|
|
2 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 2 weeks ago | |
| assignment.md | 3 weeks ago | |
README.md
पोस्टस्क्रिप्ट: मशीन लर्निंग में मॉडल डिबगिंग का जिम्मेदार AI डैशबोर्ड घटकों के साथ उपयोग
प्री-लेक्चर क्विज़
परिचय
मशीन लर्निंग हमारे दैनिक जीवन को प्रभावित करती है। AI स्वास्थ्य देखभाल, वित्त, शिक्षा, और रोजगार जैसे महत्वपूर्ण क्षेत्रों में प्रवेश कर रही है, जो हमारे व्यक्तिगत और सामाजिक जीवन को प्रभावित करती है। उदाहरण के लिए, सिस्टम और मॉडल दैनिक निर्णय लेने वाले कार्यों में शामिल होते हैं, जैसे स्वास्थ्य देखभाल निदान या धोखाधड़ी का पता लगाना। AI की प्रगति और तेजी से अपनाने के साथ, समाज की अपेक्षाएं और नियमन भी विकसित हो रहे हैं। हम लगातार देखते हैं कि AI सिस्टम अपेक्षाओं को पूरा करने में विफल रहते हैं, नई चुनौतियों को उजागर करते हैं, और सरकारें AI समाधानों को नियंत्रित करना शुरू कर रही हैं। इसलिए, यह महत्वपूर्ण है कि इन मॉडलों का विश्लेषण किया जाए ताकि सभी के लिए निष्पक्ष, विश्वसनीय, समावेशी, पारदर्शी और उत्तरदायी परिणाम प्रदान किए जा सकें।
इस पाठ्यक्रम में, हम व्यावहारिक उपकरणों पर ध्यान देंगे जो यह आकलन करने में मदद करते हैं कि क्या किसी मॉडल में जिम्मेदार AI से संबंधित समस्याएं हैं। पारंपरिक मशीन लर्निंग डिबगिंग तकनीकें आमतौर पर मात्रात्मक गणनाओं पर आधारित होती हैं, जैसे समग्र सटीकता या औसत त्रुटि हानि। कल्पना करें कि जब आप इन मॉडलों को बनाने के लिए उपयोग किए जा रहे डेटा में कुछ जनसांख्यिकी, जैसे जाति, लिंग, राजनीतिक दृष्टिकोण, धर्म, या असमान रूप से प्रतिनिधित्व करने वाले जनसांख्यिकी की कमी होती है, तो क्या हो सकता है। या जब मॉडल का आउटपुट कुछ जनसांख्यिकी को प्राथमिकता देता है। यह संवेदनशील फीचर समूहों के अति या कम प्रतिनिधित्व को पेश कर सकता है, जिससे मॉडल में निष्पक्षता, समावेशिता, या विश्वसनीयता की समस्याएं उत्पन्न हो सकती हैं। इसके अलावा, मशीन लर्निंग मॉडल को अक्सर "ब्लैक बॉक्स" माना जाता है, जिससे यह समझना और समझाना मुश्किल हो जाता है कि मॉडल की भविष्यवाणी को क्या प्रेरित करता है। ये सभी चुनौतियां डेटा वैज्ञानिकों और AI डेवलपर्स के सामने आती हैं जब उनके पास मॉडल की निष्पक्षता या विश्वसनीयता का आकलन करने के लिए पर्याप्त उपकरण नहीं होते।
इस पाठ में, आप अपने मॉडलों को डिबग करने के बारे में सीखेंगे:
- त्रुटि विश्लेषण: यह पहचानें कि आपके डेटा वितरण में मॉडल की त्रुटि दरें कहाँ अधिक हैं।
- मॉडल ओवरव्यू: विभिन्न डेटा समूहों के बीच तुलनात्मक विश्लेषण करें ताकि आपके मॉडल के प्रदर्शन मेट्रिक्स में असमानताओं की खोज की जा सके।
- डेटा विश्लेषण: यह जांचें कि आपके डेटा में कहाँ अति या कम प्रतिनिधित्व हो सकता है, जो आपके मॉडल को एक डेटा जनसांख्यिकी को दूसरे के मुकाबले प्राथमिकता देने के लिए प्रभावित कर सकता है।
- फीचर इंपॉर्टेंस: यह समझें कि कौन से फीचर्स आपके मॉडल की भविष्यवाणियों को वैश्विक स्तर या स्थानीय स्तर पर प्रेरित कर रहे हैं।
पूर्वापेक्षा
पूर्वापेक्षा के रूप में, कृपया डेवलपर्स के लिए जिम्मेदार AI उपकरण की समीक्षा करें।

त्रुटि विश्लेषण
पारंपरिक मॉडल प्रदर्शन मेट्रिक्स, जो सटीकता को मापने के लिए उपयोग किए जाते हैं, मुख्य रूप से सही बनाम गलत भविष्यवाणियों पर आधारित गणनाएँ होती हैं। उदाहरण के लिए, यह निर्धारित करना कि एक मॉडल 89% समय सटीक है और इसकी त्रुटि हानि 0.001 है, इसे अच्छा प्रदर्शन माना जा सकता है। हालांकि, त्रुटियां आपके अंतर्निहित डेटा सेट में समान रूप से वितरित नहीं होती हैं। आप 89% मॉडल सटीकता स्कोर प्राप्त कर सकते हैं, लेकिन यह पता लगा सकते हैं कि आपके डेटा के विभिन्न क्षेत्रों में मॉडल 42% समय विफल हो रहा है। इन विफलता पैटर्न के परिणामस्वरूप कुछ डेटा समूहों के साथ निष्पक्षता या विश्वसनीयता की समस्याएं हो सकती हैं। यह समझना आवश्यक है कि मॉडल कहाँ अच्छा प्रदर्शन कर रहा है और कहाँ नहीं। डेटा क्षेत्रों में जहाँ आपके मॉडल में उच्च त्रुटियां हैं, वे महत्वपूर्ण डेटा जनसांख्यिकी हो सकते हैं।

RAI डैशबोर्ड पर त्रुटि विश्लेषण घटक यह दिखाता है कि मॉडल विफलता विभिन्न समूहों में कैसे वितरित होती है, और इसे एक ट्री विज़ुअलाइज़ेशन के माध्यम से प्रदर्शित करता है। यह आपके डेटा सेट में उच्च त्रुटि दर वाले फीचर्स या क्षेत्रों की पहचान करने में उपयोगी है। यह देखने से कि मॉडल की अधिकांश त्रुटियां कहाँ से आ रही हैं, आप मूल कारण की जांच शुरू कर सकते हैं। आप डेटा समूह भी बना सकते हैं ताकि उन पर विश्लेषण किया जा सके। ये डेटा समूह डिबगिंग प्रक्रिया में मदद करते हैं ताकि यह निर्धारित किया जा सके कि मॉडल का प्रदर्शन एक समूह में अच्छा क्यों है, लेकिन दूसरे में गलत है।

ट्री मैप पर दृश्य संकेतक समस्या क्षेत्रों को तेजी से खोजने में मदद करते हैं। उदाहरण के लिए, ट्री नोड का गहरा लाल रंग त्रुटि दर को अधिक दिखाता है।
हीट मैप एक और विज़ुअलाइज़ेशन कार्यक्षमता है जिसे उपयोगकर्ता एक या दो फीचर्स का उपयोग करके त्रुटि दर की जांच करने के लिए उपयोग कर सकते हैं, ताकि पूरे डेटा सेट या समूहों में मॉडल त्रुटियों के योगदानकर्ता को खोजा जा सके।

त्रुटि विश्लेषण का उपयोग करें जब आपको आवश्यकता हो:
- यह गहराई से समझने की कि मॉडल विफलताएं डेटा सेट और कई इनपुट और फीचर आयामों में कैसे वितरित होती हैं।
- समग्र प्रदर्शन मेट्रिक्स को तोड़कर त्रुटिपूर्ण समूहों की स्वचालित खोज करें ताकि लक्षित सुधारात्मक कदमों की जानकारी प्राप्त हो सके।
मॉडल ओवरव्यू
मशीन लर्निंग मॉडल के प्रदर्शन का मूल्यांकन करने के लिए उसके व्यवहार की समग्र समझ प्राप्त करना आवश्यक है। यह त्रुटि दर, सटीकता, रिकॉल, प्रिसिजन, या MAE (मीन एब्सोल्यूट एरर) जैसे एक से अधिक मेट्रिक्स की समीक्षा करके प्राप्त किया जा सकता है ताकि प्रदर्शन मेट्रिक्स में असमानताओं का पता लगाया जा सके। एक प्रदर्शन मेट्रिक अच्छा लग सकता है, लेकिन दूसरे मेट्रिक में गलतियां उजागर हो सकती हैं। इसके अलावा, पूरे डेटा सेट या समूहों में मेट्रिक्स की तुलना करना यह दिखाने में मदद करता है कि मॉडल कहाँ अच्छा प्रदर्शन कर रहा है और कहाँ नहीं। यह विशेष रूप से संवेदनशील बनाम असंवेदनशील फीचर्स (जैसे, रोगी की जाति, लिंग, या आयु) के बीच मॉडल के प्रदर्शन को देखने में महत्वपूर्ण है ताकि संभावित अनुचितता का पता लगाया जा सके। उदाहरण के लिए, यह पता लगाना कि मॉडल एक समूह में अधिक त्रुटिपूर्ण है जिसमें संवेदनशील फीचर्स हैं, संभावित अनुचितता को उजागर कर सकता है।
RAI डैशबोर्ड का मॉडल ओवरव्यू घटक न केवल डेटा प्रतिनिधित्व के प्रदर्शन मेट्रिक्स का विश्लेषण करने में मदद करता है, बल्कि यह उपयोगकर्ताओं को विभिन्न समूहों में मॉडल के व्यवहार की तुलना करने की क्षमता भी देता है।

घटक की फीचर-आधारित विश्लेषण कार्यक्षमता उपयोगकर्ताओं को एक विशेष फीचर के भीतर डेटा उपसमूहों को संकीर्ण करने की अनुमति देती है ताकि ग्रैन्युलर स्तर पर विसंगतियों की पहचान की जा सके। उदाहरण के लिए, डैशबोर्ड में उपयोगकर्ता-चयनित फीचर (जैसे, "time_in_hospital < 3" या "time_in_hospital >= 7") के लिए स्वचालित रूप से समूह बनाने की अंतर्निहित बुद्धिमत्ता है। यह उपयोगकर्ता को एक बड़े डेटा समूह से एक विशेष फीचर को अलग करने में सक्षम बनाता है ताकि यह देखा जा सके कि यह मॉडल के गलत परिणामों का प्रमुख प्रभावक है या नहीं।

मॉडल ओवरव्यू घटक दो प्रकार के असमानता मेट्रिक्स का समर्थन करता है:
मॉडल प्रदर्शन में असमानता: ये मेट्रिक्स डेटा के उपसमूहों में चयनित प्रदर्शन मेट्रिक के मानों में असमानता (अंतर) की गणना करते हैं। यहाँ कुछ उदाहरण हैं:
- सटीकता दर में असमानता
- त्रुटि दर में असमानता
- प्रिसिजन में असमानता
- रिकॉल में असमानता
- मीन एब्सोल्यूट एरर (MAE) में असमानता
चयन दर में असमानता: यह मेट्रिक उपसमूहों के बीच चयन दर (अनुकूल भविष्यवाणी) में अंतर को शामिल करता है। इसका एक उदाहरण ऋण स्वीकृति दर में असमानता है। चयन दर का मतलब है प्रत्येक वर्ग में डेटा पॉइंट्स का अंश जिसे 1 के रूप में वर्गीकृत किया गया है (बाइनरी वर्गीकरण में) या भविष्यवाणी मानों का वितरण (रिग्रेशन में)।
डेटा विश्लेषण
"यदि आप डेटा को लंबे समय तक यातना देंगे, तो यह किसी भी निष्कर्ष को स्वीकार कर लेगा" - रोनाल्ड कोस
यह कथन अतिशयोक्तिपूर्ण लगता है, लेकिन यह सच है कि डेटा को किसी भी निष्कर्ष का समर्थन करने के लिए हेरफेर किया जा सकता है। ऐसा हेरफेर कभी-कभी अनजाने में हो सकता है। इंसानों के रूप में, हम सभी में पूर्वाग्रह होते हैं, और यह जानना अक्सर कठिन होता है कि आप डेटा में कब पूर्वाग्रह पेश कर रहे हैं। AI और मशीन लर्निंग में निष्पक्षता सुनिश्चित करना एक जटिल चुनौती बनी हुई है।
डेटा पारंपरिक मॉडल प्रदर्शन मेट्रिक्स के लिए एक बड़ा अंधा स्थान है। आपके पास उच्च सटीकता स्कोर हो सकते हैं, लेकिन यह हमेशा आपके डेटा सेट में अंतर्निहित डेटा पूर्वाग्रह को प्रतिबिंबित नहीं करता है। उदाहरण के लिए, यदि किसी कंपनी में कार्यकारी पदों पर महिलाओं का प्रतिशत 27% है और पुरुषों का 73%, तो इस डेटा पर प्रशिक्षित एक नौकरी विज्ञापन AI मॉडल वरिष्ठ स्तर की नौकरी पदों के लिए मुख्य रूप से पुरुष दर्शकों को लक्षित कर सकता है। इस डेटा असंतुलन ने मॉडल की भविष्यवाणी को एक लिंग को प्राथमिकता देने के लिए प्रभावित किया। यह एक निष्पक्षता समस्या को उजागर करता है जहाँ AI मॉडल में लिंग पूर्वाग्रह है।
RAI डैशबोर्ड पर डेटा विश्लेषण घटक यह पहचानने में मदद करता है कि डेटा सेट में कहाँ अति- और कम-प्रतिनिधित्व है। यह उपयोगकर्ताओं को डेटा असंतुलन या किसी विशेष डेटा समूह के प्रतिनिधित्व की कमी से उत्पन्न त्रुटियों और निष्पक्षता समस्याओं के मूल कारण का निदान करने में मदद करता है। यह उपयोगकर्ताओं को भविष्यवाणी और वास्तविक परिणामों, त्रुटि समूहों, और विशिष्ट फीचर्स के आधार पर डेटा सेट को विज़ुअलाइज़ करने की क्षमता देता है। कभी-कभी एक कम प्रतिनिधित्व वाले डेटा समूह की खोज यह भी उजागर कर सकती है कि मॉडल अच्छी तरह से सीख नहीं रहा है, इसलिए उच्च त्रुटियां हैं। डेटा पूर्वाग्रह वाला मॉडल न केवल एक निष्पक्षता समस्या है बल्कि यह दिखाता है कि मॉडल समावेशी या विश्वसनीय नहीं है।

डेटा विश्लेषण का उपयोग करें जब आपको आवश्यकता हो:
- विभिन्न फ़िल्टर का चयन करके अपने डेटा सेट के आँकड़ों का अन्वेषण करें ताकि अपने डेटा को विभिन्न आयामों (जिसे समूह भी कहा जाता है) में विभाजित किया जा सके।
- विभिन्न समूहों और फीचर समूहों में अपने डेटा सेट के वितरण को समझें।
- यह निर्धारित करें कि निष्पक्षता, त्रुटि विश्लेषण, और कारणता से संबंधित आपकी खोजें (अन्य डैशबोर्ड घटकों से प्राप्त) आपके डेटा सेट के वितरण का परिणाम हैं।
- यह तय करें कि किन क्षेत्रों में अधिक डेटा एकत्र करना है ताकि प्रतिनिधित्व समस्याओं, लेबल शोर, फीचर शोर, लेबल पूर्वाग्रह, और इसी तरह के कारकों से उत्पन्न त्रुटियों को कम किया जा सके।
मॉडल व्याख्या
मशीन लर्निंग मॉडल अक्सर "ब्लैक बॉक्स" होते हैं। यह समझना कि कौन से प्रमुख डेटा फीचर्स मॉडल की भविष्यवाणी को प्रेरित करते हैं, चुनौतीपूर्ण हो सकता है। यह महत्वपूर्ण है कि यह पारदर्शिता प्रदान की जाए कि मॉडल ने एक निश्चित भविष्यवाणी क्यों की। उदाहरण के लिए, यदि एक AI सिस्टम भविष्यवाणी करता है कि एक मधुमेह रोगी को 30 दिनों से कम समय में अस्पताल में फिर से भर्ती होने का जोखिम है, तो इसे अपनी भविष्यवाणी के पीछे सहायक डेटा प्रदान करना चाहिए। सहायक डेटा संकेतक पारदर्शिता लाते हैं ताकि चिकित्सक या अस्पताल अच्छी तरह से सूचित निर्णय ले सकें। इसके अलावा, यह समझाने में सक्षम होना कि मॉडल ने एक व्यक्तिगत रोगी के लिए भविष्यवाणी क्यों की, स्वास्थ्य नियमों के साथ उत्तरदायित्व को सक्षम बनाता है। जब आप मशीन लर्निंग मॉडल का उपयोग ऐसे तरीकों से कर रहे हैं जो लोगों के जीवन को प्रभावित करते हैं, तो यह समझना और समझाना महत्वपूर्ण है कि मॉडल के व्यवहार को क्या प्रभावित करता है। मॉडल व्याख्या और समझाने की क्षमता निम्नलिखित परिदृश्यों में सवालों के जवाब देने में मदद करती है:
- मॉडल डिबगिंग: मेरे मॉडल ने यह गलती क्यों की? मैं अपने मॉडल को कैसे सुधार सकता हूँ?
- मानव-AI सहयोग: मैं मॉडल के निर्णयों को कैसे समझ सकता हूँ और उन पर भरोसा कर सकता हूँ?
- नियामक अनुपालन: क्या मेरा मॉडल कानूनी आवश्यकताओं को पूरा करता है?
RAI डैशबोर्ड का फीचर इंपॉर्टेंस घटक आपको डिबग करने और यह समझने में मदद करता है कि मॉडल भविष्यवाणियाँ कैसे करता है। यह मशीन लर्निंग पेशेवरों और निर्णय लेने वालों के लिए एक उपयोगी उपकरण है ताकि मॉडल के व्यवहार को प्रभावित करने वाले फीचर्स के प्रमाण दिखाए जा सकें और नियामक अनुपालन के लिए इसे समझाया जा सके। इसके बाद, उपयोगकर्ता वैश्विक और स्थानीय व्याख्याओं का अन्वेषण कर सकते हैं ताकि यह सत्यापित किया जा सके कि कौन से फीचर्स मॉडल की भविष्यवाणी को प्रेरित करते हैं। वैश्विक व्याख्याएँ उन शीर्ष फीचर्स को सूचीबद्ध करती हैं जिन्होंने मॉडल की समग्र भविष्यवाणी को प्रभावित किया। स्थानीय व्याख्याएँ यह दिखाती हैं कि किसी व्यक्तिगत मामले के लिए मॉडल की भविष्यवाणी को कौन से फीचर्स प्रेरित करते हैं। स्थानीय व्याख्याओं का मूल्यांकन करना किसी विशेष मामले को डिबग या ऑडिट करने में भी मदद करता है ताकि यह बेहतर समझा जा सके कि मॉडल ने सही या गलत भविष्यवाणी क्यों की।
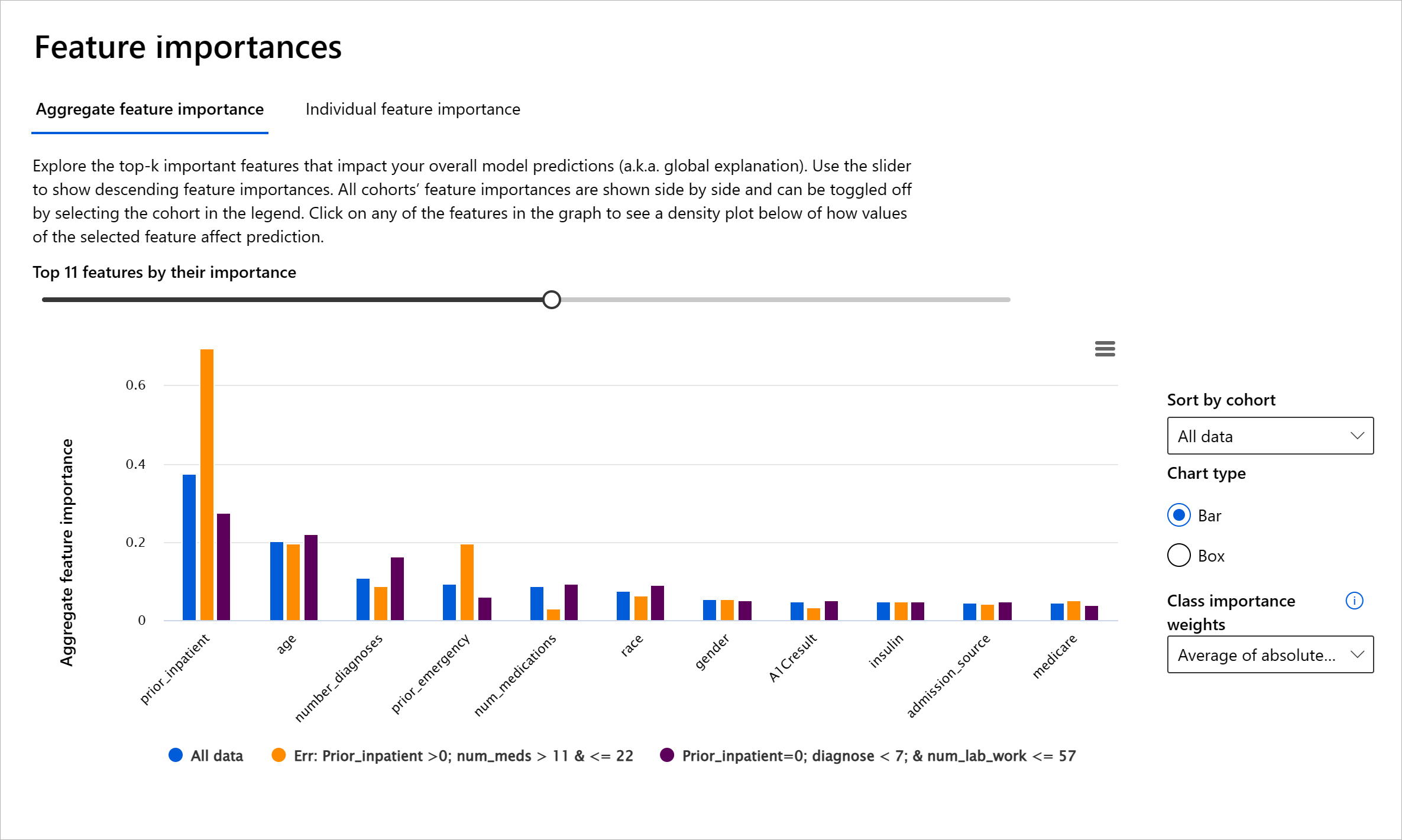
- वैश्विक व्याख्याएँ: उदाहरण के लिए, कौन से फीचर्स मधुमेह अस्पताल पुनः प्रवेश मॉडल के समग्र व्यवहार को प्रभावित करते हैं?
- स्थानीय व्याख्याएँ: उदाहरण के लिए, क्यों एक 60 वर्ष से अधिक उम्र के मधुमेह रोगी को, जिसके पास पहले अस्पताल में भर्ती होने का इतिहास है, 30 दिनों के भीतर अस्पताल में फिर से भर्ती होने या न होने की भविष्यवाणी की गई?
मॉडल के प्रदर्शन को विभिन्न समूहों में जांचने की प्रक्रिया में, फीचर इंपॉर्टेंस यह दिखाता है कि समूहों में फीचर का प्रभाव किस स्तर का है। यह तुलना करते समय विसंगतियों को उजागर करने में मदद करता है कि फीचर मॉडल की गलत भविष्यवाणियों को प्रेरित करने में कितना प्रभावशाली है। फीचर इंपॉर्टेंस घटक यह दिखा सकता है कि किसी फीचर में कौन से मान मॉडल के परिणाम को सकारात्मक या नकारात्मक रूप से प्रभावित करते हैं। उदाहरण के लिए, यदि मॉडल ने गलत भविष्यवाणी की, तो घटक आपको यह जांचने और पहचानने की क्षमता देता है कि कौन से फीचर्स या फीचर मान भविष्यवाणी को प्रेरित करते हैं। यह स्तर न केवल डिबगिंग में मदद करता है बल्कि ऑडिटिंग स्थितियों में पारदर्शिता और उत्तरदायित्व प्रदान करता है। अंत में, घटक आपको निष्पक्षता समस्याओं की पहचान करने में मदद कर सकता है। उदाहरण के लिए, यदि जातीयता या लिंग जैसे संवेदनशील फीचर्स मॉडल की भविष्यवाणी को प्रेरित करने में अत्यधिक प्रभावशाली हैं, तो यह मॉडल में जाति या लिंग पूर्वाग्रह का संकेत हो सकता है।
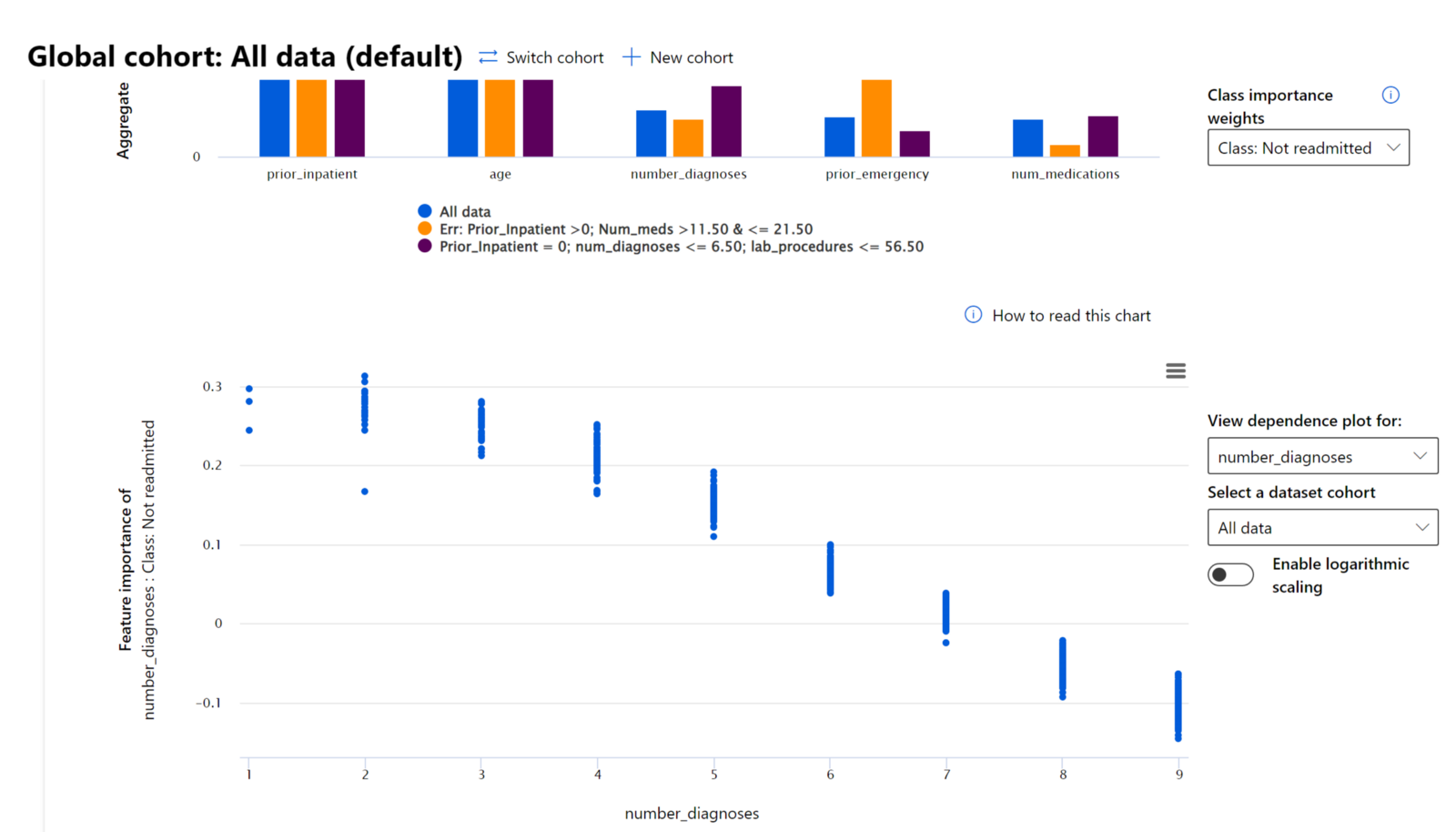
व्याख्या का उपयोग करें जब आपको आवश्यकता हो:
- यह निर्धारित करने के लिए कि आपके AI सिस्टम की भविष्यवाणियाँ कितनी भरोसेमंद हैं, यह समझकर कि कौन से फीचर्स भविष्यवाणियों के लिए सबसे महत्वपूर्ण हैं।
- अपने मॉडल को समझकर और यह पहचानकर कि क्या मॉडल स्वस्थ फीचर्स का उपयोग कर रहा है या केवल गलत सहसंबंधों का उपयोग कर रहा है, डिबगिंग प्रक्रिया को अपनाएँ।
- संभावित अनुचितता के स्रोतों को उजागर करें यह समझकर कि क्या मॉडल संवेदन
- अधिक या कम प्रतिनिधित्व। विचार यह है कि किसी विशेष समूह को किसी विशेष पेशे में नहीं देखा जाता है, और कोई भी सेवा या कार्य जो इसे बढ़ावा देता है, वह नुकसान पहुंचाने में योगदान देता है।
Azure RAI डैशबोर्ड
Azure RAI डैशबोर्ड ओपन-सोर्स टूल्स पर आधारित है, जिन्हें प्रमुख शैक्षणिक संस्थानों और संगठनों, जिनमें Microsoft भी शामिल है, द्वारा विकसित किया गया है। ये टूल डेटा वैज्ञानिकों और AI डेवलपर्स को मॉडल के व्यवहार को बेहतर ढंग से समझने, और AI मॉडलों में अवांछनीय समस्याओं की पहचान और समाधान करने में मदद करते हैं।
-
RAI डैशबोर्ड के विभिन्न घटकों का उपयोग करना सीखने के लिए डॉक्यूमेंटेशन देखें।
-
Azure Machine Learning में अधिक जिम्मेदार AI परिदृश्यों को डिबग करने के लिए कुछ RAI डैशबोर्ड उदाहरण नोटबुक्स देखें।
🚀 चुनौती
तथ्यात्मक या डेटा पूर्वाग्रहों को शुरुआत में ही रोकने के लिए, हमें:
- सिस्टम पर काम करने वाले लोगों में विभिन्न पृष्ठभूमियों और दृष्टिकोणों का समावेश करना चाहिए
- ऐसे डेटा सेट में निवेश करना चाहिए जो हमारे समाज की विविधता को दर्शाते हों
- पूर्वाग्रह का पता लगाने और उसे सुधारने के बेहतर तरीके विकसित करने चाहिए
उन वास्तविक जीवन के परिदृश्यों के बारे में सोचें जहां मॉडल निर्माण और उपयोग में अन्याय स्पष्ट है। हमें और क्या विचार करना चाहिए?
पोस्ट-लेक्चर क्विज़
समीक्षा और स्व-अध्ययन
इस पाठ में, आपने मशीन लर्निंग में जिम्मेदार AI को शामिल करने के कुछ व्यावहारिक टूल्स के बारे में सीखा है।
इन विषयों में गहराई से जाने के लिए यह वर्कशॉप देखें:
- जिम्मेदार AI डैशबोर्ड: Besmira Nushi और Mehrnoosh Sameki द्वारा व्यावहारिक रूप से RAI को लागू करने के लिए एक-स्टॉप समाधान

🎥 ऊपर दी गई छवि पर क्लिक करें वीडियो के लिए: जिम्मेदार AI डैशबोर्ड: व्यावहारिक रूप से RAI को लागू करने के लिए एक-स्टॉप समाधान, Besmira Nushi और Mehrnoosh Sameki द्वारा
जिम्मेदार AI और अधिक भरोसेमंद मॉडल बनाने के बारे में अधिक जानने के लिए निम्नलिखित सामग्रियों का संदर्भ लें:
-
ML मॉडलों को डिबग करने के लिए Microsoft के RAI डैशबोर्ड टूल्स: जिम्मेदार AI टूल्स संसाधन
-
जिम्मेदार AI टूलकिट का अन्वेषण करें: Github
-
Microsoft का RAI संसाधन केंद्र: जिम्मेदार AI संसाधन – Microsoft AI
-
Microsoft का FATE अनुसंधान समूह: FATE: AI में निष्पक्षता, जवाबदेही, पारदर्शिता, और नैतिकता - Microsoft Research
असाइनमेंट
अस्वीकरण:
यह दस्तावेज़ AI अनुवाद सेवा Co-op Translator का उपयोग करके अनुवादित किया गया है। जबकि हम सटीकता के लिए प्रयासरत हैं, कृपया ध्यान दें कि स्वचालित अनुवाद में त्रुटियां या अशुद्धियां हो सकती हैं। मूल भाषा में उपलब्ध मूल दस्तावेज़ को आधिकारिक स्रोत माना जाना चाहिए। महत्वपूर्ण जानकारी के लिए, पेशेवर मानव अनुवाद की सिफारिश की जाती है। इस अनुवाद के उपयोग से उत्पन्न किसी भी गलतफहमी या गलत व्याख्या के लिए हम उत्तरदायी नहीं हैं।