|
|
1 year ago | |
|---|---|---|
| .. | ||
| images | 3 years ago | |
| solution | 3 years ago | |
| translations | 3 years ago | |
| working | 3 years ago | |
| README.md | 1 year ago | |
| assignment.md | 3 years ago | |
README.md
Time Series Forecasting with Support Vector Regressor
In the previous lesson, you learned how to use ARIMA model to make time series predictions. Now you'll be looking at Support Vector Regressor model which is a regressor model used to predict continuous data.
Pre-lecture quiz
Introduction
In this lesson, you will discover a specific way to build models with SVM: Support Vector Machine for regression, or SVR: Support Vector Regressor.
SVR in the context of time series 1
Before understanding the importance of SVR in time series prediction, here are some of the important concepts that you need to know:
- Regression: Supervised learning technique to predict continuous values from a given set of inputs. The idea is to fit a curve (or line) in the feature space that has the maximum number of data points. Click here for more information.
- Support Vector Machine (SVM): A type of supervised machine learning model used for classification, regression and outliers detection. The model is a hyperplane in the feature space, which in case of classification acts as a boundary, and in case of regression acts as the best-fit line. In SVM, a Kernel function is generally used to transform the dataset to a space of higher number of dimensions, so that they can be easily separable. Click here for more information on SVMs.
- Support Vector Regressor (SVR): A type of SVM, to find the best fit line (which in the case of SVM is a hyperplane) that has the maximum number of data points.
Why SVR? 1
In the last lesson you learned about ARIMA, which is a very successful statistical linear method to forecast time series data. However, in many cases, time series data have non-linearity, which cannot be mapped by linear models. In such cases, the ability of SVM to consider non-linearity in the data for regression tasks makes SVR successful in time series forecasting.
Exercise - build an SVR model
The first few steps for data preparation are the same as that of the previous lesson on ARIMA.
Open the /working folder in this lesson and find the notebook.ipynb file.2
-
Run the notebook and import the necessary libraries: 2
import sys sys.path.append('../../')import os import warnings import matplotlib.pyplot as plt import numpy as np import pandas as pd import datetime as dt import math from sklearn.svm import SVR from sklearn.preprocessing import MinMaxScaler from common.utils import load_data, mape -
Load the data from the
/data/energy.csvfile into a Pandas dataframe and take a look: 2energy = load_data('../../data')[['load']] -
Plot all the available energy data from January 2012 to December 2014: 2
energy.plot(y='load', subplots=True, figsize=(15, 8), fontsize=12) plt.xlabel('timestamp', fontsize=12) plt.ylabel('load', fontsize=12) plt.show()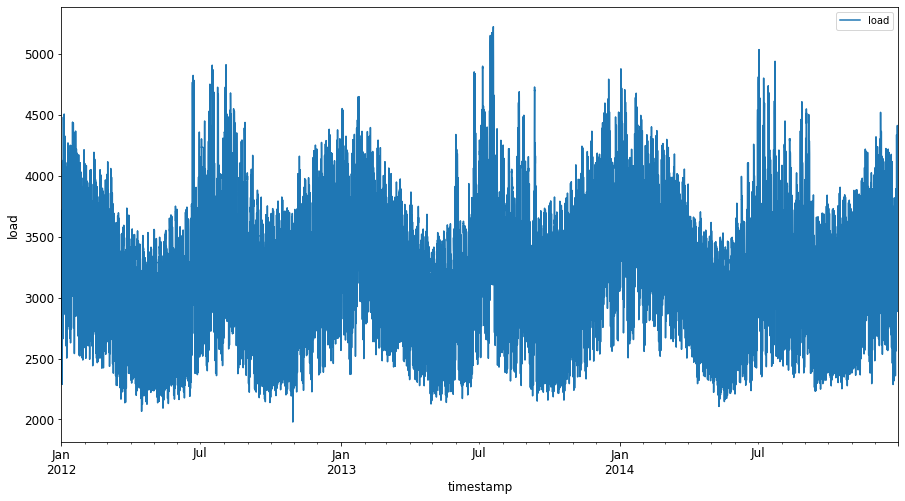
Now, let's build our SVR model.
Create training and testing datasets
Now your data is loaded, so you can separate it into train and test sets. Then you'll reshape the data to create a time-step based dataset which will be needed for the SVR. You'll train your model on the train set. After the model has finished training, you'll evaluate its accuracy on the training set, testing set and then the full dataset to see the overall performance. You need to ensure that the test set covers a later period in time from the training set to ensure that the model does not gain information from future time periods 2 (a situation known as Overfitting).
-
Allocate a two-month period from September 1 to October 31, 2014 to the training set. The test set will include the two-month period of November 1 to December 31, 2014: 2
train_start_dt = '2014-11-01 00:00:00' test_start_dt = '2014-12-30 00:00:00' -
Visualize the differences: 2
energy[(energy.index < test_start_dt) & (energy.index >= train_start_dt)][['load']].rename(columns={'load':'train'}) \ .join(energy[test_start_dt:][['load']].rename(columns={'load':'test'}), how='outer') \ .plot(y=['train', 'test'], figsize=(15, 8), fontsize=12) plt.xlabel('timestamp', fontsize=12) plt.ylabel('load', fontsize=12) plt.show()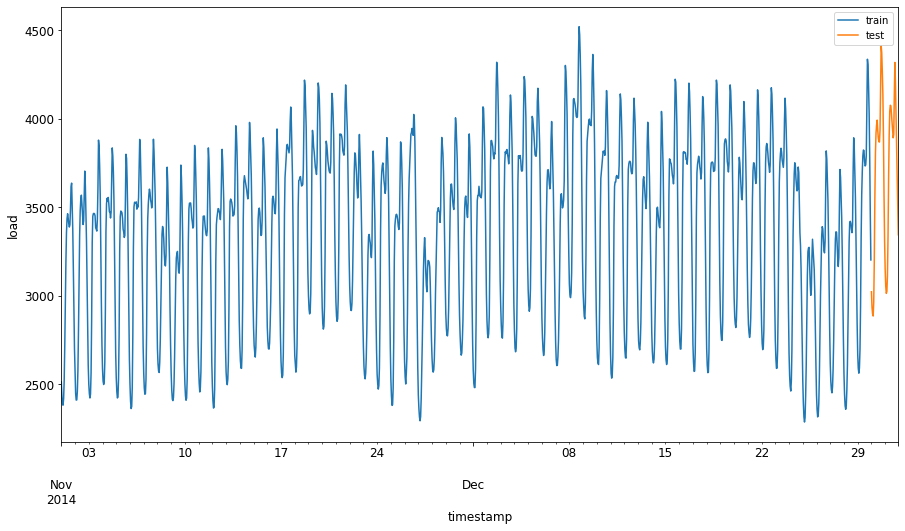
Prepare the data for training
Now, you need to prepare the data for training by performing filtering and scaling of your data. Filter your dataset to only include the time periods and columns you need, and scaling to ensure the data is projected in the interval 0,1.
-
Filter the original dataset to include only the aforementioned time periods per set and only including the needed column 'load' plus the date: 2
train = energy.copy()[(energy.index >= train_start_dt) & (energy.index < test_start_dt)][['load']] test = energy.copy()[energy.index >= test_start_dt][['load']] print('Training data shape: ', train.shape) print('Test data shape: ', test.shape)Training data shape: (1416, 1) Test data shape: (48, 1) -
Scale the training data to be in the range (0, 1): 2
scaler = MinMaxScaler() train['load'] = scaler.fit_transform(train) -
Now, you scale the testing data: 2
test['load'] = scaler.transform(test)
Create data with time-steps 1
For the SVR, you transform the input data to be of the form [batch, timesteps]. So, you reshape the existing train_data and test_data such that there is a new dimension which refers to the timesteps.
# Converting to numpy arrays
train_data = train.values
test_data = test.values
For this example, we take timesteps = 5. So, the inputs to the model are the data for the first 4 timesteps, and the output will be the data for the 5th timestep.
timesteps=5
Converting training data to 2D tensor using nested list comprehension:
train_data_timesteps=np.array([[j for j in train_data[i:i+timesteps]] for i in range(0,len(train_data)-timesteps+1)])[:,:,0]
train_data_timesteps.shape
(1412, 5)
Converting testing data to 2D tensor:
test_data_timesteps=np.array([[j for j in test_data[i:i+timesteps]] for i in range(0,len(test_data)-timesteps+1)])[:,:,0]
test_data_timesteps.shape
(44, 5)
Selecting inputs and outputs from training and testing data:
x_train, y_train = train_data_timesteps[:,:timesteps-1],train_data_timesteps[:,[timesteps-1]]
x_test, y_test = test_data_timesteps[:,:timesteps-1],test_data_timesteps[:,[timesteps-1]]
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
(1412, 4) (1412, 1)
(44, 4) (44, 1)
Implement SVR 1
Now, it's time to implement SVR. To read more about this implementation, you can refer to this documentation. For our implementation, we follow these steps:
- Define the model by calling
SVR()and passing in the model hyperparameters: kernel, gamma, c and epsilon - Prepare the model for the training data by calling the
fit()function - Make predictions calling the
predict()function
Now we create an SVR model. Here we use the RBF kernel, and set the hyperparameters gamma, C and epsilon as 0.5, 10 and 0.05 respectively.
model = SVR(kernel='rbf',gamma=0.5, C=10, epsilon = 0.05)
Fit the model on training data 1
model.fit(x_train, y_train[:,0])
SVR(C=10, cache_size=200, coef0=0.0, degree=3, epsilon=0.05, gamma=0.5,
kernel='rbf', max_iter=-1, shrinking=True, tol=0.001, verbose=False)
Make model predictions 1
y_train_pred = model.predict(x_train).reshape(-1,1)
y_test_pred = model.predict(x_test).reshape(-1,1)
print(y_train_pred.shape, y_test_pred.shape)
(1412, 1) (44, 1)
You've built your SVR! Now we need to evaluate it.
Evaluate your model 1
For evaluation, first we will scale back the data to our original scale. Then, to check the performance, we will plot the original and predicted time series plot, and also print the MAPE result.
Scale the predicted and original output:
# Scaling the predictions
y_train_pred = scaler.inverse_transform(y_train_pred)
y_test_pred = scaler.inverse_transform(y_test_pred)
print(len(y_train_pred), len(y_test_pred))
# Scaling the original values
y_train = scaler.inverse_transform(y_train)
y_test = scaler.inverse_transform(y_test)
print(len(y_train), len(y_test))
Check model performance on training and testing data 1
We extract the timestamps from the dataset to show in the x-axis of our plot. Note that we are using the first timesteps-1 values as out input for the first output, so the timestamps for the output will start after that.
train_timestamps = energy[(energy.index < test_start_dt) & (energy.index >= train_start_dt)].index[timesteps-1:]
test_timestamps = energy[test_start_dt:].index[timesteps-1:]
print(len(train_timestamps), len(test_timestamps))
1412 44
Plot the predictions for training data:
plt.figure(figsize=(25,6))
plt.plot(train_timestamps, y_train, color = 'red', linewidth=2.0, alpha = 0.6)
plt.plot(train_timestamps, y_train_pred, color = 'blue', linewidth=0.8)
plt.legend(['Actual','Predicted'])
plt.xlabel('Timestamp')
plt.title("Training data prediction")
plt.show()
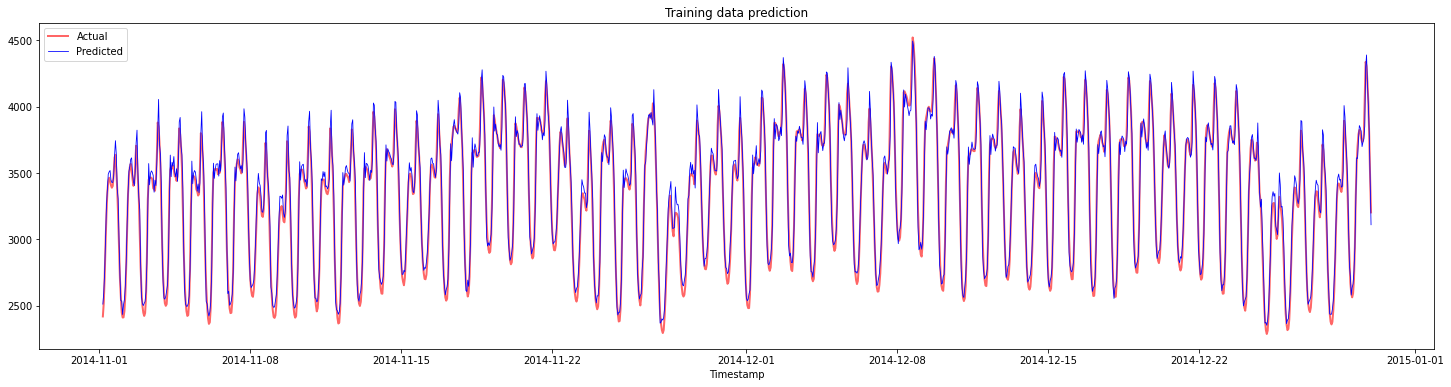
Print MAPE for training data
print('MAPE for training data: ', mape(y_train_pred, y_train)*100, '%')
MAPE for training data: 1.7195710200875551 %
Plot the predictions for testing data
plt.figure(figsize=(10,3))
plt.plot(test_timestamps, y_test, color = 'red', linewidth=2.0, alpha = 0.6)
plt.plot(test_timestamps, y_test_pred, color = 'blue', linewidth=0.8)
plt.legend(['Actual','Predicted'])
plt.xlabel('Timestamp')
plt.show()
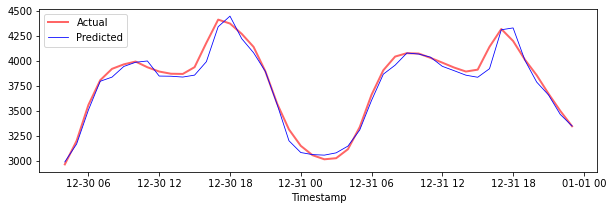
Print MAPE for testing data
print('MAPE for testing data: ', mape(y_test_pred, y_test)*100, '%')
MAPE for testing data: 1.2623790187854018 %
🏆 You have a very good result on the testing dataset!
Check model performance on full dataset 1
# Extracting load values as numpy array
data = energy.copy().values
# Scaling
data = scaler.transform(data)
# Transforming to 2D tensor as per model input requirement
data_timesteps=np.array([[j for j in data[i:i+timesteps]] for i in range(0,len(data)-timesteps+1)])[:,:,0]
print("Tensor shape: ", data_timesteps.shape)
# Selecting inputs and outputs from data
X, Y = data_timesteps[:,:timesteps-1],data_timesteps[:,[timesteps-1]]
print("X shape: ", X.shape,"\nY shape: ", Y.shape)
Tensor shape: (26300, 5)
X shape: (26300, 4)
Y shape: (26300, 1)
# Make model predictions
Y_pred = model.predict(X).reshape(-1,1)
# Inverse scale and reshape
Y_pred = scaler.inverse_transform(Y_pred)
Y = scaler.inverse_transform(Y)
plt.figure(figsize=(30,8))
plt.plot(Y, color = 'red', linewidth=2.0, alpha = 0.6)
plt.plot(Y_pred, color = 'blue', linewidth=0.8)
plt.legend(['Actual','Predicted'])
plt.xlabel('Timestamp')
plt.show()
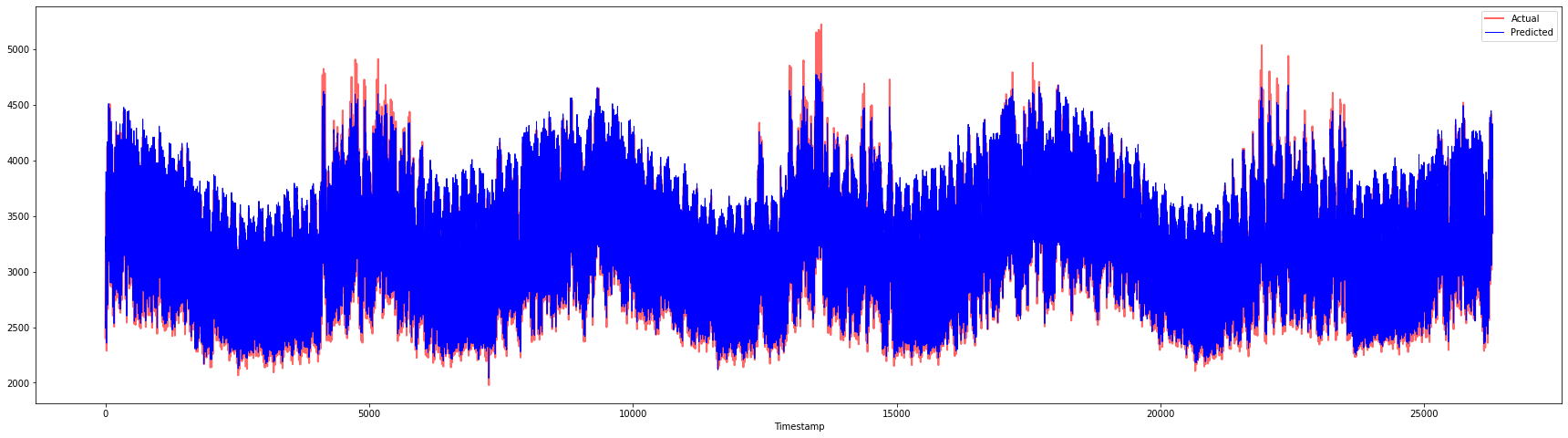
print('MAPE: ', mape(Y_pred, Y)*100, '%')
MAPE: 2.0572089029888656 %
🏆 Very nice plots, showing a model with good accuracy. Well done!
🚀Challenge
- Try to tweak the hyperparameters (gamma, C, epsilon) while creating the model and evaluate on the data to see which set of hyperparameters give the best results on the testing data. To know more about these hyperparameters, you can refer to the document here.
- Try to use different kernel functions for the model and analyze their performances on the dataset. A helpful document can be found here.
- Try using different values for
timestepsfor the model to look back to make prediction.
Post-lecture quiz
Review & Self Study
This lesson was to introduce the application of SVR for Time Series Forecasting. To read more about SVR, you can refer to this blog. This documentation on scikit-learn provides a more comprehensive explanation about SVMs in general, SVRs and also other implementation details such as the different kernel functions that can be used, and their parameters.
Assignment
Credits
-
The text, code and output in this section was contributed by @AnirbanMukherjeeXD ↩︎
-
The text, code and output in this section was taken from ARIMA ↩︎