|
|
5 years ago | |
|---|---|---|
| .. | ||
| images | 5 years ago | |
| translations | 5 years ago | |
| README.md | 5 years ago | |
| assignment.md | 5 years ago | |
README.md
Fairness in Machine Learning
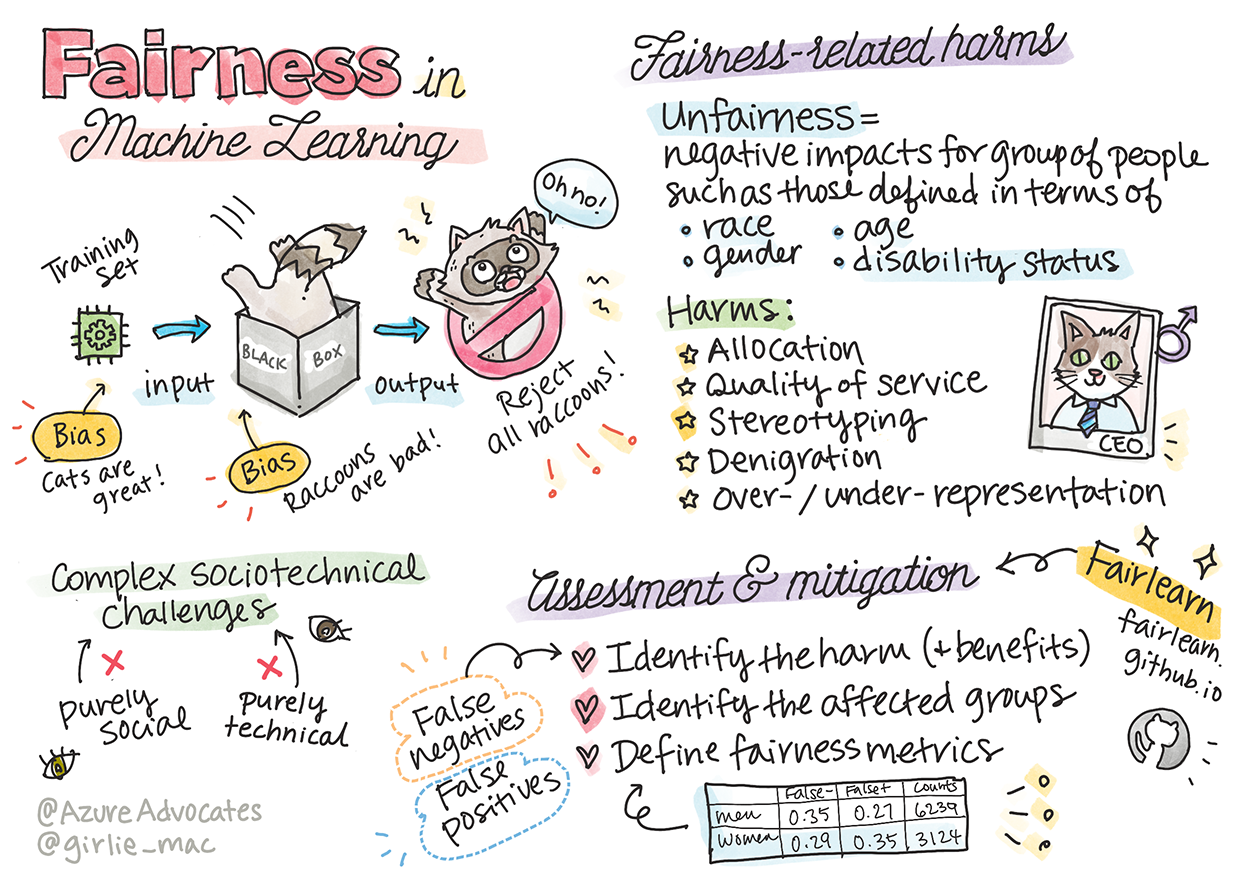
Sketchnote by Tomomi Imura
Pre-lecture quiz
Introduction
In this curriculum, you will start to discover how machine learning can and is impacting our everyday lives. Even now, systems and models are involved in daily decision-making tasks, such as health care diagnoses or detecting fraud. So it is important that these models work well in order to provide fair outcomes for everyone.
Imagine what can happen when the data you are using to build these models lacks certain demographics, such as race, gender, political view, religion, or disproportionally represents such demographics. What about when the model's output is interpreted to favor some demographic? What is the consequence for the application?
In this lesson, you will:
- Raise your awareness of the importance of fairness in machine learning.
- Learn about fairness-related harms.
- Learn about unfairness assessment and mitigation.
Prerequisite
As a prerequisite, please take the "Responsible AI Principles" Learn Path and watch the video below on the topic:
Learn more about Responsible AI by following this Learning Path

🎥 Click the image above for a video: Microsoft's Approach to Responsible AI
Unfairness in data and algorithms
"If you torture the data long enough, it will confess to anything" - Ronald Coase
This statement sounds extreme, but it is true that data can be manipulated to support any conclusion. Such manipulation can sometimes happen unintentionally. As humans, we all have bias, and it's often difficult to consciously know when you are introducing bias in data.
Guaranteeing fairness in AI and machine learning remains a complex sociotechnical challenge. Meaning that it cannot be addressed from either purely social or technical perspectives.
Fairness-related harms
What do you mean by unfairness? "Unfairness" encompasses negative impacts, or "harms", for a group of people, such as those defined in terms of race, gender, age, or disability status.
The main fairness-related harms can be classified as:
- Allocation, if a gender or ethnicity for example is favored over another.
- Quality of service. If you train the data for one specific scenario but reality is much more complex, it leads to a poor performing service.
- Stereotyping. Associating a given group with pre-assigned attributes.
- Denigration. To unfairly criticize and label something or someone.
- Over- or under- representation. The idea is that a certain group is not seen in a certain profession, and any service or function that keeps promoting that is contributing to harm.
Let’s take a look at the examples.
Allocation
Consider a hypothetical system for screening loan applications. The system tends to pick white men as better candidates over other groups. As a result, loans are withheld from certain applicants.
Another example would be an experimental hiring tool developed by a large corporation to screen candidates. The tool systemically discriminated against one gender by using the models were trained to prefer words associated with another. It resulted in penalizing candidates whose resumes contain words such as "women’s rugby team".
✅ Do a little research to find a real-world example of something like this
Quality of Service
Researchers found that several commercial gender classifiers had higher error rates around images of women with darker skin tones as opposed to images of men with lighter skin tones. Reference
Another infamous example is a hand soap dispenser that could not seem to be able to sense people with dark skin. Reference
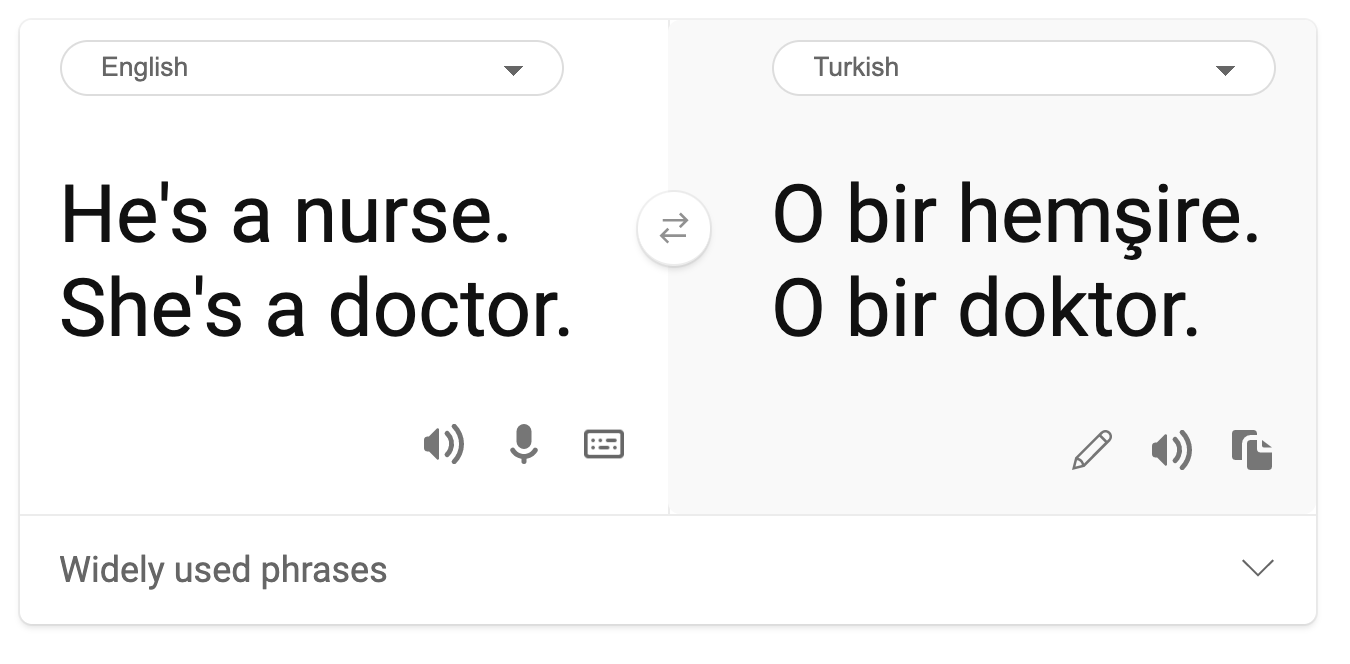
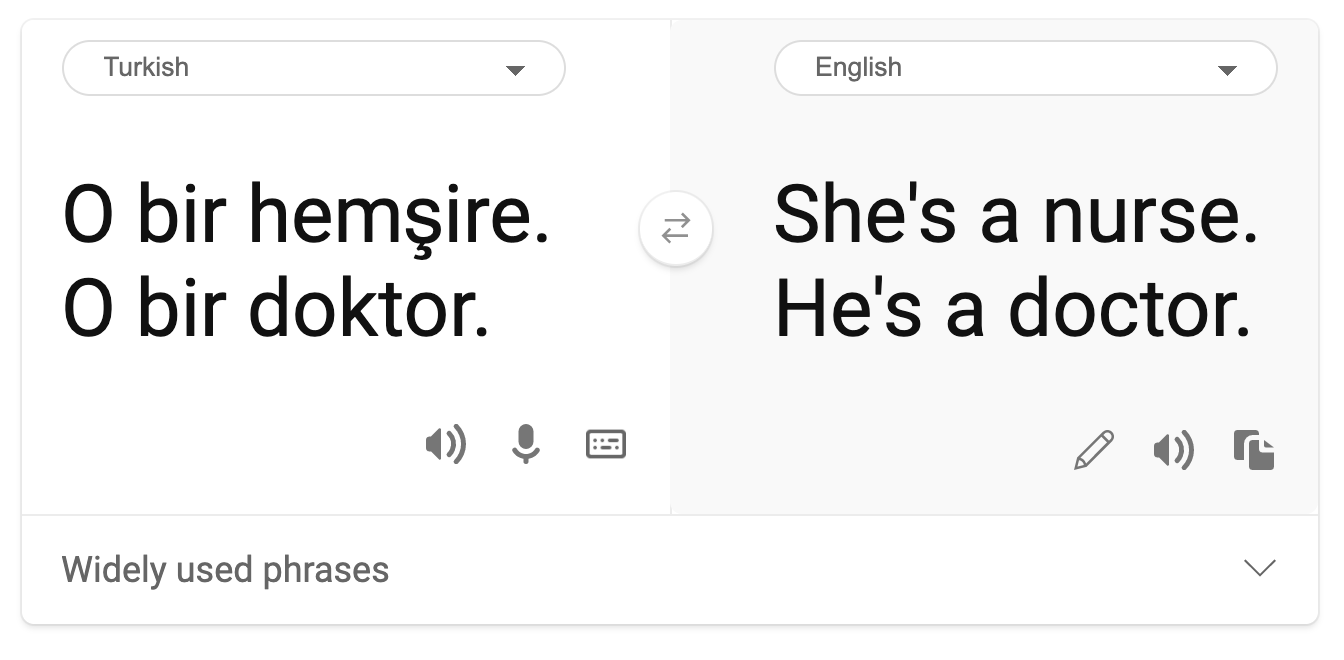
Stereotyping
Stereotypical gender view was found in machine translation. When translating “he is a nurse and she is a doctor” into Turkish, problems were encountered. Turkish is a genderless language which has one pronoun, “o” to convey a singular third person, but translating the sentence back from Turkish to English yields the stereotypical and incorrect as “she is a nurse and he is a doctor”.
Denigration
An image labeling technology infamously mislabeled images of dark-skinned people as gorillas. Mislabeling is harmful not just because the system made a mistake because it specifically applied a label that has a long history of being purposefully used to denigrate Black people.

🎥 Click the image above for a video: AI, Ain't I a Woman - a performance showing the harm caused by racist denigration by AI
Over- or under- representation
Skewed image search results can be a good example of this harm. When searching images of professions with an equal or higher percentage of men than women, such as engineering, or CEO, watch for results that are more heavily skewed towards a given gender.

This search on Bing for 'CEO' produces pretty inclusive results
These five main types of harms are not mutually exclusive, and a single system can exhibit more than one type of harm. In addition, each case varies in its severity. For instance, unfairly labeling someone as a criminal is a much more severe harm than mislabeling an image. It's important, however, to remember that even relatively non-severe harms can make people feel alienated or singled out and the cumulative impact can be extremely oppressive.
✅ Discussion: Revisit some of the examples and see if they show different harms.
| Allocation | Quality of service | Stereotyping | Denigration | Over- or under- representation | |
|---|---|---|---|---|---|
| Automated hiring system | x | x | x | x | |
| Machine translation | |||||
| Photo labeling |
Detecting unfairness
There are many reasons why a given system behaves unfairly. Social biases, for example, might be reflected in the datasets used to train them. For example, hiring unfairness might have been exacerbated by over reliance on historical data. By using the patterns in resumes submitted to the company over a 10-year period, the model determined that men were more qualified because the majority of resumes came from men, a reflection of past male dominance across the tech industry.
Inadequate data about a certain group of people can be the reason for unfairness. For example, image classifiers a have higher rate of error for images of dark-skinned people because darker skin tones were underrepresented in the data.
Wrong assumptions made during development cause unfairness too. For example, a facial analysis system intended to predict who is going to commit a crime based on images of people’s faces can lead to damaging assumptions. This could lead to substantial harms for people who are misclassified.
Understand your models and build in fairness
Although many aspects of fairness are not captured in quantitative fairness metrics, and it is not possible to fully remove bias from a system to guarantee fairness, you are still responsible to detect and to mitigate fairness issues as much as possible.
When you are working with machine learning models, it is important to understand your models by means of assuring their interpretability and by assessing and mitigating unfairness.
Let’s use the loan selection example to isolate the case to figure out each factor's level of impact on the prediction.
Assessment methods
-
Identify harms (and benefits). The first step is to identify harms and benefits. Think about how actions and decisions can affect both potential customers and a business itself.
-
Identify the affected groups. Once you understand what kind of harms or benefits that can occur, identify the groups that may be affected. Are these groups defined by gender, ethnicity, or social group?
-
Define fairness metrics. Finally, define a metric so you have something to measure against in your work to improve the situation.
Identify harms (and benefits)
What are the harms and benefits associated with lending? Think about false negatives and false positive scenarios:
False negatives (reject, but Y=1) - in this case, an applicant who will be capable of repaying a loan is rejected. This is an adverse event because the resources of the loans are withheld from qualified applicants.
False positives (accept, but Y=0) - in this case, the applicant does get a loan but eventually defaults. As a result, the applicant's case will be sent to a debt collection agency which can affect their future loan applications.
Identify affected groups
The next step is to determine which groups are likely to be affected. For example, in case of a credit card application, a model might determine that women should receive much lower credit limits compared with their spouses who share household assets. An entire demographic, defined by gender, is thereby affected.
Define fairness metrics
You have identified harms and an affected group, in this case, delineated by gender. Now, use the quantified factors to disaggregate their metrics. For example, using the data below, you can see that women have the largest false positive rate and men have the smallest, and that the opposite is true for false negatives.
✅ In a future lesson on Clustering, you will see how to build this 'confusion matrix' in code
| False positive rate | False negative rate | count | |
|---|---|---|---|
| Women | 0.37 | 0.27 | 54032 |
| Men | 0.31 | 0.35 | 28620 |
| Non-binary | 0.33 | 0.31 | 1266 |
This table tells us several things. First, we note that there are comparatively few non-binary people in the data. The data is skewed, so you need to be careful how you interpret these numbers.
In this case, we have 3 groups and 2 metrics. When we are thinking about how our system affects the group of customers with their loan applicants, this may be sufficient, but when you want to define larger number of groups, you may want to distill this to smaller sets of summaries. To do that, you can add more metrics, such as the largest difference or smallest ratio of each false negative and false positive.
✅ Stop and Think: What other groups are likely to be affected for loan application?
Mitigating unfairness
To mitigate unfairness, explore the model to generate various mitigated models and compare the tradeoffs it makes between accuracy and fairness to select the most fair model.
This introductory lesson does not dive deeply into the details of algorithmic unfairness mitigation, such as post-processing and reductions approach, but here is a tool that you may want to try.
Fairlearn
Fairlearn is an open-source Python package that allows you to assess your systems' fairness and mitigate unfairness.
The tool helps you to assesses how a model's predictions affect different groups, enabling you to compare multiple models by using fairness and performance metrics, and supplying a set of algorithms to mitigate unfairness in binary classification and regression.
-
Learn how to use the different components by checking out the Fairlearn's GitHub
-
Explore the user guide, examples
-
Try some sample notebooks.
-
Learn how to enable fairness assessments of machine learning models in Azure Machine Learning.
-
Check out these sample notebooks for more fairness assessment scenarios in Azure Machine Learning.
🚀 Challenge
To prevent biases from being introduced in the first place, we should:
- have a diversity of backgrounds and perspectives among the people working on systems
- invest in datasets that reflect the diversity of our society
- develop better methods for detecting and correcting bias when it occurs
Think about real-life scenarios where unfairness is evident in model-building and usage. What else should we consider?
Post-lecture quiz
Review & Self Study
In this lesson, you have learned some basics of the concepts of fairness and unfairness in machine learning.
Watch this workshop to dive deeper into the topics:
- YouTube: Fairness-related harms in AI systems: Examples, assessment, and mitigation by Hanna Wallach and Miro Dudik Fairness-related harms in AI systems: Examples, assessment, and mitigation - YouTube
Also, read:
-
Microsoft’s RAI resource center: Responsible AI Resources – Microsoft AI
-
Microsoft’s FATE research group: FATE: Fairness, Accountability, Transparency, and Ethics in AI - Microsoft Research
Explore the Fairlearn toolkit
Read about Azure Machine Learning's tools to ensure fairness