|
|
5 years ago | |
|---|---|---|
| .. | ||
| README.es.md | 5 years ago | |
| README.it.md | 5 years ago | |
| README.tr.md | 5 years ago | |
| assignment.it.md | 5 years ago | |
| assignment.tr.md | 5 years ago | |
README.tr.md
Mutfak sınıflandırıcıları 1
Bu derste, mutfaklarla ilgili dengeli ve temiz veriyle dolu, geçen dersten kaydettiğiniz veri setini kullanacaksınız.
Bu veri setini çeşitli sınıflandırıcılarla bir grup malzemeyi baz alarak verilen bir ulusal mutfağı öngörmek için kullanacaksınız. Bunu yaparken, sınıflandırma görevleri için algoritmaların leveraj edilebileceği yollardan bazıları hakkında daha fazla bilgi edineceksiniz.
Ders öncesi kısa sınavı
Hazırlık
Birinci dersi tamamladığınızı varsayıyoruz, dolayısıyla bu dört ders için cleaned_cuisines.csv dosyasının kök /data klasöründe var olduğundan emin olun.
Alıştırma - ulusal bir mutfağı öngörün
-
Bu dersin notebook.ipynb dosyasında çalışarak, Pandas kütüphanesiyle beraber o dosyayı da alın:
import pandas as pd cuisines_df = pd.read_csv("../data/cleaned_cuisines.csv") cuisines_df.head()Veri şöyle görünüyor:
| Unnamed: 0 | cuisine | almond | angelica | anise | anise_seed | apple | apple_brandy | apricot | armagnac | ... | whiskey | white_bread | white_wine | whole_grain_wheat_flour | wine | wood | yam | yeast | yogurt | zucchini | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | indian | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 2 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 3 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 4 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
-
Şimdi, birkaç kütüphane daha alın:
from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split, cross_val_score from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report, precision_recall_curve from sklearn.svm import SVC import numpy as np -
X ve y koordinatlarını eğitme için iki veri iskeletine bölün.
cuisineetiket veri iskeleti olabilir:cuisines_label_df = cuisines_df['cuisine'] cuisines_label_df.head()Şöyle görünecek:
0 indian 1 indian 2 indian 3 indian 4 indian Name: cuisine, dtype: object -
Unnamed: 0vecuisinesütunlarını,drop()fonksiyonunu çağırarak temizleyin. Kalan veriyi eğitilebilir öznitelikler olarak kaydedin:cuisines_feature_df = cuisines_df.drop(['Unnamed: 0', 'cuisine'], axis=1) cuisines_feature_df.head()Öznitelikleriniz şöyle görünüyor:
| almond | angelica | anise | anise_seed | apple | apple_brandy | apricot | armagnac | artemisia | artichoke | ... | whiskey | white_bread | white_wine | whole_grain_wheat_flour | wine | wood | yam | yeast | yogurt | zucchini |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
Şimdi modelinizi eğitmek için hazırsınız!
Sınıflandırıcınızı seçme
Veriniz temiz ve eğitme için hazır, şimdi bu iş için hangi algoritmanın kullanılması gerektiğine karar vermelisiniz.
Scikit-learn, sınıflandırmayı gözetimli öğrenme altında grupluyor. Bu kategoride sınıflandırma için birçok yöntem görebilirsiniz. Çeşitlilik ilk bakışta oldukça şaşırtıcı. Aşağıdaki yöntemlerin hepsi sınıflandırma yöntemlerini içermektedir:
- Doğrusal Modeller
- Destek Vektör Makineleri
- Stokastik Gradyan İnişi
- En Yakın Komşu
- Gauss Süreçleri
- Karar Ağaçları
- Topluluk Metotları (Oylama Sınıflandırıcısı)
- Çok sınıflı ve çok çıktılı algoritmalar (çok sınıflı ve çok etiketli sınıflandırma, çok sınıflı-çok çıktılı sınıflandırma)
Verileri sınıflandırmak için sinir ağlarını da kullanabilirsiniz, ancak bu, bu dersin kapsamı dışındadır.
Hangi sınıflandırıcıyı kullanmalı?
Şimdi, hangi sınıflandırıcıyı seçmelisiniz? Genellikle, birçoğunu gözden geçirmek ve iyi bir sonuç aramak deneme yollarından biridir. Scikit-learn, oluşturulmuş bir veri seti üzerinde KNeighbors, iki yolla SVC, GaussianProcessClassifier, DecisionTreeClassifier, RandomForestClassifier, MLPClassifier, AdaBoostClassifier, GaussianNB ve QuadraticDiscrinationAnalysis karşılaştırmaları yapan ve sonuçları görsel olarak gösteren bir yan yana karşılaştırma sunar:
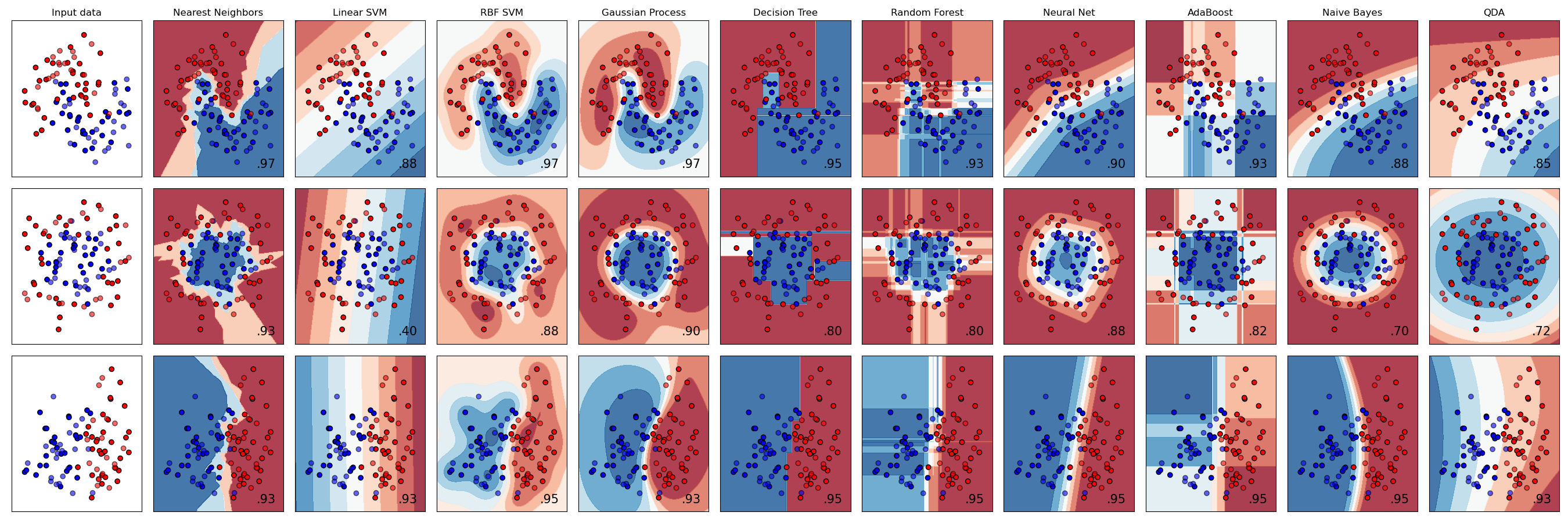
Grafikler Scikit-learn dokümantasyonlarında oluşturulmuştur.
AutoML, bu karşılaştırmaları bulutta çalıştırarak bu problemi muntazam bir şekilde çözer ve veriniz için en iyi algoritmayı seçmenizi sağlar. Buradan deneyin.
Daha iyi bir yaklaşım
Böyle tahminlerle çözmekten daha iyi bir yol ise, indirilebilir ML Kopya kağıdı içindeki fikirlere bakmaktır. Burada, bizim çok sınıflı problemimiz için bazı seçenekler olduğunu görüyoruz:

Microsoft'un Algoritma Kopya Kağıdı'ndan, çok sınıflı sınıflandırma seçeneklerini detaylandıran bir bölüm
✅ Bu kopya kağıdını indirin, yazdırın ve duvarınıza asın!
Akıl yürütme
Elimizdeki kısıtlamalarla farklı yaklaşımlar üzerine akıl yürütelim:
- Sinir ağları çok ağır. Temiz ama minimal veri setimizi ve eğitimi not defterleriyle yerel makinelerde çalıştırdığımızı göz önünde bulundurursak, sinir ağları bu görev için çok ağır oluyor.
- İki sınıflı sınıflandırıcısı yok. İki sınıflı sınıflandırıcı kullanmıyoruz, dolayısıyla bire karşı hepsi (one-vs-all) yöntemi eleniyor.
- Karar ağacı veya lojistik regresyon işe yarayabilirdi. Bir karar ağacı veya çok sınıflı veri için lojistik regresyon işe yarayabilir.
- Çok Sınıf Artırmalı Karar Ağaçları farklı bir problemi çözüyor. Çok sınıf artırmalı karar ağacı, parametrik olmayan görevler için en uygunu, mesela sıralama (ranking) oluşturmak için tasarlanan görevler. Yani, bizim için kullanışlı değil.
Scikit-learn kullanımı
Verimizi analiz etmek için Scikit-learn kullanacağız. Ancak, Scikit-learn içerisinde lojistik regresyonu kullanmanın birçok yolu var. Geçirilecek parametreler göz atın.
Aslında, Scikit-learn'den lojistik regresyon yapmasını beklediğimizde belirtmemiz gereken multi_class ve solver diye iki önemli parametre var. multi_class değeri belli bir davranış uygular. Çözücünün değeri, hangi algoritmanın kullanılacağını gösterir. Her çözücü her multi_class değeriyle eşleştirilemez.
Dokümanlara göre, çok sınıflı durumunda eğitme algoritması:
- Eğer
multi_classseçeneğiovrolarak ayarlanmışsa, bire karşı diğerleri (one-vs-rest, OvR) şemasını kullanır - Eğer
multi_classseçeneğimultinomialolarak ayarlanmışsa, çapraz düzensizlik yitimini/kaybını kullanır. (Güncel olarakmultinomialseçeneği yalnızca ‘lbfgs’, ‘sag’, ‘saga’ ve ‘newton-cg’ çözücüleriyle destekleniyor.)
🎓 Buradaki 'şema' ya 'ovr' (one-vs-rest, yani bire karşı diğerleri) ya da 'multinomial' olabilir. Lojistik regresyon aslında ikili sınıflandırmayı desteklemek için tasarlandığından, bu şemalar onun çok sınıflı sınıflandırma görevlerini daha iyi ele alabilmesini sağlıyor. kaynak
🎓 'Çözücü', "eniyileştirme probleminde kullanılacak algoritma" olarak tanımlanır. kaynak
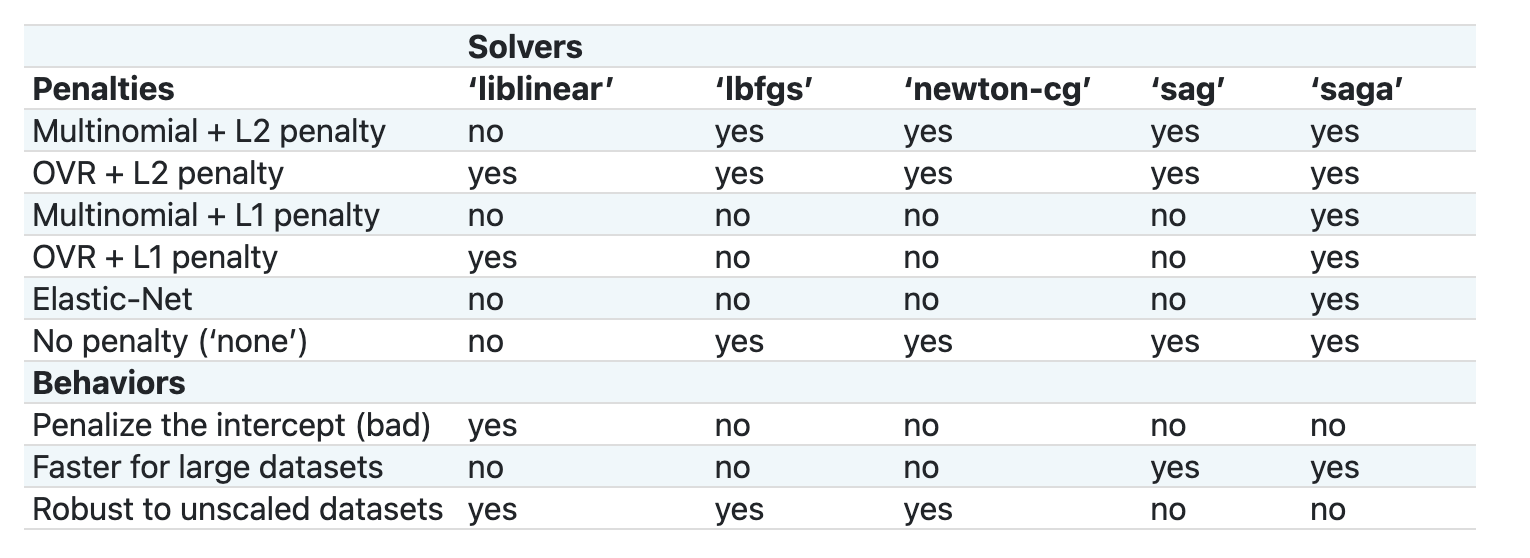
Scikit-learn, çözücülerin, farklı tür veri yapıları tarafından sunulan farklı meydan okumaları nasıl ele aldığını açıklamak için bu tabloyu sunar:
Alıştırma - veriyi bölün
İkincisini önceki derte öğrendiğinizden, ilk eğitme denememiz için lojistik regresyona odaklanabiliriz.
train_test_split() fonksiyonunu çağırarak verilerinizi eğitme ve sınama gruplarına bölün:
X_train, X_test, y_train, y_test = train_test_split(cuisines_feature_df, cuisines_label_df, test_size=0.3)
Alıştırma - lojistik regresyon uygulayın
Çok sınıflı durumu kullandığınız için, hangi şemayı kullanacağınızı ve hangi çözücüyü ayarlayacağınızı seçmeniz gerekiyor. Eğitme için, bir çok sınıflı ayarında LogisticRegression ve liblinear çözücüsünü kullanın.
-
multi_class'ı
ovrve solver'ıliblinearolarak ayarlayarak bir lojistik regresyon oluşturun:lr = LogisticRegression(multi_class='ovr',solver='liblinear') model = lr.fit(X_train, np.ravel(y_train)) accuracy = model.score(X_test, y_test) print ("Accuracy is {}".format(accuracy))✅ Genelde varsayılan olarak ayarlanan
lbfgsgibi farklı bir çözücü deneyin.Not olarak, gerektiğinde verinizi düzleştirmek için Pandas
ravelfonksiyonunu kullanın.Doğruluk %80 üzerinde iyidir!
-
Bir satır veriyi (#50) sınayarak bu modeli eylem halinde görebilirsiniz:
print(f'ingredients: {X_test.iloc[50][X_test.iloc[50]!=0].keys()}') print(f'cuisine: {y_test.iloc[50]}')Sonuç bastırılır:
ingredients: Index(['cilantro', 'onion', 'pea', 'potato', 'tomato', 'vegetable_oil'], dtype='object') cuisine: indian✅ Farklı bir satır sayısı deneyin ve sonuçları kontrol edin
-
Daha derinlemesine inceleyerek, bu öngörünün doğruluğunu kontrol edebilirsiniz:
test= X_test.iloc[50].values.reshape(-1, 1).T proba = model.predict_proba(test) classes = model.classes_ resultdf = pd.DataFrame(data=proba, columns=classes) topPrediction = resultdf.T.sort_values(by=[0], ascending = [False]) topPrediction.head()Sonuç bastırılır - Hint mutfağı iyi olasılıkla en iyi öngörü:
0 indian 0.715851 chinese 0.229475 japanese 0.029763 korean 0.017277 thai 0.007634 :while_check_mark: Modelin, bunun bir Hint mutfağı olduğundan nasıl emin olduğunu açıklayabilir misiniz?
-
Regresyon derslerinde yaptığınız gibi, bir sınıflandırma raporu bastırarak daha fazla detay elde edin:
y_pred = model.predict(X_test) print(classification_report(y_test,y_pred))precision recall f1-score support chinese 0.73 0.71 0.72 229 indian 0.91 0.93 0.92 254 japanese 0.70 0.75 0.72 220 korean 0.86 0.76 0.81 242 thai 0.79 0.85 0.82 254 accuracy 0.80 1199 macro avg 0.80 0.80 0.80 1199 weighted avg 0.80 0.80 0.80 1199
🚀 Meydan Okuma
Bu derste, bir grup malzemeyi baz alarak bir ulusal mutfağı öngörebilen bir makine öğrenimi modeli oluşturmak için temiz verinizi kullandınız. Scikit-learn'ün veri sınıflandırmak için sağladığı birçok yöntemi okumak için biraz vakit ayırın. Arka tarafta neler olduğunu anlamak için 'çözücü' kavramını derinlemesine inceleyin.
Ders sonrası kısa sınavı
Gözden geçirme & kendi kendine çalışma
Bu deste lojistik regresyonun arkasındaki matematiği derinlemesine inceleyin.