|
|
3 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 3 weeks ago | |
| assignment.md | 3 weeks ago | |
README.md
Postscript: Debuggarea modelelor de învățare automată folosind componentele tabloului de bord AI responsabil
Chestionar înainte de curs
Introducere
Învățarea automată influențează viețile noastre de zi cu zi. Inteligența artificială (AI) își face loc în unele dintre cele mai importante sisteme care ne afectează atât ca indivizi, cât și ca societate, de la sănătate, finanțe, educație și ocuparea forței de muncă. De exemplu, sistemele și modelele sunt implicate în sarcini zilnice de luare a deciziilor, cum ar fi diagnosticarea în domeniul sănătății sau detectarea fraudei. Drept urmare, progresele în AI, împreună cu adoptarea accelerată, sunt întâmpinate cu așteptări sociale în continuă evoluție și reglementări tot mai stricte. Vedem constant domenii în care sistemele AI continuă să nu îndeplinească așteptările; acestea expun noi provocări, iar guvernele încep să reglementeze soluțiile AI. Prin urmare, este important ca aceste modele să fie analizate pentru a oferi rezultate echitabile, fiabile, incluzive, transparente și responsabile pentru toată lumea.
În acest curs, vom analiza instrumente practice care pot fi utilizate pentru a evalua dacă un model are probleme legate de AI responsabil. Tehnicile tradiționale de debugare a învățării automate tind să se bazeze pe calcule cantitative, cum ar fi acuratețea agregată sau pierderea medie a erorilor. Imaginați-vă ce se poate întâmpla atunci când datele pe care le utilizați pentru a construi aceste modele lipsesc anumite demografii, cum ar fi rasa, genul, viziunea politică, religia sau reprezintă disproporționat astfel de demografii. Ce se întâmplă atunci când rezultatul modelului este interpretat ca favorizând o anumită demografie? Acest lucru poate introduce o supra-reprezentare sau o sub-reprezentare a acestor grupuri sensibile de caracteristici, rezultând probleme de echitate, incluziune sau fiabilitate ale modelului. Un alt factor este că modelele de învățare automată sunt considerate „cutii negre”, ceea ce face dificilă înțelegerea și explicarea factorilor care determină predicțiile unui model. Toate acestea sunt provocări cu care se confruntă oamenii de știință în date și dezvoltatorii AI atunci când nu dispun de instrumente adecvate pentru a depana și evalua echitatea sau încrederea unui model.
În această lecție, veți învăța cum să depanați modelele utilizând:
- Analiza erorilor: identificarea zonelor din distribuția datelor unde modelul are rate mari de eroare.
- Prezentarea generală a modelului: realizarea unei analize comparative între diferite cohorte de date pentru a descoperi disparități în metricele de performanță ale modelului.
- Analiza datelor: investigarea zonelor în care ar putea exista o supra-reprezentare sau o sub-reprezentare a datelor care pot înclina modelul să favorizeze o demografie în detrimentul alteia.
- Importanța caracteristicilor: înțelegerea caracteristicilor care determină predicțiile modelului la nivel global sau local.
Cerințe preliminare
Ca cerință preliminară, vă rugăm să consultați Instrumentele AI responsabile pentru dezvoltatori

Analiza erorilor
Metricile tradiționale de performanță ale modelului utilizate pentru măsurarea acurateței sunt în mare parte calcule bazate pe predicții corecte vs incorecte. De exemplu, determinarea faptului că un model este precis în 89% din cazuri, cu o pierdere a erorii de 0,001, poate fi considerată o performanță bună. Totuși, erorile nu sunt distribuite uniform în setul de date de bază. Puteți obține un scor de acuratețe de 89% pentru model, dar să descoperiți că există regiuni diferite ale datelor pentru care modelul eșuează în 42% din cazuri. Consecința acestor tipare de eșec pentru anumite grupuri de date poate duce la probleme de echitate sau fiabilitate. Este esențial să înțelegeți zonele în care modelul funcționează bine sau nu. Regiunile de date în care există un număr mare de inexactități ale modelului pot fi o demografie importantă a datelor.

Componenta de Analiză a Erorilor din tabloul de bord RAI ilustrează modul în care eșecurile modelului sunt distribuite pe diverse cohorte printr-o vizualizare de tip arbore. Acest lucru este util pentru identificarea caracteristicilor sau zonelor în care există o rată mare de eroare în setul de date. Văzând de unde provin cele mai multe inexactități ale modelului, puteți începe să investigați cauza principală. De asemenea, puteți crea cohorte de date pentru a efectua analize. Aceste cohorte de date ajută în procesul de depanare pentru a determina de ce performanța modelului este bună într-o cohortă, dar eronată în alta.

Indicatorii vizuali de pe harta arborelui ajută la localizarea mai rapidă a zonelor problematice. De exemplu, cu cât o ramură a arborelui are o nuanță mai închisă de roșu, cu atât rata de eroare este mai mare.
Harta termică este o altă funcționalitate de vizualizare pe care utilizatorii o pot folosi pentru a investiga rata de eroare utilizând una sau două caracteristici pentru a găsi un factor care contribuie la erorile modelului pe întregul set de date sau pe cohorte.

Utilizați analiza erorilor atunci când aveți nevoie să:
- Obțineți o înțelegere profundă a modului în care eșecurile modelului sunt distribuite pe un set de date și pe mai multe dimensiuni de intrare și caracteristici.
- Descompuneți metricele de performanță agregate pentru a descoperi automat cohorte eronate care să informeze pașii de atenuare țintiți.
Prezentarea generală a modelului
Evaluarea performanței unui model de învățare automată necesită obținerea unei înțelegeri holistice a comportamentului său. Acest lucru poate fi realizat prin revizuirea mai multor metrici, cum ar fi rata de eroare, acuratețea, recall-ul, precizia sau MAE (Eroarea Absolută Medie), pentru a găsi disparități între metricele de performanță. O metrică de performanță poate arăta bine, dar inexactitățile pot fi expuse într-o altă metrică. În plus, compararea metricelor pentru disparități pe întregul set de date sau pe cohorte ajută la evidențierea zonelor în care modelul funcționează bine sau nu. Acest lucru este deosebit de important pentru a vedea performanța modelului între caracteristici sensibile și nesensibile (de exemplu, rasa, genul sau vârsta pacienților) pentru a descoperi eventuale inechități ale modelului. De exemplu, descoperirea faptului că modelul este mai eronat într-o cohortă care are caracteristici sensibile poate dezvălui o potențială inechitate a modelului.
Componenta Prezentare Generală a Modelului din tabloul de bord RAI ajută nu doar la analizarea metricelor de performanță ale reprezentării datelor într-o cohortă, ci oferă utilizatorilor posibilitatea de a compara comportamentul modelului între diferite cohorte.

Funcționalitatea de analiză bazată pe caracteristici a componentei permite utilizatorilor să restrângă subgrupurile de date dintr-o anumită caracteristică pentru a identifica anomalii la un nivel granular. De exemplu, tabloul de bord are o inteligență încorporată pentru a genera automat cohorte pentru o caracteristică selectată de utilizator (de exemplu, "time_in_hospital < 3" sau "time_in_hospital >= 7"). Acest lucru permite utilizatorului să izoleze o anumită caracteristică dintr-un grup mai mare de date pentru a vedea dacă este un factor cheie al rezultatelor eronate ale modelului.

Componenta Prezentare Generală a Modelului susține două clase de metrici de disparitate:
Disparitate în performanța modelului: Aceste seturi de metrici calculează disparitatea (diferența) în valorile metricii de performanță selectate între subgrupurile de date. Iată câteva exemple:
- Disparitate în rata de acuratețe
- Disparitate în rata de eroare
- Disparitate în precizie
- Disparitate în recall
- Disparitate în eroarea absolută medie (MAE)
Disparitate în rata de selecție: Această metrică conține diferența în rata de selecție (predicție favorabilă) între subgrupuri. Un exemplu este disparitatea în ratele de aprobare a împrumuturilor. Rata de selecție înseamnă fracțiunea de puncte de date din fiecare clasă clasificate ca 1 (în clasificarea binară) sau distribuția valorilor predicției (în regresie).
Analiza datelor
"Dacă torturezi datele suficient de mult, vor mărturisi orice" - Ronald Coase
Această afirmație sună extrem, dar este adevărat că datele pot fi manipulate pentru a susține orice concluzie. O astfel de manipulare poate apărea uneori neintenționat. Ca oameni, toți avem prejudecăți și este adesea dificil să știm conștient când introduceți prejudecăți în date. Garantarea echității în AI și învățarea automată rămâne o provocare complexă.
Datele reprezintă un punct orb major pentru metricile tradiționale de performanță ale modelului. Puteți avea scoruri mari de acuratețe, dar acest lucru nu reflectă întotdeauna prejudecățile subiacente ale datelor care ar putea exista în setul dvs. de date. De exemplu, dacă un set de date despre angajați are 27% femei în poziții executive într-o companie și 73% bărbați la același nivel, un model AI de publicitate pentru locuri de muncă antrenat pe aceste date poate viza în principal un public masculin pentru poziții de nivel superior. Această dezechilibrare a datelor a înclinat predicția modelului să favorizeze un gen. Acest lucru dezvăluie o problemă de echitate în care există o prejudecată de gen în modelul AI.
Componenta Analiza Datelor din tabloul de bord RAI ajută la identificarea zonelor în care există o supra-reprezentare și o sub-reprezentare în setul de date. Aceasta ajută utilizatorii să diagnosticheze cauza principală a erorilor și a problemelor de echitate introduse de dezechilibrele de date sau de lipsa reprezentării unui anumit grup de date. Aceasta oferă utilizatorilor posibilitatea de a vizualiza seturile de date pe baza rezultatelor prezise și reale, a grupurilor de erori și a caracteristicilor specifice. Uneori, descoperirea unui grup de date subreprezentat poate dezvălui, de asemenea, că modelul nu învață bine, hence inexactitățile ridicate. Un model care are prejudecăți în date nu este doar o problemă de echitate, ci arată că modelul nu este incluziv sau fiabil.

Utilizați analiza datelor atunci când aveți nevoie să:
- Explorați statisticile setului dvs. de date selectând diferiți filtri pentru a împărți datele în dimensiuni diferite (cunoscute și sub numele de cohorte).
- Înțelegeți distribuția setului dvs. de date pe diferite cohorte și grupuri de caracteristici.
- Determinați dacă descoperirile dvs. legate de echitate, analiza erorilor și cauzalitate (derivate din alte componente ale tabloului de bord) sunt rezultatul distribuției setului dvs. de date.
- Decideți în ce zone să colectați mai multe date pentru a atenua erorile care provin din probleme de reprezentare, zgomot de etichetare, zgomot de caracteristici, prejudecăți de etichetare și factori similari.
Interpretabilitatea modelului
Modelele de învățare automată tind să fie „cutii negre”. Înțelegerea caracteristicilor cheie ale datelor care determină predicția unui model poate fi o provocare. Este important să oferiți transparență cu privire la motivul pentru care un model face o anumită predicție. De exemplu, dacă un sistem AI prezice că un pacient diabetic este expus riscului de a fi readmis într-un spital în mai puțin de 30 de zile, acesta ar trebui să poată oferi datele care au condus la predicția sa. Având indicatori de date de sprijin aduce transparență pentru a ajuta clinicienii sau spitalele să poată lua decizii bine informate. În plus, fiind capabil să explicați de ce un model a făcut o predicție pentru un pacient individual permite responsabilitatea în conformitate cu reglementările din domeniul sănătății. Atunci când utilizați modele de învățare automată în moduri care afectează viețile oamenilor, este crucial să înțelegeți și să explicați ce influențează comportamentul unui model. Explicabilitatea și interpretabilitatea modelului ajută la răspunsul la întrebări în scenarii precum:
- Debugarea modelului: De ce a făcut modelul meu această greșeală? Cum pot îmbunătăți modelul meu?
- Colaborarea om-AI: Cum pot înțelege și avea încredere în deciziile modelului?
- Conformitatea cu reglementările: Modelul meu îndeplinește cerințele legale?
Componenta Importanța Caracteristicilor din tabloul de bord RAI vă ajută să depanați și să obțineți o înțelegere cuprinzătoare a modului în care un model face predicții. Este, de asemenea, un instrument util pentru profesioniștii în învățarea automată și factorii de decizie pentru a explica și a arăta dovezi ale caracteristicilor care influențează comportamentul unui model pentru conformitatea cu reglementările. Utilizatorii pot explora atât explicații globale, cât și locale pentru a valida ce caracteristici determină predicția unui model. Explicațiile globale enumeră caracteristicile principale care au afectat predicția generală a unui model. Explicațiile locale afișează ce caracteristici au condus la predicția unui model pentru un caz individual. Capacitatea de a evalua explicațiile locale este, de asemenea, utilă în depanarea sau auditarea unui caz specific pentru a înțelege și interpreta mai bine de ce un model a făcut o predicție corectă sau incorectă.
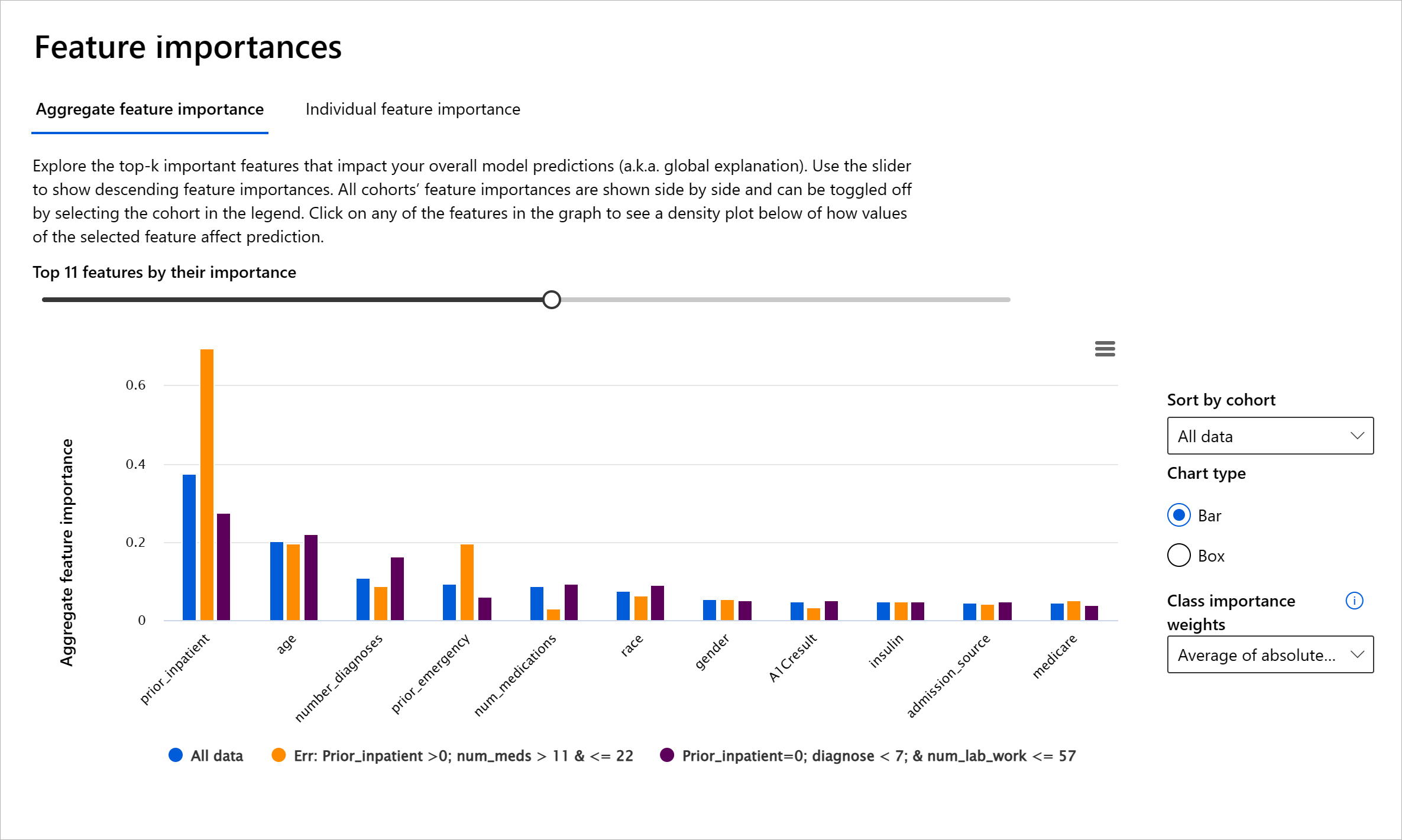
- Explicații globale: De exemplu, ce caracteristici afectează comportamentul general al unui model de readmisie în spital pentru diabetici?
- Explicații locale: De exemplu, de ce un pacient diabetic de peste 60 de ani cu spitalizări anterioare a fost prezis să fie readmis sau nu în termen de 30 de zile într-un spital?
În procesul de depanare a performanței unui model pe diferite cohorte, Importanța Caracteristicilor arată ce nivel de impact are o caracteristică pe cohorte. Aceasta ajută la dezvăluirea anomaliilor atunci când se compară nivelul de influență pe care o caracteristică îl are în determinarea predicțiilor eronate ale modelului. Componenta Importanța Caracteristicilor poate arăta ce valori dintr-o caracteristică au influențat pozitiv sau negativ rezultatul modelului. De exemplu, dacă un model a făcut o predicție inexactă, componenta vă oferă posibilitatea de a detalia și de a identifica ce caracteristici sau valori ale caracteristicilor au condus la predicție. Acest nivel de detaliu ajută nu doar în depanare, ci oferă transparență și responsabilitate în situații de audit. În cele din urmă, componenta vă poate ajuta să identificați problemele de echitate. De exemplu, dacă o caracteristică sensibilă, cum ar fi etnia sau genul, este foarte influ
- Reprezentare excesivă sau insuficientă. Ideea este că un anumit grup nu este vizibil într-o anumită profesie, iar orice serviciu sau funcție care continuă să promoveze acest lucru contribuie la prejudicii.
Azure RAI dashboard
Azure RAI dashboard este construit pe instrumente open-source dezvoltate de instituții academice și organizații de top, inclusiv Microsoft, și sunt esențiale pentru ca oamenii de știință în domeniul datelor și dezvoltatorii de AI să înțeleagă mai bine comportamentul modelelor, să descopere și să atenueze problemele nedorite ale modelelor AI.
-
Învață cum să folosești diferitele componente consultând documentația dashboard-ului RAI.
-
Consultă câteva notebook-uri de exemplu ale dashboard-ului RAI pentru a depana scenarii mai responsabile de AI în Azure Machine Learning.
🚀 Provocare
Pentru a preveni introducerea prejudecăților statistice sau de date de la bun început, ar trebui:
- să avem o diversitate de medii și perspective printre persoanele care lucrează la sisteme
- să investim în seturi de date care reflectă diversitatea societății noastre
- să dezvoltăm metode mai bune pentru detectarea și corectarea prejudecăților atunci când apar
Gândește-te la scenarii reale în care nedreptatea este evidentă în construirea și utilizarea modelelor. Ce altceva ar trebui să luăm în considerare?
Quiz post-lectură
Recapitulare și Studiu Individual
În această lecție, ai învățat câteva instrumente practice pentru integrarea AI responsabilă în învățarea automată.
Urmărește acest workshop pentru a aprofunda subiectele:
- Responsible AI Dashboard: O soluție completă pentru operaționalizarea RAI în practică, prezentată de Besmira Nushi și Mehrnoosh Sameki

🎥 Fă clic pe imaginea de mai sus pentru un videoclip: Responsible AI Dashboard: O soluție completă pentru operaționalizarea RAI în practică, prezentată de Besmira Nushi și Mehrnoosh Sameki
Consultă următoarele materiale pentru a afla mai multe despre AI responsabilă și cum să construiești modele mai de încredere:
-
Instrumentele dashboard-ului RAI de la Microsoft pentru depanarea modelelor ML: Resurse pentru instrumentele AI responsabile
-
Explorează toolkit-ul AI responsabil: Github
-
Centrul de resurse RAI de la Microsoft: Resurse AI Responsabile – Microsoft AI
-
Grupul de cercetare FATE de la Microsoft: FATE: Echitate, Responsabilitate, Transparență și Etică în AI - Microsoft Research
Temă
Declinare de responsabilitate:
Acest document a fost tradus folosind serviciul de traducere AI Co-op Translator. Deși ne străduim să asigurăm acuratețea, vă rugăm să fiți conștienți că traducerile automate pot conține erori sau inexactități. Documentul original în limba sa natală ar trebui considerat sursa autoritară. Pentru informații critice, se recomandă traducerea profesională realizată de un specialist uman. Nu ne asumăm responsabilitatea pentru eventualele neînțelegeri sau interpretări greșite care pot apărea din utilizarea acestei traduceri.