0.zip',
- 'md5':
- 'fd3ad38d83273ad51f0ea4f4abf3ab4e',
- 'ckpt': ['fastspeech2_csmsc.onnx'],
- 'phones_dict':
- 'phone_id_map.txt',
- 'sample_rate':
- 24000,
- },
- "fastspeech2_cnndecoder_csmsc_onnx-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_cnndecoder_csmsc_streaming_onnx_1.0.0.zip',
- 'md5':
- '5f70e1a6bcd29d72d54e7931aa86f266',
- 'ckpt': [
- 'fastspeech2_csmsc_am_encoder_infer.onnx',
- 'fastspeech2_csmsc_am_decoder.onnx',
- 'fastspeech2_csmsc_am_postnet.onnx',
- ],
- 'speech_stats':
- 'speech_stats.npy',
- 'phones_dict':
- 'phone_id_map.txt',
- 'sample_rate':
- 24000,
- },
-
- # mb_melgan
- "mb_melgan_csmsc_onnx-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/mb_melgan/mb_melgan_csmsc_onnx_0.2.0.zip',
- 'md5':
- '5b83ec746e8414bc29032d954ffd07ec',
- 'ckpt':
- 'mb_melgan_csmsc.onnx',
- 'sample_rate':
- 24000,
- },
-
- # hifigan
- "hifigan_csmsc_onnx-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_csmsc_onnx_0.2.0.zip',
- 'md5':
- '1a7dc0385875889e46952e50c0994a6b',
- 'ckpt':
- 'hifigan_csmsc.onnx',
- 'sample_rate':
- 24000,
- },
-}
-
-model_alias = {
- # acoustic model
- "fastspeech2":
- "paddlespeech.t2s.models.fastspeech2:FastSpeech2",
- "fastspeech2_inference":
- "paddlespeech.t2s.models.fastspeech2:FastSpeech2Inference",
-
- # voc
- "mb_melgan":
- "paddlespeech.t2s.models.melgan:MelGANGenerator",
- "mb_melgan_inference":
- "paddlespeech.t2s.models.melgan:MelGANInference",
- "hifigan":
- "paddlespeech.t2s.models.hifigan:HiFiGANGenerator",
- "hifigan_inference":
- "paddlespeech.t2s.models.hifigan:HiFiGANInference",
-}
-
-__all__ = ['TTSEngine']
+__all__ = ['TTSEngine', 'PaddleTTSConnectionHandler']
class TTSServerExecutor(TTSExecutor):
- def __init__(self, am_block, am_pad, voc_block, voc_pad, voc_upsample):
+ def __init__(self):
super().__init__()
- self.am_block = am_block
- self.am_pad = am_pad
- self.voc_block = voc_block
- self.voc_pad = voc_pad
- self.voc_upsample = voc_upsample
-
- self.pretrained_models = pretrained_models
- self.model_alias = model_alias
-
- def _get_pretrained_path(self, tag: str) -> os.PathLike:
- """
- #Download and returns pretrained resources path of current task.
- """
- support_models = list(pretrained_models.keys())
- assert tag in pretrained_models, 'The model "{}" you want to use has not been supported, please choose other models.\nThe support models includes:\n\t\t{}\n'.format(
- tag, '\n\t\t'.join(support_models))
-
- res_path = os.path.join(MODEL_HOME, tag)
- decompressed_path = download_and_decompress(pretrained_models[tag],
- res_path)
- decompressed_path = os.path.abspath(decompressed_path)
- logger.info(
- 'Use pretrained model stored in: {}'.format(decompressed_path))
- return decompressed_path
+ self.task_resource = CommonTaskResource(task='tts', model_format='onnx')
def _init_from_path(
self,
@@ -167,16 +66,21 @@ class TTSServerExecutor(TTSExecutor):
return
# am
am_tag = am + '-' + lang
+ self.task_resource.set_task_model(
+ model_tag=am_tag,
+ model_type=0, # am
+ version=None, # default version
+ )
+ self.am_res_path = self.task_resource.res_dir
if am == "fastspeech2_csmsc_onnx":
# get model info
if am_ckpt is None or phones_dict is None:
- am_res_path = self._get_pretrained_path(am_tag)
- self.am_res_path = am_res_path
self.am_ckpt = os.path.join(
- am_res_path, pretrained_models[am_tag]['ckpt'][0])
+ self.am_res_path, self.task_resource.res_dict['ckpt'][0])
# must have phones_dict in acoustic
self.phones_dict = os.path.join(
- am_res_path, pretrained_models[am_tag]['phones_dict'])
+ self.am_res_path,
+ self.task_resource.res_dict['phones_dict'])
else:
self.am_ckpt = os.path.abspath(am_ckpt[0])
@@ -189,19 +93,19 @@ class TTSServerExecutor(TTSExecutor):
elif am == "fastspeech2_cnndecoder_csmsc_onnx":
if am_ckpt is None or am_stat is None or phones_dict is None:
- am_res_path = self._get_pretrained_path(am_tag)
- self.am_res_path = am_res_path
self.am_encoder_infer = os.path.join(
- am_res_path, pretrained_models[am_tag]['ckpt'][0])
+ self.am_res_path, self.task_resource.res_dict['ckpt'][0])
self.am_decoder = os.path.join(
- am_res_path, pretrained_models[am_tag]['ckpt'][1])
+ self.am_res_path, self.task_resource.res_dict['ckpt'][1])
self.am_postnet = os.path.join(
- am_res_path, pretrained_models[am_tag]['ckpt'][2])
+ self.am_res_path, self.task_resource.res_dict['ckpt'][2])
# must have phones_dict in acoustic
self.phones_dict = os.path.join(
- am_res_path, pretrained_models[am_tag]['phones_dict'])
+ self.am_res_path,
+ self.task_resource.res_dict['phones_dict'])
self.am_stat = os.path.join(
- am_res_path, pretrained_models[am_tag]['speech_stats'])
+ self.am_res_path,
+ self.task_resource.res_dict['speech_stats'])
else:
self.am_encoder_infer = os.path.abspath(am_ckpt[0])
@@ -226,11 +130,15 @@ class TTSServerExecutor(TTSExecutor):
# voc model info
voc_tag = voc + '-' + lang
+ self.task_resource.set_task_model(
+ model_tag=voc_tag,
+ model_type=1, # vocoder
+ version=None, # default version
+ )
if voc_ckpt is None:
- voc_res_path = self._get_pretrained_path(voc_tag)
- self.voc_res_path = voc_res_path
- self.voc_ckpt = os.path.join(voc_res_path,
- pretrained_models[voc_tag]['ckpt'])
+ self.voc_res_path = self.task_resource.voc_res_dir
+ self.voc_ckpt = os.path.join(
+ self.voc_res_path, self.task_resource.voc_res_dict['ckpt'])
else:
self.voc_ckpt = os.path.abspath(voc_ckpt)
self.voc_res_path = os.path.dirname(os.path.abspath(self.voc_ckpt))
@@ -256,6 +164,115 @@ class TTSServerExecutor(TTSExecutor):
self.frontend = English(phone_vocab_path=self.phones_dict)
logger.info("frontend done!")
+
+class TTSEngine(BaseEngine):
+ """TTS server engine
+
+ Args:
+ metaclass: Defaults to Singleton.
+ """
+
+ def __init__(self, name=None):
+ """Initialize TTS server engine
+ """
+ super().__init__()
+
+ def init(self, config: dict) -> bool:
+ self.executor = TTSServerExecutor()
+ self.config = config
+ self.lang = self.config.lang
+ self.engine_type = "online-onnx"
+
+ self.am_block = self.config.am_block
+ self.am_pad = self.config.am_pad
+ self.voc_block = self.config.voc_block
+ self.voc_pad = self.config.voc_pad
+ self.am_upsample = 1
+ self.voc_upsample = self.config.voc_upsample
+
+ assert (
+ self.config.am == "fastspeech2_csmsc_onnx" or
+ self.config.am == "fastspeech2_cnndecoder_csmsc_onnx"
+ ) and (
+ self.config.voc == "hifigan_csmsc_onnx" or
+ self.config.voc == "mb_melgan_csmsc_onnx"
+ ), 'Please check config, am support: fastspeech2, voc support: hifigan_csmsc-zh or mb_melgan_csmsc.'
+
+ assert (
+ self.config.voc_block > 0 and self.config.voc_pad > 0
+ ), "Please set correct voc_block and voc_pad, they should be more than 0."
+
+ assert (
+ self.config.voc_sample_rate == self.config.am_sample_rate
+ ), "The sample rate of AM and Vocoder model are different, please check model."
+
+ try:
+ if self.config.am_sess_conf.device is not None:
+ self.device = self.config.am_sess_conf.device
+ elif self.config.voc_sess_conf.device is not None:
+ self.device = self.config.voc_sess_conf.device
+ else:
+ self.device = paddle.get_device()
+ paddle.set_device(self.device)
+ except Exception as e:
+ logger.error(
+ "Set device failed, please check if device is already used and the parameter 'device' in the yaml file"
+ )
+ logger.error("Initialize TTS server engine Failed on device: %s." %
+ (self.device))
+ logger.error(e)
+ return False
+
+ try:
+ self.executor._init_from_path(
+ am=self.config.am,
+ am_ckpt=self.config.am_ckpt,
+ am_stat=self.config.am_stat,
+ phones_dict=self.config.phones_dict,
+ tones_dict=self.config.tones_dict,
+ speaker_dict=self.config.speaker_dict,
+ am_sample_rate=self.config.am_sample_rate,
+ am_sess_conf=self.config.am_sess_conf,
+ voc=self.config.voc,
+ voc_ckpt=self.config.voc_ckpt,
+ voc_sample_rate=self.config.voc_sample_rate,
+ voc_sess_conf=self.config.voc_sess_conf,
+ lang=self.config.lang)
+
+ except Exception as e:
+ logger.error("Failed to get model related files.")
+ logger.error("Initialize TTS server engine Failed on device: %s." %
+ (self.config.voc_sess_conf.device))
+ logger(e)
+ return False
+
+ logger.info("Initialize TTS server engine successfully on device: %s." %
+ (self.config.voc_sess_conf.device))
+
+ return True
+
+
+class PaddleTTSConnectionHandler:
+ def __init__(self, tts_engine):
+ """The PaddleSpeech TTS Server Connection Handler
+ This connection process every tts server request
+ Args:
+ tts_engine (TTSEngine): The TTS engine
+ """
+ super().__init__()
+ logger.info(
+ "Create PaddleTTSConnectionHandler to process the tts request")
+
+ self.tts_engine = tts_engine
+ self.executor = self.tts_engine.executor
+ self.config = self.tts_engine.config
+ self.am_block = self.tts_engine.am_block
+ self.am_pad = self.tts_engine.am_pad
+ self.voc_block = self.tts_engine.voc_block
+ self.voc_pad = self.tts_engine.voc_pad
+ self.am_upsample = self.tts_engine.am_upsample
+ self.voc_upsample = self.tts_engine.voc_upsample
+
def depadding(self, data, chunk_num, chunk_id, block, pad, upsample):
"""
Streaming inference removes the result of pad inference
@@ -283,14 +300,7 @@ class TTSServerExecutor(TTSExecutor):
"""
Model inference and result stored in self.output.
"""
- #import pdb;pdb.set_trace()
-
- am_block = self.am_block
- am_pad = self.am_pad
- am_upsample = 1
- voc_block = self.voc_block
- voc_pad = self.voc_pad
- voc_upsample = self.voc_upsample
+
# first_flag 用于标记首包
first_flag = 1
get_tone_ids = False
@@ -299,7 +309,7 @@ class TTSServerExecutor(TTSExecutor):
# front
frontend_st = time.time()
if lang == 'zh':
- input_ids = self.frontend.get_input_ids(
+ input_ids = self.executor.frontend.get_input_ids(
text,
merge_sentences=merge_sentences,
get_tone_ids=get_tone_ids)
@@ -307,7 +317,7 @@ class TTSServerExecutor(TTSExecutor):
if get_tone_ids:
tone_ids = input_ids["tone_ids"]
elif lang == 'en':
- input_ids = self.frontend.get_input_ids(
+ input_ids = self.executor.frontend.get_input_ids(
text, merge_sentences=merge_sentences)
phone_ids = input_ids["phone_ids"]
else:
@@ -322,7 +332,7 @@ class TTSServerExecutor(TTSExecutor):
# fastspeech2_csmsc
if am == "fastspeech2_csmsc_onnx":
# am
- mel = self.am_sess.run(
+ mel = self.executor.am_sess.run(
output_names=None, input_feed={'text': part_phone_ids})
mel = mel[0]
if first_flag == 1:
@@ -330,14 +340,16 @@ class TTSServerExecutor(TTSExecutor):
self.first_am_infer = first_am_et - frontend_et
# voc streaming
- mel_chunks = get_chunks(mel, voc_block, voc_pad, "voc")
+ mel_chunks = get_chunks(mel, self.voc_block, self.voc_pad,
+ "voc")
voc_chunk_num = len(mel_chunks)
voc_st = time.time()
for i, mel_chunk in enumerate(mel_chunks):
- sub_wav = self.voc_sess.run(
+ sub_wav = self.executor.voc_sess.run(
output_names=None, input_feed={'logmel': mel_chunk})
sub_wav = self.depadding(sub_wav[0], voc_chunk_num, i,
- voc_block, voc_pad, voc_upsample)
+ self.voc_block, self.voc_pad,
+ self.voc_upsample)
if first_flag == 1:
first_voc_et = time.time()
self.first_voc_infer = first_voc_et - first_am_et
@@ -349,7 +361,7 @@ class TTSServerExecutor(TTSExecutor):
# fastspeech2_cnndecoder_csmsc
elif am == "fastspeech2_cnndecoder_csmsc_onnx":
# am
- orig_hs = self.am_encoder_infer_sess.run(
+ orig_hs = self.executor.am_encoder_infer_sess.run(
None, input_feed={'text': part_phone_ids})
orig_hs = orig_hs[0]
@@ -363,9 +375,9 @@ class TTSServerExecutor(TTSExecutor):
hss = get_chunks(orig_hs, self.am_block, self.am_pad, "am")
am_chunk_num = len(hss)
for i, hs in enumerate(hss):
- am_decoder_output = self.am_decoder_sess.run(
+ am_decoder_output = self.executor.am_decoder_sess.run(
None, input_feed={'xs': hs})
- am_postnet_output = self.am_postnet_sess.run(
+ am_postnet_output = self.executor.am_postnet_sess.run(
None,
input_feed={
'xs': np.transpose(am_decoder_output[0], (0, 2, 1))
@@ -374,9 +386,11 @@ class TTSServerExecutor(TTSExecutor):
am_postnet_output[0], (0, 2, 1))
normalized_mel = am_output_data[0][0]
- sub_mel = denorm(normalized_mel, self.am_mu, self.am_std)
- sub_mel = self.depadding(sub_mel, am_chunk_num, i, am_block,
- am_pad, am_upsample)
+ sub_mel = denorm(normalized_mel, self.executor.am_mu,
+ self.executor.am_std)
+ sub_mel = self.depadding(sub_mel, am_chunk_num, i,
+ self.am_block, self.am_pad,
+ self.am_upsample)
if i == 0:
mel_streaming = sub_mel
@@ -393,11 +407,11 @@ class TTSServerExecutor(TTSExecutor):
self.first_am_infer = first_am_et - frontend_et
voc_chunk = mel_streaming[start:end, :]
- sub_wav = self.voc_sess.run(
+ sub_wav = self.executor.voc_sess.run(
output_names=None, input_feed={'logmel': voc_chunk})
- sub_wav = self.depadding(sub_wav[0], voc_chunk_num,
- voc_chunk_id, voc_block,
- voc_pad, voc_upsample)
+ sub_wav = self.depadding(
+ sub_wav[0], voc_chunk_num, voc_chunk_id,
+ self.voc_block, self.voc_pad, self.voc_upsample)
if first_flag == 1:
first_voc_et = time.time()
self.first_voc_infer = first_voc_et - first_am_et
@@ -407,9 +421,11 @@ class TTSServerExecutor(TTSExecutor):
yield sub_wav
voc_chunk_id += 1
- start = max(0, voc_chunk_id * voc_block - voc_pad)
- end = min((voc_chunk_id + 1) * voc_block + voc_pad,
- mel_len)
+ start = max(
+ 0, voc_chunk_id * self.voc_block - self.voc_pad)
+ end = min(
+ (voc_chunk_id + 1) * self.voc_block + self.voc_pad,
+ mel_len)
else:
logger.error(
@@ -418,104 +434,6 @@ class TTSServerExecutor(TTSExecutor):
self.final_response_time = time.time() - frontend_st
-
-class TTSEngine(BaseEngine):
- """TTS server engine
-
- Args:
- metaclass: Defaults to Singleton.
- """
-
- def __init__(self, name=None):
- """Initialize TTS server engine
- """
- super().__init__()
-
- def init(self, config: dict) -> bool:
- self.config = config
- assert (
- self.config.am == "fastspeech2_csmsc_onnx" or
- self.config.am == "fastspeech2_cnndecoder_csmsc_onnx"
- ) and (
- self.config.voc == "hifigan_csmsc_onnx" or
- self.config.voc == "mb_melgan_csmsc_onnx"
- ), 'Please check config, am support: fastspeech2, voc support: hifigan_csmsc-zh or mb_melgan_csmsc.'
-
- assert (
- self.config.voc_block > 0 and self.config.voc_pad > 0
- ), "Please set correct voc_block and voc_pad, they should be more than 0."
-
- assert (
- self.config.voc_sample_rate == self.config.am_sample_rate
- ), "The sample rate of AM and Vocoder model are different, please check model."
-
- self.executor = TTSServerExecutor(
- self.config.am_block, self.config.am_pad, self.config.voc_block,
- self.config.voc_pad, self.config.voc_upsample)
-
- if "cpu" in self.config.am_sess_conf.device or "cpu" in self.config.voc_sess_conf.device:
- paddle.set_device("cpu")
- else:
- paddle.set_device(self.config.am_sess_conf.device)
-
- try:
- self.executor._init_from_path(
- am=self.config.am,
- am_ckpt=self.config.am_ckpt,
- am_stat=self.config.am_stat,
- phones_dict=self.config.phones_dict,
- tones_dict=self.config.tones_dict,
- speaker_dict=self.config.speaker_dict,
- am_sample_rate=self.config.am_sample_rate,
- am_sess_conf=self.config.am_sess_conf,
- voc=self.config.voc,
- voc_ckpt=self.config.voc_ckpt,
- voc_sample_rate=self.config.voc_sample_rate,
- voc_sess_conf=self.config.voc_sess_conf,
- lang=self.config.lang)
-
- except Exception as e:
- logger.error("Failed to get model related files.")
- logger.error("Initialize TTS server engine Failed on device: %s." %
- (self.config.voc_sess_conf.device))
- return False
-
- logger.info("Initialize TTS server engine successfully on device: %s." %
- (self.config.voc_sess_conf.device))
-
- # warm up
- try:
- self.warm_up()
- except Exception as e:
- logger.error("Failed to warm up on tts engine.")
- return False
-
- return True
-
- def warm_up(self):
- """warm up
- """
- if self.config.lang == 'zh':
- sentence = "您好,欢迎使用语音合成服务。"
- if self.config.lang == 'en':
- sentence = "Hello and welcome to the speech synthesis service."
- logger.info(
- "*******************************warm up ********************************"
- )
- for i in range(3):
- for wav in self.executor.infer(
- text=sentence,
- lang=self.config.lang,
- am=self.config.am,
- spk_id=0, ):
- logger.info(
- f"The first response time of the {i} warm up: {self.executor.first_response_time} s"
- )
- break
- logger.info(
- "**********************************************************************"
- )
-
def preprocess(self, text_bese64: str=None, text_bytes: bytes=None):
# Convert byte to text
if text_bese64:
@@ -548,7 +466,7 @@ class TTSEngine(BaseEngine):
"""
wav_list = []
- for wav in self.executor.infer(
+ for wav in self.infer(
text=sentence,
lang=self.config.lang,
am=self.config.am,
@@ -566,11 +484,9 @@ class TTSEngine(BaseEngine):
duration = len(wav_all) / self.config.voc_sample_rate
logger.info(f"sentence: {sentence}")
logger.info(f"The durations of audio is: {duration} s")
+ logger.info(f"first response time: {self.first_response_time} s")
+ logger.info(f"final response time: {self.final_response_time} s")
+ logger.info(f"RTF: {self.final_response_time / duration}")
logger.info(
- f"first response time: {self.executor.first_response_time} s")
- logger.info(
- f"final response time: {self.executor.final_response_time} s")
- logger.info(f"RTF: {self.executor.final_response_time / duration}")
- logger.info(
- f"Other info: front time: {self.executor.frontend_time} s, first am infer time: {self.executor.first_am_infer} s, first voc infer time: {self.executor.first_voc_infer} s,"
+ f"Other info: front time: {self.frontend_time} s, first am infer time: {self.first_am_infer} s, first voc infer time: {self.first_voc_infer} s,"
)
diff --git a/paddlespeech/server/engine/tts/online/python/tts_engine.py b/paddlespeech/server/engine/tts/online/python/tts_engine.py
index 1f51586bc..2e8997e0f 100644
--- a/paddlespeech/server/engine/tts/online/python/tts_engine.py
+++ b/paddlespeech/server/engine/tts/online/python/tts_engine.py
@@ -24,9 +24,7 @@ from yacs.config import CfgNode
from paddlespeech.cli.log import logger
from paddlespeech.cli.tts.infer import TTSExecutor
-from paddlespeech.cli.utils import download_and_decompress
-from paddlespeech.cli.utils import MODEL_HOME
-from paddlespeech.s2t.utils.dynamic_import import dynamic_import
+from paddlespeech.resource import CommonTaskResource
from paddlespeech.server.engine.base_engine import BaseEngine
from paddlespeech.server.utils.audio_process import float2pcm
from paddlespeech.server.utils.util import denorm
@@ -35,97 +33,14 @@ from paddlespeech.t2s.frontend import English
from paddlespeech.t2s.frontend.zh_frontend import Frontend
from paddlespeech.t2s.modules.normalizer import ZScore
-__all__ = ['TTSEngine']
-
-# support online model
-pretrained_models = {
- # fastspeech2
- "fastspeech2_csmsc-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_baker_ckpt_0.4.zip',
- 'md5':
- '637d28a5e53aa60275612ba4393d5f22',
- 'config':
- 'default.yaml',
- 'ckpt':
- 'snapshot_iter_76000.pdz',
- 'speech_stats':
- 'speech_stats.npy',
- 'phones_dict':
- 'phone_id_map.txt',
- },
- "fastspeech2_cnndecoder_csmsc-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_cnndecoder_csmsc_ckpt_1.0.0.zip',
- 'md5':
- '6eb28e22ace73e0ebe7845f86478f89f',
- 'config':
- 'cnndecoder.yaml',
- 'ckpt':
- 'snapshot_iter_153000.pdz',
- 'speech_stats':
- 'speech_stats.npy',
- 'phones_dict':
- 'phone_id_map.txt',
- },
-
- # mb_melgan
- "mb_melgan_csmsc-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/mb_melgan/mb_melgan_csmsc_ckpt_0.1.1.zip',
- 'md5':
- 'ee5f0604e20091f0d495b6ec4618b90d',
- 'config':
- 'default.yaml',
- 'ckpt':
- 'snapshot_iter_1000000.pdz',
- 'speech_stats':
- 'feats_stats.npy',
- },
-
- # hifigan
- "hifigan_csmsc-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_csmsc_ckpt_0.1.1.zip',
- 'md5':
- 'dd40a3d88dfcf64513fba2f0f961ada6',
- 'config':
- 'default.yaml',
- 'ckpt':
- 'snapshot_iter_2500000.pdz',
- 'speech_stats':
- 'feats_stats.npy',
- },
-}
-
-model_alias = {
- # acoustic model
- "fastspeech2":
- "paddlespeech.t2s.models.fastspeech2:FastSpeech2",
- "fastspeech2_inference":
- "paddlespeech.t2s.models.fastspeech2:FastSpeech2Inference",
-
- # voc
- "mb_melgan":
- "paddlespeech.t2s.models.melgan:MelGANGenerator",
- "mb_melgan_inference":
- "paddlespeech.t2s.models.melgan:MelGANInference",
- "hifigan":
- "paddlespeech.t2s.models.hifigan:HiFiGANGenerator",
- "hifigan_inference":
- "paddlespeech.t2s.models.hifigan:HiFiGANInference",
-}
-
-__all__ = ['TTSEngine']
+__all__ = ['TTSEngine', 'PaddleTTSConnectionHandler']
class TTSServerExecutor(TTSExecutor):
- def __init__(self, am_block, am_pad, voc_block, voc_pad):
+ def __init__(self):
super().__init__()
- self.am_block = am_block
- self.am_pad = am_pad
- self.voc_block = voc_block
- self.voc_pad = voc_pad
+ self.task_resource = CommonTaskResource(
+ task='tts', model_format='dynamic', inference_mode='online')
def get_model_info(self,
field: str,
@@ -146,7 +61,7 @@ class TTSServerExecutor(TTSExecutor):
[Tensor]: standard deviation
"""
- model_class = dynamic_import(model_name, model_alias)
+ model_class = self.task_resource.get_model_class(model_name)
if field == "am":
odim = self.am_config.n_mels
@@ -169,22 +84,6 @@ class TTSServerExecutor(TTSExecutor):
return model, model_mu, model_std
- def _get_pretrained_path(self, tag: str) -> os.PathLike:
- """
- Download and returns pretrained resources path of current task.
- """
- support_models = list(pretrained_models.keys())
- assert tag in pretrained_models, 'The model "{}" you want to use has not been supported, please choose other models.\nThe support models includes:\n\t\t{}\n'.format(
- tag, '\n\t\t'.join(support_models))
-
- res_path = os.path.join(MODEL_HOME, tag)
- decompressed_path = download_and_decompress(pretrained_models[tag],
- res_path)
- decompressed_path = os.path.abspath(decompressed_path)
- logger.info(
- 'Use pretrained model stored in: {}'.format(decompressed_path))
- return decompressed_path
-
def _init_from_path(
self,
am: str='fastspeech2_csmsc',
@@ -207,20 +106,24 @@ class TTSServerExecutor(TTSExecutor):
return
# am model info
am_tag = am + '-' + lang
+ self.task_resource.set_task_model(
+ model_tag=am_tag,
+ model_type=0, # am
+ version=None, # default version
+ )
if am_ckpt is None or am_config is None or am_stat is None or phones_dict is None:
- am_res_path = self._get_pretrained_path(am_tag)
- self.am_res_path = am_res_path
- self.am_config = os.path.join(am_res_path,
- pretrained_models[am_tag]['config'])
- self.am_ckpt = os.path.join(am_res_path,
- pretrained_models[am_tag]['ckpt'])
+ self.am_res_path = self.task_resource.res_dir
+ self.am_config = os.path.join(self.am_res_path,
+ self.task_resource.res_dict['config'])
+ self.am_ckpt = os.path.join(self.am_res_path,
+ self.task_resource.res_dict['ckpt'])
self.am_stat = os.path.join(
- am_res_path, pretrained_models[am_tag]['speech_stats'])
+ self.am_res_path, self.task_resource.res_dict['speech_stats'])
# must have phones_dict in acoustic
self.phones_dict = os.path.join(
- am_res_path, pretrained_models[am_tag]['phones_dict'])
+ self.am_res_path, self.task_resource.res_dict['phones_dict'])
print("self.phones_dict:", self.phones_dict)
- logger.info(am_res_path)
+ logger.info(self.am_res_path)
logger.info(self.am_config)
logger.info(self.am_ckpt)
else:
@@ -236,16 +139,21 @@ class TTSServerExecutor(TTSExecutor):
# voc model info
voc_tag = voc + '-' + lang
+ self.task_resource.set_task_model(
+ model_tag=voc_tag,
+ model_type=1, # vocoder
+ version=None, # default version
+ )
if voc_ckpt is None or voc_config is None or voc_stat is None:
- voc_res_path = self._get_pretrained_path(voc_tag)
- self.voc_res_path = voc_res_path
- self.voc_config = os.path.join(voc_res_path,
- pretrained_models[voc_tag]['config'])
- self.voc_ckpt = os.path.join(voc_res_path,
- pretrained_models[voc_tag]['ckpt'])
+ self.voc_res_path = self.task_resource.voc_res_dir
+ self.voc_config = os.path.join(
+ self.voc_res_path, self.task_resource.voc_res_dict['config'])
+ self.voc_ckpt = os.path.join(
+ self.voc_res_path, self.task_resource.voc_res_dict['ckpt'])
self.voc_stat = os.path.join(
- voc_res_path, pretrained_models[voc_tag]['speech_stats'])
- logger.info(voc_res_path)
+ self.voc_res_path,
+ self.task_resource.voc_res_dict['speech_stats'])
+ logger.info(self.voc_res_path)
logger.info(self.voc_config)
logger.info(self.voc_ckpt)
else:
@@ -285,8 +193,8 @@ class TTSServerExecutor(TTSExecutor):
am, am_mu, am_std = self.get_model_info("am", self.am_name,
self.am_ckpt, self.am_stat)
am_normalizer = ZScore(am_mu, am_std)
- am_inference_class = dynamic_import(self.am_name + '_inference',
- model_alias)
+ am_inference_class = self.task_resource.get_model_class(
+ self.am_name + '_inference')
self.am_inference = am_inference_class(am_normalizer, am)
self.am_inference.eval()
print("acoustic model done!")
@@ -296,12 +204,112 @@ class TTSServerExecutor(TTSExecutor):
voc, voc_mu, voc_std = self.get_model_info("voc", self.voc_name,
self.voc_ckpt, self.voc_stat)
voc_normalizer = ZScore(voc_mu, voc_std)
- voc_inference_class = dynamic_import(self.voc_name + '_inference',
- model_alias)
+ voc_inference_class = self.task_resource.get_model_class(self.voc_name +
+ '_inference')
self.voc_inference = voc_inference_class(voc_normalizer, voc)
self.voc_inference.eval()
print("voc done!")
+
+class TTSEngine(BaseEngine):
+ """TTS server engine
+
+ Args:
+ metaclass: Defaults to Singleton.
+ """
+
+ def __init__(self, name=None):
+ """Initialize TTS server engine
+ """
+ super().__init__()
+
+ def init(self, config: dict) -> bool:
+ self.executor = TTSServerExecutor()
+ self.config = config
+ self.lang = self.config.lang
+ self.engine_type = "online"
+
+ assert (
+ config.am == "fastspeech2_csmsc" or
+ config.am == "fastspeech2_cnndecoder_csmsc"
+ ) and (
+ config.voc == "hifigan_csmsc" or config.voc == "mb_melgan_csmsc"
+ ), 'Please check config, am support: fastspeech2, voc support: hifigan_csmsc-zh or mb_melgan_csmsc.'
+
+ assert (
+ config.voc_block > 0 and config.voc_pad > 0
+ ), "Please set correct voc_block and voc_pad, they should be more than 0."
+
+ try:
+ if self.config.device is not None:
+ self.device = self.config.device
+ else:
+ self.device = paddle.get_device()
+ paddle.set_device(self.device)
+ except Exception as e:
+ logger.error(
+ "Set device failed, please check if device is already used and the parameter 'device' in the yaml file"
+ )
+ logger.error("Initialize TTS server engine Failed on device: %s." %
+ (self.device))
+ logger.error(e)
+ return False
+
+ try:
+ self.executor._init_from_path(
+ am=self.config.am,
+ am_config=self.config.am_config,
+ am_ckpt=self.config.am_ckpt,
+ am_stat=self.config.am_stat,
+ phones_dict=self.config.phones_dict,
+ tones_dict=self.config.tones_dict,
+ speaker_dict=self.config.speaker_dict,
+ voc=self.config.voc,
+ voc_config=self.config.voc_config,
+ voc_ckpt=self.config.voc_ckpt,
+ voc_stat=self.config.voc_stat,
+ lang=self.config.lang)
+ except Exception as e:
+ logger.error("Failed to get model related files.")
+ logger.error("Initialize TTS server engine Failed on device: %s." %
+ (self.device))
+ logger.error(e)
+ return False
+
+ self.am_block = self.config.am_block
+ self.am_pad = self.config.am_pad
+ self.voc_block = self.config.voc_block
+ self.voc_pad = self.config.voc_pad
+ self.am_upsample = 1
+ self.voc_upsample = self.executor.voc_config.n_shift
+
+ logger.info("Initialize TTS server engine successfully on device: %s." %
+ (self.device))
+
+ return True
+
+
+class PaddleTTSConnectionHandler:
+ def __init__(self, tts_engine):
+ """The PaddleSpeech TTS Server Connection Handler
+ This connection process every tts server request
+ Args:
+ tts_engine (TTSEngine): The TTS engine
+ """
+ super().__init__()
+ logger.info(
+ "Create PaddleTTSConnectionHandler to process the tts request")
+
+ self.tts_engine = tts_engine
+ self.executor = self.tts_engine.executor
+ self.config = self.tts_engine.config
+ self.am_block = self.tts_engine.am_block
+ self.am_pad = self.tts_engine.am_pad
+ self.voc_block = self.tts_engine.voc_block
+ self.voc_pad = self.tts_engine.voc_pad
+ self.am_upsample = self.tts_engine.am_upsample
+ self.voc_upsample = self.tts_engine.voc_upsample
+
def depadding(self, data, chunk_num, chunk_id, block, pad, upsample):
"""
Streaming inference removes the result of pad inference
@@ -330,12 +338,6 @@ class TTSServerExecutor(TTSExecutor):
Model inference and result stored in self.output.
"""
- am_block = self.am_block
- am_pad = self.am_pad
- am_upsample = 1
- voc_block = self.voc_block
- voc_pad = self.voc_pad
- voc_upsample = self.voc_config.n_shift
# first_flag 用于标记首包
first_flag = 1
@@ -343,7 +345,7 @@ class TTSServerExecutor(TTSExecutor):
merge_sentences = False
frontend_st = time.time()
if lang == 'zh':
- input_ids = self.frontend.get_input_ids(
+ input_ids = self.executor.frontend.get_input_ids(
text,
merge_sentences=merge_sentences,
get_tone_ids=get_tone_ids)
@@ -351,7 +353,7 @@ class TTSServerExecutor(TTSExecutor):
if get_tone_ids:
tone_ids = input_ids["tone_ids"]
elif lang == 'en':
- input_ids = self.frontend.get_input_ids(
+ input_ids = self.executor.frontend.get_input_ids(
text, merge_sentences=merge_sentences)
phone_ids = input_ids["phone_ids"]
else:
@@ -366,19 +368,21 @@ class TTSServerExecutor(TTSExecutor):
# fastspeech2_csmsc
if am == "fastspeech2_csmsc":
# am
- mel = self.am_inference(part_phone_ids)
+ mel = self.executor.am_inference(part_phone_ids)
if first_flag == 1:
first_am_et = time.time()
self.first_am_infer = first_am_et - frontend_et
# voc streaming
- mel_chunks = get_chunks(mel, voc_block, voc_pad, "voc")
+ mel_chunks = get_chunks(mel, self.voc_block, self.voc_pad,
+ "voc")
voc_chunk_num = len(mel_chunks)
voc_st = time.time()
for i, mel_chunk in enumerate(mel_chunks):
- sub_wav = self.voc_inference(mel_chunk)
+ sub_wav = self.executor.voc_inference(mel_chunk)
sub_wav = self.depadding(sub_wav, voc_chunk_num, i,
- voc_block, voc_pad, voc_upsample)
+ self.voc_block, self.voc_pad,
+ self.voc_upsample)
if first_flag == 1:
first_voc_et = time.time()
self.first_voc_infer = first_voc_et - first_am_et
@@ -390,7 +394,8 @@ class TTSServerExecutor(TTSExecutor):
# fastspeech2_cnndecoder_csmsc
elif am == "fastspeech2_cnndecoder_csmsc":
# am
- orig_hs = self.am_inference.encoder_infer(part_phone_ids)
+ orig_hs = self.executor.am_inference.encoder_infer(
+ part_phone_ids)
# streaming voc chunk info
mel_len = orig_hs.shape[1]
@@ -402,13 +407,15 @@ class TTSServerExecutor(TTSExecutor):
hss = get_chunks(orig_hs, self.am_block, self.am_pad, "am")
am_chunk_num = len(hss)
for i, hs in enumerate(hss):
- before_outs = self.am_inference.decoder(hs)
- after_outs = before_outs + self.am_inference.postnet(
+ before_outs = self.executor.am_inference.decoder(hs)
+ after_outs = before_outs + self.executor.am_inference.postnet(
before_outs.transpose((0, 2, 1))).transpose((0, 2, 1))
normalized_mel = after_outs[0]
- sub_mel = denorm(normalized_mel, self.am_mu, self.am_std)
- sub_mel = self.depadding(sub_mel, am_chunk_num, i, am_block,
- am_pad, am_upsample)
+ sub_mel = denorm(normalized_mel, self.executor.am_mu,
+ self.executor.am_std)
+ sub_mel = self.depadding(sub_mel, am_chunk_num, i,
+ self.am_block, self.am_pad,
+ self.am_upsample)
if i == 0:
mel_streaming = sub_mel
@@ -425,11 +432,11 @@ class TTSServerExecutor(TTSExecutor):
self.first_am_infer = first_am_et - frontend_et
voc_chunk = mel_streaming[start:end, :]
voc_chunk = paddle.to_tensor(voc_chunk)
- sub_wav = self.voc_inference(voc_chunk)
+ sub_wav = self.executor.voc_inference(voc_chunk)
- sub_wav = self.depadding(sub_wav, voc_chunk_num,
- voc_chunk_id, voc_block,
- voc_pad, voc_upsample)
+ sub_wav = self.depadding(
+ sub_wav, voc_chunk_num, voc_chunk_id,
+ self.voc_block, self.voc_pad, self.voc_upsample)
if first_flag == 1:
first_voc_et = time.time()
self.first_voc_infer = first_voc_et - first_am_et
@@ -439,9 +446,11 @@ class TTSServerExecutor(TTSExecutor):
yield sub_wav
voc_chunk_id += 1
- start = max(0, voc_chunk_id * voc_block - voc_pad)
- end = min((voc_chunk_id + 1) * voc_block + voc_pad,
- mel_len)
+ start = max(
+ 0, voc_chunk_id * self.voc_block - self.voc_pad)
+ end = min(
+ (voc_chunk_id + 1) * self.voc_block + self.voc_pad,
+ mel_len)
else:
logger.error(
@@ -450,105 +459,6 @@ class TTSServerExecutor(TTSExecutor):
self.final_response_time = time.time() - frontend_st
-
-class TTSEngine(BaseEngine):
- """TTS server engine
-
- Args:
- metaclass: Defaults to Singleton.
- """
-
- def __init__(self, name=None):
- """Initialize TTS server engine
- """
- super().__init__()
-
- def init(self, config: dict) -> bool:
- self.config = config
- assert (
- config.am == "fastspeech2_csmsc" or
- config.am == "fastspeech2_cnndecoder_csmsc"
- ) and (
- config.voc == "hifigan_csmsc" or config.voc == "mb_melgan_csmsc"
- ), 'Please check config, am support: fastspeech2, voc support: hifigan_csmsc-zh or mb_melgan_csmsc.'
-
- assert (
- config.voc_block > 0 and config.voc_pad > 0
- ), "Please set correct voc_block and voc_pad, they should be more than 0."
-
- try:
- if self.config.device:
- self.device = self.config.device
- else:
- self.device = paddle.get_device()
- paddle.set_device(self.device)
- except Exception as e:
- logger.error(
- "Set device failed, please check if device is already used and the parameter 'device' in the yaml file"
- )
- logger.error("Initialize TTS server engine Failed on device: %s." %
- (self.device))
- return False
-
- self.executor = TTSServerExecutor(config.am_block, config.am_pad,
- config.voc_block, config.voc_pad)
-
- try:
- self.executor._init_from_path(
- am=self.config.am,
- am_config=self.config.am_config,
- am_ckpt=self.config.am_ckpt,
- am_stat=self.config.am_stat,
- phones_dict=self.config.phones_dict,
- tones_dict=self.config.tones_dict,
- speaker_dict=self.config.speaker_dict,
- voc=self.config.voc,
- voc_config=self.config.voc_config,
- voc_ckpt=self.config.voc_ckpt,
- voc_stat=self.config.voc_stat,
- lang=self.config.lang)
- except Exception as e:
- logger.error("Failed to get model related files.")
- logger.error("Initialize TTS server engine Failed on device: %s." %
- (self.device))
- return False
-
- logger.info("Initialize TTS server engine successfully on device: %s." %
- (self.device))
-
- # warm up
- try:
- self.warm_up()
- except Exception as e:
- logger.error("Failed to warm up on tts engine.")
- return False
-
- return True
-
- def warm_up(self):
- """warm up
- """
- if self.config.lang == 'zh':
- sentence = "您好,欢迎使用语音合成服务。"
- if self.config.lang == 'en':
- sentence = "Hello and welcome to the speech synthesis service."
- logger.info(
- "*******************************warm up ********************************"
- )
- for i in range(3):
- for wav in self.executor.infer(
- text=sentence,
- lang=self.config.lang,
- am=self.config.am,
- spk_id=0, ):
- logger.info(
- f"The first response time of the {i} warm up: {self.executor.first_response_time} s"
- )
- break
- logger.info(
- "**********************************************************************"
- )
-
def preprocess(self, text_bese64: str=None, text_bytes: bytes=None):
# Convert byte to text
if text_bese64:
@@ -582,7 +492,7 @@ class TTSEngine(BaseEngine):
wav_list = []
- for wav in self.executor.infer(
+ for wav in self.infer(
text=sentence,
lang=self.config.lang,
am=self.config.am,
@@ -598,13 +508,12 @@ class TTSEngine(BaseEngine):
wav_all = np.concatenate(wav_list, axis=0)
duration = len(wav_all) / self.executor.am_config.fs
+
logger.info(f"sentence: {sentence}")
logger.info(f"The durations of audio is: {duration} s")
+ logger.info(f"first response time: {self.first_response_time} s")
+ logger.info(f"final response time: {self.final_response_time} s")
+ logger.info(f"RTF: {self.final_response_time / duration}")
logger.info(
- f"first response time: {self.executor.first_response_time} s")
- logger.info(
- f"final response time: {self.executor.final_response_time} s")
- logger.info(f"RTF: {self.executor.final_response_time / duration}")
- logger.info(
- f"Other info: front time: {self.executor.frontend_time} s, first am infer time: {self.executor.first_am_infer} s, first voc infer time: {self.executor.first_voc_infer} s,"
+ f"Other info: front time: {self.frontend_time} s, first am infer time: {self.first_am_infer} s, first voc infer time: {self.first_voc_infer} s,"
)
diff --git a/paddlespeech/server/engine/tts/paddleinference/tts_engine.py b/paddlespeech/server/engine/tts/paddleinference/tts_engine.py
index db8813ba9..ab5b721ff 100644
--- a/paddlespeech/server/engine/tts/paddleinference/tts_engine.py
+++ b/paddlespeech/server/engine/tts/paddleinference/tts_engine.py
@@ -14,6 +14,7 @@
import base64
import io
import os
+import sys
import time
from typing import Optional
@@ -25,8 +26,7 @@ from scipy.io import wavfile
from paddlespeech.cli.log import logger
from paddlespeech.cli.tts.infer import TTSExecutor
-from paddlespeech.cli.utils import download_and_decompress
-from paddlespeech.cli.utils import MODEL_HOME
+from paddlespeech.resource import CommonTaskResource
from paddlespeech.server.engine.base_engine import BaseEngine
from paddlespeech.server.utils.audio_process import change_speed
from paddlespeech.server.utils.errors import ErrorCode
@@ -36,103 +36,14 @@ from paddlespeech.server.utils.paddle_predictor import run_model
from paddlespeech.t2s.frontend import English
from paddlespeech.t2s.frontend.zh_frontend import Frontend
-__all__ = ['TTSEngine']
-
-# Static model applied on paddle inference
-pretrained_models = {
- # speedyspeech
- "speedyspeech_csmsc-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/speedyspeech/speedyspeech_nosil_baker_static_0.5.zip',
- 'md5':
- 'f10cbdedf47dc7a9668d2264494e1823',
- 'model':
- 'speedyspeech_csmsc.pdmodel',
- 'params':
- 'speedyspeech_csmsc.pdiparams',
- 'phones_dict':
- 'phone_id_map.txt',
- 'tones_dict':
- 'tone_id_map.txt',
- 'sample_rate':
- 24000,
- },
- # fastspeech2
- "fastspeech2_csmsc-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_baker_static_0.4.zip',
- 'md5':
- '9788cd9745e14c7a5d12d32670b2a5a7',
- 'model':
- 'fastspeech2_csmsc.pdmodel',
- 'params':
- 'fastspeech2_csmsc.pdiparams',
- 'phones_dict':
- 'phone_id_map.txt',
- 'sample_rate':
- 24000,
- },
- # pwgan
- "pwgan_csmsc-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwg_baker_static_0.4.zip',
- 'md5':
- 'e3504aed9c5a290be12d1347836d2742',
- 'model':
- 'pwgan_csmsc.pdmodel',
- 'params':
- 'pwgan_csmsc.pdiparams',
- 'sample_rate':
- 24000,
- },
- # mb_melgan
- "mb_melgan_csmsc-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/mb_melgan/mb_melgan_csmsc_static_0.1.1.zip',
- 'md5':
- 'ac6eee94ba483421d750433f4c3b8d36',
- 'model':
- 'mb_melgan_csmsc.pdmodel',
- 'params':
- 'mb_melgan_csmsc.pdiparams',
- 'sample_rate':
- 24000,
- },
- # hifigan
- "hifigan_csmsc-zh": {
- 'url':
- 'https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_csmsc_static_0.1.1.zip',
- 'md5':
- '7edd8c436b3a5546b3a7cb8cff9d5a0c',
- 'model':
- 'hifigan_csmsc.pdmodel',
- 'params':
- 'hifigan_csmsc.pdiparams',
- 'sample_rate':
- 24000,
- },
-}
+__all__ = ['TTSEngine', 'PaddleTTSConnectionHandler']
class TTSServerExecutor(TTSExecutor):
def __init__(self):
super().__init__()
- pass
-
- def _get_pretrained_path(self, tag: str) -> os.PathLike:
- """
- Download and returns pretrained resources path of current task.
- """
- assert tag in pretrained_models, 'Can not find pretrained resources of {}.'.format(
- tag)
-
- res_path = os.path.join(MODEL_HOME, tag)
- decompressed_path = download_and_decompress(pretrained_models[tag],
- res_path)
- decompressed_path = os.path.abspath(decompressed_path)
- logger.info(
- 'Use pretrained model stored in: {}'.format(decompressed_path))
- return decompressed_path
+ self.task_resource = CommonTaskResource(
+ task='tts', model_format='static')
def _init_from_path(
self,
@@ -158,19 +69,23 @@ class TTSServerExecutor(TTSExecutor):
return
# am
am_tag = am + '-' + lang
+ self.task_resource.set_task_model(
+ model_tag=am_tag,
+ model_type=0, # am
+ version=None, # default version
+ )
if am_model is None or am_params is None or phones_dict is None:
- am_res_path = self._get_pretrained_path(am_tag)
- self.am_res_path = am_res_path
- self.am_model = os.path.join(am_res_path,
- pretrained_models[am_tag]['model'])
- self.am_params = os.path.join(am_res_path,
- pretrained_models[am_tag]['params'])
+ self.am_res_path = self.task_resource.res_dir
+ self.am_model = os.path.join(self.am_res_path,
+ self.task_resource.res_dict['model'])
+ self.am_params = os.path.join(self.am_res_path,
+ self.task_resource.res_dict['params'])
# must have phones_dict in acoustic
self.phones_dict = os.path.join(
- am_res_path, pretrained_models[am_tag]['phones_dict'])
- self.am_sample_rate = pretrained_models[am_tag]['sample_rate']
+ self.am_res_path, self.task_resource.res_dict['phones_dict'])
+ self.am_sample_rate = self.task_resource.res_dict['sample_rate']
- logger.info(am_res_path)
+ logger.info(self.am_res_path)
logger.info(self.am_model)
logger.info(self.am_params)
else:
@@ -183,31 +98,36 @@ class TTSServerExecutor(TTSExecutor):
# for speedyspeech
self.tones_dict = None
- if 'tones_dict' in pretrained_models[am_tag]:
+ if 'tones_dict' in self.task_resource.res_dict:
self.tones_dict = os.path.join(
- am_res_path, pretrained_models[am_tag]['tones_dict'])
+ self.am_res_path, self.task_resource.res_dict['tones_dict'])
if tones_dict:
self.tones_dict = tones_dict
# for multi speaker fastspeech2
self.speaker_dict = None
- if 'speaker_dict' in pretrained_models[am_tag]:
+ if 'speaker_dict' in self.task_resource.res_dict:
self.speaker_dict = os.path.join(
- am_res_path, pretrained_models[am_tag]['speaker_dict'])
+ self.am_res_path, self.task_resource.res_dict['speaker_dict'])
if speaker_dict:
self.speaker_dict = speaker_dict
# voc
voc_tag = voc + '-' + lang
+ self.task_resource.set_task_model(
+ model_tag=voc_tag,
+ model_type=1, # vocoder
+ version=None, # default version
+ )
if voc_model is None or voc_params is None:
- voc_res_path = self._get_pretrained_path(voc_tag)
- self.voc_res_path = voc_res_path
- self.voc_model = os.path.join(voc_res_path,
- pretrained_models[voc_tag]['model'])
- self.voc_params = os.path.join(voc_res_path,
- pretrained_models[voc_tag]['params'])
- self.voc_sample_rate = pretrained_models[voc_tag]['sample_rate']
- logger.info(voc_res_path)
+ self.voc_res_path = self.task_resource.voc_res_dir
+ self.voc_model = os.path.join(
+ self.voc_res_path, self.task_resource.voc_res_dict['model'])
+ self.voc_params = os.path.join(
+ self.voc_res_path, self.task_resource.voc_res_dict['params'])
+ self.voc_sample_rate = self.task_resource.voc_res_dict[
+ 'sample_rate']
+ logger.info(self.voc_res_path)
logger.info(self.voc_model)
logger.info(self.voc_params)
else:
@@ -335,7 +255,7 @@ class TTSServerExecutor(TTSExecutor):
else:
wav_all = paddle.concat([wav_all, wav])
self.voc_time += (time.time() - voc_st)
- self._outputs['wav'] = wav_all
+ self._outputs["wav"] = wav_all
class TTSEngine(BaseEngine):
@@ -352,27 +272,72 @@ class TTSEngine(BaseEngine):
def init(self, config: dict) -> bool:
self.executor = TTSServerExecutor()
-
self.config = config
- self.executor._init_from_path(
- am=self.config.am,
- am_model=self.config.am_model,
- am_params=self.config.am_params,
- am_sample_rate=self.config.am_sample_rate,
- phones_dict=self.config.phones_dict,
- tones_dict=self.config.tones_dict,
- speaker_dict=self.config.speaker_dict,
- voc=self.config.voc,
- voc_model=self.config.voc_model,
- voc_params=self.config.voc_params,
- voc_sample_rate=self.config.voc_sample_rate,
- lang=self.config.lang,
- am_predictor_conf=self.config.am_predictor_conf,
- voc_predictor_conf=self.config.voc_predictor_conf, )
+ self.lang = self.config.lang
+ self.engine_type = "inference"
+
+ try:
+ if self.config.am_predictor_conf.device is not None:
+ self.device = self.config.am_predictor_conf.device
+ elif self.config.voc_predictor_conf.device is not None:
+ self.device = self.config.voc_predictor_conf.device
+ else:
+ self.device = paddle.get_device()
+ paddle.set_device(self.device)
+ except Exception as e:
+ logger.error(
+ "Set device failed, please check if device is already used and the parameter 'device' in the yaml file"
+ )
+ logger.error("Initialize TTS server engine Failed on device: %s." %
+ (self.device))
+ logger.error(e)
+ return False
+
+ try:
+ self.executor._init_from_path(
+ am=self.config.am,
+ am_model=self.config.am_model,
+ am_params=self.config.am_params,
+ am_sample_rate=self.config.am_sample_rate,
+ phones_dict=self.config.phones_dict,
+ tones_dict=self.config.tones_dict,
+ speaker_dict=self.config.speaker_dict,
+ voc=self.config.voc,
+ voc_model=self.config.voc_model,
+ voc_params=self.config.voc_params,
+ voc_sample_rate=self.config.voc_sample_rate,
+ lang=self.config.lang,
+ am_predictor_conf=self.config.am_predictor_conf,
+ voc_predictor_conf=self.config.voc_predictor_conf, )
+ except Exception as e:
+ logger.error("Failed to get model related files.")
+ logger.error("Initialize TTS server engine Failed on device: %s." %
+ (self.device))
+ logger.error(e)
+ return False
logger.info("Initialize TTS server engine successfully.")
return True
+
+class PaddleTTSConnectionHandler(TTSServerExecutor):
+ def __init__(self, tts_engine):
+ """The PaddleSpeech TTS Server Connection Handler
+ This connection process every tts server request
+ Args:
+ tts_engine (TTSEngine): The TTS engine
+ """
+ super().__init__()
+ logger.info(
+ "Create PaddleTTSConnectionHandler to process the tts request")
+
+ self.tts_engine = tts_engine
+ self.executor = self.tts_engine.executor
+ self.config = self.tts_engine.config
+ self.frontend = self.executor.frontend
+ self.am_predictor = self.executor.am_predictor
+ self.voc_predictor = self.executor.voc_predictor
+
def postprocess(self,
wav,
original_fs: int,
@@ -423,8 +388,11 @@ class TTSEngine(BaseEngine):
ErrorCode.SERVER_INTERNAL_ERR,
"Failed to transform speed. Can not install soxbindings on your system. \
You need to set speed value 1.0.")
- except BaseException:
+ sys.exit(-1)
+ except Exception as e:
logger.error("Failed to transform speed.")
+ logger.error(e)
+ sys.exit(-1)
# wav to base64
buf = io.BytesIO()
@@ -481,7 +449,7 @@ class TTSEngine(BaseEngine):
try:
infer_st = time.time()
- self.executor.infer(
+ self.infer(
text=sentence, lang=lang, am=self.config.am, spk_id=spk_id)
infer_et = time.time()
infer_time = infer_et - infer_st
@@ -489,13 +457,16 @@ class TTSEngine(BaseEngine):
except ServerBaseException:
raise ServerBaseException(ErrorCode.SERVER_INTERNAL_ERR,
"tts infer failed.")
- except BaseException:
+ sys.exit(-1)
+ except Exception as e:
logger.error("tts infer failed.")
+ logger.error(e)
+ sys.exit(-1)
try:
postprocess_st = time.time()
target_sample_rate, wav_base64 = self.postprocess(
- wav=self.executor._outputs['wav'].numpy(),
+ wav=self._outputs["wav"].numpy(),
original_fs=self.executor.am_sample_rate,
target_fs=sample_rate,
volume=volume,
@@ -503,26 +474,28 @@ class TTSEngine(BaseEngine):
audio_path=save_path)
postprocess_et = time.time()
postprocess_time = postprocess_et - postprocess_st
- duration = len(self.executor._outputs['wav']
- .numpy()) / self.executor.am_sample_rate
+ duration = len(
+ self._outputs["wav"].numpy()) / self.executor.am_sample_rate
rtf = infer_time / duration
except ServerBaseException:
raise ServerBaseException(ErrorCode.SERVER_INTERNAL_ERR,
"tts postprocess failed.")
- except BaseException:
+ sys.exit(-1)
+ except Exception as e:
logger.error("tts postprocess failed.")
+ logger.error(e)
+ sys.exit(-1)
logger.info("AM model: {}".format(self.config.am))
logger.info("Vocoder model: {}".format(self.config.voc))
logger.info("Language: {}".format(lang))
- logger.info("tts engine type: paddle inference")
+ logger.info("tts engine type: python")
logger.info("audio duration: {}".format(duration))
- logger.info(
- "frontend inference time: {}".format(self.executor.frontend_time))
- logger.info("AM inference time: {}".format(self.executor.am_time))
- logger.info("Vocoder inference time: {}".format(self.executor.voc_time))
+ logger.info("frontend inference time: {}".format(self.frontend_time))
+ logger.info("AM inference time: {}".format(self.am_time))
+ logger.info("Vocoder inference time: {}".format(self.voc_time))
logger.info("total inference time: {}".format(infer_time))
logger.info(
"postprocess (change speed, volume, target sample rate) time: {}".
@@ -530,5 +503,6 @@ class TTSEngine(BaseEngine):
logger.info("total generate audio time: {}".format(infer_time +
postprocess_time))
logger.info("RTF: {}".format(rtf))
+ logger.info("device: {}".format(self.tts_engine.device))
return lang, target_sample_rate, duration, wav_base64
diff --git a/paddlespeech/server/engine/tts/python/tts_engine.py b/paddlespeech/server/engine/tts/python/tts_engine.py
index f153f60b9..b048b01a4 100644
--- a/paddlespeech/server/engine/tts/python/tts_engine.py
+++ b/paddlespeech/server/engine/tts/python/tts_engine.py
@@ -13,6 +13,7 @@
# limitations under the License.
import base64
import io
+import sys
import time
import librosa
@@ -28,7 +29,7 @@ from paddlespeech.server.utils.audio_process import change_speed
from paddlespeech.server.utils.errors import ErrorCode
from paddlespeech.server.utils.exception import ServerBaseException
-__all__ = ['TTSEngine']
+__all__ = ['TTSEngine', 'PaddleTTSConnectionHandler']
class TTSServerExecutor(TTSExecutor):
@@ -51,20 +52,23 @@ class TTSEngine(BaseEngine):
def init(self, config: dict) -> bool:
self.executor = TTSServerExecutor()
+ self.config = config
+ self.lang = self.config.lang
+ self.engine_type = "python"
try:
- self.config = config
- if self.config.device:
+ if self.config.device is not None:
self.device = self.config.device
else:
self.device = paddle.get_device()
paddle.set_device(self.device)
- except BaseException:
+ except Exception as e:
logger.error(
"Set device failed, please check if device is already used and the parameter 'device' in the yaml file"
)
logger.error("Initialize TTS server engine Failed on device: %s." %
(self.device))
+ logger.error(e)
return False
try:
@@ -81,16 +85,36 @@ class TTSEngine(BaseEngine):
voc_ckpt=self.config.voc_ckpt,
voc_stat=self.config.voc_stat,
lang=self.config.lang)
- except BaseException:
+ except Exception as e:
logger.error("Failed to get model related files.")
logger.error("Initialize TTS server engine Failed on device: %s." %
(self.device))
+ logger.error(e)
return False
logger.info("Initialize TTS server engine successfully on device: %s." %
(self.device))
return True
+
+class PaddleTTSConnectionHandler(TTSServerExecutor):
+ def __init__(self, tts_engine):
+ """The PaddleSpeech TTS Server Connection Handler
+ This connection process every tts server request
+ Args:
+ tts_engine (TTSEngine): The TTS engine
+ """
+ super().__init__()
+ logger.info(
+ "Create PaddleTTSConnectionHandler to process the tts request")
+
+ self.tts_engine = tts_engine
+ self.executor = self.tts_engine.executor
+ self.config = self.tts_engine.config
+ self.frontend = self.executor.frontend
+ self.am_inference = self.executor.am_inference
+ self.voc_inference = self.executor.voc_inference
+
def postprocess(self,
wav,
original_fs: int,
@@ -141,8 +165,11 @@ class TTSEngine(BaseEngine):
ErrorCode.SERVER_INTERNAL_ERR,
"Failed to transform speed. Can not install soxbindings on your system. \
You need to set speed value 1.0.")
- except BaseException:
+ sys.exit(-1)
+ except Exception as e:
logger.error("Failed to transform speed.")
+ logger.error(e)
+ sys.exit(-1)
# wav to base64
buf = io.BytesIO()
@@ -199,24 +226,27 @@ class TTSEngine(BaseEngine):
try:
infer_st = time.time()
- self.executor.infer(
+ self.infer(
text=sentence, lang=lang, am=self.config.am, spk_id=spk_id)
infer_et = time.time()
infer_time = infer_et - infer_st
- duration = len(self.executor._outputs['wav']
- .numpy()) / self.executor.am_config.fs
+ duration = len(
+ self._outputs["wav"].numpy()) / self.executor.am_config.fs
rtf = infer_time / duration
except ServerBaseException:
raise ServerBaseException(ErrorCode.SERVER_INTERNAL_ERR,
"tts infer failed.")
- except BaseException:
+ sys.exit(-1)
+ except Exception as e:
logger.error("tts infer failed.")
+ logger.error(e)
+ sys.exit(-1)
try:
postprocess_st = time.time()
target_sample_rate, wav_base64 = self.postprocess(
- wav=self.executor._outputs['wav'].numpy(),
+ wav=self._outputs["wav"].numpy(),
original_fs=self.executor.am_config.fs,
target_fs=sample_rate,
volume=volume,
@@ -228,8 +258,11 @@ class TTSEngine(BaseEngine):
except ServerBaseException:
raise ServerBaseException(ErrorCode.SERVER_INTERNAL_ERR,
"tts postprocess failed.")
- except BaseException:
+ sys.exit(-1)
+ except Exception as e:
logger.error("tts postprocess failed.")
+ logger.error(e)
+ sys.exit(-1)
logger.info("AM model: {}".format(self.config.am))
logger.info("Vocoder model: {}".format(self.config.voc))
@@ -237,10 +270,9 @@ class TTSEngine(BaseEngine):
logger.info("tts engine type: python")
logger.info("audio duration: {}".format(duration))
- logger.info(
- "frontend inference time: {}".format(self.executor.frontend_time))
- logger.info("AM inference time: {}".format(self.executor.am_time))
- logger.info("Vocoder inference time: {}".format(self.executor.voc_time))
+ logger.info("frontend inference time: {}".format(self.frontend_time))
+ logger.info("AM inference time: {}".format(self.am_time))
+ logger.info("Vocoder inference time: {}".format(self.voc_time))
logger.info("total inference time: {}".format(infer_time))
logger.info(
"postprocess (change speed, volume, target sample rate) time: {}".
@@ -248,6 +280,6 @@ class TTSEngine(BaseEngine):
logger.info("total generate audio time: {}".format(infer_time +
postprocess_time))
logger.info("RTF: {}".format(rtf))
- logger.info("device: {}".format(self.device))
+ logger.info("device: {}".format(self.tts_engine.device))
return lang, target_sample_rate, duration, wav_base64
diff --git a/paddlespeech/server/engine/vector/__init__.py b/paddlespeech/server/engine/vector/__init__.py
new file mode 100644
index 000000000..97043fd7b
--- /dev/null
+++ b/paddlespeech/server/engine/vector/__init__.py
@@ -0,0 +1,13 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
diff --git a/paddlespeech/server/engine/vector/python/__init__.py b/paddlespeech/server/engine/vector/python/__init__.py
new file mode 100644
index 000000000..97043fd7b
--- /dev/null
+++ b/paddlespeech/server/engine/vector/python/__init__.py
@@ -0,0 +1,13 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
diff --git a/paddlespeech/server/engine/vector/python/vector_engine.py b/paddlespeech/server/engine/vector/python/vector_engine.py
new file mode 100644
index 000000000..3c72f55d4
--- /dev/null
+++ b/paddlespeech/server/engine/vector/python/vector_engine.py
@@ -0,0 +1,200 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import io
+from collections import OrderedDict
+
+import numpy as np
+import paddle
+
+from paddlespeech.audio.backends import load as load_audio
+from paddlespeech.audio.compliance.librosa import melspectrogram
+from paddlespeech.cli.log import logger
+from paddlespeech.cli.vector.infer import VectorExecutor
+from paddlespeech.server.engine.base_engine import BaseEngine
+from paddlespeech.vector.io.batch import feature_normalize
+
+
+class PaddleVectorConnectionHandler:
+ def __init__(self, vector_engine):
+ """The PaddleSpeech Vector Server Connection Handler
+ This connection process every server request
+ Args:
+ vector_engine (VectorEngine): The Vector engine
+ """
+ super().__init__()
+ logger.info(
+ "Create PaddleVectorConnectionHandler to process the vector request")
+ self.vector_engine = vector_engine
+ self.executor = self.vector_engine.executor
+ self.task = self.vector_engine.executor.task
+ self.model = self.vector_engine.executor.model
+ self.config = self.vector_engine.executor.config
+
+ self._inputs = OrderedDict()
+ self._outputs = OrderedDict()
+
+ @paddle.no_grad()
+ def run(self, audio_data, task="spk"):
+ """The connection process the http request audio
+
+ Args:
+ audio_data (bytes): base64.b64decode
+
+ Returns:
+ str: the punctuation text
+ """
+ logger.info(
+ f"start to extract the do vector {self.task} from the http request")
+ if self.task == "spk" and task == "spk":
+ embedding = self.extract_audio_embedding(audio_data)
+ return embedding
+ else:
+ logger.error(
+ "The request task is not matched with server model task")
+ logger.error(
+ f"The server model task is: {self.task}, but the request task is: {task}"
+ )
+
+ return np.array([
+ 0.0,
+ ])
+
+ @paddle.no_grad()
+ def get_enroll_test_score(self, enroll_audio, test_audio):
+ """Get the enroll and test audio score
+
+ Args:
+ enroll_audio (str): the base64 format enroll audio
+ test_audio (str): the base64 format test audio
+
+ Returns:
+ float: the score between enroll and test audio
+ """
+ logger.info("start to extract the enroll audio embedding")
+ enroll_emb = self.extract_audio_embedding(enroll_audio)
+
+ logger.info("start to extract the test audio embedding")
+ test_emb = self.extract_audio_embedding(test_audio)
+
+ logger.info(
+ "start to get the score between the enroll and test embedding")
+ score = self.executor.get_embeddings_score(enroll_emb, test_emb)
+
+ logger.info(f"get the enroll vs test score: {score}")
+ return score
+
+ @paddle.no_grad()
+ def extract_audio_embedding(self, audio: str, sample_rate: int=16000):
+ """extract the audio embedding
+
+ Args:
+ audio (str): the audio data
+ sample_rate (int, optional): the audio sample rate. Defaults to 16000.
+ """
+ # we can not reuse the cache io.BytesIO(audio) data,
+ # because the soundfile will change the io.BytesIO(audio) to the end
+ # thus we should convert the base64 string to io.BytesIO when we need the audio data
+ if not self.executor._check(io.BytesIO(audio), sample_rate):
+ logger.info("check the audio sample rate occurs error")
+ return np.array([0.0])
+
+ waveform, sr = load_audio(io.BytesIO(audio))
+ logger.info(f"load the audio sample points, shape is: {waveform.shape}")
+
+ # stage 2: get the audio feat
+ # Note: Now we only support fbank feature
+ try:
+ feats = melspectrogram(
+ x=waveform,
+ sr=self.config.sr,
+ n_mels=self.config.n_mels,
+ window_size=self.config.window_size,
+ hop_length=self.config.hop_size)
+ logger.info(f"extract the audio feats, shape is: {feats.shape}")
+ except Exception as e:
+ logger.info(f"feats occurs exception {e}")
+ sys.exit(-1)
+
+ feats = paddle.to_tensor(feats).unsqueeze(0)
+ # in inference period, the lengths is all one without padding
+ lengths = paddle.ones([1])
+
+ # stage 3: we do feature normalize,
+ # Now we assume that the feats must do normalize
+ feats = feature_normalize(feats, mean_norm=True, std_norm=False)
+
+ # stage 4: store the feats and length in the _inputs,
+ # which will be used in other function
+ logger.info(f"feats shape: {feats.shape}")
+ logger.info("audio extract the feats success")
+
+ logger.info("start to extract the audio embedding")
+ embedding = self.model.backbone(feats, lengths).squeeze().numpy()
+ logger.info(f"embedding size: {embedding.shape}")
+
+ return embedding
+
+
+class VectorServerExecutor(VectorExecutor):
+ def __init__(self):
+ """The wrapper for TextEcutor
+ """
+ super().__init__()
+ pass
+
+
+class VectorEngine(BaseEngine):
+ def __init__(self):
+ """The Vector Engine
+ """
+ super(VectorEngine, self).__init__()
+ logger.info("Create the VectorEngine Instance")
+
+ def init(self, config: dict):
+ """Init the Vector Engine
+
+ Args:
+ config (dict): The server configuation
+
+ Returns:
+ bool: The engine instance flag
+ """
+ logger.info("Init the vector engine")
+ try:
+ self.config = config
+ if self.config.device:
+ self.device = self.config.device
+ else:
+ self.device = paddle.get_device()
+
+ paddle.set_device(self.device)
+ logger.info(f"Vector Engine set the device: {self.device}")
+ except BaseException as e:
+ logger.error(
+ "Set device failed, please check if device is already used and the parameter 'device' in the yaml file"
+ )
+ logger.error("Initialize Vector server engine Failed on device: %s."
+ % (self.device))
+ return False
+
+ self.executor = VectorServerExecutor()
+
+ self.executor._init_from_path(
+ model_type=config.model_type,
+ cfg_path=config.cfg_path,
+ ckpt_path=config.ckpt_path,
+ task=config.task)
+
+ logger.info("Init the Vector engine successfully")
+ return True
diff --git a/paddlespeech/server/restful/acs_api.py b/paddlespeech/server/restful/acs_api.py
new file mode 100644
index 000000000..61cb34d9f
--- /dev/null
+++ b/paddlespeech/server/restful/acs_api.py
@@ -0,0 +1,101 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import base64
+from typing import Union
+
+from fastapi import APIRouter
+
+from paddlespeech.cli.log import logger
+from paddlespeech.server.engine.engine_pool import get_engine_pool
+from paddlespeech.server.restful.request import ASRRequest
+from paddlespeech.server.restful.response import ACSResponse
+from paddlespeech.server.restful.response import ErrorResponse
+from paddlespeech.server.utils.errors import ErrorCode
+from paddlespeech.server.utils.errors import failed_response
+from paddlespeech.server.utils.exception import ServerBaseException
+
+router = APIRouter()
+
+
+@router.get('/paddlespeech/asr/search/help')
+def help():
+ """help
+
+ Returns:
+ json: the audio content search result
+ """
+ response = {
+ "success": "True",
+ "code": 200,
+ "message": {
+ "global": "success"
+ },
+ "result": {
+ "description": "acs server",
+ "input": "base64 string of wavfile",
+ "output": {
+ "asr_result": "你好",
+ "acs_result": [{
+ 'w': '你',
+ 'bg': 0.0,
+ 'ed': 1.2
+ }]
+ }
+ }
+ }
+ return response
+
+
+@router.post(
+ "/paddlespeech/asr/search",
+ response_model=Union[ACSResponse, ErrorResponse])
+def acs(request_body: ASRRequest):
+ """acs api
+
+ Args:
+ request_body (ASRRequest): the acs request, we reuse the http ASRRequest
+
+ Returns:
+ json: the acs result
+ """
+ try:
+ # 1. get the audio data via base64 decoding
+ audio_data = base64.b64decode(request_body.audio)
+
+ # 2. get single engine from engine pool
+ engine_pool = get_engine_pool()
+ acs_engine = engine_pool['acs']
+
+ # 3. no data stored in acs_engine, so we need to create the another instance process the data
+ acs_result, asr_result = acs_engine.run(audio_data)
+
+ response = {
+ "success": True,
+ "code": 200,
+ "message": {
+ "description": "success"
+ },
+ "result": {
+ "transcription": asr_result,
+ "acs": acs_result
+ }
+ }
+
+ except ServerBaseException as e:
+ response = failed_response(e.error_code, e.msg)
+ except BaseException as e:
+ response = failed_response(ErrorCode.SERVER_UNKOWN_ERR)
+ logger.error(e)
+
+ return response
diff --git a/paddlespeech/server/restful/api.py b/paddlespeech/server/restful/api.py
index d5e422e33..9722c2614 100644
--- a/paddlespeech/server/restful/api.py
+++ b/paddlespeech/server/restful/api.py
@@ -17,11 +17,12 @@ from typing import List
from fastapi import APIRouter
from paddlespeech.cli.log import logger
+from paddlespeech.server.restful.acs_api import router as acs_router
from paddlespeech.server.restful.asr_api import router as asr_router
from paddlespeech.server.restful.cls_api import router as cls_router
from paddlespeech.server.restful.text_api import router as text_router
from paddlespeech.server.restful.tts_api import router as tts_router
-
+from paddlespeech.server.restful.vector_api import router as vec_router
_router = APIRouter()
@@ -29,20 +30,24 @@ def setup_router(api_list: List):
"""setup router for fastapi
Args:
- api_list (List): [asr, tts, cls]
+ api_list (List): [asr, tts, cls, text, vecotr]
Returns:
APIRouter
"""
for api_name in api_list:
- if api_name == 'asr':
+ if api_name.lower() == 'asr':
_router.include_router(asr_router)
- elif api_name == 'tts':
+ elif api_name.lower() == 'tts':
_router.include_router(tts_router)
- elif api_name == 'cls':
+ elif api_name.lower() == 'cls':
_router.include_router(cls_router)
- elif api_name == 'text':
+ elif api_name.lower() == 'text':
_router.include_router(text_router)
+ elif api_name.lower() == 'vector':
+ _router.include_router(vec_router)
+ elif api_name.lower() == 'acs':
+ _router.include_router(acs_router)
else:
logger.error(
f"PaddleSpeech has not support such service: {api_name}")
diff --git a/paddlespeech/server/restful/asr_api.py b/paddlespeech/server/restful/asr_api.py
index cf46735dc..c7bc50ce4 100644
--- a/paddlespeech/server/restful/asr_api.py
+++ b/paddlespeech/server/restful/asr_api.py
@@ -12,11 +12,13 @@
# See the License for the specific language governing permissions and
# limitations under the License.
import base64
+import sys
import traceback
from typing import Union
from fastapi import APIRouter
+from paddlespeech.cli.log import logger
from paddlespeech.server.engine.engine_pool import get_engine_pool
from paddlespeech.server.restful.request import ASRRequest
from paddlespeech.server.restful.response import ASRResponse
@@ -68,8 +70,18 @@ def asr(request_body: ASRRequest):
engine_pool = get_engine_pool()
asr_engine = engine_pool['asr']
- asr_engine.run(audio_data)
- asr_results = asr_engine.postprocess()
+ if asr_engine.engine_type == "python":
+ from paddlespeech.server.engine.asr.python.asr_engine import PaddleASRConnectionHandler
+ elif asr_engine.engine_type == "inference":
+ from paddlespeech.server.engine.asr.paddleinference.asr_engine import PaddleASRConnectionHandler
+ else:
+ logger.error("Offline asr engine only support python or inference.")
+ sys.exit(-1)
+
+ connection_handler = PaddleASRConnectionHandler(asr_engine)
+
+ connection_handler.run(audio_data)
+ asr_results = connection_handler.postprocess()
response = {
"success": True,
diff --git a/paddlespeech/server/restful/cls_api.py b/paddlespeech/server/restful/cls_api.py
index 306d9ca9c..7cfb4a297 100644
--- a/paddlespeech/server/restful/cls_api.py
+++ b/paddlespeech/server/restful/cls_api.py
@@ -12,11 +12,13 @@
# See the License for the specific language governing permissions and
# limitations under the License.
import base64
+import sys
import traceback
from typing import Union
from fastapi import APIRouter
+from paddlespeech.cli.log import logger
from paddlespeech.server.engine.engine_pool import get_engine_pool
from paddlespeech.server.restful.request import CLSRequest
from paddlespeech.server.restful.response import CLSResponse
@@ -68,8 +70,18 @@ def cls(request_body: CLSRequest):
engine_pool = get_engine_pool()
cls_engine = engine_pool['cls']
- cls_engine.run(audio_data)
- cls_results = cls_engine.postprocess(request_body.topk)
+ if cls_engine.engine_type == "python":
+ from paddlespeech.server.engine.cls.python.cls_engine import PaddleCLSConnectionHandler
+ elif cls_engine.engine_type == "inference":
+ from paddlespeech.server.engine.cls.paddleinference.cls_engine import PaddleCLSConnectionHandler
+ else:
+ logger.error("Offline cls engine only support python or inference.")
+ sys.exit(-1)
+
+ connection_handler = PaddleCLSConnectionHandler(cls_engine)
+
+ connection_handler.run(audio_data)
+ cls_results = connection_handler.postprocess(request_body.topk)
response = {
"success": True,
@@ -85,8 +97,11 @@ def cls(request_body: CLSRequest):
except ServerBaseException as e:
response = failed_response(e.error_code, e.msg)
- except BaseException:
+ logger.error(e)
+ sys.exit(-1)
+ except Exception as e:
response = failed_response(ErrorCode.SERVER_UNKOWN_ERR)
+ logger.error(e)
traceback.print_exc()
return response
diff --git a/paddlespeech/server/restful/request.py b/paddlespeech/server/restful/request.py
index 504166270..b7a32481f 100644
--- a/paddlespeech/server/restful/request.py
+++ b/paddlespeech/server/restful/request.py
@@ -15,7 +15,10 @@ from typing import Optional
from pydantic import BaseModel
-__all__ = ['ASRRequest', 'TTSRequest', 'CLSRequest']
+__all__ = [
+ 'ASRRequest', 'TTSRequest', 'CLSRequest', 'VectorRequest',
+ 'VectorScoreRequest'
+]
#****************************************************************************************/
@@ -85,3 +88,40 @@ class CLSRequest(BaseModel):
#****************************************************************************************/
class TextRequest(BaseModel):
text: str
+
+
+#****************************************************************************************/
+#************************************ Vecotr request ************************************/
+#****************************************************************************************/
+class VectorRequest(BaseModel):
+ """
+ request body example
+ {
+ "audio": "exSI6ICJlbiIsCgkgICAgInBvc2l0aW9uIjogImZhbHNlIgoJf...",
+ "task": "spk",
+ "audio_format": "wav",
+ "sample_rate": 16000,
+ }
+ """
+ audio: str
+ task: str
+ audio_format: str
+ sample_rate: int
+
+
+class VectorScoreRequest(BaseModel):
+ """
+ request body example
+ {
+ "enroll_audio": "exSI6ICJlbiIsCgkgICAgInBvc2l0aW9uIjogImZhbHNlIgoJf...",
+ "test_audio": "exSI6ICJlbiIsCgkgICAgInBvc2l0aW9uIjogImZhbHNlIgoJf...",
+ "task": "score",
+ "audio_format": "wav",
+ "sample_rate": 16000,
+ }
+ """
+ enroll_audio: str
+ test_audio: str
+ task: str
+ audio_format: str
+ sample_rate: int
diff --git a/paddlespeech/server/restful/response.py b/paddlespeech/server/restful/response.py
index 5792959ea..3d991de43 100644
--- a/paddlespeech/server/restful/response.py
+++ b/paddlespeech/server/restful/response.py
@@ -15,7 +15,10 @@ from typing import List
from pydantic import BaseModel
-__all__ = ['ASRResponse', 'TTSResponse', 'CLSResponse']
+__all__ = [
+ 'ASRResponse', 'TTSResponse', 'CLSResponse', 'TextResponse',
+ 'VectorResponse', 'VectorScoreResponse', 'ACSResponse'
+]
class Message(BaseModel):
@@ -129,6 +132,11 @@ class CLSResponse(BaseModel):
result: CLSResult
+#****************************************************************************************/
+#************************************ Text response **************************************/
+#****************************************************************************************/
+
+
class TextResult(BaseModel):
punc_text: str
@@ -153,6 +161,59 @@ class TextResponse(BaseModel):
result: TextResult
+#****************************************************************************************/
+#************************************ Vector response **************************************/
+#****************************************************************************************/
+
+
+class VectorResult(BaseModel):
+ vec: list
+
+
+class VectorResponse(BaseModel):
+ """
+ response example
+ {
+ "success": true,
+ "code": 0,
+ "message": {
+ "description": "success"
+ },
+ "result": {
+ "vec": [1.0, 1.0]
+ }
+ }
+ """
+ success: bool
+ code: int
+ message: Message
+ result: VectorResult
+
+
+class VectorScoreResult(BaseModel):
+ score: float
+
+
+class VectorScoreResponse(BaseModel):
+ """
+ response example
+ {
+ "success": true,
+ "code": 0,
+ "message": {
+ "description": "success"
+ },
+ "result": {
+ "score": 1.0
+ }
+ }
+ """
+ success: bool
+ code: int
+ message: Message
+ result: VectorScoreResult
+
+
#****************************************************************************************/
#********************************** Error response **************************************/
#****************************************************************************************/
@@ -170,3 +231,32 @@ class ErrorResponse(BaseModel):
success: bool
code: int
message: Message
+
+
+#****************************************************************************************/
+#************************************ ACS response **************************************/
+#****************************************************************************************/
+class AcsResult(BaseModel):
+ transcription: str
+ acs: list
+
+
+class ACSResponse(BaseModel):
+ """
+ response example
+ {
+ "success": true,
+ "code": 0,
+ "message": {
+ "description": "success"
+ },
+ "result": {
+ "transcription": "你好,飞桨"
+ "acs": [(你好, 0.0, 0.45)]
+ }
+ }
+ """
+ success: bool
+ code: int
+ message: Message
+ result: AcsResult
diff --git a/paddlespeech/server/restful/tts_api.py b/paddlespeech/server/restful/tts_api.py
index d1268428a..53fe159fd 100644
--- a/paddlespeech/server/restful/tts_api.py
+++ b/paddlespeech/server/restful/tts_api.py
@@ -11,6 +11,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
+import sys
import traceback
from typing import Union
@@ -99,7 +100,16 @@ def tts(request_body: TTSRequest):
tts_engine = engine_pool['tts']
logger.info("Get tts engine successfully.")
- lang, target_sample_rate, duration, wav_base64 = tts_engine.run(
+ if tts_engine.engine_type == "python":
+ from paddlespeech.server.engine.tts.python.tts_engine import PaddleTTSConnectionHandler
+ elif tts_engine.engine_type == "inference":
+ from paddlespeech.server.engine.tts.paddleinference.tts_engine import PaddleTTSConnectionHandler
+ else:
+ logger.error("Offline tts engine only support python or inference.")
+ sys.exit(-1)
+
+ connection_handler = PaddleTTSConnectionHandler(tts_engine)
+ lang, target_sample_rate, duration, wav_base64 = connection_handler.run(
text, spk_id, speed, volume, sample_rate, save_path)
response = {
@@ -128,7 +138,7 @@ def tts(request_body: TTSRequest):
return response
-@router.post("/paddlespeech/streaming/tts")
+@router.post("/paddlespeech/tts/streaming")
async def stream_tts(request_body: TTSRequest):
text = request_body.text
@@ -136,4 +146,14 @@ async def stream_tts(request_body: TTSRequest):
tts_engine = engine_pool['tts']
logger.info("Get tts engine successfully.")
- return StreamingResponse(tts_engine.run(sentence=text))
+ if tts_engine.engine_type == "online":
+ from paddlespeech.server.engine.tts.online.python.tts_engine import PaddleTTSConnectionHandler
+ elif tts_engine.engine_type == "online-onnx":
+ from paddlespeech.server.engine.tts.online.onnx.tts_engine import PaddleTTSConnectionHandler
+ else:
+ logger.error("Online tts engine only support online or online-onnx.")
+ sys.exit(-1)
+
+ connection_handler = PaddleTTSConnectionHandler(tts_engine)
+
+ return StreamingResponse(connection_handler.run(sentence=text))
diff --git a/paddlespeech/server/restful/vector_api.py b/paddlespeech/server/restful/vector_api.py
new file mode 100644
index 000000000..6e04f48e7
--- /dev/null
+++ b/paddlespeech/server/restful/vector_api.py
@@ -0,0 +1,151 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import base64
+import traceback
+from typing import Union
+
+import numpy as np
+from fastapi import APIRouter
+
+from paddlespeech.cli.log import logger
+from paddlespeech.server.engine.engine_pool import get_engine_pool
+from paddlespeech.server.engine.vector.python.vector_engine import PaddleVectorConnectionHandler
+from paddlespeech.server.restful.request import VectorRequest
+from paddlespeech.server.restful.request import VectorScoreRequest
+from paddlespeech.server.restful.response import ErrorResponse
+from paddlespeech.server.restful.response import VectorResponse
+from paddlespeech.server.restful.response import VectorScoreResponse
+from paddlespeech.server.utils.errors import ErrorCode
+from paddlespeech.server.utils.errors import failed_response
+from paddlespeech.server.utils.exception import ServerBaseException
+router = APIRouter()
+
+
+@router.get('/paddlespeech/vector/help')
+def help():
+ """help
+
+ Returns:
+ json: The /paddlespeech/vector api response content
+ """
+ response = {
+ "success": "True",
+ "code": 200,
+ "message": {
+ "global": "success"
+ },
+ "vector": [2.3, 3.5, 5.5, 6.2, 2.8, 1.2, 0.3, 3.6]
+ }
+ return response
+
+
+@router.post(
+ "/paddlespeech/vector", response_model=Union[VectorResponse, ErrorResponse])
+def vector(request_body: VectorRequest):
+ """vector api
+
+ Args:
+ request_body (VectorRequest): the vector request body
+
+ Returns:
+ json: the vector response body
+ """
+ try:
+ # 1. get the audio data
+ # the audio must be base64 format
+ audio_data = base64.b64decode(request_body.audio)
+
+ # 2. get single engine from engine pool
+ # and we use the vector_engine to create an connection handler to process the request
+ engine_pool = get_engine_pool()
+ vector_engine = engine_pool['vector']
+ connection_handler = PaddleVectorConnectionHandler(vector_engine)
+
+ # 3. we use the connection handler to process the audio
+ audio_vec = connection_handler.run(audio_data, request_body.task)
+
+ # 4. we need the result of the vector instance be numpy.ndarray
+ if not isinstance(audio_vec, np.ndarray):
+ logger.error(
+ f"the vector type is not numpy.array, that is: {type(audio_vec)}"
+ )
+ error_reponse = ErrorResponse()
+ error_reponse.message.description = f"the vector type is not numpy.array, that is: {type(audio_vec)}"
+ return error_reponse
+
+ response = {
+ "success": True,
+ "code": 200,
+ "message": {
+ "description": "success"
+ },
+ "result": {
+ "vec": audio_vec.tolist()
+ }
+ }
+
+ except ServerBaseException as e:
+ response = failed_response(e.error_code, e.msg)
+ except BaseException:
+ response = failed_response(ErrorCode.SERVER_UNKOWN_ERR)
+ traceback.print_exc()
+
+ return response
+
+
+@router.post(
+ "/paddlespeech/vector/score",
+ response_model=Union[VectorScoreResponse, ErrorResponse])
+def score(request_body: VectorScoreRequest):
+ """vector api
+
+ Args:
+ request_body (VectorScoreRequest): the punctuation request body
+
+ Returns:
+ json: the punctuation response body
+ """
+ try:
+ # 1. get the audio data
+ # the audio must be base64 format
+ enroll_data = base64.b64decode(request_body.enroll_audio)
+ test_data = base64.b64decode(request_body.test_audio)
+
+ # 2. get single engine from engine pool
+ # and we use the vector_engine to create an connection handler to process the request
+ engine_pool = get_engine_pool()
+ vector_engine = engine_pool['vector']
+ connection_handler = PaddleVectorConnectionHandler(vector_engine)
+
+ # 3. we use the connection handler to process the audio
+ score = connection_handler.get_enroll_test_score(enroll_data, test_data)
+
+ response = {
+ "success": True,
+ "code": 200,
+ "message": {
+ "description": "success"
+ },
+ "result": {
+ "score": score
+ }
+ }
+
+ except ServerBaseException as e:
+ response = failed_response(e.error_code, e.msg)
+ except BaseException:
+ response = failed_response(ErrorCode.SERVER_UNKOWN_ERR)
+ traceback.print_exc()
+
+ return response
diff --git a/paddlespeech/server/tests/tts/offline/http_client.py b/paddlespeech/server/tests/tts/offline/http_client.py
index 1bdee4c18..24109a0e1 100644
--- a/paddlespeech/server/tests/tts/offline/http_client.py
+++ b/paddlespeech/server/tests/tts/offline/http_client.py
@@ -61,7 +61,7 @@ def tts_client(args):
temp_wav = str(random.getrandbits(128)) + ".wav"
soundfile.write(temp_wav, samples, sample_rate)
wav2pcm(temp_wav, outfile, data_type=np.int16)
- os.system("rm %s" % (temp_wav))
+ os.remove(temp_wav)
else:
print("The format for saving audio only supports wav or pcm")
diff --git a/paddlespeech/server/tests/tts/online/http_client.py b/paddlespeech/server/tests/tts/online/http_client.py
index 756f7b5be..47b781ed9 100644
--- a/paddlespeech/server/tests/tts/online/http_client.py
+++ b/paddlespeech/server/tests/tts/online/http_client.py
@@ -14,6 +14,7 @@
import argparse
from paddlespeech.server.utils.audio_handler import TTSHttpHandler
+from paddlespeech.server.utils.util import compute_delay
if __name__ == "__main__":
parser = argparse.ArgumentParser()
@@ -43,5 +44,25 @@ if __name__ == "__main__":
print("tts http client start")
handler = TTSHttpHandler(args.server, args.port, args.play)
- handler.run(args.text, args.spk_id, args.speed, args.volume,
- args.sample_rate, args.output)
+ first_response, final_response, duration, save_audio_success, receive_time_list, chunk_duration_list = handler.run(
+ args.text, args.spk_id, args.speed, args.volume, args.sample_rate,
+ args.output)
+ delay_time_list = compute_delay(receive_time_list, chunk_duration_list)
+
+ print(f"sentence: {args.text}")
+ print(f"duration: {duration} s")
+ print(f"first response: {first_response} s")
+ print(f"final response: {final_response} s")
+ print(f"RTF: {final_response/duration}")
+ if args.output is not None:
+ if save_audio_success:
+ print(f"Audio successfully saved in {args.output}")
+ else:
+ print("Audio save failed.")
+
+ if delay_time_list != []:
+ print(
+ f"Delay situation: total number of packages: {len(receive_time_list)}, the number of delayed packets: {len(delay_time_list)}, minimum delay time: {min(delay_time_list)} s, maximum delay time: {max(delay_time_list)} s, average delay time: {sum(delay_time_list)/len(delay_time_list)} s, delay rate:{len(delay_time_list)/len(receive_time_list)}"
+ )
+ else:
+ print("The sentence has no delay in streaming synthesis.")
diff --git a/paddlespeech/server/tests/tts/online/ws_client.py b/paddlespeech/server/tests/tts/online/ws_client.py
index 821d82a9a..0b1794c8a 100644
--- a/paddlespeech/server/tests/tts/online/ws_client.py
+++ b/paddlespeech/server/tests/tts/online/ws_client.py
@@ -15,6 +15,7 @@ import argparse
import asyncio
from paddlespeech.server.utils.audio_handler import TTSWsHandler
+from paddlespeech.server.utils.util import compute_delay
if __name__ == "__main__":
parser = argparse.ArgumentParser()
@@ -35,4 +36,24 @@ if __name__ == "__main__":
print("tts websocket client start")
handler = TTSWsHandler(args.server, args.port, args.play)
loop = asyncio.get_event_loop()
- loop.run_until_complete(handler.run(args.text, args.output))
+ first_response, final_response, duration, save_audio_success, receive_time_list, chunk_duration_list = loop.run_until_complete(
+ handler.run(args.text, args.output))
+ delay_time_list = compute_delay(receive_time_list, chunk_duration_list)
+
+ print(f"sentence: {args.text}")
+ print(f"duration: {duration} s")
+ print(f"first response: {first_response} s")
+ print(f"final response: {final_response} s")
+ print(f"RTF: {final_response/duration}")
+ if args.output is not None:
+ if save_audio_success:
+ print(f"Audio successfully saved in {args.output}")
+ else:
+ print("Audio save failed.")
+
+ if delay_time_list != []:
+ print(
+ f"Delay situation: total number of packages: {len(receive_time_list)}, the number of delayed packets: {len(delay_time_list)}, minimum delay time: {min(delay_time_list)} s, maximum delay time: {max(delay_time_list)} s, average delay time: {sum(delay_time_list)/len(delay_time_list)} s, delay rate:{len(delay_time_list)/len(receive_time_list)}"
+ )
+ else:
+ print("The sentence has no delay in streaming synthesis.")
diff --git a/paddlespeech/server/util.py b/paddlespeech/server/util.py
index ae3e9c6aa..32546a330 100644
--- a/paddlespeech/server/util.py
+++ b/paddlespeech/server/util.py
@@ -24,14 +24,14 @@ from typing import Any
from typing import Dict
import paddle
-import paddleaudio
import requests
import yaml
from paddle.framework import load
-from . import download
+import paddlespeech.audio
from .entry import client_commands
from .entry import server_commands
+from paddlespeech.cli import download
try:
from .. import __version__
except ImportError:
@@ -289,7 +289,7 @@ def _note_one_stat(cls_name, params={}):
if 'audio_file' in params:
try:
- _, sr = paddleaudio.load(params['audio_file'])
+ _, sr = paddlespeech.audio.load(params['audio_file'])
except Exception:
sr = -1
diff --git a/paddlespeech/server/utils/audio_handler.py b/paddlespeech/server/utils/audio_handler.py
index 1e766955b..e3d90d469 100644
--- a/paddlespeech/server/utils/audio_handler.py
+++ b/paddlespeech/server/utils/audio_handler.py
@@ -43,6 +43,7 @@ class TextHttpHandler:
else:
self.url = 'http://' + self.server_ip + ":" + str(
self.port) + '/paddlespeech/text'
+ logger.info(f"endpoint: {self.url}")
def run(self, text):
"""Call the text server to process the specific text
@@ -63,7 +64,7 @@ class TextHttpHandler:
response_dict = res.json()
punc_text = response_dict["result"]["punc_text"]
except Exception as e:
- logger.error(f"Call punctuation {self.url} occurs")
+ logger.error(f"Call punctuation {self.url} occurs error")
logger.error(e)
punc_text = text
@@ -91,8 +92,7 @@ class ASRWsAudioHandler:
if url is None or port is None or endpoint is None:
self.url = None
else:
- self.url = "ws://" + self.url + ":" + str(
- self.port) + endpoint
+ self.url = "ws://" + self.url + ":" + str(self.port) + endpoint
self.punc_server = TextHttpHandler(punc_server_ip, punc_server_port)
logger.info(f"endpoint: {self.url}")
@@ -108,8 +108,10 @@ class ASRWsAudioHandler:
"""
samples, sample_rate = soundfile.read(wavfile_path, dtype='int16')
x_len = len(samples)
+ assert sample_rate == 16000
+
+ chunk_size = int(85 * sample_rate / 1000) # 85ms, sample_rate = 16kHz
- chunk_size = 85 * 16 #80ms, sample_rate = 16kHz
if x_len % chunk_size != 0:
padding_len_x = chunk_size - x_len % chunk_size
else:
@@ -139,11 +141,11 @@ class ASRWsAudioHandler:
logging.info("send a message to the server")
if self.url is None:
- logger.error(
- "No asr server, please input valid ip and port")
+ logger.error("No asr server, please input valid ip and port")
return ""
# 1. send websocket handshake protocal
+ start_time = time.time()
async with websockets.connect(self.url) as ws:
# 2. server has already received handshake protocal
# client start to send the command
@@ -167,8 +169,7 @@ class ASRWsAudioHandler:
msg = json.loads(msg)
if self.punc_server and len(msg["result"]) > 0:
- msg["result"] = self.punc_server.run(
- msg["result"])
+ msg["result"] = self.punc_server.run(msg["result"])
logger.info("client receive msg={}".format(msg))
# 4. we must send finished signal to the server
@@ -176,7 +177,7 @@ class ASRWsAudioHandler:
{
"name": "test.wav",
"signal": "end",
- "nbest": 5
+ "nbest": 1
},
sort_keys=True,
indent=4,
@@ -189,15 +190,22 @@ class ASRWsAudioHandler:
if self.punc_server:
msg["result"] = self.punc_server.run(msg["result"])
-
+
+ # 6. logging the final result and comptute the statstics
+ elapsed_time = time.time() - start_time
+ audio_info = soundfile.info(wavfile_path)
logger.info("client final receive msg={}".format(msg))
+ logger.info(
+ f"audio duration: {audio_info.duration}, elapsed time: {elapsed_time}, RTF={elapsed_time/audio_info.duration}"
+ )
+
result = msg
return result
class ASRHttpHandler:
- def __init__(self, server_ip=None, port=None):
+ def __init__(self, server_ip=None, port=None, endpoint="/paddlespeech/asr"):
"""The ASR client http request
Args:
@@ -211,7 +219,8 @@ class ASRHttpHandler:
self.url = None
else:
self.url = 'http://' + self.server_ip + ":" + str(
- self.port) + '/paddlespeech/asr'
+ self.port) + endpoint
+ logger.info(f"endpoint: {self.url}")
def run(self, input, audio_format, sample_rate, lang):
"""Call the http asr to process the audio
@@ -254,7 +263,8 @@ class TTSWsHandler:
"""
self.server = server
self.port = port
- self.url = "ws://" + self.server + ":" + str(self.port) + "/ws/tts"
+ self.url = "ws://" + self.server + ":" + str(
+ self.port) + "/paddlespeech/tts/streaming"
self.play = play
if self.play:
import pyaudio
@@ -269,6 +279,7 @@ class TTSWsHandler:
self.start_play = True
self.t = threading.Thread(target=self.play_audio)
self.max_fail = 50
+ logger.info(f"endpoint: {self.url}")
def play_audio(self):
while True:
@@ -290,56 +301,83 @@ class TTSWsHandler:
output (str): save audio path
"""
all_bytes = b''
+ receive_time_list = []
+ chunk_duration_list = []
- # 1. Send websocket handshake protocal
+ # 1. Send websocket handshake request
async with websockets.connect(self.url) as ws:
- # 2. Server has already received handshake protocal
- # send text to engine
+ # 2. Server has already received handshake response, send start request
+ start_request = json.dumps({"task": "tts", "signal": "start"})
+ await ws.send(start_request)
+ msg = await ws.recv()
+ logger.info(f"client receive msg={msg}")
+ msg = json.loads(msg)
+ session = msg["session"]
+
+ # 3. send speech synthesis request
text_base64 = str(base64.b64encode((text).encode('utf-8')), "UTF8")
- d = {"text": text_base64}
- d = json.dumps(d)
+ request = json.dumps({"text": text_base64})
st = time.time()
- await ws.send(d)
+ await ws.send(request)
logging.info("send a message to the server")
- # 3. Process the received response
+ # 4. Process the received response
message = await ws.recv()
- logger.info(f"句子:{text}")
- logger.info(f"首包响应:{time.time() - st} s")
+ first_response = time.time() - st
message = json.loads(message)
status = message["status"]
+ while True:
+ # When throw an exception
+ if status == -1:
+ # send end request
+ end_request = json.dumps({
+ "task": "tts",
+ "signal": "end",
+ "session": session
+ })
+ await ws.send(end_request)
+ break
- while (status == 1):
- audio = message["audio"]
- audio = base64.b64decode(audio) # bytes
- all_bytes += audio
- if self.play:
- self.mutex.acquire()
- self.buffer += audio
- self.mutex.release()
- if self.start_play:
- self.t.start()
- self.start_play = False
-
- message = await ws.recv()
- message = json.loads(message)
- status = message["status"]
-
- # 4. Last packet, no audio information
- if status == 2:
- final_response = time.time() - st
- duration = len(all_bytes) / 2.0 / 24000
- logger.info(f"尾包响应:{final_response} s")
- logger.info(f"音频时长:{duration} s")
- logger.info(f"RTF: {final_response / duration}")
-
- if output is not None:
- if save_audio(all_bytes, output):
- logger.info(f"音频保存至:{output}")
+ # Rerutn last packet normally, no audio information
+ elif status == 2:
+ final_response = time.time() - st
+ duration = len(all_bytes) / 2.0 / 24000
+
+ if output is not None:
+ save_audio_success = save_audio(all_bytes, output)
else:
- logger.error("save audio error")
- else:
- logger.error("infer error")
+ save_audio_success = False
+
+ # send end request
+ end_request = json.dumps({
+ "task": "tts",
+ "signal": "end",
+ "session": session
+ })
+ await ws.send(end_request)
+ break
+
+ # Return the audio stream normally
+ elif status == 1:
+ receive_time_list.append(time.time())
+ audio = message["audio"]
+ audio = base64.b64decode(audio) # bytes
+ chunk_duration_list.append(len(audio) / 2.0 / 24000)
+ all_bytes += audio
+ if self.play:
+ self.mutex.acquire()
+ self.buffer += audio
+ self.mutex.release()
+ if self.start_play:
+ self.t.start()
+ self.start_play = False
+
+ message = await ws.recv()
+ message = json.loads(message)
+ status = message["status"]
+
+ else:
+ logger.error("infer error, return status is invalid.")
if self.play:
self.t.join()
@@ -347,6 +385,8 @@ class TTSWsHandler:
self.stream.close()
self.p.terminate()
+ return first_response, final_response, duration, save_audio_success, receive_time_list, chunk_duration_list
+
class TTSHttpHandler:
def __init__(self, server="127.0.0.1", port=8092, play: bool=False):
@@ -360,7 +400,7 @@ class TTSHttpHandler:
self.server = server
self.port = port
self.url = "http://" + str(self.server) + ":" + str(
- self.port) + "/paddlespeech/streaming/tts"
+ self.port) + "/paddlespeech/tts/streaming"
self.play = play
if self.play:
@@ -376,6 +416,7 @@ class TTSHttpHandler:
self.start_play = True
self.t = threading.Thread(target=self.play_audio)
self.max_fail = 50
+ logger.info(f"endpoint: {self.url}")
def play_audio(self):
while True:
@@ -418,13 +459,16 @@ class TTSHttpHandler:
all_bytes = b''
first_flag = 1
+ receive_time_list = []
+ chunk_duration_list = []
# 2. Send request
st = time.time()
html = requests.post(self.url, json.dumps(params), stream=True)
# 3. Process the received response
- for chunk in html.iter_content(chunk_size=1024):
+ for chunk in html.iter_content(chunk_size=None):
+ receive_time_list.append(time.time())
audio = base64.b64decode(chunk) # bytes
if first_flag:
first_response = time.time() - st
@@ -438,24 +482,116 @@ class TTSHttpHandler:
self.t.start()
self.start_play = False
all_bytes += audio
+ chunk_duration_list.append(len(audio) / 2.0 / 24000)
final_response = time.time() - st
duration = len(all_bytes) / 2.0 / 24000
-
- logger.info(f"句子:{text}")
- logger.info(f"首包响应:{first_response} s")
- logger.info(f"尾包响应:{final_response} s")
- logger.info(f"音频时长:{duration} s")
- logger.info(f"RTF: {final_response / duration}")
+ html.close() # when stream=True
if output is not None:
- if save_audio(all_bytes, output):
- logger.info(f"音频保存至:{output}")
- else:
- logger.error("save audio error")
+ save_audio_success = save_audio(all_bytes, output)
+ else:
+ save_audio_success = False
if self.play:
self.t.join()
self.stream.stop_stream()
self.stream.close()
self.p.terminate()
+
+ return first_response, final_response, duration, save_audio_success, receive_time_list, chunk_duration_list
+
+
+class VectorHttpHandler:
+ def __init__(self, server_ip=None, port=None):
+ """The Vector client http request
+
+ Args:
+ server_ip (str, optional): the http vector server ip. Defaults to "127.0.0.1".
+ port (int, optional): the http vector server port. Defaults to 8090.
+ """
+ super().__init__()
+ self.server_ip = server_ip
+ self.port = port
+ if server_ip is None or port is None:
+ self.url = None
+ else:
+ self.url = 'http://' + self.server_ip + ":" + str(
+ self.port) + '/paddlespeech/vector'
+ logger.info(f"endpoint: {self.url}")
+
+ def run(self, input, audio_format, sample_rate, task="spk"):
+ """Call the http asr to process the audio
+
+ Args:
+ input (str): the audio file path
+ audio_format (str): the audio format
+ sample_rate (str): the audio sample rate
+
+ Returns:
+ list: the audio vector
+ """
+ if self.url is None:
+ logger.error("No vector server, please input valid ip and port")
+ return ""
+
+ audio = wav2base64(input)
+ data = {
+ "audio": audio,
+ "task": task,
+ "audio_format": audio_format,
+ "sample_rate": sample_rate,
+ }
+
+ logger.info(self.url)
+ res = requests.post(url=self.url, data=json.dumps(data))
+
+ return res.json()
+
+
+class VectorScoreHttpHandler:
+ def __init__(self, server_ip=None, port=None):
+ """The Vector score client http request
+
+ Args:
+ server_ip (str, optional): the http vector server ip. Defaults to "127.0.0.1".
+ port (int, optional): the http vector server port. Defaults to 8090.
+ """
+ super().__init__()
+ self.server_ip = server_ip
+ self.port = port
+ if server_ip is None or port is None:
+ self.url = None
+ else:
+ self.url = 'http://' + self.server_ip + ":" + str(
+ self.port) + '/paddlespeech/vector/score'
+ logger.info(f"endpoint: {self.url}")
+
+ def run(self, enroll_audio, test_audio, audio_format, sample_rate):
+ """Call the http asr to process the audio
+
+ Args:
+ input (str): the audio file path
+ audio_format (str): the audio format
+ sample_rate (str): the audio sample rate
+
+ Returns:
+ list: the audio vector
+ """
+ if self.url is None:
+ logger.error("No vector server, please input valid ip and port")
+ return ""
+
+ enroll_audio = wav2base64(enroll_audio)
+ test_audio = wav2base64(test_audio)
+ data = {
+ "enroll_audio": enroll_audio,
+ "test_audio": test_audio,
+ "task": "score",
+ "audio_format": audio_format,
+ "sample_rate": sample_rate,
+ }
+
+ res = requests.post(url=self.url, data=json.dumps(data))
+
+ return res.json()
diff --git a/paddlespeech/server/utils/audio_process.py b/paddlespeech/server/utils/audio_process.py
index 6fb5bb832..416d77ac4 100644
--- a/paddlespeech/server/utils/audio_process.py
+++ b/paddlespeech/server/utils/audio_process.py
@@ -107,7 +107,7 @@ def change_speed(sample_raw, speed_rate, sample_rate):
def float2pcm(sig, dtype='int16'):
- """Convert floating point signal with a range from -1 to 1 to PCM.
+ """Convert floating point signal with a range from -1 to 1 to PCM16.
Args:
sig (array): Input array, must have floating point type.
@@ -167,7 +167,7 @@ def save_audio(bytes_data, audio_path, sample_rate: int=24000) -> bool:
channels=1,
bits=16,
sample_rate=sample_rate)
- os.system("rm ./tmp.pcm")
+ os.remove("./tmp.pcm")
else:
print("Only supports saved audio format is pcm or wav")
return False
diff --git a/paddlespeech/server/utils/buffer.py b/paddlespeech/server/utils/buffer.py
index d4e6cd493..20cd3cf62 100644
--- a/paddlespeech/server/utils/buffer.py
+++ b/paddlespeech/server/utils/buffer.py
@@ -46,7 +46,6 @@ class ChunkBuffer(object):
self.shift_ms = shift_ms
self.sample_rate = sample_rate
self.sample_width = sample_width # int16 = 2; float32 = 4
- self.remained_audio = b''
self.window_sec = float((self.window_n - 1) * self.shift_ms +
self.window_ms) / 1000.0
@@ -57,22 +56,31 @@ class ChunkBuffer(object):
self.shift_bytes = int(self.shift_sec * self.sample_rate *
self.sample_width)
+ self.remained_audio = b''
+ # abs timestamp from `start` or latest `reset`
+ self.timestamp = 0.0
+
+ def reset(self):
+ """
+ reset buffer state.
+ """
+ self.timestamp = 0.0
+ self.remained_audio = b''
+
def frame_generator(self, audio):
"""Generates audio frames from PCM audio data.
Takes the desired frame duration in milliseconds, the PCM data, and
the sample rate.
Yields Frames of the requested duration.
"""
-
audio = self.remained_audio + audio
self.remained_audio = b''
offset = 0
- timestamp = 0.0
while offset + self.window_bytes <= len(audio):
- yield Frame(audio[offset:offset + self.window_bytes], timestamp,
- self.window_sec)
- timestamp += self.shift_sec
+ yield Frame(audio[offset:offset + self.window_bytes],
+ self.timestamp, self.window_sec)
+ self.timestamp += self.shift_sec
offset += self.shift_bytes
self.remained_audio += audio[offset:]
diff --git a/paddlespeech/server/utils/onnx_infer.py b/paddlespeech/server/utils/onnx_infer.py
index ac11c534b..1c9d878f8 100644
--- a/paddlespeech/server/utils/onnx_infer.py
+++ b/paddlespeech/server/utils/onnx_infer.py
@@ -16,21 +16,34 @@ from typing import Optional
import onnxruntime as ort
+from .log import logger
+
def get_sess(model_path: Optional[os.PathLike]=None, sess_conf: dict=None):
+ logger.info(f"ort sessconf: {sess_conf}")
sess_options = ort.SessionOptions()
sess_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
+ if sess_conf.get('graph_optimization_level', 99) == 0:
+ sess_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_DISABLE_ALL
sess_options.execution_mode = ort.ExecutionMode.ORT_SEQUENTIAL
- if "gpu" in sess_conf["device"]:
+ # "gpu:0"
+ providers = ['CPUExecutionProvider']
+ if "gpu" in sess_conf.get("device", ""):
+ providers = ['CUDAExecutionProvider']
# fastspeech2/mb_melgan can't use trt now!
- if sess_conf["use_trt"]:
+ if sess_conf.get("use_trt", 0):
providers = ['TensorrtExecutionProvider']
- else:
- providers = ['CUDAExecutionProvider']
- elif sess_conf["device"] == "cpu":
- providers = ['CPUExecutionProvider']
- sess_options.intra_op_num_threads = sess_conf["cpu_threads"]
+ logger.info(f"ort providers: {providers}")
+
+ if 'cpu_threads' in sess_conf:
+ sess_options.intra_op_num_threads = sess_conf.get("cpu_threads", 0)
+ else:
+ sess_options.intra_op_num_threads = sess_conf.get(
+ "intra_op_num_threads", 0)
+
+ sess_options.inter_op_num_threads = sess_conf.get("inter_op_num_threads", 0)
+
sess = ort.InferenceSession(
model_path, providers=providers, sess_options=sess_options)
return sess
diff --git a/paddlespeech/server/utils/util.py b/paddlespeech/server/utils/util.py
index 72ee0060e..061b213c7 100644
--- a/paddlespeech/server/utils/util.py
+++ b/paddlespeech/server/utils/util.py
@@ -75,3 +75,74 @@ def get_chunks(data, block_size, pad_size, step):
else:
print("Please set correct type to get chunks, am or voc")
return chunks
+
+
+def compute_delay(receive_time_list, chunk_duration_list):
+ """compute delay
+ Args:
+ receive_time_list (list): Time to receive each packet
+ chunk_duration_list (list): The audio duration corresponding to each packet
+ Returns:
+ [list]: Delay time list
+ """
+ assert (len(receive_time_list) == len(chunk_duration_list))
+ delay_time_list = []
+ play_time = receive_time_list[0] + chunk_duration_list[0]
+ for i in range(1, len(receive_time_list)):
+ receive_time = receive_time_list[i]
+ delay_time = receive_time - play_time
+ # 有延迟
+ if delay_time > 0:
+ play_time = play_time + delay_time + chunk_duration_list[i]
+ delay_time_list.append(delay_time)
+ # 没有延迟
+ else:
+ play_time = play_time + chunk_duration_list[i]
+
+ return delay_time_list
+
+
+def count_engine(logfile: str="./nohup.out"):
+ """For inference on the statistical engine side
+ Args:
+ logfile (str, optional): server log. Defaults to "./nohup.out".
+ """
+ first_response_list = []
+ final_response_list = []
+ duration_list = []
+
+ with open(logfile, "r") as f:
+ for line in f.readlines():
+ if "- first response time:" in line:
+ first_response = float(line.splie(" ")[-2])
+ first_response_list.append(first_response)
+ elif "- final response time:" in line:
+ final_response = float(line.splie(" ")[-2])
+ final_response_list.append(final_response)
+ elif "- The durations of audio is:" in line:
+ duration = float(line.splie(" ")[-2])
+ duration_list.append(duration)
+
+ assert (len(first_response_list) == len(final_response_list) and
+ len(final_response_list) == len(duration_list))
+
+ avg_first_response = sum(first_response_list) / len(first_response_list)
+ avg_final_response = sum(final_response_list) / len(final_response_list)
+ avg_duration = sum(duration_list) / len(duration_list)
+ RTF = sum(final_response_list) / sum(duration_list)
+
+ print(
+ "************************* engine result ***************************************"
+ )
+ print(
+ f"test num: {len(duration_list)}, avg first response: {avg_first_response} s, avg final response: {avg_final_response} s, avg duration: {avg_duration}, RTF: {RTF}"
+ )
+ print(
+ f"min duration: {min(duration_list)} s, max duration: {max(duration_list)} s"
+ )
+ print(
+ f"max first response: {max(first_response_list)} s, min first response: {min(first_response_list)} s"
+ )
+ print(
+ f"max final response: {max(final_response_list)} s, min final response: {min(final_response_list)} s"
+ )
diff --git a/paddlespeech/server/ws/api.py b/paddlespeech/server/ws/api.py
index 313fd16f5..83d542a11 100644
--- a/paddlespeech/server/ws/api.py
+++ b/paddlespeech/server/ws/api.py
@@ -15,8 +15,8 @@ from typing import List
from fastapi import APIRouter
-from paddlespeech.server.ws.asr_socket import router as asr_router
-from paddlespeech.server.ws.tts_socket import router as tts_router
+from paddlespeech.server.ws.asr_api import router as asr_router
+from paddlespeech.server.ws.tts_api import router as tts_router
_router = APIRouter()
diff --git a/paddlespeech/server/ws/asr_socket.py b/paddlespeech/server/ws/asr_api.py
similarity index 74%
rename from paddlespeech/server/ws/asr_socket.py
rename to paddlespeech/server/ws/asr_api.py
index 68686d3dd..ae1c88310 100644
--- a/paddlespeech/server/ws/asr_socket.py
+++ b/paddlespeech/server/ws/asr_api.py
@@ -18,9 +18,8 @@ from fastapi import WebSocket
from fastapi import WebSocketDisconnect
from starlette.websockets import WebSocketState as WebSocketState
-from paddlespeech.server.engine.asr.online.asr_engine import PaddleASRConnectionHanddler
+from paddlespeech.cli.log import logger
from paddlespeech.server.engine.engine_pool import get_engine_pool
-
router = APIRouter()
@@ -38,7 +37,7 @@ async def websocket_endpoint(websocket: WebSocket):
#2. if we accept the websocket headers, we will get the online asr engine instance
engine_pool = get_engine_pool()
- asr_engine = engine_pool['asr']
+ asr_model = engine_pool['asr']
#3. each websocket connection, we will create an PaddleASRConnectionHanddler to process such audio
# and each connection has its own connection instance to process the request
@@ -70,7 +69,8 @@ async def websocket_endpoint(websocket: WebSocket):
resp = {"status": "ok", "signal": "server_ready"}
# do something at begining here
# create the instance to process the audio
- connection_handler = PaddleASRConnectionHanddler(asr_engine)
+ #connection_handler = PaddleASRConnectionHanddler(asr_model)
+ connection_handler = asr_model.new_handler()
await websocket.send_json(resp)
elif message['signal'] == 'end':
# reset single engine for an new connection
@@ -78,18 +78,21 @@ async def websocket_endpoint(websocket: WebSocket):
connection_handler.decode(is_finished=True)
connection_handler.rescoring()
asr_results = connection_handler.get_result()
+ word_time_stamp = connection_handler.get_word_time_stamp()
connection_handler.reset()
resp = {
"status": "ok",
"signal": "finished",
- 'result': asr_results
+ 'result': asr_results,
+ 'times': word_time_stamp
}
await websocket.send_json(resp)
break
else:
resp = {"status": "ok", "message": "no valid json data"}
await websocket.send_json(resp)
+
elif "bytes" in message:
# bytes for the pcm data
message = message["bytes"]
@@ -98,11 +101,34 @@ async def websocket_endpoint(websocket: WebSocket):
# and decode for the result in this package data
connection_handler.extract_feat(message)
connection_handler.decode(is_finished=False)
+
+ if connection_handler.endpoint_state:
+ logger.info("endpoint: detected and rescoring.")
+ connection_handler.rescoring()
+ word_time_stamp = connection_handler.get_word_time_stamp()
+
asr_results = connection_handler.get_result()
- # return the current period result
- # if the engine create the vad instance, this connection will have many period results
+ if connection_handler.endpoint_state:
+ if connection_handler.continuous_decoding:
+ logger.info("endpoint: continue decoding")
+ connection_handler.reset_continuous_decoding()
+ else:
+ logger.info("endpoint: exit decoding")
+ # ending by endpoint
+ resp = {
+ "status": "ok",
+ "signal": "finished",
+ 'result': asr_results,
+ 'times': word_time_stamp
+ }
+ await websocket.send_json(resp)
+ break
+
+ # return the current partial result
+ # if the engine create the vad instance, this connection will have many partial results
resp = {'result': asr_results}
await websocket.send_json(resp)
- except WebSocketDisconnect:
- pass
+
+ except WebSocketDisconnect as e:
+ logger.error(e)
diff --git a/paddlespeech/server/ws/tts_api.py b/paddlespeech/server/ws/tts_api.py
new file mode 100644
index 000000000..3d8b222ea
--- /dev/null
+++ b/paddlespeech/server/ws/tts_api.py
@@ -0,0 +1,118 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import json
+import uuid
+
+from fastapi import APIRouter
+from fastapi import WebSocket
+from starlette.websockets import WebSocketState as WebSocketState
+
+from paddlespeech.cli.log import logger
+from paddlespeech.server.engine.engine_pool import get_engine_pool
+
+router = APIRouter()
+
+
+@router.websocket('/paddlespeech/tts/streaming')
+async def websocket_endpoint(websocket: WebSocket):
+ """PaddleSpeech Online TTS Server api
+
+ Args:
+ websocket (WebSocket): the websocket instance
+ """
+
+ #1. the interface wait to accept the websocket protocal header
+ # and only we receive the header, it establish the connection with specific thread
+ await websocket.accept()
+
+ #2. if we accept the websocket headers, we will get the online tts engine instance
+ engine_pool = get_engine_pool()
+ tts_engine = engine_pool['tts']
+
+ connection_handler = None
+
+ if tts_engine.engine_type == "online":
+ from paddlespeech.server.engine.tts.online.python.tts_engine import PaddleTTSConnectionHandler
+ elif tts_engine.engine_type == "online-onnx":
+ from paddlespeech.server.engine.tts.online.onnx.tts_engine import PaddleTTSConnectionHandler
+ else:
+ logger.error("Online tts engine only support online or online-onnx.")
+ sys.exit(-1)
+
+ try:
+ while True:
+ # careful here, changed the source code from starlette.websockets
+ assert websocket.application_state == WebSocketState.CONNECTED
+ message = await websocket.receive()
+ websocket._raise_on_disconnect(message)
+ message = json.loads(message["text"])
+
+ if 'signal' in message:
+ # start request
+ if message['signal'] == 'start':
+ session = uuid.uuid1().hex
+ resp = {
+ "status": 0,
+ "signal": "server ready",
+ "session": session
+ }
+
+ connection_handler = PaddleTTSConnectionHandler(tts_engine)
+ await websocket.send_json(resp)
+
+ # end request
+ elif message['signal'] == 'end':
+ connection_handler = None
+ resp = {
+ "status": 0,
+ "signal": "connection will be closed",
+ "session": session
+ }
+ await websocket.send_json(resp)
+ break
+ else:
+ resp = {"status": 0, "signal": "no valid json data"}
+ await websocket.send_json(resp)
+
+ # speech synthesis request
+ elif 'text' in message:
+ text_bese64 = message["text"]
+ sentence = connection_handler.preprocess(
+ text_bese64=text_bese64)
+
+ # run
+ wav_generator = connection_handler.run(sentence)
+
+ while True:
+ try:
+ tts_results = next(wav_generator)
+ resp = {"status": 1, "audio": tts_results}
+ await websocket.send_json(resp)
+ except StopIteration as e:
+ resp = {"status": 2, "audio": ''}
+ await websocket.send_json(resp)
+ logger.info(
+ "Complete the synthesis of the audio streams")
+ break
+ except Exception as e:
+ resp = {"status": -1, "audio": ''}
+ await websocket.send_json(resp)
+ break
+
+ else:
+ logger.error(
+ "Invalid request, please check if the request is correct.")
+
+ except Exception as e:
+ logger.error(e)
diff --git a/paddlespeech/server/ws/tts_socket.py b/paddlespeech/server/ws/tts_socket.py
deleted file mode 100644
index 699ee412b..000000000
--- a/paddlespeech/server/ws/tts_socket.py
+++ /dev/null
@@ -1,61 +0,0 @@
-# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import json
-
-from fastapi import APIRouter
-from fastapi import WebSocket
-from fastapi import WebSocketDisconnect
-from starlette.websockets import WebSocketState as WebSocketState
-
-from paddlespeech.cli.log import logger
-from paddlespeech.server.engine.engine_pool import get_engine_pool
-
-router = APIRouter()
-
-
-@router.websocket('/ws/tts')
-async def websocket_endpoint(websocket: WebSocket):
- await websocket.accept()
-
- try:
- # careful here, changed the source code from starlette.websockets
- assert websocket.application_state == WebSocketState.CONNECTED
- message = await websocket.receive()
- websocket._raise_on_disconnect(message)
-
- # get engine
- engine_pool = get_engine_pool()
- tts_engine = engine_pool['tts']
-
- # 获取 message 并转文本
- message = json.loads(message["text"])
- text_bese64 = message["text"]
- sentence = tts_engine.preprocess(text_bese64=text_bese64)
-
- # run
- wav_generator = tts_engine.run(sentence)
-
- while True:
- try:
- tts_results = next(wav_generator)
- resp = {"status": 1, "audio": tts_results}
- await websocket.send_json(resp)
- except StopIteration as e:
- resp = {"status": 2, "audio": ''}
- await websocket.send_json(resp)
- logger.info("Complete the transmission of audio streams")
- break
-
- except WebSocketDisconnect:
- pass
diff --git a/paddlespeech/t2s/datasets/am_batch_fn.py b/paddlespeech/t2s/datasets/am_batch_fn.py
index 4e3ad3c12..0b278abaf 100644
--- a/paddlespeech/t2s/datasets/am_batch_fn.py
+++ b/paddlespeech/t2s/datasets/am_batch_fn.py
@@ -293,3 +293,45 @@ def transformer_single_spk_batch_fn(examples):
"speech_lengths": speech_lengths,
}
return batch
+
+
+def vits_single_spk_batch_fn(examples):
+ """
+ Returns:
+ Dict[str, Any]:
+ - text (Tensor): Text index tensor (B, T_text).
+ - text_lengths (Tensor): Text length tensor (B,).
+ - feats (Tensor): Feature tensor (B, T_feats, aux_channels).
+ - feats_lengths (Tensor): Feature length tensor (B,).
+ - speech (Tensor): Speech waveform tensor (B, T_wav).
+
+ """
+ # fields = ["text", "text_lengths", "feats", "feats_lengths", "speech"]
+ text = [np.array(item["text"], dtype=np.int64) for item in examples]
+ feats = [np.array(item["feats"], dtype=np.float32) for item in examples]
+ speech = [np.array(item["wave"], dtype=np.float32) for item in examples]
+ text_lengths = [
+ np.array(item["text_lengths"], dtype=np.int64) for item in examples
+ ]
+ feats_lengths = [
+ np.array(item["feats_lengths"], dtype=np.int64) for item in examples
+ ]
+
+ text = batch_sequences(text)
+ feats = batch_sequences(feats)
+ speech = batch_sequences(speech)
+
+ # convert each batch to paddle.Tensor
+ text = paddle.to_tensor(text)
+ feats = paddle.to_tensor(feats)
+ text_lengths = paddle.to_tensor(text_lengths)
+ feats_lengths = paddle.to_tensor(feats_lengths)
+
+ batch = {
+ "text": text,
+ "text_lengths": text_lengths,
+ "feats": feats,
+ "feats_lengths": feats_lengths,
+ "speech": speech
+ }
+ return batch
diff --git a/paddlespeech/t2s/datasets/batch.py b/paddlespeech/t2s/datasets/batch.py
index 9d83bbe09..4f21d4470 100644
--- a/paddlespeech/t2s/datasets/batch.py
+++ b/paddlespeech/t2s/datasets/batch.py
@@ -167,7 +167,6 @@ def batch_spec(minibatch, pad_value=0., time_major=False, dtype=np.float32):
def batch_sequences(sequences, axis=0, pad_value=0):
- # import pdb; pdb.set_trace()
seq = sequences[0]
ndim = seq.ndim
if axis < 0:
diff --git a/paddlespeech/t2s/datasets/get_feats.py b/paddlespeech/t2s/datasets/get_feats.py
index b4bea0bd0..21458f152 100644
--- a/paddlespeech/t2s/datasets/get_feats.py
+++ b/paddlespeech/t2s/datasets/get_feats.py
@@ -20,15 +20,14 @@ from scipy.interpolate import interp1d
class LogMelFBank():
def __init__(self,
- sr=24000,
- n_fft=2048,
- hop_length=300,
- win_length=None,
- window="hann",
- n_mels=80,
- fmin=80,
- fmax=7600,
- eps=1e-10):
+ sr: int=24000,
+ n_fft: int=2048,
+ hop_length: int=300,
+ win_length: int=None,
+ window: str="hann",
+ n_mels: int=80,
+ fmin: int=80,
+ fmax: int=7600):
self.sr = sr
# stft
self.n_fft = n_fft
@@ -54,7 +53,7 @@ class LogMelFBank():
fmax=self.fmax)
return mel_filter
- def _stft(self, wav):
+ def _stft(self, wav: np.ndarray):
D = librosa.core.stft(
wav,
n_fft=self.n_fft,
@@ -65,11 +64,11 @@ class LogMelFBank():
pad_mode=self.pad_mode)
return D
- def _spectrogram(self, wav):
+ def _spectrogram(self, wav: np.ndarray):
D = self._stft(wav)
return np.abs(D)
- def _mel_spectrogram(self, wav):
+ def _mel_spectrogram(self, wav: np.ndarray):
S = self._spectrogram(wav)
mel = np.dot(self.mel_filter, S)
return mel
@@ -90,14 +89,18 @@ class LogMelFBank():
class Pitch():
- def __init__(self, sr=24000, hop_length=300, f0min=80, f0max=7600):
+ def __init__(self,
+ sr: int=24000,
+ hop_length: int=300,
+ f0min: int=80,
+ f0max: int=7600):
self.sr = sr
self.hop_length = hop_length
self.f0min = f0min
self.f0max = f0max
- def _convert_to_continuous_f0(self, f0: np.array) -> np.array:
+ def _convert_to_continuous_f0(self, f0: np.ndarray) -> np.ndarray:
if (f0 == 0).all():
print("All frames seems to be unvoiced.")
return f0
@@ -120,9 +123,9 @@ class Pitch():
return f0
def _calculate_f0(self,
- input: np.array,
- use_continuous_f0=True,
- use_log_f0=True) -> np.array:
+ input: np.ndarray,
+ use_continuous_f0: bool=True,
+ use_log_f0: bool=True) -> np.ndarray:
input = input.astype(np.float)
frame_period = 1000 * self.hop_length / self.sr
f0, timeaxis = pyworld.dio(
@@ -139,7 +142,8 @@ class Pitch():
f0[nonzero_idxs] = np.log(f0[nonzero_idxs])
return f0.reshape(-1)
- def _average_by_duration(self, input: np.array, d: np.array) -> np.array:
+ def _average_by_duration(self, input: np.ndarray,
+ d: np.ndarray) -> np.ndarray:
d_cumsum = np.pad(d.cumsum(0), (1, 0), 'constant')
arr_list = []
for start, end in zip(d_cumsum[:-1], d_cumsum[1:]):
@@ -154,11 +158,11 @@ class Pitch():
return arr_list
def get_pitch(self,
- wav,
- use_continuous_f0=True,
- use_log_f0=True,
- use_token_averaged_f0=True,
- duration=None):
+ wav: np.ndarray,
+ use_continuous_f0: bool=True,
+ use_log_f0: bool=True,
+ use_token_averaged_f0: bool=True,
+ duration: np.ndarray=None):
f0 = self._calculate_f0(wav, use_continuous_f0, use_log_f0)
if use_token_averaged_f0 and duration is not None:
f0 = self._average_by_duration(f0, duration)
@@ -167,15 +171,13 @@ class Pitch():
class Energy():
def __init__(self,
- sr=24000,
- n_fft=2048,
- hop_length=300,
- win_length=None,
- window="hann",
- center=True,
- pad_mode="reflect"):
+ n_fft: int=2048,
+ hop_length: int=300,
+ win_length: int=None,
+ window: str="hann",
+ center: bool=True,
+ pad_mode: str="reflect"):
- self.sr = sr
self.n_fft = n_fft
self.win_length = win_length
self.hop_length = hop_length
@@ -183,7 +185,7 @@ class Energy():
self.center = center
self.pad_mode = pad_mode
- def _stft(self, wav):
+ def _stft(self, wav: np.ndarray):
D = librosa.core.stft(
wav,
n_fft=self.n_fft,
@@ -194,7 +196,7 @@ class Energy():
pad_mode=self.pad_mode)
return D
- def _calculate_energy(self, input):
+ def _calculate_energy(self, input: np.ndarray):
input = input.astype(np.float32)
input_stft = self._stft(input)
input_power = np.abs(input_stft)**2
@@ -203,7 +205,8 @@ class Energy():
np.sum(input_power, axis=0), a_min=1.0e-10, a_max=float('inf')))
return energy
- def _average_by_duration(self, input: np.array, d: np.array) -> np.array:
+ def _average_by_duration(self, input: np.ndarray,
+ d: np.ndarray) -> np.ndarray:
d_cumsum = np.pad(d.cumsum(0), (1, 0), 'constant')
arr_list = []
for start, end in zip(d_cumsum[:-1], d_cumsum[1:]):
@@ -214,8 +217,49 @@ class Energy():
arr_list = np.expand_dims(np.array(arr_list), 0).T
return arr_list
- def get_energy(self, wav, use_token_averaged_energy=True, duration=None):
+ def get_energy(self,
+ wav: np.ndarray,
+ use_token_averaged_energy: bool=True,
+ duration: np.ndarray=None):
energy = self._calculate_energy(wav)
if use_token_averaged_energy and duration is not None:
energy = self._average_by_duration(energy, duration)
return energy
+
+
+class LinearSpectrogram():
+ def __init__(
+ self,
+ n_fft: int=1024,
+ win_length: int=None,
+ hop_length: int=256,
+ window: str="hann",
+ center: bool=True, ):
+ self.n_fft = n_fft
+ self.hop_length = hop_length
+ self.win_length = win_length
+ self.window = window
+ self.center = center
+ self.n_fft = n_fft
+ self.pad_mode = "reflect"
+
+ def _stft(self, wav: np.ndarray):
+ D = librosa.core.stft(
+ wav,
+ n_fft=self.n_fft,
+ hop_length=self.hop_length,
+ win_length=self.win_length,
+ window=self.window,
+ center=self.center,
+ pad_mode=self.pad_mode)
+ return D
+
+ def _spectrogram(self, wav: np.ndarray):
+ D = self._stft(wav)
+ return np.abs(D)
+
+ def get_linear_spectrogram(self, wav: np.ndarray):
+ linear_spectrogram = self._spectrogram(wav)
+ linear_spectrogram = np.clip(
+ linear_spectrogram, a_min=1e-10, a_max=float("inf"))
+ return linear_spectrogram.T
diff --git a/paddlespeech/t2s/exps/fastspeech2/preprocess.py b/paddlespeech/t2s/exps/fastspeech2/preprocess.py
index db1842b2e..eac75f982 100644
--- a/paddlespeech/t2s/exps/fastspeech2/preprocess.py
+++ b/paddlespeech/t2s/exps/fastspeech2/preprocess.py
@@ -55,8 +55,11 @@ def process_sentence(config: Dict[str, Any],
if utt_id in sentences:
# reading, resampling may occur
wav, _ = librosa.load(str(fp), sr=config.fs)
- if len(wav.shape) != 1 or np.abs(wav).max() > 1.0:
+ if len(wav.shape) != 1:
return record
+ max_value = np.abs(wav).max()
+ if max_value > 1.0:
+ wav = wav / max_value
assert len(wav.shape) == 1, f"{utt_id} is not a mono-channel audio."
assert np.abs(wav).max(
) <= 1.0, f"{utt_id} is seems to be different that 16 bit PCM."
@@ -144,10 +147,17 @@ def process_sentences(config,
spk_emb_dir: Path=None):
if nprocs == 1:
results = []
- for fp in fps:
- record = process_sentence(config, fp, sentences, output_dir,
- mel_extractor, pitch_extractor,
- energy_extractor, cut_sil, spk_emb_dir)
+ for fp in tqdm.tqdm(fps, total=len(fps)):
+ record = process_sentence(
+ config=config,
+ fp=fp,
+ sentences=sentences,
+ output_dir=output_dir,
+ mel_extractor=mel_extractor,
+ pitch_extractor=pitch_extractor,
+ energy_extractor=energy_extractor,
+ cut_sil=cut_sil,
+ spk_emb_dir=spk_emb_dir)
if record:
results.append(record)
else:
@@ -322,7 +332,6 @@ def main():
f0min=config.f0min,
f0max=config.f0max)
energy_extractor = Energy(
- sr=config.fs,
n_fft=config.n_fft,
hop_length=config.n_shift,
win_length=config.win_length,
@@ -331,36 +340,36 @@ def main():
# process for the 3 sections
if train_wav_files:
process_sentences(
- config,
- train_wav_files,
- sentences,
- train_dump_dir,
- mel_extractor,
- pitch_extractor,
- energy_extractor,
+ config=config,
+ fps=train_wav_files,
+ sentences=sentences,
+ output_dir=train_dump_dir,
+ mel_extractor=mel_extractor,
+ pitch_extractor=pitch_extractor,
+ energy_extractor=energy_extractor,
nprocs=args.num_cpu,
cut_sil=args.cut_sil,
spk_emb_dir=spk_emb_dir)
if dev_wav_files:
process_sentences(
- config,
- dev_wav_files,
- sentences,
- dev_dump_dir,
- mel_extractor,
- pitch_extractor,
- energy_extractor,
+ config=config,
+ fps=dev_wav_files,
+ sentences=sentences,
+ output_dir=dev_dump_dir,
+ mel_extractor=mel_extractor,
+ pitch_extractor=pitch_extractor,
+ energy_extractor=energy_extractor,
cut_sil=args.cut_sil,
spk_emb_dir=spk_emb_dir)
if test_wav_files:
process_sentences(
- config,
- test_wav_files,
- sentences,
- test_dump_dir,
- mel_extractor,
- pitch_extractor,
- energy_extractor,
+ config=config,
+ fps=test_wav_files,
+ sentences=sentences,
+ output_dir=test_dump_dir,
+ mel_extractor=mel_extractor,
+ pitch_extractor=pitch_extractor,
+ energy_extractor=energy_extractor,
nprocs=args.num_cpu,
cut_sil=args.cut_sil,
spk_emb_dir=spk_emb_dir)
diff --git a/paddlespeech/t2s/exps/gan_vocoder/hifigan/train.py b/paddlespeech/t2s/exps/gan_vocoder/hifigan/train.py
index c70821e78..4c733dc9b 100644
--- a/paddlespeech/t2s/exps/gan_vocoder/hifigan/train.py
+++ b/paddlespeech/t2s/exps/gan_vocoder/hifigan/train.py
@@ -243,8 +243,7 @@ def main():
# parse args and config and redirect to train_sp
parser = argparse.ArgumentParser(description="Train a HiFiGAN model.")
- parser.add_argument(
- "--config", type=str, help="config file to overwrite default config.")
+ parser.add_argument("--config", type=str, help="HiFiGAN config file.")
parser.add_argument("--train-metadata", type=str, help="training data.")
parser.add_argument("--dev-metadata", type=str, help="dev data.")
parser.add_argument("--output-dir", type=str, help="output dir.")
diff --git a/paddlespeech/t2s/exps/gan_vocoder/multi_band_melgan/train.py b/paddlespeech/t2s/exps/gan_vocoder/multi_band_melgan/train.py
index 27ffded63..3b3ebb478 100644
--- a/paddlespeech/t2s/exps/gan_vocoder/multi_band_melgan/train.py
+++ b/paddlespeech/t2s/exps/gan_vocoder/multi_band_melgan/train.py
@@ -233,7 +233,7 @@ def main():
parser = argparse.ArgumentParser(
description="Train a Multi-Band MelGAN model.")
parser.add_argument(
- "--config", type=str, help="config file to overwrite default config.")
+ "--config", type=str, help="Multi-Band MelGAN config file.")
parser.add_argument("--train-metadata", type=str, help="training data.")
parser.add_argument("--dev-metadata", type=str, help="dev data.")
parser.add_argument("--output-dir", type=str, help="output dir.")
diff --git a/paddlespeech/t2s/exps/gan_vocoder/parallelwave_gan/train.py b/paddlespeech/t2s/exps/gan_vocoder/parallelwave_gan/train.py
index 92de7a2c4..b26407028 100644
--- a/paddlespeech/t2s/exps/gan_vocoder/parallelwave_gan/train.py
+++ b/paddlespeech/t2s/exps/gan_vocoder/parallelwave_gan/train.py
@@ -208,7 +208,7 @@ def main():
parser = argparse.ArgumentParser(
description="Train a ParallelWaveGAN model.")
parser.add_argument(
- "--config", type=str, help="config file to overwrite default config.")
+ "--config", type=str, help="ParallelWaveGAN config file.")
parser.add_argument("--train-metadata", type=str, help="training data.")
parser.add_argument("--dev-metadata", type=str, help="dev data.")
parser.add_argument("--output-dir", type=str, help="output dir.")
diff --git a/paddlespeech/t2s/exps/gan_vocoder/preprocess.py b/paddlespeech/t2s/exps/gan_vocoder/preprocess.py
index 4871bca71..546367964 100644
--- a/paddlespeech/t2s/exps/gan_vocoder/preprocess.py
+++ b/paddlespeech/t2s/exps/gan_vocoder/preprocess.py
@@ -47,8 +47,11 @@ def process_sentence(config: Dict[str, Any],
if utt_id in sentences:
# reading, resampling may occur
y, _ = librosa.load(str(fp), sr=config.fs)
- if len(y.shape) != 1 or np.abs(y).max() > 1.0:
+ if len(y.shape) != 1:
return record
+ max_value = np.abs(y).max()
+ if max_value > 1.0:
+ y = y / max_value
assert len(y.shape) == 1, f"{utt_id} is not a mono-channel audio."
assert np.abs(y).max(
) <= 1.0, f"{utt_id} is seems to be different that 16 bit PCM."
@@ -85,15 +88,17 @@ def process_sentence(config: Dict[str, Any],
y, (0, num_frames * config.n_shift - y.size), mode="reflect")
else:
y = y[:num_frames * config.n_shift]
- num_sample = y.shape[0]
+ num_samples = y.shape[0]
mel_path = output_dir / (utt_id + "_feats.npy")
wav_path = output_dir / (utt_id + "_wave.npy")
- np.save(wav_path, y) # (num_samples, )
- np.save(mel_path, logmel) # (num_frames, n_mels)
+ # (num_samples, )
+ np.save(wav_path, y)
+ # (num_frames, n_mels)
+ np.save(mel_path, logmel)
record = {
"utt_id": utt_id,
- "num_samples": num_sample,
+ "num_samples": num_samples,
"num_frames": num_frames,
"feats": str(mel_path),
"wave": str(wav_path),
@@ -108,11 +113,17 @@ def process_sentences(config,
mel_extractor=None,
nprocs: int=1,
cut_sil: bool=True):
+
if nprocs == 1:
results = []
for fp in tqdm.tqdm(fps, total=len(fps)):
- record = process_sentence(config, fp, sentences, output_dir,
- mel_extractor, cut_sil)
+ record = process_sentence(
+ config=config,
+ fp=fp,
+ sentences=sentences,
+ output_dir=output_dir,
+ mel_extractor=mel_extractor,
+ cut_sil=cut_sil)
if record:
results.append(record)
else:
@@ -147,7 +158,7 @@ def main():
"--dataset",
default="baker",
type=str,
- help="name of dataset, should in {baker, ljspeech, vctk} now")
+ help="name of dataset, should in {baker, aishell3, ljspeech, vctk} now")
parser.add_argument(
"--rootdir", default=None, type=str, help="directory to dataset.")
parser.add_argument(
@@ -261,28 +272,28 @@ def main():
# process for the 3 sections
if train_wav_files:
process_sentences(
- config,
- train_wav_files,
- sentences,
- train_dump_dir,
+ config=config,
+ fps=train_wav_files,
+ sentences=sentences,
+ output_dir=train_dump_dir,
mel_extractor=mel_extractor,
nprocs=args.num_cpu,
cut_sil=args.cut_sil)
if dev_wav_files:
process_sentences(
- config,
- dev_wav_files,
- sentences,
- dev_dump_dir,
+ config=config,
+ fps=dev_wav_files,
+ sentences=sentences,
+ output_dir=dev_dump_dir,
mel_extractor=mel_extractor,
nprocs=args.num_cpu,
cut_sil=args.cut_sil)
if test_wav_files:
process_sentences(
- config,
- test_wav_files,
- sentences,
- test_dump_dir,
+ config=config,
+ fps=test_wav_files,
+ sentences=sentences,
+ output_dir=test_dump_dir,
mel_extractor=mel_extractor,
nprocs=args.num_cpu,
cut_sil=args.cut_sil)
diff --git a/paddlespeech/t2s/exps/gan_vocoder/style_melgan/train.py b/paddlespeech/t2s/exps/gan_vocoder/style_melgan/train.py
index be3ba7425..a87cc7a18 100644
--- a/paddlespeech/t2s/exps/gan_vocoder/style_melgan/train.py
+++ b/paddlespeech/t2s/exps/gan_vocoder/style_melgan/train.py
@@ -224,8 +224,7 @@ def main():
# parse args and config and redirect to train_sp
parser = argparse.ArgumentParser(description="Train a Style MelGAN model.")
- parser.add_argument(
- "--config", type=str, help="config file to overwrite default config.")
+ parser.add_argument("--config", type=str, help="Style MelGAN config file.")
parser.add_argument("--train-metadata", type=str, help="training data.")
parser.add_argument("--dev-metadata", type=str, help="dev data.")
parser.add_argument("--output-dir", type=str, help="output dir.")
diff --git a/paddlespeech/t2s/exps/inference_streaming.py b/paddlespeech/t2s/exps/inference_streaming.py
index b680f19a9..624defc6a 100644
--- a/paddlespeech/t2s/exps/inference_streaming.py
+++ b/paddlespeech/t2s/exps/inference_streaming.py
@@ -90,7 +90,7 @@ def parse_args():
default=False,
help="whether use streaming acoustic model")
parser.add_argument(
- "--chunk_size", type=int, default=42, help="chunk size of am streaming")
+ "--block_size", type=int, default=42, help="block size of am streaming")
parser.add_argument(
"--pad_size", type=int, default=12, help="pad size of am streaming")
@@ -169,7 +169,7 @@ def main():
N = 0
T = 0
- chunk_size = args.chunk_size
+ block_size = args.block_size
pad_size = args.pad_size
get_tone_ids = False
for utt_id, sentence in sentences:
@@ -189,7 +189,7 @@ def main():
am_encoder_infer_predictor, input=phones)
if args.am_streaming:
- hss = get_chunks(orig_hs, chunk_size, pad_size)
+ hss = get_chunks(orig_hs, block_size, pad_size)
chunk_num = len(hss)
mel_list = []
for i, hs in enumerate(hss):
@@ -211,7 +211,7 @@ def main():
sub_mel = sub_mel[pad_size:]
else:
# 倒数几块的右侧也可能没有 pad 够
- sub_mel = sub_mel[pad_size:(chunk_size + pad_size) -
+ sub_mel = sub_mel[pad_size:(block_size + pad_size) -
sub_mel.shape[0]]
mel_list.append(sub_mel)
mel = np.concatenate(mel_list, axis=0)
diff --git a/paddlespeech/t2s/exps/ort_predict_streaming.py b/paddlespeech/t2s/exps/ort_predict_streaming.py
index 5d2c66bc9..d5241f1c6 100644
--- a/paddlespeech/t2s/exps/ort_predict_streaming.py
+++ b/paddlespeech/t2s/exps/ort_predict_streaming.py
@@ -97,7 +97,7 @@ def ort_predict(args):
T = 0
merge_sentences = True
get_tone_ids = False
- chunk_size = args.chunk_size
+ block_size = args.block_size
pad_size = args.pad_size
for utt_id, sentence in sentences:
@@ -115,7 +115,7 @@ def ort_predict(args):
orig_hs = am_encoder_infer_sess.run(
None, input_feed={'text': phone_ids})
if args.am_streaming:
- hss = get_chunks(orig_hs[0], chunk_size, pad_size)
+ hss = get_chunks(orig_hs[0], block_size, pad_size)
chunk_num = len(hss)
mel_list = []
for i, hs in enumerate(hss):
@@ -139,7 +139,7 @@ def ort_predict(args):
sub_mel = sub_mel[pad_size:]
else:
# 倒数几块的右侧也可能没有 pad 够
- sub_mel = sub_mel[pad_size:(chunk_size + pad_size) -
+ sub_mel = sub_mel[pad_size:(block_size + pad_size) -
sub_mel.shape[0]]
mel_list.append(sub_mel)
mel = np.concatenate(mel_list, axis=0)
@@ -236,7 +236,7 @@ def parse_args():
default=False,
help="whether use streaming acoustic model")
parser.add_argument(
- "--chunk_size", type=int, default=42, help="chunk size of am streaming")
+ "--block_size", type=int, default=42, help="block size of am streaming")
parser.add_argument(
"--pad_size", type=int, default=12, help="pad size of am streaming")
diff --git a/paddlespeech/t2s/exps/speedyspeech/preprocess.py b/paddlespeech/t2s/exps/speedyspeech/preprocess.py
index e833d1394..aa7608d6b 100644
--- a/paddlespeech/t2s/exps/speedyspeech/preprocess.py
+++ b/paddlespeech/t2s/exps/speedyspeech/preprocess.py
@@ -47,8 +47,11 @@ def process_sentence(config: Dict[str, Any],
if utt_id in sentences:
# reading, resampling may occur
wav, _ = librosa.load(str(fp), sr=config.fs)
- if len(wav.shape) != 1 or np.abs(wav).max() > 1.0:
+ if len(wav.shape) != 1:
return record
+ max_value = np.abs(wav).max()
+ if max_value > 1.0:
+ wav = wav / max_value
assert len(wav.shape) == 1, f"{utt_id} is not a mono-channel audio."
assert np.abs(wav).max(
) <= 1.0, f"{utt_id} is seems to be different that 16 bit PCM."
@@ -123,11 +126,17 @@ def process_sentences(config,
nprocs: int=1,
cut_sil: bool=True,
use_relative_path: bool=False):
+
if nprocs == 1:
results = []
for fp in tqdm.tqdm(fps, total=len(fps)):
- record = process_sentence(config, fp, sentences, output_dir,
- mel_extractor, cut_sil)
+ record = process_sentence(
+ config=config,
+ fp=fp,
+ sentences=sentences,
+ output_dir=output_dir,
+ mel_extractor=mel_extractor,
+ cut_sil=cut_sil)
if record:
results.append(record)
else:
@@ -265,30 +274,30 @@ def main():
# process for the 3 sections
if train_wav_files:
process_sentences(
- config,
- train_wav_files,
- sentences,
- train_dump_dir,
- mel_extractor,
+ config=config,
+ fps=train_wav_files,
+ sentences=sentences,
+ output_dir=train_dump_dir,
+ mel_extractor=mel_extractor,
nprocs=args.num_cpu,
cut_sil=args.cut_sil,
use_relative_path=args.use_relative_path)
if dev_wav_files:
process_sentences(
- config,
- dev_wav_files,
- sentences,
- dev_dump_dir,
- mel_extractor,
+ config=config,
+ fps=dev_wav_files,
+ sentences=sentences,
+ output_dir=dev_dump_dir,
+ mel_extractor=mel_extractor,
cut_sil=args.cut_sil,
use_relative_path=args.use_relative_path)
if test_wav_files:
process_sentences(
- config,
- test_wav_files,
- sentences,
- test_dump_dir,
- mel_extractor,
+ config=config,
+ fps=test_wav_files,
+ sentences=sentences,
+ output_dir=test_dump_dir,
+ mel_extractor=mel_extractor,
nprocs=args.num_cpu,
cut_sil=args.cut_sil,
use_relative_path=args.use_relative_path)
diff --git a/paddlespeech/t2s/exps/speedyspeech/synthesize_e2e.py b/paddlespeech/t2s/exps/speedyspeech/synthesize_e2e.py
index cb742c595..644ec250d 100644
--- a/paddlespeech/t2s/exps/speedyspeech/synthesize_e2e.py
+++ b/paddlespeech/t2s/exps/speedyspeech/synthesize_e2e.py
@@ -174,12 +174,20 @@ def main():
parser.add_argument(
"--inference-dir", type=str, help="dir to save inference models")
parser.add_argument(
- "--ngpu", type=int, default=1, help="if ngpu == 0, use cpu.")
+ "--ngpu", type=int, default=1, help="if ngpu == 0, use cpu or xpu.")
+ parser.add_argument(
+ "--nxpu",
+ type=int,
+ default=0,
+ help="if nxpu == 0 and ngpu == 0, use cpu.")
args, _ = parser.parse_known_args()
if args.ngpu == 0:
- paddle.set_device("cpu")
+ if args.nxpu == 0:
+ paddle.set_device("cpu")
+ else:
+ paddle.set_device("xpu")
elif args.ngpu > 0:
paddle.set_device("gpu")
else:
diff --git a/paddlespeech/t2s/exps/speedyspeech/train.py b/paddlespeech/t2s/exps/speedyspeech/train.py
index bda5370c1..7b422e64f 100644
--- a/paddlespeech/t2s/exps/speedyspeech/train.py
+++ b/paddlespeech/t2s/exps/speedyspeech/train.py
@@ -46,7 +46,10 @@ def train_sp(args, config):
# setup running environment correctly
world_size = paddle.distributed.get_world_size()
if (not paddle.is_compiled_with_cuda()) or args.ngpu == 0:
- paddle.set_device("cpu")
+ if (not paddle.is_compiled_with_xpu()) or args.nxpu == 0:
+ paddle.set_device("cpu")
+ else:
+ paddle.set_device("xpu")
else:
paddle.set_device("gpu")
if world_size > 1:
@@ -185,7 +188,12 @@ def main():
parser.add_argument("--dev-metadata", type=str, help="dev data.")
parser.add_argument("--output-dir", type=str, help="output dir.")
parser.add_argument(
- "--ngpu", type=int, default=1, help="if ngpu == 0, use cpu.")
+ "--nxpu",
+ type=int,
+ default=0,
+ help="if nxpu == 0 and ngpu == 0, use cpu.")
+ parser.add_argument(
+ "--ngpu", type=int, default=1, help="if ngpu == 0, use cpu or xpu")
parser.add_argument(
"--use-relative-path",
diff --git a/paddlespeech/t2s/exps/syn_utils.py b/paddlespeech/t2s/exps/syn_utils.py
index ce0aee05e..6b9f41a6b 100644
--- a/paddlespeech/t2s/exps/syn_utils.py
+++ b/paddlespeech/t2s/exps/syn_utils.py
@@ -27,11 +27,11 @@ from paddle import jit
from paddle.static import InputSpec
from yacs.config import CfgNode
-from paddlespeech.s2t.utils.dynamic_import import dynamic_import
from paddlespeech.t2s.datasets.data_table import DataTable
from paddlespeech.t2s.frontend import English
from paddlespeech.t2s.frontend.zh_frontend import Frontend
from paddlespeech.t2s.modules.normalizer import ZScore
+from paddlespeech.utils.dynamic_import import dynamic_import
model_alias = {
# acoustic model
@@ -75,13 +75,13 @@ def denorm(data, mean, std):
return data * std + mean
-def get_chunks(data, chunk_size: int, pad_size: int):
+def get_chunks(data, block_size: int, pad_size: int):
data_len = data.shape[1]
chunks = []
- n = math.ceil(data_len / chunk_size)
+ n = math.ceil(data_len / block_size)
for i in range(n):
- start = max(0, i * chunk_size - pad_size)
- end = min((i + 1) * chunk_size + pad_size, data_len)
+ start = max(0, i * block_size - pad_size)
+ end = min((i + 1) * block_size + pad_size, data_len)
chunks.append(data[:, start:end, :])
return chunks
diff --git a/paddlespeech/t2s/exps/synthesize.py b/paddlespeech/t2s/exps/synthesize.py
index 0855a6a2a..9ddab726e 100644
--- a/paddlespeech/t2s/exps/synthesize.py
+++ b/paddlespeech/t2s/exps/synthesize.py
@@ -107,8 +107,8 @@ def evaluate(args):
if args.voice_cloning and "spk_emb" in datum:
spk_emb = paddle.to_tensor(np.load(datum["spk_emb"]))
mel = am_inference(phone_ids, spk_emb=spk_emb)
- # vocoder
- wav = voc_inference(mel)
+ # vocoder
+ wav = voc_inference(mel)
wav = wav.numpy()
N += wav.size
@@ -125,7 +125,7 @@ def evaluate(args):
def parse_args():
- # parse args and config and redirect to train_sp
+ # parse args and config
parser = argparse.ArgumentParser(
description="Synthesize with acoustic model & vocoder")
# acoustic model
@@ -140,10 +140,7 @@ def parse_args():
],
help='Choose acoustic model type of tts task.')
parser.add_argument(
- '--am_config',
- type=str,
- default=None,
- help='Config of acoustic model. Use deault config when it is None.')
+ '--am_config', type=str, default=None, help='Config of acoustic model.')
parser.add_argument(
'--am_ckpt',
type=str,
@@ -179,10 +176,7 @@ def parse_args():
],
help='Choose vocoder type of tts task.')
parser.add_argument(
- '--voc_config',
- type=str,
- default=None,
- help='Config of voc. Use deault config when it is None.')
+ '--voc_config', type=str, default=None, help='Config of voc.')
parser.add_argument(
'--voc_ckpt', type=str, default=None, help='Checkpoint file of voc.')
parser.add_argument(
diff --git a/paddlespeech/t2s/exps/synthesize_e2e.py b/paddlespeech/t2s/exps/synthesize_e2e.py
index 2f14ef564..28657eb27 100644
--- a/paddlespeech/t2s/exps/synthesize_e2e.py
+++ b/paddlespeech/t2s/exps/synthesize_e2e.py
@@ -159,7 +159,7 @@ def evaluate(args):
def parse_args():
- # parse args and config and redirect to train_sp
+ # parse args and config
parser = argparse.ArgumentParser(
description="Synthesize with acoustic model & vocoder")
# acoustic model
@@ -174,10 +174,7 @@ def parse_args():
],
help='Choose acoustic model type of tts task.')
parser.add_argument(
- '--am_config',
- type=str,
- default=None,
- help='Config of acoustic model. Use deault config when it is None.')
+ '--am_config', type=str, default=None, help='Config of acoustic model.')
parser.add_argument(
'--am_ckpt',
type=str,
@@ -220,10 +217,7 @@ def parse_args():
],
help='Choose vocoder type of tts task.')
parser.add_argument(
- '--voc_config',
- type=str,
- default=None,
- help='Config of voc. Use deault config when it is None.')
+ '--voc_config', type=str, default=None, help='Config of voc.')
parser.add_argument(
'--voc_ckpt', type=str, default=None, help='Checkpoint file of voc.')
parser.add_argument(
diff --git a/paddlespeech/t2s/exps/synthesize_streaming.py b/paddlespeech/t2s/exps/synthesize_streaming.py
index 3659cb490..d8b23f1ad 100644
--- a/paddlespeech/t2s/exps/synthesize_streaming.py
+++ b/paddlespeech/t2s/exps/synthesize_streaming.py
@@ -24,7 +24,6 @@ from paddle.static import InputSpec
from timer import timer
from yacs.config import CfgNode
-from paddlespeech.s2t.utils.dynamic_import import dynamic_import
from paddlespeech.t2s.exps.syn_utils import denorm
from paddlespeech.t2s.exps.syn_utils import get_chunks
from paddlespeech.t2s.exps.syn_utils import get_frontend
@@ -33,6 +32,7 @@ from paddlespeech.t2s.exps.syn_utils import get_voc_inference
from paddlespeech.t2s.exps.syn_utils import model_alias
from paddlespeech.t2s.exps.syn_utils import voc_to_static
from paddlespeech.t2s.utils import str2bool
+from paddlespeech.utils.dynamic_import import dynamic_import
def evaluate(args):
@@ -133,7 +133,7 @@ def evaluate(args):
N = 0
T = 0
- chunk_size = args.chunk_size
+ block_size = args.block_size
pad_size = args.pad_size
for utt_id, sentence in sentences:
@@ -153,7 +153,7 @@ def evaluate(args):
# acoustic model
orig_hs = am_encoder_infer(phone_ids)
if args.am_streaming:
- hss = get_chunks(orig_hs, chunk_size, pad_size)
+ hss = get_chunks(orig_hs, block_size, pad_size)
chunk_num = len(hss)
mel_list = []
for i, hs in enumerate(hss):
@@ -171,7 +171,7 @@ def evaluate(args):
sub_mel = sub_mel[pad_size:]
else:
# 倒数几块的右侧也可能没有 pad 够
- sub_mel = sub_mel[pad_size:(chunk_size + pad_size) -
+ sub_mel = sub_mel[pad_size:(block_size + pad_size) -
sub_mel.shape[0]]
mel_list.append(sub_mel)
mel = paddle.concat(mel_list, axis=0)
@@ -201,7 +201,7 @@ def evaluate(args):
def parse_args():
- # parse args and config and redirect to train_sp
+ # parse args and config
parser = argparse.ArgumentParser(
description="Synthesize with acoustic model & vocoder")
# acoustic model
@@ -212,10 +212,7 @@ def parse_args():
choices=['fastspeech2_csmsc'],
help='Choose acoustic model type of tts task.')
parser.add_argument(
- '--am_config',
- type=str,
- default=None,
- help='Config of acoustic model. Use deault config when it is None.')
+ '--am_config', type=str, default=None, help='Config of acoustic model.')
parser.add_argument(
'--am_ckpt',
type=str,
@@ -245,10 +242,7 @@ def parse_args():
],
help='Choose vocoder type of tts task.')
parser.add_argument(
- '--voc_config',
- type=str,
- default=None,
- help='Config of voc. Use deault config when it is None.')
+ '--voc_config', type=str, default=None, help='Config of voc.')
parser.add_argument(
'--voc_ckpt', type=str, default=None, help='Checkpoint file of voc.')
parser.add_argument(
@@ -283,7 +277,7 @@ def parse_args():
default=False,
help="whether use streaming acoustic model")
parser.add_argument(
- "--chunk_size", type=int, default=42, help="chunk size of am streaming")
+ "--block_size", type=int, default=42, help="block size of am streaming")
parser.add_argument(
"--pad_size", type=int, default=12, help="pad size of am streaming")
diff --git a/paddlespeech/t2s/exps/tacotron2/preprocess.py b/paddlespeech/t2s/exps/tacotron2/preprocess.py
index 14a0d7eae..6137da7f1 100644
--- a/paddlespeech/t2s/exps/tacotron2/preprocess.py
+++ b/paddlespeech/t2s/exps/tacotron2/preprocess.py
@@ -51,8 +51,11 @@ def process_sentence(config: Dict[str, Any],
if utt_id in sentences:
# reading, resampling may occur
wav, _ = librosa.load(str(fp), sr=config.fs)
- if len(wav.shape) != 1 or np.abs(wav).max() > 1.0:
+ if len(wav.shape) != 1:
return record
+ max_value = np.abs(wav).max()
+ if max_value > 1.0:
+ wav = wav / max_value
assert len(wav.shape) == 1, f"{utt_id} is not a mono-channel audio."
assert np.abs(wav).max(
) <= 1.0, f"{utt_id} is seems to be different that 16 bit PCM."
@@ -122,9 +125,15 @@ def process_sentences(config,
spk_emb_dir: Path=None):
if nprocs == 1:
results = []
- for fp in fps:
- record = process_sentence(config, fp, sentences, output_dir,
- mel_extractor, cut_sil, spk_emb_dir)
+ for fp in tqdm.tqdm(fps, total=len(fps)):
+ record = process_sentence(
+ config=config,
+ fp=fp,
+ sentences=sentences,
+ output_dir=output_dir,
+ mel_extractor=mel_extractor,
+ cut_sil=cut_sil,
+ spk_emb_dir=spk_emb_dir)
if record:
results.append(record)
else:
@@ -296,30 +305,30 @@ def main():
# process for the 3 sections
if train_wav_files:
process_sentences(
- config,
- train_wav_files,
- sentences,
- train_dump_dir,
- mel_extractor,
+ config=config,
+ fps=train_wav_files,
+ sentences=sentences,
+ output_dir=train_dump_dir,
+ mel_extractor=mel_extractor,
nprocs=args.num_cpu,
cut_sil=args.cut_sil,
spk_emb_dir=spk_emb_dir)
if dev_wav_files:
process_sentences(
- config,
- dev_wav_files,
- sentences,
- dev_dump_dir,
- mel_extractor,
+ config=config,
+ fps=dev_wav_files,
+ sentences=sentences,
+ output_dir=dev_dump_dir,
+ mel_extractor=mel_extractor,
cut_sil=args.cut_sil,
spk_emb_dir=spk_emb_dir)
if test_wav_files:
process_sentences(
- config,
- test_wav_files,
- sentences,
- test_dump_dir,
- mel_extractor,
+ config=config,
+ fps=test_wav_files,
+ sentences=sentences,
+ output_dir=test_dump_dir,
+ mel_extractor=mel_extractor,
nprocs=args.num_cpu,
cut_sil=args.cut_sil,
spk_emb_dir=spk_emb_dir)
diff --git a/paddlespeech/t2s/exps/transformer_tts/preprocess.py b/paddlespeech/t2s/exps/transformer_tts/preprocess.py
index 9aa87e91a..28ca3de6e 100644
--- a/paddlespeech/t2s/exps/transformer_tts/preprocess.py
+++ b/paddlespeech/t2s/exps/transformer_tts/preprocess.py
@@ -125,11 +125,16 @@ def process_sentences(config,
output_dir: Path,
mel_extractor=None,
nprocs: int=1):
+
if nprocs == 1:
results = []
for fp in tqdm.tqdm(fps, total=len(fps)):
- record = process_sentence(config, fp, sentences, output_dir,
- mel_extractor)
+ record = process_sentence(
+ config=config,
+ fp=fp,
+ sentences=sentences,
+ output_dir=output_dir,
+ mel_extractor=mel_extractor)
if record:
results.append(record)
else:
@@ -247,27 +252,27 @@ def main():
# process for the 3 sections
if train_wav_files:
process_sentences(
- config,
- train_wav_files,
- sentences,
- train_dump_dir,
- mel_extractor,
+ config=config,
+ fps=train_wav_files,
+ sentences=sentences,
+ output_dir=train_dump_dir,
+ mel_extractor=mel_extractor,
nprocs=args.num_cpu)
if dev_wav_files:
process_sentences(
- config,
- dev_wav_files,
- sentences,
- dev_dump_dir,
- mel_extractor,
+ config=config,
+ fps=dev_wav_files,
+ sentences=sentences,
+ output_dir=dev_dump_dir,
+ mel_extractor=mel_extractor,
nprocs=args.num_cpu)
if test_wav_files:
process_sentences(
- config,
- test_wav_files,
- sentences,
- test_dump_dir,
- mel_extractor,
+ config=config,
+ fps=test_wav_files,
+ sentences=sentences,
+ output_dir=test_dump_dir,
+ mel_extractor=mel_extractor,
nprocs=args.num_cpu)
diff --git a/paddlespeech/t2s/exps/transformer_tts/train.py b/paddlespeech/t2s/exps/transformer_tts/train.py
index 45ecb269b..da48b6b99 100644
--- a/paddlespeech/t2s/exps/transformer_tts/train.py
+++ b/paddlespeech/t2s/exps/transformer_tts/train.py
@@ -160,7 +160,7 @@ def main():
parser = argparse.ArgumentParser(description="Train a TransformerTTS "
"model with LJSpeech TTS dataset.")
parser.add_argument(
- "--config", type=str, help="config file to overwrite default config.")
+ "--config", type=str, help="TransformerTTS config file.")
parser.add_argument("--train-metadata", type=str, help="training data.")
parser.add_argument("--dev-metadata", type=str, help="dev data.")
parser.add_argument("--output-dir", type=str, help="output dir.")
diff --git a/paddlespeech/t2s/exps/vits/normalize.py b/paddlespeech/t2s/exps/vits/normalize.py
new file mode 100644
index 000000000..6fc8adb06
--- /dev/null
+++ b/paddlespeech/t2s/exps/vits/normalize.py
@@ -0,0 +1,165 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Normalize feature files and dump them."""
+import argparse
+import logging
+from operator import itemgetter
+from pathlib import Path
+
+import jsonlines
+import numpy as np
+from sklearn.preprocessing import StandardScaler
+from tqdm import tqdm
+
+from paddlespeech.t2s.datasets.data_table import DataTable
+
+
+def main():
+ """Run preprocessing process."""
+ parser = argparse.ArgumentParser(
+ description="Normalize dumped raw features (See detail in parallel_wavegan/bin/normalize.py)."
+ )
+ parser.add_argument(
+ "--metadata",
+ type=str,
+ required=True,
+ help="directory including feature files to be normalized. "
+ "you need to specify either *-scp or rootdir.")
+
+ parser.add_argument(
+ "--dumpdir",
+ type=str,
+ required=True,
+ help="directory to dump normalized feature files.")
+ parser.add_argument(
+ "--feats-stats",
+ type=str,
+ required=True,
+ help="speech statistics file.")
+ parser.add_argument(
+ "--skip-wav-copy",
+ default=False,
+ action="store_true",
+ help="whether to skip the copy of wav files.")
+
+ parser.add_argument(
+ "--phones-dict", type=str, default=None, help="phone vocabulary file.")
+ parser.add_argument(
+ "--speaker-dict", type=str, default=None, help="speaker id map file.")
+ parser.add_argument(
+ "--verbose",
+ type=int,
+ default=1,
+ help="logging level. higher is more logging. (default=1)")
+ args = parser.parse_args()
+
+ # set logger
+ if args.verbose > 1:
+ logging.basicConfig(
+ level=logging.DEBUG,
+ format="%(asctime)s (%(module)s:%(lineno)d) %(levelname)s: %(message)s"
+ )
+ elif args.verbose > 0:
+ logging.basicConfig(
+ level=logging.INFO,
+ format="%(asctime)s (%(module)s:%(lineno)d) %(levelname)s: %(message)s"
+ )
+ else:
+ logging.basicConfig(
+ level=logging.WARN,
+ format="%(asctime)s (%(module)s:%(lineno)d) %(levelname)s: %(message)s"
+ )
+ logging.warning('Skip DEBUG/INFO messages')
+
+ dumpdir = Path(args.dumpdir).expanduser()
+ # use absolute path
+ dumpdir = dumpdir.resolve()
+ dumpdir.mkdir(parents=True, exist_ok=True)
+
+ # get dataset
+ with jsonlines.open(args.metadata, 'r') as reader:
+ metadata = list(reader)
+ dataset = DataTable(
+ metadata,
+ converters={
+ "feats": np.load,
+ "wave": None if args.skip_wav_copy else np.load,
+ })
+ logging.info(f"The number of files = {len(dataset)}.")
+
+ # restore scaler
+ feats_scaler = StandardScaler()
+ feats_scaler.mean_ = np.load(args.feats_stats)[0]
+ feats_scaler.scale_ = np.load(args.feats_stats)[1]
+ feats_scaler.n_features_in_ = feats_scaler.mean_.shape[0]
+
+ vocab_phones = {}
+ with open(args.phones_dict, 'rt') as f:
+ phn_id = [line.strip().split() for line in f.readlines()]
+ for phn, id in phn_id:
+ vocab_phones[phn] = int(id)
+
+ vocab_speaker = {}
+ with open(args.speaker_dict, 'rt') as f:
+ spk_id = [line.strip().split() for line in f.readlines()]
+ for spk, id in spk_id:
+ vocab_speaker[spk] = int(id)
+
+ # process each file
+ output_metadata = []
+
+ for item in tqdm(dataset):
+ utt_id = item['utt_id']
+ feats = item['feats']
+ wave = item['wave']
+
+ # normalize
+ feats = feats_scaler.transform(feats)
+ feats_path = dumpdir / f"{utt_id}_feats.npy"
+ np.save(feats_path, feats.astype(np.float32), allow_pickle=False)
+
+ if not args.skip_wav_copy:
+ wav_path = dumpdir / f"{utt_id}_wave.npy"
+ np.save(wav_path, wave.astype(np.float32), allow_pickle=False)
+ else:
+ wav_path = wave
+
+ phone_ids = [vocab_phones[p] for p in item['phones']]
+ spk_id = vocab_speaker[item["speaker"]]
+
+ record = {
+ "utt_id": item['utt_id'],
+ "text": phone_ids,
+ "text_lengths": item['text_lengths'],
+ 'feats': str(feats_path),
+ "feats_lengths": item['feats_lengths'],
+ "wave": str(wav_path),
+ "spk_id": spk_id,
+ }
+
+ # add spk_emb for voice cloning
+ if "spk_emb" in item:
+ record["spk_emb"] = str(item["spk_emb"])
+
+ output_metadata.append(record)
+ output_metadata.sort(key=itemgetter('utt_id'))
+ output_metadata_path = Path(args.dumpdir) / "metadata.jsonl"
+ with jsonlines.open(output_metadata_path, 'w') as writer:
+ for item in output_metadata:
+ writer.write(item)
+ logging.info(f"metadata dumped into {output_metadata_path}")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/paddlespeech/t2s/exps/vits/preprocess.py b/paddlespeech/t2s/exps/vits/preprocess.py
new file mode 100644
index 000000000..6aa139fb5
--- /dev/null
+++ b/paddlespeech/t2s/exps/vits/preprocess.py
@@ -0,0 +1,348 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+import os
+from concurrent.futures import ThreadPoolExecutor
+from operator import itemgetter
+from pathlib import Path
+from typing import Any
+from typing import Dict
+from typing import List
+
+import jsonlines
+import librosa
+import numpy as np
+import tqdm
+import yaml
+from yacs.config import CfgNode
+
+from paddlespeech.t2s.datasets.get_feats import LinearSpectrogram
+from paddlespeech.t2s.datasets.preprocess_utils import compare_duration_and_mel_length
+from paddlespeech.t2s.datasets.preprocess_utils import get_input_token
+from paddlespeech.t2s.datasets.preprocess_utils import get_phn_dur
+from paddlespeech.t2s.datasets.preprocess_utils import get_spk_id_map
+from paddlespeech.t2s.datasets.preprocess_utils import merge_silence
+from paddlespeech.t2s.utils import str2bool
+
+
+def process_sentence(config: Dict[str, Any],
+ fp: Path,
+ sentences: Dict,
+ output_dir: Path,
+ spec_extractor=None,
+ cut_sil: bool=True,
+ spk_emb_dir: Path=None):
+ utt_id = fp.stem
+ # for vctk
+ if utt_id.endswith("_mic2"):
+ utt_id = utt_id[:-5]
+ record = None
+ if utt_id in sentences:
+ # reading, resampling may occur
+ wav, _ = librosa.load(str(fp), sr=config.fs)
+ if len(wav.shape) != 1:
+ return record
+ max_value = np.abs(wav).max()
+ if max_value > 1.0:
+ wav = wav / max_value
+ assert len(wav.shape) == 1, f"{utt_id} is not a mono-channel audio."
+ assert np.abs(wav).max(
+ ) <= 1.0, f"{utt_id} is seems to be different that 16 bit PCM."
+ phones = sentences[utt_id][0]
+ durations = sentences[utt_id][1]
+ speaker = sentences[utt_id][2]
+ d_cumsum = np.pad(np.array(durations).cumsum(0), (1, 0), 'constant')
+ # little imprecise than use *.TextGrid directly
+ times = librosa.frames_to_time(
+ d_cumsum, sr=config.fs, hop_length=config.n_shift)
+ if cut_sil:
+ start = 0
+ end = d_cumsum[-1]
+ if phones[0] == "sil" and len(durations) > 1:
+ start = times[1]
+ durations = durations[1:]
+ phones = phones[1:]
+ if phones[-1] == 'sil' and len(durations) > 1:
+ end = times[-2]
+ durations = durations[:-1]
+ phones = phones[:-1]
+ sentences[utt_id][0] = phones
+ sentences[utt_id][1] = durations
+ start, end = librosa.time_to_samples([start, end], sr=config.fs)
+ wav = wav[start:end]
+ # extract mel feats
+ spec = spec_extractor.get_linear_spectrogram(wav)
+ # change duration according to mel_length
+ compare_duration_and_mel_length(sentences, utt_id, spec)
+ # utt_id may be popped in compare_duration_and_mel_length
+ if utt_id not in sentences:
+ return None
+ phones = sentences[utt_id][0]
+ durations = sentences[utt_id][1]
+ num_frames = spec.shape[0]
+ assert sum(durations) == num_frames
+
+ if wav.size < num_frames * config.n_shift:
+ wav = np.pad(
+ wav, (0, num_frames * config.n_shift - wav.size),
+ mode="reflect")
+ else:
+ wav = wav[:num_frames * config.n_shift]
+ num_samples = wav.shape[0]
+
+ spec_path = output_dir / (utt_id + "_feats.npy")
+ wav_path = output_dir / (utt_id + "_wave.npy")
+ # (num_samples, )
+ np.save(wav_path, wav)
+ # (num_frames, aux_channels)
+ np.save(spec_path, spec)
+
+ record = {
+ "utt_id": utt_id,
+ "phones": phones,
+ "text_lengths": len(phones),
+ "feats": str(spec_path),
+ "feats_lengths": num_frames,
+ "wave": str(wav_path),
+ "speaker": speaker
+ }
+ if spk_emb_dir:
+ if speaker in os.listdir(spk_emb_dir):
+ embed_name = utt_id + ".npy"
+ embed_path = spk_emb_dir / speaker / embed_name
+ if embed_path.is_file():
+ record["spk_emb"] = str(embed_path)
+ else:
+ return None
+ return record
+
+
+def process_sentences(config,
+ fps: List[Path],
+ sentences: Dict,
+ output_dir: Path,
+ spec_extractor=None,
+ nprocs: int=1,
+ cut_sil: bool=True,
+ spk_emb_dir: Path=None):
+ if nprocs == 1:
+ results = []
+ for fp in tqdm.tqdm(fps, total=len(fps)):
+ record = process_sentence(
+ config=config,
+ fp=fp,
+ sentences=sentences,
+ output_dir=output_dir,
+ spec_extractor=spec_extractor,
+ cut_sil=cut_sil,
+ spk_emb_dir=spk_emb_dir)
+ if record:
+ results.append(record)
+ else:
+ with ThreadPoolExecutor(nprocs) as pool:
+ futures = []
+ with tqdm.tqdm(total=len(fps)) as progress:
+ for fp in fps:
+ future = pool.submit(process_sentence, config, fp,
+ sentences, output_dir, spec_extractor,
+ cut_sil, spk_emb_dir)
+ future.add_done_callback(lambda p: progress.update())
+ futures.append(future)
+
+ results = []
+ for ft in futures:
+ record = ft.result()
+ if record:
+ results.append(record)
+
+ results.sort(key=itemgetter("utt_id"))
+ with jsonlines.open(output_dir / "metadata.jsonl", 'w') as writer:
+ for item in results:
+ writer.write(item)
+ print("Done")
+
+
+def main():
+ # parse config and args
+ parser = argparse.ArgumentParser(
+ description="Preprocess audio and then extract features.")
+
+ parser.add_argument(
+ "--dataset",
+ default="baker",
+ type=str,
+ help="name of dataset, should in {baker, aishell3, ljspeech, vctk} now")
+
+ parser.add_argument(
+ "--rootdir", default=None, type=str, help="directory to dataset.")
+
+ parser.add_argument(
+ "--dumpdir",
+ type=str,
+ required=True,
+ help="directory to dump feature files.")
+ parser.add_argument(
+ "--dur-file", default=None, type=str, help="path to durations.txt.")
+
+ parser.add_argument("--config", type=str, help="fastspeech2 config file.")
+
+ parser.add_argument(
+ "--verbose",
+ type=int,
+ default=1,
+ help="logging level. higher is more logging. (default=1)")
+ parser.add_argument(
+ "--num-cpu", type=int, default=1, help="number of process.")
+
+ parser.add_argument(
+ "--cut-sil",
+ type=str2bool,
+ default=True,
+ help="whether cut sil in the edge of audio")
+
+ parser.add_argument(
+ "--spk_emb_dir",
+ default=None,
+ type=str,
+ help="directory to speaker embedding files.")
+ args = parser.parse_args()
+
+ rootdir = Path(args.rootdir).expanduser()
+ dumpdir = Path(args.dumpdir).expanduser()
+ # use absolute path
+ dumpdir = dumpdir.resolve()
+ dumpdir.mkdir(parents=True, exist_ok=True)
+ dur_file = Path(args.dur_file).expanduser()
+
+ if args.spk_emb_dir:
+ spk_emb_dir = Path(args.spk_emb_dir).expanduser().resolve()
+ else:
+ spk_emb_dir = None
+
+ assert rootdir.is_dir()
+ assert dur_file.is_file()
+
+ with open(args.config, 'rt') as f:
+ config = CfgNode(yaml.safe_load(f))
+
+ if args.verbose > 1:
+ print(vars(args))
+ print(config)
+
+ sentences, speaker_set = get_phn_dur(dur_file)
+
+ merge_silence(sentences)
+ phone_id_map_path = dumpdir / "phone_id_map.txt"
+ speaker_id_map_path = dumpdir / "speaker_id_map.txt"
+ get_input_token(sentences, phone_id_map_path, args.dataset)
+ get_spk_id_map(speaker_set, speaker_id_map_path)
+
+ if args.dataset == "baker":
+ wav_files = sorted(list((rootdir / "Wave").rglob("*.wav")))
+ # split data into 3 sections
+ num_train = 9800
+ num_dev = 100
+ train_wav_files = wav_files[:num_train]
+ dev_wav_files = wav_files[num_train:num_train + num_dev]
+ test_wav_files = wav_files[num_train + num_dev:]
+ elif args.dataset == "aishell3":
+ sub_num_dev = 5
+ wav_dir = rootdir / "train" / "wav"
+ train_wav_files = []
+ dev_wav_files = []
+ test_wav_files = []
+ for speaker in os.listdir(wav_dir):
+ wav_files = sorted(list((wav_dir / speaker).rglob("*.wav")))
+ if len(wav_files) > 100:
+ train_wav_files += wav_files[:-sub_num_dev * 2]
+ dev_wav_files += wav_files[-sub_num_dev * 2:-sub_num_dev]
+ test_wav_files += wav_files[-sub_num_dev:]
+ else:
+ train_wav_files += wav_files
+
+ elif args.dataset == "ljspeech":
+ wav_files = sorted(list((rootdir / "wavs").rglob("*.wav")))
+ # split data into 3 sections
+ num_train = 12900
+ num_dev = 100
+ train_wav_files = wav_files[:num_train]
+ dev_wav_files = wav_files[num_train:num_train + num_dev]
+ test_wav_files = wav_files[num_train + num_dev:]
+ elif args.dataset == "vctk":
+ sub_num_dev = 5
+ wav_dir = rootdir / "wav48_silence_trimmed"
+ train_wav_files = []
+ dev_wav_files = []
+ test_wav_files = []
+ for speaker in os.listdir(wav_dir):
+ wav_files = sorted(list((wav_dir / speaker).rglob("*_mic2.flac")))
+ if len(wav_files) > 100:
+ train_wav_files += wav_files[:-sub_num_dev * 2]
+ dev_wav_files += wav_files[-sub_num_dev * 2:-sub_num_dev]
+ test_wav_files += wav_files[-sub_num_dev:]
+ else:
+ train_wav_files += wav_files
+
+ else:
+ print("dataset should in {baker, aishell3, ljspeech, vctk} now!")
+
+ train_dump_dir = dumpdir / "train" / "raw"
+ train_dump_dir.mkdir(parents=True, exist_ok=True)
+ dev_dump_dir = dumpdir / "dev" / "raw"
+ dev_dump_dir.mkdir(parents=True, exist_ok=True)
+ test_dump_dir = dumpdir / "test" / "raw"
+ test_dump_dir.mkdir(parents=True, exist_ok=True)
+
+ # Extractor
+
+ spec_extractor = LinearSpectrogram(
+ n_fft=config.n_fft,
+ hop_length=config.n_shift,
+ win_length=config.win_length,
+ window=config.window)
+
+ # process for the 3 sections
+ if train_wav_files:
+ process_sentences(
+ config=config,
+ fps=train_wav_files,
+ sentences=sentences,
+ output_dir=train_dump_dir,
+ spec_extractor=spec_extractor,
+ nprocs=args.num_cpu,
+ cut_sil=args.cut_sil,
+ spk_emb_dir=spk_emb_dir)
+ if dev_wav_files:
+ process_sentences(
+ config=config,
+ fps=dev_wav_files,
+ sentences=sentences,
+ output_dir=dev_dump_dir,
+ spec_extractor=spec_extractor,
+ cut_sil=args.cut_sil,
+ spk_emb_dir=spk_emb_dir)
+ if test_wav_files:
+ process_sentences(
+ config=config,
+ fps=test_wav_files,
+ sentences=sentences,
+ output_dir=test_dump_dir,
+ spec_extractor=spec_extractor,
+ nprocs=args.num_cpu,
+ cut_sil=args.cut_sil,
+ spk_emb_dir=spk_emb_dir)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/paddlespeech/t2s/exps/vits/synthesize.py b/paddlespeech/t2s/exps/vits/synthesize.py
new file mode 100644
index 000000000..074b890f9
--- /dev/null
+++ b/paddlespeech/t2s/exps/vits/synthesize.py
@@ -0,0 +1,117 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+from pathlib import Path
+
+import jsonlines
+import paddle
+import soundfile as sf
+import yaml
+from timer import timer
+from yacs.config import CfgNode
+
+from paddlespeech.t2s.datasets.data_table import DataTable
+from paddlespeech.t2s.models.vits import VITS
+
+
+def evaluate(args):
+
+ # construct dataset for evaluation
+ with jsonlines.open(args.test_metadata, 'r') as reader:
+ test_metadata = list(reader)
+ # Init body.
+ with open(args.config) as f:
+ config = CfgNode(yaml.safe_load(f))
+
+ print("========Args========")
+ print(yaml.safe_dump(vars(args)))
+ print("========Config========")
+ print(config)
+
+ fields = ["utt_id", "text"]
+
+ test_dataset = DataTable(data=test_metadata, fields=fields)
+
+ with open(args.phones_dict, "r") as f:
+ phn_id = [line.strip().split() for line in f.readlines()]
+ vocab_size = len(phn_id)
+ print("vocab_size:", vocab_size)
+
+ odim = config.n_fft // 2 + 1
+
+ vits = VITS(idim=vocab_size, odim=odim, **config["model"])
+ vits.set_state_dict(paddle.load(args.ckpt)["main_params"])
+ vits.eval()
+
+ output_dir = Path(args.output_dir)
+ output_dir.mkdir(parents=True, exist_ok=True)
+
+ N = 0
+ T = 0
+
+ for datum in test_dataset:
+ utt_id = datum["utt_id"]
+ phone_ids = paddle.to_tensor(datum["text"])
+ with timer() as t:
+ with paddle.no_grad():
+ out = vits.inference(text=phone_ids)
+ wav = out["wav"]
+ wav = wav.numpy()
+ N += wav.size
+ T += t.elapse
+ speed = wav.size / t.elapse
+ rtf = config.fs / speed
+ print(
+ f"{utt_id}, wave: {wav.size}, time: {t.elapse}s, Hz: {speed}, RTF: {rtf}."
+ )
+ sf.write(str(output_dir / (utt_id + ".wav")), wav, samplerate=config.fs)
+ print(f"{utt_id} done!")
+ print(f"generation speed: {N / T}Hz, RTF: {config.fs / (N / T) }")
+
+
+def parse_args():
+ # parse args and config
+ parser = argparse.ArgumentParser(description="Synthesize with VITS")
+ # model
+ parser.add_argument(
+ '--config', type=str, default=None, help='Config of VITS.')
+ parser.add_argument(
+ '--ckpt', type=str, default=None, help='Checkpoint file of VITS.')
+ parser.add_argument(
+ "--phones_dict", type=str, default=None, help="phone vocabulary file.")
+ # other
+ parser.add_argument(
+ "--ngpu", type=int, default=1, help="if ngpu == 0, use cpu.")
+ parser.add_argument("--test_metadata", type=str, help="test metadata.")
+ parser.add_argument("--output_dir", type=str, help="output dir.")
+
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+
+ if args.ngpu == 0:
+ paddle.set_device("cpu")
+ elif args.ngpu > 0:
+ paddle.set_device("gpu")
+ else:
+ print("ngpu should >= 0 !")
+
+ evaluate(args)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/paddlespeech/t2s/exps/vits/synthesize_e2e.py b/paddlespeech/t2s/exps/vits/synthesize_e2e.py
new file mode 100644
index 000000000..c82e5c039
--- /dev/null
+++ b/paddlespeech/t2s/exps/vits/synthesize_e2e.py
@@ -0,0 +1,146 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+from pathlib import Path
+
+import paddle
+import soundfile as sf
+import yaml
+from timer import timer
+from yacs.config import CfgNode
+
+from paddlespeech.t2s.exps.syn_utils import get_frontend
+from paddlespeech.t2s.exps.syn_utils import get_sentences
+from paddlespeech.t2s.models.vits import VITS
+
+
+def evaluate(args):
+
+ # Init body.
+ with open(args.config) as f:
+ config = CfgNode(yaml.safe_load(f))
+
+ print("========Args========")
+ print(yaml.safe_dump(vars(args)))
+ print("========Config========")
+ print(config)
+
+ sentences = get_sentences(text_file=args.text, lang=args.lang)
+
+ # frontend
+ frontend = get_frontend(lang=args.lang, phones_dict=args.phones_dict)
+
+ with open(args.phones_dict, "r") as f:
+ phn_id = [line.strip().split() for line in f.readlines()]
+ vocab_size = len(phn_id)
+ print("vocab_size:", vocab_size)
+
+ odim = config.n_fft // 2 + 1
+
+ vits = VITS(idim=vocab_size, odim=odim, **config["model"])
+ vits.set_state_dict(paddle.load(args.ckpt)["main_params"])
+ vits.eval()
+
+ output_dir = Path(args.output_dir)
+ output_dir.mkdir(parents=True, exist_ok=True)
+ merge_sentences = False
+
+ N = 0
+ T = 0
+ for utt_id, sentence in sentences:
+ with timer() as t:
+ if args.lang == 'zh':
+ input_ids = frontend.get_input_ids(
+ sentence, merge_sentences=merge_sentences)
+ phone_ids = input_ids["phone_ids"]
+ elif args.lang == 'en':
+ input_ids = frontend.get_input_ids(
+ sentence, merge_sentences=merge_sentences)
+ phone_ids = input_ids["phone_ids"]
+ else:
+ print("lang should in {'zh', 'en'}!")
+ with paddle.no_grad():
+ flags = 0
+ for i in range(len(phone_ids)):
+ part_phone_ids = phone_ids[i]
+ out = vits.inference(text=part_phone_ids)
+ wav = out["wav"]
+ if flags == 0:
+ wav_all = wav
+ flags = 1
+ else:
+ wav_all = paddle.concat([wav_all, wav])
+ wav = wav_all.numpy()
+ N += wav.size
+ T += t.elapse
+ speed = wav.size / t.elapse
+ rtf = config.fs / speed
+ print(
+ f"{utt_id}, wave: {wav.shape}, time: {t.elapse}s, Hz: {speed}, RTF: {rtf}."
+ )
+ sf.write(str(output_dir / (utt_id + ".wav")), wav, samplerate=config.fs)
+ print(f"{utt_id} done!")
+ print(f"generation speed: {N / T}Hz, RTF: {config.fs / (N / T) }")
+
+
+def parse_args():
+ # parse args and config
+ parser = argparse.ArgumentParser(description="Synthesize with VITS")
+
+ # model
+ parser.add_argument(
+ '--config', type=str, default=None, help='Config of VITS.')
+ parser.add_argument(
+ '--ckpt', type=str, default=None, help='Checkpoint file of VITS.')
+ parser.add_argument(
+ "--phones_dict", type=str, default=None, help="phone vocabulary file.")
+ # other
+ parser.add_argument(
+ '--lang',
+ type=str,
+ default='zh',
+ help='Choose model language. zh or en')
+
+ parser.add_argument(
+ "--inference_dir",
+ type=str,
+ default=None,
+ help="dir to save inference models")
+ parser.add_argument(
+ "--ngpu", type=int, default=1, help="if ngpu == 0, use cpu.")
+ parser.add_argument(
+ "--text",
+ type=str,
+ help="text to synthesize, a 'utt_id sentence' pair per line.")
+ parser.add_argument("--output_dir", type=str, help="output dir.")
+
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+
+ if args.ngpu == 0:
+ paddle.set_device("cpu")
+ elif args.ngpu > 0:
+ paddle.set_device("gpu")
+ else:
+ print("ngpu should >= 0 !")
+
+ evaluate(args)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/paddlespeech/t2s/exps/vits/train.py b/paddlespeech/t2s/exps/vits/train.py
new file mode 100644
index 000000000..dbda8b717
--- /dev/null
+++ b/paddlespeech/t2s/exps/vits/train.py
@@ -0,0 +1,260 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+import logging
+import os
+import shutil
+from pathlib import Path
+
+import jsonlines
+import numpy as np
+import paddle
+import yaml
+from paddle import DataParallel
+from paddle import distributed as dist
+from paddle.io import DataLoader
+from paddle.io import DistributedBatchSampler
+from paddle.optimizer import Adam
+from yacs.config import CfgNode
+
+from paddlespeech.t2s.datasets.am_batch_fn import vits_single_spk_batch_fn
+from paddlespeech.t2s.datasets.data_table import DataTable
+from paddlespeech.t2s.models.vits import VITS
+from paddlespeech.t2s.models.vits import VITSEvaluator
+from paddlespeech.t2s.models.vits import VITSUpdater
+from paddlespeech.t2s.modules.losses import DiscriminatorAdversarialLoss
+from paddlespeech.t2s.modules.losses import FeatureMatchLoss
+from paddlespeech.t2s.modules.losses import GeneratorAdversarialLoss
+from paddlespeech.t2s.modules.losses import KLDivergenceLoss
+from paddlespeech.t2s.modules.losses import MelSpectrogramLoss
+from paddlespeech.t2s.training.extensions.snapshot import Snapshot
+from paddlespeech.t2s.training.extensions.visualizer import VisualDL
+from paddlespeech.t2s.training.optimizer import scheduler_classes
+from paddlespeech.t2s.training.seeding import seed_everything
+from paddlespeech.t2s.training.trainer import Trainer
+
+
+def train_sp(args, config):
+ # decides device type and whether to run in parallel
+ # setup running environment correctly
+ world_size = paddle.distributed.get_world_size()
+ if (not paddle.is_compiled_with_cuda()) or args.ngpu == 0:
+ paddle.set_device("cpu")
+ else:
+ paddle.set_device("gpu")
+ if world_size > 1:
+ paddle.distributed.init_parallel_env()
+
+ # set the random seed, it is a must for multiprocess training
+ seed_everything(config.seed)
+
+ print(
+ f"rank: {dist.get_rank()}, pid: {os.getpid()}, parent_pid: {os.getppid()}",
+ )
+
+ # dataloader has been too verbose
+ logging.getLogger("DataLoader").disabled = True
+
+ fields = ["text", "text_lengths", "feats", "feats_lengths", "wave"]
+
+ converters = {
+ "wave": np.load,
+ "feats": np.load,
+ }
+
+ # construct dataset for training and validation
+ with jsonlines.open(args.train_metadata, 'r') as reader:
+ train_metadata = list(reader)
+ train_dataset = DataTable(
+ data=train_metadata,
+ fields=fields,
+ converters=converters, )
+ with jsonlines.open(args.dev_metadata, 'r') as reader:
+ dev_metadata = list(reader)
+ dev_dataset = DataTable(
+ data=dev_metadata,
+ fields=fields,
+ converters=converters, )
+
+ # collate function and dataloader
+ train_sampler = DistributedBatchSampler(
+ train_dataset,
+ batch_size=config.batch_size,
+ shuffle=True,
+ drop_last=True)
+ dev_sampler = DistributedBatchSampler(
+ dev_dataset,
+ batch_size=config.batch_size,
+ shuffle=False,
+ drop_last=False)
+ print("samplers done!")
+
+ train_batch_fn = vits_single_spk_batch_fn
+
+ train_dataloader = DataLoader(
+ train_dataset,
+ batch_sampler=train_sampler,
+ collate_fn=train_batch_fn,
+ num_workers=config.num_workers)
+
+ dev_dataloader = DataLoader(
+ dev_dataset,
+ batch_sampler=dev_sampler,
+ collate_fn=train_batch_fn,
+ num_workers=config.num_workers)
+ print("dataloaders done!")
+
+ with open(args.phones_dict, "r") as f:
+ phn_id = [line.strip().split() for line in f.readlines()]
+ vocab_size = len(phn_id)
+ print("vocab_size:", vocab_size)
+
+ odim = config.n_fft // 2 + 1
+ model = VITS(idim=vocab_size, odim=odim, **config["model"])
+ gen_parameters = model.generator.parameters()
+ dis_parameters = model.discriminator.parameters()
+ if world_size > 1:
+ model = DataParallel(model)
+ gen_parameters = model._layers.generator.parameters()
+ dis_parameters = model._layers.discriminator.parameters()
+
+ print("model done!")
+
+ # loss
+ criterion_mel = MelSpectrogramLoss(
+ **config["mel_loss_params"], )
+ criterion_feat_match = FeatureMatchLoss(
+ **config["feat_match_loss_params"], )
+ criterion_gen_adv = GeneratorAdversarialLoss(
+ **config["generator_adv_loss_params"], )
+ criterion_dis_adv = DiscriminatorAdversarialLoss(
+ **config["discriminator_adv_loss_params"], )
+ criterion_kl = KLDivergenceLoss()
+
+ print("criterions done!")
+
+ lr_schedule_g = scheduler_classes[config["generator_scheduler"]](
+ **config["generator_scheduler_params"])
+ optimizer_g = Adam(
+ learning_rate=lr_schedule_g,
+ parameters=gen_parameters,
+ **config["generator_optimizer_params"])
+
+ lr_schedule_d = scheduler_classes[config["discriminator_scheduler"]](
+ **config["discriminator_scheduler_params"])
+ optimizer_d = Adam(
+ learning_rate=lr_schedule_d,
+ parameters=dis_parameters,
+ **config["discriminator_optimizer_params"])
+
+ print("optimizers done!")
+
+ output_dir = Path(args.output_dir)
+ output_dir.mkdir(parents=True, exist_ok=True)
+ if dist.get_rank() == 0:
+ config_name = args.config.split("/")[-1]
+ # copy conf to output_dir
+ shutil.copyfile(args.config, output_dir / config_name)
+
+ updater = VITSUpdater(
+ model=model,
+ optimizers={
+ "generator": optimizer_g,
+ "discriminator": optimizer_d,
+ },
+ criterions={
+ "mel": criterion_mel,
+ "feat_match": criterion_feat_match,
+ "gen_adv": criterion_gen_adv,
+ "dis_adv": criterion_dis_adv,
+ "kl": criterion_kl,
+ },
+ schedulers={
+ "generator": lr_schedule_g,
+ "discriminator": lr_schedule_d,
+ },
+ dataloader=train_dataloader,
+ lambda_adv=config.lambda_adv,
+ lambda_mel=config.lambda_mel,
+ lambda_kl=config.lambda_kl,
+ lambda_feat_match=config.lambda_feat_match,
+ lambda_dur=config.lambda_dur,
+ generator_first=config.generator_first,
+ output_dir=output_dir)
+
+ evaluator = VITSEvaluator(
+ model=model,
+ criterions={
+ "mel": criterion_mel,
+ "feat_match": criterion_feat_match,
+ "gen_adv": criterion_gen_adv,
+ "dis_adv": criterion_dis_adv,
+ "kl": criterion_kl,
+ },
+ dataloader=dev_dataloader,
+ lambda_adv=config.lambda_adv,
+ lambda_mel=config.lambda_mel,
+ lambda_kl=config.lambda_kl,
+ lambda_feat_match=config.lambda_feat_match,
+ lambda_dur=config.lambda_dur,
+ generator_first=config.generator_first,
+ output_dir=output_dir)
+
+ trainer = Trainer(updater, (config.max_epoch, 'epoch'), output_dir)
+
+ if dist.get_rank() == 0:
+ trainer.extend(evaluator, trigger=(1, "epoch"))
+ trainer.extend(VisualDL(output_dir), trigger=(1, "iteration"))
+ trainer.extend(
+ Snapshot(max_size=config.num_snapshots), trigger=(1, 'epoch'))
+
+ print("Trainer Done!")
+ trainer.run()
+
+
+def main():
+ # parse args and config and redirect to train_sp
+
+ parser = argparse.ArgumentParser(description="Train a VITS model.")
+ parser.add_argument("--config", type=str, help="VITS config file")
+ parser.add_argument("--train-metadata", type=str, help="training data.")
+ parser.add_argument("--dev-metadata", type=str, help="dev data.")
+ parser.add_argument("--output-dir", type=str, help="output dir.")
+ parser.add_argument(
+ "--ngpu", type=int, default=1, help="if ngpu == 0, use cpu.")
+ parser.add_argument(
+ "--phones-dict", type=str, default=None, help="phone vocabulary file.")
+
+ args = parser.parse_args()
+
+ with open(args.config, 'rt') as f:
+ config = CfgNode(yaml.safe_load(f))
+
+ print("========Args========")
+ print(yaml.safe_dump(vars(args)))
+ print("========Config========")
+ print(config)
+ print(
+ f"master see the word size: {dist.get_world_size()}, from pid: {os.getpid()}"
+ )
+
+ # dispatch
+ if args.ngpu > 1:
+ dist.spawn(train_sp, (args, config), nprocs=args.ngpu)
+ else:
+ train_sp(args, config)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/paddlespeech/t2s/exps/voice_cloning.py b/paddlespeech/t2s/exps/voice_cloning.py
index 9257b07de..b51a4d7bc 100644
--- a/paddlespeech/t2s/exps/voice_cloning.py
+++ b/paddlespeech/t2s/exps/voice_cloning.py
@@ -110,10 +110,10 @@ def voice_cloning(args):
print(f"{utt_id} done!")
# Randomly generate numbers of 0 ~ 0.2, 256 is the dim of spk_emb
random_spk_emb = np.random.rand(256) * 0.2
- random_spk_emb = paddle.to_tensor(random_spk_emb)
+ random_spk_emb = paddle.to_tensor(random_spk_emb, dtype='float32')
utt_id = "random_spk_emb"
with paddle.no_grad():
- wav = voc_inference(am_inference(phone_ids, spk_emb=spk_emb))
+ wav = voc_inference(am_inference(phone_ids, spk_emb=random_spk_emb))
sf.write(
str(output_dir / (utt_id + ".wav")),
wav.numpy(),
@@ -122,7 +122,7 @@ def voice_cloning(args):
def parse_args():
- # parse args and config and redirect to train_sp
+ # parse args and config
parser = argparse.ArgumentParser(description="")
parser.add_argument(
'--am',
@@ -131,10 +131,7 @@ def parse_args():
choices=['fastspeech2_aishell3', 'tacotron2_aishell3'],
help='Choose acoustic model type of tts task.')
parser.add_argument(
- '--am_config',
- type=str,
- default=None,
- help='Config of acoustic model. Use deault config when it is None.')
+ '--am_config', type=str, default=None, help='Config of acoustic model.')
parser.add_argument(
'--am_ckpt',
type=str,
@@ -160,10 +157,7 @@ def parse_args():
help='Choose vocoder type of tts task.')
parser.add_argument(
- '--voc_config',
- type=str,
- default=None,
- help='Config of voc. Use deault config when it is None.')
+ '--voc_config', type=str, default=None, help='Config of voc.')
parser.add_argument(
'--voc_ckpt', type=str, default=None, help='Checkpoint file of voc.')
parser.add_argument(
diff --git a/paddlespeech/t2s/exps/wavernn/train.py b/paddlespeech/t2s/exps/wavernn/train.py
index 8661d311d..cf24ea268 100644
--- a/paddlespeech/t2s/exps/wavernn/train.py
+++ b/paddlespeech/t2s/exps/wavernn/train.py
@@ -180,8 +180,7 @@ def main():
# parse args and config and redirect to train_sp
parser = argparse.ArgumentParser(description="Train a WaveRNN model.")
- parser.add_argument(
- "--config", type=str, help="config file to overwrite default config.")
+ parser.add_argument("--config", type=str, help="WaveRNN config file.")
parser.add_argument("--train-metadata", type=str, help="training data.")
parser.add_argument("--dev-metadata", type=str, help="dev data.")
parser.add_argument("--output-dir", type=str, help="output dir.")
diff --git a/paddlespeech/t2s/frontend/tone_sandhi.py b/paddlespeech/t2s/frontend/tone_sandhi.py
index 07f7fa2b8..e3102b9bc 100644
--- a/paddlespeech/t2s/frontend/tone_sandhi.py
+++ b/paddlespeech/t2s/frontend/tone_sandhi.py
@@ -63,7 +63,8 @@ class ToneSandhi():
'扫把', '惦记'
}
self.must_not_neural_tone_words = {
- "男子", "女子", "分子", "原子", "量子", "莲子", "石子", "瓜子", "电子", "人人", "虎虎"
+ "男子", "女子", "分子", "原子", "量子", "莲子", "石子", "瓜子", "电子", "人人", "虎虎",
+ "幺幺"
}
self.punc = ":,;。?!“”‘’':,;.?!"
diff --git a/paddlespeech/t2s/frontend/zh_frontend.py b/paddlespeech/t2s/frontend/zh_frontend.py
index bb8ed5b49..129aa944e 100644
--- a/paddlespeech/t2s/frontend/zh_frontend.py
+++ b/paddlespeech/t2s/frontend/zh_frontend.py
@@ -195,7 +195,7 @@ class Frontend():
new_initials.append(initials[i])
return new_initials, new_finals
- def _p2id(self, phonemes: List[str]) -> np.array:
+ def _p2id(self, phonemes: List[str]) -> np.ndarray:
# replace unk phone with sp
phonemes = [
phn if phn in self.vocab_phones else "sp" for phn in phonemes
@@ -203,7 +203,7 @@ class Frontend():
phone_ids = [self.vocab_phones[item] for item in phonemes]
return np.array(phone_ids, np.int64)
- def _t2id(self, tones: List[str]) -> np.array:
+ def _t2id(self, tones: List[str]) -> np.ndarray:
# replace unk phone with sp
tones = [tone if tone in self.vocab_tones else "0" for tone in tones]
tone_ids = [self.vocab_tones[item] for item in tones]
diff --git a/paddlespeech/t2s/frontend/zh_normalization/num.py b/paddlespeech/t2s/frontend/zh_normalization/num.py
index a83b42a47..ec1367736 100644
--- a/paddlespeech/t2s/frontend/zh_normalization/num.py
+++ b/paddlespeech/t2s/frontend/zh_normalization/num.py
@@ -103,7 +103,7 @@ def replace_default_num(match):
str
"""
number = match.group(0)
- return verbalize_digit(number)
+ return verbalize_digit(number, alt_one=True)
# 数字表达式
diff --git a/paddlespeech/t2s/models/__init__.py b/paddlespeech/t2s/models/__init__.py
index 41be7c1db..0b6f29119 100644
--- a/paddlespeech/t2s/models/__init__.py
+++ b/paddlespeech/t2s/models/__init__.py
@@ -18,5 +18,6 @@ from .parallel_wavegan import *
from .speedyspeech import *
from .tacotron2 import *
from .transformer_tts import *
+from .vits import *
from .waveflow import *
from .wavernn import *
diff --git a/paddlespeech/t2s/models/hifigan/hifigan.py b/paddlespeech/t2s/models/hifigan/hifigan.py
index ac5ff204f..bea9dd9a3 100644
--- a/paddlespeech/t2s/models/hifigan/hifigan.py
+++ b/paddlespeech/t2s/models/hifigan/hifigan.py
@@ -16,6 +16,7 @@ import copy
from typing import Any
from typing import Dict
from typing import List
+from typing import Optional
import paddle
import paddle.nn.functional as F
@@ -34,6 +35,7 @@ class HiFiGANGenerator(nn.Layer):
in_channels: int=80,
out_channels: int=1,
channels: int=512,
+ global_channels: int=-1,
kernel_size: int=7,
upsample_scales: List[int]=(8, 8, 2, 2),
upsample_kernel_sizes: List[int]=(16, 16, 4, 4),
@@ -51,6 +53,7 @@ class HiFiGANGenerator(nn.Layer):
in_channels (int): Number of input channels.
out_channels (int): Number of output channels.
channels (int): Number of hidden representation channels.
+ global_channels (int): Number of global conditioning channels.
kernel_size (int): Kernel size of initial and final conv layer.
upsample_scales (list): List of upsampling scales.
upsample_kernel_sizes (list): List of kernel sizes for upsampling layers.
@@ -119,6 +122,9 @@ class HiFiGANGenerator(nn.Layer):
padding=(kernel_size - 1) // 2, ),
nn.Tanh(), )
+ if global_channels > 0:
+ self.global_conv = nn.Conv1D(global_channels, channels, 1)
+
nn.initializer.set_global_initializer(None)
# apply weight norm
@@ -128,15 +134,18 @@ class HiFiGANGenerator(nn.Layer):
# reset parameters
self.reset_parameters()
- def forward(self, c):
+ def forward(self, c, g: Optional[paddle.Tensor]=None):
"""Calculate forward propagation.
Args:
c (Tensor): Input tensor (B, in_channels, T).
+ g (Optional[Tensor]): Global conditioning tensor (B, global_channels, 1).
Returns:
Tensor: Output tensor (B, out_channels, T).
"""
c = self.input_conv(c)
+ if g is not None:
+ c = c + self.global_conv(g)
for i in range(self.num_upsamples):
c = self.upsamples[i](c)
# initialize
@@ -187,16 +196,19 @@ class HiFiGANGenerator(nn.Layer):
self.apply(_remove_weight_norm)
- def inference(self, c):
+ def inference(self, c, g: Optional[paddle.Tensor]=None):
"""Perform inference.
Args:
c (Tensor): Input tensor (T, in_channels).
normalize_before (bool): Whether to perform normalization.
+ g (Optional[Tensor]): Global conditioning tensor (global_channels, 1).
Returns:
Tensor:
Output tensor (T ** prod(upsample_scales), out_channels).
"""
- c = self.forward(c.transpose([1, 0]).unsqueeze(0))
+ if g is not None:
+ g = g.unsqueeze(0)
+ c = self.forward(c.transpose([1, 0]).unsqueeze(0), g=g)
return c.squeeze(0).transpose([1, 0])
diff --git a/paddlespeech/t2s/models/parallel_wavegan/parallel_wavegan_updater.py b/paddlespeech/t2s/models/parallel_wavegan/parallel_wavegan_updater.py
index 40cfff5a5..c1cd73308 100644
--- a/paddlespeech/t2s/models/parallel_wavegan/parallel_wavegan_updater.py
+++ b/paddlespeech/t2s/models/parallel_wavegan/parallel_wavegan_updater.py
@@ -68,8 +68,8 @@ class PWGUpdater(StandardUpdater):
self.discriminator_train_start_steps = discriminator_train_start_steps
self.lambda_adv = lambda_adv
self.lambda_aux = lambda_aux
- self.state = UpdaterState(iteration=0, epoch=0)
+ self.state = UpdaterState(iteration=0, epoch=0)
self.train_iterator = iter(self.dataloader)
log_file = output_dir / 'worker_{}.log'.format(dist.get_rank())
diff --git a/paddlespeech/t2s/models/speedyspeech/speedyspeech_updater.py b/paddlespeech/t2s/models/speedyspeech/speedyspeech_updater.py
index e30a3fe1a..b20fda1f7 100644
--- a/paddlespeech/t2s/models/speedyspeech/speedyspeech_updater.py
+++ b/paddlespeech/t2s/models/speedyspeech/speedyspeech_updater.py
@@ -16,7 +16,6 @@ from pathlib import Path
import paddle
from paddle import distributed as dist
-from paddle.fluid.layers import huber_loss
from paddle.io import DataLoader
from paddle.nn import functional as F
from paddle.nn import Layer
@@ -78,8 +77,11 @@ class SpeedySpeechUpdater(StandardUpdater):
target_durations.astype(predicted_durations.dtype),
paddle.to_tensor([1.0]))
duration_loss = weighted_mean(
- huber_loss(
- predicted_durations, paddle.log(target_durations), delta=1.0),
+ F.smooth_l1_loss(
+ predicted_durations,
+ paddle.log(target_durations),
+ delta=1.0,
+ reduction='none', ),
text_mask, )
# ssim loss
@@ -146,8 +148,11 @@ class SpeedySpeechEvaluator(StandardEvaluator):
target_durations.astype(predicted_durations.dtype),
paddle.to_tensor([1.0]))
duration_loss = weighted_mean(
- huber_loss(
- predicted_durations, paddle.log(target_durations), delta=1.0),
+ F.smooth_l1_loss(
+ predicted_durations,
+ paddle.log(target_durations),
+ delta=1.0,
+ reduction='none', ),
text_mask, )
# ssim loss
diff --git a/paddlespeech/t2s/models/vits/__init__.py b/paddlespeech/t2s/models/vits/__init__.py
new file mode 100644
index 000000000..ea43028ae
--- /dev/null
+++ b/paddlespeech/t2s/models/vits/__init__.py
@@ -0,0 +1,15 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from .vits import *
+from .vits_updater import *
diff --git a/paddlespeech/t2s/models/vits/duration_predictor.py b/paddlespeech/t2s/models/vits/duration_predictor.py
new file mode 100644
index 000000000..6197d5696
--- /dev/null
+++ b/paddlespeech/t2s/models/vits/duration_predictor.py
@@ -0,0 +1,172 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Stochastic duration predictor modules in VITS.
+
+This code is based on https://github.com/jaywalnut310/vits.
+
+"""
+import math
+from typing import Optional
+
+import paddle
+import paddle.nn.functional as F
+from paddle import nn
+
+from paddlespeech.t2s.models.vits.flow import ConvFlow
+from paddlespeech.t2s.models.vits.flow import DilatedDepthSeparableConv
+from paddlespeech.t2s.models.vits.flow import ElementwiseAffineFlow
+from paddlespeech.t2s.models.vits.flow import FlipFlow
+from paddlespeech.t2s.models.vits.flow import LogFlow
+
+
+class StochasticDurationPredictor(nn.Layer):
+ """Stochastic duration predictor module.
+ This is a module of stochastic duration predictor described in `Conditional
+ Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech`_.
+ .. _`Conditional Variational Autoencoder with Adversarial Learning for End-to-End
+ Text-to-Speech`: https://arxiv.org/abs/2106.06103
+ """
+
+ def __init__(
+ self,
+ channels: int=192,
+ kernel_size: int=3,
+ dropout_rate: float=0.5,
+ flows: int=4,
+ dds_conv_layers: int=3,
+ global_channels: int=-1, ):
+ """Initialize StochasticDurationPredictor module.
+ Args:
+ channels (int): Number of channels.
+ kernel_size (int): Kernel size.
+ dropout_rate (float): Dropout rate.
+ flows (int): Number of flows.
+ dds_conv_layers (int): Number of conv layers in DDS conv.
+ global_channels (int): Number of global conditioning channels.
+ """
+ super().__init__()
+
+ self.pre = nn.Conv1D(channels, channels, 1)
+ self.dds = DilatedDepthSeparableConv(
+ channels,
+ kernel_size,
+ layers=dds_conv_layers,
+ dropout_rate=dropout_rate, )
+ self.proj = nn.Conv1D(channels, channels, 1)
+
+ self.log_flow = LogFlow()
+ self.flows = nn.LayerList()
+ self.flows.append(ElementwiseAffineFlow(2))
+ for i in range(flows):
+ self.flows.append(
+ ConvFlow(
+ 2,
+ channels,
+ kernel_size,
+ layers=dds_conv_layers, ))
+ self.flows.append(FlipFlow())
+
+ self.post_pre = nn.Conv1D(1, channels, 1)
+ self.post_dds = DilatedDepthSeparableConv(
+ channels,
+ kernel_size,
+ layers=dds_conv_layers,
+ dropout_rate=dropout_rate, )
+ self.post_proj = nn.Conv1D(channels, channels, 1)
+ self.post_flows = nn.LayerList()
+ self.post_flows.append(ElementwiseAffineFlow(2))
+ for i in range(flows):
+ self.post_flows.append(
+ ConvFlow(
+ 2,
+ channels,
+ kernel_size,
+ layers=dds_conv_layers, ))
+ self.post_flows.append(FlipFlow())
+
+ if global_channels > 0:
+ self.global_conv = nn.Conv1D(global_channels, channels, 1)
+
+ def forward(
+ self,
+ x: paddle.Tensor,
+ x_mask: paddle.Tensor,
+ w: Optional[paddle.Tensor]=None,
+ g: Optional[paddle.Tensor]=None,
+ inverse: bool=False,
+ noise_scale: float=1.0, ) -> paddle.Tensor:
+ """Calculate forward propagation.
+ Args:
+ x (Tensor): Input tensor (B, channels, T_text).
+ x_mask (Tensor): Mask tensor (B, 1, T_text).
+ w (Optional[Tensor]): Duration tensor (B, 1, T_text).
+ g (Optional[Tensor]): Global conditioning tensor (B, channels, 1)
+ inverse (bool): Whether to inverse the flow.
+ noise_scale (float): Noise scale value.
+ Returns:
+ Tensor: If not inverse, negative log-likelihood (NLL) tensor (B,).
+ If inverse, log-duration tensor (B, 1, T_text).
+ """
+ # stop gradient
+ # x = x.detach()
+ x = self.pre(x)
+ if g is not None:
+ # stop gradient
+ x = x + self.global_conv(g.detach())
+ x = self.dds(x, x_mask)
+ x = self.proj(x) * x_mask
+
+ if not inverse:
+ assert w is not None, "w must be provided."
+ h_w = self.post_pre(w)
+ h_w = self.post_dds(h_w, x_mask)
+ h_w = self.post_proj(h_w) * x_mask
+ e_q = (paddle.randn([paddle.shape(w)[0], 2, paddle.shape(w)[2]]) *
+ x_mask)
+ z_q = e_q
+ logdet_tot_q = 0.0
+ for i, flow in enumerate(self.post_flows):
+ z_q, logdet_q = flow(z_q, x_mask, g=(x + h_w))
+ logdet_tot_q += logdet_q
+ z_u, z1 = paddle.split(z_q, [1, 1], 1)
+ u = F.sigmoid(z_u) * x_mask
+ z0 = (w - u) * x_mask
+ logdet_tot_q += paddle.sum(
+ (F.log_sigmoid(z_u) + F.log_sigmoid(-z_u)) * x_mask, [1, 2])
+ logq = (paddle.sum(-0.5 *
+ (math.log(2 * math.pi) +
+ (e_q**2)) * x_mask, [1, 2]) - logdet_tot_q)
+
+ logdet_tot = 0
+ z0, logdet = self.log_flow(z0, x_mask)
+ logdet_tot += logdet
+ z = paddle.concat([z0, z1], 1)
+ for flow in self.flows:
+ z, logdet = flow(z, x_mask, g=x, inverse=inverse)
+ logdet_tot = logdet_tot + logdet
+ nll = (paddle.sum(0.5 * (math.log(2 * math.pi) +
+ (z**2)) * x_mask, [1, 2]) - logdet_tot)
+ # (B,)
+ return nll + logq
+ else:
+ flows = list(reversed(self.flows))
+ # remove a useless vflow
+ flows = flows[:-2] + [flows[-1]]
+ z = (paddle.randn([paddle.shape(x)[0], 2, paddle.shape(x)[2]]) *
+ noise_scale)
+ for flow in flows:
+ z = flow(z, x_mask, g=x, inverse=inverse)
+ z0, z1 = paddle.split(z, 2, axis=1)
+ logw = z0
+ return logw
diff --git a/paddlespeech/t2s/models/vits/flow.py b/paddlespeech/t2s/models/vits/flow.py
new file mode 100644
index 000000000..3c8f89356
--- /dev/null
+++ b/paddlespeech/t2s/models/vits/flow.py
@@ -0,0 +1,313 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Basic Flow modules used in VITS.
+
+This code is based on https://github.com/jaywalnut310/vits.
+
+"""
+import math
+from typing import Optional
+from typing import Tuple
+from typing import Union
+
+import paddle
+from paddle import nn
+
+from paddlespeech.t2s.models.vits.transform import piecewise_rational_quadratic_transform
+
+
+class FlipFlow(nn.Layer):
+ """Flip flow module."""
+
+ def forward(self, x: paddle.Tensor, *args, inverse: bool=False, **kwargs
+ ) -> Union[paddle.Tensor, Tuple[paddle.Tensor, paddle.Tensor]]:
+ """Calculate forward propagation.
+ Args:
+ x (Tensor): Input tensor (B, channels, T).
+ inverse (bool): Whether to inverse the flow.
+ Returns:
+ Tensor: Flipped tensor (B, channels, T).
+ Tensor: Log-determinant tensor for NLL (B,) if not inverse.
+ """
+ x = paddle.flip(x, [1])
+ if not inverse:
+ logdet = paddle.zeros(paddle.shape(x)[0], dtype=x.dtype)
+ return x, logdet
+ else:
+ return x
+
+
+class LogFlow(nn.Layer):
+ """Log flow module."""
+
+ def forward(self,
+ x: paddle.Tensor,
+ x_mask: paddle.Tensor,
+ inverse: bool=False,
+ eps: float=1e-5,
+ **kwargs
+ ) -> Union[paddle.Tensor, Tuple[paddle.Tensor, paddle.Tensor]]:
+ """Calculate forward propagation.
+ Args:
+ x (Tensor): Input tensor (B, channels, T).
+ x_mask (Tensor): Mask tensor (B, 1, T).
+ inverse (bool): Whether to inverse the flow.
+ eps (float): Epsilon for log.
+ Returns:
+ Tensor: Output tensor (B, channels, T).
+ Tensor: Log-determinant tensor for NLL (B,) if not inverse.
+ """
+ if not inverse:
+ y = paddle.log(paddle.clip(x, min=eps)) * x_mask
+ logdet = paddle.sum(-y, [1, 2])
+ return y, logdet
+ else:
+ x = paddle.exp(x) * x_mask
+ return x
+
+
+class ElementwiseAffineFlow(nn.Layer):
+ """Elementwise affine flow module."""
+
+ def __init__(self, channels: int):
+ """Initialize ElementwiseAffineFlow module.
+ Args:
+ channels (int): Number of channels.
+ """
+ super().__init__()
+ self.channels = channels
+
+ m = paddle.zeros([channels, 1])
+ self.m = paddle.create_parameter(
+ shape=m.shape,
+ dtype=str(m.numpy().dtype),
+ default_initializer=paddle.nn.initializer.Assign(m))
+ logs = paddle.zeros([channels, 1])
+ self.logs = paddle.create_parameter(
+ shape=logs.shape,
+ dtype=str(logs.numpy().dtype),
+ default_initializer=paddle.nn.initializer.Assign(logs))
+
+ def forward(self,
+ x: paddle.Tensor,
+ x_mask: paddle.Tensor,
+ inverse: bool=False,
+ **kwargs
+ ) -> Union[paddle.Tensor, Tuple[paddle.Tensor, paddle.Tensor]]:
+ """Calculate forward propagation.
+ Args:
+ x (Tensor): Input tensor (B, channels, T).
+ x_mask (Tensor): Mask tensor (B, 1, T).
+ inverse (bool): Whether to inverse the flow.
+ Returns:
+ Tensor: Output tensor (B, channels, T).
+ Tensor: Log-determinant tensor for NLL (B,) if not inverse.
+ """
+ if not inverse:
+ y = self.m + paddle.exp(self.logs) * x
+ y = y * x_mask
+ logdet = paddle.sum(self.logs * x_mask, [1, 2])
+ return y, logdet
+ else:
+ x = (x - self.m) * paddle.exp(-self.logs) * x_mask
+ return x
+
+
+class Transpose(nn.Layer):
+ """Transpose module for paddle.nn.Sequential()."""
+
+ def __init__(self, dim1: int, dim2: int):
+ """Initialize Transpose module."""
+ super().__init__()
+ self.dim1 = dim1
+ self.dim2 = dim2
+
+ def forward(self, x: paddle.Tensor) -> paddle.Tensor:
+ """Transpose."""
+ len_dim = len(x.shape)
+ orig_perm = list(range(len_dim))
+ new_perm = orig_perm[:]
+ temp = new_perm[self.dim1]
+ new_perm[self.dim1] = new_perm[self.dim2]
+ new_perm[self.dim2] = temp
+
+ return paddle.transpose(x, new_perm)
+
+
+class DilatedDepthSeparableConv(nn.Layer):
+ """Dilated depth-separable conv module."""
+
+ def __init__(
+ self,
+ channels: int,
+ kernel_size: int,
+ layers: int,
+ dropout_rate: float=0.0,
+ eps: float=1e-5, ):
+ """Initialize DilatedDepthSeparableConv module.
+ Args:
+ channels (int): Number of channels.
+ kernel_size (int): Kernel size.
+ layers (int): Number of layers.
+ dropout_rate (float): Dropout rate.
+ eps (float): Epsilon for layer norm.
+ """
+ super().__init__()
+
+ self.convs = nn.LayerList()
+ for i in range(layers):
+ dilation = kernel_size**i
+ padding = (kernel_size * dilation - dilation) // 2
+ self.convs.append(
+ nn.Sequential(
+ nn.Conv1D(
+ channels,
+ channels,
+ kernel_size,
+ groups=channels,
+ dilation=dilation,
+ padding=padding, ),
+ Transpose(1, 2),
+ nn.LayerNorm(channels, epsilon=eps),
+ Transpose(1, 2),
+ nn.GELU(),
+ nn.Conv1D(
+ channels,
+ channels,
+ 1, ),
+ Transpose(1, 2),
+ nn.LayerNorm(channels, epsilon=eps),
+ Transpose(1, 2),
+ nn.GELU(),
+ nn.Dropout(dropout_rate), ))
+
+ def forward(self,
+ x: paddle.Tensor,
+ x_mask: paddle.Tensor,
+ g: Optional[paddle.Tensor]=None) -> paddle.Tensor:
+ """Calculate forward propagation.
+ Args:
+ x (Tensor): Input tensor (B, in_channels, T).
+ x_mask (Tensor): Mask tensor (B, 1, T).
+ g (Optional[Tensor]): Global conditioning tensor (B, global_channels, 1).
+ Returns:
+ Tensor: Output tensor (B, channels, T).
+ """
+ if g is not None:
+ x = x + g
+ for f in self.convs:
+ y = f(x * x_mask)
+ x = x + y
+ return x * x_mask
+
+
+class ConvFlow(nn.Layer):
+ """Convolutional flow module."""
+
+ def __init__(
+ self,
+ in_channels: int,
+ hidden_channels: int,
+ kernel_size: int,
+ layers: int,
+ bins: int=10,
+ tail_bound: float=5.0, ):
+ """Initialize ConvFlow module.
+ Args:
+ in_channels (int): Number of input channels.
+ hidden_channels (int): Number of hidden channels.
+ kernel_size (int): Kernel size.
+ layers (int): Number of layers.
+ bins (int): Number of bins.
+ tail_bound (float): Tail bound value.
+ """
+ super().__init__()
+ self.half_channels = in_channels // 2
+ self.hidden_channels = hidden_channels
+ self.bins = bins
+ self.tail_bound = tail_bound
+
+ self.input_conv = nn.Conv1D(
+ self.half_channels,
+ hidden_channels,
+ 1, )
+ self.dds_conv = DilatedDepthSeparableConv(
+ hidden_channels,
+ kernel_size,
+ layers,
+ dropout_rate=0.0, )
+ self.proj = nn.Conv1D(
+ hidden_channels,
+ self.half_channels * (bins * 3 - 1),
+ 1, )
+
+ weight = paddle.zeros(paddle.shape(self.proj.weight))
+
+ self.proj.weight = paddle.create_parameter(
+ shape=weight.shape,
+ dtype=str(weight.numpy().dtype),
+ default_initializer=paddle.nn.initializer.Assign(weight))
+
+ bias = paddle.zeros(paddle.shape(self.proj.bias))
+
+ self.proj.bias = paddle.create_parameter(
+ shape=bias.shape,
+ dtype=str(bias.numpy().dtype),
+ default_initializer=paddle.nn.initializer.Assign(bias))
+
+ def forward(
+ self,
+ x: paddle.Tensor,
+ x_mask: paddle.Tensor,
+ g: Optional[paddle.Tensor]=None,
+ inverse: bool=False,
+ ) -> Union[paddle.Tensor, Tuple[paddle.Tensor, paddle.Tensor]]:
+ """Calculate forward propagation.
+ Args:
+ x (Tensor): Input tensor (B, channels, T).
+ x_mask (Tensor): Mask tensor (B, 1, T).
+ g (Optional[Tensor]): Global conditioning tensor (B, channels, 1).
+ inverse (bool): Whether to inverse the flow.
+ Returns:
+ Tensor: Output tensor (B, channels, T).
+ Tensor: Log-determinant tensor for NLL (B,) if not inverse.
+ """
+ xa, xb = x.split(2, 1)
+ h = self.input_conv(xa)
+ h = self.dds_conv(h, x_mask, g=g)
+ # (B, half_channels * (bins * 3 - 1), T)
+ h = self.proj(h) * x_mask
+
+ b, c, t = xa.shape
+ # (B, half_channels, bins * 3 - 1, T) -> (B, half_channels, T, bins * 3 - 1)
+ h = h.reshape([b, c, -1, t]).transpose([0, 1, 3, 2])
+
+ denom = math.sqrt(self.hidden_channels)
+ unnorm_widths = h[..., :self.bins] / denom
+ unnorm_heights = h[..., self.bins:2 * self.bins] / denom
+ unnorm_derivatives = h[..., 2 * self.bins:]
+ xb, logdet_abs = piecewise_rational_quadratic_transform(
+ xb,
+ unnorm_widths,
+ unnorm_heights,
+ unnorm_derivatives,
+ inverse=inverse,
+ tails="linear",
+ tail_bound=self.tail_bound, )
+ x = paddle.concat([xa, xb], 1) * x_mask
+ logdet = paddle.sum(logdet_abs * x_mask, [1, 2])
+ if not inverse:
+ return x, logdet
+ else:
+ return x
diff --git a/paddlespeech/t2s/models/vits/generator.py b/paddlespeech/t2s/models/vits/generator.py
new file mode 100644
index 000000000..f87de91a2
--- /dev/null
+++ b/paddlespeech/t2s/models/vits/generator.py
@@ -0,0 +1,550 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Generator module in VITS.
+
+This code is based on https://github.com/jaywalnut310/vits.
+
+"""
+import math
+from typing import List
+from typing import Optional
+from typing import Tuple
+
+import numpy as np
+import paddle
+import paddle.nn.functional as F
+from paddle import nn
+
+from paddlespeech.t2s.models.hifigan import HiFiGANGenerator
+from paddlespeech.t2s.models.vits.duration_predictor import StochasticDurationPredictor
+from paddlespeech.t2s.models.vits.posterior_encoder import PosteriorEncoder
+from paddlespeech.t2s.models.vits.residual_coupling import ResidualAffineCouplingBlock
+from paddlespeech.t2s.models.vits.text_encoder import TextEncoder
+from paddlespeech.t2s.modules.nets_utils import get_random_segments
+from paddlespeech.t2s.modules.nets_utils import make_non_pad_mask
+
+
+class VITSGenerator(nn.Layer):
+ """Generator module in VITS.
+ This is a module of VITS described in `Conditional Variational Autoencoder
+ with Adversarial Learning for End-to-End Text-to-Speech`_.
+ As text encoder, we use conformer architecture instead of the relative positional
+ Transformer, which contains additional convolution layers.
+ .. _`Conditional Variational Autoencoder with Adversarial Learning for End-to-End
+ Text-to-Speech`: https://arxiv.org/abs/2006.04558
+ """
+
+ def __init__(
+ self,
+ vocabs: int,
+ aux_channels: int=513,
+ hidden_channels: int=192,
+ spks: Optional[int]=None,
+ langs: Optional[int]=None,
+ spk_embed_dim: Optional[int]=None,
+ global_channels: int=-1,
+ segment_size: int=32,
+ text_encoder_attention_heads: int=2,
+ text_encoder_ffn_expand: int=4,
+ text_encoder_blocks: int=6,
+ text_encoder_positionwise_layer_type: str="conv1d",
+ text_encoder_positionwise_conv_kernel_size: int=1,
+ text_encoder_positional_encoding_layer_type: str="rel_pos",
+ text_encoder_self_attention_layer_type: str="rel_selfattn",
+ text_encoder_activation_type: str="swish",
+ text_encoder_normalize_before: bool=True,
+ text_encoder_dropout_rate: float=0.1,
+ text_encoder_positional_dropout_rate: float=0.0,
+ text_encoder_attention_dropout_rate: float=0.0,
+ text_encoder_conformer_kernel_size: int=7,
+ use_macaron_style_in_text_encoder: bool=True,
+ use_conformer_conv_in_text_encoder: bool=True,
+ decoder_kernel_size: int=7,
+ decoder_channels: int=512,
+ decoder_upsample_scales: List[int]=[8, 8, 2, 2],
+ decoder_upsample_kernel_sizes: List[int]=[16, 16, 4, 4],
+ decoder_resblock_kernel_sizes: List[int]=[3, 7, 11],
+ decoder_resblock_dilations: List[List[int]]=[[1, 3, 5], [1, 3, 5],
+ [1, 3, 5]],
+ use_weight_norm_in_decoder: bool=True,
+ posterior_encoder_kernel_size: int=5,
+ posterior_encoder_layers: int=16,
+ posterior_encoder_stacks: int=1,
+ posterior_encoder_base_dilation: int=1,
+ posterior_encoder_dropout_rate: float=0.0,
+ use_weight_norm_in_posterior_encoder: bool=True,
+ flow_flows: int=4,
+ flow_kernel_size: int=5,
+ flow_base_dilation: int=1,
+ flow_layers: int=4,
+ flow_dropout_rate: float=0.0,
+ use_weight_norm_in_flow: bool=True,
+ use_only_mean_in_flow: bool=True,
+ stochastic_duration_predictor_kernel_size: int=3,
+ stochastic_duration_predictor_dropout_rate: float=0.5,
+ stochastic_duration_predictor_flows: int=4,
+ stochastic_duration_predictor_dds_conv_layers: int=3, ):
+ """Initialize VITS generator module.
+ Args:
+ vocabs (int): Input vocabulary size.
+ aux_channels (int): Number of acoustic feature channels.
+ hidden_channels (int): Number of hidden channels.
+ spks (Optional[int]): Number of speakers. If set to > 1, assume that the
+ sids will be provided as the input and use sid embedding layer.
+ langs (Optional[int]): Number of languages. If set to > 1, assume that the
+ lids will be provided as the input and use sid embedding layer.
+ spk_embed_dim (Optional[int]): Speaker embedding dimension. If set to > 0,
+ assume that spembs will be provided as the input.
+ global_channels (int): Number of global conditioning channels.
+ segment_size (int): Segment size for decoder.
+ text_encoder_attention_heads (int): Number of heads in conformer block
+ of text encoder.
+ text_encoder_ffn_expand (int): Expansion ratio of FFN in conformer block
+ of text encoder.
+ text_encoder_blocks (int): Number of conformer blocks in text encoder.
+ text_encoder_positionwise_layer_type (str): Position-wise layer type in
+ conformer block of text encoder.
+ text_encoder_positionwise_conv_kernel_size (int): Position-wise convolution
+ kernel size in conformer block of text encoder. Only used when the
+ above layer type is conv1d or conv1d-linear.
+ text_encoder_positional_encoding_layer_type (str): Positional encoding layer
+ type in conformer block of text encoder.
+ text_encoder_self_attention_layer_type (str): Self-attention layer type in
+ conformer block of text encoder.
+ text_encoder_activation_type (str): Activation function type in conformer
+ block of text encoder.
+ text_encoder_normalize_before (bool): Whether to apply layer norm before
+ self-attention in conformer block of text encoder.
+ text_encoder_dropout_rate (float): Dropout rate in conformer block of
+ text encoder.
+ text_encoder_positional_dropout_rate (float): Dropout rate for positional
+ encoding in conformer block of text encoder.
+ text_encoder_attention_dropout_rate (float): Dropout rate for attention in
+ conformer block of text encoder.
+ text_encoder_conformer_kernel_size (int): Conformer conv kernel size. It
+ will be used when only use_conformer_conv_in_text_encoder = True.
+ use_macaron_style_in_text_encoder (bool): Whether to use macaron style FFN
+ in conformer block of text encoder.
+ use_conformer_conv_in_text_encoder (bool): Whether to use covolution in
+ conformer block of text encoder.
+ decoder_kernel_size (int): Decoder kernel size.
+ decoder_channels (int): Number of decoder initial channels.
+ decoder_upsample_scales (List[int]): List of upsampling scales in decoder.
+ decoder_upsample_kernel_sizes (List[int]): List of kernel size for
+ upsampling layers in decoder.
+ decoder_resblock_kernel_sizes (List[int]): List of kernel size for resblocks
+ in decoder.
+ decoder_resblock_dilations (List[List[int]]): List of list of dilations for
+ resblocks in decoder.
+ use_weight_norm_in_decoder (bool): Whether to apply weight normalization in
+ decoder.
+ posterior_encoder_kernel_size (int): Posterior encoder kernel size.
+ posterior_encoder_layers (int): Number of layers of posterior encoder.
+ posterior_encoder_stacks (int): Number of stacks of posterior encoder.
+ posterior_encoder_base_dilation (int): Base dilation of posterior encoder.
+ posterior_encoder_dropout_rate (float): Dropout rate for posterior encoder.
+ use_weight_norm_in_posterior_encoder (bool): Whether to apply weight
+ normalization in posterior encoder.
+ flow_flows (int): Number of flows in flow.
+ flow_kernel_size (int): Kernel size in flow.
+ flow_base_dilation (int): Base dilation in flow.
+ flow_layers (int): Number of layers in flow.
+ flow_dropout_rate (float): Dropout rate in flow
+ use_weight_norm_in_flow (bool): Whether to apply weight normalization in
+ flow.
+ use_only_mean_in_flow (bool): Whether to use only mean in flow.
+ stochastic_duration_predictor_kernel_size (int): Kernel size in stochastic
+ duration predictor.
+ stochastic_duration_predictor_dropout_rate (float): Dropout rate in
+ stochastic duration predictor.
+ stochastic_duration_predictor_flows (int): Number of flows in stochastic
+ duration predictor.
+ stochastic_duration_predictor_dds_conv_layers (int): Number of DDS conv
+ layers in stochastic duration predictor.
+ """
+ super().__init__()
+ self.segment_size = segment_size
+ self.text_encoder = TextEncoder(
+ vocabs=vocabs,
+ attention_dim=hidden_channels,
+ attention_heads=text_encoder_attention_heads,
+ linear_units=hidden_channels * text_encoder_ffn_expand,
+ blocks=text_encoder_blocks,
+ positionwise_layer_type=text_encoder_positionwise_layer_type,
+ positionwise_conv_kernel_size=text_encoder_positionwise_conv_kernel_size,
+ positional_encoding_layer_type=text_encoder_positional_encoding_layer_type,
+ self_attention_layer_type=text_encoder_self_attention_layer_type,
+ activation_type=text_encoder_activation_type,
+ normalize_before=text_encoder_normalize_before,
+ dropout_rate=text_encoder_dropout_rate,
+ positional_dropout_rate=text_encoder_positional_dropout_rate,
+ attention_dropout_rate=text_encoder_attention_dropout_rate,
+ conformer_kernel_size=text_encoder_conformer_kernel_size,
+ use_macaron_style=use_macaron_style_in_text_encoder,
+ use_conformer_conv=use_conformer_conv_in_text_encoder, )
+ self.decoder = HiFiGANGenerator(
+ in_channels=hidden_channels,
+ out_channels=1,
+ channels=decoder_channels,
+ global_channels=global_channels,
+ kernel_size=decoder_kernel_size,
+ upsample_scales=decoder_upsample_scales,
+ upsample_kernel_sizes=decoder_upsample_kernel_sizes,
+ resblock_kernel_sizes=decoder_resblock_kernel_sizes,
+ resblock_dilations=decoder_resblock_dilations,
+ use_weight_norm=use_weight_norm_in_decoder, )
+ self.posterior_encoder = PosteriorEncoder(
+ in_channels=aux_channels,
+ out_channels=hidden_channels,
+ hidden_channels=hidden_channels,
+ kernel_size=posterior_encoder_kernel_size,
+ layers=posterior_encoder_layers,
+ stacks=posterior_encoder_stacks,
+ base_dilation=posterior_encoder_base_dilation,
+ global_channels=global_channels,
+ dropout_rate=posterior_encoder_dropout_rate,
+ use_weight_norm=use_weight_norm_in_posterior_encoder, )
+ self.flow = ResidualAffineCouplingBlock(
+ in_channels=hidden_channels,
+ hidden_channels=hidden_channels,
+ flows=flow_flows,
+ kernel_size=flow_kernel_size,
+ base_dilation=flow_base_dilation,
+ layers=flow_layers,
+ global_channels=global_channels,
+ dropout_rate=flow_dropout_rate,
+ use_weight_norm=use_weight_norm_in_flow,
+ use_only_mean=use_only_mean_in_flow, )
+ # TODO: Add deterministic version as an option
+ self.duration_predictor = StochasticDurationPredictor(
+ channels=hidden_channels,
+ kernel_size=stochastic_duration_predictor_kernel_size,
+ dropout_rate=stochastic_duration_predictor_dropout_rate,
+ flows=stochastic_duration_predictor_flows,
+ dds_conv_layers=stochastic_duration_predictor_dds_conv_layers,
+ global_channels=global_channels, )
+
+ self.upsample_factor = int(np.prod(decoder_upsample_scales))
+ self.spks = None
+ if spks is not None and spks > 1:
+ assert global_channels > 0
+ self.spks = spks
+ self.global_emb = nn.Embedding(spks, global_channels)
+ self.spk_embed_dim = None
+ if spk_embed_dim is not None and spk_embed_dim > 0:
+ assert global_channels > 0
+ self.spk_embed_dim = spk_embed_dim
+ self.spemb_proj = nn.Linear(spk_embed_dim, global_channels)
+ self.langs = None
+ if langs is not None and langs > 1:
+ assert global_channels > 0
+ self.langs = langs
+ self.lang_emb = nn.Embedding(langs, global_channels)
+
+ # delayed import
+ from paddlespeech.t2s.models.vits.monotonic_align import maximum_path
+
+ self.maximum_path = maximum_path
+
+ def forward(
+ self,
+ text: paddle.Tensor,
+ text_lengths: paddle.Tensor,
+ feats: paddle.Tensor,
+ feats_lengths: paddle.Tensor,
+ sids: Optional[paddle.Tensor]=None,
+ spembs: Optional[paddle.Tensor]=None,
+ lids: Optional[paddle.Tensor]=None,
+ ) -> Tuple[paddle.Tensor, paddle.Tensor, paddle.Tensor, paddle.Tensor,
+ paddle.Tensor, paddle.Tensor,
+ Tuple[paddle.Tensor, paddle.Tensor, paddle.Tensor, paddle.Tensor,
+ paddle.Tensor, paddle.Tensor, ], ]:
+ """Calculate forward propagation.
+ Args:
+ text (Tensor): Text index tensor (B, T_text).
+ text_lengths (Tensor): Text length tensor (B,).
+ feats (Tensor): Feature tensor (B, aux_channels, T_feats).
+ feats_lengths (Tensor): Feature length tensor (B,).
+ sids (Optional[Tensor]): Speaker index tensor (B,) or (B, 1).
+ spembs (Optional[Tensor]): Speaker embedding tensor (B, spk_embed_dim).
+ lids (Optional[Tensor]): Language index tensor (B,) or (B, 1).
+ Returns:
+ Tensor: Waveform tensor (B, 1, segment_size * upsample_factor).
+ Tensor: Duration negative log-likelihood (NLL) tensor (B,).
+ Tensor: Monotonic attention weight tensor (B, 1, T_feats, T_text).
+ Tensor: Segments start index tensor (B,).
+ Tensor: Text mask tensor (B, 1, T_text).
+ Tensor: Feature mask tensor (B, 1, T_feats).
+ tuple[Tensor, Tensor, Tensor, Tensor, Tensor, Tensor]:
+ - Tensor: Posterior encoder hidden representation (B, H, T_feats).
+ - Tensor: Flow hidden representation (B, H, T_feats).
+ - Tensor: Expanded text encoder projected mean (B, H, T_feats).
+ - Tensor: Expanded text encoder projected scale (B, H, T_feats).
+ - Tensor: Posterior encoder projected mean (B, H, T_feats).
+ - Tensor: Posterior encoder projected scale (B, H, T_feats).
+ """
+ # forward text encoder
+ x, m_p, logs_p, x_mask = self.text_encoder(text, text_lengths)
+
+ # calculate global conditioning
+ g = None
+ if self.spks is not None:
+ # speaker one-hot vector embedding: (B, global_channels, 1)
+ g = self.global_emb(paddle.reshape(sids, [-1])).unsqueeze(-1)
+ if self.spk_embed_dim is not None:
+ # pretreined speaker embedding, e.g., X-vector (B, global_channels, 1)
+ g_ = self.spemb_proj(F.normalize(spembs)).unsqueeze(-1)
+ if g is None:
+ g = g_
+ else:
+ g = g + g_
+ if self.langs is not None:
+ # language one-hot vector embedding: (B, global_channels, 1)
+ g_ = self.lang_emb(paddle.reshape(lids, [-1])).unsqueeze(-1)
+ if g is None:
+ g = g_
+ else:
+ g = g + g_
+
+ # forward posterior encoder
+ z, m_q, logs_q, y_mask = self.posterior_encoder(
+ feats, feats_lengths, g=g)
+
+ # forward flow
+ # (B, H, T_feats)
+ z_p = self.flow(z, y_mask, g=g)
+
+ # monotonic alignment search
+ with paddle.no_grad():
+ # negative cross-entropy
+ # (B, H, T_text)
+ s_p_sq_r = paddle.exp(-2 * logs_p)
+ # (B, 1, T_text)
+ neg_x_ent_1 = paddle.sum(
+ -0.5 * math.log(2 * math.pi) - logs_p,
+ [1],
+ keepdim=True, )
+ # (B, T_feats, H) x (B, H, T_text) = (B, T_feats, T_text)
+ neg_x_ent_2 = paddle.matmul(
+ -0.5 * (z_p**2).transpose([0, 2, 1]),
+ s_p_sq_r, )
+ # (B, T_feats, H) x (B, H, T_text) = (B, T_feats, T_text)
+ neg_x_ent_3 = paddle.matmul(
+ z_p.transpose([0, 2, 1]),
+ (m_p * s_p_sq_r), )
+ # (B, 1, T_text)
+ neg_x_ent_4 = paddle.sum(
+ -0.5 * (m_p**2) * s_p_sq_r,
+ [1],
+ keepdim=True, )
+ # (B, T_feats, T_text)
+ neg_x_ent = neg_x_ent_1 + neg_x_ent_2 + neg_x_ent_3 + neg_x_ent_4
+ # (B, 1, T_feats, T_text)
+ attn_mask = paddle.unsqueeze(x_mask, 2) * paddle.unsqueeze(y_mask,
+ -1)
+ # monotonic attention weight: (B, 1, T_feats, T_text)
+ attn = (self.maximum_path(
+ neg_x_ent,
+ attn_mask.squeeze(1), ).unsqueeze(1).detach())
+
+ # forward duration predictor
+ # (B, 1, T_text)
+ w = attn.sum(2)
+ dur_nll = self.duration_predictor(x, x_mask, w=w, g=g)
+ dur_nll = dur_nll / paddle.sum(x_mask)
+
+ # expand the length to match with the feature sequence
+ # (B, T_feats, T_text) x (B, T_text, H) -> (B, H, T_feats)
+ m_p = paddle.matmul(attn.squeeze(1),
+ m_p.transpose([0, 2, 1])).transpose([0, 2, 1])
+ # (B, T_feats, T_text) x (B, T_text, H) -> (B, H, T_feats)
+ logs_p = paddle.matmul(attn.squeeze(1),
+ logs_p.transpose([0, 2, 1])).transpose([0, 2, 1])
+
+ # get random segments
+ z_segments, z_start_idxs = get_random_segments(
+ z,
+ feats_lengths,
+ self.segment_size, )
+
+ # forward decoder with random segments
+ wav = self.decoder(z_segments, g=g)
+
+ return (wav, dur_nll, attn, z_start_idxs, x_mask, y_mask,
+ (z, z_p, m_p, logs_p, m_q, logs_q), )
+
+ def inference(
+ self,
+ text: paddle.Tensor,
+ text_lengths: paddle.Tensor,
+ feats: Optional[paddle.Tensor]=None,
+ feats_lengths: Optional[paddle.Tensor]=None,
+ sids: Optional[paddle.Tensor]=None,
+ spembs: Optional[paddle.Tensor]=None,
+ lids: Optional[paddle.Tensor]=None,
+ dur: Optional[paddle.Tensor]=None,
+ noise_scale: float=0.667,
+ noise_scale_dur: float=0.8,
+ alpha: float=1.0,
+ max_len: Optional[int]=None,
+ use_teacher_forcing: bool=False,
+ ) -> Tuple[paddle.Tensor, paddle.Tensor, paddle.Tensor]:
+ """Run inference.
+ Args:
+ text (Tensor): Input text index tensor (B, T_text,).
+ text_lengths (Tensor): Text length tensor (B,).
+ feats (Tensor): Feature tensor (B, aux_channels, T_feats,).
+ feats_lengths (Tensor): Feature length tensor (B,).
+ sids (Optional[Tensor]): Speaker index tensor (B,) or (B, 1).
+ spembs (Optional[Tensor]): Speaker embedding tensor (B, spk_embed_dim).
+ lids (Optional[Tensor]): Language index tensor (B,) or (B, 1).
+ dur (Optional[Tensor]): Ground-truth duration (B, T_text,). If provided,
+ skip the prediction of durations (i.e., teacher forcing).
+ noise_scale (float): Noise scale parameter for flow.
+ noise_scale_dur (float): Noise scale parameter for duration predictor.
+ alpha (float): Alpha parameter to control the speed of generated speech.
+ max_len (Optional[int]): Maximum length of acoustic feature sequence.
+ use_teacher_forcing (bool): Whether to use teacher forcing.
+ Returns:
+ Tensor: Generated waveform tensor (B, T_wav).
+ Tensor: Monotonic attention weight tensor (B, T_feats, T_text).
+ Tensor: Duration tensor (B, T_text).
+ """
+ # encoder
+ x, m_p, logs_p, x_mask = self.text_encoder(text, text_lengths)
+ g = None
+ if self.spks is not None:
+ # (B, global_channels, 1)
+ g = self.global_emb(paddle.reshape(sids, [-1])).unsqueeze(-1)
+ if self.spk_embed_dim is not None:
+ # (B, global_channels, 1)
+ g_ = self.spemb_proj(F.normalize(spembs.unsqueeze(0))).unsqueeze(-1)
+ if g is None:
+ g = g_
+ else:
+ g = g + g_
+ if self.langs is not None:
+ # (B, global_channels, 1)
+ g_ = self.lang_emb(paddle.reshape(lids, [-1])).unsqueeze(-1)
+ if g is None:
+ g = g_
+ else:
+ g = g + g_
+
+ if use_teacher_forcing:
+ # forward posterior encoder
+ z, m_q, logs_q, y_mask = self.posterior_encoder(
+ feats, feats_lengths, g=g)
+
+ # forward flow
+ # (B, H, T_feats)
+ z_p = self.flow(z, y_mask, g=g)
+
+ # monotonic alignment search
+ # (B, H, T_text)
+ s_p_sq_r = paddle.exp(-2 * logs_p)
+ # (B, 1, T_text)
+ neg_x_ent_1 = paddle.sum(
+ -0.5 * math.log(2 * math.pi) - logs_p,
+ [1],
+ keepdim=True, )
+ # (B, T_feats, H) x (B, H, T_text) = (B, T_feats, T_text)
+ neg_x_ent_2 = paddle.matmul(
+ -0.5 * (z_p**2).transpose([0, 2, 1]),
+ s_p_sq_r, )
+ # (B, T_feats, H) x (B, H, T_text) = (B, T_feats, T_text)
+ neg_x_ent_3 = paddle.matmul(
+ z_p.transpose([0, 2, 1]),
+ (m_p * s_p_sq_r), )
+ # (B, 1, T_text)
+ neg_x_ent_4 = paddle.sum(
+ -0.5 * (m_p**2) * s_p_sq_r,
+ [1],
+ keepdim=True, )
+ # (B, T_feats, T_text)
+ neg_x_ent = neg_x_ent_1 + neg_x_ent_2 + neg_x_ent_3 + neg_x_ent_4
+ # (B, 1, T_feats, T_text)
+ attn_mask = paddle.unsqueeze(x_mask, 2) * paddle.unsqueeze(y_mask,
+ -1)
+ # monotonic attention weight: (B, 1, T_feats, T_text)
+ attn = self.maximum_path(
+ neg_x_ent,
+ attn_mask.squeeze(1), ).unsqueeze(1)
+ # (B, 1, T_text)
+ dur = attn.sum(2)
+
+ # forward decoder with random segments
+ wav = self.decoder(z * y_mask, g=g)
+ else:
+ # duration
+ if dur is None:
+ logw = self.duration_predictor(
+ x,
+ x_mask,
+ g=g,
+ inverse=True,
+ noise_scale=noise_scale_dur, )
+ w = paddle.exp(logw) * x_mask * alpha
+ dur = paddle.ceil(w)
+ y_lengths = paddle.cast(
+ paddle.clip(paddle.sum(dur, [1, 2]), min=1), dtype='int64')
+ y_mask = make_non_pad_mask(y_lengths).unsqueeze(1)
+ attn_mask = paddle.unsqueeze(x_mask, 2) * paddle.unsqueeze(y_mask,
+ -1)
+ attn = self._generate_path(dur, attn_mask)
+
+ # expand the length to match with the feature sequence
+ # (B, T_feats, T_text) x (B, T_text, H) -> (B, H, T_feats)
+ m_p = paddle.matmul(
+ attn.squeeze(1),
+ m_p.transpose([0, 2, 1]), ).transpose([0, 2, 1])
+ # (B, T_feats, T_text) x (B, T_text, H) -> (B, H, T_feats)
+ logs_p = paddle.matmul(
+ attn.squeeze(1),
+ logs_p.transpose([0, 2, 1]), ).transpose([0, 2, 1])
+
+ # decoder
+ z_p = m_p + paddle.randn(
+ paddle.shape(m_p)) * paddle.exp(logs_p) * noise_scale
+ z = self.flow(z_p, y_mask, g=g, inverse=True)
+ wav = self.decoder((z * y_mask)[:, :, :max_len], g=g)
+
+ return wav.squeeze(1), attn.squeeze(1), dur.squeeze(1)
+
+ def _generate_path(self, dur: paddle.Tensor,
+ mask: paddle.Tensor) -> paddle.Tensor:
+ """Generate path a.k.a. monotonic attention.
+ Args:
+ dur (Tensor): Duration tensor (B, 1, T_text).
+ mask (Tensor): Attention mask tensor (B, 1, T_feats, T_text).
+ Returns:
+ Tensor: Path tensor (B, 1, T_feats, T_text).
+ """
+ b, _, t_y, t_x = paddle.shape(mask)
+ cum_dur = paddle.cumsum(dur, -1)
+ cum_dur_flat = paddle.reshape(cum_dur, [b * t_x])
+
+ path = paddle.arange(t_y, dtype=dur.dtype)
+ path = path.unsqueeze(0) < cum_dur_flat.unsqueeze(1)
+ path = paddle.reshape(path, [b, t_x, t_y])
+ '''
+ path will be like (t_x = 3, t_y = 5):
+ [[[1., 1., 0., 0., 0.], [[[1., 1., 0., 0., 0.],
+ [1., 1., 1., 1., 0.], --> [0., 0., 1., 1., 0.],
+ [1., 1., 1., 1., 1.]]] [0., 0., 0., 0., 1.]]]
+ '''
+
+ path = paddle.cast(path, dtype='float32')
+ path = path - F.pad(path, [0, 0, 1, 0, 0, 0])[:, :-1]
+ return path.unsqueeze(1).transpose([0, 1, 3, 2]) * mask
diff --git a/paddlespeech/t2s/models/vits/monotonic_align/__init__.py b/paddlespeech/t2s/models/vits/monotonic_align/__init__.py
new file mode 100644
index 000000000..3aa47ed72
--- /dev/null
+++ b/paddlespeech/t2s/models/vits/monotonic_align/__init__.py
@@ -0,0 +1,94 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Maximum path calculation module.
+
+This code is based on https://github.com/jaywalnut310/vits.
+
+"""
+import warnings
+
+import numpy as np
+import paddle
+from numba import njit
+from numba import prange
+
+try:
+ from .core import maximum_path_c
+
+ is_cython_avalable = True
+except ImportError:
+ is_cython_avalable = False
+ warnings.warn(
+ "Cython version is not available. Fallback to 'EXPERIMETAL' numba version. "
+ "If you want to use the cython version, please build it as follows: "
+ "`cd paddlespeech/t2s/models/vits/monotonic_align; python setup.py build_ext --inplace`"
+ )
+
+
+def maximum_path(neg_x_ent: paddle.Tensor,
+ attn_mask: paddle.Tensor) -> paddle.Tensor:
+ """Calculate maximum path.
+
+ Args:
+ neg_x_ent (Tensor): Negative X entropy tensor (B, T_feats, T_text).
+ attn_mask (Tensor): Attention mask (B, T_feats, T_text).
+
+ Returns:
+ Tensor: Maximum path tensor (B, T_feats, T_text).
+
+ """
+ dtype = neg_x_ent.dtype
+ neg_x_ent = neg_x_ent.numpy().astype(np.float32)
+ path = np.zeros(neg_x_ent.shape, dtype=np.int32)
+ t_t_max = attn_mask.sum(1)[:, 0].cpu().numpy().astype(np.int32)
+ t_s_max = attn_mask.sum(2)[:, 0].cpu().numpy().astype(np.int32)
+ if is_cython_avalable:
+ maximum_path_c(path, neg_x_ent, t_t_max, t_s_max)
+ else:
+ maximum_path_numba(path, neg_x_ent, t_t_max, t_s_max)
+
+ return paddle.cast(paddle.to_tensor(path), dtype=dtype)
+
+
+@njit
+def maximum_path_each_numba(path, value, t_y, t_x, max_neg_val=-np.inf):
+ """Calculate a single maximum path with numba."""
+ index = t_x - 1
+ for y in range(t_y):
+ for x in range(max(0, t_x + y - t_y), min(t_x, y + 1)):
+ if x == y:
+ v_cur = max_neg_val
+ else:
+ v_cur = value[y - 1, x]
+ if x == 0:
+ if y == 0:
+ v_prev = 0.0
+ else:
+ v_prev = max_neg_val
+ else:
+ v_prev = value[y - 1, x - 1]
+ value[y, x] += max(v_prev, v_cur)
+
+ for y in range(t_y - 1, -1, -1):
+ path[y, index] = 1
+ if index != 0 and (index == y or
+ value[y - 1, index] < value[y - 1, index - 1]):
+ index = index - 1
+
+
+@njit(parallel=True)
+def maximum_path_numba(paths, values, t_ys, t_xs):
+ """Calculate batch maximum path with numba."""
+ for i in prange(paths.shape[0]):
+ maximum_path_each_numba(paths[i], values[i], t_ys[i], t_xs[i])
diff --git a/paddlespeech/t2s/models/vits/monotonic_align/core.pyx b/paddlespeech/t2s/models/vits/monotonic_align/core.pyx
new file mode 100644
index 000000000..5a573dc74
--- /dev/null
+++ b/paddlespeech/t2s/models/vits/monotonic_align/core.pyx
@@ -0,0 +1,62 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Maximum path calculation module with cython optimization.
+
+This code is copied from https://github.com/jaywalnut310/vits and modifed code format.
+
+"""
+
+cimport cython
+
+from cython.parallel import prange
+
+
+@cython.boundscheck(False)
+@cython.wraparound(False)
+cdef void maximum_path_each(int[:, ::1] path, float[:, ::1] value, int t_y, int t_x, float max_neg_val=-1e9) nogil:
+ cdef int x
+ cdef int y
+ cdef float v_prev
+ cdef float v_cur
+ cdef float tmp
+ cdef int index = t_x - 1
+
+ for y in range(t_y):
+ for x in range(max(0, t_x + y - t_y), min(t_x, y + 1)):
+ if x == y:
+ v_cur = max_neg_val
+ else:
+ v_cur = value[y - 1, x]
+ if x == 0:
+ if y == 0:
+ v_prev = 0.0
+ else:
+ v_prev = max_neg_val
+ else:
+ v_prev = value[y - 1, x - 1]
+ value[y, x] += max(v_prev, v_cur)
+
+ for y in range(t_y - 1, -1, -1):
+ path[y, index] = 1
+ if index != 0 and (index == y or value[y - 1, index] < value[y - 1, index - 1]):
+ index = index - 1
+
+
+@cython.boundscheck(False)
+@cython.wraparound(False)
+cpdef void maximum_path_c(int[:, :, ::1] paths, float[:, :, ::1] values, int[::1] t_ys, int[::1] t_xs) nogil:
+ cdef int b = paths.shape[0]
+ cdef int i
+ for i in prange(b, nogil=True):
+ maximum_path_each(paths[i], values[i], t_ys[i], t_xs[i])
diff --git a/paddlespeech/t2s/models/vits/monotonic_align/setup.py b/paddlespeech/t2s/models/vits/monotonic_align/setup.py
new file mode 100644
index 000000000..8df03ab12
--- /dev/null
+++ b/paddlespeech/t2s/models/vits/monotonic_align/setup.py
@@ -0,0 +1,39 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Setup cython code."""
+from Cython.Build import cythonize
+from setuptools import Extension
+from setuptools import setup
+from setuptools.command.build_ext import build_ext as _build_ext
+
+
+class build_ext(_build_ext):
+ """Overwrite build_ext."""
+
+ def finalize_options(self):
+ """Prevent numpy from thinking it is still in its setup process."""
+ _build_ext.finalize_options(self)
+ __builtins__.__NUMPY_SETUP__ = False
+ import numpy
+
+ self.include_dirs.append(numpy.get_include())
+
+
+exts = [Extension(
+ name="core",
+ sources=["core.pyx"], )]
+setup(
+ name="monotonic_align",
+ ext_modules=cythonize(exts, language_level=3),
+ cmdclass={"build_ext": build_ext}, )
diff --git a/paddlespeech/t2s/models/vits/posterior_encoder.py b/paddlespeech/t2s/models/vits/posterior_encoder.py
new file mode 100644
index 000000000..853237557
--- /dev/null
+++ b/paddlespeech/t2s/models/vits/posterior_encoder.py
@@ -0,0 +1,120 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Text encoder module in VITS.
+
+This code is based on https://github.com/jaywalnut310/vits.
+
+"""
+from typing import Optional
+from typing import Tuple
+
+import paddle
+from paddle import nn
+
+from paddlespeech.t2s.models.vits.wavenet.wavenet import WaveNet
+from paddlespeech.t2s.modules.nets_utils import make_non_pad_mask
+
+
+class PosteriorEncoder(nn.Layer):
+ """Posterior encoder module in VITS.
+
+ This is a module of posterior encoder described in `Conditional Variational
+ Autoencoder with Adversarial Learning for End-to-End Text-to-Speech`_.
+
+ .. _`Conditional Variational Autoencoder with Adversarial Learning for End-to-End
+ Text-to-Speech`: https://arxiv.org/abs/2006.04558
+ """
+
+ def __init__(
+ self,
+ in_channels: int=513,
+ out_channels: int=192,
+ hidden_channels: int=192,
+ kernel_size: int=5,
+ layers: int=16,
+ stacks: int=1,
+ base_dilation: int=1,
+ global_channels: int=-1,
+ dropout_rate: float=0.0,
+ bias: bool=True,
+ use_weight_norm: bool=True, ):
+ """Initilialize PosteriorEncoder module.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ hidden_channels (int): Number of hidden channels.
+ kernel_size (int): Kernel size in WaveNet.
+ layers (int): Number of layers of WaveNet.
+ stacks (int): Number of repeat stacking of WaveNet.
+ base_dilation (int): Base dilation factor.
+ global_channels (int): Number of global conditioning channels.
+ dropout_rate (float): Dropout rate.
+ bias (bool): Whether to use bias parameters in conv.
+ use_weight_norm (bool): Whether to apply weight norm.
+
+ """
+ super().__init__()
+
+ # define modules
+ self.input_conv = nn.Conv1D(in_channels, hidden_channels, 1)
+ self.encoder = WaveNet(
+ in_channels=-1,
+ out_channels=-1,
+ kernel_size=kernel_size,
+ layers=layers,
+ stacks=stacks,
+ base_dilation=base_dilation,
+ residual_channels=hidden_channels,
+ aux_channels=-1,
+ gate_channels=hidden_channels * 2,
+ skip_channels=hidden_channels,
+ global_channels=global_channels,
+ dropout_rate=dropout_rate,
+ bias=bias,
+ use_weight_norm=use_weight_norm,
+ use_first_conv=False,
+ use_last_conv=False,
+ scale_residual=False,
+ scale_skip_connect=True, )
+ self.proj = nn.Conv1D(hidden_channels, out_channels * 2, 1)
+
+ def forward(
+ self,
+ x: paddle.Tensor,
+ x_lengths: paddle.Tensor,
+ g: Optional[paddle.Tensor]=None
+ ) -> Tuple[paddle.Tensor, paddle.Tensor, paddle.Tensor, paddle.Tensor]:
+ """Calculate forward propagation.
+
+ Args:
+ x (Tensor): Input tensor (B, in_channels, T_feats).
+ x_lengths (Tensor): Length tensor (B,).
+ g (Optional[Tensor]): Global conditioning tensor (B, global_channels, 1).
+
+ Returns:
+ Tensor: Encoded hidden representation tensor (B, out_channels, T_feats).
+ Tensor: Projected mean tensor (B, out_channels, T_feats).
+ Tensor: Projected scale tensor (B, out_channels, T_feats).
+ Tensor: Mask tensor for input tensor (B, 1, T_feats).
+
+ """
+ x_mask = make_non_pad_mask(x_lengths).unsqueeze(1)
+ x = self.input_conv(x) * x_mask
+ x = self.encoder(x, x_mask, g=g)
+ stats = self.proj(x) * x_mask
+ m, logs = paddle.split(stats, 2, axis=1)
+ z = (m + paddle.randn(paddle.shape(m)) * paddle.exp(logs)) * x_mask
+
+ return z, m, logs, x_mask
diff --git a/paddlespeech/t2s/models/vits/residual_coupling.py b/paddlespeech/t2s/models/vits/residual_coupling.py
new file mode 100644
index 000000000..c18beedd0
--- /dev/null
+++ b/paddlespeech/t2s/models/vits/residual_coupling.py
@@ -0,0 +1,242 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Residual affine coupling modules in VITS.
+
+This code is based on https://github.com/jaywalnut310/vits.
+
+"""
+from typing import Optional
+from typing import Tuple
+from typing import Union
+
+import paddle
+from paddle import nn
+
+from paddlespeech.t2s.models.vits.flow import FlipFlow
+from paddlespeech.t2s.models.vits.wavenet.wavenet import WaveNet
+
+
+class ResidualAffineCouplingBlock(nn.Layer):
+ """Residual affine coupling block module.
+
+ This is a module of residual affine coupling block, which used as "Flow" in
+ `Conditional Variational Autoencoder with Adversarial Learning for End-to-End
+ Text-to-Speech`_.
+
+ .. _`Conditional Variational Autoencoder with Adversarial Learning for End-to-End
+ Text-to-Speech`: https://arxiv.org/abs/2006.04558
+
+ """
+
+ def __init__(
+ self,
+ in_channels: int=192,
+ hidden_channels: int=192,
+ flows: int=4,
+ kernel_size: int=5,
+ base_dilation: int=1,
+ layers: int=4,
+ global_channels: int=-1,
+ dropout_rate: float=0.0,
+ use_weight_norm: bool=True,
+ bias: bool=True,
+ use_only_mean: bool=True, ):
+ """Initilize ResidualAffineCouplingBlock module.
+
+ Args:
+ in_channels (int): Number of input channels.
+ hidden_channels (int): Number of hidden channels.
+ flows (int): Number of flows.
+ kernel_size (int): Kernel size for WaveNet.
+ base_dilation (int): Base dilation factor for WaveNet.
+ layers (int): Number of layers of WaveNet.
+ stacks (int): Number of stacks of WaveNet.
+ global_channels (int): Number of global channels.
+ dropout_rate (float): Dropout rate.
+ use_weight_norm (bool): Whether to use weight normalization in WaveNet.
+ bias (bool): Whether to use bias paramters in WaveNet.
+ use_only_mean (bool): Whether to estimate only mean.
+
+ """
+ super().__init__()
+
+ self.flows = nn.LayerList()
+ for i in range(flows):
+ self.flows.append(
+ ResidualAffineCouplingLayer(
+ in_channels=in_channels,
+ hidden_channels=hidden_channels,
+ kernel_size=kernel_size,
+ base_dilation=base_dilation,
+ layers=layers,
+ stacks=1,
+ global_channels=global_channels,
+ dropout_rate=dropout_rate,
+ use_weight_norm=use_weight_norm,
+ bias=bias,
+ use_only_mean=use_only_mean, ))
+ self.flows.append(FlipFlow())
+
+ def forward(
+ self,
+ x: paddle.Tensor,
+ x_mask: paddle.Tensor,
+ g: Optional[paddle.Tensor]=None,
+ inverse: bool=False, ) -> paddle.Tensor:
+ """Calculate forward propagation.
+
+ Args:
+ x (Tensor): Input tensor (B, in_channels, T).
+ x_mask (Tensor): Length tensor (B, 1, T).
+ g (Optional[Tensor]): Global conditioning tensor (B, global_channels, 1).
+ inverse (bool): Whether to inverse the flow.
+
+ Returns:
+ Tensor: Output tensor (B, in_channels, T).
+
+ """
+ if not inverse:
+ for flow in self.flows:
+ x, _ = flow(x, x_mask, g=g, inverse=inverse)
+ else:
+ for flow in reversed(self.flows):
+ x = flow(x, x_mask, g=g, inverse=inverse)
+ return x
+
+
+class ResidualAffineCouplingLayer(nn.Layer):
+ """Residual affine coupling layer."""
+
+ def __init__(
+ self,
+ in_channels: int=192,
+ hidden_channels: int=192,
+ kernel_size: int=5,
+ base_dilation: int=1,
+ layers: int=5,
+ stacks: int=1,
+ global_channels: int=-1,
+ dropout_rate: float=0.0,
+ use_weight_norm: bool=True,
+ bias: bool=True,
+ use_only_mean: bool=True, ):
+ """Initialzie ResidualAffineCouplingLayer module.
+
+ Args:
+ in_channels (int): Number of input channels.
+ hidden_channels (int): Number of hidden channels.
+ kernel_size (int): Kernel size for WaveNet.
+ base_dilation (int): Base dilation factor for WaveNet.
+ layers (int): Number of layers of WaveNet.
+ stacks (int): Number of stacks of WaveNet.
+ global_channels (int): Number of global channels.
+ dropout_rate (float): Dropout rate.
+ use_weight_norm (bool): Whether to use weight normalization in WaveNet.
+ bias (bool): Whether to use bias paramters in WaveNet.
+ use_only_mean (bool): Whether to estimate only mean.
+
+ """
+ assert in_channels % 2 == 0, "in_channels should be divisible by 2"
+ super().__init__()
+ self.half_channels = in_channels // 2
+ self.use_only_mean = use_only_mean
+
+ # define modules
+ self.input_conv = nn.Conv1D(
+ self.half_channels,
+ hidden_channels,
+ 1, )
+ self.encoder = WaveNet(
+ in_channels=-1,
+ out_channels=-1,
+ kernel_size=kernel_size,
+ layers=layers,
+ stacks=stacks,
+ base_dilation=base_dilation,
+ residual_channels=hidden_channels,
+ aux_channels=-1,
+ gate_channels=hidden_channels * 2,
+ skip_channels=hidden_channels,
+ global_channels=global_channels,
+ dropout_rate=dropout_rate,
+ bias=bias,
+ use_weight_norm=use_weight_norm,
+ use_first_conv=False,
+ use_last_conv=False,
+ scale_residual=False,
+ scale_skip_connect=True, )
+ if use_only_mean:
+ self.proj = nn.Conv1D(
+ hidden_channels,
+ self.half_channels,
+ 1, )
+ else:
+ self.proj = nn.Conv1D(
+ hidden_channels,
+ self.half_channels * 2,
+ 1, )
+
+ weight = paddle.zeros(paddle.shape(self.proj.weight))
+
+ self.proj.weight = paddle.create_parameter(
+ shape=weight.shape,
+ dtype=str(weight.numpy().dtype),
+ default_initializer=paddle.nn.initializer.Assign(weight))
+
+ bias = paddle.zeros(paddle.shape(self.proj.bias))
+
+ self.proj.bias = paddle.create_parameter(
+ shape=bias.shape,
+ dtype=str(bias.numpy().dtype),
+ default_initializer=paddle.nn.initializer.Assign(bias))
+
+ def forward(
+ self,
+ x: paddle.Tensor,
+ x_mask: paddle.Tensor,
+ g: Optional[paddle.Tensor]=None,
+ inverse: bool=False,
+ ) -> Union[paddle.Tensor, Tuple[paddle.Tensor, paddle.Tensor]]:
+ """Calculate forward propagation.
+
+ Args:
+ x (Tensor): Input tensor (B, in_channels, T).
+ x_lengths (Tensor): Length tensor (B,).
+ g (Optional[Tensor]): Global conditioning tensor (B, global_channels, 1).
+ inverse (bool): Whether to inverse the flow.
+
+ Returns:
+ Tensor: Output tensor (B, in_channels, T).
+ Tensor: Log-determinant tensor for NLL (B,) if not inverse.
+
+ """
+ xa, xb = paddle.split(x, 2, axis=1)
+ h = self.input_conv(xa) * x_mask
+ h = self.encoder(h, x_mask, g=g)
+ stats = self.proj(h) * x_mask
+ if not self.use_only_mean:
+ m, logs = paddle.split(stats, 2, axis=1)
+ else:
+ m = stats
+ logs = paddle.zeros(paddle.shape(m))
+
+ if not inverse:
+ xb = m + xb * paddle.exp(logs) * x_mask
+ x = paddle.concat([xa, xb], 1)
+ logdet = paddle.sum(logs, [1, 2])
+ return x, logdet
+ else:
+ xb = (xb - m) * paddle.exp(-logs) * x_mask
+ x = paddle.concat([xa, xb], 1)
+ return x
diff --git a/paddlespeech/t2s/models/vits/text_encoder.py b/paddlespeech/t2s/models/vits/text_encoder.py
new file mode 100644
index 000000000..3afc7831a
--- /dev/null
+++ b/paddlespeech/t2s/models/vits/text_encoder.py
@@ -0,0 +1,145 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Text encoder module in VITS.
+
+This code is based on https://github.com/jaywalnut310/vits.
+
+"""
+import math
+from typing import Tuple
+
+import paddle
+from paddle import nn
+
+from paddlespeech.t2s.modules.nets_utils import make_non_pad_mask
+from paddlespeech.t2s.modules.transformer.encoder import ConformerEncoder as Encoder
+
+
+class TextEncoder(nn.Layer):
+ """Text encoder module in VITS.
+
+ This is a module of text encoder described in `Conditional Variational Autoencoder
+ with Adversarial Learning for End-to-End Text-to-Speech`_.
+
+ Instead of the relative positional Transformer, we use conformer architecture as
+ the encoder module, which contains additional convolution layers.
+
+ .. _`Conditional Variational Autoencoder with Adversarial Learning for End-to-End
+ Text-to-Speech`: https://arxiv.org/abs/2006.04558
+
+ """
+
+ def __init__(
+ self,
+ vocabs: int,
+ attention_dim: int=192,
+ attention_heads: int=2,
+ linear_units: int=768,
+ blocks: int=6,
+ positionwise_layer_type: str="conv1d",
+ positionwise_conv_kernel_size: int=3,
+ positional_encoding_layer_type: str="rel_pos",
+ self_attention_layer_type: str="rel_selfattn",
+ activation_type: str="swish",
+ normalize_before: bool=True,
+ use_macaron_style: bool=False,
+ use_conformer_conv: bool=False,
+ conformer_kernel_size: int=7,
+ dropout_rate: float=0.1,
+ positional_dropout_rate: float=0.0,
+ attention_dropout_rate: float=0.0, ):
+ """Initialize TextEncoder module.
+
+ Args:
+ vocabs (int): Vocabulary size.
+ attention_dim (int): Attention dimension.
+ attention_heads (int): Number of attention heads.
+ linear_units (int): Number of linear units of positionwise layers.
+ blocks (int): Number of encoder blocks.
+ positionwise_layer_type (str): Positionwise layer type.
+ positionwise_conv_kernel_size (int): Positionwise layer's kernel size.
+ positional_encoding_layer_type (str): Positional encoding layer type.
+ self_attention_layer_type (str): Self-attention layer type.
+ activation_type (str): Activation function type.
+ normalize_before (bool): Whether to apply LayerNorm before attention.
+ use_macaron_style (bool): Whether to use macaron style components.
+ use_conformer_conv (bool): Whether to use conformer conv layers.
+ conformer_kernel_size (int): Conformer's conv kernel size.
+ dropout_rate (float): Dropout rate.
+ positional_dropout_rate (float): Dropout rate for positional encoding.
+ attention_dropout_rate (float): Dropout rate for attention.
+
+ """
+ super().__init__()
+ # store for forward
+ self.attention_dim = attention_dim
+
+ # define modules
+ self.emb = nn.Embedding(vocabs, attention_dim)
+
+ dist = paddle.distribution.Normal(loc=0.0, scale=attention_dim**-0.5)
+ w = dist.sample(self.emb.weight.shape)
+ self.emb.weight.set_value(w)
+
+ self.encoder = Encoder(
+ idim=-1,
+ input_layer=None,
+ attention_dim=attention_dim,
+ attention_heads=attention_heads,
+ linear_units=linear_units,
+ num_blocks=blocks,
+ dropout_rate=dropout_rate,
+ positional_dropout_rate=positional_dropout_rate,
+ attention_dropout_rate=attention_dropout_rate,
+ normalize_before=normalize_before,
+ positionwise_layer_type=positionwise_layer_type,
+ positionwise_conv_kernel_size=positionwise_conv_kernel_size,
+ macaron_style=use_macaron_style,
+ pos_enc_layer_type=positional_encoding_layer_type,
+ selfattention_layer_type=self_attention_layer_type,
+ activation_type=activation_type,
+ use_cnn_module=use_conformer_conv,
+ cnn_module_kernel=conformer_kernel_size, )
+ self.proj = nn.Conv1D(attention_dim, attention_dim * 2, 1)
+
+ def forward(
+ self,
+ x: paddle.Tensor,
+ x_lengths: paddle.Tensor,
+ ) -> Tuple[paddle.Tensor, paddle.Tensor, paddle.Tensor, paddle.Tensor]:
+ """Calculate forward propagation.
+
+ Args:
+ x (Tensor): Input index tensor (B, T_text).
+ x_lengths (Tensor): Length tensor (B,).
+
+ Returns:
+ Tensor: Encoded hidden representation (B, attention_dim, T_text).
+ Tensor: Projected mean tensor (B, attention_dim, T_text).
+ Tensor: Projected scale tensor (B, attention_dim, T_text).
+ Tensor: Mask tensor for input tensor (B, 1, T_text).
+
+ """
+ x = self.emb(x) * math.sqrt(self.attention_dim)
+ x_mask = make_non_pad_mask(x_lengths).unsqueeze(1)
+ # encoder assume the channel last (B, T_text, attention_dim)
+ # but mask shape shoud be (B, 1, T_text)
+ x, _ = self.encoder(x, x_mask)
+
+ # convert the channel first (B, attention_dim, T_text)
+ x = paddle.transpose(x, [0, 2, 1])
+ stats = self.proj(x) * x_mask
+ m, logs = paddle.split(stats, 2, axis=1)
+
+ return x, m, logs, x_mask
diff --git a/paddlespeech/t2s/models/vits/transform.py b/paddlespeech/t2s/models/vits/transform.py
new file mode 100644
index 000000000..fec80377c
--- /dev/null
+++ b/paddlespeech/t2s/models/vits/transform.py
@@ -0,0 +1,238 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Flow-related transformation.
+
+This code is based on https://github.com/bayesiains/nflows.
+
+"""
+import numpy as np
+import paddle
+from paddle.nn import functional as F
+
+from paddlespeech.t2s.modules.nets_utils import paddle_gather
+
+DEFAULT_MIN_BIN_WIDTH = 1e-3
+DEFAULT_MIN_BIN_HEIGHT = 1e-3
+DEFAULT_MIN_DERIVATIVE = 1e-3
+
+
+def piecewise_rational_quadratic_transform(
+ inputs,
+ unnormalized_widths,
+ unnormalized_heights,
+ unnormalized_derivatives,
+ inverse=False,
+ tails=None,
+ tail_bound=1.0,
+ min_bin_width=DEFAULT_MIN_BIN_WIDTH,
+ min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
+ min_derivative=DEFAULT_MIN_DERIVATIVE, ):
+ if tails is None:
+ spline_fn = rational_quadratic_spline
+ spline_kwargs = {}
+ else:
+ spline_fn = unconstrained_rational_quadratic_spline
+ spline_kwargs = {"tails": tails, "tail_bound": tail_bound}
+
+ outputs, logabsdet = spline_fn(
+ inputs=inputs,
+ unnormalized_widths=unnormalized_widths,
+ unnormalized_heights=unnormalized_heights,
+ unnormalized_derivatives=unnormalized_derivatives,
+ inverse=inverse,
+ min_bin_width=min_bin_width,
+ min_bin_height=min_bin_height,
+ min_derivative=min_derivative,
+ **spline_kwargs)
+ return outputs, logabsdet
+
+
+def mask_preprocess(x, mask):
+ B, C, T, bins = paddle.shape(x)
+ new_x = paddle.zeros([mask.sum(), bins])
+ for i in range(bins):
+ new_x[:, i] = x[:, :, :, i][mask]
+ return new_x
+
+
+def unconstrained_rational_quadratic_spline(
+ inputs,
+ unnormalized_widths,
+ unnormalized_heights,
+ unnormalized_derivatives,
+ inverse=False,
+ tails="linear",
+ tail_bound=1.0,
+ min_bin_width=DEFAULT_MIN_BIN_WIDTH,
+ min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
+ min_derivative=DEFAULT_MIN_DERIVATIVE, ):
+ inside_interval_mask = (inputs >= -tail_bound) & (inputs <= tail_bound)
+ outside_interval_mask = ~inside_interval_mask
+
+ outputs = paddle.zeros(paddle.shape(inputs))
+ logabsdet = paddle.zeros(paddle.shape(inputs))
+ if tails == "linear":
+ unnormalized_derivatives = F.pad(
+ unnormalized_derivatives,
+ pad=[0] * (len(unnormalized_derivatives.shape) - 1) * 2 + [1, 1])
+ constant = np.log(np.exp(1 - min_derivative) - 1)
+ unnormalized_derivatives[..., 0] = constant
+ unnormalized_derivatives[..., -1] = constant
+
+ outputs[outside_interval_mask] = inputs[outside_interval_mask]
+ logabsdet[outside_interval_mask] = 0
+ else:
+ raise RuntimeError("{} tails are not implemented.".format(tails))
+
+ unnormalized_widths = mask_preprocess(unnormalized_widths,
+ inside_interval_mask)
+ unnormalized_heights = mask_preprocess(unnormalized_heights,
+ inside_interval_mask)
+ unnormalized_derivatives = mask_preprocess(unnormalized_derivatives,
+ inside_interval_mask)
+
+ (outputs[inside_interval_mask],
+ logabsdet[inside_interval_mask], ) = rational_quadratic_spline(
+ inputs=inputs[inside_interval_mask],
+ unnormalized_widths=unnormalized_widths,
+ unnormalized_heights=unnormalized_heights,
+ unnormalized_derivatives=unnormalized_derivatives,
+ inverse=inverse,
+ left=-tail_bound,
+ right=tail_bound,
+ bottom=-tail_bound,
+ top=tail_bound,
+ min_bin_width=min_bin_width,
+ min_bin_height=min_bin_height,
+ min_derivative=min_derivative, )
+
+ return outputs, logabsdet
+
+
+def rational_quadratic_spline(
+ inputs,
+ unnormalized_widths,
+ unnormalized_heights,
+ unnormalized_derivatives,
+ inverse=False,
+ left=0.0,
+ right=1.0,
+ bottom=0.0,
+ top=1.0,
+ min_bin_width=DEFAULT_MIN_BIN_WIDTH,
+ min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
+ min_derivative=DEFAULT_MIN_DERIVATIVE, ):
+ if paddle.min(inputs) < left or paddle.max(inputs) > right:
+ raise ValueError("Input to a transform is not within its domain")
+
+ num_bins = unnormalized_widths.shape[-1]
+
+ if min_bin_width * num_bins > 1.0:
+ raise ValueError("Minimal bin width too large for the number of bins")
+ if min_bin_height * num_bins > 1.0:
+ raise ValueError("Minimal bin height too large for the number of bins")
+
+ widths = F.softmax(unnormalized_widths, axis=-1)
+ widths = min_bin_width + (1 - min_bin_width * num_bins) * widths
+ cumwidths = paddle.cumsum(widths, axis=-1)
+ cumwidths = F.pad(
+ cumwidths,
+ pad=[0] * (len(cumwidths.shape) - 1) * 2 + [1, 0],
+ mode="constant",
+ value=0.0)
+ cumwidths = (right - left) * cumwidths + left
+ cumwidths[..., 0] = left
+ cumwidths[..., -1] = right
+ widths = cumwidths[..., 1:] - cumwidths[..., :-1]
+
+ derivatives = min_derivative + F.softplus(unnormalized_derivatives)
+
+ heights = F.softmax(unnormalized_heights, axis=-1)
+ heights = min_bin_height + (1 - min_bin_height * num_bins) * heights
+ cumheights = paddle.cumsum(heights, axis=-1)
+ cumheights = F.pad(
+ cumheights,
+ pad=[0] * (len(cumheights.shape) - 1) * 2 + [1, 0],
+ mode="constant",
+ value=0.0)
+ cumheights = (top - bottom) * cumheights + bottom
+ cumheights[..., 0] = bottom
+ cumheights[..., -1] = top
+ heights = cumheights[..., 1:] - cumheights[..., :-1]
+
+ if inverse:
+ bin_idx = _searchsorted(cumheights, inputs)[..., None]
+ else:
+ bin_idx = _searchsorted(cumwidths, inputs)[..., None]
+ input_cumwidths = paddle_gather(cumwidths, -1, bin_idx)[..., 0]
+ input_bin_widths = paddle_gather(widths, -1, bin_idx)[..., 0]
+
+ input_cumheights = paddle_gather(cumheights, -1, bin_idx)[..., 0]
+ delta = heights / widths
+ input_delta = paddle_gather(delta, -1, bin_idx)[..., 0]
+
+ input_derivatives = paddle_gather(derivatives, -1, bin_idx)[..., 0]
+ input_derivatives_plus_one = paddle_gather(derivatives[..., 1:], -1,
+ bin_idx)[..., 0]
+
+ input_heights = paddle_gather(heights, -1, bin_idx)[..., 0]
+
+ if inverse:
+ a = (inputs - input_cumheights) * (
+ input_derivatives + input_derivatives_plus_one - 2 * input_delta
+ ) + input_heights * (input_delta - input_derivatives)
+ b = input_heights * input_derivatives - (inputs - input_cumheights) * (
+ input_derivatives + input_derivatives_plus_one - 2 * input_delta)
+ c = -input_delta * (inputs - input_cumheights)
+
+ discriminant = b.pow(2) - 4 * a * c
+ assert (discriminant >= 0).all()
+
+ root = (2 * c) / (-b - paddle.sqrt(discriminant))
+ outputs = root * input_bin_widths + input_cumwidths
+
+ theta_one_minus_theta = root * (1 - root)
+ denominator = input_delta + (
+ (input_derivatives + input_derivatives_plus_one - 2 * input_delta
+ ) * theta_one_minus_theta)
+ derivative_numerator = input_delta.pow(2) * (
+ input_derivatives_plus_one * root.pow(2) + 2 * input_delta *
+ theta_one_minus_theta + input_derivatives * (1 - root).pow(2))
+ logabsdet = paddle.log(derivative_numerator) - 2 * paddle.log(
+ denominator)
+
+ return outputs, -logabsdet
+ else:
+ theta = (inputs - input_cumwidths) / input_bin_widths
+ theta_one_minus_theta = theta * (1 - theta)
+
+ numerator = input_heights * (input_delta * theta.pow(2) +
+ input_derivatives * theta_one_minus_theta)
+ denominator = input_delta + (
+ (input_derivatives + input_derivatives_plus_one - 2 * input_delta
+ ) * theta_one_minus_theta)
+ outputs = input_cumheights + numerator / denominator
+
+ derivative_numerator = input_delta.pow(2) * (
+ input_derivatives_plus_one * theta.pow(2) + 2 * input_delta *
+ theta_one_minus_theta + input_derivatives * (1 - theta).pow(2))
+ logabsdet = paddle.log(derivative_numerator) - 2 * paddle.log(
+ denominator)
+
+ return outputs, logabsdet
+
+
+def _searchsorted(bin_locations, inputs, eps=1e-6):
+ bin_locations[..., -1] += eps
+ return paddle.sum(inputs[..., None] >= bin_locations, axis=-1) - 1
diff --git a/paddlespeech/t2s/models/vits/vits.py b/paddlespeech/t2s/models/vits/vits.py
new file mode 100644
index 000000000..ab8eda26d
--- /dev/null
+++ b/paddlespeech/t2s/models/vits/vits.py
@@ -0,0 +1,412 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# Modified from espnet(https://github.com/espnet/espnet)
+"""VITS module"""
+from typing import Any
+from typing import Dict
+from typing import Optional
+
+import paddle
+from paddle import nn
+from typeguard import check_argument_types
+
+from paddlespeech.t2s.models.hifigan import HiFiGANMultiPeriodDiscriminator
+from paddlespeech.t2s.models.hifigan import HiFiGANMultiScaleDiscriminator
+from paddlespeech.t2s.models.hifigan import HiFiGANMultiScaleMultiPeriodDiscriminator
+from paddlespeech.t2s.models.hifigan import HiFiGANPeriodDiscriminator
+from paddlespeech.t2s.models.hifigan import HiFiGANScaleDiscriminator
+from paddlespeech.t2s.models.vits.generator import VITSGenerator
+from paddlespeech.t2s.modules.nets_utils import initialize
+
+AVAILABLE_GENERATERS = {
+ "vits_generator": VITSGenerator,
+}
+AVAILABLE_DISCRIMINATORS = {
+ "hifigan_period_discriminator":
+ HiFiGANPeriodDiscriminator,
+ "hifigan_scale_discriminator":
+ HiFiGANScaleDiscriminator,
+ "hifigan_multi_period_discriminator":
+ HiFiGANMultiPeriodDiscriminator,
+ "hifigan_multi_scale_discriminator":
+ HiFiGANMultiScaleDiscriminator,
+ "hifigan_multi_scale_multi_period_discriminator":
+ HiFiGANMultiScaleMultiPeriodDiscriminator,
+}
+
+
+class VITS(nn.Layer):
+ """VITS module (generator + discriminator).
+ This is a module of VITS described in `Conditional Variational Autoencoder
+ with Adversarial Learning for End-to-End Text-to-Speech`_.
+ .. _`Conditional Variational Autoencoder with Adversarial Learning for End-to-End
+ Text-to-Speech`: https://arxiv.org/abs/2006.04558
+ """
+
+ def __init__(
+ self,
+ # generator related
+ idim: int,
+ odim: int,
+ sampling_rate: int=22050,
+ generator_type: str="vits_generator",
+ generator_params: Dict[str, Any]={
+ "hidden_channels": 192,
+ "spks": None,
+ "langs": None,
+ "spk_embed_dim": None,
+ "global_channels": -1,
+ "segment_size": 32,
+ "text_encoder_attention_heads": 2,
+ "text_encoder_ffn_expand": 4,
+ "text_encoder_blocks": 6,
+ "text_encoder_positionwise_layer_type": "conv1d",
+ "text_encoder_positionwise_conv_kernel_size": 1,
+ "text_encoder_positional_encoding_layer_type": "rel_pos",
+ "text_encoder_self_attention_layer_type": "rel_selfattn",
+ "text_encoder_activation_type": "swish",
+ "text_encoder_normalize_before": True,
+ "text_encoder_dropout_rate": 0.1,
+ "text_encoder_positional_dropout_rate": 0.0,
+ "text_encoder_attention_dropout_rate": 0.0,
+ "text_encoder_conformer_kernel_size": 7,
+ "use_macaron_style_in_text_encoder": True,
+ "use_conformer_conv_in_text_encoder": True,
+ "decoder_kernel_size": 7,
+ "decoder_channels": 512,
+ "decoder_upsample_scales": [8, 8, 2, 2],
+ "decoder_upsample_kernel_sizes": [16, 16, 4, 4],
+ "decoder_resblock_kernel_sizes": [3, 7, 11],
+ "decoder_resblock_dilations": [[1, 3, 5], [1, 3, 5], [1, 3, 5]],
+ "use_weight_norm_in_decoder": True,
+ "posterior_encoder_kernel_size": 5,
+ "posterior_encoder_layers": 16,
+ "posterior_encoder_stacks": 1,
+ "posterior_encoder_base_dilation": 1,
+ "posterior_encoder_dropout_rate": 0.0,
+ "use_weight_norm_in_posterior_encoder": True,
+ "flow_flows": 4,
+ "flow_kernel_size": 5,
+ "flow_base_dilation": 1,
+ "flow_layers": 4,
+ "flow_dropout_rate": 0.0,
+ "use_weight_norm_in_flow": True,
+ "use_only_mean_in_flow": True,
+ "stochastic_duration_predictor_kernel_size": 3,
+ "stochastic_duration_predictor_dropout_rate": 0.5,
+ "stochastic_duration_predictor_flows": 4,
+ "stochastic_duration_predictor_dds_conv_layers": 3,
+ },
+ # discriminator related
+ discriminator_type: str="hifigan_multi_scale_multi_period_discriminator",
+ discriminator_params: Dict[str, Any]={
+ "scales": 1,
+ "scale_downsample_pooling": "AvgPool1D",
+ "scale_downsample_pooling_params": {
+ "kernel_size": 4,
+ "stride": 2,
+ "padding": 2,
+ },
+ "scale_discriminator_params": {
+ "in_channels": 1,
+ "out_channels": 1,
+ "kernel_sizes": [15, 41, 5, 3],
+ "channels": 128,
+ "max_downsample_channels": 1024,
+ "max_groups": 16,
+ "bias": True,
+ "downsample_scales": [2, 2, 4, 4, 1],
+ "nonlinear_activation": "leakyrelu",
+ "nonlinear_activation_params": {
+ "negative_slope": 0.1
+ },
+ "use_weight_norm": True,
+ "use_spectral_norm": False,
+ },
+ "follow_official_norm": False,
+ "periods": [2, 3, 5, 7, 11],
+ "period_discriminator_params": {
+ "in_channels": 1,
+ "out_channels": 1,
+ "kernel_sizes": [5, 3],
+ "channels": 32,
+ "downsample_scales": [3, 3, 3, 3, 1],
+ "max_downsample_channels": 1024,
+ "bias": True,
+ "nonlinear_activation": "leakyrelu",
+ "nonlinear_activation_params": {
+ "negative_slope": 0.1
+ },
+ "use_weight_norm": True,
+ "use_spectral_norm": False,
+ },
+ },
+ cache_generator_outputs: bool=True,
+ init_type: str="xavier_uniform", ):
+ """Initialize VITS module.
+ Args:
+ idim (int): Input vocabrary size.
+ odim (int): Acoustic feature dimension. The actual output channels will
+ be 1 since VITS is the end-to-end text-to-wave model but for the
+ compatibility odim is used to indicate the acoustic feature dimension.
+ sampling_rate (int): Sampling rate, not used for the training but it will
+ be referred in saving waveform during the inference.
+ generator_type (str): Generator type.
+ generator_params (Dict[str, Any]): Parameter dict for generator.
+ discriminator_type (str): Discriminator type.
+ discriminator_params (Dict[str, Any]): Parameter dict for discriminator.
+ cache_generator_outputs (bool): Whether to cache generator outputs.
+ """
+ assert check_argument_types()
+ super().__init__()
+
+ # initialize parameters
+ initialize(self, init_type)
+
+ # define modules
+ generator_class = AVAILABLE_GENERATERS[generator_type]
+ if generator_type == "vits_generator":
+ # NOTE: Update parameters for the compatibility.
+ # The idim and odim is automatically decided from input data,
+ # where idim represents #vocabularies and odim represents
+ # the input acoustic feature dimension.
+ generator_params.update(vocabs=idim, aux_channels=odim)
+ self.generator = generator_class(
+ **generator_params, )
+ discriminator_class = AVAILABLE_DISCRIMINATORS[discriminator_type]
+ self.discriminator = discriminator_class(
+ **discriminator_params, )
+
+ nn.initializer.set_global_initializer(None)
+
+ # cache
+ self.cache_generator_outputs = cache_generator_outputs
+ self._cache = None
+
+ # store sampling rate for saving wav file
+ # (not used for the training)
+ self.fs = sampling_rate
+
+ # store parameters for test compatibility
+ self.spks = self.generator.spks
+ self.langs = self.generator.langs
+ self.spk_embed_dim = self.generator.spk_embed_dim
+
+ self.reuse_cache_gen = True
+ self.reuse_cache_dis = True
+
+ def forward(
+ self,
+ text: paddle.Tensor,
+ text_lengths: paddle.Tensor,
+ feats: paddle.Tensor,
+ feats_lengths: paddle.Tensor,
+ sids: Optional[paddle.Tensor]=None,
+ spembs: Optional[paddle.Tensor]=None,
+ lids: Optional[paddle.Tensor]=None,
+ forward_generator: bool=True, ) -> Dict[str, Any]:
+ """Perform generator forward.
+ Args:
+ text (Tensor): Text index tensor (B, T_text).
+ text_lengths (Tensor): Text length tensor (B,).
+ feats (Tensor): Feature tensor (B, T_feats, aux_channels).
+ feats_lengths (Tensor): Feature length tensor (B,).
+ sids (Optional[Tensor]): Speaker index tensor (B,) or (B, 1).
+ spembs (Optional[Tensor]): Speaker embedding tensor (B, spk_embed_dim).
+ lids (Optional[Tensor]): Language index tensor (B,) or (B, 1).
+ forward_generator (bool): Whether to forward generator.
+ Returns:
+ Dict[str, Any]:
+ - loss (Tensor): Loss scalar tensor.
+ - stats (Dict[str, float]): Statistics to be monitored.
+ - weight (Tensor): Weight tensor to summarize losses.
+ - optim_idx (int): Optimizer index (0 for G and 1 for D).
+ """
+ if forward_generator:
+ return self._forward_generator(
+ text=text,
+ text_lengths=text_lengths,
+ feats=feats,
+ feats_lengths=feats_lengths,
+ sids=sids,
+ spembs=spembs,
+ lids=lids, )
+ else:
+ return self._forward_discrminator(
+ text=text,
+ text_lengths=text_lengths,
+ feats=feats,
+ feats_lengths=feats_lengths,
+ sids=sids,
+ spembs=spembs,
+ lids=lids, )
+
+ def _forward_generator(
+ self,
+ text: paddle.Tensor,
+ text_lengths: paddle.Tensor,
+ feats: paddle.Tensor,
+ feats_lengths: paddle.Tensor,
+ sids: Optional[paddle.Tensor]=None,
+ spembs: Optional[paddle.Tensor]=None,
+ lids: Optional[paddle.Tensor]=None, ) -> Dict[str, Any]:
+ """Perform generator forward.
+ Args:
+ text (Tensor): Text index tensor (B, T_text).
+ text_lengths (Tensor): Text length tensor (B,).
+ feats (Tensor): Feature tensor (B, T_feats, aux_channels).
+ feats_lengths (Tensor): Feature length tensor (B,).
+ sids (Optional[Tensor]): Speaker index tensor (B,) or (B, 1).
+ spembs (Optional[Tensor]): Speaker embedding tensor (B, spk_embed_dim).
+ lids (Optional[Tensor]): Language index tensor (B,) or (B, 1).
+ Returns:
+
+ """
+ # setup
+ feats = feats.transpose([0, 2, 1])
+
+ # calculate generator outputs
+ self.reuse_cache_gen = True
+ if not self.cache_generator_outputs or self._cache is None:
+ self.reuse_cache_gen = False
+ outs = self.generator(
+ text=text,
+ text_lengths=text_lengths,
+ feats=feats,
+ feats_lengths=feats_lengths,
+ sids=sids,
+ spembs=spembs,
+ lids=lids, )
+ else:
+ outs = self._cache
+
+ # store cache
+ if self.training and self.cache_generator_outputs and not self.reuse_cache_gen:
+ self._cache = outs
+
+ return outs
+
+ def _forward_discrminator(
+ self,
+ text: paddle.Tensor,
+ text_lengths: paddle.Tensor,
+ feats: paddle.Tensor,
+ feats_lengths: paddle.Tensor,
+ sids: Optional[paddle.Tensor]=None,
+ spembs: Optional[paddle.Tensor]=None,
+ lids: Optional[paddle.Tensor]=None, ) -> Dict[str, Any]:
+ """Perform discriminator forward.
+ Args:
+ text (Tensor): Text index tensor (B, T_text).
+ text_lengths (Tensor): Text length tensor (B,).
+ feats (Tensor): Feature tensor (B, T_feats, aux_channels).
+ feats_lengths (Tensor): Feature length tensor (B,).
+ sids (Optional[Tensor]): Speaker index tensor (B,) or (B, 1).
+ spembs (Optional[Tensor]): Speaker embedding tensor (B, spk_embed_dim).
+ lids (Optional[Tensor]): Language index tensor (B,) or (B, 1).
+ Returns:
+
+ """
+ # setup
+ feats = feats.transpose([0, 2, 1])
+
+ # calculate generator outputs
+ self.reuse_cache_dis = True
+ if not self.cache_generator_outputs or self._cache is None:
+ self.reuse_cache_dis = False
+ outs = self.generator(
+ text=text,
+ text_lengths=text_lengths,
+ feats=feats,
+ feats_lengths=feats_lengths,
+ sids=sids,
+ spembs=spembs,
+ lids=lids, )
+ else:
+ outs = self._cache
+
+ # store cache
+ if self.cache_generator_outputs and not self.reuse_cache_dis:
+ self._cache = outs
+
+ return outs
+
+ def inference(
+ self,
+ text: paddle.Tensor,
+ feats: Optional[paddle.Tensor]=None,
+ sids: Optional[paddle.Tensor]=None,
+ spembs: Optional[paddle.Tensor]=None,
+ lids: Optional[paddle.Tensor]=None,
+ durations: Optional[paddle.Tensor]=None,
+ noise_scale: float=0.667,
+ noise_scale_dur: float=0.8,
+ alpha: float=1.0,
+ max_len: Optional[int]=None,
+ use_teacher_forcing: bool=False, ) -> Dict[str, paddle.Tensor]:
+ """Run inference.
+ Args:
+ text (Tensor): Input text index tensor (T_text,).
+ feats (Tensor): Feature tensor (T_feats, aux_channels).
+ sids (Tensor): Speaker index tensor (1,).
+ spembs (Optional[Tensor]): Speaker embedding tensor (spk_embed_dim,).
+ lids (Tensor): Language index tensor (1,).
+ durations (Tensor): Ground-truth duration tensor (T_text,).
+ noise_scale (float): Noise scale value for flow.
+ noise_scale_dur (float): Noise scale value for duration predictor.
+ alpha (float): Alpha parameter to control the speed of generated speech.
+ max_len (Optional[int]): Maximum length.
+ use_teacher_forcing (bool): Whether to use teacher forcing.
+ Returns:
+ Dict[str, Tensor]:
+ * wav (Tensor): Generated waveform tensor (T_wav,).
+ * att_w (Tensor): Monotonic attention weight tensor (T_feats, T_text).
+ * duration (Tensor): Predicted duration tensor (T_text,).
+ """
+ # setup
+ text = text[None]
+ text_lengths = paddle.to_tensor(paddle.shape(text)[1])
+
+ if durations is not None:
+ durations = paddle.reshape(durations, [1, 1, -1])
+
+ # inference
+ if use_teacher_forcing:
+ assert feats is not None
+ feats = feats[None].transpose([0, 2, 1])
+ feats_lengths = paddle.to_tensor([paddle.shape(feats)[2]])
+ wav, att_w, dur = self.generator.inference(
+ text=text,
+ text_lengths=text_lengths,
+ feats=feats,
+ feats_lengths=feats_lengths,
+ sids=sids,
+ spembs=spembs,
+ lids=lids,
+ max_len=max_len,
+ use_teacher_forcing=use_teacher_forcing, )
+ else:
+ wav, att_w, dur = self.generator.inference(
+ text=text,
+ text_lengths=text_lengths,
+ sids=sids,
+ spembs=spembs,
+ lids=lids,
+ dur=durations,
+ noise_scale=noise_scale,
+ noise_scale_dur=noise_scale_dur,
+ alpha=alpha,
+ max_len=max_len, )
+ return dict(
+ wav=paddle.reshape(wav, [-1]), att_w=att_w[0], duration=dur[0])
diff --git a/paddlespeech/t2s/models/vits/vits_updater.py b/paddlespeech/t2s/models/vits/vits_updater.py
new file mode 100644
index 000000000..76271fd97
--- /dev/null
+++ b/paddlespeech/t2s/models/vits/vits_updater.py
@@ -0,0 +1,355 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import logging
+from typing import Dict
+
+import paddle
+from paddle import distributed as dist
+from paddle.io import DataLoader
+from paddle.nn import Layer
+from paddle.optimizer import Optimizer
+from paddle.optimizer.lr import LRScheduler
+
+from paddlespeech.t2s.modules.nets_utils import get_segments
+from paddlespeech.t2s.training.extensions.evaluator import StandardEvaluator
+from paddlespeech.t2s.training.reporter import report
+from paddlespeech.t2s.training.updaters.standard_updater import StandardUpdater
+from paddlespeech.t2s.training.updaters.standard_updater import UpdaterState
+
+logging.basicConfig(
+ format='%(asctime)s [%(levelname)s] [%(filename)s:%(lineno)d] %(message)s',
+ datefmt='[%Y-%m-%d %H:%M:%S]')
+logger = logging.getLogger(__name__)
+logger.setLevel(logging.INFO)
+
+
+class VITSUpdater(StandardUpdater):
+ def __init__(self,
+ model: Layer,
+ optimizers: Dict[str, Optimizer],
+ criterions: Dict[str, Layer],
+ schedulers: Dict[str, LRScheduler],
+ dataloader: DataLoader,
+ generator_train_start_steps: int=0,
+ discriminator_train_start_steps: int=100000,
+ lambda_adv: float=1.0,
+ lambda_mel: float=45.0,
+ lambda_feat_match: float=2.0,
+ lambda_dur: float=1.0,
+ lambda_kl: float=1.0,
+ generator_first: bool=False,
+ output_dir=None):
+ # it is designed to hold multiple models
+ # 因为输入的是单模型,但是没有用到父类的 init(), 所以需要重新写这部分
+ models = {"main": model}
+ self.models: Dict[str, Layer] = models
+ # self.model = model
+
+ self.model = model._layers if isinstance(model,
+ paddle.DataParallel) else model
+
+ self.optimizers = optimizers
+ self.optimizer_g: Optimizer = optimizers['generator']
+ self.optimizer_d: Optimizer = optimizers['discriminator']
+
+ self.criterions = criterions
+ self.criterion_mel = criterions['mel']
+ self.criterion_feat_match = criterions['feat_match']
+ self.criterion_gen_adv = criterions["gen_adv"]
+ self.criterion_dis_adv = criterions["dis_adv"]
+ self.criterion_kl = criterions["kl"]
+
+ self.schedulers = schedulers
+ self.scheduler_g = schedulers['generator']
+ self.scheduler_d = schedulers['discriminator']
+
+ self.dataloader = dataloader
+
+ self.generator_train_start_steps = generator_train_start_steps
+ self.discriminator_train_start_steps = discriminator_train_start_steps
+
+ self.lambda_adv = lambda_adv
+ self.lambda_mel = lambda_mel
+ self.lambda_feat_match = lambda_feat_match
+ self.lambda_dur = lambda_dur
+ self.lambda_kl = lambda_kl
+
+ if generator_first:
+ self.turns = ["generator", "discriminator"]
+ else:
+ self.turns = ["discriminator", "generator"]
+
+ self.state = UpdaterState(iteration=0, epoch=0)
+ self.train_iterator = iter(self.dataloader)
+
+ log_file = output_dir / 'worker_{}.log'.format(dist.get_rank())
+ self.filehandler = logging.FileHandler(str(log_file))
+ logger.addHandler(self.filehandler)
+ self.logger = logger
+ self.msg = ""
+
+ def update_core(self, batch):
+ self.msg = "Rank: {}, ".format(dist.get_rank())
+ losses_dict = {}
+
+ for turn in self.turns:
+ speech = batch["speech"]
+ speech = speech.unsqueeze(1)
+ outs = self.model(
+ text=batch["text"],
+ text_lengths=batch["text_lengths"],
+ feats=batch["feats"],
+ feats_lengths=batch["feats_lengths"],
+ forward_generator=turn == "generator")
+ # Generator
+ if turn == "generator":
+ # parse outputs
+ speech_hat_, dur_nll, _, start_idxs, _, z_mask, outs_ = outs
+ _, z_p, m_p, logs_p, _, logs_q = outs_
+ speech_ = get_segments(
+ x=speech,
+ start_idxs=start_idxs *
+ self.model.generator.upsample_factor,
+ segment_size=self.model.generator.segment_size *
+ self.model.generator.upsample_factor, )
+
+ # calculate discriminator outputs
+ p_hat = self.model.discriminator(speech_hat_)
+ with paddle.no_grad():
+ # do not store discriminator gradient in generator turn
+ p = self.model.discriminator(speech_)
+
+ # calculate losses
+ mel_loss = self.criterion_mel(speech_hat_, speech_)
+ kl_loss = self.criterion_kl(z_p, logs_q, m_p, logs_p, z_mask)
+ dur_loss = paddle.sum(dur_nll)
+ adv_loss = self.criterion_gen_adv(p_hat)
+ feat_match_loss = self.criterion_feat_match(p_hat, p)
+
+ mel_loss = mel_loss * self.lambda_mel
+ kl_loss = kl_loss * self.lambda_kl
+ dur_loss = dur_loss * self.lambda_dur
+ adv_loss = adv_loss * self.lambda_adv
+ feat_match_loss = feat_match_loss * self.lambda_feat_match
+ gen_loss = mel_loss + kl_loss + dur_loss + adv_loss + feat_match_loss
+
+ report("train/generator_loss", float(gen_loss))
+ report("train/generator_mel_loss", float(mel_loss))
+ report("train/generator_kl_loss", float(kl_loss))
+ report("train/generator_dur_loss", float(dur_loss))
+ report("train/generator_adv_loss", float(adv_loss))
+ report("train/generator_feat_match_loss",
+ float(feat_match_loss))
+
+ losses_dict["generator_loss"] = float(gen_loss)
+ losses_dict["generator_mel_loss"] = float(mel_loss)
+ losses_dict["generator_kl_loss"] = float(kl_loss)
+ losses_dict["generator_dur_loss"] = float(dur_loss)
+ losses_dict["generator_adv_loss"] = float(adv_loss)
+ losses_dict["generator_feat_match_loss"] = float(
+ feat_match_loss)
+
+ self.optimizer_g.clear_grad()
+ gen_loss.backward()
+
+ self.optimizer_g.step()
+ self.scheduler_g.step()
+
+ # reset cache
+ if self.model.reuse_cache_gen or not self.model.training:
+ self.model._cache = None
+
+ # Disctiminator
+ elif turn == "discriminator":
+ # parse outputs
+ speech_hat_, _, _, start_idxs, *_ = outs
+ speech_ = get_segments(
+ x=speech,
+ start_idxs=start_idxs *
+ self.model.generator.upsample_factor,
+ segment_size=self.model.generator.segment_size *
+ self.model.generator.upsample_factor, )
+
+ # calculate discriminator outputs
+ p_hat = self.model.discriminator(speech_hat_.detach())
+ p = self.model.discriminator(speech_)
+
+ # calculate losses
+ real_loss, fake_loss = self.criterion_dis_adv(p_hat, p)
+ dis_loss = real_loss + fake_loss
+
+ report("train/real_loss", float(real_loss))
+ report("train/fake_loss", float(fake_loss))
+ report("train/discriminator_loss", float(dis_loss))
+ losses_dict["real_loss"] = float(real_loss)
+ losses_dict["fake_loss"] = float(fake_loss)
+ losses_dict["discriminator_loss"] = float(dis_loss)
+
+ self.optimizer_d.clear_grad()
+ dis_loss.backward()
+
+ self.optimizer_d.step()
+ self.scheduler_d.step()
+
+ # reset cache
+ if self.model.reuse_cache_dis or not self.model.training:
+ self.model._cache = None
+
+ self.msg += ', '.join('{}: {:>.6f}'.format(k, v)
+ for k, v in losses_dict.items())
+
+
+class VITSEvaluator(StandardEvaluator):
+ def __init__(self,
+ model,
+ criterions: Dict[str, Layer],
+ dataloader: DataLoader,
+ lambda_adv: float=1.0,
+ lambda_mel: float=45.0,
+ lambda_feat_match: float=2.0,
+ lambda_dur: float=1.0,
+ lambda_kl: float=1.0,
+ generator_first: bool=False,
+ output_dir=None):
+ # 因为输入的是单模型,但是没有用到父类的 init(), 所以需要重新写这部分
+ models = {"main": model}
+ self.models: Dict[str, Layer] = models
+ # self.model = model
+ self.model = model._layers if isinstance(model,
+ paddle.DataParallel) else model
+
+ self.criterions = criterions
+ self.criterion_mel = criterions['mel']
+ self.criterion_feat_match = criterions['feat_match']
+ self.criterion_gen_adv = criterions["gen_adv"]
+ self.criterion_dis_adv = criterions["dis_adv"]
+ self.criterion_kl = criterions["kl"]
+
+ self.dataloader = dataloader
+
+ self.lambda_adv = lambda_adv
+ self.lambda_mel = lambda_mel
+ self.lambda_feat_match = lambda_feat_match
+ self.lambda_dur = lambda_dur
+ self.lambda_kl = lambda_kl
+
+ if generator_first:
+ self.turns = ["generator", "discriminator"]
+ else:
+ self.turns = ["discriminator", "generator"]
+
+ log_file = output_dir / 'worker_{}.log'.format(dist.get_rank())
+ self.filehandler = logging.FileHandler(str(log_file))
+ logger.addHandler(self.filehandler)
+ self.logger = logger
+ self.msg = ""
+
+ def evaluate_core(self, batch):
+ # logging.debug("Evaluate: ")
+ self.msg = "Evaluate: "
+ losses_dict = {}
+
+ for turn in self.turns:
+ speech = batch["speech"]
+ speech = speech.unsqueeze(1)
+ outs = self.model(
+ text=batch["text"],
+ text_lengths=batch["text_lengths"],
+ feats=batch["feats"],
+ feats_lengths=batch["feats_lengths"],
+ forward_generator=turn == "generator")
+ # Generator
+ if turn == "generator":
+ # parse outputs
+ speech_hat_, dur_nll, _, start_idxs, _, z_mask, outs_ = outs
+ _, z_p, m_p, logs_p, _, logs_q = outs_
+ speech_ = get_segments(
+ x=speech,
+ start_idxs=start_idxs *
+ self.model.generator.upsample_factor,
+ segment_size=self.model.generator.segment_size *
+ self.model.generator.upsample_factor, )
+
+ # calculate discriminator outputs
+ p_hat = self.model.discriminator(speech_hat_)
+ with paddle.no_grad():
+ # do not store discriminator gradient in generator turn
+ p = self.model.discriminator(speech_)
+
+ # calculate losses
+ mel_loss = self.criterion_mel(speech_hat_, speech_)
+ kl_loss = self.criterion_kl(z_p, logs_q, m_p, logs_p, z_mask)
+ dur_loss = paddle.sum(dur_nll)
+ adv_loss = self.criterion_gen_adv(p_hat)
+ feat_match_loss = self.criterion_feat_match(p_hat, p)
+
+ mel_loss = mel_loss * self.lambda_mel
+ kl_loss = kl_loss * self.lambda_kl
+ dur_loss = dur_loss * self.lambda_dur
+ adv_loss = adv_loss * self.lambda_adv
+ feat_match_loss = feat_match_loss * self.lambda_feat_match
+ gen_loss = mel_loss + kl_loss + dur_loss + adv_loss + feat_match_loss
+
+ report("eval/generator_loss", float(gen_loss))
+ report("eval/generator_mel_loss", float(mel_loss))
+ report("eval/generator_kl_loss", float(kl_loss))
+ report("eval/generator_dur_loss", float(dur_loss))
+ report("eval/generator_adv_loss", float(adv_loss))
+ report("eval/generator_feat_match_loss", float(feat_match_loss))
+
+ losses_dict["generator_loss"] = float(gen_loss)
+ losses_dict["generator_mel_loss"] = float(mel_loss)
+ losses_dict["generator_kl_loss"] = float(kl_loss)
+ losses_dict["generator_dur_loss"] = float(dur_loss)
+ losses_dict["generator_adv_loss"] = float(adv_loss)
+ losses_dict["generator_feat_match_loss"] = float(
+ feat_match_loss)
+
+ # reset cache
+ if self.model.reuse_cache_gen or not self.model.training:
+ self.model._cache = None
+
+ # Disctiminator
+ elif turn == "discriminator":
+ # parse outputs
+ speech_hat_, _, _, start_idxs, *_ = outs
+ speech_ = get_segments(
+ x=speech,
+ start_idxs=start_idxs *
+ self.model.generator.upsample_factor,
+ segment_size=self.model.generator.segment_size *
+ self.model.generator.upsample_factor, )
+
+ # calculate discriminator outputs
+ p_hat = self.model.discriminator(speech_hat_.detach())
+ p = self.model.discriminator(speech_)
+
+ # calculate losses
+ real_loss, fake_loss = self.criterion_dis_adv(p_hat, p)
+ dis_loss = real_loss + fake_loss
+
+ report("eval/real_loss", float(real_loss))
+ report("eval/fake_loss", float(fake_loss))
+ report("eval/discriminator_loss", float(dis_loss))
+ losses_dict["real_loss"] = float(real_loss)
+ losses_dict["fake_loss"] = float(fake_loss)
+ losses_dict["discriminator_loss"] = float(dis_loss)
+
+ # reset cache
+ if self.model.reuse_cache_dis or not self.model.training:
+ self.model._cache = None
+
+ self.msg += ', '.join('{}: {:>.6f}'.format(k, v)
+ for k, v in losses_dict.items())
+ self.logger.info(self.msg)
diff --git a/paddlespeech/t2s/models/vits/wavenet/__init__.py b/paddlespeech/t2s/models/vits/wavenet/__init__.py
new file mode 100644
index 000000000..97043fd7b
--- /dev/null
+++ b/paddlespeech/t2s/models/vits/wavenet/__init__.py
@@ -0,0 +1,13 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
diff --git a/paddlespeech/t2s/models/vits/wavenet/residual_block.py b/paddlespeech/t2s/models/vits/wavenet/residual_block.py
new file mode 100644
index 000000000..197e74975
--- /dev/null
+++ b/paddlespeech/t2s/models/vits/wavenet/residual_block.py
@@ -0,0 +1,154 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# Modified from espnet(https://github.com/espnet/espnet)
+import math
+from typing import Optional
+from typing import Tuple
+
+import paddle
+import paddle.nn.functional as F
+from paddle import nn
+
+
+class ResidualBlock(nn.Layer):
+ """Residual block module in WaveNet."""
+
+ def __init__(
+ self,
+ kernel_size: int=3,
+ residual_channels: int=64,
+ gate_channels: int=128,
+ skip_channels: int=64,
+ aux_channels: int=80,
+ global_channels: int=-1,
+ dropout_rate: float=0.0,
+ dilation: int=1,
+ bias: bool=True,
+ scale_residual: bool=False, ):
+ """Initialize ResidualBlock module.
+
+ Args:
+ kernel_size (int): Kernel size of dilation convolution layer.
+ residual_channels (int): Number of channels for residual connection.
+ skip_channels (int): Number of channels for skip connection.
+ aux_channels (int): Number of local conditioning channels.
+ dropout (float): Dropout probability.
+ dilation (int): Dilation factor.
+ bias (bool): Whether to add bias parameter in convolution layers.
+ scale_residual (bool): Whether to scale the residual outputs.
+
+ """
+ super().__init__()
+ self.dropout_rate = dropout_rate
+ self.residual_channels = residual_channels
+ self.skip_channels = skip_channels
+ self.scale_residual = scale_residual
+
+ # check
+ assert (
+ kernel_size - 1) % 2 == 0, "Not support even number kernel size."
+ assert gate_channels % 2 == 0
+
+ # dilation conv
+ padding = (kernel_size - 1) // 2 * dilation
+ self.conv = nn.Conv1D(
+ residual_channels,
+ gate_channels,
+ kernel_size,
+ padding=padding,
+ dilation=dilation,
+ bias_attr=bias, )
+
+ # local conditioning
+ if aux_channels > 0:
+ self.conv1x1_aux = nn.Conv1D(
+ aux_channels, gate_channels, kernel_size=1, bias_attr=False)
+ else:
+ self.conv1x1_aux = None
+
+ # global conditioning
+ if global_channels > 0:
+ self.conv1x1_glo = nn.Conv1D(
+ global_channels, gate_channels, kernel_size=1, bias_attr=False)
+ else:
+ self.conv1x1_glo = None
+
+ # conv output is split into two groups
+ gate_out_channels = gate_channels // 2
+
+ # NOTE: concat two convs into a single conv for the efficiency
+ # (integrate res 1x1 + skip 1x1 convs)
+ self.conv1x1_out = nn.Conv1D(
+ gate_out_channels,
+ residual_channels + skip_channels,
+ kernel_size=1,
+ bias_attr=bias)
+
+ def forward(
+ self,
+ x: paddle.Tensor,
+ x_mask: Optional[paddle.Tensor]=None,
+ c: Optional[paddle.Tensor]=None,
+ g: Optional[paddle.Tensor]=None,
+ ) -> Tuple[paddle.Tensor, paddle.Tensor]:
+ """Calculate forward propagation.
+
+ Args:
+ x (Tensor): Input tensor (B, residual_channels, T).
+ x_mask Optional[paddle.Tensor]: Mask tensor (B, 1, T).
+ c (Optional[Tensor]): Local conditioning tensor (B, aux_channels, T).
+ g (Optional[Tensor]): Global conditioning tensor (B, global_channels, 1).
+
+ Returns:
+ Tensor: Output tensor for residual connection (B, residual_channels, T).
+ Tensor: Output tensor for skip connection (B, skip_channels, T).
+
+ """
+ residual = x
+ x = F.dropout(x, p=self.dropout_rate, training=self.training)
+ x = self.conv(x)
+
+ # split into two part for gated activation
+ splitdim = 1
+ xa, xb = paddle.split(x, 2, axis=splitdim)
+
+ # local conditioning
+ if c is not None:
+ c = self.conv1x1_aux(c)
+ ca, cb = paddle.split(c, 2, axis=splitdim)
+ xa, xb = xa + ca, xb + cb
+
+ # global conditioning
+ if g is not None:
+ g = self.conv1x1_glo(g)
+ ga, gb = paddle.split(g, 2, axis=splitdim)
+ xa, xb = xa + ga, xb + gb
+
+ x = paddle.tanh(xa) * F.sigmoid(xb)
+
+ # residual + skip 1x1 conv
+ x = self.conv1x1_out(x)
+ if x_mask is not None:
+ x = x * x_mask
+
+ # split integrated conv results
+ x, s = paddle.split(
+ x, [self.residual_channels, self.skip_channels], axis=1)
+
+ # for residual connection
+ x = x + residual
+ if self.scale_residual:
+ x = x * math.sqrt(0.5)
+
+ return x, s
diff --git a/paddlespeech/t2s/models/vits/wavenet/wavenet.py b/paddlespeech/t2s/models/vits/wavenet/wavenet.py
new file mode 100644
index 000000000..44693dac6
--- /dev/null
+++ b/paddlespeech/t2s/models/vits/wavenet/wavenet.py
@@ -0,0 +1,175 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# Modified from espnet(https://github.com/espnet/espnet)
+import math
+from typing import Optional
+
+import paddle
+from paddle import nn
+
+from paddlespeech.t2s.models.vits.wavenet.residual_block import ResidualBlock
+
+
+class WaveNet(nn.Layer):
+ """WaveNet with global conditioning."""
+
+ def __init__(
+ self,
+ in_channels: int=1,
+ out_channels: int=1,
+ kernel_size: int=3,
+ layers: int=30,
+ stacks: int=3,
+ base_dilation: int=2,
+ residual_channels: int=64,
+ aux_channels: int=-1,
+ gate_channels: int=128,
+ skip_channels: int=64,
+ global_channels: int=-1,
+ dropout_rate: float=0.0,
+ bias: bool=True,
+ use_weight_norm: bool=True,
+ use_first_conv: bool=False,
+ use_last_conv: bool=False,
+ scale_residual: bool=False,
+ scale_skip_connect: bool=False, ):
+ """Initialize WaveNet module.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ kernel_size (int): Kernel size of dilated convolution.
+ layers (int): Number of residual block layers.
+ stacks (int): Number of stacks i.e., dilation cycles.
+ base_dilation (int): Base dilation factor.
+ residual_channels (int): Number of channels in residual conv.
+ gate_channels (int): Number of channels in gated conv.
+ skip_channels (int): Number of channels in skip conv.
+ aux_channels (int): Number of channels for local conditioning feature.
+ global_channels (int): Number of channels for global conditioning feature.
+ dropout_rate (float): Dropout rate. 0.0 means no dropout applied.
+ bias (bool): Whether to use bias parameter in conv layer.
+ use_weight_norm (bool): Whether to use weight norm. If set to true, it will
+ be applied to all of the conv layers.
+ use_first_conv (bool): Whether to use the first conv layers.
+ use_last_conv (bool): Whether to use the last conv layers.
+ scale_residual (bool): Whether to scale the residual outputs.
+ scale_skip_connect (bool): Whether to scale the skip connection outputs.
+
+ """
+ super().__init__()
+ self.layers = layers
+ self.stacks = stacks
+ self.kernel_size = kernel_size
+ self.base_dilation = base_dilation
+ self.use_first_conv = use_first_conv
+ self.use_last_conv = use_last_conv
+ self.scale_skip_connect = scale_skip_connect
+
+ # check the number of layers and stacks
+ assert layers % stacks == 0
+ layers_per_stack = layers // stacks
+
+ # define first convolution
+ if self.use_first_conv:
+ self.first_conv = nn.Conv1D(
+ in_channels, residual_channels, kernel_size=1, bias_attr=True)
+
+ # define residual blocks
+ self.conv_layers = nn.LayerList()
+ for layer in range(layers):
+ dilation = base_dilation**(layer % layers_per_stack)
+ conv = ResidualBlock(
+ kernel_size=kernel_size,
+ residual_channels=residual_channels,
+ gate_channels=gate_channels,
+ skip_channels=skip_channels,
+ aux_channels=aux_channels,
+ global_channels=global_channels,
+ dilation=dilation,
+ dropout_rate=dropout_rate,
+ bias=bias,
+ scale_residual=scale_residual, )
+ self.conv_layers.append(conv)
+
+ # define output layers
+ if self.use_last_conv:
+ self.last_conv = nn.Sequential(
+ nn.ReLU(),
+ nn.Conv1D(
+ skip_channels, skip_channels, kernel_size=1,
+ bias_attr=True),
+ nn.ReLU(),
+ nn.Conv1D(
+ skip_channels, out_channels, kernel_size=1, bias_attr=True),
+ )
+
+ # apply weight norm
+ if use_weight_norm:
+ self.apply_weight_norm()
+
+ def forward(
+ self,
+ x: paddle.Tensor,
+ x_mask: Optional[paddle.Tensor]=None,
+ c: Optional[paddle.Tensor]=None,
+ g: Optional[paddle.Tensor]=None, ) -> paddle.Tensor:
+ """Calculate forward propagation.
+
+ Args:
+ x (Tensor): Input noise signal (B, 1, T) if use_first_conv else
+ (B, residual_channels, T).
+ x_mask (Optional[Tensor]): Mask tensor (B, 1, T).
+ c (Optional[Tensor]): Local conditioning features (B, aux_channels, T).
+ g (Optional[Tensor]): Global conditioning features (B, global_channels, 1).
+
+ Returns:
+ Tensor: Output tensor (B, out_channels, T) if use_last_conv else
+ (B, residual_channels, T).
+
+ """
+ # encode to hidden representation
+ if self.use_first_conv:
+ x = self.first_conv(x)
+
+ # residual block
+ skips = 0.0
+ for f in self.conv_layers:
+ x, h = f(x, x_mask=x_mask, c=c, g=g)
+ skips = skips + h
+ x = skips
+ if self.scale_skip_connect:
+ x = x * math.sqrt(1.0 / len(self.conv_layers))
+
+ # apply final layers
+ if self.use_last_conv:
+ x = self.last_conv(x)
+
+ return x
+
+ def apply_weight_norm(self):
+ def _apply_weight_norm(layer):
+ if isinstance(layer, (nn.Conv1D, nn.Conv2D)):
+ nn.utils.weight_norm(layer)
+
+ self.apply(_apply_weight_norm)
+
+ def remove_weight_norm(self):
+ def _remove_weight_norm(layer):
+ try:
+ nn.utils.remove_weight_norm(layer)
+ except ValueError:
+ pass
+
+ self.apply(_remove_weight_norm)
diff --git a/paddlespeech/t2s/modules/losses.py b/paddlespeech/t2s/modules/losses.py
index db31bcfbb..e6ab93513 100644
--- a/paddlespeech/t2s/modules/losses.py
+++ b/paddlespeech/t2s/modules/losses.py
@@ -17,7 +17,6 @@ import librosa
import numpy as np
import paddle
from paddle import nn
-from paddle.fluid.layers import sequence_mask
from paddle.nn import functional as F
from scipy import signal
@@ -160,7 +159,7 @@ def sample_from_discretized_mix_logistic(y, log_scale_min=None):
return x
-# Loss for new Tacotron2
+# Loss for Tacotron2
class GuidedAttentionLoss(nn.Layer):
"""Guided attention loss function module.
@@ -428,41 +427,6 @@ class Tacotron2Loss(nn.Layer):
return l1_loss, mse_loss, bce_loss
-# Loss for Tacotron2
-def attention_guide(dec_lens, enc_lens, N, T, g, dtype=None):
- """Build that W matrix. shape(B, T_dec, T_enc)
- W[i, n, t] = 1 - exp(-(n/dec_lens[i] - t/enc_lens[i])**2 / (2g**2))
-
- See also:
- Tachibana, Hideyuki, Katsuya Uenoyama, and Shunsuke Aihara. 2017. “Efficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention.” ArXiv:1710.08969 [Cs, Eess], October. http://arxiv.org/abs/1710.08969.
- """
- dtype = dtype or paddle.get_default_dtype()
- dec_pos = paddle.arange(0, N).astype(dtype) / dec_lens.unsqueeze(
- -1) # n/N # shape(B, T_dec)
- enc_pos = paddle.arange(0, T).astype(dtype) / enc_lens.unsqueeze(
- -1) # t/T # shape(B, T_enc)
- W = 1 - paddle.exp(-(dec_pos.unsqueeze(-1) - enc_pos.unsqueeze(1))**2 /
- (2 * g**2))
-
- dec_mask = sequence_mask(dec_lens, maxlen=N)
- enc_mask = sequence_mask(enc_lens, maxlen=T)
- mask = dec_mask.unsqueeze(-1) * enc_mask.unsqueeze(1)
- mask = paddle.cast(mask, W.dtype)
-
- W *= mask
- return W
-
-
-def guided_attention_loss(attention_weight, dec_lens, enc_lens, g):
- """Guided attention loss, masked to excluded padding parts."""
- _, N, T = attention_weight.shape
- W = attention_guide(dec_lens, enc_lens, N, T, g, attention_weight.dtype)
-
- total_tokens = (dec_lens * enc_lens).astype(W.dtype)
- loss = paddle.mean(paddle.sum(W * attention_weight, [1, 2]) / total_tokens)
- return loss
-
-
# Losses for GAN Vocoder
def stft(x,
fft_size,
@@ -1006,3 +970,40 @@ class FeatureMatchLoss(nn.Layer):
feat_match_loss /= i + 1
return feat_match_loss
+
+
+# loss for VITS
+class KLDivergenceLoss(nn.Layer):
+ """KL divergence loss."""
+
+ def forward(
+ self,
+ z_p: paddle.Tensor,
+ logs_q: paddle.Tensor,
+ m_p: paddle.Tensor,
+ logs_p: paddle.Tensor,
+ z_mask: paddle.Tensor, ) -> paddle.Tensor:
+ """Calculate KL divergence loss.
+
+ Args:
+ z_p (Tensor): Flow hidden representation (B, H, T_feats).
+ logs_q (Tensor): Posterior encoder projected scale (B, H, T_feats).
+ m_p (Tensor): Expanded text encoder projected mean (B, H, T_feats).
+ logs_p (Tensor): Expanded text encoder projected scale (B, H, T_feats).
+ z_mask (Tensor): Mask tensor (B, 1, T_feats).
+
+ Returns:
+ Tensor: KL divergence loss.
+
+ """
+ z_p = paddle.cast(z_p, 'float32')
+ logs_q = paddle.cast(logs_q, 'float32')
+ m_p = paddle.cast(m_p, 'float32')
+ logs_p = paddle.cast(logs_p, 'float32')
+ z_mask = paddle.cast(z_mask, 'float32')
+ kl = logs_p - logs_q - 0.5
+ kl += 0.5 * ((z_p - m_p)**2) * paddle.exp(-2.0 * logs_p)
+ kl = paddle.sum(kl * z_mask)
+ loss = kl / paddle.sum(z_mask)
+
+ return loss
diff --git a/paddlespeech/t2s/modules/nets_utils.py b/paddlespeech/t2s/modules/nets_utils.py
index 4207d316c..598b63164 100644
--- a/paddlespeech/t2s/modules/nets_utils.py
+++ b/paddlespeech/t2s/modules/nets_utils.py
@@ -12,6 +12,8 @@
# See the License for the specific language governing permissions and
# limitations under the License.
# Modified from espnet(https://github.com/espnet/espnet)
+from typing import Tuple
+
import paddle
from paddle import nn
from typeguard import check_argument_types
@@ -129,3 +131,66 @@ def initialize(model: nn.Layer, init: str):
nn.initializer.Constant())
else:
raise ValueError("Unknown initialization: " + init)
+
+
+# for VITS
+def get_random_segments(
+ x: paddle.paddle,
+ x_lengths: paddle.Tensor,
+ segment_size: int, ) -> Tuple[paddle.Tensor, paddle.Tensor]:
+ """Get random segments.
+ Args:
+ x (Tensor): Input tensor (B, C, T).
+ x_lengths (Tensor): Length tensor (B,).
+ segment_size (int): Segment size.
+ Returns:
+ Tensor: Segmented tensor (B, C, segment_size).
+ Tensor: Start index tensor (B,).
+ """
+ b, c, t = paddle.shape(x)
+ max_start_idx = x_lengths - segment_size
+ start_idxs = paddle.cast(paddle.rand([b]) * max_start_idx, 'int64')
+ segments = get_segments(x, start_idxs, segment_size)
+
+ return segments, start_idxs
+
+
+def get_segments(
+ x: paddle.Tensor,
+ start_idxs: paddle.Tensor,
+ segment_size: int, ) -> paddle.Tensor:
+ """Get segments.
+ Args:
+ x (Tensor): Input tensor (B, C, T).
+ start_idxs (Tensor): Start index tensor (B,).
+ segment_size (int): Segment size.
+ Returns:
+ Tensor: Segmented tensor (B, C, segment_size).
+ """
+ b, c, t = paddle.shape(x)
+ segments = paddle.zeros([b, c, segment_size], dtype=x.dtype)
+ for i, start_idx in enumerate(start_idxs):
+ segments[i] = x[i, :, start_idx:start_idx + segment_size]
+ return segments
+
+
+# see https://github.com/PaddlePaddle/X2Paddle/blob/develop/docs/pytorch_project_convertor/API_docs/ops/torch.gather.md
+def paddle_gather(x, dim, index):
+ index_shape = index.shape
+ index_flatten = index.flatten()
+ if dim < 0:
+ dim = len(x.shape) + dim
+ nd_index = []
+ for k in range(len(x.shape)):
+ if k == dim:
+ nd_index.append(index_flatten)
+ else:
+ reshape_shape = [1] * len(x.shape)
+ reshape_shape[k] = x.shape[k]
+ x_arange = paddle.arange(x.shape[k], dtype=index.dtype)
+ x_arange = x_arange.reshape(reshape_shape)
+ dim_index = paddle.expand(x_arange, index_shape).flatten()
+ nd_index.append(dim_index)
+ ind2 = paddle.transpose(paddle.stack(nd_index), [1, 0]).astype("int64")
+ paddle_out = paddle.gather_nd(x, ind2).reshape(index_shape)
+ return paddle_out
diff --git a/paddlespeech/t2s/training/optimizer.py b/paddlespeech/t2s/training/optimizer.py
index 64274d538..3342cae53 100644
--- a/paddlespeech/t2s/training/optimizer.py
+++ b/paddlespeech/t2s/training/optimizer.py
@@ -14,6 +14,14 @@
import paddle
from paddle import nn
+scheduler_classes = dict(
+ ReduceOnPlateau=paddle.optimizer.lr.ReduceOnPlateau,
+ lambda_decay=paddle.optimizer.lr.LambdaDecay,
+ step_decay=paddle.optimizer.lr.StepDecay,
+ multistep_decay=paddle.optimizer.lr.MultiStepDecay,
+ exponential_decay=paddle.optimizer.lr.ExponentialDecay,
+ CosineAnnealingDecay=paddle.optimizer.lr.CosineAnnealingDecay, )
+
optim_classes = dict(
adadelta=paddle.optimizer.Adadelta,
adagrad=paddle.optimizer.Adagrad,
diff --git a/paddlespeech/t2s/utils/profile.py b/paddlespeech/t2s/utils/profile.py
deleted file mode 100644
index 5f9b49526..000000000
--- a/paddlespeech/t2s/utils/profile.py
+++ /dev/null
@@ -1,34 +0,0 @@
-# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-from contextlib import contextmanager
-
-import paddle
-from paddle.framework import core
-from paddle.framework import CUDAPlace
-
-
-def synchronize():
- """Trigger cuda synchronization for better timing."""
- place = paddle.fluid.framework._current_expected_place()
- if isinstance(place, CUDAPlace):
- paddle.fluid.core._cuda_synchronize(place)
-
-
-@contextmanager
-def nvtx_span(name):
- try:
- core.nvprof_nvtx_push(name)
- yield
- finally:
- core.nvprof_nvtx_pop()
diff --git a/paddlespeech/t2s/utils/timeline.py b/paddlespeech/t2s/utils/timeline.py
deleted file mode 100644
index 0a5509dbe..000000000
--- a/paddlespeech/t2s/utils/timeline.py
+++ /dev/null
@@ -1,315 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import argparse
-import json
-
-import paddle.fluid.proto.profiler.profiler_pb2 as profiler_pb2
-import six
-
-parser = argparse.ArgumentParser(description=__doc__)
-parser.add_argument(
- '--profile_path',
- type=str,
- default='',
- help='Input profile file name. If there are multiple file, the format '
- 'should be trainer1=file1,trainer2=file2,ps=file3')
-parser.add_argument(
- '--timeline_path', type=str, default='', help='Output timeline file name.')
-args = parser.parse_args()
-
-
-class _ChromeTraceFormatter(object):
- def __init__(self):
- self._events = []
- self._metadata = []
-
- def _create_event(self, ph, category, name, pid, tid, timestamp):
- """Creates a new Chrome Trace event.
-
- For details of the file format, see:
- https://github.com/catapult-project/catapult/blob/master/tracing/README.md
-
- Args:
- ph: The type of event - usually a single character.
- category: The event category as a string.
- name: The event name as a string.
- pid: Identifier of the process generating this event as an integer.
- tid: Identifier of the thread generating this event as an integer.
- timestamp: The timestamp of this event as a long integer.
-
- Returns:
- A JSON compatible event object.
- """
- event = {}
- event['ph'] = ph
- event['cat'] = category
- event['name'] = name.replace("ParallelExecutor::Run/", "")
- event['pid'] = pid
- event['tid'] = tid
- event['ts'] = timestamp
- return event
-
- def emit_pid(self, name, pid):
- """Adds a process metadata event to the trace.
-
- Args:
- name: The process name as a string.
- pid: Identifier of the process as an integer.
- """
- event = {}
- event['name'] = 'process_name'
- event['ph'] = 'M'
- event['pid'] = pid
- event['args'] = {'name': name}
- self._metadata.append(event)
-
- def emit_region(self, timestamp, duration, pid, tid, category, name, args):
- """Adds a region event to the trace.
-
- Args:
- timestamp: The start timestamp of this region as a long integer.
- duration: The duration of this region as a long integer.
- pid: Identifier of the process generating this event as an integer.
- tid: Identifier of the thread generating this event as an integer.
- category: The event category as a string.
- name: The event name as a string.
- args: A JSON-compatible dictionary of event arguments.
- """
- event = self._create_event('X', category, name, pid, tid, timestamp)
- event['dur'] = duration
- event['args'] = args
- self._events.append(event)
-
- def emit_counter(self, category, name, pid, timestamp, counter, value):
- """Emits a record for a single counter.
-
- Args:
- category: The event category as string
- name: The event name as string
- pid: Identifier of the process generating this event as integer
- timestamp: The timestamps of this event as long integer
- counter: Name of the counter as string
- value: Value of the counter as integer
- tid: Thread id of the allocation as integer
- """
- event = self._create_event('C', category, name, pid, 0, timestamp)
- event['args'] = {counter: value}
- self._events.append(event)
-
- def format_to_string(self, pretty=False):
- """Formats the chrome trace to a string.
-
- Args:
- pretty: (Optional.) If True, produce human-readable JSON output.
-
- Returns:
- A JSON-formatted string in Chrome Trace format.
- """
- trace = {}
- trace['traceEvents'] = self._metadata + self._events
- if pretty:
- return json.dumps(trace, indent=4, separators=(',', ': '))
- else:
- return json.dumps(trace, separators=(',', ':'))
-
-
-class Timeline(object):
- def __init__(self, profile_dict):
- self._profile_dict = profile_dict
- self._pid = 0
- self._devices = dict()
- self._mem_devices = dict()
- self._chrome_trace = _ChromeTraceFormatter()
-
- def _allocate_pid(self):
- cur_pid = self._pid
- self._pid += 1
- return cur_pid
-
- def _allocate_pids(self):
- for k, profile_pb in six.iteritems(self._profile_dict):
- for event in profile_pb.events:
- if event.type == profiler_pb2.Event.CPU:
- if (k, event.device_id, "CPU") not in self._devices:
- pid = self._allocate_pid()
- self._devices[(k, event.device_id, "CPU")] = pid
- # -1 device id represents CUDA API(RunTime) call.(e.g. cudaLaunch, cudaMemcpy)
- if event.device_id == -1:
- self._chrome_trace.emit_pid("%s:cuda_api" % k, pid)
- else:
- self._chrome_trace.emit_pid(
- "%s:cpu:block:%d" % (k, event.device_id), pid)
- elif event.type == profiler_pb2.Event.GPUKernel:
- if (k, event.device_id, "GPUKernel") not in self._devices:
- pid = self._allocate_pid()
- self._devices[(k, event.device_id, "GPUKernel")] = pid
- self._chrome_trace.emit_pid("%s:gpu:%d" %
- (k, event.device_id), pid)
- if not hasattr(profile_pb, "mem_events"):
- continue
- for mevent in profile_pb.mem_events:
- if mevent.place == profiler_pb2.MemEvent.CUDAPlace:
- if (k, mevent.device_id, "GPU") not in self._mem_devices:
- pid = self._allocate_pid()
- self._mem_devices[(k, mevent.device_id, "GPU")] = pid
- self._chrome_trace.emit_pid(
- "memory usage on %s:gpu:%d" % (k, mevent.device_id),
- pid)
- elif mevent.place == profiler_pb2.MemEvent.CPUPlace:
- if (k, mevent.device_id, "CPU") not in self._mem_devices:
- pid = self._allocate_pid()
- self._mem_devices[(k, mevent.device_id, "CPU")] = pid
- self._chrome_trace.emit_pid(
- "memory usage on %s:cpu:%d" % (k, mevent.device_id),
- pid)
- elif mevent.place == profiler_pb2.MemEvent.CUDAPinnedPlace:
- if (k, mevent.device_id,
- "CUDAPinnedPlace") not in self._mem_devices:
- pid = self._allocate_pid()
- self._mem_devices[(k, mevent.device_id,
- "CUDAPinnedPlace")] = pid
- self._chrome_trace.emit_pid(
- "memory usage on %s:cudapinnedplace:%d" %
- (k, mevent.device_id), pid)
- elif mevent.place == profiler_pb2.MemEvent.NPUPlace:
- if (k, mevent.device_id, "NPU") not in self._mem_devices:
- pid = self._allocate_pid()
- self._mem_devices[(k, mevent.device_id, "NPU")] = pid
- self._chrome_trace.emit_pid(
- "memory usage on %s:npu:%d" % (k, mevent.device_id),
- pid)
- if (k, 0, "CPU") not in self._mem_devices:
- pid = self._allocate_pid()
- self._mem_devices[(k, 0, "CPU")] = pid
- self._chrome_trace.emit_pid("memory usage on %s:cpu:%d" %
- (k, 0), pid)
- if (k, 0, "GPU") not in self._mem_devices:
- pid = self._allocate_pid()
- self._mem_devices[(k, 0, "GPU")] = pid
- self._chrome_trace.emit_pid("memory usage on %s:gpu:%d" %
- (k, 0), pid)
- if (k, 0, "CUDAPinnedPlace") not in self._mem_devices:
- pid = self._allocate_pid()
- self._mem_devices[(k, 0, "CUDAPinnedPlace")] = pid
- self._chrome_trace.emit_pid(
- "memory usage on %s:cudapinnedplace:%d" % (k, 0), pid)
- if (k, 0, "NPU") not in self._mem_devices:
- pid = self._allocate_pid()
- self._mem_devices[(k, 0, "NPU")] = pid
- self._chrome_trace.emit_pid("memory usage on %s:npu:%d" %
- (k, 0), pid)
-
- def _allocate_events(self):
- for k, profile_pb in six.iteritems(self._profile_dict):
- for event in profile_pb.events:
- if event.type == profiler_pb2.Event.CPU:
- type = "CPU"
- elif event.type == profiler_pb2.Event.GPUKernel:
- type = "GPUKernel"
- pid = self._devices[(k, event.device_id, type)]
- args = {'name': event.name}
- if event.memcopy.bytes > 0:
- args['mem_bytes'] = event.memcopy.bytes
- if hasattr(event, "detail_info") and event.detail_info:
- args['detail_info'] = event.detail_info
- # TODO(panyx0718): Chrome tracing only handles ms. However, some
- # ops takes micro-seconds. Hence, we keep the ns here.
- self._chrome_trace.emit_region(
- event.start_ns, (event.end_ns - event.start_ns) / 1.0, pid,
- event.sub_device_id, 'Op', event.name, args)
-
- def _allocate_memory_event(self):
- if not hasattr(profiler_pb2, "MemEvent"):
- return
- place_to_str = {
- profiler_pb2.MemEvent.CPUPlace: "CPU",
- profiler_pb2.MemEvent.CUDAPlace: "GPU",
- profiler_pb2.MemEvent.CUDAPinnedPlace: "CUDAPinnedPlace",
- profiler_pb2.MemEvent.NPUPlace: "NPU"
- }
- for k, profile_pb in six.iteritems(self._profile_dict):
- mem_list = []
- end_profiler = 0
- for mevent in profile_pb.mem_events:
- crt_info = dict()
- crt_info['time'] = mevent.start_ns
- crt_info['size'] = mevent.bytes
- if mevent.place in place_to_str:
- place = place_to_str[mevent.place]
- else:
- place = "UnDefine"
- crt_info['place'] = place
- pid = self._mem_devices[(k, mevent.device_id, place)]
- crt_info['pid'] = pid
- crt_info['thread_id'] = mevent.thread_id
- crt_info['device_id'] = mevent.device_id
- mem_list.append(crt_info)
- crt_info = dict()
- crt_info['place'] = place
- crt_info['pid'] = pid
- crt_info['thread_id'] = mevent.thread_id
- crt_info['device_id'] = mevent.device_id
- crt_info['time'] = mevent.end_ns
- crt_info['size'] = -mevent.bytes
- mem_list.append(crt_info)
- end_profiler = max(end_profiler, crt_info['time'])
- mem_list.sort(key=lambda tmp: (tmp.get('time', 0)))
- i = 0
- total_size = 0
- while i < len(mem_list):
- total_size += mem_list[i]['size']
- while i < len(mem_list) - 1 and mem_list[i]['time'] == mem_list[
- i + 1]['time']:
- total_size += mem_list[i + 1]['size']
- i += 1
-
- self._chrome_trace.emit_counter(
- "Memory", "Memory", mem_list[i]['pid'], mem_list[i]['time'],
- 0, total_size)
- i += 1
-
- def generate_chrome_trace(self):
- self._allocate_pids()
- self._allocate_events()
- self._allocate_memory_event()
- return self._chrome_trace.format_to_string()
-
-
-profile_path = '/tmp/profile'
-if args.profile_path:
- profile_path = args.profile_path
-timeline_path = '/tmp/timeline'
-if args.timeline_path:
- timeline_path = args.timeline_path
-
-profile_paths = profile_path.split(',')
-profile_dict = dict()
-if len(profile_paths) == 1:
- with open(profile_path, 'rb') as f:
- profile_s = f.read()
- profile_pb = profiler_pb2.Profile()
- profile_pb.ParseFromString(profile_s)
- profile_dict['trainer'] = profile_pb
-else:
- for profile_path in profile_paths:
- k, v = profile_path.split('=')
- with open(v, 'rb') as f:
- profile_s = f.read()
- profile_pb = profiler_pb2.Profile()
- profile_pb.ParseFromString(profile_s)
- profile_dict[k] = profile_pb
-
-tl = Timeline(profile_dict)
-with open(timeline_path, 'w') as f:
- f.write(tl.generate_chrome_trace())
diff --git a/examples/other/1xt2x/src_deepspeech2x/models/__init__.py b/paddlespeech/utils/__init__.py
similarity index 100%
rename from examples/other/1xt2x/src_deepspeech2x/models/__init__.py
rename to paddlespeech/utils/__init__.py
diff --git a/paddlespeech/utils/dynamic_import.py b/paddlespeech/utils/dynamic_import.py
new file mode 100644
index 000000000..99f93356f
--- /dev/null
+++ b/paddlespeech/utils/dynamic_import.py
@@ -0,0 +1,38 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# Modified from espnet(https://github.com/espnet/espnet)
+import importlib
+
+__all__ = ["dynamic_import"]
+
+
+def dynamic_import(import_path, alias=dict()):
+ """dynamic import module and class
+
+ :param str import_path: syntax 'module_name:class_name'
+ e.g., 'paddlespeech.s2t.models.u2:U2Model'
+ :param dict alias: shortcut for registered class
+ :return: imported class
+ """
+ if import_path not in alias and ":" not in import_path:
+ raise ValueError(
+ "import_path should be one of {} or "
+ 'include ":", e.g. "paddlespeech.s2t.models.u2:U2Model" : '
+ "{}".format(set(alias), import_path))
+ if ":" not in import_path:
+ import_path = alias[import_path]
+
+ module_name, objname = import_path.split(":")
+ m = importlib.import_module(module_name)
+ return getattr(m, objname)
diff --git a/paddlespeech/vector/exps/ecapa_tdnn/extract_emb.py b/paddlespeech/vector/exps/ecapa_tdnn/extract_emb.py
index e8d91bf3a..cd4538bb5 100644
--- a/paddlespeech/vector/exps/ecapa_tdnn/extract_emb.py
+++ b/paddlespeech/vector/exps/ecapa_tdnn/extract_emb.py
@@ -16,10 +16,10 @@ import os
import time
import paddle
-from paddleaudio.backends import load as load_audio
-from paddleaudio.compliance.librosa import melspectrogram
from yacs.config import CfgNode
+from paddlespeech.audio.backends import load as load_audio
+from paddlespeech.audio.compliance.librosa import melspectrogram
from paddlespeech.s2t.utils.log import Log
from paddlespeech.vector.io.batch import feature_normalize
from paddlespeech.vector.models.ecapa_tdnn import EcapaTdnn
diff --git a/paddlespeech/vector/exps/ecapa_tdnn/test.py b/paddlespeech/vector/exps/ecapa_tdnn/test.py
index f15dbf9b7..6c87dbe7b 100644
--- a/paddlespeech/vector/exps/ecapa_tdnn/test.py
+++ b/paddlespeech/vector/exps/ecapa_tdnn/test.py
@@ -18,10 +18,10 @@ import numpy as np
import paddle
from paddle.io import BatchSampler
from paddle.io import DataLoader
-from paddleaudio.metric import compute_eer
from tqdm import tqdm
from yacs.config import CfgNode
+from paddlespeech.audio.metric import compute_eer
from paddlespeech.s2t.utils.log import Log
from paddlespeech.vector.io.batch import batch_feature_normalize
from paddlespeech.vector.io.dataset import CSVDataset
diff --git a/paddlespeech/vector/exps/ecapa_tdnn/train.py b/paddlespeech/vector/exps/ecapa_tdnn/train.py
index aad148a98..961b75e29 100644
--- a/paddlespeech/vector/exps/ecapa_tdnn/train.py
+++ b/paddlespeech/vector/exps/ecapa_tdnn/train.py
@@ -20,9 +20,9 @@ import paddle
from paddle.io import BatchSampler
from paddle.io import DataLoader
from paddle.io import DistributedBatchSampler
-from paddleaudio.compliance.librosa import melspectrogram
from yacs.config import CfgNode
+from paddlespeech.audio.compliance.librosa import melspectrogram
from paddlespeech.s2t.utils.log import Log
from paddlespeech.vector.io.augment import build_augment_pipeline
from paddlespeech.vector.io.augment import waveform_augment
@@ -54,7 +54,7 @@ def main(args, config):
# stage1: we must call the paddle.distributed.init_parallel_env() api at the begining
paddle.distributed.init_parallel_env()
nranks = paddle.distributed.get_world_size()
- local_rank = paddle.distributed.get_rank()
+ rank = paddle.distributed.get_rank()
# set the random seed, it is the necessary measures for multiprocess training
seed_everything(config.seed)
@@ -112,10 +112,10 @@ def main(args, config):
state_dict = paddle.load(
os.path.join(args.load_checkpoint, 'model.pdopt'))
optimizer.set_state_dict(state_dict)
- if local_rank == 0:
+ if rank == 0:
logger.info(f'Checkpoint loaded from {args.load_checkpoint}')
except FileExistsError:
- if local_rank == 0:
+ if rank == 0:
logger.info('Train from scratch.')
try:
@@ -219,7 +219,7 @@ def main(args, config):
timer.count() # step plus one in timer
# stage 9-10: print the log information only on 0-rank per log-freq batchs
- if (batch_idx + 1) % config.log_interval == 0 and local_rank == 0:
+ if (batch_idx + 1) % config.log_interval == 0 and rank == 0:
lr = optimizer.get_lr()
avg_loss /= config.log_interval
avg_acc = num_corrects / num_samples
@@ -250,7 +250,7 @@ def main(args, config):
# stage 9-11: save the model parameters only on 0-rank per save-freq batchs
if epoch % config.save_interval == 0 and batch_idx + 1 == steps_per_epoch:
- if local_rank != 0:
+ if rank != 0:
paddle.distributed.barrier(
) # Wait for valid step in main process
continue # Resume trainning on other process
@@ -317,7 +317,7 @@ def main(args, config):
paddle.distributed.barrier() # Main process
# stage 10: create the final trained model.pdparams with soft link
- if local_rank == 0:
+ if rank == 0:
final_model = os.path.join(args.checkpoint_dir, "model.pdparams")
logger.info(f"we will create the final model: {final_model}")
if os.path.islink(final_model):
diff --git a/paddlespeech/vector/io/dataset.py b/paddlespeech/vector/io/dataset.py
index 1b514f3d6..245b29592 100644
--- a/paddlespeech/vector/io/dataset.py
+++ b/paddlespeech/vector/io/dataset.py
@@ -15,9 +15,9 @@ from dataclasses import dataclass
from dataclasses import fields
from paddle.io import Dataset
-from paddleaudio import load as load_audio
-from paddleaudio.compliance.librosa import melspectrogram
+from paddlespeech.audio import load as load_audio
+from paddlespeech.audio.compliance.librosa import melspectrogram
from paddlespeech.s2t.utils.log import Log
logger = Log(__name__).getlog()
diff --git a/paddlespeech/vector/io/dataset_from_json.py b/paddlespeech/vector/io/dataset_from_json.py
index bf04e1132..12e845771 100644
--- a/paddlespeech/vector/io/dataset_from_json.py
+++ b/paddlespeech/vector/io/dataset_from_json.py
@@ -16,9 +16,10 @@ from dataclasses import dataclass
from dataclasses import fields
from paddle.io import Dataset
-from paddleaudio import load as load_audio
-from paddleaudio.compliance.librosa import melspectrogram
-from paddleaudio.compliance.librosa import mfcc
+
+from paddlespeech.audio import load as load_audio
+from paddlespeech.audio.compliance.librosa import melspectrogram
+from paddlespeech.audio.compliance.librosa import mfcc
@dataclass
diff --git a/setup.py b/setup.py
index 912fdd6d1..679549b4d 100644
--- a/setup.py
+++ b/setup.py
@@ -24,48 +24,21 @@ from setuptools import find_packages
from setuptools import setup
from setuptools.command.develop import develop
from setuptools.command.install import install
+from setuptools.command.test import test
HERE = Path(os.path.abspath(os.path.dirname(__file__)))
-VERSION = '1.0.0a'
+VERSION = '0.0.0'
+COMMITID = 'none'
base = [
- "editdistance",
- "g2p_en",
- "g2pM",
- "h5py",
- "inflect",
- "jieba",
- "jsonlines",
- "kaldiio",
- "librosa==0.8.1",
- "loguru",
- "matplotlib",
- "nara_wpe",
- "onnxruntime",
- "pandas",
- "paddleaudio",
- "paddlenlp",
- "paddlespeech_feat",
- "praatio==5.0.0",
- "pypinyin",
- "pypinyin-dict",
- "python-dateutil",
- "pyworld",
- "resampy==0.2.2",
- "sacrebleu",
- "scipy",
- "sentencepiece~=0.1.96",
- "soundfile~=0.10",
- "textgrid",
- "timer",
- "tqdm",
- "typeguard",
- "visualdl",
- "webrtcvad",
- "yacs~=0.1.8",
- "prettytable",
- "zhon",
+ "editdistance", "g2p_en", "g2pM", "h5py", "inflect", "jieba", "jsonlines",
+ "kaldiio", "librosa==0.8.1", "loguru", "matplotlib", "nara_wpe",
+ "onnxruntime", "pandas", "paddlenlp", "paddlespeech_feat", "praatio==5.0.0",
+ "pypinyin", "pypinyin-dict", "python-dateutil", "pyworld", "resampy==0.2.2",
+ "sacrebleu", "scipy", "sentencepiece~=0.1.96", "soundfile~=0.10",
+ "textgrid", "timer", "tqdm", "typeguard", "visualdl", "webrtcvad",
+ "yacs~=0.1.8", "prettytable", "zhon", 'colorlog', 'pathos == 0.2.8'
]
server = [
@@ -97,22 +70,31 @@ requirements = {
}
-def write_version_py(filename='paddlespeech/__init__.py'):
- import paddlespeech
- if hasattr(paddlespeech,
- "__version__") and paddlespeech.__version__ == VERSION:
- return
- with open(filename, "a") as f:
- f.write(f"\n__version__ = '{VERSION}'\n")
+def check_call(cmd: str, shell=False, executable=None):
+ try:
+ sp.check_call(
+ cmd.split(),
+ shell=shell,
+ executable="/bin/bash" if shell else executable)
+ except sp.CalledProcessError as e:
+ print(
+ f"{__file__}:{inspect.currentframe().f_lineno}: CMD: {cmd}, Error:",
+ e.output,
+ file=sys.stderr)
+ raise e
-def remove_version_py(filename='paddlespeech/__init__.py'):
- with open(filename, "r") as f:
- lines = f.readlines()
- with open(filename, "w") as f:
- for line in lines:
- if "__version__" not in line:
- f.write(line)
+def check_output(cmd: str, shell=False):
+ try:
+ out_bytes = sp.check_output(cmd.split())
+ except sp.CalledProcessError as e:
+ out_bytes = e.output # Output generated before error
+ code = e.returncode # Return code
+ print(
+ f"{__file__}:{inspect.currentframe().f_lineno}: CMD: {cmd}, Error:",
+ out_bytes,
+ file=sys.stderr)
+ return out_bytes.strip().decode('utf8')
@contextlib.contextmanager
@@ -132,25 +114,14 @@ def read(*names, **kwargs):
return fp.read()
-def check_call(cmd: str, shell=False, executable=None):
- try:
- sp.check_call(
- cmd.split(),
- shell=shell,
- executable="/bin/bash" if shell else executable)
- except sp.CalledProcessError as e:
- print(
- f"{__file__}:{inspect.currentframe().f_lineno}: CMD: {cmd}, Error:",
- e.output,
- file=sys.stderr)
- raise e
-
-
def _remove(files: str):
for f in files:
f.unlink()
+################################# Install ##################################
+
+
def _post_install(install_lib_dir):
# tools/make
tool_dir = HERE / "tools"
@@ -178,7 +149,19 @@ class InstallCommand(install):
install.run(self)
- # cmd: python setup.py upload
+class TestCommand(test):
+ def finalize_options(self):
+ test.finalize_options(self)
+ self.test_args = []
+ self.test_suite = True
+
+ def run_tests(self):
+ # Run nose ensuring that argv simulates running nosetests directly
+ import nose
+ nose.run_exit(argv=['nosetests', '-w', 'tests'])
+
+
+# cmd: python setup.py upload
class UploadCommand(Command):
description = "Build and publish the package."
user_options = []
@@ -202,8 +185,45 @@ class UploadCommand(Command):
sys.exit()
-write_version_py()
+################################# Version ##################################
+def write_version_py(filename='paddlespeech/__init__.py'):
+ import paddlespeech
+ if hasattr(paddlespeech,
+ "__version__") and paddlespeech.__version__ == VERSION:
+ return
+ with open(filename, "a") as f:
+ out_str = f"\n__version__ = '{VERSION}'\n"
+ print(out_str)
+ f.write(f"\n__version__ = '{VERSION}'\n")
+
+ COMMITID = check_output("git rev-parse HEAD")
+ with open(filename, 'a') as f:
+ out_str = f"\n__commit__ = '{COMMITID}'\n"
+ print(out_str)
+ f.write(f"\n__commit__ = '{COMMITID}'\n")
+
+ print(f"{inspect.currentframe().f_code.co_name} done")
+
+def remove_version_py(filename='paddlespeech/__init__.py'):
+ with open(filename, "r") as f:
+ lines = f.readlines()
+ with open(filename, "w") as f:
+ for line in lines:
+ if "__version__" in line or "__commit__" in line:
+ continue
+ f.write(line)
+ print(f"{inspect.currentframe().f_code.co_name} done")
+
+
+@contextlib.contextmanager
+def version_info():
+ write_version_py()
+ yield
+ remove_version_py()
+
+
+################################# Steup ##################################
setup_info = dict(
# Metadata
name='paddlespeech',
@@ -243,11 +263,13 @@ setup_info = dict(
"sphinx", "sphinx-rtd-theme", "numpydoc", "myst_parser",
"recommonmark>=0.5.0", "sphinx-markdown-tables", "sphinx-autobuild"
],
+ 'test': ['nose', 'torchaudio==0.10.2'],
},
cmdclass={
'develop': DevelopCommand,
'install': InstallCommand,
'upload': UploadCommand,
+ 'test': TestCommand,
},
# Package info
@@ -273,6 +295,5 @@ setup_info = dict(
]
})
-setup(**setup_info)
-
-remove_version_py()
+with version_info():
+ setup(**setup_info)
diff --git a/speechx/CMakeLists.txt b/speechx/CMakeLists.txt
index 98d9e6374..4b5838e5c 100644
--- a/speechx/CMakeLists.txt
+++ b/speechx/CMakeLists.txt
@@ -142,4 +142,3 @@ set(DEPS ${DEPS}
set(SPEECHX_ROOT ${CMAKE_CURRENT_SOURCE_DIR}/speechx)
add_subdirectory(speechx)
-add_subdirectory(examples)
diff --git a/speechx/README.md b/speechx/README.md
index f75d8ac4e..cd1cd62c1 100644
--- a/speechx/README.md
+++ b/speechx/README.md
@@ -44,13 +44,13 @@ More details please see `README.md` under `examples`.
> If using docker please check `--privileged` is set when `docker run`.
* Fatal error at startup: `a function redirection which is mandatory for this platform-tool combination cannot be set up`
-```
+```bash
apt-get install libc6-dbg
```
* Install
-```
+```bash
pushd tools
./setup_valgrind.sh
popd
@@ -59,4 +59,4 @@ popd
## TODO
### Deepspeech2 with linear feature
-* DecibelNormalizer: there is a little bit difference between offline and online db norm. The computation of online db norm read feature chunk by chunk, which causes the feature size is different with offline db norm. In normalizer.cc:73, the samples.size() is different, which causes the difference of result.
+* DecibelNormalizer: there is a small difference between the offline and online db norm. The computation of online db norm reads features chunk by chunk, which causes the feature size to be different different with offline db norm. In `normalizer.cc:73`, the `samples.size()` is different, which causes the different result.
diff --git a/speechx/examples/CMakeLists.txt b/speechx/examples/CMakeLists.txt
deleted file mode 100644
index 3c274a20a..000000000
--- a/speechx/examples/CMakeLists.txt
+++ /dev/null
@@ -1,4 +0,0 @@
-cmake_minimum_required(VERSION 3.14 FATAL_ERROR)
-
-add_subdirectory(ds2_ol)
-add_subdirectory(dev)
\ No newline at end of file
diff --git a/speechx/examples/README.md b/speechx/examples/README.md
index 18b372812..f7f6f9ac0 100644
--- a/speechx/examples/README.md
+++ b/speechx/examples/README.md
@@ -1,8 +1,6 @@
# Examples for SpeechX
-* ds2_ol - ds2 streaming test under `aishell-1` test dataset.
-The entrypoint is `ds2_ol/aishell/run.sh`
-
+* `ds2_ol` - ds2 streaming test under `aishell-1` test dataset.
## How to run
@@ -24,14 +22,6 @@ netron exp/deepspeech2_online/checkpoints/avg_1.jit.pdmodel --port 8022 --host
## For Developer
-> Warning: Only for developer, make sure you know what's it.
-
-* dev - for speechx developer, using for test.
-
-## Build WFST
-
-> Warning: Using below example when you know what's it.
+> Reminder: Only for developer, make sure you know what's it.
-* text_lm - process text for build lm
-* ngram - using to build NGram ARPA lm.
-* wfst - build wfst for TLG.
+* codelab - for speechx developer, using for test.
diff --git a/speechx/examples/codelab/README.md b/speechx/examples/codelab/README.md
new file mode 100644
index 000000000..f89184de9
--- /dev/null
+++ b/speechx/examples/codelab/README.md
@@ -0,0 +1,8 @@
+# Codelab
+
+## introduction
+
+> The below is for developing and offline testing. Do not run it only if you know what it is.
+* nnet
+* feat
+* decoder
diff --git a/speechx/examples/ds2_ol/decoder/.gitignore b/speechx/examples/codelab/decoder/.gitignore
similarity index 100%
rename from speechx/examples/ds2_ol/decoder/.gitignore
rename to speechx/examples/codelab/decoder/.gitignore
diff --git a/speechx/examples/ds2_ol/decoder/README.md b/speechx/examples/codelab/decoder/README.md
similarity index 100%
rename from speechx/examples/ds2_ol/decoder/README.md
rename to speechx/examples/codelab/decoder/README.md
diff --git a/speechx/examples/codelab/decoder/path.sh b/speechx/examples/codelab/decoder/path.sh
new file mode 100644
index 000000000..9d2291743
--- /dev/null
+++ b/speechx/examples/codelab/decoder/path.sh
@@ -0,0 +1,14 @@
+# This contains the locations of binarys build required for running the examples.
+
+SPEECHX_ROOT=$PWD/../../../
+SPEECHX_BUILD=$SPEECHX_ROOT/build/speechx
+
+SPEECHX_TOOLS=$SPEECHX_ROOT/tools
+TOOLS_BIN=$SPEECHX_TOOLS/valgrind/install/bin
+
+[ -d $SPEECHX_BUILD ] || { echo "Error: 'build/speechx' directory not found. please ensure that the project build successfully"; }
+
+export LC_AL=C
+
+SPEECHX_BIN=$SPEECHX_ROOT/build/speechx/decoder:$SPEECHX_ROOT/build/speechx/frontend/audio
+export PATH=$PATH:$SPEECHX_BIN:$TOOLS_BIN
diff --git a/speechx/examples/ds2_ol/decoder/run.sh b/speechx/examples/codelab/decoder/run.sh
similarity index 94%
rename from speechx/examples/ds2_ol/decoder/run.sh
rename to speechx/examples/codelab/decoder/run.sh
index 40501eb41..a911eb033 100755
--- a/speechx/examples/ds2_ol/decoder/run.sh
+++ b/speechx/examples/codelab/decoder/run.sh
@@ -54,7 +54,7 @@ cmvn=$exp_dir/cmvn.ark
export GLOG_logtostderr=1
# dump json cmvn to kaldi
-cmvn-json2kaldi \
+cmvn_json2kaldi_main \
--json_file $ckpt_dir/data/mean_std.json \
--cmvn_write_path $cmvn \
--binary=false
@@ -62,17 +62,17 @@ echo "convert json cmvn to kaldi ark."
# generate linear feature as streaming
-linear-spectrogram-wo-db-norm-ol \
+compute_linear_spectrogram_main \
--wav_rspecifier=scp:$data/wav.scp \
--feature_wspecifier=ark,t:$feat_wspecifier \
--cmvn_file=$cmvn
echo "compute linear spectrogram feature."
# run ctc beam search decoder as streaming
-ctc-prefix-beam-search-decoder-ol \
+ctc_prefix_beam_search_decoder_main \
--result_wspecifier=ark,t:$exp_dir/result.txt \
--feature_rspecifier=ark:$feat_wspecifier \
--model_path=$model_dir/avg_1.jit.pdmodel \
--param_path=$model_dir/avg_1.jit.pdiparams \
--dict_file=$vocb_dir/vocab.txt \
- --lm_path=$lm
\ No newline at end of file
+ --lm_path=$lm
diff --git a/speechx/examples/ds2_ol/decoder/valgrind.sh b/speechx/examples/codelab/decoder/valgrind.sh
similarity index 100%
rename from speechx/examples/ds2_ol/decoder/valgrind.sh
rename to speechx/examples/codelab/decoder/valgrind.sh
diff --git a/speechx/examples/ds2_ol/feat/README.md b/speechx/examples/codelab/feat/README.md
similarity index 58%
rename from speechx/examples/ds2_ol/feat/README.md
rename to speechx/examples/codelab/feat/README.md
index 89cb79eca..e59e02bf9 100644
--- a/speechx/examples/ds2_ol/feat/README.md
+++ b/speechx/examples/codelab/feat/README.md
@@ -2,6 +2,6 @@
ASR audio feature test bins. We using theses bins to test linaer/fbank/mfcc asr feature as streaming manner.
-* linear_spectrogram_without_db_norm_main.cc
+* compute_linear_spectrogram_main.cc
-compute linear spectrogram w/o db norm in streaming manner.
+compute linear spectrogram without db norm in streaming manner.
diff --git a/speechx/examples/dev/glog/path.sh b/speechx/examples/codelab/feat/path.sh
similarity index 82%
rename from speechx/examples/dev/glog/path.sh
rename to speechx/examples/codelab/feat/path.sh
index 1a96a861a..3b89d01e9 100644
--- a/speechx/examples/dev/glog/path.sh
+++ b/speechx/examples/codelab/feat/path.sh
@@ -1,15 +1,14 @@
# This contains the locations of binarys build required for running the examples.
SPEECHX_ROOT=$PWD/../../../
+SPEECHX_EXAMPLES=$SPEECHX_ROOT/build/examples
SPEECHX_TOOLS=$SPEECHX_ROOT/tools
TOOLS_BIN=$SPEECHX_TOOLS/valgrind/install/bin
-
-SPEECHX_EXAMPLES=$SPEECHX_ROOT/build/examples
[ -d $SPEECHX_EXAMPLES ] || { echo "Error: 'build/examples' directory not found. please ensure that the project build successfully"; }
-SPEECHX_BIN=$SPEECHX_EXAMPLES/dev/glog
-export PATH=$PATH:$SPEECHX_BIN:$TOOLS_BIN
-
export LC_AL=C
+
+SPEECHX_BIN=$SPEECHX_ROOT/build/speechx/decoder:$SPEECHX_ROOT/build/speechx/frontend/audio
+export PATH=$PATH:$SPEECHX_BIN:$TOOLS_BIN
diff --git a/speechx/examples/ds2_ol/feat/run.sh b/speechx/examples/codelab/feat/run.sh
similarity index 95%
rename from speechx/examples/ds2_ol/feat/run.sh
rename to speechx/examples/codelab/feat/run.sh
index 757779275..1fa37f981 100755
--- a/speechx/examples/ds2_ol/feat/run.sh
+++ b/speechx/examples/codelab/feat/run.sh
@@ -41,14 +41,14 @@ mkdir -p $exp_dir
# 3. run feat
export GLOG_logtostderr=1
-cmvn-json2kaldi \
+cmvn_json2kaldi_main \
--json_file $model_dir/data/mean_std.json \
--cmvn_write_path $exp_dir/cmvn.ark \
--binary=false
echo "convert json cmvn to kaldi ark."
-linear-spectrogram-wo-db-norm-ol \
+compute_linear_spectrogram_main \
--wav_rspecifier=scp:$data_dir/wav.scp \
--feature_wspecifier=ark,t:$exp_dir/feats.ark \
--cmvn_file=$exp_dir/cmvn.ark
diff --git a/speechx/examples/ds2_ol/feat/valgrind.sh b/speechx/examples/codelab/feat/valgrind.sh
similarity index 93%
rename from speechx/examples/ds2_ol/feat/valgrind.sh
rename to speechx/examples/codelab/feat/valgrind.sh
index f8aab63f8..ea50fdc23 100755
--- a/speechx/examples/ds2_ol/feat/valgrind.sh
+++ b/speechx/examples/codelab/feat/valgrind.sh
@@ -17,7 +17,7 @@ feat_wspecifier=./feats.ark
cmvn=./cmvn.ark
valgrind --tool=memcheck --track-origins=yes --leak-check=full --show-leak-kinds=all \
- linear_spectrogram_main \
+ compute_linear_spectrogram_main \
--wav_rspecifier=scp:$model_dir/wav.scp \
--feature_wspecifier=ark,t:$feat_wspecifier \
--cmvn_write_path=$cmvn
diff --git a/speechx/examples/ds2_ol/nnet/.gitignore b/speechx/examples/codelab/nnet/.gitignore
similarity index 100%
rename from speechx/examples/ds2_ol/nnet/.gitignore
rename to speechx/examples/codelab/nnet/.gitignore
diff --git a/speechx/examples/ds2_ol/nnet/README.md b/speechx/examples/codelab/nnet/README.md
similarity index 100%
rename from speechx/examples/ds2_ol/nnet/README.md
rename to speechx/examples/codelab/nnet/README.md
diff --git a/speechx/examples/ds2_ol/feat/path.sh b/speechx/examples/codelab/nnet/path.sh
similarity index 81%
rename from speechx/examples/ds2_ol/feat/path.sh
rename to speechx/examples/codelab/nnet/path.sh
index ad2b6a4e9..7d395d648 100644
--- a/speechx/examples/ds2_ol/feat/path.sh
+++ b/speechx/examples/codelab/nnet/path.sh
@@ -1,7 +1,7 @@
# This contains the locations of binarys build required for running the examples.
SPEECHX_ROOT=$PWD/../../../
-SPEECHX_EXAMPLES=$SPEECHX_ROOT/build/examples
+SPEECHX_BUILD=$SPEECHX_ROOT/build/speechx
SPEECHX_TOOLS=$SPEECHX_ROOT/tools
TOOLS_BIN=$SPEECHX_TOOLS/valgrind/install/bin
@@ -10,5 +10,5 @@ TOOLS_BIN=$SPEECHX_TOOLS/valgrind/install/bin
export LC_AL=C
-SPEECHX_BIN=$SPEECHX_EXAMPLES/ds2_ol/feat
+SPEECHX_BIN=$SPEECHX_BUILD/codelab/nnet
export PATH=$PATH:$SPEECHX_BIN:$TOOLS_BIN
diff --git a/speechx/examples/ds2_ol/nnet/run.sh b/speechx/examples/codelab/nnet/run.sh
similarity index 75%
rename from speechx/examples/ds2_ol/nnet/run.sh
rename to speechx/examples/codelab/nnet/run.sh
index 10029f7e8..842499ba2 100755
--- a/speechx/examples/ds2_ol/nnet/run.sh
+++ b/speechx/examples/codelab/nnet/run.sh
@@ -20,19 +20,10 @@ if [ ! -f data/model/asr0_deepspeech2_online_aishell_ckpt_0.2.0.model.tar.gz ];
popd
fi
-# produce wav scp
-if [ ! -f data/wav.scp ]; then
- mkdir -p data
- pushd data
- wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
- echo "utt1 " $PWD/zh.wav > wav.scp
- popd
-fi
-
ckpt_dir=./data/model
model_dir=$ckpt_dir/exp/deepspeech2_online/checkpoints/
-ds2-model-ol-test \
+ds2_model_test_main \
--model_path=$model_dir/avg_1.jit.pdmodel \
--param_path=$model_dir/avg_1.jit.pdiparams
diff --git a/speechx/examples/ds2_ol/nnet/valgrind.sh b/speechx/examples/codelab/nnet/valgrind.sh
similarity index 71%
rename from speechx/examples/ds2_ol/nnet/valgrind.sh
rename to speechx/examples/codelab/nnet/valgrind.sh
index 2a08c6082..a5aab6637 100755
--- a/speechx/examples/ds2_ol/nnet/valgrind.sh
+++ b/speechx/examples/codelab/nnet/valgrind.sh
@@ -12,9 +12,10 @@ if [ ! -d ${SPEECHX_TOOLS}/valgrind/install ]; then
exit 1
fi
-model_dir=../paddle_asr_model
+ckpt_dir=./data/model
+model_dir=$ckpt_dir/exp/deepspeech2_online/checkpoints/
valgrind --tool=memcheck --track-origins=yes --leak-check=full --show-leak-kinds=all \
- pp-model-test \
+ ds2_model_test_main \
--model_path=$model_dir/avg_1.jit.pdmodel \
- --param_path=$model_dir/avg_1.jit.pdparams
\ No newline at end of file
+ --param_path=$model_dir/avg_1.jit.pdparams
diff --git a/speechx/examples/custom_asr/README.md b/speechx/examples/custom_asr/README.md
new file mode 100644
index 000000000..5ffa21b50
--- /dev/null
+++ b/speechx/examples/custom_asr/README.md
@@ -0,0 +1,32 @@
+# customized Auto Speech Recognition
+
+## introduction
+These scripts are tutorials to show you how build your own decoding graph.
+
+eg:
+* G with slot: 打车到 "address_slot"。
+
+
+* this is address slot wfst, you can add the address which want to recognize.
+
+
+* after replace operation, G = fstreplace(G_with_slot, address_slot), we will get the customized graph.
+
+
+These operations are in the scripts, please check out. we will lanuch more detail scripts.
+
+## How to run
+
+```
+bash run.sh
+```
+
+## Results
+
+### CTC WFST
+
+```
+Overall -> 1.23 % N=1134 C=1126 S=6 D=2 I=6
+Mandarin -> 1.24 % N=1132 C=1124 S=6 D=2 I=6
+English -> 0.00 % N=2 C=2 S=0 D=0 I=0
+```
diff --git a/speechx/examples/custom_asr/local/compile_lexicon_token_fst.sh b/speechx/examples/custom_asr/local/compile_lexicon_token_fst.sh
new file mode 100755
index 000000000..8411f7ed6
--- /dev/null
+++ b/speechx/examples/custom_asr/local/compile_lexicon_token_fst.sh
@@ -0,0 +1,89 @@
+#!/bin/bash
+# Copyright 2015 Yajie Miao (Carnegie Mellon University)
+
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# THIS CODE IS PROVIDED *AS IS* BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, EITHER EXPRESS OR IMPLIED, INCLUDING WITHOUT LIMITATION ANY IMPLIED
+# WARRANTIES OR CONDITIONS OF TITLE, FITNESS FOR A PARTICULAR PURPOSE,
+# MERCHANTABLITY OR NON-INFRINGEMENT.
+# See the Apache 2 License for the specific language governing permissions and
+# limitations under the License.
+
+# This script compiles the lexicon and CTC tokens into FSTs. FST compiling slightly differs between the
+# phoneme and character-based lexicons.
+set -eo pipefail
+. utils/parse_options.sh
+
+if [ $# -ne 3 ]; then
+ echo "usage: utils/fst/compile_lexicon_token_fst.sh "
+ echo "e.g.: utils/fst/compile_lexicon_token_fst.sh data/local/dict data/local/lang_tmp data/lang"
+ echo " should contain the following files:"
+ echo "lexicon.txt lexicon_numbers.txt units.txt"
+ echo "options: "
+ exit 1;
+fi
+
+srcdir=$1
+tmpdir=$2
+dir=$3
+mkdir -p $dir $tmpdir
+
+[ -f path.sh ] && . ./path.sh
+
+cp $srcdir/units.txt $dir
+
+# Add probabilities to lexicon entries. There is in fact no point of doing this here since all the entries have 1.0.
+# But utils/make_lexicon_fst.pl requires a probabilistic version, so we just leave it as it is.
+perl -ape 's/(\S+\s+)(.+)/${1}1.0\t$2/;' < $srcdir/lexicon.txt > $tmpdir/lexiconp.txt || exit 1;
+
+# Add disambiguation symbols to the lexicon. This is necessary for determinizing the composition of L.fst and G.fst.
+# Without these symbols, determinization will fail.
+# default first disambiguation is #1
+ndisambig=`utils/fst/add_lex_disambig.pl $tmpdir/lexiconp.txt $tmpdir/lexiconp_disambig.txt`
+# add #0 (#0 reserved for symbol in grammar).
+ndisambig=$[$ndisambig+1];
+
+( for n in `seq 0 $ndisambig`; do echo '#'$n; done ) > $tmpdir/disambig.list
+
+# Get the full list of CTC tokens used in FST. These tokens include , the blank ,
+# the actual model unit, and the disambiguation symbols.
+cat $srcdir/units.txt | awk '{print $1}' > $tmpdir/units.list
+(echo '';) | cat - $tmpdir/units.list $tmpdir/disambig.list | awk '{print $1 " " (NR-1)}' > $dir/tokens.txt
+
+# ctc_token_fst_corrected is too big and too slow for character based chinese modeling,
+# so here just use simple ctc_token_fst
+utils/fst/ctc_token_fst.py --token_file $dir/tokens.txt | \
+ fstcompile --isymbols=$dir/tokens.txt --osymbols=$dir/tokens.txt --keep_isymbols=false --keep_osymbols=false | \
+ fstarcsort --sort_type=olabel > $dir/T.fst || exit 1;
+
+# Encode the words with indices. Will be used in lexicon and language model FST compiling.
+cat $tmpdir/lexiconp.txt | awk '{print $1}' | sort | awk '
+ BEGIN {
+ print " 0";
+ }
+ {
+ printf("%s %d\n", $1, NR);
+ }
+ END {
+ printf("#0 %d\n", NR+1);
+ printf(" %d\n", NR+2);
+ printf(" %d\n", NR+3);
+ printf("ROOT %d\n", NR+4);
+ }' > $dir/words.txt || exit 1;
+
+# Now compile the lexicon FST. Depending on the size of your lexicon, it may take some time.
+token_disambig_symbol=`grep \#0 $dir/tokens.txt | awk '{print $2}'`
+word_disambig_symbol=`grep \#0 $dir/words.txt | awk '{print $2}'`
+
+utils/fst/make_lexicon_fst.pl --pron-probs $tmpdir/lexiconp_disambig.txt 0 "sil" '#'$ndisambig | \
+ fstcompile --isymbols=$dir/tokens.txt --osymbols=$dir/words.txt \
+ --keep_isymbols=false --keep_osymbols=false | \
+ fstaddselfloops "echo $token_disambig_symbol |" "echo $word_disambig_symbol |" | \
+ fstarcsort --sort_type=olabel > $dir/L.fst || exit 1;
+
+echo "Lexicon and Token FSTs compiling succeeded"
diff --git a/speechx/examples/custom_asr/local/mk_slot_graph.sh b/speechx/examples/custom_asr/local/mk_slot_graph.sh
new file mode 100755
index 000000000..8298a5d09
--- /dev/null
+++ b/speechx/examples/custom_asr/local/mk_slot_graph.sh
@@ -0,0 +1,74 @@
+#!/bin/bash
+
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License
+
+graph_slot=$1
+dir=$2
+
+[ -f path.sh ] && . ./path.sh
+
+sym=$dir/../lang/words.txt
+cat > $dir/address_slot.txt <
+0 5 上海 上海
+0 5 北京 北京
+0 5 合肥 合肥
+5 1 南站 南站
+0 6 立水 立水
+6 1 桥 桥
+0 7 青岛 青岛
+7 1 站 站
+1
+EOF
+
+fstcompile --isymbols=$sym --osymbols=$sym $dir/address_slot.txt $dir/address_slot.fst
+fstcompile --isymbols=$sym --osymbols=$sym $graph_slot/time_slot.txt $dir/time_slot.fst
+fstcompile --isymbols=$sym --osymbols=$sym $graph_slot/date_slot.txt $dir/date_slot.fst
+fstcompile --isymbols=$sym --osymbols=$sym $graph_slot/money_slot.txt $dir/money_slot.fst
+fstcompile --isymbols=$sym --osymbols=$sym $graph_slot/year_slot.txt $dir/year_slot.fst
diff --git a/speechx/examples/custom_asr/local/mk_tlg_with_slot.sh b/speechx/examples/custom_asr/local/mk_tlg_with_slot.sh
new file mode 100755
index 000000000..a5569f400
--- /dev/null
+++ b/speechx/examples/custom_asr/local/mk_tlg_with_slot.sh
@@ -0,0 +1,61 @@
+#!/bin/bash
+
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License
+
+lm=$1
+lang=$2
+tgt_lang=$3
+
+unset GREP_OPTIONS
+
+sym=$lang/words.txt
+arpa_lm=$lm/lm.arpa
+# Compose the language model to FST
+cat $arpa_lm | \
+ grep -v '' | \
+ grep -v '' | \
+ grep -v '' | \
+ grep -v -i '' | \
+ grep -v -i '' | \
+ arpa2fst --read-symbol-table=$sym --keep-symbols=true - | fstprint | \
+ utils/fst/eps2disambig.pl | utils/fst/s2eps.pl | fstcompile --isymbols=$sym \
+ --osymbols=$sym --keep_isymbols=false --keep_osymbols=false | \
+ fstrmepsilon | fstarcsort --sort_type=ilabel > $tgt_lang/G_with_slot.fst
+
+root_label=`grep ROOT $sym | awk '{print $2}'`
+address_slot_label=`grep \ $sym | awk '{print $2}'`
+time_slot_label=`grep \ $sym | awk '{print $2}'`
+date_slot_label=`grep \ $sym | awk '{print $2}'`
+money_slot_label=`grep \ $sym | awk '{print $2}'`
+year_slot_label=`grep \ $sym | awk '{print $2}'`
+
+fstisstochastic $tgt_lang/G_with_slot.fst
+
+fstreplace --epsilon_on_replace $tgt_lang/G_with_slot.fst \
+ $root_label $tgt_lang/address_slot.fst $address_slot_label \
+ $tgt_lang/date_slot.fst $date_slot_label \
+ $tgt_lang/money_slot.fst $money_slot_label \
+ $tgt_lang/time_slot.fst $time_slot_label \
+ $tgt_lang/year_slot.fst $year_slot_label $tgt_lang/G.fst
+
+fstisstochastic $tgt_lang/G.fst
+
+# Compose the token, lexicon and language-model FST into the final decoding graph
+fsttablecompose $lang/L.fst $tgt_lang/G.fst | fstdeterminizestar --use-log=true | \
+ fstminimizeencoded | fstarcsort --sort_type=ilabel > $tgt_lang/LG.fst || exit 1;
+fsttablecompose $lang/T.fst $tgt_lang/LG.fst > $tgt_lang/TLG.fst || exit 1;
+rm $tgt_lang/LG.fst
+
+echo "Composing decoding graph TLG.fst succeeded"
\ No newline at end of file
diff --git a/speechx/examples/custom_asr/local/train_lm_with_slot.sh b/speechx/examples/custom_asr/local/train_lm_with_slot.sh
new file mode 100755
index 000000000..3f557ec39
--- /dev/null
+++ b/speechx/examples/custom_asr/local/train_lm_with_slot.sh
@@ -0,0 +1,55 @@
+#!/bin/bash
+
+# To be run from one directory above this script.
+. ./path.sh
+src=ds2_graph_with_slot
+text=$src/train_text
+lexicon=$src/local/dict/lexicon.txt
+
+dir=$src/local/lm
+mkdir -p $dir
+
+for f in "$text" "$lexicon"; do
+ [ ! -f $x ] && echo "$0: No such file $f" && exit 1;
+done
+
+# Check SRILM tools
+if ! which ngram-count > /dev/null; then
+ pushd $MAIN_ROOT/tools
+ make srilm.done
+ popd
+fi
+
+# This script takes no arguments. It assumes you have already run
+# It takes as input the files
+# data/local/lm/text
+# data/local/dict/lexicon.txt
+
+
+cleantext=$dir/text.no_oov
+
+cat $text | awk -v lex=$lexicon 'BEGIN{while((getline0){ seen[$1]=1; } }
+ {for(n=1; n<=NF;n++) { if (seen[$n]) { printf("%s ", $n); } else {printf(" ");} } printf("\n");}' \
+ > $cleantext || exit 1;
+
+cat $cleantext | awk '{for(n=2;n<=NF;n++) print $n; }' | sort | uniq -c | \
+ sort -nr > $dir/word.counts || exit 1;
+# Get counts from acoustic training transcripts, and add one-count
+# for each word in the lexicon (but not silence, we don't want it
+# in the LM-- we'll add it optionally later).
+cat $cleantext | awk '{for(n=2;n<=NF;n++) print $n; }' | \
+ cat - <(grep -w -v '!SIL' $lexicon | awk '{print $1}') | \
+ sort | uniq -c | sort -nr > $dir/unigram.counts || exit 1;
+
+# filter the words which are not in the text
+cat $dir/unigram.counts | awk '$1>1{print $0}' | awk '{print $2}' | cat - <(echo ""; echo "" ) > $dir/wordlist
+
+# kaldi_lm results
+mkdir -p $dir
+cat $cleantext | awk '{for(n=2;n<=NF;n++){ printf $n; if(n $dir/train
+
+ngram-count -text $dir/train -order 3 -limit-vocab -vocab $dir/wordlist -unk \
+ -map-unk "" -gt3max 0 -gt2max 0 -gt1max 0 -lm $dir/lm.arpa
+
+#ngram-count -text $dir/train -order 3 -limit-vocab -vocab $dir/wordlist -unk \
+# -map-unk "" -lm $dir/lm2.arpa
\ No newline at end of file
diff --git a/speechx/examples/custom_asr/path.sh b/speechx/examples/custom_asr/path.sh
new file mode 100644
index 000000000..1907c79f9
--- /dev/null
+++ b/speechx/examples/custom_asr/path.sh
@@ -0,0 +1,17 @@
+# This contains the locations of binarys build required for running the examples.
+
+MAIN_ROOT=`realpath $PWD/../../../`
+SPEECHX_ROOT=`realpath $MAIN_ROOT/speechx`
+SPEECHX_EXAMPLES=$SPEECHX_ROOT/build/examples
+
+export LC_AL=C
+
+# srilm
+export LIBLBFGS=${MAIN_ROOT}/tools/liblbfgs-1.10
+export LD_LIBRARY_PATH=${LD_LIBRARY_PATH:-}:${LIBLBFGS}/lib/.libs
+export SRILM=${MAIN_ROOT}/tools/srilm
+
+# kaldi lm
+KALDI_DIR=$SPEECHX_ROOT/build/speechx/kaldi/
+OPENFST_DIR=$SPEECHX_ROOT/fc_patch/openfst-build/src
+export PATH=${PATH}:${SRILM}/bin:${SRILM}/bin/i686-m64:$KALDI_DIR/lmbin:$KALDI_DIR/fstbin:$OPENFST_DIR/bin:$SPEECHX_EXAMPLES/ds2_ol/decoder
diff --git a/speechx/examples/custom_asr/run.sh b/speechx/examples/custom_asr/run.sh
new file mode 100644
index 000000000..ed67a52be
--- /dev/null
+++ b/speechx/examples/custom_asr/run.sh
@@ -0,0 +1,87 @@
+#!/bin/bash
+set +x
+set -e
+
+export GLOG_logtostderr=1
+
+. ./path.sh || exit 1;
+
+# ds2 means deepspeech2 (acoutic model type)
+dir=$PWD/exp/ds2_graph_with_slot
+data=$PWD/data
+stage=0
+stop_stage=10
+
+mkdir -p $dir
+
+model_dir=$PWD/resource/model
+vocab=$model_dir/vocab.txt
+cmvn=$data/cmvn.ark
+text_with_slot=$data/text_with_slot
+resource=$PWD/resource
+# download resource
+if [ ! -f $cmvn ]; then
+ wget -c https://paddlespeech.bj.bcebos.com/s2t/paddle_asr_online/resource.tar.gz
+ tar xzfv resource.tar.gz
+ ln -s ./resource/data .
+fi
+
+if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
+ # make dict
+ unit_file=$vocab
+ mkdir -p $dir/local/dict
+ cp $unit_file $dir/local/dict/units.txt
+ cp $text_with_slot $dir/train_text
+ utils/fst/prepare_dict.py --unit_file $unit_file --in_lexicon $data/lexicon.txt \
+ --out_lexicon $dir/local/dict/lexicon.txt
+ # add slot to lexicon, just in case the lm training script filter the slot.
+ echo " 一" >> $dir/local/dict/lexicon.txt
+ echo " 一" >> $dir/local/dict/lexicon.txt
+ echo " 一" >> $dir/local/dict/lexicon.txt
+ echo " 一" >> $dir/local/dict/lexicon.txt
+ echo " 一" >> $dir/local/dict/lexicon.txt
+fi
+
+if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
+ # train lm
+ lm=$dir/local/lm
+ mkdir -p $lm
+ # this script is different with the common lm training script
+ local/train_lm_with_slot.sh
+fi
+
+if [ ${stage} -le 3 ] && [ ${stop_stage} -ge 3 ]; then
+ # make T & L
+ local/compile_lexicon_token_fst.sh $dir/local/dict $dir/local/tmp $dir/local/lang
+ mkdir -p $dir/local/lang_test
+ # make slot graph
+ local/mk_slot_graph.sh $resource/graph $dir/local/lang_test
+ # make TLG
+ local/mk_tlg_with_slot.sh $dir/local/lm $dir/local/lang $dir/local/lang_test || exit 1;
+ mv $dir/local/lang_test/TLG.fst $dir/local/lang/
+fi
+
+if [ ${stage} -le 4 ] && [ ${stop_stage} -ge 4 ]; then
+ # test TLG
+ model_dir=$PWD/resource/model
+ cmvn=$data/cmvn.ark
+ wav_scp=$data/wav.scp
+ graph=$dir/local/lang
+
+ recognizer_test_main \
+ --wav_rspecifier=scp:$wav_scp \
+ --cmvn_file=$cmvn \
+ --use_fbank=true \
+ --model_path=$model_dir/avg_10.jit.pdmodel \
+ --param_path=$model_dir/avg_10.jit.pdiparams \
+ --model_cache_shapes="5-1-2048,5-1-2048" \
+ --model_output_names=softmax_0.tmp_0,tmp_5,concat_0.tmp_0,concat_1.tmp_0 \
+ --word_symbol_table=$graph/words.txt \
+ --graph_path=$graph/TLG.fst --max_active=7500 \
+ --acoustic_scale=12 \
+ --result_wspecifier=ark,t:./exp/result_run.txt
+
+ # the data/wav.trans is the label.
+ utils/compute-wer.py --char=1 --v=1 data/wav.trans exp/result_run.txt > exp/wer_run
+ tail -n 7 exp/wer_run
+fi
diff --git a/speechx/examples/custom_asr/utils b/speechx/examples/custom_asr/utils
new file mode 120000
index 000000000..973afe674
--- /dev/null
+++ b/speechx/examples/custom_asr/utils
@@ -0,0 +1 @@
+../../../utils
\ No newline at end of file
diff --git a/speechx/examples/dev/glog/CMakeLists.txt b/speechx/examples/dev/glog/CMakeLists.txt
deleted file mode 100644
index b4b0e6358..000000000
--- a/speechx/examples/dev/glog/CMakeLists.txt
+++ /dev/null
@@ -1,8 +0,0 @@
-cmake_minimum_required(VERSION 3.14 FATAL_ERROR)
-
-add_executable(glog_test ${CMAKE_CURRENT_SOURCE_DIR}/glog_test.cc)
-target_link_libraries(glog_test glog)
-
-
-add_executable(glog_logtostderr_test ${CMAKE_CURRENT_SOURCE_DIR}/glog_logtostderr_test.cc)
-target_link_libraries(glog_logtostderr_test glog)
\ No newline at end of file
diff --git a/speechx/examples/dev/glog/run.sh b/speechx/examples/dev/glog/run.sh
deleted file mode 100755
index d3fcdb643..000000000
--- a/speechx/examples/dev/glog/run.sh
+++ /dev/null
@@ -1,22 +0,0 @@
-#!/bin/bash
-set +x
-set -e
-
-. ./path.sh
-
-# 1. compile
-if [ ! -d ${SPEECHX_EXAMPLES} ]; then
- pushd ${SPEECHX_ROOT}
- bash build.sh
- popd
-fi
-
-# 2. run
-glog_test
-
-echo "------"
-export FLAGS_logtostderr=1
-glog_test
-
-echo "------"
-glog_logtostderr_test
diff --git a/speechx/examples/ds2_ol/CMakeLists.txt b/speechx/examples/ds2_ol/CMakeLists.txt
deleted file mode 100644
index 08c194846..000000000
--- a/speechx/examples/ds2_ol/CMakeLists.txt
+++ /dev/null
@@ -1,6 +0,0 @@
-cmake_minimum_required(VERSION 3.14 FATAL_ERROR)
-
-add_subdirectory(feat)
-add_subdirectory(nnet)
-add_subdirectory(decoder)
-add_subdirectory(websocket)
diff --git a/speechx/examples/ds2_ol/README.md b/speechx/examples/ds2_ol/README.md
index ed88ef6b2..492d0e1ac 100644
--- a/speechx/examples/ds2_ol/README.md
+++ b/speechx/examples/ds2_ol/README.md
@@ -1,13 +1,6 @@
# Deepspeech2 Streaming ASR
-* websocket
-Streaming ASR with websocket.
+## Examples
-* aishell
-Streaming Decoding under aishell dataset, for local WER test and so on.
-
-## More
-The below is for developing and offline testing:
-* nnet
-* feat
-* decoder
+* `websocket` - Streaming ASR with websocket for deepspeech2_aishell.
+* `aishell` - Streaming Decoding under aishell dataset, for local WER test.
diff --git a/speechx/examples/ds2_ol/aishell/README.md b/speechx/examples/ds2_ol/aishell/README.md
index 01c899799..3e7af9244 100644
--- a/speechx/examples/ds2_ol/aishell/README.md
+++ b/speechx/examples/ds2_ol/aishell/README.md
@@ -1,6 +1,14 @@
# Aishell - Deepspeech2 Streaming
-## CTC Prefix Beam Search w/o LM
+## How to run
+
+```
+bash run.sh
+```
+
+## Results
+
+### CTC Prefix Beam Search w/o LM
```
Overall -> 16.14 % N=104612 C=88190 S=16110 D=312 I=465
@@ -8,7 +16,7 @@ Mandarin -> 16.14 % N=104612 C=88190 S=16110 D=312 I=465
Other -> 0.00 % N=0 C=0 S=0 D=0 I=0
```
-## CTC Prefix Beam Search w/ LM
+### CTC Prefix Beam Search w/ LM
LM: zh_giga.no_cna_cmn.prune01244.klm
```
@@ -17,7 +25,7 @@ Mandarin -> 7.86 % N=104768 C=96865 S=7573 D=330 I=327
Other -> 0.00 % N=0 C=0 S=0 D=0 I=0
```
-## CTC WFST
+### CTC WFST
LM: [aishell train](http://paddlespeech.bj.bcebos.com/speechx/examples/ds2_ol/aishell/aishell_graph.zip)
--acoustic_scale=1.2
@@ -34,3 +42,40 @@ Overall -> 10.93 % N=104765 C=93410 S=9780 D=1575 I=95
Mandarin -> 10.93 % N=104762 C=93410 S=9779 D=1573 I=95
Other -> 100.00 % N=3 C=0 S=1 D=2 I=0
```
+
+## fbank
+```
+bash run_fbank.sh
+```
+
+### CTC Prefix Beam Search w/o LM
+
+```
+Overall -> 10.44 % N=104765 C=94194 S=10174 D=397 I=369
+Mandarin -> 10.44 % N=104762 C=94194 S=10171 D=397 I=369
+Other -> 100.00 % N=3 C=0 S=3 D=0 I=0
+```
+
+### CTC Prefix Beam Search w/ LM
+
+LM: zh_giga.no_cna_cmn.prune01244.klm
+
+```
+Overall -> 5.82 % N=104765 C=99386 S=4944 D=435 I=720
+Mandarin -> 5.82 % N=104762 C=99386 S=4941 D=435 I=720
+English -> 0.00 % N=0 C=0 S=0 D=0 I=0
+```
+
+### CTC WFST
+
+LM: [aishell train](https://paddlespeech.bj.bcebos.com/s2t/paddle_asr_online/aishell_graph2.zip)
+```
+Overall -> 9.58 % N=104765 C=94817 S=4326 D=5622 I=84
+Mandarin -> 9.57 % N=104762 C=94817 S=4325 D=5620 I=84
+Other -> 100.00 % N=3 C=0 S=1 D=2 I=0
+```
+
+## build TLG graph
+```
+ bash run_build_tlg.sh
+```
diff --git a/speechx/examples/ngram/zh/local/aishell_train_lms.sh b/speechx/examples/ds2_ol/aishell/local/aishell_train_lms.sh
similarity index 100%
rename from speechx/examples/ngram/zh/local/aishell_train_lms.sh
rename to speechx/examples/ds2_ol/aishell/local/aishell_train_lms.sh
diff --git a/speechx/examples/ds2_ol/aishell/path.sh b/speechx/examples/ds2_ol/aishell/path.sh
index 520129eaf..6e8039350 100755
--- a/speechx/examples/ds2_ol/aishell/path.sh
+++ b/speechx/examples/ds2_ol/aishell/path.sh
@@ -1,14 +1,24 @@
# This contains the locations of binarys build required for running the examples.
-SPEECHX_ROOT=$PWD/../../..
-SPEECHX_EXAMPLES=$SPEECHX_ROOT/build/examples
+MAIN_ROOT=`realpath $PWD/../../../../`
+SPEECHX_ROOT=$PWD/../../../
+SPEECHX_BUILD=$SPEECHX_ROOT/build/speechx
SPEECHX_TOOLS=$SPEECHX_ROOT/tools
TOOLS_BIN=$SPEECHX_TOOLS/valgrind/install/bin
-[ -d $SPEECHX_EXAMPLES ] || { echo "Error: 'build/examples' directory not found. please ensure that the project build successfully"; }
+[ -d $SPEECHX_BUILD ] || { echo "Error: 'build/speechx' directory not found. please ensure that the project build successfully"; }
export LC_AL=C
-SPEECHX_BIN=$SPEECHX_EXAMPLES/ds2_ol/decoder:$SPEECHX_EXAMPLES/ds2_ol/feat:$SPEECHX_EXAMPLES/ds2_ol/websocket
-export PATH=$PATH:$SPEECHX_BIN:$TOOLS_BIN
+# openfst bin & kaldi bin
+KALDI_DIR=$SPEECHX_ROOT/build/speechx/kaldi/
+OPENFST_DIR=$SPEECHX_ROOT/fc_patch/openfst-build/src
+
+# srilm
+export LIBLBFGS=${MAIN_ROOT}/tools/liblbfgs-1.10
+export LD_LIBRARY_PATH=${LD_LIBRARY_PATH:-}:${LIBLBFGS}/lib/.libs
+export SRILM=${MAIN_ROOT}/tools/srilm
+
+SPEECHX_BIN=$SPEECHX_BUILD/decoder:$SPEECHX_BUILD/frontend/audio
+export PATH=$PATH:$SPEECHX_BIN:$TOOLS_BIN:${SRILM}/bin:${SRILM}/bin/i686-m64:$KALDI_DIR/lmbin:$KALDI_DIR/fstbin:$OPENFST_DIR/bin
diff --git a/speechx/examples/ds2_ol/aishell/run.sh b/speechx/examples/ds2_ol/aishell/run.sh
index b44200b0b..82e889ce5 100755
--- a/speechx/examples/ds2_ol/aishell/run.sh
+++ b/speechx/examples/ds2_ol/aishell/run.sh
@@ -69,27 +69,27 @@ export GLOG_logtostderr=1
cmvn=$data/cmvn.ark
if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
# 3. gen linear feat
- cmvn-json2kaldi --json_file=$ckpt_dir/data/mean_std.json --cmvn_write_path=$cmvn
+ cmvn_json2kaldi_main --json_file=$ckpt_dir/data/mean_std.json --cmvn_write_path=$cmvn
./local/split_data.sh $data $data/$aishell_wav_scp $aishell_wav_scp $nj
utils/run.pl JOB=1:$nj $data/split${nj}/JOB/feat.log \
- linear-spectrogram-wo-db-norm-ol \
+ compute_linear_spectrogram_main \
--wav_rspecifier=scp:$data/split${nj}/JOB/${aishell_wav_scp} \
--feature_wspecifier=ark,scp:$data/split${nj}/JOB/feat.ark,$data/split${nj}/JOB/feat.scp \
--cmvn_file=$cmvn \
- --streaming_chunk=0.36
echo "feature make have finished!!!"
fi
if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
# recognizer
utils/run.pl JOB=1:$nj $data/split${nj}/JOB/recog.wolm.log \
- ctc-prefix-beam-search-decoder-ol \
+ ctc_prefix_beam_search_decoder_main \
--feature_rspecifier=scp:$data/split${nj}/JOB/feat.scp \
--model_path=$model_dir/avg_1.jit.pdmodel \
--param_path=$model_dir/avg_1.jit.pdiparams \
--model_output_names=softmax_0.tmp_0,tmp_5,concat_0.tmp_0,concat_1.tmp_0 \
+ --nnet_decoder_chunk=8 \
--dict_file=$vocb_dir/vocab.txt \
--result_wspecifier=ark,t:$data/split${nj}/JOB/result
@@ -97,16 +97,18 @@ if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
utils/compute-wer.py --char=1 --v=1 $text $exp/${label_file} > $exp/${wer}
echo "ctc-prefix-beam-search-decoder-ol without lm has finished!!!"
echo "please checkout in ${exp}/${wer}"
+ tail -n 7 $exp/${wer}
fi
if [ ${stage} -le 3 ] && [ ${stop_stage} -ge 3 ]; then
# decode with lm
utils/run.pl JOB=1:$nj $data/split${nj}/JOB/recog.lm.log \
- ctc-prefix-beam-search-decoder-ol \
+ ctc_prefix_beam_search_decoder_main \
--feature_rspecifier=scp:$data/split${nj}/JOB/feat.scp \
--model_path=$model_dir/avg_1.jit.pdmodel \
--param_path=$model_dir/avg_1.jit.pdiparams \
--model_output_names=softmax_0.tmp_0,tmp_5,concat_0.tmp_0,concat_1.tmp_0 \
+ --nnet_decoder_chunk=8 \
--dict_file=$vocb_dir/vocab.txt \
--lm_path=$lm \
--result_wspecifier=ark,t:$data/split${nj}/JOB/result_lm
@@ -115,6 +117,7 @@ if [ ${stage} -le 3 ] && [ ${stop_stage} -ge 3 ]; then
utils/compute-wer.py --char=1 --v=1 $text $exp/${label_file}_lm > $exp/${wer}.lm
echo "ctc-prefix-beam-search-decoder-ol with lm test has finished!!!"
echo "please checkout in ${exp}/${wer}.lm"
+ tail -n 7 $exp/${wer}.lm
fi
wfst=$data/wfst/
@@ -132,13 +135,14 @@ fi
if [ ${stage} -le 4 ] && [ ${stop_stage} -ge 4 ]; then
# TLG decoder
utils/run.pl JOB=1:$nj $data/split${nj}/JOB/recog.wfst.log \
- wfst-decoder-ol \
+ tlg_decoder_main \
--feature_rspecifier=scp:$data/split${nj}/JOB/feat.scp \
--model_path=$model_dir/avg_1.jit.pdmodel \
--param_path=$model_dir/avg_1.jit.pdiparams \
--word_symbol_table=$wfst/words.txt \
--model_output_names=softmax_0.tmp_0,tmp_5,concat_0.tmp_0,concat_1.tmp_0 \
--graph_path=$wfst/TLG.fst --max_active=7500 \
+ --nnet_decoder_chunk=8 \
--acoustic_scale=1.2 \
--result_wspecifier=ark,t:$data/split${nj}/JOB/result_tlg
@@ -146,19 +150,19 @@ if [ ${stage} -le 4 ] && [ ${stop_stage} -ge 4 ]; then
utils/compute-wer.py --char=1 --v=1 $text $exp/${label_file}_tlg > $exp/${wer}.tlg
echo "wfst-decoder-ol have finished!!!"
echo "please checkout in ${exp}/${wer}.tlg"
+ tail -n 7 $exp/${wer}.tlg
fi
if [ ${stage} -le 5 ] && [ ${stop_stage} -ge 5 ]; then
# TLG decoder
utils/run.pl JOB=1:$nj $data/split${nj}/JOB/recognizer.log \
- recognizer_test_main \
+ recognizer_main \
--wav_rspecifier=scp:$data/split${nj}/JOB/${aishell_wav_scp} \
--cmvn_file=$cmvn \
--model_path=$model_dir/avg_1.jit.pdmodel \
- --to_float32=true \
- --streaming_chunk=30 \
--param_path=$model_dir/avg_1.jit.pdiparams \
--word_symbol_table=$wfst/words.txt \
+ --nnet_decoder_chunk=8 \
--model_output_names=softmax_0.tmp_0,tmp_5,concat_0.tmp_0,concat_1.tmp_0 \
--graph_path=$wfst/TLG.fst --max_active=7500 \
--acoustic_scale=1.2 \
@@ -168,4 +172,5 @@ if [ ${stage} -le 5 ] && [ ${stop_stage} -ge 5 ]; then
utils/compute-wer.py --char=1 --v=1 $text $exp/${label_file}_recognizer > $exp/${wer}.recognizer
echo "recognizer test have finished!!!"
echo "please checkout in ${exp}/${wer}.recognizer"
+ tail -n 7 $exp/${wer}.recognizer
fi
diff --git a/speechx/examples/ds2_ol/aishell/run_build_tlg.sh b/speechx/examples/ds2_ol/aishell/run_build_tlg.sh
new file mode 100755
index 000000000..2e148657b
--- /dev/null
+++ b/speechx/examples/ds2_ol/aishell/run_build_tlg.sh
@@ -0,0 +1,141 @@
+#!/bin/bash
+set -eo pipefail
+
+. path.sh
+
+# attention, please replace the vocab is only for this script.
+# different acustic model has different vocab
+ckpt_dir=data/fbank_model
+unit=$ckpt_dir/data/lang_char/vocab.txt # vocab file, line: char/spm_pice
+model_dir=$ckpt_dir/exp/deepspeech2_online/checkpoints/
+
+stage=-1
+stop_stage=100
+corpus=aishell
+lexicon=data/lexicon.txt # line: word ph0 ... phn, aishell/resource_aishell/lexicon.txt
+text=data/text # line: utt text, aishell/data_aishell/transcript/aishell_transcript_v0.8.txt
+
+. utils/parse_options.sh
+
+data=$PWD/data
+mkdir -p $data
+
+if [ $stage -le -1 ] && [ $stop_stage -ge -1 ]; then
+ if [ ! -f $data/speech.ngram.zh.tar.gz ];then
+ pushd $data
+ wget -c http://paddlespeech.bj.bcebos.com/speechx/examples/ngram/zh/speech.ngram.zh.tar.gz
+ tar xvzf speech.ngram.zh.tar.gz
+ popd
+ fi
+
+ if [ ! -f $ckpt_dir/data/mean_std.json ]; then
+ mkdir -p $ckpt_dir
+ pushd $ckpt_dir
+ wget -c https://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr0/WIP1_asr0_deepspeech2_online_wenetspeech_ckpt_1.0.0a.model.tar.gz
+ tar xzfv WIP1_asr0_deepspeech2_online_wenetspeech_ckpt_1.0.0a.model.tar.gz
+ popd
+ fi
+fi
+
+if [ ! -f $unit ]; then
+ echo "$0: No such file $unit"
+ exit 1;
+fi
+
+if ! which ngram-count; then
+ pushd $MAIN_ROOT/tools
+ make srilm.done
+ popd
+fi
+
+mkdir -p data/local/dict
+if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then
+ # Prepare dict
+ # line: char/spm_pices
+ cp $unit data/local/dict/units.txt
+
+ if [ ! -f $lexicon ];then
+ utils/text_to_lexicon.py --has_key true --text $text --lexicon $lexicon
+ echo "Generate $lexicon from $text"
+ fi
+
+ # filter by vocab
+ # line: word ph0 ... phn -> line: word char0 ... charn
+ utils/fst/prepare_dict.py \
+ --unit_file $unit \
+ --in_lexicon ${lexicon} \
+ --out_lexicon data/local/dict/lexicon.txt
+fi
+
+lm=data/local/lm
+mkdir -p $lm
+
+if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
+ # Train lm
+ cp $text $lm/text
+ local/aishell_train_lms.sh
+ echo "build LM done."
+fi
+
+# build TLG
+if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
+ # build T & L
+ utils/fst/compile_lexicon_token_fst.sh \
+ data/local/dict data/local/tmp data/local/lang
+
+ # build G & TLG
+ utils/fst/make_tlg.sh data/local/lm data/local/lang data/lang_test || exit 1;
+
+fi
+
+aishell_wav_scp=aishell_test.scp
+nj=40
+cmvn=$data/cmvn_fbank.ark
+wfst=$data/lang_test
+
+if [ ${stage} -le 3 ] && [ ${stop_stage} -ge 3 ]; then
+
+ if [ ! -d $data/test ]; then
+ pushd $data
+ wget -c https://paddlespeech.bj.bcebos.com/s2t/paddle_asr_online/aishell_test.zip
+ unzip aishell_test.zip
+ popd
+
+ realpath $data/test/*/*.wav > $data/wavlist
+ awk -F '/' '{ print $(NF) }' $data/wavlist | awk -F '.' '{ print $1 }' > $data/utt_id
+ paste $data/utt_id $data/wavlist > $data/$aishell_wav_scp
+ fi
+
+ ./local/split_data.sh $data $data/$aishell_wav_scp $aishell_wav_scp $nj
+
+ cmvn-json2kaldi --json_file=$ckpt_dir/data/mean_std.json --cmvn_write_path=$cmvn
+fi
+
+wer=aishell_wer
+label_file=aishell_result
+export GLOG_logtostderr=1
+
+if [ ${stage} -le 4 ] && [ ${stop_stage} -ge 4 ]; then
+ # TLG decoder
+ utils/run.pl JOB=1:$nj $data/split${nj}/JOB/check_tlg.log \
+ recognizer_main \
+ --wav_rspecifier=scp:$data/split${nj}/JOB/${aishell_wav_scp} \
+ --cmvn_file=$cmvn \
+ --model_path=$model_dir/avg_5.jit.pdmodel \
+ --streaming_chunk=30 \
+ --use_fbank=true \
+ --param_path=$model_dir/avg_5.jit.pdiparams \
+ --word_symbol_table=$wfst/words.txt \
+ --model_output_names=softmax_0.tmp_0,tmp_5,concat_0.tmp_0,concat_1.tmp_0 \
+ --model_cache_shapes="5-1-2048,5-1-2048" \
+ --graph_path=$wfst/TLG.fst --max_active=7500 \
+ --acoustic_scale=1.2 \
+ --result_wspecifier=ark,t:$data/split${nj}/JOB/result_check_tlg
+
+ cat $data/split${nj}/*/result_check_tlg > $exp/${label_file}_check_tlg
+ utils/compute-wer.py --char=1 --v=1 $text $exp/${label_file}_check_tlg > $exp/${wer}.check_tlg
+ echo "recognizer test have finished!!!"
+ echo "please checkout in ${exp}/${wer}.check_tlg"
+fi
+
+exit 0
diff --git a/speechx/examples/ds2_ol/aishell/run_fbank.sh b/speechx/examples/ds2_ol/aishell/run_fbank.sh
new file mode 100755
index 000000000..720728354
--- /dev/null
+++ b/speechx/examples/ds2_ol/aishell/run_fbank.sh
@@ -0,0 +1,176 @@
+#!/bin/bash
+set +x
+set -e
+
+. path.sh
+
+nj=40
+stage=0
+stop_stage=5
+
+. utils/parse_options.sh
+
+# 1. compile
+if [ ! -d ${SPEECHX_EXAMPLES} ]; then
+ pushd ${SPEECHX_ROOT}
+ bash build.sh
+ popd
+fi
+
+# input
+mkdir -p data
+data=$PWD/data
+
+ckpt_dir=$data/fbank_model
+model_dir=$ckpt_dir/exp/deepspeech2_online/checkpoints/
+vocb_dir=$ckpt_dir/data/lang_char/
+
+# output
+mkdir -p exp
+exp=$PWD/exp
+
+lm=$data/zh_giga.no_cna_cmn.prune01244.klm
+aishell_wav_scp=aishell_test.scp
+if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ];then
+ if [ ! -d $data/test ]; then
+ pushd $data
+ wget -c https://paddlespeech.bj.bcebos.com/s2t/paddle_asr_online/aishell_test.zip
+ unzip aishell_test.zip
+ popd
+
+ realpath $data/test/*/*.wav > $data/wavlist
+ awk -F '/' '{ print $(NF) }' $data/wavlist | awk -F '.' '{ print $1 }' > $data/utt_id
+ paste $data/utt_id $data/wavlist > $data/$aishell_wav_scp
+ fi
+
+ if [ ! -f $ckpt_dir/data/mean_std.json ]; then
+ mkdir -p $ckpt_dir
+ pushd $ckpt_dir
+ wget -c https://paddlespeech.bj.bcebos.com/s2t/wenetspeech/asr0/WIP1_asr0_deepspeech2_online_wenetspeech_ckpt_1.0.0a.model.tar.gz
+ tar xzfv WIP1_asr0_deepspeech2_online_wenetspeech_ckpt_1.0.0a.model.tar.gz
+ popd
+ fi
+
+ if [ ! -f $lm ]; then
+ pushd $data
+ wget -c https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm
+ popd
+ fi
+fi
+
+# 3. make feature
+text=$data/test/text
+label_file=./aishell_result_fbank
+wer=./aishell_wer_fbank
+
+export GLOG_logtostderr=1
+
+
+cmvn=$data/cmvn_fbank.ark
+if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
+ # 3. gen linear feat
+ cmvn_json2kaldi_main --json_file=$ckpt_dir/data/mean_std.json --cmvn_write_path=$cmvn --binary=false
+
+ ./local/split_data.sh $data $data/$aishell_wav_scp $aishell_wav_scp $nj
+
+ utils/run.pl JOB=1:$nj $data/split${nj}/JOB/feat.log \
+ compute_fbank_main \
+ --wav_rspecifier=scp:$data/split${nj}/JOB/${aishell_wav_scp} \
+ --feature_wspecifier=ark,scp:$data/split${nj}/JOB/fbank_feat.ark,$data/split${nj}/JOB/fbank_feat.scp \
+ --cmvn_file=$cmvn \
+ --streaming_chunk=36
+fi
+
+if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
+ # recognizer
+ utils/run.pl JOB=1:$nj $data/split${nj}/JOB/recog.fbank.wolm.log \
+ ctc_prefix_beam_search_decoder_main \
+ --feature_rspecifier=scp:$data/split${nj}/JOB/fbank_feat.scp \
+ --model_path=$model_dir/avg_5.jit.pdmodel \
+ --param_path=$model_dir/avg_5.jit.pdiparams \
+ --model_output_names=softmax_0.tmp_0,tmp_5,concat_0.tmp_0,concat_1.tmp_0 \
+ --model_cache_shapes="5-1-2048,5-1-2048" \
+ --nnet_decoder_chunk=8 \
+ --dict_file=$vocb_dir/vocab.txt \
+ --result_wspecifier=ark,t:$data/split${nj}/JOB/result_fbank
+
+ cat $data/split${nj}/*/result_fbank > $exp/${label_file}
+ utils/compute-wer.py --char=1 --v=1 $text $exp/${label_file} > $exp/${wer}
+ tail -n 7 $exp/${wer}
+fi
+
+if [ ${stage} -le 3 ] && [ ${stop_stage} -ge 3 ]; then
+ # decode with lm
+ utils/run.pl JOB=1:$nj $data/split${nj}/JOB/recog.fbank.lm.log \
+ ctc_prefix_beam_search_decoder_main \
+ --feature_rspecifier=scp:$data/split${nj}/JOB/fbank_feat.scp \
+ --model_path=$model_dir/avg_5.jit.pdmodel \
+ --param_path=$model_dir/avg_5.jit.pdiparams \
+ --model_output_names=softmax_0.tmp_0,tmp_5,concat_0.tmp_0,concat_1.tmp_0 \
+ --model_cache_shapes="5-1-2048,5-1-2048" \
+ --nnet_decoder_chunk=8 \
+ --dict_file=$vocb_dir/vocab.txt \
+ --lm_path=$lm \
+ --result_wspecifier=ark,t:$data/split${nj}/JOB/fbank_result_lm
+
+ cat $data/split${nj}/*/fbank_result_lm > $exp/${label_file}_lm
+ utils/compute-wer.py --char=1 --v=1 $text $exp/${label_file}_lm > $exp/${wer}.lm
+ tail -n 7 $exp/${wer}.lm
+fi
+
+wfst=$data/wfst_fbank/
+if [ ${stage} -le 4 ] && [ ${stop_stage} -ge 4 ]; then
+ mkdir -p $wfst
+ if [ ! -f $wfst/aishell_graph2.zip ]; then
+ pushd $wfst
+ wget -c https://paddlespeech.bj.bcebos.com/s2t/paddle_asr_online/aishell_graph2.zip
+ unzip aishell_graph2.zip
+ mv aishell_graph2/* $wfst
+ popd
+ fi
+fi
+
+if [ ${stage} -le 4 ] && [ ${stop_stage} -ge 4 ]; then
+ # TLG decoder
+ utils/run.pl JOB=1:$nj $data/split${nj}/JOB/recog.fbank.wfst.log \
+ tlg_decoder_main \
+ --feature_rspecifier=scp:$data/split${nj}/JOB/fbank_feat.scp \
+ --model_path=$model_dir/avg_5.jit.pdmodel \
+ --param_path=$model_dir/avg_5.jit.pdiparams \
+ --word_symbol_table=$wfst/words.txt \
+ --model_output_names=softmax_0.tmp_0,tmp_5,concat_0.tmp_0,concat_1.tmp_0 \
+ --model_cache_shapes="5-1-2048,5-1-2048" \
+ --nnet_decoder_chunk=8 \
+ --graph_path=$wfst/TLG.fst --max_active=7500 \
+ --acoustic_scale=1.2 \
+ --result_wspecifier=ark,t:$data/split${nj}/JOB/result_tlg
+
+ cat $data/split${nj}/*/result_tlg > $exp/${label_file}_tlg
+ utils/compute-wer.py --char=1 --v=1 $text $exp/${label_file}_tlg > $exp/${wer}.tlg
+ echo "wfst-decoder-ol have finished!!!"
+ echo "please checkout in ${exp}/${wer}.tlg"
+ tail -n 7 $exp/${wer}.tlg
+fi
+
+if [ ${stage} -le 5 ] && [ ${stop_stage} -ge 5 ]; then
+ utils/run.pl JOB=1:$nj $data/split${nj}/JOB/fbank_recognizer.log \
+ recognizer_main \
+ --wav_rspecifier=scp:$data/split${nj}/JOB/${aishell_wav_scp} \
+ --cmvn_file=$cmvn \
+ --model_path=$model_dir/avg_5.jit.pdmodel \
+ --use_fbank=true \
+ --param_path=$model_dir/avg_5.jit.pdiparams \
+ --word_symbol_table=$wfst/words.txt \
+ --model_output_names=softmax_0.tmp_0,tmp_5,concat_0.tmp_0,concat_1.tmp_0 \
+ --model_cache_shapes="5-1-2048,5-1-2048" \
+ --nnet_decoder_chunk=8 \
+ --graph_path=$wfst/TLG.fst --max_active=7500 \
+ --acoustic_scale=1.2 \
+ --result_wspecifier=ark,t:$data/split${nj}/JOB/result_fbank_recognizer
+
+ cat $data/split${nj}/*/result_fbank_recognizer > $exp/${label_file}_recognizer
+ utils/compute-wer.py --char=1 --v=1 $text $exp/${label_file}_recognizer > $exp/${wer}.recognizer
+ echo "recognizer test have finished!!!"
+ echo "please checkout in ${exp}/${wer}.recognizer"
+ tail -n 7 $exp/${wer}.recognizer
+fi
diff --git a/speechx/examples/ds2_ol/decoder/CMakeLists.txt b/speechx/examples/ds2_ol/decoder/CMakeLists.txt
deleted file mode 100644
index 62dd6862e..000000000
--- a/speechx/examples/ds2_ol/decoder/CMakeLists.txt
+++ /dev/null
@@ -1,22 +0,0 @@
-cmake_minimum_required(VERSION 3.14 FATAL_ERROR)
-
-set(bin_name ctc-prefix-beam-search-decoder-ol)
-add_executable(${bin_name} ${CMAKE_CURRENT_SOURCE_DIR}/${bin_name}.cc)
-target_include_directories(${bin_name} PRIVATE ${SPEECHX_ROOT} ${SPEECHX_ROOT}/kaldi)
-target_link_libraries(${bin_name} PUBLIC nnet decoder fst utils gflags glog kaldi-base kaldi-matrix kaldi-util ${DEPS})
-
-
-set(bin_name wfst-decoder-ol)
-add_executable(${bin_name} ${CMAKE_CURRENT_SOURCE_DIR}/${bin_name}.cc)
-target_include_directories(${bin_name} PRIVATE ${SPEECHX_ROOT} ${SPEECHX_ROOT}/kaldi)
-target_link_libraries(${bin_name} PUBLIC nnet decoder fst utils gflags glog kaldi-base kaldi-matrix kaldi-util kaldi-decoder ${DEPS})
-
-
-set(bin_name nnet-logprob-decoder-test)
-add_executable(${bin_name} ${CMAKE_CURRENT_SOURCE_DIR}/${bin_name}.cc)
-target_include_directories(${bin_name} PRIVATE ${SPEECHX_ROOT} ${SPEECHX_ROOT}/kaldi)
-target_link_libraries(${bin_name} PUBLIC nnet decoder fst utils gflags glog kaldi-base kaldi-matrix kaldi-util ${DEPS})
-
-add_executable(recognizer_test_main ${CMAKE_CURRENT_SOURCE_DIR}/recognizer_test_main.cc)
-target_include_directories(recognizer_test_main PRIVATE ${SPEECHX_ROOT} ${SPEECHX_ROOT}/kaldi)
-target_link_libraries(recognizer_test_main PUBLIC frontend kaldi-feat-common nnet decoder fst utils gflags glog kaldi-base kaldi-matrix kaldi-util kaldi-decoder ${DEPS})
diff --git a/speechx/examples/ds2_ol/decoder/local/model.sh b/speechx/examples/ds2_ol/decoder/local/model.sh
deleted file mode 100644
index 5c609a6cf..000000000
--- a/speechx/examples/ds2_ol/decoder/local/model.sh
+++ /dev/null
@@ -1,3 +0,0 @@
-#!/bin/bash
-
-
diff --git a/speechx/examples/ds2_ol/decoder/path.sh b/speechx/examples/ds2_ol/decoder/path.sh
deleted file mode 100644
index 8e26e6e7e..000000000
--- a/speechx/examples/ds2_ol/decoder/path.sh
+++ /dev/null
@@ -1,14 +0,0 @@
-# This contains the locations of binarys build required for running the examples.
-
-SPEECHX_ROOT=$PWD/../../../
-SPEECHX_EXAMPLES=$SPEECHX_ROOT/build/examples
-
-SPEECHX_TOOLS=$SPEECHX_ROOT/tools
-TOOLS_BIN=$SPEECHX_TOOLS/valgrind/install/bin
-
-[ -d $SPEECHX_EXAMPLES ] || { echo "Error: 'build/examples' directory not found. please ensure that the project build successfully"; }
-
-export LC_AL=C
-
-SPEECHX_BIN=$SPEECHX_EXAMPLES/ds2_ol/decoder:$SPEECHX_EXAMPLES/ds2_ol/feat
-export PATH=$PATH:$SPEECHX_BIN:$TOOLS_BIN
diff --git a/speechx/examples/ds2_ol/feat/.gitignore b/speechx/examples/ds2_ol/feat/.gitignore
deleted file mode 100644
index 566f2d97b..000000000
--- a/speechx/examples/ds2_ol/feat/.gitignore
+++ /dev/null
@@ -1,2 +0,0 @@
-exp
-data
diff --git a/speechx/examples/ds2_ol/feat/CMakeLists.txt b/speechx/examples/ds2_ol/feat/CMakeLists.txt
deleted file mode 100644
index db59fc8ec..000000000
--- a/speechx/examples/ds2_ol/feat/CMakeLists.txt
+++ /dev/null
@@ -1,12 +0,0 @@
-cmake_minimum_required(VERSION 3.14 FATAL_ERROR)
-
-set(bin_name linear-spectrogram-wo-db-norm-ol)
-add_executable(${bin_name} ${CMAKE_CURRENT_SOURCE_DIR}/${bin_name}.cc)
-target_include_directories(${bin_name} PRIVATE ${SPEECHX_ROOT} ${SPEECHX_ROOT}/kaldi)
-target_link_libraries(${bin_name} frontend kaldi-util kaldi-feat-common gflags glog)
-
-
-set(bin_name cmvn-json2kaldi)
-add_executable(${bin_name} ${CMAKE_CURRENT_SOURCE_DIR}/${bin_name}.cc)
-target_include_directories(${bin_name} PRIVATE ${SPEECHX_ROOT} ${SPEECHX_ROOT}/kaldi)
-target_link_libraries(${bin_name} utils kaldi-util kaldi-matrix gflags glog ${DEPS})
\ No newline at end of file
diff --git a/speechx/examples/ds2_ol/nnet/path.sh b/speechx/examples/ds2_ol/nnet/path.sh
deleted file mode 100644
index 0ee8b4787..000000000
--- a/speechx/examples/ds2_ol/nnet/path.sh
+++ /dev/null
@@ -1,14 +0,0 @@
-# This contains the locations of binarys build required for running the examples.
-
-SPEECHX_ROOT=$PWD/../../../
-SPEECHX_EXAMPLES=$SPEECHX_ROOT/build/examples
-
-SPEECHX_TOOLS=$SPEECHX_ROOT/tools
-TOOLS_BIN=$SPEECHX_TOOLS/valgrind/install/bin
-
-[ -d $SPEECHX_EXAMPLES ] || { echo "Error: 'build/examples' directory not found. please ensure that the project build successfully"; }
-
-export LC_AL=C
-
-SPEECHX_BIN=$SPEECHX_EXAMPLES/ds2_ol/nnet
-export PATH=$PATH:$SPEECHX_BIN:$TOOLS_BIN
diff --git a/speechx/examples/ngram/.gitignore b/speechx/examples/ds2_ol/onnx/.gitignore
similarity index 69%
rename from speechx/examples/ngram/.gitignore
rename to speechx/examples/ds2_ol/onnx/.gitignore
index bbd86a25b..f862f73e2 100644
--- a/speechx/examples/ngram/.gitignore
+++ b/speechx/examples/ds2_ol/onnx/.gitignore
@@ -1,2 +1,3 @@
data
+log
exp
diff --git a/speechx/examples/ds2_ol/onnx/README.md b/speechx/examples/ds2_ol/onnx/README.md
new file mode 100644
index 000000000..eaea8b6e8
--- /dev/null
+++ b/speechx/examples/ds2_ol/onnx/README.md
@@ -0,0 +1,37 @@
+# DeepSpeech2 ONNX model
+
+1. convert deepspeech2 model to ONNX, using Paddle2ONNX.
+2. check paddleinference and onnxruntime output equal.
+3. optimize onnx model
+4. check paddleinference and optimized onnxruntime output equal.
+
+Please make sure [Paddle2ONNX](https://github.com/PaddlePaddle/Paddle2ONNX) and [onnx-simplifier](https://github.com/zh794390558/onnx-simplifier/tree/dyn_time_shape) version is correct.
+
+The example test with these packages installed:
+```
+paddle2onnx 0.9.8 # develop 62c5424e22cd93968dc831216fc9e0f0fce3d819
+paddleaudio 0.2.1
+paddlefsl 1.1.0
+paddlenlp 2.2.6
+paddlepaddle-gpu 2.2.2
+paddlespeech 0.0.0 # develop
+paddlespeech-ctcdecoders 0.2.0
+paddlespeech-feat 0.1.0
+onnx 1.11.0
+onnx-simplifier 0.0.0 # https://github.com/zh794390558/onnx-simplifier/tree/dyn_time_shape
+onnxoptimizer 0.2.7
+onnxruntime 1.11.0
+```
+
+## Using
+
+```
+bash run.sh
+```
+
+For more details please see `run.sh`.
+
+## Outputs
+The optimized onnx model is `exp/model.opt.onnx`.
+
+To show the graph, please using `local/netron.sh`.
diff --git a/speechx/examples/ds2_ol/onnx/local/infer_check.py b/speechx/examples/ds2_ol/onnx/local/infer_check.py
new file mode 100755
index 000000000..f821baa12
--- /dev/null
+++ b/speechx/examples/ds2_ol/onnx/local/infer_check.py
@@ -0,0 +1,100 @@
+#!/usr/bin/env python3
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+import os
+import pickle
+
+import numpy as np
+import onnxruntime
+import paddle
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description=__doc__)
+ parser.add_argument(
+ '--input_file',
+ type=str,
+ default="static_ds2online_inputs.pickle",
+ help="aishell ds2 input data file. For wenetspeech, we only feed for infer model",
+ )
+ parser.add_argument(
+ '--model_type',
+ type=str,
+ default="aishell",
+ help="aishell(1024) or wenetspeech(2048)", )
+ parser.add_argument(
+ '--model_dir', type=str, default=".", help="paddle model dir.")
+ parser.add_argument(
+ '--model_prefix',
+ type=str,
+ default="avg_1.jit",
+ help="paddle model prefix.")
+ parser.add_argument(
+ '--onnx_model',
+ type=str,
+ default='./model.old.onnx',
+ help="onnx model.")
+
+ return parser.parse_args()
+
+
+if __name__ == '__main__':
+ FLAGS = parse_args()
+
+ # input and output
+ with open(FLAGS.input_file, 'rb') as f:
+ iodict = pickle.load(f)
+ print(iodict.keys())
+
+ audio_chunk = iodict['audio_chunk']
+ audio_chunk_lens = iodict['audio_chunk_lens']
+ chunk_state_h_box = iodict['chunk_state_h_box']
+ chunk_state_c_box = iodict['chunk_state_c_bos']
+ print("raw state shape: ", chunk_state_c_box.shape)
+
+ if FLAGS.model_type == 'wenetspeech':
+ chunk_state_h_box = np.repeat(chunk_state_h_box, 2, axis=-1)
+ chunk_state_c_box = np.repeat(chunk_state_c_box, 2, axis=-1)
+ print("state shape: ", chunk_state_c_box.shape)
+
+ # paddle
+ model = paddle.jit.load(os.path.join(FLAGS.model_dir, FLAGS.model_prefix))
+ res_chunk, res_lens, chunk_state_h, chunk_state_c = model(
+ paddle.to_tensor(audio_chunk),
+ paddle.to_tensor(audio_chunk_lens),
+ paddle.to_tensor(chunk_state_h_box),
+ paddle.to_tensor(chunk_state_c_box), )
+
+ # onnxruntime
+ options = onnxruntime.SessionOptions()
+ options.enable_profiling = True
+ sess = onnxruntime.InferenceSession(FLAGS.onnx_model, sess_options=options)
+ ort_res_chunk, ort_res_lens, ort_chunk_state_h, ort_chunk_state_c = sess.run(
+ ['softmax_0.tmp_0', 'tmp_5', 'concat_0.tmp_0', 'concat_1.tmp_0'], {
+ "audio_chunk": audio_chunk,
+ "audio_chunk_lens": audio_chunk_lens,
+ "chunk_state_h_box": chunk_state_h_box,
+ "chunk_state_c_box": chunk_state_c_box
+ })
+
+ print(sess.end_profiling())
+
+ # assert paddle equal ort
+ print(np.allclose(ort_res_chunk, res_chunk, atol=1e-6))
+ print(np.allclose(ort_res_lens, res_lens, atol=1e-6))
+
+ if FLAGS.model_type == 'aishell':
+ print(np.allclose(ort_chunk_state_h, chunk_state_h, atol=1e-6))
+ print(np.allclose(ort_chunk_state_c, chunk_state_c, atol=1e-6))
diff --git a/speechx/examples/ds2_ol/onnx/local/netron.sh b/speechx/examples/ds2_ol/onnx/local/netron.sh
new file mode 100755
index 000000000..6dd9a39c9
--- /dev/null
+++ b/speechx/examples/ds2_ol/onnx/local/netron.sh
@@ -0,0 +1,14 @@
+#!/bin/bash
+
+# show model
+
+if [ $# != 1 ];then
+ echo "usage: $0 model_path"
+ exit 1
+fi
+
+
+file=$1
+
+pip install netron
+netron -p 8082 --host $(hostname -i) $file
\ No newline at end of file
diff --git a/speechx/examples/ds2_ol/onnx/local/onnx_clone.sh b/speechx/examples/ds2_ol/onnx/local/onnx_clone.sh
new file mode 100755
index 000000000..bce22dbc8
--- /dev/null
+++ b/speechx/examples/ds2_ol/onnx/local/onnx_clone.sh
@@ -0,0 +1,7 @@
+
+#!/bin/bash
+
+# clone onnx repos
+git clone https://github.com/onnx/onnx.git
+git clone https://github.com/microsoft/onnxruntime.git
+git clone https://github.com/PaddlePaddle/Paddle2ONNX.git
\ No newline at end of file
diff --git a/speechx/examples/ds2_ol/onnx/local/onnx_infer_shape.py b/speechx/examples/ds2_ol/onnx/local/onnx_infer_shape.py
new file mode 100755
index 000000000..2d364c252
--- /dev/null
+++ b/speechx/examples/ds2_ol/onnx/local/onnx_infer_shape.py
@@ -0,0 +1,2517 @@
+# Copyright (c) Microsoft Corporation. All rights reserved.
+# Licensed under the MIT License.
+# flake8: noqa
+import argparse
+import logging
+
+import numpy as np
+import onnx
+import sympy
+from onnx import helper
+from onnx import numpy_helper
+from onnx import shape_inference
+from packaging import version
+assert version.parse(onnx.__version__) >= version.parse("1.8.0")
+
+logger = logging.getLogger(__name__)
+
+
+def get_attribute(node, attr_name, default_value=None):
+ found = [attr for attr in node.attribute if attr.name == attr_name]
+ if found:
+ return helper.get_attribute_value(found[0])
+ return default_value
+
+
+def get_dim_from_proto(dim):
+ return getattr(dim, dim.WhichOneof('value')) if type(
+ dim.WhichOneof('value')) == str else None
+
+
+def is_sequence(type_proto):
+ cls_type = type_proto.WhichOneof('value')
+ assert cls_type in ['tensor_type', 'sequence_type']
+ return cls_type == 'sequence_type'
+
+
+def get_shape_from_type_proto(type_proto):
+ assert not is_sequence(type_proto)
+ if type_proto.tensor_type.HasField('shape'):
+ return [get_dim_from_proto(d) for d in type_proto.tensor_type.shape.dim]
+ else:
+ return None # note no shape is different from shape without dim (scalar)
+
+
+def get_shape_from_value_info(vi):
+ cls_type = vi.type.WhichOneof('value')
+ if cls_type is None:
+ return None
+ if is_sequence(vi.type):
+ if 'tensor_type' == vi.type.sequence_type.elem_type.WhichOneof('value'):
+ return get_shape_from_type_proto(vi.type.sequence_type.elem_type)
+ else:
+ return None
+ else:
+ return get_shape_from_type_proto(vi.type)
+
+
+def make_named_value_info(name):
+ vi = onnx.ValueInfoProto()
+ vi.name = name
+ return vi
+
+
+def get_shape_from_sympy_shape(sympy_shape):
+ return [
+ None if i is None else (int(i) if is_literal(i) else str(i))
+ for i in sympy_shape
+ ]
+
+
+def is_literal(dim):
+ return type(dim) in [int, np.int64, np.int32, sympy.Integer] or (hasattr(
+ dim, 'is_number') and dim.is_number)
+
+
+def handle_negative_axis(axis, rank):
+ assert axis < rank and axis >= -rank
+ return axis if axis >= 0 else rank + axis
+
+
+def get_opset(mp, domain=None):
+ domain = domain or ['', 'onnx', 'ai.onnx']
+ if type(domain) != list:
+ domain = [domain]
+ for opset in mp.opset_import:
+ if opset.domain in domain:
+ return opset.version
+
+ return None
+
+
+def as_scalar(x):
+ if type(x) == list:
+ assert len(x) == 1
+ return x[0]
+ elif type(x) == np.ndarray:
+ return x.item()
+ else:
+ return x
+
+
+def as_list(x, keep_none):
+ if type(x) == list:
+ return x
+ elif type(x) == np.ndarray:
+ return list(x)
+ elif keep_none and x is None:
+ return None
+ else:
+ return [x]
+
+
+def sympy_reduce_product(x):
+ if type(x) == list:
+ value = sympy.Integer(1)
+ for v in x:
+ value = value * v
+ else:
+ value = x
+ return value
+
+
+class SymbolicShapeInference:
+ def __init__(self,
+ int_max,
+ auto_merge,
+ guess_output_rank,
+ verbose,
+ prefix=''):
+ self.dispatcher_ = {
+ 'Add':
+ self._infer_symbolic_compute_ops,
+ 'ArrayFeatureExtractor':
+ self._infer_ArrayFeatureExtractor,
+ 'AveragePool':
+ self._infer_Pool,
+ 'BatchNormalization':
+ self._infer_BatchNormalization,
+ 'Cast':
+ self._infer_Cast,
+ 'CategoryMapper':
+ self._infer_CategoryMapper,
+ 'Compress':
+ self._infer_Compress,
+ 'Concat':
+ self._infer_Concat,
+ 'ConcatFromSequence':
+ self._infer_ConcatFromSequence,
+ 'Constant':
+ self._infer_Constant,
+ 'ConstantOfShape':
+ self._infer_ConstantOfShape,
+ 'Conv':
+ self._infer_Conv,
+ 'CumSum':
+ self._pass_on_shape_and_type,
+ 'Div':
+ self._infer_symbolic_compute_ops,
+ 'Einsum':
+ self._infer_Einsum,
+ 'Expand':
+ self._infer_Expand,
+ 'Equal':
+ self._infer_symbolic_compute_ops,
+ 'Floor':
+ self._infer_symbolic_compute_ops,
+ 'Gather':
+ self._infer_Gather,
+ 'GatherElements':
+ self._infer_GatherElements,
+ 'GatherND':
+ self._infer_GatherND,
+ 'Gelu':
+ self._pass_on_shape_and_type,
+ 'If':
+ self._infer_If,
+ 'Loop':
+ self._infer_Loop,
+ 'MatMul':
+ self._infer_MatMul,
+ 'MatMulInteger16':
+ self._infer_MatMulInteger,
+ 'MaxPool':
+ self._infer_Pool,
+ 'Max':
+ self._infer_symbolic_compute_ops,
+ 'Min':
+ self._infer_symbolic_compute_ops,
+ 'Mul':
+ self._infer_symbolic_compute_ops,
+ 'NonMaxSuppression':
+ self._infer_NonMaxSuppression,
+ 'NonZero':
+ self._infer_NonZero,
+ 'OneHot':
+ self._infer_OneHot,
+ 'Pad':
+ self._infer_Pad,
+ 'Range':
+ self._infer_Range,
+ 'Reciprocal':
+ self._pass_on_shape_and_type,
+ 'ReduceSum':
+ self._infer_ReduceSum,
+ 'ReduceProd':
+ self._infer_ReduceProd,
+ 'Reshape':
+ self._infer_Reshape,
+ 'Resize':
+ self._infer_Resize,
+ 'Round':
+ self._pass_on_shape_and_type,
+ 'Scan':
+ self._infer_Scan,
+ 'ScatterElements':
+ self._infer_ScatterElements,
+ 'SequenceAt':
+ self._infer_SequenceAt,
+ 'SequenceInsert':
+ self._infer_SequenceInsert,
+ 'Shape':
+ self._infer_Shape,
+ 'Size':
+ self._infer_Size,
+ 'Slice':
+ self._infer_Slice,
+ 'SoftmaxCrossEntropyLoss':
+ self._infer_SoftmaxCrossEntropyLoss,
+ 'SoftmaxCrossEntropyLossInternal':
+ self._infer_SoftmaxCrossEntropyLoss,
+ 'NegativeLogLikelihoodLossInternal':
+ self._infer_SoftmaxCrossEntropyLoss,
+ 'Split':
+ self._infer_Split,
+ 'SplitToSequence':
+ self._infer_SplitToSequence,
+ 'Squeeze':
+ self._infer_Squeeze,
+ 'Sub':
+ self._infer_symbolic_compute_ops,
+ 'Tile':
+ self._infer_Tile,
+ 'TopK':
+ self._infer_TopK,
+ 'Transpose':
+ self._infer_Transpose,
+ 'Unsqueeze':
+ self._infer_Unsqueeze,
+ 'Where':
+ self._infer_symbolic_compute_ops,
+ 'ZipMap':
+ self._infer_ZipMap,
+ 'Neg':
+ self._infer_symbolic_compute_ops,
+ # contrib ops:
+ 'Attention':
+ self._infer_Attention,
+ 'BiasGelu':
+ self._infer_BiasGelu,
+ 'EmbedLayerNormalization':
+ self._infer_EmbedLayerNormalization,
+ 'FastGelu':
+ self._infer_FastGelu,
+ 'Gelu':
+ self._infer_Gelu,
+ 'LayerNormalization':
+ self._infer_LayerNormalization,
+ 'LongformerAttention':
+ self._infer_LongformerAttention,
+ 'PythonOp':
+ self._infer_PythonOp,
+ 'SkipLayerNormalization':
+ self._infer_SkipLayerNormalization
+ }
+ self.aten_op_dispatcher_ = {
+ 'aten::embedding': self._infer_Gather,
+ 'aten::bitwise_or': self._infer_aten_bitwise_or,
+ 'aten::diagonal': self._infer_aten_diagonal,
+ 'aten::max_pool2d_with_indices': self._infer_aten_pool2d,
+ 'aten::multinomial': self._infer_aten_multinomial,
+ 'aten::unfold': self._infer_aten_unfold,
+ 'aten::argmax': self._infer_aten_argmax,
+ 'aten::avg_pool2d': self._infer_aten_pool2d,
+ 'aten::_adaptive_avg_pool2d': self._infer_aten_pool2d,
+ 'aten::binary_cross_entropy_with_logits': self._infer_aten_bce,
+ 'aten::numpy_T': self._infer_Transpose,
+ }
+ self.run_ = True
+ self.suggested_merge_ = {}
+ self.symbolic_dims_ = {}
+ self.input_symbols_ = {}
+ self.auto_merge_ = auto_merge
+ self.guess_output_rank_ = guess_output_rank
+ self.verbose_ = verbose
+ self.int_max_ = int_max
+ self.subgraph_id_ = 0
+ self.prefix_ = prefix
+
+ def _add_suggested_merge(self, symbols, apply=False):
+ assert all([(type(s) == str and s in self.symbolic_dims_) or
+ is_literal(s) for s in symbols])
+ symbols = set(symbols)
+ for k, v in self.suggested_merge_.items():
+ if k in symbols:
+ symbols.remove(k)
+ symbols.add(v)
+ map_to = None
+ # if there is literal, map to it first
+ for s in symbols:
+ if is_literal(s):
+ map_to = s
+ break
+ # when no literals, map to input symbolic dims, then existing symbolic dims
+ if map_to is None:
+ for s in symbols:
+ if s in self.input_symbols_:
+ map_to = s
+ break
+ if map_to is None:
+ for s in symbols:
+ if type(self.symbolic_dims_[s]) == sympy.Symbol:
+ map_to = s
+ break
+ # when nothing to map to, use the shorter one
+ if map_to is None:
+ if self.verbose_ > 0:
+ logger.warning(
+ 'Potential unsafe merge between symbolic expressions: ({})'.
+ format(','.join(symbols)))
+ symbols_list = list(symbols)
+ lens = [len(s) for s in symbols_list]
+ map_to = symbols_list[lens.index(min(lens))]
+ symbols.remove(map_to)
+
+ for s in symbols:
+ if s == map_to:
+ continue
+ if is_literal(map_to) and is_literal(s):
+ assert int(map_to) == int(s)
+ self.suggested_merge_[s] = int(map_to) if is_literal(
+ map_to) else map_to
+ for k, v in self.suggested_merge_.items():
+ if v == s:
+ self.suggested_merge_[k] = map_to
+ if apply and self.auto_merge_:
+ self._apply_suggested_merge()
+
+ def _apply_suggested_merge(self, graph_input_only=False):
+ if not self.suggested_merge_:
+ return
+ for i in list(self.out_mp_.graph.input) + (
+ [] if graph_input_only else list(self.out_mp_.graph.value_info)):
+ for d in i.type.tensor_type.shape.dim:
+ if d.dim_param in self.suggested_merge_:
+ v = self.suggested_merge_[d.dim_param]
+ if is_literal(v):
+ d.dim_value = int(v)
+ else:
+ d.dim_param = v
+
+ def _preprocess(self, in_mp):
+ self.out_mp_ = onnx.ModelProto()
+ self.out_mp_.CopyFrom(in_mp)
+ self.graph_inputs_ = dict(
+ [(i.name, i) for i in list(self.out_mp_.graph.input)])
+ self.initializers_ = dict(
+ [(i.name, i) for i in self.out_mp_.graph.initializer])
+ self.known_vi_ = dict(
+ [(i.name, i) for i in list(self.out_mp_.graph.input)])
+ self.known_vi_.update(
+ dict([(i.name, helper.make_tensor_value_info(i.name, i.data_type,
+ list(i.dims)))
+ for i in self.out_mp_.graph.initializer]))
+
+ def _merge_symbols(self, dims):
+ if not all([type(d) == str for d in dims]):
+ if self.auto_merge_:
+ unique_dims = list(set(dims))
+ is_int = [is_literal(d) for d in unique_dims]
+ assert sum(
+ is_int
+ ) <= 1 # if there are more than 1 unique ints, something is wrong
+ if sum(is_int) == 1:
+ int_dim = is_int.index(1)
+ if self.verbose_ > 0:
+ logger.debug('dim {} has been merged with value {}'.
+ format(unique_dims[:int_dim] + unique_dims[
+ int_dim + 1:], unique_dims[int_dim]))
+ self._check_merged_dims(unique_dims, allow_broadcast=False)
+ return unique_dims[int_dim]
+ else:
+ if self.verbose_ > 0:
+ logger.debug('dim {} has been mergd with dim {}'.format(
+ unique_dims[1:], unique_dims[0]))
+ return dims[0]
+ else:
+ return None
+ if all([d == dims[0] for d in dims]):
+ return dims[0]
+ merged = [
+ self.suggested_merge_[d] if d in self.suggested_merge_ else d
+ for d in dims
+ ]
+ if all([d == merged[0] for d in merged]):
+ assert merged[0] in self.symbolic_dims_
+ return merged[0]
+ else:
+ return None
+
+ # broadcast from right to left, and merge symbolic dims if needed
+ def _broadcast_shapes(self, shape1, shape2):
+ new_shape = []
+ rank1 = len(shape1)
+ rank2 = len(shape2)
+ new_rank = max(rank1, rank2)
+ for i in range(new_rank):
+ dim1 = shape1[rank1 - 1 - i] if i < rank1 else 1
+ dim2 = shape2[rank2 - 1 - i] if i < rank2 else 1
+ if dim1 == 1 or dim1 == dim2:
+ new_dim = dim2
+ elif dim2 == 1:
+ new_dim = dim1
+ else:
+ new_dim = self._merge_symbols([dim1, dim2])
+ if not new_dim:
+ # warning about unsupported broadcast when not auto merge
+ # note that auto merge has the risk of incorrectly merge symbols while one of them being 1
+ # for example, 'a' = 1, 'b' = 5 at runtime is valid broadcasting, but with auto merge 'a' == 'b'
+ if self.auto_merge_:
+ self._add_suggested_merge([dim1, dim2], apply=True)
+ else:
+ logger.warning('unsupported broadcast between ' + str(
+ dim1) + ' ' + str(dim2))
+ new_shape = [new_dim] + new_shape
+ return new_shape
+
+ def _get_shape(self, node, idx):
+ name = node.input[idx]
+ if name in self.known_vi_:
+ vi = self.known_vi_[name]
+ return get_shape_from_value_info(vi)
+ else:
+ assert name in self.initializers_
+ return list(self.initializers_[name].dims)
+
+ def _get_shape_rank(self, node, idx):
+ return len(self._get_shape(node, idx))
+
+ def _get_sympy_shape(self, node, idx):
+ sympy_shape = []
+ for d in self._get_shape(node, idx):
+ if type(d) == str:
+ sympy_shape.append(self.symbolic_dims_[d] if d in
+ self.symbolic_dims_ else sympy.Symbol(
+ d, integer=True, nonnegative=True))
+ else:
+ assert None != d
+ sympy_shape.append(d)
+ return sympy_shape
+
+ def _get_value(self, node, idx):
+ name = node.input[idx]
+ assert name in self.sympy_data_ or name in self.initializers_
+ return self.sympy_data_[
+ name] if name in self.sympy_data_ else numpy_helper.to_array(
+ self.initializers_[name])
+
+ def _try_get_value(self, node, idx):
+ if idx >= len(node.input):
+ return None
+ name = node.input[idx]
+ if name in self.sympy_data_ or name in self.initializers_:
+ return self._get_value(node, idx)
+ return None
+
+ def _update_computed_dims(self, new_sympy_shape):
+ for i, new_dim in enumerate(new_sympy_shape):
+ if not is_literal(new_dim) and not type(new_dim) == str:
+ str_dim = str(new_dim)
+ if str_dim in self.suggested_merge_:
+ if is_literal(self.suggested_merge_[str_dim]):
+ continue # no need to create dim for literals
+ new_sympy_shape[i] = self.symbolic_dims_[
+ self.suggested_merge_[str_dim]]
+ else:
+ # add new_dim if it's a computational expression
+ if not str(new_dim) in self.symbolic_dims_:
+ self.symbolic_dims_[str(new_dim)] = new_dim
+
+ def _onnx_infer_single_node(self, node):
+ # skip onnx shape inference for some ops, as they are handled in _infer_*
+ skip_infer = node.op_type in [
+ 'If', 'Loop', 'Scan', 'SplitToSequence', 'ZipMap', \
+ # contrib ops
+
+
+ 'Attention', 'BiasGelu', \
+ 'EmbedLayerNormalization', \
+ 'FastGelu', 'Gelu', 'LayerNormalization', \
+ 'LongformerAttention', \
+ 'SkipLayerNormalization', \
+ 'PythonOp'
+ ]
+
+ if not skip_infer:
+ # Only pass initializers that satisfy the following condition:
+ # (1) Operator need value of some input for shape inference.
+ # For example, Unsqueeze in opset 13 uses the axes input to calculate shape of output.
+ # (2) opset version >= 9. In older version, initializer is required in graph input by onnx spec.
+ # (3) The initializer is not in graph input. The means the node input is "constant" in inference.
+ initializers = []
+ if (get_opset(self.out_mp_) >= 9) and node.op_type in ['Unsqueeze']:
+ initializers = [
+ self.initializers_[name] for name in node.input
+ if (name in self.initializers_ and
+ name not in self.graph_inputs_)
+ ]
+
+ # run single node inference with self.known_vi_ shapes
+ tmp_graph = helper.make_graph(
+ [node], 'tmp', [self.known_vi_[i] for i in node.input if i],
+ [make_named_value_info(i) for i in node.output], initializers)
+
+ self.tmp_mp_.graph.CopyFrom(tmp_graph)
+
+ self.tmp_mp_ = shape_inference.infer_shapes(self.tmp_mp_)
+
+ for i_o in range(len(node.output)):
+ o = node.output[i_o]
+ vi = self.out_mp_.graph.value_info.add()
+ if not skip_infer:
+ vi.CopyFrom(self.tmp_mp_.graph.output[i_o])
+ else:
+ vi.name = o
+ self.known_vi_[o] = vi
+
+ def _onnx_infer_subgraph(self,
+ node,
+ subgraph,
+ use_node_input=True,
+ inc_subgraph_id=True):
+ if self.verbose_ > 2:
+ logger.debug(
+ 'Inferencing subgraph of node {} with output({}...): {}'.format(
+ node.name, node.output[0], node.op_type))
+ # node inputs are not passed directly to the subgraph
+ # it's up to the node dispatcher to prepare subgraph input
+ # for example, with Scan/Loop, subgraph input shape would be trimmed from node input shape
+ # besides, inputs in subgraph could shadow implicit inputs
+ subgraph_inputs = set(
+ [i.name for i in list(subgraph.initializer) + list(subgraph.input)])
+ subgraph_implicit_input = set([
+ name for name in self.known_vi_.keys()
+ if not name in subgraph_inputs
+ ])
+ tmp_graph = helper.make_graph(
+ list(subgraph.node), 'tmp',
+ list(subgraph.input) +
+ [self.known_vi_[i] for i in subgraph_implicit_input],
+ [make_named_value_info(i.name) for i in subgraph.output])
+ tmp_graph.initializer.extend([
+ i for i in self.out_mp_.graph.initializer
+ if i.name in subgraph_implicit_input
+ ])
+ tmp_graph.initializer.extend(subgraph.initializer)
+ self.tmp_mp_.graph.CopyFrom(tmp_graph)
+
+ symbolic_shape_inference = SymbolicShapeInference(
+ self.int_max_,
+ self.auto_merge_,
+ self.guess_output_rank_,
+ self.verbose_,
+ prefix=self.prefix_ + '_' + str(self.subgraph_id_))
+ if inc_subgraph_id:
+ self.subgraph_id_ += 1
+
+ all_shapes_inferred = False
+ symbolic_shape_inference._preprocess(self.tmp_mp_)
+ symbolic_shape_inference.suggested_merge_ = self.suggested_merge_.copy()
+ while symbolic_shape_inference.run_:
+ all_shapes_inferred = symbolic_shape_inference._infer_impl(
+ self.sympy_data_.copy())
+ symbolic_shape_inference._update_output_from_vi()
+ if use_node_input:
+ # if subgraph uses node input, it needs to update to merged dims
+ subgraph.ClearField('input')
+ subgraph.input.extend(
+ symbolic_shape_inference.out_mp_.graph.input[:len(node.input)])
+ subgraph.ClearField('output')
+ subgraph.output.extend(symbolic_shape_inference.out_mp_.graph.output)
+ subgraph.ClearField('value_info')
+ subgraph.value_info.extend(
+ symbolic_shape_inference.out_mp_.graph.value_info)
+ subgraph.ClearField('node')
+ subgraph.node.extend(symbolic_shape_inference.out_mp_.graph.node)
+ # for new symbolic dims from subgraph output, add to main graph symbolic dims
+ subgraph_shapes = [
+ get_shape_from_value_info(o)
+ for o in symbolic_shape_inference.out_mp_.graph.output
+ ]
+ subgraph_new_symbolic_dims = set([
+ d for s in subgraph_shapes if s for d in s
+ if type(d) == str and not d in self.symbolic_dims_
+ ])
+ new_dims = {}
+ for d in subgraph_new_symbolic_dims:
+ assert d in symbolic_shape_inference.symbolic_dims_
+ new_dims[d] = symbolic_shape_inference.symbolic_dims_[d]
+ self.symbolic_dims_.update(new_dims)
+ return symbolic_shape_inference
+
+ def _get_int_values(self, node, broadcast=False):
+ values = [self._try_get_value(node, i) for i in range(len(node.input))]
+ if all([v is not None for v in values]):
+ # some shape compute is in floating point, cast to int for sympy
+ for i, v in enumerate(values):
+ if type(v) != np.ndarray:
+ continue
+ if len(v.shape) > 1:
+ new_v = None # ignore value for rank > 1
+ elif len(v.shape) == 0:
+ new_v = int(v.item())
+ else:
+ assert len(v.shape) == 1
+ new_v = [int(vv) for vv in v]
+ values[i] = new_v
+ values_len = [len(v) if type(v) == list else 0 for v in values]
+ max_len = max(values_len)
+ if max_len >= 1 and broadcast:
+ # broadcast
+ for i, v in enumerate(values):
+ if v is None:
+ continue # don't broadcast if value is unknown
+ if type(v) == list:
+ if len(v) < max_len:
+ values[i] = v * max_len
+ else:
+ assert len(v) == max_len
+ else:
+ values[i] = [v] * max_len
+ return values
+
+ def _compute_on_sympy_data(self, node, op_func):
+ assert len(node.output) == 1
+ values = self._get_int_values(node, broadcast=True)
+ if all([v is not None for v in values]):
+ is_list = [type(v) == list for v in values]
+ as_list = any(is_list)
+ if as_list:
+ self.sympy_data_[node.output[
+ 0]] = [op_func(vs) for vs in zip(*values)]
+ else:
+ self.sympy_data_[node.output[0]] = op_func(values)
+
+ def _pass_on_sympy_data(self, node):
+ assert len(
+ node.
+ input) == 1 or node.op_type in ['Reshape', 'Unsqueeze', 'Squeeze']
+ self._compute_on_sympy_data(node, lambda x: x[0])
+
+ def _pass_on_shape_and_type(self, node):
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[0], self.known_vi_[
+ node.input[0]].type.tensor_type.elem_type,
+ self._get_shape(node, 0)))
+
+ def _new_symbolic_dim(self, prefix, dim):
+ new_dim = '{}_d{}'.format(prefix, dim)
+ if new_dim in self.suggested_merge_:
+ v = self.suggested_merge_[new_dim]
+ new_symbolic_dim = sympy.Integer(int(v)) if is_literal(v) else v
+ else:
+ new_symbolic_dim = sympy.Symbol(
+ new_dim, integer=True, nonnegative=True)
+ self.symbolic_dims_[new_dim] = new_symbolic_dim
+ return new_symbolic_dim
+
+ def _new_symbolic_dim_from_output(self, node, out_idx=0, dim=0):
+ return self._new_symbolic_dim('{}{}_{}_o{}_'.format(
+ node.op_type, self.prefix_,
+ list(self.out_mp_.graph.node).index(node), out_idx), dim)
+
+ def _new_symbolic_shape(self, rank, node, out_idx=0):
+ return [
+ self._new_symbolic_dim_from_output(node, out_idx, i)
+ for i in range(rank)
+ ]
+
+ def _compute_conv_pool_shape(self, node):
+ sympy_shape = self._get_sympy_shape(node, 0)
+ if len(node.input) > 1:
+ W_shape = self._get_sympy_shape(node, 1)
+ rank = len(W_shape) - 2 # number of spatial axes
+ kernel_shape = W_shape[-rank:]
+ sympy_shape[1] = W_shape[0]
+ else:
+ W_shape = None
+ kernel_shape = get_attribute(node, 'kernel_shape')
+ rank = len(kernel_shape)
+
+ assert len(sympy_shape) == rank + 2
+
+ # only need to symbolic shape inference if input has symbolic dims in spatial axes
+ is_symbolic_dims = [not is_literal(i) for i in sympy_shape[-rank:]]
+
+ if not any(is_symbolic_dims):
+ shape = get_shape_from_value_info(self.known_vi_[node.output[0]])
+ if len(shape) > 0:
+ assert len(sympy_shape) == len(shape)
+ sympy_shape[-rank:] = [sympy.Integer(d) for d in shape[-rank:]]
+ return sympy_shape
+
+ dilations = get_attribute(node, 'dilations', [1] * rank)
+ strides = get_attribute(node, 'strides', [1] * rank)
+ effective_kernel_shape = [(k - 1) * d + 1
+ for k, d in zip(kernel_shape, dilations)]
+ pads = get_attribute(node, 'pads')
+ if pads is None:
+ pads = [0] * (2 * rank)
+ auto_pad = get_attribute(node, 'auto_pad',
+ b'NOTSET').decode('utf-8')
+ if auto_pad != 'VALID' and auto_pad != 'NOTSET':
+ try:
+ residual = [
+ sympy.Mod(d, s)
+ for d, s in zip(sympy_shape[-rank:], strides)
+ ]
+ total_pads = [
+ max(0, (k - s) if r == 0 else (k - r)) for k, s, r in
+ zip(effective_kernel_shape, strides, residual)
+ ]
+ except TypeError: # sympy may throw TypeError: cannot determine truth value of Relational
+ total_pads = [
+ max(0, (k - s))
+ for k, s in zip(effective_kernel_shape, strides)
+ ] # assuming no residual if sympy throws error
+ elif auto_pad == 'VALID':
+ total_pads = []
+ else:
+ total_pads = [0] * rank
+ else:
+ assert len(pads) == 2 * rank
+ total_pads = [p1 + p2 for p1, p2 in zip(pads[:rank], pads[rank:])]
+
+ ceil_mode = get_attribute(node, 'ceil_mode', 0)
+ for i in range(rank):
+ effective_input_size = sympy_shape[-rank + i]
+ if len(total_pads) > 0:
+ effective_input_size = effective_input_size + total_pads[i]
+ if ceil_mode:
+ strided_kernel_positions = sympy.ceiling(
+ (effective_input_size - effective_kernel_shape[i]) /
+ strides[i])
+ else:
+ strided_kernel_positions = (
+ effective_input_size - effective_kernel_shape[i]
+ ) // strides[i]
+ sympy_shape[-rank + i] = strided_kernel_positions + 1
+ return sympy_shape
+
+ def _check_merged_dims(self, dims, allow_broadcast=True):
+ if allow_broadcast:
+ dims = [d for d in dims if not (is_literal(d) and int(d) <= 1)]
+ if not all([d == dims[0] for d in dims]):
+ self._add_suggested_merge(dims, apply=True)
+
+ def _compute_matmul_shape(self, node, output_dtype=None):
+ lhs_shape = self._get_shape(node, 0)
+ rhs_shape = self._get_shape(node, 1)
+ lhs_rank = len(lhs_shape)
+ rhs_rank = len(rhs_shape)
+ lhs_reduce_dim = 0
+ rhs_reduce_dim = 0
+ assert lhs_rank > 0 and rhs_rank > 0
+ if lhs_rank == 1 and rhs_rank == 1:
+ new_shape = []
+ elif lhs_rank == 1:
+ rhs_reduce_dim = -2
+ new_shape = rhs_shape[:rhs_reduce_dim] + [rhs_shape[-1]]
+ elif rhs_rank == 1:
+ lhs_reduce_dim = -1
+ new_shape = lhs_shape[:lhs_reduce_dim]
+ else:
+ lhs_reduce_dim = -1
+ rhs_reduce_dim = -2
+ new_shape = self._broadcast_shapes(
+ lhs_shape[:-2],
+ rhs_shape[:-2]) + [lhs_shape[-2]] + [rhs_shape[-1]]
+ # merge reduce dim
+ self._check_merged_dims(
+ [lhs_shape[lhs_reduce_dim], rhs_shape[rhs_reduce_dim]],
+ allow_broadcast=False)
+ if output_dtype is None:
+ # infer output_dtype from input type when not specified
+ output_dtype = self.known_vi_[node.input[
+ 0]].type.tensor_type.elem_type
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[0], output_dtype,
+ new_shape))
+
+ def _fuse_tensor_type(self, node, out_idx, dst_type, src_type):
+ '''
+ update dst_tensor_type to be compatible with src_tensor_type when dimension mismatches
+ '''
+ dst_tensor_type = dst_type.sequence_type.elem_type.tensor_type if is_sequence(
+ dst_type) else dst_type.tensor_type
+ src_tensor_type = src_type.sequence_type.elem_type.tensor_type if is_sequence(
+ src_type) else src_type.tensor_type
+ if dst_tensor_type.elem_type != src_tensor_type.elem_type:
+ node_id = node.name if node.name else node.op_type
+ raise ValueError(
+ f"For node {node_id}, dst_tensor_type.elem_type != src_tensor_type.elem_type: "
+ f"{onnx.onnx_pb.TensorProto.DataType.Name(dst_tensor_type.elem_type)} vs "
+ f"{onnx.onnx_pb.TensorProto.DataType.Name(src_tensor_type.elem_type)}"
+ )
+ if dst_tensor_type.HasField('shape'):
+ for di, ds in enumerate(
+ zip(dst_tensor_type.shape.dim, src_tensor_type.shape.dim)):
+ if ds[0] != ds[1]:
+ # create a new symbolic dimension for node/out_idx/mismatch dim id in dst_tensor_type for tensor_type
+ # for sequence_type, clear the dimension
+ new_dim = onnx.TensorShapeProto.Dimension()
+ if not is_sequence(dst_type):
+ new_dim.dim_param = str(
+ self._new_symbolic_dim_from_output(node, out_idx,
+ di))
+ dst_tensor_type.shape.dim[di].CopyFrom(new_dim)
+ else:
+ dst_tensor_type.CopyFrom(src_tensor_type)
+
+ def _infer_ArrayFeatureExtractor(self, node):
+ data_shape = self._get_shape(node, 0)
+ indices_shape = self._get_shape(node, 1)
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[0], self.known_vi_[
+ node.input[0]].type.tensor_type.elem_type, data_shape[:-1] +
+ indices_shape))
+
+ def _infer_symbolic_compute_ops(self, node):
+ funcs = {
+ 'Add':
+ lambda l: l[0] + l[1],
+ 'Div':
+ lambda l: l[0] // l[1], # integer div in sympy
+ 'Equal':
+ lambda l: l[0] == l[1],
+ 'Floor':
+ lambda l: sympy.floor(l[0]),
+ 'Max':
+ lambda l: l[1] if is_literal(l[0]) and int(l[0]) < -self.int_max_ else (l[0] if is_literal(l[1]) and int(l[1]) < -self.int_max_ else sympy.Max(l[0], l[1])),
+ 'Min':
+ lambda l: l[1] if is_literal(l[0]) and int(l[0]) > self.int_max_ else (l[0] if is_literal(l[1]) and int(l[1]) > self.int_max_ else sympy.Min(l[0], l[1])),
+ 'Mul':
+ lambda l: l[0] * l[1],
+ 'Sub':
+ lambda l: l[0] - l[1],
+ 'Where':
+ lambda l: l[1] if l[0] else l[2],
+ 'Neg':
+ lambda l: -l[0]
+ }
+ assert node.op_type in funcs
+ self._compute_on_sympy_data(node, funcs[node.op_type])
+
+ def _infer_Cast(self, node):
+ self._pass_on_sympy_data(node)
+
+ def _infer_CategoryMapper(self, node):
+ input_type = self.known_vi_[node.input[0]].type.tensor_type.elem_type
+ if input_type == onnx.TensorProto.STRING:
+ output_type = onnx.TensorProto.INT64
+ else:
+ output_type = onnx.TensorProto.STRING
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[0], output_type,
+ self._get_shape(node, 0)))
+
+ def _infer_Compress(self, node):
+ input_shape = self._get_shape(node, 0)
+ # create a new symbolic dimension for Compress output
+ compress_len = str(self._new_symbolic_dim_from_output(node))
+ axis = get_attribute(node, 'axis')
+ if axis == None:
+ # when axis is not specified, input is flattened before compress so output is 1D
+ output_shape = [compress_len]
+ else:
+ output_shape = input_shape
+ output_shape[handle_negative_axis(axis, len(
+ input_shape))] = compress_len
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[0], self.known_vi_[
+ node.input[0]].type.tensor_type.elem_type, output_shape))
+
+ def _infer_Concat(self, node):
+ if any([
+ i in self.sympy_data_ or i in self.initializers_
+ for i in node.input
+ ]):
+ values = self._get_int_values(node)
+ print("=======", values, node.name, get_attribute(node, 'axis'))
+ if all([v is not None for v in values]):
+ axis = get_attribute(node, 'axis')
+ if axis < 0:
+ axis = axis + len(values[0])
+ assert 0 == axis
+ self.sympy_data_[node.output[0]] = []
+ for i in range(len(node.input)):
+ value = values[i]
+ if type(value) == list:
+ self.sympy_data_[node.output[0]].extend(value)
+ else:
+ self.sympy_data_[node.output[0]].append(value)
+
+ sympy_shape = self._get_sympy_shape(node, 0)
+ axis = handle_negative_axis(
+ get_attribute(node, 'axis'), len(sympy_shape))
+ for i_idx in range(1, len(node.input)):
+ input_shape = self._get_sympy_shape(node, i_idx)
+ if input_shape:
+ sympy_shape[axis] = sympy_shape[axis] + input_shape[axis]
+ self._update_computed_dims(sympy_shape)
+ # merge symbolic dims for non-concat axes
+ for d in range(len(sympy_shape)):
+ if d == axis:
+ continue
+ dims = [
+ self._get_shape(node, i_idx)[d]
+ for i_idx in range(len(node.input))
+ if self._get_shape(node, i_idx)
+ ]
+ if all([d == dims[0] for d in dims]):
+ continue
+ merged = self._merge_symbols(dims)
+ if type(merged) == str:
+ sympy_shape[d] = self.symbolic_dims_[merged] if merged else None
+ else:
+ sympy_shape[d] = merged
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(
+ node.output[0], self.known_vi_[node.input[0]].type.tensor_type.
+ elem_type, get_shape_from_sympy_shape(sympy_shape)))
+
+ def _infer_ConcatFromSequence(self, node):
+ seq_shape = self._get_shape(node, 0)
+ new_axis = 1 if get_attribute(node, 'new_axis') else 0
+ axis = handle_negative_axis(
+ get_attribute(node, 'axis'), len(seq_shape) + new_axis)
+ concat_dim = str(self._new_symbolic_dim_from_output(node, 0, axis))
+ new_shape = seq_shape
+ if new_axis:
+ new_shape = seq_shape[:axis] + [concat_dim] + seq_shape[axis:]
+ else:
+ new_shape[axis] = concat_dim
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(
+ node.output[0], self.known_vi_[node.input[0]]
+ .type.sequence_type.elem_type.tensor_type.elem_type, new_shape))
+
+ def _infer_Constant(self, node):
+ t = get_attribute(node, 'value')
+ self.sympy_data_[node.output[0]] = numpy_helper.to_array(t)
+
+ def _infer_ConstantOfShape(self, node):
+ sympy_shape = self._get_int_values(node)[0]
+ vi = self.known_vi_[node.output[0]]
+ if sympy_shape is not None:
+ if type(sympy_shape) != list:
+ sympy_shape = [sympy_shape]
+ self._update_computed_dims(sympy_shape)
+ # update sympy data if output type is int, and shape is known
+ if vi.type.tensor_type.elem_type == onnx.TensorProto.INT64 and all(
+ [is_literal(x) for x in sympy_shape]):
+ self.sympy_data_[node.output[0]] = np.ones(
+ [int(x) for x in sympy_shape],
+ dtype=np.int64) * numpy_helper.to_array(
+ get_attribute(node, 'value', 0))
+ else:
+ # create new dynamic shape
+ # note input0 is a 1D vector of shape, the new symbolic shape has the rank of the shape vector length
+ sympy_shape = self._new_symbolic_shape(
+ self._get_shape(node, 0)[0], node)
+
+ vi.CopyFrom(
+ helper.make_tensor_value_info(
+ node.output[0], vi.type.tensor_type.elem_type,
+ get_shape_from_sympy_shape(sympy_shape)))
+
+ def _infer_Conv(self, node):
+ sympy_shape = self._compute_conv_pool_shape(node)
+ self._update_computed_dims(sympy_shape)
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(
+ node.output[0], vi.type.tensor_type.elem_type,
+ get_shape_from_sympy_shape(sympy_shape)))
+
+ def _infer_Einsum(self, node):
+ # ref:https://github.com/onnx/onnx/blob/623dfaa0151b2e4ce49779c3ec31cbd78c592b80/onnx/defs/math/defs.cc#L3275
+ equation = get_attribute(node, 'equation')
+ equation = equation.replace(b' ', b'')
+ mid_index = equation.find(b'->')
+ left_equation = equation[:mid_index] if mid_index != -1 else equation
+
+ num_operands = 0
+ num_ellipsis = 0
+ num_ellipsis_indices = 0
+
+ letter_to_dim = {}
+
+ terms = left_equation.split(b',')
+ for term in terms:
+ ellipsis_index = term.find(b'...')
+ shape = self._get_shape(node, num_operands)
+ rank = len(shape)
+ if ellipsis_index != -1:
+ if num_ellipsis == 0:
+ num_ellipsis_indices = rank - len(term) + 3
+ num_ellipsis = num_ellipsis + 1
+ for i in range(1, rank + 1):
+ letter = term[-i]
+ if letter != 46: # letter != b'.'
+ dim = shape[-i]
+ if letter not in letter_to_dim.keys():
+ letter_to_dim[letter] = dim
+ elif type(dim) != sympy.Symbol:
+ letter_to_dim[letter] = dim
+ num_operands = num_operands + 1
+
+ new_sympy_shape = []
+ from collections import OrderedDict
+ num_letter_occurrences = OrderedDict()
+ if mid_index != -1:
+ right_equation = equation[mid_index + 2:]
+ right_ellipsis_index = right_equation.find(b'...')
+ if right_ellipsis_index != -1:
+ for i in range(num_ellipsis_indices):
+ new_sympy_shape.append(shape[i])
+ for c in right_equation:
+ if c != 46: # c != b'.'
+ new_sympy_shape.append(letter_to_dim[c])
+ else:
+ for i in range(num_ellipsis_indices):
+ new_sympy_shape.append(shape[i])
+ for c in left_equation:
+ if c != 44 and c != 46: # c != b',' and c != b'.':
+ if c in num_letter_occurrences:
+ num_letter_occurrences[c] = num_letter_occurrences[
+ c] + 1
+ else:
+ num_letter_occurrences[c] = 1
+ for key, value in num_letter_occurrences.items():
+ if value == 1:
+ new_sympy_shape.append(letter_to_dim[key])
+
+ output_dtype = self.known_vi_[node.input[0]].type.tensor_type.elem_type
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[0], output_dtype,
+ new_sympy_shape))
+
+ def _infer_Expand(self, node):
+ expand_to_shape = as_list(self._try_get_value(node, 1), keep_none=True)
+ if expand_to_shape is not None:
+ # new_shape's dim can come from shape value
+ self._update_computed_dims(expand_to_shape)
+ shape = self._get_shape(node, 0)
+ new_shape = self._broadcast_shapes(
+ shape, get_shape_from_sympy_shape(expand_to_shape))
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[0], self.known_vi_[
+ node.input[0]].type.tensor_type.elem_type, new_shape))
+
+ def _infer_Gather(self, node):
+ data_shape = self._get_shape(node, 0)
+ axis = handle_negative_axis(
+ get_attribute(node, 'axis', 0), len(data_shape))
+ indices_shape = self._get_shape(node, 1)
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[0], self.known_vi_[
+ node.input[0]].type.tensor_type.elem_type, data_shape[:axis] +
+ indices_shape + data_shape[axis +
+ 1:]))
+ # for 1D input, do some sympy compute
+ if node.input[0] in self.sympy_data_ and len(
+ data_shape) == 1 and 0 == get_attribute(node, 'axis', 0):
+ idx = self._try_get_value(node, 1)
+ if idx is not None:
+ data = self.sympy_data_[node.input[0]]
+ if type(data) == list:
+ if type(idx) == np.ndarray and len(idx.shape) == 1:
+ self.sympy_data_[node.output[
+ 0]] = [data[int(i)] for i in idx]
+ else:
+ self.sympy_data_[node.output[0]] = data[int(idx)]
+ else:
+ assert idx == 0 or idx == -1
+ self.sympy_data_[node.output[0]] = data
+
+ def _infer_GatherElements(self, node):
+ indices_shape = self._get_shape(node, 1)
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[0], self.known_vi_[
+ node.input[0]].type.tensor_type.elem_type, indices_shape))
+
+ def _infer_GatherND(self, node):
+ data_shape = self._get_shape(node, 0)
+ data_rank = len(data_shape)
+ indices_shape = self._get_shape(node, 1)
+ indices_rank = len(indices_shape)
+ last_index_dimension = indices_shape[-1]
+ assert is_literal(
+ last_index_dimension) and last_index_dimension <= data_rank
+ new_shape = indices_shape[:-1] + data_shape[last_index_dimension:]
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[0], self.known_vi_[
+ node.input[0]].type.tensor_type.elem_type, new_shape))
+
+ def _infer_If(self, node):
+ # special case for constant condition, in case there are mismatching shape from the non-executed branch
+ subgraphs = [
+ get_attribute(node, 'then_branch'), get_attribute(node,
+ 'else_branch')
+ ]
+ cond = self._try_get_value(node, 0)
+ if cond is not None:
+ if as_scalar(cond) > 0:
+ subgraphs[1].CopyFrom(subgraphs[0])
+ else:
+ subgraphs[0].CopyFrom(subgraphs[1])
+
+ for i_sub, subgraph in enumerate(subgraphs):
+ subgraph_infer = self._onnx_infer_subgraph(
+ node, subgraph, use_node_input=False)
+ for i_out in range(len(node.output)):
+ vi = self.known_vi_[node.output[i_out]]
+ if i_sub == 0:
+ vi.CopyFrom(subgraph.output[i_out])
+ vi.name = node.output[i_out]
+ else:
+ self._fuse_tensor_type(node, i_out, vi.type,
+ subgraph.output[i_out].type)
+
+ # pass on sympy data from subgraph, if cond is constant
+ if cond is not None and i_sub == (0 if as_scalar(cond) > 0 else
+ 1):
+ if subgraph.output[
+ i_out].name in subgraph_infer.sympy_data_:
+ self.sympy_data_[vi.name] = subgraph_infer.sympy_data_[
+ subgraph.output[i_out].name]
+
+ def _infer_Loop(self, node):
+ subgraph = get_attribute(node, 'body')
+ assert len(subgraph.input) == len(node.input)
+ num_loop_carried = len(
+ node.input) - 2 # minus the length and initial loop condition
+ # when sequence_type is used as loop carried input
+ # needs to run subgraph infer twice if the tensor shape in sequence contains None
+ for i, si in enumerate(subgraph.input):
+ si_name = si.name
+ si.CopyFrom(self.known_vi_[node.input[i]])
+ si.name = si_name
+
+ self._onnx_infer_subgraph(node, subgraph)
+
+ # check subgraph input/output for shape changes in loop carried variables
+ # for tensor_type, create new symbolic dim when changing, i.e., output = Concat(input, a)
+ # for sequence_type, propagate from output to input
+ need_second_infer = False
+ for i_out in range(1, num_loop_carried + 1):
+ so = subgraph.output[i_out]
+ so_shape = get_shape_from_value_info(so)
+ if is_sequence(so.type):
+ if so_shape and None in so_shape:
+ # copy shape from output to input
+ # note that loop input is [loop_len, cond, input_0, input_1, ...]
+ # while loop output is [cond, output_0, output_1, ...]
+ subgraph.input[i_out +
+ 1].type.sequence_type.elem_type.CopyFrom(
+ so.type.sequence_type.elem_type)
+ need_second_infer = True
+ else:
+ si = subgraph.input[i_out + 1]
+ si_shape = get_shape_from_value_info(si)
+ for di, dims in enumerate(zip(si_shape, so_shape)):
+ if dims[0] != dims[1]:
+ new_dim = onnx.TensorShapeProto.Dimension()
+ new_dim.dim_param = str(
+ self._new_symbolic_dim_from_output(node, i_out, di))
+ si.type.tensor_type.shape.dim[di].CopyFrom(new_dim)
+ so.type.tensor_type.shape.dim[di].CopyFrom(new_dim)
+ need_second_infer = True
+
+ if need_second_infer:
+ if self.verbose_ > 2:
+ logger.debug(
+ "Rerun Loop: {}({}...), because of sequence in loop carried variables".
+ format(node.name, node.output[0]))
+ self._onnx_infer_subgraph(node, subgraph, inc_subgraph_id=False)
+
+ # create a new symbolic dimension for iteration dependent dimension
+ loop_iter_dim = str(self._new_symbolic_dim_from_output(node))
+ for i in range(len(node.output)):
+ vi = self.known_vi_[node.output[i]]
+ vi.CopyFrom(subgraph.output[
+ i +
+ 1]) # first subgraph output is condition, not in node output
+ if i >= num_loop_carried:
+ assert not is_sequence(
+ vi.type) # TODO: handle loop accumulation in sequence_type
+ subgraph_vi_dim = subgraph.output[i +
+ 1].type.tensor_type.shape.dim
+ vi.type.tensor_type.shape.ClearField('dim')
+ vi_dim = vi.type.tensor_type.shape.dim
+ vi_dim.add().dim_param = loop_iter_dim
+ vi_dim.extend(list(subgraph_vi_dim))
+ vi.name = node.output[i]
+
+ def _infer_MatMul(self, node):
+ self._compute_matmul_shape(node)
+
+ def _infer_MatMulInteger(self, node):
+ self._compute_matmul_shape(node, onnx.TensorProto.INT32)
+
+ def _infer_NonMaxSuppression(self, node):
+ selected = str(self._new_symbolic_dim_from_output(node))
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[
+ 0], onnx.TensorProto.INT64, [selected, 3]))
+
+ def _infer_NonZero(self, node):
+ input_rank = self._get_shape_rank(node, 0)
+ # create a new symbolic dimension for NonZero output
+ nz_len = str(self._new_symbolic_dim_from_output(node, 0, 1))
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[
+ 0], vi.type.tensor_type.elem_type, [input_rank, nz_len]))
+
+ def _infer_OneHot(self, node):
+ sympy_shape = self._get_sympy_shape(node, 0)
+ depth = self._try_get_value(node, 1)
+ axis = get_attribute(node, 'axis', -1)
+ axis = handle_negative_axis(axis, len(sympy_shape) + 1)
+ new_shape = get_shape_from_sympy_shape(sympy_shape[:axis] + [
+ self._new_symbolic_dim_from_output(node)
+ if not is_literal(depth) else depth
+ ] + sympy_shape[axis:])
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[0], self.known_vi_[
+ node.input[2]].type.tensor_type.elem_type, new_shape))
+
+ def _infer_Pad(self, node):
+ if get_opset(self.out_mp_) <= 10:
+ pads = get_attribute(node, 'pads')
+ else:
+ pads = self._try_get_value(node, 1)
+
+ sympy_shape = self._get_sympy_shape(node, 0)
+ rank = len(sympy_shape)
+
+ if pads is not None:
+ assert len(pads) == 2 * rank
+ new_sympy_shape = [
+ d + pad_up + pad_down for d, pad_up, pad_down in
+ zip(sympy_shape, pads[:rank], pads[rank:])
+ ]
+ self._update_computed_dims(new_sympy_shape)
+ else:
+ # dynamic pads, create new symbolic dimensions
+ new_sympy_shape = self._new_symbolic_shape(rank, node)
+ output_tp = self.known_vi_[node.input[0]].type.tensor_type.elem_type
+
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[
+ 0], output_tp, get_shape_from_sympy_shape(new_sympy_shape)))
+
+ def _infer_Pool(self, node):
+ sympy_shape = self._compute_conv_pool_shape(node)
+ self._update_computed_dims(sympy_shape)
+ for o in node.output:
+ if not o:
+ continue
+ vi = self.known_vi_[o]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(o, vi.type.tensor_type.elem_type,
+ get_shape_from_sympy_shape(
+ sympy_shape)))
+
+ def _infer_aten_bitwise_or(self, node):
+ shape0 = self._get_shape(node, 0)
+ shape1 = self._get_shape(node, 1)
+ new_shape = self._broadcast_shapes(shape0, shape1)
+ t0 = self.known_vi_[node.input[0]]
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[
+ 0], t0.type.tensor_type.elem_type, new_shape))
+
+ def _infer_aten_diagonal(self, node):
+ sympy_shape = self._get_sympy_shape(node, 0)
+ rank = len(sympy_shape)
+ offset = self._try_get_value(node, 1)
+ dim1 = self._try_get_value(node, 2)
+ dim2 = self._try_get_value(node, 3)
+
+ assert offset is not None and dim1 is not None and dim2 is not None
+ dim1 = handle_negative_axis(dim1, rank)
+ dim2 = handle_negative_axis(dim2, rank)
+
+ new_shape = []
+ for dim, val in enumerate(sympy_shape):
+ if dim not in [dim1, dim2]:
+ new_shape.append(val)
+
+ shape1 = sympy_shape[dim1]
+ shape2 = sympy_shape[dim2]
+ if offset >= 0:
+ diag_shape = sympy.Max(0, sympy.Min(shape1, shape2 - offset))
+ else:
+ diag_shape = sympy.Max(0, sympy.Min(shape1 + offset, shape2))
+ new_shape.append(diag_shape)
+
+ if node.output[0]:
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[0], self.known_vi_[
+ node.input[0]].type.tensor_type.elem_type,
+ get_shape_from_sympy_shape(
+ new_shape)))
+
+ def _infer_aten_multinomial(self, node):
+ sympy_shape = self._get_sympy_shape(node, 0)
+ rank = len(sympy_shape)
+ assert rank in [1, 2]
+ num_samples = self._try_get_value(node, 1)
+ di = rank - 1
+ last_dim = num_samples if num_samples else str(
+ self._new_symbolic_dim_from_output(node, 0, di))
+ output_shape = sympy_shape[:-1] + [last_dim]
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(
+ node.output[0], onnx.TensorProto.INT64,
+ get_shape_from_sympy_shape(output_shape)))
+
+ def _infer_aten_pool2d(self, node):
+ sympy_shape = self._get_sympy_shape(node, 0)
+ assert len(sympy_shape) == 4
+ sympy_shape[-2:] = [
+ self._new_symbolic_dim_from_output(node, 0, i) for i in [2, 3]
+ ]
+ self._update_computed_dims(sympy_shape)
+ for i, o in enumerate(node.output):
+ if not o:
+ continue
+ vi = self.known_vi_[o]
+ elem_type = onnx.TensorProto.INT64 if i == 1 else self.known_vi_[
+ node.input[0]].type.tensor_type.elem_type
+ vi.CopyFrom(
+ helper.make_tensor_value_info(
+ o, elem_type, get_shape_from_sympy_shape(sympy_shape)))
+
+ def _infer_aten_unfold(self, node):
+ sympy_shape = self._get_sympy_shape(node, 0)
+ dimension = self._try_get_value(node, 1)
+ size = self._try_get_value(node, 2)
+ step = self._try_get_value(node, 3)
+ if dimension is not None and size is not None and step is not None:
+ assert dimension < len(sympy_shape)
+ sympy_shape[dimension] = (sympy_shape[dimension] - size) // step + 1
+ sympy_shape.append(size)
+ else:
+ rank = len(sympy_shape)
+ sympy_shape = self._new_symbolic_shape(rank + 1, node)
+ self._update_computed_dims(sympy_shape)
+ if node.output[0]:
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[0], self.known_vi_[
+ node.input[0]].type.tensor_type.elem_type,
+ get_shape_from_sympy_shape(
+ sympy_shape)))
+
+ def _infer_aten_argmax(self, node):
+ new_shape = None
+ if node.input[1] == '':
+ # The argmax of the flattened input is returned.
+ new_shape = []
+ else:
+ dim = self._try_get_value(node, 1)
+ keepdim = self._try_get_value(node, 2)
+ if keepdim is not None:
+ sympy_shape = self._get_sympy_shape(node, 0)
+ if dim is not None:
+ dim = handle_negative_axis(dim, len(sympy_shape))
+ if keepdim:
+ sympy_shape[dim] = 1
+ else:
+ del sympy_shape[dim]
+ else:
+ rank = len(sympy_shape)
+ sympy_shape = self._new_symbolic_shape(rank if keepdim else
+ rank - 1, node)
+ self._update_computed_dims(sympy_shape)
+ new_shape = get_shape_from_sympy_shape(sympy_shape)
+ if node.output[0] and new_shape is not None:
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[
+ 0], onnx.TensorProto.INT64, new_shape))
+
+ def _infer_aten_bce(self, node):
+ reduction = self._try_get_value(node, 4)
+ if reduction is None:
+ reduction = 1
+ elem_type = self.known_vi_[node.input[0]].type.tensor_type.elem_type
+ vi = self.known_vi_[node.output[0]]
+ if reduction == 0:
+ vi.type.tensor_type.elem_type = elem_type
+ vi.type.tensor_type.shape.CopyFrom(onnx.TensorShapeProto())
+ else:
+ vi.CopyFrom(
+ helper.make_tensor_value_info(vi.name, elem_type,
+ self._get_shape(node, 0)))
+
+ def _infer_BatchNormalization(self, node):
+ self._propagate_shape_and_type(node)
+
+ # this works for opsets < 14 and 14 since we check i < len(node.output) in the loop
+ for i in [1, 2, 3, 4]:
+ if i < len(node.output) and node.output[i] != "":
+ # all of these parameters have the same shape as the 1st input
+ self._propagate_shape_and_type(
+ node, input_index=1, output_index=i)
+
+ def _infer_Range(self, node):
+ vi = self.known_vi_[node.output[0]]
+ input_data = self._get_int_values(node)
+ if all([i is not None for i in input_data]):
+ start = as_scalar(input_data[0])
+ limit = as_scalar(input_data[1])
+ delta = as_scalar(input_data[2])
+ new_sympy_shape = [
+ sympy.Max(sympy.ceiling((limit - start) / delta), 0)
+ ]
+ else:
+ new_sympy_shape = [self._new_symbolic_dim_from_output(node)]
+ self._update_computed_dims(new_sympy_shape)
+ vi.CopyFrom(
+ helper.make_tensor_value_info(
+ node.output[0], self.known_vi_[node.input[0]].type.tensor_type.
+ elem_type, get_shape_from_sympy_shape(new_sympy_shape)))
+
+ def _infer_ReduceSum(self, node):
+ keep_dims = get_attribute(node, 'keepdims', 1)
+ if get_opset(self.out_mp_) >= 13 and len(node.input) > 1:
+ # ReduceSum changes axes to input[1] in opset 13
+ axes = self._try_get_value(node, 1)
+ vi = self.known_vi_[node.output[0]]
+ if axes is None:
+ assert keep_dims # can only handle keep_dims==True when axes is unknown, by generating new ranks
+ vi.CopyFrom(
+ helper.make_tensor_value_info(
+ node.output[0], self.known_vi_[node.input[
+ 0]].type.tensor_type.elem_type,
+ get_shape_from_sympy_shape(
+ self._new_symbolic_shape(
+ self._get_shape_rank(node, 0), node))))
+ else:
+ shape = self._get_shape(node, 0)
+ output_shape = []
+ axes = [handle_negative_axis(a, len(shape)) for a in axes]
+ for i, d in enumerate(shape):
+ if i in axes:
+ if keep_dims:
+ output_shape.append(1)
+ else:
+ output_shape.append(d)
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[
+ 0], self.known_vi_[node.input[
+ 0]].type.tensor_type.elem_type, output_shape))
+
+ def _infer_ReduceProd(self, node):
+ axes = get_attribute(node, 'axes')
+ keep_dims = get_attribute(node, 'keepdims', 1)
+ if keep_dims == 0 and axes == [0]:
+ data = self._get_int_values(node)[0]
+ if data is not None:
+ self.sympy_data_[node.output[0]] = sympy_reduce_product(data)
+
+ def _infer_Reshape(self, node):
+ shape_value = self._try_get_value(node, 1)
+ vi = self.known_vi_[node.output[0]]
+ if shape_value is None:
+ shape_shape = self._get_shape(node, 1)
+ assert len(shape_shape) == 1
+ shape_rank = shape_shape[0]
+ assert is_literal(shape_rank)
+ vi.CopyFrom(
+ helper.make_tensor_value_info(
+ node.output[0], vi.type.tensor_type.elem_type,
+ get_shape_from_sympy_shape(
+ self._new_symbolic_shape(shape_rank, node))))
+ else:
+ input_sympy_shape = self._get_sympy_shape(node, 0)
+ total = int(1)
+ for d in input_sympy_shape:
+ total = total * d
+ new_sympy_shape = []
+ deferred_dim_idx = -1
+ non_deferred_size = int(1)
+ for i, d in enumerate(shape_value):
+ if type(d) == sympy.Symbol:
+ new_sympy_shape.append(d)
+ elif d == 0:
+ new_sympy_shape.append(input_sympy_shape[i])
+ non_deferred_size = non_deferred_size * input_sympy_shape[i]
+ else:
+ new_sympy_shape.append(d)
+ if d == -1:
+ deferred_dim_idx = i
+ elif d != 0:
+ non_deferred_size = non_deferred_size * d
+
+ assert new_sympy_shape.count(-1) < 2
+ if -1 in new_sympy_shape:
+ new_dim = total // non_deferred_size
+ new_sympy_shape[deferred_dim_idx] = new_dim
+
+ self._update_computed_dims(new_sympy_shape)
+ vi.CopyFrom(
+ helper.make_tensor_value_info(
+ node.output[0], vi.type.tensor_type.elem_type,
+ get_shape_from_sympy_shape(new_sympy_shape)))
+
+ self._pass_on_sympy_data(node)
+
+ def _infer_Resize(self, node):
+ vi = self.known_vi_[node.output[0]]
+ input_sympy_shape = self._get_sympy_shape(node, 0)
+ if get_opset(self.out_mp_) <= 10:
+ scales = self._try_get_value(node, 1)
+ if scales is not None:
+ new_sympy_shape = [
+ sympy.simplify(sympy.floor(d * s))
+ for d, s in zip(input_sympy_shape, scales)
+ ]
+ self._update_computed_dims(new_sympy_shape)
+ vi.CopyFrom(
+ helper.make_tensor_value_info(
+ node.output[0], self.known_vi_[node.input[
+ 0]].type.tensor_type.elem_type,
+ get_shape_from_sympy_shape(new_sympy_shape)))
+ else:
+ roi = self._try_get_value(node, 1)
+ scales = self._try_get_value(node, 2)
+ sizes = self._try_get_value(node, 3)
+ if sizes is not None:
+ new_sympy_shape = [
+ sympy.simplify(sympy.floor(s)) for s in sizes
+ ]
+ self._update_computed_dims(new_sympy_shape)
+ elif scales is not None:
+ rank = len(scales)
+ if get_attribute(node, 'coordinate_transformation_mode'
+ ) == 'tf_crop_and_resize':
+ assert len(roi) == 2 * rank
+ roi_start = list(roi)[:rank]
+ roi_end = list(roi)[rank:]
+ else:
+ roi_start = [0] * rank
+ roi_end = [1] * rank
+ scales = list(scales)
+ new_sympy_shape = [
+ sympy.simplify(sympy.floor(d * (end - start) * scale))
+ for d, start, end, scale in
+ zip(input_sympy_shape, roi_start, roi_end, scales)
+ ]
+ self._update_computed_dims(new_sympy_shape)
+ else:
+ new_sympy_shape = self._new_symbolic_shape(
+ self._get_shape_rank(node, 0), node)
+
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[0], self.known_vi_[
+ node.input[0]].type.tensor_type.elem_type,
+ get_shape_from_sympy_shape(
+ new_sympy_shape)))
+
+ def _infer_Scan(self, node):
+ subgraph = get_attribute(node, 'body')
+ num_scan_inputs = get_attribute(node, 'num_scan_inputs')
+ scan_input_axes = get_attribute(node, 'scan_input_axes',
+ [0] * num_scan_inputs)
+ num_scan_states = len(node.input) - num_scan_inputs
+ scan_input_axes = [
+ handle_negative_axis(
+ ax, self._get_shape_rank(node, i + num_scan_states))
+ for i, ax in enumerate(scan_input_axes)
+ ]
+ # We may have cases where the subgraph has optionial inputs that appear in both subgraph's input and initializer,
+ # but not in the node's input. In such cases, the input model might be invalid, but let's skip those optional inputs.
+ assert len(subgraph.input) >= len(node.input)
+ subgraph_inputs = subgraph.input[:len(node.input)]
+ for i, si in enumerate(subgraph_inputs):
+ subgraph_name = si.name
+ si.CopyFrom(self.known_vi_[node.input[i]])
+ if i >= num_scan_states:
+ scan_input_dim = si.type.tensor_type.shape.dim
+ scan_input_dim.remove(
+ scan_input_dim[scan_input_axes[i - num_scan_states]])
+ si.name = subgraph_name
+ self._onnx_infer_subgraph(node, subgraph)
+ num_scan_outputs = len(node.output) - num_scan_states
+ scan_output_axes = get_attribute(node, 'scan_output_axes',
+ [0] * num_scan_outputs)
+ scan_input_dim = get_shape_from_type_proto(
+ self.known_vi_[node.input[-1]].type)[scan_input_axes[-1]]
+ for i, o in enumerate(node.output):
+ vi = self.known_vi_[o]
+ if i >= num_scan_states:
+ shape = get_shape_from_type_proto(subgraph.output[i].type)
+ new_dim = handle_negative_axis(
+ scan_output_axes[i - num_scan_states], len(shape) + 1)
+ shape = shape[:new_dim] + [scan_input_dim] + shape[new_dim:]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(o, subgraph.output[
+ i].type.tensor_type.elem_type, shape))
+ else:
+ vi.CopyFrom(subgraph.output[i])
+ vi.name = o
+
+ def _infer_ScatterElements(self, node):
+ data_shape = self._get_shape(node, 0)
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[0], self.known_vi_[
+ node.input[0]].type.tensor_type.elem_type, data_shape))
+
+ def _infer_SequenceAt(self, node):
+ # need to create new symbolic dimension if sequence shape has None:
+ seq_shape = self._get_shape(node, 0)
+ vi = self.known_vi_[node.output[0]]
+ if seq_shape is not None:
+ for di, d in enumerate(seq_shape):
+ if d is not None:
+ continue
+ new_dim = onnx.TensorShapeProto.Dimension()
+ new_dim.dim_param = str(
+ self._new_symbolic_dim_from_output(node, 0, di))
+ vi.type.tensor_type.shape.dim[di].CopyFrom(new_dim)
+
+ def _infer_SequenceInsert(self, node):
+ # workaround bug in onnx's shape inference
+ vi_seq = self.known_vi_[node.input[0]]
+ vi_tensor = self.known_vi_[node.input[1]]
+ vi_out_seq = self.known_vi_[node.output[0]]
+ vi_out_seq.CopyFrom(vi_seq)
+ vi_out_seq.name = node.output[0]
+ self._fuse_tensor_type(node, 0, vi_out_seq.type, vi_tensor.type)
+
+ def _infer_Shape(self, node):
+ self.sympy_data_[node.output[0]] = self._get_sympy_shape(node, 0)
+
+ def _infer_Size(self, node):
+ sympy_shape = self._get_sympy_shape(node, 0)
+ self.sympy_data_[node.output[0]] = sympy_reduce_product(sympy_shape)
+ self.known_vi_[node.output[0]].CopyFrom(
+ helper.make_tensor_value_info(node.output[0],
+ onnx.TensorProto.INT64, []))
+
+ def _infer_Slice(self, node):
+ def less_equal(x, y):
+ try:
+ return bool(x <= y)
+ except TypeError:
+ pass
+ try:
+ return bool(y >= x)
+ except TypeError:
+ pass
+ try:
+ return bool(-x >= -y)
+ except TypeError:
+ pass
+ try:
+ return bool(-y <= -x)
+ except TypeError:
+ # the last attempt; this may raise TypeError
+ return bool(y - x >= 0)
+
+ def handle_negative_index(index, bound):
+ """ normalizes a negative index to be in [0, bound) """
+ try:
+ if not less_equal(0, index):
+ if is_literal(index) and index <= -self.int_max_:
+ # this case is handled separately
+ return index
+ return bound + index
+ except TypeError:
+ logger.warning("Cannot determine if {} < 0".format(index))
+ return index
+
+ if get_opset(self.out_mp_) <= 9:
+ axes = get_attribute(node, 'axes')
+ starts = get_attribute(node, 'starts')
+ ends = get_attribute(node, 'ends')
+ if not axes:
+ axes = list(range(len(starts)))
+ steps = [1] * len(axes)
+ else:
+ starts = as_list(self._try_get_value(node, 1), keep_none=True)
+ ends = as_list(self._try_get_value(node, 2), keep_none=True)
+ axes = self._try_get_value(node, 3)
+ steps = self._try_get_value(node, 4)
+ if axes is None and not (starts is None and ends is None):
+ axes = list(
+ range(0, len(starts if starts is not None else ends)))
+ if steps is None and not (starts is None and ends is None):
+ steps = [1] * len(starts if starts is not None else ends)
+ axes = as_list(axes, keep_none=True)
+ steps = as_list(steps, keep_none=True)
+
+ new_sympy_shape = self._get_sympy_shape(node, 0)
+ if starts is None or ends is None:
+ if axes is None:
+ for i in range(len(new_sympy_shape)):
+ new_sympy_shape[i] = self._new_symbolic_dim_from_output(
+ node, 0, i)
+ else:
+ new_sympy_shape = get_shape_from_sympy_shape(new_sympy_shape)
+ for i in axes:
+ new_sympy_shape[i] = self._new_symbolic_dim_from_output(
+ node, 0, i)
+ else:
+ for i, s, e, t in zip(axes, starts, ends, steps):
+ e = handle_negative_index(e, new_sympy_shape[i])
+ if is_literal(e):
+ if e >= self.int_max_:
+ e = new_sympy_shape[i]
+ elif e <= -self.int_max_:
+ e = 0 if s > 0 else -1
+ elif is_literal(new_sympy_shape[i]):
+ if e < 0:
+ e = max(0, e + new_sympy_shape[i])
+ e = min(e, new_sympy_shape[i])
+ else:
+ if e > 0:
+ e = sympy.Min(
+ e, new_sympy_shape[i]
+ ) if e > 1 else e #special case for slicing first to make computation easier
+ else:
+ if is_literal(new_sympy_shape[i]):
+ e = sympy.Min(e, new_sympy_shape[i])
+ else:
+ try:
+ if not less_equal(e, new_sympy_shape[i]):
+ e = new_sympy_shape[i]
+ except Exception:
+ logger.warning(
+ 'Unable to determine if {} <= {}, treat as equal'.
+ format(e, new_sympy_shape[i]))
+ e = new_sympy_shape[i]
+
+ s = handle_negative_index(s, new_sympy_shape[i])
+ if is_literal(new_sympy_shape[i]) and is_literal(s):
+ s = max(0, min(s, new_sympy_shape[i]))
+
+ new_sympy_shape[i] = sympy.simplify(
+ (e - s + t + (-1 if t > 0 else 1)) // t)
+
+ self._update_computed_dims(new_sympy_shape)
+
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(
+ node.output[0], vi.type.tensor_type.elem_type,
+ get_shape_from_sympy_shape(new_sympy_shape)))
+
+ # handle sympy_data if needed, for slice in shape computation
+ if (node.input[0] in self.sympy_data_ and [0] == axes and
+ len(starts) == 1 and len(ends) == 1 and len(steps) == 1):
+ input_sympy_data = self.sympy_data_[node.input[0]]
+ if type(input_sympy_data) == list or (
+ type(input_sympy_data) == np.array and
+ len(input_sympy_data.shape) == 1):
+ self.sympy_data_[node.output[0]] = input_sympy_data[starts[
+ 0]:ends[0]:steps[0]]
+
+ def _infer_SoftmaxCrossEntropyLoss(self, node):
+ vi = self.known_vi_[node.output[0]]
+ elem_type = self.known_vi_[node.input[0]].type.tensor_type.elem_type
+ vi.type.tensor_type.elem_type = elem_type
+ vi.type.tensor_type.shape.CopyFrom(onnx.TensorShapeProto())
+
+ if len(node.output) > 1:
+ data_shape = self._get_shape(node, 0)
+ vi = self.known_vi_[node.output[1]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(vi.name, elem_type, data_shape))
+
+ def _infer_Split_Common(self, node, make_value_info_func):
+ input_sympy_shape = self._get_sympy_shape(node, 0)
+ axis = handle_negative_axis(
+ get_attribute(node, 'axis', 0), len(input_sympy_shape))
+ split = get_attribute(node, 'split')
+ if not split:
+ num_outputs = len(node.output)
+ split = [input_sympy_shape[axis] /
+ sympy.Integer(num_outputs)] * num_outputs
+ self._update_computed_dims(split)
+ else:
+ split = [sympy.Integer(s) for s in split]
+
+ for i_o in range(len(split)):
+ vi = self.known_vi_[node.output[i_o]]
+ vi.CopyFrom(
+ make_value_info_func(node.output[i_o], self.known_vi_[
+ node.input[0]].type.tensor_type.elem_type,
+ get_shape_from_sympy_shape(
+ input_sympy_shape[:axis] + [
+ split[i_o]
+ ] + input_sympy_shape[axis + 1:])))
+ self.known_vi_[vi.name] = vi
+
+ def _infer_Split(self, node):
+ self._infer_Split_Common(node, helper.make_tensor_value_info)
+
+ def _infer_SplitToSequence(self, node):
+ self._infer_Split_Common(node, helper.make_sequence_value_info)
+
+ def _infer_Squeeze(self, node):
+ input_shape = self._get_shape(node, 0)
+ op_set = get_opset(self.out_mp_)
+
+ # Depending on op-version 'axes' are provided as attribute or via 2nd input
+ if op_set < 13:
+ axes = get_attribute(node, 'axes')
+ assert self._try_get_value(node, 1) is None
+ else:
+ axes = self._try_get_value(node, 1)
+ assert get_attribute(node, 'axes') is None
+
+ if axes is None:
+ # No axes have been provided (neither via attribute nor via input).
+ # In this case the 'Shape' op should remove all axis with dimension 1.
+ # For symbolic dimensions we guess they are !=1.
+ output_shape = [s for s in input_shape if s != 1]
+ if self.verbose_ > 0:
+ symbolic_dimensions = [s for s in input_shape if type(s) != int]
+ if len(symbolic_dimensions) > 0:
+ logger.debug(
+ f"Symbolic dimensions in input shape of op: '{node.op_type}' node: '{node.name}'. "
+ +
+ f"Assuming the following dimensions are never equal to 1: {symbolic_dimensions}"
+ )
+ else:
+ axes = [handle_negative_axis(a, len(input_shape)) for a in axes]
+ output_shape = []
+ for i in range(len(input_shape)):
+ if i not in axes:
+ output_shape.append(input_shape[i])
+ else:
+ assert input_shape[i] == 1 or type(input_shape[i]) != int
+ if self.verbose_ > 0 and type(input_shape[i]) != int:
+ logger.debug(
+ f"Symbolic dimensions in input shape of op: '{node.op_type}' node: '{node.name}'. "
+ +
+ f"Assuming the dimension '{input_shape[i]}' at index {i} of the input to be equal to 1."
+ )
+
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[0], self.known_vi_[
+ node.input[0]].type.tensor_type.elem_type, output_shape))
+ self._pass_on_sympy_data(node)
+
+ def _infer_Tile(self, node):
+ repeats_value = self._try_get_value(node, 1)
+ new_sympy_shape = []
+ if repeats_value is not None:
+ input_sympy_shape = self._get_sympy_shape(node, 0)
+ for i, d in enumerate(input_sympy_shape):
+ new_dim = d * repeats_value[i]
+ new_sympy_shape.append(new_dim)
+ self._update_computed_dims(new_sympy_shape)
+ else:
+ new_sympy_shape = self._new_symbolic_shape(
+ self._get_shape_rank(node, 0), node)
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(
+ node.output[0], vi.type.tensor_type.elem_type,
+ get_shape_from_sympy_shape(new_sympy_shape)))
+
+ def _infer_TopK(self, node):
+ rank = self._get_shape_rank(node, 0)
+ axis = handle_negative_axis(get_attribute(node, 'axis', -1), rank)
+ new_shape = self._get_shape(node, 0)
+
+ if get_opset(self.out_mp_) <= 9:
+ k = get_attribute(node, 'k')
+ else:
+ k = self._get_int_values(node)[1]
+
+ if k == None:
+ k = self._new_symbolic_dim_from_output(node)
+ else:
+ k = as_scalar(k)
+
+ if type(k) in [int, str]:
+ new_shape[axis] = k
+ else:
+ new_sympy_shape = self._get_sympy_shape(node, 0)
+ new_sympy_shape[axis] = k
+ self._update_computed_dims(
+ new_sympy_shape
+ ) # note that TopK dim could be computed in sympy_data, so need to update computed_dims when it enters shape
+ new_shape = get_shape_from_sympy_shape(new_sympy_shape)
+
+ for i_o in range(len(node.output)):
+ vi = self.known_vi_[node.output[i_o]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[
+ i_o], vi.type.tensor_type.elem_type, new_shape))
+
+ def _infer_Transpose(self, node):
+ if node.input[0] in self.sympy_data_:
+ data_shape = self._get_shape(node, 0)
+ perm = get_attribute(node, 'perm',
+ reversed(list(range(len(data_shape)))))
+ input_data = self.sympy_data_[node.input[0]]
+ self.sympy_data_[node.output[0]] = np.transpose(
+ np.array(input_data).reshape(*data_shape),
+ axes=tuple(perm)).flatten().tolist()
+
+ def _infer_Unsqueeze(self, node):
+ input_shape = self._get_shape(node, 0)
+ op_set = get_opset(self.out_mp_)
+
+ # Depending on op-version 'axes' are provided as attribute or via 2nd input
+ if op_set < 13:
+ axes = get_attribute(node, 'axes')
+ assert self._try_get_value(node, 1) is None
+ else:
+ axes = self._try_get_value(node, 1)
+ assert get_attribute(node, 'axes') is None
+
+ output_rank = len(input_shape) + len(axes)
+ axes = [handle_negative_axis(a, output_rank) for a in axes]
+
+ input_axis = 0
+ output_shape = []
+ for i in range(output_rank):
+ if i in axes:
+ output_shape.append(1)
+ else:
+ output_shape.append(input_shape[input_axis])
+ input_axis += 1
+
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[0], self.known_vi_[
+ node.input[0]].type.tensor_type.elem_type, output_shape))
+
+ self._pass_on_sympy_data(node)
+
+ def _infer_ZipMap(self, node):
+ map_key_type = None
+ if get_attribute(node, 'classlabels_int64s') is not None:
+ map_key_type = onnx.TensorProto.INT64
+ elif get_attribute(node, 'classlabels_strings') is not None:
+ map_key_type = onnx.TensorProto.STRING
+
+ assert map_key_type is not None
+ new_vi = onnx.ValueInfoProto()
+ new_vi.name = node.output[0]
+ new_vi.type.sequence_type.elem_type.map_type.value_type.tensor_type.elem_type = onnx.TensorProto.FLOAT
+ new_vi.type.sequence_type.elem_type.map_type.key_type = map_key_type
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(new_vi)
+
+ def _infer_Attention(self, node):
+ shape = self._get_shape(node, 0)
+ shape_bias = self._get_shape(node, 2)
+ assert len(shape) == 3 and len(shape_bias) == 1
+ qkv_hidden_sizes_attr = get_attribute(node, 'qkv_hidden_sizes')
+ if qkv_hidden_sizes_attr is not None:
+ assert len(qkv_hidden_sizes_attr) == 3
+ shape[2] = int(qkv_hidden_sizes_attr[2])
+ else:
+ shape[2] = int(shape_bias[0] / 3)
+ output_dtype = self.known_vi_[node.input[0]].type.tensor_type.elem_type
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[0], output_dtype, shape))
+
+ if len(node.output) > 1:
+ # input shape: (batch_size, sequence_length, hidden_size)
+ # past shape: (2, batch_size, num_heads, past_sequence_length, head_size)
+ # mask shape: (batch_size, total_sequence_length) or (batch_size, sequence_length, total_sequence_length) or (batch_size, 1, max_seq_len, max_seq_len)
+ # present shape: (2, batch_size, num_heads, total_sequence_length, head_size), where total_sequence_length=sequence_length+past_sequence_length
+ input_shape = self._get_shape(node, 0)
+ past_shape = self._get_shape(node, 4)
+ mask_shape = self._get_shape(node, 3)
+ if len(past_shape) == 5:
+ if len(mask_shape) in [2, 3]:
+ past_shape[3] = mask_shape[-1]
+ elif isinstance(input_shape[1], int) and isinstance(
+ past_shape[3], int):
+ past_shape[3] = input_shape[1] + past_shape[3]
+ else:
+ past_shape[3] = f"{past_shape[3]}+{input_shape[1]}"
+ vi = self.known_vi_[node.output[1]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(vi.name, output_dtype,
+ past_shape))
+
+ def _infer_BiasGelu(self, node):
+ self._propagate_shape_and_type(node)
+
+ def _infer_FastGelu(self, node):
+ self._propagate_shape_and_type(node)
+
+ def _infer_Gelu(self, node):
+ self._propagate_shape_and_type(node)
+
+ def _infer_LayerNormalization(self, node):
+ self._propagate_shape_and_type(node)
+
+ def _infer_LongformerAttention(self, node):
+ self._propagate_shape_and_type(node)
+
+ def _infer_EmbedLayerNormalization(self, node):
+ input_ids_shape = self._get_shape(node, 0)
+ word_embedding_shape = self._get_shape(node, 2)
+ assert len(input_ids_shape) == 2 and len(word_embedding_shape) == 2
+ output_shape = input_ids_shape + [word_embedding_shape[1]]
+
+ word_embedding_dtype = self.known_vi_[node.input[
+ 2]].type.tensor_type.elem_type
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[0], word_embedding_dtype,
+ output_shape))
+
+ mask_index_shape = [input_ids_shape[0]]
+ vi = self.known_vi_[node.output[1]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[
+ 1], onnx.TensorProto.INT32, mask_index_shape))
+
+ if len(node.output) > 2:
+ # Optional output of add before layer nomalization is done
+ # shape is same as the output
+ vi = self.known_vi_[node.output[2]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[
+ 2], word_embedding_dtype, output_shape))
+
+ def _infer_SkipLayerNormalization(self, node):
+ self._propagate_shape_and_type(node)
+
+ def _infer_PythonOp(self, node):
+ output_tensor_types = get_attribute(node, 'output_tensor_types')
+ assert output_tensor_types
+ output_tensor_ranks = get_attribute(node, 'output_tensor_ranks')
+ assert output_tensor_ranks
+
+ # set the context output seperately.
+ # The first output is autograd's context.
+ vi = self.known_vi_[node.output[0]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[0],
+ onnx.TensorProto.INT64, []))
+
+ # Outputs after autograd's context are tensors.
+ # We assume their ranks are fixed for different model inputs.
+ for i in range(len(node.output) - 1):
+ # Process the i-th tensor outputs.
+ vi = self.known_vi_[node.output[i + 1]]
+ sympy_shape = self._new_symbolic_shape(output_tensor_ranks[i], node)
+ shape = get_shape_from_sympy_shape(sympy_shape)
+ value_info = helper.make_tensor_value_info(
+ node.output[i + 1], output_tensor_types[i], shape)
+ vi.CopyFrom(value_info)
+
+ def _propagate_shape_and_type(self, node, input_index=0, output_index=0):
+ shape = self._get_shape(node, input_index)
+ output_dtype = self.known_vi_[node.input[
+ input_index]].type.tensor_type.elem_type
+ vi = self.known_vi_[node.output[output_index]]
+ vi.CopyFrom(
+ helper.make_tensor_value_info(node.output[output_index],
+ output_dtype, shape))
+
+ def _is_none_dim(self, dim_value):
+ if type(dim_value) != str:
+ return False
+ if "unk__" not in dim_value:
+ return False
+ if dim_value in self.symbolic_dims_.keys():
+ return False
+ return True
+
+ def _is_shape_contains_none_dim(self, out_shape):
+ for out in out_shape:
+ if self._is_none_dim(out):
+ return out
+ return None
+
+ def _infer_impl(self, start_sympy_data=None):
+ self.sympy_data_ = start_sympy_data or {}
+ self.out_mp_.graph.ClearField('value_info')
+ self._apply_suggested_merge(graph_input_only=True)
+ self.input_symbols_ = set()
+ for i in self.out_mp_.graph.input:
+ input_shape = get_shape_from_value_info(i)
+ if input_shape is None:
+ continue
+
+ if is_sequence(i.type):
+ input_dims = i.type.sequence_type.elem_type.tensor_type.shape.dim
+ else:
+ input_dims = i.type.tensor_type.shape.dim
+
+ for i_dim, dim in enumerate(input_shape):
+ if dim is None:
+ # some models use None for symbolic dim in input, replace it with a string
+ input_dims[i_dim].dim_param = str(
+ self._new_symbolic_dim(i.name, i_dim))
+
+ self.input_symbols_.update(
+ [d for d in input_shape if type(d) == str])
+
+ for s in self.input_symbols_:
+ if s in self.suggested_merge_:
+ s_merge = self.suggested_merge_[s]
+ assert s_merge in self.symbolic_dims_
+ self.symbolic_dims_[s] = self.symbolic_dims_[s_merge]
+ else:
+ # Since inputs are not produced by other ops, we can assume positivity
+ self.symbolic_dims_[s] = sympy.Symbol(
+ s, integer=True, positive=True)
+ # create a temporary ModelProto for single node inference
+ # note that we remove initializer to have faster inference
+ # for tensor ops like Reshape/Tile/Expand that read initializer, we need to do sympy computation based inference anyways
+ self.tmp_mp_ = onnx.ModelProto()
+ self.tmp_mp_.CopyFrom(self.out_mp_)
+ self.tmp_mp_.graph.ClearField('initializer')
+
+ # compute prerequesite for node for topological sort
+ # node with subgraphs may have dependency on implicit inputs, which will affect topological sort
+ prereq_for_node = {
+ } # map from node to all its inputs, including implicit ones in subgraph
+
+ def get_prereq(node):
+ names = set(i for i in node.input if i)
+ subgraphs = []
+ if 'If' == node.op_type:
+ subgraphs = [
+ get_attribute(node, 'then_branch'),
+ get_attribute(node, 'else_branch')
+ ]
+ elif node.op_type in ['Loop', 'Scan']:
+ subgraphs = [get_attribute(node, 'body')]
+ for g in subgraphs:
+ g_outputs_and_initializers = {i.name for i in g.initializer}
+ g_prereq = set()
+ for n in g.node:
+ g_outputs_and_initializers.update(n.output)
+ for n in g.node:
+ g_prereq.update([
+ i for i in get_prereq(n)
+ if i not in g_outputs_and_initializers
+ ])
+ names.update(g_prereq)
+ # remove subgraph inputs from g_prereq since those are local-only
+ for i in g.input:
+ if i.name in names:
+ names.remove(i.name)
+ return names
+
+ for n in self.tmp_mp_.graph.node:
+ prereq_for_node[n.output[0]] = get_prereq(n)
+
+ # topological sort nodes, note there might be dead nodes so we check if all graph outputs are reached to terminate
+ sorted_nodes = []
+ sorted_known_vi = set([
+ i.name for i in list(self.out_mp_.graph.input) +
+ list(self.out_mp_.graph.initializer)
+ ])
+ if any([o.name in sorted_known_vi for o in self.out_mp_.graph.output]):
+ # Loop/Scan will have some graph output in graph inputs, so don't do topological sort
+ sorted_nodes = self.out_mp_.graph.node
+ else:
+ while not all(
+ [o.name in sorted_known_vi for o in self.out_mp_.graph.output]):
+ old_sorted_nodes_len = len(sorted_nodes)
+ for node in self.out_mp_.graph.node:
+ if (node.output[0] not in sorted_known_vi) and all([
+ i in sorted_known_vi
+ for i in prereq_for_node[node.output[0]] if i
+ ]):
+ sorted_known_vi.update(node.output)
+ sorted_nodes.append(node)
+ if old_sorted_nodes_len == len(sorted_nodes) and not all([
+ o.name in sorted_known_vi
+ for o in self.out_mp_.graph.output
+ ]):
+ raise Exception('Invalid model with cyclic graph')
+
+ for node in sorted_nodes:
+ assert all([i in self.known_vi_ for i in node.input if i])
+ self._onnx_infer_single_node(node)
+ known_aten_op = False
+ if node.op_type in self.dispatcher_:
+ self.dispatcher_[node.op_type](node)
+ elif node.op_type in ['ConvTranspose']:
+ # onnx shape inference ops like ConvTranspose may have empty shape for symbolic input
+ # before adding symbolic compute for them
+ # mark the output type as UNDEFINED to allow guessing of rank
+ vi = self.known_vi_[node.output[0]]
+ if len(vi.type.tensor_type.shape.dim) == 0:
+ vi.type.tensor_type.elem_type = onnx.TensorProto.UNDEFINED
+ elif node.op_type == 'ATen' and node.domain == 'org.pytorch.aten':
+ for attr in node.attribute:
+ # TODO: Is overload_name needed?
+ if attr.name == 'operator':
+ aten_op_name = attr.s.decode('utf-8') if isinstance(
+ attr.s, bytes) else attr.s
+ if aten_op_name in self.aten_op_dispatcher_:
+ known_aten_op = True
+ self.aten_op_dispatcher_[aten_op_name](node)
+ break
+
+ if self.verbose_ > 2:
+ logger.debug(node.op_type + ': ' + node.name)
+ for i, name in enumerate(node.input):
+ logger.debug(' Input {}: {} {}'.format(
+ i, name, 'initializer'
+ if name in self.initializers_ else ''))
+
+ # onnx automatically merge dims with value, i.e. Mul(['aaa', 'bbb'], [1000, 1]) -> [1000, 'bbb']
+ # symbolic shape inference needs to apply merge of 'aaa' -> 1000 in this case
+ if node.op_type in [
+ 'Add', 'Sub', 'Mul', 'Div', 'MatMul', 'MatMulInteger',
+ 'MatMulInteger16', 'Where', 'Sum'
+ ]:
+ vi = self.known_vi_[node.output[0]]
+ out_rank = len(get_shape_from_type_proto(vi.type))
+ in_shapes = [
+ self._get_shape(node, i) for i in range(len(node.input))
+ ]
+ for d in range(out_rank - (2 if node.op_type in [
+ 'MatMul', 'MatMulInteger', 'MatMulInteger16'
+ ] else 0)):
+ in_dims = [
+ s[len(s) - out_rank + d] for s in in_shapes
+ if len(s) + d >= out_rank
+ ]
+ if len(in_dims) > 1:
+ self._check_merged_dims(in_dims, allow_broadcast=True)
+
+ for i_o in range(len(node.output)):
+ vi = self.known_vi_[node.output[i_o]]
+ out_type = vi.type
+ out_type_kind = out_type.WhichOneof('value')
+
+ # do not process shape for non-tensors
+ if out_type_kind not in [
+ 'tensor_type', 'sparse_tensor_type', None
+ ]:
+ if self.verbose_ > 2:
+ if out_type_kind == 'sequence_type':
+ seq_cls_type = out_type.sequence_type.elem_type.WhichOneof(
+ 'value')
+ if 'tensor_type' == seq_cls_type:
+ logger.debug(' {}: sequence of {} {}'.format(
+ node.output[i_o],
+ str(get_shape_from_value_info(vi)),
+ onnx.TensorProto.DataType.Name(
+ vi.type.sequence_type.elem_type.
+ tensor_type.elem_type)))
+ else:
+ logger.debug(' {}: sequence of {}'.format(
+ node.output[i_o], seq_cls_type))
+ else:
+ logger.debug(' {}: {}'.format(node.output[i_o],
+ out_type_kind))
+ continue
+
+ out_shape = get_shape_from_value_info(vi)
+ out_type_undefined = out_type.tensor_type.elem_type == onnx.TensorProto.UNDEFINED
+ if self.verbose_ > 2:
+ logger.debug(' {}: {} {}'.format(
+ node.output[i_o],
+ str(out_shape),
+ onnx.TensorProto.DataType.Name(
+ vi.type.tensor_type.elem_type)))
+ if node.output[i_o] in self.sympy_data_:
+ logger.debug(' Sympy Data: ' + str(self.sympy_data_[
+ node.output[i_o]]))
+
+ # onnx >= 1.11.0, use unk__#index instead of None when the shape dim is uncertain
+ if (out_shape is not None and
+ (None in out_shape or
+ self._is_shape_contains_none_dim(out_shape))
+ ) or out_type_undefined:
+ if self.auto_merge_:
+ if node.op_type in [
+ 'Add', 'Sub', 'Mul', 'Div', 'MatMul',
+ 'MatMulInteger', 'MatMulInteger16', 'Concat',
+ 'Where', 'Sum', 'Equal', 'Less', 'Greater',
+ 'LessOrEqual', 'GreaterOrEqual'
+ ]:
+ shapes = [
+ self._get_shape(node, i)
+ for i in range(len(node.input))
+ ]
+ if node.op_type in [
+ 'MatMul', 'MatMulInteger', 'MatMulInteger16'
+ ]:
+ if None in out_shape or self._is_shape_contains_none_dim(
+ out_shape):
+ if None in out_shape:
+ idx = out_shape.index(None)
+ else:
+ idx = out_shape.index(
+ self._is_shape_contains_none_dim(
+ out_shape))
+ dim_idx = [
+ len(s) - len(out_shape) + idx
+ for s in shapes
+ ]
+ # only support auto merge for MatMul for dim < rank-2 when rank > 2
+ assert len(
+ shapes[0]) > 2 and dim_idx[0] < len(
+ shapes[0]) - 2
+ assert len(
+ shapes[1]) > 2 and dim_idx[1] < len(
+ shapes[1]) - 2
+ elif node.op_type == 'Expand':
+ # auto merge for cases like Expand([min(batch, 1), min(seq, 512)], [batch, seq])
+ shapes = [
+ self._get_shape(node, 0), self._get_value(node,
+ 1)
+ ]
+ else:
+ shapes = []
+
+ if shapes:
+ for idx in range(len(out_shape)):
+ if out_shape[
+ idx] is not None and not self._is_none_dim(
+ out_shape[idx]):
+ continue
+ # note that the broadcasting rule aligns from right to left
+ # if a tensor has a lower rank (dim_idx[idx] < 0), it would automatically broadcast and need no merge
+ dim_idx = [
+ len(s) - len(out_shape) + idx
+ for s in shapes
+ ]
+ if len(dim_idx) > 0:
+ self._add_suggested_merge([
+ s[i] if is_literal(s[i]) else str(s[i])
+ for s, i in zip(shapes, dim_idx)
+ if i >= 0
+ ])
+ self.run_ = True
+ else:
+ self.run_ = False
+ else:
+ self.run_ = False
+
+ # create new dynamic dims for ops not handled by symbolic shape inference
+ if self.run_ == False and not node.op_type in self.dispatcher_ and not known_aten_op:
+ is_unknown_op = out_type_undefined and (
+ out_shape is None or len(out_shape) == 0)
+ if is_unknown_op:
+ # unknown op to ONNX, maybe from higher opset or other domain
+ # only guess the output rank from input 0 when using guess_output_rank option
+ out_rank = self._get_shape_rank(
+ node, 0) if self.guess_output_rank_ else -1
+ else:
+ # valid ONNX op, but not handled by symbolic shape inference, just assign dynamic shape
+ out_rank = len(out_shape)
+
+ if out_rank >= 0:
+ new_shape = self._new_symbolic_shape(out_rank, node,
+ i_o)
+ if out_type_undefined:
+ # guess output data type from input vi if not defined
+ out_dtype = self.known_vi_[node.input[
+ 0]].type.tensor_type.elem_type
+ else:
+ # otherwise, use original data type
+ out_dtype = vi.type.tensor_type.elem_type
+ vi.CopyFrom(
+ helper.make_tensor_value_info(
+ vi.name, out_dtype,
+ get_shape_from_sympy_shape(new_shape)))
+
+ if self.verbose_ > 0:
+ if is_unknown_op:
+ logger.debug(
+ "Possible unknown op: {} node: {}, guessing {} shape".
+ format(node.op_type, node.name,
+ vi.name))
+ if self.verbose_ > 2:
+ logger.debug(' {}: {} {}'.format(
+ node.output[i_o],
+ str(new_shape),
+ vi.type.tensor_type.elem_type))
+
+ self.run_ = True
+ continue # continue the inference after guess, no need to stop as no merge is needed
+
+ if self.verbose_ > 0 or not self.auto_merge_ or out_type_undefined:
+ logger.debug(
+ 'Stopping at incomplete shape inference at ' +
+ node.op_type + ': ' + node.name)
+ logger.debug('node inputs:')
+ for i in node.input:
+ logger.debug(self.known_vi_[i])
+ logger.debug('node outputs:')
+ for o in node.output:
+ logger.debug(self.known_vi_[o])
+ if self.auto_merge_ and not out_type_undefined:
+ logger.debug('Merging: ' + str(
+ self.suggested_merge_))
+ return False
+
+ self.run_ = False
+ return True
+
+ def _update_output_from_vi(self):
+ for output in self.out_mp_.graph.output:
+ if output.name in self.known_vi_:
+ output.CopyFrom(self.known_vi_[output.name])
+
+ @staticmethod
+ def infer_shapes(in_mp,
+ int_max=2**31 - 1,
+ auto_merge=False,
+ guess_output_rank=False,
+ verbose=0):
+ onnx_opset = get_opset(in_mp)
+ if (not onnx_opset) or onnx_opset < 7:
+ logger.warning('Only support models of onnx opset 7 and above.')
+ return None
+ symbolic_shape_inference = SymbolicShapeInference(
+ int_max, auto_merge, guess_output_rank, verbose)
+ all_shapes_inferred = False
+ symbolic_shape_inference._preprocess(in_mp)
+ while symbolic_shape_inference.run_:
+ all_shapes_inferred = symbolic_shape_inference._infer_impl()
+ symbolic_shape_inference._update_output_from_vi()
+ if not all_shapes_inferred:
+ raise Exception("Incomplete symbolic shape inference")
+ return symbolic_shape_inference.out_mp_
+
+
+def parse_arguments():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--input', required=True, help='The input model file')
+ parser.add_argument('--output', help='The output model file')
+ parser.add_argument(
+ '--auto_merge',
+ help='Automatically merge symbolic dims when confliction happens',
+ action='store_true',
+ default=False)
+ parser.add_argument(
+ '--int_max',
+ help='maximum value for integer to be treated as boundless for ops like slice',
+ type=int,
+ default=2**31 - 1)
+ parser.add_argument(
+ '--guess_output_rank',
+ help='guess output rank to be the same as input 0 for unknown ops',
+ action='store_true',
+ default=False)
+ parser.add_argument(
+ '--verbose',
+ help='Prints detailed logs of inference, 0: turn off, 1: warnings, 3: detailed',
+ type=int,
+ default=0)
+ return parser.parse_args()
+
+
+if __name__ == '__main__':
+ args = parse_arguments()
+ logger.info('input model: ' + args.input)
+ if args.output:
+ logger.info('output model ' + args.output)
+ logger.info('Doing symbolic shape inference...')
+ out_mp = SymbolicShapeInference.infer_shapes(
+ onnx.load(args.input), args.int_max, args.auto_merge,
+ args.guess_output_rank, args.verbose)
+ if args.output and out_mp:
+ onnx.save(out_mp, args.output)
+ logger.info('Done!')
diff --git a/speechx/examples/ds2_ol/onnx/local/onnx_opt.sh b/speechx/examples/ds2_ol/onnx/local/onnx_opt.sh
new file mode 100755
index 000000000..ce2f24e58
--- /dev/null
+++ b/speechx/examples/ds2_ol/onnx/local/onnx_opt.sh
@@ -0,0 +1,20 @@
+#!/bin/bash
+
+set -e
+
+if [ $# != 3 ];then
+ # ./local/onnx_opt.sh model.old.onnx model.opt.onnx "audio_chunk:1,-1,161 audio_chunk_lens:1 chunk_state_c_box:5,1,1024 chunk_state_h_box:5,1,1024"
+ echo "usage: $0 onnx.model.in onnx.model.out input_shape "
+ exit 1
+fi
+
+# onnx optimizer
+pip install onnx-simplifier
+
+in=$1
+out=$2
+input_shape=$3
+
+check_n=3
+
+onnxsim $in $out $check_n --dynamic-input-shape --input-shape $input_shape
\ No newline at end of file
diff --git a/speechx/examples/ds2_ol/onnx/local/onnx_prune_model.py b/speechx/examples/ds2_ol/onnx/local/onnx_prune_model.py
new file mode 100755
index 000000000..5b85eef3e
--- /dev/null
+++ b/speechx/examples/ds2_ol/onnx/local/onnx_prune_model.py
@@ -0,0 +1,128 @@
+#!/usr/bin/env python3 -W ignore::DeprecationWarning
+# prune model by output names
+import argparse
+import copy
+import sys
+
+import onnx
+
+
+def parse_arguments():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ '--model',
+ required=True,
+ help='Path of directory saved the input model.')
+ parser.add_argument(
+ '--output_names',
+ required=True,
+ nargs='+',
+ help='The outputs of pruned model.')
+ parser.add_argument(
+ '--save_file', required=True, help='Path to save the new onnx model.')
+ return parser.parse_args()
+
+
+if __name__ == '__main__':
+ args = parse_arguments()
+
+ if len(set(args.output_names)) < len(args.output_names):
+ print(
+ "[ERROR] There's dumplicate name in --output_names, which is not allowed."
+ )
+ sys.exit(-1)
+
+ model = onnx.load(args.model)
+
+ # collect all node outputs and graph output
+ output_tensor_names = set()
+ for node in model.graph.node:
+ for out in node.output:
+ # may contain model output
+ output_tensor_names.add(out)
+
+ # for out in model.graph.output:
+ # output_tensor_names.add(out.name)
+
+ for output_name in args.output_names:
+ if output_name not in output_tensor_names:
+ print(
+ "[ERROR] Cannot find output tensor name '{}' in onnx model graph.".
+ format(output_name))
+ sys.exit(-1)
+
+ output_node_indices = set() # has output names
+ output_to_node = dict() # all node outputs
+ for i, node in enumerate(model.graph.node):
+ for out in node.output:
+ output_to_node[out] = i
+ if out in args.output_names:
+ output_node_indices.add(i)
+
+ # from outputs find all the ancestors
+ reserved_node_indices = copy.deepcopy(
+ output_node_indices) # nodes need to keep
+ reserved_inputs = set() # model input to keep
+ new_output_node_indices = copy.deepcopy(output_node_indices)
+
+ while True and len(new_output_node_indices) > 0:
+ output_node_indices = copy.deepcopy(new_output_node_indices)
+
+ new_output_node_indices = set()
+
+ for out_node_idx in output_node_indices:
+ # backtrace to parenet
+ for ipt in model.graph.node[out_node_idx].input:
+ if ipt in output_to_node:
+ reserved_node_indices.add(output_to_node[ipt])
+ new_output_node_indices.add(output_to_node[ipt])
+ else:
+ reserved_inputs.add(ipt)
+
+ num_inputs = len(model.graph.input)
+ num_outputs = len(model.graph.output)
+ num_nodes = len(model.graph.node)
+ print(
+ f"old graph has {num_inputs} inputs, {num_outputs} outpus, {num_nodes} nodes"
+ )
+ print(f"{len(reserved_node_indices)} node to keep.")
+
+ # del node not to keep
+ for idx in range(num_nodes - 1, -1, -1):
+ if idx not in reserved_node_indices:
+ del model.graph.node[idx]
+
+ # del graph input not to keep
+ for idx in range(num_inputs - 1, -1, -1):
+ if model.graph.input[idx].name not in reserved_inputs:
+ del model.graph.input[idx]
+
+ # del old graph outputs
+ for i in range(num_outputs):
+ del model.graph.output[0]
+
+ # new graph output as user input
+ for out in args.output_names:
+ model.graph.output.extend([onnx.ValueInfoProto(name=out)])
+
+ # infer shape
+ try:
+ from onnx_infer_shape import SymbolicShapeInference
+ model = SymbolicShapeInference.infer_shapes(
+ model,
+ int_max=2**31 - 1,
+ auto_merge=True,
+ guess_output_rank=False,
+ verbose=1)
+ except Exception as e:
+ print(f"skip infer shape step: {e}")
+
+ # check onnx model
+ onnx.checker.check_model(model)
+ # save onnx model
+ onnx.save(model, args.save_file)
+ print("[Finished] The new model saved in {}.".format(args.save_file))
+ print("[DEBUG INFO] The inputs of new model: {}".format(
+ [x.name for x in model.graph.input]))
+ print("[DEBUG INFO] The outputs of new model: {}".format(
+ [x.name for x in model.graph.output]))
diff --git a/speechx/examples/ds2_ol/onnx/local/onnx_rename_model.py b/speechx/examples/ds2_ol/onnx/local/onnx_rename_model.py
new file mode 100755
index 000000000..fc00a82ec
--- /dev/null
+++ b/speechx/examples/ds2_ol/onnx/local/onnx_rename_model.py
@@ -0,0 +1,111 @@
+#!/usr/bin/env python3 -W ignore::DeprecationWarning
+# rename node to new names
+import argparse
+import sys
+
+import onnx
+
+
+def parse_arguments():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ '--model',
+ required=True,
+ help='Path of directory saved the input model.')
+ parser.add_argument(
+ '--origin_names',
+ required=True,
+ nargs='+',
+ help='The original name you want to modify.')
+ parser.add_argument(
+ '--new_names',
+ required=True,
+ nargs='+',
+ help='The new name you want change to, the number of new_names should be same with the number of origin_names'
+ )
+ parser.add_argument(
+ '--save_file', required=True, help='Path to save the new onnx model.')
+ return parser.parse_args()
+
+
+if __name__ == '__main__':
+ args = parse_arguments()
+
+ if len(set(args.origin_names)) < len(args.origin_names):
+ print(
+ "[ERROR] There's dumplicate name in --origin_names, which is not allowed."
+ )
+ sys.exit(-1)
+
+ if len(set(args.new_names)) < len(args.new_names):
+ print(
+ "[ERROR] There's dumplicate name in --new_names, which is not allowed."
+ )
+ sys.exit(-1)
+
+ if len(args.new_names) != len(args.origin_names):
+ print(
+ "[ERROR] Number of --new_names must be same with the number of --origin_names."
+ )
+ sys.exit(-1)
+
+ model = onnx.load(args.model)
+
+ # collect input and all node output
+ output_tensor_names = set()
+ for ipt in model.graph.input:
+ output_tensor_names.add(ipt.name)
+
+ for node in model.graph.node:
+ for out in node.output:
+ output_tensor_names.add(out)
+
+ for origin_name in args.origin_names:
+ if origin_name not in output_tensor_names:
+ print(
+ f"[ERROR] Cannot find tensor name '{origin_name}' in onnx model graph."
+ )
+ sys.exit(-1)
+
+ for new_name in args.new_names:
+ if new_name in output_tensor_names:
+ print(
+ "[ERROR] The defined new_name '{}' is already exist in the onnx model, which is not allowed."
+ )
+ sys.exit(-1)
+
+ # rename graph input
+ for i, ipt in enumerate(model.graph.input):
+ if ipt.name in args.origin_names:
+ idx = args.origin_names.index(ipt.name)
+ model.graph.input[i].name = args.new_names[idx]
+
+ # rename node input and output
+ for i, node in enumerate(model.graph.node):
+ for j, ipt in enumerate(node.input):
+ if ipt in args.origin_names:
+ idx = args.origin_names.index(ipt)
+ model.graph.node[i].input[j] = args.new_names[idx]
+
+ for j, out in enumerate(node.output):
+ if out in args.origin_names:
+ idx = args.origin_names.index(out)
+ model.graph.node[i].output[j] = args.new_names[idx]
+
+ # rename graph output
+ for i, out in enumerate(model.graph.output):
+ if out.name in args.origin_names:
+ idx = args.origin_names.index(out.name)
+ model.graph.output[i].name = args.new_names[idx]
+
+ # check onnx model
+ onnx.checker.check_model(model)
+
+ # save model
+ onnx.save(model, args.save_file)
+
+ print("[Finished] The new model saved in {}.".format(args.save_file))
+ print("[DEBUG INFO] The inputs of new model: {}".format(
+ [x.name for x in model.graph.input]))
+ print("[DEBUG INFO] The outputs of new model: {}".format(
+ [x.name for x in model.graph.output]))
diff --git a/speechx/examples/ds2_ol/onnx/local/ort_opt.py b/speechx/examples/ds2_ol/onnx/local/ort_opt.py
new file mode 100755
index 000000000..8e995bcf0
--- /dev/null
+++ b/speechx/examples/ds2_ol/onnx/local/ort_opt.py
@@ -0,0 +1,45 @@
+#!/usr/bin/env python3
+import argparse
+
+import onnxruntime as ort
+
+# onnxruntime optimizer.
+# https://onnxruntime.ai/docs/performance/graph-optimizations.html
+# https://onnxruntime.ai/docs/api/python/api_summary.html#api
+
+
+def parse_arguments():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ '--model_in', required=True, type=str, help='Path to onnx model.')
+ parser.add_argument(
+ '--opt_level',
+ required=True,
+ type=int,
+ default=0,
+ choices=[0, 1, 2],
+ help='Path to onnx model.')
+ parser.add_argument(
+ '--model_out', required=True, help='path to save the optimized model.')
+ parser.add_argument('--debug', default=False, help='output debug info.')
+ return parser.parse_args()
+
+
+if __name__ == '__main__':
+ args = parse_arguments()
+
+ sess_options = ort.SessionOptions()
+
+ # Set graph optimization level
+ print(f"opt level: {args.opt_level}")
+ if args.opt_level == 0:
+ sess_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_BASIC
+ elif args.opt_level == 1:
+ sess_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_EXTENDED
+ else:
+ sess_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
+
+ # To enable model serialization after graph optimization set this
+ sess_options.optimized_model_filepath = args.model_out
+
+ session = ort.InferenceSession(args.model_in, sess_options)
diff --git a/speechx/examples/ds2_ol/onnx/local/pd_infer_shape.py b/speechx/examples/ds2_ol/onnx/local/pd_infer_shape.py
new file mode 100755
index 000000000..c6e693c6b
--- /dev/null
+++ b/speechx/examples/ds2_ol/onnx/local/pd_infer_shape.py
@@ -0,0 +1,111 @@
+#!/usr/bin/env python3 -W ignore::DeprecationWarning
+# https://github.com/jiangjiajun/PaddleUtils/blob/main/paddle/README.md#2-%E4%BF%AE%E6%94%B9paddle%E6%A8%A1%E5%9E%8B%E8%BE%93%E5%85%A5shape
+import argparse
+
+# paddle inference shape
+
+
+def process_old_ops_desc(program):
+ """set matmul op head_number attr to 1 is not exist.
+
+ Args:
+ program (_type_): _description_
+ """
+ for i in range(len(program.blocks[0].ops)):
+ if program.blocks[0].ops[i].type == "matmul":
+ if not program.blocks[0].ops[i].has_attr("head_number"):
+ program.blocks[0].ops[i]._set_attr("head_number", 1)
+
+
+def infer_shape(program, input_shape_dict):
+ # 2002002
+ model_version = program.desc._version()
+ # 2.2.2
+ paddle_version = paddle.__version__
+ major_ver = model_version // 1000000
+ minor_ver = (model_version - major_ver * 1000000) // 1000
+ patch_ver = model_version - major_ver * 1000000 - minor_ver * 1000
+ model_version = "{}.{}.{}".format(major_ver, minor_ver, patch_ver)
+ if model_version != paddle_version:
+ print(
+ f"[WARNING] The model is saved by paddlepaddle v{model_version}, but now your paddlepaddle is version of {paddle_version}, this difference may cause error, it is recommend you reinstall a same version of paddlepaddle for this model"
+ )
+
+ OP_WITHOUT_KERNEL_SET = {
+ 'feed', 'fetch', 'recurrent', 'go', 'rnn_memory_helper_grad',
+ 'conditional_block', 'while', 'send', 'recv', 'listen_and_serv',
+ 'fl_listen_and_serv', 'ncclInit', 'select', 'checkpoint_notify',
+ 'gen_bkcl_id', 'c_gen_bkcl_id', 'gen_nccl_id', 'c_gen_nccl_id',
+ 'c_comm_init', 'c_sync_calc_stream', 'c_sync_comm_stream',
+ 'queue_generator', 'dequeue', 'enqueue', 'heter_listen_and_serv',
+ 'c_wait_comm', 'c_wait_compute', 'c_gen_hccl_id', 'c_comm_init_hccl',
+ 'copy_cross_scope'
+ }
+
+ for k, v in input_shape_dict.items():
+ program.blocks[0].var(k).desc.set_shape(v)
+
+ for i in range(len(program.blocks)):
+ for j in range(len(program.blocks[0].ops)):
+ # for ops
+ if program.blocks[i].ops[j].type in OP_WITHOUT_KERNEL_SET:
+ print(f"not infer: {program.blocks[i].ops[j].type} op")
+ continue
+ print(f"infer: {program.blocks[i].ops[j].type} op")
+ program.blocks[i].ops[j].desc.infer_shape(program.blocks[i].desc)
+
+
+def parse_arguments():
+ # python pd_infer_shape.py --model_dir data/exp/deepspeech2_online/checkpoints \
+ # --model_filename avg_1.jit.pdmodel\
+ # --params_filename avg_1.jit.pdiparams \
+ # --save_dir . \
+ # --input_shape_dict="{'audio_chunk':[1,-1,161], 'audio_chunk_lens':[1], 'chunk_state_c_box':[5, 1, 1024], 'chunk_state_h_box':[5,1,1024]}"
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ '--model_dir',
+ required=True,
+ help='Path of directory saved the input model.')
+ parser.add_argument(
+ '--model_filename', required=True, help='model.pdmodel.')
+ parser.add_argument(
+ '--params_filename', required=True, help='model.pdiparams.')
+ parser.add_argument(
+ '--save_dir',
+ required=True,
+ help='directory to save the exported model.')
+ parser.add_argument(
+ '--input_shape_dict', required=True, help="The new shape information.")
+ return parser.parse_args()
+
+
+if __name__ == '__main__':
+ args = parse_arguments()
+
+ import paddle
+ paddle.enable_static()
+ import paddle.fluid as fluid
+
+ input_shape_dict_str = args.input_shape_dict
+ input_shape_dict = eval(input_shape_dict_str)
+
+ print("Start to load paddle model...")
+ exe = fluid.Executor(fluid.CPUPlace())
+
+ prog, ipts, outs = fluid.io.load_inference_model(
+ args.model_dir,
+ exe,
+ model_filename=args.model_filename,
+ params_filename=args.params_filename)
+
+ process_old_ops_desc(prog)
+ infer_shape(prog, input_shape_dict)
+
+ fluid.io.save_inference_model(
+ args.save_dir,
+ ipts,
+ outs,
+ exe,
+ prog,
+ model_filename=args.model_filename,
+ params_filename=args.params_filename)
diff --git a/speechx/examples/ds2_ol/onnx/local/pd_prune_model.py b/speechx/examples/ds2_ol/onnx/local/pd_prune_model.py
new file mode 100755
index 000000000..5386a971a
--- /dev/null
+++ b/speechx/examples/ds2_ol/onnx/local/pd_prune_model.py
@@ -0,0 +1,158 @@
+#!/usr/bin/env python3 -W ignore::DeprecationWarning
+# https://github.com/jiangjiajun/PaddleUtils/blob/main/paddle/README.md#1-%E8%A3%81%E5%89%AApaddle%E6%A8%A1%E5%9E%8B
+import argparse
+import sys
+from typing import List
+
+# paddle prune model.
+
+
+def prepend_feed_ops(program,
+ feed_target_names: List[str],
+ feed_holder_name='feed'):
+ import paddle.fluid.core as core
+ if len(feed_target_names) == 0:
+ return
+
+ global_block = program.global_block()
+ feed_var = global_block.create_var(
+ name=feed_holder_name,
+ type=core.VarDesc.VarType.FEED_MINIBATCH,
+ persistable=True, )
+
+ for i, name in enumerate(feed_target_names, 0):
+ if not global_block.has_var(name):
+ print(
+ f"The input[{i}]: '{name}' doesn't exist in pruned inference program, which will be ignored in new saved model."
+ )
+ continue
+
+ out = global_block.var(name)
+ global_block._prepend_op(
+ type='feed',
+ inputs={'X': [feed_var]},
+ outputs={'Out': [out]},
+ attrs={'col': i}, )
+
+
+def append_fetch_ops(program,
+ fetch_target_names: List[str],
+ fetch_holder_name='fetch'):
+ """in the place, we will add the fetch op
+
+ Args:
+ program (_type_): inference program
+ fetch_target_names (List[str]): target names
+ fetch_holder_name (str, optional): fetch op name. Defaults to 'fetch'.
+ """
+ import paddle.fluid.core as core
+ global_block = program.global_block()
+ fetch_var = global_block.create_var(
+ name=fetch_holder_name,
+ type=core.VarDesc.VarType.FETCH_LIST,
+ persistable=True, )
+
+ print(f"the len of fetch_target_names: {len(fetch_target_names)}")
+
+ for i, name in enumerate(fetch_target_names):
+ global_block.append_op(
+ type='fetch',
+ inputs={'X': [name]},
+ outputs={'Out': [fetch_var]},
+ attrs={'col': i}, )
+
+
+def insert_fetch(program,
+ fetch_target_names: List[str],
+ fetch_holder_name='fetch'):
+ """in the place, we will add the fetch op
+
+ Args:
+ program (_type_): inference program
+ fetch_target_names (List[str]): target names
+ fetch_holder_name (str, optional): fetch op name. Defaults to 'fetch'.
+ """
+ global_block = program.global_block()
+
+ # remove fetch
+ need_to_remove_op_index = []
+ for i, op in enumerate(global_block.ops):
+ if op.type == 'fetch':
+ need_to_remove_op_index.append(i)
+
+ for index in reversed(need_to_remove_op_index):
+ global_block._remove_op(index)
+
+ program.desc.flush()
+
+ # append new fetch
+ append_fetch_ops(program, fetch_target_names, fetch_holder_name)
+
+
+def parse_arguments():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ '--model_dir',
+ required=True,
+ help='Path of directory saved the input model.')
+ parser.add_argument(
+ '--model_filename', required=True, help='model.pdmodel.')
+ parser.add_argument(
+ '--params_filename', required=True, help='model.pdiparams.')
+ parser.add_argument(
+ '--output_names',
+ required=True,
+ help='The outputs of model. sep by comma')
+ parser.add_argument(
+ '--save_dir',
+ required=True,
+ help='directory to save the exported model.')
+ parser.add_argument('--debug', default=False, help='output debug info.')
+ return parser.parse_args()
+
+
+if __name__ == '__main__':
+ args = parse_arguments()
+
+ args.output_names = args.output_names.split(",")
+
+ if len(set(args.output_names)) < len(args.output_names):
+ print(
+ f"[ERROR] There's dumplicate name in --output_names {args.output_names}, which is not allowed."
+ )
+ sys.exit(-1)
+
+ import paddle
+ paddle.enable_static()
+ # hack prepend_feed_ops
+ paddle.fluid.io.prepend_feed_ops = prepend_feed_ops
+
+ import paddle.fluid as fluid
+
+ print("start to load paddle model")
+ exe = fluid.Executor(fluid.CPUPlace())
+ prog, ipts, outs = fluid.io.load_inference_model(
+ args.model_dir,
+ exe,
+ model_filename=args.model_filename,
+ params_filename=args.params_filename)
+
+ print("start to load insert fetch op")
+ new_outputs = []
+ insert_fetch(prog, args.output_names)
+ for out_name in args.output_names:
+ new_outputs.append(prog.global_block().var(out_name))
+
+ # not equal to paddle.static.save_inference_model
+ fluid.io.save_inference_model(
+ args.save_dir,
+ ipts,
+ new_outputs,
+ exe,
+ prog,
+ model_filename=args.model_filename,
+ params_filename=args.params_filename)
+
+ if args.debug:
+ for op in prog.global_block().ops:
+ print(op)
diff --git a/speechx/examples/ds2_ol/onnx/local/prune.sh b/speechx/examples/ds2_ol/onnx/local/prune.sh
new file mode 100755
index 000000000..64636bccf
--- /dev/null
+++ b/speechx/examples/ds2_ol/onnx/local/prune.sh
@@ -0,0 +1,23 @@
+#!/bin/bash
+
+set -e
+
+if [ $# != 5 ]; then
+ # local/prune.sh data/exp/deepspeech2_online/checkpoints avg_1.jit.pdmodel avg_1.jit.pdiparams softmax_0.tmp_0,tmp_5,concat_0.tmp_0,concat_1.tmp_0 $PWD
+ echo "usage: $0 model_dir model_filename param_filename outputs_names save_dir"
+ exit 1
+fi
+
+dir=$1
+model=$2
+param=$3
+outputs=$4
+save_dir=$5
+
+
+python local/pd_prune_model.py \
+ --model_dir $dir \
+ --model_filename $model \
+ --params_filename $param \
+ --output_names $outputs \
+ --save_dir $save_dir
\ No newline at end of file
diff --git a/speechx/examples/ds2_ol/onnx/local/tonnx.sh b/speechx/examples/ds2_ol/onnx/local/tonnx.sh
new file mode 100755
index 000000000..ffedf001c
--- /dev/null
+++ b/speechx/examples/ds2_ol/onnx/local/tonnx.sh
@@ -0,0 +1,25 @@
+#!/bin/bash
+
+if [ $# != 4 ];then
+ # local/tonnx.sh data/exp/deepspeech2_online/checkpoints avg_1.jit.pdmodel avg_1.jit.pdiparams exp/model.onnx
+ echo "usage: $0 model_dir model_name param_name onnx_output_name"
+ exit 1
+fi
+
+dir=$1
+model=$2
+param=$3
+output=$4
+
+pip install paddle2onnx
+pip install onnx
+
+# https://github.com/PaddlePaddle/Paddle2ONNX#%E5%91%BD%E4%BB%A4%E8%A1%8C%E8%BD%AC%E6%8D%A2
+paddle2onnx --model_dir $dir \
+ --model_filename $model \
+ --params_filename $param \
+ --save_file $output \
+ --enable_dev_version True \
+ --opset_version 9 \
+ --enable_onnx_checker True
+
\ No newline at end of file
diff --git a/speechx/examples/ds2_ol/onnx/path.sh b/speechx/examples/ds2_ol/onnx/path.sh
new file mode 100755
index 000000000..97d487379
--- /dev/null
+++ b/speechx/examples/ds2_ol/onnx/path.sh
@@ -0,0 +1,14 @@
+# This contains the locations of binarys build required for running the examples.
+
+MAIN_ROOT=`realpath $PWD/../../../../`
+SPEECHX_ROOT=$PWD/../../../
+SPEECHX_BUILD=$SPEECHX_ROOT/build/speechx
+
+SPEECHX_TOOLS=$SPEECHX_ROOT/tools
+TOOLS_BIN=$SPEECHX_TOOLS/valgrind/install/bin
+
+[ -d $SPEECHX_BUILD ] || { echo "Error: 'build/speechx' directory not found. please ensure that the project build successfully"; }
+
+export LC_AL=C
+
+export PATH=$PATH:$TOOLS_BIN
diff --git a/speechx/examples/ds2_ol/onnx/run.sh b/speechx/examples/ds2_ol/onnx/run.sh
new file mode 100755
index 000000000..583abda4e
--- /dev/null
+++ b/speechx/examples/ds2_ol/onnx/run.sh
@@ -0,0 +1,110 @@
+#!/bin/bash
+
+set -e
+
+. path.sh
+
+stage=0
+stop_stage=50
+tarfile=asr0_deepspeech2_online_wenetspeech_ckpt_1.0.2.model.tar.gz
+#tarfile=asr0_deepspeech2_online_aishell_fbank161_ckpt_1.0.1.model.tar.gz
+model_prefix=avg_10.jit
+#model_prefix=avg_1.jit
+model=${model_prefix}.pdmodel
+param=${model_prefix}.pdiparams
+
+. utils/parse_options.sh
+
+data=data
+exp=exp
+
+mkdir -p $data $exp
+
+dir=$data/exp/deepspeech2_online/checkpoints
+
+# wenetspeech or aishell
+model_type=$(echo $tarfile | cut -d '_' -f 4)
+
+if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ];then
+ test -f $data/$tarfile || wget -P $data -c https://paddlespeech.bj.bcebos.com/s2t/$model_type/asr0/$tarfile
+
+ # wenetspeech ds2 model
+ pushd $data
+ tar zxvf $tarfile
+ popd
+
+ # ds2 model demo inputs
+ pushd $exp
+ wget -c http://paddlespeech.bj.bcebos.com/speechx/examples/ds2_ol/onnx/static_ds2online_inputs.pickle
+ popd
+fi
+
+output_names=softmax_0.tmp_0,tmp_5,concat_0.tmp_0,concat_1.tmp_0
+if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ];then
+ # prune model by outputs
+ mkdir -p $exp/prune
+
+ # prune model deps on output_names.
+ ./local/prune.sh $dir $model $param $output_names $exp/prune
+fi
+
+# aishell rnn hidden is 1024
+# wenetspeech rnn hiddn is 2048
+if [ $model_type == 'aishell' ];then
+ input_shape_dict="{'audio_chunk':[1,-1,161], 'audio_chunk_lens':[1], 'chunk_state_c_box':[5, 1, 1024], 'chunk_state_h_box':[5,1,1024]}"
+elif [ $model_type == 'wenetspeech' ];then
+ input_shape_dict="{'audio_chunk':[1,-1,161], 'audio_chunk_lens':[1], 'chunk_state_c_box':[5, 1, 2048], 'chunk_state_h_box':[5,1,2048]}"
+else
+ echo "not support: $model_type"
+ exit -1
+fi
+if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ];then
+ # infer shape by new shape
+ mkdir -p $exp/shape
+ echo $input_shape_dict
+ python3 local/pd_infer_shape.py \
+ --model_dir $dir \
+ --model_filename $model \
+ --params_filename $param \
+ --save_dir $exp/shape \
+ --input_shape_dict="${input_shape_dict}"
+fi
+
+input_file=$exp/static_ds2online_inputs.pickle
+test -e $input_file
+
+if [ ${stage} -le 3 ] && [ ${stop_stage} -ge 3 ];then
+ # to onnx
+ ./local/tonnx.sh $dir $model $param $exp/model.onnx
+
+ ./local/infer_check.py --input_file $input_file --model_type $model_type --model_dir $dir --model_prefix $model_prefix --onnx_model $exp/model.onnx
+fi
+
+
+if [ ${stage} -le 4 ] && [ ${stop_stage} -ge 4 ] ;then
+ # ort graph optmize
+ ./local/ort_opt.py --model_in $exp/model.onnx --opt_level 0 --model_out $exp/model.ort.opt.onnx
+
+ ./local/infer_check.py --input_file $input_file --model_type $model_type --model_dir $dir --model_prefix $model_prefix --onnx_model $exp/model.ort.opt.onnx
+fi
+
+
+# aishell rnn hidden is 1024
+# wenetspeech rnn hiddn is 2048
+if [ $model_type == 'aishell' ];then
+ input_shape="audio_chunk:1,-1,161 audio_chunk_lens:1 chunk_state_c_box:5,1,1024 chunk_state_h_box:5,1,1024"
+elif [ $model_type == 'wenetspeech' ];then
+ input_shape="audio_chunk:1,-1,161 audio_chunk_lens:1 chunk_state_c_box:5,1,2048 chunk_state_h_box:5,1,2048"
+else
+ echo "not support: $model_type"
+ exit -1
+fi
+
+
+if [ ${stage} -le 51 ] && [ ${stop_stage} -ge 51 ] ;then
+ # wenetspeech ds2 model execed 2GB limit, will error.
+ # simplifying onnx model
+ ./local/onnx_opt.sh $exp/model.onnx $exp/model.opt.onnx "$input_shape"
+
+ ./local/infer_check.py --input_file $input_file --model_type $model_type --model_dir $dir --model_prefix $model_prefix --onnx_model $exp/model.opt.onnx
+fi
diff --git a/speechx/examples/ngram/zh/utils b/speechx/examples/ds2_ol/onnx/utils
similarity index 100%
rename from speechx/examples/ngram/zh/utils
rename to speechx/examples/ds2_ol/onnx/utils
diff --git a/speechx/examples/ds2_ol/websocket/CMakeLists.txt b/speechx/examples/ds2_ol/websocket/CMakeLists.txt
deleted file mode 100644
index ed542aad0..000000000
--- a/speechx/examples/ds2_ol/websocket/CMakeLists.txt
+++ /dev/null
@@ -1,9 +0,0 @@
-cmake_minimum_required(VERSION 3.14 FATAL_ERROR)
-
-add_executable(websocket_server_main ${CMAKE_CURRENT_SOURCE_DIR}/websocket_server_main.cc)
-target_include_directories(websocket_server_main PRIVATE ${SPEECHX_ROOT} ${SPEECHX_ROOT}/kaldi)
-target_link_libraries(websocket_server_main PUBLIC frontend kaldi-feat-common nnet decoder fst utils gflags glog kaldi-base kaldi-matrix kaldi-util kaldi-decoder websocket ${DEPS})
-
-add_executable(websocket_client_main ${CMAKE_CURRENT_SOURCE_DIR}/websocket_client_main.cc)
-target_include_directories(websocket_client_main PRIVATE ${SPEECHX_ROOT} ${SPEECHX_ROOT}/kaldi)
-target_link_libraries(websocket_client_main PUBLIC frontend kaldi-feat-common nnet decoder fst utils gflags glog kaldi-base kaldi-matrix kaldi-util kaldi-decoder websocket ${DEPS})
\ No newline at end of file
diff --git a/speechx/examples/ds2_ol/websocket/path.sh b/speechx/examples/ds2_ol/websocket/path.sh
index d66b5dcce..6dd6bddbf 100755
--- a/speechx/examples/ds2_ol/websocket/path.sh
+++ b/speechx/examples/ds2_ol/websocket/path.sh
@@ -1,14 +1,14 @@
# This contains the locations of binarys build required for running the examples.
-SPEECHX_ROOT=$PWD/../../..
-SPEECHX_EXAMPLES=$SPEECHX_ROOT/build/examples
+SPEECHX_ROOT=$PWD/../../../
+SPEECHX_BUILD=$SPEECHX_ROOT/build/speechx
SPEECHX_TOOLS=$SPEECHX_ROOT/tools
TOOLS_BIN=$SPEECHX_TOOLS/valgrind/install/bin
-[ -d $SPEECHX_EXAMPLES ] || { echo "Error: 'build/examples' directory not found. please ensure that the project build successfully"; }
+[ -d $SPEECHX_BUILD ] || { echo "Error: 'build/speechx' directory not found. please ensure that the project build successfully"; }
export LC_AL=C
-SPEECHX_BIN=$SPEECHX_EXAMPLES/ds2_ol/websocket:$SPEECHX_EXAMPLES/ds2_ol/feat
+SPEECHX_BIN=$SPEECHX_BUILD/protocol/websocket:$SPEECHX_BUILD/frontend/audio
export PATH=$PATH:$SPEECHX_BIN:$TOOLS_BIN
diff --git a/speechx/examples/ds2_ol/websocket/websocket_client.sh b/speechx/examples/ds2_ol/websocket/websocket_client.sh
index 2a52d2a3d..a508adfbc 100755
--- a/speechx/examples/ds2_ol/websocket/websocket_client.sh
+++ b/speechx/examples/ds2_ol/websocket/websocket_client.sh
@@ -32,4 +32,4 @@ export GLOG_logtostderr=1
# websocket client
websocket_client_main \
- --wav_rspecifier=scp:$data/$aishell_wav_scp --streaming_chunk=0.36
\ No newline at end of file
+ --wav_rspecifier=scp:$data/$aishell_wav_scp --streaming_chunk=0.5
diff --git a/speechx/examples/ds2_ol/websocket/websocket_server.sh b/speechx/examples/ds2_ol/websocket/websocket_server.sh
index 0e389f899..18d29857c 100755
--- a/speechx/examples/ds2_ol/websocket/websocket_server.sh
+++ b/speechx/examples/ds2_ol/websocket/websocket_server.sh
@@ -4,7 +4,6 @@ set -e
. path.sh
-
# 1. compile
if [ ! -d ${SPEECHX_EXAMPLES} ]; then
pushd ${SPEECHX_ROOT}
@@ -19,19 +18,6 @@ ckpt_dir=$data/model
model_dir=$ckpt_dir/exp/deepspeech2_online/checkpoints/
vocb_dir=$ckpt_dir/data/lang_char/
-# output
-aishell_wav_scp=aishell_test.scp
-if [ ! -d $data/test ]; then
- pushd $data
- wget -c https://paddlespeech.bj.bcebos.com/s2t/paddle_asr_online/aishell_test.zip
- unzip aishell_test.zip
- popd
-
- realpath $data/test/*/*.wav > $data/wavlist
- awk -F '/' '{ print $(NF) }' $data/wavlist | awk -F '.' '{ print $1 }' > $data/utt_id
- paste $data/utt_id $data/wavlist > $data/$aishell_wav_scp
-fi
-
if [ ! -f $ckpt_dir/data/mean_std.json ]; then
mkdir -p $ckpt_dir
@@ -45,7 +31,7 @@ export GLOG_logtostderr=1
# 3. gen cmvn
cmvn=$data/cmvn.ark
-cmvn-json2kaldi --json_file=$ckpt_dir/data/mean_std.json --cmvn_write_path=$cmvn
+cmvn_json2kaldi_main --json_file=$ckpt_dir/data/mean_std.json --cmvn_write_path=$cmvn
wfst=$data/wfst/
@@ -62,8 +48,6 @@ fi
websocket_server_main \
--cmvn_file=$cmvn \
--model_path=$model_dir/avg_1.jit.pdmodel \
- --streaming_chunk=0.1 \
- --to_float32=true \
--param_path=$model_dir/avg_1.jit.pdiparams \
--word_symbol_table=$wfst/words.txt \
--model_output_names=softmax_0.tmp_0,tmp_5,concat_0.tmp_0,concat_1.tmp_0 \
diff --git a/speechx/examples/ngram/en/README.md b/speechx/examples/ngram/en/README.md
deleted file mode 100644
index e69de29bb..000000000
diff --git a/speechx/examples/ngram/zh/README.md b/speechx/examples/ngram/zh/README.md
deleted file mode 100644
index e11bd3439..000000000
--- a/speechx/examples/ngram/zh/README.md
+++ /dev/null
@@ -1,101 +0,0 @@
-# ngram train for mandarin
-
-Quick run:
-```
-bash run.sh --stage -1
-```
-
-## input
-
-input files:
-```
-data/
-├── lexicon.txt
-├── text
-└── vocab.txt
-```
-
-```
-==> data/text <==
-BAC009S0002W0122 而 对 楼市 成交 抑制 作用 最 大 的 限 购
-BAC009S0002W0123 也 成为 地方 政府 的 眼中 钉
-BAC009S0002W0124 自 六月 底 呼和浩特 市 率先 宣布 取消 限 购 后
-BAC009S0002W0125 各地 政府 便 纷纷 跟进
-BAC009S0002W0126 仅 一 个 多 月 的 时间 里
-BAC009S0002W0127 除了 北京 上海 广州 深圳 四 个 一 线 城市 和 三亚 之外
-BAC009S0002W0128 四十六 个 限 购 城市 当中
-BAC009S0002W0129 四十一 个 已 正式 取消 或 变相 放松 了 限 购
-BAC009S0002W0130 财政 金融 政策 紧随 其后 而来
-BAC009S0002W0131 显示 出 了 极 强 的 威力
-
-==> data/lexicon.txt <==
-SIL sil
- sil
-啊 aa a1
-啊 aa a2
-啊 aa a4
-啊 aa a5
-啊啊啊 aa a2 aa a2 aa a2
-啊啊啊 aa a5 aa a5 aa a5
-坐地 z uo4 d i4
-坐实 z uo4 sh ix2
-坐视 z uo4 sh ix4
-坐稳 z uo4 uu un3
-坐拥 z uo4 ii iong1
-坐诊 z uo4 zh en3
-坐庄 z uo4 zh uang1
-坐姿 z uo4 z iy1
-
-==> data/vocab.txt <==
-
-
-A
-B
-C
-D
-E
-龙
-龚
-龛
-
-```
-
-## output
-
-```
-data/
-├── local
-│ ├── dict
-│ │ ├── lexicon.txt
-│ │ └── units.txt
-│ └── lm
-│ ├── heldout
-│ ├── lm.arpa
-│ ├── text
-│ ├── text.no_oov
-│ ├── train
-│ ├── unigram.counts
-│ ├── word.counts
-│ └── wordlist
-```
-
-```
-/workspace/srilm/bin/i686-m64/ngram-count
-Namespace(bpemodel=None, in_lexicon='data/lexicon.txt', out_lexicon='data/local/dict/lexicon.txt', unit_file='data/vocab.txt')
-Ignoring words 矽, which contains oov unit
-Ignoring words 傩, which contains oov unit
-Ignoring words 堀, which contains oov unit
-Ignoring words 莼, which contains oov unit
-Ignoring words 菰, which contains oov unit
-Ignoring words 摭, which contains oov unit
-Ignoring words 帙, which contains oov unit
-Ignoring words 迨, which contains oov unit
-Ignoring words 孥, which contains oov unit
-Ignoring words 瑗, which contains oov unit
-...
-...
-...
-file data/local/lm/heldout: 10000 sentences, 89496 words, 0 OOVs
-0 zeroprobs, logprob= -270337.9 ppl= 521.2819 ppl1= 1048.745
-build LM done.
-```
diff --git a/speechx/examples/ngram/zh/local/split_data.sh b/speechx/examples/ngram/zh/local/split_data.sh
deleted file mode 100755
index 2af6fc5ab..000000000
--- a/speechx/examples/ngram/zh/local/split_data.sh
+++ /dev/null
@@ -1,30 +0,0 @@
-#!/usr/bin/env bash
-
-set -eo pipefail
-
-data=$1
-scp=$2
-split_name=$3
-numsplit=$4
-
-# save in $data/split{n}
-# $scp to split
-#
-
-if [[ ! $numsplit -gt 0 ]]; then
- echo "Invalid num-split argument";
- exit 1;
-fi
-
-directories=$(for n in `seq $numsplit`; do echo $data/split${numsplit}/$n; done)
-scp_splits=$(for n in `seq $numsplit`; do echo $data/split${numsplit}/$n/${split_name}; done)
-
-# if this mkdir fails due to argument-list being too long, iterate.
-if ! mkdir -p $directories >&/dev/null; then
- for n in `seq $numsplit`; do
- mkdir -p $data/split${numsplit}/$n
- done
-fi
-
-echo "utils/split_scp.pl $scp $scp_splits"
-utils/split_scp.pl $scp $scp_splits
diff --git a/speechx/examples/ngram/zh/path.sh b/speechx/examples/ngram/zh/path.sh
deleted file mode 100644
index a3fb3d758..000000000
--- a/speechx/examples/ngram/zh/path.sh
+++ /dev/null
@@ -1,12 +0,0 @@
-# This contains the locations of binarys build required for running the examples.
-
-MAIN_ROOT=`realpath $PWD/../../../../`
-SPEECHX_ROOT=`realpath $MAIN_ROOT/speechx`
-
-export LC_AL=C
-
-# srilm
-export LIBLBFGS=${MAIN_ROOT}/tools/liblbfgs-1.10
-export LD_LIBRARY_PATH=${LD_LIBRARY_PATH:-}:${LIBLBFGS}/lib/.libs
-export SRILM=${MAIN_ROOT}/tools/srilm
-export PATH=${PATH}:${SRILM}/bin:${SRILM}/bin/i686-m64
diff --git a/speechx/examples/ngram/zh/run.sh b/speechx/examples/ngram/zh/run.sh
deleted file mode 100755
index f24ad0a7c..000000000
--- a/speechx/examples/ngram/zh/run.sh
+++ /dev/null
@@ -1,68 +0,0 @@
-#!/bin/bash
-set -eo pipefail
-
-. path.sh
-
-stage=-1
-stop_stage=100
-corpus=aishell
-
-unit=data/vocab.txt # vocab file, line: char/spm_pice
-lexicon=data/lexicon.txt # line: word ph0 ... phn, aishell/resource_aishell/lexicon.txt
-text=data/text # line: utt text, aishell/data_aishell/transcript/aishell_transcript_v0.8.txt
-
-. utils/parse_options.sh
-
-data=$PWD/data
-mkdir -p $data
-
-if [ $stage -le -1 ] && [ $stop_stage -ge -1 ]; then
- if [ ! -f $data/speech.ngram.zh.tar.gz ];then
- pushd $data
- wget -c http://paddlespeech.bj.bcebos.com/speechx/examples/ngram/zh/speech.ngram.zh.tar.gz
- tar xvzf speech.ngram.zh.tar.gz
- popd
- fi
-fi
-
-if [ ! -f $unit ]; then
- echo "$0: No such file $unit"
- exit 1;
-fi
-
-if ! which ngram-count; then
- pushd $MAIN_ROOT/tools
- make srilm.done
- popd
-fi
-
-mkdir -p data/local/dict
-if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then
- # 7.1 Prepare dict
- # line: char/spm_pices
- cp $unit data/local/dict/units.txt
-
- if [ ! -f $lexicon ];then
- local/text_to_lexicon.py --has_key true --text $text --lexicon $lexicon
- echo "Generate $lexicon from $text"
- fi
-
- # filter by vocab
- # line: word ph0 ... phn -> line: word char0 ... charn
- utils/fst/prepare_dict.py \
- --unit_file $unit \
- --in_lexicon ${lexicon} \
- --out_lexicon data/local/dict/lexicon.txt
-fi
-
-lm=data/local/lm
-mkdir -p $lm
-
-if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
- # 7.2 Train lm
- cp $text $lm/text
- local/aishell_train_lms.sh
-fi
-
-echo "build LM done."
-exit 0
diff --git a/speechx/examples/wfst/.gitignore b/speechx/examples/wfst/.gitignore
deleted file mode 100644
index 1269488f7..000000000
--- a/speechx/examples/wfst/.gitignore
+++ /dev/null
@@ -1 +0,0 @@
-data
diff --git a/speechx/examples/wfst/README.md b/speechx/examples/wfst/README.md
deleted file mode 100644
index d0bdac0fc..000000000
--- a/speechx/examples/wfst/README.md
+++ /dev/null
@@ -1,186 +0,0 @@
-# Built TLG wfst
-
-## Input
-```
-data/local/
-├── dict
-│ ├── lexicon.txt
-│ └── units.txt
-└── lm
- ├── heldout
- ├── lm.arpa
- ├── text
- ├── text.no_oov
- ├── train
- ├── unigram.counts
- ├── word.counts
- └── wordlist
-```
-
-```
-==> data/local/dict/lexicon.txt <==
-啊 啊
-啊啊啊 啊 啊 啊
-阿 阿
-阿尔 阿 尔
-阿根廷 阿 根 廷
-阿九 阿 九
-阿克 阿 克
-阿拉伯数字 阿 拉 伯 数 字
-阿拉法特 阿 拉 法 特
-阿拉木图 阿 拉 木 图
-
-==> data/local/dict/units.txt <==
-
-
-A
-B
-C
-D
-E
-F
-G
-H
-
-==> data/local/lm/heldout <==
-而 对 楼市 成交 抑制 作用 最 大 的 限 购
-也 成为 地方 政府 的 眼中 钉
-自 六月 底 呼和浩特 市 率先 宣布 取消 限 购 后
-各地 政府 便 纷纷 跟进
-仅 一 个 多 月 的 时间 里
-除了 北京 上海 广州 深圳 四 个 一 线 城市 和 三亚 之外
-四十六 个 限 购 城市 当中
-四十一 个 已 正式 取消 或 变相 放松 了 限 购
-财政 金融 政策 紧随 其后 而来
-显示 出 了 极 强 的 威力
-
-==> data/local/lm/lm.arpa <==
-
-\data\
-ngram 1=129356
-ngram 2=504661
-ngram 3=123455
-
-\1-grams:
--1.531278
--3.828829 -0.1600094
--6.157292
-
-==> data/local/lm/text <==
-BAC009S0002W0122 而 对 楼市 成交 抑制 作用 最 大 的 限 购
-BAC009S0002W0123 也 成为 地方 政府 的 眼中 钉
-BAC009S0002W0124 自 六月 底 呼和浩特 市 率先 宣布 取消 限 购 后
-BAC009S0002W0125 各地 政府 便 纷纷 跟进
-BAC009S0002W0126 仅 一 个 多 月 的 时间 里
-BAC009S0002W0127 除了 北京 上海 广州 深圳 四 个 一 线 城市 和 三亚 之外
-BAC009S0002W0128 四十六 个 限 购 城市 当中
-BAC009S0002W0129 四十一 个 已 正式 取消 或 变相 放松 了 限 购
-BAC009S0002W0130 财政 金融 政策 紧随 其后 而来
-BAC009S0002W0131 显示 出 了 极 强 的 威力
-
-==> data/local/lm/text.no_oov <==
- 而 对 楼市 成交 抑制 作用 最 大 的 限 购
- 也 成为 地方 政府 的 眼中 钉
- 自 六月 底 呼和浩特 市 率先 宣布 取消 限 购 后
- 各地 政府 便 纷纷 跟进
- 仅 一 个 多 月 的 时间 里
- 除了 北京 上海 广州 深圳 四 个 一 线 城市 和 三亚 之外
- 四十六 个 限 购 城市 当中
- 四十一 个 已 正式 取消 或 变相 放松 了 限 购
- 财政 ���融 政策 紧随 其后 而来
- 显示 出 了 极 强 的 威力
-
-==> data/local/lm/train <==
-汉莎 不 得 不 通过 这样 的 方式 寻求 新 的 发展 点
-并 计划 朝云 计算 方面 发展
-汉莎 的 基础 设施 部门 拥有 一千四百 名 员工
-媒体 就 曾 披露 这笔 交易
-虽然 双方 已经 正式 签署 了 外包 协议
-但是 这笔 交易 还 需要 得到 反 垄断 部门 的 批准
-陈 黎明 一九八九 年 获得 美国 康乃尔 大学 硕士 学位
-并 于 二零零三 年 顺利 完成 美国 哈佛 商学 院 高级 管理 课程
-曾 在 多家 国际 公司 任职
-拥有 业务 开发 商务 及 企业 治理
-
-==> data/local/lm/unigram.counts <==
- 57487 的
- 13099 在
- 11862 一
- 11397 了
- 10998 不
- 9913 是
- 7952 有
- 6250 和
- 6152 个
- 5422 将
-
-==> data/local/lm/word.counts <==
- 57486 的
- 13098 在
- 11861 一
- 11396 了
- 10997 不
- 9912 是
- 7951 有
- 6249 和
- 6151 个
- 5421 将
-
-==> data/local/lm/wordlist <==
-的
-在
-一
-了
-不
-是
-有
-和
-个
-将
-```
-
-## Output
-
-```
-fstaddselfloops 'echo 4234 |' 'echo 123660 |'
-Lexicon and Token FSTs compiling succeeded
-arpa2fst --read-symbol-table=data/lang_test/words.txt --keep-symbols=true -
-LOG (arpa2fst[5.5.0~1-5a37]:Read():arpa-file-parser.cc:94) Reading \data\ section.
-LOG (arpa2fst[5.5.0~1-5a37]:Read():arpa-file-parser.cc:149) Reading \1-grams: section.
-LOG (arpa2fst[5.5.0~1-5a37]:Read():arpa-file-parser.cc:149) Reading \2-grams: section.
-LOG (arpa2fst[5.5.0~1-5a37]:Read():arpa-file-parser.cc:149) Reading \3-grams: section.
-Checking how stochastic G is (the first of these numbers should be small):
-fstisstochastic data/lang_test/G.fst
-0 -1.14386
-fsttablecompose data/lang_test/L.fst data/lang_test/G.fst
-fstminimizeencoded
-fstdeterminizestar --use-log=true
-fsttablecompose data/lang_test/T.fst data/lang_test/LG.fst
-Composing decoding graph TLG.fst succeeded
-Aishell build TLG done.
-```
-
-```
-data/
-├── lang_test
-│ ├── G.fst
-│ ├── L.fst
-│ ├── LG.fst
-│ ├── T.fst
-│ ├── TLG.fst
-│ ├── tokens.txt
-│ ├── units.txt
-│ └── words.txt
-└── local
- ├── lang
- │ ├── L.fst
- │ ├── T.fst
- │ ├── tokens.txt
- │ ├── units.txt
- │ └── words.txt
- └── tmp
- ├── disambig.list
- ├── lexiconp_disambig.txt
- ├── lexiconp.txt
- └── units.list
-```
diff --git a/speechx/examples/wfst/path.sh b/speechx/examples/wfst/path.sh
deleted file mode 100644
index a07c1297d..000000000
--- a/speechx/examples/wfst/path.sh
+++ /dev/null
@@ -1,19 +0,0 @@
-# This contains the locations of binarys build required for running the examples.
-
-MAIN_ROOT=`realpath $PWD/../../../`
-SPEECHX_ROOT=`realpath $MAIN_ROOT/speechx`
-
-export LC_AL=C
-
-# srilm
-export LIBLBFGS=${MAIN_ROOT}/tools/liblbfgs-1.10
-export LD_LIBRARY_PATH=${LD_LIBRARY_PATH:-}:${LIBLBFGS}/lib/.libs
-export SRILM=${MAIN_ROOT}/tools/srilm
-export PATH=${PATH}:${SRILM}/bin:${SRILM}/bin/i686-m64
-
-# Kaldi
-export KALDI_ROOT=${MAIN_ROOT}/tools/kaldi
-[ -f $KALDI_ROOT/tools/env.sh ] && . $KALDI_ROOT/tools/env.sh
-export PATH=$PWD/utils/:$KALDI_ROOT/tools/openfst/bin:$PWD:$PATH
-[ ! -f $KALDI_ROOT/tools/config/common_path.sh ] && echo >&2 "The standard file $KALDI_ROOT/tools/config/common_path.sh is not present, can not using Kaldi!"
-[ -f $KALDI_ROOT/tools/config/common_path.sh ] && . $KALDI_ROOT/tools/config/common_path.sh
diff --git a/speechx/examples/wfst/run.sh b/speechx/examples/wfst/run.sh
deleted file mode 100755
index 1354646af..000000000
--- a/speechx/examples/wfst/run.sh
+++ /dev/null
@@ -1,29 +0,0 @@
-#!/bin/bash
-set -eo pipefail
-
-. path.sh
-
-stage=-1
-stop_stage=100
-
-. utils/parse_options.sh
-
-if ! which fstprint ; then
- pushd $MAIN_ROOT/tools
- make kaldi.done
- popd
-fi
-
-if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then
- # build T & L
- # utils/fst/compile_lexicon_token_fst.sh
- utils/fst/compile_lexicon_token_fst.sh \
- data/local/dict data/local/tmp data/local/lang
-
- # build G & LG & TLG
- # utils/fst/make_tlg.sh
- utils/fst/make_tlg.sh data/local/lm data/local/lang data/lang_test || exit 1;
-fi
-
-echo "build TLG done."
-exit 0
diff --git a/speechx/examples/wfst/utils b/speechx/examples/wfst/utils
deleted file mode 120000
index 256f914ab..000000000
--- a/speechx/examples/wfst/utils
+++ /dev/null
@@ -1 +0,0 @@
-../../../utils/
\ No newline at end of file
diff --git a/speechx/patch/README.md b/speechx/patch/README.md
new file mode 100644
index 000000000..1bee5ed64
--- /dev/null
+++ b/speechx/patch/README.md
@@ -0,0 +1,2 @@
+reference:
+this patch is from WeNet wenet/runtime/core/patch
diff --git a/speechx/speechx/CMakeLists.txt b/speechx/speechx/CMakeLists.txt
index b4da095d8..c8e21d486 100644
--- a/speechx/speechx/CMakeLists.txt
+++ b/speechx/speechx/CMakeLists.txt
@@ -34,6 +34,12 @@ add_subdirectory(decoder)
include_directories(
${CMAKE_CURRENT_SOURCE_DIR}
-${CMAKE_CURRENT_SOURCE_DIR}/websocket
+${CMAKE_CURRENT_SOURCE_DIR}/protocol
)
-add_subdirectory(websocket)
+add_subdirectory(protocol)
+
+include_directories(
+${CMAKE_CURRENT_SOURCE_DIR}
+${CMAKE_CURRENT_SOURCE_DIR}/codelab
+)
+add_subdirectory(codelab)
diff --git a/speechx/examples/dev/CMakeLists.txt b/speechx/speechx/codelab/CMakeLists.txt
similarity index 76%
rename from speechx/examples/dev/CMakeLists.txt
rename to speechx/speechx/codelab/CMakeLists.txt
index c8445fb82..950432637 100644
--- a/speechx/examples/dev/CMakeLists.txt
+++ b/speechx/speechx/codelab/CMakeLists.txt
@@ -1,3 +1,4 @@
cmake_minimum_required(VERSION 3.14 FATAL_ERROR)
add_subdirectory(glog)
+add_subdirectory(nnet)
diff --git a/speechx/speechx/codelab/README.md b/speechx/speechx/codelab/README.md
new file mode 100644
index 000000000..077c4cef2
--- /dev/null
+++ b/speechx/speechx/codelab/README.md
@@ -0,0 +1,6 @@
+
+## For Developer
+
+> Reminder: Only for developer.
+
+* codelab - for speechx developer, using for test.
diff --git a/speechx/speechx/codelab/glog/CMakeLists.txt b/speechx/speechx/codelab/glog/CMakeLists.txt
new file mode 100644
index 000000000..08a98641f
--- /dev/null
+++ b/speechx/speechx/codelab/glog/CMakeLists.txt
@@ -0,0 +1,8 @@
+cmake_minimum_required(VERSION 3.14 FATAL_ERROR)
+
+add_executable(glog_main ${CMAKE_CURRENT_SOURCE_DIR}/glog_main.cc)
+target_link_libraries(glog_main glog)
+
+
+add_executable(glog_logtostderr_main ${CMAKE_CURRENT_SOURCE_DIR}/glog_logtostderr_main.cc)
+target_link_libraries(glog_logtostderr_main glog)
diff --git a/speechx/examples/dev/glog/README.md b/speechx/speechx/codelab/glog/README.md
similarity index 92%
rename from speechx/examples/dev/glog/README.md
rename to speechx/speechx/codelab/glog/README.md
index 996e192e9..3282c920d 100644
--- a/speechx/examples/dev/glog/README.md
+++ b/speechx/speechx/codelab/glog/README.md
@@ -23,3 +23,16 @@ You can also modify flag values in your program by modifying global variables `F
FLAGS_log_dir = "/some/log/directory";
LOG(INFO) << "the same file";
```
+
+* this is the test script:
+```
+# run
+glog_test
+
+echo "------"
+export FLAGS_logtostderr=1
+glog_test
+
+echo "------"
+glog_logtostderr_test
+```
diff --git a/speechx/examples/dev/glog/glog_logtostderr_test.cc b/speechx/speechx/codelab/glog/glog_logtostderr_main.cc
similarity index 100%
rename from speechx/examples/dev/glog/glog_logtostderr_test.cc
rename to speechx/speechx/codelab/glog/glog_logtostderr_main.cc
diff --git a/speechx/examples/dev/glog/glog_test.cc b/speechx/speechx/codelab/glog/glog_main.cc
similarity index 100%
rename from speechx/examples/dev/glog/glog_test.cc
rename to speechx/speechx/codelab/glog/glog_main.cc
diff --git a/speechx/examples/ds2_ol/nnet/CMakeLists.txt b/speechx/speechx/codelab/nnet/CMakeLists.txt
similarity index 87%
rename from speechx/examples/ds2_ol/nnet/CMakeLists.txt
rename to speechx/speechx/codelab/nnet/CMakeLists.txt
index 6745a51ae..dcad8a9c6 100644
--- a/speechx/examples/ds2_ol/nnet/CMakeLists.txt
+++ b/speechx/speechx/codelab/nnet/CMakeLists.txt
@@ -1,6 +1,6 @@
cmake_minimum_required(VERSION 3.14 FATAL_ERROR)
-set(bin_name ds2-model-ol-test)
+set(bin_name ds2_model_test_main)
add_executable(${bin_name} ${CMAKE_CURRENT_SOURCE_DIR}/${bin_name}.cc)
target_include_directories(${bin_name} PRIVATE ${SPEECHX_ROOT} ${SPEECHX_ROOT}/kaldi)
-target_link_libraries(${bin_name} PUBLIC nnet gflags glog ${DEPS})
\ No newline at end of file
+target_link_libraries(${bin_name} PUBLIC nnet gflags glog ${DEPS})
diff --git a/speechx/examples/ds2_ol/nnet/ds2-model-ol-test.cc b/speechx/speechx/codelab/nnet/ds2_model_test_main.cc
similarity index 100%
rename from speechx/examples/ds2_ol/nnet/ds2-model-ol-test.cc
rename to speechx/speechx/codelab/nnet/ds2_model_test_main.cc
diff --git a/speechx/speechx/decoder/CMakeLists.txt b/speechx/speechx/decoder/CMakeLists.txt
index 06bf4020f..1df935112 100644
--- a/speechx/speechx/decoder/CMakeLists.txt
+++ b/speechx/speechx/decoder/CMakeLists.txt
@@ -10,3 +10,16 @@ add_library(decoder STATIC
recognizer.cc
)
target_link_libraries(decoder PUBLIC kenlm utils fst frontend nnet kaldi-decoder)
+
+set(BINS
+ ctc_prefix_beam_search_decoder_main
+ nnet_logprob_decoder_main
+ recognizer_main
+ tlg_decoder_main
+)
+
+foreach(bin_name IN LISTS BINS)
+ add_executable(${bin_name} ${CMAKE_CURRENT_SOURCE_DIR}/${bin_name}.cc)
+ target_include_directories(${bin_name} PRIVATE ${SPEECHX_ROOT} ${SPEECHX_ROOT}/kaldi)
+ target_link_libraries(${bin_name} PUBLIC nnet decoder fst utils gflags glog kaldi-base kaldi-matrix kaldi-util ${DEPS})
+endforeach()
diff --git a/speechx/examples/ds2_ol/decoder/ctc-prefix-beam-search-decoder-ol.cc b/speechx/speechx/decoder/ctc_prefix_beam_search_decoder_main.cc
similarity index 92%
rename from speechx/examples/ds2_ol/decoder/ctc-prefix-beam-search-decoder-ol.cc
rename to speechx/speechx/decoder/ctc_prefix_beam_search_decoder_main.cc
index 46a78ef99..7cfee06c9 100644
--- a/speechx/examples/ds2_ol/decoder/ctc-prefix-beam-search-decoder-ol.cc
+++ b/speechx/speechx/decoder/ctc_prefix_beam_search_decoder_main.cc
@@ -30,10 +30,10 @@ DEFINE_string(dict_file, "vocab.txt", "vocabulary of lm");
DEFINE_string(lm_path, "", "language model");
DEFINE_int32(receptive_field_length,
7,
- "receptive field of two CNN(kernel=5) downsampling module.");
+ "receptive field of two CNN(kernel=3) downsampling module.");
DEFINE_int32(downsampling_rate,
4,
- "two CNN(kernel=5) module downsampling rate.");
+ "two CNN(kernel=3) module downsampling rate.");
DEFINE_string(
model_input_names,
"audio_chunk,audio_chunk_lens,chunk_state_h_box,chunk_state_c_box",
@@ -45,6 +45,7 @@ DEFINE_string(model_cache_names,
"chunk_state_h_box,chunk_state_c_box",
"model cache names");
DEFINE_string(model_cache_shapes, "5-1-1024,5-1-1024", "model cache shapes");
+DEFINE_int32(nnet_decoder_chunk, 1, "paddle nnet forward chunk");
using kaldi::BaseFloat;
using kaldi::Matrix;
@@ -90,14 +91,16 @@ int main(int argc, char* argv[]) {
std::shared_ptr decodable(
new ppspeech::Decodable(nnet, raw_data));
- int32 chunk_size = FLAGS_receptive_field_length;
- int32 chunk_stride = FLAGS_downsampling_rate;
+ int32 chunk_size = FLAGS_receptive_field_length +
+ (FLAGS_nnet_decoder_chunk - 1) * FLAGS_downsampling_rate;
+ int32 chunk_stride = FLAGS_downsampling_rate * FLAGS_nnet_decoder_chunk;
int32 receptive_field_length = FLAGS_receptive_field_length;
LOG(INFO) << "chunk size (frame): " << chunk_size;
LOG(INFO) << "chunk stride (frame): " << chunk_stride;
LOG(INFO) << "receptive field (frame): " << receptive_field_length;
decoder.InitDecoder();
+ kaldi::Timer timer;
for (; !feature_reader.Done(); feature_reader.Next()) {
string utt = feature_reader.Key();
kaldi::Matrix feature = feature_reader.Value();
@@ -160,5 +163,7 @@ int main(int argc, char* argv[]) {
KALDI_LOG << "Done " << num_done << " utterances, " << num_err
<< " with errors.";
+ double elapsed = timer.Elapsed();
+ KALDI_LOG << " cost:" << elapsed << " s";
return (num_done != 0 ? 0 : 1);
}
diff --git a/speechx/speechx/decoder/ctc_tlg_decoder.cc b/speechx/speechx/decoder/ctc_tlg_decoder.cc
index 7b720e7ba..712d27dd4 100644
--- a/speechx/speechx/decoder/ctc_tlg_decoder.cc
+++ b/speechx/speechx/decoder/ctc_tlg_decoder.cc
@@ -47,7 +47,33 @@ void TLGDecoder::Reset() {
return;
}
+std::string TLGDecoder::GetPartialResult() {
+ if (frame_decoded_size_ == 0) {
+ // Assertion failed: (this->NumFramesDecoded() > 0 && "You cannot call
+ // BestPathEnd if no frames were decoded.")
+ return std::string("");
+ }
+ kaldi::Lattice lat;
+ kaldi::LatticeWeight weight;
+ std::vector alignment;
+ std::vector words_id;
+ decoder_->GetBestPath(&lat, false);
+ fst::GetLinearSymbolSequence(lat, &alignment, &words_id, &weight);
+ std::string words;
+ for (int32 idx = 0; idx < words_id.size(); ++idx) {
+ std::string word = word_symbol_table_->Find(words_id[idx]);
+ words += word;
+ }
+ return words;
+}
+
std::string TLGDecoder::GetFinalBestPath() {
+ if (frame_decoded_size_ == 0) {
+ // Assertion failed: (this->NumFramesDecoded() > 0 && "You cannot call
+ // BestPathEnd if no frames were decoded.")
+ return std::string("");
+ }
+
decoder_->FinalizeDecoding();
kaldi::Lattice lat;
kaldi::LatticeWeight weight;
diff --git a/speechx/speechx/decoder/ctc_tlg_decoder.h b/speechx/speechx/decoder/ctc_tlg_decoder.h
index 361c44af5..1ac46ac64 100644
--- a/speechx/speechx/decoder/ctc_tlg_decoder.h
+++ b/speechx/speechx/decoder/ctc_tlg_decoder.h
@@ -38,6 +38,7 @@ class TLGDecoder {
std::string GetBestPath();
std::vector> GetNBestPath();
std::string GetFinalBestPath();
+ std::string GetPartialResult();
int NumFrameDecoded();
int DecodeLikelihoods(const std::vector>& probs,
std::vector& nbest_words);
diff --git a/speechx/examples/ds2_ol/decoder/nnet-logprob-decoder-test.cc b/speechx/speechx/decoder/nnet_logprob_decoder_main.cc
similarity index 100%
rename from speechx/examples/ds2_ol/decoder/nnet-logprob-decoder-test.cc
rename to speechx/speechx/decoder/nnet_logprob_decoder_main.cc
diff --git a/speechx/speechx/decoder/param.h b/speechx/speechx/decoder/param.h
index ef5656212..d6ee27058 100644
--- a/speechx/speechx/decoder/param.h
+++ b/speechx/speechx/decoder/param.h
@@ -19,23 +19,23 @@
#include "decoder/ctc_tlg_decoder.h"
#include "frontend/audio/feature_pipeline.h"
+// feature
+DEFINE_bool(use_fbank, false, "False for fbank; or linear feature");
+// DEFINE_bool(to_float32, true, "audio convert to pcm32. True for linear
+// feature, or fbank");
+DEFINE_int32(num_bins, 161, "num bins of mel");
DEFINE_string(cmvn_file, "", "read cmvn");
-DEFINE_double(streaming_chunk, 0.1, "streaming feature chunk size");
-DEFINE_bool(to_float32, true, "audio convert to pcm32");
-DEFINE_string(model_path, "avg_1.jit.pdmodel", "paddle nnet model");
-DEFINE_string(param_path, "avg_1.jit.pdiparams", "paddle nnet model param");
-DEFINE_string(word_symbol_table, "words.txt", "word symbol table");
-DEFINE_string(graph_path, "TLG", "decoder graph");
-DEFINE_double(acoustic_scale, 1.0, "acoustic scale");
-DEFINE_int32(max_active, 7500, "max active");
-DEFINE_double(beam, 15.0, "decoder beam");
-DEFINE_double(lattice_beam, 7.5, "decoder beam");
+// feature sliding window
DEFINE_int32(receptive_field_length,
7,
- "receptive field of two CNN(kernel=5) downsampling module.");
+ "receptive field of two CNN(kernel=3) downsampling module.");
DEFINE_int32(downsampling_rate,
4,
- "two CNN(kernel=5) module downsampling rate.");
+ "two CNN(kernel=3) module downsampling rate.");
+DEFINE_int32(nnet_decoder_chunk, 1, "paddle nnet forward chunk");
+// nnet
+DEFINE_string(model_path, "avg_1.jit.pdmodel", "paddle nnet model");
+DEFINE_string(param_path, "avg_1.jit.pdiparams", "paddle nnet model param");
DEFINE_string(
model_input_names,
"audio_chunk,audio_chunk_lens,chunk_state_h_box,chunk_state_c_box",
@@ -48,24 +48,41 @@ DEFINE_string(model_cache_names,
"model cache names");
DEFINE_string(model_cache_shapes, "5-1-1024,5-1-1024", "model cache shapes");
+// decoder
+DEFINE_string(word_symbol_table, "words.txt", "word symbol table");
+DEFINE_string(graph_path, "TLG", "decoder graph");
+DEFINE_double(acoustic_scale, 1.0, "acoustic scale");
+DEFINE_int32(max_active, 7500, "max active");
+DEFINE_double(beam, 15.0, "decoder beam");
+DEFINE_double(lattice_beam, 7.5, "decoder beam");
namespace ppspeech {
// todo refactor later
FeaturePipelineOptions InitFeaturePipelineOptions() {
FeaturePipelineOptions opts;
opts.cmvn_file = FLAGS_cmvn_file;
- opts.linear_spectrogram_opts.streaming_chunk = FLAGS_streaming_chunk;
- opts.to_float32 = FLAGS_to_float32;
kaldi::FrameExtractionOptions frame_opts;
- frame_opts.frame_length_ms = 20;
- frame_opts.frame_shift_ms = 10;
- frame_opts.remove_dc_offset = false;
- frame_opts.window_type = "hanning";
- frame_opts.preemph_coeff = 0.0;
frame_opts.dither = 0.0;
- opts.linear_spectrogram_opts.frame_opts = frame_opts;
- opts.feature_cache_opts.frame_chunk_size = FLAGS_receptive_field_length;
- opts.feature_cache_opts.frame_chunk_stride = FLAGS_downsampling_rate;
+ frame_opts.frame_shift_ms = 10;
+ opts.use_fbank = FLAGS_use_fbank;
+ if (opts.use_fbank) {
+ opts.to_float32 = false;
+ frame_opts.window_type = "povey";
+ frame_opts.frame_length_ms = 25;
+ opts.fbank_opts.mel_opts.num_bins = FLAGS_num_bins;
+ opts.fbank_opts.frame_opts = frame_opts;
+ } else {
+ opts.to_float32 = true;
+ frame_opts.remove_dc_offset = false;
+ frame_opts.frame_length_ms = 20;
+ frame_opts.window_type = "hanning";
+ frame_opts.preemph_coeff = 0.0;
+ opts.linear_spectrogram_opts.frame_opts = frame_opts;
+ }
+ opts.assembler_opts.subsampling_rate = FLAGS_downsampling_rate;
+ opts.assembler_opts.receptive_filed_length = FLAGS_receptive_field_length;
+ opts.assembler_opts.nnet_decoder_chunk = FLAGS_nnet_decoder_chunk;
+
return opts;
}
@@ -98,4 +115,4 @@ RecognizerResource InitRecognizerResoure() {
resource.tlg_opts = InitDecoderOptions();
return resource;
}
-}
\ No newline at end of file
+}
diff --git a/speechx/speechx/decoder/recognizer.cc b/speechx/speechx/decoder/recognizer.cc
index 2c90ada99..44c3911c9 100644
--- a/speechx/speechx/decoder/recognizer.cc
+++ b/speechx/speechx/decoder/recognizer.cc
@@ -44,6 +44,10 @@ std::string Recognizer::GetFinalResult() {
return decoder_->GetFinalBestPath();
}
+std::string Recognizer::GetPartialResult() {
+ return decoder_->GetPartialResult();
+}
+
void Recognizer::SetFinished() {
feature_pipeline_->SetFinished();
input_finished_ = true;
diff --git a/speechx/speechx/decoder/recognizer.h b/speechx/speechx/decoder/recognizer.h
index 9a7e7d11e..35e1e1676 100644
--- a/speechx/speechx/decoder/recognizer.h
+++ b/speechx/speechx/decoder/recognizer.h
@@ -43,6 +43,7 @@ class Recognizer {
void Accept(const kaldi::Vector& waves);
void Decode();
std::string GetFinalResult();
+ std::string GetPartialResult();
void SetFinished();
bool IsFinished();
void Reset();
diff --git a/speechx/examples/ds2_ol/decoder/recognizer_test_main.cc b/speechx/speechx/decoder/recognizer_main.cc
similarity index 85%
rename from speechx/examples/ds2_ol/decoder/recognizer_test_main.cc
rename to speechx/speechx/decoder/recognizer_main.cc
index e6fed0ed9..232513539 100644
--- a/speechx/examples/ds2_ol/decoder/recognizer_test_main.cc
+++ b/speechx/speechx/decoder/recognizer_main.cc
@@ -19,6 +19,8 @@
DEFINE_string(wav_rspecifier, "", "test feature rspecifier");
DEFINE_string(result_wspecifier, "", "test result wspecifier");
+DEFINE_double(streaming_chunk, 0.36, "streaming feature chunk size");
+DEFINE_int32(sample_rate, 16000, "sample rate");
int main(int argc, char* argv[]) {
gflags::ParseCommandLineFlags(&argc, &argv, false);
@@ -30,7 +32,8 @@ int main(int argc, char* argv[]) {
kaldi::SequentialTableReader wav_reader(
FLAGS_wav_rspecifier);
kaldi::TokenWriter result_writer(FLAGS_result_wspecifier);
- int sample_rate = 16000;
+
+ int sample_rate = FLAGS_sample_rate;
float streaming_chunk = FLAGS_streaming_chunk;
int chunk_sample_size = streaming_chunk * sample_rate;
LOG(INFO) << "sr: " << sample_rate;
@@ -38,6 +41,9 @@ int main(int argc, char* argv[]) {
LOG(INFO) << "chunk size (sample): " << chunk_sample_size;
int32 num_done = 0, num_err = 0;
+ double tot_wav_duration = 0.0;
+
+ kaldi::Timer timer;
for (; !wav_reader.Done(); wav_reader.Next()) {
std::string utt = wav_reader.Key();
@@ -47,6 +53,7 @@ int main(int argc, char* argv[]) {
kaldi::SubVector waveform(wave_data.Data(),
this_channel);
int tot_samples = waveform.Dim();
+ tot_wav_duration += tot_samples * 1.0 / sample_rate;
LOG(INFO) << "wav len (sample): " << tot_samples;
int sample_offset = 0;
@@ -85,4 +92,9 @@ int main(int argc, char* argv[]) {
result_writer.Write(utt, result);
++num_done;
}
-}
\ No newline at end of file
+ double elapsed = timer.Elapsed();
+ KALDI_LOG << "Done " << num_done << " out of " << (num_err + num_done);
+ KALDI_LOG << " cost:" << elapsed << " s";
+ KALDI_LOG << "total wav duration is: " << tot_wav_duration << " s";
+ KALDI_LOG << "the RTF is: " << elapsed / tot_wav_duration;
+}
diff --git a/speechx/examples/ds2_ol/decoder/wfst-decoder-ol.cc b/speechx/speechx/decoder/tlg_decoder_main.cc
similarity index 92%
rename from speechx/examples/ds2_ol/decoder/wfst-decoder-ol.cc
rename to speechx/speechx/decoder/tlg_decoder_main.cc
index cb68a5a2c..b175ed135 100644
--- a/speechx/examples/ds2_ol/decoder/wfst-decoder-ol.cc
+++ b/speechx/speechx/decoder/tlg_decoder_main.cc
@@ -28,15 +28,15 @@ DEFINE_string(model_path, "avg_1.jit.pdmodel", "paddle nnet model");
DEFINE_string(param_path, "avg_1.jit.pdiparams", "paddle nnet model param");
DEFINE_string(word_symbol_table, "words.txt", "word symbol table");
DEFINE_string(graph_path, "TLG", "decoder graph");
-
DEFINE_double(acoustic_scale, 1.0, "acoustic scale");
DEFINE_int32(max_active, 7500, "decoder graph");
+DEFINE_int32(nnet_decoder_chunk, 1, "paddle nnet forward chunk");
DEFINE_int32(receptive_field_length,
7,
- "receptive field of two CNN(kernel=5) downsampling module.");
+ "receptive field of two CNN(kernel=3) downsampling module.");
DEFINE_int32(downsampling_rate,
4,
- "two CNN(kernel=5) module downsampling rate.");
+ "two CNN(kernel=3) module downsampling rate.");
DEFINE_string(
model_input_names,
"audio_chunk,audio_chunk_lens,chunk_state_h_box,chunk_state_c_box",
@@ -93,14 +93,15 @@ int main(int argc, char* argv[]) {
std::shared_ptr decodable(
new ppspeech::Decodable(nnet, raw_data, FLAGS_acoustic_scale));
- int32 chunk_size = FLAGS_receptive_field_length;
- int32 chunk_stride = FLAGS_downsampling_rate;
+ int32 chunk_size = FLAGS_receptive_field_length +
+ (FLAGS_nnet_decoder_chunk - 1) * FLAGS_downsampling_rate;
+ int32 chunk_stride = FLAGS_downsampling_rate * FLAGS_nnet_decoder_chunk;
int32 receptive_field_length = FLAGS_receptive_field_length;
LOG(INFO) << "chunk size (frame): " << chunk_size;
LOG(INFO) << "chunk stride (frame): " << chunk_stride;
LOG(INFO) << "receptive field (frame): " << receptive_field_length;
decoder.InitDecoder();
-
+ kaldi::Timer timer;
for (; !feature_reader.Done(); feature_reader.Next()) {
string utt = feature_reader.Key();
kaldi::Matrix feature = feature_reader.Value();
@@ -160,6 +161,9 @@ int main(int argc, char* argv[]) {
++num_done;
}
+ double elapsed = timer.Elapsed();
+ KALDI_LOG << " cost:" << elapsed << " s";
+
KALDI_LOG << "Done " << num_done << " utterances, " << num_err
<< " with errors.";
return (num_done != 0 ? 0 : 1);
diff --git a/speechx/speechx/frontend/audio/CMakeLists.txt b/speechx/speechx/frontend/audio/CMakeLists.txt
index 2d20edf71..8ae63256a 100644
--- a/speechx/speechx/frontend/audio/CMakeLists.txt
+++ b/speechx/speechx/frontend/audio/CMakeLists.txt
@@ -7,6 +7,25 @@ add_library(frontend STATIC
audio_cache.cc
feature_cache.cc
feature_pipeline.cc
+ fbank.cc
+ assembler.cc
)
+target_link_libraries(frontend PUBLIC kaldi-matrix kaldi-feat-common kaldi-fbank)
-target_link_libraries(frontend PUBLIC kaldi-matrix kaldi-feat-common)
+
+
+set(bin_name cmvn_json2kaldi_main)
+add_executable(${bin_name} ${CMAKE_CURRENT_SOURCE_DIR}/${bin_name}.cc)
+target_include_directories(${bin_name} PRIVATE ${SPEECHX_ROOT} ${SPEECHX_ROOT}/kaldi)
+target_link_libraries(${bin_name} utils kaldi-util kaldi-matrix gflags glog)
+
+set(BINS
+ compute_linear_spectrogram_main
+ compute_fbank_main
+)
+
+foreach(bin_name IN LISTS BINS)
+ add_executable(${bin_name} ${CMAKE_CURRENT_SOURCE_DIR}/${bin_name}.cc)
+ target_include_directories(${bin_name} PRIVATE ${SPEECHX_ROOT} ${SPEECHX_ROOT}/kaldi)
+ target_link_libraries(${bin_name} PUBLIC frontend utils kaldi-util gflags glog)
+endforeach()
diff --git a/speechx/speechx/frontend/audio/assembler.cc b/speechx/speechx/frontend/audio/assembler.cc
new file mode 100644
index 000000000..37eeec80f
--- /dev/null
+++ b/speechx/speechx/frontend/audio/assembler.cc
@@ -0,0 +1,86 @@
+// Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#include "frontend/audio/assembler.h"
+
+namespace ppspeech {
+
+using kaldi::Vector;
+using kaldi::VectorBase;
+using kaldi::BaseFloat;
+using std::unique_ptr;
+
+Assembler::Assembler(AssemblerOptions opts,
+ unique_ptr base_extractor) {
+ frame_chunk_stride_ = opts.subsampling_rate * opts.nnet_decoder_chunk;
+ frame_chunk_size_ = (opts.nnet_decoder_chunk - 1) * opts.subsampling_rate +
+ opts.receptive_filed_length;
+ receptive_filed_length_ = opts.receptive_filed_length;
+ base_extractor_ = std::move(base_extractor);
+ dim_ = base_extractor_->Dim();
+}
+
+void Assembler::Accept(const kaldi::VectorBase& inputs) {
+ // read inputs
+ base_extractor_->Accept(inputs);
+}
+
+// pop feature chunk
+bool Assembler::Read(kaldi::Vector* feats) {
+ feats->Resize(dim_ * frame_chunk_size_);
+ bool result = Compute(feats);
+ return result;
+}
+
+// read all data from base_feature_extractor_ into cache_
+bool Assembler::Compute(Vector* feats) {
+ // compute and feed
+ bool result = false;
+ while (feature_cache_.size() < frame_chunk_size_) {
+ Vector feature;
+ result = base_extractor_->Read(&feature);
+ if (result == false || feature.Dim() == 0) {
+ if (IsFinished() == false) return false;
+ break;
+ }
+ feature_cache_.push(feature);
+ }
+
+ if (feature_cache_.size() < receptive_filed_length_) {
+ return false;
+ }
+
+ while (feature_cache_.size() < frame_chunk_size_) {
+ Vector feature(dim_, kaldi::kSetZero);
+ feature_cache_.push(feature);
+ }
+
+ int32 counter = 0;
+ int32 cache_size = frame_chunk_size_ - frame_chunk_stride_;
+ int32 elem_dim = base_extractor_->Dim();
+ while (counter < frame_chunk_size_) {
+ Vector& val = feature_cache_.front();
+ int32 start = counter * elem_dim;
+ feats->Range(start, elem_dim).CopyFromVec(val);
+ if (frame_chunk_size_ - counter <= cache_size) {
+ feature_cache_.push(val);
+ }
+ feature_cache_.pop();
+ counter++;
+ }
+
+ return result;
+}
+
+} // namespace ppspeech
diff --git a/speechx/speechx/frontend/audio/assembler.h b/speechx/speechx/frontend/audio/assembler.h
new file mode 100644
index 000000000..258e61f2b
--- /dev/null
+++ b/speechx/speechx/frontend/audio/assembler.h
@@ -0,0 +1,68 @@
+// Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#pragma once
+
+#include "base/common.h"
+#include "frontend/audio/frontend_itf.h"
+
+namespace ppspeech {
+
+struct AssemblerOptions {
+ // refer:https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/paddlespeech/s2t/exps/deepspeech2/model.py
+ // the nnet batch forward
+ int32 receptive_filed_length;
+ int32 subsampling_rate;
+ int32 nnet_decoder_chunk;
+
+ AssemblerOptions()
+ : receptive_filed_length(1),
+ subsampling_rate(1),
+ nnet_decoder_chunk(1) {}
+};
+
+class Assembler : public FrontendInterface {
+ public:
+ explicit Assembler(
+ AssemblerOptions opts,
+ std::unique_ptr base_extractor = NULL);
+
+ // Feed feats or waves
+ virtual void Accept(const kaldi::VectorBase& inputs);
+
+ // feats size = num_frames * feat_dim
+ virtual bool Read(kaldi::Vector* feats);
+
+ // feat dim
+ virtual size_t Dim() const { return dim_; }
+
+ virtual void SetFinished() { base_extractor_->SetFinished(); }
+
+ virtual bool IsFinished() const { return base_extractor_->IsFinished(); }
+
+ virtual void Reset() { base_extractor_->Reset(); }
+
+ private:
+ bool Compute(kaldi::Vector* feats);
+
+ int32 dim_;
+ int32 frame_chunk_size_; // window
+ int32 frame_chunk_stride_; // stride
+ int32 receptive_filed_length_;
+ std::queue> feature_cache_;
+ std::unique_ptr base_extractor_;
+ DISALLOW_COPY_AND_ASSIGN(Assembler);
+};
+
+} // namespace ppspeech
diff --git a/speechx/speechx/frontend/audio/audio_cache.h b/speechx/speechx/frontend/audio/audio_cache.h
index 4ebcd9474..fc07d4bab 100644
--- a/speechx/speechx/frontend/audio/audio_cache.h
+++ b/speechx/speechx/frontend/audio/audio_cache.h
@@ -30,8 +30,9 @@ class AudioCache : public FrontendInterface {
virtual bool Read(kaldi::Vector* waves);
- // the audio dim is 1, one sample
- virtual size_t Dim() const { return 1; }
+ // the audio dim is 1, one sample, which is useless,
+ // so we return size_(cache samples) instead.
+ virtual size_t Dim() const { return size_; }
virtual void SetFinished() {
std::lock_guard lock(mutex_);
diff --git a/speechx/examples/ds2_ol/feat/cmvn-json2kaldi.cc b/speechx/speechx/frontend/audio/cmvn_json2kaldi_main.cc
similarity index 100%
rename from speechx/examples/ds2_ol/feat/cmvn-json2kaldi.cc
rename to speechx/speechx/frontend/audio/cmvn_json2kaldi_main.cc
diff --git a/speechx/speechx/frontend/audio/compute_fbank_main.cc b/speechx/speechx/frontend/audio/compute_fbank_main.cc
new file mode 100644
index 000000000..f7a42315f
--- /dev/null
+++ b/speechx/speechx/frontend/audio/compute_fbank_main.cc
@@ -0,0 +1,138 @@
+// Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+// todo refactor, repalce with gtest
+
+#include "base/flags.h"
+#include "base/log.h"
+#include "kaldi/feat/wave-reader.h"
+#include "kaldi/util/kaldi-io.h"
+#include "kaldi/util/table-types.h"
+
+#include "frontend/audio/audio_cache.h"
+#include "frontend/audio/data_cache.h"
+#include "frontend/audio/fbank.h"
+#include "frontend/audio/feature_cache.h"
+#include "frontend/audio/frontend_itf.h"
+#include "frontend/audio/normalizer.h"
+
+DEFINE_string(wav_rspecifier, "", "test wav scp path");
+DEFINE_string(feature_wspecifier, "", "output feats wspecifier");
+DEFINE_string(cmvn_file, "", "read cmvn");
+DEFINE_double(streaming_chunk, 0.36, "streaming feature chunk size");
+DEFINE_int32(num_bins, 161, "fbank num bins");
+
+int main(int argc, char* argv[]) {
+ gflags::ParseCommandLineFlags(&argc, &argv, false);
+ google::InitGoogleLogging(argv[0]);
+
+ kaldi::SequentialTableReader wav_reader(
+ FLAGS_wav_rspecifier);
+ kaldi::BaseFloatMatrixWriter feat_writer(FLAGS_feature_wspecifier);
+
+ int32 num_done = 0, num_err = 0;
+
+ // feature pipeline: wave cache --> povey window
+ // -->fbank --> global cmvn -> feat cache
+
+ std::unique_ptr data_source(
+ new ppspeech::AudioCache(3600 * 1600, false));
+
+ kaldi::FbankOptions opt;
+ opt.frame_opts.frame_length_ms = 25;
+ opt.frame_opts.frame_shift_ms = 10;
+ opt.mel_opts.num_bins = FLAGS_num_bins;
+ opt.frame_opts.dither = 0.0;
+
+ std::unique_ptr fbank(
+ new ppspeech::Fbank(opt, std::move(data_source)));
+
+ std::unique_ptr cmvn(
+ new ppspeech::CMVN(FLAGS_cmvn_file, std::move(fbank)));
+
+ ppspeech::FeatureCacheOptions feat_cache_opts;
+ // the feature cache output feature chunk by chunk.
+ ppspeech::FeatureCache feature_cache(feat_cache_opts, std::move(cmvn));
+ LOG(INFO) << "fbank: " << true;
+ LOG(INFO) << "feat dim: " << feature_cache.Dim();
+
+ int sample_rate = 16000;
+ float streaming_chunk = FLAGS_streaming_chunk;
+ int chunk_sample_size = streaming_chunk * sample_rate;
+ LOG(INFO) << "sr: " << sample_rate;
+ LOG(INFO) << "chunk size (s): " << streaming_chunk;
+ LOG(INFO) << "chunk size (sample): " << chunk_sample_size;
+
+ for (; !wav_reader.Done(); wav_reader.Next()) {
+ std::string utt = wav_reader.Key();
+ const kaldi::WaveData& wave_data = wav_reader.Value();
+ LOG(INFO) << "process utt: " << utt;
+
+ int32 this_channel = 0;
+ kaldi::SubVector waveform(wave_data.Data(),
+ this_channel);
+ int tot_samples = waveform.Dim();
+ LOG(INFO) << "wav len (sample): " << tot_samples;
+
+ int sample_offset = 0;
+ std::vector> feats;
+ int feature_rows = 0;
+ while (sample_offset < tot_samples) {
+ int cur_chunk_size =
+ std::min(chunk_sample_size, tot_samples - sample_offset);
+
+ kaldi::Vector wav_chunk(cur_chunk_size);
+ for (int i = 0; i < cur_chunk_size; ++i) {
+ wav_chunk(i) = waveform(sample_offset + i);
+ }
+
+ kaldi::Vector features;
+ feature_cache.Accept(wav_chunk);
+ if (cur_chunk_size < chunk_sample_size) {
+ feature_cache.SetFinished();
+ }
+ bool flag = true;
+ do {
+ flag = feature_cache.Read(&features);
+ feats.push_back(features);
+ feature_rows += features.Dim() / feature_cache.Dim();
+ } while (flag == true && features.Dim() != 0);
+ sample_offset += cur_chunk_size;
+ }
+
+ int cur_idx = 0;
+ kaldi::Matrix features(feature_rows,
+ feature_cache.Dim());
+ for (auto feat : feats) {
+ int num_rows = feat.Dim() / feature_cache.Dim();
+ for (int row_idx = 0; row_idx < num_rows; ++row_idx) {
+ for (size_t col_idx = 0; col_idx < feature_cache.Dim();
+ ++col_idx) {
+ features(cur_idx, col_idx) =
+ feat(row_idx * feature_cache.Dim() + col_idx);
+ }
+ ++cur_idx;
+ }
+ }
+ feat_writer.Write(utt, features);
+ feature_cache.Reset();
+
+ if (num_done % 50 == 0 && num_done != 0)
+ KALDI_VLOG(2) << "Processed " << num_done << " utterances";
+ num_done++;
+ }
+ KALDI_LOG << "Done " << num_done << " utterances, " << num_err
+ << " with errors.";
+ return (num_done != 0 ? 0 : 1);
+}
diff --git a/speechx/examples/ds2_ol/feat/linear-spectrogram-wo-db-norm-ol.cc b/speechx/speechx/frontend/audio/compute_linear_spectrogram_main.cc
similarity index 94%
rename from speechx/examples/ds2_ol/feat/linear-spectrogram-wo-db-norm-ol.cc
rename to speechx/speechx/frontend/audio/compute_linear_spectrogram_main.cc
index c3652ad4a..162c3529d 100644
--- a/speechx/examples/ds2_ol/feat/linear-spectrogram-wo-db-norm-ol.cc
+++ b/speechx/speechx/frontend/audio/compute_linear_spectrogram_main.cc
@@ -12,8 +12,6 @@
// See the License for the specific language governing permissions and
// limitations under the License.
-// todo refactor, repalce with gtest
-
#include "base/flags.h"
#include "base/log.h"
#include "kaldi/feat/wave-reader.h"
@@ -51,11 +49,11 @@ int main(int argc, char* argv[]) {
ppspeech::LinearSpectrogramOptions opt;
opt.frame_opts.frame_length_ms = 20;
opt.frame_opts.frame_shift_ms = 10;
- opt.streaming_chunk = FLAGS_streaming_chunk;
opt.frame_opts.dither = 0.0;
opt.frame_opts.remove_dc_offset = false;
opt.frame_opts.window_type = "hanning";
opt.frame_opts.preemph_coeff = 0.0;
+ LOG(INFO) << "linear feature: " << true;
LOG(INFO) << "frame length (ms): " << opt.frame_opts.frame_length_ms;
LOG(INFO) << "frame shift (ms): " << opt.frame_opts.frame_shift_ms;
@@ -67,17 +65,13 @@ int main(int argc, char* argv[]) {
ppspeech::FeatureCacheOptions feat_cache_opts;
// the feature cache output feature chunk by chunk.
- // frame_chunk_size : num frame of a chunk.
- // frame_chunk_stride: chunk sliding window stride.
- feat_cache_opts.frame_chunk_stride = 1;
- feat_cache_opts.frame_chunk_size = 1;
ppspeech::FeatureCache feature_cache(feat_cache_opts, std::move(cmvn));
LOG(INFO) << "feat dim: " << feature_cache.Dim();
int sample_rate = 16000;
float streaming_chunk = FLAGS_streaming_chunk;
int chunk_sample_size = streaming_chunk * sample_rate;
- LOG(INFO) << "sr: " << sample_rate;
+ LOG(INFO) << "sample rate: " << sample_rate;
LOG(INFO) << "chunk size (s): " << streaming_chunk;
LOG(INFO) << "chunk size (sample): " << chunk_sample_size;
diff --git a/speechx/speechx/frontend/audio/fbank.cc b/speechx/speechx/frontend/audio/fbank.cc
index 8273beecd..059abbbd1 100644
--- a/speechx/speechx/frontend/audio/fbank.cc
+++ b/speechx/speechx/frontend/audio/fbank.cc
@@ -12,7 +12,6 @@
// See the License for the specific language governing permissions and
// limitations under the License.
-
#include "frontend/audio/fbank.h"
#include "kaldi/base/kaldi-math.h"
#include "kaldi/feat/feature-common.h"
@@ -29,80 +28,34 @@ using kaldi::VectorBase;
using kaldi::Matrix;
using std::vector;
-Fbank::Fbank(const FbankOptions& opts,
- std::unique_ptr base_extractor)
- : opts_(opts),
- computer_(opts.fbank_opts),
- window_function_(computer_.GetFrameOptions()) {
- base_extractor_ = std::move(base_extractor);
- chunk_sample_size_ =
- static_cast(opts.streaming_chunk * opts.frame_opts.samp_freq);
-}
+FbankComputer::FbankComputer(const Options& opts)
+ : opts_(opts), computer_(opts) {}
-void Fbank::Accept(const VectorBase& inputs) {
- base_extractor_->Accept(inputs);
+int32 FbankComputer::Dim() const {
+ return opts_.mel_opts.num_bins + (opts_.use_energy ? 1 : 0);
}
-bool Fbank::Read(Vector* feats) {
- Vector wav(chunk_sample_size_);
- bool flag = base_extractor_->Read(&wav);
- if (flag == false || wav.Dim() == 0) return false;
-
- // append remaned waves
- int32 wav_len = wav.Dim();
- int32 left_len = remained_wav_.Dim();
- Vector waves(left_len + wav_len);
- waves.Range(0, left_len).CopyFromVec(remained_wav_);
- waves.Range(left_len, wav_len).CopyFromVec(wav);
-
- // compute speech feature
- Compute(waves, feats);
-
- // cache remaned waves
- kaldi::FrameExtractionOptions frame_opts = computer_.GetFrameOptions();
- int32 num_frames = kaldi::NumFrames(waves.Dim(), frame_opts);
- int32 frame_shift = frame_opts.WindowShift();
- int32 left_samples = waves.Dim() - frame_shift * num_frames;
- remained_wav_.Resize(left_samples);
- remained_wav_.CopyFromVec(
- waves.Range(frame_shift * num_frames, left_samples));
- return true;
+bool FbankComputer::NeedRawLogEnergy() {
+ return opts_.use_energy && opts_.raw_energy;
}
-// Compute spectrogram feat
-bool Fbank::Compute(const Vector& waves, Vector* feats) {
- const FrameExtractionOptions& frame_opts = computer_.GetFrameOptions();
- int32 num_samples = waves.Dim();
- int32 frame_length = frame_opts.WindowSize();
- int32 sample_rate = frame_opts.samp_freq;
- if (num_samples < frame_length) {
- return true;
- }
-
- int32 num_frames = kaldi::NumFrames(num_samples, frame_opts);
- feats->Rsize(num_frames * Dim());
-
- Vector window;
- bool need_raw_log_energy = computer_.NeedRawLogEnergy();
- for (int32 frame = 0; frame < num_frames; frame++) {
- BaseFloat raw_log_energy = 0.0;
- kaldi::ExtractWindow(0,
- waves,
- frame,
- frame_opts,
- window_function_,
- &window,
- need_raw_log_energy ? &raw_log_energy : NULL);
-
-
- Vector this_feature(computer_.Dim(), kUndefined);
- // note: this online feature-extraction code does not support VTLN.
- BaseFloat vtln_warp = 1.0;
- computer_.Compute(raw_log_energy, vtln_warp, &window, &this_feature);
- SubVector output_row(feats->Data() + frame * Dim(), Dim());
- output_row.CopyFromVec(this_feature);
+// Compute feat
+bool FbankComputer::Compute(Vector* window,
+ Vector* feat) {
+ RealFft(window, true);
+ kaldi::ComputePowerSpectrum(window);
+ const kaldi::MelBanks& mel_bank = *(computer_.GetMelBanks(1.0));
+ SubVector power_spectrum(*window, 0, window->Dim() / 2 + 1);
+ if (!opts_.use_power) {
+ power_spectrum.ApplyPow(0.5);
}
+ int32 mel_offset = ((opts_.use_energy && !opts_.htk_compat) ? 1 : 0);
+ SubVector mel_energies(
+ *feat, mel_offset, opts_.mel_opts.num_bins);
+ mel_bank.Compute(power_spectrum, &mel_energies);
+ mel_energies.ApplyFloor(1e-07);
+ mel_energies.ApplyLog();
return true;
}
-} // namespace ppspeech
\ No newline at end of file
+} // namespace ppspeech
diff --git a/speechx/speechx/frontend/audio/fbank.h b/speechx/speechx/frontend/audio/fbank.h
index 3b71ff84d..a1e654138 100644
--- a/speechx/speechx/frontend/audio/fbank.h
+++ b/speechx/speechx/frontend/audio/fbank.h
@@ -14,62 +14,37 @@
#pragma once
+#include "base/common.h"
+#include "frontend/audio/feature_common.h"
+#include "frontend/audio/frontend_itf.h"
#include "kaldi/feat/feature-fbank.h"
#include "kaldi/feat/feature-mfcc.h"
#include "kaldi/matrix/kaldi-vector.h"
namespace ppspeech {
-struct FbankOptions {
- kaldi::FbankOptions fbank_opts;
- kaldi::BaseFloat streaming_chunk; // second
-
- FbankOptions() : streaming_chunk(0.1), fbank_opts() {}
-
- void Register(kaldi::OptionsItf* opts) {
- opts->Register("streaming-chunk",
- &streaming_chunk,
- "streaming chunk size, default: 0.1 sec");
- fbank_opts.Register(opts);
- }
-};
-
-
-class Fbank : public FrontendInterface {
+class FbankComputer {
public:
- explicit Fbank(const FbankOptions& opts,
- unique_ptr base_extractor);
- virtual void Accept(const kaldi::VectorBase& inputs);
- virtual bool Read(kaldi::Vector* feats);
-
- // the dim_ is the dim of single frame feature
- virtual size_t Dim() const { return computer_.Dim(); }
+ typedef kaldi::FbankOptions Options;
+ explicit FbankComputer(const Options& opts);
- virtual void SetFinished() { base_extractor_->SetFinished(); }
-
- virtual bool IsFinished() const { return base_extractor_->IsFinished(); }
-
- virtual void Reset() {
- base_extractor_->Reset();
- remained_wav_.Resize(0);
+ kaldi::FrameExtractionOptions& GetFrameOptions() {
+ return opts_.frame_opts;
}
- private:
- bool Compute(const kaldi::Vector& waves,
- kaldi::Vector* feats);
+ bool Compute(kaldi::Vector* window,
+ kaldi::Vector* feat);
+ int32 Dim() const;
- FbankOptions opts_;
- std::unique_ptr base_extractor_;
+ bool NeedRawLogEnergy();
+ private:
+ Options opts_;
- FeatureWindowFunction window_function_;
kaldi::FbankComputer computer_;
- // features_ is the Mfcc or Plp or Fbank features that we have already
- // computed.
- kaldi::Vector features_;
- kaldi::Vector remained_wav_;
-
- DISALLOW_COPY_AND_ASSIGN(Fbank);
+ DISALLOW_COPY_AND_ASSIGN(FbankComputer);
};
-} // namespace ppspeech
\ No newline at end of file
+typedef StreamingFeatureTpl Fbank;
+
+} // namespace ppspeech
diff --git a/speechx/speechx/frontend/audio/feature_cache.cc b/speechx/speechx/frontend/audio/feature_cache.cc
index 05283bb7e..509a98c3b 100644
--- a/speechx/speechx/frontend/audio/feature_cache.cc
+++ b/speechx/speechx/frontend/audio/feature_cache.cc
@@ -26,8 +26,6 @@ using std::unique_ptr;
FeatureCache::FeatureCache(FeatureCacheOptions opts,
unique_ptr base_extractor) {
max_size_ = opts.max_size;
- frame_chunk_stride_ = opts.frame_chunk_stride;
- frame_chunk_size_ = opts.frame_chunk_size;
timeout_ = opts.timeout; // ms
base_extractor_ = std::move(base_extractor);
dim_ = base_extractor_->Dim();
@@ -74,24 +72,11 @@ bool FeatureCache::Compute() {
bool result = base_extractor_->Read(&feature);
if (result == false || feature.Dim() == 0) return false;
- // join with remained
- int32 joint_len = feature.Dim() + remained_feature_.Dim();
- Vector joint_feature(joint_len);
- joint_feature.Range(0, remained_feature_.Dim())
- .CopyFromVec(remained_feature_);
- joint_feature.Range(remained_feature_.Dim(), feature.Dim())
- .CopyFromVec(feature);
-
- // one by one, or stride with window
- // controlled by frame_chunk_stride_ and frame_chunk_size_
- int32 num_chunk =
- ((joint_len / dim_) - frame_chunk_size_) / frame_chunk_stride_ + 1;
+ int32 num_chunk = feature.Dim() / dim_;
for (int chunk_idx = 0; chunk_idx < num_chunk; ++chunk_idx) {
- int32 start = chunk_idx * frame_chunk_stride_ * dim_;
-
- Vector feature_chunk(frame_chunk_size_ * dim_);
- SubVector tmp(joint_feature.Data() + start,
- frame_chunk_size_ * dim_);
+ int32 start = chunk_idx * dim_;
+ Vector feature_chunk(dim_);
+ SubVector tmp(feature.Data() + start, dim_);
feature_chunk.CopyFromVec(tmp);
std::unique_lock lock(mutex_);
@@ -104,13 +89,6 @@ bool FeatureCache::Compute() {
cache_.push(feature_chunk);
ready_read_condition_.notify_one();
}
-
- // cache remained feats
- int32 remained_feature_len =
- joint_len - num_chunk * frame_chunk_stride_ * dim_;
- remained_feature_.Resize(remained_feature_len);
- remained_feature_.CopyFromVec(joint_feature.Range(
- frame_chunk_stride_ * num_chunk * dim_, remained_feature_len));
return result;
}
diff --git a/speechx/speechx/frontend/audio/feature_cache.h b/speechx/speechx/frontend/audio/feature_cache.h
index 0dc704bbf..b922de12c 100644
--- a/speechx/speechx/frontend/audio/feature_cache.h
+++ b/speechx/speechx/frontend/audio/feature_cache.h
@@ -21,14 +21,8 @@ namespace ppspeech {
struct FeatureCacheOptions {
int32 max_size;
- int32 frame_chunk_size;
- int32 frame_chunk_stride;
int32 timeout; // ms
- FeatureCacheOptions()
- : max_size(kint16max),
- frame_chunk_size(1),
- frame_chunk_stride(1),
- timeout(1) {}
+ FeatureCacheOptions() : max_size(kint16max), timeout(1) {}
};
class FeatureCache : public FrontendInterface {
@@ -80,7 +74,7 @@ class FeatureCache : public FrontendInterface {
std::condition_variable ready_feed_condition_;
std::condition_variable ready_read_condition_;
- // DISALLOW_COPY_AND_ASSGIN(FeatureCache);
+ DISALLOW_COPY_AND_ASSIGN(FeatureCache);
};
} // namespace ppspeech
diff --git a/speechx/speechx/frontend/audio/feature_common.h b/speechx/speechx/frontend/audio/feature_common.h
new file mode 100644
index 000000000..bad705c9f
--- /dev/null
+++ b/speechx/speechx/frontend/audio/feature_common.h
@@ -0,0 +1,55 @@
+// Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#pragma once
+
+#include "frontend_itf.h"
+#include "kaldi/feat/feature-window.h"
+
+namespace ppspeech {
+
+template
+class StreamingFeatureTpl : public FrontendInterface {
+ public:
+ typedef typename F::Options Options;
+ StreamingFeatureTpl(const Options& opts,
+ std::unique_ptr base_extractor);
+ virtual void Accept(const kaldi::VectorBase& waves);
+ virtual bool Read(kaldi::Vector* feats);
+
+ // the dim_ is the dim of single frame feature
+ virtual size_t Dim() const { return computer_.Dim(); }
+
+ virtual void SetFinished() { base_extractor_->SetFinished(); }
+
+ virtual bool IsFinished() const { return base_extractor_->IsFinished(); }
+
+ virtual void Reset() {
+ base_extractor_->Reset();
+ remained_wav_.Resize(0);
+ }
+
+ private:
+ bool Compute(const kaldi::Vector& waves,
+ kaldi::Vector* feats);
+ Options opts_;
+ std::unique_ptr base_extractor_;
+ kaldi::FeatureWindowFunction window_function_;
+ kaldi::Vector remained_wav_;
+ F computer_;
+};
+
+} // namespace ppspeech
+
+#include "frontend/audio/feature_common_inl.h"
diff --git a/speechx/speechx/frontend/audio/feature_common_inl.h b/speechx/speechx/frontend/audio/feature_common_inl.h
new file mode 100644
index 000000000..b86f79918
--- /dev/null
+++ b/speechx/speechx/frontend/audio/feature_common_inl.h
@@ -0,0 +1,97 @@
+// Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+
+namespace ppspeech {
+
+template
+StreamingFeatureTpl::StreamingFeatureTpl(
+ const Options& opts, std::unique_ptr base_extractor)
+ : opts_(opts), computer_(opts), window_function_(opts.frame_opts) {
+ base_extractor_ = std::move(base_extractor);
+}
+
+template
+void StreamingFeatureTpl::Accept(
+ const kaldi::VectorBase& waves) {
+ base_extractor_->Accept(waves);
+}
+
+template
+bool StreamingFeatureTpl::Read(kaldi::Vector* feats) {
+ kaldi::Vector wav(base_extractor_->Dim());
+ bool flag = base_extractor_->Read(&wav);
+ if (flag == false || wav.Dim() == 0) return false;
+
+ // append remaned waves
+ int32 wav_len = wav.Dim();
+ int32 left_len = remained_wav_.Dim();
+ kaldi::Vector waves(left_len + wav_len);
+ waves.Range(0, left_len).CopyFromVec(remained_wav_);
+ waves.Range(left_len, wav_len).CopyFromVec(wav);
+
+ // compute speech feature
+ Compute(waves, feats);
+
+ // cache remaned waves
+ kaldi::FrameExtractionOptions frame_opts = computer_.GetFrameOptions();
+ int32 num_frames = kaldi::NumFrames(waves.Dim(), frame_opts);
+ int32 frame_shift = frame_opts.WindowShift();
+ int32 left_samples = waves.Dim() - frame_shift * num_frames;
+ remained_wav_.Resize(left_samples);
+ remained_wav_.CopyFromVec(
+ waves.Range(frame_shift * num_frames, left_samples));
+ return true;
+}
+
+// Compute feat
+template
+bool StreamingFeatureTpl::Compute(
+ const kaldi::Vector& waves,
+ kaldi::Vector* feats) {
+ const kaldi::FrameExtractionOptions& frame_opts =
+ computer_.GetFrameOptions();
+ int32 num_samples = waves.Dim();
+ int32 frame_length = frame_opts.WindowSize();
+ int32 sample_rate = frame_opts.samp_freq;
+ if (num_samples < frame_length) {
+ return true;
+ }
+
+ int32 num_frames = kaldi::NumFrames(num_samples, frame_opts);
+ feats->Resize(num_frames * Dim());
+
+ kaldi::Vector window;
+ bool need_raw_log_energy = computer_.NeedRawLogEnergy();
+ for (int32 frame = 0; frame < num_frames; frame++) {
+ kaldi::BaseFloat raw_log_energy = 0.0;
+ kaldi::ExtractWindow(0,
+ waves,
+ frame,
+ frame_opts,
+ window_function_,
+ &window,
+ need_raw_log_energy ? &raw_log_energy : NULL);
+
+ kaldi::Vector this_feature(computer_.Dim(),
+ kaldi::kUndefined);
+ computer_.Compute(&window, &this_feature);
+ kaldi::SubVector output_row(
+ feats->Data() + frame * Dim(), Dim());
+ output_row.CopyFromVec(this_feature);
+ }
+ return true;
+}
+
+} // namespace ppspeech
diff --git a/speechx/speechx/frontend/audio/feature_pipeline.cc b/speechx/speechx/frontend/audio/feature_pipeline.cc
index 5914fedbe..9cacff9f7 100644
--- a/speechx/speechx/frontend/audio/feature_pipeline.cc
+++ b/speechx/speechx/frontend/audio/feature_pipeline.cc
@@ -22,15 +22,24 @@ FeaturePipeline::FeaturePipeline(const FeaturePipelineOptions& opts) {
unique_ptr data_source(
new ppspeech::AudioCache(1000 * kint16max, opts.to_float32));
- unique_ptr linear_spectrogram(
- new ppspeech::LinearSpectrogram(opts.linear_spectrogram_opts,
- std::move(data_source)));
+ unique_ptr base_feature;
+
+ if (opts.use_fbank) {
+ base_feature.reset(
+ new ppspeech::Fbank(opts.fbank_opts, std::move(data_source)));
+ } else {
+ base_feature.reset(new ppspeech::LinearSpectrogram(
+ opts.linear_spectrogram_opts, std::move(data_source)));
+ }
unique_ptr cmvn(
- new ppspeech::CMVN(opts.cmvn_file, std::move(linear_spectrogram)));
+ new ppspeech::CMVN(opts.cmvn_file, std::move(base_feature)));
- base_extractor_.reset(
+ unique_ptr cache(
new ppspeech::FeatureCache(opts.feature_cache_opts, std::move(cmvn)));
+
+ base_extractor_.reset(
+ new ppspeech::Assembler(opts.assembler_opts, std::move(cache)));
}
-} // ppspeech
\ No newline at end of file
+} // ppspeech
diff --git a/speechx/speechx/frontend/audio/feature_pipeline.h b/speechx/speechx/frontend/audio/feature_pipeline.h
index 580c02fa6..48f95e3f3 100644
--- a/speechx/speechx/frontend/audio/feature_pipeline.h
+++ b/speechx/speechx/frontend/audio/feature_pipeline.h
@@ -16,8 +16,10 @@
#pragma once
+#include "frontend/audio/assembler.h"
#include "frontend/audio/audio_cache.h"
#include "frontend/audio/data_cache.h"
+#include "frontend/audio/fbank.h"
#include "frontend/audio/feature_cache.h"
#include "frontend/audio/frontend_itf.h"
#include "frontend/audio/linear_spectrogram.h"
@@ -27,14 +29,21 @@ namespace ppspeech {
struct FeaturePipelineOptions {
std::string cmvn_file;
- bool to_float32;
+ bool to_float32; // true, only for linear feature
+ bool use_fbank;
LinearSpectrogramOptions linear_spectrogram_opts;
+ kaldi::FbankOptions fbank_opts;
FeatureCacheOptions feature_cache_opts;
+ AssemblerOptions assembler_opts;
+
FeaturePipelineOptions()
: cmvn_file(""),
- to_float32(false),
+ to_float32(false), // true, only for linear feature
+ use_fbank(true),
linear_spectrogram_opts(),
- feature_cache_opts() {}
+ fbank_opts(),
+ feature_cache_opts(),
+ assembler_opts() {}
};
class FeaturePipeline : public FrontendInterface {
@@ -54,4 +63,4 @@ class FeaturePipeline : public FrontendInterface {
private:
std::unique_ptr base_extractor_;
};
-}
\ No newline at end of file
+}
diff --git a/speechx/speechx/frontend/audio/linear_spectrogram.cc b/speechx/speechx/frontend/audio/linear_spectrogram.cc
index 9ef5e7664..55c039787 100644
--- a/speechx/speechx/frontend/audio/linear_spectrogram.cc
+++ b/speechx/speechx/frontend/audio/linear_spectrogram.cc
@@ -28,81 +28,31 @@ using kaldi::VectorBase;
using kaldi::Matrix;
using std::vector;
-LinearSpectrogram::LinearSpectrogram(
- const LinearSpectrogramOptions& opts,
- std::unique_ptr base_extractor)
- : opts_(opts), feature_window_funtion_(opts.frame_opts) {
- base_extractor_ = std::move(base_extractor);
+LinearSpectrogramComputer::LinearSpectrogramComputer(const Options& opts)
+ : opts_(opts) {
+ kaldi::FeatureWindowFunction feature_window_function(opts.frame_opts);
int32 window_size = opts.frame_opts.WindowSize();
- int32 window_shift = opts.frame_opts.WindowShift();
+ frame_length_ = window_size;
dim_ = window_size / 2 + 1;
- chunk_sample_size_ =
- static_cast(opts.streaming_chunk * opts.frame_opts.samp_freq);
- hanning_window_energy_ = kaldi::VecVec(feature_window_funtion_.window,
- feature_window_funtion_.window);
-}
-
-void LinearSpectrogram::Accept(const VectorBase& inputs) {
- base_extractor_->Accept(inputs);
-}
-
-bool LinearSpectrogram::Read(Vector* feats) {
- Vector input_feats(chunk_sample_size_);
- bool flag = base_extractor_->Read(&input_feats);
- if (flag == false || input_feats.Dim() == 0) return false;
-
- int32 feat_len = input_feats.Dim();
- int32 left_len = remained_wav_.Dim();
- Vector waves(feat_len + left_len);
- waves.Range(0, left_len).CopyFromVec(remained_wav_);
- waves.Range(left_len, feat_len).CopyFromVec(input_feats);
- Compute(waves, feats);
- int32 frame_shift = opts_.frame_opts.WindowShift();
- int32 num_frames = kaldi::NumFrames(waves.Dim(), opts_.frame_opts);
- int32 left_samples = waves.Dim() - frame_shift * num_frames;
- remained_wav_.Resize(left_samples);
- remained_wav_.CopyFromVec(
- waves.Range(frame_shift * num_frames, left_samples));
- return true;
+ BaseFloat hanning_window_energy = kaldi::VecVec(
+ feature_window_function.window, feature_window_function.window);
+ int32 sample_rate = opts.frame_opts.samp_freq;
+ scale_ = 2.0 / (hanning_window_energy * sample_rate);
}
// Compute spectrogram feat
-bool LinearSpectrogram::Compute(const Vector& waves,
- Vector* feats) {
- int32 num_samples = waves.Dim();
- int32 frame_length = opts_.frame_opts.WindowSize();
- int32 sample_rate = opts_.frame_opts.samp_freq;
- BaseFloat scale = 2.0 / (hanning_window_energy_ * sample_rate);
-
- if (num_samples < frame_length) {
- return true;
- }
-
- int32 num_frames = kaldi::NumFrames(num_samples, opts_.frame_opts);
- feats->Resize(num_frames * dim_);
- Vector window;
-
- for (int frame_idx = 0; frame_idx < num_frames; ++frame_idx) {
- kaldi::ExtractWindow(0,
- waves,
- frame_idx,
- opts_.frame_opts,
- feature_window_funtion_,
- &window,
- NULL);
-
- SubVector output_row(feats->Data() + frame_idx * dim_, dim_);
- window.Resize(frame_length, kaldi::kCopyData);
- RealFft(&window, true);
- kaldi::ComputePowerSpectrum(&window);
- SubVector power_spectrum(window, 0, dim_);
- power_spectrum.Scale(scale);
- power_spectrum(0) = power_spectrum(0) / 2;
- power_spectrum(dim_ - 1) = power_spectrum(dim_ - 1) / 2;
- power_spectrum.Add(1e-14);
- power_spectrum.ApplyLog();
- output_row.CopyFromVec(power_spectrum);
- }
+bool LinearSpectrogramComputer::Compute(Vector* window,
+ Vector* feat) {
+ window->Resize(frame_length_, kaldi::kCopyData);
+ RealFft(window, true);
+ kaldi::ComputePowerSpectrum(window);
+ SubVector power_spectrum(*window, 0, dim_);
+ power_spectrum.Scale(scale_);
+ power_spectrum(0) = power_spectrum(0) / 2;
+ power_spectrum(dim_ - 1) = power_spectrum(dim_ - 1) / 2;
+ power_spectrum.Add(1e-14);
+ power_spectrum.ApplyLog();
+ feat->CopyFromVec(power_spectrum);
return true;
}
diff --git a/speechx/speechx/frontend/audio/linear_spectrogram.h b/speechx/speechx/frontend/audio/linear_spectrogram.h
index 2764b7cf4..de957c235 100644
--- a/speechx/speechx/frontend/audio/linear_spectrogram.h
+++ b/speechx/speechx/frontend/audio/linear_spectrogram.h
@@ -16,6 +16,7 @@
#pragma once
#include "base/common.h"
+#include "frontend/audio/feature_common.h"
#include "frontend/audio/frontend_itf.h"
#include "kaldi/feat/feature-window.h"
@@ -23,47 +24,34 @@ namespace ppspeech {
struct LinearSpectrogramOptions {
kaldi::FrameExtractionOptions frame_opts;
- kaldi::BaseFloat streaming_chunk; // second
-
- LinearSpectrogramOptions() : streaming_chunk(0.1), frame_opts() {}
-
- void Register(kaldi::OptionsItf* opts) {
- opts->Register("streaming-chunk",
- &streaming_chunk,
- "streaming chunk size, default: 0.1 sec");
- frame_opts.Register(opts);
- }
+ LinearSpectrogramOptions() : frame_opts() {}
};
-class LinearSpectrogram : public FrontendInterface {
+class LinearSpectrogramComputer {
public:
- explicit LinearSpectrogram(
- const LinearSpectrogramOptions& opts,
- std::unique_ptr base_extractor);
- virtual void Accept(const kaldi::VectorBase& inputs);
- virtual bool Read(kaldi::Vector* feats);
- // the dim_ is the dim of single frame feature
- virtual size_t Dim() const { return dim_; }
- virtual void SetFinished() { base_extractor_->SetFinished(); }
- virtual bool IsFinished() const { return base_extractor_->IsFinished(); }
- virtual void Reset() {
- base_extractor_->Reset();
- remained_wav_.Resize(0);
+ typedef LinearSpectrogramOptions Options;
+ explicit LinearSpectrogramComputer(const Options& opts);
+
+ kaldi::FrameExtractionOptions& GetFrameOptions() {
+ return opts_.frame_opts;
}
- private:
- bool Compute(const kaldi::Vector& waves,
- kaldi::Vector* feats);
+ bool Compute(kaldi::Vector* window,
+ kaldi::Vector* feat);
- size_t dim_;
- kaldi::FeatureWindowFunction feature_window_funtion_;
- kaldi::BaseFloat hanning_window_energy_;
- LinearSpectrogramOptions opts_;
- std::unique_ptr base_extractor_;
- kaldi::Vector remained_wav_;
- int chunk_sample_size_;
- DISALLOW_COPY_AND_ASSIGN(LinearSpectrogram);
+ int32 Dim() const { return dim_; }
+
+ bool NeedRawLogEnergy() { return false; }
+
+ private:
+ kaldi::BaseFloat scale_;
+ Options opts_;
+ int32 frame_length_;
+ int32 dim_;
+ DISALLOW_COPY_AND_ASSIGN(LinearSpectrogramComputer);
};
+typedef StreamingFeatureTpl LinearSpectrogram;
+
} // namespace ppspeech
\ No newline at end of file
diff --git a/speechx/speechx/kaldi/CMakeLists.txt b/speechx/speechx/kaldi/CMakeLists.txt
index 6f7398cd1..ce6b43f63 100644
--- a/speechx/speechx/kaldi/CMakeLists.txt
+++ b/speechx/speechx/kaldi/CMakeLists.txt
@@ -7,3 +7,7 @@ add_subdirectory(matrix)
add_subdirectory(lat)
add_subdirectory(fstext)
add_subdirectory(decoder)
+add_subdirectory(lm)
+
+add_subdirectory(fstbin)
+add_subdirectory(lmbin)
\ No newline at end of file
diff --git a/speechx/speechx/kaldi/feat/CMakeLists.txt b/speechx/speechx/kaldi/feat/CMakeLists.txt
index c3a996ffb..cfbf20256 100644
--- a/speechx/speechx/kaldi/feat/CMakeLists.txt
+++ b/speechx/speechx/kaldi/feat/CMakeLists.txt
@@ -3,10 +3,10 @@ add_library(kaldi-mfcc
)
target_link_libraries(kaldi-mfcc PUBLIC kaldi-feat-common)
-add_library(fbank
+add_library(kaldi-fbank
feature-fbank.cc
)
-target_link_libraries(fbank PUBLIC kaldi-feat-common)
+target_link_libraries(kaldi-fbank PUBLIC kaldi-feat-common)
add_library(kaldi-feat-common
wave-reader.cc
diff --git a/speechx/speechx/kaldi/feat/feature-fbank.h b/speechx/speechx/kaldi/feat/feature-fbank.h
index f57d185a4..d121cc0ee 100644
--- a/speechx/speechx/kaldi/feat/feature-fbank.h
+++ b/speechx/speechx/kaldi/feat/feature-fbank.h
@@ -128,8 +128,8 @@ class FbankComputer {
~FbankComputer();
- private:
const MelBanks *GetMelBanks(BaseFloat vtln_warp);
+ private:
FbankOptions opts_;
diff --git a/speechx/speechx/kaldi/feat/mel-computations.cc b/speechx/speechx/kaldi/feat/mel-computations.cc
index bb5e9f9ac..626cb6775 100644
--- a/speechx/speechx/kaldi/feat/mel-computations.cc
+++ b/speechx/speechx/kaldi/feat/mel-computations.cc
@@ -120,8 +120,8 @@ MelBanks::MelBanks(const MelBanksOptions &opts,
last_index = i;
}
}
- KALDI_ASSERT(first_index != -1 && last_index >= first_index
- && "You may have set --num-mel-bins too large.");
+ //KALDI_ASSERT(first_index != -1 && last_index >= first_index
+ // && "You may have set --num-mel-bins too large.");
bins_[bin].first = first_index;
int32 size = last_index + 1 - first_index;
diff --git a/speechx/speechx/kaldi/fstbin/CMakeLists.txt b/speechx/speechx/kaldi/fstbin/CMakeLists.txt
new file mode 100644
index 000000000..05d0501f3
--- /dev/null
+++ b/speechx/speechx/kaldi/fstbin/CMakeLists.txt
@@ -0,0 +1,15 @@
+cmake_minimum_required(VERSION 3.14 FATAL_ERROR)
+
+set(BINS
+fstaddselfloops
+fstisstochastic
+fstminimizeencoded
+fstdeterminizestar
+fsttablecompose
+)
+
+foreach(binary IN LISTS BINS)
+ add_executable(${binary} ${CMAKE_CURRENT_SOURCE_DIR}/${binary}.cc)
+ target_include_directories(${binary} PRIVATE ${SPEECHX_ROOT} ${SPEECHX_ROOT}/kaldi)
+ target_link_libraries(${binary} PUBLIC kaldi-fstext glog gflags fst dl)
+endforeach()
diff --git a/speechx/tools/fstbin/fstaddselfloops.cc b/speechx/speechx/kaldi/fstbin/fstaddselfloops.cc
similarity index 100%
rename from speechx/tools/fstbin/fstaddselfloops.cc
rename to speechx/speechx/kaldi/fstbin/fstaddselfloops.cc
diff --git a/speechx/tools/fstbin/fstdeterminizestar.cc b/speechx/speechx/kaldi/fstbin/fstdeterminizestar.cc
similarity index 100%
rename from speechx/tools/fstbin/fstdeterminizestar.cc
rename to speechx/speechx/kaldi/fstbin/fstdeterminizestar.cc
diff --git a/speechx/tools/fstbin/fstisstochastic.cc b/speechx/speechx/kaldi/fstbin/fstisstochastic.cc
similarity index 100%
rename from speechx/tools/fstbin/fstisstochastic.cc
rename to speechx/speechx/kaldi/fstbin/fstisstochastic.cc
diff --git a/speechx/tools/fstbin/fstminimizeencoded.cc b/speechx/speechx/kaldi/fstbin/fstminimizeencoded.cc
similarity index 100%
rename from speechx/tools/fstbin/fstminimizeencoded.cc
rename to speechx/speechx/kaldi/fstbin/fstminimizeencoded.cc
diff --git a/speechx/tools/fstbin/fsttablecompose.cc b/speechx/speechx/kaldi/fstbin/fsttablecompose.cc
similarity index 100%
rename from speechx/tools/fstbin/fsttablecompose.cc
rename to speechx/speechx/kaldi/fstbin/fsttablecompose.cc
diff --git a/speechx/speechx/kaldi/fstext/CMakeLists.txt b/speechx/speechx/kaldi/fstext/CMakeLists.txt
index af91fd985..465d9dba7 100644
--- a/speechx/speechx/kaldi/fstext/CMakeLists.txt
+++ b/speechx/speechx/kaldi/fstext/CMakeLists.txt
@@ -1,5 +1,5 @@
add_library(kaldi-fstext
-kaldi-fst-io.cc
+ kaldi-fst-io.cc
)
target_link_libraries(kaldi-fstext PUBLIC kaldi-util)
diff --git a/speechx/speechx/kaldi/lm/CMakeLists.txt b/speechx/speechx/kaldi/lm/CMakeLists.txt
new file mode 100644
index 000000000..75c1567e7
--- /dev/null
+++ b/speechx/speechx/kaldi/lm/CMakeLists.txt
@@ -0,0 +1,6 @@
+
+add_library(kaldi-lm
+ arpa-file-parser.cc
+ arpa-lm-compiler.cc
+)
+target_link_libraries(kaldi-lm PUBLIC kaldi-util)
\ No newline at end of file
diff --git a/speechx/speechx/kaldi/lm/arpa-file-parser.cc b/speechx/speechx/kaldi/lm/arpa-file-parser.cc
new file mode 100644
index 000000000..81b63ed13
--- /dev/null
+++ b/speechx/speechx/kaldi/lm/arpa-file-parser.cc
@@ -0,0 +1,281 @@
+// lm/arpa-file-parser.cc
+
+// Copyright 2014 Guoguo Chen
+// Copyright 2016 Smart Action Company LLC (kkm)
+
+// See ../../COPYING for clarification regarding multiple authors
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// THIS CODE IS PROVIDED *AS IS* BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+// KIND, EITHER EXPRESS OR IMPLIED, INCLUDING WITHOUT LIMITATION ANY IMPLIED
+// WARRANTIES OR CONDITIONS OF TITLE, FITNESS FOR A PARTICULAR PURPOSE,
+// MERCHANTABLITY OR NON-INFRINGEMENT.
+// See the Apache 2 License for the specific language governing permissions and
+// limitations under the License.
+
+#include
+
+#include
+
+#include "base/kaldi-error.h"
+#include "base/kaldi-math.h"
+#include "lm/arpa-file-parser.h"
+#include "util/text-utils.h"
+
+namespace kaldi {
+
+ArpaFileParser::ArpaFileParser(const ArpaParseOptions& options,
+ fst::SymbolTable* symbols)
+ : options_(options), symbols_(symbols),
+ line_number_(0), warning_count_(0) {
+}
+
+ArpaFileParser::~ArpaFileParser() {
+}
+
+void TrimTrailingWhitespace(std::string *str) {
+ str->erase(str->find_last_not_of(" \n\r\t") + 1);
+}
+
+void ArpaFileParser::Read(std::istream &is) {
+ // Argument sanity checks.
+ if (options_.bos_symbol <= 0 || options_.eos_symbol <= 0 ||
+ options_.bos_symbol == options_.eos_symbol)
+ KALDI_ERR << "BOS and EOS symbols are required, must not be epsilons, and "
+ << "differ from each other. Given:"
+ << " BOS=" << options_.bos_symbol
+ << " EOS=" << options_.eos_symbol;
+ if (symbols_ != NULL &&
+ options_.oov_handling == ArpaParseOptions::kReplaceWithUnk &&
+ (options_.unk_symbol <= 0 ||
+ options_.unk_symbol == options_.bos_symbol ||
+ options_.unk_symbol == options_.eos_symbol))
+ KALDI_ERR << "When symbol table is given and OOV mode is kReplaceWithUnk, "
+ << "UNK symbol is required, must not be epsilon, and "
+ << "differ from both BOS and EOS symbols. Given:"
+ << " UNK=" << options_.unk_symbol
+ << " BOS=" << options_.bos_symbol
+ << " EOS=" << options_.eos_symbol;
+ if (symbols_ != NULL && symbols_->Find(options_.bos_symbol).empty())
+ KALDI_ERR << "BOS symbol must exist in symbol table";
+ if (symbols_ != NULL && symbols_->Find(options_.eos_symbol).empty())
+ KALDI_ERR << "EOS symbol must exist in symbol table";
+ if (symbols_ != NULL && options_.unk_symbol > 0 &&
+ symbols_->Find(options_.unk_symbol).empty())
+ KALDI_ERR << "UNK symbol must exist in symbol table";
+
+ ngram_counts_.clear();
+ line_number_ = 0;
+ warning_count_ = 0;
+ current_line_.clear();
+
+#define PARSE_ERR KALDI_ERR << LineReference() << ": "
+
+ // Give derived class an opportunity to prepare its state.
+ ReadStarted();
+
+ // Processes "\data\" section.
+ bool keyword_found = false;
+ while (++line_number_, getline(is, current_line_) && !is.eof()) {
+ if (current_line_.find_first_not_of(" \t\n\r") == std::string::npos) {
+ continue;
+ }
+
+ TrimTrailingWhitespace(¤t_line_);
+
+ // Continue skipping lines until the \data\ marker alone on a line is found.
+ if (!keyword_found) {
+ if (current_line_ == "\\data\\") {
+ KALDI_LOG << "Reading \\data\\ section.";
+ keyword_found = true;
+ }
+ continue;
+ }
+
+ if (current_line_[0] == '\\') break;
+
+ // Enters "\data\" section, and looks for patterns like "ngram 1=1000",
+ // which means there are 1000 unigrams.
+ std::size_t equal_symbol_pos = current_line_.find("=");
+ if (equal_symbol_pos != std::string::npos)
+ // Guaranteed spaces around the "=".
+ current_line_.replace(equal_symbol_pos, 1, " = ");
+ std::vector col;
+ SplitStringToVector(current_line_, " \t", true, &col);
+ if (col.size() == 4 && col[0] == "ngram" && col[2] == "=") {
+ int32 order, ngram_count = 0;
+ if (!ConvertStringToInteger(col[1], &order) ||
+ !ConvertStringToInteger(col[3], &ngram_count)) {
+ PARSE_ERR << "cannot parse ngram count";
+ }
+ if (ngram_counts_.size() <= order) {
+ ngram_counts_.resize(order);
+ }
+ ngram_counts_[order - 1] = ngram_count;
+ } else {
+ KALDI_WARN << LineReference()
+ << ": uninterpretable line in \\data\\ section";
+ }
+ }
+
+ if (ngram_counts_.size() == 0)
+ PARSE_ERR << "\\data\\ section missing or empty.";
+
+ // Signal that grammar order and n-gram counts are known.
+ HeaderAvailable();
+
+ NGram ngram;
+ ngram.words.reserve(ngram_counts_.size());
+
+ // Processes "\N-grams:" section.
+ for (int32 cur_order = 1; cur_order <= ngram_counts_.size(); ++cur_order) {
+ // Skips n-grams with zero count.
+ if (ngram_counts_[cur_order - 1] == 0)
+ KALDI_WARN << "Zero ngram count in ngram order " << cur_order
+ << "(look for 'ngram " << cur_order << "=0' in the \\data\\ "
+ << " section). There is possibly a problem with the file.";
+
+ // Must be looking at a \k-grams: directive at this point.
+ std::ostringstream keyword;
+ keyword << "\\" << cur_order << "-grams:";
+ if (current_line_ != keyword.str()) {
+ PARSE_ERR << "invalid directive, expecting '" << keyword.str() << "'";
+ }
+ KALDI_LOG << "Reading " << current_line_ << " section.";
+
+ int32 ngram_count = 0;
+ while (++line_number_, getline(is, current_line_) && !is.eof()) {
+ if (current_line_.find_first_not_of(" \n\t\r") == std::string::npos) {
+ continue;
+ }
+ if (current_line_[0] == '\\') {
+ TrimTrailingWhitespace(¤t_line_);
+ std::ostringstream next_keyword;
+ next_keyword << "\\" << cur_order + 1 << "-grams:";
+ if ((current_line_ != next_keyword.str()) &&
+ (current_line_ != "\\end\\")) {
+ if (ShouldWarn()) {
+ KALDI_WARN << "ignoring possible directive '" << current_line_
+ << "' expecting '" << next_keyword.str() << "'";
+
+ if (warning_count_ > 0 &&
+ warning_count_ > static_cast(options_.max_warnings)) {
+ KALDI_WARN << "Of " << warning_count_ << " parse warnings, "
+ << options_.max_warnings << " were reported. "
+ << "Run program with --max-arpa-warnings=-1 "
+ << "to see all warnings";
+ }
+ }
+ } else {
+ break;
+ }
+ }
+
+ std::vector col;
+ SplitStringToVector(current_line_, " \t", true, &col);
+
+ if (col.size() < 1 + cur_order ||
+ col.size() > 2 + cur_order ||
+ (cur_order == ngram_counts_.size() && col.size() != 1 + cur_order)) {
+ PARSE_ERR << "Invalid n-gram data line";
+ }
+ ++ngram_count;
+
+ // Parse out n-gram logprob and, if present, backoff weight.
+ if (!ConvertStringToReal(col[0], &ngram.logprob)) {
+ PARSE_ERR << "invalid n-gram logprob '" << col[0] << "'";
+ }
+ ngram.backoff = 0.0;
+ if (col.size() > cur_order + 1) {
+ if (!ConvertStringToReal(col[cur_order + 1], &ngram.backoff))
+ PARSE_ERR << "invalid backoff weight '" << col[cur_order + 1] << "'";
+ }
+ // Convert to natural log.
+ ngram.logprob *= M_LN10;
+ ngram.backoff *= M_LN10;
+
+ ngram.words.resize(cur_order);
+ bool skip_ngram = false;
+ for (int32 index = 0; !skip_ngram && index < cur_order; ++index) {
+ int32 word;
+ if (symbols_) {
+ // Symbol table provided, so symbol labels are expected.
+ if (options_.oov_handling == ArpaParseOptions::kAddToSymbols) {
+ word = symbols_->AddSymbol(col[1 + index]);
+ } else {
+ word = symbols_->Find(col[1 + index]);
+ if (word == -1) { // fst::kNoSymbol
+ switch (options_.oov_handling) {
+ case ArpaParseOptions::kReplaceWithUnk:
+ word = options_.unk_symbol;
+ break;
+ case ArpaParseOptions::kSkipNGram:
+ if (ShouldWarn())
+ KALDI_WARN << LineReference() << " skipped: word '"
+ << col[1 + index] << "' not in symbol table";
+ skip_ngram = true;
+ break;
+ default:
+ PARSE_ERR << "word '" << col[1 + index]
+ << "' not in symbol table";
+ }
+ }
+ }
+ } else {
+ // Symbols not provided, LM file should contain integers.
+ if (!ConvertStringToInteger(col[1 + index], &word) || word < 0) {
+ PARSE_ERR << "invalid symbol '" << col[1 + index] << "'";
+ }
+ }
+ // Whichever way we got it, an epsilon is invalid.
+ if (word == 0) {
+ PARSE_ERR << "epsilon symbol '" << col[1 + index]
+ << "' is illegal in ARPA LM";
+ }
+ ngram.words[index] = word;
+ }
+ if (!skip_ngram) {
+ ConsumeNGram(ngram);
+ }
+ }
+ if (ngram_count > ngram_counts_[cur_order - 1]) {
+ PARSE_ERR << "header said there would be " << ngram_counts_[cur_order - 1]
+ << " n-grams of order " << cur_order
+ << ", but we saw more already.";
+ }
+ }
+
+ if (current_line_ != "\\end\\") {
+ PARSE_ERR << "invalid or unexpected directive line, expecting \\end\\";
+ }
+
+ if (warning_count_ > 0 &&
+ warning_count_ > static_cast(options_.max_warnings)) {
+ KALDI_WARN << "Of " << warning_count_ << " parse warnings, "
+ << options_.max_warnings << " were reported. Run program with "
+ << "--max-arpa-warnings=-1 to see all warnings";
+ }
+
+ current_line_.clear();
+ ReadComplete();
+
+#undef PARSE_ERR
+}
+
+std::string ArpaFileParser::LineReference() const {
+ std::ostringstream ss;
+ ss << "line " << line_number_ << " [" << current_line_ << "]";
+ return ss.str();
+}
+
+bool ArpaFileParser::ShouldWarn() {
+ return (warning_count_ != -1) &&
+ (++warning_count_ <= static_cast(options_.max_warnings));
+}
+
+} // namespace kaldi
diff --git a/speechx/speechx/kaldi/lm/arpa-file-parser.h b/speechx/speechx/kaldi/lm/arpa-file-parser.h
new file mode 100644
index 000000000..99ffba029
--- /dev/null
+++ b/speechx/speechx/kaldi/lm/arpa-file-parser.h
@@ -0,0 +1,146 @@
+// lm/arpa-file-parser.h
+
+// Copyright 2014 Guoguo Chen
+// Copyright 2016 Smart Action Company LLC (kkm)
+
+// See ../../COPYING for clarification regarding multiple authors
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// THIS CODE IS PROVIDED *AS IS* BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+// KIND, EITHER EXPRESS OR IMPLIED, INCLUDING WITHOUT LIMITATION ANY IMPLIED
+// WARRANTIES OR CONDITIONS OF TITLE, FITNESS FOR A PARTICULAR PURPOSE,
+// MERCHANTABLITY OR NON-INFRINGEMENT.
+// See the Apache 2 License for the specific language governing permissions and
+// limitations under the License.
+
+#ifndef KALDI_LM_ARPA_FILE_PARSER_H_
+#define KALDI_LM_ARPA_FILE_PARSER_H_
+
+#include
+
+#include
+#include
+
+#include "base/kaldi-types.h"
+#include "util/options-itf.h"
+
+namespace kaldi {
+
+/**
+ Options that control ArpaFileParser
+*/
+struct ArpaParseOptions {
+ enum OovHandling {
+ kRaiseError, ///< Abort on OOV words
+ kAddToSymbols, ///< Add novel words to the symbol table.
+ kReplaceWithUnk, ///< Replace OOV words with .
+ kSkipNGram ///< Skip n-gram with OOV word and continue.
+ };
+
+ ArpaParseOptions():
+ bos_symbol(-1), eos_symbol(-1), unk_symbol(-1),
+ oov_handling(kRaiseError), max_warnings(30) { }
+
+ void Register(OptionsItf *opts) {
+ // Registering only the max_warnings count, since other options are
+ // treated differently by client programs: some want integer symbols,
+ // while other are passed words in their command line.
+ opts->Register("max-arpa-warnings", &max_warnings,
+ "Maximum warnings to report on ARPA parsing, "
+ "0 to disable, -1 to show all");
+ }
+
+ int32 bos_symbol; ///< Symbol for , Required non-epsilon.
+ int32 eos_symbol; ///< Symbol for , Required non-epsilon.
+ int32 unk_symbol; ///< Symbol for , Required for kReplaceWithUnk.
+ OovHandling oov_handling; ///< How to handle OOV words in the file.
+ int32 max_warnings; ///< Maximum warnings to report, <0 unlimited.
+};
+
+/**
+ A parsed n-gram from ARPA LM file.
+*/
+struct NGram {
+ NGram() : logprob(0.0), backoff(0.0) { }
+ std::vector words; ///< Symbols in left to right order.
+ float logprob; ///< Log-prob of the n-gram.
+ float backoff; ///< log-backoff weight of the n-gram.
+ ///< Defaults to zero if not specified.
+};
+
+/**
+ ArpaFileParser is an abstract base class for ARPA LM file conversion.
+
+ See ConstArpaLmBuilder and ArpaLmCompiler for usage examples.
+*/
+class ArpaFileParser {
+ public:
+ /// Constructs the parser with the given options and optional symbol table.
+ /// If symbol table is provided, then the file should contain text n-grams,
+ /// and the words are mapped to symbols through it. bos_symbol and
+ /// eos_symbol in the options structure must be valid symbols in the table,
+ /// and so must be unk_symbol if provided. The table is not owned by the
+ /// parser, but may be augmented, if oov_handling is set to kAddToSymbols.
+ /// If symbol table is a null pointer, the file should contain integer
+ /// symbol values, and oov_handling has no effect. bos_symbol and eos_symbol
+ /// must be valid symbols still.
+ ArpaFileParser(const ArpaParseOptions& options, fst::SymbolTable* symbols);
+ virtual ~ArpaFileParser();
+
+ /// Read ARPA LM file from a stream.
+ void Read(std::istream &is);
+
+ /// Parser options.
+ const ArpaParseOptions& Options() const { return options_; }
+
+ protected:
+ /// Override called before reading starts. This is the point to prepare
+ /// any state in the derived class.
+ virtual void ReadStarted() { }
+
+ /// Override function called to signal that ARPA header with the expected
+ /// number of n-grams has been read, and ngram_counts() is now valid.
+ virtual void HeaderAvailable() { }
+
+ /// Pure override that must be implemented to process current n-gram. The
+ /// n-grams are sent in the file order, which guarantees that all
+ /// (k-1)-grams are processed before the first k-gram is.
+ virtual void ConsumeNGram(const NGram&) = 0;
+
+ /// Override function called after the last n-gram has been consumed.
+ virtual void ReadComplete() { }
+
+ /// Read-only access to symbol table. Not owned, do not make public.
+ const fst::SymbolTable* Symbols() const { return symbols_; }
+
+ /// Inside ConsumeNGram(), provides the current line number.
+ int32 LineNumber() const { return line_number_; }
+
+ /// Inside ConsumeNGram(), returns a formatted reference to the line being
+ /// compiled, to print out as part of diagnostics.
+ std::string LineReference() const;
+
+ /// Increments warning count, and returns true if a warning should be
+ /// printed or false if the count has exceeded the set maximum.
+ bool ShouldWarn();
+
+ /// N-gram counts. Valid from the point when HeaderAvailable() is called.
+ const std::vector& NgramCounts() const { return ngram_counts_; }
+
+ private:
+ ArpaParseOptions options_;
+ fst::SymbolTable* symbols_; // the pointer is not owned here.
+ int32 line_number_;
+ uint32 warning_count_;
+ std::string current_line_;
+ std::vector ngram_counts_;
+};
+
+} // namespace kaldi
+
+#endif // KALDI_LM_ARPA_FILE_PARSER_H_
diff --git a/speechx/speechx/kaldi/lm/arpa-lm-compiler.cc b/speechx/speechx/kaldi/lm/arpa-lm-compiler.cc
new file mode 100644
index 000000000..47bd20d47
--- /dev/null
+++ b/speechx/speechx/kaldi/lm/arpa-lm-compiler.cc
@@ -0,0 +1,377 @@
+// lm/arpa-lm-compiler.cc
+
+// Copyright 2009-2011 Gilles Boulianne
+// Copyright 2016 Smart Action LLC (kkm)
+// Copyright 2017 Xiaohui Zhang
+
+// See ../../COPYING for clarification regarding multiple authors
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// THIS CODE IS PROVIDED *AS IS* BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+// KIND, EITHER EXPRESS OR IMPLIED, INCLUDING WITHOUT LIMITATION ANY IMPLIED
+// WARRANTIES OR CONDITIONS OF TITLE, FITNESS FOR A PARTICULAR PURPOSE,
+// MERCHANTABLITY OR NON-INFRINGEMENT.
+// See the Apache 2 License for the specific language governing permissions and
+// limitations under the License.
+
+#include
+#include
+#include
+#include
+
+#include "base/kaldi-math.h"
+#include "lm/arpa-lm-compiler.h"
+#include "util/stl-utils.h"
+#include "util/text-utils.h"
+#include "fstext/remove-eps-local.h"
+
+namespace kaldi {
+
+class ArpaLmCompilerImplInterface {
+ public:
+ virtual ~ArpaLmCompilerImplInterface() { }
+ virtual void ConsumeNGram(const NGram& ngram, bool is_highest) = 0;
+};
+
+namespace {
+
+typedef int32 StateId;
+typedef int32 Symbol;
+
+// GeneralHistKey can represent state history in an arbitrarily large n
+// n-gram model with symbol ids fitting int32.
+class GeneralHistKey {
+ public:
+ // Construct key from being and end iterators.
+ template
+ GeneralHistKey(InputIt begin, InputIt end) : vector_(begin, end) { }
+ // Construct empty history key.
+ GeneralHistKey() : vector_() { }
+ // Return tails of the key as a GeneralHistKey. The tails of an n-gram
+ // w[1..n] is the sequence w[2..n] (and the heads is w[1..n-1], but the
+ // key class does not need this operartion).
+ GeneralHistKey Tails() const {
+ return GeneralHistKey(vector_.begin() + 1, vector_.end());
+ }
+ // Keys are equal if represent same state.
+ friend bool operator==(const GeneralHistKey& a, const GeneralHistKey& b) {
+ return a.vector_ == b.vector_;
+ }
+ // Public typename HashType for hashing.
+ struct HashType : public std::unary_function {
+ size_t operator()(const GeneralHistKey& key) const {
+ return VectorHasher().operator()(key.vector_);
+ }
+ };
+
+ private:
+ std::vector

 -
- +
+