|
|
2 weeks ago | |
|---|---|---|
| .. | ||
| solution | 2 weeks ago | |
| README.md | 3 weeks ago | |
| assignment.md | 3 weeks ago | |
| notebook.ipynb | 2 weeks ago | |
README.md
Začnite s Pythonom in Scikit-learn za regresijske modele

Sketchnote avtorja Tomomi Imura
Predavanje kviz
To lekcijo lahko najdete tudi v jeziku R!
Uvod
V teh štirih lekcijah boste odkrili, kako zgraditi regresijske modele. Kmalu bomo razpravljali, za kaj so ti modeli uporabni. Preden pa začnete, poskrbite, da imate na voljo ustrezna orodja za začetek procesa!
V tej lekciji boste izvedeli, kako:
- Pripraviti računalnik za lokalne naloge strojnega učenja.
- Delati z Jupyter zvezki.
- Uporabljati Scikit-learn, vključno z namestitvijo.
- Raziskati linearno regresijo s praktično vajo.
Namestitve in konfiguracije

🎥 Kliknite zgornjo sliko za kratek video o konfiguraciji računalnika za strojno učenje.
-
Namestite Python. Prepričajte se, da je Python nameščen na vašem računalniku. Python boste uporabljali za številne naloge podatkovne znanosti in strojnega učenja. Večina računalniških sistemov že vključuje namestitev Pythona. Na voljo so tudi uporabni Python Coding Packs, ki olajšajo nastavitev za nekatere uporabnike.
Nekatere uporabe Pythona pa zahtevajo eno različico programske opreme, druge pa drugo. Zato je koristno delati v virtualnem okolju.
-
Namestite Visual Studio Code. Prepričajte se, da imate na računalniku nameščen Visual Studio Code. Sledite tem navodilom za namestitev Visual Studio Code za osnovno namestitev. Python boste uporabljali v Visual Studio Code v tem tečaju, zato se morda želite seznaniti z nastavitvijo Visual Studio Code za razvoj v Pythonu.
Seznanite se s Pythonom z delom skozi to zbirko učnih modulov

🎥 Kliknite zgornjo sliko za video: uporaba Pythona v VS Code.
-
Namestite Scikit-learn, tako da sledite tem navodilom. Ker morate zagotoviti uporabo Pythona 3, je priporočljivo, da uporabite virtualno okolje. Če to knjižnico nameščate na računalnik Mac z M1, so na zgoraj navedeni strani posebna navodila.
-
Namestite Jupyter Notebook. Potrebovali boste namestitev paketa Jupyter.
Vaše okolje za avtorstvo ML
Uporabljali boste zvezke za razvoj kode v Pythonu in ustvarjanje modelov strojnega učenja. Ta vrsta datoteke je pogosto orodje za podatkovne znanstvenike, prepoznate pa jih po priponi .ipynb.
Zvezki so interaktivno okolje, ki razvijalcu omogoča tako kodiranje kot dodajanje opomb in pisanje dokumentacije okoli kode, kar je zelo uporabno za eksperimentalne ali raziskovalno usmerjene projekte.

🎥 Kliknite zgornjo sliko za kratek video o tej vaji.
Vaja - delo z zvezkom
V tej mapi boste našli datoteko notebook.ipynb.
-
Odprite notebook.ipynb v Visual Studio Code.
Začel se bo Jupyter strežnik s Pythonom 3+. V zvezku boste našli območja, ki jih je mogoče
zagnati, torej dele kode. Kodo lahko zaženete tako, da izberete ikono, ki izgleda kot gumb za predvajanje. -
Izberite ikono
mdin dodajte nekaj markdowna ter naslednje besedilo # Dobrodošli v vašem zvezku.Nato dodajte nekaj kode v Pythonu.
-
Vnesite print('hello notebook') v blok kode.
-
Izberite puščico za zagon kode.
Videti bi morali natisnjeno izjavo:
hello notebook

Kodo lahko prepletate z opombami, da sami dokumentirate zvezek.
✅ Razmislite za trenutek, kako se delovno okolje spletnega razvijalca razlikuje od okolja podatkovnega znanstvenika.
Začetek dela s Scikit-learn
Zdaj, ko je Python nastavljen v vašem lokalnem okolju in ste seznanjeni z Jupyter zvezki, se enako seznanimo s Scikit-learn (izgovorjava sci kot v science). Scikit-learn ponuja obsežen API za izvajanje nalog strojnega učenja.
Po navedbah njihove spletne strani je "Scikit-learn odprtokodna knjižnica strojnega učenja, ki podpira nadzorovano in nenadzorovano učenje. Prav tako ponuja različna orodja za prileganje modelov, predobdelavo podatkov, izbiro modelov in ocenjevanje ter številne druge pripomočke."
V tem tečaju boste uporabljali Scikit-learn in druga orodja za gradnjo modelov strojnega učenja za izvajanje nalog, ki jih imenujemo 'tradicionalno strojno učenje'. Namenoma smo se izognili nevronskim mrežam in globokemu učenju, saj so bolje obravnavani v našem prihajajočem učnem načrtu 'AI za začetnike'.
Scikit-learn omogoča enostavno gradnjo modelov in njihovo ocenjevanje za uporabo. Osredotoča se predvsem na uporabo numeričnih podatkov in vsebuje več pripravljenih naborov podatkov za uporabo kot učna orodja. Prav tako vključuje vnaprej pripravljene modele, ki jih lahko študentje preizkusijo. Raziskujmo proces nalaganja vnaprej pripravljenih podatkov in uporabe vgrajenega ocenjevalnika za prvi ML model s Scikit-learn z osnovnimi podatki.
Vaja - vaš prvi zvezek s Scikit-learn
Ta vadnica je bila navdihnjena z primerom linearne regresije na spletni strani Scikit-learn.

🎥 Kliknite zgornjo sliko za kratek video o tej vaji.
V datoteki notebook.ipynb, povezani s to lekcijo, izbrišite vse celice s pritiskom na ikono 'koš za smeti'.
V tem razdelku boste delali z majhnim naborom podatkov o sladkorni bolezni, ki je vgrajen v Scikit-learn za učne namene. Predstavljajte si, da želite preizkusiti zdravljenje za bolnike s sladkorno boleznijo. Modeli strojnega učenja vam lahko pomagajo določiti, kateri bolniki bi se bolje odzvali na zdravljenje, na podlagi kombinacij spremenljivk. Tudi zelo osnovni regresijski model, ko je vizualiziran, lahko pokaže informacije o spremenljivkah, ki bi vam pomagale organizirati teoretične klinične preizkuse.
✅ Obstaja veliko vrst regresijskih metod, izbira pa je odvisna od vprašanja, na katerega želite odgovoriti. Če želite napovedati verjetno višino osebe določene starosti, bi uporabili linearno regresijo, saj iščete numerično vrednost. Če vas zanima, ali naj se določena vrsta kuhinje šteje za vegansko ali ne, iščete kategorijsko dodelitev, zato bi uporabili logistično regresijo. Kasneje boste izvedeli več o logistični regresiji. Razmislite o nekaterih vprašanjih, ki jih lahko postavite podatkom, in kateri od teh metod bi bila bolj primerna.
Začnimo s to nalogo.
Uvoz knjižnic
Za to nalogo bomo uvozili nekaj knjižnic:
- matplotlib. To je uporabno orodje za risanje grafov, ki ga bomo uporabili za ustvarjanje linijskega grafa.
- numpy. numpy je uporabna knjižnica za obdelavo numeričnih podatkov v Pythonu.
- sklearn. To je knjižnica Scikit-learn.
Uvozite nekaj knjižnic za pomoč pri nalogah.
-
Dodajte uvoze z vnosom naslednje kode:
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, model_selectionZgornja koda uvaža
matplotlib,numpyindatasets,linear_modeltermodel_selectionizsklearn.model_selectionse uporablja za razdelitev podatkov na učne in testne sklope.
Nabor podatkov o sladkorni bolezni
Vgrajeni nabor podatkov o sladkorni bolezni vključuje 442 vzorcev podatkov o sladkorni bolezni z 10 značilnimi spremenljivkami, med katerimi so nekatere:
- starost: starost v letih
- bmi: indeks telesne mase
- bp: povprečni krvni tlak
- s1 tc: T-celice (vrsta belih krvnih celic)
✅ Ta nabor podatkov vključuje koncept 'spola' kot značilne spremenljivke, pomembne za raziskave o sladkorni bolezni. Številni medicinski nabori podatkov vključujejo tovrstno binarno klasifikacijo. Razmislite, kako bi lahko takšne kategorizacije izključile določene dele populacije iz zdravljenja.
Zdaj naložite podatke X in y.
🎓 Ne pozabite, da gre za nadzorovano učenje, zato potrebujemo imenovan cilj 'y'.
V novi celici kode naložite nabor podatkov o sladkorni bolezni z uporabo load_diabetes(). Vhod return_X_y=True signalizira, da bo X matrika podatkov, y pa regresijski cilj.
-
Dodajte nekaj ukazov za izpis, da prikažete obliko matrike podatkov in njen prvi element:
X, y = datasets.load_diabetes(return_X_y=True) print(X.shape) print(X[0])Kar dobite kot odgovor, je nabor. Prva dva vrednosti nabora dodelite
Xiny. Več o naborih lahko izveste tukaj.Vidite lahko, da ti podatki vsebujejo 442 elementov, oblikovanih v poljih z 10 elementi:
(442, 10) [ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -0.04340085 -0.00259226 0.01990842 -0.01764613]✅ Razmislite o razmerju med podatki in regresijskim ciljem. Linearna regresija napoveduje razmerja med značilnostjo X in ciljno spremenljivko y. Ali lahko v dokumentaciji najdete cilj za nabor podatkov o sladkorni bolezni? Kaj ta nabor podatkov prikazuje, glede na cilj?
-
Nato izberite del tega nabora podatkov za risanje tako, da izberete 3. stolpec nabora podatkov. To lahko storite z uporabo operatorja
:za izbiro vseh vrstic, nato pa izberete 3. stolpec z uporabo indeksa (2). Podatke lahko preoblikujete v 2D matriko - kot je potrebno za risanje - z uporaboreshape(n_rows, n_columns). Če je eden od parametrov -1, se ustrezna dimenzija izračuna samodejno.X = X[:, 2] X = X.reshape((-1,1))✅ Kadarkoli natisnite podatke, da preverite njihovo obliko.
-
Zdaj, ko imate podatke pripravljene za risanje, lahko preverite, ali lahko stroj pomaga določiti logično ločnico med številkami v tem naboru podatkov. Za to morate razdeliti tako podatke (X) kot cilj (y) na testne in učne sklope. Scikit-learn ima preprost način za to; testne podatke lahko razdelite na določenem mestu.
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) -
Zdaj ste pripravljeni na učenje modela! Naložite model linearne regresije in ga naučite z učnimi sklopi X in y z uporabo
model.fit():model = linear_model.LinearRegression() model.fit(X_train, y_train)✅
model.fit()je funkcija, ki jo boste videli v številnih knjižnicah ML, kot je TensorFlow. -
Nato ustvarite napoved z uporabo testnih podatkov z uporabo funkcije
predict(). To bo uporabljeno za risanje črte med skupinami podatkov.y_pred = model.predict(X_test) -
Zdaj je čas, da prikažete podatke na grafu. Matplotlib je zelo uporabno orodje za to nalogo. Ustvarite razpršeni grafikon vseh testnih podatkov X in y ter uporabite napoved za risanje črte na najbolj primernem mestu med skupinami podatkov modela.
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_pred, color='blue', linewidth=3) plt.xlabel('Scaled BMIs') plt.ylabel('Disease Progression') plt.title('A Graph Plot Showing Diabetes Progression Against BMI') plt.show()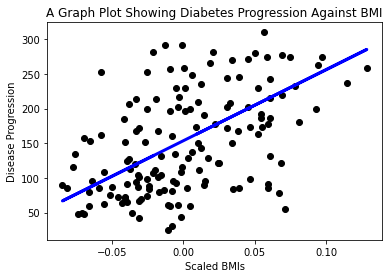 ✅ Razmislite malo o tem, kaj se tukaj dogaja. Ravna črta poteka skozi številne majhne točke podatkov, vendar kaj pravzaprav počne? Ali vidite, kako bi morali biti sposobni uporabiti to črto za napovedovanje, kje bi se nova, nevidna podatkovna točka morala uvrstiti glede na y-os grafa? Poskusite z besedami opisati praktično uporabo tega modela.
✅ Razmislite malo o tem, kaj se tukaj dogaja. Ravna črta poteka skozi številne majhne točke podatkov, vendar kaj pravzaprav počne? Ali vidite, kako bi morali biti sposobni uporabiti to črto za napovedovanje, kje bi se nova, nevidna podatkovna točka morala uvrstiti glede na y-os grafa? Poskusite z besedami opisati praktično uporabo tega modela.
Čestitke, izdelali ste svoj prvi model linearne regresije, ustvarili napoved z njim in jo prikazali na grafu!
🚀Izziv
Prikažite drugo spremenljivko iz tega nabora podatkov. Namig: uredite to vrstico: X = X[:,2]. Glede na cilj tega nabora podatkov, kaj lahko odkrijete o napredovanju sladkorne bolezni kot bolezni?
Kvizi po predavanju
Pregled & Samostojno učenje
V tem vodiču ste delali z enostavno linearno regresijo, ne pa z univariatno ali večkratno linearno regresijo. Preberite nekaj o razlikah med temi metodami ali si oglejte ta video.
Preberite več o konceptu regresije in razmislite, kakšna vprašanja je mogoče odgovoriti s to tehniko. Vzemite ta vodič, da poglobite svoje razumevanje.
Naloga
Omejitev odgovornosti:
Ta dokument je bil preveden z uporabo storitve za strojno prevajanje Co-op Translator. Čeprav si prizadevamo za natančnost, vas prosimo, da se zavedate, da lahko avtomatizirani prevodi vsebujejo napake ali netočnosti. Izvirni dokument v njegovem izvirnem jeziku je treba obravnavati kot avtoritativni vir. Za ključne informacije priporočamo strokovno človeško prevajanje. Ne prevzemamo odgovornosti za morebitna nesporazumevanja ali napačne razlage, ki izhajajo iz uporabe tega prevoda.