|
|
3 years ago | |
|---|---|---|
| .. | ||
| README.es.md | 3 years ago | |
| README.it.md | 3 years ago | |
| README.ko.md | 3 years ago | |
| README.tr.md | 3 years ago | |
| assignment.it.md | 3 years ago | |
| assignment.tr.md | 3 years ago | |
README.tr.md
Mutfak sınıflandırıcıları 2
Bu ikinci sınıflandırma dersinde, sayısal veriyi sınıflandırmak için daha fazla yöntem öğreneceksiniz. Ayrıca, bir sınıflandırıcıyı diğerlerine tercih etmenin sonuçlarını da öğreneceksiniz.
Ders öncesi kısa sınavı
Ön koşul
Önceki dersleri tamamladığınızı ve bu 4-ders klasörünün kökündeki data klasörünüzdeki cleaned_cuisines.csv adlı veri setini temizlediğinizi varsayıyoruz.
Hazırlık
Temizlenmiş veri setiyle notebook.ipynb dosyanızı yükledik ve model oluşturma sürecine hazır olması için X ve y veri iskeletlerine böldük.
Bir sınıflandırma haritası
Daha önce, Microsoft'un kopya kağıdını kullanarak veri sınıflandırmanın çeşitli yollarını öğrendiniz. Scikit-learn de buna benzer, öngörücülerinizi (sınıflandırıcı) sınırlandırmanıza ilaveten yardım edecek bir kopya kağıdı sunar.
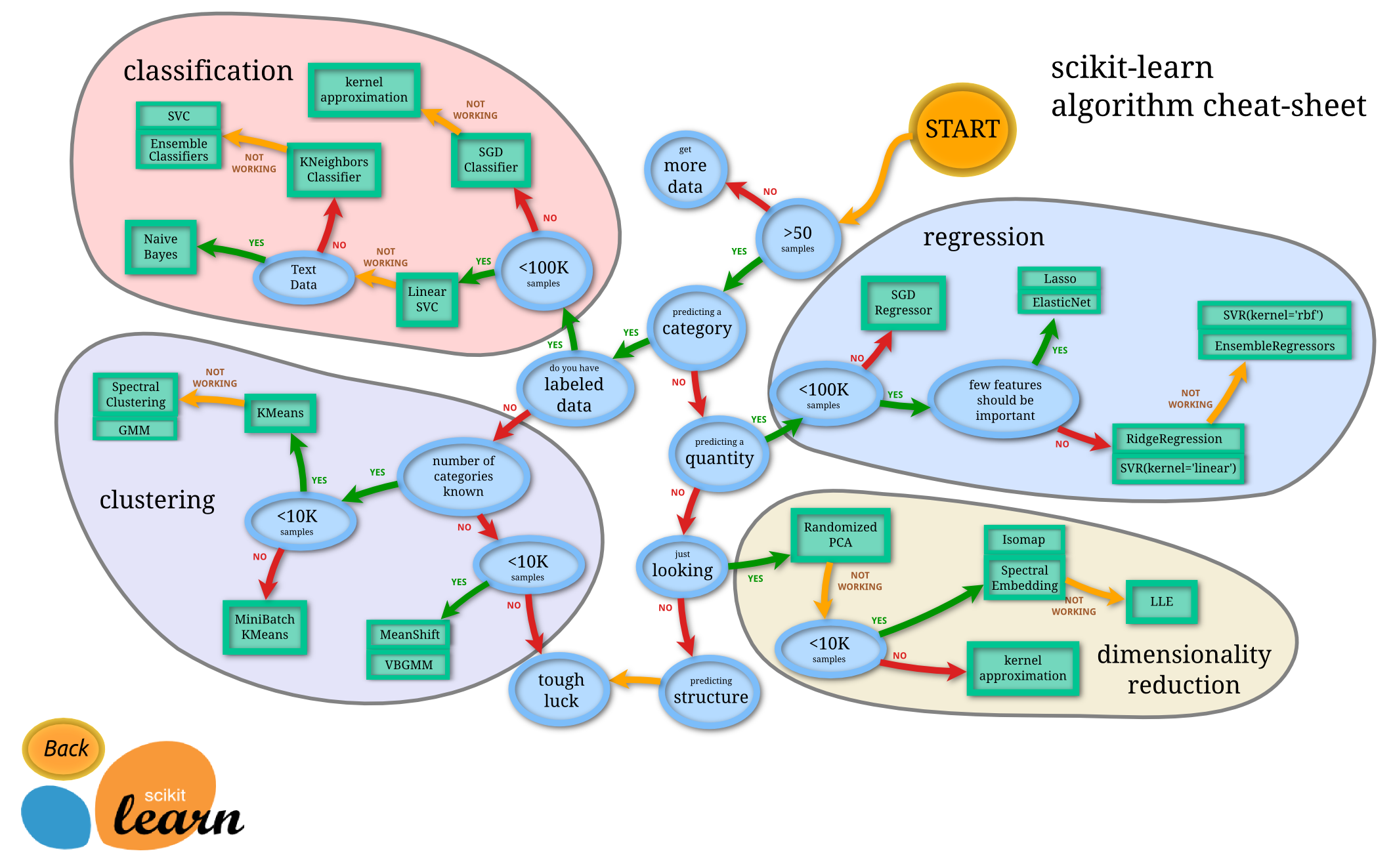
Tavsiye: Bu haritayı çevrim içi ziyaret edin ve rotayı seyrederken dokümantasyonu okumak için tıklayın.
Plan
Verinizi iyice kavradığınızda bu harita çok faydalı olacaktır, çünkü karara ulaşırken rotalarında 'yürüyebilirsiniz':
-
50 adet örneğimiz var
- Bir kategori öngörmek istiyoruz
- Etiketlenmiş veri var
- 100 binden az örneğimiz var
- ✨ Bir Linear SVC (Doğrusal Destek Vektör Sınıflandırma) seçebiliriz
- Eğer bu işe yaramazsa, verimiz sayısal olduğundan
- ✨ Bir KNeighbors (K Komşu) Sınıflandırıcı deneyebiliriz
- Eğer bu işe yaramazsa, ✨ SVC (Destek Vektör Sınıflandırma) ve ✨ Ensemble (Topluluk) Sınıflandırıcılarını deneyin
- ✨ Bir KNeighbors (K Komşu) Sınıflandırıcı deneyebiliriz
Bu çok faydalı bir yol.
Alıştırma - veriyi bölün
Bu yolu takip ederek, kullanmak için bazı kütüphaneleri alarak başlamalıyız.
-
Gerekli kütüphaneleri alın:
from sklearn.neighbors import KNeighborsClassifier from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier from sklearn.model_selection import train_test_split, cross_val_score from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report, precision_recall_curve import numpy as np -
Eğitme ve sınama verinizi bölün:
X_train, X_test, y_train, y_test = train_test_split(cuisines_feature_df, cuisines_label_df, test_size=0.3)
Linear SVC Sınıflandırıcısı
Destek Vektör kümeleme (SVC), makine öğrenimi yöntemlerinden Destek Vektör Makinelerinin (Aşağıda bunun hakkında daha fazla bilgi edineceksiniz.) alt dallarından biridir. Bu yöntemde, etiketleri nasıl kümeleyeceğinize karar vermek için bir 'kernel' seçebilirsiniz. 'C' parametresi 'düzenlileştirme'yi ifade eder ve parametrelerin etkilerini düzenler. Kernel (çekirdek) birçoğundan biri olabilir; burada, doğrusal SVC leveraj ettiğimizden emin olmak için, 'linear' olarak ayarlıyoruz. Olasılık varsayılan olarak 'false' olarak ayarlıdır; burada, olasılık öngörülerini toplamak için, 'true' olarak ayarlıyoruz. Rastgele durumu (random state), olasılıkları elde etmek için veriyi karıştırmak (shuffle) üzere, '0' olarak ayarlıyoruz.
Alıştırma - doğrusal SVC uygulayın
Sınıflandırıcıardan oluşan bir dizi oluşturarak başlayın. Sınadıkça bu diziye ekleme yapacağız.
-
Liner SVC ile başlayın:
C = 10 # Create different classifiers. classifiers = { 'Linear SVC': SVC(kernel='linear', C=C, probability=True,random_state=0) } -
Linear SVC kullanarak modelinizi eğitin ve raporu bastırın:
n_classifiers = len(classifiers) for index, (name, classifier) in enumerate(classifiers.items()): classifier.fit(X_train, np.ravel(y_train)) y_pred = classifier.predict(X_test) accuracy = accuracy_score(y_test, y_pred) print("Accuracy (train) for %s: %0.1f%% " % (name, accuracy * 100)) print(classification_report(y_test,y_pred))Sonuç oldukça iyi:
Accuracy (train) for Linear SVC: 78.6% precision recall f1-score support chinese 0.71 0.67 0.69 242 indian 0.88 0.86 0.87 234 japanese 0.79 0.74 0.76 254 korean 0.85 0.81 0.83 242 thai 0.71 0.86 0.78 227 accuracy 0.79 1199 macro avg 0.79 0.79 0.79 1199 weighted avg 0.79 0.79 0.79 1199
K-Komşu sınıflandırıcısı
K-Komşu, makine öğrenimi yöntemlerinden "neighbors" (komşular) ailesinin bir parçasıdır ve gözetimli ve gözetimsiz öğrenmenin ikisinde de kullanılabilir. Bu yöntemde, önceden tanımlanmış sayıda nokta üretilir ve veri bu noktalar etrafında, genelleştirilmiş etiketlerin veriler için öngörülebileceği şekilde toplanır.
Alıştırma - K-Komşu sınıflandırıcısını uygulayın
Önceki sınıflandırıcı iyiydi ve veriyle iyi çalıştı, ancak belki daha iyi bir doğruluk elde edebiliriz. K-Komşu sınıflandırıcısını deneyin.
-
Sınıflandırıcı dizinize bir satır ekleyin (Linear SVC ögesinden sonra bir virgül ekleyin):
'KNN classifier': KNeighborsClassifier(C),Sonuç biraz daha kötü:
Accuracy (train) for KNN classifier: 73.8% precision recall f1-score support chinese 0.64 0.67 0.66 242 indian 0.86 0.78 0.82 234 japanese 0.66 0.83 0.74 254 korean 0.94 0.58 0.72 242 thai 0.71 0.82 0.76 227 accuracy 0.74 1199 macro avg 0.76 0.74 0.74 1199 weighted avg 0.76 0.74 0.74 1199✅ K-Komşu hakkında bilgi edinin
Destek Vektör Sınıflandırıcısı
Destek Vektör sınıflandırıcıları, makine öğrenimi yöntemlerinden Destek Vektörü Makineleri ailesinin bir parçasıdır ve sınıflandırma ve regresyon görevlerinde kullanılır. SVM'ler (Destek Vektör Makineleri), iki kategori arasındaki uzaklığı en yükseğe getirmek için eğitme örneklerini boşluktaki noktalara eşler. Sonraki veri, kategorisinin öngörülebilmesi için bu boşluğa eşlenir.
Alıştırma - bir Destek Vektör Sınıflandırıcısı uygulayın
Bir Destek Vektör Sınıflandırıcısı ile daha iyi bir doğruluk elde etmeye çalışalım.
-
K-Neighbors ögesinden sonra bir virgül ekleyin, sonra bu satırı ekleyin:
'SVC': SVC(),Sonuç oldukça iyi!
Accuracy (train) for SVC: 83.2% precision recall f1-score support chinese 0.79 0.74 0.76 242 indian 0.88 0.90 0.89 234 japanese 0.87 0.81 0.84 254 korean 0.91 0.82 0.86 242 thai 0.74 0.90 0.81 227 accuracy 0.83 1199 macro avg 0.84 0.83 0.83 1199 weighted avg 0.84 0.83 0.83 1199✅ Destek Vektörleri hakkında bilgi edinin
Topluluk Sınıflandırıcıları
Önceki sınamanın oldukça iyi olmasına rağmen rotayı sonuna kadar takip edelim. Bazı Topluluk Sınıflandırıcılarını deneyelim, özellikle Random Forest ve AdaBoost'u:
'RFST': RandomForestClassifier(n_estimators=100),
'ADA': AdaBoostClassifier(n_estimators=100)
Sonuç çok iyi, özellikle Random Forest sonuçları:
Accuracy (train) for RFST: 84.5%
precision recall f1-score support
chinese 0.80 0.77 0.78 242
indian 0.89 0.92 0.90 234
japanese 0.86 0.84 0.85 254
korean 0.88 0.83 0.85 242
thai 0.80 0.87 0.83 227
accuracy 0.84 1199
macro avg 0.85 0.85 0.84 1199
weighted avg 0.85 0.84 0.84 1199
Accuracy (train) for ADA: 72.4%
precision recall f1-score support
chinese 0.64 0.49 0.56 242
indian 0.91 0.83 0.87 234
japanese 0.68 0.69 0.69 254
korean 0.73 0.79 0.76 242
thai 0.67 0.83 0.74 227
accuracy 0.72 1199
macro avg 0.73 0.73 0.72 1199
weighted avg 0.73 0.72 0.72 1199
✅ Topluluk Sınıflandırıcıları hakkında bilgi edinin
Makine Öğreniminin bu yöntemi, modelin kalitesini artırmak için, "birçok temel öngörücünün öngörülerini birleştirir." Bizim örneğimizde, Random Trees ve AdaBoost kullandık.
-
Random Forest bir ortalama alma yöntemidir, aşırı öğrenmeden kaçınmak için rastgelelikle doldurulmuş 'karar ağaçları'ndan oluşan bir 'orman' oluşturur. n_estimators parametresi, ağaç sayısı olarak ayarlanmaktadır.
-
AdaBoost, bir sınıflandıcıyı bir veri setine uydurur ve sonra o sınıflandırıcının kopyalarını aynı veri setine uydurur. Yanlış sınıflandırılmış ögelerin ağırlıklarına odaklanır ve bir sonraki sınıflandırıcının düzeltmesi için uydurma/oturtmayı ayarlar.
🚀 Meydan okuma
Bu yöntemlerden her biri değiştirebileceğiniz birsürü parametre içeriyor. Her birinin varsayılan parametrelerini araştırın ve bu parametreleri değiştirmenin modelin kalitesi için ne anlama gelebileceği hakkında düşünün.
Ders sonrası kısa sınavı
Gözden Geçirme & Kendi Kendine Çalışma
Bu derslerde çok fazla jargon var, bu yüzden yararlı terminoloji içeren bu listeyi incelemek için bir dakika ayırın.