|
|
2 weeks ago | |
|---|---|---|
| .. | ||
| solution | 3 weeks ago | |
| README.md | 2 weeks ago | |
| assignment.md | 3 weeks ago | |
| notebook.ipynb | 3 weeks ago | |
README.md
Construire une application web de recommandation de cuisine
Dans cette leçon, vous allez créer un modèle de classification en utilisant certaines des techniques apprises dans les leçons précédentes, ainsi que le délicieux ensemble de données sur les cuisines utilisé tout au long de cette série. De plus, vous allez construire une petite application web pour utiliser un modèle sauvegardé, en exploitant le runtime web d'Onnx.
L'un des usages pratiques les plus utiles de l'apprentissage automatique est la création de systèmes de recommandation, et vous pouvez faire le premier pas dans cette direction dès aujourd'hui !

🎥 Cliquez sur l'image ci-dessus pour une vidéo : Jen Looper construit une application web en utilisant des données de cuisine classifiées
Quiz avant la leçon
Dans cette leçon, vous apprendrez :
- Comment construire un modèle et le sauvegarder au format Onnx
- Comment utiliser Netron pour inspecter le modèle
- Comment utiliser votre modèle dans une application web pour effectuer des inférences
Construisez votre modèle
Construire des systèmes d'apprentissage automatique appliqué est une partie importante de l'exploitation de ces technologies pour vos systèmes d'entreprise. Vous pouvez utiliser des modèles dans vos applications web (et donc les utiliser hors ligne si nécessaire) en utilisant Onnx.
Dans une leçon précédente, vous avez construit un modèle de régression sur les observations d'OVNI, l'avez "picklé" et utilisé dans une application Flask. Bien que cette architecture soit très utile à connaître, il s'agit d'une application Python full-stack, et vos besoins peuvent inclure l'utilisation d'une application JavaScript.
Dans cette leçon, vous pouvez construire un système de base basé sur JavaScript pour effectuer des inférences. Cependant, vous devez d'abord entraîner un modèle et le convertir pour une utilisation avec Onnx.
Exercice - entraîner un modèle de classification
Commencez par entraîner un modèle de classification en utilisant l'ensemble de données nettoyé sur les cuisines que nous avons utilisé.
-
Commencez par importer des bibliothèques utiles :
!pip install skl2onnx import pandas as pdVous avez besoin de 'skl2onnx' pour aider à convertir votre modèle Scikit-learn au format Onnx.
-
Ensuite, travaillez avec vos données de la même manière que dans les leçons précédentes, en lisant un fichier CSV avec
read_csv():data = pd.read_csv('../data/cleaned_cuisines.csv') data.head() -
Supprimez les deux premières colonnes inutiles et sauvegardez les données restantes sous 'X' :
X = data.iloc[:,2:] X.head() -
Sauvegardez les étiquettes sous 'y' :
y = data[['cuisine']] y.head()
Commencez la routine d'entraînement
Nous utiliserons la bibliothèque 'SVC' qui offre une bonne précision.
-
Importez les bibliothèques appropriées de Scikit-learn :
from sklearn.model_selection import train_test_split from sklearn.svm import SVC from sklearn.model_selection import cross_val_score from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report -
Séparez les ensembles d'entraînement et de test :
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3) -
Construisez un modèle de classification SVC comme vous l'avez fait dans la leçon précédente :
model = SVC(kernel='linear', C=10, probability=True,random_state=0) model.fit(X_train,y_train.values.ravel()) -
Maintenant, testez votre modèle en appelant
predict():y_pred = model.predict(X_test) -
Affichez un rapport de classification pour vérifier la qualité du modèle :
print(classification_report(y_test,y_pred))Comme nous l'avons vu précédemment, la précision est bonne :
precision recall f1-score support chinese 0.72 0.69 0.70 257 indian 0.91 0.87 0.89 243 japanese 0.79 0.77 0.78 239 korean 0.83 0.79 0.81 236 thai 0.72 0.84 0.78 224 accuracy 0.79 1199 macro avg 0.79 0.79 0.79 1199 weighted avg 0.79 0.79 0.79 1199
Convertissez votre modèle en Onnx
Assurez-vous de faire la conversion avec le bon nombre de tenseurs. Cet ensemble de données contient 380 ingrédients listés, donc vous devez noter ce nombre dans FloatTensorType :
-
Convertissez en utilisant un nombre de tenseurs de 380.
from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType initial_type = [('float_input', FloatTensorType([None, 380]))] options = {id(model): {'nocl': True, 'zipmap': False}} -
Créez le fichier onx et sauvegardez-le sous model.onnx :
onx = convert_sklearn(model, initial_types=initial_type, options=options) with open("./model.onnx", "wb") as f: f.write(onx.SerializeToString())Notez que vous pouvez passer des options dans votre script de conversion. Dans ce cas, nous avons passé 'nocl' à True et 'zipmap' à False. Étant donné qu'il s'agit d'un modèle de classification, vous avez l'option de supprimer ZipMap qui produit une liste de dictionnaires (non nécessaire).
noclfait référence à l'inclusion des informations de classe dans le modèle. Réduisez la taille de votre modèle en définissantnoclsur 'True'.
Exécuter l'ensemble du notebook permettra maintenant de construire un modèle Onnx et de le sauvegarder dans ce dossier.
Visualisez votre modèle
Les modèles Onnx ne sont pas très visibles dans Visual Studio Code, mais il existe un excellent logiciel gratuit que de nombreux chercheurs utilisent pour visualiser le modèle et s'assurer qu'il est correctement construit. Téléchargez Netron et ouvrez votre fichier model.onnx. Vous pouvez voir votre modèle simple visualisé, avec ses 380 entrées et son classificateur listé :
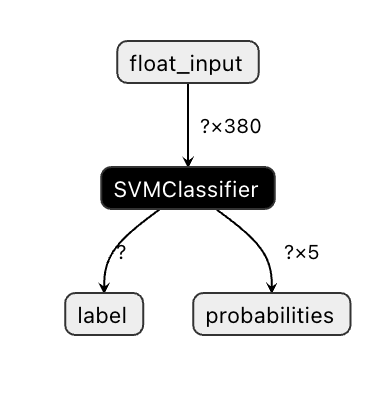
Netron est un outil utile pour visualiser vos modèles.
Vous êtes maintenant prêt à utiliser ce modèle dans une application web. Construisons une application qui sera utile lorsque vous regardez dans votre réfrigérateur et essayez de déterminer quelle combinaison de vos ingrédients restants vous pouvez utiliser pour cuisiner une cuisine donnée, comme déterminé par votre modèle.
Construisez une application web de recommandation
Vous pouvez utiliser votre modèle directement dans une application web. Cette architecture permet également de l'exécuter localement et même hors ligne si nécessaire. Commencez par créer un fichier index.html dans le même dossier où vous avez sauvegardé votre fichier model.onnx.
-
Dans ce fichier index.html, ajoutez le balisage suivant :
<!DOCTYPE html> <html> <header> <title>Cuisine Matcher</title> </header> <body> ... </body> </html> -
Ensuite, dans les balises
body, ajoutez un peu de balisage pour afficher une liste de cases à cocher reflétant certains ingrédients :<h1>Check your refrigerator. What can you create?</h1> <div id="wrapper"> <div class="boxCont"> <input type="checkbox" value="4" class="checkbox"> <label>apple</label> </div> <div class="boxCont"> <input type="checkbox" value="247" class="checkbox"> <label>pear</label> </div> <div class="boxCont"> <input type="checkbox" value="77" class="checkbox"> <label>cherry</label> </div> <div class="boxCont"> <input type="checkbox" value="126" class="checkbox"> <label>fenugreek</label> </div> <div class="boxCont"> <input type="checkbox" value="302" class="checkbox"> <label>sake</label> </div> <div class="boxCont"> <input type="checkbox" value="327" class="checkbox"> <label>soy sauce</label> </div> <div class="boxCont"> <input type="checkbox" value="112" class="checkbox"> <label>cumin</label> </div> </div> <div style="padding-top:10px"> <button onClick="startInference()">What kind of cuisine can you make?</button> </div>Notez que chaque case à cocher est attribuée une valeur. Cela reflète l'index où l'ingrédient se trouve selon l'ensemble de données. Par exemple, la pomme, dans cette liste alphabétique, occupe la cinquième colonne, donc sa valeur est '4' puisque nous commençons à compter à 0. Vous pouvez consulter le tableau des ingrédients pour découvrir l'index d'un ingrédient donné.
En continuant votre travail dans le fichier index.html, ajoutez un bloc de script où le modèle est appelé après la dernière fermeture de
</div>. -
Tout d'abord, importez le Onnx Runtime :
<script src="https://cdn.jsdelivr.net/npm/onnxruntime-web@1.9.0/dist/ort.min.js"></script>Onnx Runtime est utilisé pour permettre l'exécution de vos modèles Onnx sur une large gamme de plateformes matérielles, avec des optimisations et une API à utiliser.
-
Une fois le Runtime en place, vous pouvez l'appeler :
<script> const ingredients = Array(380).fill(0); const checks = [...document.querySelectorAll('.checkbox')]; checks.forEach(check => { check.addEventListener('change', function() { // toggle the state of the ingredient // based on the checkbox's value (1 or 0) ingredients[check.value] = check.checked ? 1 : 0; }); }); function testCheckboxes() { // validate if at least one checkbox is checked return checks.some(check => check.checked); } async function startInference() { let atLeastOneChecked = testCheckboxes() if (!atLeastOneChecked) { alert('Please select at least one ingredient.'); return; } try { // create a new session and load the model. const session = await ort.InferenceSession.create('./model.onnx'); const input = new ort.Tensor(new Float32Array(ingredients), [1, 380]); const feeds = { float_input: input }; // feed inputs and run const results = await session.run(feeds); // read from results alert('You can enjoy ' + results.label.data[0] + ' cuisine today!') } catch (e) { console.log(`failed to inference ONNX model`); console.error(e); } } </script>
Dans ce code, plusieurs choses se produisent :
- Vous avez créé un tableau de 380 valeurs possibles (1 ou 0) à définir et envoyer au modèle pour effectuer des inférences, en fonction de la case à cocher sélectionnée.
- Vous avez créé un tableau de cases à cocher et un moyen de déterminer si elles ont été cochées dans une fonction
initappelée au démarrage de l'application. Lorsqu'une case est cochée, le tableauingredientsest modifié pour refléter l'ingrédient choisi. - Vous avez créé une fonction
testCheckboxesqui vérifie si une case a été cochée. - Vous utilisez la fonction
startInferencelorsque le bouton est pressé et, si une case est cochée, vous démarrez l'inférence. - La routine d'inférence inclut :
- La mise en place d'un chargement asynchrone du modèle
- La création d'une structure Tensor à envoyer au modèle
- La création de 'feeds' qui reflètent l'entrée
float_inputque vous avez créée lors de l'entraînement de votre modèle (vous pouvez utiliser Netron pour vérifier ce nom) - L'envoi de ces 'feeds' au modèle et l'attente d'une réponse
Testez votre application
Ouvrez une session terminal dans Visual Studio Code dans le dossier où se trouve votre fichier index.html. Assurez-vous que vous avez http-server installé globalement, et tapez http-server à l'invite. Un localhost devrait s'ouvrir et vous pouvez visualiser votre application web. Vérifiez quelle cuisine est recommandée en fonction des différents ingrédients :
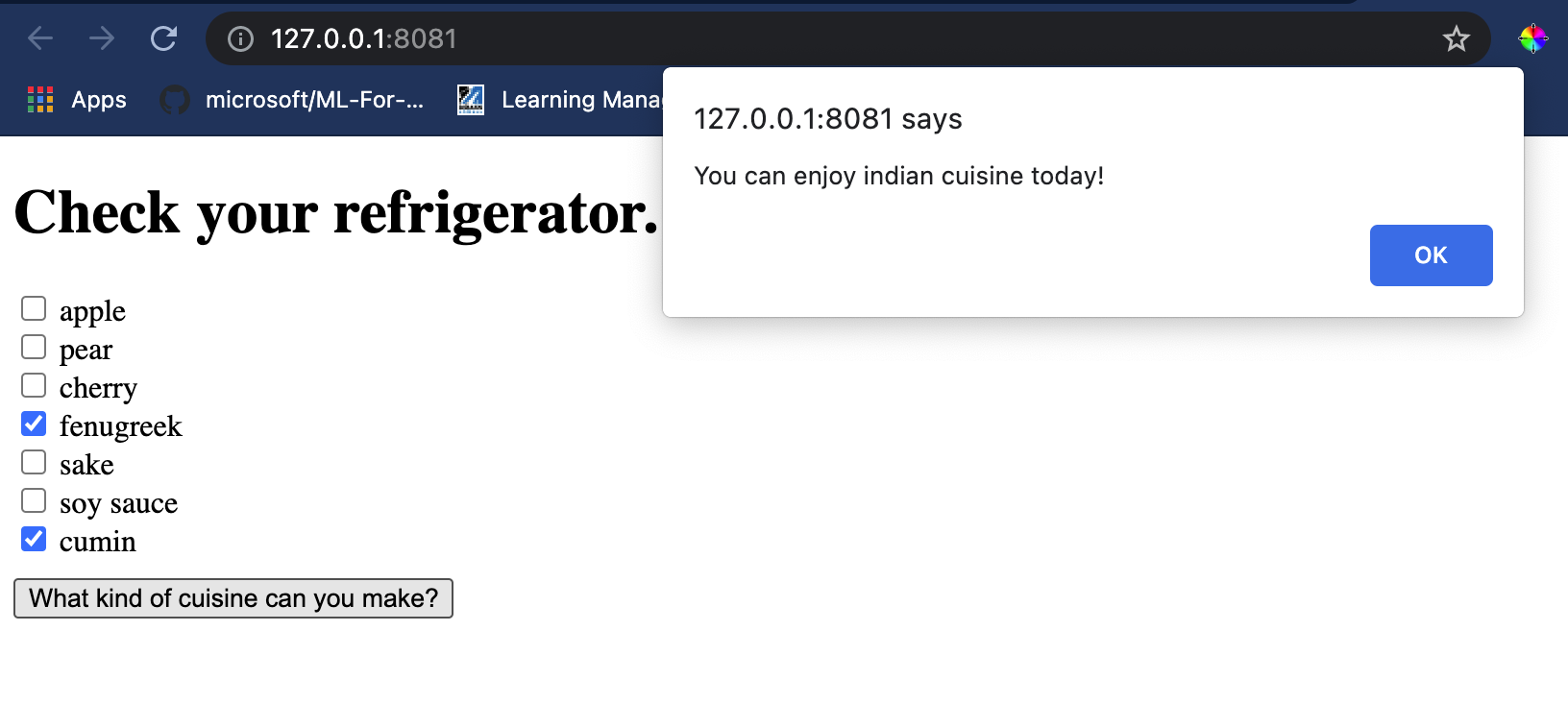
Félicitations, vous avez créé une application web de 'recommandation' avec quelques champs. Prenez le temps de développer ce système !
🚀Défi
Votre application web est très minimaliste, alors continuez à la développer en utilisant les ingrédients et leurs index issus des données ingredient_indexes. Quelles combinaisons de saveurs fonctionnent pour créer un plat national donné ?
Quiz après la leçon
Révision et auto-apprentissage
Bien que cette leçon ait seulement effleuré l'utilité de créer un système de recommandation pour les ingrédients alimentaires, ce domaine des applications d'apprentissage automatique est très riche en exemples. Lisez davantage sur la façon dont ces systèmes sont construits :
- https://www.sciencedirect.com/topics/computer-science/recommendation-engine
- https://www.technologyreview.com/2014/08/25/171547/the-ultimate-challenge-for-recommendation-engines/
- https://www.technologyreview.com/2015/03/23/168831/everything-is-a-recommendation/
Devoir
Construisez un nouveau système de recommandation
Avertissement :
Ce document a été traduit à l'aide du service de traduction automatique Co-op Translator. Bien que nous nous efforcions d'assurer l'exactitude, veuillez noter que les traductions automatisées peuvent contenir des erreurs ou des inexactitudes. Le document original dans sa langue d'origine doit être considéré comme la source faisant autorité. Pour des informations critiques, il est recommandé de recourir à une traduction professionnelle réalisée par un humain. Nous déclinons toute responsabilité en cas de malentendus ou d'interprétations erronées résultant de l'utilisation de cette traduction.