|
|
2 weeks ago | |
|---|---|---|
| .. | ||
| solution | 3 weeks ago | |
| README.md | 2 weeks ago | |
| assignment.md | 3 weeks ago | |
| notebook.ipynb | 3 weeks ago | |
README.md
Python और Scikit-learn के साथ रिग्रेशन मॉडल्स शुरू करें

स्केच नोट Tomomi Imura द्वारा
प्री-लेक्चर क्विज़
यह पाठ R में भी उपलब्ध है!
परिचय
इन चार पाठों में, आप सीखेंगे कि रिग्रेशन मॉडल्स कैसे बनाए जाते हैं। हम जल्द ही चर्चा करेंगे कि इनका उपयोग किस लिए किया जाता है। लेकिन कुछ भी शुरू करने से पहले, सुनिश्चित करें कि आपके पास सही उपकरण हैं ताकि आप प्रक्रिया शुरू कर सकें!
इस पाठ में, आप सीखेंगे:
- अपने कंप्यूटर को स्थानीय मशीन लर्निंग कार्यों के लिए कॉन्फ़िगर करना।
- Jupyter नोटबुक्स के साथ काम करना।
- Scikit-learn का उपयोग करना, जिसमें इंस्टॉलेशन शामिल है।
- एक हैंड्स-ऑन अभ्यास के साथ लीनियर रिग्रेशन का अन्वेषण करना।
इंस्टॉलेशन और कॉन्फ़िगरेशन

🎥 ऊपर दी गई छवि पर क्लिक करें ताकि आप अपने कंप्यूटर को मशीन लर्निंग के लिए कॉन्फ़िगर करने की प्रक्रिया देख सकें।
-
Python इंस्टॉल करें। सुनिश्चित करें कि Python आपके कंप्यूटर पर इंस्टॉल है। आप डेटा साइंस और मशीन लर्निंग कार्यों के लिए Python का उपयोग करेंगे। अधिकांश कंप्यूटर सिस्टम में पहले से ही Python इंस्टॉल होता है। कुछ उपयोगकर्ताओं के लिए सेटअप को आसान बनाने के लिए उपयोगी Python Coding Packs भी उपलब्ध हैं।
हालांकि, Python के कुछ उपयोगों के लिए सॉफ़्टवेयर का एक संस्करण आवश्यक होता है, जबकि अन्य के लिए अलग संस्करण। इस कारण से, वर्चुअल एनवायरनमेंट में काम करना उपयोगी होता है।
-
Visual Studio Code इंस्टॉल करें। सुनिश्चित करें कि आपके कंप्यूटर पर Visual Studio Code इंस्टॉल है। Visual Studio Code इंस्टॉल करने के लिए इन निर्देशों का पालन करें। इस पाठ्यक्रम में आप Visual Studio Code में Python का उपयोग करेंगे, इसलिए आप Python विकास के लिए Visual Studio Code को कॉन्फ़िगर करने के बारे में जानकारी प्राप्त कर सकते हैं।
Python के साथ सहज होने के लिए इस Learn modules संग्रह को देखें।

🎥 ऊपर दी गई छवि पर क्लिक करें ताकि आप Python को VS Code में उपयोग करने की प्रक्रिया देख सकें।
-
Scikit-learn इंस्टॉल करें, इन निर्देशों का पालन करके। चूंकि आपको Python 3 का उपयोग सुनिश्चित करना है, इसलिए वर्चुअल एनवायरनमेंट का उपयोग करने की सिफारिश की जाती है। ध्यान दें, यदि आप इस लाइब्रेरी को M1 Mac पर इंस्टॉल कर रहे हैं, तो ऊपर दिए गए पृष्ठ पर विशेष निर्देश हैं।
-
Jupyter Notebook इंस्टॉल करें। आपको Jupyter पैकेज इंस्टॉल करना होगा।
आपका मशीन लर्निंग लेखन वातावरण
आप नोटबुक्स का उपयोग करके Python कोड विकसित करेंगे और मशीन लर्निंग मॉडल बनाएंगे। यह प्रकार की फाइल डेटा वैज्ञानिकों के लिए एक सामान्य उपकरण है, और इन्हें उनके .ipynb एक्सटेंशन से पहचाना जा सकता है।
नोटबुक्स एक इंटरैक्टिव वातावरण हैं जो डेवलपर को कोड लिखने और उसके आसपास नोट्स और दस्तावेज़ जोड़ने की अनुमति देते हैं, जो शोध-उन्मुख परियोजनाओं के लिए काफी उपयोगी है।

🎥 ऊपर दी गई छवि पर क्लिक करें ताकि आप इस अभ्यास की प्रक्रिया देख सकें।
अभ्यास - नोटबुक के साथ काम करें
इस फ़ोल्डर में, आपको notebook.ipynb नामक फाइल मिलेगी।
-
notebook.ipynb को Visual Studio Code में खोलें।
एक Jupyter सर्वर Python 3+ के साथ शुरू होगा। आप नोटबुक के उन क्षेत्रों को पाएंगे जिन्हें
runकिया जा सकता है, यानी कोड के टुकड़े। आप कोड ब्लॉक को चलाने के लिए उस आइकन का चयन कर सकते हैं जो प्ले बटन जैसा दिखता है। -
mdआइकन का चयन करें और थोड़ा मार्कडाउन जोड़ें, और निम्नलिखित टेक्स्ट लिखें # Welcome to your notebook।इसके बाद, कुछ Python कोड जोड़ें।
-
कोड ब्लॉक में print('hello notebook') टाइप करें।
-
कोड चलाने के लिए तीर का चयन करें।
आपको प्रिंट किया गया कथन दिखाई देना चाहिए:
hello notebook

आप अपने कोड के साथ टिप्पणियां जोड़ सकते हैं ताकि नोटबुक को स्वयं दस्तावेज़ित किया जा सके।
✅ एक मिनट के लिए सोचें कि एक वेब डेवलपर का कार्य वातावरण डेटा वैज्ञानिक के कार्य वातावरण से कितना अलग है।
Scikit-learn के साथ शुरुआत
अब जब Python आपके स्थानीय वातावरण में सेटअप हो गया है, और आप Jupyter नोटबुक्स के साथ सहज हैं, तो आइए Scikit-learn के साथ भी उतना ही सहज हो जाएं। (इसे sci के रूप में उच्चारित करें, जैसे science)। Scikit-learn आपको मशीन लर्निंग कार्यों को करने में मदद करने के लिए एक विस्तृत API प्रदान करता है।
उनकी वेबसाइट के अनुसार, "Scikit-learn एक ओपन सोर्स मशीन लर्निंग लाइब्रेरी है जो सुपरवाइज्ड और अनसुपरवाइज्ड लर्निंग का समर्थन करती है। यह मॉडल फिटिंग, डेटा प्रीप्रोसेसिंग, मॉडल चयन और मूल्यांकन, और कई अन्य उपयोगिताओं के लिए विभिन्न उपकरण भी प्रदान करती है।"
इस पाठ्यक्रम में, आप Scikit-learn और अन्य उपकरणों का उपयोग करके मशीन लर्निंग मॉडल बनाएंगे ताकि 'पारंपरिक मशीन लर्निंग' कार्यों को अंजाम दिया जा सके। हमने जानबूझकर न्यूरल नेटवर्क्स और डीप लर्निंग को शामिल नहीं किया है, क्योंकि इन्हें हमारे आगामी 'AI for Beginners' पाठ्यक्रम में बेहतर तरीके से कवर किया जाएगा।
Scikit-learn मॉडल्स को बनाना और उनका मूल्यांकन करना आसान बनाता है। यह मुख्य रूप से संख्यात्मक डेटा का उपयोग करता है और सीखने के उपकरण के रूप में उपयोग के लिए कई तैयार किए गए डेटासेट्स प्रदान करता है। इसमें छात्रों के लिए आज़माने के लिए प्री-बिल्ट मॉडल्स भी शामिल हैं। आइए पहले Scikit-learn के साथ प्रीपैकेज्ड डेटा को लोड करने और एक बिल्ट-इन एस्टीमेटर का उपयोग करके पहला मशीन लर्निंग मॉडल बनाने की प्रक्रिया का अन्वेषण करें।
अभ्यास - आपका पहला Scikit-learn नोटबुक
यह ट्यूटोरियल Scikit-learn की वेबसाइट पर लीनियर रिग्रेशन उदाहरण से प्रेरित है।

🎥 ऊपर दी गई छवि पर क्लिक करें ताकि आप इस अभ्यास की प्रक्रिया देख सकें।
इस पाठ से संबंधित notebook.ipynb फाइल में, सभी सेल्स को 'trash can' आइकन दबाकर साफ़ करें।
इस सेक्शन में, आप Scikit-learn में सीखने के उद्देश्यों के लिए बनाए गए एक छोटे से डायबिटीज डेटासेट के साथ काम करेंगे। कल्पना करें कि आप डायबिटीज रोगियों के लिए एक उपचार का परीक्षण करना चाहते हैं। मशीन लर्निंग मॉडल्स आपको यह निर्धारित करने में मदद कर सकते हैं कि कौन से रोगी उपचार के लिए बेहतर प्रतिक्रिया देंगे, चर के संयोजनों के आधार पर। यहां तक कि एक बहुत ही बुनियादी रिग्रेशन मॉडल, जब विज़ुअलाइज़ किया जाता है, तो चर के बारे में जानकारी दिखा सकता है जो आपको अपने सैद्धांतिक क्लिनिकल ट्रायल्स को व्यवस्थित करने में मदद कर सकता है।
✅ रिग्रेशन विधियों के कई प्रकार होते हैं, और आप कौन सा चुनते हैं यह उस उत्तर पर निर्भर करता है जिसे आप ढूंढ रहे हैं। यदि आप किसी दिए गए उम्र के व्यक्ति की संभावित ऊंचाई की भविष्यवाणी करना चाहते हैं, तो आप लीनियर रिग्रेशन का उपयोग करेंगे, क्योंकि आप एक संख्यात्मक मान की तलाश कर रहे हैं। यदि आप यह पता लगाना चाहते हैं कि किसी प्रकार के भोजन को शाकाहारी माना जाना चाहिए या नहीं, तो आप एक श्रेणी असाइनमेंट की तलाश कर रहे हैं, इसलिए आप लॉजिस्टिक रिग्रेशन का उपयोग करेंगे। आप बाद में लॉजिस्टिक रिग्रेशन के बारे में अधिक जानेंगे। डेटा से कुछ प्रश्न पूछने के बारे में सोचें, और इनमें से कौन सी विधि अधिक उपयुक्त होगी।
आइए इस कार्य को शुरू करें।
लाइब्रेरीज़ इंपोर्ट करें
इस कार्य के लिए हम कुछ लाइब्रेरीज़ इंपोर्ट करेंगे:
- matplotlib। यह एक उपयोगी ग्राफिंग टूल है और हम इसका उपयोग लाइन प्लॉट बनाने के लिए करेंगे।
- numpy। numpy Python में संख्यात्मक डेटा को संभालने के लिए एक उपयोगी लाइब्रेरी है।
- sklearn। यह Scikit-learn लाइब्रेरी है।
अपने कार्यों में मदद के लिए कुछ लाइब्रेरीज़ इंपोर्ट करें।
-
निम्नलिखित कोड टाइप करके इंपोर्ट्स जोड़ें:
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, model_selectionऊपर आप
matplotlib,numpyऔरsklearnसेdatasets,linear_modelऔरmodel_selectionइंपोर्ट कर रहे हैं।model_selectionका उपयोग डेटा को ट्रेनिंग और टेस्ट सेट्स में विभाजित करने के लिए किया जाता है।
डायबिटीज डेटासेट
बिल्ट-इन डायबिटीज डेटासेट में डायबिटीज से संबंधित 442 नमूनों का डेटा है, जिसमें 10 फीचर वेरिएबल्स शामिल हैं, जिनमें से कुछ हैं:
- age: उम्र वर्षों में
- bmi: बॉडी मास इंडेक्स
- bp: औसत रक्तचाप
- s1 tc: टी-सेल्स (सफेद रक्त कोशिकाओं का एक प्रकार)
✅ इस डेटासेट में 'sex' की अवधारणा एक फीचर वेरिएबल के रूप में शामिल है, जो डायबिटीज के शोध के लिए महत्वपूर्ण है। कई मेडिकल डेटासेट्स में इस प्रकार का बाइनरी वर्गीकरण शामिल होता है। सोचें कि इस प्रकार की श्रेणियां आबादी के कुछ हिस्सों को उपचार से कैसे बाहर कर सकती हैं।
अब, X और y डेटा लोड करें।
🎓 याद रखें, यह सुपरवाइज्ड लर्निंग है, और हमें एक नामित 'y' टारगेट की आवश्यकता है।
एक नए कोड सेल में, डायबिटीज डेटासेट को load_diabetes() कॉल करके लोड करें। इनपुट return_X_y=True संकेत देता है कि X एक डेटा मैट्रिक्स होगा, और y रिग्रेशन टारगेट होगा।
-
डेटा मैट्रिक्स के आकार और इसके पहले तत्व को दिखाने के लिए कुछ प्रिंट कमांड जोड़ें:
X, y = datasets.load_diabetes(return_X_y=True) print(X.shape) print(X[0])जो प्रतिक्रिया आपको मिल रही है, वह एक ट्यूपल है। आप जो कर रहे हैं वह ट्यूपल के पहले दो मानों को क्रमशः
Xऔरyको असाइन करना है। ट्यूपल्स के बारे में अधिक जानें।आप देख सकते हैं कि इस डेटा में 442 आइटम हैं जो 10 तत्वों के एरे में आकारित हैं:
(442, 10) [ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -0.04340085 -0.00259226 0.01990842 -0.01764613]✅ डेटा और रिग्रेशन टारगेट के बीच संबंध के बारे में सोचें। लीनियर रिग्रेशन फीचर X और टारगेट वेरिएबल y के बीच संबंधों की भविष्यवाणी करता है। क्या आप डायबिटीज डेटासेट के लिए टारगेट को दस्तावेज़ में पा सकते हैं? यह डेटासेट क्या प्रदर्शित कर रहा है, टारगेट को देखते हुए?
-
इसके बाद, इस डेटासेट के एक हिस्से को प्लॉट करने के लिए चुनें, डेटासेट के तीसरे कॉलम का चयन करके। आप
:ऑपरेटर का उपयोग करके सभी पंक्तियों का चयन कर सकते हैं, और फिर इंडेक्स (2) का उपयोग करके तीसरे कॉलम का चयन कर सकते हैं। आप डेटा को 2D एरे में आकार देने के लिएreshape(n_rows, n_columns)का उपयोग कर सकते हैं - जैसा कि प्लॉटिंग के लिए आवश्यक है। यदि पैरामीटर में से एक -1 है, तो संबंधित आयाम स्वचालित रूप से गणना किया जाता है।X = X[:, 2] X = X.reshape((-1,1))✅ किसी भी समय, डेटा का आकार जांचने के लिए इसे प्रिंट करें।
-
अब जब आपके पास डेटा प्लॉट करने के लिए तैयार है, तो आप देख सकते हैं कि क्या मशीन इस डेटासेट में संख्याओं के बीच एक तार्किक विभाजन निर्धारित करने में मदद कर सकती है। ऐसा करने के लिए, आपको डेटा (X) और टारगेट (y) दोनों को टेस्ट और ट्रेनिंग सेट्स में विभाजित करना होगा। Scikit-learn में इसे करने का एक सीधा तरीका है; आप अपने टेस्ट डेटा को एक दिए गए बिंदु पर विभाजित कर सकते हैं।
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) -
अब आप अपने मॉडल को ट्रेन करने के लिए तैयार हैं! लीनियर रिग्रेशन मॉडल लोड करें और इसे अपने X और y ट्रेनिंग सेट्स के साथ
model.fit()का उपयोग करके ट्रेन करें:model = linear_model.LinearRegression() model.fit(X_train, y_train)✅
model.fit()एक फ़ंक्शन है जिसे आप TensorFlow जैसी कई ML लाइब्रेरीज़ में देखेंगे। -
फिर, टेस्ट डेटा का उपयोग करके एक प्रेडिक्शन बनाएं,
predict()फ़ंक्शन का उपयोग करके। इसका उपयोग डेटा समूहों के बीच लाइन खींचने के लिए किया जाएगा।y_pred = model.predict(X_test) -
अब डेटा को प्लॉट में दिखाने का समय है। Matplotlib इस कार्य के लिए एक बहुत उपयोगी टूल है। सभी X और y टेस्ट डेटा का एक स्कैटरप्लॉट बनाएं, और मॉडल के डेटा समूहों के बीच सबसे उपयुक्त स्थान पर एक लाइन खींचने के लिए प्रेडिक्शन का उपयोग करें।
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_pred, color='blue', linewidth=3) plt.xlabel('Scaled BMIs') plt.ylabel('Disease Progression') plt.title('A Graph Plot Showing Diabetes Progression Against BMI') plt.show()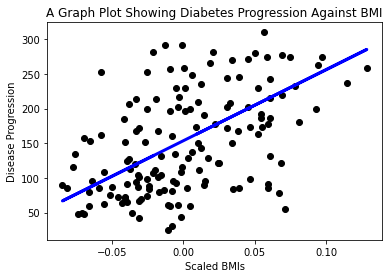 ✅ यहां क्या हो रहा है, इस पर थोड़ा विचार करें। एक सीधी रेखा कई छोटे डेटा बिंदुओं के बीच से गुजर रही है, लेकिन यह वास्तव में क्या कर रही है? क्या आप देख सकते हैं कि इस रेखा का उपयोग करके आप यह अनुमान कैसे लगा सकते हैं कि एक नया, अनदेखा डेटा बिंदु प्लॉट के y अक्ष के संबंध में कहां फिट होगा? इस मॉडल के व्यावहारिक उपयोग को शब्दों में व्यक्त करने की कोशिश करें।
✅ यहां क्या हो रहा है, इस पर थोड़ा विचार करें। एक सीधी रेखा कई छोटे डेटा बिंदुओं के बीच से गुजर रही है, लेकिन यह वास्तव में क्या कर रही है? क्या आप देख सकते हैं कि इस रेखा का उपयोग करके आप यह अनुमान कैसे लगा सकते हैं कि एक नया, अनदेखा डेटा बिंदु प्लॉट के y अक्ष के संबंध में कहां फिट होगा? इस मॉडल के व्यावहारिक उपयोग को शब्दों में व्यक्त करने की कोशिश करें।
बधाई हो, आपने अपना पहला लीनियर रिग्रेशन मॉडल बनाया, इसके साथ एक भविष्यवाणी की, और इसे एक प्लॉट में प्रदर्शित किया!
🚀चुनौती
इस डेटा सेट से एक अलग वेरिएबल को प्लॉट करें। संकेत: इस लाइन को एडिट करें: X = X[:,2]। इस डेटा सेट के टारगेट को देखते हुए, आप डायबिटीज के एक बीमारी के रूप में प्रगति के बारे में क्या पता लगा सकते हैं?
पोस्ट-लेक्चर क्विज़
समीक्षा और स्व-अध्ययन
इस ट्यूटोरियल में, आपने सिंपल लीनियर रिग्रेशन के साथ काम किया, न कि यूनिवेरिएट या मल्टीपल लीनियर रिग्रेशन के साथ। इन विधियों के बीच के अंतर के बारे में थोड़ा पढ़ें, या इस वीडियो को देखें।
रिग्रेशन की अवधारणा के बारे में अधिक पढ़ें और सोचें कि इस तकनीक द्वारा किस प्रकार के प्रश्नों का उत्तर दिया जा सकता है। अपनी समझ को गहरा करने के लिए यह ट्यूटोरियल लें।
असाइनमेंट
अस्वीकरण:
यह दस्तावेज़ AI अनुवाद सेवा Co-op Translator का उपयोग करके अनुवादित किया गया है। जबकि हम सटीकता के लिए प्रयासरत हैं, कृपया ध्यान दें कि स्वचालित अनुवाद में त्रुटियां या अशुद्धियां हो सकती हैं। मूल भाषा में उपलब्ध मूल दस्तावेज़ को आधिकारिक स्रोत माना जाना चाहिए। महत्वपूर्ण जानकारी के लिए, पेशेवर मानव अनुवाद की सिफारिश की जाती है। इस अनुवाद के उपयोग से उत्पन्न किसी भी गलतफहमी या गलत व्याख्या के लिए हम उत्तरदायी नहीं हैं।