|
|
3 years ago | |
|---|---|---|
| .. | ||
| README.es.md | 4 years ago | |
| README.id.md | 3 years ago | |
README.id.md
Bangun sebuah model regresi dengan Scikit-learn: regresi dua arah
Infografik oleh Dasani Madipalli
Kuis pra-ceramah
Pembukaan
Selama ini kamu telah menjelajahi apa regresi itu dengan data contoh yang dikumpulkan dari dataset harga labu yang kita akan gunakan terus sepanjang pelajaran ini. Kamu juga telah memvisualisasikannya dengan Matplotlib.
Sekarang kamu sudah siap terjun ke dalam regresi untuk ML. Dalam pelajaran ini, kamu akan belajar lebih tentang dua jenis regresi: regresi linear sederhana dan regresi polinomial serta sedikit matematika yang mendasari kedua teknik ini.
Sepanjang kurikulum ini, kami mengasumsi kamu punya pengetahuan matematika yang minim dan ingin tetap membuat pelajaran ini terjangkau bagi murid-murid dari bidang-bidang lain. Jadi perhatikan catatan, 🧮 info, diagram, dan alat-alat belajar lainnya untuk membantu pemahaman.
Prasyarat
Kamu harusnya sudah terbiasa sekarang dengan struktur data labu yang kita sedang teliti. Datanya harusnya sudah dimuat dan dibersihkan dalam file notebook.ipynb pelajaran ini. Dalam file ini, harga labu ditampilkan per bushel dalam dataframe yang bari. Pastikan kamu bisa menjalankan notebook-notebook ini di kernels di Visual Studio Code.
Persiapan
Ingat, kamu sedang memuat data ini untuk menanyakan pertanyaan darinya.
- Kapankah waktu terbaik untuk membeli labu?
- Saya kira-kira harus bayar berapa untuk satu kotak labu mini?
- Apa saya sebaiknya membelinya dalam keranjang-keranjang setengah bushel atau kardus-kardus 1 1/9 bushel? Ayo terjun lebih lagi ke dalam data ini.
Dalam pelajaran sebelumnya, kamu membuat sebuah dataframe Pandas, mengisinya dengan sebagian dataset orisinal, dan menstandarisasi harganya per bushel. Tetapi, dengan begitu, kamu hanya dapat mengumpul sekitar 400 titik data dan itupun hanya untuk bulan-bulan musim gugur.
Lihatlah data yang kita sudah muat dalam notebook yang terlampir pelajaran ini. Data telah di muat dan sebuah petak sebar inisial telah digambar untuk menunjukkan data per bulan. Mungkin kita bisa dapat lebih banyak detail tentang sifat datanya dengan membersih-bersihkannya lebih lagi.
Sebuah garis regresi linear
Seperti yang kamu telah belajar dalam Pelajaran 1, tujuan sebuah latihan regresi linear adalah untuk dapat menggambar sebuah garis untuk:
- Menunjukkan hubungan antar-variabel. Menunjukkan hubungan antara variabel-variabel.
- Membuat prediksi. Membuat prediksi akurat tentang di mana sebuah titik data baru akan terletak berhubungan dengan garis tersebut.
Dalam kasus Regresi Kuadrat Terkecil (Least-Squares Regression), biasanya garis seperti ini digambar. Istilah 'kuadrat terkecil' berarti semua titik data yang mengitari garis regresi dikuadratkan dan dijumlahkan. Secara ideal, harusnya jumlah akhirnya sekecil mungkin, karena kita ingin kesalahan (error) terkecil, alias kuadrat terkecil.
Kita melakukan itu sebab kita ingin memodelkan sebuah garis yang jarak kumulatifnya dari semua titik data itu sekecil mungkin. Kita juga mengkuadratkan setiap suku sebelum dijumlahkan karena kita fokus pada besarannya daripada arahnya.
🧮 Tunjukkan matematikanya kepadaku
Garis ini, dipanggil garis yang paling cocok, dapat diekspresikan dalam sebuah persamaan:
Y = a + bX
Xadalah 'variabel penerang'.Yadalah 'variabel dependen'. Gradien garisnya adalahb, danaadalah titik potong sumbu y yaitu nilaiYsaatX = 0.
Pertama, hitunglah gradien
b. Infografik oleh Jen LooperDalam kata lain, dan berhubungan pula dengan pertanyaan awal data labu kita "prediksikan harga satu bushel labu setiap bulan",
Xmerujuk pada harganya, sedangkanYakan merujuk pada bulan penjualan.
Hitunglah nilai Y. Kalau harganya $4, artinya pasti April! Infografik oleh Jen Looper
Matematika yang mengkalkulasi garis ini harus mendemonstrasikan gradien garisnya yang juga tergantung pada titik potongnya pada sumbu y, alias apa
Y-nya saatX = 0.Kamu bisa melihat metode menghitung nilai-nilai ini di situs internet Math is Fun (Matematika Itu Menyenangkan). Kunjungi kalkulator kuadrat terkecil ini juga untuk melihat bagaimana nomor-nomor ini mengubah garisnya.


Korelasi
Satu lagi yang harus dipahami adalah Koefisien Korelasi antara variabel X dan Y yang tersedia. Menggunakan sebuah petak sebar, kamu bisa memvisualisasi korelasi ini dengan cepat. Sebuah grafik dengan titik-titik data yang tersebar rapi seperti sebuah garis mempunyai korelasi yang tinggi. Namun, sebuah grafik dengan titik-titik data yang tersebar di mana-mana antara X dan Y mempunyai korelasi yang rendah.
Sebuah model regresi linear yang bagus akan mempunyai Koefisien Korelasi yang tinggi (lebih dekat ke 1 daripada ke 0) menggunakan metode Regresi Kuadrat Terkecil dengan sebuah garis regresi.
✅ Jalankan notebook yang terlampir dalam pelajaran ini dan lihatlah petak sebar City (Kota) ke Price (Harga). Apa data yang menghubungkan City ke Price untuk penjualan labu mempunyai korelasi yang tinggi atau rendah kelihatannya?
Siapkan datamu untuk regresi
Sekarang dengan pemahamanmu mengenai matematika di balik latihan ini, buatlah sebuah model regresi untuk melihat apa kamu bisa memprediksi paket labu yang mana yang harganya paling baik. Seorang pembeli labu akan ingin mengetahui informasi ini untuk mengoptimasi pembelian labu mereka.
Karena kamu akan menggunakan Scikit-learn, tidak usah mengerjakan ini dengan tangan (walaupun bisa sih!). Dalam blok memrosesan data utama notebook-mu untuk pelajaran ini, tambahlah sebuah library dari Scikit-learn untuk mengkonversi semua data string menjadi nomor secara otomatis:
from sklearn.preprocessing import LabelEncoder
new_pumpkins.iloc[:, 0:-1] = new_pumpkins.iloc[:, 0:-1].apply(LabelEncoder().fit_transform)
new_pumpkins.iloc[:, 0:-1] = new_pumpkins.iloc[:, 0:-1].apply(LabelEncoder().fit_transform)
Kalau kamu sekarang simak dataframe new_punkins, kamu akan lihat bahwa semua string sudah dijadikan nomor. Ini lebih susah untuk kita baca, tetapi jauh lebih mudah untuk Scikit-learn! Sekarang kamu bisa membuat lebih banyak keputusan berakal (tidak hanya tebak-tebak dari petak sebarnya) tentang data yang paling cocok untuk regresi.
Coba cari sebuah korelasi bagus antara dua titik data yang berpotensi untuk membangun sebuah model prediksi yang baik. Ternyata, hanya ada korelasi yang lemah antara City dan Price:
print(new_pumpkins['City'].corr(new_pumpkins['Price']))
0.32363971816089226
Meskipun begitu, ada korelasi yang sedikit lebih baik antara Package (Paket) dan Price (Harga). Masuk akal juga kan? Biasanya, lebih besar kardusnya, lebih mahal harganya.
print(new_pumpkins['Package'].corr(new_pumpkins['Price']))
0.6061712937226021
Sebuah pertanyaan bagus untuk ditanyakan dari data ini adalah "Kira-kira harga sebuah paket labu berapa?"
Mari membangun sebuah model regresi
Membangun sebuah model linear
Sebelum membangun modelmu, rapikanlah datamu sekali lagi. Buanglah sebuah data nil (null) dan periksalah sekali lagi datanya kelihatannya seperti apa.
new_pumpkins.dropna(inplace=True)
new_pumpkins.info()
Lalu, buatlah sebuah dataframe baru dari set minimal ini dan print:
new_columns = ['Package', 'Price']
lin_pumpkins = new_pumpkins.drop([c for c in new_pumpkins.columns if c not in new_columns], axis='columns')
lin_pumpkins
Package Price
70 0 13.636364
71 0 16.363636
72 0 16.363636
73 0 15.454545
74 0 13.636364
... ... ...
1738 2 30.000000
1739 2 28.750000
1740 2 25.750000
1741 2 24.000000
1742 2 24.000000
415 rows × 2 columns
-
Sekarang kamu bisa menetapkan data koordinat X dan y-mu:
X = lin_pumpkins.values[:, :1] y = lin_pumpkins.values[:, 1:2]
✅ Apa yang sedang terjadi di sini? Kamu sedang menggunakan notasi perpotongan Python (Python slice notation) untuk membuat dua array untuk mengisi X dan y.
-
Selanjutnya, mulailah rutin pembangunan model:
from sklearn.linear_model import LinearRegression from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) lin_reg = LinearRegression() lin_reg.fit(X_train,y_train) pred = lin_reg.predict(X_test) accuracy_score = lin_reg.score(X_train,y_train) print('Model Accuracy: ', accuracy_score)Karena korelasinya tidak begitu baik, model yang didapatkan tidak terlalu akurat.
Model Accuracy: 0.3315342327998987 -
Kamu bisa memvisualisasi garis yang digambarkan dalam proses ini:
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, pred, color='blue', linewidth=3) plt.xlabel('Package') plt.ylabel('Price') plt.show()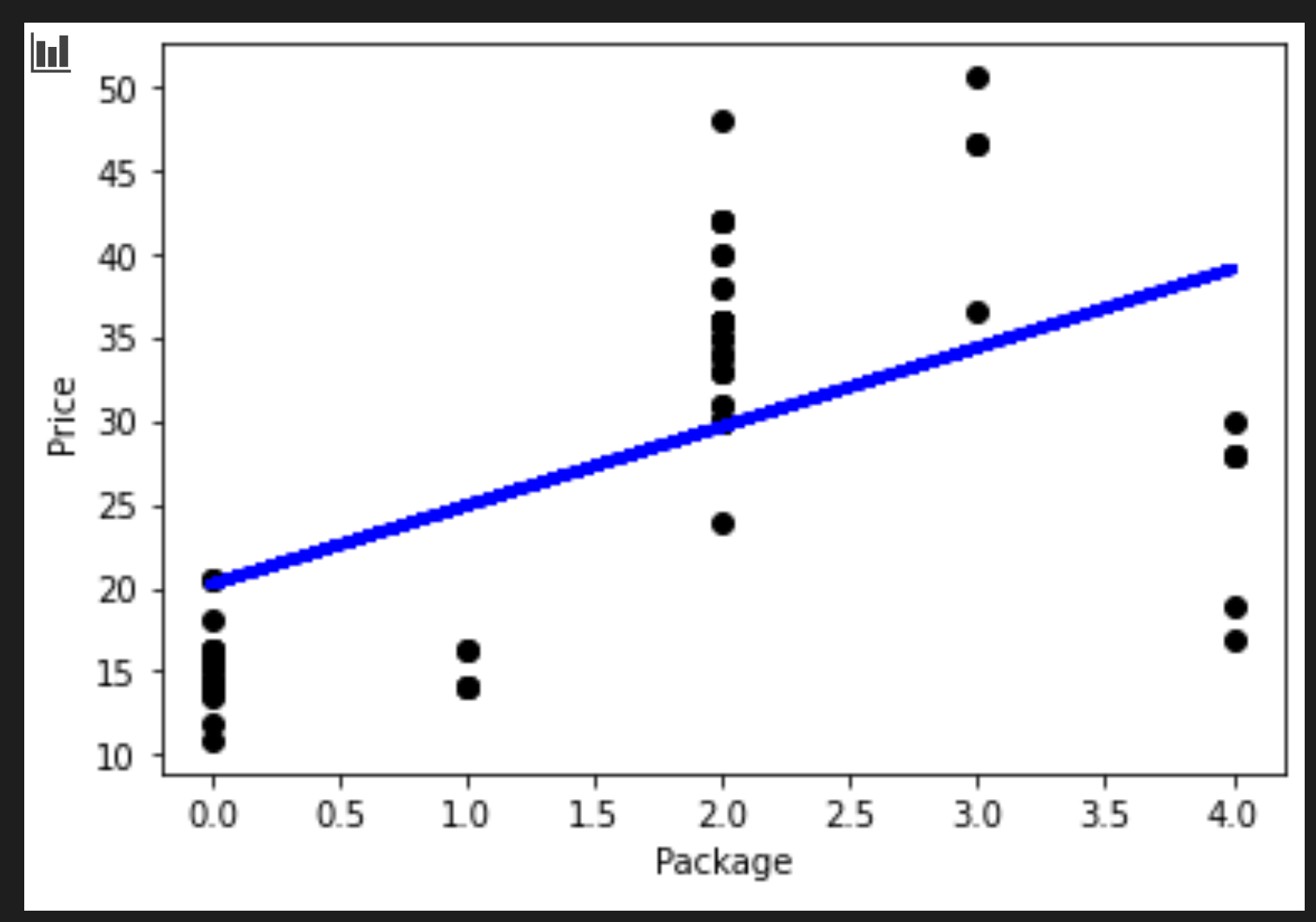
-
Ujilah modelnya dengan sebuah jenis labu hipotetis:
lin_reg.predict( np.array([ [2.75] ]) )Harga yang dihasilkan untuk jenis labu mitologis ini adalah:
array([[33.15655975]])
Nomor itu masuk akal jikalau logika garis regresinya benar.
🎃 Selamat, kamu baru saja membuat sebuah model yang bisa membantu memprediksi harga beberapa jenis labu. Namun, kamu masih bisa membuatnya lebih baik!
Regresi polinomial
Jenis lain regresi linear adalah regresi polinomial. Walaupun kadangkali ada hubungan linear antara variabel-variabel — lebih besar volume labunya, lebih tinggi harganya — kadangkali hubungan-hubungan ini tidak bisa digambarkan sebagai sebuah bidang atau garis lurus.
✅ Ini ada beberapa contoh data lain yang bisa menggunakan regresi polinomial
Tengok kembali hubungan antara Variety (Jenis) dan Price (Harga) dalam grafik sebelumnya. Apa petak sebar ini terlihat seperti harus dianalisis dengan sebuah garis lurus? Mungkin tidak. Kali ini, kamu bisa mencoba regresi polinomial.
✅ Polinomial adalah sebuah pernyataan matematika yang mempunyai satu atau lebih variabel dan koefisien disusun menjadi suku-suku.
Regresi polinomial menghasilkan sebuah garis lengkung supaya lebih cocok dengan data non-linear.
-
Mari kita membuat sebuah dataframe yang diisi sebuah segmen dari data orisinal labu:
new_columns = ['Variety', 'Package', 'City', 'Month', 'Price'] poly_pumpkins = new_pumpkins.drop([c for c in new_pumpkins.columns if c not in new_columns], axis='columns') poly_pumpkins
Sebuah cara bagus untuk memvisualisasi korelasi-korelasi antara data dalam dataframe-dataframe adalah untuk menampilkannya dalam sebuah peta 'coolwarm' (panas-dingin):
-
Gunakan fungsi
Background_gradient()dengancoolwarmsebagai argumennya:corr = poly_pumpkins.corr() corr.style.background_gradient(cmap='coolwarm')This code creates a heatmap: Kode ini membuat sebuah peta panas

Melihat peta ini, kamu bisa memvisualisasikan korelasi yang baik antara Package dan Price. Jadi kamu seharusnya bisa membuat sebuah model yang lebih baik daripada yang sebelumnya.
Buatlah sebuah pipeline
Scikit-learn mempunyai sebuah API yang berguna untuk membangun model regresi polinomial — API make_pipeline. Sebuah 'pipeline' adalah sebuah rantai penaksir. Dalam kasus ini, pipeline ini mempunyai fitur-fitur polinomial, atau prediksi-prediksi yang membuat garis non-linear.
-
Bangunlah kolom X dan y:
X=poly_pumpkins.iloc[:,3:4].values y=poly_pumpkins.iloc[:,4:5].values -
Buatlah pipeline-nya dengan fungsi
make_pipeline():from sklearn.preprocessing import PolynomialFeatures from sklearn.pipeline import make_pipeline pipeline = make_pipeline(PolynomialFeatures(4), LinearRegression()) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) pipeline.fit(np.array(X_train), y_train) y_pred=pipeline.predict(X_test)
Buatlah sebuah barisan
Di sini, kamu harus membuat sebuah dataframe baru dengan data yang berurutan supaya pipeline-nya bisa membuat sebuah barisan.
Tambahlah kode ini:
df = pd.DataFrame({'x': X_test[:,0], 'y': y_pred[:,0]})
df.sort_values(by='x',inplace = True)
points = pd.DataFrame(df).to_numpy()
plt.plot(points[:, 0], points[:, 1],color="blue", linewidth=3)
plt.xlabel('Package')
plt.ylabel('Price')
plt.scatter(X,y, color="black")
plt.show()
Kamu membuat sebuah dataframe baru dengan fungsi pd.DataFrame. Lalu kamu mengurutkan isinya dengan fungsi sort_values(). Akhirnya kamu membuat sebuah bagan polinomial:

Kamu bisa melihat garis lengkungnya yang lebih cocok terhadap datamu.
Ayo periksa akurasi modelnya:
accuracy_score = pipeline.score(X_train,y_train)
print('Model Accuracy: ', accuracy_score)
Nah!
Model Accuracy: 0.8537946517073784
Itu bagus! Coba memprediksi harga:
Buatlah sebuah prediksi
Apa kita bisa memberi input dan dapat sebuah prediksi?
Pakai fungsi predict() untuk membuat prediksi:
pipeline.predict( np.array([ [2.75] ]) )
Kamu diberi prediksi ini:
array([[46.34509342]])
Itu sangat masuk akal dengan bagan sebelumnya! Selain itu, jika ini model lebih baik daripada yang sebelumnya dengan data ini, kamu bisa siap untuk labu-labu yang lebih mahal ini!
🏆 Mantap sekali! Kamu membuat dua model regresi dalam satu pelajaran. Dalam bagian terakhir mengenai regresi, kamu akan belajar tentang regresi logistik untuk pengkategorisasian.
🚀 Tantangan
Coba-cobalah variabel-variabel yang lain di notebook ini untuk melihat bagaimana korelasi berhubungan dengan akurasi model.
Kuis pasca-ceramah
Review & Pembelajaran Mandiri
Dalam pelajaran ini kita belajar tentang regresi linear. Ada banyak jenis regresi lain yang penting pula. Bacalah tentang teknik Stepwise, Ridge, Lasso, dan Elasticnet. Kursus Pembelajaran Statistik Stanford juga baik untuk belajar lebih lanjut.