|
|
1 month ago | |
|---|---|---|
| .. | ||
| solution | 1 month ago | |
| README.md | 1 month ago | |
| assignment.md | 1 month ago | |
| notebook.ipynb | 1 month ago | |
README.md
K-Means grozdenje
Pre-lecture quiz
V tej lekciji se boste naučili, kako ustvariti grozde z uporabo Scikit-learn in nigerijskega glasbenega nabora podatkov, ki ste ga uvozili prej. Pokrili bomo osnove K-Means za grozdenje. Upoštevajte, da obstaja veliko načinov za delo z grozdi, kot ste se naučili v prejšnji lekciji, in metoda, ki jo uporabite, je odvisna od vaših podatkov. Poskusili bomo K-Means, saj je to najpogostejša tehnika grozdenja. Začnimo!
Pojmi, o katerih se boste učili:
- Silhuetno ocenjevanje
- Metoda komolca
- Inercija
- Varianca
Uvod
K-Means grozdenje je metoda, ki izvira iz področja obdelave signalov. Uporablja se za razdelitev in razvrščanje skupin podatkov v 'k' grozde z uporabo serije opazovanj. Vsako opazovanje deluje tako, da razvrsti določeno podatkovno točko najbližje njenemu 'povprečju' ali središčni točki grozda.
Grozde je mogoče vizualizirati kot Voronoijeve diagrame, ki vključujejo točko (ali 'seme') in njeno ustrezno regijo.

Infografika avtorice Jen Looper
Postopek K-Means grozdenja poteka v treh korakih:
- Algoritem izbere k-število središčnih točk z vzorčenjem iz nabora podatkov. Nato se zanka nadaljuje:
- Vsak vzorec dodeli najbližjemu centroidu.
- Ustvari nove centroide z izračunom povprečne vrednosti vseh vzorcev, dodeljenih prejšnjim centroidom.
- Nato izračuna razliko med novimi in starimi centroidi ter ponavlja, dokler se centroidi ne stabilizirajo.
Ena od pomanjkljivosti uporabe K-Means je, da morate določiti 'k', torej število centroidov. Na srečo metoda 'komolca' pomaga oceniti dobro začetno vrednost za 'k'. To boste poskusili čez trenutek.
Predpogoj
Delali boste v datoteki notebook.ipynb, ki vključuje uvoz podatkov in predhodno čiščenje, ki ste ga opravili v prejšnji lekciji.
Naloga - priprava
Začnite tako, da ponovno pregledate podatke o pesmih.
-
Ustvarite boxplot za vsak stolpec z uporabo funkcije
boxplot():plt.figure(figsize=(20,20), dpi=200) plt.subplot(4,3,1) sns.boxplot(x = 'popularity', data = df) plt.subplot(4,3,2) sns.boxplot(x = 'acousticness', data = df) plt.subplot(4,3,3) sns.boxplot(x = 'energy', data = df) plt.subplot(4,3,4) sns.boxplot(x = 'instrumentalness', data = df) plt.subplot(4,3,5) sns.boxplot(x = 'liveness', data = df) plt.subplot(4,3,6) sns.boxplot(x = 'loudness', data = df) plt.subplot(4,3,7) sns.boxplot(x = 'speechiness', data = df) plt.subplot(4,3,8) sns.boxplot(x = 'tempo', data = df) plt.subplot(4,3,9) sns.boxplot(x = 'time_signature', data = df) plt.subplot(4,3,10) sns.boxplot(x = 'danceability', data = df) plt.subplot(4,3,11) sns.boxplot(x = 'length', data = df) plt.subplot(4,3,12) sns.boxplot(x = 'release_date', data = df)Ti podatki so nekoliko hrupni: z opazovanjem vsakega stolpca kot boxplota lahko vidite odstopajoče vrednosti.
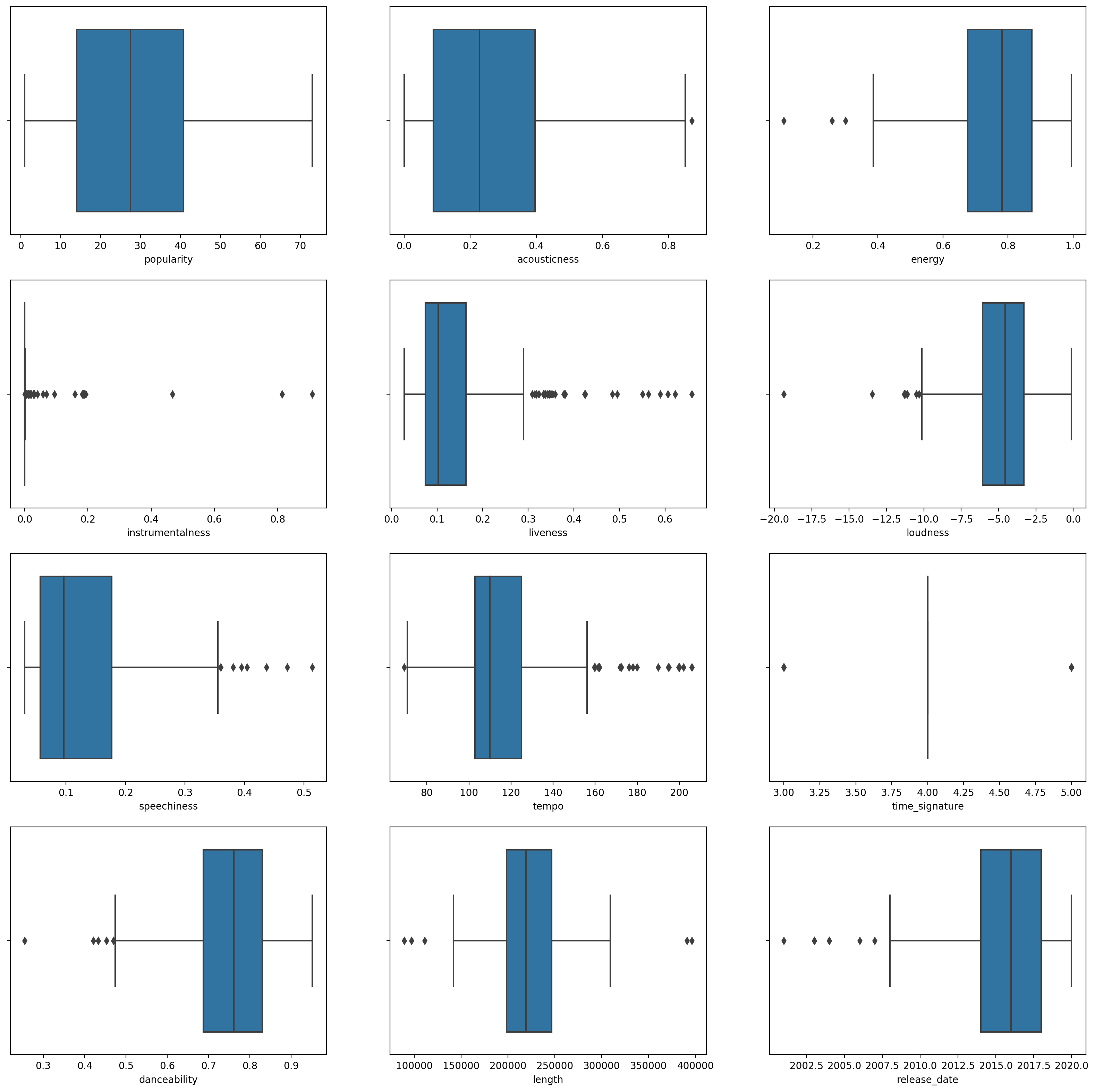
Lahko bi pregledali nabor podatkov in odstranili te odstopajoče vrednosti, vendar bi to podatke precej zmanjšalo.
-
Za zdaj izberite, katere stolpce boste uporabili za nalogo grozdenja. Izberite tiste s podobnimi razponi in kodirajte stolpec
artist_top_genrekot numerične podatke:from sklearn.preprocessing import LabelEncoder le = LabelEncoder() X = df.loc[:, ('artist_top_genre','popularity','danceability','acousticness','loudness','energy')] y = df['artist_top_genre'] X['artist_top_genre'] = le.fit_transform(X['artist_top_genre']) y = le.transform(y) -
Zdaj morate izbrati, koliko grozdov boste ciljali. Veste, da obstajajo 3 glasbeni žanri, ki smo jih izluščili iz nabora podatkov, zato poskusimo s 3:
from sklearn.cluster import KMeans nclusters = 3 seed = 0 km = KMeans(n_clusters=nclusters, random_state=seed) km.fit(X) # Predict the cluster for each data point y_cluster_kmeans = km.predict(X) y_cluster_kmeans
Vidite natisnjen niz s predvidenimi grozdi (0, 1 ali 2) za vsako vrstico podatkovnega okvira.
-
Uporabite ta niz za izračun 'silhuetne ocene':
from sklearn import metrics score = metrics.silhouette_score(X, y_cluster_kmeans) score
Silhuetna ocena
Iščite silhuetno oceno bližje 1. Ta ocena se giblje od -1 do 1, in če je ocena 1, je grozd gost in dobro ločen od drugih grozdov. Vrednost blizu 0 predstavlja prekrivajoče se grozde z vzorci, ki so zelo blizu odločitveni meji sosednjih grozdov. (Vir)
Naša ocena je 0,53, torej nekje na sredini. To kaže, da naši podatki niso posebej primerni za to vrsto grozdenja, vendar nadaljujmo.
Naloga - izdelava modela
-
Uvozite
KMeansin začnite postopek grozdenja.from sklearn.cluster import KMeans wcss = [] for i in range(1, 11): kmeans = KMeans(n_clusters = i, init = 'k-means++', random_state = 42) kmeans.fit(X) wcss.append(kmeans.inertia_)Tukaj je nekaj delov, ki jih je vredno pojasniti.
🎓 range: To so iteracije postopka grozdenja.
🎓 random_state: "Določa generacijo naključnih števil za inicializacijo centroidov." Vir
🎓 WCSS: "vsota kvadratov znotraj grozda" meri povprečno kvadratno razdaljo vseh točk znotraj grozda do centroida grozda. Vir.
🎓 Inercija: Algoritmi K-Means poskušajo izbrati centroide, da minimizirajo 'inercijo', "merilo, kako notranje koherentni so grozdi." Vir. Vrednost se doda spremenljivki wcss pri vsaki iteraciji.
🎓 k-means++: V Scikit-learn lahko uporabite optimizacijo 'k-means++', ki "inicializira centroide tako, da so (na splošno) oddaljeni drug od drugega, kar vodi do verjetno boljših rezultatov kot naključna inicializacija."
Metoda komolca
Prej ste domnevali, da bi morali izbrati 3 grozde, ker ste ciljali 3 glasbene žanre. Je to res?
-
Uporabite metodo 'komolca', da se prepričate.
plt.figure(figsize=(10,5)) sns.lineplot(x=range(1, 11), y=wcss, marker='o', color='red') plt.title('Elbow') plt.xlabel('Number of clusters') plt.ylabel('WCSS') plt.show()Uporabite spremenljivko
wcss, ki ste jo ustvarili v prejšnjem koraku, da ustvarite graf, ki prikazuje, kje je 'pregib' v komolcu, kar označuje optimalno število grozdov. Morda je res 3!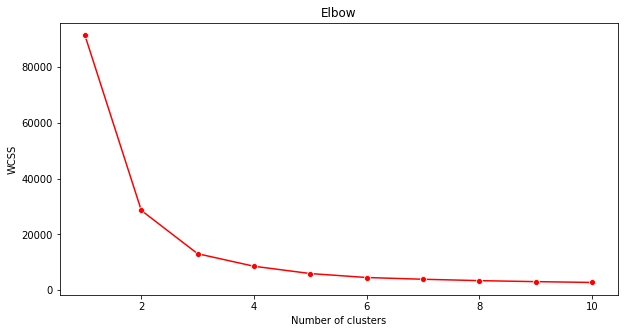
Naloga - prikaz grozdov
-
Poskusite postopek znova, tokrat nastavite tri grozde in prikažite grozde kot razpršen diagram:
from sklearn.cluster import KMeans kmeans = KMeans(n_clusters = 3) kmeans.fit(X) labels = kmeans.predict(X) plt.scatter(df['popularity'],df['danceability'],c = labels) plt.xlabel('popularity') plt.ylabel('danceability') plt.show() -
Preverite natančnost modela:
labels = kmeans.labels_ correct_labels = sum(y == labels) print("Result: %d out of %d samples were correctly labeled." % (correct_labels, y.size)) print('Accuracy score: {0:0.2f}'. format(correct_labels/float(y.size)))Natančnost tega modela ni zelo dobra, oblika grozdov pa vam daje namig, zakaj.

Ti podatki so preveč neuravnoteženi, premalo korelirani in med vrednostmi stolpcev je preveč variance, da bi jih dobro razvrstili v grozde. Pravzaprav so grozdi, ki se oblikujejo, verjetno močno vplivani ali pristranski zaradi treh kategorij žanrov, ki smo jih opredelili zgoraj. To je bil učni proces!
V dokumentaciji Scikit-learn lahko vidite, da ima model, kot je ta, z grozdi, ki niso dobro razmejeni, težavo z 'varianco':
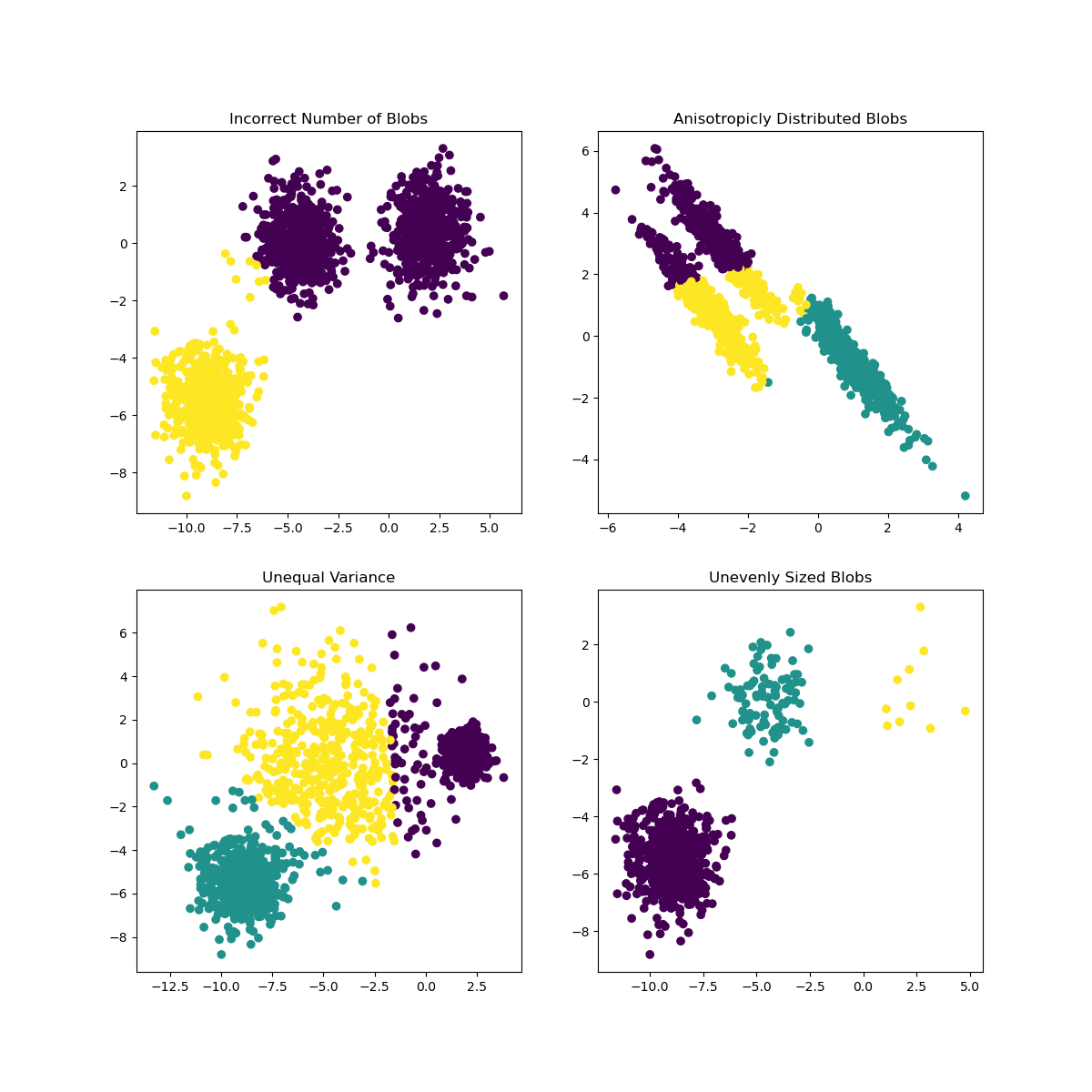
Infografika iz Scikit-learn
Varianca
Varianca je definirana kot "povprečje kvadratnih razlik od povprečja" (Vir). V kontekstu tega problema grozdenja se nanaša na podatke, pri katerih se številke našega nabora podatkov preveč oddaljujejo od povprečja.
✅ To je odličen trenutek, da razmislite o vseh načinih, kako bi lahko odpravili to težavo. Bi še malo prilagodili podatke? Uporabili druge stolpce? Uporabili drugačen algoritem? Namig: Poskusite normalizirati podatke in preizkusiti druge stolpce.
Poskusite ta 'kalkulator variance', da bolje razumete koncept.
🚀Izziv
Preživite nekaj časa s tem zvezkom in prilagodite parametre. Ali lahko izboljšate natančnost modela z dodatnim čiščenjem podatkov (na primer odstranjevanjem odstopajočih vrednosti)? Lahko uporabite uteži, da določene vzorce podatkov bolj poudarite. Kaj še lahko storite, da ustvarite boljše grozde?
Namig: Poskusite normalizirati podatke. V zvezku je komentirana koda, ki dodaja standardno skaliranje, da stolpci podatkov bolj spominjajo drug na drugega glede na razpon. Ugotovili boste, da se silhuetna ocena zniža, vendar se 'pregib' v grafu komolca zgladi. To je zato, ker neobdelani podatki omogočajo, da podatki z manj varianco nosijo večjo težo. Preberite več o tej težavi tukaj.
Post-lecture quiz
Pregled in samostojno učenje
Oglejte si simulator K-Means kot je ta. S tem orodjem lahko vizualizirate vzorčne podatkovne točke in določite njihove centroide. Lahko urejate naključnost podatkov, število grozdov in število centroidov. Ali vam to pomaga pridobiti predstavo o tem, kako je mogoče podatke razvrstiti?
Prav tako si oglejte ta priročnik o K-Means s Stanforda.
Naloga
Preizkusite različne metode grozdenja
Omejitev odgovornosti:
Ta dokument je bil preveden z uporabo storitve za prevajanje z umetno inteligenco Co-op Translator. Čeprav si prizadevamo za natančnost, vas prosimo, da upoštevate, da lahko avtomatizirani prevodi vsebujejo napake ali netočnosti. Izvirni dokument v njegovem maternem jeziku je treba obravnavati kot avtoritativni vir. Za ključne informacije priporočamo profesionalni človeški prevod. Ne prevzemamo odgovornosti za morebitna napačna razumevanja ali napačne interpretacije, ki bi nastale zaradi uporabe tega prevoda.