|
|
4 months ago | |
|---|---|---|
| .. | ||
| solution | 4 months ago | |
| README.md | 4 months ago | |
| assignment.md | 4 months ago | |
| notebook.ipynb | 9 months ago | |
README.md
ਸਕਾਈਟ-ਲਰਨ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਰਿਗ੍ਰੈਸ਼ਨ ਮਾਡਲ ਬਣਾਉਣਾ: ਡਾਟਾ ਤਿਆਰ ਕਰਨਾ ਅਤੇ ਵਿਜੁਅਲਾਈਜ਼ ਕਰਨਾ
ਇਨਫੋਗ੍ਰਾਫਿਕ ਦਸਾਨੀ ਮਾਡੀਪੱਲੀ ਦੁਆਰਾ
ਪ੍ਰੀ-ਲੈਕਚਰ ਕਵਿਜ਼
ਇਹ ਪਾਠ ਰ ਵਿੱਚ ਉਪਲਬਧ ਹੈ!
ਤਾਰਫ਼
ਹੁਣ ਜਦੋਂ ਤੁਹਾਡੇ ਕੋਲ ਸਕਾਈਟ-ਲਰਨ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਮਸ਼ੀਨ ਲਰਨਿੰਗ ਮਾਡਲ ਬਣਾਉਣ ਲਈ ਜ਼ਰੂਰੀ ਸੰਦ ਹਨ, ਤੁਸੀਂ ਆਪਣੇ ਡਾਟਾ ਤੋਂ ਸਵਾਲ ਪੁੱਛਣ ਲਈ ਤਿਆਰ ਹੋ। ਜਦੋਂ ਤੁਸੀਂ ਡਾਟਾ ਨਾਲ ਕੰਮ ਕਰਦੇ ਹੋ ਅਤੇ ML ਹੱਲ ਲਾਗੂ ਕਰਦੇ ਹੋ, ਇਹ ਸਮਝਣਾ ਬਹੁਤ ਜ਼ਰੂਰੀ ਹੈ ਕਿ ਸਹੀ ਸਵਾਲ ਕਿਵੇਂ ਪੁੱਛਣਾ ਹੈ ਤਾਂ ਜੋ ਆਪਣੇ ਡਾਟਾਸੈੱਟ ਦੀ ਸੰਭਾਵਨਾਵਾਂ ਨੂੰ ਸਹੀ ਤਰੀਕੇ ਨਾਲ ਖੋਲ੍ਹਿਆ ਜਾ ਸਕੇ।
ਇਸ ਪਾਠ ਵਿੱਚ, ਤੁਸੀਂ ਸਿੱਖੋਗੇ:
- ਮਾਡਲ-ਬਿਲਡਿੰਗ ਲਈ ਆਪਣੇ ਡਾਟਾ ਨੂੰ ਕਿਵੇਂ ਤਿਆਰ ਕਰਨਾ ਹੈ।
- ਡਾਟਾ ਵਿਜੁਅਲਾਈਜ਼ੇਸ਼ਨ ਲਈ ਮੈਟਪਲਾਟਲਿਬ ਦੀ ਵਰਤੋਂ ਕਿਵੇਂ ਕਰਨੀ ਹੈ।
ਆਪਣੇ ਡਾਟਾ ਤੋਂ ਸਹੀ ਸਵਾਲ ਪੁੱਛਣਾ
ਜਿਸ ਸਵਾਲ ਦਾ ਤੁਹਾਨੂੰ ਜਵਾਬ ਚਾਹੀਦਾ ਹੈ, ਉਹ ਨਿਰਧਾਰਤ ਕਰੇਗਾ ਕਿ ਤੁਸੀਂ ਕਿਹੜੇ ਕਿਸਮ ਦੇ ML ਐਲਗੋਰਿਦਮ ਦੀ ਵਰਤੋਂ ਕਰੋਗੇ। ਅਤੇ ਤੁਹਾਨੂੰ ਵਾਪਸ ਮਿਲਣ ਵਾਲੇ ਜਵਾਬ ਦੀ ਗੁਣਵੱਤਾ ਤੁਹਾਡੇ ਡਾਟਾ ਦੀ ਪ੍ਰਕਿਰਤੀ 'ਤੇ ਬਹੁਤ ਨਿਰਭਰ ਕਰੇਗੀ।
ਇਸ ਪਾਠ ਲਈ ਦਿੱਤੇ ਡਾਟਾ ਨੂੰ ਵੇਖੋ। ਤੁਸੀਂ ਇਸ .csv ਫਾਈਲ ਨੂੰ VS ਕੋਡ ਵਿੱਚ ਖੋਲ੍ਹ ਸਕਦੇ ਹੋ। ਇੱਕ ਛੋਟਾ ਜਿਹਾ ਜਾਇਜ਼ਾ ਲੈਣ 'ਤੇ ਤੁਰੰਤ ਪਤਾ ਲੱਗਦਾ ਹੈ ਕਿ ਇਸ ਵਿੱਚ ਖਾਲੀ ਜਗ੍ਹਾ ਅਤੇ ਸਤਰਾਂ ਅਤੇ ਗਿਣਤੀ ਡਾਟਾ ਦਾ ਮਿਸ਼ਰਣ ਹੈ। ਇੱਥੇ ਇੱਕ ਅਜੀਬ ਕਾਲਮ 'ਪੈਕੇਜ' ਹੈ ਜਿੱਥੇ ਡਾਟਾ 'ਸੈਕਸ', 'ਬਿਨ' ਅਤੇ ਹੋਰ ਮੁੱਲਾਂ ਦੇ ਮਿਸ਼ਰਣ ਵਿੱਚ ਹੈ। ਡਾਟਾ, ਦਰਅਸਲ, ਕੁਝ ਗੜਬੜ ਹੈ।

🎥 ਉੱਪਰ ਦਿੱਤੀ ਤਸਵੀਰ 'ਤੇ ਕਲਿਕ ਕਰੋ ਇਸ ਪਾਠ ਲਈ ਡਾਟਾ ਤਿਆਰ ਕਰਨ ਦੀ ਪ੍ਰਕਿਰਿਆ ਦੇਖਣ ਲਈ ਇੱਕ ਛੋਟਾ ਵੀਡੀਓ।
ਅਸਲ ਵਿੱਚ, ਇਹ ਬਹੁਤ ਆਮ ਨਹੀਂ ਹੈ ਕਿ ਤੁਹਾਨੂੰ ਇੱਕ ਡਾਟਾਸੈੱਟ ਮਿਲੇ ਜੋ ਬਾਕਸ ਤੋਂ ਬਾਹਰ ਇੱਕ ML ਮਾਡਲ ਬਣਾਉਣ ਲਈ ਪੂਰੀ ਤਰ੍ਹਾਂ ਤਿਆਰ ਹੋ। ਇਸ ਪਾਠ ਵਿੱਚ, ਤੁਸੀਂ ਸਿੱਖੋਗੇ ਕਿ ਮਿਆਰੀ ਪਾਈਥਨ ਲਾਇਬ੍ਰੇਰੀਆਂ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਕੱਚੇ ਡਾਟਾ ਨੂੰ ਕਿਵੇਂ ਤਿਆਰ ਕਰਨਾ ਹੈ। ਤੁਸੀਂ ਡਾਟਾ ਨੂੰ ਵਿਜੁਅਲਾਈਜ਼ ਕਰਨ ਦੇ ਵੱਖ-ਵੱਖ ਤਰੀਕੇ ਵੀ ਸਿੱਖੋਗੇ।
ਕੇਸ ਸਟਡੀ: 'ਕੱਦੂ ਦਾ ਬਾਜ਼ਾਰ'
ਇਸ ਫੋਲਡਰ ਵਿੱਚ ਤੁਹਾਨੂੰ ਰੂਟ data ਫੋਲਡਰ ਵਿੱਚ ਇੱਕ .csv ਫਾਈਲ ਮਿਲੇਗੀ ਜਿਸਦਾ ਨਾਮ US-pumpkins.csv ਹੈ, ਜਿਸ ਵਿੱਚ ਕੱਦੂ ਦੇ ਬਾਜ਼ਾਰ ਬਾਰੇ 1757 ਲਾਈਨਾਂ ਦਾ ਡਾਟਾ ਸ਼ਾਮਲ ਹੈ, ਜੋ ਸ਼ਹਿਰਾਂ ਦੁਆਰਾ ਸਮੂਹਬੱਧ ਹੈ। ਇਹ ਕੱਚਾ ਡਾਟਾ Specialty Crops Terminal Markets Standard Reports ਤੋਂ ਪ੍ਰਾਪਤ ਕੀਤਾ ਗਿਆ ਹੈ, ਜੋ ਸੰਯੁਕਤ ਰਾਜ ਦੇ ਖੇਤੀਬਾੜੀ ਵਿਭਾਗ ਦੁਆਰਾ ਵੰਡਿਆ ਜਾਂਦਾ ਹੈ।
ਡਾਟਾ ਤਿਆਰ ਕਰਨਾ
ਇਹ ਡਾਟਾ ਪਬਲਿਕ ਡੋਮੇਨ ਵਿੱਚ ਹੈ। ਇਸਨੂੰ USDA ਵੈਬਸਾਈਟ ਤੋਂ ਵੱਖ-ਵੱਖ ਸ਼ਹਿਰਾਂ ਦੇ ਅਲੱਗ-ਅਲੱਗ ਫਾਈਲਾਂ ਵਿੱਚ ਡਾਊਨਲੋਡ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ। ਬਹੁਤ ਸਾਰੀਆਂ ਵੱਖ-ਵੱਖ ਫਾਈਲਾਂ ਤੋਂ ਬਚਣ ਲਈ, ਅਸੀਂ ਸਾਰੇ ਸ਼ਹਿਰਾਂ ਦੇ ਡਾਟਾ ਨੂੰ ਇੱਕ ਸਪ੍ਰੈਡਸ਼ੀਟ ਵਿੱਚ ਜੋੜ ਦਿੱਤਾ ਹੈ, ਇਸ ਤਰ੍ਹਾਂ ਅਸੀਂ ਪਹਿਲਾਂ ਹੀ ਡਾਟਾ ਨੂੰ ਕੁਝ ਹੱਦ ਤੱਕ ਤਿਆਰ ਕਰ ਦਿੱਤਾ ਹੈ। ਹੁਣ, ਆਓ ਡਾਟਾ ਨੂੰ ਧਿਆਨ ਨਾਲ ਵੇਖੀਏ।
ਕੱਦੂ ਦਾ ਡਾਟਾ - ਸ਼ੁਰੂਆਤੀ ਨਤੀਜੇ
ਤੁਸੀਂ ਇਸ ਡਾਟਾ ਬਾਰੇ ਕੀ ਧਿਆਨ ਦਿੰਦੇ ਹੋ? ਤੁਸੀਂ ਪਹਿਲਾਂ ਹੀ ਦੇਖਿਆ ਕਿ ਸਤਰਾਂ, ਗਿਣਤੀ, ਖਾਲੀ ਜਗ੍ਹਾ ਅਤੇ ਅਜੀਬ ਮੁੱਲਾਂ ਦਾ ਮਿਸ਼ਰਣ ਹੈ ਜਿਸਨੂੰ ਤੁਹਾਨੂੰ ਸਮਝਣਾ ਪਵੇਗਾ।
ਤੁਸੀਂ ਰਿਗ੍ਰੈਸ਼ਨ ਤਕਨੀਕ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਇਸ ਡਾਟਾ ਤੋਂ ਕਿਹੜਾ ਸਵਾਲ ਪੁੱਛ ਸਕਦੇ ਹੋ? ਜਿਵੇਂ ਕਿ "ਕੱਦੂ ਦੀ ਕੀਮਤ ਦੀ ਪੇਸ਼ਗੋਈ ਕਰੋ ਜੋ ਕਿਸੇ ਦਿੱਤੇ ਮਹੀਨੇ ਦੌਰਾਨ ਵਿਕਰੀ ਲਈ ਉਪਲਬਧ ਹੈ।" ਡਾਟਾ ਨੂੰ ਦੁਬਾਰਾ ਵੇਖਦੇ ਹੋਏ, ਤੁਹਾਨੂੰ ਟਾਸਕ ਲਈ ਜ਼ਰੂਰੀ ਡਾਟਾ ਸਟ੍ਰਕਚਰ ਬਣਾਉਣ ਲਈ ਕੁਝ ਬਦਲਾਅ ਕਰਨੇ ਪੈਣਗੇ।
ਅਭਿਆਸ - ਕੱਦੂ ਦੇ ਡਾਟਾ ਦਾ ਵਿਸ਼ਲੇਸ਼ਣ ਕਰੋ
ਆਓ Pandas ਦੀ ਵਰਤੋਂ ਕਰੀਏ, (ਇਸਦਾ ਨਾਮ Python Data Analysis ਲਈ ਹੈ) ਜੋ ਡਾਟਾ ਨੂੰ ਸ਼ੇਪ ਕਰਨ ਲਈ ਬਹੁਤ ਹੀ ਲਾਭਦਾਇਕ ਸੰਦ ਹੈ, ਕੱਦੂ ਦੇ ਡਾਟਾ ਦਾ ਵਿਸ਼ਲੇਸ਼ਣ ਅਤੇ ਤਿਆਰੀ ਕਰਨ ਲਈ।
ਪਹਿਲਾਂ, ਗੁੰਮ ਹੋਈਆਂ ਤਾਰੀਖਾਂ ਦੀ ਜਾਂਚ ਕਰੋ
ਤੁਹਾਨੂੰ ਪਹਿਲਾਂ ਇਹ ਜਾਂਚਣ ਲਈ ਕਦਮ ਲੈਣੇ ਪੈਣਗੇ ਕਿ ਕੀ ਤਾਰੀਖਾਂ ਗੁੰਮ ਹਨ:
- ਤਾਰੀਖਾਂ ਨੂੰ ਮਹੀਨੇ ਦੇ ਫਾਰਮੈਟ ਵਿੱਚ ਬਦਲੋ (ਇਹ US ਤਾਰੀਖਾਂ ਹਨ, ਇਸ ਲਈ ਫਾਰਮੈਟ
MM/DD/YYYYਹੈ)। - ਮਹੀਨੇ ਨੂੰ ਇੱਕ ਨਵੇਂ ਕਾਲਮ ਵਿੱਚ ਕੱਢੋ।
ਨੋਟਬੁੱਕ.ipynb ਫਾਈਲ ਨੂੰ Visual Studio Code ਵਿੱਚ ਖੋਲ੍ਹੋ ਅਤੇ ਸਪ੍ਰੈਡਸ਼ੀਟ ਨੂੰ ਇੱਕ ਨਵੇਂ Pandas ਡਾਟਾਫਰੇਮ ਵਿੱਚ ਇੰਪੋਰਟ ਕਰੋ।
-
ਪਹਿਲੀਆਂ ਪੰਜ ਲਾਈਨਾਂ ਦੇਖਣ ਲਈ
head()ਫੰਕਸ਼ਨ ਦੀ ਵਰਤੋਂ ਕਰੋ।import pandas as pd pumpkins = pd.read_csv('../data/US-pumpkins.csv') pumpkins.head()✅ ਤੁਸੀਂ ਪਿਛਲੀਆਂ ਪੰਜ ਲਾਈਨਾਂ ਦੇਖਣ ਲਈ ਕਿਹੜੇ ਫੰਕਸ਼ਨ ਦੀ ਵਰਤੋਂ ਕਰੋਗੇ?
-
ਮੌਜੂਦਾ ਡਾਟਾਫਰੇਮ ਵਿੱਚ ਗੁੰਮ ਹੋਏ ਡਾਟਾ ਦੀ ਜਾਂਚ ਕਰੋ:
pumpkins.isnull().sum()ਗੁੰਮ ਹੋਇਆ ਡਾਟਾ ਹੈ, ਪਰ ਸ਼ਾਇਦ ਇਹ ਟਾਸਕ ਲਈ ਮਹੱਤਵਪੂਰਨ ਨਹੀਂ ਹੋਵੇਗਾ।
-
ਆਪਣੇ ਡਾਟਾਫਰੇਮ ਨੂੰ ਕੰਮ ਕਰਨ ਲਈ ਆਸਾਨ ਬਣਾਉਣ ਲਈ, ਸਿਰਫ਼ ਜ਼ਰੂਰੀ ਕਾਲਮ ਚੁਣੋ,
locਫੰਕਸ਼ਨ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਜੋ ਮੂਲ ਡਾਟਾਫਰੇਮ ਤੋਂ ਲਾਈਨਾਂ (ਪਹਿਲੇ ਪੈਰਾਮੀਟਰ ਵਜੋਂ ਪਾਸ ਕੀਤੀ ਗਈ) ਅਤੇ ਕਾਲਮ (ਦੂਜੇ ਪੈਰਾਮੀਟਰ ਵਜੋਂ ਪਾਸ ਕੀਤੀ ਗਈ) ਨੂੰ ਕੱਢਦਾ ਹੈ। ਹੇਠਾਂ ਦਿੱਤੇ ਕੇਸ ਵਿੱਚ:ਦਾ ਅਰਥ ਹੈ "ਸਭ ਲਾਈਨਾਂ"।columns_to_select = ['Package', 'Low Price', 'High Price', 'Date'] pumpkins = pumpkins.loc[:, columns_to_select]
ਦੂਜਾ, ਕੱਦੂ ਦੀ ਔਸਤ ਕੀਮਤ ਦਾ ਨਿਰਧਾਰਨ ਕਰੋ
ਇਹ ਸੋਚੋ ਕਿ ਦਿੱਤੇ ਮਹੀਨੇ ਵਿੱਚ ਕੱਦੂ ਦੀ ਔਸਤ ਕੀਮਤ ਦਾ ਨਿਰਧਾਰਨ ਕਿਵੇਂ ਕਰਨਾ ਹੈ। ਇਸ ਟਾਸਕ ਲਈ ਤੁਸੀਂ ਕਿਹੜੇ ਕਾਲਮ ਚੁਣੋਗੇ? ਸੰਕੇਤ: ਤੁਹਾਨੂੰ 3 ਕਾਲਮਾਂ ਦੀ ਲੋੜ ਹੋਵੇਗੀ।
ਹੱਲ: Low Price ਅਤੇ High Price ਕਾਲਮਾਂ ਦੀ ਔਸਤ ਲੈ ਕੇ ਨਵੇਂ Price ਕਾਲਮ ਨੂੰ ਭਰੋ, ਅਤੇ Date ਕਾਲਮ ਨੂੰ ਸਿਰਫ਼ ਮਹੀਨਾ ਦਿਖਾਉਣ ਲਈ ਬਦਲੋ। ਖੁਸ਼ਕਿਸਮਤੀ ਨਾਲ, ਉੱਪਰ ਦਿੱਤੀ ਜਾਂਚ ਦੇ ਅਨੁਸਾਰ, ਤਾਰੀਖਾਂ ਜਾਂ ਕੀਮਤਾਂ ਲਈ ਕੋਈ ਗੁੰਮ ਹੋਇਆ ਡਾਟਾ ਨਹੀਂ ਹੈ।
-
ਔਸਤ ਦੀ ਗਣਨਾ ਕਰਨ ਲਈ, ਹੇਠਾਂ ਦਿੱਤਾ ਕੋਡ ਸ਼ਾਮਲ ਕਰੋ:
price = (pumpkins['Low Price'] + pumpkins['High Price']) / 2 month = pd.DatetimeIndex(pumpkins['Date']).month✅
print(month)ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਤੁਸੀਂ ਕੋਈ ਵੀ ਡਾਟਾ ਪ੍ਰਿੰਟ ਕਰ ਸਕਦੇ ਹੋ ਜਿਸਨੂੰ ਤੁਸੀਂ ਜਾਂਚਣਾ ਚਾਹੁੰਦੇ ਹੋ। -
ਹੁਣ, ਆਪਣੇ ਬਦਲੇ ਹੋਏ ਡਾਟਾ ਨੂੰ ਇੱਕ ਨਵੇਂ Pandas ਡਾਟਾਫਰੇਮ ਵਿੱਚ ਕਾਪੀ ਕਰੋ:
new_pumpkins = pd.DataFrame({'Month': month, 'Package': pumpkins['Package'], 'Low Price': pumpkins['Low Price'],'High Price': pumpkins['High Price'], 'Price': price})ਆਪਣੇ ਡਾਟਾਫਰੇਮ ਨੂੰ ਪ੍ਰਿੰਟ ਕਰਨ ਨਾਲ ਤੁਹਾਨੂੰ ਇੱਕ ਸਾਫ਼, ਸਵੱਛ ਡਾਟਾਸੈੱਟ ਦਿਖਾਈ ਦੇਵੇਗਾ ਜਿਸ 'ਤੇ ਤੁਸੀਂ ਆਪਣਾ ਨਵਾਂ ਰਿਗ੍ਰੈਸ਼ਨ ਮਾਡਲ ਬਣਾਉਣ ਲਈ ਕੰਮ ਕਰ ਸਕਦੇ ਹੋ।
ਪਰ ਰੁਕੋ! ਇੱਥੇ ਕੁਝ ਅਜੀਬ ਹੈ
ਜੇ ਤੁਸੀਂ Package ਕਾਲਮ ਨੂੰ ਵੇਖੋ, ਤਾਂ ਕੱਦੂ ਵੱਖ-ਵੱਖ ਸੰਰਚਨਾਵਾਂ ਵਿੱਚ ਵੇਚੇ ਜਾਂਦੇ ਹਨ। ਕੁਝ '1 1/9 bushel' ਮਾਪ ਵਿੱਚ ਵੇਚੇ ਜਾਂਦੇ ਹਨ, ਕੁਝ '1/2 bushel' ਮਾਪ ਵਿੱਚ, ਕੁਝ ਪ੍ਰਤੀ ਕੱਦੂ, ਕੁਝ ਪ੍ਰਤੀ ਪੌਂਡ, ਅਤੇ ਕੁਝ ਵੱਡੇ ਬਾਕਸਾਂ ਵਿੱਚ ਵੱਖ-ਵੱਖ ਚੌੜਾਈਆਂ ਦੇ ਨਾਲ।
ਕੱਦੂ ਨੂੰ ਸਥਿਰ ਤੌਰ 'ਤੇ ਤੋਲਣਾ ਬਹੁਤ ਮੁਸ਼ਕਲ ਹੈ
ਮੂਲ ਡਾਟਾ ਵਿੱਚ ਖੋਜ ਕਰਦੇ ਹੋਏ, ਇਹ ਦਿਲਚਸਪ ਹੈ ਕਿ ਜਿਹਨਾਂ ਦਾ Unit of Sale 'EACH' ਜਾਂ 'PER BIN' ਹੈ, ਉਹਨਾਂ ਦੇ Package ਕਿਸਮ ਪ੍ਰਤੀ ਇੰਚ, ਪ੍ਰਤੀ ਬਿਨ, ਜਾਂ 'each' ਹੈ। ਕੱਦੂ ਨੂੰ ਸਥਿਰ ਤੌਰ 'ਤੇ ਤੋਲਣਾ ਬਹੁਤ ਮੁਸ਼ਕਲ ਹੈ, ਇਸ ਲਈ ਆਓ Package ਕਾਲਮ ਵਿੱਚ ਸਿਰਫ਼ 'bushel' ਸ਼ਬਦ ਵਾਲੇ ਕੱਦੂ ਨੂੰ ਚੁਣ ਕੇ ਫਿਲਟਰ ਕਰੀਏ।
-
ਫਾਈਲ ਦੇ ਸ਼ੁਰੂ ਵਿੱਚ, ਸ਼ੁਰੂਆਤੀ .csv ਇੰਪੋਰਟ ਦੇ ਹੇਠਾਂ ਇੱਕ ਫਿਲਟਰ ਸ਼ਾਮਲ ਕਰੋ:
pumpkins = pumpkins[pumpkins['Package'].str.contains('bushel', case=True, regex=True)]ਜੇ ਤੁਸੀਂ ਹੁਣ ਡਾਟਾ ਪ੍ਰਿੰਟ ਕਰੋ, ਤਾਂ ਤੁਸੀਂ ਦੇਖ ਸਕਦੇ ਹੋ ਕਿ ਤੁਹਾਨੂੰ ਸਿਰਫ਼ 415 ਜਾਂ ਇਸ ਤੋਂ ਵੱਧ ਲਾਈਨਾਂ ਦਾ ਡਾਟਾ ਮਿਲ ਰਿਹਾ ਹੈ ਜਿਸ ਵਿੱਚ ਬਸੇਲ ਦੁਆਰਾ ਕੱਦੂ ਸ਼ਾਮਲ ਹਨ।
ਪਰ ਰੁਕੋ! ਇੱਕ ਹੋਰ ਕੰਮ ਕਰਨ ਦੀ ਲੋੜ ਹੈ
ਕੀ ਤੁਸੀਂ ਧਿਆਨ ਦਿੱਤਾ ਕਿ ਬਸੇਲ ਦੀ ਮਾਤਰਾ ਹਰ ਲਾਈਨ ਵਿੱਚ ਵੱਖ-ਵੱਖ ਹੈ? ਤੁਹਾਨੂੰ ਕੀਮਤਾਂ ਨੂੰ ਨਾਰਮਲਾਈਜ਼ ਕਰਨ ਦੀ ਲੋੜ ਹੈ ਤਾਂ ਜੋ ਤੁਸੀਂ ਬਸੇਲ ਪ੍ਰਤੀ ਕੀਮਤ ਦਿਖਾ ਸਕੋ, ਇਸ ਲਈ ਕੀਮਤਾਂ ਨੂੰ ਸਥਿਰ ਕਰਨ ਲਈ ਕੁਝ ਗਣਿਤ ਕਰੋ।
-
ਨਵੇਂ_pumpkins ਡਾਟਾਫਰੇਮ ਬਣਾਉਣ ਵਾਲੇ ਬਲਾਕ ਦੇ ਬਾਅਦ ਇਹ ਲਾਈਨਾਂ ਸ਼ਾਮਲ ਕਰੋ:
new_pumpkins.loc[new_pumpkins['Package'].str.contains('1 1/9'), 'Price'] = price/(1 + 1/9) new_pumpkins.loc[new_pumpkins['Package'].str.contains('1/2'), 'Price'] = price/(1/2)
✅ The Spruce Eats ਦੇ ਅਨੁਸਾਰ, ਬਸੇਲ ਦਾ ਵਜ਼ਨ ਉਤਪਾਦ ਦੇ ਕਿਸਮ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ, ਕਿਉਂਕਿ ਇਹ ਇੱਕ ਵਾਲੀਅਮ ਮਾਪ ਹੈ। "ਟਮਾਟਰਾਂ ਦਾ ਇੱਕ ਬਸੇਲ, ਉਦਾਹਰਣ ਲਈ, 56 ਪੌਂਡ ਦਾ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ... ਪੱਤੇ ਅਤੇ ਹਰੇ ਪੱਤੇ ਵਧੇਰੇ ਜਗ੍ਹਾ ਲੈਂਦੇ ਹਨ ਅਤੇ ਘੱਟ ਵਜ਼ਨ ਹੁੰਦੇ ਹਨ, ਇਸ ਲਈ ਸਪਿਨੇਚ ਦਾ ਇੱਕ ਬਸੇਲ ਸਿਰਫ਼ 20 ਪੌਂਡ ਹੈ।" ਇਹ ਸਭ ਕੁਝ ਕਾਫ਼ੀ ਜਟਿਲ ਹੈ! ਆਓ ਬਸੇਲ-ਤੋਂ-ਪੌਂਡ ਬਦਲਾਅ ਕਰਨ ਦੀ ਝੰਝਟ ਨਾ ਕਰੀਏ, ਅਤੇ ਬਸੇਲ ਦੁਆਰਾ ਕੀਮਤ ਲਗਾਈਏ। ਕੱਦੂ ਦੇ ਬਸੇਲਾਂ ਦਾ ਇਹ ਸਾਰਾ ਅਧਿਐਨ, ਹਾਲਾਂਕਿ, ਇਹ ਦਿਖਾਉਂਦਾ ਹੈ ਕਿ ਆਪਣੇ ਡਾਟਾ ਦੀ ਪ੍ਰਕਿਰਤੀ ਨੂੰ ਸਮਝਣਾ ਕਿੰਨਾ ਮਹੱਤਵਪੂਰਨ ਹੈ!
ਹੁਣ, ਤੁਸੀਂ ਬਸੇਲ ਮਾਪ ਦੇ ਅਧਾਰ 'ਤੇ ਯੂਨਿਟ ਪ੍ਰਤੀ ਕੀਮਤ ਦਾ ਵਿਸ਼ਲੇਸ਼ਣ ਕਰ ਸਕਦੇ ਹੋ। ਜੇ ਤੁਸੀਂ ਡਾਟਾ ਨੂੰ ਇੱਕ ਵਾਰ ਫਿਰ ਪ੍ਰਿੰਟ ਕਰੋ, ਤਾਂ ਤੁਸੀਂ ਦੇਖ ਸਕਦੇ ਹੋ ਕਿ ਇਹ ਸਥਿਰ ਕੀਤਾ ਗਿਆ ਹੈ।
✅ ਕੀ ਤੁਸੀਂ ਧਿਆਨ ਦਿੱਤਾ ਕਿ ਅੱਧੇ-ਬਸੇਲ ਦੁਆਰਾ ਵੇਚੇ ਗਏ ਕੱਦੂ ਬਹੁਤ ਮਹਿੰਗੇ ਹਨ? ਕੀ ਤੁਸੀਂ ਪਤਾ ਲਗਾ ਸਕਦੇ ਹੋ ਕਿ ਕਿਉਂ? ਸੰਕੇਤ: ਛੋਟੇ ਕੱਦੂ ਵੱਡੇ ਕੱਦੂਆਂ ਨਾਲੋਂ ਕਾਫ਼ੀ ਮਹਿੰਗੇ ਹੁੰਦੇ ਹਨ, ਸ਼ਾਇਦ ਇਸ ਲਈ ਕਿ ਇੱਕ ਵੱਡੇ ਖਾਲੀ ਪਾਈ ਕੱਦੂ ਦੁਆਰਾ ਲਿਆ ਗਿਆ ਖਾਲੀ ਜਗ੍ਹਾ ਦੇ ਕਾਰਨ ਬਸੇਲ ਵਿੱਚ ਉਹਨਾਂ ਦੀ ਗਿਣਤੀ ਕਾਫ਼ੀ ਵੱਧ ਹੁੰਦੀ ਹੈ।
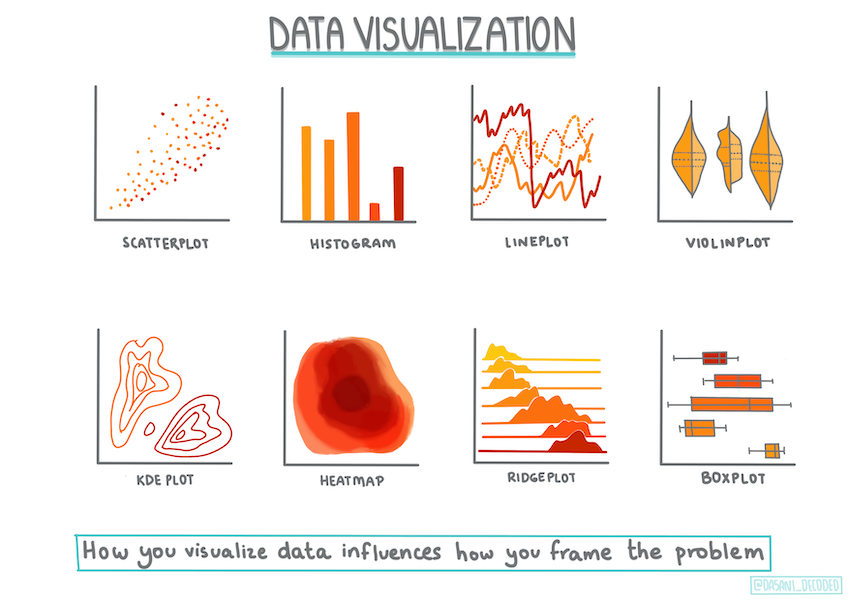
ਵਿਜੁਅਲਾਈਜ਼ੇਸ਼ਨ ਰਣਨੀਤੀਆਂ
ਡਾਟਾ ਸਾਇੰਟਿਸਟ ਦੀ ਭੂਮਿਕਾ ਡਾਟਾ ਦੀ ਗੁਣਵੱਤਾ ਅਤੇ ਪ੍ਰਕਿਰਤੀ ਨੂੰ ਦਰਸਾਉਣਾ ਹੈ ਜਿਸ ਨਾਲ ਉਹ ਕੰਮ ਕਰ ਰਹੇ ਹਨ। ਇਸ ਲਈ, ਉਹ ਅਕਸਰ ਦਿਲਚਸਪ ਵਿਜੁਅਲਾਈਜ਼ੇਸ਼ਨ, ਜਾਂ ਪਲਾਟ, ਗ੍ਰਾਫ, ਅਤੇ ਚਾਰਟ ਬਣਾਉਂਦੇ ਹਨ, ਜੋ ਡਾਟਾ ਦੇ ਵੱਖ-ਵੱਖ ਪਹਲੂਆਂ ਨੂੰ ਦਿਖਾਉਂਦੇ ਹਨ। ਇਸ ਤਰੀਕੇ ਨਾਲ, ਉਹ ਦ੍ਰਿਸ਼ਟੀਗਤ ਤੌਰ 'ਤੇ ਸੰਬੰਧਾਂ ਅਤੇ ਖਾਲੀਆਂ ਜਗ੍ਹਾ ਦਿਖਾ ਸਕਦੇ ਹਨ ਜੋ ਹੋਰ ਤਰੀਕੇ ਨਾਲ ਖੋਜਣ ਲਈ ਮੁਸ਼ਕਲ ਹੁੰਦੀਆਂ ਹਨ।

🎥 ਉੱਪਰ ਦਿੱਤੀ ਤਸਵੀਰ 'ਤੇ ਕਲਿਕ ਕਰੋ ਇਸ ਪਾਠ ਲਈ ਡਾਟਾ ਨੂੰ ਵਿਜੁਅਲਾਈਜ਼ ਕਰਨ ਦੀ ਪ੍ਰਕਿਰਿਆ ਦੇਖਣ ਲਈ ਇੱਕ ਛੋਟਾ ਵੀਡੀਓ।
ਵਿਜੁਅਲਾਈਜ਼ੇਸ਼ਨ ਇਹ ਵੀ ਨਿਰਧਾਰਤ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦੇ ਹਨ ਕਿ ਡਾਟਾ ਲਈ ਸਭ ਤੋਂ ਉਚਿਤ ਮਸ਼ੀਨ ਲਰਨਿੰਗ ਤਕਨੀਕ ਕਿਹੜੀ ਹੈ। ਇੱਕ ਸਕੈਟਰਪਲ
ਅਸਵੀਕਰਤੀ:
ਇਹ ਦਸਤਾਵੇਜ਼ AI ਅਨੁਵਾਦ ਸੇਵਾ Co-op Translator ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਅਨੁਵਾਦ ਕੀਤਾ ਗਿਆ ਹੈ। ਜਦੋਂ ਕਿ ਅਸੀਂ ਸਹੀ ਹੋਣ ਦਾ ਯਤਨ ਕਰਦੇ ਹਾਂ, ਕਿਰਪਾ ਕਰਕੇ ਧਿਆਨ ਦਿਓ ਕਿ ਸਵੈਚਾਲਿਤ ਅਨੁਵਾਦਾਂ ਵਿੱਚ ਗਲਤੀਆਂ ਜਾਂ ਅਸੁੱਤੀਆਂ ਹੋ ਸਕਦੀਆਂ ਹਨ। ਇਸ ਦੀ ਮੂਲ ਭਾਸ਼ਾ ਵਿੱਚ ਮੌਜੂਦ ਮੂਲ ਦਸਤਾਵੇਜ਼ ਨੂੰ ਪ੍ਰਮਾਣਿਕ ਸਰੋਤ ਮੰਨਿਆ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ। ਮਹੱਤਵਪੂਰਨ ਜਾਣਕਾਰੀ ਲਈ, ਪੇਸ਼ੇਵਰ ਮਨੁੱਖੀ ਅਨੁਵਾਦ ਦੀ ਸਿਫਾਰਸ਼ ਕੀਤੀ ਜਾਂਦੀ ਹੈ। ਇਸ ਅਨੁਵਾਦ ਦੇ ਪ੍ਰਯੋਗ ਤੋਂ ਪੈਦਾ ਹੋਣ ਵਾਲੇ ਕਿਸੇ ਵੀ ਗਲਤਫਹਿਮੀ ਜਾਂ ਗਲਤ ਵਿਆਖਿਆ ਲਈ ਅਸੀਂ ਜ਼ਿੰਮੇਵਾਰ ਨਹੀਂ ਹਾਂ।