|
|
3 weeks ago | |
|---|---|---|
| .. | ||
| solution | 3 weeks ago | |
| README.md | 3 weeks ago | |
| assignment.md | 3 weeks ago | |
| notebook.ipynb | 3 weeks ago | |
README.md
Початок роботи з Python та Scikit-learn для регресійних моделей

Скетчнот від Tomomi Imura
Тест перед лекцією
Цей урок доступний у R!
Вступ
У цих чотирьох уроках ви дізнаєтеся, як створювати регресійні моделі. Ми скоро обговоримо, для чого вони потрібні. Але перед тим, як щось робити, переконайтеся, що у вас є всі необхідні інструменти для початку роботи!
У цьому уроці ви навчитеся:
- Налаштовувати комп'ютер для локальних завдань машинного навчання.
- Працювати з Jupyter Notebook.
- Використовувати Scikit-learn, включаючи встановлення.
- Досліджувати лінійну регресію через практичну вправу.
Встановлення та налаштування

🎥 Натисніть на зображення вище, щоб переглянути коротке відео про налаштування комп'ютера для ML.
-
Встановіть Python. Переконайтеся, що Python встановлений на вашому комп'ютері. Ви будете використовувати Python для багатьох завдань у сфері науки про дані та машинного навчання. Більшість комп'ютерних систем вже мають встановлений Python. Також доступні корисні Python Coding Packs, які спрощують налаштування для деяких користувачів.
Деякі завдання з використанням Python вимагають однієї версії програмного забезпечення, тоді як інші — іншої. Тому корисно працювати у віртуальному середовищі.
-
Встановіть Visual Studio Code. Переконайтеся, що Visual Studio Code встановлений на вашому комп'ютері. Дотримуйтесь цих інструкцій для встановлення Visual Studio Code для базової установки. Ви будете використовувати Python у Visual Studio Code у цьому курсі, тому вам може бути корисно ознайомитися з тим, як налаштувати Visual Studio Code для розробки на Python.
Ознайомтеся з Python, пройшовши цей набір модулів Learn

🎥 Натисніть на зображення вище, щоб переглянути відео: використання Python у VS Code.
-
Встановіть Scikit-learn, дотримуючись цих інструкцій. Оскільки вам потрібно переконатися, що ви використовуєте Python 3, рекомендується використовувати віртуальне середовище. Зверніть увагу, якщо ви встановлюєте цю бібліотеку на Mac з процесором M1, на сторінці за посиланням вище є спеціальні інструкції.
-
Встановіть Jupyter Notebook. Вам потрібно встановити пакет Jupyter.
Ваше середовище для створення ML
Ви будете використовувати ноутбуки для розробки коду на Python і створення моделей машинного навчання. Цей тип файлу є поширеним інструментом для науковців, які працюють з даними, і його можна ідентифікувати за суфіксом або розширенням .ipynb.
Ноутбуки — це інтерактивне середовище, яке дозволяє розробнику як писати код, так і додавати нотатки та документацію навколо коду, що дуже корисно для експериментальних або дослідницьких проектів.

🎥 Натисніть на зображення вище, щоб переглянути коротке відео про виконання цієї вправи.
Вправа - робота з ноутбуком
У цій папці ви знайдете файл notebook.ipynb.
-
Відкрийте notebook.ipynb у Visual Studio Code.
Jupyter сервер запуститься з Python 3+. Ви знайдете області ноутбука, які можна
запустити, тобто блоки коду. Ви можете запустити блок коду, вибравши значок, який виглядає як кнопка відтворення. -
Виберіть значок
mdі додайте трохи markdown, а також наступний текст # Ласкаво просимо до вашого ноутбука.Далі додайте трохи коду на Python.
-
Введіть print('hello notebook') у блоці коду.
-
Виберіть стрілку, щоб запустити код.
Ви повинні побачити надруковане повідомлення:
hello notebook

Ви можете чергувати свій код із коментарями, щоб самодокументувати ноутбук.
✅ Подумайте хвилину, наскільки відрізняється робоче середовище веб-розробника від середовища науковця, який працює з даними.
Початок роботи з Scikit-learn
Тепер, коли Python налаштований у вашому локальному середовищі, і ви комфортно працюєте з Jupyter Notebook, давайте так само комфортно освоїмо Scikit-learn (вимовляється як sci, як у science). Scikit-learn надає широкий API, який допоможе вам виконувати завдання машинного навчання.
Згідно з їх вебсайтом, "Scikit-learn — це бібліотека машинного навчання з відкритим кодом, яка підтримує навчання з учителем і без учителя. Вона також надає різні інструменти для підгонки моделей, попередньої обробки даних, вибору моделей та їх оцінки, а також багато інших утиліт."
У цьому курсі ви будете використовувати Scikit-learn та інші інструменти для створення моделей машинного навчання для виконання того, що ми називаємо "традиційними завданнями машинного навчання". Ми свідомо уникали нейронних мереж і глибокого навчання, оскільки вони краще висвітлюються в нашій майбутній навчальній програмі "AI для початківців".
Scikit-learn робить створення моделей та їх оцінку простим і зручним. Вона зосереджена на використанні числових даних і містить кілька готових наборів даних для використання як навчальні інструменти. Вона також включає попередньо створені моделі для студентів. Давайте дослідимо процес завантаження готових даних і використання вбудованого оцінювача для першої моделі машинного навчання з Scikit-learn на основі базових даних.
Вправа - ваш перший ноутбук з Scikit-learn
Цей підручник був натхненний прикладом лінійної регресії на вебсайті Scikit-learn.

🎥 Натисніть на зображення вище, щоб переглянути коротке відео про виконання цієї вправи.
У файлі notebook.ipynb, пов'язаному з цим уроком, очистіть усі комірки, натиснувши значок "сміттєвий бак".
У цьому розділі ви будете працювати з невеликим набором даних про діабет, який вбудований у Scikit-learn для навчальних цілей. Уявіть, що ви хочете протестувати лікування для пацієнтів із діабетом. Моделі машинного навчання можуть допомогти вам визначити, які пацієнти краще реагуватимуть на лікування, виходячи з комбінацій змінних. Навіть дуже базова регресійна модель, коли її візуалізувати, може показати інформацію про змінні, які допоможуть вам організувати ваші теоретичні клінічні випробування.
✅ Існує багато типів методів регресії, і який із них ви оберете, залежить від питання, на яке ви хочете отримати відповідь. Якщо ви хочете передбачити ймовірний зріст людини певного віку, вам слід використовувати лінійну регресію, оскільки ви шукаєте числове значення. Якщо вас цікавить визначення, чи слід вважати певну кухню веганською чи ні, ви шукаєте категоріальне призначення, тому вам слід використовувати логістичну регресію. Ви дізнаєтеся більше про логістичну регресію пізніше. Подумайте трохи про питання, які ви можете поставити даним, і який із цих методів буде більш доречним.
Давайте розпочнемо виконання цього завдання.
Імпорт бібліотек
Для цього завдання ми імпортуємо деякі бібліотеки:
- matplotlib. Це корисний інструмент для побудови графіків, і ми будемо використовувати його для створення лінійного графіка.
- numpy. numpy — це корисна бібліотека для роботи з числовими даними в Python.
- sklearn. Це бібліотека Scikit-learn.
Імпортуйте деякі бібліотеки для виконання завдань.
-
Додайте імпорти, ввівши наступний код:
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, model_selectionВи імпортуєте
matplotlib,numpy, а також імпортуєтеdatasets,linear_modelіmodel_selectionзsklearn.model_selectionвикористовується для розділення даних на навчальні та тестові набори.
Набір даних про діабет
Вбудований набір даних про діабет містить 442 зразки даних про діабет із 10 змінними, серед яких:
- age: вік у роках
- bmi: індекс маси тіла
- bp: середній артеріальний тиск
- s1 tc: Т-клітини (тип білих кров'яних клітин)
✅ Цей набір даних включає концепцію "статі" як змінної, важливої для досліджень діабету. Багато медичних наборів даних включають цей тип бінарної класифікації. Подумайте трохи про те, як такі категоризації можуть виключати певні частини населення з лікування.
Тепер завантажте дані X та y.
🎓 Пам'ятайте, це навчання з учителем, і нам потрібна цільова змінна 'y'.
У новій комірці коду завантажте набір даних про діабет, викликавши load_diabetes(). Вхідний параметр return_X_y=True сигналізує, що X буде матрицею даних, а y буде цільовою змінною регресії.
-
Додайте кілька команд print, щоб показати форму матриці даних та її перший елемент:
X, y = datasets.load_diabetes(return_X_y=True) print(X.shape) print(X[0])Те, що ви отримуєте у відповідь, — це кортеж. Ви призначаєте два перші значення кортежу відповідно до
Xтаy. Дізнайтеся більше про кортежі.Ви можете побачити, що ці дані мають 442 елементи, організовані у масиви з 10 елементів:
(442, 10) [ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -0.04340085 -0.00259226 0.01990842 -0.01764613]✅ Подумайте трохи про взаємозв'язок між даними та цільовою змінною регресії. Лінійна регресія прогнозує взаємозв'язки між змінною X та цільовою змінною y. Чи можете ви знайти цільову змінну для набору даних про діабет у документації? Що демонструє цей набір даних, враховуючи цільову змінну?
-
Далі виберіть частину цього набору даних для побудови графіка, вибравши 3-й стовпець набору даних. Ви можете зробити це, використовуючи оператор
:, щоб вибрати всі рядки, а потім вибрати 3-й стовпець за допомогою індексу (2). Ви також можете змінити форму даних на 2D-масив — як це потрібно для побудови графіка — використовуючиreshape(n_rows, n_columns). Якщо один із параметрів дорівнює -1, відповідний розмір обчислюється автоматично.X = X[:, 2] X = X.reshape((-1,1))✅ У будь-який момент друкуйте дані, щоб перевірити їх форму.
-
Тепер, коли дані готові до побудови графіка, ви можете перевірити, чи може машина допомогти визначити логічний розподіл між числами в цьому наборі даних. Для цього вам потрібно розділити як дані (X), так і цільову змінну (y) на тестові та навчальні набори. Scikit-learn має простий спосіб зробити це; ви можете розділити ваші тестові дані в заданій точці.
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) -
Тепер ви готові навчити вашу модель! Завантажте модель лінійної регресії та навчіть її за допомогою ваших навчальних наборів X та y, використовуючи
model.fit():model = linear_model.LinearRegression() model.fit(X_train, y_train)✅
model.fit()— це функція, яку ви побачите в багатьох бібліотеках ML, таких як TensorFlow. -
Потім створіть прогноз, використовуючи тестові дані, за допомогою функції
predict(). Це буде використано для побудови лінії між групами даних.y_pred = model.predict(X_test) -
Тепер настав час показати дані на графіку. Matplotlib — дуже корисний інструмент для цього завдання. Створіть діаграму розсіювання для всіх тестових даних X та y, і використовуйте прогноз для побудови лінії в найбільш відповідному місці між групами даних моделі.
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_pred, color='blue', linewidth=3) plt.xlabel('Scaled BMIs') plt.ylabel('Disease Progression') plt.title('A Graph Plot Showing Diabetes Progression Against BMI') plt.show()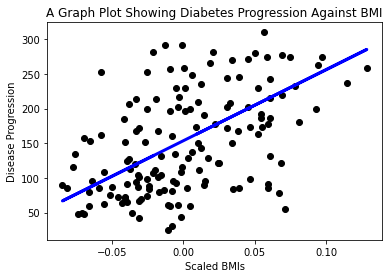 ✅ Подумайте трохи над тим, що тут відбувається. Пряма лінія проходить через багато маленьких точок даних, але що саме вона робить? Чи можете ви побачити, як ця лінія може допомогти передбачити, де нова, невидима точка даних повинна розташуватися відносно осі y графіка? Спробуйте сформулювати практичне застосування цієї моделі.
✅ Подумайте трохи над тим, що тут відбувається. Пряма лінія проходить через багато маленьких точок даних, але що саме вона робить? Чи можете ви побачити, як ця лінія може допомогти передбачити, де нова, невидима точка даних повинна розташуватися відносно осі y графіка? Спробуйте сформулювати практичне застосування цієї моделі.
Вітаємо, ви створили свою першу модель лінійної регресії, зробили прогноз за її допомогою та відобразили його на графіку!
🚀Завдання
Побудуйте графік для іншої змінної з цього набору даних. Підказка: змініть цей рядок: X = X[:,2]. Враховуючи ціль цього набору даних, що ви можете дізнатися про прогресування діабету як хвороби?
Тест після лекції
Огляд і самостійне навчання
У цьому уроці ви працювали з простою лінійною регресією, а не з уніваріантною чи багатофакторною регресією. Почитайте трохи про відмінності між цими методами або перегляньте це відео.
Дізнайтеся більше про концепцію регресії та подумайте, які типи питань можна вирішити за допомогою цієї техніки. Пройдіть цей навчальний курс, щоб поглибити своє розуміння.
Завдання
Відмова від відповідальності:
Цей документ було перекладено за допомогою сервісу автоматичного перекладу Co-op Translator. Хоча ми прагнемо до точності, зверніть увагу, що автоматичні переклади можуть містити помилки або неточності. Оригінальний документ мовою оригіналу слід вважати авторитетним джерелом. Для критично важливої інформації рекомендується професійний людський переклад. Ми не несемо відповідальності за будь-які непорозуміння або неправильні тлумачення, що виникли внаслідок використання цього перекладу.