|
|
2 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 2 weeks ago | |
| assignment.md | 2 weeks ago | |
README.md
Izgradnja rješenja za strojno učenje s odgovornom umjetnom inteligencijom
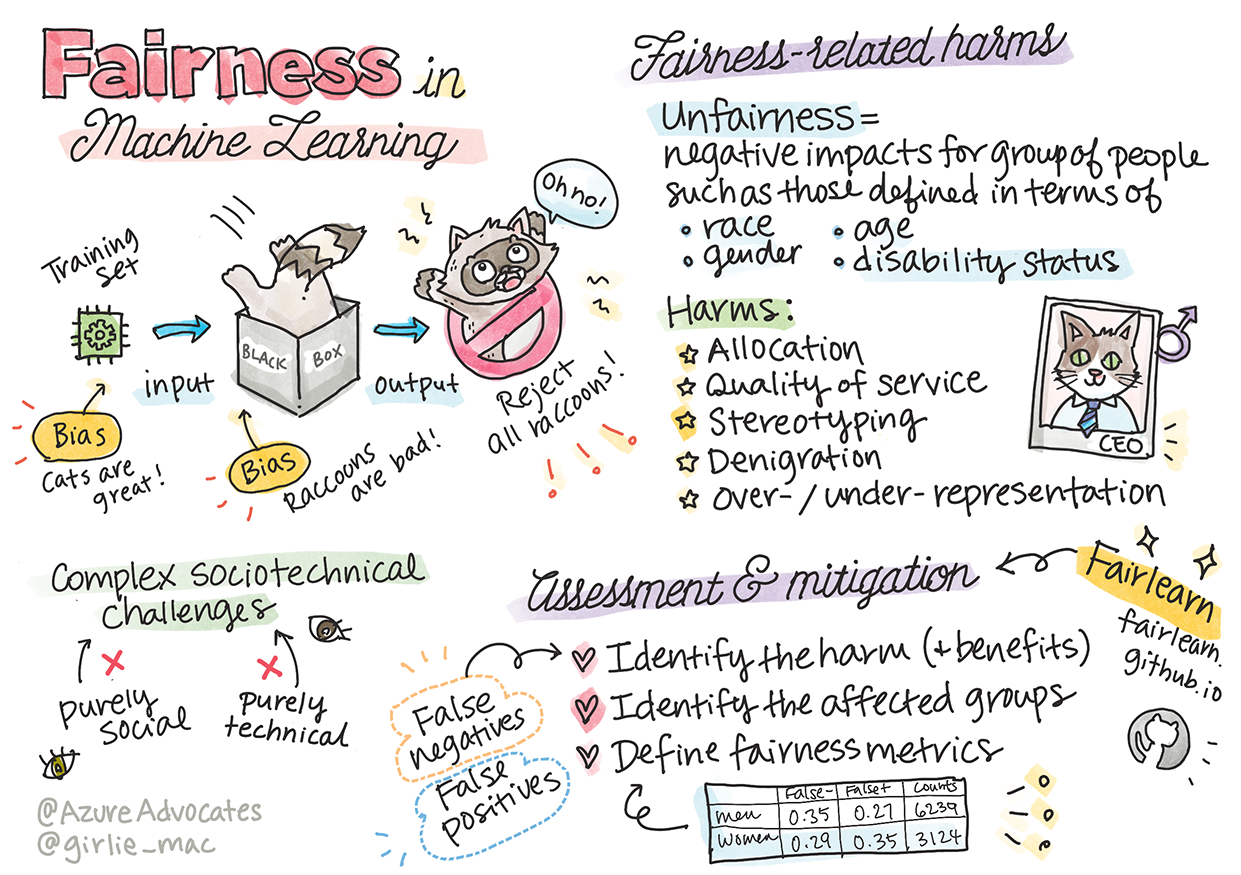
Sketchnote autorice Tomomi Imura
Kviz prije predavanja
Uvod
U ovom kurikulumu počet ćete otkrivati kako strojno učenje može utjecati na naše svakodnevne živote. Već sada sustavi i modeli sudjeluju u svakodnevnim zadacima donošenja odluka, poput dijagnoza u zdravstvenoj skrbi, odobravanja kredita ili otkrivanja prijevara. Stoga je važno da ti modeli dobro funkcioniraju kako bi pružili pouzdane rezultate. Kao i svaka softverska aplikacija, sustavi umjetne inteligencije mogu podbaciti u ispunjavanju očekivanja ili imati neželjene ishode. Zato je ključno razumjeti i objasniti ponašanje AI modela.
Zamislite što se može dogoditi kada podaci koje koristite za izgradnju tih modela nedostaju određene demografske skupine, poput rase, spola, političkih stavova, religije, ili kada su te demografske skupine neproporcionalno zastupljene. Što ako se izlaz modela interpretira tako da favorizira određenu demografsku skupinu? Koje su posljedice za aplikaciju? Osim toga, što se događa kada model ima negativan ishod koji šteti ljudima? Tko je odgovoran za ponašanje AI sustava? Ovo su neka od pitanja koja ćemo istražiti u ovom kurikulumu.
U ovoj lekciji ćete:
- Povećati svijest o važnosti pravednosti u strojnome učenju i štetama povezanim s nepravednošću.
- Upoznati se s praksom istraživanja odstupanja i neobičnih scenarija kako biste osigurali pouzdanost i sigurnost.
- Steći razumijevanje o potrebi osnaživanja svih kroz dizajniranje inkluzivnih sustava.
- Istražiti koliko je važno zaštititi privatnost i sigurnost podataka i ljudi.
- Uvidjeti važnost pristupa "staklene kutije" za objašnjavanje ponašanja AI modela.
- Biti svjesni kako je odgovornost ključna za izgradnju povjerenja u AI sustave.
Preduvjeti
Kao preduvjet, molimo vas da završite "Principi odgovorne umjetne inteligencije" Learn Path i pogledate videozapis u nastavku na tu temu:
Saznajte više o odgovornoj umjetnoj inteligenciji prateći ovaj Learning Path

🎥 Kliknite na sliku iznad za video: Microsoftov pristup odgovornoj umjetnoj inteligenciji
Pravednost
AI sustavi trebali bi tretirati sve ljude jednako i izbjegavati različito utjecanje na slične skupine ljudi. Na primjer, kada AI sustavi pružaju smjernice o medicinskom tretmanu, aplikacijama za kredite ili zapošljavanju, trebali bi davati iste preporuke svima sličnih simptoma, financijskih okolnosti ili profesionalnih kvalifikacija. Svaki od nas kao ljudi nosi naslijeđene pristranosti koje utječu na naše odluke i postupke. Te pristranosti mogu biti vidljive u podacima koje koristimo za treniranje AI sustava. Takva manipulacija ponekad se događa nenamjerno. Često je teško svjesno znati kada uvodite pristranost u podatke.
"Nepravednost" obuhvaća negativne utjecaje ili "štete" za skupinu ljudi, poput onih definiranih prema rasi, spolu, dobi ili statusu invaliditeta. Glavne štete povezane s pravednošću mogu se klasificirati kao:
- Dodjela, ako je, na primjer, spol ili etnička pripadnost favorizirana u odnosu na drugu.
- Kvaliteta usluge. Ako trenirate podatke za jedan specifičan scenarij, ali stvarnost je mnogo složenija, to dovodi do loše izvedbe usluge. Na primjer, dozator sapuna koji ne može prepoznati ljude s tamnom kožom. Referenca
- Omalovažavanje. Nepravedno kritiziranje i označavanje nečega ili nekoga. Na primjer, tehnologija za označavanje slika neslavno je pogrešno označila slike tamnoputih ljudi kao gorile.
- Prekomjerna ili nedovoljna zastupljenost. Ideja da određena skupina nije viđena u određenoj profesiji, a svaka usluga ili funkcija koja to nastavlja promovirati doprinosi šteti.
- Stereotipiziranje. Povezivanje određene skupine s unaprijed dodijeljenim atributima. Na primjer, sustav za prevođenje između engleskog i turskog može imati netočnosti zbog riječi sa stereotipnim asocijacijama na spol.
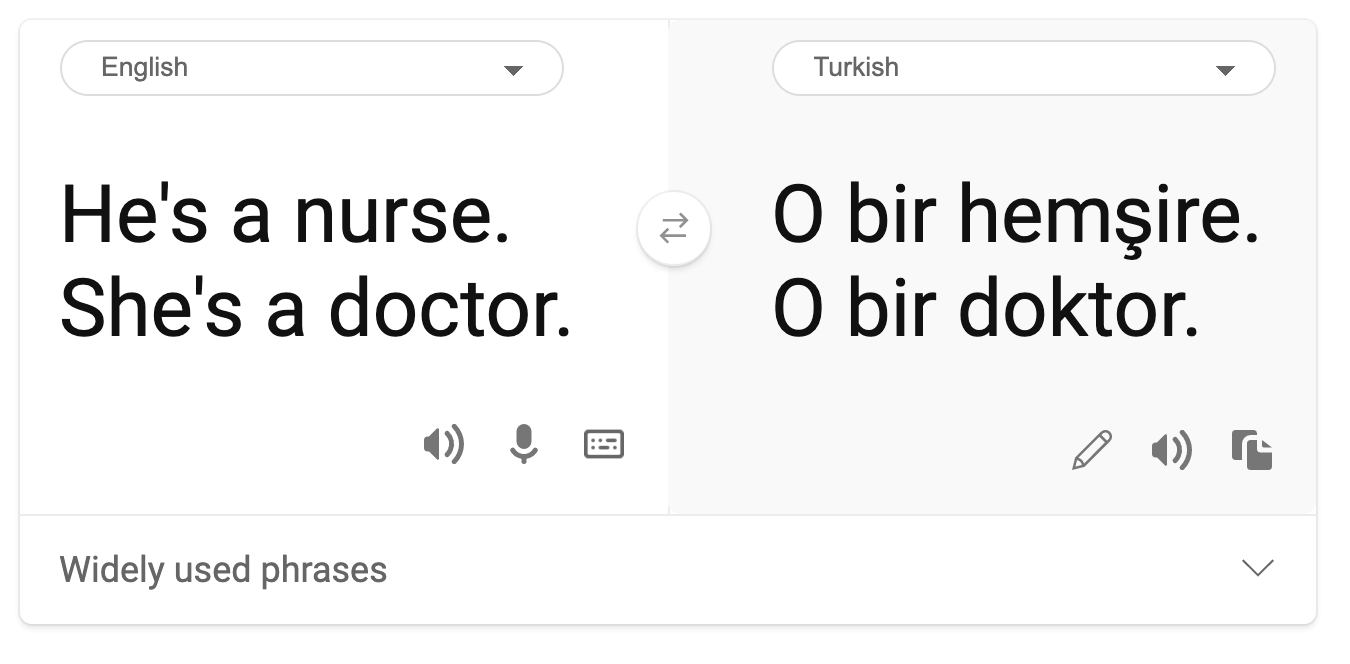
prijevod na turski

prijevod natrag na engleski
Prilikom dizajniranja i testiranja AI sustava, moramo osigurati da AI bude pravedan i da nije programiran za donošenje pristranih ili diskriminatornih odluka, koje su zabranjene i ljudima. Osiguravanje pravednosti u AI i strojnome učenju ostaje složen sociotehnički izazov.
Pouzdanost i sigurnost
Kako bismo izgradili povjerenje, AI sustavi moraju biti pouzdani, sigurni i dosljedni u normalnim i neočekivanim uvjetima. Važno je znati kako će se AI sustavi ponašati u raznim situacijama, posebno kada su u pitanju odstupanja. Prilikom izgradnje AI rješenja, potrebno je posvetiti značajnu pažnju tome kako se nositi s raznim okolnostima koje AI rješenja mogu susresti. Na primjer, samovozeći automobil mora staviti sigurnost ljudi kao glavni prioritet. Kao rezultat toga, AI koji pokreće automobil mora uzeti u obzir sve moguće scenarije s kojima se automobil može susresti, poput noći, oluja, snježnih mećava, djece koja trče preko ulice, kućnih ljubimaca, radova na cesti itd. Koliko dobro AI sustav može pouzdano i sigurno upravljati širokim rasponom uvjeta odražava razinu predviđanja koju je podatkovni znanstvenik ili AI programer uzeo u obzir tijekom dizajna ili testiranja sustava.
Inkluzivnost
AI sustavi trebali bi biti dizajnirani tako da angažiraju i osnažuju sve ljude. Prilikom dizajniranja i implementacije AI sustava, podatkovni znanstvenici i AI programeri identificiraju i rješavaju potencijalne prepreke u sustavu koje bi mogle nenamjerno isključiti ljude. Na primjer, postoji 1 milijarda ljudi s invaliditetom diljem svijeta. S napretkom AI-a, oni mogu lakše pristupiti širokom rasponu informacija i prilika u svakodnevnom životu. Rješavanjem prepreka stvaraju se prilike za inovacije i razvoj AI proizvoda s boljim iskustvima koja koriste svima.
Sigurnost i privatnost
AI sustavi trebali bi biti sigurni i poštovati privatnost ljudi. Ljudi imaju manje povjerenja u sustave koji ugrožavaju njihovu privatnost, informacije ili živote. Prilikom treniranja modela strojnog učenja, oslanjamo se na podatke kako bismo postigli najbolje rezultate. Pritom se mora uzeti u obzir podrijetlo podataka i njihov integritet. Na primjer, jesu li podaci korisnički dostavljeni ili javno dostupni? Nadalje, dok radimo s podacima, ključno je razviti AI sustave koji mogu zaštititi povjerljive informacije i odoljeti napadima. Kako AI postaje sve prisutniji, zaštita privatnosti i osiguranje važnih osobnih i poslovnih informacija postaje sve kritičnija i složenija. Problemi privatnosti i sigurnosti podataka zahtijevaju posebnu pažnju za AI jer je pristup podacima ključan za to da AI sustavi donose točne i informirane predikcije i odluke o ljudima.
- Industrija je postigla značajan napredak u privatnosti i sigurnosti, potaknut značajno regulativama poput GDPR-a (Opća uredba o zaštiti podataka).
- Ipak, s AI sustavima moramo priznati napetost između potrebe za više osobnih podataka kako bi sustavi bili osobniji i učinkovitiji – i privatnosti.
- Kao i s pojavom povezanih računala putem interneta, također vidimo veliki porast broja sigurnosnih problema povezanih s AI-jem.
- Istovremeno, vidimo da se AI koristi za poboljšanje sigurnosti. Na primjer, većina modernih antivirusnih skenera danas se pokreće AI heuristikom.
- Moramo osigurati da naši procesi podatkovne znanosti skladno surađuju s najnovijim praksama privatnosti i sigurnosti.
Transparentnost
AI sustavi trebali bi biti razumljivi. Ključni dio transparentnosti je objašnjavanje ponašanja AI sustava i njihovih komponenti. Poboljšanje razumijevanja AI sustava zahtijeva da dionici shvate kako i zašto funkcioniraju kako bi mogli identificirati potencijalne probleme s izvedbom, zabrinutosti za sigurnost i privatnost, pristranosti, isključujuće prakse ili neželjene ishode. Također vjerujemo da oni koji koriste AI sustave trebaju biti iskreni i otvoreni o tome kada, zašto i kako odlučuju implementirati te sustave, kao i o ograničenjima sustava koje koriste. Na primjer, ako banka koristi AI sustav za podršku svojim odlukama o kreditiranju potrošača, važno je ispitati ishode i razumjeti koji podaci utječu na preporuke sustava. Vlade počinju regulirati AI u različitim industrijama, pa podatkovni znanstvenici i organizacije moraju objasniti ispunjava li AI sustav regulatorne zahtjeve, posebno kada dođe do neželjenog ishoda.
- Budući da su AI sustavi toliko složeni, teško je razumjeti kako funkcioniraju i interpretirati rezultate.
- Taj nedostatak razumijevanja utječe na način na koji se ti sustavi upravljaju, operacionaliziraju i dokumentiraju.
- Taj nedostatak razumijevanja još važnije utječe na odluke donesene na temelju rezultata koje ti sustavi proizvode.
Odgovornost
Ljudi koji dizajniraju i implementiraju AI sustave moraju biti odgovorni za način na koji njihovi sustavi funkcioniraju. Potreba za odgovornošću posebno je važna kod osjetljivih tehnologija poput prepoznavanja lica. Nedavno je porasla potražnja za tehnologijom prepoznavanja lica, posebno od strane organizacija za provedbu zakona koje vide potencijal tehnologije u primjenama poput pronalaženja nestale djece. Međutim, te tehnologije potencijalno bi mogle biti korištene od strane vlada za ugrožavanje temeljnih sloboda građana, primjerice omogućavanjem kontinuiranog nadzora određenih pojedinaca. Stoga podatkovni znanstvenici i organizacije moraju biti odgovorni za način na koji njihov AI sustav utječe na pojedince ili društvo.
🎥 Kliknite na sliku iznad za video: Upozorenja o masovnom nadzoru putem prepoznavanja lica
Na kraju, jedno od najvećih pitanja za našu generaciju, kao prvu generaciju koja donosi AI u društvo, jest kako osigurati da računala ostanu odgovorna ljudima i kako osigurati da ljudi koji dizajniraju računala ostanu odgovorni svima ostalima.
Procjena utjecaja
Prije treniranja modela strojnog učenja, važno je provesti procjenu utjecaja kako biste razumjeli svrhu AI sustava; koja je namjeravana upotreba; gdje će biti implementiran; i tko će komunicirati sa sustavom. Ovo je korisno za recenzente ili testere koji procjenjuju sustav kako bi znali koje čimbenike uzeti u obzir prilikom identificiranja potencijalnih rizika i očekivanih posljedica.
Sljedeća su područja fokusa prilikom provođenja procjene utjecaja:
- Negativan utjecaj na pojedince. Svijest o bilo kakvim ograničenjima ili zahtjevima, nepodržanoj upotrebi ili poznatim ograničenjima koja ometaju izvedbu sustava ključna je kako bi se osiguralo da sustav nije korišten na način koji bi mogao nanijeti štetu pojedincima.
- Zahtjevi za podatke. Razumijevanje kako i gdje će sustav koristiti podatke omogućuje recenzentima da istraže sve zahtjeve za podatke na koje treba obratiti pažnju (npr. GDPR ili HIPPA regulative). Osim toga, provjerite je li izvor ili količina podataka dovoljna za treniranje.
- Sažetak utjecaja. Prikupite popis potencijalnih šteta koje bi mogle nastati korištenjem sustava. Tijekom životnog ciklusa ML-a, provjerite jesu li identificirani problemi ublaženi ili riješeni.
- Primjenjivi ciljevi za svaki od šest osnovnih principa. Procijenite jesu li ciljevi iz svakog principa ispunjeni i postoje li praznine.
Otklanjanje pogrešaka s odgovornom umjetnom inteligencijom
Slično otklanjanju pogrešaka u softverskoj aplikaciji, otklanjanje pogrešaka u AI sustavu nužan je proces identificiranja i rješavanja problema u sustavu. Postoji mnogo čimbenika koji mogu utjecati na to da model ne funkcionira kako se očekuje ili odgovorno. Većina tradicionalnih metrika izvedbe modela su kvantitativni agregati izvedbe modela, što nije dovoljno za analizu kako model krši principe odgovorne umjetne inteligencije. Nadalje, model strojnog učenja je "crna kutija" koja otežava razumijevanje što pokreće njegov ishod ili pružanje objašnjenja kada pogriješi. Kasnije u ovom tečaju naučit ćemo kako koristiti nadzornu ploču odgovorne umjetne inteligencije za pomoć pri otklanjanju pogrešaka u AI sustavima. Nadzorna ploča pruža holistički alat za podatkovne znanstvenike i AI programere za obavljanje:
- Analize pogrešaka. Identificiranje distribucije pogrešaka modela koje mogu utjecati na pravednost ili pouzdanost sustava.
- Pregleda modela. Otkrivanje gdje postoje razlike u izvedbi modela među skupovima podataka.
- Analize podataka. Razumijevanje distribucije podataka i identificiranje potencijalne pristranosti u podacima koja bi mogla dovesti do problema s pravednošću, inkluzivnošću i pouzdanošću.
- Interpretacije modela. Razumijevanje što utječe ili utječe na predikcije modela. Ovo pomaže u objašnjavanju ponašanja modela, što je važno za transparentnost i odgovornost.
🚀 Izazov
Kako bismo spriječili da se štete uopće uvedu, trebali bismo:
- imati raznolikost pozadina i perspektiva među ljudima koji rade na sustavima
- ulagati u skupove podataka koji odražavaju raznolikost našeg društva
- razviti bolje metode tijekom životnog ciklusa strojnog učenja za otkrivanje i ispravljanje odgovorne umjetne inteligencije kada se pojavi
Razmislite o stvarnim scenarijima gdje je nepouzdanost modela očita u Pogledajte ovu radionicu za dublje razumijevanje tema:
- U potrazi za odgovornom umjetnom inteligencijom: Primjena principa u praksi od Besmire Nushi, Mehrnoosh Sameki i Amita Sharme

🎥 Kliknite na sliku iznad za video: RAI Toolbox: Otvoreni okvir za izgradnju odgovorne umjetne inteligencije od Besmire Nushi, Mehrnoosh Sameki i Amita Sharme
Također, pročitajte:
-
Microsoftov centar resursa za odgovornu umjetnu inteligenciju: Responsible AI Resources – Microsoft AI
-
Microsoftova FATE istraživačka grupa: FATE: Fairness, Accountability, Transparency, and Ethics in AI - Microsoft Research
RAI Toolbox:
Pročitajte o alatima Azure Machine Learninga za osiguranje pravednosti:
Zadatak
Odricanje od odgovornosti:
Ovaj dokument je preveden korištenjem AI usluge za prevođenje Co-op Translator. Iako nastojimo osigurati točnost, imajte na umu da automatski prijevodi mogu sadržavati pogreške ili netočnosti. Izvorni dokument na izvornom jeziku treba smatrati mjerodavnim izvorom. Za ključne informacije preporučuje se profesionalni prijevod od strane stručnjaka. Ne preuzimamo odgovornost za bilo kakva nesporazuma ili pogrešna tumačenja koja mogu proizaći iz korištenja ovog prijevoda.