|
|
2 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 2 weeks ago | |
| assignment.md | 2 weeks ago | |
README.md
História da aprendizagem automática
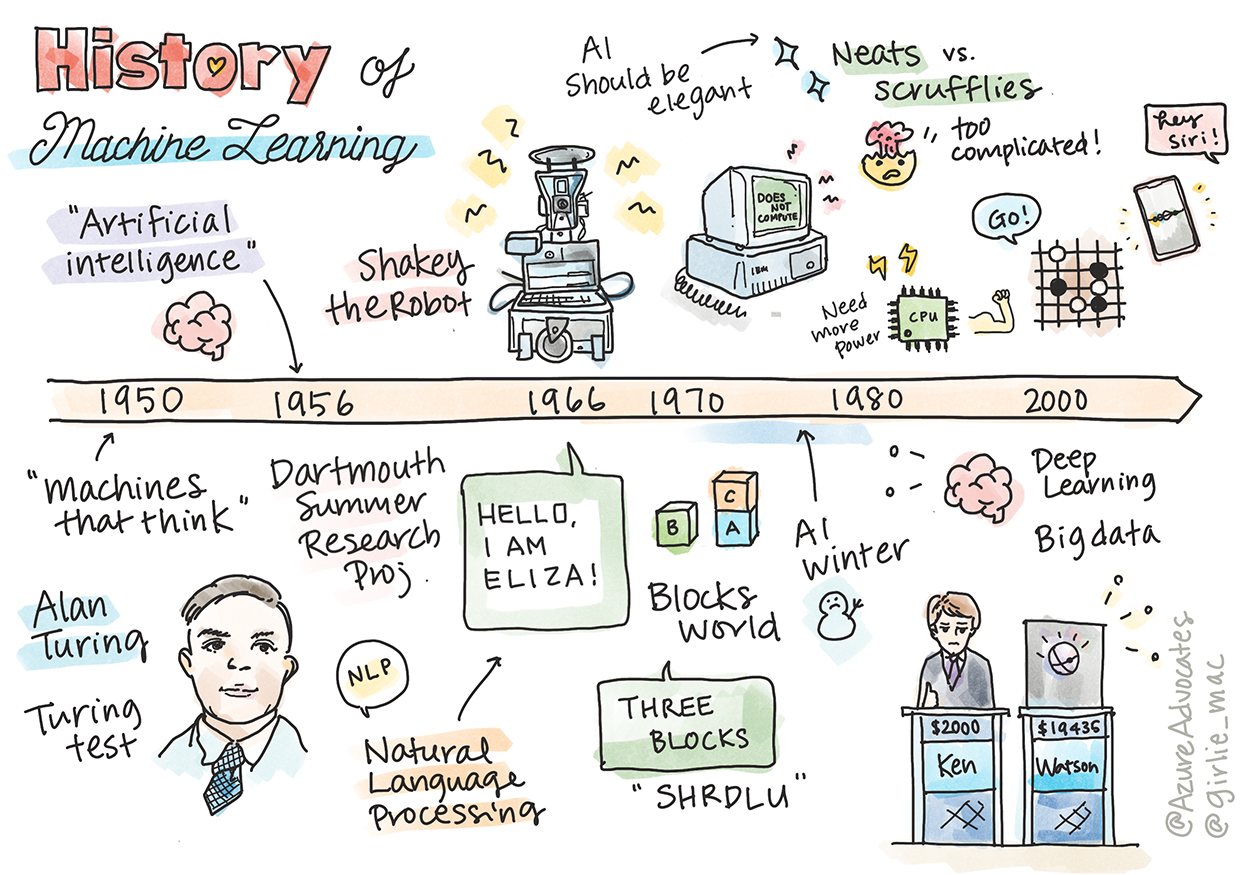
Sketchnote por Tomomi Imura
Questionário pré-aula

🎥 Clique na imagem acima para assistir a um vídeo curto sobre esta lição.
Nesta lição, vamos explorar os principais marcos na história da aprendizagem automática e da inteligência artificial.
A história da inteligência artificial (IA) como campo está entrelaçada com a história da aprendizagem automática, já que os algoritmos e avanços computacionais que sustentam a aprendizagem automática contribuíram para o desenvolvimento da IA. É útil lembrar que, embora esses campos como áreas distintas de investigação tenham começado a se cristalizar na década de 1950, importantes descobertas algorítmicas, estatísticas, matemáticas, computacionais e técnicas precederam e se sobrepuseram a essa era. Na verdade, as pessoas têm pensado sobre essas questões há centenas de anos: este artigo discute os fundamentos intelectuais históricos da ideia de uma 'máquina pensante'.
Descobertas notáveis
- 1763, 1812 Teorema de Bayes e seus predecessores. Este teorema e suas aplicações fundamentam a inferência, descrevendo a probabilidade de um evento ocorrer com base em conhecimento prévio.
- 1805 Teoria dos Mínimos Quadrados pelo matemático francês Adrien-Marie Legendre. Esta teoria, que você aprenderá na nossa unidade de Regressão, ajuda no ajuste de dados.
- 1913 Cadeias de Markov, nomeadas em homenagem ao matemático russo Andrey Markov, são usadas para descrever uma sequência de eventos possíveis com base em um estado anterior.
- 1957 Perceptron é um tipo de classificador linear inventado pelo psicólogo americano Frank Rosenblatt que fundamenta avanços em aprendizagem profunda.
- 1967 Vizinho Mais Próximo é um algoritmo originalmente projetado para mapear rotas. No contexto de aprendizagem automática, é usado para detectar padrões.
- 1970 Retropropagação é usada para treinar redes neurais feedforward.
- 1982 Redes Neurais Recorrentes são redes neurais artificiais derivadas de redes neurais feedforward que criam gráficos temporais.
✅ Faça uma pequena pesquisa. Quais outras datas se destacam como marcos na história da aprendizagem automática e da IA?
1950: Máquinas que pensam
Alan Turing, uma pessoa verdadeiramente notável que foi eleito pelo público em 2019 como o maior cientista do século XX, é creditado por ajudar a estabelecer as bases para o conceito de uma 'máquina que pode pensar'. Ele enfrentou críticos e sua própria necessidade de evidências empíricas desse conceito, em parte criando o Teste de Turing, que você explorará nas nossas lições de PNL.
1956: Projeto de Pesquisa de Verão em Dartmouth
"O Projeto de Pesquisa de Verão em Dartmouth sobre inteligência artificial foi um evento seminal para a inteligência artificial como campo", e foi aqui que o termo 'inteligência artificial' foi cunhado (fonte).
Todo aspecto de aprendizagem ou qualquer outra característica da inteligência pode, em princípio, ser descrito tão precisamente que uma máquina pode ser feita para simulá-lo.
O pesquisador principal, professor de matemática John McCarthy, esperava "prosseguir com base na conjectura de que todo aspecto de aprendizagem ou qualquer outra característica da inteligência pode, em princípio, ser descrito tão precisamente que uma máquina pode ser feita para simulá-lo." Os participantes incluíram outro luminar na área, Marvin Minsky.
O workshop é creditado por ter iniciado e incentivado várias discussões, incluindo "a ascensão de métodos simbólicos, sistemas focados em domínios limitados (primeiros sistemas especialistas) e sistemas dedutivos versus sistemas indutivos." (fonte).
1956 - 1974: "Os anos dourados"
Dos anos 1950 até meados dos anos 70, o otimismo era alto na esperança de que a IA pudesse resolver muitos problemas. Em 1967, Marvin Minsky afirmou confiantemente que "Dentro de uma geração ... o problema de criar 'inteligência artificial' será substancialmente resolvido." (Minsky, Marvin (1967), Computation: Finite and Infinite Machines, Englewood Cliffs, N.J.: Prentice-Hall)
A pesquisa em processamento de linguagem natural floresceu, a busca foi refinada e tornou-se mais poderosa, e o conceito de 'micro-mundos' foi criado, onde tarefas simples eram realizadas usando instruções em linguagem simples.
A pesquisa foi bem financiada por agências governamentais, avanços foram feitos em computação e algoritmos, e protótipos de máquinas inteligentes foram construídos. Algumas dessas máquinas incluem:
-
Shakey o robô, que podia se movimentar e decidir como realizar tarefas 'inteligentemente'.

Shakey em 1972
-
Eliza, um dos primeiros 'chatterbots', podia conversar com pessoas e agir como um 'terapeuta' primitivo. Você aprenderá mais sobre Eliza nas lições de PNL.
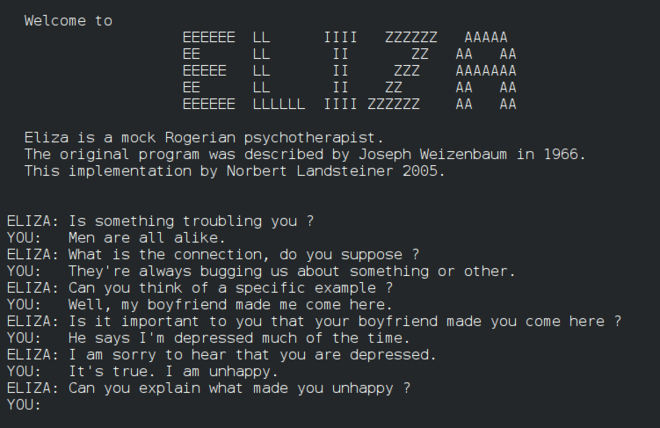
Uma versão de Eliza, um chatbot
-
"Blocks world" foi um exemplo de micro-mundo onde blocos podiam ser empilhados e organizados, e experimentos em ensinar máquinas a tomar decisões podiam ser testados. Avanços construídos com bibliotecas como SHRDLU ajudaram a impulsionar o processamento de linguagem.

🎥 Clique na imagem acima para assistir a um vídeo: Blocks world com SHRDLU
1974 - 1980: "Inverno da IA"
Por volta de meados dos anos 1970, tornou-se evidente que a complexidade de criar 'máquinas inteligentes' havia sido subestimada e que sua promessa, dada a potência computacional disponível, havia sido exagerada. O financiamento secou e a confiança na área diminuiu. Alguns problemas que impactaram a confiança incluíram:
- Limitações. A potência computacional era muito limitada.
- Explosão combinatória. A quantidade de parâmetros necessários para treinar cresceu exponencialmente à medida que mais era exigido dos computadores, sem uma evolução paralela da potência e capacidade computacional.
- Escassez de dados. Havia uma escassez de dados que dificultava o processo de testar, desenvolver e refinar algoritmos.
- Estamos fazendo as perguntas certas?. As próprias perguntas que estavam sendo feitas começaram a ser questionadas. Pesquisadores começaram a enfrentar críticas sobre suas abordagens:
- Os testes de Turing foram questionados por meio, entre outras ideias, da 'teoria da sala chinesa', que postulava que, "programar um computador digital pode fazê-lo parecer entender a linguagem, mas não poderia produzir compreensão real." (fonte)
- A ética de introduzir inteligências artificiais como o "terapeuta" ELIZA na sociedade foi desafiada.
Ao mesmo tempo, várias escolas de pensamento sobre IA começaram a se formar. Uma dicotomia foi estabelecida entre práticas de "IA desleixada" vs. "IA organizada". Laboratórios desleixados ajustavam programas por horas até obterem os resultados desejados. Laboratórios organizados "focavam em lógica e resolução formal de problemas". ELIZA e SHRDLU eram sistemas desleixados bem conhecidos. Nos anos 1980, à medida que surgia a demanda por tornar os sistemas de aprendizagem automática reproduzíveis, a abordagem organizada gradualmente tomou a dianteira, pois seus resultados são mais explicáveis.
Sistemas especialistas nos anos 1980
À medida que a área crescia, seus benefícios para os negócios tornaram-se mais claros, e nos anos 1980 também ocorreu a proliferação de 'sistemas especialistas'. "Os sistemas especialistas estavam entre as primeiras formas verdadeiramente bem-sucedidas de software de inteligência artificial (IA)." (fonte).
Este tipo de sistema é na verdade híbrido, consistindo parcialmente de um motor de regras que define os requisitos de negócios e um motor de inferência que utiliza o sistema de regras para deduzir novos fatos.
Esta era também viu uma atenção crescente às redes neurais.
1987 - 1993: "Resfriamento da IA"
A proliferação de hardware especializado para sistemas especialistas teve o efeito infeliz de se tornar muito especializado. O surgimento dos computadores pessoais também competiu com esses sistemas grandes, especializados e centralizados. A democratização da computação havia começado, e isso eventualmente abriu caminho para a explosão moderna de big data.
1993 - 2011
Este período viu uma nova era para a aprendizagem automática e a IA resolverem alguns dos problemas causados anteriormente pela falta de dados e potência computacional. A quantidade de dados começou a aumentar rapidamente e a se tornar mais amplamente disponível, para o bem e para o mal, especialmente com o advento do smartphone por volta de 2007. A potência computacional expandiu-se exponencialmente, e os algoritmos evoluíram junto. A área começou a ganhar maturidade à medida que os dias livres do passado começaram a se cristalizar em uma verdadeira disciplina.
Hoje
Hoje, a aprendizagem automática e a IA tocam quase todas as partes de nossas vidas. Esta era exige uma compreensão cuidadosa dos riscos e dos potenciais efeitos desses algoritmos na vida humana. Como Brad Smith, da Microsoft, afirmou: "A tecnologia da informação levanta questões que vão ao cerne das proteções fundamentais dos direitos humanos, como privacidade e liberdade de expressão. Essas questões aumentam a responsabilidade das empresas de tecnologia que criam esses produtos. Em nossa visão, elas também exigem uma regulamentação governamental cuidadosa e o desenvolvimento de normas sobre usos aceitáveis" (fonte).
Ainda não se sabe o que o futuro reserva, mas é importante entender esses sistemas computacionais e o software e os algoritmos que eles executam. Esperamos que este currículo o ajude a obter uma melhor compreensão para que você possa decidir por si mesmo.

🎥 Clique na imagem acima para assistir a um vídeo: Yann LeCun discute a história da aprendizagem profunda nesta palestra
🚀Desafio
Aprofunde-se em um desses momentos históricos e aprenda mais sobre as pessoas por trás deles. Há personagens fascinantes, e nenhuma descoberta científica foi criada em um vácuo cultural. O que você descobre?
Questionário pós-aula
Revisão e Estudo Individual
Aqui estão itens para assistir e ouvir:
Este podcast onde Amy Boyd discute a evolução da IA

Tarefa
Aviso Legal:
Este documento foi traduzido utilizando o serviço de tradução por IA Co-op Translator. Embora nos esforcemos para garantir a precisão, esteja ciente de que traduções automáticas podem conter erros ou imprecisões. O documento original na sua língua nativa deve ser considerado a fonte oficial. Para informações críticas, recomenda-se uma tradução profissional realizada por humanos. Não nos responsabilizamos por quaisquer mal-entendidos ou interpretações incorretas resultantes do uso desta tradução.