You can not select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
79 lines
3.6 KiB
79 lines
3.6 KiB
|
3 years ago
|
([简体中文](./PPVPR_cn.md)|English)
|
||
|
|
# PP-VPR
|
||
|
|
|
||
|
|
## Catalogue
|
||
|
|
- [1. Introduction](#1)
|
||
|
|
- [2. Characteristic](#2)
|
||
|
|
- [3. Tutorials](#3)
|
||
|
|
- [3.1 Pre-trained Models](#31)
|
||
|
|
- [3.2 Training](#32)
|
||
|
|
- [3.3 Inference](#33)
|
||
|
|
- [3.4 Service Deployment](#33)
|
||
|
|
- [4. Quick Start](#4)
|
||
|
|
|
||
|
|
<a name="1"></a>
|
||
|
|
## 1. Introduction
|
||
|
|
|
||
|
|
PP-VPR is a tool that provides voice print feature extraction and retrieval functions. Provides a variety of quasi-industrial solutions, easy to solve the difficult problems in complex scenes, support the use of command line model reasoning. PP-VPR also supports interface operations and container deployment.
|
||
|
|
|
||
|
|
<a name="2"></a>
|
||
|
|
## 2. Characteristic
|
||
|
|
The basic process of VPR is shown in the figure below:
|
||
|
|
<center><img src=https://ai-studio-static-online.cdn.bcebos.com/3aed59b8c8874046ad19fe583d15a8dd53c5b33e68db4383b79706e5add5c2d0 width="800" ></center>
|
||
|
|
|
||
|
|
|
||
|
|
The main characteristics of PP-ASR are shown below:
|
||
|
|
- Provides pre-trained models on Chinese open source datasets: VoxCeleb(English). The models include ecapa-tdnn.
|
||
|
|
- Support model training/evaluation.
|
||
|
|
- Support model inference using the command line. You can use to use `paddlespeech vector --task spk --input xxx.wav` to use the pre-trained model to do model inference.
|
||
|
|
- Support interface operations and container deployment.
|
||
|
|
|
||
|
|
<a name="3"></a>
|
||
|
|
## 3. Tutorials
|
||
|
|
|
||
|
|
<a name="31"></a>
|
||
|
|
## 3.1 Pre-trained Models
|
||
|
|
The support pre-trained model list: [released_model](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/released_model.md).
|
||
|
|
For more information about model design, you can refer to the aistudio tutorial:
|
||
|
|
- [ecapa-tdnn](https://aistudio.baidu.com/aistudio/projectdetail/4027664)
|
||
|
|
|
||
|
|
<a name="32"></a>
|
||
|
|
## 3.2 Training
|
||
|
|
The referenced script for model training is stored in [examples](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples) and stored according to "examples/dataset/model". The dataset mainly supports VoxCeleb. The model supports ecapa-tdnn.
|
||
|
|
The specific steps of executing the script are recorded in `run.sh`.
|
||
|
|
|
||
|
|
For more information, you can refer to [sv0](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/voxceleb/sv0)
|
||
|
|
|
||
|
|
|
||
|
|
<a name="33"></a>
|
||
|
|
## 3.3 Inference
|
||
|
|
|
||
|
|
PP-VPR supports use `paddlespeech vector --task spk --input xxx.wav` to use the pre-trained model to do inference after install `paddlespeech` by `pip install paddlespeech`.
|
||
|
|
|
||
|
|
Specific supported functions include:
|
||
|
|
|
||
|
|
- Prediction of single audio
|
||
|
|
- Score the similarity between the two audios
|
||
|
|
- Support RTF calculation
|
||
|
|
|
||
|
|
For specific usage, please refer to: [speaker_verification](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/demos/speaker_verification/README_cn.md)
|
||
|
|
|
||
|
|
|
||
|
|
<a name="34"></a>
|
||
|
|
## 3.4 Service Deployment
|
||
|
|
|
||
|
|
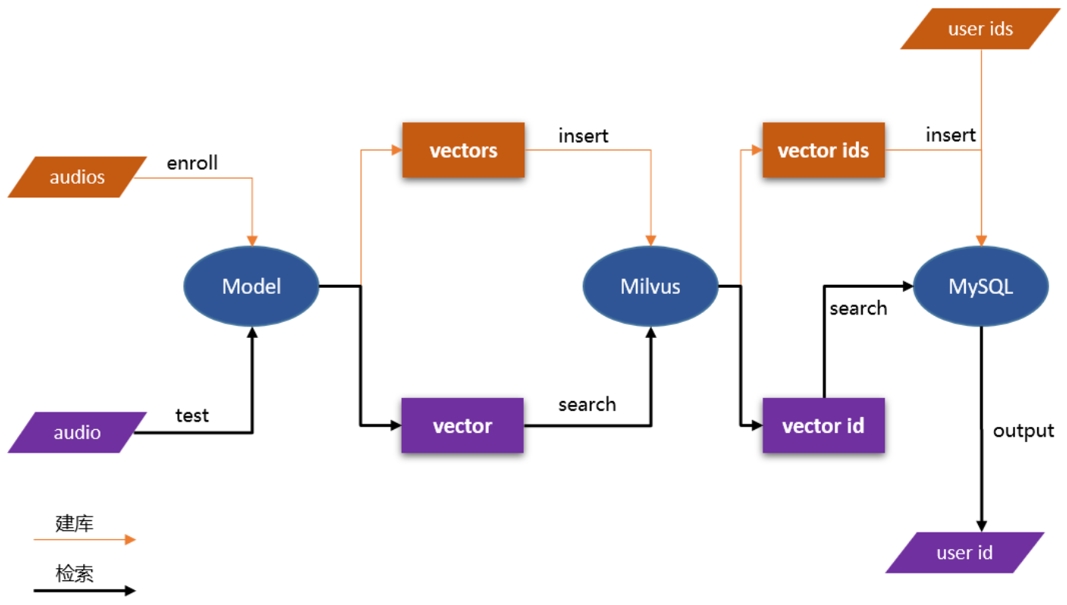
PP-VPR supports Docker containerized service deployment. Through Milvus, MySQL performs high performance library building search.
|
||
|
|
|
||
|
|
Demo of VPR Server: [audio_searching](https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/audio_searching)
|
||
|
|
|
||
|
|
|
||
|
|
|
||
|
|
For more information about service deployment, you can refer to the aistudio tutorial:
|
||
|
|
- [speaker_recognition](https://aistudio.baidu.com/aistudio/projectdetail/4027664)
|
||
|
|
|
||
|
|
<a name="4"></a>
|
||
|
|
|
||
|
|
## 4. Quick Start
|
||
|
|
|
||
|
|
To use PP-VPR, you can see here [install](https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install_cn.md), It supplies three methods to install `paddlespeech`, which are **Easy**, **Medium** and **Hard**. If you want to experience the inference function of paddlespeech, you can use **Easy** installation method.
|