|
|
2 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 2 weeks ago | |
| assignment.md | 3 weeks ago | |
README.md
مشین لرننگ کے حل کو ذمہ دارانہ AI کے ساتھ بنانا
خاکہ: Tomomi Imura
لیکچر سے پہلے کا کوئز
تعارف
اس نصاب میں، آپ یہ دریافت کرنا شروع کریں گے کہ مشین لرننگ کس طرح اور کس حد تک ہماری روزمرہ کی زندگیوں پر اثر ڈال رہی ہے۔ آج بھی، سسٹمز اور ماڈلز روزمرہ کے فیصلوں میں شامل ہیں، جیسے صحت کی تشخیص، قرض کی منظوری، یا دھوکہ دہی کا پتہ لگانا۔ اس لیے یہ ضروری ہے کہ یہ ماڈلز ایسے نتائج فراہم کریں جو قابل اعتماد ہوں۔ جیسے کسی بھی سافٹ ویئر ایپلیکیشن میں، AI سسٹمز بھی توقعات پر پورا نہ اتر سکتے ہیں یا ناپسندیدہ نتائج دے سکتے ہیں۔ اسی لیے یہ سمجھنا اور وضاحت کرنا ضروری ہے کہ AI ماڈل کس طرح کام کرتا ہے۔
سوچیں کہ کیا ہو سکتا ہے جب آپ کے ماڈلز بنانے کے لیے استعمال ہونے والے ڈیٹا میں کچھ مخصوص گروہوں کی نمائندگی نہ ہو، جیسے نسل، جنس، سیاسی نظریہ، مذہب، یا ان کی غیر متناسب نمائندگی ہو۔ اگر ماڈل کے نتائج کسی خاص گروہ کو ترجیح دیتے ہیں تو اس کا اطلاق پر کیا اثر ہوگا؟ مزید یہ کہ، اگر ماڈل کے نتائج نقصان دہ ہوں تو اس کے اثرات کیا ہوں گے؟ AI سسٹمز کے رویے کے لیے کون ذمہ دار ہوگا؟ یہ وہ سوالات ہیں جنہیں ہم اس نصاب میں تلاش کریں گے۔
اس سبق میں، آپ:
- مشین لرننگ میں انصاف پسندی اور اس سے جڑے نقصانات کی اہمیت کو سمجھیں گے۔
- غیر معمولی حالات کا جائزہ لینے کی مشق سے واقف ہوں گے تاکہ سسٹمز کی قابل اعتمادیت اور حفاظت کو یقینی بنایا جا سکے۔
- سب کے لیے شمولیتی نظام ڈیزائن کرنے کی ضرورت کو سمجھیں گے۔
- ڈیٹا اور لوگوں کی پرائیویسی اور سیکیورٹی کے تحفظ کی اہمیت کو دریافت کریں گے۔
- AI ماڈلز کے رویے کو سمجھنے کے لیے شفافیت کی اہمیت کو دیکھیں گے۔
- اس بات کا شعور حاصل کریں گے کہ AI سسٹمز میں اعتماد پیدا کرنے کے لیے جوابدہی کتنی ضروری ہے۔
پیشگی شرط
پیشگی شرط کے طور پر، براہ کرم "ذمہ دارانہ AI اصول" کا لرن پاتھ مکمل کریں اور نیچے دی گئی ویڈیو دیکھیں:
ذمہ دارانہ AI کے بارے میں مزید جانیں

🎥 اوپر دی گئی تصویر پر کلک کریں: Microsoft کا ذمہ دارانہ AI کے لیے نقطہ نظر
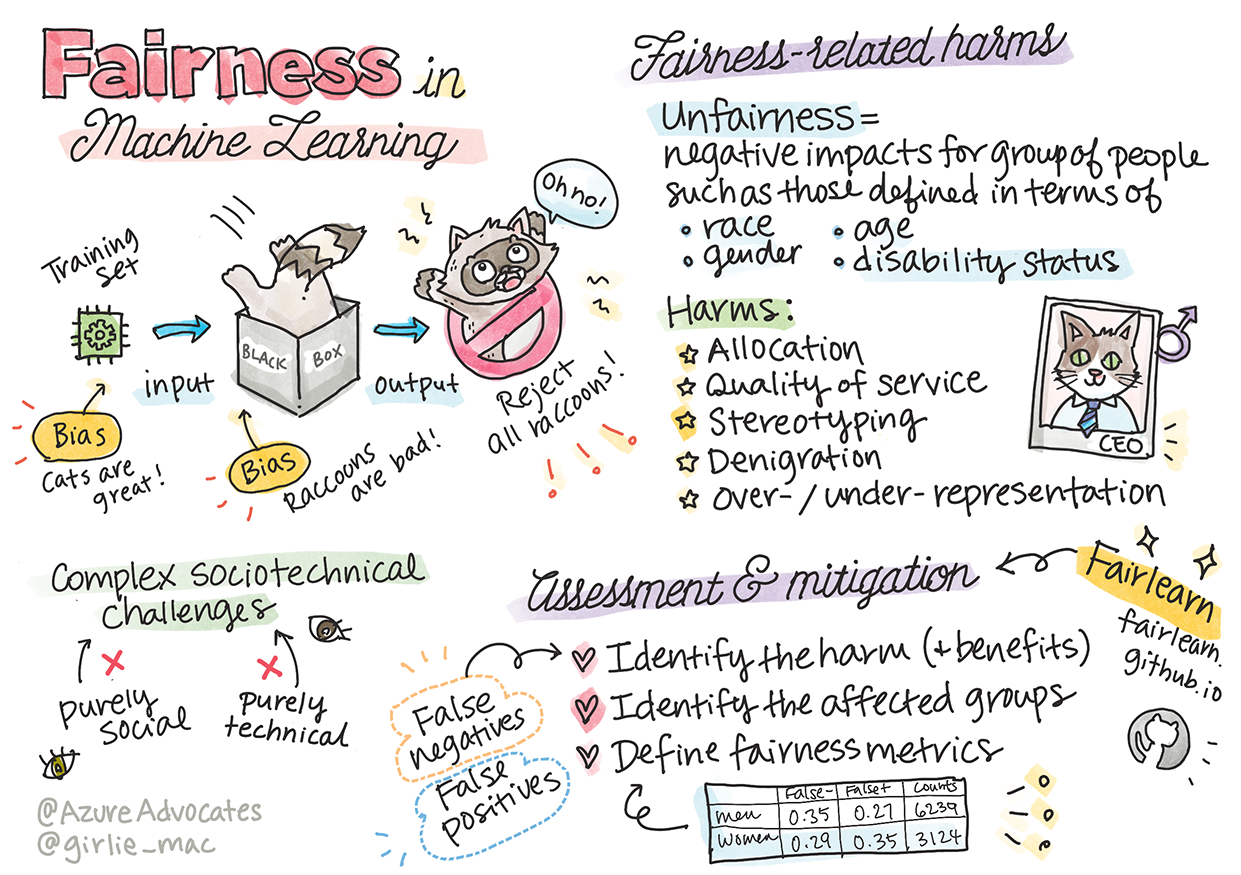
انصاف پسندی
AI سسٹمز کو سب کے ساتھ منصفانہ سلوک کرنا چاہیے اور مختلف گروہوں پر مختلف اثرات ڈالنے سے گریز کرنا چاہیے۔ مثال کے طور پر، جب AI سسٹمز طبی علاج، قرض کی درخواستوں، یا ملازمت کے بارے میں رہنمائی فراہم کرتے ہیں، تو انہیں ایک جیسے حالات والے تمام افراد کو یکساں سفارشات دینی چاہئیں۔ ہم سب انسانوں میں وراثتی تعصبات ہوتے ہیں جو ہمارے فیصلوں اور اعمال کو متاثر کرتے ہیں۔ یہ تعصبات اس ڈیٹا میں ظاہر ہو سکتے ہیں جو ہم AI سسٹمز کو تربیت دینے کے لیے استعمال کرتے ہیں۔ یہ تعصب بعض اوقات غیر ارادی طور پر بھی ہو سکتا ہے۔
"ناانصافی" ان منفی اثرات یا "نقصانات" کو ظاہر کرتی ہے جو کسی گروہ پر پڑ سکتے ہیں، جیسے نسل، جنس، عمر، یا معذوری کی حیثیت کے لحاظ سے۔ انصاف پسندی سے متعلق نقصانات کو درج ذیل اقسام میں تقسیم کیا جا سکتا ہے:
- تقسیم: اگر کسی جنس یا نسل کو دوسرے پر ترجیح دی جائے۔
- سروس کا معیار: اگر آپ نے ڈیٹا کو کسی خاص منظرنامے کے لیے تربیت دی ہو لیکن حقیقت زیادہ پیچیدہ ہو، تو یہ ناقص کارکردگی کا باعث بن سکتا ہے۔ مثال کے طور پر، ایک صابن ڈسپنسر جو گہرے رنگ کی جلد والے لوگوں کو پہچاننے میں ناکام رہا۔ حوالہ
- تنقید: کسی چیز یا شخص پر غیر منصفانہ تنقید کرنا۔ مثال کے طور پر، ایک امیج لیبلنگ ٹیکنالوجی نے گہرے رنگ کی جلد والے لوگوں کی تصاویر کو غلط طور پر گوریلا کے طور پر لیبل کیا۔
- زیادہ یا کم نمائندگی: یہ تصور کہ کسی خاص گروہ کو کسی پیشے میں نہیں دیکھا جاتا، اور کوئی بھی سروس یا فنکشن جو اس کو فروغ دیتا ہے، نقصان کا باعث بنتا ہے۔
- اسٹیریو ٹائپنگ: کسی گروہ کو پہلے سے طے شدہ خصوصیات کے ساتھ جوڑنا۔ مثال کے طور پر، انگریزی اور ترکی کے درمیان زبان کے ترجمے کا نظام جنس سے متعلق دقیانوسی الفاظ کی وجہ سے غلطیاں کر سکتا ہے۔
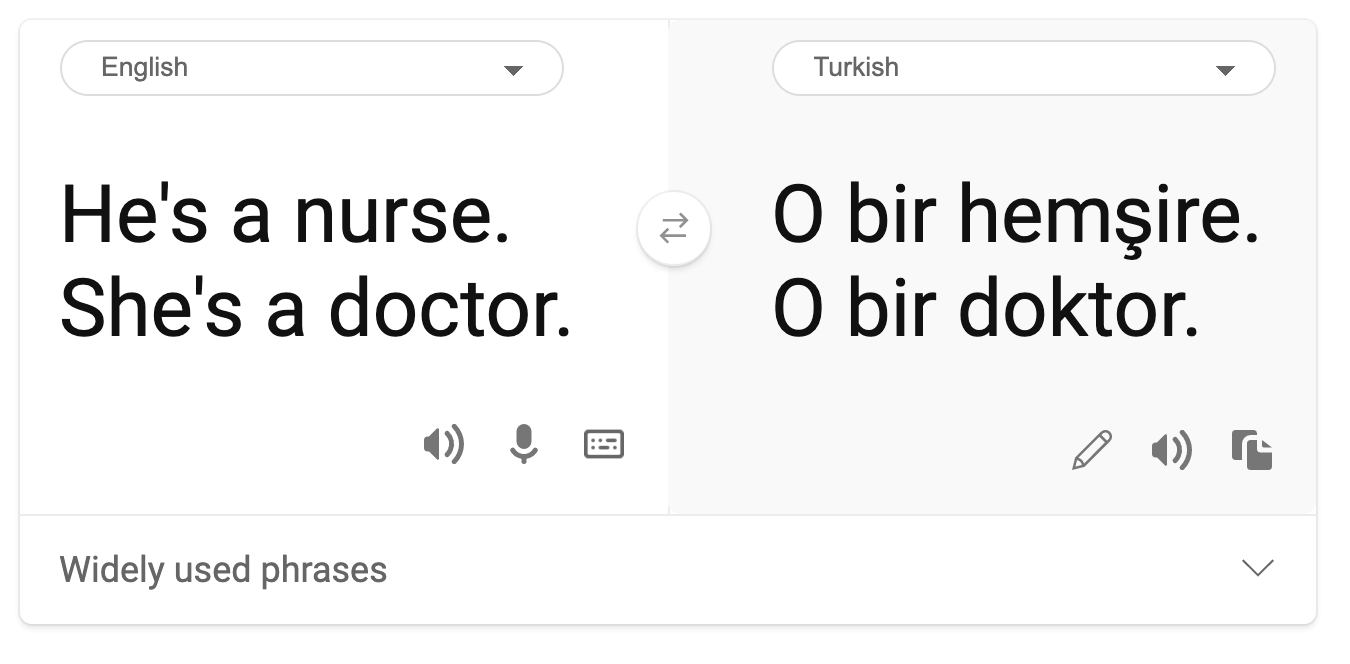
ترکی زبان میں ترجمہ

انگریزی میں واپس ترجمہ
AI سسٹمز کو ڈیزائن اور ٹیسٹ کرتے وقت، ہمیں یہ یقینی بنانا ہوگا کہ AI منصفانہ ہو اور تعصبی یا امتیازی فیصلے کرنے کے لیے پروگرام نہ کیا گیا ہو، جو انسانوں کے لیے بھی ممنوع ہیں۔ AI اور مشین لرننگ میں انصاف کو یقینی بنانا ایک پیچیدہ سماجی-تکنیکی چیلنج ہے۔
قابل اعتمادیت اور حفاظت
اعتماد پیدا کرنے کے لیے، AI سسٹمز کو قابل اعتماد، محفوظ، اور عام اور غیر متوقع حالات میں مستقل ہونا چاہیے۔ یہ جاننا ضروری ہے کہ AI سسٹمز مختلف حالات میں کیسے کام کریں گے، خاص طور پر جب وہ غیر معمولی ہوں۔ AI حل بناتے وقت، ان تمام حالات پر توجہ مرکوز کرنا ضروری ہے جن کا سامنا AI حل کو ہو سکتا ہے۔ مثال کے طور پر، ایک خودکار گاڑی کو لوگوں کی حفاظت کو اولین ترجیح دینی چاہیے۔ اس کے نتیجے میں، گاڑی کو چلانے والے AI کو ان تمام ممکنہ منظرناموں پر غور کرنا ہوگا جن کا سامنا گاڑی کو ہو سکتا ہے، جیسے رات، طوفان، برفباری، سڑک پر دوڑتے بچے، پالتو جانور، سڑک کی تعمیرات وغیرہ۔
شمولیت
AI سسٹمز کو اس طرح ڈیزائن کیا جانا چاہیے کہ وہ سب کو شامل کریں اور سب کو بااختیار بنائیں۔ AI سسٹمز کو ڈیزائن اور نافذ کرتے وقت، ڈیٹا سائنسدان اور AI ڈویلپرز ان ممکنہ رکاوٹوں کی نشاندہی کرتے ہیں اور ان کا حل نکالتے ہیں جو غیر ارادی طور پر لوگوں کو خارج کر سکتی ہیں۔ مثال کے طور پر، دنیا بھر میں 1 ارب افراد معذوری کے ساتھ رہتے ہیں۔ AI کی ترقی کے ساتھ، وہ اپنی روزمرہ کی زندگی میں معلومات اور مواقع تک زیادہ آسانی سے رسائی حاصل کر سکتے ہیں۔ ان رکاوٹوں کو دور کرنے سے جدت کے مواقع پیدا ہوتے ہیں اور بہتر تجربات کے ساتھ AI مصنوعات تیار ہوتی ہیں جو سب کے لیے فائدہ مند ہیں۔
سیکیورٹی اور پرائیویسی
AI سسٹمز کو محفوظ ہونا چاہیے اور لوگوں کی پرائیویسی کا احترام کرنا چاہیے۔ لوگ ان سسٹمز پر کم اعتماد کرتے ہیں جو ان کی پرائیویسی، معلومات، یا زندگیوں کو خطرے میں ڈال دیتے ہیں۔ مشین لرننگ ماڈلز کو تربیت دیتے وقت، ہم بہترین نتائج حاصل کرنے کے لیے ڈیٹا پر انحصار کرتے ہیں۔ ایسا کرتے وقت، ڈیٹا کے ماخذ اور اس کی سالمیت پر غور کرنا ضروری ہے۔ مثال کے طور پر، کیا ڈیٹا صارف نے فراہم کیا یا یہ عوامی طور پر دستیاب تھا؟ مزید برآں، ڈیٹا کے ساتھ کام کرتے وقت، یہ ضروری ہے کہ AI سسٹمز کو اس طرح تیار کیا جائے کہ وہ خفیہ معلومات کی حفاظت کر سکیں اور حملوں کے خلاف مزاحمت کر سکیں۔ جیسے جیسے AI زیادہ عام ہو رہا ہے، پرائیویسی کی حفاظت اور اہم ذاتی اور کاروباری معلومات کو محفوظ بنانا زیادہ اہم اور پیچیدہ ہوتا جا رہا ہے۔
- صنعت میں ہم نے پرائیویسی اور سیکیورٹی میں نمایاں پیش رفت کی ہے، خاص طور پر GDPR (جنرل ڈیٹا پروٹیکشن ریگولیشن) جیسے ضوابط کی بدولت۔
- تاہم، AI سسٹمز کے ساتھ ہمیں اس تناؤ کو تسلیم کرنا ہوگا کہ زیادہ ذاتی ڈیٹا کی ضرورت سسٹمز کو زیادہ ذاتی اور مؤثر بناتی ہے – اور پرائیویسی۔
- جیسے انٹرنیٹ کے ساتھ جڑے کمپیوٹرز کے آغاز کے وقت، ہم AI سے متعلق سیکیورٹی مسائل میں بھی زبردست اضافہ دیکھ رہے ہیں۔
- اسی وقت، ہم نے دیکھا ہے کہ AI سیکیورٹی کو بہتر بنانے کے لیے استعمال ہو رہا ہے۔ مثال کے طور پر، آج کے زیادہ تر جدید اینٹی وائرس اسکینرز AI ہیورسٹکس کے ذریعے چلتے ہیں۔
- ہمیں یہ یقینی بنانا ہوگا کہ ہمارے ڈیٹا سائنس کے عمل جدید پرائیویسی اور سیکیورٹی کے طریقوں کے ساتھ ہم آہنگ ہوں۔
شفافیت
AI سسٹمز کو سمجھنے کے قابل ہونا چاہیے۔ شفافیت کا ایک اہم حصہ AI سسٹمز اور ان کے اجزاء کے رویے کی وضاحت کرنا ہے۔ AI سسٹمز کی سمجھ کو بہتر بنانے کے لیے ضروری ہے کہ اسٹیک ہولڈرز یہ سمجھیں کہ وہ کیسے اور کیوں کام کرتے ہیں تاکہ وہ ممکنہ کارکردگی کے مسائل، سیکیورٹی اور پرائیویسی کے خدشات، تعصبات، اخراجی طریقوں، یا غیر ارادی نتائج کی نشاندہی کر سکیں۔ ہم یہ بھی یقین رکھتے ہیں کہ جو لوگ AI سسٹمز استعمال کرتے ہیں، انہیں ایماندار اور واضح ہونا چاہیے کہ وہ کب، کیوں، اور کیسے ان کا استعمال کرتے ہیں۔ نیز، ان سسٹمز کی حدود کے بارے میں بھی وضاحت ہونی چاہیے۔
- AI سسٹمز اتنے پیچیدہ ہیں کہ یہ سمجھنا مشکل ہے کہ وہ کیسے کام کرتے ہیں اور ان کے نتائج کی تشریح کیسے کی جائے۔
- اس عدم تفہیم کا اثر ان سسٹمز کے انتظام، آپریشن، اور دستاویزات پر پڑتا ہے۔
- اس سے زیادہ اہم بات یہ ہے کہ یہ عدم تفہیم ان فیصلوں پر اثر ڈالتی ہے جو ان سسٹمز کے نتائج کی بنیاد پر کیے جاتے ہیں۔
جوابدہی
جو لوگ AI سسٹمز کو ڈیزائن اور نافذ کرتے ہیں، انہیں ان کے کام کرنے کے طریقے کے لیے جوابدہ ہونا چاہیے۔ جوابدہی کی ضرورت خاص طور پر حساس ٹیکنالوجیز جیسے چہرے کی شناخت کے لیے اہم ہے۔ حالیہ دنوں میں، چہرے کی شناخت کی ٹیکنالوجی کی مانگ میں اضافہ ہوا ہے، خاص طور پر قانون نافذ کرنے والے اداروں کی طرف سے جو اس ٹیکنالوجی کو گمشدہ بچوں کو تلاش کرنے جیسے استعمالات میں ممکنہ طور پر دیکھتے ہیں۔ تاہم، یہ ٹیکنالوجیز حکومت کے ذریعے شہریوں کی بنیادی آزادیوں کو خطرے میں ڈال سکتی ہیں، جیسے مخصوص افراد کی مسلسل نگرانی کو فعال کرنا۔ اس لیے، ڈیٹا سائنسدانوں اور تنظیموں کو اس بات کے لیے ذمہ دار ہونا چاہیے کہ ان کے AI سسٹمز افراد یا معاشرے پر کیا اثر ڈال رہے ہیں۔
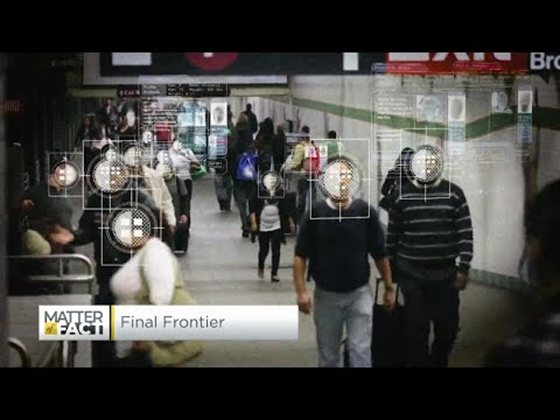
🎥 اوپر دی گئی تصویر پر کلک کریں: چہرے کی شناخت کے ذریعے نگرانی کے خطرات
آخرکار، ہماری نسل کے لیے سب سے بڑے سوالات میں سے ایک یہ ہے کہ ہم یہ کیسے یقینی بنائیں کہ کمپیوٹرز لوگوں کے لیے جوابدہ رہیں گے اور یہ کہ کمپیوٹرز کو ڈیزائن کرنے والے لوگ سب کے لیے جوابدہ رہیں۔
اثرات کی تشخیص
مشین لرننگ ماڈل کو تربیت دینے سے پہلے، یہ ضروری ہے کہ AI سسٹم کے مقصد کو سمجھنے کے لیے اثرات کی تشخیص کی جائے؛ اس کا ارادہ کیا ہے؛ یہ کہاں تعینات ہوگا؛ اور کون اس سسٹم کے ساتھ تعامل کرے گا۔ یہ جائزہ لینے والوں یا ٹیسٹرز کے لیے مددگار ثابت ہوتا ہے تاکہ وہ ان عوامل کو جان سکیں جن پر ممکنہ خطرات اور متوقع نتائج کی نشاندہی کرتے وقت غور کرنا چاہیے۔
اثرات کی تشخیص کرتے وقت درج ذیل نکات پر توجہ مرکوز کریں:
- افراد پر منفی اثرات: کسی بھی پابندی یا ضرورت، غیر معاون استعمال، یا کسی معلوم حدود سے آگاہ ہونا ضروری ہے تاکہ یہ یقینی بنایا جا سکے کہ سسٹم کو اس طرح استعمال نہ کیا جائے جو افراد کو نقصان پہنچا سکے۔
- ڈیٹا کی ضروریات: یہ سمجھنا کہ سسٹم ڈیٹا کو کیسے اور کہاں استعمال کرے گا، جائزہ لینے والوں کو ان ڈیٹا کی ضروریات کو تلاش کرنے میں مدد دیتا ہے جن کا آپ کو خیال رکھنا ہوگا (مثلاً، GDPR یا HIPPA ڈیٹا کے ضوابط)۔ مزید برآں، یہ جانچنا کہ آیا ڈیٹا کا ماخذ یا مقدار تربیت کے لیے کافی ہے۔
- اثرات کا خلاصہ: ان ممکنہ نقصانات کی فہرست جمع کریں جو سسٹم کے استعمال سے پیدا ہو سکتے ہیں۔ ML کے پورے لائف سائیکل کے دوران، یہ جائزہ لیں کہ آیا شناخت شدہ مسائل کو کم کیا گیا ہے یا حل کیا گیا ہے۔
- چھ بنیادی اصولوں کے لیے قابل اطلاق اہداف: جائزہ لیں کہ آیا ہر اصول کے اہداف پورے کیے گئے ہیں اور کیا کوئی خلا موجود ہے۔
ذمہ دارانہ AI کے ساتھ ڈیبگنگ
جیسے سافٹ ویئر ایپلیکیشن کو ڈیبگ کرنا ضروری ہے، ویسے ہی AI سسٹم کو ڈیبگ کرنا بھی ضروری ہے تاکہ سسٹم میں موجود مسائل کی نشاندہی اور ان کا حل نکالا جا سکے۔ بہت سے عوامل ماڈل کی کارکردگی کو متاثر کر سکتے ہیں۔ زیادہ تر روایتی ماڈل کارکردگی کے میٹرکس ماڈل کی کارکردگی کے مقداری مجموعے ہوتے ہیں، جو یہ تجزیہ کرنے کے لیے کافی نہیں ہیں کہ ماڈل ذمہ دارانہ AI اصولوں کی خلاف ورزی کیسے کرتا ہے۔ مزید برآں، مشین لرننگ ماڈل ایک "بلیک باکس" ہوتا ہے، جس کی وجہ سے یہ سمجھنا مشکل ہوتا ہے کہ اس کے نتائج کو کیا چیز متاثر کرتی ہے یا جب یہ غلطی کرتا ہے تو اس کی وضاحت کیسے کی جائے۔ اس کورس کے بعد کے حصے میں، ہم سیکھیں گے کہ AI سسٹمز کو ڈیبگ کرنے کے لیے ذمہ دارانہ AI ڈیش بورڈ کا استعمال کیسے کریں۔ یہ ڈیش بورڈ ڈیٹا سائنسدانوں اور AI ڈویلپرز کے لیے ایک جامع ٹول فراہم کرتا ہے تاکہ وہ درج ذیل کام انجام دے سکیں:
- غلطی کا تجزیہ: ماڈل کی غلطی کی تقسیم کی نشاندہی کرنا جو سسٹم کی انصاف پسندی یا قابل اعتمادیت کو متاثر کر سکتی ہے۔
- ماڈل کا جائزہ: یہ دریافت کرنا کہ ماڈل کی کارکردگی میں ڈیٹا کے مختلف گروہوں کے درمیان کہاں فرق ہے۔
- ڈیٹا کا تجزیہ: ڈیٹا کی تقسیم کو سمجھنا اور ڈیٹا میں کسی بھی ممکنہ تعصب کی نشاندہی کرنا جو انصاف پسندی، شمولیت، اور قابل اعتمادیت کے مسائل کا باعث بن سکتا ہے۔
- ماڈل کی وضاحت: یہ سمجھنا کہ ماڈل کی پیش گوئیوں کو کیا چیز متاثر کرتی ہے۔ یہ ماڈل کے رویے کی وضاحت کرنے میں مدد کرتا ہے، جو شفافیت اور جوابدہی کے لیے اہم ہے۔
🚀 چیلنج
نقصانات کو شروع میں ہی روکنے کے لیے، ہمیں:
- سسٹمز پر کام کرنے والے لوگوں میں مختلف پس منظر اور نقطہ نظر شامل کرنے کی ضرورت ہے۔
- ایسے ڈیٹا سیٹس میں سرمایہ کاری کرنی چاہیے جو ہمارے معاشرے کی تنوع کی عکاسی کرتے ہوں۔
- مشین لرننگ کے لائف سائیکل کے دوران بہتر طریقے تیار کرنے کی ضرورت ہے تاکہ ذمہ دارانہ AI کی نشاندہی اور اصلاح کی جا سکے۔
حقیقی زندگی کے ان منظرناموں کے بارے میں سوچیں جہاں ماڈل کی ناقابل اعتمادیت ماڈل کی تعمیر اور استعمال میں ظاہر ہوتی ہے۔ ہمیں اور کیا غور کرنا چاہیے؟
لیکچر کے بعد کا کوئز
جائزہ اور خود مطالعہ
اس سبق میں، آپ نے مشین لرننگ میں انصاف اور ناانصافی کے تصورات کے بنیادی اصولوں کے بارے میں سیکھا۔ اس ورکشاپ کو دیکھیں تاکہ موضوعات کو مزید گہرائی سے سمجھ سکیں:
- ذمہ دار AI کی تلاش: اصولوں کو عملی جامہ پہنانا، پیشکش از بسمیرا نوشی، مہرنوش سمیقی اور امت شرما

🎥 اوپر دی گئی تصویر پر کلک کریں ویڈیو کے لیے: RAI Toolbox: ذمہ دار AI بنانے کے لیے ایک اوپن سورس فریم ورک، پیشکش از بسمیرا نوشی، مہرنوش سمیقی اور امت شرما
یہ بھی پڑھیں:
-
مائیکروسافٹ کا RAI ریسورس سینٹر: ذمہ دار AI وسائل – Microsoft AI
-
مائیکروسافٹ کا FATE ریسرچ گروپ: FATE: AI میں انصاف، جوابدہی، شفافیت، اور اخلاقیات - Microsoft Research
RAI ٹول باکس:
Azure Machine Learning کے ٹولز کے بارے میں پڑھیں تاکہ انصاف کو یقینی بنایا جا سکے:
اسائنمنٹ
ڈسکلیمر:
یہ دستاویز AI ترجمہ سروس Co-op Translator کا استعمال کرتے ہوئے ترجمہ کی گئی ہے۔ ہم درستگی کے لیے کوشش کرتے ہیں، لیکن براہ کرم آگاہ رہیں کہ خودکار ترجمے میں غلطیاں یا غیر درستیاں ہو سکتی ہیں۔ اصل دستاویز کو اس کی اصل زبان میں مستند ذریعہ سمجھا جانا چاہیے۔ اہم معلومات کے لیے، پیشہ ور انسانی ترجمہ کی سفارش کی جاتی ہے۔ ہم اس ترجمے کے استعمال سے پیدا ہونے والی کسی بھی غلط فہمی یا غلط تشریح کے ذمہ دار نہیں ہیں۔