|
|
2 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 2 weeks ago | |
| assignment.md | 3 weeks ago | |
README.md
後書き: 責任あるAIダッシュボードコンポーネントを使用した機械学習モデルのデバッグ
講義前クイズ
はじめに
機械学習は私たちの日常生活に大きな影響を与えています。AIは、医療、金融、教育、雇用など、個人や社会に影響を与える重要なシステムに浸透しています。例えば、医療診断や詐欺検出など、日々の意思決定に関わるシステムやモデルが存在します。このようなAIの進歩と急速な普及に伴い、社会的期待が進化し、規制が強化されています。AIシステムが期待を裏切る場面が頻繁に見られ、新たな課題が浮き彫りになり、政府はAIソリューションの規制を始めています。そのため、これらのモデルを分析し、公平で信頼性があり、包括的で透明性が高く、責任ある結果を提供することが重要です。
このカリキュラムでは、モデルに責任あるAIの問題があるかどうかを評価するための実用的なツールを紹介します。従来の機械学習デバッグ技術は、集計された精度や平均誤差損失などの定量的計算に基づいていることが多いです。しかし、モデル構築に使用するデータが特定の属性(人種、性別、政治的見解、宗教など)を欠いている場合や、これらの属性が偏って表現されている場合に何が起こるかを想像してみてください。また、モデルの出力が特定の属性を優遇するように解釈される場合はどうでしょうか。このような状況は、モデルの公平性、包括性、信頼性に問題を引き起こす可能性があります。さらに、機械学習モデルはブラックボックスと見なされることが多く、モデルの予測を駆動する要因を理解し説明することが困難です。これらは、モデルの公平性や信頼性を評価するための適切なツールを持たないデータサイエンティストやAI開発者が直面する課題です。
このレッスンでは、以下の方法でモデルをデバッグする方法を学びます:
- エラー分析: データ分布内でモデルのエラー率が高い箇所を特定する。
- モデル概要: 異なるデータコホート間で比較分析を行い、モデルのパフォーマンス指標の格差を発見する。
- データ分析: データの過剰または不足表現がモデルを特定のデータ属性に偏らせる可能性がある箇所を調査する。
- 特徴重要度: モデルの予測をグローバルまたはローカルレベルで駆動する特徴を理解する。
前提条件
前提条件として、開発者向け責任あるAIツールをレビューしてください。

エラー分析
従来のモデルパフォーマンス指標は、正しい予測と誤った予測に基づく計算が主流です。例えば、モデルが89%の精度で誤差損失が0.001である場合、良好なパフォーマンスと見なされることがあります。しかし、エラーは基礎となるデータセット内で均一に分布しているわけではありません。モデルの精度が89%であると評価されても、データの特定の領域でモデルが42%の確率で失敗していることが判明する場合があります。このような特定のデータグループにおける失敗パターンは、公平性や信頼性の問題を引き起こす可能性があります。モデルがどの領域で良好に動作しているか、またはそうでないかを理解することが重要です。モデルの不正確さが多いデータ領域は、重要なデータ属性である可能性があります。

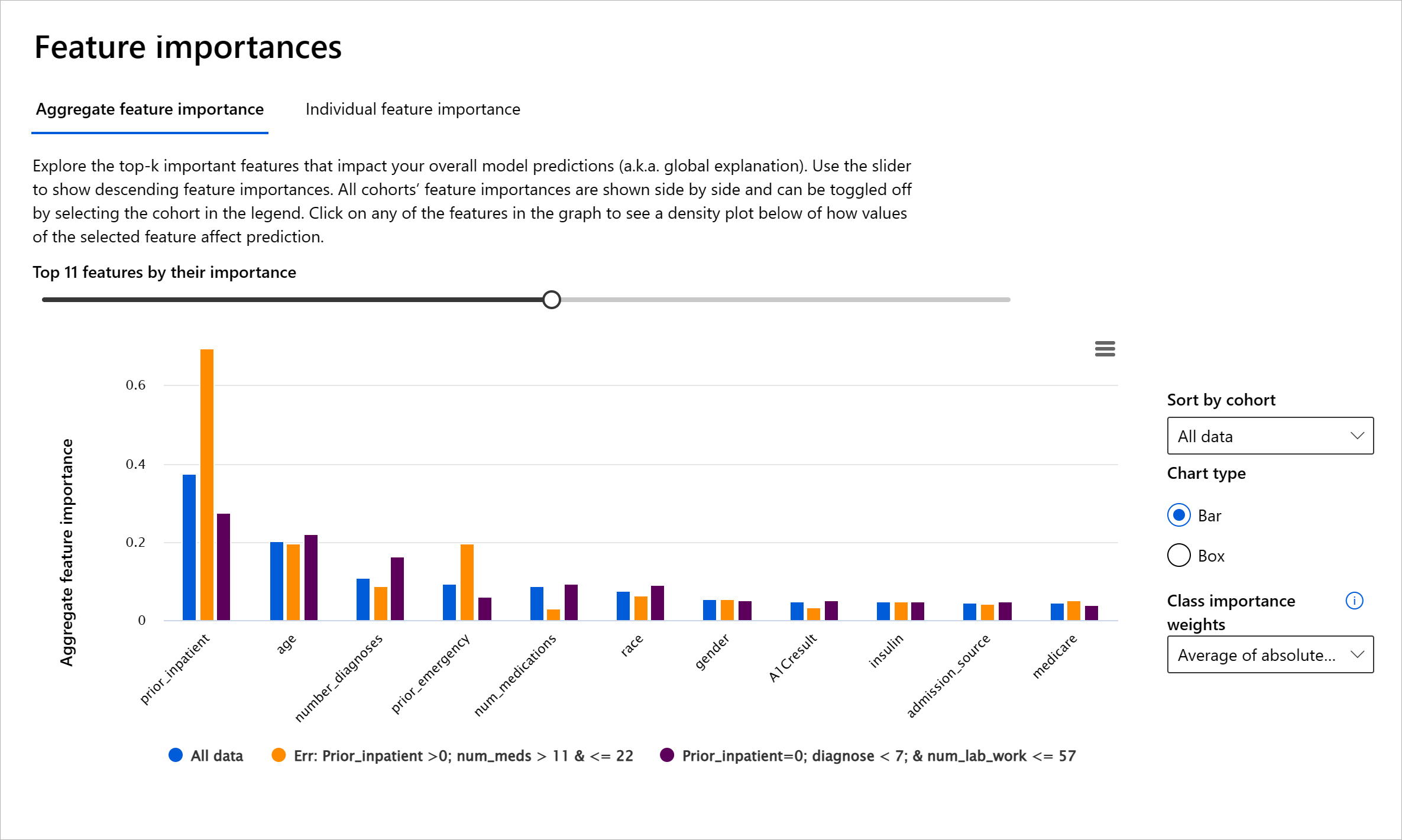
RAIダッシュボードのエラー分析コンポーネントは、ツリーの視覚化を使用してモデルの失敗がさまざまなコホートにどのように分布しているかを示します。これにより、データセット内でエラー率が高い特徴や領域を特定するのに役立ちます。モデルの不正確さの多くがどこから来ているかを確認することで、根本原因の調査を開始できます。また、データコホートを作成して分析を行うことも可能です。これらのデータコホートは、あるコホートでモデルのパフォーマンスが良好である理由、別のコホートで誤りが多い理由を特定するデバッグプロセスに役立ちます。

ツリーマップの視覚的指標は、問題領域を迅速に特定するのに役立ちます。例えば、ツリーノードの赤色が濃いほど、エラー率が高いことを示します。
ヒートマップは、1つまたは2つの特徴を使用してエラー率を調査し、データセット全体やコホート全体でモデルエラーの原因を特定するための別の視覚化機能です。

エラー分析を使用する場面:
- モデルの失敗がデータセット全体や複数の入力・特徴次元にどのように分布しているかを深く理解する。
- 集計パフォーマンス指標を分解し、誤りのあるコホートを自動的に発見して、ターゲットを絞った緩和策を講じる。
モデル概要
機械学習モデルのパフォーマンスを評価するには、その挙動を包括的に理解する必要があります。これを達成するには、エラー率、精度、再現率、適合率、MAE(平均絶対誤差)など、複数の指標をレビューし、パフォーマンス指標間の格差を見つけることが重要です。1つの指標が良好に見えても、別の指標で不正確さが露呈することがあります。さらに、データセット全体やコホート間で指標を比較して格差を見つけることで、モデルがどこで良好に動作しているか、そうでないかを明らかにすることができます。特に、敏感な特徴(例:患者の人種、性別、年齢)と非敏感な特徴の間でモデルのパフォーマンスを確認することで、モデルが持つ潜在的な不公平性を明らかにすることができます。例えば、敏感な特徴を持つコホートでモデルがより多くの誤りを犯していることを発見することで、モデルの不公平性が明らかになる可能性があります。
RAIダッシュボードのモデル概要コンポーネントは、データコホート内のデータ表現のパフォーマンス指標を分析するだけでなく、異なるコホート間でモデルの挙動を比較する機能を提供します。

このコンポーネントの特徴ベースの分析機能により、特定の特徴内のデータサブグループを絞り込み、詳細レベルで異常を特定することができます。例えば、ダッシュボードには、ユーザーが選択した特徴(例:"time_in_hospital < 3" または "time_in_hospital >= 7")に基づいてコホートを自動生成するインテリジェンスが組み込まれています。これにより、ユーザーは大きなデータグループから特定の特徴を分離し、それがモデルの誤った結果の主要な影響要因であるかどうかを確認できます。

モデル概要コンポーネントは、以下の2種類の格差指標をサポートしています:
モデルパフォーマンスの格差: これらの指標は、選択したパフォーマンス指標の値の格差(差異)をデータのサブグループ間で計算します。以下はその例です:
- 精度率の格差
- エラー率の格差
- 適合率の格差
- 再現率の格差
- 平均絶対誤差(MAE)の格差
選択率の格差: この指標は、サブグループ間での選択率(好ましい予測)の差異を含みます。例えば、ローン承認率の格差がこれに該当します。選択率とは、各クラスで1に分類されたデータポイントの割合(バイナリ分類の場合)や予測値の分布(回帰の場合)を意味します。
データ分析
「データを十分に拷問すれば、何でも白状する」 - ロナルド・コース
この言葉は極端に聞こえるかもしれませんが、データはどんな結論を支持するようにでも操作可能であるという点で真実です。このような操作は時に意図せずに発生することがあります。人間は誰しもバイアスを持っており、データにバイアスを導入していることを意識的に認識するのは難しいことがあります。AIや機械学習における公平性を保証することは依然として複雑な課題です。
データは従来のモデルパフォーマンス指標にとって大きな盲点です。高い精度スコアを持っていても、それがデータセット内の潜在的なデータバイアスを反映しているとは限りません。例えば、ある企業の役員ポジションにおける従業員データセットが女性27%、男性73%である場合、このデータでトレーニングされた求人広告AIモデルは、主に男性を対象にしたシニアレベルの求人を予測する可能性があります。このようなデータの不均衡は、モデルの予測を特定の性別に偏らせ、公平性の問題を引き起こします。
RAIダッシュボードのデータ分析コンポーネントは、データセット内で過剰または不足している表現を特定するのに役立ちます。これにより、データの不均衡や特定のデータグループの欠如から生じるエラーや公平性の問題の根本原因を診断することができます。ユーザーは予測結果や実際の結果、エラーグループ、特定の特徴に基づいてデータセットを視覚化することができます。時には、過小表現されているデータグループを発見することで、モデルが十分に学習していないことが明らかになり、それが高い不正確さの原因となることがあります。データバイアスを持つモデルは、公平性の問題だけでなく、包括性や信頼性の欠如を示しています。

データ分析を使用する場面:
- 異なるフィルターを選択してデータをさまざまな次元(コホートとも呼ばれる)に分割し、データセット統計を探索する。
- データセットの分布を異なるコホートや特徴グループ間で理解する。
- 公平性、エラー分析、因果関係(他のダッシュボードコンポーネントから得られる)に関連する発見がデータセットの分布によるものかどうかを判断する。
- 表現の問題、ラベルノイズ、特徴ノイズ、ラベルバイアスなどの要因から生じるエラーを緩和するために、どの領域でデータを収集するべきかを決定する。
モデルの解釈性
機械学習モデルはブラックボックスと見なされることが多いです。モデルの予測を駆動する主要なデータ特徴を理解することは困難です。モデルが特定の予測を行う理由に透明性を提供することが重要です。例えば、AIシステムが糖尿病患者が30日以内に再入院するリスクがあると予測した場合、その予測に至った根拠となるデータを提供するべきです。このような根拠データの指標は、医療従事者や病院が十分な情報に基づいた意思決定を行うのに役立ちます。また、個々の患者に対するモデルの予測理由を説明することで、医療規制における責任を果たすことができます。人々の生活に影響を与える方法で機械学習モデルを使用する場合、モデルの挙動に影響を与える要因を理解し説明することが重要です。モデルの説明可能性と解釈性は、以下のようなシナリオで疑問に答えるのに役立ちます:
- モデルデバッグ: なぜモデルがこの誤りを犯したのか?モデルをどのように改善できるのか?
- 人間とAIの協力: モデルの決定をどのように理解し信頼できるのか?
- 規制遵守: モデルは法的要件を満たしているか?
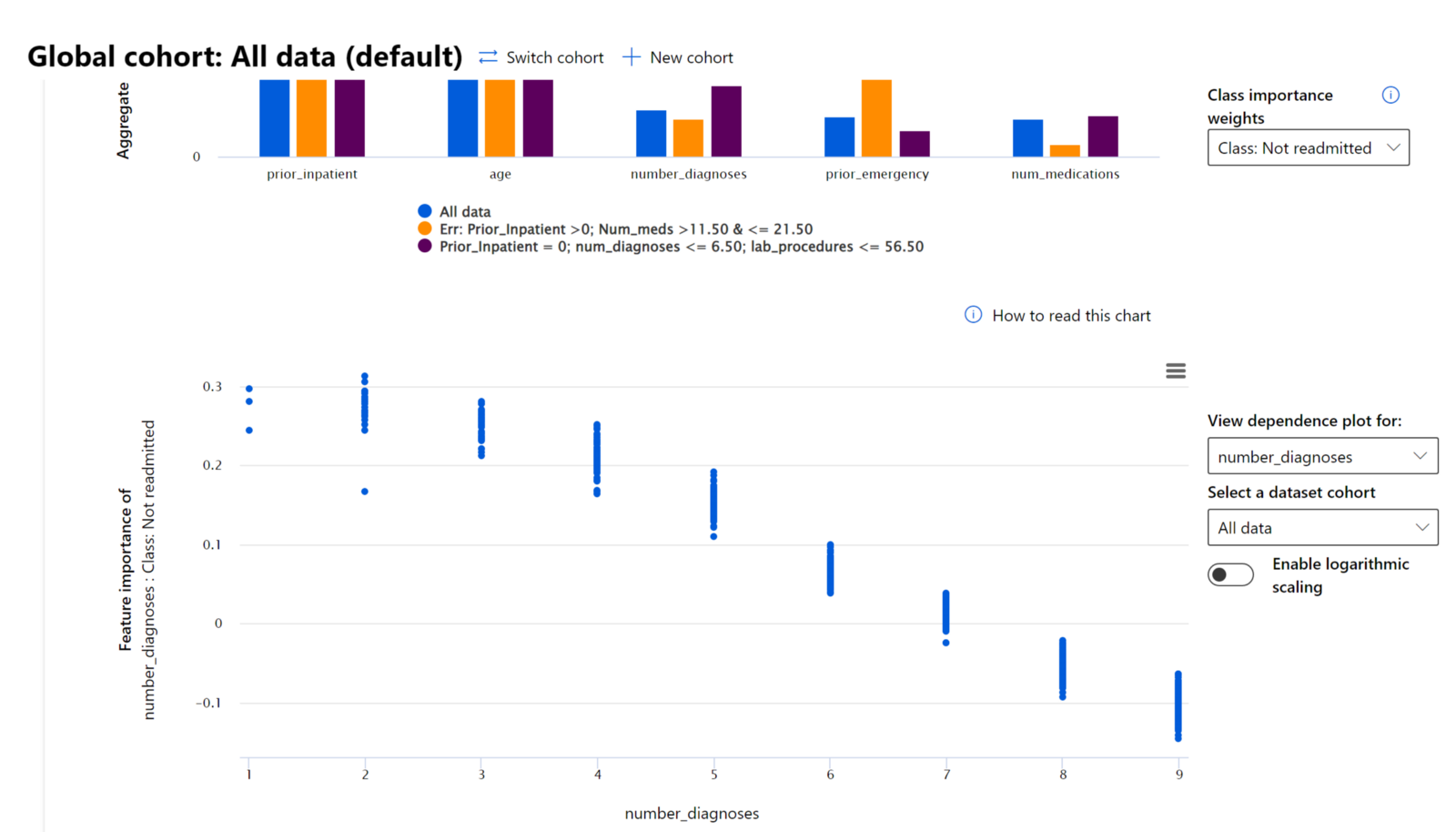
RAIダッシュボードの特徴重要度コンポーネントは、モデルの予測がどのように行われるかを包括的に理解しデバッグするのに役立ちます。また、機械学習の専門家や意思決定者がモデルの挙動に影響を与える特徴の証拠を説明し、規制遵守のために示すのに役立つツールです。次に、ユーザーはグローバルおよびローカルの説明を探索し、モデルの予測を駆動する特徴を検証できます。グローバル説明は、モデルの全体的な予測に影響を与えた主要な特徴をリストします。ローカル説明は、個々のケースに対するモデルの予測理由を表示します。ローカル説明を評価する能力は、特定のケースをデバッグまたは監査し、モデルが正確または不正確な予測を行った理由をよりよく理解し解釈するのに役立ちます。
- グローバル説明: 例えば、糖尿病患者の病院再入院モデルの全体的な挙動に影響を与える特徴は何か?
- ローカル説明: 例えば、60歳以上で以前に入院した糖尿病患者が30日以内に再入院すると予測された理由は何か?
異なるコホート間でモデルのパフォーマンスを調査するデバッグプロセスでは、特徴重要度がコホート全体でどの程度の影響を持つかを示します。特徴がモデルの誤った予測を駆動する際の影響レベルを比較することで異常を明らかにするのに役立ちます。特徴重要度コンポーネントは、特徴内の値がモデルの結果にどのように正または負の影響を与えたかを示すことができます。例えば、モデルが不正確な予測を行った場合、このコンポーネントは予測を駆動した特徴や特徴値を特定する能力を提供します。この詳細レベルは、デバッグだけでなく、監査状況での透明性と責任を提供するのに役立ちます。最後に、このコンポーネントは公平性の問題を特定するのにも役立ちます。例えば、民族性や性別などの敏感な特徴がモデルの予測を駆動する際に非常に影響力がある場合、これはモデルに人種や性別のバイアスがある兆候である可能性があります。
解釈性を使用する場面:
- モデルの予測がどの程度信頼できるかを判断するために、予測に最も重要な特徴を理解する。
- モデルを理解し、誤った相関ではなく
- 過剰または不足の表現。特定のグループがある職業で見られない場合、その状況を促進し続けるサービスや機能は害を与えることに寄与していると考えられます。
Azure RAI ダッシュボード
Azure RAI ダッシュボード は、Microsoftを含む主要な学術機関や組織によって開発されたオープンソースツールを基盤としており、データサイエンティストやAI開発者がモデルの挙動をより深く理解し、AIモデルから生じる望ましくない問題を発見し、軽減するのに役立ちます。
-
RAIダッシュボードのドキュメントを確認して、さまざまなコンポーネントの使い方を学びましょう。
-
Azure Machine Learningでより責任あるAIシナリオをデバッグするためのRAIダッシュボードのサンプルノートブックをチェックしてください。
🚀 チャレンジ
統計的またはデータの偏りが最初から導入されるのを防ぐために、以下を行うべきです:
- システムに取り組む人々の背景や視点の多様性を確保する
- 社会の多様性を反映したデータセットに投資する
- 偏りが発生した際にそれを検出し修正するためのより良い方法を開発する
モデルの構築や使用において不公平が明らかになる現実のシナリオについて考えてみましょう。他に何を考慮すべきでしょうか?
講義後のクイズ
復習と自己学習
このレッスンでは、機械学習に責任あるAIを組み込むための実践的なツールについて学びました。
以下のワークショップを視聴して、トピックをさらに深掘りしてください:
- 責任あるAIダッシュボード:RAIを実践で運用するためのワンストップショップ(Besmira NushiとMehrnoosh Samekiによる)

🎥 上の画像をクリックして動画を視聴してください:Besmira NushiとMehrnoosh Samekiによる「責任あるAIダッシュボード:RAIを実践で運用するためのワンストップショップ」
責任あるAIについてさらに学び、より信頼性の高いモデルを構築する方法を知るために以下の資料を参照してください:
-
MLモデルをデバッグするためのMicrosoftのRAIダッシュボードツール:責任あるAIツールのリソース
-
責任あるAIツールキットを探索する:Github
-
MicrosoftのRAIリソースセンター:責任あるAIリソース – Microsoft AI
-
MicrosoftのFATE研究グループ:FATE: AIにおける公平性、説明責任、透明性、倫理 - Microsoft Research
課題
免責事項:
この文書は、AI翻訳サービス Co-op Translator を使用して翻訳されています。正確性を期すよう努めておりますが、自動翻訳には誤りや不正確な部分が含まれる可能性があります。元の言語で記載された原文が正式な情報源と見なされるべきです。重要な情報については、専門の人間による翻訳を推奨します。本翻訳の利用に起因する誤解や誤認について、当社は一切の責任を負いません。